If you only need the first 32 columns, and you know how many columns there are, you can set the other columns classes to NULL.
read.csv("C:\N0_07312014.CSV", na.string=c("","null","NaN","X"),
header=T, stringsAsFactors=FALSE,
colClasses=c(rep("character",32),rep("NULL",10)))
If you do not want to code up each colClass and you like the guesses read.csv then just save that csv and open it again.
Alternatively, you can skip the header and name the columns yourself and remove the misbehaved rows.
A<-data.frame(read.csv("N0_07312014.CSV",
header=F,stringsAsFactors=FALSE,
colClasses=c(rep("character",32),rep("NULL",5)),
na.string=c("","null","NaN","X")))
Yournames<-as.character(A[1,])
names(A)<-Yournames
yourdata<-unique(A)[-1,]
The code above assumes you do not want any duplicate rows. You can alternatively remove rows that have the first entry equal to the first column name, but I’ll leave that to you.
17 авг. 2022 г.
читать 2 мин
Одна ошибка, с которой вы можете столкнуться в R:
Error in read.table("my_data.csv", header=TRUE) :
more columns than column names
Эта ошибка обычно возникает, когда вы пытаетесь прочитать CSV-файл в R с помощью функции read.table() и не можете указать, что разделителем ( sep ) должна быть запятая.
В этом руководстве рассказывается, как именно исправить эту ошибку.
Как воспроизвести ошибку
Предположим, у нас есть следующий CSV-файл с именем баскетбол_данные.csv :

Теперь предположим, что мы пытаемся импортировать этот файл в R, используя функцию read.table() :
#attempt to import CSV into data frame
df <- read.table ("basketball_data.csv", header= TRUE )
Error in read.table("basketball_data.csv", header = TRUE) :
more columns than column names
Мы получаем ошибку, потому что мы не указали, что значения в нашем файле разделяются запятыми.
Поскольку между значениями в строках фрейма данных есть пробелы, но не в заголовке, функция read.table() считает, что существует только один столбец.
Таким образом, это говорит нам о том, что столбцов больше, чем имен столбцов.
Как исправить ошибку
Чтобы исправить эту ошибку, просто используйте sep=»» при импорте файла:
#import CSV file into data frame
df <- read.table ("basketball_data.csv", header= TRUE , sep=",")
#view data frame
df
team points rebounds
1 A 22 10
2 B 14 9
3 C 29 6
4 D 30 2
Мы можем успешно импортировать файл CSV без каких-либо ошибок, потому что мы указали, что значения в файле разделены запятыми.
В качестве альтернативы мы могли бы просто использовать read.csv() для импорта файла, если мы знаем, что это файл CSV:
#import CSV file into data frame
df <- read.csv ("basketball_data.csv", header= TRUE )
#view data frame
df
team points rebounds
1 'A' 22 10
2 'B' 14 9
3 'C' 29 6
4 'D' 30 2
Обратите внимание, что и на этот раз мы не получаем никаких ошибок при импорте CSV-файла.
Дополнительные ресурсы
В следующих руководствах объясняется, как устранять другие распространенные ошибки в R:
Как исправить в R: имена не совпадают с предыдущими именами
Как исправить в R: более длинная длина объекта не кратна более короткой длине объекта
Как исправить в R: контрасты могут применяться только к факторам с 2 или более уровнями
In this R tutorial you’ll learn how to handle the error message “more columns than column names”.
The content of the page is structured as follows:
You’re here for the answer, so let’s get straight to the examples…
Example 1: Reproduce the Error – more columns than column names
In this example, I’ll show how to replicate the read.table error message “more columns than column names” in R.
Let’s assume that we want to import a CSV file (or any other type of file) to R using the read.table function. Then, we might try to use the following R code:
read.table("your_data.csv", header = TRUE) # Error # more columns than column names
However, the previous R code might return the error message “more columns than column names” to the RStudio console.
The reason for this is that our data might be separated with a comma (i.e. “,”) and the data.table function is not taking that into account properly.
So how can we solve this problem? In the following part of the tutorial, I’ll show you two alternatives on how to get rid of the error “more columns than column names”.
Example 2: Fix the Error Using read.table() Function & sep = “,”
In this section, I’ll illustrate how to avoid the error message “more columns than column names” by specifying the sep argument within the read.table function.
Have a look at the following R code:
read.table("your_data.csv", header = TRUE, sep = ",") # Specifying sep argument
As you can see, we have specified the sep argument to be equal to “,”.
Example 3: Fix the Error Using read.csv() Function
Another alternative to the sep argument (explained in the previous example) is provided by the read.csv function:
read.csv("your_data.csv") # Applying read.csv function
The read.csv function uses a comma as separator by default. Therefore, we don’t have to specify anything within the function.
Video & Further Resources
Have a look at the following video of my YouTube channel. In the video, I illustrate the R programming syntax of this article in a live session:
The YouTube video will be added soon.
Furthermore, you could read the other tutorials of this website. I have published several articles on related topics.
- Solving Error & Warning Messages in R
- R Programming Language
To summarize: In this R tutorial you have learned how to deal with the error “more columns than column names”. In case you have additional questions, please tell me about it in the comments section. Furthermore, don’t forget to subscribe to my email newsletter to get regular updates on new articles.
The “more columns than column names” error message is a tricky one because it represents a problem with a data file rather than your code. If you have no control over the data file then there is a way to use code to work around the problem however this approach is not elegant and actually requires recreating the data file or text file to make it useful.
The circumstances of this error.
The “more columns than column names” message occurs when loading a dataframe from an external data file or text file.
# r error more columns that column names
c2020.csv
Bob_T,Tom_B,Sue_C,Tim_M
5,6,4,0
2,8,6,8
4,4,4,1
0,3,7,3
3,7,5,5
1,9,2,6This is an example of a proper format file for a .csv data type. When it is loaded with the read.csv() function this data type works the way it is supposed to.
# more columns than column names r error
> x = read.csv(file="C:/Users/Owner/Desktop/c2020.csv")
> x
Bob_T Tom_B Sue_C Tim_M
1 5 6 4 0
2 2 8 6 8
3 4 4 4 1
4 0 3 7 3
5 3 7 5 5
6 1 9 2 6It produces a data frame consisting of a header for the column names with the separated data in columns underneath. However, if the data or excel file is not formatted properly then you get our command line message.
What is causing this error?
The cause of the “more columns than column names” message is the improper formatting of a datafile preventing the function from properly reading the column headers. This does not involve either row names or missing values but this is a problem that can arise in a data set with multiple columns. This often happens when trying to load an excel spreadsheet into your working directory, but the input is not reading the column headers properly. You can load an excel spreadsheet into R, but you may run into some value errors like this one.
# cause of more columns than names r error
c2021.csv
Bob_T,Tom_B Sue_C Tim_M
5,6,4,0
2,8,6,8
4,4,4,1
0,3,7,3
3,7,5,5
1,9,2,6In this case, the excel file has spaces instead of a comma as the field separator between column names in two places. When the read.csv() function is run in this case it produces our message.
# r error message more columns than column names
> x = read.csv(file="C:/Users/Owner/Desktop/c2021.csv")
Error in read.table(file = file, header = header, sep = sep, quote = quote, :
more columns than column namesThis is because it is not reading enough column names because it does not recognize the spaces as a column name field separator like it would a comma. This is what is triggering the error message.
There a two main fixes for the “more columns than column names” message. You can use the first if you have direct access to the datafile. In such a case all you have to do is open it in a text editor and make necessary corrections. That will fix the problem in a simple way by correcting the original problem. Replace the spaces with decimal commas between the character columns, and you should be on your way to a working R session.
# r error more columns than names solution
> x = read.csv(file="C:/Users/Owner/Desktop/c2021.csv", sep = 't')
> x
Bob_T.Tom_B.Sue_C.Tim_M
1 5,6,4,0
2 2,8,6,8
3 4,4,4,1
4 0,3,7,3
5 3,7,5,5
6 1,9,2,6This example simply inserts a second argument “sep = ‘t’” which blocks the separation of the header line and columns resulting in a single column. Contrary to how it may look there are no blank fields but there is just one column type. After this first run, you then use the data frame to recreate the data in a properly formatted .csv file or to create a data frame in your code. This fixes the problem but it requires extra steps. However, if you cannot correct the original file this is the best option.
This error message is the result of bad formatting of a data file and it is not necessarily a problem with your code. If you have access to the data then you can simply fix it. Otherwise, you can use code to get access data so that you can put it in the proper format and that will fix the problem for you. In either case, once you have the data in its proper format you can continue to process it as needed.
R Error more columns than column names
Содержание
- Как исправить в R: столбцов больше, чем имен столбцов
- Как воспроизвести ошибку
- Как исправить ошибку
- Дополнительные ресурсы
- Ошибка R read.csv «Больше столбцов, чем имен столбцов»
- R Error in read.table : more columns than column names (3 Examples)
- Example 1: Reproduce the Error – more columns than column names
- Example 2: Fix the Error Using read.table() Function & sep = “,”
- Example 3: Fix the Error Using read.csv() Function
- Video & Further Resources
- R read.csv «More columns than column names» error
- 8 Answers 8
- Как загрузить свои данные в среду R
- Правильная структура таблицы — залог успеха!
- Загрузка данных в среду R напрямую из Excel таблиц
- Классический вариант: импорт таблиц форматов .txt или .csv в среду R
- Полезная информация, небольшой трюк и заключение.
- Трюк с ярлыком R
- И напоследок, пара советов.
Одна ошибка, с которой вы можете столкнуться в R:
Эта ошибка обычно возникает, когда вы пытаетесь прочитать CSV-файл в R с помощью функции read.table() и не можете указать, что разделителем ( sep ) должна быть запятая.
В этом руководстве рассказывается, как именно исправить эту ошибку.
Как воспроизвести ошибку
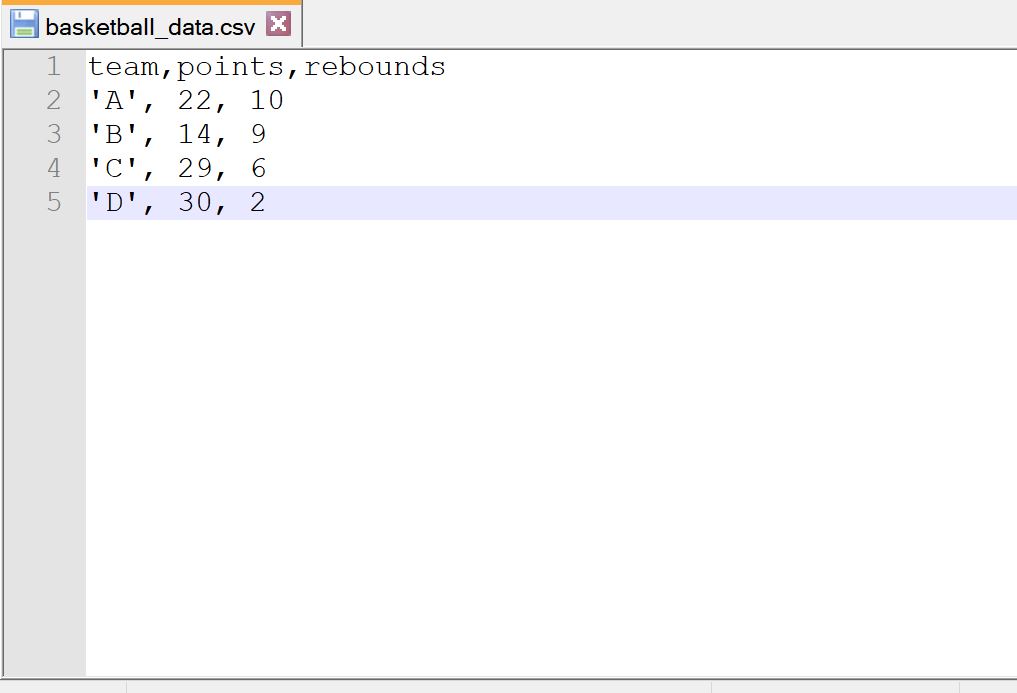
Предположим, у нас есть следующий CSV-файл с именем баскетбол_данные.csv :
Теперь предположим, что мы пытаемся импортировать этот файл в R, используя функцию read.table() :
Мы получаем ошибку, потому что мы не указали, что значения в нашем файле разделяются запятыми.
Поскольку между значениями в строках фрейма данных есть пробелы, но не в заголовке, функция read.table() считает, что существует только один столбец.
Таким образом, это говорит нам о том, что столбцов больше, чем имен столбцов.
Как исправить ошибку
Чтобы исправить эту ошибку, просто используйте sep=»» при импорте файла:
Мы можем успешно импортировать файл CSV без каких-либо ошибок, потому что мы указали, что значения в файле разделены запятыми.
В качестве альтернативы мы могли бы просто использовать read.csv() для импорта файла, если мы знаем, что это файл CSV:
Обратите внимание, что и на этот раз мы не получаем никаких ошибок при импорте CSV-файла.
Дополнительные ресурсы
В следующих руководствах объясняется, как устранять другие распространенные ошибки в R:
Источник
Ошибка R read.csv «Больше столбцов, чем имен столбцов»
У меня проблема при импорте .csv файла в R. С моим кодом:
R сообщает об ошибке и не делает то, что я хочу:
Я предполагаю, что проблема в том, что мои данные плохо отформатированы. Мне нужны данные только из [,1:32] . Все остальные должны быть удалены.
Откройте .csv как текстовый файл (например, используйте TextEdit на Mac) и проверьте, разделены ли столбцы запятыми.
csv — это «векторы, разделенные запятыми». По какой-то причине, когда Excel сохраняет мои файлы csv, вместо них используются точки с запятой.
При открытии вашего csv используйте:
Точка с запятой — это просто пример, но, как кто-то ранее предлагал, не предполагайте, что, поскольку ваш csv хорошо выглядит в Excel, это так.
Это один шаткий файл CSV. Перепутаны несколько заголовков (попробуйте вставить их в CSV Fingerprint ), чтобы понять, что я имею в виду.
Поскольку я не знаю данных, невозможно быть уверенным, что следующее даст вам точные результаты, но это требует использования readLines и других функций R для предварительной обработки текста:
Если вам нужны только первые 32 столбца и вы знаете, сколько столбцов существует, вы можете установить для других классов столбцов значение NULL.
Если вы не хотите кодировать каждый colClass и вам нравятся предположения read.csv , просто сохраните этот csv и откройте его снова.
Кроме того, вы можете пропустить заголовок и назвать столбцы самостоятельно, а также удалить некорректно работающие строки.
Приведенный выше код предполагает, что вам не нужны повторяющиеся строки. В качестве альтернативы вы можете удалить строки, в которых первая запись равна имени первого столбца, но я оставлю это на ваше усмотрение.
Источник
R Error in read.table : more columns than column names (3 Examples)
In this R tutorial you’ll learn how to handle the error message “more columns than column names”.
The content of the page is structured as follows:
You’re here for the answer, so let’s get straight to the examples…
Example 1: Reproduce the Error – more columns than column names
In this example, I’ll show how to replicate the read.table error message “more columns than column names” in R.
Let’s assume that we want to import a CSV file (or any other type of file) to R using the read.table function. Then, we might try to use the following R code:
read.table(«your_data.csv», header = TRUE) # Error # more columns than column names
However, the previous R code might return the error message “more columns than column names” to the RStudio console.
The reason for this is that our data might be separated with a comma (i.e. “,”) and the data.table function is not taking that into account properly.
So how can we solve this problem? In the following part of the tutorial, I’ll show you two alternatives on how to get rid of the error “more columns than column names”.
Example 2: Fix the Error Using read.table() Function & sep = “,”
In this section, I’ll illustrate how to avoid the error message “more columns than column names” by specifying the sep argument within the read.table function.
Have a look at the following R code:
read.table(«your_data.csv», header = TRUE, sep = «,») # Specifying sep argument
As you can see, we have specified the sep argument to be equal to “,”.
Example 3: Fix the Error Using read.csv() Function
Another alternative to the sep argument (explained in the previous example) is provided by the read.csv function:
read.csv(«your_data.csv») # Applying read.csv function
The read.csv function uses a comma as separator by default. Therefore, we don’t have to specify anything within the function.
Video & Further Resources
Have a look at the following video of my YouTube channel. In the video, I illustrate the R programming syntax of this article in a live session:
The YouTube video will be added soon.
Furthermore, you could read the other tutorials of this website. I have published several articles on related topics.
To summarize: In this R tutorial you have learned how to deal with the error “more columns than column names”. In case you have additional questions, please tell me about it in the comments section. Furthermore, don’t forget to subscribe to my email newsletter to get regular updates on new articles.
Источник
R read.csv «More columns than column names» error
I have a problem when importing .csv file into R. With my code:
R reports an error and does not do what I want:
I guess the problem is because my data is not well formatted. I only need data from [,1:32] . All others should be deleted.
8 Answers 8
That’s one wonky CSV file. Multiple headers tossed about (try pasting it to CSV Fingerprint) to see what I mean.
Since I don’t know the data, it’s impossible to be sure the following produces accurate results for you, but it involves using readLines and other R functions to pre-process the text:
Open the .csv as a text file (for example, use TextEdit on a Mac) and check to see if columns are being separated with commas.
csv is «comma separated vectors». For some reason when Excel saves my csv’s it uses semicolons instead.
When opening your csv use:
Semi colon is just an example but as someone else previously suggested don’t assume that because your csv looks good in Excel that it’s so.
If you only need the first 32 columns, and you know how many columns there are, you can set the other columns classes to NULL.
If you do not want to code up each colClass and you like the guesses read.csv then just save that csv and open it again.
Alternatively, you can skip the header and name the columns yourself and remove the misbehaved rows.
The code above assumes you do not want any duplicate rows. You can alternatively remove rows that have the first entry equal to the first column name, but I’ll leave that to you.
Источник
Как загрузить свои данные в среду R

Начинающие пользователи часто сталкиваются с проблемой загрузки своих данных в среду R: данные просто не загружаются или неправильно отображаются, возникают разного рода ошибки. Особенно эта проблема актуальна для тех, кто хранит свои данные в таблицах Excel и пытается именно их загрузить в R. Проблемы загрузки данных в среду R не всегда подробно рассматриваются в учебниках или на курсах, поэтому я решил написать эту статью и надеюсь, она облегчит жизнь тем, кто только заинтересовался R!
Правильная структура таблицы — залог успеха!
Большинство студентов, аналитиков и ученых работают с таблицами данных, поэтому именно их мы и загрузим в среду R. В качестве примера я создал таблицу в Excel с физическими данными студентов одного из военных ВУЗов (все данные вымышлены, любое совпадение имен и событий с реальными являются случайностью). В ней я заведомо нарушил все каноны построения таблиц, потому что неправильная структура таблицы является главным препятствием для загрузки данных не только в R, но и в другие статистические программы. Скачать таблицу можно по этой ссылке.
Как видно на рисунке ниже наша «таблица данных» имеет ряд структурных ошибок.

Во-первых, мы фактически имеем две таблицы в одной. Названия столбцов в этих таблицах кажутся разными, но на самом деле они просто написаны на разных языках. Так что мы можем смело объединить данные в одну таблицу. Я рекомендую использовать английский, так как это упростит работу в R. Теперь наша таблица стала единой.

Во-вторых, в некоторых столбцах мы имеем неоднородность данных. Например, в «Weight» и «Blood group» часть данных отображена числами, а часть словами. Всегда приводите данные одного столбца к одному формату. То же самое касается и «Rhesus factor». Также убедитесь, что в Excel листе нет заполненных ячеек , находящихся за пределами созданной таблицы. В итоге, результат должен получиться такой же, как на рисунке ниже.

Загрузка данных в среду R напрямую из Excel таблиц
Итак, теперь наша таблица имеет правильную структуру. Для загрузки файлов в форматах программы Excel (.xsl или .xlsx) существует R-пакет «xlsx» , который позволяет загружать их без особых проблем.
Сначала загружаем пакет «xlsx» в среду R:
Подключаем этот пакет при помощи команды:
Потом прописываем путь и имя файла, указываем номер листа, в котором находится таблица:
В нашем случае имя файла » voenvuz.xlsx» , а имя таблицы данных в среде R — «voenvuz1» :
Проверим, все ли нормально со структурой таблицы, вызвав имя таблицы «voenvuz1» в командной строке :

Все готово, наша таблица загружена корректно в среду R. Но прежде чем перейти к анализу загруженных данных, следует также освоить другой, более популярный среди опытных пользователей R метод загрузки данных — импортирование .txt и .csv файлов. В своей работе я использую именно его!
Классический вариант: импорт таблиц форматов .txt или .csv в среду R
Есть по крайней мере три причины, почему большинство пользователей R предпочитают пользоваться именно этим вариантом. Во-первых, не нужно подключать в R никаких дополнительных пакетов. Во-вторых, множество «сырых» данных сохраняется именно в форматах .txt и .csv. В третьих, эти форматы меньше весят в сравнении с тяжелыми .xls и .xlsx, и в них нет никаких ограничений по количеству строк или столбцов. Другими словами, они универсальны.
Создадим файлы voenvuz.txt и voenvuz.csv прямо в программе Excel. Для этого проделаем следующее:
- Нажимаем на вкладку «Файл» в левом верхнем углу;
- Выбираем «Экспорт» и находим опцию «Изменить тип файла»;
- Кликаем на нее и видим перед собой список различных форматов;
- Выбираем .txt (разделитель — знак табуляцией ‘tab’) или .csv (разделитель — запятая);
- Прописываем расположение и имя файла.
Теперь необходимо лишь импортировать полученные файлы в среду R. Для этого воспользуемся командами:
Несмотря на то, что мы загружали данные из разных форматов (.xlsx, .csv, .txt), результат должен получиться одним и тем же. Именно поэтому в среде R у нас появилось три абсолютно одинаковых таблицы под именами «voenvuz1» , «voenvuz2» , «voenvuz3» .
Полезная информация, небольшой трюк и заключение.
Чтобы быстро и эффективно загружать свои данные в среду R важно понимать, что такое «рабочая директория». Говоря простыми словами — это папка (директория), где расположен исполняемый файл программы. Для того, чтобы узнать рабочую папку R, следует набрать команду: > getwd()
Файлы, расположенные в этой папке, не нуждаются в указании «пути к файлу» при загрузке в среду R, что существенно экономит время, и уменьшает количество букв в коде. Именно поэтому важно не только знать, но и уметь изменять расположение рабочей папки. Измените расположение рабочей директории R на ту папку, в которой Вы разместили файлы voenvuz.xlsx , voenvuz.csv , voenvuz.txt .
Теперь Вы можете загрузить любую из таблиц, используя гораздо более короткий код, например:
Трюк с ярлыком R

Есть способ, при котором не нужно прописывать путь рабочей директории в R консоли, он будет создан автоматически. Для этого надо кликнуть по ярлыку программы R правой кнопкой и выбрать «Свойства». Во вкладке ярлык Вы увидите окошко «Рабочая папка». Удалите все, что там написано, чтобы оно было пустым, и нажмите «Применить».
Теперь просто скопируйте ярлык и вставьте его туда, где хранятся Ваши таблицы данных. Запустите R через этот ярлык. Все, Вы уже автоматически установили рабочую папку там, куда вставили ярлык. Для проверки можете воспользоваться командой dir() , которая выведет в консоль список файлов, находящихся в рабочей папке.
И напоследок, пара советов.
I. Если по каким-то причинам, таблица загрузилась в среду R неправильно, обратите внимание на аргументы функции read.table(). Возможно, стоит вручную прописать разделитель столбцов (sep = «») и десятичный знак (dec = «»). Аргумент header = TRUE, говорит о том, что у Вас в таблице присутствует заголовок для столбцов. Если его нет, замените на header = FALSE. Больше справочной информации об аргументах вы найдете, написав в консоли ?read.table
В качестве примера, я прописал некоторые аргументы для импорта нашей «voenvuz.txt» таблицы:
II. Если Ваш путь к таблице данных прописан на кириллице, то при вводе кода в консоль, убедитесь, что у Вас стоит английская раскладка. В противном случае, Вы увидите ошибку, проиллюстрированную ниже.

Если у Вас возникли вопросы или проблемы с загрузкой Ваших данных, пишите в комментариях к этой статье. Я обязательно отвечу и постараюсь Вам помочь. Спасибо за внимание!
Источник