Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
Информационной системой считается инфраструктура предприятия, которая задействована в управлении информационными и документальными потоками, которые поступают в предприятие.[1]
Одним из самых важных процессов в управлении инфраструктурой предприятия являются составляющие корпоративную информационную систему и функционирующие на отдельном предприятии программные продукты, а также их сопровождение.
Также неотъемлемой частью процесса сопровождения комплекса продуктов программного обеспечения считается сбор и консолидация данных об ошибках, которые возникают в процессе его работы.[3]
Корпоративные информационные системы охватывают весь цикл работы предприятия включая планирование деятельности и сбыт продукции и используют для автоматизации все функции предприятия: организационные и производственные.
Данные системы включают в себя некоторые подсистемы, которые работают в едином информационном пространстве и поддерживают соответствующие направления деятельности.[5, 29с]
Для внедрения корпоративной информационной системы необходимо соблюдение нескольких критериев: высокая стоимость продукта и разнообразие корпоративных информационных систем.
Длительность подготовки к внедрению продукта и длительность самого внедрения отличаются, первый период длится от полугода до года, а второй от двух месяцев до нескольких лет.[2]
В разработанный макет системы анализа протоколов его функции входит: сбор программных протоколов, поиск аналогов ошибок в базе прецедентов, управление обратной связью с пользователем и идентификация ошибок на основе последовательностей записей протокола.
Для создания полноценной системы сбора и анализа ошибок как части комплекса сопровождения программного обеспечения необходимо расширить функционал системы за счёт расширения адаптационных возможностей системы, средств сбора сведений об ошибках, включения функций обеспечения безопасности передаваемых данных и интеграции с корпоративной базой знаний.[3]
Сбор информации представляет собой процесс исследования накоплений и записей, которые сформированы программным продуктом для их последующего анализа
Выделяется два вида сбора: активный и пассивный.
В активном средства сбора интегрированы с подсистемой протоколирования и могут работать в режиме реального времени, а в пассивном они производят сканирование уже записанных протоколов через определённые интервалы времени.
Ключевым компонентом системы является программный агент, который устанавливается на каждой рабочей станции и взаимодействует с каждым пользователем. Его функциями являются: обеспечение обратной связи пользователя с администратором, мониторинг операционной системы, ресурсов рабочей станции, сбора протоколов и отслеживание процесса выполнения, выдача уведомлений об возникших ошибках и методах их устранения и локальный анализ ошибок.[3]
Большое количество таких систем не подвержены различным сложным процессам, которые требуют высокой производительности и надёжности. Такие системы являются расширенными интерфейсами баз данных, которые хранят информацию о запросах пользователей.
База данных является совокупностью файлов данных и массивов поступающей информации, которая организовывается по установленным правилам, которые предусматривают стандартные принципы описания, сбора, хранения и обработки данных информации вне зависимости от их вида.
Функциональность и эффективность всех видов информационных систем практически одинаковая и различаются он только следующими критериями: перечнями полей, описывающих запрос на модификацию, этапов обработки запросов на модификацию, способов добавления запросов на модификацию и удобством пользовательского интерфейса.[3]
Причинами затруднения автоматического анализа сообщений от пользователей следующие: отчёты об ошибках, выраженные в текстовом виде, сложно классифицировать, а также неправильное или неполное описание ошибки может дать сам пользователь.
Для решения первой проблемы необходимо применение различных методов интеллектуального анализа текстов.
А для решения второй нужна фиксация набора полей, заполняемых пользователем и после этого проверка данных на достаточность и корректность.
Часто ошибка в программном обеспечении связана с некоторыми особенностями предметной области или специфичностью взаимодействия участников процесса сопровождения. Разработка онтологии предметной области и создание централизованной корпоративной базы знаний и её интеграция с системой анализа ошибок позволит повысить качество сопровождения программного обеспечения.
Интерфейс пользователей может предоставлять поддержку в процессе поиска первичных ошибок и этим самым отображать результаты в виде специальных диаграмм, например, «деревья ошибок».
Алгоритм анализа ошибок условно состоит из четырёх этапов и выглядит таким образом:
На первом этапе программный агент собирает данные о работе программного обеспечения, о состоянии операционной системы и потреблении аппаратных ресурсов. Позже собранные данные передаются подсистеме локального анализа ошибок. Результатом анализа является заключение о соответствии данных потенциальной ошибке.[3]
На втором этапе, при положительном решении, программный агент формирует заявку на обслуживание, включает в неё информацию о рабочей станции, программном обеспечении, вызвавшем ошибку и перечень программных протоколов, которые соответствуют ошибке. После этого, центральная подсистема анализа ошибок производит поиск аналогов ошибки в базе прецедентов. Если прецедент будет обнаружен, то агенту передаётся указание на выполнение действия, которое ассоциировано с прецедентом. Если прецедент не будет обнаружен, то агенту будет передано указание на запрос от пользователя дополнительной информации. Дополнительная информация от пользователя собирается программным агентом и передаётся подсистеме анализа текстов отчётов.[3]
Третий этап представляет собой передачу консолидированной информации, которая получается в результате анализа данных о рабочей станции, программном обеспечении, ошибке и отчёте пользователя, на рассмотрение администратора.[3]
На четвёртом этапе администратор либо принимает и утверждает, либо отклоняет полученную информацию. В первом случае администратор принимает решение по возникшей ошибке. На основе полученной информации и принятого решения формируется прецедент, сохраняющийся в базе знаний предприятия. При необходимости копия прецедента передаётся разработчику для возможности исправления возникшей ошибки.[3]
Такой алгоритм используется большинством компаний и нужен для удобства обработки информации, а также облегчения работы и занятости работников компании. За счёт того, что пользователям будет легче предоставить информацию компании, не нужно будет делать звонки и занимать лишнее время работников, ведь можно будет просто ввести данные на сайте предприятия, программа проверит их на наличие ошибок и сама направит работнику. В итоге такая система является уникальной и востребованной на сегодняшний день.
Исходя из всего вышесказанного можно сделать вывод, что выявление ошибок с помощью определённого алгоритма является достаточно эффективным способом, но требует много усилий и выполнения определённых требований и принципов его действия. Также можно сказать и то, что алгоритм анализа ошибок, представленный выше, является не совсем идеальным, но в то же время является стандартным для всех систем и, соответственно, эффективным.
Я думаю, что внедрение такой информационной системы, которая может выявлять ошибки, как пользовательские, так и текстовые ошибок, которые обычная программа не может выявить из-за сложности её классификации, будет достаточно эффективно при укреплении деятельности предприятия и его статуса, а также поможет быстрее разобраться во входящей информации.
Многие специалисты в этой области утверждают, что в корпоративных информационных системах разработка комплекса анализа ошибок достаточно сложна и не всем удаётся, но приносит хорошие результаты, поэтому они советуют внедрять подобные системы без колебаний, ведь этим можно снизить загрузку работников и вывести предприятие на новый уровень.
Также стоит добавить и то, что не всегда использование таких методов и алгоритмов позволяет эффективно пользоваться системой поиска и анализа ошибок, так как многие предприятия неверно их внедряют, не придерживаются определённых требований внедрения, условий и не выполняют принципы анализа ошибок и его разработки.
Список литературы
Верников, Г.Г. Корпоративные информационные системы: не повторяйте пройденных ошибок [Электронный ресурс] : URL : https://www.klerk.ru/soft/articles/3011/ (Дата обращения: 10.01.2021).
Кошкарова, А.А. Анализ корпоративных информационных систем / А. А. Кошкарова, А. Ж. Амиров, С. Н. Попов. — Текст : непосредственный // Молодой ученый. — 2016. — № 9 (113). — С. 63-66. — [Электронный ресурс] : URL : https://moluch.ru/archive/113/29461/ (Дата обращения: 10.01.2021).
Крайнов, А.Ю., Смагин, А. А. Разработка комплекса анализа ошибок в корпоративных информационных системах [Электронный ресурс] : URL : https://www.bestreferat.ru/referat-413488.html (Дата обращения: 10.01.2021).
Медведенко, С.А. Анализ корпоративных информационных систем [Электронный ресурс] : URL : https://revolution.allbest.ru/management/00480529_0.html (Дата обращения: 10.01.2021).
Федорова, Г.Н. Информационные системы, Учебник, Москва, Издательский центр «Академия», 2013.-199с.
Яковлев, В.П. Основы корпоративных информационных систем, учебное пособие, Санкт-Петербург, 2016. -84с.
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
Информационной системой считается инфраструктура предприятия, которая задействована в управлении информационными и документальными потоками, которые поступают в предприятие.[1]
Одним из самых важных процессов в управлении инфраструктурой предприятия являются составляющие корпоративную информационную систему и функционирующие на отдельном предприятии программные продукты, а также их сопровождение.
Также неотъемлемой частью процесса сопровождения комплекса продуктов программного обеспечения считается сбор и консолидация данных об ошибках, которые возникают в процессе его работы.[3]
Корпоративные информационные системы охватывают весь цикл работы предприятия включая планирование деятельности и сбыт продукции и используют для автоматизации все функции предприятия: организационные и производственные.
Данные системы включают в себя некоторые подсистемы, которые работают в едином информационном пространстве и поддерживают соответствующие направления деятельности.[5, 29с]
Для внедрения корпоративной информационной системы необходимо соблюдение нескольких критериев: высокая стоимость продукта и разнообразие корпоративных информационных систем.
Длительность подготовки к внедрению продукта и длительность самого внедрения отличаются, первый период длится от полугода до года, а второй от двух месяцев до нескольких лет.[2]
В разработанный макет системы анализа протоколов его функции входит: сбор программных протоколов, поиск аналогов ошибок в базе прецедентов, управление обратной связью с пользователем и идентификация ошибок на основе последовательностей записей протокола.
Для создания полноценной системы сбора и анализа ошибок как части комплекса сопровождения программного обеспечения необходимо расширить функционал системы за счёт расширения адаптационных возможностей системы, средств сбора сведений об ошибках, включения функций обеспечения безопасности передаваемых данных и интеграции с корпоративной базой знаний.[3]
Сбор информации представляет собой процесс исследования накоплений и записей, которые сформированы программным продуктом для их последующего анализа
Выделяется два вида сбора: активный и пассивный.
В активном средства сбора интегрированы с подсистемой протоколирования и могут работать в режиме реального времени, а в пассивном они производят сканирование уже записанных протоколов через определённые интервалы времени.
Ключевым компонентом системы является программный агент, который устанавливается на каждой рабочей станции и взаимодействует с каждым пользователем. Его функциями являются: обеспечение обратной связи пользователя с администратором, мониторинг операционной системы, ресурсов рабочей станции, сбора протоколов и отслеживание процесса выполнения, выдача уведомлений об возникших ошибках и методах их устранения и локальный анализ ошибок.[3]
Большое количество таких систем не подвержены различным сложным процессам, которые требуют высокой производительности и надёжности. Такие системы являются расширенными интерфейсами баз данных, которые хранят информацию о запросах пользователей.
База данных является совокупностью файлов данных и массивов поступающей информации, которая организовывается по установленным правилам, которые предусматривают стандартные принципы описания, сбора, хранения и обработки данных информации вне зависимости от их вида.
Функциональность и эффективность всех видов информационных систем практически одинаковая и различаются он только следующими критериями: перечнями полей, описывающих запрос на модификацию, этапов обработки запросов на модификацию, способов добавления запросов на модификацию и удобством пользовательского интерфейса.[3]
Причинами затруднения автоматического анализа сообщений от пользователей следующие: отчёты об ошибках, выраженные в текстовом виде, сложно классифицировать, а также неправильное или неполное описание ошибки может дать сам пользователь.
Для решения первой проблемы необходимо применение различных методов интеллектуального анализа текстов.
А для решения второй нужна фиксация набора полей, заполняемых пользователем и после этого проверка данных на достаточность и корректность.
Часто ошибка в программном обеспечении связана с некоторыми особенностями предметной области или специфичностью взаимодействия участников процесса сопровождения. Разработка онтологии предметной области и создание централизованной корпоративной базы знаний и её интеграция с системой анализа ошибок позволит повысить качество сопровождения программного обеспечения.
Интерфейс пользователей может предоставлять поддержку в процессе поиска первичных ошибок и этим самым отображать результаты в виде специальных диаграмм, например, «деревья ошибок».
Алгоритм анализа ошибок условно состоит из четырёх этапов и выглядит таким образом:
На первом этапе программный агент собирает данные о работе программного обеспечения, о состоянии операционной системы и потреблении аппаратных ресурсов. Позже собранные данные передаются подсистеме локального анализа ошибок. Результатом анализа является заключение о соответствии данных потенциальной ошибке.[3]
На втором этапе, при положительном решении, программный агент формирует заявку на обслуживание, включает в неё информацию о рабочей станции, программном обеспечении, вызвавшем ошибку и перечень программных протоколов, которые соответствуют ошибке. После этого, центральная подсистема анализа ошибок производит поиск аналогов ошибки в базе прецедентов. Если прецедент будет обнаружен, то агенту передаётся указание на выполнение действия, которое ассоциировано с прецедентом. Если прецедент не будет обнаружен, то агенту будет передано указание на запрос от пользователя дополнительной информации. Дополнительная информация от пользователя собирается программным агентом и передаётся подсистеме анализа текстов отчётов.[3]
Третий этап представляет собой передачу консолидированной информации, которая получается в результате анализа данных о рабочей станции, программном обеспечении, ошибке и отчёте пользователя, на рассмотрение администратора.[3]
На четвёртом этапе администратор либо принимает и утверждает, либо отклоняет полученную информацию. В первом случае администратор принимает решение по возникшей ошибке. На основе полученной информации и принятого решения формируется прецедент, сохраняющийся в базе знаний предприятия. При необходимости копия прецедента передаётся разработчику для возможности исправления возникшей ошибки.[3]
Такой алгоритм используется большинством компаний и нужен для удобства обработки информации, а также облегчения работы и занятости работников компании. За счёт того, что пользователям будет легче предоставить информацию компании, не нужно будет делать звонки и занимать лишнее время работников, ведь можно будет просто ввести данные на сайте предприятия, программа проверит их на наличие ошибок и сама направит работнику. В итоге такая система является уникальной и востребованной на сегодняшний день.
Исходя из всего вышесказанного можно сделать вывод, что выявление ошибок с помощью определённого алгоритма является достаточно эффективным способом, но требует много усилий и выполнения определённых требований и принципов его действия. Также можно сказать и то, что алгоритм анализа ошибок, представленный выше, является не совсем идеальным, но в то же время является стандартным для всех систем и, соответственно, эффективным.
Я думаю, что внедрение такой информационной системы, которая может выявлять ошибки, как пользовательские, так и текстовые ошибок, которые обычная программа не может выявить из-за сложности её классификации, будет достаточно эффективно при укреплении деятельности предприятия и его статуса, а также поможет быстрее разобраться во входящей информации.
Многие специалисты в этой области утверждают, что в корпоративных информационных системах разработка комплекса анализа ошибок достаточно сложна и не всем удаётся, но приносит хорошие результаты, поэтому они советуют внедрять подобные системы без колебаний, ведь этим можно снизить загрузку работников и вывести предприятие на новый уровень.
Также стоит добавить и то, что не всегда использование таких методов и алгоритмов позволяет эффективно пользоваться системой поиска и анализа ошибок, так как многие предприятия неверно их внедряют, не придерживаются определённых требований внедрения, условий и не выполняют принципы анализа ошибок и его разработки.
Список литературы
Верников, Г.Г. Корпоративные информационные системы: не повторяйте пройденных ошибок [Электронный ресурс] : URL : https://www.klerk.ru/soft/articles/3011/ (Дата обращения: 10.01.2021).
Кошкарова, А.А. Анализ корпоративных информационных систем / А. А. Кошкарова, А. Ж. Амиров, С. Н. Попов. — Текст : непосредственный // Молодой ученый. — 2016. — № 9 (113). — С. 63-66. — [Электронный ресурс] : URL : https://moluch.ru/archive/113/29461/ (Дата обращения: 10.01.2021).
Крайнов, А.Ю., Смагин, А. А. Разработка комплекса анализа ошибок в корпоративных информационных системах [Электронный ресурс] : URL : https://www.bestreferat.ru/referat-413488.html (Дата обращения: 10.01.2021).
Медведенко, С.А. Анализ корпоративных информационных систем [Электронный ресурс] : URL : https://revolution.allbest.ru/management/00480529_0.html (Дата обращения: 10.01.2021).
Федорова, Г.Н. Информационные системы, Учебник, Москва, Издательский центр «Академия», 2013.-199с.
Яковлев, В.П. Основы корпоративных информационных систем, учебное пособие, Санкт-Петербург, 2016. -84с.
Предупреждение,
обнаружение, исправление ошибок,
обеспечение устойчивости к ошибкам.
Тестирование, доказательство, контроль,
испытание, аттестация, отладка.
ПРОВЕРКА
ПРАВИЛЬНОСТИ ПРОГРАММ.
Программу
нельзя использовать до тех пор, пока не
будет уверенности в ее надежности.
Надежность — это свойство программы,
более строгое, чем корректность, поскольку
программа может быть корректной, но не
быть надежной. Программа является
корректной, если удовлетворяет внешним
спецификациям, т.е. выдает ожидаемые
ответы на определенные комбинации
значений входных данных. Программа
является надежной, если она корректна,
приемлемо реагирует на неточные входные
данные и удовлетворительно функционирует
в необычных условиях.
В
процессе создания программы программист
старается предвидеть все возможные
ситуации и написать программу так, чтобы
она реагировала на них вполне
удовлетворительно. Этап тестирования
является последней попыткой определить
надежность и корректность программы.
Проверка надежности включает в себя
просмотр проектной документации и
текста программы, анализ текста программы,
тестирование и, наконец, демонстрацию
заказчику того, что программа работает
надежно.
Все
принципы и методы разработки надежного
программного обеспечения можно разбить
на четыре группы:
1.
Предупреждение ошибок.
2.
Обнаружение ошибок.
3.
Исправление ошибок.
4.
Обеспечение устойчивости к ошибкам.
Предупреждение
ошибок.
К этой группе относятся принципы и
методы, цель которых — не допустить
появление ошибок в готовой программе.
Большинство методов концентрируется
на отдельных процессах перевода и
направлено на предупреждение ошибок в
этих процессах (упрощение программ,
достижение большей точности при переводе,
немедленное обнаружение и устранение
ошибок).
Обнаружение
ошибок.
Если предполагать, что в программном
обеспечении какие-то ошибки все же
будут, то лучшая стратегия в этом случае
— включить средства обнаружения ошибок
в само программное обеспечение.
Немедленное обнаружение имеет два
преимущества: можно минимизировать как
влияние ошибки, так и последующие
затруднения для человека, которому
придется извлекать информацию об этой
ошибке, находить ее место и исправлять.
Исправление
ошибок.
После того, как ошибка обнаружена, либо
она сама, либо ее последствия должны
быть исправлены программным обеспечением.
Некоторые устройства способны обнаружить
неисправные компоненты и перейти к
использованию резервных. Другой метод
— восстановление информации (например,
при сбое питания).
Устойчивость
к ошибкам.
Методы этой группы ставят своей целью
обеспечит функционирование программной
системы при наличии в ней ошибок. Они
разбиваются на три подгруппы: динамическая
избыточность (методы голосования,
резервных копий); методы отступления
(когда необходимо корректно закончить
работу — например, закрыть базу данных);
изоляция ошибок (основная идея — не дать
последствиям ошибки выйти за пределы
как можно меньшей части системы
программного обеспечения, так, чтобы
если ошибка возникнет, то не вся система
оказалась бы неработоспособной).
8.1.
Основные определения.
Тестирование
— процесс выполнения программы с
намерением найти ошибки. Если Ваша цель
— показать отсутствие ошибок, Вы их
найдете не слишком много. Если же Ваша
цель — показать наличие ошибок, Вы найдете
значительную их часть.
Доказательство
— попытка найти ошибки в программе
безотносительно к внешней для программы
среде. Большинство методов доказательства
предполагает формулировку утверждений
о поведении программы и затем вывод и
доказательство математических теорем
о правильности программы. Доказательства
могут рассматриваться как форма
тестирования, хотя они и не предполагают
прямого выполнения программы.
Контроль
— попытка найти ошибки, выполняя программу
в тестовой, или моделируемой, среде.
Испытание
— попытка найти ошибки, выполняя программу
в заданной реальной среде.
Аттестация
— авторитетное подтверждение правильности
программы. При тестировании с целью
аттестации выполняется сравнение с
некоторым заранее определенным
стандартом.
Отладка
— не является разновидностью тестирования.
Хотя слова «отладка» и «тестирование»
часто используются как синонимы, под
ними подразумеваются разные виды
деятельности. Тестирование — деятельность,
направленная на обнаружение ошибок;
отладка направлена на установление
точной природы известной ошибки, а затем
— на исправление этой ошибки. Эти два
вида деятельности связаны — результаты
тестирования являются исходными данными
для отладки.
Тестирование
модуля, или автономное тестирование —
контроль отдельного программного
модуля, обычно в изолированной среде.
Тестирование модуля иногда включает
также математическое доказательство.
Тестирование
сопряжений — контроль сопряжений между
частями системы (модулями, компонентами,
подсистемами).
Тестирование
внешних функций — контроль внешнего
поведения системы, определенного
внешними спецификациями.
Комплексное
тестирование — контроль и испытание
системы по отношению к исходным целям.
Комплексное тестирование является
процессом испытания, если выполняется
в среде реальной, жизненной.
Тестирование
приемлемости — проверка соответствия
программы требованиям пользователя.
Тестирование
настройки — проверка соответствия
каждого конкретного варианта установки
системы с целью выявить любые ошибки,
возникшие в процессе настройки системы.
8.2.
Базовые правила тестирования.
Обсудим
некоторые из важнейших аксиом тестирования.
они приведены в настоящем разделе и
являются фундаментальными принципами
тестирования.
Хорош
тот тест, для которого высока вероятность
обнаружить ошибку, а не тот, который
демонстрирует правильную работу
программы. Поскольку невозможно показать,
что программа не имеет ошибок и, значит,
все такие попытки бесплодны, процесс
тестирования должен представлять собой
попытки обнаружить а программе прежде
не найденные ошибки.
Одна
из самых сложных проблем при тестировании
— решить, когда нужно закончить. Как уже
говорилось, исчерпывающее тестирование
(т.е. испытание всех входных значений)
невозможно. Таким образом, при тестировании
мы сталкиваемся с экономической
проблемой: как выбрать конечное число
тестов, которое дает максимальную отдачу
(вероятность обнаружения ошибок) для
данных затрат. Известно слишком много
случаев, когда написанные тесты имели
крайне малую вероятность обнаружения
новых ошибок, в то время как довольно
очевидные хорошие тесты оставались
незамеченными.
Невозможно
тестировать свою собственную программу.
Ни один программист не должен пытаться
тестировать свою собственную программу.
Тестирование должно быть в высшей
степени разрушительным процессом, но
имеются глубокие психологические
причины, по которым программист не может
относится к своей программе как
разрушитель.
Необходимая
часть всякого теста — описание ожидаемых
выходных данных или результатов. Одна
из самых распространенных ошибок при
тестировании состоит в том, что результаты
каждого теста не прогнозируются до его
выполнения. Ожидаемые результаты нужно
определять заранее, чтобы не возникла
ситуация, когда «глаз видит то, что
хочет увидеть». Чтобы совсем исключить
такую возможность, лучше разрабатывать
самопроверяющиеся тесты, либо пользоваться
инструментами тестирования, способными
автоматически сверять ожидаемые и
фактические результаты.
Избегайте
невоспроизводимых тестов, не тестируйте
«с лету». В условиях диалога
программист слишком часто выполняет
тестирование «с лету», т.е., сидя за
терминалом, задает конкретные значения
и выполняет программу, чтобы посмотреть,
что получится. Это -неряшливая и
нежелательная форма тестирования.
Основной ее недостаток в том, что такие
тесты мимолетны; они исчезают по окончании
их выполнения. Никогда не используйте
тестов, которые тут же выбрасываются.
Готовьте
тесты как для правильных, так и для
неправильных входных данных. Многие
программисты ориентируются в своих
тестах на «разумные» условия на
входе, забывая о последствиях появления
непредусмотренных или ошибочных входных
данных. Однако многие ошибки, которые
потом неожиданно обнаруживаются в
работающих программах, проявляются
вследствии никак не предусмотренных
действий пользователя программы. Тесты,
представляющие неожиданные или
неправильные входные данные, часто
лучше обнаруживают ошибки, чем «правильные»
тесты.
Детально
изучите результаты каждого теста. Самые
изощренные тесты ничего не стоят, если
их результаты удостаиваются лишь беглого
взгляда. Тестирование программы означает
большее, нежели выполнение достаточного
количества тестов; оно также предполагает
изучение результатов каждого теста.
По
мере того как число ошибок, обнаруженных
в некоторой компоненте программного
обеспечения увеличивается, растет также
относительная вероятность существования
в ней необнаруженных ошибок. Этот феномен
наблюдался во многих системах. Его
понимание способно повысить качество
тестирования, обеспечивая обратную
связь между результатами прогона тестов
и их проектированием. Если конкретная
часть системы окажется при тестировании
полной ошибок, для нее следует подготовить
дополнительные тесты.
Поручайте
тестирование самым способным программистам.
Тестирование, и в особенности проектирование
тестов, — этап в разработке программного
обеспечения, требующий особенно
творческого подхода. К сожалению, во
многих организациях на тестирование
смотрят совсем не так. Его часто считают
рутинной, нетворческой работой. Однако
практика показывает, что проектирование
тестов требует даже больше творчества,
чем разработка архитектуры и проектирование
программного обеспечения.
Считайте
тестируемость ключевой задачей Вашей
разработки. Хотя «тестируемость»
и не фигурировала явно в «проектных»
главах, сложность тестирования программы
напрямую зависит от ее структуры и
качества проектирования. Несмотря на
то, что эта связь осознана еще недостаточно
глубоко, можно утверждать, что многие
характеристики хорошего проекта
(например, небольшие, в значительной
степени независимые модули и независимые
подсистемы), улучшают и тестируемость
программы.
Никогда
не изменяйте программу, чтобы облегчить
ее тестируемость. Часто возникает
соблазн изменить программу, чтобы было
легче ее тестировать. Например,
программист, тестируя модуль, содержащий
цикл, который должен повторяться 100 раз,
меняет его так, чтобы цикл повторялся
только 10 раз.
8.3.
Отладка.
Рекомендуемый
подход к методам отладки аналогичен
особенностям проектирования и включает
в себя следующие этапы:
1.
Поймите задачу. Многие программисты
начинают процесс отладки бессистемно,
пропуская жизненно важный этап детального
анализа имеющихся данных. Первым делом
нужно тщательно исследовать, что в
программе выполнено правильно, а что —
неправильно, чтобы выработать одну или
несколько гипотез о природе ошибки.
Одна из самых распространенных причин
затруднений при отладке — не учтен
какой-нибудь существенный фактор в
выходных данных программы. Важно
исследовать данные в поисках противоречий
гипотезе (например, ошибка возникает
только в каждой второй записи), потому
что это поведет к уточнению гипотезы
или, возможно, покажет, что имеется не
одна причина ошибки.
2.
Разработайте план. Следующий шаг —
построить одну или несколько гипотез
об ошибке и разработать план проверки
этих гипотез.
3.
Выполните план. Следуя своему плану,
пытайтесь доказать гипотезу. Если план
включает несколько шагов, нужно проверить
каждый.
4.
Проверьте решение. Если кажется, что
точное местоположение ошибки обнаружено,
необходимо выполнить еще несколько
проверок, прежде чем пытаться исправить
ошибку. Проанализируйте, может ли
предполагаемая ошибка давать в точности
известные симптомы. Убедитесь, что
найденная причина полностью объясняет
все симптомы, а не только их часть.
Проверьте, не вызовет ли ее исправление
новой ошибки.
Главная
причина затруднений при отладке — такая
психологическая установка, когда разум
видит то, что он ожидает увидеть, а совсем
не то, что имеет место в действительности.
Один из способов преодоления такой
установки — скептицизм в отношении
всего, что Вы изучаете, в особенности
комментариев и документации. Опытные
специалисты по отладке, изучая модуль,
часто закрывают комментарии, поскольку
комментарии нередко описывают, что
программа делает, по мнению ее создателя.
Обратный просмотр (чтение программы в
обратном направлении) — еще один полезный
тактический прием, поскольку он помогает
по-новому взглянуть на алгоритм.
Еще
одна трудность при отладке — такое
состояние, когда все идеи зашли в тупик
и найти местоположение ошибки кажется
просто невозможно. Это означает, что Вы
либо смотрите не туда, куда нужно, и
следует еще раз изучить симптомы и
построить новую гипотезу, либо подозрения
правильные, но разум уже не способен
заметить ошибку. Если кажется, что именно
так и есть , то лучший принцип — «утро
вечера мудренее». Переключите внимание
на другую деятельность, и пусть над
задачей работает Ваше подсознание.
Многие программисты признают, что самые
трудные свои задачи они решают во время
бритья или по дороге на работу.
Когда
Вы найдете и проверите ошибку и убедитесь
в том, что нашли ее правильно, не забудьте
о том, что вероятность других ошибок в
этой части программы теперь выше. Изучите
программу в окрестности найденной
ошибки в поисках новых неприятностей.
Проверьте, не была ли сделана такая же
ошибка в других местах программы.
Исследования
методов отладки вначале концентрировались
на сравнении отладки в пакетном и
диалоговом режимах, причем большинство
исследований приходило к выводу, что
диалоговый режим предпочтительнее.
Однако более поздняя работа показала,
что, вероятно, наилучший способ отладки
— просто читать программу и изо всех сил
стараться вникнуть в алгоритм, хотя это
требует усердия и собранности.
Важно
подчеркнуть, что многие из методов
проектирования помогают и в процессе
отладки, такие методы, как структурное
программирование и хороший стиль
программирования не только уменьшают
исходное количество ошибок, но и облегчают
отладку, делая программу более простой
для понимания.
После
того, как точно установлено, где находится
ошибка, надо ее исправить. Самая большая
трудность на этом шаге — суметь охватить
проблему целиком; самая распространенная
неприятность — устранить только некоторые
симптомы ошибки. Избегайте «экспериментальных»
исправлений; они показывают, что Вы еще
недостаточно подготовлены к отладке
этой программы, поскольку не понимаете
ее.
В
деле исправления ошибок очень важно
понимать, что оно возвращает нас назад,
к стадии проектирования. Обидно, если
после завершения хорошо организованного
проектирования весь его строгий порядок
нарушается, когда вносятся поправки.
Исправления должны выполняться по
крайней мере так же строго, как
первоначальное выполнение программы.
Если необходимо, следует обновить
документацию, поправки должны проходить
сквозной структурный контроль или
другие формы контрольного чтения
программы. Ни одна поправка не «мала»
настолько, чтобы не нуждаться в
тестировании.
По
самой своей природе исправления всегда
имеют некоторое отрицательное влияние
на структуру программы и легкость ее
чтения. Тот факт, что они делаются в
условиях жесткого давления, усиливает
это влияние. Опыт показывает, что при
исправлении довольно высока вероятность
внесения в программу новой ошибки
(обычно от 20 до 50).
Из этого следует, что отладка должна
выполняться лучшими программистами
проекта.
Изучение
процесса отладки.
Один
из лучших способов повысить надежность
программного обеспечения в нынешних
или в будущих проектах — очевидный, но
часто упускаемый из виду процесс обучения
на сделанных ошибках. Каждую ошибку
следует внимательно изучить, чтобы
понять, почему она возникла и что должно
было бы сделано, чтобы ее предотвратить
или обнаружить раньше. Редко можно
встретить программиста или организацию,
которые выполняли бы такой полезный
анализ, а когда он проводится, то обычно
имеет поверхностный характер и сводится,
например, к классификации ошибок: ошибки
проектирования, логические ошибки,
ошибки сопряжения или другие, не имеющие
особого смысла категории.
Нужно
уделять время изучению природы каждой
обнаруженной ошибки. Необходимо
подчеркнуть, что анализ ошибок должен
быть в значительной мере качественным
и не сводиться просто к упражнению в
количественном подсчете. Чтобы понять
причины , лежащие в основе ошибок, и
усовершенствовать процессы проектирования
и тестирования, нужно ответить на
следующие вопросы:
1.
Почему возникла именно такая ошибка? В
ответе должны быть указаны как
первоисточник, так и непосредственный
источник ошибки. Например, ошибка могла
быть сделана при программировании
конкретного модуля, но в ее основе могла
лежать неоднозначность в спецификациях
или исправление другой ошибки.
2.
Как и когда ошибка была обнаружена?
Поскольку мы только что добились
значительного успеха, почему бы нам не
воспользоваться приобретенным опытом?
3.
Почему эта ошибка не была обнаружена
при проектировании, контроле или на
предыдущей фазе тестирования?
4.
Что следовало сделать при проектировании
или тестировании, чтобы предупредить
появление этой ошибки или обнаружить
ее раньше?
Собирать
эту информацию нужно не только для того,
чтобы учиться на ошибках. Официально
отчетность об ошибках и об их исправлении
необходима и для того, чтобы гарантировать,
что обнаруженные ошибки в работающих
или тестируемых системах не упущены и
что исправления выполнены в соответствии
с принятыми нормами.
Другой
способ обучения на ошибках в программном
обеспечении — учиться на опыте других
организаций. К сожалению, это не жизненный
вариант, поскольку даже в лучшие времена
научного книгоиздания, такие материалы
если и встречались то крайне редко.
Аннотация: Контроль по четности, CRC, алгоритм Хэмминга. Введение в коды Рида-Соломона: принципы, архитектура и реализация. Метод коррекции ошибок FEC (Forward Error Correction).
Каналы передачи данных ненадежны (шумы, наводки и т.д.), да и само оборудование обработки информации работает со сбоями. По этой причине важную роль приобретают механизмы детектирования ошибок. Ведь если ошибка обнаружена, можно осуществить повторную передачу данных и решить проблему. Если исходный код по своей длине равен полученному коду, обнаружить ошибку передачи не предоставляется возможным. Можно, конечно, передать код дважды и сравнить, но это уже двойная избыточность.
Простейшим способом обнаружения ошибок является контроль по четности. Обычно контролируется передача блока данных ( М бит). Этому блоку ставится в соответствие кодовое слово длиной N бит, причем N>M. Избыточность кода характеризуется величиной 1-M/N. Вероятность обнаружения ошибки определяется отношением M/N (чем меньше это отношение, тем выше вероятность обнаружения ошибки, но и выше избыточность).
При передаче информации она кодируется таким образом, чтобы с одной стороны характеризовать ее минимальным числом символов, а с другой – минимизировать вероятность ошибки при декодировании получателем. Для выбора типа кодирования важную роль играет так называемое расстояние Хэмминга.
Пусть А и Б — две двоичные кодовые последовательности равной длины. Расстояние Хэмминга между двумя этими кодовыми последовательностями равно числу символов, которыми они отличаются. Например, расстояние Хэмминга между кодами 00111 и 10101 равно 2.
Можно показать, что для детектирования ошибок в n битах схема кодирования требует применения кодовых слов с расстоянием Хэмминга не менее N + 1. Можно также показать, что для исправления ошибок в N битах необходима схема кодирования с расстоянием Хэмминга между кодами не менее 2N + 1. Таким образом, конструируя код, мы пытаемся обеспечить расстояние Хэмминга между возможными кодовыми последовательностями большее, чем оно может возникнуть из-за ошибок.
Широко распространены коды с одиночным битом четности. В этих кодах к каждым М бит добавляется 1 бит, значение которого определяется четностью (или нечетностью) суммы этих М бит. Так, например, для двухбитовых кодов 00, 01, 10, 11 кодами с контролем четности будут 000, 011, 101 и 110. Если в процессе передачи один бит будет передан неверно, четность кода из М+1 бита изменится.
Предположим, что частота ошибок ( BER – Bit Error Rate) равна р = 10-4. В этом случае вероятность передачи 8 бит с ошибкой составит 1 – (1 – p)8 = 7,9 х 10-4. Добавление бита четности позволяет детектировать любую ошибку в одном из переданных битах. Здесь вероятность ошибки в одном из 9 битов равна 9p(1 – p)8. Вероятность же реализации необнаруженной ошибки составит 1 – (1 – p)9 – 9p(1 – p)8 = 3,6 x 10-7. Таким образом, добавление бита четности уменьшает вероятность необнаруженной ошибки почти в 1000 раз. Использование одного бита четности типично для асинхронного метода передачи. В синхронных каналах чаще используется вычисление и передача битов четности как
для строк, так и для столбцов передаваемого массива данных. Такая схема позволяет не только регистрировать, но и исправлять ошибки в одном из битов переданного блока.
Контроль по четности достаточно эффективен для выявления одиночных и множественных ошибок в условиях, когда они являются независимыми. При возникновении ошибок в кластерах бит метод контроля четности неэффективен, и тогда предпочтительнее метод вычисления циклических сумм ( CRC — Cyclic Redundancy Check). В этом методе передаваемый кадр делится на специально подобранный образующий полином. Дополнение остатка от деления и является контрольной суммой.
В Ethernet вычисление CRC производится аппаратно. На
рис.
4.1 показан пример реализации аппаратного расчета CRC для образующего полинома R(x) = 1 + x2 + x3 + x5 + x7. В этой схеме входной код приходит слева.
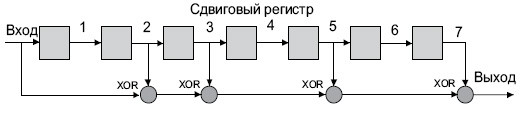
Рис.
4.1.
Схема реализации расчета CRC
Эффективность CRC для обнаружения ошибок на многие порядки выше простого контроля четности. В настоящее время стандартизовано несколько типов образующих полиномов. Для оценочных целей можно считать, что вероятность невыявления ошибки в случае использования CRC, если ошибка на самом деле имеет место, равна (1/2)r, где r — степень образующего полинома.
Таблица
4.1.
| CRC -12 | x12 + x11 + x3 + x2 + x1 + 1 |
| CRC -16 | x16 + x15 + x2 + 1 |
| CRC -CCITT | x16 + x12 + x5 + 1 |
4.1. Алгоритмы коррекции ошибок
Исправлять ошибки труднее, чем их детектировать или предотвращать. Процедура коррекции ошибок предполагает два совмещеных процесса: обнаружение ошибки и определение места (идентификации сообщения и позиции в сообщении). После решения этих двух задач исправление тривиально — надо инвертировать значение ошибочного бита. В наземных каналах связи, где вероятность ошибки невелика, обычно используется метод детектирования ошибок и повторной пересылки фрагмента, содержащего дефект. Для спутниковых каналов с типичными для них большими задержками системы коррекции ошибок становятся привлекательными. Здесь используют коды Хэмминга или коды свертки.
Код Хэмминга представляет собой блочный код, который позволяет выявить и исправить ошибочно переданный бит в пределах переданного блока. Обычно код Хэмминга характеризуется двумя целыми числами, например, (11,7), используемыми при передаче 7-битных ASCII-кодов. Такая запись говорит, что при передаче 7-битного кода используется 4 контрольных бита (7 + 4 = 11). При этом предполагается, что имела место ошибка в одном бите и что ошибка в двух или более битах существенно менее вероятна. С учетом этого исправление ошибки осуществляется с определенной вероятностью. Например, пусть возможны следующие правильные коды (все они, кроме первого и последнего, отстоят друг от друга на расстояние Хэмминга 4):
00000000
11110000
00001111
11111111
При получении кода 00000111 нетрудно предположить, что правильное значение полученного кода равно 00001111. Другие коды отстоят от полученного на большее расстояние Хэмминга.
Рассмотрим пример передачи кода буквы s = 0x073 = 1110011 с использованием кода Хэмминга (11,7). Таблица 4.2.
Таблица
4.2.
| Позиция бита | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Значение бита | 1 | 1 | 1 | * | 0 | 0 | 1 | * | 1 | * | * |
Символами * помечены четыре позиции, где должны размещаться контрольные биты. Эти позиции определяются целой степенью 2 (1, 2, 4, 8 и т.д.). Контрольная сумма формируется путем выполнения операции XoR (исключающее ИЛИ) над кодами позиций ненулевых битов. В данном случае это 11, 10, 9, 5 и 3. Вычислим контрольную сумму:
| 11= | 1011 |
| 10= | 1010 |
| 09= | 1001 |
| 05= | 0101 |
| 03= | 0011 |
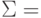 |
1110 |
Таким образом, приемник получит код
| Позиция бита | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Значение бита | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
Просуммируем снова коды позиций ненулевых битов и получим нуль;
| 11= | 1011 |
| 10= | 1010 |
| 09= | 1001 |
| 08= | 1000 |
| 05= | 0101 |
| 04= | 0100 |
| 03= | 0011 |
| 02= | 0010 |
|
0000 |
Ну а теперь рассмотрим два случая ошибок в одном из битов посылки, например в бите 7 (1 вместо 0) и в бите 5 (0 вместо 1). Просуммируем коды позиций ненулевых битов еще раз:
В обоих случаях контрольная сумма равна позиции бита, переданного с ошибкой. Теперь для исправления ошибки достаточно инвертировать бит, номер которого указан в контрольной сумме. Понятно, что если ошибка произойдет при передаче более чем одного бита, код Хэмминга при данной избыточности окажется бесполезен.
В общем случае код имеет N = M + C бит и предполагается, что не более чем один бит в коде может иметь ошибку. Тогда возможно N+1 состояние кода (правильное состояние и n ошибочных). Пусть М = 4, а N = 7, тогда слово-сообщение будет иметь вид: M4, M3, M2, C3, M1, C2, C1. Теперь попытаемся вычислить значения С1, С2, С3. Для этого используются уравнения, где все операции представляют собой сложение по модулю 2:
С1 = М1 + М2 + М4 С2 = М1 + М3 + М4 С3 = М2 + М3 + М4
Для определения того, доставлено ли сообщение без ошибок, вычисляем следующие выражения (сложение по модулю 2):
С11 = С1 + М4 + М2 + М1 С12 = С2 + М4 + М3 + М1 С13 = С3 + М4 + М3 + М2
Результат вычисления интерпретируется следующим образом:
Таблица
4.4.
| C11 | C12 | C13 | Значение |
|---|---|---|---|
| 1 | 2 | 4 | Позиция бит |
| 0 | 0 | 0 | Ошибок нет |
| 0 | 0 | 1 | Бит С3 неверен |
| 0 | 1 | 0 | Бит С2 неверен |
| 0 | 1 | 1 | Бит M3 неверен |
| 1 | 0 | 0 | Бит С1 неверен |
| 1 | 0 | 1 | Бит M2 неверен |
| 1 | 1 | 0 | Бит M1 неверен |
| 1 | 1 | 1 | Бит M4 неверен |
Описанная схема легко переносится на любое число n и М.
Число возможных кодовых комбинаций М помехоустойчивого кода делится на n классов, где N — число разрешенных кодов. Разделение на классы осуществляется так, чтобы в каждый класс вошел один разрешенный код и ближайшие к нему (по расстоянию Хэмминга ) запрещенные коды. В процессе приема данных определяется, к какому классу принадлежит пришедший код. Если код принят с ошибкой, он заменяется ближайшим разрешенным кодом. При этом предполагается, что кратность ошибки не более qm.
В теории кодирования существуют следующие оценки максимального числа N n -разрядных кодов с расстоянием D.
| d=1 | n=2n |
| d=2 | n=2n-1 |
| d=3 | N 2n/(1 + n) |
| d = 2q + 1 | (для кода Хэмминга это неравенство превращается в равенство) |
В случае кода Хэмминга первые k разрядов используются в качестве информационных, причем
K = n – log(n + 1), откуда следует (логарифм по основанию 2), что k может принимать значения 0, 1, 4, 11, 26, 57 и т.д., это и определяет соответствующие коды Хэмминга (3,1); (7,4); (15,11); (31,26); (63,57) и т.д.
Обобщением кодов Хэмминга являются циклические коды BCH (Bose-Chadhuri-hocquenghem). Эти коды имеют широкий выбор длин и возможностей исправления ошибок.
Одной из старейших схем коррекции ошибок является двух-и трехмерная позиционная схема (
рис.
4.2). Для каждого байта вычисляется бит четности (бит <Ч>, направление Х). Для каждого столбца также вычисляется бит четности (направление Y. Производится вычисление битов четности для комбинаций битов с координатами (X,Y) (направление Z, слои с 1 до N ). Если при транспортировке будет искажен один бит, он может быть найден и исправлен по неверным битам четности X и Y. Если же произошло две ошибки в одной из плоскостей, битов четности данной плоскости недостаточно. Здесь поможет плоскость битов четности N+1.
Таким образом, на 512 передаваемых байтов данных пересылается около 200 бит четности.
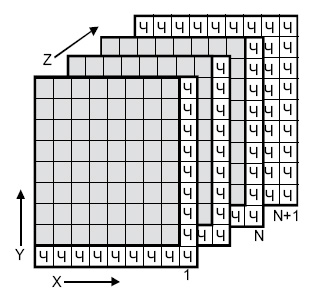
Рис.
4.2.
Позиционная схема коррекции ошибок
УДК 004.416:004.896
РАЗРАБОТКА КОМПЛЕКСА АНАЛИЗА ОШИБОК В КОРПОРАТИВНЫХ ИНФОРМАЦИОННЫХ СИСТЕМАХ
© 2013 А.Ю. Крайнов, А. А. Смагин
Ульяновский государственный университет
Поступила в редакцию 21.06.2013
В данной статье описана концепция системы анализа ошибок, возникающих в процессе функционирования корпоративных программных систем. Приведён анализ современных средств мониторинга работы информационных систем. Разработанная структура системы обеспечивает эффективное выполнение всех основных процессов, связанных с идентификацией и анализом ошибок ПО. Ключевые слова: предприятие, корпоративная информационная система, сопровождение программного обеспечения, анализ ошибок.
ВВЕДЕНИЕ
Сопровождение комплекса программных продуктов, функционирующих на отдельно взятом предприятии и составляющих его корпоративную информационную систему (КИС), — один из важнейших процессов управления его инфраструктурой. Неотъемлемой частью процесса сопровождения программного обеспечения (ПО) является сбор и консолидация данных об ошибках, возникающих в процессе его работы.
Источниками данных об ошибках могут быть как пользователи ПО, так и средства мониторинга вычислительных систем. В работе [1] для сопровождения ПО (в том числе для проведения мониторинга и организации обратной связи) был предложен подход на основе программных агентов. В работе [2] указанный подход был применён авторами при создании системы сбора и анализа протоколов, генерируемых ПО.
Целью настоящей работы является разработка концепции и структуры централизованной системы сбора и консолидации данных об ошибках в работе КИС.
1. СИСТЕМА АНАЛИЗА ПРОТОКОЛОВ
Разработанный макет системы анализа протоколов [2] включает программный агент, систему управления бизнес-правилами и базу прецедентов ошибок (рис. 1). В его функции входит:
— сбор программных протоколов;
— идентификация ошибок на основе последовательностей записей протокола;
Крайнов Александр Юрьевич, аспирант кафедры телекоммуникационных технологий и сетей. E-mail: kralyu@mail.ru
Смагин Алексей Аркадьевич, доктор технических наук, профессор, заведующий кафедрой телекоммуникационных технологий и сетей. E-mail: alsmagin@ulsu.ru
— поиск аналогов ошибок в базе прецедентов;
— управление обратной связью с пользователем.
Вместе с тем для создания полноценной системы сбора и анализа ошибок как части комплекса сопровождения программного обеспечения необходимо расширить функционал системы за счёт:
— расширения средств сбора сведений об ошибках;
— расширения адаптационных возможностей системы;
— включения функций обеспечения безопасности передаваемых данных;
— интеграции с корпоративной базой знаний.
2. РАСШИРЕНИЕ СРЕДСТВ СБОРА ДАННЫХ ОБ ОШИБКАХ
Сбор протоколов (англ. logcollection) представляет собой процесс исследования накопления и записей, сформированных программным продуктом, с цельюих последующего анализа и может быть двух видов:
— активный: средства сбора интегрированы с подсистемой протоколирования и, как следствие, могут работать в режиме реального времени;
— пассивный: средства сбора производят сканирование уже записанных протоколов через определённые интервалы времени.
Несмотря на эффективность активных средств анализа, их применение на практике затруднено из-за различий в языках программирования, использованных для разработки ПО. Для решения этой проблемы можно использовать специализированные средства сбора протоколов, такие как Apache Flume, Lilith, log.io или Log Expert.
Зачастую анализ протоколов не может выявить всех проблем в работе ПО. В этом случае можно воспользоваться средствами мониторинга процесса выполнения приложений.
Предметная область, занимающаяся исследованием возможностей и средств наблюдения за
Рис. 1. Структура системы анализа протоколов
выполнением приложений, называется управлением производительностью приложений (англ. Application performance management) [3]. Для сбора дополнительных данных о производительности программ в программной инженерии разработаны следующие методы:
1. Профилирование (англ. profiling). Это процесс сбора низкоуровневых характеристик выполняемой программы. Обычно применяется на стадии разработки ПО для выявления проблем в производительности. Существует два основных вида профилирования: (а) событийное — основанное на механизмах перехвата событий, встроенных в язык программирования; (б) статистическое — основанное на сканировании контекста выполнения программы через определённые интервалы времени.
2. Инструментирование (англ. instrumentation). Это процесс анализа производительности программы, происходящий благодаря внедрению в программный код специальных блоков, собирающих данные о процессе её выполнения.
3. Анализ процесса выполнения (англ. runtime intelligence). Это комплексный процесс исследования статистики использования пользователями одного или нескольких программных продуктов. Связан с областью бизнес-аналитики и, как правило, применяется в корпоративных системах.
Не все перечисленные методы могут быть применены при разработке агента системы сопровождения. При выборе подходящих средств должны быть выполнены следующие условия:
1. оригинальный программный продукт не должен быть изменён указанными средствами ни на этапе разработки, ни на этапе выполнения;
2. применение указанных средств не должно приводить к нестабильной работе продукта.
Применение указанных средств не должно приводить к существенному падению производи-
тельности рабочей станции.
Полезную информацию о причинах возникшей ошибки может дать также наблюдение за окружением нестабильно работающей программы, например, аппаратными ресурсами, сервисами операционной системы, загрузкой сети. Подобная информация может быть получена при использовании средств мониторинга сетевыхресур-сов (англ. network monitorin gsystems).
Данный класс систем предназначен, в первую очередь, для отслеживания статуса серверов и сетевого оборудования. Большинство систем данного класса поддерживают также мониторинг рабочих станций, включая наблюдение за использованием жёсткого диска, памяти, процессорного времени и т. д. Примерами подобным систем являются Cacti, Nagios, Pandora FMS, Zabbix, Zenoss.
Традиционными средствами сбора описаний ошибок и заявок на модификацию ПО от пользователей являются системы отслеживания ошибок (англ. Bug trackingsystems) [4]. Большинство подобных системы не выполняют каких-либо сложных бизнес-процессов, требующих высокой производительности и надёжности, а являются, фактически расширенными веб-интерфейсами к базам данных, хранящим информацию о запросах.
Как следствие, их функциональность практически одинакова; различия могут наблюдаться в следующем:
1. удобство пользовательского интерфейса;
2. перечень состояний (этапов обработки) запросов на модификацию;
3. перечень полей, описывающих запрос на модификацию;
4. перечень способов добавления запросов на модификацию.
Примерами подобных систем являются Bugzilla, Fossil, Mantis, Redmine, Trac.
3. ПОВЫШЕНИЕ АДАПТАЦИОННОЙ СПОСОБНОСТИ СИСТЕМЫ
На эффективность системы анализа ошибок, выражающуюся в сокращении трудозатрат её пользователей и снижении потребляемых аппаратных ресурсов (в первую очередь — пропускной способности сети передачи данных), влияет также возможность системы к адаптации под изменяющиеся условия рабочей среды.
Последовательности событий, приводящие к ошибкам, могут автоматически выявляться на основе методов ассоциации, широко применяющихся в настоящее время для анализа рыночной корзины (англ. marketbasketanalysis) [5, с. 281]. Автоматически созданные таким образом правила далее могут предоставляться пользователю для утверждения.
Полнота и детализированность данных, принимаемых системой анализа ошибок, сильно влияет на качество принимаемых ей решений. Очевидно, отслеживание записей только наивысшего уровня критичности («ERROR») не позволит в полной мере применить методы анализа цепочек событий. Включение наблюдения за наименее критичными записями («TRACE») сильно увеличит нагрузку на сеть. Решение этой проблемы заключается в создании «толстого клиента», когда программным агентом будет осуществляться предварительная фильтрация явно бесполезных записей протоколов.
Очевидно также, что это потребует внедрения средств сетевой синхронизации для поддержании в актуальном состоянии локальных баз знаний агентов. В качестве таких средств могут выступить системы управления конфигурацией (англ. configuration management software). Данный класс систем предназначен для автоматизированного управления настройками рабочих станций, серверов и прочих узлов локальной (как правило, корпоративной) сети. Подобные системы могут быть выполнены в 2-х вариантах:
1. клиент-серверном, где клиентская часть представляет собой агента, периодически обращающегося к серверу за информацией об обновлениях конфигурации;
2. децентрализованном, где каждый узел может выступать в виде источника конфигурации.
Большинство популярных систем управления конфигурацией являются кроссплатформен-ными. Примерами систем управления конфигурацией являются Chef, Opsi, Puppet, Smart Frog, Spacewalk.
Текстовые сообщения, поступившие через систему обратной связи программного агента или систему отслеживания ошибок, часто содержат важную информацию для идентификации и ана-
лиза ошибки. Вместе с тем автоматический анализ сообщений от пользователей, как правило, затруднён по следующим причинам:
1. пользователь может дать неправильное или неполное описание ошибки;
2. отчёты об ошибках, выраженные в текстовом виде, сложно классифицировать.
Первая проблема может частично решаться путём фиксации набора полей, которые должен заполнить пользователь, после чего проверять данные на достаточность и корректность.
Для решения второй проблемы могут применяться различные методы интеллектуального анализа текстов (англ. Textmining)[6], в частности, алгоритмы извлечения информации (англ. Information extraction). Применение подобных технологий, однако, требует проведения специальных исследований по предметной области. В то же время для анализа текстовых пояснений к событиям, автоматически сгенерированных программой-источником ошибки, можно использовать более простые подходы, например, извлечение фрагментов с помощью регулярных выражений.
4. ПОВЫШЕНИЕ БЕЗОПАСНОСТИ
Распределённый характер информационной системы предъявляет усиленные требования к обеспечению безопасности как системы в целом, так и отдельных её компонентов.
Данные, пересылаемые как внутри рабочей станции (при взаимодействии сокетов), так и по сетевым каналам (например, при отправке сообщений JMS), могут содержать конфиденциальные данные. Необходимо предусмотреть средства криптографической защиты этих данных, а также защиты компонентов системы (в первую очередь, программного агента) от перехвата управления.
Не менее важной задачей следует считать повышение стабильности работы программного агента и его взаимодействия с пользователем. Испытания макета показали, что неполнота описания предметной области приводит повышенной «чувствительностью» к новым ошибкам. Неосторожное создание пользовательских правил может существенно повредить эргономич-ности системы. Поэтому при создании действующего комплекса необходимо обеспечить предотвращение неадекватной реакции агента из-за неправильной или неполной конфигурации базы знаний путём разработки набора ограничений для создания пользовательских правил, а также предусмотреть возможности работы агента в автономном режиме, не требующим ответа пользователя.
5. РАЗРАБОТКА КОРПОРАТИВНОМ БАЗЫ ЗНАНИЙ
Часто ошибка в программном обеспечении связана с некоторыми особенностями предметной области или специфичностью взаимодействия участников процесса сопровождения. Разработка онтологии предметной области [7], создание централизованной корпоративной базы знаний и интеграция её, в частности, с системой анализа ошибок позволит повысить качество сопровождения ПО [8]. Общий интерфейс для базы знаний может быть реализован на базе Drools Guvnor или аналогичной системы.
Создание комплексной системы сопровождения (особенно основанной на знаниях) потребует проектирования эффективной системы пользовательского интерфейса и визуализации данных, что является одним из критериев качества современных систем бизнес-аналитики [5, с. 173].
Пользовательский интерфейс может также предоставлять инструменты для поддержки процесса поиска первичных ошибок (анализа первопричин — англ. root cause analysis), в том отображать результаты в виде специализированных диаграмм, таких как деревья ошибок (англ. faulttrees) и др.[9].
6. ОБЩАЯ СХЕМА КОМПЛЕКСА
Перечисленные выше средства можно представить в виде комплекса (рис. 2).
Ключевым компонентом системы является программный агент, устанавливаемый на каждой рабочей станции и взаимодействующий с пользователем. В его функции входят:
— обеспечение обратной связи пользователя с администратором (получение отчётов);
— выдача уведомлений об возникших ошибках и методах их устранения;
— мониторинг ПО (сбора протоколов, отслеживание процесса выполнения);
— мониторинг операционной системы и ресурсов рабочей станции;
— первичный (локальный) анализ ошибок.
Консолидация поступающих от программных
агентов данных выполняется централизованной системой анализа ошибок, управляемой администратором. Помимо сбора и анализа данных о выполнении ПО и текстовых отчётов пользователей, в её функции входит удалённое управление программными агентами.
Важным компонентом комплекса является подсистема интеграции с корпоративной базой знаний, которая позволяет накапливать информацию об ошибках и производить более тщательный их анализ и поиск первопричин. Накопленная информация может также передаваться разработчику ПО для устранения ошибок.
Обобщённый алгоритм анализа ошибки с помощью данного комплекса выглядит следующим образом:
1. Программный агент собирает данные о работе ПО, состоянии операционной системы и потреблении аппаратных ресурсов.
2. Через определённые промежутки времени собранные данные передаются подсистеме локального анализа ошибок. Результатом анализа является заключение о том, соответствуют ли данные потенциальной ошибке.
3. При положительном решении программный агент формирует заявку на обслуживание, в которую включает информацию о рабочей станции, вызвавшем ошибку ПО и перечень программных протоколов, соответствующих ошибке.
4. Центральная подсистема анализа ошибок производит поиск аналогов ошибки в базе прецедентов. При обнаружении прецедента агенту передаётся указание на выполнение действия, ассоциированного с прецедентом. Если прецедент не
Рис. 2. Структурная схема комплекса анализа ошибок на предприятии
был найден, агенту передаётся указание на запрос от пользователя дополнительной информации.
5. Дополнительная информация от пользователя собирается программным агентом и передаётся подсистеме анализа текстов отчётов.
6. Консолидированная информация, полученная в результате анализа данных о рабочей станции, ПО, ошибке и отчёте пользователя, передаётся на рассмотрение администратора.
7. Администратор либо утверждает, либо отклоняет полученную информацию. В первом случае администратор также принимает решение по возникшей ошибке.На основе полученной информации и принятого решения формируется прецедент, который сохраняется в базе знаний предприятия.
8. При необходимости копия прецедента передаётся разработчику для возможности исправления возникшей ошибки.
ЗАКЛЮЧЕНИЕ
Разработанная концепция системы анализа ошибок позволяет создать программный комплекс, обеспечивающий эффективное выполнение всех основных процессов, связанных с идентификацией и анализом ошибок, возникающих в процессе функционирования корпоративных программных систем.
Приоритетными направлениями при разработке комплекса анализа ошибок должны стать: использование специализированных средств сбора протоколов, повышение стабильности работы и повышение безопасности. Перспективными направлениями, требующими проведения дополнительных научных исследований, являются: автоматическая генерация правил, анализ текстов пользовательских протоколов и разработка корпоративной базы знаний.
Работа выполнена в рамках государственного задания Министерства образования и науки Российской Федерации.
СПИСОК ЛИТЕРАТУРЫ
1. Захаров В. Г., Крайнов А. Ю., Липатова С. В., Смагин А. А. Построение системы доставки обновлений программных продуктов // Учёные записки Ульяновского государственного университета. 2012. № 1 (4). С. 161-174.
2. Крайнов А. Ю., Смагин А. А. Автоматизация сбора протоколов в системе сопровождения программного обеспечения на основе обработки сложных событий // Автоматизация процессов управления. 2013. № 2 (32). [В печати].
3. Уайтхед Н. Мониторинг работы Java-приложений [Электронный ресурс] // IBM DeveloperWorks. 2009. URL: http://www.ibm.com/developerworks/ru/ library/j-rtm1/index.html (дата обращения 12.05.2013).
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
4. КолинА. Обзор систем отслеживания ошибок [Электронный ресурс] / / Центр Компетенций Atlassian. 2010. URL: http://www.teamlead.ru/x/ZwDx (дата обращения 12.05.2013).
5. Паклин Н., Орешков В. Бизнес-аналитика. От данных к знаниям. 2-е изд. Питер, 2013. 704 с.
6. Пескова О.В. Алгоритмы классификации полнотекстовых документов // Автоматическая обработка текстов на естественном языке и компьютерная Лингвистика. М.: МИЭМ, 2011. С. 170-212.
7. Куприянов А.А., Мельниченко А.С. Модели структуризации и формализации онтологии предметной области на стадиях проектирования автоматизированных систем // Автоматизация процессов управления. 2010. № 2 (20). С. 70-75.
8. Rodriguez O.M. et al. Using a Multi-agent Architecture to Manage Knowledge in the Software Maintenance Process // Knowledge-Based Intelligent Information Engineering Systems / Ed. by Negoita M.G., Howlett R.J., Jain L.C. Springer Berlin Heidelberg, 2004. P. 1181-1188.
9. Hari A.Yu. The Shortcomings of Existing Root Cause Analysis Tools // Proc. World Congr. Eng. 2012 / Ed. by S. I. Ao et al. UK: London: Newswood Limited, 2012. Vol. 3.
DEVELOPMENT OF THE BUG PROCESSING SYSTEM FOR ENTERPRISE INFORMATION SYSTEMS
© 2013 A.Yu. Krainov, A.A. Smagin
Ulyanovsk State University
The article presents the conception of the bug processing system for enterprise software. We have analyzed a range of modern tools for information systems operation monitoring. Developed system architecture provides an effective execution of all main processes of software bug detection and processing. Keywords: enterprise information system, software maintenance, bug processing.
Alexander Krainov, Graduate Student at the Telecommunication Systems and Networks Department. E-mail: kralyu@mail.ru Alexey Smagin, Doctor of Technics, Professor, Head at the Telecommunication Systems and Networks Department. E-mail: alsmagin@ulsu.ru
Подборка по базе: Практическая работа 9_ Кара «СТРУКТУРНО-ФУНКЦИОНАЛЬНАЯ ОРГАНИЗАЦ, ДИПЛОМНАЯ РАБОТА На тему_ Охрана труда «Законодательная и нормат, Введение в анализ больших данных 3 семестр.docx, Алгоритм оценки статистического анализа данных.doc, РАЗРАБОТКА И ПРИМЕНЕНИЕ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ДЛЯ СБОРА И АНА, ПЗ 4. Организация и нормативно-правовые основы архивного дела. П, практическая обработка эксперементальных данных.pdf, Рейтинговая работа.Территориальная организация населения.docx, тестовые-задания организация досуговой деятельности.doc, Тема 5. Организация психолого-педагогической и коррекционной пом
ОРГАНИЗАЦИЯ СБОРА ДАННЫХ ОБ ОШИБКАХ В ИНФОРМАЦИОННЫХ СИСТЕМАХ, ИСТОЧНИКИ СВЕДЕНИЙ
Система сбора данных (ССД) — комплекс средств, предназначенный для работы совместно сперсональным компьютером, либо специализированной ЭВМ и осуществляющий автоматизированный сбор информации о значениях физических параметров в заданных точках объекта исследования с аналоговых и/или цифровых источников сигнала, а также первичную обработку, накопление и передачу данных.
Совместно с персональной ЭВМ, оснащенной специализированным программным обеспечением, система сбора данных образует информационно-измерительную систему (ИИС). ИИС — это многоканальный измерительный прибор с широкими возможностями обработки и анализа данных.
По способу сопряжения с компьютером системы сбора данных можно разделить на:
- ССД на основе встраиваемых плат сбора данных со стандартным системным интерфейсом (наиболее распространен интерфейс PCI).
- ССД на основе модулей сбора данных с внешним интерфейсом (RS-232, RS-485, USB).
- ССД, выполненные в виде крейтов (магистрально-модульные ССД —КАМАК,VXI).
- группы цифровых измерительных приборов (ЦИП) или интеллектуальных датчиков. Для их организации применяются интерфейсы: GPIB (IEEE-488), 1wire,CAN,HART.
По способу получения информации ССД делятся на:
- сканирующие. Сканирующий принцип построения ССД используется там, где надо измерить поле распределения параметров: тепловизор, аппарат УЗИ, томограф.
- мультиплексные (мультиплексорные, иногда говорят «многоточечные»). Мультиплексная (мультиплексорная) ССД имеет на каждый измерительный канал индивидуальные средства аналоговой обработки сигнала и общий для всех каналов блок аналого-цифрового преобразования. Наибольшее распространение в настоящее время имеют именно мультиплексные системы сбора данных.
- параллельные. Параллельными системами сбора данных следует считать ССД на основе интеллектуальных датчиков (ИД).
- мультиплицированные. Этот тип ССД практически не используется в силу своего исключительно низкого быстродействия. Единственное достоинство ССД этого типа — относительная простота — полностью нивелируется современными технологиями изготовления интегральных схем.
Сбои информационных систем
Автоматизированным информационным системам могут угрожать случайные или умышленные сбои. Случайные сбои непреднамеренны, они могут быть вызваны либо ошибками, либо естественными причинами. Умышленные сбои являются результатом атаки, фальсификации, злоумышленного кодирования или взлома.
Ошибки. Проблемы с информационными системами чаще всего возникают из-за ошибок. Обычно ошибки делают люди, а не машины. В число таких ошибок входят:
1. Ошибки в процессе изготовления или при сборке технического оборудования: компоненты (в частности, механические составляющие, диски или принтеры) не соответствуют друг другу или неправильно собраны в процессе производства или в процессе текущего или профилактического обслуживания. 2. Ошибки при проектировании системы, обычно связанные с упущениями при анализе задачи.
- Ошибки ввода данных: опечатки, западание курсора или некорректный выбор, сделанный оператором.
- Ошибки программирования при разработке программного обеспечения на соответствующем языке программирования.
- Небрежность или обычная невнимательность со стороны людей, работающих с данной технологией.
Виды ошибок
Природные явления — это неожиданное насильственное нарушение работоспособности системы без вмешательства человека. Природные явления включают повреждения механических или электрических компонент и последствия стихийных бедствий: наводнений, гроз, землетрясений или торнадо. К отказам компонент системы относят не только компьютерные сбои, но и перебои электропитания или электрические помехи.
Атаки — это самый простой и частый вид умышленных угроз со стороны «чужих». Эти угрозы включают материальные повреждения компьютерного или телекоммуникационного оборудования, носителей, рабочих комнат, строений и вспомогательных устройств. Это также и физические атаки на компьютерные установки, такие как злоупотребления, подслушивание, взлом, заимствование прав.
Фальсификация — это наиболее распространенная умышленная угроза со стороны «своих». Эта угроза включает ввод ложной информации в систему, использование компьютерных технологий для создания неверных данных или замену исходной информации. Информационная система продолжает нормально работать, но цели ее работы изменены. Сама природа автоматизированных информационных систем часто допускает возможность проведения необычных транзакций, которые долгое время могут оставаться незамеченными.
Злоумышленное кодирование — это нелегальные программы и фрагменты программ, выполняемые на системных компьютерах. Эти программы могут перенаправлять компьютерные ресурсы, изменять данные или делать доступной секретную информацию. Поскольку такие программы невидимы для пользователей компьютера, то злоумышленное кодирование — это самый зловещий способ привлечь компьютер к собственному уничтожению. Вот различные типы злоумышленного кодирования:
- «логические бомбы» — выполняют деструктивные процедуры (например, уничтожение файлов, сбой в системе и т. д.) при определенных условиях (например, в пятницу 13-го);
- «троянский конь» — программа, замаскированная под другую программу, например, компьютерную игру; такая программа может незаметно копировать личные файлы игрока, пока он занят игрой;
- «вирус» — фрагмент кода, способный при активизации нелегально присоединяться к другим программам, найденным в компьютере; обычно вирусы содержат и «логическую бомбу»;
- «червяк» — это еще один вид самовоспроизводящейся программы, но она не присоединяется к другим программам, а сама распространяется по сетям или системным устройствам (например, используя электронную почту);
- «черный ход» — неавторизованные фрагменты кода, которые обходят систему защиты и другие стандартные процедуры (часто используются программистами при разработке программы и иногда случайно остаются в системе);
- «салями-коды» — программы, которые срезают «по кусочку» с каждой из транзакций и аккумулируют эти кусочки на счете похитителя;
- «мистификаторы» — программы, которые притворяются другими программами; например, фальсификатор входа в систему притворяется системной утилитой, а на самом деле копирует идентификаторы и пароли пользователей и записывает их в скрытый файл.
Взлом, или хакерство, — это проникновение в компьютерную систему или программу путем разгадывания или расшифровки кодов доступа, номеров счетов, паролей и файлов. Взломщики, проникают в защищенные системы и загружают нелегальные программы, разрушают файлы пользователя или закрывают доступ к ресурсам компьютера. При взломе систем хакеры часто прибегают к сканированию коммуникационных сетей и массивов данных. По отношению к системе взломщики совершают также следующие действия:
- Просмотр файлов и электронной почты или просмотр неиспользованной памяти и диска (часто система физически не удаляет информацию из областей памяти, уже освобожденных программами, а это значит, что фрагменты программ и данных могут быть восстановлены талантливыми хакерами).
- Компрометация баз данных, включая использование механизма запросов для получения или отслеживания ранее неизвестной информации об индивидууме.
- Получение неавторизованных или неоплачиваемых телефонных, или информационных услуг (часто со взломом телекоммуникационного оборудования). Умышленные угрозы имеют дополнительный параметр — мотив. Мотивы умышленных нарушений это мошенничество, шпионаж и вандализм.
Мошенничество — это использование информационных ресурсов путем умышленного обмана в целях получения незаконной прибыли. Поскольку большинство ценных товаров (деньги, ценные металлы, сырье) запрашиваются через компьютеры, то простое коммерческое мошенничество все чаще осуществляется путем компьютерных атак. Кроме незаконного использования информационных систем для перевода денежных средств распространены и другие виды мошенничества:
- Взлом банкоматов, заключающийся в использовании краденых или фальшивых банковских и кредитных карточек.
- Использование пиратского программного обеспечения, что включает подделку коммерческих пакетов программ и незаконное копирование программного обеспечения внутри или вне предприятия.
- Хищение ресурсов, т. е. использование информационных ресурсов организации в своих целях, что может включать использование компьютеров фирмы, копировальных автоматов, телефонов и незаконный обмен данными.
Шпионаж имеет целью получение информации, не подлежащей огласке. Шпионаж обычно включает три ступени: получение доступа к секретным данным, сбор данных и анализ данных. Конечным результатом шпионажа является неизбежное снижение информационной ценности данных. Ведь данные, которые пытаются украсть, обычно и считаются секретными именно из-за того, что они представляют ценность. Если данные публикуются или становятся известны конкурентам, то их ценность падает. Шпионажем может заниматься злоумышленник, получивший несанкционированный доступ к компьютерной системе путем мошенничества или взлома; предприятие, которое получает права авторизованного пользования компьютером, что позволяет получить доступ и к секретным данным в том числе; или другие лица, имеющие доступ к компьютерам.
Вандализм — это преднамеренное или злоумышленное повреждение компьютерных ресурсов, включая оборудование, данные и программное обеспечение.
Мотивы вандализма:
- Озорство юных программистов-взломщиков, пробующих свои силы в освоении компьютерных систем.
- Личная месть со стороны уволенных служащих или потребителей, желающих навредить фирме, разрушив ее информационную систему.
- Общественные беспорядки, бессмысленный вандализм как часть общественных волнений.
- Терроризм, экстремальное разрушение информационных систем социального масштаба организованными группами, преследующими политические или идеологические цели.
- Военные атаки; обычно они направлены на военные или имеющие к ним отношение промышленные компьютеры, могут включать чрезвычайно интенсивные нападения (например, диверсионные отряды), хакерство (например, суперкомпьютерный криптоанализ) и злоумышленное кодирование (например, «логические бомбы» в компьютере наведения ракет на цель).
Организация сбора данных об ошибках
Сопровождение комплекса программных продуктов, функционирующих на отдельно взятом предприятии и составляющих его корпоративную информационную систему (КИС), — один из важнейших процессов управления его инфраструктурой. Неотъемлемой частью процесса сопровождения программного обеспечения (ПО) является сбор и консолидация данных об ошибках, возникающих в процессе его работы.
Источниками данных об ошибках могут быть как пользователи ПО, так и средства мониторинга вычислительных систем.
Для сопровождения ПО (в том числе для проведения мониторинга и организации обратной связи) используются подход на основе программных агентов.
Система анализа протоколов
Разработанный макет системы анализа протоколов включает программный агент, систему управления бизнес-правилами и базу прецедентов ошибок (рис. 1). В его функции входит:
- сбор программных протоколов;
- идентификация ошибок на основе последовательностей записей протокола; поиск аналогов ошибок в базе прецедентов; управление обратной связью с пользователем.
Вместе с тем для создания полноценной системы сбора и анализа ошибок как части комплекса сопровождения программного обеспечения необходимо расширить функционал системы за счёт:
- расширения средств сбора сведений об ошибках;
- расширения адаптационных возможностей системы;
- включения функций обеспечения безопасности передаваемых данных; интеграции с корпоративной базой знаний.

Рис. 1 — Структура системы анализа протоколов
Расширение средств сбора данных об ошибках
Сбор протоколов (англ. logcollection) представляет собой процесс исследования накопления и записей, сформированных программным продуктом, с целью их последующего анализа и может быть двух видов:
- активный: средства сбора интегрированы с подсистемой протоколирования и, как следствие, могут работать в режиме реального времени;
- пассивный: средства сбора производят сканирование уже записанных протоколов через определённые интервалы времени.
Несмотря на эффективность активных средств анализа, их применение на практике затруднено из-за различий в языках программирования, использованных для разработки ПО. Для решения этой проблемы можно использовать специализированные средства сбора протоколов, такие как Apache Flume, Lilith, log.io или Log Expert.
Зачастую анализ протоколов не может выявить всех проблем в работе ПО. В этом случае можно воспользоваться средствами мониторинга процесса выполнения приложений.
Предметная область, занимающаяся исследованием возможностей и средств наблюдения за выполнением приложений, называется управлением производительностью приложений (англ. Application performance management). Для сбора дополнительных данных о производительности программ в программной инженерии разработаны следующие методы: 1. Профилирование. Это процесс сбора низкоуровневых характеристик выполняемой программы. Обычно применяется на стадии разработки ПО для выявления проблем в производительности. Существует два основных вида профилирования:
(а) событийное — основанное на механизмах перехвата событий, встроенных в язык программирования;
(б) статистическое — основанное на сканировании контекста выполнения программы через определённые интервалы времени.
2. Инструментирование. Это процесс анализа производительности программы, происходящий благодаря внедрению в программный код специальных блоков, собирающих данные о процессе её выполнения.
Анализ процесса выполнения — это комплексный процесс исследования статистики использования пользователями одного или нескольких программных продуктов. Связан с областью бизнес-аналитики и, как правило, применяется в корпоративных системах.
Не все перечисленные методы могут быть применены при разработке агента системы сопровождения. При выборе подходящих средств должны быть выполнены следующие условия:
- оригинальный программный продукт не должен быть изменён указанными средствами ни на этапе разработки, ни на этапе выполнения;
- применение указанных средств не должно приводить к нестабильной работе продукта.
Применение указанных средств не должно приводить к существенному падению производительности рабочей станции.
Полезную информацию о причинах возникшей ошибки может дать также наблюдение за окружением нестабильно работающей программы, например, аппаратными ресурсами, сервисами операционной системы, загрузкой сети. Подобная информация может быть получена при использовании средств мониторинга сетевых ресурсов.
Данный класс систем предназначен, в первую очередь, для отслеживания статуса серверов и сетевого оборудования. Большинство систем данного класса поддерживают также мониторинг рабочих станций, включая наблюдение за использованием жёсткого диска, памяти, процессорного времени и т. д. Примерами подобным систем являются Cacti, Nagios, Pandora FMS, Zabbix, Zenoss.
Традиционными средствами сбора описаний ошибок и заявок на модификацию ПО от пользователей являются системы отслеживания ошибок. Большинство подобных системы не выполняют каких-либо сложных бизнес-процессов, требующих высокой производительности и надёжности, а являются, фактически расширенными веб-интерфейсами к базам данных, хранящим информацию о запросах.
Как следствие, их функциональность практически одинакова; различия могут наблюдаться в следующем:
- удобство пользовательского интерфейса;
- перечень состояний (этапов обработки) запросов на модификацию; перечень полей, описывающих запрос на модификацию;
- перечень способов добавления запросов на модификацию.
Примерами подобных систем являются Bugzilla, Fossil, Mantis, Redmine, Trac.
Повышение адаптационной способности системы
На эффективность системы анализа ошибок, выражающуюся в сокращении трудозатрат её пользователей и снижении потребляемых аппаратных ресурсов (в первую очередь — пропускной способности сети передачи данных), влияет также возможность системы к адаптации под изменяющиеся условия рабочей среды.
Последовательности событий, приводящие к ошибкам, могут автоматически выявляться на основе методов ассоциации, широко применяющихся в настоящее время для анализа рыночной корзины. Автоматически созданные таким образом правила далее могут предоставляться пользователю для утверждения.
Полнота и детализированность данных, принимаемых системой анализа ошибок, сильно влияет на качество принимаемых ей решений. Очевидно, отслеживание записей только наивысшего уровня критичности (“ERROR”) не позволит в полной мере применить методы анализа цепочек событий. Включение наблюдения за наименее критичными записями (“TRACE”) сильно увеличит нагрузку на сеть. Решение этой проблемы заключается в создании “толстого клиента”, когда программным агентом будет осуществляться предварительная фильтрация явно бесполезных записей протоколов.
Очевидно также, что это потребует внедрения средств сетевой синхронизации для поддержания в актуальном состоянии локальных баз знаний агентов. В качестве таких средств могут выступить системы управления конфигурацией. Данный класс систем предназначен для автоматизированного управления настройками рабочих станций, серверов и прочих узлов локальной (как правило, корпоративной) сети. Подобные системы могут быть выполнены в 2х вариантах:
- клиент-серверном, где клиентская часть представляет собой агента, периодически обращающегося к серверу за информацией об обновлениях конфигурации;
- децентрализованном, где каждый узел может выступать в виде источника конфигурации.
Большинство популярных систем управления конфигурацией являются кроссплатформенными. Примерами систем управления конфигурацией являются Chef, Opsi, Puppet, Smart Frog, Spacewalk.
Текстовые сообщения, поступившие через систему обратной связи программного агента или систему отслеживания ошибок, часто содержат важную информацию для идентификации и анализа ошибки. Вместе с тем автоматический анализ сообщений от пользователей, как правило, затруднён по следующим причинам:
- пользователь может дать неправильное или неполное описание ошибки; отчёты об ошибках, выраженные в текстовом виде, сложно классифицировать.
Первая проблема может частично решаться путём фиксации набора полей, которые должен заполнить пользователь, после чего проверять данные на достаточность и корректность.
Для решения второй проблемы могут применяться различные методы интеллектуального анализа текстов, в частности, алгоритмы извлечения информации. Применение подобных технологий, однако, требует проведения специальных исследований по предметной области. В то же время для анализа текстовых пояснений к событиям, автоматически сгенерированных программой-источником ошибки, можно использовать более простые подходы, например, извлечение фрагментов с помощью регулярных выражений.
Создание комплексной системы сопровождения
Создание комплексной системы сопровождения потребует проектирования эффективной системы пользовательского интерфейса и визуализации данных. Перечисленные выше средства можно представить в виде комплекса (рис. 2).

Рис. 2 — Структурная схема комплекса анализа ошибок на предприятии Ключевым компонентом системы является программный агент, устанавливаемый на каждой рабочей станции и взаимодействующий с пользователем. В его функции входят: обеспечение обратной связи пользователя с администратором (получение отчётов);
- выдача уведомлений об возникших ошибках и методах их устранения;
- мониторинг ПО (сбора протоколов, отслеживание процесса выполнения); мониторинг операционной системы и ресурсов рабочей станции; первичный (локальный) анализ ошибок.
Консолидация поступающих от программных агентов данных выполняется централизованной системой анализа ошибок, управляемой администратором. Помимо сбора и анализа данных о выполнении ПО и текстовых отчётов пользователей, в её функции входит удалённое управление программными агентами.
Важным компонентом комплекса является подсистема интеграции с корпоративной базой знаний, которая позволяет накапливать информацию об ошибках и производить более тщательный их анализ и поиск первопричин. Накопленная информация может также передаваться разработчику ПО для устранения ошибок.
Обобщённый алгоритм анализа ошибки с помощью данного комплекса выглядит следующим образом:
- Программный агент собирает данные о работе ПО, состоянии операционной системы и потреблении аппаратных ресурсов.
- Через определённые промежутки времени собранные данные передаются подсистеме локального анализа ошибок. Результатом анализа является заключение о том, соответствуют ли данные потенциальной ошибке.
- При положительном решении программный агент формирует заявку на обслуживание, в которую включает информацию о рабочей станции, вызвавшем ошибку ПО и перечень программных протоколов, соответствующих ошибке.
- Центральная подсистема анализа ошибок производит поиск аналогов ошибки в базе прецедентов. При обнаружении прецедента агенту передаётся указание на выполнение действия, ассоциированного с прецедентом. Если прецедент не был найден, агенту передаётся указание на запрос от пользователя дополнительной информации.
- Дополнительная информация от пользователя собирается программным агентом и передаётся подсистеме анализа текстов отчётов.
- Консолидированная информация, полученная в результате анализа данных о рабочей станции, ПО, ошибке и отчёте пользователя, передаётся на рассмотрение администратора.
- Администратор либо утверждает, либо отклоняет полученную информацию. В первом случае администратор также принимает решение по возникшей ошибке. На основе полученной информации и принятого решения формируется прецедент, который сохраняется в базе знаний предприятия.
- При необходимости копия прецедента передаётся разработчику для возможности исправления возникшей ошибки.
Аннотация: Контроль по четности, CRC, алгоритм Хэмминга. Введение в коды Рида-Соломона: принципы, архитектура и реализация. Метод коррекции ошибок FEC (Forward Error Correction).
Каналы передачи данных ненадежны (шумы, наводки и т.д.), да и само оборудование обработки информации работает со сбоями. По этой причине важную роль приобретают механизмы детектирования ошибок. Ведь если ошибка обнаружена, можно осуществить повторную передачу данных и решить проблему. Если исходный код по своей длине равен полученному коду, обнаружить ошибку передачи не предоставляется возможным. Можно, конечно, передать код дважды и сравнить, но это уже двойная избыточность.
Простейшим способом обнаружения ошибок является контроль по четности. Обычно контролируется передача блока данных ( М бит). Этому блоку ставится в соответствие кодовое слово длиной N бит, причем N>M. Избыточность кода характеризуется величиной 1-M/N. Вероятность обнаружения ошибки определяется отношением M/N (чем меньше это отношение, тем выше вероятность обнаружения ошибки, но и выше избыточность).
При передаче информации она кодируется таким образом, чтобы с одной стороны характеризовать ее минимальным числом символов, а с другой – минимизировать вероятность ошибки при декодировании получателем. Для выбора типа кодирования важную роль играет так называемое расстояние Хэмминга.
Пусть А и Б — две двоичные кодовые последовательности равной длины. Расстояние Хэмминга между двумя этими кодовыми последовательностями равно числу символов, которыми они отличаются. Например, расстояние Хэмминга между кодами 00111 и 10101 равно 2.
Можно показать, что для детектирования ошибок в n битах схема кодирования требует применения кодовых слов с расстоянием Хэмминга не менее N + 1. Можно также показать, что для исправления ошибок в N битах необходима схема кодирования с расстоянием Хэмминга между кодами не менее 2N + 1. Таким образом, конструируя код, мы пытаемся обеспечить расстояние Хэмминга между возможными кодовыми последовательностями большее, чем оно может возникнуть из-за ошибок.
Широко распространены коды с одиночным битом четности. В этих кодах к каждым М бит добавляется 1 бит, значение которого определяется четностью (или нечетностью) суммы этих М бит. Так, например, для двухбитовых кодов 00, 01, 10, 11 кодами с контролем четности будут 000, 011, 101 и 110. Если в процессе передачи один бит будет передан неверно, четность кода из М+1 бита изменится.
Предположим, что частота ошибок ( BER – Bit Error Rate) равна р = 10-4. В этом случае вероятность передачи 8 бит с ошибкой составит 1 – (1 – p)8 = 7,9 х 10-4. Добавление бита четности позволяет детектировать любую ошибку в одном из переданных битах. Здесь вероятность ошибки в одном из 9 битов равна 9p(1 – p)8. Вероятность же реализации необнаруженной ошибки составит 1 – (1 – p)9 – 9p(1 – p)8 = 3,6 x 10-7. Таким образом, добавление бита четности уменьшает вероятность необнаруженной ошибки почти в 1000 раз. Использование одного бита четности типично для асинхронного метода передачи. В синхронных каналах чаще используется вычисление и передача битов четности как
для строк, так и для столбцов передаваемого массива данных. Такая схема позволяет не только регистрировать, но и исправлять ошибки в одном из битов переданного блока.
Контроль по четности достаточно эффективен для выявления одиночных и множественных ошибок в условиях, когда они являются независимыми. При возникновении ошибок в кластерах бит метод контроля четности неэффективен, и тогда предпочтительнее метод вычисления циклических сумм ( CRC — Cyclic Redundancy Check). В этом методе передаваемый кадр делится на специально подобранный образующий полином. Дополнение остатка от деления и является контрольной суммой.
В Ethernet вычисление CRC производится аппаратно. На
рис.
4.1 показан пример реализации аппаратного расчета CRC для образующего полинома R(x) = 1 + x2 + x3 + x5 + x7. В этой схеме входной код приходит слева.
Рис.
4.1.
Схема реализации расчета CRC
Эффективность CRC для обнаружения ошибок на многие порядки выше простого контроля четности. В настоящее время стандартизовано несколько типов образующих полиномов. Для оценочных целей можно считать, что вероятность невыявления ошибки в случае использования CRC, если ошибка на самом деле имеет место, равна (1/2)r, где r — степень образующего полинома.
| CRC -12 | x12 + x11 + x3 + x2 + x1 + 1 |
| CRC -16 | x16 + x15 + x2 + 1 |
| CRC -CCITT | x16 + x12 + x5 + 1 |
4.1. Алгоритмы коррекции ошибок
Исправлять ошибки труднее, чем их детектировать или предотвращать. Процедура коррекции ошибок предполагает два совмещеных процесса: обнаружение ошибки и определение места (идентификации сообщения и позиции в сообщении). После решения этих двух задач исправление тривиально — надо инвертировать значение ошибочного бита. В наземных каналах связи, где вероятность ошибки невелика, обычно используется метод детектирования ошибок и повторной пересылки фрагмента, содержащего дефект. Для спутниковых каналов с типичными для них большими задержками системы коррекции ошибок становятся привлекательными. Здесь используют коды Хэмминга или коды свертки.
Код Хэмминга представляет собой блочный код, который позволяет выявить и исправить ошибочно переданный бит в пределах переданного блока. Обычно код Хэмминга характеризуется двумя целыми числами, например, (11,7), используемыми при передаче 7-битных ASCII-кодов. Такая запись говорит, что при передаче 7-битного кода используется 4 контрольных бита (7 + 4 = 11). При этом предполагается, что имела место ошибка в одном бите и что ошибка в двух или более битах существенно менее вероятна. С учетом этого исправление ошибки осуществляется с определенной вероятностью. Например, пусть возможны следующие правильные коды (все они, кроме первого и последнего, отстоят друг от друга на расстояние Хэмминга 4):
00000000
11110000
00001111
11111111
При получении кода 00000111 нетрудно предположить, что правильное значение полученного кода равно 00001111. Другие коды отстоят от полученного на большее расстояние Хэмминга.
Рассмотрим пример передачи кода буквы s = 0x073 = 1110011 с использованием кода Хэмминга (11,7). Таблица 4.2.
| Позиция бита | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Значение бита | 1 | 1 | 1 | * | 0 | 0 | 1 | * | 1 | * | * |
Символами * помечены четыре позиции, где должны размещаться контрольные биты. Эти позиции определяются целой степенью 2 (1, 2, 4, 8 и т.д.). Контрольная сумма формируется путем выполнения операции XoR (исключающее ИЛИ) над кодами позиций ненулевых битов. В данном случае это 11, 10, 9, 5 и 3. Вычислим контрольную сумму:
| 11= | 1011 |
| 10= | 1010 |
| 09= | 1001 |
| 05= | 0101 |
| 03= | 0011 |
|
1110 |
Таким образом, приемник получит код
| Позиция бита | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Значение бита | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
Просуммируем снова коды позиций ненулевых битов и получим нуль;
| 11= | 1011 |
| 10= | 1010 |
| 09= | 1001 |
| 08= | 1000 |
| 05= | 0101 |
| 04= | 0100 |
| 03= | 0011 |
| 02= | 0010 |
|
0000 |
Ну а теперь рассмотрим два случая ошибок в одном из битов посылки, например в бите 7 (1 вместо 0) и в бите 5 (0 вместо 1). Просуммируем коды позиций ненулевых битов еще раз:
|
|
В обоих случаях контрольная сумма равна позиции бита, переданного с ошибкой. Теперь для исправления ошибки достаточно инвертировать бит, номер которого указан в контрольной сумме. Понятно, что если ошибка произойдет при передаче более чем одного бита, код Хэмминга при данной избыточности окажется бесполезен.
В общем случае код имеет N = M + C бит и предполагается, что не более чем один бит в коде может иметь ошибку. Тогда возможно N+1 состояние кода (правильное состояние и n ошибочных). Пусть М = 4, а N = 7, тогда слово-сообщение будет иметь вид: M4, M3, M2, C3, M1, C2, C1. Теперь попытаемся вычислить значения С1, С2, С3. Для этого используются уравнения, где все операции представляют собой сложение по модулю 2:
С1 = М1 + М2 + М4 С2 = М1 + М3 + М4 С3 = М2 + М3 + М4
Для определения того, доставлено ли сообщение без ошибок, вычисляем следующие выражения (сложение по модулю 2):
С11 = С1 + М4 + М2 + М1 С12 = С2 + М4 + М3 + М1 С13 = С3 + М4 + М3 + М2
Результат вычисления интерпретируется следующим образом:
| C11 | C12 | C13 | Значение |
|---|---|---|---|
| 1 | 2 | 4 | Позиция бит |
| 0 | 0 | 0 | Ошибок нет |
| 0 | 0 | 1 | Бит С3 неверен |
| 0 | 1 | 0 | Бит С2 неверен |
| 0 | 1 | 1 | Бит M3 неверен |
| 1 | 0 | 0 | Бит С1 неверен |
| 1 | 0 | 1 | Бит M2 неверен |
| 1 | 1 | 0 | Бит M1 неверен |
| 1 | 1 | 1 | Бит M4 неверен |
Описанная схема легко переносится на любое число n и М.
Число возможных кодовых комбинаций М помехоустойчивого кода делится на n классов, где N — число разрешенных кодов. Разделение на классы осуществляется так, чтобы в каждый класс вошел один разрешенный код и ближайшие к нему (по расстоянию Хэмминга ) запрещенные коды. В процессе приема данных определяется, к какому классу принадлежит пришедший код. Если код принят с ошибкой, он заменяется ближайшим разрешенным кодом. При этом предполагается, что кратность ошибки не более qm.
В теории кодирования существуют следующие оценки максимального числа N n -разрядных кодов с расстоянием D.
| d=1 | n=2n |
| d=2 | n=2n-1 |
| d=3 | N 2n/(1 + n) |
| d = 2q + 1 | (для кода Хэмминга это неравенство превращается в равенство) |
В случае кода Хэмминга первые k разрядов используются в качестве информационных, причем
K = n – log(n + 1), откуда следует (логарифм по основанию 2), что k может принимать значения 0, 1, 4, 11, 26, 57 и т.д., это и определяет соответствующие коды Хэмминга (3,1); (7,4); (15,11); (31,26); (63,57) и т.д.
Обобщением кодов Хэмминга являются циклические коды BCH (Bose-Chadhuri-hocquenghem). Эти коды имеют широкий выбор длин и возможностей исправления ошибок.
Одной из старейших схем коррекции ошибок является двух-и трехмерная позиционная схема (
рис.
4.2). Для каждого байта вычисляется бит четности (бит <Ч>, направление Х). Для каждого столбца также вычисляется бит четности (направление Y. Производится вычисление битов четности для комбинаций битов с координатами (X,Y) (направление Z, слои с 1 до N ). Если при транспортировке будет искажен один бит, он может быть найден и исправлен по неверным битам четности X и Y. Если же произошло две ошибки в одной из плоскостей, битов четности данной плоскости недостаточно. Здесь поможет плоскость битов четности N+1.
Таким образом, на 512 передаваемых байтов данных пересылается около 200 бит четности.
Рис.
4.2.
Позиционная схема коррекции ошибок