![]()
Фаза
Критерий качества Скорость Правильность/Надёжность
|
Задержка |
||
|
Установление |
установления |
|
|
транспортного соединения |
транспортного |
|
|
соединения |
||
|
Перенос данных |
Пропускная |
|
|
способность |
||
|
Транзитная задержка |
||
|
Задержка |
||
|
Разрушение транспортного |
разрушения |
|
|
соединения |
транспортного |
|
|
соединения |
Вероятность неудачи установления транспортного соединения (неправильное соединение/отказ)
Остаточный коэффициент ошибки (искажение, дублирование/потеря)
Вероятность неудачи передачи данных
Вероятность неудачного разрушения транспортного соединения
Вероятность неудачи установления транспортного соединения – отношение общего количества неудачных

попыток установления соединения к общему количеству попыток установления соединения.
Неудача в установлении соединения имеет место, когда транспортное соединение не установлено в пределах указанной максимальной задержки установления соединения в результате неправильного соединения или отказа в установлении соединения.
Пропускная способность определена для каждого направления передачи в транспортном соединении. Для каждого направления определены максимальное значение пропускной способности и среднее значение пропускной способности. Максимальное значение – это максимальная скорость при которой транспортный уровень непрерывно принимает и отправляет данные при отсутствии управления потоком данных.
Среднее значение пропускной способности – это ожидаемая скорость передачи в транспортном соединении, включая

эффекты, возникающие при управлении потоком данных. Транзитная задержка – время прошедшее между посылкой
транспортного сервисного блока данных и его приёмом. Рассчитывается транзитная задержка только по тем транспортным сервисным блокам данных, которые успешно переданы их получателю. Под успешностью понимается пересылка транспортных сервисных блоков данных без ошибок, в надлежащей последовательности и до разъединения транспортного соединения.
Остаточный коэффициент ошибки – отношение общего количества ошибочных, потерянных и дублированных транспортных сервисных блоков данных к общему количеству транспортных сервисных блоков данных перенесённых транспортной службой в течение периода измерения.
Вероятность неудачи передачи данных – отношение общего
|
количества неудачных передач к общему |
числу |
передач, |
||
|
составляющих |
выборку, |
наблюдаемых |
в |
течение |

измерения.
Выборка передач – это те передачи сервисных транспортных блоков данных за которыми было установлено наблюдение.
Вероятность неудачного разрушения транспортного соединения – отношение общего количества неудачных запросов на разрушение транспортного соединения к общему количеству запросов на разрушение транспортного соединения, включенных в выборку измерений. Этот параметр обычно определяется независимо для каждого пользователя TS.
Приоритет транспортного соединения – определяет отношения между транспортными соединениями. Этот параметр определяет относительную значимость транспортного соединения по следующим аспектам:
1. Порядок, в котором транспортные соединения должны ухудшить качество обслуживания в случае необходимости.
2. Порядок, в котором транспортные соединения будут нарушены, в случае необходимости возврата ресурсов,

которые они используют.
5.3 КАЧЕСТВО ТРАНСПОРТНОГО ОБСЛУЖИВАНИЯ В РЕЖИМЕ БЕЗ УСТАНОВЛЕНИЯ СОЕДИНЕНИЯ
Отличительной чертой обслуживания в режиме без установления соединения является отсутствие переговоров о качестве обслуживания во время передачи данных. То есть пользователь TS не может договариваться с транспортным уровнем о значениях параметров качества обслуживания. Единственное, чем обеспечиваются пользователи TS в режиме без установления соединения – это знанием значений параметров качества обслуживания.
Параметры качества обслуживания, определённые для режима передачи без установления соединения: транзитная задержка, защита, остаточная вероятность ошибки, приоритет.
Определение транзитной задержки такое же, как и в случае режима с установлением соединения, но с учётом следующей

особенности – транзитная задержка определяется для каждой посылки транспортного сервисного блока данных отдельно, в то время как в режиме с установлением соединения транзитная задержка может быть определена по соединению в целом.
Определение остаточной вероятности ошибки тоже соответствует определению, данному для режима с установлением соединения, но с той же поправкой.
Приоритет – этот параметр определяет относительную значимость передач транспортных сервисных блоков данных по следующим аспектам:
1. Порядок, в котором для транспортных сервисных блоков данных, в случае необходимости, понизится качество обслуживания (причём качество обслуживания понижается для всех транспортных сервисных блоков данных, которыми обмениваются пользователи TS).
2. Порядок, в котором транспортные сервисные блоки данных, в случае необходимости, должны быть отброшены, для

того, чтобы возвратить используемые ресурсы.
6. СЕТЕВОЙ УРОВЕНЬ
Сетевой уровень (Network Layer) обеспечивает функциональные и процедурные средства для транспортных объектов, благодаря которым транспортные объекты освобождаются от функций ретрансляции и маршрутизации.
Сетевой уровень обеспечивает установку, поддержку и завершение сетевых соединений между открытыми системами, которые содержат взаимодействующие прикладные объекты.
Сетевой уровень обеспечивает обмен сетевыми сервисными блоками данных (network-service-data-units, далее как сетевые SDU) между транспортными объектами через сетевые соединения.
Сетевой уровень служит для образования единой транспортной системы, объединяющей несколько сетей, причём эти сети могут использовать совершенно различные принципы

передачи сообщений между конечными узлами и обладать произвольной структурой связей.
Услуги, предоставляемые транспортному уровню в режиме с установлением соединения:
Основная услуга сетевого уровня заключается в обеспечении прозрачного переноса данных между транспортными объектами. Благодаря этой услуге содержимое передаваемой информации детально интерпретируется только верхними уровнями (то есть уровнями располагающимися выше сетевого).
1. Сетевые адреса.
Транспортные объекты известны сетевому уровню благодаря сетевым адресам. С помощью сетевых адресов транспортный объект уникально идентифицирует тот транспортный объект, с которым он хочет связаться.

Например, в протоколе TCP отправитель и получатель уникально идентифицируется сокетами. Как уже было отмечено ранее, сокет — это номер порта в совокупности с номером сети и номером конечного узла. Номер сети и номер узла составляют сетевой адрес, а именно IP-адрес.
Протокол межсетевого взаимодействия IP (Internet Protocol), относится к сетевому уровню, он работает в режиме без установления соединения и обеспечивает передачу дейтаграмм от отправителя к получателю через объединённую систему компьютерных сетей.
Например в заголовке протокола IPv4 (четвёртая версия) под IP-адрес источника отведено 32 бита (под IP-адрес назначения также отведено 32 бита). Из этих 32 бит какая-то часть отведена для номера сети (в зависимости от класса IP-адреса), а остальная часть для номера узла в этой сети. Например IP- адрес 127.220.64.23 относится к классу A. В двоичном виде он будет выглядеть так: 01111111.11011100.01000000.00010111.

Номер сети Номер узла
IP-адрес класса А 01111111  11011100
11011100  01000000
01000000  00010111
00010111
Рисунок 6.1 – Пример сетевого адреса
Например, в протоколе X.25 на сетевом уровне может использоваться адрес любой длины (в пределах формата поля адреса). Максимальная длина поля адреса в пакете X.25 составляет 16 байт. Сетевым уровнем в технологии X.25 является протокол который так и называется X.25. Сеть X.25 – это сеть с коммутацией пакетов, ориентированная на передачу по ненадёжным линиям. Сетевой уровень X.25 может работать в режиме с установлением соединения.
Ещё одним примером сетевой адресации может послужить адресация на уровне 3 MTP стека протоколов ОКС7. Уровень 3 MTP относится к сетевому уровню. На этом уровне отправитель идентифицируется кодом исходящего пункта OPC (Origination
11.1. Задачи обеспечения качества услуг в сетях 3 поколения
Современная концепция
пользовательских услуг различает 4
класса трафика:
-
Голосовой
трафик -
Потоковый
трафик -
Интерактивный
трафик -
Фоновый
трафик
Для каждого класса
установлены определенные характеристики
качества услуг QoS.
QoS
характеризуют следующие атрибуты:
-
Класс
трафика. -
Порядок
доставки. Несущий канал обеспечивает
последовательную доставку пакетов
или не обеспечивает. -
Максимальная
длина пакетов данных SDU
(Service
data
unit)
в октетах. -
Формат
SDU
в битах. Список возможных размеров
(длин) SDU,
в том числе при защите данных от ошибок. -
Возможность
доставки пакетов с ошибками. -
Остаточный
коэффициент ошибок (BER). -
Относительный
уровень ошибочных SDU. -
Задержка
(на уровне 95% потока). -
Максимальная
скорость передачи.
10.Гарантированная
скорость передачи.
11.Приоритет
трафика на данной несущей.
12.
Назначение (снятие) приоритетов.
13.
Класс приоритетов.
14.
Класс задержек. Приоритеты трафика
интерактивного и фонового классов.
15.
Класс надежности. Комбинация остаточного
BER
и относительного уровня ошибок SDU.
16.
Класс пропускной способности. Максимальная
скорость.
Как
пример, возможны классы VIP
пользователей, бюджетных и обычных
абонентов. На практике при организации
каналов (bearer)
предлагают использовать классы
обслуживания TREC
(Treatment
Class)
(табл. 11.1). В
табл.11.1 ARP
– Allocation
and
Retention
Priority,
выделенный и поддерживаемый приоритет
трафика, соответствующий THP
– Traffic
Handling
Priority,
“интегральному” приоритету, определяемому
классом трафика и приоритетом пользователя.
Повышению приоритета соответствует
увеличение номера TREC.
Максимальный приоритет имеют потоки с
TREC
= 9.
При
этом следует учесть, что некоторые
атрибуты QoS
взаимно противоречивы, например, задержка
и надежность (относительный уровень
ошибочных SDU).
Так при передаче телефонного трафика
сквозная задержка не должна превышать
150 мс при допустимой потере информационных
блоков не более 3%; при потоковом трафике
допустимы потери блоков менее 1%, а при
передаче интерактивного трафика потери
блоков недопустимы, в то время как
задержка может составлять единицы
секунд при передаче одной страницы
данных. Интерактивный и фоновый трафик
передают с подтверждением, так что
необходимость повторной передачи
блоков, принятых с ошибками, не позволяет
фиксировать величину допустимой
задержки, которая может быть определена
лишь статистически.
Таблица 11.1
-
Телефонный
трафикПотоковый
трафикИнтерактивный
трафикФоновый
трафик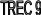

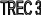
ARP/THP
=1

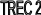
ARP/THP
=2
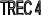
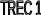
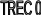
ARP/THP
=3
Развитие
пользовательских услуг связано прежде
всего с расширением услуг, предоставляемым
пользователям в пакетном режиме. При
этом в основе обеспечения QoS
лежат понятия PDP
контекста и несущего канала (bearer).
Несколько потоков с одинаковыми
характеристиками образуют совокупный
QoS
профиль. Это то качество, которое следует
обеспечить на участке между MS
и SGSN.
Что касается ядра сети, то в этой
подсистеме вводят приоритеты IP-пакетов
с использованием IETF
Diff.Serv,
что обеспечивает CN
BS
(Core
Network
Bearer
Service).
В
процессе передачи пакетного трафика
между UE
и SGSN
при необходимости обеспечения требуемого
качества услуги происходят переговоры
об атрибутах QoS.
В этой процедуре также участвует HLR.
Возможны ситуации, когда после активизации
первичного PDP
контекста и переговоров, касающихся
реализации требуемой услуги, будет
установлен вторичный PDP
контекст. Возможны различные комбинации
организации PDP
контекста с использованием одной или
нескольких точек доступа (APN)
(рис. 11.1).
Так
как при обеспечении услуг в пакетном
режиме могут взаимодействовать несколько
структур или несколько операторов
(например, мобильной связи и Интернета),
качество услуг характеризуют
пользовательские сквозные характеристики
QoS
(end-to-end
Quality).
QoS
пользователя
определяют следующие факторы и процессы:
-
На
физическом уровне – помехи, ограниченность
канального ресурса. -
На
уровне соединений, сетевом и транспортном
– заголовки, пакеты подтверждений
доставки, установление логических
соединений. Так заголовки MAC/RLC
снижает реальную пропускную способность
на 11%. -
Задержки,
которые определяют по RTT
(Round
Trip
Time)
– времени передачи пакета от сервера
к терминалу и обратного пакета
подтверждения. -
Задержки
в установке TCP
соединений, вызванные медленным стартом
передачи ТСР пакетов, возможным
насыщением трафика и лишними повторными
передачами пакетов при запаздывании
подтверждений из-за выбросов RTT.




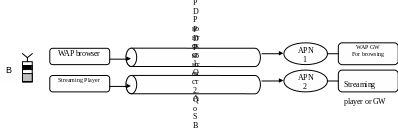

Рис.
11.1. Структуры организации сквозных
каналов.
Приведем
в заключение перечень основных услуг
пакетной связи:
-
передача
Интернет файлов – WEB
Browsing), -
загрузка
игр и музыкальных программ, -
передача
мультимедийных сообщений MMS
– Multimedia
Messaging
Service
и мультимедийное вещание, -
потоковое
видео – Streaming, -
игры
в реальном времени (Online
Gaming), -
доставка
электронной почты, -
передача
речи
в
пакетном
режиме:
PoC (Push-to-talk over Cellular) и
VoIP (Voice over IP).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
What Is Residual Standard Deviation?
Residual standard deviation is a statistical term used to describe the difference in standard deviations of observed values versus predicted values as shown by points in a regression analysis.
Regression analysis is a method used in statistics to show a relationship between two different variables, and to describe how well you can predict the behavior of one variable from the behavior of another.
Residual standard deviation is also referred to as the standard deviation of points around a fitted line or the standard error of estimate.
Key Takeaways
- Residual standard deviation is the standard deviation of the residual values, or the difference between a set of observed and predicted values.
- The standard deviation of the residuals calculates how much the data points spread around the regression line.
- The result is used to measure the error of the regression line’s predictability.
- The smaller the residual standard deviation is compared to the sample standard deviation, the more predictive, or useful, the model is.
Understanding Residual Standard Deviation
Residual standard deviation is a goodness-of-fit measure that can be used to analyze how well a set of data points fit with the actual model. In a business setting for example, after performing a regression analysis on multiple data points of costs over time, the residual standard deviation can provide a business owner with information on the difference between actual costs and projected costs, and an idea of how much-projected costs could vary from the mean of the historical cost data.
Formula for Residual Standard Deviation
Residual
=
(
Y
−
Y
e
s
t
)
S
r
e
s
=
∑
(
Y
−
Y
e
s
t
)
2
n
−
2
where:
S
r
e
s
=
Residual standard deviation
Y
=
Observed value
Y
e
s
t
=
Estimated or projected value
n
=
Data points in population
begin{aligned} &text{Residual}=left(Y-Y_{est}right) &S_{res}=sqrt{frac{sum left(Y-Y_{est}right)^2}{n-2}} &textbf{where:} &S_{res}=text{Residual standard deviation} &Y=text{Observed value} &Y_{est}=text{Estimated or projected value} &n=text{Data points in population} end{aligned}
Residual=(Y−Yest)Sres=n−2∑(Y−Yest)2where:Sres=Residual standard deviationY=Observed valueYest=Estimated or projected valuen=Data points in population
How to Calculate Residual Standard Deviation
To calculate the residual standard deviation, the difference between the predicted values and actual values formed around a fitted line must be calculated first. This difference is known as the residual value or, simply, residuals or the distance between known data points and those data points predicted by the model.
To calculate the residual standard deviation, plug the residuals into the residual standard deviation equation to solve the formula.
Example of Residual Standard Deviation
Start by calculating residual values. For example, assuming you have a set of four observed values for an unnamed experiment, the table below shows y values observed and recorded for given values of x:
If the linear equation or slope of the line predicted by the data in the model is given as yest = 1x + 2 where yest = predicted y value, the residual for each observation can be found.
The residual is equal to (y — yest), so for the first set, the actual y value is 1 and the predicted yest value given by the equation is yest = 1(1) + 2 = 3. The residual value is thus 1 – 3 = -2, a negative residual value.
For the second set of x and y data points, the predicted y value when x is 2 and y is 4 can be calculated as 1 (2) + 2 = 4.
In this case, the actual and predicted values are the same, so the residual value will be zero. You would use the same process for arriving at the predicted values for y in the remaining two data sets.
Once you’ve calculated the residuals for all points using the table or a graph, use the residual standard deviation formula.
Expanding the table above, you calculate the residual standard deviation:
|
x |
y |
yest |
Residual (y-yest) |
Sum of each residual squared, or Σ(y-yest)2 |
|
1 |
1 |
3 |
-2 |
4 |
|
2 |
4 |
4 |
0 |
0 |
|
3 |
6 |
5 |
1 |
1 |
|
4 |
7 |
6 |
1 |
1 |
Observe that the sum of the squared residuals = 6, which represents the numerator of the residual standard deviation equation.
For the bottom portion or denominator of the residual standard deviation equation, n = the number of data points, which is 4 in this case. Calculate the denominator of the equation as:
- (Number of residuals — 2) = (4 — 2) = 2
Finally, calculate the square root of the results:
- Residual standard deviation: √(6/2) = √3 ≈ 1.732
The magnitude of a typical residual can give you a sense of generally how close your estimates are. The smaller the residual standard deviation, the closer is the fit of the estimate to the actual data. In effect, the smaller the residual standard deviation is compared to the sample standard deviation, the more predictive, or useful, the model is.
The residual standard deviation can be calculated when a regression analysis has been performed, as well as an analysis of variance (ANOVA). When determining a limit of quantitation (LoQ), the use of a residual standard deviation is permissible instead of the standard deviation.
What Is Residual Standard Deviation?
Residual standard deviation is a statistical term used to describe the difference in standard deviations of observed values versus predicted values as shown by points in a regression analysis.
Regression analysis is a method used in statistics to show a relationship between two different variables, and to describe how well you can predict the behavior of one variable from the behavior of another.
Residual standard deviation is also referred to as the standard deviation of points around a fitted line or the standard error of estimate.
Key Takeaways
- Residual standard deviation is the standard deviation of the residual values, or the difference between a set of observed and predicted values.
- The standard deviation of the residuals calculates how much the data points spread around the regression line.
- The result is used to measure the error of the regression line’s predictability.
- The smaller the residual standard deviation is compared to the sample standard deviation, the more predictive, or useful, the model is.
Understanding Residual Standard Deviation
Residual standard deviation is a goodness-of-fit measure that can be used to analyze how well a set of data points fit with the actual model. In a business setting for example, after performing a regression analysis on multiple data points of costs over time, the residual standard deviation can provide a business owner with information on the difference between actual costs and projected costs, and an idea of how much-projected costs could vary from the mean of the historical cost data.
Formula for Residual Standard Deviation
Residual
=
(
Y
−
Y
e
s
t
)
S
r
e
s
=
∑
(
Y
−
Y
e
s
t
)
2
n
−
2
where:
S
r
e
s
=
Residual standard deviation
Y
=
Observed value
Y
e
s
t
=
Estimated or projected value
n
=
Data points in population
begin{aligned} &text{Residual}=left(Y-Y_{est}right) &S_{res}=sqrt{frac{sum left(Y-Y_{est}right)^2}{n-2}} &textbf{where:} &S_{res}=text{Residual standard deviation} &Y=text{Observed value} &Y_{est}=text{Estimated or projected value} &n=text{Data points in population} end{aligned}
Residual=(Y−Yest)Sres=n−2∑(Y−Yest)2where:Sres=Residual standard deviationY=Observed valueYest=Estimated or projected valuen=Data points in population
How to Calculate Residual Standard Deviation
To calculate the residual standard deviation, the difference between the predicted values and actual values formed around a fitted line must be calculated first. This difference is known as the residual value or, simply, residuals or the distance between known data points and those data points predicted by the model.
To calculate the residual standard deviation, plug the residuals into the residual standard deviation equation to solve the formula.
Example of Residual Standard Deviation
Start by calculating residual values. For example, assuming you have a set of four observed values for an unnamed experiment, the table below shows y values observed and recorded for given values of x:
If the linear equation or slope of the line predicted by the data in the model is given as yest = 1x + 2 where yest = predicted y value, the residual for each observation can be found.
The residual is equal to (y — yest), so for the first set, the actual y value is 1 and the predicted yest value given by the equation is yest = 1(1) + 2 = 3. The residual value is thus 1 – 3 = -2, a negative residual value.
For the second set of x and y data points, the predicted y value when x is 2 and y is 4 can be calculated as 1 (2) + 2 = 4.
In this case, the actual and predicted values are the same, so the residual value will be zero. You would use the same process for arriving at the predicted values for y in the remaining two data sets.
Once you’ve calculated the residuals for all points using the table or a graph, use the residual standard deviation formula.
Expanding the table above, you calculate the residual standard deviation:
|
x |
y |
yest |
Residual (y-yest) |
Sum of each residual squared, or Σ(y-yest)2 |
|
1 |
1 |
3 |
-2 |
4 |
|
2 |
4 |
4 |
0 |
0 |
|
3 |
6 |
5 |
1 |
1 |
|
4 |
7 |
6 |
1 |
1 |
Observe that the sum of the squared residuals = 6, which represents the numerator of the residual standard deviation equation.
For the bottom portion or denominator of the residual standard deviation equation, n = the number of data points, which is 4 in this case. Calculate the denominator of the equation as:
- (Number of residuals — 2) = (4 — 2) = 2
Finally, calculate the square root of the results:
- Residual standard deviation: √(6/2) = √3 ≈ 1.732
The magnitude of a typical residual can give you a sense of generally how close your estimates are. The smaller the residual standard deviation, the closer is the fit of the estimate to the actual data. In effect, the smaller the residual standard deviation is compared to the sample standard deviation, the more predictive, or useful, the model is.
The residual standard deviation can be calculated when a regression analysis has been performed, as well as an analysis of variance (ANOVA). When determining a limit of quantitation (LoQ), the use of a residual standard deviation is permissible instead of the standard deviation.
6.1. Определения коэффициента ошибок
6.2. Математическое выражение коэффициента битовых ошибок
6.3. Нормы на параметры ошибок систем передачи
6.4. Принципы построения измерителей ошибок
6.5. Техника измерения коэффициента ошибок
6.1. Определения коэффициента ошибок
Коэффициент ошибок – важнейшая характеристика линейного тракта. Он измеряется как для отдельных участков регенерации, так и для тракта в целом. Определяется коэффициент ошибок kОШ, по формуле:
kОШ = NОШ /N, (6.1)
где N – общее число символов, переданных за интервал измерения; NОШ – число ошибочно принятых символов за интервал измерения.
Измерение коэффициента ошибок носит статистический характер, так как получаемый за конечное время результат является случайной величиной. Относительную погрешность измерения в случае нормального закона распределения числа ошибок, что допустимо при N≥10, можно определить по формуле:
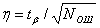 . (6.2)
. (6.2)
Здесь ![]() — коэффициент, зависящий от доверительной вероятности результата измерений:
— коэффициент, зависящий от доверительной вероятности результата измерений:
![]() , (6.3)
, (6.3)
где ![]() — обратная функция интеграла вероятности
— обратная функция интеграла вероятности ![]() :
:
![]() . (6.4)
. (6.4)
Значение kОШ позволяет оценивать вероятность ошибки pОШ – количественную оценку помехоустойчивости. Область возможных значений оценки, в которой с заданной доверительной вероятностью будет находиться значение pОШ, определяется верхней (pВ) и нижней (pН) доверительными границами. При нормальном законе распределения числа ошибок значения pВ и pН определяются по формулам:
![]() , (6.5)
, (6.5)
![]() , (6.6)
, (6.6)
Очевидно, что точность оценок вероятности ошибки и коэффициента ошибки растет с увеличением N. Общее число символов цифрового сигнала, переданных за интервал измерения T, зависит от скорости передачи B: N = TB. Отсюда следует, что чем больше скорость передачи, тем быстрее и точнее можно оценить коэффициент ошибок.
6.2. Математическое выражение коэффициента битовых ошибок
Определим коэффициент битовых ошибок для реальных приёмников, которым свойственно наличие различных источников шумов. При этом будем считать, что приёмник принимает решение, какой бит (0 или 1) был передан в каждом битовом интервале путем стробирования фототока. Очевидно, что из-за наличия шумов данное решение может быть неверным, что приводит к появлению ошибочных битов. Поэтому, чтобы определить коэффициент битовых ошибок, необходимо понять, каким образом приемник принимает решение относительно переданного бита.
Обозначим через I1 и I0 фототоки, стробированные приемником в течение 1 и 0 битов, соответственно, а через s12 и s02 соответствующие шумы. Принимая, что последние имеют гауссовское распределение, проблема установления истинного значения принятого бита имеет следующую математическую формулировку. Фототок для битов 1 и 0 является выборкой гауссовской переменной со средним значением I1 и вариацией s1, а приёмник должен отслеживать этот сигнал и решать, является ли переданный бит 0 или 1. При этом существует много возможных правил принятия решения, которые могут быть реализованы в приёмнике с целью минимизации коэффициента битовых ошибок. Для значения фототока I этим оптимальным решением является наиболее вероятное значение переданного бита, которое определяется путём сравнения текущего значения фототока с пороговым значением Iп, используемым для принятия решения.
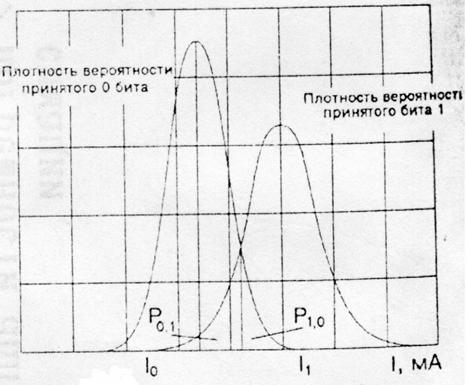
Рисунок 6.1. Функция плотности вероятности фототока принятых сигналов
Пусть при I ³ Iп принимается решение о том, что был передан бит 1, в противном случае – бит 0. Когда биты 1 и 0 равновероятны, что и рассматривается в дальнейшем, пороговый ток приблизительно равен:
![]() (6.7)
(6.7)
Геометрически Iп представляет собой значение тока I, для которого две кривые плотности вероятностей (рис. 6.1) пересекаются.
Вероятность того, что I < Iп, т. е. вероятность ошибки при передаче бита 1, обозначим через Р0,1, а вероятность решения для переданного бита 1, когда I ³ Iп при переданном 0, обозначим Р1,0.
Пусть Q(х) обозначает вероятность того, что нулевая средняя вариация гауссовской переменной превышает значение х, тогда:
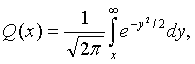 (6.8)
(6.8)
а
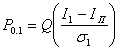 (6.9)
(6.9)
а
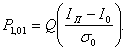 (6.10)
(6.10)
Можно показать [14], что BER определяется,
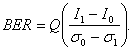 (6.11)
(6.11)
Очень важно отметить, что в ряде случаев эффективным является использование изменяемого в зависимости от уровня сигнала порога принятия решения, как, например, шума оптического усилителя. Многие высокоскоростные приёмники обладают такой особенностью. Однако более простые приемники имеют порог, соответствующий среднему уровню принимаемого тока, а именно (I1 + I0)/2. Такая настройка порогового значения дает большой коэффициент битовых ошибок, определяемый выражением [14].
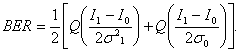 (6.12)
(6.12)
Выражение (6.11) можно использовать для оценки BER, когда известны как мощность полученного сигнала, соответствующего битам 0 и 1, так и статистика шумов.
6.3. Нормы на параметры ошибок систем передачи
Битовые ошибки являются основным источником ухудшения качества связи, проявляющегося в искажении речи в телефонных каналах, недостоверности передачи информации или снижении пропускной способности передачи данных, и характеризуются статистическими параметрами и нормами на них, которые определены соответствующей вероятностью выполнения этих норм. Последние делятся на долговременные и оперативные нормы, первые из которых определяются рекомендациями ITU-T G.821 и G.826, а вторые – М.2100, М.2110 и М.2120, при этом, согласно М.2100, качество цифрового тракта по критерию ошибок делят на три категории:
- нормальное – BER < 10-6;
- пониженное – 10-6 ≤ BER < 10-3 (предаварийное состояние);
- неприемлемое – BER ≥ 10-3 (аварийное состояние).
Так как появление ошибок является следствием совокупности всех текущих условий передачи цифровых сигналов, имеющих случайный характер, то при отсутствии данных о законе распределения ошибок его отдельные элементы могут быть определены с определенной степенью достоверности только по результатам продолжительных измерений. В то же время на практике необходимо, чтобы значения параметров ошибок для ввода в эксплуатацию и технического обслуживания систем передачи основывались на достаточно коротких интервалах времени измерения. Исходя из этого, были определены следующие параметры ошибок [14]:
- секунда с ошибками (error second, ES) – односекундный интервал, содержащий хотя бы один ошибочный бит;
- секунда, пораженная ошибками (severely error second, SES) – односекундный интервал с BER ≥ 10-3.
Данные параметры ошибок должны оцениваться в течение времени готовности (available time), отсчет которого начинается с первой секунды из десяти следующих друг за другом секунд, в каждой из которых BER<10-3. ITU-T M.2100 регламентирует нормы качества (performance objectives, PO) на выраженные максимальным процентом времени параметры ошибок, которые зависят только от скорости передачи и приводятся для условного эталонного соединения (hypothetical reference connection, HRC/HRX/) длиной 27500 км. При этом нормы качества распределяются по участкам соединения соответствующей категории качества. В качестве эталонной модели такого распределения принимается участок высокой категории качества протяженностью 25000 км, которому присваивается 40% от общей нормы качества на параметры ошибок передачи точка-точка, что в пересчете на 1 км, дает 0.0016 %/км.. Остальные 4 участка (2 среднего качества и 2 с приемлемым качеством) длиной 2 х 1250 км расположены по обе стороны от центрального. Поэтому распределение, пропорциональное протяженности L км тракта высокой категории качества, будет определяться, как
AL = 0.0016 · L %/км. (6.13)
Нормы качества на цифровые тракты и каналы подразделяются на настроечные и эксплуатационные, причем вводимые в эксплуатацию впервые или после проведения корректирующих действий они должны сдаваться по настроечным нормам качества, а в процессе эксплуатации должны соответствовать эксплуатационным нормам. Обычно [105] эксплуатационная норма представляется в виде эталонной нормы качества (reference performance objective, RPO)
RPO = A · T · PO, (6.14)
а настроечная, включающая запас на старение, используемая при вводе в эксплуатацию (bringing into service objective, BISO), определяется, как половина RPO, т.е.
BISO = RPO/2. (6.15)
Здесь PO – норма качества оцениваемого параметра, а T = 86400 с (одни сутки) – продолжительность измерений (количество односекундных интервалов).
Для анализа результатов, полученных в процессе измерений, используются также предельные значения S1и S2 норм (рисунок 6.2), которые соответствуют числу событий (ES,SES) и определяются, как:
S1 = RPO/2 – D и S2 = RPO/2 + D, (6.16)
где D = 2![]() — дисперсия оцениваемого параметра.
— дисперсия оцениваемого параметра.
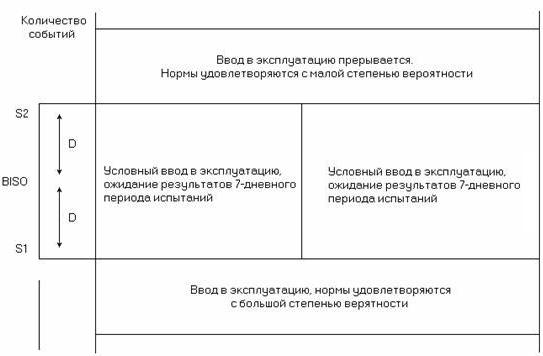
Рисунок 6.2. Предельные значения и условия ввода в эксплуатацию системы передачи
При соответствии результатов измерений норме S1 цифровой тракт может быть введен в эксплуатацию без всякого сомнения, а при превышении нормы S2 в обязательном порядке требуется повышение качества испытываемого цифрового тракта, т.е. должны быть проведены корректирующие действия с повторными измерениями. Если значение ES или SES лежит в интервале от S1 до S2, цифровой тракт может быть введен в эксплуатацию условно или временно с продолжением измерений в течение 7 суток. Данный подход к оценке качества цифровых систем передачи по параметрам ошибок позволяет сократить время измерений и получить норму цифрового тракта суммированием норм цифровых участков. При этом значения RPO, D, S1 и S2 выражаются в виде числа событий за установленный интервал времени, а не в виде процентов времени.
Для измерения коэффициента ошибок разработан ряд специальных BER анализаторов – измерителей коэффициента ошибок, включающих генераторы псевдослучайных и детерминированных последовательностей передаваемых кодированных символов, а также приемное оборудование, осуществляющее собственно измерение коэффициента ошибок. В случае посимвольного сравнения кодов измерение может быть выполнено с использованием шлейфа, т.е. путем измерения ошибок с одной оконечной станции при установке на противоположном конце шлейфа. Другой метод основан на выделении ошибок благодаря избыточности используемых кодов и используется для измерений от передающей до приемной сторон тракта или участка линии, т.е. когда выделение и фиксация ошибок производятся на ее приемном конце. Очевидно, что в первом случае требуется использование одного комплекта, а во втором – двух комплектов приборов. При этом измеренное значение коэффициента ошибок отражает качество передачи при прохождении сигнала в обоих направлениях и в каждом направлении соответственно.
6.4. Принципы построения измерителей ошибок
В зависимости от скорости передачи контролируемой системы передачи в анализаторе используются различные схемотехнические решения.
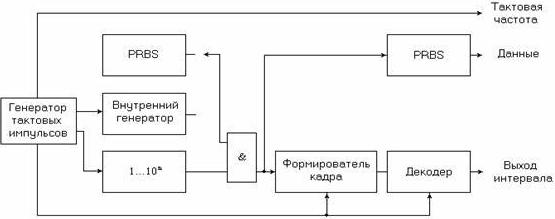
Рисунок 6.3. Генератор низкоскоростного BER анализатора
Низкоскоростной генератор тестовых кодов и детектор ошибок. Используемый в телекоммуникациях анализатор BER, состоящий [106] из генератора тестовых кодов и собственно анализатора ошибок, представлен на рисунках 6.3 и 6.4. Он предназначен для невысоких (до 200 Мбит/с) битовых скоростей, учитывая, что максимальные типовые скорости составляют 44.736 Мбит/с (DS3) в Северной Америке и 139.364 Мбит/с – за пределами Северной Америки.
PRBS с генератором кодовых групп, представленный на рис. 6.16, синхронизируется либо от источника тактового сигнала с фиксированной частотой (согласно G.703), либо от синтезатора, осуществляя тем самым изменение частоты синхронизации. В связи с этим использование данных средств требует задания некоторых определенных частот синхронизации и наличия возможности обеспечения их небольших смещений от ±15 до ±50 ppm. Для повторения тестовых кодов схема PRBS и генератор кодовых групп обычно имеют триггерную схему, управляющую либо выходным усилителем бинарных данных, который обеспечивает данные и данные с сопровождающим синхросигналом, либо выходную схему кодированных данных. Это позволяет создавать цикловую синхронизацию сигнала в соответствии с требованием, например, системы SONET/SDH. Кроме этого, данная схема способствует созданию соответствующего интерфейсного кода для эффективного восстановления тактовой синхронизации. Выходной усилитель обеспечивает необходимый уровень сигнала в соответствии со спецификацией электрического интерфейса, в том числе сигнала с чередованием полярности импульсов.
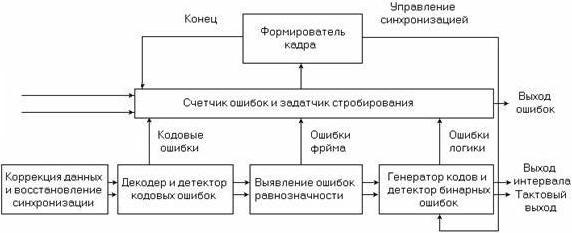
Рисунок 6.4. Низкоскоростной детектор ошибок
Детектор ошибок, показанный на рисунке 6.4, получает стандартный кодированный сигнал, восстанавливает генератор синхросигнала и устраняет кодирование для обеспечения бинарной даты и синхросигналов. Он обнаруживает любые нарушения алгоритма интерфейсного кода и посылает сигналы на счетчик ошибок, что составляет первый уровень процесса обнаружения ошибок. При работе с цикловыми сигналами приемник захватывает любой присутствующий элемент цикловой синхронизации, проверяет наличие цикловых ошибок и декодирует любые встроенные сигналы тревоги, или CRC биты, тем самым обеспечивая возможность измерения.
Наконец, бинарные данные и синхросигнал направляются на детектор ошибок и генератор эталонных тестовых кодов, которые проверяют полученный тестовый код бит за битом на предмет обнаружения логических ошибок. Временная база контролирует пропускание измерения для непрерывного, периодического и ручного режима. Накопленное количество ошибок обрабатывается для получения значения BER и анализа функционирования при наличии ошибок.
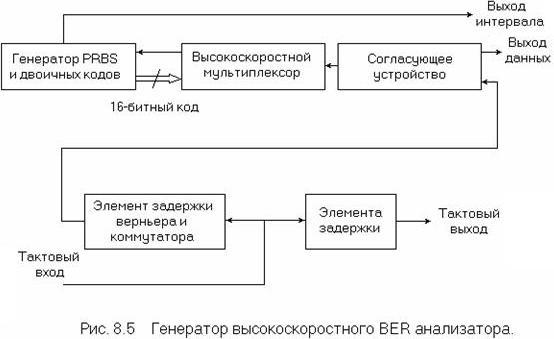
Высокоскоростной генератор тестовых кодов и детектор ошибок. На рисунках 6.5 и 6.6 показаны схемы [14] для 3 Гбит/с генератора тестовых кодов и детектора ошибок. Вследствие высокой битовой скорости генерация последовательных PRBS и кодовых групп на этой скорости не представляется целесообразной. Поэтому тестовые коды генерируются (рисунок 6.5) как параллельные 16-битные кодовые группы при максимальной скорости 200 Мбит/с, используя затем выполненные по биполярной технологии регистраторы смещения и высокоемкостную память. Высокоскоростные схемы обычно выполняются на основе арсенид-галлиевых логических схем, преобразующих параллельные данные в последовательный поток на скорости до 3 Гбит/с.
Согласно данной схеме, вход синхросигнала генерируется синтезатором частоты, согласующее устройство управляется через линию фиксированной задержки, а генератор тестовых кодов и выходной усилитель синхронизируются через схему дискретной и плавно изменяемой задержки, так что фаза синхросигнала/данных может изменяться как в положительном направлении, так и в отрицательном. Дискретные значения задержки составляют 250, 500 и 1000 пс, тогда как диапазон плавной задержки лежит в пределах от 0 до 250 пс с 1 пс инкрементом.
Корректор временной диаграммы, связанный с выходным усилителем, пересинхронизирует данные через триггер D типа для поддержания минимального фазового дрожания. Так как подобный тип тестового устройства обычно используется при проведении лабораторных измерений, выходные уровни синхросигнала и данных и постоянные смещения могут варьироваться для того или иного конкретного случая использования.
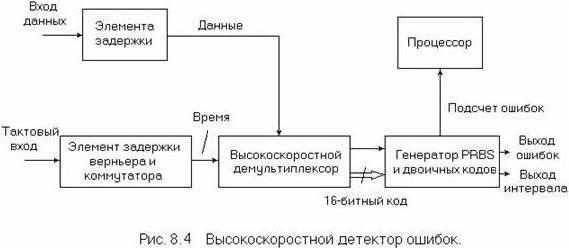
Детектор ошибок, показанный на рис. 6.6, имеет простое параллельное соединение, в связи с чем входы синхросигнала и данных проходят через схемы дискретной и плавной задержки, обеспечивая оптимальную настройку при обнаружении ошибок для любой фазы синхросигнала/данных. Действительно, путем настройки под контролем внутреннего процессора решающего порога и фазы синхросигнала условия функционирования детектора ошибок могут быть оптимизированы автоматически. Высокоскоростной демультиплексор преобразует последовательный поток данных в 16-битные параллельные кодовые группы наряду с поделенным на 16 синхросигналом. Параллельно соединенный генератор эталонных тестовых кодов синхронизируется с входными данными и осуществляет сравнение битов, поэтому любая ошибка фиксируется одним из двух счетчиков, первый из которых подсчитывает число ошибок, а второй – общее число битов. Процессор измерения обеспечивает анализ функционирования при наличии ошибок с разрешением до 1 мс.
6.5. Техника измерения коэффициента ошибок
Рассмотрим измерение коэффициента ошибок путем посимвольного сравнения и подсчета ошибочно принятых элементарных импульсов. Для этого вначале (перед измерением) на передающей станции с помощью оптического аттенюатора устанавливают заданный в технических условиях на аппаратуру линейного тракта уровень оптического излучения. Затем на передающем конце подключают генератор испытательных сигналов, а на приемном – измеритель коэффициента ошибок и, изменяя значения уровней средней мощности, измеряют коэффициент ошибок. Время измерения определяют в зависимости от скорости передачи, объема информации и значений коэффициента ошибок Кошi (BERi).
Коэффициент ошибок при заданном уровне оптического излучения вычисляют по формуле [14]
![]() (6.17)
(6.17)
где
![]() ,
, 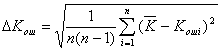 , (6.18)
, (6.18)
где ![]() и
и ![]() — погрешность и среднее значение коэффициента ошибок при пяти и более измерениях с интервалом 3 мин, соответственно, a — коэффициент, учитывающий наличие погрешности измерения при проведении n измерений.
— погрешность и среднее значение коэффициента ошибок при пяти и более измерениях с интервалом 3 мин, соответственно, a — коэффициент, учитывающий наличие погрешности измерения при проведении n измерений.
остаточный коэффициент ошибок
- остаточный коэффициент ошибок
-
3.18 остаточный коэффициент ошибок (residual error rate): Отношение числа необнаруженных ошибочных сообщений к общему числу отправленных сообщений.
Словарь-справочник терминов нормативно-технической документации.
.
2015.
Смотреть что такое «остаточный коэффициент ошибок» в других словарях:
-
Остаточный коэффициент битовых ошибок — (RBER) коэффициент ошибки, при подсчете которого исключаются пораженные кадры… Источник: СРЕДСТВА ИЗМЕРЕНИЙ ЭЛЕКТРОСВЯЗИ СЕТЕЙ ПОДВИЖНОЙ СВЯЗИ СТАНДАРТА GSM 900/1800. ТЕХНИЧЕСКИЕ ТРЕБОВАНИЯ. РД 45.301 2002 (утв. Минсвязи РФ, введен Приказом… … Официальная терминология
-
Остаточный коэффициент битовых ошибок — 1. Коэффициент ошибки, при подсчете которого исключаются пораженные кадры Употребляется в документе: РД 45.301 2002 Средства измерений электросвязи сетей подвижной связи стандарта GSM 900/1800. Технические требования … Телекоммуникационный словарь
-
ГОСТ Р 53195.3-2009: Безопасность функциональная, связанных с безопасностью зданий и сооружений систем. Часть 3. Требования к системам — Терминология ГОСТ Р 53195.3 2009: Безопасность функциональная, связанных с безопасностью зданий и сооружений систем. Часть 3. Требования к системам оригинал документа: 3.1 автоматизированное рабочее место; АРМ (local control station): Рабочее… … Словарь-справочник терминов нормативно-технической документации
-
порог — 3.3 порог: Нижняя часть притвора дверного полотна или ворот. Источник: ГОСТ Р 53307 2009: Конструкции строительные. Противопожарные двери и ворота. Метод испытаний на огнестойкость … Словарь-справочник терминов нормативно-технической документации
-
ГОСТ Р 27.002-2009: Надежность в технике. Термины и определения — Терминология ГОСТ Р 27.002 2009: Надежность в технике. Термины и определения оригинал документа: A(t): Вероятность того, что изделие в данный момент времени находится в работоспособном состоянии. Определения термина из разных документов: A(t) l… … Словарь-справочник терминов нормативно-технической документации
-
СТО Газпром 2-2.3-141-2007: Энергохозяйство ОАО «Газпром». Термины и определения — Терминология СТО Газпром 2 2.3 141 2007: Энергохозяйство ОАО «Газпром». Термины и определения: 3.1.31 абонент энергоснабжающей организации : Потребитель электрической энергии (тепла), энергоустановки которого присоединены к сетям… … Словарь-справочник терминов нормативно-технической документации
-
ГОСТ Р 53480-2009: Надежность в технике. Термины и определения — Терминология ГОСТ Р 53480 2009: Надежность в технике. Термины и определения оригинал документа: 120 автоматическое техническое обслуживание : Техническое обслуживание, выполняемое без вмешательства человека. Определения термина из разных… … Словарь-справочник терминов нормативно-технической документации
-
защита — 3.25 защита (security): Сохранение информации и данных так, чтобы недопущенные к ним лица или системы не могли их читать или изменять, а допущенные лица или системы не ограничивались в доступе к ним. Источник: ГОСТ Р ИСО/МЭК 12207 99:… … Словарь-справочник терминов нормативно-технической документации
-
БАРОМЕТРЫ ДЕЛОВОЙ АКТИВНОСТИ — BUSINESS BAROMETERSДанные по отраслям экономики; индексы промышленного производства и торговли; статистические индикаторы состояния деловой активности; фундаментальная и сравнительная статистика деловой активности, на основании к рой проводятся… … Энциклопедия банковского дела и финансов
6.1. Определения коэффициента ошибок
6.2. Математическое выражение коэффициента битовых ошибок
6.3. Нормы на параметры ошибок систем передачи
6.4. Принципы построения измерителей ошибок
6.5. Техника измерения коэффициента ошибок
6.1. Определения коэффициента ошибок
Коэффициент ошибок – важнейшая характеристика линейного тракта. Он измеряется как для отдельных участков регенерации, так и для тракта в целом. Определяется коэффициент ошибок kОШ, по формуле:
kОШ = NОШ /N, (6.1)
где N – общее число символов, переданных за интервал измерения; NОШ – число ошибочно принятых символов за интервал измерения.
Измерение коэффициента ошибок носит статистический характер, так как получаемый за конечное время результат является случайной величиной. Относительную погрешность измерения в случае нормального закона распределения числа ошибок, что допустимо при N≥10, можно определить по формуле:
. (6.2)
Здесь ![]() — коэффициент, зависящий от доверительной вероятности результата измерений:
— коэффициент, зависящий от доверительной вероятности результата измерений:
![]() , (6.3)
, (6.3)
где ![]() — обратная функция интеграла вероятности
— обратная функция интеграла вероятности ![]() :
:
![]() . (6.4)
. (6.4)
Значение kОШ позволяет оценивать вероятность ошибки pОШ – количественную оценку помехоустойчивости. Область возможных значений оценки, в которой с заданной доверительной вероятностью будет находиться значение pОШ, определяется верхней (pВ) и нижней (pН) доверительными границами. При нормальном законе распределения числа ошибок значения pВ и pН определяются по формулам:
![]() , (6.5)
, (6.5)
![]() , (6.6)
, (6.6)
Очевидно, что точность оценок вероятности ошибки и коэффициента ошибки растет с увеличением N. Общее число символов цифрового сигнала, переданных за интервал измерения T, зависит от скорости передачи B: N = TB. Отсюда следует, что чем больше скорость передачи, тем быстрее и точнее можно оценить коэффициент ошибок.
6.2. Математическое выражение коэффициента битовых ошибок
Определим коэффициент битовых ошибок для реальных приёмников, которым свойственно наличие различных источников шумов. При этом будем считать, что приёмник принимает решение, какой бит (0 или 1) был передан в каждом битовом интервале путем стробирования фототока. Очевидно, что из-за наличия шумов данное решение может быть неверным, что приводит к появлению ошибочных битов. Поэтому, чтобы определить коэффициент битовых ошибок, необходимо понять, каким образом приемник принимает решение относительно переданного бита.
Обозначим через I1 и I0 фототоки, стробированные приемником в течение 1 и 0 битов, соответственно, а через s12 и s02 соответствующие шумы. Принимая, что последние имеют гауссовское распределение, проблема установления истинного значения принятого бита имеет следующую математическую формулировку. Фототок для битов 1 и 0 является выборкой гауссовской переменной со средним значением I1 и вариацией s1, а приёмник должен отслеживать этот сигнал и решать, является ли переданный бит 0 или 1. При этом существует много возможных правил принятия решения, которые могут быть реализованы в приёмнике с целью минимизации коэффициента битовых ошибок. Для значения фототока I этим оптимальным решением является наиболее вероятное значение переданного бита, которое определяется путём сравнения текущего значения фототока с пороговым значением Iп, используемым для принятия решения.
Рисунок 6.1. Функция плотности вероятности фототока принятых сигналов
Пусть при I ³ Iп принимается решение о том, что был передан бит 1, в противном случае – бит 0. Когда биты 1 и 0 равновероятны, что и рассматривается в дальнейшем, пороговый ток приблизительно равен:
![]() (6.7)
(6.7)
Геометрически Iп представляет собой значение тока I, для которого две кривые плотности вероятностей (рис. 6.1) пересекаются.
Вероятность того, что I < Iп, т. е. вероятность ошибки при передаче бита 1, обозначим через Р0,1, а вероятность решения для переданного бита 1, когда I ³ Iп при переданном 0, обозначим Р1,0.
Пусть Q(х) обозначает вероятность того, что нулевая средняя вариация гауссовской переменной превышает значение х, тогда:
(6.8)
а
(6.9)
а
(6.10)
Можно показать [14], что BER определяется,
(6.11)
Очень важно отметить, что в ряде случаев эффективным является использование изменяемого в зависимости от уровня сигнала порога принятия решения, как, например, шума оптического усилителя. Многие высокоскоростные приёмники обладают такой особенностью. Однако более простые приемники имеют порог, соответствующий среднему уровню принимаемого тока, а именно (I1 + I0)/2. Такая настройка порогового значения дает большой коэффициент битовых ошибок, определяемый выражением [14].
(6.12)
Выражение (6.11) можно использовать для оценки BER, когда известны как мощность полученного сигнала, соответствующего битам 0 и 1, так и статистика шумов.
6.3. Нормы на параметры ошибок систем передачи
Битовые ошибки являются основным источником ухудшения качества связи, проявляющегося в искажении речи в телефонных каналах, недостоверности передачи информации или снижении пропускной способности передачи данных, и характеризуются статистическими параметрами и нормами на них, которые определены соответствующей вероятностью выполнения этих норм. Последние делятся на долговременные и оперативные нормы, первые из которых определяются рекомендациями ITU-T G.821 и G.826, а вторые – М.2100, М.2110 и М.2120, при этом, согласно М.2100, качество цифрового тракта по критерию ошибок делят на три категории:
- нормальное – BER < 10-6;
- пониженное – 10-6 ≤ BER < 10-3 (предаварийное состояние);
- неприемлемое – BER ≥ 10-3 (аварийное состояние).
Так как появление ошибок является следствием совокупности всех текущих условий передачи цифровых сигналов, имеющих случайный характер, то при отсутствии данных о законе распределения ошибок его отдельные элементы могут быть определены с определенной степенью достоверности только по результатам продолжительных измерений. В то же время на практике необходимо, чтобы значения параметров ошибок для ввода в эксплуатацию и технического обслуживания систем передачи основывались на достаточно коротких интервалах времени измерения. Исходя из этого, были определены следующие параметры ошибок [14]:
- секунда с ошибками (error second, ES) – односекундный интервал, содержащий хотя бы один ошибочный бит;
- секунда, пораженная ошибками (severely error second, SES) – односекундный интервал с BER ≥ 10-3.
Данные параметры ошибок должны оцениваться в течение времени готовности (available time), отсчет которого начинается с первой секунды из десяти следующих друг за другом секунд, в каждой из которых BER<10-3. ITU-T M.2100 регламентирует нормы качества (performance objectives, PO) на выраженные максимальным процентом времени параметры ошибок, которые зависят только от скорости передачи и приводятся для условного эталонного соединения (hypothetical reference connection, HRC/HRX/) длиной 27500 км. При этом нормы качества распределяются по участкам соединения соответствующей категории качества. В качестве эталонной модели такого распределения принимается участок высокой категории качества протяженностью 25000 км, которому присваивается 40% от общей нормы качества на параметры ошибок передачи точка-точка, что в пересчете на 1 км, дает 0.0016 %/км.. Остальные 4 участка (2 среднего качества и 2 с приемлемым качеством) длиной 2 х 1250 км расположены по обе стороны от центрального. Поэтому распределение, пропорциональное протяженности L км тракта высокой категории качества, будет определяться, как
AL = 0.0016 · L %/км. (6.13)
Нормы качества на цифровые тракты и каналы подразделяются на настроечные и эксплуатационные, причем вводимые в эксплуатацию впервые или после проведения корректирующих действий они должны сдаваться по настроечным нормам качества, а в процессе эксплуатации должны соответствовать эксплуатационным нормам. Обычно [105] эксплуатационная норма представляется в виде эталонной нормы качества (reference performance objective, RPO)
RPO = A · T · PO, (6.14)
а настроечная, включающая запас на старение, используемая при вводе в эксплуатацию (bringing into service objective, BISO), определяется, как половина RPO, т.е.
BISO = RPO/2. (6.15)
Здесь PO – норма качества оцениваемого параметра, а T = 86400 с (одни сутки) – продолжительность измерений (количество односекундных интервалов).
Для анализа результатов, полученных в процессе измерений, используются также предельные значения S1и S2 норм (рисунок 6.2), которые соответствуют числу событий (ES,SES) и определяются, как:
S1 = RPO/2 – D и S2 = RPO/2 + D, (6.16)
где D = 2![]() — дисперсия оцениваемого параметра.
— дисперсия оцениваемого параметра.
Рисунок 6.2. Предельные значения и условия ввода в эксплуатацию системы передачи
При соответствии результатов измерений норме S1 цифровой тракт может быть введен в эксплуатацию без всякого сомнения, а при превышении нормы S2 в обязательном порядке требуется повышение качества испытываемого цифрового тракта, т.е. должны быть проведены корректирующие действия с повторными измерениями. Если значение ES или SES лежит в интервале от S1 до S2, цифровой тракт может быть введен в эксплуатацию условно или временно с продолжением измерений в течение 7 суток. Данный подход к оценке качества цифровых систем передачи по параметрам ошибок позволяет сократить время измерений и получить норму цифрового тракта суммированием норм цифровых участков. При этом значения RPO, D, S1 и S2 выражаются в виде числа событий за установленный интервал времени, а не в виде процентов времени.
Для измерения коэффициента ошибок разработан ряд специальных BER анализаторов – измерителей коэффициента ошибок, включающих генераторы псевдослучайных и детерминированных последовательностей передаваемых кодированных символов, а также приемное оборудование, осуществляющее собственно измерение коэффициента ошибок. В случае посимвольного сравнения кодов измерение может быть выполнено с использованием шлейфа, т.е. путем измерения ошибок с одной оконечной станции при установке на противоположном конце шлейфа. Другой метод основан на выделении ошибок благодаря избыточности используемых кодов и используется для измерений от передающей до приемной сторон тракта или участка линии, т.е. когда выделение и фиксация ошибок производятся на ее приемном конце. Очевидно, что в первом случае требуется использование одного комплекта, а во втором – двух комплектов приборов. При этом измеренное значение коэффициента ошибок отражает качество передачи при прохождении сигнала в обоих направлениях и в каждом направлении соответственно.
6.4. Принципы построения измерителей ошибок
В зависимости от скорости передачи контролируемой системы передачи в анализаторе используются различные схемотехнические решения.
Рисунок 6.3. Генератор низкоскоростного BER анализатора
Низкоскоростной генератор тестовых кодов и детектор ошибок. Используемый в телекоммуникациях анализатор BER, состоящий [106] из генератора тестовых кодов и собственно анализатора ошибок, представлен на рисунках 6.3 и 6.4. Он предназначен для невысоких (до 200 Мбит/с) битовых скоростей, учитывая, что максимальные типовые скорости составляют 44.736 Мбит/с (DS3) в Северной Америке и 139.364 Мбит/с – за пределами Северной Америки.
PRBS с генератором кодовых групп, представленный на рис. 6.16, синхронизируется либо от источника тактового сигнала с фиксированной частотой (согласно G.703), либо от синтезатора, осуществляя тем самым изменение частоты синхронизации. В связи с этим использование данных средств требует задания некоторых определенных частот синхронизации и наличия возможности обеспечения их небольших смещений от ±15 до ±50 ppm. Для повторения тестовых кодов схема PRBS и генератор кодовых групп обычно имеют триггерную схему, управляющую либо выходным усилителем бинарных данных, который обеспечивает данные и данные с сопровождающим синхросигналом, либо выходную схему кодированных данных. Это позволяет создавать цикловую синхронизацию сигнала в соответствии с требованием, например, системы SONET/SDH. Кроме этого, данная схема способствует созданию соответствующего интерфейсного кода для эффективного восстановления тактовой синхронизации. Выходной усилитель обеспечивает необходимый уровень сигнала в соответствии со спецификацией электрического интерфейса, в том числе сигнала с чередованием полярности импульсов.
Рисунок 6.4. Низкоскоростной детектор ошибок
Детектор ошибок, показанный на рисунке 6.4, получает стандартный кодированный сигнал, восстанавливает генератор синхросигнала и устраняет кодирование для обеспечения бинарной даты и синхросигналов. Он обнаруживает любые нарушения алгоритма интерфейсного кода и посылает сигналы на счетчик ошибок, что составляет первый уровень процесса обнаружения ошибок. При работе с цикловыми сигналами приемник захватывает любой присутствующий элемент цикловой синхронизации, проверяет наличие цикловых ошибок и декодирует любые встроенные сигналы тревоги, или CRC биты, тем самым обеспечивая возможность измерения.
Наконец, бинарные данные и синхросигнал направляются на детектор ошибок и генератор эталонных тестовых кодов, которые проверяют полученный тестовый код бит за битом на предмет обнаружения логических ошибок. Временная база контролирует пропускание измерения для непрерывного, периодического и ручного режима. Накопленное количество ошибок обрабатывается для получения значения BER и анализа функционирования при наличии ошибок.
Высокоскоростной генератор тестовых кодов и детектор ошибок. На рисунках 6.5 и 6.6 показаны схемы [14] для 3 Гбит/с генератора тестовых кодов и детектора ошибок. Вследствие высокой битовой скорости генерация последовательных PRBS и кодовых групп на этой скорости не представляется целесообразной. Поэтому тестовые коды генерируются (рисунок 6.5) как параллельные 16-битные кодовые группы при максимальной скорости 200 Мбит/с, используя затем выполненные по биполярной технологии регистраторы смещения и высокоемкостную память. Высокоскоростные схемы обычно выполняются на основе арсенид-галлиевых логических схем, преобразующих параллельные данные в последовательный поток на скорости до 3 Гбит/с.
Согласно данной схеме, вход синхросигнала генерируется синтезатором частоты, согласующее устройство управляется через линию фиксированной задержки, а генератор тестовых кодов и выходной усилитель синхронизируются через схему дискретной и плавно изменяемой задержки, так что фаза синхросигнала/данных может изменяться как в положительном направлении, так и в отрицательном. Дискретные значения задержки составляют 250, 500 и 1000 пс, тогда как диапазон плавной задержки лежит в пределах от 0 до 250 пс с 1 пс инкрементом.
Корректор временной диаграммы, связанный с выходным усилителем, пересинхронизирует данные через триггер D типа для поддержания минимального фазового дрожания. Так как подобный тип тестового устройства обычно используется при проведении лабораторных измерений, выходные уровни синхросигнала и данных и постоянные смещения могут варьироваться для того или иного конкретного случая использования.
Детектор ошибок, показанный на рис. 6.6, имеет простое параллельное соединение, в связи с чем входы синхросигнала и данных проходят через схемы дискретной и плавной задержки, обеспечивая оптимальную настройку при обнаружении ошибок для любой фазы синхросигнала/данных. Действительно, путем настройки под контролем внутреннего процессора решающего порога и фазы синхросигнала условия функционирования детектора ошибок могут быть оптимизированы автоматически. Высокоскоростной демультиплексор преобразует последовательный поток данных в 16-битные параллельные кодовые группы наряду с поделенным на 16 синхросигналом. Параллельно соединенный генератор эталонных тестовых кодов синхронизируется с входными данными и осуществляет сравнение битов, поэтому любая ошибка фиксируется одним из двух счетчиков, первый из которых подсчитывает число ошибок, а второй – общее число битов. Процессор измерения обеспечивает анализ функционирования при наличии ошибок с разрешением до 1 мс.
6.5. Техника измерения коэффициента ошибок
Рассмотрим измерение коэффициента ошибок путем посимвольного сравнения и подсчета ошибочно принятых элементарных импульсов. Для этого вначале (перед измерением) на передающей станции с помощью оптического аттенюатора устанавливают заданный в технических условиях на аппаратуру линейного тракта уровень оптического излучения. Затем на передающем конце подключают генератор испытательных сигналов, а на приемном – измеритель коэффициента ошибок и, изменяя значения уровней средней мощности, измеряют коэффициент ошибок. Время измерения определяют в зависимости от скорости передачи, объема информации и значений коэффициента ошибок Кошi (BERi).
Коэффициент ошибок при заданном уровне оптического излучения вычисляют по формуле [14]
![]() (6.17)
(6.17)
где
![]() , , (6.18)
, , (6.18)
где ![]() и
и ![]() — погрешность и среднее значение коэффициента ошибок при пяти и более измерениях с интервалом 3 мин, соответственно, a — коэффициент, учитывающий наличие погрешности измерения при проведении n измерений.
— погрешность и среднее значение коэффициента ошибок при пяти и более измерениях с интервалом 3 мин, соответственно, a — коэффициент, учитывающий наличие погрешности измерения при проведении n измерений.