Статистическая погрешность — это та неопределенность в оценке истинного значения измеряемой величины, которая возникает из-за того, что несколько повторных измерений тем же самым инструментом дали различающиеся результаты. Возникает она, как правило, из-за того, что результаты измерения в микромире не фиксированы, а вероятностны. Она тесно связана с объемом статистики: обычно чем больше данных, тем меньше статистическая погрешность и тем точнее результат измерения. Среди всех типов погрешностей она, пожалуй, самая безобидная: понятно, как ее считать, и понятно, как с ней бороться.
Статистическая погрешность: чуть подробнее
Предположим, что ваш детектор может очень точно измерить какую-то величину в каждом конкретном столкновении. Это может быть энергия или импульс какой-то родившейся частицы, или дискретная величина (например, сколько мюонов родилось в событии), или вообще элементарный ответ «да» или «нет» на какой-то вопрос (например, родилась ли в этом событии хоть одна частица с импульсом больше 100 ГэВ).
Это конкретное число, полученное в одном столкновении, почти бессмысленно. Скажем, взяли вы одно событие и выяснили, что в нём хиггсовский бозон не родился. Никакой научной пользы от такого единичного факта нет. Законы микромира вероятностны, и если вы организуете абсолютно такое же столкновение протонов, то картина рождения частиц вовсе не обязана повторяться, она может оказаться совсем другой. Если бозон не родился сейчас, не родился в следующем столкновении, то это еще ничего не говорит о том, может ли он родиться вообще и как это соотносится с теоретическими предсказаниями. Для того, чтобы получить какое-то осмысленное число в экспериментах с элементарными частицами, надо повторить эксперимент много раз и набрать статистику одинаковых столкновений. Всё свое рабочее время коллайдеры именно этим и занимаются, они накапливают статистику, которую потом будут обрабатывать экспериментаторы.
В каждом конкретном столкновении результат измерения может быть разный. Наберем статистику столкновений и усредним по ней результат. Этот средний результат, конечно, тоже не фиксирован, он может меняться в зависимости от статистики, но он будет намного стабильнее, он не будет так сильно прыгать от одной статистической выборки к другой. У него тоже есть некая неопределенность (в статистическом анализе она так и называется: «неопределенность среднего»), но она обычно небольшая. Вот эта величина и называется статистической погрешностью измерения.
Итак, когда экспериментаторы предъявляют измерение какой-то величины, то они сообщают результат усреднения этой величины по всей набранной статистике столкновений и сопровождают его статистической погрешностью. Именно такие средние значения имеют физический смысл, только их может предсказывать теория.
Есть, конечно, и иной источник статистической погрешности: недостаточный контроль условий эксперимента при повторном измерении. Если в физике частиц этот источник можно попытаться устранить, по крайней мере, в принципе, то в других разделах естественных наук он выходит на первый план; например, в медицинских исследованиях каждый человек отличается от другого по большому числу параметров.
Как считать статистическую погрешность?
Существует теория расчета статистической погрешности, в которую мы, конечно, вдаваться не будем. Но есть одно очень простое правило, которое легко запомнить и которое срабатывает почти всегда. Пусть у вас есть статистическая выборка из N столкновений и в ней присутствует n событий какого-то определенного типа. Тогда в другой статистической выборке из N событий, набранной в тех же условиях, можно ожидать примерно n ± √n таких событий. Поделив это на N, мы получим среднюю вероятность встретить такое событие и погрешность среднего: n/N ± √n/N. Оценка истинного значения вероятности такого типа события примерно соответствует этому выражению.
Сразу же, впрочем, подчеркнем, что эта простая оценка начинает сильно «врать», когда количество событий очень мало. В науке обсчета маленькой статистики есть много дополнительных тонкостей.
Более серьезное (но умеренно краткое) введение в методы статистической обработки данных в применении к экспериментам на LHC см. в лекциях arXiv.1307.2487.
Именно поэтому эксперименты в физике элементарных частиц стараются оптимизировать не только по энергии, но и по светимости. Ведь чем больше светимость, тем больше столкновений будет произведено — значит, тем больше будет статистическая выборка. И уже это позволит сделать измерения более точными — даже без каких-либо улучшений в эксперименте. Примерная зависимость тут такая: если вы увеличите статистику в k раз, то относительные статистические погрешности уменьшатся примерно в √k раз.
Этот пример — некая симуляция того, как могло бы происходить измерение массы ρ-мезона свыше полувека назад, на заре адронной физики, если бы он был вначале обнаружен в процессе e+e– → π+π–. А теперь перенесемся в наше время.

Сейчас этот процесс изучен вдоль и поперек, статистика набрана огромная (миллионы событий), а значит, и масса ρ-мезона сейчас определена несравнимо точнее. На рис. 3 показано современное состояние дел в этой области масс. Если ранние эксперименты еще имели какие-то существенные погрешности, то сейчас они практически неразличимы глазом. Огромная статистика позволила не только измерить массу (примерно равна 775 МэВ с точностью в десятые доли МэВ), но и заметить очень странную форму этого пика. Такая форма получается потому, что практически в том же месте на шкале масс находится и другой мезон, ω(782), который «вмешивается» в процесс и искажает форму ρ-мезонного пика.
Другой, гораздо более реальный пример влияния статистики на процесс поиска и изучения хиггсовского бозона обсуждался в новости Анимации показывают, как в данных LHC зарождался хиггсовский сигнал.
Статистические ошибки
Использование
методов биометрии позволяет исследователю
на ограниченном по численности материале
делать заключения о проявлении признака,
его изменчивости и других параметрах
в генеральной совокупности. Но так
как выборочная совокупность — часть
генеральной и ее формируют методом
случайного отбора, то в выборку могут
попасть животные с более низкими
продуктивными качествами, или несколько
лучшие особи. В этом случае вычисленные
значения M, б, Cv и
других биометрических величин будут
отличаться от значений этих величин в
генеральной совокупности, то есть
выборка отражает генеральную совокупность
с ошибкой. Эти ошибки, связанные с
методом выборочности, называются
статистическими и устранить их нельзя.
Ошибки не будет лишь в том случае, когда
в обработку включаются все члены
генеральной совокупности. Величины
статистических ошибок зависят от
изменчивости признаков и объема выборки:
чем более изменчив признак, тем больше
ошибка, и чем больше объем выборки, тем
она меньше. Ошибки статистических
величин в биометрии принято обозначать
буквой m.
Ошибки
имеют все статистические величины.
Вычисляют их по формулам:
![]()
Все
ошибки измеряют в тех же единицах, что
и сами показатели, и записывают обычно
рядом с ними.
Статистические
ошибки указывают интервал, в котором
находится величина того или иного
статистического показателя в генеральной
совокупности. Зная среднее значение
признака (М) и его ошибку (m), можно
установить доверительные границы
средней величины в генеральной
совокупности по формуле: Мген.=Мв.
tm, где t — нормированное отклонение,
которое зависит от уровня вероятности
и объема выборки. Цифровое значение t
для каждого конкретного случая находят
с помощью специальной таблицы. Например,
нас интересует средняя частота пульса
у овец породы прекос. Для изучения этого
показателя была сформирована выборка
в количестве 50 голов и определена у
этих животных средняя частота пульса.
Оказалось, что этот показатель равен
75 ударов в минуту, изменчивость его б =
12 ударов. Ошибка средней арифметической
величины в этом случае составит:
б
12
m
= ──── = ──── = 1,7 (уд./мин).
n
50
Итоговая
запись будет иметь вид: М
m или 75
1,7, то есть частота пульса 75 ударов в
минуту — среднее значение для 50 голов.
Чтобы определить среднюю частоту пульса
в генеральной совокупности животных,
возьмем в качестве доверительной
вероятности P = 0,95. В этом случае, исходя
из таблицы, t = 2,01. Определим доверительные
границы частоты пульса в генеральной
совокупности M
tm.
75,0
+ 2,01 x 1,7 = 75,0 + 3,4 = 78,4 (уд./мин)
75,0
— 2,01 x 1,7 = 75,0 — 3,4 = 71,6 (уд./мин)
Таким
образом, средняя частота пульса для
генеральной совокупности будет в
пределах от 71,6 до 78,4 ударов в минуту.
Зная
величину статистических ошибок,
устанавливают также, правильно ли
выборочная совокупность отражает тот
или иной параметр генеральной, то есть
устанавливают критерий доверительности
выборочных величин.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)
Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.









Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
Статистическая погрешность — это та неопределенность в оценке истинного значения измеряемой величины, которая возникает из-за того, что несколько повторных измерений тем же самым инструментом дали различающиеся результаты. Возникает она, как правило, из-за того, что результаты измерения в микромире не фиксированы, а вероятностны. Она тесно связана с объемом статистики: обычно чем больше данных, тем меньше статистическая погрешность и тем точнее результат измерения. Среди всех типов погрешностей она, пожалуй, самая безобидная: понятно, как ее считать, и понятно, как с ней бороться.
Статистическая погрешность: чуть подробнее
Предположим, что ваш детектор может очень точно измерить какую-то величину в каждом конкретном столкновении. Это может быть энергия или импульс какой-то родившейся частицы, или дискретная величина (например, сколько мюонов родилось в событии), или вообще элементарный ответ «да» или «нет» на какой-то вопрос (например, родилась ли в этом событии хоть одна частица с импульсом больше 100 ГэВ).
Это конкретное число, полученное в одном столкновении, почти бессмысленно. Скажем, взяли вы одно событие и выяснили, что в нём хиггсовский бозон не родился. Никакой научной пользы от такого единичного факта нет. Законы микромира вероятностны, и если вы организуете абсолютно такое же столкновение протонов, то картина рождения частиц вовсе не обязана повторяться, она может оказаться совсем другой. Если бозон не родился сейчас, не родился в следующем столкновении, то это еще ничего не говорит о том, может ли он родиться вообще и как это соотносится с теоретическими предсказаниями. Для того, чтобы получить какое-то осмысленное число в экспериментах с элементарными частицами, надо повторить эксперимент много раз и набрать статистику одинаковых столкновений. Всё свое рабочее время коллайдеры именно этим и занимаются, они накапливают статистику, которую потом будут обрабатывать экспериментаторы.
В каждом конкретном столкновении результат измерения может быть разный. Наберем статистику столкновений и усредним по ней результат. Этот средний результат, конечно, тоже не фиксирован, он может меняться в зависимости от статистики, но он будет намного стабильнее, он не будет так сильно прыгать от одной статистической выборки к другой. У него тоже есть некая неопределенность (в статистическом анализе она так и называется: «неопределенность среднего»), но она обычно небольшая. Вот эта величина и называется статистической погрешностью измерения.
Итак, когда экспериментаторы предъявляют измерение какой-то величины, то они сообщают результат усреднения этой величины по всей набранной статистике столкновений и сопровождают его статистической погрешностью. Именно такие средние значения имеют физический смысл, только их может предсказывать теория.
Есть, конечно, и иной источник статистической погрешности: недостаточный контроль условий эксперимента при повторном измерении. Если в физике частиц этот источник можно попытаться устранить, по крайней мере, в принципе, то в других разделах естественных наук он выходит на первый план; например, в медицинских исследованиях каждый человек отличается от другого по большому числу параметров.
Как считать статистическую погрешность?
Существует теория расчета статистической погрешности, в которую мы, конечно, вдаваться не будем. Но есть одно очень простое правило, которое легко запомнить и которое срабатывает почти всегда. Пусть у вас есть статистическая выборка из N столкновений и в ней присутствует n событий какого-то определенного типа. Тогда в другой статистической выборке из N событий, набранной в тех же условиях, можно ожидать примерно n ± √n таких событий. Поделив это на N, мы получим среднюю вероятность встретить такое событие и погрешность среднего: n/N ± √n/N. Оценка истинного значения вероятности такого типа события примерно соответствует этому выражению.
Сразу же, впрочем, подчеркнем, что эта простая оценка начинает сильно «врать», когда количество событий очень мало. В науке обсчета маленькой статистики есть много дополнительных тонкостей.
Более серьезное (но умеренно краткое) введение в методы статистической обработки данных в применении к экспериментам на LHC см. в лекциях arXiv.1307.2487.
Именно поэтому эксперименты в физике элементарных частиц стараются оптимизировать не только по энергии, но и по светимости. Ведь чем больше светимость, тем больше столкновений будет произведено — значит, тем больше будет статистическая выборка. И уже это позволит сделать измерения более точными — даже без каких-либо улучшений в эксперименте. Примерная зависимость тут такая: если вы увеличите статистику в k раз, то относительные статистические погрешности уменьшатся примерно в √k раз.
Этот пример — некая симуляция того, как могло бы происходить измерение массы ρ-мезона свыше полувека назад, на заре адронной физики, если бы он был вначале обнаружен в процессе e+e– → π+π–. А теперь перенесемся в наше время.
Сейчас этот процесс изучен вдоль и поперек, статистика набрана огромная (миллионы событий), а значит, и масса ρ-мезона сейчас определена несравнимо точнее. На рис. 3 показано современное состояние дел в этой области масс. Если ранние эксперименты еще имели какие-то существенные погрешности, то сейчас они практически неразличимы глазом. Огромная статистика позволила не только измерить массу (примерно равна 775 МэВ с точностью в десятые доли МэВ), но и заметить очень странную форму этого пика. Такая форма получается потому, что практически в том же месте на шкале масс находится и другой мезон, ω(782), который «вмешивается» в процесс и искажает форму ρ-мезонного пика.
Другой, гораздо более реальный пример влияния статистики на процесс поиска и изучения хиггсовского бозона обсуждался в новости Анимации показывают, как в данных LHC зарождался хиггсовский сигнал.
Статистические ошибки
Использование
методов биометрии позволяет исследователю
на ограниченном по численности материале
делать заключения о проявлении признака,
его изменчивости и других параметрах
в генеральной совокупности. Но так
как выборочная совокупность — часть
генеральной и ее формируют методом
случайного отбора, то в выборку могут
попасть животные с более низкими
продуктивными качествами, или несколько
лучшие особи. В этом случае вычисленные
значения M, б, Cv и
других биометрических величин будут
отличаться от значений этих величин в
генеральной совокупности, то есть
выборка отражает генеральную совокупность
с ошибкой. Эти ошибки, связанные с
методом выборочности, называются
статистическими и устранить их нельзя.
Ошибки не будет лишь в том случае, когда
в обработку включаются все члены
генеральной совокупности. Величины
статистических ошибок зависят от
изменчивости признаков и объема выборки:
чем более изменчив признак, тем больше
ошибка, и чем больше объем выборки, тем
она меньше. Ошибки статистических
величин в биометрии принято обозначать
буквой m.
Ошибки
имеют все статистические величины.
Вычисляют их по формулам:
![]()
Все
ошибки измеряют в тех же единицах, что
и сами показатели, и записывают обычно
рядом с ними.
Статистические
ошибки указывают интервал, в котором
находится величина того или иного
статистического показателя в генеральной
совокупности. Зная среднее значение
признака (М) и его ошибку (m), можно
установить доверительные границы
средней величины в генеральной
совокупности по формуле: Мген.=Мв.
tm, где t — нормированное отклонение,
которое зависит от уровня вероятности
и объема выборки. Цифровое значение t
для каждого конкретного случая находят
с помощью специальной таблицы. Например,
нас интересует средняя частота пульса
у овец породы прекос. Для изучения этого
показателя была сформирована выборка
в количестве 50 голов и определена у
этих животных средняя частота пульса.
Оказалось, что этот показатель равен
75 ударов в минуту, изменчивость его б =
12 ударов. Ошибка средней арифметической
величины в этом случае составит:
б
12
m
= ──── = ──── = 1,7 (уд./мин).
n
50
Итоговая
запись будет иметь вид: М
m или 75
1,7, то есть частота пульса 75 ударов в
минуту — среднее значение для 50 голов.
Чтобы определить среднюю частоту пульса
в генеральной совокупности животных,
возьмем в качестве доверительной
вероятности P = 0,95. В этом случае, исходя
из таблицы, t = 2,01. Определим доверительные
границы частоты пульса в генеральной
совокупности M
tm.
75,0
+ 2,01 x 1,7 = 75,0 + 3,4 = 78,4 (уд./мин)
75,0
— 2,01 x 1,7 = 75,0 — 3,4 = 71,6 (уд./мин)
Таким
образом, средняя частота пульса для
генеральной совокупности будет в
пределах от 71,6 до 78,4 ударов в минуту.
Зная
величину статистических ошибок,
устанавливают также, правильно ли
выборочная совокупность отражает тот
или иной параметр генеральной, то есть
устанавливают критерий доверительности
выборочных величин.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
In statistics and optimization, errors and residuals are two closely related and easily confused measures of the deviation of an observed value of an element of a statistical sample from its «true value» (not necessarily observable). The error of an observation is the deviation of the observed value from the true value of a quantity of interest (for example, a population mean). The residual is the difference between the observed value and the estimated value of the quantity of interest (for example, a sample mean). The distinction is most important in regression analysis, where the concepts are sometimes called the regression errors and regression residuals and where they lead to the concept of studentized residuals.
In econometrics, «errors» are also called disturbances.[1][2][3]
Introduction[edit]
Suppose there is a series of observations from a univariate distribution and we want to estimate the mean of that distribution (the so-called location model). In this case, the errors are the deviations of the observations from the population mean, while the residuals are the deviations of the observations from the sample mean.
A statistical error (or disturbance) is the amount by which an observation differs from its expected value, the latter being based on the whole population from which the statistical unit was chosen randomly. For example, if the mean height in a population of 21-year-old men is 1.75 meters, and one randomly chosen man is 1.80 meters tall, then the «error» is 0.05 meters; if the randomly chosen man is 1.70 meters tall, then the «error» is −0.05 meters. The expected value, being the mean of the entire population, is typically unobservable, and hence the statistical error cannot be observed either.
A residual (or fitting deviation), on the other hand, is an observable estimate of the unobservable statistical error. Consider the previous example with men’s heights and suppose we have a random sample of n people. The sample mean could serve as a good estimator of the population mean. Then we have:
- The difference between the height of each man in the sample and the unobservable population mean is a statistical error, whereas
- The difference between the height of each man in the sample and the observable sample mean is a residual.
Note that, because of the definition of the sample mean, the sum of the residuals within a random sample is necessarily zero, and thus the residuals are necessarily not independent. The statistical errors, on the other hand, are independent, and their sum within the random sample is almost surely not zero.
One can standardize statistical errors (especially of a normal distribution) in a z-score (or «standard score»), and standardize residuals in a t-statistic, or more generally studentized residuals.
In univariate distributions[edit]
If we assume a normally distributed population with mean μ and standard deviation σ, and choose individuals independently, then we have

and the sample mean

is a random variable distributed such that:

The statistical errors are then

with expected values of zero,[4] whereas the residuals are

The sum of squares of the statistical errors, divided by σ2, has a chi-squared distribution with n degrees of freedom:

However, this quantity is not observable as the population mean is unknown. The sum of squares of the residuals, on the other hand, is observable. The quotient of that sum by σ2 has a chi-squared distribution with only n − 1 degrees of freedom:

This difference between n and n − 1 degrees of freedom results in Bessel’s correction for the estimation of sample variance of a population with unknown mean and unknown variance. No correction is necessary if the population mean is known.
[edit]
It is remarkable that the sum of squares of the residuals and the sample mean can be shown to be independent of each other, using, e.g. Basu’s theorem. That fact, and the normal and chi-squared distributions given above form the basis of calculations involving the t-statistic:

where 



The probability distributions of the numerator and the denominator separately depend on the value of the unobservable population standard deviation σ, but σ appears in both the numerator and the denominator and cancels. That is fortunate because it means that even though we do not know σ, we know the probability distribution of this quotient: it has a Student’s t-distribution with n − 1 degrees of freedom. We can therefore use this quotient to find a confidence interval for μ. This t-statistic can be interpreted as «the number of standard errors away from the regression line.»[6]
Regressions[edit]
In regression analysis, the distinction between errors and residuals is subtle and important, and leads to the concept of studentized residuals. Given an unobservable function that relates the independent variable to the dependent variable – say, a line – the deviations of the dependent variable observations from this function are the unobservable errors. If one runs a regression on some data, then the deviations of the dependent variable observations from the fitted function are the residuals. If the linear model is applicable, a scatterplot of residuals plotted against the independent variable should be random about zero with no trend to the residuals.[5] If the data exhibit a trend, the regression model is likely incorrect; for example, the true function may be a quadratic or higher order polynomial. If they are random, or have no trend, but «fan out» — they exhibit a phenomenon called heteroscedasticity. If all of the residuals are equal, or do not fan out, they exhibit homoscedasticity.
However, a terminological difference arises in the expression mean squared error (MSE). The mean squared error of a regression is a number computed from the sum of squares of the computed residuals, and not of the unobservable errors. If that sum of squares is divided by n, the number of observations, the result is the mean of the squared residuals. Since this is a biased estimate of the variance of the unobserved errors, the bias is removed by dividing the sum of the squared residuals by df = n − p − 1, instead of n, where df is the number of degrees of freedom (n minus the number of parameters (excluding the intercept) p being estimated — 1). This forms an unbiased estimate of the variance of the unobserved errors, and is called the mean squared error.[7]
Another method to calculate the mean square of error when analyzing the variance of linear regression using a technique like that used in ANOVA (they are the same because ANOVA is a type of regression), the sum of squares of the residuals (aka sum of squares of the error) is divided by the degrees of freedom (where the degrees of freedom equal n − p − 1, where p is the number of parameters estimated in the model (one for each variable in the regression equation, not including the intercept)). One can then also calculate the mean square of the model by dividing the sum of squares of the model minus the degrees of freedom, which is just the number of parameters. Then the F value can be calculated by dividing the mean square of the model by the mean square of the error, and we can then determine significance (which is why you want the mean squares to begin with.).[8]
However, because of the behavior of the process of regression, the distributions of residuals at different data points (of the input variable) may vary even if the errors themselves are identically distributed. Concretely, in a linear regression where the errors are identically distributed, the variability of residuals of inputs in the middle of the domain will be higher than the variability of residuals at the ends of the domain:[9] linear regressions fit endpoints better than the middle. This is also reflected in the influence functions of various data points on the regression coefficients: endpoints have more influence.
Thus to compare residuals at different inputs, one needs to adjust the residuals by the expected variability of residuals, which is called studentizing. This is particularly important in the case of detecting outliers, where the case in question is somehow different from the others in a dataset. For example, a large residual may be expected in the middle of the domain, but considered an outlier at the end of the domain.
Other uses of the word «error» in statistics[edit]
The use of the term «error» as discussed in the sections above is in the sense of a deviation of a value from a hypothetical unobserved value. At least two other uses also occur in statistics, both referring to observable prediction errors:
The mean squared error (MSE) refers to the amount by which the values predicted by an estimator differ from the quantities being estimated (typically outside the sample from which the model was estimated).
The root mean square error (RMSE) is the square-root of MSE.
The sum of squares of errors (SSE) is the MSE multiplied by the sample size.
Sum of squares of residuals (SSR) is the sum of the squares of the deviations of the actual values from the predicted values, within the sample used for estimation. This is the basis for the least squares estimate, where the regression coefficients are chosen such that the SSR is minimal (i.e. its derivative is zero).
Likewise, the sum of absolute errors (SAE) is the sum of the absolute values of the residuals, which is minimized in the least absolute deviations approach to regression.
The mean error (ME) is the bias.
The mean residual (MR) is always zero for least-squares estimators.
See also[edit]
- Absolute deviation
- Consensus forecasts
- Error detection and correction
- Explained sum of squares
- Innovation (signal processing)
- Lack-of-fit sum of squares
- Margin of error
- Mean absolute error
- Observational error
- Propagation of error
- Probable error
- Random and systematic errors
- Reduced chi-squared statistic
- Regression dilution
- Root mean square deviation
- Sampling error
- Standard error
- Studentized residual
- Type I and type II errors
References[edit]
- ^ Kennedy, P. (2008). A Guide to Econometrics. Wiley. p. 576. ISBN 978-1-4051-8257-7. Retrieved 2022-05-13.
- ^ Wooldridge, J.M. (2019). Introductory Econometrics: A Modern Approach. Cengage Learning. p. 57. ISBN 978-1-337-67133-0. Retrieved 2022-05-13.
- ^ Das, P. (2019). Econometrics in Theory and Practice: Analysis of Cross Section, Time Series and Panel Data with Stata 15.1. Springer Singapore. p. 7. ISBN 978-981-329-019-8. Retrieved 2022-05-13.
- ^ Wetherill, G. Barrie. (1981). Intermediate statistical methods. London: Chapman and Hall. ISBN 0-412-16440-X. OCLC 7779780.
- ^ a b Frederik Michel Dekking; Cornelis Kraaikamp; Hendrik Paul Lopuhaä; Ludolf Erwin Meester (2005-06-15). A modern introduction to probability and statistics : understanding why and how. London: Springer London. ISBN 978-1-85233-896-1. OCLC 262680588.
- ^ Peter Bruce; Andrew Bruce (2017-05-10). Practical statistics for data scientists : 50 essential concepts (First ed.). Sebastopol, CA: O’Reilly Media Inc. ISBN 978-1-4919-5296-2. OCLC 987251007.
- ^ Steel, Robert G. D.; Torrie, James H. (1960). Principles and Procedures of Statistics, with Special Reference to Biological Sciences. McGraw-Hill. p. 288.
- ^ Zelterman, Daniel (2010). Applied linear models with SAS ([Online-Ausg.]. ed.). Cambridge: Cambridge University Press. ISBN 9780521761598.
- ^ «7.3: Types of Outliers in Linear Regression». Statistics LibreTexts. 2013-11-21. Retrieved 2019-11-22.
- Cook, R. Dennis; Weisberg, Sanford (1982). Residuals and Influence in Regression (Repr. ed.). New York: Chapman and Hall. ISBN 041224280X. Retrieved 23 February 2013.
- Cox, David R.; Snell, E. Joyce (1968). «A general definition of residuals». Journal of the Royal Statistical Society, Series B. 30 (2): 248–275. JSTOR 2984505.
- Weisberg, Sanford (1985). Applied Linear Regression (2nd ed.). New York: Wiley. ISBN 9780471879572. Retrieved 23 February 2013.
- «Errors, theory of», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
External links[edit]
 Media related to Errors and residuals at Wikimedia Commons
Media related to Errors and residuals at Wikimedia Commons
2.1. Стандартное отклонение среднего выборочного значения (ошибка среднего) и доверительный интервал
Результаты измерений обычно показывают с так называемой «средней статистической ошибкой средней величины» и для нашего случая (см. табл. 1.1) это будет запись: «высота сеянцев в опыте составила 5,0 ± 0,28 см». Словосочетание «средняя статистическая ошибка» обычно сокращают до названия «ошибка среднего» или просто «ошибка», обозначают буквой m и определяют по очень простой формуле. Для итогов упомянутой таблицы, где расчеты по 25 высотам дали значение δ = 1,42 см, эта ошибка составит:
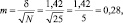 (2.1)
(2.1)
|
где δ – |
стандартное отклонение; |
|
N – |
число наблюдений или объем выборки, шт. |
Если объем выборки взять 100 шт., то ошибка снизится в 2 раза: 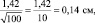 а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
Рассмотрим эту «среднюю статистическую ошибку» (далее просто ошибка) подробно, так как именно в ней скрыто понимание того, что называют статистическим мышлением. Интуитивно мы понимаем, что малая выборка дает большую ошибку, т.е. неточное определение среднего значения. Последний термин настолько привычен, что мы даже не задумываемся о том, что его правильное и полное название «среднее выборочное значение», т.е. среднее, определяемое в некоторой выборке. И выборки могут быть очень разные по численности. Начнем с самых малых. Например, что произойдет с ошибкой, если объем выборки сократить до 2 измерений? Такие выборки бывают, например, в почвенных исследованиях, когда каждое измерение достается дорогой ценой. Для этого вернемся к рис. 1.1. На нем стандартное отклонение ±δ, которое отражает разброс значений вокруг среднего в левую и правую сторону в виде холма, наблюдается при объеме выборки 1 шт. В этом случае ошибка среднего выборочного значения будет равна стандартному отклонению: m = δ = 1,42. С увеличением N ошибка уменьшается:
при объеме выборки N = 2 ошибка будет
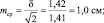
при объеме выборки N = 4 ошибка будет
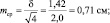
при объеме выборки N = 16 ошибка будет
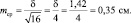
Важно понять, что ряд распределения частот этих выборочных средних будет постепенно как бы съеживаться и приближаться к центру, где находится так называемое «генеральное» среднее. Поясним, что в математике генеральное среднее значение называется математическим ожиданием и его обозначают буквой «М». Например, это может быть средняя высота, рассчитанная по всем измеренным в теплице сеянцам, или среднее число семян в 1 шишке у дерева после подсчета семян во всех собранных с дерева шишках (50, 100, 500 и т.д., т.е. весьма небольшая генеральная совокупность). Распределение частот значений выборочных средних, которых может быть множество, будет иметь форму такого же холма, как и распределение единичных значений на рис. 1.1. При этом, если выборка будет из 1 шт., то холм будет в точности таким же, но при выборках из 2 шт. его форма съежится в 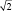 = в 1,41 раза; при выборках из 4 шт. –
= в 1,41 раза; при выборках из 4 шт. –
в 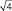 = в 2 раза; при выборках из 9 шт. – в
= в 2 раза; при выборках из 9 шт. – в 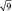 = в 3 раза и т.д.
= в 3 раза и т.д.
Для этих сокращающихся рядов распределения выборочных средних можно рассчитать свое, особое стандартное отклонение. Вероятно, чтобы не путать его со СТАНДОТКЛ, его стали называть по-другому, т.е. «средней статистической ошибкой средней величины». Чем больше по объему выборки, тем короче ряд распределения средних значений этих выборок с его «хвостами» в левую и правую сторону, и тем меньше величина этого особого стандартного отклонения. Закон распределения частот выборочных средних точно такой же, и имеет те же свойства: в пределах ±2m находится 95 % всех значений выборочных средних, в пределах ±3m – 99,5 %, а в пределах ±4m находится 100 % всех значений xср. Форма этого распределения меняется от пологой при малых выборках до очень крутой, вплоть до «схлопывания» в центре при выборках большого объема, когда ошибка среднего стремится к нулю.
Здесь следует пояснить, что, на наш взгляд, словосочетание «средняя статистическая ошибка средней величины», сокращаемое до «ошибки среднего значения» или просто до «ошибки», вводит нас в некоторое заблуждение, так как мы привыкли со школы, что ошибки надобно исправлять. Более правильным, вместо слов «ошибка среднего значения», будет использование слов «стандартное отклонение выборочных средних значений от генерального среднего». Не случайно математики выбрали для обозначения величины этого отклонения букву «m», а для обозначения генерального среднего (математического ожидания) – букву «М». Слова для объяснения этих сложных явлений могут быть разными, но и у математиков, и у биологов есть единодушие в понимании статистического смысла, лежащего за этими буквенными символами. Вообще, лучше было бы ввести некий иной термин вместо слов «ошибка» или «отклонение», так как они изначально имеют в нашем сознании иной смысл; на наш взгляд, более всего подходит слово «скачок» (чем сильнее отскакивает выборочное среднее от генерального среднего, тем реже оно встречается). Но так уж получилось, что не нашлось нейтрального (иностранного) слова, и слово «ошибка» традиционно используют, и мы также будем его использовать; важно понимать его иной, чем в обыденном употреблении, математический и статистический смысл.
Для самого точного определения средней высоты сеянцев нужно измерять все растения в питомнике, и тогда мы получим «генеральное среднее значение». Но так не делают, а измеряют несколько сотен растений в разных местах и этого бывает достаточно для определения среднего выборочного значения с приемлемой точностью. В нашем примере при 100 растениях ошибка его определения составит 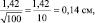 а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
Вообще, точность опыта не самоцель; гораздо важнее сократить численность (объем) выборки до минимума. Представим себе, что средняя высота сеянцев xср = 5,0 см, а ее ±δ = 1,42 см, рассмотренные выше, получены при измерении 1000 растений потомства сосны, например, из Кунгура. Поделив ±δ на корень из 1000 получаем ошибку опыта m = ±0,045 см. Далее получаем точность опыта
Р = m/xср×100 = 0,045/5,0×100 = 0,9 %.
Точность получилась очень высокой. Но в питомнике есть потомства и из других мест и такой уровень точности совершенно не нужен, так как нужно узнать еще высоты сеянцев, например, из Очера, Осы, Добрянки и других районов. Если выборку из 1 тыс. растений снижать, то будет увеличиваться ошибка в определении средней высоты. И нужно найти приемлемую величину такой ошибки, которая позволит нам, тем не менее, уверенно утверждать, что это потомство растет быстрее, либо медленнее других. Причем происхождений может быть несколько сотен и минимизация выборок крайне важна, так как масштабы работ ограничены физическими возможностями бригады селекционеров. Следовательно, надо сокращать объем выборки. Как это сделать правильно?
Рассмотрим два потомства. Первое – это упомянутые сеянцы происхождением из Кунгура (хср1), второе – сеянцы из Кизела с хср2 = 6,0 см и δ2 = ± 1,0 см (превышение высоты на 20 %). Надо это превышение доказать. При выборках из 100 растений ранее определенная ошибка m1 была равна 0,14 см, вторая ошибка m2 после расчетов по формуле (2.1) составит 0,1 см. По закону нормального распределения 99,5 % всех возможных значений этих средних хср1 и хср2 будут в пределах «плюс-минус три ошибки», что можно показать графически (рис. 2.1) или в виде формул:
хср1 ± 3m1 = 5,0 ± 3×0,14 = 5,0 ± 0,4 см
и
хср2 ± 3m2 = 6,0 ± 3×0,1 = 6,0 ± 0,3 см.
Возможные теоретические значения средних в генеральной совокупности не перекрывают друг друга, значит, различие достоверно. А если сократить выборки до 50 сеянцев? Тогда 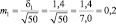 и
и 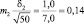 и пределы колебаний возможных значений средних будут:
и пределы колебаний возможных значений средних будут:
хср1 ± 3m1 = 5,0 ± 3×0,20 = 5,0 ± 0,6 см;
хср2 ± 3m2 = 6,0 ± 3×0,14 = 6,0 ± 0,3 см.

Рис. 2.1. Средние значения по выборкам из 100 растений и их тройные ошибки (пределы возможных значений выборочных средних в 99,5 % случаев)
Снова вынесем эти пределы на график (рис. 2.2).

Рис. 2.2. Средние значения при N = 50 растений и их тройные ошибки
Как видим, пределы сблизились и если еще сократить выборки, то они перекроются. Можно ли далее снижать объем выборки?
Можно, но здесь вступает в силу так называемое условие безошибочного прогноза. Мы это условие задали на уровне 99,5 % и для этого взяли ±3m для распределения ошибок. Но можно взять уровень пониже, с пределами ±2δ (уровень 95 %) и даже с пределами ±1,7δ (уровень 90 %).
При выборках из 25 штук сеянцев, получаем две ошибки: 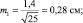
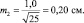 Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
хср1 ± 2m1 = 5,0 ± 2×0,28 = 5,0 ± 0,56 см;
хср2 ± 2m2 = 6,0 ± 2×0,20 = 6,0 ± 0,40 см.
Выносим эти пределы опять на график (рис. 2.3).
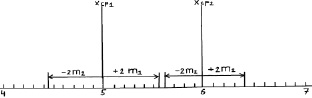
Рис. 2.3. Средние значения при N = 25 растений и их двойные ошибки (пределы возможных значений средних в 95 % случаев)
Как видим, просвет все еще есть, и поэтому между возможными значениями средних высот сеянцев в других выборках из происхождений Кунгур и Кизел различия будут опять доказаны. Но уровень доказательства понизился до 95 %, и для 5 % оставшихся случаев нет гарантии, что различия будут иметь место при выборке из 25 растений. Их может и не быть, но эту вероятность в 5 % мы допускаем.