
Нейросети кажутся людям чем-то очень сложным и запутанным, однако это вовсе не так. Простую нейросеть можно написать менее чем за час с нуля. В нашей статье мы создадим нейронную сеть прямого распространения (также называемую многослойным перцептроном), используя лишь массивы, циклы и условные операторы, а значит этот код легко можно будет перенести на любой язык программирования, предоставляющий эти возможности. А если язык предоставляет библиотеку для матричных и векторных вычислений (как, например, numpy в языке Python, то написание займёт ещё меньше времени).
Что такое нейросеть?
Согласно Википедии, искусственная нейронная сеть (ИНС) — математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма.
Более простыми словами, это некий чёрный ящик, который превращает входные данные в выходные, или, говоря более математическим языком, является отображением пространства входных признаков X в пространство выходных признаков Y: X → Y. То есть мы хотим найти какую-то функцию F, которая сможет выполнять это преобразование. Для начала этой информации нам будет достаточно. Для более подробного ознакомления рекомендуем ознакомиться с этой статьёй на хабре.
Коротко об искусственном нейроне
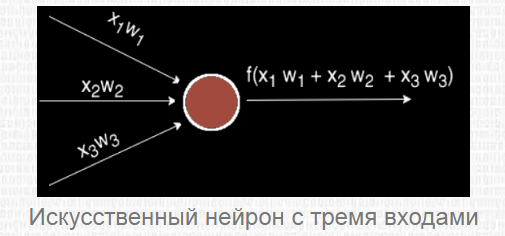
Чаще всего в подобных статьях начинают расписывать про устройство биологического нейрона, связь с его искусственной моделью и прочую лирику. Мы же этого делать не будем, а сразу перейдём к сути. Искусственный нейрон — это всего лишь взвешенная сумма значений входного вектора элементов, которая передаётся на нелинейную функцию активации f: z = f(y), где y = w0·x0 + w1·x1 + ... + wm - 1·xm - 1. Здесь w0, ..., wm - 1 — коэффициенты, веса каждого элемента вектора, x0, ..., xm - 1 — значения входного вектора X, y — взвешенная сумма элементов X, а z — результат применения функции активации. Мы вернёмся к функции активации немного позднее, а пока давайте придумаем, как вместо одного выходного значения получить n.
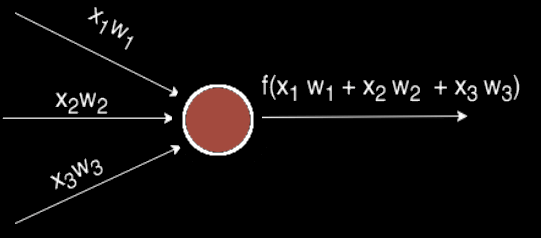
Искусственный нейрон с тремя входами
Нейронный слой
Один нейрон способен входной вектор превратить в одну точку, однако по условию мы хотим получить несколько точек, так как выходной вектор Y может иметь произвольную размерность, определяемую лишь конкретной ситуацией (один выход для XOR, 10 выходов для определения принадлежности к одному из 10 классов и т.д.). Как же нам получить n точек, преобразуя элементы входного вектора X? Оказывается, всё довольно просто: для того, чтобы получить n выходных значений, необходимо использовать не один нейрон, а n. Тогда для каждого из элементов выходного вектора Y будет использовано ровно n различных взвешенных сумм от вектора X. То есть мы получаем, что zi = f(yi) = f(wi0·x0 + wi1·x1 + ... + wim - 1·xm - 1)
Если внимательно посмотреть, то оказывается, что написанная выше формула является определением умножения матрицы на вектор. И действительно, если взять матрицу W размера n на m и умножить её на вектор X размерности m, то получится другой вектор размерности n, то есть ровно то, что нам и нужно. Таким образом, получение выходного вектора по входному для n нейронов можно записать в более удобной матричной форме: Y = W·X, где W — матрица весовых коэффициентов, X — входной вектор и Y — выходной вектор. Однако полученный вектор является неактивированным состоянием (промежуточным, невыходным) всех нейронов, а чтобы получить выходное значение,, необходимо каждое неактивированное значение подать на вход функции активации. Результат её применения и будет выходным значением слоя.
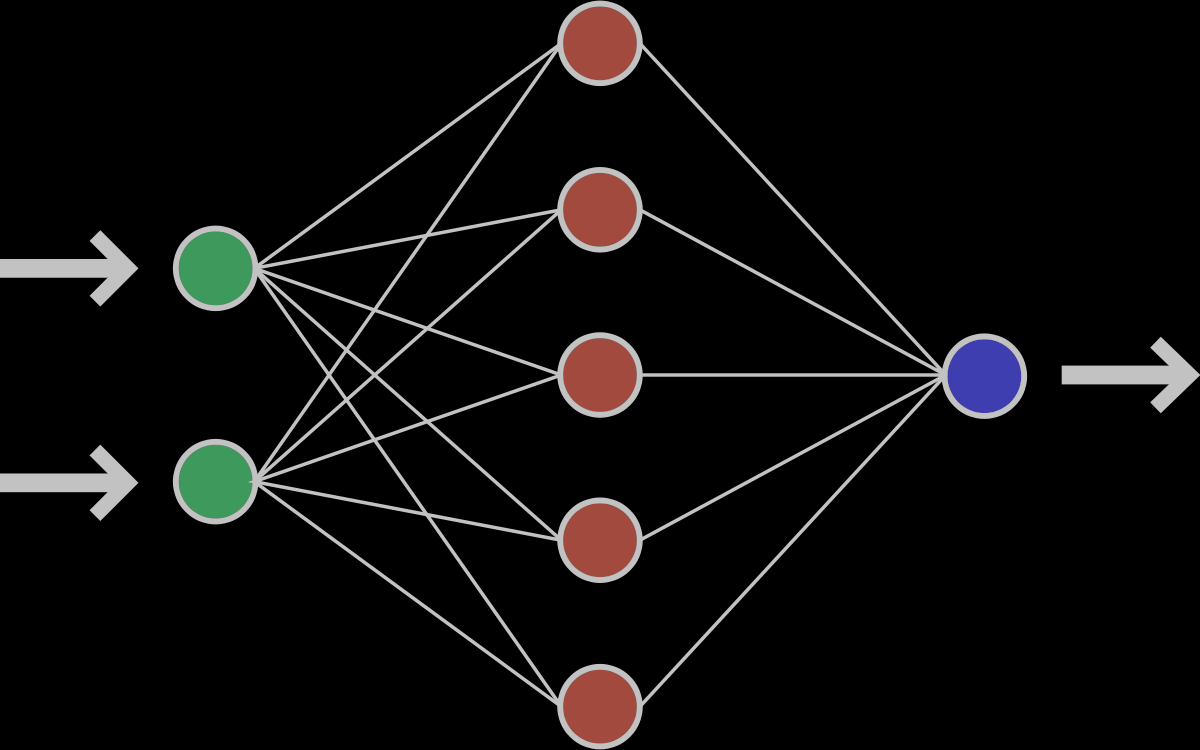
Пример нейронной сети с двумя входами, пятью нейронами в скрытом слое и одним выходом
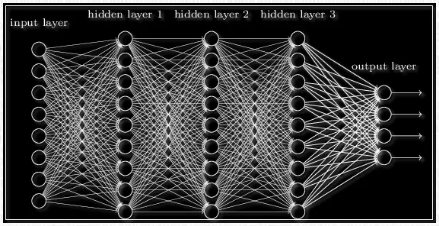
Забегая вперёд скажем о том, что нередко используют последовательность нейронных слоёв для более глубокого обучения сети и большей формализации данных. Поэтому для получения итогового выходного вектора необходимо проделать описанную выше операцию несколько раз подряд от одного слоя к другому. Тогда для первого слоя входным вектором будет X, а для всех последующих входом будет являться выход предыдущего слоя. К примеру, сеть с 3 скрытыми слоями может выглядеть так:
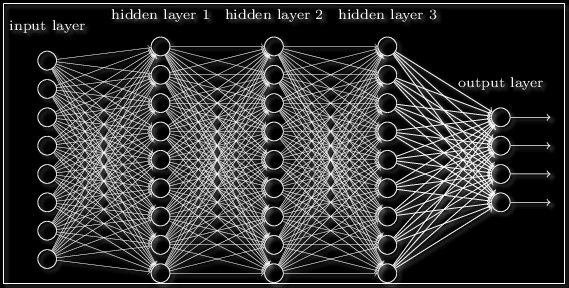
Пример многослойной нейронной сети
Функция активации
Функция активации — это функция, которая добавляет в сеть нелинейность, благодаря чему нейроны могут довольно точно имитировать любую функцию. Наиболее распространёнными функциями активации являются:
- Сигмоида:
f(x) = 1 / (1 + e-x) - Гиперболический тангенс:
f(x) = tanh(x) - ReLU:
f(x) = max(x,0)
У каждой из них есть свои особенности, но об этом лучше почитать в другой статье.
Хватит бла бла, давайте писать код
Теперь нам достаточно знаний, чтобы написать код получения результата нейронной сети. Мы будем писать код на языке C#, однако, уверяем, код будет практически идентичным для других языков программирования. Давайте разберёмся, что нам потребуется для реализации сети прямого распространения:
- Вектор (входные, выходные);
- Матрица (каждый слой содержит матрицу весовых коэффициентов);
- Нейросеть.
1. Вектор:
- Вектор можно создавать из количества элементов (длины);
- Вектор можно создавать из перечисления вещественных чисел;
- Можно получать значения по индексу i.
- Можно изменять значения по индексу i.
Напишем же это:
class Vector {
public double[] v; // значения вектора
public int n; // длина вектора
// конструктор из длины
public Vector(int n) {
this.n = n; // копируем длину
v = new double[n]; // создаём массив
}
// создание вектора из вещественных значений
public Vector(params double[] values) {
n = values.Length;
v = new double[n];
for (int i = 0; i < n; i++)
v[i] = values[i];
}
// обращение по индексу
public double this[int i] {
get { return v[i]; } // получение значение
set { v[i] = value; } // изменение значения
}
}
2. Матрица:
- Матрицу можно создавать из числа строк, столбцов и генератора случайных чисел для заполнения случайными значениями;
- Можно получать значения по индексам i и j;
- Можно изменять значения по индексам i и j;
Напишем же это:
class Matrix {
double[][] v; // значения матрицы
public int n, m; // количество строк и столбцов
// создание матрицы заданного размера и заполнение случайными числами из интервала (-0.5, 0.5)
public Matrix(int n, int m, Random random) {
this.n = n;
this.m = m;
v = new double[n][];
for (int i = 0; i < n; i++) {
v[i] = new double[m];
for (int j = 0; j < m; j++)
v[i][j] = random.NextDouble() - 0.5; // заполняем случайными числами
}
}
// обращение по индексу
public double this[int i, int j] {
get { return v[i][j]; } // получение значения
set { v[i][j] = value; } // изменение значения
}
}
3. Сама нейросеть:
class Network {
Matrix[] weights; // матрицы весов слоя
int layersN; // число слоёв
// создание сети из массива количества нейронов в каждом слое
public Network(int[] sizes) {
Random random = new Random(DateTime.Now.Millisecond); // создаём генератор случайных чисел
layersN = sizes.Length - 1; // запоминаем число слоёв
weights = new Matrix[layersN]; // создаём массив матриц
// для каждого слоя создаём матрицы весовых коэффициентов
for (int k = 1; k < sizes.Length; k++) {
weights[k - 1] = new Matrix(sizes[k], sizes[k - 1], random);
}
}
// получение выхода сети (прямое распространение)
Vector Forward(Vector input) {
Vector output; // будущий выходной вектор
for (int k = 0; k < layersN; k++) {
output = new Vector(weights[k].n); // создаём новый выходной вектор для каждого слоя
for (int i = 0; i < weights[k].n; i++) {
double y = 0; // неактивированный выход нейрона
for (int j = 0; j < weights[k].m; j++)
y += weights[k][i, j] * input[j];
// выполняем активацию с помощью сигмоидальной функции
output[i] = 1 / (1 + Math.Exp(-y));
// выполняем активацию с помощью гиперболического тангенса
// output[i] = Math.Tanh(y);
// выполняем активацию с помощью ReLU
// output[i] = Math.Max(0, y);
}
}
return output;
}
}
Сеть есть, но её ответы случайны. Как обучать?
На данный момент мы имеем случайную (необученную) нейронную сеть, которая может по входному вектору input выдать случайный ответ, однако нам требуется ответы, удовлетворяющие конкретной задаче. Чтобы добиться этого нашу сеть необходимо обучить. Для этого нам необходима база тренировочных примеров, то есть множество пар векторов X — Y, на которых будет обучаться сеть. Обучать нейросеть мы будем с помощью алгоритма обратного распространения ошибки. Если кратко, то он работает следующим образом:
- Подать на вход сети обучающий пример (один входной вектор)
- Распространить сигнал по сети вперёд (получить выход сети)
- Вычислить ошибку (разница получившегося и ожидаемого векторов)
- Распространить ошибку на предыдущие слои
- Обновить весовые коэффициенты для уменьшения ошибки
Сам же алгоритм обучения выглядит так:
error = 0 epoch = 1 повторять: Для каждого обучающего примера: Найти ошибку e = f - d Прибавить к error сумму квадратов значений e Распространенить ошибку к первому слою Обновить веса если error < eps выйти если epoch > maxEpoch выйти из-за ограничения на число эпох epoch = epoch + 1
Обучаем нейронную сеть
Для обратного распространения ошибки нам потребуется знать значения входов, выходов и значения производных функции активации сети на каждом из слоёв, поэтому создадим структуру LayerT, в которой будет 3 вектора: x — вход слоя, z — выход слоя, df — производная функции активации. Также для каждого слоя потребуются векторы дельт, поэтому добавим в наш класс ещё и их. С учётом вышесказанного наш класс станет выглядеть так:
class Network {
struct LayerT {
public Vector x; // вход слоя
public Vector z; // активированный выход слоя
public Vector df; // производная функции активации слоя
}
Matrix[] weights; // матрицы весов слоя
LayerT[] L; // значения на каждом слое
Vector[] deltas; // дельты ошибки на каждом слое
int layersN; // число слоёв
public Network(int[] sizes) {
Random random = new Random(DateTime.Now.Millisecond); // создаём генератор случайных чисел
layersN = sizes.Length - 1; // запоминаем число слоёв
weights = new Matrix[layersN]; // создаём массив матриц весовых коэффициентов
L = new LayerT[layersN]; // создаём массив значений на каждом слое
deltas = new Vector[layersN]; // создаём массив для дельт
for (int k = 1; k < sizes.Length; k++) {
weights[k - 1] = new Matrix(sizes[k], sizes[k - 1], random); // создаём матрицу весовых коэффициентов
L[k - 1].x = new Vector(sizes[k - 1]); // создаём вектор для входа слоя
L[k - 1].z = new Vector(sizes[k]); // создаём вектор для выхода слоя
L[k - 1].df = new Vector(sizes[k]); // создаём вектор для производной слоя
deltas[k - 1] = new Vector(sizes[k]); // создаём вектор для дельт
}
}
// прямое распространение
public Vector Forward(Vector input) {
for (int k = 0; k < layersN; k++) {
if (k == 0) {
for (int i = 0; i < input.n; i++)
L[k].x[i] = input[i];
}
else {
for (int i = 0; i < L[k - 1].z.n; i++)
L[k].x[i] = L[k - 1].z[i];
}
for (int i = 0; i < weights[k].n; i++) {
double y = 0;
for (int j = 0; j < weights[k].m; j++)
y += weights[k][i, j] * L[k].x[j];
// активация с помощью сигмоидальной функции
L[k].z[i] = 1 / (1 + Math.Exp(-y));
L[k].df[i] = L[k].z[i] * (1 - L[k].z[i]);
// активация с помощью гиперболического тангенса
//L[k].z[i] = Math.Tanh(y);
//L[k].df[i] = 1 - L[k].z[i] * L[k].z[i];
// активация с помощью ReLU
//L[k].z[i] = y > 0 ? y : 0;
//L[k].df[i] = y > 0 ? 1 : 0;
}
}
return L[layersN - 1].z; // возвращаем результат
}
}
Обратное распространение ошибки
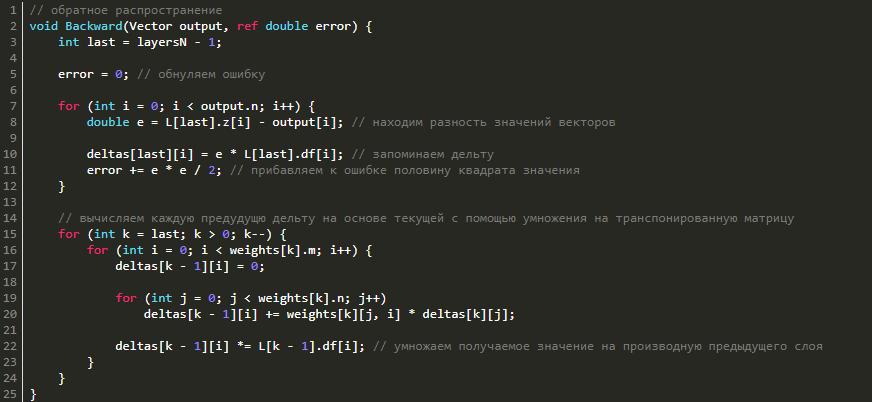
Перейдём к обратному распространению ошибки. В качестве функции оценки сети E(W) возьмём среднее квадратичное отклонение: E = 0.5 · Σ(y1i - y2i)2. Чтобы найти значение ошибки E, нам нужно найти сумму квадратов разности значений вектора, который выдала сеть в качестве ответа, и вектора, который мы ожидаем увидеть при обучении. Также нам потребуется найти дельту для каждого слоя, причём для последнего слоя она будет равна вектору разности полученного и ожидаемого векторов, умноженному (покомпонентно) на вектор значений производных последнего слоя: δlast = (zlast - d)·f'last, где zlast — выход последнего слоя сети, d — ожидаемый вектор сети, f'last — вектор значений производной функции активации последнего слоя.
Теперь, зная дельту последнего слоя, мы можем найти дельты всех предыдущих слоёв. Для этого нужно умножить транспонированную матрицы текущего слоя на дельту текущего слоя и затем умножить полученный вектор на вектор производных функции активации предыдущего слоя: δk-1 = WTk·δk·f'k.
Что ж, давайте реализуем это в коде:
// обратное распространение
void Backward(Vector output, ref double error) {
int last = layersN - 1;
error = 0; // обнуляем ошибку
for (int i = 0; i < output.n; i++) {
double e = L[last].z[i] - output[i]; // находим разность значений векторов
deltas[last][i] = e * L[last].df[i]; // запоминаем дельту
error += e * e / 2; // прибавляем к ошибке половину квадрата значения
}
// вычисляем каждую предудущю дельту на основе текущей с помощью умножения на транспонированную матрицу
for (int k = last; k > 0; k--) {
for (int i = 0; i < weights[k].m; i++) {
deltas[k - 1][i] = 0;
for (int j = 0; j < weights[k].n; j++)
deltas[k - 1][i] += weights[k][j, i] * deltas[k][j];
deltas[k - 1][i] *= L[k - 1].df[i]; // умножаем получаемое значение на производную предыдущего слоя
}
}
}
Изменение весов
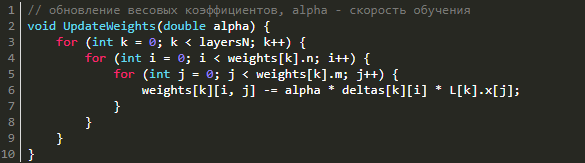
Для того, чтобы уменьшить ошибку сети нужно изменить весовые коэффициенты каждого слоя. Как же именно нужно менять весовые коэффициенты матриц на каждом слое? Оказывается, всё довольно просто. Для этого используется метод градиентного спуска, а значит нам необходимо вычислить градиент по весам и сделать шаг в отрицательную сторону от этого градиента. На этапе прямого распространения мы зачем-то запоминали входные сигналы, а при обратном распространении ошибки мы вычисляли дельты в каждом слое. Именно их мы и будем сейчас использовать для нахождения градиента! Градиент по весам равен перемножению входного вектора и вектора дельт (не покомпонентно). Поэтому, чтобы обновить весовые коэффициенты и уменьшить тем самым ошибку сети нужно всего лишь вычесть из матрицы весов результат перемножения дельт и входных векторов, умноженный на скорость обучения. Это можно записать в таком виде: Wt+1 = Wt - η·δ·X, где Wt+1 — новая матрица весов, Wt — текущая матрица весов, X — входное значение слоя, δ — дельта этого слоя. Почему именно так с математической точки зрения хорошо описано в этой статье.
// обновление весовых коэффициентов, alpha - скорость обучения
void UpdateWeights(double alpha) {
for (int k = 0; k < layersN; k++) {
for (int i = 0; i < weights[k].n; i++) {
for (int j = 0; j < weights[k].m; j++) {
weights[k][i, j] -= alpha * deltas[k][i] * L[k].x[j];
}
}
}
}
Обучение сети
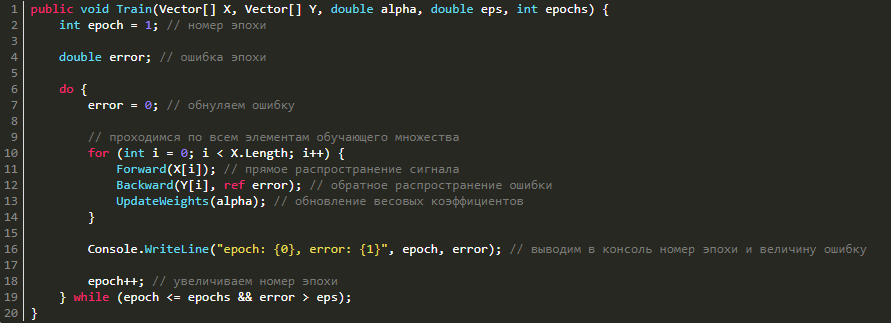
Теперь, имея методы прямого распространения сигнала, обратного распространения ошибки и изменения весовых коэффициентов, нам остаётся лишь соединить всё вместе в один метод обучения.
public void Train(Vector[] X, Vector[] Y, double alpha, double eps, int epochs) {
int epoch = 1; // номер эпохи
double error; // ошибка эпохи
do {
error = 0; // обнуляем ошибку
// проходимся по всем элементам обучающего множества
for (int i = 0; i < X.Length; i++) {
Forward(X[i]); // прямое распространение сигнала
Backward(Y[i], ref error); // обратное распространение ошибки
UpdateWeights(alpha); // обновление весовых коэффициентов
}
Console.WriteLine("epoch: {0}, error: {1}", epoch, error); // выводим в консоль номер эпохи и величину ошибку
epoch++; // увеличиваем номер эпохи
} while (epoch <= epochs && error > eps);
}
Сеть готова. Давайте же её чему-нибудь научим!
Тренируем нейросеть на функции XOR
Почему функция XOR так интересна? Просто потому, что её невозможно получить одним нейроном: 0 ^ 0 = 0, 0 ^ 1 = 1, 1 ^ 0 = 1, 1 ^ 1 = 0. Однако она легко получается увеличением числа нейронов. Мы же попробуем выполнить обучение сети с 3 нейронами в скрытом слое и 1 выходным (так как выход у нас всего один). Для этого нам необходимо создать массив векторов X и Y с обучающими данными и саму нейросеть:
// массив входных обучающих векторов
Vector[] X = {
new Vector(0, 0),
new Vector(0, 1),
new Vector(1, 0),
new Vector(1, 1)
};
// массив выходных обучающих векторов
Vector[] Y = {
new Vector(0.0), // 0 ^ 0 = 0
new Vector(1.0), // 0 ^ 1 = 1
new Vector(1.0), // 1 ^ 0 = 1
new Vector(0.0) // 1 ^ 1 = 0
};
Network network = new Network(new int[]{2, 3, 1}); // создаём сеть с двумя входами, тремя нейронами в скрытом слое и одним выходом
После чего запустим обучение со следующими параметрами: скорость обучения — 0.5, число эпох — 100000, величина ошибки — 1e-7:
network.Train(X, Y, 0.5, 1e-7, 100000); // запускаем обучение сети
После обучения посмотрим на результаты выполнив прямой проход для всех элементов:
for (int i = 0; i < 4; i++) {
Vector output = network.Forward(X[i]);
Console.WriteLine("X: {0} {1}, Y: {2}, output: {3}", X[i][0], X[i][1], Y[i][0], output[0]);
}
В результате вывод может быть таким:
X: 0 0, Y: 0, output: 0,00503439463431083 X: 0 1, Y: 1, output: 0,996036009216668 X: 1 0, Y: 1, output: 0,996036033202241 X: 1 1, Y: 0, output: 0,00550270947767007
Проверять результаты на тренировочной же выборке довольно скучно, ведь как никак на ней мы сеть обучали, но, увы, для XOR проблемы ничего другого не остаётся. В качестве более серьёзного примера рекомендуем выполнить задачу распознавания картинок с рукописными цифрами MNIST. Это база содержит 60000 картинок написанных от руки цифр размером 28 на 28 пикселей и используется как один из основных датасетов для начала изучения машинного обучения. Не смотря на простоту нашей сети, при грамотном выборе параметров (число нейронов, число слоёв, скорость обучения, число эпох…) можно получить точность распознавания до 98%! Проверить свою сеть вы можете, поучаствовав в соревновании на сайте Kaggle. Нашей команде удалось достичь точности в 98.171%! А вы сможете больше?
В заключение
Мы написали с вами нейронную сеть прямого распространения и даже обучили её функции XOR. При этом мы позаботились об универсальности, благодаря чему нейросеть может быть обучена на любых данных, главное только подготовить два массива обучающих векторов X и Y, подобрать параметры обучения и запустить само обучение, после чего наблюдать за процессом. Важно помнить, что при использовании сигмоидальной функции активации, выходные значения сети не будут превышать 1, а значит, для обучения данным, которые значительно больше 1 необходимо отнормировать их, то есть привести к отрезку [0, 1].
Возможно, будет интересно: Свёрточная нейронная сеть с нуля. Часть 0. Введение.
Прямое распространение¶
- Простая сеть
- Прямой проход по шагам
- Код
- Более сложная сеть
- Архитектура
- Инициализация весов
- Bias Terms
- Working with Matrices
- Dynamic Resizing
- Refactoring Our Code
- Final Result
Простая сеть¶
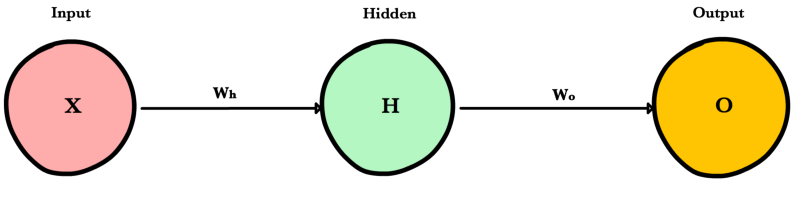
Прямое распространение — это процесс с помощью которого сеть делает предсказание (prediction). Также это основной режим работы обученной нейронной сети. Входные данные «распространяются» через каждый слой сети и выходной слой выдает финальный результат — предсказание. Для простой учебной нейронной сети один проход данных можно выразить математически как:
[Prediction = A(;A(;X W_h;)W_o;)]
Где (A) это функция активации, например ReLU, (X) это входные данные, (W_h) и (W_o) это веса слоев.
Прямой проход по шагам¶
- Вычислить значения входов скрытого слоя умножениием (X) на веса скрытого слоя (W_h) и получить (Z_h).
- Применить функцию активации к (Z_h) и передать результат (H) в выходной слой.
- Вычислить значения входов выходного слоя умножением значения (H) на веса выходного слоя (W_o) и получить (Z_o)
- Применить функцию активации к (Z_o). Результатом будет предсказание сети.
Код¶
Давайте напишем метод feed_forward() для распространения входных данных через нейронную сеть с 1-м скрытым слоем. Выход этого метода будет представлять собой предсказание модели.
def relu(z): return max(0,z) def feed_forward(x, Wh, Wo): # Hidden layer Zh = x * Wh H = relu(Zh) # Output layer Zo = H * Wo output = relu(Zo) return output
x это вход сети, Zo и Zh это «взвешенный» вход слоев, a Wo и Wh это веса слоев.
Более сложная сеть¶
Простая сеть очень помогает в учебном процессе, но реальные сети намного больше и сложнее устроены. Современные нейронные сети имеют гораздо больше скрытых слоев, больше нейронов в каждом слое, больше входных переменных. Рассмотрим более крупную (но всё ещё простую) нейронную сеть, которая позволит нам показать универсальный подход, основанный на матричном умножении, используемом в больших, «промышленных» нейронных сетях.
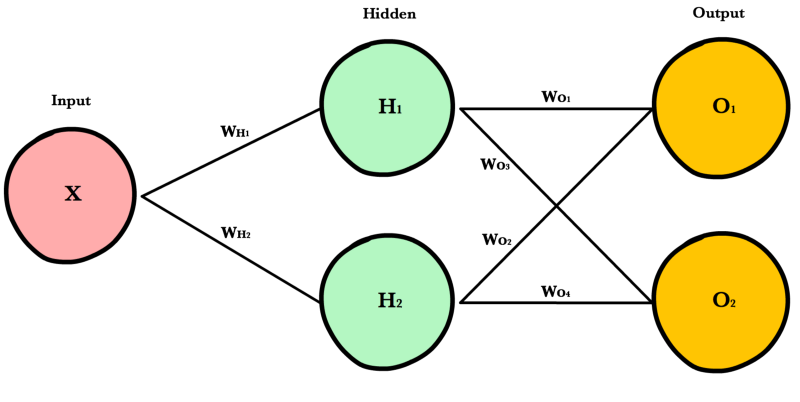
Архитектура¶
Для произвольного изменения количества входов или выходов сети, мы должны сделать наш код более гибким с помощью добавления новых параметров в __init_ метод: inputLayerSize, hiddenLayerSize,outputLayerSize. Мы будем продолжать ограничивать себя в количестве скрытых слоев, но сейчас это не так важно, потому что мы можем менять ширину (количество нейронов) имеющихся слоев.
INPUT_LAYER_SIZE = 1 HIDDEN_LAYER_SIZE = 2 OUTPUT_LAYER_SIZE = 2
Инициализация весов¶
Unlike last time where Wh and Wo were scalar numbers, our new weight variables will be numpy arrays. Each array will hold all the weights for its own layer — one weight for each synapse. Below we initialize each array with the numpy’s np.random.randn(rows, cols) method, which returns a matrix of random numbers drawn from a normal distribution with mean 0 and variance 1.
def init_weights(): Wh = np.random.randn(INPUT_LAYER_SIZE, HIDDEN_LAYER_SIZE) * np.sqrt(2.0/INPUT_LAYER_SIZE) Wo = np.random.randn(HIDDEN_LAYER_SIZE, OUTPUT_LAYER_SIZE) * np.sqrt(2.0/HIDDEN_LAYER_SIZE)
Here’s an example calling random.randn():
arr = np.random.randn(1, 2) print(arr) >> [[-0.36094661 -1.30447338]] print(arr.shape) >> (1,2)
As you’ll soon see, there are strict requirements on the dimensions of these weight matrices. The number of rows must equal the number of neurons in the previous layer. The number of columns must match the number of neurons in the next layer.
A good explanation of random weight initalization can be found in the Stanford CS231 course notes [1] chapter on neural networks.
Bias Terms¶
Смещение (Bias) terms allow us to shift our neuron’s activation outputs left and right. This helps us model datasets that do not necessarily pass through the origin.
Using the numpy method np.full() below, we create two 1-dimensional bias arrays filled with the default value 0.2. The first argument to np.full is a tuple of array dimensions. The second is the default value for cells in the array.
def init_bias(): Bh = np.full((1, HIDDEN_LAYER_SIZE), 0.1) Bo = np.full((1, OUTPUT_LAYER_SIZE), 0.1) return Bh, Bo
Working with Matrices¶
To take advantage of fast linear algebra techniques and GPUs, we need to store our inputs, weights, and biases in matrices. Here is our neural network diagram again with its underlying matrix representation.
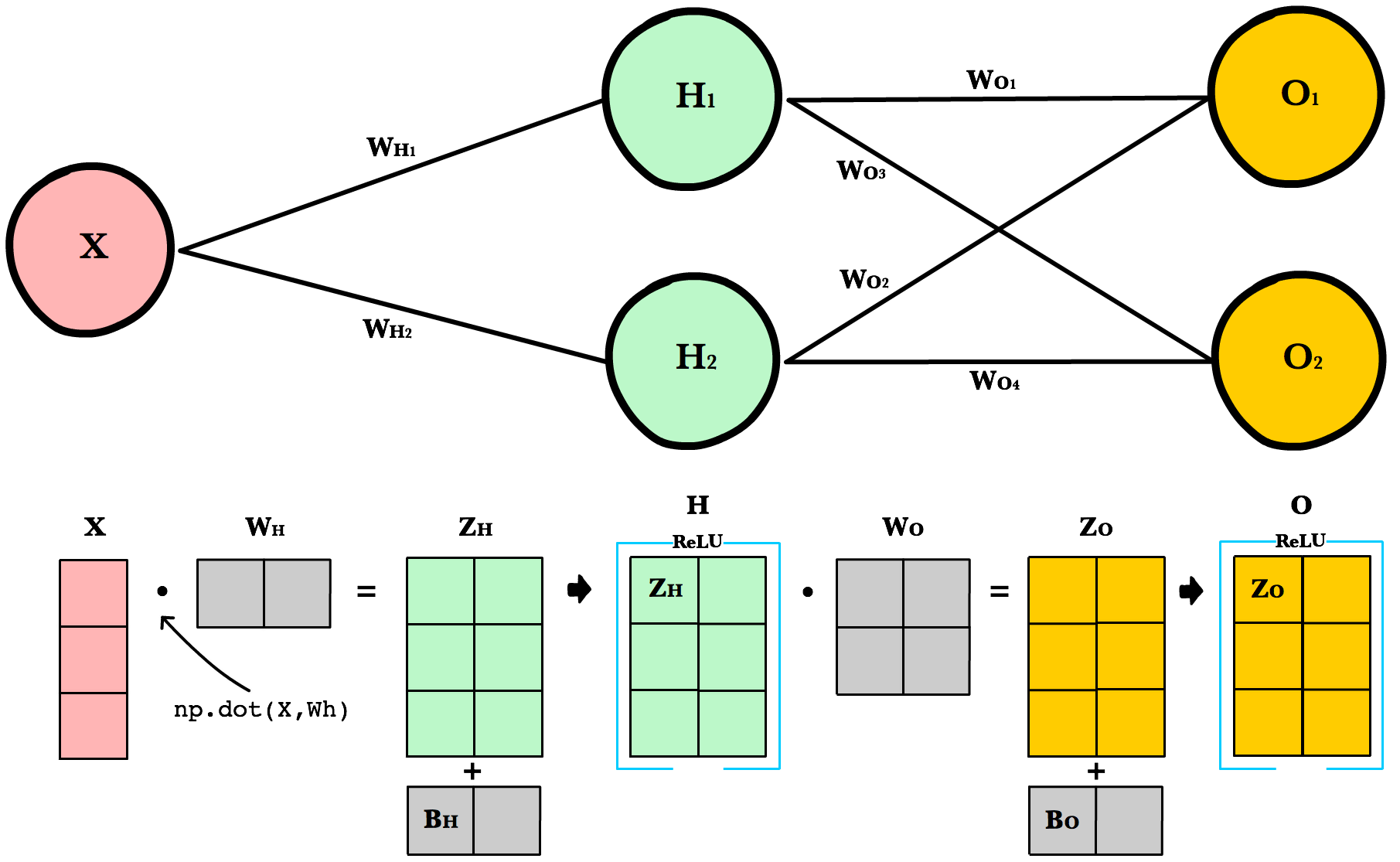
What’s happening here? To better understand, let’s walk through each of the matrices in the diagram with an emphasis on their dimensions and why the dimensions are what they are. The matrix dimensions above flow naturally from the architecture of our network and the number of samples in our training set.
Matrix dimensions
| Var | Name | Dimensions | Explanation |
X |
Input | (3, 1) | Includes 3 rows of training data, and each row has 1 attribute (height, price, etc.) |
Wh |
Hidden weights | (1, 2) | These dimensions are based on number of rows equals the number of attributes for the observations in our training set. The number columns equals the number of neurons in the hidden layer. The dimensions of the weights matrix between two layers is determined by the sizes of the two layers it connects. There is one weight for every input-to-neuron connection between the layers. |
Bh |
Hidden bias | (1, 2) | Each neuron in the hidden layer has is own bias constant. This bias matrix is added to the weighted input matrix before the hidden layer applies ReLU. |
Zh |
Hidden weighted input | (1, 2) | Computed by taking the dot product of X and Wh. The dimensions (1,2) are required by the rules of matrix multiplication. Zh takes the rows of in the inputs matrix and the columns of weights matrix. We then add the hidden layer bias matrix Bh. |
H |
Hidden activations | (3, 2) | Computed by applying the Relu function to Zh. The dimensions are (3,2) — the number of rows matches the number of training samples and the number of columns equals the number of neurons. Each column holds all the activations for a specific neuron. |
Wo |
Output weights | (2, 2) | The number of rows matches the number of hidden layer neurons and the number of columns equals the number of output layer neurons. There is one weight for every hidden-neuron-to-output-neuron connection between the layers. |
Bo |
Output bias | (1, 2) | There is one column for every neuron in the output layer. |
Zo |
Output weighted input | (3, 2) | Computed by taking the dot product of H and Wo and then adding the output layer bias Bo. The dimensions are (3,2) representing the rows of in the hidden layer matrix and the columns of output layer weights matrix. |
O |
Output activations | (3, 2) | Each row represents a prediction for a single observation in our training set. Each column is a unique attribute we want to predict. Examples of two-column output predictions could be a company’s sales and units sold, or a person’s height and weight. |
Dynamic Resizing¶
Before we continue I want to point out how the matrix dimensions change with changes to the network architecture or size of the training set. For example, let’s build a network with 2 input neurons, 3 hidden neurons, 2 output neurons, and 4 observations in our training set.
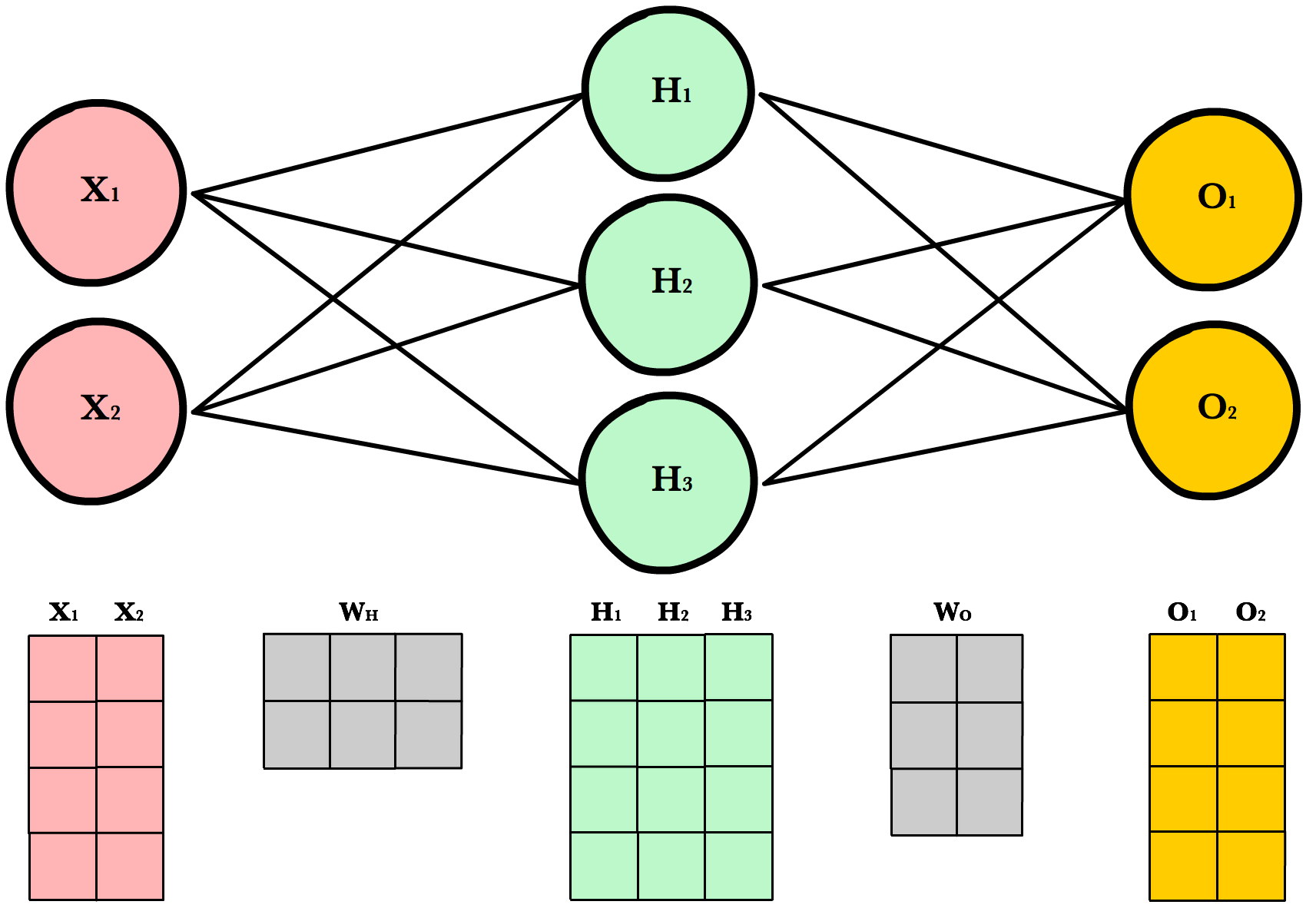
Now let’s use same number of layers and neurons but reduce the number of observations in our dataset to 1 instance:
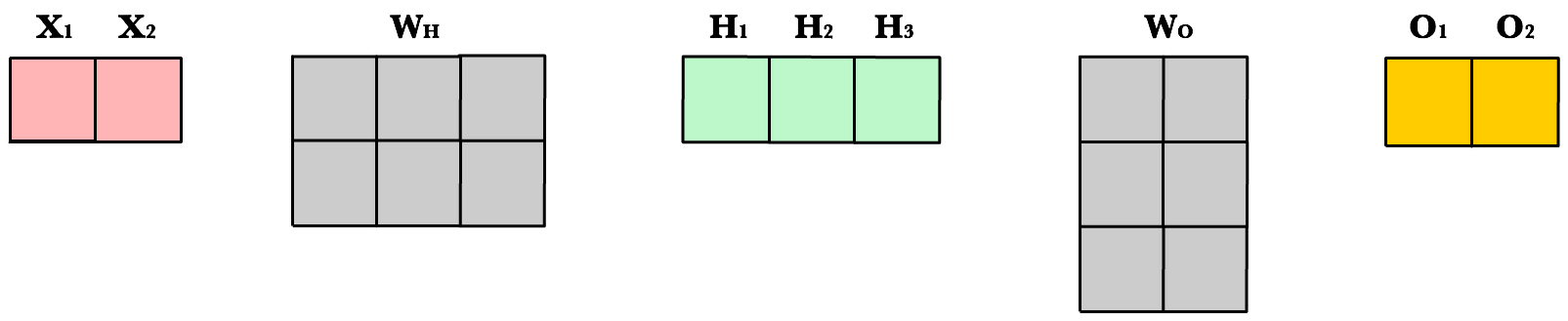
As you can see, the number of columns in all matrices remains the same. The only thing that changes is the number of rows the layer matrices, which fluctuate with the size of the training set. The dimensions of the weight matrices remain unchanged. This shows us we can use the same network, the same lines of code, to process any number of observations.
Refactoring Our Code¶
Here is our new feed forward code which accepts matrices instead of scalar inputs.
def feed_forward(X): ''' X - input matrix Zh - hidden layer weighted input Zo - output layer weighted input H - hidden layer activation y - output layer yHat - output layer predictions ''' # Hidden layer Zh = np.dot(X, Wh) + Bh H = relu(Zh) # Output layer Zo = np.dot(H, Wo) + Bo yHat = relu(Zo) return yHat
Weighted input
The first change is to update our weighted input calculation to handle matrices. Using dot product, we multiply the input matrix by the weights connecting them to the neurons in the next layer. Next we add the bias vector using matrix addition.
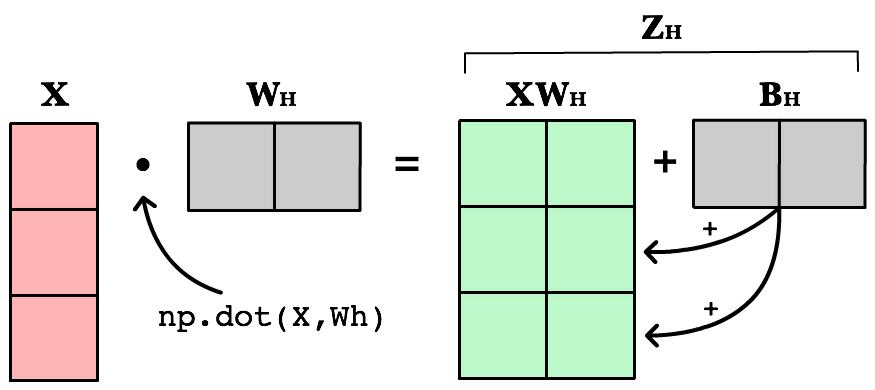
The first column in Bh is added to all the rows in the first column of resulting dot product of X and Wh. The second value in Bh is added to all the elements in the second column. The result is a new matrix, Zh which has a column for every neuron in the hidden layer and a row for every observation in our dataset. Given all the layers in our network are fully-connected, there is one weight for every neuron-to-neuron connection between the layers.
The same process is repeated for the output layer, except the input is now the hidden layer activation H and the weights Wo.
ReLU activation
The second change is to refactor ReLU to use elementwise multiplication on matrices. It’s only a small change, but its necessary if we want to work with matrices. np.maximum() is actually extensible and can handle both scalar and array inputs.
def relu(Z): return np.maximum(0, Z)
In the hidden layer activation step, we apply the ReLU activation function np.maximum(0,Z) to every cell in the new matrix. The result is a matrix where all negative values have been replaced by 0. The same process is repeated for the output layer, except the input is Zo.
Final Result¶
Putting it all together we have the following code for forward propagation with matrices.
INPUT_LAYER_SIZE = 1 HIDDEN_LAYER_SIZE = 2 OUTPUT_LAYER_SIZE = 2 def init_weights(): Wh = np.random.randn(INPUT_LAYER_SIZE, HIDDEN_LAYER_SIZE) * np.sqrt(2.0/INPUT_LAYER_SIZE) Wo = np.random.randn(HIDDEN_LAYER_SIZE, OUTPUT_LAYER_SIZE) * np.sqrt(2.0/HIDDEN_LAYER_SIZE) def init_bias(): Bh = np.full((1, HIDDEN_LAYER_SIZE), 0.1) Bo = np.full((1, OUTPUT_LAYER_SIZE), 0.1) return Bh, Bo def relu(Z): return np.maximum(0, Z) def relu_prime(Z): ''' Z - weighted input matrix Returns gradient of Z where all negative values are set to 0 and all positive values set to 1 ''' Z[Z < 0] = 0 Z[Z > 0] = 1 return Z def cost(yHat, y): cost = np.sum((yHat - y)**2) / 2.0 return cost def cost_prime(yHat, y): return yHat - y def feed_forward(X): ''' X - input matrix Zh - hidden layer weighted input Zo - output layer weighted input H - hidden layer activation y - output layer yHat - output layer predictions ''' # Hidden layer Zh = np.dot(X, Wh) + Bh H = relu(Zh) # Output layer Zo = np.dot(H, Wo) + Bo yHat = relu(Zo)
References
| [1] | http://cs231n.github.io/neural-networks-2/#init |
В этой статье поговорим о том, как создавать нейросети и в качестве примера рассмотрим, как сделать нейронную сеть прямого распространения с нуля. Для реализации поставленной задачи воспользуемся языком программирования C#.
Только ленивый не слышал сегодня о существовании и разработке нейронных сетей и такой сфере, как машинное обучение. Для некоторых создание нейросети кажется чем-то очень запутанным, однако на самом деле они создаются не так уж и сложно. Как же их делают? Давайте попробуем самостоятельно создать нейросеть прямого распространения, которую еще называют многослойным перцептроном. В процессе работы будем использовать лишь циклы, массивы и условные операторы. Что означает этот набор данных? Только то, что нам подойдет любой язык программирования, поддерживающий вышеперечисленные возможности. Если же у языка есть библиотеки для векторных и матричных вычислений (вспоминаем NumPy в Python), то реализация с их помощью займет совсем немного времени. Но мы не ищем легких путей и воспользуемся C#, причем полученный код по своей сути будет почти аналогичным и для прочих языков программирования.
Что же такое нейронная сеть?
Под искусственной нейронной сетью (ИНС) понимают математическую модель (включая ее программное либо аппаратное воплощение), которая построена и работает по принципу функционирования биологических нейросетей — речь идет о нейронных сетях нервных клеток живых организмов.
Говоря проще, ИНС можно назвать неким «черным ящиком», превращающим входные данные в выходные данные. Если же посмотреть на это с точки зрения математики, то речь идет о том, чтобы отобразить пространство входных X-признаков в пространство выходных Y-признаков: X → Y. Таким образом, нам надо найти некую F-функцию, которая сможет выполнить данное преобразование. На первом этапе этой информации достаточно в качестве основы.
Какую роль играет искусственный нейрон?
В нашей статье мы не будем вдаваться в лирику и рассказывать об устройстве биологического нейрона в контексте его связи с искусственной моделью. Лучше сразу перейдем к делу.
Искусственный нейрон представляет собой взвешенную сумму векторных значений входных элементов. Эта сумма передается на нелинейную функцию активации f:

Но об активации поговорим после, т. к. сейчас стоит задача узнать, каким образом вместо одного выходного значения можно получить n-значений.
Нейрослой
Один нейрон может превратить в одну точку входной вектор, но по условию мы желаем получить несколько точек, т. к. выходное Y способно иметь произвольную размерность, которая определяется лишь ситуацией (один выход для XOR, десять выходов, чтобы определить принадлежность к одному из десяти классов, и так далее). Каким же образом получить n точек? На деле все просто: для получения n выходных значений, надо задействовать не один нейрон, а n. В результате для каждого элемента выходного Y будет использовано n разных взвешенных сумм от X. В итоге мы придем к следующему соотношению:
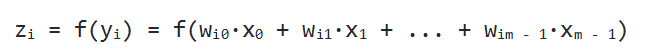
Давайте внимательно посмотрим на него. Вышенаписанная формула — это не что иное, как определение умножения матрицы на вектор. И в самом деле, если мы возьмем матрицу W размера n на m и выполним ее умножение на X размерности m, то мы получим другое векторное значение n-размерности, то есть как раз то, что надо.
Таким образом, мы можем записать похожее выражение в более удобной матричной форме:

Но полученный вектор представляет собой неактивированное состояние (промежуточное, невыходное) всех нейронов, а для того, чтобы нам получить выходное значение, нужно каждое неактивированное значение подать на вход вышеупомянутой функции активации. Итогом ее применения и станет выходное значение слоя.
Ниже показан пример нейронной сети, имеющей 2 входа, 5 нейронов и 1 выход:

Последовательность нейрослоев часто применяют для более глубокого обучения нейронной сети и большей формализации имеющихся данных. Именно поэтому, чтобы получить итоговый выходной вектор, нужно проделать вышеописанную операцию пару раз подряд по направлению от одного слоя к другому. В результате для 1-го слоя входным вектором будет являться X, а для последующих входом будет выход предыдущего слоя. То есть нейронная сеть может выглядеть следующим образом:
Функция активации
Речь идет о функции, добавляющей в нейронную сеть нелинейность. В результате нейроны смогут относительно точно сымитировать любую функцию. Широко распространены следующие функции активации:

Каждая из них имеет свои особенности.
Пишем код
Теперь мы знаем достаточно, чтобы создать простую нейронную сеть. Чтобы сделать то, что задумали, нам потребуются:
- Вектор.
- Матрица (каждый слой включает в себя матрицу весовых коэффициентов).
- Нейронная сеть.
Начнем с вектора. Создавать его можно:
- из количества элементов;
- из перечисления вещественных чисел.
Также мы можем получать и менять значения по индексу i.
Пишем код:
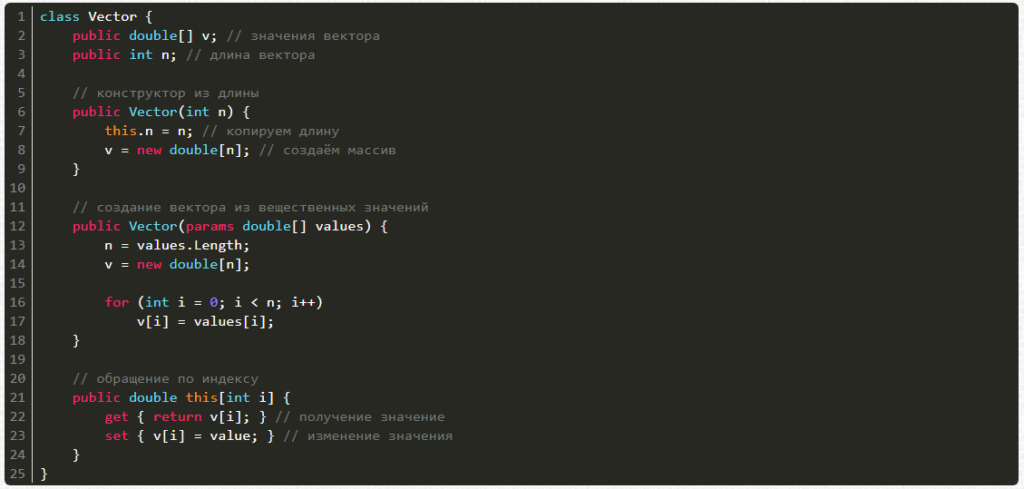
Теперь очередь матрицы. Ее можно создавать из числа строк и столбцов, а также генератора случайных чисел, причем есть возможность получать и менять значения по индексам i и j.
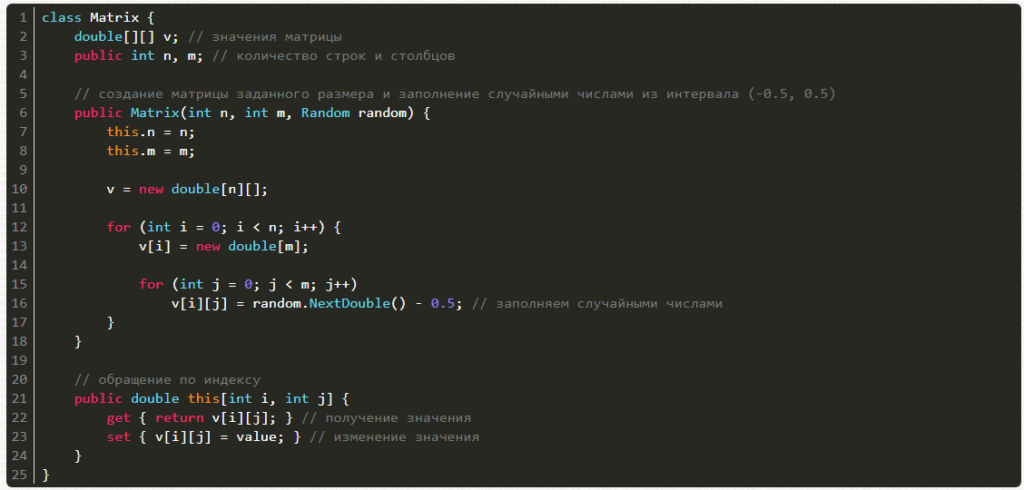
А вот и сама нейронная сеть:
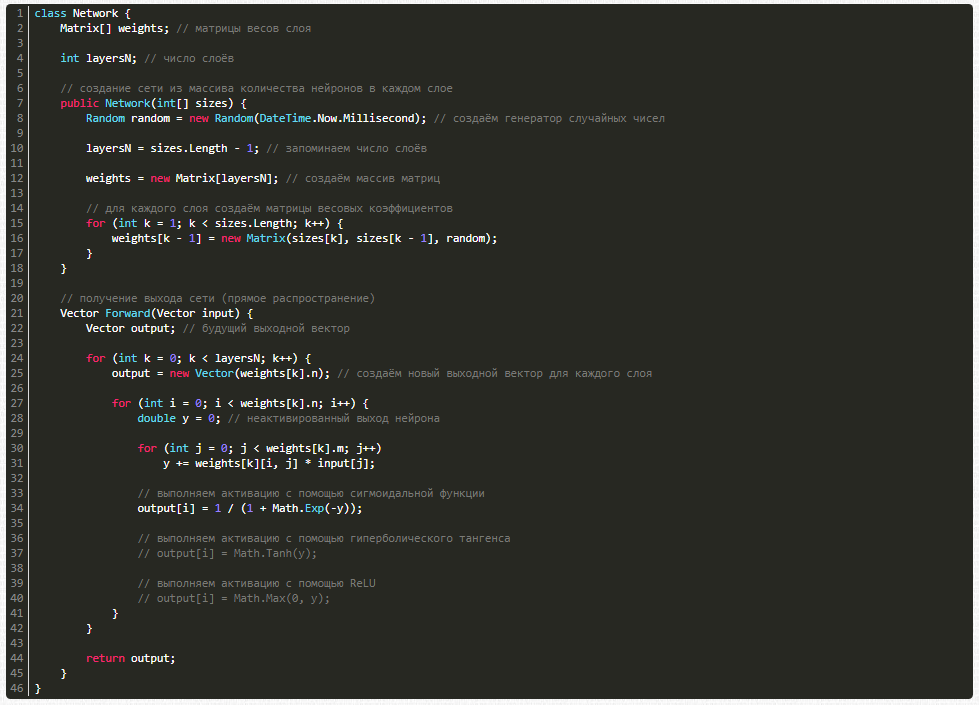
Как будем обучать?
Пусть у нас уже есть нейронная сеть, но ведь ее ответы являются случайными, то есть наша нейросеть не обучена. Сейчас она способна лишь по входному вектору input выдавать случайный ответ, но нам нужны ответы, которые удовлетворяют конкретной поставленной задаче. Дабы этого достичь, сеть надо обучить. Здесь потребуется база тренировочных примеров и множество пар X — Y, на которых и будет происходить обучение, причем с использованием известного алгоритма обратного распространения ошибки.
Некоторые особенности работы этого алгоритма:
- на вход сети подается обучающий пример (1 входной вектор);
- сигнал распространяется по нейросети вперед (получаем выход сети);
- вычисляется ошибка (это разница между получившимся и ожидаемым векторами);
- ошибка распространяется на предыдущие слои;
- происходит обновление весовых коэффициентов в целях уменьшения ошибки.
Вот как выглядит алгоритм обучения:

Переходим к обучению
Для обратного распространения ошибки нужно знать значения выходов и входов, а также значения производных функции активации нейросети, причем послойно, следовательно, нужно создать структуру LayerT, где будут три векторных значения:
- x — вход слоя,
- z — выход,
- df — производная функции активации.
Для каждого слоя нам потребуются векторы дельт, в результате чего надо будет добавить в класс еще и их. В итоге класс будет выглядеть следующим образом:
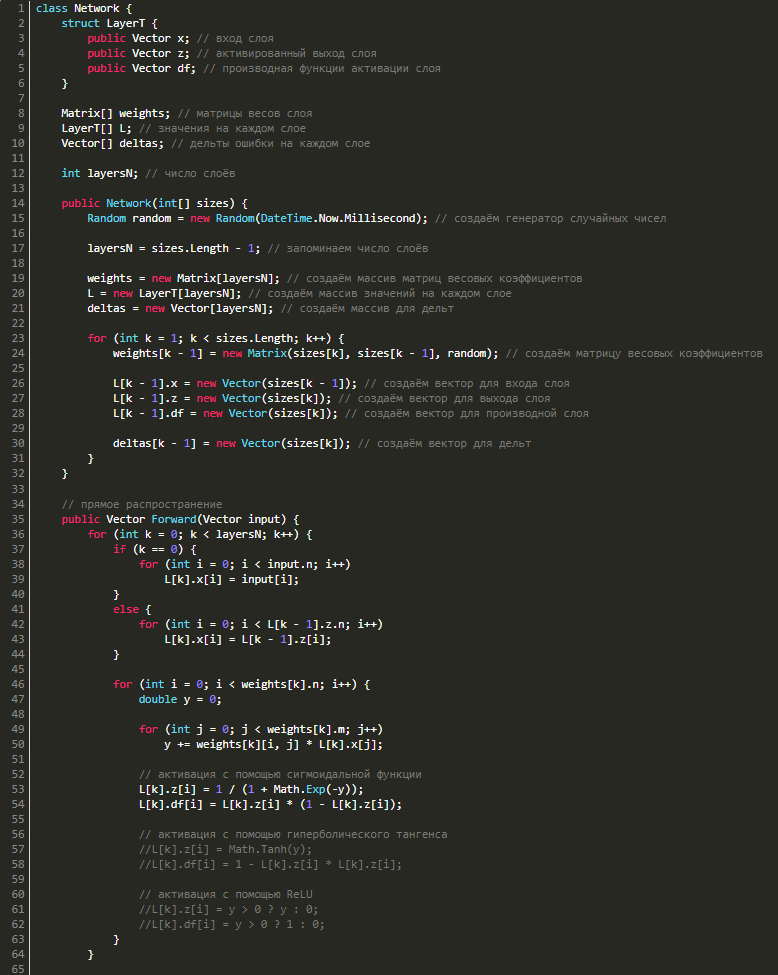
Несколько слов об обратном распространении ошибки
В качестве функции оценки нейросети E(W) мы берем среднее квадратичное отклонение:
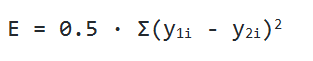
Дабы найти значение ошибки E, надо найти сумму квадратов разности векторных значений, которые были выданы нейронной сетью в виде ответа, а также вектора, который ожидается увидеть при обучении. Еще надо будет найти дельту каждого слоя и учесть, что для последнего слоя дельта будет равняться векторной разности фактического и ожидаемого результатов, покомпонентно умноженной на векторное значение производных последнего слоя:

Когда мы узнаем дельту последнего слоя, мы сможем найти дельты и всех предыдущих слоев. Чтобы это сделать, нужно будет лишь перемножить для текущего слоя транспонированную матрицу с дельтой, а потом перемножить результат с вектором производных функции активации предыдущего слоя:
![]()
Смотрим реализацию в коде:
Обновление весовых коэффициентов
Для уменьшения ошибки нейронной сети надо поменять весовые коэффициенты, причем послойно. Каким же образом это осуществить? Ничего сложного в этом нет: надо воспользоваться методом градиентного спуска. То есть нам надо рассчитать градиент по весам и сделать шаг от полученного градиента в отрицательную сторону. Давайте вспомним, что на этапе прямого распространения мы запоминали входные сигналы, а во время обратного распространения ошибки вычисляли дельты, причем послойно. Как раз ими и надо воспользоваться в целях нахождения градиента. Градиент по весам будет равняться не по компонентному перемножению дельт и входного вектора. Дабы обновить весовые коэффициенты, снизив таким образом ошибку нейросети, нужно просто вычесть из матрицы весов итог перемножения входных векторов и дельт, помноженный на скорость обучения. Все вышеперечисленное можно записать в следующем виде:

Вот оно, обучение!
Теперь мы имеем все нужные нам методы, поэтому остается лишь всё это вместе соединить, сформировав единый метод обучения.
Наша сеть готова, но мы пока ее еще ничему не научили. Сейчас это исправим.
Тренировка нейронной сети. Функции XOR
Функция XOR интересна тем, что ее нельзя получить одним нейроном:
![]()
Но ее легко получить путем увеличения количества нейронов. Давайте попробуем реализовать обучение с тремя нейронами в скрытом слое и одним выходным (выход ведь у нас только один). Чтобы все получилось, создадим массив X и Y, имеющий обучающие данные и саму нейронную сеть:
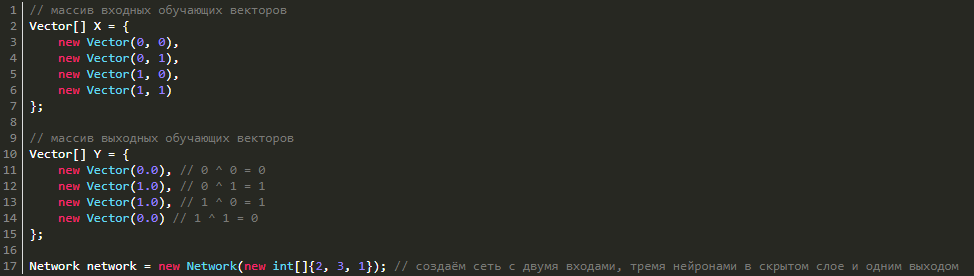
Теперь запускаем обучение с параметрами ниже:
- скорость обучения — 0.5,
- количество эпох — 100000,
- значение ошибки — 1e-7.
![]()
Выполнив обучение, посмотрим итоги, для чего надо будет сделать прямой проход для всех элементов:

В итоге вывод будет следующим:

Результаты
Мы написали нейронную сеть прямого распространения и не только написали, но и обучили ее функции XOR. Также была обеспечена универсальность, поэтому эту нейросеть можно обучать на любых данных — потребуется лишь:
- подготовить 2 векторных обучающих массива векторов X и Y,
- подобрать параметры,
- запустить само обучение,
- наблюдать за процессом.
Однако помните, что если используется сигмоидальная функция активации, выходные числа не будут больше единицы, что означает, что для обучения данным, которые существенно больше единицы, нужно будет нормировать их, приводя к отрезку [0, 1].
Надеемся, что материал был вам полезен и теперь вы знаете, как сделать нейросеть, и какие нюансы разработки стоит учитывать. Если же интересуют более продвинутые знания, обратите внимание на курсы, которые разработала команда Otus:

По материалам: https://programforyou.ru/poleznoe/pishem-neuroset-pryamogo-rasprostraneniya.
- Подробная прямая нейронная сеть и алгоритм BP
- 1. Понятие нейронной сети
- 1.1 Базовая единица искусственной нейронной сети -> Персептрон
- 1.1.1 Объяснение модели персептрона
- 1.1.2 Функция потерь модели персептрона
- 1.1.3 Метод оптимизации функции потерь персептрона и описание алгоритма потока
- 1.1.3.1 Метод оптимизации
- 1.1.3.2 Описание алгоритма
- 1.2 Глубокая нейронная сеть (DNN) и алгоритм прямого распространения
- 1.2.1 Введение в глубокие нейронные сети
- 1.2.2 Алгоритм прямого распространения
- 1.3 Алгоритм обратного распространения BP (обратное распространение)
- 1.3.1 Проблемы, которые необходимо решить путем обратного распространения
- 1.3.2 Основная идея алгоритма обратного распространения
- 1.3.3 Процесс алгоритма обратного распространения DNN
- 1.3.4 Мышление на основе алгоритма обратного распространения DNN
- 1.1 Базовая единица искусственной нейронной сети -> Персептрон
- Во-вторых, практика кодирования прямой нейронной сети на основе TensorFlow
- 2.1 Функции библиотеки TensorFlow участвуют
- 2.2 Подгонка нелинейной регрессии данных
- 2.3 Использование Keras для моделирования непрерывных переменных
- 2.4 Задача мультиклассификации, многоузловой выходной слой
- 1. Понятие нейронной сети
Подробная прямая нейронная сеть и алгоритм BP
1. Понятие нейронной сети
1.1 Базовая единица искусственной нейронной сети -> Персептрон
1.1.1 Объяснение модели персептрона
- Прежде всего, нам необходимо прояснить, что для SVM с функциями ядра или многослойных нейронных сетей с несколькими скрытыми слоями + функциями активации или других моделей, которые могут иметь дело с нелинейной разделимостью, персептроны часто называют нейронами, но Это также можно рассматривать как двухслойную нейронную сеть (То есть только входной слой и выходной слой, нет скрытого слоя ), хотя он может иметь дело только с линейно разделимыми проблемами, он все еще является краеугольным камнем нашего изучения нейронных сетей и глубокого обучения.

- Соответствующие символы на рисунке имеют следующие значения:
- Вход (x1, …, xn)
- Смещение b и синаптические веса (w1, …, wn), обратите внимание, что мы нажимаем ниже, чтобы использовать
θ
i
Вместо wi для вывода формулы.
- Комбинированная функция c (·)
- Функция активации а (·)
- Выход у
- На математическом языке, если у нас есть m выборок, каждая выборка соответствует n-мерным элементам и выводу двоичной категории следующим образом:
(
x
1
(
0
)
,
x
2
(
0
)
,
.
.
.
x
n
(
0
)
,
y
0
)
,
(
x
1
(
1
)
,
x
2
(
1
)
,
.
.
.
x
n
(
1
)
,
y
1
)
,
.
.
.
(
x
1
(
m
)
,
x
2
(
m
)
,
.
.
.
x
n
(
m
)
,
y
m
)
- Наша цель — найти гиперплоскость, а именно:
θ
0
+
θ
1
x
1
+
.
.
.
+
θ
n
x
n
=
0
Когда элементы выборки каждой категории приводятся в уравнение, они либо больше 0, либо меньше 0, так что выборки разделяются с обеих сторон гиперплоскости, так что они линейно разделимы. Как правило, если выборка линейно разделима, такая гиперплоскость будет иметь несколько решений, которые не являются уникальными.
- Чтобы упростить модель, мы добавляем x0 = 1, делая уравнение гиперплоскости сокращенным
∑
i
=
0
n
θ
i
x
i
=
0
Следующая записываемая векторная форма
θ
∙
x
=
0
среди них
θ
И X оба n * 1 векторов,
∙
Для внутреннего продукта мы будем использовать его для представления гиперплоскости ниже.
- Следовательно, модель персептрона может быть определена как
y
=
s
i
g
n
(
θ
∙
x
)
Где знак — это функция активации, которая является функцией знака, также известной как функция шага.
s
i
g
n
(
x
)
=
{
−
1
x
<
0
1
x
≥
0
- В многослойных нейронных сетях мы можем использовать другие функции активации, а именно:

1.1.2 Функция потерь модели персептрона
- Основываясь на приведенном выше анализе, мы будем
θ
∙
x
>
0
Выходное значение категории выборки принимается за 1, а выборка категории менее 0 принимается за -1, поэтому преимущество его определения состоит в том, что нам удобно определять функцию потерь. Из-за вышеупомянутого соглашения правильно классифицированные образцы удовлетворяют:
y
θ
∙
x
>
0
И неправильный образец классификации удовлетворяет
y
θ
∙
x
<
0
, Следовательно, метод оптимизации функции потерь состоит в том, чтобы сделать сумму расстояний до гиперплоскости всех выборок, которые неправильно классифицированы, равными наименьшему (то есть, чтобы неправильно классифицированные выборки постепенно исчезали).
- из-за
y
θ
∙
x
<
0
Таким образом, для каждого неправильно классифицированного образца i расстояние до гиперплоскости равно:
−
y
(
i
)
θ
∙
x
(
i
)
/
|
|
θ
|
|
2
- среди них,
|
|
θ
|
|
2
Является ли норма L2. (Если формула расстояния здесь не понята, вы можете самостоятельно проверить расстояние от точки до прямой линии или изучить соответствующие главы машинного обучения)
- Далее мы предполагаем, что множество всех ошибочно классифицированных точек равно M, тогда сумма расстояний всех ошибочно классифицированных выборок до гиперплоскости равна:
−
∑
x
i
∈
M
y
(
i
)
θ
∙
x
(
i
)
/
|
|
θ
|
|
2
Таким образом, мы получили функцию потерь предварительной модели персептрона.
- Кроме того, нам также нужно упростить его, мы можем заметить, что как числитель, так и знаменатель имеют
θ
(Т.е. числитель и знаменатель имеют одинаковое увеличение), когда числитель
θ
При увеличении в N раз норма L2 его знаменателя также увеличится в N раз. Поскольку мы изучаем проблему максимизации, мы можем зафиксировать числитель или знаменатель равным 1, затем решить вопрос минимизации оставшегося числителя или обратной величины знаменателя и затем использовать его в качестве функции потерь. Это может упростить нашу функцию потерь и облегчить решение последующих проблем.Примечание. В модели персептрона используется числитель удержания, а фиксированный знаменатель равен 1.То есть функция потерь конечного персептрона равна:
J
(
θ
)
=
−
∑
x
i
∈
M
y
(
i
)
θ
∙
x
(
i
)
В дополнение к нам также необходимо обратить внимание наДля SVM он использует фиксированный числитель 1, а затем решает
1
|
|
θ
|
|
2
Проблема максимизации (Почему проблема максимизации, а не проблема минимизации, это связано с идеей оптимизации SVM, и я не буду ее здесь приводить.)
1.1.3 Метод оптимизации функции потерь персептрона и описание алгоритма потока
1.1.3.1 Метод оптимизации
- После приведенных выше рассуждений, мы получаем функцию потери перцептрона,
J
(
θ
)
=
−
∑
x
i
∈
M
y
(
i
)
θ
∙
x
(
i
)
, Где M — множество всех ошибочно классифицированных точек, и это выпуклая функция, может использовать метод градиентного спуска или квазиньютоновского метода, обычно используемый SGD (случайный градиентный спуск), что означает, что каждый раз необходимо использовать только одну ошибочно классифицированную точку Обновите градиент. Из-за ограничения в нашей функции потерь, только выборки из неправильно классифицированного набора М могут участвовать в оптимизации функции потерь. Следовательно, BGD (пакетный градиентный спуск) нельзя использовать, только SGD или MSGD (небольшой пакетный градиентный спуск).
- Функция потери
θ
Частная производная вектора:
∂
∂
θ
J
(
θ
)
=
−
∑
x
i
∈
M
y
(
i
)
x
(
i
)
θ
Формула градиентного спуска:
θ
=
θ
+
α
∑
x
i
∈
M
y
(
i
)
x
(
i
)
- Поскольку мы используем стохастический градиентный спуск, для вычисления градиента за один раз используется только одна неправильно классифицированная выборка. Предполагая, что i-я выборка используется для обновления градиента, упрощенная
θ
Итерационная формула градиентного спуска:
θ
=
θ
+
α
y
(
i
)
x
(
i
)
- Где α — размер шага,
y
(
i
)
Чтобы вывести 1 или -1 для выборки, x (i) является вектором (n + 1) x 1.
1.1.3.2 Описание алгоритма
- Здесь мы подведем итоги вышеприведенного обсуждения и сходимся в алгоритм алгоритма.
- Алгоритм ввода
- Входными данными алгоритма являются m выборок, каждая выборка соответствует n-мерным элементам и выводу двоичной категории 1 или -1 следующим образом:
(
x
1
(
0
)
,
x
2
(
0
)
,
.
.
.
x
n
(
0
)
,
y
0
)
,
(
x
1
(
1
)
,
x
2
(
1
)
,
.
.
.
x
n
(
1
)
,
y
1
)
,
.
.
.
(
x
1
(
m
)
,
x
2
(
m
)
,
.
.
.
x
n
(
m
)
,
y
m
)
- Входными данными алгоритма являются m выборок, каждая выборка соответствует n-мерным элементам и выводу двоичной категории 1 или -1 следующим образом:
- Вывод:
- Модельный коэффициент θ вектора разделяющей гиперплоскости
- Процесс выполнения алгоритма:
- Определить все х0 до 1. Выберите начальное значение вектора θ и начальное значение шага α. Вектор θ может быть установлен на вектор 0, а размер шага установлен на 1. Следует отметить, что, поскольку решение персептрона не является уникальным, два используемых начальных значения будут влиять на конечный результат итерации вектора θ.
- Выберите ошибочно классифицированную точку в тренировочном наборе
(
x
1
(
i
)
,
x
2
(
i
)
,
.
.
.
x
n
(
i
)
,
y
i
)
Выражается в векторах т.е.
(
x
(
i
)
,
y
(
i
)
)
, Этот пункт должен удовлетворять:
y
(
i
)
θ
∙
x
(
i
)
<
0
- Выполните итерацию стохастического градиентного спуска на векторе:
θ
=
θ
+
α
y
(
i
)
x
(
i
)
- Проверьте, есть ли в обучающем наборе все еще неправильно классифицированные точки, в противном случае алгоритм завершается, и вектор θ в это время является окончательным результатом. Если это так, перейдите к шагу 2.
- Наконец, также необходимо упомянуть, что когда алгоритм фактически был реализован в прошлом, мы использовали двойную форму алгоритма персептрона для решения параметров и оптимизации модели, поскольку она может оптимизировать скорость выполнения алгоритма. Читатели могут учиться самостоятельно. Мы все еще сосредоточены на следующем объяснении знаний, связанных с нейронными сетями.
1.2 Глубокая нейронная сеть (DNN) и алгоритм прямого распространения
1.2.1 Введение в глубокие нейронные сети
- С помощью персептрона его можно использовать только для задач двоичной классификации, но он не может решить нелинейные задачи.Нейронные сети сделали много расширений, главным образом отраженных в следующих аспектах:
- Добавлены скрытые слои. Скрытые слои могут иметь несколько слоев, чтобы усилить выразительные возможности модели, поэтому ее сложность также значительно возросла.
- На входном слое имеется более одного нейрона с несколькими выходами. Кроме того, существует полная связь между верхним уровнем и следующим уровнем, и нет связи между нейронами в одном и том же слое, и они не зависят друг от друга. Таким образом, модель может гибко применяться для классификации и регрессии (обычно разница заключается только в функции активации последнего прохода структуры. Если требуется регрессия и требуется непрерывное значение, не используйте стандартизированную функцию сжатия, такую как Sigmoid)
- Функция активации была расширена, чтобы заменить Sign (z) функцией Sigmod или другими функциями активации, tanx, softmax, ReLU и т. Д. Так выглядит следующая картина:

- DNN можно понимать как нейронную сеть с несколькими скрытыми слоями. Кроме того, его иногда называют многослойным персептроном (Multi-Layer Perceptron, MLP). Внутренний уровень нейронной сети делится на три категории: входной слой, скрытый слой и выходной слой. Как показано выше, в целом, первый слой является входным слоем, последний слой является выходным слоем, а все средние слои являются скрытыми слоями. Слои полностью связаны, то есть любой нейрон в слое i должен быть связан с любым нейроном в слое i + 1. Хотя DNN выглядит сложным, маленькая локальная модель остается такой же, как персептрон, то есть линейная зависимость
z
=
∑
w
i
x
i
+
b
Добавьте функцию активации σ (z). Однако с увеличением количества слоев количество линейных соотношений W и смещения b также увеличивается. Определение следующее:
-
Сначала давайте взглянем на определение коэффициента линейной зависимости w. На следующем рисунке в качестве примера показан трехслойный DNN. Линейный коэффициент четвертого нейрона во втором слое ко второму нейрону в третьем слое определяется как
w
24
3
Верхний индекс 3 представляет количество слоев, в которых расположен линейный коэффициент w, а нижний индекс соответствует выходному индексу третьего уровня 2 и входному индексу второго уровня 4. Вы можете спросить, почему нет
w
42
3
Вместо
w
24
3
Какой? Это главным образом для облегчения модели для операций матричного представления, если это
w
42
3
И каждый раз, когда выполняется матричная операция
w
T
x
+
b
Нужно транспонировать. Если выходной индекс помещен вперед, вес W не должен быть перемещен в линейной операции. То есть линейные коэффициенты k-го нейрона в слое l-1 до j-го нейрона в слое l определяются как
w
j
k
l
Где входной слой не имеет параметра w.

-
Давайте посмотрим на определение смещения б. На примере этого трехслойного DNN смещение, соответствующее третьему нейрону во втором слое, определяется как
b
3
2
Среди них верхний индекс 2 представляет количество слоев, а нижний индекс 3 представляет индекс нейронов, в которых находится смещение. Таким же образом, смещение первого нейрона в третьем должно быть выражено как
b
1
3
Аналогично, входной слой не имеет параметра смещения b.

1.2.2 Алгоритм прямого распространения
-
Выше мы ввели определение коэффициента линейной зависимости w и смещения b каждого слоя DNN. Предполагая, что выбранная нами функция активации σ (z), выходное значение скрытого слоя и выходного слоя равно a, а затем для трехслойного DNN на следующем рисунке, используя ту же идею, что и персептрон, мы можем использовать выходные данные предыдущего слоя для вычисления Выход первого уровня — это так называемый алгоритм прямого распространения DNN.

- Для вывода второго слоя
a
1
2
,
a
2
2
,
a
3
2
,У нас есть:
a
1
2
=
σ
(
z
1
2
)
=
σ
(
w
11
2
x
1
+
w
12
2
x
2
+
w
13
2
x
3
+
b
1
2
)
a
2
2
=
σ
(
z
2
2
)
=
σ
(
w
21
2
x
1
+
w
22
2
x
2
+
w
23
2
x
3
+
b
2
2
)
a
3
2
=
σ
(
z
3
2
)
=
σ
(
w
31
2
x
1
+
w
32
2
x
2
+
w
33
2
x
3
+
b
3
2
)
- Для вывода третьего слоя
a
1
3
,У нас есть:
a
1
3
=
σ
(
z
1
3
)
=
σ
(
w
11
3
a
1
2
+
w
12
3
a
2
2
+
w
13
3
a
3
2
+
b
1
3
)
- Обобщая вышеприведенный пример, предполагая, что в слое l-1 имеется m нейронов, для вывода j-го нейрона в слое l
a
j
l
,У нас есть:
a
j
l
=
σ
(
z
j
l
)
=
σ
(
∑
k
=
1
m
w
j
k
l
a
k
l
−
1
+
b
j
l
)
- Среди них, если
l
= 2, тогда a_k ^ 1 для входного слоя
x
k
。
- Далее, ключевой момент — матричная запись, потому что алгебраический метод означает, что выходные данные являются сложными, а матричный метод означает, что выходные данные просты. предполагать
l
-1 слой имеет в общей сложности m нейронов, в то время как слой 1 имеет в общей сложности n нейронов, тогда
l
Линейный коэффициент w слоя образует матрицу Wl n × m, первый
l
Смещение b слоя формирует вектор n × 1
b
l
, Раздел
l
Выход a слоя -1 формирует вектор m × 1
a
l
−
1
, Раздел
l
Неактивный линейный выход z слоя формирует вектор n × 1
z
l
, Раздел
l
Выход a слоя формирует вектор n × 1
a
l
, Выражается матричным методом, первым
l
Выход слоя:
a
l
=
σ
(
z
l
)
=
σ
(
W
l
a
l
−
1
+
b
l
)
- Это выражено очень кратко, поэтому последующее обсуждение будет выведено на основе этого матричного метода.
- Описание алгоритма потока:
- Вход: общее количество слоев L, матрица W, соответствующая всем скрытым слоям и выходным слоям, вектор смещения b, вектор входных значений x
- Выход: выходной слой
a
L
- Обработать:
- Initialize
a
1
=x
- for
l
=2 to
L
Расчет:
a
l
=
σ
(
z
l
)
=
σ
(
W
l
a
l
−
1
+
b
l
)
- Конечный результат — выход
a
L
- Initialize
- DNN алгоритм прямого распространения, как получить параметры, соответствующие большой матрице W и вектору смещения b? Как получить оптимальную матрицу W и вектор смещения b? Это должно быть решено алгоритмом обратного распространения DNN. Предпосылка понимания алгоритма обратного распространения состоит в том, чтобы понять модель DNN и алгоритм прямого распространения. Далее идет легендарный алгоритм БП.
1.3 Алгоритм обратного распространения BP (обратное распространение)
1.3.1 Проблемы, которые необходимо решить путем обратного распространения
- Прежде, чем понять алгоритм обратного распространения DNN, мы должны сначала знать проблему, которую должен решить алгоритм обратного распространения DNN, то есть, когда нам нужен этот алгоритм обратного распространения?
- Возвращаясь к нашей общей проблеме контролируемого обучения, предположим, что у нас есть m обучающих образцов:
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
m
,
y
m
)
}
Где x — входной вектор, а размерность объекта — n_in, а y — выходной вектор, а размерность объекта — n_out. Нам нужно использовать эти m образцов для обучения модели, когда есть новый тестовый образец (
x
t
e
s
t
?) Когда мы придем, мы можем предсказать
y
t
e
s
t
Векторный вывод.
- Если мы примем модель DNN, у нас будет n_in нейронов на входном слое и n_out нейронов на выходном слое. Плюс несколько скрытых слоев, содержащих несколько нейронов. В настоящее время нам нужно найти соответствующую матрицу линейных коэффициентов W и вектор смещения b для всех скрытых слоев и выходных слоев, чтобы выходной сигнал, рассчитанный по всем входным сигналам обучающей выборки, был как можно ближе к выходным данным выборки или близко к ним. Как найти подходящие параметры?
- Вы можете подумать, что вы можете использовать подходящую функцию потерь для измерения выходных потерь обучающей выборки, а затем оптимизировать эту функцию потерь, чтобы минимизировать экстремальное значение. Соответствующий ряд матриц W линейного коэффициента, вектор смещения b является нашей Окончательные результаты. В DNN процесс оптимизации экстремума функции потерь обычно повторяется шаг за шагом по методу градиентного спуска.Конечно, можно использовать и другие итерационные методы, такие как метод Ньютона и квазиньютоновский метод.
- Процесс итеративной оптимизации функции потерь DNN путем градиентного спуска для нахождения минимального значения является нашим алгоритмом обратного распространения.
1.3.2 Основная идея алгоритма обратного распространения
- Перед выполнением алгоритма обратного распространения DNN нам нужно выбрать функцию потерь, чтобы измерить потери между вычисленным выходным значением обучающей выборки и фактическим выходным значением обучающей выборки. Вы можете спросить: как рассчитывается результат на основе обучающей выборки? Эти выходные данные выбираются случайным образом из ряда W, b и вычисляются с использованием алгоритма прямого распространения в нашем предыдущем разделе. То есть с помощью ряда расчетов:
a
l
=
σ
(
z
l
)
=
σ
(
W
l
a
l
−
1
+
b
l
)
, Рассчитать соответствующий L-й слой выходного слоя
a
L
Это выходной сигнал, рассчитанный по алгоритму прямого распространения. — В отличие от функции потерь, существует множество функций потерь, которые DNN может выбрать. Чтобы сосредоточиться на алгоритме, здесь мы используем наиболее распространенную среднеквадратичную ошибку для измерения потерь. То есть для каждого образца мы ожидаем минимизировать следующую формулу:
J
(
W
,
b
,
x
,
y
)
=
1
2
|
|
a
L
−
y
|
|
2
2
- среди них,
a
L
И у — векторы с размерностью объекта n_out, и
|
|
S
|
|
2
Является ли L2 нормой S.
- С функцией потерь, теперь мы начинаем использовать градиентный спуск, чтобы итеративно решить W, b для каждого слоя.
- Первый — это L-й слой выходного слоя. Обратите внимание, что W, b в выходном слое удовлетворяет следующей формуле:
a
L
=
σ
(
z
L
)
=
σ
(
W
L
a
L
−
1
+
b
L
)
- Таким образом, для параметров выходного слоя наша функция потерь становится:
J
(
W
,
b
,
x
,
y
)
=
1
2
|
|
a
L
−
y
|
|
2
2
=
1
2
|
|
σ
(
W
L
a
L
−
1
+
b
L
)
−
y
|
|
2
2
- Решить градиент W, b таким образом просто:
∂
J
(
W
,
b
,
x
,
y
)
∂
W
L
=
∂
J
(
W
,
b
,
x
,
y
)
∂
z
L
∂
z
L
∂
W
L
=
(
a
L
−
y
)
⊙
σ
′
(
z
L
)
(
a
L
−
1
)
T
∂
J
(
W
,
b
,
x
,
y
)
∂
b
L
=
∂
J
(
W
,
b
,
x
,
y
)
∂
z
L
∂
z
L
∂
b
L
=
(
a
L
−
y
)
⊙
σ
′
(
z
L
)
- Обратите внимание, что в приведенной выше формуле есть символ
⊙
, Который представляет произведение Адамара, для двух векторов одного измерения
A
(
a
1
,
a
2
,
.
.
.
a
n
)
T
с участием
B
(
b
1
,
b
2
,
.
.
.
b
n
)
T
, Затем
A
⊙
B
=
(
a
1
b
1
,
a
2
b
2
,
.
.
.
a
n
b
n
)
T
- Мы заметили, что при решении W, b в выходном слое, есть общая часть
∂
J
(
W
,
b
,
x
,
y
)
∂
z
L
Таким образом, мы можем относиться к публичной части как
z
L
Сначала рассчитайте его и запишите как:
δ
L
=
∂
J
(
W
,
b
,
x
,
y
)
∂
z
L
=
(
a
L
−
y
)
⊙
σ
′
(
z
L
)
- Теперь, когда мы наконец рассчитали градиент выходного слоя, как рассчитать градиент верхнего слоя L − 1 и верхнего и верхнего слоя L − 2? Здесь нам нужно повторить шаг за шагом, отметив, что для неактивного вывода слоя l
z
l
Его градиент может быть выражен как:
δ
l
=
∂
J
(
W
,
b
,
x
,
y
)
∂
z
l
=
∂
J
(
W
,
b
,
x
,
y
)
∂
z
L
∂
z
L
∂
z
L
−
1
∂
z
L
−
1
∂
z
L
−
2
.
.
.
∂
z
l
+
1
∂
z
l
- Если мы можем рассчитать первое
l
Многослойные
δ
l
Тогда слой
W
l
,
b
l
Это легко рассчитать? y Поскольку согласно алгоритму прямого распространения, мы имеем:
z
l
=
W
l
a
l
−
1
+
b
l
- Таким образом, согласно приведенной выше формуле мы можем легко вычислить первое
l
Многослойные
W
l
,
b
l
Градиент выглядит следующим образом:
∂
J
(
W
,
b
,
x
,
y
)
∂
W
l
=
∂
J
(
W
,
b
,
x
,
y
)
∂
z
l
∂
z
l
∂
W
l
=
δ
l
(
a
l
−
1
)
T
∂
J
(
W
,
b
,
x
,
y
)
∂
b
l
=
∂
J
(
W
,
b
,
x
,
y
)
∂
z
l
∂
z
l
∂
b
l
=
δ
l
- Тогда ключ к проблеме сейчас заключается в том, чтобы попросить
δ
l
Слишком. Здесь мы используем математическую индукцию, слой L
δ
L
Мы нашли выше, предполагая, что первое
l
+1
δ
l
+
1
Уже
через
нищенство
Вне
Приходить
от
,
который
какой
я
Мы
Такие как
какие
нищенство
Вне
Первый
l
Пол
из
А как насчет δ ^ l $? Мы заметили: (цепное правило)
δ
l
=
∂
J
(
W
,
b
,
x
,
y
)
∂
z
l
=
∂
J
(
W
,
b
,
x
,
y
)
∂
z
l
+
1
∂
z
l
+
1
∂
z
l
=
δ
l
+
1
∂
z
l
+
1
∂
z
l
- Видимо, рекурсивно по индукции
δ
l
+
1
с участием
δ
l
Ключ должен решить
∂
z
l
+
1
∂
z
l
- Пока
z
l
+
1
с участием
z
l
Отношения на самом деле очень легко найти:
z
l
+
1
=
W
l
+
1
a
l
+
b
l
+
1
=
W
l
+
1
σ
(
z
l
)
+
b
l
+
1
- Это легко найти:
∂
z
l
+
1
∂
z
l
=
(
W
l
+
1
)
T
⊙
(
σ
′
(
z
l
)
,
.
.
,
σ
′
(
z
l
)
)
⏟
n
l
+
1
- Доведите вышеупомянутое до вершины
δ
l
+
1
с участием
δ
l
Мы получили:
δ
l
=
δ
l
+
1
∂
z
l
+
1
∂
z
l
=
(
W
l
+
1
)
T
δ
l
+
1
⊙
σ
′
(
z
l
)
- Теперь мы получили
δ
l
Для рекурсивных отношений требуется только определенный уровень
δ
l
, Решить
W
l
,
b
l
Соответствующий градиент очень прост.
1.3.3 Процесс алгоритма обратного распространения DNN
- Здесь мы обсуждаем пакетный градиентный спуск.На самом деле, Mini-Batch обычно используется в разработке, но алгоритм имеет небольшой эффект.
- Войти:
- Общее количество слоев L и количество нейронов в каждом скрытом слое и выходном слое, функция активации, функция потерь, размер шага итерации α, максимальное количество итераций MAX и порог остановки итерации ϵ, ввод m обучающих выборок.
- Вывод:
- Матрица коэффициентов линейных отношений W и вектор смещения b каждого скрытого слоя и выходного слоя
-
Алгоритм потока:
- (1) Инициализируйте значения матрицы W коэффициента линейного отношения и вектора b смещения каждого скрытого слоя и выходного слоя случайным значением.
- (2) for iter to 1 to MAX:
- (2.1) for i =1 to m:
- (а) Входной DNN
a
1
Установить на Си
- (b) для l = 2 до L, для вычисления алгоритма прямого распространения,
a
i
,
l
=
σ
(
z
i
,
l
)
=
σ
(
W
l
a
i
,
l
−
1
+
b
l
)
- (c) Рассчитать выходной слой
δ
i
,
L
- (d) для l = L до 2 выполнить расчет алгоритма обратного распространения
δ
i
,
l
=
(
W
l
+
1
)
T
δ
i
,
l
+
1
⊙
σ
′
(
z
i
,
l
)
- (а) Входной DNN
- (2.2) для l = 2 до L обновите слой 1
W
l
,
b
l
:
W
l
=
W
l
−
α
∑
i
=
1
m
δ
i
,
l
(
a
i
,
l
−
1
)
T
b
l
=
b
l
−
α
∑
i
=
1
m
δ
i
,
l
- (2.3) Если значения изменения всех W, b меньше порога остановки итерации ϵ, то выпрыгните из цикла итерации к шагу 3
- (2.1) for i =1 to m:
- (3) Выведите матрицу коэффициентов линейных отношений W и вектор смещения b каждого скрытого слоя и выходного слоя
-
Если вы видите здесь, вы можете подумать, что вы не понимаете очень глубоко, или если вы думаете, что это слишком теоретически выведено, и нет никакого практического примера, чтобы понять интуитивно, тогда блоггер рекомендует вам изучить эту статью. Он использует яркие изображения Для иллюстрации на примерах, я думаю, это поможет вам понять алгоритм BP.Используйте небольшой пример, чтобы проиллюстрировать алгоритм BP
1.3.4 Мышление на основе алгоритма обратного распространения DNN
- Основываясь на приведенном выше алгоритме вывода, мы знаем, что существует множество параметров DNN, и количество вычислений матрицы также очень велико. При непосредственном использовании возникнут различные проблемы. Каковы проблемы и как попытаться решить эти проблемы и оптимизировать модель и алгоритм DNN.Конечно, многие ученые дали некоторые решения или изучают эти проблемы, и для нас это тоже очень стоящее исследование. Что касается аспектов, ниже кратко обсуждаются эти вопросы без теоретического вывода.
- С точки зрения функции потери и активации:
- Функция активации, которую мы выбрали ранее, является функцией Sigmoid, и, как видно из изображения, приведенного в начале, для Sigmoid, когда значение z становится все больше и больше, кривая функции становится все более плавной, что означает, что в это время Производная σ ′ (z) становится все меньше и меньше. Точно так же, когда значение z становится все меньше и меньше, эта проблема также существует. Только когда значение z составляет около 0, значение производной σ (z) больше. В рассмотренном выше алгоритме обратного распространения среднеквадратичной ошибки + сигмоида каждая прямая рекурсия уровня должна быть умножена на σ (z), чтобы получить значение изменения градиента. Судя по его функциональной кривой изображения, большую часть времени наше значение изменения градиента очень мало, что приводит к более медленной скорости обновления W, b до экстремального значения, то есть скорость сходимости алгоритма ниже.
- Функциональные характеристики сигмоида приводят к проблеме медленной сходимости алгоритма обратного распространения, так как его улучшить? Заменить сигмоид? Это конечно вариант. Другим распространенным вариантом является замена функции среднеквадратичной потери на функцию кросс-энтропийной потери. Давайте сначала обсудим функцию обменных потерь как функцию кросс-энтропии + сигмоидной активации следующим образом:
J
(
W
,
b
,
a
,
y
)
=
−
y
∙
l
n
a
−
(
1
−
y
)
∙
l
n
(
1
−
a
)
- Затем мы рассчитываем выходной слой
δ
L
Ситуация с градиентом, обнаружено, что градиента нет в градиенте
σ
′
(
z
)
Таким образом, даже если обратная функция сигмоида чрезвычайно мала с обеих сторон, это не повлияет на нашу скорость сходимости.
- Кроме того, когда мы решаем задачи классификации, мы обычно рассматриваем функцию потери логарифмического правдоподобия и функцию активации softmax. Мы не будем здесь обсуждать причину. Заинтересованные читатели могут изучить ее самостоятельно. Функция активации нейрона определяется следующим образом:
a
i
L
=
e
z
i
L
∑
j
=
1
n
L
e
z
j
L
- Третья проблема заключается в том, что градиент взрыва градиента DNN исчезает, и функция активации ReLU чаще используется для активации исчезновения градиента в CNN с помощью функции активации градиента ReLU. Что такое градиентные взрывы и исчезновения градиентов? Ниже, попробуйте описать это на общем языке, потому что это очень сложно, и может привести к большой книге, поэтому вот краткое описание.
- Проще говоря, в процессе обратного распространения, поскольку мы используем цепное правило матричного дифференцирования (ниже), существует большой ряд умножений. Если число умножений меньше 1 в каждом слое, Затем, чем меньше градиент, тем меньше умножение, и градиент исчезает.Если число умножений больше 1, градиент умножается и градиент взрывается.
δ
l
=
∂
J
(
W
,
b
,
x
,
y
)
∂
z
l
=
∂
J
(
W
,
b
,
x
,
y
)
∂
z
L
∂
z
L
∂
z
L
−
1
∂
z
L
−
1
∂
z
L
−
2
.
.
.
∂
z
l
+
1
∂
z
l
- Обычно используемые в общем машиностроении:
- Для градиентного взрыва это обычно можно решить, отрегулировав параметры инициализации в нашей модели DNN.
- Для проблемы исчезновения градиента, которая не может быть полностью решена, одним из возможных решений проблемы исчезновения градиента является использование функции активации ReLU (выпрямленная линейная единица) ReLU широко используется в CNN. Выражение очень простое: больше или равно 0 останется неизменным, меньше 0 будет равно 0 после активации.
σ
(
z
)
=
m
a
x
(
0
,
z
)
- Кроме того, для решения проблемы переоснащения для регулярности общая регулярность L2 здесь не повторяется, и ее можно использовать как для функции среднеквадратичной ошибки, так и для функции перекрестной энтропии. Кроме того, для регуляризации можно использовать метод интегрированного обучения (Bagging), но из-за дальнейшего увеличения параметров, как правило, производится только 5-10 моделей DNN. Здесь мы обращаем внимание на регуляризацию отсева, которая очень похожа на метод Bagging, но есть некоторые отличия.
- Так называемое выпадение относится к использованию алгоритма прямого распространения и алгоритма обратного распространения для обучения модели DNN.При итерации пакета данных часть нейронов скрытого слоя случайным образом удаляется из полностью подключенной сети DNN. Сеть нейронов с удаленными скрытыми слоями используется, чтобы соответствовать нашей партии обучающих данных. Используйте эту сеть нейронов с удаленным скрытым слоем, чтобы выполнить цикл итераций, обновляя все W, b.В заключениеТаким образом, в каждом цикле итерации градиентного спуска необходимо разделить обучающие данные на несколько пакетов, а затем выполнить итерацию в пакетах. Итеративно обновить W, b. После итеративного обновления каждого пакета данных неполная модель DNN должна быть восстановлена до исходной модели DNN.
- Разница между ним и Bagging, W, b в выпадающей модели — это совокупность. Все итеративные итерации DNN обновляют один и тот же набор W, b, при регуляризации по Бэггингу каждая модель DNN имеет свой уникальный набор параметров W, b, которые не зависят друг от друга. Конечно, они используют наборы пакетных данных на основе исходного набора данных для обучения модели каждый раз, что аналогично.
Во-вторых, практика кодирования прямой нейронной сети на основе TensorFlow
2.1 Функции библиотеки TensorFlow участвуют
-
Функция активации TensorFlow
- стандартная сигмоидная функция tf.sigmoid (x)
- tf.tanh (x) гиперболическая касательная функция
- tf.nn.relu (x) модифицированная линейная функция
-
Другие функции в TensorFlow
- tf.nn.elu (x) экспоненциальная линейная единица: если входное значение меньше 0, оно возвращает exp (x) -1, в противном случае возвращается x
- tf.softsign (x) возвращает x / (abs (x) + 1)
- tf.nn.bias_add (значение, смещение) добавляет смещение к значению
-
Некоторые методы оптимизации потерь Tensorflow
- tf.train.GradientDescentOptimizer (learning_rate, use_locking, name) Оригинальный метод градиентного спуска, единственным параметром является скорость обучения
- tf.train.AdagradOptimizer адаптивно регулирует скорость обучения, в качестве знаменателя используется квадрат накопленного исторического градиента, чтобы предотвратить слишком большое значение градиента в некоторых направлениях, повысить эффективность оптимизации и хорошо справляться с разреженными градиентами
- tf.train.AdadeltaOptimizer Расширенный метод оптимизации AdaGrad накапливает только самое последнее значение градиента и не накапливает градиент во всей истории.
- tf.train.AdamOptimizer Градиентная оценка момента первого порядка и оценка момента второго порядка динамически регулирует скорость обучения каждого параметра.Адам является аббревиатурой для адаптивной оценки момента.
2.2 Подгонка нелинейной регрессии данных
# В этом примере мы вручную генерируем квадратичную функцию плюс набор данных шума, а затем подгоняем ее через простейшую нейронную сеть для достижения цели обучения
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.utils import shuffle
from sklearn.metrics import accuracy_score
# Определение размера набора данных
trainsamples = 200
testsamples = 60
# Here we will represent the model,a simple imput,
# a hidden layer of sigmoid activation,
# Определить город ввода, слой вывода и сеть скрытых слоев с 10 узлами
def model(X,hidden_weights1,hidden_bias1,ow):
hidden_layer = tf.nn.sigmoid(tf.matmul(X,hidden_weights1) + hidden_bias1)
return tf.matmul(hidden_layer, ow)
# Создать набор данных
dsX = np.linspace(-1, 1, trainsamples + testsamplt).transpose()
dsY = 0.4 * pow(dsX,2) + 2 * dsX + np.random.randn(*dsX.shape) * 0.22 + 0.8
plt.figure() # create a new figure
plt.title('Origial data')
plt.scatter(dsX,dsY) <matplotlib.collections.PathCollection at 0x114554110>

X = tf.placeholder('float')
Y = tf.placeholder('float')
# create first hidden layer
hw1 = tf.Variable(tf.random_normal([1, 10],stddev=0.01))
# create output connection
ow = tf.Variable(tf.random_normal([10, 1],stddev=0.01))
# create bias
b = tf.Variable(tf.random_normal([10],stddev=0.01))
model_y = model(X,hw1,b,ow)
# cost Function
cost = tf.pow(model_y - Y,2) / (2)
# create train Operator
train_op = tf.train.AdamOptimizer(0.01).minimize(cost)# Launch the graph in a session
with tf.Session() as sess:
tf.initialize_all_variables().run()
# Начать итерацию
for i in range(1,35):
trainX, trainY = dsX[0:trainsamples], dsY[0:trainsamples]
for x1, y1 in zip(trainX,trainY):
sess.run(train_op,feed_dict={X:[[x1]],Y:y1})
testX, testY = dsX[trainsamples:trainsamples + testsamples],dsY[trainsamples:trainsamples+testsamples]
# print testY
cost1 = 0.
for x1, y1 in zip(testX,testY):
cost1 += sess.run(cost,feed_dict={X: [[x1]], Y: y1}) / testsamples
print "Average cost for epoch" + str(i) + ':' + str(cost1)
Average cost for epoch1:[[0.26329115]]
Average cost for epoch2:[[0.22221012]]
Average cost for epoch3:[[0.14709872]]
Average cost for epoch4:[[0.10356887]]
Некоторый контент здесь опущен:
Average cost for epoch29:[[0.02887413]]
Average cost for epoch30:[[0.02915836]]
Average cost for epoch31:[[0.029492]]
Average cost for epoch32:[[0.0298766]]
Average cost for epoch33:[[0.0303134]]
Average cost for epoch34:[[0.03080252]]
2.3 Использование Keras для моделирования непрерывных переменных
%matplotlib inline
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn import datasets, cross_validation,metrics
from sklearn import preprocessing
from tensorflow.contrib import learn
from keras.models import Sequential
from keras.layers import Dense
# Read the original dataset
data = pd.read_csv('mpg.csv',header=0)
print data.describe()
# Convert the displacement column as float
data['displacement'] = data['displacement'].astype(float)
# Игнорировать первый и последний столбец
X = data[data.columns[1:8]]
y = data['mpg']
plt.figure()
f, ax1 = plt.subplots()
for i in range(1,8):
number = 420 + i
ax1.locator_params(bnbins=3)
ax1 = plt.subplot(number)
plt.title(list(data)[i])
ax1.scatter(data[data.columns[i]],y)
plt.tight_layout(pad=0.4,w_pad=0.5,h_pad=1.0) mpg cylinders displacement horsepower weight
count 398.000000 398.000000 398.000000 398.000000 398.000000
mean 23.514573 5.454774 193.425879 102.894472 2970.424623
std 7.815984 1.701004 104.269838 40.269544 846.841774
min 9.000000 3.000000 68.000000 0.000000 1613.000000
25% 17.500000 4.000000 104.250000 75.000000 2223.750000
50% 23.000000 4.000000 148.500000 92.000000 2803.500000
75% 29.000000 8.000000 262.000000 125.000000 3608.000000
max 46.600000 8.000000 455.000000 230.000000 5140.000000
<matplotlib.figure.Figure at 0x11d0fd990>

# Split the datasets
X_train, x_test, y_train, y_test = cross_validation.train_test_split(X,y,test_size=0.25)
# Scale the data for convergency optimization
scaler = preprocessing.StandardScaler()
# set the transform parameters
X_train = scaler.fit_transform(X_train)
# Build a 2 layer fully connected DNN with 10 and 5 units respectively
model = Sequential()
model.add(Dense(10,input_dim=7,init='normal',activation='relu'))
model.add(Dense(5,init='normal',activation='relu'))
# Вывод
model.add(Dense(1,init='normal'))
# Compile the model, which the mean squared error as a loss function
model.compile(loss='mean_squared_error',optimizer='adam')
# Fit the model,in 1000 epochs
# verbose: журналы показывают, что 0 не выводит журнальную информацию о стандартном потоке вывода, 1 - выходные записи индикатора выполнения, а 2 - запись одной строки за эпоху
# epochs: целое число, значение эпохи в конце обучения, обучение остановится, когда будет достигнуто значение эпохи
model.fit(X_train,y_train,nb_epoch=1200,validation_split=0.33,shuffle=True,verbose=2)
Train on 199 samples, validate on 99 samples
Epoch 1/1200
- 0s - loss: 624.4550 - val_loss: 609.7046
Epoch 2/1200
- 0s - loss: 624.0735 - val_loss: 609.3263
Epoch 3/1200
Части здесь опущены ...
Epoch 1197/1200
- 0s - loss: 6.9051 - val_loss: 8.6608
Epoch 1198/1200
- 0s - loss: 6.9028 - val_loss: 8.6282
Epoch 1199/1200
- 0s - loss: 6.8984 - val_loss: 8.6874
Epoch 1200/1200
- 0s - loss: 6.8917 - val_loss: 8.8152
<keras.callbacks.History at 0x11ec65ed0>
2.4 Задача мультиклассификации, многоузловой выходной слой
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.utils import shuffle
from sklearn import preprocessing
# Чтение данных
data = pd.read_csv('./wine.csv',header=0)
print (data.describe())
for i in range(1,8):
number = 420 + i
ax1 = plt.subplot(number)
ax1.locator_params(nbins=3)
plt.title(list(data)[i])
ax1.scatter(data[data.columns[i]],data['Wine'])
plt.tight_layout(pad=0.4,w_pad=0.5,h_pad=1.0) Wine Alcohol Malic.acid Ash Acl Mg
count 178.000000 178.000000 178.000000 178.000000 178.000000 178.000000
mean 1.938202 13.000618 2.336348 2.366517 19.494944 99.741573
std 0.775035 0.811827 1.117146 0.274344 3.339564 14.282484
min 1.000000 11.030000 0.740000 1.360000 10.600000 70.000000
25% 1.000000 12.362500 1.602500 2.210000 17.200000 88.000000
50% 2.000000 13.050000 1.865000 2.360000 19.500000 98.000000
75% 3.000000 13.677500 3.082500 2.557500 21.500000 107.000000
max 3.000000 14.830000 5.800000 3.230000 30.000000 162.000000

sess = tf.InteractiveSession()
X = data[data.columns[1:13]].values
# Сами данные начинаются с 1, вычитают отклонение от данных и затем отображают Y в одноразовое кодирование
y = data['Wine'].values - 1
Y = tf.one_hot(indices=y,depth=3,on_value=1.,off_value=0.,axis=1,name='a').eval()
X, Y = shuffle(X, Y)
# Регуляризация тренировочных данных
scaler = preprocessing.StandardScaler()
X = scaler.fit_transform(X)
# Здесь скрытый слой нейронной сети, предназначенный для обучения, выберите соответствующий скрытый слой для сложности модели
# Создайте модель, используйте функцию активации softmax + относительную энтропию в качестве функции потерь, в качестве мультиклассификации
x = tf.placeholder(tf.float32,[None,12]) # Особенности ввода х имеют 12 измерений
W = tf.Variable(tf.zeros([12,3])) # Вес 12 * 3
b = tf.Variable(tf.zeros([3])) # Смещение 1 * 3
y = tf.nn.softmax(tf.matmul(x,W) + b)
# Определяем потери и оптимизатор, функция кросс-энтропии потерь определяется следующим образом:
y_ = tf.placeholder(tf.float32,[None,3])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y),reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(cross_entropy)
# Train
tf.initialize_all_variables().run() # Инициализировать переменные
for i in range(20):
X, Y = shuffle(X,Y,random_state=1) # Случайно перемешивать данные, чтобы увеличить способность
Xtr = X[0:140,:]
Ytr = Y[0:140,:]
Xt = X[140:178,:]
Yt = Y[140:178,:]
Xtr, Ytr = shuffle(Xtr,Ytr,random_state=0)
batch_xs, batch_ys = Xtr, Ytr
train_step.run({x:batch_xs,y_:batch_ys})
cost = sess.run(cross_entropy,feed_dict={x:batch_xs,y_:batch_ys})
# Test trained model
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
print(accuracy.eval({x:Xt,y_:Yt})) Некоторые вещи здесь опущены ...
0.94736844
0.94736844
0.94736844
0.94736844
0.9736842
1.0
0.9736842
Кодовые слова не легки. Если это поможет вам, пожалуйста, оставьте свои следы или вдохновите меня продолжать.
Примечание: ссылки в этой статье следующие: (Большое спасибо следующим замечательным блоггерам за то, что они позволили мне узнать много полезного)
1、 http://www.cnblogs.com/pinard/p/6472666.html
2、 https://www.jianshu.com/p/964345dddb70
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
В нашей статье мы создадим нейронную сеть прямого распространения на языке программирования Python. В качестве библиотеки работы с векторами и матрицами будет использоваться библиотека Numpy. Для работы с изображениями потребуется библиотека PLT. Данная работа выполнена в рамках курсового проекта по дисциплине «Machine Learning. Обучающиеся технические системы [1].
Введение
Нейронная сеть — математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма [3].
Искусственный нейрон — это всего лишь взвешенная сумма значений входного вектора элементов, которая передаётся на нелинейную функцию активации f: z = f(y), где y = w0·x0 + w1·x1 + … + wm — 1·xm — 1. Здесь w0, …, wm — 1 — коэффициенты, веса каждого элемента вектора, x0, …, xm — 1 — значения входного вектора X, y — взвешенная сумма элементов X, а z— результат применения функции активации.
Функция активации — это функция, которая добавляет в нейронную сеть нелинейность, благодаря чему нейроны могут довольно точно интерполировать произвольную функцию. В настоящее время существует довольно много различных функций активации, но наиболее распространёнными функциями являются следующие:
Сигмоида: f(x) = 1 / (1 + e-x)
Гиперболический тангенс: f(x) = tanh(x)
ReLU: f(x) = max(x, 0)
Написание кода нейронной сети
Для реализации сети прямого назначения нам потребуется:
Вектор (входные, выходные) – из библиотеки Numpy;
Матрица (каждый слой содержит матрицу весовых коэффициентов) – из библиотеки Numpy;
Нейросеть.
Напишем метод, который будет получать выход нейронной сети по заданному входному вектору input:
# инициализация матрицы случайными значениями
def InitWeight(n, m):
w = np.zeros((n, m))
# заполняем матрицу случайными числами из интервала (-0.5, 0.5)
for i in range(n):
for j in range(m):
w[i][j] = random.uniform(-0.5, 0.5)
return w
# инициализация списка матриц весов случайными значениями
def InitWeights(struct):
W = []
# для каждого из весов задаём матрицу
for k in range(1, len(struct)):
w = InitWeight(struct[k], struct[k — 1])
W.append(w)
return W
def Sigmoid(x):
return 1 / (1 + np.exp(-x))
# прямое распространение сигнала по сети
def Forward (weights, input):
z = input;
# проходимся по всем слоям
for k in range(len(weights))
# создаём вектора для текущего слоя
y = weights[k].dot(z) # производим умножения матриц весов на входное значение
z = Sigmoid(y) # применяем сигмоидальную активационную функцию
return z # возвращаем активированный выход последнего слоя
Рис. 1. Код входных значений
Создали нейронную сеть. Теперь необходимо её обучить. Обучать нейросеть мы будем с помощью алгоритма обратного распространения ошибки, который работает следующим образом:
Подать на вход сети обучающий пример (один входной вектор)
Распространить сигнал по сети вперёд (получить выход сети)
Вычислить ошибку (разница получившегося и ожидаемого векторов)
Распространить ошибку на предыдущие слои
Обновить весовые коэффициенты для уменьшения ошибки
Обучаем сеть
Для обратного распространения ошибки нам потребуется знать значения входов, выходов и значения производных функции активации сети на каждом из слоёв, поэтому будем хранить список из структур 3 векторов: x — вход слоя, z — выход слоя, df — производная функции активации. Также для каждого слоя потребуются векторы дельт, поэтому добавим ещё и их. С учётом вышесказанного прямое распространение сигнала по сети будет выглядеть следующим образом:
# инициализация матрицы случайными значениями
def InitWeight(n, m):
w = np.zeros((n, m))
# заполняем матрицу случайными числами из интервала (-0.5, 0.5)
for i in range(n):
for j in range(m):
w[i][j] = random.uniform(-0.5, 0.5)
return w
# инициализация списка матриц весов случайными значениями
def InitWeights(struct):
W = []
# для каждого из весов задаём матрицу
for k in range(1, len(struct)):
w = InitWeight(struct[k], struct[k — 1])
W.append(w)
return W
def Sigmoid(x):
return 1 / (1 + np.exp(-x))
def SigmoidDerivative(y):
return y * (1 — y)
# прямое распространение сигнала по сети
def Forward (weights, input):
X = [] # входные значения слоёв
Z = [] # активированные значения слоёв
D = [] # значения производной функции активации
# проходимся по всем слоям
for k in range(len(weights)):
if k == 0: # если в первом слое, то входом является входной вектор
X.append(np.array(input))
else: # иначе входом является выход предыдущего слоя
X.append(Z[k — 1])
# создаём вектора для текущего слоя
y = weights[k].dot(X[k]) # производим умножения матриц весов на входное значение
z = Sigmoid(y) # применяем сигмоидальную активационную функцию
df = SigmoidDerivative(z) # вычисляем производную функции активации через уже известное значение выхода
Z.append(z)
D.append(df);
return X, Z, D # возвращаем список входов, выходов, активированных выходов и производных
Рис. 2. Код прямого распространения сигнала
Обратное распространение ошибки
В качестве функции оценки сети E(W) возьмём минимальное квадратичное отклонение: E = 0.5 · Σ(y1i — y2i)2. Чтобы найти значение ошибки E, нам нужно найти сумму квадратов разности значений вектора, который выдала сеть в качестве ответа, и вектора, который мы ожидаем увидеть при обучении. Также нам потребуется найти дельту для каждого слоя, причём для последнего слоя она будет равна вектору разности полученного и ожидаемого векторов, умноженному (покомпонентно) на вектор значений производных последнего слоя: δlast = (zlast — d)·f’last, где zlast — выход последнего слоя сети, d — ожидаемый вектор сети, f’last — вектор значений производной функции активации последнего слоя.
Теперь, зная дельту последнего слоя, мы можем найти дельты всех предыдущих слоёв. Для этого нужно умножить транспонированную матрицы текущего слоя на дельту текущего слоя и затем умножить полученный вектор на вектор производных функции активации предыдущего слоя: δk-1 = WTk · δk · f’k. Добавим это в код:
# обратное распространение ошибки
def Backward(weights, Z, df, output):
deltas = []
layersN = len(weights)
last = layersN — 1
error = 0
for k in range(layersN):
deltas.append([])
# расчитываем ошибку на выходном слое
e = Z[last] — output
deltas[last] = np.multiply(e, df[last])
error += np.sum(e**2)
# распространяем ошибку выше по слоям
for k in range(last, 0, -1):
deltas[k — 1] = np.multiply(weights[k].T.dot(deltas[k]), df[k — 1])
return deltas, error # возвращаем дельты и величину ошибки
Рис. 3. Код обратного распространения ошибки
Изменение весов
Для того чтобы уменьшить ошибку сети нужно изменить весовые коэффициенты каждого слоя. Для этого используется метод градиентного спуска. Градиент по весам равен перемножению входного вектора и вектора дельт (не покомпонентно). Поэтому, чтобы обновить весовые коэффициенты и уменьшить тем самым ошибку сети нужно вычесть из матрицы весов результат перемножения дельт и входных векторов, умноженный на скорость обучения. Записываем в виде: Wt+1 = Wt – η · δ · X, где Wt+1 — новая матрица весов, Wt — текущая матрица весов, X — входное значение слоя, δ — дельта этого слоя.
# обновлениевесов
def UpdateWeights(weights, X, deltas, alpha):
for k in range(len(weights)):
weights[k] -= alpha * np.outer(deltas[k], X[k])
Рис. 4. Код изменения весов
Обучение сети
Теперь, имея методы прямого распространения сигнала, обратного распространения ошибки и изменения весовых коэффициентов, нам остаётся лишь соединить всё вместе в один метод обучения.
# обучениесети
def Train(weights, inputData, outputData, alpha, eps, epochs):
print(‘nStart train process:’)
epoch = 1
while True:
error = 0
for i in range(len(inputData)):
X, Z, D = Forward(weights, inputData[i]) # прямое распространение сигнала
deltas, err = Backward(weights, Z, D, outputData[i]) # обратное распространение ошибки
UpdateWeights(weights, X, deltas, alpha) # обновление весовых коэффициентов
error += err / 2
if epoch % 1 == 0:
print(«epoch:», epoch, «alpha:», alpha, «error:», error)
# выходим, если ошибка стала меньше точности
if error < eps:
break;
# выходим, если достигли большого числа эпох
if epoch >= epochs:
print(‘Warning! Max epochs reached’)
break
epoch += 1# увеличиваемчислоэпохна 1
alpha *= 0.999
Рис. 5. Код обучения сети
Тренируем сеть
Создаем массив векторов X и Y с обучающими данными и саму нейросеть:
# массив входных обучающих векторов
X = [
[ 0, 0 ],
[ 0, 1 ],
[ 1, 0 ],
[ 1, 1 ],
];
# массив выходных обучающих векторов
Y = {
[ 0 ], # 0 ^ 0 = 0
[ 1 ], # 0 ^ 1 = 1
[ 1 ], # 1 ^ 0 = 1
[ 0 ] # 1 ^ 1 = 0
}
struct = [ 2, 3, 1 ] # структура сети: 2 входных нейрона, 3 нейрона в скрытом слое, 1 выходной нейрон
W = InitWeights(struct) # матрицы весовых коэффициентов
Рис. 6. Код функции XOR
Запускаем обучение со следующими параметрами: скорость обучения — 0.5, число эпох — 100000, величина ошибки — 1e-7:
Train(W, x, y, 0.5, 1e-7, 100000)
После обучения посмотрим на результаты, выполнив прямой проход для всех элементов:
for i in range(len(X)):
output = Forward(X[i]);
print«X: «, X[i][0], X[i][1], «Y: «, Y[i][0], «output: «, output[0]);
}
В результате вывод может быть таким:
X: 0 0, Y: 0, output: 0,00503439463431083
X: 0 1, Y: 1, output: 0,996036009216668
X: 1 0, Y: 1, output: 0,996036033202241
X: 1 1, Y: 0, output: 0,00550270947767007
Далее будем учить сеть распознавать цифры на картинках с рукописными цифрами из выборки MNIST.
Получаем тренировочную выборку
Файл с тренировочной выборкой train.csv находится по ссылке: http://www.pjreddie.com/media/files/mnist_train.csv [2]
# получение обучающей выборки
def GetTrainData(path, maxLen):
f = open(path, ‘r’)
lines = f.readlines() # считываемстрокифайла
trainInput = []
trainOutput = []
# проходимся по строкам файла, но не более, чем maxLen
for i in range(1, min(maxLen + 1, len(lines))):
splited = lines[i].split(‘,’)
x = []
y = []
# сохраняем нормализованные значения в вектор
for j in range(1, len(splited)):
v = 0.01 + float(splited[j]) / 255 * 0.99
x.append(v)
for j in range(10):
y.append(0);
y[int(splited[0])] = 1 # задаём выходной вектор
# добавляем в обучающую выборку цифру
trainInput.append(x)
trainOutput.append(y)
print(‘nReaded train data:’, len(trainInput), ‘elements’); # выводиминформациюосчитанныхданных
return trainInput, trainOutput
Рис. 7. Код с обучающей выборкой
Получив обучающее множество, состоящее из 42000 примеров, запустим обучений нейронной сети на 20 эпох обучения со скоростью 0.65.
struct = [ 784, 100, 10 ] # структура сети: 784 входных нейрона, 100 в скрытом слое, 10 выходных
W = InitWeights(struct) # матрицы весовых коэффициентов
learningRate = 0.65 # скорость обучения
maxEpoch = 20 # максимальное число эпох
eps = 1e-7 # точность
trainPath = ‘train.csv’ # путь к файлу с обучающей выборкой
testPath = ‘test.csv’ # путь к файлу с тестовой выборкой
answersPath = ‘answers.csv’ # путь к файлу с ответами
print(‘Network structure:’, struct)
print(‘Learning rate (alpha):’, learningRate)
print(‘Max epochs: ‘, maxEpoch)
print(‘Accuracy (eps):’, eps)
x, y = GetTrainData(trainPath, 42000) # считываем обучающую выборку
Train(W, x, y, learningRate, eps, maxEpoch)
Рис. 8. Код запуска обучения
Тестируем сеть
Файл с тестовой выборкой находится по ссылке:
http://www.pjreddie.com/media/files/mnist_test.csv [2]
# проверка точности на обучающей выборке
def Test(weights, testPath, answersPath):
print(‘nStart test process:’);
test = open(testPath, ‘r’)
answers = open(answersPath, ‘r’)
testLine = test.readlines()
answersLine = answers.readlines()
correct = 0
total = 0
# проходимся по всем тестовым строкам кроме первой
for i in range(1, len(testLine)):
splited = testLine[i].split(‘,’) # разбиваем строку по запятым
x = []
# сохраняем нормализованные значения в вектор
for j in range(len(splited)):
v = 0.01 + float(splited[j]) / 255 * 0.99
x.append(v)
d = np.argmax(GetOutput(weights, x)); # получаемцифру, предсказаннуюсетью
y = int(answersLine[i].split(‘,’)[1]) # получаем цифру из ответов
if y == d: # если цифры совпали, увеличиваем на 1 число корректно распознанных
correct += 1
total += 1 # увеличиваем число обработанных строк
if total % 1000 == 0:
print(‘accuracy:’, correct, » / «, total, «: «, (100.0 * correct / total), ‘%’) # выводиминформациюпопредсказаниям
print(‘accuracy:’, correct, » / «, total, «: «, (100.0 * correct / total), ‘%’) # выводим информацию по предсказаниям
Рис. 8. Код с тестовой выборкой
В результате запуска теста мы получили точность около 97%. Таким образом мы научились распознавать изображения.
# предсказание по картинке
def Predict(weights, path):
img = plt.imread(path)
x = 0.01 + img.flatten() * 256 / 255 * 0.99
return GetOutput(weights, x)
while True:
path = input(‘Enter path to image:’);
if path == »:
break;
d = Predict(W, path)
print(‘For image », path, » probably it is’, np.argmax(d))
Рис. 8. Код распознавания
Выводы
Нейронная сеть успешно обучилась функции исключающего ИЛИ (XOR), а также смогла распознавать изображения рукописных цифр с точностью более 97%.
СПИСОК ИСТОЧНИКОВ И ЛИТЕРАТУРЫ
Воронова Л.И., Воронов В.И.. Machine Learning: регрессионные методы интеллектуального анализа данных: учебное пособие / МТУСИ.– М., 2017.- 92с.
Рашид Т. Создаем нейронную сеть.: Пер. с англ. – СПб.: ООО «Диалектика», 2018 – 272 с.: ил. – Парал. тит. англ.
Википедия [Электронный ресурс]. Режим доступа: https://ru.wikipedia.org
Нейронные сети: объяснение прямой связи и обратного распространения
Перевод
Ссылка на автора
(первоначально опубликовано на mlfromscratch )
КдействительноПонимание нейронных сетей. Одним из наиболее признанных понятий в глубоком обучении (подполе машинного обучения) являются нейронные сети.
Что-то довольно важное в том, чтоВсе типы нейронных сетей представляют собой разные комбинации одних и тех же основных принципов., Когда вы знаете основы работы нейронных сетей, новые архитектуры — это всего лишь небольшие дополнения ко всему, что вы уже знаете о нейронных сетях.
В дальнейшем все вышеперечисленное будет основной мотивацией для каждого поста с углубленным изучением mlfromscratch,
- Обзор нейронных сетей
- Что такое нейронная сеть?
- Детали, обозначения и математика используются
- Обратное распространение: оптимизация всех весов
- Оптимизация нейронной сети
- Ввод нейронных сетей в шаги
- Дальнейшее чтение (рекомендуемые книги)
обзор
Общая картина в нейронных сетях — это то, как мы получаем некоторые данные, добавляем их в какой-то алгоритм и надеемся на лучшее. Но что происходит внутри этого алгоритма? На этот вопрос важно ответить по многим причинам; одна из них заключается в том, что в противном случае вы могли бы просто рассматривать внутреннюю работу нейронных сетей как черный ящик.
Нейронные сети состоят из нейронов, связей между этими нейронами, называемых весами, и некоторых смещений, связанных с каждым нейроном. Мы различаем входной, скрытый и выходной слои, где мы надеемся, что каждый слой помогает нам в решении нашей проблемы.
Для продвижения вперед по сети, называемой прямой передачей, мы итеративно используем формулу для расчета каждого нейрона в следующем слое. Оставьте здесь полное игнорирование обозначений, но мы называем нейроны для активаций $ a $, весавеси уклоныб— который накапливается в векторах.

Это продвигает нас вперед, пока мы не получим выход. Мы измеряем, насколько хорош этот выводу шляпыпо функции стоимостиСи результат, который мы хотели в выходном слоеYи мы делаем это для каждого примера. Это обычно называют среднеквадратичной ошибкой (MSE):

Учитывая первый результат, мы возвращаемся и корректируем веса и смещения, чтобы оптимизировать функцию стоимости, называемую проходом в обратном направлении. Мы по существу пытаемся настроить всю нейронную сеть, чтобы оптимизировать выходное значение. В некотором смысле, именно так мы сообщаем алгоритму, что он работает плохо или хорошо. Мы продолжаем пытаться оптимизировать функцию стоимости, просматривая новые наблюдения из нашего набора данных.
Для обновления сети мы рассчитываем так называемыеградиенты, который является маленькими толчками (обновлениями) отдельных весов в каждом слое.


Мы просто проходим каждый вес, например в выходном слое вычтите значение скорости обучения, умноженное на стоимость конкретного веса, из исходного значения, которое имело конкретный вес.

Добавьте что-то, называемое мини-пакетами, где мы усредняем градиент некоторого количества определенных наблюдений на мини-пакет, и тогда у вас есть базовая настройка нейронной сети.
Я собираюсь объяснить каждую часть очень подробно, если вы продолжите читать дальше. Обратитесь к оглавлению, если вы хотите прочитать что-то конкретное.
Мы начнем с нейронных сетей с прямой связью, затем немного поговорим о нотации, затем начнем глубокое объяснение обратного распространения и, наконец, обзор того, как оптимизаторы помогают нам использовать алгоритм обратного распространения, в частности стохастический градиентный спуск.
Что такое нейронная сеть?
Здесь так много терминологии. Позвольте мне сделать это шаг за шагом, и тогда вам нужно будет сидеть сложа руки.
Нейронные сети — это алгоритм, вдохновленный нейронами нашего мозга. Он предназначен для распознавания шаблонов в сложных данных и часто работает лучше всего при распознавании шаблонов в аудио, изображениях или видео.
Нейроны — связаны
Нейронная сеть просто состоит из нейронов (также называемых узлами). Эти узлы связаны каким-то образом. Тогда каждый нейрон содержит номер, икаждое соединение имеет вес.
Эти нейроны делятся междувходной, скрытый и выходной слой, На практике существует много слоев, и нет лучшего общего числа слоев.

Идея состоит в том, что мы вводим данные на входной слой, который отправляет числа от нашего пинг-понга вперед через разные соединения от одного нейрона к другому в сети. Как только мы достигаем выходного слоя, мы надеемся получить желаемое число.
Входные данные — это просто ваш набор данных, где каждое наблюдение проходит последовательно от x = 1 до x = i. Каждый нейрон имеет несколькоактивация— значение между 0 и 1, где 1 — максимальная активация, а 0 — минимальная активация, которую может иметь нейрон То есть, если мы используем функцию активации под названием sigmoid, объясненную чуть ниже (второй следующий заголовок). Таким образом, рекомендуется масштабировать ваши данные до значений от 0 до 1 (например, используя MinMaxScaler от Scikit-Learn).
От входного слоя к скрытому слою
Мы как бы передали нам входной слой из набора данных, который мы вводим, но как насчет слоев после этого? То, что происходит, — это просто пинг-понг чисел, это не более чем основные математические операции. Мы смотрим на все нейроны во входном слое, которые связаны с новым нейроном в следующем слое (который является скрытым слоем).
Запомните это:каждый нейрон имеет активациюи каждый нейрон, который связан с новым нейроном, имеет весвес, Активации обычно представляют собой число в диапазоне от 0 до 1, а вес удваивается, например, 2,2, -1,2, 0,4 и т. Д.

(см. Stochastic Gradient Descent для объяснения веса)
Затем..можно умножить активации на веса и получить один нейрон в следующем слое, начиная с первых весов и активацийw1 * a1вплоть дошп *:

То есть умножитьNколичество весов и активаций, чтобы получить значение нового нейрона.

Процедура аналогична движению вперед в сети нейронов, отсюда и названиепрямая нейронная сеть.
Функции активации
Но .. все не так просто. У нас также естьфункция активациичаще всего это сигмовидная функция, которая просто масштабирует выходной сигнал в диапазоне от 0 до 1, так что это логистическая функция. В будущих публикациях будет опубликовано сравнение или пошаговое описание многих функций активации.

Мы обернем уравнение для новых нейронов с помощью активации, то есть кратного суммирования результата умножения весов и активаций


Теперь нам просто нужно объяснить добавлениесмещениек уравнению, и тогда у вас есть базовая установка для расчета значения нового нейрона.
предвзятостьпытается приблизиться, где значение нового нейрона начинает иметь значение. Таким образом, вы попытаетесь добавить или вычесть смещение из умножения активаций и весов.

Есть много типов функций активации, вот обзор:

Это все, что нужно для очень простой нейронной сети, прямой нейронной сети. Но нам нужно ввести в алгоритм другие алгоритмы, чтобы познакомить вас с тем, как на самом деле учится такая сеть.
Прежде чем перейти к сути того, что заставляет нейронные сети учиться, мы должны поговорить о нотации. По крайней мере, я сначала запутался в обозначениях, потому что не так много людей тратят время на их объяснение.
Математика для нейронных сетей
Прежде чем перейти к более продвинутым алгоритмам, я хотел бы предоставить некоторые нотации и общие знания по математике для нейронных сетей — или, по крайней мере, ресурсы для этого, если вы не знаете линейную алгебру или исчисление.
Обозначение: линейная алгебра
При изучении теории нейронных сетей часто можно обнаружить, что большинство нейронов и слоев отформатированы в линейной алгебре. Обратите внимание, что я сделал короткая серия статей где вы можете изучить линейную алгебру снизу вверх. Я бы порекомендовал прочитать большинство из них и попытаться понять их. Оставьте комментарий, если вы этого не сделаете, и я сделаю все возможное, чтобы ответить вовремя.
Обозначения довольно аккуратные, но могут быть и громоздкими. Позвольте мне начать с нижней части окончательного уравнения, а затем объяснить мой путь к предыдущему уравнению:

Итак, с чего мы начинаем — это организацию активаций и весов в соответствующую матрицу.
Мы обозначаем каждую активацию

например где

будет соответствовать нейрону номер три во втором слое (мы считаем от 0). Таким образом, число ниже (нижний индекс) соответствует тому нейрону, о котором мы говорим, а число выше (верхний индекс) соответствует тому слою, о котором мы говорим, считая от нуля.
Обозначим каждый вес

гдевобозначается какJа такжеотобозначается какКнапример,

средствавтретий нейрон в третьем слое,отнейрон четыре в предыдущем слое (второй слой), так как мы считаем с нуля. Это также имеет смысл при проверке матрицы длявесно я не буду вдаваться в подробности здесь

Чтобы рассчитать каждую активацию в следующем слое, нам нужны все активации из предыдущего слоя:

И все веса, связанные с каждым нейроном в следующем слое:

Комбинируя эти два, мы можем сделать умножение матриц, добавив матрицу смещения и обернув все уравнение в сигмоидную функцию, получим:

Это последнее выражение, аккуратное и, возможно, громоздкое, если вы не выполняете:

Иногда мы могли бы даже уменьшить обозначение еще больше и заменить веса, активации и смещения в сигмовидной функции на простыеZ:

Чтобы прочитать это:
Мы берем все активации с первого слояа ^ 0, делайте матричное умножение со всеми весами, соединяющими каждый нейрон от первого до второго слояWдобавьте матрицу смещения и, наконец, используйте сигмоидную функцию для результата. Отсюда получаем матрицу всех активаций во втором слое.
Исчисление знаний
Вы должны знать, как найти наклон касательной линии — найти производную функции. На практике вам не нужно знать, как делать каждый дериват, но вы должны хотя бы понять, что означает производный.
Существуют разные правила для дифференциации, одно из самых важных и используемых правил цепное правило, но вот список нескольких правил для дифференциации, это хорошо знать, если вы хотите рассчитать градиенты в следующих алгоритмах. Частная производная, где мы находим производную одной переменной и позволяем остальным быть постоянными, также полезна для некоторых знаний.
Мое собственное мнение таково, что вам не нужно уметь делать математику, вы просто должны уметь понимать процесс, лежащий в основе этих алгоритмов. Я выберу каждый алгоритм для более глубокого понимания математики, стоящей за этими выдающимися алгоритмами.
ОбобщитьВы должны понимать, что означают эти термины, или уметь выполнять вычисления для:
- Матрицы; умножение матриц и сложение, обозначения матриц.
- Производные; измерение крутизны в определенной точке склона на графике.
- Частная производная; производная от одной переменной, в то время как остальные постоянны.
- Цепное правило; найти композицию из двух или более функций.
Теперь, когда вы понимаете обозначения, мы должны перейти к сути того, что заставляет нейронные сети работать. Этот алгоритм является частью любой нейронной сети. Когда я ломаю это, есть некоторая математика, но не пугайтесь. То, что делает математика, на самом деле довольно просто, если вы получите общую картину обратного распространения.
обратное распространение
Обратное распространение — это сердце каждой нейронной сети. Во-первых, мы должны сделать различие между обратным распространением и оптимизаторами.
Обратное распространение предназначено для эффективного расчета градиентов, а оптимизаторы — для обучения нейронной сети с использованием градиентов, рассчитанных с использованием обратного распространения. Короче говоря, все обратное распространение делает для нас вычисление градиентов. Больше ничего.
ТАК .. Эээ, как мы пойдем назад?
Мы всегда начинаем с выходного слоя и распространяемся в обратном направлении, обновляя веса и смещения для каждого слоя.
Идея проста:отрегулируйте веса и смещения по всей сети, чтобы получить желаемый результат в выходном слое. Скажем, мы хотели, чтобы выходной нейрон был 1,0, тогда нам нужно сместить веса и смещения, чтобы мы получили выход ближе к 1,0.
Мы можем только изменять весовые коэффициенты и смещения, но активации являются прямыми вычислениями этих весовых коэффициентов и смещений, что означает, что мы можем косвенно настраивать каждую часть нейронной сети, чтобы получить желаемый результат — за исключением входного слоя, поскольку это набор данных что вы вводите.
Вычислительные градиенты
Теперь, перед уравнениями, давайте определим, что означает каждая переменная. Некоторые из них мы уже определили, но подытожим. Что-то из этого должно быть вам знакомо, если вы читаете пост.
ПОЖАЛУЙСТА! Обратите внимание на обозначения, используемые между L, L-1 иL, Я намеренно перепутал это, чтобы вы могли понять, как они оба работают.

Во-первых, давайте начнем с определения соответствующих уравнений. Обратите внимание, что любая индексация, объясненная ранее, здесь опущена, и мы абстрагируемся для каждого слоя вместо каждого веса, смещения или активации:


Подробнее о функции стоимости позже в разделе функции стоимости.
Задумавшись над этим вопросом, мы можем узнать, как рассчитать градиенты в алгоритме обратного распространения:
Как мы можем измерить изменение функции стоимости по отношению к конкретному весу, смещению или активации?
Математически, именно поэтому нам необходимо понимать частные производные, поскольку они позволяют нам вычислить взаимосвязь между компонентами нейронной сети и функцией стоимости. И как должно быть очевидно, мы хотим минимизировать функцию стоимости Когда мы знаем, что на это влияет, мы можем эффективно изменить соответствующие веса и отклонения, чтобы минимизировать функцию затрат.

Если вы не изучаете математику или не изучали исчисление, это не совсем понятно. Итак, позвольте мне попытаться сделать это более ясным.
Сжатое «d» — это знак частной производной.дС / с.в.означает, что мы смотрим на функцию стоимостиСи в нем мы берем только производнуювес(в слое L), то есть остальные переменные остаются как есть. В этой статье я не показываю, как провести различие, поскольку для этого есть много полезных ресурсов.
Хотяш ^ Lнепосредственно не найден в функции стоимости, мы начнем с рассмотрения изменения w в уравнении z, так как это уравнение z содержит a w. Далее мы рассмотрим изменениег ^ Lва ^ Lи затем изменениеа ^ Lв функцииС, По сути, это измеряет изменение определенного веса по отношению к функции стоимости.
Мы измеряем соотношение между весами (и отклонениями) и функцией стоимости. Те из них, которые имеют наибольшее соотношение, будут иметь наибольшее влияние на функцию стоимости и дадут нам «максимальную отдачу от наших денег».
Три уравнения для расчета градиента
Нам нужно двигаться назад в сети и обновлять веса и уклоны. Давайте рассмотрим, как это сделать с помощью математики. Одно уравнение для весов, одно для смещений и одно для активаций:


Помните, что эти уравнения просто измеряют соотношение того, как конкретный вес влияет на функцию стоимости, которую мы хотим оптимизировать. Мы оптимизируем, шагая в направлении вывода этих уравнений. Это действительно (почти) так просто.
Каждая частная производная от весов и смещений сохраняется вградиентный векторЭто имеет столько же размеров, сколько у вас весов и уклонов. Градиент — это символ перевернутого треугольниканабла, а такжеNКоличество весов и уклонов:

Активации также являются хорошей идеей, чтобы отслеживать, как сеть реагирует на изменения, но мы не сохраняем их в градиентном векторе. Важно отметить, что они также помогают нам измерить, какие веса имеют наибольшее значение, поскольку веса умножаются на активацию. С точки зрения эффективности это важно для нас.
Вы вычисляете градиент в соответствии с мини-пакетом (часто 16 или 32 лучше) ваших данных, то есть вы подразделяете свои наблюдения на партии. Для каждого наблюдения в вашей мини-партии вы усредняете выход для каждого веса и смещения. Затем среднее значение этих весов и смещений становится выходом градиента, который создает шаг в среднем лучшем направлении по размеру мини-партии.
Затем вы будете обновлять веса и смещения после каждой мини-партии. Каждый вес и смещение «подталкиваются» определенное количество для каждого слояL:


Скорость обучения обычно записывается как альфа или эта.
Но это еще не все. Три уравнения, которые я показал, относятся только к выходному слою. Если бы мы переместили один слой назад по сети, было бы больше частных производных для вычисления для каждого веса, смещения и активации. Мы должны пройти весь путь назад по сети и корректировать каждый вес и уклон.
Пример: идти глубже
Принимая во внимание остальные слои, нам нужно объединить в цепочку больше частных производных, чтобы найти вес в первом слое, но нам не нужно ничего вычислять.
Если мы посмотрим на скрытый слой в предыдущем примере, нам нужно будет использовать предыдущие частичные производные, а также два новых вычисленных частных производных. Чтобы понять почему, вам следует взглянуть на график зависимостей ниже, поскольку он помогает объяснить зависимости каждого уровня от предыдущих весов и смещений.

Обновление весов и смещений в слое 2 (илиL) зависит только от функции стоимости и весов и смещений, связанных со слоем 2. Аналогично, для обновления слоя 1 (илиL-1), зависимости находятся на вычислениях в слое 2 и весах и смещениях в слое 1. Это сложило бы, если бы у нас было больше слоев, было бы больше зависимостей. Как вы можете обнаружить, именно поэтому мы называем это «обратным распространением».
Как показано на графике выше, для вычисления весов, связанных со скрытым слоем, нам придется повторно использовать предыдущие вычисления для выходного слоя (L или слой 2). Позвольте мне напомнить о них:


Если бы мы хотели вычислить обновления для весов и смещений, связанных со скрытым слоем (L-1 или слой 1), нам пришлось бы повторно использовать некоторые из предыдущих вычислений.


Мы используем все предыдущие вычисления, за исключением частных производных по весам или уклонам слоя, например мы не используем повторно dz ^ (1) / dw ^ (1) (мы, очевидно, используем некоторые из dC / dw ^ (1))
Если вы посмотрите на график зависимостей выше, вы можете соединить эти два последних уравнения с большой фигурной скобкой, которая говорит«Зависимости уровня 1»налево. Попытайтесь разобраться в обозначениях, используемых, связывая, какой слой L-1 находится на графике. Это должно прояснить ситуацию, и если у вас есть сомнения, просто оставьте комментарий.
Небольшая деталь, оставленная здесь, заключается в том, что если вы сначала рассчитываете весовые коэффициенты, то вы можете повторно использовать 4 первых частных производных, поскольку они одинаковы при расчете обновлений для смещения. И конечно наоборот.
Что-то здесь сбивает с толку? Позвольте мне ответить на ваш комментарий.
Предположим, у нас есть еще один скрытый слой, то есть если у нас есть input-hidden-hidden-output — всего четыре слоя. Тогда мы просто использовали бы предыдущие расчеты для обновления предыдущего слоя. По сути, мы делаем это для каждого веса и смещения для каждого слоя, повторно используя вычисления.

Итак … если мы предположим, что у нас есть дополнительный скрытый слой, уравнение будет выглядеть так:

Если вы ищете конкретный пример с явными числами, я могу порекомендовать посмотреть Лекс Фридман с 7:55 до 20:33,
Суммирование
- Сделайте прямой проход с помощью этого уравнения
- Для весов и смещений каждого слоя, соединяющихся с новым слоем, обратное распространение с использованием алгоритма обратного распространения по этим уравнениям (замените ww на bb при расчете смещений)


Продолжайте добавлять дополнительные частичные производные для каждого дополнительного слоя таким же образом, как здесь.
- Повторите для каждого наблюдения / образца (или мини-партии размером менее 32)
оптимизаторы
Оптимизаторы — это то, как обучаются нейронные сети, используя обратное распространение для вычисления градиентов.
Многие факторы влияют на то, насколько хорошо модель работает. То, как мы измеряем производительность, что может быть очевидно для некоторых, — это функция затрат.
Функция стоимости
Функция стоимости дает нам значение, которое мы хотим оптимизировать. Слишком много функций стоимости, чтобы упомянуть их все, но одной из наиболее простых и часто используемых функций стоимости является сумма квадратов разностей.
гдеYэто то, что мы хотим, чтобы результат был иу шляпыбыть фактическим прогнозируемым выходом из нейронной сети. В основном, для каждого образцаNначинаем суммирование с первого примераI = 1и по всем квадратам различий между выходом мы хотимYи прогнозируемый выходу шляпыза каждое наблюдение.
Очевидно, есть много факторов, влияющих на то, насколько хорошо работает конкретная нейронная сеть. Сложность модели, гиперпараметры (скорость обучения, функции активации и т. Д.), Размер набора данных и многое другое.
Стохастический градиентный спуск
В Stochastic Gradient Descent мы берем мини-партию случайной выборки и выполняем обновление весов и смещений на основе среднего уклона мини-партии. Веса для каждой мини-партии случайным образом инициализируются небольшим значением, таким как 0,1. Уклоны инициализируются во многих различные пути ; самый простой инициализируется в 0.
- Определите функцию стоимости с вектором в качестве входных данных (вектор веса или смещения)
- Начните со случайной точки вдоль оси X и двигайтесь в любом направлении.
Спросите, каким путем мы должны пойти, чтобы быстрее уменьшить функцию стоимости? - Рассчитайте градиент, используя обратное распространение, как объяснялось ранее
- Шаг в противоположном направлении градиента — мы вычисляем градиентное восхождение, поэтому мы просто ставим минус перед уравнением или движемся в противоположном направлении, чтобы сделать его градиентным спуском.
Получить представление о том, как выглядит стохастический градиентный спуск, довольно просто из GIF ниже. Каждый шаг, который вы видите на графике, является шагом спуска градиента, то есть мы рассчитали градиент с обратным распространением для некоторого количества выборок, чтобы двигаться в направлении.

Мы говорим, что хотим достичь глобальных минимумов, самой низкой точки функции. Хотя это не всегда возможно. Скорее всего, мы достигнем локальных минимумов, которые являются точкой между склонами, движущимися вверх как слева, так и справа. Если мы найдем минимумы, мы скажем, что наша нейронная сеть сошлась. Если мы этого не сделаем или увидим странное падение производительности, мы скажем, что нейронная сеть разошлась.
Если мы вычисляем положительную производную, мы двигаемся влево на склоне, а если отрицательно, мы двигаемся вправо, пока не достигнем локальных минимумов.
Ввод нейронных сетей в шаги
Здесь я кратко разделю то, что нейронные сети делают на более мелкие шаги
Повторите для каждой мини-партии:
- Инициализируйте веса для небольшого случайного числа и пусть все смещения будут равны 0
- Начните прямой проход для следующего образца в мини-партии и выполните прямой переход с уравнением для расчета активаций

- Рассчитайте градиенты и обновите вектор градиента (среднее количество обновлений из мини-пакета) путем итеративного распространения в обратном направлении через нейронную сеть. Пример вычисления частной производной $ w¹ $ в нейронной сети input-hidden-hidden-output (4 слоя)
- Поместите минус перед вектором градиента и обновите веса и смещения на основе вектора градиента, рассчитанного по усреднению по толчкам мини-партии.
дальнейшее чтение
Самая рекомендуемая книга — это первый пункт. Он проведет вас через новейшие и лучшие, объясняя концепции в мельчайших деталях, сохраняя при этом практичность. Вероятно, лучшая книга для изучения, если вы новичок или полу-новичок.
- ЛУЧШАЯ практическая книга:
Практическое машинное обучение с Scikit-Learn и TensorFlow - БОЛЬШАЯ точная книга с математикой и кодом на 100 страницах:
Строградная книга по машинному обучению Андрея Буркова - АКАДЕМИЧЕСКАЯ книга со всей математикой, которая вам нужна:
Глубокое обучениеЙен Гудфеллоу, Йошуа Бенжио и Аарон Курвиль - FANTASTIC прочитано Нильсеном
Нейронные сети и глубокое обучениеМайкл Нильсен
Есть вопросы? Оставьте комментарий ниже. Я здесь, чтобы ответить или уточнить что-нибудь.
Первоначально опубликовано на https://mlfromscratch.com 5 августа 2019 г.
Подписаться на мой список рассылки для получения дополнительной информации,
![]()
В предыдущей части мы учились рассчитывать изменения сигнала при проходе по нейросети. Мы познакомились с матрицами, их произведением и вывели простые формулы для расчетов.
В 6 части перевода выкладываю сразу 4 раздела книги. Все они посвящены одной из самых важных тем в области нейросетей — методу обратного распространения ошибки. Вы научитесь рассчитывать погрешность всех нейронов нейросети основываясь только на итоговой погрешности сети и весах связей.
Материал сложный, так что смело задавайте свои вопросы на форуме.
Вы можете скачать PDF версию перевода.
Приятного чтения!
Оглавление
1 Глава. Как они работают.
- 1.1 Легко для меня, тяжело для тебя
- 1.2 Простая предсказательная машина
- 1.3 Классификация это почти что предсказание
- 1.4 Тренировка простого классификатора
- 1.5 Иногда одного классификатора недостаточно
- 1.6 Нейроны — природные вычислительные машины
- 1.7 Проход сигнала через нейросеть
- 1.8 Умножать матрицы полезно… Серьезно!
- 1.9 Трехслойная нейросеть и произведение матриц
- 1.10 Калибровка весов нескольких связей
- 1.11 Обратное распространение ошибки от выходных нейронов
- 1.12 Обратное распространение ошибки на множество слоев
- 1.13 Обратное распространение ошибки и произведение матриц
1.10 Калибровка весов нескольких связей
Ранее мы настраивали линейный классификатор с помощью изменения постоянного коэффициента уравнения прямой. Мы использовали погрешность, разность между полученным и желаемым результатами, для настройки классификатора.
Все те операции были достаточно простые, так как сама связь между погрешностью и величины, на которую надо было изменить коэффициент прямой оказалось очень простой.
Но как нам калибровать веса связей, когда на получаемый результат, а значит и на погрешность, влияют сразу несколько нейронов? Рисунок ниже демонстрирует проблему:

Очень легко работать с погрешностью, когда вход у нейрона всего один. Но сейчас уже два нейрона подают сигналы на два входа рассматриваемого нейрона. Что же делать с погрешностью?
Нет никакого смысла использовать погрешность целиком для корректировки одного веса, потому что в этом случае мы забываем про второй вес. Ведь оба веса задействованы в создании полученного результата, а значит оба веса виновны в итоговой погрешности.
Конечно, существует очень маленькая вероятность того, что только один вес внес погрешность, а второй был идеально откалиброван. Но даже если мы немного поменяем вес, который и так не вносит погрешность, то в процессе дальнейшего обучения сети он все равно придет в норму, так что ничего страшного.
Можно попытаться разделить погрешность одинаково на все нейроны:

Классная идея. Хотя я никогда не пробовал подобный вариант использования погрешности в реальных нейросетях, я уверен, что результаты вышли бы очень достойными.
Другая идея тоже заключается в разделении погрешности, но не поровну между всеми нейронами. Вместо этого мы кладем большую часть ответственности за погрешность на нейроны с большим весом связи. Почему? Потому что за счет своего большего веса они внесли больший вклад в выход нейрона, а значит и в погрешность.

На рисунке изображены два нейрона, которые подают сигналы третьему, выходному нейрону. Веса связей: ( 3 ) и ( 1 ). Согласно нашей идее о переносе погрешности на нейроны мы используем ( frac{3}{4} ) погрешности на корректировку первого (большего) веса и ( frac{1}{4} ) на корректировку второго (меньшего) веса.
Идею легко развить до любого количества нейронов. Пусть у нас есть 100 нейронов и все они соединены с результирующим нейроном. В таком случае, мы распределяем погрешность на все 100 связей так, чтобы на каждую связь пришлась часть погрешности, соответствующая ее весу.
Как видно, мы используем веса связей для двух задач. Во-первых, мы используем веса в процессе распространения сигнала от входного до выходного слоя. Мы уже разобрались, как это делается. Во-вторых, мы используем веса для распространения ошибки в обратную сторону: от выходного слоя к входному. Из-за этого данный метод использования погрешности называют методом обратного распространения ошибки.
Если у нашей сети 2 нейрона выходного слоя, то нам пришлось бы использовать этот метод еще раз, но уже для связей, которые повлияли на выход второго нейрона выходного слоя. Рассмотрим эту ситуацию подробнее.
1.11 Обратное распространение ошибки от выходных нейронов
На диаграмме ниже изображена нейросеть с двумя нейронами во входном слое, как и в предыдущем примере. Но теперь у сети имеется два нейрона и в выходном слое.

Оба выхода сети могут иметь погрешность, особенно в тех случаях, когда сеть еще не натренирована. Мы должны использовать полученные погрешности для настройки весов связей. Можно использовать метод, который мы получили в предыдущем разделе — больше изменяем те нейроны, которые сделали больший вклад в выход сети.
То, что сейчас у нас больше одного выходного нейрона по сути ни на что не влияет. Мы просто используем наш метод дважды: для первого и второго нейронов. Почему так просто? Потому что связи с конкретным выходным нейроном никак не влияют на остальные выходные нейроны. Их изменение повлияет только на конкретный выходной нейрон. На диаграмме выше изменение весов ( w_{1,2} ) и ( w_{2,2} ) не повлияет на результат ( o_1 ).
Погрешность первого нейрона выходного слоя мы обозначили за ( e_1 ). Погрешность равна разнице между желаемым выходом нейрона ( t_1 ), который мы имеем в обучающей выборке и полученным реальным результатом ( o_1 ).
[ e_1 = t_1 — o_1 ]
Погрешность второго нейрона выходного слоя равна ( e_2 ).
На диаграмме выше погрешность ( e_1 ) разделяется на веса ( w_{1,1} ) и ( w_{2,1} ) соответственно их вкладу в эту погрешность. Аналогично, погрешность ( e_2 ) разделяется на веса ( w_{1,2} ) и ( w_{2,2} ).
Теперь надо определить, какой вес оказал большее влияние на выход нейрона. Например, мы можем определить, какая часть ошибки ( e_1 ) пойдет на исправление веса ( w_{1,1} ):
[ frac{w_{1,1}}{w_{1,1}+w_{2,1}} ]
А вот так находится часть ( e_1 ), которая пойдет на корректировку веса ( w_{2,1} ):
[ frac{w_{2,1}}{w_{1,1} + w_{2,1}} ]
Теперь разберемся, что означают два этих выражения выше. Изначально наша идея заключается в том, что мы хотим сильнее изменить связи с большим весом и слегка изменить связи с меньшим весом.
А как нам понять величину веса относительно всех остальных весов? Для этого мы должны сравнить какой-то конкретный вес (например ( w_{1,1} )) с абстрактной «общей» суммой всех весов, повлиявших на выход нейрона. На выход нейрона повлияли два веса: ( w_{1,1} ) и ( w_{2,1} ). Мы складываем их и смотрим, какая часть от общего вклада приходится на ( w_{1,1} ) с помощью деления этого веса на полученную ранее общую сумму:
[ frac{w_{1,1}}{w_{1,1}+w_{2,1}} ]
Пусть ( w_{1,1} ) в два раза больше, чем ( w_{2,1} ): ( w_{1,1} = 6 ) и ( w_{2,1} = 3 ). Тогда имеем ( 6/(6+3) = 6/9 = 2/3 ), а значит ( 2/3 ) погрешности ( e_1 ) пойдет на корректировку ( w_{1,1} ), а ( 1/3 ) на корректировку ( w_{2,1} ).
В случае, когда оба веса равны, то каждому достанется по половине погрешности. Пусть ( w_{1,1} = 4 ) и ( w_{2,1}=4 ). Тогда имеем ( 4/(4+4)=4/8=1/2 ), а значит на каждый вес пойдет ( 1/2 ) погрешности ( e_1 ).
Прежде чем мы двинемся дальше, давайте на секунду остановимся и посмотрим, чего мы достигли. Нам нужно что-то менять в нейросети для уменьшения получаемой погрешности. Мы решили, что будем менять веса связей между нейронами. Мы также нашли способ, как распределять полученную на выходном слое сети погрешность между весами связей. В этом разделе мы получили формулы для вычисления конкретной части погрешности для каждого веса. Отлично!
Но есть еще одна проблема. Сейчас мы знаем, что делать с весами связей слое, который находится прямо перед выходным слоем сети. А что если наша нейросеть имеет больше 2 слоев? Что делать с весами связей в слоях, которые находятся за предпоследним слоем сети?
1.12 Обратное распространение ошибки на множество слоев
На диаграмме ниже изображена простая трехслойная нейросеть с входным, скрытым и выходным слоями.

Сейчас мы наблюдаем процесс, который обсуждался в разделе выше. Мы используем погрешность выходного слоя для настройки весов связей, которые соединяют предпоследний слой с выходным слоем.
Для простоты обозначения были обобщены. Погрешности нейронов выходного слоя мы в целом назвали ( e_{text{out}} ), а все веса связей между скрытым и выходным слоем обозначили за ( w_{text{ho}} ).
Еще раз повторю, что для корректировки весов ( w_{text{ho}} ) мы распределяем погрешность нейрона выходного слоя по всем весам в зависимости от их вклада в выход нейрона.
Как видно из диаграммы ниже, для корректировки весов связей между входным и скрытым слоем нам надо повторить ту же операцию еще раз. Мы берем погрешности нейронов скрытого слоя ( e_{text{hi}} ) и распределяем их по весам связей между входным и скрытым слоем ( w_{text{ih}} ):

Если бы у нас было бы больше слоев, то мы бы и дальше повторяли этот процесс корректировки, распространяющийся от выходного ко входному слою. И снова вы видите, почему этот способ называется методом обратного распространения ошибки.
Для корректировки связей между предпоследним и выходным слоем мы использовали погрешность выходов сети ( e_{text{out}} ). А чему же равна погрешность выходов нейронов скрытых слоев ( e_{text{hi}} )? Это отличный вопрос потому что сходу на этот вопрос ответить трудно. Когда сигнал распространяется по сети от входного к выходному слою мы точно знаем значения выходных нейронов скрытых слоев. Мы получали эти значения с помощью функции активации, у которой в качестве аргумента использовалась сумма взвешенных сигналов, поступивших на вход нейрона. Но как из выходного значения нейрона скрытого слоя получить его погрешность?
У нас нет никаких ожидаемых или заранее подготовленных правильных ответов для выходов нейронов скрытого слоя. У нас есть готовые правильные ответы только для выходов нейронов выходного слоя. Эти выходы мы сравниваем с заранее правильными ответами из обучающей выборки и получаем погрешность. Давайте вновь проанализируем диаграмму выше.
Мы видим, что из первого нейрона скрытого слоя выходят две связи с двумя нейронами выходного слоя. В предыдущем разделе мы научились распределять погрешность на веса связей. Поэтому мы можем получить две погрешности для обоих весов этих связей, сложить их и получить общую погрешность данного нейрона скрытого слоя. Наглядная демонстрация:

Уже из рисунка можно понять, что делать дальше. Но давайте все-таки еще раз пройдемся по всему алгоритму. Нам нужно получить погрешность выхода нейрона скрытого слоя для того, чтобы скорректировать веса связей между текущим и предыдущим слоями. Назовем эту погрешность ( e_{text{hi}} ). Но мы не можем получить значение погрешности напрямую. Погрешность равна разности между ожидаемым и полученным значениями, но проблема заключается в том, что у нас есть ожидаемые значения только для нейронов выходного слоя нейросети.
В невозможности прямого нахождения погрешности нейронов скрытого слоя и заключается основная сложность.
Но выход есть. Мы умеем распределять погрешность нейронов выходного слоя по весам связей. Значит на каждый вес связи идет часть погрешности. Поэтому мы складываем части погрешностей, которые относятся к весам связей, исходящих из данного скрытого нейрона. Полученная сумма и будем считать за погрешность выхода данного нейрона. На диаграмме выше часть погрешности ( e_{text{out 1}} ) идет на вес ( w_{1,1} ), а часть погрешности ( e_{text{out 2}} ) идет на вес ( w_{1,2} ). Оба этих веса относятся к связям, исходящим из первого нейрона скрытого слоя. А значит мы можем найти его погрешность:
[ e_{text{hi 1}} = text{сумма частей погрешностей для весов } w_{1,1} text{ и } w_{1,2} ]
[ e_{text{hi 1}} = left(e_{text{out 1}}cdotfrac{w_{1,1}}{w_{1,1} + w_{2,1}}right) + left(e_{text{out 2}}cdotfrac{w_{1,2}}{w_{1,2} + w_{2,2}}right) ]
Рассмотрим алгоритм на реальной трехслойной нейросети с двумя нейронами в каждом слое:

Давайте отследим обратное распространение одной ошибки/погрешности. Погрешность второго выходного нейрона равна ( 0.5 ) и она распределяется на два веса. На вес ( w_{12} ) идет погрешность ( 0.1 ), а на вес ( w_{22} ) идет погрешность ( 0.4 ). Дальше у нас идет второй нейрон скрытого слоя. От него отходят две связи с весами ( w_{21} ) и ( w_{22} ). На эти веса связей также распределяется погрешность как от ( e_1 ), так и от ( e_2 ). На вес ( w_{21} ) идет погрешность ( 0.9 ), а на вес ( w_{22} ) идет погрешность ( 0.4 ). Сумма этих погрешностей и дает нам погрешность выхода второго нейрона скрытого слоя: ( 0.4 + 0.9 = 1.3 ).
Но это еще не конец. Теперь надо распределить погрешность нейронов выходного слоя на веса связей между входным и скрытым слоями. Проиллюстрируем этот процесс дальнейшего распространения ошибки:

Ключевые моменты
- Обучение нейросетей заключается в корректировки весов связей. Корректировка зависит от погрешности — разности между ожидаемым ответом из обучающей выборки и реально полученным результатами.
- Погрешность для нейронов выходного слоя рассчитывается как разница между желаемым и полученным результатами.
- Однако, погрешность скрытых нейронов определить напрямую нельзя. Одно из популярных решений — сначала необходимо распределить известную погрешность на все веса связей, а затем сложить те части погрешностей, которые относятся к связям, исходящим из одного нейрона. Сумма этих частей погрешностей и будет являться общей погрешностью этого нейрона.
1.13 Обратное распространение ошибки и произведение матриц
А можно ли использовать матрицы для упрощения всех этих трудных вычислений? Они ведь помогли нам ранее, когда мы рассчитывали проход сигнала по сети от входного к выходному слою.
Если бы мы могли выразить обратное распространение ошибки через произведение матриц, то все наши вычисления разом бы уменьшились, а компьютер бы сделал всю грязную и повторяющуюся работу за нас.
Начинаем мы с самого конца нейросети — с матрицы погрешностей ее выходов. В примере выше у нас имеется две погрешности сети: ( e_1 ) и ( e_2 ).
[ mathbf{E}_{text{out}} = left(begin{matrix}e_1 e_2end{matrix}right) ]
Теперь нам надо получить матрицу погрешностей выходов нейронов скрытого слоя. Звучит довольно жутко, поэтому давайте действовать по шагам. Из предыдущего раздела вы помните, что погрешность нейрона скрытого слоя высчитывается как сумма частей погрешностей весов связей, исходящих из этого нейрона.
Сначала рассматриваем первый нейрон скрытого слоя. Как было показано в предыдущем разделе, погрешность этого нейрона высчитывается так:
[ e_{text{hi 1}} = left(e_1cdotfrac{w_{11}}{w_{11} + w_{21}}right) + left(e_2cdotfrac{w_{12}}{w_{12} + w_{22}}right) ]
Погрешность второго нейрона скрытого слоя высчитывается так:
[ e_{text{hi 2}} = left(e_1cdotfrac{w_{21}}{w_{11} + w_{21}}right) + left(e_2cdotfrac{w_{22}}{w_{12} + w_{22}}right) ]
Получаем матрицу погрешностей скрытого слоя:
[ mathbf{E}_{text{hid}} = left(begin{matrix}e_{text{hid 1}} e_{text{hid 2}}end{matrix}right) = left(begin{matrix} e_1cdotdfrac{w_{11}}{w_{11} + w_{21}} hspace{5pt} + hspace{5pt} e_2cdotdfrac{w_{12}}{w_{12} + w_{22}} e_1cdotdfrac{w_{21}}{w_{11} + w_{21}} hspace{5pt} + hspace{5pt} e_2cdotdfrac{w_{22}}{w_{12} + w_{22}} end{matrix}right) ]
Многие из вас уже заметили произведение матриц:
[ mathbf{E}_{text{hid}} = left(begin{matrix} dfrac{w_{11}}{w_{11} + w_{21}} & dfrac{w_{12}}{w_{12} + w_{22}} dfrac{w_{21}}{w_{11} + w_{21}} & dfrac{w_{22}}{w_{12} + w_{22}} end{matrix}right)times left(begin{matrix} e_1 e_2 end{matrix}right) ]
Таким образом, мы смогли выразить вычисление матрицы погрешностей нейронов выходного слоя через произведение матриц. Однако выражение выше получилось немного сложнее, чем мне хотелось бы.
В формуле выше мы используем большую и неудобную матрицу, в которой делим каждый вес связи на сумму весов, приходящих в данный нейрон. Мы самостоятельно сконструировали эту матрицу.
Было бы очень удобно записать произведение из уже имеющихся матриц. А имеются у нас только матрицы весов связей, входных сигналов и погрешностей выходного слоя.
К сожалению, формулу выше никак нельзя записать в мега-простом виде, который мы получили для прохода сигнала в предыдущих разделах. Вся проблема заключается в жутких дробях, с которыми трудно что-то поделать.
Но нам очень нужно получить простую формулу для удобного и быстрого расчета матрицы погрешностей.
Пора немного пошалить!
Вновь обратим взор на формулу выше. Можно заметить, что самым главным является умножение погрешности выходного нейрона ( e_n ) на вес связи ( w_{ij} ), которая к этому выходному нейрону подсоединена. Чем больше вес, тем большую погрешность получит нейрон скрытого слоя. Эту важную деталь мы сохраняем. А вот знаменатели дробей служат лишь нормализующим фактором. Если их убрать, то мы лишимся масштабирования ошибки на предыдущие слои, что не так уж и страшно. Таким образом, мы можем избавиться от знаменателей:
[ e_1cdot frac{w_{11}}{w_{11} + w_{21}} hspace{5pt} longrightarrow hspace{5pt} e_1 cdot w_{11} ]
Запишем теперь формулу для получения матрицы погрешностей, но без знаменателей в левой матрице:
[ mathbf{E}_{text{hid}} = left(begin{matrix} w_{11} & w_{12} w_{21} & w_{22} end{matrix}right)times left(begin{matrix} e_1 e_2 end{matrix}right) ]
Так гораздо лучше!
В разделе по использованию матриц при расчетах прохода сигнала по сети мы использовали следующую матрицу весов:
[ left(begin{matrix} w_{11} & w_{21} w_{12} & w_{22} end{matrix}right) ]
Сейчас, для расчета матрицы погрешностей мы используем такую матрицу:
[ left(begin{matrix} w_{11} & w_{12} w_{21} & w_{22} end{matrix}right) ]
Можно заметить, что во второй матрице элементы как бы отражены относительно диагонали матрицы, идущей от левого верхнего до правого нижнего края матрицы: ( w_{21} ) и ( w_{12} ) поменялись местами. Такая операция над матрицами существует и называется она textbf{транспонированием} матрицы. Ранее мы использовали матрицу весов ( mathbf{W} ). Транспонированные матрицы имеют специальный значок справа сверху: ( ^intercal ). В расчете матрицы погрешностей мы используем транспонированную матрицу весов: ( mathbf{W}^intercal ).
Вот два примера для иллюстрации транспонирования матриц. Заметьте, что данную операцию можно выполнять даже для матриц, в которых число столбцов и строк различно.
[ left(begin{matrix} 1 & 2 & 3 4 & 5 & 6 7 & 8 & 9 end{matrix}right)^intercal = left(begin{matrix} 1 & 4 & 7 2 & 5 & 8 3 & 6 & 9 end{matrix}right) ]
[ left(begin{matrix} 1 & 2 & 3 4 & 5 & 6 end{matrix}right)^intercal = left(begin{matrix} 1 & 4 2 & 5 3 & 6 end{matrix}right) ]
Мы получили то, что хотели — простую формулу для расчета матрицы погрешностей нейронов скрытого слоя:
[ mathbf{E}_{text{hid}} = mathbf{W}^intercal times mathbf{E}_{text{out}} ]
Это все конечно отлично, но правильно ли мы поступили, просто проигнорировав знаменатели? Да.
Дело в том, что сеть обучается не мгновенно, а проходит через множество шагов обучения. Таким образом она постепенно калибрует и корректирует собственные веса до приемлемого значения. Поэтому способ, с помощью которого мы находим погрешность не так важен. Я уже упоминал ранее, что мы могли бы разделить всю погрешность просто пополам между всеми весами, вносящими вклад в выход нейрона и даже тогда, по окончанию обучения, сеть выдавала бы неплохие результаты.
Безусловно, игнорирование знаменателей повлияет на процесс обучения сети, но рано или поздно, через сотни и тысячи шагов обучения, она дойдет до правильных результатов что со знаменателями, что без них.
Убрав знаменатели, мы сохранили общую суть обратного распространения ошибки — чем больше вес, тем больше его надо скорректировать. Мы просто убрали смягчающий фактор.
Ключевые моменты
- Обратное распространение ошибки может быть выражено через произведение матриц.
- Это позволяет нам удобно и эффективно производить расчеты вне зависимости от размеров нейросети.
- Получается что и прямой проход сигнала по нейросети и обратно распространение ошибки можно выразить через матрицы с помощью очень похожих формул.
Сделайте перерыв. Вы его заслужили. Следующие несколько разделов будут финальными и очень крутыми. Но их надо проходить на свежую голову.
Нейронная сеть — попытка с помощью математических моделей воспроизвести работу человеческого мозга для создания машин, обладающих искусственным интеллектом.
Искусственная нейронная сеть обычно обучается с учителем. Это означает наличие обучающего набора (датасета), который содержит примеры с истинными значениями: тегами, классами, показателями.
Неразмеченные наборы также используют для обучения нейронных сетей, но мы не будем здесь это рассматривать.
Например, если вы хотите создать нейросеть для оценки тональности текста, датасетом будет список предложений с соответствующими каждому эмоциональными оценками. Тональность текста определяют признаки (слова, фразы, структура предложения), которые придают негативную или позитивную окраску. Веса признаков в итоговой оценке тональности текста (позитивный, негативный, нейтральный) зависят от математической функции, которая вычисляется во время обучения нейронной сети.
Раньше люди генерировали признаки вручную. Чем больше признаков и точнее подобраны веса, тем точнее ответ. Нейронная сеть автоматизировала этот процесс.
Искусственная нейронная сеть состоит из трех компонентов:
- Входной слой;
- Скрытые (вычислительные) слои;
- Выходной слой.
Обучение нейросетей происходит в два этапа:
- Прямое распространение ошибки;
- Обратное распространение ошибки.
Во время прямого распространения ошибки делается предсказание ответа. При обратном распространении ошибка между фактическим ответом и предсказанным минимизируется.
Прямое распространение ошибки
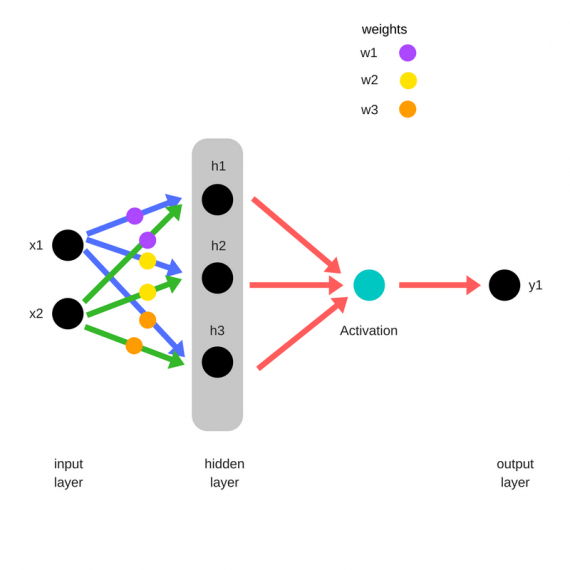
Зададим начальные веса случайным образом:
- w1
- w2
- w3
Умножим входные данные на веса для формирования скрытого слоя:
- h1 = (x1 * w1) + (x2 * w1)
- h2 = (x1 * w2) + (x2 * w2)
- h3 = (x1 * w3) + (x2 * w3)
Выходные данные из скрытого слоя передается через нелинейную функцию (функцию активации), для получения выхода сети:
- y_ = fn(h1 , h2, h3)
Обратное распространение
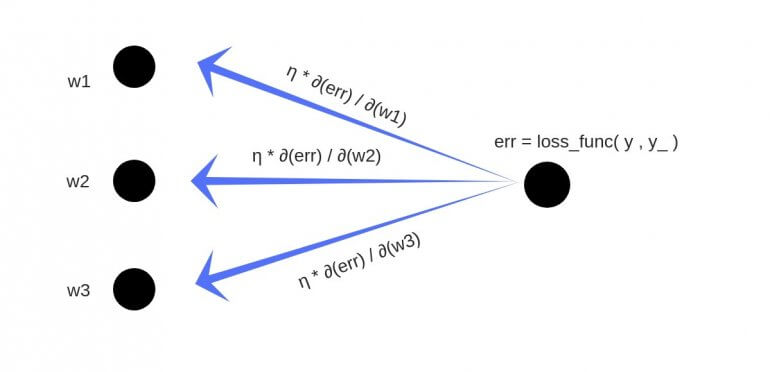
- Суммарная ошибка (total_error) вычисляется как разность между ожидаемым значением «y» (из обучающего набора) и полученным значением «y_» (посчитанное на этапе прямого распространения ошибки), проходящих через функцию потерь (cost function).
- Частная производная ошибки вычисляется по каждому весу (эти частные дифференциалы отражают вклад каждого веса в общую ошибку (total_loss)).
- Затем эти дифференциалы умножаются на число, называемое скорость обучения или learning rate (η).
Полученный результат затем вычитается из соответствующих весов.
В результате получатся следующие обновленные веса:
- w1 = w1 — (η * ∂(err) / ∂(w1))
- w2 = w2 — (η * ∂(err) / ∂(w2))
- w3 = w3 — (η * ∂(err) / ∂(w3))
То, что мы предполагаем и инициализируем веса случайным образом, и они будут давать точные ответы, звучит не вполне обоснованно, тем не менее, работает хорошо.

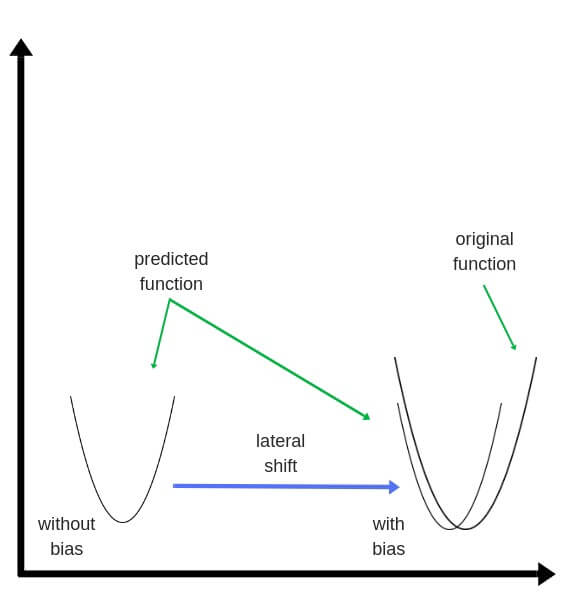 Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Смещения – это веса, добавленные к скрытым слоям. Они тоже случайным образом инициализируются и обновляются так же, как скрытый слой. Роль скрытого слоя заключается в том, чтобы определить форму базовой функции в данных, в то время как роль смещения – сдвинуть найденную функцию в сторону так, чтобы она частично совпала с исходной функцией.
Частные производные
Частные производные можно вычислить, поэтому известно, какой был вклад в ошибку по каждому весу. Необходимость производных очевидна. Представьте нейронную сеть, пытающуюся найти оптимальную скорость беспилотного автомобиля. Eсли машина обнаружит, что она едет быстрее или медленнее требуемой скорости, нейронная сеть будет менять скорость, ускоряя или замедляя автомобиль. Что при этом ускоряется/замедляется? Производные скорости.
Разберем необходимость частных производных на примере.
Предположим, детей попросили бросить дротик в мишень, целясь в центр. Вот результаты:
Теперь, если мы найдем общую ошибку и просто вычтем ее из всех весов, мы обобщим ошибки, допущенные каждым. Итак, скажем, ребенок попал слишком низко, но мы просим всех детей стремиться попадать в цель, тогда это приведет к следующей картине:
Ошибка нескольких детей может уменьшиться, но общая ошибка все еще увеличивается.
Найдя частные производные, мы узнаем ошибки, соответствующие каждому весу в отдельности. Если выборочно исправить веса, можно получить следующее:
Гиперпараметры
Нейронная сеть используется для автоматизации отбора признаков, но некоторые параметры настраиваются вручную.
Скорость обучения (learning rate)
Скорость обучения является очень важным гиперпараметром. Если скорость обучения слишком мала, то даже после обучения нейронной сети в течение длительного времени она будет далека от оптимальных результатов. Результаты будут выглядеть примерно так:
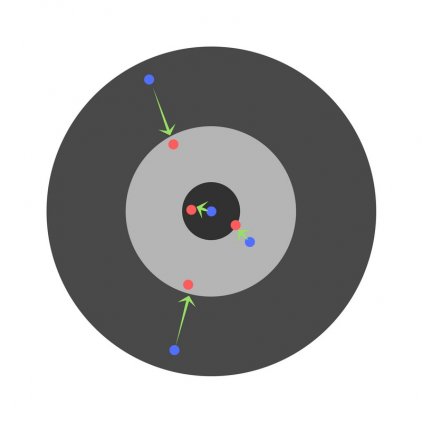
С другой стороны, если скорость обучения слишком высока, то сеть очень быстро выдаст ответы. Получится следующее:
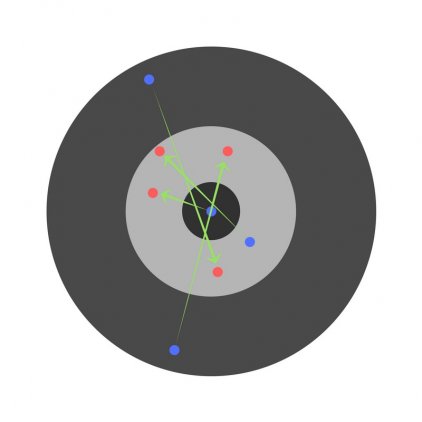
Функция активации (activation function)
Функция активации — это один из самых мощных инструментов, который влияет на силу, приписываемую нейронным сетям. Отчасти, она определяет, какие нейроны будут активированы, другими словами и какая информация будет передаваться последующим слоям.
Без функций активации глубокие сети теряют значительную часть своей способности к обучению. Нелинейность этих функций отвечает за повышение степени свободы, что позволяет обобщать проблемы высокой размерности в более низких измерениях. Ниже приведены примеры распространенных функций активации:
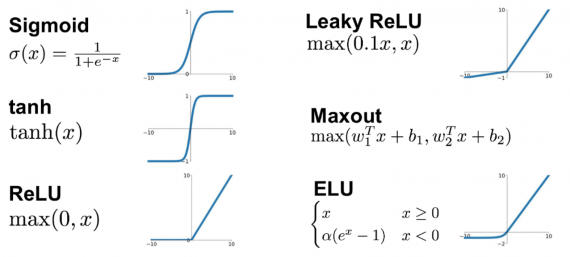
Функция потери (loss function)
Функция потерь находится в центре нейронной сети. Она используется для расчета ошибки между реальными и полученными ответами. Наша глобальная цель — минимизировать эту ошибку. Таким образом, функция потерь эффективно приближает обучение нейронной сети к этой цели.
Функция потерь измеряет «насколько хороша» нейронная сеть в отношении данной обучающей выборки и ожидаемых ответов. Она также может зависеть от таких переменных, как веса и смещения.
Функция потерь одномерна и не является вектором, поскольку она оценивает, насколько хорошо нейронная сеть работает в целом.
Некоторые известные функции потерь:
- Квадратичная (среднеквадратичное отклонение);
- Кросс-энтропия;
- Экспоненциальная (AdaBoost);
- Расстояние Кульбака — Лейблера или прирост информации.
Cреднеквадратичное отклонение – самая простая фукция потерь и наиболее часто используемая. Она задается следующим образом:
Функция потерь в нейронной сети должна удовлетворять двум условиям:
- Функция потерь должна быть записана как среднее;
- Функция потерь не должна зависеть от каких-либо активационных значений нейронной сети, кроме значений, выдаваемых на выходе.
Глубокие нейронные сети
Глубокое обучение (deep learning) – это класс алгоритмов машинного обучения, которые учатся глубже (более абстрактно) понимать данные. Популярные алгоритмы нейронных сетей глубокого обучения представлены на схеме ниже.
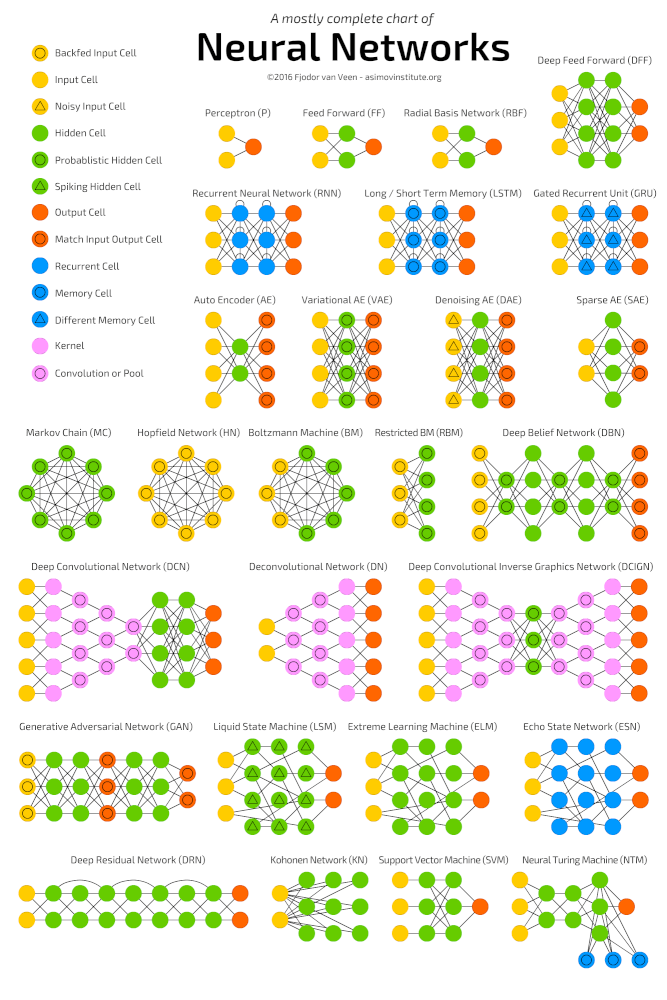
Более формально в deep learning:
- Используется каскад (пайплайн, как последовательно передаваемый поток) из множества обрабатывающих слоев (нелинейных) для извлечения и преобразования признаков;
- Основывается на изучении признаков (представлении информации) в данных без обучения с учителем. Функции более высокого уровня (которые находятся в последних слоях) получаются из функций нижнего уровня (которые находятся в слоях начальных слоях);
- Изучает многоуровневые представления, которые соответствуют разным уровням абстракции; уровни образуют иерархию представления.
Пример
Рассмотрим однослойную нейронную сеть:
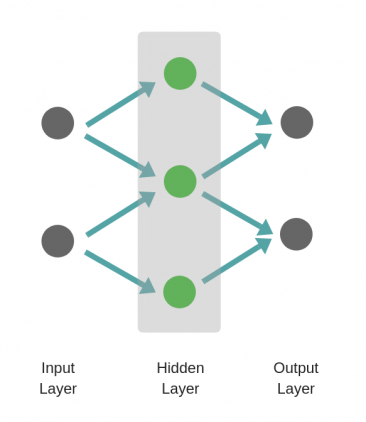
Здесь, обучается первый слой (зеленые нейроны), он просто передается на выход.
В то время как в случае двухслойной нейронной сети, независимо от того, как обучается зеленый скрытый слой, он затем передается на синий скрытый слой, где продолжает обучаться:
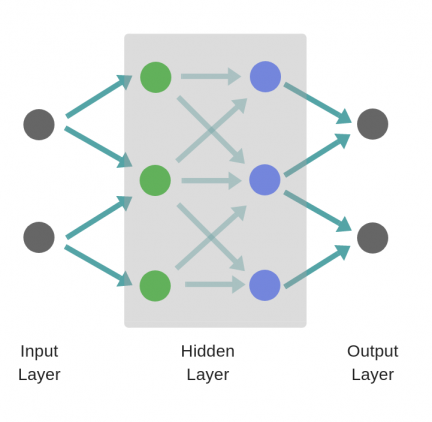
Следовательно, чем больше число скрытых слоев, тем больше возможности обучения сети.
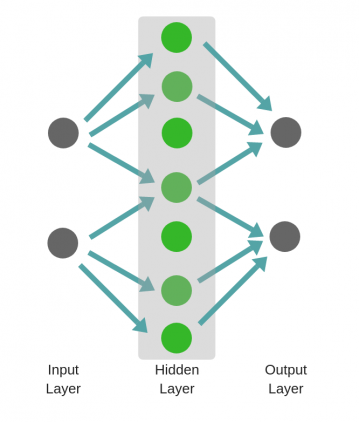
Не следует путать с широкой нейронной сетью.
В этом случае большое число нейронов в одном слое не приводит к глубокому пониманию данных. Но это приводит к изучению большего числа признаков.
Пример:
Изучая английскую грамматику, требуется знать огромное число понятий. В этом случае однослойная широкая нейронная сеть работает намного лучше, чем глубокая нейронная сеть, которая значительно меньше.
Но
В случае изучения преобразования Фурье, ученик (нейронная сеть) должен быть глубоким, потому что не так много понятий, которые нужно знать, но каждое из них достаточно сложное и требует глубокого понимания.
Главное — баланс
Очень заманчиво использовать глубокие и широкие нейронные сети для каждой задачи. Но это может быть плохой идеей, потому что:
- Обе требуют значительно большего количества данных для обучения, чтобы достичь минимальной желаемой точности;
- Обе имеют экспоненциальную сложность;
- Слишком глубокая нейронная сеть попытается сломать фундаментальные представления, но при этом она будет делать ошибочные предположения и пытаться найти псевдо-зависимости, которые не существуют;
- Слишком широкая нейронная сеть будет пытаться найти больше признаков, чем есть. Таким образом, подобно предыдущей, она начнет делать неправильные предположения о данных.
Проклятье размерности
Проклятие размерности относится к различным явлениям, возникающим при анализе и организации данных в многомерных пространствах (часто с сотнями или тысячами измерений), и не встречается в ситуациях с низкой размерностью.
Грамматика английского языка имеет огромное количество аттрибутов, влияющих на нее. В машинном обучении мы должны представить их признаками в виде массива/матрицы конечной и существенно меньшей длины (чем количество существующих признаков). Для этого сети обобщают эти признаки. Это порождает две проблемы:
- Из-за неправильных предположений появляется смещение. Высокое смещение может привести к тому, что алгоритм пропустит существенную взаимосвязь между признаками и целевыми переменными. Это явление называют недообучение.
- От небольших отклонений в обучающем множестве из-за недостаточного изучения признаков увеличивается дисперсия. Высокая дисперсия ведет к переобучению, ошибки воспринимаются в качестве надежной информации.
Компромисс
На ранней стадии обучения смещение велико, потому что выход из сети далек от желаемого. А дисперсия очень мала, поскольку данные имеет пока малое влияние.
В конце обучения смещение невелико, потому что сеть выявила основную функцию в данных. Однако, если обучение слишком продолжительное, сеть также изучит шум, характерный для этого набора данных. Это приводит к большому разбросу результатов при тестировании на разных множествах, поскольку шум меняется от одного набора данных к другому.
Действительно,
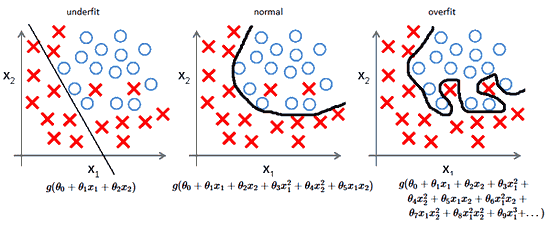
алгоритмы с большим смещением обычно в основе более простых моделей, которые не склонны к переобучению, но могут недообучиться и не выявить важные закономерности или свойства признаков. Модели с маленьким смещением и большой дисперсией обычно более сложны с точки зрения их структуры, что позволяет им более точно представлять обучающий набор. Однако они могут отображать много шума из обучающего набора, что делает их прогнозы менее точными, несмотря на их дополнительную сложность.
Следовательно, как правило, невозможно иметь маленькое смещение и маленькую дисперсию одновременно.
Сейчас есть множество инструментов, с помощью которых можно легко создать сложные модели машинного обучения, переобучение занимает центральное место. Поскольку смещение появляется, когда сеть не получает достаточно информации. Но чем больше примеров, тем больше появляется вариантов зависимостей и изменчивостей в этих корреляциях.
Время на прочтение
6 мин
Количество просмотров 21K
Заранее хочу отметить, что тот кто знает как обучается персептрон — в этой статье вряд ли найдет что-то новое. Вы можете смело пропускать ее. Почему я решил это написать — я хотел бы написать цикл статей, связанных с нейронными сетями и применением TensorFlow.js, ввиду этого я не мог опустить общие теоретические выдержки. Поэтому прошу отнестись с большим терпением и пониманием к конечной задумке.
При классическом программировании разработчик описывает на конкретном языке программирования определённый жестко заданный набор правил, который был определен на основании его знаний в конкретной предметной области и который в первом приближении описывает процессы, происходящие в человеческом мозге при решении аналогичной задачи.
Например, может быть запрограммирована стратегия игры в крестики-нолики, шахмат и другое (рисунок 1).

Рисунок 1 – Классический подход решения задач
В то время как алгоритмы машинного обучения могут определять набор правил для решения задач без участия разработчика, а только на базе наличия тренировочного набора данных.
Тренировочный набор — это какой-то набор входных данных ассоциированный с набором ожидаемых результатов (ответами, выходными данными). На каждом шаге обучения, модель за счет изменения внутреннего состояния, будет оптимизировать и уменьшать ошибку между фактическим выходным результатом модели и ожидаемым результатом (рисунок 2).

Рисунок 2 – Машинное обучение
Нейронные сети
Долгое время учёные, вдохновляясь процессами происходящими в нашем мозге, пытались сделать реверс-инжиниринг центральной нервной системы и попробовать сымитировать работу человеческого мозга. Благодаря этому родилось целое направление в машинном обучении — нейронные сети.
На рисунке 3 вы можете увидеть сходство между устройством биологического нейрона и математическим представлением нейрона, используемого в машинном обучении.

Рисунок 3 – Математическое представление нейрона
В биологическом нейроне, нейрон получает электрические сигналы от дендритов, модулирующих электрические сигналы с разной силой, которые могут возбуждать нейрон при достижении некоторого порогового значения, что в свою очередь приведёт к передаче электрического сигнала другим нейронам через синапсы.
Персептрон
Математическая модель нейронной сети, состоящего из одного нейрона, который выполняет две последовательные операции (рисунок 4):
- вычисляет сумму входных сигналов с учетом их весов (проводимости или сопротивления) связи

- применяет активационную функцию к общей сумме воздействия входных сигналов.

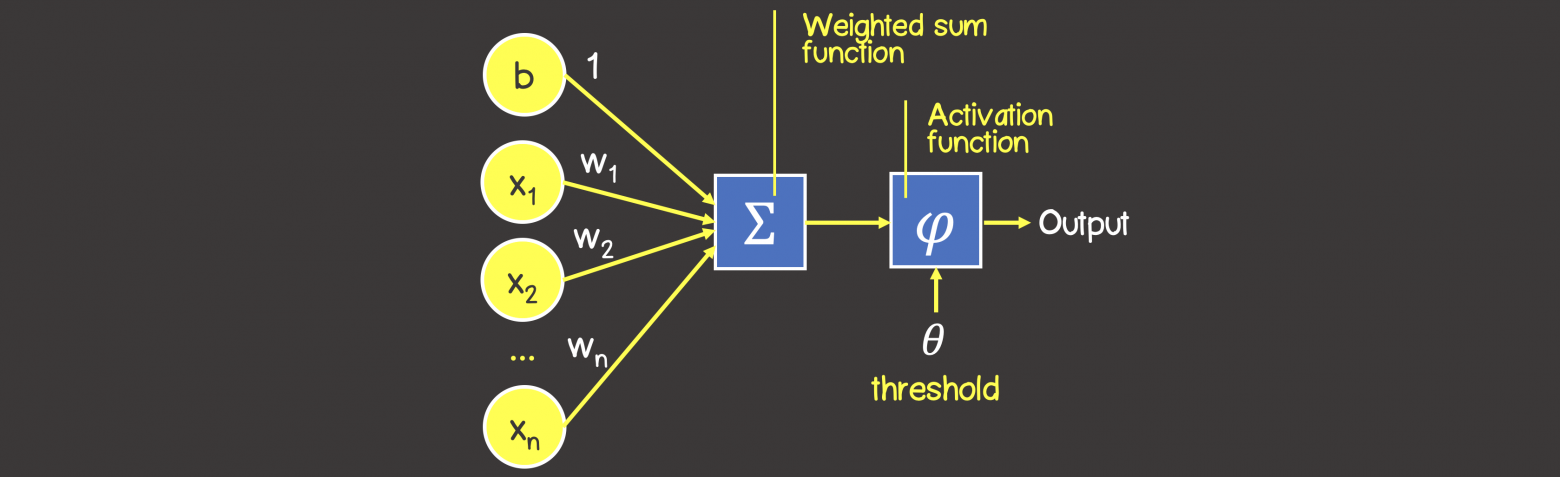
Рисунок 4 – Математическая модель персептрона
В качестве активационной функции может использоваться любая дифференцируемая функция, наиболее часто используемые приведены в таблице 1. Выбор активационной функции ложиться на плечи инженера, и обычно этот выбор основан или на уже имеющемся опыте решения похожих задач, ну или просто методом подбора.
Заметка
Однако есть рекомендация – что если нужна нелинейность в нейронной сети, то в качестве активационной функции лучше всего подходит ReLU функция, которая имеет лучшие показатели сходимости модели во время процесса обучения.
Таблица 1 — Распространенные активационные функции
Процесс обучения персептрона
Процесс обучения состоит из несколько шагов. Для большей наглядности, рассмотрим некую вымышленную задачу, которую мы будем решать нейронной сетью, состоящей из одного нейрона с линейной активационной функции (это по сути персептрон без активационной функции вовсе), также для упрощения задачи – исключим в нейроне узел смещения b (рисунок 5).

Рисунок 5 – Обучающий набор данных и состояние нейронной сети на предыдущем шаге обучения
На данном этапе мы имеем нейронную сеть в некотором состоянии с определенными весами соединений, которые были вычислены на предыдущем этапе обучения модели или если это первая итерация обучения – то значения весов соединений выбраны в произвольном порядке.
Итак, представим, что мы имеем некоторый набор тренировочных данных, значения каждого элемента из набора представлены вектором входных данных (input data), содержащих 2 параметра (feature)  . Под в модели в зависимости от рассматриваемой предметной области может подразумеваться все что угодно: количество комнат в доме, расстояние дома от моря, ну или мы просто пытаемся обучить нейронную сеть логической операции И, или ИЛИ.
. Под в модели в зависимости от рассматриваемой предметной области может подразумеваться все что угодно: количество комнат в доме, расстояние дома от моря, ну или мы просто пытаемся обучить нейронную сеть логической операции И, или ИЛИ.
Каждый вектор входных данных в тренировочном наборе сопоставлен с вектором ожидаемого результата (expected output). В данном случае вектор выходных данных содержит только один параметр, которые опять же в зависимости от выбранной предметной области может означать все что угодно – цена дома, результат выполнения логической операции И или ИЛИ.
ШАГ 1 — Прямое распространение ошибки (feedforward process)
На данном шаге мы вычисляем сумму входных сигналов с учетом веса каждой связи и применяем активационную функцию (в нашем случае активационной функции нет). Сделаем вычисления для первого элемента в обучающем наборе:


Рисунок 6 – Прямое распространение ошибки
Обратите внимание, что написанная формула выше – это упрощенное математическое уравнение для частного случая операций над тензорами.
Тензор – это по сути контейнер данных, который может иметь N осей и произвольное число элементов вдоль каждой из осей. Большинство с тензорами знакомы с математики – векторы (тензор с одной осью), матрицы (тензор с двумя осями – строки, колонки).
Формулу можно написать в следующем виде, где вы увидите знакомые матрицы (тензоры) и их перемножение, а также поймете о каком упрощении шла речь выше:
![${vec{Y}}_{predicted}= {vec{X}}^Tvec{W}=left[begin{matrix}x_1\x_2\end{matrix}right]^Tcdot left [ begin{matrix} w_1\ w_2 end{matrix} right ]=left [ begin{matrix} x_1 & x_2 end{matrix} right ] cdot left [ begin{matrix} w_1\ w_2 end{matrix} right ] =left [ x_1w_1+x_2w_2 right ]$](https://habrastorage.org/getpro/habr/formulas/a36/9d4/929/a369d49299583d08cbd19bea1e116daf.svg)
ШАГ 2 — Расчет функции ошибки
Функция ошибка – это метрика, отражающая расхождение между ожидаемыми и полученными выходными данными. Обычно используют следующие функции ошибки:
— среднеквадратичная ошибка (Mean Squared Error, MSE) – данная функция ошибки особенно чувствительна к выбросам в тренировочном наборе, так как используется квадрат от разности фактического и ожидаемого значений (выброс — значение, которое сильно удалено от других значений в наборе данных, которые могут иногда появляться в следствии ошибок данных, таких как смешивание данных с разными единицами измерения или плохие показания датчиков):

— среднеквадратичное отклонение (Root MSE) – по сути это тоже самое что, среднеквадратичная ошибка в контексте нейронных сетей, но может отражать реальную физическую единицу измерения, например, если в нейронной сети выходным параметров нейронной сети является цена дома выраженной в долларах, то единица измерения среднеквадратичной ошибки будет доллар квадратный ( ), а для среднеквадратичного отклонения это доллар ($), что естественно немного упрощает задачу анализа человеком:
), а для среднеквадратичного отклонения это доллар ($), что естественно немного упрощает задачу анализа человеком:

— среднее отклонение (Mean Absolute Error, MAE) -в отличии от двух выше указанных значений, является не столь чувствительной к выбросам:

— перекрестная энтропия (Cross entropy) – использует для задач классификации:

где
 – число экземпляров в тренировочном наборе
– число экземпляров в тренировочном наборе
 – число классов при решении задач классификации
– число классов при решении задач классификации
 — ожидаемое выходное значение
— ожидаемое выходное значение
 – фактическое выходное значение обучаемой модели
– фактическое выходное значение обучаемой модели
Для нашего конкретного случая воспользуемся MSE:

ШАГ 3 — Обратное распространение ошибки (backpropagation)
Цель обучения нейронной сети проста – это минимизация функции ошибки:

Одним способом найти минимум функции – это на каждом очередном шаге обучения модифицировать веса соединений в направлении противоположным вектору-градиенту – метод градиентного спуска, и это математически выглядит так:

где  – k -ая итерация обучения нейронной сети;
– k -ая итерация обучения нейронной сети;
 – шаг обучения (learning rate) и задается инженером, обычно это может быть 0.1; 0.01 (о том как шаг обучения влияет на процесс сходимости обучения отметить чуть позже)
– шаг обучения (learning rate) и задается инженером, обычно это может быть 0.1; 0.01 (о том как шаг обучения влияет на процесс сходимости обучения отметить чуть позже)
 – градиент функции-ошибки
– градиент функции-ошибки
Для нахождения градиента, используем частные производные по настраиваемым аргументам  :
:
![$nabla Lleft(vec{w}right)=left[begin{matrix}frac{partial L}{partial w_1}\vdots\frac{partial L}{partial w_N}\end{matrix}right]$](https://habrastorage.org/getpro/habr/formulas/d25/bb0/a13/d25bb0a13bb5593a7c26f98f0ed48352.svg)
В нашем конкретном случае с учетом всех упрощений, функция ошибки принимает вид:


Памятка формул производных
Напомним некоторые формулы производных, которые пригодятся для вычисления частных производных
Найдем следующие частные производные:




Тогда процесс обратного распространения ошибки – движение по модели от выхода по направлению к входу с модификацией весов модели в направлении обратном вектору градиента. Задавая обучающий шаг 0.1 (learning rate) имеем (рисунок 7):



Рисунок 7 – Обратное распространение ошибки
Таким образом мы завершили k+1 шаг обучения, чтобы убедиться, что ошибка снизилась, а выход от модели с новыми весами стал ближе к ожидаемому выполним процесс прямого распространения ошибки по модели с новыми весами (см. ШАГ 1):

Как видим, выходное значение увеличилось на 0.2 единица в верном направлении к ожидаемому результату – единице (1). Ошибка тогда составит:

Как видим, на предыдущем шаге обучения ошибка составила 0.64, а с новыми весами – 0.36, следовательно мы настроили модель в верном направлении.
Следующая часть статьи:
Машинное обучение. Нейронные сети (часть 2): Моделирование OR; XOR с помощью TensorFlow.js
Машинное обучение. Нейронные сети (часть 3) — Convolutional Network под микроскопом. Изучение АПИ Tensorflow.js
В этой статье мы узнаем о нейронных сетях прямого распространения, также известных как сети с глубокой прямой связью или многослойные персептроны. Они составляют основу многих важных нейронных сетей, используемых в последнее время, таких как сверточные нейронные сетиએ (широко используемые в приложениях компьютерного зрения), рекуррентные нейронные сетиએ (широко используемые для понимания естественного языка и последовательного обучения) и так далее. Мы постараемся понять важные концепции, используя интуитивно понятную игрушку и не будем вдаваясь в математику. Если вы хотите погрузиться в глубокое обучение, но не обладаете достаточным опытом в области статистики и машинного обучения, то эта статья станет идеальной отправной точкой.
Мы будем использовать сеть прямого распространения для решения задачи двоичной классификации. В машинном обучении классификация — это тип метода контролируемого обучения, в котором задача состоит в том, чтобы разделить образцы данных на заранее определенные группы с помощью функции принятия решений. Когда есть только две группы, это называется двоичной классификацией. На приведенном ниже рисунке показан пример. Точки синего цвета принадлежат одной группе (или классу), а оранжевые точки — другой. Воображаемые линии, разделяющие группы, называются границами принятия решений. Функция принятия решения извлекается из набора помеченных образцов, который называется обучающими данными, а процесс обучения функции принятия решения называется обучением.
В приведенном примере верхняя строка показывает два разных распределения данных, а нижняя строка показывает границу решения. На левом изображении показан пример данных, которые можно разделить линейно. Это означает, что линейная граница (например, прямой линии) достаточно, чтобы разделить данные на группы. С другой стороны, изображение справа показывает пример данных, которые нельзя разделить линейно. Граница решения в этом случае должна быть круговой или многоугольной, как показано на рисунке.
1. Что есть нейронная сеть?
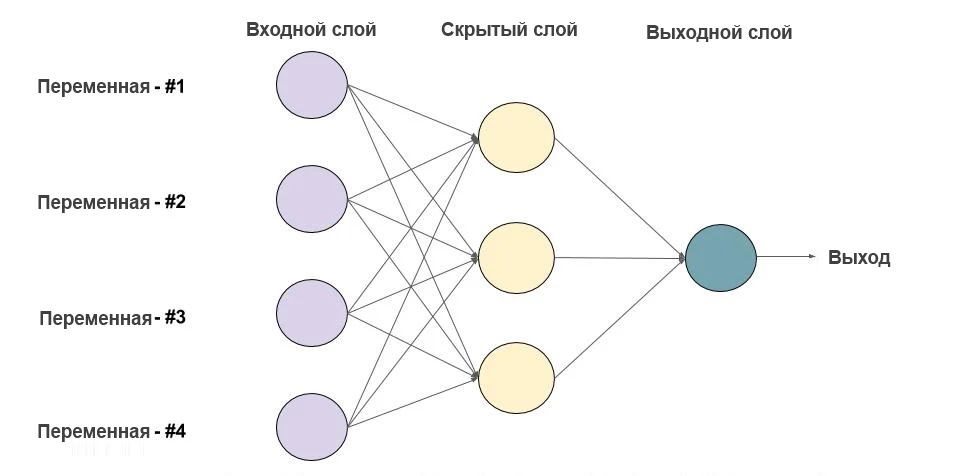
Ниже приведен пример нейронной сети прямого распространения. Это направленный ациклический граф, что означает, что в сети нет обратных связей или петель. У него есть входной слой, выходной слой и скрытый слой. Как правило, может быть несколько скрытых слоев. Каждый узел в слое — нейрон, который можно рассматривать как основной процессор нейронной сети.
1.1. Что есть нейрон?
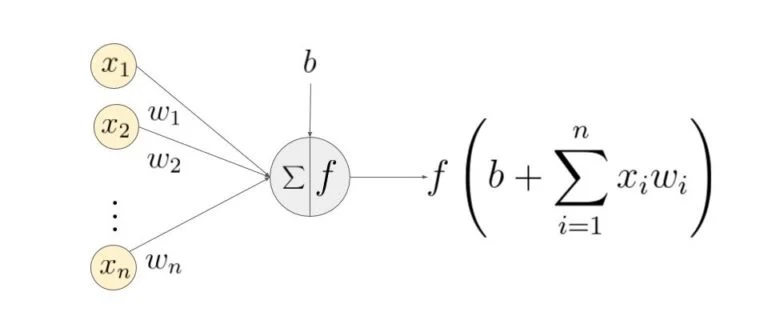
Искусственный нейрон — это основная единица нейронной сети. Принципиальная схема нейрона приведена ниже.
Как видно выше, он работает в два этапа: вычисляет взвешенную сумму своих входных данных, а затем применяет функцию активации для нормализации суммы. Функции активации могут быть линейными или нелинейными. Также, есть веса, связанные с каждым входом нейрона. Это параметры, которые сеть должна приобрести на этапе обучения.
1.2. Функции активации
Функция активацииએ используется как орган принятия решений на выходе нейрона. Нейрон изучает линейные или нелинейные границы принятия решений на основе функции активации. Он также оказывает нормализующее влияние на выход нейронов, что предотвращает выход нейронов после нескольких слоев, чтобы стать очень большим, за счет каскадного эффекта. Есть три наиболее часто используемых функции активации.
Сигмоидаએ
Он отображает входные данные (ось x) на значения от 0 до 1.
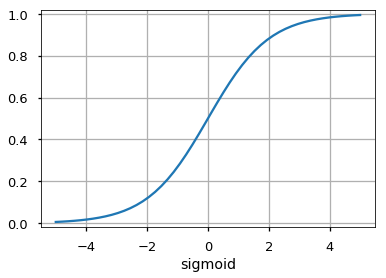
Tanh
Похожа на сигмовидную функцию, но отображает входные данные в значения от -1 до 1.
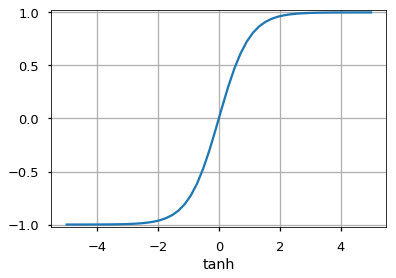
Rectified Linear Unit (ReLU)
Он позволяет проходить через него только положительным значениям. Отрицательные значения отображаются на ноль.
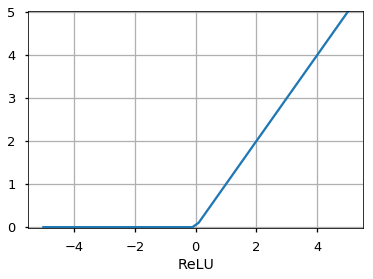
Функция активацииએ может быть другой, например, функция Unit Step, leaky ReLU, Noisy ReLU, Exponential LU и т.д., которые имеют свои плюсы и минусы.
1.3. Входной слой
Это первый слой нейронной сети. Он используется для передачи и приёма входных данных или функций в сеть.
1.4. Выходной слой
Это слой, который выдает прогнозы. Функция активации, используемая на этом уровне, различается для разных задач. Для задачи двоичной классификации мы хотим, чтобы на выходе было либо 0, либо 1. Таким образом, используется сигмовидная функция активации. Для задачи мультиклассовой классификации используется Softmaxએ (воспринимайте это как обобщение сигмоида на несколько классов). Для задачи регрессии, когда результат не является предопределенной категорией, мы можем просто использовать линейную единицу.
1.5. Скрытый слой
Сеть прямого распространения применяет к входу ряд функций. Имея несколько скрытых слоев, мы можем вычислять сложные функции, каскадируя более простые функции. Предположим, мы хотим вычислить седьмую степень числа, но хотим, чтобы вещи были простыми (поскольку их легко понять и реализовать). Вы можете использовать более простые степени, такие как квадрат и куб, для вычисления функций более высокого порядка. Точно так же вы можете вычислять очень сложные функции с помощью этого каскадного эффекта. Наиболее широко используемый скрытый блок — это тот, где функция активацииએ использует выпрямленный линейный блок (ReLU). Выбор скрытых слоёв — очень активная область исследований в машинном обучении. Тип скрытого слоя отличает разные типы нейронных сетей, такие как CNNએ, RNNએ и т.д. Количество скрытых слоев называется глубиной нейронной сети. Вы можете задать вопрос: сколько слоев в сети делают ее глубокой? На это нет правильного ответа. В общем случае, более глубокие сети могут научиться более сложным функциям.
1.6. Как сеть учится?
Обучающие образцы передаются по сети, и выходные данные, полученные от сети, сравниваются с фактическими выходными данными. Эта ошибка используется для изменения веса нейронов таким образом, чтобы ошибка постепенно уменьшалась. Это делается с помощью алгоритма обратного распространения ошибки, также называемого обратным распространением. Итеративная передача пакетов данных по сети и обновление весов для уменьшения ошибки называется стохастический градиентный спускએ (SGD). Величина, на которую изменяются веса, определяется параметром, называемым «Скорость обучения». Подробности SGD и backprop будут описаны в отдельном посте.
2.Зачем использовать скрытые слои?
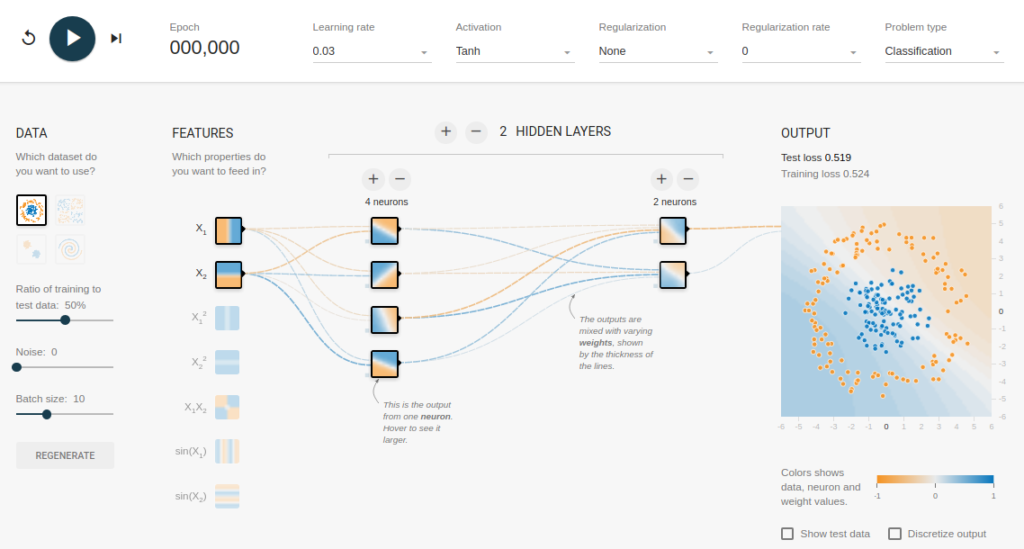
Чтобы понять значение скрытых слоев, мы попытаемся решить проблему двоичной классификации без скрытых слоев. Для этого мы будем использовать интерактивную платформу от Google, plays.tensorflow.org, которая представляет собой веб-приложение, где вы можете создавать простые нейронные сети с прямой связью и видеть эффекты обучения в реальном времени. Вы можете поиграть, изменив количество скрытых слоев, количество нейронов в скрытом слое, тип функции активации, тип данных, скорость обучения, параметры регуляризации и т.д. Выше приведен снимок экрана веб-страницы.
На приведенной выше странице вы можете выбрать данные и нажать кнопку воспроизведения, чтобы начать обучение.
Он покажет вам изученную границу решения и кривые потерь в правом верхнем углу.
2.1. Без скрытого слоя
Нам нужна сеть без скрытого слоя, который я создал по этой ссылке. Здесь нет скрытых слоев, поэтому он становится простым нейроном, способным изучать линейную границу принятия решения. Мы можем выбрать тип данных в верхнем левом углу. В случае линейно разделяемых данных (3-й тип), он сможет получить (когда вы нажмете кнопку воспроизведения) линейную границу, как показано ниже.
Однако, если вы выберете первые данные, вы не сможете для них узнать границу кругового решения.
Поскольку данные находятся в круговой области, можно сказать, что использование квадратов значений функций в качестве входных данных может помочь. Оказывается, после обучения нейрон сможет найти круговую границу принятия решения.
Теперь, если вы выберете 2-е данные, та же конфигурация не сможет узнать соответствующую границу решения.
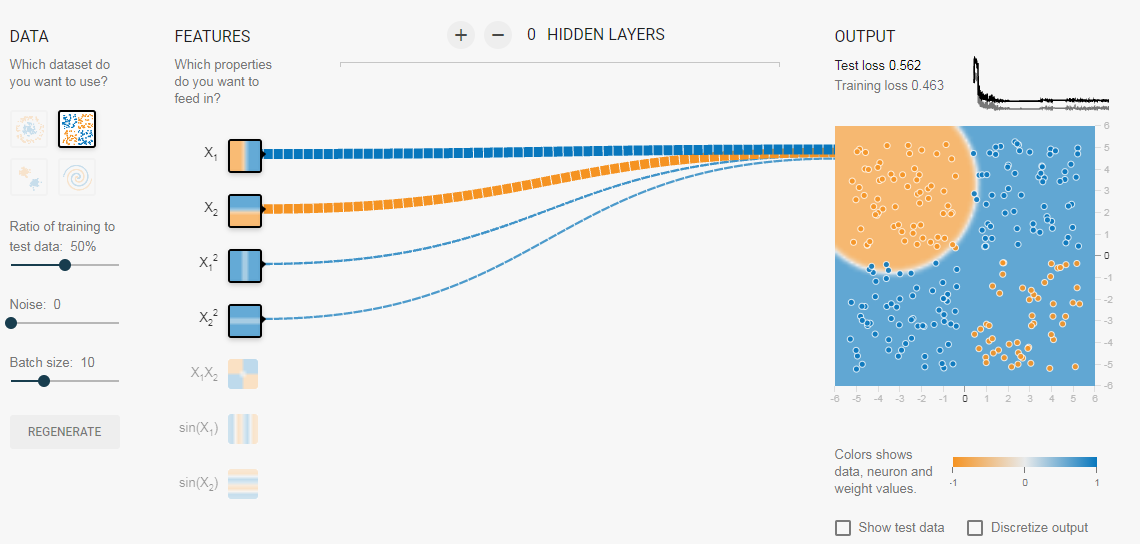
Опять же интуитивно кажется, что граница решения — это коническое сечение (например, парабола или гипербола). Итак, если мы включим продукт функции (например, X_1 X_2), нейрон сможет узнать желаемую границу принятия решения.
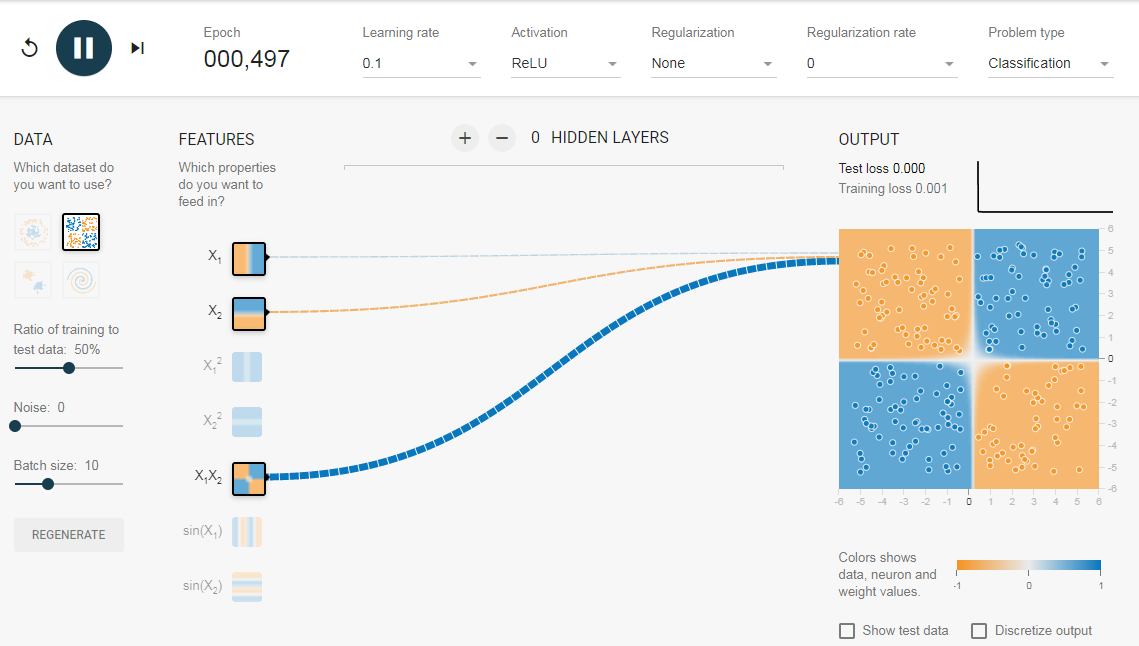
Описанные эксперименты показали:
- Используя один нейрон, мы можем узнать только линейную границу решения.
- Нам пришлось придумать преобразования функций (например, квадрат функций или продукт функций) путем визуализации данных. Этот шаг может быть сложным для данных, которые нелегко визуализировать.
2.2. Добавление скрытого слоя
Добавив скрытый слой, как показано в этой ссылке, мы можем избавиться от этой функции проектирования и получить единую сеть, которая может изучить все три границы принятия решений. Нейронная сеть с одним скрытым слоем с нелинейными функциями активации считается универсальным аппроксиматором функций, теорема Цыбенкоએ (т.е. способной к обучению любой функции). Однако количество единиц в скрытом слое не фиксировано. Результат добавления скрытого слоя всего с 3 нейронами показан ниже:
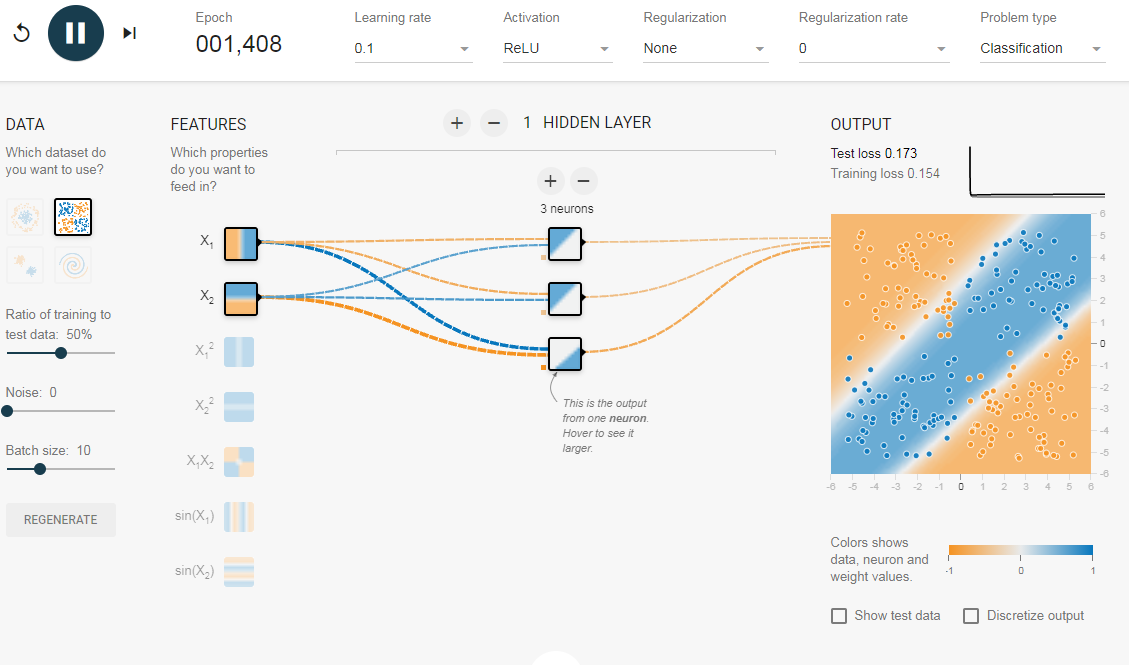
3. Регуляризация
Как мы видели в предыдущем разделе, многослойная сеть может изучать нелинейные границы принятия решений. Однако, если в данных есть шум (что часто бывает), сеть может попытаться изучить нелинейность, вносимую шумом, пытаясь подогнать зашумленные выборки. В таких случаях зашумленные образцы следует рассматривать как выбросы. В этой ссылке я добавил немного шума к линейно разделяемым данным. Также, чтобы продемонстрировать идею, я увеличил количество скрытых нейронов.
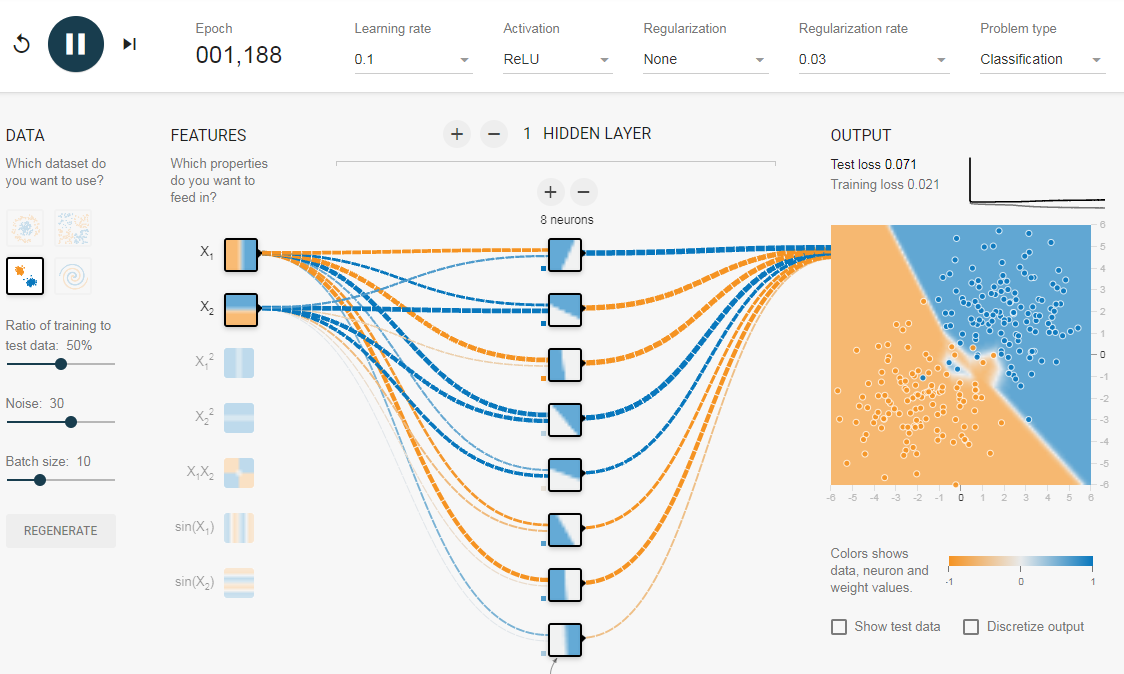
На приведенном выше рисунке можно увидеть, что граница принятия решения очень старается приспособить зашумленные выборки, чтобы уменьшить ошибку. Но, как видите, это ошибочно из-за шумных сэмплов. Другими словами, сеть будет неустойчивой при наличии шума. Это явление называется переобучением. В таких случаях, ошибка обучающих данных может уменьшиться, но сеть плохо работает с невидимыми данными. Это видно по кривым потерь в правом верхнем углу.
Потери в обучении уменьшаются, но потери в тестах увеличиваются. Также, можно видеть, что некоторые веса стали очень большими (очень толстые соединения или вы можете увидеть веса, если наведете курсор на соединения). Это можно исправить, наложив некоторые ограничения на значения весов (например, не позволяя весам становиться очень высокими). Это называется регуляризацией. Мы накладываем ограничения на остальные параметры сети. В некотором смысле мы не полностью доверяем обучающим данным и хотим, чтобы сеть усвоила «хорошие» границы принятия решений. Я добавил регуляризацию L2 в приведенную выше конфигурацию по этой ссылке, и результат показан ниже.
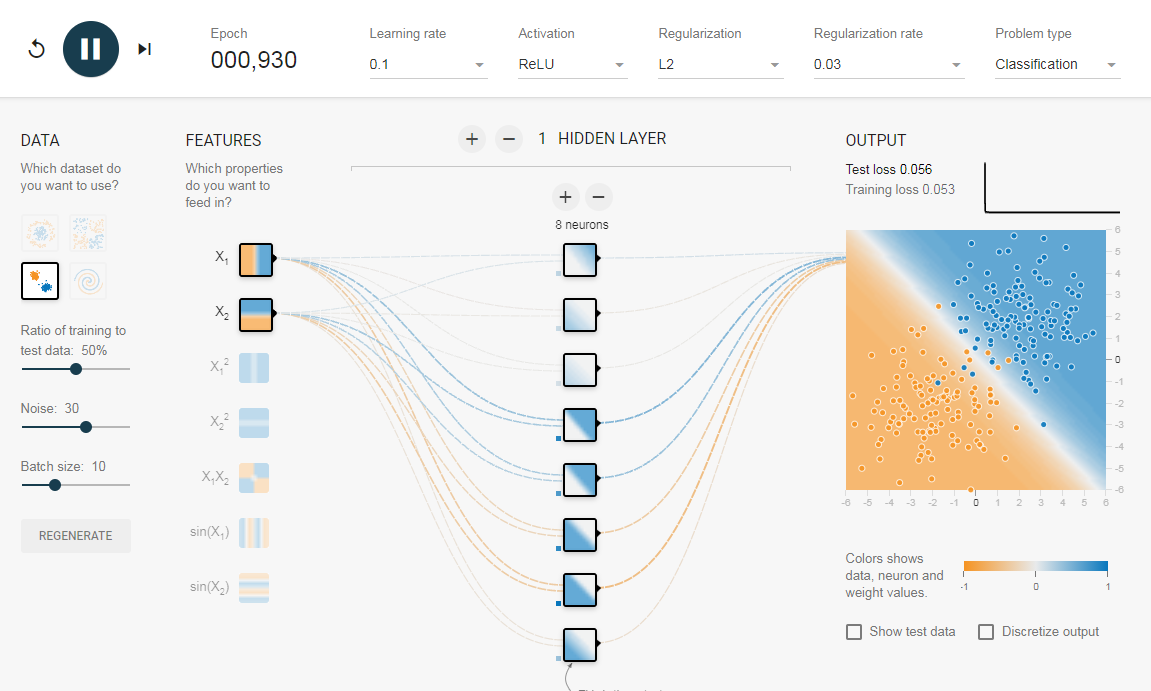
После включения регуляризации L2 граница принятия решения, изученная сетью, становится более гладкой и аналогичной случаю, когда не было шума. Эффект регуляризации также можно увидеть из кривых потерь и значений весов.
В следующем посте, если он случится мы узнаем, как реализовать нейронную сеть прямого распространения в Keras для решения нескольких проблема классификации и узнайте ещё больше о сетях прямого распространения.
Использованы материалы Understanding Feedforward Neural Networks

Прямое распространение¶
- Простая сеть
- Прямой проход по шагам
- Код
- Более сложная сеть
- Архитектура
- Инициализация весов
- Bias Terms
- Working with Matrices
- Dynamic Resizing
- Refactoring Our Code
- Final Result
Простая сеть¶
Прямое распространение — это процесс с помощью которого сеть делает предсказание (prediction). Также это основной режим работы обученной нейронной сети. Входные данные «распространяются» через каждый слой сети и выходной слой выдает финальный результат — предсказание. Для простой учебной нейронной сети один проход данных можно выразить математически как:
[Prediction = A(;A(;X W_h;)W_o;)]
Где (A) это функция активации, например ReLU, (X) это входные данные, (W_h) и (W_o) это веса слоев.
Прямой проход по шагам¶
- Вычислить значения входов скрытого слоя умножениием (X) на веса скрытого слоя (W_h) и получить (Z_h).
- Применить функцию активации к (Z_h) и передать результат (H) в выходной слой.
- Вычислить значения входов выходного слоя умножением значения (H) на веса выходного слоя (W_o) и получить (Z_o)
- Применить функцию активации к (Z_o). Результатом будет предсказание сети.
Код¶
Давайте напишем метод feed_forward() для распространения входных данных через нейронную сеть с 1-м скрытым слоем. Выход этого метода будет представлять собой предсказание модели.
def relu(z): return max(0,z) def feed_forward(x, Wh, Wo): # Hidden layer Zh = x * Wh H = relu(Zh) # Output layer Zo = H * Wo output = relu(Zo) return output
x это вход сети, Zo и Zh это «взвешенный» вход слоев, a Wo и Wh это веса слоев.
Более сложная сеть¶
Простая сеть очень помогает в учебном процессе, но реальные сети намного больше и сложнее устроены. Современные нейронные сети имеют гораздо больше скрытых слоев, больше нейронов в каждом слое, больше входных переменных. Рассмотрим более крупную (но всё ещё простую) нейронную сеть, которая позволит нам показать универсальный подход, основанный на матричном умножении, используемом в больших, «промышленных» нейронных сетях.
Архитектура¶
Для произвольного изменения количества входов или выходов сети, мы должны сделать наш код более гибким с помощью добавления новых параметров в __init_ метод: inputLayerSize, hiddenLayerSize,outputLayerSize. Мы будем продолжать ограничивать себя в количестве скрытых слоев, но сейчас это не так важно, потому что мы можем менять ширину (количество нейронов) имеющихся слоев.
INPUT_LAYER_SIZE = 1 HIDDEN_LAYER_SIZE = 2 OUTPUT_LAYER_SIZE = 2
Инициализация весов¶
Unlike last time where Wh and Wo were scalar numbers, our new weight variables will be numpy arrays. Each array will hold all the weights for its own layer — one weight for each synapse. Below we initialize each array with the numpy’s np.random.randn(rows, cols) method, which returns a matrix of random numbers drawn from a normal distribution with mean 0 and variance 1.
def init_weights(): Wh = np.random.randn(INPUT_LAYER_SIZE, HIDDEN_LAYER_SIZE) * np.sqrt(2.0/INPUT_LAYER_SIZE) Wo = np.random.randn(HIDDEN_LAYER_SIZE, OUTPUT_LAYER_SIZE) * np.sqrt(2.0/HIDDEN_LAYER_SIZE)
Here’s an example calling random.randn():
arr = np.random.randn(1, 2) print(arr) >> [[-0.36094661 -1.30447338]] print(arr.shape) >> (1,2)
As you’ll soon see, there are strict requirements on the dimensions of these weight matrices. The number of rows must equal the number of neurons in the previous layer. The number of columns must match the number of neurons in the next layer.
A good explanation of random weight initalization can be found in the Stanford CS231 course notes [1] chapter on neural networks.
Bias Terms¶
Смещение (Bias) terms allow us to shift our neuron’s activation outputs left and right. This helps us model datasets that do not necessarily pass through the origin.
Using the numpy method np.full() below, we create two 1-dimensional bias arrays filled with the default value 0.2. The first argument to np.full is a tuple of array dimensions. The second is the default value for cells in the array.
def init_bias(): Bh = np.full((1, HIDDEN_LAYER_SIZE), 0.1) Bo = np.full((1, OUTPUT_LAYER_SIZE), 0.1) return Bh, Bo
Working with Matrices¶
To take advantage of fast linear algebra techniques and GPUs, we need to store our inputs, weights, and biases in matrices. Here is our neural network diagram again with its underlying matrix representation.
What’s happening here? To better understand, let’s walk through each of the matrices in the diagram with an emphasis on their dimensions and why the dimensions are what they are. The matrix dimensions above flow naturally from the architecture of our network and the number of samples in our training set.
Matrix dimensions
| Var | Name | Dimensions | Explanation |
X |
Input | (3, 1) | Includes 3 rows of training data, and each row has 1 attribute (height, price, etc.) |
Wh |
Hidden weights | (1, 2) | These dimensions are based on number of rows equals the number of attributes for the observations in our training set. The number columns equals the number of neurons in the hidden layer. The dimensions of the weights matrix between two layers is determined by the sizes of the two layers it connects. There is one weight for every input-to-neuron connection between the layers. |
Bh |
Hidden bias | (1, 2) | Each neuron in the hidden layer has is own bias constant. This bias matrix is added to the weighted input matrix before the hidden layer applies ReLU. |
Zh |
Hidden weighted input | (1, 2) | Computed by taking the dot product of X and Wh. The dimensions (1,2) are required by the rules of matrix multiplication. Zh takes the rows of in the inputs matrix and the columns of weights matrix. We then add the hidden layer bias matrix Bh. |
H |
Hidden activations | (3, 2) | Computed by applying the Relu function to Zh. The dimensions are (3,2) — the number of rows matches the number of training samples and the number of columns equals the number of neurons. Each column holds all the activations for a specific neuron. |
Wo |
Output weights | (2, 2) | The number of rows matches the number of hidden layer neurons and the number of columns equals the number of output layer neurons. There is one weight for every hidden-neuron-to-output-neuron connection between the layers. |
Bo |
Output bias | (1, 2) | There is one column for every neuron in the output layer. |
Zo |
Output weighted input | (3, 2) | Computed by taking the dot product of H and Wo and then adding the output layer bias Bo. The dimensions are (3,2) representing the rows of in the hidden layer matrix and the columns of output layer weights matrix. |
O |
Output activations | (3, 2) | Each row represents a prediction for a single observation in our training set. Each column is a unique attribute we want to predict. Examples of two-column output predictions could be a company’s sales and units sold, or a person’s height and weight. |
Dynamic Resizing¶
Before we continue I want to point out how the matrix dimensions change with changes to the network architecture or size of the training set. For example, let’s build a network with 2 input neurons, 3 hidden neurons, 2 output neurons, and 4 observations in our training set.
Now let’s use same number of layers and neurons but reduce the number of observations in our dataset to 1 instance:
As you can see, the number of columns in all matrices remains the same. The only thing that changes is the number of rows the layer matrices, which fluctuate with the size of the training set. The dimensions of the weight matrices remain unchanged. This shows us we can use the same network, the same lines of code, to process any number of observations.
Refactoring Our Code¶
Here is our new feed forward code which accepts matrices instead of scalar inputs.
def feed_forward(X): ''' X - input matrix Zh - hidden layer weighted input Zo - output layer weighted input H - hidden layer activation y - output layer yHat - output layer predictions ''' # Hidden layer Zh = np.dot(X, Wh) + Bh H = relu(Zh) # Output layer Zo = np.dot(H, Wo) + Bo yHat = relu(Zo) return yHat
Weighted input
The first change is to update our weighted input calculation to handle matrices. Using dot product, we multiply the input matrix by the weights connecting them to the neurons in the next layer. Next we add the bias vector using matrix addition.
The first column in Bh is added to all the rows in the first column of resulting dot product of X and Wh. The second value in Bh is added to all the elements in the second column. The result is a new matrix, Zh which has a column for every neuron in the hidden layer and a row for every observation in our dataset. Given all the layers in our network are fully-connected, there is one weight for every neuron-to-neuron connection between the layers.
The same process is repeated for the output layer, except the input is now the hidden layer activation H and the weights Wo.
ReLU activation
The second change is to refactor ReLU to use elementwise multiplication on matrices. It’s only a small change, but its necessary if we want to work with matrices. np.maximum() is actually extensible and can handle both scalar and array inputs.
def relu(Z): return np.maximum(0, Z)
In the hidden layer activation step, we apply the ReLU activation function np.maximum(0,Z) to every cell in the new matrix. The result is a matrix where all negative values have been replaced by 0. The same process is repeated for the output layer, except the input is Zo.
Final Result¶
Putting it all together we have the following code for forward propagation with matrices.
INPUT_LAYER_SIZE = 1 HIDDEN_LAYER_SIZE = 2 OUTPUT_LAYER_SIZE = 2 def init_weights(): Wh = np.random.randn(INPUT_LAYER_SIZE, HIDDEN_LAYER_SIZE) * np.sqrt(2.0/INPUT_LAYER_SIZE) Wo = np.random.randn(HIDDEN_LAYER_SIZE, OUTPUT_LAYER_SIZE) * np.sqrt(2.0/HIDDEN_LAYER_SIZE) def init_bias(): Bh = np.full((1, HIDDEN_LAYER_SIZE), 0.1) Bo = np.full((1, OUTPUT_LAYER_SIZE), 0.1) return Bh, Bo def relu(Z): return np.maximum(0, Z) def relu_prime(Z): ''' Z - weighted input matrix Returns gradient of Z where all negative values are set to 0 and all positive values set to 1 ''' Z[Z < 0] = 0 Z[Z > 0] = 1 return Z def cost(yHat, y): cost = np.sum((yHat - y)**2) / 2.0 return cost def cost_prime(yHat, y): return yHat - y def feed_forward(X): ''' X - input matrix Zh - hidden layer weighted input Zo - output layer weighted input H - hidden layer activation y - output layer yHat - output layer predictions ''' # Hidden layer Zh = np.dot(X, Wh) + Bh H = relu(Zh) # Output layer Zo = np.dot(H, Wo) + Bo yHat = relu(Zo)
References
| [1] | http://cs231n.github.io/neural-networks-2/#init |