Точность измерений
Никакое
измерение не может быть выполнено
абсолютно точно, всегда содержится та
или иная погрешность. Чем точнее метод
измерения и измерительный прибор тем
меньше величина погрешности. Принято
различать несколько видов погрешностей:
основная и дополнительная, абсолютная
и относительная, систематическая и
случайная, которые необходимо учитывать
при измерении в спорте.
Основная
погрешность
связана с методом измерения или
измерительного прибора, которая имеет
место в нормальных условиях их применения.
Например, точность измерения прыжка в
длину с помощью метра или рулетки;
точность измерения времени пробегания
короткой дистанции с помощью разных
(механического или электронного)
секундомеров будет не одинаковой и
определяется точностью самого средства
измерения. Эта погрешность, как правило,
указана в инструкции измерительного
прибора.
Дополнительная
погрешность
вызвана отклонением условий работы
измерительной системы от нормальных.
Например, при существенных колебаниях
(выше нормы) электрического напряжения
в сети может возникать погрешность
измерения. Другой пример — прибор,
предназначенный для работы при комнатной
температуре, будет давать неточные
показания, если пользоваться им в
условиях низких или высоких внешних
температур. К дополнительным погрешностям
относятся и так называемая динамическая
погрешность, обусловленная инерционностью
измерительного прибора и возникающая
в тех случаях, когда измеряемая величина
колеблется выше технических возможностей
регистрирующего устройства. Например,
некоторые пульсотахометры рассчитаны
на измерение средних величин ЧСС и не
способны улавливать непродолжительные
отклонения частоты от среднего уровня.
Величины
основной и дополнительной погрешности
могут быть представлены в абсолютных
и относительных единицах.
Абсолютная
погрешность равна
разности между показанием измерительного
пробора (А) и истинным значением измеряемой
величины
Она
измеряется в тех же единицах, что и
измеряемая величина.
Относительной
погрешностью называется
отношение абсолютной погрешности к
истинному значению измеряемой величины:
Поскольку
относительная погрешность измеряется
в процентах, то знак абсолютной погрешности
не учитывается.
Систематическая
погрешность
– это величина, которая не меняется от
измерения к измерению. Поэтому она часто
может быть предсказана заранее или, в
крайнем случае обнаружена и устранена
по окончании процесса измерения.
Определение систематической погрешности
измерения возможно способами: тарировки,
калибровки измерительной аппаратуры
или рандомизации.
Тарированием
называется
проверка показаний измерительных
приборов путем сравнения с показаниями
образцовых значений мер (эталонов) во
всем диапазоне измеряемой величины.
Калибровкой
называется
определение погрешностей или поправка
для совокупности мер. И при тарировке
и при калибровке к входу измерительной
системы подключается источник эталонного
сигнала известной величины. Например,
процедура проверки чувствительности
усилителя, заключающаяся в записи и
регулировке амплитуды ответов каналов
на подаваемое на вход напряжение,
сопоставляемое впоследствии с амплитудой
регистрируемых физиологических
параметров. Другой пример, – процедура
проверки скорости движения бумаги на
регистрирующем приборе с помощью
счетчика времени.
Рандомизацией
(от англ.
random – случайный) называется превращение
систематической погрешности в случайную.
По методу рандомизации измерение
изучаемой величины производится
несколько раз (например, многократные
исследования физической работоспособности
разными способами дозирования нагрузки).
По окончании всех измерений их результаты
усредняются по правилам математической
статистики.
Случайные
погрешности неустранимы
и возникают
под действием разнообразных факторов,
которые сложно заранее предсказать и
учесть. Единственно, с помощь методов
математической статистики можно оценить
величину случайной погрешности и учесть
ее при интерпретации результатов
измерения.
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
5 |
|
|
6 |
|
 Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
Случайной Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
Случайной Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
Случайной Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
Случайной Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
Случайной Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
СлучайнойСТАТИСТИЧЕСКИЕ
ХАРАКТЕРИСТИКИ
Без
статистической обработки результаты
измерений не могут считаться достоверными.
Средняя
арифметическая характеризует
групповые свойства признака, занимает
центральное положение в общей массе
варьирующих признаков. Представляет
собой частное от деления суммы всех
вариант совокупности на их общее число.
Средняя арифметическая – величина
именованная, она выражается теми же
единицами измерения, что и характеризуемый
ею признак. Средняя арифметическая –
важнейшая статистическая характеристика,
но она ничего не говорит о величине
варьирования изучаемого признака.
Стандартное
или среднее квадратическое отклонение
(s) характеризует
вариации, или колеблемости признака.
Стандартное отклонение – величина
именованная, и выражается в тех же
единицах измерения, что и исследуемый
признак, т.е. характеризует степень
отклонения результатов от среднего
значения в абсолютных единицах. Этот
показатель не зависит от числа наблюдений,
и потому может использоваться для оценки
варьирования однородных признаков.
Однако для сравнения вариации двух и
более признаков, имеющих различные
единицы измерения (например, результаты
в беге на 100 м, прыжках в высоту, метаниях
гранаты и т.п.), эта характеристика не
пригодна. Для этого используется
коэффициент вариации.
Коэффициент
вариации (CV)
определяется как отношение стандартного
отклонения к среднему арифметическому,
выраженное в процентах. Коэффициент
вариации, будучи величиной относительной,
позволяет сравнивать между собой
колеблемость результатов измерений,
имеющих различные единицы измерения.
При нормальных распределениях CV обычно
не превышает 45-50%. В случаях асимметричных
распределений он может быть довольно
высоким (до 100% и выше). На практике
внутренняя вариабельность признака
считается небольшой при CV= 0-10%, средней
– 11-20% и большой – больше 20%.
Ошибка
средней арифметической (m) величина
не техническая, а статистическая, и
характеризует закономерные колебания
(вариации) средней арифметической
величины. Выборочная ошибка показывает
варьирование выборочных показателей
вокруг их генеральных параметров. Она
обладает теми же свойствами, что и
среднее квадратическое отклонение. Чем
больше объем выборки, тем точнее средний
результат, тем меньше выборочная средняя
будет отличаться от средней генеральной
совокупности. Следовательно, при
увеличении числа испытаний ошибка
выборочной средней будет уменьшаться.
Отсюда становится яснее значение
выборочной ошибки: она указывает на
точность, с какой определена сопровождаемая
ею средняя величина.
Оценка
по критерию Т-Стьюдента. В
спорте часто на одних и тех же спортсменах
проводится измерение через некоторое
время (например, в начале и в конце этапа
подготовки) или сравнение результатов
одной группы (контрольной) с другой
(экспериментальной). Во всех этих и
подобных случаях ставится, практически,
одна задача – достоверно или нет одни
результаты исследования отличаются от
других? Для этих целей используется
метод сравнения
двух выборочных средних арифметических
по критерию Т-Стьюдента. Принципиально
важным является то, что применение
указанного метода возможно лишь для
однородных признаков.
Ответом
на вопрос о достоверности различий
между признаками служит уровень
значимости (Р),
определяемый по таблице (стандартные
значения критерия Т-Стьюдента). При
уровне значимости Р<0,05 (что соответствует
95% вероятности события) можно говорить
о наличие достоверных различий между
сравниваемыми средними, при Р<0,01 и
особенно при Р<0,001 (когда 99,9% случаев
подлежат общей закономерности) можно
утверждать, что средние значения
отличаются друг от друга с высокой
вероятностью, или закономерностью.
Свидетельством отсутствия достоверных
(статистических) различий между средними
является Р>0,05 (т.е. менее 95% случаев
подлежат общей закономерности).
Корреляционный
анализ сводится
к измерению тесноты или степени
сопряженности между разнородными
признаками, а также к определению формы
и направления существующей между ними
связи. Критерием связи служит коэффициент
корреляции,
который имеет значения от 0 до 1. Чем
больше коэффициент корреляции приближается
к 1, тем теснее связь между признаками
и наоборот. Знак плюс или минус говорят
о направленности связи — положительной
(прямой) или отрицательной (обратной).
Коэффициент корреляции служит мерилом
только качественной связи между
изучаемыми признаками. С помощью
специальных расчетных процедур, в каждом
конкретном случае, устанавливается
форма (линейная, нелинейная) связи.
Существуют методы: парной и множественной
корреляции; для определения связи между
количесвенными и качественными признаками
(ранговая корреляция).
Регрессионный
анализ есть
продолжение корреляционного анализа,
где с помощью выведенного уравнения
регрессии можно показать количественную
степень связи (или взаимовлияния одного
признака на другой). Например, насколько
повысится результат в прыжках в длину
с разбега, если скорость бега на 30 м
увеличится на 2 м/с.
Дисперсионный
анализ позволяет
оценить влияние разнообразных факторов
на результат исследования. Например,
какие из факторов физической
подготовленности в большей мере влияют
на спортивный результат. Дисперсионный
анализ проводится как на малых, так и
на больших выборках, на однородных и
неоднородных признаках, на количественных
и качественных характеристиках. В основе
дисперсионного анализа лежит сравнение
выборочных дисперсий, или их отношений
с критическими значениями критерия
F-Фишера.
Более
подробно с методами математической
статистики можно ознакомиться в следующей
литературе.
1.
Ашмарин Б.А. Теория и методика педагогических
исследований в физическом воспитании.-
М.: ФиС, 1978.
2.
Бейл Н. Статистические методы в биологии.-
М.: Мир, 1964.
3.
Гласс Дж., Стэнли Дж. Статистические
методы в педагогике и психологии.- М.:
Прогресс, 1976.
4.
Друзь В.А. Моделирование процесса
спортивной тренировки.- Киев: Здоровье,
1976.
5.
Лакин Г.Ф. Биометрия: Учебник для
университетов и педагогических
институтов.- М.: Высшая школа, 1973.
6.
Основы общей и прикладной акмеологии.-
М.: ФиС, 1995. Плохинский Н.А. Биометрия.-
М.: МГУ, 1970.
7.
Рокицкий П.Ф. Биологическая статистика.-
Минск: Высшая школа, 1973.
8.Садовский
Л.Е., Садовский А.Л. Математика и спорт.-
М.: Наука, 1985.
9.
Фишер Р.А. Статистические методы для
исследователей / Перевод с англ. В.Н.
Перегудова – М.: Госстатиздат, 1958.
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
5 |
|
|
6 |
|
|
7 |
|
|
8 |
|
|
9 |
|
 Относительную
Относительную Среднее
Среднее Закономерные
Закономерные Вариабельность
Вариабельность Относительную
Относительную Среднее
Среднее Закономерные
Закономерные Вариабельность
Вариабельность Относительную
Относительную Среднее
Среднее Закономерные
Закономерные Вариабельность
Вариабельность Относительную
Относительную Среднее
Среднее Закономерные
Закономерные Вариабельность
Вариабельность Определения
Определения Определения
Определения Определения
Определения Исследования
Исследования Определения
Определения Определения
Определения Определения
Определения Исследования
Исследования Определения
Определения Определения
Определения Определения
Определения Исследования
Исследования Определения
Определения Определения
Определения Определения
Определения Исследования
Исследования Р<0,01
Р<0,01 Р<0,05
Р<0,05 Р>0,05
Р>0,05 Р<0,001
Р<0,001
Лекция 01. Погрешности вычислений
1.1. Погрешности и их учёт
Численное решение любой задачи, осуществляется приближённо, с различной точностью. Это может быть обусловлено неточностью исходных данных, конечной разрядностью вычислений и т. п.
Главная задача численных методов – фактическое нахождение решения с требуемой или, по крайней мере, оцениваемой точностью.
Отклонение истинного решения от приближённого называется погрешностью. Полная погрешность вычислений состоит из двух составляющих:
• неустранимая погрешность;
• устранимая погрешность.
Неустранимая погрешность обусловлена неточностью исходных данных и никаким образом не может быть уменьшена в процессе вычислений. Эти погрешности связаны с недостаточным знанием или упрощением исследуемых физических явлений. Т. е. причиной этого вида погрешности является неадекватность математической модели. Мера адекватности математической модели может быть оценена путём сравнения течения реального физического процесса и реализованной на ЭВМ модели процесса. Это очень сложная задача, т.к. реализация модели на ЭВМ включает много составляющих погрешностей, исследование реального процесса также происходит с погрешностью. Оценка погрешности математической модели выходит за рамки данного курса.
Устранимая погрешность может быть уменьшена выбором более точных методов и увеличением разрядности вычислений. К ним относятся:
• погрешность аппроксимации (погрешность дискретизации)– это погрешность от замены непрерывной модели дискретной; примером дискретизации является замена дифференциального уравнения системой алгебраических уравнений; решение системы алгебраических уравнений отличается от решения дифференциального уравнения, что и составляет погрешность дискретизации; обычно дискретная модель зависит от некоторых параметров, варьируя которые теоретически можно свести погрешность дискретизации к нулю; в приведённом примере, уменьшая шаг дискретизации (и увеличивая порядок системы алгебраических уравнений) можно заметно уменьшить погрешность дискретизации;
• трансформированная погрешность (погрешность искажения) – это погрешность, возникающая за счёт погрешности исходных данных, которые, как правило, являются результатом измерений некоторых физических величин, которые всегда производятся с некоторой погрешностью; кроме того, из-за ограниченной разрядности компьютеров возникает погрешность представления исходных данных (погрешность округления);многие задачи являются весьма чувствительными к погрешностям исходных данных и погрешностям, возникающим в ходе реализации алгоритма; в этом случае говорят, что задача является плохо обусловленной; для плохо обусловленной задачи погрешности исходных данных, даже при отсутствии погрешностей вычислений могут преобразоваться (трансформироваться) в значительные погрешности результата;
• методические погрешности возникают из-за применения приближённых алгоритмов; например, решая систему алгебраических уравнений итерационным методом, теоретически можно получить точное решение при бесконечно большом числе итераций; практически всегда число итераций приходится ограничивать, что приводит к погрешности метода;
• погрешности округления возникают из-за того, что все вычисления выполняются с ограниченным числом цифр, т.е. производится округление чисел; погрешности округления могут накапливаться и при плохой обусловленности задачи могут привести к очень большим погрешностям.
Как выбирать допустимые погрешности? В общем случае надо стремиться, чтобы все погрешности имели один и тот же порядок. Не следует очень точно решать задачу с неточными исходными данными. Точнее говоря, погрешность решения всей задачи (всей последовательности действий вычислительного эксперимента) должна быть соизмерима с погрешностью исходных данных.
В дальнейшем будем рассматривать только корректно поставленные задачи вычисления.
Задача вычисления называется корректно поставленной, если для любых входных данных из некоторого класса решение задачи существует, единственно и устойчиво по входным данным (т. е. непрерывно зависит от входных данных задачи).
В сформулированном понятии корректности учтены достаточно естественные требования, т. к. чтобы численно решать задачу, нужно быть уверенным, что её решение существует. Столь же естественны требования единственности и устойчивости решения.
Рассмотрим подробнее понятие устойчивости. Обычно нас интересует решение , соответствующее входным данным , т.е. . Реально мы имеем возмущённые входные данные с погрешностью, т.е. , и находим возмущённое решение.
Эта погрешность входных данных порождает неустранимую погрешность решения.
Если решение непрерывно зависит от входных данных, то при , задача называется устойчивой по входным данным.
Если – точное значение величины, а – приближённое значение, то абсолютная погрешность приближения определяется выражением.
Относительной погрешностью величины называется отношение абсолютной погрешности к модулю её точного значения:.
Абсолютная и относительная погрешности тесно связаны с понятием верных значащих цифр. Значащими цифрами числа называют все цифры в его записи, начиная с первой ненулевой цифры слева. Например, число 0,000129 имеет три значащих цифры (1, 2 и 9).
Значащая цифра называется верной, если абсолютная погрешность числа не превышает половины веса разряда, соответствующего этой цифре.
Например, число равно, абсолютная погрешность числа равна . Тогда число а имеет четыре верных значащих цифры (1, 0, 3 и 0).
Одной из самых распространённых ошибок записи приближённых чисел является отбрасывание значащих нулей в конце числа. При этом верная значащая цифра не обязана совпадать с соответствующей цифрой точного числа.
Например число равно, абсолютная погрешность числа равна , тогда верными значащими цифрами являются все цифры после запятой, в то время как точное значение .
В общем случае , где – порядок (вес) старшей цифры, – число верных значащих цифр.
В нашем примере
Относительная погрешность связана с количеством верных цифр приближённого числа соотношением
где – старшая значащая цифра числа.
Для двоичного представления чисел имеем
Достаточно часто точное значение величины неизвестно, поэтому определяются границы погрешности:
(1.1)
(1.2)
причём числа и записываются с одинаковым количеством знаков после запятой, например,
Запись видаозначает, что число является приближённым значением числа с относительной погрешностью .
Отметим важную деталь. Так как точное решение задачи как правило неизвестно, то погрешности приходится оценивать (и часто весьма приближённо, обычно завышено) через исходные данные и особенности алгоритма. Если оценка может быть вычислена до решения задачи, то она называется априорной. Если оценка вычисляется после получения приближённого решения задачи, то она называется апостериорной.
Очень часто степень точности решения задачи характеризуется некоторыми косвенными вспомогательными величинами. Например, точность решения системы алгебраических уравненийхарактеризуется невязкой, где – приближённое решение системы. Причём невязка достаточно сложным образом связана с погрешностью решения,при малой невязке, погрешность может быть значительной.
1.2. Погрешности округления
Рассмотрим подробнее погрешность округления чисел, участвующих в вычислениях. В позиционной системе счисления с основанием запись
(1.3)
означает, что
Здесь – целое число, большее единицы. Каждое из чисел может принимать одно из значений . Числа называются разрядами.
Запись вещественного числа в виде (1.3) называется также его представлением в форме числа с фиксированной запятой. В ЭВМ чаще всего используется представление чисел в форме с плавающей запятой. Так как наиболее часто в компьютерах применяется двоичная система с плавающей запятой, то вещественное число можно представить виде
(1.4)
где – основание системы счисления, – порядок числа , – мантисса числа, причём должно выполняться условие нормировки:
Большинство персональных компьютеров поддерживают IEEE-стандарт двоичной арифметики. Стандарт предусматривает два типа чисел с плавающей точкой: числа обычной точности (представляются 32 битами – 4 байтами):
• 1 бит – знак;
• 2 – 9 бит – порядок;
• 10 – 32 бит – мантисса.
Числа удвоенной точности (представляется 64 битами – 8 байтами):
• 1 бит – знак;
• 2 – 12 бит – порядок;
• 13 – 64 бит – мантисса.
IEEE-арифметика включает субнормальные числа–очень малые ненормализованные числа, находящиеся между 0 и наименьшим по абсолютной величине нормализованным числом. Наличие субнормальных чисел обеспечивает то, что малые числа не превращаются в машинный ноль. Например, равенствовозможно только при. IEEE-арифметика поддерживает специальные числа и .Число генерируются при переполнении. Правила для символа:
, ,
Любая операция, результат которой (конечный или бесконечный) не определён корректно, генерирует символ (Not a Number – НеЧисло). Например, символ генерируется при операциях:
, , , , где – любая операция.
Вычислительные системы(например MATLAB, SciLab) обрабатывают специальные символы, что позволяет обнаруживать и исправлять особые случаи,в которых программы на языках высокого уровня аварийно завершаются.
Из-за конечности разрядной сетки компьютера можно представить не все числа. Число , не представимое в компьютере, подвергается округлению, т.е. заменяется близким числом, представимым в компьютере точно.
Найдём границу относительной погрешности представления числа с плавающей точкой. Допустим, что применяется простейшее округление – отбрасывание всех разрядов числа, выходящих за пределы разрядной сетки. Система счисления – двоичная. Пусть надо записать число, представляющее бесконечную двоичную дробь
где – цифры мантиссы.
Пусть под запись мантиссы отводитсядвоичных разрядов. Отбрасывая лишние разряды, получим округлённое число
Абсолютная погрешность округления в этом случае равна
Наибольшая погрешность будет в случае , тогда
Из условия нормировки получаем , поэтому всегда . Тогда и относительная погрешность равна .На практике применяют более точные методы округления и погрешность представления чисел равнат.е. точность представления чисел определяется разрядностью мантиссы.
Тогда приближённо представленное в компьютере число можно записать в виде, где– «машинный эпсилон» – относительная погрешность представления чисел.
1.3. Погрешности арифметических операций
При вычислениях с плавающей точкой операция округления может потребоваться после выполнения любой из арифметических операций. Так умножение или деление двух чисел сводится к умножению или делению мантисс. Так как в общем случае количество разрядов мантисс произведений и частных больше допустимой разрядности мантиссы, то требуется округление мантиссы результатов. При сложении или вычитании чисел с плавающей точкой операнды должны быть предварительно приведены к одному порядку, что осуществляется сдвигом вправо мантиссы числа, имеющего меньший порядок, и увеличением в соответствующее число раз порядка этого числа. Сдвиг мантиссы вправо может привести к потере младших разрядов мантиссы, т.е. появляется погрешность округления.
Будем обозначать округлённое в системе с плавающей точкой число, соответствующее точному числу , через(от англ. floating – плавающий). Выполнение каждой арифметической операции вносит относительную погрешность, не большую, чем погрешность представления чисел с плавающей точкой. Следовательно:
, где– любая арифметическая операция, а .
Рассмотрим трансформированные погрешности арифметических операций. Будем считать, что арифметические операции проводятся над приближёнными числами, ошибку арифметических операций учитывать не будем (эту ошибку легко учесть, прибавив ошибку округления соответствующей операции к вычисленной ошибке).
Рассмотрим сложение и вычитание приближённых чисел. Абсолютная погрешность алгебраической суммынескольких приближённых чисел не превосходит суммы абсолютных погрешностей слагаемых.
Действительно, пусть сумма точных чисел равна
сумма приближённых чисел равна
, где –абсолютные погрешности представления чисел.
Тогда абсолютная погрешность суммы равна
Относительная погрешность суммы нескольких чисел равна
где – относительные погрешности представления чисел.
Из этого следует, что относительная погрешность суммы нескольких чисел одного и того же знака заключена между наименьшей и наибольшей из относительных погрешностей слагаемых
При сложении чисел разного знака или вычитании чисел одного знака относительная погрешность может быть очень большой (если числа близки между собой). Так как даже при малыхвеличинаможет быть очень малой. Поэтому вычислительные алгоритмы необходимо строить таким образом, чтобы избегать вычитания близких чисел.
Отметим так же, что погрешности вычислений зависят от порядка вычислений.
Пример 1.1. Рассмотрим пример сложения трёх чисел.
При другой последовательности действий погрешность будет другой
Из сказанного видно, что результат выполнения некоторого алгоритма, искажённый погрешностями округления, совпадает с результатом выполнения того же алгоритма, но с неточными исходными данными. Т.е. можно применять обратный анализ и свести влияние погрешностей округления к возмущению исходных данных.
Т.е. можно записать:
, где
При умножении и делении приближённых чисел складываются и вычитаются их относительные погрешности.
с точностью величин второго порядка малости относительно .
Тогда
Если , то
При большом числе арифметических операций можно пользоваться приближённой статистической оценкой погрешности арифметических операций, учитывающей частичную компенсацию погрешностей разных знаков
, где
– суммарная погрешность,
– погрешность выполнения операций с плавающей точкой.
Лекция 02. Вычислительные алгоритмы и их погрешности
2.1. Трансформированная погрешность
Приведём несколько примеров иллюстрирующих приёмы уменьшения вычислительной погрешности путём алгебраических преобразований.Рассмотрим типичный пример, в котором порядок выполнения операций существенно влияет на погрешность результата.
Пример 2.1. Необходимо отыскать минимальный корень уравнения. Вычисления производим в десятичной системе счисления, причём в результате после округления оставляем четыре значимые цифры (разряда):
Рассмотрим другой алгоритм вычисления корня уравнения, для чего избавимся от иррациональности в числителе, помножив и числитель и знаменатель на :
Как видно из сравнения полученных результатов, применение «неудачного» алгоритма серьёзно влияет на полученный результат вычислений. Это явление в прикладной математике (в практике вычислений) называется потерей значащих цифр, и часто наблюдается при вычитании близких величин. Потеря значащих цифр, например, довольно часто приводит к существенному искажению результатов при решении даже сравнительно небольших систем линейных алгебраических уравнений.
Следовательно, для увеличения точности получаемого результата необходимо по возможности избегать вычитания близких по значению величин.
Пример 2.2. На машине с плавающей запятой необходимо вычислить значение суммы.
Эту сумму можно вычислить двумя способами:
Оказывается, для второго алгоритма вычислительная погрешность будет существенно меньше. Тестовые расчёты на одном и том же компьютере по первому и второму алгоритмам показали, что величина погрешности для обоих алгоритмов составляет и соответственно. Причина этого ясна, если вспомним, как числа представлены в ЭВМ (см. рис. 2.1).
Рис. 2.1. Представление чисел с плавающей точкой в типичном 32-бит формате.
а) Число; b) число 3; c) число ; d) число , представленное в машине с максимальной точностью (нормализованное); e) то же самое число , но представленное с тем же порядком, что и число 3; f) сумма чисел , которая эквивалентна 3.Этот пример ярко иллюстрирует и тот факт, что даже если оба слагаемых представлены в компьютере точно, то их сумма может быть представлена с погрешностью, особенно если слагаемые различаются на порядки.
Таким образом, в машинной арифметике, порядок выполнения операций значим и сложение чисел следует проводить по мере их возрастания.
Рассмотрим трансформированную погрешность вычисления значений функций. Абсолютная трансформированная погрешность дифференцируемой функции, вызываемая достаточно малой погрешностью аргумента , оценивается величиной .
Относительная погрешность:
Абсолютная погрешность дифференцируемой функции многих аргументов , вызываемая достаточно малыми погрешностями аргументов оценивается величиной
Практически важно определять не только допустимую погрешность функции, но и допустимую погрешность аргумента. Эта задача имеет однозначное решение только для функций одной переменной:
Для функций многих переменных задача не имеет однозначного решения, необходимо ввести дополнительные ограничения. Например, если функция наиболее критична к погрешности то можно пренебречь погрешностью других аргументов
Если вклад погрешностей всех аргументов примерно одинаков, то применяют принцип равных влияний:
Пример 2.3. Рассмотрим ещё один пример – использование рядов для вычисления значения функции в точке:
Выпишем разложение функции :
По признаку Лейбница, погрешность частичной суммы знакопеременного ряда по модулю не превышает значения первого отброшенного члена этого ряда.
Вычислим значение при (30º), не учитывая члены ряда, меньшие .
Это отличный результат в рамках принятой точности. Из курса математики известно, что данная функция определена для любого , посчитаем её значения для (390º).
Мы получили относительную погрешность 0,034, против ожидаемой 0,0001 по признаку Лейбница.
Применяя эту же формулу для вычисления при мы даже для очень высокой точности получим значение .
В программах, использующих степенные ряды для вычисления значений функции, для улучшения получаемого результата могут быть использованы различные подходы, одним из них может быть преобразование аргумента так, чтобы .
2.2. Оценка погрешностей с помощью графов вычислительных процессов
Применяя формулы, полученные в прошлой лекции для описания трансформации ошибок при выполнении арифметических операций, удобно для подсчёта распространения ошибок использовать граф. Граф следует читать снизу вверх по стрелкам. Сначала выполняются операции, расположенные на каком-либо нижнем горизонтальном уровне, затем операции более высокого уровня и т.д. Арифметические операции отображаются узлами графа. Рёбра графа снабжают весами в соответствии с формулами оценки относительных погрешностей для арифметических операций.
Относительная ошибка результата любой операции, отображаемой узлами графа, входит как слагаемое в результат следующей операции, умножаясь на коэффициент у стрелки, соединяющей эти две операции. Кроме того, необходимо учитывать погрешность, возникающую в каждой операции.
Пример 2.4.
Пусть вычисляется выражение . Сначала находится , затем
рис.2.1.
Граф, изображённый на рис.2.1, является только изображением самого вычислительного процесса. Для подсчёта общей погрешности результата необходимо дополнить этот граф коэффициентами, которые пишутся около стрелок согласно следующим правилам.
Сложение
Пусть две стрелки, которые входят в кружок сложения, выходят из двух кружков с величинами и . Эти величины могут быть как исходными, так и результатами предыдущих вычислений. Тогда стрелка, ведущая от к знаку «+» в кружке, получает коэффициент , стрелка же, ведущая отк знаку «+» в кружке, получает коэффициент.
Вычитание
Если выполняется операция , то соответствующие стрелки получают коэффициенты и .
Умножение
Обе стрелки, входящие в кружок умножения, получают коэффициент +1.
Деление
Если выполняется деление , то стрелка от к косой черте в кружке получает коэффициент +1, а стрелка от к косой черте в кружке получает коэффициент −1.
Смысл всех этих коэффициентов следующий: относительная ошибка результата любой операции (кружка) входит в результат следующей операции, умножаясь на коэффициенты у стрелки, соединяющей эти две операции.
Таким образом
Если все ошибки не превосходят, то
Пример 2.5.
Рассмотрим задачу сложения четырёх положительных чисел: , где . Граф этого процесса изображён на рис.2.2.
рис.2.2.
Предположим, что все исходные величины заданы точно и не имеют ошибок, и пусть, и являются относительными ошибками округления после каждой следующей операции сложения.
Последовательное применение правила для подсчёта полной ошибки окончательного результата приводит к формуле
Сокращая сумму в первом члене и умножая всё выражение на, получаем
Учитывая, что ошибка округления равна (в данном случае предполагается, что действительное число в ЭВМ представляется в виде десятичной дроби с значащими цифрами), окончательно имеем
Из этой формулы ясно, что максимально возможная ошибка (абсолютная или относительная), обусловленная округлением, становится меньше, если сначала складывать меньшие числа. Результат довольно удивительный, так как вся классическая математика основана на предположении, что при перемене мест слагаемых или их группировке сумма не изменяется. Разница заключается в том, что ЭВМ не может производить вычисления с бесконечно большой точностью, а именно такие вычисления рассматриваются в классической математике.
Рассмотрим вычитание двух почти равных чисел. Предположим, что необходимо вычислить . Тогда из формулы распространения ошибки при вычитании имеем
Предположим, кроме того, что и являются соответствующим образом округлёнными положительными числами, так что
и
Если разность мала, то относительная ошибка может стать большой, даже если абсолютная ошибка мала. Так как в дальнейших вычислениях эта большая относительная ошибка будет распространяться, то она может поставить под сомнение точность окончательного результата вычислений.
Пример 2.6.
Тогда
Зная и , мы можем написать
Как видим, относительные ошибки и малы. Однако
Эта относительная ошибка очень велика, и, что важнее всего, она будет распространяться в ходе последующих вычислений.
Граф вычислительного процесса даёт наглядное представление о структуре возникающей погрешности, однако с помощью графов нельзя оценивать погрешность циклических и итерационных вычислительных процессов.
На основании выше сказанного и рассмотренных примеров можно выработать следующие правила организации вычислительного процесса и округления полученных результатов:
• при сложении и вычитании приближённых чисел в результате следует сохранять столько десятичных знаков, сколько их в слагаемом с наименьшим числом десятичных знаков;
• при умножении и делении в результате следует сохранять столько значащих цифр, сколько их имеет приближённое данное с наименьшим числом значащих цифр;
• при возведении в квадрат или куб в результате следует сохранять столько значащих цифр, сколько их имеет возводимое в степень приближённое число ( последняя цифра квадрата и особенно куба при этом менее надёжна, чем последняя цифра основания);
• при вычислении квадратного и кубического корней в результате следует брать столько значащих цифр, сколько их имеет приближённое значение подкоренного числа (последняя цифра квадратного и особенно кубического корня при этом более надёжна, чем последняя цифра подкоренного числа);
• во всех промежуточных результатах следует сохранять на одну цифру больше, чем рекомендуют предыдущие правила; в окончательном результате последняя цифра отбрасывается;
• если некоторые данные имеют больше десятичных знаков (при сложении и вычитании) или больше значащих цифр (при умножении, делении, возведении в степень, извлечении корня), чем другие, то их предварительно следует округлить, сохраняя лишь одну лишнюю цифру;
• если необходимо произвести сложение-вычитание длинной последовательности чисел, следует начинать с меньших чисел;
• по возможности следует избегать вычитания двух почти равных чисел; формулы, содержащие такое вычитание, часто можно преобразовать так, чтобы избежать подобной операции;
• выражение вида можно представить в виде ;если числа в разности почти равны друг другу, следует производить вычитание до умножения или деления; при этом задача не будет осложнена дополнительными ошибками округления;
• в любом случае следует минимизировать число необходимых арифметических операций.
2.3. Методы оценки сложности алгоритмов
Анализ скорости выполнения алгоритмов
Есть несколько способов оценки сложности алгоритмов. Программисты обычно сосредотачивают внимание на скорости алгоритма, но важны и другие требования, например, к объёму оперативной памяти, свободному пространству дисковой памяти или другим ресурсам.
Многие алгоритмы предоставляют выбор между скоростью выполнения и используемыми программой ресурсами. Задача может выполняться быстрее, используя больше памяти, или наоборот, медленнее, заняв меньший объём памяти.
Хорошим примером в данном случае может служить алгоритм нахождения кратчайшего пути. Задав карту улиц города в виде графа, можно написать алгоритм, вычисляющий кратчайшее расстояние между любыми двумя точками в этогографа. Вместо того чтобы каждый раз заново пересчитывать кратчайшее расстояние между двумя заданными точками, можно заранее просчитать его для всех пар точек и сохранить результаты в таблице. Тогда, чтобы найти кратчайшее расстояние для двух заданных точек, достаточно будет просто взять готовое значение из таблицы.
При этом мы получим результат практически мгновенно, но это потребует большого объёма памяти. Карта улиц для большого города, такого как Москва или Лондон, может содержать сотни тысяч точек. Для такой сети таблица кратчайших расстояний содержала бы более 10 миллиардов записей. В этом случае выбор между временем исполнения и объёмом требуемой памяти очевиден: поставив дополнительные 10 гигабайт оперативной памяти, можно заставить программу выполняться гораздо быстрее.
Временная сложность алгоритма
Одним из важнейших качеств алгоритма является эффективность, характеризующая прежде всего время выполнения программыв зависимости от объёма входных данных (параметра ).
Нахождение точной зависимости для конкретной программы – задача достаточно сложная. По этой причине обычно ограничиваются асимптотическими оценками этой функции, то есть описанием её примерного поведения при больших значениях параметра . Чаще всего для асимптотических оценок используют традиционное отношение между двумя функциями .
Определение:– функции и имеют один порядок малости, если при существует конечный ненулевой .
Приведём некоторые примеры оценки сложности.
Пример 2.7. Рассмотрим программу нахождения факториала числа. Легко видеть, что количество операций, которые должны быть выполнены для нахождения факториала числа в первом приближении прямо пропорционально этому числу, ибо количество повторений цикла (итераций) в данной программе равно . В подобной ситуации принято говорить, что программа (или алгоритм) имеет линейную сложность (сложность).
Не менее интересен и пример вычисления -го числа Фибоначчи:.
Пример 2.8. Программа, печатающая -тое число Фибоначчи, которая имеет линейную сложность, (переменные и содержат значения двух последовательных чисел Фибоначчи).
static void Main () {
int n = int.Parse(Console.ReadLine());
if (n< 0) Console.WriteLine(«Не верно определено n»);
else if (n< 2)
Console.WriteLine(«{0} — е число Фибоначчи = {1}», n, n);
else {
long i = 0;
long j = 1;
long k;
int m = n;
while (—m > 0) {
k = j;
j += i;
i = k;
}
Console.WriteLine(«{0} — е число Фибоначчи = {1}», n, j);
}
}
}
Возникает вполне естественный вопрос: а можно ли находить числа Фибоначчи ещё быстрее? После изучения определённых разделов математики становится известной следующая формула для -ого числа Фибоначчи, которую легко проверить для небольших значений :
Может показаться, что основываясь на ней, легко написать программу со сложностью, не использующую итерации или рекурсии.
static void Main() {
int n = int.Parse(Console.ReadLine());
double f = (1.0 + Math.Sqrt(5.0)) / 2.0;
int j = (int)(Math.Pow(f, n) / Math.Sqrt(5.0) + 0.5);
Console.WriteLine(«{0} — ечислоФибоначчи = {1}», n, j);
}
На самом деле эта программа использует вызов функции возведения в степень Math.Pow(f,n), которая в лучшем случае имеет сложность .Таким образом, существенного выигрыша мы не получаем.
Про алгоритмы, в которых количество операций примерно пропорционально говорят, что они имеют логарифмическую сложность ().
В заключение приведём сравнительную таблицу времени выполнения алгоритмов с различной сложностью и объясним, почему с увеличением быстродействия компьютеров важность использования быстрых алгоритмов значительно возрастает.
Рассмотрим четыре алгоритма решения одной и той же задачи, имеющие сложности , , и соответственно. Предположим, что второй из этих алгоритмов требует для своего выполнения на некотором компьютере при значении параметра ровно одну минуту времени. Тогда времена выполнения всех этих четырёх алгоритмов на том же компьютере при различных значениях параметра будут примерно такими, как в таблице 1.
Таблица 1.
Сравнительная таблица времени выполнения алгоритмов
Сложность алгоритма
0,2 сек.
0,6 сек.
1,2 сек.
0,6 сек.
1 мин.
16,6 час.
6 сек.
16,6 час.
1902 года
1 мин.
лет
лет
С увеличением быстродействия компьютеров возрастают и значения параметров, для которых работа того или иного алгоритма завершается за приемлемое время. Таким образом, увеличивается среднее значение величины , и, следовательно, возрастает величина отношения времени выполнения быстрого и медленного алгоритмов. Чем быстрее компьютер, тем больше относительный проигрыш при использовании плохого алгоритма!
При сравнении различных алгоритмов важно понимать, как сложность алгоритма соотносится со сложностью решаемой задачи. При расчётах по одному алгоритму сортировка тысячи чисел может занять 1 секунду, а сортировка миллиона – 10 секунд, в то время как расчёты по другому алгоритму могут потребовать 2 и 5 секунд соответственно. В этом случае нельзя однозначно сказать, какая из двух программ лучше – это будет зависеть от исходных данных.
Лекция 03. Численные методы линейной алгебры
Выделяют четыре задачи линейной алгебры: решение системы линейных уравнений, вычисление определителя, нахождение обратной матрицы, определение собственных значений и собственных векторов матрицы.
Рассмотрим первую из перечисленных задач. Она является одной из важнейших и одной из наиболее распространённых задач вычислительной математики. К системе линейных алгебраических уравнений (СЛАУ) часто приходят при исследовании самых различных проблем науки и техники, в частности, приближённое решение обыкновенных дифференциальных уравнений и в частных производных сводится к решению алгебраических систем.
Рассмотрим систему линейных уравнений:
,
где – матрица – матрица коэффициентов левой части системы;
– вектор правой части,
– вектор решений системы уравнений.
Известно, что если , то система линейных неоднородных уравнений имеет единственное решение.
Для применения численных методов нахождения единственного решения системы линейных уравнений важна её устойчивость относительно погрешностей правой части.
Формально устойчивость существует, ибо при обратная матрица существует. Но если матрица имеет большие элементы, то можно указать такой вид погрешности исходных данных, который сильно изменит решение. У плохо обусловленной системы . Однако этот признак плохой обусловленности является необходимым, но недостаточным. Плохо обусловленная система геометрически соответствует почти параллельным прямым.
Число неизвестных в СЛАУ может достигать нескольких десятков, сотен и даже тысяч. Например, задача надёжного прогноза погоды в принципе сводится к решению систем линейных алгебраических уравнений с несколькими тысячами неизвестных. Один из методов решения систем линейных алгебраических уравнений был разработан в 1750 г. Г. Крамером. Если решать систему совместных уравнений по формулам Крамера (метод определителей), то можно подсчитать, что число только умножений и делений будет равно
,
например, для системы из десяти уравнений число этих операций будет
Разработке эффективных методов решения систем линейных уравнений уделяли и продолжают уделять внимание очень многие исследователи, однако только применение ЭВМ дало возможность решать системы при достаточно больших . Очень удачную схему вычисления методом исключения разработал К.Ф. Гаусс в 1849 г. По схеме Гаусса необходимо выполнить только
делений и умножений. При будем иметь всего лишь
,
т.е. почти в 84000 раз меньше чем . Однако необходимо учитывать не только время, требуемое для проведения большого количества умножений, делений и сложений в каком-либо методе, но и то, что накопление ошибок округления, появляющихся в результате большого числа операций, является очень серьёзной проблемой. Методы нахождения решения СЛАУ делятся на прямые, т.е. методы, которые представляют собой конечные алгоритмы для вычисления корней систем линейных уравнений и итерационные, которые дают решение системы как предел последовательных приближений вычисляемых по единообразной схеме.
Следует отметить, что вследствие неизбежных округлений результаты, полученные с помощью прямых методов, являются приближёнными, причём оценка погрешностей корней в общем случае затруднительна. Прямые методы применяются на практике для решения СЛАУ на ЭВМ, для .
3.1. Метод Гаусса для решения систем линейных уравнений
Пусть дана хорошо обусловленная система линейных уравнений, для которой существует единственное решение
Метод Гаусса – метод решения систем линейных алгебраических уравнений, состоит в том, что расширенная матрица системы (т.е. матрица, состоящая из коэффициентов системы и свободных членов ) преобразуется к треугольной матрице, все элементы которой ниже главной диагонали равны нулю. Выпишем формулы процесса для -того столбца. В этот момент ненулевые элементы ниже главной диагонали содержат уравнения
Умножим -ую строку на
и вычтем из -той строки.
т.о. производя такие операции для каждой строки исключим элементы -того столбца. В результате получим треугольную матрицу с ненулевыми элементами выше главной диагонали.
Замечания
Исключения нельзя производить, если на главной диагонали . Эту проблему можно решить перестановкой строк, т.к. все элементы -того столбца не могут быть нулевыми.
Для эффективного использования алгоритма каждый цикл алгоритма начинают с перестановки строк, находя среди элементов -того столбца наибольший по модулю и именно его помещая на главную диагональ.
Рассмотрим эти преобразования подробно. Проанализируем, например, коэффициенты первого столбца матрицы. Может оказаться, что максимальный коэффициент при находится, например, в пятом уравнении (т.е. это ). Если в системе алгебраических уравнений поменять любые два уравнения местами, то решение не изменится. Поэтому поменяем местами первое уравнение с тем уравнением, в котором находится максимальный коэффициент при , а затем уже будем исключать .
Возможен случай, когда максимальный элемент при находится в первом уравнении, тогда нет необходимости менять строки местами. В качестве примера мы рассмотрели переменную . Её будем исключать из второго, третьего, … , — го уравнений. В общем случае — я переменная исключается из — го, — го, … , — го уравнений. Ниже приводится описание алгоритма:
1. Из уравнений с номерами , ,…, выбираем то, в котором коэффициент при максимален по модулю, а точнее – определяем номер этого уравнения и поменяем местами -ое и -ое уравнения.
2. Разделим -ое уравнение на коэффициент при , т.е. на и вычтем его из уравнений с номерами больше , каждый раз предварительно домножая -ое уравнение на коэффициент при , уравнения из которого мы вычитаем.
Обратным ходом вычисляем :
1) .
2). Уравнение для определения имеет вид
Отсюда находим
где меняется от до 1.
Следует отметить, что количество арифметических действий прямого хода , обратного .
Пример 3.1. Решить систему линейных алгебраических уравнений методом Гаусса с выбором главных элементов
Решение:
В первом столбце максимальный по модулю элемент – , следовательно разделим на него второе уравнение и для удобства выпишем его первым в системе:
Теперь, домножим первое уравнение на коэффициент при во втором уравнении – и вычтем результат из второго уравнения:
Аналогично преобразуем третье и четвёртое уравнения:
Максимальный по модулю коэффициент при в четвёртом столбце, разделим на него четвёртое уравнение и выпишем его вторым:
Проведём преобразования, аналогичные предыдущим, домножая второе уравнение сначала на и вычитая его из третьего, а потом на и вычитая из четвёртого:
Аналогично система преобразовывается и относительно . Окончательно система приобретает вид:
Описанный выше алгоритм можно реализовать на языке C# в следующей программе:
static void Main () {
const int n = 4; // Размерность системы
double[,] a = {{1.87,5.38, 1.03, 1.17, 9.45},
{7.03,8.04,9.05,6.08,30.20},
{1.11,2.02,2.03,-.04,5.12},
{3.41,-4.52,7.28,5.18,11.35}};
double[] x = new double[n];
for (int i = 0; i < n; i++){
double m = Math.Abs(a[i, i]);
int k = i;
for (int j = i+1; j < n; j++)
if (Math.Abs(a[j,i]) > m) {
m = Math.Abs(a[j,i]);
k = j;
}
if (k != i)
for (int j = i;j <= n; j++){
double z = a[i, j];
a[i,j] = a[k,j];
a[k,j] = z;
}
double r = a[i, i];
for (int j = i;j <= n; j++)
a[i,j] /= r;
for (int l = i+1; l < n; l++){
r = a[l,i];
for (int j = i+1; j <= n; j++)
a[l,j] -= a[i,j]*r;
}
}
x[n-1] = a[n-1,n];
for (int i = n-1; i >= 0; i—){
x[i] = a[i,n];
for (int k = i+1; k < n; k++)
x[i] -= a[i,k]*x[k];
}
for (int i = 0; i < n; i++)
Console.WriteLine(«X({0}) = {1}», i + 1, x[i]);
}
Нетрудно заметить, что приведённая система имеет единичное решение. В результате выполнения программы получается следующее решение:
Отметим, что благодаря выбору наибольшего по модулю ведущего элемента, уменьшаются множители, используемые для преобразования уравнений, что способствует снижению погрешности вычислений.
Метод Гаусса целесообразно использовать для решения систем с плотно заполненной матрицей. Помимо аналитического решения СЛАУ, метод Гаусса также применяется для:
• нахождения матрицы, обратной к данной;
• определения ранга матрицы.
Рассмотрим подробнее вопрос о погрешностях решения СЛАУ методом Гаусса. Запишем систему в матричном виде . Решение этой системы можно представить в виде . Однако вычисленное решение отличается от точного решения из-за погрешностей округлений и ограниченности разрядной сетки компьютера. Существует две величины, характеризующие степень отклонения полученного решения от точного: погрешность и невязка .
Можно показать, что если одна из этих величин равна нулю, то и другая должна равняться нулю. Однако из малости одной величины не следует малость другой. При обычно , но обратное утверждение справедливо не всегда. В частности для плохо обусловленных систем при погрешность решения может быть большой. Вместе с тем, в практических расчётах, если система не является плохо обусловленной, контроль точности решения осуществляется с помощью невязки. Можно отметить, что метод Гаусса с выбором главного элемента в этих случаях даёт малые невязки.
3.2. Применение метода Гаусса для нахождения определителя матрицы
Непосредственное нахождение определителя матрицы требует большого объёма вычислений. Вместе с тем, легко вычислить определитель треугольной матрицы. Для приведения исходной матрицы к диагональному виду можно (и нужно!) использовать прямой ход метода Гаусса. В процессе исключения элементов абсолютное значение определителя матрицы не меняется. Знак же определителя меняется от перестановки его столбцов или строк. Следовательно, значение определителя матрицы , после приведения её к треугольному виду вычисляется по формуле:
Пример 3.2. Найти определитель матрицы методом Гаусса с выбором главных элементов.
Решение:
Максимальный по модулю элемент в первом столбце . Следовательно поменяем местами первую и вторую строки. Определитель в данный момент равен . Разделим все элементы первой строки на и домножая полученную строку на элемент в первом столбце поочерёдно второй, третьей и четвёртой строки вычтем первую строку:
Во втором столбце максимальный по модулю элемент находится в четвёртой строке, следовательно, меняем местами вторую и четвёртую строки. Полученную вторую строку делим на и вычитаем эту строку последовательно из третьей и четвёртой строки предварительно домножив сначала на (для третьей строки) и после на . Определитель становится равным . Матрица примет вид:
Аналогичные преобразования следует провести и для третьего столбца. В результате определитель станет равным , а матрица:
На последнем шаге определитель равен . Поскольку мы сделали чётное количество перестановок знак определителя менять не будем.
Модифицируем алгоритм, реализующий метод Гаусса, для получения определителя квадратной матрицы.
static void Main () {
const int n = 4; // Размерность системы
double[,] a = {{1.87,5.38, 1.03, 1.17},
{7.03,8.04,9.05,6.08},
{1.11,2.02,2.03,-.04},
{3.41,-4.52,7.28,5.18}};
int Перестановки = 0;
double Определитель = 1;
for (int i = 0; i < n; i++){
double m = Math.Abs(a[i, i]);
int k = i;
for (int j = i+1; j < n; j++)
if (Math.Abs(a[j,i]) > m) {
m = Math.Abs(a[j,i]);
k = j;
}
if (k != i){
for (int j = i;j < n; j++){
double z = a[i, j];
a[i,j] = a[k,j];
a[k,j] = z;
}
Перестановки++;
}
double r = a[i, i];
Определитель *= r;
for (int j = i;j < n; j++)
a[i,j] /= r;
for (int l = i+1; l < n; l++){
r = a[l,i];
for (int j = i+1; j < n; j++)
a[l,j] -= a[i,j]*r;
}
}
if ((Перестановки != 0) & (Перестановки % 2 == 1))
Определитель *=-1;
Console.WriteLine(«Определитель = {0}», Определитель);
}
Лекция 04. Вычисление обратной матрицы
Обратная матрица – это такая матрица , при умножении на которую исходная матрица даёт в результате единичную матрицу :
Квадратная матрица обратима тогда и только тогда, когда она невырожденная, то есть её определитель не равен нулю. Для неквадратных матриц и сингулярных матриц обратных матриц не существует.
Свойства обратной матрицы:
• .
• для любых двух обратимых матриц и .
• .
• для любого коэффициента .
• если необходимо решить систему линейных уравнений , (где – ненулевой вектор, а – искомый вектор), и если существует, то .
4.1. Метод Гаусса
Возьмём две квадратные матрицы одинаковой размерности: саму и единичную . Приведём матрицу к единичной матрице методом Гаусса. После применения каждой операции к первой матрице применим ту же операцию ко второй. Когда приведение первой матрицы к единичному виду будет завершено, вторая матрица окажется равной .
При использовании метода Гаусса первая матрица будет умножаться слева на одну из элементарных матриц (трансвекцию или диагональную матрицу с единицами на главной диагонали, кроме одной позиции):
Вторая матрица после применения всех операций станет равна , то есть будет искомой. Сложность алгоритма – .
Пример 4.1. Найти обратную матрицу методом Гаусса.
Решение:
На первом шаге
Умножив слева на , получим:
,а
,а
,а
На последнем шаге:
,а
Матрица и будет обратной к матрице .
Программа на языке C#, реализующая данный метод:
class Program {
const int n = 4; // Размерность системы
static void Main () {
double[,] Заданная = { { 1.87, 5.38, 1.03, 1.17 },
{ 7.03, 8.04, 9.05, 6.08 },
{ 1.11, 2.02, 2.03, -.04 },
{ 3.41, -4.52, 7.28, 5.18 } };
double[,] Обратная = new double[n, n];
for (int i = 0; i < n; i++)
Обратная[i, i] = 1.0;
for (int i = 0; i < n; i++) {
double[,] Вспомогательная = new double[n, n];
for (int j = 0; j < n; j++)
Вспомогательная[j, j] = 1.0;
for (int j = 0; j < n; j++)
if (j != i)
Вспомогательная[j, i] = -Заданная[j, i] / Заданная[i, i];
else
Вспомогательная[j, i] = 1 / Заданная[i, i];
Заданная = ПроизведениеМатриц(Вспомогательная, Заданная);
Обратная = ПроизведениеМатриц(Вспомогательная, Обратная);
}
for (int j = 0; j < n; j++, Console.WriteLine())
for (int k = 0; k < n; k++)
Console.Write(«{0} t», Обратная[j, k]);
}
static double[,] ПроизведениеМатриц (double[,] Левая, double[,] Правая) {
double[,] Результат = new double[n, n];
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++) {
double элемент = 0;
for (int t = 0; t < n; t++)
элемент += Левая[j, t] * Правая[t, k];
Результат[j, k] = элемент;
}
return (Результат);
}
}
4.2. Использование LU/LUP-разложения
Матричное уравнение для обратной матрицы можно рассматривать как совокупность систем вида . Обозначим -ый столбец матрицы через ; тогда , , поскольку -ым столбцом матрицы является единичный вектор , другими словами, нахождение обратной матрицы сводится к решению уравнений с одной матрицей и разными правыми частями. После выполнения LUP-разложения (время ) на решение каждого из уравнений нужно время , так что и эта часть работы требует времени .
Если матрица невырождена то для неё можно рассчитать LU-разложение . Пусть , . Тогда из свойств обратной матрицы можно записать: . Если умножить это равенство на и то можно получить два равенства вида и . Первое из этих равенств представляет собой систему из линейных уравнений для из которых известны правые части (из свойств треугольных матриц). Второе представляет также систему из линейных уравнений для из которых известны правые части (также из свойств треугольных матриц). Вместе они представляют собой систему из равенств. С помощью этих равенств можно рекуррентно определить все элементов матрицы . Тогда из равенства . получаем равенство .
Пример 4.2. Найти обратную матрицу с помощью метода LU-разложения.
Решение:
Обычно эту задачу разбивают на две части: нахождения LU-разложения матрицы и нахождения с помощью полученного разложения обратной матрицы. Покажем сначала разложение матрицы.
Матрица – нижнетреугольная матрица с единицами по главной диагонали, первый столбец этой матрицы получается из первого столбца заданной матрицы путём деления всех элементов на , матрица – верхнетреугольная, первая строка которой совпадает с первой строкой заданной матрицы. Выпишем известные элементы матриц и .
Неизвестные элементы матриц и найдём из соображений, что . Так, элемент найдём из уравнения . Подставив значения, , получаем . и находятся аналогично из уравнений: и . Следовательно, .
Так, после проведённых операций матрицы принимают следующий вид:
и
На следующем шаге можно найти из уравнения . Решив уравнение получим, что . Поскольку теперь известны все элементы третьей строки матрицы , можно найти все элементы третьей строки матрицы как решения уравнений и . Получаем, и .
и
Элемент найдём из уравнения: , , а элемент из , . А элемент из уравнения:
.
и
На втором этапе нам требуется найти обратные матрицы и . Матрица обратная к нижнетреугольной так же является нижнетреугольной и сохраняет единицы по главной диагонали. Выпишем
Неизвестные найдём из соображений, что . Получим систему однородных уравнений:
– умножение 2-ой строки матрицы на 1-ый столбец матрицы ;
– 3-ей строки матрицы на 1-ый столбец матрицы ;
– 3-ей строки матрицы на 2-ой столбец матрицы ;
Решая эту систему получаем: , , , . Таким образом:
Аналогичны рассуждения и для матрицы . Обратная для неё так же будет верхнетреугольной матрицей, элементы которой находятся как решения СЛАУ:
Произведение и даст нам матрицу, обратную к заданной.
Ниже представлен код на языке C# алгоритма обращения матрицы с помощью LU-разложения с комментариями.
Замечание: В алгоритме сознательно сделано LU разложение в разные матрицы, для наглядной демонстрации структуры этих матриц, однако в алгоритме используется и стандартное хранение этих матриц в виде вспомогательной матрицы С, в которой элементы ниже главной диагонали – это элементы матрицы L, а на главной диагонали и выше – элементы матрицы U.
static void Main () {
const int n = 4; //размерность исходной матрицы
double[,] A = {{1.87,5.38, 1.03, 1.17},
{7.03,8.04,9.05,6.08},
{1.11,2.02,2.03,-.04},
{3.41,-4.52,7.28,5.18}};
double[,] X = new double[n, n];
double[,] L = new double[n, n];
double[,] U = new double[n, n];
double[,] С = new double[n, n];
for (int i = 0; i < n; i++){
for (int j = 0; j < n; j++) {
U[0, i] = A[0, i];
L[i, 0] = A[i, 0] / U[0, 0];
double sum = 0;
for (int k = 0; k < i; k++)
sum += L[i, k] * U[k, j];
U[i, j] = A[i, j] — sum;
if (i > j)
L[j, i] = 0;
else {
sum = 0;
for (int k = 0; k < i; k++)
sum += L[j, k] * U[k, i];
L[j, i] = (A[j, i] — sum) / U[i, i];
}
}
}
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
С[i, j] = L[i, j];
for (int i = 0; i < n; i++)
for (int j = i; j < n; j++)
С[i, j] = U[i, j];
for (int k = n — 1; k >= 0; k—){
X[k,k] = 1;
for (int j = n — 1; j > k; j—)
X[k, k] -= С[k, j] * X[j, k];
X[k, k] /= С[k, k];
for (int i = k — 1; i >= 0; i—){
for (int j = n — 1; j > i; j—) {
X[i, k] -= С[i, j] * X[j, k];
X[k, i] -= С[j, i] * X[k, j];
}
X[i, k] /= С[i, i];
}
}
for (int i = 0; i < n; i++, Console.WriteLine() )
for (int j = 0; j < n; j++)
Console.Write(«{0}t», X[i, j]);
}
В случае использования LU-разложения не требуется перестановки столбцов матрицы , но решение может разойтись даже если матрица невырождена.
Сложность алгоритма – .
Использование LUP-разложения
Идея метода та же, что и в использовании LU разложения. Однако с целью уменьшения погрешности при нахождении LU разложения исходной матрицы, используется тот же приём, что и при выборе разрешающего элемента метода Гаусса. Сделанные перестановки строк запоминаются в матрице P, на которую и следует умножить полученную матрицу в завершении алгоритма.
4.3. Обновление обратной матрицы при изменении нескольких элементов матрицы A
В некоторых случаях надо решить такую задачу: есть матрица , которую мы обратили, получив . Затем мы изменили несколько элементов матрицы , получив матрицу , и нам требуется обратить матрицу .
Разумеется, эта задача может быть решена «в лоб» путём применения алгоритма обращения к матрице . Однако есть более эффективный алгоритм, позволяющий использовать тот факт, что у нас уже есть матрица , а матрица лишь незначительно отличается от матрицы .
Алгоритм обновления обратной матрицы
В основе алгоритма лежит формула Шермана-Моррисона:
Здесь – квадратная матрица размером , чья обратная матрица нам известна, а – столбец, а – строка высоты , задающие модификацию матрицы (к элементу добавляется ). Можно видеть, что для обновления обратной матрицы по этой формуле требуется порядка операций с вещественными числами, что в раз лучше, чем обращение более общим алгоритмом.
В зависимости от выбора векторов и возможны различные варианты модификации матрицы и обновления матрицы , выполняющиеся с различной трудоёмкостью. Рассмотрим основные варианты:
• если только -ая компонента вектора и -ая компонента вектора неравны нолю, то такой набор векторов обозначает добавление к элементу числа ;
• если -ая компонента вектора равна единице, а остальные равны нолю, то к -ой строке матрицы добавляется строка ;
• если -ая компонента вектора равна единице, а остальные равны нолю, то к -ому столбцу матрицы добавляется вектор ;
• если нет ограничений на компоненты векторов и , то это можно трактовать, как добавление строки (или столбца ) к разным строкам (столбцам) матрицы с разными множителями.
Различные варианты обновления могут быть осуществлены с разной эффективностью, учитывая особую структуру векторов и . Самым быстрым является обновление обратной матрицы при модификации только одного элемента исходной матрицы, поэтому имеет смысл выбрать его эталоном.
Обновление обратной матрицы при модификации строки или столбца исходной матрицы всего лишь в два раза медленнее (так что при модификации трёх и более элементов, расположенных в одном столбце или строке, оно является более выгодным, чем многократный вызов предыдущего алгоритма). Обновление обратной матрицы при произвольном выборе векторов и в три раза медленнее, чем обновление при модификации только одного элемента.
Замечание: Устойчивость алгоритма находится под вопросом, но как минимум один шаг алгоритма достаточно устойчив, если матрицы и хорошо обусловлены.
Пример 4.3. Пусть задана матрица
, обратная к ней
Найти обратную матрицу для .
Решение:
отличается от только элементом , который увеличился на 2 единицы. Обозначим это изменение .
Рассчитаем значение поправки: .
Преобразуем второй столбец матрицы , домножив его поэлементно на и разделив на .
Теперь возьмём третью строку матрицы , домножим её на первый полученный коэффициент и вычтем из первой строки матрицы , домножим на второй коэффициент и вычтем из второй строки, и домножив на тертий коэффициент вычтем из третьей строки.
Программная реализация приведена ниже.
static void Main() {
double[,] ОбратнаяА = { { -0.1428571, -0.8571429, 1.4285714 },
{ 0.0, 1.0, -1.0 },
{ 0.2857143, -0.2857143, 0.1428571 } };
int n = 3;
int строка = 1;
int столбец = 2;
double Значение = 2.0;
double[] t1 = new double[n];
double[] t2 = new double[n];
for(int i = 0; i < n; i++)
t1[i] = ОбратнаяА[i, строка];
for(int i = 0; i < n ;i++)
t2[i] = ОбратнаяА[столбец, i];
double Поправка = Значение * ОбратнаяА[столбец, строка];
for(int i = 0; i < n; i++){
double vt = (Значение * t1[i]) / (1 + Поправка);
for(int j = 0; j < n; j++)
ОбратнаяА[i, j] = ОбратнаяА[i, j] — vt * t2[j];
}
for (int i = 0; i < n; i++, Console.WriteLine())
for (int j = 0; j < n; j++)
Console.Write(«{0}t», ОбратнаяА[i, j]);
}
Пример 4.4. В матрице предыдущего примера изменения затрагивают только элементы второй строки, т.е. . Найти .
Решение:
Строка изменений, т.е. строка поэлементно прибавленная к матрице имеет вид: .
Посчитаем столбец изменений :
Значение поправки (поскольку изменения вносятся во вторую строку).
Преобразуем второй столбец матрицы , разделив на :
Программная реализация данного алгоритма приведена ниже.
static void Main() {
double[,] ОбратнаяА = { { -0.1428571, -0.8571429, 1.4285714 },
{ 0.0, 1.0, -1.0 },
{ 0.2857143, -0.2857143, 0.1428571 } };
int n = 3;
int НомерСтроки = 1;
double[ ] Строка = { 1.0, 2.0, 3.0 };
double[ ] t1 = new double[n];
double[ ] t2 = new double[n];
for (int i = 0; i < n; i++)
t1[i] = ОбратнаяА[i, НомерСтроки];
for (int j = 0; j < n; j++) {
double Пересчет = 0.0;
for (int i = 0; i < n; i++)
Пересчет += Строка[i] * ОбратнаяА[i, j];
t2[j] = Пересчет;
}
double Поправка = t2[НомерСтроки];
for(int i = 0; i < n; i++){
double Пересчет = t1[i] / (1 + Поправка);
for(int j = 0; j < n; j++)
ОбратнаяА[i, j] -= Пересчет * t2[j];
}
for (int i = 0; i < n; i++, Console.WriteLine() )
for (int j = 0; j < n; j++)
Console.Write(«{0}t», ОбратнаяА[i, j]);
}
Внесём изменение в каждый элемент одного столбца матрицы (в данном примере 1), и посчитаем новое значение обратной матрицы. Программная реализация приведена ниже, считаем, что каждый элемент второй строки заданной матрицы увеличили на единицу.
static void Main() {
double[,] ОбратнаяА = { { -0.1428571, -0.8571429, 1.4285714 },
{ 0.0, 1.0, -1.0 },
{ 0.2857143, -0.2857143, 0.1428571 } };
int n = 3;
int НомерСтолбца = 0;
double [] Столбец = {0.0,0.0,1.0};
double[ ] t1 = new double[n];
double[ ] t2 = new double[n];
for (int i = 0; i < n; i++) {
double vt = 0.0;
for (int j = 0; j < n; j++)
vt += ОбратнаяА[i, j] * Столбец[j];
t1[i] = vt;
}
double Поправка = t1[НомерСтолбца];
for(int j = 0; j < n; j++)
t2[j] = ОбратнаяА[НомерСтолбца, j];
for(int i = 0; i < n; i++){
double vt = t1[i] / (1 + Поправка);
for(int j = 0; j < n; j++)
ОбратнаяА[i, j] -= vt * t2[j];
}
for (int i = 0; i < n; i++, Console.WriteLine())
for (int j = 0; j < n; j++)
Console.Write(«{0}t», ОбратнаяА[i, j]);
}
Лекция 05. Интерполяционные методы
5.1. Метод простых итераций
Пусть дана линейная система
Предполагая, что , разрешим первое уравнение относительно, второе уравнение относительно и т.д., тогда получим эквивалентную систему:
где Система называется системой, приведённой к нормальному виду. Считая и обозначая
система запишется в матрично-векторном виде:
Систему будем решать методом последовательных приближений. За нулевое приближение можно взять столбец свободных членов, . Далее последовательно строятся матрицы-столбцы: – первое приближение, – второе приближение и т.д.
Любое — е приближение вычисляется по формуле
Если последовательность приближений имеет предел , то этот предел является решением системы. В самом деле, переходя к пределу, будем иметь: или Предельный вектор является решением системы. Метод последовательных приближений, определённый формулой, носит название метода итераций.Заметим, что иногда лучше приводить систему к виду так, чтобы коэффициенты не были равными нулю. Например, можно положить: где. Тогда исходная система эквивалентна приведённой системе:
где. Существует множество способов приведения системы к нужному виду. Для того, чтобы последовательность приближений сходилась, необходимо выполнение условия, которое следует из принципа сжатых отображений:
Условие будет выполнено, если сделать следующие преобразования. Вычисляем . Если , то делим-е уравнение на , в противном случае делим -е уравнение на . То есть, мы делаем следующие преобразования: если ,то,при , .
Пример 5.1. Дана система линейных алгебраических уравнений:
Преобразовать исходную систему к нормальному видуи решить её методом простых итераций.
Решение:
Обозначим исходное приближение, а следующее приближение, которое вычисляется по формулам:
Вычисления продолжаются до тех пор, пока для всех , где – заданная точность вычислений. Если условие не выполнено по крайней мере для одного , то за исходное приближение на следующем шаге берём , т.е. полагаем и вычисляем очередное приближение по формуле приведённой выше.
Посчитаем значениепервой компоненты вектора .
Аналогично вычисляются остальные компоненты, . Вычислим элементы первой строки преобразованной матрицы: поскольку , , , , , .
Исходная система после преобразования к нормальному виду будет такой:
Взяв за начальное приближение вектор , на первом шаге получаем:
Поскольку модуль разности , полагаем и продолжаем вычисления по той же схеме.
Результаты реализации метода простых итераций:
Реализация данного алгоритма на языке C#:
staticvoidMain() {
constintn = 4; //размерность исходной матрицы
constdoubleeps = 0.001;
double[,] A = { { 5.38, 1.87, 1.03, 1.17 },
{ 1.03, 9.05, 1.04, 1.08 },
{ 1.11, 2.02, 7.04, 2.03, },
{ 1.41, 2.52, 2.18, 7.28 } };
double[ ] B = {11.32, 21.25, 14.22, 15.91};
double[ ] M = new double[n];
double[ ] X = { 0.0, 0.0, 0.0, 0.0 };
double[ ] TempX = new double[n];
double Norma;
for (int i = 0; i < n; i++) {
M[i] = Math.Abs(B[i]);
for (int j = 0; j < n; j++)
M[i] += Math.Abs(A[i, j]);
}
for (int i = 0; i < n; i++) {
int p;
if (A[i, i] < 0) p = 1;
else p = -1;
for (int j = 0; j < n; j++)
A[i, j] = p * A[i, j] / M[i];
B[i] = -p * B[i] / M[i];
A[i, i]++;
}
do {
for (int i = 0; i < n; i++) {
TempX[i] = B[i];
for (int g = 0; g < n; g++)
TempX[i] += A[i, g] * X[g];
}
Norma = Math.Abs(X[0] — TempX[0]);
for (int h = 0; h < n; h++) {
if (Math.Abs(X[h] — TempX[h]) > Norma)
Norma = Math.Abs(X[h] — TempX[h]);
X[h] = TempX[h];
}
} while (Norma > eps);
for (int i = 0; i < n; i++)
Console.WriteLine(«X{0} = {1}», i + 1, X[i]);
}
Следует отметить, что метод простых итераций (иногда называемый методом Якоби наиболее эффективен в случае матриц с преобладающими элементами по главной диагонали).
5.2. Метод Гаусса – Зейделя
Чтобы пояснить суть метода, перепишем задачу в виде:
Здесь в -м уравнении мы перенесли в правую часть все члены, содержащие , для . Эта запись может быть представлена:
где в принятых обозначениях означает матрицу, у которой на главной диагонали стоят соответствующие элементы матрицы , а все остальные нули; тогда как матрицы и содержат верхнюю и нижнюю треугольные части , на главной диагонали которых нули.
Итеративный процесс в методе Гаусса-Зейделя строится по формуле:
после выбора соответствующего начального приближения .
Метод Гаусса-Зейделя можно рассматривать как модификацию метода Якоби. Основная идея модификации состоит в том, что новые значения используются здесь сразу же по мере получения, в то время как в методе Якоби они не используются до следующей итерации:
где, ,
Таким образом,-тая компонента -го приближения вычисляется по формуле:
,
Условие сходимости
Пусть, где, – матрица, обратная к . Тогда при любом выборе начального приближения :
• метод Гаусса-Зейделя сходится;
• скорость сходимости метода равна скорости сходимости геометрической прогрессии со знаменателем ;
• верна оценка погрешности:.
Условие окончания
Условие окончания итерационного процесса Зейделя при достижении точности в упрощённой форме имеет вид:
Более точное условие окончания итерационного процесса имеет вид:
и требует больше вычислений. Хорошо подходит для разрежённых матриц.
Пример 5.2. Дана система линейных алгебраических уравнений:
Решить систему методом Гаусса – Зейделя с точностью 0,01.
Решение:
Обозначим за –решение полученное на -том шаге, а за –решение, получаемое на -ом шаге. За начальное приближение возьмём нулевой вектор.. И преобразуем систему:
Откуда:
На первом шаге получаем:
На втором шаге:
Текст программы на языке С#, реализующей метод Зейделя-Гаусса:
class Program {
const double eps = 0.001;
const int n = 4;
static void Main() {
double[,] A = { { 5.38, 1.87, 1.03, 1.17 },
{ 1.03, 9.05, 1.04, 1.08 },
{ 1.11, 2.02, 7.04, 2.03, },
{ 1.41, 2.52, 2.18, 7.28 } };
double[ ] B = { 11.32, 21.25, 14.22, 15.91 };
double[ ] P = new double [n];
double[ ] X = { 0.0, 0.0, 0.0, 0.0 };
do {
for (int i = 0; i < n; i++) {
double Сумма = 0;
for (int j = 0; j < n; j++)
if (j != i) { Сумма += (A[i, j] * X[j]); }
P[i] = X[i];
X[i] = (B[i] — Сумма) / A[i, i];
}
} while (Сходимость(X, P));
for (int j = 0; j < n; j++)
Console.Write(«{0} t», X[j]);
}
static bool Сходимость(double[] Xk, double[] Xkp){
bool b = false;
for (int i = 0; i < n; i++){
if (Math.Abs(Xk[i]-Xkp[i]) > eps){
b = true;
break;
}
}
return b;
}
}
5.3. Метод релаксации
Метод релаксации относится к итерационным методам, где на каждом шаге меняется значение только одной из компонент вектора приближения к решению.
Исходную систему уравнений (например, делением на диагональные элементы) преобразуем к виду
Возьмём начальное приближение. Подставляя его в преобразованную систему, получаем «невязки»
или в компактной форме
Выберем максимальную по модулю невязку и положим в очередном приближении
Очевидно, что
,
Среди найденных невязок вновь отыскиваем наибольшую по модулю и, положив , получаем
,
и т.д., до максимальной невязки в пределах заданной точности.
Пример 5.3. Дана система линейных алгебраических уравнений:
Решить систему методом релаксаций с точностью 0,01.
Решение:
Преобразуем систему, сразу выписав невязки и посчитаем их значения, взяв за начальное приближение единичный вектор:
Максимальная невязка в четвёртой строке, поэтому на следующей итерации вектор имеет вид: . Считаем новые невязки:
Так продолжаем до тех пор, пока все невязки не станут меньше 0,01. Программа, реализующаяданныйметод:
class Program {
const double eps = 0.001;
const int n = 3;
static void Main() {
double[,] A = { { 10.0, -2.0, -2.0 },
{ -1.0, 10.0, -2.0 },
{ -1.0, -1.0, 10.0}};
double[ ] B = { 6.0, 7.0, 8.0};
double[ ] Невязка = new double[n];
double[ ] X1 = { 0.0, 0.0, 0.0};
// Преобразуемсистему
for (int i = 0; i < n; i++) {
B[i] /= A[i, i];
for (int j = 0; j < n; j++)
if (i !=j) A[i, j] /= -A[i, i];
A[i, i] = -1;
}
// Считаемневязку
for (int i = 0; i < n; i++) {
Невязка[i] = B[i];
for (int j = 0; j < n; j++)
Невязка[i] += A[i, j] * X1[i];
}
while (true) {
double[ ] X2 = new double[n];
for (int i = 0; i < n; i++)
X2[i] = X1[i];
double Значение = Math.Abs(Невязка[0]);
int Номер = 0;
for (int i = 0; i < n; i++)
if (Math.Abs(Невязка[i]) >Значение) {
Значение = Math.Abs(Невязка[i]);
Номер = i;
}
X2[Номер] += Невязка[Номер];
double[ ] НевязкаНовая = newdouble[n];
НевязкаНовая[Номер] = 0;
for (int i = 0; i < n; i++)
if (i != Номер)
НевязкаНовая[i] = Невязка[i] + (A[i,Номер]*Невязка[Номер]);
if (Сходимость(X1, X2)) {
for (int i = 0; i < n; i++) {
X1[i] = X2[i];
Невязка[i] = НевязкаНовая[i];
}
continue;
}
else break;
}
for (int i = 0; i < n; i++)
Console.Write(«{0} t», X1[i]);
Console.WriteLine();
}
static bool Сходимость(double[] Xk, double[] Xkp){
bool b = false;
for (int i = 0; i < n; i++)
if (Math.Abs(Xk[i]-Xkp[i]) > eps){
b = true;
break;
}
return b;
}
}
Лекция 06. Проблема собственных значений матрицы
Если квадратная матрица -того порядка и при ,то называется собственным значением матрицы, а – соответствующим ему собственным вектором.
Эту же задачу можно переписать в виде
Нетривиальное решение существует, если выполняется следующее условие
Этот определитель является многочленом -той степени относительно , и его называют характеристическим многочленом. Значит, существует собственных значений – корней этого многочлена, возможно кратных. Каждому простому (не кратному) собственному значению соответствует один нормированный собственный вектор. Т.о. если все собственные значения простые, то им соответствуют линейно-независимые собственные вектора, образующие базис пространства.
Пример 6.1. Вычислить собственные значения и собственные вектора для матрицы
Решение:
Составим характеристический многочлен
Корни этого многочлена:
Для нахождения собственных векторов , соответствующих составим для каждого из них систему уравнений:
или в виде системы уравнений
После преобразований получим:
Поскольку уравнения линейно зависимы, получаем, что , и положив вычислим . Таким образом, собственный вектор, соответствующий собственному значению , или , где – единичные орты выбранной базисной системы.
Аналогично находим собственный вектор, соответствующий :
Отсюда , , .
В общем случае, для матриц высокого порядка, задача нахождения собственных значений матрицы и её собственных векторов не сводится к нахождению решения характеристического уравнения, поскольку осложнена хотя бы тем, что вычисление коэффициентов характеристического уравнения сопряжено со значительными сложностями, более того, зачастую, характеристический многочлен содержит кратные корни, что так же затрудняет применение вычислительных методов.
Задача нахождения собственных значения просто решается для матриц определённого вида: диагональной, треугольной или почти треугольной, трёх диагональной. Характеристический многочлен треугольной и диагональной матрицы равен произведению элементов, стоящих на главной диагонали, и следовательно, его собственные значения – это элементы главной диагонали матрицы.
Многие численные методы решения задач нахождения собственных значений связаны с приведением матриц к одному из перечисленных видов при помощи преобразования подобия.
Матрица называется подобной матрице , если существует невырожденная матрица , такая что: .
6.1. Метод Якоби
Метод Якоби применим только для симметрических матриц () и решает полную проблему собственных значений и собственных векторов таких матриц. Он основан на отыскании с помощью итерационных процедур матрицы в преобразовании подобия , а поскольку для симметрических матриц матрица преобразования подобия является ортогональной (), то , где – диагональная матрица с собственными значениями на главной диагонали
.
Пусть дана симметрическая матрица . Требуется для неё вычислить с точностью все собственные значения и соответствующие им собственные векторы. Изложем суть метода Якоби. Пусть известна матрица на — ой итерации, при этом для . Выбирается максимальный по модулю недиагональный элемент матрицы ( =) и ищется такая ортогональная матрица , чтобы в результате преобразования подобия произошло обнуление элемента матрицы . В качестве ортогональной матрицы выбирается матрица вращения, имеющая следующий вид:
,
В матрице вращения на пересечении — ой строки и — ого столбца находится элемент где – угол вращения, подлежащий определению. Симметрично относительно главной диагонали ( — ая строка, — ый столбец) расположен элемент ; Диагональные элементы и равны соответственно , ; другие диагональные элементы остальные элементы в матрице вращения равны нулю.
Угол вращения определяется из условия :
причём если то .
Высчитывается матрица в которой элемент
В качестве критерия окончания итерационного процесса используется условие малости суммы квадратов внедиагональных элементов:
Если то итерационный процесс продолжается. Если , то итерационный процесс останавливается, и в качестве искомых собственных значений принимаются .
Координатными столбцами собственных векторов матрицы в единичном базисе будут столбцы матрицы т.е.
причём эти собственные векторы будут ортогональны между собой, т.е.
Пример 6.2. С точностью вычислить собственные значения и собственные векторы матрицы
Решение:
Выбираем максимальный по модулю внедиагональный элемент матрицы , т.е. находим , такой что =. Им является элемент .
Находим соответствующую этому элементу матрицу вращения:
.
Вычисляем матрицу :
.
В полученной матрице с точностью до ошибок округления элемент .
, следовательно итерационный процесс необходимо продолжить.
Переходим к следующей итерации , максимальные внедиагональный элемент .
.
Переходим к следующей итерации . Максимальный элемент .
.
Переходим к следующей итерации . Максимальный элемент .
Таким образом в качестве искомых собственных значений могут быть приняты диагональные элементы матрицы :
Собственные векторы определяются из произведения
; .
Программная реализация этого метода выглядит следующим образом:
class Program {
const int n = 3;
const double e = 0.3; //погрешностьвычисления
public static double[,] A = { { 4.0, 2.0, 1.0 },
{ 2.0, 5.0, 3.0 },
{ 1.0, 3.0, 6.0 } };
static double Погрешность ( ) {
double Сумма = 0.0;
for (int i = 0; i < n; i++)
for (int j = i + 1; j < n; j++)
Сумма += Math.Pow(A[i, j], 2);
return (Math.Sqrt(Сумма));
}
static void Максимум (out int I, out int J){
I = 0;
J = 1;
double Значение = A[I, J];
for (int i = 0; i < n; i++)
for (int j = i + 1; j < n; j++)
if (Значение< Math.Abs(A[i,j])){
Значение = Math.Abs(A[i,j]);
I = i;
J = j;
}
}
static double[,] Произведение ( double[,] B, double[,] C ) {
double[,] Результат = new double[n, n];
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
Результат[i, j] += B[i, k] * C[k, j];
return (Результат);
}
static double[,] МатрицаВращения ( int i, int j ) {
double[,] Результат = new double[n, n];
for (int k = 0; k < n; k++)
Результат[k, k] = 1.0;
double Fi;
if (A[i, i] != A[j, j])
Fi = 0.5 * Math.Atan(2.0 * A[i, j] / (A[i, i] — A[j, j]));
else
Fi = 0.5 * Math.Atan(Math.PI / 4.0);
Результат[i, i] = Результат[j, j] = Math.Cos(Fi);
Результат[i, j] = -Math.Sin(Fi);
Результат[j, i] = Math.Sin(Fi);
return (Результат);
}
static double[,] Транспонированная ( double[,] Матрица, int i, int j ) {
double[,] Результат = new double[n, n];
Array.Copy(Матрица, Результат, n * n);
Результат[i, j] *= -1;
Результат[j, i] *= -1;
return (Результат);
}
static void Main ( ) {
double[,] СобственныеВекторы = new double[n, n];
for (int i = 0; i < n; i++)
СобственныеВекторы[i, i] = 1.0;
do {
int I, J;
Максимум(out I, out J);
double[,] P = МатрицаВращения(I, J);
A = Произведение(Транспонированная(P, I, J), Произведение(A, P));
СобственныеВекторы = Произведение(СобственныеВекторы,P);
} while (Погрешность() > e);
for (int i = 0; i < n; i++, Console.WriteLine())
for (int j = 0; j < n; j++)
Console.Write(«{0}t», A[i, j]);
for (int i = 0; i < n; i++, Console.WriteLine())
for (int j = 0; j < n; j++)
Console.Write(«{0}t», СобственныеВекторы[i, j]);
}
}
6.2. Метод вращений
Метод Якоби, рассмотренный в этой главе довольно неэффективем, поскольку является итерационным. Существует ряд методов, также основанных на использовании преобразования подобия, которые сводят заданную матрицу к матрице более сложной структуры, нежели диагональная матрица, но за конечное часло шагов. Одним из таких методов является метод вращения. Он позволяет привести исходную симметричную матрицу к трёхдиагональному виду и основан на специально подбираемом вращении системы координат в -мерном пространстве. Поскольку любое вращение можно заменить последовательностью плоских вращений, то решение задачи можно разбить на ряд шагов, на каждом из которых осуществляется плоское вращение. Таким образом, на каждом шаге выбираются две оси -тая и -тая и поворот производится в плоскости, проходящей через эти оси, остальные же оси остаются неподвижными.
По-прежнему, матрица вида
в которой отличны от единичных -тая и -тая строка и -тый и -тый столбец, так что – называется матрицей вращения. При этом, , а . Метод состоит в таком подборе матриц вращения, чтобы свести матрицу к трёхдиагональному виду. Угол поворота на каждом шаге выбирается таким, чтобы в преобразованной матрице обратился в ноль один элемент (в симметричной матрице – два)лежащий вне трёх диагоналей исходной матрицы. Преобразованная на — том шаге матрица , отличается от матрицы элементами строк и столбцов номерами и.
Обнуляя элемент коэффициенты и находятся по формулам:
Тогда элементы — ого и — ого столбца преобразовываются по формулам:
, для
Пример 6.3.Привести матрицу к трёхдиагональному виду.
3,31
4,71
-2,31
1,01
4,71
17,02
-5,58
9,61
-2,31
-5,58
9,99
-6,11
1,01
9,61
-6,11
12,01
Сначала, обнулим элементы и . Из этих соображений подбираем значения и в матрицу вращения , для этого умножим матрицу справа на и затем слева на . Получаем систему уравнений для определения параметров и .
Решая эту систему, находим
Используя эти значения можно вычислить значения элементов, в строках и столбцах с номерами , остальные элементы матрицы не изменились.
Остальные элементы матрицы остаются неизменными:
3,31
5,24
0,0
1,01
5,24
20,07
-0,64
11,31
0,0
-0,64
6,94
-1,26
1,01
11,31
-1,26
12,01
На следующем шаге будем обнулять элементы и , следовательно строим матрицу вращения и вычисляем элементы в строках и столбцах
3,31
5,34
0,0
0,0
5,34
23,98
-0,862
9.01
0,0
-0,86
6,94
-1,11
0,0
9.01
-1,11
8,1
На следующем шаге будем обнулять элементы и , следовательно, строим матрицу вращения и вычисляем элементы в строках и столбцах
3,31
5,34
0,0
0,0
5,34
23,98
9,05
0,0
0,0
9,05
8,29
0,98
0,0
0,0
0,98
6,74
static void Main() {
const int n = 4;
double[,] A = {{3.31,4.71,-2.31,1.01} ,{4.71,17.02,-5.58,9.61}, {-2.31,-5.58,9.99,-6.11}, {1.01,9.61,-6.11,12.01}};
for (int i = 1; i < n — 1; i++)
for (int j = i + 1; j < n; j++) {
double c, s, aki, akj, aii, ajj, aij;
c=A[i-1,i]/Math.Sqrt(Math.Pow(A[i-1,i],2.0)+Math.Pow(A[i-1,j],2.0));
s=A[i-1,j]/Math.Sqrt(Math.Pow(A[i-1,i],2.0)+Math.Pow(A[i-1,j],2.0));
Console.WriteLine(«c = {0} s = {1}», c,s);
for (int k = 0; k < n; k++)
if ((k != i) & (k != j)) {
aki = A[k, i];
akj = A[k, j];
A[k, i] = c * aki + s * akj;
A[i, k] = A[k, i];
A[k, j] = c * akj — s * aki;
A[j, k] = A[k, j];
}
aii = A[i, i];
ajj = A[j, j];
aij = A[i, j];
A[i, i] = c * c * aii + s * s * ajj + 2 * s * c * A[i, j];
A[j, j] = s * s * aii + c * c * ajj — 2 * s * c * A[i, j];
A[i, j] = aij * (c * c — s * s) + c * s * (ajj — aii);
A[j, i] = A[i, j];
for (int k = 0; k < n; k++, Console.WriteLine())
for (int t = 0; t < n; t++)
Console.Write(«{0} t», A[k, t]);
}
}
6.3. Вычисление характеристического полинома
После того, как заданная действительная симметричная матрица была сведена к трёхдиагональной форме, одним из способов отыскать её собственные значения становится прямое вычисление корней характеристического полинома . Эти корни можно найти методом факторизации.
Алгоритмы QR и QL
Основная идея алгоритма заключается в том, что любая действительная матрица может быть представлена в форме , где ортогональная, а – верхняя треугольная матрицы. Для матрицы общего вида это разложение строится применением алгоритма преобразования Хаусхолдера с целью уничтожения элементов столбцов матрицы ниже главной диагонали.
Теперь рассмотрим матрицу, сформированную произведением этих факторов в обратном порядке:
Поскольку ортогональна, получаем . Таким образом, . Видно, что является ортогональной трансформацией . Следует отметить, что -преобразование сохраняет симметрию и трёхдиагональность матрицы.
Алгоритм состоит из цепочки ортогональных преобразований:
Следующая теорема является основой для алгоритма в применении к матрице общего вида:
• Если имеет собственные значения, различные по модулю , то стремится к нижней треугольной форме при неограниченном возрастании . Собственные значения на диагонали при этом появляются в порядке возрастания модуля.
• Если имеет собственное значение кратности , то стремится к нижней треугольной форме, за исключением блока размерности , примыкающего к диагонали, собственные значения этого блока стремятся к .
Объём арифметических действий алгоритма имеет порядок на итерацию для матрицы общего вида, что является недопустимым. Однако для трёхдиагональной матрицы этот объём составляет на итерацию.
При доказательстве вышеупомянутой теоремы обнаруживается, что в целом наддиагональный элемент стремится к нулю как:
Хотя
сходимость может быть медленной при близости этих значений. Сходимость может быть ускорена методом сдвига: если – любая константа, то (), где – единичная матрица соответствующей размерности) имеет собственные значения (). Если разложить , так что , то скорость сходимости будет определяться отношением . Самое главное здесь выбрать на каждой стадии такое , чтобы максимально ускорить сходимость. На начальном этапе хорошим выбором является значение , близкое к , наименьшему собственному значению. В этом случае первая строка внедиагональных элементов будет быстро сведена к нулю. Однако, величина априорно неизвестна. На практике, очень эффективной стратегией (хотя и не доказано, что она оптимальна) является вычисление собственных значений начального минора размером () матрицы . После этого полагается равной тому собственному значению, которое ближе к .
Обобщая, представим, что уже найдены () собственных значений . Тогда матрицу можно уменьшить, обнулив первые () столбцов и строк:
Значение выбирается равным тому собственному значению ведущего минора размером (), которое ближе к . Можно показать, что скорость сходимости алгоритма при выборе этой стратегии обычно кубическая (и в худшем случае квадратичная при вырожденных собственных значениях). Эта исключительно быстрая сходимость делает алгоритм весьма привлекательным.
При использовании сдвига собственные значения уже не обязательно появляются на главной диагонали в порядке возрастания величины. Если это необходимо, следует отсортировать значения.
Как уже говорилось выше, -декомпозиция матрицы общего вида производится последовательностью преобразований Хаусхолдера.
QL-алгоритм с неявными сдвигами
Алгоритм, описанный выше, может быть очень эффективным. Однако когда элементы сильно различаются по порядку величины, вычитание большого из диагональных элементов может привести к потере точности для собственных значений с небольшой величиной. Эта трудность обходится применением – алгоритма с неявными сдвигами. Неявный – алгоритм математически эквивалентен исходному, однако при вычислениях не используется явное вычитание из .
Алгоритм основан на следующей лемме. Пусть – симметричная невырожденная матрица и , где – ортогональна, а – трёхдиагональна с положительными внедиагональными элементами. Тогда и полностью определяются на основании только последней строки .
Доказательство. Пусть обозначает -ую строку матрицы , а – -ый столбец матрицы . Соотношение может быть записано как
-ая строка этого матричного уравнения выглядит как
Поскольку матрица ортогональна, . Если теперь умножим обе части уравнения на , то найдём: , которая однозначно известна при заданном . Кроме того, из уравнения следует: , где обозначено , последняя величина также известна. Таким образом, , или , а также .(Поскольку согласно гипотезе ненулевое). Аналогично можно по индукции доказать, что если нам известны , , …, , а также все , и вплоть до уровня , то мы можем определить все значения на уровне (.
Для практического применения этой леммы предположим, что мы как-то нашли трёхдиагональную матрицу , такую что
, где
ортогональна и её последняя строка совпадает с последней строкой матрицы из оригинального — алгоритма. Тогда будем иметь и .
Далее, из оригинального алгоритма видно, что последняя строка совпадает с последней строкой . Но вспомним, что служит для плоской ротации с целью обнуления элемента матрицы . Простое вычисление показывает, что параметры и этой матрицы должны иметь вид:
Матрица является трёхдиагональной с двумя дополнительными элементами:
Она должна быть приведена к трёхдиагональной форме с помощью ортогональной матрицы, имеющей последнюю строку вида [0,0, …, 0,1]; таким образом, последняя строка останется равной строке . Это можно сделать последовательностью преобразований Хаусхолдера или Гивенса. Для матрицы указанного вида преобразование Гивенса эффективнее. Производим поворот в плоскости для обнуления элемента (по симметрии, будет также обнулен элемент ). После этого трёхдиагональная форма сохраняется за исключением дополнительных элементов и . Эти в свою очередь обнуляются поворотом в плоскости и т.д. Таким образом, требуется последовательность трансформаций Гивенса. В результате будем иметь:
, где
– матрицы трансформаций Гивенса, а – плоская ротация из оригинального алгоритма. По значению находим значение на новой итерации. Заметим, что сдвиг производится неявно при вычислении параметров и .
Пример 6.3: найти собственные значения трёхдиагональной матрицы предыдущего примера.
3,31
5,34
0,0
0,0
5,34
23,98
9,05
0,0
0,0
9,05
8,29
0,98
0,0
0,0
0,98
6,74
Решение:
Рассмотрим главный минор
3,31
5,34
5,34
23,98
Сформируем сдвиг
Реализация этого алгоритма на языке C# выглядит следующим образом:
class Program{
static double hipot( double x, double y ) {
return(Math.Sqrt(Math.Pow(x,2) + Math.Pow(y,2)));
}
staticvoidMain() {
int n = 3; //задали размерность матрицы
double[] d = {1.0, 2.0, 3.0 }; //элементы главной диагонали
double[] e = {1.0, 2.0, 0.0 }; //задали элементы поддиагонали,
int MAXITER = 30; // максимальное число итераций
for(intl = 0; l<n; l++) {
int iter = 0;
int m;
do {
for(m = l; m < n-1; m++) {
double dd = Math.Abs(d[m]) + Math.Abs(d[m + 1]);
if((Math.Abs(e[m] + dd) == dd)) break;
}
if(m != l) {
if( ++iter >= MAXITER) break;
double g = (d[l + 1] — d[l]) / (2.0 * e[l]);
double r = hipot(1.0, g);
if(g >= 0.0)
g += Math.Abs(r);
else
g -= Math.Abs(r);
g = d[m] — d[l] + e[l]/g;
double s = 1.0;
double c = 1.0;
double p = 0.0;
for(int i = m-1; i >= l; i—) {
double f = s * e[i];
double b = c * e[i];
e[i + 1] = r = hipot(f, g);
if(r == 0.0) {
d[i+1] -= p;
e[m]=0.0;
break;
}
s = f/r;
c = g/r;
g = d[i+1] — p;
r = (d[i] — g) * s + 2.0 * c * b;
d[i+1] = g +(p = s * r);
g = c * r — b;
}
if(r == 0.0 )
continue;
d[l] -= p; e[l] = g; e[m] = 0.0;
}
} while(m != l);
}
}
Лекция 07. Приближение функции. Вычисление значения функции
7.1. Понятие приближения функции
В вычислительной практике часто приходится встречаться с заменой функций более простыми, близкими к данным функциям в каком-либо смысле, с тем, чтобы найти с достаточной степенью точности более быстро простое решение.
Чаще всего в качестве приближающих функций берутся многочлены. Это связано с некоторыми свойствами многочленов в классе непрерывных функций:
• свойство полноты, которое выражается теоремой Вейерштрасса (1885г.)
Теорема. Если – непрерывная на конечном замкнутом промежутке функция, то для любого существует такой многочлен , что для .
• другое важное свойство многочленов – это функции простой природы; чтобы вычислить многочлен, нужно исполнить конечное число арифметических операций.
Теорема Вейерштрасса указывает лишь на возможность приближения функции многочленами, но не даёт способа построения такого многочлена. Существуют различные способы приближения функции при помощи многочленов. Большое распространение в вычислительной практике получил способ интерполирования функций.
Общая задача интерполирования заключается в построении функции, вообще говоря, отличной от данной, которая может быть известна, но задана слишком сложным аналитическим выражением, или неизвестна и задана в виде таблицы значений. Построенная функция должна принимать в заданных точках те же значения, что и данная функция . Таким образом мы сформулировали две задачи:
• построения для функции, имеющей аналитическое выражение, такой более простой функции, которая заменила бы данную в вычислениях;
• нахождения для функции, заданной таблицей, такой формулы, которая давала бы возможность находить значения функции для промежуточных значений аргумента.
Пусть на отрезке заданы точка:. Эти точки называются узлами интерполяции. И даны значения некоторой функции в этих точках .
Требуется построить функцию (интерполирующую функцию), принадлежащую определённому классу и принимающую в узлах интерполяции те же значения, что и , т.е. .
Геометрически это означает, что нужно найти кривую, некоторого определённого типа, проходящую через заданную систему точек .
В такой общей постановке задача может иметь бесконечное множество решений. Однако эта задача становится однозначной, если в качестве приближающей функции искать многочлен степени не выше , удовлетворяющий условиям . Полученную интерполяционную формулу обычно используют для приближённого вычисления значений данной функции . При этом различают интерполирование, когда, и экстраполирование, когда .
7.2. Вычисление значения многочлена
Займёмся общим многочленом вида:
Мы будем предполагать, что все коэффициенты известны, постоянны и записаны в массив. Это означает, что единственным входным данным для вычисления многочлена служит значение , а результатом программы должно быть значение многочлена в точке .
Программа, реализующая стандартный алгоритм вычисления выглядит так:
static void Main() {
double[] A = {1.56, 2.34, 4.07, 3.58, -1.43};
double X = 2.778;
double Результат = A[0] + A[1]*X;
double Степень = X;
for (int i = 2; i < A.Length; i++){
Степень *= X;
Результат += (A[i]*Степень);
}
Console.WriteLine(«{0}», Результат);
}
В цикле содержится два умножения, которые выполняются раз. Кроме того, одно умножение выполняется перед циклом, поэтому общее число умножений равно . В цикле выполняется также одно сложение, и одно сложение выполняется перед циклом, поэтому общее число сложений равно .
Вычисление по схеме Горнера оказывается более эффективным, причём оно не очень усложняется. Эта схема основывается на следующем представлении многочлена:
Можно легко проверить, что это представление задаёт тот же многочлен, что и выше.
Пример 7.1. Посчитать в точке значение полинома по схеме Горнера.
Решение:
На первом шаге значение полинома равно: . Далее полученный результат умножаем на и добавляем 4,07:, снова домножаем на и добавляем 2,34 : , и в последний раз домножаем на и добавляем 1,56. Значение полинома: 32,859.
Соответствующий алгоритм выглядит так:
staticvoidMain() {
double[] A = {1.56, 2.34, 4.07, 3.58, -1.43};
double X = 2.778;
double Результат = A[A.Length — 1];
for (int i = (A.Length — 2); i >=0; i—)
Результат = Результат * X + A[i];
Console.WriteLine(«{0}», Результат);
}
Цикл выполняется раз, причём внутри цикла есть одно умножение и одно сложение. Поэтому вычисление по схеме Горнера требует умножений и сложений – двукратное уменьшение числа умножений по сравнению со стандартным алгоритмом.
Результат можно даже улучшить, если обработать коэффициенты многочлена до начала работы алгоритма. Основная идея состоит в том, чтобы выразить многочлен через многочлены меньшей степени. Например, для вычисления значения можно воспользоваться таким же циклом, как в первом алгоритме этого раздела; в результате будет выполнено 255 умножений. Альтернативный подход состоит в том, чтобы положить Степень= x*x, а затем семь раз выполнить операцию Степень= Степень* Степень. После первого выполнения переменная Результат будет содержать, после второго , после третьего , после четвёртого , после пятого , после шестого , и после седьмого .
Для того, чтобы метод предварительной обработки коэффициентов работал, нужно, чтобы многочлен был унимодальным (то есть старший коэффициент должен равняться 1) , а степень многочлена должна быть на единицу меньше некоторой степени двойки ( для некоторого ). В таком случае многочлен можно представить в виде:
, где
В обоих многочленах и будет вдвое меньше членов, чем в . Для получения нужного результата мы вычислим по отдельности и , а затем сделаем одно дополнительное умножение и два сложения. Если при этом правильно выбрать значение , то оба многочлена и оказываются унимодальными, причем степень каждого из них позволяет применить к каждому из них ту же самую процедуру. Мы увидим, что её последовательное применение позволяет сэкономить вычисления.
Вместо того, чтобы вести речь о многочленах общего вида, обратимся к примеру.
Пример 7.2. Рассмотрим многочлен:
Определим сначала множитель . Степень многочлена равна 7, то есть, поэтому. Отсюда вытекает, что. Выберем значение таким образом, чтобы оба многочлена и были унимодальными. Для этого нужно посмотреть на коэффициенты в и положить . В нашем случае это означает, что . Теперь мы хотим найти значения и , удовлетворяющие уравнению:
Многочлены и совпадают соответственно с частным и остатком от деления на . Деление с остатком дает:
На следующем шаге мы можем применить ту же самую процедуру к каждому из многочленов и :
В результате получаем:
Посмотрев на этот многочлен, мы видим, что для вычисления требуется одно умножение; ещё одно умножение необходимо для подсчёта . Помимо этих двух умножений в вычислении правой части равенства участвуют ещё три умножения. Кроме того, выполняется 10 операций сложения. Применение подобного подхода целесообразно в случае, если значение полинома вычисляется много кратно в разных точках.
7.3. Интерполяционный многочлен Лагранжа
Пусть функция известна в узлах некоторой решётки – т. е. задана таблицей. Метод интерполяции заключается в упрощённом нахождении значений функции внутри интервала. Необходимо подобрать некоторую функцию которая близка в некотором смысле к . В методе интерполяции будем подбирать функцию из тех соображений, чтобы она совпадала с табличными значениями в узлах сетки.
Из которой можно получить параметры . Этот метод подбора называется интерполяцией Лагранжа. Если нелинейно зависит от параметров, то интерполяция называется нелинейной и нахождение параметров из системы может быть сильно затруднено. Рассмотрим линейную интерполяцию, когда линейно зависит от параметров т.е. представима в виде обобщённого многочлена
следует считать линейно-независимыми. Следовательно, необходимо найти решение системы
Чтобы задача интерполяции всегда имела единственное решение, необходимо, чтобы при любом расположении узлов (обязательно несовпадающих)
Система функций, удовлетворяющих этому условию, называется Чебышевской. Т.о. при линейной интерполяции необходимо строить обобщённый многочлен по какой-нибудь Чебышевской системе функций. В теории рассматриваются методы интерполирования тригонометрическими многочленами и экспонентами.
Рассмотрим систему , предложенную Лагранжем для вычисления таких многочленов. В этом случае
– определитель Вандермонда
и
где базисные полиномы определяются по формуле:
обладают следующими свойствами:
• являются многочленами степени ;
• ;
• при.
Отсюда следует, что , как линейная комбинация , может иметь степень не больше , и .
Пример 7.3. Дана функция в виде таблицы значений.
1.5
3.873
1.54
3.924
1.56
3.950
1.60
4.00
1.63
4.037
1.70
4.123
Требуется получить значение этой функции в точке, используя интерполяционный многочлен Лагранжа.
Решение:
Посчитаем значения базисных полиномов для точки .
Тогда значение функции в точке равно:
Программа для данного примера может быть такой:
classProgram {
// Функция, вычисляющая коэффициенты Лагранжа
static double L( double[] X, double xp, int n, int i ) {
double Числитель = 1;
double Знаменатель = 1;
for (int k = 0; k < n; k++ ){
if ( k == i ) continue;
Числитель *= xp — X[k];
}
for(int k = 0; k < n; k++){
if (X[i] == X[k]) continue;
Знаменатель *= X[i] — X[k];
}
return Числитель/Знаменатель;
}
staticvoidMain() {
double[] X = {1.5, 1.54, 1.56, 1.60,1.63, 1.70};
double[] Y = {3.873,3.924,3.950,4.00,4.037, 4.123};
int n = X.Length;
double Результат = 0;
double px = 1.55;
for (int i = 0; i < n; i++)
Результат += Y[i]*L(X, px, n, i);
Console.WriteLine(«Результат : {0} «,Результат);
}
}
Результаты выполнения программы: ,.
7.5. Интерполяционный многочлен Ньютон
Интерполяционные формулы Ньютона – формулы вычислительной математики, применяющиеся для полиномиального интерполирования.
Если узлы интерполяции равноотстоящие и упорядочены по величине, так что – const, то есть , то интерполяционный многочлен можно записать в форме Ньютона.
Интерполяционные полиномы в форме Ньютона удобно использовать, если точка интерполирования находится вблизи начала (прямая формула Ньютона) или конца таблицы (обратная формула Ньютона).
В случае равноудалённых центров интерполяции, находящихся на единичном расстоянии друг от друга, справедлива формула:
где – обобщённые на область действительных чисел биномиальные коэффициенты.
Прямая интерполяционная формула Ньютона:
где , , а выражения вида – конечные разности.
Обратная интерполяционная формула Ньютона:
где.
Определим разделённые разности
и т.д. – разделённые разности первого, второго и т.д. порядка. Разделённые разности обычно располагают в следующей таблице:
…
.
.
.
.
.
.
Эти разности дают приближённое значение производных. Эти разности любого порядка можно непосредственно вычислить через значение узлов сетки, но удобнее пользоваться рекуррентным соотношением. Проведя нехитрые преобразования получим формулу Ньютона
Пример 7.4.Посчитать значение функции, заданной в предыдущем примере в точке, с помощью интерполяционного многочлена Ньютона.
Решение:
Посчитать разделённые разности удобно в следующей таблице:
1.5
3.873
1.54
3.924
1.56
3.950
1.60
4.00
1.63
4.037
1.70
4.123
Программа на языке С#, реализующая приведённый метод может выглядеть например так:
static void Main() {
const int n = 6;
double[] X = {1.5, 1.54, 1.56, 1.60,1.63, 1.70};
double[] Y = {3.873,3.924,3.950,4.00,4.037, 4.123};
double Точка = 1.55;
double XX = 1.0;
double LN = Y[0];
for (int i = 1; i < n; i++) {
XX *= (Точка — X[i-1]);
double f = 0;
for (int j = 0; j <= i; j++){
double XXX = 1.0;
for (int k = 0; k <= i; k++){
if (k != j)
XXX *= X[j] — X[k];
}
f += Y[j] / XXX;
}
LN += XX * f;
}
Console.WriteLine(«{0}», LN);
}
7.6. Оценка погрешности
Погрешность удобно представлять в виде
Это погрешность заведомо равна нулю в узлах решетки. Будем считать, что функция имеет непрерывную производную. Введя дополнительную функцию, в которой играет роль параметра и принимает любое фиксированное значение, заметим, что эта функция обращается в ноль в узлах решётки и в точке . Из предположения, что имеет непрерывную производную следует, что на любом участке между нолями функции лежит ноль её производной. Последовательно пользуясь этим свойством, получим, что между крайними из нулей функции лежит нуль производной.
Если в какой-то точке , лежащей между указанными нулями, она обращается в нуль, то
заменим погрешность максимально возможной и получим
где максимум производной берётся по отрезку между наименьшим и наибольшим значением из значений сетки.
Оценить легче всего при постоянном шаге задания сетки. В этом случае имеет приблизительно такой вид: вблизи центрального узла интерполяции экстремумы невелики, вблизи крайних узлов – больше, а если выходит за крайние узлы интерполяции, то быстро растёт.
При равномерной сетке выгодно выбирать из таблицы узлы так, чтобы искомая точка попадала ближе к центру интерполяции – это обеспечит более высокую точность. Оценив погрешность на центральном интервале и преобразовав её, получаем окончательный результат:
если величины производных можно оценить, то отсюда легко определить число узлов, достаточное для получения заданной точности.
Более грубо можно сказать, что многочлен Ньютона имеет погрешность и обеспечивает порядок точности интерполяции.
Задачей обратного интерполирования называют задачу нахождения для произвольного , если задана таблица . Для монотонных функций между прямым и обратным интерполированием нет никакой разницы: можно считать таблицу, как задание . Единственное отличие будет в том, что «обратная» таблица будет иметь переменный шаг, даже если прямая таблица имела шаг постоянный.
Важный пример обратного интерполирования – решение уравнения . Вычислим несколько значений функции и запишем эти значения в виде . При помощи уже знакомого многочлена Ньютона вычислим приближённое значение .
Пример 7.5. Используя формулу Ньютона, найти решение уравнения:
Решение:
Составим таблицу 4 значений функции:
-1,500
0,000
0,540
-0,574
0,500
0,365
-0,076
0,797
1,000
Точное значение
Единственное существенное замечание: для повышения точности в этом способе целесообразно взять новые узлы, близко расположенные к грубо найденному корню, а не увеличивать число узлов.
Лекция 08. Нелинейная интерполяция
При повышении порядка точности на единицу при маленьком шаге погрешность уменьшается, а при достаточно большом шаге она может увеличиваться. Такое же явление мы наблюдаем, если производные быстро растут с увеличение порядка. Это чаще всего происходит при работе с быстро меняющимися функциями.
Пример 8.1.Найти значение функции заданной таблично в точке
1
1
11
10
2
121
110
50
3
1351
1230
560
170
Решение:
Этот ряд содержит быстро возрастающие члены и не похож на сходящийся, следовательно, вычислить с его помощью функцию не удастся.
Выяснив качественной поведение функции, обычно сравнивая её с графиками хорошо изученных элементарных функций, стараются подобрать такое преобразование переменных и , чтобы в новых переменных график мало отличался от прямой. Тогда в переменных интерполяция многочленом невысокой степени будет давать хорошую точность. Вычисления заключаются в составлении таблицы для новых переменных, интерполяции по ней и нахождении обратным преобразованием.
Можно заметить, что в приведённом выше примере зависимость близка к показательной , значит можно ввести переменные и. Составим новую таблицу:
0,0000
1
1,0414
1,0414
2
2,0828
1,0414
0,0000
3
3,1306
1,0478
0,0032
0,0011
теперь члены ряда быстро убывают, обеспечивая быструю сходимость и хорошую точность. Считая, что точность приблизительно равна порядку последнего слагаемого, обратным преобразованием получим
Удачно подобное выравнивание позволило получить высокую точность интерполяции.
Замечания:
Для каждой конкретной функции подбирают свой способ интерполяции. Для других функций этот вид будет давать плохую точность.
Оценка погрешности такой интерполяции содержит старшие производные , их трудно посчитать, поэтому на практике удобнее оценивать точность по скорости убывания членов ряда в формуле Ньютона.
Преобразования и должны выражаться несложными формулами, иначе этот метод будет мало пригодным на практике.
В исходных переменных интерполяция нелинейна относительно параметров. Однако в новых переменных она линейна. Такая интерполяция называется квазилинейной.
8.1. Метод наименьших квадратов
Будем считать, что значения некоторой функции получены экспериментально, и следовательно, эта функция задана таблично. Более того, проделана некоторая предварительная работа по анализу характера поведения искомой функции. Если значения функции пропорциональны значению аргумента, то ищем зависимость вида . Следовательно, задача сводится к определению коэффициента .Каждый отдельный опыт даёт свое значение
Можно получить среднее значение
Это самый простой, но не самый лучший способ. Изменим понимание проблемы. Будем считать, что результат опытов содержит некоторую ошибку . Которая приблизительно одинакова для любого значения . Тогда ошибка в значении тем больше, чем меньше . Найдём значение , при котором функция наилучшим способом соответствует опытным данным. Будем достигать этого минимизируя величину . В качестве меры общей ошибки будем рассматривать
Обратите внимание, что одна величинадобавляет в величину 100 единиц. В то же время, десять точек с ошибкой 1 добавит в только 10 единиц. Т.е. большие, но редкие ошибки сильнее влияют на значение ошибки, в то время, как много небольших ошибок мало влияют на эту величину.
Для того чтобы найти при котором наименьшее, решим уравнение
Если , то будем искать в виде. В этом случае
Если бы уже было найдено, то должно было быть
Из этих двух условий получаем систему уравнений.
Поставим задачу шире, пусть функция задана таблицей значений, в точках . Используя метод наименьших квадратов, найдём многочлен – наилучшего среднеквадратичного приближения оптимальной степени. За оптимальное значение примем ту степень многочлена, для которой величина
минимальна.
Пример 8.2.Пусть функция задана следующей таблицей. Методом наименьших квадратов определить коэффициенты полиномов первой и второй степени, выбрать оптимальный из них.
-2.75
-2.0
-1.0
0.5
1.0
-0.2
-1.1
-2.3
0.1
1.1
Решение:
Многочлен первой степени ищем в виде . Следовательно, функция суммарной ошибки имеет вид . Продифференцировав её по и по и прировняв полученные производные к нулю значения и находим как решение системы уравнений
Посчитаем коэффициенты этих уравнений:
1
-2,75
-0,20
7,56
0,55
2
-2,00
-1,10
4,00
2,20
3
-1,00
-2,30
1,00
2,30
4
0,50
0,10
0,25
0,05
5
1,00
1,10
1,00
1,10
-4,25
-2,40
13,81
6,20
Решим систему уравнений:
Откуда , . Подставив эти значения в формулу посчитаем значение функции .
Многочлен второй степени будем искать в виде . Следовательно, функция суммарной ошибки имеет вид . Продифференцировав её по , и , и прировняв полученные производные к нулю, значения переменных находим как решение системы уравнений:
Необходимые коэффициенты этих уравнений приведены в следующей таблице:
1
-2,75
-0,20
7,56
-20,80
57,19
-1,51
0,55
2
-2,00
-1,10
4,00
-8,00
16,00
-4,40
2,20
3
-1,00
-2,30
1,00
-1,00
1,00
-2,30
2,30
4
0,50
0,10
0,25
0,13
0,06
0,03
0,05
5
1,00
1,10
1,00
1,00
1,00
1,10
1,10
-4,25
-2,40
13,81
-28,67
75,25
-7,09
6,20
Получаем систему уравнений:
Решив которую, получаем, что , , . Посчитаем значение функции .
Поскольку накопленная суммарная ошибка меньше для полинома второй степени, то его использование для аппроксимации функции предпочтительнее.
Программа, реализующая этот подход может выглядеть так:
namespace МетодНаименьшихКвадратов {
class Program {
static double[] МетодГаусса ( double[,] A,
double[] B){
int n = B.Length;
double[,] a = new double[n, n + 1];
double[] x = new double[n];
for (int i = 0; i < n; i++){
for (int j = 0; j < n; j++)
a[i,j] = A[i,j];
a[i,n] = B[i];
}
for (int i = 0; i < n; i++){
double m = Math.Abs(a[i, i]);
int k = i;
for (int j = i+1; j < n; j++)
if (Math.Abs(a[j,i]) > m) {
m = Math.Abs(a[j,i]);
k = j;
}
if (k != i)
for (int j = i;j <= n; j++){
double z = a[i, j];
a[i,j] = a[k,j];
a[k,j] = z;
}
double r = a[i, i];
for (int j = i;j <= n; j++)
a[i,j] /=r;
for (int l = i+1; l < n; l++){
r = a[l,i];
for (int j = i+1; j <= n; j++)
a[l,j] -= a[i,j]*r;
}
}
x[n-1] = a[n-1,n];
for (int i = n-1; i >= 0; i—){
x[i] = a[i,n];
for (int k = i+1; k < n; k++)
x[i] -=a[i,k]*x[k];
}
return(x);
}
static double[ ] МетодНК( double[ ] X,
double[ ] Y,
int n,
int m ) {
double[ ] B = new double[m + 1];
double[,] G = new double[m + 1, m + 1];
for (int j = 0; j <= m; j++) {
B[j] = 0;
for (int i = 0; i < n; i++)
B[j] += Y[i] * Math.Pow(X[i], j );
for (int k = 0; k <= m; k++) {
G[j, k] = 0;
for (int i = 0; i < n; i++)
G[j, k] += Math.Pow(X[i], k + j);
}
}
double[ ] коэффициенты = МетодГаусса(G, B);
return (коэффициенты);
}
static double ЗначениеПолинома(double[,] Коэффициенты,
int ПорядокПолинома,
double Точка ) {
double Значение = 0.0;
for (int i = 0; i <= ПорядокПолинома; i++)
Значение += Коэффициенты[ПорядокПолинома, i] * Math.Pow(Точка, i);
return (Значение);
}
static void Main() {
double[ ] X = { -2.75, -2.0, -1.0, 0.5, 1.0 };
double[ ] Y = { -0.2,-1.1, -2.3, 0.1, 1.1 };
int n = X.Length;
double[,] Коэффициенты = new double[n+1,n+1];
for (int i = 0; i <= n; i++) {
double[ ] Результат = МетодНК(X, Y, n, i);
for (int j = 0; j <= i; j++)
Коэффициенты[i,j] = Результат[j];
}
double МинимальнаяПогрешность = 0;
int Порядок = -1;
for (int i = 0; i <= n; i++){
double Погрешность = 0;
for (int j = 0; j < n; j++)
Погрешность += Math.Pow((ЗначениеПолинома(Коэффициенты, i, X[j]) — Y[j]),2);
Погрешность = Math.Sqrt(Погрешность/(n — i));
if ((МинимальнаяПогрешность ==0) || (МинимальнаяПогрешность > Погрешность)){
МинимальнаяПогрешность = Погрешность;
Порядок = i;
}
}
}
}
}
8.2. Интерполяция сплайнами
Если надо провести график функции по известным, но редким точкам, то можно воспользоваться гибкой металлической линейкой, изгибая её так, чтобы она проходила через известные точки. Таким способом часто пользуются инженеры-практики. Этот метод можно описать математически. Рассматривая гибкую линейку, как упругий брусок. Из курса сопротивления материалов известно, что уравнение свободного равновесия . Т.е. в промежутке между каждой парой соседних узлов интерполяционная функция задаётся многочленом третьей степени:
Интерполяция сплайнами третьего порядка – это быстрый, эффективный и устойчивый способ интерполяции функций.
В основе сплайн-интерполяции лежит следующий принцип. Интервал интерполяции разбивается на небольшие отрезки, на каждом из которых функция задаётся полиномом третьей степени. Коэффициенты полинома подбираются таким образом, чтобы выполнялись определённые условия (какие именно, зависит от способа интерполяции). Общие для всех типов сплайнов третьего порядка требования – непрерывность функции и, разумеется, прохождение через предписанные ей точки. Дополнительными требованиями могут быть линейность функции между узлами, непрерывность высших производных и т.д.
Основными достоинствами сплайн-интерполяции являются её устойчивость и малая трудоёмкость. Системы линейных уравнений, которые требуется решать для построения сплайнов, очень хорошо обусловлены, что позволяет получать коэффициенты полиномов с высокой точностью. В результате даже про очень больших вычислительная схема не теряет устойчивость. Построение таблицы коэффициентов сплайна требует операций, а вычисление значения сплайна в заданной точке – всего лишь .
Ниже рассмотрены различные типы интерполирующих сплайнов.
Линейный сплайн
Линейный сплайн – это сплайн, составленный из полиномов первой степени, т.е. из отрезков прямых линий. Точность интерполяции линейными сплайнами невысока, также следует отметить, что они не обеспечивают непрерывности даже первых производных. Однако в некоторых случаях кусочно-линейная аппроксимация функции может оказаться предпочтительнее, чем аппроксимация более высокого порядка. Например, линейный сплайн сохраняет монотонность переданного в него набора точек.
На графике приведён пример линейного сплайна, интерполирующего функцию на отрезке [-1, 1].
Таблица коэффициентов линейного сплайна строится следующей программой. С технической точки зрения, линейный сплайн реализован, как сплайн третьего порядка с коэффициентами при второй и третьей степенях равными нулю. Это сделано для обобщения программы вызова вычисления значения функции в точке.
Пример 8.3. Пусть функция задана следующей таблице. С помощью линейного сплайне посчитать значение этой функции в точке .
0,000
0,628
1,257
1,885
2,513
1,000
0,809
0,309
-0,309
-0,809
Решение:
Посчитаем значения сплайна по формуле и запишем третьей строкой таблицы:
1
2
3
4
5
0,000
0,628
1,257
1,885
2,513
1,000
0,809
0,309
-0,309
-0,809
-0,304
-0,796
-0,984
0,796
Значение в точке будем считать по формуле:
, где – номер узла сетки, наиболее близкого к точке слева. В нашем примере = 2.
Программа на С# строящая линейный сплайн приведена ниже.
staticdouble[ ] ПостроениеСплайна( double[ ] x,
double[ ] y,
int n ) {
double[ ] z;
int tblsize = 0;
tblsize = 3 + n + (n — 1) * 4;
z = new double[tblsize];
z[0] = tblsize;
z[1] = 3;
z[2] = n;
for (int i = 0; i < n; i++)
z[3 + i] = x[i];
for (int i = 0; i < n — 1; i++) {
z[3 + n + 4 * i + 0] = y[i];
z[3 + n + 4 * i + 1] = (y[i + 1] — y[i]) / (x[i + 1] — x[i]);
z[3 + n + 4 * i + 2] = 0.0;
z[3 + n + 4 * i + 3] = 0.0;
}
return (z);
}
Сплайн Эрмита
Сплайн Эрмита – это сплайн третьего порядка, производная которого принимает в узлах сплайна заданные значения. В каждом узле сплайна Эрмита задано не только значение функции, но и значение её первой производной. Сплайн Эрмита имеет непрерывную первую производную, но вторая производная у него разрывна.
На графике приведён пример сплайна Эрмита, интерполирующего функцию на отрезке [-1, 1]. Можно видеть, что точность интерполяции значительно лучше, чем у линейного сплайна.
Таблица коэффициентов сплайна Эрмита строится следующей подпрограммой:
static double[ ] ПостроениеСплайнаЭрмита( double[ ] x,
double[ ] y,
double[ ] d,// первая производная
int n ) {
double[ ] z;
int tblsize = 3 + n + (n — 1) * 4;
z = new double[tblsize];
z[0] = tblsize;
z[1] = 3;
z[2] = n;
for (int i = 0; i < n; i++)
z[3 + i] = x[i];
for (int i = 0; i < n — 1; i++) {
double delta = x[i + 1] — x[i];
double delta2 = Math.Sqrt(delta);
double delta3 = delta * delta2;
z[3 + n + 4 * i + 0] = y[i];
z[3 + n + 4 * i + 1] = d[i];
z[3 + n + 4 * i + 2] = (3 * (y[i + 1] — y[i]) — 2 * d[i] * delta — d[i + 1] * delta) / delta2;
z[3 + n + 4 * i + 3] = (2 * (y[i] — y[i + 1]) + d[i] * delta + d[i + 1] * delta) / delta3;
}
return (z);
}
Кубический сплайн
Все сплайны, рассмотренные в этомразделе, являются кубическими сплайнами – в том смысле, что они являются кусочно-кубическими функциями. Однако, когда говорят «кубический сплайн», то обычно имеют в виду конкретный вид кубического сплайна, который получается, если потребовать непрерывности первой и второй производных. Кубический сплайн задаётся значениями функции в узлах и значениями производных на границе отрезка интерполяции (либо первых, либо вторых производных).
Если известно точное значение первой производной на обеих границах, то такой сплайн называют фундаментальным. Погрешность интерполяции таким сплайном равна .
Если значение первой (или второй) производной на границе неизвестно, то можно задать т.н. естественные граничные условия, , и получить естественный сплайн. Погрешность интерполяции естественным сплайном составляет . Максимум погрешности наблюдается в окрестностях граничных узлов, во внутренних узлах точность интерполяции значительно выше.
Ещё одним видом граничного условия, которое можно использовать, если неизвестны граничные производные функции, является условие типа «сплайн, завершающийся параболой». В этом случае граничный отрезок сплайна представляется полиномом второй степени вместо третьей (для внутренних отрезков по-прежнему используются полиномы третьей степени). В ряде случаев это обеспечивает большую точность, чем естественные граничные условия.
Наконец, можно сочетать различные типы граничных условий на разных границах. Обычно так имеет смысл делать, если у нас есть только часть информации о поведении функции на границе (например, производная на левой границе – и никакой информации о производной на правой границе).
На графике приведён пример кубического сплайна, интерполирующего функцию на отрезке [-1, 1]. Можно видеть, что точность интерполяции близка к точности Эрмитова сплайна.
Таблица коэффициентов кубического сплайна строится следующей подпрограммой:
static double[] РешениеСистемы(double[] a,
double[] b,
double[] c,
double[] d,
int n){
double[] x = new double[n];
a[0] = 0;
c[n-1] = 0;
for(int k = 1; k <= n-1; k++) {
double t = a[k]/b[k-1];
b[k] = b[k]-t*c[k-1];
d[k] = d[k]-t*d[k-1];
}
x[n — 1] = d[n — 1]/b[n — 1];
for(int k = n — 2; k >= 0; k—)
x[k] = (d[k] — c[k] * x[k + 1]) / b[k];
return(x);
}
static double[] ПостроениеСплайна(double[] x,
double[] y,
int n,
int boundltype,
double boundl,
int boundrtype,
double boundr) {
double[] a1 = new double[n];
double[] a2 = new double[n];
double[] a3 = new double[n];
double[] b = new double[n];
int tblsize = 3 + n + (n — 1) * 4; ;
if( n==2 & boundltype==0 & boundrtype==0 ){
boundltype = 2;
boundl = 0;
boundrtype = 2;
boundr = 0;
}
switch (boundltype){
case 0:
a1[0] = 0;
a2[0] = 1;
a3[0] = 1;
b[0] = 2*(y[1]-y[0])/(x[1]-x[0]);
break;
case 1:
a1[0] = 0;
a2[0] = 1;
a3[0] = 0;
b[0] = boundl;
break;
case 2:
a1[0] = 0;
a2[0] = 2;
a3[0] = 1;
b[0] = 3*(y[1]-y[0])/(x[1]-x[0])-0.5*boundl*(x[1]-x[0]);
break;
}
for(int i = 1; i <= n — 2; i++){
a1[i] = x[i+1]-x[i];
a2[i] = 2*(x[i+1]-x[i-1]);
a3[i] = x[i]-x[i-1];
b[i] = 3*(y[i]-y[i-1])/(x[i]-x[i-1])*(x[i+1]-x[i])+3*(y[i+1]-
y[i])/(x[i+1]-x[i])*(x[i]-x[i-1]);
}
switch (boundrtype){
case 0:
a1[n-1] = 1;
a2[n-1] = 1;
a3[n-1] = 0;
b[n-1] = 2*(y[n-1]-y[n-2])/(x[n-1]-x[n-2]);
break;
case 1:
a1[n-1] = 0;
a2[n-1] = 1;
a3[n-1] = 0;
b[n-1] = boundr;
break;
case 2:
a1[n-1] = 1;
a2[n-1] = 2;
a3[n-1] = 0;
b[n-1] = 3*(y[n-1]-y[n-2])/(x[n-1]-x[n-2])+0.5*boundr*(x[n-1]-x[n-2]);
break;
}
double[] D = РешениеСистемы(a1, a2, a3, b, n);
double[ ] Z = ПостроениеСплайнаЭрмита(x, y, D, n);
return (Z);
}
Сплайн Акимы
Сплайн Акимы – это особый вид сплайна, устойчивый к выбросам. Недостатком кубических сплайнов является то, что они склонны осциллировать в окрестностях точки, существенно отличающейся от своих соседей. На графике справа приведён набор точек, содержащий один выброс. Зелёным цветом обозначен кубический сплайн с естественными граничными условиями. На отрезках интерполяции, граничащих с выбросом, сплайн заметно отклоняется от интерполируемой функции – сказывается влияние выброса. Красным цветом обозначен сплайн Акимы. Можно видеть, что, в отличие от кубического сплайна, сплайн Акимы в меньшей мере подвержен влиянию выбросов – на отрезках, граничащих с выбросом, практически отсутствуют признаки осцилляции.
Важным свойством сплайна Акимы является его локальность – значения функции на отрезке зависят только от . Вторым свойством, которое следует принимать во внимание, является нелинейность интерполяции сплайнами Акимы – результат интерполяции суммы двух функций не равен сумме интерполяционных схем, построенных на основе отдельных функций. Для построения сплайна Акимы требуется не менее 5 точек. Во внутренней области (т.е. между и ) погрешность интерполяции имеет порядок .
Таблица коэффициентов сплайна Акимы строится следующей подпрограммой:
static double Дифференцирование(double t,
double x0,
double f0,
double x1,
double f1,
double x2,
double f2 ) {
double result = 0;
double a = 0;
double b = 0;
t = t — x0;
x1 = x1 — x0;
x2 = x2 — x0;
a = (f2 — f0 — x2 / x1 * (f1 — f0)) / (Math.Sqrt(x2) — x1 * x2);
b = (f1 — f0 — a * Math.Sqrt(x1)) / x1;
return (2 * a * t + b);
}
static double[ ] ПостроениеСплайнаАкимы( double[ ] x,
double[ ] y,
int n ) {
double[ ] w = new double[n — 1];
double[ ] diff = new double[n — 1];
for (int i = 0; i < n — 1; i++)
diff[i] = (y[i + 1] — y[i]) / (x[i + 1] — x[i]);
for (int i = 1; i < n — 1; i++)
w[i] = Math.Abs(diff[i] — diff[i — 1]);
double[ ] d = new double[n];
for (int i = 2; i < n — 2; i++)
if (Math.Abs(w[i — 1]) + Math.Abs(w[i + 1]) != 0)
d[i] = (w[i + 1] * diff[i — 1] + w[i — 1] * diff[i]) / (w[i + 1] +
w[i — 1]);
else
d[i] = ((x[i + 1] — x[i]) * diff[i — 1] + (x[i] — x[i — 1]) *
diff[i]) / (x[i + 1] — x[i — 1]);
d[0] = Дифференцирование (x[0], x[0], y[0], x[1], y[1], x[2], y[2]);
d[1] = Дифференцирование (x[1], x[0], y[0], x[1], y[1], x[2], y[2]);
d[n — 2] = Дифференцирование(x[n — 2], x[n — 3], y[n — 3], x[n — 2],
y[n — 2], x[n — 1], y[n — 1]);
d[n — 1] = Дифференцирование (x[n — 1], x[n — 3], y[n — 3], x[n — 2],
y[n — 2], x[n — 1], y[n — 1]);
double[ ] z = ПостроениеСплайнаЭрмита(x, y, d, n);
return (z);
}
Вызов перечисленных программ, реализованный на языке С# выглядит следующим образом:
static void Main() {
double result = 0;
int n = 5; int l = 0; int r = 0; int m = 0;
double[ ] X = new double[n]; double[ ] Y = new double[n];
double Точка = 1.02;
if (n < 2) Console.WriteLine(» n < 2″);
else {
for (int i = 0; i < n; i++) {
X[i] = (i * Math.PI) / n;
Y[i] = Math.Cos(X[i]);
}
double[ ] Z = ПостроениеСплайна(X, Y, n);
l = 3;
r = 3 + n — 2 + 1;
while (l != r — 1) {
m = (l + r) / 2;
if (Z[m] >= Точка) r = m;
else l = m;
}
Точка -= Z[l];
m = 3 + n + 4 * (l — 3);
result = Z[m] + Точка * (Z[m + 1] + Точка * (Z[m + 2] + Точка * Z[m + 3]));
Console.WriteLine(«{0}», result);
}
Лекция 09. Понятие численного дифференцирования
9.1. Формулы приближённого дифференцирования, основанные на интерполяционной формуле Ньютона
Пусть дана функция , заданная в равноотстоящих точках отрезка . Обозначим . Для нахождения производных , и т.д., функцию приближённо заменим интерполяционным полиномом Ньютона, построенным для системы узлов , , … , .
Тогда
где , , , , – разделённые разности.
Производя перемножение биномов, получим:
Так как , то
.
Аналогично, так как
.
Таким же способом в случае необходимости можно найти производные любого порядка. Заметим, что при нахождении производных в фиксированной точке в качестве следует выбирать ближайшее табличное значение аргумента. Иногда требуется находить производные функции в основных табличных точках, т.е. в узлах . В этом случае формулы численного дифференцирования упрощаются. Так как каждое табличное значение можно считать за начальное, то положив , получаем . Тогда будем иметь:
Если – интерполяционный полином Ньютона, содержащий конечные разности до — того порядка включительно, то его погрешность выражается формулой:
Находим погрешность основной формулы:
Полагая и учитывая, что и
,
будем иметь
.
Так как, то
.
Пример 9.1. Пусть функция задана на отрезке [0,1] с шагом 0,2 следующей таблицей:
0,0
0,2
0,4
0,6
0,8
1,0
1,0
1,221
1,491
1,822
2,256
2,718
Посчитать значения первой и второй производной в точке с помощью многочлена Ньютона и оценить полученную погрешность.
Решение:
В данном случае удобнее воспользоваться формулой:
Где , a . Обозначим за , и посчитаем их значения:
0,0
1,0
0,221
0,049
0,012
0,028
0,005
0,2
1,221
0,270
0,061
0,04
0,033
0,4
1,491
0,331
0,101
0,073
0,6
1,822
0,434
0,028
0,8
2,256
0,462
1,0
2,718
Точное значение – 1,1051, следовательно, погрешность равна 0,0032.
Вторую производную посчитаем по формуле:
9.2. Дифференцирование функций, интерполированных полиномами Лагранжа
Пусть даны равноотстоящие точки , , … , , и известны значения некоторой функции в этих точках, , . Построим многочлен Лагранжа:
.
Полагая, получаем:
Следовательно, для многочлена Лагранжа в случае равноотстоящих узлов имеем выражение:
Для оценки погрешности воспользуемся известной формулой погрешности интерполяционной формулы Лагранжа.
.
.
Для узловых точек имеем:
Например, посчитаем формулу для первой производной в случае, когда известны значения функции в трёх точках. Выпишем многочлен Лагранжа
Тогда
Посчитаем значение
аналогично можно вывести формулы и для точек и .
.
Аналогично получаются формулы для случая четырёх узлов:
И для пяти узлов:
Обратим внимание, что при чётных наиболее простые выражения получаются для производных в центральных узлах. Так для произвольного узла при и формулы выглядят следующим образом:
Эти формулы часто используются на практике и называются апроксимацией производных с помощью центральных разностей.
Аналогично можно получить выражения и для второй производной:
• в случае трёх узлов:
• в случае четырёх узлов:
• в случае пяти узлов:
Аппроксимации вторых производных с помощью центральных разностей для чётных так же наиболее выгодно.
Пример 9.2. Пусть функция задана на отрезке [0,1] с шагом 0,25 следующей таблицей:
0,0
0,25
0,5
0,75
1,0
1,0
1,284
1,649
2,117
2,718
Посчитать значения первой и второй производной, используя формулы для пяти точек.
Решение:
Значения первой производной считаем по формулам:
Значения второй производной:
Численное дифференцирование необходимо также при решении дифференциальных уравнений с помощью разностных методов. Если узлов много, т.е. точек разбиения интервала много, то погрешность функции неограниченно убывает, а погрешность производной неограниченно растёт. Чтобы уменьшить погрешность дифференцирования, предварительно сглаживают кривую, обычно по методу наименьших квадратов. Формулы численного дифференцирования позволяют решать и более сложные задачи, такие как определение экстремальных точек или точек перегиба функции , заданной таблично. В этом случае полагаем соответственно , и решаем полученные алгебраические уравнения. Однако при этом следует проявлять осторожность, т.к. указанным путём мы найдём экстремальные точки или точки перегиба не самой функции, а интерполирующего многочлена.
9.3. Вычисление M – той производной с помощью полинома Чебышева
Для вычисления производных высших порядков существует метод, который позволяет эффективно посчитать производную произвольного порядка на основе произвольного числа точек . Единственный недостаток метода – он требует специального выбора точек вычисления функции, а именно размещения их в корнях полинома Чебышева — ой степени.
Метод использует свойство дискретной ортогональности полиномов Чебышева: если – полином Чебышева — ой степени, – его корни, а , то
Таким образом, узнав значения функции в указанных точках, легко построить её разложение по полиномам Чебышева, которое легко и быстро дифференцируется.
Замечание:
Есть два способа для повышения точности вычисления производной. Можно уменьшать шаг дифференцирования , а можно увеличивать число точек . Не рекомендуется делать слишком малым, особенно для производных высших порядков – начинают проявляться погрешности операций с вещественными числами. В таких случаях лучше увеличить число точек , оставив шаг довольно-таки большим.
Замечание:
Следует быть осторожным при вычислении производных высших порядков. С ростом порядка производной растёт число точек, которое требуется для её вычисления. Если вы вычисляете десятую производную, то будьте готовы, что для её вычисления вам потребуется двадцать точек, а при меньшем их числе погрешность будет слишком велика.
class Program {
static double f( double x ) {
return (Math.Cos(x));
}
static void Main() {
double result = 0;
double x = 1.02;
int n = 5;
int m = 4;
double h = 0.1;
double[ ] c = new double[0];
double[ ] p = new double[0];
double b1 = 0;
double b2 = 0;
double e = 0;
if (n == 0)
result = 0;
else
if (n == 1)
if (m == 0)
result = f(x);
else
result = 0;
else {
double[ ] fk = new double[n + 1];
for (int k = 1; k <= n; k++)
fk[k] = f(x + h * f(Math.PI * (k — 0.5) / n));
double[ ] Z = new double[n];
for (int j = 0; j <= n — 1; j++) {
Z[j] = 0;
for (int k = 1; k <= n; k++)
Z[j] = Z[j] + fk[k] * f(Math.PI * j * (k — 0.5) / n);
if (j == 0)
Z[j] = Z[j] / n;
else
Z[j] = 2 * Z[j] / n;
}
p = new double[n];
for (int t = 0; t <= n — 1; t++)
p[t] = 0;
double d = 0;
int i = 0;
do {
int k = i;
do {
e = p[k];
p[k] = 0;
if (i <= 1 & k == i)
p[k] = 1;
else {
if (i != 0)
p[k] = 2 * d;
if (k > i + 1)
p[k] = p[k] — p[k — 2];
}
d = e;
k++;
} while (k <= n — 1);
d = p[i];
e = 0;
k = i;
while (k <= n — 1) {
e = e + p[k] * Z[k];
k = k + 2;
}
p[i] = e;
i++;
} while (i <= n — 1);
if (m > n — 1)
result = 0;
else {
result = p[m];
for (int t = 1; t <= m; t++)
result *= t / h;
}
}
Console.WriteLine(«{0}», result);
}
}
9.4. Дифференцирование сплайнов
Уже хорошо известные нам сплайны также хорошо пригодны для нахождения производной. Следующая программа демонстрирует использование построенного сплайна Эрмита для нахождения первой и второй производной функции в точке:
class Program {
static double[ ] ПостроениеСплайнаЭрмита( double[ ] x,
double[ ] y,
double[ ] d,
int n )
static void Main() {
int n = 5;
double[ ] X = new double[n];
double[ ] Y = new double[n];
double[ ] D = new double[n];
double Точка = 1.02;
if (n < 2) Console.WriteLine(» n < 2″);
else {
for (int i = 0; i < n; i++) {
X[i] = (i * Math.PI) / n;
Y[i] = Math.Cos(X[i]);
D[i] = -Math.Sin(X[i]);
}
double[ ] Z = ПостроениеСплайнаЭрмита(X, Y, D, n);
int l = 3;
int r = 3+n-2+1;
while (l != r — 1) {
int t = (l + r) / 2;
if (Z[t] >= Точка)
r = t;
else
l = t;
}
Точка = Точка — Z[l];
int m = 3 + n + 4 * (l — 3);
double Функция = Z[m] + Точка * (Z[m + 1] + Точка * (Z[m + 2] +
Точка * Z[m + 3]));
double ПерваяПроизводная = Z[m + 1] + 2 * Точка* Z[m + 2] + 3 *
Math.Sqrt(Точка) * Z[m + 3];
double ВтораяПроизводная = 2 * Z[m + 2] + 6 * Точка * Z[m + 3];
Console.WriteLine(«{0} t {1} t {2}», Функция, ПерваяПроизводная,
ВтораяПроизводная);
}
}
}
Лекция 10. Понятие численного интегрирования
10.1. Метод прямоугольников
Собственное значение определённого интеграла
находится методом прямоугольников. Отрезок разбивается на частей, , …, с шагом . На каждом отрезке вычисляется значения интеграла по формуле прямоугольников, таким образом:
Пример 10.1. Посчитать методом прямоугольников с шагом 0,1 значение .
Решение:
Построим сначала таблицу значений подынтегральной функции:
0,00
1,000
0,35
0,885
0,70
0,613
0,05
0,998
0,40
0,852
0,75
0,570
0,10
0,990
0,45
0,817
0,80
0,527
0,15
0,978
0,50
0,779
0,85
0,486
0,20
0,960
0,55
0,739
0,90
0,445
0,25
0,939
0,60
0,698
0,95
0,406
0,30
0,913
0,65
0,655
1,00
0,368
Если точность вычисления не устраивает, количество точек разбиения удваивается и считается новое значение. Программа, реализующая данный метод:
classProgram {
staticdoublef(doublex){
return (Math.Exp(Math.Pow(x,2)));
}
static void Main() {
const double a = 1.345;
const double b = 2.150;
const double epsilon = 0.01;
int n = 1;
double result = 0;
double h = b — a;
double s1 = 0;
double s2 = h * f((a + b)/2);
do {
n = 2 * n;
s1 = s2;
h /= 2;
s2 = 0;
int i = 1;
do {
s2 = s2 + f(a + h/2 + h * (i-1));
i++;
} while( i <= n );
s2 = s2 * h;
} while( Math.Abs(s2 — s1) > 3 * epsilon );
result = s2;
Console.WriteLine(«{0}», result);
}
}
10.2. Квадратурные формулы Ньютона – Котеса
Пусть для данной функции требуется вычислить интеграл . Квадратурные формулы Ньютона – Котеса получаются тогда, когда подынтегральную функцию заменяют интерполяционной формулой Лагранжа, т.е. . Чтобы построить формулу Лагранжа, выбираем шаг и строим систему равноотстоящих точек,, .
Вычисляем и используем формулу:
,
где .
Сделаем замену переменных, изменив и пределы интегрирования получаем:
Подставляя , получаем квадратурные формулы Ньютона – Котеса:
,
где
Постоянные называются коэффициентами Котеса. Эти коэффициенты не зависят от функции , а являются функцией только от – степени интерполяционного многочлена. Поэтому коэффициенты Котеса можно вычислить заранее для различных значений , что и сделано, и сведено в справочную таблицу.
10.3. Формула трапеций и её погрешность
Формула трапеций получается из квадратурных формул Ньютона – Котеса при , т.е. степень интерполяционного многочлена, которым заменяют подынтегральную функцию, равна единице. Посчитав коэффициенты Котеса для получаем:
, ,
подставив которые и получаем формулу трапеций
.
Фактически, в этом случае площадь под кривой заменяется площадью трапеции, поэтому соответствующая формула численного интегрирования получила название формулы трапеций.
Остаточный член или погрешность формулы трапеции равен
Предположим, что функция имеет вторую производную на интервале . Будем рассматривать как функцию шага. Тогда можно записать:
.
Дифференцируя последнее выражение по последовательно два раза, получим:
.
Интегральная теорема о среднем
Если функция и непрерывны на и на сохраняет знак, т.е. на или на , то в интервале существует такое число , такое что
.
Интегрируя по и используя интегральную теорему о среднем, последовательно выводим:
,
где
,
где.
Таким образом.
Из последнего утверждения, в частности, следует, что если то формула трапеции даёт значение интеграла с недостатком, в противном случае – с избытком. Сказанное проиллюстрировано на рисунках ниже.
Погрешность формулы трапеции обычно бывает очень велика. Эту погрешность можно значительно снизить, если применять формулу трапеций не сразу ко всему отрезку , а разбить его сначала и к каждой части в отдельности применять формулу трапеции. Если разбить отрезок на равных частей длины , обозначив через , ,…, последовательные ординаты, то получим обобщенную формулу трапеции:
Для уменьшения времени, затрачиваемого на вычисления в алгоритме при получении , используется формула:
Пример 10.2. Посчитать методом трапеций с шагом 0,1 значение .
Решение:
Воспользуемся таблицей значений подынтегральной функции примера 10.1
Если точность вычисление не устраивает можно удвоить количество узлов и повторить вычисления. Программа, реализующая данный метод:
classProgram {
staticdoublef(doublex){
return (Math.Exp(Math.Pow(x,2)));
}
static void Main() {
const double a = 1.345;
const double b = 2.150;
const double epsilon = 0.01;
int n = 1;
double result = 0;
double h = b — a;
double s2 = h * (f(a) + f(b))/2;
double s1;
do {
s1 = s2;
s2 = 0;
int i = 1;
do {
s2 = s2 + f(a — h/2 + h * i);
i++;
} while( i <= n );
s2 = s1/2 + s2 * h/2;
n = 2 * n;
h = h / 2;
} while( Math.Abs(s2 — s1) > 3 * epsilon );
result = s2;
Console.WriteLine(«{0}», result);
}
}
10.4. Формула Симпсона и её погрешность
Формула Симпсона получается из квадратурных формул Ньютона – Котеса при , т.е. интерполяционный многочлен, которым заменяют подынтегральную функцию, многочлен второго порядка.
,
,
.
Подставив которые и получаем формулу Cимпсона.
Геометрически формула Симпсона получается в результате замены кривой параболой , проходящей через точки: , , .
Погрешность формулы Симпсона вычисляется из соображений
.
Предположим, что функция имеет четвёртую производную на . Аналогично тому, как это делалось для формулы трапеций, выведем более простое выражение для. Фиксируем среднюю точку и рассматриваем как функцию шага, будем иметь
.
Дифференцируя функциюпопоследовательно три раза, получим:
.
.
Теорема о среднем: Если функция непрерывна на и дифференцируема на , то в интервале существует такое число, что.
Применяя простую теорему о среднем для функции на получаем:, где . Кроме того, имеем:. Последовательно интегрируя и используя интегральную теорему о среднем, находим:
.
.
.
Где . Таким образом, окончательно имеем .
Из последней формулы видно, что она является точной для многочленов не только второй, но и третьей степени, т.е. формула Симпсона при относительно малом числе ординат обладает повышенной точностью.
Формула Симпсона также может быть применена не сразу ко всему отрезку, а к отдельным частям его. Если разобьём на равных частей c шагом , то получим обобщённую формулу Симпсона:
Введём обозначения: , .
Обобщённая формула Симпсона запишется в новых обозначениях так:
Пример 10.3. Посчитать методом Симпсона с шагом 0,1 значение .
Решение:
Воспользуемся таблицей значений подынтегральной функции примера 10.1
0,00
1,000
0,35
0,885
0,70
0,613
0,05
0,998
0,40
0,852
0,75
0,570
0,10
0,990
0,45
0,817
0,80
0,527
0,15
0,978
0,50
0,779
0,85
0,486
0,20
0,960
0,55
0,739
0,90
0,445
0,25
0,939
0,60
0,698
0,95
0,406
0,30
0,913
0,65
0,655
1,00
0,368
Если точность вычисление не устраивает можно удвоить количество узлов и повторить вычисления. Программа, реализующая данный метод:
classProgram {
staticdoublef( doublex ) {
return (Math.Exp(-Math.Pow(x, 2)));
}
static void Main() {
const double a = 1.345;
const double b = 2.150;
const double epsilon = 0.01;
double result = 0.0;
double h = b — a;
double x = 0.0;
double s1 = 0.0;
double s = 0.0;
double s2 = h * f((a + b) / 2);
double s3 = 0.0;
do {
s3 = s2;
h /= 2;
s1 = 0;
x = a + h;
do {
s1 = s1 + 2 * f(x);
x = x + 2 * h;
} while (x < b);
s = s + s1;
s2 = (s + s1) * h / 3;
x = Math.Abs(s3 — s2) / 15;
} while (x > epsilon);
result = s2;
Console.WriteLine(«{0}», result);
}
10.5. Погрешность формул Ньютона – Котеса
При вычислении приближённого значения интеграла допускается погрешность, которая зависит от шага разбиения и может быть представлена как . Трудно сравнить достоинства и недостатки различных методов интегрирования. Сравнение их точности ставит закономерный вопрос: «Что больше или ». Это зависит от подынтегральной функции и поведения её производных.
При изложении методов интегрирования, упоминался самый примитивный способ уточнения значений: удваивание количества точек разбиения.
Следует упомянуть другую схему уточнения значения интеграла – процесс Эйткена. Он даёт возможность оценить погрешность метода и указывает алгоритм уточнения результатов. Расчёт проводится три раза при различных значениях шага разбиения , и , таких что и в результате получены значения интегралов , и . Тогда уточнённое значение интеграла вычисляется по формуле:
.
Порядок точности используемого метода интегрирования оценивается соотношением
Лекция 11. Квадратурные формулы интегрирования
11.1. Квадратурные формулы Чебышева
Рассмотрим квадратурную формулу
где – постоянные коэффициенты. Чебышев предложил выбирать абсциссы таким образом, чтобы:
1) коэффициенты были равны между собой;
2) квадратурная формула являлась точной для всех полиномов до степени включительно.
Покажем, как могут быть найдены в этом случае величины и . Полагая , взяв, получаем:
. , следовательно .
Таким образом, квадратурная формула Чебышева имеет вид:
Для определения используем требование точности формулы для функций вида: . Подставляя эти функции в формулу, получим систему уравнений:
Из которой могут быть определены неизвестные .
Чебышев показал, что решение данной системы сводится к нахождению корней некоторого алгебраического уравнения — той степени. Узлы являются действительными при . При и среди узлов всегда имеются комплексные. В этом состоит принципиальный недостаток квадратурной формулы Чебышева. Свою формулу Чебышев П.Л. вывел в 1873 году.
Пример 11.1. Вывести формулу Чебышева с тремя ординатами .
Решение. Для определения имеем систему уравнений.
Определение. Многочлен называется симметрическим, если для любого множества значений значение этого многочлена не изменяется при какой угодно перестановки .
Элементарными симметрическими функциями от называются многочлены определяемые следующим образом:
. . . . . . . .
Каждый симметрический многочлен относительно может быть единственным образом записан, как многочлен относительно . Например, для квадратного многочлена, если и , то корни уравнения .
Так как в примере , то есть корни вспомогательного уравнения
,
Где симметрические функции корней:
.
.
.
Из первоначальной системы видно, что . Вычислим , для этого рассмотрим
.
Из последнего выражения находим.
.
Для нахождения рассмотрим
.
Отсюда находим
В результате получаем, что есть корни вспомогательного уравнения:
.
Решая его, находим: , , .
Таким образом, в данном случае формула Чебышева принимает вид:
.
Чтобы применить квадратурную формулу Чебышева к интегралу вида , следует сделать замену переменных , которая переводит отрезок в отрезок . Применяя к преобразованному интегралу формулу Чебышева, будем иметь:
где , .
Значения в формуле Чебышева для некоторых значений приведены в таблице.
2
1; 2
3
1; 3
2
4
1;4
2;3
5
1; 5
2; 4
3
Пример 11.2. Посчитать значение с использованием формулы Чебышева для .
Решение:
Вычисления удобно представить в следующей таблице:
1
-0,794654
2,2053
0,00772
2
-0,187592
2,8124
0,00037
3
0,187592
3,1876
0,00004
4
0,794654
3,7947
0,0000006
0,00813
Программная реализация этого метода может выглядеть следующим образом:
namespace МетодЧебышева {
class Program {
static double f(double x){
return (Math.Exp(Math.Pow(x,2)));
}
static void Main() {
const double a = 1.345;
const double b = 2.150;
double result = 0;
double s = 0.5 * (b + a);
double c = 0.5 * (b — a);
double t = 0;
int n = int.Parse(Console.ReadLine());
switch (n){
case 2:
t = Math.Sqrt(3)/3;
result = f(s + c * t) + f(s — c * t);
result *=(b — a)/2;
break;
case 3:
t = Math.Sqrt(2)/2;
result = f(s + c * t) + f(s)+f(s — c * t);
result *=(b — a)/3;
break;
case 4:
t = Math.Sqrt((Math.Sqrt(5) — 2)/(3 * Math.Sqrt(5)));
result = f(s + c * t)+f(s — c * t);
t = Math.Sqrt((Math.Sqrt(5) + 2)/(3*Math.Sqrt(5)));
result += f(s + c * t) + f(s — c * t);
result *= (b — a)/4;
break;
case 5:
result = f(s);
t = 0.5 * Math.Sqrt((5 — Math.Sqrt(11))/3);
result = result + f(s + c * t) + f(s — c * t);
t = 0.5 * Math.Sqrt((5 + Math.Sqrt(11))/3);
result += f(s + c * t) + f(s — c * t);
result *= (b — a)/5;
break;
case 6:
result = 0;
t = 0.866247;
result = result + f(s + c * t) + f(s — c * t);
t = 0.422519;
result +=f(s + c * t) + f(s — c * t);
t = 0.266635;
result += f(s + c * t) + f(s — c * t);
result *= (b — a)/6;
break;
case 7:
result = f(s);
t = 0.883862;
result = result + f(s + c * t) + f(s — c * t);
t = 0.529657;
result += f(s + c * t) + f(s — c * t);
t = 0.323912;
result +=f(s + c * t) + f(s — c * t);
result *=(b — a)/7;
break;
case 9:
result = f(s);
t = 0.911589;
result +=f(s + c * t) + f(s — c * t);
t = 0.601019;
result += f(s + c * t) + f(s — c * t);
t = 0.528762;
result +=f(s + c * t) + f(s — c * t);
t = 0.167906;
result += f(s + c * t) + f(s — c * t);
result *= (b — a)/9;
break;
default:
result = 0;
break;
}
Console.WriteLine(«{0}», result);
}
}
}
11.2. Квадратурная формула Гаусса
За счёт выбора узлов можно получить квадратурные формулы, которые будут точны для алгебраического многочлена степени . В этом разделе нам потребуются некоторые сведения о полиномах Лежандра.
Определение. Полиномы вида , называются полиномами Лежандра.
Отметим важнейшие свойства полиномов Лежандра:
1). .
2). , где – любой многочлен степени , меньшей (свойство ортогональности).
3). Многочлен Лежандра имеет различных действительных корней, которые расположены на интервале .
Выпишем первые пять полиномов Лежандра:
.
.
.
.
.
Озвучив необходимую вспомогательную информацию, переходим к выводу квадратурной формулы Гаусса.
Рассмотрим функцию , заданную на промежутке . Общий случай легко свести к данному, путём линейной замены независимой переменной.
Поставим задачу: как нужно подобрать точки и коэффициенты , чтобы квадратурная формула была бы точной для всех полиномов наивысшей возможной степени .
Так как имеется постоянных и , а полином степени определяется константами, то эта наивысшая степень в общем случае, очевидно, равна . Для обеспечения равенства необходимо и достаточно, чтобы оно было верным при .
Полагая
и ,
будем иметь:
меняем порядок суммирования
.
Таким образом, учитывая соотношения:
для решения поставленной задачи достаточно определить и из системы уравнений.
Система является нелинейной и её решение обычным путём представляет большие математические трудности. Однако здесь можно применить следующий искусственный приём. Рассмотрим полиномы
Где – полином Лежандра. Так как степени этих полиномов не превышают , то на основании системы для них должна быть справедлива формула.
С другой стороны, в силу свойства ортогональности полиномов Лежандра (свойство 2) выполнимы равенства
поэтому
Равенства заведомо будут обеспечены при любых значениях , если положить .
Т.е. для достижения наивысшей точности квадратурной формулы в качестве точек достаточно взять нули соответствующего полинома Лежандра. Как известно (свойство 3), эти нули – корни действительны, различны и расположены на интервале .
Зная величины легко можно найти из линейной системы первых уравнений системы коэффициенты . Определитель этой подсистемы есть определитель Вандермонда , и, следовательно, определяются однозначно.
Формула , где – корни полинома Лежандра и определяются из системы, называется квадратурной формулой Гаусса.
Пример 11.2. Вывести квадратурную формулу Гаусса для случая трёх ординат .
Решение. Полином Лежандра 3 — й степени есть
.
приравниваем его нулю, находим корни.
Для определения коэффициентов из системы имеем:
Находим . Следовательно,
.
Значения и в формуле Гаусса для некоторых значений приведены в таблице.
1
1
2
2
1;2
1
3
1;3
2
4
1;4
2;3
Неудобство применения квадратурной формулы Гаусса состоит в том, что абсциссы точек и коэффициенты – вообще говоря, иррациональные числа. Этот недостаток отчасти искупается её высокой точностью при сравнительно малом числе ординат.
Рассмотрим теперь использование квадратурной формулы Гаусса для вычисления общего интеграла . Делая замену , получим:
.
Применяя к последнему интегралу квадратурную формулу Гаусса будем иметь:
,
где
— корни полинома Лежандра , т. е. .
Погрешность формулы Гаусса с узлами выражается следующей формулой:
.
Например
.
.
Пример 11.4. Найти значение интеграла используя квадратурную формулу Гаусса для .
Решение:
В данном случае
Для
Для
Для
Программная реализация этого метода может выглядеть следующим образом:
using System;
namespace МетодГауссаЛежандра {
class Program {
const double Epsilon = 0.001;
static double f( double x ) {
return (Math.Pow(Math.Cos(x),2));
}
static void ПересчетКоэффициентов( double a,
double b,
int n,
ref double[ ] x,
ref double[ ] w ) {
for (int i = 0; i <= n — 1; i++) {
x[i] = 0.5 * (x[i] + 1) * (b — a) + a;
w[i] = 0.5 * w[i] * (b — a);
}
}
static void ПостроениеМногочлена(int n,
ref double[ ] x,
ref double[ ] w ) {
double r = 0;
double r1 = 0;
double p1 = 0;
double p2 = 0;
double p3 = 0;
double dp3 = 0;
x = new double[n];
w = new double[n];
for (int i = 0; i <= (n + 1) / 2 — 1; i++) {
r = Math.Cos(Math.PI * (4 * i + 3) / (4 * n + 2));
do {
p2 = 0;
p3 = 1;
for (int j = 0; j <= n — 1; j++) {
p1 = p2;
p2 = p3;
p3 = ((2 * j + 1) * r * p2 — j * p1) / (j + 1);
}
dp3 = n * (r * p3 — p2) / (r * r — 1);
r1 = r;
r = r — p3 / dp3;
} while (Math.Abs(r — r1) >= Epsilon * (1 + Math.Abs(r)) * 100);
x[i] = r;
x[n — 1 — i] = -r;
w[i] = 2 / ((1 — r * r) * dp3 * dp3);
w[n — 1 — i] = 2 / ((1 — r * r) * dp3 * dp3);
}
}
static void Main( string[ ] args ) {
double a = -1;
double b = 1;
double[ ] x = new double[0];
double[ ] w = new double[0];
int n = 10;
double v1 = 0;
double v2 = 0;
double h = b — a;
double s = f(a) + f(b);
double s1 = 0;
double s2 = 1;
double s3 = 0;
double tx = 0;
int simpfunccalls = 2;
double nodedist = 0;
double nodesectstart = 0;
double nodesectend = 0;
double tmp = 0;
do {
s3 = s2;
h = h / 2;
s1 = 0;
tx = a + h;
do {
s1 = s1 + 2 * f(tx);
simpfunccalls = simpfunccalls + 1;
tx = tx + 2 * h;
} while (tx < b);
s = s + s1;
s2 = (s + s1) * h / 3;
tx = Math.Abs(s3 — s2) / 15;
} while (tx > Epsilon);
v1 = s2;
v2 = 0;
for (int i = 0; i <= n — 1; i++)
v2 = v2 + w[i] * f(x[i]);
a = 5.2;
b = 9.6;
v1 = 0;
simpfunccalls = 2;
s2 = 1;
h = b — a;
s = f(a) + f(b);
do {
s3 = s2;
h = h / 2;
s1 = 0;
tx = a + h;
do {
s1 = s1 + 2 * f(tx);
simpfunccalls = simpfunccalls + 1;
tx = tx + 2 * h;
}
while (tx < b);
s = s + s1;
s2 = (s + s1) * h / 3;
tx = Math.Abs(s3 — s2) / 15;
}
while (tx > Epsilon);
v1 = s2;
ПостроениеМногочлена(n, ref x, ref w);
ПересчетКоэффициентов(a, b, n, ref x, ref w);
v2 = 0;
for (int i = 0; i <= n — 1; i++) {
v2 = v2 + w[i] * f(x[i]);
}
n = 56;
ПостроениеМногочлена(n, ref x, ref w);
for (int i = 0; i <= n — 1; i++) {
for (int j = 0; j <= n — 2 — i; j++) {
if (x[j] >= x[j + 1]) {
tmp = x[j];
x[j] = x[j + 1];
x[j + 1] = tmp;
tmp = w[j];
w[j] = w[j + 1];
w[j + 1] = tmp;
}
}
}
for (int i = 0; i <= 4; i++) {
nodedist = x[n — 1] — x[0];
nodesectstart = nodedist * (0.2 * i — 0.5);
nodesectend = nodedist * (0.2 * (i + 1) — 0.5);
for (int j = 0; j <= n — 2; j++) {
if (x[j] >= nodesectstart & x[j] <= nodesectend | x[j + 1] >=
nodesectstart & x[j + 1] <= nodesectend) {
if (nodedist > x[j + 1] — x[j]) {
nodedist = x[j + 1] — x[j];
}
}
}
}
for (int i = 0; i <= 4; i++) {
tmp = x[n — 1] — x[0];
nodesectstart = tmp * (0.2 * i — 0.5);
nodesectend = tmp * (0.2 * (i + 1) — 0.5);
nodedist = 0;
for (int j = 0; j <= n — 1; j++) {
if (x[j] >= nodesectstart & x[j] <= nodesectend) {
if (nodedist < Math.Abs(w[j])) {
nodedist = Math.Abs(w[j]);
}
}
}
}
}
}
}
11.3. Некоторые замечания о применении квадратурных формул
Получен ряд квадратурных формул. Естественно возникает вопрос: какую квадратурную формулу целесообразно применять в том или ином случае? Ответ на этот вопрос зависит от ряда обстоятельств: от способа задания, свойств и поведения подынтегральной функции, от требуемой точности, с которой нужно получить приближённое значение интеграла. Если подынтегральная функция задана таблицей значений, то целесообразно использовать квадратурные формулы с узлами, в которых заданы значения функции.
Весьма существенно учесть свойства функции и её поведение на отрезке интегрирования. Если функция имеет малую гладкость, то нет смысла применять квадратурные формулы, погрешности которых содержат производные более высокого порядка, чем порядок имеющихся у функции производных. Так, например, для использования формулы трапеций подынтегральная функция должна принадлежать классу , формула Симпсона применима для функции, принадлежащей классу .
Как уже говорилось, постоянные Котеса зависят только от – степени интерполяционного многочлена. Они сосчитаны и сведены в таблицы. Так, например, если многочлен степени , то имеем:
Наиболее точной из рассмотренных квадратурных формул является формула Гаусса, которая при точках деления промежутка интегрирования обеспечивает совершенно точные результаты для многочлена — ой степени. Точки деления в формуле Гаусса берут уже не на равных расстояниях одна от другой. На практике также широко применяются квадратурная формула Чебышева, в которой точки деления (также неравномерные) выбраны так, чтобы вес всех значений был одним и тем же. Благодаря этой особенности формула Чебышева даёт наиболее обоснованные результаты при вычислении интегралов от функции , найденной экспериментально, когда вероятность погрешности каждого измерения одна и та же. Действительно, в этом случае нет никаких оснований различным значениям приписывать различные веса, как, например, в формуле Симпсона, где первое и последнее значения берутся с весом 1, все промежуточные значения с нечётными индексами – с весом 4, а с чётными индексами — с весом 2. Когда речь идёт о точности той или другой квадратурной формулы, то это понятие довольно условное, так как всегда можно выбрать надлежащим образом значение , получить результат с какой угодно степенью точности. Поэтому нельзя не согласиться со словами французского математика П.Лорана, что «эти формулы дают числовое значение искомого интеграла с точностью, которая главным образом зависит от терпения вычислителя».
Лекция 12. Решение нелинейных уравнений
12.1. Постановка задачи
Пусть задана непрерывная функция и требуется найти один или все корни уравнения .
Во-первых, надо исследовать количество, характер и расположение корней. Во-вторых, найти приближённое значение корней, выбрать интересующие нас корни и вычислить их с необходимой точностью.
Первая задача решается аналитически и графически. Например, многочлен имеет комплексных корней, и все корни лежат внутри круга, радиуса
Правда, эта оценка не оптимальная, и модули всех корней могут быть значительно меньше данной величины.
Когда ищутся только действительные корни, бывает полезно составить таблицу значений многочлена с некоторым шагом. Если в соседних узлах этой решетки значение функции меняет знак, то на данном участке обязательно имеется корень многочлена.
12.2.Метод дихотомии
Пусть, мы нашли такие точки , что , т.е. на отрезке лежит не менее одного корня уравнения. Найдём середину отрезка и вычислим значение функции в этой точке. Из двух половин отрезка выберем тот, для которого сохраняется условие разных знаков. Затем новый отрезок опять делим пополам и т.д. С помощью этого простого и надёжного метода, для любых непрерывных функций , в том числе недифференцируемых можно с любой наперёд заданной точностью найти корень уравнения. Данный метод устойчив к ошибкам округления. При этом невелика скорость сходимости, но сходимость гарантирована. Опишем недостатки метода:
• требуется найти интервал , если на этом отрезке несколько корней, то заранее неизвестно к какому из них метод сойдётся;
• метод неприменим к корням чётной кратности;
• для корней нечётной высокой кратности он сходится, но менее точен и хуже устойчив к ошибкам округления;
• на системы уравнения дихотомия не распространяется.
Недостаток дихотомии – сходимость неизвестно к какому корню (общий почти для всех итерационных методов) можно устранить удалением уже найденного корня. Если – простой корень уравнения , то функция непрерывна, при чём все нули функции и совпадают кроме корня , который не является корнем уравнения .
Т.о. на втором этапе мы ищем корни уравнения , и найдя один из корней снова удаляем его, получая новую функцию.
Поскольку мы находим лишь приближённое значение корня, то, учитывая возможность близкого расположения различных корней, необходимо вычислять удаляемые корни с очень высокой степенью точности. При этом в любом методе окончательные итерации вблизи определяемого корня рекомендуется делать по функции .
Пример 12.1. Найти на интервале [1; 1,5] решение уравнения с помощью метода дихотомии с точностью 0,01.
Решение:
№ итерации
1
1,0
1,5
0,205
-0.043
0,5
1,25
0,035
2
1,25
1,5
0,035
-0.043
0,25
1,375
-0,020
3
1,25
1,375
0,035
-0,020
0,125
1,313
0,020
4
1,313
1,375
0,020
-0,020
0,062
1,344
-0,01
5
1,313
1,344
0,020
-0,01
0,031
1,329
-0,004
6
1,313
1,329
0,020
-0,004
0,016
1,321
-0,001
7
1,313
1,321
0,020
-0,001
0,008
1,317
0,0005
Программа, реализующая данный метод:
class Program {
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static void Main() {
double a = 1.0;
double b = 1.5;
double Eps = 0.00001;
double x, fa, fb, fx;
while (Math.Abc(b — a) > Eps){
x = (a + b )/2;
fa = f(a);
fb = f(b);
fx = f(x);
if (fa * fx < 0)
b = x;
else
a = x;
}
x = (a + b)/2;
Console.WriteLine(«{0}», x);
}
}
12.3. Метод секущих — хорд
Если на интервале непрерывная функция удовлетворяет условию , то корень уравнения может быть найден методом секущих:
Погрешность значения корня оценивается по формуле .
Пример 12.2. Найти на интервале [1; 1,5] решение уравнения с помощью метода секущих-хорд с точностью 0,01.
Решение:
2
1,0
1,5
0,205
-0.043
1,414
0,086
3
1,5
1,414
-0.043
-0.030
1,202
0,212
4
1,414
1,202
-0.030
0,058
1,341
0,139
5
1,202
1,341
0,058
-0,009
1,323
0,018
6
1,341
1,323
-0,009
-0,002
1,318
0,005
7
1,323
1,318
-0,002
0,00005
1,318
Программа, реализующая данный метод:
class Program {
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static void Main() {
double Eps = 0.00001;
double x1 = 1.0;
double x2 = 1.5;
double x;
double x3 = 0;
while( Math.Abs(x1 — x2) > Eps){
x3 = x2 — f(x2)*(x2 — x1)/(f(x2) — f(x1));
x1 = x2;
x2 = x3;
}
x = x2;
Console.WriteLine(«{0}», x);
}
}
12.4. Метод Риддлера
Метод Риддлера применяется для поиска корней на отрезке , на котором функция меняет свой знак, т.е. . Метод прост в реализации, не требует знания производной функции и с некоторого шага удваивает число значащих цифр результата за каждые два вычисления функции, т.е. скорость сходимости квадратичная.
Пусть , , , , , .
Тогда ,
Перейдём к следующему шагу метода. Если , то полагаем , . В противном случае за берём тот из отрезков , на котором функция меняет знак.
Алгоритм останавливает работу, если достигнута заданная точность или выполнено указанное число итераций.
Пример 12.3. Найти на интервале [1; 1,5] решение уравнения с помощью метода Риддлера с точностью 0,01.
Решение:
№ итерации
1
1,0
1,5
1,25
0,205
-0.043
0,031
1,33
-0,005
2
1,25
1,33
1,29
0,031
-0,005
0,012
1,318
-0,0003
Программа, реализующая данный метод:
class Program {
const int itmax = 100;
const double epsilon = 0.00001;
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static void Main() {
double x3, x4, f1, f2, f3, f4;
double x = 0;
double x1 = 1.0;
double x2 = 1.5;
f1 = f(x1);
f2 = f(x2);
if( f1 * f2 >= 0 )
Console.WriteLine(«Неверно задан интервал»);
else{
int i = 1;
do {
if( Math.Abs(x2 — x1) < epsilon ){
if( Math.Abs(f1) > Math.Abs(f2) )
x = x1;
else
x = x2;
break;
}
else {
x3 = 0.5*(x1 + x2);
f3 = f(x3);
x4 = x3 + (x3 — x1) * Math.Sign(f1 — f2) * f3/Math.Sqrt(f3 * f3 –f1
* f2);
f4 = f(x4);
i++;
if( f3 * f4 <= 0 ){
x1 = x3;
f1 = f3;
x2 = x4;
f2 = f4;
}
else {
if(f1 * f4 <= 0){
x2 = x4;
f2 = f4;
}
else {
x1 = x4;
f1 = f4;
}
}
}
} while (i < itmax);
Console.WriteLine(«{0}», x);
}
}
12.5. Метод касательных (Ньютона)
Обычно начинают с нахождения грубого приближённого решения «нулевого приближения». Если решается физическая задача, то такое приближение часто известно из физического смысла задачи. Пусть это решение . Обозначим точное решение (нам ещё неизвестное) через и, пользуясь формулой Тейлора, получим
В силу постановки задачи, левая часть этого равенства должна быть равна 0, отбросим все члены высшего порядка малости и получим
, следовательно .
Обозначим правую часть через и получим первое приближение. Точно также можно получить второе, третье и т.д. приближение
Т.к. отбрасывание членов высокого порядка малости равносильно замене графика функции на касательную в точке , то геометрический смысл метода состоит в последовательном построении касательных к графику и нахождении пересечения этих касательных с осью .
Пример 12.4. Найти на интервале [1; 1,5] решение уравнения с помощью метода Ньютона с точностью 0,01.
Решение:
№ итерации
1
1
0,205
-0,839
1,245
2
1,245
0,034
-0,528
1,31
3
1,31
0,003
-0,419
1,318
class Program {
const double Eps = 0.00001;
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static double dfdx(double x){
double sin = Math.Sin(x);
return(-2 * Math.Cos(x) * sin + sin/12);
}
static void Main() {
double x1 = 1;
double x = x1;
double a = f(x)/dfdx(x);
while(Math.Abs(a) > Eps){
x -= a;
a = f(x)/dfdx(x);
}
Console.WriteLine(«{0}», x);
}
}
12.6. Метод Ньютона с аппроксимацией производной
Если вычисление производной в методе Ньютона затруднено, можно заменить её вычисление оценкой.
class Program {
const double Eps = 0.00001;
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static void Main() {
double x = 1;
double h = 0.0001;
double fx = f(x);
double y = fx * h/(f(x + h) — fx);
while(Math.Abs(y) > Eps){
x = x — y;
fx = f(x);
y = fx * h/(f(x + h) — fx);
}
Console.WriteLine(«{0}», x);
}
}
12.7. Метод Брента
Метод Брента – метод поиска корней, окружённых на интервале (это значит, что ). Он сочетает в себе высокую скорость сходимости метода Риддлера с надёжностью метода дихотомии. В то время, как метод Риддлера быстр, но может очень сильно замедлиться на какой-нибудь сложной функции, скорость работы дихотомии не столь высока, но не зависит от обрабатываемой функции. Метод Брента сочетает в себе одновременно два подхода – на «хороших» функциях используется трёхточечная интерполяционная схема, дающая квадратичную скорость сходимости, а в случае слишком низкой скорости работы «продвинутого» подхода (или расходимости) используется деление отрезка на две части.
using System;
namespace МетодБрента {
class Program {
const double Eps = 0.00001;
const int itmax = 100;
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static void Main() {
double a = 1.0;
double b = 1.5;
double fa = f(a);
double fb = f(b);
double fc = fb;
double x = 0.0;
double c = 0, d = 0, e = 0.0;
double min1, min2, min0;
double p, q, r, s;
double tol1, xm, iter = 1;
bool hasroot = false;
do {
if( fb * fc > 0 ){
c = a;
fc = fa;
d = b — a;
e = d;
}
if( Math.Abs(fc) < Math.Abs(fb) ){
a = b;
b = c;
c = a;
fa = fb;
fb = fc;
fc = fa;
}
tol1 = 2 * Eps * Math.Abs(b) + 0.5 * Eps;
xm = 0.5 * (c — b);
if( Math.Abs(xm) <= tol1 | fb == 0 ){
x = b;
hasroot = true;
break;
}
if(Math.Abs(fa) > Math.Abs(fb) ) {
s = fb / fa;
if(a == c) {
p = 2.0 * xm * s;
q = 1.0 — s;
}
else {
q = fa / fc;
r = fb / fc;
p = s * (2.0 * xm * q * (q — r) — (b — a) * (r — 1.0));
q = (q — 1.0) * (r — 1.0) * (s — 1.0);
}
if(p > 0)
q = -q;
p = Math.Abs(p);
min1 = 3 * xm * q — Math.Abs(tol1 * q);
min2 = Math.Abs(e * q);
if(min1 < min2)
min0 = min1;
else
min0 = min2;
if(2 * p < min0 ){
e = d;
d = p/q;
}
else {
d = xm;
e = d;
}
}
else {
d = xm;
e = d;
}
a = b;
fa = fb;
if( Math.Abs(d) > tol1 )
b = b + d;
else
if( xm > 0 )
b = b + Math.Abs(tol1);
else
b = b — Math.Abs(tol1);
fb = f(b);
iter++;
} while (iter <= itmax);
if (hasroot)
Console.WriteLine(«{0}», x);
else
Console.WriteLine(«Корень не найден»);
}
}
}
12.8. Безопасный метод Ньютона
Этот метод является аналогом метода Брента для случая, когда известна производная функции . Сочетая в себе гарантированную сходимость метода дихотомии с высокой скоростью сходимости обычного метода Ньютона, он требует не только знания производной функции, но и отрезка, на концах которого функция имеет разные знаки.
Сначала метод делает шаг по правилу Ньютона. Если сделанный шаг не укладывается в указанный отрезок или же сходимость слишком низкая, то делается один шаг метода дихотомии. Затем процесс повторяется.
using System;
namespace МетодБезопасныйНьютона {
class Program {
const int itmax = 100;
const double Eps = 0.00001;
static double f( double x ) {
return (Math.Pow(Math.Cos(x), 2) — Math.Cos(x) / 12 — 1 / 24);
}
static double dff( double x ) {
double sin = Math.Sin(x);
return (-2 * Math.Cos(x) * sin + sin / 12);
}
static void Main() {
double x1 = 1.0;
double x2 = 1.5;
double f0 = 0;
double xh = 0;
double xl = 0;
double root = 0;
bool hasroot = false;
double fl = f(x1);
double fh = f(x2);
double df = dff(xh);
if (fl * fh < 0) {
if (fl < 0) {
xl = x1;
xh = x2;
}
else {
xh = x1;
xl = x2;
double swap = fl;
fl = fh;
fh = swap;
}
double rts = 0.5 * (x1 + x2);
double dxold = Math.Abs(x2 — x1);
double dx = dxold;
f0 = f(rts);
df = dff(rts);
int j = 1;
while (j <= itmax) {
if (((rts — xh) * df — f0) * ((rts — xl) * df — f0) >= 0 |
Math.Abs(2 * f0) > Math.Abs(dxold * df)) {
dxold = dx;
dx = 0.5 * (xh — xl);
rts = xl + dx;
if (xl == rts) {
root = rts;
hasroot = true;
break;
}
}
else {
dxold = dx;
dx = f0 / df;
double temp = rts;
rts = rts — dx;
if (temp == rts) {
root = rts;
hasroot = true;
break;
}
}
if (Math.Abs(dx) < Eps) {
root = rts;
hasroot = true;
break;
}
f0 = f(rts);
df = dff(rts);
j++;
if (f0 < 0) {
xl = rts;
fl = f0;
}
else {
xh = rts;
fh = f0;
}
}
}
if (hasroot)
Console.WriteLine(«{0}», root);
else
Console.WriteLine(«Корни не найдены»);
}
}
}
}
Лекция 13. Решение систем нелинейных уравнений
В задачах проектирования и исследования поведения реальных объектов, процессов и систем (ОПС) математические модели должны отображать реальные физические нелинейные процессы. При этом эти процессы зависят, как правило, от многих переменных. В результате математические модели реальных ОПС описываются системами нелинейных уравнений.
Дана система нелинейных уравнений
Или
Необходимо решить эту систему, т.е. найти вектор , удовлетворяющий систему уравнений с точностью .
Вектор определяет точку в — мерном Евклидовом пространстве, т.е. принадлежит этому пространству и удовлетворяет всем уравнениям системы.
В отличие от систем линейных уравнений для систем нелинейных уравнений неизвестны прямые методы решения. При решении систем нелинейных уравнений используются итерационные методы. Эффективность всех итерационных методов зависит от выбора начального приближения (начальной точки), т.е. вектора .
Область, в которой начальное приближение сходится к искомому решению, называется областью сходимости . Если начальное приближение лежит за пределами , то решение системы получить не удаётся.
Выбор начальной точки во многом определяется интуицией и опытом специалиста.
13.1. Метод простых итераций
Для применения этого метода исходная система должна быть преобразована к виду
Или
Далее, выбрав начальное приближение и используя преобразованную систему, строим итерационный процесс поиска по схеме:
т.е. на — ом шаге поиска вектор переменных находим, используя значения переменных, полученных на шаге.
Итерационный процесс поиска прекращается, как только выполнится условие
Метод простых итераций используется для решения таких систем линейных уравнений, в которых выполняется условие сходимости итерационного процесса поиска, а именно:
т.е. сумма абсолютных величин частных производных всех преобразованных уравнений преобразованной системы по — ой переменной меньше единицы.
Пример 13.1. Дана система нелинейных уравнений:
Необходимо определить область сходимости системы, выбрать начальную точку и найти одно из решений системы.
Строим графики уравнений:
Преобразуем систему для решения методом итераций
Проверяем условие сходимости. Для заданной системы оно имеет вид:
Находим:
В результате условие сходимости будет иметь вид:
Определяем область сходимости .
Граница области сходимости определится при решении системы:
Отсюда
В результате область сходимости определится при и
На графике уравнений строим область сходимости :
Выбираем начальную точку , принадлежащую области сходимости . Используя выбранную начальную точку решаем заданную систему нелинейных уравнений.
Текст программы, реализующей данный метод приведён ниже:
using System;
namespace НелинейныеСистемыМетодИтераций {
class Program {
const double Eps = 0.00001;
static void f(double[] СтароеЗначение, out double[] НовоеЗначение) {
НовоеЗначение = new double[2];
НовоеЗначение[0] = Math.Sqrt(1 — СтароеЗначение[1]);
НовоеЗначение[1] = -0.5 — 0.5 * Math.Log(СтароеЗначение[0]);
}
static void Main( string[ ] args ) {
double[ ] СтароеЗначение = { 0.8, -0.6 };
double[ ] НовоеЗначение;
bool Продолжать = true;
while (Продолжать) {
f(СтароеЗначение, out НовоеЗначение );
Продолжать = false;
for (int i = 0; i < 2; i++)
if (Math.Abs(НовоеЗначение[i] — СтароеЗначение[i]) > Eps)
Продолжать = true;
for (int i = 0; i < 2; i++)
СтароеЗначение[i] = НовоеЗначение[i];
}
for (int i = 0; i < 2; i++)
Console.WriteLine(«{0}», СтароеЗначение[i]);
Console.ReadLine();
}
}
}
13.2. Метод Ньютона
Метод Ньютона наиболее распространённый метод решения систем нелинейных уравнений. Он обеспечивает более быструю сходимость по сравнению с методом итераций. В основе метода Ньютона лежит идея линеаризации всех нелинейных уравнений заданной системы. Для этого сообщим всей системе малые приращения и разложим каждое уравнение системы в ряд Тейлора:
— приращение по каждой ;
— остаточные нелинейные члены второго и более высоких порядков каждого ряда Тейлора.
Если приращения таковы, что переменные принимают значения близкие к корню, то будем считать, что левые части уравнений системы обращаются в нули. Тогда отбросив сведём задачу решения системы нелинейных уравнений к решению системы линейных уравнений, в которой неизвестными являются приращения ,
Система – система линейных уравнений с неизвестными ,. Запишем её в матричной форме
где
— матрица коэффициентов системы
— вектор свободных членов
— вектор неизвестных системы
Матрица , составленная из частных производных ; называется матрицей Якоби или Якобианом.
Метод Ньютона состоит из двух этапов:
На первом этапе реализации метода Ньютона необходимо построить систему линейных уравнений.
На втором этапе, начиная с начальной точки , необходимо решать систему на каждом шаге итерационного процесса поиска методом Гаусса. Найденные значения приращений используются как поправки к решению, полученному на предыдущем шаге поиска, т.е.
(5.7)
Или
Итерационный процесс прекращается, как только выполнится условие
(5.8)
по всем приращениям одновременно.
Определение матрицы Якоби
В методе Ньютона на каждом шаге итерационного процесса поиска необходимо формировать матрицу Якоби, при этом каждый элемент матрицы можно определить аналитически, как частную производную , методом численного дифференцирования, как отношение приращения функции к приращению аргумента, т.е.
В результате частная производная по первой координате определится как
а частная производная по координате определится как
где .
Лекция 14. Решение обыкновенных дифференциальных уравнений
14.1. Задача Коши и краевая задача для обыкновенных дифференциальных уравнений
Пусть дано обыкновенное дифференциальное уравнение первого порядка . Задача Коши для этого уравнения формулируется так: найти решение уравнения , удовлетворяющее начальному условию . Если функция непрерывна в области , определённой неравенствами , , то существует хотя бы одно решение дифференциального уравнения , определённое в некоторой окрестности , . Это решение единственное, если в выполнено условие Липшица: , где константа, зависящая в общем случае от ,. Если имеет ограниченную производную в , то можно положить . Для дифференциального уравнения — ого порядка задача Коши состоит в нахождении решения удовлетворяющего начальным условиям , , …, , где ,, , заданные числа.
14.2. Метод Эйлера
Пусть дано дифференциальное уравнение с начальными условиями , . Пусть – малый шаг, и . Искомую интегральную кривую , проходящую через точку , приближённо заменим ломаной с вершинами звенья которой прямолинейны между прямыми и имеют тангенс угла наклона . Звенья ломаной Эйлера к каждой вершине имеют направление , совпадающие с направлением касательной к интегральной кривой уравнения в точке . Значения могут быть определены выражением , . Метод Эйлера может быть распространён на системы дифференциальных уравнений и на дифференциальные уравнения высших порядков.
К достоинствам данного метода следует отнести его простоту, к недостаткам малую точность и систематическое накопление ошибок.
Метод Эйлера можно усовершенствовать следующим образом. Сначала определяется грубое приближение решения . Исходя из этого приближения находиться направление поля интегральных кривых . Затем приближенно полагаем . Этот подход ещё называется методом Эйлера — Коши. Программа, реализующая метод Эйлера:
using System;
namespace МетодЭйлераОДУ {
class Program {
static double f( double x, double y ) {
return (y / x + x * x);
}
static void Main( string[ ] args ) {
double x = 1;
double y = 0;
double x1 = 2;
int n = 10;
double h = (x1 — x) / n;
double y1 = y;
for (int i = 1; i <= n; i++) {
double f1 = f(x, y);
x += h;
y += f1 * h;
y = y1 + h * (f1 + f(x, y)) / 2;
y1 = y;
}
Console.WriteLine(«y = {0}», y);
Console.ReadLine();
}
}
}
Метод Рунге-Кутта
Пусть дано дифференциальное уравнение с начальным условием , . Пусть – шаг и , где . Пусть .
Рассмотрим числа
Согласно данному методу, последовательные значения находятся по формуле:
,
Метод Рунге — Кутта применим для решения систем обыкновенных дифференциальных уравнений. Пусть дана система дифференциальных уравнений и начальные условия . Задавшись некоторым шагом и введя обозначения и и , где
Положим
Согласно данному методу, последовательные значения находятся по формуле:
Погрешность этого метода пропорциональна , т.е. . Приведём программу, реализующую данный метод:
using System;
namespace МетодРунгеКуттаОДУ {
class Program {
static double f( double x, double y ) {
return (y / x + x * x);
}
static void Main( string[ ] args ) {
double x = 1;
double y = 0;
double x1 = 2;
int n = 10;
double h = (x1 — x) / n;
double y1 = y;
for (int i = 1; i <= n; i++) {
double k1 = h * f(x, y);
x += h / 2;
y = y1 + k1 / 2;
double k2 = f(x, y) * h;
y = y1 + k2 / 2;
double k3 = f(x, y) * h;
x += h / 2;
y = y1 + k3;
y = y1 + (k1 + 2*k2 + 2*k3 + f(x, y)*h)/6;
y1 = y;
}
Console.WriteLine(«y = {0}», y);
Console.ReadLine();
}
}
}
Методы Эйлера и Рунге-Кутта относятся к так называемым одношаговым методам, поскольку для вычисления значения функции в точке требуется знать только значение функции в одной предыдущей точке .
Метод Адамса
Многошаговые методы, называемые также методами Адамса, построены путём интерполирования по нескольким соседним точкам, для их использования необходимо знать значение функции в нескольких предыдущих точках. Достоинство многошаговых методов состоит в том, что независимо от порядка метода для вычисления значения функции в одной точке требуется один раз вычислить функцию .
Метод Адамса второго порядка записывается следующим образом:
где .
Методы Адамса третьего и четвёртого порядков имеют вид:
Погрешность решения найденного многошаговым методом оценивается равенством , где – порядок метода.
Таким образом, метод Рунге-Кутта 4-го порядка и метод Адамса четвёртого порядка имеют одинаковую оценку погрешности, но метод Адамса требует примерно вчетверо меньшего объёма вычислений.
При получении формулы Эйлера была использована замена производной правой конечной разностью , если использовать левую конечную разность получим уравнение в которое искомая величина входит нелинейным образом. Для решения такого уравнения можно использовать итерационные методы. Задавая начальное приближение и последовательно уточняя значение по формуле
получаем неявный метод Эйлера (или метод Эйлера с итерационной обработкой). Итерации выполняют до тех пор, пока не выполнится условие
Если после 3-х 4-х итераций требуемая точность не достигается, то производиться уменьшение шага .
Неявную схему можно применить и для методов высших порядков при этом получаются, так называемые, методы прогноза и коррекции.
Метод Эйлера — Коши можно рассматривать как один из простейших методов типа прогноза и коррекции, согласно которому вначале вычисляется грубое приближение по методу Эйлера, а затем оно используется для уточнения, причём коррекция может быть использована многократно:
Методы прогноза и коррекции можно получить на основе использования многошаговых методов:
метод второго порядка
метод третьего порядка
метод четвёртого порядка
Во всех этих формулах для вычисления используется значение полученное в текущем приближении
В методе Милна используются формулы прогноза и коррекции, построенные по разным точкам
7.3. Решение краевой задачи для обыкновенного дифференциального уравнения методом конечных разностей, методом прогонки и методом стрельбы
Рассмотрим случай, когда дифференциальное уравнение и краевые условия линейны. Такая краевая задача называется линейной краевой задачей. Линейное дифференциальное уравнение можно записать в следующем виде
где – линейный дифференциальный оператор
причём обычно предполагается, что и известные непрерывные функции на отрезке . Для простоты будем предполагать, что в краевые условия входят две абсциссы концы отрезка . Такие условия называют двухточечными.
Краевые условия называют линейными, если они имеют вид
, – заданные постоянные.
Линейная краевая задача состоит в нахождении функции , удовлетворяющей дифференциальному уравнению и краевым условиям, причём последние – линейно независимые.
Линейная краевая задача называется однородной, если:
1. ;
2.
в противном случае задача неоднородная.
Метод конечных разностей
Рассмотрим линейное дифференциальное уравнение
с двухточечными краевыми условиями
где – непрерывны на отрезке . Одним из самых простых способов решения данной задачи является сведение её к системе конечно-разностных уравнений. Для этого необходимо разбить отрезок на равных частей длины (шаг). Точками разбиения абсциссы будут , где , .
Значение функции в точках и её производных обозначим соответственно , , .
Введём следующие обозначения: , , .
Заменим производные конечно-разностными отношениями. Для внутренних точек отрезка , будем иметь:
при
Для крайних точек , , чтобы не выходить за концы отрезка , можно положить:
Однако, если функция достаточно гладкая, то более точные значения дают следующие формулы:
Таким образом, краевую задачу можно представить в виде:
Таким образом, получили систему линейных уравнений с неизвестными , решение которой позволяют найти значение искомой функции в точках . Система является трёхдиагональной и для её решения используется метод прогонки.
При использовании подстановок получаем систему линейных уравнений:
Для решения такой системы можно использовать какой-либо итерационный метод.
Лекция 15. Решение обыкновенных дифференциальных уравнений (продолжение)
Метод Галеркина
Основан на одной теореме из теории общих рядов Фурье.
Теорема. Пусть полная система функций ортогональных на интервале с ненулевой нормой. Если непрерывная функция ортогональна на ко всем функциям , то есть
при
то при
Пусть имеем двухточечную линейную краевую задачу , где
с линейными краевыми условиями
Выберем конечную систему базисных функций , составляющих часть некоторой полной системы, причём потребуем, чтобы удовлетворяла неоднородным краевым условиям
а остальные функции удовлетворяли однородным краевым условиям
Решение краевой задачи будем искать в виде
При таком выборе базисных функций функция очевидно удовлетворяет краевым условиям при любом выборе .
Если подставить в левую часть дифференциального уравнения выражение и вычесть из правую часть, то получим функцию невязки
Эта функция характеризует уклонение формы от действительного решения краевой задачи. Если форма при некоторых значениях коэффициентов совпадает с решением краевой задачи, то невязка будет равна нулю при , поэтому для получения приближённого решения, близкого к точному, нужно подобрать так, чтобы функция невязки была в каком-то смысле мала.
Согласно приведённой выше теореме для того, чтобы функция невязки была равна нулю необходимо, чтобы невязка была ортогональна ко всем базисным функциям
При достаточно большом это обеспечивает малость невязки в среднем, насколько приближённое решение будет при этом близко к точному вопрос остается открытым.
Используя выражение для невязки, после преобразований получим систему линейных уравнений вида
решив которую можно найти значения коэффициентов .
Согласно условиям теоремы используемая система функций должна быть полной и ортогональной, но на практике подобрать такую систему не всегда представляется возможным, поэтому при использовании этого метода требуют чтобы система функций была линейно-независимой на .
Метод коллокаций
В этом методе выбирают точек? принадлежащих рассматриваемому участку, , называемых точками коллокации, и требуют чтобы невязка в этих точках была равна нулю
После преобразований получим систему линейных уравнений
Следует иметь в виду, что получаемая система будет хорошо обусловленной, если точки коллокации являются корнями ортогональных многочленов (например многочленов Чебышева), при равноотстоящих точках получаемая система, особенно при большой размерности, может быть плохо обусловленной.
Метод экспоненциальной прогонки
Во многих приложениях, особенно в механике жидкости, при моделировании электрических цепей, химических реакций и в теории управления, возникают задачи с начальными данными, которым присуще свойство, называемое «жёсткостью». Жёсткие уравнения – это такие уравнения, решения которых имеют одновременно как быстрое, так и медленно изменяющиеся компоненты. Первые из них часто не представляют интереса, однако если используются классические методы интегрирования, то эти быстро затухающие компоненты могут привести к возникновению трудных вычислительных задач. Следовательно, важно создать подходящие численные методы для решения таких задач. С этой целью был предложен ряд схем.
Некоторые методы предназначаются для систем средней жесткости и требуют использования очень малых шагов в области быстрого изменения решения. Фактически это означает, что эффективность этих способов уменьшается с увеличением жесткости.
Для того чтобы показать, как пограничный слой может возникнуть в случае простых задач, мы приводим здесь пример линейной двухточечной краевой задачи с таким поведением.
Приведённые ниже восемь графиков иллюстрируют возникновение такого пограничного слоя по мере изменения коэффициента при второй производной от средних до малых значений. На этих рисунках приведены графики точных решений задачи
для восьми значений параметра .
В этой части мы рассмотрим двухточечные краевые задачи, являющиеся математическими моделями диффузионно – конвективных процессов или родственных физических явлений. Диффузионным членом является член, включающий производные второго порядка, а конвективный член включает производные первого порядка.
Решения указанного выше типа задач обычно не могут быть представлены в виде рядов по возрастающим степеням коэффициента диффузии. Таким образом, эти задачи не являются регулярными возмущениями соответствующих задач более низкого порядка. Они называются сингулярно-возмущёнными задачами. Так как в предельном случае при нулевом коэффициенте диффузии дифференциальные уравнения имеют более низкий порядок, некоторые из граничных условий станут излишними. Решение задачи может быстро изменяться вблизи граничных точек, что соответствует наличию пограничного слой.
При решении указанного выше типа задач стандартными численными методами возникают большие трудности. Часто причина этих трудностей заключается в неустойчивости численного процесса. Чтобы избавиться от неустойчивости, мы используем модифицированную дискретизацию диффузионного члена. Если нужно, то результирующие схемы могут быть представлены в консервативной форме.
Нельзя рассчитывать на то, что классические методы будут работать одинаково хорошо во всей области изменения величин и . Их использование аналогично аппроксимации экспоненциальной функции отрезком ряда Тейлора. Эти классические методы также требуют строгих ограничений на величину шага для обеспечения устойчивости при малых , за исключением специальных случаев. Например, хорошо известный метод направленных разностей приводит к схемам, не требующим наложения ограничений на величину шага для обеспечения устойчивости. Ошибка схемы с направленной разностью всегда содержит член порядка . Это приемлемо, если достаточно мало по сравнению с , но может быть неприемлемым в других случаях.
Рассмотрим задачу следующего вида:
где — малый параметр.
Случай, когда приводится к данной системе заменой независимой переменной на .
В случае, , схема решения задачи имеет следующий вид:
,
где ,
Приведённая система уравнений связывают три соседние точки искомого решения, её можно решать, например методом прогонки.
В случае, , схема решения задачи имеет следующий вид:
где выражаются теми же зависимостями, что и в случае .
Решение систем обыкновенных дифференциальных уравнений
Нормальной системой — ого порядка обыкновенных дифференциальных уравнений, называют систему:
где – независимая переменная; независимые функции. Систему, содержащую производные высших порядков и разрешённую относительно старших производных искомых функций, путём введения новых неизвестных функций, можно привести к представленному виду. Для дифференциального уравнения -ого порядка , полагая , , …, получим следующую систему:
систему можно записать в виде .
Под решением системы понимается любая совокупность функций которые будучи подставленными в уравнения обращают их в тождества т.к. система дифференциальных уравнений имеет бесчисленное множество решений, то для выделения одного конкретного решения, необходимы дополнительные условия, в простейшем случае задаются начальные условия . Это приводит к задаче Коши: Найти решения системы, удовлетворяющие заданным начальным условиям , где – фиксированное значение независимой переменной, а – заданная система чисел.
Система обыкновенных дифференциальных уравнений высшего порядка путём введения новых неизвестных может быть сведена к системе уравнений первого порядка. Рассмотрим такую систему
где ; ; . Метод Рунге-Кутта вычисляет по формуле:
где
– количество шагов интегрирования.
1) Кислотно-основного титриметрического определения уксусной кислоты в уксусной эссенции;
2) Гравиметрического определения хроматов в электролите для хромирования.
Абсолютная погрешность аналитических
весов 0,1мг
Абсолютная погрешность (ошибка)
∆x=xi—xист.
Xi-измеренное
значениеXист-истинное
значение ( если истинное значение не
известно – берется среднее)
Абсолютная погрешность не может ясно
охарактеризовать точность измерения,
так как она не связана с измеренным
значением.
Относительная погрешность (ошибка)
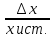 ·100%
·100%
Систематические погрешности (ошибки)– возникают при действии постоянных
причин, их можно выявить устранить или
учесть изменяются по постоянно
действующему закону .
-
Инструментальные погрешности–связанные с инструментами для измерения
аналитического сигнала (весы, посуда)
уменьшить можно периодической проверкой
аналитических приборов. Обычно составляют
небольшую долю . -
Методические ошибки–
обусловлены методом анализа (например
погрешности пробоотбора и пробоподготовки.)
вносят основной вклад в общую погрешность. -
Реактивные– связаны с чистотой
используемых реактивов. -
Оперативные ошибки –зависят
от правильности и точности выполнения
аналитических операций (например,
недостаточное или излишнее промывание
или прокаливания осадков, недостаточное
тщательное перемещение осадка из одной
посуды в другую, неправильный способ
выливания раствора из пипетки и т.д.) -
Индивидуальные ошибки(личные) – это результат некоторых
физических недостатков экспериментатора,
которые мешают ему правильно проводить
известные операции.
Способы выявления систематических
погрешностей
1)варьирование величин пробы
Увеличив размер в кратное число раз
можно обнаружить по изменению найденного
содержания постоянную систематическую
погрешность
2)способ «введено найдено»
Добавить точно известное количество
компонента в той же форме, в которой
находится аналитический объект. Введенная
добавка проводится через все стадии
анализа. Если на конечной стадии
определяется добавка с точностью, то
систематической ошибки нет.
3) сравнение результата анализа с
результатом, полученным другим независимым
методом
4)анализ стандартного образца
Проведение всех стадий анализа, на
стадии обработки сравнивается с
паспортом, если все совпадает , то
систематической ошибки нет.
Типы погрешностей
-
Погрешности известной природы, могут
быть рассчитаны и учтены введение
соответствующей поправки -
Погрешности известной природы, значение
которых может быть оценены в ходе
химического анализа
Релятивизация — способ устранения
систематической погрешности, когда в
идентичных условиях проводят отдельные
аналитические операции таким образом,
что происходит нивелирование
систематической ошибки
-
Погрешность невыясненной природы,
значение который неизвестно, их сложно
выявить и устранить , используют прием
рандомизации
Рандомизация – переведение систематической
ошибки в разряд случайной
Случайные ошибки– обрабатываются
по правилам матемтической статистики,
связаны с влиянием неконтролируемых
параметров, непредвиденны и неучтимы.
Промахи– грубые ошибки, сильно
искажающие результаты анализа (ошибки
при расчётах, неправильный отчёт по
шкале, проливание раствора или просыпание
осадка). Результат с промахом отбрасывается
при выводе среднего значения.
6. Случайные
ошибки. Метрологические характеристики,
отражающие случайные ошибки. Оценка и
критерии воспроизводимости и правильности.
Рассмотрите на примере титриметрического
комплексонометрического определения
меди (II).
Случайные ошибки–отражают
неопределенность результата , присущую
любому измерению, обрабатываются по
правилам матемтической статистики,
связаны с влиянием неконтролируемых
параметров, непредвиденны и неучтимы.
Причины таких погрешностей:
Изменение температуры во время измерения,
ослабление внимания при работе, случайные
потери, загрязнение, использование
разной посуды, весов и тд.
метрологические характеристики:
Правильность— характеризует степень
близости измеренного результата
некоторой величины к её истинному
значению
Воспроизводимость— характеризует
степень близости друг к другу единичный
определений (рассеяние единичных
результатов относительно среднего
значения
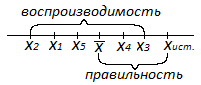
Точность— собирательная характеристика
метода или методики , включающая их
правильность и воспроизводимость .
Чувствительность— величина,
определяемая минимальным количеством
вещества, которое можно обнаружить
данным методом
Чувствительность – собирательное
понятие , включающее три характеристики:
1)Коэффициент чувствительности
коэффициент чувствительности sхарактеризует отклик аналитического
сигналаyна содержание
компонентаc,s-
это значение первой производной
градуировочной функции при определенном
содержании компонента, для прямолинейных
градуировочных графиковs– это тангенс угла наклона прямойy=Sc+b
s=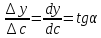
чем больше s, тем меньшие
количества компонента можно обнаружить
, используя один и тот же аналитический
сигнал, чем большеs, тем
точнее можно определить одно и то же
количество вещества
2)предел обнаружения Сminнаименьшее содержание при котором по
данной методике можно обнаружить
присутствие компонента с заданной
доверительной вероятностью, относится
к области качественного анализа и
определяет минимальное содержание
компонента
3)нижняя граница определяемого содержания
Сн
В количественном анализе обычно приводят
интервал определяемых содержаний-
область значений определяемых содержаний,
предусмотренная данной методикой и
ограниченная нижней и верхней границами.
Верхняя граница Свнаибольшее
значение количества или концентрации
компонента, определяемое по данной
методике.
нижняя граница Сн-наименьшее
содержание компонента , определяемое
по данной методике . З нижнюю границу
обычно принимают то минимальное
количество или концентрацию, которые
можно определить с относительным
стандартным отклонением Ϭr≤0,33
Оценка и критерии воспроизводимости
1)Среднее арифметическое
 =
=
2)Отклонение
di=xi—
3)Медиана— тот единичный результат
, относительно которого число результатов
с большими и меньшими значениями
одинаковое, если количество значений
нечетное, то медиана совпадает с
центральным результатом ранжированной
выборки , если количество значений
четное, то медиана есть среднее
арифметическое между двумя центральными
значениями ранжированной выборки
4)среднее отклонение-среднее
арифметическое единичных отклонений,
без учет знака
 =
=
5)Дисперсия
Ϭ2илиs2
Ϭ2=
еслиn>10
Ϭ2=
еслиn≤10
6)стандартное отклонениеϬx=
7)Относительное стандартное отклонение
Ϭr=
Титриметрическое комплексонометрическое
определения меди (II).
Выполнение определениея
1)Титрование исследуемого раствора
стандартным раствором ЭДТА
2)расчет граммового содержания меди
Ход анализа:Титрование исследуемого
раствора стандартным раствором ЭДТА.
Анализируемый раствор помещают в мерную
колбу на 100 мл, довдят водой до метки,
тщательно перемешивают. В коническую
колбу дл титрования берут аликвоту,
добавляют индикатор мурексид на кончике
шпателя и титруют раствором ЭДТА сначала
до грязно-розового цвета, натем добавляют
несколько капель 10%-ного раствора аммиака
до появления изумрудной или желтой
окраски раствора и дотитровывают
раствором ЭДТА до перехода окраски в
фиолетовую.
Формула для расчета граммового содержания
меди:
mCu,г=C( ЭДТА)·
ЭДТА)· ЭДТА·K
ЭДТА·K
ЭДТА·Mэкв(Cu)·P·10-3
Формула для расчета процентного
содержания меди:
ωCu= ·100%
·100%
Возможные причины возникновения
случайных ошибокв комплексонометрическом
титровании меди возникают в процессе
измерения объемов: неточное доведение
до метки мерной колбы, использование
разных пипеток, потеря титранта (капнуло
мимо), использование непромытой посуды.
Так же могут возникать ошибки из-за
неточного определения перехода окраски
, но эти ошибки будут относиться к
категории систематических индивидуальных
ошибок.
7. Гравиметрическое
определение бария в минерале альстонит:
этапы определения, возможные формулы
осадителей, осаждаемой и гравиметрической
формы, механизм образования осадка,
возможные варианты загрязнения осадка,
приемы повышения чистоты осадка,
погрешности определения. Условия
аналитического выделения осадков бария.
Минерал альстонит минерал, безводный
двойной карбонат бария и кальция
BaCa(CO3)2
Этапы определения:
1)взятие навески и её растворение
2)расчет количества осадителя
3)приготовление раствора осадителя
4)осаждение
5)фильтрование и промывание
6)высушивание и прокаливание осадка
7)взвешивание осадка, расчёт содержания
бария
Для количественного определения бария
его осаждают в виде сульфата BaSO4
(осаждаемая форма)
BaCO3+H2SO4=
BaSO4+H2CO3
В качестве осадителя, посташика
сульфат-ионов используют серную кислоту
H2SO4(осадитель)
После прокаливания осадка его формула
не меняется и остается так же в виде
сульфата бария BaSO4
(гравиметрическая форма)
Механизм образования осадка:
В процессе образования осадка различают
три стадии :
1)образование зародышей кристаллов
2)рост кристаллов
3)объединение (агрегация) хаотично
ориентированных кристаллов
Насыщение=>пересыщение=>ПКИ>ПР=>
образование мельчайших зародышей
кристаллов
Осаждение происходит при определенной
степени пересыщения раствора
P= =
= s-растворимость,
s-растворимость, -относительное
-относительное
пересыщение,Q-концентрация
кристаллизующегося вещества в растворе
Центром кристалла может служить твердая
частица этого вещества или любая другая
твердая частица, которую мы вносим в
раствор, твердые частицы могут изначально
присутствовать в растворе как примесь.
Если осаждение происходи из разбавленных
растворов, то появление осадка занимает
время-индукцинный период.
В процессе добавления каждой новой
порции осадителя происходит мгновенное
пересыщение раствора, зародыши растут
быстро за счет окружающих их ионов, как
только зародыш дотиг определенного
размера выпадает осадок
Рост кристаллов идет параллельно 1-ой
стадии, происходит за счет диффузии
ионов к поверхности растущего кристалла.
Число и размер частиц осадка (дисперсность
системы кол-во в единицы объёма) зависит
от соотношения скоростей 1-ой и 2-ой
стадий
V1— скорость образования
зародышейV2-скорость
роста кристаллов
V1>>V2-мелкодисперсный
осадокV1<<V2-крупнокристаллический
осадок
Лимитирующую стадию определяет скорость
осаждения и концентрации ионов
При медленном осаждении лимитирующей
стадией является кристаллизация ,
частица окружена однородным слоем
осаждаемый ионов в результате получается
кристалл правильной форм
При высокой концентрации ионов
лимитирующей стадией становится диффузия
, образуются кристаллы не правильной
формы с большой площадью поверхности
Следует отметить, что на скорость
процесса кристаллизации влияет
 ,
,
влияние различно на скорость образования
различно на скорость образования
зародышей и на скорость роста кристаллов
В случае образования зародышей
V1=k·( экспоненциальный
экспоненциальный
закон
В случае роста кристаллов V2=k·
При высокой степени
 образуются
образуются
мелкодисперсные осадки, при уменьшении ,
,
образуются крупнокристаллические
осадки
Агрегация происходит в гетерогенной
системе, в значительной степени
определяется числом центров кристаллизации.
Чем больше центров кристаллизации , тем
в меньшей степени они укрупняются на
второй стадии , тем хуже структура и тем
выше дисперсность осадков.
К аналитическим свойствам осадка
относятся: растворимость, чистота,
фильтруемость.
Лучшими свойствами обладают
крупнокристаллические осадки.
Загрязнение осадков
В гарвиметрическом определении часто
возникают ошибки , вызванные переходом
осадка в раствор или веществ из раствора
в осадок-соосождение
Соосаждение происходит в процессе
образования осадка
Отрицательная роль : загрязнение осадка
Положительная роль :используется для
концентрирования микропримесей
Существует три типа соосаждения:
1)Адсорбция- соосаждение примесей на
поверхности уже сформированного осадка,
происходит в результате нескомпенсированности
зарядов внутри и на поверхности.
Характеризуется ярко выраженной
избирательность, преимущественно
адсорбируются те ионы, которые входят
в структуру осадка, противоионы-примеси
Адсорбция противоионов подчиняется
правилам Панета-Фаянса-Гана
А)при одинаковых концентрациях
адсорбируются многозарядные ионы
Б)при одинаковых зарядах адсорбируются
те, концентрация которых выше
В)при одинаковых концентрациях и
зарядах-те, которые образуют с ионами
решетки менее растворимое соединение
Г)в кислой среде соосаждение ионов
уменьшается в следствии конкурентной
адсорбции H3O+
Количество адсорбируемой примеси
зависит от величины поверхности осадка,
концентрации адсорбируемой примеси и
температуры ( с ↑ поверхности и ↑
концентрации- адсорбция ↑; с ↑ температуры
адсорбция ↓)
2)Окклюзия- загрязнение осадка в результате
захвата примеси внутрь растущего
кристалла, происходит в процессе
формирования осадка.
Различают 2-х видов: абсорбционная и
механическая
Механическа- случайный захват частиц
маточного раствора внутрь твердой фазы
вследствие нарушения механической
структуры
Характерна при выделении аморфных
осадков.
Окклюзированные примеси равномерно
распределены внутри, но не принимают
участие в построении решетки кристалла.
Адсорбционная-возникает при быстром
росте кристалла, когда ионы на поверхности
обратают кристаллизованным веществом.
Протекает вследствии адсорбции примесей
по микротрещинам кристаллической
структуры.
Окклюзия подчиняется тем же правилам,
что и адсорбция
Общие правила понижения окклюзии–замедление процесса выделения твердой
фазы-осаждение при малом пересыщении
, работают с разбавленными растворами
, осадитель добавляют по каплям, при
постоянном перемешивании.
3)изоморфное соосаждение характерно
для изоморфно кристаллизующегося
веществ, которые могут образовывать
смешанные кристаллы, примесь участвует
в построении кристаллической решетки,
наблюдается лишь в тех случаях, когда
вещества сходны по химическим свойствам
или ионы имеют одинаковые кч и радиус.
Совместное осаждение-выделение в твердую
фазу нескольких веществ, для которых в
услових осаждения достигнуты величины
их Kst
Последовательное осаждение- веделение
примеси на поверхности уже сформированного
осадка
Приемы и методы повышения чистоты
осадка
Зависят от типа соосаждения
1)адсорбционные примеси хорошо удаляются
промыванием осадка, более эффективно
многократное промывание малыми порциями
Выбор промывочной жидкости:
Не увеличивает растворимость осадка и
не ухудшает его фильтруемость, водой
промывают осадки с k~10-11/-12,
не подвергаемых пептизации, кристаллические
осадки с конст, растворимости 10-9/-11промывают разбавленным раствором
осадителя, аморфные осадки промывают
разбавленными растворами электролитов
коагуляторов, чтобы избежать пептизации
Промывние кристаллических осадков
проводят холодной промывочной жидкостью,
чтоб не увеличивать растворимость,
аморфные наоборот горячими
2)окклюзированные примеси , для избавления
от них:
Для кристаллических осадков-старение
Для аморфных-переосаждение
Погрешность гравиметрического
метода анализа
Общая погрешность анализа
Ϭ2=
 +
+
 -погрешность
-погрешность
пробоотбораm-число пробn-число параллельных
определений
 -погрешность
-погрешность
измерений
Результат находится по формуле
P,%= ·100%
·100%
Методическая ошибка, обусловлена
неколичественным выпадением осадка,
её устранить нельзя
Qоб= s-растворимость осадка
s-растворимость осадка
г/100мл воды, -объём
-объём
фильтрата, —
—
масса гравиметрической формы
Случайные ошибки
Относительное стандартное отклонение
 =
=
 -дисперсия
-дисперсия
массы гравиметрической формы
 -масса
-масса
гравиметрической формы
Ϭa1-погрешность
взвешивания тары
Ϭa2-погрешность
взвешивания тары с навеской
 =
= =0,0003
=0,0003
г Ϭa1= Ϭa2=0,0002г
Суммарная ошибка
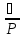 =
=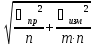
n-число проб
m-число измерений
 -погрешность
-погрешность
прибора
 -погрешность
-погрешность
измерения
8. Гравиметрическое
определение алюминия в каолине: этапы
определения, возможные формулы осадителей,
осаждаемой и гравиметрической формы,
механизм образования осадка, возможные
варианты загрязнения осадка, приемы
повышения чистоты осадка, погрешности
определения. Преимущества органических
осадителей. Условия аналитического
выделения осадков алюминия.
Механизм образования осадка:
В процессе образования осадка различают
три стадии :
1)образование зародышей кристаллов
2)рост кристаллов
3)объединение (агрегация) хаотично
ориентированных кристаллов
Насыщение=>пересыщение=>ПКИ>ПР=>
образование мельчайших зародышей
кристаллов
Осаждение происходит при определенной
степени пересыщения раствора
P= =
= s-растворимость,
s-растворимость, -относительное
-относительное
пересыщение,Q-концентрация
кристаллизующегося вещества в растворе
Центром кристалла может служить твердая
частица этого вещества или любая другая
твердая частица, которую мы вносим в
раствор, твердые частицы могут изначально
присутствовать в растворе как примесь.
Если осаждение происходи из разбавленных
растворов, то появление осадка занимает
время-индукцинный период.
В процессе добавления каждой новой
порции осадителя происходит мгновенное
пересыщение раствора, зародыши растут
быстро за счет окружающих их ионов, как
только зародыш дотиг определенного
размера выпадает осадок
Рост кристаллов идет параллельно 1-ой
стадии, происходит за счет диффузии
ионов к поверхности растущего кристалла.
Число и размер частиц осадка (дисперсность
системы кол-во в единицы объёма) зависит
от соотношения скоростей 1-ой и 2-ой
стадий
V1— скорость образования
зародышейV2-скорость
роста кристаллов
V1>>V2-мелкодисперсный
осадокV1<<V2-крупнокристаллический
осадок
Лимитирующую стадию определяет скорость
осаждения и концентрации ионов
При медленном осаждении лимитирующей
стадией является кристаллизация ,
частица окружена однородным слоем
осаждаемый ионов в результате получается
кристалл правильной форм
При высокой концентрации ионов
лимитирующей стадией становится диффузия
, образуются кристаллы не правильной
формы с большой площадью поверхности
Следует отметить, что на скорость
процесса кристаллизации влияет
 ,
,
влияние различно на скорость образования
различно на скорость образования
зародышей и на скорость роста кристаллов
В случае образования зародышей
V1=k·( экспоненциальный
экспоненциальный
закон
В случае роста кристаллов V2=k·
При высокой степени
 образуются
образуются
мелкодисперсные осадки, при уменьшении ,
,
образуются крупнокристаллические
осадки
Агрегация происходит в гетерогенной
системе, в значительной степени
определяется числом центров кристаллизации.
Чем больше центров кристаллизации , тем
в меньшей степени они укрупняются на
второй стадии , тем хуже структура и тем
выше дисперсность осадков.
К аналитическим свойствам осадка
относятся: растворимость, чистота,
фильтруемость.
Лучшими свойствами обладают
крупнокристаллические осадки.
Загрязнение осадков
В гарвиметрическом определении часто
возникают ошибки , вызванные переходом
осадка в раствор или веществ из раствора
в осадок-соосождение
Соосаждение происходит в процессе
образования осадка
Отрицательная роль : загрязнение осадка
Положительная роль :используется для
концентрирования микропримесей
Существует три типа соосаждения:
1)Адсорбция- соосаждение примесей на
поверхности уже сформированного осадка,
происходит в результате нескомпенсированности
зарядов внутри и на поверхности.
Характеризуется ярко выраженной
избирательность, преимущественно
адсорбируются те ионы, которые входят
в структуру осадка, противоионы-примеси
Адсорбция противоионов подчиняется
правилам Панета-Фаянса-Гана
А)при одинаковых концентрациях
адсорбируются многозарядные ионы
Б)при одинаковых зарядах адсорбируются
те, концентрация которых выше
В)при одинаковых концентрациях и
зарядах-те, которые образуют с ионами
решетки менее растворимое соединение
Г)в кислой среде соосаждение ионов
уменьшается в следствии конкурентной
адсорбции H3O+
Количество адсорбируемой примеси
зависит от величины поверхности осадка,
концентрации адсорбируемой примеси и
температуры ( с ↑ поверхности и ↑
концентрации- адсорбция ↑; с ↑ температуры
адсорбция ↓)
2)Окклюзия- загрязнение осадка в результате
захвата примеси внутрь растущего
кристалла, происходит в процессе
формирования осадка.
Различают 2-х видов: абсорбционная и
механическая
Механическа- случайный захват частиц
маточного раствора внутрь твердой фазы
вследствие нарушения механической
структуры
Характерна при выделении аморфных
осадков.
Окклюзированные примеси равномерно
распределены внутри, но не принимают
участие в построении решетки кристалла.
Адсорбционная-возникает при быстром
росте кристалла, когда ионы на поверхности
обратают кристаллизованным веществом.
Протекает вследствии адсорбции примесей
по микротрещинам кристаллической
структуры.
Окклюзия подчиняется тем же правилам,
что и адсорбция
Общие правила понижения окклюзии–замедление процесса выделения твердой
фазы-осаждение при малом пересыщении
, работают с разбавленными растворами
, осадитель добавляют по каплям, при
постоянном перемешивании.
3)изоморфное соосаждение характерно
для изоморфно кристаллизующегося
веществ, которые могут образовывать
смешанные кристаллы, примесь участвует
в построении кристаллической решетки,
наблюдается лишь в тех случаях, когда
вещества сходны по химическим свойствам
или ионы имеют одинаковые кч и радиус.
Совместное осаждение-выделение в твердую
фазу нескольких веществ, для которых в
услових осаждения достигнуты величины
их Kst
Последовательное осаждение- веделение
примеси на поверхности уже сформированного
осадка
Приемы и методы повышения чистоты
осадка
Зависят от типа соосаждения
1)адсорбционные примеси хорошо удаляются
промыванием осадка, более эффективно
многократное промывание малыми порциями
Выбор промывочной жидкости:
Не увеличивает растворимость осадка и
не ухудшает его фильтруемость, водой
промывают осадки с k~10-11/-12,
не подвергаемых пептизации, кристаллические
осадки с конст, растворимости 10-9/-11промывают разбавленным раствором
осадителя, аморфные осадки промывают
разбавленными растворами электролитов
коагуляторов, чтобы избежать пептизации
Промывние кристаллических осадков
проводят холодной промывочной жидкостью,
чтоб не увеличивать растворимость,
аморфные наоборот горячими
2)окклюзированные примеси , для избавления
от них:
Для кристаллических осадков-старение
Для аморфных-переосаждение
Погрешность гравиметрического
метода анализа
Общая погрешность анализа
Ϭ2=
 +
+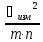
 -погрешность
-погрешность
пробоотбораm-число пробn-число параллельных
определений
 -погрешность
-погрешность
измерений
Результат находится по формуле
P,%= ·100%
·100%
Методическая ошибка, обусловлена
неколичественным выпадением осадка,
её устранить нельзя
Qоб= s-растворимость осадка
s-растворимость осадка
г/100мл воды, -объём
-объём
фильтрата, —
—
масса гравиметрической формы
Случайные ошибки
Относительное стандартное отклонение
 =
=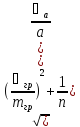
 -дисперсия
-дисперсия
массы гравиметрической формы
 -масса
-масса
гравиметрической формы
Ϭa1-погрешность
взвешивания тары
Ϭa2-погрешность
взвешивания тары с навеской
 =
= =0,0003
=0,0003
г Ϭa1= Ϭa2=0,0002г
Суммарная ошибка
 =
=
n-число проб
m-число измерений
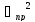 -погрешность
-погрешность
прибора
 -погрешность
-погрешность
измерения
9. Гравиметрическое
определение железа в руде: этапы
определения, возможные формулы осадителя,
осаждаемой и гравиметрической формулы,
механизм образования коллоидной частицы,
процессы, приводящие к образованию
осадка, возможные варианты загрязнения
осадка, приемы повышения чистоты осадка,
погрешности. Условия аналитического
выделения осадков железа.
Гравиметрическое определение железа(III)
основано на его осаждении в виде
гидроксида железа(III)Fe(OH)3.
Трехвалентное железо осаждают раствором
аммиака, осаждаемой формой являетсяFe(OH)3.
Реакция:Fe(NO3)3+3NH3·H2O=Fe(OH)3+3NH4NO3.
При прокаливании гидроксид железа(III)
превращается в оксид железа(III),
который является гравиметрической
формой:Fe(OH)3=(t°)Fe2O3+3H2O.
Этапы определения:1) взятие навески
и ее растворение; 2) приготовление
раствора осадителя; 3) осаждение; 4)
фильтрование и промывание осадка; 5)
высушивание и прокаливание; 6) взвешивание
осадка, расчет содержания железа.
Расчет ведут по формулам


ωFe2O3=
 ,
,
ωFe
=

Механизм образования коллоидной
частицы:
Fe(NO3)3+3NH4OH(изб.)=Fe(OH)3↓+3NH4NO3
{[Fe(OH)3]m
· nOH—
·(n-x)NH4+}-x
·xNH4+


агрегат плотный слой
диффузный слой Мицелла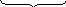
Ядро 
Коллоидная частица
Вещество в коллоидной системе имеет
большую развитую поверхность и
нескомпенсированный заряд на границе
разлела фаз. Существование
нескомпенсированного силового поля
ведет к адсорбции из раствора молекул
или ионов. Если коллоидная система
возникла в результате проведения
химической реакции осаждения, то частицы
адсорбируют в первую очередь те ионы,
которые могут достраивать кристаллическую
решетку. Адсорбированные ионы сообщают
частице «+» или «-« заряд. Слой
адсорбированных ионов на ядре – это
первичный адсорбционный слой. Заряд,
созданный таким слоем, достаточно высок
и обуславливает электростатическое
взаимодействие с иоами противоположного
знака. В результате образуется слой
противоионов, который выравнивает заряд
первичного слоя. Слой противоионов
имеет диффузный характер. Часть
противоионов, прочно связанных с
первичным слоем – это плотный слой,
остальные противоионы составляют
диффузный слой.
Образование осадкапроисходит
тогда, когда раствор становится
пересыщенным, т.е. [A+]m[B-]n>Ks(ПКИ>ПР). Образование осадков связано
с процессом укрупнения частиц, с
образованием кристаллической решетки
вещества. Этот процесс определяется
числом центров кристаллизации: чем
больше центров, тем в меньшей степени
они укрупняются и тем хуже структура и
выше дисперсность осадка.
Возможные варианты загрязнения:
1)Путем адсорбции ( для конкретного
примера хлорид-ионов на поверхности
осадка); 2)Окклюзия; 3)Изоморфное
соосаждение; 4) Совместное осаждение;
5) Последующее осаждение.
Приемы повышения чистоты осадка:
1) Адсорбированные на поверхности примеси
хорошо удаляются при промывании осадков
на фильтре при помощи промывных жидкостей,
т.к. примеси переходят в промывную
жидкость и уходят через поры фильтра.
Эффективно многократное промывание
небольшими порциями промывной жидкости.
Промывную жидкость выбирают максимально
тщательно, чтобы не увеличивать
растворимость осадка и не ухудшать его
фильтрацию. Кристаллические осадки
промывают холодными промывными
жидкостями, чтобы не увеличить
растворимость осадка, а аморфные –
наоборот горячими. Водой промывают
осадки с низкими константами растворимости
(ниже 10-11-10-12), а также те,
которые не подвергаются пептизации.
Если константа растворимости осадка
10-9-10-11и он кристаллический,
то его промывают разбавленным раствором
осадителя. Аморфные осадки промывают
разбавленными растворами
электролитов-коагулянтов (солиNH4+),
чтобы избежать пептизации(в опыте с
железом осадок промывали растворомNH4NO3).
Повышение температуры также способствует
уменьшению адсорбции (на конкретном
примере горячий раствор, содержащий
10% аммиак разбавляют горячей водой для
уменьшения адсорбции хлорид-ионов на
поверхности осадка). 2) Для очищения
окклюдированных примесей в случае
кристаллических осадков используют
старение, в случае аморфных осадков –
переосаждение.Степень окклюзии в
процессе осаждения можно уменьшить
медленным добавлением осадителя по
каплям, при перемешивании.
Погрешности:
1) Общая погрешность анализа σ2=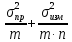 ,
,
где σпр2– погрешность
пробоотбора, σизм2–
погрешность измерения,m– число проб,n– число
параллельных определений.
2) Методическая ошибка OобOоб=
—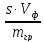 ,
,
гдеs– растворимость
осадка, г/100 мл воды;Vф
– объем фильтрата и промывных вод,
мл;mгр– масса
полученного осадка, г.
3) Относительное стандартное отклонение
 =
= , гдеσгр – дисперсия
, гдеσгр – дисперсия
массы гравиметрической формы;mгр– масса гравиметрической формы; σa– дисперсия массы исходной навески;a– масса исходной навески;p– процентное содержание вещества в
исследуемой пробе;n–число
измерений.
4) Погрешность взвешивания тары σa1и тары с навескойσa2σa1=σa2=0,0002
г, σгр= = 0,0003 г. 5) Относительное стандартное
= 0,0003 г. 5) Относительное стандартное
отклонение с учетом стадий пробоотбора
и пробоподготовки =
= , гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
, гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
Fe(OH)3– типичный пример осадка в аморфном
состоянии, легко дающий коллоидный
раствор.
Условия его осаждения следующие:
1)осаждение проводят из горячего раствора
анализируемого вещества горячим
раствором осадителя при перемешивании;
2)осаждение проводят из достаточно
концентрированного исследуемого
раствора концентрированным раствором
осадителя с последующим разбавлением(при
разбавлении устанавливается адсорбционное
равновесие, часть адсорбированных ионов
переходи в раствор, и осадок становится
более чистым); 3)осаждение проводят в
присутствии подходящего
электролита-коагулятора;
4)аморфные осадки почти не требуют
времени для созревания, их необходимо
фильтровать сразу после разбавления
раствора. Аморфные осадки нельзя
оставлять более, чем на несколько минут,
т.к. сильное уплотнение их затрудняет
последующее отмывание примесей, а также
при стоянии увеличивается количество
примесей, адсорбированных поверхностью
осадка.
10. Гравиметрическое определение никеля
в нихромовом сплаве: этапы определения,
возможные формулы осадителей, осаждаемой
и гравиметрической формулы, механизм
образования осадка, возможные варианты
загрязнения осадка, приемы повышения
чистоты осадка, погрешности. Условия
аналитического выделения осадков
никеля.
Гравиметрическое определение никеля
в нихромовом сплаве основано на его
осаждении в виде диметилглиоксимата
никеля Ni(HDMG)2.
Никель осаждают 1 %-ным спиртовым раствором
диметикглиоксимаH2DMG,
осаждаемой формой являетсяNi(HDMG)2.
Реакция:Ni2++2H2DMG=Ni(HDMG)2+2H+.
После высушивания осадка остается сухойNi(HDMG)2,
который является гравиметрической
формой.
Этапы определения:1) взятие навески
и ее растворение; 2) приготовление
раствора осадителя; 3) осаждение; 4)
фильтрование и промывание осадка; 5)
высушивание; 6) взвешивание осадка,
расчет содержания никеля.
Расчет ведут по формуле ωNi=

Механизм образования осадка:в
процессе образования осадка различают
3 параллельных процесса: 1) образование
зародышей кристалла (центров
кристаллизации); 2) рост кристаллов; 3)
объединение (агрегация) хаотично
ориентированных мелких кристаллов. В
начальный момент происходит насыщение
раствора, а затем его пересыщение. В
момент определенной пересыщенности
раствора, начинается выпадение
осадка.Центром кристалла может служить
твердая частица этого вещества или
любая другая твердая частица, которую
мы вносим в раствор, твердые частицы
могут изначально присутствовать в
растворе как примесь.
Если осаждение происходит из разбавленных
растворов, то появление осадка занимает
время-индукционный период.
В процессе добавления каждой новой
порции осадителя происходит мгновенное
пересыщение раствора, зародыши растут
быстро за счет окружающих их ионов, как
только зародыш достиг определенного
размера выпадает осадок.
Рост кристаллов идет параллельно 1-ой
стадии, происходит за счет диффузии
ионов к поверхности растущего кристалла.
Число и размер частиц осадка (дисперсность
системы кол-во в единицы объёма) зависит
от соотношения скоростей 1-ой и 2-ой
стадий (V1— скорость
образования зародышей,V2-скорость
роста кристаллов):V1>>V2-мелкодисперсный
осадок,V1<<V2-крупнокристаллический
осадок. Какая из стадий будет лимитировать
определяет скорость осаждения и
концентрации ионов. При медленном
осаждении лимитирующей стадией является
кристаллизация, частица окружена
однородным слоем осаждаемых ионов в
результате получается кристалл правильной
формы. При высокой концентрации ионов
лимитирующей стадией становится
диффузия, образуются кристаллы
неправильной формы с большой площадью
поверхности. Следует отметить, что на
скорость процесса кристаллизации влияет ,
,
влияние различно на скорость образования
различно на скорость образования
зародышей и на скорость роста кристаллов.
При высокой степени образуются
образуются
мелкодисперсные осадки, при уменьшении образуются крупнокристаллические
образуются крупнокристаллические
осадки. Агрегация происходит в гетерогенной
системе, в значительной степени
определяется числом центров
кристаллизации.Чем больше центров
кристаллизации, тем в меньшей степени
они укрупняются на второй стадии, тем
хуже структура и тем выше дисперсность
осадков.
К аналитическим свойствам осадка
относятся: растворимость, чистота,
фильтруемость.Лучшими свойствами
обладают крупнокристаллические осадки.
Возможные варианты загрязнения: 1)
Путем адсорбции ( для конкретного примера
хлорид-ионов на поверхности осадка); 2)
Окклюзия; 3) Изоморфное соосаждение; 4)
Совместное осаждение; 5) Последующее
осаждение.
Приемы повышения чистоты осадка:
1) Адсорбированные на поверхности примеси
хорошо удаляются при промывании осадков
на фильтре при помощи промывных жидкостей,
т.к. примеси переходят в промывную
жидкость и уходят через поры фильтра.
Эффективно многократное промывание
небольшими порциями промывной жидкости.
Промывную жидкость выбирают максимально
тщательно, чтобы не увеличивать
растворимость осадка и не ухудшать его
фильтрацию. Кристаллические осадки
промывают холодными промывными
жидкостями, чтобы не увеличить
растворимость осадка, а аморфные –
наоборот горячими. Водой промывают
осадки с низкими константами растворимости
(ниже 10-11-10-12), а также те,
которые не подвергаются пептизации.
Если константа растворимости осадка
10-9-10-11и он кристаллический,
то его промывают разбавленным раствором
осадителя. Аморфные осадки промывают
разбавленными растворами
электролитов-коагулянтов (солиNH4+),
чтобы избежать пептизации (в опыте с
железом осадок промывали растворомNH4NO3).
Повышение температуры также способствует
уменьшению адсорбции (на конкретном
примере горячий раствор, содержащий
10% аммиак разбавляют горячей водой для
уменьшения адсорбции хлорид-ионов на
поверхности осадка). 2) Для очищения
окклюдированных примесей в случае
кристаллических осадков используют
старение, в случае аморфных осадков –
переосаждение.Степень окклюзии в
процессе осаждения можно уменьшить
медленным добавлением осадителя по
каплям, при перемешивании.
Погрешности:1) Общая погрешность
анализа σ2=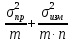 ,
,
где σпр2– погрешность
пробоотбора, σизм2–
погрешность измерения,m– число проб,n– число
параллельных определений.
2) Методическая ошибка OобOоб=
— ,
,
гдеs– растворимость
осадка, г/100 мл воды;Vф
– объем фильтрата и промывных вод,
мл;mгр– масса
полученного осадка, г.
3) Относительное стандартное отклонение
 =
= , гдеσгр – дисперсия
, гдеσгр – дисперсия
массы гравиметрической формы;mгр– масса гравиметрической формы; σa– дисперсия массы исходной навески;a– масса исходной навески;p– процентное содержание вещества в
исследуемой пробе;n–число
измерений.
4) Погрешность взвешивания тары σa1и тары с навескойσa2σa1=σa2=0,0002
г, σгр= = 0,0003 г.
= 0,0003 г.
5) Относительное стандартное отклонение
с учетом стадий пробоотбора и
пробоподготовки
 =
= , гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
, гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
Ni(HDMG)2– кристаллический осадок.
Условия его осаждения следующие:
1) осаждение ведут из достаточно
разбавленного исследуемого раствора
разбавленным раствором осадителя
(концентрации исследуемого раствора и
раствора осадителя должны быть примерно
одинаковыми);
2) раствор осадителя прибавляют медленно,
по каплям, при постоянном перемешивании
стеклянной палочкой (это предотвращает
явление окклюзии);
3) осаждение ведут из подогретого
исследуемого раствора горячим раствором
осадителя (для предотвращения пептизации);
4) к раствору прибавляют вещества,
способствующие повышению растворимости
осадка (увеличивают Iраствора), а затем понижают его
растворимость путем прибавления избытка
осадителя;
5) осадок оставляют на «созревание».
11. Гравиметрическое определение меди:
этапы определения, возможные формулы
осадителей, осаждаемой и гравиметрической
формулы, механизм образования осадка,
возможные варианты загрязнения осадка,
приемы повышения чистоты осадка,
погрешности. Преимущества органических
осадителей. Условия выделения осадков.
При гравиметрическом определении меди
медь из раствора осаждают различными
осадителями: 1) раствор аммиака осаждает
из нагретого раствора осадок Cu(OH)2;
2) Тиокарбонат калияK2CS3осаждает из нагретого раствора осадокCuS, который сушат при
100-110 ;
;
3) В виде оксалата медь осаждается в
присутствиеCH3COOH;
4) При определении меди в виде
тетророданомеркуриатамедиCu[Hg(SCN)4]
медь осаждают из нагретого до кипения
раствора содержащего серную или азотную
кислоту, действиемK2[Hg(SCN)4].
Метод рекомендован для определения
меди в медных рудах; 5) Соль Рейнеке
(тетрароданодиаминохромат аммония)
NH4[Cr(NH3)2(SCN)4]
является избирательным реагентом для
определения меди в присутствие многих
посторонних ионов. Осаждение проводят
как в кислом, так и в аммиачном растворе
в виде [Cu(NH3)4][Cr(NH3)2(SCN)4]2
после предварительного восстановления
меди до одновалентного состояния
оловом(II). Для осаждения меди используются
также различные органические реагенты:
1) 8- оксихинолин осаждает медь в
уксуснокислом, аммиачном и щелочном
растворах при pH=5.33 — 14.55. Осадок, высушенный
при 105-110°С, соответствует составу
Cu(C9H6ON)2; 2) Медь осаждается
спиртовым раствором β-бензоиноксима в
слабощелочной среде в виде хлопьевидного
зеленого осадка составаCu(C6H5CHOCNOC6H5)2.
Осадок высушивают при 105-110 ;
;
3) Салицилальдиоксим осаждает Cu (II) в
виде внутрикомплексного соединения
Cu(C7H6O2N)2в
уксуснокислой среде, среде ацетатного
буфера или ацетата аммония; 4) При действии
купферона наCu(II)
образуется купферонат меди (II)
с формулой Cu(C6H5N(NO)O)2;
5) При действии глицина на медь образуется
кристаллический осадок глицината меди
(II)Cu(NH2CH2COO)2.
Рассмотрим гравиметрическое определение
меди на примере осаждения ее
глицином.Реакция:CuO+2NH2CH2COOH=Cu(NH2CH2COO)2+H2OВданном случае глицинNH2CH2COOHявляется
осадителем, глицинат меди (II)Cu(NH2CH2COO)2– осаждаемой формой. При высушивании
получается гравиметрическая форма
сухогоCu(NH2CH2COO)2.
Этапы определения:1) взятие навески
и её растворение;2) приготовление раствора
осадителя;3) осаждение;4) фильтрование
и промывание;5) высушивание осадка;6)
взвешивание осадка, расчёт содержания
меди.
Механизм образования осадка:в
процессе образования осадка различают
3 параллельных процесса: 1) образование
зародышей кристалла (центров
кристаллизации); 2) рост кристаллов; 3)
объединение (агрегация) хаотично
ориентированных мелких кристаллов. В
начальный момент происходит насыщение
раствора, а затем его пересыщение. В
момент определенной пересыщенности
раствора, начинается выпадение осадка.
Центром кристалла может служить твердая
частица этого вещества или любая другая
твердая частица, которую мы вносим в
раствор, твердые частицы могут изначально
присутствовать в растворе как примесь.
Если осаждение происходит из разбавленных
растворов, то появление осадка занимает
время-индукционный период.
В процессе добавления каждой новой
порции осадителя происходит мгновенное
пересыщение раствора, зародыши растут
быстро за счет окружающих их ионов, как
только зародыш достиг определенного
размера выпадает осадок.
Рост кристаллов идет параллельно 1-ой
стадии, происходит за счет диффузии
ионов к поверхности растущего кристалла.
Число и размер частиц осадка (дисперсность
системы кол-во в единицы объёма) зависит
от соотношения скоростей 1-ой и 2-ой
стадий (V1— скорость
образования зародышей,V2-скорость
роста кристаллов):V1>>V2-мелкодисперсный
осадок,V1<<V2-крупнокристаллический
осадок. Какая из стадий будет лимитировать
определяет скорость осаждения и
концентрации ионов. При медленном
осаждении лимитирующей стадией является
кристаллизация, частица окружена
однородным слоем осаждаемых ионов в
результате получается кристалл правильной
формы. При высокой концентрации ионов
лимитирующей стадией становится
диффузия, образуются кристаллы
неправильной формы с большой площадью
поверхности. Следует отметить, что на
скорость процесса кристаллизации влияет ,
,
влияние различно на скорость образования
различно на скорость образования
зародышей и на скорость роста кристаллов.
При высокой степени образуются
образуются
мелкодисперсные осадки, при уменьшении образуются крупнокристаллические
образуются крупнокристаллические
осадки. Агрегация происходит в гетерогенной
системе, в значительной степени
определяется числом центров
кристаллизации.Чем больше центров
кристаллизации, тем в меньшей степени
они укрупняются на второй стадии, тем
хуже структура и тем выше дисперсность
осадков.
К аналитическим свойствам осадка
относятся: растворимость, чистота,
фильтруемость.Лучшими свойствами
обладают крупнокристаллические осадки.
Возможные варианты загрязнения: 1)
Путем адсорбции ( для конкретного примера
хлорид-ионов на поверхности осадка); 2)
Окклюзия; 3) Изоморфное соосаждение; 4)
Совместное осаждение; 5) Последующее
осаждение.
Приемы повышения чистоты осадка:
1) Адсорбированные на поверхности примеси
хорошо удаляются при промывании осадков
на фильтре при помощи промывных жидкостей,
т.к. примеси переходят в промывную
жидкость и уходят через поры фильтра.
Эффективно многократное промывание
небольшими порциями промывной жидкости.
Промывную жидкость выбирают максимально
тщательно, чтобы не увеличивать
растворимость осадка и не ухудшать его
фильтрацию. Кристаллические осадки
промывают холодными промывными
жидкостями, чтобы не увеличить
растворимость осадка, а аморфные –
наоборот горячими. Водой промывают
осадки с низкими константами растворимости
(ниже 10-11-10-12), а также те,
которые не подвергаются пептизации.
Если константа растворимости осадка
10-9-10-11и он кристаллический,
то его промывают разбавленным раствором
осадителя. Аморфные осадки промывают
разбавленными растворами
электролитов-коагулянтов (солиNH4+),
чтобы избежать пептизации (в опыте с
железом осадок промывали растворомNH4NO3).
Повышение температуры также способствует
уменьшению адсорбции (на конкретном
примере горячий раствор, содержащий
10% аммиак разбавляют горячей водой для
уменьшения адсорбции хлорид-ионов на
поверхности осадка). 2) Для очищения
окклюдированных примесей в случае
кристаллических осадков используют
старение, в случае аморфных осадков –
переосаждение.Степень окклюзии в
процессе осаждения можно уменьшить
медленным добавлением осадителя по
каплям, при перемешивании.
Погрешности:1) Общая погрешность
анализа σ2 =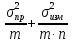 ,
,
где σпр2– погрешность
пробоотбора, σизм2–
погрешность измерения,m– число проб,n– число
параллельных определений
2) Методическая ошибка OобOоб=
— ,
,
гдеs– растворимость
осадка, г/100 мл воды;Vф
– объем фильтрата и промывных вод,
мл;mгр– масса
полученного осадка, г.
3) Относительное стандартное отклонение
 =
= , гдеσгр – дисперсия
, гдеσгр – дисперсия
массы гравиметрической формы;mгр– масса гравиметрической формы; σa– дисперсия массы исходной навески;a– масса исходной навески;p– процентное содержание вещества в
исследуемой пробе;n–число
измерений.
4) Погрешность взвешивания тары σa1и тары с навескойσa2σa1=σa2=0,0002
г, σгр= = 0,0003 г.
= 0,0003 г.
5) Относительное стандартное отклонение
с учетом стадий пробоотбора и
пробоподготовки
 =
= , гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
, гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
Преимущества органических осадителей:
1. Пользуясь органическими осадителями,
можно осаждать и разделять различные
элементы из очень сложных смесей.
Например, при помощи диметилглиоксима
возможно количественное осаждение
катионов никеля в присутствии многих
других катионов.
2. Осадки, получающиеся с органическими
осадителями, хорошо отфильтровываются
и промываются (например, осадки комплексных
соединений катионов, содержащих в
качестве лигандов пиридин или другие
органические соединения). Это дает
возможность легко отмывать от осадков
примеси, содержащиеся в анализируемом
растворе.
3. Осадки, получающиеся при действии на
катионы или анионы органических
осадителей, отличаются большим
молекулярным весом. Вследствие этого
точность анализа повышается. Например,
определение магния, алюминия и других
катионов проводится с большой точностью
осаждением их в виде оксихинолятов,
обладающих большим молекулярным весом.
4. В составе осадков, являющихся
соединениями неорганических веществ
с органическими компонентами, обычно
содержится мало соосаждающихся пиримесей.
Cu(NH2CH2COO)2– кристаллический осадок, поэтому
условия его выделения следующие:
1) осаждение ведут из достаточно
разбавленного исследуемого раствора
разбавленным раствором осадителя
(концентрации исследуемого раствора и
раствора осадителя должны быть примерно
одинаковыми);
2) раствор осадителя прибавляют медленно,
по каплям, при постоянном перемешивании
стеклянной палочкой (это предотвращает
явление окклюзии);
3) осаждение ведут из подогретого
исследуемого раствора горячим раствором
осадителя (для предотвращения пептизации);
4) к раствору прибавляют вещества,
способствующие повышению растворимости
осадка (увеличивают Iраствора), а затем понижают его
растворимость путем прибавления избытка
осадителя;
5) осадок оставляют на «созревание».
12. Гравиметрическое определение
кремния в силикатных породах: этапы
определения, возможные формулы осадителя,
осаждаемой и гравиметрической формулы,
механизм образования коллоидной частицы,
процессы, приводящие к образованию
осадка, возможные варианты загрязнения
осадка, приемы повышения чистоты осадка,
погрешности. Классификация коллоидных
систем. Условия аналитического выделения
кремнекислоты.
При гравиметрическом определении
кремния растворимый силикат натрия
Na2SiO3,
полученный в результате сплавления не
разлагаемой кремниевой кислоты с содойNa2CO3,
обрабатывается сильной кислотойHCl.
Реакция:Na2SiO3+2HCl=H2SiO3↓+2NaCl.
Осадителем в данном случае являетсяHCl, осаждаемой формой –H2SiO3.
При высушивании и прокаливании получается
гравиметрическая формаSiO2.
Этапы определения:1) взятие навески
и ее растворение; 2) приготовление
раствора осадителя; 3) осаждение; 4)
фильтрование и промывание осадка; 5)
высушивание и прокаливание осадка;; 6)
взвешивание осадка, расчет содержания
кремния.
Механизм образования коллоидной
частицы: Вещество в коллоидной системе
имеет большую развитую поверхность и
нескомпенсированный заряд на границе
разлела фаз. Существование
нескомпенсированного силового поля
ведет к адсорбции из раствора молекул
или ионов. Если коллоидная система
возникла в результате проведения
химической реакции осаждения, то частицы
адсорбируют в первую очередь те ионы,
которые могут достраивать кристаллическую
решетку. Адсорбированные ионы сообщают
частице “+» или “-“ заряд. Слой
адсорбированных ионов на ядре – это
первичный адсорбционный слой. Заряд,
созданный таким слоем, достаточно высок
и обуславливает электростатическое
взаимодействие с иоами противоположного
знака. В результате образуется слой
противоионов, который выравнивает заряд
первичного слоя. Слой противоионов
имеет диффузный характер. Часть
противоионов, прочно связанных с
первичным слоем – это плотный слой,
остальные противоионы составляют
диффузный слой.
Образование осадкапроисходит
тогда, когда раствор становится
пересыщенным, т.е. [A+]m[B-]n>Ks(ПКИ>ПР). Образование осадков связано
с процессом укрупнения частиц, с
образованием кристаллической решетки
вещества. Этот процесс определяется
числом центров кристаллизации: чем
больше центров, тем в меньшей степени
они укрупняются и тем хуже структура и
выше дисперсность осадка.
Возможные варианты загрязнения:1)
Путем адсорбции ( для конкретного примера
хлорид-ионов на поверхности осадка); 2)
Окклюзия; 3) Изоморфное соосаждение; 4)
Совместное осаждение; 5) Последующее
осаждение.
Приемы повышения чистоты осадка:
1) Адсорбированные на поверхности примеси
хорошо удаляются при промывании осадков
на фильтре при помощи промывных жидкостей,
т.к. примеси переходят в промывную
жидкость и уходят через поры фильтра.
Эффективно многократное промывание
небольшими порциями промывной жидкости.
Промывную жидкость выбирают максимально
тщательно, чтобы не увеличивать
растворимость осадка и не ухудшать его
фильтрацию. Кристаллические осадки
промывают холодными промывными
жидкостями, чтобы не увеличить
растворимость осадка, а аморфные –
наоборот горячими. Водой промывают
осадки с низкими константами растворимости
(ниже 10-11-10-12), а также те,
которые не подвергаются пептизации.
Если константа растворимости осадка
10-9-10-11и он кристаллический,
то его промывают разбавленным раствором
осадителя. Аморфные осадки промывают
разбавленными растворами
электролитов-коагулянтов (солиNH4+),
чтобы избежать пептизации (в опыте с
железом осадок промывали растворомNH4NO3).
Повышение температуры также способствует
уменьшению адсорбции (на конкретном
примере горячий раствор, содержащий
10% аммиак разбавляют горячей водой для
уменьшения адсорбции хлорид-ионов на
поверхности осадка). 2) Для очищения
окклюдированных примесей в случае
кристаллических осадков используют
старение, в случае аморфных осадков –
переосаждение.Степень окклюзии в
процессе осаждения можно уменьшить
медленным добавлением осадителя по
каплям, при перемешивании.
Погрешности:
1) Общая погрешность анализа σ2 = ,
,
где σпр2– погрешность
пробоотбора, σизм2–
погрешность измерения,m– число проб,n– число
параллельных определений.
2) Методическая ошибка OобOоб=
— ,
,
гдеs– растворимость
осадка, г/100 мл воды;Vф
– объем фильтрата и промывных вод,
мл;mгр– масса
полученного осадка, г.
3) Относительное стандартное отклонение
 =
= , гдеσгр – дисперсия
, гдеσгр – дисперсия
массы гравиметрической формы;mгр– масса гравиметрической формы; σa– дисперсия массы исходной навески;a– масса исходной навески;p– процентное содержание вещества в
исследуемой пробе;n–число
измерений.
4) Погрешность взвешивания тары σa1и тары с навескойσa2σa1=σa2=0,0002
г, σгр= = 0,0003 г.
= 0,0003 г.
5) Относительное стандартное отклонение
с учетом стадий пробоотбора и
пробоподготовки
 =
= , гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
, гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
Классификация коллоидных систем. В
зависимости от характера межмолекулярных
сил, которые действуют на границе раздела
фаз коллоидные растворы делят на
лиофильные и лиофобные. Вокруг лиофильной
частицы располагается прочная сольватная
оболочка. В этих оболочках молекулы
ориентированы определенным образом и
образуют более или менее правильные
структуры. Вокруг лиофобной частицы
раствора также имеются сольватные
оболочки, но они непрочные и не предохраняют
молекулы от слипания.
H2SiO3– аморфный осадок, поэтому
условия его осаждения следующие:
1)осаждение проводят из горячего раствора
анализируемого вещества горячим
раствором осадителя при перемешивании;
2)осаждение проводят из достаточно
концентрированного исследуемого
раствора концентрированным раствором
осадителя с последующим разбавлением(при
разбавлении устанавливается адсорбционное
равновесие, часть адсорбированных ионов
переходи в раствор, и осадок становится
более чистым); 3)осаждение проводят в
присутствии подходящего
электролита-коагулятора;
4)аморфные осадки почти не требуют
времени для созревания, их необходимо
фильтровать сразу после разбавления
раствора. Аморфные осадки нельзя
оставлять более, чем на несколько минут,
т.к. сильное уплотнение их затрудняет
последующее отмывание примесей, а также
при стоянии увеличивается количество
примесей, адсорбированных поверхностью
осадка.
Ошибки в программировании – дело обычное, хоть и неприятное. В данной статье будет рассказано о том, какими бывают ошибки (баги), а также что собой представляют исключения.
Определение
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Баги обнаруживаются чаще всего в момент отладки или бета-тестирования. Реже – после итогового релиза готовой программы. Вот несколько вариантов багов:
- Появляется сообщение об ошибке, но приложение продолжает функционировать.
- ПО вылетает или зависает. Никаких предупреждений или предпосылок этому не было. Процедура осуществляется неожиданно для пользователя. Возможен вариант, при котором контент перезапускается самостоятельно и непредсказуемо.
- Одно из событий, описанных ранее, сопровождается отправкой отчетов разработчикам.
Ошибки в программах могут привести соответствующее приложение в негодность, а также к непредсказуемым алгоритмам функционирования. Желательно обнаруживать баги на этапе ранней разработки или тестирования. Лишь в этом случае программист сможет оперативно и относительно недорого внести необходимые изменения в код для отладки ПО.
История происхождения термина
Баг – слово, которое используется разработчиками в качестве сленга. Оно произошло от слова «bug» – «жук». Точно неизвестно, откуда в программировании и IT возник соответствующий термин. Существуют две теории:
- 9 сентября 1945 года ученые из Гарварда тестировали очередную вычислительную машину. Она называлась Mark II Aiken Relay Calculator. Устройство начало работать с ошибками. Когда его разобрали, то ученые заметили мотылька, застрявшего между реле. Тогда некая Грейс Хоппер назвала произошедший сбой упомянутым термином.
- Слово «баг» появилось задолго до появления Mark II. Термин использовался Томасом Эдисоном и указывал на мелкие недочеты и трудности. Во время Второй Мировой войны «bugs» называли проблемы с радарной электроникой.
Второй вариант кажется более реалистичным. Это факт, который подтвержден документально. Со временем научились различать различные типы багов в IT. Далее они будут рассмотрены более подробно.
Как классифицируют
Ошибки работы программ разделяются по разным факторам. Классификация у рядовых пользователей и разработчиков различается. То, что для первых – «просто программа вылетела» или «глючит», для вторых – огромная головная боль. Но существует и общепринятая классификация ошибок. Пример – по критичности:
- Серьезные неполадки. Это нарушения работоспособности приложения, которые могут приводить к непредвиденным крупным изменениям.
- Незначительные ошибки в программах. Чаще всего не оказывают серьезного воздействия на функциональность ПО.
- Showstopper. Критические проблемы в приложении или аппаратном обеспечении. Приводят к выходу программы из строя почти всегда. Для примера можно взять любое клиент-серверное приложение, в котором не получается авторизоваться через логин и пароль.
Последний вариант требует особого внимания со стороны программистов. Их стараются обнаружить и устранить в первую очередь. Критические ошибки могут отложить релиз исходной программы на неопределенный срок.
Также существуют различные виды сбоев в плане частоты проявления: постоянные и «разовые». Вторые встречаются редко, чаще – при определенных настройках и действиях со стороны пользователя. Первые появляются независимо от используемой платформы и выполненных клиентом манипуляций.
Иногда может получиться так, что ошибка возникает только на устройстве конкретного пользователя. В данном случае устранение неполадки требует индивидуального подхода. Иногда – полной замены компьютера. Связано это с тем, что никто не будет редактировать исходный код, когда он «глючит» только у одного пользователя.
Виды
Существуют различные типы ошибок в программах в зависимости от типовых условий использования приложений. Пример – сбои, которые возникают при возрастании нагрузки на оперативную память или центральный процессор устройства. Есть баги граничных условий, сбоя идентификаторов, несовместимости с архитектурой процессора (наиболее распространенная проблема на мобильных устройствах).
Разработчики выделяют следующие типы ошибок по уровню сложности:
- «Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
- «Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
- «Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
- «Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Также есть классификация «по критичности». Тут всего два варианта – warning («варнинги») и критические весомые сбои. Первые сопровождаются характерными сообщениями и отчетами для разработчиков. Они не представляют серьезной опасности для работоспособности приложения. При компилировании такие сбои легко исправляются. В отдельных случаях компилятор справляется с этой задачей самостоятельно. А вот критические весомые сбои говорят сами за себя. Они приводят к серьезным нарушениям ПО. Исправляются обычно путем проработки логики и значительных изменений программного кода.
Типы багов
Ошибки в программах бывают:
- логическими;
- синтаксическими;
- взаимодействия;
- компиляционные;
- ресурсные;
- арифметические;
- среды выполнения.
Это – основная классификация сбоев в приложениях и операционных системах. Логические, синтаксические и «среды выполнения» встречаются в разработке чаще остальных. На них будет сделан основной акцент.
Ошибки синтаксиса
Синтаксические баги распространены среди новичков. Они относятся к категории «самых безобидных». С данной категорией ошибок способны справиться компиляторы тех или иных языков. Соответствующие инструменты показывают, где допущена неточность. Остается лишь понять, как исправить ее.
Синтаксические ошибки – ошибки синтаксиса, правил языка. Вот пример в Паскале:

Код написан неверно. Согласно действующим синтаксическим нормам, в Pascal в первой строчке нужно в конце поставить точку с запятой.
Логические
Тут стоит выделить обычные и арифметические типы. Вторые возникают, когда программе при работе необходимо вычислить много переменных, но на каком-то этапе расчетов возникают неполадки или нечто непредвиденное. Пример – получение в результатах «бесконечности».
Логические сбои обычного типа – самые сложные и неприятные. Их тяжелее всего обнаружить и исправить. С точки зрения языка программа может быть написана идеально, но работать неправильно. Подобное явление – следствие логической ошибки. Компиляторы их не обнаруживают.

Выше – пример логической ошибки в программе. Тут:
- Происходит сравнение значения i с 15.
- На экран выводится сообщение, если I = 15.
- В заданном цикле i не будет равно 15. Связано это с диапазоном значений – от 1 до 10.
Может показаться, что ошибка безобидная. В приведенном примере так и есть, но в более крупных программах такое явление приводит к серьезным последствиям.
Время выполнения
Run-time сбои – это ошибка времени выполнения программы. Встречается даже когда исходный код лишен логических и синтаксических ошибок. Связаны такие неполадки с ходом выполнения программного продукта. Пример – в процессе функционирования ПО был удален файл, считываемый программой. Если игнорировать подобные неполадки, можно столкнуться с аварийным завершением работы контента.
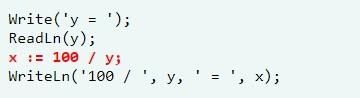
Самый распространенный пример в данной категории – это неожиданное деление на ноль. Предложенный фрагмент кода с точки зрения синтаксиса и логики написан грамотно. Но, если клиент наберет 0, произойдет сбой системы.
Компиляционный тип
Встречается при разработке на языках высокого уровня. Во время преобразований в машинный тип «что-то идет не так». Причиной служат синтаксические ошибки или сбои непосредственно в компиляторе.
Наличие подобных неполадок делает бета-тестирование невозможным. Компиляционные ошибки устраняются при разработке-отладке.
Ресурсные
Ресурсный тип ошибок – это сбои вроде «переполнение буфера» или «нехватка памяти». Тесно связаны с «железом» устройства. Могут быть вызваны действиями пользователя. Пример – запуск «свежих» игр на стареньких компьютерах.
Исправить ситуацию помогают основательные работы над исходным кодом. А именно – полное переписывание программы или «проблемного» фрагмента.
Взаимодействие
Подразумевается взаимодействие с аппаратным или программным окружением. Пример – ошибка при использовании веб-протоколов. Это приведет к тому, что облачный сервис не будет нормально функционировать. При постоянном возникновении соответствующей неполадки остается один путь – полностью переписывать «проблемный» участок кода, ответственный за соответствующий баг.
Исключения и как избежать багов
Исключение – событие, при возникновении которых начинается «неправильное» поведение программы. Механизм, необходимый для стабилизации обработки неполадок независимо от типа ПО, платформ и иных условий. Помогают разрабатывать единые концепции ответа на баги со стороны операционной системы или контента.
Исключения бывают:
- Программными. Они генерируются приложением или ОС.
- Аппаратными. Создаются процессором. Пример – обращение к невыделенной памяти.
Исключения нужны для охвата критических багов. Избежать неполадок помогут отладчики на этапе разработки. А еще – своевременное поэтапное тестирование программы.
P. S. Большой выбор курсов по тестированию есть и в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.