-
-
May 7 2007, 17:28
- Кино
- Cancel
Запись опубликована IPTV в России.Пожалуйста, оставляйте коментарии там.
В связи с тем, что тема мониторинга достаточно актуальна, но практически не раскрыта на блоге, я решил написать немного на эту тему… Начать же хочу с описания самой распространенной на данный момент методики — RFC 4445.
Видеосигнал, в процессе его прохождения по пути HeadEnd — STB претерпевает различные изменения, и изменения эти не в лучшую сторону. Для качественного мониторинга и своевременного устранения проблемы возникла задача определить некие параметры качества и контролировать их на всем протяжении транспортной сети.
В связи с этим был утвержден индекс MDI (Media Delivery Index) определенный в методике RFC 4445. Он основан на принципе формирования интегральной оценки качества по совокупности двух самых важных параметров качества на всех участках транспорта IPTV инфраструктуры — джиттера и количества потерянных пакетов. И логика метода MDI заключается в том, что если с транспортом пакетов проблем не будет, то не будет проблем и с контентом. Эти параметры определены как уровень задержки Delay Factor (DF) и уровень потерянных пакетов Media Loss Rate (MLR).
MDI вычисляется за произвольный промежуток времени, обычно это 1 секунда
- MDI-DF показывает наибольшее значение параметра джиттера пакетов за период измерения
- MDI-MLR показывает количество транспортных пакетов , потерянных за период измерения
И если с измерениями уровня MLR, выполняющимися методами пассивного мониторинга все предельно понятно, то с DF дело обстоит сложнее. Джиттером в MDI является задержка между ожидаемым и реальным временем приема пакета (см. рисунок).

где IAT — среднее время доставки соседних IP-фреймов.
По сути DF определяет критический размер буфера на стороне приемника, и в отличие от MLR измерение параметра задержки DF не может быть реализовано методами пассивного мониторинга.
MDI — это простой алгоритм мониторинга уровня транспорта для квалификации качества уровня услуг. За счет применения MDI можно осуществить мониторинг параметров качества на всех основных узлах транспорта начиная HeadEnd и заканчивая STB, выявить участок, где происходит ухудшение качества, и определить в какой степени это критично для услуги IPTV.
Повышение QoE — залог удержания клиентов
Системы кеширования становятся одними из наиболее востребованных элементов сетевой инфраструктуры, таким же как коммутатор доступа или пограничный маршрутизатор. При этом данный элемент необходим как провайдерам и операторам связи для оптимального планирования расширения каналов передачи данных, так и корпоративным структурам для оптимизации бизнес-приложений.
Для больших корпоративных структур системы кеширования используются для оптимизации арендованных каналов связи для работы CRM и ERP систем.
Cервис-провайдеры сталкиваются с растущими проблемами. P2P и Internet HTTP/video приложения потребляют значительную часть производительности сети, вдобавок к растущему количеству мобильных устройств, с которых осуществляется выход в интернет отовсюду. Подписчики требуют все больше и больше сервисов, а также оперативности действий по их немедленной доступности.
Системы кеширования повышают QoE провайдеров.
Для избежания неудовлетворености услугами и потери клиентов мы рекомендуем провайдерам внедрять системы кеширования для оптимизации производительности аплинк- каналов и увеличения скорости доставки наиболее часто запрашиваемого контента.
Компоненты MDI
На рис. 1 приведена стандартная схема подключения сетевой инфраструктуры провайдера связи.

Рис.1. Обычная сетевая инфраструктура
MDI относится ко всей сети и может быть определен между точками источника видео и STB приставкой пользователя. MDI обычно отображается как два отдельных значения, которые разделяются двоеточием — Delay factor (DF) и Media loss rate (MLR) (DF: MLR)
DF: MLR

Рис.2. Пакеты принятые за интервал времени с джиттером и без
DF (Фактор задержки)
Для того, что бы понять суть параметра Delay Factor (DF), полезно рассмотреть соотношение между джиттером (дрожанием) и буферизацией. Джиттером является изменение задержки сигнала по времени. Пакеты, прибывающие в место назначения с постоянной задержкой по времени имеют нулевой джиттер, а пакеты с непостоянной задержкой — не нулевой. Схемы на рис. 2 иллюстрируют это отличие.
Проходя через сеть между источником и точкой назначения, находясь в очередях, маршрутизируясь и коммутируясь различными сетевыми элементами, пакет прибывает в место назначения с разными скоростями на протяжении времени. Это может быть, например, вызвано временными перегрузками сети, в связи с большим количеством P2P трафика или активных действий абонентов, таких как VoIP звонки, которые имеют больший приоритет в сети и ограничивают обработку трафика из других источников. В любом случае, если мгновенная скорость передачи данных не совпадает со скоростью получения данных принимающей стороной, то пакеты нуждаются в буферизации по прибытию.
Рассмотрим типичный MPEG видеопоток (3,75 Mb/s). Декодер в точке назначения будет принимать поток 3,75 Mb/s, но данные могут приходить со скоростью выше и ниже заявленной величины. Буферы в декодере используются для сбора определенного количества пакетов, прибывающих с разными скоростями и передачи их для декодирования, с постоянной скоростью. Чем больше джиттер, тем больше буферов необходимо для его устранения. Задача больших буферов в том, что они вносят задержку для сигнала большой степени дрожания. Кроме того, буферы ограниченных размеров в совокупности с чрезмерным джиттером приходят к переполнению или не дополнению. Переполнение происходит тогда, когда пакеты приходят с такой скоростью, что происходит полное заполнение буфера, тогда происходит потеря пакетов в приемнике.
Не дополнение к этому ситуация, когда пакеты прибывают так медленно, что буферу недостаточно данных для передачи их в декодер. Обе эти ситуации нежелательны, так как они ведут к ухудшению QoE пользователя.
Пользователи могут наблюдать остановку картинки или прерывание изображения или же картинка на экране пользователей может иметь искажения в результате потерянных пакетов.
DF — это компонент MDI, который является временным значением и определяет количество секунд, которое буфер должен удерживать пакет для устранения явления джиттера. Он определяет, насколько прибывающие пакеты доходят до пользователя, через заданные интервалы времени (обычно 1 секунда) и вычисляется как:
Разница между принятыми буфером и доставленными до пользователя байтами в каждом приходящем пакете – виртуальная глубина буфера MDI (∆):
∆ = “принятые байты” – “доставленные байты”
Отношение разницы между минимальной и максимальной величиной виртуальных глубин буферов к скорости потока данных:
DF=((max(∆)- min(∆)))/(скорость потока);
В качестве примера еще раз рассмотрим видео поток MPEG. Если в течении односекундного интервала, максимальная величина виртуальной глубины буфера MDI составляет 3.775 Mb, а минимальная около 3.740 Mb, то фактор задержки (DF) будет определяться как:
DF=(3.755Mb-3.740Mb)/(3.75Mb/s)= 15kb/(3.75Mb/s)=4ms;
Следовательно, для того чтобы избежать потери пакетов при наличии такого джиттера, буфер приемника должны быть 15kb, что вводит 4 миллисекунды задержки.
DF может быть использован при доставке видео контента, как оценка качества видео с точки зрения пользователей и обозначать QoE. Он также может быть использован для определения влияния каждого сетевого элемента вдоль пути доставки видео. При сравнении DF на входе и DF выходе из устройства, можно определить задержку (footprint), которую вносит устройство. Устройства не вносящие джиттер, должны иметь наименьшее значение задержки (footprint) – они лучше подходят для построения сетей доставки видео.
Acceptable Delay Factor (Допустимый фактор задержки)

Рис.3. Рекомендованный максимально допустимый фактор задержки
Фактор задержки допустимый для множества сетевых элементов сильно варьируется, так как в них доступен широкий диапазон размеров буфера. В большинстве STBs используются RAM модули. Только часть этого RAM используется по прямому назначению, а часть в используется в качестве буфера для ликвидации джиттера входящих IP потоков, именно поэтому большинство STBs не имеет, в списке общих характеристик, указания величины размера буфера. Фактический размер буфера каждого STB может быть определен путем тестирования в конкретных условиях. Множество QoE стандартов, которые разработаны DSL форумом в части WT-126 рекомендуют, что бы джиттер элементов сетевой инфраструктуры не превышал значения 50мс, тем не менее, большинство STBs среднего и высокого уровней могут предложить значение намного ниже. Тестирования ряда STBs низкого уровня показали среднее значение величины джиттера равное 9ms.
Эти два значения немного меняются в зависимости от величин потов, но незначительно (менее чем 10%). Расхождение между двумя значениями (50 мс и 9 мс) объясняется большим разбросом в качестве доступных STBs. Точный максимально допустимый DF должен быть настроен на размер буфера STB. Необходимо установить максимальный размер джиттера, который поддерживает ваша STB, с целью предотвращения появления какие-нибудь искажений.
Media loss rate (MLR)
Media loss rate (MLR) просто определяется, как количество потерянных или пришедших не по порядку медиа пакетов в секунду. Неупорядоченность пакетов важна, потому что большинство устройств не питаются изменить их порядок перед представлением в декодер. Любые потери пакетов – представляются как не нулевой MLR – негативно повлияют на качество видео, приведут к негативным искажениям или к неравномерности воспроизведения видео. MLR является удобным параметром для определения уровня обслуживания (SLA) с точки зрения потерь пакетов. Так, в совокупности с предыдущим параметром DF, показатель MDI 4:0.001 говорит о том, что устройство имеет фактор задержки 4 мс и показатель потерь пакетов в секунду 0.001.
количества пропущенных пакетов. Так, взятые в контексте с предыдущим компонентом DF, устройство с MDI из 4:0.001 будет означать, что устройство имеет задержку в 4 раза миллисекунд и скорости СМИ потере 0,001 СМИ пакетов в секунду.
Acceptable MLR (Допустимый MLR)

Рис.4. Рекомендованный максимально допустимый MLR при переключении каналов, для всех сервисов и кодеков

Рис.5. Рекомендованный максимально допустимый средний MLR
MDI есть простым и понятным способом определения оценки влияния сети на видео, а следовательно и на QoEпользователя. Два компонента, составляющих MDI, фактор задержки и коэффициент потери пакетов, в целом определяют качество предоставления услуг IPTV.
Данные характеристики были рассмотрены с целью более детального понимания необходимости использования систем кэширования. Поскольку расстояния в пределах страны достаточно велики, а задержки сигналов передачи данных зависимы от физических свойств каналов передачи неотвратимы – система кэширования является единственным инструментом, который позволяет стабилизировать QoE в допустимых пределах.
Как выбрать систему кеширования?
Что бы подойти к выбору системы кеширования удовлетворяющей требованиям конкретной сети, необходимо понимать основные параметры и их влияние на работу сети. Конечно же, одним из важнейших параметров любой системы является производительность и система кеширования не исключение. Тем не менее, некоторые параметры нуждаются в рассмотрении для правильного понимания их истинного значения.
Определение производительности системы кеширования (Net Cache Out)
Трафик, входящий в кэш определяется как Cache In, а трафик выходящий из кеш как Cache Out. Мы не должны путать Cache Out с показателями производительности всей системы кеширования. Есть небольшие отличия в функциональности систем кеширования с точки зрения определения параметра Cache Out — out-of-band и in-line системы:
— out-of-band – в данном случае Cache Out зависит только от кешированного контента. В этм случае Cache Out можно сопоставлять со значением производительности системы кеширования.
— В in-line системах, Cache Out параметр является суммой значения кешированного контента распространяющегося из кеш и добавления потока трафика проходящего через систему от входа к выходу без кеширования. Это связано с требованием симметричности маршрутизации. Таким образом, с точки зрения in-line систем кеширования, Cache Out не может быть использован как показатель производительности системы кеширования.

Рис.6. Определение значений Cache Out
Развертывания систем кеширования больших провайдеров показывают, что производительности out-of-band систем кеширования могут достигать 100Gbps (Cache Out = 100gbps). В то время как in-line системы кеширования призванные отрабатывать 20Gbps, обычно дают не более 4Gbps Cache Out – производительности кеширования.
Максимальная эффективность (наивысший коэффициент попадания в кэш)
Важным параметром HTTP/Video производительности есть коэффициент попадания в кэш. Этот коэффициент на HCS (HTTP Cache Server) считается как общее количество видео запросов, которые успешно были доставлены кэш-сервером по отношению к общему количеству запросов пользователей. Коэффициент попадания в кэш может составлять 80% для YouTube трафика или даже 100% для MS обновлений. Очевидно, что высокий коэффициент попадания в кэш определяет высокую эффективность кэширования.
На рисунках представлен возможный вид графиков для YouTube и MS update контента.

Рис.7. Коэффициент попадания в кэш — YouTube

Рис.8. Коэффициент попадания в кэш — MS update
Стоит отметить, что in-line решения кэширования, разворачиваемые в больших сетях, требуют множества систем кэширования и не поддерживают глобального анализа трафика. Ко всему, множество систем кэширования – без централизованного управления – дублируют одинаковых контент много раз. Как результат, in-line решения кэширования дают намного меньшую производительность и есть намного менее эффективными, чем решения out-of-band.
mlr is designed to make usage errors due to typos or invalid parameter values as unlikely as possible. Occasionally, you might want to break those barriers and get full access, for example to reduce the amount of output on the console or to turn off checks. For all available options simply refer to the documentation of configureMlr(). In the following we show some common use cases.
Generally, function configureMlr() permits to set options globally for your current R session.
It is also possible to set options locally.
- All options referring to the behavior of learners (these are all options except
show.info) can be set for an individual learner via theconfigargument ofmakeLearner(). The local precedes the global configuration. - Some functions like
resample(),benchmark(),selectFeatures(),tuneParams(), andtuneParamsMultiCrit()have ashow.infoflag that controls if progress messages are shown. The default value ofshow.infocan be set byconfigureMlr().
Example: Reducing the output on the console
You are bothered by all the output on the console like in this example?
rdesc = makeResampleDesc("Holdout")
r = resample("classif.multinom", iris.task, rdesc)
## Resampling: holdout
## Measures: mmce
## # weights: 18 (10 variable)
## initial value 109.861229
## iter 10 value 8.635871
## iter 20 value 0.942436
## iter 30 value 0.225516
## iter 40 value 0.144303
## iter 50 value 0.139259
## iter 60 value 0.123724
## iter 70 value 0.089635
## iter 80 value 0.084994
## iter 90 value 0.058982
## iter 100 value 0.056564
## final value 0.056564
## stopped after 100 iterations
## [Resample] iter 1: 0.0400000
##
## Aggregated Result: mmce.test.mean=0.0400000
## You can suppress the output for this Learner makeLearner() and this resample() call as follows:
lrn = makeLearner("classif.multinom", config = list(show.learner.output = FALSE))
r = resample(lrn, iris.task, rdesc, show.info = FALSE)(Note that nnet::multinom() has a trace switch that can alternatively be used to turn off the progress messages.)
To globally suppress the output for all subsequent learners and calls to resample(), benchmark() etc. do the following:
configureMlr(show.learner.output = FALSE, show.info = FALSE)
r = resample("classif.multinom", iris.task, rdesc)Accessing and resetting the configuration
Function getMlrOptions() returns a base::list() with the current configuration.
getMlrOptions()
## $show.info
## [1] FALSE
##
## $on.learner.error
## [1] "stop"
##
## $on.learner.warning
## [1] "warn"
##
## $on.par.without.desc
## [1] "stop"
##
## $on.par.out.of.bounds
## [1] "stop"
##
## $on.measure.not.applicable
## [1] "stop"
##
## $show.learner.output
## [1] FALSE
##
## $on.error.dump
## [1] FALSETo restore the default configuration call configureMlr() with an empty argument list.
getMlrOptions()
## $show.info
## [1] TRUE
##
## $on.learner.error
## [1] "stop"
##
## $on.learner.warning
## [1] "warn"
##
## $on.par.without.desc
## [1] "stop"
##
## $on.par.out.of.bounds
## [1] "stop"
##
## $on.measure.not.applicable
## [1] "stop"
##
## $show.learner.output
## [1] TRUE
##
## $on.error.dump
## [1] FALSEExample: Turning off parameter checking
It might happen that you want to set a parameter of a Learner (makeLearner(), but the parameter is not registered in the learner’s parameter set (ParamHelpers::makeParamSet()) yet. In this case you might want to contact us or open an issue as well! But until the problem is fixed you can turn off mlr’s parameter checking. The parameter setting will then be passed to the underlying function without further ado.
# Support Vector Machine with linear kernel and new parameter 'newParam'
lrn = makeLearner("classif.ksvm", kernel = "vanilladot", newParam = 3)
## Error in setHyperPars2.Learner(learner, insert(par.vals, args)): classif.ksvm: Setting parameter newParam without available description object!
## Did you mean one of these hyperparameters instead: degree scaled kernel
## You can switch off this check by using configureMlr!
# Turn off parameter checking completely
configureMlr(on.par.without.desc = "quiet")
lrn = makeLearner("classif.ksvm", kernel = "vanilladot", newParam = 3)
train(lrn, iris.task)
## Setting default kernel parameters
## Model for learner.id=classif.ksvm; learner.class=classif.ksvm
## Trained on: task.id = iris-example; obs = 150; features = 4
## Hyperparameters: fit=FALSE,kernel=vanilladot,newParam=3
# Option "quiet" also masks typos
lrn = makeLearner("classif.ksvm", kernl = "vanilladot")
train(lrn, iris.task)
## Model for learner.id=classif.ksvm; learner.class=classif.ksvm
## Trained on: task.id = iris-example; obs = 150; features = 4
## Hyperparameters: fit=FALSE,kernl=vanilladot
# Alternatively turn off parameter checking, but still see warnings
configureMlr(on.par.without.desc = "warn")
lrn = makeLearner("classif.ksvm", kernl = "vanilladot", newParam = 3)
## Warning in setHyperPars2.Learner(learner, insert(par.vals, args)): classif.ksvm: Setting parameter kernl without available description object!
## Did you mean one of these hyperparameters instead: kernel nu degree
## You can switch off this check by using configureMlr!
## Warning in setHyperPars2.Learner(learner, insert(par.vals, args)): classif.ksvm: Setting parameter newParam without available description object!
## Did you mean one of these hyperparameters instead: degree scaled kernel
## You can switch off this check by using configureMlr!
train(lrn, iris.task)
## Model for learner.id=classif.ksvm; learner.class=classif.ksvm
## Trained on: task.id = iris-example; obs = 150; features = 4
## Hyperparameters: fit=FALSE,kernl=vanilladot,newParam=3Example: Handling errors in a learning method
If a learning method throws an error the default behavior of mlr is to generate an exception as well. However, in some situations, for example if you conduct a larger bechmark experiment with multiple data sets and learners, you usually don’t want the whole experiment stopped due to one error. You can prevent this using the on.learner.error option of configureMlr().
# This call gives an error caused by the low number of observations in class "virginica"
train("classif.qda", task = iris.task, subset = 1:104)
## Error in qda.default(x, grouping, ...): some group is too small for 'qda'
# Get a warning instead of an error
configureMlr(on.learner.error = "warn")
mod = train("classif.qda", task = iris.task, subset = 1:104)
## Warning in train("classif.qda", task = iris.task, subset = 1:104): Could not train learner classif.qda: Error in qda.default(x, grouping, ...) :
## some group is too small for 'qda'
mod
## Model for learner.id=classif.qda; learner.class=classif.qda
## Trained on: task.id = iris-example; obs = 104; features = 4
## Hyperparameters:
## Training failed: Error in qda.default(x, grouping, ...) :
## some group is too small for 'qda'
##
## Training failed: Error in qda.default(x, grouping, ...) :
## some group is too small for 'qda'
# mod is an object of class FailureModel
isFailureModel(mod)
## [1] TRUE
# Retrieve the error message
getFailureModelMsg(mod)
## [1] "Error in qda.default(x, grouping, ...) : n some group is too small for 'qda'n"
# predict and performance return NA's
pred = predict(mod, iris.task)
pred
## Prediction: 150 observations
## predict.type: response
## threshold:
## time: NA
## id truth response
## 1 1 setosa <NA>
## 2 2 setosa <NA>
## 3 3 setosa <NA>
## 4 4 setosa <NA>
## 5 5 setosa <NA>
## 6 6 setosa <NA>
## ... (#rows: 150, #cols: 3)
performance(pred)
## mmce
## NAIf on.learner.error = "warn" a warning is issued instead of an exception and an object of class FailureModel() is created. You can extract the error message using function getFailureModelMsg(). All further steps like prediction and performance calculation work and return NA's.
I tried to train a h2o model using the following code and make a prediction for new data, but it leads to an error. How can I avoid this error?
library(mlr)
a <- data.frame(y=factor(c(1,1,1,1,1,1,1,1,0,0,1,0)),
x1=rep(c("a","b","c"), times=c(6,3,3)))
aTask <- makeClassifTask(data = a, target = "y", positive = "1")
h2oLearner <- makeLearner("classif.h2o.deeplearning",
predict.type = "prob")
model <- train(h2oLearner, aTask)
b <- data.frame(x1=rep(c("a","b", "c"), times=c(3,5,4)))
pred <- predict(model, newdata=b)
leads to the following error:
Error in checkPredictLearnerOutput(.learner, .model, p) :
predictLearner for classif.h2o.deeplearning has returned not the class
levels as column names: p0,p1
If I change predict.type to «response» it works. So how to predict probabilities?
Все курсы > Оптимизация > Занятие 4 (часть 1)
Прежде чем обратиться к теме множественной линейной регрессии, давайте вспомним, что было сделано до сих пор. Возможно, будет полезно посмотреть эти уроки, чтобы освежить знания.
- В рамках вводного курса мы узнали про моделирование взаимосвязи переменных и минимизацию ошибки при обучении алгоритма, а также научились строить несложные модели линейной регрессии с помощью библиотеки sklearn.
- При изучении объектно-ориентированного программирования мы создали класс простой линейной регрессии. Сегодня эти знания пригодятся при создании классов более сложных моделей.
- Также рекомендую вспомнить умножение векторов и матриц.
- Кроме того, в рамках текущего курса по оптимизации мы познакомились с понятием производной и методом градиентного спуска, а также построили модель простой линейной регрессии (использовав метод наименьших квадратов и градиент).
- Наконец, на прошлом занятии мы вновь поговорили про взаимосвязь переменных.
В рамках сегодняшнего занятия мы с нуля построим несколько алгоритмов множественной линейной регрессии.
Регрессионный анализ
Прежде чем обратиться к практике, обсудим некоторые теоретические вопросы регрессионного анализа.
Генеральная совокупность и выборка
Как мы уже знаем, множество всех имеющихся наблюдений принято считать генеральной совокупностью (population). И эти наблюдения, если в них есть взаимосвязи, можно теоретически аппроксимировать, например, линией регрессии. При этом важно понимать, что это некоторая идеальная модель, которую мы никогда не сможем построить.
Единственное, что мы можем сделать, взять выборку (sample) и на ней построить нашу модель, предполагая, что если выборка достаточно велика, она сможет достоверно описать генсовокупность.

Отклонение прогнозного значения от фактического для «идеальной» линии принято называть ошибкой (error или true error).
$$ varepsilon = y-hat{y} $$
Отклонение прогноза от факта для выборочной модели (которую мы и строим) называют остатками (residuals или residual error).
$$ varepsilon = y-f(x) $$
В этом смысле среднеквадратическую ошибку (mean squared error, MSE) корректнее называть средними квадратичными остатками (mean squared residuals).
На практике ошибку и остатки нередко используют как взаимозаменяемые термины.
Уравнение множественной линейной регрессии
Посмотрим на уравнение множественной линейной регрессии.
$$ y = theta_0 + theta_1x_1 + theta_2x_2 + … + theta_jx_j + varepsilon $$
В отличие от простой линейной регрессии в данном случае у нас несколько признаков x (независимых переменных) и несколько коэффициентов $ theta $ («тета»).
Интерпретация результатов модели
Коэффициент $ theta_0 $ задает некоторый базовый уровень (baseline) при условии, что остальные коэффициенты равны нулю и зачастую не имеет смысла с точки зрения интерпретации модели (нужен лишь для того, что поднять линию на нужный уровень).
Параметры $ theta_1, theta_2, …, theta_n $ показывают изменение зависимой переменной при условии «неподвижности» остальных коэффициентов. Например, каждая дополнительная комната может увеличивать цену дома в 1.3 раза.
Переменная $ varepsilon $ (ошибка) представляет собой отклонение фактических данных от прогнозных. В этой переменной могут быть заложены две составляющие. Во-первых, она может включать вариативность целевой переменной, описанную другими (не включенными в нашу модель) признаками. Во-вторых, «улавливать» случайный шум, случайные колебания.
Категориальные признаки
Модель линейной регрессии может включать категориальные признаки. Продолжая пример с квартирой, предположим, что мы строим модель, в которой цена зависит от того, находится ли квартира в центре города или в спальном районе.
Перед этим переменную необходимо закодировать, создав, например, через Label Encoder признак «центр», который примет значение 1, если квартира в центре, и 0, если она находится в спальном районе.
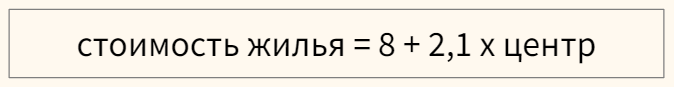
В модели, представленной выше, если квартира находится в центре (переменная «центр» равна единице), ее стоимость составит 10,1 миллиона рублей, если на окраине (переменная «центр» равна нулю) — лишь восемь.
Для категориального признака с множеством классов можно использовать one-hot encoding, если между классами признака отсутствует иерархия,
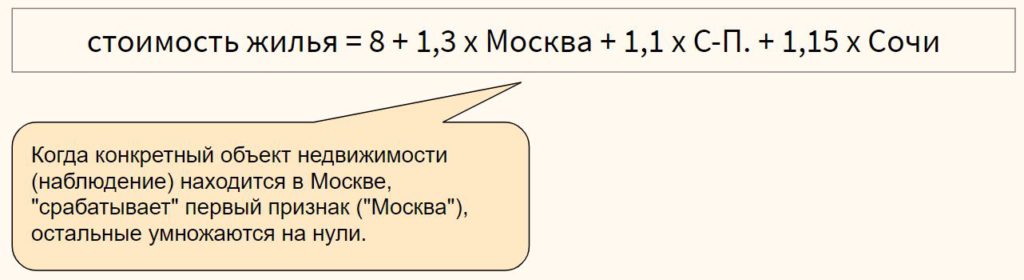
или, например, ordinal encoding в случае наличия иерархии классов в признаке

Выбросы в линейной регрессии
Как и коэффициент корреляции Пирсона, модель линейной регрессии чувствительна к выбросам (outliers), то есть наблюдениям, серьезно выпадающим из общей совокупности. Сравните рисунки ниже.

При наличии выброса (слева), линия регрессии имеет наклон и может использоваться для построения прогноза. Удалив это наблюдение (справа), линия регрессии становится горизонтальной и построение прогноза теряет смысл.
При этом различают два типа выбросов:
- горизонтальные выбросы или влиятельные точки (leverage points) — они сильно отклоняются от среднего по оси x; и
- вертикальные выбросы или просто выбросы (influential points) — отклоняются от среднего по оси y
Ключевое отличие заключается в том, что вертикальные выбросы влияют на наклон модели (изменяют ее коэффициенты), а горизонтальные — нет.
Сравним два графика.

На левом графике черная точка (leverage point) сильно отличается от остальных наблюдений, но наклон прямой линии регрессии с ее появлением не изменился. На правом графике, напротив, появление выброса (influential point) существенно изменяет наклон прямой.
На практике нас конечно больше интересуют influential points, потому что именно они существенно влияют на качество модели.
Если в простой линейной регрессии мы можем оценить leverage и influence наблюдения графически⧉, в многомерной модели это сделать сложнее. Можно использовать график остатков (об этом ниже) или применить один из уже известных нам методов выявления выбросов.
Про выявление leverage и infuential points можно почитать здесь⧉.
Допущения модели регрессии
Применение алгоритма линейной регрессии предполагает несколько допущений (assumptions) или условий, при выполнении которых мы можем говорить о качественно построенной модели.
1. Правильный выбор модели
Вначале важно убедиться, что данные можно аппроксимировать с помощью линейной модели (correct model specification).
Оценить распределение данных можно через график остатков (residuals plot), где по оси x отложен прогноз модели, а на оси y — сами остатки.

В отличие от простой линейной регрессии мы не используем точечную диаграмму X vs. y, потому что хотим оценить зависимость целевой переменной от всех признаков сразу.
Остатки модели относительно ее прогнозных значений должны быть распределены случайным образом без систематической составляющей (residuals do not follow a pattern).
- Если вы попробовали применить линейную модель с коэффициентами первой степени ($x_n^1$) и выявили некоторый паттерн в данных, можно попробовать полиномиальную или какую-либо еще функцию (об этом ниже).
- Кроме того, количественные признаки можно попробовать преобразовать таким образом, чтобы их можно было аппроксимировать прямой линией.
- Если ни то, ни другое не помогло, вероятно данные не стоит моделировать линейной регрессией.
Также замечу, что график остатков показывает выбросы в данных.

2. Нормальность распределения остатков
Среднее значение остатков должно быть равно нулю. Если это не так, и среднее значение меньше нуля (скажем –5), то это значит, что модель регулярно недооценивает (underestimates) фактические значения. В противном случае, если среднее больше нуля, переоценивает (overestimated).

Кроме того, предполагается, что остатки следуют нормальному распределению.
$$ varepsilon sim N(0, sigma) $$
Проверить нормальность остатков можно визуально с помощью гистограммы или рассмотренных ранее критериев нормальности распределения.
Если остатки не распределены нормально, мы не сможем провести статистические тесты на значимость коэффициентов или построить доверительные интервалы. Иначе говоря, мы не сможем сделать статистически значимый вывод о надежности нашей модели.
Причинами могут быть (1) выбросы в данных или (2) неверный выбор модели. Решением может быть, соответственно, исследование выбросов, выбор новой модели и преобразование как признаков, так и целевой переменной.
3. Гомоскедастичность остатков
Гомоскедастичность (homoscedasticity) или одинаковая изменчивость остатков предполагают, что дисперсия остатков не изменяется для различных наблюдений. Противоположное и нежелательное явление называется гетероскедастичностью (heteroscedasticity) или разной изменчивостью.

Гетероскедастичность остатков показывает, что модель ошибается сильнее при более высоких или более низких значениях признаков. Как следствие, если для разных прогнозов у нас разная погрешность, модель нельзя назвать надежной (robust).
Как правило, гетероскедастичность бывает изначально заложена в данные. Ее можно попробовать исправить через преобразование целевой переменной (например, логарифмирование)
4. Отсутствие мультиколлинеарности
Еще одним важным допущением является отсутствие мультиколлинеарности. Мультиколлинеарность (multicollinearity) — это корреляция между зависимыми переменными. Например, если мы предсказываем стоимость жилья по квадратным метрам и количеству комнат, то метры и комнаты логичным образом также будут коррелировать между собой.
Почему плохо, если такая корреляция существует? Базовое предположение линейной регрессии — каждый коэффициент $theta$ оказывает влияние на конечный результат при условии, что остальные коэффициенты постоянны. При мультиколлинеарности на целевую переменную оказывают эффект сразу несколько признаков, и мы не можем с точностью интерпретировать каждый из них.
Также говорят о том, что нужно стремиться к экономной (parsimonious) модели то есть такой модели, которая при наименьшем количестве признаков в наибольшей степени объясняет поведение целевой переменной.
Variance inflation factor
Расчет коэффициента
Variance inflation factor (VIF) или коэффициент увеличения дисперсии позволяет выявить корреляцию между признаками модели.
Принцип расчета VIF заключается в том, чтобы поочередно делать каждый из признаков целевой переменной и строить модель линейной регрессии на основе оставшихся независимых переменных. Например, если у нас есть три признака $x_1, x_2, x_3$, мы поочередно построим три модели линейной регрессии: $x_1 sim x_2 + x_3, x_2 sim x_1 + x_3$ и $x_3 sim x_1 + x_3$.
Обратите внимание на новый для нас формат записи целевой и зависимых переменных модели через символ $sim$.
Затем для каждой модели (то есть для каждого признака $x_1, x_2, x_3$) мы рассчитаем коэффициент детерминации $R^2$. Если он велик, значит данный признак можно объяснить с помощью других независимых переменных и имеется мультиколлинеарность. Если $R^2$ мал, то нельзя и мультиколлинеарность отсутствует.
Теперь рассчитаем VIF на основе $R^2$:
$$ VIF = frac{1}{1-R^2} $$
При таком способе расчета большой (близкий к единице) $R^2$ уменьшит знаменатель и существенно увеличит VIF, при небольшом коэффициенте детерминации коэффициент увеличения дисперсии наоборот уменьшится.
Замечу, что $1-R^2$ принято называть tolerance.
Другие способы выявления мультиколлинеарности
Для выявления корреляции между независимыми переменными можно использовать точечные диаграммы или корреляционные матрицы. При этом важно понимать, что в данном случае мы выявляем зависимость лишь между двумя признаками. Корреляцию множества признаков выявляет только коэффициент увеличения дисперсии.
Интерпретация VIF
VIF находится в диапазон от единицы до плюс бесконечности. Как правило, при интерпретации показателей variance inflation factor придерживаются следующих принципов:
- VIF = 1, между признаками отсутствует корреляция
- 1 < VIF $leq$ 5 — умеренная корреляция
- 5 < VIF $leq$ 10 — высокая корреляция
- Более 10 — очень высокая
После расчета VIF можно по одному удалять признаки с наибольшей корреляцией и смотреть как изменится этот показатель для оставшихся независимых переменных.
5. Отсутствие автокорреляции остатков
На занятии по временным рядам (time series), мы сказали, что автокорреляция (autocorrelation) — это корреляция между значениями одной и той же переменной в разные моменты времени.
Применительно к модели линейной регрессии автокорреляция целевой переменной (для простой линейной регрессии) и автокорреляция остатков, residuals autocorrelation (для модели множественной регрессии) означает, что результат или прогноз зависят не от признаков, а от самой этой целевой переменной. В такой ситуации признаки теряют свою значимость и применение модели регрессии становится нецелесообразным.
Причины автокорреляции остатков
Существует несколько возможных причин:
- Прогнозирование целевой переменной с высокой автокорреляцией (например, если мы моделируем цену акций с помощью других переменных, то можем ожидать высокую автокорреляцию остатков, поскольку цена акций как правило сильно зависит от времени)
- Удаление значимых признаков
- Другие причины
Автокорреляция первого порядка
Дадим формальное определение автокорреляции первого порядка (first order correlation), то есть автокорреляции с лагом 1.
$$ varepsilon_t = pvarepsilon_{t-1} + u_t $$
где $u_t$ — некоррелированная при различных t одинаково распределенная случайная величина (independent and identically distributed (i.i.d.) random variable), а $p$ — коэффициент автокорреляции, который находится в диапазоне $-1 < p < 1$. Чем он ближе к нулю, тем меньше зависимость остатка $varepsilon_t$ от остатка предыдущего периода $varepsilon_{t-1}$.
Такое уравнение также называется схемой Маркова первого порядка (Markov first-order scheme).
Обратите внимание, что для модели автокорреляции первого порядка коэффициент автокорреляции $p$ совпадает с коэффициентом авторегрессии AR(1) $varphi$.
$$ y_t = c + varphi cdot y_{t-1} $$
Разумеется, мы можем построить модель автокорреляции, например, третьего порядка.
$$ varepsilon_t = p_1varepsilon_{t-1} + p_2varepsilon_{t-2} + p_3varepsilon_{t-3} + u_t $$
Выявление автокорреляции остатков
Для выявления автокорреляции остатков можно использовать график последовательности и график остатков с лагом 1, график автокорреляционной функции или критерий Дарбина-Уотсона.
График последовательности и график остатков с лагом 1
На графике последовательности (sequence plot) по оси x откладывается время (или порядковый номер наблюдения), а по оси y — остатки модели. Кроме того, на графике остатков с лагом 1 (lag-1 plot) остатки (ось y) можно сравнить с этими же значениями, взятыми с лагом 1 (ось x).
Рассмотрим вариант положительной автокорреляции (positive autocorrelation) на графиках остатков типа (а) и (б).
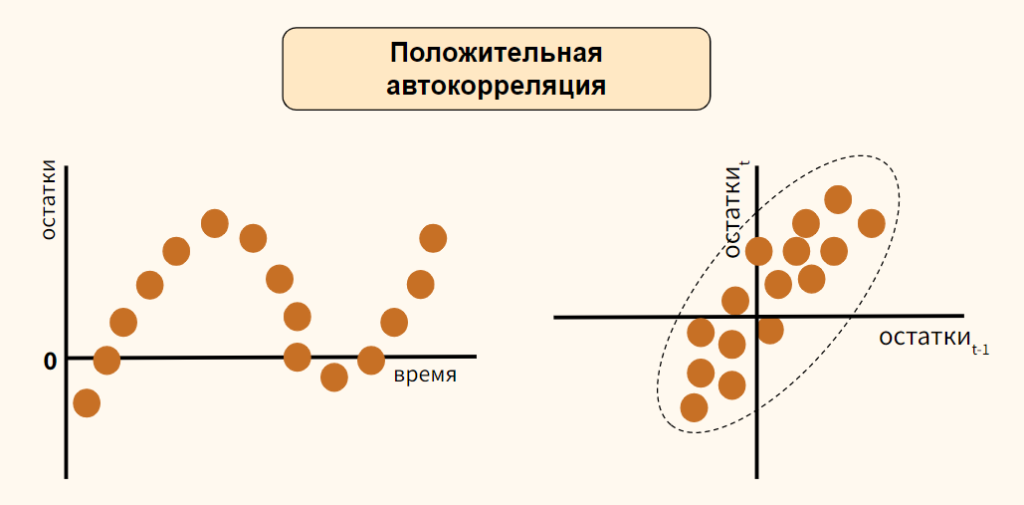
Как вы видите, при положительной автокорреляции в большинстве случаев, если одно наблюдение демонстрирует рост по отношению к предыдущему значению, то и последующее будет демонстрировать рост, и наоборот.
Теперь обратимся к отрицательной автокорреляции (negative autocorrelation).
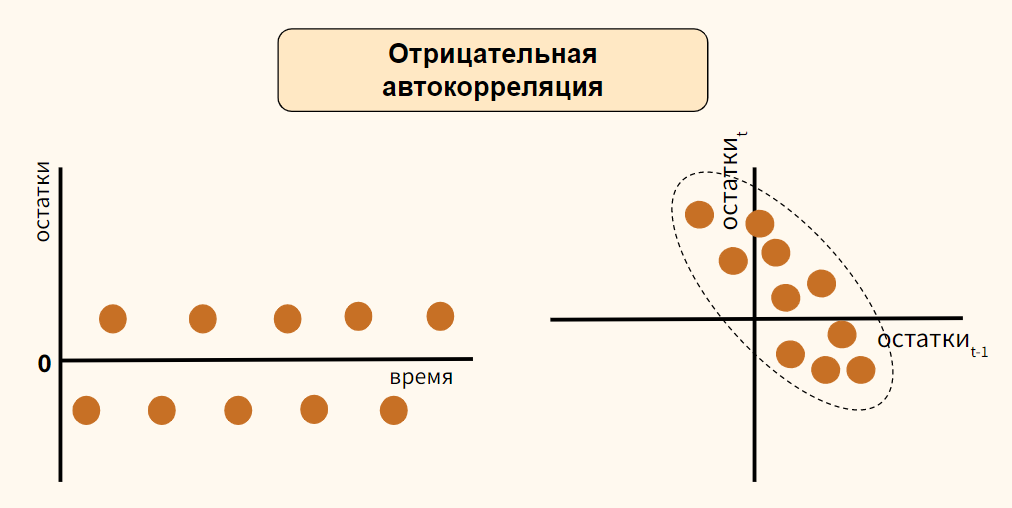
Здесь наоборот, если одно наблюдение демонстрирует рост показателя по отношению к предыдущему значению, то последующее наблюдение будет наоборот снижением. Опять же справедливо и обратное утверждение.
В случае отсутствия автокорреляции мы не должны увидеть на графиках какого-либо паттерна.

График автокорреляционной функции
Еще один способ выявить автокорреляцию — построить график автокорреляционной функции (autocorrelation function, ACF).

Напомню, такой график показывает автокорреляцию данных с этими же данными, взятыми с первым, вторым и последующими лагами.
Критерий Дарбина-Уотсона
Количественным выражением автокорреляции является критерий Дарбина-Уотсона (Durbin-Watson test). Этот критерий выявляет только автокорреляцию первого порядка.
- Нулевая гипотеза утверждает, что такая автокорреляция отсутствует ($p=0$),
- Альтернативная гипотеза соответственно утверждает, что присутствует
- Положительная ($p approx -1$) или
- Отрицательная ($p approx 1$) автокорреляция
Значение теста находится в диапазоне от 0 до 4.
- При показателе близком к двум можно говорить об отсутствии автокорреляции
- Приближение к четырем говорит о положительной автокорреляции
- К нулю, об отрицательной
Как избавиться от автокорреляции
Автокорреляцию можно преодолеть, добавив значимый признак в модель, выбрав иной тип модели (например, полиномиальную регрессию) или в целом перейдя к моделированию и прогнозированию временного ряда.
Рассмотрение этих методов находится за рамками сегодняшнего занятия. Перейдем к практике.