New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and
privacy statement. We’ll occasionally send you account related emails.
Already on GitHub?
Sign in
to your account
Comments
Can’t download anything. After hangin a long time at «Getting snapshot pages» the downloader fails with an error. Checked on 2 different servers, in different countries, the same problem. Web wersion of wayback machine, by the way, is not working properly too — «connection lost» way too often.
The question is — is it me being unlucky, or web archive servers are in trouble? A month ago downloader was working just fine…
+1
I’m not sure why the other issue was closed. This is still a problem.
Getting snapshot pagesC:/Ruby31-x64/lib/ruby/3.1.0/net/http.rb:1001:in `rescue in connect': Failed to open TCP connectio
n to web.archive.org:443 (A connection attempt failed because the connected party did not properly respond after a perio
d of time, or established connection failed because connected host has failed to respond. - user specified timeout) (Net
::OpenTimeout)
from C:/Ruby31-x64/lib/ruby/3.1.0/net/http.rb:997:in `connect'
from C:/Ruby31-x64/lib/ruby/3.1.0/net/http.rb:976:in `do_start'
from C:/Ruby31-x64/lib/ruby/3.1.0/net/http.rb:965:in `start'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:323:in `open_http'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:741:in `buffer_open'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:212:in `block in open_loop'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:210:in `catch'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:210:in `open_loop'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:151:in `open_uri'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:721:in `open'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader/arch
ive_api.rb:13:in `get_raw_list_from_api'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader.rb:8
8:in `get_all_snapshots_to_consider'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader.rb:1
05:in `get_file_list_curated'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader.rb:1
64:in `get_file_list_by_timestamp'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader.rb:3
09:in `file_list_by_timestamp'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader.rb:1
92:in `download_files'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/bin/wayback_machine_downloader:72:i
n `<top (required)>'
from C:/Ruby31-x64/bin/wayback_machine_downloader:32:in `load'
from C:/Ruby31-x64/bin/wayback_machine_downloader:32:in `<main>'
C:/Ruby31-x64/lib/ruby/3.1.0/socket.rb:61:in `connect_internal': A connection attempt failed because the connected party
did not properly respond after a period of time, or established connection failed because connected host has failed to
respond. - user specified timeout (Errno::ETIMEDOUT)
from C:/Ruby31-x64/lib/ruby/3.1.0/socket.rb:137:in `connect'
from C:/Ruby31-x64/lib/ruby/3.1.0/socket.rb:642:in `block in tcp'
from C:/Ruby31-x64/lib/ruby/3.1.0/socket.rb:227:in `each'
from C:/Ruby31-x64/lib/ruby/3.1.0/socket.rb:227:in `foreach'
from C:/Ruby31-x64/lib/ruby/3.1.0/socket.rb:632:in `tcp'
from C:/Ruby31-x64/lib/ruby/3.1.0/net/http.rb:998:in `connect'
from C:/Ruby31-x64/lib/ruby/3.1.0/net/http.rb:976:in `do_start'
from C:/Ruby31-x64/lib/ruby/3.1.0/net/http.rb:965:in `start'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:323:in `open_http'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:741:in `buffer_open'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:212:in `block in open_loop'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:210:in `catch'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:210:in `open_loop'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:151:in `open_uri'
from C:/Ruby31-x64/lib/ruby/3.1.0/open-uri.rb:721:in `open'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader/arch
ive_api.rb:13:in `get_raw_list_from_api'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader.rb:8
8:in `get_all_snapshots_to_consider'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader.rb:1
05:in `get_file_list_curated'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader.rb:1
64:in `get_file_list_by_timestamp'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader.rb:3
09:in `file_list_by_timestamp'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/lib/wayback_machine_downloader.rb:1
92:in `download_files'
from C:/Ruby31-x64/lib/ruby/gems/3.1.0/gems/wayback_machine_downloader-2.3.1/bin/wayback_machine_downloader:72:i
n `<top (required)>'
from C:/Ruby31-x64/bin/wayback_machine_downloader:32:in `load'
from C:/Ruby31-x64/bin/wayback_machine_downloader:32:in `<main>'
Same issue here, but I got a message related to SSL:
/usr/lib/ruby/2.7.0/net/protocol.rb:44:in `connect_nonblock’: SSL_connect SYSCALL returned=5 errno=0 state=SSLv3/TLS write client hello (OpenSSL::SSL::SSLError)
So if I keep retrying, I can sometimes get it to connect. We get the same 443 error on files, but also this:
http://cvp.com/pdf/sb200-os-one-sheet.pdf # An existing connection was forcibly closed by the remote host. - SSL_connect
websites/cvp.com%2a/pdf/sb200-os-one-sheet.pdf was empty and was removed.
So, it is an issue with Archive.org servers then. Today after restarting a task like 10 times, I was able to successfully download a site, but it was slow and had to restart a couple times to get pages that were not downloaded due to timeout…
I’ve had similar issues this week. Each download worked after retrying a few times.
Hi all,
Firstly thank you to the original coders of this. I’ve been looking for such a tool for ages!
I’m having an issue though (latest ubuntu x64, latest Ruby)
When trying to download a desired site I get this error:
jay@jay-VirtualBox:~/wayback-machine-downloader$ sudo wayback_machine_downloader http://www.sitename.co.uk
Downloading http://www.sitename.co.uk to websites/www.sitename.co.uk/ from Wayback Machine…
/usr/lib/ruby/1.9.1/net/http.rb:763:in initialize': getaddrinfo: Name or service not known (SocketError) from /usr/lib/ruby/1.9.1/net/http.rb:763:inopen’
from /usr/lib/ruby/1.9.1/net/http.rb:763:in block in connect' from /usr/lib/ruby/1.9.1/timeout.rb:55:intimeout’
from /usr/lib/ruby/1.9.1/timeout.rb💯in timeout' from /usr/lib/ruby/1.9.1/net/http.rb:763:inconnect’
from /usr/lib/ruby/1.9.1/net/http.rb:756:in do_start' from /usr/lib/ruby/1.9.1/net/http.rb:745:instart’
from /usr/lib/ruby/1.9.1/open-uri.rb:306:in open_http' from /usr/lib/ruby/1.9.1/open-uri.rb:775:inbuffer_open’
from /usr/lib/ruby/1.9.1/open-uri.rb:203:in block in open_loop' from /usr/lib/ruby/1.9.1/open-uri.rb:201:incatch’
from /usr/lib/ruby/1.9.1/open-uri.rb:201:in open_loop' from /usr/lib/ruby/1.9.1/open-uri.rb:146:inopen_uri’
from /usr/lib/ruby/1.9.1/open-uri.rb:677:in open' from /usr/lib/ruby/1.9.1/open-uri.rb:33:inopen’
from /var/lib/gems/1.9.1/gems/wayback_machine_downloader-0.2.0/lib/wayback_machine_downloader.rb:42:in get_file_list_curated' from /var/lib/gems/1.9.1/gems/wayback_machine_downloader-0.2.0/lib/wayback_machine_downloader.rb:72:inget_file_list_by_timestamp’
from /var/lib/gems/1.9.1/gems/wayback_machine_downloader-0.2.0/lib/wayback_machine_downloader.rb:83:in download_files' from /var/lib/gems/1.9.1/gems/wayback_machine_downloader-0.2.0/bin/wayback_machine_downloader:32:in<top (required)>’
from /usr/local/bin/wayback_machine_downloader:23:in load' from /usr/local/bin/wayback_machine_downloader:23:in
‘
I’m new to github so it could very well be user error but I’m pretty sure I did it correctly.. although i did get errors during the install:
jay@jay-VirtualBox:~/wayback-machine-downloader$ sudo gem install wayback_machine_downloader
WARNING: Error fetching data: SocketError: getaddrinfo: Name or service not known (http://rubygems.org/latest_specs.4.8.gz)
Fetching: wayback_machine_downloader-0.2.0.gem (100%)
Successfully installed wayback_machine_downloader-0.2.0
1 gem installed
Installing ri documentation for wayback_machine_downloader-0.2.0…
Installing RDoc documentation for wayback_machine_downloader-0.2.0…
Any help or advice greatly appreciated.
Как скачать и восстановить сайт из вебархива?
Содержание
- 1 Как скачать и восстановить сайт из вебархива?
- 1.1 Чем восстановить сайт из веб архива?
- 1.1.1 Устанавливаем утилиту для восстановления сайтов из archive.org
- 1.1.2 Запускаем выкачивание сайта из веб архива
- 1.1.3 Создание конфигурации nginx для восстановленного сайта
- 1.2 Как проверить сайт без смены DNS?
- 1.3 Очистка кода восстановленного сайта
- 1.3.1 Как удалить фрагменты html кода на множестве статических страниц?
- 1.4 Как массово редактировать тайтлы и другие элементы на статическом сайте?
- 1.5 Как перевести статический сайт с www на без www?
- 1.6 Как создать карту сайта sitemap.xml для статического сайта?
- 1.7 Как установить счётчик на все страницы статического сайта?
- 1.1 Чем восстановить сайт из веб архива?
Наткнулся на битую ссылку. Ссылка была на мануал по настройке бэкапов для сайта. Тема интересовала настолько, что полез в archive.org смотреть, что там за мануал такой. Там обнаружил блог человека, который когда-то занимался сайтостроительством, какими-то темами в интернете. Но видимо бросил всё это. Блог существовал до декабря 2013 года, потом еще год висела заглушка. Я возьми да и проверь домен сайта. Он оказался свободным. Дело в том, что меня интересовали подобные сайты давно, я время от времени захожу на telderi и присматриваю себе недорогой сайт IT-тематики для покупки. Пока ничего подходящего по цене/качеству не подобрал.
Зачем мне нужен такой сайт? Я вынашиваю план сделать что-то вроде слияния или поглощения. Соединить такой сайт, с вот этим. Чтобы увеличить на нем трафик и прочие ништяки. Кто-то скажет — а как же диверсификация? Безусловно, диверсификация — дело хорошее. Но тут ещё диверсифицировать пока нечего, нужно сначала что-нибудь развить. И вот, видится мне идея слияния сайтов очень перспективной.
Итак, это всё предыстория. Задумал я найденный сайт восстановить. Оказалось на нём около 300 страниц. Зарегистрировал домен и принялся разыскивать инструмент для выкачивания сайта.
Чем восстановить сайт из веб архива?
Процедура-то нехитрая. Бери и качай. Но дело осложняется тем, что страниц много, и все они будут в виде статических html-файлов. Вручную качать замучаешься. Стал спрашивать у людей, которые таким делом занимались. Люди посоветовали r-tools.org. Он оказался платным. Стал гуглить, поскольку я-то знаю, что это простая процедура, и платить за нее не хотелось, пусть и такую небольшую плату. Решение нашлось очень быстро в виде приложения на ruby. Как я и предполагал, всё очень просто, инструкция прилагается.
Устанавливаем утилиту для восстановления сайтов из archive.org
Недолго думая, устанавливаю всё на сервер и запускаю восстановление.
#устанавливаем руби:
apt-get install ruby
#Ставим сам инструмент:
gem install wayback_machine_downloader
Запускаем выкачивание сайта из веб архива

wayback_machine_downloader http://www.site.ru --timestamp 20131209110704
Здесь в опции timestamp можно указывать отметку снапшота. Поскольку сайт может иметь десятки или сотни снимков в веб-архиве. Я указываю последний, когда сайт был еще жив, логично. Утилита сразу же определяет количество страниц и выводит на консоль выкачиваемые страницы.
Все скачивается и сохраняется, получаем россыпь статических файлов в папке. Создаем у себя папку в нужном месте, и кладем туда выкачанные файлы. Я люблю использовать rsync:
rsync -avh ./websites/www.site.com/ /var/www/site.com/
Остается только создать конфигурацию в nginx, дождаться обновления dns.
Предлагаю!
Если вы не хотите вдаваться в подробности и вам просто нужно восстановить сайт с чисткой кода, заменой или установкой счётчиков или баннеров, рекламных кодов, у меня есть для вас предложение.
Восстановить сайт из вебархива всего за 500 рублей:
Ну а для тех, кто хочет много букв с непонятными командами и скриптами, разобраться и делать самостоятельно — продолжаем.
Создание конфигурации nginx для восстановленного сайта
Я делаю универсальный конфиг, с прицелом на будущее — обработку php. Возможно понадобится, если захочется оживить сайт и доработать фунционал, например формы отправки сообщений, подписки.
А вообще, минимальная конфигурация для статического сайта будет выглядеть примерно так:
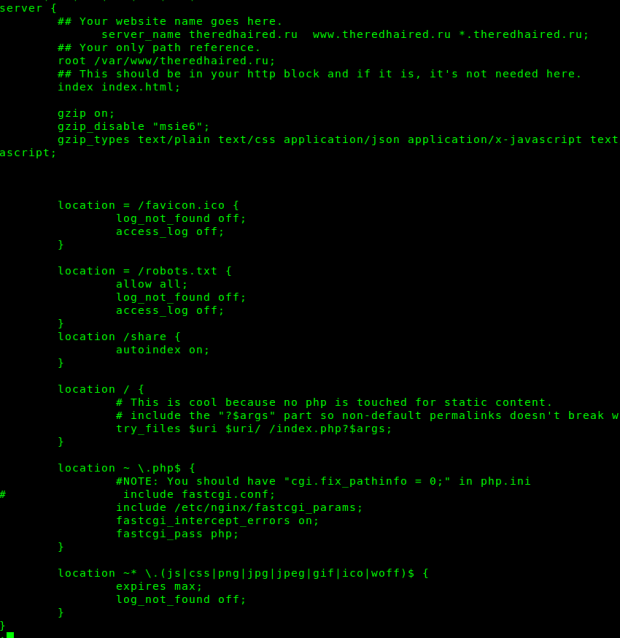
server {
server_name site.ru www.site.ru *.site.ru;
root /var/www/site.ru;
index index.html;
gzip on;
gzip_disable «msie6»;
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript;
location = /robots.txt {
allow all;
log_not_found off;
access_log off;
}
location ~* .(js|css|png|jpg|jpeg|gif|ico|woff)$ {
expires max;
log_not_found off;
}
}
Эта конфигурация заодно включает в себя настройки оптимизации для Google Pagespeed — сжатие и кэширование в браузере.
Перезапускаем вебсервер:
service nginx restart
Как проверить сайт без смены DNS?
В принципе можно ждать обновления dns после регистрации домена. Но хочется поскорее увидеть результат. Да и работу можно сразу начать. Для этого есть нехитрый способ — записать IP сервера для нужного домена в файл hosts, запись такого вида:
10.10.1.1 site.ru
После этого нужный сайт станет открываться исключительно у вас на компьютере.
Вот так. Чувствую себя некромантом

Сайт будет показываться ровно так, как видели его пользователи. Все ссылки будут работать, поскольку у вас есть все нужные файлы. Возможно какие-то из них будут битыми, где-то будет не хватать изображений, стилей или чего-нибудь ещё. Но это не суть важно — ведь самое главное для любого сайта — контент. А он, скорее всего, сохранится.
Очистка кода восстановленного сайта
Но это ещё не всё. Хотя можно и оставить в таком виде. Но чтобы добиться лучшего эффекта, есть смысл немного причесать восстановленный сайт. Это вообще самая сложная часть во всей этой затее. Дело в том, что раз сайт будет показываться так, как видели его пользователи, в коде страниц будет куча всевозможного мусора. Это в первую очередь реклама, баннеры и счётчики. Также какие-то элементы, которые на статическом сайте ни к чему. К примеру, ссылка для входа в админку сайта. Формы для отправки комментариев, подписки, какие-нибудь кнопки и другие элементы, доставшиеся в наследство от динамической CMS, на которой сайт работал раньше. В моём случае это был WordPress.
Как удалить фрагменты html кода на множестве статических страниц?
Как же это всё можно убрать? Очень просто. Смотреть в коде — и просто удалять ненужное. Легко сказать. Но страниц у нас несколько сотен. Поэтому тут нужна магия.
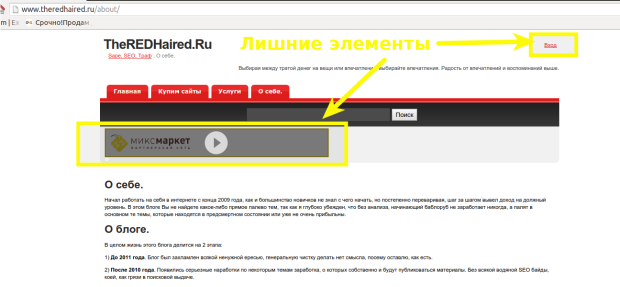
Удаляем сквозные элементы в коде статического сайта
Вот так я убираю ссылку «Вход» на всех html-файлах в указанной папке:
find ./site.ru/ -type f -name '*.html' -exec sed -i 's|<p id="top_info"> <a href="http://www.site.ru/wp-login.php">Вход</a></p>||g'
{} ;
Вот такой конструкцией можно убрать ВСЕ html-теги из файла. Самое простое. У вас тогда получатся текстовые файлы
sed -e 's/<[^>]*>//g' test.html
Нормальный подход, если вы просто качаете контент и потом будете использовать только полезное содержимое для чего-либо другого — для написания новых статей, для дорвеев, или чего-то ещё.
Но мне это не подходит, я хочу сначала воссоздать сайт полностью и посмотреть как он будет оживать и будет ли вообще. Поэтому работа по очистке кода занимает у меня пару часов кропотливой работы. Я открываю страницы сайта, отладчиком смотрю исходный код страниц, нахожу ненужные мне javascript, баннеры, счетчики, формы.
Вот так я убираю счетчик Liveinternet cо всех страниц моего статического сайта:
find site.ru/ -type f -name '*.html' -exec sed -i '/<!--LiveInternet counter-->/,/<!--/LiveInternet-->/d' {} ;
Вот так убираю подключение рекламного баннера:
find site.ru/ -type f -name '*.html' -exec sed -i 's|<link type="text/css" rel="stylesheet" href="http://mixmarket.biz/uni/partner.css">||g' {
} ;
Несмотря на конструкции, которые несведущему человеку могут показаться страшными — это довольно простые вещи, поскольку в этом счетчике есть уникальные теги-комментарии, по которым мы определяем часть кода для удаления, указав их в качестве паттернов.
В некоторых случаях приходится поломать голову, чтобы вырезать лишнее и не задеть нужное, ведь некоторые элементы могут повторяться на страницах. Например, для удаления счетчика Google Analytics пришлось сочинять вот такое:
Сначала удаляю строку <script type=»text/javascript»> с которой начинается счетчик. Эта команда удаляет строку над паттерном var gaJsHost, поскольку мне нужно удалить её только в этом месте и не трогать нигде больше:
find site.ru/ -type f -name '*.html' -exec sed -i -n '/var gaJsHost/{x;d;};1h;1!{x;p;};${x;p;}' {} ;
Теперь вырезаем остальную часть, которую становится легко идентифицировать по уникальным паттернам в первой и последней строках:
find site.ru/ -type f -name '*.html' -exec sed -i '/var gaJsHost/,/catch(err)/d' {} ;
Аналогичным образом я убираю форму добавления комментариев:
Зачищаю 4 строки с неуникальными закрывающими тегами после строки с уникальным паттерном:
find theredhaired.ru/ -type f -iname '*.html' -exec sed -i '/block_links/{N;N;N;N;s/n.*//;}' {} ;
А теперь вырезаю довольно большой блок строк на 30, указав уникальные паттерны его первой строки и последней:
find theredhaired.ru/ -type f -iname '*.html' -exec sed -i '/<h2> Подписка/,/block_links/d' {} ;
Вот эти последние пару случаев можно конечно попытаться выпилить с помощью мультистрочных паттернов, но я их так и не осилил, сколько не гуглил. Примеров с multi-line находил много, но они все простые, где нету спецсимоволов, escape-символов (табы, переводы строки).
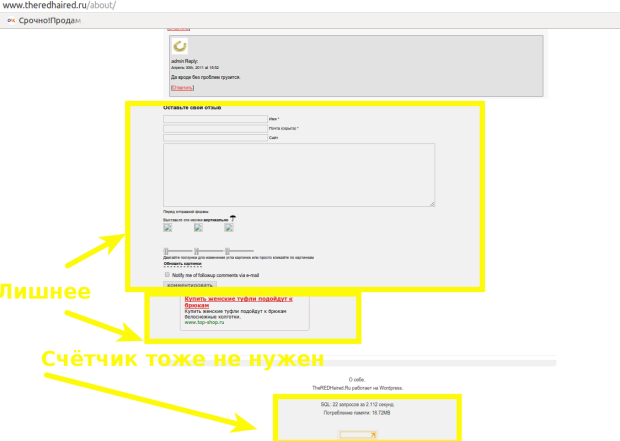
Удаляем счётчики, баннеры и формы с восстановленного сайта
Возможно всю эту очистку будет проще сделать на php или даже perl, для которого обработка текста это предназначение. Но я, к сожалению, оными не владею, поэтому использую bash и sed.
Всё это я проделывал на отдельной копии сайта с кучей итераций, тестов, чтобы всегда была возможность откатить изменения я сохранял копии после каждого значительного изменения, опять же с помощью rsync.
Как массово редактировать тайтлы и другие элементы на статическом сайте?
Поскольку моя задача не просто воскресить сайт, а добиться его индексации, ранжирования в поиске и даже получения трафика из поиска — мне нужно подумать о каком-никаком SEO. Оригинальные тайтлы мне однозначно не подходят, поэтому я хочу их изменить. В наследие от WordPress досталась схема %sitename% » %postname%. Тем более sitename у нас невнятный — сам домен сайта. Самый простой вариант выпилить первую часть тайтла. Но это мне тоже не годится. Поэтому я поменяю эту часть тайтла на хитрый запрос. Вот так я это делаю:
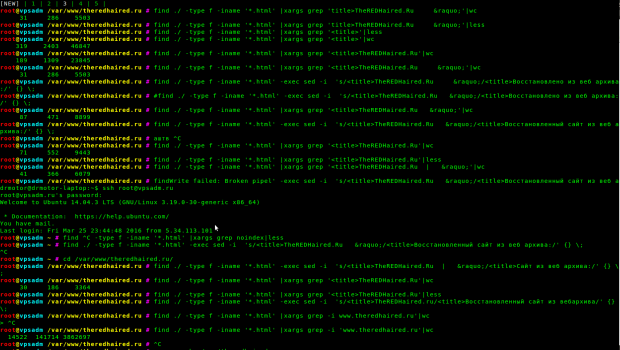
Как видите, множество проверок и итераций. Но в итоге, тайтлы становятся такими, какими нужно. Можно догадаться, что я затеял попытку собирать на этот сайт трафик по запросам о восстановлении сайтов из веб архива. Зачем мне это нужно — я собираюсь оказывать платную услугу по восстановлению таких сайтов. Как видите, в данном случае довольно просто сделать замену. Можно было не заморачиваться несколькими вариантами, а подвести всё под один. Но мне захотелось убрать или поменять лишние символы, а раз уж вариантов оказалось несколько, то я и поменял их на несколько своих. Такое вот SEO.
Теперь я собираюсь добавить Яндекс Метрику во все html-файлы моего сайта. А заодно перевести его со старой схемы www на без www.
Как перевести статический сайт с www на без www?
Это делается простой заменой:
find ./ -type f -iname ‘*.html’ -exec sed -i ‘s/http://www.site.ru/http://site.ru/g’ {} ;
После чего на всякий случай в конфигурации nginx вынесем вариант с www в редирект:
server {
server_name www.site.ru;
return 301 $scheme://site.ru$request_uri;
}
Как создать карту сайта sitemap.xml для статического сайта?
Это понадобится, когда мы будем добавлять сайт в поисковые системы. Это очень важно, учитывая что наш сайт восстановленный, на нем возможно отстутствует какая-нибудь навигация, и на какие-то страницы вообще не будет ссылок. Карта сайта этот момент сглаживает — даже если переходом по самому сайту на страницу попасть нельзя — мы указав ее в sitemap.xml позволим её проиндексировать, что потенциально может привести трафик из поиска прямо на страницу.
Генерирую карту с помощью сервиса, который создаёт её из списка страниц. Как получить такой список? Всё оттуда же, из консоли:
find site.ru/ -type f -iname ‘*.html’|grep -v ‘site.ru/go|wp-login|wp-admin’|less
На выходе получаю чистенький список страниц и сразу же скармливаю его в сервис. Я тут при генерации списка исключил кое-какой мусор. go — это бывшие внешние ссылки ну и страницы админки, которые у нас всё равно закрыты в robots.txt.
Как установить счётчик на все страницы статического сайта?
Последний штрих. Я ведь собираюсь отслеживать свои успехи. Поэтому мне нужно обязательно добавить какой-нибудь счётчик. Я ставлю на свои сайты обычно и Google аналитику и метрику яндекса. Но работаю больше с метрикой, analytics пользуюсь изредка для специфичных вещей. Здесь же мне счетчик гугла вообще не понадобится, по крайней мере первое время.
Итак, чтобы добавить во все страницы счётчик метрики, я воспользовался способом с выносом кода счётчика в отдельный js-файл. Просто потому, что так будет проще добавить потом код его вызова на все страницы. Создал счётчик, и записал его код в metrika.js
Теперь добавляю строку с его вызовом на все страницы перед закрывающим тегом body:
find site.ru/ -type f -iname ‘*.html’ -exec sed -i ‘/</body>/i
<script type=»text/javascript» src=»/metrika.js»></script>’ {} ;
Теперь проверяю, везде ли установилось:
find site.ru/ -type f -iname ‘*.html’|xargs grep ‘metrika.js’|wc -l
173
И получаю неприятный сюрприз — установлено не везде. Около сотни страниц упущено. Это могло произойти только в том случае, если в каких то файлах нету тега </body>. Смотрим:
find site.ru/ -type f -iname ‘*.html’|xargs grep -L ‘</body>’|wc -l
119
Как раз в 119 файлах этого тега нету. Это совсем плохо, видимо на каком то из этапов по очистке что-то пошло не так, и был срублен этот тег. Можно конечно выяснить когда это случилось и откатиться до того момента, но это куча работы. Поэтому я просто добавлю в эти файлы недостающие теги, и потом таки добавлю счётчик.
find site.ru/ -type f -iname '*.html'|xargs grep -L '</body>'|xargs sed -i '$ i
> </body></html>'
Я делаю это одной строкой, чтобы указать паттерном именно теги в паре. Иначе, если я воспользуюсь для добавления счётчика той же командой, что я уже сделал — то я продублирую вызов счётчика там, где он уже есть. Чтобы этого избежать можно конечно удалить строку там где она есть и потом добавить её снова, но я просто укажу спаренный тег в виде паттерна и добавлю только в те файлы. Вот так:
find site.ru/ -type f -iname '*.html' -exec sed -i '/</body></html>/i
> <script type="text/javascript" src="/metrika.js"></script>' {} ;
Проверяю снова:
find theredhaired.ru/ -type f -iname '*.html'|xargs grep 'metrika.js'|wc -l
266
Ну вот, 266 из 290 это уже лучше Там оказалось еще что 30 страниц не попали под какой-то из скриптов из-за кривых имен с вопросительными знаками. Я думаю мне достаточно и тех что есть
Что дальше?
Дальше мне пришла в голову мысль заточить имеющуюся на сайте страницу об услугах под предложение восстановления сайтов из веб архива.
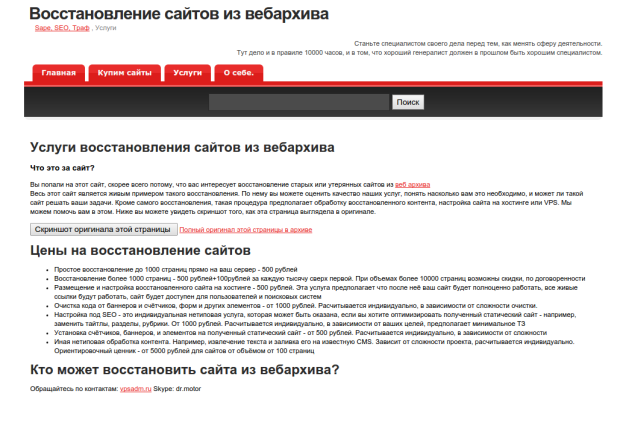
Вот что получилось после очистки и правки страницы под свои нужды
Кроме того, через некоторое время я проведу анализ результатов, которых я достиг с этим сайтом. Трафик, лиды или что-то ещё. Так что, следите за обновлениями на сайте, через 2-6 месяцев вы увидите продолжение истории. Покажу стату, если таковая будет и т. д. Если вы читаете эту статью спустя полгода, а ссылки на продолжение до сих пор нет — напомните мне об этом в комментариях, пожалуйста
Разобрались, не?
Если вы прониклись, во всём разобрались и собираетесь делать самостоятельно — низкий вам поклон и уважуха. Мне нравятся люди, которые хотят во всём разобраться и постичь.
Если же вы кроме хаоса в мыслях ничего не испытываете после прочтения, а решить задачу надо, я отношусь со столь же большим уважением к тем, кто умеет находить профессионалов и просто делегировать свои задачи
Позвольте мне стать богаче на 500 рублей от решения вашей задачи
I’m trying to run a ruby gem command called wayback-machine-downloader from R using the shell command:
shell(ruby_call)
but I get the following error messages:
‘wayback_machine_downloader’ is not recognized as an internal or external command, operable program or batch file.
Warning messages:
1: running command ‘C:WINDOWSsystem32cmd.exe /c wayback_machine_downloader https://undergroundreptiles.com/ —directory C:/Users/oliver/websites/underground_19981212033710 —from 19981212033710 —concurrency 200’ had status 1
2: In shell(ruby_call) :
‘wayback_machine_downloader https://undergroundreptiles.com/ —directory C:/Users/oliver/websites/underground_19981212033710 —from 19981212033710 —concurrency 200’ execution failed with error code 1`
When I run the exact same code directly from the command line it runs perfectly. Is there some setting I need to change in R/RStudio?
I also tried the system command, but that doesn’t work either:
system(ruby_call)
Warning message:
running command ‘wayback_machine_downloader https://undergroundreptiles.com/ —directory C:/Users/oliver/websites/underground_19981212033710 —from 19981212033710 —concurrency 200’ had status 127 `
22 ноября 2015, 21:30
Потребовалось мне недавно выкачать сайт из Интернет архива. И чтоб не руками каждый файлик, а то дюже их там много получалось.
А нормальной тулзы-то, как оказалось, для нас, криворуких похапэшников, и нет.
Какой-то дикий баш-скрипт, выкачивающий только 1 страницу — есть. Приличная версия на Руби есть. А PHP — нет. Беда  Может, искал плохо, может, карма не той системы — не знаю.
Может, искал плохо, может, карма не той системы — не знаю.
Сайт-то я в итоге выкачал. Но осадочек, как говорится, остался. И шило в одном месте проснулось. Поганая погода на выходных подсобила. Так что, встречаем первую версию WayBack downloader.
На данный момент оно умеет выкачивать последнюю версию сайта со всем содержимым, причём, тянутся все возможные сохранённые файлы. Выкачает всё что было сохранено.
php downloader.php -h http://example.com
Или только начиная с какой-то временной метки:
php downloader.php -h http://example.com -t 20060716231334
Опций пока не много:
-h, --host — адрес сайта -t, --timestamp — временная отметка в формате YYYYMMddhhmmss
На этом из плюшек всё. TODO длинный, так что фиксы и дополнения приветствуются.
Ну, и ссылки, как водится:
- репозиторий
- API
Вконтакте