 Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решения этой проблемы не плохо подошла одна из моделей для проверки орфографии в тексте, хотя конечно слегка модифицированная под контекст задачи. Этот пост будет посвящен модели Noisy Channel, которая позволяет осуществлять автоматическую проверку орфографии, мы изучим математическую модель, напишем на c# немного кода, обучим модель на базе Питера Норвига, и под конец протестируем то что у нас получится.
Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решения этой проблемы не плохо подошла одна из моделей для проверки орфографии в тексте, хотя конечно слегка модифицированная под контекст задачи. Этот пост будет посвящен модели Noisy Channel, которая позволяет осуществлять автоматическую проверку орфографии, мы изучим математическую модель, напишем на c# немного кода, обучим модель на базе Питера Норвига, и под конец протестируем то что у нас получится.
Математическая модель — 1
Для начала постановка задачи. Итак вы хотите написать некоторое слово w состоящее из m букв, но каким то неведомым вам способом на бумаге выходит слово x состоящее из n букв. Кстати вы как раз и есть тот самый noisy channel, канал передачи информации с шумами, который исказил правильное слово w (из вселенной правильных слов) до не правильного x (множества всех написанных слов).

Мы хотим найти такое слово, которое вы наиболее вероятно подразумевали при написании слова x. Запишем эту мысль математически, модель по своей идее похожа на модель наивного байесовского классификатора, хотя даже проще:

- V — список всех слов естественного языка.
Далее используя теорему Байеса развернем причину и следствие, полную вероятность x мы можем убрать из знаменателя, т.к. он при argmax не зависит от w:

- P(w) — априорная вероятность слова w в языке; этот член представляет из себя статистическую модель естественного языка (language model), мы будем использовать модель unigram, хотя конечно вы в праве использовать и более сложные модели; так же заметим, что значение этого члена легко вычисляется из базы слов языка;
- P(x | w) — вероятность того, что правильное слово w было ошибочно написано как x, этот член называется channel model; в принципе обладая достаточно большой базой, которая содержит все способы ошибиться при написании каждого слова языка, то вычисление этого члена не вызвало бы трудностей, но к сожалению такой большой базы нет, но есть похожие базы меньшего размера, так что придется как то выкручиваться (например здесь находится база из 333333 слов английского языка, и только для 7481 есть слова с ошибками).
Вычисление значения вероятности P(x | w)
Тут к нам на помощь приходит расстояние Дамерау-Левенштейна — это мера между двумя последовательностями символов, определяемая как минимальное количество операций вставки, удаления, замены и перестановки соседних символов для приведения строки source к строке target. Мы же далее будем использовать расстояние Левенштейна, которое отличается тем, что не поддерживает операцию перестановки соседних символов, так будет проще. Оба эти алгоритма с примерами хорошо описаны в тут, так что я повторяться не буду, а сразу приведу код:
Расстояние Левенштейна
public static int LevenshteinDistance(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
d[i, j] = (new int[]
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
}).Min();
}
}
return d[s.Length, t.Length];
}
Эта функция сообщает нам сколько операций удаления, вставки и замены нужно произвести для приведения одного слова к другому, но нам этого не достаточно, а хотелось бы получить так же список этих самых операций, назовем это backtrace алгоритма. Нам необходим модифицировать приведенный код таким образом, что бы при вычислении матрицы расстояний d, так же записывалась матрица операций b. Рассмотрим пример для слов ca и abc:
Как вы помните, значение ячейки (i,j) в матрице расстояний d вычисляется следующим образом:
d[i, j] = (new int[]
{
d[i - 1, j] + 1, // del - 0
d[i, j - 1] + 1, // ins - 1
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub - 2
}).Min();
Нам остается в ячейку (i,j) матрицы операций b записывать индекс операции (0 для удаления, 1 для вставки и 2 для замены), соответственно этот кусок кода преобразуется следующим образом:
IList<int> vals = new List<int>()
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
};
d[i, j] = vals.Min();
int idx = vals.IndexOf(d[i, j]);
b[i, j] = idx;
Как только обе матрицы заполнены, не составит труда вычислить backtrace (стрелочки на картинках выше). Это путь из правой нижней ячейки матрицы операций, по пути наименьшей стоимости матрицы расстояний. Опишем алгоритм:
- обозначим правую нижнюю ячейку как текущую
- делаем одно из следующих действий
- если удаление, то записываем удаленный символ, и сдвигаем текущую ячейку вверх (красная стрелка)
- если вставка, то записываем вставленный символ и сдвигаем текущую ячейку влево (красная стрелка)
- если замена, а так же заменяемые символы не равны, то записываем заменяемые символы и сдвигаем текущую ячейку налево и вверх (красная стрелка)
- если замена, но заменяемые символы равны, то только сдвигаем текущую ячейку налево и вверх (синяя стрелка)
- если количество записанных операций не равно расстоянию Левенштейна, то на пункт назад, иначе стоп
В итоге получим следующую функцию, вычисляющую расстояние Левенштейна, а так же backtrace:
Расстояние Левенштейна с backtrace’ом
//del - 0, ins - 1, sub - 2
public static Tuple<int, IList<Tuple<int, string>>> LevenshteinDistanceWithBacktrace(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
int[,] b = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
b[0, j] = 1;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
IList<int> vals = new List<int>()
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
};
d[i, j] = vals.Min();
int idx = vals.IndexOf(d[i, j]);
b[i, j] = idx;
}
}
List<Tuple<int, string>> bt = new List<Tuple<int, string>>();
int x = s.Length;
int y = t.Length;
while (bt.Count != d[s.Length, t.Length])
{
switch (b[x, y])
{
case 0:
x--;
bt.Add(new Tuple<int, string>(0, s[x].ToString()));
break;
case 1:
y--;
bt.Add(new Tuple<int, string>(1, t[y].ToString()));
break;
case 2:
x--;
y--;
if (s[x] != t[y])
{
bt.Add(new Tuple<int, string>(2, s[x] + "" + t[y]));
}
break;
}
}
bt.Reverse();
return new Tuple<int, IList<Tuple<int, string>>>(d[s.Length, t.Length], bt);
}
Эта функция возвращает кортеж, в первом элементе которого записано расстояние Левенштейна, а во втором список пар <id операции, строка>, строка состоит из одного символа для операций удаления и вставки, и из двух символов для операции замены (подразумевается замена первого символа на второй).
PS: внимательный читатель заметит, что из правой нижней ячейки часто существует несколько способов движения по пути наименьшей стоимости, это один из способов увеличить выборку, но мы его для простоты так же опустим.
Математическая модель — 2
Теперь опишем полученный выше результат на языке формул. Для двух слов x и w мы можем вычислить список операций необходимых для приведений первого слова ко второму, обозначим список операции буквой f, тогда вероятность написать слово x как w будет равна вероятности произвести весь список ошибок f при условии, что мы писали именно x, а подразумевали w:

Вот тут начинаются упрощения, похожие на те что были в наивном байесовском классификаторе:
- порядок следования операций ошибки не имеет значения
- ошибка не будет зависеть от того какое слово мы написали и от того что подразумевали

Теперь для того что бы вычислить вероятности ошибок (независимо от того в каких словах они были сделаны) достаточно иметь на руках любую базу слов с их ошибочным написанием. Запишем финальную формулу, во избежание работы с числами близкими к нулю, будем работать в log space:

Итак, что же мы имеем? Если у нас на руках есть достаточный набор текстов мы можем вычислить априорные вероятности слов в языке; так же имея на руках базу слов с их ошибочным написанием, мы можем вычислить вероятности ошибок, этих двух баз достаточно что бы реализовать модель.
Размытие вероятностей ошибок
При пробеге по все базе слов при argmax, мы ни разу не наткнемся на слова с нулевой вероятностью. Но вот при вычислении операций редактирования для приведения слова x к слову w могут возникнуть такие операции, которые не встречались в нашей базе ошибок. В этом случае нам поможет additive smoothing или размытие по Лапласу (оно так же использовалось в наивном байесовском классификаторе). Напомню формулу, в контексте текущей задачи. Если некоторая операция коррекции f встречается в базе n раз, при том что всего ошибок в базе m, а типов коррекции t (например для замены, не то сколько раз встречается замена «a на b«, а сколько всего уникальных пар «* на *»), то размытая вероятность выглядит следующим образом, где k — коэффициент размытия:
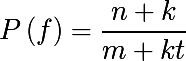
Тогда вероятность операции которая ни разу не встречалась в обучающей базе (n = 0) будет равна:
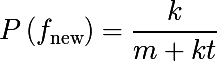
Скорость
Возникает естественный вопрос, а как быть со скоростью работы алгоритма, ведь нам придется пробегать по всей базе слов, а это сотни тысяч вызовов функции вычисления расстояния Левенштейна с backtrace’ом, а так же вычислять для всех слов вероятности ошибки (сумма чисел, если хранить в базе предвычисленные логарифмы). Тут приходит на помощь следующий статистический факт:
- 80% всех печатных ошибок находятся в пределах 1 операции редактирования, т.е. расстояния Левенштейна равным единице
- почти все печатные ошибки находятся в пределах 2 операций редактирования
Ну а далее вы можете придумывать различные алгоритмические трюки. Я использовал очевидный и очень простой способ ускорить работу алгоритма. Очевидно, что если мне требуются только слова не более чем в t операций редактирования от текущего слова, то их длина отличается от текущего не более чем на t. При инициализации класса, я создаю хэш-таблицу, в которой ключами является длины слов, а значениями — множества слов этой длины, это позволяет значительно сокращать пространство поиска.
Код
Приведу код класса NoisyChannel который у меня получился:
NoisyChannel
public class NoisyChannel
{
#region vars
private string[] _words = null;
private double[] _wLogPriors = null;
private IDictionary<int, IList<int>> _wordLengthDictionary = null; //length of word - word indices
private IDictionary<int, IDictionary<string, double>> _mistakeLogProbs = null;
private double _lf = 1d;
private IDictionary<int, int> _mNorms = null;
#endregion
#region ctor
public NoisyChannel(string[] words, long[] wordFrequency,
IDictionary<int, IDictionary<string, int>> mistakeFrequency,
int mistakeProbSmoothing = 1)
{
_words = words;
_wLogPriors = new double[_words.Length];
_wordLengthDictionary = new SortedDictionary<int, IList<int>>();
double wNorm = wordFrequency.Sum();
for (int i = 0; i < _words.Length; i++)
{
_wLogPriors[i] = Math.Log((wordFrequency[i] + 0d)/wNorm);
int wl = _words[i].Length;
if (!_wordLengthDictionary.ContainsKey(wl))
{
_wordLengthDictionary.Add(wl, new List<int>());
}
_wordLengthDictionary[wl].Add(i);
}
_lf = mistakeProbSmoothing;
_mistakeLogProbs = new Dictionary<int, IDictionary<string, double>>();
_mNorms = new Dictionary<int, int>();
foreach (int mType in mistakeFrequency.Keys)
{
int mNorm = mistakeFrequency[mType].Sum(m => m.Value);
_mNorms.Add(mType, mNorm);
int mUnique = mistakeFrequency[mType].Count;
_mistakeLogProbs.Add(mType, new Dictionary<string, double>());
foreach (string m in mistakeFrequency[mType].Keys)
{
_mistakeLogProbs[mType].Add(m,
Math.Log((mistakeFrequency[mType][m] + _lf)/
(mNorm + _lf*mUnique))
);
}
}
}
#endregion
#region correction
public IDictionary<string, double> GetCandidates(string s, int maxEditDistance = 2)
{
IDictionary<string, double> candidates = new Dictionary<string, double>();
IList<int> dists = new List<int>();
for (int i = s.Length - maxEditDistance; i <= s.Length + maxEditDistance; i++)
{
if (i >= 0)
{
dists.Add(i);
}
}
foreach (int dist in dists)
{
foreach (int tIdx in _wordLengthDictionary[dist])
{
string t = _words[tIdx];
Tuple<int, IList<Tuple<int, string>>> d = LevenshteinDistanceWithBacktrace(s, t);
if (d.Item1 > maxEditDistance)
{
continue;
}
double p = _wLogPriors[tIdx];
foreach (Tuple<int, string> m in d.Item2)
{
if (!_mistakeLogProbs[m.Item1].ContainsKey(m.Item2))
{
p += _lf/(_mNorms[m.Item1] + _lf*_mistakeLogProbs[m.Item1].Count);
}
else
{
p += _mistakeLogProbs[m.Item1][m.Item2];
}
}
candidates.Add(_words[tIdx], p);
}
}
candidates = candidates.OrderByDescending(c => c.Value).ToDictionary(c => c.Key, c => c.Value);
return candidates;
}
#endregion
#region static helper
//del - 0, ins - 1, sub - 2
public static Tuple<int, IList<Tuple<int, string>>> LevenshteinDistanceWithBacktrace(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
int[,] b = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
b[0, j] = 1;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
IList<int> vals = new List<int>()
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
};
d[i, j] = vals.Min();
int idx = vals.IndexOf(d[i, j]);
b[i, j] = idx;
}
}
List<Tuple<int, string>> bt = new List<Tuple<int, string>>();
int x = s.Length;
int y = t.Length;
while (bt.Count != d[s.Length, t.Length])
{
switch (b[x, y])
{
case 0:
x--;
bt.Add(new Tuple<int, string>(0, s[x].ToString()));
break;
case 1:
y--;
bt.Add(new Tuple<int, string>(1, t[y].ToString()));
break;
case 2:
x--;
y--;
if (s[x] != t[y])
{
bt.Add(new Tuple<int, string>(2, s[x] + "" + t[y]));
}
break;
}
}
bt.Reverse();
return new Tuple<int, IList<Tuple<int, string>>>(d[s.Length, t.Length], bt);
}
public static int LevenshteinDistance(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
d[i, j] = (new int[]
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
}).Min();
}
}
return d[s.Length, t.Length];
}
#endregion
}
Инициализируется класс следующими параметрами:
- string[] words — список слов языка;
- long[] wordFrequency — частота слов;
- IDictionary<int, IDictionary<string, int>> mistakeFrequency
- int mistakeProbSmoothing = 1 — коэффициент размытия частоты ошибок
Тестирование
Для тестирования используем базу Питера Норвига, в которой содержится 333333 слов с частотами, а также 7481 слово с ошибочными написаниями. Следующий код используется для вычисления значений необходимых для ининциализации класса NoisyChannel:
чтение базы
string[] words = null;
long[] wordFrequency = null;
#region read priors
if (!File.Exists("../../../Data/words.bin") || !File.Exists("../../../Data/wordFrequency.bin"))
{
IDictionary<string, long> wf = new Dictionary<string, long>();
Console.Write("Reading data:");
using (StreamReader sr = new StreamReader("../../../Data/count_1w.txt"))
{
string line = sr.ReadLine();
while (line != null)
{
string[] parts = line.Split('t');
wf.Add(parts[0].Trim(), Convert.ToInt64(parts[1]));
line = sr.ReadLine();
Console.Write(".");
}
sr.Close();
}
Console.WriteLine("Done!");
words = wf.Keys.ToArray();
wordFrequency = wf.Values.ToArray();
using (FileStream fs = File.Create("../../../Data/words.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
bf.Serialize(fs, words);
fs.Flush();
fs.Close();
}
using (FileStream fs = File.Create("../../../Data/wordFrequency.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
bf.Serialize(fs, wordFrequency);
fs.Flush();
fs.Close();
}
}
else
{
using (FileStream fs = File.OpenRead("../../../Data/words.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
words = bf.Deserialize(fs) as string[];
fs.Close();
}
using (FileStream fs = File.OpenRead("../../../Data/wordFrequency.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
wordFrequency = bf.Deserialize(fs) as long[];
fs.Close();
}
}
#endregion
//del - 0, ins - 1, sub - 2
IDictionary<int, IDictionary<string, int>> mistakeFrequency = new Dictionary<int, IDictionary<string, int>>();
#region read mistakes
IDictionary<string, IList<string>> misspelledWords = new SortedDictionary<string, IList<string>>();
using (StreamReader sr = new StreamReader("../../../Data/spell-errors.txt"))
{
string line = sr.ReadLine();
while (line != null)
{
string[] parts = line.Split(':');
string wt = parts[0].Trim();
misspelledWords.Add(wt, parts[1].Split(',').Select(w => w.Trim()).ToList());
line = sr.ReadLine();
}
sr.Close();
}
mistakeFrequency.Add(0, new Dictionary<string, int>());
mistakeFrequency.Add(1, new Dictionary<string, int>());
mistakeFrequency.Add(2, new Dictionary<string, int>());
foreach (string s in misspelledWords.Keys)
{
foreach (string t in misspelledWords[s])
{
var d = NoisyChannel.LevenshteinDistanceWithBacktrace(s, t);
foreach (Tuple<int, string> ml in d.Item2)
{
if (!mistakeFrequency[ml.Item1].ContainsKey(ml.Item2))
{
mistakeFrequency[ml.Item1].Add(ml.Item2, 0);
}
mistakeFrequency[ml.Item1][ml.Item2]++;
}
}
}
#endregion
Следующий код инициализирует модель и выполняет поиск правильных слов для слова «he;;o» (конечно подразумевается hello, точка-с-запятой находятся справа от l и легко было ошибиться при печати, в базе в списке ошибочных написания слова hello нет слова he;;o) на расстоянии не более 2, с засечением времени:
NoisyChannel nc = new NoisyChannel(words, wordFrequency, mistakeFrequency, 1);
Stopwatch timer = new Stopwatch();
timer.Start();
IDictionary<string, double> c = nc.GetCandidates("he;;o", 2);
timer.Stop();
TimeSpan ts = timer.Elapsed;
Console.WriteLine(ts.ToString());
У меня такое вычисление занимает в среднем чуть менее 1 секунды, хотя конечно процесс оптимизации не исчерпывается приведенными способами, а наоборот, только начинается с них. Взглянем на варианты замены и их вероятности:
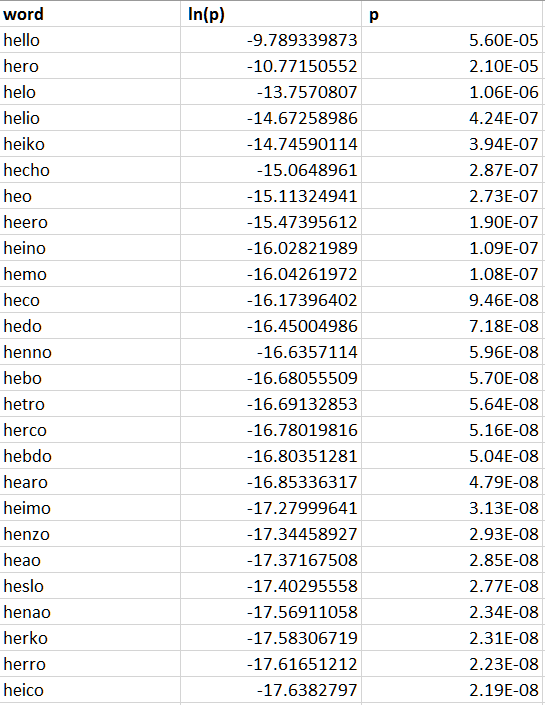
Ссылки
- курс Natural Language Processing на курсере
- Natural Language Corpus Data: Beautiful Data
- годное описание алгоритмов Левенштейна и Домерау-Левенштейна
Архив с кодом можно слить от сюда.
Такташкин Денис Витальевич1, Мокроусова Елена Александровна2
1Пензенский государственный университет, кандидат технических наук, доцент кафедры «МОиПЭВМ»
2Пензенский казачий институт технологий, (филиал) ФГБОУ ВО «Московский государственный университет технологий и управления имени К.Г. Разумовского, магистрант кафедры «ПиБИ»
Аннотация
В статье описаны алгоритмы проверки орфографии текстовых документов. Обосновывается актуальность использования специализированного программного обеспечения, с помощью которого проверяется орфография. Демонстрируется диаграмма вариантов использования, на которой показаны существующие методы и алгоритмы. Приводятся определения основных терминов предметной области.
Библиографическая ссылка на статью:
Такташкин Д.В., Мокроусова Е.А. Методы и алгоритмы проверки орфографии тестовых документов // Современные научные исследования и инновации. 2017. № 5 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2017/05/72892 (дата обращения: 23.01.2023).
Читая любой документ, мы невольно обращаем внимание на стиль изложения, легкость восприятия, содержательность и краткость повествования. Однако нередко мы сталкиваемся с опечатками и ошибками в документах. Они могут испортить все положительное впечатление об авторе, а порой и нанести серьезный урон авторитету автора.
Общаясь на родном языке, мы практически всегда можем заметить, что тексте автор ошибся. Кроме того, мы обычно можем догадаться, что он имел в виду на самом деле. Гораздо сложнее дело обстоит в тех случаях, когда мы общаемся с иностранцами. Допущенная ошибка или опечатка в написании слова, может значительно исказить смысл всего сообщения, и даже интуиция не сможет помочь получателю текста, поскольку язык общения для него не родной.
Для исправления набранного текста и были созданы программы проверки орфографии, синтаксиса, грамматических правил построения предложений, расстановки переносов и т.д. Первыми и наиболее активными пользователями подобных программ стали те, кто занимается созданием и редактированием текстов [1].
Впоследствии такие программы были встроены в популярные текстовые редакторы. Например, компания «Информатик» лицензировала свою технологию проверки правописания компании Microsoft для MS Office. Благодаря этому огромное число пользователей получили возможность автоматически исправлять тексты, не теряя свое время на длительную проверку текста [2].
Существует множество алгоритмов проверки орфографии текстовых документов. На рисунке 1 изображена диаграмма вариантов использования, которая показывает, какие существуют алгоритмы проверки.

Рисунок 1 – Диаграмма вариантов использования
Проверить орфографию можно двумя способами.
Первый способ это проверить орфографию со словарем.
Проверка со словарем делится на проверку через словарь всех слов и на проверку через словарь, который использует набор правил.
Проверка через словарь всех слов.
Словарем является файл в формате .txt, который содержит все слова русского языка, включая все склонения и спряжения слов. Слова расположены в алфавитном порядке, каждое слово находится на новой строке.
Проверка через словарь всех слов самый популярный метод обнаружения ошибок в тексте. Проверка осуществляется обычным поиском слова в словаре. Компьютер ищет слово в словаре так же как, если бы человек взял словарь в руки и искал нужное слово. Слова расположены в алфавитном порядке, поэтому компьютер может идти в нужное место в словаре и проверять слово. Если все буквы слова будут совпадать со словом в словаре, то оно является правильным. Если же такого слова нет, то оно является ошибкой или опечаткой.
В случае если слово отсутствует в словаре, например, фамилия, название или научный термин, относящийся к какой-либо предметной области, имеется возможность − добавить данное слово в словарь. После добавления слово не будет считаться ошибкой, так как в словаре будет полное совпадение букв.
Проверка орфографии, через словарь, который использует набор правил.
Словарь, который использует набор правил – это документ в формате .txt, который содержит все слова, кроме склонений и спряжений. С помощью правил русского языка, проверяются все слова на правильность написания.
Такой словарь надо организовать так, чтобы были указаны все правила русского языка. Главное надо учесть исключения из правил.
Метод проверки орфографии, который использует набор правил, так же называется методом сохранения пространства. Такой метод, экономя пространство хранения, удерживают в словаре только стебли слов. Например, вместо слов «сомнения», «сомневался», «сомневаясь», в словаре хранится только слово «сомневаюсь», используя правила русского языка удаляя окончания, суффиксы, приставки или добавляя их, слова будут меняться до слова находящегося в словаре.
Второй способ это проверка орфографии без помощи словаря, который включает в себя проверку на заглавную букву в начале предложения, проверка на повторы и проверка с помощью сограмм.
Проверка на заглавную букву, т.е. каждая буква после точки должна автоматически становиться заглавной.
Проверка на повторы показывает, что пользователь написал два одинаковых слова подряд. Проверяются на совпадения все буквы одного слова с буквами другого слова, если же они полностью совпадают, то это является ошибкой.
Сограммами называется фиксированное сочетание букв, которое в русском языке встречается, в разных словах на разных позициях.
Проверить орфографию с помощью сограмм можно двумя способами. Первый способ проверки через сограммы это проверять через уже существую таблицу сограмм. Метод использует словарь косвенно. Проверка начинается с перехода в словарь или таблицу всех сограмм. Вооружившись таблицей сограмм, программа проверки орфографии делит текст на сограмм и ищет их в таблице, если попадаются сограммы, которые никогда не имели место в словаре, слово, которое содержит эту сограмму, является опечаткой. Этот способ содержит таблицу, заполненную всеми сограммами. И при анализе текста, происходит поиск сограмм в таблице, если совпадения нет, то слово является опечаткой.
И способ анализа текста на похожие сограммы. Программа делит текст на сограммы, и сама создает таблицу из всех сограмм встречающихся в тексте, отметив как часто каждая сограмма встречается в тексте. Затем программа анализирует текст еще раз и выявляет индекс особенности каждого слова, потому на сколько сограмм разделено слово и сколько раз эти сограммы встречаются в тексте. После расчета индекса, программа обращает внимание пользователя на слова с высоким индексом особенности. Такой метод более подходит для выявления опечаток в тексте.
Существуют ошибки в режиме реального слова, к таким ошибкам в большинстве случаев относятся имена собственные и неизвестные слова. Частоту этих ложных ошибок можно уменьшить, имея большой словарь или специализированный словарь именно для этого текста. Так же избежать таких ошибок можно добавлением неизвестных слов и имен собственных в словарь, с помощью дополнительной функции «Добавить слово в словарь».
Существует множество методов и алгоритмов проверки орфографии текстовых документов. Каждый из них подходит для проверки текста, но они имеют недостатки. Для более точной проверки подходит метод, в котором нужно объединить несколько алгоритмов проверки орфографии.
Библиографический список
- Такташкин Д.В., Масенко И.А. Модель вариантов использования программы для писателей «Сюжет» // Современные научные исследования и инновации. 2016. № 3 [Электронный ресурс]. URL:http://web.snauka.ru/issues/2016/03/64882 (дата обращения: 28.05.2016)
- Поваляев Е. Системы проверки орфографии [Электронный ресурс] . URL:http://compress.ru/article.aspx?id=9511 (дата обращения: 05.11.2015).
Количество просмотров публикации: Please wait
Все статьи автора «Мокроусова Елена Алексанровна»
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
Орфография в последнее время стала менее востребованной и её важность значительно уменьшилась за счёт средств проверки орфографии, которые есть во многих программах по обработке текста.
Некоторые реформаторы образования считают, что учащиеся с помощью подобных программ будут развивать навыки правописания через чтение обработанных данными программами текстов.
Современные технологии являются мощнейшим инструментом, облегчающим процесс обучения. Некоторые утверждают, что он достаточно мощный, чтобы делать обучение написанию ненужным. В конце концов, для чего нужна проверка орфографии? Проверка орфографии — прекрасный инструмент для исправления мелких ошибок, которые допускают хорошие орфографы, и для типичных опечаток.
Если учащийся обладает достаточными языковыми знаниями, программа для проверки правописания значительно экономит время.
Программы для проверки орфографии встроены во многие популярные текстовые редакторы, например, компания «Информатик» лицензировала свою технологию проверки правописания компании Microsoft для MS Office.
Благодаря этому внедрению огромное число пользователей получили возможность автоматически исправлять тексты, не теряя свое время на длительную проверку текста [2]. В современном обществе это является одним из самых важных достоинств текстовых программ.
При написании различных текстов, таких как рефераты, научные статьи, курсовые работы, различного рода проекты, дипломные работы, юридические документы, заявления и другие тексты, часто требуется его проверка на наличие орфографических или пунктуационных ошибок. Эти программы созданы для того, чтобы не искать справочник по русскому языку и не занимать этим много времени, а также на случай если многие правила основательно забыты после окончания школы.
Особенно важно грамотное написание текстов юридической направленности, здесь каждая лишняя запятая может привести к длительным судебным тяжбам и многочисленным лингвистическим экспертизам.
Текстовый редактор Microsoft Word необходим для анализа представленного вами документа и предложения вам наиболее выгодным для вас условиям написания текста, таких как орфография, грамматика и стилистика, например, сделать предложения более краткими, выбрать более простые слова или написать более формально.
Для более эффективной работы по поиску и исправлению ошибок в редакторе есть дополнительные инструменты, которые мы рассмотрим на примере Word 2016. Однако интерфейс отчасти схож с предыдущими выпусками приложения.
По умолчанию, Word использует подчеркивание красной линией незнакомых ему слов, которые он считает за ошибку.
Для того, чтобы исправить неизвестное ему слово необходимо нажать правой клавишей мыши на подчеркнутое слово или области этого слова и приложение автоматически предложит варианты его исправления. Но в некоторых случаях бывает и так, что альтернативы подчёркнутого слова нет или предлагаемые программой варианты вам не подходят.
В большинстве случаев Word не знаком с названиями различных компаний и мест, фамилиями и некоторыми именами. Для того, чтобы в будущем при использовании подчёркнутых слов они не были не известны программе, необходимо добавить его в словарь, выбрав через контекстное меню опцию «Добавить в словарь» и слово не будет считаться за ошибку и запомнится программой на всё время. К тому же, если выбрать в контекстном меню пункт «Пропустить все» в текущем документе вы избавитесь от назойливых подчеркиваний.
Подобным образом работает и проверка грамматики в документе. Разница лишь в том, что цвет подчеркивания не красный, а синий. Ошибкой это является не всегда, часто это является мнение тектового редактора, которое основывается на встроенных в него правилах.
Настроить набор доступных грамматических правил, включить или отключить данную опцию можно через меню «Файл» – «Параметры» – вкладка «Правописание».
Для того, чтобы проверить все ошибки в документе последовательно необходимо перейти во вкладку под названием «Рецензирование» и нажать на кнопку «Правописание». После этого Word будет показывать вам ошибки последовательно и справа в документе откроется окно, в котором будут представлены варианты исправления ошибки и кнопки по управлению процедурой. Данная опция действительно в значимой степени экономит время при работе с большими документами, последовательно показывая вам ошибки в тексте, вместо того, чтобы вы самостоятельно выискивали каждое подчеркнутое редактором слово.
Также средство проверки правописания Word может помочь и в проверке пунктуации. Так, если в предложении есть или возможны пунктуационные ошибки, то оно будет подчёркнуто зелёным цветом. Причину «недовольства» Word можно узнать, нажав на контекстное меню. Причина отобразится на экране и сообщит пользователю о возможных проблемах с расставлением знаков препинаний.
Конечно, создание программы, обнаруживающей абсолютно все ошибки практически невозможно, ведь алгоритм, используемый для проверки русского языка достаточно сложен. Учитывая особенности употребления различных языковых конструкций в конкретных ситуациях, все многообразие форм и другие нюансы, можно сказать, что включение их в программу практически невозможно.
Одним из самых сложных задач, возложенных на программу является оценивание правильности расстановки запятых. Так, если проверяет человек, он может подойти к процессу творчески и чем лучше он знает базовые правила языка, тем быстрее и качественнее будет проверка. В том случае, если проверяет программа, некоторые ошибки ей могут просто игнорироваться, а некоторые, наоборот, без оснований выделяются. Подобные случаи происходят довольно таки часто.
Для подобных программ также важен набор включенных в них словарей. Так качество и быстрота проверки в основном зависит от количества слов в подключенных словарях. Например, многие программы не знакомыы с такими словами, как биткоины, блогер или файервол, несмотря на то, что они давно задействованы в русском языке.
Программы и системы для проверки правописания в документах, которые используются в огромном количестве современных текстовых редакторов, могут позволить выявление большей части допущенных опечаток и ошибок. Принципом действия таких систем является сдедующий: система для проверки правописания находит проверяемое слово во встроенном в неё словаре в нужной пользователю грамматической форме. В случае, если программа нашла слово, то оно будет считаться написанным по правилам, а если слово не было найдено программой во встроенном словаре, но есть похожие слова, то программа выдаёт сообщение об ошибке и предлагаются возможные варианты замены.
В случае, если программа не смогла найти ни это слово, ни похожие на него слова, то она предлагает либо исправить его, либо занести его в словарь.
Также проверка орфографии по словарю не выявляет случаи, в которых ошибка допущена так, что слово есть в словаре. Такие ошибки скрыты от программы, но человек их легко заметит. Примерами таких случаев можно считать следующие: 1. «Иван Петрович шлет Вам по клон». В данном случае нам сразу же видно где ошибка, здесь подразумевалось слово поклон. 2. «Я не нашел нежный файл». Здесь ошибка в слове «нежный» и сразу понятно, что необходимо было написать слово нужный. В обоих случаях программа не увидела ошибки, так как эти слова соответствовали словам в словаре, но не подходили по смыслу, что сразу видно человеку.
Но также существуют и программы, являющиеся более интеллектуальными, которые позволяют выявлять ошибки в согласовании форм слов и расстановке знаков препинания. Они хранят в себе набор специальных правил, которые записаны в формальном виде. Подобная система позволяет обратить внимание пользователя на подозрительные места, напрмер, в фразе про Ивана Петровича, она предположит, что слово «клон» употреблено не в том падеже или пропущено связующее слово между ним и предлогом «по». В любом из этих случаев, пользователь обратит внимание на выделенную ошибку и исправит её.
Подводя итог, мы можем сказать, что программы для проверки правописания обнаруживают достаточно много ошибок и опечаток и чем больше словарь программы, тем больше правил и алгоритмов для проверки текстов она знает, и, соответственно, процент обнаружения ей ошибок достаточно велик. Но любая система для проверки правописания не может гарантировать полное отсутствие ошибок и опечаток в тексте, а также абсолютной правильности построения смысловых цепочек.
В работе предложен метод и алгоритм проверки орфографии в научном тексте.
Список литературы
1.Алгазина, Н.Н. Методика изучения орфографических правил/- М.: Просвещение. 1982.- 48с.
2.Жиленко А.Г. Использование алгоритмов при изучении орфографии // РЯШ. — 1986. — N5. — С.53-55.
3.Методика развития речи / Под ред. Ладыженской Т. А. — М., 1991.,242 с.
4.Такташкин Д.В., Масенко И.А.. Модель вариантов использования программы для писателей «Сюжет» // Современные научные исследования и инновации 2016. № 3 [Электронный ресурс]. URL:http://web.sna.uka..ru/issues/2016/03/64882 (дата. обращения: 05.12.2020)
5.Поваляев Е. Системы проверки орфографии [Электронный ресурс] . URL:http://compress.ru/a.rticle.a.spx?id=9511 (дата обращения: 05.12.2020).
Во
время проверки орфографии Word просматривает
текст документа (или выделенную область)
и все слова сравнивает со словами,
содержащимися в нескольких встроенных
словарях. Если в тексте документа
содержится слово, отсутствующее в
словарях, Word помечает его как содержащее
орфографическую ошибку. Часто-густо
под такие слова попадают специфические
термины, фамилии людей, географические
названия и т.д. При желании такие слова
можно включать в словарь, при этом Word
будет их «запоминать» и в будущем
не будет помечать как ошибочные.
Существует
и обратная сторона медали. Word пропускает
слова, которые написаны правильно с
точки зрения орфографии, однако неверно
используются в контексте. Например,
«подоходный залог», вместо «подоходный
налог».
Функция
проверки орфографии выявляет и помечает
в документе одинаковые слова, следующие
одно за другим.
Проверка грамматики
Эта
функция проверяет текст на соответствие
грамматических и стилистических правил.
Проверка грамматических правил выявляет
такие ошибки, как неправильное
использование предлогов, согласование
слов в предложении и т.д.
Проверка
стилистики позволяет выявлять в документе
малоупотребительные, просторечные
слова и выражения.
По
большому счету не следует полностью
полагаться на возможности программы
по устранению ошибок, а по возможности,
делать проверку самому по окончании
набора текста документа.
Автоматическая проверка правописания
При
наборе текста Word подчеркивает красной
волнистой линией слова, содержащие
орфографические ошибки, и зеленой линией
— грамматические и стилистические
ошибки.
Чтобы
исправить орфографическую ошибку надо
щелкнуть правой кнопкой мыши на
подчеркнутом слове. При этом на экране
будет отображено контекстное меню.
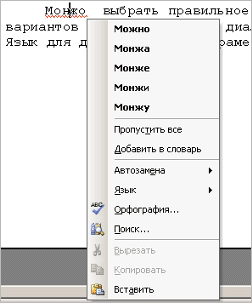
Можно
выбрать правильное написание из числа
предлагаемых вариантов или открыть
окно диалога «Орфография…»,
Автозамена или Язык для дополнительных
параметров соответствующих функций.
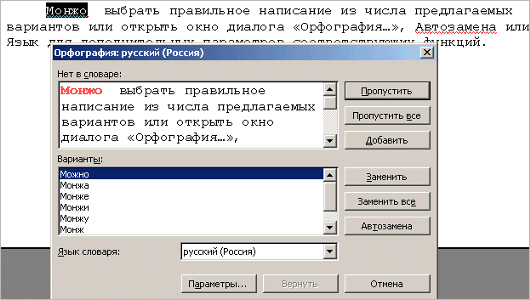
В
поле «Нет в словаре» отображается
фрагмент текста, содержащий слово с
ошибкой, а в поле «Варианты» — список
вариантов замены. Ошибку можно
отредактировать прямо в поле «Нет в
словаре» или выбрать один из предлагаемых
вариантов замены. После завершения
обработки текущей ошибки Word возобновляет
поиск и отображение следующей ошибки.
Кнопка
«Пропустить все» используется для
пропуска текущей ошибки и всех последующих
ее включений. Кнопка «Заменить»
позволяет заменить ошибку выбранным
вариантом замены или принять исправления,
выполненные в поле «Нет в словаре».
Кнопка
«Заменить все» позволяет заменить
все включения ошибочного слова выбранным
вариантом замены. При сброшенном флажке
«Грамматика» Word не производит
проверку текста на наличие грамматических
ошибок. Это позволяет сосредоточиться
исключительно на проверке орфографии.
Кнопка
«Параметры» обеспечивает доступ
к параметрам проверки правописания.
Кнопка
«Вернуть» отменяет последнее
выполненное исправление.
При
обнаружении в тексте документа
грамматической ли стилистической ошибки
Word отображает в окне диалога «Грамматика…»
следующее окно.
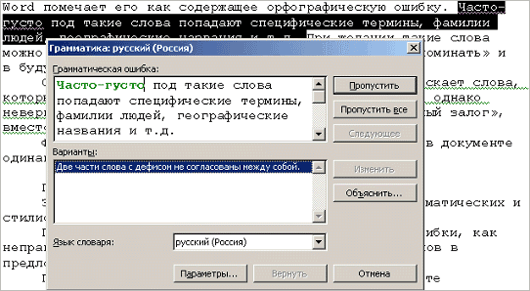
В
поле «Варианты» отображается
описание фрагмента, содержащего
грамматическую ошибку.
Как
и при исправлении орфографических
ошибок, при проверке грамматики можно
править текст непосредственно в поле
с ошибочным фрагментом или использовать
один из вариантов замены.
-
Кнопка
«Пропустить все» используется для
пропуска всех встречающихся в тексте
подобных ошибок. -
Кнопка
«Следующее» позволяет пропустить
текущую ошибку и перейти к следующему
проблемному фрагменту. -
Кнопка
«Объяснить» предлагает общие
рекомендации относительно устранения
грамматических ошибок подобного рода.
Надпись в
документе Word можно рассматривать как
контейнер, в котором размещаются
вложенные документы. Над всеми объектами,
находящимися в таком контейнере, можно
выполнять совместные операции: удаление,
перемещение, копирование и др.
Для
создания надписи в документе Word
выполняется команда Надпись меню
Вставка.
Положение
надписи в документе можно настраивать,
выделив ее и выбрав в контекстном меню,
вызванном на границе надписи, опцию
Формат надписи. Появляющееся диалоговое
окно содержит несколько вкладок, с
помощью которых можно изменять размер,
положение надписи относительно текста,
цветовое оформление надписи и др.
Страницы
документов Word могут содержать верхние
и нижние колонтитулы —
области, располагающиеся в верхней и
нижней части каждой страницы и содержащие
определенный текст. Простейший колонтитул
состоит из номера страницы. Однако в
него также может быть включена любая
информация, отражающаяся в верхней или
нижней части страницы. Создание
колонтитулов выполняется с помощью
команды Колонтитулы меню Вид.
При
выполнении этой команды на экран
выводится панель инструментов Колонтитулы,
кнопки которой позволяют создать и
отредактировать колонтитулы.
Области
верхнего и нижнего колонтитулов обычно
располагаются от левого до правого поля
страницы по горизонтали, а по вертикали
их положение определяется размерами
верхнего и нижнего поля и расстоянием
от края страницы до колонтитула, заданными
в окне диалога Параметры страницы. Если
вставленные в колонтитул данные требуют
больше места, то Word увеличивает размер
соответствующего поля страницы, чтобы
расширить область колонтитула. При этом
элементы колонтитула не накладываются
на основной текст. Однако часть колонтитула
можно расположить и за пределами области
колонтитулов. Для этого применяются
следующие приемы:
-
чтобы
изменить положение верхней или нижней
границы колонтитула, следует перетащить
маркер на вертикальной линейке. Кроме
того, можно отрегулировать положение
области колонтитула на вкладке Поля
окна диалога Параметры страницы; -
чтобы
сдвинуть текст колонтитула влево или
вправо от полей, следует задать для
одного или нескольких абзацев
колонтитулов отрицательное значение
левого или правого отступа. Для этого
используется горизонтальная линейка
или окно диалога Абзац; -
текст
колонтитула можно частично или полностью
вставить в надпись Word и перетащить его
в любое место страницы. Несмотря на
это, полученный кадр продолжает
оставаться частью колонтитула, поэтому
изменить его можно только выполнением
команды Колонтитулы меню Вид.
Обычно
на каждой странице документа выводится
один и тот же колонтитул. Тем не менее
существует несколько способов добиться
отображения в документе различных
колонтитулов. Прежде всего, можно создать
отличающийся колонтитул для первой
страницы документа или раздела. Можно
задавать разные колонтитулы для четных
и нечетных страниц документа. Указанные
действия задаются установкой
соответствующих флажков на вкладке
Макет диалогового окна Параметры
страницы меню Файл. Следует заметить,
что отличающийся колонтитул первой
страницы устанавливается для отдельного
раздела документа, но различия между
колонтитулами четных и нечетных страниц
устанавливаются для всего документа.
Наконец, если документ разбит на разделы,
их колонтитулы могут иметь разное
содержание. Изначально колонтитулы
каждого следующего раздела соединяются
с колонтитулами предыдущего раздела,
т. е. выглядят точно так же.
К
документу Word можно добавить оглавление,
в котором будут перечислены все заголовки
и номера страниц, на которых они находится.
Для создания оглавления следует выполнить
следующие действия:
-
убедиться
в том, что каждому заголовку, включаемому
в оглавление, назначен стиль. Проще
всего воспользоваться встроенными
стилями Заголовок 1 — Заголовок 9, -
установить
курсор в том месте документа, где будет
вставлено оглавление; -
выполнить
команду Оглавление и указатели меню
Вставка; -
выбрать
вкладку Оглавление; -
если
требуется вместо встроенных стилей
заголовков воспользоваться другими,
нажать кнопку Параметры, чтобы открыть
окно диалога Параметры оглавления. В
этом окне можно выбрать стили, включаемые
в оглавление, и связать с ними определенные
уровни в оглавлении; -
для
изменения внешнего вида оглавления
подбирать значения параметров до тех
пор, пока примерный вид оглавления в
поле Образец не будет соответствовать
желаемому. Можно задать формат оглавления,
способ выравнивания номеров страниц,
число уровней и символ-заполнитель.
Также можно разрешить или запретить
показ номеров страниц.
Определенные
места в документе могут быть помечены
для быстрого возврата к ним в дальнейшем.
Чтобы пометить какое-либо место документа,
надо создать закладку. Создание закладки
осуществляется с помощью команды
Закладка меню Вставка. В диалоговом
окне команды следует ввести имя
создаваемой закладки. Этот способ может
применяться для пометки любого количества
мест в документе. Закладки можно сделать
видимыми, выполнив команду Параметры
меню Сервис и установив на вкладке Вид
флажок Закладки.
Чтобы
быстро переместить курсор в место,
помеченное закладкой, следует выполнить
команду Закладка меню Вставка или нажать
комбинацию клавиш Ctrl+Shift+F5, в открывшемся
диалоговом окне Закладка выбрать ее
имя, присвоенное при пометке текста, и
нажать кнопку Церейти. Word переместит
курсор в помеченную позицию. К аналогичному
результату приведет выполнение команды
Перейти меню Правка. В диалоговом окне
команды в списке Объект перехода следует
выбрать Закладка.
Пакет
MS Office. Текстовый редактор Word. Функции
поиска и замены символов. Поиск и замена
специальных символов (непечатных).
Автозамена при вводе. Пользовательские
настройки автозамены вводимых символов.
При
создании новых документов могут также
использоваться специальные шаблоны —
мастера, обеспечивающие настройку
создаваемых документов в процессе
диалога с пользователем.
В
текстовом процессоре Word существуют три
способа быстрой вставки часто используемой
текстовой или графической информации
в документ, основанные на
использованииАвтотекста,
Автозамены и Копилки.
С
помощью команды Автозамена меню Сервис
ранее созданные элементы (фрагменты
текста, рисунки, таблицы и т. д.) могут
быть многократно автоматически вставлены
в документ. По этой команде также может
производиться расшифровка аббревиатур
и автоматическое исправление наиболее
типичных опечаток. В диалоговом окне
команды можно:
-
создать,
применить, удалить элемент автозамены; -
использовать
автозамену в процессе набора текста; -
выполнить
общую настройку преобразования текста,
используя соответствующие флажки в
верхней части диалогового окна.
С
помощью команды Автотекст меню
Вставка (или вкладка Автотекст в
диалоговом окне команды Автозамена меню
Сервис) ранее созданные элементы
(фрагменты текста, рисунки, таблицы и
т. д.) могут быть многократно вставлены
в документ по команде пользователя. С
помощью диалогового окна команды можно
создавать и удалять элементы автотекста.
Копилка —
это инструмент для накопления и
объединения различных блоков информации
из разных частей документов и вставки
их в документ как единого целого. Копилка
создается на основе автотекста. Выделенный
фрагмент документа переносится в копилку
при нажатии комбинации клавиш Ctrl+F3.
Лодобное действие может быть выполнено
для одного или нескольких документов,
открытых в разных окнах. Просмотреть
содержимое копилки можно с помощью
команды Автотекст меню Вставка, выделив
в списке имен Копилка. Для вставки
содержимого копилки в текст вводится
слово копилка и нажимается комбинация
клавиш Ctrl+Shift+F3 для переноса содержимого
копилки или клавиша F3 для копирования
содержимого.
Текст
документа Word может быть проверен на
правильность правописания на нескольких
десятках языков. Перечень языков
устанавливается командой Язык меню
Сервис. Имеется возможность проверять
тексты на наличие в них орфографических
и грамматических ошибок. Проверку
правописания можно производить
непосредственно при вводе текста или
в ранее введенных текстах. Для
автоматической проверки правописания
при вводе текста следует настроить
вкладку Правописание диалогового окна
команды Параметры меню Сервис. Проверка
правописания в выделенном фрагменте
ранее введенного текста выполняется
командой Правописание меню Сервис или
при нажатии на соответствующую кнопку
на панели инструментов.
При
проверке правописания Word подчеркивает
красной волнистой линией возможную
орфографическую ошибку, зеленой волнистой
линией — возможную грамматическую
ошибку.
Основная
работа ведется в диалоговом окне команды
Правописание с помощью кнопок. Пользователь
может пропустить слово, заменить его
одним из слов, содержащихся в поле
Варианты, добавить это слово в
пользовательский словарь, добавить его
в список автозамены для автоматического
исправления ошибок и т. д.
Настройка
параметров проверки правописания
(установка нужных флажков в диалоговом
окне, вызываемом нажатием кнопки
Параметры в окне Правописание, и нажатием
кнопки Настройка) позволяет добиться
оптимального соотношения между строгостью
и скоростью проверки.
В
процессе редактирования иногда требуется
выполнить поиск текста. Поиск текста
часто выполняется затем, чтобы заменить
его. Для поиска текста щелкните
ссылку Найти
в документе на
панели Поиск в
области задач или выберите команду Найти в
меню Правка или
щелкните клавиши Ctrl+F.
В поле Найти введите
искомый текст и нажмите кнопку «Найти
далее».
После этого будет выполняться поиск.
Чтобы прервать поиск, нажмите клавишу Esc.
Примечание.
Для отображения в окне дополнительных
возможностей поиска щелкните кнопку
«Больше». После этого в окне поиска
будут отображены поля, в которых вы
можете задать направление поиска,
включить учет регистра, задать формат.
Щелкнув кнопку «Специальный», вы можете
задать поиск специальных символов. Если
вам для описания образа поиска не
требуется задавать дополнительные
параметры, то щелкните кнопку «Меньше»
для уменьшения окна, чтобы скрыть
ненужные поля.
Для
замены текста выберите в
меню Правка команду Заменить.
В поле Найти введите
искомый текст, а в поле Заменить па
введите текст для замены. Щелкните
кнопку «Найти
далее».
Если данный текст будет найден, то поиск
будет остановлен, искомый текст будет
выделен жирным начертанием. Щелкните
кнопку «Заменить»
для замены текста. Если вы хотите заменить
все вхождения искомого текста, то
щелкните кнопку «Заменить
все».
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
In software, a spell checker (or spelling checker or spell check) is a software feature that checks for misspellings in a text. Spell-checking features are often embedded in software or services, such as a word processor, email client, electronic dictionary, or search engine.
Eye have a spelling chequer,
It came with my Pea Sea.
It plane lee marks four my revue
Miss Steaks I can knot sea.
Eye strike the quays and type a whirred
And weight four it two say
Weather eye am write oar wrong
It tells me straight a weigh.
Eye ran this poem threw it,
Your shore real glad two no.
Its vary polished in its weigh.
My chequer tolled me sew.
A chequer is a bless thing,
It freeze yew lodes of thyme.
It helps me right all stiles of righting,
And aides me when eye rime.
Each frays come posed up on my screen
Eye trussed too bee a joule.
The chequer pours o’er every word
Two cheque sum spelling rule.
The original version of this poem was written by Jerrold H. Zar in 1992. An unsophisticated spell checker will find little or no fault with this poem because it checks words in isolation. A more sophisticated spell checker will make use of a language model to consider the context in which a word occurs.

Google Chrome spell checker in action for the above poem, the word «chequer» marked as unrecognized word
Design[edit]
A basic spell checker carries out the following processes:
- It scans the text and extracts the words contained in it.
- It then compares each word with a known list of correctly spelled words (i.e. a dictionary). This might contain just a list of words, or it might also contain additional information, such as hyphenation points or lexical and grammatical attributes.
- An additional step is a language-dependent algorithm for handling morphology. Even for a lightly inflected language like English, the spell checker will need to consider different forms of the same word, such as plurals, verbal forms, contractions, and possessives. For many other languages, such as those featuring agglutination and more complex declension and conjugation, this part of the process is more complicated.
It is unclear whether morphological analysis—allowing for many forms of a word depending on its grammatical role—provides a significant benefit for English, though its benefits for highly synthetic languages such as German, Hungarian, or Turkish are clear.
As an adjunct to these components, the program’s user interface allows users to approve or reject replacements and modify the program’s operation.
Spell checkers can use approximate string matching algorithms such as Levenshtein distance to find correct spellings of misspelled words.[1] An alternative type of spell checker uses solely statistical information, such as n-grams, to recognize errors instead of correctly-spelled words. This approach usually requires a lot of effort to obtain sufficient statistical information. Key advantages include needing less runtime storage and the ability to correct errors in words that are not included in a dictionary.[2]
In some cases, spell checkers use a fixed list of misspellings and suggestions for those misspellings; this less flexible approach is often used in paper-based correction methods, such as the see also entries of encyclopedias.
Clustering algorithms have also been used for spell checking[3] combined with phonetic information.[4]
History[edit]
Pre-PC[edit]
In 1961, Les Earnest, who headed the research on this budding technology, saw it necessary to include the first spell checker that accessed a list of 10,000 acceptable words.[5] Ralph Gorin, a graduate student under Earnest at the time, created the first true spelling checker program written as an applications program (rather than research) for general English text: SPELL for the DEC PDP-10 at Stanford University’s Artificial Intelligence Laboratory, in February 1971.[6] Gorin wrote SPELL in assembly language, for faster action; he made the first spelling corrector by searching the word list for plausible correct spellings that differ by a single letter or adjacent letter transpositions and presenting them to the user. Gorin made SPELL publicly accessible, as was done with most SAIL (Stanford Artificial Intelligence Laboratory) programs, and it soon spread around the world via the new ARPAnet, about ten years before personal computers came into general use.[7] SPELL, its algorithms and data structures inspired the Unix ispell program.
The first spell checkers were widely available on mainframe computers in the late 1970s. A group of six linguists from Georgetown University developed the first spell-check system for the IBM corporation.[8]
Henry Kučera invented one for the VAX machines of Digital Equipment Corp in 1981.[9]
PCs[edit]
The first spell checkers for personal computers appeared in 1980, such as «WordCheck» for Commodore systems which was released in late 1980 in time for advertisements to go to print in January 1981.[10] Developers such as Maria Mariani[8] and Random House[11] rushed OEM packages or end-user products into the rapidly expanding software market. On the pre-Windows PCs, these spell checkers were standalone programs, many of which could be run in terminate-and-stay-resident mode from within word-processing packages on PCs with sufficient memory.
However, the market for standalone packages was short-lived, as by the mid-1980s developers of popular word-processing packages like WordStar and WordPerfect had incorporated spell checkers in their packages, mostly licensed from the above companies, who quickly expanded support from just English to many European and eventually even Asian languages. However, this required increasing sophistication in the morphology routines of the software, particularly with regard to heavily-agglutinative languages like Hungarian and Finnish. Although the size of the word-processing market in a country like Iceland might not have justified the investment of implementing a spell checker, companies like WordPerfect nonetheless strove to localize their software for as many national markets as possible as part of their global marketing strategy.
When Apple developed «a system-wide spelling checker» for Mac OS X so that «the operating system took over spelling fixes,»[12] it was a first: one «didn’t have to maintain a separate spelling checker for each» program.[13] Mac OS X’s spellcheck coverage includes virtually all bundled and third party applications.
Visual Tools’ VT Speller, introduced in 1994, was «designed for developers of applications that support Windows.»[14][15] It came with a dictionary but had the ability to build and incorporate use of secondary dictionaries.[16]
Browsers[edit]
Firefox 2.0, a web browser, has spell check support for user-written content,[17] such as when editing Wikitext, writing on many webmail sites, blogs, and social networking websites. The web browsers Google Chrome, Konqueror, and Opera, the email client Kmail and the instant messaging client Pidgin also offer spell checking support, transparently using previously GNU Aspell and currently Hunspell as their engine.
Specialties[edit]
Some spell checkers have separate support for medical dictionaries to help prevent medical errors.[18][19][20]
Functionality[edit]
The first spell checkers were «verifiers» instead of «correctors.» They offered no suggestions for incorrectly spelled words. This was helpful for typos but it was not so helpful for logical or phonetic errors. The challenge the developers faced was the difficulty in offering useful suggestions for misspelled words. This requires reducing words to a skeletal form and applying pattern-matching algorithms.
It might seem logical that where spell-checking dictionaries are concerned, «the bigger, the better,» so that correct words are not marked as incorrect. In practice, however, an optimal size for English appears to be around 90,000 entries. If there are more than this, incorrectly spelled words may be skipped because they are mistaken for others. For example, a linguist might determine on the basis of corpus linguistics that the word baht is more frequently a misspelling of bath or bat than a reference to the Thai currency. Hence, it would typically be more useful if a few people who write about Thai currency were slightly inconvenienced than if the spelling errors of the many more people who discuss baths were overlooked.

The first MS-DOS spell checkers were mostly used in proofing mode from within word processing packages. After preparing a document, a user scanned the text looking for misspellings. Later, however, batch processing was offered in such packages as Oracle’s short-lived CoAuthor and allowed a user to view the results after a document was processed and correct only the words that were known to be wrong. When memory and processing power became abundant, spell checking was performed in the background in an interactive way, such as has been the case with the Sector Software produced Spellbound program released in 1987 and Microsoft Word since Word 95.
Spell checkers became increasingly sophisticated; now capable of recognizing grammatical errors. However, even at their best, they rarely catch all the errors in a text (such as homophone errors) and will flag neologisms and foreign words as misspellings. Nonetheless, spell checkers can be considered as a type of foreign language writing aid that non-native language learners can rely on to detect and correct their misspellings in the target language.[21]
Spell-checking for languages other than English[edit]
English is unusual in that most words used in formal writing have a single spelling that can be found in a typical dictionary, with the exception of some jargon and modified words. In many languages, words are often concatenated into new combinations of words. In German, compound nouns are frequently coined from other existing nouns. Some scripts do not clearly separate one word from another, requiring word-splitting algorithms. Each of these presents unique challenges to non-English language spell checkers.
Context-sensitive spell checkers[edit]
There has been research on developing algorithms that are capable of recognizing a misspelled word, even if the word itself is in the vocabulary, based on the context of the surrounding words. Not only does this allow words such as those in the poem above to be caught, but it mitigates the detrimental effect of enlarging dictionaries, allowing more words to be recognized. For example, baht in the same paragraph as Thai or Thailand would not be recognized as a misspelling of bath. The most common example of errors caught by such a system are homophone errors, such as the bold words in the following sentence:
- Their coming too sea if its reel.
The most successful algorithm to date is Andrew Golding and Dan Roth’s «Winnow-based spelling correction algorithm»,[22] published in 1999, which is able to recognize about 96% of context-sensitive spelling errors, in addition to ordinary non-word spelling errors. Context-sensitive spell checkers appeared in the now-defunct applications Microsoft Office 2007[23] and Google Wave.[24]
Grammar checkers attempt to fix problems with grammar beyond spelling errors, including incorrect choice of words.
See also[edit]
- Cupertino effect
- Grammar checker
- Record linkage problem
- Spelling suggestion
- Words (Unix)
- Autocorrection
- LanguageTool
References[edit]
- ^ Perner, Petra (2010-07-05). Advances in Data Mining: Applications and Theoretical Aspects: 10th Industrial Conference, ICDM 2010, Berlin, Germany, July 12-14, 2010. Proceedings. Springer Science & Business Media. ISBN 978-3-642-14399-1.
- ^ U.S. Patent 6618697, Method for rule-based correction of spelling and grammar errors
- ^ de Amorim, R.C.; Zampieri, M. (2013) Effective Spell Checking Methods Using Clustering Algorithms. Archived 2017-08-17 at the Wayback Machine Proceedings of Recent Advances in Natural Language Processing (RANLP2013). Hissar, Bulgaria. p. 172-178.
- ^ Zampieri, M.; de Amorim, R.C. (2014) Between Sound and Spelling: Combining Phonetics and Clustering Algorithms to Improve Target Word Recovery. Proceedings of the 9th International Conference on Natural Language Processing (PolTAL). Lecture Notes in Computer Science (LNCS). Springer. p. 438-449.
- ^ Earnest, Les. «The First Three Spelling Checkers» (PDF). Stanford University. Archived from the original (PDF) on 22 October 2012. Retrieved 10 October 2011.
- ^ Peterson, James (December 1980). Computer Programs for Detecting and Correcting Spelling Errors (PDF). Retrieved 2011-02-18.
- ^ Earnest, Les. Visible Legacies for Y3K (PDF). Archived from the original (PDF) on 2011-07-20. Retrieved 2011-02-18.
- ^ a b «Georgetown U Faculty & Staff: The Center for Language, Education & Development». Archived from the original on 2009-02-05. Retrieved 2008-12-18., citation: «Maria Mariani… was one of a group of six linguists from Georgetown University who developed the first spell-check system for the IBM corporation.»
- ^ Harvey, Charlotte Bruce (May–June 2010). «Teaching Computers to Spell (obituary for Henry Kučera)». Brown Alumni Magazine. p. 79.
- ^ Advertisement (January 1981). «Micro Computer Industries, Ltd» (PDF). Compute! Magazine, Issue 8, Vol. 3, No. 1. p. 119.
- ^ Advertisement (November 1982). «The Spelling Bee Is Over». PC Magazine. p. 165. Retrieved 21 October 2013.
- ^ David Pogue (2009). Mac OS X Snow Leopard: The Missing Manual.
- ^ David Pogue (2015). Switching to the Mac: The Missing Manual.
- ^ «VisualTools VT-Speller». Computerworld. February 21, 1994. p. 68.
- ^ «Browse September 27, 1993».
VT-SPELLER
- ^ Peter G. Aitken (November 8, 1994). «Spell-Checking for your Apps». PC Magazine. p. 299.
- ^ «Check my email for spelling errors | Workspace Email — GoDaddy Help US». www.godaddy.com.
- ^ «Medical Spell Checker for Firefox and Thunderbird». e-MedTools. 2017. Archived from the original on 2019-05-04. Retrieved 2018-08-29.
- ^ Quathamer, Dr. Tobias (2016). «German medical dictionary words». Dr. Tobias Quathamer. Retrieved 2018-08-29.
- ^ Friedman, Richard A.; D, M (2003). «CASES; Do Spelling and Penmanship Count? In Medicine, You Bet». The New York Times. Retrieved 2018-08-29.
- ^ Banks, T. (2008). Foreign Language Learning Difficulties and Teaching Strategies. (pp. 29). Master’s Thesis, Dominican University of California. Retrieved 19 March 2012.
- ^ Golding, Andrew R.; Roth, Dan (1999). «Journal Article». Machine Learning. SpringerLink. 34: 107–130. doi:10.1023/A:1007545901558.
- ^ Walt Mossberg (4 January 2007). «Review». Wall Street Journal. Retrieved 24 September 2010.
- ^ «Google Operating System». googlesystem.blogspot.com. 29 May 2009. Retrieved 25 September 2010. «Google’s Context-Sensitive Spell Checker». May 29, 2009. Retrieved 25 September 2010.
External links[edit]
- List of spell checkers at Curlie
- Norvig.com, «How to Write a Spelling Corrector», by Peter Norvig
- BBK.ac.uk, «Spellchecking by computer», by Roger Mitton
- CBSNews.com, Spell-Check Crutch Curtails Correctness, by Lloyd de Vries
- History and text of «Candidate for a Pullet Surprise» by Mark Eckman and Jerrold H. Zar
From Wikipedia, the free encyclopedia
In software, a spell checker (or spelling checker or spell check) is a software feature that checks for misspellings in a text. Spell-checking features are often embedded in software or services, such as a word processor, email client, electronic dictionary, or search engine.
Eye have a spelling chequer,
It came with my Pea Sea.
It plane lee marks four my revue
Miss Steaks I can knot sea.
Eye strike the quays and type a whirred
And weight four it two say
Weather eye am write oar wrong
It tells me straight a weigh.
Eye ran this poem threw it,
Your shore real glad two no.
Its vary polished in its weigh.
My chequer tolled me sew.
A chequer is a bless thing,
It freeze yew lodes of thyme.
It helps me right all stiles of righting,
And aides me when eye rime.
Each frays come posed up on my screen
Eye trussed too bee a joule.
The chequer pours o’er every word
Two cheque sum spelling rule.
The original version of this poem was written by Jerrold H. Zar in 1992. An unsophisticated spell checker will find little or no fault with this poem because it checks words in isolation. A more sophisticated spell checker will make use of a language model to consider the context in which a word occurs.
Google Chrome spell checker in action for the above poem, the word «chequer» marked as unrecognized word
Design[edit]
A basic spell checker carries out the following processes:
- It scans the text and extracts the words contained in it.
- It then compares each word with a known list of correctly spelled words (i.e. a dictionary). This might contain just a list of words, or it might also contain additional information, such as hyphenation points or lexical and grammatical attributes.
- An additional step is a language-dependent algorithm for handling morphology. Even for a lightly inflected language like English, the spell checker will need to consider different forms of the same word, such as plurals, verbal forms, contractions, and possessives. For many other languages, such as those featuring agglutination and more complex declension and conjugation, this part of the process is more complicated.
It is unclear whether morphological analysis—allowing for many forms of a word depending on its grammatical role—provides a significant benefit for English, though its benefits for highly synthetic languages such as German, Hungarian, or Turkish are clear.
As an adjunct to these components, the program’s user interface allows users to approve or reject replacements and modify the program’s operation.
Spell checkers can use approximate string matching algorithms such as Levenshtein distance to find correct spellings of misspelled words.[1] An alternative type of spell checker uses solely statistical information, such as n-grams, to recognize errors instead of correctly-spelled words. This approach usually requires a lot of effort to obtain sufficient statistical information. Key advantages include needing less runtime storage and the ability to correct errors in words that are not included in a dictionary.[2]
In some cases, spell checkers use a fixed list of misspellings and suggestions for those misspellings; this less flexible approach is often used in paper-based correction methods, such as the see also entries of encyclopedias.
Clustering algorithms have also been used for spell checking[3] combined with phonetic information.[4]
History[edit]
Pre-PC[edit]
In 1961, Les Earnest, who headed the research on this budding technology, saw it necessary to include the first spell checker that accessed a list of 10,000 acceptable words.[5] Ralph Gorin, a graduate student under Earnest at the time, created the first true spelling checker program written as an applications program (rather than research) for general English text: SPELL for the DEC PDP-10 at Stanford University’s Artificial Intelligence Laboratory, in February 1971.[6] Gorin wrote SPELL in assembly language, for faster action; he made the first spelling corrector by searching the word list for plausible correct spellings that differ by a single letter or adjacent letter transpositions and presenting them to the user. Gorin made SPELL publicly accessible, as was done with most SAIL (Stanford Artificial Intelligence Laboratory) programs, and it soon spread around the world via the new ARPAnet, about ten years before personal computers came into general use.[7] SPELL, its algorithms and data structures inspired the Unix ispell program.
The first spell checkers were widely available on mainframe computers in the late 1970s. A group of six linguists from Georgetown University developed the first spell-check system for the IBM corporation.[8]
Henry Kučera invented one for the VAX machines of Digital Equipment Corp in 1981.[9]
PCs[edit]
The first spell checkers for personal computers appeared in 1980, such as «WordCheck» for Commodore systems which was released in late 1980 in time for advertisements to go to print in January 1981.[10] Developers such as Maria Mariani[8] and Random House[11] rushed OEM packages or end-user products into the rapidly expanding software market. On the pre-Windows PCs, these spell checkers were standalone programs, many of which could be run in terminate-and-stay-resident mode from within word-processing packages on PCs with sufficient memory.
However, the market for standalone packages was short-lived, as by the mid-1980s developers of popular word-processing packages like WordStar and WordPerfect had incorporated spell checkers in their packages, mostly licensed from the above companies, who quickly expanded support from just English to many European and eventually even Asian languages. However, this required increasing sophistication in the morphology routines of the software, particularly with regard to heavily-agglutinative languages like Hungarian and Finnish. Although the size of the word-processing market in a country like Iceland might not have justified the investment of implementing a spell checker, companies like WordPerfect nonetheless strove to localize their software for as many national markets as possible as part of their global marketing strategy.
When Apple developed «a system-wide spelling checker» for Mac OS X so that «the operating system took over spelling fixes,»[12] it was a first: one «didn’t have to maintain a separate spelling checker for each» program.[13] Mac OS X’s spellcheck coverage includes virtually all bundled and third party applications.
Visual Tools’ VT Speller, introduced in 1994, was «designed for developers of applications that support Windows.»[14][15] It came with a dictionary but had the ability to build and incorporate use of secondary dictionaries.[16]
Browsers[edit]
Firefox 2.0, a web browser, has spell check support for user-written content,[17] such as when editing Wikitext, writing on many webmail sites, blogs, and social networking websites. The web browsers Google Chrome, Konqueror, and Opera, the email client Kmail and the instant messaging client Pidgin also offer spell checking support, transparently using previously GNU Aspell and currently Hunspell as their engine.
Specialties[edit]
Some spell checkers have separate support for medical dictionaries to help prevent medical errors.[18][19][20]
Functionality[edit]
The first spell checkers were «verifiers» instead of «correctors.» They offered no suggestions for incorrectly spelled words. This was helpful for typos but it was not so helpful for logical or phonetic errors. The challenge the developers faced was the difficulty in offering useful suggestions for misspelled words. This requires reducing words to a skeletal form and applying pattern-matching algorithms.
It might seem logical that where spell-checking dictionaries are concerned, «the bigger, the better,» so that correct words are not marked as incorrect. In practice, however, an optimal size for English appears to be around 90,000 entries. If there are more than this, incorrectly spelled words may be skipped because they are mistaken for others. For example, a linguist might determine on the basis of corpus linguistics that the word baht is more frequently a misspelling of bath or bat than a reference to the Thai currency. Hence, it would typically be more useful if a few people who write about Thai currency were slightly inconvenienced than if the spelling errors of the many more people who discuss baths were overlooked.
The first MS-DOS spell checkers were mostly used in proofing mode from within word processing packages. After preparing a document, a user scanned the text looking for misspellings. Later, however, batch processing was offered in such packages as Oracle’s short-lived CoAuthor and allowed a user to view the results after a document was processed and correct only the words that were known to be wrong. When memory and processing power became abundant, spell checking was performed in the background in an interactive way, such as has been the case with the Sector Software produced Spellbound program released in 1987 and Microsoft Word since Word 95.
Spell checkers became increasingly sophisticated; now capable of recognizing grammatical errors. However, even at their best, they rarely catch all the errors in a text (such as homophone errors) and will flag neologisms and foreign words as misspellings. Nonetheless, spell checkers can be considered as a type of foreign language writing aid that non-native language learners can rely on to detect and correct their misspellings in the target language.[21]
Spell-checking for languages other than English[edit]
English is unusual in that most words used in formal writing have a single spelling that can be found in a typical dictionary, with the exception of some jargon and modified words. In many languages, words are often concatenated into new combinations of words. In German, compound nouns are frequently coined from other existing nouns. Some scripts do not clearly separate one word from another, requiring word-splitting algorithms. Each of these presents unique challenges to non-English language spell checkers.
Context-sensitive spell checkers[edit]
There has been research on developing algorithms that are capable of recognizing a misspelled word, even if the word itself is in the vocabulary, based on the context of the surrounding words. Not only does this allow words such as those in the poem above to be caught, but it mitigates the detrimental effect of enlarging dictionaries, allowing more words to be recognized. For example, baht in the same paragraph as Thai or Thailand would not be recognized as a misspelling of bath. The most common example of errors caught by such a system are homophone errors, such as the bold words in the following sentence:
- Their coming too sea if its reel.
The most successful algorithm to date is Andrew Golding and Dan Roth’s «Winnow-based spelling correction algorithm»,[22] published in 1999, which is able to recognize about 96% of context-sensitive spelling errors, in addition to ordinary non-word spelling errors. Context-sensitive spell checkers appeared in the now-defunct applications Microsoft Office 2007[23] and Google Wave.[24]
Grammar checkers attempt to fix problems with grammar beyond spelling errors, including incorrect choice of words.
See also[edit]
- Cupertino effect
- Grammar checker
- Record linkage problem
- Spelling suggestion
- Words (Unix)
- Autocorrection
- LanguageTool
References[edit]
- ^ Perner, Petra (2010-07-05). Advances in Data Mining: Applications and Theoretical Aspects: 10th Industrial Conference, ICDM 2010, Berlin, Germany, July 12-14, 2010. Proceedings. Springer Science & Business Media. ISBN 978-3-642-14399-1.
- ^ U.S. Patent 6618697, Method for rule-based correction of spelling and grammar errors
- ^ de Amorim, R.C.; Zampieri, M. (2013) Effective Spell Checking Methods Using Clustering Algorithms. Archived 2017-08-17 at the Wayback Machine Proceedings of Recent Advances in Natural Language Processing (RANLP2013). Hissar, Bulgaria. p. 172-178.
- ^ Zampieri, M.; de Amorim, R.C. (2014) Between Sound and Spelling: Combining Phonetics and Clustering Algorithms to Improve Target Word Recovery. Proceedings of the 9th International Conference on Natural Language Processing (PolTAL). Lecture Notes in Computer Science (LNCS). Springer. p. 438-449.
- ^ Earnest, Les. «The First Three Spelling Checkers» (PDF). Stanford University. Archived from the original (PDF) on 22 October 2012. Retrieved 10 October 2011.
- ^ Peterson, James (December 1980). Computer Programs for Detecting and Correcting Spelling Errors (PDF). Retrieved 2011-02-18.
- ^ Earnest, Les. Visible Legacies for Y3K (PDF). Archived from the original (PDF) on 2011-07-20. Retrieved 2011-02-18.
- ^ a b «Georgetown U Faculty & Staff: The Center for Language, Education & Development». Archived from the original on 2009-02-05. Retrieved 2008-12-18., citation: «Maria Mariani… was one of a group of six linguists from Georgetown University who developed the first spell-check system for the IBM corporation.»
- ^ Harvey, Charlotte Bruce (May–June 2010). «Teaching Computers to Spell (obituary for Henry Kučera)». Brown Alumni Magazine. p. 79.
- ^ Advertisement (January 1981). «Micro Computer Industries, Ltd» (PDF). Compute! Magazine, Issue 8, Vol. 3, No. 1. p. 119.
- ^ Advertisement (November 1982). «The Spelling Bee Is Over». PC Magazine. p. 165. Retrieved 21 October 2013.
- ^ David Pogue (2009). Mac OS X Snow Leopard: The Missing Manual.
- ^ David Pogue (2015). Switching to the Mac: The Missing Manual.
- ^ «VisualTools VT-Speller». Computerworld. February 21, 1994. p. 68.
- ^ «Browse September 27, 1993».
VT-SPELLER
- ^ Peter G. Aitken (November 8, 1994). «Spell-Checking for your Apps». PC Magazine. p. 299.
- ^ «Check my email for spelling errors | Workspace Email — GoDaddy Help US». www.godaddy.com.
- ^ «Medical Spell Checker for Firefox and Thunderbird». e-MedTools. 2017. Archived from the original on 2019-05-04. Retrieved 2018-08-29.
- ^ Quathamer, Dr. Tobias (2016). «German medical dictionary words». Dr. Tobias Quathamer. Retrieved 2018-08-29.
- ^ Friedman, Richard A.; D, M (2003). «CASES; Do Spelling and Penmanship Count? In Medicine, You Bet». The New York Times. Retrieved 2018-08-29.
- ^ Banks, T. (2008). Foreign Language Learning Difficulties and Teaching Strategies. (pp. 29). Master’s Thesis, Dominican University of California. Retrieved 19 March 2012.
- ^ Golding, Andrew R.; Roth, Dan (1999). «Journal Article». Machine Learning. SpringerLink. 34: 107–130. doi:10.1023/A:1007545901558.
- ^ Walt Mossberg (4 January 2007). «Review». Wall Street Journal. Retrieved 24 September 2010.
- ^ «Google Operating System». googlesystem.blogspot.com. 29 May 2009. Retrieved 25 September 2010. «Google’s Context-Sensitive Spell Checker». May 29, 2009. Retrieved 25 September 2010.
External links[edit]
- List of spell checkers at Curlie
- Norvig.com, «How to Write a Spelling Corrector», by Peter Norvig
- BBK.ac.uk, «Spellchecking by computer», by Roger Mitton
- CBSNews.com, Spell-Check Crutch Curtails Correctness, by Lloyd de Vries
- History and text of «Candidate for a Pullet Surprise» by Mark Eckman and Jerrold H. Zar
Грамотность в нашем менталитете — базовая прошивка, поэтому так бросаются в глаза чужие ошибки. И соответственно, доверие к неграмотным продавцам пропадает где-то на подсознательном уровне. Это как тест на уважение к читателю. Мы собрали 12 сервисов для проверки текста на ошибки и 6 лайфхаков, которые помогут вам всегда оставаться на высоте.
Содержание
- Проверка текста на ошибки: пошаговый алгоритм действий
- Сервисы для проверки текста на ошибки
- Как улучшить навык грамотного письма во взрослом возрасте
- Что делать, если ошибка все-таки попала на сайт и на нее указал читатель?
Влияют ли ошибки в текстах на уровень доверия потенциальных клиентов и читателей к вашей компании? Или современное интернет-пространство достаточно лояльно и прощает неграмотность? Как считаете?
Недавно я участвовала в обсуждении на Facebook, темой которого был вопрос: обращаете ли вы внимание на ошибки в текстах интернет-магазинов и влияют ли они на дальнейшее решение о покупке.
Большинство комментаторов писали о том, что замечают ошибки, даже специально не вычитывая текст. Ошибки подрывают доверие, а для первого знакомства с сайтом и решения заказать — это критично.
Особенность ошибок в текстах в том, что они сами бросаются в глаза. И если единичные опечатки или небольшие неточности в знаках препинания бренду еще могут простить, то более грубые ошибки сигнализируют: что-то с этим сайтом не так, даже ошибки не вычитали, может, и с услугами/курсами/экспертностью у них тоже проблемы?
Как влияют ошибки в текстах на восприятие бренда:
- раздражают — «ох, даже ошибки не могли вычитать»;
- портят репутацию компании — «если вы пишете с ошибками, какие же вы профи»;
- усложняют чтение — особенно стилистические и логические ошибки;
- показывают неуважение к читателю.
Проверка текста на ошибки: пошаговый алгоритм действий
Идеальная картина мира — ваш текст вычитывает профессиональный редактор или корректор. И дело тут не только в профессионализме. Ошибки в тексте, над которым вы корпели несколько часов или дней, сложно увидеть, так как глаз замылился. А вот в чужих текстах они виднее.
Совет: не думайте об ошибках, стилистике и редактировании сразу в момент написания текста — это может парализовать вас и убить творческий настрой. Сначала думайте о смыслах, пишите и только потом, после того как текст немного «отлежится», начинайте редактирование и исправление ошибок.
Но если проверить ошибки все-таки нужно самостоятельно, действуйте следующим образом:
- Напишите текст, думая о смыслах, и дайте ему «отдохнуть» хотя бы 1–2 часа.
- Перечитайте текст — грубые ошибки и опечатки вы увидите уже на этом этапе.
- Проверьте текст, используя специальные программы и сервисы. Они не помогут избавиться от всех ошибок, поскольку не всесильны, но большую часть заметят. О сервисах и программах проверки текстов ниже расскажу подробнее.
- Перечитайте текст еще раз — вслух, используя один из методов: «орфографическое чтение» или чтение задом наперед. В первом случае вы читаете слова так, как они пишутся, побуквенно или по слогам, четко произнося каждую букву без фонетических изменений, которые мы обычно делаем в речи, формируя в памяти привычку писать правильно. Например, читаем [ко-то-рый], а не [ка-то-рый]. Во втором — читаете текст слово за словом, но с конца, не проглатывая куски предложений, как мы это делаем, когда читаем знакомый текст.
- Засомневались в слове, знаке препинания, слитном или раздельном написании? Проверяйте! Гуглите свой вопрос и ищите достоверные источники. Например, в случаях написания частицы «не» слитно или раздельно, -н- или -нн- сервисы часто допускают ошибки, так как не чувствуют оттенков смыслов.

Сервисы для проверки текста на ошибки
Редакторы Word или Google Doc
Начните проверку ошибок со встроенных возможностей того редактора, где вы набираете текст. Они постоянно совершенствуются, поэтому их способность находить грамматические ошибки и предлагать правильный вариант написания растет. При хорошем уровне внимательности и базовых знаниях языка этого может быть достаточно.

Онлайн-сервис проверки «Орфограммка»
«Орфограммка» копируете текст в форму проверки и смотрите рекомендации. Сервис платный: вы получаете 6000 знаков для знакомства, а потом выбираете тариф коммерческой лицензии по количеству знаков или на определенный срок действия.
Сервис «Орфограф» от студии Лебедева
Сервис «Орфограф» визуально похож на обычный редактор: подчеркивает красным ошибки и при выделении слова предлагает варианты правильного написания.
Расширение для браузера Languagetool (languagetool.org)
Сервис Languagetool можно добавить в браузер Google Chrome или Firefox, а также использовать в отдельной вкладке, как и предыдущие сервисы. Он подходит для проверки орфографии и грамматики, работает онлайн, с MS Word, LibreOffice, Google Docs, более чем на 10 языках.
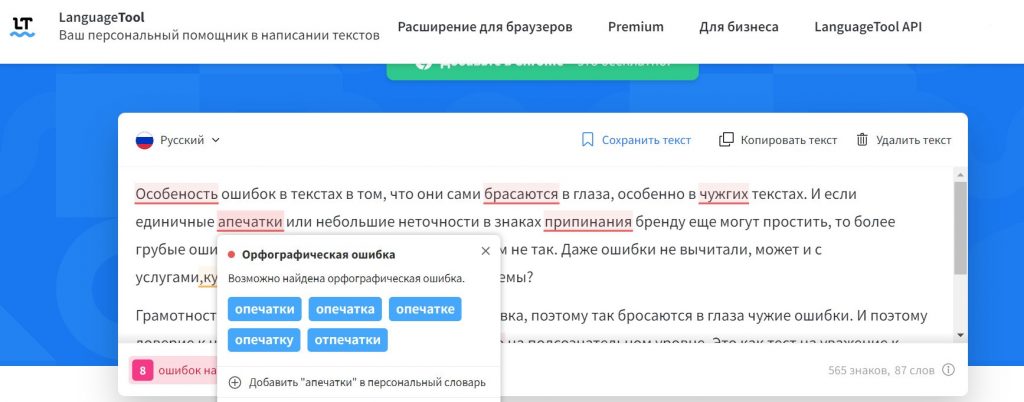
Или так:

Практически аналогично работают такие сервисы и программы проверки ошибок: «Яндекс.Спеллер», «Орфо», Spell-Checker, PerevodSpell. Поэтому попробуйте разные варианты и выберите тот, с которым вам будет наиболее комфортно.
Сервис проверки отдельных слов «Грамота.ру»
Этот сервис мне нравится тем, что здесь можно не просто посмотреть, как пишется то или иное слово, но и вспомнить правила. Используйте его, когда вам нужно уточнить написание одного слова или сложного случая.
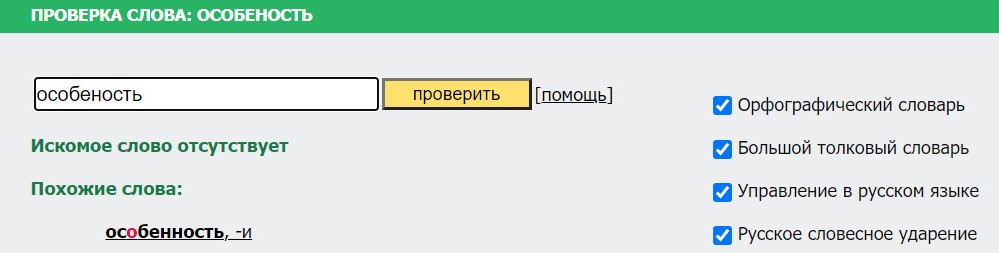
Сервисы проверки уникальности текста
Сервисы проверки уникальности текста и SEO-анализа, которые созданы для проверки текста на плагиат, показывают допущенные орфографические ошибки. Некоторые из них выделяют все неправильно написанные слова отдельной строкой. Эти сервисы удобны в том случае, если вы хотите выполнить проверку и на уникальность, и на ошибки одновременно. Самые популярные программы проверки: text.ru, content-watch и advego.
Вот так выглядит проверка на Аdvego:

Сервис для проверки стилистики текста «Главред»
Если вы хотите проверить текст не только на грамматические ошибки, но и поработать со стилистикой и редактурой, обратите внимание на сервис «Главред», разработанный Максимом Ильяховым. Сервис сразу проверит ошибки и предложит рекомендации по доработке стилистики. Возможно, не ко всем рекомендациям вы прислушаетесь, но от каких-то лишних слов точно сможете избавиться без потери смысла.
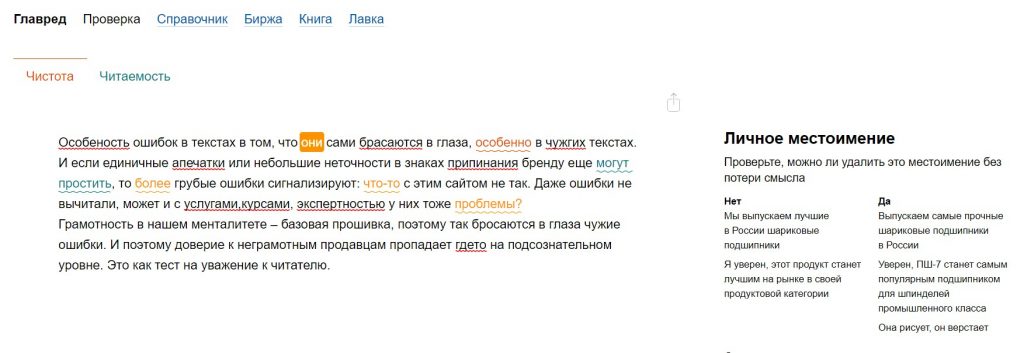
Сервисы оформления текста для размещения на сайте
Перед публикацией на сайте будет нелишним прогнать текст через «Типограф», чтобы проставить неразрывные пробелы, исправить кавычки и тире, спецсимволы. Сейчас это выглядит как абракадабра, но при добавлении на сайт в виде готового HTML-кода, который можно выделить с помощью кнопки «Выделить все» и скопировать, вы получите правильно отформатированный текст.

Как улучшить навык грамотного письма во взрослом возрасте
Никогда не верьте сервисам на 100%, прокачивайте собственную грамотность.
Для этого:
- Регулярно читайте книги — подойдет художественная литература и бизнес-книги.
- Интересуйтесь сложными случаями орфографии и пунктуации.
- Регулярно, но понемногу (много вы просто не запомните) читайте о сложных случаях. Почитать можно такие ресурсы: mel.fm, gramota.ru. Вот, например, несколько хороших подборок: одна и вторая.
- Пишите тексты и онлайн-диктанты. Например, на сайте gramota.ru есть интерактивные диктанты в этом разделе.
- Работайте с редактором и корректором, которые не просто исправят ошибки, но и расскажут, почему так правильно.
- Смотрите, что особо выделяют в редполитиках крупных интернет-СМИ. Часто это не орфограммы, а рекомендации по написанию отдельных слов. При том, что правильное написание может быть двойным, вы будете знать, какие варианты предпочитают издательства. Например, как это описано здесь:
- Если ошибок регулярно много и вы не чувствуете язык, с этим тоже можно бороться, например, используя методики повышения грамотности для взрослых людей. Посмотрите интересные методики на этом ресурсе.
Что делать, если ошибка все-таки попала на сайт и на нее указал читатель?
Поблагодарить за внимательность и исправить. Это сложно, особенно с первыми текстами, но не стоит делать из этого трагедию, лучше сделать выводы.
Воспользуйтесь этой подборкой и составьте свой пошаговый план действий, который поможет победить врага, способного испортить сетевую репутацию.

Всем доброго дня!
Прежде чем давать читать свой написанный текст/документ кому-либо (или отправлять его куда-то) — хорошо бы его проверить на ошибки. (Сам правда я не всегда это соблюдаю, но блог — это ведь вроде как и не документ, и веду я его не по русскому языку. Наверное, простительно?.. 🙂)
Ни один человек (даже тот, который очень хорошо разбирается в тонкостях правописания) не застрахован от опечаток, ошибок из-за невнимательности и пр. Порой и двухразовая вычитка не позволяет исправить оставшиеся неточности…
Причем, иногда ошибки не просто «режут» глаз, а мешают понять смысл сказанного. Не поняв одно слово (или пропустив одну запятую), можно уловить совсем другой смысл из текста, что крайне не хотелось бы (как я думаю 👌).
И чтобы не допустить сей момент — в этой заметке я решил рассмотреть несколько программ и онлайн-сервисов, которые помогут проверить орфографию вашего текста, и указать на основные ошибки (по примерным прикидкам, удается исправить около 80%-95% всех ошибок в тексте!).
Итак…
*
📌 В помощь!
Кстати, у меня на блоге есть заметка с лучшими офисными программами на сегодняшний день (можно подыскать замену для Excel и Word): https://ocomp.info/chem-zamenit-word-i-excel.html
*
Содержание статьи
- 1 С помощью офисных программ
- 1.1 👉 В MS Word
- 1.2 👉 В OpenOffice
- 1.3 👉 В LibreOffice
- 2 С помощью словарей браузера
- 3 С помощью онлайн-сервисов

→ Задать вопрос | дополнить
С помощью офисных программ
👉 В MS Word
Несомненно, что MS Word одна из самых популярных программ для редактирования и написания самых различных текстов: от обычных заметок, и до больших трактатов в целые романы и книги…
У большинства пользователей на компьютерах/ноутбуках эта программа установлена, поэтому с неё и предлагаю начать.
Должен Вам сказать, что в MS Word встроен один из лучших словарей для проверки правописания и грамматики (речь, конечно, идет о новых версиях программы. Относительно старые до 2010 — в расчет не беру).
Благодаря этому словарю удается довести текст до очень высокой степени грамотности.
👉 Будем считать, что текст у Вас есть (либо вы его набрали самостоятельно в Word, либо туда скопировали (используйте сочетание кнопок Ctrl+С и Ctrl+V — скопировать и вставить)).
*
Далее зайдите в раздел «Рецензирование», и щелкните по кнопке «Правописание» (см. стрелки 1 и 2 на скриншоте ниже 👇). Также можете воспользоваться клавишей F7.
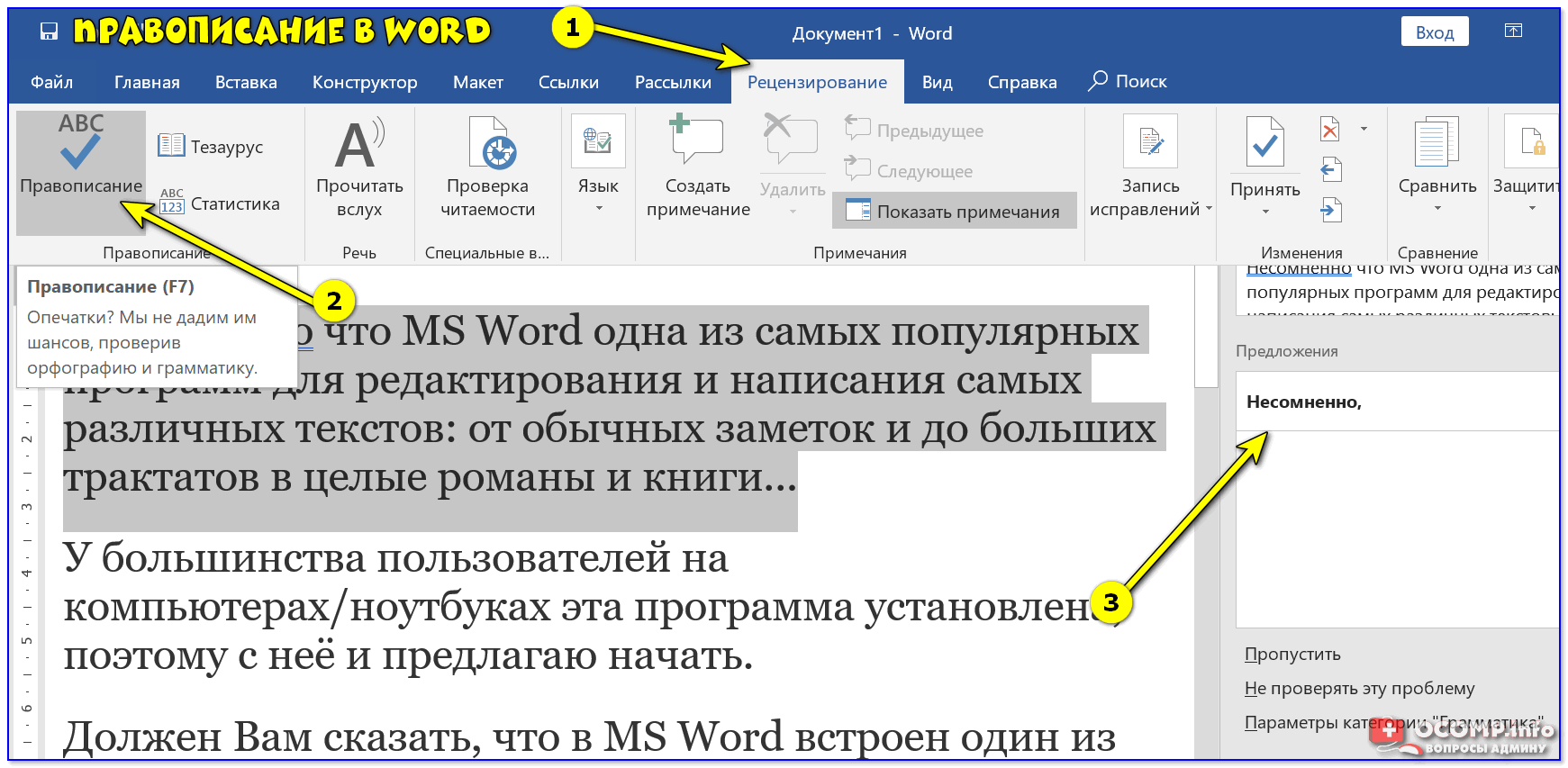
Правописание в Word — как проверить
Кстати, в Word есть еще один интересный и полезный инструмент — проверка читаемости! Этот инструмент позволяет найти сложно-читаемые участки текста, длинные ссылки, не совсем корректные заголовки и пр. В общем, рекомендую к использованию!
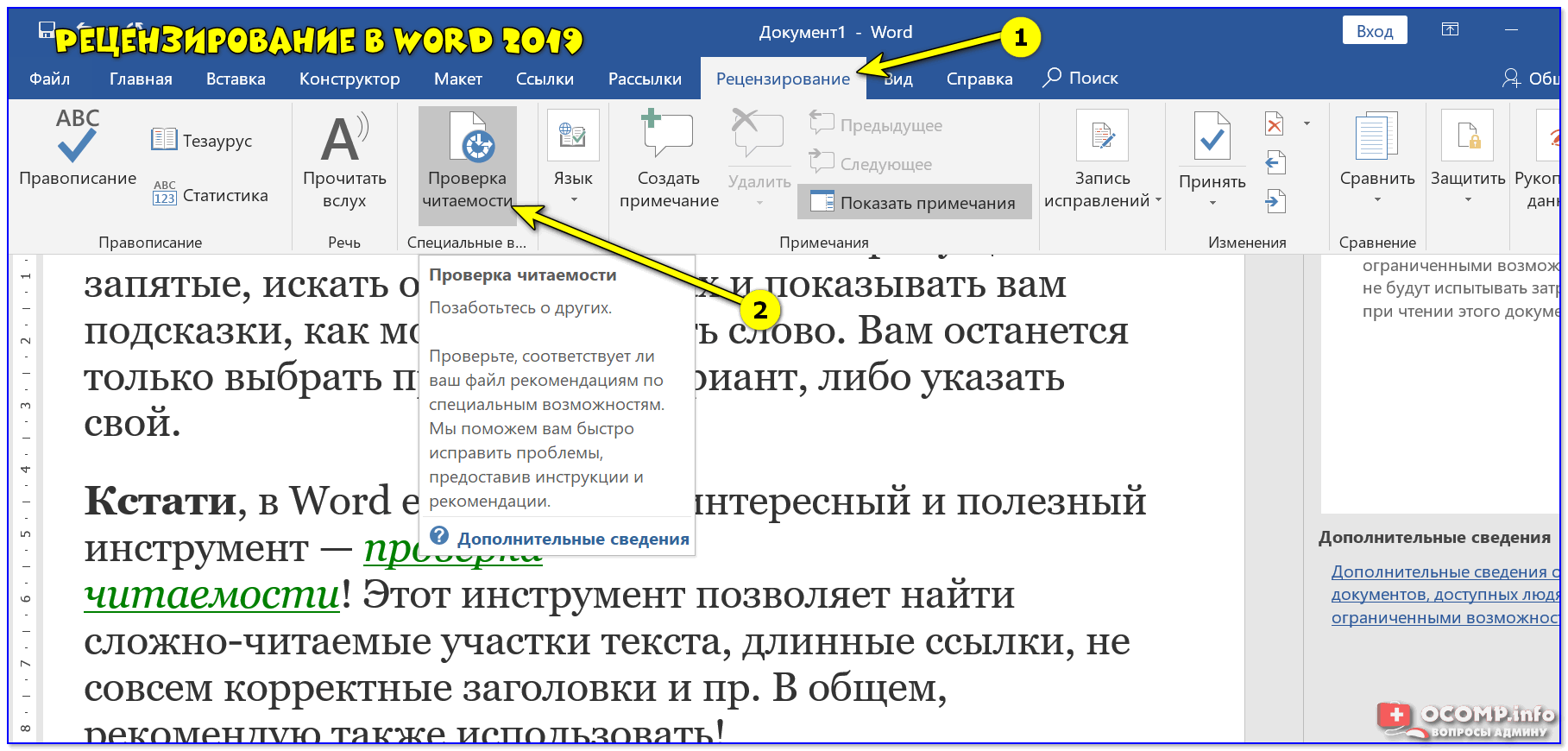
Рецензирование в Word 2019 — проверка читаемости
Также обратите внимание на параметры в Word. Чтобы открыть их: нажмите меню «Файл», затем кнопку «Параметры» (см. стрелки 1 и на 2 на скриншоте ниже 👇).
Файл — параметры — Word 2019
В разделе «Правописание» можно настроить детально проверку орфографии, например, следующее:
- проверять ли текст в процессе его набора;
- учитывать ли сложные слова;
- помечать ли повторяющиеся слова;
- проверять ли грамматику при проверке орфографии и многое другое (скрин со всеми параметрами показан ниже).
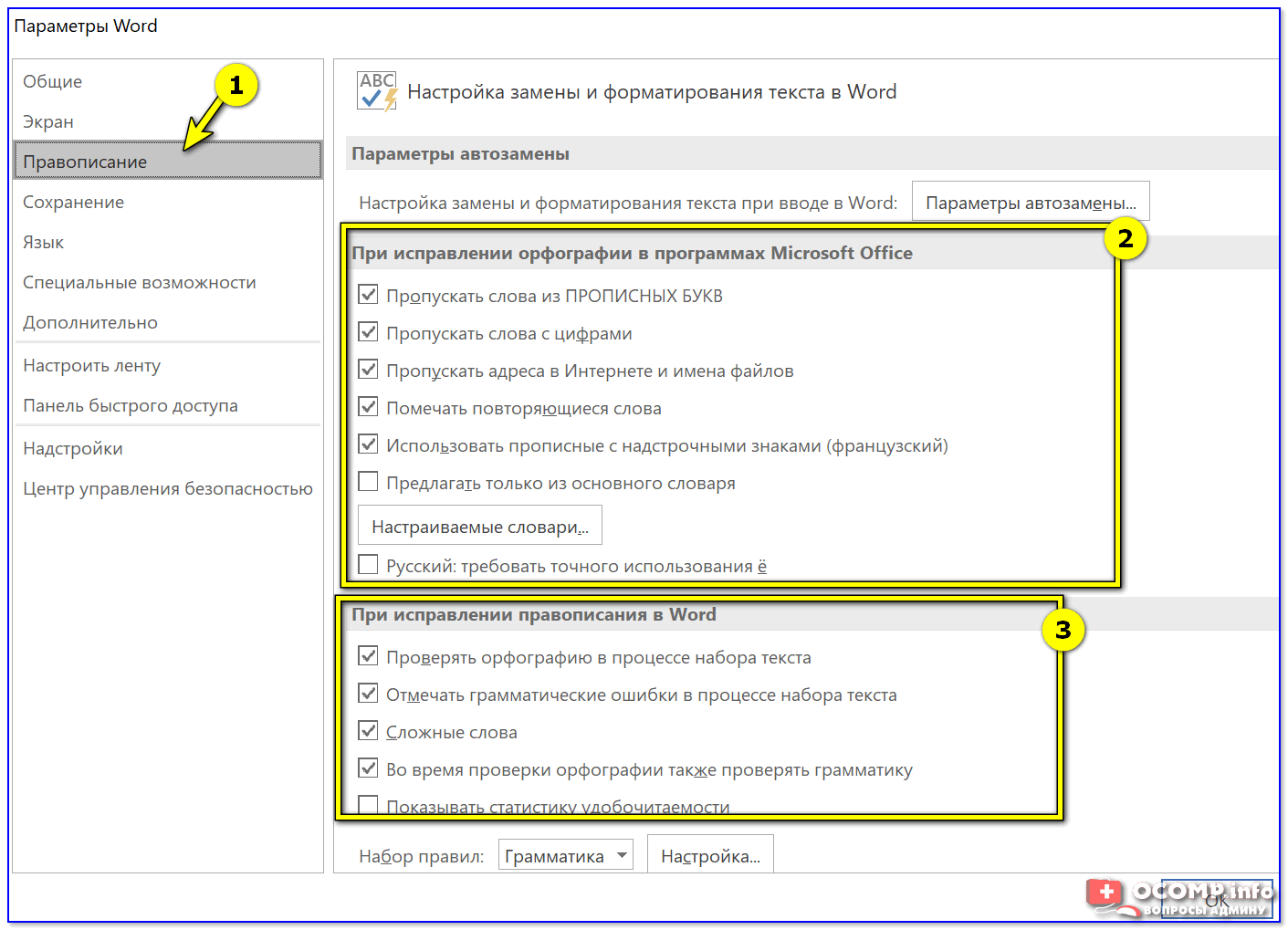
Параметры Word — правописание
*
👉 В OpenOffice
Более подробно об этом пакете: ссылка
Проверка в MS Word реализована, конечно, хорошо. Но вот что делать, если купить и установить Word вы не можете (программа-то всё-таки платная и стоит не мало)?
В этом случае поможет бесплатный аналог OpenOffice. Программа достаточно многофункциональна, и для обычного пользователя (который не пользуется большим количеством фишек и «тонкостей» MS Word), с легкостью его заменит! 👌
👉 Что касается проверки орфографии — то в OpenOffice есть два удобных варианта. Во-первых, по умолчанию включена автопроверка орфографии (см. на значок под цифрой 1 на скрине ниже — ![]() ).
).
При подобной проверке весь набираемый текст (либо вставляемый) будет проверяться, и подозрительные слова, которые вероятно с ошибкой (или их еще нет в вашем словарике) — будут подчеркиваться. Пример ниже. 👇
Поиск ошибок в тексте с помощью OpenOffice
Примечание: кстати, программа само-обучаема — когда вы добавите какое-нибудь слово в словарь, она больше не будет подчеркивать его и считать ошибкой.
*
Что касается второго варианта — то это ручная проверка, нажмите соответствующую кнопку ![]() (цифра 1 на скрине ниже), либо клавишу F7.
(цифра 1 на скрине ниже), либо клавишу F7.
Далее перед вами появиться окно, в котором поочередно будут показываться найденные ошибки: ваше дело либо пропускать их (если ошибки нет), либо исправлять по-своему или с помощью подсказок программы. В общем-то, рутинная работа…
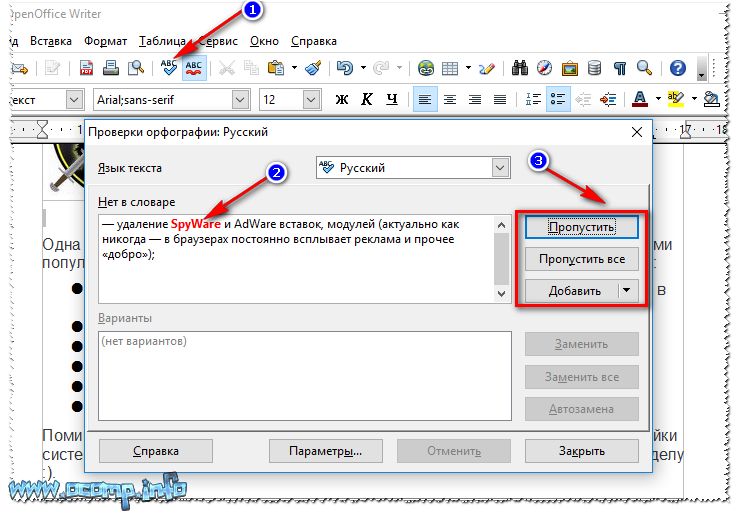
Ручная проверка орфографии / OpenOffice
*
👉 В LibreOffice
Подробно об этой программе: ссылка
В LibreOffice проверка текста на правописание осуществляется аналогичным образом, как в OpenOffice. Если зайти в меню «Сервис» — Вы найдете там два варианта проверок:
- автоматическую — она активна по умолчанию, благодаря ее проверки, при наборе текста — сразу же подсвечиваются и подчеркиваются ошибки);
- ручную — ее можно запустить также по клавише F7.
👉 Пример проверки грамматики и орфографии представлен на скриншоте ниже: практически идентичная предыдущему офисному пакету.
При проверке от вас требуется совершить одно из трех действий: пропустить ошибку, исправить ее (можно также воспользоваться подсказками), или добавить ее в словарь, чтобы в дальнейшем программа не считала ошибкой такое написание слова.
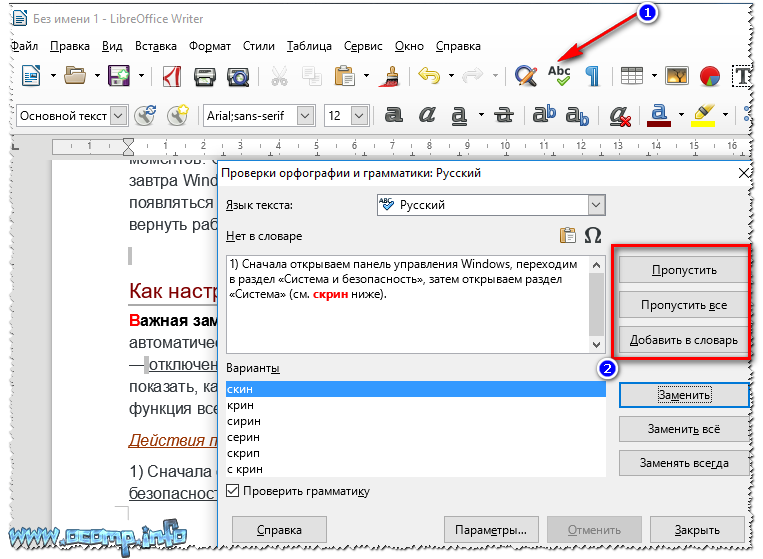
Проверка орфографии и грамматики / LibreOffice
*
👉 Из недостатков проверки: все-таки словарь у LibreOffice уступает в качестве тому же Word, особенно это касается запятых. Часть пропущенных запятых программа «не видит», к сожалению…
*
С помощью словарей браузера
Большинство современных браузеров оснащены модулями проверки орфографии.
Кстати, это очень удобно при наборе различного текста в интернете: не будешь же в самом деле все посты на форуме, комментарии и пр. переписку с людьми — проверять до единого?! А легкая проверка в самом браузере позволяет не казаться таким уж необразованным… 😎
Обычно, подобный модуль правописания в браузерах включен (по умолчанию). Рассмотрю вопрос более конкретно и подробно на примере популярнейшего браузера Google Chrome.
*
👉 Google Chrome
Чтобы настроить параметры проверки грамматики в Chrome, нужно:
- сначала зайти в настройки программы (нажмите значок с тремя точками
 и откройте «Настройки»);
и откройте «Настройки»); - далее нужно нажать ссылку внизу страницы «Показать дополнительные настройки»;
- затем найдите подраздел «Языки» и включите расширенную проверку орфографии;
Языки — расширенная проверка правописания — Chrome
- Собственно, теперь в Chrome при наборе текста, слова с ошибками будут подсвечиваться. Согласитесь, это удобно?! 👌
- Кстати, когда заметите ошибку или подчеркнутое слово, щелкните по нему правой кнопкой мышки и браузер вам предложит правильное написание слова. Стоит отметить, что браузер теперь не только будет находить ошибки, но и часто подсказывать варианты слов, на которые можно исправить ошибочное (пример ниже).👇
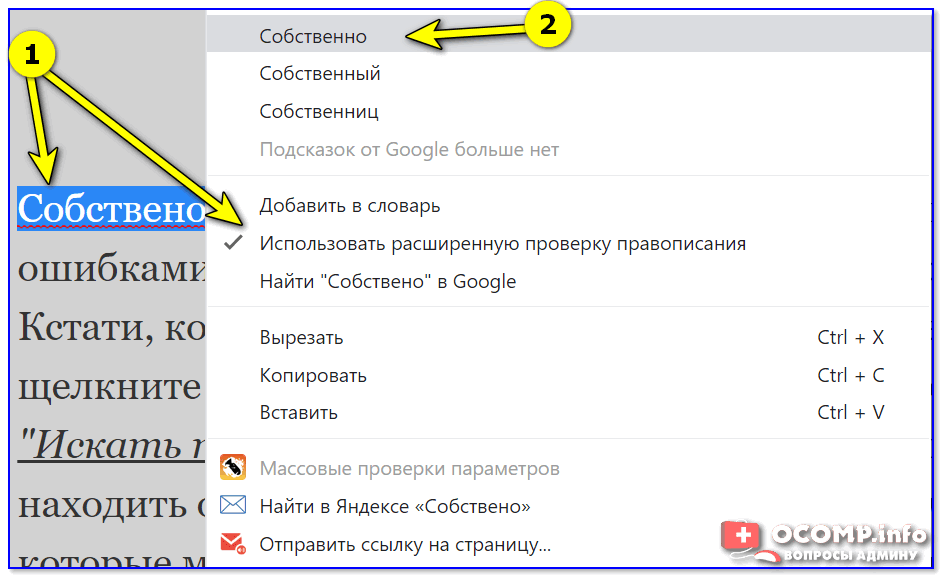
Найденная ошибка при наборе текста — Chrome
👉 Кстати!
Для многих браузеров есть доп. словари и плагины, которые могут существенно усилить программу в плане проверки правописания!
*
👉 ДОПОЛНЕНИЕ!
В принципе, проверка грамматики включается/отключается во многих браузерах аналогично. Например, 👉 в Firefox достаточно нажать правой кнопкой мышки по набираемому тексту (прим.: по окну, в котором вы его набираете), и после чего поставить галочку напротив пункта «Проверка орфографии».
Далее браузер автоматически подсветит красной чертой те слова, где согласно его словарю, допущены ошибки.
Кстати, Firefox также «обучаем», вы можете нажать правой кнопкой мышки по подчеркнутому слову и занести его в словарь исключений, чтобы более такое слово не светилось ошибкой…
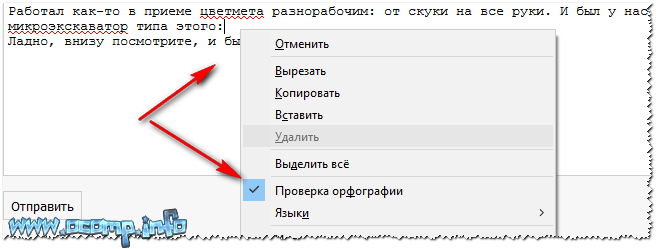
Firefox — проверка орфографии набираемого текста / комментария
*
С помощью онлайн-сервисов
Если на компьютере нет ни одного офисного пакета, то браузер вкупе с одним (или несколькими) сервисами, представленными ниже, может дать вполне приемлемые результаты проверки и поиска ошибок. Но повторюсь, всё же максимального качества удается достичь в MS Word (на мой взгляд ✌).
*
👉 Орфо-онлайн
Сайт: http://www.orfo.ru/

Очень удобный сайт для проверки грамматики. Пользоваться можно сразу же, после перехода по ссылке (приведена выше), регистрироваться не нужно. Все найденные ошибки будут подчеркнуты волнистой чертой. Кстати, сервис неплохо справляется с пропущенными запятыми…
Помимо основной задачи, Орфо-онлайн позволяет форматировать текст (правда, на мой взгляд это мало актуально для такого сервиса).
*
👉 TEXT.ru
Сайт: https://text.ru/spelling

Еще один достойный сервис для проверки орфографии. Слова с ошибками будут выделены отдельным цветом, при наведении на такое слово — будет предложена подсказка.
Также сервис анализирует текст на уникальность, заспамленность, определит количество символов, слов. Довольно неплохо!
Кстати, регистрироваться не нужно.
*
👉 Яндекс-Спеллер
Сайт: https://tech.yandex.ru/speller/
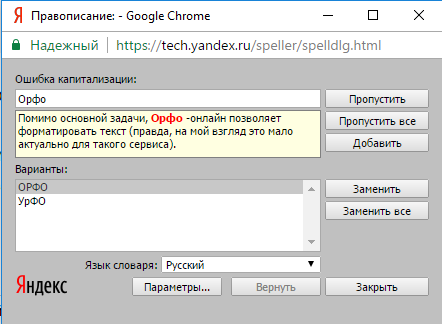
Работа в Яндекс-Спеллер
Интересный сервис от Яндекса. Позволяет проверить текст на различные ошибки: неправильно-написанные слова, пропущенные запятые, повторные слова и пр.
По использованию: очень похож на проверку в Word — вам также будут поочередно показываться ошибки, и предлагаться одно из трех действий: пропустить, исправить или добавить в словарик исключений.
В общем-то, довольно удобно, рекомендую к использованию.
*
👉 Адвего
Сайт: https://advego.ru/text/
![]()
Довольно качественная и добротная проверка текста. Кстати, Адвего позволяет проверять большие по объему тексты даже без регистрации. Максимальная длина проверяемого текста — 100000 символов!
В конце отчета, помимо слов с ошибками, вам будет представлен анализ текста: заспамленность, вода, кол-во символов и слов, кол-во найденных ошибок и т.д.
*
👉 5-EGE
Сайт: https://5-ege.ru/proverit-orfografiyu-onlajn/

Простой и удобный сервис для проверки орфографии (всего-то нужно вставить текст в форму и нажать на кнопку проверки).
На сайте нет ничего лишнего, что могло бы отвлекать от «главного». Кстати, позиционируют себя как сайт для подготовки к ЕГЭ. Поэтому, помимо самой проверки текста, вы на нем сможете найти и другую полезную информацию…
*
PS
Примечание: данный текст статьи был проверен в MS Word 2019, и в браузере Chrome… 👌
*
Думаю, что на этом борьбу с ошибками пора заканчивать…
За дополнения по теме — отдельное мерси.
Удачи!
👋
Первая публикация: 17.04.2017
Корректировка: 16.11.2022


Полезный софт:
-

- Видео-Монтаж
Отличное ПО для создания своих первых видеороликов (все действия идут по шагам!).
Видео сделает даже новичок!
-

- Ускоритель компьютера
Программа для очистки Windows от «мусора» (удаляет временные файлы, ускоряет систему, оптимизирует реестр).
Как проверить правописание текста при помощи компьютера










- Биржа копирайтинга
- Биржа рерайтинга
- Биржа переводов
- Статья для Яндекс.Дзен

- Письменные работы на заказ

Сервис проверки орфографии и пунктуации онлайн — это уникальный бесплатный сервис поиска ошибок и опечаток.
Эффективный алгоритм Text.ru находит множество ошибок, среди которых:
- непарные скобки и апострофы;
- две запятые или точки подряд;
- выделение запятыми вводных слов;
- ошибки в согласовании;
- грамматические и логические ошибки;
- опечатки;
- лишние пробелы;
- повтор слов;
- строчная буква в начале предложения;
- правописание через дефис;
- и многое другое.
На нашем сервисе вы сможете не только узнать уникальность текста, но и проверить его орфографию и пунктуацию. При проверке текста можно так же легко избавиться и от опечаток, которые не всегда заметны при быстром наборе. При использовании данного сервиса вы будете уверены в качестве текста.
Исправление ошибок в тексте онлайн, проверка орфографии и пунктуации позволят проверить грамотность текста.
Проверка ошибок онлайн поможет найти ошибки и опечатки в тексте. Проверка текста на ошибки пригодится при анализе любого текста, если вы хотите проверить его качество и найти имеющиеся ошибки. Если же у вас возникают трудности в первую очередь с пунктуацией, а не с орфографией, оцените возможность проверки запятых. Сервис укажет на проблемные места, где были найдены лишние или отсутствующие знаки препинания, например, несколько запятых подряд или непарные скобки.
Одной из ключевых особенностей бесплатной проверки на ошибки на Text.ru является возможность исправить их прямо в тексте. Алгоритм проверки прост.
- Вставьте нужный текст в окно проверки орфографии и пунктуации.
- Нажмите на кнопку «Проверить на ошибки».
- Обратите внимание на подсвеченные контрастным цветом места и количество найденных ошибок под полем проверки.
- Нажмите на выделенное слово и выберите верный вариант написания из открывшегося списка.
Если вы цените свое время, рекомендуем проверить орфографию и пунктуацию онлайн на Text.ru и оценить преимущества самостоятельно.
Проверка правописания текста доступна через API. Подробнее в API-проверке.
Проверка орфографии и пунктуации
Инструмент проверки текста на орфографические и грамматические ошибки онлайн, позволит исправить самые громоздкие ошибки, с высокой степенью точности и скорости, а также улучшить свой письменный русский язык.
Если возможно несколько исправлений, вам будет предложено выбрать одно из них. Слова в которых допущены ошибки выделяются разными цветами, можно кликнуть на подсвеченное слово, посмотреть описание ошибки и выбрать исправленный вариант.
Инструмент поддерживает 8 языков.
Орфография
Написать текст без каких-либо орфографических или пунктуационных ошибок достаточно сложно даже специалистам. Наша автоматическая проверка орфографии может помочь профессионалам, студентам, владельцам веб-сайтов, блогерам и авторам получать текст практически без ошибок. Это не только поможет им исправить текст, но и получить информацию о том, почему использование слова неправильно в данном контексте.
Что входит в проверку текста?
- грамматические ошибки;
- стиль;
- логические ошибки;
- проверка заглавных/строчных букв;
- типографика;
- проверка пунктуации;
- общие правила правописания;
- дополнительные правила;
Грамматика
Для поиска грамматических ошибок инструмент содержит более 130 правил.
- Деепричастие и предлог
- Деепричастие и предлог
- «Не» с прилагательными/причастиями
- «Не» с наречиями
- Числительные «оба/обе»
- Согласование прилагательного с существительным
- Число глагола при однородных членах
- И другие
Грамматические ошибки вида: «Идя по улице, у меня развязался шнурок»
Грамматическая ошибка: Идя по улице , у меня.
Правильно выражаться: Когда я шёл по улице, у меня развязался шнурок.
Пунктуация
Чтобы найти пунктуационные ошибки и правильно расставить запятые в тексте, инструмент содержит более 60 самых важных правил.
- Пунктуация перед союзами
- Слова не являющиеся вводными
- Сложные союзы не разделяются «тогда как», «словно как»
- Союзы «а», «но»
- Устойчивое выражение
- Цельные выражения
- Пробелы перед знаками препинания
- И другие
Разберем предложение, где пропущена запятая «Парень понял как мальчик сделал эту модель»
Пунктуационная ошибка, пропущена запятая: Парень понял ,
«Парень понял, как мальчик сделал эту модель»
Какие языки поддерживает инструмент?
Для поиска ошибок вы можете вводить текст не только на Русском языке, инструмент поддерживает проверку орфографии на Английском, Немецком и Французском
Проверка орфографии онлайн
Онлайн проверка орфографии Advego — это сервис по проверке текста на ошибки. Оценивайте грамотность и правописание статей бесплатно! Мультиязычная проверка ошибок в тексте орфо онлайн! Корректировка текста онлайн — ваш инструмент и ежедневный помощник!
Результаты проверки
Текст
Статистика текста
| Наименование показателя | Значение |
|---|---|
| Количество символов | |
| Количество символов без пробелов | |
| Количество слов | |
| Количество уникальных слов | |
| Количество значимых слов | |
| Количество стоп-слов | |
| Вода | % |
| Количество грамматических ошибок | |
| Классическая тошнота документа | |
| Академическая тошнота документа | % |
Проверьте грамотность текста онлайн, чтобы исправить все орфографические ошибки. Сервис проверки правописания Адвего работает на 20 языках совершенно бесплатно и без регистрации.
Какие ошибки исправляет проверка орфографии и корректор текста?
- Орфографические ошибки — несовпадение с мультиязычным словарем.
- Опечатки, пропущенные или лишние буквы.
- Пропущенные пробелы между словами.
- Грамматические и морфологические ошибки
Разместите текст в поле «Текст» и нажмите кнопку «Проверить» — система покажет найденные предположительные ошибки и выделит их в тексте подчеркиванием и цветом.
На каком языке проверяется правописание и ошибки?
По умолчанию грамотность текста анализируется на русском языке.
Для проверки орфографии на другом языке выберите его из выпадающего меню: английский, немецкий, испанский, французский, китайский, украинский, японский, португальский, польский, итальянский, турецкий, арабский, вьетнамский, корейский, урду, персидский, хинди, голландский, финский.
Пример отчета проверки орфографии и грамматики онлайн
Какой объем текста можно проверить на орфографию?
Максимальный объем текста для одной проверки — 100 000 символов с пробелами. Чтобы проверить статью или документ большего размера, разбейте его на фрагменты и проверьте их по очереди.
Вы можете проверить неограниченное количество текстов бесплатно и без регистрации во время коррекции.
Проверка пунктуации онлайн — исправление ошибок в тексте от Адвего
Сервис Адвего поможет не только найти плагиат онлайн бесплатно и определить уникальность текста, но и сможет провести проверку пунктуации с указанием опечаток в знаках препинания и указать наличие орфографических ошибок онлайн.
Адвего рекомендует проверить орфографию и пунктуацию онлайн на русском, украинском, английском и еще более чем 20 языках в своем качественном мультиязычном сервисе орфо онлайн!
источники:
http://rustxt.ru/check-spelling
http://advego.com/text/
Такташкин Денис Витальевич1, Мокроусова Елена Александровна2
1Пензенский государственный университет, кандидат технических наук, доцент кафедры «МОиПЭВМ»
2Пензенский казачий институт технологий, (филиал) ФГБОУ ВО «Московский государственный университет технологий и управления имени К.Г. Разумовского, магистрант кафедры «ПиБИ»
Аннотация
В статье описаны алгоритмы проверки орфографии текстовых документов. Обосновывается актуальность использования специализированного программного обеспечения, с помощью которого проверяется орфография. Демонстрируется диаграмма вариантов использования, на которой показаны существующие методы и алгоритмы. Приводятся определения основных терминов предметной области.
Библиографическая ссылка на статью:
Такташкин Д.В., Мокроусова Е.А. Методы и алгоритмы проверки орфографии тестовых документов // Современные научные исследования и инновации. 2017. № 5 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2017/05/72892 (дата обращения: 02.06.2023).
Читая любой документ, мы невольно обращаем внимание на стиль изложения, легкость восприятия, содержательность и краткость повествования. Однако нередко мы сталкиваемся с опечатками и ошибками в документах. Они могут испортить все положительное впечатление об авторе, а порой и нанести серьезный урон авторитету автора.
Общаясь на родном языке, мы практически всегда можем заметить, что тексте автор ошибся. Кроме того, мы обычно можем догадаться, что он имел в виду на самом деле. Гораздо сложнее дело обстоит в тех случаях, когда мы общаемся с иностранцами. Допущенная ошибка или опечатка в написании слова, может значительно исказить смысл всего сообщения, и даже интуиция не сможет помочь получателю текста, поскольку язык общения для него не родной.
Для исправления набранного текста и были созданы программы проверки орфографии, синтаксиса, грамматических правил построения предложений, расстановки переносов и т.д. Первыми и наиболее активными пользователями подобных программ стали те, кто занимается созданием и редактированием текстов [1].
Впоследствии такие программы были встроены в популярные текстовые редакторы. Например, компания «Информатик» лицензировала свою технологию проверки правописания компании Microsoft для MS Office. Благодаря этому огромное число пользователей получили возможность автоматически исправлять тексты, не теряя свое время на длительную проверку текста [2].
Существует множество алгоритмов проверки орфографии текстовых документов. На рисунке 1 изображена диаграмма вариантов использования, которая показывает, какие существуют алгоритмы проверки.
Рисунок 1 – Диаграмма вариантов использования
Проверить орфографию можно двумя способами.
Первый способ это проверить орфографию со словарем.
Проверка со словарем делится на проверку через словарь всех слов и на проверку через словарь, который использует набор правил.
Проверка через словарь всех слов.
Словарем является файл в формате .txt, который содержит все слова русского языка, включая все склонения и спряжения слов. Слова расположены в алфавитном порядке, каждое слово находится на новой строке.
Проверка через словарь всех слов самый популярный метод обнаружения ошибок в тексте. Проверка осуществляется обычным поиском слова в словаре. Компьютер ищет слово в словаре так же как, если бы человек взял словарь в руки и искал нужное слово. Слова расположены в алфавитном порядке, поэтому компьютер может идти в нужное место в словаре и проверять слово. Если все буквы слова будут совпадать со словом в словаре, то оно является правильным. Если же такого слова нет, то оно является ошибкой или опечаткой.
В случае если слово отсутствует в словаре, например, фамилия, название или научный термин, относящийся к какой-либо предметной области, имеется возможность − добавить данное слово в словарь. После добавления слово не будет считаться ошибкой, так как в словаре будет полное совпадение букв.
Проверка орфографии, через словарь, который использует набор правил.
Словарь, который использует набор правил – это документ в формате .txt, который содержит все слова, кроме склонений и спряжений. С помощью правил русского языка, проверяются все слова на правильность написания.
Такой словарь надо организовать так, чтобы были указаны все правила русского языка. Главное надо учесть исключения из правил.
Метод проверки орфографии, который использует набор правил, так же называется методом сохранения пространства. Такой метод, экономя пространство хранения, удерживают в словаре только стебли слов. Например, вместо слов «сомнения», «сомневался», «сомневаясь», в словаре хранится только слово «сомневаюсь», используя правила русского языка удаляя окончания, суффиксы, приставки или добавляя их, слова будут меняться до слова находящегося в словаре.
Второй способ это проверка орфографии без помощи словаря, который включает в себя проверку на заглавную букву в начале предложения, проверка на повторы и проверка с помощью сограмм.
Проверка на заглавную букву, т.е. каждая буква после точки должна автоматически становиться заглавной.
Проверка на повторы показывает, что пользователь написал два одинаковых слова подряд. Проверяются на совпадения все буквы одного слова с буквами другого слова, если же они полностью совпадают, то это является ошибкой.
Сограммами называется фиксированное сочетание букв, которое в русском языке встречается, в разных словах на разных позициях.
Проверить орфографию с помощью сограмм можно двумя способами. Первый способ проверки через сограммы это проверять через уже существую таблицу сограмм. Метод использует словарь косвенно. Проверка начинается с перехода в словарь или таблицу всех сограмм. Вооружившись таблицей сограмм, программа проверки орфографии делит текст на сограмм и ищет их в таблице, если попадаются сограммы, которые никогда не имели место в словаре, слово, которое содержит эту сограмму, является опечаткой. Этот способ содержит таблицу, заполненную всеми сограммами. И при анализе текста, происходит поиск сограмм в таблице, если совпадения нет, то слово является опечаткой.
И способ анализа текста на похожие сограммы. Программа делит текст на сограммы, и сама создает таблицу из всех сограмм встречающихся в тексте, отметив как часто каждая сограмма встречается в тексте. Затем программа анализирует текст еще раз и выявляет индекс особенности каждого слова, потому на сколько сограмм разделено слово и сколько раз эти сограммы встречаются в тексте. После расчета индекса, программа обращает внимание пользователя на слова с высоким индексом особенности. Такой метод более подходит для выявления опечаток в тексте.
Существуют ошибки в режиме реального слова, к таким ошибкам в большинстве случаев относятся имена собственные и неизвестные слова. Частоту этих ложных ошибок можно уменьшить, имея большой словарь или специализированный словарь именно для этого текста. Так же избежать таких ошибок можно добавлением неизвестных слов и имен собственных в словарь, с помощью дополнительной функции «Добавить слово в словарь».
Существует множество методов и алгоритмов проверки орфографии текстовых документов. Каждый из них подходит для проверки текста, но они имеют недостатки. Для более точной проверки подходит метод, в котором нужно объединить несколько алгоритмов проверки орфографии.
Библиографический список
- Такташкин Д.В., Масенко И.А. Модель вариантов использования программы для писателей «Сюжет» // Современные научные исследования и инновации. 2016. № 3 [Электронный ресурс]. URL:http://web.snauka.ru/issues/2016/03/64882 (дата обращения: 28.05.2016)
- Поваляев Е. Системы проверки орфографии [Электронный ресурс] . URL:http://compress.ru/article.aspx?id=9511 (дата обращения: 05.11.2015).
Количество просмотров публикации: Please wait
Все статьи автора «Мокроусова Елена Алексанровна»
Время на прочтение
11 мин
Количество просмотров 9.9K
Доброго времени суток. На днях у меня возникла задача по реализации алгоритма пост-обработки результатов оптического распознавания текста. Для решения этой проблемы не плохо подошла одна из моделей для проверки орфографии в тексте, хотя конечно слегка модифицированная под контекст задачи. Этот пост будет посвящен модели Noisy Channel, которая позволяет осуществлять автоматическую проверку орфографии, мы изучим математическую модель, напишем на c# немного кода, обучим модель на базе Питера Норвига, и под конец протестируем то что у нас получится.
Математическая модель — 1
Для начала постановка задачи. Итак вы хотите написать некоторое слово w состоящее из m букв, но каким то неведомым вам способом на бумаге выходит слово x состоящее из n букв. Кстати вы как раз и есть тот самый noisy channel, канал передачи информации с шумами, который исказил правильное слово w (из вселенной правильных слов) до не правильного x (множества всех написанных слов).
Мы хотим найти такое слово, которое вы наиболее вероятно подразумевали при написании слова x. Запишем эту мысль математически, модель по своей идее похожа на модель наивного байесовского классификатора, хотя даже проще:
- V — список всех слов естественного языка.
Далее используя теорему Байеса развернем причину и следствие, полную вероятность x мы можем убрать из знаменателя, т.к. он при argmax не зависит от w:
- P(w) — априорная вероятность слова w в языке; этот член представляет из себя статистическую модель естественного языка (language model), мы будем использовать модель unigram, хотя конечно вы в праве использовать и более сложные модели; так же заметим, что значение этого члена легко вычисляется из базы слов языка;
- P(x | w) — вероятность того, что правильное слово w было ошибочно написано как x, этот член называется channel model; в принципе обладая достаточно большой базой, которая содержит все способы ошибиться при написании каждого слова языка, то вычисление этого члена не вызвало бы трудностей, но к сожалению такой большой базы нет, но есть похожие базы меньшего размера, так что придется как то выкручиваться (например здесь находится база из 333333 слов английского языка, и только для 7481 есть слова с ошибками).
Вычисление значения вероятности P(x | w)
Тут к нам на помощь приходит расстояние Дамерау-Левенштейна — это мера между двумя последовательностями символов, определяемая как минимальное количество операций вставки, удаления, замены и перестановки соседних символов для приведения строки source к строке target. Мы же далее будем использовать расстояние Левенштейна, которое отличается тем, что не поддерживает операцию перестановки соседних символов, так будет проще. Оба эти алгоритма с примерами хорошо описаны в тут, так что я повторяться не буду, а сразу приведу код:
Расстояние Левенштейна
public static int LevenshteinDistance(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
d[i, j] = (new int[]
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
}).Min();
}
}
return d[s.Length, t.Length];
}
Эта функция сообщает нам сколько операций удаления, вставки и замены нужно произвести для приведения одного слова к другому, но нам этого не достаточно, а хотелось бы получить так же список этих самых операций, назовем это backtrace алгоритма. Нам необходим модифицировать приведенный код таким образом, что бы при вычислении матрицы расстояний d, так же записывалась матрица операций b. Рассмотрим пример для слов ca и abc:
Как вы помните, значение ячейки (i,j) в матрице расстояний d вычисляется следующим образом:
d[i, j] = (new int[]
{
d[i - 1, j] + 1, // del - 0
d[i, j - 1] + 1, // ins - 1
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub - 2
}).Min();
Нам остается в ячейку (i,j) матрицы операций b записывать индекс операции (0 для удаления, 1 для вставки и 2 для замены), соответственно этот кусок кода преобразуется следующим образом:
IList<int> vals = new List<int>()
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
};
d[i, j] = vals.Min();
int idx = vals.IndexOf(d[i, j]);
b[i, j] = idx;
Как только обе матрицы заполнены, не составит труда вычислить backtrace (стрелочки на картинках выше). Это путь из правой нижней ячейки матрицы операций, по пути наименьшей стоимости матрицы расстояний. Опишем алгоритм:
- обозначим правую нижнюю ячейку как текущую
- делаем одно из следующих действий
- если удаление, то записываем удаленный символ, и сдвигаем текущую ячейку вверх (красная стрелка)
- если вставка, то записываем вставленный символ и сдвигаем текущую ячейку влево (красная стрелка)
- если замена, а так же заменяемые символы не равны, то записываем заменяемые символы и сдвигаем текущую ячейку налево и вверх (красная стрелка)
- если замена, но заменяемые символы равны, то только сдвигаем текущую ячейку налево и вверх (синяя стрелка)
- если количество записанных операций не равно расстоянию Левенштейна, то на пункт назад, иначе стоп
В итоге получим следующую функцию, вычисляющую расстояние Левенштейна, а так же backtrace:
Расстояние Левенштейна с backtrace’ом
//del - 0, ins - 1, sub - 2
public static Tuple<int, IList<Tuple<int, string>>> LevenshteinDistanceWithBacktrace(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
int[,] b = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
b[0, j] = 1;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
IList<int> vals = new List<int>()
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
};
d[i, j] = vals.Min();
int idx = vals.IndexOf(d[i, j]);
b[i, j] = idx;
}
}
List<Tuple<int, string>> bt = new List<Tuple<int, string>>();
int x = s.Length;
int y = t.Length;
while (bt.Count != d[s.Length, t.Length])
{
switch (b[x, y])
{
case 0:
x--;
bt.Add(new Tuple<int, string>(0, s[x].ToString()));
break;
case 1:
y--;
bt.Add(new Tuple<int, string>(1, t[y].ToString()));
break;
case 2:
x--;
y--;
if (s[x] != t[y])
{
bt.Add(new Tuple<int, string>(2, s[x] + "" + t[y]));
}
break;
}
}
bt.Reverse();
return new Tuple<int, IList<Tuple<int, string>>>(d[s.Length, t.Length], bt);
}
Эта функция возвращает кортеж, в первом элементе которого записано расстояние Левенштейна, а во втором список пар <id операции, строка>, строка состоит из одного символа для операций удаления и вставки, и из двух символов для операции замены (подразумевается замена первого символа на второй).
PS: внимательный читатель заметит, что из правой нижней ячейки часто существует несколько способов движения по пути наименьшей стоимости, это один из способов увеличить выборку, но мы его для простоты так же опустим.
Математическая модель — 2
Теперь опишем полученный выше результат на языке формул. Для двух слов x и w мы можем вычислить список операций необходимых для приведений первого слова ко второму, обозначим список операции буквой f, тогда вероятность написать слово x как w будет равна вероятности произвести весь список ошибок f при условии, что мы писали именно x, а подразумевали w:
Вот тут начинаются упрощения, похожие на те что были в наивном байесовском классификаторе:
- порядок следования операций ошибки не имеет значения
- ошибка не будет зависеть от того какое слово мы написали и от того что подразумевали
Теперь для того что бы вычислить вероятности ошибок (независимо от того в каких словах они были сделаны) достаточно иметь на руках любую базу слов с их ошибочным написанием. Запишем финальную формулу, во избежание работы с числами близкими к нулю, будем работать в log space:
Итак, что же мы имеем? Если у нас на руках есть достаточный набор текстов мы можем вычислить априорные вероятности слов в языке; так же имея на руках базу слов с их ошибочным написанием, мы можем вычислить вероятности ошибок, этих двух баз достаточно что бы реализовать модель.
Размытие вероятностей ошибок
При пробеге по все базе слов при argmax, мы ни разу не наткнемся на слова с нулевой вероятностью. Но вот при вычислении операций редактирования для приведения слова x к слову w могут возникнуть такие операции, которые не встречались в нашей базе ошибок. В этом случае нам поможет additive smoothing или размытие по Лапласу (оно так же использовалось в наивном байесовском классификаторе). Напомню формулу, в контексте текущей задачи. Если некоторая операция коррекции f встречается в базе n раз, при том что всего ошибок в базе m, а типов коррекции t (например для замены, не то сколько раз встречается замена «a на b«, а сколько всего уникальных пар «* на *»), то размытая вероятность выглядит следующим образом, где k — коэффициент размытия:
Тогда вероятность операции которая ни разу не встречалась в обучающей базе (n = 0) будет равна:
Скорость
Возникает естественный вопрос, а как быть со скоростью работы алгоритма, ведь нам придется пробегать по всей базе слов, а это сотни тысяч вызовов функции вычисления расстояния Левенштейна с backtrace’ом, а так же вычислять для всех слов вероятности ошибки (сумма чисел, если хранить в базе предвычисленные логарифмы). Тут приходит на помощь следующий статистический факт:
- 80% всех печатных ошибок находятся в пределах 1 операции редактирования, т.е. расстояния Левенштейна равным единице
- почти все печатные ошибки находятся в пределах 2 операций редактирования
Ну а далее вы можете придумывать различные алгоритмические трюки. Я использовал очевидный и очень простой способ ускорить работу алгоритма. Очевидно, что если мне требуются только слова не более чем в t операций редактирования от текущего слова, то их длина отличается от текущего не более чем на t. При инициализации класса, я создаю хэш-таблицу, в которой ключами является длины слов, а значениями — множества слов этой длины, это позволяет значительно сокращать пространство поиска.
Код
Приведу код класса NoisyChannel который у меня получился:
NoisyChannel
public class NoisyChannel
{
#region vars
private string[] _words = null;
private double[] _wLogPriors = null;
private IDictionary<int, IList<int>> _wordLengthDictionary = null; //length of word - word indices
private IDictionary<int, IDictionary<string, double>> _mistakeLogProbs = null;
private double _lf = 1d;
private IDictionary<int, int> _mNorms = null;
#endregion
#region ctor
public NoisyChannel(string[] words, long[] wordFrequency,
IDictionary<int, IDictionary<string, int>> mistakeFrequency,
int mistakeProbSmoothing = 1)
{
_words = words;
_wLogPriors = new double[_words.Length];
_wordLengthDictionary = new SortedDictionary<int, IList<int>>();
double wNorm = wordFrequency.Sum();
for (int i = 0; i < _words.Length; i++)
{
_wLogPriors[i] = Math.Log((wordFrequency[i] + 0d)/wNorm);
int wl = _words[i].Length;
if (!_wordLengthDictionary.ContainsKey(wl))
{
_wordLengthDictionary.Add(wl, new List<int>());
}
_wordLengthDictionary[wl].Add(i);
}
_lf = mistakeProbSmoothing;
_mistakeLogProbs = new Dictionary<int, IDictionary<string, double>>();
_mNorms = new Dictionary<int, int>();
foreach (int mType in mistakeFrequency.Keys)
{
int mNorm = mistakeFrequency[mType].Sum(m => m.Value);
_mNorms.Add(mType, mNorm);
int mUnique = mistakeFrequency[mType].Count;
_mistakeLogProbs.Add(mType, new Dictionary<string, double>());
foreach (string m in mistakeFrequency[mType].Keys)
{
_mistakeLogProbs[mType].Add(m,
Math.Log((mistakeFrequency[mType][m] + _lf)/
(mNorm + _lf*mUnique))
);
}
}
}
#endregion
#region correction
public IDictionary<string, double> GetCandidates(string s, int maxEditDistance = 2)
{
IDictionary<string, double> candidates = new Dictionary<string, double>();
IList<int> dists = new List<int>();
for (int i = s.Length - maxEditDistance; i <= s.Length + maxEditDistance; i++)
{
if (i >= 0)
{
dists.Add(i);
}
}
foreach (int dist in dists)
{
foreach (int tIdx in _wordLengthDictionary[dist])
{
string t = _words[tIdx];
Tuple<int, IList<Tuple<int, string>>> d = LevenshteinDistanceWithBacktrace(s, t);
if (d.Item1 > maxEditDistance)
{
continue;
}
double p = _wLogPriors[tIdx];
foreach (Tuple<int, string> m in d.Item2)
{
if (!_mistakeLogProbs[m.Item1].ContainsKey(m.Item2))
{
p += _lf/(_mNorms[m.Item1] + _lf*_mistakeLogProbs[m.Item1].Count);
}
else
{
p += _mistakeLogProbs[m.Item1][m.Item2];
}
}
candidates.Add(_words[tIdx], p);
}
}
candidates = candidates.OrderByDescending(c => c.Value).ToDictionary(c => c.Key, c => c.Value);
return candidates;
}
#endregion
#region static helper
//del - 0, ins - 1, sub - 2
public static Tuple<int, IList<Tuple<int, string>>> LevenshteinDistanceWithBacktrace(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
int[,] b = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
b[0, j] = 1;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
IList<int> vals = new List<int>()
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
};
d[i, j] = vals.Min();
int idx = vals.IndexOf(d[i, j]);
b[i, j] = idx;
}
}
List<Tuple<int, string>> bt = new List<Tuple<int, string>>();
int x = s.Length;
int y = t.Length;
while (bt.Count != d[s.Length, t.Length])
{
switch (b[x, y])
{
case 0:
x--;
bt.Add(new Tuple<int, string>(0, s[x].ToString()));
break;
case 1:
y--;
bt.Add(new Tuple<int, string>(1, t[y].ToString()));
break;
case 2:
x--;
y--;
if (s[x] != t[y])
{
bt.Add(new Tuple<int, string>(2, s[x] + "" + t[y]));
}
break;
}
}
bt.Reverse();
return new Tuple<int, IList<Tuple<int, string>>>(d[s.Length, t.Length], bt);
}
public static int LevenshteinDistance(string s, string t)
{
int[,] d = new int[s.Length + 1, t.Length + 1];
for (int i = 0; i < s.Length + 1; i++)
{
d[i, 0] = i;
}
for (int j = 1; j < t.Length + 1; j++)
{
d[0, j] = j;
}
for (int i = 1; i <= s.Length; i++)
{
for (int j = 1; j <= t.Length; j++)
{
d[i, j] = (new int[]
{
d[i - 1, j] + 1, // del
d[i, j - 1] + 1, // ins
d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub
}).Min();
}
}
return d[s.Length, t.Length];
}
#endregion
}
Инициализируется класс следующими параметрами:
- string[] words — список слов языка;
- long[] wordFrequency — частота слов;
- IDictionary<int, IDictionary<string, int>> mistakeFrequency
- int mistakeProbSmoothing = 1 — коэффициент размытия частоты ошибок
Тестирование
Для тестирования используем базу Питера Норвига, в которой содержится 333333 слов с частотами, а также 7481 слово с ошибочными написаниями. Следующий код используется для вычисления значений необходимых для ининциализации класса NoisyChannel:
чтение базы
string[] words = null;
long[] wordFrequency = null;
#region read priors
if (!File.Exists("../../../Data/words.bin") || !File.Exists("../../../Data/wordFrequency.bin"))
{
IDictionary<string, long> wf = new Dictionary<string, long>();
Console.Write("Reading data:");
using (StreamReader sr = new StreamReader("../../../Data/count_1w.txt"))
{
string line = sr.ReadLine();
while (line != null)
{
string[] parts = line.Split('t');
wf.Add(parts[0].Trim(), Convert.ToInt64(parts[1]));
line = sr.ReadLine();
Console.Write(".");
}
sr.Close();
}
Console.WriteLine("Done!");
words = wf.Keys.ToArray();
wordFrequency = wf.Values.ToArray();
using (FileStream fs = File.Create("../../../Data/words.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
bf.Serialize(fs, words);
fs.Flush();
fs.Close();
}
using (FileStream fs = File.Create("../../../Data/wordFrequency.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
bf.Serialize(fs, wordFrequency);
fs.Flush();
fs.Close();
}
}
else
{
using (FileStream fs = File.OpenRead("../../../Data/words.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
words = bf.Deserialize(fs) as string[];
fs.Close();
}
using (FileStream fs = File.OpenRead("../../../Data/wordFrequency.bin"))
{
BinaryFormatter bf = new BinaryFormatter();
wordFrequency = bf.Deserialize(fs) as long[];
fs.Close();
}
}
#endregion
//del - 0, ins - 1, sub - 2
IDictionary<int, IDictionary<string, int>> mistakeFrequency = new Dictionary<int, IDictionary<string, int>>();
#region read mistakes
IDictionary<string, IList<string>> misspelledWords = new SortedDictionary<string, IList<string>>();
using (StreamReader sr = new StreamReader("../../../Data/spell-errors.txt"))
{
string line = sr.ReadLine();
while (line != null)
{
string[] parts = line.Split(':');
string wt = parts[0].Trim();
misspelledWords.Add(wt, parts[1].Split(',').Select(w => w.Trim()).ToList());
line = sr.ReadLine();
}
sr.Close();
}
mistakeFrequency.Add(0, new Dictionary<string, int>());
mistakeFrequency.Add(1, new Dictionary<string, int>());
mistakeFrequency.Add(2, new Dictionary<string, int>());
foreach (string s in misspelledWords.Keys)
{
foreach (string t in misspelledWords[s])
{
var d = NoisyChannel.LevenshteinDistanceWithBacktrace(s, t);
foreach (Tuple<int, string> ml in d.Item2)
{
if (!mistakeFrequency[ml.Item1].ContainsKey(ml.Item2))
{
mistakeFrequency[ml.Item1].Add(ml.Item2, 0);
}
mistakeFrequency[ml.Item1][ml.Item2]++;
}
}
}
#endregion
Следующий код инициализирует модель и выполняет поиск правильных слов для слова «he;;o» (конечно подразумевается hello, точка-с-запятой находятся справа от l и легко было ошибиться при печати, в базе в списке ошибочных написания слова hello нет слова he;;o) на расстоянии не более 2, с засечением времени:
NoisyChannel nc = new NoisyChannel(words, wordFrequency, mistakeFrequency, 1);
Stopwatch timer = new Stopwatch();
timer.Start();
IDictionary<string, double> c = nc.GetCandidates("he;;o", 2);
timer.Stop();
TimeSpan ts = timer.Elapsed;
Console.WriteLine(ts.ToString());
У меня такое вычисление занимает в среднем чуть менее 1 секунды, хотя конечно процесс оптимизации не исчерпывается приведенными способами, а наоборот, только начинается с них. Взглянем на варианты замены и их вероятности:
Ссылки
- курс Natural Language Processing на курсере
- Natural Language Corpus Data: Beautiful Data
- годное описание алгоритмов Левенштейна и Домерау-Левенштейна
Архив с кодом можно слить от сюда.
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
Орфография в последнее время стала менее востребованной и её важность значительно уменьшилась за счёт средств проверки орфографии, которые есть во многих программах по обработке текста.
Некоторые реформаторы образования считают, что учащиеся с помощью подобных программ будут развивать навыки правописания через чтение обработанных данными программами текстов.
Современные технологии являются мощнейшим инструментом, облегчающим процесс обучения. Некоторые утверждают, что он достаточно мощный, чтобы делать обучение написанию ненужным. В конце концов, для чего нужна проверка орфографии? Проверка орфографии — прекрасный инструмент для исправления мелких ошибок, которые допускают хорошие орфографы, и для типичных опечаток.
Если учащийся обладает достаточными языковыми знаниями, программа для проверки правописания значительно экономит время.
Программы для проверки орфографии встроены во многие популярные текстовые редакторы, например, компания «Информатик» лицензировала свою технологию проверки правописания компании Microsoft для MS Office.
Благодаря этому внедрению огромное число пользователей получили возможность автоматически исправлять тексты, не теряя свое время на длительную проверку текста [2]. В современном обществе это является одним из самых важных достоинств текстовых программ.
При написании различных текстов, таких как рефераты, научные статьи, курсовые работы, различного рода проекты, дипломные работы, юридические документы, заявления и другие тексты, часто требуется его проверка на наличие орфографических или пунктуационных ошибок. Эти программы созданы для того, чтобы не искать справочник по русскому языку и не занимать этим много времени, а также на случай если многие правила основательно забыты после окончания школы.
Особенно важно грамотное написание текстов юридической направленности, здесь каждая лишняя запятая может привести к длительным судебным тяжбам и многочисленным лингвистическим экспертизам.
Текстовый редактор Microsoft Word необходим для анализа представленного вами документа и предложения вам наиболее выгодным для вас условиям написания текста, таких как орфография, грамматика и стилистика, например, сделать предложения более краткими, выбрать более простые слова или написать более формально.
Для более эффективной работы по поиску и исправлению ошибок в редакторе есть дополнительные инструменты, которые мы рассмотрим на примере Word 2016. Однако интерфейс отчасти схож с предыдущими выпусками приложения.
По умолчанию, Word использует подчеркивание красной линией незнакомых ему слов, которые он считает за ошибку.
Для того, чтобы исправить неизвестное ему слово необходимо нажать правой клавишей мыши на подчеркнутое слово или области этого слова и приложение автоматически предложит варианты его исправления. Но в некоторых случаях бывает и так, что альтернативы подчёркнутого слова нет или предлагаемые программой варианты вам не подходят.
В большинстве случаев Word не знаком с названиями различных компаний и мест, фамилиями и некоторыми именами. Для того, чтобы в будущем при использовании подчёркнутых слов они не были не известны программе, необходимо добавить его в словарь, выбрав через контекстное меню опцию «Добавить в словарь» и слово не будет считаться за ошибку и запомнится программой на всё время. К тому же, если выбрать в контекстном меню пункт «Пропустить все» в текущем документе вы избавитесь от назойливых подчеркиваний.
Подобным образом работает и проверка грамматики в документе. Разница лишь в том, что цвет подчеркивания не красный, а синий. Ошибкой это является не всегда, часто это является мнение тектового редактора, которое основывается на встроенных в него правилах.
Настроить набор доступных грамматических правил, включить или отключить данную опцию можно через меню «Файл» – «Параметры» – вкладка «Правописание».
Для того, чтобы проверить все ошибки в документе последовательно необходимо перейти во вкладку под названием «Рецензирование» и нажать на кнопку «Правописание». После этого Word будет показывать вам ошибки последовательно и справа в документе откроется окно, в котором будут представлены варианты исправления ошибки и кнопки по управлению процедурой. Данная опция действительно в значимой степени экономит время при работе с большими документами, последовательно показывая вам ошибки в тексте, вместо того, чтобы вы самостоятельно выискивали каждое подчеркнутое редактором слово.
Также средство проверки правописания Word может помочь и в проверке пунктуации. Так, если в предложении есть или возможны пунктуационные ошибки, то оно будет подчёркнуто зелёным цветом. Причину «недовольства» Word можно узнать, нажав на контекстное меню. Причина отобразится на экране и сообщит пользователю о возможных проблемах с расставлением знаков препинаний.
Конечно, создание программы, обнаруживающей абсолютно все ошибки практически невозможно, ведь алгоритм, используемый для проверки русского языка достаточно сложен. Учитывая особенности употребления различных языковых конструкций в конкретных ситуациях, все многообразие форм и другие нюансы, можно сказать, что включение их в программу практически невозможно.
Одним из самых сложных задач, возложенных на программу является оценивание правильности расстановки запятых. Так, если проверяет человек, он может подойти к процессу творчески и чем лучше он знает базовые правила языка, тем быстрее и качественнее будет проверка. В том случае, если проверяет программа, некоторые ошибки ей могут просто игнорироваться, а некоторые, наоборот, без оснований выделяются. Подобные случаи происходят довольно таки часто.
Для подобных программ также важен набор включенных в них словарей. Так качество и быстрота проверки в основном зависит от количества слов в подключенных словарях. Например, многие программы не знакомыы с такими словами, как биткоины, блогер или файервол, несмотря на то, что они давно задействованы в русском языке.
Программы и системы для проверки правописания в документах, которые используются в огромном количестве современных текстовых редакторов, могут позволить выявление большей части допущенных опечаток и ошибок. Принципом действия таких систем является сдедующий: система для проверки правописания находит проверяемое слово во встроенном в неё словаре в нужной пользователю грамматической форме. В случае, если программа нашла слово, то оно будет считаться написанным по правилам, а если слово не было найдено программой во встроенном словаре, но есть похожие слова, то программа выдаёт сообщение об ошибке и предлагаются возможные варианты замены.
В случае, если программа не смогла найти ни это слово, ни похожие на него слова, то она предлагает либо исправить его, либо занести его в словарь.
Также проверка орфографии по словарю не выявляет случаи, в которых ошибка допущена так, что слово есть в словаре. Такие ошибки скрыты от программы, но человек их легко заметит. Примерами таких случаев можно считать следующие: 1. «Иван Петрович шлет Вам по клон». В данном случае нам сразу же видно где ошибка, здесь подразумевалось слово поклон. 2. «Я не нашел нежный файл». Здесь ошибка в слове «нежный» и сразу понятно, что необходимо было написать слово нужный. В обоих случаях программа не увидела ошибки, так как эти слова соответствовали словам в словаре, но не подходили по смыслу, что сразу видно человеку.
Но также существуют и программы, являющиеся более интеллектуальными, которые позволяют выявлять ошибки в согласовании форм слов и расстановке знаков препинания. Они хранят в себе набор специальных правил, которые записаны в формальном виде. Подобная система позволяет обратить внимание пользователя на подозрительные места, напрмер, в фразе про Ивана Петровича, она предположит, что слово «клон» употреблено не в том падеже или пропущено связующее слово между ним и предлогом «по». В любом из этих случаев, пользователь обратит внимание на выделенную ошибку и исправит её.
Подводя итог, мы можем сказать, что программы для проверки правописания обнаруживают достаточно много ошибок и опечаток и чем больше словарь программы, тем больше правил и алгоритмов для проверки текстов она знает, и, соответственно, процент обнаружения ей ошибок достаточно велик. Но любая система для проверки правописания не может гарантировать полное отсутствие ошибок и опечаток в тексте, а также абсолютной правильности построения смысловых цепочек.
В работе предложен метод и алгоритм проверки орфографии в научном тексте.
Список литературы
1.Алгазина, Н.Н. Методика изучения орфографических правил/- М.: Просвещение. 1982.- 48с.
2.Жиленко А.Г. Использование алгоритмов при изучении орфографии // РЯШ. — 1986. — N5. — С.53-55.
3.Методика развития речи / Под ред. Ладыженской Т. А. — М., 1991.,242 с.
4.Такташкин Д.В., Масенко И.А.. Модель вариантов использования программы для писателей «Сюжет» // Современные научные исследования и инновации 2016. № 3 [Электронный ресурс]. URL:http://web.sna.uka..ru/issues/2016/03/64882 (дата. обращения: 05.12.2020)
5.Поваляев Е. Системы проверки орфографии [Электронный ресурс] . URL:http://compress.ru/a.rticle.a.spx?id=9511 (дата обращения: 05.12.2020).
#c #algorithm #language-agnostic #nlp #spell-checking
#c #алгоритм #язык не зависит от языка #nlp #проверка орфографии
Вопрос:
Мне было поручено создать простую проверку орфографии для задания, но я не дал почти никаких указаний, поэтому мне было интересно, может ли кто-нибудь мне помочь. Я не хочу, чтобы кто-то выполнял задание за меня, но любое направление или помощь с алгоритмом были бы потрясающими! Если то, о чем я спрашиваю, не входит в список гильдий сайта, то мне жаль, и я буду искать в другом месте. 🙂
Проект загружает правильно написанные строчные слова, а затем должен сделать предложения по правописанию на основе двух критериев:
-
Разница в одну букву (добавляется или вычитается, чтобы слово совпадало со словом в словаре). Например, ‘stack’ будет предложением для ‘staick’, а ‘cool’ будет предложением для ‘coo’.
-
Замена одной буквы. Так, например, ‘bad’ было бы предложением для ‘bod’.
Итак, просто чтобы убедиться, что я правильно объяснил.. Я мог бы загрузить слова [hello, goodbye, fantastic, good, god], а затем предложения для (неправильно написанного) слова «godd» будут [good, god] .
Скорость — мое главное соображение здесь, поэтому, хотя я думаю, что знаю способ выполнить эту работу, я действительно не слишком уверен в том, насколько это будет эффективно. Способ, которым я собираюсь это сделать, состоит в том, чтобы создать map<string, vector<string>> , а затем для каждого загруженного слова с правильным написанием, добавить правильно написанную работу в качестве ключа на карте и заполнить вектор всеми возможными «неправильными» перестановками этого слова.
Затем, когда я захочу найти слово, я просмотрю каждый вектор на карте, чтобы увидеть, является ли это слово перестановкой одного из правильно написанных слов. Если это так, я добавлю ключ в качестве предложения по правописанию.
Похоже, что это займет КУЧУ памяти, хотя, потому что наверняка будут тысячи перестановок для каждого слова? Также кажется, что это было бы очень медленно, если бы мой первоначальный словарь правильно написанных слов был большим?
Я подумал, что, возможно, я мог бы немного сократить время, только просматривая ключи, похожие на слово, на которое я смотрю. Но опять же, если они чем-то похожи, это, вероятно, означает, что ключом будет предложение, означающее, что мне не нужны все эти перестановки!
Так что да, я немного озадачен тем, в каком направлении мне следует искать. Я был бы очень признателен за любую помощь, поскольку я действительно не уверен, как оценить скорость различных способов выполнения действий (нас этому вообще не учили в классе).
Комментарии:
1. Существует довольно много инструментов обработки естественного языка с открытым исходным кодом, которые могут быть использованы в качестве источника вдохновения для использования алгоритмов. Для задания C просмотр инструмента с открытым исходным кодом Java может быть, например, хорошим выбором, чтобы убедиться, что вы выбираете только алгоритмы: см. languagetool.org для примера.
Ответ №1:
Более простым способом решения проблемы действительно является предварительно вычисленная карта [плохое слово] -> [предложения].
Проблема в том, что, хотя удаление буквы создает несколько «плохих слов», для добавления или замены у вас есть много кандидатов.
Поэтому я бы предложил другое решение 😉
Примечание: расстояние редактирования, которое вы описываете, называется расстоянием Левенштейна
Решение описано поэтапно, обычно скорость поиска должна постоянно улучшаться при каждой идее, и я попытался сначала организовать их с помощью более простых идей (с точки зрения реализации). Не стесняйтесь останавливаться, когда вас устраивают результаты.
0. Предварительный
- Реализация алгоритма расстояния Левенштейна
- Храните словарь в отсортированной последовательности (
std::setнапример, хотя сортировкаstd::dequeилиstd::vectorбыла бы более эффективной с точки зрения производительности)
Ключевые моменты:
- Вычисление расстояния Левенштейна использует массив, на каждом шаге следующая строка вычисляется исключительно с предыдущей строкой
- Минимальное расстояние в строке всегда больше (или равно) минимальному значению в предыдущей строке
Последнее свойство допускает реализацию с коротким замыканием: если вы хотите ограничить себя 2 ошибками (пороговым значением), то всякий раз, когда минимум текущей строки превышает 2, вы можете отказаться от вычисления. Простая стратегия заключается в возврате порога 1 в качестве расстояния.
1. Первый предварительный
Давайте начнем с простого.
Мы реализуем линейное сканирование: для каждого слова мы вычисляем расстояние (короткое замыкание) и перечисляем те слова, которые достигли меньшего расстояния до сих пор.
Он очень хорошо работает с небольшими словарями.
2. Улучшение структуры данных
Расстояние Левенштейна, по крайней мере, равно разнице в длине.
Используя в качестве ключа пару (длина, слово) вместо просто word, вы можете ограничить поиск диапазоном длины [length - edit, length edit] и значительно сократить пространство поиска.
3. Префиксы и обрезка
Чтобы улучшить это, мы можем заметить, что когда мы строим матрицу расстояний, строка за строкой, один мир полностью сканируется (слово, которое мы ищем), а другой (референт) — нет: мы используем только одну букву для каждой строки.
Это очень важное свойство означает, что для двух ссылок, которые используют одну и ту же начальную последовательность (префикс), тогда первые строки матрицы будут идентичными.
Помните, что я прошу вас сохранить словарь отсортированным ? Это означает, что слова, имеющие один и тот же префикс, являются смежными.
Предположим, что вы проверяете свое слово cartoon и car понимаете, что оно не работает (расстояние уже слишком велико), тогда любое слово, начинающееся с car , тоже не будет работать, вы можете пропускать слова, пока они начинаются car .
Сам пропуск может быть выполнен либо линейно, либо с помощью поиска (найдите первое слово, у которого префикс выше, чем car ):
- линейный работает лучше всего, если префикс длинный (несколько слов для пропуска)
- двоичный поиск лучше всего подходит для короткого префикса (много слов, которые нужно пропустить)
Длина «long» зависит от вашего словаря, и вам придется измерить. Я бы начал с бинарного поиска.
Примечание: разделение по длине работает против разделения по префиксу, но оно значительно сокращает пространство поиска
4. Префиксы и повторное использование
Теперь мы также попытаемся повторно использовать вычисления как можно чаще (а не только результат «это не работает»)
Предположим, что у вас есть два слова:
- Мультфильм
- автомойка
Сначала вы вычисляете матрицу, строка за строкой, для cartoon . Затем при чтении carwash вам нужно определить длину общего префикса (здесь car ), и вы можете сохранить первые 4 строки матрицы (соответствующие void, c , a , r ).
Поэтому, когда вы начинаете вычисления carwash , вы фактически начинаете итерацию w .
Для этого просто используйте массив, выделенный непосредственно в начале вашего поиска, и сделайте его достаточно большим, чтобы вместить большую ссылку (вы должны знать, какова наибольшая длина в вашем словаре).
5. Использование «лучшей» структуры данных
Чтобы упростить работу с префиксами, вы могли бы использовать дерево Trie или дерево Patricia для хранения словаря. Однако это не структура данных STL, и вам нужно будет дополнить ее, чтобы сохранить в каждом поддереве диапазон длины слов, которые хранятся, поэтому вам придется создать свою собственную реализацию. Это не так просто, как кажется, потому что есть проблемы с расширением памяти, которые могут уничтожить локальность.
Это крайний вариант. Это дорого для реализации.
Комментарии:
1. Хм, Trie, реализованный в виде vector of
Node{unsigned short prevIndex, bool end; unsigned short nextIndex[26];}, может содержать 65536 слов всего в 3,5 МБАЙТ пространства (помещается в кэш L3 i7!), И это сделало бы проверку орфографии относительно простой рекурсивной задачей. Я собираюсь поиграть с этим2. @MooingDuck: вам не нужно
prevIndex, если вы поддерживаете «толстый» итератор.3. Вероятно, проще использовать prevIndex в рекурсии, чем итератор. Но вы правы, что это не обязательно должно быть там.
4. Первоначальное тестирование показывает, что мой Trie в два раза превышает время моей хэш-таблицы. Хэш-таблица принимает строку, размывает ее и проверяет, есть ли в хэш-таблице какие-либо нечеткости, ранжируя по тому, насколько она размыта и насколько. Ничего не значит, пока я не проверю точность для любого из них.
5. Извините, что так долго отвечаю, но огромное спасибо за это, действительно очень полезно. 🙂
Ответ №2:
Вы должны взглянуть на это объяснение Питера Норвига о том, как написать корректор орфографии .
Как написать корректор орфографии
В этой статье все хорошо объяснено, в качестве примера код python для проверки орфографии выглядит следующим образом :
import re, collections
def words(text): return re.findall('[a-z] ', text.lower())
def train(features):
model = collections.defaultdict(lambda: 1)
for f in features:
model[f] = 1
return model
NWORDS = train(words(file('big.txt').read()))
alphabet = 'abcdefghijklmnopqrstuvwxyz'
def edits1(word):
splits = [(word[:i], word[i:]) for i in range(len(word) 1)]
deletes = [a b[1:] for a, b in splits if b]
transposes = [a b[1] b[0] b[2:] for a, b in splits if len(b)>1]
replaces = [a c b[1:] for a, b in splits for c in alphabet if b]
inserts = [a c b for a, b in splits for c in alphabet]
return set(deletes transposes replaces inserts)
def known_edits2(word):
return set(e2 for e1 in edits1(word) for e2 in edits1(e1) if e2 in NWORDS)
def known(words): return set(w for w in words if w in NWORDS)
def correct(word):
candidates = known([word]) or known(edits1(word)) or known_edits2(word) or [word]
return max(candidates, key=NWORDS.get)
Надеюсь, вы сможете найти то, что вам нужно, на веб-сайте Питера Норвига.
Ответ №3:
для проверки орфографии многие структуры данных были бы полезны, например, BK-Tree. Проверьте чертовски крутые алгоритмы, часть 1: BK-деревья, для которых я сделал реализацию здесь
Моя предыдущая ссылка на код может вводить в заблуждение, эта верна для корректора правописания.
Ответ №4:
с моей точки зрения, вы могли бы разделить свои предложения на основе длины и построить древовидную структуру, в которой дочерние элементы являются более длинными вариантами более короткого родительского элемента.
должно быть довольно быстро, но я не уверен в самом коде, я не очень хорошо разбираюсь в c