В данном разделе рассматриваются некоторые подходы к проверке наличия стандартных свойств (2.20)–(2.23) у “истинной” ошибки эконометрической модели et на основе анализа соответствующих свойств фактической ошибки еt.
В этой связи сразу следует отметить, что наличие у ошибки еt каждого из этих свойств не всегда является доказательством присутствия соответствующего свойства и у ошибки et. Иными словами, наличие определенных свойств у ошибки еt не является необходимым условием существования этих свойств и у истинной ошибки et. Дело в том, что некоторые свойства фактической ошибки еt являются своего рода ограничениями на ее значения, которые вытекают из критерия МНК как метода оценки параметров модели, т. е. выполняются практически всегда. В то же время свойства “истинной” ошибки определены теоретическими предпосылками, положенными в основу этой модели. Поэтому вывод о правомочности использования МНК на основе существования таких “априорных” свойств фактической ошибки модели не может считаться обоснованным.
Вместе с тем, если фактическая ошибка et не обладает некоторым свойством, то можно говорить о том, что теоретические предпосылки эконометрической модели не подтверждены полученными эмпирическими данными и “качество” ее уравнения не достаточно высоко.
В этой связи отметим, что к “априорным” свойствам фактической ошибки еt, которые выполняются при использовании МНК всегда, относятся свойства (2.20) и (2.23). Приведем доказательства этого утверждения.
1. Сумма значений фактической ошибки равна нулю
![]()
Условие (2.43) является аналогом свойства (2.20), поскольку ![]() рассматривается как оценка математического ожидания фактической ошибки.
рассматривается как оценка математического ожидания фактической ошибки.
Использование МНК обеспечивает выполнение условия (2.43) автоматически. В самом деле, дифференцируя сумму квадратов ошибки еt s2 (см. выражение (2.31)) по параметру a0 , получим
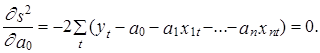
Из этого выражения автоматически вытекает, что
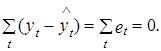
2. Произведение транспонированной матрицы Х¢ на вектор фактической ошибки е равно нулевому вектору.
Х¢е=0. (2.44)
Условие (2.44) является аналогом условия (2.23), поскольку произведение каждой строки матрицы Х¢ на вектор e представляет собой скалярное произведение вектора значений соответствующих факторов хit на вектор ошибки.
Внимание!
Если вам нужна помощь в написании работы, то рекомендуем обратиться к
профессионалам. Более 70 000 авторов готовы помочь вам прямо сейчас. Бесплатные
корректировки и доработки. Узнайте стоимость своей работы.
Тогда векторно-матричное выражение (2.44) можно представить в виде следующей системы скалярных произведений:
![]()
где х0t º1 для t=1, 2,…, Т.
Для доказательства справедливости выражения (2.44) представим вектор ошибки е в виде разности фактических и расчетных значений независимой переменной yt
е=у –![]() =у–Х×a.
=у–Х×a.
Получим
Х¢×e=Х¢×(у–Х×a)=Х¢×у–Х¢×Х×a=(Х¢×Х)–1×Х¢×у–(Х¢×Х)–1 ×(Х¢×Х)×a=0.
Из (2.44) и (2.45) автоматически следует, что
![]()
Еще раз отметим, что выполнение условий (2.45) и (2.46) не может считаться доказательством отсутствия корреляционных взаимосвязей между значениями независимых переменных хit и “истинной” ошибкой et. В данном случае эти условия сами являются следствием результатов применения МНК для оценки коэффициентов эконометрической модели, т. е. они как бы выполняются автоматически. Для некоторых классов эконометрических моделей, как это будет показано в главах V и VIII, уже априорно, т. е. до построения модели, можно доказать существование ковариационной связи между некоторыми независимыми переменными и истинной ошибкой модели et. Выполнение условия (2.45) в таком случае не является свидетельством корректности применения “классического” МНК для оценки ее параметров.
3. Из условий (2.43) и (2.45) также вытекает, что сумма произведений отклонений расчетных значений независимых переменных от ее среднего значения и расчетных значений ошибки равна нулю.

Раскрывая скобки в выражении (2.47), непосредственно получим
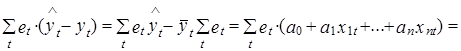
![]()
Выражение (2.47) включает в себя также и следующее условие:

означающее, что сумма произведений расчетных значений зависимой переменной ![]() и ошибки еt равна нулю.
и ошибки еt равна нулю.
Здесь еще раз подчеркнем, что условия (2.43)–(2.48) для фактической ошибки еt эконометрической модели автоматически вытекают из метода оценки ее параметров – МНК, и поэтому их непосредственно нельзя переносить на условия (2.20)–(2.23), характеризующие свойства истинной ошибки e t.
Вместе с тем, условия (2.21) и (2.22) для фактической ошибки еt не являются “априорными”. Они выполняются лишь в том случае, если исходные предпосылки МНК оказались справедливыми для данной модели, что является свидетельством обоснованного выбора формы ее уравнения, состава учтенных факторов и т. п.
Получить выполненную работу или консультацию специалиста по вашему
учебному проекту
Узнать стоимость
Как отмечалось в п.2.1, по ограниченным
данным выборки объема n можно
построить модель лишь с некоторой
точностью. её параметры a и b
являются оценками истинных значений α
и β, которые определяются генеральной
совокупностью объема N >> n.
Последней приписываются вероятностные
свойства с применением аксиом теории
вероятности, определений случайной
величины, вероятности, плотности
вероятности, оператора усреднения и
т.д. В рамках свойств генеральной
совокупности объема N рассматривается
спецификация модели линейной
регрессии
![]()
,
в
которой α, β, xi –
детерминированные (фиксированные или
известные) величины, а значения показателя
yi и ошибки модели i
– случайные величины (СВ) с
заданным распределением (например,
плотности вероятности). Часто yi,
i считаются
нормальными СВ (НСВ), тогда модель
называют нормальной.
Ограниченные данные выборки объема n
<< N позволяют вместо точной
модели (2.1) с параметрами α и β
построить приближенную модель (2.2)
![]()
.
Здесь еі – остатки
регрессии, вероятностные свойства
которых считаются аналогичными ошибкам
i , а
a, b – некоторые оценки (приближенные
значения) параметров модели.
Мы
будем оценивать дисперсии и
среднеквадратичные ошибки (СКО) для
оценок параметров модели и величины :
![]()
;
![]()
;
![]()
,
где M[X], D[X] – математическое
ожидание и дисперсия случайной величины
Х.
Для непрерывной случайной величины Х
с плотностью вероятности р(х)
они определяются как
![]()
,
![]()
.
Следовательно, для точного определения
того или иного параметра случайной
величины достаточно знать (или задать)
её распределение плотности вероятности.
2.4.1. Основные условия (гипотезы) анализа ошибок
Поскольку в корреляционно-регрессионном
анализе мы опираемся на методы
математической статистики и теории
вероятности, любые оценки ошибок
моделирования являются корректными
лишь при выполнении исходно принятых
условий (гипотез) в отношении величин
и переменных, входящих в модель. Примем
следующие гипотезы:
1. В спецификации модели (2.1) фактор х
и параметры модели α, β – детерминированные
величины, а показатель уi
и ошибки моделирования i
– случайные величины.
2. Ошибки моделирования имеют нулевое
среднее значение и некоррелированны:
![]()
Невыполнение второго условия называют
автокорреляцией ошибок модели.
3. Дисперсия ошибок моделирования i
показателя не зависят от номера i
(гомоскедастичность):
![]()
Невыполнение этого условия называют
гетероскедастичностью.
Дополнительным условием, которое может
не выполняться в ряде случаев, является
свойство нормальной модели:
4. Ошибки i
являются нормальными СВ:
N(0,
2) c нулевым
математическим ожиданием mε
= 0 и дисперсией 2.
2.4.2. Ошибки оценок параметров модели
Покажем сначала, что оценки МНК параметров
линейной модели являются несмещенными,
т.е. математические ожидания оценок
совпадают с истинными значениями
параметров:
M[b] = β, M[a] = α.
Действительно, согласно (2.12) и (2.7) имеем:

. (2.27)
С учетом (2.1), детерминированности vi
и условия
M[i]
= 0 гипотезы 2 получим в результате
усреднения оценки b в рамках
генеральной совокупности
![]()
.
Здесь использовано одно из свойств для
коэффициентов vi

(2.28)
которые
следуют из (2.27).
Аналогично, для параметра a с учетом
(2.6) и несмещенности b получим
![]()
.
Таким
образом, обе оценки МНК параметров
линейной модели являются несмещенными,
то есть сходятся при неограниченном
увеличении объема выборки к точным
значениям параметров α и β. Поэтому при
определении их дисперсий усредняются
квадраты разностей оценок и истинных
значений параметров.
Определим дисперсию коэффициента
регрессии. Известными свойствами
дисперсии СВ Х, умножаемой или
складываемой с константой с, являются:
![]()
. (2.29)
Тогда
с использованием (2.27) – (2.29)

.(2.30)
Здесь принято во внимание, что дисперсии
D[yi] =D[i],
так как показатель и ошибка модели
как случайные величины отличаются на
детерминированное слагаемое a+ bxi.
Дисперсию
постоянной составляющей модели определим
как
![]()
. (2.31)
Так как
![]()
. (2.32)
и
![]()
, (2.33)
то с
учетом (2.32), (2.33) дисперсия (2.31) становится
равной

. (2.34)
Более
сложным является определение оценки
дисперсии ошибок модели. Опуская вывод,
приведем окончательную формулу для
несмещенной оценки дисперсии ошибок
моделирования
![]()
, (2.35)
выраженную
через остатки регрессии (2.2).
Выражения (2.30), (2.34) дают точные значения
дисперсий оценок параметров модели,
однако практически воспользоваться
ими нельзя, так как точное значение
дисперсии ошибок 2
неизвестно (оно определяется из
генеральной совокупности, а не из
выборки). На основе выборочных данных
можно лишь оценить с помощью (2.35) эту
дисперсию. Поэтому на практике в формулы
(2.31), (2.35) вместо 2
подставляют её оценку (2.35) и получают
оценки дисперсий параметров b и a:

, (2.36)

. (2.37)
Эти
оценки используют лишь выборочные
данные. СКО этих оценок равны положительным
значениям квадратного корня из дисперсий.
В
лияние
СКО оценок параметров на точность модели
отражается на рис.2.5, а, б. Сдвиг
постоянной составляющей в пределах а
а
не является существенным при моделировании,
так как он не изменяется при всех
значениях фактора х и его можно
легко скорректировать. Более существенные
последствия имеет ошибка в определении
коэффициента регрессии b. Как видно
из рис.2.5, б, ошибки в прогнозах
показателя у* становятся тем
больше, чем больше отклонение от среднего
значения фактора х. Стандартное отклонение
у* b
имеет место при
![]()
.
В общем случае граничная ошибка регрессии
(с доверительной вероятностью 68%)
пропорциональна величине
![]()
.
Иначе говоря, чем больше отличается
значение фактора х при прогнозе от
среднего, тем больше можно ошибиться в
результате прогнозирования. Ясно также,
что СКО b
уменьшается с ростом объема выборки n,
так как растет число положительных
слагаемых в знаменателе (2.36).

а б
Рис.2.5
Пример 2.2. Оценим
СКО и доверительные интервалы оценок
параметров модели примера 2.1 для малой
выборки объема n
= 5, приняв доверительную вероятность Р
= 0,954.
Оценка дисперсии
ошибок модели согласно (2.36) и расчетов,
приведенных в таблице 2.1, равна
![]()
.
Тогда СКО оценок
b
= 0,588 a
= – 0,529 параметров модели в соответствии
с (2.37), (2.38) равны
![]()
.
Ошибки оказались
сравнительно большими в связи с малым
объемом выборки (n
= 5). Найденные значения СКО являются
точечными ошибками оценок параметров.
Определим далее доверительные интервалы
этих оценок. Для нормальной модели
граничная ошибка равна
Δ = tσ,
где
параметр доверия t
= 1 при доверительной вероятности Р
= 0,68,
t = 2
при Р
= 0,954,
t =
3 при Р
= 0,997.
В нашем примере
t = 2
(Р
= 0,954), Δb
= 0,256, Δa
= 1,678,
тогда
доверительные интервалы для истинных
значений параметров
и α с границами b
Δb,
a
Δa
определяются как
[0,332; 0,844],
α
[ – 2,207; 1,149].
Это значит, что
при доверительной вероятности 95,4%
коэффициент регрессии
b (и,
соответственно, наклон прямой линии
модели) может измениться более чем в
2,5 раза, а девиация (отклонение) постоянной
составляющей а
близка к
1,7 у.е. Очевидно, подобные ошибки малой
выборки неприемлемы для практических
целей, поэтому реальные объемы выборки
должны составлять десятки, сотни и более
элементов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Условия Гаусса-Маркова
Свойства коэффициентов регрессии
проверка гипотез
Источники
1. Доугерти, К. Введение в эконометрику : учеб. для экон.
специальностей вузов / К. Доугерти; пер. с англ. Е. Н. Лукаш
[и др.]. – М. : ИНФРА-М, 1997. [Глава 3].
2. Магнус, Я. Р. Эконометрика. Начальный курс : учеб. /
Я. Р. Магнус, П. К. Катышев, А. А. Пересецкий. – 3-е изд.,
перераб. и доп. – М. : Дело, 2000. [Глава 2, разделы 2.3-2.4]
Теоретическая регрессия
u4
u1
u2
u3
случайного члена
yi = α + βxi + ui
где i=1,…,n ;
xi — неслучайная (детерминированная) величина, yi и ui — случайные величины.
yi – зависимая переменная, состоит из (1) неслучайной составляющей α + βxi,
где xi – объясняющая (независимая) переменная, а постоянные α и β
параметры уравнения;
(2) случайного члена (ошибки) ui .
xi и yi — координаты точек Р1 , Р2 , Р3, Р4, это фактические значения (реально
собранные данные/наблюдения).
Используя метод МНК получаем
^
расчетную регрессию (y = a + b x )
i
i
где a и b – оценки параметров теоретической регрессии, т.е. α и β.
Обращаем внимание, что a и b зависят от исходных значений y!
А y зависит от случайного члена/ошибок, yi = α + βxi + ui
значит и оценки a и b зависят от случайного члена/ошибок ui
Основная наша задача определить значения истинных
параметров α и β.
Методом МНК мы находим их оценки – a и b,
и они оказываются зависимы от случайной
составляющей — от случайного члена/ошибок ui .
Для того чтобы судить насколько a и b являются
точными/хорошими оценками истинных
параметров α и β нам необходимо знать свойства
случайной составляющей — ui .
=> Пришлось ввести предположения о случайном
члене ui
Предположения о случайном члене ui
(Условия Гаусса-Маркова)
Пусть у нас есть модель парной линейной регрессии yi = α + βxi + ui
I. Регрессионная модель линейна по параметрам (коэффициентам), корректно
специфицирована (т.е. выбрана правильная функциональная форма, включены
необходимые факторы и нет лишних), и содержит аддитивный случайный член (ui);
II. Случайный член имеет нулевое математическое ожидание E(ui) = 0;
III. Случайный член имеет постоянную дисперсию для всех наблюдений,
Var(ui)=D(ui)= σu2 , i= 1,…,n (гомоскедастичность)
Замечание: величина σu неизвестна (основана на данных генеральной совокупности),
одна из задач регрессионного анализа состоит в том чтобы оценить σu (найти оценку
для этого параметра).
IV. Случайные члены с разными номерами не коррелируют друг с другом,
Cov(ui, uj) = 0 (для i ǂ j);
V. Объясняющая переменная не коррелированна со случайным членом, Cov(ui,
xi ) = 0 ;
Тогда оценки МНК (а и b) являются наиболее эффективными и несмещенными
оценками коэффициентов регрессии [BLUE (Best Linear Unbiased Estimator)].
Классическая линейная регрессия
VI. Предположение о нормальности распределения случайного
члена/ошибок/возмущений
ui ~ N (0, ),
2
u
тог да
коэффициенты регресии также будут иметь нормальное распределение:
Что дает нам возможность проверять гипотезы о значимости коэффициента
регресии и строить доверительные интервалы
7
Несмещенные оценки коэффициентов регрессии
Есть теоретическая модель парной линейной регрессии
yi = α + βxi + ui
^
Есть расчетная регрессия yi = a + b xi
где a и b это оценки истинных значений α и β
Тогда несмещенность означает следующее
Мат. ожидание E(a) = α
Мат. ожидание E(b) = β
Эффективные оценки коэффициентов регрессии
Т.е. среди всех несмещенных оценок оценки a и b обладают
наименьшей дисперсией
Одно из предположений о случайном члене ui
(условие Гаусса-Маркова)
III. Случайный член имеет постоянную дисперсию
для всех наблюдений, Var(ui)=D(ui)= σu2 , i= 1,…,n
(гомоскедастичность)
Замечание: величина σu неизвестна (основана на данных
генеральной совокупности), одна из задач регрессионного
анализа состоит в том чтобы оценить σu (найти оценку для
этого параметра).
Оценкой для дисперсии случайного члена (σu2 )является
величина:
Т.е. оценкой для дисперсии случайного члена/ошибок ui
является сумма квадратов остатков / на (n-2).
Остатки (ei)
Упростили обозначения, опускаем в обозначениях индекс «i».
a и b – оценки параметров теоретической регрессии (методом МНК),
т.е. оценки параметров α и β.
Расчетные значения
это ординаты точек R1, R2, R3, R4 ,лежащих на
линии регрессии = a + bx.
т.е. каждое получаем подставив в уравнение регрессии для
каждого x значения а и b.
Вспомним, что
для каждой выборки своя
^
расчетная регрессия (yi = a + b xi )
Пусть первая выборка включает наблюдения P1, P2, P4
^
Pасcчетная регрессия (yi = a + b xi ) для выборки (P1, P2, P4)
Пусть первая выборка включает наблюдения P1, P2, P4
^
Расcчетная регрессия (yi = a + b xi ) для выборки (P1, P3, P4)
А вторая выборка включает наблюдения P1, P3, P4
Для каждой выборки своя
^
расчетная регрессия (yi = a + b xi )
Для каждой выборки получили свою линии расчетной регрессии;
как результат, для каждой выборки оценки параметров (a, b) будут
отличатся => a, b – оценки регрессии это случайные величины!
• Так как оценки a, b –это случайные
величины и они изменяются от выборки к
выборке, то нам необходимо задаться
мерой «надежности» нашей оценки.
Для этих целей используют стандартные
ошибки.
Вспомним, что наши оценки – нормально
распределенные величины
Тогда стандартные ошибки для оценок a, b
принимают вид:
— оценкой для дисперсии (σu2 )случайного члена ui .
Значимость коэффициентов регрессии
На прошлой лекции мы рассмотрели как проверить
значимость коэффициентов по P-значению (P-value), в
данной лекции посмотрим как проверить значимость
коэффициентов по их стандартным ошибкам.
Сравнивая значение коэффициента с его стандартной
ошибкой, можно судить о значимости коэффициента;
Коэффициент называется значимым, если есть
достаточно высокая вероятность того, что его
истинное значение отлично от нуля;
Для стандартных ошибок нет таблиц критических
уровней – для точного суждения о значимости
коэффициентов используется t-статистика.
t-статистика для проверки значимости
коэффициентов регрессии
t-статистика соизмеряет значения
коэффициента с его стандартной ошибкой
(s.e., еще используется обозначение c.o.)
См. word/pdf файл
Коэффициент детерминации R2
Напомним
Рассмотрели вариацию (разброс) зависимой переменной yi вокруг ее среднего , т.е.
Которую можно разложить на
.
Обозначили
общую/всю вариацию
= TSS (total sum of squares)
не объясненную регрессией вариацию
= ESS (error sum of squares),
объясненную регрессией вариацию
= RSS (regression sum of squares).
Получили выражение для R2
коэффициента детерминации, или доли
объясненной дисперсии:
F тест на качество оценивания/значимости
уравнения регрессии в целом
Для парной регрессии F-тест, нулевая и альтернативная
гипотезы примут вид:
yi = α + βxi + ui
Ho: β = 0, H1: β ǂ 0
к – количество оцененных
в регрессии параметров
n – количество
наблюдений
Заметим, что для парной линейной регрессии нулевая и альтернативная
гипотеза F-теста соответствуют двухстороннему t-тесту (тестирование гипотезы о
значимости коэффициента регрессии при объясняющей переменной).
Может ли так случиться, что F-тест и t-тест приведут к различным выводам?
20
F тест на качество оценивания/значимости
уравнения регрессии в целом
Для парной регрессии F-тест, нулевая и альтернативная
гипотезы примут вид:
yi = α + βxi + ui
Ho: β = 0, H1: β ǂ 0
к – количество оцененных
в регрессии параметров
n – количество
наблюдений
Ответ: конечно нет.
И мы продемонстрируем, что F-тест (на качество оценивания/значимости
уравнения регрессии в целом), в случае парной линейной регрессии равен
квадрату t- статистики соответствующего коэффициента при объясняющей
переменной.
20
F тест на качество оценивания/значимости уравнения регрессии в целом
Начнем с того, что запишем формулу F-теста для случая
k=2 (т.е. парной линейной регрессии) и запишем ESS и RSS
через yi и ei .
22
F тест на качество оценивания/значимости уравнения регрессии в целом
— оценка дисперсии случайного члена ui
В знаменателе у нас «оценка дисперсии случайного члена» (см.
слайд 10). Числитель распишем через оценки коэффициентов
регрессии (т.е. a и b).
22
F тест на качество оценивания/значимости уравнения регрессии в целом
В знаменателе у нас «оценка дисперсии случайного члена».
Числитель распишем через оценки регрессии (т.е. a и b).
23
F тест на качество оценивания/значимости уравнения регрессии в целом
Упростим, сократив в числителе a и вынеся за скобку b.
24
F тест на качество оценивания/значимости уравнения регрессии в целом
Вынесем b2 из под знака суммы.
25
F тест на качество оценивания/значимости уравнения регрессии в целом
Преобразуем выражение.
26
F тест на качество оценивания/значимости уравнения регрессии в целом
Вспомним выражение стандартной ошибки коэффициента
при объясняющей переменной (т.е. коэффициента b) (см.
слайд 17).
F тест на качество оценивания/значимости уравнения регрессии в целом
Т. е. в знаменателе у нас квадрат стандартной ошибки b.
27
F тест на качество оценивания/значимости уравнения регрессии в целом
Вспомним выражение t-статистики для коэффициента
регрессии.
F тест на качество оценивания/значимости уравнения регрессии в целом
Таким образом мы получили t-статистику в квадрате (t2 ).
28
F тест на качество оценивания/значимости уравнения регрессии в целом
Так как F-тест эквивалентен двухстороннему t-тесту, то в случае парной
регрессии нет необходимости проводить оба теста (т.е. тестировать
значимость уравнения в целом, если уже протестировали значимость
коэффициента при объясняющей переменной).
30
F тест на качество оценивания/значимости уравнения регрессии в целом
В случае множественной регрессии F-тест тестирует гипотезу о значимости
/отличия от нуля нескольких коэффициентов при объясняющих переменных;
в этом случае t-тест и F-тест не эквивалентны.
30
F тест на качество оценивания
Данные/анализ данных/регрессия
Регрессионная статистика
Множественный R
0,7865947
R-квадрат
0,6187313
Нормированный R-квадрат
0,5710727
Стандартная ошибка
402,8516
Наблюдения
10
Дисперсионный анализ
df
1
8
9
Регрессия
Остаток
Итого
SS
2106934,736
1298315,264
3405250
MS
2106934,736
162289,408
F
12,982577
Значимость F
0,006950592
Коэффициен Стандартная
tНижние Верхние Нижние Верхние
P-Значение
ты
ошибка
статистика
95%
95%
95,0% 95,0%
Y-пересечение
-82,32524964
732,0218651
-0,112462829
0,9132272 -1770,37 1605,72 -1770,37 1605,72
Переменная X 1
77,532097
21,51795906
3,603134331
0,0069506 27,91159 127,1526 27,91159 127,1526
Дана оценка регрессионного уравнения зависимости «y -цена
квартиры, тыс. руб.» от «x — размера жилой площади». Количество
наблюдений = 10.
Необходимо поверить гипотезу о значимости уравнения в целом;
32
F тест на качество оценивания
Данные/анализ данных/регрессия
Регрессионная статистика
Множественный R
0,7865947
R-квадрат
0,6187313
Нормированный R-квадрат
0,5710727
Стандартная ошибка
402,8516
Наблюдения
10
Дисперсионный анализ
df
1
8
9
Регрессия
Остаток
Итого
SS
2106934,736
1298315,264
3405250
MS
2106934,736
162289,408
F
12,982577
Значимость F
0,006950592
Коэффициен Стандартная
tНижние Верхние Нижние Верхние
P-Значение
ты
ошибка
статистика
95%
95%
95,0% 95,0%
Y-пересечение
-82,32524964
732,0218651
-0,112462829
0,9132272 -1770,37 1605,72 -1770,37 1605,72
Переменная X 1
77,532097
21,51795906
3,603134331
0,0069506 27,91159 127,1526 27,91159 127,1526
Значение RSS = 2106934,736
32
F тест на качество оценивания
Данные/анализ данных/регрессия
Регрессионная статистика
Множественный R
0,7865947
R-квадрат
0,6187313
Нормированный R-квадрат
0,5710727
Стандартная ошибка
402,8516
Наблюдения
10
Дисперсионный анализ
df
1
8
9
Регрессия
Остаток
Итого
SS
2106934,736
1298315,264
3405250
MS
2106934,736
162289,408
F
12,982577
Значимость F
0,006950592
Коэффициен Стандартная
tНижние Верхние Нижние Верхние
P-Значение
ты
ошибка
статистика
95%
95%
95,0% 95,0%
Y-пересечение
-82,32524964
732,0218651
-0,112462829
0,9132272 -1770,37 1605,72 -1770,37 1605,72
Переменная X 1
77,532097
21,51795906
3,603134331
0,0069506 27,91159 127,1526 27,91159 127,1526
Значение ESS = 1298315,264
32
F тест на качество оценивания
Данные/анализ данных/регрессия
Регрессионная статистика
Множественный R
0,7865947
R-квадрат
0,6187313
Нормированный R-квадрат
0,5710727
Стандартная ошибка
402,8516
Наблюдения
10
Дисперсионный анализ
df
1
8
9
Регрессия
Остаток
Итого
SS
2106934,736
1298315,264
3405250
MS
2106934,736
162289,408
F
12,982577
Значимость F
0,006950592
Коэффициен Стандартная
tНижние Верхние Нижние Верхние
P-Значение
ты
ошибка
статистика
95%
95%
95,0% 95,0%
Y-пересечение
-82,32524964
732,0218651
-0,112462829
0,9132272 -1770,37 1605,72 -1770,37 1605,72
Переменная X 1
77,532097
21,51795906
3,603134331
0,0069506 27,91159 127,1526 27,91159 127,1526
Запишем формулу для расчета F-статистики
32
F тест на качество оценивания
Данные/анализ данных/регрессия
Регрессионная статистика
Множественный R
0,7865947
R-квадрат
0,6187313
Нормированный R-квадрат
0,5710727
Стандартная ошибка
402,8516
Наблюдения
10
Дисперсионный анализ
df
1
8
9
Регрессия
Остаток
Итого
SS
2106934,736
1298315,264
3405250
MS
2106934,736
162289,408
F
12,982577
Значимость F
0,006950592
Коэффициен Стандартная
tНижние Верхние Нижние Верхние
P-Значение
ты
ошибка
статистика
95%
95%
95,0% 95,0%
Y-пересечение
-82,32524964
732,0218651
-0,112462829
0,9132272 -1770,37 1605,72 -1770,37 1605,72
Переменная X 1
77,532097
21,51795906
3,603134331
0,0069506 27,91159 127,1526 27,91159 127,1526
Запишем формулу для расчета F-статистики, проверим степени
свободы.
32
F тест на качество оценивания
Данные/анализ данных/регрессия
Регрессионная статистика
Множественный R
0,7865947
R-квадрат
0,6187313
Нормированный R-квадрат
0,5710727
Стандартная ошибка
402,8516
Наблюдения
10
Дисперсионный анализ
df
1
8
9
Регрессия
Остаток
Итого
SS
2106934,736
1298315,264
3405250
MS
2106934,736
162289,408
F
12,982577
Значимость F
0,006950592
Коэффициен Стандартная
tНижние Верхние Нижние Верхние
P-Значение
ты
ошибка
статистика
95%
95%
95,0% 95,0%
Y-пересечение
-82,32524964
732,0218651
-0,112462829
0,9132272 -1770,37 1605,72 -1770,37 1605,72
Переменная X 1
77,532097
21,51795906
3,603134331
0,0069506 27,91159 127,1526 27,91159 127,1526
Наш результат F-статистики = 12,982577
32
F тест на качество оценивания
Данные/анализ данных/регрессия
Регрессионная статистика
Множественный R
0,7865947
R-квадрат
0,6187313
Нормированный R-квадрат
0,5710727
Стандартная ошибка
402,8516
Наблюдения
10
Дисперсионный анализ
df
1
8
9
Регрессия
Остаток
Итого
SS
2106934,736
1298315,264
3405250
MS
2106934,736
162289,408
F
12,982577
Значимость F
0,006950592
Коэффициен Стандартная
tНижние Верхние Нижние Верхние
P-Значение
ты
ошибка
статистика
95%
95%
95,0% 95,0%
Y-пересечение
-82,32524964
732,0218651
-0,112462829
0,9132272
Переменная X 1
77,532097
21,51795906
3,603134331
0,0069506 27,91159 127,1526 27,91159 127,1526
-1770,37 1605,72 -1770,37 1605,72
(или) Рассчитаем F-статистику через R2
32
F тест на качество оценивания
Данные/анализ данных/регрессия
Регрессионная статистика
Множественный R
0,7865947
R-квадрат
0,6187313
Нормированный R-квадрат
0,5710727
Стандартная ошибка
402,8516
Наблюдения
10
Дисперсионный анализ
df
1
8
9
Регрессия
Остаток
Итого
SS
2106934,736
1298315,264
3405250
MS
2106934,736
162289,408
F
12,982577
Значимость F
0,006950592
Коэффициен Стандартная
tНижние Верхние Нижние Верхние
P-Значение
ты
ошибка
статистика
95%
95%
95,0% 95,0%
Y-пересечение
-82,32524964
732,0218651
-0,112462829
0,9132272 -1770,37 1605,72 -1770,37 1605,72
Переменная X 1
77,532097
21,51795906
3,603134331
0,0069506 27,91159 127,1526 27,91159 127,1526
Сравним наш результат с расчетом Excel F-статистики = 12,982577
32
F тест на качество оценивания
Данные/анализ данных/регрессия
Регрессионная статистика
Множественный R
0,7865947
R-квадрат
0,6187313
Нормированный R-квадрат
0,5710727
Стандартная ошибка
402,8516
Наблюдения
10
Дисперсионный анализ
df
1
8
9
Регрессия
Остаток
Итого
SS
2106934,736
1298315,264
3405250
MS
2106934,736
162289,408
F
12,982577
Значимость F
0,006950592
Коэффициен Стандартная
tНижние Верхние Нижние Верхние
P-Значение
ты
ошибка
статистика
95%
95%
95,0% 95,0%
Y-пересечение
-82,32524964
732,0218651
-0,112462829
0,9132272 -1770,37 1605,72 -1770,37 1605,72
Переменная X 1
77,532097
21,51795906
3,603134331
0,0069506 27,91159 127,1526 27,91159 127,1526
Проверим также, что F-статистика = t2
32
F тест на качество оценивания
Данные/анализ данных/регрессия
Регрессионная статистика
Множественный R
0,7865947
R-квадрат
0,6187313
Нормированный R-квадрат
0,5710727
Стандартная ошибка
402,8516
Наблюдения
10
Дисперсионный анализ
df
1
8
9
Регрессия
Остаток
Итого
SS
2106934,736
1298315,264
3405250
MS
2106934,736
162289,408
F
12,982577
Значимость F
0,006950592
Коэффициен Стандартная
tНижние Верхние Нижние Верхние
P-Значение
ты
ошибка
статистика
95%
95%
95,0% 95,0%
Y-пересечение
-82,32524964
732,0218651
-0,112462829
0,9132272
Переменная X 1
77,532097
21,51795906
3,603134331
0,0069506 27,91159 127,1526 27,91159 127,1526
-1770,37 1605,72 -1770,37 1605,72
Проверим также, что F-статистика = t2
12,982577 = 3,6031343312 = 12,982577
Все верно.
32
F тест на качество оценивания
Теоретическая модель множественной линейной
регрессии имеет вид:
yi = α + β1x1i + β2x2i + …+ βmxmi + ui, i = 1,…, n
где n – число наблюдений, x1i,…, xmi – объясняющие
переменные, yi – зависимая переменная, ui –
случайный член, α, β1, β2, …βm — параметры
теоретической модели.
И расчетная регрессия:
a+ b1x1i + b2x2i + …+ bmxmi , где a, b 1, b2, …bm
— оценки параметров α, β1, β2, …βm
теоретической модели.
F тест на качество оценивания
Проверка гипотезы о значимости уравнения в
целом сводится к проверке гипотезы
H0: β1 = β2 = ..= βm = 0 (все параметры при
объясняющих переменных одновременно = 0)
против альтернативной
HА: не все коэффициенты при объясняющих
переменных одновременно = 0
(или формализовано,
F тест на качество оценивания
Вычисляется расчетная статистика:
Затем рассчитанная статистика F (т.е. сравнивается с
табличным критическим значением при выбранном
уровне значимости α, т.е.
Если Fрасчетн. превышает критическое (
)
то гипотеза H0: β1 = β2 = ..=βm =0 отклоняется в пользу
альтернативной (HА) при выбранном уровне значимости
α, и мы заключаем, что регрессия является значимой (или
адекватной).
Иначе, регрессия считается незначимой (неадекватной).
F тест на качество оценивания
Данные/анализ данных/регрессия
Регрессионная статистика
Множественный R
0,7865947
R-квадрат
0,6187313
Нормированный R-квадрат
0,5710727
Стандартная ошибка
402,8516
Наблюдения
10
В случае парной регрессии
Ho: β = 0,
HА: β ǂ 0
Дисперсионный анализ
df
1
8
9
Регрессия
Остаток
Итого
SS
2106934,736
1298315,264
3405250
MS
2106934,736
162289,408
F
12,982577
Значимость F
0,006950592
Коэффициен Стандартная
tНижние Верхние Нижние Верхние
P-Значение
ты
ошибка
статистика
95%
95%
95,0% 95,0%
Y-пересечение
-82,32524964
732,0218651
-0,112462829
0,9132272 -1770,37 1605,72 -1770,37 1605,72
Переменная X 1
77,532097
21,51795906
3,603134331
0,0069506 27,91159 127,1526 27,91159 127,1526
Вывод!
Наша уравнение статистически значимо на 5%-ом уровне значимости т.к.
(1) Это парная регрессия и значим коэффициент при единственной объясняющей переменной X1,
t_расчетное = 3,60313 > t_крит (α = 0.05, n – k = 10 – 2) = 2,306.
(2) Или по результатам F-теста
F_расчетное = 12,983 > F_критическое (α = 0.05; k-1, n – k = 1;8) = 5,32
47