Привет, %хабрачитатель%!
Несколько месяцев назад у нас возникли проблемы с одной виртуальной машиной, запущенной на сервере Dell PowerEdge R720 с ESXi 5.5. Перезагрузка этой VM длилась довольно долго и вызвала сильное падение производительности на самом хосте.
Lifecycle-лог на сервере был наполнен сообщениями вида:
PDR47
A block on Disk 0 in Backplane 1 of Integrated RAID Controller 1 was
punctured by the controller.PDR64
An unrecoverable disk media error occurred on Disk 0 in Backplane 1 of
Integrated RAID Controller 1.
Гугление привело к неутешительному выводу: рейд-массив поврежден и восстановить его невозможно. А именно — повредились данные, относящиеся к одному блоку (страйпу), сразу на нескольких дисках (double fault):
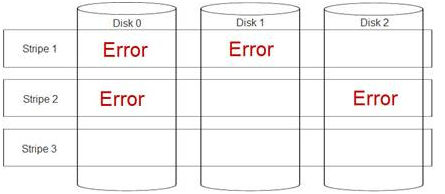
К счастью, делловские RAID-контроллеры обладают фичей продолжать работу, несмотря на неконсисентное состояние массива — puncture (https://www.dell.com/support/Article/us/en/04/438291/EN#Unique-Hyphenated-Issue-Here-2), что позволяет сохранить хотя бы ту часть данных, которая не повредились. Это, конечно, не никак отменяет необходимость последующей замены дисков и пересборки рейд-массива «с нуля».
Для предотвращения подобных ситуаций Dell рекомендует запускать проверку целостности массива не реже одного раза в месяц. Увы, но мы об этом узнали слишком поздно.
Такую проверку можно запускать как через веб-интерфейс Dell OpenManage Server Administrator (http://www.dell.com/support/contents/us/en/19/article/Product-Support/Self-support-Knowledgebase/enterprise-resource-center/Enterprise-Tools/OMSA/), так и через утилиты omconfig/omreport, входящие в OMSA. И, если бы разработчики из Dell не «забыли» включить эти утилиты в OpenManage для ESXi, то проблем с автоматизацией бы не возникло, т.к. понятно, что ручная проверка целостности массива на каждом сервере, совершенно не IT-way. Не говоря уже о том, что интерфейс OMSA очень медленный и работать с ним удовольствие еще то.
Ребята из Dell «поработали на славу» и простым способом автоматизировать проверку (например, через открытие в cURL заранее подготовленной ссылки) невозможно, т.к. веб-интерфейс генерируется динамически и постоянные ссылки в нем отсутствуют.
Что же делать?
Пришлось немного повозиться и написать утилиту проверки самому. Встречайте: Consistency Check Task Automation Tool for Dell servers with iDRAC (https://github.com/jazzl0ver/dell_raid_cc). Утилита написана с помощью фреймворка CasperJS, который позволяет автоматизировать работу как раз с подобными динамическими сайтами.
Для использования dell_raid_cc необходимо:
1. Сервер с установленным OMSA (см. ссылку выше)
2. Скачать и установить phantomjs (http://phantomjs.org/download.html)
3. Скачать и установить casperjs (http://docs.casperjs.org/en/latest/installation.html)
4. Вытащить утилиту из git:
git clone https://github.com/jazzl0ver/dell_raid_cc
5. Создать файл с параметрами доступа (например, creds.txt):
export OMSAHOST=192.168.1.191
export OMSAPORT=1311
export USERNAME=root
export PASSWORD=password
export DELLHOST=192.168.1.30
6. Загрузить его и можно запускать утилиту или ставить ее запуск в кронтаб:
source creds.txt
casperjs --ignore-ssl-errors=true --cookies-file=/tmp/dell_raid_cc_cookie.jar dell_raid_cc.js
Если все в порядке, то вывод будет примерно такой:
Found: Virtual Disk 0 [state: Ready; layout: RAID-10; size: 1,862.00GB]
CC for Virtual Disk 0 has been started
Found: Virtual Disk 1 [state: Ready; layout: RAID-1; size: 931.00GB]
CC for Virtual Disk 1 has been started
Если запустить еще раз, можно увидеть прогресс проверки, например:
Found: Virtual Disk 0 [state: Resynching; layout: RAID-6; size: 5,026.50GB]
CC for Virtual Disk 0 is still running, progress: 19% complete
Стоит сказать, что утилита не поддерживает многоконтроллерные системы (у меня просто таких нет и протестировать, соответственно, не на чем).
Надеюсь, утилита окажется полезной не только мне.
UPD. Как подсказали коллеги в комментариях, более правильно настроить запуск проверки на целостность по расписанию с помощью утилиты megacli. Например:
./MegaCli -AdpCcSched -SetStartTime 20140822 04 -aALL
Инструкции по установке на сервер с CentOS/RedHat — здесь
Настройка расписания CC — здесь
Под ESXi также легко устанавливается. Можно поставить vib напрямую, либо сделать из него bundle и поставить в качестве обновления через vCenter.
UPD. #2 Контроллеры Perc5 не поддерживают настройку расписания через MegaCli:
cd /opt/lsi/MegaCLI; ./MegaCli -AdpCcSched -Info -aALL
Adapter 0: Scheduled Chceck Consistency is not supported.
Exit Code: 0x01
Для них использование dell_raid_cc — единственный способ автоматизации.
Contents
- 1 Detecting, querying and testing
- 1.1 Detecting a drive failure
- 1.2 Querying the array status
- 1.3 Simulating a drive failure
- 1.3.1 Force-fail by hardware
- 1.3.2 Force-fail by software
- 1.4 Simulating data corruption
- 1.5 Monitoring RAID arrays
Detecting, querying and testing
This section is about life with a software RAID system, that’s
communicating with the arrays and tinkertoying them.
Note that when it comes to md devices manipulation, you should always
remember that you are working with entire filesystems. So, although
there could be some redundancy to keep your files alive, you must
proceed with caution.
Detecting a drive failure
Firstly: mdadm has an excellent ‘monitor’ mode which will send an email when a problem is detected in any array (more about that later).
Of course the standard log and stat files will record more details about a drive failure.
It’s always a must for /var/log/messages to fill screens with tons of
error messages, no matter what happened. But, when it’s about a disk
crash, huge lots of kernel errors are reported. Some nasty examples,
for the masochists,
kernel: scsi0 channel 0 : resetting for second half of retries.
kernel: SCSI bus is being reset for host 0 channel 0.
kernel: scsi0: Sending Bus Device Reset CCB #2666 to Target 0
kernel: scsi0: Bus Device Reset CCB #2666 to Target 0 Completed
kernel: scsi : aborting command due to timeout : pid 2649, scsi0, channel 0, id 0, lun 0 Write (6) 18 33 11 24 00
kernel: scsi0: Aborting CCB #2669 to Target 0
kernel: SCSI host 0 channel 0 reset (pid 2644) timed out - trying harder
kernel: SCSI bus is being reset for host 0 channel 0.
kernel: scsi0: CCB #2669 to Target 0 Aborted
kernel: scsi0: Resetting BusLogic BT-958 due to Target 0
kernel: scsi0: *** BusLogic BT-958 Initialized Successfully ***
Most often, disk failures look like these,
kernel: sidisk I/O error: dev 08:01, sector 1590410
kernel: SCSI disk error : host 0 channel 0 id 0 lun 0 return code = 28000002
or these
kernel: hde: read_intr: error=0x10 { SectorIdNotFound }, CHS=31563/14/35, sector=0
kernel: hde: read_intr: status=0x59 { DriveReady SeekComplete DataRequest Error }
And, as expected, the classic /proc/mdstat look will also reveal problems,
Personalities : [linear] [raid0] [raid1] [translucent]
read_ahead not set
md7 : active raid1 sdc9[0] sdd5[8] 32000 blocks [2/1] [U_]
Later on this section we will learn how to monitor RAID with mdadm so
we can receive alert reports about disk failures. Now it’s time to
learn more about /proc/mdstat interpretation.
Querying the array status
You can always take a look at the array status by doing cat /proc/mdstat
It won’t hurt. Take a look at the /proc/mdstat page to learn how to read the file.
Finally, remember that you can also use mdadm to check
the arrays out.
mdadm --detail /dev/mdx
These commands will show spare and failed disks loud and clear.
Simulating a drive failure
If you plan to use RAID to get fault-tolerance, you may also want to
test your setup, to see if it really works. Now, how does one
simulate a disk failure?
The short story is, that you can’t, except perhaps for putting a fire
axe thru the drive you want to «simulate» the fault on. You can never
know what will happen if a drive dies. It may electrically take the
bus it is attached to with it, rendering all drives on that bus
inaccessible. The drive may also just report a read/write fault
to the SCSI/IDE/SATA layer, which, if done properly, in turn makes the RAID layer handle this
situation gracefully. This is fortunately the way things often go.
Remember, that you must be running RAID-{1,4,5,6,10} for your array to be
able to survive a disk failure. Linear- or RAID-0 will fail
completely when a device is missing.
Force-fail by hardware
If you want to simulate a drive failure, you can just plug out the
drive. If your HW does not support disk hot-unplugging, you should do this with the power off (if you are interested in testing whether your data can survive with a disk less than the usual number, there is no point in being a hot-plug cowboy here. Take the system down, unplug the disk, and boot it up again)
Look in the syslog, and look at /proc/mdstat to see how the RAID is
doing. Did it work? Did you get an email from the mdadm monitor?
Faulty disks should appear marked with an (F) if you look at
/proc/mdstat. Also, users of mdadm should see the device state as
faulty.
When you’ve re-connected the disk again (with the power off, of
course, remember), you can add the «new» device to the RAID again,
with the mdadm —add’ command.
Force-fail by software
You can just simulate a drive failure without unplugging things.
Just running the command
mdadm --manage --set-faulty /dev/md1 /dev/sdc2
should be enough to fail the disk /dev/sdc2 of the array /dev/md1.
Now things move up and fun appears. First, you should see something
like the first line of this on your system’s log. Something like the
second line will appear if you have spare disks configured.
kernel: raid1: Disk failure on sdc2, disabling device.
kernel: md1: resyncing spare disk sdb7 to replace failed disk
Checking /proc/mdstat out will show the degraded array. If there was a
spare disk available, reconstruction should have started.
Another useful command at this point is:
mdadm --detail /dev/md1
Enjoy the view.
Now you’ve seen how it goes when a device fails. Let’s fix things up.
First, we will remove the failed disk from the array. Run the command
mdadm /dev/md1 -r /dev/sdc2
Note that mdadm cannot pull a disk out of a running array.
For obvious reasons, only faulty disks can be hot-removed from an
array (even stopping and unmounting the device won’t help — if you ever want
to remove a ‘good’ disk, you have to tell the array to put it into the
‘failed’ state as above).
Now we have a /dev/md1 which has just lost a device. This could be a
degraded RAID or perhaps a system in the middle of a reconstruction
process. We wait until recovery ends before setting things back to
normal.
So the trip ends when we send /dev/sdc2 back home.
mdadm /dev/md1 -a /dev/sdc2
As the prodigal son returns to the array, we’ll see it becoming an
active member of /dev/md1 if necessary. If not, it will be marked as
a spare disk. That’s management made easy.
Simulating data corruption
RAID (be it hardware or software), assumes that if a write to a disk
doesn’t return an error, then the write was successful. Therefore, if
your disk corrupts data without returning an error, your data will
become corrupted. This is of course very unlikely to happen, but it
is possible, and it would result in a corrupt filesystem.
RAID cannot, and is not supposed to, guard against data corruption on
the media. Therefore, it doesn’t make any sense either, to purposely
corrupt data (using dd for example) on a disk to see how the RAID
system will handle that. It is most likely (unless you corrupt the
RAID superblock) that the RAID layer will never find out about the
corruption, but your filesystem on the RAID device will be corrupted.
This is the way things are supposed to work. RAID is not a guarantee
for data integrity, it just allows you to keep your data if a disk
dies (that is, with RAID levels above or equal one, of course).
Monitoring RAID arrays
You can run mdadm as a daemon by using the follow-monitor mode. If
needed, that will make mdadm send email alerts to the system
administrator when arrays encounter errors or fail. Also, follow mode
can be used to trigger contingency commands if a disk fails, like
giving a second chance to a failed disk by removing and reinserting
it, so a non-fatal failure could be automatically solved.
Let’s see a basic example. Running
mdadm --monitor --daemonise --mail=root@localhost --delay=1800 /dev/md2
should release a mdadm daemon to monitor /dev/md2. The —daemonise switch tells mdadm to run as a deamon. The delay parameter means that polling will be done in intervals of 1800 seconds.
Finally, critical events and fatal errors should be e-mailed to the
system manager. That’s RAID monitoring made easy.
Finally, the —program or —alert parameters specify the program to be
run whenever an event is detected.
Note that, when supplying the -f switch, the mdadm daemon will never exit once it decides that there
are arrays to monitor, so it should normally be run in the background.
Remember that your are running a daemon, not a shell command.
If mdadm is ran to monitor without the -f switch, it will behave as a normal shell command and wait for you to stop it.
Using mdadm to monitor a RAID array is simple and effective. However,
there are fundamental problems with that kind of monitoring — what
happens, for example, if the mdadm daemon stops? In order to overcome
this problem, one should look towards «real» monitoring solutions.
There are a number of free software, open source, and even commercial
solutions available which can be used for Software RAID monitoring on
Linux. A search on FreshMeat should return a good number of matches.
Содержание
Эта страница целиком списана с исходной, где рассматриваются вопросы создания и обслуживания программного RAID-массива в операционной системе Linux. К сожалению, исходная страница недоступна, приходится держать копию на этом wiki.
Краткое описание mdadm
Управление программным RAID-массивом в Linux выполняется с помощью программы mdadm.
У программы mdadm есть несколько режимов работы.
Assemble(сборка)
Собрать компоненты ранее созданного массива в массив. Компоненты можно указывать явно, но можно и не указывать — тогда выполняется их поиск по суперблокам.
Build(построение)
Собрать массив из компонентов, у которых нет суперблоков. Не выполняются никакие проверки, создание и сборка массива в принципе ничем не отличаются.
Create(создание)
Создать новый массив на основе указанных устройств. Использовать суперблоки размещённые на каждом устройстве.
Monitor(наблюдение)
Следить за изменением состояния устройств. Для RAID0 этот режим не имеет смысла.
Grow (расширение или уменьшение)
Расширение или уменьшение массива, включаются или удаляются новые диски.
Incremental Assembly (инкрементальная сборка)
Добавление диска в массив.
Manage (управление)
Разнообразные операции по управлению массивом, такие как замена диска и пометка как сбойного.
Misc (разное)
Действия, которые не относятся ни к одному из перечисленных выше режимов работы.
Auto-detect (автоообнаружение)
Активация автоматически обнаруживаемых массивов в ядре Linux.
Формат вызова
mdadm [mode] [array] [options]
Режимы:
-
-A, –assemble — режим сборки
-
-B, –build — режим построения
-
-C, –create — режим создания
-
-F, –follow, –monitor — режим наблюдения
-
-G, –grow — режим расширения
-
-I, –incremental — режим инкрементальной сборки
Настройка программного RAID-массива
Рассмотрим как выполнить настройку RAID-массива 10 уровня на четырёх дисковых разделах. Мы будем использовать разделы:
/dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
В том случае если разделы иные, не забудьте использовать соответствующие имена файлов.
Создание разделов
Нужно определить на каких физических разделах будет создаваться RAID-массив. Если разделы уже есть, нужно найти свободные (fdisk -l). Если разделов ещё нет, но есть неразмеченное место, их можно создать с помощью программ fdisk или cfdisk.
Просмотреть какие есть разделы:
%# fdisk -l
Disk /dev/hda: 12.0 GB, 12072517632 bytes 255 heads, 63 sectors/track, 1467 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System /dev/hda1 * 1 13 104391 83 Linux /dev/hda2 14 144 1052257+ 83 Linux /dev/hda3 145 209 522112+ 82 Linux swap /dev/hda4 210 1467 10104885 5 Extended /dev/hda5 210 655 3582463+ 83 Linux ... ... /dev/hda15 1455 1467 104391 83 Linux
Просмотреть, какие разделы куда смонтированы, и сколько свободного места есть на них (размеры в килобайтах):
%# df -k Filesystem 1K-blocks Used Available Use% Mounted on /dev/hda2 1035692 163916 819164 17% / /dev/hda1 101086 8357 87510 9% /boot /dev/hda15 101086 4127 91740 5% /data1 ... ... ... /dev/hda7 5336664 464228 4601344 10% /var
Размонтирование
Если вы будете использовать созданные ранее разделы, обязательно размонтируйте их. RAID-массив нельзя создавать поверх разделов, на которых находятся смонтированные файловые системы.
%# umount /dev/sda1 %# umount /dev/sdb1 %# umount /dev/sdc1 %# umount /dev/sdd1
Изменение типа разделов
Желательно (но не обязательно) изменить тип разделов, которые будут входить в RAID-массив и установить его равным FD (Linux RAID autodetect). Изменить тип раздела можно с помощью fdisk.
Рассмотрим, как это делать на примере раздела /dev/hde1.
%# fdisk /dev/hde The number of cylinders for this disk is set to 8355. There is nothing wrong with that, but this is larger than 1024, and could in certain setups cause problems with: 1) software that runs at boot time (e.g., old versions of LILO) 2) booting and partitioning software from other OSs (e.g., DOS FDISK, OS/2 FDISK)
Command (m for help):
Use FDISK Help
Now use the fdisk m command to get some help:
Command (m for help): m ... ... p print the partition table q quit without saving changes s create a new empty Sun disklabel t change a partition's system id ... ... Command (m for help):
Set The ID Type To FD
Partition /dev/hde1 is the first partition on disk /dev/hde. Modify its type using the t command, and specify the partition number and type code. You also should use the L command to get a full listing of ID types in case you forget.
Command (m for help): t Partition number (1-5): 1 Hex code (type L to list codes): L
... ... ... 16 Hidden FAT16 61 SpeedStor f2 DOS secondary 17 Hidden HPFS/NTF 63 GNU HURD or Sys fd Linux raid auto 18 AST SmartSleep 64 Novell Netware fe LANstep 1b Hidden Win95 FA 65 Novell Netware ff BBT Hex code (type L to list codes): fd Changed system type of partition 1 to fd (Linux raid autodetect)
Command (m for help):
Make Sure The Change Occurred
Use the p command to get the new proposed partition table:
Command (m for help): p
Disk /dev/hde: 4311 MB, 4311982080 bytes 16 heads, 63 sectors/track, 8355 cylinders Units = cylinders of 1008 * 512 = 516096 bytes
Device Boot Start End Blocks Id System /dev/hde1 1 4088 2060320+ fd Linux raid autodetect /dev/hde2 4089 5713 819000 83 Linux /dev/hde4 6608 8355 880992 5 Extended /dev/hde5 6608 7500 450040+ 83 Linux /dev/hde6 7501 8355 430888+ 83 Linux
Command (m for help):
Save The Changes
Use the w command to permanently save the changes to disk /dev/hde:
Command (m for help): w The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy. The kernel still uses the old table. The new table will be used at the next reboot. Syncing disks.
Аналогичным образом нужно изменить тип раздела для всех остальных разделов, входящих в RAID-массив.
Создание RAID-массива
Создание RAID-массива выполняется с помощью программы mdadm (ключ –create). Мы воспользуемся опцией –level, для того чтобы создать RAID-массив 10 уровня. С помощью ключа –raid-devices укажем устройства, из которых будет собираться RAID-массив.
mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 64K
mdadm: /dev/hde1 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27 23:11:39 2007
mdadm: /dev/hdf2 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27 23:11:39 2007
mdadm: /dev/hdg1 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27 23:11:39 2007
mdadm: size set to 48064K
Continue creating array? y
mdadm: array /dev/md0 started.
Если вы хотите сразу создать массив, где диска не хватает (degraded) просто укажите слово missing вместо имени устройства. Для RAID5 это может быть только один диск; для RAID6 — не более двух; для RAID1 — сколько угодно, но должен быть как минимум один рабочий.
Проверка правильности сборки
Убедиться, что RAID-массив проинициализирован корректно можно просмотрев файл /proc/mdstat. В этом файле отражается текущее состояние RAID-массива.
%# cat /proc/mdstat
Personalities : [raid5]
read_ahead 1024 sectors
md0 : active raid5 hdg1[2] hde1[1] hdf2[0]
4120448 blocks level 5, 32k chunk, algorithm 3 [3/3] [UUU]
unused devices: <none>
Обратите внимание на то, как называется новый RAID-массив. В нашем случае он называется /dev/md0. Мы будем обращаться к массиву по этому имени.
Создание файловой системы поверх RAID-массива
Новый RAID-раздел нужно отформатировать, т.е. создать на нём файловую систему. Сделать это можно при помощи программы из семейства mkfs. Если мы будем создавать файловую систему ext3, воспользуемся программой mkfs.ext3. :
%# mkfs.ext3 /dev/md0
mke2fs 1.39 (29-May-2006)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
36144 inodes, 144192 blocks
7209 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
18 block groups
8192 blocks per group, 8192 fragments per group
2008 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done Creating journal (4096 blocks): done Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 33 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
Имеет смысл для лучшей производительности файловой системы указывать при создании количество дисков в рейде и количество блоков файловой системы которое может поместиться в один страйп ( chunk ), это особенно важно при создании массивов уровня RAID0,RAID5,RAID6,RAID10. Для RAID1 ( mirror ) это не имеет значения так как запись идёт всегда на один device, a в других типах рейдов дата записывается последовательно на разные диски порциями соответствующими размеру stripe. Например если мы используем RAID5 из 3 дисков, с дефолтным размером страйпа в 64К и используем файловую систему ext3 с размером блока в 4К то можно вызывать команду mkfs.ext вот так:
%# mkfs.ext3 -b 4096 -E stride=16,stripe-width=32 /dev/md0
stripe-width обычно рассчитывается как stride * N ( N это дата диски в массиве — например в RAID5 — два дата диска и один parity ) Для не менее популярной файловой системы XFS надо указывать не количество блоков файловой системы соответствующих размеру stripe в массиве, а непосредственно размер самого страйпа
%# mkfs.xfs -d su=64k,sw=3 /dev/md0
Создание конфигурационного файла mdadm.conf
Система сама не запоминает какие RAID-массивы ей нужно создать и какие компоненты в них входят. Эта информация находится в файле mdadm.conf.
Строки, которые следует добавить в этот файл, можно получить при помощи команды
mdadm –detail –scan –verbose
Вот пример её использования:
%# mdadm --detail --scan --verbose ARRAY /dev/md0 level=raid5 num-devices=4 UUID=77b695c4:32e5dd46:63dd7d16:17696e09 devices=/dev/hde1,/dev/hdf2,/dev/hdg1
Если файла mdadm.conf ещё нет, можно его создать:
%# echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
%# mdadm --detail --scan --verbose | awk '/ARRAY/ {print}' >> /etc/mdadm/mdadm.conf
Создание точки монтирования для RAID-массива
Поскольку мы создали новую файловую систему, вероятно, нам понадобится и новая точка монтирования. Назовём её /raid.
%# mkdir /raid
Изменение /etc/fstab
Для того чтобы файловая система, созданная на новом RAID-массиве, автоматически монтировалась при загрузке, добавим соответствующую запись в файл /etc/fstab хранящий список автоматически монтируемых при загрузке файловых систем.
/dev/md0 /raid ext3 defaults 1 2
Если мы объединяли в RAID-массив разделы, которые использовались раньше, нужно отключить их монтирование: удалить или закомментировать соответствующие строки в файле /etc/fstab. Закомментировать строку можно символом #.
#/dev/hde1 /data1 ext3 defaults 1 2 #/dev/hdf2 /data2 ext3 defaults 1 2 #/dev/hdg1 /data3 ext3 defaults 1 2
Монтирование файловой системы нового RAID-массива
Для того чтобы получить доступ к файловой системе, расположенной на новом RAID-массиве, её нужно смонтировать. Монтирование выполняется с помощью команды mount.
Если новая файловая система добавлена в файл /etc/fstab, можно смонтировать её командой mount -a (смонтируются все файловые системы, которые должны монтироваться при загрузке, но сейчас не смонтированы).
%# mount -a
Можно смонтировать только нужный нам раздел (при условии, что он указан в /etc/fstab).
%# mount /raid
Если раздел в /etc/fstab не указан, то при монтировании мы должны задавать как минимум два параметра — точку монтирования и монтируемое устройство:
%# mount /dev/md0 /raid
Проверка состояния RAID-массива
Информация о состоянии RAID-массива находится в файле /proc/mdstat.
%# raidstart /dev/md0
%# cat /proc/mdstat
Personalities : [raid5]
read_ahead 1024 sectors
md0 : active raid5 hdg1[2] hde1[1] hdf2[0]
4120448 blocks level 5, 32k chunk, algorithm 3 [3/3] [UUU]
unused devices: <none>
Если в файле информация постоянно изменяется, например, идёт пересборка массива, то постоянно изменяющийся файл удобно просматривать при помощи программы watch:
%$ watch cat /proc/mdstat
Как выполнить проверку целостности программного RAID-массива md0:
echo ‘check’ >/sys/block/md0/md/sync_action
Как посмотреть нашлись ли какие-то ошибки в процессе проверки программного RAID-массива по команде check или repair:
cat /sys/block/md0/md/mismatch_cnt
Проблема загрузки на многодисковых системах
В некоторых руководствах по mdadm после первоначальной сборки массивов рекомендуется добавлять в файл /etc/mdadm/mdadm.conf вывод команды «mdadm –detail –scan –verbose»:
ARRAY /dev/md/1 level=raid1 num-devices=2 metadata=1.2 name=linuxWork:1 UUID=147c5847:dabfe069:79d27a05:96ea160b
devices=/dev/sda1
ARRAY /dev/md/2 level=raid1 num-devices=2 metadata=1.2 name=linuxWork:2 UUID=68a95a22:de7f7cab:ee2f13a9:19db7dad
devices=/dev/sda2
, в котором жёстко прописаны имена разделов (/dev/sda1, /dev/sda2 в приведённом примере).
Если после этого обновить образ начальной загрузки (в Debian вызвать ‘update-initramfs -u’ или ‘dpkg-reconfigure mdadm’), имена разделов запишутся в файл mdadm.conf образа начальной загрузки, и вы не сможете загрузиться с массива, если конфигурация жёстких дисков изменится (нужные разделы получат другие имена). Для этого не обязательно добавлять или убирать жёсткие диски: в многодисковых системах их имена могут меняться от загрузки к загрузке.
Решение: записывать в /etc/mdadm/mdadm.conf вывод команды «mdadm –detail –scan» (без –verbose).
При этом в файле mdadm.conf будут присутствовать UUID разделов, составляющих каждый RAID-массив. При загрузке системы mdadm находит нужные разделы независимо от их символических имён по UUID.
mdadm.conf, извлечённый из образа начальной загрузки Debian:
DEVICE partitions
HOMEHOST <system>
ARRAY /dev/md/1 metadata=1.2 UUID=147c5847:dabfe069:79d27a05:96ea160b name=linuxWork:1
ARRAY /dev/md/2 metadata=1.2 UUID=68a95a22:de7f7cab:ee2f13a9:19db7dad name=linuxWork:2
Результат исследования раздела командой ‘mdadm –examine’«
/dev/sda1:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : 147c5847:dabfe069:79d27a05:96ea160b
Name : linuxWork:1
Creation Time : Thu May 23 09:17:01 2013
Raid Level : raid1 Raid Devices : 2
Раздел c UUID 147c5847:dabfe069:79d27a05:96ea160b войдёт в состав массива, даже если станет /dev/sdb1 при очередной загрузке системы.
Вообще, существует 2 файла mdadm.conf, влияющих на автоматическую сборку массивов:
один при загрузке системы, записывется в образ начальной загрузки при его обновлении; другой находится в каталоге /etc/mdadm/ и влияет на автосборку массивов внутри работающей системы.
Соответственно, вы можете иметь информацию:
1) в образе начальной загрузки (ОНЗ) и в /etc/mdadm/mdadm.conf;
2) только в ОНЗ (попадает туда при его создании обновлении);
3) только в /etc/mdadm/mdadm.conf;
4) нигде.
В том месте, где есть mdadm.conf, сборка происходит по правилам; где нет — непредсказуемо.
Примечание: если вы не обновили ОНЗ после создания RAID-массивов, их конфигурация всё равно в него попадёт — при обновлении образа другой программой / при обновлении системы (но вы не будете об этом знать со всеми вытекающими).
[править] Дальнейшая работа с массивом
[править] Пометка диска как сбойного
Диск в массиве можно условно сделать сбойным, ключ –fail (-f):
%# mdadm /dev/md0 --fail /dev/hde1 %# mdadm /dev/md0 -f /dev/hde1
[править] Удаление сбойного диска
Сбойный диск можно удалить с помощью ключа –remove (-r):
%# mdadm /dev/md0 --remove /dev/hde1 %# mdadm /dev/md0 -r /dev/hde1
[править] Добавление нового диска
Добавить новый диск в массив можно с помощью ключей –add (-a) и –re-add:
%# mdadm /dev/md0 --add /dev/hde1 %# mdadm /dev/md0 -a /dev/hde1
Сборка существующего массива
Собрать существующий массив можно с помощью mdadm –assemble. Как дополнительный аргумент указывается, нужно ли выполнять сканирование устройств, и если нет, то какие устройства нужно собирать.
%# mdadm --assemble /dev/md0 /dev/hde1 /dev/hdf2 /dev/hdg1 %# mdadm --assemble --scan
Расширение массива
Расширить массив можно с помощью ключа –grow (-G). Сначала добавляется диск, а потом массив расширяется:
%# mdadm /dev/md0 --add /dev/hdh2
Проверяем, что диск (раздел) добавился:
%# mdadm --detail /dev/md0 %# cat /proc/mdstat
Если раздел действительно добавился, мы можем расширить массив:
%# mdadm -G /dev/md0 --raid-devices=4
Опция –raid-devices указывает новое количество дисков, используемое в массиве. Например, было 3 диска, а теперь расширяем до 4-х — указываем 4.
Рекомендуется задать файл бэкапа на случай прерывания перестроения массива, например добавить:
-
-backup-file=/var/backup
При необходимости можно регулировать скорость процесса расширения массива, указав нужное значение в файлах
/proc/sys/dev/raid/speed_limit_min /proc/sys/dev/raid/speed_limit_max
Убедитесь, что массив расширился:
%# cat /proc/mdstat
Нужно обновить конфигурационный файл с учётом сделанных изменений:
%# mdadm --detail --scan >> /etc/mdadm/mdadm.conf %# vi /etc/mdadm/mdadm.conf
Возобновление отложенной синхронизации
Отложенная синхронизация:
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active(auto-read-only) raid1 sda1[0] sdb1[1]
78148096 blocks [2/2] [UU]
resync=PENDING
Возобновить:
echo idle > /sys/block/md0/md/sync_action
P.S.: Если вы увидели «active (auto-read-only)» в файле /proc/mdstat, то возможно вы просто ничего не записывали в этот массив. К примеру, после монтирования раздела и любых изменений в примонтированном каталоге, статус автоматически меняется:
md0 : active raid1 sdc[0] sdd[1]
Переименование массива
Для начала отмонтируйте и остановите массив:
%# umount /dev/md0 %# mdadm --stop /dev/md0
Затем необходимо пересобрать как md5 каждый из разделов sd[abcdefghijk]1
%# mdadm --assemble /dev/md5 /dev/sd[abcdefghijk]1 --update=name
или так
%# mdadm --assemble /dev/md5 /dev/sd[abcdefghijk]1 --update=super-minor
Удаление массива
Для начала отмонтируйте и остановите массив:
%# umount /dev/md0 %# mdadm -S /dev/md0
Затем необходимо затереть superblock каждого из составляющих массива:
%# mdadm --zero-superblock /dev/hde1 %# mdadm --zero-superblock /dev/hdf2
Если действие выше не помогло, то затираем так:
%# dd if=/dev/zero of=/dev/hde1 bs=512 count=1 %# dd if=/dev/zero of=/dev/hdf2 bs=512 count=1
Создание пустого массива без сихронизации данных
Не каноничный метод, применять на дисках без данных!
Смотрим информацию по массивам и выбираем жертву
%# cat /proc/mdstat
Предварительно разбираем массив
%# mdadm --stop /dev/md124
Создаём директорию для metadata файлов
%# mkdir /tmp/metadata
Снимаем дамп metadata с одного из raid дисков
%# mdadm --dump=/tmp/metadata /dev/sda1
Копируем метаданные
%# cp /tmp/metadata/sda1 /tmp/metadata/sdb1
Накатываем бекап
%# mdadm --restore=/tmp/metadata /dev/sdb1
Собираем массив
%# mdadm --create --verbose /dev/md124 --level=0 --raid-devices=2 /dev/sda /dev/sdb
Радуемся отсутствию синка и данных
%# cat /proc/mdstat
Дополнительная информация
man mdadm (англ.) man mdadm.conf (англ.) Linux Software RAID (англ.) Gentoo Install on Software RAID (англ.) HOWTO Migrate To RAID (англ.) Remote Conversion to Linux Software RAID-1 for Crazy Sysadmins HOWTO (англ.) Migrating To RAID1 Mirror on Sarge (англ.) Настройка программного RAID-1 на Debian Etch (рус.), а также обсуждение на ЛОРе Недокументированные фишки программного RAID в Linux (рус.)
Производительность программных RAID-массивов
Adventures With Linux RAID: Part 1, Part 2 (англ.) Параметры, влияющие на производительность программного RAID (рус.)
Разные заметки, имеющие отношение к RAID
BIO_RW_BARRIER - what it means for devices, filesystems, and dm/md. (англ.)
Привет, друзья. В прошлой статье мы с вами создали RAID 1 массив (Зеркало) — отказоустойчивый массив из двух жёстких дисков SSD. Смысл создания RAID 1 массива заключается в повышении надёжности хранения данных на компьютере. Когда два жёстких диска объединены в одно хранилище, информация на обоих дисках записывается параллельно (зеркалируется). Диски являются точными копиями друг друга, и если один из них выйдет из строя, мы получим доступ к операционной системе и нашим данным, ибо их целостность будет обеспечена работой другого диска. Также конфигурация RAID 1 повышает производительность при чтении данных, так как считывание происходит с двух дисков. В этой же статье мы рассмотрим, как восстановить массив RAID 1, если он развалится. Другими словами, мы рассмотрим, как сделать Rebuild RAID 1.

 Развал RAID 1 массива может произойти по нескольким причинам: отказ одного из дисков, ошибки микропрограммы БИОСа, неправильные действия пользователя компьютера. При развале RAID 1 в БИОСе у него будет статус «Degraded».
Развал RAID 1 массива может произойти по нескольким причинам: отказ одного из дисков, ошибки микропрограммы БИОСа, неправильные действия пользователя компьютера. При развале RAID 1 в БИОСе у него будет статус «Degraded».
 В таких случаях нужно произвести восстановление (Rebuild) массива. Каким образом это можно сделать? К примеру, при отказе одного накопителя мы просто подсоединяем другой исправный, затем жмём в БИОСе кнопку «Rebuild», и происходит синхронизация данных на дисках. Таким вот образом RAID 1 массив восстанавливается, и мы можем работать дальше. Вроде, всё просто. Однако на практике при возникновении такой проблемы много нюансов. Давайте подробно рассмотрим все особенности восстановления RAID.
В таких случаях нужно произвести восстановление (Rebuild) массива. Каким образом это можно сделать? К примеру, при отказе одного накопителя мы просто подсоединяем другой исправный, затем жмём в БИОСе кнопку «Rebuild», и происходит синхронизация данных на дисках. Таким вот образом RAID 1 массив восстанавливается, и мы можем работать дальше. Вроде, всё просто. Однако на практике при возникновении такой проблемы много нюансов. Давайте подробно рассмотрим все особенности восстановления RAID.
Если созданный с помощью БИОСа материнской платы RAID 1 массив развалился, неопытный пользователь может этого сразу и не понять. Мы не получим ни звукового оповещения, ни оповещения в иной форме, сигнализирующих о проблеме развала RAID 1. Возможностями аварийной сигнализации при развале массивов обладают только отдельные SAS/SATA/RAID-контроллеры, работающие через интерфейс PCI Express. За аварийную сигнализацию при проблемах с массивами отвечает специальное ПО таких контроллеров. Не имея таких контроллеров, можем использовать программы типа CrystalDiskInfo или Hard Disk Sentinel Pro, которые предупредят нас о выходе из строя одного из накопителей массива звуковым сигналом, либо электронным письмом на почту.
 Если заглянем в управление дисками Windows, о развале RAID 1 можем догадаться, например, по исчезновению разметки одного из дисков.
Если заглянем в управление дисками Windows, о развале RAID 1 можем догадаться, например, по исчезновению разметки одного из дисков.
 Но лучше, конечно, чтобы на компьютере был установлен родной софт от производителя чипсета материнской платы, выполняющий задачи по обслуживанию RAID-массивов. И именно этот софт должен вывести сообщение о деградации массива из-за выхода из строя одного из накопителей. Ещё такой софт должен выполнять постоянное наблюдение за техническим состоянием массива. И при замене вышедшего из строя диска на исправный на таком софте лежит ответственность за быстрое перестроение рассыпавшегося массива.
Но лучше, конечно, чтобы на компьютере был установлен родной софт от производителя чипсета материнской платы, выполняющий задачи по обслуживанию RAID-массивов. И именно этот софт должен вывести сообщение о деградации массива из-за выхода из строя одного из накопителей. Ещё такой софт должен выполнять постоянное наблюдение за техническим состоянием массива. И при замене вышедшего из строя диска на исправный на таком софте лежит ответственность за быстрое перестроение рассыпавшегося массива.
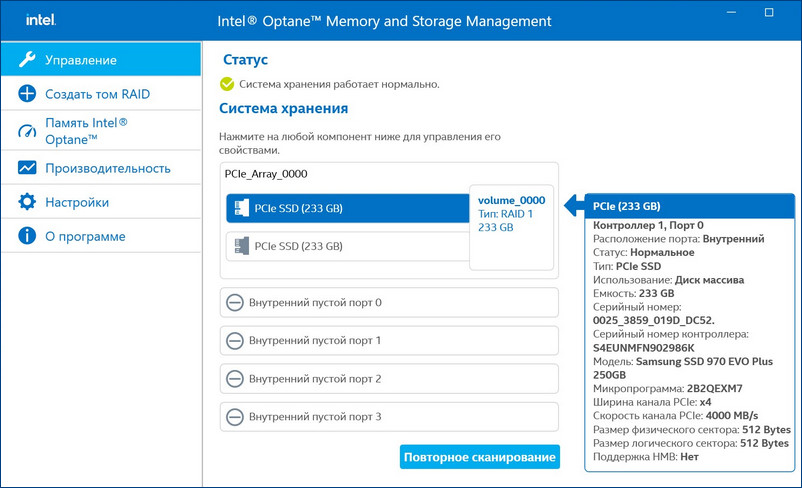
Для примера возьмём мою материнскую плату на чипсете Z490 от Intel, для которого существует специальное программное обеспечение Intel Rapid Storage Technology (Intel RST). Технология Intel Rapid Storage поддерживает SSD SATA и SSD PCIe M.2 NVMe, повышает производительность компьютеров с SSD-накопителями за счёт собственных разработок. Всесторонне обслуживает массивы RAID в конфигурациях 0, 1, 5, 10. Предоставляет пользовательский интерфейс Intel Optane Memory and Storage Management для управления системой хранения данных, в том числе дисковых массивов.

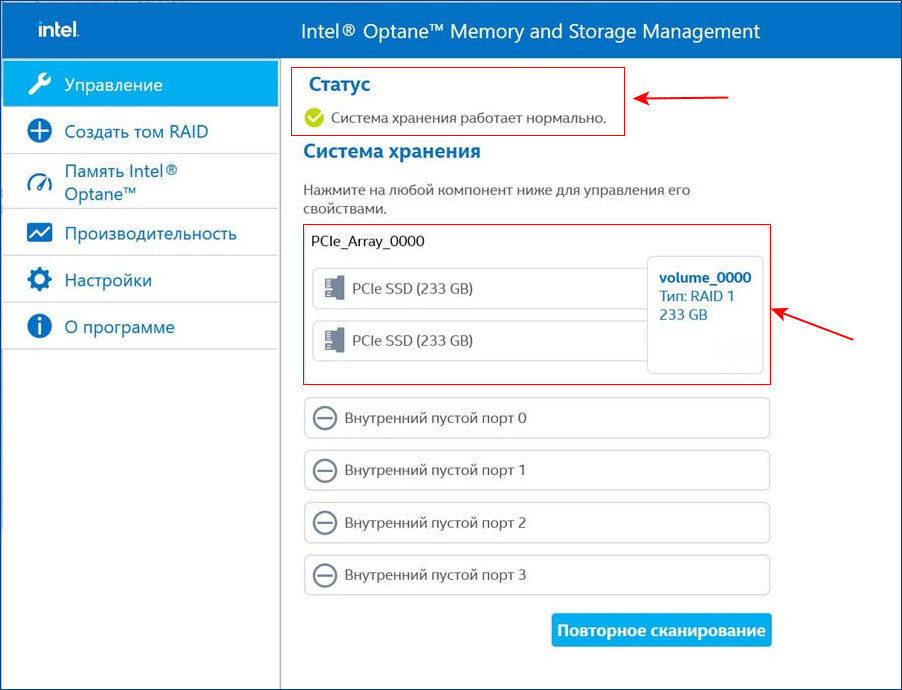
После установки Intel RST в главном окне увидим созданный нами из двух SSD M.2 NVMe Samsung 970 EVO Plus (250 Гб) RAID 1 массив, исправно функционирующий.
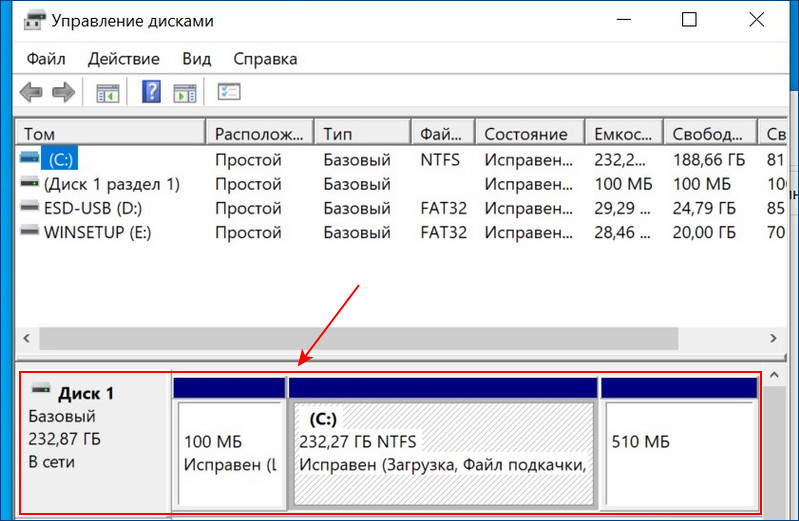
 Вот этот массив в управлении дисками Windows.
Вот этот массив в управлении дисками Windows.
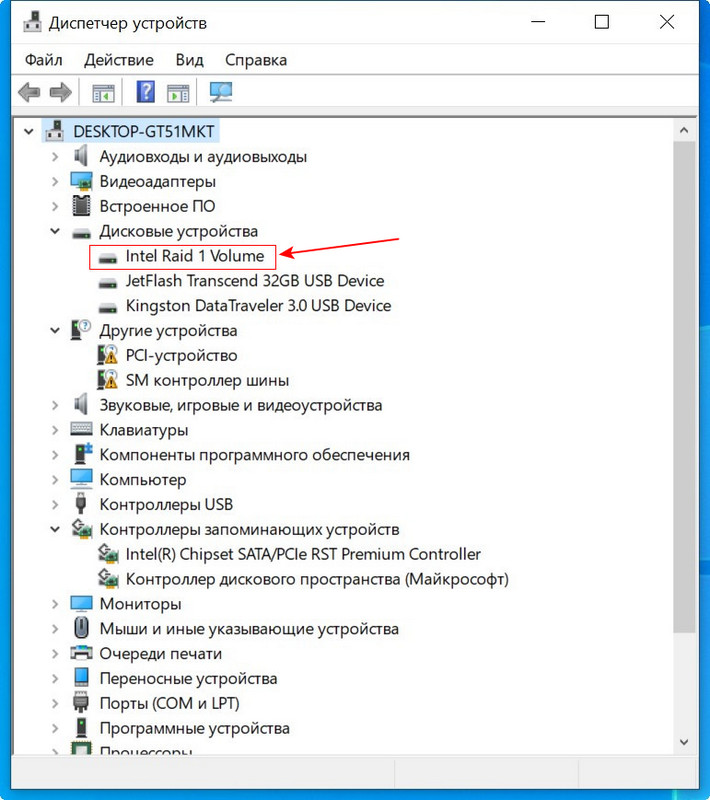
 И в диспетчере устройств.
И в диспетчере устройств.
 Технология Intel Rapid Storage имеет свою службу и постоянно мониторит состояние накопителей. На данный момент все находящиеся в рейде диски исправны.
Технология Intel Rapid Storage имеет свою службу и постоянно мониторит состояние накопителей. На данный момент все находящиеся в рейде диски исправны.
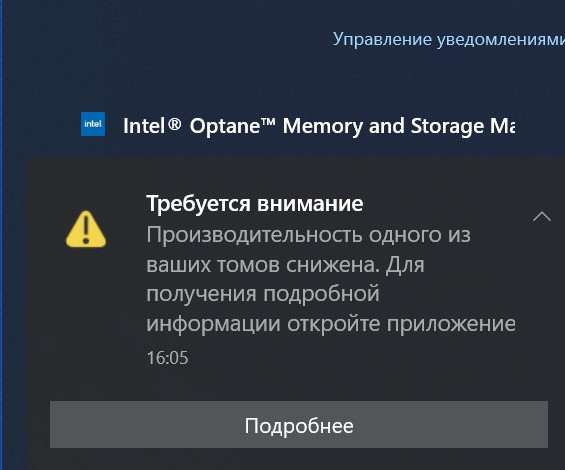
 Если какой-либо накопитель неисправен, драйвер Intel RST сразу предупредит всплывающим окном о проблеме «Требуется внимание. Производительность одного из ваших томов снижена».
Если какой-либо накопитель неисправен, драйвер Intel RST сразу предупредит всплывающим окном о проблеме «Требуется внимание. Производительность одного из ваших томов снижена».
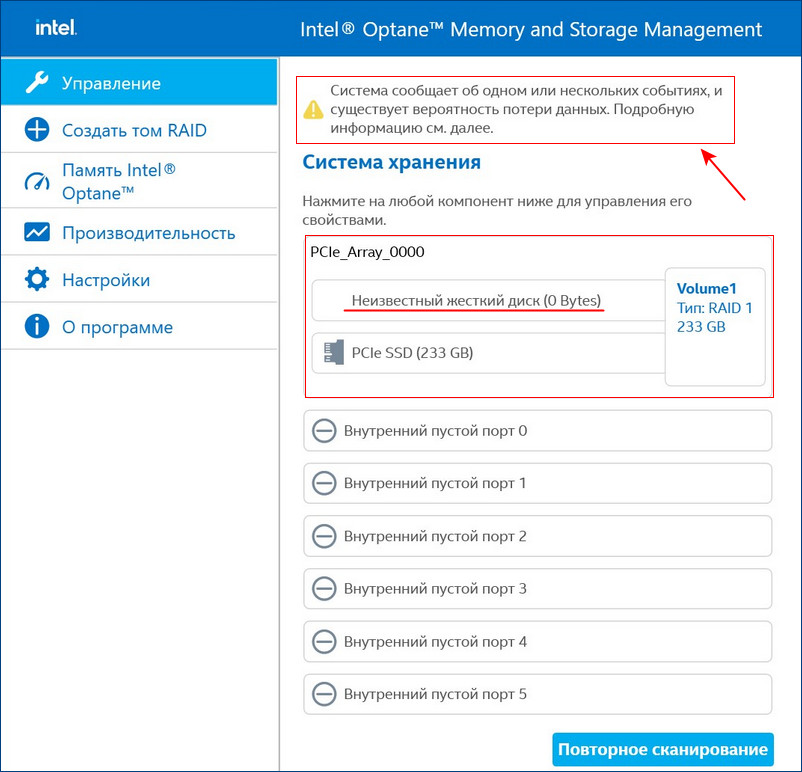
 И в главном окне программы будет значиться, что один из дисков массива неисправен.
И в главном окне программы будет значиться, что один из дисков массива неисправен.
 В этом случае можно произвести диагностику неисправного накопителя специальным софтом, к примеру, программой Hard Disk Sentinel Pro. Если диск неисправен или отработал свой ресурс, выключаем компьютер и заменяем диск на новый. Затем делаем Rebuild (восстановление) RAID 1 массива.
В этом случае можно произвести диагностику неисправного накопителя специальным софтом, к примеру, программой Hard Disk Sentinel Pro. Если диск неисправен или отработал свой ресурс, выключаем компьютер и заменяем диск на новый. Затем делаем Rebuild (восстановление) RAID 1 массива.
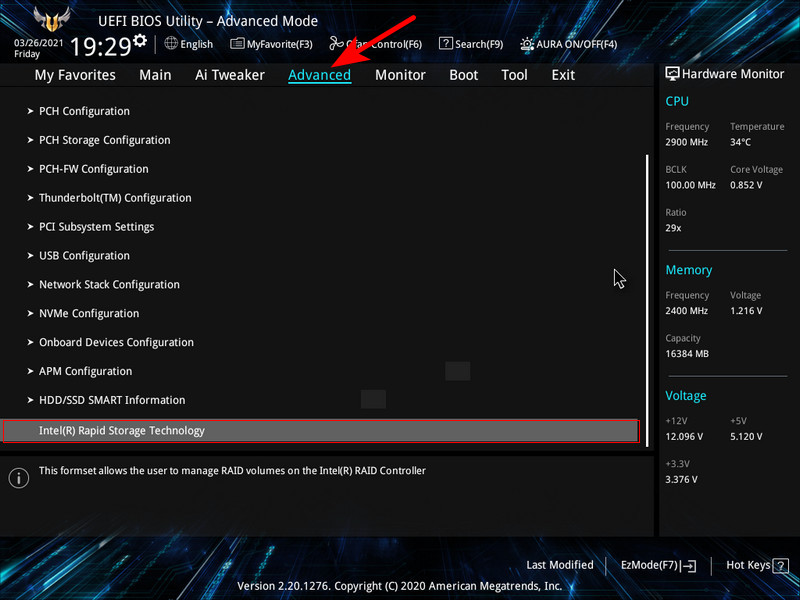
После замены неисправного диска включаем ПК и входим в БИОС. Заходим в расширенные настройки «Advanced Mode», идём во вкладку «Advanced». Переходим в пункт «Intel Rapid Storage Technology».
Видим, что наш RAID 1 массив с названием Volume 1 неработоспособен — «Volume 1 RAID 1 (mirroring), Degraded».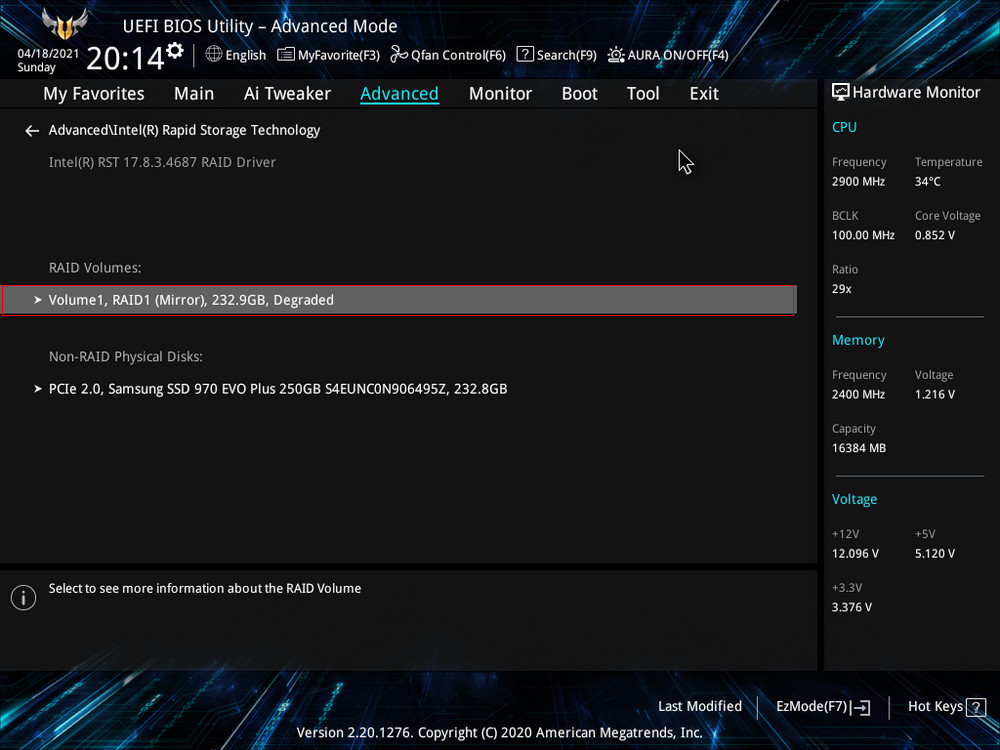 Выбираем «Rebuild» (Восстановить).
Выбираем «Rebuild» (Восстановить).
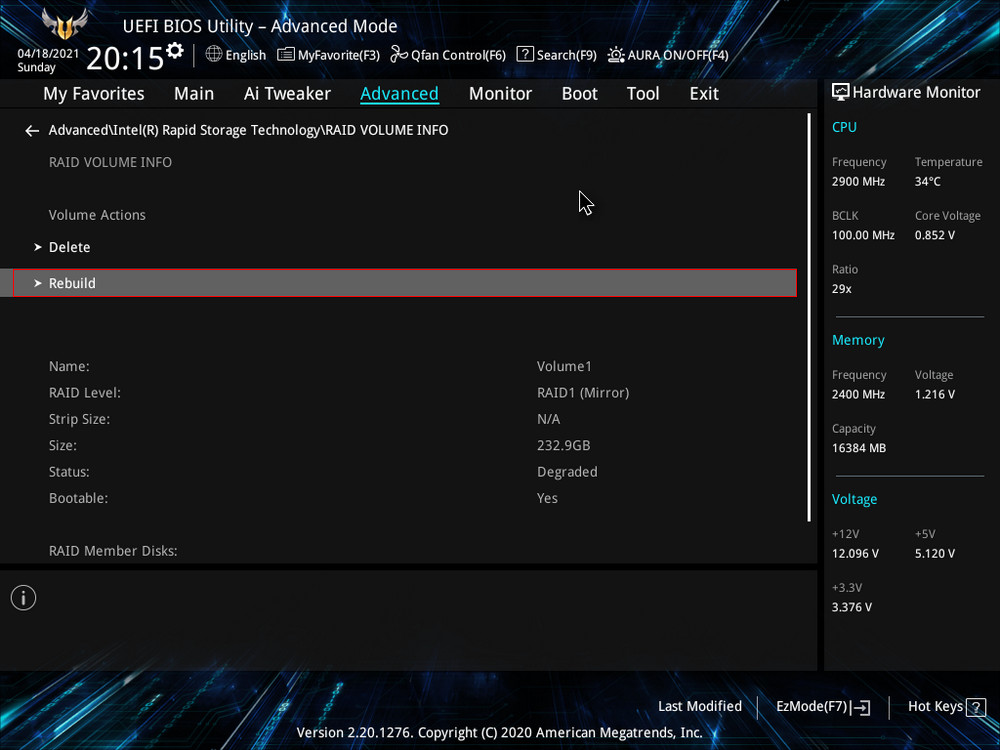 Обратим внимание на уведомление внизу: «Selecting a disk initiates a rebuild. Rebuild completes in the operating system», переводится как «Выбор диска инициирует перестройку массива. Восстановление завершается в операционной системе». Выбираем новый накопитель, который нужно добавить в массив для его восстановления, жмём Enter. Появится следующий экран, указывающий, что после входа в операционную систему будет выполнено автоматическое восстановление — «All disk data will be lost», переводится как «Все данные на диске будут потеряны».
Обратим внимание на уведомление внизу: «Selecting a disk initiates a rebuild. Rebuild completes in the operating system», переводится как «Выбор диска инициирует перестройку массива. Восстановление завершается в операционной системе». Выбираем новый накопитель, который нужно добавить в массив для его восстановления, жмём Enter. Появится следующий экран, указывающий, что после входа в операционную систему будет выполнено автоматическое восстановление — «All disk data will be lost», переводится как «Все данные на диске будут потеряны».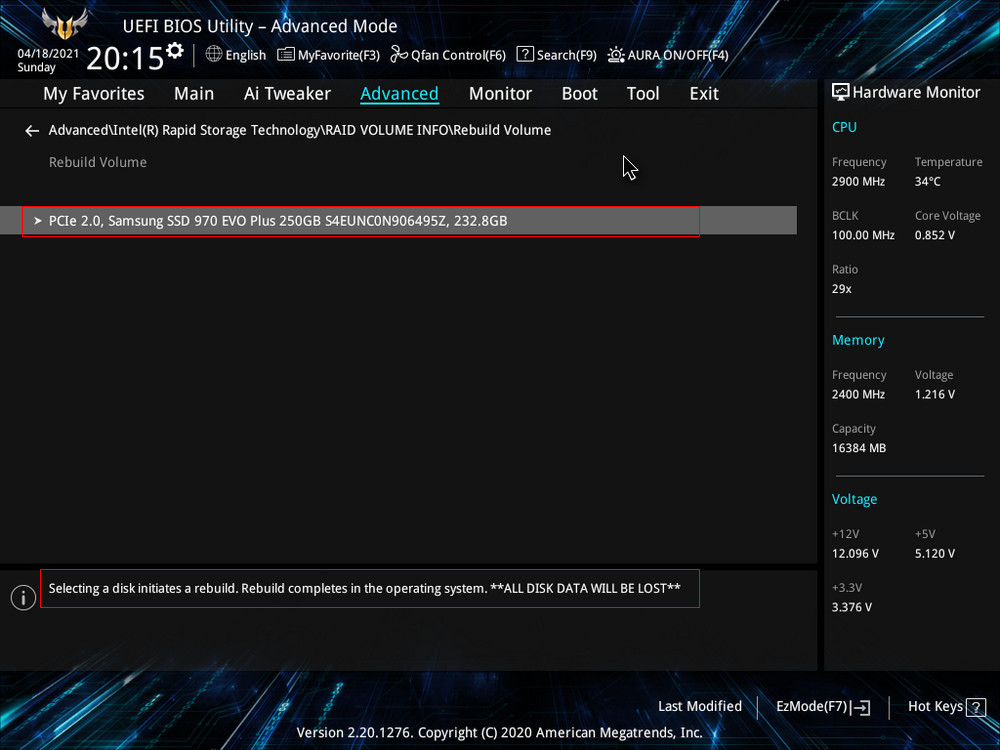 RAID 1 массив восстановлен.
RAID 1 массив восстановлен.
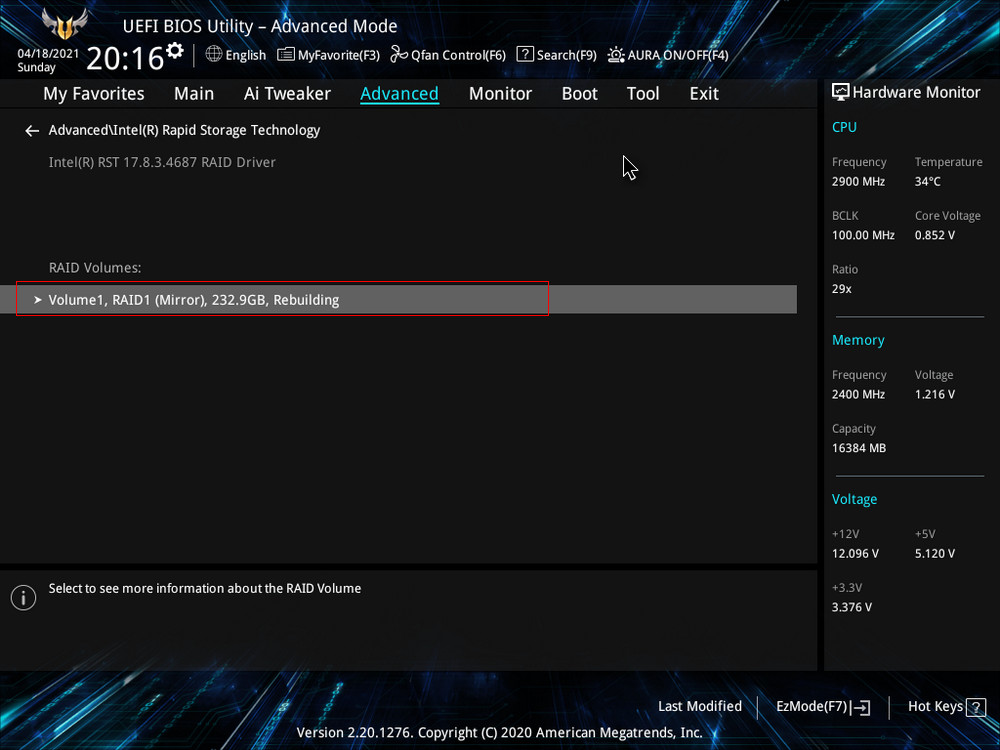 Жмём F10, сохраняем настройки, произведённые нами в БИОСе, и перезагружаемся.
Жмём F10, сохраняем настройки, произведённые нами в БИОСе, и перезагружаемся.
После перезагрузки открываем программу Intel Optane Memory and Storage Management и видим, что всё ещё происходит перестроение массива, но операционной системой уже можно пользоваться.
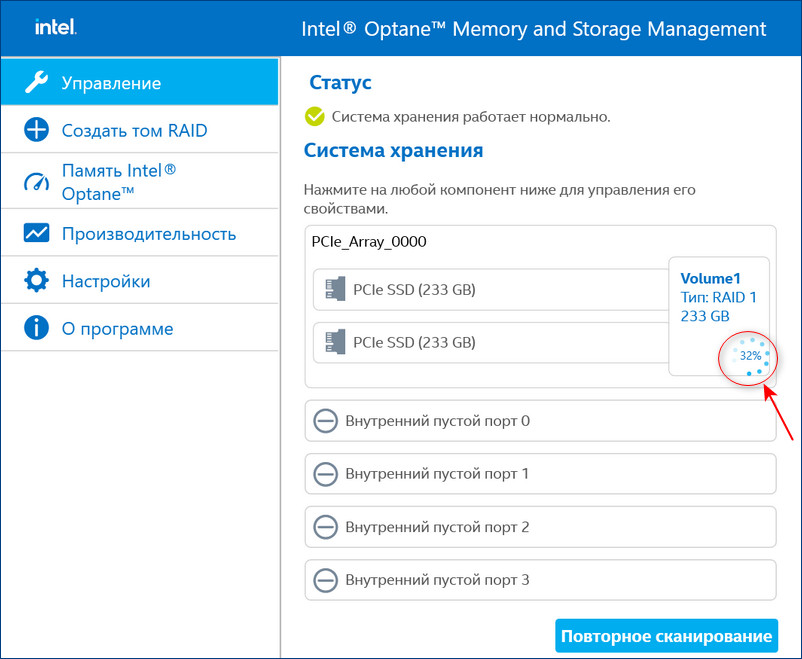
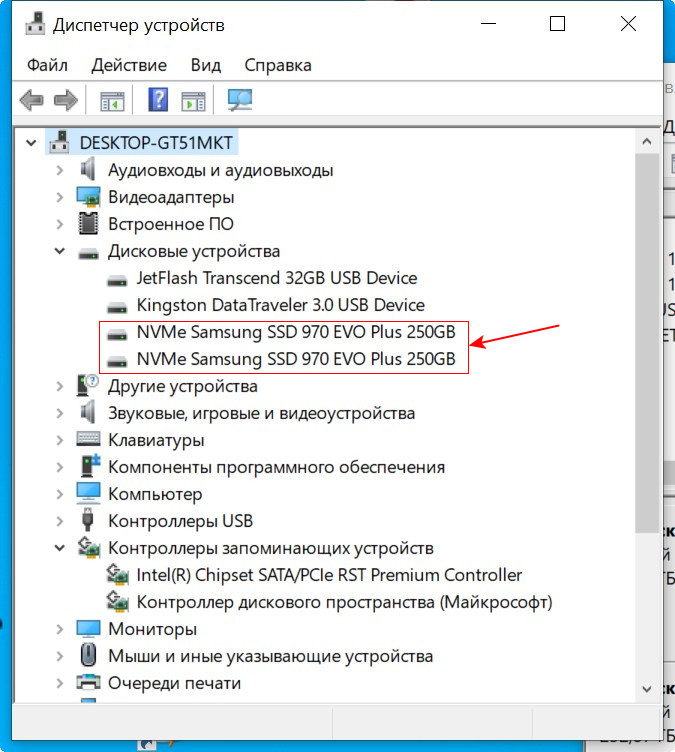
Восстановить дисковый массив можно непосредственно в программе Intel Optane Memory and Storage Management. К примеру, у нас неисправен один диск массива, и Windows 10 загружается с исправного накопителя. Выключаем компьютер, отсоединяем неисправный, а затем устанавливаем новый SSD PCIe M.2 NVMe, включаем ПК. Программа Intel Optane Memory and Storage Management определяет его как неизвестный жёсткий диск.
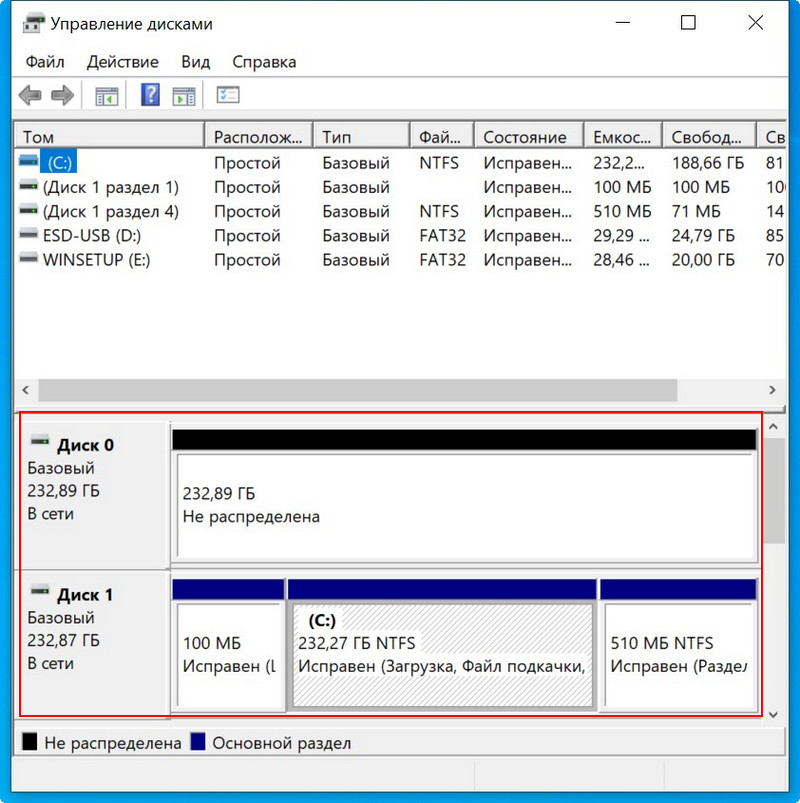 Диспетчер устройств, как и управление дисками, не видит целостный RAID, а видит два разных SSD.
Диспетчер устройств, как и управление дисками, не видит целостный RAID, а видит два разных SSD.
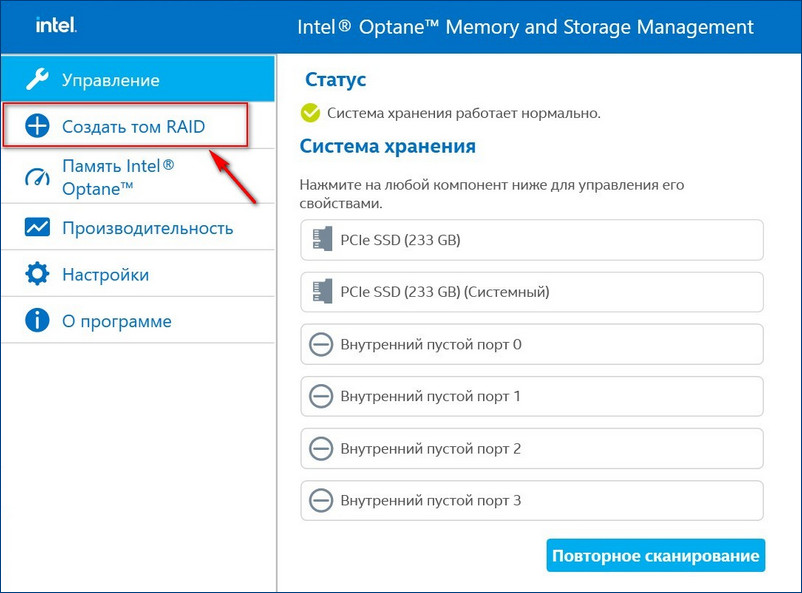
 В главном окне программы жмём «Создать том RAID».
В главном окне программы жмём «Создать том RAID».
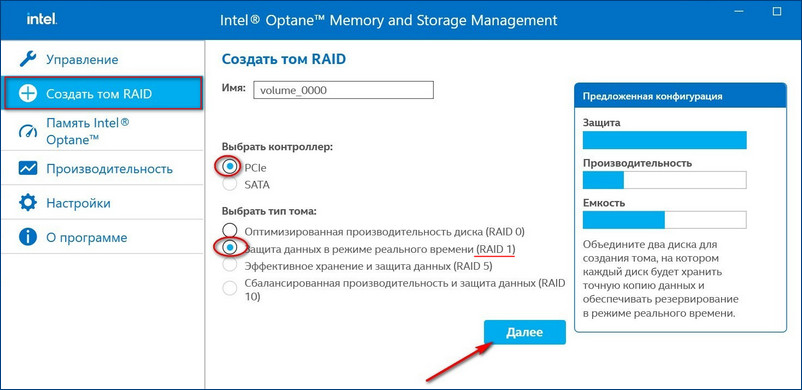
 У нас SSD нового поколения с интерфейсом PCIe M.2 NVMe, значит, выбираем контроллер PCIe. Тип дискового массива — «Защита данных в режиме реального времени (RAID 1)».
У нас SSD нового поколения с интерфейсом PCIe M.2 NVMe, значит, выбираем контроллер PCIe. Тип дискового массива — «Защита данных в режиме реального времени (RAID 1)».
 Выбираем два наших диска SSD PCIe M.2 NVMe.
Выбираем два наших диска SSD PCIe M.2 NVMe.
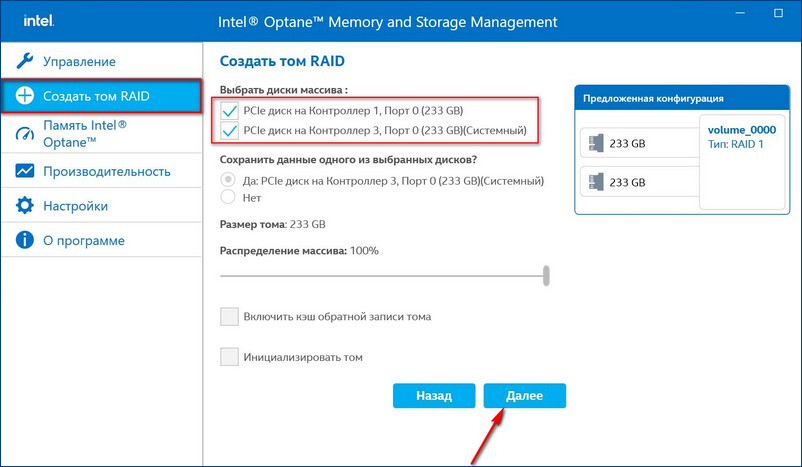 Если на новом диске были данные, после перестроения массива данные на нём удалятся. Жмём «Создать том RAID».
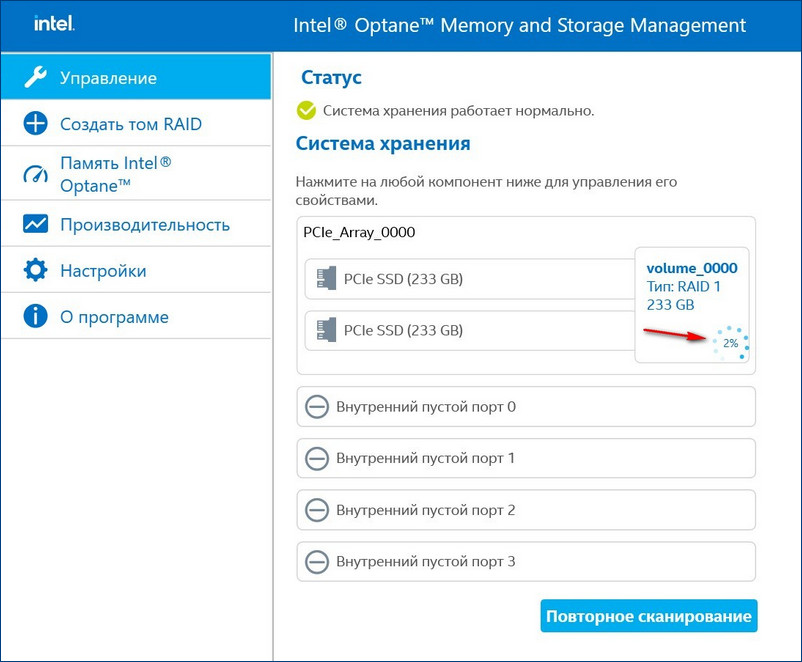
Если на новом диске были данные, после перестроения массива данные на нём удалятся. Жмём «Создать том RAID».  Можем наблюдать процесс восстановления массива.
Можем наблюдать процесс восстановления массива.
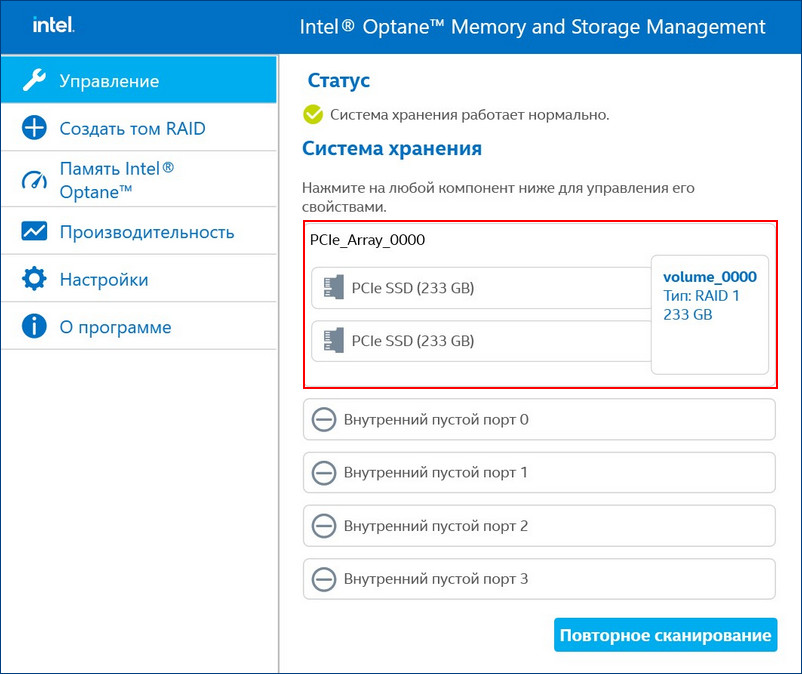
 RAID 1 массив восстановлен.
RAID 1 массив восстановлен.
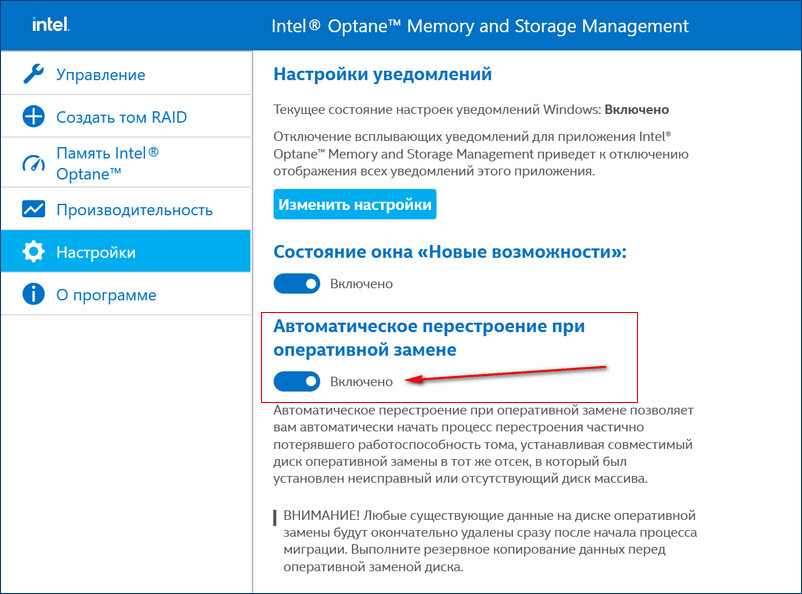
Если включить в настройках программы Intel RST «Автоматическое перестроение при оперативной замене», при замене неисправного накопителя не нужно будет ничего настраивать. Восстановление дискового массива начнётся автоматически.
Если у вас выйдут из строя сразу оба накопителя, то покупаем новые, устанавливаем в системный блок, затем создаём RAID 1 заново и разворачиваем на него резервную копию.
Управление дисковым массивом работающего на аппаратном контроллере LSI MegaRAID, мы рекомендуем производить с помощью консольного клиента MegaCLI
Установка MegaCLI:
wget http://www.lsi.com/downloads/Public/RAID%20Controllers/RAID%20Controllers%20Common%20Files/.zip
unzip 8.07.07_MegaCLI.zip
cd 8.07.07_MegaCLI/
chmod +x MegaCli
Основные команды для работы:
Получить статус и конфигурацию всех адаптеров
megacli -AdpAllInfo -aAll
Cтатус и параметры всех логических дисков
megacli -LDInfo -LAll -aAll
Статус и параметры физических устройств
megacli -PDList -a0
Статус и параметры диска в 4-м слоте
megacli -pdInfo -PhysDrv[252:4] -a0
Создание RAID6 массив MegaCLI
Давайте предположим, что у нас есть сервер с MegaRAID SAS
Получим список физических дисков:
megacli -PDlist -a0 | grep -e ‘^Enclosure Device ID:’ -e ‘^Slot Number:’
Enclosure Device ID: 29
Slot Number: 0
Enclosure Device ID: 29
Slot Number: 1
Enclosure Device ID: 29
Slot Number: 2
Enclosure Device ID: 29
Slot Number: 3
Enclosure Device ID: 29
Slot Number: 4
Enclosure Device ID: 29
Slot Number: 5
Enclosure Device ID: 29
Slot Number: 6
Enclosure Device ID: 29
Slot Number: 7
Enclosure Device ID: 29
Slot Number: 8
Enclosure Device ID: 245
Slot Number: 12
Пример конфигурирования JBOD на LSI 2208 (Supermicro X9DRH-7TF) При загрузке BIOS эти команды можно выполнить если зайти в preboot CLI по комбинации клавиш Ctrl+Y
Команды megacli и preboot CLI различаются по виду.
Например команда проверки поддержки JBOD для BIOS preboot CLI будет выглядеть так:
AdpGetProp enablejbod -aALL
А для megacli это используется как набор опций и параметров:
megacli -AdpGetProp enablejbod -aALL
Включить поддержку JBOB
megacli -AdpSetProp EnableJBOD 1 -aALL
Список доступных физических устройств:
megacli -PDList -aALL -page24
В списке надо найти значения полей Enclosure Device ID (например 252), Slot Number и Firmware state
Нужно отметить каждое из устройств которое надо сделать JBOD, как Good в поле Firmware state .
megacli -PDMakeGood -PhysDrv[252:0] -Force -a0
Или сразу много устройств:
megacli -PDMakeGood -PhysDrv[252:1,252:2,252:3,252:4,252:5,252:6,252:7] -Force -a0
Теперь можно создавать JBOD
megacli -PDMakeJBOD -PhysDrv[252:0] -a0
megacli -PDMakeJBOD -PhysDrv[252:1,252:2,252:3,252:4,252:5,252:6,252:7] -a0
Создать виртуальный диск RAID
Перед настройкой массива, возможно, потребуется удалить использованную ранее конфигурацию. Для того чтобы просто удалить логические устройства используйте CfgLdDel
megacli -CfgLdDel -Lall -aAll
Для того чтобы удалить всё (в том числе политику кэша) используйте «Очистку конфигурации»
megacli -CfgClr -aAll
Настройка RAID-0, 1 или 5. Вместо «r0» введите соответственно «r1» или «r5» (диски находятся в Enclosure 29, на портах 0 и 1, WriteBack включен, ReadCache адаптивный, Cache также включен без BBU)
megacli -CfgLdAdd -r0 [29:0,29:1] WB ADRA Cached CachedBadBBU -sz196GB -a0
Создать RAID10 Получить список дисков
megacli -PDList -aAll | egrep «Enclosure Device ID:|Slot Number:|Inquiry Data:|Error Count:|state»
Создать массив из 6 дисков
megacli -CfgSpanAdd -r10 -Array0[252:0,252:1] -Array1[252:2,252:4] [-Array2[252:5,252:6] -a0
Показать как диски были определены в RAID-массиве:
megacli -CfgDsply -a0
Удалить массив с ID=2
MegaCli –CfgLDDel -L2 -a0
Инициализация массива Начать полную инициализацию для массива с ID=0
MegaCli -LDInit -Start -full -L0 -a0
Проверить текущий статус инициализации:
MegaCli -LDInit -ShowProg -L0 -a0
Управление CacheCade
Создать и назначить CacheCade для массива 0 (-L0) из зеркала (-r1) в режиме обратной записи (WB) на основе SSD дисков в слотах 6 и 7 (-Physdrv[252:6,252:7])
megacli -CfgCacheCadeAdd -r1 -Physdrv[252:6,252:7] WB -assign -L0 -a0
Включить
megacli -Cachecade -assign -L0 -a0
Отключить
megacli -Cachecade -remove -L0 -a0
Successfully removed VD from Cache
Просмотреть состояние:
megacli -CfgCacheCadeDsply -a0
megacli -LDInfo -LAll -a0
Замена неисправного диска
Отключить писк:
megacli -AdpSetProp -AlarmSilence -a0
Обратите внимание, что это не навсегда отключает сигнализацию, а просто выключает сигнал по текущей аварии.
Просмотреть состояние диска (подставьте нужное значение [E:S]):
megacli -pdInfo -PhysDrv [29:8] -a0
Пометить диск требующий замены как потерянный (если контроллер не сделал этого сам)
megacli -PDMarkMissing -PhysDrv [E:S] -aN
Получить параметры потерянного диска
megacli -Pdgetmissing -a0
Вы должны получить ответ подобный этому:
Adapter 0 — Missing Physical drives
No. Array Row Size Expected
0 0 4 1907200 MB
Подсветить диск который надо менять (подставьте нужное значение [E:S]):
megacli -PdLocate -start -PhysDrv [29:8] -a0
На некоторых шасси могут быть проблемы с индикацией. Это лечится такой командой:
megacli -AdpSetProp {UseDiskActivityforLocate -1} -aALL
В этом случае для маркировки диска будет использоваться лампочка активности.
Удаляем неисправный и вставляем новый диск.
Прекращаем подсветку и проверяем состояние диска:
megacli -PdLocate -stop -PhysDrv [29:8] -a0
megacli -pdInfo -PhysDrv [29:8] -a0
Может так случится, что он содержит метаданные от другого массива RAID (Foreign Configuration). Ваш контроллер не позволит использовать такой диск. Для проверки наличия Foreign Configuration
megacli -CfgForeign -Scan -aALL
Команда удаления Foreign Configuration (если вы уверены)
megacli -CfgForeign -Сlear -aALL<code>
Запускаем процесс замены
<code>megacli -PdReplaceMissing -PhysDrv [32:4] -Array0 -row4 -a0
[32:4] — это параметры диска которым вы меняете неисправный
Rebuild drive
megacli -PDRbld -Start -PhysDrv [32:4] -a0
Проверка процесса ребилда
megacli -PDRbld -ShowProg -PhysDrv [32:4] -a0
Использование smartctl
Получить список id
megacli -PDlist -a0 | grep ‘^Device Id:’| awk ‘{print $3}’
Получить данные смарт по диску с ID=9
smartctl /dev/sda -d megaraid,9 -a
для диска с интерфейсом sata
smartctl /dev/sda -d sat+megaraid,9 -a
пример скрипта для получения данных о всех дисках
#!/bin/sh
for arg in `megacli -PDlist -a0 | grep ‘^Device Id:’| awk ‘{print $3}’`
do
smartctl /dev/sda -d sat+megaraid,${arg} -l devstat
#smartctl /dev/sda -d sat+megaraid,${arg} -a
done
Для контроля состояния дисков с помощью демона smartd нужно закомментировать DEVICESCAN в /etc/smartd.conf и добавить:
/dev/sda -d sat+megaraid,0 -a -s L/../../3/02
/dev/sda -d sat+megaraid,1 -a -s L/../../3/03
/dev/sda -d sat+megaraid,2 -a -s L/../../3/04
/dev/sda -d sat+megaraid,3 -a -s L/../../3/05
Значения параметров типа /3/02 — /3/05 определяют время запуска тестов для заданного диска
Соберу в одном месте список полезных команд для mdadm.
mdadm — утилита для управления программными RAID-массивами в Linux.
С помощью mdadm можно выполнять следующие операции:
- mdadm —create, C Создать новый массив на основе указанных устройств. Использовать суперблоки размещённые на каждом устройстве.
- mdadm —assemble, -A Собрать компоненты ранее созданного массива в массив. Компоненты можно указывать явно, но можно и не указывать — тогда выполняется их поиск по суперблокам.
- mdadm —build, -B Собрать массив из компонентов, у которых нет суперблоков. Не выполняются никакие проверки, создание и сборка массива в принципе ничем не отличаются.
- mdadm —manage Разнообразные операции по управлению массивом, такие как замена диска и пометка как сбойного.
- mdadm —misc Действия, которые не относятся ни к одному из других режимов работы.
- mdadm —grow, G Расширение или уменьшение массива, включаются или удаляются новые диски.
- mdadm —incremental, I Добавление диска в массив.
- mdadm —monitor, —follow, -F Следить за изменением состояния устройств. Для RAID0 этот режим не имеет смысла.
И другие: mdadm —help.
Формат вызова:
mdadm [mode] [array] [options]
Создание массива
Для создания массива нужно использовать не смонтированные разделы. Убедитесь в этом, при необходимости демонтируйте и уберите из fstab.
Пример создания RAID5 массива из трёх дисков:
- /dev/nvme0n1
- /dev/nvme1n1
- /dev/nvme2n1
Я использую NVMe диски, у вас названия дисков будут другие.
Желательно изменить тип разделов на FD (Linux RAID autodetect). Это можно сделать с помощью fdisk (t).
Занулить суперблоки дисков:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Стереть подпись и метаданные:
wipefs --all --force /dev/nvme0n1
wipefs --all --force /dev/nvme1n1
wipefs --all --force /dev/nvme2n1С помощью ключа —create создать RAID5 массив:
mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1где:
- /dev/md0 — массив, который мы создаём;
- —level 5 — уровень RAID;
- —raid-devices=3 — количество дисков, из которых собирается массив;
- /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 — диски.
Для примера RAID1 из двух дисков /dev/sdb и /dev/sdc можно создать так:
mdadm --create --verbose /dev/md2 -l 1 -n 2 /dev/sd{b,c}где:
- /dev/md2 — массив, который мы создаём;
- -l 5 — уровень RAID;
- -n 2 — количество дисков, из которых собирается массив;
- /dev/sd{b,c} — диски sdb и sdc.
Состояние массива
Посмотреть инициализацию массива и текущее состояние можно с помощью команды:
cat /proc/mdstatПример 1:
root@ch01:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md127 : active raid1 nvme1n1[1] nvme0n1[0]
3750607192 blocks super 1.2 [2/2] [UU]
unused devices: <none>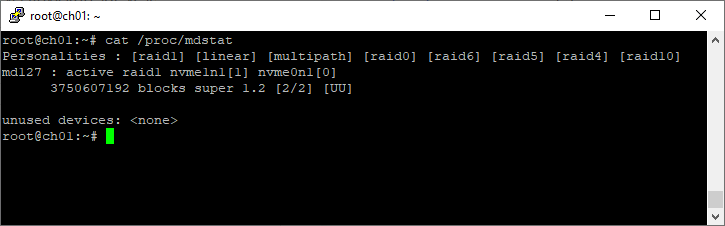
Пример 2:
[root@dbk00 ~]# cat /proc/mdstat
Personalities : [raid1] [raid0]
md10 : active raid0 sdb1[1] sda1[0]
70319335424 blocks super 1.2 512k chunks
md20 : active raid0 sdc1[0] sdd1[1]
70319335424 blocks super 1.2 512k chunks
md126 : active raid1 sde[1] sdf[0]
927881216 blocks super external:/md127/0 [2/2] [UU]
md127 : inactive sdf[1](S) sde[0](S)
10402 blocks super external:imsm
unused devices: <none>Подробный статус выбранного массива
mdadm --detail /dev/md2Пример:
root@ch01:~# mdadm --detail /dev/md127
/dev/md127:
Version : 1.2
Creation Time : Wed May 6 16:39:32 2020
Raid Level : raid1
Array Size : 3750607192 (3576.86 GiB 3840.62 GB)
Used Dev Size : 3750607192 (3576.86 GiB 3840.62 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Fri Aug 14 17:09:47 2020
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : VirtualDisk01
UUID : 1728ebed:ad0b0000:faad83b7:37070000
Events : 173
Number Major Minor RaidDevice State
0 259 0 0 active sync /dev/nvme0n1
1 259 1 1 active sync /dev/nvme1n1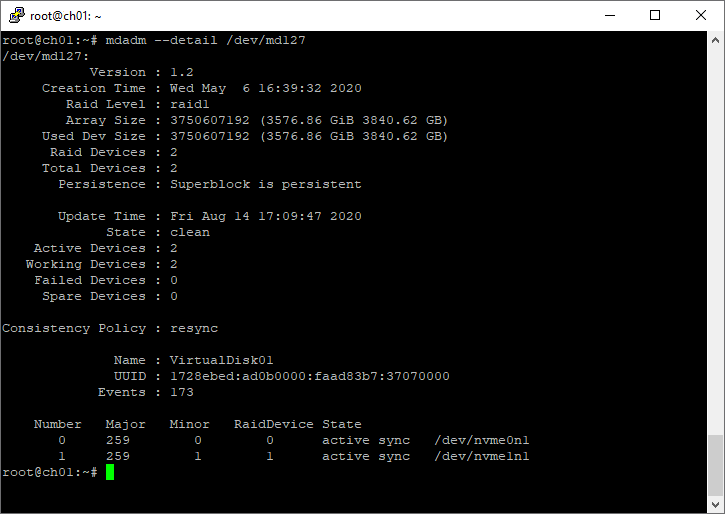
Список массивов
mdadm --detail --scan --verboseПример:
root@ch01:~# mdadm --detail --scan --verbose
ARRAY /dev/md/VirtualDisk01 level=raid1 num-devices=2 metadata=1.2 name=VirtualDisk01 UUID=1728ebed:ad0b0000:faad83b7:37070000
devices=/dev/nvme0n1,/dev/nvme1n1
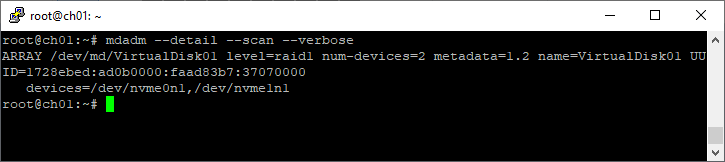
Создание файловой системы
Файловую систему в массиве можно создать с помощью mkfs, например:
mkfs.ext4 -m 0 /dev/md0Для лучшей производительности файловой системы имеет смысл указывать при её создании количество дисков в рейде и количество блоков файловой системы, которое может поместиться в один страйп (chunk), это касается массивов уровня RAID0, RAID5 ,RAID6 ,RAID10. Для RAID1 (mirror) это не имеет значения так как запись идет всегда на один device, a в других типах массивов данные записываются последовательно на разные диски порциями, соответствующими размеру stripe. Например, если мы используем RAID5 из 3 дисков с дефолтным размером страйпа в 64К и файловую систему ext3 с размером блока в 4К то можно вызывать команду mkfs.ext3 так:
mkfs.ext3 -b 4096 -E stride=16,stripe-width=32 /dev/md0stripe-width обычно рассчитывается как
stride * N
где N — это диски с данными в массиве, например, в RAID5 два диска с данными и один parity для контрольных сумм. Для файловой системы XFS нужно указывать не количество блоков файловой системы, соответствующих размеру stripe в массиве, а размер самого страйпа:
mkfs.xfs -d su=64k,sw=3 /dev/md0Создание mdadm.conf
Операционная система не запоминает какие RAID-массивы ей нужно создать и какие диски в них входят. Эта информация содержится в файле mdadm.conf.
mkdir /etc/mdadm
echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
mdadm --detail --scan | awk '/ARRAY/ {print}' >> /etc/mdadm/mdadm.confВ интернете советуют применять команду mdadm —detail —scan —verbose, но я не рекомендую, т.к. она пишет в конфигурационный файл названия разделов, а они в некоторых случаях могут измениться, тогда RAID-массив не соберётся. А mdadm —detail —scan записывает UUID разделов, которые не изменятся.
Проверка целостности массива
echo 'check' >/sys/block/md0/md/sync_actionЕсть ли ошибки в процессе проверки программного RAID-массива по команде check или repair:
cat /sys/block/md0/md/mismatch_cntРабота с дисками
Диск в массиве можно условно сделать сбойным с помощью ключа —fail (-f):
mdadm /dev/md0 --fail /dev/nvme0n1
mdadm /dev/md0 -f /dev/nvme0n1Удалить из массива отказавший диск:
mdadm /dev/md0 --remove /dev/nvme0n1
mdadm /dev/md0 -r /dev/nvme0n1Добавить в массив заменённый диск:
mdadm /dev/md0 --add /dev/nvme0n1
mdadm /dev/md0 -a /dev/nvme0n1Сборка существующего массива
Собрать существующий массив можно с помощью mdadm —assemble:
mdadm --assemble /dev/md0 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1
mdadm --assemble --scanРасширение массива
Расширить массив можно с помощью ключа —grow (-G). Сначала добавляется диск, а потом массив расширяется:
mdadm /dev/md0 --add /dev/nvme3n1Проверяем, что диск добавился:
mdadm --detail /dev/md0
cat /proc/mdstatЕсли диск добавился, расширяем массив:
mdadm -G /dev/md0 --raid-devices=4Опция —raid-devices указывает новое количество дисков в массиве с учётом добавленного. Рекомендуется задать файл бэкапа на случай прерывания перестроения массива, например, добавить опцию:
--backup-file=/var/backup
При необходимости, можно регулировать скорость процесса расширения массива, указав нужное значение в файлах:
- /proc/sys/dev/raid/speed_limit_min
- /proc/sys/dev/raid/speed_limit_max
Убедитесь, что массив расширился:
cat /proc/mdstatНужно обновить конфигурационный файл с учётом сделанных изменений:
mdadm --detail --scan >> /etc/mdadm/mdadm.confВозобновление отложенной синхронизации resync=PENDING
Если синхронизации массива отложена, состояние массива resync=PENDING, то синхронизацию можно возобновить:
echo idle > /sys/block/md0/md/sync_actionили
mdadm --readwrite /dev/md0Переименовать массив
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Собираем массив с новым именем:
mdadm --assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 --update=nameИли для старых версий:
mdadm –assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 –update=super-minorУдаление массива
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Затем необходимо затереть superblock каждого из составляющих массива:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Или с помощью dd:
dd if=/dev/zero of=/dev/nvme0n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme1n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme2n1 bs=512 count=1Содержание
- Как проверить raid массив windows
- Поиск и замена диска поврежденного диска в Raid-1
- Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
- Элементы управления окна Проверка корректности RAID
- Мониторинг raid массивов в Windows Core
- Объединение 2-х дисков в 1: настройка RAID-массива на домашнем компьютере (просто о сложном)
- Настройка RAID
- Основы, какими могут быть RAID массивы (т.е. то, как будем объединять диски)
- Пару слов о дисках и мат. плате
- Пример настройки RAID 0 в BIOS
- Как создать RAID 0, RAID 1 программно (в ОС Windows 10)
Как проверить raid массив windows

Сообщения: 26925
Благодарности: 3917
Если же вы забыли свой пароль на форуме, то воспользуйтесь данной ссылкой для восстановления пароля.

Сообщения: 8627
Благодарности: 2126
А посмотреть в Диспетчере Устройств?
Возможно что CrystalDiskInfo сможет показать состояние SMART винчестеров, входящих в ваш RAID: при контроллерах Intel он это уже несколько лет позволяет.
Ну а утилита контроля и обслуживания RAID (или у вас такая не установлена?) позволяет хотя бы качественно оценить состояние дисков, а также произвести анализ и исправление ошибок, связанных с проблемами самого RAID (у них бывают собственные проблемы, не зависящие от входящих в них дисков и их состояния).
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″> » width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
Сообщения: 8627
Благодарности: 2126
Видимо у вас там два RAID-1 по два диска. И вы видите не физические диски, а фиктивные, которыми и являются RAID (видимо те самые два «Intel MegaSR SCSI Disk Device» – и пускай вас не смущают слова SCSI и SAS).
Источник
Рассмотрим порядок действий проверки дисков выделенного сервера, с которого пришла ошибка SMART, выявления и замены неисправного диска в массиве Raid-1.

в данном примере всё с raid всё в порядке. Если бы было так: [U_], то диск sdb неисправен, если так: [_U], то sda (смотрим порядок в md-устройствах, например: md2 : active raid1 sda3[2] sdb3[3])
[X] меняем на a или b в зависимости от диска, список дисков можно посмотреть командой:
Оцениваем состояние диска по параметрам и выявляем неисправный, смотрим:

В зависимости от количества разделов выполняем соответственно для разных разделов:
Далее команда на удаление из RAID
Для проверки типа разбиения надо выполнить следующую команду:
на не замененном диске
После этого выполнить команду:
(для MBR), и
(структура разделов в этой команде копируется из /dev/sda в /dev/sdb)
(для GPT)
Источник
Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
Вы можете проверить целостность данных RAID (правильность блоков четности на RAID).
Чтобы проверить целостность данных RAID
| * | Щелкните правой кнопкой мыши по RAID и выберите пункт Проверить корректность RAID. контекстного меню |
| > | Откроется окно Проверка корректности RAID, в котором будет отображаться ход выполнения (прогресс) операции. |

Окно Проверка корректности RAID
После окончания проверки можно просмотреть ее результаты.
Блок четности RAID корректен.
Блок четности RAID некорректен.
Если подвести указатель мыши к блоку, то можно будет увидеть номера находящихся в нем секторов, а также число корректных и некорректных секторов. Если дважды щелкнуть по блоку мышью, то он сместится в левый верхний угол и масштаб данных увеличится а 2 раза.
 Элементы управления окна Проверка корректности RAID
Элементы управления окна Проверка корректности RAID
Номер первого сектора в ряде.
Переход к предыдущей/следующей порции данных.
Источник
Мониторинг raid массивов в Windows Core

За последние годы мы привыкли что можно и нужно все мониторить, множество инструментов начиная от простых логов, заканчивая Zabbix и все можно связать. Microsoft в свою очередь тоже дала нам отличный инструмент WinRM, с помощью которого мы можем отслеживать состояние операционных систем и не только. Но как всегда есть ложка дегтя, собственно об «обходе» этой ложки дегтя и пойдет речь.
Как выше было сказано, мы имеем все необходимые инструменты для мониторинга IT структуры, но так сложилось что мы не имеем «автоматизированный» инструмент для мониторинга состояния Intel raid массивов в Windows core. Обращаю Ваше внимание на то, что речь идет об обычном «желтом железе».
Все мы знаем что есть софт от Intel, rapid и matrix storage, но к сожалению на стандартном Windows core он не работает, также есть утилита raidcfg32, она работает в режиме командной строки, умеет обслуживать в ручном режиме и показывать статус, тоже в ручном режиме. Думаю Америку не для кого не открыл.
Постоянно в ручном режиме проверять состояние raid или ждать выхода из строя сервера виртуализации не самый лучший выбор.
Для реализации коварного плана по автоматизации мониторинга Intel raid мы используем
основные инструменты:
Копируем raidcfg32.exe в c:raidcfg32
Проверяем корректно ли установлен драйвер:
cmd.exe C:raidcfg32raidcfg32.exe /stv
Если получаем состояние raid и дисков, то все ок.
Создаем источник в журнале application:
*Дальше все выполняется в powershell
Выполняем запрос состояния raid, удаляем кавычки для упрощения парсинга, подключаем содержимое файла.
Ищем ключевые слова, если одно из слов ниже будет найдено, то в файле errorRAID.txt появится значение true, это будет говорить о наличии ошибки, если совпадений не найдено, то будет записано значение false.
Подключаем файл с записаными true и false, ищем в файле true, если true найдено то заменяем его на Error, заменяем false на Information.
Записывам результат в EntryType.txt
Записываем в EventLog сообщение, где в случае если будут найдены ключевые слова, уровень сообщения будет Error, если не будут найдены, то Information.
Сохраняем код в *.ps1
Создаем в планировщике задание на запуск скрипта, я запускаю задание 1 раз в сутки и при каждой загрузке.
Если будет производится сбор логов другой Windows ОС в Eventlog, то на коллекторе логов необходимо создать источник «RAID», пример есть выше.
Мы транспортируем логи в rsyslog через Adison rsyslog для Windows.
На выходе получается вот такая картинка:

UPD.
По поводу использования store space, все сервера с windows core на борту используются в филиалах, в филиале установлен только 1 сервер и для получения «бесплатного» гипервизора и уменьшения стоимости лицензии используется именно core.
Источник
Объединение 2-х дисков в 1: настройка RAID-массива на домашнем компьютере (просто о сложном)
 Доброго дня!
Доброго дня!
Согласитесь, звучит заманчиво?! Однако, многим пользователям слово «RAID» — либо вообще ничего не говорит, либо напоминает что-то такое отдаленное и сложное (явно-недоступное для повседневных нужд на домашнем ПК/ноутбуке). На самом же деле, все проще, чем есть. 👌 (разумеется, если мы не говорим о каких-то сложных производственных задачах, которые явно не нужны на обычном ПК)
Собственно, ниже в заметке попробую на доступном языке объяснить, как можно объединить диски в эти RAID-массивы, в чем может быть их отличие, и «что с чем едят».

Основы, какими могут быть RAID массивы (т.е. то, как будем объединять диски)
Обратите внимание также на табличку ниже.


Разумеется, видов RAID-массивов гораздо больше (RAID 5, RAID 6, RAID 10 и др.), но все они представляют из себя разновидности вышеприведенных (и, как правило, в домашних условиях не используются).
Пару слов о дисках и мат. плате
Не все материнские платы поддерживают работу с дисковыми массивами RAID. И прежде, чем переходить к вопросу объединению дисков, необходимо уточнить этот момент.
Как это сделать : сначала с помощью спец. утилит (например, AIDA 64) нужно узнать точную модель материнской платы компьютера.
Далее найти спецификацию к вашей мат. плате на официальном сайте производителя и посмотреть вкладку «Хранение» (в моем примере ниже, мат. плата поддерживает RAID 0, RAID 1, RAID 10).

Спецификация материнской платы
Если ваша плата не поддерживает нужный вам вид RAID-массива, то у вас есть два варианта выхода из положения:

RAID-контроллер (в качестве примера)
Важная заметка : RAID-массив при форматировании логического раздела, переустановки Windows и т.д. — не разрушится. Но при замене материнской платы (при обновлении чипсета и RAID-контроллера) — есть вероятность, что вы не сможете прочитать информацию с этого RAID-массива (т.е. информация не будет недоступна. ).
Что касается дисков под RAID-массив :
Пример настройки RAID 0 в BIOS
Важно : при этом способе информация с дисков будет удалена!
Примечание : создать RAID-массив можно и из-под Windows (например, если вы хотите в целях безопасности сделать зеркальную копию своего диска).
1) И так, первым делом необходимо подключить диски к компьютеру (ноутбуку). Здесь на этом не останавливаюсь.
2) Далее нужно зайти в BIOS и установить 2 опции:
Затем нужно сохранить настройки (чаще всего это клавиша F10) и перезагрузить компьютер.


Intel Rapid Storage Technology

Create RAID Volume
5) Теперь нужно указать:
После нажатия на кнопку Create Volume — RAID-массив будет создан, им можно будет пользоваться как обычным отдельным накопителем.


Как создать RAID 0, RAID 1 программно (в ОС Windows 10)
Рассмотрю ниже пару конкретных примеров.
2) Открываете управление дисками (для этого нужно: нажать Win+R, и в появившемся окне ввести команду diskmgmt.msc).
3) Теперь действия могут несколько отличаться.
Вариант 1 : допустим вы хотите объединить два новых диска в один, чтобы у вас был большой накопитель для разного рода файлов. В этом случае просто кликните правой кнопкой мышки по одному из новых дисков и выберите создание чередующегося тома (это подразумевает RAID 0). Далее укажите какие диски объединяете, файловую систему и пр.

Создать чередующийся или зеркальный том

Вариант 2 : если же вы беспокоитесь за сохранность своих данных — то можно подключенный к системе новый диск сделать зеркальным вашему основному диску с ОС Windows, причем эта операция будет без потери данных (прим.: RAID 1).

4) После Windows начнет автоматическую синхронизацию накопителей: т.е. с выбранного вами раздела все данные будут также скопированы на новый диск.

5) В общем-то, всё, RAID 1 настроен — теперь при любых изменениях файлов на основном диске с Windows — они автоматически будут синхронизированы (перенесены) на второй диск.
6) Удалить зеркало, кстати, можно также из управления дисками : пример на скрине ниже.
Источник
Adblock
detector
| RAID 0 (распределение) | RAID 1 (зеркалирование) |
The point of RAID with redundancy is that it will keep going as long as it can, but obviously it will detect errors that put it into a degraded mode, such as a failing disk. You can show the current status of an array with mdadm --detail (abbreviated as mdadm -D):
# mdadm -D /dev/md0
<snip>
0 8 5 0 active sync /dev/sda5
1 8 23 1 active sync /dev/sdb7
Furthermore the return status of mdadm -D is nonzero if there is any problem such as a failed component (1 indicates an error that the RAID mode compensates for, and 2 indicates a complete failure).
You can also get a quick summary of all RAID device status by looking at /proc/mdstat. You can get information about a RAID device in /sys/class/block/md*/md/* as well; see Documentation/md.txt in the kernel documentation. Some /sys entries are writable as well; for example you can trigger a full check of md0 with echo check >/sys/class/block/md0/md/sync_action.
In addition to these spot checks, mdadm can notify you as soon as something bad happens. Make sure that you have MAILADDR root in /etc/mdadm.conf (some distributions (e.g. Debian) set this up automatically). Then you will receive an email notification as soon as an error (a degraded array) occurs.
Make sure that you do receive mail send to root on the local machine (some modern distributions omit this, because they consider that all email goes through external providers — but receiving local mail is necessary for any serious system administrator). Test this by sending root a mail: echo hello | mail -s test root@localhost. Usually, a proper email setup requires two things:
-
Run an MTA on your local machine. The MTA must be set up at least to allow local mail delivery. All distributions come with suitable MTAs, pick anything (but not nullmailer if you want the email to be delivered locally).
-
Redirect mail going to system accounts (at least
root) to an address that you read regularly. This can be your account on the local machine, or an external email address. With most MTAs, the address can be configured in/etc/aliases; you should have a line likeroot: djsmiley2kfor local delivery, or
root: djsmiley2k@mail-provider.example.comfor remote delivery. If you choose remote delivery, make sure that your MTA is configured for that. Depending on your MTA, you may need to run the
newaliasescommand after editing/etc/aliases.
Содержание
- Мониторинг raid массивов в Windows Core
- Мониторинг Intel raid с помощью raidcfg и Zabbix
- Цели статьи
- Введение
- Скрипт для внешних проверок raid массивов
- Шаблон для мониторинга за intel raid
- Заключение
- Состояние raid массива windows
- Аппаратный RAID: особенности использования
- Внешний вид
- Технические характеристики
- Температура
- Скорость работы
- С программным RAID
- С аппаратным RAID
- Управление контроллером
- Настройка кэширования
- Настройка мониторинга
- Прошивка
- Заключение
- Как создать и настроить программный RAID 0, 1 массив в Windows
- Содержание:
- Создание программного RAID с помощью встроенных инструментов Windows 8 или Windows 10
- Как добавить или удалить диск в уже существующем массиве RAID
- Как добавить диск в RAID
- Как удалить диск из RAID-массива
- Создайте программный RAID с помощью командной строки
- RAID 0
- RAID 1
- Программное создание RAID в Windows 7
- Что делать, если вы потеряли важные данные на RAID-массиве
- Часто задаваемые вопросы
Мониторинг raid массивов в Windows Core
За последние годы мы привыкли что можно и нужно все мониторить, множество инструментов начиная от простых логов, заканчивая Zabbix и все можно связать. Microsoft в свою очередь тоже дала нам отличный инструмент WinRM, с помощью которого мы можем отслеживать состояние операционных систем и не только. Но как всегда есть ложка дегтя, собственно об «обходе» этой ложки дегтя и пойдет речь.
Как выше было сказано, мы имеем все необходимые инструменты для мониторинга IT структуры, но так сложилось что мы не имеем «автоматизированный» инструмент для мониторинга состояния Intel raid массивов в Windows core. Обращаю Ваше внимание на то, что речь идет об обычном «желтом железе».
Все мы знаем что есть софт от Intel, rapid и matrix storage, но к сожалению на стандартном Windows core он не работает, также есть утилита raidcfg32, она работает в режиме командной строки, умеет обслуживать в ручном режиме и показывать статус, тоже в ручном режиме. Думаю Америку не для кого не открыл.
Постоянно в ручном режиме проверять состояние raid или ждать выхода из строя сервера виртуализации не самый лучший выбор.
Для реализации коварного плана по автоматизации мониторинга Intel raid мы используем
основные инструменты:
Копируем raidcfg32.exe в c:raidcfg32
Проверяем корректно ли установлен драйвер:
cmd.exe C:raidcfg32raidcfg32.exe /stv
Если получаем состояние raid и дисков, то все ок.
Создаем источник в журнале application:
*Дальше все выполняется в powershell
Выполняем запрос состояния raid, удаляем кавычки для упрощения парсинга, подключаем содержимое файла.
Ищем ключевые слова, если одно из слов ниже будет найдено, то в файле errorRAID.txt появится значение true, это будет говорить о наличии ошибки, если совпадений не найдено, то будет записано значение false.
Подключаем файл с записаными true и false, ищем в файле true, если true найдено то заменяем его на Error, заменяем false на Information.
Записывам результат в EntryType.txt
Записываем в EventLog сообщение, где в случае если будут найдены ключевые слова, уровень сообщения будет Error, если не будут найдены, то Information.
Сохраняем код в *.ps1
Создаем в планировщике задание на запуск скрипта, я запускаю задание 1 раз в сутки и при каждой загрузке.
Если будет производится сбор логов другой Windows ОС в Eventlog, то на коллекторе логов необходимо создать источник «RAID», пример есть выше.
Мы транспортируем логи в rsyslog через Adison rsyslog для Windows.
На выходе получается вот такая картинка:
UPD.
По поводу использования store space, все сервера с windows core на борту используются в филиалах, в филиале установлен только 1 сервер и для получения «бесплатного» гипервизора и уменьшения стоимости лицензии используется именно core.
Источник
Мониторинг Intel raid с помощью raidcfg и Zabbix
У меня есть группа серверов с настроенным intel raid и установленными поверх Windows Hyper-V Server. Возникло больше желание с помощью zabbix наблюдать за состоянием массивов и предупреждать в случае проблем. Готового решения нигде не нашел, поэтому пораскинул мозгами и придумал свое, чем и хочу поделиться с вами.
Цели статьи
Введение
На серверах уже настроен мониторинг состояния SMART дисков. При использовании встроенного intel raid, состояние дисков с целевой системы нормально наблюдается. В принципе, мне этого хватало, но подумал, почему бы и состояние массивов не замониторить, ведь массив может развалиться и при нормальных показателях смарта дисков.
В первую очередь погуглил и не нашел практически ничего, что помогло бы настроить мониторинг интел рейдов в zabbix. На целевых системах установлена интеловская утилита raidcfg, с помощью которой можно посмотреть на состояние массивов и дисков. Например, с ключом /st получается вот такой вывод.

Красиво и наглядно, но для автоматизации не очень подходит. Лучше подойдет ключ /stv.

В этот раз мне не захотелось такие костыли городить на каждом сервере. Я в итоге решил поступить по-другому. На zabbix сервере сделать скрипт для внешних проверок. Этот скрипт будет на целевом сервере с помощью zabbix_get забирать вывод команды raidcfg.exe /stv, запущенной через system.run. Дальше вывод команды в исходном виде поступает на zabbix сервер. Его можно парсить каким-то образом, но я решил этого не делать. Вывод и так короткий, много места не занимает. Проверка на наличие тревожных слов будет уже в триггере с помощью regexp.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
Скрипт для внешних проверок raid массивов
В директорию на zabbix сервере /usr/lib/zabbix/externalscripts кладем скрипт intelraid.sh для внешних проверок.
Скрипт, как вы видите, очень простой. Для того, чтобы он работал, вам обязательно нужно на каждом агенте разрешить выполнение внешних команд. По-умолчанию они отключены. Добавляем в агенте параметр:
И перезапускаем агент. Это все, что надо делать на целевых серверах. Теперь можно проверить работу скрипта. Для этого выбираете любой сервер и передаем его ip адрес в качестве параметра скрипту.
Если получаете результат работы утилиты raidcfg, значит все в порядке. Можно переходить в web интерфейс сервера мониторинга.
Шаблон для мониторинга за intel raid

А вот триггер к нему.

Если в строке будет найдено одно из слов Failed|Disabled|Degraded|Rebuild|Updating|Critical, то он сработает. Я на практике не проверял работу триггера, так как не хотелось рейд ломать. А потестил следующим образом. Добавил в проверочную строку название одного из массивов, к примеру, Storage, который встречается не на всех серверах. В итоге, триггер сработал только там, где было такое название. Так что в теории, проверка должна работать корректно.
Теперь можно добавлять шаблон к необходимым хостам и ждать поступление данных. В Latest Data должны увидеть следующее содержимое итема.

Вот и все. Теперь все intel raid массивы подключены к мониторингу.
Заключение
Так быстро и просто решается прикладная задача по мониторингу с помощью Zabbix. Сел, прикинул и сразу сделал. Вариантов решения обычно несколько, выбирай на свой вкус. Можно было на клиенте распарсить вывод и передавать в Zabbix сразу состояние массива в одно слово. А можно было просто True/False или 1/0.
Источник
Состояние raid массива windows
Сообщения: 26925
Благодарности: 3917
Если же вы забыли свой пароль на форуме, то воспользуйтесь данной ссылкой для восстановления пароля.
Сообщения: 8627
Благодарности: 2126
А посмотреть в Диспетчере Устройств?
Возможно что CrystalDiskInfo сможет показать состояние SMART винчестеров, входящих в ваш RAID: при контроллерах Intel он это уже несколько лет позволяет.
Ну а утилита контроля и обслуживания RAID (или у вас такая не установлена?) позволяет хотя бы качественно оценить состояние дисков, а также произвести анализ и исправление ошибок, связанных с проблемами самого RAID (у них бывают собственные проблемы, не зависящие от входящих в них дисков и их состояния).
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″> » width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
Сообщения: 8627
Благодарности: 2126
Видимо у вас там два RAID-1 по два диска. И вы видите не физические диски, а фиктивные, которыми и являются RAID (видимо те самые два «Intel MegaSR SCSI Disk Device» – и пускай вас не смущают слова SCSI и SAS).
Источник
Аппаратный RAID: особенности использования
Организация единого дискового пространства — задача, легко решаемая с помощью аппаратного RAID-контроллера. Однако следует вначале ознакомиться с особенностями использования и управления таким контроллером. Об этом сегодня расскажем в нашей статье.
Надежность и скорость работы дисковых накопителей — вопрос, волнующий каждого системного администратора. Несмотря на заверения производителей о качестве собственных устройств — HDD и SSD продолжают выходить из строя в самое неподходящее время, теряя драгоценные данные. Технология S.M.A.R.T. в большинстве случаев дает возможность оценить «здоровье» накопителя, но это не гарантирует того, что диск будет продолжать беспроблемно работать.
Предсказать выход диска из строя со 100%-ой точностью невозможно, поэтому следует предусмотреть вариант, при котором это не станет проблемой или причиной остановки сервисов. Использование RAID-массивов решает эту задачу. Рассмотрим три основных подхода, применяющихся для этой задачи:
Внешний вид
Мы выбрали решения Adaptec от компании Microsemi. Это RAID-контроллеры, зарекомендовавшие себя удобством использования и высокой производительностью. Их мы устанавливаем, если наш клиент решил заказать сервер произвольной или фиксированной конфигурации.
Для подключения дисков используются специальные интерфейсные кабели. Со стороны контроллера используются разъемы SFF8643. Каждый кабель позволяет подключить до 4-х дисков SAS или SATA (в зависимости от модели). Помимо этого интерфейсный кабель еще имеет восьмипиновый разъем SFF-8485 для шины SGPIO, о назначении которой поговорим чуть позже.
Помимо самого RAID-контроллера существует еще два дополнительных устройства, позволяющих увеличить надежность:
После того, как электропитание сервера восстановлено, содержимое кэша автоматически будет записано на диски. Именно такие модули устанавливаются в наши серверы с аппаратным RAID-контроллером и Cache Protection.
Это особенно важно, когда включен режим отложенной записи кэша (Writeback). При пропадании электропитания содержимое кэша не будет сброшено на диски, что приведет к потере данных и, как следствие, штатная работа дискового массива будет нарушена.
Технические характеристики
Температура
Вначале хотелось бы затронуть такую важную вещь, как температурный режим аппаратных RAID-контроллеров Adaptec. Все они оснащены небольшими пассивными радиаторами, что может вызвать ложное представление о небольшом тепловыделении.
Производитель контроллера приводит в качестве рекомендуемого значения воздушного потока — 200 LFM (linear feet per minute), что соответствует показателю 8,24 литра в секунду (или 1,02 метра в секунду). Рассчитаны такие контроллеры исключительно на установку в rackmount-корпусы, где такой воздушный поток создается скоростными штатными кулерами.
От 0°C до 40-55°C — рабочая температура большинства RAID-контроллеров Adaptec (в зависимости от наличия установленных модулей), рекомендованная производителем. Максимальная рабочая температура чипа составляет 100°C. Функционирование контроллера при повышенной температуре (более 85°C) может вывести его из строя. Удобства ради приводим под спойлером табличку рекомендуемых температур для разных серий контроллеров Adaptec.
| Series 2 (2405, 2045, 2805) and 2405Q | 55°C без модулей |
| Series 5 (5405, 5445, 5085, 5805, 51245, 51645, 52445) | 55°C без батарейного модуля, 40°C с батарейным модулем ABM-800 |
| Series 5Z (5405Z, 5445Z, 5805Z, 5805ZQ) | 50°C с модулем ZMCP |
| Series 5Q (5805Q) | 55°C без батарейного модуля, 40°C с батарейным модулем ABM-800 |
| Series 6E (6405E, 6805E) | 55°C без модулей |
| Series 6/6T (6405, 6445, 6805, 6405T, 6805T) | 55°C без ZMCP модуля, 50°C с ZMCP модулем AFM-600 |
| Series 6Q (6805Q, 6805TQ) | 50°C с ZMCP модулем AFM-600 |
| Series 7E (71605E) | 55°C без модулей |
| Series 7 (7805, 71605, 71685, 78165, 72405) | 55°C без ZMCP модуля, 50°C с ZMCP модулем AFM-700 |
| Series 7Q (7805Q, 71605Q) | 50°C с ZMCP модулем AFM-700 |
| Series 8E (8405E, 8805E) | 55°C без модулей |
| Series 8 (8405, 8805, 8885) | 55°C без ZMCP модуля, 50°C с ZMCP модулем AFM-700 |
| Series 8Q (8885Q, 81605Z, 81605ZQ) | 50°C с ZMCP модулем AFM-700 |
Нашим клиентам не приходится беспокоиться о перегреве контроллеров, поскольку в наших дата-центрах поддерживается постоянный температурный режим, а сборка серверов произвольной конфигурации происходит с учетом особенностей таких комплектующих (о чем мы упоминали в нашей предыдущей статье).
Скорость работы
Для того чтобы продемонстрировать, как наличие аппаратного RAID-контроллера способствует увеличению скорости работы сервера, мы решили собрать тестовый стенд со следующей конфигурацией:
Затем в этот же стенд поставим RAID-контроллер Adaptec ASR 7805 с модулем защиты кэша AFM-700, подключим к нему эти же жесткие диски и выполним точно такое же тестирование.
С программным RAID
Несомненное преимущество программного RAID — простота использования. Массив в ОС Linux создается с помощью штатной утилиты mdadm. При установке операционной системы чаще всего создание массива предусмотрено непосредственно из установщика. В случае, когда такой возможности установщик не предоставляет, достаточно всего лишь перейти в соседнюю консоль с помощью сочетания клавиш Ctrl+Alt+F2 (где номер функциональной клавиши — это номер вызываемой tty).
Проверяем, чтобы на дисках не было метаданных, например, от предыдущего массива:
На всех 4-х дисках должно быть сообщение:
В случае, если на одном или нескольких дисках будут метаданные, удалить их можно следующим образом (где sdX — требуемый диск):
Создадим на каждом диске разделы для будущего массива c помощью fdisk. В качестве типа раздела следует указать fd (Linux RAID autodetect).
Собираем массив RAID 10 из созданных разделов с помощью команды:
Сразу после этого будет создан массив /dev/md0 и будет запущен процесс перестроения данных на дисках. Для отслеживания текущего статуса процесса введите:
Пока процесс перестроения данных не будет завершен, скорость работы дискового массива будет снижена.
После установки операционной системы и Bitrix24 на созданный массив мы запустили стандартный тест и получили следующие результаты:
С аппаратным RAID
Прежде чем сервер сможет использовать единое дисковое пространство RAID-массива, необходимо выполнить базовую настройку контроллера и логических дисков. Сделать это можно двумя способами:
Утилита позволяет не только управлять настройками контроллера, но и логическими устройствами. Инициализируем физические диски (вся информация на дисках при инициализации будет уничтожена) и создадим массив RAID-10 с помощью раздела Create Array. При создании система запросит желаемый размер страйпа, то есть размер блока данных за одну I/O-операцию:
Важно — размер страйпа задается только один раз (при создании массива) и это значение в дальнейшем изменить нельзя.
Сразу после того, как контроллеру отдана команда создания массива, также, как и с программным RAID, начинается процесс перестроения данных на дисках. Этот процесс работает в фоновом режиме, при этом логический диск становится сразу доступен для BIOS. Производительность дисковой подсистемы будет также снижена до завершения процесса. В случае, если было создано несколько массивов, то необходимо определить загрузочный массив с помощью сочетания клавиш Ctrl + B.
После того как статус массива изменился на Optimal, мы установили Bitrix24 и провели точно такой же тест. Результат теста:
Сразу становится понятно, что аппаратный RAID-контроллер ускоряет операции чтения и записи на дисковый носитель за счет использования кэша, что позволяет быстрее обрабатывать массовые обращения пользователей.
Управление контроллером
Непосредственно из операционной системы управление контроллером производится с помощью программного обеспечения, доступного для скачивания с сайта производителя. Доступны варианты для большинства операционных систем и гипервизоров:
С помощью указанных утилит можно, не прерывая работу сервера, легко управлять логическими и физическими дисками. Также можно задействовать такой полезный функционал, как «подсветка диска». Мы уже упоминали про пятый кабель для подключения SGPIO — этот кабель подключается напрямую в бэкплейн (от англ. backplane — соединительная плата для накопителей сервера) и позволяет RAID-контроллеру полностью управлять световой индикацей каждого диска.
Следует помнить, что бэкплэйны поддерживают не только SGPIO, но и I2C. Переключение между этими режимами осуществляется чаще всего с помощью джамперов на самом бэкплэйне.
Каждому устройству, подключенному к аппаратному RAID-контроллеру Adaptec, присваивается идентификатор, состоящий из номера канала и номера физического диска. Номера каналов соответствуют номерам портов на контроллере.
Замена диска — штатная операция, впрочем, требующая однозначной идентификации. Если допустить ошибку при этой операции, можно потерять данные и прервать работу сервера. С аппаратным RAID-контроллером такая ошибка является редкостью.
Делается это очень просто:
Контроллер даст соответствующую команду на бэкплэйн, и светодиод нужного диска начнет равномерно моргать цветом, отличающимся от стандартного рабочего.
Например, на платформах Supermicro штатная работа диска — зеленый или синий цвет, а «подсвеченный» диск будет моргать красным. Перепутать диски в этом случае невозможно, что позволит избежать ошибки из-за человеческого фактора.
Настройка кэширования
Теперь пару слов о вариантах работы кэша на запись. Вариант Write Through означает, что контроллер сообщает операционной системе об успешном выполнении операции записи только после того, как данные будут фактически записаны на диски. Это повышает надежность сохранности данных, но никак не увеличивает производительность.
Чтобы достичь максимальной скорости работы, необходимо использовать вариант Write Back. При такой схеме работы контроллер будет сообщать операционной системе об успешной IO-операции сразу после того, как данные поступят в кэш.
Важно — при использовании Write Back настоятельно рекомендуется использовать BBU или ZMCP-модуль, поскольку без него при внезапном отключении электричества часть данных может быть утеряна.
Настройка мониторинга
Вопрос мониторинга статуса работы оборудования и возможности оповещения стоит достаточно остро для любого системного администратора. Для того чтобы настроить «связку» из Zabbix и RAID-контроллера Adaptec рекомендуем воспользоваться перечисленными решениями.
Зачастую требуется отслеживать состояние контроллера напрямую из гипервизора, например, VMware ESXi. Задача решается с помощью установки CIM-провайдера с помощью инструкции Microsemi.
Прошивка
Необходимость прошивки RAID-контроллера возникает чаще всего для исправления выявленных производителем проблем с работой устройства. Несмотря на то, что прошивки доступны для самостоятельного обновления, к этой операции следует подойти очень ответственно, особенно если процедура выполняется на «боевой» системе.
Если нашему клиенту требуется сменить версию прошивки контроллера, то ему достаточно создать тикет в нашей панели управления. Системные инженеры выполнят перепрошивку RAID-контроллера до требуемой версии в указанное время и сделают это максимально корректно.
Важно — не следует выполнять перепрошивку самостоятельно, поскольку любая ошибка может привести к потере данных!
Заключение
Использование аппаратного RAID-контроллера оправдано в большинстве случаев, когда требуется высокая скорость и надежность работы дисковой подсистемы.
Системные инженеры Selectel бесплатно выполнят базовую настройку дискового массива на аппаратном RAID-контроллере при заказе сервера произвольной конфигурации. В случае, если потребуется дополнительная помощь с настройкой, мы будем рады помочь в рамках нашей услуги администрирования. Также мы подготовили для наших читателей небольшую памятку по командам утилиты arcconf.
Используете ли вы аппаратные RAID-контроллеры? Ждем вас в комментариях.
Источник
Как создать и настроить программный RAID 0, 1 массив в Windows
Каким бы мощным ни был ваш компьютер, у него все же есть одно слабое место: жесткий диск. Он отвечает за целостность и безопасность ваших данных и оказывает значительное влияние на производительность вашего ПК. При этом жесткий диск – единственное устройство в системном блоке, внутри которого есть движущиеся механические части, что и делает его слабым звеном, способным полностью вывести из строя ваш компьютер.

Сегодня есть два способа ускорить работу вашего компьютера: первый – купить дорогой SSD, а второй – по максимуму использовать материнскую плату, то есть настроить массив RAID 0 из двух жестких дисков. Тем более RAID-массив можно использовать и для повышения безопасности ваших важных данных.
В этой статье мы рассмотрим, как создать программный RAID с помощью встроенных инструментов Windows.
Содержание:
Современные материнские платы позволяют создавать дисковые RAID-массивы без необходимости докупать оборудование. Это позволяет значительно сэкономить на сборке массива в целях повышения безопасности данных или ускорения работы компьютера.
Создание программного RAID с помощью встроенных инструментов Windows 8 или Windows 10
Windows 10 имеет встроенную функцию «Дисковые пространства», которая позволяет объединять жесткие диски или твердотельные накопители в один дисковый массив, называемый RAID. Эта функция была впервые представлена в Windows 8 и значительно улучшена в Windows 10, что упростило создание многодисковых массивов.
Чтобы создать массив RAID, вы можете использовать как функцию «Дисковые пространства», так и командную строку или «Windows PowerShell».
Перед созданием программного RAID необходимо определить его тип и для чего он будет использоваться. Сегодня Windows 10 поддерживает три типа программных массивов: RAID 0, RAID 1, RAID 5 (Windows Server).
Вы можете прочитать о том, какие типы RAID существуют и какой RAID в каких целях лучше использовать, в статье «Типы RAID и какой RAID лучше всего использовать».
Итак, мы определились с типом RAID. Затем для создания дискового массива мы подключаем все диски к компьютеру и загружаем операционную систему.
Стоит отметить, что все диски будущего RAID должны быть одинаковыми не только по объему памяти, но желательно и по всем другим параметрам. Это поможет избежать многих неприятностей в будущем.
Далее, чтобы создать программный RAID-массив, выполните следующие действия:
Шаг 1. Откройте «Панель управления», щелкнув правой кнопкой мыши «Пуск» и выбрав «Панель управления» («Control Panel»).

Шаг 2: В открывшемся окне выберите «Дисковые пространства» («Storage Spaces»)

Шаг 3. Затем выберите «Создать новый пул и дисковое пространство» («Create a new pool and storage space»).

Шаг 4: Выберите диски, которые вы хотите добавить в массив RAID, и нажмите «Создание пула носителей» («Create pool»).

Важно: все данные на дисках, из которых создается RAID-массив, будут удалены. Поэтому заранее сохраните все важные файлы на другой диск или внешний носитель.
После того, как вы настроили массив, вы должны дать ему имя и правильно настроить.
Шаг 5: В поле «Имя» введите имя нашего RAID-массива.

Шаг 6: Затем выберите букву и файловую систему для будущего RAID

Именно с этим именем и буквой массив будет отображаться в системе Windows.
Шаг 7: Теперь вы должны выбрать тип устойчивости.
В зависимости от выбранного типа RAID мастер автоматически установит максимально доступную емкость дискового массива.

Обычно это значение немного ниже, чем фактический объем доступных данных, и вы также можете установить больший размер дискового пространства. Однако имейте в виду, что это сделано для того, чтобы вы могли установить дополнительные жесткие диски, когда массив будет заполнен, без необходимости перестраивать его.
Шаг 8. Нажмите «Create storage space».
После того, как мастер настроит ваш новый RAID, он будет доступен как отдельный диск в окне «Этот компьютер».

Новый диск не будет отличаться от обычного жесткого диска, и вы можете выполнять с ним любые операции, даже зашифровать его с помощью BitLocker.
Об использовании BitLocker вы можете прочитать в статье «Как зашифровать данные на жестком диске с помощью BitLocker».
Вы можете создать еще один программный RAID. Только количество жестких дисков, подключенных к ПК, ограничивает количество создаваемых RAID-массивов.
Как добавить или удалить диск в уже существующем массиве RAID
Как добавить диск в RAID
Предположим, у вас уже есть программный RAID-массив, и вы его используете. Однажды может возникнуть ситуация, когда вам станет не хватать места на диске. К счастью, Windows 10 позволяет добавить еще один диск в уже существующий массив с помощью встроенных инструментов.
Чтобы добавить диск, вы должны открыть утилиту «Дисковые пространства», используя метод, описанный выше, и выбрать «Добавить диски».

В открывшемся меню выберите диск, который хотите добавить, и нажмите «Добавить диск». Жесткий диск будет добавлен к уже существующему массиву RAID.
Как удалить диск из RAID-массива
Чтобы удалить диск из RAID-массива, следуйте алгоритму:
Шаг 1: Откройте утилиту «Дисковые пространства», как описано выше, и нажмите кнопку «Изменить параметры».
Шаг 2. Откройте существующий массив RAID и выберите «Физические диски».
Шаг 3. Во всплывающем списке выберите диск, который вы хотите удалить, и нажмите «Подготовить к удалению».

Windows автоматически перенесет данные на другие диски, а кнопка «Подготовить к удалению» изменится на «Удалить».
После нажатия кнопки «Удалить» система удалит диск из RAID. Для дальнейшей работы с этим накопителем вам потребуется создать на нем новый раздел. Для этого вы можете использовать встроенную утилиту diskpart или утилиту Disk Management.
Создайте программный RAID с помощью командной строки
Другой способ создать программный RAID – использовать командную строку или Windows PowerShell.
Чтобы создать программный RAID с помощью командной строки:
Шаг 1. Щелкните правой кнопкой мыши «Пуск» и выберите «Командная строка (Администратор)» или «Windows PowerShell (Admin)».

Шаг 2: В открывшемся окне введите команду «diskpart» и нажмите «Enter».

Шаг 3: Чтобы отобразить список дисков, введите «list disk».
Утилита Diskpart отобразит все диски, подключенные к вашему ПК.

Шаг 4: Выберите диски, которые вы хотите добавить в массив RAID, один за другим, и превратите их в динамические диски с помощью команд:
Теперь, когда мы преобразовали наши диски, мы можем создать том RAID, введя следующие команды:
После этого следует убедиться, что массив создан.
Для этого введите команду «list disk».
Все диски будут объединены в один диск.

Шаг 5: Теперь все, что вам нужно сделать, это отформатировать диск и присвоить ему букву. Для этого введите следующие команды:
Шаг 6. Введите «exit» и нажмите Enter.
После этого выбранные диски будут объединены в RAID-массив.
Отметим, что с помощью этого метода будет создан RAID 5.
RAID 0
Если вы хотите создать RAID 0, в утилите Diskpart введите:
RAID 1
Чтобы создать RAID 1, вам необходимо ввести следующие команды одну за другой:
Внимание! Иногда появляется сообщение «Вам следует перезагрузить компьютер, чтобы завершить эту операцию». Если оно появилось – перезагрузите компьютер. Если есть только сообщение об успешной конвертации – продолжайте работу и введите:
После этого будет создан массив RAID 1.
Программное создание RAID в Windows 7
В Windows 7 вы можете использовать утилиту «Управление дисками» для создания программного RAID. Следует отметить, что диск, с которого загружается система, нельзя использовать в RAID, так как он будет преобразован в динамический. Вы можете использовать любые диски, кроме системных.
Шаг 1. Откройте «Пуск», щелкните правой кнопкой мыши «Компьютер» и выберите «Управление».

Шаг 2: В появившемся мастере нажмите «Далее».

Шаг 3. В открывшемся меню вы должны выбрать диски, которые вы хотите объединить в массив RAID, и нажать «Далее».

Шаг 4: Выберите букву для созданного RAID-массива и нажмите «Далее».

Шаг 5: В следующем окне выберите тип файловой системы (NTFS), укажите размер блока и укажите имя тома. После этого нажмите «Далее».

Шаг 6: После того, как система создаст новый массив RAID, нажмите кнопку «Готово».

После нажатия кнопки «Готово» появится окно с предупреждением о том, что будет выполнено преобразование базового диска в динамический и загрузка ОС с динамического диска будет невозможна. Просто нажмите «ОК».
После этого созданный RAID-массив отобразится в окне «Мой компьютер» как обычный жесткий диск, с которым можно выполнять любые операции.
Что делать, если вы потеряли важные данные на RAID-массиве
Использование RAID-массивов может значительно повысить безопасность данных, что очень важно в современном мире. Однако нельзя исключать человеческий фактор.
Потеря важных файлов возможна из-за случайного удаления, форматирования, изменения логической структуры файловой системы и многих других причин. Кроме того, не исключен сбой RAID.
В этой ситуации лучше не принимать поспешных решений. Оптимальный вариант — обратиться к специалистам или воспользоваться специализированным ПО для восстановления данных.
RS RAID Retrieve способен восстановить любой тип RAID-массива, поддерживает все файловые системы, используемые в современных операционных системах.
Восстановление данных с любых RAID массивов

Часто задаваемые вопросы
Это сильно зависит от емкости вашего жесткого диска и производительности вашего компьютера. В основном, большинство операций восстановления жесткого диска можно выполнить примерно за 3-12 часов для жесткого диска объемом 1 ТБ в обычных условиях.
Если файл не открывается, это означает, что файл был поврежден или испорчен до восстановления.
Используйте функцию «Предварительного просмотра» для оценки качества восстанавливаемого файла.
Когда вы пытаетесь получить доступ к диску, то получаете сообщение диск «X: не доступен». или «Вам нужно отформатировать раздел на диске X:», структура каталога вашего диска может быть повреждена. В большинстве случаев данные, вероятно, все еще остаются доступными. Просто запустите программу для восстановления данных и отсканируйте нужный раздел, чтобы вернуть их.
Пожалуйста, используйте бесплатные версии программ, с которыми вы можете проанализировать носитель и просмотреть файлы, доступные для восстановления.
Сохранить их можно после регистрации программы – повторное сканирование для этого не потребуется.
Источник
Содержание
- Как проверить, настроен ли аппаратный RAID?
- 5 ответов
- Как посмотреть текущее состояние дисков, подключенных к модулю Intel® Integrated RAID, без перезагрузки сервера
- Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
- Элементы управления окна Проверка корректности RAID
- Мониторинг Intel raid с помощью raidcfg и Zabbix
- Цели статьи
- Введение
- Скрипт для внешних проверок raid массивов
- Шаблон для мониторинга за intel raid
- Заключение
- Как проверить raid массив windows
- RAID — 0
- RAID — 1
- Собираем RAID в Windows
Как проверить, настроен ли аппаратный RAID?
У меня есть несколько серверов под управлением Windows 2008 и Red Hat 5, способных к аппаратным RAID. Как проверить, настроен ли аппаратный RAID?
5 ответов
Предыдущие ответы от Aug пересматривают это на стороне Windows.
а. У вас есть Server 2008
B. Возможности дисков в аппаратном RAID-массиве или нет.
- Рик щелкните по значку «компьютер» на рабочем столе или в элементе компьютера в меню «Пуск»
- Выберите «Управление»
- Развернуть хранилище
- Нажмите «Управление дисками»
- В нижней центральной области вы увидите диск 0, диск 1 и т. д.
- В левом столбце под номером диска вы увидите слово Basic или Dynamic
Если ваши диски говорят Basic, то у вас либо нет RAID-массивов, либо у вас есть аппаратный RAID.
Если ваши диски говорят динамически, и вы видите одну и ту же букву диска на нескольких дисках, у вас есть программный RAID.
Еще один простой способ взглянуть на это —
- Рик щелкните по значку «компьютер» на рабочем столе или в элементе компьютера в меню «Пуск»
- Выберите «Управление»
- Развернуть диагностику
- Нажмите «Диспетчер устройств»
- Разверните диски (в средней панели)
Если вы видите диски, названные настоящими производителями жестких дисков + модель, у вас нет RAID или программного RAID на этих дисках.
Если вы видите диски, названные как производители RAID, или которые говорят что-то вроде «Dell VIRTUAL DISK SCSI Disk Device», у вас есть аппаратный RAID-массив (ы). И да, роль в кавычках как избыточная, поскольку она выглядит, — это фактическое имя массива в диспетчере устройств на одном из моих серверов.
Установив Dell OpenManage, перезагрузив и перейдя в конфигурацию BIOS или RAID, все хорошо, но вы можете выполнить описанные выше шаги с подключений к удаленному рабочему столу даже в системе без каких-либо специализированных инструментов.
У меня не работает Red Hat 5, но я должен предположить, что есть подсказки, которые вы можете вытащить из какой-либо части пользовательского интерфейса или опции командной строки, чтобы сделать то же самое, RAID-драйв описывает себя, а также программный RAID, а также аппаратный RAID.
Если RAID-контроллер официально поддерживает вашу ОС, тогда у него будет набор инструментов для его мониторинга. Вероятно, они были оснащены оборудованием, но также будут загружены с веб-сайта производителя.
Если ваш RAID-контроллер полностью поддерживается Linux как RAID-контроллер (т. е. видит его как RAID-контроллер, а не стандартный контроллер SCSI /SATA /PATA), вы можете найти полезную информацию в файловой системе /proc и найти инструменты, которые отображают /контролируют эту информацию для вас. Если вы знаете RAID-контроллеры, которые находятся на ваших компьютерах, вы можете добавить эту деталь к своему вопросу, тогда люди, обладающие конкретными знаниями о том, что этот контроллер может обрабатывать более конкретную информацию.
Если у вас нет инструментов уровня ОС для мониторинга оборудования, вам необходимо перезагрузить компьютеры и взаимодействовать с конфигурационным кодом загрузки контроллера RAID.
Если вы наберете dmesg в Redhat, вы можете увидеть драйвер для контроллера RAID, но в целом аппаратные RAID-массивы прозрачны для операционной системы.
Лучший способ — посмотреть процесс загрузки и посмотреть, есть ли сообщение перед началом загрузки ОС. Это может что-то вроде:
Затем вы нажимаете все, что он говорит, чтобы перейти в BIOS SCSI и посмотреть, настроен ли массив.
Это может работать на вашей системе. Кажется, он работает на Red Hat 5.5 на некоторых аппаратных средствах (не все).
Показывает уровень RAID и размер логического диска.
Ну, я не знаю вашей системы, но я думаю, что один из лучших способов просмотра текущей настройки RAID в системе — через ее BIOS. ПРИМЕР в меню BIOS HP DL380p gen 8, вы можете нажать F8 для просмотра логических дисков.
Как посмотреть текущее состояние дисков, подключенных к модулю Intel® Integrated RAID, без перезагрузки сервера
Проверено. Это решение проверено нашими клиентами с целью устранения ошибки, связанной с этими переменными среды
Тип материала Обслуживание и производительность
Идентификатор статьи 000057913
Последняя редакция 19.11.2020
Как узнать текущее состояние дисков, подключенных к модулю Intel® Integrated RAID, без перезагрузки сервера?
Интегрированные контроллеры Intel® RAID на базе RAID (IR):
- Интегрированный RAID-модуль Intel® RMS3JC080
- Intel® RAID Controller RS3UC080
- Intel® RAID Controller RS3FC044
Как это исправить:
Вы можете использовать любой из приведенных далее методов для отображения состояния накопителей, подключенных к упомянутым выше контроллерам Intel® RAID на базе ИК-связи:
- Веб Консоль Intel® RAID 3 (RWC3)
RWC3 поддерживается на Окон И Управлением Это может контролировать и контролировать продукты Intel RAID. См. в Руководство пользователя RWC3 для получения информации об установке и использовании.
SAS3IRCU
SAS3IRCU — это приложение на базе командной строки, которое можно найти в страница встроенного по. См. в Руководство пользователя по(Приложение A. Использование встроенного по конфигурации RAID SAS-3) для получения дополнительной информации о параметрах и синтаксисе команд.
Для отображения состояния накопителей может использоваться следующая синтаксическая конструкция:
sas3ircu.exe 0 display
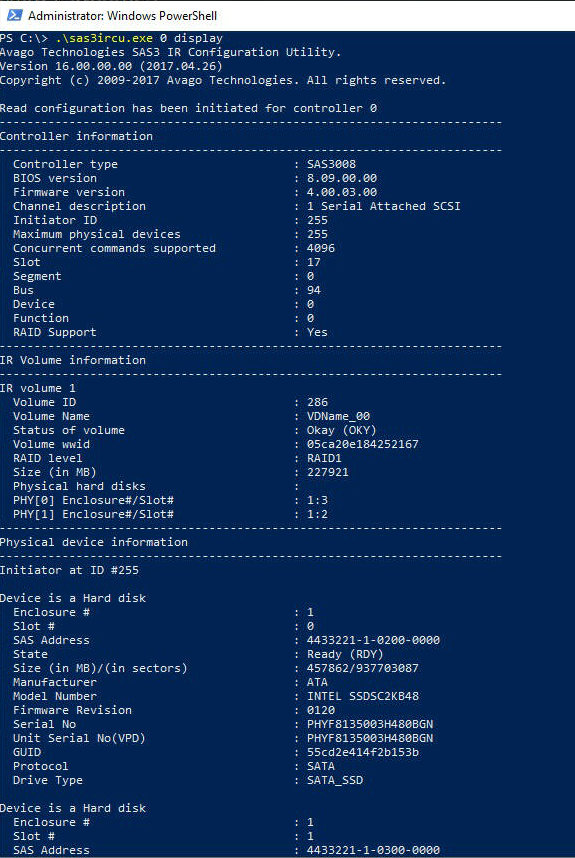
Привести к & получения дополнительной информации:
См. также см. раздел
ИНФОРМАЦИЯ, ПРЕДСТАВЛЕННАЯ В ЭТОЙ СТАТЬЕ, ИСПОЛЬЗОВАЛАСЬ НАШИМИ КЛИЕНТАМИ, НО НЕ ТЕСТИРОВАЛАСЬ, ПОЛНОСТЬЮ НЕ ПРОШЛА РЕПЛИКАЦИЯ ИЛИ НЕ ПРОВЕРЯЛАСЬ КОРПОРАЦИЕЙ INTEL. ОТДЕЛЬНЫЕ РЕЗУЛЬТАТЫ МОГУТ РАЗЛИЧАТЬСЯ. ВСЕ публикации и использование материалов на данном сайте задаются в соответствии с положениями и условиями использования веб-узла.
Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
Вы можете проверить целостность данных RAID (правильность блоков четности на RAID).
Чтобы проверить целостность данных RAID
| * | Щелкните правой кнопкой мыши по RAID и выберите пункт Проверить корректность RAID. контекстного меню |
| > | Откроется окно Проверка корректности RAID, в котором будет отображаться ход выполнения (прогресс) операции. |
Окно Проверка корректности RAID
После окончания проверки можно просмотреть ее результаты.
Блок четности RAID корректен.
Блок четности RAID некорректен.
Если подвести указатель мыши к блоку, то можно будет увидеть номера находящихся в нем секторов, а также число корректных и некорректных секторов. Если дважды щелкнуть по блоку мышью, то он сместится в левый верхний угол и масштаб данных увеличится а 2 раза.
Элементы управления окна Проверка корректности RAID
Номер первого сектора в ряде.
Смещение данных. Введите адрес, к которому вы хотите перейти, и нажмите клавишу Enter .
Задает размерность данных поля Смещение .
Переход к предыдущей/следующей порции данных.
Мониторинг Intel raid с помощью raidcfg и Zabbix

У меня есть группа серверов с настроенным intel raid и установленными поверх Windows Hyper-V Server. Возникло больше желание с помощью zabbix наблюдать за состоянием массивов и предупреждать в случае проблем. Готового решения нигде не нашел, поэтому пораскинул мозгами и придумал свое, чем и хочу поделиться с вами.
Цели статьи
- Настроить передачу в zabbix состояния рейд массивов, настроенных с помощью встроенной в материнскую плату технологии intel raid.
- При настройке совершать минимум действий на целевых серверах, а максимум на zabbix сервере.
- Настроить триггеры и уведомления на случай, если состояние рейда отличается от рабочего Normal.
Введение
На серверах уже настроен мониторинг состояния SMART дисков. При использовании встроенного intel raid, состояние дисков с целевой системы нормально наблюдается. В принципе, мне этого хватало, но подумал, почему бы и состояние массивов не замониторить, ведь массив может развалиться и при нормальных показателях смарта дисков.
В первую очередь погуглил и не нашел практически ничего, что помогло бы настроить мониторинг интел рейдов в zabbix. На целевых системах установлена интеловская утилита raidcfg, с помощью которой можно посмотреть на состояние массивов и дисков. Например, с ключом /st получается вот такой вывод.
Красиво и наглядно, но для автоматизации не очень подходит. Лучше подойдет ключ /stv.
С такими данными уже можно работать. В целом, ничего сложного, нужно распарсить вывод любым удобным способом и передать на сервер мониторинга информацию о статуте рейд массива. Как можно с помощью батников парсить различные текстовые файлы я показывал на нескольких примерах в отдельной статье — Мониторинг значений из текстового файла в Zabbix.
В этот раз мне не захотелось такие костыли городить на каждом сервере. Я в итоге решил поступить по-другому. На zabbix сервере сделать скрипт для внешних проверок. Этот скрипт будет на целевом сервере с помощью zabbix_get забирать вывод команды raidcfg.exe /stv, запущенной через system.run. Дальше вывод команды в исходном виде поступает на zabbix сервер. Его можно парсить каким-то образом, но я решил этого не делать. Вывод и так короткий, много места не занимает. Проверка на наличие тревожных слов будет уже в триггере с помощью regexp.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
Скрипт для внешних проверок raid массивов
В директорию на zabbix сервере /usr/lib/zabbix/externalscripts кладем скрипт intelraid.sh для внешних проверок.
Скрипт, как вы видите, очень простой. Для того, чтобы он работал, вам обязательно нужно на каждом агенте разрешить выполнение внешних команд. По-умолчанию они отключены. Добавляем в агенте параметр:
И перезапускаем агент. Это все, что надо делать на целевых серверах. Теперь можно проверить работу скрипта. Для этого выбираете любой сервер и передаем его ip адрес в качестве параметра скрипту.
Если получаете результат работы утилиты raidcfg, значит все в порядке. Можно переходить в web интерфейс сервера мониторинга.
Шаблон для мониторинга за intel raid
Шаблон очень простой — один элемент и один триггер, поэтому экспорт шаблона делать не буду, лучше создать вручную, чтобы точно работало на всех версиях Zabbix. Вот элемент данных.
А вот триггер к нему.
Если в строке будет найдено одно из слов Failed|Disabled|Degraded|Rebuild|Updating|Critical, то он сработает. Я на практике не проверял работу триггера, так как не хотелось рейд ломать. А потестил следующим образом. Добавил в проверочную строку название одного из массивов, к примеру, Storage, который встречается не на всех серверах. В итоге, триггер сработал только там, где было такое название. Так что в теории, проверка должна работать корректно.
Теперь можно добавлять шаблон к необходимым хостам и ждать поступление данных. В Latest Data должны увидеть следующее содержимое итема.
Вот и все. Теперь все intel raid массивы подключены к мониторингу.
Заключение
Так быстро и просто решается прикладная задача по мониторингу с помощью Zabbix. Сел, прикинул и сразу сделал. Вариантов решения обычно несколько, выбирай на свой вкус. Можно было на клиенте распарсить вывод и передавать в Zabbix сразу состояние массива в одно слово. А можно было просто True/False или 1/0.
Я последнее время стараюсь максимально выполнять на сервере и минимально на клиенте, благо в заббиксе появилась куча средств для этого — пост обработка данных, зависимые элементы и т.д. Буду рад замечаниям и предложениям по теме в комментариях. Если вам интересен Zabbix, читайте мои остальные статьи по нему.
Как проверить raid массив windows
В данной статье будет рассказано о сборке и подключении RAID в Windows. Соберем программный RAID 1 на базе windows 10.
Аналогичным способом можно собрать программный рейд и в предыдущих версиях windows, таких как 7,8, 8,1.
О том, что такое RAID какие они бывают, спецификацию и особенности, можете прочитать тут. Там вы найдете всю исчерпывающую информацию на эту тему.
Для сборки и подключения RAID в windows необходимо как минимум два диска.
На основе двух дисков можно собрать два вида массива.
RAID — 0
RAID 0 — это рейд который объединяет два диска в один. В результате мы получаем один диск. Объем этого диска будет равняться сумме двух дисков включенных в рейд и в системе вы его будете видеть как один.
Минус этого массива в том, что если сломается любой из этих дисков, мы потеряем всю информацию.
RAID — 1
RAID 1 — это так называемый зеркальный рейд массив. В этом массиве все данные одного диска в точности копируются на второй. Так обеспечивается сохранность нашей информации.
В случае выхода из строя одного диска всю информацию можно получить без проблем со второго диска. Заменив вышедший из строя диск массив восстанавливается и можно дальше продолжать его использовать.
Так как, совершенно одинаковая информация расположена на двух дисках одновременно, то скорость ее считывания увеличивается. Скорость записи к сожалению остается прежней.
Минус этого массива в том, что используя два диска вы теряете объем второго диска, так как используете для работы только один диск. Второй диск, по сути своей, служит резервным хранилищем — копией первого.
Но для сохранения информации это вполне оправданные расходы.
Собираем RAID в Windows
Перед тем как приступить к сборке программного RAID 1 нам необходимо подключить наши диски к компьютеру.
Желательно использовать два одинаковых диска, не только по производителю но и одним объемом.
В моем случае это будет два диска по 20Гб.
После подключения дисков включаем наш компьютер.
Меню «Пуск» — кликаем правой кнопкой, выбираем пункт Управление дисками
Перед нами откроется консоль управления дисками.

В консоли мы видим наши два новых подключенных диска. В моем случае это Диск 1 и Диск 2, объемом 20Гб каждый.
Кликаем по одному из наших новых дисков правой кнопкой мыши и выбираем пункт «Создать зеркальный том».
Если выберите пункт «Создать чередующийся том» то соберете таким же способом RAID 0. В данной ситуации.
Откроется окно в котором нажимаем «далее»

На следующем этапе нам необходимо выбрать второй диск для сборки RAID 1 и кнопкой добавить переместить его в правую половину.

Нажимаем кнопку «Далее»
Теперь нам предложат выбрать букву для будущего диска, я оставляю все по умолчанию и нажимаю «Далее»

В следующем окне выбираем файловую систему и метку тома, для ускорения процесса ставим галочку быстрое форматирование.

Ну и на завершающем этапе нажимаем «Готово»

Наши диски будут преобразованы в Динамические, о чем нас предупредят и мы должны с этим согласится

Спустя несколько секунд произойдет сборка RAID 1 и диски начнут синхронизироваться. В консоли управления дисками мы увидим как они поменяю цвет на красноватый.
Так же появится диск в проводнике Windows.

На этом сборка RAID 1 закончена и его можно полноценно использовать для хранения наших файлов.
В последствии если необходимо будет заменить один из дисков, выбираем наш массив и правой кнопкой мыши выбираем «разделить зеркальный том».

Диски поменяют цвет на коричневый — что говорит об успешном разделении рейда.
Меняем неисправный диск.
При замене диска нее забываем выключить наш компьютер.
После замены выбираем наш исправный диск и нажимаем добавить зеркало. В качестве зеркала выбираем новый исправный диск и нажимаем добавить зеркало.

Рейд соберется снова, дождитесь его Ресинхронизации и можно будет продолжить им пользоваться.

Если есть, что добавить или сказать оставляйте комментарии.
Время на прочтение
4 мин
Количество просмотров 21K
Всем привет!
За последние годы мы привыкли что можно и нужно все мониторить, множество инструментов начиная от простых логов, заканчивая Zabbix и все можно связать. Microsoft в свою очередь тоже дала нам отличный инструмент WinRM, с помощью которого мы можем отслеживать состояние операционных систем и не только. Но как всегда есть ложка дегтя, собственно об «обходе» этой ложки дегтя и пойдет речь.
Как выше было сказано, мы имеем все необходимые инструменты для мониторинга IT структуры, но так сложилось что мы не имеем «автоматизированный» инструмент для мониторинга состояния Intel raid массивов в Windows core. Обращаю Ваше внимание на то, что речь идет об обычном «желтом железе».
Все мы знаем что есть софт от Intel, rapid и matrix storage, но к сожалению на стандартном Windows core он не работает, также есть утилита raidcfg32, она работает в режиме командной строки, умеет обслуживать в ручном режиме и показывать статус, тоже в ручном режиме. Думаю Америку не для кого не открыл.
Постоянно в ручном режиме проверять состояние raid или ждать выхода из строя сервера виртуализации не самый лучший выбор.
Для реализации коварного плана по автоматизации мониторинга Intel raid мы используем
основные инструменты:
- Powershell
- EventLog
- Raidcfg32.exe
- Вспомогательные:
- WinRM
- Rsyslog
- LogAnalyzer
Первым делом нужно установить драйвер для raid контроллера:
cmd.exe pnputil.exe -i -a [путь до *.inf]
Копируем raidcfg32.exe в c:raidcfg32
Проверяем корректно ли установлен драйвер:
cmd.exe C:raidcfg32raidcfg32.exe /stv
Если получаем состояние raid и дисков, то все ок.
Создаем источник в журнале application:
*Дальше все выполняется в powershell
New-EventLog -Source "RAID" -LogName "Application"
Выполняем запрос состояния raid, удаляем кавычки для упрощения парсинга, подключаем содержимое файла.
c:RAIDCFG32RAIDCFG32.exe /stv > c:RAIDCFG32raidcfgStatus.txt
Get-Content "c:RAIDCFG32raidcfgStatus.txt" | ForEach-Object {$_ -replace ('"'),' '} > c:RAIDCFG32raidstatus.txt
$1 = Get-Content c:RAIDCFG32raidstatus.txt
$2 = "$1"
Ищем ключевые слова, если одно из слов ниже будет найдено, то в файле errorRAID.txt появится значение true, это будет говорить о наличии ошибки, если совпадений не найдено, то будет записано значение false.
$2 -match "failed" > c:RAIDCFG32errorRAID.txt
$2 -match "disabled" >> c:RAIDCFG32errorRAID.txt
$2 -match "degraded" >> c:RAIDCFG32errorRAID.txt
$2 -match "rebuild" >> c:RAIDCFG32errorRAID.txt
$2 -match "updating" >> c:RAIDCFG32errorRAID.txt
$2 -match "critical" >> c:RAIDCFG32errorRAID.txt
Подключаем файл с записаными true и false, ищем в файле true, если true найдено то заменяем его на Error, заменяем false на Information.
Записывам результат в EntryType.txt
$3 = Get-Content c:RAIDCFG32errorRAID.txt
$4 = "$3"
$5 = $4 -match "true"
$6 = "$5"
$7 = $6 -replace "true", "Error" > c:RAIDCFG32EntryType.txt
$8 = $6 -replace "false", "Information" >> c:RAIDCFG32EntryType.txt
Подключаем содержимое файла EntryType.txt и удаляем в нем False, тем самым выводим корректный -EntryType что в свою очередь и является «Уровнем» сообщения.
Записываем в EventLog сообщение, где в случае если будут найдены ключевые слова, уровень сообщения будет Error, если не будут найдены, то Information.
$9 = Get-Content c:RAIDCFG32EntryType.txt
$10 = "$9"
$11 = $10 -replace "False"
Write-EventLog -LogName Application -Source "RAID" -EventID 9999 -EntryType "$11" -Message "$1"
exit
Сохраняем код в *.ps1
Создаем в планировщике задание на запуск скрипта, я запускаю задание 1 раз в сутки и при каждой загрузке.
Если будет производится сбор логов другой Windows ОС в Eventlog, то на коллекторе логов необходимо создать источник «RAID», пример есть выше.
Мы транспортируем логи в rsyslog через Adison rsyslog для Windows.
На выходе получается вот такая картинка:
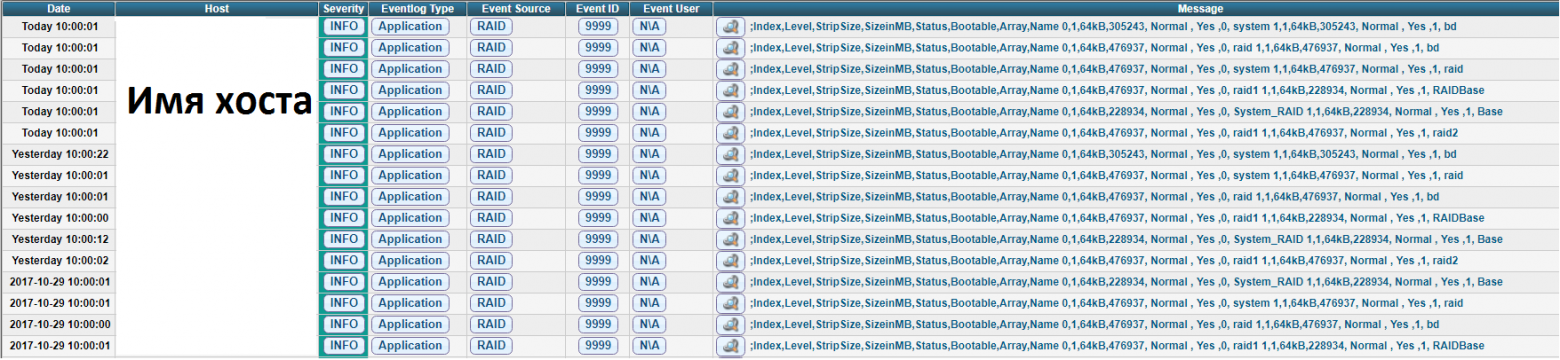
UPD.
По поводу использования store space, все сервера с windows core на борту используются в филиалах, в филиале установлен только 1 сервер и для получения «бесплатного» гипервизора и уменьшения стоимости лицензии используется именно core.
для windows логов
c:RAIDCFG32RAIDCFG32.exe /stv > c:RAIDCFG32raidcfgStatus.txt
Get-Content "c:RAIDCFG32raidcfgStatus.txt" | ForEach-Object {$_ -replace ('"'),' '} > c:RAIDCFG32raidstatus.txt
$1 = Get-Content c:RAIDCFG32raidstatus.txt
$2 = "$1"
$2 -match "failed" > c:RAIDCFG32errorRAID.txt
$2 -match "disabled" >> c:RAIDCFG32errorRAID.txt
$2 -match "degraded" >> c:RAIDCFG32errorRAID.txt
$2 -match "rebuild" >> c:RAIDCFG32errorRAID.txt
$2 -match "updating" >> c:RAIDCFG32errorRAID.txt
$2 -match "critical" >> c:RAIDCFG32errorRAID.txt
$3 = Get-Content c:RAIDCFG32errorRAID.txt
$4 = "$3"
$5 = $4 -match "true"
$6 = "$5"
$7 = $6 -replace "true", "Error" > c:RAIDCFG32EntryType.txt
$8 = $6 -replace "false", "Information" >> c:RAIDCFG32EntryType.txt
$9 = Get-Content c:RAIDCFG32EntryType.txt
$10 = "$9"
$11 = $10 -replace "False"
Write-EventLog -LogName Application -Source "RAID" -EventID 9999 -EntryType "$11" -Message "$1"UPD2.
В zabbix конфиг на клиенте вносим:
UserParameter=raid.status,powershell c:raidcfg32raidstatusZabbix.ps1
В zabbix добавляем новый элемент данных raid.status, числовой. Создаём триггер — если 0 то всё хорошо, если 1 то беда.
Скрипт ps2 немного меняется:
для zabbix
c:RAIDCFG32RAIDCFG32.exe /stv > c:RAIDCFG32raidcfgStatus.txt
Get-Content "c:RAIDCFG32raidcfgStatus.txt" | ForEach-Object {$_ -replace ('"'),' '} > c:RAIDCFG32raidstatus.txt
$1 = Get-Content c:RAIDCFG32raidstatus.txt
$2 = "$1"
$2 -match "failed" > c:RAIDCFG32errorRAID.txt
$2 -match "disabled" >> c:RAIDCFG32errorRAID.txt
$2 -match "degraded" >> c:RAIDCFG32errorRAID.txt
$2 -match "rebuild" >> c:RAIDCFG32errorRAID.txt
$2 -match "updating" >> c:RAIDCFG32errorRAID.txt
$2 -match "critical" >> c:RAIDCFG32errorRAID.txt
$3 = Get-Content c:RAIDCFG32errorRAID.txt
$4 = "$3"
$5 = $4 -match "true"
$6 = "$5"
$7 = $6 -replace "true", "1" > c:RAIDCFG32EntryType.txt
$8 = $6 -replace "false", "0" >> c:RAIDCFG32EntryType.txt
$9 = Get-Content c:RAIDCFG32EntryType.txt
$10 = "$9"
$11 = $10 -replace "False"
$11
Содержание
- Как проверить raid массив windows
- Поиск и замена диска поврежденного диска в Raid-1
- Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
- Элементы управления окна Проверка корректности RAID
- Мониторинг raid массивов в Windows Core
- Объединение 2-х дисков в 1: настройка RAID-массива на домашнем компьютере (просто о сложном)
- Настройка RAID
- Основы, какими могут быть RAID массивы (т.е. то, как будем объединять диски)
- Пару слов о дисках и мат. плате
- Пример настройки RAID 0 в BIOS
- Как создать RAID 0, RAID 1 программно (в ОС Windows 10)
Как проверить raid массив windows
Сообщения: 26925
Благодарности: 3917
Если же вы забыли свой пароль на форуме, то воспользуйтесь данной ссылкой для восстановления пароля.
Сообщения: 8627
Благодарности: 2126
А посмотреть в Диспетчере Устройств?
Возможно что CrystalDiskInfo сможет показать состояние SMART винчестеров, входящих в ваш RAID: при контроллерах Intel он это уже несколько лет позволяет.
Ну а утилита контроля и обслуживания RAID (или у вас такая не установлена?) позволяет хотя бы качественно оценить состояние дисков, а также произвести анализ и исправление ошибок, связанных с проблемами самого RAID (у них бывают собственные проблемы, не зависящие от входящих в них дисков и их состояния).
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
SMART не виден в CrystalDiskInfo и подобных утилитах, использовал Hirens.BootCD.15.2
Victoria пишет:
Подскажите где утилиту взять о которой вы говорите, я так понял есть утилита контроля RAID, она же позволяет и состояние дисков посмотреть, а так же есть утилиты состояния дисков от самих производителей.
Сообщения: 8627
Благодарности: 2126
Видимо у вас там два RAID-1 по два диска. И вы видите не физические диски, а фиктивные, которыми и являются RAID (видимо те самые два «Intel MegaSR SCSI Disk Device» – и пускай вас не смущают слова SCSI и SAS).
Источник
Поиск и замена диска поврежденного диска в Raid-1
Рассмотрим порядок действий проверки дисков выделенного сервера, с которого пришла ошибка SMART, выявления и замены неисправного диска в массиве Raid-1.
в данном примере всё с raid всё в порядке. Если бы было так: [U_], то диск sdb неисправен, если так: [_U], то sda (смотрим порядок в md-устройствах, например: md2 : active raid1 sda3[2] sdb3[3])
[X] меняем на a или b в зависимости от диска, список дисков можно посмотреть командой:
Оцениваем состояние диска по параметрам и выявляем неисправный, смотрим:
В зависимости от количества разделов выполняем соответственно для разных разделов:
Далее команда на удаление из RAID
Для проверки типа разбиения надо выполнить следующую команду:
на не замененном диске
После этого выполнить команду:
(для MBR), и
(структура разделов в этой команде копируется из /dev/sda в /dev/sdb)
(для GPT)
Источник
Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
Вы можете проверить целостность данных RAID (правильность блоков четности на RAID).
Чтобы проверить целостность данных RAID
| * | Щелкните правой кнопкой мыши по RAID и выберите пункт Проверить корректность RAID. контекстного меню |
| > | Откроется окно Проверка корректности RAID, в котором будет отображаться ход выполнения (прогресс) операции. |
Окно Проверка корректности RAID
После окончания проверки можно просмотреть ее результаты.
Блок четности RAID корректен.
Блок четности RAID некорректен.
Если подвести указатель мыши к блоку, то можно будет увидеть номера находящихся в нем секторов, а также число корректных и некорректных секторов. Если дважды щелкнуть по блоку мышью, то он сместится в левый верхний угол и масштаб данных увеличится а 2 раза.
Элементы управления окна Проверка корректности RAID
Номер первого сектора в ряде.
Переход к предыдущей/следующей порции данных.
Источник
Мониторинг raid массивов в Windows Core
За последние годы мы привыкли что можно и нужно все мониторить, множество инструментов начиная от простых логов, заканчивая Zabbix и все можно связать. Microsoft в свою очередь тоже дала нам отличный инструмент WinRM, с помощью которого мы можем отслеживать состояние операционных систем и не только. Но как всегда есть ложка дегтя, собственно об «обходе» этой ложки дегтя и пойдет речь.
Как выше было сказано, мы имеем все необходимые инструменты для мониторинга IT структуры, но так сложилось что мы не имеем «автоматизированный» инструмент для мониторинга состояния Intel raid массивов в Windows core. Обращаю Ваше внимание на то, что речь идет об обычном «желтом железе».
Все мы знаем что есть софт от Intel, rapid и matrix storage, но к сожалению на стандартном Windows core он не работает, также есть утилита raidcfg32, она работает в режиме командной строки, умеет обслуживать в ручном режиме и показывать статус, тоже в ручном режиме. Думаю Америку не для кого не открыл.
Постоянно в ручном режиме проверять состояние raid или ждать выхода из строя сервера виртуализации не самый лучший выбор.
Для реализации коварного плана по автоматизации мониторинга Intel raid мы используем
основные инструменты:
Копируем raidcfg32.exe в c:raidcfg32
Проверяем корректно ли установлен драйвер:
cmd.exe C:raidcfg32raidcfg32.exe /stv
Если получаем состояние raid и дисков, то все ок.
Создаем источник в журнале application:
*Дальше все выполняется в powershell
Выполняем запрос состояния raid, удаляем кавычки для упрощения парсинга, подключаем содержимое файла.
Ищем ключевые слова, если одно из слов ниже будет найдено, то в файле errorRAID.txt появится значение true, это будет говорить о наличии ошибки, если совпадений не найдено, то будет записано значение false.
Подключаем файл с записаными true и false, ищем в файле true, если true найдено то заменяем его на Error, заменяем false на Information.
Записывам результат в EntryType.txt
Записываем в EventLog сообщение, где в случае если будут найдены ключевые слова, уровень сообщения будет Error, если не будут найдены, то Information.
Сохраняем код в *.ps1
Создаем в планировщике задание на запуск скрипта, я запускаю задание 1 раз в сутки и при каждой загрузке.
Если будет производится сбор логов другой Windows ОС в Eventlog, то на коллекторе логов необходимо создать источник «RAID», пример есть выше.
Мы транспортируем логи в rsyslog через Adison rsyslog для Windows.
На выходе получается вот такая картинка:
UPD.
По поводу использования store space, все сервера с windows core на борту используются в филиалах, в филиале установлен только 1 сервер и для получения «бесплатного» гипервизора и уменьшения стоимости лицензии используется именно core.
Источник
Объединение 2-х дисков в 1: настройка RAID-массива на домашнем компьютере (просто о сложном)
Доброго дня!
Согласитесь, звучит заманчиво?! Однако, многим пользователям слово «RAID» — либо вообще ничего не говорит, либо напоминает что-то такое отдаленное и сложное (явно-недоступное для повседневных нужд на домашнем ПК/ноутбуке). На самом же деле, все проще, чем есть. 👌 (разумеется, если мы не говорим о каких-то сложных производственных задачах, которые явно не нужны на обычном ПК)
Собственно, ниже в заметке попробую на доступном языке объяснить, как можно объединить диски в эти RAID-массивы, в чем может быть их отличие, и «что с чем едят».
Настройка RAID
Основы, какими могут быть RAID массивы (т.е. то, как будем объединять диски)
Обратите внимание также на табличку ниже.
Разумеется, видов RAID-массивов гораздо больше (RAID 5, RAID 6, RAID 10 и др.), но все они представляют из себя разновидности вышеприведенных (и, как правило, в домашних условиях не используются).
Пару слов о дисках и мат. плате
Не все материнские платы поддерживают работу с дисковыми массивами RAID. И прежде, чем переходить к вопросу объединению дисков, необходимо уточнить этот момент.
Как это сделать : сначала с помощью спец. утилит (например, AIDA 64) нужно узнать точную модель материнской платы компьютера.
Далее найти спецификацию к вашей мат. плате на официальном сайте производителя и посмотреть вкладку «Хранение» (в моем примере ниже, мат. плата поддерживает RAID 0, RAID 1, RAID 10).
Спецификация материнской платы
Если ваша плата не поддерживает нужный вам вид RAID-массива, то у вас есть два варианта выхода из положения:
RAID-контроллер (в качестве примера)
Важная заметка : RAID-массив при форматировании логического раздела, переустановки Windows и т.д. — не разрушится. Но при замене материнской платы (при обновлении чипсета и RAID-контроллера) — есть вероятность, что вы не сможете прочитать информацию с этого RAID-массива (т.е. информация не будет недоступна. ).
Что касается дисков под RAID-массив :
Пример настройки RAID 0 в BIOS
Важно : при этом способе информация с дисков будет удалена!
Примечание : создать RAID-массив можно и из-под Windows (например, если вы хотите в целях безопасности сделать зеркальную копию своего диска).
1) И так, первым делом необходимо подключить диски к компьютеру (ноутбуку). Здесь на этом не останавливаюсь.
2) Далее нужно зайти в BIOS и установить 2 опции:
Затем нужно сохранить настройки (чаще всего это клавиша F10) и перезагрузить компьютер.
Intel Rapid Storage Technology
Create RAID Volume
5) Теперь нужно указать:
После нажатия на кнопку Create Volume — RAID-массив будет создан, им можно будет пользоваться как обычным отдельным накопителем.
Как создать RAID 0, RAID 1 программно (в ОС Windows 10)
Рассмотрю ниже пару конкретных примеров.
2) Открываете управление дисками (для этого нужно: нажать Win+R, и в появившемся окне ввести команду diskmgmt.msc).
3) Теперь действия могут несколько отличаться.
Вариант 1 : допустим вы хотите объединить два новых диска в один, чтобы у вас был большой накопитель для разного рода файлов. В этом случае просто кликните правой кнопкой мышки по одному из новых дисков и выберите создание чередующегося тома (это подразумевает RAID 0). Далее укажите какие диски объединяете, файловую систему и пр.
Создать чередующийся или зеркальный том
Вариант 2 : если же вы беспокоитесь за сохранность своих данных — то можно подключенный к системе новый диск сделать зеркальным вашему основному диску с ОС Windows, причем эта операция будет без потери данных (прим.: RAID 1).
4) После Windows начнет автоматическую синхронизацию накопителей: т.е. с выбранного вами раздела все данные будут также скопированы на новый диск.
5) В общем-то, всё, RAID 1 настроен — теперь при любых изменениях файлов на основном диске с Windows — они автоматически будут синхронизированы (перенесены) на второй диск.
6) Удалить зеркало, кстати, можно также из управления дисками : пример на скрине ниже.
Источник
| RAID 0 (распределение) | RAID 1 (зеркалирование) |
О LENOVO
+
О LENOVO
-
Наша компания
-
Новости
-
Контакт
-
Соответствие продукта
-
Работа в Lenovo
-
Общедоступное программное обеспечение Lenovo
КУПИТЬ
+
КУПИТЬ
-
Где купить
-
Рекомендованные магазины
-
Стать партнером
Поддержка
+
Поддержка
-
Драйверы и Программное обеспечение
-
Инструкция
-
Инструкция
-
Поиск гарантии
-
Свяжитесь с нами
-
Поддержка хранилища
РЕСУРСЫ
+
РЕСУРСЫ
-
Тренинги
-
Спецификации продуктов ((PSREF)
-
Доступность продукта
-
Информация об окружающей среде
©
Lenovo.
|
|
|
|
Вы можете проверить целостность данных RAID (правильность блоков четности на RAID).
|
* |
Щелкните правой кнопкой мыши по RAID и выберите пункт Проверить корректность RAID… контекстного меню |
|
> |
Откроется окно Проверка корректности RAID, в котором будет отображаться ход выполнения (прогресс) операции. |
Окно Проверка корректности RAID
После окончания проверки можно просмотреть ее результаты.
|
|
|
|
|
|
|
|
|
|
|
|
Если подвести указатель мыши к блоку, то можно будет увидеть номера находящихся в нем секторов, а также число корректных и некорректных секторов. Если дважды щелкнуть по блоку мышью, то он сместится в левый верхний угол и масштаб данных увеличится а 2 раза.
Элементы управления окна Проверка корректности RAID
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Привет, %хабрачитатель%!
Несколько месяцев назад у нас возникли проблемы с одной виртуальной машиной, запущенной на сервере Dell PowerEdge R720 с ESXi 5.5. Перезагрузка этой VM длилась довольно долго и вызвала сильное падение производительности на самом хосте.
Lifecycle-лог на сервере был наполнен сообщениями вида:
PDR47
A block on Disk 0 in Backplane 1 of Integrated RAID Controller 1 was
punctured by the controller.PDR64
An unrecoverable disk media error occurred on Disk 0 in Backplane 1 of
Integrated RAID Controller 1.
Гугление привело к неутешительному выводу: рейд-массив поврежден и восстановить его невозможно. А именно — повредились данные, относящиеся к одному блоку (страйпу), сразу на нескольких дисках (double fault):
К счастью, делловские RAID-контроллеры обладают фичей продолжать работу, несмотря на неконсисентное состояние массива — puncture (https://www.dell.com/support/Article/us/en/04/438291/EN#Unique-Hyphenated-Issue-Here-2), что позволяет сохранить хотя бы ту часть данных, которая не повредились. Это, конечно, не никак отменяет необходимость последующей замены дисков и пересборки рейд-массива «с нуля».
Для предотвращения подобных ситуаций Dell рекомендует запускать проверку целостности массива не реже одного раза в месяц. Увы, но мы об этом узнали слишком поздно.
Такую проверку можно запускать как через веб-интерфейс Dell OpenManage Server Administrator (http://www.dell.com/support/contents/us/en/19/article/Product-Support/Self-support-Knowledgebase/enterprise-resource-center/Enterprise-Tools/OMSA/), так и через утилиты omconfig/omreport, входящие в OMSA. И, если бы разработчики из Dell не «забыли» включить эти утилиты в OpenManage для ESXi, то проблем с автоматизацией бы не возникло, т.к. понятно, что ручная проверка целостности массива на каждом сервере, совершенно не IT-way. Не говоря уже о том, что интерфейс OMSA очень медленный и работать с ним удовольствие еще то.
Ребята из Dell «поработали на славу» и простым способом автоматизировать проверку (например, через открытие в cURL заранее подготовленной ссылки) невозможно, т.к. веб-интерфейс генерируется динамически и постоянные ссылки в нем отсутствуют.
Что же делать?
Пришлось немного повозиться и написать утилиту проверки самому. Встречайте: Consistency Check Task Automation Tool for Dell servers with iDRAC (https://github.com/jazzl0ver/dell_raid_cc). Утилита написана с помощью фреймворка CasperJS, который позволяет автоматизировать работу как раз с подобными динамическими сайтами.
Для использования dell_raid_cc необходимо:
1. Сервер с установленным OMSA (см. ссылку выше)
2. Скачать и установить phantomjs (http://phantomjs.org/download.html)
3. Скачать и установить casperjs (http://docs.casperjs.org/en/latest/installation.html)
4. Вытащить утилиту из git:
git clone https://github.com/jazzl0ver/dell_raid_cc
5. Создать файл с параметрами доступа (например, creds.txt):
export OMSAHOST=192.168.1.191
export OMSAPORT=1311
export USERNAME=root
export PASSWORD=password
export DELLHOST=192.168.1.30
6. Загрузить его и можно запускать утилиту или ставить ее запуск в кронтаб:
source creds.txt
casperjs --ignore-ssl-errors=true --cookies-file=/tmp/dell_raid_cc_cookie.jar dell_raid_cc.js
Если все в порядке, то вывод будет примерно такой:
Found: Virtual Disk 0 [state: Ready; layout: RAID-10; size: 1,862.00GB]
CC for Virtual Disk 0 has been started
Found: Virtual Disk 1 [state: Ready; layout: RAID-1; size: 931.00GB]
CC for Virtual Disk 1 has been started
Если запустить еще раз, можно увидеть прогресс проверки, например:
Found: Virtual Disk 0 [state: Resynching; layout: RAID-6; size: 5,026.50GB]
CC for Virtual Disk 0 is still running, progress: 19% complete
Стоит сказать, что утилита не поддерживает многоконтроллерные системы (у меня просто таких нет и протестировать, соответственно, не на чем).
Надеюсь, утилита окажется полезной не только мне.
UPD. Как подсказали коллеги в комментариях, более правильно настроить запуск проверки на целостность по расписанию с помощью утилиты megacli. Например:
./MegaCli -AdpCcSched -SetStartTime 20140822 04 -aALL
Инструкции по установке на сервер с CentOS/RedHat — здесь
Настройка расписания CC — здесь
Под ESXi также легко устанавливается. Можно поставить vib напрямую, либо сделать из него bundle и поставить в качестве обновления через vCenter.
UPD. #2 Контроллеры Perc5 не поддерживают настройку расписания через MegaCli:
cd /opt/lsi/MegaCLI; ./MegaCli -AdpCcSched -Info -aALL
Adapter 0: Scheduled Chceck Consistency is not supported.
Exit Code: 0x01
Для них использование dell_raid_cc — единственный способ автоматизации.
Contents
- 1 Detecting, querying and testing
- 1.1 Detecting a drive failure
- 1.2 Querying the array status
- 1.3 Simulating a drive failure
- 1.3.1 Force-fail by hardware
- 1.3.2 Force-fail by software
- 1.4 Simulating data corruption
- 1.5 Monitoring RAID arrays
Detecting, querying and testing
This section is about life with a software RAID system, that’s
communicating with the arrays and tinkertoying them.
Note that when it comes to md devices manipulation, you should always
remember that you are working with entire filesystems. So, although
there could be some redundancy to keep your files alive, you must
proceed with caution.
Detecting a drive failure
Firstly: mdadm has an excellent ‘monitor’ mode which will send an email when a problem is detected in any array (more about that later).
Of course the standard log and stat files will record more details about a drive failure.
It’s always a must for /var/log/messages to fill screens with tons of
error messages, no matter what happened. But, when it’s about a disk
crash, huge lots of kernel errors are reported. Some nasty examples,
for the masochists,
kernel: scsi0 channel 0 : resetting for second half of retries.
kernel: SCSI bus is being reset for host 0 channel 0.
kernel: scsi0: Sending Bus Device Reset CCB #2666 to Target 0
kernel: scsi0: Bus Device Reset CCB #2666 to Target 0 Completed
kernel: scsi : aborting command due to timeout : pid 2649, scsi0, channel 0, id 0, lun 0 Write (6) 18 33 11 24 00
kernel: scsi0: Aborting CCB #2669 to Target 0
kernel: SCSI host 0 channel 0 reset (pid 2644) timed out - trying harder
kernel: SCSI bus is being reset for host 0 channel 0.
kernel: scsi0: CCB #2669 to Target 0 Aborted
kernel: scsi0: Resetting BusLogic BT-958 due to Target 0
kernel: scsi0: *** BusLogic BT-958 Initialized Successfully ***
Most often, disk failures look like these,
kernel: sidisk I/O error: dev 08:01, sector 1590410
kernel: SCSI disk error : host 0 channel 0 id 0 lun 0 return code = 28000002
or these
kernel: hde: read_intr: error=0x10 { SectorIdNotFound }, CHS=31563/14/35, sector=0
kernel: hde: read_intr: status=0x59 { DriveReady SeekComplete DataRequest Error }
And, as expected, the classic /proc/mdstat look will also reveal problems,
Personalities : [linear] [raid0] [raid1] [translucent]
read_ahead not set
md7 : active raid1 sdc9[0] sdd5[8] 32000 blocks [2/1] [U_]
Later on this section we will learn how to monitor RAID with mdadm so
we can receive alert reports about disk failures. Now it’s time to
learn more about /proc/mdstat interpretation.
Querying the array status
You can always take a look at the array status by doing cat /proc/mdstat
It won’t hurt. Take a look at the /proc/mdstat page to learn how to read the file.
Finally, remember that you can also use mdadm to check
the arrays out.
mdadm --detail /dev/mdx
These commands will show spare and failed disks loud and clear.
Simulating a drive failure
If you plan to use RAID to get fault-tolerance, you may also want to
test your setup, to see if it really works. Now, how does one
simulate a disk failure?
The short story is, that you can’t, except perhaps for putting a fire
axe thru the drive you want to «simulate» the fault on. You can never
know what will happen if a drive dies. It may electrically take the
bus it is attached to with it, rendering all drives on that bus
inaccessible. The drive may also just report a read/write fault
to the SCSI/IDE/SATA layer, which, if done properly, in turn makes the RAID layer handle this
situation gracefully. This is fortunately the way things often go.
Remember, that you must be running RAID-{1,4,5,6,10} for your array to be
able to survive a disk failure. Linear- or RAID-0 will fail
completely when a device is missing.
Force-fail by hardware
If you want to simulate a drive failure, you can just plug out the
drive. If your HW does not support disk hot-unplugging, you should do this with the power off (if you are interested in testing whether your data can survive with a disk less than the usual number, there is no point in being a hot-plug cowboy here. Take the system down, unplug the disk, and boot it up again)
Look in the syslog, and look at /proc/mdstat to see how the RAID is
doing. Did it work? Did you get an email from the mdadm monitor?
Faulty disks should appear marked with an (F) if you look at
/proc/mdstat. Also, users of mdadm should see the device state as
faulty.
When you’ve re-connected the disk again (with the power off, of
course, remember), you can add the «new» device to the RAID again,
with the mdadm —add’ command.
Force-fail by software
You can just simulate a drive failure without unplugging things.
Just running the command
mdadm --manage --set-faulty /dev/md1 /dev/sdc2
should be enough to fail the disk /dev/sdc2 of the array /dev/md1.
Now things move up and fun appears. First, you should see something
like the first line of this on your system’s log. Something like the
second line will appear if you have spare disks configured.
kernel: raid1: Disk failure on sdc2, disabling device.
kernel: md1: resyncing spare disk sdb7 to replace failed disk
Checking /proc/mdstat out will show the degraded array. If there was a
spare disk available, reconstruction should have started.
Another useful command at this point is:
mdadm --detail /dev/md1
Enjoy the view.
Now you’ve seen how it goes when a device fails. Let’s fix things up.
First, we will remove the failed disk from the array. Run the command
mdadm /dev/md1 -r /dev/sdc2
Note that mdadm cannot pull a disk out of a running array.
For obvious reasons, only faulty disks can be hot-removed from an
array (even stopping and unmounting the device won’t help — if you ever want
to remove a ‘good’ disk, you have to tell the array to put it into the
‘failed’ state as above).
Now we have a /dev/md1 which has just lost a device. This could be a
degraded RAID or perhaps a system in the middle of a reconstruction
process. We wait until recovery ends before setting things back to
normal.
So the trip ends when we send /dev/sdc2 back home.
mdadm /dev/md1 -a /dev/sdc2
As the prodigal son returns to the array, we’ll see it becoming an
active member of /dev/md1 if necessary. If not, it will be marked as
a spare disk. That’s management made easy.
Simulating data corruption
RAID (be it hardware or software), assumes that if a write to a disk
doesn’t return an error, then the write was successful. Therefore, if
your disk corrupts data without returning an error, your data will
become corrupted. This is of course very unlikely to happen, but it
is possible, and it would result in a corrupt filesystem.
RAID cannot, and is not supposed to, guard against data corruption on
the media. Therefore, it doesn’t make any sense either, to purposely
corrupt data (using dd for example) on a disk to see how the RAID
system will handle that. It is most likely (unless you corrupt the
RAID superblock) that the RAID layer will never find out about the
corruption, but your filesystem on the RAID device will be corrupted.
This is the way things are supposed to work. RAID is not a guarantee
for data integrity, it just allows you to keep your data if a disk
dies (that is, with RAID levels above or equal one, of course).
Monitoring RAID arrays
You can run mdadm as a daemon by using the follow-monitor mode. If
needed, that will make mdadm send email alerts to the system
administrator when arrays encounter errors or fail. Also, follow mode
can be used to trigger contingency commands if a disk fails, like
giving a second chance to a failed disk by removing and reinserting
it, so a non-fatal failure could be automatically solved.
Let’s see a basic example. Running
mdadm --monitor --daemonise --mail=root@localhost --delay=1800 /dev/md2
should release a mdadm daemon to monitor /dev/md2. The —daemonise switch tells mdadm to run as a deamon. The delay parameter means that polling will be done in intervals of 1800 seconds.
Finally, critical events and fatal errors should be e-mailed to the
system manager. That’s RAID monitoring made easy.
Finally, the —program or —alert parameters specify the program to be
run whenever an event is detected.
Note that, when supplying the -f switch, the mdadm daemon will never exit once it decides that there
are arrays to monitor, so it should normally be run in the background.
Remember that your are running a daemon, not a shell command.
If mdadm is ran to monitor without the -f switch, it will behave as a normal shell command and wait for you to stop it.
Using mdadm to monitor a RAID array is simple and effective. However,
there are fundamental problems with that kind of monitoring — what
happens, for example, if the mdadm daemon stops? In order to overcome
this problem, one should look towards «real» monitoring solutions.
There are a number of free software, open source, and even commercial
solutions available which can be used for Software RAID monitoring on
Linux. A search on FreshMeat should return a good number of matches.
Содержание
Эта страница целиком списана с исходной, где рассматриваются вопросы создания и обслуживания программного RAID-массива в операционной системе Linux. К сожалению, исходная страница недоступна, приходится держать копию на этом wiki.
Краткое описание mdadm
Управление программным RAID-массивом в Linux выполняется с помощью программы mdadm.
У программы mdadm есть несколько режимов работы.
Assemble(сборка)
Собрать компоненты ранее созданного массива в массив. Компоненты можно указывать явно, но можно и не указывать — тогда выполняется их поиск по суперблокам.
Build(построение)
Собрать массив из компонентов, у которых нет суперблоков. Не выполняются никакие проверки, создание и сборка массива в принципе ничем не отличаются.
Create(создание)
Создать новый массив на основе указанных устройств. Использовать суперблоки размещённые на каждом устройстве.
Monitor(наблюдение)
Следить за изменением состояния устройств. Для RAID0 этот режим не имеет смысла.
Grow (расширение или уменьшение)
Расширение или уменьшение массива, включаются или удаляются новые диски.
Incremental Assembly (инкрементальная сборка)
Добавление диска в массив.
Manage (управление)
Разнообразные операции по управлению массивом, такие как замена диска и пометка как сбойного.
Misc (разное)
Действия, которые не относятся ни к одному из перечисленных выше режимов работы.
Auto-detect (автоообнаружение)
Активация автоматически обнаруживаемых массивов в ядре Linux.
Формат вызова
mdadm [mode] [array] [options]
Режимы:
-
-A, –assemble — режим сборки
-
-B, –build — режим построения
-
-C, –create — режим создания
-
-F, –follow, –monitor — режим наблюдения
-
-G, –grow — режим расширения
-
-I, –incremental — режим инкрементальной сборки
Настройка программного RAID-массива
Рассмотрим как выполнить настройку RAID-массива 10 уровня на четырёх дисковых разделах. Мы будем использовать разделы:
/dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
В том случае если разделы иные, не забудьте использовать соответствующие имена файлов.
Создание разделов
Нужно определить на каких физических разделах будет создаваться RAID-массив. Если разделы уже есть, нужно найти свободные (fdisk -l). Если разделов ещё нет, но есть неразмеченное место, их можно создать с помощью программ fdisk или cfdisk.
Просмотреть какие есть разделы:
%# fdisk -l
Disk /dev/hda: 12.0 GB, 12072517632 bytes 255 heads, 63 sectors/track, 1467 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System /dev/hda1 * 1 13 104391 83 Linux /dev/hda2 14 144 1052257+ 83 Linux /dev/hda3 145 209 522112+ 82 Linux swap /dev/hda4 210 1467 10104885 5 Extended /dev/hda5 210 655 3582463+ 83 Linux ... ... /dev/hda15 1455 1467 104391 83 Linux
Просмотреть, какие разделы куда смонтированы, и сколько свободного места есть на них (размеры в килобайтах):
%# df -k Filesystem 1K-blocks Used Available Use% Mounted on /dev/hda2 1035692 163916 819164 17% / /dev/hda1 101086 8357 87510 9% /boot /dev/hda15 101086 4127 91740 5% /data1 ... ... ... /dev/hda7 5336664 464228 4601344 10% /var
Размонтирование
Если вы будете использовать созданные ранее разделы, обязательно размонтируйте их. RAID-массив нельзя создавать поверх разделов, на которых находятся смонтированные файловые системы.
%# umount /dev/sda1 %# umount /dev/sdb1 %# umount /dev/sdc1 %# umount /dev/sdd1
Изменение типа разделов
Желательно (но не обязательно) изменить тип разделов, которые будут входить в RAID-массив и установить его равным FD (Linux RAID autodetect). Изменить тип раздела можно с помощью fdisk.
Рассмотрим, как это делать на примере раздела /dev/hde1.
%# fdisk /dev/hde The number of cylinders for this disk is set to 8355. There is nothing wrong with that, but this is larger than 1024, and could in certain setups cause problems with: 1) software that runs at boot time (e.g., old versions of LILO) 2) booting and partitioning software from other OSs (e.g., DOS FDISK, OS/2 FDISK)
Command (m for help):
Use FDISK Help
Now use the fdisk m command to get some help:
Command (m for help): m ... ... p print the partition table q quit without saving changes s create a new empty Sun disklabel t change a partition's system id ... ... Command (m for help):
Set The ID Type To FD
Partition /dev/hde1 is the first partition on disk /dev/hde. Modify its type using the t command, and specify the partition number and type code. You also should use the L command to get a full listing of ID types in case you forget.
Command (m for help): t Partition number (1-5): 1 Hex code (type L to list codes): L
... ... ... 16 Hidden FAT16 61 SpeedStor f2 DOS secondary 17 Hidden HPFS/NTF 63 GNU HURD or Sys fd Linux raid auto 18 AST SmartSleep 64 Novell Netware fe LANstep 1b Hidden Win95 FA 65 Novell Netware ff BBT Hex code (type L to list codes): fd Changed system type of partition 1 to fd (Linux raid autodetect)
Command (m for help):
Make Sure The Change Occurred
Use the p command to get the new proposed partition table:
Command (m for help): p
Disk /dev/hde: 4311 MB, 4311982080 bytes 16 heads, 63 sectors/track, 8355 cylinders Units = cylinders of 1008 * 512 = 516096 bytes
Device Boot Start End Blocks Id System /dev/hde1 1 4088 2060320+ fd Linux raid autodetect /dev/hde2 4089 5713 819000 83 Linux /dev/hde4 6608 8355 880992 5 Extended /dev/hde5 6608 7500 450040+ 83 Linux /dev/hde6 7501 8355 430888+ 83 Linux
Command (m for help):
Save The Changes
Use the w command to permanently save the changes to disk /dev/hde:
Command (m for help): w The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy. The kernel still uses the old table. The new table will be used at the next reboot. Syncing disks.
Аналогичным образом нужно изменить тип раздела для всех остальных разделов, входящих в RAID-массив.
Создание RAID-массива
Создание RAID-массива выполняется с помощью программы mdadm (ключ –create). Мы воспользуемся опцией –level, для того чтобы создать RAID-массив 10 уровня. С помощью ключа –raid-devices укажем устройства, из которых будет собираться RAID-массив.
mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 64K
mdadm: /dev/hde1 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27 23:11:39 2007
mdadm: /dev/hdf2 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27 23:11:39 2007
mdadm: /dev/hdg1 appears to contain an ext2fs file system
size=48160K mtime=Sat Jan 27 23:11:39 2007
mdadm: size set to 48064K
Continue creating array? y
mdadm: array /dev/md0 started.
Если вы хотите сразу создать массив, где диска не хватает (degraded) просто укажите слово missing вместо имени устройства. Для RAID5 это может быть только один диск; для RAID6 — не более двух; для RAID1 — сколько угодно, но должен быть как минимум один рабочий.
Проверка правильности сборки
Убедиться, что RAID-массив проинициализирован корректно можно просмотрев файл /proc/mdstat. В этом файле отражается текущее состояние RAID-массива.
%# cat /proc/mdstat
Personalities : [raid5]
read_ahead 1024 sectors
md0 : active raid5 hdg1[2] hde1[1] hdf2[0]
4120448 blocks level 5, 32k chunk, algorithm 3 [3/3] [UUU]
unused devices: <none>
Обратите внимание на то, как называется новый RAID-массив. В нашем случае он называется /dev/md0. Мы будем обращаться к массиву по этому имени.
Создание файловой системы поверх RAID-массива
Новый RAID-раздел нужно отформатировать, т.е. создать на нём файловую систему. Сделать это можно при помощи программы из семейства mkfs. Если мы будем создавать файловую систему ext3, воспользуемся программой mkfs.ext3. :
%# mkfs.ext3 /dev/md0
mke2fs 1.39 (29-May-2006)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
36144 inodes, 144192 blocks
7209 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
18 block groups
8192 blocks per group, 8192 fragments per group
2008 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done Creating journal (4096 blocks): done Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 33 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
Имеет смысл для лучшей производительности файловой системы указывать при создании количество дисков в рейде и количество блоков файловой системы которое может поместиться в один страйп ( chunk ), это особенно важно при создании массивов уровня RAID0,RAID5,RAID6,RAID10. Для RAID1 ( mirror ) это не имеет значения так как запись идёт всегда на один device, a в других типах рейдов дата записывается последовательно на разные диски порциями соответствующими размеру stripe. Например если мы используем RAID5 из 3 дисков, с дефолтным размером страйпа в 64К и используем файловую систему ext3 с размером блока в 4К то можно вызывать команду mkfs.ext вот так:
%# mkfs.ext3 -b 4096 -E stride=16,stripe-width=32 /dev/md0
stripe-width обычно рассчитывается как stride * N ( N это дата диски в массиве — например в RAID5 — два дата диска и один parity ) Для не менее популярной файловой системы XFS надо указывать не количество блоков файловой системы соответствующих размеру stripe в массиве, а непосредственно размер самого страйпа
%# mkfs.xfs -d su=64k,sw=3 /dev/md0
Создание конфигурационного файла mdadm.conf
Система сама не запоминает какие RAID-массивы ей нужно создать и какие компоненты в них входят. Эта информация находится в файле mdadm.conf.
Строки, которые следует добавить в этот файл, можно получить при помощи команды
mdadm –detail –scan –verbose
Вот пример её использования:
%# mdadm --detail --scan --verbose ARRAY /dev/md0 level=raid5 num-devices=4 UUID=77b695c4:32e5dd46:63dd7d16:17696e09 devices=/dev/hde1,/dev/hdf2,/dev/hdg1
Если файла mdadm.conf ещё нет, можно его создать:
%# echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
%# mdadm --detail --scan --verbose | awk '/ARRAY/ {print}' >> /etc/mdadm/mdadm.conf
Создание точки монтирования для RAID-массива
Поскольку мы создали новую файловую систему, вероятно, нам понадобится и новая точка монтирования. Назовём её /raid.
%# mkdir /raid
Изменение /etc/fstab
Для того чтобы файловая система, созданная на новом RAID-массиве, автоматически монтировалась при загрузке, добавим соответствующую запись в файл /etc/fstab хранящий список автоматически монтируемых при загрузке файловых систем.
/dev/md0 /raid ext3 defaults 1 2
Если мы объединяли в RAID-массив разделы, которые использовались раньше, нужно отключить их монтирование: удалить или закомментировать соответствующие строки в файле /etc/fstab. Закомментировать строку можно символом #.
#/dev/hde1 /data1 ext3 defaults 1 2 #/dev/hdf2 /data2 ext3 defaults 1 2 #/dev/hdg1 /data3 ext3 defaults 1 2
Монтирование файловой системы нового RAID-массива
Для того чтобы получить доступ к файловой системе, расположенной на новом RAID-массиве, её нужно смонтировать. Монтирование выполняется с помощью команды mount.
Если новая файловая система добавлена в файл /etc/fstab, можно смонтировать её командой mount -a (смонтируются все файловые системы, которые должны монтироваться при загрузке, но сейчас не смонтированы).
%# mount -a
Можно смонтировать только нужный нам раздел (при условии, что он указан в /etc/fstab).
%# mount /raid
Если раздел в /etc/fstab не указан, то при монтировании мы должны задавать как минимум два параметра — точку монтирования и монтируемое устройство:
%# mount /dev/md0 /raid
Проверка состояния RAID-массива
Информация о состоянии RAID-массива находится в файле /proc/mdstat.
%# raidstart /dev/md0
%# cat /proc/mdstat
Personalities : [raid5]
read_ahead 1024 sectors
md0 : active raid5 hdg1[2] hde1[1] hdf2[0]
4120448 blocks level 5, 32k chunk, algorithm 3 [3/3] [UUU]
unused devices: <none>
Если в файле информация постоянно изменяется, например, идёт пересборка массива, то постоянно изменяющийся файл удобно просматривать при помощи программы watch:
%$ watch cat /proc/mdstat
Как выполнить проверку целостности программного RAID-массива md0:
echo ‘check’ >/sys/block/md0/md/sync_action
Как посмотреть нашлись ли какие-то ошибки в процессе проверки программного RAID-массива по команде check или repair:
cat /sys/block/md0/md/mismatch_cnt
Проблема загрузки на многодисковых системах
В некоторых руководствах по mdadm после первоначальной сборки массивов рекомендуется добавлять в файл /etc/mdadm/mdadm.conf вывод команды «mdadm –detail –scan –verbose»:
ARRAY /dev/md/1 level=raid1 num-devices=2 metadata=1.2 name=linuxWork:1 UUID=147c5847:dabfe069:79d27a05:96ea160b
devices=/dev/sda1
ARRAY /dev/md/2 level=raid1 num-devices=2 metadata=1.2 name=linuxWork:2 UUID=68a95a22:de7f7cab:ee2f13a9:19db7dad
devices=/dev/sda2
, в котором жёстко прописаны имена разделов (/dev/sda1, /dev/sda2 в приведённом примере).
Если после этого обновить образ начальной загрузки (в Debian вызвать ‘update-initramfs -u’ или ‘dpkg-reconfigure mdadm’), имена разделов запишутся в файл mdadm.conf образа начальной загрузки, и вы не сможете загрузиться с массива, если конфигурация жёстких дисков изменится (нужные разделы получат другие имена). Для этого не обязательно добавлять или убирать жёсткие диски: в многодисковых системах их имена могут меняться от загрузки к загрузке.
Решение: записывать в /etc/mdadm/mdadm.conf вывод команды «mdadm –detail –scan» (без –verbose).
При этом в файле mdadm.conf будут присутствовать UUID разделов, составляющих каждый RAID-массив. При загрузке системы mdadm находит нужные разделы независимо от их символических имён по UUID.
mdadm.conf, извлечённый из образа начальной загрузки Debian:
DEVICE partitions
HOMEHOST <system>
ARRAY /dev/md/1 metadata=1.2 UUID=147c5847:dabfe069:79d27a05:96ea160b name=linuxWork:1
ARRAY /dev/md/2 metadata=1.2 UUID=68a95a22:de7f7cab:ee2f13a9:19db7dad name=linuxWork:2
Результат исследования раздела командой ‘mdadm –examine’«
/dev/sda1:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : 147c5847:dabfe069:79d27a05:96ea160b
Name : linuxWork:1
Creation Time : Thu May 23 09:17:01 2013
Raid Level : raid1 Raid Devices : 2
Раздел c UUID 147c5847:dabfe069:79d27a05:96ea160b войдёт в состав массива, даже если станет /dev/sdb1 при очередной загрузке системы.
Вообще, существует 2 файла mdadm.conf, влияющих на автоматическую сборку массивов:
один при загрузке системы, записывется в образ начальной загрузки при его обновлении; другой находится в каталоге /etc/mdadm/ и влияет на автосборку массивов внутри работающей системы.
Соответственно, вы можете иметь информацию:
1) в образе начальной загрузки (ОНЗ) и в /etc/mdadm/mdadm.conf;
2) только в ОНЗ (попадает туда при его создании обновлении);
3) только в /etc/mdadm/mdadm.conf;
4) нигде.
В том месте, где есть mdadm.conf, сборка происходит по правилам; где нет — непредсказуемо.
Примечание: если вы не обновили ОНЗ после создания RAID-массивов, их конфигурация всё равно в него попадёт — при обновлении образа другой программой / при обновлении системы (но вы не будете об этом знать со всеми вытекающими).
[править] Дальнейшая работа с массивом
[править] Пометка диска как сбойного
Диск в массиве можно условно сделать сбойным, ключ –fail (-f):
%# mdadm /dev/md0 --fail /dev/hde1 %# mdadm /dev/md0 -f /dev/hde1
[править] Удаление сбойного диска
Сбойный диск можно удалить с помощью ключа –remove (-r):
%# mdadm /dev/md0 --remove /dev/hde1 %# mdadm /dev/md0 -r /dev/hde1
[править] Добавление нового диска
Добавить новый диск в массив можно с помощью ключей –add (-a) и –re-add:
%# mdadm /dev/md0 --add /dev/hde1 %# mdadm /dev/md0 -a /dev/hde1
Сборка существующего массива
Собрать существующий массив можно с помощью mdadm –assemble. Как дополнительный аргумент указывается, нужно ли выполнять сканирование устройств, и если нет, то какие устройства нужно собирать.
%# mdadm --assemble /dev/md0 /dev/hde1 /dev/hdf2 /dev/hdg1 %# mdadm --assemble --scan
Расширение массива
Расширить массив можно с помощью ключа –grow (-G). Сначала добавляется диск, а потом массив расширяется:
%# mdadm /dev/md0 --add /dev/hdh2
Проверяем, что диск (раздел) добавился:
%# mdadm --detail /dev/md0 %# cat /proc/mdstat
Если раздел действительно добавился, мы можем расширить массив:
%# mdadm -G /dev/md0 --raid-devices=4
Опция –raid-devices указывает новое количество дисков, используемое в массиве. Например, было 3 диска, а теперь расширяем до 4-х — указываем 4.
Рекомендуется задать файл бэкапа на случай прерывания перестроения массива, например добавить:
-
-backup-file=/var/backup
При необходимости можно регулировать скорость процесса расширения массива, указав нужное значение в файлах
/proc/sys/dev/raid/speed_limit_min /proc/sys/dev/raid/speed_limit_max
Убедитесь, что массив расширился:
%# cat /proc/mdstat
Нужно обновить конфигурационный файл с учётом сделанных изменений:
%# mdadm --detail --scan >> /etc/mdadm/mdadm.conf %# vi /etc/mdadm/mdadm.conf
Возобновление отложенной синхронизации
Отложенная синхронизация:
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active(auto-read-only) raid1 sda1[0] sdb1[1]
78148096 blocks [2/2] [UU]
resync=PENDING
Возобновить:
echo idle > /sys/block/md0/md/sync_action
P.S.: Если вы увидели «active (auto-read-only)» в файле /proc/mdstat, то возможно вы просто ничего не записывали в этот массив. К примеру, после монтирования раздела и любых изменений в примонтированном каталоге, статус автоматически меняется:
md0 : active raid1 sdc[0] sdd[1]
Переименование массива
Для начала отмонтируйте и остановите массив:
%# umount /dev/md0 %# mdadm --stop /dev/md0
Затем необходимо пересобрать как md5 каждый из разделов sd[abcdefghijk]1
%# mdadm --assemble /dev/md5 /dev/sd[abcdefghijk]1 --update=name
или так
%# mdadm --assemble /dev/md5 /dev/sd[abcdefghijk]1 --update=super-minor
Удаление массива
Для начала отмонтируйте и остановите массив:
%# umount /dev/md0 %# mdadm -S /dev/md0
Затем необходимо затереть superblock каждого из составляющих массива:
%# mdadm --zero-superblock /dev/hde1 %# mdadm --zero-superblock /dev/hdf2
Если действие выше не помогло, то затираем так:
%# dd if=/dev/zero of=/dev/hde1 bs=512 count=1 %# dd if=/dev/zero of=/dev/hdf2 bs=512 count=1
Создание пустого массива без сихронизации данных
Не каноничный метод, применять на дисках без данных!
Смотрим информацию по массивам и выбираем жертву
%# cat /proc/mdstat
Предварительно разбираем массив
%# mdadm --stop /dev/md124
Создаём директорию для metadata файлов
%# mkdir /tmp/metadata
Снимаем дамп metadata с одного из raid дисков
%# mdadm --dump=/tmp/metadata /dev/sda1
Копируем метаданные
%# cp /tmp/metadata/sda1 /tmp/metadata/sdb1
Накатываем бекап
%# mdadm --restore=/tmp/metadata /dev/sdb1
Собираем массив
%# mdadm --create --verbose /dev/md124 --level=0 --raid-devices=2 /dev/sda /dev/sdb
Радуемся отсутствию синка и данных
%# cat /proc/mdstat
Дополнительная информация
man mdadm (англ.) man mdadm.conf (англ.) Linux Software RAID (англ.) Gentoo Install on Software RAID (англ.) HOWTO Migrate To RAID (англ.) Remote Conversion to Linux Software RAID-1 for Crazy Sysadmins HOWTO (англ.) Migrating To RAID1 Mirror on Sarge (англ.) Настройка программного RAID-1 на Debian Etch (рус.), а также обсуждение на ЛОРе Недокументированные фишки программного RAID в Linux (рус.)
Производительность программных RAID-массивов
Adventures With Linux RAID: Part 1, Part 2 (англ.) Параметры, влияющие на производительность программного RAID (рус.)
Разные заметки, имеющие отношение к RAID
BIO_RW_BARRIER - what it means for devices, filesystems, and dm/md. (англ.)
Привет, друзья. В прошлой статье мы с вами создали RAID 1 массив (Зеркало) — отказоустойчивый массив из двух жёстких дисков SSD. Смысл создания RAID 1 массива заключается в повышении надёжности хранения данных на компьютере. Когда два жёстких диска объединены в одно хранилище, информация на обоих дисках записывается параллельно (зеркалируется). Диски являются точными копиями друг друга, и если один из них выйдет из строя, мы получим доступ к операционной системе и нашим данным, ибо их целостность будет обеспечена работой другого диска. Также конфигурация RAID 1 повышает производительность при чтении данных, так как считывание происходит с двух дисков. В этой же статье мы рассмотрим, как восстановить массив RAID 1, если он развалится. Другими словами, мы рассмотрим, как сделать Rebuild RAID 1.
Развал RAID 1 массива может произойти по нескольким причинам: отказ одного из дисков, ошибки микропрограммы БИОСа, неправильные действия пользователя компьютера. При развале RAID 1 в БИОСе у него будет статус «Degraded».
В таких случаях нужно произвести восстановление (Rebuild) массива. Каким образом это можно сделать? К примеру, при отказе одного накопителя мы просто подсоединяем другой исправный, затем жмём в БИОСе кнопку «Rebuild», и происходит синхронизация данных на дисках. Таким вот образом RAID 1 массив восстанавливается, и мы можем работать дальше. Вроде, всё просто. Однако на практике при возникновении такой проблемы много нюансов. Давайте подробно рассмотрим все особенности восстановления RAID.
Если созданный с помощью БИОСа материнской платы RAID 1 массив развалился, неопытный пользователь может этого сразу и не понять. Мы не получим ни звукового оповещения, ни оповещения в иной форме, сигнализирующих о проблеме развала RAID 1. Возможностями аварийной сигнализации при развале массивов обладают только отдельные SAS/SATA/RAID-контроллеры, работающие через интерфейс PCI Express. За аварийную сигнализацию при проблемах с массивами отвечает специальное ПО таких контроллеров. Не имея таких контроллеров, можем использовать программы типа CrystalDiskInfo или Hard Disk Sentinel Pro, которые предупредят нас о выходе из строя одного из накопителей массива звуковым сигналом, либо электронным письмом на почту.
Если заглянем в управление дисками Windows, о развале RAID 1 можем догадаться, например, по исчезновению разметки одного из дисков.
Но лучше, конечно, чтобы на компьютере был установлен родной софт от производителя чипсета материнской платы, выполняющий задачи по обслуживанию RAID-массивов. И именно этот софт должен вывести сообщение о деградации массива из-за выхода из строя одного из накопителей. Ещё такой софт должен выполнять постоянное наблюдение за техническим состоянием массива. И при замене вышедшего из строя диска на исправный на таком софте лежит ответственность за быстрое перестроение рассыпавшегося массива.
Для примера возьмём мою материнскую плату на чипсете Z490 от Intel, для которого существует специальное программное обеспечение Intel Rapid Storage Technology (Intel RST). Технология Intel Rapid Storage поддерживает SSD SATA и SSD PCIe M.2 NVMe, повышает производительность компьютеров с SSD-накопителями за счёт собственных разработок. Всесторонне обслуживает массивы RAID в конфигурациях 0, 1, 5, 10. Предоставляет пользовательский интерфейс Intel Optane Memory and Storage Management для управления системой хранения данных, в том числе дисковых массивов.
После установки Intel RST в главном окне увидим созданный нами из двух SSD M.2 NVMe Samsung 970 EVO Plus (250 Гб) RAID 1 массив, исправно функционирующий.
Вот этот массив в управлении дисками Windows.
И в диспетчере устройств.
Технология Intel Rapid Storage имеет свою службу и постоянно мониторит состояние накопителей. На данный момент все находящиеся в рейде диски исправны.
Если какой-либо накопитель неисправен, драйвер Intel RST сразу предупредит всплывающим окном о проблеме «Требуется внимание. Производительность одного из ваших томов снижена».
И в главном окне программы будет значиться, что один из дисков массива неисправен.
В этом случае можно произвести диагностику неисправного накопителя специальным софтом, к примеру, программой Hard Disk Sentinel Pro. Если диск неисправен или отработал свой ресурс, выключаем компьютер и заменяем диск на новый. Затем делаем Rebuild (восстановление) RAID 1 массива.
После замены неисправного диска включаем ПК и входим в БИОС. Заходим в расширенные настройки «Advanced Mode», идём во вкладку «Advanced». Переходим в пункт «Intel Rapid Storage Technology».
Видим, что наш RAID 1 массив с названием Volume 1 неработоспособен — «Volume 1 RAID 1 (mirroring), Degraded».Выбираем «Rebuild» (Восстановить).
Обратим внимание на уведомление внизу: «Selecting a disk initiates a rebuild. Rebuild completes in the operating system», переводится как «Выбор диска инициирует перестройку массива. Восстановление завершается в операционной системе». Выбираем новый накопитель, который нужно добавить в массив для его восстановления, жмём Enter. Появится следующий экран, указывающий, что после входа в операционную систему будет выполнено автоматическое восстановление — «All disk data will be lost», переводится как «Все данные на диске будут потеряны».RAID 1 массив восстановлен.
Жмём F10, сохраняем настройки, произведённые нами в БИОСе, и перезагружаемся.
После перезагрузки открываем программу Intel Optane Memory and Storage Management и видим, что всё ещё происходит перестроение массива, но операционной системой уже можно пользоваться.
Восстановить дисковый массив можно непосредственно в программе Intel Optane Memory and Storage Management. К примеру, у нас неисправен один диск массива, и Windows 10 загружается с исправного накопителя. Выключаем компьютер, отсоединяем неисправный, а затем устанавливаем новый SSD PCIe M.2 NVMe, включаем ПК. Программа Intel Optane Memory and Storage Management определяет его как неизвестный жёсткий диск.
Диспетчер устройств, как и управление дисками, не видит целостный RAID, а видит два разных SSD.
В главном окне программы жмём «Создать том RAID».
У нас SSD нового поколения с интерфейсом PCIe M.2 NVMe, значит, выбираем контроллер PCIe. Тип дискового массива — «Защита данных в режиме реального времени (RAID 1)».
Выбираем два наших диска SSD PCIe M.2 NVMe.
Если на новом диске были данные, после перестроения массива данные на нём удалятся. Жмём «Создать том RAID». Можем наблюдать процесс восстановления массива.
RAID 1 массив восстановлен.
Если включить в настройках программы Intel RST «Автоматическое перестроение при оперативной замене», при замене неисправного накопителя не нужно будет ничего настраивать. Восстановление дискового массива начнётся автоматически.
Если у вас выйдут из строя сразу оба накопителя, то покупаем новые, устанавливаем в системный блок, затем создаём RAID 1 заново и разворачиваем на него резервную копию.
Управление дисковым массивом работающего на аппаратном контроллере LSI MegaRAID, мы рекомендуем производить с помощью консольного клиента MegaCLI
Установка MegaCLI:
wget http://www.lsi.com/downloads/Public/RAID%20Controllers/RAID%20Controllers%20Common%20Files/.zip
unzip 8.07.07_MegaCLI.zip
cd 8.07.07_MegaCLI/
chmod +x MegaCli
Основные команды для работы:
Получить статус и конфигурацию всех адаптеров
megacli -AdpAllInfo -aAll
Cтатус и параметры всех логических дисков
megacli -LDInfo -LAll -aAll
Статус и параметры физических устройств
megacli -PDList -a0
Статус и параметры диска в 4-м слоте
megacli -pdInfo -PhysDrv[252:4] -a0
Создание RAID6 массив MegaCLI
Давайте предположим, что у нас есть сервер с MegaRAID SAS
Получим список физических дисков:
megacli -PDlist -a0 | grep -e ‘^Enclosure Device ID:’ -e ‘^Slot Number:’
Enclosure Device ID: 29
Slot Number: 0
Enclosure Device ID: 29
Slot Number: 1
Enclosure Device ID: 29
Slot Number: 2
Enclosure Device ID: 29
Slot Number: 3
Enclosure Device ID: 29
Slot Number: 4
Enclosure Device ID: 29
Slot Number: 5
Enclosure Device ID: 29
Slot Number: 6
Enclosure Device ID: 29
Slot Number: 7
Enclosure Device ID: 29
Slot Number: 8
Enclosure Device ID: 245
Slot Number: 12
Пример конфигурирования JBOD на LSI 2208 (Supermicro X9DRH-7TF) При загрузке BIOS эти команды можно выполнить если зайти в preboot CLI по комбинации клавиш Ctrl+Y
Команды megacli и preboot CLI различаются по виду.
Например команда проверки поддержки JBOD для BIOS preboot CLI будет выглядеть так:
AdpGetProp enablejbod -aALL
А для megacli это используется как набор опций и параметров:
megacli -AdpGetProp enablejbod -aALL
Включить поддержку JBOB
megacli -AdpSetProp EnableJBOD 1 -aALL
Список доступных физических устройств:
megacli -PDList -aALL -page24
В списке надо найти значения полей Enclosure Device ID (например 252), Slot Number и Firmware state
Нужно отметить каждое из устройств которое надо сделать JBOD, как Good в поле Firmware state .
megacli -PDMakeGood -PhysDrv[252:0] -Force -a0
Или сразу много устройств:
megacli -PDMakeGood -PhysDrv[252:1,252:2,252:3,252:4,252:5,252:6,252:7] -Force -a0
Теперь можно создавать JBOD
megacli -PDMakeJBOD -PhysDrv[252:0] -a0
megacli -PDMakeJBOD -PhysDrv[252:1,252:2,252:3,252:4,252:5,252:6,252:7] -a0
Создать виртуальный диск RAID
Перед настройкой массива, возможно, потребуется удалить использованную ранее конфигурацию. Для того чтобы просто удалить логические устройства используйте CfgLdDel
megacli -CfgLdDel -Lall -aAll
Для того чтобы удалить всё (в том числе политику кэша) используйте «Очистку конфигурации»
megacli -CfgClr -aAll
Настройка RAID-0, 1 или 5. Вместо «r0» введите соответственно «r1» или «r5» (диски находятся в Enclosure 29, на портах 0 и 1, WriteBack включен, ReadCache адаптивный, Cache также включен без BBU)
megacli -CfgLdAdd -r0 [29:0,29:1] WB ADRA Cached CachedBadBBU -sz196GB -a0
Создать RAID10 Получить список дисков
megacli -PDList -aAll | egrep «Enclosure Device ID:|Slot Number:|Inquiry Data:|Error Count:|state»
Создать массив из 6 дисков
megacli -CfgSpanAdd -r10 -Array0[252:0,252:1] -Array1[252:2,252:4] [-Array2[252:5,252:6] -a0
Показать как диски были определены в RAID-массиве:
megacli -CfgDsply -a0
Удалить массив с ID=2
MegaCli –CfgLDDel -L2 -a0
Инициализация массива Начать полную инициализацию для массива с ID=0
MegaCli -LDInit -Start -full -L0 -a0
Проверить текущий статус инициализации:
MegaCli -LDInit -ShowProg -L0 -a0
Управление CacheCade
Создать и назначить CacheCade для массива 0 (-L0) из зеркала (-r1) в режиме обратной записи (WB) на основе SSD дисков в слотах 6 и 7 (-Physdrv[252:6,252:7])
megacli -CfgCacheCadeAdd -r1 -Physdrv[252:6,252:7] WB -assign -L0 -a0
Включить
megacli -Cachecade -assign -L0 -a0
Отключить
megacli -Cachecade -remove -L0 -a0
Successfully removed VD from Cache
Просмотреть состояние:
megacli -CfgCacheCadeDsply -a0
megacli -LDInfo -LAll -a0
Замена неисправного диска
Отключить писк:
megacli -AdpSetProp -AlarmSilence -a0
Обратите внимание, что это не навсегда отключает сигнализацию, а просто выключает сигнал по текущей аварии.
Просмотреть состояние диска (подставьте нужное значение [E:S]):
megacli -pdInfo -PhysDrv [29:8] -a0
Пометить диск требующий замены как потерянный (если контроллер не сделал этого сам)
megacli -PDMarkMissing -PhysDrv [E:S] -aN
Получить параметры потерянного диска
megacli -Pdgetmissing -a0
Вы должны получить ответ подобный этому:
Adapter 0 — Missing Physical drives
No. Array Row Size Expected
0 0 4 1907200 MB
Подсветить диск который надо менять (подставьте нужное значение [E:S]):
megacli -PdLocate -start -PhysDrv [29:8] -a0
На некоторых шасси могут быть проблемы с индикацией. Это лечится такой командой:
megacli -AdpSetProp {UseDiskActivityforLocate -1} -aALL
В этом случае для маркировки диска будет использоваться лампочка активности.
Удаляем неисправный и вставляем новый диск.
Прекращаем подсветку и проверяем состояние диска:
megacli -PdLocate -stop -PhysDrv [29:8] -a0
megacli -pdInfo -PhysDrv [29:8] -a0
Может так случится, что он содержит метаданные от другого массива RAID (Foreign Configuration). Ваш контроллер не позволит использовать такой диск. Для проверки наличия Foreign Configuration
megacli -CfgForeign -Scan -aALL
Команда удаления Foreign Configuration (если вы уверены)
megacli -CfgForeign -Сlear -aALL<code>
Запускаем процесс замены
<code>megacli -PdReplaceMissing -PhysDrv [32:4] -Array0 -row4 -a0
[32:4] — это параметры диска которым вы меняете неисправный
Rebuild drive
megacli -PDRbld -Start -PhysDrv [32:4] -a0
Проверка процесса ребилда
megacli -PDRbld -ShowProg -PhysDrv [32:4] -a0
Использование smartctl
Получить список id
megacli -PDlist -a0 | grep ‘^Device Id:’| awk ‘{print $3}’
Получить данные смарт по диску с ID=9
smartctl /dev/sda -d megaraid,9 -a
для диска с интерфейсом sata
smartctl /dev/sda -d sat+megaraid,9 -a
пример скрипта для получения данных о всех дисках
#!/bin/sh
for arg in `megacli -PDlist -a0 | grep ‘^Device Id:’| awk ‘{print $3}’`
do
smartctl /dev/sda -d sat+megaraid,${arg} -l devstat
#smartctl /dev/sda -d sat+megaraid,${arg} -a
done
Для контроля состояния дисков с помощью демона smartd нужно закомментировать DEVICESCAN в /etc/smartd.conf и добавить:
/dev/sda -d sat+megaraid,0 -a -s L/../../3/02
/dev/sda -d sat+megaraid,1 -a -s L/../../3/03
/dev/sda -d sat+megaraid,2 -a -s L/../../3/04
/dev/sda -d sat+megaraid,3 -a -s L/../../3/05
Значения параметров типа /3/02 — /3/05 определяют время запуска тестов для заданного диска
Соберу в одном месте список полезных команд для mdadm.
mdadm — утилита для управления программными RAID-массивами в Linux.
С помощью mdadm можно выполнять следующие операции:
- mdadm —create, C Создать новый массив на основе указанных устройств. Использовать суперблоки размещённые на каждом устройстве.
- mdadm —assemble, -A Собрать компоненты ранее созданного массива в массив. Компоненты можно указывать явно, но можно и не указывать — тогда выполняется их поиск по суперблокам.
- mdadm —build, -B Собрать массив из компонентов, у которых нет суперблоков. Не выполняются никакие проверки, создание и сборка массива в принципе ничем не отличаются.
- mdadm —manage Разнообразные операции по управлению массивом, такие как замена диска и пометка как сбойного.
- mdadm —misc Действия, которые не относятся ни к одному из других режимов работы.
- mdadm —grow, G Расширение или уменьшение массива, включаются или удаляются новые диски.
- mdadm —incremental, I Добавление диска в массив.
- mdadm —monitor, —follow, -F Следить за изменением состояния устройств. Для RAID0 этот режим не имеет смысла.
И другие: mdadm —help.
Формат вызова:
mdadm [mode] [array] [options]
Создание массива
Для создания массива нужно использовать не смонтированные разделы. Убедитесь в этом, при необходимости демонтируйте и уберите из fstab.
Пример создания RAID5 массива из трёх дисков:
- /dev/nvme0n1
- /dev/nvme1n1
- /dev/nvme2n1
Я использую NVMe диски, у вас названия дисков будут другие.
Желательно изменить тип разделов на FD (Linux RAID autodetect). Это можно сделать с помощью fdisk (t).
Занулить суперблоки дисков:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Стереть подпись и метаданные:
wipefs --all --force /dev/nvme0n1
wipefs --all --force /dev/nvme1n1
wipefs --all --force /dev/nvme2n1С помощью ключа —create создать RAID5 массив:
mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1где:
- /dev/md0 — массив, который мы создаём;
- —level 5 — уровень RAID;
- —raid-devices=3 — количество дисков, из которых собирается массив;
- /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 — диски.
Для примера RAID1 из двух дисков /dev/sdb и /dev/sdc можно создать так:
mdadm --create --verbose /dev/md2 -l 1 -n 2 /dev/sd{b,c}где:
- /dev/md2 — массив, который мы создаём;
- -l 5 — уровень RAID;
- -n 2 — количество дисков, из которых собирается массив;
- /dev/sd{b,c} — диски sdb и sdc.
Состояние массива
Посмотреть инициализацию массива и текущее состояние можно с помощью команды:
cat /proc/mdstatПример 1:
root@ch01:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md127 : active raid1 nvme1n1[1] nvme0n1[0]
3750607192 blocks super 1.2 [2/2] [UU]
unused devices: <none>
Пример 2:
[root@dbk00 ~]# cat /proc/mdstat
Personalities : [raid1] [raid0]
md10 : active raid0 sdb1[1] sda1[0]
70319335424 blocks super 1.2 512k chunks
md20 : active raid0 sdc1[0] sdd1[1]
70319335424 blocks super 1.2 512k chunks
md126 : active raid1 sde[1] sdf[0]
927881216 blocks super external:/md127/0 [2/2] [UU]
md127 : inactive sdf[1](S) sde[0](S)
10402 blocks super external:imsm
unused devices: <none>Подробный статус выбранного массива
mdadm --detail /dev/md2Пример:
root@ch01:~# mdadm --detail /dev/md127
/dev/md127:
Version : 1.2
Creation Time : Wed May 6 16:39:32 2020
Raid Level : raid1
Array Size : 3750607192 (3576.86 GiB 3840.62 GB)
Used Dev Size : 3750607192 (3576.86 GiB 3840.62 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Fri Aug 14 17:09:47 2020
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : VirtualDisk01
UUID : 1728ebed:ad0b0000:faad83b7:37070000
Events : 173
Number Major Minor RaidDevice State
0 259 0 0 active sync /dev/nvme0n1
1 259 1 1 active sync /dev/nvme1n1
Список массивов
mdadm --detail --scan --verboseПример:
root@ch01:~# mdadm --detail --scan --verbose
ARRAY /dev/md/VirtualDisk01 level=raid1 num-devices=2 metadata=1.2 name=VirtualDisk01 UUID=1728ebed:ad0b0000:faad83b7:37070000
devices=/dev/nvme0n1,/dev/nvme1n1
Создание файловой системы
Файловую систему в массиве можно создать с помощью mkfs, например:
mkfs.ext4 -m 0 /dev/md0Для лучшей производительности файловой системы имеет смысл указывать при её создании количество дисков в рейде и количество блоков файловой системы, которое может поместиться в один страйп (chunk), это касается массивов уровня RAID0, RAID5 ,RAID6 ,RAID10. Для RAID1 (mirror) это не имеет значения так как запись идет всегда на один device, a в других типах массивов данные записываются последовательно на разные диски порциями, соответствующими размеру stripe. Например, если мы используем RAID5 из 3 дисков с дефолтным размером страйпа в 64К и файловую систему ext3 с размером блока в 4К то можно вызывать команду mkfs.ext3 так:
mkfs.ext3 -b 4096 -E stride=16,stripe-width=32 /dev/md0stripe-width обычно рассчитывается как
stride * N
где N — это диски с данными в массиве, например, в RAID5 два диска с данными и один parity для контрольных сумм. Для файловой системы XFS нужно указывать не количество блоков файловой системы, соответствующих размеру stripe в массиве, а размер самого страйпа:
mkfs.xfs -d su=64k,sw=3 /dev/md0Создание mdadm.conf
Операционная система не запоминает какие RAID-массивы ей нужно создать и какие диски в них входят. Эта информация содержится в файле mdadm.conf.
mkdir /etc/mdadm
echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
mdadm --detail --scan | awk '/ARRAY/ {print}' >> /etc/mdadm/mdadm.confВ интернете советуют применять команду mdadm —detail —scan —verbose, но я не рекомендую, т.к. она пишет в конфигурационный файл названия разделов, а они в некоторых случаях могут измениться, тогда RAID-массив не соберётся. А mdadm —detail —scan записывает UUID разделов, которые не изменятся.
Проверка целостности массива
echo 'check' >/sys/block/md0/md/sync_actionЕсть ли ошибки в процессе проверки программного RAID-массива по команде check или repair:
cat /sys/block/md0/md/mismatch_cntРабота с дисками
Диск в массиве можно условно сделать сбойным с помощью ключа —fail (-f):
mdadm /dev/md0 --fail /dev/nvme0n1
mdadm /dev/md0 -f /dev/nvme0n1Удалить из массива отказавший диск:
mdadm /dev/md0 --remove /dev/nvme0n1
mdadm /dev/md0 -r /dev/nvme0n1Добавить в массив заменённый диск:
mdadm /dev/md0 --add /dev/nvme0n1
mdadm /dev/md0 -a /dev/nvme0n1Сборка существующего массива
Собрать существующий массив можно с помощью mdadm —assemble:
mdadm --assemble /dev/md0 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1
mdadm --assemble --scanРасширение массива
Расширить массив можно с помощью ключа —grow (-G). Сначала добавляется диск, а потом массив расширяется:
mdadm /dev/md0 --add /dev/nvme3n1Проверяем, что диск добавился:
mdadm --detail /dev/md0
cat /proc/mdstatЕсли диск добавился, расширяем массив:
mdadm -G /dev/md0 --raid-devices=4Опция —raid-devices указывает новое количество дисков в массиве с учётом добавленного. Рекомендуется задать файл бэкапа на случай прерывания перестроения массива, например, добавить опцию:
--backup-file=/var/backup
При необходимости, можно регулировать скорость процесса расширения массива, указав нужное значение в файлах:
- /proc/sys/dev/raid/speed_limit_min
- /proc/sys/dev/raid/speed_limit_max
Убедитесь, что массив расширился:
cat /proc/mdstatНужно обновить конфигурационный файл с учётом сделанных изменений:
mdadm --detail --scan >> /etc/mdadm/mdadm.confВозобновление отложенной синхронизации resync=PENDING
Если синхронизации массива отложена, состояние массива resync=PENDING, то синхронизацию можно возобновить:
echo idle > /sys/block/md0/md/sync_actionили
mdadm --readwrite /dev/md0Переименовать массив
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Собираем массив с новым именем:
mdadm --assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 --update=nameИли для старых версий:
mdadm –assemble /dev/md3 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 –update=super-minorУдаление массива
Останавливаем массив:
umount /dev/md0
mdadm --stop /dev/md0Затем необходимо затереть superblock каждого из составляющих массива:
mdadm --zero-superblock --force /dev/nvme0n1
mdadm --zero-superblock --force /dev/nvme1n1
mdadm --zero-superblock --force /dev/nvme2n1Или с помощью dd:
dd if=/dev/zero of=/dev/nvme0n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme1n1 bs=512 count=1
dd if=/dev/zero of=/dev/nvme2n1 bs=512 count=1Содержание
- Как проверить raid массив windows
- Поиск и замена диска поврежденного диска в Raid-1
- Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
- Элементы управления окна Проверка корректности RAID
- Мониторинг raid массивов в Windows Core
- Объединение 2-х дисков в 1: настройка RAID-массива на домашнем компьютере (просто о сложном)
- Настройка RAID
- Основы, какими могут быть RAID массивы (т.е. то, как будем объединять диски)
- Пару слов о дисках и мат. плате
- Пример настройки RAID 0 в BIOS
- Как создать RAID 0, RAID 1 программно (в ОС Windows 10)
Как проверить raid массив windows
Сообщения: 26925
Благодарности: 3917
Если же вы забыли свой пароль на форуме, то воспользуйтесь данной ссылкой для восстановления пароля.
Сообщения: 8627
Благодарности: 2126
А посмотреть в Диспетчере Устройств?
Возможно что CrystalDiskInfo сможет показать состояние SMART винчестеров, входящих в ваш RAID: при контроллерах Intel он это уже несколько лет позволяет.
Ну а утилита контроля и обслуживания RAID (или у вас такая не установлена?) позволяет хотя бы качественно оценить состояние дисков, а также произвести анализ и исправление ошибок, связанных с проблемами самого RAID (у них бывают собственные проблемы, не зависящие от входящих в них дисков и их состояния).
» width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″> » width=»100%» style=»BORDER-RIGHT: #719bd9 1px solid; BORDER-LEFT: #719bd9 1px solid; BORDER-BOTTOM: #719bd9 1px solid» cellpadding=»6″ cellspacing=»0″ border=»0″>
Сообщения: 8627
Благодарности: 2126
Видимо у вас там два RAID-1 по два диска. И вы видите не физические диски, а фиктивные, которыми и являются RAID (видимо те самые два «Intel MegaSR SCSI Disk Device» – и пускай вас не смущают слова SCSI и SAS).
Источник
Рассмотрим порядок действий проверки дисков выделенного сервера, с которого пришла ошибка SMART, выявления и замены неисправного диска в массиве Raid-1.
в данном примере всё с raid всё в порядке. Если бы было так: [U_], то диск sdb неисправен, если так: [_U], то sda (смотрим порядок в md-устройствах, например: md2 : active raid1 sda3[2] sdb3[3])
[X] меняем на a или b в зависимости от диска, список дисков можно посмотреть командой:
Оцениваем состояние диска по параметрам и выявляем неисправный, смотрим:
В зависимости от количества разделов выполняем соответственно для разных разделов:
Далее команда на удаление из RAID
Для проверки типа разбиения надо выполнить следующую команду:
на не замененном диске
После этого выполнить команду:
(для MBR), и
(структура разделов в этой команде копируется из /dev/sda в /dev/sdb)
(для GPT)
Источник
Главная > Восстановление Данных при помощи R-Studio > Наборы Томов и RAID > Проверка Целостности Данных RAID
Вы можете проверить целостность данных RAID (правильность блоков четности на RAID).
Чтобы проверить целостность данных RAID
| * | Щелкните правой кнопкой мыши по RAID и выберите пункт Проверить корректность RAID. контекстного меню |
| > | Откроется окно Проверка корректности RAID, в котором будет отображаться ход выполнения (прогресс) операции. |
Окно Проверка корректности RAID
После окончания проверки можно просмотреть ее результаты.
Блок четности RAID корректен.
Блок четности RAID некорректен.
Если подвести указатель мыши к блоку, то можно будет увидеть номера находящихся в нем секторов, а также число корректных и некорректных секторов. Если дважды щелкнуть по блоку мышью, то он сместится в левый верхний угол и масштаб данных увеличится а 2 раза.
Элементы управления окна Проверка корректности RAID
Номер первого сектора в ряде.
Переход к предыдущей/следующей порции данных.
Источник
Мониторинг raid массивов в Windows Core
За последние годы мы привыкли что можно и нужно все мониторить, множество инструментов начиная от простых логов, заканчивая Zabbix и все можно связать. Microsoft в свою очередь тоже дала нам отличный инструмент WinRM, с помощью которого мы можем отслеживать состояние операционных систем и не только. Но как всегда есть ложка дегтя, собственно об «обходе» этой ложки дегтя и пойдет речь.
Как выше было сказано, мы имеем все необходимые инструменты для мониторинга IT структуры, но так сложилось что мы не имеем «автоматизированный» инструмент для мониторинга состояния Intel raid массивов в Windows core. Обращаю Ваше внимание на то, что речь идет об обычном «желтом железе».
Все мы знаем что есть софт от Intel, rapid и matrix storage, но к сожалению на стандартном Windows core он не работает, также есть утилита raidcfg32, она работает в режиме командной строки, умеет обслуживать в ручном режиме и показывать статус, тоже в ручном режиме. Думаю Америку не для кого не открыл.
Постоянно в ручном режиме проверять состояние raid или ждать выхода из строя сервера виртуализации не самый лучший выбор.
Для реализации коварного плана по автоматизации мониторинга Intel raid мы используем
основные инструменты:
Копируем raidcfg32.exe в c:raidcfg32
Проверяем корректно ли установлен драйвер:
cmd.exe C:raidcfg32raidcfg32.exe /stv
Если получаем состояние raid и дисков, то все ок.
Создаем источник в журнале application:
*Дальше все выполняется в powershell
Выполняем запрос состояния raid, удаляем кавычки для упрощения парсинга, подключаем содержимое файла.
Ищем ключевые слова, если одно из слов ниже будет найдено, то в файле errorRAID.txt появится значение true, это будет говорить о наличии ошибки, если совпадений не найдено, то будет записано значение false.
Подключаем файл с записаными true и false, ищем в файле true, если true найдено то заменяем его на Error, заменяем false на Information.
Записывам результат в EntryType.txt
Записываем в EventLog сообщение, где в случае если будут найдены ключевые слова, уровень сообщения будет Error, если не будут найдены, то Information.
Сохраняем код в *.ps1
Создаем в планировщике задание на запуск скрипта, я запускаю задание 1 раз в сутки и при каждой загрузке.
Если будет производится сбор логов другой Windows ОС в Eventlog, то на коллекторе логов необходимо создать источник «RAID», пример есть выше.
Мы транспортируем логи в rsyslog через Adison rsyslog для Windows.
На выходе получается вот такая картинка:
UPD.
По поводу использования store space, все сервера с windows core на борту используются в филиалах, в филиале установлен только 1 сервер и для получения «бесплатного» гипервизора и уменьшения стоимости лицензии используется именно core.
Источник
Объединение 2-х дисков в 1: настройка RAID-массива на домашнем компьютере (просто о сложном)
Доброго дня!
Согласитесь, звучит заманчиво?! Однако, многим пользователям слово «RAID» — либо вообще ничего не говорит, либо напоминает что-то такое отдаленное и сложное (явно-недоступное для повседневных нужд на домашнем ПК/ноутбуке). На самом же деле, все проще, чем есть. 👌 (разумеется, если мы не говорим о каких-то сложных производственных задачах, которые явно не нужны на обычном ПК)
Собственно, ниже в заметке попробую на доступном языке объяснить, как можно объединить диски в эти RAID-массивы, в чем может быть их отличие, и «что с чем едят».
Настройка RAID
Основы, какими могут быть RAID массивы (т.е. то, как будем объединять диски)
Обратите внимание также на табличку ниже.
Разумеется, видов RAID-массивов гораздо больше (RAID 5, RAID 6, RAID 10 и др.), но все они представляют из себя разновидности вышеприведенных (и, как правило, в домашних условиях не используются).
Пару слов о дисках и мат. плате
Не все материнские платы поддерживают работу с дисковыми массивами RAID. И прежде, чем переходить к вопросу объединению дисков, необходимо уточнить этот момент.
Как это сделать : сначала с помощью спец. утилит (например, AIDA 64) нужно узнать точную модель материнской платы компьютера.
Далее найти спецификацию к вашей мат. плате на официальном сайте производителя и посмотреть вкладку «Хранение» (в моем примере ниже, мат. плата поддерживает RAID 0, RAID 1, RAID 10).
Спецификация материнской платы
Если ваша плата не поддерживает нужный вам вид RAID-массива, то у вас есть два варианта выхода из положения:
RAID-контроллер (в качестве примера)
Важная заметка : RAID-массив при форматировании логического раздела, переустановки Windows и т.д. — не разрушится. Но при замене материнской платы (при обновлении чипсета и RAID-контроллера) — есть вероятность, что вы не сможете прочитать информацию с этого RAID-массива (т.е. информация не будет недоступна. ).
Что касается дисков под RAID-массив :
Пример настройки RAID 0 в BIOS
Важно : при этом способе информация с дисков будет удалена!
Примечание : создать RAID-массив можно и из-под Windows (например, если вы хотите в целях безопасности сделать зеркальную копию своего диска).
1) И так, первым делом необходимо подключить диски к компьютеру (ноутбуку). Здесь на этом не останавливаюсь.
2) Далее нужно зайти в BIOS и установить 2 опции:
Затем нужно сохранить настройки (чаще всего это клавиша F10) и перезагрузить компьютер.
Intel Rapid Storage Technology
Create RAID Volume
5) Теперь нужно указать:
После нажатия на кнопку Create Volume — RAID-массив будет создан, им можно будет пользоваться как обычным отдельным накопителем.
Как создать RAID 0, RAID 1 программно (в ОС Windows 10)
Рассмотрю ниже пару конкретных примеров.
2) Открываете управление дисками (для этого нужно: нажать Win+R, и в появившемся окне ввести команду diskmgmt.msc).
3) Теперь действия могут несколько отличаться.
Вариант 1 : допустим вы хотите объединить два новых диска в один, чтобы у вас был большой накопитель для разного рода файлов. В этом случае просто кликните правой кнопкой мышки по одному из новых дисков и выберите создание чередующегося тома (это подразумевает RAID 0). Далее укажите какие диски объединяете, файловую систему и пр.
Создать чередующийся или зеркальный том
Вариант 2 : если же вы беспокоитесь за сохранность своих данных — то можно подключенный к системе новый диск сделать зеркальным вашему основному диску с ОС Windows, причем эта операция будет без потери данных (прим.: RAID 1).
4) После Windows начнет автоматическую синхронизацию накопителей: т.е. с выбранного вами раздела все данные будут также скопированы на новый диск.
5) В общем-то, всё, RAID 1 настроен — теперь при любых изменениях файлов на основном диске с Windows — они автоматически будут синхронизированы (перенесены) на второй диск.
6) Удалить зеркало, кстати, можно также из управления дисками : пример на скрине ниже.
Источник
Adblock
detector
| RAID 0 (распределение) | RAID 1 (зеркалирование) |
The point of RAID with redundancy is that it will keep going as long as it can, but obviously it will detect errors that put it into a degraded mode, such as a failing disk. You can show the current status of an array with mdadm --detail (abbreviated as mdadm -D):
# mdadm -D /dev/md0
<snip>
0 8 5 0 active sync /dev/sda5
1 8 23 1 active sync /dev/sdb7
Furthermore the return status of mdadm -D is nonzero if there is any problem such as a failed component (1 indicates an error that the RAID mode compensates for, and 2 indicates a complete failure).
You can also get a quick summary of all RAID device status by looking at /proc/mdstat. You can get information about a RAID device in /sys/class/block/md*/md/* as well; see Documentation/md.txt in the kernel documentation. Some /sys entries are writable as well; for example you can trigger a full check of md0 with echo check >/sys/class/block/md0/md/sync_action.
In addition to these spot checks, mdadm can notify you as soon as something bad happens. Make sure that you have MAILADDR root in /etc/mdadm.conf (some distributions (e.g. Debian) set this up automatically). Then you will receive an email notification as soon as an error (a degraded array) occurs.
Make sure that you do receive mail send to root on the local machine (some modern distributions omit this, because they consider that all email goes through external providers — but receiving local mail is necessary for any serious system administrator). Test this by sending root a mail: echo hello | mail -s test root@localhost. Usually, a proper email setup requires two things:
-
Run an MTA on your local machine. The MTA must be set up at least to allow local mail delivery. All distributions come with suitable MTAs, pick anything (but not nullmailer if you want the email to be delivered locally).
-
Redirect mail going to system accounts (at least
root) to an address that you read regularly. This can be your account on the local machine, or an external email address. With most MTAs, the address can be configured in/etc/aliases; you should have a line likeroot: djsmiley2kfor local delivery, or
root: djsmiley2k@mail-provider.example.comfor remote delivery. If you choose remote delivery, make sure that your MTA is configured for that. Depending on your MTA, you may need to run the
newaliasescommand after editing/etc/aliases.