💡Почему важно знать причины неоплаты?
Оплата банковской картой через интернет — эту услугу сейчас предлагает практически любой интернет магазин. Вы можете например купить билет на поезд, оплатив банковской картой, сделать покупку на ozon.ru, купить ЖД билет онлайн.
Я всегда заказывал и оплачивал билеты банковской картой через интернет(я использую только дебетовые карты, у меня нет кредитной карты). Самое интересное, что и эта услуга иногда дает сбой — зависают деньги на карте, не проходит оплата.
Но у меня был случай, когда оплата просто не проходила. Робокасса писала сообщение — оплата отменена. Я не знал, в чем причина. В личном кабинете найти ошибку мне не удалось.
Существует множество разных причин ошибок — они бывают по причине банка или владельца карты. Важно хотя бы предполагать причину ошибки, чтоб понимать как действовать дальше? К примеру, если не удается оплатить горячий билет, то нужно понимать в чем причина и попытаться исправить проблему. Иначе билет может быть куплен другим человеком.
Основные причины ошибок при оплате банковской картой
Первая причина, которая является самой распространенной — отсутствие нужной суммы на карте. Рекомендуется проверить ваш баланс — для этого нужно позвонить в банк или войти в интернет банк. Иногда по карте устанавливают ежемесячный или ежедневный лимит трат. Чтоб это проверить — нужно позвонить в банк.
Эта причина может быть не ясна сразу — при отказе в оплате может не отображаться ваш баланс. Ошибка аутентификации 3D secure может быть также связана с неверным вводом реквизитов карты на предыдущем шаге. В таком случае просто повторите платеж и укажите правильные данные.
Вторая причина — на стороне платежной системы. Например, терминал оплаты РЖД не позволяет платить картами MasterCard. Можно использовать только карты Visa.
Заданный магазин может не поддерживать данный способ оплаты. К примеру, Робокасса, которую подключают к множеству магазинов предлагает различные тарифы для оплаты.

Я сначала хотел оплатить вебмани, однако я позвонил в магазин. Оказалось, оплатить вебмани нельзя. У них не подключена эта опция. Хотя способ оплаты через вебмани предлагается на странице оплаты.
Третья причина — возможно ваша карта заблокирована. Опять же можно позвонить в банк и проверить это. Блокировка может быть осуществлена банком автоматически в случае наличия подозрительных операций у клиента.
Четвертая причина — у вас не подключена опция 3d Secure(MasterCard SecureCode в случае MasterCard).
Технология 3D Secure заключается в следующем: при оплате вам приходит СМС от банка, которую вы должны ввести в специальном окне. Эту СМС знаете только вы и банк. Мошенничество в данном случае достаточно трудно, для него потребуется и ваш телефон.
Эта опция нужна вам для оплаты на сумму больше 3 тыс. рублей. Это как раз мой случай. Я купил в интернет магазине газовую плиту Bosh. При оплате товара на сумму 22 тыс. рублей мне выдалось вот такое сообщение:


Я был в замешательстве, не знал что делать. Сначала я думал, что это проблема магазина. Но сначала я все таки позвонил в банк. В моем случае это был Промсвязьбанк и карта Доходная.
Позвонив в поддержку Промсвязьбанка, мне предложили сначала пройти процедуру аутентификации
- Назвать 4 последних цифры номера карты
- Назвать фамилию имя отчество полностью
- Назвать кодовое слово.
Далее для подключения услуги 3d Secure от меня потребовали 2 номера из таблицы разовых ключей. Вроде как услугу подключили, но через полчаса оплата снова не прошла. Позвонил в банк — сказали ожидайте когда подключится — услуга подключается не сразу. Нужно подождать.
Я решил проверить, подключена ли услуга. Я залогинился в Интернет-банк — увидел, что такая услуга есть(в ПСБ ритейл это можно посмотреть на странице карты, щелкнув по номеру карты)

Еще раз попытка оплаты — мне высветилось окно, где я должен был ввести код подтверждения. После заполнения данных карты мне пришло СМС с кодом для оплаты

Далее вуаля — заказ наконец то оплачен. Я получил следующее окно и статус заказа в магазине изменился на «Оплачен»
Мой заказ доставили в пункт назначения, где я его заберу в течение месяца. Главное оплата прошла.

Самая частая ошибка 11070: ошибка аутентификации 3d-secure — причины
Самая частая ошибка, которая происходит при оплате картой — 11070: ошибка аутентификации 3dsecure. Есть 2 возможных причины этой ошибки
- Введен неверный одноразовый код. Вам пришел код, но при вводе вы допустили ошибку в цифре. В результате получили ошибку
- Одноразовый код протух. Время, которое вам дают на ввод одноразового кода при оплате, составляет не более 5 минут. Далее вам придется повторить оплату.
В любом случае, советуем повторить процесс оплаты и удостовериться, что вы ввели одноразовый пароль 3D Secure сразу после получения и пароль введен верно.
Ошибка процессинга карты — что это такое?
Процессинг банка — это сложная программа, которая отвечает за обработку транзакций по картам. Когда вы снимаете деньги в банкомате, делаете покупку, то идет запрос по интернет в данную систему. Проверяется есть ли на вашей карте деньги. Эта программа находится на серверах в Интернет.
Вы не можете повлиять на данную ошибку никак. Вам стоит обратиться на горячую линию банка или интернет-магазина, где вы осуществляете транзакцию. Исправление ошибки — дело специалистов, поддерживающих данную систему. Остается только ждать.
Вы можете попробовать осуществить оплату повторно примерно через пол-часа. По идее такие ошибки должны исправляться очень быстро. Аналогичная ошибка бывает с сообщением «Сервис временно недоступен». Это значит, что сломалась серверная сторона и сделать ничего нельзя. Только ждать починки
Что значит хост недоступен при оплате картой
Хост — это определенный сетевой адрес. Это может быть ip адрес или же просто доменное имя(к примеру, server1.sberbak.online). При оплате картой через терминал происходит подключение к определенному сетевому адресу(хосту). На данном хосте находится программное обеспечение, которое производит оплату — снимает с карты деньги, проверяет баланс и т.д.
Если хост недоступен, значит деньги снять нельзя. Есть 2 основных причины недоступности:
- Нет интернет на устройстве, с которого производится оплата. В современных терминалах может быть вшит Интернет-модуль, через который терминал связывается с сервером. Возможно он потерял сеть или завис. В этом случае может помочь перезагрузка или же выход по голое небо, где Мобильный интернет ловит отлично
- Хост недоступен по причине поломки. В этом случае рекомендуется обратиться на горячую линию банка, который поддерживает ваш терминал. Данная проблема должна решаться на стороне хоста. Он может быть недоступен по разным причинам: завис, упал сервер, идет обновление программного обеспечения.
Что такое ошибка в CVC карты?
CVC-код — это трехзначный код, который находится на обратной стороне вашей банковской карты. Если появляется ошибка в CVC карты, то рекомендуем проверить, правильно ли вы ввели этот код? Если все правильно, пожалуйста проверьте, введены ли правильно другие данные вашей карты Сбербанка, ВТБ или другого банка.

CVC код нужен для того, чтоб проверить, есть ли у вас на руках данная карта в руках. Данная ошибка значит, что CVC код введен неверно. Просто осуществите оплату повторно и введите все данные верно
Проблема при регистрации токена — как решить?
Проблема при регистрации токена — частая ошибка, которая проявляется на сайте РЖД при оплате билетов.
Токен — это уникальный идентификатор(стока типа 23hjsdfjsdhfjhj2323dfgg), которая формируется когда вы заказываете билет. Это как бы ваша сессия оплаты. Ошибка возникает на стороне сервера оплаты.
Решений может быть два
- Проблемы на сервере РЖД. Сервер оплаты очень занят и перегружен из-за числа заказов. Возможно на нем ошибка. Рекомендуем в этом случае попробывать повторить оплату позднее
- Токен Истек. Это вина того, кто платит. Рассмотрим ситуацию: если вы оформили билет, а потом отошли от компьютера на полчаса, а потом вернулись и нажали оплатить. Ваш заказ аннулирован, т.к. вы не оплатили вовремя. При оплате вы получите ошибку. Нужно заново купить билет и оплатить его в течение 10 минут.
Если ошибка в течение часа сохраняется, рекомендуем обратиться на горячую линию РЖД.
Ошибка банковской карты — карта не поддерживается
Ошибка «карта не поддерживается» может возникать, если вы оплачиваете какую-либо услугу картой другой платежной системы, предоплаченной картой либо же Виртуальной картой. Это не значит, что карта у вас «неправильная», на ней нет денег или еще что-либо. Просто в данном конкретном случае нельзя использовать карту вашего типа. К примеру, виртуальные карты нельзя использовать при оплате в Google Play Market.
Решение простое: попробуйте использовать другую карту. Если ошибка повторится, то обратитесь в службу поддержки интернет-магазина или платежного сервиса, где осуществляете оплату.
Таблица с кодами ошибок при оплате.
Немногие знают, что при оплате картой система обычно выдает код ошибки. Например, E00 при оплате. Иногда по ошибке можно понять, в чем проблема
| Код ошибки и описание |
|---|
| Код 00 – успешно проведенная операция. |
| Код 01 – отказать, позвонить в банк, который выпустил карту. |
| Код 02 – отказать, позвонить в банк, который выпустил карту (специальные условия). |
| Код 04 — изъять карту без указания причины. |
| Код 05 – отказать без указания причины. |
| Код 17 – отказать, отклонено пользователем карты. |
| код 19 — тех. ошибка на стороне банка |
| Код 41 – изъять, утерянная карта. |
| Код 43 – изъять, украденная карта. |
| код 50 — ? |
| Код 51 – отказать, на счете недостаточно средств. |
| Код 55 – отказать, неверно введенный ПИН-код. |
| Код 57 – отказать, недопустимый тип операции для данного вида карты (например, попытка оплаты в магазине по карте предназначенной только для снятия наличных). |
| Код 61 – отказать, превышение максимальной суммы операции для данной карты. |
| Код 62 – отказать, заблокированная карта. |
| Код 65 – отказать, превышение максимального количества операции для данной карты. |
| Код 75 — отказать, превышение максимального количества неверных ПИН-кодов для данной карты. |
| Код 83 – отказать, ошибка сети (технические проблемы). |
| Код 91 – отказать, невозможно направить запрос (технические проблемы). |
| Код 96 – отказать, невозможно связаться с банком, который выдал карту. |
| Код Z3 — онлайн не работает, а в оффлайне терминал отклонил транзакцию. |
Что делать, если с картой все ОК, но оплата не проходит?
Самая типичная проблема, когда оплата не проходит — сбой в банковской системе. В работе банка могут наблюдаться перебои. Это может быть не обязательно ваш банк, а банк который принимает платеж на стороне клиента(которому принадлежит терминал). В этом случае можно дать 2 совета
- Подождать и оплатить позднее. Сбои в работе оперативно решаются и уже через час оплата может пройти без проблем. Обычно о сбоях можно узнать по СМС сообщениям или позвонив на горячую линию вашего банка.
- Использовать другую карту. Если нельзя оплатить одной — нужно попробывать оплатить другой картой. Если оплата и другой картой не проходит, то это скорее всего сбой на стороне, принимающей платеж. Тут остается только ждать.
3 полезных совета при оплате картой через Интернет
Во первых — заведите себе специальную карту. Не используйте для оплаты зарплатную карту, на которой у вас все деньги. Оптимально — кредитная карта. Она позволяет в отдельных случаях вернуть часть суммы покупки(CashBack). Обычно это сумма до 5 процентов от покупки. Будьте внимательны, некоторые сервисы при оплате катой берут комиссии. И конечно же адрес страницы оплаты всегда должен начинаться с https и рядом с адресом должен стоять значок в виде замка(Соединение https).
Во вторых — не держите много денег на карте. На карте должно быть немногим больше суммы, необходимой вам для покупки. Примерно плюс 10% от общей стоимости покупки. Логика проста — с нулевой карты ничего не могут снять.
Делаете покупку — просто пополняете карту в интернет банке и получаете нужную сумму.
В третьих — Делайте оплату картой в известных магазинах. Почитайте отзывы о магазинах на Яндекс.Маркет. Если вы платите картой, будьте готовы к тому, что при отмене заказа могут вернуться на вашу карту не сразу.
В последний раз, когда я делал оплату заказа и потом возвращал заказ и деньги, возврат на карту шел в течение 7 дней. Помните — никто деньги вам сразу не вернет. Будьте готовы ждать.
Популярные вопросы и ответы про оплату
Может ли пройти онлайн-оплата, если вы указали неверный cvv/cvc, но в системе 3d- secure ввели верный код из SMS?
Это вопрос из IT диктанта. Ответ на него ДА, может.
Код cvv/cvc известен только банку, который выпустил карту. И именно банк решает, пропустить транзакцию или нет. Данный код может и не передаваться при оплате, хотя и его нужно будет вводить при оплате. Авторизовать операцию возможно и без данного кода. Т.е. пройдет эта операция или нет — решает банк.
Пройдет ли оплата картой, если неверно ввести ФИО плательщика
ФИО плательщика практически не влияет на успешность оплаты. Можно ввести любое имя, хоть «Котик Вася» и при верном вводе других реквизитов карты оплата пройдет.

Дмитрий Тачков
Работник банка или другого фин. учреждения
Подробнее
Создатель проекта, финансовый эксперт
Привет, я автор этой статьи и создатель всех калькуляторов данного проекта. Имею более чем 3х летний опыт работы банках Ренессанс Кредит и Промсвязьбанк. Отлично разбираюсь в кредитах, займах и в досрочном погашении. Пожалуйста оцените эту статью, поставьте оценку ниже.
Анализ клиентских баз данных. Выявление мошенничества (fraud detection) на базе STATISTICA Data Miner
Содержание
Введение
Краткий обзор Data Mining
Вербальная постановка задачи
Структура данных
Основные подходы обнаружения мошенничества
Почему именно технология Data Mining, а не отдельные методы классификации и кластеризации?
Алгоритмы кластеризации
Описательный анализ
Кластеризация K-средних
EM-алгоритм
Автоматизация
Выводы
Приложение 1. Алгоритм запуска Алгоритма К-средних
Приложение 2. Алгоритм запуска EM-алгоритма
Введение
Основа любого бизнеса — клиентские базы данных, в которых представлена информация об отношениях клиентов с компанией.
Например, в области коммуникации в базе данных хранится информация о времени заключения договоров на использование услуг, времени расторжения договора, регионе, тарифе и т.д.
В торговле книгами пол, возраст, купленные книги и т.д.
В интернет-торговле купленные товары, их количество, время покупки и т.д.
В этом кейсе мы рассмотрим медицинские базы данных. Реальный кейс описан в статье.
Цель анализа: выявление дантистов, умышлено завышающих стоимость услуг — выявление потенциальных мошенников (fraud detection).
В начало
Краткий обзор Data Mining
Data Mining – исследование и обнаружение «машиной» (алгоритмами, средствами искусственного интеллекта) в сырых данных скрытых знаний, которые ранее не были известны, нетривиальны, практически полезны, доступны для интерпретации человеком. (Основатель направления Data Mining Пятецкий-Шапиро.)
Методы Data Mining помогают решить многие задачи, с которыми сталкивается аналитик. Из них основными являются: классификация, регрессия, поиск ассоциативных правил и кластеризация, обнаружение нетипичных наблюдений.
Ниже приведено краткое описание основных задач анализа данных.
Выявление нетипичных наблюдений. Обнаружение в данных нетипичных наблюдений, которые представляют «особый» интерес или обнаружение ошибок, от которых необходимо избавиться для проведения дальнейшего анализа.
Классификация. Задача – определить принадлежность объекта к классу по его характеристикам. Необходимо заметить, что в этой задаче множество классов, к которым может быть отнесен объект, заранее известно.
Регрессия. Поиск функции, которая описывает зависимость характеристиками объекта с наименьшей ошибкой.
Ассоциативный правила. Используя правила ассоциация, менеджер магазина может выявить товары, которые чаще всего покупают вместе (т.е. если покупают товар 1, то покупают и товар 2) и использовать эту информацию для маркетинговых кампаний.
Кластеризация. Выявление в данных скрытой структуры или наблюдений, которые так или иначе схожи.
В этом кейсе мы уделим внимание методу выявления нетипичных наблюдений.
В начало
Вербальная постановка задачи
Страховая компания имеет контракты с 10 клиниками, в которых работает 100 дантистов. База данных состоит из 20000 пациентов. С помощью SQL выгружаем из базы данных тех дантистов, которые выполняли услуги по страховке более 25 раз.
Всего было найдено 30 таких дантистов. Длина выборки составила 1000 – общее количество работ, которые они выполнили по страховке. Общая сумма страховки составила 500000$.
В выборке имеется информация об оказанных услугах дантистов, выполненных по страховке:
- Возраст клиента;
- Тип работ;
- Дополнительные услуги;
- Стоимость оказанных услуг в $;
- Персональный номер дантиста.
Необходимо определить дантистов, умышлено завышающих стоимость услуг – выявить потенциальных мошенников (fraud detection).
В начало
Структура данных
Данные были выгружены из базы данных компании, занимающейся медицинским страхованием.
Данные представляют их себя отчеты об оказанных клиентам услугах различными дантистами в течение одного сеанса.
Рассматриваются только те дантисты, у которых количество работ, выполненных по страховке, превышает 25.
Размер выборки – 1000 наблюдений.
Ниже приведен фрагмент таблицы:

В представленной таблице приводится информация о 1000 выполненных работ различными дантистами.
По строчкам стоят Выполненные работы, по столбцам — следующие параметры:
- Возраст клиента;
- Тип работы (1- незначительная, 2 — значительная, 3 — специализированная);
- Дополнительные услуги (1 – не было; 2 – недорогостоящие дополнительные услуги; 3- дорогостоящие);
- Стоимость оказанных услуг в $;
- Личный номер дантиста (используется для точной идентификации дантиста).
К примеру, первая строчку в таблице выше предоставляет информацию о проделанной работе – Возраст клиента 35, Проведена значительная работа с использованием дорогостоящих дополнительные процедуры, работу выполнил Дантист 10.
В начало
Основные подходы обнаружения мошенничества
Большинство методов, применяемых для обнаружения мошенничества (fraud detection), решают задачу классификации. Они требуют наличия объектов, для которых заранее известно к какому из двух классов они принадлежат Мошенничество или Не мошенничество (при чем достаточно большого количества для построения качественной модели). Такие методы принадлежат к классу supervised learning (обучение с учителем).
В нашей задаче, необходимо выявить потенциальных мошенников, не обладая информацией к какому классу принадлежат те или иные наблюдения.
Кластеризация в отличие от классификации не требует наличия информации о принадлежности к классу и соответственно принадлежит к классу unsupervised learning (обучение без учителя).
Задача кластеризации решается на начальных этапах исследования. Ее решение помогает лучше понять данные, их природу.
Большое достоинство кластерного анализа состоит в том, что он позволяет проводить разбиение объектов не по одному, а по целому набору признаков.
В начало
Почему именно технология Data Mining, а не отдельные методы классификации и кластеризации?
Технология Data Mining позволяет в отличие от отдельных методов кластеризации и классификации:
- Определить автоматически оптимальное количество кластеров;
- Работать с большим массивом данных;
- Не требуется наличия объектов, для которых заранее известно к какому из классов они принадлежат;
- Анализ баз данных на месте (In-Place Database Processing).
Анализ баз данных на месте (In-Place Database Processing)
Обработка баз данных на месте In-Place Database Processing (IDP) — это развитая технология доступа к базам данных, разработанная в StatSoft для достижения высокой производительности прямого интерфейса между данными внешних серверов и аналитической функциональностью продуктов STATISTICA.
IDP технология разработана, чтобы помочь обеспечить доступ к данным в больших БД, используя одношаговый процесс, который не требует создания локальных копий данных. IDP значительно увеличивает производительность STATISTICA; в частности хорошо приспособлена для задач data mining и исследовательских Анализов данных.
Причина большой скорости IDP
Большая скорость IDP технологии по сравнению с традиционным способом обусловлена не только тем фактом, что IDP позволяет STATISTICA обращаться к данным напрямую в БД и пропускать лишний шаг импорта данных и создания локального файла данных, но также из-за ее «многозадачной» (асинхронная и распределенная обработка) архитектуры. В частности IDP использует ресурсы (несколько процессоров) сервера БД для проведения операций с запросами, извлечения записей из данных, и пересылке их на компьютер с установленной программой STATISTICA, в то время как STATISTICA сразу обрабатывает эти записи, как только они поступают.
В начало
Алгоритмы кластеризации
Алгоритм К-средних
Разбивает множество элементов векторного пространства на заранее известное число кластеров k. Действие алгоритма таково, что он стремится минимизировать среднеквадратичное отклонение на точках каждого кластера. Основная идея заключается в том, что на каждой итерации перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике. Алгоритм завершается, когда на какой-то итерации не происходит изменения центров кластеров.
EM-алгоритм
В основе идеи EM-алгоритма лежит предположение, что распределение исходного множества является линейной комбинации подмножеств, имеющих нормальное распределение. Целью алгоритма является декомпозиция(разделение) множества на подмножества, а также оценка параметров распределения каждого подмножества, которые максимизируют логарифмическую функцию правдоподобия, используемую в качестве меры качества модели. Параметры нормального распределения – математическое ожидание и дисперсия.
В начало
Описательный анализ

Из таблицы видно, что непрерывные переменные Возраст клиента и Стоимость услуг имеют разную вариабельность (разброс) – Стандартное отклонение (последний столбец).
При кластеризации очень важно, чтобы переменные имели одинаковую вариабельность (разброс). Для этого используем процедуру Стандартизация.
Стандартизация
- Выберем вкладку Данные;
- Выберем Стандартизовать… Откроется диалоговое окно;
- Выберем переменные – Возраст клиента, Стоимость услуг. Нажмем кнопку ОК .

В начало
Кластеризация K-средних
Анализ результатов — вкладка Quick

В верхней части диалогового окна расположено рабочая область, где показаны основные характеристики кластеризации:
- Algorithm (Алгоритм) – К-средних;
- Distance method (мера связи) — Евклидова;
- Initial centers (определение центров кластеров) – Максимальное расстояние между кластеров;
- MD casewise deletion (удаление пропущенных значений) — Да;
- Cross-validation (кросс-проверка) – 10 кратная;
- Testing sample (Контрольная выборка) — 0;
- Training cases (Обучающая выборка) — 1000;
- Training error (ошибка на обучающей выборке) – 0,492645;
- Number of cluster (Число кластеров) – 4.
Во вкладке Quick (Быстрый) можно просмотреть следующие результаты:
Результаты анализа: Описание кластеров
Средние в каждом кластере (Cluster Means):

По строчкам стоят номера кластеров.
По столбцам — переменные, выбранные в начале анализа.
Последний столбец показывает долю наблюдений в каждом кластере.
Были получены следующие кластеры:
- Кластер 1: Специализированная работа с использованием дорогостоящих дополнительных процедур, средний возраст клиента – 25, средняя стоимость услуг – 715$;
- Кластер 2: Незначительная работа без использования дополнительных процедур, средний возраст клиента – 21, средняя стоимость услуг – 286$;
- Кластер 3: Значительная работа с использованием дорогостоящих дополнительных процедур, средний возраст клиента – 38, средняя стоимость услуг – 819$;
- Кластер 4: Значительная работа с использованием дешевых жополнительных процедур, средний возраст клиента – 27, средняя стоимость услуг – 551$.
Расстояние между кластерами (Cluster distance):

К примеру, расстояние между Кластер 1 и Кластер 2 — 1,465 (по метрики Евклида).
Объекты кластеров и расстояния:

Исходя из нее, можно понять какие наблюдения к какому кластеру принадлежат.
Определение значимых факторов
1. Сначала рассмотрим непрерывные переменные.
1.1 Построим график среднего возраста клиентов и стоимости услуг в каждом из кластеров.

Исходя из графика, в Кластере 2 средний возраст клиентов и средняя стоимость услуг максимальны по сравнению с другими кластерами.
1.2. Проведем Дисперсионный анализ для определения факторов, влияющих на принадлежность объекта кластеру.

Исходя из дисперсионного анализа, переменные Возраст клиента и Стоимость оказанных услуг влияют на принадлежность объекта кластеру, т.к. p-уровень меньше 0,05. Другими словам, и факторы Возраст и Стоимость оказанных услуг значимы.
2. Рассмотрим категориальные переменные.
Будем строить Таблицы частот и Графики частот для категориальных переменных (тип работы, дополнительные процедуры) для каждого кластера.
2.1. Тип работы.
Таблица частот:

График частот:

Исходя из построенного графика видим:
- В Кластере 2 наибольшее количество незначительных работ;
- В Кластере 1 наибольшее количество специализированных работ.
2.2. Дополнительные процедуры.
Таблица частот:

График частот:

Исходя из построенного графика видим:
- В Кластере 2 наибольшее количество работ, выполненных без использование дополнительных процедур;
- В Кластере 3 наибольшее количество работ, выполненных с использование дешевых дополнительных процедур;
- В Кластере 1 наибольшее количество работ, выполненных с использование дорогих дополнительных процедур.
2.3. Определим, какие переменные оказывают значимое влияние на принадлежность к кластеру. Воспользуемся критерием Хи-Квадрат для категориальных переменных:

Исходя из таблицы, Тип работы и Дополнительные процедуры влияют на принадлежность объекта к кластеру, т.к. p-уровень меньше 0,05. Другими словами факторы Тип работы и Дополнительные процедуры значимы.
Алгоритм запуска алгоритма k-средних рассмотрен в Приложении 1.
Выявление потенциальных мошенников
Нас интересуют те дантисты, которые завышают стоимость своих услуг.
Для выявления таких дантистов, необходимо сравнить среднюю общую стоимость оказанных услуг для каждого кластера и среднюю стоимость оказанных услуг дантиста в каждом кластере.
График общей средней стоимости оказанных услуг в каждом кластере:

Дантист 0
График средней стоимости оказанных услуг Дантиста 0 и График средней общей стоимости оказанных услуг в каждом кластере:

Как видно из графика, в Кластере 1 стоимость услуг Дантиста 0 значительно превышают среднюю общую стоимость услуг. Дантист 0 – потенциальный мошенник.
Дантист 5
График средней стоимости оказанных услуг Дантиста 5 и График средней общей стоимости оказанных услуг в каждом кластере:

Как видно из графика, средняя стоимость услуг Дантиста 5 в Кластере 4 и в Кластере 2 значительно выше по сравнению со средней общей стоимостью в этом кластере. Дантист 5 потенциальный мошенник.
Дантист 13
График средней стоимости оказанных услуг Дантиста 13 и График средней общей стоимости оказанных услуг в каждом кластере:

Как видно из графика, средняя стоимость услуг Дантиста 13 в Кластере 1 значительно превосходят общую среднюю стоимость в этом кластере. Дантист 13 потенциальный мошенник.
Дантист 19

Исходя из графика, средняя стоимость услуг Дантиста 19 значительно превышает общую среднюю стоимость в Кластере 4. Дантист 19 потенциальный мошенник.
В начало
EM-алгоритм
Анализ результатов – вкладка Quick

При EM-кластеризации получилось всего 2 кластера.
Результаты анализа: Описание кластеров

Были получены следующие кластеры:
Кластер 1: Специализированные работы с использованием дешевый дополнительных процедур, средний возраст клиента – 34, средняя стоимость услуг – 882$;
Кластер 2: Значительные и незначительные работы с использованием дешевый дополнительных процедур, средний возраст клиента — 26,5, средняя стоимость услуг – 256$.
Определение значимых факторов
1. Сначала рассмотрим непрерывные переменные;
1.1 Построим график среднего возраста клиентов и стоимости услуг в каждом из кластеров.

1.2. Проведем Дисперсионный анализ для определения факторов, влияющих на принадлежность объекта кластеру.

Исходя из дисперсионного анализа, переменные Возраст клиента и Стоимость оказанных услуг влияют на принадлежность объекта кластеру, т.к. p-уровень меньше 0,05. Другими словами факторы Возраст и Стоимость оказанных услуг значимы.
2. Рассмотрим категориальные переменные.
Будем строить Таблицу частот и График частот для категориальных переменных (тип работы, дополнительные процедуры) для каждого кластера.
2.1 Тип работы.
Таблица частот:

График частот:

Исходя из построенного графика видим:
- В Кластере 2 наибольшее количество незначительных и значительных работ;
- В Кластере 3 наибольшее количество специализированных работ.
2.2 Дополнительные процедуры.
Таблица частот:

График частот:

Исходя из построенного графика видим:
- В Кластере 1 наибольшее количество работ без использования дополнительных процедур;
- В Кластере 2 наибольшее количество работ с использованием дорогостоящих и недорогостоящих дополнительных процедур.
2.3. Определим, какие переменные оказывают значимое влияние на принадлежность к кластеру. Воспользуемся критерием Хи-Квадрат для категориальных переменных:
![]()
Исходя из таблицы, Тип работы и Дополнительные процедуры влияют на принадлежность объекта к кластеру, т.к. p-уровень меньше 0,05. Другими словами факторы Тип работы и Дополнительные процедуры значимы.
Алгоритм запуска модуля см. в Приложении 2.
Выявление потенциальных мошенников
График общей средней стоимости оказанных услуг в каждом кластере:

Дантист 15
График средней стоимости оказанных услуг Дантиста 15 и График средней общей стоимости оказанных услуг в каждом кластере:

Как видно из графика, в Кластере 1 стоимость услуг Дантиста 15 значительно превышают среднюю общую стоимость услуг. Дантист 15 – потенциальный мошенник.
Дантист 5
График средней стоимости оказанных услуг Дантиста 5 и График средней общей стоимости оказанных услуг в каждом кластере:

Как видно из графика, средняя стоимость услуг Дантиста 5 в Кластере 2 значительно выше по сравнению со средней общей стоимостью в этом кластере. Дантист 5 потенциальный мошенник.
Дантист 27
График средней стоимости оказанных услуг Дантиста 5 и График средней общей стоимости оказанных услуг в каждом кластере:

Как видно из графика, средняя стоимость услуг Дантиста 27 в Кластере 1 значительно превосходят общую среднюю стоимость в этом кластере. Дантист 13 потенциальный мошенник.
Дантист 14

Исходя из графика, средняя стоимость услуг Дантиста 14 значительно превышает общую среднюю стоимость в Кластере 1 и Кластере 2. Дантист 14 потенциальный мошенник.
В начало
Автоматизация
Для автоматического вычисления описательных статистик и построения графиков в STATISTICA Data Miner есть модуль построения проекта. Фрагмент интерактивного построения проекта показан ниже.

На рисунке выше на первом шаге вносим переменные, которые будут подвергнуты анализу (в первой красном прямоугольнике).
На втором шаге происходит чистка и фильтрация данных — процесс анализа пропущенных данных и замена пропущенных данных средним (во втором красном прямоугольнике).
На третьем шаге вычисляются описательные статистики, таблицы частот, график средних в каждом кластере, диаграммы (во третьем красном прямоугольнике).
Последний прямоугольник (зеленый) – результаты анализа. В них можно просмотреть полученные результаты.
В начало
Выводы
В ходе анализа было выявлено 7 дантистов из 31, которые умышленно завышают стоимость выполненных по страховке работ.
Алгоритм k-средних
С помощью алгоритма k-средних образовалось 4 кластера:
- Кластер 1: Специализированная работа с использованием дорогостоящих дополнительных процедур, средний возраст клиента – 25, средняя стоимость услуг – 715$;
- Кластер 2: Незначительная работа без использования дополнительных процедур, средний возраст клиента – 21, средняя стоимость услуг – 286$;
- Кластер 3: Значительная работа с использованием дорогостоящих дополнительных процедур, средний возраст клиента – 38, средняя стоимость услуг – 819$;
- Кластер 4: Значительная работа с использованием дешевых дополнительных процедур, средний возраст клиента – 27, средняя стоимость услуг – 551$.
При сравнении общей средней стоимости услуг в каждом кластере со средней стоимостью услуг каждого дантиста было выявлено 4 дантиста, которые являются потенциальными мошенниками.
Дантист 0

Сильно завышает стоимость своих работ по оказанию специализированных услуг с использованием дорогостоящих процедур.
Дантист 5
Сильно завышает стоимость своих работ по оказанию незначительных услуг без использования дополнительных процедур и стоимость работ по оказанию значительных услуг с использованием дорогостоящих работ.
Дантист 13

Сильно завышает стоимость своих работ по оказанию специализированных услуг с использованием дорогостоящих процедур.
Дантист 19
Сильно завышает стоимость работ по оказанию значительных услуг с использованием дорогостоящих работ.
EM-алгоритм
С помощью алгоритма EM образовалось 2 кластера:
- Кластер 1: Специализированные работы с использованием дешевый дополнительных процедур, средний возраст клиента – 34, средняя стоимость услуг – 882$;
- Кластер 2: Значительные и незначительные работы с использованием дешевый дополнительных процедур, средний возраст клиента — 26,5, средняя стоимость услуг – 256$.
При сравнении общей средней стоимости услуг в каждом кластере со средней стоимостью услуг каждого дантиста было выявлено 4 дантиста, которые являются потенциальными мошенниками.
Дантист 15
Сильно завышает стоимость работ по оказанию специализированных услуг с использованием дешевых дополнительных работ.
Дантист 5

Сильно завышает стоимость работ по оказанию значительных и незначительных услуг с использованием дешевых дополнительных работ.
Дантист 27

Сильно завышает стоимость работ по оказанию специализированных услуг с использованием дешевых дополнительных работ.
Дантист 14

Сильно завышает стоимость работ по оказанию значительных и незначительных услуг с использованием дешевых дополнительных работ.
В результате было выявлено 7 потенциальных мошенников:
Дантист 0
Дантист 5
Дантист 13
Дантист 14
Дантист 15
Дантист 19
Дантист 27
Применяемые техники для анализа данных страховых случаев позволяют подсчитать, как много работ определенных дантистов отличаются от нормы. Решаются важные вопросы: Как много дантистов-мошенников? Сколько денег подвержено риску из-за деятельности последних?
Алгоритмы кластеризации (алгоритм K-средних и EM-алгоритм) являются удобными инструментами для ответа на поставленные вопросы.
В начало
Приложение 1. Алгоритм запуска Алгоритма К-средних
Шаг 0 (Модуль)
Откроем вкладку Добыча данных (Data Miner) и выберем модуль Обобщенные методы кластерного анализа (Generalized EM and k-Means Cluster Analysis).

Откроется диалоговое окно:

Шаг 1 (Выбор переменных).
Нажмем на кнопку Variables (Переменные).

В качестве категориальных переменных выберем:
- Тип работы;
- Дополнительные процедуры.
В качестве непрерывных переменных:
- Возраст клиента;
- Стоимость оказанных услуг в $.
Шаг 2 (Настройка параметров кластеризации).
Во вкладке Quick (Быстрый) выберем:
- k-Means (к-средних);
- Number of cluster — 2;
- Number of iterations – 50,
как показано на рисунке выше.
Перейдем во вкладку k-means:

В этой вкладке настраиваются следующие параметры:
- начальные центры кластеров;
- мера связи.
Оставим по умолчанию.
Начальные центры кластеров будут определяться так, чтобы между ними было максимальное расстояние.
Мера связи (метрика в многомерном пространстве) – Евклидова.
Шаг 3 (Проверка).
Во вкладке Validation (Проверка) поставим галку рядом с кросс-проверкой. Остальные параметры оставим без изменений. Нажмем кнопку ОК.

В начало
Приложение 2. Алгоритм запуска EM-алгоритма
Повторить Шаг 0, Шаг 1 (см. Приложение 1).
Шаг 2 (Настройка параметров кластеризации).
Во вкладке Quick (Быстрый) выберем:
- EM algoritm;
- Number of cluster — 2;
- Number of iterations – 50.
Перейдем во вкладку EM:

В этой вкладке настраиваются следующие параметры:
- random seed;
- минимальный рост логарифма правдоподобия (minimum increase of log-likehood).
Оставляем их по умолчанию.
Для непрерывных переменных выберем в качестве распределения – нормальное.
Шаг 3 (Проверка).
Во вкладке Validation (Проверка) поставим галку рядом с кросс-проверкой. Остальные параметры оставим без изменений. Нажмем кнопку OK.

Читать подробнее о методах и инструментах STATISTICA Data Miner
💡Почему важно знать причины неоплаты?
Оплата банковской картой через интернет — эту услугу сейчас предлагает практически любой интернет магазин. Вы можете например купить билет на поезд, оплатив банковской картой, сделать покупку на ozon.ru, купить ЖД билет онлайн.
Я всегда заказывал и оплачивал билеты банковской картой через интернет(я использую только дебетовые карты, у меня нет кредитной карты). Самое интересное, что и эта услуга иногда дает сбой — зависают деньги на карте, не проходит оплата.
Но у меня был случай, когда оплата просто не проходила. Робокасса писала сообщение — оплата отменена. Я не знал, в чем причина. В личном кабинете найти ошибку мне не удалось.
Существует множество разных причин ошибок — они бывают по причине банка или владельца карты. Важно хотя бы предполагать причину ошибки, чтоб понимать как действовать дальше? К примеру, если не удается оплатить горячий билет, то нужно понимать в чем причина и попытаться исправить проблему. Иначе билет может быть куплен другим человеком.
Основные причины ошибок при оплате банковской картой
Первая причина, которая является самой распространенной — отсутствие нужной суммы на карте. Рекомендуется проверить ваш баланс — для этого нужно позвонить в банк или войти в интернет банк. Иногда по карте устанавливают ежемесячный или ежедневный лимит трат. Чтоб это проверить — нужно позвонить в банк.
Эта причина может быть не ясна сразу — при отказе в оплате может не отображаться ваш баланс. Ошибка аутентификации 3D secure может быть также связана с неверным вводом реквизитов карты на предыдущем шаге. В таком случае просто повторите платеж и укажите правильные данные.
Вторая причина — на стороне платежной системы. Например, терминал оплаты РЖД не позволяет платить картами MasterCard. Можно использовать только карты Visa.
Заданный магазин может не поддерживать данный способ оплаты. К примеру, Робокасса, которую подключают к множеству магазинов предлагает различные тарифы для оплаты.
Я сначала хотел оплатить вебмани, однако я позвонил в магазин. Оказалось, оплатить вебмани нельзя. У них не подключена эта опция. Хотя способ оплаты через вебмани предлагается на странице оплаты.
Третья причина — возможно ваша карта заблокирована. Опять же можно позвонить в банк и проверить это. Блокировка может быть осуществлена банком автоматически в случае наличия подозрительных операций у клиента.
Четвертая причина — у вас не подключена опция 3d Secure(MasterCard SecureCode в случае MasterCard).
Технология 3D Secure заключается в следующем: при оплате вам приходит СМС от банка, которую вы должны ввести в специальном окне. Эту СМС знаете только вы и банк. Мошенничество в данном случае достаточно трудно, для него потребуется и ваш телефон.
Эта опция нужна вам для оплаты на сумму больше 3 тыс. рублей. Это как раз мой случай. Я купил в интернет магазине газовую плиту Bosh. При оплате товара на сумму 22 тыс. рублей мне выдалось вот такое сообщение:
Я был в замешательстве, не знал что делать. Сначала я думал, что это проблема магазина. Но сначала я все таки позвонил в банк. В моем случае это был Промсвязьбанк и карта Доходная.
Позвонив в поддержку Промсвязьбанка, мне предложили сначала пройти процедуру аутентификации
- Назвать 4 последних цифры номера карты
- Назвать фамилию имя отчество полностью
- Назвать кодовое слово.
Далее для подключения услуги 3d Secure от меня потребовали 2 номера из таблицы разовых ключей. Вроде как услугу подключили, но через полчаса оплата снова не прошла. Позвонил в банк — сказали ожидайте когда подключится — услуга подключается не сразу. Нужно подождать.
Я решил проверить, подключена ли услуга. Я залогинился в Интернет-банк — увидел, что такая услуга есть(в ПСБ ритейл это можно посмотреть на странице карты, щелкнув по номеру карты)
Еще раз попытка оплаты — мне высветилось окно, где я должен был ввести код подтверждения. После заполнения данных карты мне пришло СМС с кодом для оплаты
Далее вуаля — заказ наконец то оплачен. Я получил следующее окно и статус заказа в магазине изменился на «Оплачен»
Мой заказ доставили в пункт назначения, где я его заберу в течение месяца. Главное оплата прошла.
Самая частая ошибка 11070: ошибка аутентификации 3d-secure — причины
Самая частая ошибка, которая происходит при оплате картой — 11070: ошибка аутентификации 3dsecure. Есть 2 возможных причины этой ошибки
- Введен неверный одноразовый код. Вам пришел код, но при вводе вы допустили ошибку в цифре. В результате получили ошибку
- Одноразовый код протух. Время, которое вам дают на ввод одноразового кода при оплате, составляет не более 5 минут. Далее вам придется повторить оплату.
В любом случае, советуем повторить процесс оплаты и удостовериться, что вы ввели одноразовый пароль 3D Secure сразу после получения и пароль введен верно.
Ошибка процессинга карты — что это такое?
Процессинг банка — это сложная программа, которая отвечает за обработку транзакций по картам. Когда вы снимаете деньги в банкомате, делаете покупку, то идет запрос по интернет в данную систему. Проверяется есть ли на вашей карте деньги. Эта программа находится на серверах в Интернет.
Вы не можете повлиять на данную ошибку никак. Вам стоит обратиться на горячую линию банка или интернет-магазина, где вы осуществляете транзакцию. Исправление ошибки — дело специалистов, поддерживающих данную систему. Остается только ждать.
Вы можете попробовать осуществить оплату повторно примерно через пол-часа. По идее такие ошибки должны исправляться очень быстро. Аналогичная ошибка бывает с сообщением «Сервис временно недоступен». Это значит, что сломалась серверная сторона и сделать ничего нельзя. Только ждать починки
Что значит хост недоступен при оплате картой
Хост — это определенный сетевой адрес. Это может быть ip адрес или же просто доменное имя(к примеру, server1.sberbak.online). При оплате картой через терминал происходит подключение к определенному сетевому адресу(хосту). На данном хосте находится программное обеспечение, которое производит оплату — снимает с карты деньги, проверяет баланс и т.д.
Если хост недоступен, значит деньги снять нельзя. Есть 2 основных причины недоступности:
- Нет интернет на устройстве, с которого производится оплата. В современных терминалах может быть вшит Интернет-модуль, через который терминал связывается с сервером. Возможно он потерял сеть или завис. В этом случае может помочь перезагрузка или же выход по голое небо, где Мобильный интернет ловит отлично
- Хост недоступен по причине поломки. В этом случае рекомендуется обратиться на горячую линию банка, который поддерживает ваш терминал. Данная проблема должна решаться на стороне хоста. Он может быть недоступен по разным причинам: завис, упал сервер, идет обновление программного обеспечения.
Что такое ошибка в CVC карты?
CVC-код — это трехзначный код, который находится на обратной стороне вашей банковской карты. Если появляется ошибка в CVC карты, то рекомендуем проверить, правильно ли вы ввели этот код? Если все правильно, пожалуйста проверьте, введены ли правильно другие данные вашей карты Сбербанка, ВТБ или другого банка.
CVC код нужен для того, чтоб проверить, есть ли у вас на руках данная карта в руках. Данная ошибка значит, что CVC код введен неверно. Просто осуществите оплату повторно и введите все данные верно
Проблема при регистрации токена — как решить?
Проблема при регистрации токена — частая ошибка, которая проявляется на сайте РЖД при оплате билетов.
Токен — это уникальный идентификатор(стока типа 23hjsdfjsdhfjhj2323dfgg), которая формируется когда вы заказываете билет. Это как бы ваша сессия оплаты. Ошибка возникает на стороне сервера оплаты.
Решений может быть два
- Проблемы на сервере РЖД. Сервер оплаты очень занят и перегружен из-за числа заказов. Возможно на нем ошибка. Рекомендуем в этом случае попробывать повторить оплату позднее
- Токен Истек. Это вина того, кто платит. Рассмотрим ситуацию: если вы оформили билет, а потом отошли от компьютера на полчаса, а потом вернулись и нажали оплатить. Ваш заказ аннулирован, т.к. вы не оплатили вовремя. При оплате вы получите ошибку. Нужно заново купить билет и оплатить его в течение 10 минут.
Если ошибка в течение часа сохраняется, рекомендуем обратиться на горячую линию РЖД.
Ошибка банковской карты — карта не поддерживается
Ошибка «карта не поддерживается» может возникать, если вы оплачиваете какую-либо услугу картой другой платежной системы, предоплаченной картой либо же Виртуальной картой. Это не значит, что карта у вас «неправильная», на ней нет денег или еще что-либо. Просто в данном конкретном случае нельзя использовать карту вашего типа. К примеру, виртуальные карты нельзя использовать при оплате в Google Play Market.
Решение простое: попробуйте использовать другую карту. Если ошибка повторится, то обратитесь в службу поддержки интернет-магазина или платежного сервиса, где осуществляете оплату.
Таблица с кодами ошибок при оплате.
Немногие знают, что при оплате картой система обычно выдает код ошибки. Например, E00 при оплате. Иногда по ошибке можно понять, в чем проблема
| Код ошибки и описание |
|---|
| Код 00 – успешно проведенная операция. |
| Код 01 – отказать, позвонить в банк, который выпустил карту. |
| Код 02 – отказать, позвонить в банк, который выпустил карту (специальные условия). |
| Код 04 — изъять карту без указания причины. |
| Код 05 – отказать без указания причины. |
| Код 17 – отказать, отклонено пользователем карты. |
| код 19 — тех. ошибка на стороне банка |
| Код 41 – изъять, утерянная карта. |
| Код 43 – изъять, украденная карта. |
| код 50 — ? |
| Код 51 – отказать, на счете недостаточно средств. |
| Код 55 – отказать, неверно введенный ПИН-код. |
| Код 57 – отказать, недопустимый тип операции для данного вида карты (например, попытка оплаты в магазине по карте предназначенной только для снятия наличных). |
| Код 61 – отказать, превышение максимальной суммы операции для данной карты. |
| Код 62 – отказать, заблокированная карта. |
| Код 65 – отказать, превышение максимального количества операции для данной карты. |
| Код 75 — отказать, превышение максимального количества неверных ПИН-кодов для данной карты. |
| Код 83 – отказать, ошибка сети (технические проблемы). |
| Код 91 – отказать, невозможно направить запрос (технические проблемы). |
| Код 96 – отказать, невозможно связаться с банком, который выдал карту. |
| Код Z3 — онлайн не работает, а в оффлайне терминал отклонил транзакцию. |
Что делать, если с картой все ОК, но оплата не проходит?
Самая типичная проблема, когда оплата не проходит — сбой в банковской системе. В работе банка могут наблюдаться перебои. Это может быть не обязательно ваш банк, а банк который принимает платеж на стороне клиента(которому принадлежит терминал). В этом случае можно дать 2 совета
- Подождать и оплатить позднее. Сбои в работе оперативно решаются и уже через час оплата может пройти без проблем. Обычно о сбоях можно узнать по СМС сообщениям или позвонив на горячую линию вашего банка.
- Использовать другую карту. Если нельзя оплатить одной — нужно попробывать оплатить другой картой. Если оплата и другой картой не проходит, то это скорее всего сбой на стороне, принимающей платеж. Тут остается только ждать.
3 полезных совета при оплате картой через Интернет
Во первых — заведите себе специальную карту. Не используйте для оплаты зарплатную карту, на которой у вас все деньги. Оптимально — кредитная карта. Она позволяет в отдельных случаях вернуть часть суммы покупки(CashBack). Обычно это сумма до 5 процентов от покупки. Будьте внимательны, некоторые сервисы при оплате катой берут комиссии. И конечно же адрес страницы оплаты всегда должен начинаться с https и рядом с адресом должен стоять значок в виде замка(Соединение https).
Во вторых — не держите много денег на карте. На карте должно быть немногим больше суммы, необходимой вам для покупки. Примерно плюс 10% от общей стоимости покупки. Логика проста — с нулевой карты ничего не могут снять.
Делаете покупку — просто пополняете карту в интернет банке и получаете нужную сумму.
В третьих — Делайте оплату картой в известных магазинах. Почитайте отзывы о магазинах на Яндекс.Маркет. Если вы платите картой, будьте готовы к тому, что при отмене заказа могут вернуться на вашу карту не сразу.
В последний раз, когда я делал оплату заказа и потом возвращал заказ и деньги, возврат на карту шел в течение 7 дней. Помните — никто деньги вам сразу не вернет. Будьте готовы ждать.
Популярные вопросы и ответы про оплату
Может ли пройти онлайн-оплата, если вы указали неверный cvv/cvc, но в системе 3d- secure ввели верный код из SMS?
Это вопрос из IT диктанта. Ответ на него ДА, может.
Код cvv/cvc известен только банку, который выпустил карту. И именно банк решает, пропустить транзакцию или нет. Данный код может и не передаваться при оплате, хотя и его нужно будет вводить при оплате. Авторизовать операцию возможно и без данного кода. Т.е. пройдет эта операция или нет — решает банк.
Пройдет ли оплата картой, если неверно ввести ФИО плательщика
ФИО плательщика практически не влияет на успешность оплаты. Можно ввести любое имя, хоть «Котик Вася» и при верном вводе других реквизитов карты оплата пройдет.
Дмитрий Тачков
Работник банка или другого фин. учреждения
Подробнее
Создатель проекта, финансовый эксперт
Привет, я автор этой статьи и создатель всех калькуляторов данного проекта. Имею более чем 3х летний опыт работы банках Ренессанс Кредит и Промсвязьбанк. Отлично разбираюсь в кредитах, займах и в досрочном погашении. Пожалуйста оцените эту статью, поставьте оценку ниже.
Анализ клиентских баз данных. Выявление мошенничества (fraud detection) на базе STATISTICA Data Miner
Содержание
Введение
Краткий обзор Data Mining
Вербальная постановка задачи
Структура данных
Основные подходы обнаружения мошенничества
Почему именно технология Data Mining, а не отдельные методы классификации и кластеризации?
Алгоритмы кластеризации
Описательный анализ
Кластеризация K-средних
EM-алгоритм
Автоматизация
Выводы
Приложение 1. Алгоритм запуска Алгоритма К-средних
Приложение 2. Алгоритм запуска EM-алгоритма
Введение
Основа любого бизнеса — клиентские базы данных, в которых представлена информация об отношениях клиентов с компанией.
Например, в области коммуникации в базе данных хранится информация о времени заключения договоров на использование услуг, времени расторжения договора, регионе, тарифе и т.д.
В торговле книгами пол, возраст, купленные книги и т.д.
В интернет-торговле купленные товары, их количество, время покупки и т.д.
В этом кейсе мы рассмотрим медицинские базы данных. Реальный кейс описан в статье.
Цель анализа: выявление дантистов, умышлено завышающих стоимость услуг — выявление потенциальных мошенников (fraud detection).
В начало
Краткий обзор Data Mining
Data Mining – исследование и обнаружение «машиной» (алгоритмами, средствами искусственного интеллекта) в сырых данных скрытых знаний, которые ранее не были известны, нетривиальны, практически полезны, доступны для интерпретации человеком. (Основатель направления Data Mining Пятецкий-Шапиро.)
Методы Data Mining помогают решить многие задачи, с которыми сталкивается аналитик. Из них основными являются: классификация, регрессия, поиск ассоциативных правил и кластеризация, обнаружение нетипичных наблюдений.
Ниже приведено краткое описание основных задач анализа данных.
Выявление нетипичных наблюдений. Обнаружение в данных нетипичных наблюдений, которые представляют «особый» интерес или обнаружение ошибок, от которых необходимо избавиться для проведения дальнейшего анализа.
Классификация. Задача – определить принадлежность объекта к классу по его характеристикам. Необходимо заметить, что в этой задаче множество классов, к которым может быть отнесен объект, заранее известно.
Регрессия. Поиск функции, которая описывает зависимость характеристиками объекта с наименьшей ошибкой.
Ассоциативный правила. Используя правила ассоциация, менеджер магазина может выявить товары, которые чаще всего покупают вместе (т.е. если покупают товар 1, то покупают и товар 2) и использовать эту информацию для маркетинговых кампаний.
Кластеризация. Выявление в данных скрытой структуры или наблюдений, которые так или иначе схожи.
В этом кейсе мы уделим внимание методу выявления нетипичных наблюдений.
В начало
Вербальная постановка задачи
Страховая компания имеет контракты с 10 клиниками, в которых работает 100 дантистов. База данных состоит из 20000 пациентов. С помощью SQL выгружаем из базы данных тех дантистов, которые выполняли услуги по страховке более 25 раз.
Всего было найдено 30 таких дантистов. Длина выборки составила 1000 – общее количество работ, которые они выполнили по страховке. Общая сумма страховки составила 500000$.
В выборке имеется информация об оказанных услугах дантистов, выполненных по страховке:
- Возраст клиента;
- Тип работ;
- Дополнительные услуги;
- Стоимость оказанных услуг в $;
- Персональный номер дантиста.
Необходимо определить дантистов, умышлено завышающих стоимость услуг – выявить потенциальных мошенников (fraud detection).
В начало
Структура данных
Данные были выгружены из базы данных компании, занимающейся медицинским страхованием.
Данные представляют их себя отчеты об оказанных клиентам услугах различными дантистами в течение одного сеанса.
Рассматриваются только те дантисты, у которых количество работ, выполненных по страховке, превышает 25.
Размер выборки – 1000 наблюдений.
Ниже приведен фрагмент таблицы:
В представленной таблице приводится информация о 1000 выполненных работ различными дантистами.
По строчкам стоят Выполненные работы, по столбцам — следующие параметры:
- Возраст клиента;
- Тип работы (1- незначительная, 2 — значительная, 3 — специализированная);
- Дополнительные услуги (1 – не было; 2 – недорогостоящие дополнительные услуги; 3- дорогостоящие);
- Стоимость оказанных услуг в $;
- Личный номер дантиста (используется для точной идентификации дантиста).
К примеру, первая строчку в таблице выше предоставляет информацию о проделанной работе – Возраст клиента 35, Проведена значительная работа с использованием дорогостоящих дополнительные процедуры, работу выполнил Дантист 10.
В начало
Основные подходы обнаружения мошенничества
Большинство методов, применяемых для обнаружения мошенничества (fraud detection), решают задачу классификации. Они требуют наличия объектов, для которых заранее известно к какому из двух классов они принадлежат Мошенничество или Не мошенничество (при чем достаточно большого количества для построения качественной модели). Такие методы принадлежат к классу supervised learning (обучение с учителем).
В нашей задаче, необходимо выявить потенциальных мошенников, не обладая информацией к какому классу принадлежат те или иные наблюдения.
Кластеризация в отличие от классификации не требует наличия информации о принадлежности к классу и соответственно принадлежит к классу unsupervised learning (обучение без учителя).
Задача кластеризации решается на начальных этапах исследования. Ее решение помогает лучше понять данные, их природу.
Большое достоинство кластерного анализа состоит в том, что он позволяет проводить разбиение объектов не по одному, а по целому набору признаков.
В начало
Почему именно технология Data Mining, а не отдельные методы классификации и кластеризации?
Технология Data Mining позволяет в отличие от отдельных методов кластеризации и классификации:
- Определить автоматически оптимальное количество кластеров;
- Работать с большим массивом данных;
- Не требуется наличия объектов, для которых заранее известно к какому из классов они принадлежат;
- Анализ баз данных на месте (In-Place Database Processing).
Анализ баз данных на месте (In-Place Database Processing)
Обработка баз данных на месте In-Place Database Processing (IDP) — это развитая технология доступа к базам данных, разработанная в StatSoft для достижения высокой производительности прямого интерфейса между данными внешних серверов и аналитической функциональностью продуктов STATISTICA.
IDP технология разработана, чтобы помочь обеспечить доступ к данным в больших БД, используя одношаговый процесс, который не требует создания локальных копий данных. IDP значительно увеличивает производительность STATISTICA; в частности хорошо приспособлена для задач data mining и исследовательских Анализов данных.
Причина большой скорости IDP
Большая скорость IDP технологии по сравнению с традиционным способом обусловлена не только тем фактом, что IDP позволяет STATISTICA обращаться к данным напрямую в БД и пропускать лишний шаг импорта данных и создания локального файла данных, но также из-за ее «многозадачной» (асинхронная и распределенная обработка) архитектуры. В частности IDP использует ресурсы (несколько процессоров) сервера БД для проведения операций с запросами, извлечения записей из данных, и пересылке их на компьютер с установленной программой STATISTICA, в то время как STATISTICA сразу обрабатывает эти записи, как только они поступают.
В начало
Алгоритмы кластеризации
Алгоритм К-средних
Разбивает множество элементов векторного пространства на заранее известное число кластеров k. Действие алгоритма таково, что он стремится минимизировать среднеквадратичное отклонение на точках каждого кластера. Основная идея заключается в том, что на каждой итерации перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике. Алгоритм завершается, когда на какой-то итерации не происходит изменения центров кластеров.
EM-алгоритм
В основе идеи EM-алгоритма лежит предположение, что распределение исходного множества является линейной комбинации подмножеств, имеющих нормальное распределение. Целью алгоритма является декомпозиция(разделение) множества на подмножества, а также оценка параметров распределения каждого подмножества, которые максимизируют логарифмическую функцию правдоподобия, используемую в качестве меры качества модели. Параметры нормального распределения – математическое ожидание и дисперсия.
В начало
Описательный анализ
Из таблицы видно, что непрерывные переменные Возраст клиента и Стоимость услуг имеют разную вариабельность (разброс) – Стандартное отклонение (последний столбец).
При кластеризации очень важно, чтобы переменные имели одинаковую вариабельность (разброс). Для этого используем процедуру Стандартизация.
Стандартизация
- Выберем вкладку Данные;
- Выберем Стандартизовать… Откроется диалоговое окно;
- Выберем переменные – Возраст клиента, Стоимость услуг. Нажмем кнопку ОК .
В начало
Кластеризация K-средних
Анализ результатов — вкладка Quick
В верхней части диалогового окна расположено рабочая область, где показаны основные характеристики кластеризации:
- Algorithm (Алгоритм) – К-средних;
- Distance method (мера связи) — Евклидова;
- Initial centers (определение центров кластеров) – Максимальное расстояние между кластеров;
- MD casewise deletion (удаление пропущенных значений) — Да;
- Cross-validation (кросс-проверка) – 10 кратная;
- Testing sample (Контрольная выборка) — 0;
- Training cases (Обучающая выборка) — 1000;
- Training error (ошибка на обучающей выборке) – 0,492645;
- Number of cluster (Число кластеров) – 4.
Во вкладке Quick (Быстрый) можно просмотреть следующие результаты:
Результаты анализа: Описание кластеров
Средние в каждом кластере (Cluster Means):
По строчкам стоят номера кластеров.
По столбцам — переменные, выбранные в начале анализа.
Последний столбец показывает долю наблюдений в каждом кластере.
Были получены следующие кластеры:
- Кластер 1: Специализированная работа с использованием дорогостоящих дополнительных процедур, средний возраст клиента – 25, средняя стоимость услуг – 715$;
- Кластер 2: Незначительная работа без использования дополнительных процедур, средний возраст клиента – 21, средняя стоимость услуг – 286$;
- Кластер 3: Значительная работа с использованием дорогостоящих дополнительных процедур, средний возраст клиента – 38, средняя стоимость услуг – 819$;
- Кластер 4: Значительная работа с использованием дешевых жополнительных процедур, средний возраст клиента – 27, средняя стоимость услуг – 551$.
Расстояние между кластерами (Cluster distance):
К примеру, расстояние между Кластер 1 и Кластер 2 — 1,465 (по метрики Евклида).
Объекты кластеров и расстояния:
Исходя из нее, можно понять какие наблюдения к какому кластеру принадлежат.
Определение значимых факторов
1. Сначала рассмотрим непрерывные переменные.
1.1 Построим график среднего возраста клиентов и стоимости услуг в каждом из кластеров.
Исходя из графика, в Кластере 2 средний возраст клиентов и средняя стоимость услуг максимальны по сравнению с другими кластерами.
1.2. Проведем Дисперсионный анализ для определения факторов, влияющих на принадлежность объекта кластеру.
Исходя из дисперсионного анализа, переменные Возраст клиента и Стоимость оказанных услуг влияют на принадлежность объекта кластеру, т.к. p-уровень меньше 0,05. Другими словам, и факторы Возраст и Стоимость оказанных услуг значимы.
2. Рассмотрим категориальные переменные.
Будем строить Таблицы частот и Графики частот для категориальных переменных (тип работы, дополнительные процедуры) для каждого кластера.
2.1. Тип работы.
Таблица частот:
График частот:
Исходя из построенного графика видим:
- В Кластере 2 наибольшее количество незначительных работ;
- В Кластере 1 наибольшее количество специализированных работ.
2.2. Дополнительные процедуры.
Таблица частот:
График частот:
Исходя из построенного графика видим:
- В Кластере 2 наибольшее количество работ, выполненных без использование дополнительных процедур;
- В Кластере 3 наибольшее количество работ, выполненных с использование дешевых дополнительных процедур;
- В Кластере 1 наибольшее количество работ, выполненных с использование дорогих дополнительных процедур.
2.3. Определим, какие переменные оказывают значимое влияние на принадлежность к кластеру. Воспользуемся критерием Хи-Квадрат для категориальных переменных:
Исходя из таблицы, Тип работы и Дополнительные процедуры влияют на принадлежность объекта к кластеру, т.к. p-уровень меньше 0,05. Другими словами факторы Тип работы и Дополнительные процедуры значимы.
Алгоритм запуска алгоритма k-средних рассмотрен в Приложении 1.
Выявление потенциальных мошенников
Нас интересуют те дантисты, которые завышают стоимость своих услуг.
Для выявления таких дантистов, необходимо сравнить среднюю общую стоимость оказанных услуг для каждого кластера и среднюю стоимость оказанных услуг дантиста в каждом кластере.
График общей средней стоимости оказанных услуг в каждом кластере:
Дантист 0
График средней стоимости оказанных услуг Дантиста 0 и График средней общей стоимости оказанных услуг в каждом кластере:
Как видно из графика, в Кластере 1 стоимость услуг Дантиста 0 значительно превышают среднюю общую стоимость услуг. Дантист 0 – потенциальный мошенник.
Дантист 5
График средней стоимости оказанных услуг Дантиста 5 и График средней общей стоимости оказанных услуг в каждом кластере:
Как видно из графика, средняя стоимость услуг Дантиста 5 в Кластере 4 и в Кластере 2 значительно выше по сравнению со средней общей стоимостью в этом кластере. Дантист 5 потенциальный мошенник.
Дантист 13
График средней стоимости оказанных услуг Дантиста 13 и График средней общей стоимости оказанных услуг в каждом кластере:
Как видно из графика, средняя стоимость услуг Дантиста 13 в Кластере 1 значительно превосходят общую среднюю стоимость в этом кластере. Дантист 13 потенциальный мошенник.
Дантист 19
Исходя из графика, средняя стоимость услуг Дантиста 19 значительно превышает общую среднюю стоимость в Кластере 4. Дантист 19 потенциальный мошенник.
В начало
EM-алгоритм
Анализ результатов – вкладка Quick
При EM-кластеризации получилось всего 2 кластера.
Результаты анализа: Описание кластеров
Были получены следующие кластеры:
Кластер 1: Специализированные работы с использованием дешевый дополнительных процедур, средний возраст клиента – 34, средняя стоимость услуг – 882$;
Кластер 2: Значительные и незначительные работы с использованием дешевый дополнительных процедур, средний возраст клиента — 26,5, средняя стоимость услуг – 256$.
Определение значимых факторов
1. Сначала рассмотрим непрерывные переменные;
1.1 Построим график среднего возраста клиентов и стоимости услуг в каждом из кластеров.
1.2. Проведем Дисперсионный анализ для определения факторов, влияющих на принадлежность объекта кластеру.
Исходя из дисперсионного анализа, переменные Возраст клиента и Стоимость оказанных услуг влияют на принадлежность объекта кластеру, т.к. p-уровень меньше 0,05. Другими словами факторы Возраст и Стоимость оказанных услуг значимы.
2. Рассмотрим категориальные переменные.
Будем строить Таблицу частот и График частот для категориальных переменных (тип работы, дополнительные процедуры) для каждого кластера.
2.1 Тип работы.
Таблица частот:
График частот:
Исходя из построенного графика видим:
- В Кластере 2 наибольшее количество незначительных и значительных работ;
- В Кластере 3 наибольшее количество специализированных работ.
2.2 Дополнительные процедуры.
Таблица частот:
График частот:
Исходя из построенного графика видим:
- В Кластере 1 наибольшее количество работ без использования дополнительных процедур;
- В Кластере 2 наибольшее количество работ с использованием дорогостоящих и недорогостоящих дополнительных процедур.
2.3. Определим, какие переменные оказывают значимое влияние на принадлежность к кластеру. Воспользуемся критерием Хи-Квадрат для категориальных переменных:
![]()
Исходя из таблицы, Тип работы и Дополнительные процедуры влияют на принадлежность объекта к кластеру, т.к. p-уровень меньше 0,05. Другими словами факторы Тип работы и Дополнительные процедуры значимы.
Алгоритм запуска модуля см. в Приложении 2.
Выявление потенциальных мошенников
График общей средней стоимости оказанных услуг в каждом кластере:
Дантист 15
График средней стоимости оказанных услуг Дантиста 15 и График средней общей стоимости оказанных услуг в каждом кластере:
Как видно из графика, в Кластере 1 стоимость услуг Дантиста 15 значительно превышают среднюю общую стоимость услуг. Дантист 15 – потенциальный мошенник.
Дантист 5
График средней стоимости оказанных услуг Дантиста 5 и График средней общей стоимости оказанных услуг в каждом кластере:
Как видно из графика, средняя стоимость услуг Дантиста 5 в Кластере 2 значительно выше по сравнению со средней общей стоимостью в этом кластере. Дантист 5 потенциальный мошенник.
Дантист 27
График средней стоимости оказанных услуг Дантиста 5 и График средней общей стоимости оказанных услуг в каждом кластере:
Как видно из графика, средняя стоимость услуг Дантиста 27 в Кластере 1 значительно превосходят общую среднюю стоимость в этом кластере. Дантист 13 потенциальный мошенник.
Дантист 14
Исходя из графика, средняя стоимость услуг Дантиста 14 значительно превышает общую среднюю стоимость в Кластере 1 и Кластере 2. Дантист 14 потенциальный мошенник.
В начало
Автоматизация
Для автоматического вычисления описательных статистик и построения графиков в STATISTICA Data Miner есть модуль построения проекта. Фрагмент интерактивного построения проекта показан ниже.
На рисунке выше на первом шаге вносим переменные, которые будут подвергнуты анализу (в первой красном прямоугольнике).
На втором шаге происходит чистка и фильтрация данных — процесс анализа пропущенных данных и замена пропущенных данных средним (во втором красном прямоугольнике).
На третьем шаге вычисляются описательные статистики, таблицы частот, график средних в каждом кластере, диаграммы (во третьем красном прямоугольнике).
Последний прямоугольник (зеленый) – результаты анализа. В них можно просмотреть полученные результаты.
В начало
Выводы
В ходе анализа было выявлено 7 дантистов из 31, которые умышленно завышают стоимость выполненных по страховке работ.
Алгоритм k-средних
С помощью алгоритма k-средних образовалось 4 кластера:
- Кластер 1: Специализированная работа с использованием дорогостоящих дополнительных процедур, средний возраст клиента – 25, средняя стоимость услуг – 715$;
- Кластер 2: Незначительная работа без использования дополнительных процедур, средний возраст клиента – 21, средняя стоимость услуг – 286$;
- Кластер 3: Значительная работа с использованием дорогостоящих дополнительных процедур, средний возраст клиента – 38, средняя стоимость услуг – 819$;
- Кластер 4: Значительная работа с использованием дешевых дополнительных процедур, средний возраст клиента – 27, средняя стоимость услуг – 551$.
При сравнении общей средней стоимости услуг в каждом кластере со средней стоимостью услуг каждого дантиста было выявлено 4 дантиста, которые являются потенциальными мошенниками.
Дантист 0
Сильно завышает стоимость своих работ по оказанию специализированных услуг с использованием дорогостоящих процедур.
Дантист 5
Сильно завышает стоимость своих работ по оказанию незначительных услуг без использования дополнительных процедур и стоимость работ по оказанию значительных услуг с использованием дорогостоящих работ.
Дантист 13
Сильно завышает стоимость своих работ по оказанию специализированных услуг с использованием дорогостоящих процедур.
Дантист 19
Сильно завышает стоимость работ по оказанию значительных услуг с использованием дорогостоящих работ.
EM-алгоритм
С помощью алгоритма EM образовалось 2 кластера:
- Кластер 1: Специализированные работы с использованием дешевый дополнительных процедур, средний возраст клиента – 34, средняя стоимость услуг – 882$;
- Кластер 2: Значительные и незначительные работы с использованием дешевый дополнительных процедур, средний возраст клиента — 26,5, средняя стоимость услуг – 256$.
При сравнении общей средней стоимости услуг в каждом кластере со средней стоимостью услуг каждого дантиста было выявлено 4 дантиста, которые являются потенциальными мошенниками.
Дантист 15
Сильно завышает стоимость работ по оказанию специализированных услуг с использованием дешевых дополнительных работ.
Дантист 5
Сильно завышает стоимость работ по оказанию значительных и незначительных услуг с использованием дешевых дополнительных работ.
Дантист 27
Сильно завышает стоимость работ по оказанию специализированных услуг с использованием дешевых дополнительных работ.
Дантист 14
Сильно завышает стоимость работ по оказанию значительных и незначительных услуг с использованием дешевых дополнительных работ.
В результате было выявлено 7 потенциальных мошенников:
Дантист 0
Дантист 5
Дантист 13
Дантист 14
Дантист 15
Дантист 19
Дантист 27
Применяемые техники для анализа данных страховых случаев позволяют подсчитать, как много работ определенных дантистов отличаются от нормы. Решаются важные вопросы: Как много дантистов-мошенников? Сколько денег подвержено риску из-за деятельности последних?
Алгоритмы кластеризации (алгоритм K-средних и EM-алгоритм) являются удобными инструментами для ответа на поставленные вопросы.
В начало
Приложение 1. Алгоритм запуска Алгоритма К-средних
Шаг 0 (Модуль)
Откроем вкладку Добыча данных (Data Miner) и выберем модуль Обобщенные методы кластерного анализа (Generalized EM and k-Means Cluster Analysis).
Откроется диалоговое окно:
Шаг 1 (Выбор переменных).
Нажмем на кнопку Variables (Переменные).
В качестве категориальных переменных выберем:
- Тип работы;
- Дополнительные процедуры.
В качестве непрерывных переменных:
- Возраст клиента;
- Стоимость оказанных услуг в $.
Шаг 2 (Настройка параметров кластеризации).
Во вкладке Quick (Быстрый) выберем:
- k-Means (к-средних);
- Number of cluster — 2;
- Number of iterations – 50,
как показано на рисунке выше.
Перейдем во вкладку k-means:
В этой вкладке настраиваются следующие параметры:
- начальные центры кластеров;
- мера связи.
Оставим по умолчанию.
Начальные центры кластеров будут определяться так, чтобы между ними было максимальное расстояние.
Мера связи (метрика в многомерном пространстве) – Евклидова.
Шаг 3 (Проверка).
Во вкладке Validation (Проверка) поставим галку рядом с кросс-проверкой. Остальные параметры оставим без изменений. Нажмем кнопку ОК.
В начало
Приложение 2. Алгоритм запуска EM-алгоритма
Повторить Шаг 0, Шаг 1 (см. Приложение 1).
Шаг 2 (Настройка параметров кластеризации).
Во вкладке Quick (Быстрый) выберем:
- EM algoritm;
- Number of cluster — 2;
- Number of iterations – 50.
Перейдем во вкладку EM:
В этой вкладке настраиваются следующие параметры:
- random seed;
- минимальный рост логарифма правдоподобия (minimum increase of log-likehood).
Оставляем их по умолчанию.
Для непрерывных переменных выберем в качестве распределения – нормальное.
Шаг 3 (Проверка).
Во вкладке Validation (Проверка) поставим галку рядом с кросс-проверкой. Остальные параметры оставим без изменений. Нажмем кнопку OK.
Читать подробнее о методах и инструментах STATISTICA Data Miner
- Ошибка W0015;
- Ошибка W0051;
- Ошибка W0052;
- Ошибка W0058;
- Ошибка W0225
- Ошибка W0246;
- Ошибка W0545;
Ошибка W0545
При выполнении платежа клиент видит такую картину:
Платеж отклонен. Текст ошибки error_dbt_tr_915
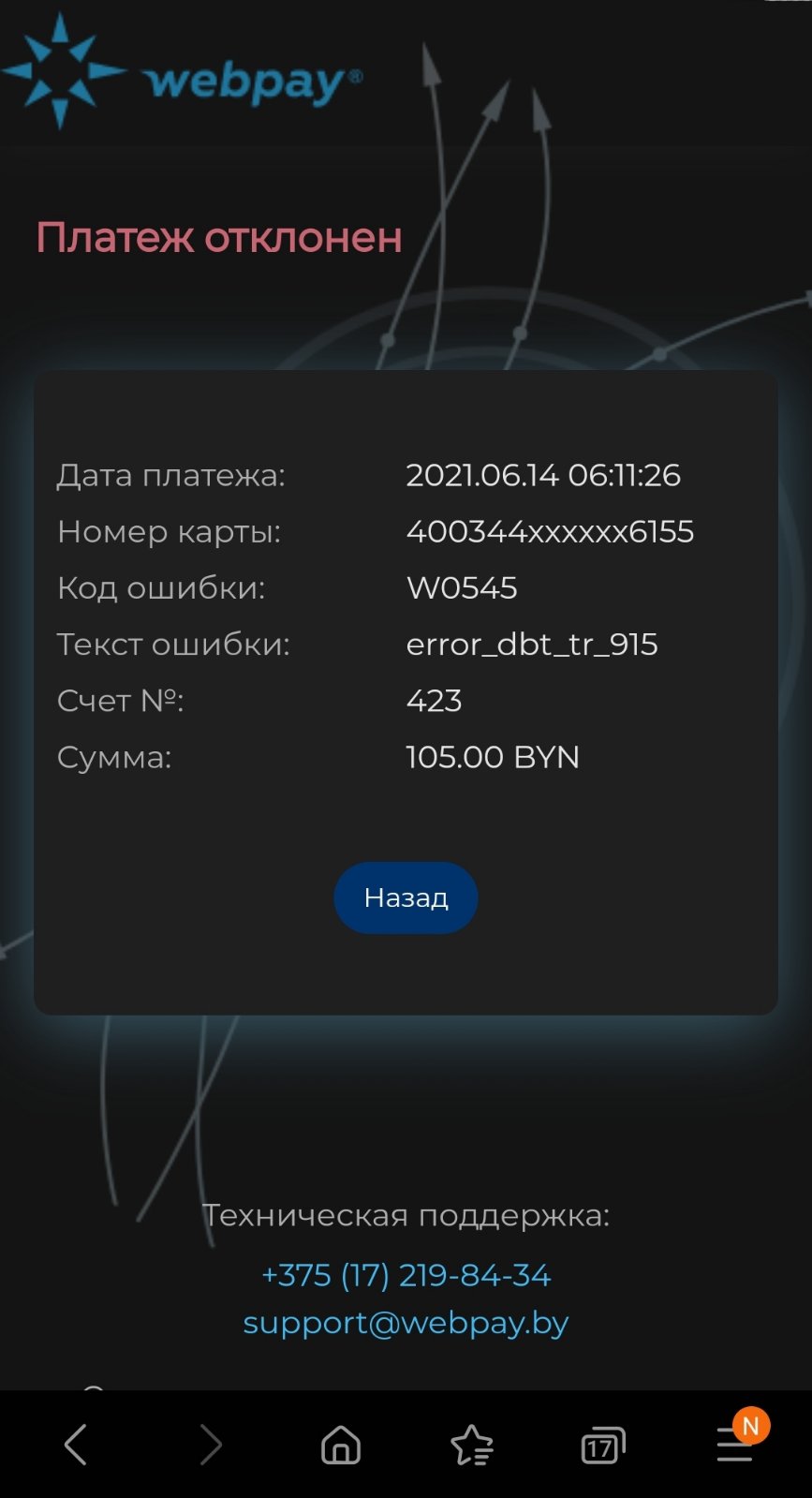
Причина:
Недостаточно средств на карте, с которой производят оплату:

Устранение:
Пополнить баланс карты.
Ошибка W0246
При попытке выполнить оплату заказа клиенту даже не появляется форма, где он бы мог ввести платежные данные, а сразу выскакивает эта ошибка с текстом:
Malformed order signature
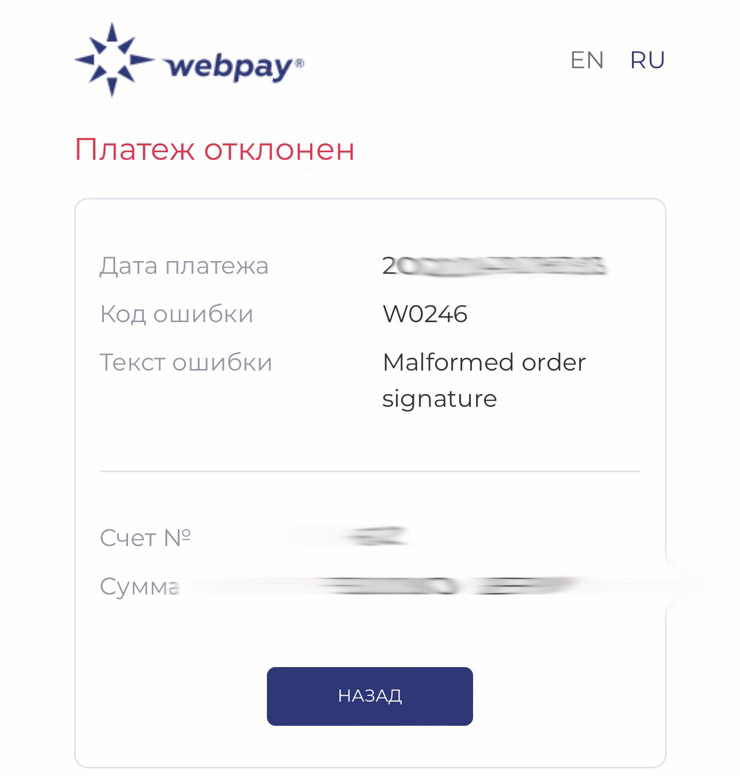
Причина:
Ошибка в введённом секретном ключе на стороне интернет-магазина.
В данном случае в кабинете Webpay был создан секретный ключ для сайта более чем из 30 различных символов. При вводе данного ключа на стороне магазина ключ сохранялся менее 30 символов. В результате чего не верно формировалась подпись заказа.
Решение:
Секретный ключ меньшей длины пересоздан в кабинете Webpay и интегрирован на стороне сайта.
Ошибка W0225
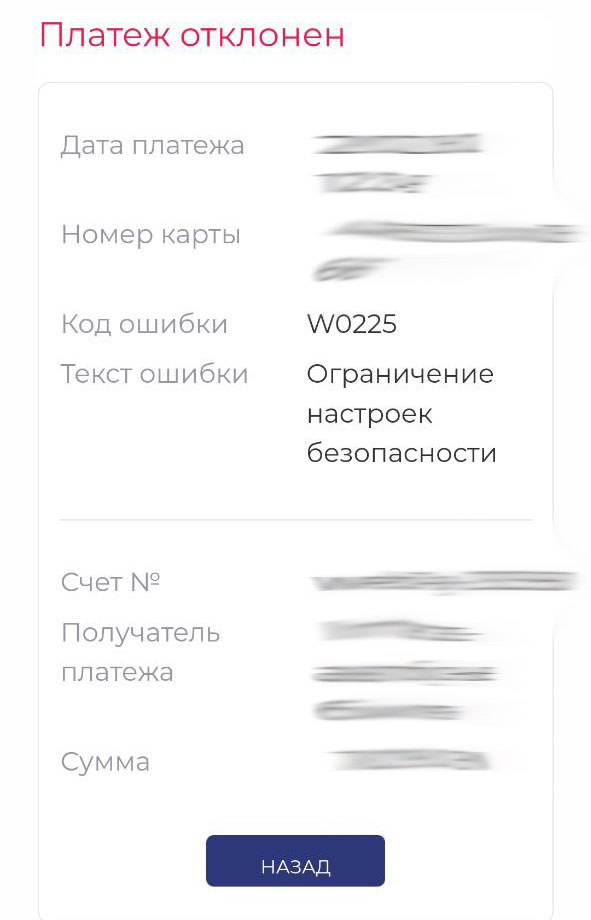
Причина:
Не включен 3D-Secure для карты. Также возможны проблемы на стороне оператора.
Решение:
Установка 3D-Secure в личном кабинете интернет-банкинга. Если эта защита установлена — обращайтесь в техническую поддержку оператора сопровождающие онлайн оплату.
Ошибка W0058
Причина:
Означает, что данный тип операции запрещен для владельца карты. То есть этой картой нельзя расплачиваться в конкретном интернет-магазине.
Решение:
Использовать другую карту для онлайн оплаты.
Ошибка W0051 и W0052
Причина:
Недостаточно денежных средств
Решение:
Пополнить карту или воспользоваться другой.
Ошибка W0015
При оплате на белорусском сайте заказчиком и России появилась ошибка:
Карточка не существует
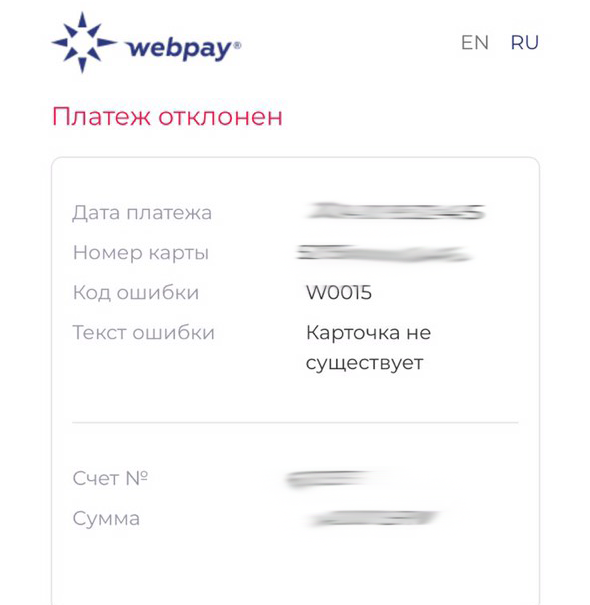
Причина:
С 10.03 платежные системы VISA и MasterCard прекратили сотрудничество с банками РФ, по этой причине оплата такими картами в счет иностранных поставщиков услуг недоступна.
Решение:
Воспользоваться картой другой платежной системы: МИР, Белкарт.
Many people come here wondering why there is a charge in their credit card from VZ-WIRELESS-VE-VZW-WEBPAY. They usually don’t like to hear that this is probably a scam.
No problem, read all this and we will teach you how to stop this fraud and recover your money. VZ-WIRELESS-VE-VZW-WEBPAY credit card scams and many other are usual when people buy online (and also offline), in this case we’re not talking about hackers, it is the actual business who scammed you..
Users did a total of 31 votes, and 28 voted that it is a FRAUD CHARGE.
VZ-WIRELESS-VE-VZW-WEBPAY was detected in our DB the number 758. The charge comes from the country Vatican City. There are a total 30 people that have came here asking for vz wireless ve vzw webpay or something similar.

More information about credit cards and frauds
- Search the official Fraug.org website also learn from their tutorials or directly contact them.
- Also, check VISA or Mastercard sites to ask for help, or open a dispute on PayPal might be worth it.
- Please comment in the comments section if this worked for you or if you know any other detail from the company.
Other data about VZ-WIRELESS-VE-VZW-WEBPAY scam credit charge
This scam in credit cards has also been found on Pakistan, Gabon and Gabon.
Our combinate score with VISA says that it is a 67% charge fraud rate and the score for PayPal and Mastercard (other credit card providers like Revolut, N26, BBVA, Banco Santander, JPMorgan Chase, Bank of America, Wells Fargo, Citigroup, Goldman Sachs, Morgan Stanley and Capital One says it is a 30% credit charge fraud rate.
VZ-WIRELESS-VE-VZW-WEBPAY credit card notice was found Friday at 4 in 2016.
Обнаружение мошеннических операций – одна из популярнейших задач Машинного обучения (ML), нацеленная на выделение правонарушений из общего потока событий. Рассмотрим в качестве примера распознавание воровства средств с банковских карт.
Для начала импортируем необходимые библиотеки:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
from xgboost import XGBClassifier
from xgboost import plot_importance
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_predict
from sklearn.ensemble import RandomForestClassifier
from sklearn import svm
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import confusion_matrix
from sklearn import metrics
from sklearn.metrics import roc_auc_score
from sklearn.metrics import average_precision_score
from sklearn.metrics import roc_curve, aucИмпортируем хронологию операций:
data = pd.read_csv('../input/creditcardfraud/creditcard.csv')Посмотрим, из чего состоит Датасет (Dataset):
data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 284807 entries, 0 to 284806
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Time 284807 non-null float64
1 V1 284807 non-null float64
2 V2 284807 non-null float64
3 V3 284807 non-null float64
4 V4 284807 non-null float64
5 V5 284807 non-null float64
6 V6 284807 non-null float64
7 V7 284807 non-null float64
8 V8 284807 non-null float64
9 V9 284807 non-null float64
10 V10 284807 non-null float64
11 V11 284807 non-null float64
12 V12 284807 non-null float64
13 V13 284807 non-null float64
14 V14 284807 non-null float64
15 V15 284807 non-null float64
16 V16 284807 non-null float64
17 V17 284807 non-null float64
18 V18 284807 non-null float64
19 V19 284807 non-null float64
20 V20 284807 non-null float64
21 V21 284807 non-null float64
22 V22 284807 non-null float64
23 V23 284807 non-null float64
24 V24 284807 non-null float64
25 V25 284807 non-null float64
26 V26 284807 non-null float64
27 V27 284807 non-null float64
28 V28 284807 non-null float64
29 Amount 284807 non-null float64
30 Class 284807 non-null int64
dtypes: float64(30), int64(1)
memory usage: 67.4 MBКроме Признаков (Feature) «Время» (Time), «Количество» (Amount) и «Класс» (Class) другие не стоит интерпретировать в одиночку. Но все мы знаем, что значения столбцов V1 — V28 были преобразованы с помощью Анализа главных компонент (PCA). Эти загадочные колонки – результат защиты конфиденциальных данных пользователей.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 284807 entries, 0 to 284806
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Time 284807 non-null float64
1 V1 284807 non-null float64
2 V2 284807 non-null float64
3 V3 284807 non-null float64
4 V4 284807 non-null float64
5 V5 284807 non-null float64
6 V6 284807 non-null float64
7 V7 284807 non-null float64
8 V8 284807 non-null float64
9 V9 284807 non-null float64
10 V10 284807 non-null float64
11 V11 284807 non-null float64
12 V12 284807 non-null float64
13 V13 284807 non-null float64
14 V14 284807 non-null float64
15 V15 284807 non-null float64
16 V16 284807 non-null float64
17 V17 284807 non-null float64
18 V18 284807 non-null float64
19 V19 284807 non-null float64
20 V20 284807 non-null float64
21 V21 284807 non-null float64
22 V22 284807 non-null float64
23 V23 284807 non-null float64
24 V24 284807 non-null float64
25 V25 284807 non-null float64
26 V26 284807 non-null float64
27 V27 284807 non-null float64
28 V28 284807 non-null float64
29 Amount 284807 non-null float64
30 Class 284807 non-null int64
dtypes: float64(30), int64(1)
memory usage: 67.4 MB
Посмотрим, насколько наши данные сбалансированы:
plt.figure(figsize=(10,10))
sns.countplot(
y="Class",
data=data,
facecolor=(0, 0, 0, 0),
linewidth=5,
edgecolor=sns.color_palette("dark", 2))
plt.title('Fraudulent Transaction Summary')
plt.xlabel('Count')
plt.ylabel('Fraudulent Transaction Non-Fraudulent Transaction', fontsize=12)Мы имеем дело с Несбалансированным датасетом (Imbalanced Dataset), то есть соотношение представителей класса неравное.

График показывает, что существует огромная разница между классами операций. Несбалансированные данные могут вызвать проблемы Классификации (Classification), такие как неправильная Точность (Accuracy). В этом проекте мы будем использовать Метод удаления примеров мажоритарного класса (Undersampling Method).
Преобразуем признак «Класс» в категориальный:
data['Class']= data['Class'].astype('category')Посмотрим, как транзакции распределены по времени. Time – это количество секунд, прошедших между рассматриваемой и первой транзакцией в наборе данных:
plt.figure(figsize=(15,10))
sns.distplot(data['Time'])
Следующим делом посмотрим на распределение признака «Количество»:
plt.figure(figsize=(10,10))
sns.distplot(data['Amount'])
Приведенные выше графики показывают, что столбцы «Время» и «Количество» необходимо подвергнуть Стандартизации (Standartization). Этот метод позволит создавать признаки, которые имеют схожие диапазоны значений.
Перед стандартизацией я хочу создать функцию «Час», которая поможет лучше использовать «Время» и его связь с остальными столбцами.
data['Hour'] = data['Time'].apply(lambda x: np.ceil(float(x)/3600) % 24)
pd.pivot_table(
columns="Class",
index="Hour",
values= 'Amount',
aggfunc='count',
data=data)
Посмотрим, в какое время дня мошенники наиболее активны и сравним с активностью нормальных операций:
#Hour vs Class
fig, axes = plt.subplots(2, 1, figsize=(15, 10))
sns.countplot(
x="Hour",
data=data[data['Class'] == 0],
color="#98D8D8",
ax=axes[0])
axes[0].set_title("Non-Fraudulent Transaction")
sns.countplot(
x="Hour",
data=data[data['Class'] == 1],
color="#F08030",
ax=axes[1])
axes[1].set_title("Fraudulent Transaction")
Приведенные выше графики показывают, что обычные и мошеннические транзакции совершались каждый час. Для мошеннических транзакций третий и двенадцатый часы – самые «горячие».
Понижение размерности
Результаты исследования данных показывают, что набор данных большой, а размеры классов несбалансированы, поэтому уменьшение размерности поможет интерпретировать результаты. Для этого будет использоваться Стохастическое вложение соседей с t-распределением (t-SNE). Этот метод хорошо работает с данными большого размера и «проецирует» их в двух- или трехмерном пространстве.
data_nonfraud = data[data['Class'] == 0].sample(2000)
data_fraud = data[data['Class'] == 1]
data_new = data_nonfraud.append(data_fraud).sample(frac=1)
X = data_new.drop(['Class'], axis = 1).values
y = data_new['Class'].values
tsne = TSNE(n_components=2, random_state=42)
X_transformation = tsne.fit_transform(X)
plt.figure(figsize=(10, 10))
plt.title("t-SNE Dimensionality Reduction")
def plot_data(X, y):
plt.scatter(X[y == 0, 0], X[y == 0, 1], label="Non_Fraudulent", alpha=0.5, linewidth=0.15, c='#17becf')
plt.scatter(X[y == 1, 0], X[y == 1, 1], label="Fraudulent", alpha=0.5, linewidth=0.15, c='#d62728')
plt.legend()
return plt.show()
plot_data(X_transformation, y)
На приведенном выше графике показано, что мошеннические и нормальные транзакции плохо разделены на два разных кластера в двухмерном пространстве. Это означает, что два типа операций сильно похожи. Также этот график демонстрирует, что показаний точности недостаточно для выбора лучшего алгоритма.
Стандартизация
data[['Time', 'Amount']] = StandardScaler().fit_transform(data[['Time', 'Amount']])Оптимизация гиперпараметров
Этот метод помогает найти оптимальные параметры для алгоритмов машинного обучения. Алгоритм поиска по сетке (Grid Search) будет использоваться для настройки Гиперпараметров (Hyperparameter). Затем будет выполнен Экстремальный градиентный бустинг (XGBoost) для построения графика Важности признаков (Feature Importance). Этот график помогает выбрать параметры, которые будут использоваться в Модели (Model).
train_data, label_data = data.iloc[:,:-1],data.iloc[:,-1]
data_dmatrix = xgb.DMatrix(data=train_data, label= label_data)
X_train, X_test, y_train, y_test = train_test_split(
train_data, label_data, test_size=0.3,random_state=42)
params = {
'objective':'reg:logistic',
'colsample_bytree': 0.3,
'learning_rate': 0.1,
'bootstrap': True,
'criterion': 'gini',
'max_depth': 4,
'max_features': 'auto',
'n_estimators': 50
}
xg_reg = xgb.train(params=params, dtrain=data_dmatrix, num_boost_round=10)
#Feature importance graph
plt.rcParams['figure.figsize'] = [20, 10]
xgb.plot_importance(xg_reg)
На приведенном выше графике показано, что самый важный столбец – это V16. Параметры с наименьшей важностью — V13, V25, Time, V20, V22, V8, V15, V19 и V2 будут удалены из данных перед построением модели.
data_model = data.drop(['V13', 'V25', 'Time', 'V20', 'V22', 'V8', 'V15', 'V19', 'V2'], axis=1)Метод удаления примеров мажоритарного класса
Перед построением модели будет применен метод случайного недосэмплирования. В этом проекте было выбрано 5% нормальных транзакций.
data_under_nonfraud = data_model[data_model['Class'] == 0].sample(15000)
data_under_fraud = data_model[data_model['Class'] == 1]
data_undersampling = data_under_nonfraud.append(data_under_fraud,
ignore_index=True, sort=False)
plt.figure(figsize=(10,10))
sns.countplot(y="Class", data=data_undersampling,palette='Dark2')
plt.title('Fraudulent Transaction Summary')
plt.xlabel('Count')
plt.ylabel('Fraudulent Transaction, Non-Fraudulent Transaction')
Новые данные будут случайным образом разделены на Тренировочные данные (Train Data) и Тестовые данные (Test Data). Доля первых составляет 70%, вторых – 30%.
k-блочная кросс-валидация
kfold_cv=KFold(n_splits=5, random_state=42, shuffle=True)
for train_index, test_index in kfold_cv.split(X,y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]Случайный лес
modelRF = RandomForestClassifier(
n_estimators=500,
criterion = 'gini',
max_depth = 4,
class_weight='balanced',
random_state=42
).fit(X_train, y_train)
# Obtain predictions from the test data
predict_RF = modelRF.predict(X_test)Метод опорных векторов
modelSVM = svm.SVC(
kernel='rbf',
class_weight='balanced',
gamma='scale',
probability=True,
random_state=42
).fit(X_train, y_train)
# Obtain predictions from the test data
predict_SVM = modelSVM.predict(X_test)Логистическая регрессия
modelLR = LogisticRegression(
solver='lbfgs',
multi_class='multinomial',
class_weight='balanced',
max_iter=500,
random_state=42
).fit(X_train, y_train)
# Obtain predictions from the test data
predict_LR = modelLR.predict(X_test)Многослойный перцептрон
modelMLP = MLPClassifier(
solver='lbfgs',
activation='logistic',
hidden_layer_sizes=(100,),
learning_rate='constant',
max_iter=1500,
random_state=42
).fit(X_train, y_train)
# Obtain predictions from the test data
predict_MLP = modelMLP.predict(X_test)Сравнение методов
RF_matrix = confusion_matrix(y_test, predict_RF)
SVM_matrix = confusion_matrix(y_test, predict_SVM)
LR_matrix = confusion_matrix(y_test, predict_LR)
MLP_matrix = confusion_matrix(y_test, predict_MLP)
fig, ax = plt.subplots(1, 2, figsize=(15, 8))
sns.heatmap(RF_matrix, annot=True, fmt="d",cbar=False, cmap="Paired", ax = ax[0])
ax[0].set_title("Random Forest", weight='bold')
ax[0].set_xlabel('Predicted Labels')
ax[0].set_ylabel('Actual Labels')
ax[0].yaxis.set_ticklabels(['Non-Fraud', 'Fraud'])
ax[0].xaxis.set_ticklabels(['Non-Fraud', 'Fraud'])
sns.heatmap(SVM_matrix, annot=True, fmt="d",cbar=False, cmap="Dark2", ax = ax[1])
ax[1].set_title("Support Vector Machine", weight='bold')
ax[1].set_xlabel('Predicted Labels')
ax[1].set_ylabel('Actual Labels')
ax[1].yaxis.set_ticklabels(['Non-Fraud', 'Fraud'])
ax[1].xaxis.set_ticklabels(['Non-Fraud', 'Fraud'])
fig, axe = plt.subplots(1, 2, figsize=(15, 8))
sns.heatmap(LR_matrix, annot=True, fmt="d",cbar=False, cmap="Pastel1", ax = axe[0])
axe[0].set_title("Logistic Regression", weight='bold')
axe[0].set_xlabel('Predicted Labels')
axe[0].set_ylabel('Actual Labels')
axe[0].yaxis.set_ticklabels(['Non-Fraud', 'Fraud'])
axe[0].xaxis.set_ticklabels(['Non-Fraud', 'Fraud'])
sns.heatmap(MLP_matrix, annot=True, fmt="d",cbar=False, cmap="Pastel1", ax = axe[1])
axe[1].set_title("Multilayer Perceptron", weight='bold')
axe[1].set_xlabel('Predicted Labels')
axe[1].set_ylabel('Actual Labels')
axe[1].yaxis.set_ticklabels(['Non-Fraud', 'Fraud'])
axe[1].xaxis.set_ticklabels(['Non-Fraud', 'Fraud'])Для несбалансированных данных результаты матрицы путаницы могут быть неверными. Однако полезно сказать, сколько мошеннических транзакций предсказано верно. На основе графиков Многослойного персептрона (MLP), Случайного леса (Random Forest) и Логистической регрессии (Logistic Regression) предсказывают одну и ту же долю мошеннических транзакций (сумма нижних двух ячеек каждой из матриц равна 109).

print("Classification_RF:")
print(classification_report(y_test, predict_RF))
print("Classification_SVM:")
print(classification_report(y_test, predict_SVM))
print("Classification_LR:")
print(classification_report(y_test, predict_LR))
print("Classification_MLP:")
print(classification_report(y_test, predict_MLP))В приведенной ниже таблице показаны результаты по точности, Отзыву (Recall) и Критерий F1 (F1 Score).
- Модель логистической регрессии имеет самый высокий уровень отзыва. Это означает, что она лучше «разыскивает» фактическую мошенническую транзакцию. Однако, когда мы смотрим на показатель точности, логистическая регрессия показывает один из самых худших результатов.
- Наивысший удалось достигнуть случайному лесу. Высокая точность связана с низким уровнем ложных срабатываний, поэтому можно сказать, что модель случайного леса предсказывает наименьшее количество ложных мошеннических транзакций.
- Критерий F1 дает лучшее объяснение на том основании, что он рассчитывается из Гармонических средних значений (Harmonic Mean) точности и отзыва. F1 – это лучшая метрика для выбора наиболее предсказуемой модели. В свете этой информации мы можем сказать, что алгоритм Случайного леса является наилучшим.
Classification_RF:
precision recall f1-score support
0 0.98 0.99 0.99 389
1 0.98 0.92 0.95 109
accuracy 0.98 498
macro avg 0.98 0.96 0.97 498
weighted avg 0.98 0.98 0.98 498
Classification_SVM:
precision recall f1-score support
0 0.83 0.50 0.62 389
1 0.26 0.64 0.37 109
accuracy 0.53 498
macro avg 0.55 0.57 0.50 498
weighted avg 0.71 0.53 0.57 498
Classification_LR:
precision recall f1-score support
0 0.98 0.96 0.97 389
1 0.86 0.94 0.89 109
accuracy 0.95 498
macro avg 0.92 0.95 0.93 498
weighted avg 0.95 0.95 0.95 498
Classification_MLP:
precision recall f1-score support
0 0.86 1.00 0.92 389
1 0.98 0.41 0.58 109
accuracy 0.87 498
macro avg 0.92 0.71 0.75 498
weighted avg 0.88 0.87 0.85 498
Окончательное сравнение будет выполнено с ROC-кривая (AUC ROC):
#RF AUC
rf_predict_probabilities = modelRF.predict_proba(X_test)[:,1]
rf_fpr, rf_tpr, _ = roc_curve(y_test, rf_predict_probabilities)
rf_roc_auc = auc(rf_fpr, rf_tpr)
#SVM AUC
svm_predict_probabilities = modelSVM.predict_proba(X_test)[:,1]
svm_fpr, svm_tpr, _ = roc_curve(y_test, svm_predict_probabilities)
svm_roc_auc = auc(svm_fpr, svm_tpr)
#LR AUC
lr_predict_probabilities = modelLR.predict_proba(X_test)[:,1]
lr_fpr, lr_tpr, _ = roc_curve(y_test, lr_predict_probabilities)
lr_roc_auc = auc(lr_fpr, lr_tpr)
#MLP AUC
mlp_predict_probabilities = modelMLP.predict_proba(X_test)[:,1]
mlp_fpr, mlp_tpr, _ = roc_curve(y_test, mlp_predict_probabilities)
mlp_roc_auc = auc(mlp_fpr, mlp_tpr)
plt.figure()
plt.plot(rf_fpr, rf_tpr, color='red',lw=2,
label='Random Forest (area = %0.2f)' % rf_roc_auc)
plt.plot(svm_fpr, svm_tpr, color='blue',lw=2,
label='Support Vector Machine (area = %0.2f)' % svm_roc_auc)
plt.plot(lr_fpr, lr_tpr, color='green',lw=2,
label='Logistic Regression (area = %0.2f)' % lr_roc_auc)
plt.plot(mlp_fpr, mlp_tpr, color='orange',lw=2,
label='Multilayer Perceptron (area = %0.2f)' % mlp_roc_auc)
plt.plot([0, 1], [0, 1], color='black', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc="lower right")
plt.show()Основываясь на кривой, мы можем сказать, что алгоритмы логистической регрессии, случайного леса и нейронной сети – многослойного персептрона имеют почти одинаковые результаты AUC. У отличной модели AUC близка к 1, что означает, что у нее хороший показатель отделимости.
Этот вывод можно продемонстрировать и по результатам кривой ROC. Эти алгоритмы склоняются к истинно положительной скорости, а не к ложноположительной. В результате можно сказать, что эти алгоритмы имеют хорошую производительность классификации.

Наконец, мы можем вычислить средний балл точности для этих трех моделей. Результаты показывают, что все модели имеют почти одинаковый балл.
print("Average precision score of Logistic Regression", average_precision_score(y_test, modelLR.predict_proba(X_test)[:,1]))
print("Average precision score of Random Forest", average_precision_score(y_test, modelRF.predict_proba(X_test)[:,1]))
print("Average precision score of Multilayer Perceptron", average_precision_score(y_test, modelMLP.predict_proba(X_test)[:,1]))Average precision score of Logistic Regression 0.9651191598439374
Average precision score of Random Forest 0.9728045908653973
Average precision score of Multilayer Perceptron 0.8624254915524178Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор: Akashdeep Kuila