This example shows how to compute and compare the statistics of the signal quantization error when using various rounding methods. Quantization occurs when a data type cannot represent a value exactly. In these cases, the value must be rounded to the nearest value that can be represented by the data type.
First, a random signal is created that spans the range of the quantizer object. Next, the signal is quantized, respectively, with rounding methods 'fix', 'floor', 'ceil', 'nearest', and 'convergent', and the statistics of the signal are estimated.
The theoretical probability density function of the quantization error is computed with the errpdf function, the theoretical mean of the quantization error is computed with the errmean function, and the theoretical variance of the quantization error is computed with the errvar function.
Create Uniformly Distributed Random Signal
Create a uniformly distributed random signal that spans the domain -1 to 1 of the fixed-point quantizer object q.
q = quantizer([8 7]); r = realmax(q); u = r*(2*rand(50000,1) - 1); xi = linspace(-2*eps(q),2*eps(q),256);
Fix: Round Towards Zero
With 'fix' rounding, the probability density function is twice as wide as the others. For this reason, the variance is four times that of the others.
q = quantizer('fix',[8 7]);
err = quantize(q,u) - u;
f_t = errpdf(q,xi);
mu_t = errmean(q);
v_t = errvar(q);
qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -46.8586 Theoretical error variance (dB) = -46.9154 Estimated mean = 7.788e-06 Theoretical mean = 0
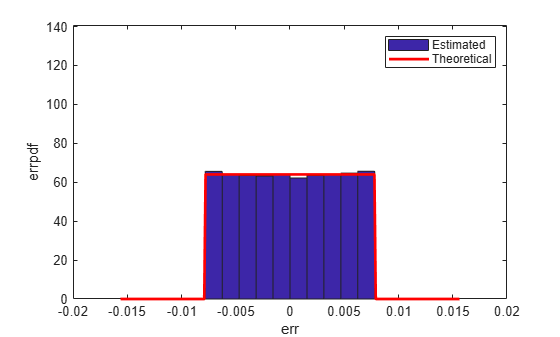
The theoretical variance is eps(q)^2/3 and the theoretical mean is 0.
Floor: Round Towards Negative Infinity
'floor' rounding is often called truncation when used with integers and fixed-point numbers that are represented using two’s complement notation. It is the most common rounding mode of DSP processors because it requires no hardware to implement. 'floor' does not produce quantized values that are as close to the true values as 'round' will, but it has the same variance. Using 'floor', small signals that vary in sign will be detected, whereas in 'round' they will be lost.
q = quantizer('floor',[8 7]);
err = quantize(q,u) - u;
f_t = errpdf(q,xi);
mu_t = errmean(q);
v_t = errvar(q);
qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9148 Theoretical error variance (dB) = -52.936 Estimated mean = -0.0038956 Theoretical mean = -0.0039062
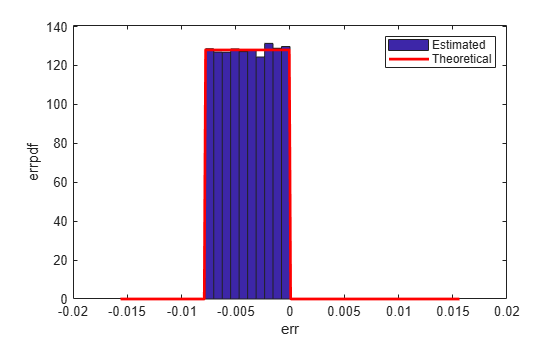
The theoretical variance is eps(q)^2/12 and the theoretical mean is -eps(q)/2.
Ceil: Round Towards Positive Infinity
q = quantizer('ceil',[8 7]);
err = quantize(q,u) - u;
f_t = errpdf(q,xi);
mu_t = errmean(q);
v_t = errvar(q);
qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9148 Theoretical error variance (dB) = -52.936 Estimated mean = 0.0039169 Theoretical mean = 0.0039062
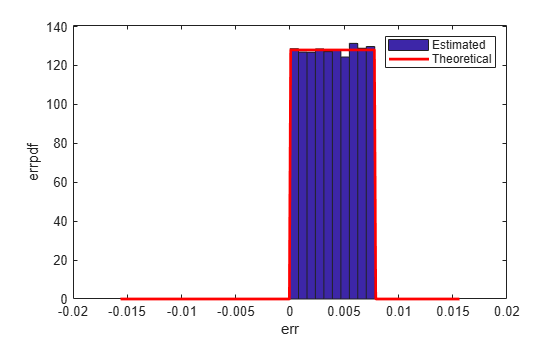
The theoretical variance is eps(q)^2/12 and the theoretical mean is eps(q)/2.
Round: Round to Nearest; In a Tie Round to Largest Magnitude
'round' is more accurate than 'floor', but all values smaller than eps(q) get rounded to zero and are lost.
q = quantizer('nearest',[8 7]);
err = quantize(q,u) - u;
f_t = errpdf(q,xi);
mu_t = errmean(q);
v_t = errvar(q);
qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9579 Theoretical error variance (dB) = -52.936 Estimated mean = -2.212e-06 Theoretical mean = 0
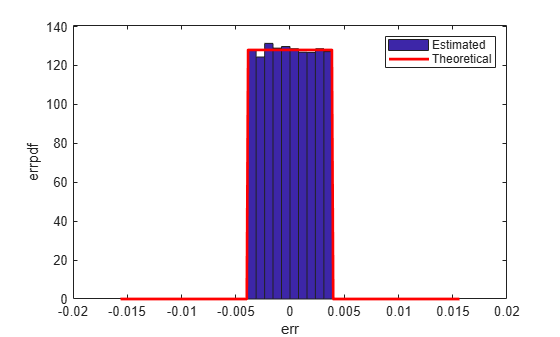
The theoretical variance is eps(q)^2/12 and the theoretical mean is 0.
Convergent: Round to Nearest; In a Tie Round to Even
'convergent' rounding eliminates the bias introduced by ordinary 'round' caused by always rounding the tie in the same direction.
q = quantizer('convergent',[8 7]);
err = quantize(q,u) - u;
f_t = errpdf(q,xi);
mu_t = errmean(q);
v_t = errvar(q);
qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9579 Theoretical error variance (dB) = -52.936 Estimated mean = -2.212e-06 Theoretical mean = 0
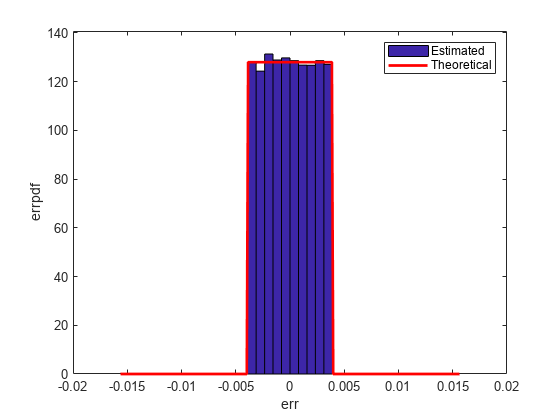
The theoretical variance is eps(q)^2/12 and the theoretical mean is 0.
Compare Nearest and Convergent Rounding
The error probability density function for convergent rounding is difficult to distinguish from that of round-to-nearest by looking at the plot.
The error probability density function of convergent is
f(err) = 1/eps(q), for -eps(q)/2 <= err <= eps(q)/2, and 0 otherwise
while the error probability density function of round is
f(err) = 1/eps(q), for -eps(q)/2 < err <= eps(q)/2, and 0 otherwise
The error probability density function of convergent is symmetric, while round is slightly biased towards the positive.
The only difference is the direction of rounding in a tie.
x = (-3.5:3.5)'; [x convergent(x) nearest(x)]
ans = 8×3
-3.5000 -4.0000 -3.0000
-2.5000 -2.0000 -2.0000
-1.5000 -2.0000 -1.0000
-0.5000 0 0
0.5000 0 1.0000
1.5000 2.0000 2.0000
2.5000 2.0000 3.0000
3.5000 4.0000 4.0000
See Also
quantizer | quantize | Rounding
Ошибки квантования
В реальных
устройствах цифровой обработки сигналов
необходимо учитывать
эффекты, обусловленные квантованием
входных сигналов
и конечной разрядностью всех регистров.
Источниками ошибок
в процессах обработки сигналов являются
округление (усечение)
результатов арифметических операций,
шум аналого-цифрового квантования
входных аналоговых сигналов, неточность
реализации характеристик цифровых
фильтров из-за округления их коэффициентов
(параметров). В дальнейшем с целью
упрощения анализа предполагается, что
вес источники ошибок независимы и не
коррелируют с входным сигналом (хотя
мы и рассмотрим явление предельных
циклов, обусловленных коррелированным
шумом округления).
Эффект квантования
приводят в конечном итоге к погрешностями выходных сигналах цифровых фильтров
(ЦФ), а в некоторыхслучаяхи к неустойчивым
режимам. Выходную ошибку ЦФ будем
рассчитыватькаксуперпозицию ошибок, обусловленных
каждым независимымисточником.
Квантование
чисел– нелинейная операция;m-разрядное
двоичное числоА
представляетсяb-разрядным
двоичнымчислом
B=F(A),
причем b
< m. В
результате квантования число А
представляется
с ошибкой
е
=B–А= F(А)
–А.
Шаг квантования
Q
=
2–b
определяется весом младшего
числовогоразряда.
При квантовании
используется усечение или округление.
Усечение
числаА
состоит в отбрасываниит
– b
младших разрядов числа, при этом
ошибка усечения
eус=
Fус(А) –А.
Оценим величину
ошибки в предположении m
» b.
Для положительных чисел при любом
способе кодирования –2–b
<еус
0. Для
отрицательных чисел при использовании
прямого и обратного кодов ошибка усечения
неотрицательна: 0еус
< 2–b,
а в дополнительном коде эта ошибка
неположительна: 0еус
> –2–b.
Таким образом, во всех случаях
абсолютное значение ошибки усечения
не превосходит шага квантования:maxeус
< 2–b
=Q.
Округление
m-разрядного
числаA
доb
разрядов (b «
m)b-й
разряд остается неизменным или
увеличивается на единицув
зависимости от соотношения (больше –
меньше) между отбрасываемой дробью
0,аb+1…ат
и величиной
![]() ,
,
гдеаi–i-й
разряд числаA;
i =
b+1,
…,m.
Округление можно практически выполнить
путемприбавления
единицы к (b+1)-му
разряду и усечения полученного числа
до b разрядов.
В таком случае ошибка округления еoк
=
fок(А)–
А
при всех способах кодирования лежит в
пределах
–2–(b+1)
<
еoк
< 2–(b+1)
(1.11)
и, следовательно,
max![]() <2–b
<2–b
= Q/2.
(1.12)
В задачах ЦОС
ошибки квантования чисел рассматриваются
как стационарный
шумоподобный процесс с равномерным
распределением
вероятности по диапазону распределения
ошибок квантования.
(nT)


x(nT)

e(nT)
Рис. 3. Линейная модель квантования
сигналов:
(nT) —дискретный
или m-разрядный
цифровой сигнал (m
> b);
x(nT) —квантованный
b-разрядный
цифровой сигнал;
e(nT)
= x(nT)
–f(nT)
— ошибка
квантования.
Квантование
дискретных сигналов состоит в
представлении отсчета
(выборки сигнала) числамиx(nT),
содержащими b
числовых разрядов. Квантование сигналов,
как и квантование
чисел – нелинейная операция. Однако
при анализе процессов в ЦФ целесообразно
использовать линейную модель квантования
сигналов – рис. 3.
Верхнее значение ошибки квантования
![]() определяетсясоотношением
определяетсясоотношением
(1.11) или (1.12).
Вероятностные
оценки ошибок квантования основаны на
предположениях о том, что
последовательностье(пТ)являетсястационарным
случайным процессом с равномерным
распределением вероятности по
диапазону ошибок квантования ие(пТ)
не коррелирован
с f(nT).
Математическое
ожидание (среднее значение) e
и дисперсия
![]() ошибки квантованияе
ошибки квантованияе
определяются
по формулам:
![]() =E(е)
=E(е)
=![]() ,
,
![]() =
=![]() =
=![]() =E(е2)
=E(е2)
–![]() ,
,
где ре
— плотность вероятности ошибки. По
этим формуламвычисляются
математическое ожидание и дисперсия
для ошибок
округления и усечения:
![]() =
=
![]() =
=
![]()
В логарифмическоммасштабе
![]() =
=![]()
Лекция 2
Ошибки квантования
В реальных
устройствах цифровой обработки сигналов
необходимо учитывать
эффекты, обусловленные квантованием
входных сигналов
и конечной разрядностью всех регистров.
Источниками ошибок
в процессах обработки сигналов являются
округление (усечение)
результатов арифметических операций,
шум аналого-цифрового квантования
входных аналоговых сигналов, неточность
реализации характеристик цифровых
фильтров из-за округления их коэффициентов
(параметров). В дальнейшем с целью
упрощения анализа предполагается, что
вес источники ошибок независимы и не
коррелируют с входным сигналом (хотя
мы и рассмотрим явление предельных
циклов, обусловленных коррелированным
шумом округления).
Эффект квантования
приводят в конечном итоге к погрешностями выходных сигналах цифровых фильтров
(ЦФ), а в некоторыхслучаяхи к неустойчивым
режимам. Выходную ошибку ЦФ будем
рассчитыватькаксуперпозицию ошибок, обусловленных
каждым независимымисточником.
Квантование
чисел– нелинейная операция;m-разрядное
двоичное числоА
представляетсяb-разрядным
двоичнымчислом
B=F(A),
причем b
< m. В
результате квантования число А
представляется
с ошибкой
е
=B–А= F(А)
–А.
Шаг квантования
Q
=
2–b
определяется весом младшего
числовогоразряда.
При квантовании
используется усечение или округление.
Усечение
числаА
состоит в отбрасываниит
– b
младших разрядов числа, при этом
ошибка усечения
eус=
Fус(А) –А.
Оценим величину
ошибки в предположении m
» b.
Для положительных чисел при любом
способе кодирования –2–b
<еус
0. Для
отрицательных чисел при использовании
прямого и обратного кодов ошибка усечения
неотрицательна: 0еус
< 2–b,
а в дополнительном коде эта ошибка
неположительна: 0еус
> –2–b.
Таким образом, во всех случаях
абсолютное значение ошибки усечения
не превосходит шага квантования:maxeус
< 2–b
=Q.
Округление
m-разрядного
числаA
доb
разрядов (b «
m)b-й
разряд остается неизменным или
увеличивается на единицув
зависимости от соотношения (больше –
меньше) между отбрасываемой дробью
0,аb+1…ат
и величиной
![]() ,
,
гдеаi–i-й
разряд числаA;
i =
b+1,
…,m.
Округление можно практически выполнить
путемприбавления
единицы к (b+1)-му
разряду и усечения полученного числа
до b разрядов.
В таком случае ошибка округления еoк
=
fок(А)–
А
при всех способах кодирования лежит в
пределах
–2–(b+1)
<
еoк
< 2–(b+1)
(1.11)
и, следовательно,
max![]() <2–b
<2–b
= Q/2.
(1.12)
В задачах ЦОС
ошибки квантования чисел рассматриваются
как стационарный
шумоподобный процесс с равномерным
распределением
вероятности по диапазону распределения
ошибок квантования.
(nT)
x(nT)
e(nT)
Рис. 3. Линейная модель квантования
сигналов:
(nT) —дискретный
или m-разрядный
цифровой сигнал (m
> b);
x(nT) —квантованный
b-разрядный
цифровой сигнал;
e(nT)
= x(nT)
–f(nT)
— ошибка
квантования.
Квантование
дискретных сигналов состоит в
представлении отсчета
(выборки сигнала) числамиx(nT),
содержащими b
числовых разрядов. Квантование сигналов,
как и квантование
чисел – нелинейная операция. Однако
при анализе процессов в ЦФ целесообразно
использовать линейную модель квантования
сигналов – рис. 3.
Верхнее значение ошибки квантования
![]() определяетсясоотношением
определяетсясоотношением
(1.11) или (1.12).
Вероятностные
оценки ошибок квантования основаны на
предположениях о том, что
последовательностье(пТ)являетсястационарным
случайным процессом с равномерным
распределением вероятности по
диапазону ошибок квантования ие(пТ)
не коррелирован
с f(nT).
Математическое
ожидание (среднее значение) e
и дисперсия
![]() ошибки квантованияе
ошибки квантованияе
определяются
по формулам:
![]() =E(е)
=E(е)
=![]() ,
,
![]() =
=![]() =
=![]() =E(е2)
=E(е2)
–![]() ,
,
где ре
— плотность вероятности ошибки. По
этим формуламвычисляются
математическое ожидание и дисперсия
для ошибок
округления и усечения:
![]() =
=
![]() =
=
![]()
В логарифмическоммасштабе
![]() =
=![]()
Лекция 2
Вычислите ошибку квантования
В этом примере показано, как вычислить и сравнить статистику ошибки квантования сигнала при использовании различных методов округления.
Во-первых, случайный сигнал создается, который порождает линейную оболочку столбцов квантизатора.
Затем сигнал квантуется, соответственно, с округлением методов ‘фиксируют’, ‘ставят в тупик’, ‘перекрывают’, ‘самый близкий’, и ‘конвергентный’, и статистические данные сигнала оцениваются.
Теоретическая функция плотности вероятности ошибки квантования будет вычислена с ERRPDF, теоретическое среднее значение ошибки квантования будет вычислено с ERRMEAN, и теоретическое отклонение ошибки квантования будет вычислено с ERRVAR.
Равномерно распределенный случайный сигнал
Сначала мы создаем равномерно распределенный случайный сигнал, который охватывает область-1 к 1 из квантизаторов фиксированной точки, на которые мы посмотрим.
q = quantizer([8 7]);
r = realmax(q);
u = r*(2*rand(50000,1) - 1); % Uniformly distributed (-1,1)
xi=linspace(-2*eps(q),2*eps(q),256);
Фиксация: вокруг по направлению к нулю.
Заметьте, что с округлением ‘фиксации’, функция плотности вероятности вдвое более широка, чем другие. Поэтому отклонение в четыре раза больше чем это других.
q = quantizer('fix',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 3 % Theoretical mean = 0 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -46.8586 Theoretical error variance (dB) = -46.9154 Estimated mean = 7.788e-06 Theoretical mean = 0

Пол: вокруг к минус бесконечность.
Пол, округляющийся, часто называется усечением, когда используется с целыми числами и числами фиксированной точки, которые представлены в дополнении two. Это — наиболее распространенный режим округления процессоров DSP, потому что это требует, чтобы никакое оборудование не реализовало. Пол не производит квантованные значения, которые являются как близко к истинным значениям, когда ROUND будет, но это имеет то же отклонение, и маленькие сигналы, которые варьируются по знаку, будут обнаружены, тогда как в ROUND они будут потеряны.
q = quantizer('floor',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = -eps(q)/2 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9148 Theoretical error variance (dB) = -52.936 Estimated mean = -0.0038956 Theoretical mean = -0.0039062

Потолок: вокруг к плюс бесконечность.
q = quantizer('ceil',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = eps(q)/2 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9148 Theoretical error variance (dB) = -52.936 Estimated mean = 0.0039169 Theoretical mean = 0.0039062

Вокруг: вокруг к самому близкому. Вничью, вокруг к самой большой величине.
Вокруг более точно, чем пол, но все значения, меньшие, чем eps (q), округлены, чтобы обнулить и потеряны — также.
q = quantizer('nearest',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = 0 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9579 Theoretical error variance (dB) = -52.936 Estimated mean = -2.212e-06 Theoretical mean = 0

Конвергентный: вокруг к самому близкому. Вничью, вокруг к даже.
Конвергентное округление устраняет смещение, введенное обычным «раундом», вызванным, всегда округляя связь в том же направлении.
q = quantizer('convergent',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = 0 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9579 Theoretical error variance (dB) = -52.936 Estimated mean = -2.212e-06 Theoretical mean = 0

Сравнение самых близких по сравнению с конвергентным
Функция плотности вероятности появления ошибки для конвергентного округления затрудняет, чтобы различать от того из раунда-к-самому-близкому путем рассмотрения графика.
Ошибка p.d.f. из конвергентных
f(err) = 1/eps(q), for -eps(q)/2 <= err <= eps(q)/2, and 0 otherwise
в то время как ошибка p.d.f. из раунда
f(err) = 1/eps(q), for -eps(q)/2 < err <= eps(q)/2, and 0 otherwise
Обратите внимание на то, что ошибка p.d.f. из конвергентных симметрично, в то время как вокруг немного склоняется к положительному.
Единственной разницей является направление округления вничью.
x=(-3.5:3.5)'; [x convergent(x) nearest(x)]
ans =
-3.5000 -4.0000 -3.0000
-2.5000 -2.0000 -2.0000
-1.5000 -2.0000 -1.0000
-0.5000 0 0
0.5000 0 1.0000
1.5000 2.0000 2.0000
2.5000 2.0000 3.0000
3.5000 4.0000 4.0000
Постройте функцию помощника
Функция помощника, которая использовалась, чтобы сгенерировать графики в этом примере, описана ниже.
type(fullfile(matlabroot,'toolbox','fixedpoint','fidemos','+fidemo','qerrordemoplot.m')) %#ok<*NOPTS>
function qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
%QERRORDEMOPLOT Plot function for QERRORDEMO.
% QERRORDEMOPLOT(Q,F_T,XI,MU_T,V_T,ERR) produces the plot and display
% used by the example function QERRORDEMO, where Q is the quantizer
% whose attributes are being analyzed; F_T is the theoretical
% quantization error probability density function for quantizer Q
% computed by ERRPDF; XI is the domain of values being evaluated by
% ERRPDF; MU_T is the theoretical quantization error mean of quantizer Q
% computed by ERRMEAN; V_T is the theoretical quantization error
% variance of quantizer Q computed by ERRVAR; and ERR is the error
% generated by quantizing a random signal by quantizer Q.
%
% See QERRORDEMO for examples of use.
% Copyright 1999-2014 The MathWorks, Inc.
v=10*log10(var(err));
disp(['Estimated error variance (dB) = ',num2str(v)]);
disp(['Theoretical error variance (dB) = ',num2str(10*log10(v_t))]);
disp(['Estimated mean = ',num2str(mean(err))]);
disp(['Theoretical mean = ',num2str(mu_t)]);
[n,c]=hist(err);
figure(gcf)
bar(c,n/(length(err)*(c(2)-c(1))),'hist');
line(xi,f_t,'linewidth',2,'color','r');
% Set the ylim uniformly on all plots
set(gca,'ylim',[0 max(errpdf(quantizer(q.format,'nearest'),xi)*1.1)])
legend('Estimated','Theoretical')
xlabel('err'); ylabel('errpdf')
Ошибка квантования E = em — ea — это разность между реальной продолжительностью события ea и его измеренной продолжительностью em. У вас нет возможности узнать реальную продолжительность события, следовательно, нельзя и обнаружить ошибку квантования, основываясь на отдельном значении. Однако можно доказать наличие ошибки квантования, исследуя группы родственных статистик. Мы уже рассматривали пример, в котором удалось выявить ошибку квантования. В примере 7.5 наличие ошибки квантования удалось определить, заметив, что:

Ошибку квантования легко выявить, исследуя вызов базы данных и выполняемые им события ожидания в системе с низкой загрузкой, где минимизировано влияние других факторов, способных нарушить отношение e и c + Eela.
Рассмотрим фрагмент файла трассировки Oracle8i, который демонстрирует эффект ошибки квантования:

Данный вызов выборки инициировал ровно три события ожидания. Мы знаем, что приведенные значения c, e и ela должны быть связаны таким приблизительным равенством:

В системе с низкой загрузкой величина, на которую отличаются левая и правая части приблизительного равенства, указывает на общую ошибку квантования, присутствующую в пяти измерениях (одно значение c, одно значение e и три значения ela):

С учетом того, что отдельному вызову gettimeofday в большинстве систем соответствует лишь несколько микросекунд ошибки, вызванной влиянием измерителя, получается, что ошибка квантования вносит значительный вклад в «разность» длиной в одну сантисекунду в данных трассировки.
Следующий фрагмент файла трассировки Oracle8i демонстрирует простейший вариант избыточного учета продолжительности, в результате которого возникает отрицательная величина неучтенного времени:
WAIT #96: nam=’db file sequential read’ ela= 0 p1=1 p2=1691 p3=1
FETCH #96:c=1,e=0,p=1,cr=4,cu=0,mis=0,r=1,dep=1,og=4,tim=116694789 В данном случае E = -1 сантисекунда:

При наличии «отрицательной разности» (подобного только что рассмотренному) невозможно все объяснить эффектом влияния измерителя, ведь этот эффект может быть причиной появления только положительных значений неучтенного времени. Можно было бы подумать, что имел место двойной учет использования процессора, но и это не соответствует действительности, т. к. нулевое значение ela свидетельствует о том, что время занятости процессора вообще не учитывалось для события ожидания. В данном случае ошибка квантования имеет преобладающее влияние и приводит к излишнему учету времени для выборки.

В данном случае E = 640 мкс:
В Oracle9i разрешение временной статистики улучшено, но и эта версия отнюдь не защищена от воздействия ошибки квантования, что видно в предложенном ниже фрагменте файла трассировки для E > 0:

Некоторая часть этой ошибки, несомненно, является ошибкой квантования (невозможно, чтобы общее время использования процессора данной выборкой действительно равнялось нулю). Несколько микросекунд следует отнести на счет эффекта влияния измерителя.
Наконец, рассмотрим пример ошибки квантования E < 0 в данных трассировки Oracle9i:


Возможно, в данном случае имел место двойной учет использования процессора. Также вероятно, что именно ошибка квантования внесла основной вклад в полученное время вызова выборки. Избыточный учет 8784 микросекунд говорит о том, что фактический общий расход процессорного времени вызовом базы данных составил, вероятно, всего около (10000 — 8784) мкс = 1,216 мкс.
Диапазон значений ошибки квантования
Величину ошибки квантования, содержащейся во временных статистиках Oracle, нельзя измерить напрямую. Зато можно проанализировать статистические свойства ошибки квантования в данных расширенной трассировки SQL. Во-первых, величина ошибки квантования для конкретного набора данных трассировки ограничена сверху. Легко представить ситуацию, в которой ошибка квантования, вносимая такими характеристиками продолжительности, как e и ela, будет максимальной. Наибольшего значения данная ошибка достигает в том случае, когда в последовательности значений e и ela все отдельные ошибки квантования имеют максимальную величину и их знаки совпадают.
На рис. 7.9 показан пример возникновения описанной ситуации: имеется восемь очень непродолжительных системных вызовов, причем все они попадают на такты интервального таймера. Фактическая длительность каждого события близка к нулю, но измеренная длительность каждого такого события равна одному такту системного таймера. В итоге суммарная фактическая продолжительность всех вызовов близка к нулю, а общая измеренная продолжительность равна 8 тактам. Для такого набора из n = 8 системных вызовов ошибка квантования по существу равна nrx, где rx — это разрешение интервального таймера, с помощью которого измеряется характеристика x.
Думаю, вы обратили внимание, что изображенный на рис. 7.9 случай выглядит надуманно и изобретен исключительно для прояснения вопроса. В реальной жизни подобная ситуация чрезвычайно маловероятна. Вероятность, что n ошибок квантования будут иметь одинаковые знаки, равна всего 0,5n. Вероятность того, что n=8 последовательных

Рис. 7.9. Наихудший вариант накопления ошибки квантования для последовательности измеренных продолжительностей
ошибок квантования будут отрицательными, равна всего 0,00390625 (т. е. приблизительно четыре шанса из тысячи). Для 266 значений шанс совпадения знаков у всех ошибок квантования меньше, чем один из 1080.
Для больших наборов значений длительностей совпадение знаков всех ошибок квантования практически невозможно. Но это не единственное, в чем состоит надуманность ситуации, изображенной на рис. 7.9. Она также предполагает, что абсолютная величина каждой ошибки квантования максимальна. Шансы наступления такого события еще более иллюзорны, чем у совпадения всех знаков ошибок. Например, вероятность того, что величина каждой из n имеющихся ошибок квантования превышает 0,9, равна (1 — 0,9)n. Вероятность того, что величина каждой из n = 266 ошибок квантования превысит 0,9, составляет всего 1 из 10266.
Вероятность того, что все n ошибок квантования имеют одинаковый знак и абсолютная величина всех из них больше m, чрезвычайно мала и равна произведению рассмотренных ранее вероятностей:
P (значения всех n ошибок квантования больше m или меньше -m)=
= (0.5)n(1- m)n
Ошибки квантования для продолжительностей (например, значений e и ela в Oracle) — это случайные числа в диапазоне:
-rx < E < rx где rx — это разрешение интервального таймера, с помощью которого измеряется характеристика x (x- это e или ela).
Так как положительные и отрицательные ошибки квантования возникают c равной вероятностью, средняя ошибка квантования для выбранного набора статистик стремится к нулю даже для больших файлов трассировки. Опираясь на теорему Лапласа (Pierre Simon de Laplace, 1810), можно предсказать вероятность того, что ошибки квантования для статистик e и ela будут превышать указанное пороговое значение для файла трассировки, содержащего определенное количество статистик.
Я начал работать над вычислением вероятности того, что общая ошибка квантования файла трассировки (включая ошибку, вносимую статистикой c) будет превышать заданную величину, однако мое исследование еще не завершено. Мне предстоит получить распределение ошибки квантования для статистики c, что, как я уже говорил, осложняется особенностями получения этой статистики в процессе опроса. Результаты этих изысканий планируется воплотить в одном из будущих проектов.
К счастью, относительно ошибки квантования есть и оптимистические соображения, которые позволяют не слишком расстраиваться по поводу невозможности определения ее величины:
• Во многих сотнях файлов трассировки Oracle, проанализированных нами в hotsos.com, общая продолжительность неучтенного вре-
Что означает «один шанс из десяти в [очень большой] степени»?
Для того чтобы представить себе, что такое «один шанс из 1080», задумайтесь над следующим фактом: ученые утверждают, что в наблюдаемой вселенной содержится всего около 1080 атомов (по данным http:// www.sunspot.noao.edu/sunspot/pr/answerbook/universe.html#q70, http:/ /www.nature.com/nsu/020527/020527-16.html и др.). Это означает, что если бы вам удалось написать на каждом атоме нашей вселенной 266 равномерно распределенных случайных чисел от -1 до +1, то лишь на одном из этих атомов можно было бы ожидать наличия всех 266 чисел с одинаковым знаком.
Представить вторую упомянутую вероятность — «один шанс из 10266»-еще труднее. На этот раз представим себе три уровня вложенных вселенных. То есть что каждый из 1080 атомов нашей вселенной сам по себе является вселенной, состоящей из 1080 вселенных, каждая из которых в свою очередь содержит 1080 атомов. Теперь у нас достаточно атомов для того, чтобы представить себе возможность возникновения ситуации с вероятностью «один из 10240». Даже во вселенных третьего уровня вложенности вероятность появления атома, для которого все 266 его случайных чисел по абсолютной величине больше 0,9, составит один из 100 000 000 000 000 000 000 000 000.
мени в случае корректного сбора данных (см. главу 6) чрезвычайно редко превышала 10% общего времени отклика.
Несмотря на то, что и ошибка квантования, и двойной учет использования процессора могут привести к такому результату, файл трассировки чрезвычайно редко содержит отрицательное неучтенное время, абсолютная величина которого превышала бы 10% общего времени отклика.
В случаях, когда неучтенное время оценивается более чем в 25% времени отклика для корректно собранных данных трассировки, такой объем неучтенного времени почти всегда объясняется одним из двух явлений, описанных в последующих разделах.
Наличие ошибки квантования не лишает нас возможности правильно диагностировать основные причины проблем производительности при помощи файлов расширенной трассировки SQL в Oracle (даже в файлах трассировки Oracle8i, в которых вся статистика приводится с точностью лишь до сотых долей секунды).
Ошибка квантования становится еще менее значимой в Oracle9i благодаря повышению точности измерений.
В некоторых случаях влияние ошибки квантования способно привести к утрате доверия к достоверности данных трассировки Oracle. Наверное, ничто не может так подорвать боевой дух, как подозрение в недостоверности данных, на которые вы полагаетесь. Думаю, что лучшим средством, призванным укрепить веру в получаемые данные, должно служить четкое понимание влияния ошибки квантования.
| Следующая > |
|---|
Погрешность восстановления сигнала. Информационный расчёт системы. Квантование сообщений. Ошибки квантования
Мы охотно слушаем музыку, пение птиц, приятный человеческий голос. Напротив, тарахтенье телеги, визг пилы, мощные удары молота нам неприятны и нередко раздражают и утомляют.
Таким образом, по действию, производимому на нас, все звуки делятся на две группы: музыкальные звуки и шумы. Чем отличаются они друг от друга?
Чистый музыкальный звук всегда имеет определённую высоту. Это как бы организованная звуковая волна. Напротив, в шуме царит полный беспорядок. Прислушайтесь, например, к дневному шуму городской улицы. В нём вы услышите и краткие быстро исчезающие высокие звуки, и длительный низкий гул, и резкий лязг. Шум-это множество самых различных, одновременно несущихся звуков. Чем быстрее и резче изменяются их высота и сила, тем неприятнее на нас действует шум.
Каждый из вас легко обнаружит разницу между звуком рояля и скрипом сапога. Но не всегда можно провести резкую границу между музыкальным звуком и шумом. В шуме очень часто можно уловить музыкальные звуки. В свою очередь, и к музыкальным звукам всегда примешивается шум. От него не свободно даже самое искусное музыкальное исполнение. Попробуйте внимательно прислушаться к игре на рояле, и вы услышите, кроме звуков музыки, и стук клавишей, и удары пальцев по ним, и шелест переворачиваемых нотных листов. Точно так же и к пению всегда примешивается шум дыхания певца. Но обычно мы сосредоточиваем своё внимание на звуках самой музыки и не замечаем этого шума.Получить чистый звук со строго определённой частотой колебания, даже при полном отсутствии посторонних шумов, очень трудно, и вот почему. Любое колеблющееся тело издаёт не только один основной звук. Его постоянно сопровождают звуки других частот. Эти «спутники» всегда выше основного звука и называются поэтому обертонами, то есть верхними тонами. Однако не стоит огорчаться существованием этих «спутников». Именно они-то и позволяют нам отличать звук одного инструмента от другого и голоса различных людей, если даже они равны по высоте. Каждому звуку обертоны придают своеобразную окраску или, как говорят, тембр. И если основной звук сопровождается близкими ему по высоте обертонами, то сам звук кажется нам мягким, «бархатным». Когда же обертоны значительно выше основного тона, мы говорим о неприятном «металлическом» голосе или звуке.
Причина появления обертонов сложна. Она лежит в физической природе колебания тел, и мы не станем её здесь рассматривать.
Шум вредно отражается на здоровье и работоспособности людей. Человек может работать при шуме, привыкает к нему, но продолжительное действие шума вызывает утомление, часто приводит к понижению остроты слуха, а в отдельных случаях и к глухоте. Поэтому борьба с шумом — очень важная задача.
Развивая технику, человек старается свой мускульный труд заменить работой машины. А применение машин, как иногда представляют себе, влечёт за собой увеличение шума. Неверно, однако, думать, что чем выше техника и чем больше механических средств применяет человек, тем больше он подвергает себя воздействию шума. История развития техники показывает, что с улучшением действия отдельных механизмов снижается или совсем устраняется шум при их работе. Вместе с изобретением новых машин открываются и новые пути борьбы с шумом. Действительно, паровая машина уступает своё место бесшумной турбине, грохочущий локомотив старой конструкции — менее шумному современному паровозу и электровозу. На смену звуковым сигналам, гудкам, свисткам, звонкам, там, где это возможно, приходят световые сигналы. Моторы, машины, дающие много шума, закрываются поглощающими звук оболочками, ставятся на особые фундаменты и т. д. Чтобы ослабить шум внутри помещений, на стены вешают ковры, драпируют двери и окна. Телефонные будки обивают войлоком или прессованными пробковыми плитами.
Но защититься полностью от внешнего шума очень трудно. Ведь звук проникает внутрь зданий не только по воздуху. Он пробирается и через стены, по водопроводным и канализационным трубам, через вентиляторы. Когда нужно полностью устранить всякий шум, например, при граммофонной записи или записи звуковых кинофильмов, строят специальные здания с особым фундаментом. В этих зданиях отдельные комнаты как бы «плавают» на упругих прокладках или пружинах. Двойные стены, изолированные одна от другой, двойные или даже тройные окна и двери, полное отсутствие щелей- вот какие сложные меры приходится применять для полного ограждения от шума.
А. Т. Бизин
Сибирская Государственная Академия телекоммуникаций и информатики
Новосибирск 1998 г.
Последовательность кодовых слов на выходе цифрового фильтра необходимо преобразовать в аналоговый сигнал. Преобразование осуществляется с помощью двух устройств: ЦАП и ФНЧ. В ЦАП происходит преобразование каждого кодового слова в узкий импульс, амплитуда которого соответствует значению кодового слова. В ФНЧ происходит выделение той части спектра, которая соответствует спектру аналогового сигнала.
Характеристики ЦАП
Цап преобразует отсчеты сигнала в виде кодовых слов в отсчеты сигнала в виде импульсов. Преобразование происходит с постоянным коэффициентом преобразования, не зависящим от величины отсчета. Следовательно ЦАП является линейной системой, импульсная характеристика которой совпадает с формой импульсов на выходе ЦАП. Поэтому сигнал на выходе ЦАП можно определить по формуле свертки аналоговых сигналов
yцап(t) = y(t) Е hцап(t) (5.1)
где y(t)=y(nT) — дискретный сигнал на входе ЦАП,
hцап(t) — импульсная характеристика ЦАП.
На рис. 5.1, а,в показана форма сигналов на входе и выходе ЦАП на примере импульсной характеристики в форме прямоугольного импульса длительностью t (Рис. 5.1, б)
В частотной области свертке (5.1) соответствует произведение спектров
Yцап (jw) = Y (jw) * Hцап (jw)
(5.2)
где, согласно (1.3),
Y (jw) = 
Yа(jw) — спектр аналогового сигнала, подлежащего восстановлению,
Hцап(jw) — передаточная функция ЦАП.
Множитель Т-1 в формуле Y (jw) принято относить к передаточной функции ЦАП, поэтому передаточная функция ЦАП для случая, соответствующего импульсу на Рис. 5.1, б, запишется так
Hцап(jw) = ![]() (5.3)
(5.3)
Отсюда, если t << Т, получаем
Hцап(jw) » t / Т
(5.4)
что подтверждается известным фактом спектральной теории: спектр короткого импульса равен его площади и не зависит от формы импульса.
Погрешности восстановления
Аналоговый сигнал ya(t) обращается на выходе ФНЧ, который выделяет спектр частот , соответствующий спектру Yа(jw).
Yа(jw) = Y (jw) * Hцап (jw) * Hфнч (jw) (5.5)
Неравномерность реальных частотных характеристик ЦАП и ФНЧ приводит к искажениям восстанавливаемого непрерывного сигнала. На рис. 5.2 показаны характерные особенности реальных АЧХ восстанавливающих устройств.

Искажения ЦАП обусловлены наклоном АЧХ. На Рис. 5.2 АЧХ соответствует импульсной характеристике в форме прямоугольного импульса длительностью t. Но с уменьшением t, согласно (5.3) и (5.4), падает усиление ЦАП, что приводит к малым уровням сигнала и, соответственно, к низкой помехозащищенности сигнала по отношению к собственным помехам системы.
Искажения ФНЧ увеличиваются по мере приближения к частоте среза ФНЧ wс = 0,5wд. Поэтому рабочую полосу частот сигнала Y (jw) целесообразно размещать на неискаженном участке полосы пропускания ФНЧ, что можно сделать увеличением тактовой частоты wд цифрового фильтра. Таким образом, если имеется возможность увеличить тактовую частоту, то в качестве ФНЧ можно использовать простую цепочку RC. В противном случае качественные показатели восстанавливающего устройства приходится улучшать усложнением схемы ФНЧ. Наконец, погрешности восстановления можно скомпенсировать, если создавать соответствующие предыскажения в ЦФ. В этом случае нормы на проектируемый ЦФ необходимо поправить в расчете на реальные характеристики ЦАП и ФНЧ.





Частота дискретизации Fд >= 2Fв. Для восстановления непрерывного сигнала из последовательности его дискретных отсчетов в пункте приема используется ФНЧ (фильтр низких частот) с частотой среза равной Fв. На выходе фильтра в результате суммирования отдельных откликов переданный сигнал непрерывный сигнал вновь восстанавливается. При амплитудно-импульсной модуляции (АИМ) по закону модулирующего





стемы. Содержание Нормативные ссылки Введение 1 Расчет информационных характеристик источников дискретных сообщений 2 Расчет информационных характеристик дискретного канала 3 Согласование дискретного источника с дискретным каналом 4 Дискретизация и квантование Заключение Нормативные ссылки В настоящем отчете использованы ссылки на следующие стандарты: — ГОСТ 1.5 – 93 …





Кодовыми словами конечной размерности (ошибки квантования). Поэтому сигнал на выходе цифровой цепи отличается от идеального варианта на величину погрешности квантования. Цифровая техника позволяет получить высокое качество обработки сигналов несмотря на ошибки квантования: ошибки (шумы) квантования можно привести в норму увеличением разрядности кодовых слов. Рациональные способы конструирования…





Функций в виде зависимости их значений от определенных аргументов Δвремени, линейной или пространственной координаты и т.п.) при анализе и обработке данных широко используется математическое описание сигналов по аргументам, обратным аргументам динамического представления. Так, например, для времени обратным аргументом является частота. Возможность такого описания определяется тем, что любой…
При
выборе шага дискретизации непрерывных процессов, в частности сигналов и помех,
необходимо оценить погрешность замены непрерывных процессов дискретными. В
настоящем параграфе рассматриваются вопросы оценки этой погрешности.
Пусть
непрерывный процесс изображается,
на ЦВМ. в виде последовательности его значений в равноотстоящих точках . Ясно, что дискретный
процесс лишь приближенно изображает непрерывный процесс. Требуется найти
количественную меру этого приближения, т. е. найти погрешность дискретизации. Величина
погрешности дискретизации, очевидно, зависит от того, что понимается под
погрешностью. Определение погрешности дискретизации зависит от той задачи, в
которой используется дискретный процесс вместо непрерывного. При рассмотрении некоторой
конкретной задачи погрешность дискретизации целесообразно определить как
величину отклонения результата ее решения при использовании дискретного
процесса от результата решения этой же задачи при использовании непрерывного
процесса. Поскольку задачи могут быть самыми разнообразными, то определить
заранее, к чему может привести дискретизация, не представляется возможным.
Поэтому обычно под погрешностью дискретизации процессов понимается та
погрешность, с которой может быть восстановлен непрерывный процесс по его
дискретным значениям, т. е. понимается погрешность в задаче интерполяции непрерывного
процесса по дискретным точкам.

Восстановление
непрерывного процесса по соответствующему ему дискретному
процессу обычно
можно представить как пропускание последовательности «мгновенных» импульсов (-функций) с огибающей и периодом через линейный
интерполирующий фильтр (ИФ) (восстанавливающий элемент) с некоторой импульсной
переходной характеристикой (интерполирующей функцией) . Этому соответствует схема
восстановления, показанная на рис. 1.4. Она содержит ключ, замыкающийся в
моменты времени ,
и интерполирующий фильтр (восстановление как процесс прерывания и сглаживания
). В результате восстановления образуется сигнал
 (1.34)
(1.34)
В
соответствии с данной схемой осуществляется восстановление процессов при
наиболее распространенных видах интерполяции: ступенчатой несимметричной и симметричной
(метод прямоугольников, рис. 1.5 а, б), линейной (метод трапеций, рис. 1.5, в)
и др.

Ошибку
интерполяции
![]() (1.35)
(1.35)
можно рассматривать как выходной
сигнал схемы, представленной на рис. 1.6, при воздействии на входе сигнала .
Ниже
найдены достаточно простые общие выражения для корреляционной функции,
энергетического спектра и дисперсии ошибки в предположении, что — стационарный центрированный
случайный процесс. Из общих соотношений в качестве примеров выведены частные
соотношения, соответствующие наиболее распространенным типам интерполирующих
фильтров.
Аналогичная
задача, но иными методами, решалась в работах ![]() . Однако в них получены более сложные, а в
. Однако в них получены более сложные, а в
ряде случаев лишь частные и приближенные решения. Здесь предложен новый подход
к рассматриваемой задаче, позволяющий найти ее общее точное решение,
отличающееся, кроме того, тем, что из него следует простое решение задачи
оптимизации характеристик интерполирующих фильтров по критерию минимума
среднеквадратической ошибки интерполяции.

Для информационного расчёта в качестве исходного критерия будем использовать допустимую среднеквадратическую погрешность системы, которая определяется через погрешность отдельных узлов. В нашем случае она определяется по следующей формуле:
где — среднеквадратическая погрешность АЦП, возникающая за счёт шума квантования (погрешность квантования АЦП);
Погрешность восстановления сигнала.
Для упрощения расчётов все указанные погрешности предварительно принимаются равными. Таким образом, из формулы (1) следует, что
![]()
В соответствии с техническим заданием погрешность преобразования
1%, следовательно
![]()
Расчет разрядности АЦП
АЦП преобразуют аналоговые сигналы в цифровую форму и являются оконечными устройствами в интерфейсе ввода информации в ЭВМ. Основными характеристиками АЦП являются: разрешающая способность, точность и быстродействие. Разрешающая способность определяется разрядностью и максимальным диапазоном входного аналогового напряжения.
Относительная среднеквадратическая погрешность, вносимая за счет квантования АЦП, вычисляется по формуле

где — среднеквадратическое значение шума квантования.
Шаг квантования АЦП, определяемый диапазоном изменения сигнала U с. и числом разрядов АЦП n.
Таким образом, погрешность квантования АЦП

Из этого выражения можно определить минимально необходимую разрядность АЦП:

Исходя из,
![]()
Следовательно, минимальная разрядность АЦП для решения поставленной задачи — 6 разрядов. Но поскольку АЦП в модуле ADAM-6024 имеет 16 разрядов, то его реальная погрешность преобразования будет равна

Расчет максимально возможной погрешности восстановления
Так как в задании указано, что максимальная погрешность преобразования составляет 1%, то для удовлетворения этому условию погрешность восстановления должна быть меньше либо равна
Восстановление непрерывного сигнала U(t) с помощью интерполяционного метода
Интерполяционный метод восстановления очень широко распространён в наши дни. Этот метод наиболее приспособлен для обработки сигналов с помощью средств вычислительной техники. Этот метод восстановления основан на использовании интерполяционного многочлена Лагранжа. Из соображений простоты реализации интерполирующих устройств обычно используют многочлен не выше второго порядка, применяя в основном интерполяцию нулевого и первого порядка (ступенчатая и линейная). Восстановление сигналов с помощью ступенчатой (а) и линейной (б) интерполяции поясняется на рисунке 13.

Рисунок 13. Восстановление сигналов с помощью ступенчатой (а) и линейной (б) интерполяции
При ступенчатой интерполяции мгновенные значения U(kT) дискретного сигнала U(t) сохраняются постоянными на всём интервале дискретизации Т (рисунок 13, а).
Линейная интерполяция заключается в соединении отрезками прямых мгновенных значений U(kT), как показано на рисунке 13, б.
Интерполяционный способ восстановления обладает погрешностью, которую на практике часто выражают через максимальное относительное значение

где — восстановленный интерполяционным способом сигнал (при ступенчатой интерполяции, при линейной); — диапазон изменения дискретного сигнала U(t).
Период дискретизации выбирается с учетом допустимой погрешности из формулы.
· для ступенчатого интерполятора
· при линейной интерполяции
при параболической интерполяции

Определим период дискретизации для одного канала по Котельникову:

По заданию дипломного проекта частота процессов должна быть меньше 0,1 Гц. Модуль аналогового ввода-вывода ADAM-6024 имеет fmax = 10 Гц (на 1 канал). Так как в разрабатываемой системе используются 4 канала аналогового ввода, то предельная частота дискретизации по каждому из каналов составит fmax = 2,5 Гц. Тогда необходимая частота дискретизации при ступенчатой интерполяции составит:
![]()
Следовательно, для удовлетворения требованиям к разрабатываемой системе ступенчатая интерполяция не подходит, так как частота дискретизации при ступенчатой интерполяции существенно больше 2,5 Гц.
Частота дискретизации при линейной интерполяции составляет
![]()
Частота дискретизации при параболической интерполяции равна
![]()
Можно заметить, что частота дискретизации при линейной и параболической интерполяции меньше предельной частоты дискретизации модуля на канал. Но интерполяция второго и большего порядков практически не используют, так как её реализация усложняется, поэтому для восстановления сигналов будем использовать линейную интерполяцию.
Теорема
Котельникова точно справедлива только
для сигналов с финитным (конечным)
спектром. На рис. 4.15 показаны некоторые
варианты финитных спектров.
Однако
спектры реальных информационных сигналов
бесконечны (рис. 4.16). В этом случае теорема
Котельникова справедлива с погрешностью.

Погрешность
дискретизации определяется энергией
спектральных составляющих сигнала,
лежащих за пределами частоты
 (рис. 4.16).
(рис. 4.16).
 .
.
Вторая причина
возникновения погрешностей — неидеальность
восстанавливающего ФНЧ.
Таким
образом? погрешность дискретизации и
восстановления непрерывного сигнала
определяется следующими причинами:
Спектры реальных
сигналов не финитны.
АЧХ реальных ФНЧ
неидеальны.

Рис.4.17.
Структурная схема RC-фильтра
Например,
если в качестве ФНЧ использовать
RC-фильтр
(рис.4.17), то восстановленный сигнал на
его выходе будет иметь вид, представленный
на рис.4.18.

Импульсная
реакция RC-фильтра
равна:
 .
.
Вывод:
чем выше
 и чем ближе характеристики ФНЧ к
и чем ближе характеристики ФНЧ к
идеальным, тем ближе восстановленный
сигнал к исходному.
4.6. Квантование сообщений. Ошибки квантования
Итак
показано, что передачу практически
любых сообщений
 можно свести к передаче их отсчетов,
можно свести к передаче их отсчетов,
или чисел ,
,
следующих друг за другом с интервалом
дискретности .
.
Тем самым непрерывное (бесконечное
)
множество возможных значений сообщения
 заменяетсяконечным
заменяетсяконечным
числом его дискретных значений
 .
.
Однако сами эти числа имеют непрерывную
шкалу уровней (значений), то есть
принадлежат опять же континуальному
множеству. Дляабсолютно
точного
представления таких чисел, к примеру,
в десятичной (или двоичной) форме,
необходимо теоретически бесконечное
число разрядов. Вместе с тем, на практике
нет необходимости в абсолютно точном
представлении значений
 ,
,
как и любых чисел вообще.
Во-первых,
сами источники сообщений обладают
ограниченным динамическим диапазоном
и вырабатывают исходные сообщения с
определенным уровнем искажений и ошибок.
Этот уровень может быть большим или
меньшим, но абсолютной точности
воспроизведения достичь невозможно.
Во-вторых,
передача сообщений по каналам связи
всегда производится в присутствии
различного рода помех. Поэтому, принятое
(воспроизведенное) сообщение (оценка
сообщения
 )
)
всегда в определенной степени отличается
от переданного, то есть на практикеневозможна
абсолютно точная передача
сообщений
при наличии помех в канале связи.
Наконец,
сообщения передаются для их восприятия
и использования получателем. Получатели
же информации — органы чувств человека,
исполнительные механизмы и т.д. — также
обладают конечной разрешающей
способностью, то есть не замечают
незначительной разницы между абсолютно
точным
и
приближенным
значениями
воспроизводимого сообщения. Порог
чувствительности к искажениям также
может быть различным, но он всегда есть.
С
учетом этих замечаний процедуру
дискретизации сообщений можно продолжить,
а именно подвергнуть отсчеты

квантованию.
Процесс
квантования состоит в замене непрерывного
множества значений отсчетов
дискретным
множеством
 .
.
Тем самым точные значения чисел заменяются их приблизительными
заменяются их приблизительными
(округленными до ближайшего разрешенного
уровня) значениями. Интервал между
соседними разрешенными уровнями ,
,
или уровнями квантования, называетсяшагом
называетсяшагом
квантования
.
Различают
равномерное и неравномерное квантование.
В большинстве случаев применяется и
далее подробно рассматривается
равномерное квантование (рис. 4.19), при
котором шаг квантования постоянный:
;
однако иногда определенное преимущество
дает неравномерное квантование, при
котором шаг квантования
разный
для различных
 (рис. 4.20).
(рис. 4.20).

Квантование
приводит к искажению сообщений. Если
квантованное сообщение, полученное в
результате квантования отсчета
 ,
,
обозначить как
 ,
,
то

где

— разность между истинным значением
элементарного сообщения

и
квантованным
сообщением (ближайшим разрешенным
уровнем)
 ,
,
называемая ошибкой
квантования, или
шумом
квантования
.
Шум квантования оказывает на процесс
передачи информации по существу такое
же влияние, как и помехи в канале связи.
Помехи, так же как и квантование, приводят
к тому, что оценки
 ,
,
получаемые на приемной стороне системы
связи, отличаются на некоторую величину
от истинного значения .
.
Поскольку
квантование сообщений приводит к
появлению ошибок и потере некоторой
части информации, можно определить
цену таких потерь
 и среднюю величину ошибки, обусловленной
и среднюю величину ошибки, обусловленной
квантованием:

Чаще
всего в качестве функции потерь (цены
потерь) используется квадратичная
функция вида

В
этом случае мерой ошибок квантования
служит дисперсия этих ошибок. Для
равномерного
 -уровневого
-уровневого
квантования с шагом
дисперсия ошибок квантования определяется
следующим образом:
Абсолютное
значение ошибки квантования не превосходит
половины шага квантования
 ,
,
и
тогда при
достаточно большом числе уровней
квантования
 и малой величине
и малой величине
плотность
распределения вероятностей ошибок
квантования

можно
считать равномерной на интервале +
…
— :
:

В
результате величина ошибки квантования
определится соотношением
и
соответствующим выбором шага квантования

может быть сделана сколь угодно малой
или сведена к любой наперед заданной
величине.
Относительно
требуемой точности передачи отсчетов
сообщений можно высказать те же
соображения, что и для ошибок временной
дискретизации: шумы квантования или
искажения, обусловленные квантованием,
не имеют существенного значения, если
эти искажения меньше ошибок, обусловленных
помехами и допустимых техническими
условиями.
Template:Unreferenced
The difference between the actual analog value and quantized digital value due is called quantization error. This error is due either to rounding or truncation.
Many physical quantities are actually quantized by physical entities. Examples of fields where this limitation applies include electronics (due to electrons), optics (due to photons), biology (due to DNA), and chemistry (due to molecules). This is sometimes known as the «quantum noise limit» of systems in those fields. This is a different manifestation of «quantization error,» in which theoretical models may be analog but physics occurs digitally. Around the quantum limit, the distinction between analog and digital quantities vanishes.
Quantization noise model of quantization error[]
File:Quanterr.png
Quantization noise. The difference between the blue and red signals in the upper graph is the quantization error, which is «added» to the original signal and is the source of noise.
Quantization noise is a model of quantization error introduced by quantization in the analog-to-digital conversion (ADC) process in telecommunication systems and signal processing. It is a rounding error between the analogue input voltage to the ADC and the output digitized value. The noise is non-linear and signal-dependent. It can be modelled in several different ways.
In an ideal analog-to-digital converter, where the quantization error is uniformly distributed between −1/2 LSB and +1/2 LSB, and the signal has a uniform distribution covering all quantization levels, the signal-to-noise ratio (SNR) can be calculated from

The most common test signals that fulfil this are full amplitude triangle waves and sawtooth waves.
In this case a 16-bit ADC has a maximum signal-to-noise ratio of 6.0206 · 16=96.33 dB.
When the input signal is a full-amplitude sine wave the distribution of the signal is no longer uniform, and the corresponding equation is instead

Here, the quantization noise is once again assumed to be uniformly distributed. When the input signal has a high amplitude and a wide frequency spectrum this is the case.[1]
In this case a 16-bit ADC has a maximum signal-to-noise ratio of 98.09 dB.
For complex signals in high-resolution ADCs this is an accurate model. For low-resolution ADCs, low-level signals in high-resolution ADCs, and for simple waveforms the quantization noise is not uniformly distributed, making this model inaccurate.[2] In these cases the quantization noise distribution is strongly affected by the exact amplitude of the signal.
Template:Listen
References[]
- ↑ Template:Cite book
- ↑ Template:Cite book
See also[]
- Round-off error
- Dither
- Analog to digital converter
- Quantization
- Quantization noise
- Discretization error
- Signal-to-noise ratio
- Bit resolution
- SQNR
External links[]
- Quantization noise in Digital Computation, Signal Processing, and Control, Bernard Widrow and István Kollár, 2007.
- The Relationship of Dynamic Range to Data Word Size in Digital Audio Processing
- Round-Off Error Variance — derivation of noise power of q²/12 for round-off error
- Dynamic Evaluation of High-Speed, High Resolution D/A Converters Outlines HD, IMD and NPR measurements, also includes a derivation of quantization noise
- Signal to quantization noise in quantized sinusoidal
de:Quantisierungsrauschen
es:Ruido de cuantificación
ja:量子化雑音
ja:量子化誤差
pl:Szum kwantyzacji
ru:Шум квантования
Вычислите ошибку квантования
В этом примере показано, как вычислить и сравнить статистику ошибки квантования сигнала при использовании различных методов округления.
Во-первых, случайный сигнал создается, который порождает линейную оболочку столбцов квантизатора.
Затем сигнал квантуется, соответственно, с округлением методов ‘фиксируют’, ‘ставят в тупик’, ‘перекрывают’, ‘самый близкий’, и ‘конвергентный’, и статистические данные сигнала оцениваются.
Теоретическая функция плотности вероятности ошибки квантования будет вычислена с ERRPDF, теоретическое среднее значение ошибки квантования будет вычислено с ERRMEAN, и теоретическое отклонение ошибки квантования будет вычислено с ERRVAR.
Равномерно распределенный случайный сигнал
Сначала мы создаем равномерно распределенный случайный сигнал, который охватывает область-1 к 1 из квантизаторов фиксированной точки, на которые мы посмотрим.
q = quantizer([8 7]);
r = realmax(q);
u = r*(2*rand(50000,1) - 1); % Uniformly distributed (-1,1)
xi=linspace(-2*eps(q),2*eps(q),256);
Фиксация: вокруг по направлению к нулю.
Заметьте, что с округлением ‘фиксации’, функция плотности вероятности вдвое более широка, чем другие. Поэтому отклонение в четыре раза больше чем это других.
q = quantizer('fix',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 3 % Theoretical mean = 0 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -46.8586 Theoretical error variance (dB) = -46.9154 Estimated mean = 7.788e-06 Theoretical mean = 0

Пол: вокруг к минус бесконечность.
Пол, округляющийся, часто называется усечением, когда используется с целыми числами и числами фиксированной точки, которые представлены в дополнении two. Это — наиболее распространенный режим округления процессоров DSP, потому что это требует, чтобы никакое оборудование не реализовало. Пол не производит квантованные значения, которые являются как близко к истинным значениям, когда ROUND будет, но это имеет то же отклонение, и маленькие сигналы, которые варьируются по знаку, будут обнаружены, тогда как в ROUND они будут потеряны.
q = quantizer('floor',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = -eps(q)/2 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9148 Theoretical error variance (dB) = -52.936 Estimated mean = -0.0038956 Theoretical mean = -0.0039062

Потолок: вокруг к плюс бесконечность.
q = quantizer('ceil',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = eps(q)/2 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9148 Theoretical error variance (dB) = -52.936 Estimated mean = 0.0039169 Theoretical mean = 0.0039062

Вокруг: вокруг к самому близкому. Вничью, вокруг к самой большой величине.
Вокруг более точно, чем пол, но все значения, меньшие, чем eps (q), округлены, чтобы обнулить и потеряны — также.
q = quantizer('nearest',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = 0 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9579 Theoretical error variance (dB) = -52.936 Estimated mean = -2.212e-06 Theoretical mean = 0

Конвергентный: вокруг к самому близкому. Вничью, вокруг к даже.
Конвергентное округление устраняет смещение, введенное обычным «раундом», вызванным, всегда округляя связь в том же направлении.
q = quantizer('convergent',[8 7]); err = quantize(q,u) - u; f_t = errpdf(q,xi); mu_t = errmean(q); v_t = errvar(q); % Theoretical variance = eps(q)^2 / 12 % Theoretical mean = 0 fidemo.qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
Estimated error variance (dB) = -52.9579 Theoretical error variance (dB) = -52.936 Estimated mean = -2.212e-06 Theoretical mean = 0

Сравнение самых близких по сравнению с конвергентным
Функция плотности вероятности появления ошибки для конвергентного округления затрудняет, чтобы различать от того из раунда-к-самому-близкому путем рассмотрения графика.
Ошибка p.d.f. из конвергентных
f(err) = 1/eps(q), for -eps(q)/2 <= err <= eps(q)/2, and 0 otherwise
в то время как ошибка p.d.f. из раунда
f(err) = 1/eps(q), for -eps(q)/2 < err <= eps(q)/2, and 0 otherwise
Обратите внимание на то, что ошибка p.d.f. из конвергентных симметрично, в то время как вокруг немного склоняется к положительному.
Единственной разницей является направление округления вничью.
x=(-3.5:3.5)'; [x convergent(x) nearest(x)]
ans =
-3.5000 -4.0000 -3.0000
-2.5000 -2.0000 -2.0000
-1.5000 -2.0000 -1.0000
-0.5000 0 0
0.5000 0 1.0000
1.5000 2.0000 2.0000
2.5000 2.0000 3.0000
3.5000 4.0000 4.0000
Постройте функцию помощника
Функция помощника, которая использовалась, чтобы сгенерировать графики в этом примере, описана ниже.
type(fullfile(matlabroot,'toolbox','fixedpoint','fidemos','+fidemo','qerrordemoplot.m')) %#ok<*NOPTS>
function qerrordemoplot(q,f_t,xi,mu_t,v_t,err)
%QERRORDEMOPLOT Plot function for QERRORDEMO.
% QERRORDEMOPLOT(Q,F_T,XI,MU_T,V_T,ERR) produces the plot and display
% used by the example function QERRORDEMO, where Q is the quantizer
% whose attributes are being analyzed; F_T is the theoretical
% quantization error probability density function for quantizer Q
% computed by ERRPDF; XI is the domain of values being evaluated by
% ERRPDF; MU_T is the theoretical quantization error mean of quantizer Q
% computed by ERRMEAN; V_T is the theoretical quantization error
% variance of quantizer Q computed by ERRVAR; and ERR is the error
% generated by quantizing a random signal by quantizer Q.
%
% See QERRORDEMO for examples of use.
% Copyright 1999-2014 The MathWorks, Inc.
v=10*log10(var(err));
disp(['Estimated error variance (dB) = ',num2str(v)]);
disp(['Theoretical error variance (dB) = ',num2str(10*log10(v_t))]);
disp(['Estimated mean = ',num2str(mean(err))]);
disp(['Theoretical mean = ',num2str(mu_t)]);
[n,c]=hist(err);
figure(gcf)
bar(c,n/(length(err)*(c(2)-c(1))),'hist');
line(xi,f_t,'linewidth',2,'color','r');
% Set the ylim uniformly on all plots
set(gca,'ylim',[0 max(errpdf(quantizer(q.format,'nearest'),xi)*1.1)])
legend('Estimated','Theoretical')
xlabel('err'); ylabel('errpdf')
Ошибка квантования E = em — ea — это разность между реальной продолжительностью события ea и его измеренной продолжительностью em. У вас нет возможности узнать реальную продолжительность события, следовательно, нельзя и обнаружить ошибку квантования, основываясь на отдельном значении. Однако можно доказать наличие ошибки квантования, исследуя группы родственных статистик. Мы уже рассматривали пример, в котором удалось выявить ошибку квантования. В примере 7.5 наличие ошибки квантования удалось определить, заметив, что:
Ошибку квантования легко выявить, исследуя вызов базы данных и выполняемые им события ожидания в системе с низкой загрузкой, где минимизировано влияние других факторов, способных нарушить отношение e и c + Eela.
Рассмотрим фрагмент файла трассировки Oracle8i, который демонстрирует эффект ошибки квантования:
Данный вызов выборки инициировал ровно три события ожидания. Мы знаем, что приведенные значения c, e и ela должны быть связаны таким приблизительным равенством:
В системе с низкой загрузкой величина, на которую отличаются левая и правая части приблизительного равенства, указывает на общую ошибку квантования, присутствующую в пяти измерениях (одно значение c, одно значение e и три значения ela):
С учетом того, что отдельному вызову gettimeofday в большинстве систем соответствует лишь несколько микросекунд ошибки, вызванной влиянием измерителя, получается, что ошибка квантования вносит значительный вклад в «разность» длиной в одну сантисекунду в данных трассировки.
Следующий фрагмент файла трассировки Oracle8i демонстрирует простейший вариант избыточного учета продолжительности, в результате которого возникает отрицательная величина неучтенного времени:
WAIT #96: nam=’db file sequential read’ ela= 0 p1=1 p2=1691 p3=1
FETCH #96:c=1,e=0,p=1,cr=4,cu=0,mis=0,r=1,dep=1,og=4,tim=116694789 В данном случае E = -1 сантисекунда:
При наличии «отрицательной разности» (подобного только что рассмотренному) невозможно все объяснить эффектом влияния измерителя, ведь этот эффект может быть причиной появления только положительных значений неучтенного времени. Можно было бы подумать, что имел место двойной учет использования процессора, но и это не соответствует действительности, т. к. нулевое значение ela свидетельствует о том, что время занятости процессора вообще не учитывалось для события ожидания. В данном случае ошибка квантования имеет преобладающее влияние и приводит к излишнему учету времени для выборки.
В данном случае E = 640 мкс:
В Oracle9i разрешение временной статистики улучшено, но и эта версия отнюдь не защищена от воздействия ошибки квантования, что видно в предложенном ниже фрагменте файла трассировки для E > 0:
Некоторая часть этой ошибки, несомненно, является ошибкой квантования (невозможно, чтобы общее время использования процессора данной выборкой действительно равнялось нулю). Несколько микросекунд следует отнести на счет эффекта влияния измерителя.
Наконец, рассмотрим пример ошибки квантования E < 0 в данных трассировки Oracle9i:
Возможно, в данном случае имел место двойной учет использования процессора. Также вероятно, что именно ошибка квантования внесла основной вклад в полученное время вызова выборки. Избыточный учет 8784 микросекунд говорит о том, что фактический общий расход процессорного времени вызовом базы данных составил, вероятно, всего около (10000 — 8784) мкс = 1,216 мкс.
Диапазон значений ошибки квантования
Величину ошибки квантования, содержащейся во временных статистиках Oracle, нельзя измерить напрямую. Зато можно проанализировать статистические свойства ошибки квантования в данных расширенной трассировки SQL. Во-первых, величина ошибки квантования для конкретного набора данных трассировки ограничена сверху. Легко представить ситуацию, в которой ошибка квантования, вносимая такими характеристиками продолжительности, как e и ela, будет максимальной. Наибольшего значения данная ошибка достигает в том случае, когда в последовательности значений e и ela все отдельные ошибки квантования имеют максимальную величину и их знаки совпадают.
На рис. 7.9 показан пример возникновения описанной ситуации: имеется восемь очень непродолжительных системных вызовов, причем все они попадают на такты интервального таймера. Фактическая длительность каждого события близка к нулю, но измеренная длительность каждого такого события равна одному такту системного таймера. В итоге суммарная фактическая продолжительность всех вызовов близка к нулю, а общая измеренная продолжительность равна 8 тактам. Для такого набора из n = 8 системных вызовов ошибка квантования по существу равна nrx, где rx — это разрешение интервального таймера, с помощью которого измеряется характеристика x.
Думаю, вы обратили внимание, что изображенный на рис. 7.9 случай выглядит надуманно и изобретен исключительно для прояснения вопроса. В реальной жизни подобная ситуация чрезвычайно маловероятна. Вероятность, что n ошибок квантования будут иметь одинаковые знаки, равна всего 0,5n. Вероятность того, что n=8 последовательных
Рис. 7.9. Наихудший вариант накопления ошибки квантования для последовательности измеренных продолжительностей
ошибок квантования будут отрицательными, равна всего 0,00390625 (т. е. приблизительно четыре шанса из тысячи). Для 266 значений шанс совпадения знаков у всех ошибок квантования меньше, чем один из 1080.
Для больших наборов значений длительностей совпадение знаков всех ошибок квантования практически невозможно. Но это не единственное, в чем состоит надуманность ситуации, изображенной на рис. 7.9. Она также предполагает, что абсолютная величина каждой ошибки квантования максимальна. Шансы наступления такого события еще более иллюзорны, чем у совпадения всех знаков ошибок. Например, вероятность того, что величина каждой из n имеющихся ошибок квантования превышает 0,9, равна (1 — 0,9)n. Вероятность того, что величина каждой из n = 266 ошибок квантования превысит 0,9, составляет всего 1 из 10266.
Вероятность того, что все n ошибок квантования имеют одинаковый знак и абсолютная величина всех из них больше m, чрезвычайно мала и равна произведению рассмотренных ранее вероятностей:
P (значения всех n ошибок квантования больше m или меньше -m)=
= (0.5)n(1- m)n
Ошибки квантования для продолжительностей (например, значений e и ela в Oracle) — это случайные числа в диапазоне:
-rx < E < rx где rx — это разрешение интервального таймера, с помощью которого измеряется характеристика x (x- это e или ela).
Так как положительные и отрицательные ошибки квантования возникают c равной вероятностью, средняя ошибка квантования для выбранного набора статистик стремится к нулю даже для больших файлов трассировки. Опираясь на теорему Лапласа (Pierre Simon de Laplace, 1810), можно предсказать вероятность того, что ошибки квантования для статистик e и ela будут превышать указанное пороговое значение для файла трассировки, содержащего определенное количество статистик.
Я начал работать над вычислением вероятности того, что общая ошибка квантования файла трассировки (включая ошибку, вносимую статистикой c) будет превышать заданную величину, однако мое исследование еще не завершено. Мне предстоит получить распределение ошибки квантования для статистики c, что, как я уже говорил, осложняется особенностями получения этой статистики в процессе опроса. Результаты этих изысканий планируется воплотить в одном из будущих проектов.
К счастью, относительно ошибки квантования есть и оптимистические соображения, которые позволяют не слишком расстраиваться по поводу невозможности определения ее величины:
• Во многих сотнях файлов трассировки Oracle, проанализированных нами в hotsos.com, общая продолжительность неучтенного вре-
Что означает «один шанс из десяти в [очень большой] степени»?
Для того чтобы представить себе, что такое «один шанс из 1080», задумайтесь над следующим фактом: ученые утверждают, что в наблюдаемой вселенной содержится всего около 1080 атомов (по данным http:// www.sunspot.noao.edu/sunspot/pr/answerbook/universe.html#q70, http:/ /www.nature.com/nsu/020527/020527-16.html и др.). Это означает, что если бы вам удалось написать на каждом атоме нашей вселенной 266 равномерно распределенных случайных чисел от -1 до +1, то лишь на одном из этих атомов можно было бы ожидать наличия всех 266 чисел с одинаковым знаком.
Представить вторую упомянутую вероятность — «один шанс из 10266»-еще труднее. На этот раз представим себе три уровня вложенных вселенных. То есть что каждый из 1080 атомов нашей вселенной сам по себе является вселенной, состоящей из 1080 вселенных, каждая из которых в свою очередь содержит 1080 атомов. Теперь у нас достаточно атомов для того, чтобы представить себе возможность возникновения ситуации с вероятностью «один из 10240». Даже во вселенных третьего уровня вложенности вероятность появления атома, для которого все 266 его случайных чисел по абсолютной величине больше 0,9, составит один из 100 000 000 000 000 000 000 000 000.
мени в случае корректного сбора данных (см. главу 6) чрезвычайно редко превышала 10% общего времени отклика.
Несмотря на то, что и ошибка квантования, и двойной учет использования процессора могут привести к такому результату, файл трассировки чрезвычайно редко содержит отрицательное неучтенное время, абсолютная величина которого превышала бы 10% общего времени отклика.
В случаях, когда неучтенное время оценивается более чем в 25% времени отклика для корректно собранных данных трассировки, такой объем неучтенного времени почти всегда объясняется одним из двух явлений, описанных в последующих разделах.
Наличие ошибки квантования не лишает нас возможности правильно диагностировать основные причины проблем производительности при помощи файлов расширенной трассировки SQL в Oracle (даже в файлах трассировки Oracle8i, в которых вся статистика приводится с точностью лишь до сотых долей секунды).
Ошибка квантования становится еще менее значимой в Oracle9i благодаря повышению точности измерений.
В некоторых случаях влияние ошибки квантования способно привести к утрате доверия к достоверности данных трассировки Oracle. Наверное, ничто не может так подорвать боевой дух, как подозрение в недостоверности данных, на которые вы полагаетесь. Думаю, что лучшим средством, призванным укрепить веру в получаемые данные, должно служить четкое понимание влияния ошибки квантования.
| Следующая > |
|---|