-
Точность статистического наблюдения. Ошибки регистрации и ошибки репрезентативности. Арифметический и логический контроль качества информации.
Точность
статистического наблюдения
называют степень соответстия величины
какого – либо показателя (значение
какого- либо признака), определенной по
материалам статистического наблюдения
действительной его величине.
Ошибки рагистрации
– отклонения значения показателя,
полученного в ходе статистического
наблюдения от фактического, действительного
его значения. Возможны как при сплошном,
так и при несплошном наблюдении. Ошибки
регистрации деляться на случайные и
систематические.
Ошибка
репрезентативности
– это отклонение значения показателя
обследований совокупности от его
величины по исходной совокупности.
Такие ошибки характерны только для
несплошного наблюдени. Возникают потому,
что отобранная и обследованная
совокупность недостаточно точно
воспроизводит (репрезентирует) всю
исходную совокупность в целом. Также
бывают случайными и систиматическими.
Чтобы устранить
обнаруженные ошибки в материалах
статистического наблюдения, производиться
контроль собранных данных первичного
учета, который осуществляеться в двух
напрвлениях:
-
Счетный, или
арифметический контроль – заключается
в проверке точности арифметических
расчетов, применявшихся при составлении
отчетности или заполнении формуляров
статистического наблюдения; -
Логический контроль
– заключается в проверке ответов на
вопросы программы наблюдения путем их
логического осмысления или путем
сравнения полученных данных с другими
источниками по этому же вопросу.
-
Виды статистического наблюдения по времени регистрации фактов: непрерывное (текущее), периодическое и единовременное.
Статистические
признаки классифицируют по 3 признакам:
-
по времени
-
по способу
проведения -
по полноте охвата
По времени наблюдения
различают:
-
текущие наблюдения
– сбор данных, который проводиться
постоянно, т.к. данные фиксируются по
мере их возникновения. -
периодическое
наблюдение – это сбор данных через
равные промежутки времени -
единовременное
наблюдение – это сбор данных, который
проводиться время от времени без
закономерности определения.
-
Виды статистического наблюдения по охвату единиц совокупности: сплошное, выборочное, основного массива, монографическое.
Статистические
признаки классифицируют по 3 признакам:
-
по времени
-
по способу
проведения -
по полноте охвата
По полноте охвата
различают:
-
сплошное наблюдение
– это сбор данных о всех единицах
совокупности. -
несплошное
наблюдение – это сбор данных не о всех
единицах совокупности. (выборочное
анкетирование) -
монографическое
наблюдение или монографическое
обследование – это подробное описание
отдельных единиц наблюдения в
статистической совокупности. -
обследование
основного массива – это наблюдение за
частью наиболее крупных единиц, которые
преобладают в исследованной совокупности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
-
Помощь студентам
-
Онлайн тесты
-
Экономика
-
Тесты с ответами по статистике
Тест по теме «Тесты с ответами по статистике»
-

Обновлено: 15.04.2021
-

480 775
97 вопросов
Выполним любые типы работ
- Дипломные работы
- Курсовые работы
- Рефераты
- Контрольные работы
- Отчет по практике
- Эссе
Популярные тесты по экономике

Экономика
Тесты с ответами по статистике
Экономика
Тесты с ответами по Макроэкономике
Экономика
Тесты с ответами по предмету экономика предприятия
Экономика
Тест с ответами по Мировой экономике
Экономика
Тесты с ответами по АФХД
Экономика
Тест с ответами по инвестициям
Экономика
Тест с ответами по Инновационному менеджменту
Экономика
Тесты по логистике с ответами
Экономика
Экономическая теория. Тема 6. Эластичность спроса и предложения
Мы поможем сдать на отлично и без пересдач
-
Контрольная работа
-
Курсовая работа
-
Дипломная работа
-
Реферат
-
Онлайн-помощь
Нужна помощь с тестами?
Оставляй заявку — и мы пройдем все тесты за тебя!
From Wikipedia, the free encyclopedia
«Systematic bias» redirects here. For the sociological and organizational phenomenon, see Systemic bias.
Observational error (or measurement error) is the difference between a measured value of a quantity and its true value.[1] In statistics, an error is not necessarily a «mistake». Variability is an inherent part of the results of measurements and of the measurement process.
Measurement errors can be divided into two components: random and systematic.[2]
Random errors are errors in measurement that lead to measurable values being inconsistent when repeated measurements of a constant attribute or quantity are taken. Systematic errors are errors that are not determined by chance but are introduced by repeatable processes inherent to the system.[3] Systematic error may also refer to an error with a non-zero mean, the effect of which is not reduced when observations are averaged.[citation needed]
Measurement errors can be summarized in terms of accuracy and precision.
Measurement error should not be confused with measurement uncertainty.
Science and experiments[edit]
When either randomness or uncertainty modeled by probability theory is attributed to such errors, they are «errors» in the sense in which that term is used in statistics; see errors and residuals in statistics.
Every time we repeat a measurement with a sensitive instrument, we obtain slightly different results. The common statistical model used is that the error has two additive parts:
- Systematic error which always occurs, with the same value, when we use the instrument in the same way and in the same case.
- Random error which may vary from observation to another.
Systematic error is sometimes called statistical bias. It may often be reduced with standardized procedures. Part of the learning process in the various sciences is learning how to use standard instruments and protocols so as to minimize systematic error.
Random error (or random variation) is due to factors that cannot or will not be controlled. One possible reason to forgo controlling for these random errors is that it may be too expensive to control them each time the experiment is conducted or the measurements are made. Other reasons may be that whatever we are trying to measure is changing in time (see dynamic models), or is fundamentally probabilistic (as is the case in quantum mechanics — see Measurement in quantum mechanics). Random error often occurs when instruments are pushed to the extremes of their operating limits. For example, it is common for digital balances to exhibit random error in their least significant digit. Three measurements of a single object might read something like 0.9111g, 0.9110g, and 0.9112g.
Characterization[edit]
Measurement errors can be divided into two components: random error and systematic error.[2]
Random error is always present in a measurement. It is caused by inherently unpredictable fluctuations in the readings of a measurement apparatus or in the experimenter’s interpretation of the instrumental reading. Random errors show up as different results for ostensibly the same repeated measurement. They can be estimated by comparing multiple measurements and reduced by averaging multiple measurements.
Systematic error is predictable and typically constant or proportional to the true value. If the cause of the systematic error can be identified, then it usually can be eliminated. Systematic errors are caused by imperfect calibration of measurement instruments or imperfect methods of observation, or interference of the environment with the measurement process, and always affect the results of an experiment in a predictable direction. Incorrect zeroing of an instrument leading to a zero error is an example of systematic error in instrumentation.
The Performance Test Standard PTC 19.1-2005 “Test Uncertainty”, published by the American Society of Mechanical Engineers (ASME), discusses systematic and random errors in considerable detail. In fact, it conceptualizes its basic uncertainty categories in these terms.
Random error can be caused by unpredictable fluctuations in the readings of a measurement apparatus, or in the experimenter’s interpretation of the instrumental reading; these fluctuations may be in part due to interference of the environment with the measurement process. The concept of random error is closely related to the concept of precision. The higher the precision of a measurement instrument, the smaller the variability (standard deviation) of the fluctuations in its readings.
Sources[edit]
Sources of systematic error[edit]
Imperfect calibration[edit]
Sources of systematic error may be imperfect calibration of measurement instruments (zero error), changes in the environment which interfere with the measurement process and sometimes imperfect methods of observation can be either zero error or percentage error. If you consider an experimenter taking a reading of the time period of a pendulum swinging past a fiducial marker: If their stop-watch or timer starts with 1 second on the clock then all of their results will be off by 1 second (zero error). If the experimenter repeats this experiment twenty times (starting at 1 second each time), then there will be a percentage error in the calculated average of their results; the final result will be slightly larger than the true period.
Distance measured by radar will be systematically overestimated if the slight slowing down of the waves in air is not accounted for. Incorrect zeroing of an instrument leading to a zero error is an example of systematic error in instrumentation.
Systematic errors may also be present in the result of an estimate based upon a mathematical model or physical law. For instance, the estimated oscillation frequency of a pendulum will be systematically in error if slight movement of the support is not accounted for.
Quantity[edit]
Systematic errors can be either constant, or related (e.g. proportional or a percentage) to the actual value of the measured quantity, or even to the value of a different quantity (the reading of a ruler can be affected by environmental temperature). When it is constant, it is simply due to incorrect zeroing of the instrument. When it is not constant, it can change its sign. For instance, if a thermometer is affected by a proportional systematic error equal to 2% of the actual temperature, and the actual temperature is 200°, 0°, or −100°, the measured temperature will be 204° (systematic error = +4°), 0° (null systematic error) or −102° (systematic error = −2°), respectively. Thus the temperature will be overestimated when it will be above zero and underestimated when it will be below zero.
Drift[edit]
Systematic errors which change during an experiment (drift) are easier to detect. Measurements indicate trends with time rather than varying randomly about a mean. Drift is evident if a measurement of a constant quantity is repeated several times and the measurements drift one way during the experiment. If the next measurement is higher than the previous measurement as may occur if an instrument becomes warmer during the experiment then the measured quantity is variable and it is possible to detect a drift by checking the zero reading during the experiment as well as at the start of the experiment (indeed, the zero reading is a measurement of a constant quantity). If the zero reading is consistently above or below zero, a systematic error is present. If this cannot be eliminated, potentially by resetting the instrument immediately before the experiment then it needs to be allowed by subtracting its (possibly time-varying) value from the readings, and by taking it into account while assessing the accuracy of the measurement.
If no pattern in a series of repeated measurements is evident, the presence of fixed systematic errors can only be found if the measurements are checked, either by measuring a known quantity or by comparing the readings with readings made using a different apparatus, known to be more accurate. For example, if you think of the timing of a pendulum using an accurate stopwatch several times you are given readings randomly distributed about the mean. Hopings systematic error is present if the stopwatch is checked against the ‘speaking clock’ of the telephone system and found to be running slow or fast. Clearly, the pendulum timings need to be corrected according to how fast or slow the stopwatch was found to be running.
Measuring instruments such as ammeters and voltmeters need to be checked periodically against known standards.
Systematic errors can also be detected by measuring already known quantities. For example, a spectrometer fitted with a diffraction grating may be checked by using it to measure the wavelength of the D-lines of the sodium electromagnetic spectrum which are at 600 nm and 589.6 nm. The measurements may be used to determine the number of lines per millimetre of the diffraction grating, which can then be used to measure the wavelength of any other spectral line.
Constant systematic errors are very difficult to deal with as their effects are only observable if they can be removed. Such errors cannot be removed by repeating measurements or averaging large numbers of results. A common method to remove systematic error is through calibration of the measurement instrument.
Sources of random error[edit]
The random or stochastic error in a measurement is the error that is random from one measurement to the next. Stochastic errors tend to be normally distributed when the stochastic error is the sum of many independent random errors because of the central limit theorem. Stochastic errors added to a regression equation account for the variation in Y that cannot be explained by the included Xs.
Surveys[edit]
The term «observational error» is also sometimes used to refer to response errors and some other types of non-sampling error.[1] In survey-type situations, these errors can be mistakes in the collection of data, including both the incorrect recording of a response and the correct recording of a respondent’s inaccurate response. These sources of non-sampling error are discussed in Salant and Dillman (1994) and Bland and Altman (1996).[4][5]
These errors can be random or systematic. Random errors are caused by unintended mistakes by respondents, interviewers and/or coders. Systematic error can occur if there is a systematic reaction of the respondents to the method used to formulate the survey question. Thus, the exact formulation of a survey question is crucial, since it affects the level of measurement error.[6] Different tools are available for the researchers to help them decide about this exact formulation of their questions, for instance estimating the quality of a question using MTMM experiments. This information about the quality can also be used in order to correct for measurement error.[7][8]
Effect on regression analysis[edit]
If the dependent variable in a regression is measured with error, regression analysis and associated hypothesis testing are unaffected, except that the R2 will be lower than it would be with perfect measurement.
However, if one or more independent variables is measured with error, then the regression coefficients and standard hypothesis tests are invalid.[9]: p. 187 This is known as attenuation bias.[10]
See also[edit]
- Bias (statistics)
- Cognitive bias
- Correction for measurement error (for Pearson correlations)
- Errors and residuals in statistics
- Error
- Replication (statistics)
- Statistical theory
- Metrology
- Regression dilution
- Test method
- Propagation of uncertainty
- Instrument error
- Measurement uncertainty
- Errors-in-variables models
- Systemic bias
References[edit]
- ^ a b Dodge, Y. (2003) The Oxford Dictionary of Statistical Terms, OUP. ISBN 978-0-19-920613-1
- ^ a b John Robert Taylor (1999). An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements. University Science Books. p. 94, §4.1. ISBN 978-0-935702-75-0.
- ^ «Systematic error». Merriam-webster.com. Retrieved 2016-09-10.
- ^ Salant, P.; Dillman, D. A. (1994). How to conduct your survey. New York: John Wiley & Sons. ISBN 0-471-01273-4.
- ^ Bland, J. Martin; Altman, Douglas G. (1996). «Statistics Notes: Measurement Error». BMJ. 313 (7059): 744. doi:10.1136/bmj.313.7059.744. PMC 2352101. PMID 8819450.
- ^ Saris, W. E.; Gallhofer, I. N. (2014). Design, Evaluation and Analysis of Questionnaires for Survey Research (Second ed.). Hoboken: Wiley. ISBN 978-1-118-63461-5.
- ^ DeCastellarnau, A. and Saris, W. E. (2014). A simple procedure to correct for measurement errors in survey research. European Social Survey Education Net (ESS EduNet). Available at: http://essedunet.nsd.uib.no/cms/topics/measurement Archived 2019-09-15 at the Wayback Machine
- ^ Saris, W. E.; Revilla, M. (2015). «Correction for measurement errors in survey research: necessary and possible» (PDF). Social Indicators Research. 127 (3): 1005–1020. doi:10.1007/s11205-015-1002-x. hdl:10230/28341. S2CID 146550566.
- ^ Hayashi, Fumio (2000). Econometrics. Princeton University Press. ISBN 978-0-691-01018-2.
- ^ Angrist, Joshua David; Pischke, Jörn-Steffen (2015). Mastering ‘metrics : the path from cause to effect. Princeton, New Jersey. p. 221. ISBN 978-0-691-15283-7. OCLC 877846199.
The bias generated by this sort of measurement error in regressors is called attenuation bias.
Further reading[edit]
- Cochran, W. G. (1968). «Errors of Measurement in Statistics». Technometrics. 10 (4): 637–666. doi:10.2307/1267450. JSTOR 1267450.
From Wikipedia, the free encyclopedia
«Systematic bias» redirects here. For the sociological and organizational phenomenon, see Systemic bias.
Observational error (or measurement error) is the difference between a measured value of a quantity and its true value.[1] In statistics, an error is not necessarily a «mistake». Variability is an inherent part of the results of measurements and of the measurement process.
Measurement errors can be divided into two components: random and systematic.[2]
Random errors are errors in measurement that lead to measurable values being inconsistent when repeated measurements of a constant attribute or quantity are taken. Systematic errors are errors that are not determined by chance but are introduced by repeatable processes inherent to the system.[3] Systematic error may also refer to an error with a non-zero mean, the effect of which is not reduced when observations are averaged.[citation needed]
Measurement errors can be summarized in terms of accuracy and precision.
Measurement error should not be confused with measurement uncertainty.
Science and experiments[edit]
When either randomness or uncertainty modeled by probability theory is attributed to such errors, they are «errors» in the sense in which that term is used in statistics; see errors and residuals in statistics.
Every time we repeat a measurement with a sensitive instrument, we obtain slightly different results. The common statistical model used is that the error has two additive parts:
- Systematic error which always occurs, with the same value, when we use the instrument in the same way and in the same case.
- Random error which may vary from observation to another.
Systematic error is sometimes called statistical bias. It may often be reduced with standardized procedures. Part of the learning process in the various sciences is learning how to use standard instruments and protocols so as to minimize systematic error.
Random error (or random variation) is due to factors that cannot or will not be controlled. One possible reason to forgo controlling for these random errors is that it may be too expensive to control them each time the experiment is conducted or the measurements are made. Other reasons may be that whatever we are trying to measure is changing in time (see dynamic models), or is fundamentally probabilistic (as is the case in quantum mechanics — see Measurement in quantum mechanics). Random error often occurs when instruments are pushed to the extremes of their operating limits. For example, it is common for digital balances to exhibit random error in their least significant digit. Three measurements of a single object might read something like 0.9111g, 0.9110g, and 0.9112g.
Characterization[edit]
Measurement errors can be divided into two components: random error and systematic error.[2]
Random error is always present in a measurement. It is caused by inherently unpredictable fluctuations in the readings of a measurement apparatus or in the experimenter’s interpretation of the instrumental reading. Random errors show up as different results for ostensibly the same repeated measurement. They can be estimated by comparing multiple measurements and reduced by averaging multiple measurements.
Systematic error is predictable and typically constant or proportional to the true value. If the cause of the systematic error can be identified, then it usually can be eliminated. Systematic errors are caused by imperfect calibration of measurement instruments or imperfect methods of observation, or interference of the environment with the measurement process, and always affect the results of an experiment in a predictable direction. Incorrect zeroing of an instrument leading to a zero error is an example of systematic error in instrumentation.
The Performance Test Standard PTC 19.1-2005 “Test Uncertainty”, published by the American Society of Mechanical Engineers (ASME), discusses systematic and random errors in considerable detail. In fact, it conceptualizes its basic uncertainty categories in these terms.
Random error can be caused by unpredictable fluctuations in the readings of a measurement apparatus, or in the experimenter’s interpretation of the instrumental reading; these fluctuations may be in part due to interference of the environment with the measurement process. The concept of random error is closely related to the concept of precision. The higher the precision of a measurement instrument, the smaller the variability (standard deviation) of the fluctuations in its readings.
Sources[edit]
Sources of systematic error[edit]
Imperfect calibration[edit]
Sources of systematic error may be imperfect calibration of measurement instruments (zero error), changes in the environment which interfere with the measurement process and sometimes imperfect methods of observation can be either zero error or percentage error. If you consider an experimenter taking a reading of the time period of a pendulum swinging past a fiducial marker: If their stop-watch or timer starts with 1 second on the clock then all of their results will be off by 1 second (zero error). If the experimenter repeats this experiment twenty times (starting at 1 second each time), then there will be a percentage error in the calculated average of their results; the final result will be slightly larger than the true period.
Distance measured by radar will be systematically overestimated if the slight slowing down of the waves in air is not accounted for. Incorrect zeroing of an instrument leading to a zero error is an example of systematic error in instrumentation.
Systematic errors may also be present in the result of an estimate based upon a mathematical model or physical law. For instance, the estimated oscillation frequency of a pendulum will be systematically in error if slight movement of the support is not accounted for.
Quantity[edit]
Systematic errors can be either constant, or related (e.g. proportional or a percentage) to the actual value of the measured quantity, or even to the value of a different quantity (the reading of a ruler can be affected by environmental temperature). When it is constant, it is simply due to incorrect zeroing of the instrument. When it is not constant, it can change its sign. For instance, if a thermometer is affected by a proportional systematic error equal to 2% of the actual temperature, and the actual temperature is 200°, 0°, or −100°, the measured temperature will be 204° (systematic error = +4°), 0° (null systematic error) or −102° (systematic error = −2°), respectively. Thus the temperature will be overestimated when it will be above zero and underestimated when it will be below zero.
Drift[edit]
Systematic errors which change during an experiment (drift) are easier to detect. Measurements indicate trends with time rather than varying randomly about a mean. Drift is evident if a measurement of a constant quantity is repeated several times and the measurements drift one way during the experiment. If the next measurement is higher than the previous measurement as may occur if an instrument becomes warmer during the experiment then the measured quantity is variable and it is possible to detect a drift by checking the zero reading during the experiment as well as at the start of the experiment (indeed, the zero reading is a measurement of a constant quantity). If the zero reading is consistently above or below zero, a systematic error is present. If this cannot be eliminated, potentially by resetting the instrument immediately before the experiment then it needs to be allowed by subtracting its (possibly time-varying) value from the readings, and by taking it into account while assessing the accuracy of the measurement.
If no pattern in a series of repeated measurements is evident, the presence of fixed systematic errors can only be found if the measurements are checked, either by measuring a known quantity or by comparing the readings with readings made using a different apparatus, known to be more accurate. For example, if you think of the timing of a pendulum using an accurate stopwatch several times you are given readings randomly distributed about the mean. Hopings systematic error is present if the stopwatch is checked against the ‘speaking clock’ of the telephone system and found to be running slow or fast. Clearly, the pendulum timings need to be corrected according to how fast or slow the stopwatch was found to be running.
Measuring instruments such as ammeters and voltmeters need to be checked periodically against known standards.
Systematic errors can also be detected by measuring already known quantities. For example, a spectrometer fitted with a diffraction grating may be checked by using it to measure the wavelength of the D-lines of the sodium electromagnetic spectrum which are at 600 nm and 589.6 nm. The measurements may be used to determine the number of lines per millimetre of the diffraction grating, which can then be used to measure the wavelength of any other spectral line.
Constant systematic errors are very difficult to deal with as their effects are only observable if they can be removed. Such errors cannot be removed by repeating measurements or averaging large numbers of results. A common method to remove systematic error is through calibration of the measurement instrument.
Sources of random error[edit]
The random or stochastic error in a measurement is the error that is random from one measurement to the next. Stochastic errors tend to be normally distributed when the stochastic error is the sum of many independent random errors because of the central limit theorem. Stochastic errors added to a regression equation account for the variation in Y that cannot be explained by the included Xs.
Surveys[edit]
The term «observational error» is also sometimes used to refer to response errors and some other types of non-sampling error.[1] In survey-type situations, these errors can be mistakes in the collection of data, including both the incorrect recording of a response and the correct recording of a respondent’s inaccurate response. These sources of non-sampling error are discussed in Salant and Dillman (1994) and Bland and Altman (1996).[4][5]
These errors can be random or systematic. Random errors are caused by unintended mistakes by respondents, interviewers and/or coders. Systematic error can occur if there is a systematic reaction of the respondents to the method used to formulate the survey question. Thus, the exact formulation of a survey question is crucial, since it affects the level of measurement error.[6] Different tools are available for the researchers to help them decide about this exact formulation of their questions, for instance estimating the quality of a question using MTMM experiments. This information about the quality can also be used in order to correct for measurement error.[7][8]
Effect on regression analysis[edit]
If the dependent variable in a regression is measured with error, regression analysis and associated hypothesis testing are unaffected, except that the R2 will be lower than it would be with perfect measurement.
However, if one or more independent variables is measured with error, then the regression coefficients and standard hypothesis tests are invalid.[9]: p. 187 This is known as attenuation bias.[10]
See also[edit]
- Bias (statistics)
- Cognitive bias
- Correction for measurement error (for Pearson correlations)
- Errors and residuals in statistics
- Error
- Replication (statistics)
- Statistical theory
- Metrology
- Regression dilution
- Test method
- Propagation of uncertainty
- Instrument error
- Measurement uncertainty
- Errors-in-variables models
- Systemic bias
References[edit]
- ^ a b Dodge, Y. (2003) The Oxford Dictionary of Statistical Terms, OUP. ISBN 978-0-19-920613-1
- ^ a b John Robert Taylor (1999). An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements. University Science Books. p. 94, §4.1. ISBN 978-0-935702-75-0.
- ^ «Systematic error». Merriam-webster.com. Retrieved 2016-09-10.
- ^ Salant, P.; Dillman, D. A. (1994). How to conduct your survey. New York: John Wiley & Sons. ISBN 0-471-01273-4.
- ^ Bland, J. Martin; Altman, Douglas G. (1996). «Statistics Notes: Measurement Error». BMJ. 313 (7059): 744. doi:10.1136/bmj.313.7059.744. PMC 2352101. PMID 8819450.
- ^ Saris, W. E.; Gallhofer, I. N. (2014). Design, Evaluation and Analysis of Questionnaires for Survey Research (Second ed.). Hoboken: Wiley. ISBN 978-1-118-63461-5.
- ^ DeCastellarnau, A. and Saris, W. E. (2014). A simple procedure to correct for measurement errors in survey research. European Social Survey Education Net (ESS EduNet). Available at: http://essedunet.nsd.uib.no/cms/topics/measurement Archived 2019-09-15 at the Wayback Machine
- ^ Saris, W. E.; Revilla, M. (2015). «Correction for measurement errors in survey research: necessary and possible» (PDF). Social Indicators Research. 127 (3): 1005–1020. doi:10.1007/s11205-015-1002-x. hdl:10230/28341. S2CID 146550566.
- ^ Hayashi, Fumio (2000). Econometrics. Princeton University Press. ISBN 978-0-691-01018-2.
- ^ Angrist, Joshua David; Pischke, Jörn-Steffen (2015). Mastering ‘metrics : the path from cause to effect. Princeton, New Jersey. p. 221. ISBN 978-0-691-15283-7. OCLC 877846199.
The bias generated by this sort of measurement error in regressors is called attenuation bias.
Further reading[edit]
- Cochran, W. G. (1968). «Errors of Measurement in Statistics». Technometrics. 10 (4): 637–666. doi:10.2307/1267450. JSTOR 1267450.
Ошибки регистрации
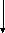

Систематические ошибки
Случайные ошибки– ошибки регистрации, которые могут
быть допущены как опрашиваемыми в их
ответах, так и регистраторами при
заполнении бланков.

Преднамеренные
ошибкиполучаются в результате
того, что опрашиваемый, зная действительное
положение дела, сознательно сообщает
неправильные данные.
Непреднамеренные
ошибкивызываются различными
случайными причинами (небрежность,
невнимание регистратора; неисправность
измерительных приборов).



Рис.
2.1. Виды ошибок регистрации.
Для
выявления и устранения допущенных при
регистрации ошибок может применяться
счетный и логический контроль собранного
материала.
Счетный
контроль
заключается в проверке точности
арифметических расчетов, применявшихся
при составлении отчетности или заполнении
формуляров обследования.
Логический
контроль
заключается в проверке ответов на
вопросы программы наблюдения путем их
логического осмысления или путем
сравнения полученных данных с другими
источниками по этому же вопросу.
Примером
логического сравнения могут служить
листы переписи населения: в переписном
листе двухлетний ребенок имеет высшее
образование, а девятилетний мальчик
женат. Ясно, что полученные ответы на
вопросы не верны и требуют уточнения и
исправления допущенных ошибок.
Так же примером
логического контроля может являться
сопоставление сведений о фонде заработной
платы, содержащихся в отчете по труду
и в отчете по издержкам обращения.
Контрольные вопросы и задания к теме 2:
-
Что такое
статистическая информация. Особенности
ее формирования. -
Организация
государственной и международной
статистики. -
Виды и формы
статистического наблюдения. Основные
требования, предъявляемые к его
организации и проведению. -
Сущность и
содержание программно-методологических
вопросов статистического наблюдения. -
Приведите пример
объекта и единицы статистического
наблюдения. -
Виды и содержание
статистических формуляров. -
Какими методами
проверяют достоверность отчетных
данных.
Тема 3. Сводка и группировка статистических данных.
-
Понятие о
статистической сводке. -
Статистическая
группировка как основной метод обобщения
информации. -
Ряды распределения.
-
Статистические
таблицы. -
Графическое
изображение статистических показателей.
-
Понятие о
статистической сводке.
В результате статистического
наблюдения получают материала, которые
содержат данные о каждой единице
совокупности. Дальнейшая задача
заключается в том, чтобы привести эти
материалы в определенный порядок,
систематизировать их и не этой основе
дать сводную характеристику всей
совокупности фактов при помощи обобщающих
статистических показателей. Этого
достигают при помощи статистической
сводки.
Статистическая
сводка
– это научная обработка первичных
материалов статистического наблюдения
для характеристики совокупности
обобщающими показателями.
Это вторая стадия статистического
исследования.
Основная
цель и
содержание
статистической сводки состоит в том,
чтобы, обобщив материл, дать полную и
объективную характеристику всей
совокупности фактов, вскрыть закономерности
массовых процессов, которые в нем
содержатся и которые проявляются в
обобщающих показателях.
Статистические
сводки различаются по ряду признаков:
сложности построения, месту проведения
и способу разработки материалов
статистического наблюдения.
По
сложности
построения
сводка может, прежде всего, представлять
общие итоги по изучаемой совокупности
в целом без какой-либо предварительной
систематизации собранного материала.
Она определяет общий размер изучаемого
явления по заданным показателям. Это
так называемая простая сводка. Она может
быть вспомогательной, если содержащаяся
в ней информация используется в дальнейшем
для углубленного изучения статистической
совокупности.
Примером могут выступать результата
переписи населения в декабре 2001 года,
в соответствие с которыми численность
населения в Донецкой области составила
4,8 млн. чел. Данные о численности населения
в Украине могут быть более детально
рассмотрены по различным направлениям:
пол, возраст, семейное положение, место
жительства, образования и т.д.
Статистическая
сводка в широком ее понимании предполагает
систематизацию и группировку цифровых
данных, характеристику образованных
групп системой показателей, подсчет
соответствующих итогов и представление
результатов сводки в виде таблиц,
графиков.
Выделение однородных
в социально-экономическом отношении
групп является основой статистической
сводки исходной информации, непременным
условием ее научной разработки и
практического использования в коммерческой
деятельности.
Последовательность
работ по
статистической сводке исходной информации
подразделяется на следующие этапы:
-
формулировка
задач сводки на основе цели статистического
исследования; -
формирование
групп и подгрупп, определение
группировочных признаков, числа групп
и величины интервала. Решение вопросов,
связанных с осуществлением группировки,
включая выделение существенных
признаков, установление специализированных
интервалов, построение комбинированных
группировок; -
осуществление
технической стороны сводки, то есть
проверка полноты и качества собранного
материала, подсчет различных итогов и
исчисление необходимых показателей
для характеристики всей совокупности
и ее частей.
Статистическую
сводку производят по определенной
программе, составленной в соответствии
с задачами статистического исследования,
и с учетом принятой формы организации
сводки и техники разработки. Программа
содержит перечень групп, на которые
должна быть расчленена совокупность
по отдельным признакам, а так же перечень
показателей, которые следует подсчитать
для характеристики каждой группы. В ней
так же предусматривают территориальные
границы, в которых надо произвести
разработку материала, степень детализации
материала.
По результатам
переписи в Донецкой области проживает
90% городского населения и 10% сельского;
женщин 54%, а мужчин соответственно –
46%.
Способ
разработки
статистической сводки может быть
централизованным и децентрализованным.
При централизованной
сводке
все данные сосредотачиваются в одном
месте и сводятся по разработанной
методике. При децентрализованной
сводке
обобщение материала осуществляется
снизу вверх по иерархической лестнице
управления, подвергаясь на каждом из
них соответствующей обработке.
Положив начало
научной систематизации и обработке
исходной информации, сводка и группировка
статистических данных служат тем самым
базой для осуществления всестороннего
анализа и прогнозирования коммерческой
деятельности.
П
-
Статистическая
группировка как основной метод обобщения
информации.
ри сводке статистических материалов
не ограничиваются простым подсчетом
общей численности учтенных единиц и
объема зарегистрированных признаков.
Как правило, в процессе сводки
статистические материалы упорядочиваются,
систематизируются, делятся на группы
по существенным признакам. Это достигается
с помощью группировки.
Группировка
– это процесс образования однородных
групп на основе расчленения статистической
совокупности на части или объединение
изучаемых единиц в частные совокупности
по существенным для них признакам.
Иначе говоря, группировка – выделение
единиц, однородных в заданном смысле.
Группировка всегда отвечает поставленным
задачам,
а именно:
-
Выделение
социально-экономических типов явлений. -
Изучение структуры
изучаемого явления. -
Выявление
взаимосвязи между изучаемыми признаками.
Для решения этих
задач соответственно применяют различные
виды группировок:
-
Типологические
группировки.
Важнейшим их содержанием является
выделение из множества признаков,
характеризующих изучаемые явления,
основных типов в качественно однородные.
Особое значение имеет правильный выбор
группировочного признака. При атрибутивном
признаке с незначительным разнообразием
его значений число групп определяется
свойствами изучаемого явления
(группировка
населения по половому признаку).
Выделение типов на основе количественно
признака состоит в определении групп
с учетом значений изучаемых признаков.
При этом очень важно правильно установить
интервал группировки, на основе которого
количественно различаются одни группы
от других, намечаются границы выделения
их нового качества. -
Структурные
группировки.
Представляет собой группировку изучаемых
единиц в пределах одного типа явления
или однокачественной совокупности.
Такие группировки имеют задачей либо
изучение состава (структуры) совокупности
по какому-либо варьирующему признаку,
либо изучение в пределах этой совокупности
взаимосвязей варьирующих признаков
(состав
населения по полу, возрасту, образованию). -
Аналитические
группировки.
Дают возможность исследовать взаимосвязь
между изменяющихся признаков в пределах
однородной совокупности. Взаимосвязанные
признаки делятся на факторные, те
которые оказывают влияние, и результативные,
те которые изменяются под воздействием
фактора. Группировка позволяет выявить
и изучить формы зависимости между
варьирующими признаками, отражающими
различные свойства совокупности
(зависимость
товарооборота от производительности
труда). -
Комбинированные
группировки.
Происходит образование групп по двум
и более признакам, взятым в определенном
сочетании (зависимость
товарооборота от производительности
труда и средней заработной платы).
Признаки
единиц совокупности, положенные в
основание группировки статистического
материала, называются группировочными
признаками.
Следует различать признаки, имеющие
количественное выражение, которые
называются количественными, и признаки,
не имеющие количественного выражения
– атрибутивные.
Разновидностью
атрибутивные признаков являются признаки
альтернативные, которые может иметь
данная единица совокупности, а может и
не иметь (студент может быть отличником,
а может и не быть).
Важнейшим
вопросом теории группировки является
выбор группировочных признаков. От
правильного выбора группировочного
признака зависят выводы, которые получают
в результате статистической разработки.
Выбор
группировочного признака
необходимо проводить с учетом следующих
основополагающих моментов:
-
Руководствуясь
знанием сущности данного явления,
законов его развития, в основание
группировки необходимо положить
наиболее существенные признаки,
отвечающие задачам исследования. -
Следует исходить
из тех конкретных исторических и
территориальных условий, в которых
протекает процесс развития изучаемого
явления, так как с изменением конкретных
условий могут меняться и группировочные
признаки. -
При изучении
явлений, на которые воздействует
несколько различных закономерностей,
необходимо в основание группировки
класть не один, а несколько признаков,
взятых в комбинации.
Специфический
характер образования групп зависит от
признаков, на которых основывается
группировка, и от задач группировки.
При группировке по количественным
признакам возникает вопрос о количестве
групп и величине интервала. Количество
групп во многом зависит от того, какой
признак служит основанием группировки.
Интервалы групп устанавливаются только
при значительной колеблемости дискретного
признака и тем более при непрерывно
изменяющемся количественном признаке.
Под
величиной
интервала
обычно понимают разность между
максимальными и минимальными значениями
признака в каждой группе. Для определения
величины интервала (i)
при выделении равновеликих групп разница
между максимальным (xmax)
и минимальным значениями (xmin)
изучаемого признака делится на число
выделяемых групп (n):
i
=
![]()
Намечаемые
при группировке интервалы бывают
открытые
(у них указана одно граница – верхняя
или нижняя) и закрытые
(имеют и верхнюю и нижнюю границы). При
дальнейшем исследовании изучаемой
совокупности открытые интервалы
закрывают путем определения границ
интервала на основе его величины.
Для определения
нижней границы интервала: из верхней
границы вычитают величину интервала.
Для закрытия верхней границы наоборот:
к нижней границе прибавляют величину
интервала.
Если с помощью
группировки исследуют структуру той
или иной совокупности, то показателями
такой группировки обычно бывают единицы
совокупности – их число и процент к
итогу. Когда группировка преследует
аналитические цели выявления и измерения
зависимостей в каждой группе, то кроме
числа единиц совокупности, обязательно
приводят среднее значение того признака,
изменение которого изучают в зависимости
от изменения группировочного признака.
Р
-
Ряды распределения.
езультаты сводки и группировки
материалов статистического наблюдения
оформляются в виде статистических рядов
распределения и таблиц.
Статистические
ряды распределения представляют собой
упорядоченное расположение единиц
изучаемой совокупности на группы по
группировочному признаку.
Они характеризуют состав изучаемого
явления, позволяют судить об однородности
совокупности, границах ее изменения,
закономерностях развития наблюдаемого
объекта.
Распределение
может быть по признакам, не имеющим
количественной меры (атрибутивным),
и по признакам, в которых изменяется их
количественная
мера.
Атрибутивные
ряды
распределения показывают состав
совокупности по тем или иным существенным
признакам. В изменении состава выявляются
важные черты закономерности изучаемого
явления.
Ряды
распределения единиц совокупности по
количественным признакам, называю
вариационными
рядами.
Вариационные ряды дают возможность
установить характер распределения
единиц совокупности по тому или иному
количественному признаку.
Однодневный
товарооборот продовольственных товаров
по предприятиям розничной торговли
Ворошиловского района составил:
-
до 1000 грн. –10
магазинов; -
от 1000 до 2000 грн.
– 17магазинов; -
от 2000 до 3000 грн.
– 6 магазинов; -
более 3000 грн.- 2
магазина.
В
вариационном ряду различают два элемента:
варианты и частоты. Вариантами
называются отдельные значения
группировочного признака, которые он
принимает в вариационном ряду. Числа,
которые показывают как часто встречаются
те или иные варианты в ряду распределения,
называют частотами.
Частоты, выраженные в долях единицы или
процентах к итогу, называются частностями.
Сумма частот составляет объем ряда
распределения.
Вариационные
ряды, как и сами вариации, бывают
интервальными и дискретными. Интервальные
вариационные ряды
– это такие ряды, где значения варианты
даны в виде интервалов. Дискретные
вариационные ряды
основаны на прерывной вариации признака,
то есть отдельные варианты имеют
определенные значения.
Примером
дискретного вариационного ряда могут
являться средние цены на продовольственные
товары. Средняя цена на сахар по Донецкой
области составляла:
-
1995 год – 1,28 грн.;
-
1998 год – 1,27 грн.;
-
2001 год – 2,62 грн.
В
дискретных рядах распределение
изображается как ряд перпендикулярных
линий к соответствующим значениям
вариант, при этом высота этих линий
определяется частотой данной варианты.
Если концы этих линий соединить прямыми,
то график будет называться полигоном
распределения.
Интервальные
ряды распределения изображаются
графически в виде гистограммы. При
ее построении на оси абсцисс откладывают
интервалы ряда, высота которых равна
частотам, отложенным на оси ординат.
Над осью абсцисс строятся прямоугольники,
площадь которых соответствует величинам
произведений интервалов и их частоты.
На
основании ранжированных рядов, то есть
рядов, расположенных в порядке убывания
или возрастания могут строится кумуляты
накопленных частот.
Накопленные частоты определяются путем
последовательного прибывления к частотам
первой группы этих показателей последующих
групп ряда распределения. Накопленные
частоты наносятся на график в виде
перпендикуляров к оси х,
в точках, отмечающих полусуммы интервалов.
Длина перпендикуляра равна сумме
накопленных частот в данном интервале.
Перпендикуляры затем соединяем прямыми,
в результате чего получаем ломанную
линию, которая начиная от нуля, все время
возрастает до тех пор, пока не достигнет
высоты, равной общей сумме частот.
Р
-
Статистические
таблицы.
езультаты сводки и группировки
материалов наблюдения, как правило,
представляются в виде статистических
таблиц. Значение статистических таблиц
состоит в том, что они позволяют охватить
материалы статистической сводки в
целом. Статистическая таблица, по
существу, является системой мыслей об
исследуемом объекте, излагаемых цифрами
на основе определенного порядка в
расположении систематизированной
информации.
Статистические
таблицы
– это форма систематизированного
рационального и наглядного изложения
цифрового материала характеризующего
изучаемые явления и процессы.
По внешнему виду
статистическая таблица представляет
собой ряд пересекающихся горизонтальных
(строк) и вертикальных линий (граф,
столбцов, колонок). Составленную, но не
заполненную таблицу принято называть
макетом таблицы. В таблице имеются два
основных элемента:
-
подлежащее
– то, о чем говориться в таблице, объект
изучения. Может быть представлен в виде
групп и подгрупп, которые характеризуются
рядом показателей; -
сказуемое
– перечень числовых показателей,
которыми характеризуется объект
изучения.
Подлежащее обычно
располагается в левой части таблиц;
сказуемое – в верхней части таблицы в
виде названий граф.
Вид
статистической таблицы зависит от
построения подлежащего – рисунок 3.1.
Ошибки регистрации
Систематические ошибки
Случайные ошибки– ошибки регистрации, которые могут
быть допущены как опрашиваемыми в их
ответах, так и регистраторами при
заполнении бланков.
Преднамеренные
ошибкиполучаются в результате
того, что опрашиваемый, зная действительное
положение дела, сознательно сообщает
неправильные данные.
Непреднамеренные
ошибкивызываются различными
случайными причинами (небрежность,
невнимание регистратора; неисправность
измерительных приборов).
Рис.
2.1. Виды ошибок регистрации.
Для
выявления и устранения допущенных при
регистрации ошибок может применяться
счетный и логический контроль собранного
материала.
Счетный
контроль
заключается в проверке точности
арифметических расчетов, применявшихся
при составлении отчетности или заполнении
формуляров обследования.
Логический
контроль
заключается в проверке ответов на
вопросы программы наблюдения путем их
логического осмысления или путем
сравнения полученных данных с другими
источниками по этому же вопросу.
Примером
логического сравнения могут служить
листы переписи населения: в переписном
листе двухлетний ребенок имеет высшее
образование, а девятилетний мальчик
женат. Ясно, что полученные ответы на
вопросы не верны и требуют уточнения и
исправления допущенных ошибок.
Так же примером
логического контроля может являться
сопоставление сведений о фонде заработной
платы, содержащихся в отчете по труду
и в отчете по издержкам обращения.
Контрольные вопросы и задания к теме 2:
-
Что такое
статистическая информация. Особенности
ее формирования. -
Организация
государственной и международной
статистики. -
Виды и формы
статистического наблюдения. Основные
требования, предъявляемые к его
организации и проведению. -
Сущность и
содержание программно-методологических
вопросов статистического наблюдения. -
Приведите пример
объекта и единицы статистического
наблюдения. -
Виды и содержание
статистических формуляров. -
Какими методами
проверяют достоверность отчетных
данных.
Тема 3. Сводка и группировка статистических данных.
-
Понятие о
статистической сводке. -
Статистическая
группировка как основной метод обобщения
информации. -
Ряды распределения.
-
Статистические
таблицы. -
Графическое
изображение статистических показателей.
-
Понятие о
статистической сводке.
В результате статистического
наблюдения получают материала, которые
содержат данные о каждой единице
совокупности. Дальнейшая задача
заключается в том, чтобы привести эти
материалы в определенный порядок,
систематизировать их и не этой основе
дать сводную характеристику всей
совокупности фактов при помощи обобщающих
статистических показателей. Этого
достигают при помощи статистической
сводки.
Статистическая
сводка
– это научная обработка первичных
материалов статистического наблюдения
для характеристики совокупности
обобщающими показателями.
Это вторая стадия статистического
исследования.
Основная
цель и
содержание
статистической сводки состоит в том,
чтобы, обобщив материл, дать полную и
объективную характеристику всей
совокупности фактов, вскрыть закономерности
массовых процессов, которые в нем
содержатся и которые проявляются в
обобщающих показателях.
Статистические
сводки различаются по ряду признаков:
сложности построения, месту проведения
и способу разработки материалов
статистического наблюдения.
По
сложности
построения
сводка может, прежде всего, представлять
общие итоги по изучаемой совокупности
в целом без какой-либо предварительной
систематизации собранного материала.
Она определяет общий размер изучаемого
явления по заданным показателям. Это
так называемая простая сводка. Она может
быть вспомогательной, если содержащаяся
в ней информация используется в дальнейшем
для углубленного изучения статистической
совокупности.
Примером могут выступать результата
переписи населения в декабре 2001 года,
в соответствие с которыми численность
населения в Донецкой области составила
4,8 млн. чел. Данные о численности населения
в Украине могут быть более детально
рассмотрены по различным направлениям:
пол, возраст, семейное положение, место
жительства, образования и т.д.
Статистическая
сводка в широком ее понимании предполагает
систематизацию и группировку цифровых
данных, характеристику образованных
групп системой показателей, подсчет
соответствующих итогов и представление
результатов сводки в виде таблиц,
графиков.
Выделение однородных
в социально-экономическом отношении
групп является основой статистической
сводки исходной информации, непременным
условием ее научной разработки и
практического использования в коммерческой
деятельности.
Последовательность
работ по
статистической сводке исходной информации
подразделяется на следующие этапы:
-
формулировка
задач сводки на основе цели статистического
исследования; -
формирование
групп и подгрупп, определение
группировочных признаков, числа групп
и величины интервала. Решение вопросов,
связанных с осуществлением группировки,
включая выделение существенных
признаков, установление специализированных
интервалов, построение комбинированных
группировок; -
осуществление
технической стороны сводки, то есть
проверка полноты и качества собранного
материала, подсчет различных итогов и
исчисление необходимых показателей
для характеристики всей совокупности
и ее частей.
Статистическую
сводку производят по определенной
программе, составленной в соответствии
с задачами статистического исследования,
и с учетом принятой формы организации
сводки и техники разработки. Программа
содержит перечень групп, на которые
должна быть расчленена совокупность
по отдельным признакам, а так же перечень
показателей, которые следует подсчитать
для характеристики каждой группы. В ней
так же предусматривают территориальные
границы, в которых надо произвести
разработку материала, степень детализации
материала.
По результатам
переписи в Донецкой области проживает
90% городского населения и 10% сельского;
женщин 54%, а мужчин соответственно –
46%.
Способ
разработки
статистической сводки может быть
централизованным и децентрализованным.
При централизованной
сводке
все данные сосредотачиваются в одном
месте и сводятся по разработанной
методике. При децентрализованной
сводке
обобщение материала осуществляется
снизу вверх по иерархической лестнице
управления, подвергаясь на каждом из
них соответствующей обработке.
Положив начало
научной систематизации и обработке
исходной информации, сводка и группировка
статистических данных служат тем самым
базой для осуществления всестороннего
анализа и прогнозирования коммерческой
деятельности.
П
-
Статистическая
группировка как основной метод обобщения
информации.
ри сводке статистических материалов
не ограничиваются простым подсчетом
общей численности учтенных единиц и
объема зарегистрированных признаков.
Как правило, в процессе сводки
статистические материалы упорядочиваются,
систематизируются, делятся на группы
по существенным признакам. Это достигается
с помощью группировки.
Группировка
– это процесс образования однородных
групп на основе расчленения статистической
совокупности на части или объединение
изучаемых единиц в частные совокупности
по существенным для них признакам.
Иначе говоря, группировка – выделение
единиц, однородных в заданном смысле.
Группировка всегда отвечает поставленным
задачам,
а именно:
-
Выделение
социально-экономических типов явлений. -
Изучение структуры
изучаемого явления. -
Выявление
взаимосвязи между изучаемыми признаками.
Для решения этих
задач соответственно применяют различные
виды группировок:
-
Типологические
группировки.
Важнейшим их содержанием является
выделение из множества признаков,
характеризующих изучаемые явления,
основных типов в качественно однородные.
Особое значение имеет правильный выбор
группировочного признака. При атрибутивном
признаке с незначительным разнообразием
его значений число групп определяется
свойствами изучаемого явления
(группировка
населения по половому признаку).
Выделение типов на основе количественно
признака состоит в определении групп
с учетом значений изучаемых признаков.
При этом очень важно правильно установить
интервал группировки, на основе которого
количественно различаются одни группы
от других, намечаются границы выделения
их нового качества. -
Структурные
группировки.
Представляет собой группировку изучаемых
единиц в пределах одного типа явления
или однокачественной совокупности.
Такие группировки имеют задачей либо
изучение состава (структуры) совокупности
по какому-либо варьирующему признаку,
либо изучение в пределах этой совокупности
взаимосвязей варьирующих признаков
(состав
населения по полу, возрасту, образованию). -
Аналитические
группировки.
Дают возможность исследовать взаимосвязь
между изменяющихся признаков в пределах
однородной совокупности. Взаимосвязанные
признаки делятся на факторные, те
которые оказывают влияние, и результативные,
те которые изменяются под воздействием
фактора. Группировка позволяет выявить
и изучить формы зависимости между
варьирующими признаками, отражающими
различные свойства совокупности
(зависимость
товарооборота от производительности
труда). -
Комбинированные
группировки.
Происходит образование групп по двум
и более признакам, взятым в определенном
сочетании (зависимость
товарооборота от производительности
труда и средней заработной платы).
Признаки
единиц совокупности, положенные в
основание группировки статистического
материала, называются группировочными
признаками.
Следует различать признаки, имеющие
количественное выражение, которые
называются количественными, и признаки,
не имеющие количественного выражения
– атрибутивные.
Разновидностью
атрибутивные признаков являются признаки
альтернативные, которые может иметь
данная единица совокупности, а может и
не иметь (студент может быть отличником,
а может и не быть).
Важнейшим
вопросом теории группировки является
выбор группировочных признаков. От
правильного выбора группировочного
признака зависят выводы, которые получают
в результате статистической разработки.
Выбор
группировочного признака
необходимо проводить с учетом следующих
основополагающих моментов:
-
Руководствуясь
знанием сущности данного явления,
законов его развития, в основание
группировки необходимо положить
наиболее существенные признаки,
отвечающие задачам исследования. -
Следует исходить
из тех конкретных исторических и
территориальных условий, в которых
протекает процесс развития изучаемого
явления, так как с изменением конкретных
условий могут меняться и группировочные
признаки. -
При изучении
явлений, на которые воздействует
несколько различных закономерностей,
необходимо в основание группировки
класть не один, а несколько признаков,
взятых в комбинации.
Специфический
характер образования групп зависит от
признаков, на которых основывается
группировка, и от задач группировки.
При группировке по количественным
признакам возникает вопрос о количестве
групп и величине интервала. Количество
групп во многом зависит от того, какой
признак служит основанием группировки.
Интервалы групп устанавливаются только
при значительной колеблемости дискретного
признака и тем более при непрерывно
изменяющемся количественном признаке.
Под
величиной
интервала
обычно понимают разность между
максимальными и минимальными значениями
признака в каждой группе. Для определения
величины интервала (i)
при выделении равновеликих групп разница
между максимальным (xmax)
и минимальным значениями (xmin)
изучаемого признака делится на число
выделяемых групп (n):
i
=
![]()
Намечаемые
при группировке интервалы бывают
открытые
(у них указана одно граница – верхняя
или нижняя) и закрытые
(имеют и верхнюю и нижнюю границы). При
дальнейшем исследовании изучаемой
совокупности открытые интервалы
закрывают путем определения границ
интервала на основе его величины.
Для определения
нижней границы интервала: из верхней
границы вычитают величину интервала.
Для закрытия верхней границы наоборот:
к нижней границе прибавляют величину
интервала.
Если с помощью
группировки исследуют структуру той
или иной совокупности, то показателями
такой группировки обычно бывают единицы
совокупности – их число и процент к
итогу. Когда группировка преследует
аналитические цели выявления и измерения
зависимостей в каждой группе, то кроме
числа единиц совокупности, обязательно
приводят среднее значение того признака,
изменение которого изучают в зависимости
от изменения группировочного признака.
Р
-
Ряды распределения.
езультаты сводки и группировки
материалов статистического наблюдения
оформляются в виде статистических рядов
распределения и таблиц.
Статистические
ряды распределения представляют собой
упорядоченное расположение единиц
изучаемой совокупности на группы по
группировочному признаку.
Они характеризуют состав изучаемого
явления, позволяют судить об однородности
совокупности, границах ее изменения,
закономерностях развития наблюдаемого
объекта.
Распределение
может быть по признакам, не имеющим
количественной меры (атрибутивным),
и по признакам, в которых изменяется их
количественная
мера.
Атрибутивные
ряды
распределения показывают состав
совокупности по тем или иным существенным
признакам. В изменении состава выявляются
важные черты закономерности изучаемого
явления.
Ряды
распределения единиц совокупности по
количественным признакам, называю
вариационными
рядами.
Вариационные ряды дают возможность
установить характер распределения
единиц совокупности по тому или иному
количественному признаку.
Однодневный
товарооборот продовольственных товаров
по предприятиям розничной торговли
Ворошиловского района составил:
-
до 1000 грн. –10
магазинов; -
от 1000 до 2000 грн.
– 17магазинов; -
от 2000 до 3000 грн.
– 6 магазинов; -
более 3000 грн.- 2
магазина.
В
вариационном ряду различают два элемента:
варианты и частоты. Вариантами
называются отдельные значения
группировочного признака, которые он
принимает в вариационном ряду. Числа,
которые показывают как часто встречаются
те или иные варианты в ряду распределения,
называют частотами.
Частоты, выраженные в долях единицы или
процентах к итогу, называются частностями.
Сумма частот составляет объем ряда
распределения.
Вариационные
ряды, как и сами вариации, бывают
интервальными и дискретными. Интервальные
вариационные ряды
– это такие ряды, где значения варианты
даны в виде интервалов. Дискретные
вариационные ряды
основаны на прерывной вариации признака,
то есть отдельные варианты имеют
определенные значения.
Примером
дискретного вариационного ряда могут
являться средние цены на продовольственные
товары. Средняя цена на сахар по Донецкой
области составляла:
-
1995 год – 1,28 грн.;
-
1998 год – 1,27 грн.;
-
2001 год – 2,62 грн.
В
дискретных рядах распределение
изображается как ряд перпендикулярных
линий к соответствующим значениям
вариант, при этом высота этих линий
определяется частотой данной варианты.
Если концы этих линий соединить прямыми,
то график будет называться полигоном
распределения.
Интервальные
ряды распределения изображаются
графически в виде гистограммы. При
ее построении на оси абсцисс откладывают
интервалы ряда, высота которых равна
частотам, отложенным на оси ординат.
Над осью абсцисс строятся прямоугольники,
площадь которых соответствует величинам
произведений интервалов и их частоты.
На
основании ранжированных рядов, то есть
рядов, расположенных в порядке убывания
или возрастания могут строится кумуляты
накопленных частот.
Накопленные частоты определяются путем
последовательного прибывления к частотам
первой группы этих показателей последующих
групп ряда распределения. Накопленные
частоты наносятся на график в виде
перпендикуляров к оси х,
в точках, отмечающих полусуммы интервалов.
Длина перпендикуляра равна сумме
накопленных частот в данном интервале.
Перпендикуляры затем соединяем прямыми,
в результате чего получаем ломанную
линию, которая начиная от нуля, все время
возрастает до тех пор, пока не достигнет
высоты, равной общей сумме частот.
Р
-
Статистические
таблицы.
езультаты сводки и группировки
материалов наблюдения, как правило,
представляются в виде статистических
таблиц. Значение статистических таблиц
состоит в том, что они позволяют охватить
материалы статистической сводки в
целом. Статистическая таблица, по
существу, является системой мыслей об
исследуемом объекте, излагаемых цифрами
на основе определенного порядка в
расположении систематизированной
информации.
Статистические
таблицы
– это форма систематизированного
рационального и наглядного изложения
цифрового материала характеризующего
изучаемые явления и процессы.
По внешнему виду
статистическая таблица представляет
собой ряд пересекающихся горизонтальных
(строк) и вертикальных линий (граф,
столбцов, колонок). Составленную, но не
заполненную таблицу принято называть
макетом таблицы. В таблице имеются два
основных элемента:
-
подлежащее
– то, о чем говориться в таблице, объект
изучения. Может быть представлен в виде
групп и подгрупп, которые характеризуются
рядом показателей; -
сказуемое
– перечень числовых показателей,
которыми характеризуется объект
изучения.
Подлежащее обычно
располагается в левой части таблиц;
сказуемое – в верхней части таблицы в
виде названий граф.
Вид
статистической таблицы зависит от
построения подлежащего – рисунок 3.1.
2.4. Точность статистического наблюдения
Под точностью статистического наблюдения понимают степень соответствия значения наблюдаемого показателя, вычисленного по материалам обследования, его действительной величине. Расхождение, или разница, между ними называется ошибкой статистического наблюдения.
Различают две группы ошибок:
- ошибки регистрации;
- ошибки репрезентативности.
Ошибки регистрации присущи любому статистическому наблюдению, как сплошному, так и несплошному. Они делятся на случайные ошибки регистрации и систематические ошибки регистрации.
Случайными ошибками регистрации называют ошибки, возникающие вследствие действия случайных факторов. К ним можно отнести различного рода непреднамеренные описки: например, вместо возраста человека «15 лет» указано «5 лет», у Ивановой Марии Петровны в графе пол отмечен «Мужской» и т. п. Такие ошибки легко выявляются методом логического анализа, например, если человеку 8 лет, но имеется высшее образование, а в графе «Семейное положение» указано «Состоит в браке», то, естественно, следует исправить возраст. Если объем исследуемой совокупности велик или велика доля отбора при выборочном наблюдении, случайные ошибки регистрации имеют тенденцию взаимопогашаться вследствие действия закона больших чисел, поскольку ошибки, как правило, разнонаправлены и искажают статистический показатель как в большую, так и в меньшую сторону. При небольшом объеме наблюдения требуется тщательная выверка его результатов — логический анализ данных.
Систематические ошибки регистрации чаще всего имеют однонаправленные искажения: они либо увеличивают, либо уменьшают статистический показатель, и, что характерно, подобная ситуация повторяется от обследования к обследованию. Так, по результатам переписей (практически всех!) число замужних женщин превышает число женатых мужчин — мужчинам приятнее ощущать себя неженатыми, а для женщины как бы «стыдно» быть не замужем. Другой пример, когда человек округляет свой возраст — вместо 32 лет говорит 30, вместо 79-80 и т. п. (это явление широко известно и даже получило свое название — «аккумуляция возрастов»). Систематические ошибки регистрации могут возникать и из-за неточностей измерительных приборов, если сбор информации проводят путем непосредственного наблюдения.
Ошибки репрезентативности присущи только несплошному обследованию. Они также делятся на случайные и систематические ошибки.
Случайные ошибки репрезентативности возникают из-за того, что обследованию подвергается не вся совокупность в целом, а только ее часть, и, следовательно, при несплошном наблюдении они присутствуют всегда. В теории статистики разработаны специальные методы для оценки величин таких ошибок, на их основе для наблюдаемых показателей строят доверительные интервалы, т.д. эти ошибки вычисляются и находятся как бы «под контролем».
Хуже обстоит дело, если наряду со случайными ошибками имеются и ошибки систематические.
Систематические ошибки репрезентативности возникают, если при несплошном наблюдении кардинально нарушаются технологии отбора единиц из генеральной совокупности объектов, но чаще — если в ходе обследования не удается получить информацию обо всех отобранных для наблюдения единицах, например, вследствие отказа отвечать на вопросы анкеты, или если человека не удалось застать дома и т. п.
Ошибки статистического наблюдения для наглядности можно изобразить в виде схемы (рис. 2.1).
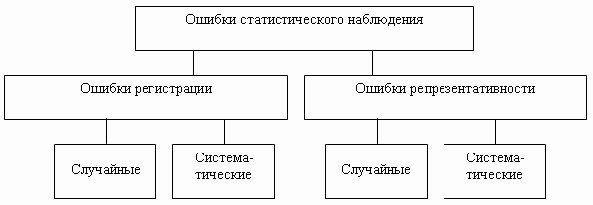
Рис.
2.1.
Виды ошибок статистического наблюдения
Для повышения точности наблюдения необходимо:
- правильно разработать формуляр статистического наблюдения: вопросы должны быть четкими, однозначными, не допускающими двойного толкования;
- иметь хорошо обученный персонал для проведения обследования;
- строго придерживаться выбранной технологии обследования (если проводится несплошное наблюдение) и помнить, что если не удается опросить какую-то конкретную единицу, отобранную для наблюдения, замена ее на другую единицу может привести к возникновению систематической ошибки репрезентативности;
- провести логический анализ данных, основанный на логических взаимосвязях показателей, после сбора всей совокупности анкет или формуляров;
- целесообразно провести и арифметический контроль данных, т.д. заново пересчитать расчетные величины, если какие-либо показатели получаются в результате определенных арифметических действий;
- предпринять определенные меры по восстановлению данных при наличии незаполненных анкет или формуляров либо при получении результатов обследования сделать поправку на неответы респондентов.
[c.57]
Другое дело систематические ошибки — они являются неслучайными и имеют определенную направленность. Такие ошибки очень опасны, так как приводят к искажению результатов статистического исследования. Эти ошибки, как правило, являются преднамеренными. Известно, например, что люди предпочитают преуменьшать свои доходы, округлять возраст, стараются показать большую осведомленность в области культуры, науки, чем это есть на самом деле. Предприятия также могут внести элементы недостоверности в свою информацию, особенно в те характеристики, от которых зависят величина налоговых платежей, расчеты с кредиторами и т. п. Все ошибки такого рода необходимо выявить и исправить. Поэтому после проверки полноты данных проводится их контроль — счетный и логический.
[c.39]
Ошибки регистрации — это отклонения между значением показателя, полученного в ходе статистического наблюдения, и фактическим, действительным его значением. Такой вид ошибок имеет место и при сплошном, и при несплошном наблюдениях. Ошибки регистрации бывают случайными и систематическими. Случайные ошибки — это результат действия различных случайных факторов (например, цифры переставлены местами, перепутаны соседние строки или графы при заполнении статистического формуляра). Систематические ошибки регистрации всегда имеют одинаковую тенденцию либо к увеличению, либо к уменьшению значения показателей по каждой единице наблюдения, и поэтому величина показателя по совокупности в целом будет включать в себя накопленную ошибку. Примером статистической ошибки регистрации при проведении социологических опросов может служить округление возраста населения, как правило, на цифрах, оканчивающихся на 5 и 0. Многие
[c.21]
Систематические ошибки репрезентативности появляются вследствие нарушения принципов отбора единиц из исходной совокупности, которые должны быть подвергнуты наблюдению. Для устранения ошибок наблюдения необходимо осуществить контроль полученной информации.
[c.22]
Генеральную совокупность при механическом отборе можно ранжировать или упорядочить по величине изучаемого или коррелирующего с ним признака, что позволит повысить репрезентативность выборки. Однако в этом случае возрастает опасность систематической ошибки, связанной с занижением значений изучаемого признака (когда из каждого интервала регистрируется первое значение) или его завышением (если из каждого интервала регистрируется последнее значение). Поэтому отбор целесообразно начинать с середины первого интервала, например при 5%-ной выборке отобрать 10, 30, 50, 70-ю и с таким же интервалом последующие единицы.
[c.136]
Однако может оказаться, что данные о доходе, полученные в результате опроса, на самом деле являются искаженными, — например, в среднем заниженными, т.е. объясняющие переменные измеряются с систематическими ошибками. В этом случае люди, действительно обладающие доходом X, будут на самом деле тратить на исследуемый товар в среднем величину, меньшую, чем ДА), т.е. в рассмотренном примере объ-
[c.12]
Систематические ошибки измерения объясняющих переменных — одна из возможных причин того, что эконометрическая модель не является регрессионной. В экономических исследованиях подобная ситуация встречается достаточно часто. Одним из возможных путей устранения этого, как правило, довольно неприятного обстоятельства, является выбор других объясняющих переменных (эти вопросы рассматриваются в гл. 8 настоящего учебника).
[c.13]
Определение стандартных затрат имеет ряд недостатков, например, возможны систематические ошибки в определении нормативов и деструктивный результат от задания неадекватных норм и стандартов.
[c.101]
Если систематические ошибки (износ режущего инструмента, температурные деформации и т. д.) приводят к смещению средних значений, то применяются контрольные диаграммы для среднего значения или для медиан. Если же систематические ошибки приводят к увеличению разброса параметров,
[c.90]
Это означает, что отсутствует систематическая ошибка в определении линии регрессии, следовательно оценки параметров регрессии являются несмещенными, то есть математическое ожидание оценки каждого параметра равно его истинному значению.
[c.107]
В противном случае мы принимаем гипотезу HI. Это означает, что при заданном уровне значимости в уравнении регрессии присутствует систематическая ошибка, и это уравнение должно быть уточнено.
[c.125]
Текущие процедуры матричной оценки вторичных ценных бумаг, выпущенных на базе пула ипотек, подвергались критике за неадекватный учет возможностей, предоставляемых этими ценными бумагами (таких, как предоставляемая домовладельцам возможность производить авансовые выплаты по закладным в рассрочку). Эта возможность имеет свою внутреннюю стоимость, и то, что модель не в состоянии адекватно включить ее в цену вторичной ценной бумаги, порождает систематические ошибки.
[c.441]
В принципе надо учитывать только случайные потери, не поддающиеся прямому расчету, непосредственному прогнозированию и потому не учтенные в предпринимательском проекте. Если потери можно заранее предвидеть, то они должны рассматриваться не как потери, а как неизбежные расходы и входить в расчетную калькуляцию. Так, предвидимое движение цен, налогов, их изменение в ходе осуществления хозяйственной деятельности предприниматель обязан учесть в бизнес-плане. Только в силу несовершенства используемых методов расчета предпринимательской деятельности или недостаточно глубокой проработки бизнес-плана систематические ошибки могут рассматриваться как потери в том смысле что они способны изменить ожидаемый результат в худшую сторону. Следовательно, прежде, чем оценивать риск, обусловленный действием сугубо случайных факторов, крайне желательно отделить систематическую составляющую потери от случайных.
[c.117]
В рассмотренных показателях множественной корреляции (индекс и коэффициент) используется остаточная дисперсия, которая имеет систематическую ошибку в сторону преуменьшения, тем более значительную, чем больше параметров определяется в уравнении регрессии при заданном объеме наблюдений п. Если число параметров при х — равно от и приближается к объему наблюдений, то остаточная дисперсия будет близка к нулю и коэффициент (индекс) корреляции приблизится к единице даже при слабой связи факторов с результатом. Для того чтобы не допустить возможного преувеличения тесноты связи, используется скорректированный индекс (коэффициент) множественной корреляции.
[c.119]
Экспериментальные торговые районы были выбраны случайным образом из числа разрешенных, и таким же образом были сформированы 27 комбинаций условий. Очевидно, что использование заданного перечня районов могло внести систематическую ошибку в наши результаты, но мы надеялись, что и на этот раз
[c.175]
Общий объем выборки при этом остался равным 64. Во избежание систематической ошибки, связанной с различным количеством листвы в ярусах, ветви в каждом из них брались с таким расчетом, чтобы количество листьев на них было пропорционально общей массе листьев в этом ярусе.
[c.150]
При изучении правильности устанавливается общая приемлемость данного способа измерения (шкалы или системы шкал). Непосредственно понятие правильности связано с возможностью учета в результате измерения различного рода систематических ошибок. Систематические ошибки имеют некоторую стабильную природу возникновения либо они являются постоянными, либо меняются по определенному закону. Возможно, что последующие этапы окажутся излишними, если в самом начале выяснится полная неспособность данного инструмента на требуемом уровне дифференцировать изучаемую совокупность, иначе говоря, если окажется, что систематически не используется какая-то часть шкалы либо та или иная градация шкалы или вопроса. И, наконец, возможно, что исходный признак не обладает дифференцирующей способностью в отношении объекта измерения. Прежде всего нужно ликвидировать или уменьшить такого рода недостатки шкалы и только затем использовать ее в исследовании.
[c.155]
Визуализация объектов и процессов управления. При внедрении системы визуализации необходимо согласовывать характеристики электронных карт и образов управляемых объектов, используемых разными менеджерами. Это особенно важно из-за больших объемов данных. Пользователи-менеджеры, не имеющие опыта работы с ВИС-приложениями, пытаются создать план-карты образов в малом масштабе. В то же время для решения задач информационного менеджмента, например наладки тепловой сети, и для визуализации других управляемых сетей необходимо для исключения систематической ошибки иметь образы большого масштаба.
[c.199]
Надежность. При изучении различных аспектов разработки и использования тестов важную роль играет анализ ошибок измерения, ибо при составлении тестов, как и в любой работе, возможны ошибки. Обычно выделяют три класса ошибок промахи, систематические ошибки и случайные ошибки.
[c.78]
Систематические ошибки остаются постоянными или закономерно меняются от измерения к измерению и в силу этих особенностей могут быть предсказаны заранее, а в некоторых случаях и устранены. К этой группе относятся ошибки, возникающие в связи с использованием различных методов сбора данных.
[c.78]
Систематическую ошибку можно устранить, изменив процедуру формирования выборки. Случайная же ошибка будет присутствовать всегда, при любом выборочном опросе для общего результата значительно опаснее систематическая, так как по выборке ее невозможно выявить и оценить. Случайная ошибка подчиняется определенным законам и, используя статистические методы, ее можно оценить.
[c.150]
В-третьих, метод статистических испытаний дает систематическую ошибку, возникающую вследствие подмены подлинных вероятностей относительными частотами, и для получения выводов с необходимой точностью иногда требуется огромное количество испытаний, находящееся на пределе возможностей вычислительной техники (чтобы получить в ответе еще один верный десятичный знак, нужно увеличить число имитаций в 100 раз).
[c.24]
Правильность анализа определяется близостью к нулю его систематической ошибки (отклонением математического ожидания серии измерений от истинного значения).
[c.63]
Правильность анализа характеризуется близостью к нулю его систематической ошибки, оцениваемой по результатам внешнего геологического контроля. При внешнем контроле повторный (контрольный) анализ проб выполняется в другой, более квалифицированной лаборатории. Критерием правильности анализов служит при этом величина t [c.88]
Средние содержания ценных компонентов обычно рассчитывают способом взвешивания по мощности. Однако при подсчете часто приходится иметь дело со столовыми (видимыми) значениями мощности, причем пересчет их в истинные значения не всегда может быть осуществлен достаточно надежно. Расчет средних при этом обычно ведут со взвешиванием по значениям стволовых мощностей. Такое взвешивание может приводить к систематическим ошибкам, если между углами встречи тела полезного ископаемого выработками и качеством сырья в отдельных его частях возникает некоторая связь. Так, на полиметаллическом месторождении Степное (Казахстан) вертикальные скважины закономерно пересекали среднюю часть седловидной залежи под углами, близкими к прямому, а фланговые части — под более острыми углами, что определяло повышенные значения стволовых мощностей на флангах и пониженные в центре (рис. 3.8). Однако фланговые части залежи на крыльях антиклинали как раз характеризовались пониженным качеством руд. Взвешивание по стволовым мощностям приводило в данном случае к занижению среднего качества руд по залежи в целом. Аналогичные погрешности могут возникать при разведке неоднородных по качеству сырья линейных тел веерными скважинами.
[c.90]
Особенно необходимо учитывать случайные потери, не поддающиеся прямому расчету, непосредственному прогнозированию и потому неучтенные в предпринимательском проекте. Если потери можно заранее предвидеть, то они должны рассматриваться не как потери, а как неизбежные расходы и включаться в расчетную калькуляцию. Так, предвидимое движение цен, налогов, их изменение в ходе осуществления хозяйственной деятельности необходимо учесть в бизнес-плане. Только в силу несовершенства используемых методов расчета производственной деятельности систематические ошибки могут рассматриваться как потери в том смысле, что они способны изменить в худшую сторону ожидаемый результат.
[c.35]
Задача может быть модифицирована и обобщена в различных направлениях. Жесткое ограничение — несмещенность оценки (равенство нулю систематической ошибки) обычно можно ослабить и заменить ограничениями сверху и снизу величины первого момента ошибок про-
[c.41]
В общем случае при постановке задачи о сглаживании и прогнозе случайных процессов исключение систематических ошибок экстраполяции (равенство нулю первого момента ошибок упреждения) не является обязательным и тем более единственным требованием рациональной фильтрации или рационального прогнозирования. Больше того, в ряде случаев целесообразно расширить область определения задачи и заменить требование о нулевых систематических ошибках ограничениями на их величину. Могут быть указаны и другие неравенства и логические соотношения, которым в тех или иных содержательных задачах фильтрации и прогноза должны удовлетворять, сглаженные или упрежденные точки. Например, может быть ограничена дисперсия или корреляционные моменты случайных величин, зависящих от г (/о + п) и (М- Можно указать содержательные постановки, в которых область определения задачи естественно задавать вероятностными или жесткими ограничениями. Таким образом, в общем случае ограничения задачи сглаживания и экстраполяции высекают в Я не линейное подпространство и не линейное многообразие, а некоторую выпуклую или невыпуклую область G.
[c.309]
Свяжем с задачей А задачу А» прогнозирования по минимуму дисперсии при [нулевых систематических ошибках прогноза. Задача А формулируется следующим образом.
[c.329]
Увольнение в связи с обнаружившимся несоответствием рабочего или служащего занимаемой должности или выполняемой работе вследствие недостаточной квалификации либо состояния здоровья, препятствующих продолжению данной работы (п. 2 ст. 33 КЗоТ). Признаками несоответствия вследствие недостаточной квалификации могут быть систематические ошибки при выполнении порученной работнику работы, невыполнение нормы выработки, брак и т. п. Расторжение трудового договора в случаях, предусмотренных в п. 2 ст. 33 КЗоТ, недопустимо с работниками, не имеющими необходимого опыта работы в связи с непродолжительностью трудового стажа, а также по мотиву отсутствия специального образования, если оно, согласно закону, не является обязательным условием при заключении трудового договора (79, п. И).
[c.545]
Оба вида ошибок могут иметь случайный и систематический характер. Случайные ошибки возникают по разным случайным причинам (описка, пропуск, неточный подсчет и т. д.) и воздействуют на точность данных как в сторону их увеличения, так и уменьшения. При достаточно большом количестве наблюдений согласно закону больших чисел эти ошибки взаимно погашаются и не оказывают существенного влияния на точность наблюдений. Систематические ошибки возникают по какой-либо определенной причине и вызывают одностороннее изменение данных (ошибки программы наблюдений, нарушение принципов отбора объектов наблюдения и т. п.), искажая их. Мерами предупреждения этих ошибок является правильное определение количества наблюдений, обоснованный выбор объектов наблюдения и др.
[c.91]
Такая же опасность возникает при замене по какой-либо причине единиц, попавших в выборку, другими единицами (например, вместо отобранного домохозяйства, где в момент прихода интервьюера никто не открыл дверь, был проведен опрос в соседней квартире или интервьюер встретил решительный отказ участвовать в опросе и был вынужден пойти на замену домохозяйства). Как отмечает социолог В. И. Паниотто, систематические ошибки представляют собой некоторое постоянное смещение, которое не уменьшается с увеличением числа опрошенных и вызвано недостатками и просчетами в системе отбора респондентов. Если, например, для изучения общественного мнения жителей города в архитектурном управлении получить сведения о жилом фонде и из всех имеющихся в городе квартир отобрать случайным образом 400 квартир, а затем предложить интервьюерам опросить всех, кого они застанут в момент посещения в этих квартирах, то полученные данные не будут репрезентативны. Допущена систематическая ошибка более подвижная часть населения попадает в выборку в меньшей пропорции, а менее подвижная — в большей пропорции, чем в генеральной совокупности. Пенсионеров, например, можно чаще застать дома, чем студентов-вечерников. При увеличении выборки эта ошибка не устраняется если мы проведем опрос в 800 квартирах или даже во всех квартирах города (сплошной опрос), то полученные данные будут репрезентативны для населения, находящегося дома в момент прихода интервьюера, а не для всех жителей города.
[c.164]
Чтобы минимизировать систематическую ошибку, возникающую при оптимизации, мы ограничились простым перекрестным правилом скользящих средних (СМА = rossing-Moving-Averages) — это правило торговли пропагандируют Брок и др. [56]. Правило очень простое в том отношении, что в вычислении индикатора не участвуют числа Фибоначчи. Здесь важно, что технический анализ стремится предсказать, главным образом, направление изменения цены (вниз, вверх, на том же уровне), а не величину этого изменения.
[c.215]
Можно еще дальше усовершенствовать эксперимент, связанный с определением урожайности культуры и зависимый от качества обработки почвы. Если каждого рабочего закрепить за определенным полем, то вследствие различности почв может появиться систематическая ошибка. Обозначим поля буквами W, X, У, ZH определим условия эксперимента рабочих между полями таким образом, чтобы каждый из них обслуживал поле только один день. В этом случае получим план, называемый греко-латинским квадратом, который позволяет усреднить влияние таких факторов, как день, поле, рабочий (табл. 4.6).
[c.160]
НЕСМЕЩЕННАЯ ОЦЕНКА [unbiased estimator] — статистическая точечная оценка, математическое ожидание которой совпадает с оцениваемой величиной (у нее нет систематической ошибки).
[c.226]
СИСТЕМАТИЧЕСКАЯ ОШИБКА [systemati error] — понятие математической статистики — ошибка, которая постоянно либо преувеличивает, либо преуменьшает результаты измерений оценок наблюдаемых величин) в результате воздействия определенных факторов, систематически влияющих на эти измерения и изменяющих их в одном направлении (в отличие от случайных ошибок). Оценки, лишенные систематических ошибок, называются несмещенными оценками.
[c.327]
Расчетное значение критерия t сравнивается с табличным значением статистического критерия Стьюдента для данного числа пар и выбранного уровня значимости. Систематическая ошибка считается отсутствующей, если tpa 4 < табл.
[c.88]
Однострелочные секундомеры простого действия используют для измерения элементов операций по отдельным отсчетам затрат времени при выборочном и цикловом методах хронометража. Они имеют одну основную центральную стрелку, движущуюся по круговому циферблату, шкала которого может иметь секундную или деся- тичную градуировку. Пределы измерения шкалы 30 или 60 с. Секундомер может иметь один или два дополнительных счетчика для отсчета целого числа минут, прошедших с момента начала наблюдения. Их недостаток — малая точность при хронометрировании по текущему времени вследствие накопления систематической ошибки, вызываемой накапливанием запаздываний в пуске стрелки после считывания показаний. Этого недостатка лишен однострелочный секундомер суммирующего действия. Но он более сложен по конструкции и менее надежен в работе.
[c.139]
Минимизация систематической ошибки. Практическое использование излагаемых выше предложений по повышению устойчивости оценок коэффициентов регрессии наталкивается на следующие неопределенности. Какую минимизируемую функцию риска выбрать Все предлагаемые оценки содержат параметры v — в п. 7.2.1, k — в п. 7.2.2 и К — в п. 7.2.3 и 7.2.4. Какими брать значения этих параметров Если полезно уменьшать веса больших отклонений прогнозируемой переменной, то, может быть, полезно взвешивать и предикторные переменные [c.221]
| Главная Контакты Случайная статья
|
||
Время наблюдения. Статистический. формуляр. Точность наблюдения. Ошибка наблюдения. Виды ошибок наблюдения. Ошибки регистрации. Ошибки репрезентативности⇐ ПредыдущаяСтр 2 из 2 Время наблюдения |
Срок наблюдения | период, в течение которого будет проводиться наблюдение |
| Объективное время наблюдения | время, к которому относятся регистрируемые сведения | |
|
Статистический формуляр |
это документ единого образца, содержащий программу и результаты наблюдения. |
|
| Обязательные элементы формуляра | − титульная часть − адресная часть |
|
| Виды статистического формуляра | − индивидуальный − списочный |
2.3. Точность наблюдения
— степень соответствия величины какого-либо показателя (значение какого-либо признака), определенной по материалам статистического наблюдения, действительной его величине.
Ошибка наблюдения
Расхождение между расчетным и действительным значением изучаемых величин называется
Виды ошибок наблюдения
Регистрации, репрезентативности
Случайные, систематические
Преднамеренные, непреднамеренные
Действительные, мнимые
Счетные, методологические
Ошибки регистрации
это отклонения между значением показателя, полученного в ходе статистического наблюдения, и фактическим, действительным его значением
• случайные
это результат действия различных случайных факторов
• систематические
регистрации всегда имеют одинаковую тенденцию либо к увеличению, либо к уменьшению значения показателей по каждой единице наблюдения, и поэтому величина показателя по совокупности в целом будет включать в себя накопленную ошибку
Ошибки репрезентативности
отклонение значения показателя обследованной совокупности от его величины по исходной совокупности
• случайные
возникают, если отобранная совокупность неполно воспроизводит всю совокупность в целом.
• систематические
появляются вследствие нарушения принципов отбора единиц из исходной совокупности, которые должны быть подвергнуты наблюдению.
|
© helpiks.su При использовании или копировании материалов прямая ссылка на сайт обязательна. |