Канальный уровень
должен обнаруживать ошибки передачи
данных, связанные с искажением бит в
принятом кадре данных или с потерей
кадра, и по возможности их корректировать.
Большая часть протоколов
канального уровня выполняет только
первую задачу — обнаружение ошибок,
считая, что корректировать ошибки, то
есть повторно передавать данные,
содержавшие искаженную информацию,
должны протоколы верхних уровней. Так
работают такие популярные протоколы
локальных сетей, как Ethernet, Token Ring, FDDI и
другие. Однако существуют протоколы
канального уровня, например LLC2 или
LAP-B, которые самостоятельно решают
задачу восстановления искаженных или
потерянных кадров.
Очевидно, что протоколы
должны работать наиболее эффективно в
типичных условиях работы сети. Поэтому
для сетей, в которых искажения и потери
кадров являются очень редкими событиями,
разрабатываются протоколы типа Ethernet,
в которых не предусматриваются процедуры
устранения ошибок. Действительно,
наличие процедур восстановления данных
потребовало бы от конечных узлов
дополнительных вычислительных затрат,
которые в условиях надежной работы сети
являлись бы избыточными.
Напротив, если в сети
искажения и потери случаются часто, то
желательно уже на канальном уровне
использовать протокол с коррекцией
ошибок, а не оставлять эту работу
протоколам верхних уровней. Протоколы
верхних уровней, например транспортного
или прикладного, работая с большими
тайм-аутами, восстановят потерянные
данные с большой задержкой. В глобальных
сетях первых поколений, например сетях
Х.25, которые работали через ненадежные
каналы связи, протоколы канального
уровня всегда выполняли процедуры
восстановления потерянных и искаженных
кадров.
Поэтому нельзя считать,
что один протокол лучше другого потому,
что он восстанавливает ошибочные кадры,
а другой протокол — нет. Каждый протокол
должен работать в тех условиях, для
которых он разработан.
Методы обнаружения ошибок
Все методы обнаружения
ошибок основаны на передаче в составе
кадра данных служебной избыточной
информации, по которой можно судить с
некоторой степенью вероятности о
достоверности принятых данных. Эту
служебную информацию принято называть
контрольной суммойили
(последовательностью контроля кадра
— Frame Check Sequence, FCS). Контрольная сумма
вычисляется как функция от основной
информации, причем необязательно только
путем суммирования. Принимающая сторона
повторно вычисляет контрольную сумму
кадра по известному алгоритму и в случае
ее совпадения с контрольной суммой,
вычисленной передающей стороной, делает
вывод о том, что данные были переданы
через сеть корректно.
Существует несколько
распространенных алгоритмов вычисления
контрольной суммы, отличающихся
вычислительной сложностью и способностью
обнаруживать ошибки в данных.
Контроль по паритетупредставляет собой наиболее простой
метод контроля данных. В то же время это
наименее мощный алгоритм контроля, так
как с его помощью можно обнаружить
только одиночные ошибки в проверяемых
данных. Метод заключается в суммировании
по модулю 2 всех бит контролируемой
информации. Например, для данных 100101011
результатом контрольного суммирования
будет значение 1. Результат суммирования
также представляет собой один бит
данных, который пересылается вместе с
контролируемой информацией. При искажении
при пересылке любого одного бита исходных
данных (или контрольного разряда)
результат суммирования будет отличаться
от принятого контрольного разряда, что
говорит об ошибке. Однако двойная ошибка,
например 110101010, будет неверно принята
за корректные данные. Поэтому контроль
по паритету применяется к небольшим
порциям данных, как правило, к каждому
байту, что дает коэффициент избыточности
для этого метода 1/8. Метод редко применяется
в вычислительных сетях из-за его большой
избыточности и невысоких диагностических
способностей.
Вертикальный и
горизонтальный контроль по паритетупредставляет собой модификацию описанного
выше метода. Его отличие состоит в том,
что исходные данные рассматриваются в
виде матрицы, строки которой составляют
байты данных. Контрольный разряд
подсчитывается отдельно для каждой
строки и для каждого столбца матрицы.
Этот метод обнаруживает большую часть
двойных ошибок, однако обладает еще
большей избыточностью. На практике
сейчас также почти не применяется.
Циклический избыточный
контроль (Cyclic Redundancy Check, CRC)является
в настоящее время наиболее популярным
методом контроля в вычислительных сетях
(и не только в сетях, например, этот метод
широко применяется при записи данных
на диски и дискеты). Метод основан на
рассмотрении исходных данных в виде
одного многоразрядного двоичного числа.
Например, кадр стандарта Ethernet, состоящий
из 1024 байт, будет рассматриваться как
одно число, состоящее из 8192 бит. В качестве
контрольной информации рассматривается
остаток от деления этого числа на
известный делитель R. Обычно в качестве
делителя выбирается семнадцати- или
тридцати трехразрядное число, чтобы
остаток от деления имел длину 16 разрядов
(2 байт) или 32 разряда (4 байт). При получении
кадра данных снова вычисляется остаток
от деления на тот же делитель R, но при
этом к данным кадра добавляется и
содержащаяся в нем контрольная сумма.
Если остаток от деления на R равен нулю1(1Существуетнесколько модифицированная
процедура вычисления остатка, приводящая
к получению в случае отсутствия ошибок
известного ненулевого остатка, что
является более надежным показателем
корректности.), то делается вывод об
отсутствии ошибок в полученном кадре,
в противном случае кадр считается
искаженным.
Этот метод обладает
более высокой вычислительной сложностью,
но его диагностические возможности
гораздо выше, чем у методов контроля по
паритету. Метод CRC обнаруживает все
одиночные ошибки, двойные ошибки и
ошибки в нечетном числе бит. Метод
обладает также невысокой степенью
избыточности. Например, для кадра
Ethernet размером в 1024 байт контрольная
информация длиной в 4 байт составляет
только 0,4 %.
Обнаруже́ние оши́бок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды).
Содержание
- 1 Способы борьбы с ошибками
- 2 Коды обнаружения и исправления ошибок
- 2.1 Блоковые коды
- 2.1.1 Линейные коды общего вида
- 2.1.1.1 Минимальное расстояние и корректирующая способность
- 2.1.1.2 Коды Хемминга
- 2.1.1.3 Общий метод декодирования линейных кодов
- 2.1.2 Линейные циклические коды
- 2.1.2.1 Порождающий (генераторный) полином
- 2.1.2.2 Коды CRC
- 2.1.2.3 Коды БЧХ
- 2.1.2.4 Коды коррекции ошибок Рида — Соломона
- 2.1.3 Преимущества и недостатки блоковых кодов
- 2.1.1 Линейные коды общего вида
- 2.2 Свёрточные коды
- 2.2.1 Преимущества и недостатки свёрточных кодов
- 2.3 Каскадное кодирование. Итеративное декодирование
- 2.4 Сетевое кодирование
- 2.5 Оценка эффективности кодов
- 2.5.1 Граница Хемминга и совершенные коды
- 2.5.2 Энергетический выигрыш
- 2.6 Применение кодов, исправляющих ошибки
- 2.1 Блоковые коды
- 3 Автоматический запрос повторной передачи
- 3.1 Запрос ARQ с остановками (stop-and-wait ARQ)
- 3.2 Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
- 3.3 Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
- 4 См. также
- 5 Литература
- 6 Ссылки
Способы борьбы с ошибками
В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях сетевой модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
- обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков — этот подход применяется, в основном, на канальном и транспортном уровнях;
- обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
- исправление ошибок (англ. forward error correction) применяется на физическом уровне.
Коды обнаружения и исправления ошибок
Корректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении.
Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её.
В действительности используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить).
По способу работы с данными коды, исправляющие ошибки, делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком.
Блоковые коды
Пусть кодируемая информация делится на фрагменты длиной 



Если исходные 
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из
- способность исправлять как можно большее число ошибок,
- как можно меньшая избыточность,
- простота кодирования и декодирования.
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
Линейные коды общего вида
Линейный блоковый код — такой код, что множество его кодовых слов образует 
Это значит, что операция кодирования соответствует умножению исходного 
Пусть 



Минимальное расстояние и корректирующая способность
Расстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами 

.
Минимальное расстояние Хемминга 
.
Корректирующая способность определяет, сколько ошибок передачи кода (типа 




Таким образом, получив искажённую кодовую комбинацию из
Поясним на примере. Предположим, что есть два кодовых слова 
Коды Хемминга
Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
, где
— принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.
Общий метод декодирования линейных кодов
Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова 

Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора 




Линейные циклические коды
Несмотря на то, что декодирование линейных кодов значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды, кроме более простого декодирования, обладают и другими важными свойствами.
Циклическим кодом является линейный код, обладающий следующим свойством: если
Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово 



В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным, то есть 
Порождающий (генераторный) полином
Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному 
С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности:
Коды CRC
Коды CRC (англ. cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путём деления 
Таким образом, вид полинома
| Название кода | Степень | Полином |
|---|---|---|
| CRC-12 | 12 | 
|
| CRC-16 | 16 | 
|
| CRC-CCITT | 16 | 
|
| CRC-32 | 32 | 
|
Коды БЧХ
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача.
Коды коррекции ошибок Рида — Соломона
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (октетами).
Математически коды Рида — Соломона являются кодами БЧХ.
Преимущества и недостатки блоковых кодов
Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ), менее высока.
Свёрточные коды

Свёрточный кодер (
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных.
Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия.
Преимущества и недостатки свёрточных кодов
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок.
Каскадное кодирование. Итеративное декодирование
Преимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение.
Например, популярной является следующая конструкция: данные кодируются кодом Рида-Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона.
Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPC-коды (коды Галлагера).
Сетевое кодирование
Оценка эффективности кодов
Эффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ).
Граница Хемминга и совершенные коды
Пусть имеется двоичный блоковый 

Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными.
Энергетический выигрыш
При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом, при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения.
Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования.
Применение кодов, исправляющих ошибки
Коды, исправляющие ошибки, применяются:
- в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам.
- в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней.
Автоматический запрос повторной передачи
Системы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса:
Запрос ARQ с остановками (stop-and-wait ARQ)
Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем, как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание.
Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть передается ошибочный блок и все последующие).
Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
При этом подходе осуществляется передача только ошибочно принятых блоков данных.
См. также
- Цифровая связь
- Код ответа (Код причины завершения)
- Линейный код
- Циклический код
- Код Боуза — Чоудхури — Хоквингема
- Код Рида — Соломона
- LDPC
- Свёрточный код
- Турбо-код
Литература
- Блейхут Р. Теория и практика кодов, контролирующих ошибки = Theory and Practice of Error Control Codes. — М.: Мир, 1986. — 576 с.
- Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки. М.: Радио и связь, 1979.
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение / пер. с англ. В. Б. Афанасьева. — М.: Техносфера, 2006. — 320 с. — (Мир связи). — 2000 экз. — ISBN 5-94836-035-0.
Ссылки
- Помехоустойчивое кодирование (11 ноября 2001). — реферат по проблеме кодирования сообщений с исправлением ошибок. Проверено 25 декабря 2006. Архивировано 25 августа 2011 года.
- Коды Рида-Соломона. Простой пример. Просто, доступно, на конкретных числах. Для начинающих.
Сразу хочу сказать, что здесь никакой воды про обучение с учителем, и только нужная информация. Для того чтобы лучше понимать что такое
обучение с учителем, метод коррекции ошибки, метод обратного распространения ошибки , настоятельно рекомендую прочитать все из категории Машинное обучение.
обучение с учителем (англ. Supervised learning) — один из способов машинного обучения, в ходе которого испытуемая система принудительно обучается с помощью примеров «стимул-реакция». С точки зрения кибернетики, является одним из видов кибернетического эксперимента. Между входами и эталонными выходами (стимул-реакция) может существовать некоторая зависимость, но она не известна. Известна только конечная совокупность прецедентов — пар «стимул-реакция», называемая обучающей выборкой. На основе этих данных требуется восстановить зависимость (построить модель отношений стимул-реакция, пригодных для прогнозирования), то есть построить алгоритм, способный для любого объекта выдать достаточно точный ответ. Для измерения точности ответов, так же как и в обучении на примерах, может вводиться функционал качества.
Виды машинного обучения
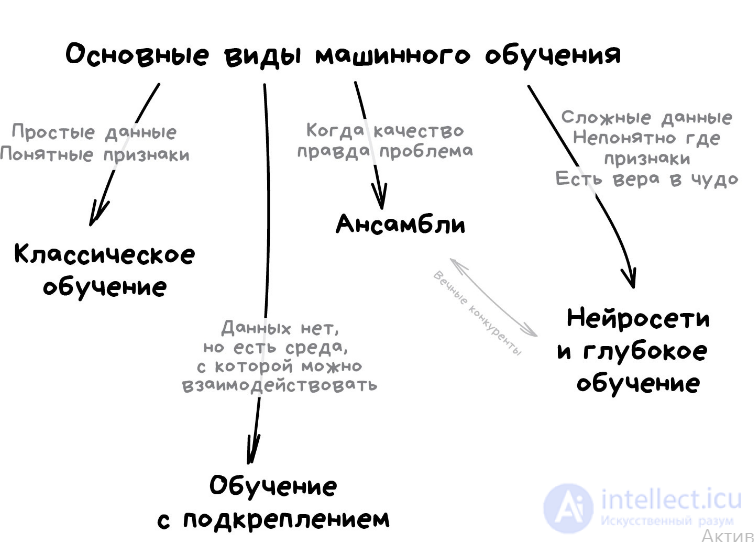
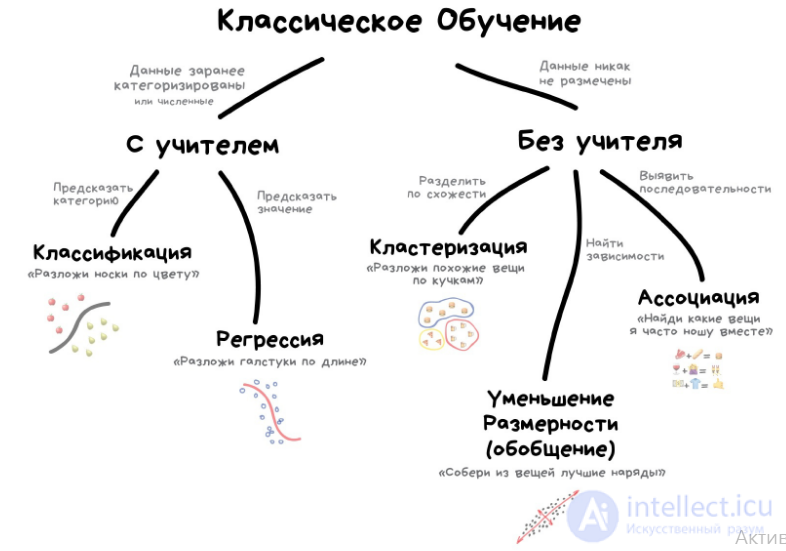
Классическое обучение
Принцип постановки данного эксперимента
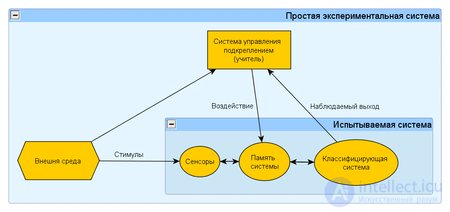
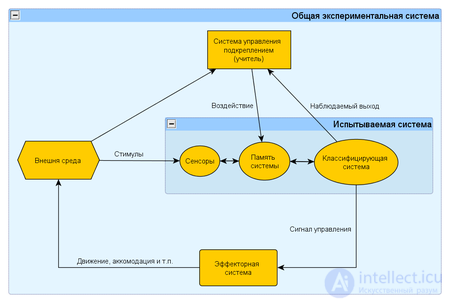
Данный эксперимент представляет собой частный случай кибернетического эксперимента с обратной связью. Постановка данного эксперимента предполагает наличие экспериментальной системы, метода обучения и метода испытания системы или измерения характеристик.
Экспериментальная система в свою очередь состоит из испытываемой (используемой) системы, пространства стимулов получаемых из внешней среды и системы управления подкреплением (регулятора внутренних параметров). В качестве системы управления подкреплением может быть использовано автоматическое регулирующие устройство (например, термостат) или человек-оператор (учитель), способный реагировать на реакции испытываемой системы и стимулы внешней среды путем применения особых правил подкрепления, изменяющих состояние памяти системы.
Различают два варианта: (1) когда реакция испытываемой системы не изменяет состояние внешней среды, и (2) когда реакция системы изменяет стимулы внешней среды. Эти схемы указывают принципиальное сходство такой системы общего вида с биологической нервной системой.
Типология задач обучения с учителем
Типы входных данных
- Признаковое описание — наиболее распространенный случай. Каждый объект описывается набором своих характеристик, называемых признаками. Признаки могут быть числовыми или нечисловыми.
- Матрица расстояний между объектами. Каждый объект описывается расстояниями до всех остальных объектов обучающей выборки. С этим типом входных данных работают немногие методы, в частности, метод ближайших соседей, метод парзеновского окна, метод потенциальных функций.
- Временной ряд или сигнал представляет собой последовательность измерений во времени. Каждое измерение может представляться числом, вектором, а в общем случае — признаковым описанием исследуемого объекта в данный момент времени.
- Изображение или видеоряд.
- Встречаются и более сложные случаи, когда входные данные представляются в виде графов, текстов, результатов запросов к базе данных, и т. д. Как правило, они приводятся к первому или второму случаю путем предварительной обработки данных и извлечения признаков.
Типы откликов
- Когда множество возможных ответов бесконечно (ответы являются действительными числами или векторами), говорят о задачах регрессии и аппроксимации ;
- Когда множество возможных ответов конечно, говорят о задачах классификации и распознавания образов;
- Когда ответы характеризуют будущие поведение процесса или явления, говорят о задачах прогнозирования.
Вырожденные виды систем управления подкреплением («учителей»)
- Система подкрепления с управлением по реакции (R — управляемая система) — характеризуется тем, что информационный канал от внешней среды к системе подкрепления не функционирует. Данная система несмотря на наличие системы управления относится к спонтанному обучению, так как испытуемая система обучается автономно, под действием лишь своих выходных сигналов независимо от их «правильности». При таком методе обучения для управления изменением состояния памяти не требуется никакой внешней информации;
- Система подкрепления с управлением по стимулам (S — управляемая система) — характеризуется тем, что информационный канал от испытываемой системы к системе подкрепления не функционирует. Несмотря на не функционирующий канал от выходов испытываемой системы относится к обучению с учителем, так как в этом случае система подкрепления (учитель) заставляет испытываемую систему вырабатывать реакции согласно определенному правилу, хотя и не принимается во внимание наличие истиных реакций испытываемой системы.
Данное различие позволяет более глубоко взглянуть на различия между различными способами обучения, так как грань между обучением с учителем и обучением без учителя более тонка. Кроме этого, такое различие позволило показать дляискусственных нейронных сетей определенные ограничения для S и R — управляемых систем (см. Теорема сходимости перцептрона).
Обучение с учителем
Обучение с учителем (supervised learning) предполагает наличие полного набора размеченных данных для тренировки модели на всех этапах ее построения.
Наличие полностью размеченного датасета означает, что каждому примеру в обучающем наборе соответствует ответ, который алгоритм и должен получить. Таким образом, размеченный датасет из фотографий цветов обучит нейронную сеть, где изображены розы, ромашки или нарциссы. Когда сеть получит новое фото, она сравнит его с примерами из обучающего датасета, чтобы предсказать ответ.
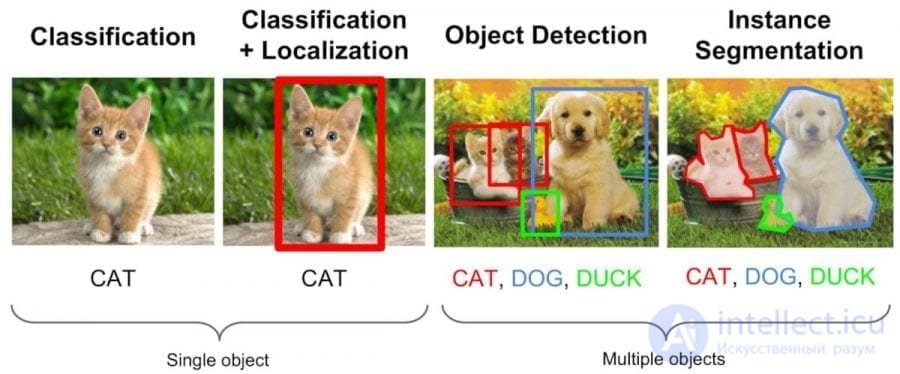
Пример обучения с учителем — классификация (слева), и дальнейшее ее использование для сегментации и распознавания объектов
В основном обучение с учителем применяется для решения двух типов задач: классификации и регрессии.
В задачах классификации алгоритм предсказывает дискретные значения, соответствующие номерам классов, к которым принадлежат объекты. В обучающем датасете с фотографиями животных каждое изображение будет иметь соответствующую метку — «кошка», «коала» или «черепаха». Качество алгоритма оценивается тем, насколько точно он может правильно классифицировать новые фото с коалами и черепахами.
А вот задачи регрессии связаны с непрерывными данными. Один из примеров, линейная регрессия, вычисляет ожидаемое значение переменной y, учитывая конкретные значения x.
Более утилитарные задачи машинного обучения задействуют большое число переменных. Как пример, нейронная сеть, предсказывающая цену квартиры в Сан-Франциско на основе ее площади, местоположения и доступности общественного транспорта. Алгоритм выполняет работу эксперта, который рассчитывает цену квартиры исходя из тех же данных.
Таким образом, обучение с учителем больше всего подходит для задач, когда имеется внушительный набор достоверных данных для обучения алгоритма. Но так бывает далеко не всегда. Недостаток данных — наиболее часто встречающаяся проблема в машинном обучении .
Классическое обучение любят делить на две категории — с учителем и без. Часто можно встретить их английские наименования — Supervised и Unsupervised Learning.
В первом случае у машины есть некий учитель, который говорит ей как правильно. Рассказывает, что на этой картинке кошка, а на этой собака. То есть учитель уже заранее разделил (разметил) все данные на кошек и собак, а машина учится на конкретных примерах.
В обучении без учителя, машине просто вываливают кучу фотографий животных на стол и говорят «разберись, кто здесь на кого похож». Данные не размечены, у машины нет учителя, и она пытается сама найти любые закономерности. Об этих методах поговорим ниже.
Очевидно, что с учителем машина обучится быстрее и точнее, потому в боевых задачах его используют намного чаще. Эти задачи делятся на два типа: классификация — предсказание категории объекта, и регрессия — предсказание места на числовой прямой.
4 комментария
Классификация
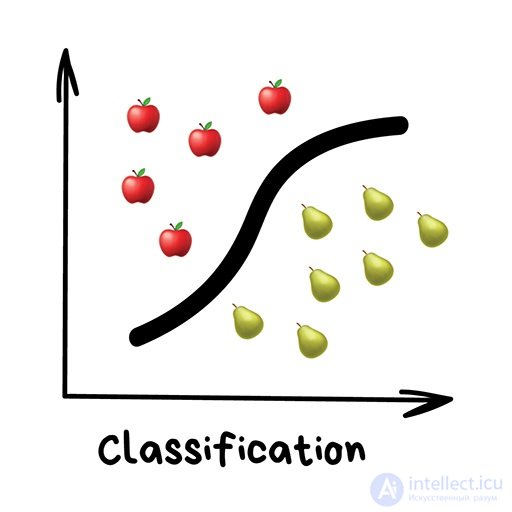
«Разделяет объекты по заранее известному признаку. Носки по цветам, документы по языкам, музыку по жанрам»
Сегодня используют для:
- Спам-фильтры
- Определение языка
- Поиск похожих документов
- Анализ тональности
- Распознавание рукописных букв и цифр
- Определение подозрительных транзакций
Популярные алгоритмы: Наивный Байес, Деревья Решений, Логистическая Регрессия, K-ближайших соседей, Машины Опорных Векторов
Здесь и далее в комментах можно дополнять эти блоки. Приводите свои примеры задач, областей и алгоритмов, потому что описанные мной взяты из субъективного опыта.
6 комментариев
Классификация вещей — самая популярная задача во всем машинном обучении. Машина в ней как ребенок, который учится раскладывать игрушки: роботов в один ящик, танки в другой. Опа, а если это робот-танк? Штош, время расплакаться и выпасть в ошибку.
Старый доклад Бобука про повышение конверсии лендингов с помощью SVM
Для классификации всегда нужен учитель — размеченные данные с признаками и категориями, которые машина будет учиться определять по этим признакам. Дальше классифицировать можно что угодно: пользователей по интересам — так делают алгоритмические ленты, статьи по языкам и тематикам — важно для поисковиков, музыку по жанрам — вспомните плейлисты Спотифая и Яндекс.Музыки, даже письма в вашем почтовом ящике.
Раньше все спам-фильтры работали на алгоритме Наивного Байеса. Машина считала сколько раз слово «виагра» встречается в спаме, а сколько раз в нормальных письмах. Перемножала эти две вероятности по формуле Байеса, складывала результаты всех слов и бац, всем лежать, у нас машинное обучение!
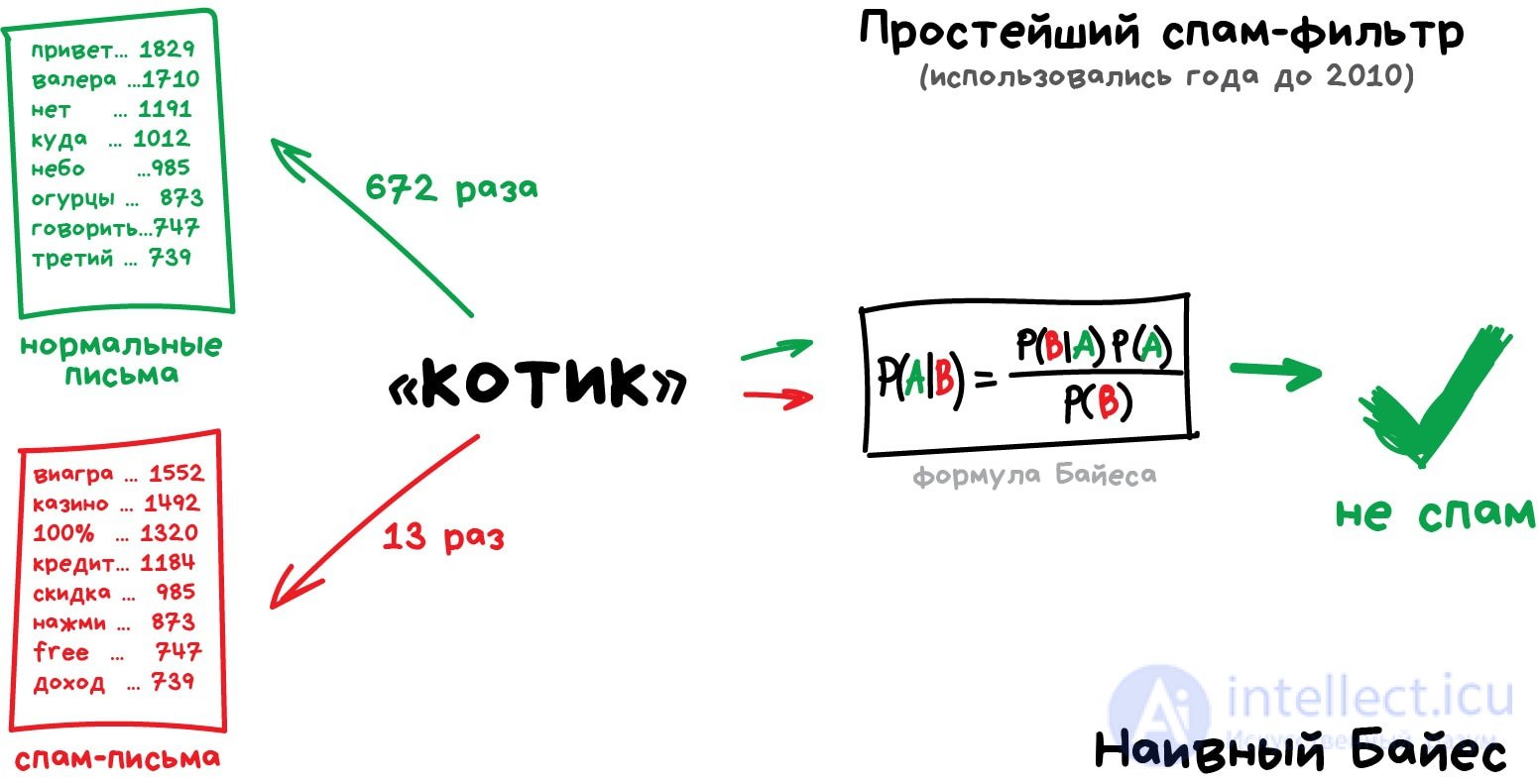
Позже спамеры научились обходить фильтр Байеса, просто вставляя в конец письма много слов с «хорошими» рейтингами. Метод получил ироничное название Отравление Байеса, а фильтровать спам стали другими алгоритмами. Но метод навсегда остался в учебниках как самый простой, красивый и один из первых практически полезных.
Возьмем другой пример полезной классификации. Вот берете вы кредит в банке . Об этом говорит сайт https://intellect.icu . Как банку удостовериться, вернете вы его или нет? Точно никак, но у банка есть тысячи профилей других людей, которые уже брали кредит до вас. Там указан их возраст, образование, должность, уровень зарплаты и главное — кто из них вернул кредит, а с кем возникли проблемы.
Да, все догадались, где здесь данные и какой надо предсказать результат. Обучим машину, найдем закономерности, получим ответ — вопрос не в этом. Проблема в том, что банк не может слепо доверять ответу машины, без объяснений. Вдруг сбой, злые хакеры или бухой админ решил скриптик исправить.
Для этой задачи придумали Деревья Решений. Машина автоматически разделяет все данные по вопросам, ответы на которые «да» или «нет». Вопросы могут быть не совсем адекватными с точки зрения человека, например «зарплата заемщика больше, чем 25934 рубля?», но машина придумывает их так, чтобы на каждом шаге разбиение было самым точным.
Так получается дерево вопросов. Чем выше уровень, тем более общий вопрос. Потом даже можно загнать их аналитикам, и они навыдумывают почему так.
Деревья нашли свою нишу в областях с высокой ответственностью: диагностике, медицине, финансах.
Два самых популярных алгоритма построения деревьев — CART и C4.5.
В чистом виде деревья сегодня используют редко, но вот их ансамбли (о которых будет ниже) лежат в основе крупных систем и зачастую уделывают даже нейросети. Например, когда вы задаете вопрос Яндексу, именно толпа глупых деревьев бежит ранжировать вам результаты.

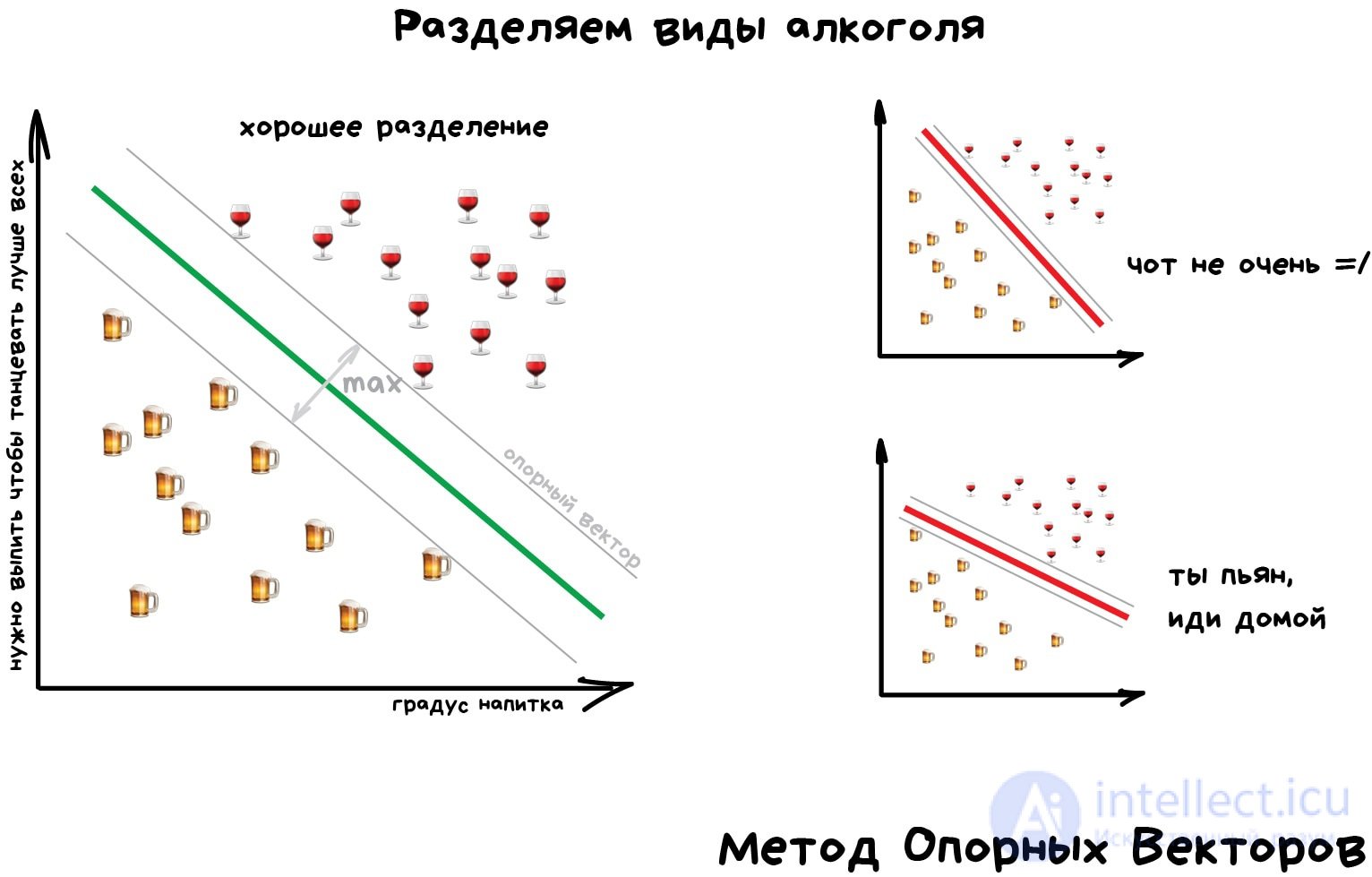
Но самым популярным методом классической классификации заслуженно является Метод Опорных Векторов (SVM). Им классифицировали уже все: виды растений, лица на фотографиях, документы по тематикам, даже странных Playboy-моделей. Много лет он был главным ответом на вопрос «какой бы мне взять классификатор».
Идея SVM по своей сути проста — он ищет, как так провести две прямые между категориями, чтобы между ними образовался наибольший зазор. На картинке видно нагляднее:
У классификации есть полезная обратная сторона — поиск аномалий. Когда какой-то признак объекта сильно не вписывается в наши классы, мы ярко подсвечиваем его на экране. Сейчас так делают в медицине: компьютер подсвечивает врачу все подозрительные области МРТ или выделяет отклонения в анализах. На биржах таким же образом определяют нестандартных игроков, которые скорее всего являются инсайдерами. Научив компьютер «как правильно», мы автоматически получаем и обратный классификатор — как неправильно.
Сегодня для классификации все чаще используют нейросети, ведь по сути их для этого и изобрели.
Правило буравчика такое: сложнее данные — сложнее алгоритм. Для текста, цифр, табличек я бы начинал с классики. Там модели меньше, обучаются быстрее и работают понятнее. Для картинок, видео и другой непонятной бигдаты — сразу смотрел бы в сторону нейросетей.
Лет пять назад еще можно было встретить классификатор лиц на SVM, но сегодня под эту задачу сотня готовых сеток по интернету валяются, чо бы их не взять. А вот спам-фильтры как на SVM писали, так и не вижу смысла останавливаться.
Регрессия
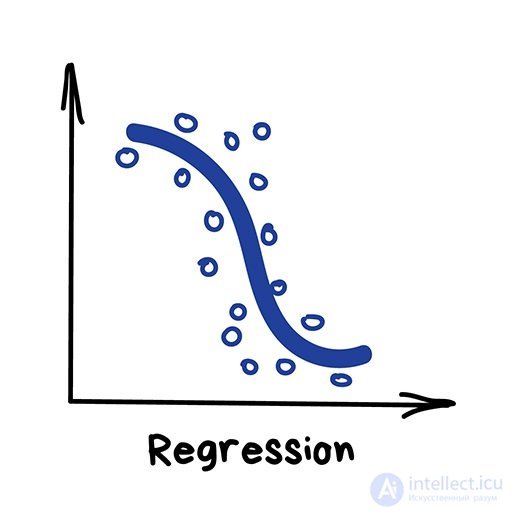
«Нарисуй линию вдоль моих точек. Да, это машинное обучение»
Сегодня используют для:
- Прогноз стоимости ценных бумаг
- Анализ спроса, объема продаж
- Медицинские диагнозы
- Любые зависимости числа от времени
Популярные алгоритмы: Линейная или Полиномиальная Регрессия
Регрессия — та же классификация, только вместо категории мы предсказываем число. Стоимость автомобиля по его пробегу, количество пробок по времени суток, объем спроса на товар от роста компании и.т.д. На регрессию идеально ложатся любые задачи, где есть зависимость от времени.
Регрессию очень любят финансисты и аналитики, она встроена даже в Excel. Внутри все работает, опять же, банально: машина тупо пытается нарисовать линию, которая в среднем отражает зависимость. Правда, в отличии от человека с фломастером и вайтбордом, делает она это математически точно — считая среднее расстояние до каждой точки и пытаясь всем угодить.

Когда регрессия рисует прямую линию, ее называют линейной, когда кривую — полиномиальной. Это два основных вида регрессии, дальше уже начинаются редкоземельные методы. Но так как в семье не без урода, есть Логистическая Регрессия, которая на самом деле не регрессия, а метод классификации, от чего у всех постоянно путаница. Не делайте так.
Схожесть регрессии и классификации подтверждается еще и тем, что многие классификаторы, после небольшого тюнинга, превращаются в регрессоры. Например, мы можем не просто смотреть к какому классу принадлежит объект, а запоминать, насколько он близок — и вот, у нас регрессия.
Для желающих понять это глубже, но тоже простыми словами, рекомендую цикл статей Machine Learning for Humans
метод коррекции ошибки
Эта статья о нейросетях; о коррекции ошибок в информатике см.: обнаружение и исправление ошибок.
Метод коррекции ошибки — метод обучения перцептрона, предложенный Фрэнком Розенблаттом. Представляет собой такой метод обучения, при котором вес связи не изменяется до тех пор, пока текущая реакция перцептрона остается правильной. При появлении неправильной реакции вес изменяется на единицу, а знак (+/-) определяется противоположным от знака ошибки.
Модификации метода
В теореме сходимости перцептрона различаются различные виды этого метода, доказано, что любой из них позволяет получить схождение при решении любой задачи классификации.
Метод коррекции ошибок без квантования
Если реакция на стимул 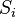 правильная, то никакого подкрепления не вводится, но при появлении ошибок к весу каждого активного А-элемента прибавляется величина
правильная, то никакого подкрепления не вводится, но при появлении ошибок к весу каждого активного А-элемента прибавляется величина 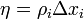 , где
, где 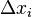 — число единиц подкрепления, выбирается так, чтобы величина сигнала превышала порог θ, а
— число единиц подкрепления, выбирается так, чтобы величина сигнала превышала порог θ, а 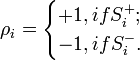 , при этом
, при этом 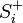 — стимул, принадлежащий положительному классу, а
— стимул, принадлежащий положительному классу, а 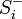 — стимул, принадлежащий отрицательному классу.
— стимул, принадлежащий отрицательному классу.
Метод коррекции ошибок с квантованием
Отличается от метода коррекции ошибок без квантования только тем, что 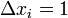 , то есть равно одной единице подкрепления.
, то есть равно одной единице подкрепления.
Этот метод и метод коррекции ошибок без квантованиея являются одинаковыми по скорости достижения решения в общем случае, и более эффективными по сравнению с методами коррекции ошибок со случайным знаком или случайными возмущениями.
Метод коррекции ошибок со случайным знаком подкрепления
Отличается тем, что знак подкрепления 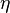 выбирается случайно независимо от реакции перцептрона и с равной вероятностью может быть положительным или отрицательным. Но так же как и в базовом методе — если перцептрон дает правильную реакцию, то подкрепление равно нулю.
выбирается случайно независимо от реакции перцептрона и с равной вероятностью может быть положительным или отрицательным. Но так же как и в базовом методе — если перцептрон дает правильную реакцию, то подкрепление равно нулю.
Метод коррекции ошибок со случайными возмущениями
Отличается тем, что величина и знак для каждой связи в системе выбираются отдельно и независимо в соответствии с некоторым распределением вероятностей. Это метод приводит к самой медленной сходимости, по сравнению с выше описанными модификациями.
метод обратного распространения ошибки .
Метод обратного распространения ошибки (англ. backpropagation)— метод обучения многослойного перцептрона. Впервые метод был описан в 1974 г. А.И. Галушкиным , а также независимо и одновременно Полом Дж. Вербосом . Далее существенно развит в 1986 г. Дэвидом И. Румельхартом, Дж. Е. Хинтоном и Рональдом Дж. Вильямсом и независимо и одновременно С.И. Барцевым и В.А. Охониным (Красноярская группа) .. Это итеративный градиентный алгоритм, который используется с целью минимизации ошибки работы многослойного перцептрона и получения желаемого выхода.
Основная идея этого метода состоит в распространении сигналов ошибки от выходов сети к ее входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы. Барцев и Охонин предложили сразу общий метод («принцип двойственности»), приложимый к более широкому классу систем, включая системы с запаздыванием, распределенные системы, и т. п.
Для возможности применения метода обратного распространения ошибки передаточная функция нейронов должна быть дифференцируема. Метод является модификацией классического метода градиентного спуска.
Сигмоидальные функции активации
Наиболее часто в качестве функций активации используются следующие виды сигмоид:
Функция Ферми (экспоненциальная сигмоида):

Рациональная сигмоида:
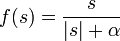
Гиперболический тангенс:
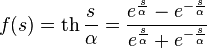 ,
,
где s — выход сумматора нейрона,  — произвольная константа.
— произвольная константа.
Менее всего, сравнительно с другими сигмоидами, процессорного времени требует расчет рациональной сигмоиды. Для вычисления гиперболического тангенса требуется больше всего тактов работы процессора. Если же сравнивать с пороговыми функциями активации, то сигмоиды рассчитываются очень медленно. Если после суммирования в пороговой функции сразу можно начинать сравнение с определенной величиной (порогом), то в случае сигмоидальной функции активации нужно рассчитать сигмоид (затратить время в лучшем случае на три операции: взятие модуля, сложение и деление), и только потом сравнивать с пороговой величиной (например, нулем). Если считать, что все простейшие операции рассчитываются процессором за примерно одинаковое время, то работа сигмоидальной функции активации после произведенного суммирования (которое займет одинаковое время) будет медленнее пороговой функции активации как 1:4.
Функция оценки работы сети
В тех случаях, когда удается оценить работу сети, обучение нейронных сетей можно представить как задачу оптимизации. Оценить — означает указать количественно, хорошо или плохо сеть решает поставленные ей задачи. Для этого строится функция оценки. Она, как правило, явно зависит от выходных сигналов сети и неявно (через функционирование) — от всех ее параметров. Простейший и самый распространенный пример оценки — сумма квадратов расстояний от выходных сигналов сети до их требуемых значений:
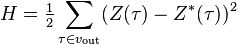 ,
,
где 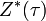 — требуемое значение выходного сигнала.
— требуемое значение выходного сигнала.
Метод наименьших квадратов далеко не всегда является лучшим выбором оценки. Тщательное конструирование функции оценки позволяет на порядок повысить эффективность обучения сети, а также получать дополнительную информацию — «уровень уверенности» сети в даваемом ответе .
Описание алгоритма
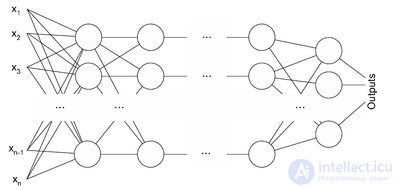
Архитектура многослойного перцептрона
Алгоритм обратного распространения ошибки применяется для многослойного перцептрона. У сети есть множество входов 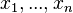 , множество выходов Outputs и множество внутренних узлов. Перенумеруем все узлы (включая входы и выходы) числами от 1 до N (сквозная нумерация, вне зависимости от топологии слоев). Обозначим через
, множество выходов Outputs и множество внутренних узлов. Перенумеруем все узлы (включая входы и выходы) числами от 1 до N (сквозная нумерация, вне зависимости от топологии слоев). Обозначим через  вес, стоящий на ребре, соединяющем i-й и j-й узлы, а через
вес, стоящий на ребре, соединяющем i-й и j-й узлы, а через  — выход i-го узла. Если нам известен обучающий пример (правильные ответы сети
— выход i-го узла. Если нам известен обучающий пример (правильные ответы сети 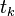 ,
, 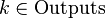 ), то функция ошибки, полученная по методу наименьших квадратов, выглядит так:
), то функция ошибки, полученная по методу наименьших квадратов, выглядит так:
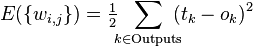
Как модифицировать веса? Мы будем реализовывать стохастический градиентный спуск, то есть будем подправлять веса после каждого обучающего примера и, таким образом, «двигаться» в многомерном пространстве весов. Чтобы «добраться» до минимума ошибки, нам нужно «двигаться» в сторону, противоположную градиенту, то есть, на основании каждой группы правильных ответов, добавлять к каждому весу
 ,
,
где 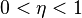 — множитель, задающий скорость «движения».
— множитель, задающий скорость «движения».
Производная считается следующим образом. Пусть сначала 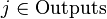 , то есть интересующий нас вес входит в нейрон последнего уровня. Сначала отметим, что влияет на выход сети только как часть суммы
, то есть интересующий нас вес входит в нейрон последнего уровня. Сначала отметим, что влияет на выход сети только как часть суммы 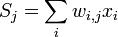 , где сумма берется по входам j-го узла. Поэтому
, где сумма берется по входам j-го узла. Поэтому
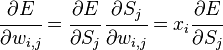
Аналогично, 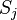 влияет на общую ошибку только в рамках выхода j-го узла
влияет на общую ошибку только в рамках выхода j-го узла 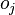 (напоминаем, что это выход всей сети). Поэтому
(напоминаем, что это выход всей сети). Поэтому
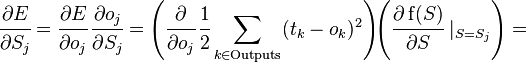
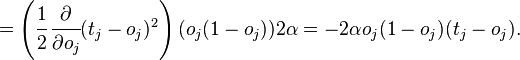
где 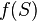 — соответствующая сигмоида, в данном случае — экспоненциальная
— соответствующая сигмоида, в данном случае — экспоненциальная

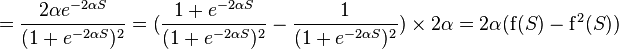
Если же j-й узел — не на последнем уровне, то у него есть выходы; обозначим их через Children(j). В этом случае
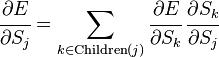 ,
,
и
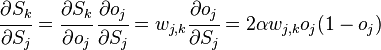 .
.
Ну а 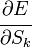 — это в точности аналогичная поправка, но вычисленная для узла следующего уровня будем обозначать ее через
— это в точности аналогичная поправка, но вычисленная для узла следующего уровня будем обозначать ее через 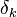 — от
— от 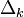 она отличается отсутствием множителя
она отличается отсутствием множителя  . Поскольку мы научились вычислять поправку для узлов последнего уровня и выражать поправку для узла более низкого уровня через поправки более высокого, можно уже писать алгоритм. Именно из-за этой особенности вычисления поправок алгоритм называется алгоритмом обратного распространения ошибки (backpropagation). Краткое резюме проделанной работы:
. Поскольку мы научились вычислять поправку для узлов последнего уровня и выражать поправку для узла более низкого уровня через поправки более высокого, можно уже писать алгоритм. Именно из-за этой особенности вычисления поправок алгоритм называется алгоритмом обратного распространения ошибки (backpropagation). Краткое резюме проделанной работы:
- для узла последнего уровня
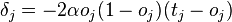
- для внутреннего узла сети
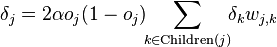
- для всех узлов

, где 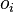 это тот же
это тот же 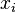 в формуле для
в формуле для 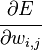
Получающийся алгоритм представлен ниже. На вход алгоритму, кроме указанных параметров, нужно также подавать в каком-нибудь формате структуру сети. На практике очень хорошие результаты показывают сети достаточно простой структуры, состоящие из двух уровней нейронов — скрытого уровня (hidden units) и нейронов-выходов (output units); каждый вход сети соединен со всеми скрытыми нейронами, а результат работы каждого скрытого нейрона подается на вход каждому из нейронов-выходов. В таком случае достаточно подавать на вход количество нейронов скрытого уровня.
Алгоритм
Алгоритм: BackPropagation 
- Инициализировать
 маленькими случайными значениями,
маленькими случайными значениями, 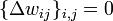
- Повторить NUMBER_OF_STEPS раз:
Для всех d от 1 до m:
- Подать
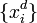 на вход сети и подсчитать выходы каждого узла.
на вход сети и подсчитать выходы каждого узла. - Для всех

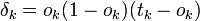 .
. - Для каждого уровня l, начиная с предпоследнего:
Для каждого узла j уровня l вычислить
 .
. - Для каждого ребра сети {i, j}
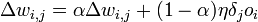 .
.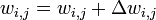 .
.
- Подать
- Выдать значения
 .
.
где — коэффициент инерциальнности для сглаживания резких скачков при перемещении по поверхности целевой функции
Математическая интерпретация обучения нейронной сети
На каждой итерации алгоритма обратного распространения весовые коэффициенты нейронной сети модифицируются так, чтобы улучшить решение одного примера. Таким образом, в процессе обучения циклически решаются однокритериальные задачи оптимизации.
Обучение нейронной сети характеризуется четырьмя специфическими ограничениями, выделяющими обучение нейросетей из общих задач оптимизации: астрономическое число параметров, необходимость высокого параллелизма при обучении, многокритериальность решаемых задач, необходимость найти достаточно широкую область, в которой значения всех минимизируемых функций близки к минимальным. В остальном проблему обучения можно, как правило, сформулировать как задачу минимизации оценки. Осторожность предыдущей фразы («как правило») связана с тем, что на самом деле нам неизвестны и никогда не будут известны все возможные задачи для нейронных сетей, и, быть может, где-то в неизвестности есть задачи, которые несводимы к минимизации оценки. Минимизация оценки — сложная проблема: параметров астрономически много (для стандартных примеров, реализуемых на РС — от 100 до 1000000), адаптивный рельеф (график оценки как функции от подстраиваемых параметров) сложен, может содержать много локальных минимумов.
Недостатки алгоритма
Несмотря на многочисленные успешные применения обратного распространения, оно не является панацеей. Больше всего неприятностей приносит неопределенно долгий процесс обучения. В сложных задачах для обучения сети могут потребоваться дни или даже недели, она может и вообще не обучиться. Причиной может быть одна из описанных ниже.
Паралич сети
В процессе обучения сети значения весов могут в результате коррекции стать очень большими величинами. Это может привести к тому, что все или большинство нейронов будут функционировать при очень больших значениях OUT, в области, где производная сжимающей функции очень мала. Так как посылаемая обратно в процессе обучения ошибка пропорциональна этой производной, то процесс обучения может практически замереть. В теоретическом отношении эта проблема плохо изучена. Обычно этого избегают уменьшением размера шага η, но это увеличивает время обучения. Различные эвристики использовались для предохранения от паралича или для восстановления после него, но пока что они могут рассматриваться лишь как экспериментальные.
Локальные минимумы
Обратное распространение использует разновидность градиентного спуска, то есть осуществляет спуск вниз по поверхности ошибки, непрерывно подстраивая веса в направлении к минимуму. Поверхность ошибки сложной сети сильно изрезана и состоит из холмов, долин, складок и оврагов в пространстве высокой размерности. Сеть может попасть в локальный минимум (неглубокую долину), когда рядом имеется гораздо более глубокий минимум. В точке локального минимума все направления ведут вверх, и сеть неспособна из него выбраться. Основную трудность при обучении нейронных сетей составляют как раз методы выхода из локальных минимумов: каждый раз выходя из локального минимума снова ищется следующий локальный минимум тем же методом обратного распространения ошибки до тех пор, пока найти из него выход уже не удается.
Размер шага
Внимательный разбор доказательства сходимости показывает, что коррекции весов предполагаются бесконечно малыми. Ясно, что это неосуществимо на практике, так как ведет к бесконечному времени обучения. Размер шага должен браться конечным. Если размер шага фиксирован и очень мал, то сходимость слишком медленная, если же он фиксирован и слишком велик, то может возникнуть паралич или постоянная неустойчивость. Эффективно увеличивать шаг до тех пор, пока не прекратится улучшение оценки в данном направлении антиградиента и уменьшать, если такого улучшения не происходит. П. Д. Вассерман описал адаптивный алгоритм выбора шага, автоматически корректирующий размер шага в процессе обучения. В книге А. Н. Горбаня предложена разветвленная технология оптимизации обучения.
Следует также отметить возможность переобучения сети, что является скорее результатом ошибочного проектирования ее топологии. При слишком большом количестве нейронов теряется свойство сети обобщать информацию. Весь набор образов, предоставленных к обучению, будет выучен сетью, но любые другие образы, даже очень похожие, могут быть классифицированы неверно.
Вау!! 😲 Ты еще не читал? Это зря!
- Обучение без учителя
- Обучение с подкреплением
- Обучение на примерах
- Задачи прогнозирования
- обучение без учителя , алгоритм k-means , обучение с частичным привлечением учителя ,
А как ты думаешь, при улучшении обучение с учителем, будет лучше нам? Надеюсь, что теперь ты понял что такое обучение с учителем, метод коррекции ошибки, метод обратного распространения ошибки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Машинное обучение
Ответы на вопросы для самопроверки пишите в комментариях,
мы проверим, или же задавайте свой вопрос по данной теме.

To clean up transmission errors introduced by Earth’s atmosphere (left), Goddard scientists applied Reed–Solomon error correction (right), which is commonly used in CDs and DVDs. Typical errors include missing pixels (white) and false signals (black). The white stripe indicates a brief period when transmission was interrupted.
In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
Definitions[edit]
Error detection is the detection of errors caused by noise or other impairments during transmission from the transmitter to the receiver.
Error correction is the detection of errors and reconstruction of the original, error-free data.
History[edit]
In classical antiquity, copyists of the Hebrew Bible were paid for their work according to the number of stichs (lines of verse). As the prose books of the Bible were hardly ever written in stichs, the copyists, in order to estimate the amount of work, had to count the letters.[1] This also helped ensure accuracy in the transmission of the text with the production of subsequent copies.[2][3] Between the 7th and 10th centuries CE a group of Jewish scribes formalized and expanded this to create the Numerical Masorah to ensure accurate reproduction of the sacred text. It included counts of the number of words in a line, section, book and groups of books, noting the middle stich of a book, word use statistics, and commentary.[1] Standards became such that a deviation in even a single letter in a Torah scroll was considered unacceptable.[4] The effectiveness of their error correction method was verified by the accuracy of copying through the centuries demonstrated by discovery of the Dead Sea Scrolls in 1947–1956, dating from c. 150 BCE-75 CE.[5]
The modern development of error correction codes is credited to Richard Hamming in 1947.[6] A description of Hamming’s code appeared in Claude Shannon’s A Mathematical Theory of Communication[7] and was quickly generalized by Marcel J. E. Golay.[8]
Principles[edit]
All error-detection and correction schemes add some redundancy (i.e., some extra data) to a message, which receivers can use to check consistency of the delivered message and to recover data that has been determined to be corrupted. Error detection and correction schemes can be either systematic or non-systematic. In a systematic scheme, the transmitter sends the original (error-free) data and attaches a fixed number of check bits (or parity data), which are derived from the data bits by some encoding algorithm. If error detection is required, a receiver can simply apply the same algorithm to the received data bits and compare its output with the received check bits; if the values do not match, an error has occurred at some point during the transmission. If error correction is required, a receiver can apply the decoding algorithm to the received data bits and the received check bits to recover the original error-free data. In a system that uses a non-systematic code, the original message is transformed into an encoded message carrying the same information and that has at least as many bits as the original message.
Good error control performance requires the scheme to be selected based on the characteristics of the communication channel. Common channel models include memoryless models where errors occur randomly and with a certain probability, and dynamic models where errors occur primarily in bursts. Consequently, error-detecting and correcting codes can be generally distinguished between random-error-detecting/correcting and burst-error-detecting/correcting. Some codes can also be suitable for a mixture of random errors and burst errors.
If the channel characteristics cannot be determined, or are highly variable, an error-detection scheme may be combined with a system for retransmissions of erroneous data. This is known as automatic repeat request (ARQ), and is most notably used in the Internet. An alternate approach for error control is hybrid automatic repeat request (HARQ), which is a combination of ARQ and error-correction coding.
Types of error correction[edit]
There are three major types of error correction:[9]
Automatic repeat request[edit]
Automatic repeat request (ARQ) is an error control method for data transmission that makes use of error-detection codes, acknowledgment and/or negative acknowledgment messages, and timeouts to achieve reliable data transmission. An acknowledgment is a message sent by the receiver to indicate that it has correctly received a data frame.
Usually, when the transmitter does not receive the acknowledgment before the timeout occurs (i.e., within a reasonable amount of time after sending the data frame), it retransmits the frame until it is either correctly received or the error persists beyond a predetermined number of retransmissions.
Three types of ARQ protocols are Stop-and-wait ARQ, Go-Back-N ARQ, and Selective Repeat ARQ.
ARQ is appropriate if the communication channel has varying or unknown capacity, such as is the case on the Internet. However, ARQ requires the availability of a back channel, results in possibly increased latency due to retransmissions, and requires the maintenance of buffers and timers for retransmissions, which in the case of network congestion can put a strain on the server and overall network capacity.[10]
For example, ARQ is used on shortwave radio data links in the form of ARQ-E, or combined with multiplexing as ARQ-M.
Forward error correction[edit]
Forward error correction (FEC) is a process of adding redundant data such as an error-correcting code (ECC) to a message so that it can be recovered by a receiver even when a number of errors (up to the capability of the code being used) are introduced, either during the process of transmission or on storage. Since the receiver does not have to ask the sender for retransmission of the data, a backchannel is not required in forward error correction. Error-correcting codes are used in lower-layer communication such as cellular network, high-speed fiber-optic communication and Wi-Fi,[11][12] as well as for reliable storage in media such as flash memory, hard disk and RAM.[13]
Error-correcting codes are usually distinguished between convolutional codes and block codes:
- Convolutional codes are processed on a bit-by-bit basis. They are particularly suitable for implementation in hardware, and the Viterbi decoder allows optimal decoding.
- Block codes are processed on a block-by-block basis. Early examples of block codes are repetition codes, Hamming codes and multidimensional parity-check codes. They were followed by a number of efficient codes, Reed–Solomon codes being the most notable due to their current widespread use. Turbo codes and low-density parity-check codes (LDPC) are relatively new constructions that can provide almost optimal efficiency.
Shannon’s theorem is an important theorem in forward error correction, and describes the maximum information rate at which reliable communication is possible over a channel that has a certain error probability or signal-to-noise ratio (SNR). This strict upper limit is expressed in terms of the channel capacity. More specifically, the theorem says that there exist codes such that with increasing encoding length the probability of error on a discrete memoryless channel can be made arbitrarily small, provided that the code rate is smaller than the channel capacity. The code rate is defined as the fraction k/n of k source symbols and n encoded symbols.
The actual maximum code rate allowed depends on the error-correcting code used, and may be lower. This is because Shannon’s proof was only of existential nature, and did not show how to construct codes that are both optimal and have efficient encoding and decoding algorithms.
Hybrid schemes[edit]
Hybrid ARQ is a combination of ARQ and forward error correction. There are two basic approaches:[10]
- Messages are always transmitted with FEC parity data (and error-detection redundancy). A receiver decodes a message using the parity information and requests retransmission using ARQ only if the parity data was not sufficient for successful decoding (identified through a failed integrity check).
- Messages are transmitted without parity data (only with error-detection information). If a receiver detects an error, it requests FEC information from the transmitter using ARQ and uses it to reconstruct the original message.
The latter approach is particularly attractive on an erasure channel when using a rateless erasure code.
Types of error detection[edit]
Error detection is most commonly realized using a suitable hash function (or specifically, a checksum, cyclic redundancy check or other algorithm). A hash function adds a fixed-length tag to a message, which enables receivers to verify the delivered message by recomputing the tag and comparing it with the one provided.
There exists a vast variety of different hash function designs. However, some are of particularly widespread use because of either their simplicity or their suitability for detecting certain kinds of errors (e.g., the cyclic redundancy check’s performance in detecting burst errors).
Minimum distance coding[edit]
A random-error-correcting code based on minimum distance coding can provide a strict guarantee on the number of detectable errors, but it may not protect against a preimage attack.
Repetition codes[edit]
A repetition code is a coding scheme that repeats the bits across a channel to achieve error-free communication. Given a stream of data to be transmitted, the data are divided into blocks of bits. Each block is transmitted some predetermined number of times. For example, to send the bit pattern 1011, the four-bit block can be repeated three times, thus producing 1011 1011 1011. If this twelve-bit pattern was received as 1010 1011 1011 – where the first block is unlike the other two – an error has occurred.
A repetition code is very inefficient and can be susceptible to problems if the error occurs in exactly the same place for each group (e.g., 1010 1010 1010 in the previous example would be detected as correct). The advantage of repetition codes is that they are extremely simple, and are in fact used in some transmissions of numbers stations.[14][15]
Parity bit[edit]
A parity bit is a bit that is added to a group of source bits to ensure that the number of set bits (i.e., bits with value 1) in the outcome is even or odd. It is a very simple scheme that can be used to detect single or any other odd number (i.e., three, five, etc.) of errors in the output. An even number of flipped bits will make the parity bit appear correct even though the data is erroneous.
Parity bits added to each word sent are called transverse redundancy checks, while those added at the end of a stream of words are called longitudinal redundancy checks. For example, if each of a series of m-bit words has a parity bit added, showing whether there were an odd or even number of ones in that word, any word with a single error in it will be detected. It will not be known where in the word the error is, however. If, in addition, after each stream of n words a parity sum is sent, each bit of which shows whether there were an odd or even number of ones at that bit-position sent in the most recent group, the exact position of the error can be determined and the error corrected. This method is only guaranteed to be effective, however, if there are no more than 1 error in every group of n words. With more error correction bits, more errors can be detected and in some cases corrected.
There are also other bit-grouping techniques.
Checksum[edit]
A checksum of a message is a modular arithmetic sum of message code words of a fixed word length (e.g., byte values). The sum may be negated by means of a ones’-complement operation prior to transmission to detect unintentional all-zero messages.
Checksum schemes include parity bits, check digits, and longitudinal redundancy checks. Some checksum schemes, such as the Damm algorithm, the Luhn algorithm, and the Verhoeff algorithm, are specifically designed to detect errors commonly introduced by humans in writing down or remembering identification numbers.
Cyclic redundancy check[edit]
A cyclic redundancy check (CRC) is a non-secure hash function designed to detect accidental changes to digital data in computer networks. It is not suitable for detecting maliciously introduced errors. It is characterized by specification of a generator polynomial, which is used as the divisor in a polynomial long division over a finite field, taking the input data as the dividend. The remainder becomes the result.
A CRC has properties that make it well suited for detecting burst errors. CRCs are particularly easy to implement in hardware and are therefore commonly used in computer networks and storage devices such as hard disk drives.
The parity bit can be seen as a special-case 1-bit CRC.
Cryptographic hash function[edit]
The output of a cryptographic hash function, also known as a message digest, can provide strong assurances about data integrity, whether changes of the data are accidental (e.g., due to transmission errors) or maliciously introduced. Any modification to the data will likely be detected through a mismatching hash value. Furthermore, given some hash value, it is typically infeasible to find some input data (other than the one given) that will yield the same hash value. If an attacker can change not only the message but also the hash value, then a keyed hash or message authentication code (MAC) can be used for additional security. Without knowing the key, it is not possible for the attacker to easily or conveniently calculate the correct keyed hash value for a modified message.
Error correction code[edit]
Any error-correcting code can be used for error detection. A code with minimum Hamming distance, d, can detect up to d − 1 errors in a code word. Using minimum-distance-based error-correcting codes for error detection can be suitable if a strict limit on the minimum number of errors to be detected is desired.
Codes with minimum Hamming distance d = 2 are degenerate cases of error-correcting codes and can be used to detect single errors. The parity bit is an example of a single-error-detecting code.
Applications[edit]
Applications that require low latency (such as telephone conversations) cannot use automatic repeat request (ARQ); they must use forward error correction (FEC). By the time an ARQ system discovers an error and re-transmits it, the re-sent data will arrive too late to be usable.
Applications where the transmitter immediately forgets the information as soon as it is sent (such as most television cameras) cannot use ARQ; they must use FEC because when an error occurs, the original data is no longer available.
Applications that use ARQ must have a return channel; applications having no return channel cannot use ARQ.
Applications that require extremely low error rates (such as digital money transfers) must use ARQ due to the possibility of uncorrectable errors with FEC.
Reliability and inspection engineering also make use of the theory of error-correcting codes.[16]
Internet[edit]
In a typical TCP/IP stack, error control is performed at multiple levels:
- Each Ethernet frame uses CRC-32 error detection. Frames with detected errors are discarded by the receiver hardware.
- The IPv4 header contains a checksum protecting the contents of the header. Packets with incorrect checksums are dropped within the network or at the receiver.
- The checksum was omitted from the IPv6 header in order to minimize processing costs in network routing and because current link layer technology is assumed to provide sufficient error detection (see also RFC 3819).
- UDP has an optional checksum covering the payload and addressing information in the UDP and IP headers. Packets with incorrect checksums are discarded by the network stack. The checksum is optional under IPv4, and required under IPv6. When omitted, it is assumed the data-link layer provides the desired level of error protection.
- TCP provides a checksum for protecting the payload and addressing information in the TCP and IP headers. Packets with incorrect checksums are discarded by the network stack and eventually get retransmitted using ARQ, either explicitly (such as through three-way handshake) or implicitly due to a timeout.
Deep-space telecommunications[edit]
The development of error-correction codes was tightly coupled with the history of deep-space missions due to the extreme dilution of signal power over interplanetary distances, and the limited power availability aboard space probes. Whereas early missions sent their data uncoded, starting in 1968, digital error correction was implemented in the form of (sub-optimally decoded) convolutional codes and Reed–Muller codes.[17] The Reed–Muller code was well suited to the noise the spacecraft was subject to (approximately matching a bell curve), and was implemented for the Mariner spacecraft and used on missions between 1969 and 1977.
The Voyager 1 and Voyager 2 missions, which started in 1977, were designed to deliver color imaging and scientific information from Jupiter and Saturn.[18] This resulted in increased coding requirements, and thus, the spacecraft were supported by (optimally Viterbi-decoded) convolutional codes that could be concatenated with an outer Golay (24,12,8) code. The Voyager 2 craft additionally supported an implementation of a Reed–Solomon code. The concatenated Reed–Solomon–Viterbi (RSV) code allowed for very powerful error correction, and enabled the spacecraft’s extended journey to Uranus and Neptune. After ECC system upgrades in 1989, both crafts used V2 RSV coding.
The Consultative Committee for Space Data Systems currently recommends usage of error correction codes with performance similar to the Voyager 2 RSV code as a minimum. Concatenated codes are increasingly falling out of favor with space missions, and are replaced by more powerful codes such as Turbo codes or LDPC codes.
The different kinds of deep space and orbital missions that are conducted suggest that trying to find a one-size-fits-all error correction system will be an ongoing problem. For missions close to Earth, the nature of the noise in the communication channel is different from that which a spacecraft on an interplanetary mission experiences. Additionally, as a spacecraft increases its distance from Earth, the problem of correcting for noise becomes more difficult.
Satellite broadcasting[edit]
The demand for satellite transponder bandwidth continues to grow, fueled by the desire to deliver television (including new channels and high-definition television) and IP data. Transponder availability and bandwidth constraints have limited this growth. Transponder capacity is determined by the selected modulation scheme and the proportion of capacity consumed by FEC.
Data storage[edit]
Error detection and correction codes are often used to improve the reliability of data storage media.[19] A parity track capable of detecting single-bit errors was present on the first magnetic tape data storage in 1951. The optimal rectangular code used in group coded recording tapes not only detects but also corrects single-bit errors. Some file formats, particularly archive formats, include a checksum (most often CRC32) to detect corruption and truncation and can employ redundancy or parity files to recover portions of corrupted data. Reed-Solomon codes are used in compact discs to correct errors caused by scratches.
Modern hard drives use Reed–Solomon codes to detect and correct minor errors in sector reads, and to recover corrupted data from failing sectors and store that data in the spare sectors.[20] RAID systems use a variety of error correction techniques to recover data when a hard drive completely fails. Filesystems such as ZFS or Btrfs, as well as some RAID implementations, support data scrubbing and resilvering, which allows bad blocks to be detected and (hopefully) recovered before they are used.[21] The recovered data may be re-written to exactly the same physical location, to spare blocks elsewhere on the same piece of hardware, or the data may be rewritten onto replacement hardware.
Error-correcting memory[edit]
Dynamic random-access memory (DRAM) may provide stronger protection against soft errors by relying on error-correcting codes. Such error-correcting memory, known as ECC or EDAC-protected memory, is particularly desirable for mission-critical applications, such as scientific computing, financial, medical, etc. as well as extraterrestrial applications due to the increased radiation in space.
Error-correcting memory controllers traditionally use Hamming codes, although some use triple modular redundancy. Interleaving allows distributing the effect of a single cosmic ray potentially upsetting multiple physically neighboring bits across multiple words by associating neighboring bits to different words. As long as a single-event upset (SEU) does not exceed the error threshold (e.g., a single error) in any particular word between accesses, it can be corrected (e.g., by a single-bit error-correcting code), and the illusion of an error-free memory system may be maintained.[22]
In addition to hardware providing features required for ECC memory to operate, operating systems usually contain related reporting facilities that are used to provide notifications when soft errors are transparently recovered. One example is the Linux kernel’s EDAC subsystem (previously known as Bluesmoke), which collects the data from error-checking-enabled components inside a computer system; besides collecting and reporting back the events related to ECC memory, it also supports other checksumming errors, including those detected on the PCI bus.[23][24][25] A few systems[specify] also support memory scrubbing to catch and correct errors early before they become unrecoverable.
See also[edit]
- Berger code
- Burst error-correcting code
- ECC memory, a type of computer data storage
- Link adaptation
- List of algorithms § Error detection and correction
- List of hash functions
References[edit]
- ^ a b «Masorah». Jewish Encyclopedia.
- ^ Pratico, Gary D.; Pelt, Miles V. Van (2009). Basics of Biblical Hebrew Grammar: Second Edition. Zondervan. ISBN 978-0-310-55882-8.
- ^ Mounce, William D. (2007). Greek for the Rest of Us: Using Greek Tools Without Mastering Biblical Languages. Zondervan. p. 289. ISBN 978-0-310-28289-1.
- ^ Mishneh Torah, Tefillin, Mezuzah, and Sefer Torah, 1:2. Example English translation: Eliyahu Touger. The Rambam’s Mishneh Torah. Moznaim Publishing Corporation.
- ^ Brian M. Fagan (5 December 1996). «Dead Sea Scrolls». The Oxford Companion to Archaeology. Oxford University Press. ISBN 0195076184.
- ^ Thompson, Thomas M. (1983), From Error-Correcting Codes through Sphere Packings to Simple Groups, The Carus Mathematical Monographs (#21), The Mathematical Association of America, p. vii, ISBN 0-88385-023-0
- ^ Shannon, C.E. (1948), «A Mathematical Theory of Communication», Bell System Technical Journal, 27 (3): 379–423, doi:10.1002/j.1538-7305.1948.tb01338.x, hdl:10338.dmlcz/101429, PMID 9230594
- ^ Golay, Marcel J. E. (1949), «Notes on Digital Coding», Proc.I.R.E. (I.E.E.E.), 37: 657
- ^ Gupta, Vikas; Verma, Chanderkant (November 2012). «Error Detection and Correction: An Introduction». International Journal of Advanced Research in Computer Science and Software Engineering. 2 (11). S2CID 17499858.
- ^ a b A. J. McAuley, Reliable Broadband Communication Using a Burst Erasure Correcting Code, ACM SIGCOMM, 1990.
- ^ Shah, Pradeep M.; Vyavahare, Prakash D.; Jain, Anjana (September 2015). «Modern error correcting codes for 4G and beyond: Turbo codes and LDPC codes». 2015 Radio and Antenna Days of the Indian Ocean (RADIO): 1–2. doi:10.1109/RADIO.2015.7323369. ISBN 978-9-9903-7339-4. S2CID 28885076. Retrieved 22 May 2022.
- ^ «IEEE SA — IEEE 802.11ac-2013». IEEE Standards Association.
- ^ «Transition to Advanced Format 4K Sector Hard Drives | Seagate US». Seagate.com. Retrieved 22 May 2022.
- ^ Frank van Gerwen. «Numbers (and other mysterious) stations». Archived from the original on 12 July 2017. Retrieved 12 March 2012.
- ^ Gary Cutlack (25 August 2010). «Mysterious Russian ‘Numbers Station’ Changes Broadcast After 20 Years». Gizmodo. Retrieved 12 March 2012.
- ^ Ben-Gal I.; Herer Y.; Raz T. (2003). «Self-correcting inspection procedure under inspection errors» (PDF). IIE Transactions. IIE Transactions on Quality and Reliability, 34(6), pp. 529-540. Archived from the original (PDF) on 2013-10-13. Retrieved 2014-01-10.
- ^ K. Andrews et al., The Development of Turbo and LDPC Codes for Deep-Space Applications, Proceedings of the IEEE, Vol. 95, No. 11, Nov. 2007.
- ^ Huffman, William Cary; Pless, Vera S. (2003). Fundamentals of Error-Correcting Codes. Cambridge University Press. ISBN 978-0-521-78280-7.
- ^ Kurtas, Erozan M.; Vasic, Bane (2018-10-03). Advanced Error Control Techniques for Data Storage Systems. CRC Press. ISBN 978-1-4200-3649-7.[permanent dead link]
- ^ Scott A. Moulton. «My Hard Drive Died». Archived from the original on 2008-02-02.
- ^ Qiao, Zhi; Fu, Song; Chen, Hsing-Bung; Settlemyer, Bradley (2019). «Building Reliable High-Performance Storage Systems: An Empirical and Analytical Study». 2019 IEEE International Conference on Cluster Computing (CLUSTER): 1–10. doi:10.1109/CLUSTER.2019.8891006. ISBN 978-1-7281-4734-5. S2CID 207951690.
- ^ «Using StrongArm SA-1110 in the On-Board Computer of Nanosatellite». Tsinghua Space Center, Tsinghua University, Beijing. Archived from the original on 2011-10-02. Retrieved 2009-02-16.
- ^ Jeff Layton. «Error Detection and Correction». Linux Magazine. Retrieved 2014-08-12.
- ^ «EDAC Project». bluesmoke.sourceforge.net. Retrieved 2014-08-12.
- ^ «Documentation/edac.txt». Linux kernel documentation. kernel.org. 2014-06-16. Archived from the original on 2009-09-05. Retrieved 2014-08-12.
Further reading[edit]
- Shu Lin; Daniel J. Costello, Jr. (1983). Error Control Coding: Fundamentals and Applications. Prentice Hall. ISBN 0-13-283796-X.
- SoftECC: A System for Software Memory Integrity Checking
- A Tunable, Software-based DRAM Error Detection and Correction Library for HPC
- Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing
External links[edit]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, contains chapters on elementary error-correcting codes; on the theoretical limits of error-correction; and on the latest state-of-the-art error-correcting codes, including low-density parity-check codes, turbo codes, and fountain codes.
- ECC Page — implementations of popular ECC encoding and decoding routines