Питон использует кодировку терминала для печати, которая не имеет никакого отношения к sys.getdefaultencoding().
Иногда переменные окружения, определяющие язык, такие как LANGUAGE, LC_ALL,LC_CTYPE, LANG могут быть не установлены, например, в окружении используемом ssh, upstart, Salt, mod_wsgi, crontab, etc. В этом случае используется C (POSIX) локаль, которая использует ascii кодировку, что приводит к UnicodeEncodeError ошибке, т.к. русские буквы не представимы в ascii. В Python 3.7, реализована PEP 540: Forced UTF-8 Runtime Mode: utf-8 режим включается по умолчанию для «C» локали.
Серверные варианты Linux могут использовать C локаль по умолчанию. Настольные инсталяции дитрибутивов Linux обычно имеют utf-8 локаль.
Ошибка в вопросе связана с Питон багом: Python 3 raises Unicode errors with the C locale. Разработчики решили следовать ascii кодировке из C локали, даже если это ошибка в подавляющем большинстве случаев, но в Python 3.7 ситуация может улучшится в поведении по умолчанию, см. PEP 538 — Coercing the legacy C locale to a UTF-8 based locale.
Чтобы временно изменить используемую кодировку можно определить PYTHONIOENCODING:
$ PYTHONIOENCODING=utf-8 python your-script.py
В качестве более постоянного решения, нужно убедиться что используется utf-8 локаль в окружении, которое запускает python. Не обязательно русскую локаль устанавливать, чтобы напечатать русский текст. В этом достоинство Юникода, что можно работать с многими языками одновременно. Например, существует C.UTF-8 локаль.
Если locale -a не показывает ни одной utf-8 локали, то на Debian системах следует установить locales пакет и выбрать utf-8 локаль для использования:
root# aptitude install locales
root# dpkg-reconfigure locales
Индивидульно, каждый пользователь может настроить переменные окружения (см. Не сохраняются переменные XUBUNTU ), например:
export LANG=en_US.UTF-8
Используется первая доступная переменная из списка: LC_ALL, LC_CTYPE, LANG.
Может потребоваться сконфигурировать для работы с utf-8 индивидуальные программы, такие как xterm, Gnome Terminal, screen, отдельно.
- Posted on 03.09.201426.04.2018
Часто при попытке обработать данные с помощью различных функций языка Python, возникает ошибка вида:
UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xd0 in position 0: ordinal not in range(12)
Ошибка как правило возникает при использовании символов, отличных от латиницы и никак не описана в документации к ArcGIS.
Что является причиной ошибки? Существуют так называемые кодировки символов – это таблицы соответствия определенных символов и числовых кодов (байтов), которые хранятся в памяти компьютера. Один и тот же символ в разных кодировках может быть представлен разными числами, которые хранятся в разных форматах (двоичные, десятичные и т.д.). По мере развития операционных систем и прикладных программ кодировок становилось все больше и преобразования между ними представляли большую проблему для программистов. То есть, для того, чтобы программы могли корректно считывать текстовые данные, они сначала должны узнать какая кодировка используется для хранения этой информации. Одним из вариантов решения проблемы является использование Юникода (Unicode) – стандарта и набора кодировок, который вмещает в себя практически все возможные и часто используемые символы. В том числе иероглифы, символы арабского, кириллического алфавита, технические символы и многое другое.
В языке программирования Python все строковые переменные хранятся и обрабатываются исключительно в Юникоде. Это означает, что любая строка, которая будет обрабатываться средствами Python, должна быть конвертирована в Юникод. Стандартные инструменты ArcGIS обычно делают это автоматически. Если слой создан и редактировался средствами ArcGIS, то любые символы в таблицах будут по умолчанию храниться в Юникоде. Если исходные данные импортированы из внешнего источника, то не исключено, что они хранятся в одной из стандартных кодировок.
В каких случаях могут возникать ошибки? Наиболее распространенные варианты: при запуске скриптов, использующих модуль arcpy, при использовании Python в калькуляторе поля ArcGIS, при использовании выражений на Python для создания подписей на карте.
Как избежать проблем? Если у вас встречаются строки на русском языке или с кириллическими символами, перекодируйте их в юникод с помощью встроенного метода decode(). В качестве параметра нужно указать название кодировки исходной строки. Например:
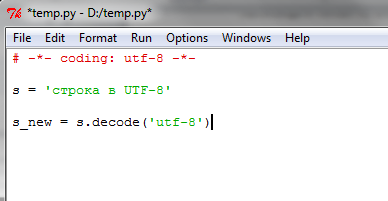
В данном случае переменной s присвоено строковое значение, содержащее символы в кодировке UTF-8. Далее это строковое значение (переменная) обрабатывается методом decode() и результат присваивается новой переменной s_new. Теперь строка закодирована с помощью Юникода, с которым работает Python, и дальнейшая ее обработка не будет вызывать ошибок типа UnicodeDecodeError.
Тот же самый метод можно использовать в калькуляторе полей ArcGIS. К примеру, если вы попробуете произвести заменить сокращение “ул” на слово “улица” с помощью метода replace(), то обнаружите, что он перестает работать в случае использования русских символов.
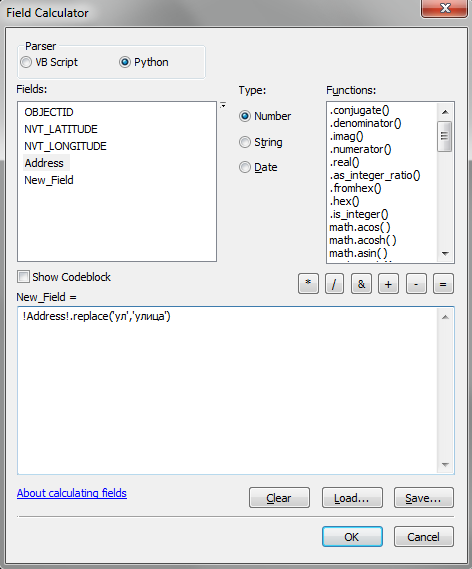
Происходит это потому, что в редакторе кода используется кодировка, которая определяется текущими региональными настройками Windows. Для русских символов это обычно кодировка ‘cp1251’. Для того, чтобы ошибка не возникала, нужно указать интерпретатору Python, что строки с кириллическими символами нужно перекодировать в юникод. Сделать это можно несколькими способами. Один способ, это использование метода decode(). Строка кода в таком случае будет выглядеть так:
!Address!.repalce(‘ул’.decode(‘cp1251’),’улица’.decode(‘cp1251’))
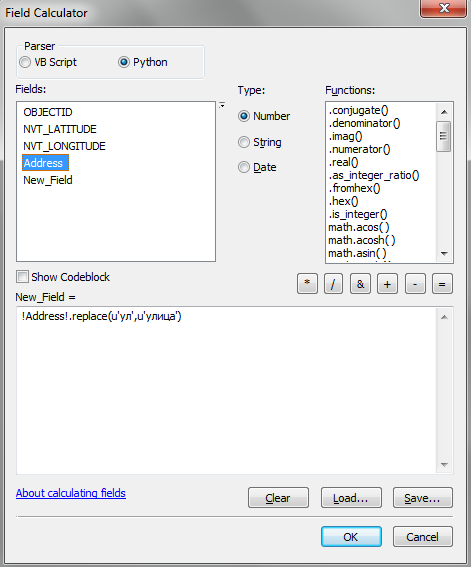
Кроме метода decode, есть метод unicode(). Для его использования вы можете указать перед текстовой строкой, что ее нужно конвертировать в Юникод. Краткая и наиболее удобная запись будет выглядеть так:
!Address!.repalce(u‘ул’,u’улица’)
То есть, перед строковым значением нужно поставить символ u. Такая форма записи является укороченным вариантом выражения unicode(‘строка’). Работающий вариант выражения в калькуляторе растров будет выглядеть следующим образом:
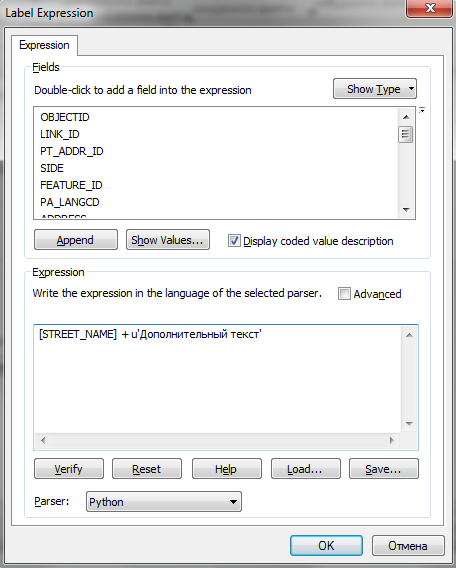
Проблемы с русскими символами возникают при использовании выражений на Python в инструментах создания подписей на карте. Решаются они аналогичным образом – с помощью указания интерпретатору кода, что данная строка должна быть перекодирована в Юникод.
Просмотров:
8 978
Метки
- ArcPy
- Python
Вот выдержка из документации к Питону 3.5.1:
Python » 3.5.1 Documentation » The Python Standard Library » 29. Python Runtime Services » sys
The character encoding is platform-dependent.
Under Windows, if the stream is interactive (that is, if
its isatty() method returns True), the console codepage is
used, otherwise the ANSI code page.Under other platforms, the locale encoding is used (see
locale.getpreferredencoding()).Under all platforms though, you can override this value
by setting the PYTHONIOENCODING environment variable
before starting Python.When interactive, standard streams are line-buffered. Otherwise,
they are block-buffered like regular text files. You can override
this value with the -u command-line option.
Далее, текущая кодировка консоли в Windows (для России это cp866), ну и строка для ANSI получаются вот так:
import ctypes
def ansi_encoding():
return 'cp'+str(ctypes.windll.kernel32.GetACP())
def console_output_encoding():
return 'cp'+str(ctypes.windll.kernel32.GetConsoleOutputCP())Еще может помочь значение sys.stdout.encoding и прочих подобных…
Сделать консоль Windows юникодной можно командой chcp 65001.
Теперь про Pycharm: он устанавливает environment переменную
PYTHONIOENCODING=utf-8
ну и консоль у него юникодная. Шрифт для консоли рекомендую DejaVu Sans Mono — единственный правильно выводит формулы из sympy.
Про то, что текст программы должен быть в utf-8, уже писали. Строчка про encoding не обязательно, но чтобы и питон 2 и питон 3 правильно выводили текст хоть на консоль, хоть в pycharm, программа должна выглядеть так:
# -*- encoding: utf-8 -*-
from __future__ import print_function
import sys
print(sys.version)
print(u'Здравствуй жопа, новый год!')Специфика работы в Python со строками на русском языке проистекает из того, что существует множество независимых кодировок для представления на компьютере букв, отличных от латинских. Попробуем ответить на вопросы, что такое кодировка символов, почему их так много, и как нам работать с русскими символами и строками в Python.
Вы, конечно, слышали, что все данные в компьютере представлены в цифровом виде. Компьютер в принципе хранит и обрабатывает только числа.
Однако человек работает с текстами, состоящими из букв, цифр, знаков пунктуации и некоторых специальных символов, например, @, #, $. Посмотрите внимательно на символы, из которых состоит текст на экране компьютера. Вы видите их потому, что компьютер, для передачи данных пользователю, представляет хранящиеся в нем числовые данные в виде символов.
И наоборот, для передачи данных в компьютер пользователь вводит символы с клавиатуры. Посмотрите на клавиатуру и найдите кнопки для ввода букв, цифр, знаков пунктуации и специальных символов %, ^ и &. Введенные вами с клавиатуры символы хранятся в памяти компьютера в виде чисел. Потому что ничего, кроме чисел, в компьютере не может храниться.
Поэтому каждый символ, отображаемый или принимаемый компьютером, кодируется некоторым числом. Ниже представлена таблица кодировки ASCII, которая использует числа от 0 до 127 для кодирования символов, включая латиницу (буквы латинского алфавита), цифры от 0 до 9, знаки пунктуации и специальные символы. Кроме того, коды от 0 до 31 кодируют специальные управляющие символы, такие как табуляция TAB, перевод строки LF и другие. Подробнее познакомиться с таблицей ASCII можно в Википедии.
| 0 | NULL | 32 | Space | 64 | @ | 96 | ` |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | “ | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | ‘ | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | TAB | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | — | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DC1 | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | ETB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | 124 | | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ~ |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
Все современные компьютеры и программы понимают и широко используют кодировку ASCII. Вот почему латиница является самым распространенным алфавитом на компьютерах, а англоязычные пользователи компьютеров, по большей части, лишены необходимости задумываться о кодировках символов и переключать раскладку клавиатуры.
Закодируем, используя приведенную выше таблицу кодов ASCII, слово “Hello”. Мы получим следующую последовательностью числовых кодов: 72, 101, 108, 108, 111. Проверить (и узнать) соответствие букв и кодов можно при помощи встроенных функций Python chr и ord. Функция chr принимает в качестве аргумента целочисленный код и возвращает соответствующий ему символ. Функция ord, наоборот, принимает символ и возвращает кодирующее его целое число:
>>> ord('H') 72 >>> ord('e') 101 >>> chr(101) 'e' >>> type(chr(101)) <type 'str'> >>>
Посмотрите еще раз на таблицу ASCII. Как видите, в ней нет букв русского алфавита. А также в ней греческих, арабских, японских и других букв и иероглифов, использующихся в разных языках Земли. Для кодирования букв и других символов, отсутствующих в таблице ASCII, используются числа больше 128. На следующем рисунке представлена кодировка cp866, использующая числа от 128 до 255 для кодирования символов кириллицы (букв русского алфавита) и специальных графических символов.
| 128 | А | 160 | а | 192 | └ | 224 | р |
| 129 | Б | 161 | б | 193 | ┴ | 225 | с |
| 130 | В | 162 | в | 194 | ┬ | 226 | т |
| 131 | Г | 163 | г | 195 | ├ | 227 | у |
| 132 | Д | 164 | д | 196 | ─ | 228 | ф |
| 133 | Е | 165 | е | 197 | ┼ | 229 | х |
| 134 | Ж | 166 | ж | 198 | ╞ | 230 | ц |
| 135 | З | 167 | з | 199 | ╟ | 231 | ч |
| 136 | И | 168 | и | 200 | ╚ | 232 | ш |
| 137 | Й | 169 | й | 201 | ╔ | 233 | щ |
| 138 | К | 170 | к | 202 | ╩ | 234 | ъ |
| 139 | Л | 171 | л | 203 | ╦ | 235 | ы |
| 140 | М | 172 | м | 204 | ╠ | 236 | ь |
| 141 | Н | 173 | н | 205 | ═ | 237 | э |
| 142 | О | 174 | о | 206 | ╬ | 238 | ю |
| 143 | П | 175 | п | 207 | ╧ | 239 | я |
| 144 | Р | 176 | ░ | 208 | ╨ | 240 | Ё |
| 145 | С | 177 | ▒ | 209 | ╤ | 241 | ё |
| 146 | Т | 178 | ▓ | 210 | ╥ | 242 | Є |
| 147 | У | 179 | │ | 211 | ╙ | 243 | є |
| 148 | Ф | 180 | ┤ | 212 | ╘ | 244 | Ї |
| 149 | Х | 181 | ╡ | 213 | ╒ | 245 | ї |
| 150 | Ц | 182 | ╢ | 214 | ╓ | 246 | Ў |
| 151 | Ч | 183 | ╖ | 215 | ╫ | 247 | ў |
| 152 | Ш | 184 | ╕ | 216 | ╪ | 248 | ° |
| 153 | Щ | 185 | ╣ | 217 | ┘ | 249 | ∙ |
| 154 | Ъ | 186 | ║ | 218 | ┌ | 250 | · |
| 155 | Ы | 187 | ╗ | 219 | █ | 251 | √ |
| 156 | Ь | 188 | ╝ | 220 | ▄ | 252 | № |
| 157 | Э | 189 | ╜ | 221 | ▌ | 253 | ¤ |
| 158 | Ю | 190 | ╛ | 222 | ▐ | 254 | ■ |
| 159 | Я | 191 | ┐ | 223 | ▀ | 255 |
Кодировка cp866 использовалась в операционной системе MS DOS и теперь по умолчанию используется в консоли MS Windows. Буквы cp в названии этой и других кодировок — сокращение от code page (англ.: кодовая страница).
Случилось так, что числа от 128 до 255 стали использоваться в разных странах для кодирования букв алфавитов разных языков, а не только русского. Но даже если вести речь только о кириллице, то, кроме кодировки cp866, существуют несколько других кодировок, которые иначе сопоставляют буквы кириллицы кодам в диапазоне от 128 до 255. В качестве примера еще одной кириллической кодировки ниже приведена таблица кодов cp1251, используемая графическими приложениями в ОС MS Windows, такими как Блокнот, MS Office и другими.
| 128 | Ђ | 160 | 192 | А | 224 | а | |
| 129 | Ѓ | 161 | Ў | 193 | Б | 225 | б |
| 130 | ‚ | 162 | ў | 194 | В | 226 | в |
| 131 | ѓ | 163 | Ј | 195 | Г | 227 | г |
| 132 | „ | 164 | ¤ | 196 | Д | 228 | д |
| 133 | … | 165 | Ґ | 197 | Е | 229 | е |
| 134 | † | 166 | ¦ | 198 | Ж | 230 | ж |
| 135 | ‡ | 167 | § | 199 | З | 231 | з |
| 136 | € | 168 | Ё | 200 | И | 232 | и |
| 137 | ‰ | 169 | © | 201 | Й | 233 | й |
| 138 | Љ | 170 | Є | 202 | К | 234 | к |
| 139 | ‹ | 171 | « | 203 | Л | 235 | л |
| 140 | Њ | 172 | ¬ | 204 | М | 236 | м |
| 141 | Ќ | 173 | | 205 | Н | 237 | н |
| 142 | Ћ | 174 | ® | 206 | О | 238 | о |
| 143 | Џ | 175 | Ї | 207 | П | 239 | п |
| 144 | ђ | 176 | ° | 208 | Р | 240 | р |
| 145 | ‘ | 177 | ± | 209 | С | 241 | с |
| 146 | ’ | 178 | І | 210 | Т | 242 | т |
| 147 | “ | 179 | і | 211 | У | 243 | у |
| 148 | ” | 180 | ґ | 212 | Ф | 244 | ф |
| 149 | • | 181 | µ | 213 | Х | 245 | х |
| 150 | – | 182 | ¶ | 214 | Ц | 246 | ц |
| 151 | — | 183 | · | 215 | Ч | 247 | ч |
| 152 | | 184 | ё | 216 | Ш | 248 | ш |
| 153 | ™ | 185 | № | 217 | Щ | 249 | щ |
| 154 | љ | 186 | є | 218 | Ъ | 250 | ъ |
| 155 | › | 187 | » | 219 | Ы | 251 | ы |
| 156 | њ | 188 | ј | 220 | Ь | 252 | ь |
| 157 | ќ | 189 | Ѕ | 221 | Э | 253 | э |
| 158 | ћ | 190 | ѕ | 222 | Ю | 254 | ю |
| 159 | џ | 191 | ї | 223 | Я | 255 | я |
Из сказанного можно сделать вывод о том, что для правильного отображения символов на экране компьютеру необходимо знать, в какой кодировке представлены данные, которые нужно отобразить. Например, пускай нам дана следующая последовательность кодов: 232, 227, 226. Если принять, что это символы, представленные в кодировке cp866, то мы получим слово “шут”. А если принять, что это символы, представленные в кодировке cp1251, то мы получим слово “игв”. А в греческой кодировке cp1253 эти же коды дадут нам “θγβ”! На сегодняшний день существуют десятки кодировок, сопоставляющих числовые коды от 128 до 255 различным символам!
Если вы запускаете интерпретатор Python в консоли русскоязычной Windows, то Python ожидает, что строки используют кодировку cp866. Давайте проведем небольшое исследование для того, чтобы подтвердить или опровергнуть это утверждение. Воспользуемся функцией ord для получения числовых кодов нескольких русских букв, введенных с клавиатуры, и таблицей кодов cp866, приведенной выше, чтобы убедиться, что функция ord вернула нам коды букв в кодировке cp866:
>>> print ord('э'), ord('ю'), ord('я') 237 238 239 >>>
А функция chr выведет буквы русского алфавита, соответствующие кодам, взятым нами из таблицы cp866:
>>> print chr(128), chr(129), chr(130) А Б В >>>
Итак, русские буквы, которые мы вводим с клавиатуры при работе в интерактивном режиме Python, представлены в кодировке cp866. Работая в интерактивном режиме Python, мы можем смело использовать русские буквы в строковых значениях:
>>> name = 'мир' >>> print 'Привет', name Привет мир >>>
Таким образом, все примеры работы в интерактивном режиме, приведенные в книге, можно безболезненно русифицировать, заменяя английские слова и предложения на русские.
Однако, для русификации скриптов Python, сохраненных в файлах, нам осталось сделать еще один шаг. Нам нужно ответить на вопрос, в какой кодировке сохранен наш скрипт в файле? Это зависит от текстового редактора, в котором был написан и сохранен скрипт, и от того, была ли явно указана кодировка при сохранении файла.
Как было сказано выше, Блокнот, или Notepad, простой текстовый редактор, имеющийся в ОС Windows, использует кириллическую кодировку cp1251, а консоль Windows, или окно для работы с командной строкой, по умолчанию использует кириллическую кодировку cp866. Это очень неудобно для русскоязычных пользователей.
Например, создайте в Блокноте файл C:russian.txt с единственной строкой:
А теперь откройте окно с командной строкой и выведите содержимое этого файла на экран:
C:>type russian.txt ╧ЁштхЄ ьшЁ!
Что это за кракозябры?
Если вы отыщете эти символы, один за одним, в приведенной выше таблице кодов cp866, то получится последовательность кодов: 207, 240, 232, 226, 229, 242, 32, 252, 248, 240, 33. (Пробел и восклицательный знак имеют коды из диапазона 0 — 127 и кодируются таблицей ASCII.) Теперь переведите эти коды в символы, используя таблицу кодировки cp1251, и вы получите “Привет мир!” Кракозябры в консольном окне мы видим потому, что Блокнот сохранил файл в кодировке cp1251, а консольное окно считает, что коды от 128 до 255 представляют символы из кодировки cp866!
Преодолеть эту проблему можно с помощью консольной команды chcp. Команда chcp без параметров показывает, какая кодировка является текущей:
C:>chcp Active code page: 866
А в качестве параметра команда chcp принимает номер кодировки, которую необходимо сделать текущей. Если с ее помощью изменить текущую кодировку консольного окна на cp1251, то мы, наконец, сможем увидеть содержимое файла russian.txt неискаженным:
C:>chcp 1251 Active code page: 1251 C:>type russian.txt Привет мир!
Скрипт на Python является текстовым файлом точно так же, как файл russian.txt, с которым мы экспериментировали. И если создать и сохранить скрипт, использующий русские буквы, в Блокноте, то скрипт будет сохранен в кодировке cp1251. Давайте откроем в Блокноте файл russian.txt и сохраним его как russian.py, слегка изменив его содержимое:
Теперь это файл с очень простым скриптом на языке Python. Выполним его:
C:>python russian.py File "russian.py", line 1 SyntaxError: Non-ASCII character 'xcf' in file russian.py on line 1, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
Вместо ожидаемого приветствия на русском языке Python вывел сообщение об ошибке. Сообщение говорит о том, что в 1-ой строке файла встретился символ, не являющийся символом ASCII, а кодировка не объявлена. Очевидно, что символы, не являющиеся символами ASCII, в нашем файле — это русские буквы. Но что же в этом плохого?
Дело в том, что Python по умолчанию ожидает, что скрипты, переданные ему для выполнения, имеют кодировку ASCII, то есть, содержат символы с кодами в диапазоне 0 — 127. Для всех, кто использует в своих скриптах только латиницу, цифры и другие символы ASCII, это работает прекрасно. Пользователи, использующие в своих программах строковые значения и комментарии на английском языке, чувствуют себя совершенно комфортно в этой ситуации и, по большей части, не подозревают о проблеме, с которой мы только что столкнулись.
Чтобы сообщить Python о том, что скрипт использует кодировку, отличную от ASCII, нужно в начале файла поместить комментарий специального вида, содержащий информацию о кодировке файла. Для скрипта russian.py, созданного в Блокноте, укажем кодировку cp1251, после чего скрипт будет выглядеть так:
# -*- coding: cp1251 -*- print 'Привет мир!'
После этого сможем успешно выполнить скрипт в консольном окне Windows (только не забудьте установить текущую кодировку командой chcp 1251):
C:>chcp 1251 Active code page: 1251 C:>python russian.py Привет мир!
Итак, для того, чтобы скрипт Python заговорил по-русски в консольном окне Windows, необходимо:
-
Указать в начале скрипта кодировку, которую использует файл. Например:
-
Установить в консольном окне Windows кодировку, которую использует выполняемый скрипт. Например:
C:> chcp 1251 Active code page: 1251
В общем случае, скрипт с русскими строками и комментариями может использовать любую из кириллических кодировок, в частности, любую из рассмотренных выше, cp1251 или cp866. Важно, чтобы объявленная в начале файла кодировка была та самая, в которой сохранен файл.
Если скрипт использует кодировку cp866, то в консольном окне русскоязычной Windows не нужно предпринимать никаких специальных действий перед выполнением скрипта, ведь cp866 — кодировка, установленная в консоли по умолчанию. Но если скрипт использует кодировку cp1251, то перед его выполнением в консоли нужно установить текущую кодировку командой chcp 1251.
|
-19 / 0 / 0 Регистрация: 13.04.2013 Сообщений: 26 |
|
|
1 |
|
|
13.02.2022, 22:31. Показов 12617. Ответов 9
Питон в Visual-studio 2022 не признаёт кирилицу даже внутри кавычек. Можно ли его уговорить этого не делать?
0 |

|
16 / 16 / 2 Регистрация: 23.02.2012 Сообщений: 132 |
|
|
14.02.2022, 12:52 |
2 |
|
Попробуй в начале файла написать:
0 |
|
-19 / 0 / 0 Регистрация: 13.04.2013 Сообщений: 26 |
|
|
14.02.2022, 18:04 [ТС] |
3 |
|
SyntaxError: (unicode error) ‘utf-8’ codec can’t decode byte 0xea in position 0: invalid continuation byte
0 |
|
16 / 16 / 2 Регистрация: 23.02.2012 Сообщений: 132 |
|
|
14.02.2022, 20:27 |
4 |
|
У меня во всех исходниках в проекте первой строкой прописано И все ошибки исчезли. Нужно, что бы эта строка была во всех файлах проекта.
0 |
|
5407 / 3831 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
|
|
14.02.2022, 20:37 |
5 |
|
# coding=windows-1251 Эта декларация давно уже не нужна. Степень подробности с какой топикстартер объясняет свою проблему просто впечатляет.
1 |

|
16 / 16 / 2 Регистрация: 23.02.2012 Сообщений: 132 |
|
|
14.02.2022, 21:23 |
6 |
|
Давай тогда свое решение, как VS 2022 заставить работать без этой декларации. По умолчанию VS работает в win 1251. Дал простое решение проблемы. Чем понты кидать — дай простое решение проблемы. Или ума не хватит? Добавлено через 8 минут
0 |
|
5407 / 3831 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
|
|
14.02.2022, 22:58 |
7 |
|
Или ума не хватит? Я не знаю о чьем уме ты говоришь. Вероятно, что о своем.
По умолчанию VS работает в win 1251 Что такое VS? VS Code или MSVS? В любом случае это ложь: Также в документации MSVS написано: Про VS Code:»Кодировка VS Code по умолчанию — UTF-8 без метки порядка байтов.« P.S. C тех пор как в Python официальная кодировка исходников объявлена как utf-8, использование локальных кодовых страниц для кодирования исходников считается bad practice.
0 |
|
16 / 16 / 2 Регистрация: 23.02.2012 Сообщений: 132 |
|
|
15.02.2022, 07:16 |
8 |
|
Ты запусти MSVS 2022 и создай проект из нескольких исходников. А потом пиши тут свои догадки. Я перед тем, как ответить челу с его проблемой, которая прекрасно описана, но некоторым особам тяжело вникать, пока им по полочкам не разложишь, проверил. Файлы создаются в 1251 кодировке. Добавлено через 10 минут
Также в документации MSVS написано: Не каждый начинающий знает, где прописывать параметры MSVS. Был дан наипростейший способ обойти проблему.
P.S. C тех пор как в Python официальная кодировка исходников объявлена как utf-8, использование локальных кодовых страниц для кодирования исходников считается bad practice. А вот тут я тебя забыл спросить.
Я не знаю о чьем уме ты говоришь. Вероятно, что о своем. Ты видимо зациклен на своем utf-8. Флаг тебе в руки. p.s. Как вы задолбали, диванные спецы. Стырят старый API, под себя сделают и звезды. Можно сказать, сами все сделали.
0 |
|
5407 / 3831 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
|
|
15.02.2022, 14:20 |
9 |
|
Ты видимо зациклен на своем utf-8. Он не мой. Его придумал Роб Пайк. И теперь его использует весь мир. Но, ты, видимо не в курсе.
Не каждый начинающий знает, где прописывать параметры MSVS. Не смеши меня. Таким начинающим сначала нужно батники писать научиться прежде чем в программирование лезть.
А вот тут я тебя забыл спросить. В следующий раз не забудь. ОК? Добавлено через 1 минуту
диванные спецы. С Ты опять про себя дорогой? Не слишком ли часто?
0 |
|
5407 / 3831 / 1214 Регистрация: 28.10.2013 Сообщений: 9,554 Записей в блоге: 1 |
|
|
15.02.2022, 15:37 |
10 |
|
Питон в Visual-studio 2022 не признаёт кирилицу даже внутри кавычек Признает.
И не надо людям голову морочить. Visual Studio создает файлы исходного кода в кодировке локали текущего пользователя. Это не есть хорошо, ну да ладно. К тому же файл всегда можно пересохранить на utf-8 (меню сохранить как -> сохранить с кодировкой-> выбрать utf-8 без BOM). И тогда никаких проблем с не ASCII символами не будет.
0 |