Stranger03 писал(а):
shab2 писал(а):И уберите из подписи — «С уважением»
Бан на 2-е недели за хамство.
Геннадий, а Вы точно не перегибаете палку?
Да, по поводу подписи у shab2 вышло резко, возможно даже неуважительно резко — но всё же до хамства, на мой взгляд, никак не дотягивает (кстати, как давний и регулярный посетитель и участник данного форума я неоднократно замечал за Вами не менее резкие ответы, однако Вас никто не одёргивал и не банил).
Другое дело, что Вы, как мне кажется, вольно или невольно форсировали развитие довольно таки безобидной ситуации, доведя её до модераториала.
Ув.Лис обратился к ув.shab2 на «ты». Ув.shab2 мог проигнорировать (ответив на «Вы»), мог возмутиться (мол, я с Вами, сударь, на брудершафт не пил»). Однако он ответил в том же ключе (на «ты»), не заморачиваясь формой. Ситуация замкнулась «сам на сам».
Вы же не преминули сделать замечание (почему-то топикстартеру, а не первому «тыкнувшему»), притом что никто из них не возражал против такого обращения; ну а кроме того «принято»(на «Вы») <> «обязательно»(на «Вы») — в правилах форума нигде ничего такого действительно не регламентировано.
В этой связи непонятны причины, побудившие Вас сделать ув.shab2 замечание и пригрозить баном — его (развёрнутый) ответ Вам не выходит, как мне кажется, за рамки приличий. Да, без расшаркиваний, но по-большому счёту всё правильно — нет запрета, нет и повода для одёргиваний.
Ув.shab2 мне, конечно, не сват, не брат, однако не хотелось бы создания грустного прецедента типа «попала шлея под мантию» (никогда не знаешь, что и в какой момент придётся Вам не по вкусу).
Плюс к тому подобное реагирование с Вашей стороны может изрядно подпортить Ваше реноме. В конце концов, Ваши ответы по техническим вопросам неплохо характеризуют Вас как специалиста, тогда как подобные эксцессы могут создать о Вас впечатление уже как о человеке — и не самое благоприятное.
Про то, что кто-то может просто не захотеть лишний раз иметь дело с фирмой, сотрудники которой ведут себя как высокомерные снобы и самодуры, уж и упоминать-то неудобно.
С уважением,
Umlyaut.
P.S. Полагаю, просить о пересмотре решения о бане ув.shab2 будет уместно…
Вам нужен HBA-адаптер (кто-то называет HBA-контроллером).
Можно взять б/у на eBay, хламаде, или авито.
без серверной железки с RAID-массивом … RAID-ы не нужны
RAID-контроллер вам не только не нужен, но и противопоказан.
Ряд контроллеров могут нормально переключаться в HBA-режим, но многие могут отчаянно и неожиданно чудить — автоматом инициализировать диски и проделывать прочие подобные вещи.
Так что мы обычно рекомендуем избегать рэйд-плат для подобных задач.
несколько SAS дисков … есть желание их протестировать, проверить поверхность на BAD-сектора
Обзаводитесь железом и берите R.tester. Насколько нам известно, у него, как минимум, среди бесплатных утилит, наиболее широкий набор возможностей для работы со SCSI и SAS-дисками: https://rlab.ru/tools/rtester.html
К примеру, программа позволяет посмотреть SMART для САС и СКАЗИ-винчестеров, и имеет шикарный встроенный SCSI-коммандер с подсказками.
S.M.A.R.T. (часть 1). Мониторинг SCSI дисков под LSI 2108 (megaraid) RAID контроллером
 Навожу короткую инструкция по мониторингу физических дисков под хардварным LSI 2108 RAID контроллером. Так же эта инструкция может пригодиться для мониторинга дисков под HP/Compaq Smart Array Controller, Areca SATA[/SAS] RAID controller и другими, используя инструмент smart в сочетании с специализированными программами. Перечень контроллеров, за которыми можно мониторить физические диски используя smartctl наведен здесь.
Навожу короткую инструкция по мониторингу физических дисков под хардварным LSI 2108 RAID контроллером. Так же эта инструкция может пригодиться для мониторинга дисков под HP/Compaq Smart Array Controller, Areca SATA[/SAS] RAID controller и другими, используя инструмент smart в сочетании с специализированными программами. Перечень контроллеров, за которыми можно мониторить физические диски используя smartctl наведен здесь.
Немного о HDD интерфейсах
Аббревиатуры:
SCSI— Small Computer System Interface
SAS— Serial Attached SCSI
SATA — Serial ATA
ATA — AT Attachment
Чтобы визуально понять как выглядят те, или иные интерфейсы навожу картинки.

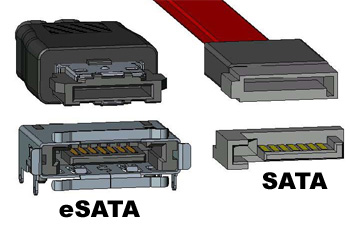

С интерфейсами все понятно, переходим к практике.
Мониторинг дисков используя megacli
Смотрим какие у нас есть диски.
SMC2108 — означает, что у нас Supermicro MC2108 контроллер. Так же можно убедиться, что у нас Megaraid контроллер используя эту команду.
Как видим, у нас LSI SAS MegaRAID контроллер, диски которого можно мониторить используя smartctl или же используя специализированную утилиту megacli. Для начала присмотримся к megacli. В стандартных репозиториях ее нет, но можно скачать с официального сайта и собрать с исходников. Но я рекомендую использовать специальный репозиторий (за который хочу сказать ОГРОМНОЕ спасибо) в котором есть почти весь набор специализированных утилиты под любой тип аппаратных рейдов.
Перечень всех доступных в репозитории утилит наведен здесь
Проверяем на ошибки физический диск megaraid используя megacli.
Как видим, на первом физическом диске есть «Media Error Count: 38». Это означает, что запасные(зарезервированные) сектора для remap(замены) битых секторов диска — закончились. И нужно проводить замену диска.
Так же нужно мониторить следующие параметры используя команду:
Теперь напишем маленький скрипт для мониторинга всех нужных параметров включая BBU.
Данный скрипт проверяет все диски на наличие проблем с прошивкой,состояние рейда,ошибки физических дисков и состояние батареи. Если есть проблема с батареей — код выхода скрипта будет больше 250, если проблемы с остальными устройствами, то будет выведено только количество ошибок. Скрипт запускается без аргументов. Если добавить аргумент log, будет выведено текст с указанием проблемного элемента. Проверяем работу скрипта:
Как видим у нас проблема с батареей (BBU) и ее нужно заменить.
По роботе с magacli есть целая книга-руководство.
Из полезных команд:
Мониторинг дисков используя smartctl
Для этого нам понадобиться тот же megacli, используя который, мы узнаем ID физических дисков и соответствующие им логические носители. Начнем.
Узнаем ID всех физических дисков за мегарейд контроллером ну и номера соответствующих логических дисков.
Расшифрую эту команду:
- -LdPdInfo — получить информацию(Info) по логическим (Ld) и физическим(Pd) устройствам …
- -aALL — … на всех адаптерах
Теперь видно, что у нас три логических(виртуальных) диска в которые входят по несколько физических дисков с соответствующими ID. Посмотрим на сервере, сколько у нас есть дисков:
Все верно, у нас три логических диска в системе. Проводим аналогию с выводом команды megacli:
-
Virtual Drive: 0 == /dev/sda и в него входит 4 физических диска с Drive: 1 == /dev/sdb и в него входит 2 физических диска с Drive: 2 == /dev/sdc и в него входит 6 физических дисков с >Теперь нам осталось запустить SMART проверку по каждому с дисков используя собранные данные.
К примеру возьмем первый диск.
Как видим у нас есть 60 ошибок с которыми не смогла справиться система исправления ошибок.
Немного расшифрую выводу ошибок:
Журнал ошибок (если он доступен) отображается в отдельных строках:
- write error counters — ошибки записи
- read error counters — ошибки считывания
- verify error counters (отображаются только когда не нулевое значение) — ошибки выполнения
- non-medium error counter (определенное число) — число восстанавливаемых ошибок отличных от ошибок записи/считывания/выполнения
Так же может выводиться детальное описание последних ошибок с кодом, если устройство его поддерживает(если нет поддержки — выводиться сообщение «Error Events logging not supported»). К примеру:
Каждая из ошибок имеет различные коды. Оригинал описания кодов взято из мануала по SCSI Seagate дискам:
Errors Corrected by ECC, fast [Errors corrected without substantial delay: 00h]. An error correction was applied to get perfect data (a.k.a. ECC on-the-fly). «Without substantial delay» means the correction did not postpone reading of later sectors (e.g. a revolution was not lost). The counter is incremented once for each logical block that requires correction. Two different blocks corrected during the same command are counted as two events.
Errors Corrected by ECC: delayed [Errors corrected with possible delays: 01h]. An error code or algorithm (e.g. ECC, checksum) is applied in order to get perfect data with substantial delay. «With possible delay» means the correction took longer than a sector time so that reading/writing of subsequent sectors was delayed (e.g. a lost revolution). The counter is incremented once for each logical block that requires correction. A block with a double error that is correctable counts as one event and two different blocks corrected during the same command count as two events.
Error corrected by rereads/rewrites [Total (e.g. rewrites and rereads): 02h]. This parameter code specifies the counter counting the number of errors that are corrected by applying retries. This counts errors recovered, not the number of retries. If five retries were required to recover one block of data, the counter increments by one, not five. The counter is incremented once for each logical block that is recovered using retries. If an error is not recoverable while applying retries and is recovered by ECC, it isn’t counted by this counter; it will be counted by the counter specified by parameter code 01h — Errors Corrected With Possible Delays.
Total errors corrected [Total errors corrected: 03h]. This counter counts the total of parameter code errors 00h, 01h and 02h (i.e. error corrected by ECC: fast and delayed plus errors corrected by rereads and rewrites). There is no «double counting» of data errors among these three counters. The sum of all correctable errors can be reached by adding parameter code 01h and 02h errors, not by using this total. [The author does not understand the previous sentence from the Seagate manual.]
Correction algorithm invocations [Total times correction algorithm processed: 04h]. This parameter code specifies the counter that counts the total number of retries, or «times the retry algorithm is invoked». If after five attempts a counter 02h type error is recovered, then five is added to this counter. If three retries are required to get stable ECC syndrome before a counter 01h type error is corrected, then those three retries are also counted here. The number of retries applied to unsuccessfully recover an error (counter 06h type error) are also counted by this counter.
Gigabytes processed [Total bytes processed: 05h]. This parameter code specifies the counter that counts the total number of bytes either successfully or unsuccessfully read, written or verified (depending on the log page) from the drive. If a transfer terminates early because of an unrecoverable error, only the logical blocks up to and including the one with the uncorrected data are counted. [smartmontools divides this counter by 10^9 before displaying it with three digits to the right of the decimal point. This makes this 64 bit counter easier to read.]
Total uncorrected errors [Total uncorrected errors: 06h]. This parameter code specifies the counter that contains the total number of blocks for which an uncorrected data error has occurred.
С всего этого нас интересует параметр Total uncorrected errors который показывает количество не исправленных ошибок. Если это число велико, то нужно запускать long тест и проверить, дополнительно, параметры физического диска в Megaraid контроллере.
Мониторинг дисков используя smartd
Предыдущие способы мониторинга дисков были ручными, т.е. нужно вручную запускать проверку дисков находясь на конкретном сервере, или же настроить систему мониторинга, которая будет использовать написанные выше скрипты для сбора информации о состоянии дисков. Но есть еще один способ мониторинга — это использование демона smartd, который будет отправлять нам письма о проблемных дисках. Детально о настройках демона smartd можно почитать здесь
Для начала добавим демон в автозагрузку.
Утилиты для тестирования HDD SAS
Имею в серверном парке SAS диски Seagate и Hitachi. В боевую они работают через RAID контроллеры Adaptec или LSI.
Бывает такое, что появляется на диске на media error.
Если провести медиа сканирование с помощью, например, Adaptec Storage Manager, то эта media error в свойствах диска исчезает.
В smart-е показывает, что все ок — одной строчкой.
Маловато информации показывает этот софт.
Хотелось бы внимательно посмотреть на smart диска и провести дополнительное сканирование поверхности, перепрошить прошивку
Оставляю один Seagate диск на контроллере LSI 92618i, не конфигурирую его никак.
Seatool for DOS видит other контроллер, из пераметром диска только обьем, на диске можно сделать только диагностическое сканирование.
Seatool for windows видит диск MR9261-81, на диске можно сделать только диагностическое сканирование, прошивка обламывается
Seatool Enterprise не видит контроллер.
Пытался запустить DFT for dos c драйвером LSI 320x — не видит контроллер.
Поделитесь, пожалуйста, рабочими вариантами сочетания ПО и контроллеров.
С уважением,
Александр
Re: Утилиты для тестирования HDD SAS
Сообщение Лис » 24 мар 2013, 04:29
Re: Утилиты для тестирования HDD SAS
Сообщение shab2 » 25 мар 2013, 10:03
Stranger03 Сотрудник Тринити
Сообщения: 12979 Зарегистрирован: 14 ноя 2003, 16:25 Откуда: СПб, Екатеринбург Контактная информация:
Re: Утилиты для тестирования HDD SAS
Сообщение Stranger03 » 25 мар 2013, 10:21
Re: Утилиты для тестирования HDD SAS
Сообщение shab2 » 25 мар 2013, 11:07
Ответ на ты адресовался не Вам. Если Вы модератор, прошу дать ссылку на пункт правил, где запрещается обращение на ты.
По существу темы: Все использованные утилиты упомянуты. Если Вы знаете о других, скажите. Кроме контроллера LSI SAS 9261 использовался LSI SAS 8208XLP. Однако разницы в поведении программ не было. «Взять любой SAS HBA» — это платить деньги. Хотелось бы заранее знать модель с которой утилиты производителей умеют работать.
С уважением, Александр
Stranger03 Сотрудник Тринити
Сообщения: 12979 Зарегистрирован: 14 ноя 2003, 16:25 Откуда: СПб, Екатеринбург Контактная информация:
Re: Утилиты для тестирования HDD SAS
Сообщение Stranger03 » 26 мар 2013, 08:50
Re: Утилиты для тестирования HDD SAS
Сообщение shab2 » 26 мар 2013, 10:08
И уберите из подписи — «С уважением»
Re: Утилиты для тестирования HDD SAS
Сообщение Helium » 28 мар 2013, 00:08
Re: Утилиты для тестирования HDD SAS
Сообщение brass » 28 мар 2013, 10:02
Stranger03 Сотрудник Тринити
Сообщения: 12979 Зарегистрирован: 14 ноя 2003, 16:25 Откуда: СПб, Екатеринбург Контактная информация:
Re: Утилиты для тестирования HDD SAS
Сообщение Stranger03 » 28 мар 2013, 10:21
Re: Утилиты для тестирования HDD SAS
Сообщение Umlyaut » 31 мар 2013, 16:03
Геннадий, а Вы точно не перегибаете палку?
Да, по поводу подписи у shab2 вышло резко, возможно даже неуважительно резко — но всё же до хамства, на мой взгляд, никак не дотягивает (кстати, как давний и регулярный посетитель и участник данного форума я неоднократно замечал за Вами не менее резкие ответы, однако Вас никто не одёргивал и не банил).
Другое дело, что Вы, как мне кажется, вольно или невольно форсировали развитие довольно таки безобидной ситуации, доведя её до модераториала.
Ув.Лис обратился к ув.shab2 на «ты». Ув.shab2 мог проигнорировать (ответив на «Вы»), мог возмутиться (мол, я с Вами , сударь, на брудершафт не пил»). Однако он ответил в том же ключе (на «ты»), не заморачиваясь формой. Ситуация замкнулась «сам на сам».
Вы же не преминули сделать замечание (почему-то топикстартеру, а не первому «тыкнувшему»), притом что никто из них не возражал против такого обращения; ну а кроме того «принято»(на «Вы») <> «обязательно»(на «Вы») — в правилах форума нигде ничего такого действительно не регламентировано.
В этой связи непонятны причины, побудившие Вас сделать ув.shab2 замечание и пригрозить баном — его (развёрнутый) ответ Вам не выходит, как мне кажется, за рамки приличий. Да, без расшаркиваний, но по-большому счёту всё правильно — нет запрета, нет и повода для одёргиваний.
Ув.shab2 мне, конечно, не сват, не брат, однако не хотелось бы создания грустного прецедента типа «попала шлея под мантию» (никогда не знаешь, что и в какой момент придётся Вам не по вкусу).
Плюс к тому подобное реагирование с Вашей стороны может изрядно подпортить Ваше реноме. В конце концов, Ваши ответы по техническим вопросам неплохо характеризуют Вас как специалиста, тогда как подобные эксцессы могут создать о Вас впечатление уже как о человеке — и не самое благоприятное.
Про то, что кто-то может просто не захотеть лишний раз иметь дело с фирмой, сотрудники которой ведут себя как высокомерные снобы и самодуры, уж и упоминать-то неудобно.
Полигон призраков
Какой программой можно посмотреть SMART SCSI диска?
Нашел «Active SMART SCSI Edition (trial)» от http://www.ariolic.com, но это что-то не то — на трех разных дисках все параметры по нулям, только температура разная.
Контроллер Adaptec 29160.
Еще слышал, что у серверов HP фича есть — тест и мониторинг состояния дисков. В распоряжении ProLiant ML350 G3, RAID контроллера в нем нет, просто 2х канальный Ultra3.
Какой софт на сервак поставить, чтобы сабж?
Применимость: Linux, LSI
Слова для поиска:
Необходимо определить исправность диска с интерфейсом SAS
yum install lsscsi sg3_utils smartmontools
Загрузить модуль
modprobe sg
Список устройств можно получить различным способами
Получить список устройств
/usr/bin/lsscsi -g
parted -lm
Для диагностики неисправный диск лучше сконфигурировать как диск JBOD
Проверить наличие поддержки устройств JBOD:
megacli -AdpGetProp enablejbod -aALL
Включить поддержку JBOD:
megacli -AdpSetProp EnableJBOD 1 -aALL
Создать JBOD из диска:
megacli -PDMakeJBOD -PhysDrv[<ID шасси>:<Номер слота>] -a0
Например:
megacli -PDMakeJBOD -PhysDrv[252:4] -a0
Использование smartctl
Получить список id для использования в smartctl
megacli -PDlist -a0 | grep '^Device Id:'| awk '{print $3}'
Получить данные смарт по диску с ID=9
smartctl /dev/sda -d megaraid,9 -a
для диска с интерфейсом sata
smartctl /dev/sda -d sat+megaraid,9 -a
пример срипта для получения данных о всех дисках
#!/bin/sh
for arg in `megacli -PDlist -a0 | grep '^Device Id:'| awk '{print $3}'`
do
smartctl /dev/sda -d sat+megaraid,${arg} -l devstat
#smartctl /dev/sda -d sat+megaraid,${arg} -a
done
Использование sg3_utils
Алгоритм простой — смотрим нужные счетчики, отправляем диск на форматирование, проверяем поверхность, снова смотрим счетчики на предмет роста ошибок. Для начала желательно собрать о «пациенте» побольше сведений. IMHO, лучший инструмент для этого — пакет smartmontools (в состав которого входит утилита smartctl):
Актуальность: 2014/06/30 08:55
Stranger03 писал(а):
shab2 писал(а):И уберите из подписи — «С уважением»
Бан на 2-е недели за хамство.
Геннадий, а Вы точно не перегибаете палку?
Да, по поводу подписи у shab2 вышло резко, возможно даже неуважительно резко — но всё же до хамства, на мой взгляд, никак не дотягивает (кстати, как давний и регулярный посетитель и участник данного форума я неоднократно замечал за Вами не менее резкие ответы, однако Вас никто не одёргивал и не банил).
Другое дело, что Вы, как мне кажется, вольно или невольно форсировали развитие довольно таки безобидной ситуации, доведя её до модераториала.
Ув.Лис обратился к ув.shab2 на «ты». Ув.shab2 мог проигнорировать (ответив на «Вы»), мог возмутиться (мол, я с Вами, сударь, на брудершафт не пил»). Однако он ответил в том же ключе (на «ты»), не заморачиваясь формой. Ситуация замкнулась «сам на сам».
Вы же не преминули сделать замечание (почему-то топикстартеру, а не первому «тыкнувшему»), притом что никто из них не возражал против такого обращения; ну а кроме того «принято»(на «Вы») <> «обязательно»(на «Вы») — в правилах форума нигде ничего такого действительно не регламентировано.
В этой связи непонятны причины, побудившие Вас сделать ув.shab2 замечание и пригрозить баном — его (развёрнутый) ответ Вам не выходит, как мне кажется, за рамки приличий. Да, без расшаркиваний, но по-большому счёту всё правильно — нет запрета, нет и повода для одёргиваний.
Ув.shab2 мне, конечно, не сват, не брат, однако не хотелось бы создания грустного прецедента типа «попала шлея под мантию» (никогда не знаешь, что и в какой момент придётся Вам не по вкусу).
Плюс к тому подобное реагирование с Вашей стороны может изрядно подпортить Ваше реноме. В конце концов, Ваши ответы по техническим вопросам неплохо характеризуют Вас как специалиста, тогда как подобные эксцессы могут создать о Вас впечатление уже как о человеке — и не самое благоприятное.
Про то, что кто-то может просто не захотеть лишний раз иметь дело с фирмой, сотрудники которой ведут себя как высокомерные снобы и самодуры, уж и упоминать-то неудобно.
С уважением,
Umlyaut.
P.S. Полагаю, просить о пересмотре решения о бане ув.shab2 будет уместно…

Здравствуйте.
Есть физический сервер, на нем установлены 2 SAS диска на 146 гб.
Самостоятельно нужно мониторить состояние дисков.
Решил использовать smartctl, но мне не совсем понятен вывод некоторой информации.
Проверкой здоровья вроде как показывает, что все норм:
Вывод smartctl
smartctl -H /dev/sda
smartctl 6.6 2017-11-05 r4594 [x86_64-linux-4.19.0-13-amd64] (local build)
Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Health Status: OK
smartctl -H /dev/sdb
smartctl 6.6 2017-11-05 r4594 [x86_64-linux-4.19.0-13-amd64] (local build)
Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Health Status: OK
Но…
smartctl -a /dev/sda
smartctl 6.6 2017-11-05 r4594 [x86_64-linux-4.19.0-13-amd64] (local build)
Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Vendor: FUJITSU
Product: MBA3147RC
Revision: 0103
User Capacity: 147,086,327,808 bytes [147 GB]
Logical block size: 512 bytes
Rotation Rate: 15000 rpm
Logical Unit id: 0x500000e01b717ab0
Serial number: BJA0P8502D8M
Device type: disk
Transport protocol: SAS (SPL-3)
Local Time is: Sat Jun 5 09:40:29 2021 EDT
SMART support is: Available — device has SMART capability.
SMART support is: Enabled
Temperature Warning: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Health Status: OK
Current Drive Temperature: 28 C
Drive Trip Temperature: 65 C
Manufactured in week 21 of year 2008
Specified cycle count over device lifetime: 50000
Accumulated start-stop cycles: 32
Elements in grown defect list: 0
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 0 3064 0 0 0 743273.006 0
write: 0 0 0 0 0 297758.540 0
Non-medium error count: 27
No self-tests have been logged
smartctl -a /dev/sdb
smartctl 6.6 2017-11-05 r4594 [x86_64-linux-4.19.0-13-amd64] (local build)
Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Vendor: FUJITSU
Product: MAX3147RC
Revision: 0104
User Capacity: 147,086,327,808 bytes [147 GB]
Logical block size: 512 bytes
Rotation Rate: 15000 rpm
Logical Unit id: 0x500000e0137d1e10
Serial number: DQ00P6B00K3R
Device type: disk
Transport protocol: SAS (SPL-3)
Local Time is: Sat Jun 5 09:41:34 2021 EDT
SMART support is: Available — device has SMART capability.
SMART support is: Enabled
Temperature Warning: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Health Status: OK
Current Drive Temperature: 26 C
Drive Trip Temperature: 65 C
Manufactured in week 47 of year 2006
Specified cycle count over device lifetime: 10000
Accumulated start-stop cycles: 36
Elements in grown defect list: 0
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 0 2861 0 0 0 106968.637 0
write: 0 1014 0 0 0 20376.950 0
Non-medium error count: 83
No self-tests have been logged
Пожалуйста, помогите расшифровать этот вывод. На что следует обращать внимание?
К примеру. За что отвечают:
Specified cycle count over device lifetime: 50000
Specified cycle count over device lifetime: 10000
Non-medium error count: 27
Non-medium error count: 83
При каких значениях вывода лучше проводить замену?
И почему не отображается сам SMART?
Заранее благодарен!
__________________
Помощь в написании контрольных, курсовых и дипломных работ, диссертаций здесь
Применимость: Linux, LSI
Слова для поиска:
Необходимо определить исправность диска с интерфейсом SAS
yum install lsscsi sg3_utils smartmontools
Загрузить модуль
modprobe sg
Список устройств можно получить различным способами
Получить список устройств
/usr/bin/lsscsi -g
parted -lm
Для диагностики неисправный диск лучше сконфигурировать как диск JBOD
Проверить наличие поддержки устройств JBOD:
megacli -AdpGetProp enablejbod -aALL
Включить поддержку JBOD:
megacli -AdpSetProp EnableJBOD 1 -aALL
Создать JBOD из диска:
megacli -PDMakeJBOD -PhysDrv[<ID шасси>:<Номер слота>] -a0
Например:
megacli -PDMakeJBOD -PhysDrv[252:4] -a0
Использование smartctl
Получить список id для использования в smartctl
megacli -PDlist -a0 | grep '^Device Id:'| awk '{print $3}'
Получить данные смарт по диску с ID=9
smartctl /dev/sda -d megaraid,9 -a
для диска с интерфейсом sata
smartctl /dev/sda -d sat+megaraid,9 -a
пример срипта для получения данных о всех дисках
#!/bin/sh
for arg in `megacli -PDlist -a0 | grep '^Device Id:'| awk '{print $3}'`
do
smartctl /dev/sda -d sat+megaraid,${arg} -l devstat
#smartctl /dev/sda -d sat+megaraid,${arg} -a
done
Использование sg3_utils
Алгоритм простой — смотрим нужные счетчики, отправляем диск на форматирование, проверяем поверхность, снова смотрим счетчики на предмет роста ошибок. Для начала желательно собрать о «пациенте» побольше сведений. IMHO, лучший инструмент для этого — пакет smartmontools (в состав которого входит утилита smartctl):
Актуальность: 2014/06/30 08:55
Навожу короткую инструкция по мониторингу физических дисков под хардварным LSI 2108 RAID контроллером. Так же эта инструкция может пригодиться для мониторинга дисков под HP/Compaq Smart Array Controller, Areca SATA[/SAS] RAID controller и другими, используя инструмент smart в сочетании с специализированными программами. Перечень контроллеров, за которыми можно мониторить физические диски используя smartctl наведен здесь.
Немного о HDD интерфейсах
Аббревиатуры:
SCSI— Small Computer System Interface
SAS— Serial Attached SCSI
SATA — Serial ATA
ATA — AT Attachment
Чтобы визуально понять как выглядят те, или иные интерфейсы навожу картинки.
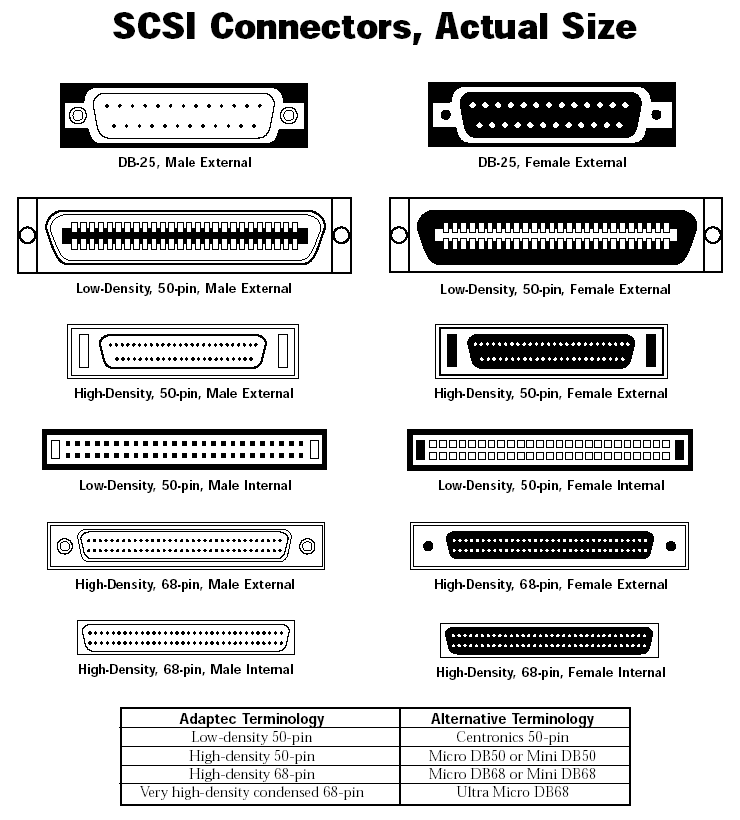
С интерфейсами все понятно, переходим к практике.
Мониторинг дисков используя megacli
Смотрим какие у нас есть диски.
root@il-nv-s06:~# lshw -c disk
*-disk:0
description: SCSI Disk
product: SMC2108
vendor: SMC
physical id: 2.0.0
bus info: scsi@0:2.0.0
logical name: /dev/sda
version: 2.90
serial: 0074df64060b7e521510538600800403
size: 2791GiB (2996GB)
capabilities: gpt-1.00 partitioned partitioned:gpt
configuration: ansiversion=5 guid=02712922-3f89-4077-8a1b-2ed197f3c54c
*-disk:1
description: SCSI Disk
product: SMC2108
vendor: SMC
physical id: 2.1.0
bus info: scsi@0:2.1.0
logical name: /dev/sdb
version: 2.90
serial: 00405d940d100d0a1810538600800403
size: 54GiB (58GB)
capabilities: gpt-1.00 partitioned partitioned:gpt
configuration: ansiversion=5 guid=992168b5-1ecd-4e43-ab0f-f2e0b945ab27
*-disk:2
description: SCSI Disk
product: SMC2108
vendor: SMC
physical id: 2.2.0
bus info: scsi@0:2.2.0
logical name: /dev/sdc
version: 2.90
serial: 00074cce4a116a071810538600800403
size: 7446GiB (7995GB)
capabilities: gpt-1.00 partitioned partitioned:gpt
configuration: ansiversion=5 guid=92c542ab-7199-4525-89e3-057744b8397d
SMC2108 — означает, что у нас Supermicro MC2108 контроллер. Так же можно убедиться, что у нас Megaraid контроллер используя эту команду.
root@il-nv-s06:~# cat /proc/devices | grep mega 250 megaraid_sas_ioctl
Как видим, у нас LSI SAS MegaRAID контроллер, диски которого можно мониторить используя smartctl или же используя специализированную утилиту megacli. Для начала присмотримся к megacli. В стандартных репозиториях ее нет, но можно скачать с официального сайта и собрать с исходников. Но я рекомендую использовать специальный репозиторий (за который хочу сказать ОГРОМНОЕ спасибо) в котором есть почти весь набор специализированных утилиты под любой тип аппаратных рейдов.
root@il-nv-s06:~# echo 'deb http://hwraid.le-vert.net/ubuntu precise main' > /etc/apt/sources.list.d/raid.list root@il-nv-s06:~# wget -O - http://hwraid.le-vert.net/debian/hwraid.le-vert.net.gpg.key | sudo apt-key add - root@il-nv-s06:~# apt-get update root@il-nv-s06:~# apt-get install megacli
Перечень всех доступных в репозитории утилит наведен здесь
Проверяем на ошибки физический диск megaraid используя megacli.
root@il-nv-s06:~# megacli -pdinfo -physdrv [4:0] -aALL Enclosure Device ID: 4 Slot Number: 0 Drive's position: DiskGroup: 0, Span: 0, Arm: 0 Enclosure position: 1 Device Id: 0 WWN: 5000C5002130CD08 Sequence Number: 2 Media Error Count: 38 Other Error Count: 0 Predictive Failure Count: 0 Last Predictive Failure Event Seq Number: 0 PD Type: SAS Raw Size: 931.512 GB [0x74706db0 Sectors] Non Coerced Size: 931.012 GB [0x74606db0 Sectors] Coerced Size: 930.390 GB [0x744c8000 Sectors] Sector Size: 0 Firmware state: Online, Spun Up Device Firmware Level: 0005 Shield Counter: 0 Successful diagnostics completion on : N/A SAS Address(0): 0x5000c5002130cd09 SAS Address(1): 0x0 Connected Port Number: 0(path0) Inquiry Data: SEAGATE ST31000424SS 00059WK1D042 FDE Capable: Not Capable FDE Enable: Disable Secured: Unsecured Locked: Unlocked Needs EKM Attention: No Foreign State: None Device Speed: 6.0Gb/s Link Speed: 6.0Gb/s Media Type: Hard Disk Device Drive: Not Certified Drive Temperature :29C (84.20 F) PI Eligibility: No Drive is formatted for PI information: No PI: No PI Port-0 : Port status: Active Port's Linkspeed: 6.0Gb/s Port-1 : Port status: Active Port's Linkspeed: Unknown Drive has flagged a S.M.A.R.T alert : No
Как видим, на первом физическом диске есть «Media Error Count: 38». Это означает, что запасные(зарезервированные) сектора для remap(замены) битых секторов диска — закончились. И нужно проводить замену диска.
Так же нужно мониторить следующие параметры используя команду:
root@il-nv-s06:~# megacli -LdPdInfo -aALL | grep -E "(Id|State |Bad Blocks|Firmware state|Error Count|Predictive Failure Count)" # Первый виртуальный диск - он же /dev/sda Virtual Drive: 0 (Target Id: 0) # Статус RAID-a (Degraded - если проблема с одним из дисков; Optimal - нормальный статус) State : Degraded # Наличие бедблоков на виртуальном диске Bad Blocks Exist: No # ID физического диска Device Id: 14 # Количество ошибок, которые нет возможности исправить - самый важный компонент Media Error Count: 0 # Количество иных ошибок не связанных с бедблоками Other Error Count: 0 # Определение количества возможных ошибок Predictive Failure Count: 0 # Статус физического диска (Rebuild - добавляется в RAID; Online - в RAID-e) # Также есть "Failed", "Online, Spun Up", "Online, Spun Down", "Unconfigured(bad)", "Unconfigured(good), Spun down","Hotspare, Spun down", "Hotspare, Spun up" or "not Online". Firmware state: Rebuild Device Id: 1 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Firmware state: Online, Spun Up Device Id: 2 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Firmware state: Online, Spun Up Device Id: 3 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Firmware state: Online, Spun Up Virtual Drive: 1 (Target Id: 1) State : Optimal Bad Blocks Exist: No Device Id: 13 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Firmware state: Online, Spun Up Media Type: Solid State Device Device Id: 12 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Firmware state: Online, Spun Up Media Type: Solid State Device
Теперь напишем маленький скрипт для мониторинга всех нужных параметров включая BBU.
root@il-nv-s06:~# cat megaraid.sh
#!/bin/bash
#Вся информация по физическим и логическим дискам
VD_PDID_ERRORS=`megacli -ldpdinfo -aALL | grep -E "(Id|State |Media Error|Firmware state)"`
#Вся информация по батарее
BBU_OUT=`megacli -AdpBbuCmd -aAll | grep -E "(Full Charge|^Max Error|Battery State)"`
while read line
do
#Ловим название (ID) логического диска
VD=`echo ${line} | grep -Eo "Virtual Drive: [0-9]"`
#Ловим название (ID) физического диска
PD_ID=`echo ${line} | grep -E "Device Id:"`
#Ловим важные ошибки физических дисков
PD_ERRORS=`echo ${line} | grep -E "(Media Error)"`
#Ловим статус рейда
RAID_STAT=`echo ${line} | grep -E "State"`
#Ловим статус прошивки
PD_FIRMWARE=`echo ${line} | grep -E "Firmware"`
if [ -n "${VD}" ]
then
DRIVE="${VD} ==> "
elif [ -n "${RAID_STAT}" ]
then
VD_RAID_STAT=`echo "${RAID_STAT}" | awk '{print $3}'`
VD_RAID="${DRIVE}${RAID_STAT} ==> "
#Если статус рейда отличается от нормального - число ошибок растет
if [ ${VD_RAID_STAT} != 'Optimal' ]
then
#echo "Raid with problem"
VDRIVE_WITH_FAIL="${VD_RAID}
${VDRIVE_WITH_FAIL}"
let "ERROR_COUNT += 1"
fi
elif [ -n "${PD_ID}" ]
then
PD_DRIVE="${DRIVE}${PD_ID} ==> "
elif [ -n "${PD_ERRORS}" ]
then
#Если есть ошибка - ловим их количество
PD_ERR=${PD_DRIVE}${PD_ERRORS}
let "ERROR_COUNT +=`echo ${PD_ERRORS} | awk '{print $4}'`"
TRAP=`echo ${PD_ERRORS} | awk '{print $4}'`
if [ ${TRAP} -ne 0 ]
then
DISK_WITH_FAIL="${PD_ERR}
${DISK_WITH_FAIL}"
fi
elif [ -n "${PD_FIRMWARE}" ]
then
#Проверяем или прошивка в порядке, если нет - число ошибок растет
PD_FIRM_STATUS=`echo "${PD_FIRMWARE}" | cut --delimiter=":" -f2 | sed 's/ //g'`
PD_FIRM=${PD_DRIVE}${PD_FIRMWARE}
if [ ${PD_FIRM_STATUS} != "Online,SpunUp" ]
then
#echo "PD firmware with problem"
PDFIRM_WITH_FAIL="${PD_FIRM}
${PDFIRM_WITH_FAIL}"
let "ERROR_COUNT += 1"
fi
fi
done <<< "${VD_PDID_ERRORS}"
while read bbu_log
do
BBU_STATE=`echo ${bbu_log} | grep -E "Battery State"`
BBU_ERROR=`echo ${bbu_log} | grep -E "Max Error"`
BBU_CHARGE=`echo ${bbu_log} | grep -E "Full Charge"`
if [ -n "${BBU_STATE}" ]
then
BBU_ST=`echo "${BBU_STATE}" | awk '{print $3}'`
#echo ${BBU_ST}
if [ ${BBU_ST} = "Unknown" ]
then
#echo "Battery status is Unknown"
let "ERROR_COUNT = 250"
BBUSU_WITH_FAIL="${BBU_STATE}"
elif [ ${BBU_ST} != "Optimal" ]
then
#echo "Battery STATUS is BAD"
BBUS_WITH_FAIL="${BBU_STATE}"
let "ERROR_COUNT = 251"
fi
elif [ -n "${BBU_ERROR}" ]
then
BBU_ER=`echo ${BBU_ERROR} | awk '{print $4}'`
#echo ${BBU_ER}
if [ "${BBU_ER}" -ge "11" ]
then
#echo "Battery has ERRORS"
BBUE_WITH_FAIL="${BBU_ERROR}"
let "ERROR_COUNT = 252"
fi
elif [ -n "${BBU_CHARGE}" ]
then
BBU_CHAR=`echo ${BBU_CHARGE} | awk '{print $4}'`
#echo ${BBU_CHAR}
if [ "${BBU_CHAR}" -lt "675" ]
then
#echo "Battery has low CHARGE"
BBUC_WITH_FAIL="${BBU_CHARGE}"
let "ERROR_COUNT = 253"
fi
fi
done <<< "${BBU_OUT}"
if [[ -n $1 ]] && [ $1 == 'log' ]
then
echo "${VDRIVE_WITH_FAIL}
${DISK_WITH_FAIL}
${PDFIRM_WITH_FAIL}
${BBUS_WITH_FAIL}
${BBUSU_WITH_FAIL}
${BBUE_WITH_FAIL}
${BBUC_WITH_FAIL} "
else
echo $ERROR_COUNT
fi
exit 0
Данный скрипт проверяет все диски на наличие проблем с прошивкой,состояние рейда,ошибки физических дисков и состояние батареи. Если есть проблема с батареей — код выхода скрипта будет больше 250, если проблемы с остальными устройствами, то будет выведено только количество ошибок. Скрипт запускается без аргументов. Если добавить аргумент log, будет выведено текст с указанием проблемного элемента. Проверяем работу скрипта:
root@il-nv-s06:~# ./megaraid.sh 252 root@il-nv-s06:~# ./megaraid.sh log Max Error = 14 %
Как видим у нас проблема с батареей (BBU) и ее нужно заменить.
По роботе с magacli есть целая книга-руководство.
Из полезных команд:
# Просмотр журнала событий BBU, где можно найти информацию по проверкам и автоисправлению битых секторов megacli -fwtermlog -dsply -aall > /tmp/ttylog.txt # Полная информация о всех адаптеров контроллера megacli -AdpAllInfo -aALL # Полная информация о настройках и дисках megacli -CfgDsply -aALL # Информация о последних событиях, где можно найти информацию о сбои в работе дисков megacli -AdpEventLog -GetLatest 4000 -f events.log -aALL megacli -AdpEventLog -GetEvents -f events.log -aALL # Информация о всех доступных корпусах контроллера megacli -EncInfo -aALL # Список всех логических дисков и типе RAID-а в котором они собраны megacli -LDInfo -Lall -aALL # Список всех физических дисков megacli -PDList -aALL # Информация о конкретном физическом диске # Типовая комманда megacli -pdinfo -physdrv [E1:S2] -aALL # E1 - Enclosure Device ID: 1, S2 - Slot Number: 2 # To get it need to run - megacli -LdPdInfo -aALL | grep -E "ID|Slot" megacli -pdinfo -physdrv [4:2] -aALL # Засветить диск #Start blinking megacli -PdLocate -start -physdrv[4:3] -aALL megacli -PdLocate -start -physdrv[4:2] -aALL megacli -PdLocate -start -physdrv[4:1] -aALL #Stop blinking megacli -PdLocate -stop -physdrv[4:1] -aALL megacli -PdLocate -stop -physdrv[4:2] -aALL megacli -PdLocate -stop -physdrv[4:3] -aALL # Проверка состояния BBU (Battery Backup Unit) megacli -adpbbucmd -aall # Посмотреть прогресс добавления диска в RAID megacli -pdrbld -showprog -physdrv[4:0] -aAll
Мониторинг дисков используя smartctl
Для этого нам понадобиться тот же megacli, используя который, мы узнаем ID физических дисков и соответствующие им логические носители. Начнем.
Узнаем ID всех физических дисков за мегарейд контроллером ну и номера соответствующих логических дисков.
root@il-nv-s06:~# megacli -LdPdInfo -aALL | grep Id Virtual Drive: 0 (Target Id: 0) Device Id: 0 Device Id: 1 Device Id: 2 Device Id: 3 Virtual Drive: 1 (Target Id: 1) Device Id: 13 Device Id: 12 Virtual Drive: 2 (Target Id: 2) Device Id: 11 Device Id: 10 Device Id: 9 Device Id: 6 Device Id: 7 Device Id: 8
Расшифрую эту команду:
- -LdPdInfo — получить информацию(Info) по логическим (Ld) и физическим(Pd) устройствам …
- -aALL — … на всех адаптерах
Теперь видно, что у нас три логических(виртуальных) диска в которые входят по несколько физических дисков с соответствующими ID. Посмотрим на сервере, сколько у нас есть дисков:
root@il-nv-s06:~# ls /dev/sd[a-Z] /dev/sda /dev/sdb /dev/sdc
Все верно, у нас три логических диска в системе. Проводим аналогию с выводом команды megacli:
- Virtual Drive: 0 == /dev/sda и в него входит 4 физических диска с ID=0,1,2,3
- Virtual Drive: 1 == /dev/sdb и в него входит 2 физических диска с ID=13,12
- Virtual Drive: 2 == /dev/sdc и в него входит 6 физических дисков с ID=6,7,8,9,10,11
Теперь нам осталось запустить SMART проверку по каждому с дисков используя собранные данные.
root@il-nv-s06:~# cat smartcheck.sh #!/bin/bash echo "=============================================" echo "================== /dev/sda =================" echo "=============================================" smartctl -d megaraid,0 -a /dev/sda smartctl -d megaraid,1 -a /dev/sda smartctl -d megaraid,2 -a /dev/sda smartctl -d megaraid,3 -a /dev/sda echo "=============================================" echo "================== /dev/sdb =================" echo "=============================================" smartctl -d megaraid,13 -a /dev/sdb smartctl -d megaraid,12 -a /dev/sdb echo "=============================================" echo "================== /dev/sdc =================" echo "=============================================" smartctl -d megaraid,11 -a /dev/sdc smartctl -d megaraid,10 -a /dev/sdc smartctl -d megaraid,9 -a /dev/sdc smartctl -d megaraid,6 -a /dev/sdc smartctl -d megaraid,7 -a /dev/sdc smartctl -d megaraid,8 -a /dev/sdc
К примеру возьмем первый диск.
root@il-nv-s06:~# smartctl -d megaraid,0 -a /dev/sda
smartctl 5.41 2011-06-09 r3365 [x86_64-linux-3.8.0-26-generic] (local build)
Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net
Vendor: SEAGATE
Product: ST31000424SS
Revision: 0005
User Capacity: 1,000,204,886,016 bytes [1.00 TB]
Logical block size: 512 bytes
Logical Unit id: 0x5000c5002130cd0b
Serial number: 9WK1D0420000C1051TRW
Device type: disk
Transport protocol: SAS
Local Time is: Fri Feb 7 20:24:25 2014 IST
Device supports SMART and is Enabled
Temperature Warning Enabled
SMART Health Status: OK
Current Drive Temperature: 29 C
Drive Trip Temperature: 68 C
Manufactured in week 32 of year 2010
Specified cycle count over device lifetime: 10000
Accumulated start-stop cycles: 30
Specified load-unload count over device lifetime: 300000
Accumulated load-unload cycles: 2
Elements in grown defect list: 0
Vendor (Seagate) cache information
Blocks sent to initiator = 920579338
Blocks received from initiator = 3734205770
Blocks read from cache and sent to initiator = 2669309657
Number of read and write commands whose size <= segment size = 101596876 Number of read and write commands whose size > segment size = 1211
Vendor (Seagate/Hitachi) factory information
number of hours powered up = 24230.63
number of minutes until next internal SMART test = 20
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 3033913199 210 0 3033913409 3033913469 39052.656 60
write: 0 0 0 0 0 4141.743 0
verify: 75533051 10 0 75533061 75533061 1001.100 0
Non-medium error count: 14
[GLTSD (Global Logging Target Save Disable) set. Enable Save with '-S on']
SMART Self-test log
Num Test Status segment LifeTime LBA_first_err [SK ASC ASQ]
Description number (hours)
# 1 Background long Completed - 24200 - [- - -]
Long (extended) Self Test duration: 11100 seconds [185.0 minutes]
Как видим у нас есть 60 ошибок с которыми не смогла справиться система исправления ошибок.
Немного расшифрую выводу ошибок:
Журнал ошибок (если он доступен) отображается в отдельных строках:
- write error counters — ошибки записи
- read error counters — ошибки считывания
- verify error counters (отображаются только когда не нулевое значение) — ошибки выполнения
- non-medium error counter (определенное число) — число восстанавливаемых ошибок отличных от ошибок записи/считывания/выполнения
Так же может выводиться детальное описание последних ошибок с кодом, если устройство его поддерживает(если нет поддержки — выводиться сообщение «Error Events logging not supported»). К примеру:
Error 3 occurred at disk power-on lifetime: 23855 hours (993 days + 23 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 10 51 08 4c 08 0f e0 Error: IDNF at LBA = 0x000f084c = 985164 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- ca 00 08 4c 08 0f 00 08 19d+06:08:39.873 WRITE DMA ca 00 08 5c 05 0f 00 08 19d+06:08:39.873 WRITE DMA c8 00 10 9c a0 25 00 08 19d+06:08:39.866 READ DMA c8 00 08 94 a0 25 00 08 19d+06:08:39.866 READ DMA c8 00 08 8c a0 25 00 08 19d+06:08:39.862 READ DMA
Каждая из ошибок имеет различные коды. Оригинал описания кодов взято из мануала по SCSI Seagate дискам:
Errors Corrected by ECC, fast [Errors corrected without substantial delay: 00h]. An error correction was applied to get perfect data (a.k.a. ECC on-the-fly). «Without substantial delay» means the correction did not postpone reading of later sectors (e.g. a revolution was not lost). The counter is incremented once for each logical block that requires correction. Two different blocks corrected during the same command are counted as two events.
Errors Corrected by ECC: delayed [Errors corrected with possible delays: 01h]. An error code or algorithm (e.g. ECC, checksum) is applied in order to get perfect data with substantial delay. «With possible delay» means the correction took longer than a sector time so that reading/writing of subsequent sectors was delayed (e.g. a lost revolution). The counter is incremented once for each logical block that requires correction. A block with a double error that is correctable counts as one event and two different blocks corrected during the same command count as two events.
Error corrected by rereads/rewrites [Total (e.g. rewrites and rereads): 02h]. This parameter code specifies the counter counting the number of errors that are corrected by applying retries. This counts errors recovered, not the number of retries. If five retries were required to recover one block of data, the counter increments by one, not five. The counter is incremented once for each logical block that is recovered using retries. If an error is not recoverable while applying retries and is recovered by ECC, it isn’t counted by this counter; it will be counted by the counter specified by parameter code 01h — Errors Corrected With Possible Delays.
Total errors corrected [Total errors corrected: 03h]. This counter counts the total of parameter code errors 00h, 01h and 02h (i.e. error corrected by ECC: fast and delayed plus errors corrected by rereads and rewrites). There is no «double counting» of data errors among these three counters. The sum of all correctable errors can be reached by adding parameter code 01h and 02h errors, not by using this total. [The author does not understand the previous sentence from the Seagate manual.]
Correction algorithm invocations [Total times correction algorithm processed: 04h]. This parameter code specifies the counter that counts the total number of retries, or «times the retry algorithm is invoked». If after five attempts a counter 02h type error is recovered, then five is added to this counter. If three retries are required to get stable ECC syndrome before a counter 01h type error is corrected, then those three retries are also counted here. The number of retries applied to unsuccessfully recover an error (counter 06h type error) are also counted by this counter.
Gigabytes processed {10^9} [Total bytes processed: 05h]. This parameter code specifies the counter that counts the total number of bytes either successfully or unsuccessfully read, written or verified (depending on the log page) from the drive. If a transfer terminates early because of an unrecoverable error, only the logical blocks up to and including the one with the uncorrected data are counted. [smartmontools divides this counter by 10^9 before displaying it with three digits to the right of the decimal point. This makes this 64 bit counter easier to read.]
Total uncorrected errors [Total uncorrected errors: 06h]. This parameter code specifies the counter that contains the total number of blocks for which an uncorrected data error has occurred.
С всего этого нас интересует параметр Total uncorrected errors который показывает количество не исправленных ошибок. Если это число велико, то нужно запускать long тест и проверить, дополнительно, параметры физического диска в Megaraid контроллере.
Мониторинг дисков используя smartd
Предыдущие способы мониторинга дисков были ручными, т.е. нужно вручную запускать проверку дисков находясь на конкретном сервере, или же настроить систему мониторинга, которая будет использовать написанные выше скрипты для сбора информации о состоянии дисков. Но есть еще один способ мониторинга — это использование демона smartd, который будет отправлять нам письма о проблемных дисках. Детально о настройках демона smartd можно почитать здесь
Для начала добавим демон в автозагрузку.
root@il-nv-s06:~# cat /etc/default/smartmontools start_smartd=yes smartd_opts="--interval=3600"
Так же было добавлено интервал запуска проверок. Далее нам нужно добавить диски на мониторинг, для чего служит файл smartd.conf.
root@il-nv-s06:~# cat /etc/smartd.conf #Диски, которые нужно мониторить /dev/sda -d megaraid,0 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sda -d megaraid,1 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sda -d megaraid,2 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sda -d megaraid,3 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdb -d megaraid,13 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdb -d megaraid,12 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,11 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,10 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,9 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,6 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,7 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,8 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) root@il-nv-s06:~# /etc/init.d/smartd restart
Немного расшифрую вывод. Для все дисков включено запуск офлайн тестов (-o on) для обновление и сохранения значений атрибутов (-S on). Так же добавлена проверка всех текущих параметров (-а) и назначено запуск дополнительных коротких тестов каждый день в полночь (S/../.././00) и долгих тестов каждое воскресенье с 3 часов ночи (L/../../7/03). Если будет проблема хотя бы с одной из метрик — будет отправлено письмо на соответствующий адрес (-m your@emailaddress.com). При этом письма будут отправляться систематически — 1,2,4,8,16,… дни (-M diminishing), пока проблема не будет устранена.
В следующей статье я постараюсь описать решение проблемы с батареей Megaraid та и любого другого RAID-контролера. Потом поговорим о мониторинге дисков под HP контроллером (HP/Compaq SmartArray)
Системное администрирование, Хостинг, Серверное администрирование, Блог компании ua-hosting.company
Рекомендация: подборка платных и бесплатных курсов системных администраторов — https://katalog-kursov.ru/
Команду «smartctl -d ata -a /dev/sdb» можно использовать для проверки жесткого диска и текущего состояния его соединения с системой. Но как с помощью команд smartctl проверить SAS или SCSI диски, спрятанные за RAID контроллером Adaptec в системах под управлением Linux ОС? Для этого необходимо использовать последовательные синтаксисы проверки SAS или SATA. Как правило — это логические диски для каждого массива физических накопителей в операционной системы. Команду /dev/sgX возможно использовать в качестве перехода через контроллеры ввода/вывода, которые обеспечиваюь прямой доступ к каждому физическому диску, подключенному к RAID контроллеру Adaptec.

Распознает ли Linux контроллер Adaptec RAID?
Для проверки Вы можете использовать следующую команду:
# lspci | egrep -i 'raid|adaptec'
В результате выполнения команды получите следующее:
81:00.0 RAID bus controller: Adaptec AAC-RAID (rev 09)
Загрузка и установка Adaptec Storage Manager для Linux
Необходимо установить Adaptec Storage Manager в соответсвии собранному дисковому массиву.
Проверяем состояния SATA диска
Команда для сканирования накопителя выглядит довольно просто:
# smartctl --scan
В результате у Вас должно получится следующее:
/dev/sda -d scsi # /dev/sda, SCSI device
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg {1,2,3,4}. Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
# smartctl -d sat --all /dev/sgX
# smartctl -d sat --all /dev/sg1
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
# smartctl -d sat --all /dev/sg1 -H
Для SAS диск используют следующий синтаксис:
# smartctl -d scsi --all /dev/sgX
# smartctl -d scsi --all /dev/sg1
### Ask the device to report its SMART health status or pending TapeAlert message ###
# smartctl -d scsi --all /dev/sg1 -H
В результате получим что то похожее на:
smartctl version 5.38 [x86_64-redhat-linux-gnu] Copyright (C) 2002-8 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
Device: SEAGATE ST3146855SS Version: 0002
Serial number: xxxxxxxxxxxxxxx
Device type: disk
Transport protocol: SAS
Local Time is: Wed Jul 7 04:34:30 2010 CDT
Device supports SMART and is Enabled
Temperature Warning Enabled
SMART Health Status: OK
Current Drive Temperature: 24 C
Drive Trip Temperature: 68 C
Elements in grown defect list: 0
Vendor (Seagate) cache information
Blocks sent to initiator = 1857385803
Blocks received from initiator = 1967221471
Blocks read from cache and sent to initiator = 804439119
Number of read and write commands whose size <= segment size = 312098925
Number of read and write commands whose size > segment size = 45998
Vendor (Seagate/Hitachi) factory information
number of hours powered up = 13224.42
number of minutes until next internal SMART test = 42
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 58984049 1 0 58984050 58984050 3151.730 0
write: 0 0 0 0 0 9921230881.600 0
verify: 1308 0 0 1308 1308 0.000 0
Non-medium error count: 0
No self-tests have been logged
Long (extended) Self Test duration: 1367 seconds [22.8 minutes]
А вот команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
# smartctl -d scsi --all /dev/sg2 -H
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
/dev/sg0 - RAID 10 контроллер.
/dev/sg1 - Первый диск в массиве RAID 10.
/dev/sg2 - Второй диск в массиве RAID 10.
/dev/sg3 - Третий диск в массиве RAID 10.
/dev/sg4 - Четвертый диск в массиве RAID 10.
Проверить жесткий диск можно с помощью следующих команд:
# smartctl -t short -d scsi /dev/sg2
# smartctl -t long -d scsi /dev/sg2
Где,
-t short : Запуск быстрого теста.
-t long : Запуск полного теста.
-d scsi : Указывает scsi, как тип устройства.
--all : Отображает всю SMART информацию для устройства.
Использование Adaptec Storage Manager
Другие простые команды для проверки базового состояния выглядят следующим образом:
# /usr/StorMan/arcconf getconfig 1 | more
# /usr/StorMan/arcconf getconfig 1 | grep State
# /usr/StorMan/arcconf getconfig 1 | grep -B 3 State
Пример результата:
Device #0
Device is a Hard drive
State : Online
--
S.M.A.R.T. : No
Device #1
Device is a Hard drive
State : Online
--
S.M.A.R.T. : No
Device #2
Device is a Hard drive
State : Online
--
S.M.A.R.T. : No
Device #3
Device is a Hard drive
State : Online
Обратите внимание на то, что более новая версия arcconf расположена в архиве /usr/Adaptec_Event_Monitor. Таким образом, весь путь должен выглядеть так:
# /usr/Adaptec_Event_Monitor/arcconf getconfig [AD | LD [LD#] | PD | MC | [AL]] [nologs]
Где,
Prints controller configuration information.
Option AD : Информация исключительно о контроллере Adapter
LD : Информация исключительно о логических устройствах
LD# : Дополнительная информация об указанном логическом устройстве
PD : Информация исключительно о физическом устройстве
MC : Информация исключительно о Maxcache 3.0
AL : Вся информация
Вы можете самостоятельно проверить состояние массива Adaptec RAID на Linux с помощью ввода простой команды:
# /usr/Adaptec_Event_Monitor/arcconf getconfig 1
Или (более поздняя версия):
# /usr/StorMan/arcconf getconfig 1
Примерный результат на фото:
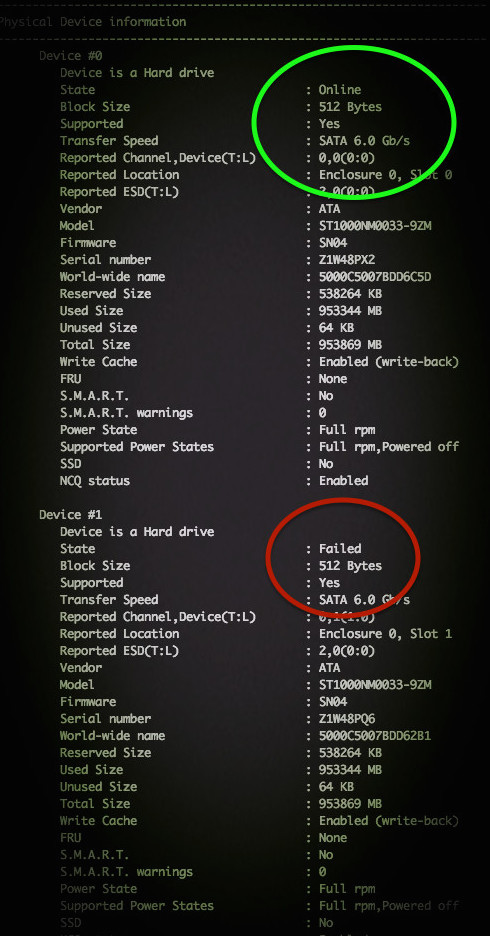
??По традиции, немного рекламы в подвале, где она никому не помешает. Напоминаем, что в связи с тем, что общая емкость сети нидерландского дата-центра, в котором мы предоставляем услуги, достигла значения 5 Тбит / с (58 точек присутствия, включения в 36 точек обмена, более, чем в 20 странах и 4213 пиринговых включений), мы предлагаем выделенные серверы в аренду по невероятно низким ценам, только неделю!.
Часто задаваемый вопрос: «есть ли у SAS-дисков SMART и как его посмотреть?»
Да, в некотором виде есть, в виде лог-страниц с различной полезной информацией. В статье будет рассказано о том, как эту информацию получить и интерпретировать.
Хочется подчеркнуть что, речь ниже пойдет не о домашних пользователях, для которых регулярная проверка здоровья и производительности родного железа может быть чем-то вроде хобби. Да и в случае появления признаков неисправности на том же HDD первой мыслью будет не «немедленно списать и заменить», а «сколько он еще протянет и нельзя ли как-нибудь его починить?». Такой подход вполне имеет право на жизнь, ведь ценность «домашних» данных и объем IT-бюджета, как правило, не очень высоки.
Ситуация в корпоративном секторе или в гарантийном отделе поставщика (как раз наш случай) будет немного другой. Хорошему администратору совершенно не должно быть интересно, к примеру, значение SMART-атрибута Seek_Error_Rate на диске. Логика действий проста: получив информацию от RAID-контроллера о проблемах с диском, выкинуть его из массива и запустить ребилд на новый диск (эту процедуру можно и оптимизировать). Подробности сбоя и «нельзя ли как-нибудь его починить?» никого не интересуют — стоимость потери данных и/или возможного простоя просто не позволяют адекватному сотруднику тратить время на подобные вопросы.
И все же дальнейшая судьба сбойнувшего диска — диагностика. В ней может быть заинтересован либо владелец (например, с целью пристроить более-менее живой диск для каких-либо «небоевых» нужд) и, конечно, гарантийный отдел поставщика — при этом диски могут поступать не по 1-2, а десятками. А проверить нужно в ограниченные сроки, т.е. одновременно по нескольку штук, так что времени на последовательную проверку через MHDD, HDDScan, различные утилиты от производителей и format/verify средствами контроллера просто нет.
Софт
И так — диагностика. Алгоритм простой — смотрим нужные счетчики, отправляем диск на форматирование, проверяем поверхность, снова смотрим счетчики на предмет роста ошибок. Для начала желательно собрать о «пациенте» побольше сведений. IMHO, лучший инструмент для этого — пакет smartmontools (в состав которого входит утилита smartctl):
- Изначально разрабатывался под Linux, но на данный момент портирован на большое количество платформ, включая различные *BSD и Windows. Кстати, для тех, кто предпочитает GUI — под Linux/FreeBSD/Windows есть отличный фронтенд GSmartControl
- Выводит подробную информацию о диске, включая не только SMART-атрибуты (с расшифровкой многих нестандартных атрибутов), но и страницы с логами ошибок.
- Позволяет запускать поддерживаемые современными ATA и SCSI дисками внутренние тесты самодиагностики (short selftest и long selftest).
- Может работать как при прямом подключении диска, так и через различные USB и Firewire конвертеры. Версии под Linux и FreeBSD позволяют «достучаться» до дисков, подключенных к различным RAID контроллерам (3ware, Areca, HighPoint, HP Smart Array, LSI MegaRAID).
- Может выводить в удобочитаемом виде некоторые лог-страницы SCSI-дисков (к которым, естественно, относится и SAS) — что нам и нужно.
Инструмент номер два — пакет sg3_utils, набор утилит для работы со SCSI-устройствами. Пакет портирован под большое количество ОС, включая Windows. Во многих дистрибутивах Linux присутствует устаревшая на 1-2 года версия, но последнюю легко собрать из исходников. Для наших задач представляют ценность следующие утилиты:
- sg_logs — выводит лог-страницы устройства в более подробном виде, чем smartctl. Пример вывода с разъяснениями будет ниже
- sg_format — выполняет форматирование диска. При очень большом желании можно изменить объем и даже размер сектора.
- sg_verify — выполняет недеструктивную проверку выбранных блоков командой SCSI VERIFY.
- sg_reassign — ручной ремап нужных блоков через SCSI-команду REASSIGN BLOCKS с помещением в Grown defect list
- sg_senddiag — отправка команд на запуск встроенных тестов (то же, что и smartctl —selftest для ATA дисков).
Оборудование и ОС
В качестве оборудования подойдет любой SAS HBA, т.е. простой контроллер, без аппаратного RAID или с отключаемым хост-RAID’ом. В TrueSystem используются LSI 9211 или набортные контроллеры на базе чипов LSI 2008 или 1068E (с IT-прошивкой). Изредка в гарантию попадают диски под параллельный SCSI, на этот случай под рукой есть Adaptec AHA2930 и переходник с 68pin на SCA.
Операционная система — вопрос личных предпочтений. Вышеуказанные утилиты имеют порт под Windows, но в Linux с ними работать чуть удобнее. При параллельном тестировании множества дисков возникает проблема неудобства множества консольных сессий. Решение для Windows — терминал Console, для Linux/FreeBSD показался удобным удаленный доступ через SSH (если с Windows — через PuTTY) и запуск в SSH-сессии консольного менеджера screen.
Проверяем
Пациент номер один: относительно 300ГБ старый U320-SCSI диск Fujitsu MAW3300NC. Подключаем и определяем, где его искать (через lsscsi или sg_scan). Далее можно посмотреть на вывод smartctl или sg_logs. Начнем со smartctl:
# smartctl -a /dev/sdb
Vendor: FUJITSU
Product: MAW3300NC
Revision: 0104
User Capacity: 300,000,000,000 bytes [300 GB]
Logical block size: 512 bytes
Serial number: DA00P8B037VT
Device type: disk
Transport protocol: Parallel SCSI (SPI-4)
Local Time is: Fri Oct 14 16:35:21 2011 MSK
Device supports SMART and is Disabled
Temperature Warning Disabled or Not Supported
SMART Health Status: FIRMWARE IMPENDING FAILURE TOO MANY BLOCK REASSIGNS [asc=5d, ascq=64]
Current Drive Temperature: 26 C
Drive Trip Temperature: 65 C
Manufactured in week 45 of year 2008
Specified cycle count over device lifetime: 10000
Accumulated start-stop cycles: 8
Elements in grown defect list: 8191
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 0 39965378 3599 0 0 345061.500 3599
write: 0 9 0 0 0 45798.649 0
verify: 0 210 1 0 0 0.026 1
Non-medium error count: 25
No self-tests have been logged
Long (extended) Self Test duration: 6325 seconds [105.4 minutes]
Примерно тоже можно было бы получить, запустив sg_logs -a, для SAS дисков — с добавкой в виде страницы Protocol Specific port log page for SAS SSP, где перечислены оба phy SAS диска (если он 2-портовыйСразу в глаза бросаются огромное количество ошибок чтения, большое кол-во ремапов (Elements in grown defect list) и предупреждение «SMART Health Status: FIRMWARE IMPENDING FAILURE TOO MANY BLOCK REASSIGNS [asc=5d, ascq=64]«. Последнее хранится на странице Informational exceptions в логах диска и говорит нам о том, что дальше его можно и не тестировать: алгоритм, заложенный в firmware уже сделал вывод о предсмертном состоянии диска по большому количеству ремапов.
Отличное от нуля значение счетчика Non-medium error count не всегда указывает на проблемы с диском. Было несколько случаев с SAS-дисками и контроллером Adaptec, когда причиной был некачественный noname кабель.
Можно еще немного помучить диск, запустив самодиагностику, например «длинный» фоновый тест:
# sg_senddiag --selftest=2 /dev/sdb
Тест прерывается с ошибкой о найденных бэдах, о чем можно узнать, запустив
# sg_logs -a /dev/sdb
и посмотрев на соответствующую страницу:
Self-test results page
Parameter code = 1, accumulated power-on hours = 20912
self-test code: background extended [2]
self-test result: another segment in self test failed [7]
self-test number = 3
sense key = 0x6, asc = 0x5d, asq = 0x64
Собственно, при помощи smartctl со SCSI/SAS дисками можно сделать то же, что при запуске sg_logs и sg_senddiag — посмотреть логи и запустить self-test’ы.
Следующий шаг — форматирование. Запускаем
# sg_format --format /dev/sdb
и ждем окончания. Собственно форматированием занимается firmware диска, для SCSI/SAS данная процедура является самым верным способом заставить диск заремапить все сбойные сектора. Именно ту же процедуру выполняет, например, контроллер Adaptec при выборе в меню пункта «Format disk», только в данном случае мы имеем информацию о ходе выполнения и, что самое важное — возможность форматировать несколько дисков. Многие современные диски SAS (например, Hitachi) понимают некоторые SCSI команды и могут работать с утилитами sg_format и sg_verify, только вот ручной ремап через sg_reassign не воспринимают (его можно сделать при помощи hdparm).
В данном случае форматирование завершилось успешно (сообщение FORMAT COMPLETE после 99%), смотрим в логи и видим, что счетчик Elements in grown defect list уменьшился до 166 (просто данные о ремапах были перенесены в p-list). Нужен еще один тест поверхности. Вместо selftest’а можно попробовать что-нибудь наглядное, например badblocks в деструктивном режиме:
# badblocks -svw /dev/sdb
При запуске с этими ключами badblocks совершит 4 пары проходов по диску, записывая и считывая различные паттерны. Занимает очень много времени (5,5 часов для этого диска и почти двое суток для 2ТБ диска).
Итак — 13 бэдов, снова смотрим в логи, видим растущее количество ремапов ошибок чтения. Для очистки совести можно запустить еще раз badblocks или внутренний тест и убедиться в том, что диск по-прежнему находится в совершенно плачевном состоянии. Можно его остановить перед отключением командой
# sg_start --stop /dev/sdb
и отправить в утиль.