Last updated on
Feb 10, 2022
In this post, you can find several solutions for:
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
While this error can appear in different situations the reason for the error is one and the same:
- there are special characters( escape sequence — characters starting with backslash — » ).
- From the error above you can recognize that the culprit is ‘U’ — which is considered as unicode character.
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘x’, ‘u’
- codec can’t decode bytes in position 2-3: truncated xXX escape
- codec can’t decode bytes in position 2-3: truncated uXXXX escape
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘x’, ‘u’
Step #1: How to solve SyntaxError: (unicode error) ‘unicodeescape’ — Double slashes for escape characters
Let’s start with one of the most frequent examples — windows paths. In this case there is a bad character sequence in the string:
import json
json_data=open("C:Userstest.txt").read()
json_obj = json.loads(json_data)
The problem is that U is considered as a special escape sequence for Python string. In order to resolved you need to add second escape character like:
import json
json_data=open("C:\Users\test.txt").read()
json_obj = json.loads(json_data)
Step #2: Use raw strings to prevent SyntaxError: (unicode error) ‘unicodeescape’
If the first option is not good enough or working then raw strings are the next option. Simply by adding r (for raw string literals) to resolve the error. This is an example of raw strings:
import json
json_data=open(r"C:Userstest.txt").read()
json_obj = json.loads(json_data)
If you like to find more information about Python strings, literals
2.4.1 String literals
In the same link we can find:
When an r' or R’ prefix is present, backslashes are still used to quote the following character, but all backslashes are left in the string. For example, the string literal r»n» consists of two characters: a backslash and a lowercase `n’.
Step #3: Slashes for file paths -SyntaxError: (unicode error) ‘unicodeescape’
Another possible solution is to replace the backslash with slash for paths of files and folders. For example:
«C:Userstest.txt»
will be changed to:
«C:/Users/test.txt»
Since python can recognize both I prefer to use only the second way in order to avoid such nasty traps. Another reason for using slashes is your code to be uniform and homogeneous.
Step #4: PyCharm — SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
The picture below demonstrates how the error will look like in PyCharm. In order to understand what happens you will need to investigate the error log.
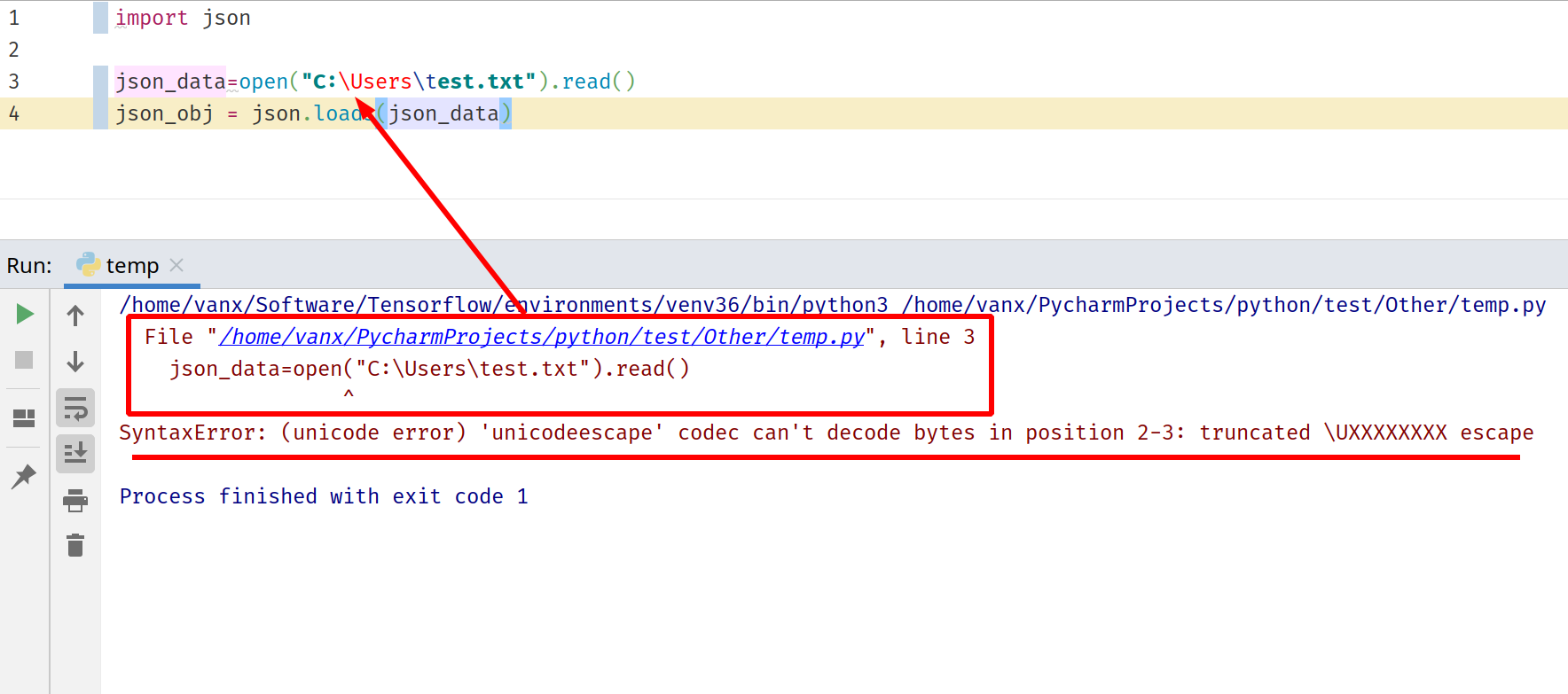
The error log will have information for the program flow as:
/home/vanx/Software/Tensorflow/environments/venv36/bin/python3 /home/vanx/PycharmProjects/python/test/Other/temp.py
File "/home/vanx/PycharmProjects/python/test/Other/temp.py", line 3
json_data=open("C:Userstest.txt").read()
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated UXXXXXXXX escape
You can see the latest call which produces the error and click on it. Once the reason is identified then you can test what could solve the problem.
I am using Python 3.1 on a Windows 7 machine. Russian is the default system language, and utf-8 is the default encoding.
Looking at the answer to a previous question, I have attempting using the «codecs» module to give me a little luck. Here’s a few examples:
>>> g = codecs.open("C:UsersEricDesktopbeeline.txt", "r", encoding="utf-8")
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-4: truncated UXXXXXXXX escape (<pyshell#39>, line 1)
>>> g = codecs.open("C:UsersEricDesktopSite.txt", "r", encoding="utf-8")
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-4: truncated UXXXXXXXX escape (<pyshell#40>, line 1)
>>> g = codecs.open("C:Python31Notes.txt", "r", encoding="utf-8")
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 11-12: malformed N character escape (<pyshell#41>, line 1)
>>> g = codecs.open("C:UsersEricDesktopSite.txt", "r", encoding="utf-8")
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-4: truncated UXXXXXXXX escape (<pyshell#44>, line 1)
My last idea was, I thought it might have been the fact that Windows «translates» a few folders, such as the «users» folder, into Russian (though typing «users» is still the correct path), so I tried it in the Python31 folder. Still, no luck. Any ideas?
Table of Contents
Hide
- What is SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
- How to fix SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
- Solution 1 – Using Double backslash (\)
- Solution 2 – Using raw string by prefixing ‘r’
- Solution 3 – Using forward slash
- Conclusion
The SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape occurs if you are trying to access a file path with a regular string.
In this tutorial, we will take a look at what exactly (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape means and how to fix it with examples.
The Python String literals can be enclosed in matching single quotes (‘) or double quotes (“).
String literals can also be prefixed with a letter ‘r‘ or ‘R‘; such strings are called raw strings and use different rules for backslash escape sequences.
They can also be enclosed in matching groups of three single or double quotes (these are generally referred to as triple-quoted strings).
The backslash () character is used to escape characters that otherwise have a special meaning, such as newline, backslash itself, or the quote character.
Now that we have understood the string literals. Let us take an example to demonstrate the issue.
import pandas
# read the file
pandas.read_csv("C:UsersitsmycodeDesktoptest.csv")
Output
File "c:PersonalIJSCodeprogram.py", line 4
pandas.read_csv("C:UsersitsmycodeDesktoptest.csv") ^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated UXXXXXXXX escapeWe are using the single backslash in the above code while providing the file path. Since the backslash is present in the file path, it is interpreted as a special character or escape character (any sequence starting with ‘’). In particular, “U” introduces a 32-bit Unicode character.
How to fix SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
Solution 1 – Using Double backslash (\)
In Python, the single backslash in the string is interpreted as a special character, and the character U(in users) will be treated as the Unicode code point.
We can fix the issue by escaping the backslash, and we can do that by adding an additional backslash, as shown below.
import pandas
# read the file
pandas.read_csv("C:\Users\itsmycode\Desktop\test.csv")Solution 2 – Using raw string by prefixing ‘r’
We can also escape the Unicode by prefixing r in front of the string. The r stands for “raw” and indicates that backslashes need to be escaped, and they should be treated as a regular backslash.
import pandas
# read the file
pandas.read_csv("C:\Users\itsmycode\Desktop\test.csv")Solution 3 – Using forward slash
Another easier way is to avoid the backslash and instead replace it with the forward-slash character(/), as shown below.
import pandas
# read the file
pandas.read_csv("C:/Users/itsmycode/Desktop/test.csv")
Conclusion
The SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape occurs if you are trying to access a file path and provide the path as a regular string.
We can solve the issue by escaping the single backslash with a double backslash or prefixing the string with ‘r,’ which converts it into a raw string. Alternatively, we can replace the backslash with a forward slash.
Srinivas Ramakrishna is a Solution Architect and has 14+ Years of Experience in the Software Industry. He has published many articles on Medium, Hackernoon, dev.to and solved many problems in StackOverflow. He has core expertise in various technologies such as Microsoft .NET Core, Python, Node.JS, JavaScript, Cloud (Azure), RDBMS (MSSQL), React, Powershell, etc.
Sign Up for Our Newsletters
Subscribe to get notified of the latest articles. We will never spam you. Be a part of our ever-growing community.
By checking this box, you confirm that you have read and are agreeing to our terms of use regarding the storage of the data submitted through this form.
Introduction
The following error message is a common Python error, the «SyntaxError» represents a Python syntax error and the «unicodeescape» means that we made a mistake in using unicode escape character.
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-5: truncated UXXXXXXXX escapeSimply to put, the «SyntaxError» can be occurred accidentally in Python and it is often happens because the (ESCAPE CHARACTER) is misused in a python string, it caused the unicodeescape error.
(Note: «escape character» can convert your other character to be a normal character.)
SyntaxError Example
Let’s look at an example:
print('It's a nice day.')Looks like we want to print «It’s a nice day.«, right? But the program will report an error message.
File "<stdin>", line 1
print('It's a nice day.')
^
SyntaxError: invalid syntaxThe reason is very easy-to-know. In Python, we can use print('xxx') to print out xxx. But in our code, if we had used the ' character, the Python interpreter will misinterpret the range of our characters so it will report an error.
To solve this problem, we need to add an escape character «» to convert our ‘ character to be a normal character, not a superscript of string.
print('It's a nice day.')Output:
It's a nice day.We print it successfully!
So how did the syntax error happen? Let me talk about my example:
One day, I run my program for experiment, I saved some data in a csv file. In order for this file can be viewed on the Windows OS, I add a new code uFFEF in the beginning of file.
This is «BOM» (Byte Order Mark), Explain to the system that the file format is «Big-Ending«.
I got the error message.
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-5: truncated UXXXXXXXX escapeAs mentioned at the beginning of this article, this is an escape character error in Python.
Solutions
There are three solutions you can try:
- Add a «r» character in the right of string
- Change
to be/ - Change
to be\
Solution 1: Add a «r» character in the beginning of string.
title = r'uFFEF'After we adding a r character at right side of python string, it means a complete string not anything else.
Solution 2: Change /.
open("C:UsersClayDesktoptest.txt")Change to:
open("C:/Users/Clay/Desktop/test.txt")This way is avoid to use escape character.
Solution 3: Change \.
open("C:UsersClayDesktoptest.txt")Change the code to:
open("C:\Users\Clay\Desktop\test.txt")It is similar to the solution 2 that it also avoids the use of escape characters.
The above are three common solutions. We can run normally on Windows.
Reference
- https://stackoverflow.com/questions/37400974/unicode-error-unicodeescape-codec-cant-decode-bytes-in-position-2-3-trunca
- https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Error-unicodeescape-codec-can-t-decode-bytes/td-p/427540
Read More
- [Solved][Python] ModuleNotFoundError: No module named ‘cStringIO’

Introduction to Python Unicode Error
Python defines Unicode as a string type that facilitates the representation of characters, enabling Python programs to handle a vast array of different characters. For example, any directory path or link address as a string. When we use such a string as a parameter to any function, there is a possibility of the occurrence of an error. Such an error is known as a Unicode error in Python. We get such an error because any character after the Unicode escape sequence (“ u ”) produces an error which is a typical error on Windows.
Working of Unicode Error in Python with Examples
Unicode standard in Python is the representation of characters in code point format. These standards are made to avoid ambiguity between the characters specified, which may occur Unicode errors. For example, let us consider “ I ” as roman number one. It can even be considered the capital alphabet “ i ”; they look the same but are two different characters with different meanings. To avoid such ambiguity, we use Unicode standards.
In Python, Unicode standards have two error types: Unicode encodes error and Unicode decode error. In Python, it includes the concept of Unicode error handlers. Whenever an error or problem occurs during the encoding or decoding process of a string or given text, these handlers are invoked. To include Unicode characters in the Python program, we first use the Unicode escape symbol you before any string, which can be considered a Unicode-type variable.
Syntax:
Unicode characters in Python programs can be written as follows:
"u dfskgfkdsg"Or
"sakjhdxhj"Or
"u1232hgdsa"In the above syntax, we can see 3 different ways of declaring Unicode characters. In the Python program, we can write Unicode literals with prefixes either “u” or “U” followed by a string containing alphabets and numerals, where we can see the above two syntax examples. At the end last syntax sample, we can also use the “u” Unicode escape sequence to declare Unicode characters in the program. In this, we have to note that using “u,” we can write a string containing any alphabet or numerical, but when we want to declare any hex value, then we have to “x” escape sequence, which takes two hex digits and for octal, it will take digit 777.
Example #1
Now let us see an example below for declaring Unicode characters in the program.
Code:
#!/usr/bin/env python
# -*- coding: latin-1 -*-
a= u'dfsfxacu1234'
print("The value of the above unicode literal is as follows:")
print(ord(a[-1]))Output:
![]()
In the above program, we can see the sample of Unicode literals in the Python program. Still, before that, we need to declare encoding, which is different in different versions of Python, and in this program, we can see it in the first two lines of the program.
Now we’ll see that Unicode faults, such as Unicode encoding and decoding failures, are promptly invoked if the problems arise.. There are 3 typical errors in Python Unicode error handlers.
In Python, strict error raises UnicodeEncodeError and UnicodeDecodeError for encoding and decoding failures, respectively.
Example #2
UnicodeEncodeError demonstration and its example.
In Python, it cannot detect Unicode characters, and therefore it throws an encoding error as it cannot encode the given Unicode string.
Code:
str(u'éducba')Output:

In the above program, we can see we have passed the argument to the str() function, which is a Unicode string. But this function will use the default encoding process ASCII. The program mentioned above throws an error due to the lack of encoding specification at the start. The default encoding used is a 7-bit encoding, which cannot recognize characters beyond the range of 0 to 128. Therefore, we can see the error that is displayed in the above screenshot.
The above program can be fixed by manually encoding the Unicode string, such as.encode(‘utf8’), before providing it to the str() function.
Example #3
In this program, we have called the str() function explicitly, which may again throw an UnicodeEncodeError.
Code:
a = u'café'
b = a.encode('utf8')
r = str(b)
print("The unicode string after fixing the UnicodeEncodeError is as follows:")
print(r)Output:
![]()
In the above, we can show how to avoid UnicodeEncodeError manually by using .encode(‘utf8’) to the Unicode string.
Example #4
Now we will see the UnicodeDecodeError demonstration and its example and how to avoid it.
Code:
a = u'éducba'
b = a.encode('utf8')
unicode(b)Output:
In the above program, we can see we are trying to print the Unicode characters by encoding first; then, we are trying to convert the encoded string into Unicode characters, which means decoding back to Unicode characters as given at the start. In the above program, we get an error as UnicodeDecodeError when we run. So to avoid this error, we have to decode the Unicode character “b manually.”

So we can fix it by using the below statement, and we can see it in the above screenshot.
b.decode(‘utf8’)
![]()
Conclusion
In this article, we conclude that in Python, Unicode literals are other types of string for representing different types of string. In this article, we also saw how to fix these errors manually by passing the string to the function.
Recommended Articles
We hope that this EDUCBA information on “Python Unicode Error” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
- Python String Operations
- Python Sort List
- Quick Sort in Python
- Python Constants