На примере операционной системы CentOS Stream я покажу вам как можно проверить состояние жесткого диска hdd или ssd используя технологию S.M.A.R.T.
S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя. Технология S.M.A.R.T. является частью протоколов ATA и SATA.
В данной статье проверим состояние диска используя программу smartmontools.
Для начала установим утилиту smartmontools в дистрибутиве Centos 7.
sudo yum install smartmontools -y
Выведем список наших дисков командой fdisk:
sudo fdisk -l
У меня будет диск sda.
Теперь проверим смарт данного диска:
smartctl -a /dev/sda
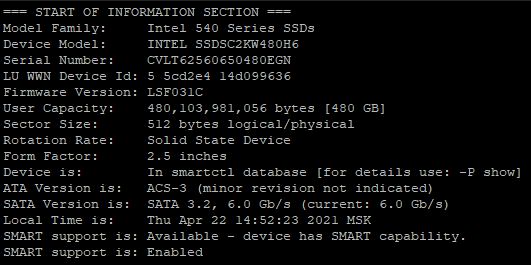
В начале система выведет информацию о модели вашего hdd или ssd диска:
Ниже будут показаны смарт атрибуты диска (тип атрибутов меняется в зависимости от производителя диска):
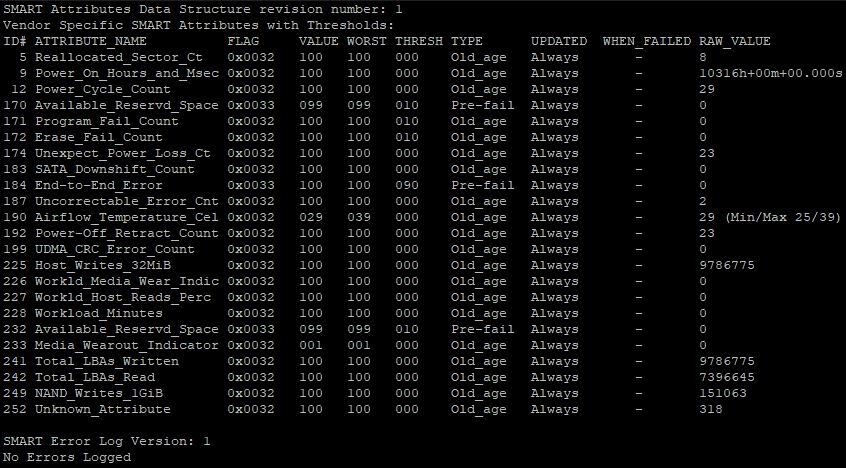
На основе данной таблицы можно сделать вывод, что диск начинает выходить из строя, так как параметр Reallocated_Sector_Ct начинает увеличиваться.
Приведу таблицу с описанием всех атрибутов S.M.A.R.T
| #ID | HEX | Имя атрибута | Описание |
| 1 | 1 | Raw Read Error Rate | Частота ошибок при чтении данных с жёсткого диска. Происхождение их обусловлено аппаратной частью винчестера. |
| 2 | 2 | Throughput Performance | Общая производительность накопителя. Если значение атрибута уменьшается перманентно, то велика вероятность проблем с винчестером. |
| 3 | 3 | Spin-Up Time | Время раскрутки шпинделя из состояния покоя (0 rpm) до рабочей скорости. В поле Raw_value содержится время в миллисекундах/секундах в зависимости от производителя |
| 4 | 4 | Start/Stop Count | Полное число запусков, остановок шпинделя. Иногда в том числе количество включений режима энергосбережения. В поле raw value хранится общее количество запусков/остановок жёсткого диска. |
| 5 | 5 | Reallocated Sectors Count | Число операций переназначения секторов. При обнаружении повреждённого сектора на винчестере, информация из него помечается и переносится в специально отведённую зону, происходит утилизация bad блоков, с последующим консервированием этих мест на диске. Этот процесс называют remapping. Чем больше значение Reallocated Sectors Count, тем хуже состояние поверхности дисков — физический износ поверхности. Поле raw value содержит общее количество переназначенных секторов. |
| 7 | 7 | Seek Error Rate | Частота ошибок при позиционировании блока магнитных головок. Чем больше значение, тем хуже состояние механики, или поверхности жёсткого диска. |
| 8 | 8 | Seek Time Performance | Средняя производительность операции позиционирования. Если значение атрибута уменьшается, то велика вероятность проблем с механической частью. |
| 9 | 9 | Power-On Hours (POH) | Время, проведённое устройством, во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ. |
| 10 | 0A | Spin-Up Retry Count | Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. |
| 11 | 0B | Recalibration Retries | Количество повторов рекалибровки в случае, если первая попытка была неудачной. |
| 12 | 0C | Device Power Cycle Count | Число циклов включения-выключения винчестера. |
| 13 | 0D | Soft Read Error Rate | Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. |
| 187 | BB | Reported UNC Errors | Неустранимые аппаратные ошибки. |
| 190 | BE | Airflow Temperature | Температура воздуха внутри корпуса жёсткого диска. Целое значение, либо значение по формуле 100 — Airflow Temperature |
| 191 | BF | G-sense error rate | Количество ошибок, возникающих в результате ударов. |
| 192 | C0 | Power-off retract count | Число циклов аварийных выключений. |
| 193 | C1 | Load/Unload Cycle | Количество циклов перемещения блока головок в парковочную зону. |
| 194 | C2 | HDA temperature | Показания встроенного термодатчика накопителя. |
| 195 | C3 | Hardware ECC Recovered | Число коррекции ошибок аппаратной частью диска (ошибок чтения, ошибок позиционирования, ошибок передачи по внешнему интерфейсу). |
| 196 | C4 | Reallocation Event Count | Число операций переназначения в резервную область, успешные и неудавшиеся попытки. |
| 197 | C5 | Current Pending Sector Count | Число секторов- кандидатов на перенос в резервную зону. Помечены как не надёжные. При последующих корректных операциях атрибут может быть снят. |
| 198 | C6 | Uncorrectable Sector Count | Число некорректируемых ошибок при обращении к сектору. |
| 199 | C7 | UltraDMA CRC Error Count | Число ошибок при передаче данных по внешнему интерфейсу. |
Данная утилита работает и в дистрибутивах Ubuntu. Надеюсь данная статья оказалась вам полезна. Удачи!
Hard disks can fail unexpectedly and it is always best to keep recent backups of all important data. Please keep in mind that even if a current or oncoming failure is detected, there may not be enough time to backup the data. Below are several methods that can be used to identify bad blocks or disk errors in CentOS/RHEL.
Using smartctl
If there are several I/O errors in /var/log/messages or one simply suspects the hard disks may be failing, smartctl can be a helpful tool in checking them. S.M.A.R.T. stands for Self-Monitoring, Analysis and Reporting Technology. You have to enable the S.M.A.R.T. support in the BIOS before using it.
Next, install the needed packages to run /usr/sbin/smartctl. In Red Hat Enterprise Linux, it is provided by the smartmontools package.
1. Verify if your hard disk supports S.M.A.R.T. :
Replace /dev/xxx with the hard disk of interest when using the commands outlined in this post.
2. For SATA drives use:
# smartctl -i -d ata /dev/xxx
3. Enable S.M.A.R.T. support with:
# smartctl -s on /dev/xxx ### For SCSI Disks # smartctl -s on -d ata /dev/xxx ### for SATA Disks
4. Running the following command as root can be a quick PASS/FAIL test but more thorough testing discussed below is generally more conclusive:
Running smartctl in the background
To start a background test run the following as root:
# smartctl -t long /dev/xxx
To access the results, use the following command:
To learn more about various options that can be used with smartctl view the man page of the command:
Using badblocks
You can also use the “badblocks” command in order to check for bad blocks on a disk device. The “badblocks” command can be very useful in isolating problems with syncing LVM partitions within Linux. LVM operations will fail due to bad blocks on a disk. Bad blocks on either the source or destination disk within a LVM mirror will cause a synchronization failure.
Badblocks can also be used in conjunction with the fsck and makefs to mark the blocks as bad. If the output of badblocks is going to be fed to the e2fsck or mke2fs programs, it is important that the block size is properly specified, since the block numbers which are generated are very dependent on the block size in use by the filesystem. For this reason, it is strongly recommended that users not run badblocks directly, but rather use the -c option of the e2fsck and mke2fs programs.
Warning: The mis-use of these commands can cause data loss. Additional information on the command “badblocks” is available using the “man badblocks” command.
1. Use the disk checking tool badblocks to scan the specified hard disk block by block. For example, to scan /dev/sdd issue the commands:
# mount | grep sdd # find all mounted partitions of sdd # umount /dev/sdd1 # unmount the partitions (may be more then one) # badblocks -n -vv /dev/sdd
Where -n is use non-destructive read-write mode. By default only a non-destructive read-only test is done.
Note: Never use the -w option on a device containing an existing file system. This option erases data! If write-mode testing needs to be performed on an existing file system, use the -n option instead. It is slower, but it will preserve the data.
2. If the messages similar to the examples found below appear in /var/log/messages or to the console following the running of badblocks it is recommended to backup any data on the affected devices and replace the device:
Apr 4 13:50:40 test kernel: sdd: dma_intr: status=0x51 { DriveReady SeekComplete Error }
Apr 4 13:50:40 test kernel: sdd: dma_intr: error=0x40 { UncorrectableError }, LBAsect=74367249, sector=74367232
Apr 4 13:50:40 test kernel: ide: failed opcode was: unknown
Apr 4 13:50:40 test kernel: end_request: I/O error, dev sdd, sector 74367232
Apr 4 13:50:42 test kernel: sdd: dma_intr: status=0x51 { DriveReady SeekComplete Error }
Apr 4 13:50:42 test kernel: sdd: dma_intr: error=0x40 { UncorrectableError }, LBAsect=74367249, sector=74367240
Apr 4 13:50:42 test kernel: ide: failed opcode was: unknown
Apr 4 13:50:42 test kernel: end_request: I/O error, dev sdd, sector 74367240
Apr 4 13:50:44 test kernel: sdd: dma_intr: status=0x51 { DriveReady SeekComplete Error }
3. The command below will dump found bad blocks to the output file: badblocks.log.
# badblocks -v -o badblocks.log /dev/sdd
Common disk errors include physical failures, bad sectors or blocks, and inconsistent filesystems, which can lead to various problems. Diagnosing these issues in Linux can be done using built-in command line tools.

The disk must not be mounted when performing these tests. If it’s necessary to check the root filesystem and it cannot be unmounted due to logged-in users, you can boot into a live Linux system, such as the Ubuntu installer disk. This method is also helpful for recovering partition tables.
Steps to scan for disk error and bad sector in Linux:
-
Open the terminal application.
-
Display the list of available disks on your system.
$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop0 7:0 0 55.4M 1 loop /snap/core18/1997 loop1 7:1 0 219M 1 loop /snap/gnome-3-34-1804/66 loop2 7:2 0 64.8M 1 loop /snap/gtk-common-themes/1514 loop3 7:3 0 32.3M 1 loop /snap/snapd/11588 loop4 7:4 0 51M 1 loop /snap/snap-store/518 loop5 7:5 0 65.1M 1 loop /snap/gtk-common-themes/1515 sda 8:0 0 20G 0 disk ├─sda1 8:1 0 1M 0 part ├─sda2 8:2 0 513M 0 part /boot/efi └─sda3 8:3 0 19.5G 0 part / sdb 8:16 0 20G 0 disk /mnt/data sr0 11:0 1 1024M 0 rom
-
Ensure the disk you wish to examine is unmounted.
$ sudo umount /dev/sdb [sudo] password for user:
-
Assess the disk’s S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) health status using smartctl.
$ sudo smartctl -H /dev/sdb smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.11.0-16-generic] (local build) Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org === START OF READ SMART DATA SECTION === SMART Health Status: OK
-
Examine the filesystem consistency on the disk with fsck.
$ sudo fsck /dev/sdb fsck from util-linux 2.36.1 e2fsck 1.45.7 (28-Jan-2021) /dev/sdb: clean, 11/1310720 files, 126322/5242880 block
-
Inspect the disk for bad blocks or bad sectors using badblocks.
$ sudo badblocks -v /dev/sdb Checking blocks 0 to 20971519 Checking for bad blocks (read-only test): done Pass completed, 0 bad blocks found. (0/0/0 errors)

Discuss the article:
Comment anonymously. Login not required.
What’s the best way to check for HDD errors and early signs of failure on CentOS?
![]()
030
5,87113 gold badges67 silver badges109 bronze badges
asked Jun 11, 2010 at 14:55
1
I would recommend installing smartmon (http://sourceforge.net/apps/trac/smartmontools/wiki) to your machine this is some software which can check the health of your disks otherwise its going to be checking /var/log/messages or /var/log/syslog for any mentions of scsi errors
answered Jun 11, 2010 at 15:03
PaulPaul
5932 silver badges6 bronze badges
2
dmesg
The kernel will log any diagnostic messages about I/O devices, so you can check those messages out with the dmesg command.
answered Jun 11, 2010 at 15:12
BanjerBanjer
3,94412 gold badges41 silver badges47 bronze badges
2
SMART monitoring is a good way. As root, smartctl -a /dev/hda, where hda is the drive you want… could be hdb, sda, etc. Also recommend setting your email address in /etc/aliases as the person who should get root’s mail.
That’s a very vague answer though. If you have a server made by any of the big manufacturers (Dell, HP, etc), chances are there are better monitoring capabilities available.
answered Jun 11, 2010 at 15:39
churndchurnd
4,0175 gold badges34 silver badges42 bronze badges
You can run fsck on the device to check for errors.
answered Jun 11, 2010 at 15:04
cdatedcdated
1991 gold badge1 silver badge9 bronze badges
As Paul says, the SMART logs are a good place to check.
I’d also recommend running BadBlocks. If you’ve got a RAID card, you might have to use the monitoring on that.
answered Jun 11, 2010 at 15:26
DentrasiDentrasi
3,7421 gold badge24 silver badges19 bronze badges
You can try full check of partition /dev/sda1 (for example) as
fsck -f /dev/sda1
or, try full write-read non-descructive test of given partition
badblocks -vn /dev/sda1
answered Jul 30, 2013 at 15:58
LiiboLiibo
1091 bronze badge
3
FSCK – очень важная утилита для Linux / Unix, она используется для проверки и исправления ошибок в файловой системе.
Она похоже на утилиту «chkdsk» в операционных системах Windows.
Она также доступна для операционных систем Linux, MacOS, FreeBSD.
FSCK означает «File System Consistency Check», и в большинстве случаев он запускается во время загрузки, но может также запускаться суперпользователем вручную, если возникнет такая необходимость.
Может использоваться с 3 режимами работы,
1- Проверка наличия ошибок и позволить пользователю решить, что делать с каждой ошибкой,
2- Проверка на наличие ошибок и возможность сделать фикс автоматически, или,
3- Проверка наличия ошибок и возможность отобразить ошибку, но не выполнять фикс.
Содержание
- Синтаксис использования команды FSCK
- Команда Fsck с примерами
- Выполним проверку на ошибки в одном разделе
- Проверьте файловую систему на ошибки и исправьте их автоматически
- Проверьте файловую систему на наличие ошибок, но не исправляйте их
- Выполним проверку на ошибки на всех разделах
- Проверим раздел с указанной файловой системой
- Выполнять проверку только на несмонтированных дисках
Синтаксис использования команды FSCK
$ fsck options drives
Опции, которые можно использовать с командой fsck:
- -p Автоматический фикс (без вопросов)
- -n не вносить изменений в файловую систему
- -у принять «yes» на все вопросы
- -c Проверить наличие плохих блоков и добавить их в список.
- -f Принудительная проверка, даже если файловая система помечена как чистая
- -v подробный режим
- -b использование альтернативного суперблока
- -B blocksize Принудительный размер блоков при поиске суперблока
- -j external_journal Установить местоположение внешнего журнала
- -l bad_blocks_file Добавить в список плохих блоков
- -L bad_blocks_file Установить список плохих блоков
Мы можем использовать любую из этих опций, в зависимости от операции, которую нам нужно выполнить.
Давайте обсудим некоторые варианты команды fsck с примерами.
Команда Fsck с примерами
Примечание: – Прежде чем обсуждать какие-либо примеры, прочтите это. Мы не должны использовать FSCK на смонтированных дисках, так как высока вероятность того, что fsck на смонтированном диске повредит диск навсегда.
Поэтому перед выполнением fsck мы должны отмонтировать диск с помощью следующей команды:
$ umount drivename
Например:
$ umount /dev/sdb1
Вы можете проверить номер раздела с помощью следующей команды:
$ fdisk -l
Также при запуске fsck мы можем получить некоторые коды ошибок.
Ниже приведен список кодов ошибок, которые мы могли бы получить при выполнении команды вместе с их значениями:
- 0 – нет ошибок
- 1 – исправлены ошибки файловой системы
- 2 – система должна быть перезагружена
- 4 – Ошибки файловой системы оставлены без исправлений
- 8 – Операционная ошибка
- 16 – ошибка использования или синтаксиса
- 32 – Fsck отменен по запросу пользователя
- 128 – Ошибка общей библиотеки
Теперь давайте обсудим использование команды fsck с примерами в системах Linux.
Выполним проверку на ошибки в одном разделе
Чтобы выполнить проверку на одном разделе, выполните следующую команду из терминала:
$ umount /dev/sdb1 $ fsck /dev/sdb1
Проверьте файловую систему на ошибки и исправьте их автоматически
Запустите команду fsck с параметром «a» для проверки целостности и автоматического восстановления, выполните следующую команду.
Мы также можем использовать опцию «у» вместо опции «а».
$ fsck -a /dev/sdb1
Проверьте файловую систему на наличие ошибок, но не исправляйте их
В случае, если нам нужно только увидеть ошибки, которые происходят в нашей файловой системе, и не нужно их исправлять, тогда мы должны запустить fsck с опцией “n”,
$ fsck -n /dev/sdb1
Выполним проверку на ошибки на всех разделах
Чтобы выполнить проверку файловой системы для всех разделов за один раз, используйте fsck с опцией «A»
$ fsck -A
Чтобы отключить проверку корневой файловой системы, мы будем использовать опцию «R»
$ fsck -AR
Проверим раздел с указанной файловой системой
Чтобы запустить fsck на всех разделах с указанным типом файловой системы, например, «ext4», используйте fsck с опцией «t», а затем тип файловой системы,
$ fsck -t ext4 /dev/sdb1
или
$ fsck -t -A ext4
Выполнять проверку только на несмонтированных дисках
Чтобы убедиться, что fsck выполняется только на несмонтированных дисках, мы будем использовать опцию «M» при запуске fsck,
$ fsck -AM
Вот наше короткое руководство по команде fsck с примерами.
Пожалуйста, не стесняйтесь присылать нам свои вопросы, используя поле для комментариев ниже.