
Книга посвящена всего лишь одному виду тестирования — тестированию доменного анализа (также его называют доменный анализ либо доменное тестирование).
Что это за вид тестирования, которому посвятили целых 488 страниц? Давайте разберемся.
Если мы с вами обратимся к глоссарию ISTQB, то определение доменного тестирования звучит следующим образом:
Доменное тестирование (domain analysis) — методика разработки тестов, относящаяся к методу черного ящика, использующаяся для определения действенных и эффективных тестовых сценариев в случаях, когда множественные параметры могут или должны быть протестированы одновременно. Методика базируется и обобщает методы эквивалентного разбиения и анализа граничных значений.
Если переформулировать проще, то определение будет следующим:
Доменное тестирование — это вид тестирования, направленный на анализ различных значений, поиск их взаимосвязи и составление эффективных тестов.
То есть суть доменного тестирования заключается в том, чтобы разделить набор условий тестирования на те значения, которые можно считать одинаковыми, и за счет этого протестировать эффективней.
Для понимания возьмем простой пример. Скажем, что у нас есть поле Логин и Пароль. В идеале, нам необходимо каждое поле протестировать по отдельности. Однако доменное тестирование позволяет сделать так, чтобы в одном тесте мы смогли проверить оба поля одновременно и без потери в качестве тестирования.
Пример из жизни. Возьмем два действия: 1. ехать в автобусе в качестве пассажира и 2. слушать аудиокнигу. Мы можем просто ехать в автобусе без прослушивания книги, как и слушать книгу, не едучи в автобусе. Но мы можем объединить эти два действия и слушать книгу, пока едем в автобусе. При таком объединении мы без потери качества и до нужного места доберемся, и книгу послушаем.
Конечно, тут тоже есть свои ограничения и нюансы. Например, будет так шумно, что мы ничего не услышим. Но и при реальном тестировании они тоже есть. Например, при вводе логина и пароля сайт выводит “общее” предупреждение, которое гласит: “Логин или пароль введены неверно”. То есть в этом случае мы не сможем понять, что именно неверно.
Разновидности доменного тестирования: признаки эквивалентности и анализ граничных значений
В основе использования доменного тестирования лежат различные техники, но наиболее популярные — это определение классов эквивалентности и граничных значений.
Давайте вспомним, что они означают.
Классы эквивалентности — это набор тестов, полное выполнение которого является избыточным и не приводит к обнаружению новых дефектов. Если мы ожидаем одинакового результата от выполнения двух и более тестов, эти тесты эквивалентны.
Граничные значения — это те места, в которых один класс эквивалентности переходит в другой. Эти места очень важны, их обязательно следует проверять в тестах, т.к. именно в этом месте чаще всего и обнаруживаются ошибки.
Цель доменного тестирования
Цель доменного тестирования — предоставить стратегию по выбору минимального набора показательных тестов.

Нет, естественно, не один, но должно остаться минимум тестов, которые будут самые эффективными.
Шаги для достижения цели:
- Для начала нужно разделить предполагаемые значения на отдельные группы, условия — это могут быть цифры, буквы, допустимый диапазон цифр, предполагаемые граничные значения.
- Далее необходимо выявить конкретный набор значений и выбрать из них наиболее показательные, представляющие каждую группу, включая обязательно границы. Здесь мы уже определяем значения, которые будем проверять.
- И далее необходимо скомбинировать эти значения таким образом, чтобы отдельные параметры можно было протестировать одновременно.
Давайте разберем все на конкретном примере.

К нам на тестирование поступает задача «протестировать форму авторизации». Форма состоит из двух полей: логин и пароль. Длина логина и пароля — от 5 до 10 символов. Логин может принимать различные символы, цифры и буквы на латинице. Пароль тоже может принимать символы, цифры и латиницу.
Решение:
- Для начала разделим все предполагаемые значения на группы:
- Кол-во значений от — ∞ до 4
- Кол-во значений от 5 до 10
- Кол-во значений 11 до + ∞
- Спец. символы
- Буквы (латиница)
- Цифры
2. Выявляем наборы значений, представляющие каждую группу:
- 4
- 5, 7, 10
- 11
- @, !, $
- a, b, w, l
- 2, 4
3. И далее скомбинируем эти значения в виде таблицы.

Таким образом, мы добились наиболее эффективных тестов, которые не только максимально покрывают необходимые проверки, но и экономят наше время.
Плюсы и минусы доменного тестирования
У доменного тестирования есть свои как плюсы, так и свои минусы.
К достоинствам можно отнести:
- Обнаружение ошибок при минимальном количестве тестов.
- Простой и понятный подход.
Недостатки:
- Низкая вероятность обнаружения ошибок за пределами границ допущенных значений. Потому что данный метод использует технику граничных значений.
- Низкая вероятность обнаружения ошибок в сложных формах, когда, например, возможно большое кол-во различных полей, символов или значений. Так как всегда присутствует человеческий фактор, можно запутаться и что-то не учесть.
- Часто бывает сложно разделить на группы, необходимые для тестирования, так как не всегда бывает легко применить технику классы эквивалентности.
Полезные хитрости
Также есть и свои полезные трюки, которые вам могут пригодиться.
- Производите сразу несколько позитивных тестов (например, ввод данных в несколько полей), вместо одного.
- Не стоит комбинировать больше семи позитивных значений одновременно, иначе тест будет громоздким. В случае обнаружения ошибки ее придется долго локализовывать.
- С негативными тестами так комбинировать, к сожалению, не получится, так как мы должны быть уверены, что тестируемая программа корректно отслеживает проблемы с каждым из полей.
- Не стоит в одном тесте комбинировать позитивные и негативные сценарии. Каждое негативное условие всегда проверяется отдельно.
- Начинайте проверку с граничных значений, так вы откините большое количество ненужных проверок.
Если подытожить, то доменное тестирование — это не новый вид тестирования, а рекомбинация и формализация уже существующих техник.
Основное его преимущество — это сокращение количества проверяемых значений без потери эффективности тестирования. То есть правильное применение техники приводит к уменьшению количества тестов без ухудшения качества тестирования.
Last updated on Jul 13,2020 4K Views
A Data Science Enthusiast with in-hand skills in programming languages such as… A Data Science Enthusiast with in-hand skills in programming languages such as Java & Python.
14 / 15 Blog from Introduction to Software Testing
Domain testing is a well-known software testing technique. This is a type of Functional Testing that tests the application or the software by inserting inputs and accessing appropriate outputs. In this article, we will get into the depth of domain testing in the following sequence:
- What is Domain Testing in Software Testing?
- Domain Testing Strategy
- What domain are we testing?
- How to group the values into classes?
- Which values of the classes are to be tested?
- How to determine the result?
- Domain Knowledge
- Domain Testing Structure
Let’s begin!
What is Domain Testing in Software Testing?
Domain testing is a software testing technique. The output has to be tested with a minimum number of inputs, to make sure that the system does not accept invalid values or values which are out of range.
Have you heard about White Box Testing? Well, it is a fine example of domain testing. The prime goal of domain testing is to validate whether the system is intaking the input within the specified range or not. It also checks the delivery of the required output.
After understanding the meaning of domain testing, let us look at the next topic.
Domain Testing Strategy
In domain testing strategy, there are few points that have to be kept in mind:
- What domain are we testing?
- How to group the values into classes?
- Which values of the classes are to be tested?
- How to determine the result?
What domain are we testing?
Whichever domain you test, comprises of an input and output functionality. After entering the input values, the output is verified.
How to group the values into classes?
To group the values into classes we need to bifurcate the values into some subsets. We call the process, partitioning the values. Now, to clarify the concept, there are two types of partitioning:
-
Equivalence Partitioning :
It divides the input data of a software unit into partitions of equivalent data from which test cases can be derived.
-
Boundary-value Analysis:
The tests are designed to include representatives of boundary values in a range.
To gain clarity, I am citing here an example. Here, we are partitioning the values into a subset or the subset. With a simple example, let me explain:
-
Group 1 : Employees with salary from 5 to 10 lacs
-
Group 2 : Employees with salary from 10 to 15 lacs
-
Group 3 : Employees with salary from 15 to 20 lacs
-
Group 4 : Employees with salary more than 20 lacs
Which values of the classes are to be tested?
For the values of the class to be tested we need the boundary values. By boundary values I mean,
Group 1 : Employees with salary from 5 to 10 lacs
Here, the values that should be considered are:
- Equal to or lesser than 5 lacs. Hence, the amount of 10 lacs should be included in this class.
- Greater than 5. Hence, the amount 5 lacs should not be included in this class.
- Equal to or lesser than 10. Hence, amount of 11 lacs should not be included in this class.
- Greater than 5. Hence, amount of 6 lacs should be included in this class.
After boundary values, the next key to understand is equivalence partition values.
Again citing the same example: Employees with salary from 5 to 10 lacs
As the values from 6 to 10 are valid ones, one of the values among 6,7,8,9 and 10 has to be picked. Suppose you select 8, Hence, the selected value “8” is a valid input for the group between (Salary >5 lacs and <=10 Lacs).
This sort of partition is referred to as equivalence partition.
Hence, this is the way we group our values!
How to determine the result?
The input is given and the expected output will give us the results and this is accomplished through domain knowledge.
Now, what is domain knowledge?
Domain Knowledge
Domain knowledge is a fine understanding of a particular sphere. It means that a person is familiar with specific terms of the discipline. It helps to reduce the delivery cycle and shorten development time. It also improves customer service and enhances flexibility.
Moving further, let us understand the structure of domain testing
Domain Testing Structure
There are certain key points that formulate the structure of domain testing:
- Decide what can go wrong with the boundaries set.
- Find strategies to handle each case.
- Pick several points to test for each error.
- Use one test point to check the adjacent domains.
- Check off redundant test points.
- Start running the tests.
- Determine if any boundaries contain error/fault.
- Verify each boundary of all the domains.
With this, I have reached towards the end of my blog. I hope the content added value to your Software Testing knowledge. Stay tuned!
Now that you have understood Domain Testing in Software Testing, check out the Software Testing Fundamentals Course by Edureka. This course is designed to introduce you to the complete software testing life-cycle. You will be learning different levels of testing, test environment setup, test case design technique, test data creation, test execution, bug reporting, CI/CD pipeline in DevOps, and other essential concepts of software testing. Got a question for us? Please mention it in the comments section of “What is Software Testing” and we will get back to you.
Got a question for us? Please mention it in the comments section of this “Domain Testing in Software Testing” blog and we will get back to you as soon as possible.
Last updated on Jul 13,2020 4K Views
A Data Science Enthusiast with in-hand skills in programming languages such as… A Data Science Enthusiast with in-hand skills in programming languages such as Java & Python.
14 / 15 Blog from Introduction to Software Testing
Domain testing is a well-known software testing technique. This is a type of Functional Testing that tests the application or the software by inserting inputs and accessing appropriate outputs. In this article, we will get into the depth of domain testing in the following sequence:
- What is Domain Testing in Software Testing?
- Domain Testing Strategy
- What domain are we testing?
- How to group the values into classes?
- Which values of the classes are to be tested?
- How to determine the result?
- Domain Knowledge
- Domain Testing Structure
Let’s begin!
What is Domain Testing in Software Testing?
Domain testing is a software testing technique. The output has to be tested with a minimum number of inputs, to make sure that the system does not accept invalid values or values which are out of range.
Have you heard about White Box Testing? Well, it is a fine example of domain testing. The prime goal of domain testing is to validate whether the system is intaking the input within the specified range or not. It also checks the delivery of the required output.
After understanding the meaning of domain testing, let us look at the next topic.
Domain Testing Strategy
In domain testing strategy, there are few points that have to be kept in mind:
- What domain are we testing?
- How to group the values into classes?
- Which values of the classes are to be tested?
- How to determine the result?
What domain are we testing?
Whichever domain you test, comprises of an input and output functionality. After entering the input values, the output is verified.
How to group the values into classes?
To group the values into classes we need to bifurcate the values into some subsets. We call the process, partitioning the values. Now, to clarify the concept, there are two types of partitioning:
-
Equivalence Partitioning :
It divides the input data of a software unit into partitions of equivalent data from which test cases can be derived.
-
Boundary-value Analysis:
The tests are designed to include representatives of boundary values in a range.
To gain clarity, I am citing here an example. Here, we are partitioning the values into a subset or the subset. With a simple example, let me explain:
-
Group 1 : Employees with salary from 5 to 10 lacs
-
Group 2 : Employees with salary from 10 to 15 lacs
-
Group 3 : Employees with salary from 15 to 20 lacs
-
Group 4 : Employees with salary more than 20 lacs
Which values of the classes are to be tested?
For the values of the class to be tested we need the boundary values. By boundary values I mean,
Group 1 : Employees with salary from 5 to 10 lacs
Here, the values that should be considered are:
- Equal to or lesser than 5 lacs. Hence, the amount of 10 lacs should be included in this class.
- Greater than 5. Hence, the amount 5 lacs should not be included in this class.
- Equal to or lesser than 10. Hence, amount of 11 lacs should not be included in this class.
- Greater than 5. Hence, amount of 6 lacs should be included in this class.
After boundary values, the next key to understand is equivalence partition values.
Again citing the same example: Employees with salary from 5 to 10 lacs
As the values from 6 to 10 are valid ones, one of the values among 6,7,8,9 and 10 has to be picked. Suppose you select 8, Hence, the selected value “8” is a valid input for the group between (Salary >5 lacs and <=10 Lacs).
This sort of partition is referred to as equivalence partition.
Hence, this is the way we group our values!
How to determine the result?
The input is given and the expected output will give us the results and this is accomplished through domain knowledge.
Now, what is domain knowledge?
Domain Knowledge
Domain knowledge is a fine understanding of a particular sphere. It means that a person is familiar with specific terms of the discipline. It helps to reduce the delivery cycle and shorten development time. It also improves customer service and enhances flexibility.
Moving further, let us understand the structure of domain testing
Domain Testing Structure
There are certain key points that formulate the structure of domain testing:
- Decide what can go wrong with the boundaries set.
- Find strategies to handle each case.
- Pick several points to test for each error.
- Use one test point to check the adjacent domains.
- Check off redundant test points.
- Start running the tests.
- Determine if any boundaries contain error/fault.
- Verify each boundary of all the domains.
With this, I have reached towards the end of my blog. I hope the content added value to your Software Testing knowledge. Stay tuned!
Now that you have understood Domain Testing in Software Testing, check out the Software Testing Fundamentals Course by Edureka. This course is designed to introduce you to the complete software testing life-cycle. You will be learning different levels of testing, test environment setup, test case design technique, test data creation, test execution, bug reporting, CI/CD pipeline in DevOps, and other essential concepts of software testing. Got a question for us? Please mention it in the comments section of “What is Software Testing” and we will get back to you.
Got a question for us? Please mention it in the comments section of this “Domain Testing in Software Testing” blog and we will get back to you as soon as possible.
Какие есть методы поиска доменных ошибок
 Как вы все знаете в локальных сетях построенных на использовании контроллеров домена Active Directory, они несут самую наиважнейшую роль, так как без их нормальной работы, можно забыть про стабильность данной конструкции. В первоочередные обязанности системного администратора, входит проверка наличия ошибок на DC и их устранение. Для меня наиболее удобным вариантом оказался простейший пакетный файл, который состоит всего из пары строк:
Как вы все знаете в локальных сетях построенных на использовании контроллеров домена Active Directory, они несут самую наиважнейшую роль, так как без их нормальной работы, можно забыть про стабильность данной конструкции. В первоочередные обязанности системного администратора, входит проверка наличия ошибок на DC и их устранение. Для меня наиболее удобным вариантом оказался простейший пакетный файл, который состоит всего из пары строк:
Содержание скрипта
Приведенный выше файл автоматически тестирует все контроллеры домена в лесу и выводит отчет на экран. Ваша задача – визуально проверить отчет на наличие строк, в которых встречается слово “failed”. Если все тесты содержат “passed’, значит с высокой долей вероятности Active Directory в вашей сети повышенного внимания не требует. Вот реальный пример показывающий, что есть проблемы с доступностью некоторых DC.

На втором шаге, так же обнаружены неисправности, которые требуют устранения.

Я бы рекомендовал запускать такой пакетный файл каждое утро перед началом работы.
Дополнительная информация об утилите dcdiag:
ссылка
Источник
Доменное тестирование (domain testing)
Доменное тестирование (domain testing) – вид тестирования, направленный на анализ показательных значений и взаимосвязи элементов. Доменный анализ в тестировании также известен как:
В доменном тестировании входные данные считаются эквивалентными, если программа проходит один и тот же путь выполнения для их обработки.
Класс эквивалентности (equivalence class) – набор тестов, полное выполнение которого является избыточным и не приводит к обнаружению новых дефектов. Другими словами, если мы ожидаем одинакового результата от выполнения двух и более тестов, эти тесты эквивалентны. Такие множества тестов называются классами эквивалентности.
Доменное тестирование (domain testing, domain analysis) — техника создания эффективных и результативных тест кейсов в случае, когда несколько переменных могут или должны быть протестированы одновременно. – Определение доменного тестирования из «Тестирование программного обеспечения. Базовый курс» / С. С. Куликов. — Минск, 2017.
Доменное тестирование: признаки эквивалентности
Идея этого метода состоит в том, чтобы разделить набор условий тестирования на, которые можно считать одинаковыми (т. е. система должна обрабатывать их одинаково), таким образом, признаками эквивалентности можно считать (несколько тестов эквивалентны, если):
Основная цель доменного тестирования — это предоставить стратегию по выбору минимального набора показательных тестов. Конечно, должен остаться не один тест, но минимум, при чем именно показательные тесты.

Domain testing: подход к достижению цели
Если очертить подход к достижению цели доменного тестирования, то можно выделить следующие шаги:
Сформировать конечный набор «наиболее показательных» значений и провести тесты с их использованием
Плюсы и минусы доменного тестирования
Нужно признать, что Доменное тестирование имеет как достоинства так и недостатки, поэтому давайте их перечислим.
Плюсы:
Минусы:
Доменное тестирование: эквивалентность и анализ граничных значений
Анализ граничных значений одна из наиболее популярных разновидностей domain testing, поэтому приведем пример. Доменный анализ в тестировании основной целью имеет то, чтобы проверить, принимает ли система входные данные в допустимом диапазоне и выдает требуемые выходные данные. Кроме того, он проверяет, что система не должна принимать входные данные, условия и индексы за пределами указанного или действительного диапазона.
Следующее поле пароля может содержать не менее 6 и не более 10 символов. Это означает, что результаты для значений в разделах 0-5, 6-10, 11-14 должны быть эквивалентны.

| Тестовый сценарий № | Описание сценария теста | Ожидаемый результат |
|---|---|---|
| 1 | Введите от 0 до 5 символов в поле пароля | Система не должна принимать |
| 2 | Введите от 6 до 10 символов в поле пароля | Система должна принять |
| 3 | Введите от 11 до 14 символов в поле пароля | Система не должна принимать |
Таким образом, нам нет необходимости проверять все возможные значения, потому что, если это будет сделано, число тестов станет больше. Чтобы решить эту проблему, мы используем гипотезу разделения эквивалентности, где мы тестируем возможные значения из каждой группы, как показано выше, где поведение системы можно считать одинаковым.
Такое разделение и есть классами эквивалентности. Затем мы выбираем только одно значение из каждого раздела для тестирования. Гипотеза, лежащая в основе этого метода, заключается в том, что если одно условие / значение в разделе проходит, все остальные также будут проходить. Аналогичным образом, если одно условие в разделе не выполняется, все остальные условия в этом разделе не будут выполнены.
Анализ граничных значений — вы проверяете границы между разделами эквивалентности. В нашем примере вместо проверки одного значения для каждого раздела вы будете проверять значения в таких разделах, как 0, 5, 6, 10, 11. Как вы можете заметить, вы проверяете значения как на допустимых, так и на недопустимых границах.
Разделение эквивалентности и анализ граничных значений (BVA) тесно связаны между собой и могут использоваться вместе на всех уровнях тестирования.
Доменное тестирование: полезные трюки

И напоследок полезные трюки, которые можно применять при доменном тестировании и не только.
Делим или умножаем на два
Позитивное вместе, негативное отдельно

Используем готовые чек-листы:
Источник
Как проверить историю доменного имени: 7 способов

Нет времени читать статью?
Но вам требуется продвижение сайта или создание сайта-лидера, идеального для SEO? Тогда вы можете оставить заявку на продвижение или заявку на создание сайта. Если вы собираетесь продвигать сайт самостоятельно — продолжайте чтение!
Всем привет, сегодня мы будем рассказывать снова про домены, к слову, недавно мы уже писали, что такое домен, не читали? Переходите по ссылке. В новой статье мы расскажем, как проверить историю домена и почему это нужно делать обязательно перед покупкой домена.
Если вы создаете себе сайт, либо собираетесь заказывать у профессионалов, вам обязательно нужно определиться с будущем вашем именем домене, и понимать какой именно домен вам нужен — новый, либо с хорошей историей.
Зачем нужен проверить историю домена?
Если вы делаете сайт в первый, значит вы еще не сталкивались еще с такими проблемами, как фильтры поисковых систем, репутация вашего домена, ранжирование сайта и так далее. Сейчас в интернете много разных алгоритмов, которые анализируют ваш сайт по разным показателям, в том числе и как работал ваш сайт.
Узнать про все возможные фильтры и блокировки поисковых систем почти нереально, можно лишь догадываться или анализировать данные домена, которые у него есть в истории домена. Именно об этом способе и поговорим подробнее.
Методы проверки истории домена
Проверка на сайте Reg.ru (платный способ)
Это самый простой способ проверки, который основа на специальном сервисе проверки, он находится у регистратора REG.RU (ссылка на регистратор).

Если вы хотите проверить с десяток доменов, да это может быть дорого, особенно учитывая, что вы будете искать хороший свободный домен.
Мы понимаем, что не каждый готов платить, поэтому дальше предлагаем вам бесплатные сервисы проверки истории доменов.
Сервис Whoishistory.ru (он же who.ru)
У сайта есть две версии, простая и расширенная, вторую можно не использовать, потому что ничего глобального она не дает и важного юзеру по проверке домена. Проверить историю домена, можно указав в зеленой зоне (поле) адрес нужного домена и нажать кнопку «найти».


То есть мы видим, что наш домен был за последнее время, как доступен к регистрации, где был размещен по хостингу. Кем был именно зарегистрирован, компания или физическое лицо. Также дата регистрации, и даты когда домен продлевали.
Самое главное вы поймете использовали его или нет, и кто и когда.
Linkpad.ru
Сайт Linkpad.ru — это поиск внутренних, внешних и исходящих ссылок на вашем сайте. Если вдруг домен раньше регистрировался, то вы можете посмотреть все его ссылки, когда он нормально индексировался, что с ним случилось и кто ссылался на него.
Кроме тематики бывшего сайта, вы также сможете понять, какие у него были ссылки с сайтов.


Как мы видим, домен регистрировался, однако у него нормальная история, поэтому можно регистрироваться или покупать. Но учитывая, что он трастовый, сервис регистрации предлагает его купить больше чем за 28 000 рублей.
whois.domaintools.com
Сервис domaintools.com, позволяет быстро получить Whois, то есть историю домена бесплатно в пару кликов.

Чтобы проверить историю домена на сайте, просто вводим домен и нажимаем найти историю.

После мы видим, что у нас есть история домена, когда регистрировалась, кем. Кроме этого показывает еще историю самого сайта, где находится, как работает.
Archive.org
Сайт вебархив — это крутой сайт, где есть много историй сайтов. Робот сайта часто сохраняет данные разных сайтов, так к примеру вы можете посмотреть как раньше выглядел ВК в 2015, когда были стены. Подробнее о нем мы уже писали в блоге.

Пишем сюда домен, и нажимаем просто Enter, дальше ждем историю домена.

На этой странице вы сможете понять, когда впервые появились снимки домена, например у нашего домена регистрация началась с 2013 года, хотя был зареган с 2011 года. Вы можете нажать на синий кружок, откроется история и можете посмотреть историю за нужную дату.
Данными крайними двумя способами можно определить, что за сайт находился на домене, и нарушал ли он какие-либо нормы интернета.
Как проверить историю домена в поиске
Часто бывает так, что историю о бывшем домене может рассказать и поисковая система. Вы просто вводите адрес домена, и смотрите сколько результатов найдено. Если же вы напишите домен в кавычках или же поставите восклицательный знак спереди, то получите только точные вхождения, где есть информация о домене.

Вот пример о том, что точное вхождение нашего сайта есть на 2000+ сайтов/адресов.
RDS bar
Расширение RDS bar для браузера, оно помогает разным вебмастера узнать информацию о сайте. Когда вы заходите на домен и видите, что у домена есть история, значит он зареган был когда то и его данные сейчас не нулевые.
Вы должны установить расширение, а после ввести адрес сайта, и увидеть его статистику, даже если сайт недоступен, но нужно ждать полной загрузке.

Сегодня рассказал об основных способах проверки истории домена, которые сами используем. Однако нужно понимать, что есть и другие ресурсы, которые помогают вам получить еще информацию.
В сети много есть сайтов, которые делают бесплатный быстрый анализ сайта:
Они также могут показать историю домена, однако некоторые требуют оплату к полному функционалу. Если у вас остались вопросы или хотите сказать спасибо, пишите в комментарии, они открыты для всех.
Источник
Технический аудит сайта: когда проводить, какие инструменты использовать и что проверять
Когда нужно проводить технический аудит, с какой периодичностью
Технический аудит сайта обязательно проводится перед запуском проекта, после редизайна, переезда, изменения структуры, а также не реже одного раза в один-два месяца (зависит от размера ресурса).
Какие инструменты использовать
Для проведения технического аудита вам понадобятся:
C помощью сервиса Яндекс.Вебмастер можно узнать:
— какие страницы проиндексированы и участвуют в поиске, а какие – отдают ошибки;
— информацию о добавленных или удалённых страницах;
— о вирусах и вредоносном коде, наложенных фильтрах;
— скорость загрузки страниц;
— настройки региональности сайта;
— файл robots.txt;
— файлы Sitemap и т. д.
C помощью сервиса Google Search Console можно проверить:
— нет ли на сайте внутренних дублей или дублирования заголовков и метаописаний;
— применённые к сайту фильтры;
— ошибки внутри сайта, связанные с недоступностью страниц;
— информацию о поисковой видимости и посещаемости сайта;
— внешние ссылки: общее количество ссылок, какие сайты и страницы ссылаются на вас, на какие страницы вашего сайта ведут ссылки, какие анкоры (тексты) у ссылок;
— как распределяются внутренние ссылки сайта;
— удобство просмотра на мобильных устройствах;
— заблокированные ресурсы;
— ошибки сканирования;
— файл robots.txt;
— файлы Sitemap.
С помощью парсера можно проанализировать техническую составляющую сайта. Программа позволяет выявить множество технических ошибок: битые ссылки, дубли Title, Description и заголовков H, неисправные редиректы, уровень вложенности и т. д.
Есть платные (ComparseR, Netpeak Spider, Screaming Frog и др.) и бесплатные (WildShark SEO Spider, Xenu, Majento SiteAnalayzer 1.4.4.91 и т. д.) программы. Они помогут выявить и устранить технические ошибки, которые мешают продвижению.
Подробный обзор наиболее популярных парсеров в нашем блоге – «Обзор ТОП-6 парсеров сайтов».
Что нужно проверять
Код ответа сервера
При проверке кода ответа сервера убедитесь, что:
— Для склеивания страниц на сайте используется 301 редирект вместо 302.
— Все несуществующие страницы отдают 404 код ответа сервера. Также проверьте, настроена ли страница 404 ошибки. Для этого введите любую несуществующую страницу на сайте и посмотрите, что будет видеть пользователь: понятно ли, что это страница ошибки, есть ли ссылки на другие разделы сайта, логотип и т. д. О том, как оформить страницу 404, подробно описано в статье «Error 404 — что значит, как найти и исправить ошибку».
— Все существующие и нужные страницы отдают 200 ОК.
Код ответа сервера можно проверить с помощью онлайн-сервиса Mainspy.ru.
Для проверки нужно ввести URL страницы и нажать на кнопку «Проверить».

Также можно использовать Яндекс.Вебмастер или расширения для браузеров:
С их помощью можно в один клик получить информацию по отдельным страницам.
Битые ссылки
Чаще всего причиной появления битых ссылок становится удаление старых ненужных страниц и файлов или изменения в структуре сайта.
Для проверки сайта на наличие внутренних и внешних битых ссылок можно использовать:
Для этого перейдите в «Индексирование» → «Страницы в поиске» → «Исключенные страницы» → «Ошибка 404»:

Зайдите в Search Console → «Сканирование» → «Ошибки сканирования» → «Ошибка 404»:

— бесплатные программы WildShark SEO Spider, Xenu, Majento SiteAnalayzer 1.4.4.
После того как будут найдены битые ссылки, определите, что делать с каждой из них:
Корректная настройка зеркал сайта
Чаще всего зеркало сайта возникает из-за www-префикса. Также бывают случаи, когда при переезде на другой домен забывают настроить 301-й редирект.
Убедитесь, что у сайта одно главное зеркало. Для этого надо проверить:
— настроен ли 301-й редирект с дубликатов на основной сайт;
— правильно ли указан основной домен в панелях Google Search Console, Яндекс.Вебмастере и файле robots.txt.
Внутренние дубли
Проверьте, нет ли на сайте дублей. Внутренние дубли могут привести к ухудшению индексации сайта, смене релевантной страницы в выдаче и понижению позиций.
Часто встречаются внутренние дубли, когда:
Основные методы поиска дублей на сайте
1. Яндекс.Вебмастер
Зайдите в Яндекс.Вебмастер → «Индексирование» → «Страницы в поиске» → «Исключенные страницы», выберите статус «Дубль».

2. Панели вебмастеров Google
Зайдите в Search Console → «Оптимизация» → «Оптимизация HTML». На этой странице можно увидеть количество повторяющихся метатегов и заголовков Title.
Так можно найти полные дубли страниц:

3. Парсер
Для поиска дублей можно воспользоваться одним из популярных парсеров. Например: WildShark SEO Spider, Xenu, Majento SiteAnalayzer 1.4.4.91, SEO Spider и т. д.
Для этого просканируйте сайт, отсортируйте результаты по заголовку и ищите визуальные совпадения заголовков.

Скорость загрузки сайта
Проверьте скорость загрузки сайта. Исходя из собственной практики и рекомендаций поисковых систем, мы можем определить следующие требования:
— Время до первого байта (TTFB): до 300 мс. Google в своей справке рекомендует 200 мс, но на практике загрузка и 300 мс. не всегда возможна.
— Время загрузки страницы: 3–5 с.
— Время рендеринга: до 1,5 с.
Нужно отметить, что на ранжирование, прежде всего, влияет время ответа сервера (получение первого байта).
Если ваше значение выше, постарайтесь ускорить загрузку сайта.
Сервисы проверки скорости загрузки:
Увидеть, есть ли недочёты, можно с помощью сервиса Google PageSpeed

Подробнее узнать, как оптимизировать скорость загрузки сайта, можно здесь.
Наличие корректно настроенного файла robots.txt
Проверьте, заполнен ли robots.txt в соответствии с правилами, не допущены ли при его создании ошибки.
Перечень ошибок, возникающих при анализе robots.txt, можно посмотреть в Яндекс.Помощь.
Проверить файл можно с помощью сервисов:
— Яндекс.Вебмастер
Яндекс.Вебмастер → «Анализ robots.txt».

— Google Search Console

Гайд по robots.txt: как создать, настроить и проверить.
Sitemap
Убедитесь, что на сайте создана карта в формате XML (Sitemap) и добавлена в панель инструментов для вебмастеров Google и Яндекса.
Проверьте, не допущены ли в ней ошибки. Сделать это можно с помощью специальных инструментов поисковых систем Яндекс и Google.
Яндекс.Вебмастер → «Инструменты» → «Анализ файлов Sitemap»

Зайдите в Search Console → «Сканирование» → «Ошибки сканирования» → «файлы Sitemap»

Недостаточно качественные страницы
Убедитесь, что на сайте нет удалённых низкокачественных страниц. Найти исключённые страницы можно с помощью Яндекс.Вебмастера и Google Search Console.
Яндекс.Вебмастер
Переходим в раздел «Индексирование» → «Страницы в поиске» → «Исключенные страницы», выбираем фильтр «Недостаточно качественные».

Google Search Console
Сигналом от Google о том, какие страницы были удалены из поиска из-за качества, можно считать «Отправленный URL возвращает ложную ошибку 404». В таких случаях нужно проанализировать страницы, убедиться, что они существуют, а не удалены (и просто ответ сервера некорректен).
Подробнее о мягкой 404 можно прочитать в нашем блоге.
Подробнее о страницах низкого качества написано в этой статье «Страницы низкого качества или как понять, что твой сайт “не очень”»
Адаптивный дизайн сайта
Доля мобильного трафика постоянно растёт, поэтому важно проверить адаптивность сайта под мобильные устройства.
Для проверки можно использовать:
Инструмент позволяет проверить скорость загрузки страниц и даёт рекомендации, как эту скорость повысить.

Инструмент позволяет проанализировать, как выглядит сайт на смартфоне, скорость загрузки и отображения информации.

— Посмотреть как Googlebot (в панели Google Search Console).
Инструмент позволяет проанализировать отображение сайта на разных устройствах.

— Яндекс.Вебмастер → «Инструменты» → «Проверка мобильных страниц».
Инструмент позволяет проверить сайт на мобилопригодность.

О том, как влияет адаптивность сайта на ранжирование в ПС, как проверить и оптимизировать сайт под мобильные устройства, подробно описано в статье «Мобильная адаптация сайта – ответы на вопросы».
Заключение
В этой статье перечислены основные инструменты, которые понадобятся для проведения технического аудит сайта, и основные базовые параметры, которые нужно анализировать. Если вы не уверены в своих силах и знаниях, мы можем провести технический аудит вашего сайта и написать инструкции по решению проблемы.

Оптимизирую сайты с 2009 года. Люблю сложные кейсы, которые оказались не по зубам специалистам с других компаний. Делаю очень подробные аудиты.
Пишу статьи-инструкции на блог SiteClinic по SEO-инструментам и аналитике.
Любимая цитата: Чтобы добиться успеха, надо искренне любить то, чем вы занимаетесь.
Источник
Как проверить историю доменного имени и узнать всю информацию о нём перед покупкой: 7 простых способов
Всё о доменах. Часть 5.

Привет, друзья! С вами снова Василий Блинов и в сегодняшней очередной части про доменные имена, я расскажу, как проверить историю домена и зачем это нужно обязательно делать перед покупкой.

В рамках своего курса “Как создать свой блог/информационный сайт и зарабатывать на нём” в Базе знаний, я настоятельно рекомендую ученикам делать проверку домена и брать только с нулевой или хорошей историей. Сейчас объясню почему.

Зачем проверять историю?
Если вы новичок и не знакомы с тем, что такое фильтры поисковых систем, репутация домена, индексация и ранжирование сайта, то давайте вкратце объясню простыми словами.
В интернете и в любой поисковой системе существует масса алгоритмов, анализирующих каждый ресурс по многим показателям. За время работы сайта он проходит тысячи проверок. Так как на сами данные ресурса не наложить никакие показатели, из-за того, что они постоянно меняются, все параметры проверок закрепляются за его адресом, то есть доменом.
Встречали в социальных сетях, когда переходите по ссылке, пишет, что сайт небезопасный и не даёт перейти на сайт? Вот это один из примеров блокировки сайта.
Поэтому, когда вы покупаете подобный домен с плохой историей, будьте готовы, что возникнут проблемы с индексацией и продвижением. Такую ситуацию в онлайне можно сравнить с тюремным заключением, статус “ранее судимый” на имени останется надолго, возможно даже, навсегда, и будет мешать в развитии.
Узнать про все фильтры и блокировки нереально, можно лишь догадываться, анализируя данные, сохранившиеся в истории на некоторых специальных сервисах. Разберём подробно как ими пользоваться.
7 методов проверки истории
Reg.ru (платный способ)
Первый способ, которым вы можете воспользоваться, — это специальный инструмент проверки истории у официального регистратора REG.RU.
Перейдя по прямой ссылке: reg.ru/whois/history. Регистрируетесь, пополняете баланс на нужную сумму и запрашиваете данную проверку.

Все адреса во время поиска и выбора подходящего, конечно, проверять будет дороговато. Поэтому им лучше пользоваться в случае, если вы уже конкретно определились с каким-то свободным вариантом.
Все последующие способы бесплатные.
Whoishistory.ru
Необязательно пользоваться расширенным функционалом, сколько не пробовал, особо важных данных он не показывает. Просто вводите адрес в зелёном поле и нажимаете “Найти”.

Далее открывается окно с данными.

Показываются отдельно данные за каждый год, в моём случае — за 3 года:
По этим данным самое главное, что можно увидеть, — был он ранее кем-то занят или нет и как давно занят.
Если увидите, что он уже использовался, анализируем следующими сервисами.
Linkpad.ru
Linkpad.ru — инструмент для анализа входящих, исходящих и внутренних ссылок на сайте. Если ранее на домене находился сайт, и он нормально индексировался, то данный сервис покажет, какие ссылки на этом сайте стояли и какие на него ссылались.
Можно таким образом определить тематику бывшего ресурса и качество ссылок.

В моём случае домен абсолютно новый и все данные за последние 5 лет по нулям. Вот пример занятого домена, сайт на котором уже не работает, выставлен на продажу и, который я хотел купить.
Можно ещё увидеть, какие страницы недавно были на сайте.

Ничего страшного в таком домене нет, можно считать, что история нормальная. Вот только цену за него предложили 28 000 рублей. А моим принципам противоречит покупать доменные имена у киберсквоттеров.
Screenshots.com
Screenshots.com — сервис, делающий скриншоты сайтов и сохраняющий их в истории. Минус его в том, что он делает скрины только популярных сайтов.

Разные мелкие ресурсы, которые находились на домене недолго, он не показывает. С этой задачей лучше справляется следующий сервис.
Archive.org
Archive.org — всемирный архив интернета, периодично сохраняет вид сайтов на протяжении всей его работы. Можно посмотреть, как выглядели популярные интернет-гиганты ранее и менялись с момента создания.

В шкале сверху показываются все года и количество сохранений. А в календаре — обведённые и выделенные жирным цифры, когда был сохранён архив. При нажатии на них вы можете его посмотреть. Так выглядел мой блог, когда я его только запустил в 2014 году.

Данными крайними двумя способами можно определить, что за сайт находился на домене, и нарушал ли он какие-либо нормы интернета.
Проверка в поиске
Не помешает также спросить Яндекс и Гугл, что они помнят о бывшем веб-сайте, расположенном на выбранном вами домене. Для этого в поисковой строке вбиваете доменное имя полностью и смотрите результаты.
Если обнести домен в кавычки и поставить перед словом знак восклицания (рекомендую почитать статью про секреты поиска), то Яндекс покажет только прямые вхождения того слова, которое вы ищете.

Нашлось 12 тыс. страниц, где упоминается мой домен. По данному анализу можно понять, что за ресурсы ссылаются на доменное имя, и определить хороший или плохой был расположенный на нём материал.
RDS bar
RDS bar — это расширение для браузера, помогающее вебмастерам быстро получить доступную информацию о сайте. Даже если сайт по нужному доменному имени не открывается, он всё равно покажет статистику.
Для этого устанавливаете расширение. В браузерной строке вводите нужный адрес и пытаетесь его открыть. Когда выдаст ошибку о недоступности, нажимаете на значок.

Если цифры не по нулям, то значит он использовался ранее и индексировался. Нажимая на цифры, увидите подробные данные.
Заключение
Я перечислил все основные способы проверки истории, которыми пользуюсь. Есть ещё и другие, аналогичные этим, но они не покажут больше информации.
Можно ещё прогнать адрес по общим анализаторам, например, этим:
Тоже что-то полезное могут показать при наличии истории.
Желаю успехов в проверке! Если есть вопросы, то задавайте их в комментариях. Также делитесь своими инструментами, которыми вы пользуетесь.
В следующей части покажу, как зарегистрировать и купить домен. Следите за обновлениями!
Источник
1.
Раздел 1: «Общие навыки»
Тема 2
«Функциональное и доменное тестирование»
2.
3.
Ранее мы определили
функциональное тестирование
(functional testing) как «проверку на
соответствие требованиям и
спецификациям».
Теперь мы посмотрим на этот
вопрос более пристально.
4.
Функциональное
тестирование (functional
testing) – проверка на
соответствие требованиям и
спецификациям.
Может быть ручным (manual
testing) или
автоматизированным
(automated testing).
5.
Функциональное тестирование
(functional testing) – вид
тестирования, направленный на
исследование отдельных
(изолированных) функций
приложения.
Здесь нет противоречия с
предыдущим определением. Мы
лишь конкретизировали область
применения функционального
тестирования в чистом виде.
6.
Те виды тестирования, которые
ставят во главу угла проверку
некоторых нефункциональных
требований.
Однако, очень часто нефункциональные
требования невозможно проверить в
отрыве от выполнения функции.
7.
Посмотрим на нефункциональные виды
тестирования…
Вид тестирования
«Нуждается» в ФТ
Доменное тестирование
Очень сильно
Тестирование на основе спецификаций
Очень сильно
Тестирование на основе рисков
Очень сильно
Стрессовое тестирование
Очень сильно
Исследовательское тестирование
Очень сильно
Сценарное тестирование
Очень сильно
Тестирование интернационализации
Сильно
Тестирование локализации
Сильно
И т.д.
Сильно
8. Какие бывают тесты
Основные виды тестов:
позитивные;
негативные.
Направления тестирования:
статическое;
динамическое.
Методы тестирования:
чёрный ящик;
белый ящик;
серый ящик.
Виды тестирования:
инсталляционное;
регрессионное;
нового функционала;
конфигурационное;
совместимости;
удобство использования;
интернационалиазации;
локализации;
исследовательское.
9.
Хорош для своих целей
Каждый
вид/метод…
Пропускает часть ошибок
Не может заменить собой
другие
Опытный
тестировщик…
Может использовать разные
виды/методы
Может выбирать лучший
вид/метод
10.
К чему мы готовимся?
Типичные вопросы на собеседовании:
• Назовите плюсы и минусы функционального
тестирования.
• Что такое классы эквивалентности и граничные
условия?
• Назовите и объясните типичные тесты для
следующих полей: текстовое, числовое, даты, двух
связанных дат и т.п.
• Определите переменные, представленные в
требовании или на рисунке. Определите, какие из них
являются независимыми, а какие – связанными.
Сформируйте чек-лист.
11.
Итак, о функциональном тестировании
Основная цель
тестировать каждую
функцию в
отдельности
Источники информации
для тестов
экран приложения,
каждое отдельное
поле
меню, каждый пункт
в отдельности
12.
«+» и «-» функционального тестирования
Глубокий анализ
каждой отдельной
функции.
Нет учёта
взаимозависимостей.
Слабая ориентация на
исследование основных
преимуществ
программы.
13.
Задачи функционального тестирования
• Определить набор функций.
• Определить переменные и граничные
условия.
• Определить переменные окружения,
которые могут повлиять на выполнение
функции.
• Проверить каждую функцию в
А вот и доменное
«обычных условиях» (позитивное
тестирование!
тестирование) и «нестандартных
ситуациях» (негативное тестирование).
14.
15.
Доменное тестирование (domain
testing) – вид тестирования,
направленный на анализ
показательных значений и
взаимосвязи элементов.
… также известно как:
• «тестирование разделением» (partitioning testing);
• «анализ эквивалентности» (equivalence analysis);
• «анализ граничных условий» (boundary analysis).
16.
В доменном тестировании входные
данные считаются
эквивалентными, если программа
проходит один и тот же путь
выполнения для их обработки.
17.
Основная цель доменного
тестирования: предоставить
стратегию по выбору минимального
набора показательных тестов.
Должен остаться
только один…
18.
Классический подход к достижению цели:
• Разделить пространство значений на группы.
• Выбрать значения, представляющие каждую
группу.
• Особое внимание обратить на граничные
значения групп.
• Сформировать конечный набор «наиболее
показательных» значений и провести тесты с их
использованием.
19.
«В конце рабочего дня клерк заносит в БД
информацию о количестве обработанных
заказов. Если количество превышает 100,
система запрашивает подтверждение «Вы
уверены?»
20.
Решение примера
1. Разделить пространство значений на
группы.
Количество заказов:
• MinInt — -1
• 0 — 100
• 101 — MaxInt
• Нецелые числа и не числа
Из условия задачи автоматически следует, что данное поле
принимает только целые числа (при условии, что фиксируется
количество полностью выполненных заказов).
21.
Решение примера
2. Выбрать значения, представляющие
каждую группу.
3. Особое внимание обратить на граничные
значения групп.
Выбранные значения:
• 0, 50, 100, 101, 500, MaxInt
• -1, -200, 1.98
• [empty], буквы, пробелы, спецсимволы
22.
Решение примера
4. Сформировать конечный набор «наиболее
показательных» значений и провести
тесты с их использованием.
Значения:
• 0, 100, 101, MaxInt
• -1, 1.7
• [empty], «абв», пробел(ы), !#@%
23.
Расширенный подход к достижению цели:
• Скомбинировать наиболее показательные
тесты, полученные в результате
«классического подхода».
• Уменьшить полученный набор, определяя
наиболее показательные комбинации.
24.
«+» и «-» доменного тестирования
Обнаружение ошибок
при минимальном
количестве тестов.
Интуитивно понятный,
универсальный
подход.
Низкая вероятность
обнаружения ошибок
НЕ на граничных
условиях.
Низкая вероятность
обнаружения ошибок в
сложных
взаимодействиях.
Пространство значений
часто бывает сложно
формализовать.
25.
Ключевые действия при доменном
тестировании:
• Определение классов
эквивалентности.
• Определение наиболее
показательных значений.
• Создание таблиц эквивалентности.
• Комбинирование нескольких
тестов.
• Определение
взаимозависимостей.
26.
Частые возражения: «Мы тестируем на
реальных пользовательских данных. Нам всё
это не нужно!»
• Конкретные ограничения часто являются
не более, чем предположениями.
• Баги живут годами.
• Пользовательские данные – лишь
пример, но не полный перечень.
• Осознанный подход приносит больше
пользы.
• Изучим сейчас – быстро применим, когда
понадобится.
27.
Полезные навыки
• Определение неоднозначности
(неполноты) в требованиях.
• Определение диапазонов
значений.
• Определение «многомерных»
значений, эквивалентных в
одном контексте и не
эквивалентных в другом.
• Определение переменных
на экране.
28.
Определение неоднозначности
(неполноты) в требованиях
Игрок вводит целое число. Компьютер
отвечает:
• «Меньше», если введено число
большее, чем загаданное.
• «Больше», если введено число
меньшее, чем загаданное.
• «Угадал», если введено число,
равное загаданному.
29.
Определение диапазонов значений
Программа позволяет использовать
любое допустимое целое число.
30.
Определение «многомерных» значений
«Измерение»
Длина
Символы
Классы эквивалентности
Примеры значений
min-max, внутри диапазона
min, max
0, min-1
0, min-1
max+1, бесконечность
max +1, очень большое число
алфавитно-цифровые
123abc
спецсимволы
[email protected]#$%^&*()_+|-={}[]:»;'<>?,./
разные языки
ÀÇÈÌÑÒÙßàçèìíñò
разные кодировки (вкл. UTF)
Пробелы
Уникальность,
Регистр
Способ заполнения
нет пробелов
a
пробелы в начале, в конце
_a, _a_, a_
пробелы в середине
a_a
разные значения
aaa / bbb
одинаковые значения
aaa / aaa
различия в регистре
aaa / aAa
набор с клавиатуры
набрать текст
вставка
вставить текст
31.
Определение переменных на экране
Проблемы:
Некоторые переменные выглядят как
простые надписи.
Некоторые поля не заполнены и/или не
видны.
Некоторые переменные связаны друг с
другом и должны быть протестированы
совместно.
32.
33.
34.
35.
Имя сотрудника, роли, вид календаря.
Поля даты.
Проект, список сотрудников, задачи проекта.
Суммы времени, поля времени.
36. Простой вопрос:
• Не нашли или нашли мало ошибок.
Плохое тестирование?
Хорошее качество?
• А если это последний релиз-кандидат?
• А если это приемочный тест?
37. Простой вопрос:
• Нашли много или очень много ошибок.
Хорошее тестирование?
Плохое качество?
• Получается, что разработка – плохая?
• А если раз за разом?
• А если добавлено много нового
функционала?
38.
A*B=C
Итак, у нас есть три
переменные…
39.
[7 значений для A] *
[7 значений для B] =
49 тестов
Почему здесь именно
такие числа? И всё ли с
этими числами в
порядке?
40.
Тип данных
Байты
Биты
Min
Max
signed char
1
8
— 128
127
unsigned char
1
8
0
255
signed short
2
16
-32768
32767
enum
2
16
-32768
32767
unsigned short
2
16
0
65535
signed int
2
16
-32768
32767
unsigned int
2
16
0
65535
signed long
4
32
-2147483648
2147483647
unsigned long
4
32
0
4294967295
Здесь также многое зависит от реализации. По крайней мере, для Borland C++ 4.5,
основные характеристики целочисленных типов выглядят следующим образом
http://citforum.ru/programming/cpp_march/cpp_017.shtml
http://tinyurl.com/7utf88x
41.
Идеальный программист
1.Изучает проблемы (найденные самостоятельно
или их обнаружили тестировщики)
2.Обобщает проблемы (подброшенные идеи)
3.Исследует ПО на выявление и исправление
таких же или подобных ошибок
42.
Итак, тестов всегда много, а времени
всегда недостаточно!
Что же делать?! Что нас
может спасти???!!!
Эвристические стратегии:
• Тестирование экстремальных точек
(граничных значений / особых
значений)
• Тестирование комбинаций
(типична, популярна, плохо
управляема)
• Число тестов растет
экспоненциально с увеличением
количества входных переменных
43.
Эвристическая стратегия
Предельные значения = 26 тестов
44.
«1×1, слабая стратегия» (Бейзер)
1 тест на границе, 1 вне = 16 тестов
45.
«1x1xN, сильная стратегия» (Бейзер)
1 тест на границе, 1 вне, N между ними
= 24 теста
46.
Выводы:
• Всегда используйте графическое
представление.
• Помните о значениях:
• входных;
• выходных;
• промежуточных.
• Лишние тесты следует убрать.
47.
48.
Увы, часто в требованиях не указаны длины,
допустимые символы, форматы и т.п.
Проблема:
Разработчики принимают свои решения и
могут отклонять отчёты о существующих
ошибках.
Приложение может работать некорректно.
Сбои при нетипичном поведении
пользователя могут остаться
незамеченными.
49.
Решение проблемы:
Создать список переменных (не полей!)
Сделать разумные допущения о
• допустимых значениях;
• недопустимых значениях и реакции приложения;
Согласовать полученное с разработчиками.
Согласовать полученное с заказчиком.
50.
Решение проблемы, пример:
Переменная
Тип
Обяз
Уник
Мин Макс
Дополнительно
Логин
Строка Да
Да
1
100 Любые символы
UTF-32,
НЕчувствителен к
регистру
Пароль
(ввод)
Строка Да
Нет
6
50 Любые символы
UTF-32,
чувствителен к
регистру
Пароль
Строка n/a
(хранение)
Нет
40
40 40
51.
Затем создаём чек-лист:
Экран
Переменная
Идеи тестов
Да/Нет
Создание
пользоват
еля
Логин
Корректный несуществующий логин
Да
Оставить пустым
Нет
Минимальная длина -1
Нет
Максимальная длина +1
Нет
Спецсимволы — [email protected]#$%^&*()_+|={}[]:»;'<>,.?/
Да
Существующий логин
Нет
Существующий логин в другом регистре
Нет
52.
53.
Делим или умножаем на два
Вводим в поле, не принимающее спецсимволы,
полный набор таковых. Если что-то пошло не
так, вводим половину, потом половину
половины и т.д.
Если надо выяснить максимальную длину
принимаемого текста, каждый раз удваиваем
её. Когда нашли проблему, добавляем по ¼ от
предыдущего успешного результата.
54.
Считаем слова/символы автоматически
Если у вас под рукой нет удобного
средства анализа данных, можно
воспользоваться word’ом для подсчёта
длин.
Если хочется «всего и сразу», можно
написать программу, которая будет
выдавать вам полную информацию об
анализируемом тексте.
Какую информацию о тексте
имеет смысл собрать?
Ваши идеи!
55.
Позитивное вместе, негативное отдельно
Несколько позитивных тестов (например,
ввод данных в несколько полей) можно
провести за раз.
При этом негативные тесты так
комбинировать нельзя, т.к. мы должны
убедиться, что программа корректно
отслеживает проблемы с каждым из полей.
56.
Используем готовые чек-листы
В большинстве случаев кто-то уже
сталкивался с тем, с чем сейчас
столкнулись мы.
Спрашиваем коллег, ищем в
корпоративной библиотеке.
57.
58.
Есть вопросы? Давайте обсудим!
При подготовке презентации
использованы материалы тренингов
Eduard Shymkus (EPAM)
Привет, Хабр! Да-да, про тестирование ПО тут уже куча статей. Здесь я просто буду стараться структурировать как можно более полный охват данных из разных источников (чтобы по теории все основное было сразу в одном месте, и новичкам, например, было легче ориентироваться). При этом, чтобы статья не казалась слишком громоздкой, информация будет представлена без излишней детализации, как необходимая и достаточная для прохождения собеседования (согласно моему опыту), рассчитанное на стажеров/джунов (как вариант, эта информация может быть для общего понимания полезна ИТ-рекрутерам, которые проводят первичное собеседование и попутно задают некоторые около-технические вопросы).
ОСНОВНЫЕ ТЕРМИНЫ
Тестирование ПО (Software Testing) — проверка соответствия между реальным и ожидаемым поведением программы, проводится на наборе тестов, который выбирается некоторым образом. Чем занимаются в тестировании:
-
планированием работ (Test Management)
-
проектированием тестов (Test Design) — этап, на котором создаются тестовые сценарии (тест кейсы), в соответствии с определёнными ранее критериями. Т.е., определяется, КАК будет тестироваться продукт.
-
выполнением тестирования (Test Execution)
-
анализом результатов (Test Analysis)
Основные цели тестирования
-
техническая: предоставление актуальной информации о состоянии продукта на данный момент.
-
коммерческая: повышение лояльности к компании и продукту, т.к. любой обнаруженный дефект негативно влияет на доверие пользователей.
|
Верификация (verification) |
Валидация (validation) |
|
Соответствие продукта требованиям (спецификации) |
Соответствие продукта потребностям пользователей |
Дефект (баг) — это несоответствие фактического результата выполнения программы ожидаемому результату.
Следует уметь различать, что:
-
Error — это ошибка пользователя, то есть он пытается использовать программу иным способом (например, вводит буквы в поля, где требуется вводить цифры). В качественной программе предусмотрены такие ситуации и выдаются сообщение об ошибке (error message).
-
Bug (defect) — это ошибка программиста (или дизайнера или ещё кого, кто принимает участие в разработке), то есть когда в программе, что-то идёт не так, как планировалось. Например, внутри программа построена так, что изначально не соответствует тому, что от неё ожидается.
-
Failure — это сбой в работе компонента, всей программы или системы (может быть как аппаратным, так и вызванным дефектом).
Жизненный цикл бага
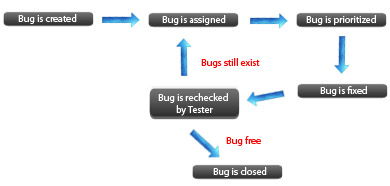
Атрибуты дефекта
-
Серьезность (Severity) — характеризует влияние дефекта на работоспособность приложения. Выставляется тестировщиком.
Градация Серьезности дефекта
-
Blocker — ошибка, приводящая приложение в нерабочее состояние, из-за которой дальнейшая работа с системой или ее ключевыми функциями становится невозможна, т.е. тестирование значительной части функциональности становится недоступно
-
Крит (Critical) — неправильно работающая ключевая бизнес-логика, дыра в системе безопасности, проблема, приведшая к временному падению сервера или приводящая в нерабочее состояние некоторую часть системы, без возможности решения проблемы, используя другие непрямые пути (workaround).
-
Значительный (Major) — часть основной бизнес логики работает некорректно, есть возможность для работы с тестируемой функцией, используя обходные пути (workaround); либо дефект с высоким visibility – обычно не сильно влияющие на функциональность дефекты дизайна, которые, однако, сразу бросаются в глаза.
-
Minor — часто ошибки GUI, которые не влияют на функциональность, но портят юзабилити или внешний вид; либо незначительная функциональная ошибка, не нарушающая бизнес-логику тестируемой части приложения.
-
Тривиальная (Trivial) — ошибка, не касающаяся бизнес-логики приложения, не оказывающая никакого влияния на общее качество продукта, например, опечатки в тексте, несоответствие шрифта и оттенка и т.д.
-
Приоритет (Priority) — указывает на очередность выполнения задачи или устранения дефекта. Чем выше приоритет, тем быстрее нужно исправлять дефект. Выставляется менеджером, тимлидом или заказчиком.
НЕКОТОРЫЕ ТЕХНИКИ ТЕСТ-ДИЗАЙНА
-
Эквивалентное Разделение (Equivalence Partitioning) — это техника, при которой функционал (часто диапазон возможных вводимых значений) разделяется на группы эквивалентных по своему влиянию на систему значений. ПРИМЕР: есть диапазон допустимых значений от 1 до 10, выбирается одно верное значение внутри интервала (например, 5) и одно неверное значение вне интервала — 0.
-
Анализ Граничных Значений (Boundary Value Analysis) — это техника проверки поведения продукта на крайних (граничных) значениях входных данных. Если брать выше ПРИМЕР: в качестве значений для позитивного тестирования берется минимальная и максимальная границы (1 и 10), и значения больше и меньше границ (0 и 11). BVA может применяться к полям, записям, файлам, или к любого рода сущностям имеющим ограничения.
-
Доменный анализ (Domain Analysis Testing) — это техника основана на разбиении диапазона возможных значений переменной на поддиапазоны, с последующим выбором одного или нескольких значений из каждого домена для тестирования.
-
Предугадывание ошибки (Error Guessing — EG). Это когда тестировщик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку.
-
Причина / Следствие (Cause/Effect — CE). Подразумевается ввод условий, для получения ответа от системы (следствие).
-
Сценарий использования (Use Case Testing) — Use Case описывает сценарий взаимодействия двух и более участников (как правило — пользователя и системы).
-
Исчерпывающее тестирование (Exhaustive Testing — ET) — подразумевается проверка всех возможные комбинации входных значений. На практике не используется.
-
Попарное тестирование (Pairwise Testing) — это техника формирования наборов тестовых данных из полного набора входных данных в системе, которая позволяет существенно сократить общее количество тест-кейсов. Используется для тестирования, например, фильтров, сортировок. Этот интересный метод заслуживает отдельного внимания и более подробно рассматривается в статье по ссылке (в конце которой упоминаются инструменты для автоматизации применения PT).
-
Тестирование на основе состояний и переходов (State-Transition Testing) — применяется для фиксирования требований и описания дизайна приложения.
-
Таблица принятия решений (decision table) — инструмент для упорядочения бизнес-требований, которые должны быть реализованы в продукте. Применяется для систем со сложной логикой. В таблицах решений представлен набор условий, одновременное выполнение которых приводит к определенному действию.

ВИДЫ ТЕСТИРОВАНИЯ

Классификация по целям
-
Функциональное тестирование (functional testing) рассматривает заранее указанное поведение и основывается на анализе спецификации компонента или системы в целом, т.е. проверяется корректность работы функциональности приложения.
Нефункциональное тестирование (non-functional testing) — тестирование атрибутов компонента или системы, не относящихся к функциональности.
-
Тестирование пользовательского интерфейса (GUI Testing) — проверка интерфейса на соответствие требованиям (размер, шрифт, цвет, consistent behavior).
-
Тестирование удобства использования (Usability Testing) — это метод тестирования, направленный на установление степени удобства использования, обучаемости, понятности и привлекательности для пользователей разрабатываемого продукта в контексте заданных условий. Состоит из: UX — что испытывает пользователь во время использования цифрового продукта, и UI — инструмент, позволяющий осуществлять интеракцию «пользователь — веб-ресурс».
-
Тестирование безопасности (security testing) — это стратегия тестирования, используемая для проверки безопасности системы, а также для анализа рисков, связанных с обеспечением целостного подхода к защите приложения, атак хакеров, вирусов, несанкционированного доступа к конфиденциальным данным.
-
Инсталляционное тестирование (installation testing) направленно на проверку успешной установки и настройки, а также обновления или удаления приложения.
-
Конфигурационное тестирование (Configuration Testing) — специальный вид тестирования, направленный на проверку работы программного обеспечения при различных конфигурациях системы (заявленных платформах, поддерживаемых драйверах, при различных конфигурациях компьютеров и т.д.)
-
Тестирование на отказ и восстановление (Failover and Recovery Testing) проверяет тестируемый продукт с точки зрения способности противостоять и успешно восстанавливаться, т.е. обеспечивать сохранность и целостность данных, после возможных сбоев, возникших в связи с ошибками программного обеспечения, отказами оборудования или проблемами связи (например, отказ сети).
-
Тестирование локализации (localization testing) — проверка адаптации программного обеспечения для определенной аудитории в соответствии с ее культурными особенностями.
Тестирование производительности (performance testing) — определение стабильности и потребления ресурсов в условиях различных сценариев использования и нагрузок.
-
Нагрузочное тестирование (load testing) — определение или сбор показателей производительности и времени отклика программно-технической системы или устройства в ответ на внешний запрос с целью установления соответствия требованиям, предъявляемым к данной системе (устройству).
-
Тестирование стабильности или надежности (Stability / Reliability Testing) — это проверка работоспособности приложения при длительном (многочасовом) тестировании со средним уровнем нагрузки.
-
Стрессовое тестирование (Stress Testing) позволяет проверить насколько приложение и система в целом работоспособны в условиях стресса (например, повышение интенсивности выполнения операций до очень высоких значений или аварийное изменение конфигурации сервера) и также оценить способность системы к регенерации, т.е. к возвращению к нормальному состоянию после прекращения воздействия стресса.
-
Объемное тестирование (Volume Testing) — тестирование, которое проводится для получения оценки производительности при увеличении объемов данных в базе данных приложения.
-
Тестирование масштабируемости (scalability testing) — тестирование, которое измеряет производительность сети или системы, когда количество пользовательских запросов увеличивается или уменьшается.
Классификация по позитивности сценария
-
Позитивное — тест кейс использует только корректные данные и проверяет, что приложение правильно выполнило вызываемую функцию.
-
Негативное — тест кейс оперирует как корректными так и некорректными данными (минимум 1 некорректный параметр) и ставит целью проверку исключительных ситуаций; при таком тестировании часто выполняются некорректные операции.
Классификация по знанию системы
-
Тестирование белого ящика (White Box) — метод тестирования ПО, который предполагает полный доступ к коду проекта, т.е. внутренняя структура/устройство/реализация системы известны тестировщику.
-
Тестирование серого ящика — метод тестирования ПО, который предполагает частичный доступ к коду проекта (комбинация White Box и Black Box методов).
-
Тестирование чёрного ящика (Black Box) — метод тестирования ПО, также известный как тестирование, основанное на спецификации или тестирование поведения — техника тестирования, которая не предполагает доступа (полного или частичного) к системе, т.е. основывается на работе исключительно с внешним интерфейсом тестируемой системы.
Классификация по исполнителям тестирования
-
Альфа-тестирование — является ранней версией программного продукта, тестирование которой проводится внутри организации-разработчика; может быть вероятно частичное привлечение конечных пользователей.
-
Бета-тестирование — практически готовое ПО, выпускаемое для ограниченного количества пользователей, разрабатывается в первую очередь для тестирования конечными пользователями и получения отзывов клиентов о продукте для внесения соответствующих изменений.
Классификация по уровню тестирования
-
Модульное (компонентное) тестирование (Unit Testing) проводится самими разработчиками, т.к. предполагает полный доступ к коду, для тестирования какого-либо одного логически выделенного и изолированного элемента (модуля) системы в коде, проверяет функциональность и ищет дефекты в частях приложения, которые доступны и могут быть протестированы по-отдельности (модули программ, объекты, классы, функции и т.д.).
-
Интеграционное тестирование (Integration Testing) направлено на проверку корректности взаимодействия нескольких модулей, объединенных в единое целое, т.е. проверяется взаимодействие между компонентами системы после проведения компонентного тестирования.
Подходы к интеграционному тестированию
-
Снизу вверх (Bottom Up Integration) Все низкоуровневые модули, процедуры или функции собираются воедино и затем тестируются. После чего собирается следующий уровень модулей для проведения интеграционного тестирования. Данный подход считается полезным, если все или практически все модули, разрабатываемого уровня, готовы. Также данный подход помогает определить по результатам тестирования уровень готовности приложения.
-
Сверху вниз (Top Down Integration) Вначале тестируются все высокоуровневые модули, и постепенно один за другим добавляются низкоуровневые. Все модули более низкого уровня симулируются заглушками с аналогичной функциональностью, затем по мере готовности они заменяются реальными активными компонентами.
-
Большой взрыв («Big Bang» Integration) Все или практически все разработанные модули собираются вместе в виде законченной системы или ее основной части, и затем проводится интеграционное тестирование. Такой подход очень хорош для сохранения времени. Однако если тест кейсы и их результаты записаны не верно, то сам процесс интеграции сильно осложнится, что станет преградой для команды тестирования при достижении основной цели интеграционного тестирования.
-
Системное тестирование (System Testing) — это проверка как функциональных, так и не функциональных требований в системе в целом. При этом выявляются дефекты, такие как неверное использование ресурсов системы, непредусмотренные комбинации данных пользовательского уровня, несовместимость с окружением, непредусмотренные сценарии использования и т.д., и оцениваются характеристики качества системы — ее устойчивость, надежность, безопасность и производительность.
-
Операционное тестирование (Release Testing). Даже если система удовлетворяет всем требованиям, важно убедиться в том, что она удовлетворяет нуждам пользователя и выполняет свою роль в среде своей эксплуатации. Поэтому так важно провести операционное тестирование как финальный шаг валидации. Кроме этого, тестирование в среде эксплуатации позволяет выявить и нефункциональные проблемы, такие как: конфликт с другими системами, смежными в области бизнеса или в программных и электронных окружениях и др. Очевидно, что нахождение подобных вещей на стадии внедрения — критичная и дорогостоящая проблема.
Классификация по исполнению кода
-
Статическое тестирование — процесс тестирования, который проводится для верификации практически любого артефакта разработки. Например, путем анализа кода (code review). Анализ может производиться как вручную, так и с помощью специальных инструментальных средств. Целью анализа является раннее выявление ошибок и потенциальных проблем в продукте. Также к этому виду относится тестирование требований, спецификаций и прочей документации.
-
Динамическое тестирование проводится на работающей системе, т.е. с осуществлением запуска программного кода приложения.
Классификация по хронологии выполнения
-
Повторное/подтверждающее тестирование (re-testing/confirmation testing) — тестирование, во время которого исполняются тестовые сценарии, выявившие ошибки во время последнего запуска, для подтверждения успешности исправления этих ошибок, т.е. проверяется исправление багов.
-
Регрессионное тестирование (regression testing) — это тестирование после внесения изменений в код приложения (починка дефекта, слияние кода, миграция на другую операционную систему, базу данных, веб сервер или сервер приложения), для подтверждения того факта, что эти изменения не внесли ошибки в областях, которые не подверглись изменениям, т.е. проверяется то, что исправление багов, а также любые изменения в коде приложения, не повлияли на другие модули ПО и не вызвали новых багов.
-
Приёмочное тестирование проверяет соответствие системы потребностям, требованиям и бизнес-процессам пользователя.
ДОКУМЕНТАЦИЯ
Требования — это спецификация (описание) того, что должно быть реализовано. Требования описывают то, что необходимо реализовать, без детализации технической стороны решения.
Основные атрибуты требований:
-
Полнота — в требовании должна содержаться вся необходимая для реализации функциональности информация.
-
Непротиворечивость — требование не должно содержать внутренних противоречий и противоречий другим требованиям и документам.
-
Недвусмысленность — требование должно содержать однозначные формулировки.
-
Проверяемость (тестопригодность) — формулировка требований таким образом, чтобы можно было выставить однозначный вердикт, выполнено все в соответствии с требованиями или нет.
-
Приоритетность — у каждого требования должен быть приоритет (количественная оценка степени значимости требования).
Тест план (Test Plan) — документ, описывающий весь объем работ по тестированию:
-
Что нужно тестировать?
-
Как будет проводиться тестирование?
-
Когда будет проводиться тестирование?
-
Критерии начала тестирования.
-
Критерии окончания тестирования.
Основные пункты из которых может состоять тест-план перечислены в стандарте IEEE 829.
Неотъемлемой частью тест-плана является Traceability matrix — Матрица соответствия требований (МСТ) — это таблица, содержащая соответствие функциональных требований (functional requirements) продукта и подготовленных тестовых сценариев (test cases). В заголовках колонок таблицы расположены требования, а в заголовках строк — тестовые сценарии. На пересечении — отметка, означающая, что требование текущей колонки покрыто тестовым сценарием текущей строки. МСТ используется для покрытия продукта тестами.
|
Тестовые сценарии |
Функциональное требование 1 |
Функциональное требование 2 |
Функциональное требование 3 |
… |
|
test case 1 |
+ |
+ |
||
|
test case 2 |
+ |
+ |
||
|
test case 3 |
+ |
+ |
+ |
|
|
… |
+ |
Чек-лист (check list) — это документ, описывающий что должно быть протестировано. На сколько детальным будет чек-лист зависит от требований к отчетности, уровня знания продукта сотрудниками и сложности продукта. Чаще всего, в ЧЛ содержатся только действия, без ожидаемого результата. ЧЛ менее формализован, чем тестовый сценарий.
Тестовый сценарий (Test Case) — это документ, в котором содержатся условия, шаги и другие параметры для проверки реализации тестируемой функции или её части.
Атрибуты тест кейса:
-
Предусловия (PreConditions) используются, если предварительно систему нужно приводить к состоянию пригодному для проведения проверки; т.е. указываются либо действия, с помощью которых система оказывается в нужном состоянии, либо список условий, выполнение которых говорит о том, что система находится в нужном состоянии для основного теста.
-
Шаги (Steps) — cписок действий, переводящих систему из одного состояния в другое, для получения результата.
-
Ожидаемый результат (Expected result), на основании которого можно делать вывод о удовлетворении поставленным требованиям.
-
иногда используются Постусловия (PostConditions), как некоторое напоминание для перевода системы в первоначальное состояние, как до проведения теста (initial state)
Из тестовых сценариев, сгруппированных по некоему признаку (например, тестируемой функциональности), получаются некоторые наборы. Они могут быть как зависящими от последовательности выполнения (результат выполнения предыдущего является предварительным условием для следующего для Test script), так и независимыми (Test suite).
Отчёт о дефекте (Bug Report) — это документ, описывающий ситуацию или последовательность действий приведшую к некорректной работе функциональности.
|
Шапка |
Название/тема: Краткое описание (Summary) некорректного поведения, составляется по схеме WWW, т.е. ЧТО ГДЕ КОГДА (при каких условиях) |
|
Назначен на (Assigned To) сотрудника, который будет с ним разбираться |
|
|
Статус (Status) бага в соответствии с workflow |
|
|
Компонент приложения (Component): название тестируемой функции или ее части |
|
|
Информация по сборке, на которой была найдена ошибка: Номер версии (Version), название ветки |
|
|
Информация об окружении (Environment): ОС + версия, модель девайса (для мобильных устройств) и т.д. |
|
|
Серьезность (Severity) |
|
|
Приоритет (Priority) |
|
|
Описание |
Подробное описание (Description): указывается по необходимости; как правило, сюда вносятся предусловия (PreConditions) или другая дополнительная полезная информация, например, если для воспроизведения бага нужны специальные знания/данные/инструменты |
|
Шаги воспроизведения (Steps to Reproduce), по которым воспроизводится ситуация, приведшая к ошибке |
|
|
Фактический Результат (Result), полученный после прохождения шагов воспроизведения, часто может быть = теме/краткому описанию (Summary) + расшифровка чего-либо (например, ошибки по коду), если нужно |
|
|
Ожидаемый результат (Expected Result): который правильный, т.е. описание того, как именно должна работать система в соответствии с требованиями |
|
|
Прикрепленные файлы |
Вложения (Attachment): файлы с логами, скриншот или видео каст либо их комбинация для прояснения причины ошибки |
Огромное спасибо @alexlobach и @Gennadii_M за статьи! Большая часть информации взята именно оттуда.
UPD: статья пополняется. Спасибо @yakoeka
Спасибо большое всем за фидбэк, благодаря которому материал обновляется и дополняется

Введение в тестирование домена
Тестирование предметной области — это метод тестирования программного обеспечения, при котором приложение тестируется путем предоставления входных данных и проверки соответствующих результатов. Тестирование предметной области также называется проверкой эквивалентности или анализом границ. При тестировании домена тестирование проводится с минимальным количеством входных данных, поэтому приложение не допускает недопустимых данных и данных вне диапазона и оценивает ожидаемый диапазон выходных данных. Тестирование домена гарантирует, что приложение не имеет входных данных за пределами указанного допустимого диапазона.
Лучшие 4 стратегии доменного тестирования
Теперь давайте обсудим стратегию тестирования домена:
Тестирование домена делится на субдомены. После этого приложение рассматривается для тестирования домена вместе с поддоменом, при этом единичные или комбинации входных данных проверяются через поддомен. Это обеспечивает упрощение сложных сценариев, поскольку домен разделен на поддомен. Тест, проводимый на границах субдомена, называется анализом граничных значений (BVA). Когда условия теста делятся на наборы или группы тестов, тогда это называется классом эквивалентности тестирования. Домен тестер должен разбираться в домене в деталях.
1. Выбор домена
Домен, который имеет менее сложную функциональность, можно считать тестированием домена. В приложении будут входные переменные, которые должны быть назначены, и надлежащий результат должен быть проверен.
2. Сгруппируйте входные данные в классы
Подобный тип входных данных разбивается на подмножества. Существует два типа разделения: разделение по эквивалентным классам и анализ граничных значений (BVA). Разделение по классам эквивалентности разбивает входные данные на эквивалентные разделы данных для определения контрольных примеров. Здесь тестовые случаи разработаны таким образом, что каждый раздел покрывается за один раз. В тестировании анализа граничных значений (BVA) тестовые случаи разрабатываются с учетом недопустимого диапазона граничных значений.
3. Входные данные классов для тестирования
Граничные значения следует рассматривать как данные для тестирования. Границы представляют классы эквивалентности, которые с большей вероятностью обнаружат ошибку, чем другие члены класса. Данные между диапазонами являются лучшим представителем класса эквивалентности.
4. Проверка выходных данных
Когда входные данные присваиваются приложению, эти выходные данные проверяются. Выходные данные должны быть недействительными и указывать диапазон.
Примеры доменного тестирования
Давайте рассмотрим два сценария в качестве примера:
1. Тестовые данные с одним входом
Рассмотрим x & y — входную переменную для любого выражения, а переменная z — выход. Здесь выражение представляет собой один входной сценарий, который включает переменную x & y, следовательно, нет комбинированной входной переменной.
Примеры выражений: (z = x + y) или (z = xy) или (z = x * y) или (z = x / y) и т. Д.
2. Тест с несколькими входными переменными
В этом примере несколько или комбинации входных переменных проверяются на предмет соответствующего вывода. Давайте рассмотрим приложение School Management для системы аттестации детей, в отношении их системы оценок назначены классы.
В соответствии с вышеуказанными условиями испытаний могут быть определены следующие сценарии:
- Сценарий 1: баллы учащихся> 80 и <= 100, при этом предмет «Наука» должен быть в классе А.
- Сценарий 2: баллы учеников> 80 и <= 100, при этом учетная запись должна быть в классе B.
- Сценарий 3: студент набирает 65 баллов, предмет по естественным наукам должен быть в классе C.
- Сценарий 4: учащийся набирает 65 баллов, предмет «Счета» должен быть в классе D.
- Сценарий 5: студент набирает 50 баллов, предмет по науке должен быть в классе Е.
- Сценарий 6: учащийся набирает 50 баллов, предмет Счета должен быть в классе F.
- Сценарий 7: баллы учащихся <= 50, предмет науки должен быть в классе G.
- Сценарий 8: баллы учащегося <= 50, предмет Счета должен быть в классе H.
Здесь, в приведенном выше примере, входными данными будут Marks & Subject, касающиеся тех классов, которые будут распределены. Этот случай относится к разделу входов или группировке входных значений. Диапазон оценочных баллов подразделяется на следующие классы:
- Класс 1: учащиеся, набравшие> 80 и <100.
- Класс 2: студенты, набравшие 65 баллов.
- Класс 3: студенты, набравшие 50 баллов.
- Класс 4: учащиеся, набравшие <= 50.
Граничные значения следует рассматривать как данные для тестирования, границы представляют классы эквивалентности, которые стремятся найти ошибку или ошибку, чем другие члены класса. Данные между диапазонами являются лучшим представителем класса эквивалентности. Для каждого класса, упомянутого выше, требуется тест.
Для класса 1 — учащиеся, набравшие более 80 баллов (оценки> 80 и оценки <= 100).
Граничные значения:
- Знаки 80 не должны учитываться в этом классе, так как значения должны быть больше 80.
- В этом классе следует учитывать отметки 81, так как значения должны быть больше 80.
- В этом классе следует учитывать отметки 100, так как значения должны быть меньше 100 или равны 100.
- Знаки 101 не должны учитываться в этом классе, поскольку значения должны быть меньше 100 или равны 100.
Значения раздела эквивалентности: входные значения от 81 до 100 действительны, поэтому необходимо включить одно из значений от 81, 82, 83 до 100. Следовательно, выбранные отметки «90» являются действительными отметками для этого класса.
Проверка выходных данных
Здесь из каждого раздела выполняется только одно условие теста. Если одно условие теста работает правильно в разделе, то все остальные условия теста должны работать правильно. И, если одно условие теста в разделе работает неправильно, предполагается, что никакие другие условия не будут работать правильно.
Структура доменного тестирования
Структура тестирования домена описана ниже:
- Проанализируйте заявку относительно домена.
- Узнайте допустимые входные переменные.
- По поводу вывода найдите, проанализируйте входные переменные и отсортируйте их.
- Относительно анализа разделов BVA & Equivalence создайте / найдите входные переменные.
- Найти и проанализировать выходные переменные относительно входных переменных.
- Найти неанализированные входные переменные. Соберите информацию для дальнейшей оценки.
- Суммируйте весь анализ теста относительно таблиц риска.
Вывод
Тестирование предметной области — это метод тестирования программного обеспечения, который требует базовых знаний в области для проверки с правильным вводом для достижения необходимого результата. Домен должен быть разделен на поддоменов для эффективной работы. Тестирование предметной области также называется тестом на эквивалентность или тестированием на границе, где входные переменные анализируются и идентифицируются как граничные значения и значения класса эквивалентности для достижения ожидаемого результата.
Рекомендуемая статья
Это руководство по тестированию домена. Здесь мы обсуждаем Введение в тестирование домена и его стратегию тестирования, а также структуру с примером. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше —
- Уровни тестирования программного обеспечения | Топ 4
- Топ 6 видов ручного тестирования
- 10 лучших инструментов тестирования безопасности с открытым исходным кодом
- Введение в жизненный цикл тестирования программного обеспечения
- Как генерировать тестовые данные с их преимуществами?
- Что такое тест-кейс? Как писать?

Самый первый метод тест-анализа, который каждый начинающий тестировщик постигает инстинктивно, – это метод граничных значений. Но так ли он прост, как это кажется на первый взгляд? Давайте разберемся!
Для сравнения разных подходов возьмем конкретный пример. Пусть у нас на сайте есть форма предварительного расчета стоимости страховки жизни, базирующаяся на очень простой формуле. Клиент вводит возраст и сумму в рублях, на которую он хочет застраховать свою жизнь. Если клиент моложе 18 лет или старше 60, выводится сообщение: «К сожалению, на данный момент у нас нет для вас подходящих предложений». Во всех остальных случаях мы просто считаем процент от введенной суммы; этот процент равен возрасту клиента. Да, я знаю, что в реальности расчет будет гораздо сложнее, но для наших целей такая модель подойдет.
Что нам говорит здравый смысл
Итак, любой новичок, который буквально пару дней придумывает тесты, сразу понимает, что нужно как-то проверить условия 18 и 60 лет. Скорее всего, для надежности он выберет (17, 18, 19 лет) и (59, 60, 61 год). И это хороший выбор! Действительно, если сбой есть хоть на каких-то значениях, то его будет видно и около границы с той или другой стороны. Более того, сбой чаще всего проявляется именно на самих граничных значениях.
Что нам говорит определение ISTQB FL
Теперь посмотрим, что нам рекомендует такой надежный источник, как Силлабус ISTQB FL: «Минимальные и максимальные значения сегмента являются граничными значениями. Граничное значение для валидного сегмента является валидным граничным значением, для невалидного сегмента – невалидным». Другими словами, мы имеем тут три диапазона (… по 17, от 18 до 60, от 61 и выше) и только по два значения на каждую границу (17, 18 и 60, 61). Именно такой ответ будет требоваться на экзаменах ISTQB, и это часто сбивает с толку новичков, которым хочется проверить границы со всех сторон.
Определенная логика в подходе составителей Силлабуса есть: если на 18 и 60 годах система правильно посчитала процент, то ожидать, что на 19 и 59 она вдруг опять покажет ошибку «ваш возраст нам не подходит», было бы странно. Точнее, ошибка на этих значениях возникнуть может, но с такой же вероятностью, как и на любых других числах диапазона (а мы уже решили, что такая вероятность невысока).
Что нам говорит Ли Копленд про тестирование границ
Теперь давайте обратимся к классику тест-анализа Ли Копленду и его известной книге «A Practitioner’s Guide to Software Test Design», которая, к сожалению, не переводилась на русский. Заглянув в раздел «Граничные значения», мы увидим все то же решение, первым приходящее в голову: (граница — 1), граница, (граница + 1). Кстати, именно у Копленда вы можете прочитать подробное обоснование того, почему ошибки в коде чаще всего заметны на границах диапазона и очень редко встречаются на одиноком случайном значении внутри диапазона.
При этом в разделе «Доменный анализ» (термин можно понимать как «Анализ диапазонов», используется он для случаев учета границы не у одного параметра, а у двух и более) терминология резко меняется. Появляются такие понятия как ON, OFF, IN и OUT. Чтобы понять, откуда они взялись, и почему их четыре, нам понадобится ознакомиться с предысторией вопроса.
На заре эры тестирования некоторые параметры программы были просты, как выключатели. Например, человек вводил ответ на тест – число, правильным ответом было 10. На ввод всех прочих чисел система должна была писать «неверно», а на 10 – «молодец». Для таких параметров ввели первые очень простые границы – ON/OFF. ON – это в данном случае 10, то есть значение или граница, на котором выключатель включился. Все остальные значения попадали в OFF. Другие параметры могли быть сложнее, и результаты стали задаваться не просто точкой, а целыми интервалами. Скажем, в нашем примере клиент мог застраховать жизнь при возрасте 18 до 60 лет – следовательно, появились границы IN/OUT (внутри и вне диапазона). Все числа от 18 до 60 попадали в IN, остальные – в OUT.
Пока все было логично, но появилась новая проблема: теперь названия границ могут быть разными в разных параметрах. А если параметр работает как выключатель, но в двух точках? А если есть и точка и интервал? В конечном итоге все эти 4 границы решили определить для любого параметра; тестировщикам предоставлялся выбор конкретного варианта.
Были приняты такие определения (они фигурируют и в книге Копленда), которые мы проиллюстрируем числами из нашего примера:
- ON – любая точка строго на границе (не важно, в диапазоне или нет), у нас это 18 и 60.
- OFF – любая точка не на границе (не важно, в диапазоне или нет). Все числа, кроме 18 и 60. Для тестирования Копленд рекомендует выбирать максимально близкие к границам диапазона значения (17 и 61).
- IN – любая точка в диапазоне, но только не на границе (все числа от 19 до 59).
- OUT – любая точка вне диапазона. В нашем примере это все числа меньше 18 и больше 60. В дальнейшем описании метода этот термин Копленд не использует.
Итак, для применения метод «доменного анализа» к нашему примеру нам потребуется установить ограничения и на сумму в рублях, которую вводит пользователь. Предположим, что эта сумма будет не меньше 100 000 рублей, но не больше 2 000 000. Во всех остальных случаях мы тоже пишем «К сожалению, на данный момент у нас нет для вас подходящих предложений». Сами по себе границы нам понятны:
- ON – 100 000 и 2 000 000;
- IN – 100 001 и 1 999 999;
- OFF – 99 999 и 2 000 001.
Правда, хорошо, что у нас нет копеек? Здесь, кстати, я хотела бы сделать первую ремарку.
Метод граничных значений отлично работает на самих целых числах, а также на таких целочисленных параметрах, как количество символов в поле или количество товара в корзине. Однако, как только вы перейдете хотя бы к десятичным дробям, сложностей станет больше. Однажды я тестировала границы диапазона поля, где можно было вводить числа в экспоненциальной форме, и тут попытка найти число, ближайшее к 1.0Е-15 не увенчалась успехом. Нет, это не 1.0Е-14, ведь 1.1Е-15 будет ближе. А 1.00001Е-15 еще ближе. А может попробовать 1.0000000000001Е-15 ? В конечном счете решение пришлось строить не от ближайшего числа (которого, строго говоря, и не существует с математической точки зрения), а от самого длинного из «влезающих» в форму.
В нашем примере все числа целые, так что попробуем использовать метод Копленда и составить таблицу доменного анализа так, чтобы проверить границы обоих параметров.
В соответствии с методикой нельзя совмещать два ON, ON и OFF или два OFF, ведь такое совмещение при падении теста усложнит локализацию, особенно если тесты подлежат автоматизации. Тем не менее иногда такие тесты делают специально (например, «нарушить границы в нескольких полях в форме и проверить, что система покажет все сообщения об ошибках разом»). Мы пока все делаем строго по методике и проверяем все границы по одной. В первую очередь расставляем все значения ON и OFF, которые нам надо проверить. Получается восемь тестов:

По клику на картинку откроется полная версия.
Мы не можем провести тесты, указав только одно значение, поэтому теперь везде, где не хватает значения, мы ставим недостающее IN. Пусть для возраста это будет 40, а для суммы – 200 000 рублей.
Вот мы и получили 8 тестов для проверки границы уже не одного, а сразу двух параметров, имеющих ограниченные позитивные диапазоны:

По клику на картинку откроется полная версия.
Уверена, что при взгляде на эту таблицу вам инстинктивно хочется добавить девятый тест, в котором оба значения – IN. Но Копленд рассматривает именно проверки границ, а тесты, где все значения IN, к граничным не относятся.
А теперь десерт!

Что делать, если диапазон и границы заданы не только для входных параметров, но и для итога работы программы?
Вот реальные примеры:
Дата окончания договора рассчитывается автоматически от даты заключения с добавлением продолжительности договора. При этом в зависимости от года окончания договора он хранится в разных хранилищах и имеет разные условия расторжения.
Программа обработки изображений позволяет изменить качество и размер изображения, но если у выходного изображения размер будет больше 3 MB или произведение сторон будет больше 16 мегапикселей, то получить изображение можно будет только как внешнюю ссылку на хранилище.
Назначенные в таск-трекере на одного человека задачи не должны превышать 8 часов за сутки (или уж хотя бы 24 часа за сутки, так и быть!).
То есть, мы изначально имеем границы на результат обработки данных, но при этом для тестирования указываем значения только тех параметров, которые можем напрямую задать программе. Получается, что результат зависит от параметров, имеющих собственные границы. Кроме того, иногда в обработке возникают и промежуточные этапы; параметры на этих этапах также могут иметь промежуточные значения.
Для наглядности давайте вернемся к нашему примеру и введем дополнительное ограничение: мы не хотим связываться с теми, кто заплатит нам за страховку меньше 50 000 рублей, они также получат сообщение «К сожалению, на данный момент у нас нет для вас подходящих предложений».
Как нам составить набор тестов для такого случая? Вновь используем технику «доменного анализа» Копленда, но теперь таблица станет чуть-чуть сложнее: у нас появится еще один параметр «к оплате». Сначала, как и прошлый раз, расставим все значения ON и OFF, которые нам надо проверить. Добавляем два дополнительных граничных теста для значения «к оплате»:
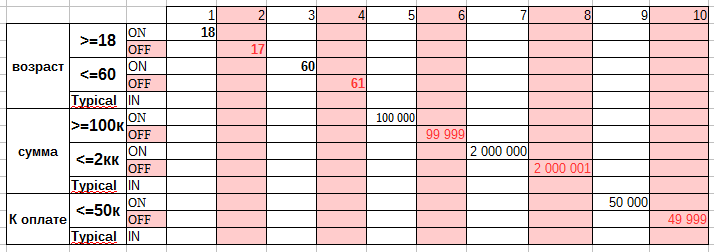
По клику на картинку откроется полная версия.
Мы не можем провести тесты, указывая только одно значение или вообще ничего не вводя. Нам снова надо заполнить недостающие данные, но теперь у нас нет возможности сделать это произвольно. Дело в том, что значение параметра «к оплате» у нас равно проценту от суммы, которую ввел клиент, а этот процент равен его возрасту.
Если мы (как в прошлый раз) подставим сумму 200 000 рублей и возраст 40 лет, а потом посчитаем, то у нас получится куча тестов либо с двумя OFF, либо с совпадением ON и OFF. Как мы помним, это совершенно недопустимо!
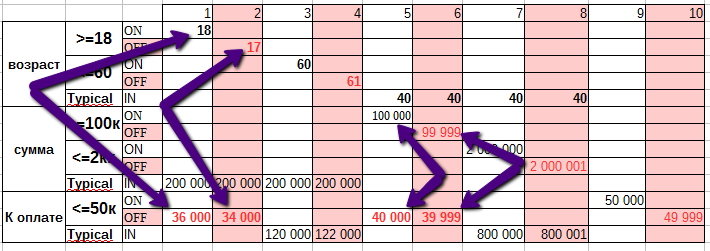
По клику на картинку откроется полная версия.
А ведь мы еще даже не начали указывать значения суммы и возраста для двух последних тестов, но и их тоже нельзя брать наугад – они должны дать нам именно наши граничные значения параметра «К оплате»! Что же делать?
Вообще говоря, мы можем использовать обычный метод тыка: сдвигать по чуть-чуть значения суммы и возраста до тех пор, пока не попадем в нужный нам диапазон. Копленд предлагает другое решение.
Давайте нарисуем график зависимости параметра «к оплате» от суммы и возраста и отметим на графике наши границы. Красная кривая показывает нам область, где параметр «к оплате» будет равняться 50 000 рублей. Пары значений ниже этой линии брать нельзя (то есть, для возраста 18 мы сразу видим, что сумма должна быть больше 282 000 рублей).
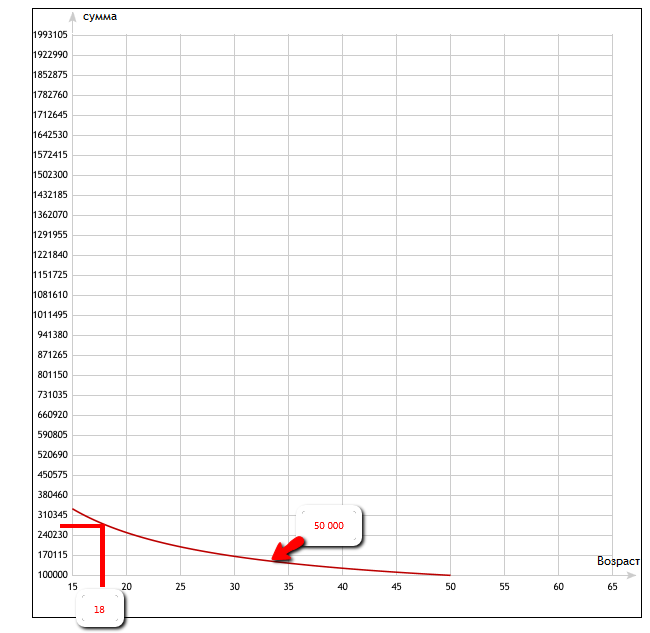
По клику на картинку откроется полная версия.
Теперь, глядя на этот график, мы легко выберем те граничные значения, которые нам подойдут, и получим, например, такой набор тестов:
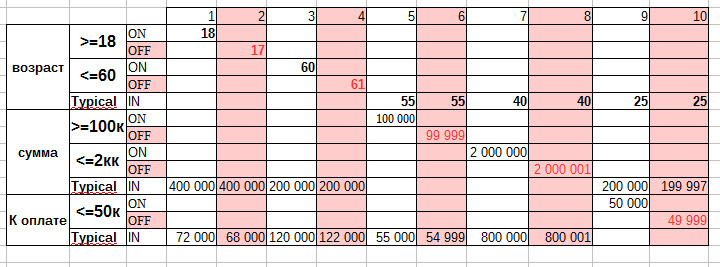
По клику на картинку откроется полная версия.
Как видите, все границы всех диапазонов проверены. Более того, нам удалось выполнить правило «в тесте может быть только одно значение OFF или ON, а все остальные обязательно должны быть IN».
Теперь я бы хотела сделать вторую ремарку.
Я уже много лет являюсь тренером в Школе Тест-аналитика от Натальи Руколь, где мы подробно разбираем именно эту методику. Все эти годы я слышу один и тот же вопрос: «Погодите, а как же ноль? Разве нам не надо проверить его? А если пользователь введет возраст 0 или сумму 0?». Этот вопрос имеет под собой глубокие корни. Дело в том, что любой тестировщик, хотя бы полгода проработавший на любом проекте, очень быстро обнаруживает, что ноль – это всегда слабое место в системе, это проверенная наживка, на которую всегда ловится большое количество жирных багов. Многие алгоритмы с трудом переваривают такое «невкусное» число, как ноль. До сих пор классическим примером негативного теста простого калькулятора является именно деление на ноль. Однако, надо понимать, что в прямом смысле слова ноль не является вечной границей для абсолютно любого параметра, поэтому я согласна с Ольгой Киселевой, которая в своей статье обозначила его как отдельный класс эквивалентности. Поэтому в этой статье я не уделила ему много внимания.
Итак, я надеюсь, что теперь, разобрав разные школы и подходы к тестированию границ, вы убедились: метод этот хоть и не столь прост, как кажется на первый взгляд, но все-таки крайне полезен для начинающего тест-аналитика. Я рекомендую сначала освоить все перечисленные мной методы, а потом определить тот, который выгоднее всего использовать именно на вашем проекте.
Уровень сложности
Простой
Время на прочтение
11 мин
Количество просмотров 3.2K
Статья написана в рамках моего личного блога о тестировании и QA: https://t.me/qanva_blog
При изучении техники тест‑дизайна «доменный анализ», я столкнулся с тем, что многие авторы описывают ее по‑своему, что вполне логично. Перелопатить много разных статей об одном и том же, чтобы найти подходящее изложение материала и в конце концов понять желаемое — естественный процесс обучения. Но в случае доменного анализа, я заметил расхождение: кто‑то описывает данную технику сложно, а кто‑то ограничивается простой позицией — «это просто работа с классами эквивалентности и граничными значениями».
Определение доменного анализа
У данной техники тест‑дизайна много названий: «доменный анализ», «анализ классов эквивалентности», «доменное тестирование», «анализ эквивалентного разбиения», «тестирование областей определения», «domain analysis».
Это, чтобы вы не растерялись на собесе =)
Прежде, чем штудировать источники информации, давайте посмотрим, что можно вытащить из различных определений понятия «Доменный анализ»:
Доменный анализ — методика разработки тестов, относящаяся к методу черного ящика, использующаяся для определения действенных и эффективных тестовых сценариев в случаях, когда множественные параметры могут или должны быть протестированы одновременно. — ISTQB
Доменный анализ — техника, которая основана на разбиении диапазона возможных значений переменной (или переменных) на поддиапазоны (или, иначе, домены), с последующим выбором одного или нескольких значений из каждого домена для тестирования. — из статьи Антона Алексеева «Кто такие тест‑дизайнеры и зачем они нужны»
Доменный анализ — это техника, которая может применяться для определения эффективных и действенных тест‑кейсов, когда несколько переменных могут или должны тестироваться вместе — Ли Копланд «A Practitioner’s Guide to Software Test Design«
Доменный анализ — техника создания эффективных и результативных тест‑кейсов в случае, когда несколько переменных могут или должны быть протестированы одновременно. — Святослав Куликов «Тестирование программного обеспечения»
Для себя я вынес следующее:
-
данная техника позволяет сократить кол‑во тестов, не теряя при этом в эффективности тестового покрытия;
-
так как, некоторые переменные могут и должны тестироваться вместе, то следует проанализировать зависимости между этими переменными, пахнет комбинаторикой и попарным тестированием;
-
чтобы объединить множество значений, необходимо выделить определенную область, называемую доменом;
-
так, как из подобласти значений мы выбираем только определенных представителей, то тут пахнет классами эквивалентности и граничными значениями.
Сформулировать свое полное определение попытаемся в конце =)
Что такое “домен”?
В большинстве источников игнорируют это понятие и сразу идут в бой с примерами использования техники. Для меня это было проблемно, так как ни сразу понятно, что конкретно нужно объединять в область значений и где здесь сам «домен».
Для примера возьмем сайт создания блокнота по описанию пользователя. На нем есть такая форма:

Домен, в данном случае, это сама форма с ее полями, так как поля формы относятся к одной части функционала и объеденины общей логикой. Мы не будем тестировать каждое поле по отдельности, а заполнив каждое отдельное поле подобранным, определенным образом, значением, нажмем кнопку «Создать блокнот«.
То есть «домен» — это логически связанные между собой шаги/переменные/объекты, в рамках одного функционала: форма авторизации, форма регистрации, оформление заказа в интернет магазине, заполнение данных о пользователе, конвертирование различных форматов файла на разных ОС, окно редактирования изображения, отдельная зона игровой локации, инвентарь персонажа, окно крафта конкретной вещи из инвентаря персонажа и т. д.
Хочу заметить, так понятие «домен» понимаю лично я. И в данной статье буду опираться на него.
Но, что интересно: как правило, в других источниках «доменом» называют конкретный параметр. Например, в форме авторизации, поле ввода логина мы можем ввести определенный текст. В данном случае текст(строка) — домен. Далее, строку логически делят на поддомены: латиница, кириллица, символьная строка, длинная строка, короткая строка..все это классы эквивалентности. И далее выбирают определенных представителей из диапазона эквивалентности, а также граничные значения.
Мне кажется что «домен» это про объединение параметров общей логикой и про множественность параметров, а не про отдельные параметры.
Моя логика следующая: логически объединяем набор параметров ( домен ) > каждый параметр( поддомен) разбиваем на классы эквивалентности > выбираем представителей из каждого класса эквивалентности:

Алгоритм использования техники
Для успешного использования техники, в разных источниках, в совокупности прослеживаются следующие шаги:
-
Выбор домена.
-
Анализ входных параметров (поддомены).
-
Разбиение входных параметров на классы эквивалентности.
-
Выбор представителей классов эквивалентности и граничных значений для каждого поддомена.
-
Анализ взаимосвязанных параметров и объединение их с помощью комбинаторики/попарного тестирования.
-
Создание тестов на основе полученных данных о входных значениях.
-
Анализ выходных параметров.
-
Разбиение выходных параметров на классы эквивалентности.
-
Выбор представителей классов эквивалентности и граничных значений для выходных параметров.
-
Определение входных параметров для проверки представителей выходных значений.
-
Дополнение тестов на основе полученных данных о выходных значениях.
-
Объединение тестов.
Анализ входных параметров
Как мы можем заметить, мы постоянно анализируем наши параметры и пытаемся найти связи их друг другом, какие-то ограничения и риски.
Выделяем входные параметры:
Поле ФИО:
-
Количество символов <= 25 и >=3 (если введены данные)
-
Необязательно к заполнению, если заполнено поле Описание
-
Принимает на вход латинские буквы и буквы кириллицы
-
Не принимает на вход символы и числа, кроме пробела “_”
-
Пробел нельзя ставить в начале строки и в конце строки
Поле Описание:
-
Количество символов <=120, если формат = А5
-
Количество символов <=200, если формат = А4
-
Количество символов >=3 (если введены данные)
-
Необязательно к заполнению
-
Принимает на вход латинские буквы и буквы кириллицы
-
Не принимает на вход символы, кроме пробела “_”, запятой “,”, восклицательного знака “!”, точки “.”, дефиса “-”
-
Принимает на вход числа, если они стоят не в начале и не в конце строки
Поле Количество страниц:
-
Значение количества страниц >=250 и <=1000
-
Значение должно быть целым числом
-
Поле принимает только числовое значение
-
Если формат выбран А4 , то значение <=500
-
Количество символов для ввода >=3 и <=4
Загрузить изображение:
-
Доступные форматы файла .png , .jpeg
-
Размер файла от 500КБ до 5МБ
-
Минимальный размер изображения >= 250x250px
-
Если формат А5, то размер изображения <=650x650px
-
Если формат А4, то размер изображения <=1200х1200px
-
Имя файла не должно содержать символы и буквы кириллицы
-
Длина имени файла <=15 и >=3 символов
-
Имя файла содержит латинские буквы и цифры
-
Необязательное поле
Применение уже знакомых техник тест дизайна
Итак, поддомен для нас это совокупность всех возможных значений переменной. Перед нами стоит задача выделить подобласти для каждого параметра, все элементы которых предположительно приводят к одинаковому результату выполнения программы для сокращения количества тестов. Как минимум мы можем разбить на две подобласти — валидные и невалидные значения.
Эту задачу как раз прекрасно решает техника разбиения на классы эквивалентности.
-
Если диапазон значений упорядочен, то выделяем внутренние интервалы и точки перехода: слева от диапазона и справа от диапазона — невалидные значения, сам диапазон — валидные значения.
-
Если диапазон значений не упорядочен, то выполнить разбиение согласно логике, согласно рискам, согласно частоте использования значений. Например, буквы можно разбить на латиницу и кириллицу, а их в свою очередь дробить на верхний регистр и нижний регистр.
Также необходимо убедиться, что границы области заданы верно, в чем нам поможет анализ граничных значений.
Но данную технику не всегда можно применить, так как существуют упорядоченные и неупорядоченные классы эквивалентности, и в неупорядоченных нет способа выделить граничные значения, которые с большей вероятности могут привести к возникновению сбоя. В таком случае можно попробовать разбить неупорядоченный класс эквивалентности на подклассы и взять по значению из каждого. Например, множество символов с клавиатуры: класс эквивалентности — символы с клавиатуры, подклассы: числовые символы, специальные символы на разных раскладках, буквенные символы на разных раскладках, сочетания двух клавиш, сочетания трех клавиш.
При использовании граничных значений, важно помнить, что данная техника не ограничивается числовыми границами диапазонов. Также существуют:
-
Временные границы: ограничение на выбор даты в прошлом, ограничение на выбор даты в будущем, таймеры и т.д.
-
Технические границы: ограничение оперативной памяти, ограничение физической памяти на жестком диске, ограничения на типы данных для ввода, ограничение на загрузку некоторых форматов файлов, ограничения на размеры изображений и т.д.
-
Границы итераций: ограничение на ввод пароля, ограничение на повторное использование части функционала и т.д.
-
Границы окружения: ограничение на использование символов в именах файлов на разных ОС.
-
и т.д.
Также важно выделение особых точек:
-
значения на которые программа не реагирует;
-
наиболее часто встречающиеся;
-
специфичные значения, которые определяются предметной областью;
-
0 и null;
-
дефолтные значения / значения по умолчанию.
В этом поможет спецификация и коллеги, которые лучше разбираются в продукте — аналитики, разработчики, да и просто другие тестировщики, дольше вас работающие на проекте.
Проанализировав входные параметры, мы получили следующие данные:
-
Значения входных данных для поля ФИО — ссылка на таблицу
-
Значения входных данных для поля Описание — ссылка на таблицу
-
Значения входных данных для поля Количество страниц — ссылка на таблицу
-
Значения входных данных для поля Загрузка изображения — ссылка на таблицу

Объединение тестов
Не будем забывать, что суть доменного анализа не только в выборе показательных значений параметров, но и в одновременной проверке множества позитивных условий одновременно. Таким образом из набора позитивных значений различных классов эквивалентностей формируем поддомены:
-
Описание поддомена для поля ФИО — ссылка на таблицу
-
Описание поддомена для поля Описание — ссылка на таблицу
-
Описание поддомена для поля Количество страниц — ссылка на таблицу
-
Описание поддомена для поля файла изображения — ссылка на таблицу

Имена поддоменов заданы для удобства их использования в будущем.
Суть доменного тестирования в объединении множества позитивных независимых значений для более эффективного выбора тестовых значений и построения меньшего количества тестов, не теряя при этом в тестовом покрытии. Именно поэтому мы объединяли позитивные значения параметров одного поддомена в одно тестовое значение.
Значения считаются независимыми, если значение одного класса эквивалентности не влияет на диапазон валидных значений другого класса эквивалентности.
Но следует понимать, что такое объединение увеличивает время локализации ошибки, при обнаружении бага.
В таком случае, поможет алгоритм похожий на бинарный поиск:
-
Поделить упавшее значение на 2
-
Если оба значения не проходят, то каждое нужно ещё раз поделить на 2
-
Если в одном значении ошибка пропала, то оставшиеся делим на 4
Тем не менее даже с этим алгоритмом, не стоит комбинировать более восьми значений или параметров.
Теперь, по тому же принципу, мы можем объединить позитивные независимые значения разных поддоменов в один позитивный тест, и так для всех представителей всех поддоменов — ссылка на таблицу
Значение поддомена считается независимым, если оно не влияет на диапазон валидных значений другого поддомена.

В получившейся таблице намерено скрыты негативные тесты, которые объединять мы не имеем право, так как это приводит к непониманию какое именно негативное значение привело к ошибке. Негативные проверки удобнее будет выписать отдельно.
Для меня удобнее выписать получившиеся тесты в отдельную таблицу да да еще одна таблица горизонтально — начало таблицы и конец таблицы.

В итоге, мы пришли к 5 позитивным тестам и 51 негативному. На данном примере мы наблюдаем сокращение количества проверяемых значений без потери эффективности тестирования.
Анализ выходных параметров
В используемом мной примере, я намерено опускаю анализ выходных параметров. После заполнения необходимых полей, просто жмем на кнопку «Создать блокнот» и представим, что нас перебрасывает на страничку с надписью «Прекрасный блокнот получился! Наш менеджер с вами свяжется!». Анализировать тут особо нечего.
Тем не менее это важный этап, на котором вы сможете найти тестовые входящие значения для различных выходных данных.
Сами выходные данные мы никак не вводим и не можем повлиять на них напрямую, но зато мы можем повлиять на них путем различных комбинаций значений входных данных.
Часто приводят следующий пример — есть программа сложения двух целых чисел:

Если начать анализировать какие значения может принимать выходной параметр, то на ум приходит следующее:
-
0 + 0 = 0 — минимальный результат равен нулю;
-
1 + 1 = 2 — результат может быть длиной один символ;
-
1 + 10 = 11 — результат может быть длиной два символа;
-
99 + 99 = 208 — максимальный результат может быть равен 208 и максимальная длина результата 3 символа;
-
Результат не может быть отрицательным числом, так как поля ввода не принимают отрицательные целые числа.
Можно дальше развивать мысль, но давайте просто выделим:
-
класс эквивалентности “Допустимые значения выходного параметра” — [0, 208]
-
класс эквивалентности “Допустимая длина результата” — 1, 2, 3
Выделим представителей: 0 , 1, 99, 208
Эти представители будут ожидаемым результатом в тесте и чтобы его добиться, на вход мы выбираем следующие тестовые значения входных данных:

А далее мы уже смотрим, входят ли эти значения в выбранные при анализе входных данных или необходимо обновить. В данном примере мы ограничились рассуждениями о данных, но это не должно ограничивать вас в мышлении.
В нашем случае с формой создания блокнота, после клика на кнопку «Создать блокнот«, вполне могло всплывать модальное окно с расчитаной стоимостью собранного блокнота, где мы бы анализировали сумму в зависимости от выбранных значений. Или, к примеру, открывалась бы другая форма с динамическими полями, где в зависимости от выбранных нами значений, предлагались другие возможности кастомизации блокнота и мы бы анализировали зависимости и условия.
Важно было передать суть, а дальше вы уже сами.
Заключение
Доменное тестирование это не совсем отдельная техника тест‑дизайна, а комбинация различных техник: классы эквивалентности, граничные значения, комбинаторика и попарное тестирование (зависимости), тестирование на основе рисков, предугадывание ошибок, таблицы похожие на «таблицы принятия решений» и даже белый ящик (когда вы анализируете значения переменных).
Доменный анализ только формализует все перечисленные техники и результат применения будет тем эффективнее, чем лучше вы разбираетесь в тест‑дизайне и чем опытнее вы специалист.
Именно поэтому, в комментариях к различным статьям и видосам можно увидеть радостные и удивленные откровения людей по типу: «О, а я так и делаю! Не знал, что это называется доменный анализ!».
Ну и на последок, попробуем сформулировать определение своими словами:
Доменный анализ — это методика разработки тестов, позволяющая сократить тестовый набор без потери эффективности тестового покрытия, путем применения различных техник тест‑дизайна, направленных на сокращение данных, а также на анализ, систематизацию и обобщение входных и выходных параметров.
На всякий случай, вот вам ссылка не на скрины таблиц а на гугл таблицу.
Тест дизайн — то, что отличает хорошего тестировщика от манки тестера. Ведь именно благодаря этим практикам тестировщики могут находить самые серьёзные дефекты с большей вероятностью, чем случайное тестирование. В этой статье мы познакомимся с самой популярной техникой тестирования — доменное тестирование.
Данная статья состоит из следующих частей:
- Введение.
- Эквивалентное разбиения (Equivalence partitioning).
- Анализ граничных значений (Boundary value analysis)
- Доменное тестирование в деталях (Domain testingDomain analysis)
- Примеры:
- Текстовое поле.
- Целочисленное поле.
- Файл.
Введение
Ранее в одной из статей мы уже познакомились с тем что такое тест дизайн и техники тестирования.
Список всех техник мы уже упоминали в статье Виды, уровни, методы и техники тестирования.
Доменное тестирование — это одно из самых главных оружий тестировщика. В умелых руках оно позволяет находить большое количество багов за небольшое время. А разве не это ли нам нужно?
Техника заключается в комбинации эквивалентного разбиения и анализа граничных значений. И сегодня мы познакомимся с ними поближе.
Техника эквивалентного разбиения (Equivalence partitioning)
Суть техники эквивалентного разбиения в том, чтобы:
- Разделить данные на группы (классы эквивалентности), которые, как предполагается, обрабатываются системой схожим образом (то есть ведут систему к одному состоянию);
- Из каждой группы (класса) выбрать одно значение и проверить его.
Мы предполагаем, что каждое значение в одном классе обкатывается системой одинаково. Таким образом нам достаточно проверить только одно значение из класса, чтобы подтвердить, что все значения внутри класса будут работать.
Два теста можно назвать эквивалентными если выполняются все нижеперечисленные условия:
- Оба теста направлены на поиск одной и той же ошибки;
- Если один из тестов обнаруживает ошибку, другой скорее всего, тоже её обнаружит;
- Если один из тестов не обнаруживает ошибку, другой, скорее всего, тоже её не обнаружит;
- Тесты используют схожие наборы входных данных;
- Для выполнения тестов мы совершаем одни и те же операции;
- Тесты генерируют одинаковые выходные данные или приводят приложение в одно и то же состояние;
- Все тесты приводят к срабатыванию одного и того же блока обработки ошибок;
- Ни один из тестов не приводит к срабатыванию блока обработки ошибок.
Например, возьмём поле Username:

В котором система вводит ограничение по длине от 3 до 20 символов.
Соответственно для проверки длины поля, мы можем выделить следующие классы:
- 0-2 символов — выдаст ошибку, что Username имеет недостаточное количество символов
- 3-20 символов — обработается верно
- 21-бесконечность — выдаст ошибку, что Username превышает разрешённое количество символов
Таким образом, нам совсем не обязательно проверять все значения всех классов, а достаточно выбрать только по одному из класса.
Например, следующие значение: Za, Batman, SupperPupperMegaWarrior.
Этими значениями мы проверили все классы по длине поля. Тем самым мы существенно сократили количество тестов.
Я думаю вы уже заметили главный недостаток этой техники. А именно — отсутствие проверок поведения на границах классов. Об этом мы и поговорим дальше.
Техника анализа граничных значений (Boundary value analysis)
Техника анализа граничных значений основана на проверке значений на переходах из одних границах классов эквивалентности в другие. Для применения этой техники нужно знать минимальные и максимальные значения классов. Довольно часто тестировщики используют эту технику интуитивно. Но сейчас мы познакомимся с ней поближе.
Продолжим разбирать пример с полем Username:
Для проверки длины поля мы уже выделили 3 класса: от 0 до 2, от 3 до 20, от 21 и выше.
Соответственно можно выделить следующие границы переходов:

В рамках техники анализа граничных значений мы должны сделать тесты для проверки вышеуказанных значений:
- 2: Bo
- 3: Bat
- 20: BatmanAndRobinReturn
- 21: BatmanAndRobinForever
Тем самым мы убедимся в том, что все переходы из одного класса в другой обрабатываются правильно.
Существует 2 подхода к анализу граничных значений:
- 2 значения на границе (Two-value boundaries);
- 3 значения на границе (Three-value boundaries).
Проверка 2 значений на границе предполагает использование только граничного значения и на один минимальный шаг меньше (в случае с минимальной границей) или на один минимальный шаг больше (в случае с максимальной границей). Собственно говоря, в примере выше мы использовали именно этот подход. На каждой из границ позитивного класса мы проверили по 2 значения.
- Минимальная граница: 2, 3 символов
- Максимальная граница 20, 21 символов
Проверка 3 значений на границе предполагает использование граничного значения, на один минимальный шаг больше и на один минимальный шаг меньше границы. Таким образом для примера выше нам необходимо будет сделать следующие проверки:
- Минимальная граница: 2, 3, 4 символов
- Максимальная граница 19, 20, 21 символов
Выбор подхода обычно основывается на уровне рисков связанных с тестируемой областью. Чаще всего мы используем 2 значения, но в системах с повышенными рисками лучше использовать 3 значения.
Техника доменного тестирования (Domain testingDomain analysis)
Практика показала, что в большинстве случаев использование только одной техники не даёт нужного результата.
Именно поэтому была придумана техника доменного тестирования (Анализа доменов).
Доменное тестирование — это техника тестирования метода чёрного ящика, направленная на уменьшение количества тестов путём одновременной проверки множества различных позитивных значений. Данная техника базируется на одновременном использовании техник эквивалентного разбиения и анализа граничных значений.
Пример техники доменного тестирования №1.
Для проверки длины поля Username комбинацию этих техник можно представить так:

Тем самым мы проверили поведение на границах и для надёжности ещё убедились в том, что поле работает не только на границах, использовав среднее значение 11.
Но достаточно ли этого для проверки поля? Однозначно нет.
Мы должны определить какие ещё могут быть классы и какие у них граничные значения.
Представим, что мы хотим отправить значение поля Username для создания нового пользователя.
Ниже я выделил ещё несколько типов классов по различным характеристикам и определил в них классы эквивалентности.

Итого получилось 19 показательных значений, то есть 19 тестов.
Неплохо поработали. Из бесконечного числа значений мы выбрали только 19, которые вероятнее всего найдут все самые критичные и очевидные баги. Но можно сделать ещё лучше.
Что если я скажу, что многие позитивные проверки можно объединить?
Суть доменного тестирования не только в том, чтобы выбирать показательные значения при помощи 2 техник, но ещё и одновременной проверке множества позитивных условий одновременно.
Например, мы можем сделать так:

Наши 19 тестов превратились в 11. Разве не круто?
Мы объединили значения из нескольких позитивных классов и если, например, в значении BatМэн2!@#$%^&*()-_= хотя бы одно из условий выполняться не будет (например ввод спецсимволов), то упадёт весь тест и мы быстро найдём ошибку.
Для того чтобы понять, какое условие вызвало ошибку, можно использовать следующий алгоритм:
- Поделить упавшее значение на 2
- Если оба значения не проходят, то каждое нужно ещё раз поделить на 2
- Если в одном значении ошибка пропала, то оставшиеся делим на 4
Тем самым мы быстро определим, а что именно вызвало ошибку в нашем тесте.
Очевидно, что не все позитивные тесты мы можем объединить друг другом. Например, мы не можем одновременно использовать и минимальное и максимальное значение вместе.
Однако, негативные тесты ни в коем случае нельзя объединять друг с другом!
Представим, что мы проверяем вместе значение меньше минимального с добавлением пробела в начале » Bo». Мы предполагаем, что оба эти условия должны вызывать ошибку.
По итогу, если одно из условий по факту вызывает ошибку, а второе нет, то на экране мы увидим ошибку. И ложно подумаем, что тест был пройден успешно. А во втором условии у нас будет баг, который мы не обнаружим.
Именно поэтому негативные тесты нельзя объединять друг с другом.
Важно помнить!
Во избежание эффекта пестицида, при повторе тестов использовать разные эквивалентные значения. Но в поле Username нам в любом случае придётся каждый раз вводить уникальные значения. Показательные значения представлены для примера, чтобы можно было выбрать похожее эквивалентное значение, а не для того, чтобы постоянно вводить одни и те же значения.
Пример техники доменного тестирования №2.
Представим форму отправки суммы для подсчёта процента налога.

Которая работает по следующим правилам:
- Если сумма меньше 1000, то процент 0;
- Если сумма от 1000 до 2000, то процент 10;
- В случае, если сумма больше 2000, то процент 15;
- Форма принимает только целочисленные значения;
- Длина поля от 1 до 7 символов.
Применяя техники эквивалентного разбиения и анализа граничных значений получаем следующую таблицу значений:

Несколько замечаний по этой таблице:
Чем меньше позитивных тестов, тем меньше мы сможем сократить количество тестов. В данном случае мы сможем объединить только 2 теста: минимальное число символов и минимальное значение, то есть 0.
В случае, если использование спецсимволов ведёт к ошибке, то рекомендуется каждый спецсимвол проверять отдельно.
Пример техники доменного тестирования №3.
Представим, что нам нужно протестировать форму загрузки иконки.

Которая работает по следующим правилам:
- Размер файла: от 128кб до 10240кб
- Имя файла: от 6 до 128 символов, любой регистр, цифры, буквы, любые языки, разрешённые Windows спецсимволы, пробелы только в середине и конце.
- Форматы файлов: только изображения
Применяя техники эквивалентного разбиения и анализа граничных значений получаем следующую таблицу значений:

Несколько замечаний по этой таблице:
Наличие пробелов — имя файла не может начинаться с пробела, поэтому проверка не применялась.
Допустимые и недопустимые форматы файлов — чем больше рисков продуктовых рисков мы имеем, тем больше различных форматов необходимо проверить.
Попробуем теперь сократить количество тестов:

По итогу мы получили всего 18 тестов вместо 32.
Вот как-то так 🙂
Книга посвящена всего лишь одному виду тестирования — тестированию доменного анализа (также его называют доменный анализ либо доменное тестирование).
Что это за вид тестирования, которому посвятили целых 488 страниц? Давайте разберемся.
Если мы с вами обратимся к глоссарию ISTQB, то определение доменного тестирования звучит следующим образом:
Доменное тестирование (domain analysis) — методика разработки тестов, относящаяся к методу черного ящика, использующаяся для определения действенных и эффективных тестовых сценариев в случаях, когда множественные параметры могут или должны быть протестированы одновременно. Методика базируется и обобщает методы эквивалентного разбиения и анализа граничных значений.
Если переформулировать проще, то определение будет следующим:
Доменное тестирование — это вид тестирования, направленный на анализ различных значений, поиск их взаимосвязи и составление эффективных тестов.
То есть суть доменного тестирования заключается в том, чтобы разделить набор условий тестирования на те значения, которые можно считать одинаковыми, и за счет этого протестировать эффективней.
Для понимания возьмем простой пример. Скажем, что у нас есть поле Логин и Пароль. В идеале, нам необходимо каждое поле протестировать по отдельности. Однако доменное тестирование позволяет сделать так, чтобы в одном тесте мы смогли проверить оба поля одновременно и без потери в качестве тестирования.
Пример из жизни. Возьмем два действия: 1. ехать в автобусе в качестве пассажира и 2. слушать аудиокнигу. Мы можем просто ехать в автобусе без прослушивания книги, как и слушать книгу, не едучи в автобусе. Но мы можем объединить эти два действия и слушать книгу, пока едем в автобусе. При таком объединении мы без потери качества и до нужного места доберемся, и книгу послушаем.
Конечно, тут тоже есть свои ограничения и нюансы. Например, будет так шумно, что мы ничего не услышим. Но и при реальном тестировании они тоже есть. Например, при вводе логина и пароля сайт выводит “общее” предупреждение, которое гласит: “Логин или пароль введены неверно”. То есть в этом случае мы не сможем понять, что именно неверно.
Разновидности доменного тестирования: признаки эквивалентности и анализ граничных значений
В основе использования доменного тестирования лежат различные техники, но наиболее популярные — это определение классов эквивалентности и граничных значений.
Давайте вспомним, что они означают.
Классы эквивалентности — это набор тестов, полное выполнение которого является избыточным и не приводит к обнаружению новых дефектов. Если мы ожидаем одинакового результата от выполнения двух и более тестов, эти тесты эквивалентны.
Граничные значения — это те места, в которых один класс эквивалентности переходит в другой. Эти места очень важны, их обязательно следует проверять в тестах, т.к. именно в этом месте чаще всего и обнаруживаются ошибки.
Цель доменного тестирования
Цель доменного тестирования — предоставить стратегию по выбору минимального набора показательных тестов.
Нет, естественно, не один, но должно остаться минимум тестов, которые будут самые эффективными.
Шаги для достижения цели:
- Для начала нужно разделить предполагаемые значения на отдельные группы, условия — это могут быть цифры, буквы, допустимый диапазон цифр, предполагаемые граничные значения.
- Далее необходимо выявить конкретный набор значений и выбрать из них наиболее показательные, представляющие каждую группу, включая обязательно границы. Здесь мы уже определяем значения, которые будем проверять.
- И далее необходимо скомбинировать эти значения таким образом, чтобы отдельные параметры можно было протестировать одновременно.
Давайте разберем все на конкретном примере.
К нам на тестирование поступает задача «протестировать форму авторизации». Форма состоит из двух полей: логин и пароль. Длина логина и пароля — от 5 до 10 символов. Логин может принимать различные символы, цифры и буквы на латинице. Пароль тоже может принимать символы, цифры и латиницу.
Решение:
- Для начала разделим все предполагаемые значения на группы:
- Кол-во значений от — ∞ до 4
- Кол-во значений от 5 до 10
- Кол-во значений 11 до + ∞
- Спец. символы
- Буквы (латиница)
- Цифры
2. Выявляем наборы значений, представляющие каждую группу:
- 4
- 5, 7, 10
- 11
- @, !, $
- a, b, w, l
- 2, 4
3. И далее скомбинируем эти значения в виде таблицы.
Таким образом, мы добились наиболее эффективных тестов, которые не только максимально покрывают необходимые проверки, но и экономят наше время.
Плюсы и минусы доменного тестирования
У доменного тестирования есть свои как плюсы, так и свои минусы.
К достоинствам можно отнести:
- Обнаружение ошибок при минимальном количестве тестов.
- Простой и понятный подход.
Недостатки:
- Низкая вероятность обнаружения ошибок за пределами границ допущенных значений. Потому что данный метод использует технику граничных значений.
- Низкая вероятность обнаружения ошибок в сложных формах, когда, например, возможно большое кол-во различных полей, символов или значений. Так как всегда присутствует человеческий фактор, можно запутаться и что-то не учесть.
- Часто бывает сложно разделить на группы, необходимые для тестирования, так как не всегда бывает легко применить технику классы эквивалентности.
Полезные хитрости
Также есть и свои полезные трюки, которые вам могут пригодиться.
- Производите сразу несколько позитивных тестов (например, ввод данных в несколько полей), вместо одного.
- Не стоит комбинировать больше семи позитивных значений одновременно, иначе тест будет громоздким. В случае обнаружения ошибки ее придется долго локализовывать.
- С негативными тестами так комбинировать, к сожалению, не получится, так как мы должны быть уверены, что тестируемая программа корректно отслеживает проблемы с каждым из полей.
- Не стоит в одном тесте комбинировать позитивные и негативные сценарии. Каждое негативное условие всегда проверяется отдельно.
- Начинайте проверку с граничных значений, так вы откините большое количество ненужных проверок.
Если подытожить, то доменное тестирование — это не новый вид тестирования, а рекомбинация и формализация уже существующих техник.
Основное его преимущество — это сокращение количества проверяемых значений без потери эффективности тестирования. То есть правильное применение техники приводит к уменьшению количества тестов без ухудшения качества тестирования.
Почему тестирование необходимо?
В этом разделе мы рассмотрим самые базовые понятия и принципы, которые используются в процессе тестирования. Мы узнаем, что же, собственно, собой представляет тестирование, зачем оно нужно и кто им занимается. Рассмотрим цели, принципы и основные этапы тестирования. Почувствуем, каким должен быть психологический настрой настоящего тестировщика и развенчаем напоследок несколько мифов о тестировании. Уверены, Вам будет интересно.
Начнем с того, что же такое «тестирование». Для начала, давайте абстрагируемся от сухих академических определений и посмотрим на это понятие с точки зрения повседневного использования.
Когда мы что-то тестируем, то задаем себе простой вопрос: «работает ли это так, как мы ожидаем?» или, другими словами: соответствует ли реальное поведение объекта тестирования нашим ожиданиям? Если ответ положительный – замечательно, если нет, – мы обмануты в своих ожиданиях, а значит что-то нужно исправлять.
Тестирование необходимо потому, что все мы совершаем ошибки. Некоторые из них могут быть незначительными, в то время как другие – иметь самые разрушительные последствия. Все, что производится человеком, может содержать ошибки (так уж мы, люди, устроены). Именно поэтому любой продукт нуждается в проверке – тестировании, прежде чем его можно будет эффективно и безопасно использовать.
То же самое справедливо и для программного обеспечения (англ. Software).
Программное обеспечение (Software) – компьютерные программы, функции, а также сопровождающая их документация и данные, имеющие отношение к эксплуатации компьютерной системы.
Компьютерные технологии все глубже проникают в нашу повседневную жизнь. Программное обеспечение управляет работой множества окружающих нас вещей – от мобильных телефонов и компьютеров до стиральных машин и кредитных карт. В любом случае, все мы сталкивались с теми или иными ошибками в программах: текстовый редактор, намертво зависший при работе над дипломным проектом, банкомат, «съевший» карточку или просто сайт, который никак не загрузится – все это отнюдь не облегчает нам жизнь.
Однако не все ошибки одинаково опасны – для разных программных систем уровни риска могут отличаться.
Риск (risk):
– фактор, который может привести к негативным последствиям в будущем; как правило, выражается через вероятность наступления таких последствий и их влияние на систему.
– то, что еще не произошло, и может вообще не произойти; потенциальная проблема.
Кроме того, уровень риска будет зависеть от вероятности наступления негативных последствий.
К примеру, одна и та же незначительная ошибка, скажем опечатка, может иметь совершенно разные уровни риска для разных программ:
– опечатка в описании интересов на персональной страничке в социальной сети вряд ли будет иметь существенные последствия, разве что вызовет улыбку у Ваших друзей;
– такая же простая опечатка, допущенная в описании деятельности крупной компании, размещенном на ее сайте, уже опасна, так как косвенно свидетельствует о непрофессионализме ее сотрудников;
– опечатка в коде программы, которая подсчитывает уровни облучения при работе рентгеновского аппарата (например, 100 вместо 10) может иметь самые печальные последствия – вред, нанесенный здоровью и безопасности людей, выльется в потерю доверия к компании и судебные иски со многими нулями.
- Tutorial
Доброго времени суток!
Хочу собрать всю самую необходимую теорию по тестирвоанию, которую спрашивают на собеседованиях у trainee, junior и немножко middle. Собственно, я собрал уже не мало. Цель сего поста в том, чтобы сообща добавить упущенное и исправить/перефразировать/добавить/сделатьЧтоТоЕщё с тем, что уже есть, чтобы стало хорошо и можно было взять всё это и повторить перед очередным собеседованием про всяк случай. Вообщем, коллеги, прошу под кат, кому почерпнуть что-то новое, кому систематизировать старое, а кому внести свою лепту.
В итоге должна получиться исчерпывающая шпаргалка, которую нужно перечитать по дороге на собеседование.
Всё ниже перечисленное не выдумано мной лично, а взято с разных источников, где мне лично формулировка и определение понравилось больше. В конце список источников.
В теме: определение тестирования, качество, верификация / валидация, цели, этапы, тест план, пункты тест плана, тест дизайн, техники тест дизайна, traceability matrix, tets case, чек-лист, дефект, error/deffect/failure, баг репорт, severity vs priority, уровни тестирования, виды / типы, подходы к интеграционному тестированию, принципы тестирования, статическое и динамическое тестирование, исследовательское / ad-hoc тестирование, требования, жизненный цикл бага, стадии разработки ПО, decision table, qa/qc/test engineer, диаграмма связей.
Поехали!
Тестирование программного обеспечения
— проверка соответствия между реальным и ожидаемым поведением программы, осуществляемая на конечном наборе тестов, выбранном определенным образом. В более широком смысле, тестирование — это одна из техник контроля качества, включающая в себя активности по планированию работ (Test Management), проектированию тестов (Test Design), выполнению тестирования (Test Execution) и анализу полученных результатов (Test Analysis).
Качество программного обеспечения (Software Quality)
— это совокупность характеристик программного обеспечения, относящихся к его способности удовлетворять установленные и предполагаемые потребности.
Верификация (verification)
— это процесс оценки системы или её компонентов с целью определения удовлетворяют ли результаты текущего этапа разработки условиям, сформированным в начале этого этапа. Т.е. выполняются ли наши цели, сроки, задачи по разработке проекта, определенные в начале текущей фазы.
Валидация (validation)
— это определение соответствия разрабатываемого ПО ожиданиям и потребностям пользователя, требованиям к системе .
Также можно встретить иную интерпритацию:
Процесс оценки соответствия продукта явным требованиям (спецификациям) и есть верификация (verification), в то же время оценка соответствия продукта ожиданиям и требованиям пользователей — есть валидация (validation). Также часто можно встретить следующее определение этих понятий:
Validation — ’is this the right specification?’.
Verification — ’is the system correct to specification?’.
Цели тестирвоания
Повысить вероятность того, что приложение, предназначенное для тестирования, будет работать правильно при любых обстоятельствах.
Повысить вероятность того, что приложение, предназначенное для тестирования, будет соответствовать всем описанным требованиям.
Предоставление актуальной информации о состоянии продукта на данный момент.
Этапы тестирования:
1. Анализ
2. Разработка стратегии тестирования
и планирование процедур контроля качества
3. Работа с требованиями
4. Создание тестовой документации
5. Тестирование прототипа
6. Основное тестирование
7. Стабилизация
8. Эксплуатация
Тест план (Test Plan)
— это документ, описывающий весь объем работ по тестированию, начиная с описания объекта, стратегии, расписания, критериев начала и окончания тестирования, до необходимого в процессе работы оборудования, специальных знаний, а также оценки рисков с вариантами их разрешения.
Отвечает на вопросы:
Что надо тестировать?
Что будете тестировать?
Как будете тестировать?
Когда будете тестировать?
Критерии начала тестирования.
Критерии окончания тестирования.
Основные пункты тест плана
В стандарте IEEE 829 перечислены пункты, из которых должен (пусть — может) состоять тест-план:
a) Test plan identifier;
b) Introduction;
c) Test items;
d) Features to be tested;
e) Features not to be tested;
f) Approach;
g) Item pass/fail criteria;
h) Suspension criteria and resumption requirements;
i) Test deliverables;
j) Testing tasks;
k) Environmental needs;
l) Responsibilities;
m) StafÞng and training needs;
n) Schedule;
o) Risks and contingencies;
p) Approvals.
Тест дизайн
— это этап процесса тестирования ПО, на котором проектируются и создаются тестовые случаи (тест кейсы), в соответствии с определёнными ранее критериями качества и целями тестирования.
Роли, ответственные за тест дизайн:
Тест аналитик — определяет «ЧТО тестировать?»
Тест дизайнер — определяет «КАК тестировать?»
Техники тест дизайна
Эквивалентное Разделение (Equivalence Partitioning — EP)
. Как пример, у вас есть диапазон допустимых значений от 1 до 10, вы должны выбрать одно верное значение внутри интервала, скажем, 5, и одно неверное значение вне интервала — 0.
Анализ Граничных Значений (Boundary Value Analysis — BVA)
. Если взять пример выше, в качестве значений для позитивного тестирования выберем минимальную и максимальную границы (1 и 10), и значения больше и меньше границ (0 и 11). Анализ Граничный значений может быть применен к полям, записям, файлам, или к любого рода сущностям имеющим ограничения.
Причина / Следствие (Cause/Effect — CE)
. Это, как правило, ввод комбинаций условий (причин), для получения ответа от системы (Следствие). Например, вы проверяете возможность добавлять клиента, используя определенную экранную форму. Для этого вам необходимо будет ввести несколько полей, таких как «Имя», «Адрес», «Номер Телефона» а затем, нажать кнопку «Добавить» — эта «Причина». После нажатия кнопки «Добавить», система добавляет клиента в базу данных и показывает его номер на экране — это «Следствие».
Исчерпывающее тестирование (Exhaustive Testing — ET)
— это крайний случай. В пределах этой техники вы должны проверить все возможные комбинации входных значений, и в принципе, это должно найти все проблемы. На практике применение этого метода не представляется возможным, из-за огромного количества входных значений.
Traceability matrix
— Матрица соответствия требований — это двумерная таблица, содержащая соответсвие функциональных требований (functional requirements) продукта и подготовленных тестовых сценариев (test cases). В заголовках колонок таблицы расположены требования, а в заголовках строк — тестовые сценарии. На пересечении — отметка, означающая, что требование текущей колонки покрыто тестовым сценарием текущей строки.
Матрица соответсвия требований используется QA-инженерами для валидации покрытия продукта тестами. МСТ является неотъемлемой частью тест-плана.
Тестовый случай (Test Case)
— это артефакт, описывающий совокупность шагов, конкретных условий и параметров, необходимых для проверки реализации тестируемой функции или её части.
Пример:
Action Expected Result Test Result
(passed/failed/blocked)
Open page «login» Login page is opened Passed
Каждый тест кейс должен иметь 3 части:
PreConditions Список действий, которые приводят систему к состоянию пригодному для проведения основной проверки. Либо список условий, выполнение которых говорит о том, что система находится в пригодном для проведения основного теста состояния.
Test Case Description Список действий, переводящих систему из одного состояния в другое, для получения результата, на основании которого можно сделать вывод о удовлетворении реализации, поставленным требованиям
PostConditions Список действий, переводящих систему в первоначальное состояние (состояние до проведения теста — initial state)
Виды Тестовых Случаев:
Тест кейсы разделяются по ожидаемому результату на позитивные и негативные:
Позитивный тест кейс использует только корректные данные и проверяет, что приложение правильно выполнило вызываемую функцию.
Негативный тест кейс оперирует как корректными так и некорректными данными (минимум 1 некорректный параметр) и ставит целью проверку исключительных ситуаций (срабатывание валидаторов), а также проверяет, что вызываемая приложением функция не выполняется при срабатывании валидатора.
Чек-лист (check list)
— это документ, описывающий что должно быть протестировано. При этом чек-лист может быть абсолютно разного уровня детализации. На сколько детальным будет чек-лист зависит от требований к отчетности, уровня знания продукта сотрудниками и сложности продукта.
Как правило, чек-лист содержит только действия (шаги), без ожидаемого результата. Чек-лист менее формализован чем тестовый сценарий. Его уместно использовать тогда, когда тестовые сценарии будут избыточны. Также чек-лист ассоциируются с гибкими подходами в тестировании.
Дефект (он же баг)
— это несоответствие фактического результата выполнения программы ожидаемому результату. Дефекты обнаруживаются на этапе тестирования программного обеспечения (ПО), когда тестировщик проводит сравнение полученных результатов работы программы (компонента или дизайна) с ожидаемым результатом, описанным в спецификации требований.
Error
— ошибка пользователя, то есть он пытается использовать программу иным способом.
Пример — вводит буквы в поля, где требуется вводить цифры (возраст, количество товара и т.п.).
В качественной программе предусмотрены такие ситуации и выдаются сообщение об ошибке (error message), с красным крестиком которые.
Bug (defect)
— ошибка программиста (или дизайнера или ещё кого, кто принимает участие в разработке), то есть когда в программе, что-то идёт не так как планировалось и программа выходит из-под контроля. Например, когда никак не контроллируется ввод пользователя, в результате неверные данные вызывают краши или иные «радости» в работе программы. Либо внутри программа построена так, что изначально не соответствует тому, что от неё ожидается.
Failure
— сбой (причём не обязательно аппаратный) в работе компонента, всей программы или системы. То есть, существуют такие дефекты, которые приводят к сбоям (A defect caused the failure) и существуют такие, которые не приводят. UI-дефекты например. Но аппаратный сбой, никак не связанный с software, тоже является failure.
Баг Репорт (Bug Report)
— это документ, описывающий ситуацию или последовательность действий приведшую к некорректной работе объекта тестирования, с указанием причин и ожидаемого результата.
Шапка
Короткое описание (Summary) Короткое описание проблемы, явно указывающее на причину и тип ошибочной ситуации.
Проект (Project) Название тестируемого проекта
Компонент приложения (Component) Название части или функции тестируемого продукта
Номер версии (Version) Версия на которой была найдена ошибка
Серьезность (Severity) Наиболее распространена пятиуровневая система градации серьезности дефекта:
S1 Блокирующий (Blocker)
S2 Критический (Critical)
S3 Значительный (Major)
S4 Незначительный (Minor)
S5 Тривиальный (Trivial)
Приоритет (Priority) Приоритет дефекта:
P1 Высокий (High)
P2 Средний (Medium)
P3 Низкий (Low)
Статус (Status) Статус бага. Зависит от используемой процедуры и жизненного цикла бага (bug workflow and life cycle)
Автор (Author) Создатель баг репорта
Назначен на (Assigned To) Имя сотрудника, назначенного на решение проблемы
Окружение
ОС / Сервис Пак и т.д. / Браузера + версия /… Информация об окружении, на котором был найден баг: операционная система, сервис пак, для WEB тестирования — имя и версия браузера и т.д.
…
Описание
Шаги воспроизведения (Steps to Reproduce) Шаги, по которым можно легко воспроизвести ситуацию, приведшую к ошибке.
Фактический Результат (Result) Результат, полученный после прохождения шагов к воспроизведению
Ожидаемый результат (Expected Result) Ожидаемый правильный результат
Дополнения
Прикрепленный файл (Attachment) Файл с логами, скриншот или любой другой документ, который может помочь прояснить причину ошибки или указать на способ решения проблемы.
Severity vs Priority
Серьезность (Severity) — это атрибут, характеризующий влияние дефекта на работоспособность приложения.
Приоритет (Priority) — это атрибут, указывающий на очередность выполнения задачи или устранения дефекта. Можно сказать, что это инструмент менеджера по планированию работ. Чем выше приоритет, тем быстрее нужно исправить дефект.
Severity выставляется тестировщиком
Priority — менеджером, тимлидом или заказчиком
Градация Серьезности дефекта (Severity)
S1 Блокирующая (Blocker)
Блокирующая ошибка, приводящая приложение в нерабочее состояние, в результате которого дальнейшая работа с тестируемой системой или ее ключевыми функциями становится невозможна. Решение проблемы необходимо для дальнейшего функционирования системы.
S2 Критическая (Critical)
Критическая ошибка, неправильно работающая ключевая бизнес логика, дыра в системе безопасности, проблема, приведшая к временному падению сервера или приводящая в нерабочее состояние некоторую часть системы, без возможности решения проблемы, используя другие входные точки. Решение проблемы необходимо для дальнейшей работы с ключевыми функциями тестируемой системой.
S3 Значительная (Major)
Значительная ошибка, часть основной бизнес логики работает некорректно. Ошибка не критична или есть возможность для работы с тестируемой функцией, используя другие входные точки.
S4 Незначительная (Minor)
Незначительная ошибка, не нарушающая бизнес логику тестируемой части приложения, очевидная проблема пользовательского интерфейса.
S5 Тривиальная (Trivial)
Тривиальная ошибка, не касающаяся бизнес логики приложения, плохо воспроизводимая проблема, малозаметная посредствам пользовательского интерфейса, проблема сторонних библиотек или сервисов, проблема, не оказывающая никакого влияния на общее качество продукта.
Градация Приоритета дефекта (Priority)
P1 Высокий (High)
Ошибка должна быть исправлена как можно быстрее, т.к. ее наличие является критической для проекта.
P2 Средний (Medium)
Ошибка должна быть исправлена, ее наличие не является критичной, но требует обязательного решения.
P3 Низкий (Low)
Ошибка должна быть исправлена, ее наличие не является критичной, и не требует срочного решения.
Уровни Тестирования
1. Модульное тестирование (Unit Testing)
Компонентное (модульное) тестирование проверяет функциональность и ищет дефекты в частях приложения, которые доступны и могут быть протестированы по-отдельности (модули программ, объекты, классы, функции и т.д.).
2. Интеграционное тестирование (Integration Testing)
Проверяется взаимодействие между компонентами системы после проведения компонентного тестирования.
3. Системное тестирование (System Testing)
Основной задачей системного тестирования является проверка как функциональных, так и не функциональных требований в системе в целом. При этом выявляются дефекты, такие как неверное использование ресурсов системы, непредусмотренные комбинации данных пользовательского уровня, несовместимость с окружением, непредусмотренные сценарии использования, отсутствующая или неверная функциональность, неудобство использования и т.д.
4. Операционное тестирование (Release Testing).
Даже если система удовлетворяет всем требованиям, важно убедиться в том, что она удовлетворяет нуждам пользователя и выполняет свою роль в среде своей эксплуатации, как это было определено в бизнес моделе системы. Следует учесть, что и бизнес модель может содержать ошибки. Поэтому так важно провести операционное тестирование как финальный шаг валидации. Кроме этого, тестирование в среде эксплуатации позволяет выявить и нефункциональные проблемы, такие как: конфликт с другими системами, смежными в области бизнеса или в программных и электронных окружениях; недостаточная производительность системы в среде эксплуатации и др. Очевидно, что нахождение подобных вещей на стадии внедрения — критичная и дорогостоящая проблема. Поэтому так важно проведение не только верификации, но и валидации, с самых ранних этапов разработки ПО.
5. Приемочное тестирование (Acceptance Testing)
Формальный процесс тестирования, который проверяет соответствие системы требованиям и проводится с целью:
определения удовлетворяет ли система приемочным критериям;
вынесения решения заказчиком или другим уполномоченным лицом принимается приложение или нет.
Виды / типы тестирования
Функциональные виды тестирования
Функциональное тестирование (Functional testing)
Тестирование безопасности (Security and Access Control Testing)
Тестирование взаимодействия (Interoperability Testing)
Нефункциональные виды тестирования
Все виды тестирования производительности:
o нагрузочное тестирование (Performance and Load Testing)
o стрессовое тестирование (Stress Testing)
o тестирование стабильности или надежности (Stability / Reliability Testing)
o объемное тестирование (Volume Testing)
Тестирование установки (Installation testing)
Тестирование удобства пользования (Usability Testing)
Тестирование на отказ и восстановление (Failover and Recovery Testing)
Конфигурационное тестирование (Configuration Testing)
Связанные с изменениями виды тестирования
Дымовое тестирование (Smoke Testing)
Регрессионное тестирование (Regression Testing)
Повторное тестирование (Re-testing)
Тестирование сборки (Build Verification Test)
Санитарное тестирование или проверка согласованности/исправности (Sanity Testing)
Функциональное тестирование
рассматривает заранее указанное поведение и основывается на анализе спецификаций функциональности компонента или системы в целом.
Тестирование безопасности
— это стратегия тестирования, используемая для проверки безопасности системы, а также для анализа рисков, связанных с обеспечением целостного подхода к защите приложения, атак хакеров, вирусов, несанкционированного доступа к конфиденциальным данным.
Тестирование взаимодействия (Interoperability Testing)
— это функциональное тестирование, проверяющее способность приложения взаимодействовать с одним и более компонентами или системами и включающее в себя тестирование совместимости (compatibility testing) и интеграционное тестирование
Нагрузочное тестирование
— это автоматизированное тестирование, имитирующее работу определенного количества бизнес пользователей на каком-либо общем (разделяемом ими) ресурсе.
Стрессовое тестирование (Stress Testing)
позволяет проверить насколько приложение и система в целом работоспособны в условиях стресса и также оценить способность системы к регенерации, т.е. к возвращению к нормальному состоянию после прекращения воздействия стресса. Стрессом в данном контексте может быть повышение интенсивности выполнения операций до очень высоких значений или аварийное изменение конфигурации сервера. Также одной из задач при стрессовом тестировании может быть оценка деградации производительности, таким образом цели стрессового тестирования могут пересекаться с целями тестирования производительности.
Объемное тестирование (Volume Testing)
. Задачей объемного тестирования является получение оценки производительности при увеличении объемов данных в базе данных приложения
Тестирование стабильности или надежности (Stability / Reliability Testing)
. Задачей тестирования стабильности (надежности) является проверка работоспособности приложения при длительном (многочасовом) тестировании со средним уровнем нагрузки.
Тестирование установки
направленно на проверку успешной инсталляции и настройки, а также обновления или удаления программного обеспечения.
Тестирование удобства пользования
— это метод тестирования, направленный на установление степени удобства использования, обучаемости, понятности и привлекательности для пользователей разрабатываемого продукта в контексте заданных условий. Сюда также входит:
Тестирование пользовательского интерфейса (англ. UI Testing) — это вид тестирования исследования, выполняемого с целью определения, удобен ли некоторый искусственный объект (такой как веб-страница, пользовательский интерфейс или устройство) для его предполагаемого применения.
User eXperience (UX) — ощущение, испытываемое пользователем во время использования цифрового продукта, в то время как User interface — это инструмент, позволяющий осуществлять интеракцию «пользователь — веб-ресурс».
Тестирование на отказ и восстановление (Failover and Recovery Testing)
проверяет тестируемый продукт с точки зрения способности противостоять и успешно восстанавливаться после возможных сбоев, возникших в связи с ошибками программного обеспечения, отказами оборудования или проблемами связи (например, отказ сети). Целью данного вида тестирования является проверка систем восстановления (или дублирующих основной функционал систем), которые, в случае возникновения сбоев, обеспечат сохранность и целостность данных тестируемого продукта.
Конфигурационное тестирование (Configuration Testing)
— специальный вид тестирования, направленный на проверку работы программного обеспечения при различных конфигурациях системы (заявленных платформах, поддерживаемых драйверах, при различных конфигурациях компьютеров и т.д.)
Дымовое (Smoke)
тестирование рассматривается как короткий цикл тестов, выполняемый для подтверждения того, что после сборки кода (нового или исправленного) устанавливаемое приложение, стартует и выполняет основные функции.
Регрессионное тестирование
— это вид тестирования направленный на проверку изменений, сделанных в приложении или окружающей среде (починка дефекта, слияние кода, миграция на другую операционную систему, базу данных, веб сервер или сервер приложения), для подтверждения того факта, что существующая ранее функциональность работает как и прежде. Регрессионными могут быть как функциональные, так и нефункциональные тесты.
Повторное тестирование
— тестирование, во время которого исполняются тестовые сценарии, выявившие ошибки во время последнего запуска, для подтверждения успешности исправления этих ошибок.
В чем разница между regression testing и re-testing?
Re-testing — проверяется исправление багов
Regression testing — проверяется то, что исправление багов не повлияло на другие модули ПО и не вызвало новых багов.
Тестирование сборки или Build Verification Test
— тестирование направленное на определение соответствия, выпущенной версии, критериям качества для начала тестирования. По своим целям является аналогом Дымового Тестирования, направленного на приемку новой версии в дальнейшее тестирование или эксплуатацию. Вглубь оно может проникать дальше, в зависимости от требований к качеству выпущенной версии.
Санитарное тестирование
— это узконаправленное тестирование достаточное для доказательства того, что конкретная функция работает согласно заявленным в спецификации требованиям. Является подмножеством регрессионного тестирования. Используется для определения работоспособности определенной части приложения после изменений произведенных в ней или окружающей среде. Обычно выполняется вручную.
Предугадывание ошибки (Error Guessing — EG)
. Это когда тест аналитик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку. Например, спецификация говорит: «пользователь должен ввести код». Тест аналитик, будет думать: «Что, если я не введу код?», «Что, если я введу неправильный код? », и так далее. Это и есть предугадывание ошибки.
Подходы к интеграционному тестированию:
Снизу вверх (Bottom Up Integration)
Все низкоуровневые модули, процедуры или функции собираются воедино и затем тестируются. После чего собирается следующий уровень модулей для проведения интеграционного тестирования. Данный подход считается полезным, если все или практически все модули, разрабатываемого уровня, готовы. Также данный подход помогает определить по результатам тестирования уровень готовности приложения.
Сверху вниз (Top Down Integration)
Вначале тестируются все высокоуровневые модули, и постепенно один за другим добавляются низкоуровневые. Все модули более низкого уровня симулируются заглушками с аналогичной функциональностью, затем по мере готовности они заменяются реальными активными компонентами. Таким образом мы проводим тестирование сверху вниз.
Большой взрыв («Big Bang» Integration)
Все или практически все разработанные модули собираются вместе в виде законченной системы или ее основной части, и затем проводится интеграционное тестирование. Такой подход очень хорош для сохранения времени. Однако если тест кейсы и их результаты записаны не верно, то сам процесс интеграции сильно осложнится, что станет преградой для команды тестирования при достижении основной цели интеграционного тестирования.
Принципы тестирования
Принцип 1
— Тестирование демонстрирует наличие дефектов (Testing shows presence of defects)
Тестирование может показать, что дефекты присутствуют, но не может доказать, что их нет. Тестирование снижает вероятность наличия дефектов, находящихся в программном обеспечении, но, даже если дефекты не были обнаружены, это не доказывает его корректности.
Принцип 2
— Исчерпывающее тестирование недостижимо (Exhaustive testing is impossible)
Полное тестирование с использованием всех комбинаций вводов и предусловий физически невыполнимо, за исключением тривиальных случаев. Вместо исчерпывающего тестирования должны использоваться анализ рисков и расстановка приоритетов, чтобы более точно сфокусировать усилия по тестированию.
Принцип 3
— Раннее тестирование (Early testing)
Чтобы найти дефекты как можно раньше, активности по тестированию должны быть начаты как можно раньше в жизненном цикле разработки программного обеспечения или системы, и должны быть сфокусированы на определенных целях.
Принцип 4
— Скопление дефектов (Defects clustering)
Усилия тестирования должны быть сосредоточены пропорционально ожидаемой, а позже реальной плотности дефектов по модулям. Как правило, большая часть дефектов, обнаруженных при тестировании или повлекших за собой основное количество сбоев системы, содержится в небольшом количестве модулей.
Принцип 5
— Парадокс пестицида (Pesticide paradox)
Если одни и те же тесты будут прогоняться много раз, в конечном счете этот набор тестовых сценариев больше не будет находить новых дефектов. Чтобы преодолеть этот «парадокс пестицида», тестовые сценарии должны регулярно рецензироваться и корректироваться, новые тесты должны быть разносторонними, чтобы охватить все компоненты программного обеспечения, или системы, и найти как можно больше дефектов.
Принцип 6
— Тестирование зависит от контекста (Testing is concept depending)
Тестирование выполняется по-разному в зависимости от контекста. Например, программное обеспечение, в котором критически важна безопасность, тестируется иначе, чем сайт электронной коммерции.
Принцип 7
— Заблуждение об отсутствии ошибок (Absence-of-errors fallacy)
Обнаружение и исправление дефектов не помогут, если созданная система не подходит пользователю и не удовлетворяет его ожиданиям и потребностям.
Cтатическое и динамическое тестирование
Статическое тестирование отличается от динамического тем, что производится без запуска программного кода продукта. Тестирование осуществляется путем анализа программного кода (code review) или скомпилированного кода. Анализ может производиться как вручную, так и с помощью специальных инструментальных средств. Целью анализа является раннее выявление ошибок и потенциальных проблем в продукте. Также к статическому тестирвоанию относится тестирования спецификации и прочей документации.
Исследовательское / ad-hoc тестирование
Простейшее определение исследовательского тестирования — это разработка и выполнения тестов в одно и то же время. Что является противоположностью сценарного подхода (с его предопределенными процедурами тестирования, неважно ручными или автоматизированными). Исследовательские тесты, в отличие от сценарных тестов, не определены заранее и не выполняются в точном соответствии с планом.
Разница между ad hoc и exploratory testing в том, что теоретически, ad hoc может провести кто угодно, а для проведения exploratory необходимо мастерство и владение определенными техниками. Обратите внимание, что определенные техники это не только техники тестирования.
Требования
— это спецификация (описание) того, что должно быть реализовано.
Требования описывают то, что необходимо реализовать, без детализации технической стороны решения. Что, а не как.
Требования к требованиям:
Корректность
Недвусмысленность
Полнота набора требований
Непротиворечивость набора требований
Проверяемость (тестопригодность)
Трассируемость
Понимаемость
Жизненный цикл бага

Стадии разработки ПО
— это этапы, которые проходят команды разработчиков ПО, прежде чем программа станет доступной для широко круга пользователей. Разработка ПО начинается с первоначального этапа разработки (стадия «пре-альфа») и продолжается стадиями, на которых продукт дорабатывается и модернизируется. Финальным этапом этого процесса становится выпуск на рынок окончательной версии программного обеспечения («общедоступного релиза»).
Программный продукт проходит следующие стадии:
анализ требований к проекту;
проектирование;
реализация;
тестирование продукта;
внедрение и поддержка.
Каждой стадии разработки ПО присваивается определенный порядковый номер. Также каждый этап имеет свое собственное название, которое характеризует готовность продукта на этой стадии.
Жизненный цикл разработки ПО:
Пре-альфа
Альфа
Бета
Релиз-кандидат
Релиз
Пост-релиз
Таблица принятия решений (decision table)
— великолепный инструмент для упорядочения сложных бизнес требований, которые должны быть реализованы в продукте. В таблицах решений представлен набор условий, одновременное выполнение которых должно привести к определенному действию.
QA/QC/Test Engineer

Таким образом, мы можем построить модель иерархии процессов обеспечения качества: Тестирование — часть QC. QC — часть QA.
Диаграмма связей
— это инструмент управления качеством, основанный на определении логических взаимосвязей между различными данными. Применяется этот инструмент для сопоставления причин и следствий по исследуемой проблеме.

Тестирование программного обеспечения (ПО) выявляет недоработки, изъяны и ошибки в коде, которые необходимо устранить. Его также можно определить как процесс оценки функциональных возможностей и корректности ПО с помощью анализа. Основные методы интеграции и тестирования программных продуктов обеспечивают качество приложений и заключаются в проверке спецификации, дизайна и кода, оценке надежности, валидации и верификации.
Методы
Главная цель тестирования ПО — подтверждение качества программного комплекса путем систематической отладки приложений в тщательно контролируемых условиях, определение их полноты и корректности, а также обнаружение скрытых ошибок.
Методы можно разделить на статические и динамические.
К первым относятся неформальное, контрольное и техническое рецензирование, инспекция, пошаговый разбор, аудит, а также статический анализ потока данных и управления.
Динамические техники следующие:
- Тестирование методом белого ящика.
Это подробное исследование внутренней логики и структуры программы. При этом необходимо знание исходного кода. - Тестирование методом черного ящика.
Данная техника не требует каких-либо знаний о внутренней работе приложения. Рассматриваются только основные аспекты системы, не связанные или мало связанные с ее внутренней логической структурой. - Метод серого ящика.
Сочетает в себе предыдущие два подхода. Отладка с ограниченным знанием о внутреннем функционировании приложения сочетается со знанием основных аспектов системы.
Прозрачное тестирование
В методе белого ящика используются тестовые сценарии контрольной структуры процедурного проекта. Данная техника позволяет выявить ошибки реализации, такие как плохое управление системой кодов, путем анализа внутренней работы части программного обеспечения. Данные методы тестирования применимы на интеграционном, модульном и системном уровнях. Тестировщик должен иметь доступ к исходному коду и, используя его, выяснить, какой блок ведет себя несоответствующим образом.
Тестирование программ методом белого ящика обладает следующими преимуществами:
- позволяет выявить ошибку в скрытом коде при удалении лишних строк;
- возможность использования побочных эффектов;
- максимальный охват достигается путем написания тестового сценария.
Недостатки:
- высокозатратный процесс, требующий квалифицированного отладчика;
- много путей останутся неисследованными, поскольку тщательная проверка всех возможных скрытых ошибок очень сложна;
- некоторая часть пропущенного кода останется незамеченной.
Тестирование методом белого ящика иногда еще называют тестированием методом прозрачного или открытого ящика, структурным, логическим тестированием, тестированием на основе исходных текстов, архитектуры и логики.
Основные разновидности:
1) тестирование управления потоком — структурная стратегия, использующая поток управления программой в качестве модели и отдающая предпочтение большему количеству простых путей перед меньшим числом более сложных;
2) отладка ветвления имеет целью исследование каждой опции (истинной или ложной) каждого оператора управления, который также включает в себя объединенное решение;
3) тестирование основного пути, которое позволяет тестировщику установить меру логической сложности процедурного проекта для выделения базового набора путей выполнения;
4) проверка потока данных — стратегия исследования потока управления путем аннотации графа информацией об объявлении и использовании переменных программы;
5) тестирование циклов — полностью сосредоточено на правильном выполнении циклических процедур.

Поведенческая отладка
Тестирование методом черного ящика рассматривает ПО как «черный ящик» — сведения о внутренней работе программы не учитываются, а проверяются только основные аспекты системы. При этом тестировщику необходимо знать системную архитектуру без доступа к исходному коду.
Преимущества такого подхода:
- эффективность для большого сегмента кода;
- простота восприятия тестировщиком;
- перспектива пользователя четко отделена от перспективы разработчика (программист и тестировщик независимы друг от друга);
- более быстрое создание теста.
Тестирование программ методами черного ящика имеет следующие недостатки:
- в действительности выполняется избранное число тестовых сценариев, результатом чего является ограниченный охват;
- отсутствие четкой спецификации затрудняет разработку тестовых сценариев;
- низкая эффективность.
Другие названия данной техники — поведенческое, непрозрачное, функциональное тестирование и отладка методом закрытого ящика.
1) эквивалентное разбиение, которое может уменьшить набор тестовых данных, так как входные данные программного модуля разбиваются на отдельные части;
2) краевой анализ фокусируется на проверке границ или экстремальных граничных значений — минимумах, максимумах, ошибочных и типичных значениях;
3) фаззинг — используется для поиска погрешностей реализации с помощью ввода искаженных или полуискаженных данных в автоматическом или полуавтоматическом режиме;
4) графы причинно-следственных связей — методика, основанная на создании графов и установлении связи между действием и его причинами: тождественность, отрицание, логическое ИЛИ и логическое И — четыре основных символа, выражающие взаимозависимость между причиной и следствием;
5) проверка ортогональных массивов, применяемая к проблемам с относительно небольшой областью ввода, превышающей возможности исчерпывающего исследования;
6) тестирование всех пар — техника, набор тестовых значений которой включает все возможные дискретные комбинации каждой пары входных параметров;

Тестирование методом черного ящика: примеры
Техника основана на спецификациях, документации, а также описаниях интерфейса программного обеспечения или системы. Кроме того, возможно использование моделей (формальных или неформальных), представляющих ожидаемое поведение ПО.
Обычно данный метод отладки применяется для пользовательских интерфейсов и требует взаимодействия с приложением путем введения данных и сбора результатов — с экрана, из отчетов или распечаток.
Тестировщик, таким образом, взаимодействует с ПО путем ввода, воздействуя на переключатели, кнопки или другие интерфейсы. Выбор входных данных, порядок их введения или очередность действий могут привести к гигантскому суммарному числу комбинаций, как это видно на следующем примере.
Какое количество тестов необходимо произвести, чтобы проверить все возможные значения для 4 окон флажка и одного двухпозиционного поля, задающего время в секундах? На первый взгляд расчет прост: 4 поля с двумя возможными состояниями — 24 = 16, которые необходимо умножить на число возможных позиций от 00 до 99, то есть 1600 возможных тестов.
Тем не менее этот расчет ошибочен: мы можем определить, что двухпозиционное поле может также содержать пробел, т. е. оно состоит из двух буквенно-цифровых позиций и может включать символы алфавита, специальные символы, пробелы и т. д. Таким образом, если система представляет собой 16-битный компьютер, то получится 216 = 65 536 вариантов для каждой позиции, результирующих в 4 294 967 296 тестовых случаев, которые необходимо умножить на 16 комбинаций для флажков, что в общей сложности дает 68 719 476 736. Если их выполнить со скоростью 1 тест в секунду, то общая продолжительность тестирования составит 2 177,5 лет. Для 32 или 64-битных систем, длительность еще больше.
Поэтому возникает необходимость уменьшить этот срок до приемлемого значения. Таким образом, должны применяться приемы для сокращения количества тестовых случаев без уменьшения охвата тестирования.

Эквивалентное разбиение
Эквивалентное разбиение представляет собой простой метод, применимый для любых переменных, присутствующих в программном обеспечении, будь то входные или выходные значения, символьные, числовые и др. Он основан на том принципе, что все данные из одного эквивалентного разбиения будут обрабатываться тем же образом и теми же инструкциями.
Во время тестирования выбирается по одному представителю от каждого определенного эквивалентного разбиения. Это позволяет систематически сокращать число возможных тестовых случаев без потери охвата команд и функций.
Другим следствием такого разбиения является сокращение комбинаторного взрыва между различными переменными и связанное с ними сокращение тестовых случаев.
Например, в (1/x) 1/2 используется три последовательности данных, три эквивалентных разбиения:
1. Все положительные числа будут обрабатываться таким же образом и должны давать правильные результаты.
2. Все отрицательные числа будут обрабатываться так же, с таким же результатом. Это неверно, так как корень из отрицательного числа является мнимым.
3. Ноль будет обрабатываться отдельно и даст ошибку «деление на ноль». Это раздел с одним значением.
Таким образом, мы видим три различных раздела, один из которых сводится к единственному значению. Есть один «правильный» раздел, дающий достоверные результаты, и два «неправильных», с некорректными результатами.
Краевой анализ
Обработка данных на границах эквивалентного разбиения может выполняться иначе, чем ожидается. Исследование граничных значений — хорошо известный способ анализа поведения ПО в таких областях. Эта техника позволяет выявить такие ошибки:
- неправильное использование операторов отношения (, =, ≠, ≥, ≤);
- единичные ошибки;
- проблемы в циклах и итерациях,
- неправильные типы или размер переменных, используемых для хранения информации;
- искусственные ограничения, связанные с данными и типами переменных.

Полупрозрачное тестирование
Метод серого ящика увеличивает охват проверки, позволяя сосредоточиться на всех уровнях сложной системы путем сочетания методов белого и черного.
При использовании этой техники тестировщик для разработки тестовых значений должен обладать знаниями о внутренних структурах данных и алгоритмах. Примерами методики тестирования серого ящика являются:
- архитектурная модель;
- унифицированный язык моделирования (UML);
- модель состояний (конечный автомат).
В методе серого ящика для разработки тестовых случаев изучаются коды модулей по технике белого, а фактическое испытание выполняется на интерфейсах программы по технологии черного.
Такие методы тестирования обладают следующими преимуществами:
- сочетание преимуществ техник белого и черного ящиков;
- тестировщик опирается на интерфейс и функциональную спецификацию, а не на исходный код;
- отладчик может создавать отличные тестовые сценарии;
- проверка производится с точки зрения пользователя, а не дизайнера программы;
- создание настраиваемых тестовых разработок;
- объективность.
Недостатки:
- тестовое покрытие ограничено, так как отсутствует доступ к исходному коду;
- сложность обнаружения дефектов в распределенных приложениях;
- многие пути остаются неисследованными;
- если разработчик программного обеспечения уже запускал проверку, то дальнейшее исследование может быть избыточным.
Другое название техники серого ящика — полупрозрачная отладка.
1) ортогональный массив — использование подмножества всех возможных комбинаций;
2) матричная отладка с использованием данных о состоянии программы;
3) проводимая при внесении новых изменений в ПО;
4) шаблонный тест, который анализирует дизайн и архитектуру добротного приложения.

тестирования ПО
Использование всех динамических методов приводит к комбинаторному взрыву количества тестов, которые должны быть разработаны, воплощены и проведены. Каждую технику следует использовать прагматично, принимая во внимание ее ограничения.
Единственно верного метода не существует, есть только те, которые лучше подходят для конкретного контекста. Структурные техники позволяют найти бесполезный или вредоносный код, но они сложны и неприменимы к крупным программам. Методы на основе спецификации — единственные, которые способны выявить недостающий код, но они не могут идентифицировать посторонний. Одни техники больше подходят для конкретного уровня тестирования, типа ошибок или контекста, чем другие.
Ниже приведены основные отличия трех динамических техник тестирования — дана таблица сравнения между тремя формами отладки ПО.
|
Аспект |
Метод черного ящика |
Метод серого ящика |
Метод белого ящика |
|
Наличие сведений о составе программы |
Анализируются только базовые аспекты |
Частичное знание о внутреннем устройстве программы |
Полный доступ к исходному коду |
|
Степень дробления программы |
|||
|
Кто производит отладку? |
Конечные пользователи, тестировщики и разработчики |
Конечные пользователи, отладчики и девелоперы |
Разработчики и тестировщики |
|
Тестирование базируется на внешних внештатных ситуациях. |
Диаграммы БД, диаграммы потока данных, внутренние состояния, знание алгоритма и архитектуры |
Внутреннее устройство полностью известно |
|
|
Степень охвата |
Наименее исчерпывающая и требует минимума времени |
Потенциально наиболее исчерпывающая. Требует много времени |
|
|
Данные и внутренние границы |
Отладка исключительно методом проб и ошибок |
Могут проверяться домены данных и внутренние границы, если они известны |
Лучшее тестирование доменов данных и внутренних границ |
|
Пригодность для тестирования алгоритма |
Автоматизация
Автоматические методы тестирования программных продуктов намного упрощают процесс проверки независимо от технической среды или контекста ПО. Их используют в двух случаях:
1) для автоматизации выполнение утомительных, повторяющихся или скрупулезных задач, таких как сравнение файлов в нескольких тысяч строк с целью высвобождения времени тестировщика для концентрации на более важных моментах;
2) для выполнения или отслеживания задач, которые не могут быть легко осуществимы людьми, таких как проверка производительности или анализ времени отклика, которые могут измеряться в сотых долях секунды.

Тестовые инструменты могут быть классифицированы по-разному. Следующее деление основано на поддерживаемых ими задачах:
- управление тестированием, которое включает поддержку управления проектом, версиями, конфигурациями, риск-анализ, отслеживание тестов, ошибок, дефектов и инструменты создания отчетов;
- управление требованиями, которое включает хранение требований и спецификаций, их проверку на полноту и многозначность, их приоритет и отслеживаемость каждого теста;
- критический просмотр и статический анализ, включая мониторинг потока и задач, запись и хранение комментариев, обнаружение дефектов и плановых коррекций, управление ссылками на проверочные списки и правила, отслеживание связи исходных документов и кода, статический анализ с обнаружением дефектов, обеспечением соответствия стандартам написания кода, разбором структур и их зависимостей, вычислением метрических параметров кода и архитектуры. Кроме того, используются компиляторы, анализаторы связей и генераторы кросс-ссылок;
- моделирование, которое включает инструменты моделирования бизнес-поведения и проверки созданных моделей;
- разработка тестов обеспечивает генерацию ожидаемых данных исходя из условий и интерфейса пользователя, моделей и кода, управление ими для создания или изменения файлов и БД, сообщений, проверки данных исходя из правил управления, анализа статистики условий и рисков;
- критический просмотр путем ввода данных через графический интерфейс пользователя, API, командные строки с использованием компараторов, помогающих определить успешные и неудавшиеся тесты;
- поддержка сред отладки, которая позволяет заменить отсутствующее оборудование или ПО, в т. ч. симуляторы оборудования на основе подмножества детерминированного выхода, эмуляторы терминалов, мобильных телефонов или сетевого оборудования, среды для проверки языков, ОС и аппаратного обеспечения путем замены недостающих компонентов драйверами, фиктивными модулями и др., а также инструменты для перехвата и модификации запросов ОС, симуляции ограничений ЦПУ, ОЗУ, ПЗУ или сети;
- сравнение данных файлов, БД, проверка ожидаемых результатов во время и по окончании тестирования, в т. ч. динамическое и пакетное сравнение, автоматические «оракулы»;
- измерение покрытия для локализации утечек памяти и некорректного управления ею, оценки поведения системы в условиях симулированной нагрузки, генерации нагрузки приложений, БД, сети или серверов по реалистичным сценариям ее роста, для измерения, анализа, проверки и отчета о системных ресурсах;
- обеспечение безопасности;
- тестирование производительности, нагрузки и динамический анализ;
- другие инструменты, в т. ч. для проверки правописания и синтаксиса, сетевой безопасности, наличия всех страниц веб-сайта и др.
Перспектива
С изменением тенденций в индустрии ПО процесс его отладки также подвержен изменениям. Существующие новые методы тестирования программных продуктов, такие как сервис-ориентированнае архитектура (SOA), беспроводные технологии, мобильные услуги и т. д., открыли новые способы проверки ПО. Некоторые из изменений, которые ожидаются в этой отрасли в течение следующих нескольких лет, перечислены ниже:
- тестировщики будут предоставлять легковесные модели, с помощью которых разработчики смогут проверять свой код;
- разработка методов тестирования, включающих просмотр и моделирование программ на раннем этапе, позволит устранить многие противоречия;
- наличие множества тестовых перехватов сократит время обнаружения ошибок;
- статический анализатор и средства обнаружения будут применяться более широко;
- применение полезных матриц, таких как охват спецификации, охват модели и покрытие кода, будет определять разработку проектов;
- комбинаторные инструменты позволят тестировщикам определять приоритетные направления отладки;
- тестировщики будут предоставлять более наглядные и ценные услуги на протяжении всего процесса разработки ПО;
- отладчики смогут создавать средства и методы тестирования программного обеспечения, написанные на и взаимодействующие с различными языками программирования;
- специалисты по отладке станут более профессионально подготовленными.
На смену придут новые бизнес-ориентированные методы тестирования программ, изменятся способы взаимодействия с системами и предоставляемой ими информацией с одновременным снижением рисков и ростом преимуществ от бизнес-изменений.
| Планирование уроков на учебный год
| Основные этапы моделирования
Изучив эту тему, вы узнаете:
Что такое моделирование;
— что может служить прототипом для моделирования;
— какое место занимает моделирование в деятельности человека;
— каковы основные этапы моделирования;
— что такое компьютерная модель;
— что такое компьютерный эксперимент.
Компьютерный эксперимент
Чтобы дать жизнь новым конструкторским разработкам, внедрить новые технические решения в производство или проверить новые идеи, нужен эксперимент. Эксперимент — это опыт, который производится с объектом или моделью. Он заключается в выполнении некоторых действий и определении, как реагирует экспериментальный образец на эти действия.
В школе вы проводите опыты на уроках биологии, химии, физики, географии.
Эксперименты проводят при испытании новых образцов продукции на предприятиях. Обычно для этого используется специально создаваемая установка, позволяющая провести эксперимент в лабораторных условиях, либо сам реальный продукт подвергается всякого рода испытаниям (натурный эксперимент). Для исследования, к примеру, эксплуатационных свойств какого-либо агрегата или узла его помещают в термостат, замораживают в специальных камерах, испытывают на вибростендах, роняют и т. п. Хорошо, если это новые часы или пылесос — не велика потеря при разрушении. А если самолет или ракета?
Лабораторные и натурные эксперименты требуют больших материальных затрат и времени, но их значение, тем не менее, очень велико.
С развитием компьютерной техники появился новый уникальный метод исследования — компьютерный эксперимент. В помощь, а иногда и на смену экспериментальным образцам и испытательным стендам во многих случаях пришли компьютерные исследования моделей. Этап проведения компьютерного эксперимента включает две стадии: составление плана эксперимента и проведение исследования.
План эксперимента
План эксперимента должен четко отражать последовательность работы с моделью. Первым пунктом такого плана всегда является тестирование модели.
Тестирование — процесс проверки правильности построенной модели.
Тест — набор исходных данных, позволяющий определить пра- — вильность построения мЪдели.
Чтобы быть уверенным в правильности получаемых результатов моделирования, надо:
♦ проверить разработанный алгоритм построения модели;
♦ убедиться, что построенная модель правильно отражает свойства оригинала, которые учитывались при моделировании.
Для проверки правильности алгоритма построения модели используется тестовый набор исходных данных, для которых конечный результат заранее известен или предварительно определен другими способами.
Например, если вы используете при моделировании расчетные формулы, то надо подобрать несколько вариантов исходных данных и просчитать их «вручную». Это тестовые задания. Когда модель построена, вы проводите тестирование с теми же вариантами исходных данных и сравниваете результаты моделирования с выводами, полученными расчетным путем. Если результаты совпадают, то алгоритм разработан верно, если нет — надо искать и устранять причину их расхождения. Тестовые данные могут совершенно не отражать реальную ситуацию и не нести смыслового содержания. Однако полученные в процессе тестирования результаты могут натолкнуть вас на мысль об изменении исходной информационной или знаковой модели, прежде всего в той ее части, где заложено смысловое содержание.
Чтобы убедиться, что построенная модель отражает свойства оригинала, которые учитывались при моделировании, надо подобрать тестовый пример с реальными исходными данными.
Проведение исследования
После тестирования, когда у вас появилась уверенность в правильности построенной модели, можно переходить непосредственно к проведению исследования.
В плане должен быть предусмотрен эксперимент или серия экспериментов, удовлетворяющих целям моделирования. Каждый эксперимент должен сопровождаться осмыслением итогов, что служит основой анализа результатов моделирования и принятия решений.
Схема подготовки и проведения компьютерного эксперимента приведена на рисунке 11.7.

Рис. 11.7. Схема компьютерного эксперимента
Анализ результатов моделирования
Конечная цель моделирования — принятие решения, которое должно быть выработано на основе всестороннего анализа результатов моделирования. Этот этап решающий — либо вы продолжаете исследование, либо заканчиваете. На рисунке 11.2 видно, что этап анализа результатов не может существовать автономно. Полученные выводы часто способствуют проведению дополнительной серии экспериментов, а подчас и изменению задачи.
Основой выработки решения служат результаты тестирования и экспериментов. Если результаты не соответствуют целям
поставленной задачи, значит, на предыдущих этапах были допущены ошибки. Это может быть либо неправильная постановка задачи, либо слишком упрощённое построение информационной модели, либо неудачный выбор метода или среды моделирования, либо нарушение технологических приемов при построении модели. Если такие ошибки выявлены, то требуется корректировка модели у то есть возврат к одному из предыдущих этапов. Процесс повторяется до тех пор, пока результаты эксперимента не будут отвечать целям моделирования.
Главное, надо всегда помнить: выявленная ошибка — тоже результат. Как гласит народная мудрость, на ошибках учатся. Об этом писал и великий русский поэт А. С. Пушкин:
О, сколько нам открытий чудных
Готовят просвещенья дух
И опыт, сын ошибок трудных,
И гений, парадоксов друг,
И случай, бог изобретатель…
Контрольные вопросы и задания
1.
Назовите два основных типа постановки задач моделирования.
2.
В известном «Задачнике» Г. Остера есть следущая задача:
Злая колдунья, работая не покладая рук, превращает в гусениц по 30 принцесс в день. Сколько дней ей понадобится, чтобы превратить в гусениц 810 принцесс? Сколько принцесс в день придется превращать в гусениц, чтобы управиться с работой за 15 дней?
Какой вопрос можно отнести к типу «что будет, если…», а какой — к типу «как сделать, чтобы…»?
3.
Перечислите наиболее известные цели моделирования.
4.
Формализуйте шутливую задачу из «Задачника» Г. Остера:
Из двух будок, находящихся на расстоянии 27 км одна от другой, навстречу друг другу выскочили в одно и то же время две драчливые собачки. Первая бежит со скоростью 4 км/час, а вторая — 5 км/час.
Через сколько времени начнется драка?
5.
Назовите как можно больше характеристик объекта «пара ботинок ». Составьте информационную модель объекта для разных целей:
■ выбор обуви для туристского похода;
■ подбор подходящей коробки для обуви;
■ покупка крема для ухода за обувью.
6.
Какие характеристики подростка существенны для рекомендации по выбору профессии?
7.
По каким причинам компьютер широко используется в моделировании?
8.
Назовите известные вам инструменты компьютерного моделирования.
9.
Что такое компьютерный эксперимент? Приведите пример.
10.
Что такое тестирование модели?
11.
Какие ошибки встречаются в процессе моделирования? Что надо делать, когда ошибка обнаружена?
12.
В чем заключается анализ результатов моделирования? Какие выводы обычно делаются?
18.09.2003
Александр Петренко, Елена Бритвина, Сергей Грошев, Александр Монахов, Ольга Петренко
Многие знают, как разработать программу; по крайней мере, каждый это делал много раз, но объяснить, как создать программу с высоким качеством, оказывается значительно труднее.
Индустрия программного обеспечения постоянно пытается решить вопрос качества, но насколько значимы ее успехи, на данный момент сказать довольно сложно. В статье идет речь о новом поколении инструментов тестирования, которые призваны повысить качество программ. Однако инструменты, даже автоматические, не в состоянии помочь, если их используют неправильно. Поэтому обсуждение инструментов предваряет изложение общих положений «правильного» тестирования.
Подходы к улучшению качества программ
«Борьба за качество» программ может вестись двумя путями. Первый путь «прост»: собрать команду хороших программистов с опытом участия в аналогичных проектах, дать им хорошо поставленную задачу, хорошие инструменты, создать хорошие условия работы. С большой вероятностью можно ожидать, что удастся разработать программную систему с хорошим качеством.
Второй путь не так прост, но позволяет получать качественные программные продукты и тогда, когда перечисленные условия соблюсти не удается — не хватает хороших программистов, четкости в поставке задачи и т.д. Этот путь предписывает стандартизировать процессы разработки: ввести единообразные требования к этапам работ, документации, организовать регулярные совещания, проводить инспекцию кода и проч. Одним из первых продвижений на этом фронте стало введение понятия жизненного цикла программной системы, четко определявшее необходимость рассмотрения многих задач, без решения которых нельзя рассчитывать на успех программного проекта.
В простейшем варианте набор этапов жизненного цикла таков:
- анализ требований;
- проектирование (предварительное и детальное);
- кодирование и отладка («программирование»);
- тестирование;
- эксплуатация и сопровождение.
Стандартизованная схема жизненного цикла с четкой регламентацией необходимых работ и с перечнем соответствующей документации легла в основу так называемой «водопадной» или каскадной модели. Водопадная модель подразумевает жесткое разбиение процесса разработки программного обеспечения на этапы, причем переход с одного этапа на другой осуществляется только после того, как будут полностью завершены работы на предыдущем этапе. Каждый этап завершается выпуском полного комплекта документации, достаточной для того, чтобы разработка могла быть продолжена другой командой. Водопадная модель стала доминирующей в стандартах процессов разработки Министерства обороны США. Многие волей или неволей, даже отклоняясь от этой модели, в целом соглашались с ее разумностью и полезностью.
Водопадная модель требовала точно и полно сформулировать все требования; изменение требований было возможно только после завершения всех работ. Водопадная модель не давала ответ на вопрос, что делать, когда требования меняются или меняется понимание этих требований непосредственно во время разработки.
В конце 80-х годов была предложена так называемая спиральная модель, был развит и проверен на практике метод итеративной и инкрементальной разработки (Iterative and Incremental Development, IID). В спиральной модели были учтены проблемы водопадной модели. Главный упор в спиральной модели делается на итеративности процесса. Описаны опыты использования IID с длиной итерации всего в полдня. Каждая итерация завершается выдачей новой версии программного обеспечения. На каждой версии уточняются (и, возможно, меняются) требования к целевой системе и принимаются меры к тому, чтобы удовлетворить и новые требования. В целом Rational Unified Process (RUP) также следует этой модели.
Позволило ли это решить проблему качества? Лишь в некоторой степени.
Проблема повышения качества программного обеспечения в целом и повышения качества тестирования привлекает все большее внимание; в университетах вводят специальные дисциплины по тестированию и обеспечению качества, готовят узких специалистов по тестированию и инженеров по обеспечению качества. Однако по-прежнему ошибки обходятся только в США от 20 до 60 млрд. долл. ежегодно. При этом примерно 60% убытков ложится на плечи конечных пользователей. Складывается ситуация, при которой потребители вынуждены покупать заведомо бракованный товар.
Вместе с тем, ситуация не безнадежна. Исследование, проведенное Национальным институтом стандартов и технологии США, показало, что размер убытков, связанных со сбоями в программном обеспечении, можно уменьшить примерно на треть, если вложить дополнительные усилия в инфраструктуру тестирования, в частности, в разработку инструментов тестирования.
Каково же направление главного удара? Что предлагают «наилучшие практики»?
В 80-е и 90-е годы ответ на этот вопрос звучал примерно так. Наиболее дорогие ошибки совершаются на первых фазах жизненного цикла — это ошибки в определении требований, выборе архитектуры, высокоуровневом проектировании. Поэтому надо концентрироваться на поиске ошибок на всех фазах, включая самые ранние, не дожидаясь, пока они обнаружатся при тестировании уже готовой реализации. В целом тезис звучал так: «Сократить время между моментом?внесения? ошибки и моментом ее обнаружения». Тезис в целом хорош, однако не очень конструктивен, поскольку не дает прямых рекомендаций, как сокращать это время.
В последние годы в связи с появлением методов, которые принято обозначать эпитетом agile («шустрый», «проворный») предлагаются и внедряются новые конструктивные методы раннего обнаружения ошибок. Скажем, современные модели, такие как Microsoft Solutions Framework (MSF) и eXtreme Programming (XP), выделяют следующие рекомендации к разработке тестов:
- все необходимые тесты должны быть готовы к моменту реализации той или иной части программы; при этом обычно один тест соответствует одному требованию;
- совокупность ранее созданных тестов должна (при неизменных требованиях) выполняться на любой версии программы;
- если же в требования вносятся изменения, то тесты должны меняться максимально оперативно.
Иными словами, ошибка — будь она в требованиях, в проекте или в реализации — не живет дольше момента запуска теста, проверяющего реализацию данного требования. Значит, хотя астрономическое время между «внесением» ошибки и ее обнаружением может оказаться и большим, но впустую усилий потрачено не очень много, реализация не успела уйти далеко.
Не будем останавливаться на справедливости этих положений и их эффективности. Как часто бывает, побочный эффект новшества оказался более значимым, чем собственно реализация этой идеи. В данном случае дискуссии вокруг «шустрых» методов привели к новому пониманию места тестирования в процессе разработки программного обеспечения. Оказалось, тестирование в широком понимании этого слова, т.е. разработка, пропуск тестов и анализ результатов, решают не только задачу поиска уже допущенных в программном коде ошибок. Серьезное отношение к тестированию позволяет предупреждать ошибки: стоит перед тем, как писать код, подумать о том, какие ошибки в нем можно было бы сделать, и написать тест, нацеленный на эти ошибки, как качество кода улучшается.
В новых моделях жизненного цикла тестирование как бы растворяется в других фазах разработки. Так, MSF не содержит фазы тестирования — тесты пишутся и используются всегда!
Итак, различные работы в процессе производства программ должны быть хорошо интегрированы с работами по тестированию. Соответственно, инструменты тестирования должны быть хорошо интегрированы со многими другими инструментами разработки. Из крупных производителей инструментов разработки программ, первыми это поняли компании Telelogic (набор инструментов для проектирования, моделирования, реализации и тестирования телекоммуникационного ПО, базирующийся на нотациях SDL/MSC/TTCN) и Rational Software (аналогичный набор, преимущественно базирующийся на нотации UML). Следующий шаг сделала компания IBM, начав интеграцию возможностей инструментов от Rational в среду разработки программ Eclipse.
Тезис XP — «Пиши тест перед реализацией» — хорош как лозунг, но в реальности столь же неконструктивен. Для крупных программных комплексов приходится разрабатывать тесты различного назначения: тесты модулей, интеграционные или компонентные тесты, системные тесты.
Три составляющие тестирования — экскурс в теорию
Модульному тестированию
подвергаются небольшие модули (процедуры, классы и т.п.). При тестировании относительного небольшого модуля размером 100-1000 строк есть возможность проверить, если не все, то, по крайней мере, многие логические ветви в реализации, разные пути в графе зависимости данных, граничные значения параметров. В соответствии с этим строятся критерии тестового покрытия (покрыты все операторы, все логические ветви, все граничные точки и т.п.).
Проверка корректности всех модулей, к сожалению, не гарантирует корректности функционирования системы модулей. В литературе иногда рассматривается «классическая» модель неправильной организации тестирования системы модулей, часто называемая методом «большого скачка». Суть метода состоит в том, чтобы сначала оттестировать каждый модуль в отдельности, потом объединить их в систему и протестировать систему целиком. Для крупных систем это нереально. При таком подходе будет потрачено очень много времени на локализацию ошибок, а качество тестирования останется невысоким. Альтернатива «большому скачку» — интеграционное тестирование
, когда система строится поэтапно, группы модулей добавляются постепенно.
Распространение компонентных технологий породило термин «компонентное тестирование»
как частный случай интеграционного тестирования.
Полностью реализованный программный продукт подвергается системному тестированию
. На данном этапе тестировщика интересует не корректность реализации отдельных процедур и методов, а вся программа в целом, как ее видит конечный пользователь. Основой для тестов служат общие требования к программе, включая не только корректность реализации функций, но и производительность, время отклика, устойчивость к сбоям, атакам, ошибкам пользователя и т.д. Для системного и компонентного тестирования используются специфические виды критериев тестового покрытия (например, покрыты ли все типовые сценарии работы, все сценарии с нештатными ситуациями, попарные композиции сценариев и проч.).
Инструменты тестирования — реальная практика
Закончив экскурс в методику, вернемся к вопросу, какие инструменты тестирования используются в настоящее время и насколько они соответствуют новым представлениям о месте тестирования в процессе разработки программ.
На данный момент в наибольшей мере автоматизированы следующие этапы работ: исполнение тестов, сбор полученных данных, анализ тестового покрытия (для модульного тестирования обычно собирают информацию о покрытых операторах и о покрытых логических ветвях), отслеживание статуса обработки запросов на исправление ошибок.
Обзор инструментов тестирования будем вести в обратном порядке — от системного тестирования к модульному.
Широко распространены инструменты тестирования приложений с графическим пользовательским интерфейсом. Их часто называют инструментами функционального тестирования
. Если уровень ответственности приложения не велик, то таким тестированием можно ограничиться; подобное тестирование наиболее дешево.
В данном виде тестирования широко применяются инструменты записи-воспроизведения (record/playback); из наиболее известных продуктов можно назвать Rational Robot (компания IBM/Rational), WinRunner (Mercury Interactive), QARun (Compuware). Наряду с этим существуют инструменты для текстовых терминальных интерфейсов, например, QAHiperstation компании Compuware.
Для системного нагрузочного тестирования Web-приложений и других распределенных систем широко используется инструментарий LoadRunner от Mercury Interactive; он не нацелен на генерацию изощренных сценариев тестирования, зато дает богатый материал для анализа производительности, поиска узких мест, сказывающихся на производительности распределенной системы.
Примерная общая схема использования инструментов записи-воспроизведения такова:
- придумать сценарий (желательно, на основе систематического анализа требований);
- провести сеанс работы в соответствии с данным сценарием; инструмент запишет всю входную информацию, исходившую от пользователя (нажатия клавиш на клавиатуре, движения мыши и проч.), и сгенерирует соответствующий скрипт.
Полученный скрипт можно многократно запускать, внося в него при необходимости небольшие изменения.
При записи скрипта можно делать остановки для того, чтобы указывать, какие ответы системы в конкретной ситуации надо рассматривать как правильные, какие вариации входных данных пользователя возможны и т.д. При наличии таких вариаций при очередном воспроизведении теста инструмент самостоятельно будет выбирать одну из определенных альтернатив. При несовпадении ответа системы с ожидаемым ответом будет фиксироваться ошибка.
Впрочем, возможности данного вида тестирования ограничены:
- запись скриптов возможна только при наличии прототипа будущего графического интерфейса;
- поддержка скриптов очень трудоемка; часто скрипт легче записать заново, чем отредактировать;
- как следствие, проводить работы по созданию тестов параллельно с разработкой самой системы не эффективно, а до создания прототипа вообще невозможно.
Следующий класс инструментов — инструменты тестирования компонентов
. Примером является Test Architect (IBM/Rational). Такие инструменты помогают организовать тестирование приложений, построенных по одной из компонентных технологий (например, EJB). Предусматривается набор шаблонов для создания различных компонентов тестовой программы, в частности, тестов для модулей, сценариев, заглушек.
Отвечает ли этот инструмент требованию опережающей разработки тестов? В целом, да: для создания теста достаточно описания интерфейсов компонентов. Но есть и слабые места, которые, впрочем, присущи и большинству других инструментов. Так, сценарий тестирования приходится писать вручную. Кроме того, нет единой системы задания критериев тестового покрытия и связи этих критериев с функциональными требованиями к системе.
Последний из рассматриваемых здесь классов инструментов — инструменты тестирования модулей
. Примером может служить Test RealTime (IBM/Rational), предназначенный для тестирования модулей на C++. Важной составляющей этого инструмента является механизм проверочных «утверждений» (assertion). При помощи утверждений можно сформулировать требования к входным и выходным данным функций/методов классов в форме логических условий, в аналогичной форме можно задавать инвариантные требования к данным объектов. Это существенный шаг вперед по сравнению с Test Architect. Аппарат утверждений позволяет систематическим образом представлять функциональные требования и на базе этих требований строить критерии тестового покрытия (правда, Test RealTime автоматизированной поддержки анализа покрытия не предоставляет).
В принципе, этим инструментом можно пользоваться при опережающей разработке тестов, но остается нереализованной все та же функция генерации собственно тестовых воздействий — эта работа должна выполняться вручную. Нет никакой технической и методической поддержки повторного использования тестов и утверждений.
Решение перечисленных проблем предлагает новое поколение инструментов, которые следуют подходу тестирования на основе модели (model based testing) или на основе спецификаций (specification based testing).
Чем могут помочь модели
В голове разработчика и тестировщика всегда присутствует та или иная «модель» устройства программы, а также «модель» ее желаемого поведения, исходя из которой, в частности, составляются списки проверяемых свойств и создаются соответствующие тестовые примеры. (Заметим, что это разные модели; первые часто называют архитектурными, а вторые — функциональными или поведенческими.) Они зачастую составляются на основе документов или обсуждений в неформальном виде.
Разработка моделей и спецификаций связана с «математизацией» программирования. Попытки использовать различные математические подходы для конструирования и даже генерации программ предпринимались с первых лет возникновения компьютеров. Относительный успех был достигнут в теории компиляторов, реляционных баз данных и в нескольких узкоспециальных областях; серьезных результатов в большинстве практических областей достичь не удалось. Многие стали относиться к формальным методам в программировании скептически.
Новый всплеск интереса к формальным методам произошел в первой половине 90-х. Его вызвали первые результаты, полученные при использовании формальных моделей и формальных спецификаций в тестировании.
Преимущества тестирования на основе моделей виделись в том, что:
- тесты на основе спецификации функциональных требований более эффективны, так как они в большей степени нацелены на проверку функциональности, чем тесты, построенные только на знании реализации;
- на основе формальных спецификаций можно создавать самопроверяющие (self-checking) тесты, так как из формальных спецификаций часто можно извлечь критерии проверки результатов целевой системы.
Однако не было ясности в отношении качества подобных тестов. Модели обычно проще реализации, поэтому можно было предположить, что тесты, хорошо «покрывающие» модель, слишком бедны для покрытия реальных систем. Требовались широкие эксперименты в реальных проектах.
Модель — некоторое отражение структуры и поведения системы. Модель может описываться в терминах состояния системы, входных воздействий на нее, конечных состояний, потоков данных и потоков управления, возвращаемых системой результатов и т.д. Для отражения разных аспектов системы применяются и различные наборы терминов. Формальная спецификация представляет собой законченное описание модели системы и требований к ее поведению в терминах того или иного формального метода. Для описания характеристик системы можно воспользоваться несколькими моделями в рамках нескольких формализмов. Обычно, чем более общей является нотация моделирования, тем больше трудностей возникает при автоматизации тестирования программы на основе модели/спецификации, описанной в этой нотации. Одни нотации и языки больше ориентированы на доступность и прозрачность описания, другие — на последующий анализ и трансляцию, в частности, трансляцию спецификации в тест. Предпринимались попытки разработки языка формальных спецификаций, удовлетворяющего требованиям промышленного использования (например, методология RAISE), однако широкого применения они не нашли.
Имеется несколько ставших уже классическими нотаций формальных спецификаций: VDM, Z, B, CCS, LOTOS и др. Некоторые из них, например, VDM, используются преимущественно для быстрого прототипирования. Язык B удобен для анализа, в частности для аналитической верификации моделей. Все эти языки активно используются в рамках университетских программ. В реальной практике для описания архитектурных моделей используется UML, а для построения поведенческих моделей — языки SDL/MSC, исполнимые диаграммы UML и близкие к ним нотации.
Перечисленные языки и нотации для поведенческих моделей, к сожалению, не обладают достаточной общностью. Они хорошо себя зарекомендовали в телекоммуникационных приложениях и практически бесполезны для описания функциональности программных систем «общего вида»: операционных систем, компиляторов, СУБД и т.д.
На роль инструментов разработки тестов для подобных систем претендует новое поколение средств описания моделей/спецификаций и средства генерации тестов на проверку согласованности поведения реализации заданной модели.
Инструменты тестирования на основе моделей
Test Real Time — один из первых представителей этой группы. Более широкие возможности предоставляет Jtest компании Parasoft. Интересен инструментарий компании Comformiq. Семейство инструментов разработки тестов на основе моделей предлагает Институт системного программирования РАН в кооперации с компанией ATS. Поскольку семейство UniTesK авторам знакомо существенно ближе, мы изложим общую схему подхода тестирования на основе моделей на примерах из UniTesK.
 |
| Рис. 1. Фазы процесса разработки спецификаций и тестов |
Общая схема процесса разработки спецификаций и тестов состоит из четырех фаз (рис. 1).
Первая фаза относительно коротка, но в реальных проектах она важна. Именно здесь закладывается уровень абстрактности модели. Модель должна быть максимально простой: это позволит требовать исчерпывающего набора тестов. В то же время, модель должна быть содержательной, раскрывать специфику тестируемой реализации. Таким образом, задача первой фазы — найти компромисс между абстрактностью и детальностью.
Задача второй фазы — описание требований к поведению системы. Многие подходы (например, SDL) предлагают описывать исполнимые модели, которые можно рассматривать как прототипы будущей реализации. Задание требований в таком случае определяется формулой «реализация должна вести себя так же, как модель». Подход понятен, но, к сожалению, во многих реальных ситуациях он не работает. Допустим, в заголовке некоего сообщения, построенного моделью, указано одно время, а в аналогичном заголовке от реализации — несколько другое. Это ошибка или нет? Еще один пример. Модель системы управления памятью сгенерировала указатель на свободный участок памяти, а реальная система выдала другой указатель: модель и система работают в разных адресных пространствах. Ошибка ли это?
UniTesK — унифицированное решение
UniTesK предлагает использовать так называемые неявные спецификации или спецификации ограничений. Они задаются в виде пред- и постусловий процедур и инвариантных ограничений на типы данных. Этот механизм не позволяет описывать в модели алгоритмы вычисления ожидаемых значений функций, а только их свойства. Скажем, в случае системы управления памятью модель будет задана булевским выражением в постусловии типа «значение указателя принадлежит области свободной памяти». Простой пример постусловия для функции «корень квадратный» приведен на ; одна и та же спецификация представлена в трех разных нотациях: в стиле языков Cи, Java и C#. Использование спецификационных расширений обычных языков программирования вместо классических языков формальных спецификаций — шаг, на который идут почти все разработчики подобных инструментов. Их различает только выразительная мощность нотаций и возможности анализа и трансляции спецификаций.
Третья фаза — разработка тестового сценария. В простейшем случае сценарий можно написать вручную, но в данной группе инструментов — это плохой тон. Тест, т.е. последовательность вызовов операций целевой системы с соответствующими параметрами, можно сгенерировать, отталкиваясь от некоторого описания программы или структуры данных. Будем называть такое описание сценарием
. Компания Conformiq предлагает описать конечный автомат. Различные состояния автомата соответствуют различным значениям переменных целевой системы, переходы — вызовам операций этой системы. Определить автомат — это значит для каждого состояния описать, в какое состояние мы перейдем из данного, если обратимся к любой наперед заданной операции с любыми наперед заданными параметрами. Если такое описание получить легко, больше ничего делать не понадобится: инструмент сгенерирует тест автоматически и представит результаты тестирования, например, в виде MSC-диаграмм. Но легко ли это, скажем, для программы с одной целочисленной переменной и двумя-тремя операциями? Скорее всего, да. Однако в общем случае сделать попросту невозможно.
В UniTesK для генерации тестовых последовательностей конечный автомат не описывается, а генерируется по мере исполнения теста. Все, что требуется от разработчика теста, — это задание способа вычисления состояния модели на основании состояния целевой системы и способа перебора применяемых в текущем состоянии тестовых воздействий. Эти вычисления записываются в тестовых сценариях. Очередное тестовое воздействие выбирается на основании спецификации сценария в зависимости от результатов предыдущих воздействий. Такой подход обладает двумя важными преимуществами. Во-первых, это позволяет строить сложные тестовые последовательности в чрезвычайно компактной и легкой для написания и понимания форме. Во-вторых, тесты приобретают высокую гибкость: они легко могут быть параметризованы в зависимости от текущих потребностей тестирования и даже могут автоматически подстраиваться под незначительные изменения модели. На рис. 3 приведен пример сценарного метода.
В целом тестовый сценарий описывает итераторы для всех методов данного класса, однако каждый раз разработчик теста решает только локальную проблему — как перебрать входные параметры одного-единственного метода. Общую задачу — как организовать последовательность вызов; как нужное число раз вернуться в одно и то же состояние, чтобы провести испытание еще для одного метода, еще для одного значения параметра; когда остановиться, чтобы не делать лишней работы — все это берет на себя инструмент.
В UniTesK используется единая архитектура тестов, подходящая для тестирования систем различной сложности, относящихся к разным предметным областям, и обеспечивающая масштабируемость тестов. Компоненты тестов, требующие написания человеком, отделены от библиотечных и генерируемых автоматически (рис. 4).
В реальных системах количество различимых состояний и количество допустимых в каждом из них тестовых воздействий очень велико, что приводит к комбинаторному «взрыву состояний». Для борьбы с этим эффектом разработан механизм факторизации модели: те состояния целевой системы, различие между которыми несущественно с точки зрения задач данного теста, объединяются в одно обобщенное состояние модели; аналогичным образом объединяются в группы и тестовые воздействия. Процесс факторизации предоставляет разработчику свободу творчества, но, вместе с тем, он поддержан строгими исследованиями, определяющими достаточные условия, при соблюдении которых гарантированы корректность результатов и существенное сокращение времени тестирования при сохранении достигаемого тестового покрытия.

Рис. 4. Архитектура тестовой программ
Создатели UniTesK, полагая, что не должно быть отдельной среды для разработки тестов, не только наделили его возможностью мимикрии под различные языки программирования, но обеспечили интеграцию составляющих его инструментов в популярные средства разработки программ. На рис. 5 представлен сеанс использования UniTesK в среде разработки Forte 4.0 компании Sun Microsystems.
Новое качество, которое обещают новые инструменты
Как отмечалось выше, создатели инструментов тестирования обычно сталкиваются со следующими проблемами:
- отсутствие или нечеткость определения критериев тестового покрытия, отсутствие прямой связи с функциональными требованиями;
- отсутствие поддержки повторного использования тестов;
- отсутствие автоматической генерации собственно теста (это касается как входных воздействий, так и эталонных результатов или автоматических анализаторов корректности реализации).
Имеются ли у инструментов тестирования, которые для генерации теста используют модель или формальную спецификацию целевой системы, принципиальные преимущества перед традиционными средствами? Чтобы ответить на этот вопрос, укажем, как отмеченные проблемы решаются для инструментов, использующих модели.
Критерии тестового покрытия.
Основной критерий — проверка всех утверждений, в частности, утверждений, определяющих постусловия процедур или методов. Он легко проверяется и легко связывается с функциональными требованиями к целевой системе. Так, инструменты UniTesK, инструменты для платформ Java и C# предоставляют четыре уровня вложенных критериев.
Повторное использование тестов.
Уровень повторного использования существенно выше, чем у традиционных инструментов. Разработчик тестов пишет не тестовый скрипт, а критерии проверки утверждения и тестовый сценарий. И то, и другое лишено многих реализационных деталей, и поэтому их проще переиспользовать для новой версии целевой системы или для адаптации спецификаций и тестов для сходного проекта. Например, статистика UniTesK показывает, что уровень переиспользования для тестирования ядер разных операционных систем превышает 50%.
Автоматическая генерация тестов.
Это главное достоинство новых инструментов; здесь они существенно опережают традиционные средства, поскольку используют не произвольные виды нотаций и методов моделирования и спецификации, а именно те, которые дают преимущества при автоматической генерации тестов. Так, утверждения позволяют сгенерировать тестовые «оракулы» — программы для автоматического анализа корректности результата; различные виды конечных автоматов или их аналоги позволяют сгенерировать тестовые последовательности. К тому же, поскольку модели обычно проще, чем реализации, для них удается провести более тщательный анализ, поэтому набор тестов становится более систематическим.
Рассмотренные инструменты опробованы на реальных, масштабных проектах. Конечно, каждый проект несет в себе некоторую специфику, возможно, препятствующую исчерпывающему тестированию. Однако опыт использования данных инструментов показывает, что обычно удается достичь хороших результатов, лучших, чем результаты, полученные в аналогичных проектах при помощи ручного тестирования. Пользователи UniTesK, обычно, за приемлемый уровень качества принимают 70-80% покрытия кода целевой системы; при этом должен быть удовлетворен, как минимум, критерий покрытия всех логических ветвей в постусловиях. Для некоторых сложных программ (в том числе, для блока оптимизации компилятора GCC) был достигнут уровень покрытия 90-95%.
Есть ли принципиальные ограничения в применимости данного подхода? Его практически невозможно применять в случае, когда по той или иной причине никто в цепочке заказчик — разработчик — тестировщик не смог или не захотел четко сформулировать требования к целевой системе. Впрочем, это не только ограничение, но и дополнительный стимул для улучшения процессов разработки, еще один повод объяснить заказчику, что вложения в фазу проектирования с лихвой окупаются сокращением общих сроков разработки и стоимости проекта.
Обозначения элементов общей структуры спецификации метода:
S
— Сигнатура операции
A
— Спецификация доступа
— Предусловие
B
— Определение ветвей функциональности
>
— Постусловие
Java:
Class SqrtSpecification {
S Specification static double sqrt(double x)
A reads x, epsilon
{
= 0; }
post {
> if(x == 0) {
B branch «Zero argument»;
> return sqrt == 0;
> } else {
B branch «Positive argument»;
> return sqrt >= 0 &&
> Math.abs((sqrt*sqrt-x)/x) }
}
}
}
Си:
S specification double SQRT(double x)
A reads (double)x, epsilon
{
= 0.; }
coverage ZP {
if(x == 0) {
B return(ZERO, «Zero argument»);
} else {
B return(POS, «Positive argument»);
}
}
post {
> if(coverage(ZP, ZERO)) {
> return SQRT == 0.;
> } else {
> return SQRT >= 0. &&
> abs((SQRT*SQRT — x)/x) }
}
}
C#:
namespace Examples {
specification class SqrtSpecification {
S specification static double Sqrt(double x)
A reads x, epsilon
{
= 0; }
post {
> if(x == 0) {
B branch ZERO («Zero argument»);
> return $this.Result == 0;
> } else {
B branch POS («Positive argument»);
> return $this.Result >= 0 &&
> Math.Abs(($this.Result *
$this.Result — x)/x) }
> }
> }
}
}