В
статистике выделяют два основных метода
исследования — сплошной и выборочный.
При проведении выборочного исследования
обязательным является соблюдение
следующих требований: репрезентативность
выборочной совокупности и достаточное
число единиц наблюдений. При выборе
единиц наблюдения возможны ошибки
смещения,
т.е. такие события, появление которых
не может быть точно предсказуемым. Эти
ошибки являются объективными и
закономерными. При определении степени
точности выборочного исследования
оценивается величина ошибки, которая
может произойти в процессе выборки
— случайная
ошибка репрезентативности (m)
— является
фактической разностью между средними
или относительными величинами, полученными
при проведении выборочного исследования
и аналогичными величинами, которые были
бы получены при проведении исследования
на генеральной совокупности.
Оценка
достоверности результатов исследования
предусматривает определение:
1.
ошибки репрезентативности
2.
доверительных границ средних (или
относительных) величин в генеральной
совокупности
3.
достоверности разности средних (или
относительных) величин (по критерию t)
Расчет
ошибки репрезентативности
(mм)
средней арифметической величины
(М):
![]()
![]() ,
,
где σ
— среднее квадратическое отклонение; n
— численность выборки (>30).
Расчет
ошибки репрезентативности (mР)
относительной величины (Р):
![]() ,
,
где Р — соответствующая относительная
величина (рассчитанная, например, в %);
q
=100 — Ρ%
— величина, обратная Р; n
— численность выборки (n>30)
В
клинических и экспериментальных работах
довольно часто приходится использовать
малую
выборку, когда
число наблюдений меньше или равно 30.
При малой выборке для расчета ошибок
репрезентативности, как средних, так
и относительных величин,
число
наблюдений уменьшается на единицу,
т.е.
![]() ;
;
![]() .
.
Величина
ошибки репрезентативности зависит от
объема выборки: чем больше число
наблюдений, тем меньше ошибка. Для оценки
достоверности выборочного показателя
принят следующий подход: показатель
(или средняя величина) должен в 3 раза
превышать свою ошибку, в этом случае он
считается достоверным.
83. Определение доверительных границ средних и относительных величин.
Знание
величины ошибки недостаточно для того,
чтобы быть уверенным в результатах
выборочного исследования, так как
конкретная ошибка выборочного
исследования может быть значительно
больше (или меньше) величины средней
ошибки репрезентативности. Для
определения точности, с которой
исследователь желает получить результат,
в статистике используется такое понятие,
как вероятность безошибочного
прогноза, которая является характеристикой
надежности результатов выборочных
медико-биологических статистических
исследований. Обычно, при проведении
медико-биологических статистических
исследований используют вероятность
безошибочного прогноза 95% или 99%. В
наиболее ответственных случаях, когда
необходимо сделать особенно важные
выводы в теоретическом или практическом
отношении, используют вероятность
безошибочного прогноза 99,7%
Определенной
степени вероятности безошибочного
прогноза соответствует определенная
величина предельной
ошибки случайной выборки (Δ
— дельта),
которая определяется по формуле:
Δ=t
* m
, где t
— доверительный коэффициент, который
при большой выборке при вероятности
безошибочного прогноза 95% равен 2,6;
при вероятности безошибочного
прогноза 99% — 3,0; при вероятности
безошибочного прогноза 99,7% — 3,3, а при
малой выборке определяется по специальной
таблице значений t
Стьюдента.
Используя
предельную ошибку выборки (Δ),
можно определить доверительные
границы,
в которых с определенной вероятностью
безошибочного прогноза заключено
действительное значение статистической
величины,
характеризующей
всю генеральную совокупность (средней
или относительной).
Для
определения доверительных границ
используются следующие формулы:
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Справочник /
Лекторий Справочник /
Лекционные и методические материалы по статистике /
Ошибка репрезентативности и доверительный интервал для
генерального параметра
Конспект лекции по дисциплине «Ошибка репрезентативности и доверительный интервал для
генерального параметра»,
pdf
![]()
Файл загружается
Благодарим за ожидание, осталось немного.
Конспект лекции по дисциплине «Ошибка репрезентативности и доверительный интервал для
генерального параметра».
pdf
txt
Конспект лекции по дисциплине «Ошибка репрезентативности и доверительный интервал для
генерального параметра», текстовый формат
Лекция 2. Ошибка репрезентативности и доверительный интервал для
генерального параметра
Выборочные характеристики, представляющие собой числа (точки на
шкале) называют точечными оценками (существуют также и интервальные
оценки). Оценки должны удовлетворять следующим требованиям: быть
состоятельными, эффективными, несмещенными. Только при удовлетворении
этих требований оценки хорошо представляют соответствующие параметры.
В математической статистике введено понятие статистической ошибки
или ошибки репрезентативности; она связана с точностью, с которой
выборочная оценка представляет, репрезентирует свой параметр.
Когда ошибка оценивания генерального параметра стремится к нулю при
возрастании объема выборки, т.е. значение оценки стремится к значению
параметра, то такая оценка называется состоятельной. Оценка называется
эффективной,
если
она
имеет
наименьшую
дисперсию
выборочного
распределения по сравнению с другими аналогичными оценками.
К примеру,
из трех показателей, описывающих положение центра
нормального распределения (средняя, медиана, мода), наиболее эффективной
является средняя арифметическая, наименее эффективной — мода.
Оценка
ожидание)
называется
ее
несмещенной,
выборочного
если
распределения
среднее
совпадает
(математическое
со
значением
генерального параметра. Выборочная средняя является несмещенной оценкой
генеральной средней, а тогда как выборочная дисперсия представляет собой
смещенную оценку.
Например, чтобы получить несмещенную оценку, надо при вычислении
выборочной дисперсии использовать формулу, где в знаменателе (N — 1):
D=S2=
1
2
( Xi X )
N 1
Для понимания смысла этих требований нужно рассмотреть понятие
выборочного распределения оценок какого-либо параметра.
Рассмотрим
условный
пример
для
такого
понятия,
как
арифметическое среднее: пусть ГС представляет собой 5 результатов
выполнения некоторого психологического теста: 8 16 20 24 32:
=
8 16 20 24 32
= 20
5
Таким образом, 20 — это значение генерального параметра.
Заменим изучение генеральной совокупности изучением выборок объемом
n = 4. Рассмотрим все возможные варианты таких выборок:
1) 8
16 20 24
= 17
2) 16 20 24 32
= 23
3) 8
16 24 32
= 20
4) 8
16 20 32
= 19
Из нашего примера видно, что из 5 оценок средних лишь одна совпала
с параметром. Заранее мы не можем знать, как составить (отобрать) выборку,
чтобы оценка параметра по ней была близка к параметру.
Однако очевидно, что чем больше объем выборки, тем меньше вероятность
того, что , определяемое по выборке, будет значительно отличаться от
генерального среднего (крайние случаи n=N-1 и n=2 ,т.е. N>>n) .
Когда
генеральная совокупность велика и, соответственно, число
возможных выборок велико, то совокупность выборочных оценок средних для
каждой
из
этих
концентрирующееся
выборок
вокруг
«концентрация» (дисперсия)
Дисперсия
образует
генерального
тем
выше,
нормальное
среднего,
чем
больше
распределение,
причем
эта
объемы выборок.
распределения средних имеет особое название, она именуется
ошибкой репрезентативности.
Выше речь шла о распределении выборочных средних.
Это же
рассуждение можно повторить для оценок дисперсии, моды, коэффициентов
корреляции и т.д.
В теории математической статистики доказано, что нормального
распределения при достаточном объеме выборки (на практике n 30),
стандартное отклонение среднего арифметического равно:
Sx =
S
N
; где
S — стандартное отклонение
N — объем выборки.
Эту величину называют также статистической ошибкой или ошибкой
репрезентативности, т.е. это средняя ошибка, которая допускается, когда
рассматривается как генеральный параметр.
Для других параметров ошиб ки репрезентативности таковы:
Ошибка репрезентативности дисперсии:
Ss2=S2/ 2N
Ошибка репрезентативности стандартного отклонения
Ss=S/ 2N
Ошибка репрезентативности показателя асимметрии:
Sa= 6 / N
Ошибка репрезентативности показателя эксцесса:
Se= 24 / N
Теперь перейдем к понятию доверительного интервала, которое применяется
для любого параметра. Мы рассмотрим его для генеральной средней. По
известным выборочным характеристикам можно построить интервал, в котором
с той или иной степенью вероятности находится генеральное среднее. Понятие
доверительного интервала связано с понятием доверительной вероятности.
Согласно этому принципу, маловероятные события считаются практически
невозможными,
а
события,
вероятность
которых
близка
к
единице,
принимаются за почти достоверные. Обычно в психологии в качестве
доверительных используют вероятности р = 0,95 и р = 0,99. Это означает, что
при оценивании генерального параметра по известной выборочной оценке риск
ошибиться в первом случае — один раз на 20 испытаний, во втором случае 1 раз
на 100 испытаний.
С доверительной вероятностью связано понятие уровня значимости
= 1- р
Геометрически — это площадь под нормальной кривой выборочного
распределения, выходящая за пределы той его части, которая соответствует
Р%, поскольку в сумме они соответствуют всей площади под кривой. Иначе
говоря,
означает площадь двух хвостов под кривой нормального
распределения. При при р = 0,95 и = 0, 05 на каждый «хвост» приходится
по 2,5 % площади.
Вероятность того, что будет находиться в пределах
доверительного интервала x — t SX + t SX,
описывается
особой функцией, которая сведена в таблице (обычно это таблица 1 в
приложении учебников по математической статистике)
для р= 0,95
t=1,96
для р=0,99
t = 2,58
для p=0, 999 t =3,29
График нормальной кривой
Выбор того или иного уровня доверительной вероятности зависит от
исследователя, от его оценки ответственности за ошибочность выводов
относительно генерального параметра .
Пример: При измерении объема памяти у 100 испытуемых
получено среднее значение числа запоминаемых сигналов
было
= 9 и
стандартное отклонение S = 3. 27. Построить доверительный
интервал для генеральной средней .
Вычисления проводятся по формуле:
x — t SX + t SX
9 — 1,96
3271
.
327
.
92+1,96
100
100
или 9+ 0.196 3,27 9 + 1..96 3,27 или 8. 36 9.64.
Таким образом, с вероятностью р = 0.95 генеральный параметр
находится в интервале 8.36 — 9.64.
95%
Статистика
Статистика
Курс : Статистика
Статистика В.М. Гусаров Москва, Юнити , 2003г
Статистика В.С. Мхиторян , Москва, Экономист, 2005г.
Статистика И.И. Елисеева
Статисти…
Смотреть все
Поделись лекцией и получи скидку!
Заполни поля, отправь лекцию и мы вышлем тебе скидку-промокод на Автор24
Предмет
Название лекции
Авторы
Описание
Другие Экономические предметы
-
Экономика
-
Менеджмент
-
Бухгалтерский учет и аудит
-
Управление персоналом
-
Статистика
-
Маркетинг
-
Экономика предприятия
-
Государственное и муниципальное управление
-
Финансовый менеджмент
-
Эконометрика
-
Финансы
-
Менеджмент организации
-
Бизнес-планирование
-
Управление проектами
-
Экономический анализ
-
Экономическая теория
-
Микро-, макроэкономика
-
Инновационный менеджмент
-
Логистика
-
Анализ хозяйственной деятельности
Доверительный интервал за 15 минут
Добрый день, уважаемые читатели!
Меня зовут Кирилл Мильчаков. Сегодня мы продолжаем наш разговор о биостатистике. Тема сегодняшней нашей беседы будет «Доверительный интервал». Что такое доверительный интервал? Вы наверняка встречались с ним в научной литературе. Доверительный интервал 95 %, либо сочетание символов ДИ и CI (confidence interval) 95 %. Что же означают эти 95 %? Какие он еще может принимать значения? И как его рассчитывать самостоятельно? Об этом обо всем сегодня мы и поговорим в этой статье.
Видео-версия статьи о доверительном интервале
Генеральная совокупность и выборочная совокупность
Прежде чем углубляться в тайны доверительного интервала, хотел бы вспомнить с вами 2 основных понятия статистической совокупности, с которыми чаще всего работают – это генеральная совокупность или выборочная совокупность или выборка.
Генеральная совокупность – это тот массив данных, о которых вы хотите сделать выводы.
Выборка является частью генеральной совокупности, которая участвует непосредственно в вашем эксперименте. Есть такое понятие как репрезентативность, сегодня мы не будем его касаться, главное запомнить, что выборка должна быть репрезентативной.
Если привести небольшой пример относительно генеральной совокупности и выборки, то можно вспомнить о простом случае из вашей жизни. Когда вы хотите узнать, достаточно ли посолен суп, вы берете ложку супа и пробуете его. Вам необязательно есть весь суп, чтобы понять, насколько он посолен. Ложка в данном случае является выборкой, по которой вы делаете вывод обо всей кастрюле супа. В данном случае кастрюля супа является генеральной совокупностью, а ложка супа является выборкой.
Итак, мы вспомнили с вами о 2 ключевых статистических совокупностях – о генеральной совокупности и выборочной совокупности. Теперь нужно вспомнить, что типы исследования, которые проводятся над генеральной совокупностью и выборочной совокупностью, называют по-разному. Над генеральной совокупностью проводятся так называемые сплошные исследования, над выборочной совокупностью – выборочные.
Теперь вспомним небольшие отличия между параметрами этих 2 совокупностей. Сегодня для того, чтобы понять, что такое доверительный интервал, нам понадобятся следующие вещи: во-первых, отличие средней арифметической в генеральной совокупности и в выборочной совокупности. В генеральной совокупности она имеет значок µ (мю), в выборочной – это x̅ (х с чертой) — это средние арифметические по каждому виду совокупности.

Далее нужно знать, что стандартное отклонение имеет значок выборочной – либо S, либо SD (standard deviation), а в случае генеральной совокупности оно носит название среднеквадратичного отклонения и обозначается буквой σ (сигма).
Приведем пример расчета доврительного интервала
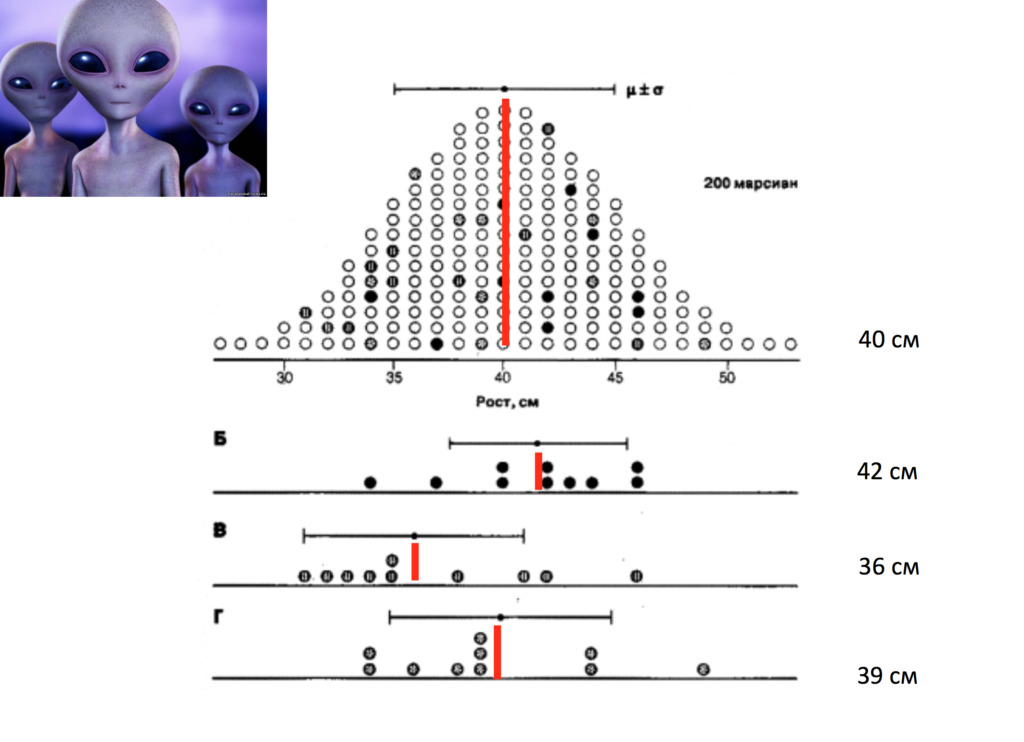
Представьте чисто гипотетическую ситуацию, когда перед нами стоит задача исследований среднего роста марсианина. Для того, чтобы его узнать, было отправлено 3 экспедиции. Первой из них повезло больше всего: они смогли поймать каждого из 200 марсианин и померить его рост.
Как мы помним, по закону нормального распределения по оси Х находится величина изучаемого признака, либо варианта (в данном случае это рост в сантиметрах), а по оси Y – частота встречаемости какого-то признака (мы его обозначаем буквой П.
Итак, оказалось, что у всех 200 марсиан средний рост составил 40 сантиметров. Таким образом, первая экспедиция смогла провести так называемое сплошное исследование, так как поработала со всеми единицами наблюдения генеральной совокупности. Поэтому мы имеем право назвать этот параметр µ.
Однако, второй и третьей экспедиции повезло гораздо меньше. Они попали в самые плохо населенные участки Марса и смогли отобрать только 10 марсиан. В данном случае оказалось, что средний рост по их выборке составил всего 38 сантиметров в первом случае и 41 сантиметр во втором случае.
Что же делать? Да, у нас есть данные из самого полного исследования, которое относится к первой экспедиции. Но представьте, что ни одна бы из них не смогла бы поработать со всей совокупностью полностью, и у нас были бы данные только от второй и третьей экспедиции. Что же в этой ситуации делать? Видно, что никто 40 сантиметров в действительности не достиг: во второй экспедиции Б она равна 38 сантиметрам, а в экспедиции В – 41 сантиметр. То есть в реальности никто не достиг 40 сантиметров. Что же делать в данном случае?
И вот здесь на помощь к нам приходит доверительный интервал, точнее оценка параметра. Доверительный интервал является вторым этапом оценки параметра. Прежде чем строить доверительный интервал, нам нужно понять, насколько в принципе этот параметр наша средняя (x̅б, x̅в) может отличаться, ошибаться от реального параметра в генеральной совокупности. Насколько?
И тут нам помогает оценка параметра или нахождение ошибки репрезентативности. Ошибка репрезентативности обозначается mr или mx. Чаще я использую mr. Что же это значит? mr по-английски обозначается как standard error, по-русски она часто называется стандартная ошибка средней или ошибка репрезентативности. Как же она находится? А находится она следующим образом? Она учитывает стандартное квадратичное отклонение в генеральной совокупности и размер в выборке. От чего же зависит ошибка репрезентативности? А зависит она от 2 вещей: от среднеквадратичного отклонения в генеральной совокупности (я напоминаю, это насколько каждая варианта отличается от средней, о законе нормального распределения мы с вами поговорим в следующий раз) и от размера выборки или . То есть, таким образом, чем менее разбросан признак генеральной совокупности, и чем больше у нас размер выборки, тем меньше наша ошибка репрезентативности.
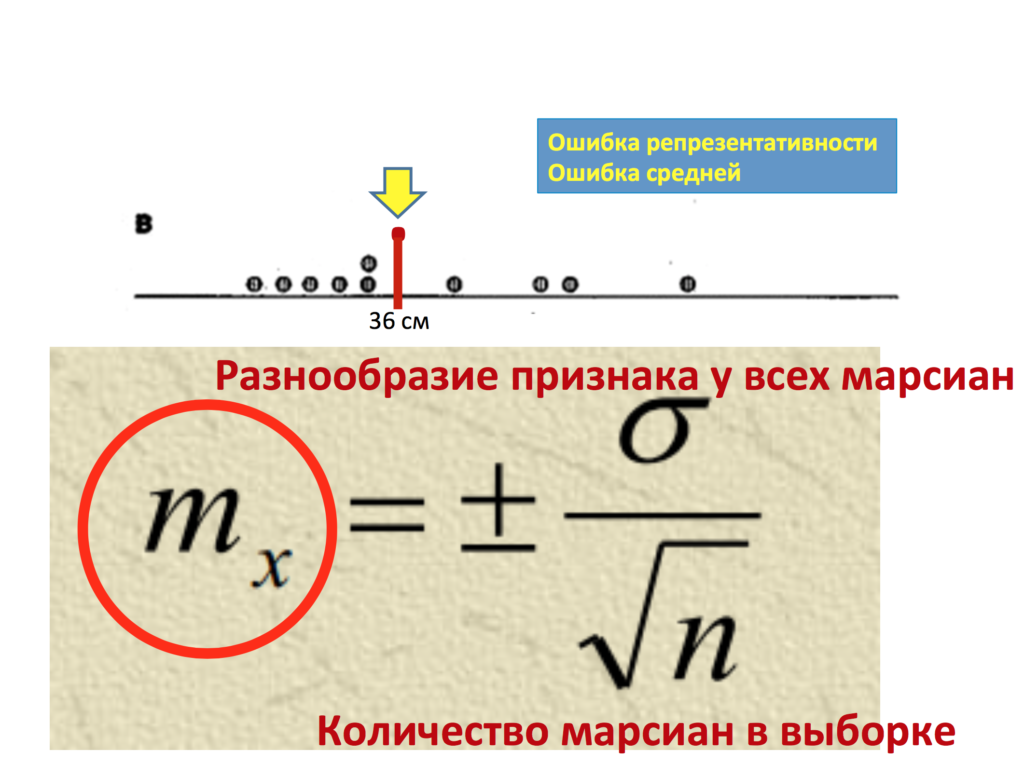
Итак, предположим, мы нашли нашу ошибку репрезентативности mr. В данном случае она составила 2,7 сантиметра. Но что же это нам дает? А дает нам это уже достаточно много. Теперь мы, зная, насколько в принципе наша выборка может ошибаться относительно генеральной совокупности, можем составить определенное предположение о том, где же находится реальный параметр – реальные 40 сантиметров генеральной совокупности на основании данных лишь нашей выборки.
Каким же образом это происходит? Мы провели точечную оценку нашего параметра. Дальше происходит второй этап построения доверительного интервала – это интервальная оценка параметра. Каким же образом строится этот интервал? А складывается он из 2 вещей: так называемой предельной ошибки +∆ и -∆. Формула нахождения предельной ошибки достаточно проста и составляет:
±∆ = t*mr
Для того, чтобы не залезать в критерий Стьюдента сегодня, я скажу лишь, что:
для доверительного интервала 95 % используется t=2,
для доверительного интервала 99 % используется t=3
и для доверительного интервала 68 % используется t=1.
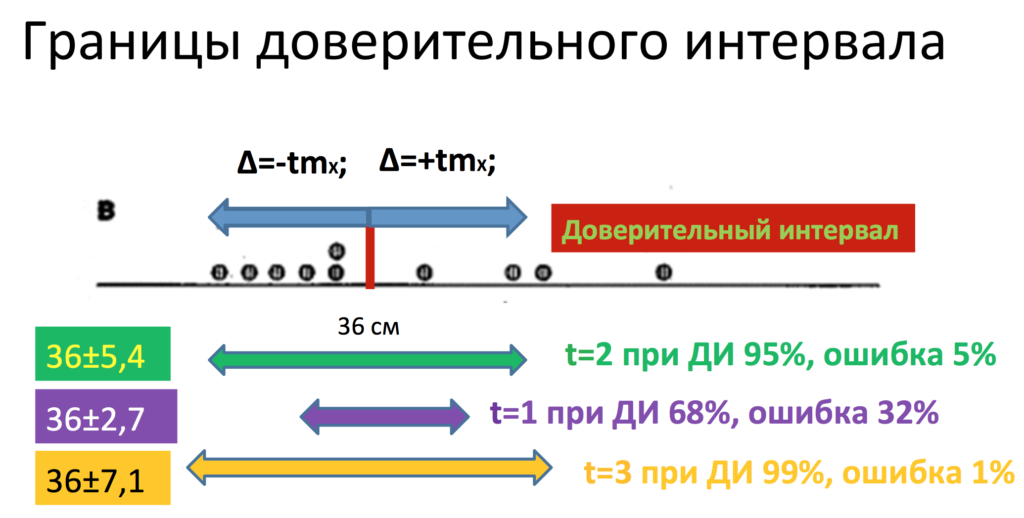
Итак, после того, как мы нашли нашу предельную ошибку, мы можем построить доверительный интервал. Но для этого нам нужно самим задать тот доверительный интервал, который для нас подходит больше всего. Чаще всего в медицине используется вероятность ошибки 5 %, то есть доверительный интервал 95 % или вероятность ошибки 5 % (р=0,05, р=5 %).
Что же значат эти 95 %? А значат они следующее, что с 95%-ной вероятностью в нашем интервале лежит реальное значение, и лишь в 5 % случаев мы ошибаемся. То есть в нашем конкретном случае наша ошибка репрезентативности составила 2,7 сантиметра. Предельная ошибка отсюда будет равна чему? Именно 5,4 сантиметра, то есть доверительный интервал, так как здесь и плюс, и минус, то есть нам нужно ошибку умножить на 2, составил 10,8 сантиметров. А именно наши 38 см±5,4 см. Ширина всего доверительного интервала составляет 10,8 см. Напомню, что он складывается из положительной и отрицательной предельных ошибок вокруг нашей выборочной средней.
Итак, говоря о доверительном интервале, нужно сделать ряд важных выводов.
- Во-первых, доверительный интервал относится к выборочной совокупности. Он показывает, насколько параметры из выборочной совокупности могут отличаться от реально существующих данных в генеральной совокупности. Насколько мы ошибаемся при формировании той или иной выборки, мы закладываем в так называемую ошибку репрезентативности, в ошибку средней и вокруг нее собственно и строим доверительный интервал.
- Ширину доверительного интервала задает собственно сам исследователь, варьируя тот критерий t, который он принимает в качестве необходимого. Чаще всего применяется t=2, которое и соответствует ширине доверительного интервала 95 %. 95 % означает, что с 95%-ной вероятностью действительно вокруг выборочной средней существует определенный доверительный интервал, в который и попадает реально существующая средняя из генеральной совокупности. Этот доверительный интервал может быть либо уже, если t=1; либо шире, если t=3.
- Доверительный интервал задается самостоятельно исследователем. Чаще всего он равен 95 %.
Если это видео оказалось Вам полезным, оно хотя бы немного раскрыло тайны доверительного интервала, ставьте лайки, подписывайтесь на наши рассылки и в комментариях пишите, какие темы по биостатистике вам бы были интересны для следующих выпусков. На этом я с вами прощаюсь. Меня зовут Кирилл. Пока!

Если Вам понравилась статья и оказалась полезной, Вы можете поделиться ею с коллегами и друзьями в социальных сетях:
Лекция 2. Ошибка репрезентативности и доверительный интервал для
генерального параметра
Выборочные характеристики, представляющие собой числа (точки на
шкале) называют точечными оценками (существуют также и интервальные
оценки). Оценки должны удовлетворять следующим требованиям: быть
состоятельными, эффективными, несмещенными. Только при удовлетворении
этих требований оценки хорошо представляют соответствующие параметры.
В математической статистике введено понятие статистической ошибки
или ошибки репрезентативности; она связана с точностью, с которой
выборочная оценка представляет, репрезентирует свой параметр.
Когда ошибка оценивания генерального параметра стремится к нулю при
возрастании объема выборки, т.е. значение оценки стремится к значению
параметра, то такая оценка называется состоятельной. Оценка называется
эффективной,
если
она
имеет
наименьшую
дисперсию
выборочного
распределения по сравнению с другими аналогичными оценками.
К примеру,
из трех показателей, описывающих положение центра
нормального распределения (средняя, медиана, мода), наиболее эффективной
является средняя арифметическая, наименее эффективной — мода.
Оценка
ожидание)
называется
ее
несмещенной,
выборочного
если
распределения
среднее
совпадает
(математическое
со
значением
генерального параметра. Выборочная средняя является несмещенной оценкой
генеральной средней, а тогда как выборочная дисперсия представляет собой
смещенную оценку.
Например, чтобы получить несмещенную оценку, надо при вычислении
выборочной дисперсии использовать формулу, где в знаменателе (N — 1):
D=S2=
1
2
( Xi X )
N 1
Для понимания смысла этих требований нужно рассмотреть понятие
выборочного распределения оценок какого-либо параметра.
Рассмотрим
условный
пример
для
такого
понятия,
как
арифметическое среднее: пусть ГС представляет собой 5 результатов
выполнения некоторого психологического теста: 8 16 20 24 32:
=
8 16 20 24 32
= 20
5
Таким образом, 20 — это значение генерального параметра.
Заменим изучение генеральной совокупности изучением выборок объемом
n = 4. Рассмотрим все возможные варианты таких выборок:
1) 8
16 20 24
= 17
2) 16 20 24 32
= 23
3) 8
16 24 32
= 20
4) 8
16 20 32
= 19
Из нашего примера видно, что из 5 оценок средних лишь одна совпала
с параметром. Заранее мы не можем знать, как составить (отобрать) выборку,
чтобы оценка параметра по ней была близка к параметру.
Однако очевидно, что чем больше объем выборки, тем меньше вероятность
того, что , определяемое по выборке, будет значительно отличаться от
генерального среднего (крайние случаи n=N-1 и n=2 ,т.е. N>>n) .
Когда
генеральная совокупность велика и, соответственно, число
возможных выборок велико, то совокупность выборочных оценок средних для
каждой
из
этих
концентрирующееся
выборок
вокруг
«концентрация» (дисперсия)
Дисперсия
образует
генерального
тем
выше,
нормальное
среднего,
чем
больше
распределение,
причем
эта
объемы выборок.
распределения средних имеет особое название, она именуется
ошибкой репрезентативности.
Выше речь шла о распределении выборочных средних.
Это же
рассуждение можно повторить для оценок дисперсии, моды, коэффициентов
корреляции и т.д.
В теории математической статистики доказано, что нормального
распределения при достаточном объеме выборки (на практике n 30),
стандартное отклонение среднего арифметического равно:
Sx =
S
N
; где
S — стандартное отклонение
N — объем выборки.
Эту величину называют также статистической ошибкой или ошибкой
репрезентативности, т.е. это средняя ошибка, которая допускается, когда
рассматривается как генеральный параметр.
Для других параметров ошиб ки репрезентативности таковы:
Ошибка репрезентативности дисперсии:
Ss2=S2/ 2N
Ошибка репрезентативности стандартного отклонения
Ss=S/ 2N
Ошибка репрезентативности показателя асимметрии:
Sa= 6 / N
Ошибка репрезентативности показателя эксцесса:
Se= 24 / N
Теперь перейдем к понятию доверительного интервала, которое применяется
для любого параметра. Мы рассмотрим его для генеральной средней. По
известным выборочным характеристикам можно построить интервал, в котором
с той или иной степенью вероятности находится генеральное среднее. Понятие
доверительного интервала связано с понятием доверительной вероятности.
Согласно этому принципу, маловероятные события считаются практически
невозможными,
а
события,
вероятность
которых
близка
к
единице,
принимаются за почти достоверные. Обычно в психологии в качестве
доверительных используют вероятности р = 0,95 и р = 0,99. Это означает, что
при оценивании генерального параметра по известной выборочной оценке риск
ошибиться в первом случае — один раз на 20 испытаний, во втором случае 1 раз
на 100 испытаний.
С доверительной вероятностью связано понятие уровня значимости
= 1- р
Геометрически — это площадь под нормальной кривой выборочного
распределения, выходящая за пределы той его части, которая соответствует
Р%, поскольку в сумме они соответствуют всей площади под кривой. Иначе
говоря,
означает площадь двух хвостов под кривой нормального
распределения. При при р = 0,95 и = 0, 05 на каждый «хвост» приходится
по 2,5 % площади.
Вероятность того, что будет находиться в пределах
доверительного интервала x — t SX + t SX,
описывается
особой функцией, которая сведена в таблице (обычно это таблица 1 в
приложении учебников по математической статистике)
для р= 0,95
t=1,96
для р=0,99
t = 2,58
для p=0, 999 t =3,29
График нормальной кривой
Выбор того или иного уровня доверительной вероятности зависит от
исследователя, от его оценки ответственности за ошибочность выводов
относительно генерального параметра .
Пример: При измерении объема памяти у 100 испытуемых
получено среднее значение числа запоминаемых сигналов
было
= 9 и
стандартное отклонение S = 3. 27. Построить доверительный
интервал для генеральной средней .
Вычисления проводятся по формуле:
x — t SX + t SX
9 — 1,96
3271
.
327
.
92+1,96
100
100
или 9+ 0.196 3,27 9 + 1..96 3,27 или 8. 36 9.64.
Таким образом, с вероятностью р = 0.95 генеральный параметр
находится в интервале 8.36 — 9.64.
95%
Ошибка
репрезентативности
— расхождение между выборочной
характеристикой и характеристикой
генеральной совокупности.
Ошибки
репрезентативности
-
Систематические
— возникают в результате нарушения
научных принципов отбора единиц
совокупности (преднамеренные и
непреднамеренные). -
Случайные
возникают в результате несплошного
характера наблюдения (средняя и
предельная ошибки выбора).
Случайные
ошибки могут быть доведены до незначительных
размеров, а главное, их размеры и пределы
можно определить с достаточной точностью
на основании закона больших чисел.
Средняя
ошибка выборки
— такое расхождение между средними
выборочной и генеральной совокупностями,
которое не превышает ±.
В
математической статистике доказывается,
что значения средней ошибки выборки
определяются по формулам:
Формула
для определения величины средней ошибки
выборки для количественного признака:
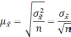
Формула
для определения величины средней ошибки
выборки для альтернативного признака:

Полученное
значение средней ошибки необходимо для
установления возможного значения 
 .
.
Которое определяется по формуле:
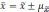
Но
такое суждение можно гарантировать не
с абсолютной
достоверностью, а лишь с определенной
степенью
вероятности.
В
математической статистике доказывается,
что пределы значений характеристик
генеральной совокупности отличаются
от характеристик выборочной совокупности
лишь с вероятностью, которая определена
числом 0,683.
Это
означает, что в 683 случаях из 1000 генеральная
средняя будет находиться в установленных
пределах, т.е. отклонение ГС от ВС не
превысит однократной средней ошибки
выборки. В остальных 317 случаях они могут
выйти за эти пределы. Вероятность можно
повысить, если расширить пределы
отклонений. Так, при удвоенном значении

 ,
,
вероятность достигает 0,954 (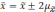
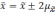 ).
).
Если утроить значение то вероятность
увеличится до 0,997 (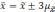
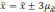 ).
).
|
Возможное |
Вероятность |
|
|
0,683 |
|
|
0,954 |
|
|
0,997 |
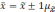
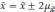
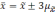
Если
обозначить значение увеличения 

за
t,
то можно записать в общем виде:
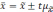
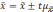
Множитель
t
называется коэффициентом
доверия.
Известный русский математик А.М.Ляпунов
дал выражение конкретных значений
множителя t
для различных степеней вероятности в
виде функции:
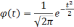
На
практике пользуются готовыми таблицами
этой функции.
|
t |
0 |
0,1 |
0,5 |
1 |
1,5 |
2 |
2,5 |
2,6 |
3 |
4 |
|
(t) |
0,1 |
0,0797 |
0,3829 |
0,6827 |
0,8664 |
0,9545 |
0,9876 |
0,9907 |
0,9973 |
0,99994 |
Из
вышесказанного следует, что лишь с
определенной степенью вероятности
можно утверждать, что показатели
генеральной совокупности и их отклонения
не превысят величину 
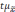 .
.
Полученную величину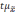
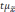 называетсяпредельной
называетсяпредельной
ошибкой выборки.
Предельная
ошибка выборки
—
максимально
возможное расхождение выборочной и
генеральной средних,
т.е.
максимум ошибки при заданной вероятности
ее появления.
Предельная
ошибка выборки для количественного
признака:
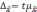
Предельная
ошибка выборки для альтернативного
признака:
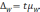
В
связи с тем, что существуют различные
методы, виды и способы отбора единиц из
генеральной совокупности формулы для
расчета средней ошибки выборки также
будут различаться:
|
Способ |
Оцениваемый |
Повторный |
Бесповторный |
|
Собственно случайный механический |
Средняя |
|
|
|
Доля |
|
|
|
|
Типический |
Средняя |
|
|
|
Доля |
|
|
|
|
Серийный |
Средняя |
|
|
|
Доля |
|
|
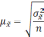
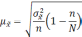
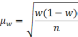
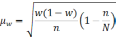
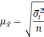
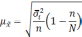
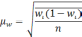
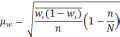
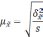
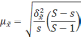

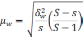
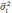
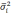
— средняя из групповых дисперсий;
wi
— доля
единиц совокупности, обладающих изучаемым
признаком в i-й
типической
группе;
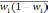
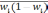
— средняя из групповых дисперсий для
доли. В табл. 6.6 представлены формулы
для исчисления средней ошибки выборки
при типическом отборе;
S
– общее число серий;
s
– число отобранных серий;

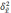 —
—
межгрупповая дисперсия средних,
определяемая по формуле:
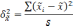
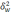
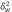 —
—
межгрупповая дисперсия доли, определяемая
по формуле:
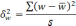
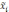
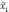
— средняя
i-й
серии;


—
средняя по всей выборочной совокупности;
w
— доля признака i-й
серии;


— общая доля признака во всей выборочной
совокупности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Простая случайная выборка
заключается в отборе единиц из генеральной совокупности в целом, без разделения ее на группы, подгруппы или серии отдельных единиц. При этом единицы отбираются в случайном порядке, не зависящем ни от последовательности расположения единиц в совокупности, ни от значений их признаков. Прежде чем производить собственно-случайный отбор, необходимо убедиться, что все без исключения единицы генеральной совокупности имеют абсолютно равные шансы попадания в выборку, в списках или перечне отсутствуют пропуски, игнорирования отдельных единиц и т.п.
Упрощенным вариантом метода прямой реализации является отбор единиц в выборочную совокупность на основе таблицы случайных чисел. Для проведения отбора могут быть использованы цифры любого столбца данной таблицы, при этом необходимо учитывать объем генеральной совокупности.
При проведении бесповторного отбора повторяющиеся номера следует учитывать только один раз. При повторном отборе, если тот или иной номер случайно встретится еще один или более раз, соответствующая этому номеру единица в каждом случае повторно включается в выборочную совокупность.
После проведения отбора с использованием какого-либо алгоритма, реализующего принцип случайности, или на основе таблицы случайных чисел, необходимо определить границы генеральных характеристик. Для этого рассчитываются средняя и предельная ошибки выборки.
Между признаками выборочной совокупности и признаками генеральной совокупности, как правило, существует некоторое расхождение, которое называют ошибкой статистического наблюдения. При массовом наблюдении ошибки неизбежны, но возникают они в результате действия различных причин. Величина возможной ошибки выборочного признака слагается из ошибок регистрации и ошибок репрезентативности. Ошибки регистрации, или технические ошибки, связаны с недостаточной квалификацией наблюдателей, неточностью подсчетов, несовершенством приборов и т. п.
Под ошибкой репрезентативности (представительства) понимают расхождение между выборочной характеристикой и предполагаемой характеристикой генеральной совокупности.
Ошибки репрезентативности бывают случайными и систематическими.
Систематические ошибки связаны с нарушением установленных правил отбора.
Случайные ошибки объясняются недостаточно равномерным представлением в выборочной совокупности различных категорий единиц генеральной совокупности.
В результате первой причины (систематические ошибки) выборка легко может оказаться смещенной, так как при отборе каждой единицы допускается ошибка, всегда направленная в одну и ту же сторону. Эта ошибка получила название ошибки смещения. Ее размер может превышать величину случайной ошибки. Особенность ошибки смещения состоит в том, что, представляя собой постоянную часть ошибки репрезентативности, она увеличивается с увеличением объема выборки. Случайная же ошибка с увеличением объема выборки уменьшается. Кроме того, величину случайной ошибки можно определить, в то время как размер ошибки смещения непосредственно практически определить очень сложно, а иногда и невозможно. Поэтому важно знать причины, вызывающие ошибку смещения, и предусмотреть мероприятия по ее устранению.
Ошибки смещения бывают преднамеренными и непреднамеренными. Причиной возникновения преднамеренной ошибки является тенденциозный подход к выбору единиц из генеральной совокупности. Чтобы не допустить появления такой ошибки, необходимо соблюдать принцип случайности отбора единиц.
Непреднамеренные ошибки могут возникать на стадии подготовки выборочного наблюдения, формирования выборочной совокупности и анализа ее данных. Чтобы не допустить появления таких ошибок, необходима хорошая основа выборки, т. е. та генеральная совокупность, из которой предполагается производить отбор, например список единиц отбора. Основа выборки должна быть достоверной, полной и соответствовать цели исследования, а единицы отбора и их характеристики должны соответствовать действительному их состоянию на момент подготовки выборочного наблюдения. Нередки случаи, когда в отношении некоторых единиц, попавших в выборку, трудно собрать сведения из-за их отсутствия на момент наблюдения, нежелания дать сведения и т. п. В таких случаях эти единицы приходится заменять другими. Необходимо следить, чтобы замена осуществлялась равноценными единицами.
Случайная ошибка выборки возникает в результате случайных различий между единицами, попавшими в выборку, и единицами генеральной совокупности, т. е. она связана со случайным отбором. Теоретическим обоснованием появления случайных ошибок выборки являются теория вероятностей и ее предельные теоремы.
Сущность предельных теорем состоит в том, что в массовых явлениях совокупное влияние различных случайных причин на формирование закономерностей и обобщающих характеристик будет сколь угодно малой величиной или практически не зависит от случая. Так как случайная ошибка выборки возникает в результате случайных различий между единицами выборочной и генеральной совокупностей, то при достаточно большом объеме выборки она будет сколь угодно мала.
Предельные теоремы теории вероятностей позволяют определять размер случайных ошибок выборки. Различают среднюю (стандартную) и предельную ошибку выборки. Под средней (стандартной) ошибкой выборки понимают расхождение между средней выборочной и генеральной совокупностей. Предельной ошибкой выборки принято считать максимально возможное расхождение, т. е. максимум ошибки при заданной вероятности ее появления.
Внимание!
Если вам нужна помощь в написании работы, то рекомендуем обратиться к
профессионалам. Более 70 000 авторов готовы помочь вам прямо сейчас. Бесплатные
корректировки и доработки. Узнайте стоимость своей работы.
В математической теории выборочного метода сравниваются средние характеристики признаков выборочной и генеральной совокупностей и доказывается, что с увеличением объема выборки вероятность появления больших ошибок и пределы максимально возможной ошибки уменьшаются. Чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик. На основании теоремы, доказанной П. Л. Чебышевым, величину средней (стандартной) ошибки повторной простой случайной выборки при достаточно большом объеме выборки (n) можно определить по формуле:
![]()
где ![]() — стандартная ошибка.
— стандартная ошибка.
Из этой формулы средней (стандартной) ошибки повторной простой случайной выборки видно, что величина ![]() зависит от изменчивости признака в генеральной совокупности (чем больше вариация признака, тем больше ошибка выборки) и от объема выборки n чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик).
зависит от изменчивости признака в генеральной совокупности (чем больше вариация признака, тем больше ошибка выборки) и от объема выборки n чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик).
В математической статистике употребляют коэффициент доверия t, и значения функции F(t) табулированы при разных его значениях, при этом получают соответствующие уровни доверительной вероятности.
Коэффициент доверия или коэффициент кратности ошибки репрезентативности, (t-критерий Стьюдента) позволяет вычислить предельную ошибку простой случайной выборки. С учетом выбранного уровня вероятности и соответствующего ему значения t
предельная ошибка повторной простой случайной выборки составит:
![]()
Из формулы вытекает, что предельная ошибка выборки равна кратному числу средних ошибок выборки.
Таким образом, величина предельной ошибки выборки может быть установлена с определенной вероятностью.
Выборочное наблюдение дает возможность определить среднюю арифметическую выборочной совокупности ![]() и величину предельной ошибки этой средней
и величину предельной ошибки этой средней ![]() которая показывает с определенной вероятностью, насколько выборочная может отличаться от генеральной средней в большую или меньшую сторону.
которая показывает с определенной вероятностью, насколько выборочная может отличаться от генеральной средней в большую или меньшую сторону.
Тогда величина генеральной средней будет представлена интервальной оценкой. Интервал, в который с данной степенью вероятности будет заключена неизвестная величина оцениваемого параметра, называю доверительным, а вероятность Р – доверительной вероятностью. Чаще всего доверительную вероятность принимают равной 0,95 или 0,99. Это означает, что доверительный интервал с заданной вероятностью заключает в себе генеральную среднюю.
Тогда можно утверждать, что при заданной вероятности генеральная средняя будет находиться в следующих границах:
![]()
Чем больше величина средней ошибки выборки, тем больше величина доверительного интервала и тем, следовательно, ниже точность оценки. Средняя (стандартная) ошибка выборки зависит от объема выборки и степени вариации признака в генеральной совокупности.
Пример.
Предположим, в результате выборочного обследования доходов домохозяйств региона, осуществленного на основе собственно-случайной повторной выборки, получен следующий ряд распределения.

Рассмотрим определение границ генеральной средней, в данном примере – среднего дохода домохозяйства в целом по данному региону, опираясь только на результаты выборочного обследования. Для определения средней ошибки выборки нам необходимо прежде всего рассчитать выборочную среднюю величину и дисперсию изучаемого признака.


Средняя ошибка выборки составит:
![]()
Определим предельную ошибку выборки с вероятностью 0,954 (t=2):
![]()
Установим границы генеральной средней (тыс.руб.):
![]() или
или ![]()
Таким образом, на основании проведенного выборочного обследования с вероятностью 0,954 можно заключить, что средний доход домохозяйства в целом по региону лежит в пределах от 11,3 до 11,9 тыс.руб.
При расчете средней ошибки простой случайной бесповторной выборки необходимо учитывать поправку на бесповторность отбора:

Если предположить, что представленные в таблице данные являются результатом 5%-ного бесповторного отбора (следовательно, генеральная совокупность включает 22000 домохозяйств), то средняя ошибка выборки будет несколько меньше:
![]()
Соответственно уменьшится и предельная ошибка выборки, что вызовет сужение границ генеральной средней. Особенно ощутимо влияние поправки на бесповторность отбора при относительно большом проценте выборки.
Получить выполненную работу или консультацию специалиста по вашему
учебному проекту
Узнать стоимость
Доверительный интервал за 15 минут
Добрый день, уважаемые читатели!
Меня зовут Кирилл Мильчаков. Сегодня мы продолжаем наш разговор о биостатистике. Тема сегодняшней нашей беседы будет «Доверительный интервал». Что такое доверительный интервал? Вы наверняка встречались с ним в научной литературе. Доверительный интервал 95 %, либо сочетание символов ДИ и CI (confidence interval) 95 %. Что же означают эти 95 %? Какие он еще может принимать значения? И как его рассчитывать самостоятельно? Об этом обо всем сегодня мы и поговорим в этой статье.
Видео-версия статьи о доверительном интервале
Генеральная совокупность и выборочная совокупность
Прежде чем углубляться в тайны доверительного интервала, хотел бы вспомнить с вами 2 основных понятия статистической совокупности, с которыми чаще всего работают – это генеральная совокупность или выборочная совокупность или выборка.
Генеральная совокупность – это тот массив данных, о которых вы хотите сделать выводы.
Выборка является частью генеральной совокупности, которая участвует непосредственно в вашем эксперименте. Есть такое понятие как репрезентативность, сегодня мы не будем его касаться, главное запомнить, что выборка должна быть репрезентативной.
Если привести небольшой пример относительно генеральной совокупности и выборки, то можно вспомнить о простом случае из вашей жизни. Когда вы хотите узнать, достаточно ли посолен суп, вы берете ложку супа и пробуете его. Вам необязательно есть весь суп, чтобы понять, насколько он посолен. Ложка в данном случае является выборкой, по которой вы делаете вывод обо всей кастрюле супа. В данном случае кастрюля супа является генеральной совокупностью, а ложка супа является выборкой.
Итак, мы вспомнили с вами о 2 ключевых статистических совокупностях – о генеральной совокупности и выборочной совокупности. Теперь нужно вспомнить, что типы исследования, которые проводятся над генеральной совокупностью и выборочной совокупностью, называют по-разному. Над генеральной совокупностью проводятся так называемые сплошные исследования, над выборочной совокупностью – выборочные.
Теперь вспомним небольшие отличия между параметрами этих 2 совокупностей. Сегодня для того, чтобы понять, что такое доверительный интервал, нам понадобятся следующие вещи: во-первых, отличие средней арифметической в генеральной совокупности и в выборочной совокупности. В генеральной совокупности она имеет значок µ (мю), в выборочной – это x̅ (х с чертой) — это средние арифметические по каждому виду совокупности.
Далее нужно знать, что стандартное отклонение имеет значок выборочной – либо S, либо SD (standard deviation), а в случае генеральной совокупности оно носит название среднеквадратичного отклонения и обозначается буквой σ (сигма).
Приведем пример расчета доврительного интервала
Представьте чисто гипотетическую ситуацию, когда перед нами стоит задача исследований среднего роста марсианина. Для того, чтобы его узнать, было отправлено 3 экспедиции. Первой из них повезло больше всего: они смогли поймать каждого из 200 марсианин и померить его рост.
Как мы помним, по закону нормального распределения по оси Х находится величина изучаемого признака, либо варианта (в данном случае это рост в сантиметрах), а по оси Y – частота встречаемости какого-то признака (мы его обозначаем буквой П.
Итак, оказалось, что у всех 200 марсиан средний рост составил 40 сантиметров. Таким образом, первая экспедиция смогла провести так называемое сплошное исследование, так как поработала со всеми единицами наблюдения генеральной совокупности. Поэтому мы имеем право назвать этот параметр µ.
Однако, второй и третьей экспедиции повезло гораздо меньше. Они попали в самые плохо населенные участки Марса и смогли отобрать только 10 марсиан. В данном случае оказалось, что средний рост по их выборке составил всего 38 сантиметров в первом случае и 41 сантиметр во втором случае.
Что же делать? Да, у нас есть данные из самого полного исследования, которое относится к первой экспедиции. Но представьте, что ни одна бы из них не смогла бы поработать со всей совокупностью полностью, и у нас были бы данные только от второй и третьей экспедиции. Что же в этой ситуации делать? Видно, что никто 40 сантиметров в действительности не достиг: во второй экспедиции Б она равна 38 сантиметрам, а в экспедиции В – 41 сантиметр. То есть в реальности никто не достиг 40 сантиметров. Что же делать в данном случае?
И вот здесь на помощь к нам приходит доверительный интервал, точнее оценка параметра. Доверительный интервал является вторым этапом оценки параметра. Прежде чем строить доверительный интервал, нам нужно понять, насколько в принципе этот параметр наша средняя (x̅б, x̅в) может отличаться, ошибаться от реального параметра в генеральной совокупности. Насколько?
И тут нам помогает оценка параметра или нахождение ошибки репрезентативности. Ошибка репрезентативности обозначается mr или mx. Чаще я использую mr. Что же это значит? mr по-английски обозначается как standard error, по-русски она часто называется стандартная ошибка средней или ошибка репрезентативности. Как же она находится? А находится она следующим образом? Она учитывает стандартное квадратичное отклонение в генеральной совокупности и размер в выборке. От чего же зависит ошибка репрезентативности? А зависит она от 2 вещей: от среднеквадратичного отклонения в генеральной совокупности (я напоминаю, это насколько каждая варианта отличается от средней, о законе нормального распределения мы с вами поговорим в следующий раз) и от размера выборки или . То есть, таким образом, чем менее разбросан признак генеральной совокупности, и чем больше у нас размер выборки, тем меньше наша ошибка репрезентативности.
Итак, предположим, мы нашли нашу ошибку репрезентативности mr. В данном случае она составила 2,7 сантиметра. Но что же это нам дает? А дает нам это уже достаточно много. Теперь мы, зная, насколько в принципе наша выборка может ошибаться относительно генеральной совокупности, можем составить определенное предположение о том, где же находится реальный параметр – реальные 40 сантиметров генеральной совокупности на основании данных лишь нашей выборки.
Каким же образом это происходит? Мы провели точечную оценку нашего параметра. Дальше происходит второй этап построения доверительного интервала – это интервальная оценка параметра. Каким же образом строится этот интервал? А складывается он из 2 вещей: так называемой предельной ошибки +∆ и -∆. Формула нахождения предельной ошибки достаточно проста и составляет:
±∆ = t*mr
Для того, чтобы не залезать в критерий Стьюдента сегодня, я скажу лишь, что:
для доверительного интервала 95 % используется t=2,
для доверительного интервала 99 % используется t=3
и для доверительного интервала 68 % используется t=1.
Итак, после того, как мы нашли нашу предельную ошибку, мы можем построить доверительный интервал. Но для этого нам нужно самим задать тот доверительный интервал, который для нас подходит больше всего. Чаще всего в медицине используется вероятность ошибки 5 %, то есть доверительный интервал 95 % или вероятность ошибки 5 % (р=0,05, р=5 %).
Что же значат эти 95 %? А значат они следующее, что с 95%-ной вероятностью в нашем интервале лежит реальное значение, и лишь в 5 % случаев мы ошибаемся. То есть в нашем конкретном случае наша ошибка репрезентативности составила 2,7 сантиметра. Предельная ошибка отсюда будет равна чему? Именно 5,4 сантиметра, то есть доверительный интервал, так как здесь и плюс, и минус, то есть нам нужно ошибку умножить на 2, составил 10,8 сантиметров. А именно наши 38 см±5,4 см. Ширина всего доверительного интервала составляет 10,8 см. Напомню, что он складывается из положительной и отрицательной предельных ошибок вокруг нашей выборочной средней.
Итак, говоря о доверительном интервале, нужно сделать ряд важных выводов.
- Во-первых, доверительный интервал относится к выборочной совокупности. Он показывает, насколько параметры из выборочной совокупности могут отличаться от реально существующих данных в генеральной совокупности. Насколько мы ошибаемся при формировании той или иной выборки, мы закладываем в так называемую ошибку репрезентативности, в ошибку средней и вокруг нее собственно и строим доверительный интервал.
- Ширину доверительного интервала задает собственно сам исследователь, варьируя тот критерий t, который он принимает в качестве необходимого. Чаще всего применяется t=2, которое и соответствует ширине доверительного интервала 95 %. 95 % означает, что с 95%-ной вероятностью действительно вокруг выборочной средней существует определенный доверительный интервал, в который и попадает реально существующая средняя из генеральной совокупности. Этот доверительный интервал может быть либо уже, если t=1; либо шире, если t=3.
- Доверительный интервал задается самостоятельно исследователем. Чаще всего он равен 95 %.
Если это видео оказалось Вам полезным, оно хотя бы немного раскрыло тайны доверительного интервала, ставьте лайки, подписывайтесь на наши рассылки и в комментариях пишите, какие темы по биостатистике вам бы были интересны для следующих выпусков. На этом я с вами прощаюсь. Меня зовут Кирилл. Пока!
Если Вам понравилась статья и оказалась полезной, Вы можете поделиться ею с коллегами и друзьями в социальных сетях: