Время на прочтение
5 мин
Количество просмотров 65K
Если вы уже освоились с основами терминала, возможно, вы уже готовы к тому, чтобы комбинировать изученные команды. Иногда выполнения команд оболочки по одной вполне достаточно для решения некоей задачи, но в некоторых случаях вводить команду за командой слишком утомительно и нерационально. В подобной ситуации нам пригодятся некоторые особые символы, вроде угловых скобок.

Для оболочки, интерпретатора команд Linux, эти дополнительные символы — не пустая трата места на экране. Они — мощные команды, которые могут связывать воедино различные фрагменты информации, разделять то, что было до этого цельным, и делать ещё много всего. Одна из самых простых, и, в то же время, мощных и широко используемых возможностей оболочки — это перенаправление стандартных потоков ввода/вывода.
Три стандартных потока ввода/вывода
Для того, чтобы понять то, о чём мы будем тут говорить, важно знать, откуда берутся данные, которые можно перенаправлять, и куда они идут. В Linux существует три стандартных потока ввода/вывода данных.
Первый — это стандартный поток ввода (standard input). В системе это — поток №0 (так как в компьютерах счёт обычно начинается с нуля). Номера потоков ещё называют дескрипторами. Этот поток представляет собой некую информацию, передаваемую в терминал, в частности — инструкции, переданные в оболочку для выполнения. Обычно данные в этот поток попадают в ходе ввода их пользователем с клавиатуры.
Второй поток — это стандартный поток вывода (standard output), ему присвоен номер 1. Это поток данных, которые оболочка выводит после выполнения каких-то действий. Обычно эти данные попадают в то же окно терминала, где была введена команда, вызвавшая их появление.
И, наконец, третий поток — это стандартный поток ошибок (standard error), он имеет дескриптор 2. Этот поток похож на стандартный поток вывода, так как обычно то, что в него попадает, оказывается на экране терминала. Однако, он, по своей сути, отличается от стандартного вывода, как результат, этими потоками, при желании, можно управлять раздельно. Это полезно, например, в следующей ситуации. Есть команда, которая обрабатывает большой объём данных, выполняя сложную и подверженную ошибкам операцию. Нужно, чтобы полезные данные, которые генерирует эта команда, не смешивались с сообщениями об ошибках. Реализуется это благодаря раздельному перенаправлению потоков вывода и ошибок.
Как вы, вероятно, уже догадались, перенаправление ввода/вывода означает работу с вышеописанными потоками и перенаправление данных туда, куда нужно программисту. Делается это с использованием символов > и < в различных комбинациях, применение которых зависит от того, куда, в итоге, должны попасть перенаправляемые данные.
Перенаправление стандартного потока вывода
Предположим, вы хотите создать файл, в который будут записаны текущие дата и время. Дело упрощает то, что имеется команда, удачно названная date, которая возвращает то, что нам нужно. Обычно команды выводят данные в стандартный поток вывода. Для того, чтобы эти данные оказались в файле, нужно добавить символ > после команды, перед именем целевого файла. До и после > надо поставить пробел.
При использовании перенаправления любой файл, указанный после > будет перезаписан. Если в файле нет ничего ценного и его содержимое можно потерять, в нашей конструкции допустимо использовать уже существующий файл. Обычно же лучше использовать в подобном случае имя файла, которого пока не существует. Этот файл будет создан после выполнения команды. Назовём его date.txt. Расширение файла после точки обычно особой роли не играет, но расширения помогают поддерживать порядок. Итак, вот наша команда:
$ date > date.txt
Нельзя сказать, что сама по себе эта команда невероятно полезна, однако, основываясь на ней, мы уже можем сделать что-то более интересное. Скажем, вы хотите узнать, как меняются маршруты вашего трафика, идущего через интернет к некоей конечной точке, ежедневно записывая соответствующие данные. В решении этой задачи поможет команда traceroute, которая сообщает подробности о маршруте трафика между нашим компьютером и конечной точкой, задаваемой при вызове команды в виде URL. Данные включают в себя сведения обо всех маршрутизаторах, через которые проходит трафик.
Так как файл с датой у нас уже есть, будет вполне оправдано просто присоединить к этому файлу данные, полученные от traceroute. Для того, чтобы это сделать, надо использовать два символа >, поставленные один за другим. В результате новая команда, перенаправляющая вывод в файл, но не перезаписывающая его, а добавляющая новые данные после старых, будет выглядеть так:
$ traceroute google.com >> date.txt
Теперь нам осталось лишь изменить имя файла на что-нибудь более осмысленное, используя команду mv, которой, в качестве первого аргумента, передаётся исходное имя файла, а в качестве второго — новое:
$ mv date.txt trace1.txtПеренаправление стандартного потока ввода
Используя знак < вместо > мы можем перенаправить стандартный ввод, заменив его содержимым файла.
Предположим, имеется два файла: list1.txt и list2.txt, каждый из которых содержит неотсортированный список строк. В каждом из списков имеются уникальные для него элементы, но некоторые из элементов список совпадают. Мы можем найти строки, которые имеются и в первом, и во втором списках, применив команду comm, но прежде чем её использовать, списки надо отсортировать.
Существует команда sort, которая возвращает отсортированный список в терминал, не сохраняя отсортированные данные в файл, из которого они были взяты. Можно отправить отсортированную версию каждого списка в новый файл, используя команду >, а затем воспользоваться командой comm. Однако, такой подход потребует как минимум двух команд, хотя то же самое можно сделать в одной строке, не создавая при этом ненужных файлов.
Итак, мы можем воспользоваться командой < для перенаправления отсортированной версии каждого файла команде comm. Вот что у нас получилось:
$ comm <(sort list1.txt) <(sort list2.txt)
Круглые скобки тут имеют тот же смысл, что и в математике. Оболочка сначала обрабатывает команды в скобках, а затем всё остальное. В нашем примере сначала производится сортировка строк из файлов, а потом то, что получилось, передаётся команде comm, которая затем выводит результат сравнения списков.
Перенаправление стандартного потока ошибок
И, наконец, поговорим о перенаправлении стандартного потока ошибок. Это может понадобиться, например, для создания лог-файлов с ошибками или объединения в одном файле сообщений об ошибках и возвращённых некоей командой данных.
Например, что если надо провести поиск во всей системе сведений о беспроводных интерфейсах, которые доступны пользователям, у которых нет прав суперпользователя? Для того, чтобы это сделать, можно воспользоваться мощной командой find.
Обычно, когда обычный пользователь запускает команду find по всей системе, она выводит в терминал и полезные данные и ошибки. При этом, последних обычно больше, чем первых, что усложняет нахождение в выводе команды того, что нужно. Решить эту проблему довольно просто: достаточно перенаправить стандартный поток ошибок в файл, используя команду 2> (напомним, 2 — это дескриптор стандартного потока ошибок). В результате на экран попадёт только то, что команда отправляет в стандартный вывод:
$ find / -name wireless 2> denied.txtКак быть, если нужно сохранить результаты работы команды в отдельный файл, не смешивая эти данные со сведениями об ошибках? Так как потоки можно перенаправлять независимо друг от друга, в конец нашей конструкции можно добавить команду перенаправления стандартного потока вывода в файл:
$ find / -name wireless 2> denied.txt > found.txt
Обратите внимание на то, что первая угловая скобка идёт с номером — 2>, а вторая без него. Это так из-за того, что стандартный вывод имеет дескриптор 1, и команда > подразумевает перенаправление стандартного вывода, если номер дескриптора не указан.
И, наконец, если нужно, чтобы всё, что выведет команда, попало в один файл, можно перенаправить оба потока в одно и то же место, воспользовавшись командой &>:
$ find / -name wireless &> results.txtИтоги
Тут мы разобрали лишь основы механизма перенаправления потоков в интерпретаторе командной строки Linux, однако даже то немногое, что вы сегодня узнали, даёт вам практически неограниченные возможности. И, кстати, как и всё остальное, что касается работы в терминале, освоение перенаправления потоков требует практики. Поэтому рекомендуем вам приступить к собственным экспериментам с > и <.
Уважаемые читатели! Знаете ли вы интересные примеры использования перенаправления потоков в Linux, которые помогут новичкам лучше освоиться с этим приёмом работы в терминале?
Одна из самых интересных и полезных тем для системных администраторов и новых пользователей, которые только начинают разбираться в работе с терминалом — это перенаправление потоков ввода вывода Linux. Эта особенность терминала позволяет перенаправлять вывод команд в файл, или содержимое файла на ввод команды, объединять команды вместе, и образовать конвейеры команд.
В этой статье мы рассмотрим как выполняется перенаправление потоков ввода вывода в Linux, какие операторы для этого используются, а также где все это можно применять.
Как работает перенаправление ввода вывода
Все команды, которые мы выполняем, возвращают нам три вида данных:
- Результат выполнения команды, обычно текстовые данные, которые запросил пользователь;
- Сообщения об ошибках — информируют о процессе выполнения команды и возникших непредвиденных обстоятельствах;
- Код возврата — число, которое позволяет оценить правильно ли отработала программа.
В Linux все субстанции считаются файлами, в том числе и потоки ввода вывода linux — файлы. В каждом дистрибутиве есть три основных файла потоков, которые могут использовать программы, они определяются оболочкой и идентифицируются по номеру дескриптора файла:
- STDIN или 0 — этот файл связан с клавиатурой и большинство команд получают данные для работы отсюда;
- STDOUT или 1 — это стандартный вывод, сюда программа отправляет все результаты своей работы. Он связан с экраном, или если быть точным, то с терминалом, в котором выполняется программа;
- STDERR или 2 — все сообщения об ошибках выводятся в этот файл.
Перенаправление ввода / вывода позволяет заменить один из этих файлов на свой. Например, вы можете заставить программу читать данные из файла в файловой системе, а не клавиатуры, также можете выводить ошибки в файл, а не на экран и т д. Все это делается с помощью символов «<« и «>».
Перенаправить вывод в файл
Все очень просто. Вы можете перенаправить вывод в файл с помощью символа >. Например, сохраним вывод команды top:
top -bn 5 > top.log
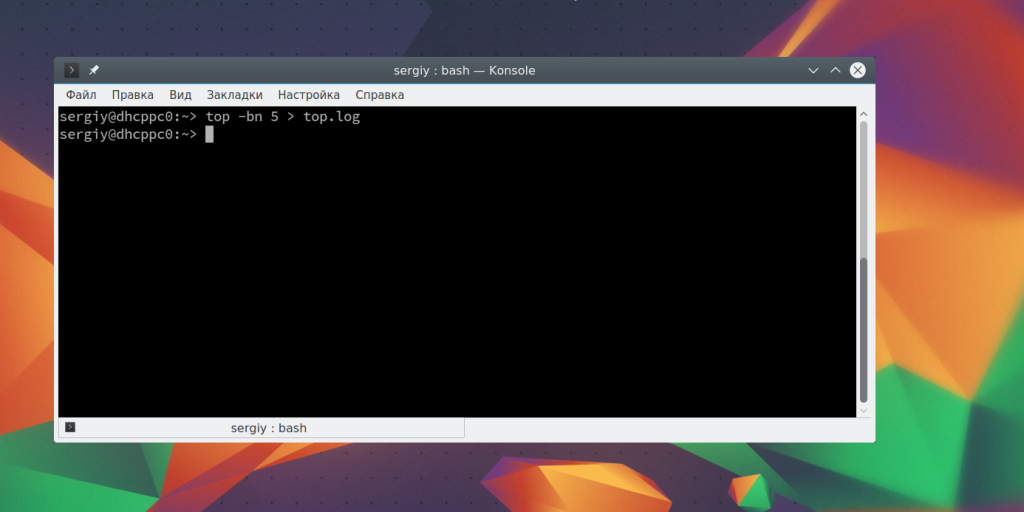
Опция -b заставляет программу работать в не интерактивном пакетном режиме, а n — повторяет операцию пять раз, чтобы получить информацию обо всех процессах. Теперь смотрим что получилось с помощью cat:
cat top.log
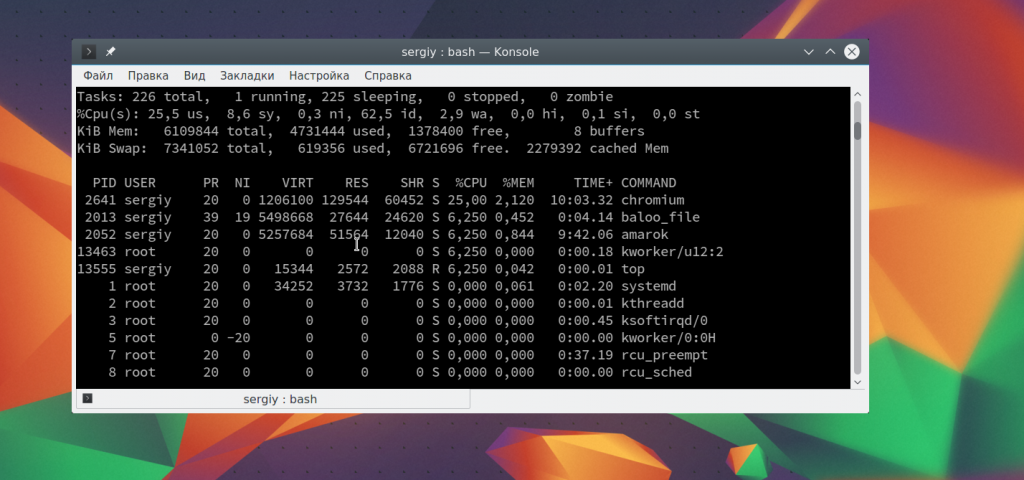
Символ «>» перезаписывает информацию из файла, если там уже что-то есть. Для добавления данных в конец используйте «>>». Например, перенаправить вывод в файл linux еще для top:
top -bn 5 >> top.log
По умолчанию для перенаправления используется дескриптор файла стандартного вывода. Но вы можете указать это явно. Эта команда даст тот же результат:
top -bn 5 1>top.log
Перенаправить ошибки в файл
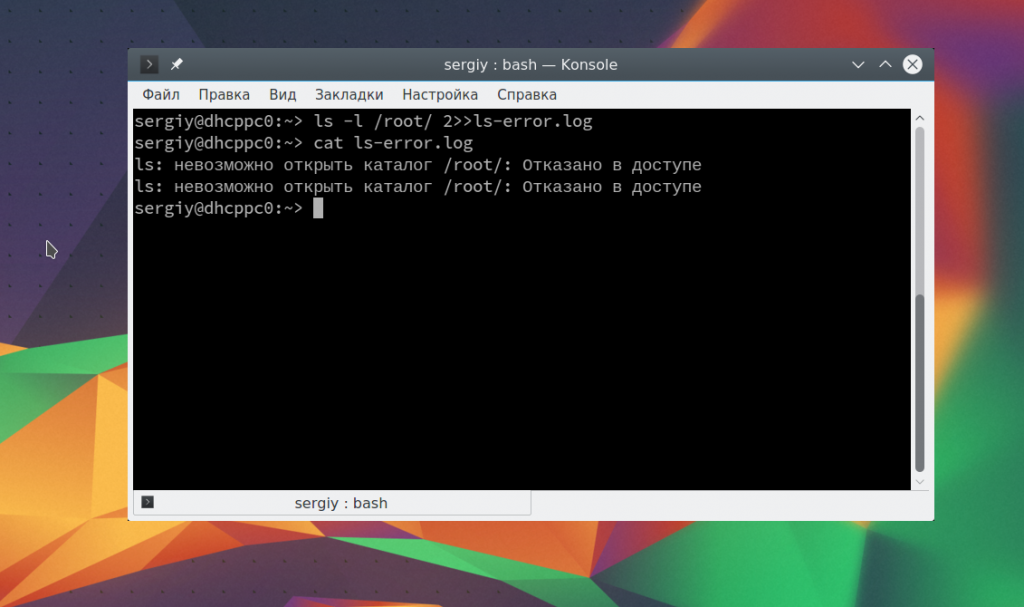
Чтобы перенаправить вывод ошибок в файл вам нужно явно указать дескриптор файла, который собираетесь перенаправлять. Для ошибок — это номер 2. Например, при попытке получения доступа к каталогу суперпользователя ls выдаст ошибку:
ls -l /root/
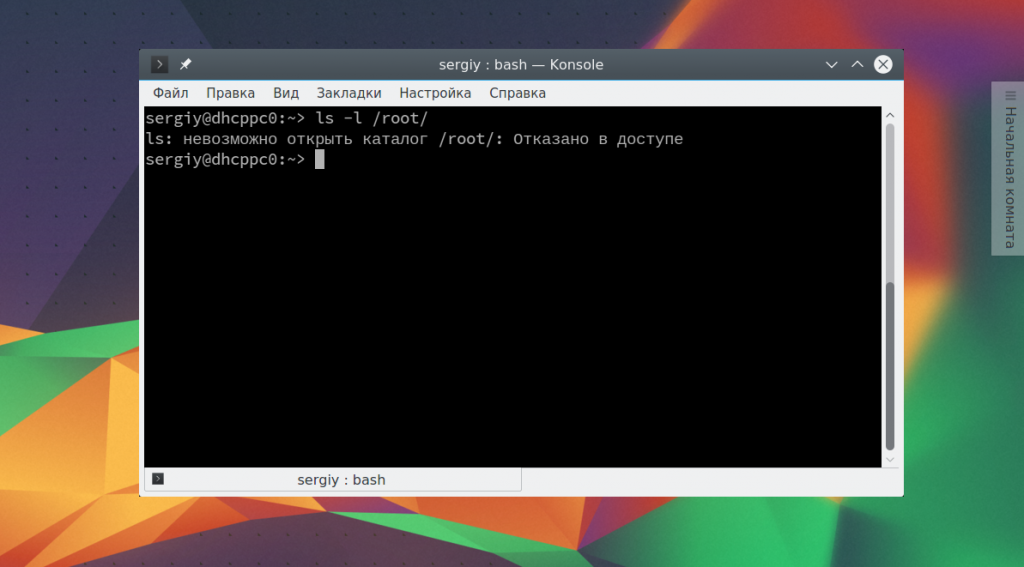
Вы можете перенаправить стандартный поток ошибок в файл так:
ls -l /root/ 2> ls-error.log
$ cat ls-error.log
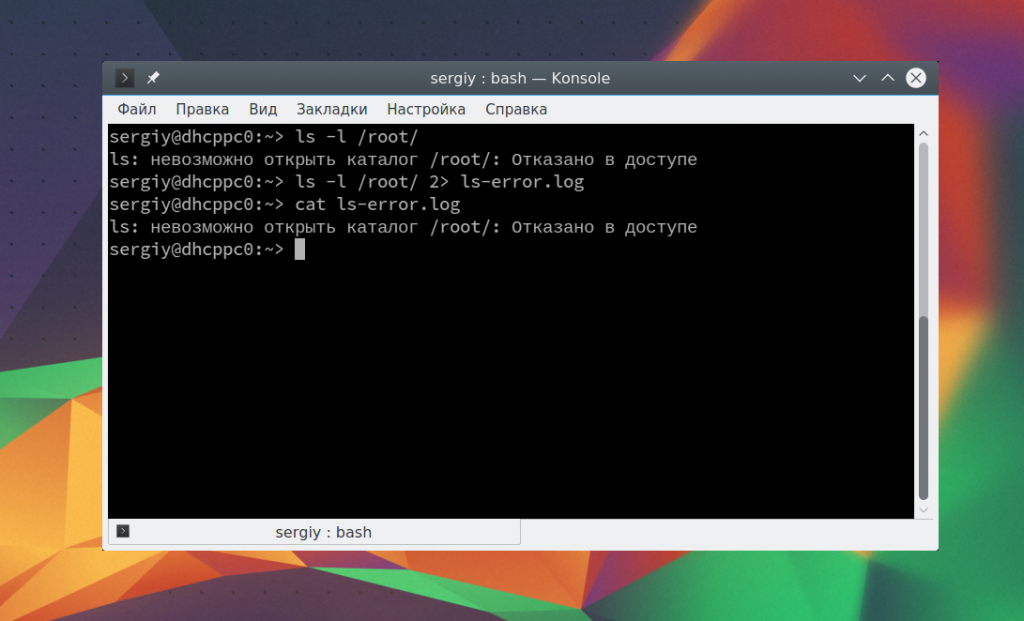
Чтобы добавить данные в конец файла используйте тот же символ:
ls -l /root/ 2>>ls-error.log
Перенаправить стандартный вывод и ошибки в файл
Вы также можете перенаправить весь вывод, ошибки и стандартный поток вывода в один файл. Для этого есть два способа. Первый из них, более старый, состоит в том, чтобы передать оба дескриптора:
ls -l /root/ >ls-error.log 2>&1
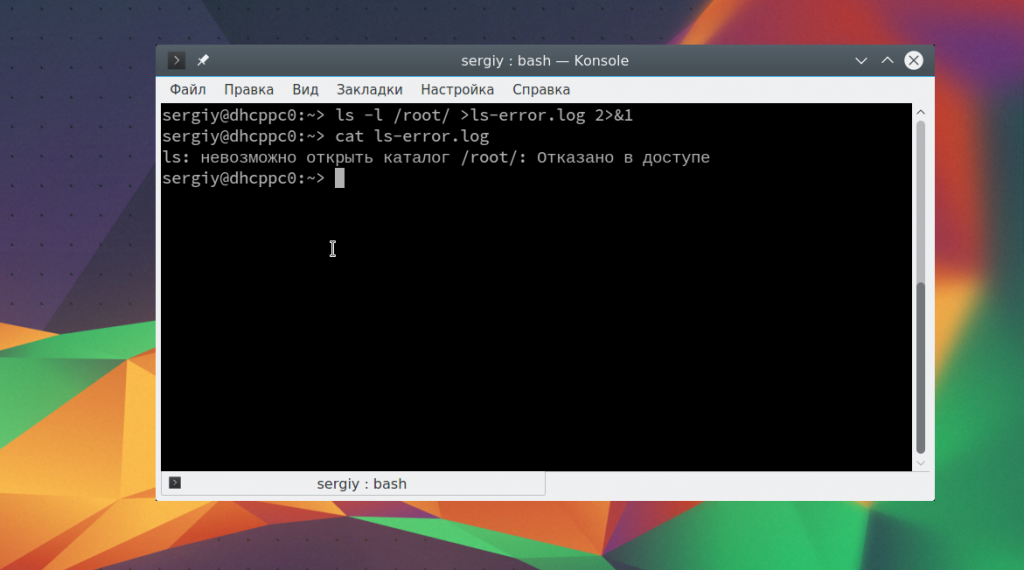
Сначала будет отправлен вывод команды ls в файл ls-error.log c помощью первого символа перенаправления. Дальше в тот же самый файл будут направлены все ошибки. Второй метод проще:
ls -l /root/ &> ls-error.log
Также можно использовать добавление вместо перезаписи:
ls -l /root/ &>> ls-error.log
Стандартный ввод из файла
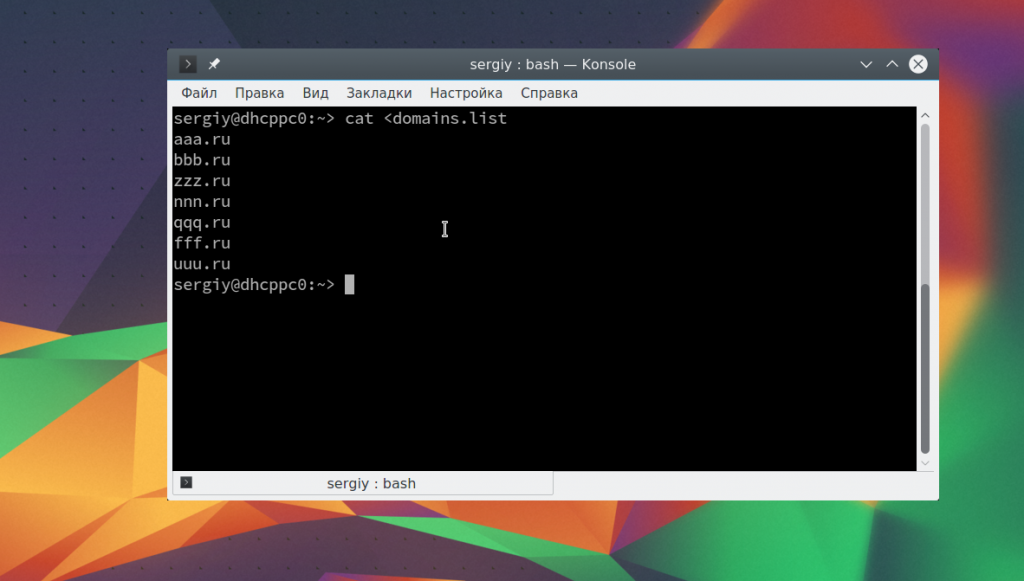
Большинство программ, кроме сервисов, получают данные для своей работы через стандартный ввод. По умолчанию стандартный ввод ожидает данных от клавиатуры. Но вы можете заставить программу читать данные из файла с помощью оператора «<«:
cat <domains.list
Вы также можете сразу же перенаправить вывод тоже в файл. Например, пересортируем список:
sort <domains.list >sort.output
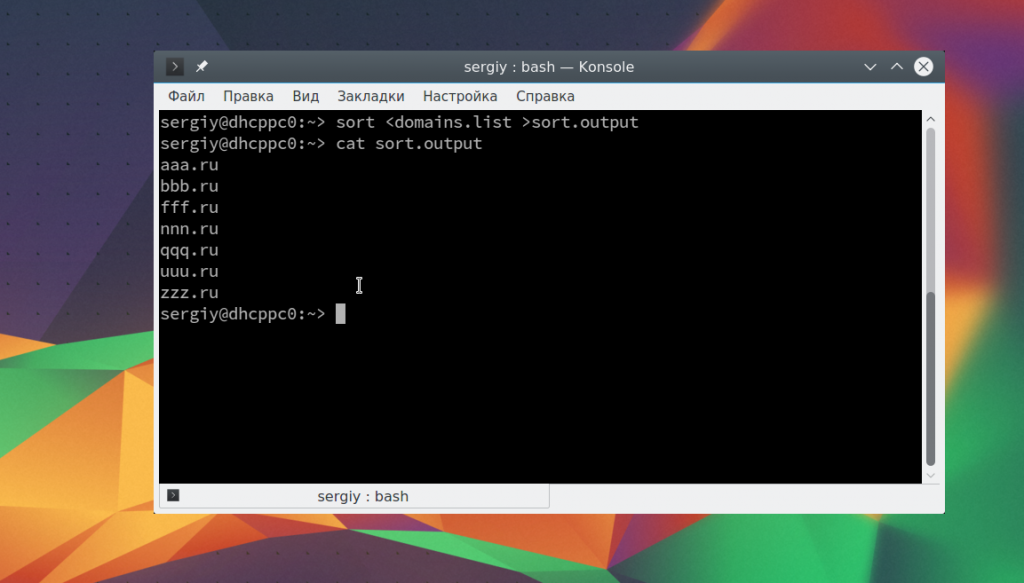
Таким образом, мы в одной команде перенаправляем ввод вывод linux.
Использование тоннелей
Можно работать не только с файлами, но и перенаправлять вывод одной команды в качестве ввода другой. Это очень полезно для выполнения сложных операций. Например, выведем пять недавно измененных файлов:
ls -lt | head -n 5
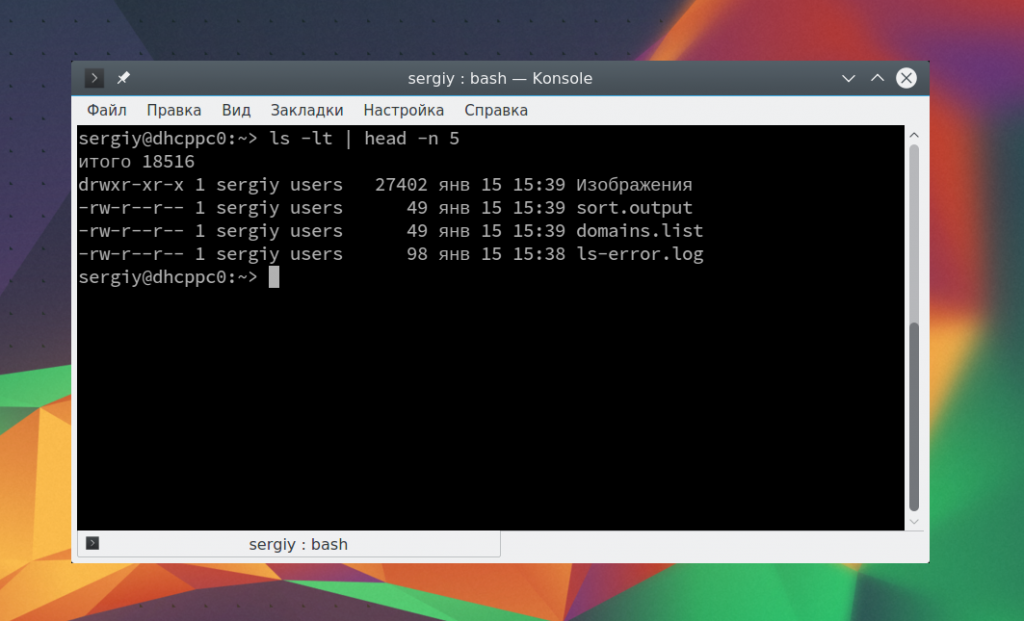
С помощью утилиты xargs вы можете комбинировать команды таким образом, чтобы стандартный ввод передавался в параметры. Например, скопируем один файл в несколько папок:
echo test/ tmp/ | xargs -n 1 cp -v testfile.sh
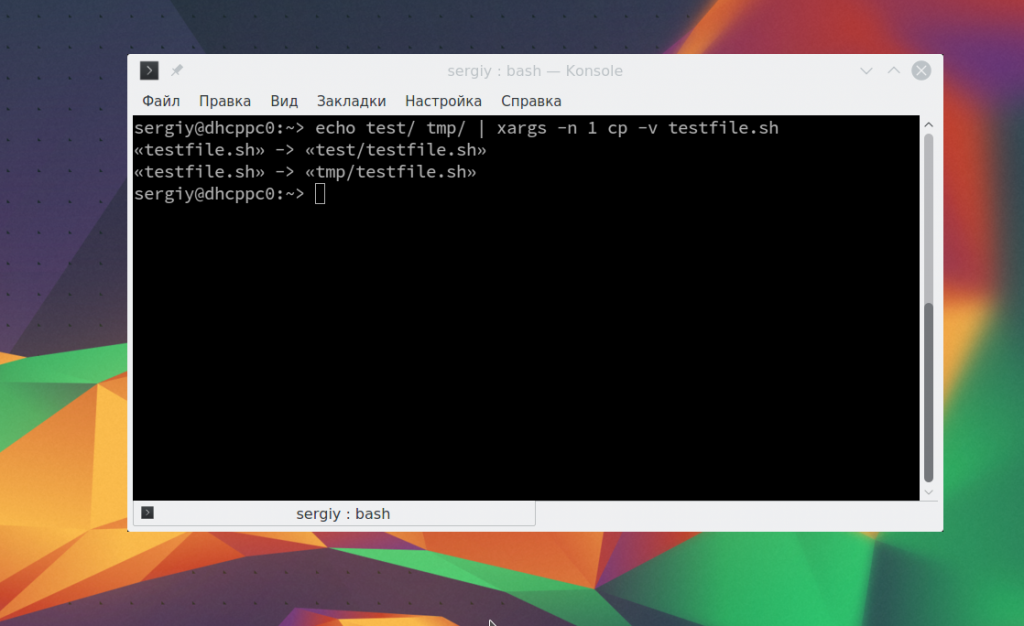
Здесь параметр -n 1 задает, что для одной команды нужно подставлять только один параметр, а опция -v в cp позволяет выводить подробную информацию о перемещениях. Еще одна, полезная в таких случаях команда — это tee. Она читает данные из стандартного ввода и записывает в стандартный вывод или файлы. Например:
echo "Тест работы tee" | tee file1
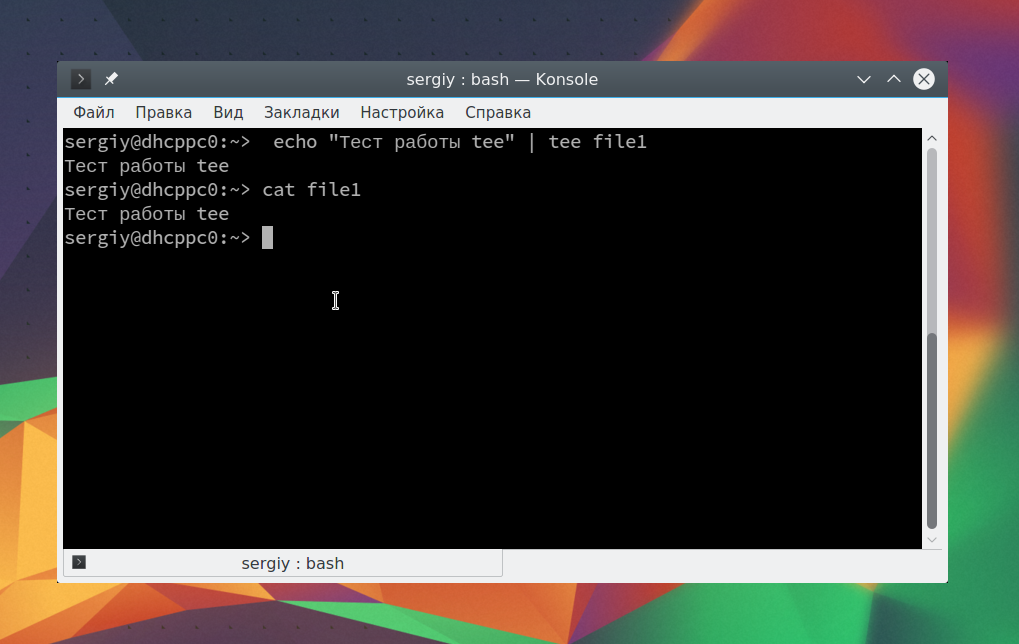
В сочетании с другими командами все это может использоваться для создания сложных инструкций из нескольких команд.
Выводы
В этой статье мы рассмотрели основы перенаправления потоков ввода вывода Linux. Теперь вы знаете как перенаправить вывод в файл linux или вывод из файла. Это очень просто и удобно. Если у вас остались вопросы, спрашивайте в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Введение
Стандартные потоки ввода и вывода в Linux являются одним из наиболее распространенных средств для обмена информацией процессов, а перенаправление >, >> и | является одной из самых популярных конструкций командного интерпретатора.
В данной статье мы ознакомимся с возможностями перенаправления потоков ввода/вывода, используемых при работе файлами и командами.
Требования
- Linux-система, например, Ubuntu 20.04
Потоки
Стандартный ввод при работе пользователя в терминале передается через клавиатуру.
Стандартный вывод и стандартная ошибка отображаются на дисплее терминала пользователя в виде текста.
Ввод и вывод распределяется между тремя стандартными потоками:
- stdin — стандартный ввод (клавиатура),
- stdout — стандартный вывод (экран),
- stderr — стандартная ошибка (вывод ошибок на экран).
Потоки также пронумерованы:
- stdin — 0,
- stdout — 1,
- stderr — 2.
Из стандартного ввода команда может только считывать данные, а два других потока могут использоваться только для записи. Данные выводятся на экран и считываются с клавиатуры, так как стандартные потоки по умолчанию ассоциированы с терминалом пользователя. Потоки можно подключать к чему угодно: к файлам, программам и даже устройствам. В командном интерпретаторе bash такая операция называется перенаправлением:
- < file — использовать файл как источник данных для стандартного потока ввода.
- > file — направить стандартный поток вывода в файл. Если файл не существует, он будет создан, если существует — перезаписан сверху.
- 2> file — направить стандартный поток ошибок в файл. Если файл не существует, он будет создан, если существует — перезаписан сверху.
- >>file — направить стандартный поток вывода в файл. Если файл не существует, он будет создан, если существует — данные будут дописаны к нему в конец.
- 2>>file — направить стандартный поток ошибок в файл. Если файл не существует, он будет создан, если существует — данные будут дописаны к нему в конец.
- &>file или >&file — направить стандартный поток вывода и стандартный поток ошибок в файл. Другая форма записи: >file 2>&1.
Стандартный ввод
Стандартный входной поток обычно переносит данные от пользователя к программе. Программы, которые предполагают стандартный ввод, обычно получают входные данные от устройства типа клавиатура. Стандартный ввод прекращается по достижении EOF (конец файла), который указывает на то, что данных для чтения больше нет.
EOF вводится нажатием сочетания клавиш Ctrl+D.
Рассмотрим работу со стандартным выводом на примере команды cat (от CONCATENATE, в переводе «связать» или «объединить что-то»).
Cat обычно используется для объединения содержимого двух файлов.
Cat отправляет полученные входные данные на дисплей терминала в качестве стандартного вывода и останавливается после того как получает EOF.
Пример
catВ открывшейся строке введите, например, 1 и нажмите клавишу Enter. На дисплей выводится 1. Введите a и нажмите клавишу Enter. На дисплей выводится a.
Дисплей терминала выглядит следующим образом:
test@111:~/stream$ cat
1
1
a
aДля завершения ввода данных следует нажать сочетание клавиш Ctrl + D.
Стандартный вывод
Стандартный вывод записывает данные, сгенерированные программой. Когда стандартный выходной поток не перенаправляется в какой-либо файл, он выводит текст на дисплей терминала.
При использовании без каких-либо дополнительных опций, команда echo выводит на экран любой аргумент, который передается ему в командной строке:
echo ПримерАргументом является то, что получено программой, в результате на дисплей терминала будет выведено:
ПримерПри выполнении echo без каких-либо аргументов, возвращается пустая строка.
Пример
Команда объединяет три файла: file1, file2 и file3 в один файл bigfile:
cat file1 file1 file1 > bigfileКоманда cat по очереди выводит содержимое файлов, перечисленных в качестве параметров на стандартный поток вывода. Стандартный поток вывода перенаправлен в файл bigfile.
Стандартная ошибка
Стандартная ошибка записывает ошибки, возникающие в ходе исполнения программы. Как и в случае стандартного вывода, по умолчанию этот поток выводится на терминал дисплея.
Пример
Рассмотрим пример стандартной ошибки с помощью команды ls, которая выводит список содержимого каталогов.
При запуске без аргументов ls выводит содержимое в пределах текущего каталога.
Введем команду ls с каталогом % в качестве аргумента:
ls %В результате должно выводиться содержимое соответствующей папки. Но так как каталога % не существует, на дисплей терминала будет выведен следующий текст стандартной ошибки:
ls: cannot access %: No such file or directoryПеренаправление потока
Linux включает в себя команды перенаправления для каждого потока.
Команды со знаками > или < означают перезапись существующего содержимого файла:
- > — стандартный вывод,
- < — стандартный ввод,
- 2> — стандартная ошибка.
Команды со знаками >> или << не перезаписывают существующее содержимое файла, а присоединяют данные к нему:
- >> — стандартный вывод,
- << — стандартный ввод,
- 2>> — стандартная ошибка.
Пример
В приведенном примере команда cat используется для записи в файл file1, который создается в результате цикла:
cat > file1
a
b
cДля завершения цикла нажмите сочетание клавиш Ctrl + D.
Если файла file1 не существует, то в текущем каталоге создается новый файл с таким именем.
Для просмотра содержимого файла file1 введите команду:
cat file1В результате на дисплей терминала должно быть выведено следующее:
a
b
cДля перезаписи содержимого файла введите следующее:
cat > file1
1
2
3Для завершения цикла нажмите сочетание клавиш Ctrl + D.
В результате на дисплей терминала должно быть выведено следующее:
1
2
3Предыдущего текста в текущем файле больше не существует, так как содержимое файла было переписано командой >.
Для добавления нового текста к уже существующему в файле с помощью двойных скобок >> выполните команду:
cat >> file1
a
b
cДля завершения цикла нажмите сочетание клавиш Ctrl + D.
Откройте file1 снова и в результате на дисплее монитора должно быть отражено следующее:
1
2
3
a
b
cКаналы
Каналы используются для перенаправления потока из одной программы в другую. Стандартный вывод данных после выполнения одной команды перенаправляется в другую через канал. Данные первой программы, которые получает вторая программа, не будут отображаться. На дисплей терминала будут выведены только отфильтрованные данные, возвращаемые второй командой.
Пример
Введите команду:
ls | lessВ результате каждый файл текущего каталога будет размещен на новой строке:
file1
file2
t1
t2Перенаправлять данные с помощью каналов можно как из одной команды в другую, так и из одного файла к другому, а перенаправление с помощью > и >> возможно только для перенаправления данных в файлах.
Пример
Для сохранения имен файлов, содержащих строку «LOG», используется следующая команда:
dir /catalog | find "LOG" > loglistВывод команды dir отсылается в команду-фильтр find. Имена файлов, содержащие строку «LOG», хранятся в файле loglist в виде списка (например, Config.log, Logdat.svd и Mylog.bat).
При использовании нескольких фильтров в одной команде рекомендуется разделять их с помощью знака канала |.
Фильтры
Фильтры представляют собой стандартные команды Linux, которые могут быть использованы без каналов:
- find — возвращает файлы с именами, которые соответствуют передаваемому аргументу.
- grep — возвращает только строки, содержащие (или не содержащие) заданное регулярное выражение.
- tee — перенаправляет стандартный ввод как стандартный вывод и один или несколько файлов.
- tr — находит и заменяет одну строку другой.
- wc — подсчитывает символы, линии и слова.
Как правило, все нижеприведенные команды работают как фильтры, если у них нет аргументов (опции могут быть):
- cat — считывает данные со стандартного потока ввода и передает их на стандартный поток вывода. Без опций работает как простой повторитель. С опциями может фильтровать пустые строки, нумеровать строки и делать другую подобную работу.
- head — показывает первые 10 строк (или другое заданное количество), считанных со стандартного потока ввода.
- tail — показывает последние 10 строк (или другое заданное количество), считанные со стандартного потока ввода. Важный частный случай tail -f, который в режиме слежения показывает концовку файла. Это используется, в частности, для просмотра файлов журнальных сообщений.
- cut — вырезает столбец (по символам или полям) из потока ввода и передает на поток вывода. В качестве разделителей полей могут использоваться любые символы.
- sort — сортирует данные в соответствии с какими-либо критериями, например, арифметически по второму столбцу.
- uniq — удаляет повторяющиеся строки. Или (с ключом -с) не просто удалить, а написать сколько таких строк было. Учитываются только подряд идущие одинаковые строки, поэтому часто данные сортируются перед тем как отправить их на вход программе.
- bc — вычисляет каждую отдельную строку потока и записывает вместо нее результат вычисления.
- hexdump — показывает шестнадцатеричное представление данных, поступающих на стандартный поток ввода.
- strings — выделяет и показывает в стандартном потоке (или файле) то, что напоминает строки. Всё что не похоже на строковые последовательности, игнорируется. Команда полезна в сочетании с grep для поиска интересующих строковых последовательностей в бинарных файлах.
- sed — обрабатывает текст в соответствии с заданным скриптом. Наиболее часто используется для замены текста в потоке: sed s/было/стало/g.
- awk — обрабатывает текст в соответствии с заданным скриптом. Как правило, используется для обработки текстовых таблиц, например, вывод ps aux и т.д.
- sh -s — текст, который передается на стандартный поток ввода sh -s. может интерпретироваться как последовательность команд shell. На выход передается результат их исполнения.
- ssh — средство удаленного доступа ssh, может работать как фильтр, который подхватывает данные, переданные ему на стандартный поток ввода, затем передает их на удаленный хост и подает на вход процессу программы, имя которой было передано ему в качестве аргумента. Результат выполнения программы (то есть то, что она выдала на стандартный поток вывода) передается со стандартного вывода ssh.
Если в качестве аргумента передается файл, команда-фильтр считывает данные из этого файла, а не со стандартного потока ввода (есть исключения, например, команда tr, обрабатывающая данные, поступающие исключительно через стандартный поток ввода).
Пример
Команда tee, как правило, используется для просмотра выводимого содержимого при одновременном сохранении его в файл.
wc ~/stream | tee file2Пример
Допускается перенаправление нескольких потоков в один файл:
ls -z >> file3 2>&1В результате сообщение о неверной опции «z» в команде ls будет записано в файл t2, поскольку stderr перенаправлен в файл.
Для просмотра содержимого файла file3 введите команду cat:
cat file3В результате на дисплее терминала отобразиться следующее:
ls: invalid option -- 'z'
Try 'ls --help' for more information.Заключение
Мы рассмотрели возможности работы с перенаправлениями потоков >, >> и |, использование которых позволяет лучше работать с bash-скриптами.
Введение
Одним из ключевых моментов философии UNIX было то, что все команды в командной строке (CLI) должны принимать текст в качестве ввода и выдавать текст в качестве вывода. Поскольку эта концепция была применена при разработке UNIX (и позже Linux), были разработаны команды для приема текста в качестве входных данных, выполнения какой-либо операции с текстом и последующего создания текста в качестве вывода. Команды, которые считывают текст в качестве входных данных, каким-либо образом изменяют этот текст, а затем создают текст в качестве выходных данных, иногда называют фильтрами.
Чтобы иметь возможность применять команды фильтрации и работать с текстовыми потоками, полезно понимать несколько форм перенаправления, которые можно использовать с большинством команд: конвейеры, стандартное перенаправление вывода, перенаправление вывода ошибок и перенаправление ввода.
Стандартный вывод
Когда команда выполняется без каких-либо ошибок, создаваемый вывод называется стандартным выводом, также называемым STDOUT. По умолчанию этот вывод будет отправлен на терминал, где выполняется команда.
Стандартный вывод можно перенаправить из команды, чтобы он перешел к файлу, а не к терминалу. Стандартное перенаправление вывода достигается выполнением команды с символом больше > и конечным файлом. Например, команда ls ~ выведет список файлов в домашнем каталоге. Чтобы сохранить список файлов в домашнем каталоге, вы должны направить вывод в текстовый файл.
timeweb@localhost:~$ ls ~ > /tmp/home.txtПосле чего содержимое файла home.txt будет иметь следующий вид:
timeweb@localhost:~$cat /tmp/home.txt
Desktop Documents Downloads Music Pictures Public Templates Videos
Перенаправление вывода с использованием одного символа больше > создаст новый файл или перезапишет содержимое существующего файла с тем же именем. Перенаправление стандартного вывода с двумя символами больше >> также создаст новый файл, если он не существует. Разница в том, что при использовании символов >> вывод команды будет добавлен в конец файла, если он уже существует. Например, чтобы добавить в конец файла вывод команды date, выполните следующее:
timeweb@localhost:~$ date >> /tmp/home.txt
timeweb@localhost:~$cat /tmp/home.txt
Desktop Documents Downloads Music Pictures Public Templates Videos Sun Jan 30 17:36:02 UTC 2022
Стандартная ошибка
Когда команда обнаруживает ошибку, она выдает вывод, известный как стандартная ошибка, также называемая stderr или STDERR. Как и стандартный вывод, стандартный вывод ошибок обычно отправляется на тот же терминал, где в данный момент выполняется команда. Число, связанное со стандартным дескриптором файла ошибок, равно 2.
Если вы попытаетесь выполнить команду ls /junk, то эта команда выдаст стандартные сообщения об ошибках, поскольку каталога /junk не существует.
timeweb@localhost:~$ ls /junk
ls: cannot access /junk: No such file or directoryПоскольку этот вывод переходит в стандартную ошибку, один только символ больше > не будет успешно перенаправлять его, и вывод команды все равно будет отправлен на терминал:
timeweb@localhost:~$ ls /junk > output
ls: cannot access /junk: No such file or directoryЧтобы перенаправить эти сообщения об ошибках, вы должны использовать правильный дескриптор файла, который для стандартной ошибки имеет номер 2. Выполните следующее, и ошибка будет перенаправлена в файл /tmp/ls.err:
timeweb@localhost:~$ ls /junk 2> /tmp/ls.errКак и при стандартном выводе, использование одного символа > для перенаправления либо создаст файл, если он не существует, либо уничтожит (перезапишет) содержимое существующего файла. Чтобы предотвратить стирание существующего файла при перенаправлении стандартной ошибки, вместо этого используйте двойные символы >> после числа 2 для добавления:
timeweb@localhost:~$ ls /junk 2>> /tmp/ls.errНекоторые команды будут выводить как stdout, так и stderr:
timeweb@localhost:~$ find /etc -name passwd
/etc/pam.d/passwd
/etc/passwd
find: '/etc/ssl/private': Permission deniedЭти два разных вывода можно перенаправить в два отдельных файла, используя следующий синтаксис:
timeweb@localhost:~$ find /etc -name passwd > /tmp/output.txt 2> /tmp/error.txtКоманду cat можно использовать для проверки успешности перенаправления выше:
timeweb@localhost:~$ cat /tmp/output.txt
/etc/pam.d/passwd
/etc/passwd
timeweb@localhost:~$ cat /tmp/error.txt
find: '/etc/ssl/private': Permission deniedИногда бесполезно отображать сообщения об ошибках в терминале или сохранять их в файле. Чтобы не сохранять эти сообщения об ошибках, используйте файл /dev/null.
Файл /dev/null похож на мусорное ведро, где все отправленное в него исчезает из системы; его иногда называют черной дырой. Любой тип вывода может быть перенаправлен в файл /dev/null; чаще всего пользователи перенаправляют стандартную ошибку в этот файл, а не в стандартный вывод.
Синтаксис использования файла /dev/null такой же, как и для перенаправления на обычный файл:
timeweb@localhost:~$ find /etc -name passw 2> /dev/null
/etc/pam.d/passwd
/etc/passwdЧто, если вы хотите, чтобы весь вывод (стандартная ошибка и стандартный вывод) отправлялся в один файл? Существует два метода перенаправления как стандартных ошибок, так и стандартных выходов:
timeweb@localhost:~$ ls > /tmp/ls.all 2>&1
timeweb@localhost:~$ ls &> /tmp/ls.all Обе предыдущие командные строки создадут файл с именем /tmp/ls.all, содержащий все стандартные выходные данные и стандартные ошибки. Первая команда перенаправляет стандартный вывод на /tmp/ls.all, а выражение 2>&1 означает «отправлять stderr туда, куда направляется stdout». Во втором примере выражение &> означает «перенаправить весь вывод».
Стандартный ввод
Стандартный ввод, также называемый stdin или STDIN, обычно поступает с клавиатуры, ввод осуществляется пользователем, выполняющим команду. Хотя большинство команд могут считывать ввод из файлов, некоторые ожидают, что пользователь введет их с помощью клавиатуры.
Одним из распространенных способов использования текстовых файлов в качестве стандартного ввода для команд является создание файлов сценариев. Скрипты представляют собой простые текстовые файлы, которые интерпретируются оболочкой при наличии соответствующих разрешений и начинаются с #!/bin/sh в первой строке, что указывает оболочке интерпретировать сценарий как стандартный ввод:
timeweb@localhost:~$ cat examplescriptfile.sh
#!/bin/sh
echo HelloWorldКогда файл скрипта вызывается в командной строке с использованием синтаксиса ./, оболочка выполнит все команды в файле скрипта и вернет результат в окно терминала или туда, куда указан вывод для отправки:
timeweb@localhost:~$ ./examplescriptfile.sh
HelloWorldВ некоторых случаях полезно перенаправить стандартный ввод, чтобы он поступал из файла, а не с клавиатуры. Хорошим примером того, когда желательно перенаправление ввода, является команда tr. Команда tr переводит символы, считывая данные со стандартного ввода; перевод одного набора символов в другой набор символов, а затем запись измененного текста в стандартный вывод.
Например, следующая команда tr будет принимать данные от пользователя (через клавиатуру), чтобы выполнить преобразование всех символов нижнего регистра в символы верхнего регистра. Выполните следующую команду, введите текст и нажмите Enter, чтобы увидеть перевод:
timeweb@localhost:~$ tr 'a-z' 'A-Z'
hello
HELLOКоманда tr не прекращает чтение из стандартного ввода, если только она не завершена. Это можно сделать, нажав комбинацию клавиш Ctrl+D.
Команда tr не принимает имя файла в качестве аргумента в командной строке. Чтобы выполнить перевод с использованием файла в качестве входных данных, используйте перенаправление ввода. Чтобы использовать перенаправление ввода, введите команду с ее параметрами и аргументами, за которыми следует символ меньше чем < и путь к файлу, который будет использоваться для ввода. Например:
timeweb@localhost:~$ cat Documents/animals.txt
1 retriever
2 badger
3 bat
4 wolf
5 eagle
timeweb@localhost:~$ tr 'a-z' 'A-Z' < Documents/animals.txt
1 RETRIEVER
2 BADGER
3 BAT
4 WOLF
5 EAGLEКонвейеры команд
Конвейеры команд часто используются для эффективного использования команд фильтрации. В командном конвейере выходные данные одной команды отправляются другой команде в качестве входных данных. В Linux и большинстве операционных систем вертикальная черта | используется между двумя командами для представления конвейера команд.
Например, представьте, что вывод команды history очень велик. Чтобы отправить этот вывод команде less, которая отображает одну страницу данных за раз, можно использовать следующий конвейер команд:
timeweb@localhost:~$ history | lessЕще лучше пример, взять вывод команды history и отфильтровать вывод с помощью команды grep. В следующем примере текст, выводимый командой history, перенаправляется в команду grep в качестве входных данных. Команда grep сопоставляет строки ls и отправляет вывод на стандартный вывод:
timeweb@localhost:~$ history | grep "ls"
1 ls ~ > /tmp/home.txt
5 ls l> /tmp/ls.txt
6 ls 1> /tmp/ls.txt
7 date 1>> /tmp/ls.txt
8 ls /junk
9 ls /junk > output
10 ls /junk 2> /tmp/ls.err
11 ls /junk 2>> /tmp/ls.err
14 ls > /tmp/ls.all 2>&1
15 ls &> /tmp/ls.all
16 ls /etc/au* >> /tmp/ls.all 2>&1
17 ls /etc/au* &>> /tmp.ls.all
20 history | grep "ls"Командные конвейеры становятся действительно мощными, когда объединяются в три или более команд. Например, просмотрите содержимое файла os.csv в каталоге Documents:
timeweb@localhost:~$ cat Documents/os.csv
1970,Unix,Richie
1987,Minix,Tanenbaum
1970,Unix,Thompson
1991,Linux,TorvaldsСледующая командная строка извлечет некоторые поля из файла os.csv с помощью команды cut, затем отсортирует эти строки с помощью команды sort и, наконец, удалит повторяющиеся строки с помощью команды uniq:
timeweb@localhost:~$ cut -f1 -d',' Documents/os.csv | sort -n | uniq
1970
1987
1991Команда tee
Администратор сервера работает как сантехник, используя «трубы» и иногда команду tee. Команда tee разбивает вывод команды на два потока: один направляется на стандартный вывод, который отображается в терминале, а другой — в файл.
Команда tee может быть очень полезна для создания журнала команды или сценария. Например, чтобы записать время выполнения процесса, начните с команды date и скопируйте вывод в файл timer.txt:
timeweb@localhost:~$ date | tee timer.txt
Mon Jan 1 02:21:24 UTC 2022Файл timer.txt теперь содержит копию даты, тот же вывод, что и в предыдущем примере:
timeweb@localhost:~$ cat timer.txt
Mon Jan 1 02:21:24 UTC 2022Чтобы добавить время в конец файла timer.txt, используйте параметр -a:
timeweb@localhost:~$ date | tee -a timer.txt
Mon Jan 1 02:28:43 UTC 2022Чтобы запустить несколько команд как одну команду, используйте точку с запятой; символ в качестве разделителя:
timeweb@localhost:~$ date | tee timer.txt; sleep 15; date | tee -a timer.txt
Mon Jan 1 02:35:47 UTC 2022
Mon Jan 1 02:36:02 UTC 2022Приведенная выше команда отобразит и запишет первый вывод команды date, сделает паузу на 15 секунд, затем отобразит и запишет вывод второй команды date. Файл timer.txt теперь содержит постоянный журнал среды выполнения.
Команда xargs
Опции и параметры команды обычно указываются в командной строке, как аргументы командной строки. В качестве альтернативы мы можем использовать команду xargs для сбора аргументов из другого источника ввода (например, файла или стандартного ввода), а затем передать эти аргументы команде. Команду xargs можно вызывать напрямую, и она примет любой ввод:
timeweb@localhost:~$ xargs
Hello
ThereЧтобы выйти из команды xargs, нажмите Ctrl+C.
По умолчанию команда xargs передает ввод команде echo, когда за ней явно не следует другая команда. После нажатия Ctrl+D команда xargs отправит ввод в команду echo:
Важно знать: Нажатие Ctrl+D после выхода из команды xargs с помощью Ctrl+C приведет к выходу из текущей оболочки. Чтобы отправить ввод команды xargs в команду echo без выхода из оболочки, нажмите Ctrl+D во время выполнения команды xargs.
Команда xargs наиболее полезна, когда она вызывается в канале. В следующем примере с помощью команды touch будут созданы четыре файла. Файлы будут называться 1a, 1b, 1c и 1d на основе вывода команды echo.
timeweb@localhost:~$ echo '1a 1b 1c 1d' | xargs touch
timeweb@localhost:~$ ls
1a 1c Desktop Downloads Pictures Templates timer.txt
1b 1d Documents Music Public VideosЗаключение
Мы рассмотрели перенаправление потоков ввода-вывода в Linux: стандартное перенаправление вывода, перенаправление вывода ошибок, перенаправление ввода и конвейеры. Понимание их возможностей упростит работу с bash-скриптами и позволит удобнее администрировать серверы cloud.timeweb.com с операционными системами семейства Linux.
Фундаментальные основы Linux. Часть IV. Программные каналы и команды
Оригинал: Linux Fundamentals
Автор: Paul Cobbaut
Дата публикации: 16 октября 2014 г.
Перевод: А.Панин
Дата перевода: 15 декабря 2014 г.
Глава 16. Перенаправление потоков ввода/вывода
Одной из мощных возможностей командной оболочки системы Unix является механизм перенаправления потоков ввода/вывода с возможностью задействования программных каналов.
В данной главе даются пояснения относительно перенаправления стандартных потоков ввода, вывода и ошибок.
Потоки данных stdin, stdout и stderr
Командная оболочка bash поддерживает три типа базовых потоков данных; она принимает данные из стандартного потока ввода stdin (поток 0), отправляет данные в стандартный поток вывода stdout (поток 1), а также отправляет сообщения об ошибках в стандартный поток ошибок stderr (поток 2).
Приведенная ниже иллюстрация является графической интерпретацией этих трех потоков данных.
Клавиатура обычно служит источником данных для стандартного потока ввода stdin, в то время, как стандартные потоки вывода stdout и ошибок stderr используются для вывода данных. Новых пользователей Linux может смущать подобное разделение, так как не существует очевидного способа дифференцирования стандартных потоков вывода stdout и ошибок stderr. Опытные же пользователи знают о том, что разделение стандартных потоков вывода и ошибок может оказаться весьма полезным.

В следующем разделе будет рассказано о том, как осуществляется перенаправление упомянутых потоков данных.
Перенаправление стандартного потока вывода
Операция перенаправления потока данных stdout (>)
Перенаправление стандартного потока вывода stdout может быть осуществлено с помощью символа знака "больше". В том случае, если при разборе строки команды командная оболочка обнаруживает символ знака >, она удаляет данные из файла и перенаправлет данные из стандартного потока вывода в него.

Нотация > фактически является аббревиатурой для 1> (в данном случае стандартный поток вывода обозначается как поток номер 1).
[paul@RHELv4u3 ~]$ echo Сегодня холодно! Сегодня холодно! [paul@RHELv4u3 ~]$ echo Сегодня холодно! > winter.txt [paul@RHELv4u3 ~]$ cat winter.txt Сегодня холодно! [paul@RHELv4u3 ~]$
Обратите внимание на то, что командная оболочка bash фактически удаляет описание операции перенаправления потока данных из строки команды перед исполнением этой команды, представленной аргументом 0. Это значит, что в случае исполнения данной команды:
echo привет > greetings.txt
командная оболочка будет рассматривать только два аргумента (echo = аргумент 0, привет = аргумент 1). Описание операции перенаправления потока данных удаляется перед началом подсчета количества аргументов.
Содержимое выходного файла удаляется
В том случае, если в процессе разбора строки команды командная оболочка обнаружит символ знака >, содержимое указанного после него файла будет удалено! Ввиду того, что описанная процедура выполняется перед извлечением аргумента 0, содержимое файла будет удалено даже в случае неудачного исполнения команды!
[paul@RHELv4u3 ~]$ cat winter.txt Сегодня холодно! [paul@RHELv4u3 ~]$ zcho Сегодня холодно! > winter.txt -bash: zcho: команда не найдена.. [paul@RHELv4u3 ~]$ cat winter.txt [paul@RHELv4u3 ~]$
Параметр командной оболочки noclobber
Удаление содержимого файла при использовании оператора > может быть предотвращено путем установки параметра командной оболочки noclobber.
[paul@RHELv4u3 ~]$ cat winter.txt Сегодня холодно! [paul@RHELv4u3 ~]$ set -o noclobber [paul@RHELv4u3 ~]$ echo Сегодня холодно! > winter.txt -bash: winter.txt: не могу переписать уже существующий файл [paul@RHELv4u3 ~]$ set +o noclobber [paul@RHELv4u3 ~]$
Нейтрализация влияния параметра командной оболочки noclobber
Влияние параметра командной оболочки noclobber может быть нейтрализовано с помощью оператора >|.
[paul@RHELv4u3 ~]$ set -o noclobber [paul@RHELv4u3 ~]$ echo Сегодня холодно! > winter.txt -bash: winter.txt: не могу переписать уже существующий файл [paul@RHELv4u3 ~]$ echo Сегодня очень холодно! >| winter.txt [paul@RHELv4u3 ~]$ cat winter.txt Сегодня очень холодно! [paul@RHELv4u3 ~]$
Оператор дополнения >>
Следует использовать оператор >> для записи данных из стандартного потока вывода в конец файла без предварительного удаления содержимого этого файла.
[paul@RHELv4u3 ~]$ echo Сегодня холодно! > winter.txt [paul@RHELv4u3 ~]$ cat winter.txt Сегодня холодно! [paul@RHELv4u3 ~]$ echo Когда же наступит лето ? >> winter.txt [paul@RHELv4u3 ~]$ cat winter.txt Сегодня холодно! Когда же наступит лето ? [paul@RHELv4u3 ~]$
Перенаправление стандартного потока ошибок
Операция перенаправления потока данных stderr (2>)
Перенаправление стандартного потока ошибок осуществляется с помощью оператора 2>. Такое перенаправление может оказаться очень полезным для предотвращения заполнения вашего экрана сообщениями об ошибках.

В примере ниже показана методика перенаправления данных из стандартного потока вывода в файл, а данных из стандартного потока ошибок — в специальный файл устройства /dev/null. Запись 1> идентична записи >.
[paul@RHELv4u3 ~]$ find / > allfiles.txt 2> /dev/null [paul@RHELv4u3 ~]$
Операция перенаправления нескольких потоков данных 2>&1
Для перенаправления данных как из стандартного потока вывода, так и из стандартного потока ошибок в один и тот же файл следует использовать конструкцию 2>&1.
[paul@RHELv4u3 ~]$ find / > allfiles_and_errors.txt 2>&1 [paul@RHELv4u3 ~]$
Помните о том, что последовательность операций перенаправления потоков данных имеет значение. К примеру, команда
ls > dirlist 2>&1
позволяет перенаправить как данные из стандартного потока вывода (с файловым дескриптором 1), так и данные из стандартного потока ошибок (с файловым дескриптором 2) в файл dirlist, в то время, как команда
ls 2>&1 > dirlist
позволяет перенаправить только данные из стандартного потока вывода в файл dirlist, так как с помощью данной команды осуществляется копирование дескриптора стандартного потока вывода в дескриптор стандартного потока ошибок перед тем, как стандартный поток вывода перенаправляется в файл dirlist.
Перенаправление стандартного потока вывода и программные каналы
По умолчанию вы не можете использовать утилиту grep для обработки данных стандартного потока ошибок stderr приложения при использовании программных каналов в рамках строки команды, так как данная утилита получает данные исключительно из стандартного потока вывода stdout приложения.
paul@debian7:~$ rm file42 file33 file1201 | grep file42 rm: невозможно удалить "file42": Нет такого файла или каталога rm: невозможно удалить "file33": Нет такого файла или каталога rm: невозможно удалить "file1201": Нет такого файла или каталога
С помощью конструкции 2>&1 вы можете переправить данные из стандартного потока ошибок stderr в стандартный поток вывода stdout приложения. Это обстоятельство позволяет обрабатывать передаваемые посредством программного канала данные из обоих потоков с помощью следующей команды.
paul@debian7:~$ rm file42 file33 file1201 2>&1 | grep file42 rm: невозможно удалить "file42": Нет такого файла или каталога
Вы не можете одновременно использовать конструкции 1>&2 и 2>&1 для осуществления обмена файловых дескрипторов между стандартным потоком вывода stdout и стандартным потоком ошибок stderr.
paul@debian7:~$ rm file42 file33 file1201 2>&1 1>&2 | grep file42 rm: невозможно удалить "file42": Нет такого файла или каталога paul@debian7:~$ echo file42 2>&1 1>&2 | sed 's/file42/FILE42/' FILE42
Вам потребуется третий поток данных для осуществления обмена файловых дескрипторов между стандартным потоком вывода stdout и стандартным потоком ошибок stderr перед символом для создания программного канала.
paul@debian7:~$ echo file42 3>&1 1>&2 2>&3 | sed 's/file42/FILE42/' file42 paul@debian7:~$ rm file42 3>&1 1>&2 2>&3 | sed 's/file42/FILE42/' rm: невозможно удалить "FILE42": Нет такого файла или каталога
Объединение стандартных потоков вывода stdout и ошибок stderr
Конструкция &> позволяет объединить стандартные потоки вывода stdout и ошибок stderr в рамках одного потока данных (причем данные будут сохраняться в файле).
paul@debian7:~$ rm file42 &> out_and_err paul@debian7:~$ cat out_and_err rm: невозможно удалить "file42": Нет такого файла или каталога paul@debian7:~$ echo file42 &> out_and_err paul@debian7:~$ cat out_and_err file42 paul@debian7:~$
Перенаправление стандартного потока ввода
Операция перенаправления потока данных stdin (<)
Перенаправление стандартного потока ввода stdin осуществляется с помощью оператора < (являющегося краткой версией оператора 0<).
[paul@RHEL4b ~]$ cat < text.txt one two [paul@RHEL4b ~]$ tr 'onetw' 'ONEZZ' < text.txt ONE ZZO [paul@RHEL4b ~]$
Структура < here document
Структура here document (иногда называемая структурой here-is-document) является механизмом для ввода данных до момента обнаружения определенной последовательности символов (обычно EOF). Маркер EOF может быть либо введен вручную, либо вставлен автоматически при нажатии комбинации клавиш Ctrl-D.
[paul@RHEL4b ~]$ cat <EOF > text.txt > один > два > EOF [paul@RHEL4b ~]$ cat text.txt один два [paul@RHEL4b ~]$ cat <brol > text.txt > brel > brol [paul@RHEL4b ~]$ cat text.txt brel [paul@RHEL4b ~]$
Структура < here string
Структура here string может использоваться для непосредственной передачи строк команде. При использовании данной структуры достигается такой же эффект, как и при использовании команды echo строка | команда (но вы сможете избежать создания одного дополнительного процесса).
paul@ubu1110~$ base64 < linux-training.be bGludXgtdHJhaW5pbmcuYmUK paul@ubu1110~$ base64 -d << bGludXgtdHJhaW5pbmcuYmUK linux-training.be
Для получения дополнительной информации об алгоритме base64 следует обратиться к стандарту rfc 3548.
Неоднозначное перенаправление потоков ввода/вывода
Командная оболочка будет осуществлять разбор всей строки команды перед осуществлением перенаправления потоков ввода/вывода. Следующая команда является хорошо читаемой и корректной:
cat winter.txt > snow.txt 2> errors.txt
Но следующая команды также является корректной, хотя и хуже читается:
2> errors.txt cat winter.txt > snow.txt
Даже следующая команда будет прекрасно интерпретироваться командной оболочкой:
< winter.txt > snow.txt 2> errors.txt cat
Быстрая очистка содержимого файла
Так какой же самый быстрый способ очистки содержимого файла?
>foo
А какой самый быстрый способ очистки содержимого файла в случае активации параметра командной оболочки noclobber?
>|bar
Практическое задание: перенаправление потоков ввода/вывода
-
1. Активируйте параметр командной оболочки
noclobber. -
2. Проверьте, активирован ли параметр
noclobber, повторив вызов команды вывода содержимого директорииlsдля директории/etcс перенаправлением данных из стандартного потока вывода в файл. -
3. Какой из символов представляет параметр
noclobberв списке всех параметров командной оболочки. -
4. Деактивируйте параметр
noclobber. -
5. Убедитесь в том, что вы имеете доступ к двум командным оболочкам, открытым на одном компьютере. Создайте пустой файл
tailing.txt. После этого выполните командуtail -f tailing.txt. Используйте вторую командную оболочку длядобавлениястроки текста в этот файл. Убедитесь в том, что эта строка была выведена в первой командной оболочке. -
6. Создайте файл, содержащий имена пяти людей. Используйте команду
catи механизм перенаправления потоков ввода/вывода для создания файла, а также структуруhere documentдля завершения ввода.
Корректная процедура выполнения практического задания: перенаправление потоков ввода/вывода
-
1. Активируйте параметр командной оболочки
noclobber. -
2. Проверьте, активирован ли параметр
noclobber, повторив вызов команды вывода содержимого директорииlsдля директории/etcс перенаправлением данных из стандартного потока вывода в файл. -
ls /etc > etc.txt ls /etc > etc.txt (команда не должна работать)
-
3. Какой из символов представляет параметр
noclobberв списке всех параметров командной оболочки. -
echo $- (параметр noclobber представлен символом C)
-
4. Деактивируйте параметр
noclobber. -
5. Убедитесь в том, что вы имеете доступ к двум командным оболочкам, открытым на одном компьютере. Создайте пустой файл
tailing.txt. После этого выполните командуtail -f tailing.txt. Используйте вторую командную оболочку длядобавлениястроки текста в этот файл. Убедитесь в том, что эта строка была выведена в первой командной оболочке. -
paul@deb503:~$ > tailing.txt paul@deb503:~$ tail -f tailing.txt hello world в другой командной оболочке: paul@deb503:~$ echo hello >> tailing.txt paul@deb503:~$ echo world >> tailing.txt
-
6. Создайте файл, содержащий имена пяти людей. Используйте команду
catи механизм перенаправления потоков ввода/вывода для создания файла, а также структуруhere documentдля завершения ввода. -
paul@deb503:~$ cat > tennis.txt < ace > Justine Henin > Venus Williams > Serena Williams > Martina Hingis > Kim Clijsters > ace paul@deb503:~$ cat tennis.txt Justine Henin Venus Williams Serena Williams Martina Hingis Kim Clijsters paul@deb503:~$