Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:

где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.
Условное
обозначение средней арифметической
величины через М (от латинского слова
Media) чаще применяется в медицинских и
педагогических исследованиях. В
математической статистике предпочитают
обозначение через ![]() .
.
Средняя арифметическая величина является
производной, обобщающей количественные
признаки ряда однородных показателей
(совокупности). Выражая одним числом
определенную совокупность, она как бы
ослабляет влияние случайных индивидуальных
отклонений, и акцентирует некую обобщенную
количественную характеристику, наиболее
типичное свойство изучаемого ряда
показателей.
Определяя
значение средней арифметической
величины, следует придерживаться
некоторых правил.
1.
Средняя арифметическая величина может
характеризовать только те признаки
изучаемого объекта, которые присущи
всей совокупности, но в разной
количественной мере (например, уровень
развития быстроты движений характерен
для каждого человека, хотя и в разной
количественной мере). Средняя арифметическая
величина не может характеризовать
количественную меру тех признаков,
которые одной части совокупности
присущи, а другой нет, т. е. она не может
отражать присутствие или отсутствие
того или иного признака (например, умение
или неумение выполнять то или иное
двигательное действие).
2.
Средняя арифметическая величина должна
включать все показатели, полученные в
данном исследовании. Произвольное
исключение даже некоторых из них
неизбежно приведет к искажению конечного
результата.
3.
Средняя арифметическая величина обязана
отражать только однородную совокупность.
Нельзя, например, определять средний
уровень физического развития школьников,
не разделив их предварительно по возрасту
и полу.
4.
Средняя арифметическая величина должна
вычисляться на достаточно большой
совокупности, размеры которой определяются
в каждом конкретном случае отдельно
(см. «Подбор исследуемых»).
5.
Необходимо стремиться к тому, чтобы
средняя арифметическая величина имела
четкие и простые свойства, позволяющие
легко и быстро ее вычислять.
6.
Средняя арифметическая величина должна
обладать достаточной устойчивостью к
действию случайных факторов. Только в
этом случае она будет отражать
действительное состояние изучаемого
явления, а не его случайные изменения.
7.
Точность вычисления средней арифметической
величины должна соответствовать
содержанию изучаемого педагогического
явления. В некоторых случаях нет
необходимости в расчетах с большой
точностью, в других — большая точность
нужна при вычислениях, но совершенно
не нужна в выводах. Например, при расчете
средних величин числа подтягиваний на
перекладине можно пользоваться и сотыми
долями целого, но представлять и выводах,
что исследуемые в среднем подтянулись
7,83 раза, было бы неграмотна, так как
невозможно измерение с подобной
точностью. В этом случае необходимо в
выводах представлять числа, округленные
до целых единиц.
В
простейшем случае этот показатель
вычисляется путем сложения всех
полученных значений (которые называются
вариантами) и деления суммы на число
вариант:
![]()
где
S — знак суммирования;
V
— полученные в исследовании значения
(варианты);
п
— число вариант.
По
этой формуле вычисляется так называемая
простая средняя арифметическая величина.
Применяется она в тех случаях, когда
имеется небольшое число вариант.
При
большом числе вариант прибегают к
вычислению так называемой взвешенной
средней арифметической величины. С этой
целью строят ряд распределения, или
вариационный ряд, который представляет
собой ряд вариант и их частот,
характеризующих какой-нибудь признак
в убывающем или возрастающем порядке.
Например, в нашем случае измерение
точности попадания мячом в цель дало
125 вариант, т. е. в группе I, где применялась
методика обучения «А», одноразово
исследовалось 125 детей с числовым
выражением от 0 (точное попадание в цель)
до 21,5 см (максимальное отклонение от
цели). Каждое числовое выражение
встречалось в исследовании один и более
раз, например «0» встретился 28 раз.
Другими словами, 28 участников эксперимента
точно попали в цель. Этот показатель
называется числом наблюдений или
частотой вариант и условно обозначается
буквой «Р» (число наблюдений составляет
часть числа вариант).
Для
упрощения числовых операций все 125
вариант разбиваются на классы с величиной
интервала 1,9 см. Число классов зависит
от величины колебаний вариант (разности
между максимальной и минимальной
вариантами), наличия вариант для каждого
класса (если, например, для первого
класса — «0 — 1,9» — нет соответствующих
вариант, т.е. ни один исследуемый не имел
точных попаданий или отклонений от цели
в пределах от 0 до 1,9 см, то подобный класс
не вносится в вариационный ряд) и,
наконец, требуемой точности вычисления,
(чем больше классов, тем точность
вычисления выше). Вполне понятно, что
чем больше величина интервала, тем
меньше число классов при одной и той же
величине колебаний вариант.
После
разбивки вариант по классам в каждом
классе определяется срединная варианта
«Vc»,
и для каждой срединной варианты
проставляется число наблюдений. Пример
этих операций, и дальнейший ход вычислений
приведены в следующей таблице:
|
Классы |
Серединные |
Число |
VCP |
VC-M=d |
d2 |
d2P |
|
0 |
1 |
28 |
28 |
-4.6 |
21.16 |
592.48 |
|
2 |
3 |
29 |
87 |
-2.6 |
6.76 |
196.04 |
|
4 |
5 |
22 |
110 |
-0.6 |
0.36 |
7.92 |
|
6 |
7 |
13 |
91 |
1.4 |
1.96 |
25.48 |
|
8 |
9 |
11 |
99 |
3.4 |
11.56 |
127.16 |
|
10 |
11 |
13 |
143 |
5.4 |
29.16 |
379.08 |
|
12 |
13 |
4 |
52 |
7.4 |
54.76 |
219.04 |
|
14 |
15 |
2 |
30 |
9.4 |
88.36 |
176.72 |
|
16 |
17 |
1 |
17 |
11.4 |
130.00 |
130.00 |
|
18 |
19 |
1 |
19 |
13.4 |
179.60 |
179.60 |
|
20 |
21 |
1 |
21 |
15.4 |
237.20 |
237.20 |
|
125 |
697 |
2270.72 |
Очередность
числовых операций:
1)
вычислить сумму числа наблюдений (в
нашем примере она равна 125);
2)
вычислить произведение каждой срединной
варианты на ее частоту (например, 1*28 =
28);
3)
вычислить сумму произведений срединных
вариант на их частоты (в нашем примере
она равна 697);
4)
вычислить взвешенную среднюю арифметическую
величину по формуле:
![]()
Средняя
арифметическая величина позволяет
сравнивать и оценивать группы изучаемых
явлений в целом. Однако для характеристики
группы явлений только этой величины
явно недостаточно, так как размер
колебаний вариант, из которых она
складывается, может быть различным.
Поэтому в характеристику группы явлений
необходимо ввести такой показатель,
который давал бы представление о величине
колебаний вариант около их средней
величины.
Вычисление
средней ошибки среднего арифметического.
Условное обозначение средней ошибки
среднего арифметического — т. Следует
помнить, что под «ошибкой» в статистике
понимается не ошибка исследования, а
мера представительства данной величины,
т. е. мера, которой средняя арифметическая
величина, полученная на выборочной
совокупности (в нашем примере — на 125
детях), отличается от истинной средней
арифметической величины, которая была
бы получена на генеральной совокупности
(в нашем примере это были бы все дети
аналогичного возраста, уровня
подготовленности и т. д.). Например, в
приведенном ранее примере определялась
точность попадания малым мячом в цель
у 125 детей и была получена средняя
арифметическая величина примерно равная
5,6 см. Теперь надо установить, в какой
мере эта величина будет характерна,
если взять для исследования 200, 300, 500 и
больше аналогичных детей. Ответ на этот
вопрос и даст вычисление средней ошибки
среднего арифметического, которое
производится по формуле:
![]()
Для
приведенного примера величина средней
ошибки среднего арифметического будет
равна:
![]()
Следовательно,
M±m = 5,6±0,38. Это означает, что полученная
средняя арифметическая величина (M =
5,6) может иметь в других аналогичных
исследованиях значения от 5,22 (5,6 — 0,38 =
5,22) до 5,98 (5,6+0,38 = 5,98).
Соседние файлы в предмете Ветеринарная генетика
- #
- #
- #
Условное
обозначение средней арифметической
величины через М (от латинского слова
Media) чаще применяется в медицинских и
педагогических исследованиях. В
математической статистике предпочитают
обозначение через ![]() .
.
Средняя арифметическая величина является
производной, обобщающей количественные
признаки ряда однородных показателей
(совокупности). Выражая одним числом
определенную совокупность, она как бы
ослабляет влияние случайных индивидуальных
отклонений, и акцентирует некую обобщенную
количественную характеристику, наиболее
типичное свойство изучаемого ряда
показателей.
Определяя
значение средней арифметической
величины, следует придерживаться
некоторых правил.
1.
Средняя арифметическая величина может
характеризовать только те признаки
изучаемого объекта, которые присущи
всей совокупности, но в разной
количественной мере (например, уровень
развития быстроты движений характерен
для каждого человека, хотя и в разной
количественной мере). Средняя арифметическая
величина не может характеризовать
количественную меру тех признаков,
которые одной части совокупности
присущи, а другой нет, т. е. она не может
отражать присутствие или отсутствие
того или иного признака (например, умение
или неумение выполнять то или иное
двигательное действие).
2.
Средняя арифметическая величина должна
включать все показатели, полученные в
данном исследовании. Произвольное
исключение даже некоторых из них
неизбежно приведет к искажению конечного
результата.
3.
Средняя арифметическая величина обязана
отражать только однородную совокупность.
Нельзя, например, определять средний
уровень физического развития школьников,
не разделив их предварительно по возрасту
и полу.
4.
Средняя арифметическая величина должна
вычисляться на достаточно большой
совокупности, размеры которой определяются
в каждом конкретном случае отдельно
(см. «Подбор исследуемых»).
5.
Необходимо стремиться к тому, чтобы
средняя арифметическая величина имела
четкие и простые свойства, позволяющие
легко и быстро ее вычислять.
6.
Средняя арифметическая величина должна
обладать достаточной устойчивостью к
действию случайных факторов. Только в
этом случае она будет отражать
действительное состояние изучаемого
явления, а не его случайные изменения.
7.
Точность вычисления средней арифметической
величины должна соответствовать
содержанию изучаемого педагогического
явления. В некоторых случаях нет
необходимости в расчетах с большой
точностью, в других — большая точность
нужна при вычислениях, но совершенно
не нужна в выводах. Например, при расчете
средних величин числа подтягиваний на
перекладине можно пользоваться и сотыми
долями целого, но представлять и выводах,
что исследуемые в среднем подтянулись
7,83 раза, было бы неграмотна, так как
невозможно измерение с подобной
точностью. В этом случае необходимо в
выводах представлять числа, округленные
до целых единиц.
В
простейшем случае этот показатель
вычисляется путем сложения всех
полученных значений (которые называются
вариантами) и деления суммы на число
вариант:
![]()
где
S — знак суммирования;
V
— полученные в исследовании значения
(варианты);
п
— число вариант.
По
этой формуле вычисляется так называемая
простая средняя арифметическая величина.
Применяется она в тех случаях, когда
имеется небольшое число вариант.
При
большом числе вариант прибегают к
вычислению так называемой взвешенной
средней арифметической величины. С этой
целью строят ряд распределения, или
вариационный ряд, который представляет
собой ряд вариант и их частот,
характеризующих какой-нибудь признак
в убывающем или возрастающем порядке.
Например, в нашем случае измерение
точности попадания мячом в цель дало
125 вариант, т. е. в группе I, где применялась
методика обучения «А», одноразово
исследовалось 125 детей с числовым
выражением от 0 (точное попадание в цель)
до 21,5 см (максимальное отклонение от
цели). Каждое числовое выражение
встречалось в исследовании один и более
раз, например «0» встретился 28 раз.
Другими словами, 28 участников эксперимента
точно попали в цель. Этот показатель
называется числом наблюдений или
частотой вариант и условно обозначается
буквой «Р» (число наблюдений составляет
часть числа вариант).
Для
упрощения числовых операций все 125
вариант разбиваются на классы с величиной
интервала 1,9 см. Число классов зависит
от величины колебаний вариант (разности
между максимальной и минимальной
вариантами), наличия вариант для каждого
класса (если, например, для первого
класса — «0 — 1,9» — нет соответствующих
вариант, т.е. ни один исследуемый не имел
точных попаданий или отклонений от цели
в пределах от 0 до 1,9 см, то подобный класс
не вносится в вариационный ряд) и,
наконец, требуемой точности вычисления,
(чем больше классов, тем точность
вычисления выше). Вполне понятно, что
чем больше величина интервала, тем
меньше число классов при одной и той же
величине колебаний вариант.
После
разбивки вариант по классам в каждом
классе определяется срединная варианта
«Vc»,
и для каждой срединной варианты
проставляется число наблюдений. Пример
этих операций, и дальнейший ход вычислений
приведены в следующей таблице:
|
Классы |
Серединные |
Число |
VCP |
VC-M=d |
d2 |
d2P |
|
0 |
1 |
28 |
28 |
-4.6 |
21.16 |
592.48 |
|
2 |
3 |
29 |
87 |
-2.6 |
6.76 |
196.04 |
|
4 |
5 |
22 |
110 |
-0.6 |
0.36 |
7.92 |
|
6 |
7 |
13 |
91 |
1.4 |
1.96 |
25.48 |
|
8 |
9 |
11 |
99 |
3.4 |
11.56 |
127.16 |
|
10 |
11 |
13 |
143 |
5.4 |
29.16 |
379.08 |
|
12 |
13 |
4 |
52 |
7.4 |
54.76 |
219.04 |
|
14 |
15 |
2 |
30 |
9.4 |
88.36 |
176.72 |
|
16 |
17 |
1 |
17 |
11.4 |
130.00 |
130.00 |
|
18 |
19 |
1 |
19 |
13.4 |
179.60 |
179.60 |
|
20 |
21 |
1 |
21 |
15.4 |
237.20 |
237.20 |
|
125 |
697 |
2270.72 |
Очередность
числовых операций:
1)
вычислить сумму числа наблюдений (в
нашем примере она равна 125);
2)
вычислить произведение каждой срединной
варианты на ее частоту (например, 1*28 =
28);
3)
вычислить сумму произведений срединных
вариант на их частоты (в нашем примере
она равна 697);
4)
вычислить взвешенную среднюю арифметическую
величину по формуле:
![]()
Средняя
арифметическая величина позволяет
сравнивать и оценивать группы изучаемых
явлений в целом. Однако для характеристики
группы явлений только этой величины
явно недостаточно, так как размер
колебаний вариант, из которых она
складывается, может быть различным.
Поэтому в характеристику группы явлений
необходимо ввести такой показатель,
который давал бы представление о величине
колебаний вариант около их средней
величины.
Вычисление
средней ошибки среднего арифметического.
Условное обозначение средней ошибки
среднего арифметического — т. Следует
помнить, что под «ошибкой» в статистике
понимается не ошибка исследования, а
мера представительства данной величины,
т. е. мера, которой средняя арифметическая
величина, полученная на выборочной
совокупности (в нашем примере — на 125
детях), отличается от истинной средней
арифметической величины, которая была
бы получена на генеральной совокупности
(в нашем примере это были бы все дети
аналогичного возраста, уровня
подготовленности и т. д.). Например, в
приведенном ранее примере определялась
точность попадания малым мячом в цель
у 125 детей и была получена средняя
арифметическая величина примерно равная
5,6 см. Теперь надо установить, в какой
мере эта величина будет характерна,
если взять для исследования 200, 300, 500 и
больше аналогичных детей. Ответ на этот
вопрос и даст вычисление средней ошибки
среднего арифметического, которое
производится по формуле:
![]()
Для
приведенного примера величина средней
ошибки среднего арифметического будет
равна:
![]()
Следовательно,
M±m = 5,6±0,38. Это означает, что полученная
средняя арифметическая величина (M =
5,6) может иметь в других аналогичных
исследованиях значения от 5,22 (5,6 — 0,38 =
5,22) до 5,98 (5,6+0,38 = 5,98).
Соседние файлы в предмете Ветеринарная генетика
- #
- #
- #
Рассмотрим инструмент Описательная статистика, входящий в надстройку Пакет Анализа. Рассчитаем показатели выборки: среднее, медиана, мода, дисперсия, стандартное отклонение и др.
Задача
описательной статистики
(descriptive statistics) заключается в том, чтобы с использованием математических инструментов свести сотни значений
выборки
к нескольким итоговым показателям, которые дают представление о
выборке
.В качестве таких статистических показателей используются:
среднее
,
медиана
,
мода
,
дисперсия, стандартное отклонение
и др.
Опишем набор числовых данных с помощью определенных показателей. Для чего нужны эти показатели? Эти показатели позволят сделать определенные
статистические выводы о распределении
, из которого была взята
выборка
. Например, если у нас есть
выборка
значений толщины трубы, которая изготавливается на определенном оборудовании, то на основании анализа этой
выборки
мы сможем сделать, с некой определенной вероятностью, заключение о состоянии процесса изготовления.
Содержание статьи:
- Надстройка Пакет анализа;
- Среднее выборки
;
- Медиана выборки
;
- Мода выборки
;
- Мода и среднее значение
;
- Дисперсия выборки
;
- Стандартное отклонение выборки
;
- Стандартная ошибка
;
- Ассиметричность
;
- Эксцесс выборки
;
- Уровень надежности
.
Надстройка Пакет анализа
Для вычисления статистических показателей одномерных
выборок
, используем
надстройку Пакет анализа
. Затем, все показатели рассчитанные надстройкой, вычислим с помощью встроенных функций MS EXCEL.
СОВЕТ
: Подробнее о других инструментах надстройки
Пакет анализа
и ее подключении – читайте в статье
Надстройка Пакет анализа MS EXCEL
.
Выборку
разместим на
листе
Пример
в файле примера
в диапазоне
А6:А55
(50 значений).
Примечание
: Для удобства написания формул для диапазона
А6:А55
создан
Именованный диапазон
Выборка.
В диалоговом окне
Анализ данных
выберите инструмент
Описательная статистика
.

После нажатия кнопки
ОК
будет выведено другое диалоговое окно,
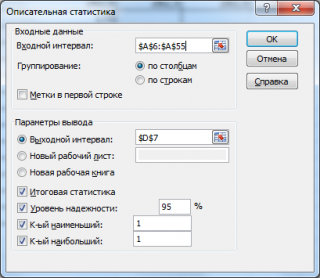
в котором нужно указать:
входной интервал
(Input Range) – это диапазон ячеек, в котором содержится массив данных. Если в указанный диапазон входит текстовый заголовок набора данных, то нужно поставить галочку в поле
Метки в первой строке (
Labels
in
first
row
).
В этом случае заголовок будет выведен в
Выходном интервале.
Пустые ячейки будут проигнорированы, поэтому нулевые значения необходимо обязательно указывать в ячейках, а не оставлять их пустыми;
выходной интервал
(Output Range). Здесь укажите адрес верхней левой ячейки диапазона, в который будут выведены статистические показатели;
Итоговая статистика (
Summary
Statistics
)
. Поставьте галочку напротив этого поля – будут выведены основные показатели выборки:
среднее, медиана, мода, стандартное отклонение
и др.;- Также можно поставить галочки напротив полей
Уровень надежности (
Confidence
Level
for
Mean
)
,
К-й наименьший
(Kth Largest) и
К-й наибольший
(Kth Smallest).
В результате будут выведены следующие статистические показатели:
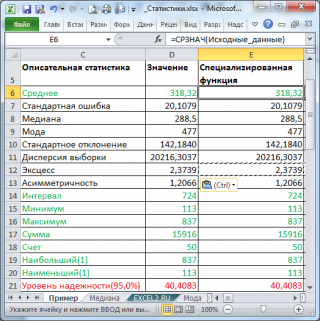
Все показатели выведены в виде значений, а не формул. Если массив данных изменился, то необходимо перезапустить расчет.
Если во
входном интервале
указать ссылку на несколько столбцов данных, то будет рассчитано соответствующее количество наборов показателей. Такой подход позволяет сравнить несколько наборов данных. При сравнении нескольких наборов данных используйте заголовки (включите их во
Входной интервал
и установите галочку в поле
Метки в первой строке
). Если наборы данных разной длины, то это не проблема — пустые ячейки будут проигнорированы.
Зеленым цветом на картинке выше и в
файле примера
выделены показатели, которые не требуют особого пояснения. Для большинства из них имеется специализированная функция:
Интервал
(Range) — разница между максимальным и минимальным значениями;
Минимум
(Minimum) – минимальное значение в диапазоне ячеек, указанном во
Входном интервале
(см.статью про функцию
МИН()
);
Максимум
(Maximum)– максимальное значение (см.статью про функцию
МАКС()
);
Сумма
(Sum) – сумма всех значений (см.статью про функцию
СУММ()
);
Счет
(Count) – количество значений во
Входном интервале
(пустые ячейки игнорируются, см.статью про функцию
СЧЁТ()
);
Наибольший
(Kth Largest) – выводится К-й наибольший. Например, 1-й наибольший – это максимальное значение (см.статью про функцию
НАИБОЛЬШИЙ()
);
Наименьший
(Kth Smallest) – выводится К-й наименьший. Например, 1-й наименьший – это минимальное значение (см.статью про функцию
НАИМЕНЬШИЙ()
).
Ниже даны подробные описания остальных показателей.
Среднее выборки
Среднее
(mean, average) или
выборочное среднее
или
среднее выборки
(sample average) представляет собой
арифметическое среднее
всех значений массива. В MS EXCEL для вычисления среднего выборки используется функция
СРЗНАЧ()
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) оценкой
математического ожидания
случайной величины (подробнее см. статью
Среднее и Математическое ожидание в MS EXCEL
).
Медиана выборки
Медиана
(Median) – это число, которое является серединой множества чисел (в данном случае выборки): половина чисел множества больше, чем
медиана
, а половина чисел меньше, чем
медиана
. Для определения
медианы
необходимо сначала
отсортировать множество чисел
. Например,
медианой
для чисел 2, 3, 3,
4
, 5, 7, 10 будет 4.
Если множество содержит четное количество чисел, то вычисляется
среднее
для двух чисел, находящихся в середине множества. Например,
медианой
для чисел 2, 3,
3
,
5
, 7, 10 будет 4, т.к. (3+5)/2.
Если имеется длинный хвост распределения, то
Медиана
лучше, чем
среднее значение
, отражает «типичное» или «центральное» значение. Например, рассмотрим несправедливое распределение зарплат в компании, в которой руководство получает существенно больше, чем основная масса сотрудников.
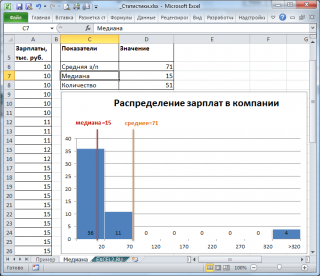
Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что
как минимум
у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Для определения
медианы
в MS EXCEL существует одноименная функция
МЕДИАНА()
, английский вариант — MEDIAN().
Медиану
также можно вычислить с помощью формул
=КВАРТИЛЬ.ВКЛ(Выборка;2) =ПРОЦЕНТИЛЬ.ВКЛ(Выборка;0,5).
Подробнее о
медиане
см. специальную статью
Медиана в MS EXCEL
.
СОВЕТ
: Подробнее про
квартили
см. статью, про
перцентили (процентили)
см. статью.
Мода выборки
Мода
(Mode) – это наиболее часто встречающееся (повторяющееся) значение в
выборке
. Например, в массиве (1; 1;
2
;
2
;
2
; 3; 4; 5) число 2 встречается чаще всего – 3 раза. Значит, число 2 – это
мода
. Для вычисления
моды
используется функция
МОДА()
, английский вариант MODE().
Примечание
: Если в массиве нет повторяющихся значений, то функция вернет значение ошибки #Н/Д. Это свойство использовано в статье
Есть ли повторы в списке?
Начиная с
MS EXCEL 2010
вместо функции
МОДА()
рекомендуется использовать функцию
МОДА.ОДН()
, которая является ее полным аналогом. Кроме того, в MS EXCEL 2010 появилась новая функция
МОДА.НСК()
, которая возвращает несколько наиболее часто повторяющихся значений (если количество их повторов совпадает). НСК – это сокращение от слова НеСКолько.
Например, в массиве (1; 1;
2
;
2
;
2
; 3;
4
;
4
;
4
; 5) числа 2 и 4 встречаются наиболее часто – по 3 раза. Значит, оба числа являются
модами
. Функции
МОДА.ОДН()
и
МОДА()
вернут значение 2, т.к. 2 встречается первым, среди наиболее повторяющихся значений (см.
файл примера
, лист
Мода
).
Чтобы исправить эту несправедливость и была введена функция
МОДА.НСК()
, которая выводит все
моды
. Для этого ее нужно ввести как
формулу массива
.
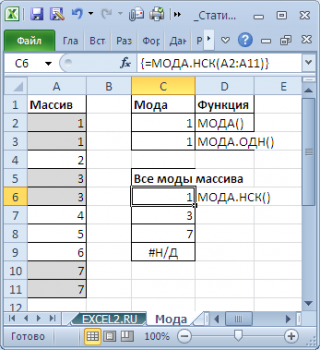
Как видно из картинки выше, функция
МОДА.НСК()
вернула все три
моды
из массива чисел в диапазоне
A2:A11
: 1; 3 и 7. Для этого, выделите диапазон
C6:C9
, в
Строку формул
введите формулу
=МОДА.НСК(A2:A11)
и нажмите
CTRL+SHIFT+ENTER
. Диапазон
C
6:
C
9
охватывает 4 ячейки, т.е. количество выделяемых ячеек должно быть больше или равно количеству
мод
. Если ячеек больше чем м
о
д, то избыточные ячейки будут заполнены значениями ошибки #Н/Д. Если
мода
только одна, то все выделенные ячейки будут заполнены значением этой
моды
.
Теперь вспомним, что мы определили
моду
для выборки, т.е. для конечного множества значений, взятых из
генеральной совокупности
. Для
непрерывных случайных величин
вполне может оказаться, что выборка состоит из массива на подобие этого (0,935; 1,211; 2,430; 3,668; 3,874; …), в котором может не оказаться повторов и функция
МОДА()
вернет ошибку.
Даже в нашем массиве с
модой
, которая была определена с помощью
надстройки Пакет анализа
, творится, что-то не то. Действительно,
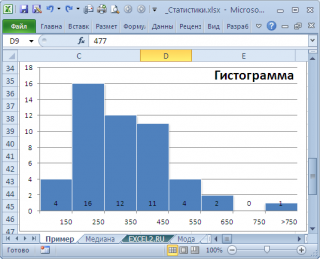
модой
нашего массива значений является число 477, т.к. оно встречается 2 раза, остальные значения не повторяются. Но, если мы посмотрим на
гистограмму распределения
, построенную для нашего массива, то увидим, что 477 не принадлежит интервалу наиболее часто встречающихся значений (от 150 до 250).
Проблема в том, что мы определили
моду
как наиболее часто встречающееся значение, а не как наиболее вероятное. Поэтому,
моду
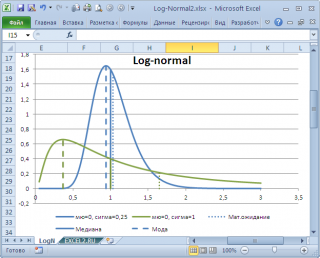
в учебниках статистики часто определяют не для выборки (массива), а для функции распределения. Например, для
логнормального распределения
мода
(наиболее вероятное значение непрерывной случайной величины х), вычисляется как
exp
(
m
—
s
2
)
, где m и s параметры этого распределения.
Понятно, что для нашего массива число 477, хотя и является наиболее часто повторяющимся значением, но все же является плохой оценкой для
моды
распределения, из которого взята
выборка
(наиболее вероятного значения или для которого плотность вероятности распределения максимальна).
Для того, чтобы получить оценку
моды
распределения, из
генеральной совокупности
которого взята
выборка
, можно, например, построить
гистограмму
. Оценкой для
моды
может служить интервал наиболее часто встречающихся значений (самого высокого столбца). Как было сказано выше, в нашем случае это интервал от 150 до 250.
Вывод
: Значение
моды
для
выборки
, рассчитанное с помощью функции
МОДА()
, может ввести в заблуждение, особенно для небольших выборок. Эта функция эффективна, когда случайная величина может принимать лишь несколько дискретных значений, а размер
выборки
существенно превышает количество этих значений.
Например, в рассмотренном примере о распределении заработных плат (см. раздел статьи выше, о Медиане),
модой
является число 15 (17 значений из 51, т.е. 33%). В этом случае функция
МОДА()
дает хорошую оценку «наиболее вероятного» значения зарплаты.
Примечание
: Строго говоря, в примере с зарплатой мы имеем дело скорее с
генеральной совокупностью
, чем с
выборкой
. Т.к. других зарплат в компании просто нет.
О вычислении
моды
для распределения
непрерывной случайной величины
читайте статью
Мода в MS EXCEL
.
Мода и среднее значение
Не смотря на то, что
мода
– это наиболее вероятное значение случайной величины (вероятность выбрать это значение из
Генеральной совокупности
максимальна), не следует ожидать, что
среднее значение
обязательно будет близко к
моде
.
Примечание
:
Мода
и
среднее
симметричных распределений совпадает (имеется ввиду симметричность
плотности распределения
).
Представим, что мы бросаем некий «неправильный» кубик, у которого на гранях имеются значения (1; 2; 3; 4; 6; 6), т.е. значения 5 нет, а есть вторая 6.
Модой
является 6, а среднее значение – 3,6666.
Другой пример. Для
Логнормального распределения
LnN(0;1)
мода
равна =EXP(m-s2)= EXP(0-1*1)=0,368, а
среднее значение
1,649.
Дисперсия выборки
Дисперсия выборки
или
выборочная дисперсия (
sample
variance
) характеризует разброс значений в массиве, отклонение от
среднего
.
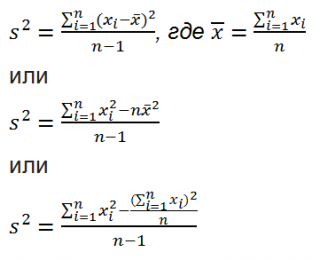
Из формулы №1 видно, что
дисперсия выборки
это сумма квадратов отклонений каждого значения в массиве
от среднего
, деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления
дисперсии выборки
используется функция
ДИСП()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог — функцию
ДИСП.В()
.
Дисперсию
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1) =(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1)
–
формула массива
Дисперсия выборки
равна 0, только в том случае, если все значения равны между собой и, соответственно, равны
среднему значению
.
Чем больше величина
дисперсии
, тем больше разброс значений в массиве относительно
среднего
.
Размерность
дисперсии
соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность
дисперсии
будет кг
2
. Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из
дисперсии – стандартное отклонение
.
Подробнее о
дисперсии
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартное отклонение выборки
Стандартное отклонение выборки
(Standard Deviation), как и
дисперсия
, — это мера того, насколько широко разбросаны значения в выборке
относительно их среднего
.
По определению,
стандартное отклонение
равно квадратному корню из
дисперсии
:
![]()
Стандартное отклонение
не учитывает величину значений в
выборке
, а только степень рассеивания значений вокруг их
среднего
. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х
выборок
: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у
выборок
существенно отличается.
В MS EXCEL 2007 и более ранних версиях для вычисления
Стандартного отклонения выборки
используется функция
СТАНДОТКЛОН()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
СТАНДОТКЛОН.В()
.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Подробнее о
стандартном отклонении
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартная ошибка
В
Пакете анализа
под термином
стандартная ошибка
имеется ввиду
Стандартная ошибка среднего
(Standard Error of the Mean, SEM).
Стандартная ошибка среднего
— это оценка
стандартного отклонения
распределения
выборочного среднего
.
Примечание
: Чтобы разобраться с понятием
Стандартная ошибка среднего
необходимо прочитать о
выборочном распределении
(см. статью
Статистики, их выборочные распределения и точечные оценки параметров распределений в MS EXCEL
) и статью про
Центральную предельную теорему
.
Стандартное отклонение распределения выборочного среднего
вычисляется по формуле σ/√n, где n — объём
выборки, σ — стандартное отклонение исходного
распределения, из которого взята
выборка
. Т.к. обычно
стандартное отклонение
исходного распределения неизвестно, то в расчетах вместо
σ
используют ее оценку
s
—
стандартное отклонение выборки
. А соответствующая величина s/√n имеет специальное название —
Стандартная ошибка среднего.
Именно эта величина вычисляется в
Пакете анализа.
В MS EXCEL
стандартную ошибку среднего
можно также вычислить по формуле
=СТАНДОТКЛОН.В(Выборка)/ КОРЕНЬ(СЧЁТ(Выборка))
Асимметричность
Асимметричность
или
коэффициент асимметрии
(skewness) характеризует степень несимметричности распределения (
плотности распределения
) относительно его
среднего
.
Положительное значение
коэффициента асимметрии
указывает, что размер правого «хвоста» распределения больше, чем левого (относительно среднего). Отрицательная асимметрия, наоборот, указывает на то, что левый хвост распределения больше правого.
Коэффициент асимметрии
идеально симметричного распределения или выборки равно 0.

Примечание
:
Асимметрия выборки
может отличаться расчетного значения асимметрии теоретического распределения. Например,
Нормальное распределение
является симметричным распределением (
плотность его распределения
симметрична относительно
среднего
) и, поэтому имеет асимметрию равную 0. Понятно, что при этом значения в
выборке
из соответствующей
генеральной совокупности
не обязательно должны располагаться совершенно симметрично относительно
среднего
. Поэтому,
асимметрия выборки
, являющейся оценкой
асимметрии распределения
, может отличаться от 0.
Функция
СКОС()
, английский вариант SKEW(), возвращает коэффициент
асимметрии выборки
, являющейся оценкой
асимметрии
соответствующего распределения, и определяется следующим образом:
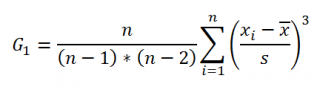
где n – размер
выборки
, s –
стандартное отклонение выборки
.
В
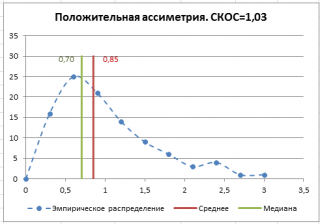
файле примера на листе СКОС
приведен расчет коэффициента
асимметрии
на примере случайной выборки из
распределения Вейбулла
, которое имеет значительную положительную
асимметрию
при параметрах распределения W(1,5; 1).
Эксцесс выборки
Эксцесс
показывает относительный вес «хвостов» распределения относительно его центральной части.
Для того чтобы определить, что относится к хвостам распределения, а что к его центральной части, можно использовать границы μ +/-
σ
.
Примечание
: Не смотря на старания профессиональных статистиков, в литературе еще попадается определение
Эксцесса
как меры «остроконечности» (peakedness) или сглаженности распределения. Но, на самом деле, значение
Эксцесса
ничего не говорит о форме пика распределения.
Согласно определения,
Эксцесс
равен четвертому
стандартизированному моменту:
![]()
Для
нормального распределения
четвертый момент равен 3*σ
4
, следовательно,
Эксцесс
равен 3. Многие компьютерные программы используют для расчетов не сам
Эксцесс
, а так называемый Kurtosis excess, который меньше на 3. Т.е. для
нормального распределения
Kurtosis excess равен 0. Необходимо быть внимательным, т.к. часто не очевидно, какая формула лежит в основе расчетов.
Примечание
: Еще большую путаницу вносит перевод этих терминов на русский язык. Термин Kurtosis происходит от греческого слова «изогнутый», «имеющий арку». Так сложилось, что на русский язык оба термина Kurtosis и Kurtosis excess переводятся как
Эксцесс
(от англ. excess — «излишек»). Например, функция MS EXCEL
ЭКСЦЕСС()
на самом деле вычисляет Kurtosis excess.
Функция
ЭКСЦЕСС()
, английский вариант KURT(), вычисляет на основе значений выборки несмещенную оценку
эксцесса распределения
случайной величины и определяется следующим образом:
![]()
Как видно из формулы MS EXCEL использует именно Kurtosis excess, т.е. для выборки из
нормального распределения
формула вернет близкое к 0 значение.
Если задано менее четырех точек данных, то функция
ЭКСЦЕСС()
возвращает значение ошибки #ДЕЛ/0!
Вернемся к
распределениям случайной величины
.
Эксцесс
(Kurtosis excess) для
нормального распределения
всегда равен 0, т.е. не зависит от параметров распределения μ и σ. Для большинства других распределений
Эксцесс
зависит от параметров распределения: см., например,
распределение Вейбулла
или
распределение Пуассона
, для котрого
Эксцесс
= 1/λ.
Уровень надежности
Уровень
надежности
— означает вероятность того, что
доверительный интервал
содержит истинное значение оцениваемого параметра распределения.
Вместо термина
Уровень
надежности
часто используется термин
Уровень доверия
. Про
Уровень надежности
(Confidence Level for Mean) читайте статью
Уровень значимости и уровень надежности в MS EXCEL
.
Задав значение
Уровня
надежности
в окне
надстройки Пакет анализа
, MS EXCEL вычислит половину ширины
доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Тот же результат можно получить по формуле (см.
файл примера
):
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95;s;n)
s —
стандартное отклонение выборки
, n – объем
выборки
.
Подробнее см. статью про
построение доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
From Wikipedia, the free encyclopedia

For a value that is sampled with an unbiased normally distributed error, the above depicts the proportion of samples that would fall between 0, 1, 2, and 3 standard deviations above and below the actual value.
The standard error (SE)[1] of a statistic (usually an estimate of a parameter) is the standard deviation of its sampling distribution[2] or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).[1]
The sampling distribution of a mean is generated by repeated sampling from the same population and recording of the sample means obtained. This forms a distribution of different means, and this distribution has its own mean and variance. Mathematically, the variance of the sampling mean distribution obtained is equal to the variance of the population divided by the sample size. This is because as the sample size increases, sample means cluster more closely around the population mean.
Therefore, the relationship between the standard error of the mean and the standard deviation is such that, for a given sample size, the standard error of the mean equals the standard deviation divided by the square root of the sample size.[1] In other words, the standard error of the mean is a measure of the dispersion of sample means around the population mean.
In regression analysis, the term «standard error» refers either to the square root of the reduced chi-squared statistic or the standard error for a particular regression coefficient (as used in, say, confidence intervals).
Standard error of the sample mean[edit]
Exact value[edit]
Suppose a statistically independent sample of 




.
Practically this tells us that when trying to estimate the value of a population mean, due to the factor 
Estimate[edit]
The standard deviation 
.
As this is only an estimator for the true «standard error», it is common to see other notations here such as:
or alternately
.
A common source of confusion occurs when failing to distinguish clearly between:
Accuracy of the estimator[edit]
When the sample size is small, using the standard deviation of the sample instead of the true standard deviation of the population will tend to systematically underestimate the population standard deviation, and therefore also the standard error. With n = 2, the underestimate is about 25%, but for n = 6, the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect.[3] Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20.[4] See unbiased estimation of standard deviation for further discussion.
Derivation[edit]
The standard error on the mean may be derived from the variance of a sum of independent random variables,[5] given the definition of variance and some simple properties thereof. If

which due to the Bienaymé formula, will have variance

where we’ve approximated the standard deviations, i.e., the uncertainties, of the measurements themselves with the best value for the standard deviation of the population. The mean of these measurements
.
The variance of the mean is then

The standard error is, by definition, the standard deviation of
.
For correlated random variables the sample variance needs to be computed according to the Markov chain central limit theorem.
Independent and identically distributed random variables with random sample size[edit]
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size 

[6]
If 




(since the standard deviation is the square root of the variance)
Student approximation when σ value is unknown[edit]
In many practical applications, the true value of σ is unknown. As a result, we need to use a distribution that takes into account that spread of possible σ’s.
When the true underlying distribution is known to be Gaussian, although with unknown σ, then the resulting estimated distribution follows the Student t-distribution. The standard error is the standard deviation of the Student t-distribution. T-distributions are slightly different from Gaussian, and vary depending on the size of the sample. Small samples are somewhat more likely to underestimate the population standard deviation and have a mean that differs from the true population mean, and the Student t-distribution accounts for the probability of these events with somewhat heavier tails compared to a Gaussian. To estimate the standard error of a Student t-distribution it is sufficient to use the sample standard deviation «s» instead of σ, and we could use this value to calculate confidence intervals.
Note: The Student’s probability distribution is approximated well by the Gaussian distribution when the sample size is over 100. For such samples one can use the latter distribution, which is much simpler.
Assumptions and usage[edit]
An example of how 
- Upper 95% limit
and
- Lower 95% limit

In particular, the standard error of a sample statistic (such as sample mean) is the actual or estimated standard deviation of the sample mean in the process by which it was generated. In other words, it is the actual or estimated standard deviation of the sampling distribution of the sample statistic. The notation for standard error can be any one of SE, SEM (for standard error of measurement or mean), or SE.
Standard errors provide simple measures of uncertainty in a value and are often used because:
- in many cases, if the standard error of several individual quantities is known then the standard error of some function of the quantities can be easily calculated;
- when the probability distribution of the value is known, it can be used to calculate an exact confidence interval;
- when the probability distribution is unknown, Chebyshev’s or the Vysochanskiï–Petunin inequalities can be used to calculate a conservative confidence interval; and
- as the sample size tends to infinity the central limit theorem guarantees that the sampling distribution of the mean is asymptotically normal.
Standard error of mean versus standard deviation[edit]
In scientific and technical literature, experimental data are often summarized either using the mean and standard deviation of the sample data or the mean with the standard error. This often leads to confusion about their interchangeability. However, the mean and standard deviation are descriptive statistics, whereas the standard error of the mean is descriptive of the random sampling process. The standard deviation of the sample data is a description of the variation in measurements, while the standard error of the mean is a probabilistic statement about how the sample size will provide a better bound on estimates of the population mean, in light of the central limit theorem.[7]
Put simply, the standard error of the sample mean is an estimate of how far the sample mean is likely to be from the population mean, whereas the standard deviation of the sample is the degree to which individuals within the sample differ from the sample mean.[8] If the population standard deviation is finite, the standard error of the mean of the sample will tend to zero with increasing sample size, because the estimate of the population mean will improve, while the standard deviation of the sample will tend to approximate the population standard deviation as the sample size increases.
Extensions[edit]
Finite population correction (FPC)[edit]
The formula given above for the standard error assumes that the population is infinite. Nonetheless, it is often used for finite populations when people are interested in measuring the process that created the existing finite population (this is called an analytic study). Though the above formula is not exactly correct when the population is finite, the difference between the finite- and infinite-population versions will be small when sampling fraction is small (e.g. a small proportion of a finite population is studied). In this case people often do not correct for the finite population, essentially treating it as an «approximately infinite» population.
If one is interested in measuring an existing finite population that will not change over time, then it is necessary to adjust for the population size (called an enumerative study). When the sampling fraction (often termed f) is large (approximately at 5% or more) in an enumerative study, the estimate of the standard error must be corrected by multiplying by a »finite population correction» (a.k.a.: FPC):[9]
[10]

which, for large N:

to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
This happens in survey methodology when sampling without replacement. If sampling with replacement, then FPC does not come into play.
Correction for correlation in the sample[edit]

Expected error in the mean of A for a sample of n data points with sample bias coefficient ρ. The unbiased standard error plots as the ρ = 0 diagonal line with log-log slope −½.
If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:

where the sample bias coefficient ρ is the widely used Prais–Winsten estimate of the autocorrelation-coefficient (a quantity between −1 and +1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover, this formula works for positive and negative ρ alike.[11] See also unbiased estimation of standard deviation for more discussion.
See also[edit]
- Illustration of the central limit theorem
- Margin of error
- Probable error
- Standard error of the weighted mean
- Sample mean and sample covariance
- Standard error of the median
- Variance
- Variance of the mean and predicted responses
References[edit]
- ^ a b c d Altman, Douglas G; Bland, J Martin (2005-10-15). «Standard deviations and standard errors». BMJ: British Medical Journal. 331 (7521): 903. doi:10.1136/bmj.331.7521.903. ISSN 0959-8138. PMC 1255808. PMID 16223828.
- ^ Everitt, B. S. (2003). The Cambridge Dictionary of Statistics. CUP. ISBN 978-0-521-81099-9.
- ^ Gurland, J; Tripathi RC (1971). «A simple approximation for unbiased estimation of the standard deviation». American Statistician. 25 (4): 30–32. doi:10.2307/2682923. JSTOR 2682923.
- ^ Sokal; Rohlf (1981). Biometry: Principles and Practice of Statistics in Biological Research (2nd ed.). p. 53. ISBN 978-0-7167-1254-1.
- ^ Hutchinson, T. P. (1993). Essentials of Statistical Methods, in 41 pages. Adelaide: Rumsby. ISBN 978-0-646-12621-0.
- ^ Cornell, J R, and Benjamin, C A, Probability, Statistics, and Decisions for Civil Engineers, McGraw-Hill, NY, 1970, ISBN 0486796094, pp. 178–9.
- ^ Barde, M. (2012). «What to use to express the variability of data: Standard deviation or standard error of mean?». Perspect. Clin. Res. 3 (3): 113–116. doi:10.4103/2229-3485.100662. PMC 3487226. PMID 23125963.
- ^ Wassertheil-Smoller, Sylvia (1995). Biostatistics and Epidemiology : A Primer for Health Professionals (Second ed.). New York: Springer. pp. 40–43. ISBN 0-387-94388-9.
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
- ^ Bondy, Warren; Zlot, William (1976). «The Standard Error of the Mean and the Difference Between Means for Finite Populations». The American Statistician. 30 (2): 96–97. doi:10.1080/00031305.1976.10479149. JSTOR 2683803. (Equation 2)
- ^ Bence, James R. (1995). «Analysis of Short Time Series: Correcting for Autocorrelation». Ecology. 76 (2): 628–639. doi:10.2307/1941218. JSTOR 1941218.