Во время работы вашего приложения часто будут возникать исключительные ситуации. Когда у вас простое консольное приложение, то все просто – ошибка выводится в консоль. Но как быть с веб-приложением?
Допустим у пользователя отсутсвует доступ, или он передал некорректные данные. Лучшим вариантом будет в ответ на такие ситуации, отправлять пользователю сообщения с описанием ошибки. Это позволит клиенту вашего API скорректировать свой запрос.
В данной статье разберём основные возможности, которые предоставляет SpringBoot для решения этой задачи и на простых примерах посмотрим как всё работает.
@ExceptionHandler
@ExceptionHandler позволяет обрабатывать исключения на уровне отдельного контроллера. Для этого достаточно объявить метод в контроллере, в котором будет содержаться вся логика обработки нужного исключения, и пометить его аннотацией.
Для примера у нас будет сущность Person, бизнес сервис к ней и контроллер. Контроллер имеет один эндпойнт, который возвращает пользователя по логину. Рассмотрим классы нашего приложения:
Сущность Person:
package dev.struchkov.general.sort;
import java.text.MessageFormat;
public class Person {
private String lastName;
private String firstName;
private Integer age;
//getters and setters
}Контроллер PersonController:
package dev.struchkov.example.controlleradvice.controller;
import dev.struchkov.example.controlleradvice.domain.Person;
import dev.struchkov.example.controlleradvice.service.PersonService;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.UUID;
@Slf4j
@RestController
@RequestMapping("api/person")
@RequiredArgsConstructor
public class PersonController {
private final PersonService personService;
@GetMapping
public ResponseEntity<Person> getByLogin(@RequestParam("login") String login) {
return ResponseEntity.ok(personService.getByLoginOrThrown(login));
}
@GetMapping("{id}")
public ResponseEntity<Person> getById(@PathVariable("id") UUID id) {
return ResponseEntity.ok(personService.getById(id).orElseThrow());
}
}И наконец PersonService, который будет возвращать исключение NotFoundException, если пользователя не будет в мапе persons.
package dev.struchkov.example.controlleradvice.service;
import dev.struchkov.example.controlleradvice.domain.Person;
import dev.struchkov.example.controlleradvice.exception.NotFoundException;
import lombok.NonNull;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.Map;
import java.util.Optional;
import java.util.UUID;
@Service
public class PersonService {
private final Map<UUID, Person> people = new HashMap<>();
public PersonService() {
final UUID komarId = UUID.randomUUID();
people.put(komarId, new Person(komarId, "komar", "Алексей", "ertyuiop"));
}
public Person getByLoginOrThrown(@NonNull String login) {
return people.values().stream()
.filter(person -> person.getLogin().equals(login))
.findFirst()
.orElseThrow(() -> new NotFoundException("Пользователь не найден"));
}
public Optional<Person> getById(@NonNull UUID id) {
return Optional.ofNullable(people.get(id));
}
}Перед тем, как проверить работу исключения, давайте посмотрим на успешную работу эндпойнта.
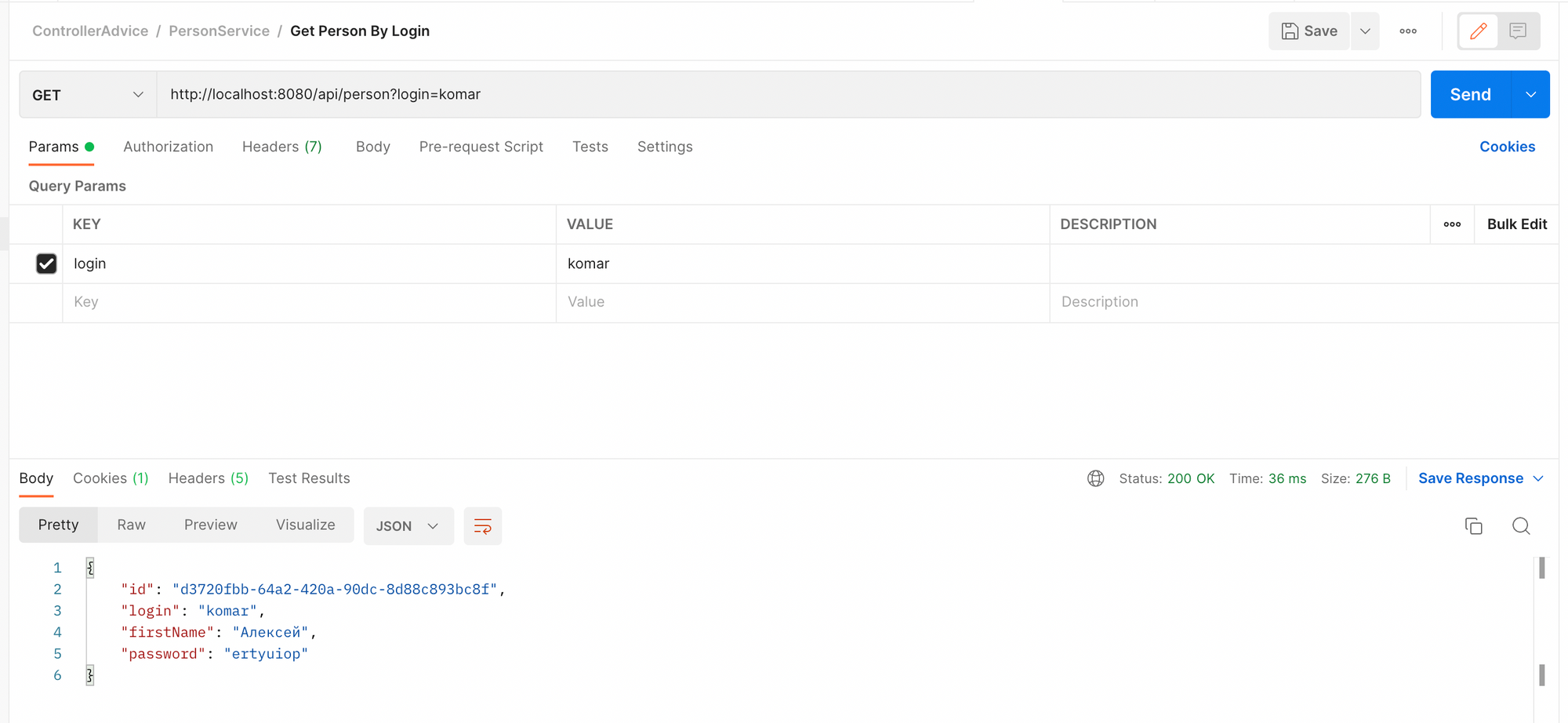
Все отлично. Нам в ответ пришел код 200, а в теле ответа пришел JSON нашей сущности. А теперь мы отправим запрос с логином пользователя, которого у нас нет. Посмотрим, что сделает Spring по умолчанию.
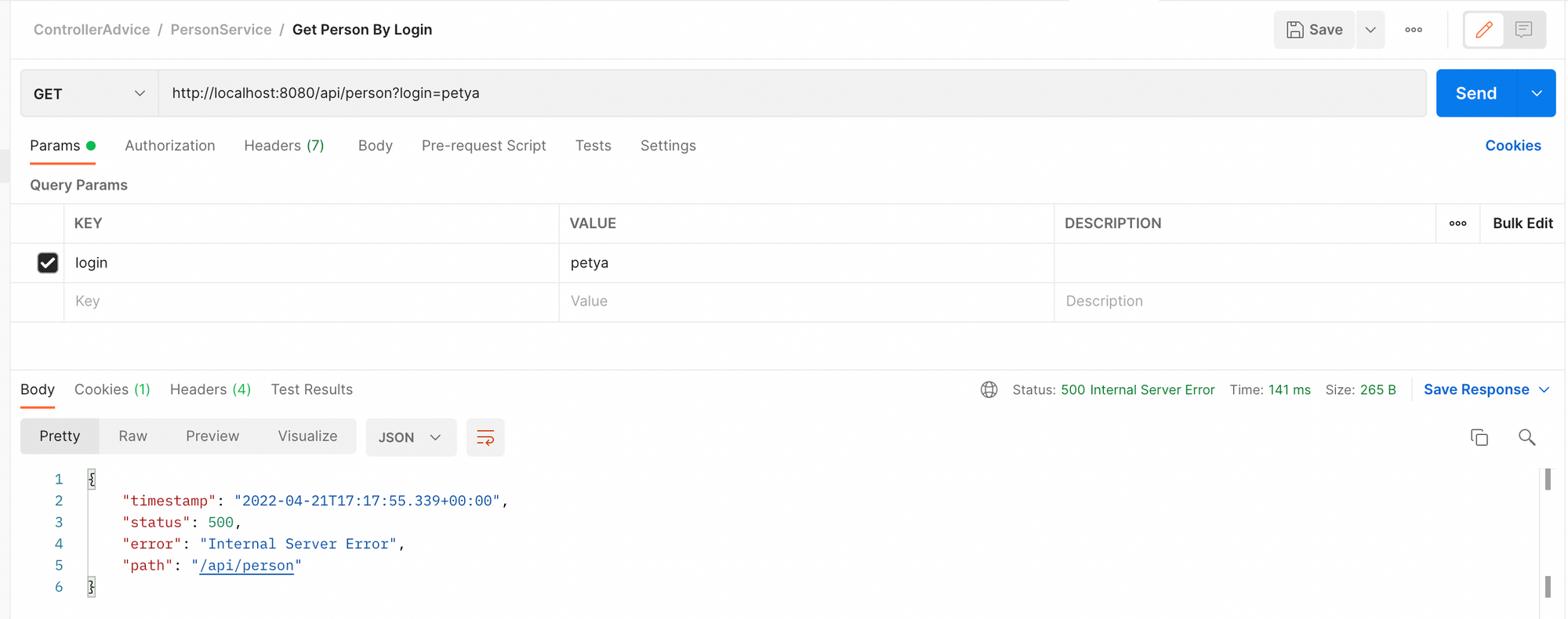
Обратите внимание, ошибка 500 – это стандартный ответ Spring на возникновение любого неизвестного исключения. Также исключение было выведено в консоль.

Как я уже говорил, отличным решением будет сообщить пользователю, что он делает не так. Для этого добавляем метод с аннотацией @ExceptionHandler, который будет перехватывать исключение и отправлять понятный ответ пользователю.
@RequestMapping("api/person")
@RequiredArgsConstructor
public class PersonController {
private final PersonService personService;
@GetMapping
public ResponseEntity<Person> getByLogin(@RequestParam("login") String login) {
return ResponseEntity.ok(personService.getByLoginOrThrown(login));
}
@ExceptionHandler(NotFoundException.class)
public ResponseEntity<ErrorMessage> handleException(NotFoundException exception) {
return ResponseEntity
.status(HttpStatus.NOT_FOUND)
.body(new ErrorMessage(exception.getMessage()));
}
}Вызываем повторно наш метод и видим, что мы стали получать понятное описание ошибки.
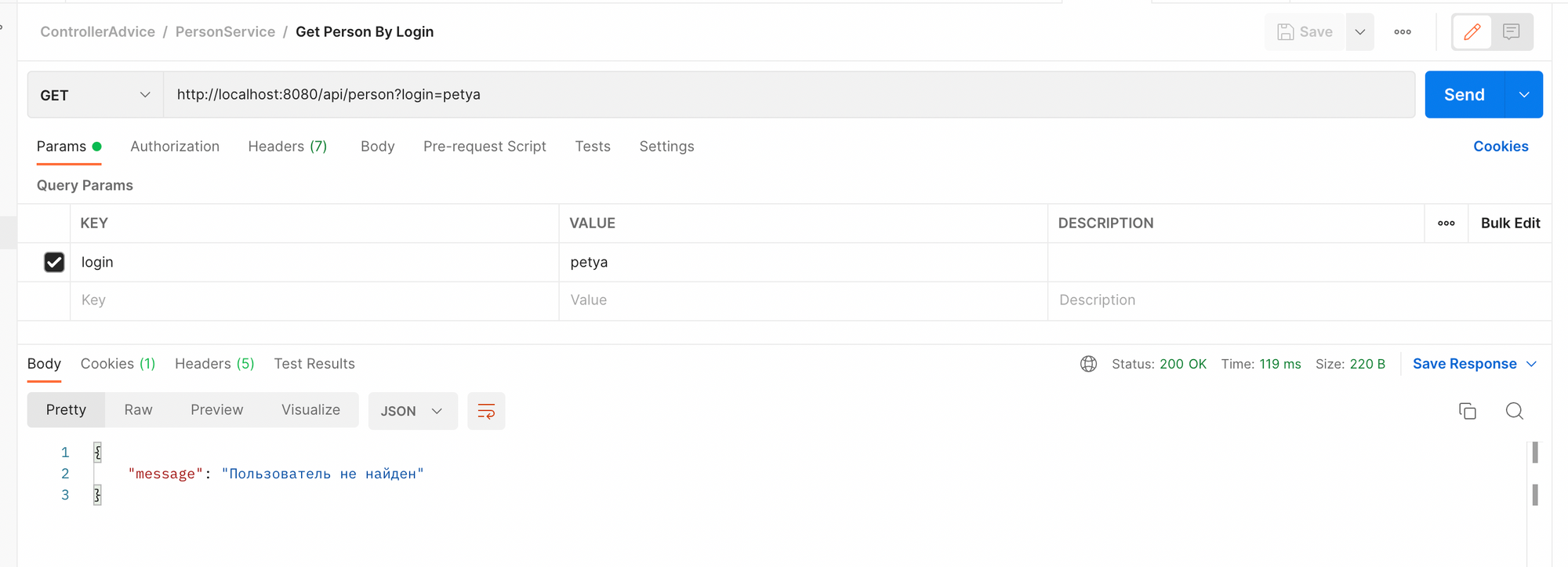
Но теперь вернулся 200 http код, куда корректнее вернуть 404 код.
Однако некоторые разработчики предпочитают возвращать объект, вместо ResponseEntity<T>. Тогда вам необходимо воспользоваться аннотацией @ResponseStatus.
import org.springframework.web.bind.annotation.ResponseStatus;
@ResponseStatus(HttpStatus.NOT_FOUND)
@ExceptionHandler(NotFoundException.class)
public ErrorMessage handleException(NotFoundException exception) {
return new ErrorMessage(exception.getMessage());
}Если попробовать совместить ResponseEntity<T> и @ResponseStatus, http-код будет взят из ResponseEntity<T>.
Главный недостаток @ExceptionHandler в том, что он определяется для каждого контроллера отдельно. Обычно намного проще обрабатывать все исключения в одном месте.
Хотя это ограничение можно обойти если @ExceptionHandler будет определен в базовом классе, от которого будут наследоваться все контроллеры в приложении, но такой подход не всегда возможен, особенно если перед нами старое приложение с большим количеством легаси.
HandlerExceptionResolver
Как мы знаем в программировании магии нет, какой механизм задействуется, чтобы перехватывать исключения?
Интерфейс HandlerExceptionResolver является общим для обработчиков исключений в Spring. Все исключений выброшенные в приложении будут обработаны одним из подклассов HandlerExceptionResolver. Можно сделать как свою собственную реализацию данного интерфейса, так и использовать существующие реализации, которые предоставляет нам Spring из коробки.
Давайте разберем стандартные для начала:
ExceptionHandlerExceptionResolver — этот резолвер является частью механизма обработки исключений помеченных аннотацией @ExceptionHandler, которую мы рассмотрели выше.
DefaultHandlerExceptionResolver — используется для обработки стандартных исключений Spring и устанавливает соответствующий код ответа, в зависимости от типа исключения:
| Exception | HTTP Status Code |
|---|---|
| BindException | 400 (Bad Request) |
| ConversionNotSupportedException | 500 (Internal Server Error) |
| HttpMediaTypeNotAcceptableException | 406 (Not Acceptable) |
| HttpMediaTypeNotSupportedException | 415 (Unsupported Media Type) |
| HttpMessageNotReadableException | 400 (Bad Request) |
| HttpMessageNotWritableException | 500 (Internal Server Error) |
| HttpRequestMethodNotSupportedException | 405 (Method Not Allowed) |
| MethodArgumentNotValidException | 400 (Bad Request) |
| MissingServletRequestParameterException | 400 (Bad Request) |
| MissingServletRequestPartException | 400 (Bad Request) |
| NoSuchRequestHandlingMethodException | 404 (Not Found) |
| TypeMismatchException | 400 (Bad Request) |
Мы можем создать собственный HandlerExceptionResolver. Назовем его CustomExceptionResolver и вот как он будет выглядеть:
package dev.struchkov.example.controlleradvice.service;
import dev.struchkov.example.controlleradvice.exception.NotFoundException;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.ModelAndView;
import org.springframework.web.servlet.handler.AbstractHandlerExceptionResolver;
import org.springframework.web.servlet.view.json.MappingJackson2JsonView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@Component
public class CustomExceptionResolver extends AbstractHandlerExceptionResolver {
@Override
protected ModelAndView doResolveException(HttpServletRequest request, HttpServletResponse response, Object handler, Exception e) {
final ModelAndView modelAndView = new ModelAndView(new MappingJackson2JsonView());
if (e instanceof NotFoundException) {
modelAndView.setStatus(HttpStatus.NOT_FOUND);
modelAndView.addObject("message", "Пользователь не найден");
return modelAndView;
}
modelAndView.setStatus(HttpStatus.INTERNAL_SERVER_ERROR);
modelAndView.addObject("message", "При выполнении запроса произошла ошибка");
return modelAndView;
}
}
Мы создаем объект представления – ModelAndView, который будет отправлен пользователю, и заполняем его. Для этого проверяем тип исключения, после чего добавляем в представление сообщение о конкретной ошибке и возвращаем представление из метода. Если ошибка имеет какой-то другой тип, который мы не предусмотрели в этом обработчике, то мы отправляем сообщение об ошибке при выполнении запроса.
Так как мы пометили этот класс аннотацией @Component, Spring сам найдет и внедрит наш резолвер куда нужно. Посмотрим, как Spring хранит эти резолверы в классе DispatcherServlet.
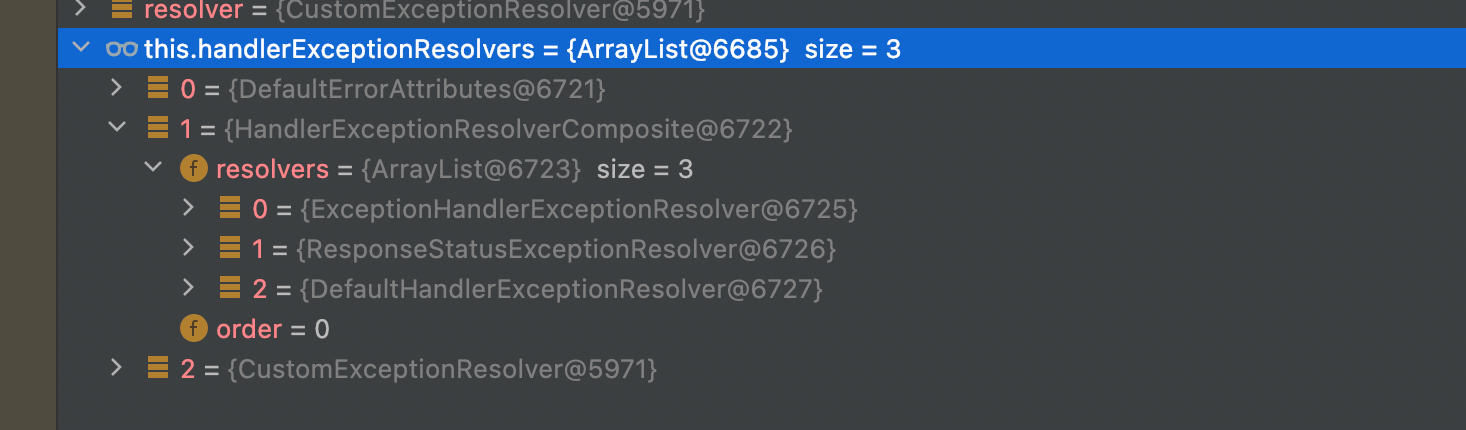
Все резолверы хранятся в обычном ArrayList и в случае исключнеия вызываются по порядку, при этом наш резолвер оказался последним. Таким образом, если непосредственно в контроллере окажется @ExceptionHandler обработчик, то наш кастомный резолвер не будет вызван, так как обработка будет выполнена в ExceptionHandlerExceptionResolver.
Важное замечание. У меня не получилось перехватить здесь ни одно Spring исключение, например MethodArgumentTypeMismatchException, которое возникает если передавать неверный тип для аргументов @RequestParam.
Этот способ был показан больше для образовательных целей, чтобы показать в общих чертах, как работает этот механизм. Не стоит использовать этот способ, так как есть вариант намного удобнее.
@RestControllerAdvice
Исключения возникают в разных сервисах приложения, но удобнее всего обрабатывать все исключения в каком-то одном месте. Именно для этого в SpringBoot предназначены аннотации @ControllerAdvice и @RestControllerAdvice. В статье мы рассмотрим @RestControllerAdvice, так как у нас REST API.
На самом деле все довольно просто. Мы берем методы помеченные аннотацией @ExceptionHandler, которые у нас были в контроллерах и переносим в отдельный класс аннотированный @RestControllerAdvice.
package dev.struchkov.example.controlleradvice.controller;
import dev.struchkov.example.controlleradvice.domain.ErrorMessage;
import dev.struchkov.example.controlleradvice.exception.NotFoundException;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import org.springframework.web.method.annotation.MethodArgumentTypeMismatchException;
@RestControllerAdvice
public class ExceptionApiHandler {
@ExceptionHandler(NotFoundException.class)
public ResponseEntity<ErrorMessage> notFoundException(NotFoundException exception) {
return ResponseEntity
.status(HttpStatus.NOT_FOUND)
.body(new ErrorMessage(exception.getMessage()));
}
@ExceptionHandler(MethodArgumentTypeMismatchException.class)
public ResponseEntity<ErrorMessage> mismatchException(MethodArgumentTypeMismatchException exception) {
return ResponseEntity
.status(HttpStatus.NOT_FOUND)
.body(new ErrorMessage(exception.getMessage()));
}
}За обработку этих методов класса точно также отвечает класс ExceptionHandlerExceptionResolver. При этом мы можем здесь перехватывать даже стандартные исключения Spring, такие как MethodArgumentTypeMismatchException.
На мой взгляд, это самый удобный и простой способ обработки возвращаемых пользователю исключений.
Еще про обработку
Все написанное дальше относится к любому способу обработки исключений.
Запись в лог
Важно отметить, что исключения больше не записываются в лог. Если помимо ответа пользователю, вам все же необходимо записать это событие в лог, то необходимо добавить строчку записи в методе обработчике, например вот так:
@ExceptionHandler(NotFoundException.class)
public ResponseEntity<ErrorMessage> handleException(NotFoundException exception) {
log.error(exception.getMessage(), exception);
return ResponseEntity
.status(HttpStatus.NOT_FOUND)
.body(new ErrorMessage(exception.getMessage()));
}Перекрытие исключений
Вы можете использовать иерархию исключений с наследованием и обработчики исключений для всей своей иерархии. В таком случае обработка исключения будет попадать в самый специализированный обработчик.
Допустим мы бросаем NotFoundException, как в примере выше, который наследуется от RuntimeException. И у вас будет два обработчика исключений для NotFoundException и RuntimeException. Исключение попадет в обработчик для NotFoundException. Если этот обработчик убрать, то попадет в обработчик для RuntimeException.
Резюмирую
Обработка исключений это важная часть REST API. Она позволяет возвращать клиентам информационные сообщения, которые помогут им скорректировать свой запрос.
Мы можем по разному реализовать обработку в зависимости от нашей архитектуры. Предпочитаемым способом считаю вариант с @RestControllerAdvice. Этот вариант самый чистый и понятный.
Автор оригинала: Justin Albano.
1. введение
REST-это архитектура без состояния, в которой клиенты могут получать доступ к ресурсам на сервере и управлять ими. Как правило, службы REST используют HTTP для объявления набора ресурсов, которыми они управляют, и предоставляют API, который позволяет клиентам получать или изменять состояние этих ресурсов.
В этом уроке мы познакомимся с некоторыми из лучших практик обработки ошибок REST API, включая полезные подходы для предоставления пользователям соответствующей информации, примеры из крупномасштабных веб-сайтов и конкретную реализацию с использованием примера приложения Spring REST.
Дальнейшее чтение:
Обработка ошибок для ОТДЫХА с пружиной
Spring ResponseStatusException
2. Коды состояния HTTP
Когда клиент делает запрос к HTTP — серверу — и сервер успешно получает запрос – сервер должен уведомить клиента, был ли запрос успешно обработан или нет . HTTP выполняет это с помощью пяти категорий кодов состояния:
- 100-уровневый (информационный) — Сервер подтверждает запрос
- 200-уровень (Успех) — Сервер выполнил запрос, как и ожидалось
- 300-уровень (Перенаправление) — Клиенту необходимо выполнить дальнейшие действия для завершения запроса
- 400-level (Ошибка клиента) — Клиент отправил неверный запрос
- 500-level (Server error) — Серверу не удалось выполнить допустимый запрос из-за ошибки с сервером
Основываясь на коде ответа, клиент может предположить результат конкретного запроса.
3. Обработка Ошибок
Первым шагом в обработке ошибок является предоставление клиенту правильного кода состояния. Кроме того, нам может потребоваться предоставить дополнительную информацию в теле ответа.
3.1. Основные Ответы
Самый простой способ обработки ошибок-это ответить соответствующим кодом состояния .
Некоторые распространенные коды ответов включают в себя:
- 400 Плохой запрос — Клиент отправил недопустимый запрос — например, отсутствует требуемое тело запроса или параметр
- 401 Неавторизованный — Клиенту не удалось пройти аутентификацию на сервере
- 403 Forbidden — Клиент аутентифицирован, но не имеет разрешения на доступ к запрошенному ресурсу
- 404 Не найден — Запрошенный ресурс не существует
- 412 Ошибка предварительного условия — одно или несколько условий в полях заголовка запроса оцениваются как ложные.
- 500 Внутренняя ошибка сервера — На сервере произошла общая ошибка
- 503 Услуга Недоступна — Запрошенная услуга недоступна
Будучи базовыми, эти коды позволяют клиенту понять широкий характер возникшей ошибки. Например, мы знаем, если получаем ошибку 403, что у нас нет разрешений на доступ к запрошенному ресурсу.
Во многих случаях, однако, мы должны предоставить дополнительные детали в наших ответах.
500 ошибок сигнализируют о том, что при обработке запроса на сервере возникли некоторые проблемы или исключения. Как правило, эта внутренняя ошибка не является делом нашего клиента.
Следовательно, чтобы свести к минимуму такого рода ответы клиенту, мы должны усердно пытаться обрабатывать или улавливать внутренние ошибки и отвечать другими соответствующими кодами состояния, где это возможно . Например, если исключение возникает из-за того, что запрошенный ресурс не существует, мы должны выставить это как ошибку 404, а не 500.
Это не означает, что 500 никогда не должны быть возвращены, только то, что он должен использоваться для непредвиденных условий – таких как отключение службы – которые мешают серверу выполнить запрос.
3.2. Ответы На Весенние ошибки По Умолчанию
Эти принципы настолько распространены, что Spring кодифицировала их в своем механизме обработки ошибок по умолчанию .
Чтобы продемонстрировать это, предположим, что у нас есть простое приложение Spring REST , которое управляет книгами, с конечной точкой для извлечения книги по ее идентификатору:
curl -X GET -H "Accept: application/json" http://localhost:8082/spring-rest/api/book/1
Если нет книги с идентификатором 1, мы ожидаем, что наш контроллер выдаст исключение BookNotFoundException . Выполняя GET на этой конечной точке, мы видим, что это исключение было выброшено, и тело ответа:
{
"timestamp":"2019-09-16T22:14:45.624+0000",
"status":500,
"error":"Internal Server Error",
"message":"No message available",
"path":"/api/book/1"
}
Обратите внимание, что этот обработчик ошибок по умолчанию включает метку времени возникновения ошибки, код состояния HTTP, заголовок (поле error ), сообщение (по умолчанию пустое) и URL-адрес, по которому произошла ошибка.
Эти поля предоставляют клиенту или разработчику информацию, помогающую устранить проблему , а также составляют несколько полей, составляющих стандартные механизмы обработки ошибок.
Кроме того, обратите внимание, что Spring автоматически возвращает код состояния HTTP 500 при вызове нашего BookNotFoundException . Хотя некоторые API будут возвращать код состояния 500 или другие общие коды, как мы увидим с API Facebook и Twitter — для всех ошибок ради простоты лучше всего использовать наиболее конкретный код ошибки, когда это возможно .
В нашем примере мы можем добавить @ControllerAdvice так, чтобы при возникновении BookNotFoundException наш API возвращал статус 404 для обозначения Not Found вместо 500 Internal Server Error .
3.3. Более Подробные Ответы
Как видно из приведенного выше примера Spring, иногда кода состояния недостаточно, чтобы показать специфику ошибки. При необходимости мы можем использовать тело ответа, чтобы предоставить клиенту дополнительную информацию. При предоставлении подробных ответов мы должны включать:
- Error — Уникальный идентификатор ошибки
- Сообщение — Краткое читаемое человеком сообщение
- Детализация — более подробное объяснение ошибки
Например, если клиент отправляет запрос с неверными учетными данными, мы можем отправить ответ 401 с телом:
{
"error": "auth-0001",
"message": "Incorrect username and password",
"detail": "Ensure that the username and password included in the request are correct"
}
Поле error не должно совпадать с кодом ответа . Вместо этого это должен быть код ошибки, уникальный для нашего приложения. Как правило, нет никакого соглашения для поля error , ожидайте, что оно будет уникальным.
Обычно это поле содержит только буквенно-цифровые символы и соединительные символы, такие как тире или подчеркивание. Например, 0001 , auth-0001 и incorrect-user-pass являются каноническими примерами кодов ошибок.
Часть тела message обычно считается презентабельной на пользовательских интерфейсах. Поэтому мы должны перевести это название, если мы поддерживаем интернационализацию . Таким образом, если клиент отправляет запрос с заголовком Accept-Language , соответствующим французскому языку, значение title должно быть переведено на французский.
Часть detail предназначена для использования разработчиками клиентов , а не конечным пользователем , поэтому перевод не требуется.
Кроме того, мы также можем предоставить URL — адрес — например, поле help , по которому клиенты могут перейти для получения дополнительной информации:
{
"error": "auth-0001",
"message": "Incorrect username and password",
"detail": "Ensure that the username and password included in the request are correct",
"help": "https://example.com/help/error/auth-0001"
}
Иногда мы можем захотеть сообщить более чем об одной ошибке для запроса . В этом случае мы должны вернуть ошибки в список:
{
"errors": [
{
"error": "auth-0001",
"message": "Incorrect username and password",
"detail": "Ensure that the username and password included in the request are correct",
"help": "https://example.com/help/error/auth-0001"
},
...
]
}
И когда возникает единственная ошибка, мы отвечаем списком, содержащим один элемент. Обратите внимание, что ответ с несколькими ошибками может быть слишком сложным для простых приложений. Во многих случаях достаточно ответить на первую или самую значительную ошибку.
3.4. Стандартизированные Органы реагирования
В то время как большинство API REST следуют аналогичным соглашениям, специфика обычно варьируется, включая имена полей и информацию, включенную в тело ответа. Эти различия затрудняют единообразную обработку ошибок библиотеками и фреймворками.
Стремясь стандартизировать обработку ошибок REST API, |/IETF разработала RFC 7807 , который создает обобщенную схему обработки ошибок .
Эта схема состоит из пяти частей:
- тип — Идентификатор URI, который классифицирует ошибку
- заголовок — Краткое, читаемое человеком сообщение об ошибке
- status — Код ответа HTTP (необязательно)
- подробно — Читаемое человеком объяснение ошибки
- экземпляр — URI, идентифицирующий конкретное возникновение ошибки
Вместо того чтобы использовать наше пользовательское тело ответа на ошибку, мы можем преобразовать ваше тело в:
{
"type": "/errors/incorrect-user-pass",
"title": "Incorrect username or password.",
"status": 401,
"detail": "Authentication failed due to incorrect username or password.",
"instance": "/login/log/abc123"
}
Обратите внимание, что поле type классифицирует тип ошибки, в то время как instance идентифицирует конкретное возникновение ошибки аналогично классам и объектам соответственно.
Используя URI, клиенты могут следовать этим путям, чтобы найти дополнительную информацию об ошибке таким же образом, как ссылки HATEOAS могут использоваться для навигации по REST API.
Придерживаться RFC 7807 необязательно, но выгодно, если требуется однородность.
4. Примеры
Описанные выше методы являются общими для некоторых наиболее популярных API REST. В то время как конкретные имена полей или форматов могут варьироваться между сайтами, общие шаблоны почти универсальны .
4.1. Твиттер
Например, давайте отправим запрос GET без предоставления необходимых аутентификационных данных:
curl -X GET https://api.twitter.com/1.1/statuses/update.json?include_entities=true
API Twitter отвечает ошибкой со следующим телом:
{
"errors": [
{
"code":215,
"message":"Bad Authentication data."
}
]
}
Этот ответ включает в себя список, содержащий одну ошибку, с ее кодом ошибки и сообщением. В случае Twitter нет подробного сообщения, и общая ошибка — а не более конкретная ошибка 401 — используется для обозначения того, что аутентификация не удалась.
Иногда более общий код состояния проще реализовать, как мы увидим в нашем весеннем примере ниже. Это позволяет разработчикам перехватывать группы исключений и не различать код состояния, который должен быть возвращен. Однако, когда это возможно, следует использовать наиболее конкретный код состояния .
4.2. Facebook
Подобно Twitter, Facebook Graph REST API также включает подробную информацию в свои ответы.
Например, давайте выполним POST-запрос для аутентификации с помощью API Facebook Graph:
curl -X GET https://graph.facebook.com/oauth/access_token?client_id=foo&client_secret=bar&grant_type=baz
Мы получаем следующую ошибку:
{
"error": {
"message": "Missing redirect_uri parameter.",
"type": "OAuthException",
"code": 191,
"fbtrace_id": "AWswcVwbcqfgrSgjG80MtqJ"
}
}
Как и Twitter, Facebook также использует общую ошибку — а не более конкретную ошибку 400-го уровня — для обозначения сбоя. В дополнение к сообщению и числовому коду Facebook также включает в себя поле type , которое классифицирует ошибку, и идентификатор трассировки ( fbtrace_id ), который действует как внутренний идентификатор поддержки .
5. Заключение
В этой статье мы рассмотрели некоторые из лучших практик обработки ошибок REST API, в том числе:
- Предоставление конкретных кодов состояния
- Включение дополнительной информации в органы реагирования
- Единообразная обработка исключений
Хотя детали обработки ошибок будут варьироваться в зависимости от приложения, эти общие принципы применимы почти ко всем API REST и должны соблюдаться, когда это возможно .
Это не только позволяет клиентам последовательно обрабатывать ошибки, но и упрощает код, который мы создаем при реализации REST API.
Код, на который ссылается эта статья, доступен на GitHub .
Время на прочтение
6 мин
Количество просмотров 16K
Почти все разработчики так или иначе постоянно работают с api по http, клиентские разработчики работают с api backend своего сайта или приложения, а бэкендеры «дергают» бэкенды других сервисов, как внутренних, так и внешних. И мне кажется, одна из самых главных вещей в хорошем API это формат передачи ошибок. Ведь если это сделано плохо/неудобно, то разработчик, использующий это API, скорее всего не обработает ошибки, а клиенты будут пользоваться молчаливо ломающимся продуктом.
За 7 лет я как поддерживал множество legacy API, так и разрабатывал c нуля. И я поработал, наверное, с большинством стратегий по возвращению ошибок, но каждая из них создавала дискомфорт в той или иной мере. В последнее время я нащупал оптимальный вариант, о котором и хочу рассказать, но с начала расскажу о двух наиболее популярных вариантах.
№1: HTTP статусы
Если почитать апологетов REST, то для кодов ошибок надо использовать HTTP статусы, а текст ошибки отдавать в теле или в специальном заголовке. Например:
Success:
HTTP 200 GET /v1/user/1
Body: { name: 'Вася' }Error:
HTTP 404 GET /v1/user/1
Body: 'Не найден пользователь'Если у вас примитивная бизнес-логика или API из 5 url, то в принципе это нормальный подход. Однако как-только бизнес-логика станет сложнее, то начнется ряд проблем.
Http статусы предназначались для описания ошибок при передаче данных, а про логику вашего приложения никто не думал. Статусов явно не хватает для описания всего разнообразия ошибок в вашем проекте, да они и не были для этого предназначены. И тут начинается натягивание «совы на глобус»: все начинают спорить, какой статус ошибки дать в том или ином случае. Пример: Есть API для task manager. Какой статус надо вернуть в случае, если пользователь хочет взять задачу, а ее уже взял в работу другой пользователь? Ссылка на http статусы. И таких проблемных примеров можно придумать много.
REST скорее концепция, чем формат общения из чего следует неоднозначность использования статусов. Разработчики используют статусы как им заблагорассудится. Например, некоторые API при отсутствии сущности возвращают 404 и текст ошибки, а некоторые 200 и пустое тело.
Бэкенд разработчику в проекте непросто выбрать статус для ошибки, а клиентскому разработчику неочевидно какой статус предназначен для того или иного типа ошибок бизнес-логики. По-хорошему в проекте придется держать enum для того, чтобы описать какие ошибки относятся к тому или иному статусу.
Когда бизнес-логика приложения усложняется, начинают делать как-то так:
HTTP 400 PUT /v1/task/1 { status: 'doing' }
Body: { error_code: '12', error_message: 'Задача уже взята другим исполнителем' }
Из-за ограниченности http статусов разработчики начинают вводить “свои” коды ошибок для каждого статуса и передавать их в теле ответа. Другими словами, пользователю API приходится писать нечто подобное:
if (status === 200) {
// Success
} else if (status === 500) {
// some code
} else if (status === 400) {
if (body.error_code === 1) {
// some code
} else if (body.error_code === 2) {
// some code
} else {
// some code
}
} else if (status === 404) {
// some code
} else {
// some code
}Из-за этого ветвление клиентского кода начинает стремительно расти: множество http статусов и множество кодов в самом сообщении. Для каждого ошибочного http статуса необходимо проверить наличие кодов ошибок в теле сообщения. От комбинаторного взрыва начинает конкретно пухнуть башка! А значит обработку ошибок скорее всего сведут к сообщению типа “Произошла ошибка” или к молчаливому некорректному поведению.
Многие системы мониторинга сервисов привязываются к http статусам, но это не помогает в мониторинге, если статусы используются для описания ошибок бизнес логики. Например, у нас резкий всплеск ошибок 429 на графике. Это началась DDOS атака, или кто-то из разработчиков выбрал неудачный статус?
Итог: Начать с таким подходом легко и просто и для простого API это вполне подойдет. Но если логика стала сложнее, то использование статусов для описания того, что не укладывается в заданные рамки протокола http приводит к неоднозначности использования и последующим костылям для работы с ошибками. Или что еще хуже к формализму, что ведет к неприятному пользовательскому опыту.
№2: На все 200
Есть другой подход, даже более старый, чем REST, а именно: на все ошибки связанные с бизнес-логикой возвращать 200, а уже в теле ответа есть информация об ошибке. Например:
Вариант 1:
Success:
HTTP 200 GET /v1/user/1
Body: { ok: true, data: { name: 'Вася' } }
Error:
HTTP 200 GET /v1/user/1
Body: { ok: false, error: { code: 1, msg: 'Не найден пользователь' } }Вариант 2:
Success:
HTTP 200 GET /v1/user/1
Body: { data: { name: 'Вася' }, error: null }
Error:
HTTP 200 GET /v1/user/1
Body: { data: null, error: { code: 1, msg: 'Не найден пользователь' } }
На самом деле формат зависит от вас или от выбранной библиотеки для реализации коммуникации, например JSON-API.
Звучит здорово, мы теперь отвязались от http статусов и можем спокойно ввести свои коды ошибок. У нас больше нет проблемы “впихнуть невпихуемое”. Выбор нового типа ошибки не вызывает споров, а сводится просто к введению нового числового номера (например, последовательно) или строковой константы. Например:
module.exports = {
NOT_FOUND: 1,
VALIDATION: 2,
// ….
}
module.exports = {
NOT_FOUND: ‘NOT_AUTHORIZED’,
VALIDATION: ‘VALIDATION’,
// ….
}
Клиентские разработчики просто основываясь на кодах ошибок могут создать классы/типы ошибок и притом не бояться, что сервер вернет один и тот же код для разных типов ошибок (из-за бедности http статусов).
Обработка ошибок становится менее ветвящейся, множество http статусов превратились в два: 200 и все остальные (ошибки транспорта).
if (status === 200) {
if (body.error) {
var error = body.error;
if (error.code === 1) {
// some code
} else if (error.code === 2) {
// some code
} else {
// some code
}
} else {
// Success
}
} else {
// transport erros
}
В некоторых случаях, если есть библиотека десериализации данных, она может взять часть работы на себя. Писать SDK вокруг такого подхода проще нежели вокруг той или иной имплементации REST, ведь реализация зависит от того, как это видел автор. Кроме того, теперь никто не вызовет случайное срабатывание alert в мониторинге из-за того, что выбрал неудачный код ошибки.
Но неудобства тоже есть:
-
Избыточность полей при передаче данных, т.е. нужно всегда передавать 2 поля: для данных и для ошибки. Это усложняет чтение логов и написание документации.
-
При использовании средств отладки (Chrome DevTools) или других подобных инструментов вы не сможете быстро найти ошибочные запросы бизнес логики, придется обязательно заглянуть в тело ответа (ведь всегда 200)
-
Мониторинг теперь точно будет срабатывать только на ошибки транспорта, а не бизнес-логики, но для мониторинга логики надо будет дописывать парсинг тела сообщения.
В некоторых случаях данный подход вырождается в RPC, то есть по сути вообще отказываются от использования url и шлют все на один url методом POST, а в теле сообщения передают все параметры. Мне кажется это не правильным, ведь url это прекрасный именованный namespace, зачем от этого отказываться, не понятно?! Кроме того, RPC создает проблемы:
-
нельзя кэшировать по http GET запросы, так как замешали чтение и запись в один метод POST
-
нельзя делать повторы для неудавшихся GET запросов (на backend) на реверс-прокси (например, nginx) по указанной выше причине
-
имеются проблемы с документированием – swagger и ApiDoc не подходят, а удобных аналогов я не нашел
Итог: Для сложной бизнес-логики с большим количеством типов ошибок такой подход лучше, чем расплывчатый REST, не зря в проектах c “разухабистой” бизнес-логикой часто именно такой подход и используют.
№3: Смешанный
Возьмем лучшее от двух миров. Мы выберем один http статус, например, 400 или 422 для всех ошибок бизнес-логики, а в теле ответа будем указывать код ошибки или строковую константу. Например:
Success:
HTTP 200 /v1/user/1
Body: { name: 'Вася' }Error:
HTTP 400 /v1/user/1
Body: { error: { code: 1, msg: 'Не найден пользователь' } }Коды:
-
200 – успех
-
400 – ошибка бизнес логики
-
остальное ошибки в транспорте
Тело ответа для удачного запроса у нас имеет произвольную структуру, а вот для ошибки есть четкая схема. Мы избавляемся от избыточности данных (поле ошибки/данных) благодаря использованию http статуса в сравнении со вторым вариантом. Клиентский код упрощается в плане обработки ошибки (в сравнении с первым вариантом). Также мы снижаем его вложенность за счет использования отдельного http статуса для ошибок бизнес логики (в сравнении со вторым вариантом).
if (status === 200) {
// Success
} else if (status === 400) {
if (body.error.code === 1) {
// some code
} else if (body.error.code === 2) {
// some code
} else {
// some code
}
} else {
// transport erros
}
Мы можем расширять объект ошибки для детализации проблемы, если хотим. С мониторингом все как во втором варианте, дописывать парсинг придется, но и риска “стрельбы” некорректными alert нету. Для документирования можем спокойно использовать Swagger и ApiDoc. При этом сохраняется удобство использования инструментов разработчика, таких как Chrome DevTools, Postman, Talend API.
Итог: Использую данный подход уже в нескольких проектах, где множество типов ошибок и все крайне довольны, как клиентские разработчики, так и бэкендеры. Внедрение новой ошибки не вызывает споров, проблем и противоречий. Данный подход объединяет преимущества первого и второго варианта, при этом код более читабельный и структурированный.
Самое главное какой бы формат ошибок вы бы не выбрали лучше обговорить его заранее и следовать ему. Если эту вещь пустить на “самотек”, то очень скоро обработка ошибок в проекте станет невыносимо сложной для всех.
P.S. Иногда ошибки любят передавать массивом
{ error: [{ code: 1, msg: 'Не найден пользователь' }] }Но это актуально в основном в двух случаях:
-
Когда наш API выступает в роли сервиса без фронтенда (нет сайта/приложения). Например, сервис платежей.
-
Когда в API есть url для загрузки какого-нибудь длинного отчета в котором может быть ошибка в каждой строке/колонке. И тогда для пользователя удобнее, чтобы ошибки в приложении сразу показывались все, а не по одной.
В противном случае нет особого смысла закладываться сразу на массив ошибок, потому что базовая валидация данных должна происходить на клиенте, зато код упрощается как на сервере, так и на клиенте. А user-experience хакеров, лезущих напрямую в наше API, не должен нас волновать?HTTP
I’m looking for guidance on good practices when it comes to return errors from a REST API. I’m working on a new API so I can take it any direction right now. My content type is XML at the moment, but I plan to support JSON in future.
I am now adding some error cases, like for instance a client attempts to add a new resource but has exceeded his storage quota. I am already handling certain error cases with HTTP status codes (401 for authentication, 403 for authorization and 404 for plain bad request URIs). I looked over the blessed HTTP error codes but none of the 400-417 range seems right to report application specific errors. So at first I was tempted to return my application error with 200 OK and a specific XML payload (ie. Pay us more and you’ll get the storage you need!) but I stopped to think about it and it seems to soapy (/shrug in horror). Besides it feels like I’m splitting the error responses into distinct cases, as some are http status code driven and other are content driven.
So what is the industry recommendations? Good practices (please explain why!) and also, from a client pov, what kind of error handling in the REST API makes life easier for the client code?
gorn
5,0337 gold badges31 silver badges46 bronze badges
asked Jun 3, 2009 at 3:39
Remus RusanuRemus Rusanu
287k40 gold badges437 silver badges567 bronze badges
4
So at first I was tempted to return my application error with 200 OK and a specific XML payload (ie. Pay us more and you’ll get the storage you need!) but I stopped to think about it and it seems to soapy (/shrug in horror).
I wouldn’t return a 200 unless there really was nothing wrong with the request. From RFC2616, 200 means «the request has succeeded.»
If the client’s storage quota has been exceeded (for whatever reason), I’d return a 403 (Forbidden):
The server understood the request, but is refusing to fulfill it. Authorization will not help and the request SHOULD NOT be repeated. If the request method was not HEAD and the server wishes to make public why the request has not been fulfilled, it SHOULD describe the reason for the refusal in the entity. If the server does not wish to make this information available to the client, the status code 404 (Not Found) can be used instead.
This tells the client that the request was OK, but that it failed (something a 200 doesn’t do). This also gives you the opportunity to explain the problem (and its solution) in the response body.
What other specific error conditions did you have in mind?
answered Jun 3, 2009 at 4:08
![]()
Rich ApodacaRich Apodaca
28.2k16 gold badges102 silver badges129 bronze badges
9
The main choice is do you want to treat the HTTP status code as part of your REST API or not.
Both ways work fine. I agree that, strictly speaking, one of the ideas of REST is that you should use the HTTP Status code as a part of your API (return 200 or 201 for a successful operation and a 4xx or 5xx depending on various error cases.) However, there are no REST police. You can do what you want. I have seen far more egregious non-REST APIs being called «RESTful.»
At this point (August, 2015) I do recommend that you use the HTTP Status code as part of your API. It is now much easier to see the return code when using frameworks than it was in the past. In particular, it is now easier to see the non-200 return case and the body of non-200 responses than it was in the past.
The HTTP Status code is part of your api
-
You will need to carefully pick 4xx codes that fit your error conditions. You can include a rest, xml, or plaintext message as the payload that includes a sub-code and a descriptive comment.
-
The clients will need to use a software framework that enables them to get at the HTTP-level status code. Usually do-able, not always straight-forward.
-
The clients will have to distinguish between HTTP status codes that indicate a communications error and your own status codes that indicate an application-level issue.
The HTTP Status code is NOT part of your api
-
The HTTP status code will always be 200 if your app received the request and then responded (both success and error cases)
-
ALL of your responses should include «envelope» or «header» information. Typically something like:
envelope_ver: 1.0 status: # use any codes you like. Reserve a code for success. msg: "ok" # A human string that reflects the code. Useful for debugging. data: ... # The data of the response, if any.
-
This method can be easier for clients since the status for the response is always in the same place (no sub-codes needed), no limits on the codes, no need to fetch the HTTP-level status-code.
Here’s a post with a similar idea: http://yuiblog.com/blog/2008/10/15/datatable-260-part-one/
Main issues:
-
Be sure to include version numbers so you can later change the semantics of the api if needed.
-
Document…
![]()
shA.t
16.5k5 gold badges54 silver badges111 bronze badges
answered Jun 3, 2009 at 4:13
Larry KLarry K
47.5k15 gold badges86 silver badges138 bronze badges
6
Remember there are more status codes than those defined in the HTTP/1.1 RFCs, the IANA registry is at http://www.iana.org/assignments/http-status-codes. For the case you mentioned status code 507 sounds right.
answered Jun 3, 2009 at 5:46
![]()
Julian ReschkeJulian Reschke
39.8k8 gold badges95 silver badges98 bronze badges
11
As others have pointed, having a response entity in an error code is perfectly allowable.
Do remember that 5xx errors are server-side, aka the client cannot change anything to its request to make the request pass. If the client’s quota is exceeded, that’s definitly not a server error, so 5xx should be avoided.
answered Jun 4, 2009 at 13:54
SerialSebSerialSeb
6,70123 silver badges28 bronze badges
2
There are two sorts of errors. Application errors and HTTP errors. The HTTP errors are just to let your AJAX handler know that things went fine and should not be used for anything else.
5xx Server Error
500 Internal Server Error
501 Not Implemented
502 Bad Gateway
503 Service Unavailable
504 Gateway Timeout
505 HTTP Version Not Supported
506 Variant Also Negotiates (RFC 2295 )
507 Insufficient Storage (WebDAV) (RFC 4918 )
509 Bandwidth Limit Exceeded (Apache bw/limited extension)
510 Not Extended (RFC 2774 )
2xx Success
200 OK
201 Created
202 Accepted
203 Non-Authoritative Information (since HTTP/1.1)
204 No Content
205 Reset Content
206 Partial Content
207 Multi-Status (WebDAV)
However, how you design your application errors is really up to you. Stack Overflow for example sends out an object with response, data and message properties. The response I believe contains true or false to indicate if the operation was successful (usually for write operations). The data contains the payload (usually for read operations) and the message contains any additional metadata or useful messages (such as error messages when the response is false).
answered Jun 3, 2009 at 9:21
aleembaleemb
31.2k19 gold badges98 silver badges114 bronze badges
1
Agreed. The basic philosophy of REST is to use the web infrastructure. The HTTP Status codes are the messaging framework that allows parties to communicate with each other without increasing the HTTP payload. They are already established universal codes conveying the status of response, and therefore, to be truly RESTful, the applications must use this framework to communicate the response status.
Sending an error response in a HTTP 200 envelope is misleading, and forces the client (api consumer) to parse the message, most likely in a non-standard, or proprietary way. This is also not efficient — you will force your clients to parse the HTTP payload every single time to understand the «real» response status. This increases processing, adds latency, and creates an environment for the client to make mistakes.
answered Nov 21, 2013 at 17:38
![]()
KingzKingz
5,0263 gold badges35 silver badges25 bronze badges
4
Please stick to the semantics of protocol. Use 2xx for successful responses and 4xx , 5xx for error responses — be it your business exceptions or other. Had using 2xx for any response been the intended use case in the protocol, they would not have other status codes in the first place.
answered Apr 14, 2016 at 6:42
rahil008rahil008
1731 silver badge7 bronze badges
Don’t forget the 5xx errors as well for application errors.
In this case what about 409 (Conflict)? This assumes that the user can fix the problem by deleting stored resources.
Otherwise 507 (not entirely standard) may also work. I wouldn’t use 200 unless you use 200 for errors in general.
answered Jun 3, 2009 at 15:38
Kathy Van StoneKathy Van Stone
25.5k3 gold badges32 silver badges40 bronze badges
If the client quota is exceeded it is a server error, avoid 5xx in this instance.
answered May 6, 2010 at 0:02
2
Some Background
REST APIs use the Status-Line part of an HTTP response message to inform clients of their request’s overarching result.
RFC 2616 defines the Status-Line syntax as shown below:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
A great amount of applications are using Restful APIs that are based on the HTTP protocol for connecting their clients. In all the calls, the server and the endpoint at the client both return a call status to the client which can be in the form of:
- The success of API call.
- Failure of API call.
In both the cases, it is necessary to let the client know so that they can proceed to the next step. In the case of a successful API call they can proceed to the next call or whatever their intent was in the first place but in the case of latter they will be forced to modify their call so that the failed call can be recovered.
RestCase
To enable the best user experience for your customer, it is necessary on the part of the developers to make excellent error messages that can help their client to know what they want to do with the information they get. An excellent error message is precise and lets the user know about the nature of the error so that they can figure their way out of it.
A good error message also allows the developers to get their way out of the failed call.
Next step is to know what error messages to integrate into your framework so that the clients on the end point and the developers at the server are constantly made aware of the situation which they are in. in order to do so, the rule of thumb is to keep the error messages to a minimum and only incorporate those error messages which are helpful.
HTTP defines over 40 standard status codes that can be used to convey the results of a client’s request. The status codes are divided into the five categories presented here:
- 1xx: Informational — Communicates transfer protocol-level information
- 2xx: Success -Indicates that the client’s request was accepted successfully.
- 3xx: Redirection — Indicates that the client must take some additional action in order to complete their request.
- 4xx: Client Error — This category of error status codes points the finger at clients.
- 5xx: Server Error — The server takes responsibility for these error status codes.

If you would ask me 5 years ago about HTTP Status codes I would guess that the talk is about web sites, status 404 meaning that some page was not found and etc. But today when someone asks me about HTTP Status codes, it is 99.9% refers to REST API web services development. I have lots of experience in both areas (Website development, REST API web services development) and it is sometimes hard to come to a conclusion about what and how use the errors in REST APIs.
There are some cases where this status code is always returned, even if there was an error that occurred. Some believe that returning status codes other than 200 is not good as the client did reach your REST API and got response.
Proper use of the status codes will help with your REST API management and REST API workflow management.
If for example the user asked for “account” and that account was not found there are 2 options to use for returning an error to the user:
-
Return 200 OK Status and in the body return a json containing explanation that the account was not found.
-
Return 404 not found status.
The first solution opens up a question whether the user should work a bit harder to parse the json received and to see whether that json contains error or not. -
There is also a third solution: Return 400 Error — Client Error. I will explain a bit later why this is my favorite solution.
It is understandable that for the user it is easier to check the status code of 404 without any parsing work to do.
I my opinion this solution is actually miss-use of the HTTP protocol
We did reach the REST API, we did got response from the REST API, what happens if the users misspells the URL of the REST API – he will get the 404 status but that is returned not by the REST API itself.
I think that these solutions should be interesting to explore and to see the benefits of one versus the other.
There is also one more solution that is basically my favorite – this one is a combination of the first two solutions, he is also gives better Restful API services automatic testing support because only several status codes are returned, I will try to explain about it.
Error handling Overview
Error responses should include a common HTTP status code, message for the developer, message for the end-user (when appropriate), internal error code (corresponding to some specific internally determined ID), links where developers can find more info. For example:
‘{ «status» : 400,
«developerMessage» : «Verbose, plain language description of the problem. Provide developers suggestions about how to solve their problems here»,
«userMessage» : «This is a message that can be passed along to end-users, if needed.»,
«errorCode» : «444444»,
«moreInfo» : «http://www.example.gov/developer/path/to/help/for/444444,
http://tests.org/node/444444»,
}’
How to think about errors in a pragmatic way with REST?
Apigee’s blog post that talks about this issue compares 3 top API providers.

No matter what happens on a Facebook request, you get back the 200 status code — everything is OK. Many error messages also push down into the HTTP response. Here they also throw an #803 error but with no information about what #803 is or how to react to it.
Twilio
Twilio does a great job aligning errors with HTTP status codes. Like Facebook, they provide a more granular error message but with a link that takes you to the documentation. Community commenting and discussion on the documentation helps to build a body of information and adds context for developers experiencing these errors.
SimpleGeo
Provides error codes but with no additional value in the payload.
Error Handling — Best Practises
First of all: Use HTTP status codes! but don’t overuse them.
Use HTTP status codes and try to map them cleanly to relevant standard-based codes.
There are over 70 HTTP status codes. However, most developers don’t have all 70 memorized. So if you choose status codes that are not very common you will force application developers away from building their apps and over to wikipedia to figure out what you’re trying to tell them.
Therefore, most API providers use a small subset.
For example, the Google GData API uses only 10 status codes, Netflix uses 9, and Digg, only 8.

How many status codes should you use for your API?
When you boil it down, there are really only 3 outcomes in the interaction between an app and an API:
- Everything worked
- The application did something wrong
- The API did something wrong
Start by using the following 3 codes. If you need more, add them. But you shouldn’t go beyond 8.
- 200 — OK
- 400 — Bad Request
- 500 — Internal Server Error
Please keep in mind the following rules when using these status codes:
200 (OK) must not be used to communicate errors in the response body
Always make proper use of the HTTP response status codes as specified by the rules in this section. In particular, a REST API must not be compromised in an effort to accommodate less sophisticated HTTP clients.
400 (Bad Request) may be used to indicate nonspecific failure
400 is the generic client-side error status, used when no other 4xx error code is appropriate. For errors in the 4xx category, the response body may contain a document describing the client’s error (unless the request method was HEAD).
500 (Internal Server Error) should be used to indicate API malfunction 500 is the generic REST API error response.
Most web frameworks automatically respond with this response status code whenever they execute some request handler code that raises an exception. A 500 error is never the client’s fault and therefore it is reasonable for the client to retry the exact same request that triggered this response, and hope to get a different response.
If you’re not comfortable reducing all your error conditions to these 3, try adding some more but do not go beyond 8:
- 401 — Unauthorized
- 403 — Forbidden
- 404 — Not Found
Please keep in mind the following rules when using these status codes:
A 401 error response indicates that the client tried to operate on a protected resource without providing the proper authorization. It may have provided the wrong credentials or none at all.
403 (Forbidden) should be used to forbid access regardless of authorization state
A 403 error response indicates that the client’s request is formed correctly, but the REST API refuses to honor it. A 403 response is not a case of insufficient client credentials; that would be 401 (“Unauthorized”). REST APIs use 403 to enforce application-level permissions. For example, a client may be authorized to interact with some, but not all of a REST API’s resources. If the client attempts a resource interaction that is outside of its permitted scope, the REST API should respond with 403.
404 (Not Found) must be used when a client’s URI cannot be mapped to a resource
The 404 error status code indicates that the REST API can’t map the client’s URI to a resource.
RestCase
Conclusion
I believe that the best solution to handle errors in a REST API web services is the third option, in short:
Use three simple, common response codes indicating (1) success, (2) failure due to client-side problem, (3) failure due to server-side problem:
- 200 — OK
- 400 — Bad Request (Client Error) — A json with error more details should return to the client.
- 401 — Unauthorized
- 500 — Internal Server Error — A json with an error should return to the client only when there is no security risk by doing that.
I think that this solution can also ease the client to handle only these 4 status codes and when getting either 400 or 500 code he should take the response message and parse it in order to see what is the problem exactly and on the other hand the REST API service is simple enough.
The decision of choosing which error messages to incorporate and which to leave is based on sheer insight and intuition. For example: if an app and API only has three outcomes which are; everything worked, the application did not work properly and API did not respond properly then you are only concerned with three error codes. By putting in unnecessary codes, you will only distract the users and force them to consult Google, Wikipedia and other websites.
Most important thing in the case of an error code is that it should be descriptive and it should offer two outputs:
- A plain descriptive sentence explaining the situation in the most precise manner.
- An ‘if-then’ situation where the user knows what to do with the error message once it is returned in an API call.
The error message returned in the result of the API call should be very descriptive and verbal. A code is preferred by the client who is well versed in the programming and web language but in the case of most clients they find it hard to get the code.
As I stated before, 404 is a bit problematic status when talking about Restful APIs. Does this status means that the resource was not found? or that there is not mapping to the requested resource? Everyone can decide what to use and where 