Итак, предположив,
что в модели наблюдений
![]()
![]()
ошибки
![]() —независимые случайные величины,
—независимые случайные величины,
имеющие одинаковое распределение (i.
i. d), мы должны сделать и
предположение о том,каким именноявляется это распределение.
Классические
методы статистического анализа линейных
моделей наблюдений предполагают, что
таковым является распределение
Гаусса (Gaussian distribution),
функция плотности которого имеет вид
![]()
График указанной
функции плотности имеет колоколообразную
форму
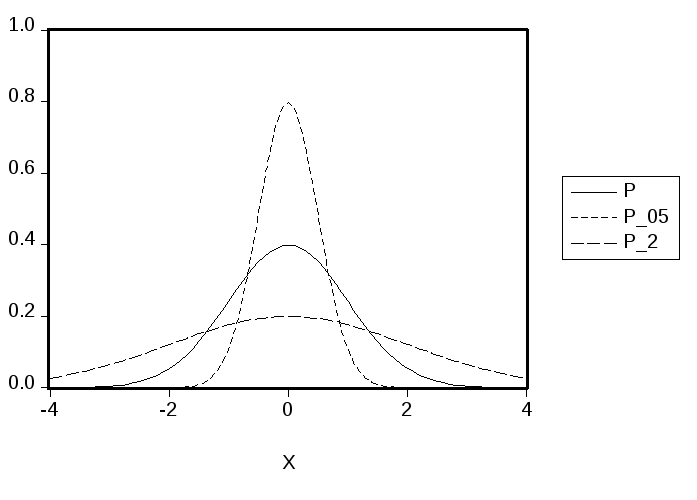
Параметр
![]() характеризует степень рассредоточения
характеризует степень рассредоточения
распределения вдоль оси абсцисс. На
диаграмме представлены графики функций
плотности гауссовского распределения
при трех различных значениях параметра![]() .
.
Из трех представленных функций наибольшее
значение в нуле имеет функция плотности
с![]() ,
,
наименьшее — функция плотности с![]() ,
,
а промежуточное между ними — функция
плотности с![]() .
.
Эти значения равны, соответственно,
![]()
Гауссовское
распределение симметрично относительно
нуля, и это предполагает, чтоположительные ошибки столь же вероятны,
как и отрицательные; при этом, малые
ошибки встречаются чаще, чем большие.
Если случайная ошибка имеет гауссовское
распределение с параметром![]() ,
,
тос вероятностью ![]() ее значение будет заключено в пределах
ее значение будет заключено в пределах
от ![]()
до ![]() .
.
Соответственно, для трех рассмотренных
случаев получаем: с вероятностью![]() значение случайной ошибки заключено в
значение случайной ошибки заключено в
интервале
![]() —при
—при
![]() ,
,![]() —
—
при![]() ,
,![]() —
—
при![]() .
.
Хотя гауссовское
распределение довольно часто вполне
приемлемо для описания случайных ошибок
в моделях наблюдений, оно вовсе не
является универсальным. Такое распределение
характерно для ситуаций, когда
результирующая ошибка является следствием
сложения большого количества независимых
случайных ошибок, каждая из которых
достаточно мала.
Мы будем далее в
этом параграфе предполагать, что процесс
порождения данных (ППД,
или DGP- data generating process)устроен
следующим образом. Значения![]() известны точнои рассматриваются
известны точнои рассматриваются
какзаданные, а значения![]() получаютсяналожениемна значения
получаютсяналожениемна значения![]() случайных ошибок
случайных ошибок![]() .
.
В этом контексте,
![]() рассматриваются как некоторыепостоянные(хотя ине известныенаблюдателю).
рассматриваются как некоторыепостоянные(хотя ине известныенаблюдателю).
Напротив, значения![]() носятслучайныйхарактер, определяемый
носятслучайныйхарактер, определяемый
случайным характером значений![]() .
.
Собственно,![]() отличается от случайной величины
отличается от случайной величины![]() лишьсдвигом на постоянную
лишьсдвигом на постоянную ![]() ,
,
и потому также является случайной
величиной. Мы будем обозначать ее в
этом качестве как случайную величину![]() .
.
Функция распределения этой случайной
величины имеет вид

где
![]() — функция распределения случайной
— функция распределения случайной
величины![]() (одинаковаядля всех
(одинаковаядля всех![]() ).
).
Соответственно, функция плотности
распределения случайной величины![]() имеет вид
имеет вид
![]()
где
![]() — функция плотности распределения
— функция плотности распределения
случайной величины![]() .
.
Таким образом,
случайные величины
![]() хотя и являются взаимно независимыми
хотя и являются взаимно независимыми
(в силу предполагаемой взаимной
независимости случайных величин![]() ),
),
но имеютразные распределения,отличающиеся сдвигом. На следующем
рисунке представлены графики функции
плотности![]() распределения
распределения![]() (гауссовское распределение с параметром
(гауссовское распределение с параметром![]() )
)
и функции плотности![]() распределения случайной величины
распределения случайной величины![]() при значении
при значении![]() .
.

Заметим, что если
случайная ошибка
![]() имеетгауссовское распределение с
имеетгауссовское распределение с
плотностью
![]()
то отличающаяся
от нее сдвигом случайная величина
![]() имеет функцию плотности
имеет функцию плотности
![]()
Эта функция
плотности принадлежит двухпараметрическому
семейству функций плотности вида
![]() Функции
Функции
плотности такого вида называются
нормальными плотностями, а
определяемые ими распределения
вероятностей называютсянормальными
распределениями вероятностей. Если
некоторая случайная величина![]() имеет плотность распределения, заданную
имеет плотность распределения, заданную
последним соотношением, то говорят, чтослучайная величина Y имеет нормальное
распределение с параметрами
и 2.
Распределение такой случайной величины
симметрично относительно своегосреднего
значения.
Максимальное значение функции плотности
этой случайной величины достигается
при![]() .
.
Таким образом,
строго говоря, гауссовское распределение
— это нормальное распределение с нулевым
средним значением.Однако, в современной
научной литературе терминынормальное
распределение игауссовское
распределение используются как
синонимы:нормальное распределение
с параметрами
и 2 называют
такжегауссовским распределением
с параметрами
и 2.
Важнейшая роль
предположения о нормальном (гауссовском)
распределении ошибок в линейной модели
наблюдений
![]()
![]()
определяется тем
обстоятельством, что при добавлении
такого предположения к стандартному
предположениюо том, что ошибки![]() —независимые случайные величины,
—независимые случайные величины,
имеющие одинаковое распределение,
можно легко найти точный вид распределения
оценок наименьших квадратов для
неизвестных значений параметров модели.
Вспомним, в этой
связи, полученное ранее выражение

Обозначая
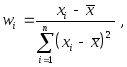
мы можем записать
выражение для
![]() в виде
в виде
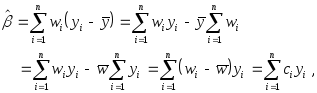
где
![]()
Таким образом,
![]()
где
![]() —фиксированные величины, а
—фиксированные величины, а![]() —наблюдаемые значения случайных
—наблюдаемые значения случайных
величин ![]() .
.
Поэтомувычисленноепо последней
формуле значение![]() являетсянаблюдаемым значением
являетсянаблюдаемым значением
случайной величины
![]()
![]()
которая является
линейной комбинацией случайных величин![]() и имеет некоторое распределение
и имеет некоторое распределение
вероятностей, зависящее от распределения
последних.
В общем случае,
аналитическое описание распределения
![]() как случайной величины довольно
как случайной величины довольно
затруднительно. Более просто эта задача
решается в ситуации, когда![]() имеетгауссовскоераспределение.
имеетгауссовскоераспределение.
Если ошибки![]() —независимые случайные величины,
—независимые случайные величины,
имеющие одинаковое нормальное
распределение с нулевым средним, то
тогда оценка наименьших квадратов![]() параметра
параметра![]() также имеет нормальное распределение.
также имеет нормальное распределение.
Чтобы указать параметры этого нормального
распределения и иметь возможность
проводить статистический анализ
подобранной модели линейной связи между
переменными факторами, нам придется
уделить внимание некоторым важным
числовым характеристикам случайных
величин и их свойствам.
![]()
Распределение ошибок Гаусса
Карл Гаусс в начале XIX века вывел закон распределения ошибок величины, получаемой в эксперименте. При этом он принял как постулаты следующие допущения:
1) Равные по модулю ошибки равновероятны.
2) Чем больше ошибка, тем меньше её вероятность.
3) При увеличении ошибки вероятность её стремится к нулю.
4) «Постулат Гаусса»: из серии проведённых измерений наиболее точным является среднее значение.
Этот закон записывается следующей формулой:
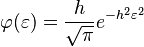
Здесь φ — вероятность, ε — величина ошибки, h — мера точности (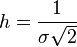 , где σ — стандартное отклонение).
, где σ — стандартное отклонение).
Из результатов исследования исключают грубые ошибки — промахи. Для установления границы между грубыми и случайными ошибками пользуются критериями Райта или Шовене. По критерию Райта отклонения от центра группирования размеров, подчиняющихся закону Гаусса, по абсолютной величине больше За, т. е. I л I > За они относятся к грубым ошибкам. [c.49]
Случайные ошибки характеризуются неопределенностью величины и знака. Они сопровождают любое измерение. Вероятность появления случайной ошибки тем больше, чем меньше эта ошибка по абсолютной величине. Случайные ошибки подчиняются так называемому нормальному распределению (закону Гаусса). Сущность его ясна из графика на рис. 4. По горизонтальной оси откладывается измеряемая величина х, а по вертикальной оси — вероятность (Р1) получения каждого данного значения Х , отличающегося от среднего значения Хо на Ах = — Хг — Хц. График показывает, что чем больше отклонение Ах, тем меньше вероятность получения соответствующего х,-. Отклонения от среднего значения в положительную и отрицательную стороны равновероятны. [c.14]
Нормальный закон распределения случайных ошибок. Случайные ошибки измерения характеризуются определенным законом их распределения. К наиболее простым и достаточно точно отражающим действительность, относится нормальный закон распределения, или закон Гаусса [c.313]
Гауссом был найден закон распределения случайных ошибок. Этот закон справедлив почти для любых измерений, в том числе и для количественного спектрального анализа. На рис. 135, а графически показана зависимость числа измерений, в которых встречается та или иная ошибка, от ее величины при достаточно большом числе измерений. [c.226]
Теперь необходимо выяснить важный практический вопрос какое же наименьшее количество измерений нужно сделать, чтобы достаточно надежно характеризовать данную методику. Если число измерений мало, то среди них может оказаться слишком много или наоборот слишком мало результатов с большой ошибкой, чем ЭТО следует из закона распределения. Поэтому, прежде чем подсчитывать ошибку, которую дает данная методика, необходимо убедиться, что хотя бы примерно выполняется закон распределения Гаусса. В этом случае [c.229]
Корректность макроскопического закона (9.3.1) была доказана строго в следующем смысле. Выберем временной интервал (О, Т) с допустимой ошибкой б > 0. Тогда вероятность того, что для всех (0, Т) истинное значение х отличается от <р(/) не более чем на б, стремится к 1 при 2- оо. Было также доказано , что ошибка стремится к распределению Гаусса, как это дается приближением линейного шума. Отметим, однако, что здесь Т фиксируется до того, как й устремляется к бесконечности, а это означает, что ничего [c.249]
Следуя [1], можно определить диаметр с з электронного зонда с током 1. Плотность тока в сфокусированном зонде приблизительно распределена по закону Гаусса, и поэтому можно определить размер зонда с з. Для практических целей диаметр зонда определяется как величина, внутри которой содержится некоторая определенная доля полного тока ( 85%). При расчете тока 3 обычно предполагается, что все значительные аберрации вызываются конечной линзой. Учитываются хроматическая II сферическая аберрации, а также дифракционная ошибка. Способ расчета состоит в вычислении отдельных диаметров зонда (1, хр, сф и йд, которые рассматриваются как функции ошибок, а эффективный размер пятна йз равняется корню квадратному из суммы квадратов отдельных диаметров [c.12]
Классическая теория ошибок, развитая Гауссом, базируется на предположении, что результаты измерений, подверженных случайным ошибкам, следуют нормальному закону распределения (распределению Гаусса) [c.417]
Часто требуется сравнить значения одних и тех же кинетических параметров, полученных разными авторами. В такой ситуации необходимо применять для сравнения статистические критерии [13], так как параметры определяются с ошибкой. Почти все статистические критерии основаны на предположении о том, что сравниваемые величины распределены по закону Гаусса. Исходя из этого удобно, чтобы определяемые на ЭВМ константы скоростей имели бы гауссовское (нормальное) распределение. [c.88]
В последнем примере в таблице (см. стр. 231) даны средние квадратичные ошибки, рассчитанные по одному измерению. Сравнение средней квадратичной ошибки, рассчитанной на основании закона Гаусса и равной 18,6 с соответствуюш,ими значениями, полученными на основании закона Пуассона, указывает на значительный вклад статистической ошибки в общую ошибку. [c.233]
Общепринятая модель основана на том, что количество вещества прямо пропорционально отклику датчика. Если допустить, что все необходимые условия для сохранения этой пропорциональности соблюдены, то полученная оценка логически справедлива. При прямом методе обработки для получения оценки нужно просто умножить полученное значение на коэффициент пропорциональности. Два разных наблюдения должны, всего вероятнее, дать две разных оценки, и более полная модель даст возможность определить окончательную ошибку, вызванную специфической причиной. При графическом анализе для получения оценки на основании ряда наблюдений строится прямая линия. Методом минимаксного оценивания определяется наилучшая прямая линия путем уменьшения максимальных отклонений. Этот метод требует по меньшей мере трех точек и не рационален в тех случаях, когда исследователь использует главным образом наблюдения с максимальными отклонениями. При исиользовании метода наименьших квадратов сумма квадратов абсолютных отклонений сводится к минимуму наблюдения взвешиваются в соответствии с обратной величиной их стандартных отклонений. Метод наибольшей вероятности более сложен, но в случаях, когда ошибка подчиняется закону распределения Гаусса, он дает те же результаты, что и метод наименьших квадратов. Этот метод можно неограниченно применять и для случаев с другими видами распределений. Основной особенностью байесовского метода, как уже упоминалось, является распределение истинных величин относительно измеренного наблюдения, а не распределение измерений относительно истинной величины [9]. Процедура вычислений при этом методе еще более сложна и утомительна. Выбор метода заключает в себе компромисс между сложностью математических расчетов и достижением желаемой точности результатов. [c.569]
Случайные ошибки могут не подчиняться закону распределения Гаусса, которое обычно используют для анализа данных. И опять-таки статистические исследования можно использовать для того, чтобы определить, имеется ли значительное отклонение от распределения Гаусса, и соответственно этому интерпретировать данные. [c.571]
Таким образом, влияние величины случайной ошибки на точность результатов наиболее полно характеризуется доверительным интервалом х Ах и величиной доверительной вероятности а. Если случайные ошибки распределены по нормальному закону (т. е. в соответствии с кривой Гаусса), то существует количественная зависимость между величиной стандартной ошибки серии измерений и значением доверительной вероятности а [c.35]
Другая трудность применения функций Гаусса — Лапласа связана с необходимостью предварительно установить, что результаты химического анализа распределены именно по нормальному закону. Чаще всего на практике дело обстоит именно так, ибо совокупная случайная ошибка химического анализа включает в себя большое число небольших по величине ошибок, каждая из которых имеет свой источник и свою причину. И каким бы ИИ было распределение каждой из таких частичных ошибок, суммарная случайная ошибка распределена по нормальному закону, е сли среди всех частных ошибок нет явно доминирующих по величине. Это положение — следствие так называемой предельной теоремы Ляпунова. [c.72]
Если число измерений достаточно велико, то распределение случай» ных ошибок отдельных измерений по величине удовлетворяет некоторому общему закону, известному под названием нормального закона распределения (или закона Гаусса) число измерений обладающих ошибкой, лежащей в интервале между —Йг и даётся выра- [c.218]
Когда имеют место только случайные ошибки, кривая распределения следует закону Гаусса, она симметрична, а максимум совпадает с действительным содержанием определяемого элемента в пробе. В этом случае средняя арифметическая величина будет совпадать в пределах погрешности с действительным содержанием. Если имеют место систематические ошибки определения, то это может привести к некоторому сдвигу результатов отдельных определений в ту или иную сторону. В этом случае кривая может оказаться несимметричной, а максимум кривой не совпадает с действительным содержанием элемента. Средняя арифметическая величина, рассчитанная по всем определениям, в этом случае также не отвечает действительному содержанию элемента. Если в первом случае, увеличивая число определений, посредством статистической теории ошибок можно определить [c.96]
Случайные ошибки, обусловленные рядом причин, действие которых неодинаково в каждом опыте и не может быть учтено. Для уменьшения случайных ошибок надо проводить несколько измерений и брать средний арифметический результат. Это следует из закона распределения ошибок, называемого законом Гаусса, справедливого для большинства простых измерений. [c.340]
Среднее число частиц в дозе. При использовании приборов с одноканальными анализаторами (интегральными или дифференциальными дискриминаторами) среднее число частиц в дозе зависит от допустимой величины статистической ошибки. Так как числа частиц по дозам распределены по закону Гаусса с дисперсией, равной среднему значению [826], то вероятная ошибка числа частиц (коэффициент вариации) [c.125]
Если ошибки замыкающего звена распределены не по закону Гаусса, находят значения коэффициентов и Kj,. Затем, по одной из расчетных формул, определяются половина поля рассеяния и среднее отклонение размера замыкающего звена. [c.179]
Опыт показывает, что при спектральном анализе величины х — хх с достаточной точностью распределены по закону Гаусса (нормальное распределение, см. рис. 127). Это приводит к определенным соотношениям между экспериментально определенными значениями х — Ж п вероятностью того, что ошибка определения величины Хо не превзойдет наперед [c.162]
Графически закон нормального распределения может быть представлен в виде кривой Гаусса. На рис. 32 представлены кривые Гаусса с различными значениями дисперсии а <02 <0з. Сравнение этих кривых показывает, что с уменьшением величины дисперсии улучшается распределение и уменьшается предел, который практически могут достигнуть ошибки. Например, ошибки, достигающие значений от 10 до 15%, наблюдаются только при дисперсии и а ошибки, составляющие от 5 до 10%, при дисперсии 02 и а ошибки от О до 5% встре- [c.84]
Гауссова кривая ошибок. Зная закон распределения, можно производить количественную оценку вероятности получения при измерении результата т, отличающегося от ожидаемой истинной средней величины М. Для этой цели удобно использовать распределение Гаусса. Принимая что распределение можно рассматривать непрерывным, и обозначив абсолютную ошибку сокращенно, М — т [ = е, получим выражение определяющее вероятность того, что ошибка лежит между е и е + йе [c.188]
Согласно закону нормального распределения или закону Гаусса ошибки данного ряда измерений распределяются в зависимости от своей величины. [c.50]
Однако можно очень легко проверить, дает ли полученное в результате измерений распределение ошибок строгую кривую Гаусса. Систематические ошибки, связанные с плохой работой регистрируюш,ей установки, вызывают заметные отклонения полученного распределения от нормального распределения Гаусса. По Беккелю, лучше всего для этого применить бумагу, имеющую масштаб интегрального закона распределения. Полученное опытным путем распределение представляют в виде интегральной кривой Гаусса (о) (IV, причем в данных координатах она изображается прямой [c.36]
Экспериментальный закон распределения износов имеет вид нормального закона, описуемого формулой Гаусса, Коэффициент вэриации (относительная величина средней квадратичной ошибки) равен 4, . [c.116]
Закон нормального распределения Гаусса. Определяя понятие случайных ошибок химического анализа, мы подчеркивали, что в отличие от систематических ошибок они не имеют видимых причин. Точнее говоря, ввиду крайней многочисленности отдельных случайных ошибок и незначительности величины каждой из них химик-аналитик сознательно отказывается от выяснения причин и оценки значений индивидуальных случайных ошибок. Ценой этого отказа он получает право изучать и описывать совокупную случайную ошибку и оценивать результаты анализа методами математической статистики, рассматривая их как случайные величины. Аналогичным образом поступает исследователь-фивик, который ценой отказа от измерения скоростей и иапра1Бления движения отдельных молекул газа приобретает возможность статистического описания огромного макроскопического ансамбля молекул — газа как физического тела с помощью усредненных параметров температуры, давления, теплоемкости, энтропии и т. д. В равной мере биолог-селекционер, оценивая продуктивность нового сорта пшеницы путем пересчета числа зерен в отдельных колосьях, сознательно отказывается от выяснения причин того, почему в разных колосьях число зерен неодинаково, и характеризует продуктивность средним числом зерен в колосе и рядом других параметров статистического характера. [c.65]
Это среднее значение при наличии правилрлюсти анализа будет очень мало отличаться от истигпюго значения и представляет собой наиболее вероятное значение измеряемой величины. Отклонение каждого отдельного измерения от этого среднего назовем ошибкой этого измерения, т. е. е =С— . Ехли эти онп1бки распределены случайно и число измерений п достаточно велико, тО число измерений П/, обладающих ошибкой г , лежащей в интервале г —бе — и е +бе/, определяется законом Гаусса [c.115]
Прежде всего необходимо, чтобы все причины, вызывающие систематические ошибки результатов измерений, были вскрыты, устранены или учтены разброс результатов должен определяться только случайными неконтролируемыми ошибками. Распределение самих случайных ошибок долл<но подчиняться нормальному закону распределения (закону Гаусса). Выполнение первого требования проверяется методами, описанными Колдером [2], Юде-ном [3] или Налимовым [4]. Если разброс результатов обусловлен только случайными ошибками, закон Гаусса почти всегда удовлетворяется. [c.11]
Считается что первым, кто нашел и начал использовать аналитическое выражение (формулу) закона нормального распределения был английский математик А. Муавр (1667-1754). Позже немецкий математик К. Гаусс (1777-1855) доказал и опубликовал в работе «Теория комбинации наблюдений, подверженных наименьшим ошибкам» [37] результаты, применение которых в отдельных случаях позволяет судить о величинах по их средним значениям. В связи с этам закон нормального распределения назьшают иногда законом Гаусса. Решения некоторых задач о границах применимости нормального закона найдены французским математиком П. Лапласом (1749-1827) и опубликованы в [45]. Поэтому одно из аналитических выражений, описьшаюпщх часто применяемый частаый случай нормального закона назьшают функцией Лапласа. В дореволюционной России сочинения по теории вероятностей ведущих ученых Западной Европы многократно издавались в русских переводах. Папример, был издан перевод книги П. Лапласа «Опыт философии теории вероятаостей»[47. [c.70]
Не так давно мой сын Алексей, вернувшись из школы, сообщил об оценке по английскому, полученной им за последнее сочинение. Ему поставили 93 балла. Будь все как обычно, я бы поздравил его с высшей оценкой — A. Но поскольку в пределах A это невысокий балл, а я знаю, что он способен на большее, я бы не преминул добавить: оценка говорит о том, что если в следующий раз он приложит чуть больше усилий, то получит более высокий балл. Однако все было отнюдь не как обычно, и я счел 93 балла возмутительной недооценкой сочинения. Здесь вам, верно, подумалось, что предыдущие несколько предложений говорят больше обо мне, нежели об Алексее. Что ж, вы совершенно правы. На самом деле, вся эта история обо мне, потому что сочинение за Алексея написал я.
О да, позор на мою голову! В свою защиту должен сказать, что в более мирных обстоятельствах скорее дотянулся бы за Алексея пяткой до подбородка на его занятиях по кунг-фу, чем писал бы за него сочинение. Но дело в том, что Алексей подошел ко мне с просьбой взглянуть на его работу как обычно, поздно вечером, в день перед сдачей сочинения. И я пообещал взглянуть. Начав читать сочинение с экрана компьютера, я поначалу внес несколько незначительных изменений — ничего такого, на что стоило бы обратить внимание. Однако затем редактор во мне начал шаг за шагом переставлять и перефразировать то и это, а когда дошел до конца, оказалось, что Алексей уже спит крепким сном, а я по сути написал новое сочинение. На следующее утро, смущенно признавшись, что поленился сохранить файл под новым именем, я сказал ему, чтобы он просто сдал мой вариант.
Сын протянул мне проверенное сочинение, похвалив его весьма сдержанно. «Неплохо, — сказал он. — Оно, конечно, 93 балла — это скорее A с минусом, чем A, но было уже поздно, и если бы у тебя не слипались глаза, наверняка справился бы лучше». Не сказать, чтобы я был рад. Во-первых, мало приятного в том, что твой пятнадцатилетний сын говорит тебе те самые слова, которые ты прежде обращал к нему, и при этом они кажутся тебе совершенно пустыми. Но кроме того, как могло мое сочинение — труд человека, которого даже собственная мать считает профессиональным писателем, — не получить достойной оценки у школьного учителя английского? Понятное дело, я был не одинок. Уже потом мне рассказали о другом писателе, с которым приключилась точно такая же история, с той лишь разницей, что его дочь получила еще более низкую оценку — B. Тексты, выходившие из-под пера этого писателя с докторской степенью по английскому языку, вполне удовлетворяли даже столь взыскательные издания, как «Роллинг Стоун», «Эсквайр» и «Нью-Йорк Таймс», но только не учителя средней школы. Алексей попытался утешить меня, поведав еще одну историю. Как-то раз двое его друзей сдали одно и то же сочинение. Сын решил, что они сглупили, и их немедленно разоблачат. Однако перегруженная учительница не только не заметила удвоения, но и поставила за одно сочинение 90 баллов (A), а за другое — 79 (C). На первый взгляд, странно, но только если вам не доводилось, как мне, ночь напролет проверять здоровенную стопку работ, гоняя по кругу, чтобы ненароком не заснуть, музыку из «Стар Трек».
Числам всегда приписывается особый вес. Рассуждение, во всяком случае, неосознанно, строится примерно так: если учитель оценивает сочинение по сто-балльной шкале, эти незначительные различия и в самом деле что-то значат. Но если десять издателей сочли, что рукопись первого тома «Гарри Поттера» не заслуживает публикации, то каким образом бедная миссис Финнеган (на самом деле ее зовут не так) проводит тонкое различение между двумя школьными сочинениями, ставя за одно 92 балла, а за другое 93? Если мы допускаем, что качество сочинения в принципе поддается определению, то нам придется признать, что оценка — не описание качества сочинения, но его измерение, а измерение, как ничто другое, подвержено случайности. В случае с сочинением измерительный инструмент — учитель, а в выставляемых им оценках, как и в любом измерении, проявляются случайная дисперсия и ошибки.
Еще один вид измерения — голосование. В этом случае мы измеряем не столько количество людей, поддерживающих того или иного кандидата на момент выборов, сколько количество тех, кто не поленился прийти в избирательный участок и проголосовать. В этом измерении тоже множество источников случайной ошибки. Одни законные избиратели, приходя в участок, обнаруживают, что их имя не внесено в списки для голосования. Другие по ошибке голосуют не за того, за кого собирались. Конечно же, ошибки возникают и при подсчете голосов. Часть бюллетеней ошибочно признается недействительными или, напротив, действительными. Еще часть может быть утеряна. Как правило, даже все эти факторы в совокупности не могут повлиять на исход выборов. Однако в случае выборов, где у соперников шансы на победу приблизительно равны, они могут сыграть свою роль, и тогда голоса обычно подсчитываются не один, а несколько раз, как если бы второй или третий подсчет были меньше подвержены влиянию случайной ошибки, чем первый.
Например, в 2004 г. во время выборов губернатора штата Вашингтон победителем в конечном счете был объявлен кандидат от демократов, хотя при первом подсчете кандидат от республиканцев обходил его на 261 из приблизительно 3 млн голосов{119}. Поскольку результаты обоих кандидатов были столь близки друг к другу, по закону штата требовался повторный подсчет голосов. По результатам этого подсчета республиканец вновь обошел демократа, но только на 42 голоса. Неизвестно, счел ли кто-нибудь дурным предзнаменованием тот факт, что разница в 219 голосов между первым и вторым подсчетами в несколько раз превосходила новое значение перевеса в количестве голосов, но в итоге состоялся третий подсчет голосов, на сей раз полностью «вручную». Перевес в 42 голоса получался благодаря лишь одному голосу на каждые 70 000, а потому ручной пересчет голосов можно сопоставить с попыткой попросить 42 человек посчитать от 1 до 70 000 в надежде, что каждый сделает в среднем меньше 1 ошибки. Естественно, результат вновь изменился. На сей раз получился перевес в 10 голосов в пользу демократа. Впоследствии он вырос до 129 голосов, когда в подсчет было включено 700 вновь обнаруженных «утерянных бюллетеней».
Ни процесс подсчета голосов, ни сам процесс голосования нельзя назвать совершенным. Если, например, по причине ошибки в работе почтовой службы 1 из 100 потенциальных избирателей не получит извещения с адресом избирательного участка, а еще 1 на каждых 100 таких избирателей по этой причине не проголосует, то в вашингтонских выборах это вылилось бы в 300 избирателей, которые хотели бы проголосовать, но не получили такой возможности в силу ошибки правительства. Выборы, как и любое измерение, неточны, пересчеты тоже, поэтому когда кандидаты набирают близкое количество голосов, разумнее принять результаты выборов такими, какие они есть, или попросту подбросить монетку, а не тратить время на бесконечные пересчеты.
Вопрос неточности измерений приобрел особо важное значение в середине XVIII в., когда в центре внимания астрономов и математиков оказалась проблема согласования законов Ньютона и наблюдаемого движения Луны и планет. Один из способов получения единственного значения на основе целого ряда не совпадающих измерений — усреднение, или вычисление среднего значения. По всей видимости, первым эту процедуру использовал в оптических исследованиях молодой Исаак Ньютон{120}. Однако, как и в целом ряде других случаев, Ньютон опередил здесь свое время. В ту пору, да и в следующем веке, большинство ученых не занимались подсчетом среднего. Вместо этого они выбирали среди своих измерений «золотой стандарт» — значение, которое интуитивно признавали наиболее надежным среди своих результатов. Дело в том, что отклонения в измерениях они рассматривали не как неизбежный побочный продукт процесса измерения, но как свидетельство небрежности, у которой могли быть последствия, в том числе и этического характера. Они даже избегали публиковать результаты множественных измерений одного и того показателя, полагая, что это будет сочтено проявлением неаккуратности в работе и вызовет недоверие. Но к середине XVIII в. положение дел начало меняться. В наши дни рассчитать примерные орбиты небесных тел, представляющие собой набор эллипсов, приближенных по форме к окружности, может любой сообразительный старшеклассник, который при этом даже не подумает снять наушники с громыхающей в них музыкой. Однако же описать движение планет с большей точностью, учитывая не только силу притяжения Солнца, но также и притяжение других планет, а кроме того, отклонения в форме Луны и планет от совершенной сферы, непросто даже сейчас. Чтобы достигнуть этой цели, необходимо согласовать сложные и приближенные математические вычисления с неточностями наблюдений и измерений.
Но есть еще одна причина, по которой в конце XVIII в. оказалась востребована математическая теория измерения: в 1780-х гг. во Франции начала складываться новая область точной экспериментальной физики{121}. До этого времени в физике сосуществовали две не связанные друг с другом исследовательские традиции. С одной стороны, математики занимались изучением строгих следствий из ньютоновых теорий движения и тяготения. С другой стороны, те, кого принято именовать экспериментальными философами, проводили эмпирические исследования электричества, магнетизма, света и температур. Представителей экспериментальной философии, зачастую ученых-любителей, строгая научная методология занимала в значительно меньшей степени, нежели математически ориентированных исследователей, и потому возникло движение, направленное на то, чтобы реформировать и математизировать экспериментальную физику. И вновь ведущую роль здесь сыграл Пьер-Симон де Лаплас.
Лаплас заинтересовался физикой благодаря работам своего коллеги и соотечественника, французского ученого Антуана Лорана Лавуазье, которого считают отцом современной химии{122}. Лаплас и Лавуазье много лет работали вместе, однако Лавуазье в значительно меньшей степени преуспел в искусстве выживания в то беспокойное время. Чтобы заработать деньги на свои многочисленные опыты, ему пришлось стать членом привилегированной частной коллегии откупщиков, работавших под защитой государства. Я не представляю себе времен, когда человека, занимающегося сбором налогов, жаждали бы пригласить домой на чашечку горячего кофе с имбирными пряниками, но когда грянула Французская революция, должность эта оказалась особенно ненадежным прикрытием. В 1794 г. Лавуазье арестовали вместе со всеми членами коллегии и приговорили к смертной казни. Будучи человеком до конца преданным науке, Лавуазье попросил об отсрочке исполнения приговора, чтобы закончить некоторые опыты и опубликовать результаты. На что председатель трибунала дал знаменитый ответ: «Республике ученые не нужны». Отца современной химии безотлагательно обезглавили, а тело бросили в общую могилу. По легенде, он поручил своему ассистенту подсчитать количество слов, которые попытается выговорить его лишенная тела голова.
Работы Лапласа и Лавуазье, а также ряда других ученых, прежде всего Шарля-Огюстена де Кулона, проводившего опыты с электричеством и магнетизмом, преобразили экспериментальную физику. Кроме того, эти работы внесли вклад в развитие в 1790-х гг. новой метрической системы, пришедшей на смену множеству разрозненных и несопоставимых систем, тормозивших развитие науки и нередко служивших причиной споров между торговцами. Новую метрическую систему, разработанную группой ученых, сформированной по указу Людовика XVI, революционное правительство узаконило уже после падения Людовика. По иронии судьбы, Лавуазье был одним из членов этой группы.
Требования как астрономии, так и экспериментальной физики были таковы, что на долю математиков конца XVIII — начала XIX вв. выпали прежде всего осмысление и подсчет случайной ошибки. Их усилиями возникла новая область — математическая статистика, занимающаяся разработкой методов для интерпретации данных наблюдений и опытов. Специалисты в области статистики зачастую считают, что рост современной науки начался именно с этих разработок — с развития теории измерения. Однако статистические методы используются и для решения задач повседневной жизни: например, для оценки эффективности лекарственных препаратов или популярности политиков. Поэтому понимание правил осуществления статистических выводов важно не только для тех, кто занимается наукой, но и для каждого из нас.
Один из парадоксов нашей жизни заключается в том, что хотя измерения всегда несут в себе некоторую погрешность, когда речь заходит об измерениях, реже всего говорят именно о погрешности. Если въедливый полицейский докладывает судье, что его радиолокатор показал, будто бы вы ехали со скоростью 62 км в час в зоне, где допустимый предел скорости — 56, то штрафа вам не избежать, хотя в показаниях прибора возможны отклонения на несколько км в час{123}. И хотя большинство школьников (не говоря уже об их родителях) согласились бы даже спрыгнуть с крыши, если бы это увеличило балл на выпускном тесте по математике с 598 до 625, исследования, о которых вам расскажет редкий работник в области образования, показывают: достаточно высока вероятность получить лишних 30 баллов, если пройти тест еще разок-другой{124}. А иногда малозначащие различия попадают в выпуски новостей. Некоторое время тому назад в августе Статистическое управление министерства труда США сообщило, что безработица находится на уровне 4,7%. В июле управление сообщало о показателе 4,8%. Изменение показателя немедленно нашло отражение в газетных заголовках; к примеру, вот что напечатала на первой странице «Нью-Йорк Таймс»: «Количество рабочих мест и уровень заработной платы за прошлый месяц несколько выросли»{125}. Однако, как замечает Джин Эпштейн, редактор отдела экономики «Barron’s», «из того, что изменилась цифра, совершенно не обязательно следует, что изменилось положение дел. Например, всякий раз, когда показатель безработицы изменяется на десятую долю процента… изменение это столь незначительно, что никоим образом нельзя утверждать, будто бы оно вообще имело место»{126}. Иными словами, если Статистическое управление измерит показатель безработицы в августе и повторит измерение через час, то лишь благодаря случайной ошибке второе измерение будет с высокой вероятностью отличаться от первого по меньшей мере на десятую долю процента. И что. неужели мы прочитаем в «Нью-Йорк Таймс»: «Количество рабочих мест и уровень заработной платы к двум часам пополудни несколько выросли»?
Погрешность измерения становится еще более серьезной проблемой, когда количественные показатели приписываются субъективно, как в случае с сочинением Алексея. Например, группа исследователей в Пенсильванском университете Клэрион собрала 120 курсовых работ и проверила их с таким тщанием, с каким работы вашего ребенка не будут проверяться никогда: каждую курсовую независимо друг от друга оценивали восемь сотрудников факультета. Итоговые оценки (по шкале от A до F) иногда различались на два и более деления шкалы. В среднем различие между ними составило около одного деления шкалы{127}. Поскольку будущее студентов очень часто зависит от подобного рода оценок, столь высокая погрешность — факт довольно печальный. Однако ее можно понять, если учесть, что взгляды и философия профессоров любого факультета в любом из университетов охватывают весь диапазон от Карла Маркса до Граучо Маркса. Можно ли подвергнуть этот фактор контролю? Например, дать экзаменаторам четкие критерии оценивания и потребовать следования этим критериям? Исследователь в университете штата Айова предъявил около 100 студенческих работ группе аспирантов, специалистов в области риторики и коммуникации, которых заранее обучил применению подобных критериев{128}. Каждую работу оценивали по шкале от 1 до 4 два независимых «экзаменатора». При сопоставлении оценок выяснилось, что мнения экзаменаторов совпали лишь примерно в половине случаев. Аналогичные результаты были получены в Техасском университете при анализе оценок за вступительное сочинение{129}. Даже почтенная Центральная приемная комиссия признается, что в случае двух экзаменаторов, согласно ее ожиданиям, «92% сочинений получат оценки, различающиеся в пределах ±1 балла по шестибалльной шкале для сочинений»{130}.
Еще одна область субъективных измерений, которым доверяют больше, чем следовало бы — оценка вин. В 1970-х гг. винный бизнес явно не переживал расцвета, а если и развивался, то преимущественно в сфере продаж дешевого столового вина. Однако в 1978 г. произошло событие, с которым часто связывают последующее стремительное развитие отрасли: некий юрист, Роберт М. Паркер-младший, объявил себя экспертом в области вин и решил, что вдобавок к своим публикуемым в прессе критическим обзорам будет давать винам количественную оценку по сто-балльной шкале. Со временем большинство изданий, печатавших материалы о винах, последовали его примеру. На сегодняшний день американцы ежегодно выкладывают за винную продукцию более 20 млрд долларов, однако же среди миллионов любителей спиртных напитков редко когда найдется простак, который согласится раскошелиться, не взглянув предварительно на рейтинг приглянувшегося ему вина. Поэтому, когда журнал «Вайн Спектейтор» выставил, скажем, аргентинскому каберне-совиньону «Валентин Бьянки» 2004 г. не 89, а 90 баллов, этот единственный балл привел к огромному увеличению объема продаж «Валентин Бьянки»{131}. В самом деле, заглянув в местную винную лавку, американец обнаружит, что вина, выставленные на распродажу со скидкой, как правило, получают оценки на один или несколько баллов ниже 90. Но какова вероятность того, что аргентинское каберне «Валентин Бьянки» 2004 г., удостоенное 90 баллов, не получило бы 89, если бы процесс оценивания был повторен, предположим, час спустя?
В увидевшей свет в 1890 г. книге «Принципы психологии» Уильям Джеймс выдвинул предположение: умение разбираться в винах может дойти до способности различить вкус старой мадеры из верхней и нижней части бутылки{132}. Во время дегустаций вин, на которых мне нередко доводилось бывать, я заметил, что если бородач слева от меня бормочет: «Прекрасный букет!», его поддерживает целый хор голосов. Но если оценивать предлагается самостоятельно и без обсуждений, то зачастую оказывается, что бородач написал «Прекрасный букет», его бритоголовый сосед нацарапал «Вообще никакого букета», а блондинка с перманентом пометила: «Интересный букет с оттенками петрушки и свеже-выдубленной кожи».
С теоретической точки зрения, есть множество оснований поставить под сомнение результаты оценивания вин. Для начала скажем, что вкусовые ощущения определяются сложным взаимодействием между вкусовыми и обонятельными стимулами. Строго говоря, любое вкусовое ощущение определяется пятью типами рецепторов, располагающихся на поверхности языка: рецепторами соленого, сладкого, кислого, горького и «мясного» (умами[12]). Последняя группа рецепторов соотносится с определенными аминокислотами (преобладающими, например, в соевом соусе). Но если бы этим все и ограничивалось, то вкус любой пищи — например, вашего любимого бифштекса, жареной картошки, праздничного яблочного пирога и изысканных спагетти по-болонски — можно было бы имитировать, используя лишь столовую соль, сахар, уксус, хинин и глутамат натрия. К счастью, этим дело не обходится, и на помощь приходит обоняние. Именно оно объясняет, почему, если взять два стакана с одинаковым раствором сахара и добавить в один из них клубничную эссенцию (не содержащую сахара), жидкость в этом стакане покажется вам слаще{133}. Вкус вина определяется воздействием от 600 до 800 изменчивых органических составляющих на рецепторы как языка, так и носа{134}. И что с этим делать — непонятно, ведь исследования показывают: даже профессиональные дегустаторы редко могут с уверенностью определить более 3–4 компонентов в смеси{135}.
На восприятие вкуса влияют и ожидания. В 1963 г. трое исследователей тайком добавили в белое вино немного красного пищевого красителя, что придало вину розоватый оттенок. После этого группу экспертов попросили оценить сладость этого вина по сравнению с неподкрашенным. Эксперты, сообразно своим ожиданиям, оценили подкрашенное розовое вино как более сладкое. Другая группа исследователей предъявляла два образца вина будущим виноделам. Это были совершенно одинаковые образцы белого вина, но в один была добавлена капля безвкусного красителя — виноградного антоциана, в результате чего вино стало выглядеть как красное. Ученики-виноделы также сообщили о различиях во вкусе вин в соответствии со своими ожиданиями{136}. А в 2008 г. группа добровольцев, которых попросили оценить пять бутылок вина, оценила бутылку с этикеткой «90 долларов» выше, чем бутылку с этикеткой «10 долларов», хотя хитрые ученые налили в обе бутылки одно и то же вино. Более того, во время этого опыта с помощью функционального магнитно-резонансного томографа регистрировалась активность мозга испытуемых. Обнаружилось, что зона мозга, активация которой обычно соотносится с переживанием удовольствия, действительно активируется в большей степени, когда испытуемые пьют вино, которое считают более дорогим{137}. Но прежде чем осудить этих горе-ценителей, примите к сведению следующий факт: когда исследователи выяснили у 30 любителей колы, предпочитают ли они «Пепси-колу» или «Кока-колу», а потом попросили проверить свои предпочтения, продегустировав оба напитка, стоящие бок о бок, 21 человек из 30 сообщили, что проверка подтвердила их выбор, хотя коварные исследователи налили «Кока-колу» в бутылки от «Пепси-колы», и наоборот{138}. Когда мы оцениваем или измеряем, наш мозг полагается отнюдь не только на непосредственно воспринимаемое, но использует и другие источники информации — например, ожидания.
Дегустаторов вин часто сбивает с толку и оборотная сторона ошибки ожидания — недостаток контекста. Поднося к носу корень хрена, вы едва ли перепутаете его с зубчиком чеснока, а запах чеснока не спутаете с запахом, скажем, стелек из ваших ношеных кроссовок. Но если вам приходится иметь дело с ароматом прозрачных жидкостей, оттолкнуться не от чего. В отсутствие контекста высока вероятность того, что ароматы будут перепутаны. Именно это случилось, когда исследователи предъявили экспертам набор из шестнадцати случайно отобранных запахов: эксперты неверно определили в среднем каждый четвертый запах{139}.
Имея все основания для скептицизма, ученые разработали методы прямой оценки различения вкусов экспертами. Один из таких методов — использование «треугольника вин». Это не собственно треугольник, скорее метафора: каждому эксперту предъявляется три сорта вина, два из которых идентичны. Задача состоит в том, чтобы выявить отличающийся от остальных сорт вина. В исследовании 1990 г. эксперты успешно справились с этой задачей только в 2/3 случаев, то есть на каждые три пробы приходилась одна, в которой эти гуру не могли отличить пино нуар, допустим, «с роскошным букетом земляники, сочной ежевики и малины», от пино «с выраженным ароматом сушеного чернослива, желтой черешни и бархатистой черной смородины»{140}. В том же исследовании группу экспертов попросили оценить ряд вин по 12 параметрам: таким, как содержание алкоголя, присутствие танинов, сладость и фруктовый запах. Эксперты существенно разошлись в своих оценках по 9 из 12 параметров. Наконец, когда их попросили подобрать вина, подходящие под описания, данные другими экспертами, испытуемые выполнили задачу правильно только в 70% случаев.
Сами дегустаторы в курсе всех этих трудностей. «Во многих планах… {система оценивания} лишена смысла», — говорит редактор журнала «Уайн энд спирит мэгэзин»{141}. А по мнению бывшего редактора «Уайн Энтузиаст», «чем глубже ты во все это погружаешься, тем больше понимаешь, насколько оно ошибочно и обманчиво»{142}. Тем не менее система оценивания процветает. Почему? Сами дегустаторы говорят, что когда они пытаются определить качество вина, используя систему звездочек или простейшие словесные ярлыки наподобие «хорошее», «плохое», «безобразное», их мнение звучит неубедительно. Но стоит перейти к использованию цифр, как покупатели начинают относиться к оценкам словно к божественному откровению. Как бы ни были сомнительны количественные оценки, именно они дают покупателям уверенность, что среди многообразия марок, производителей и урожаев им, словно в стоге сена, удастся отыскать золотую иголку (или хотя бы серебряную, если бюджет не позволяет).
Если качество вина (или сочинения) в самом деле может быть подвергнуто измерению в числовом выражении, то перед теорией измерения встает два вопроса. Во-первых, как получить это число на основе ряда отличающихся друг от друга измерений? Во-вторых, имея в виду, что число измерений ограничено, как вычислить вероятность того, что оценка верна? Рассмотрим эти вопросы, поскольку независимо от того, объективен или субъективен источник данных, теория измерения ставит себе целью найти на них ответы.
Ключ к пониманию измерения — постижение природы разброса данных, обусловленного случайной ошибкой. Предположим, мы попросили пятнадцать дегустаторов оценить некоторое вино, или же предложили оценить его несколько раз в разные дни одному и тому же дегустатору, или прибегли к обеим процедурам. Мы можем подвести итоги оценивания, используя усреднение полученных оценок. Однако важную информацию содержит не только среднее значение: если все пятнадцать дегустаторов выставляют оценку 90, это одно, а если они выставляют оценки 80, 81, 82, 87, 89, 89, 90, 90, 90, 91, 94, 97, 99 и 100 — это совсем другое. Среднее значение обоих наборов данных одно и то же, но они различаются разбросом данных относительно этого среднего. А поскольку распределение данных — важный источник информации, для его описания математики предложили количественную меру разброса. Эта мера называется выборочным стандартным отклонением. Кроме того, математики измеряют разброс посредством квадратичной меры, которую называют выборочной дисперсией.
Стандартное отклонение показывает, насколько данные по выборке близки к среднему — или, в практическом смысле, какова погрешность измерения. Если оно невысоко, все данные группируются вокруг среднего. Например, для случая, когда все дегустаторы поставили вину оценку 90, стандартное отклонение равно 0, указывая на то, что все измерения идентичны среднему значению. В случае же высокого стандартного отклонения данные разбросаны относительно среднего. Например, когда вино оценивается дегустаторами в диапазоне от 80 до 100, выборочное стандартное отклонение равно 6. Это означает, что на практике большинство оценок попадет в диапазон от ?6 до +6 относительно среднего. В рассмотренном случае о вине можно с высокой степенью уверенности сказать, что его истинная оценка, скорее всего, относится к диапазону от 84 до 96.
Пытаясь понять значение своих измерений, ученые XVIII–XIX вв. сталкивались с теми же проблемами, что и скептически настроенные ценители хороших вин. Ибо если группа исследователей осуществляет ряд наблюдений и измерений, результаты почти всегда получаются разными. Один астроном мог столкнуться с неблагоприятными погодными условиями, другой — покачнуться из-за порыва ветра, третий, возможно, только что вернулся от Уильяма Джеймса, с которым вместе дегустировал мадеру. В 1838 г. математик и астроном Ф.В. Бессель выделил одиннадцать классов случайных ошибок, которые могут возникнуть в ходе любого наблюдения с использованием телескопа. Даже если один и тот же астроном осуществляет ряд повторных измерений, результаты могут различаться из-за таких факторов, как неустойчивая острота зрения и влияние температуры воздуха на аппаратуру. Поэтому астрономам пришлось разбираться, как на основе ряда несовпадающих измерений установить истинное положение небесного тела. Но из того, что ценители вин и ученые сталкиваются с одной и той же проблемой, совсем не обязательно следует, что для них годится одно и то же решение. Можно ли выделить универсальные характеристики случайной ошибки, или же ее природа зависит от контекста?
Одним из первых предположение о том, что для разных типов измерений характерны одни и те же особенности, выдвинул Даниил Бернулли, племянник Якоба Бернулли. В 1777 г. он уподобил случайную ошибку в астрономическом наблюдении отклонениям в траектории выпущенной из лука стрелы. В обоих случаях, рассуждал он, цель — истинное значение измеряемой переменной или же «яблочко» мишени — располагается где-то посреди, а наблюдаемые результаты группируются вокруг нее, причем большинство должны лежать в окрестностях цели, и лишь немногие выпадают за их пределы. Закон, который Бернулли предложил для описания этого распределения, оказался неверен, однако важно само понимание того, что распределение ошибок лучника может быть сходно с распределением ошибок в наблюдениях астрономов.
Идея о том, что распределение ошибок подчиняется некому универсальному закону, который называют законом случайного распределения ошибок, является основополагающей для теории измерения. И вот что примечательно: допущение состоит в том, что при условии удовлетворения определенных условий довольно общего характера установить истинное значение некоторой переменной на основе ряда измерений можно с использованием одного и того же математического аппарата. Если в дело вступает универсальный закон, то задача установления истинного положения небесного тела на основе ряда наблюдений астрономов приравнивается к задаче нахождения центра мишени на основе дырочек от стрел или определения «качества» вина на основе ряда экспертных оценок. Именно поэтому математическая статистика — последовательная и согласованная область, а не просто набор трюков: неважно, осуществляете ли вы ряд измерений для того, чтобы установить положение Юпитера в 4 часа утра на Рождество или средний вес булок с изюмом, выходящих с конвейера, распределение ошибок будет одним и тем же.
Однако отсюда не следует, что случайная ошибка — единственный вид ошибок, которые могут повлиять на измерение. Если половина дегустаторов предпочитает красное вино, а другая половина — белое, однако во всех остальных отношениях они сходятся в своих суждениях (и предельно последовательны в их вынесении), то оценка каждого конкретного вина не будет определяться законом случайного распределения ошибок: распределение получится резко двугорбым, причем причиной появления одного из пиков станут любители красного вина, а другого — любители белого. Но даже в тех случаях, когда применимость закона случайного распределения ошибок не столь очевидна (начиная от футбольного тотализатора{143} и заканчивая измерением коэффициента интеллекта), зачастую он все же оказывается применим. Много лет назад мне в руки попали несколько тысяч регистрационных карточек покупателей компьютерной программы, которую разработал для восьми- и девятилетних школьников мой приятель. Продажи шли не так хорошо, как ожидалось. Кто же покупал программу? После некоторых подсчетов я установил, что наибольшее число пользователей приходится на семилетних, указывая на нежелательное, но не то чтобы неожиданное расхождение. Но вот что самое удивительное: когда я построил гистограмму зависимости количества пользователей от возраста, взяв семь лет за среднее значение, я обнаружил, что построенный мною график принял крайне знакомую форму — форму закона случайного распределения ошибок.
Одно дело — подозревать, что лучники и астрономы, химики и маркетологи сталкиваются с одним и тем же законом распределения ошибок, и совсем другое — самому натолкнуться на частный случай этого закона. Подталкиваемые необходимостью анализировать данные астрономических наблюдений ученые, такие как Даниил Бернулли и Лаплас, постулировали в конце XVIII в. несколько вариантов закона, оказавшихся неверными. Однако выяснилось, что математическая функция, верно отражающая закон случайного распределения ошибок, — колоколообразная кривая — все это время была у них под носом. За много десятилетий до них она была открыта в Лондоне в контексте решения совсем иных задач.
Среди троих ученых, благодаря которым на колоколообразную кривую обратили внимание, реже всех воздается по заслугам именно ее первооткрывателю. Абрахам де Муавр совершил свое открытие в 1733 г., когда ему было за шестьдесят, однако до появления второго издания его книги «Об измерении случайности», вышедшего в свет пять лет спустя, об этом никто не знал. Де Муавр пришел к искомой форме кривой, когда пытался аппроксимировать числа, заполняющие треугольник Паскаля значительно дальше той строки, на которой оборвал его я, — сотнями и даже тысячами строк ниже. Когда Якоб Бернулли обосновывал свой вариант закона больших чисел, ему пришлось столкнуться с некоторыми свойствами чисел, появляющихся в этих строках. А числа действительно очень велики: например, одно из чисел в двухсотой строке треугольника Паскаля состоит из пятидесяти девяти цифр! Во времена Бернулли, да и вообще до тех пор, пока не появились компьютеры, эти числа было очень трудно высчитать. Именно поэтому, как я сказал, Бернулли обосновывал свой закон больших чисел, используя различные способы приближенного вычисления, что снижало практическую значимость результатов его работы. Де Муавр со своей кривой осуществил несравненно более точную аппроксимацию и потому значительно улучшил оценки Бернулли.
Как де Муавр осуществил свою аппроксимацию, становится понятно, если числа в ряду треугольника представить в виде высоты столбика на гистограмме — я поступил так с регистрационными карточками. Например, числа в третьей строке треугольника — 1, 2, 1. Тогда на гистограмме первый столбик будет высотой в одно деление, второй — вдвое выше, а третий — вновь высотой в одно деление. Рассмотрим теперь пять чисел в пятой строке: 1, 4, 6, 4, 1. На гистограмме будет пять столбиков, она вновь начнется с минимальной высоты, достигнет максимума в центре и продемонстрирует симметричное снижение. Если спуститься по треугольнику вниз, получатся гистограммы с огромным количеством столбиков, но поведение их будет тем же самым. Гистограммы для 10-й, 100-й и 1000-й строк треугольника Паскаля приведены ниже.
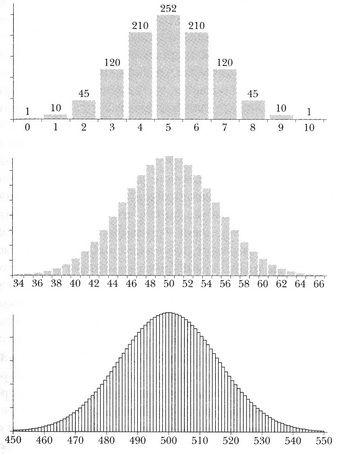
Столбцы в представленных выше гистограммах отображают относительную величину числа в 10-м, 100-м и 1000-м рядах треугольника Паскаля (см. выше). Числа по оси абсцисс — элементы строки треугольника, к которым относятся столбики. По традиции нумерация начинается с 0, а не с 1 (средняя и нижняя гистограммы обрезаны так, что элементы, столбики для которых имеют пренебрежимую высоту, на рисунке не представлены).
Если теперь провести кривые, соединяющие вершины столбиков на каждой из гистограмм, все они окажутся характерной формы, напоминающей колокол. А если несколько сгладить эти кривые, можно подобрать соответствующее им математическое выражение. Колоколообразная кривая — не просто визуализация чисел в треугольнике Паскаля: это инструмент, позволяющий получить точные и удобные в употреблении оценки значений чисел, появляющихся в расположенных ниже строках треугольника. В этом и состояло открытие де Муавра.
Сегодня колоколообразную кривую называют обычно нормальным распределением, а иногда — Гауссовой кривой (вскоре читатель узнает, откуда взялось это название). Нормальное распределение — не отдельная фиксированная кривая, но целое семейство кривых, определяемых двумя параметрами, задающими положение кривой и ее форму. Первый из них — расположение пика: в графиках выше это 5, 50 и 500 соответственно. Второй — степень разброса. Этот показатель, получивший свое современное наименование лишь в 1894 г., называется стандартным отклонением и представляет собой теоретический аналог понятия, о котором я уже упоминал — выборочного стандартного отклонения. Грубо говоря, это половина ширины кривой в той точке, где кривая достигает своей 60%-ной высоты. В наше время значение нормального распределения выходит далеко за пределы аппроксимации чисел в треугольнике Паскаля. Это самая распространенная форма распределения любого рода данных.
При описании распределения данных колоколообразная кривая демонстрирует, что в том случае, когда вы делаете много замеров, большинство их результатов будут примыкать к среднему значению, что отображается в виде пика. Симметрично снижаясь по обе стороны от пика, кривая показывает, как убывает число результатов замеров ниже и выше среднего, поначалу довольно резко, а потом не столь круто. Если данные распределены нормально, около 68% (т. е. приблизительно 2/3) результатов измерений попадают в пределы одного стандартного отклонения, около 95% — в пределы двух стандартных отклонений и 99,7% — в пределы трех стандартных отклонений.
Чтобы представить себе эту картину, взгляните на графики ниже. Квадратики соответствуют результатам угадывания 300 студентами исходов десятикратного подбрасывания монеты{144}. По оси абсцисс отложено количество верных угадываний — от 0 до 10. По оси ординат — количество студентов, продемонстрировавших соответствующее количество верных угадываний. Кривая имеет колоколообразную форму с пиком на уровне 5 верных угадываний: столько раз верно угадали исход подбрасывания 75 студентов. Двух третей максимальной высоты (соответствующее количество студентов — 51) кривая достигает посередине между 3 и 4 верными угадываниями слева и между 6 и 7 верными угадываниями справа. Колоколообразная кривая с таким стандартным отклонением типична для стохастических процессов вроде угадывания исходов подбрасывания монеты.
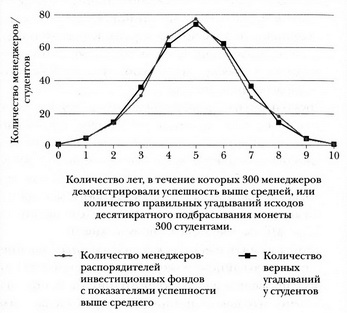
Угадывание исходов подбрасывания монет и подбор акций: сопоставительный анализ.
Кружочками на том же графике отображен еще один набор данных — успешность работы 300 менеджеров паевых инвестиционных фондов. Для этого набора данных по оси абсцисс отложено не количество верных угадываний исходов подбрасывания монеты, а количество лет (из 10), когда показатели успешности работы менеджера были выше группового среднего. Обратите внимание на сходство! Мы еще вернемся к нему в главе 9.
Чтобы понять связь между нормальным распределением и случайной ошибкой, можно рассмотреть процесс проведения выборочного опроса. Вспомним опрос относительно популярности мэра Базеля, который я упоминал в главе 5. В этом городе часть жителей одобряет деятельность мэра, а часть осуждает. Для простоты примем, что тех и других по 50%. Но, как мы видели, результаты опроса не обязательно будут полностью соответствовать этой пропорции 50/50. И в самом деле, если выборочно опросить N горожан, то вероятность, что любое произвольное их число поддержит мэра, пропорциональна числам в строке N треугольника Паскаля. А раз так, то, согласно работам де Муавра, если служба общественного мнения опросит большое число горожан, вероятность всех возможных результатов опроса можно будет описать с помощью кривой нормального распределения. Иными словами, около 95% случаев одобрения попадет в пределы 2 стандартных отклонений от истинного рейтинга мэра, 50%. Для описания этой погрешности службы общественного мнения используют понятие «допустимый предел погрешности». Сообщая средствам массовой информации, что предел погрешности опроса составляет ±5%, они имеют в виду, что если повторить опрос много раз подряд, 19 из 20 раз (т. е. в 95% случаев) результат его будет в пределах 5% от истинного значения измеряемой переменной. (И хотя службы общественного мнения редко на это указывают, в 1 случае из 20 результат опроса будет мало соответствовать действительности.) На практике размеру выборки в 100 человек соответствует такой допустимый предел погрешности, который никуда не годится. А вот для выборки в 1000 человек предел погрешности обычно составляет около 3%, что уже вполне пригодно для большинства целей.
Однако, проводя опрос любого рода, важно сознавать, что при любом повторении опроса результат хоть немного, но изменится. Например, если в действительности 40% зарегистрированных избирателей дают положительную оценку деятельности президента, шесть независимых опросов скорее покажут что-то вроде 37%, 39%, 39%, 40%, 42% и 42%, нежели сойдутся на показателе в 40%. (Эти шесть чисел — действительные результаты шести независимых опросов, призванных выявить количество граждан, которые положительно оценивали деятельность президента в первые две недели сентября 2006 года{145}.) Вот почему на практике на изменчивость данных в рамках допустимого предела погрешности не следует обращать внимания. Но даже если «Нью-Йорк Таймс» никогда и не вынесет на первую страницу заголовок «Количество рабочих мест и уровень заработной платы к двум часам пополудни несколько выросли», в публикациях, посвященных политическим опросам, подобного рода заголовки — не редкость. Например, после Национального партийного съезда республиканцев в 2004 г. «Си-эн-эн» разродилась выпуском новостей, озаглавленным так: «Похоже, рейтинг Буша несколько вырос»{146}. Эксперты «Си-эн-эн» пояснили, что «в результате проведения съезда рейтинг Буша увеличился на 2%… Если до съезда в его пользу склонялись 50% потенциальных избирателей, то сразу после съезда — 52%». Лишь позднее репортер оговорил, что предел погрешности для данного опроса составлял 3,5%, а это означает, что экстренный выпуск новостей по сути не имел смысла. Похоже, слово «похоже» на самом деле означало «непохоже».
Как правило, при проведении опросов предел погрешности выше 5% считается недопустимым, однако в повседневной жизни мы основываем свои суждения на значительно меньшем количестве наблюдений. Разве найдешь человека, который 100 лет играет в профессиональный баскетбол, вложил деньги в 100 многоквартирных жилых домов или основал 100 компаний, выпускающих шоколадное печенье? Так что, когда мы делаем выводы об успешности этих людей, мы берем за основу лишь незначительное число наблюдений. Следует ли футбольной команде раскошелиться на 50 млн долларов, чтобы заполучить игрока, чья игра была поистине чемпионской лишь в течение года? С какой вероятностью биржевой маклер, который в очередной раз просит у вас денег и говорит, что дело верное, вновь добьется успеха? Означает ли успех процветающего изобретателя такой игрушки, как морские обезьяны, что его новые изобретения — невидимые золотые рыбки и растворимые лягушки — скорее всего, станут пользоваться таким же спросом? (Кстати сказать, не стали{147}.) Сталкиваясь с успехом или с неудачей, мы имеем дело лишь с одним наблюдением, с одной из множества точек колоколообразной кривой, отображающей все наблюдавшиеся ранее возможности. И мы не знаем, что представляет собой это наблюдение — среднее или явный выброс, событие, в котором можно быть абсолютно уверенным, или редкий случай, который едва ли повторится. Так или иначе, мы должны иметь в виду, что точечное наблюдение — это не более чем точечное наблюдение, и прежде чем принимать его как факт, следует рассмотреть его в контексте соответствующего ему стандартного отклонения или разброса значений. Даже если некоторое вино получило оценку в 91 балл, эта оценка не имеет смысла, пока мы не узнаем, каков был бы разброс, если бы то же самое вино подверглось повторному оцениванию или если бы его стали оценивать другие люди. В качестве примера полезно вспомнить, как несколько лет назад «Путеводитель по хорошим австралийским винам» издательства «Penguin» и «Ежегодник австралийских вин», выпускаемый «On Wine», написали о рислинге «Митчелтон Блэквуд Парк» урожая 1999 г., причем «Путеводитель…» присвоил вину пять звездочек из пяти и назвал лучшим вином года по версии «Penguin», а «Ежегодник…» оценил ниже всех прочих вин, о которых писал в тот год, и счел худшим вином данной марки за последнее десятилетие{148}. Нормальное распределение не только помогает понять подобные разногласия, но и применяется в великом множестве областей науки и торговли: например, когда фармацевтическая компания решает, считать ли результаты клинических испытаний значимыми, производитель — отражает ли случайная выборка реальный процент деталей с браком, а закупщик — принять ли к действию результаты опроса.
Тот факт, что нормальное распределение описывает распределение ошибки измерения, открыл десятилетия спустя после выхода работы де Муавра человек, имя которого носит колоколообразная кривая, — немецкий математик Карл Фридрих Гаусс. Эта мысль — во всяком случае, в отношении астрономических измерений, — пришла Гауссу в голову, когда он работал над проблемой траекторий движения планет. Однако же «доказательство» Гаусса было, по его собственному позднейшему признанию, ошибочным{149}, а далеко идущие последствия этого открытия тоже не пришли ему на ум. Поэтому он, дабы не привлекать излишнего внимания, сунул обнаруженный закон в один из последних параграфов своей книги «Теория движения небесных тел, обращающихся вокруг Солнца по коническим сечениям». Там бы она и сгинула, эта еще одна из многочисленных отвергнутых наукой идей о том, как должен выглядеть закон распределения ошибок.
Однако нормальное распределение вернул из небытия Лаплас, наткнувшийся на работу Гаусса в 1810 г., вскоре после того, как подал в Академию наук статью с доказательством так называемой центральной предельной теоремы, гласящей, что сумма большого количества независимых случайных величин имеет распределение, близкое к нормальному. Например, предположим, что вы выпекаете 100 буханок хлеба, каждый раз основываясь на рецепте, по которому должны получаться буханки весом в 1000 граммов. Но иногда вы случайно добавляете то чуть меньше, то чуть больше муки или молока, а иногда чуть меньше или чуть больше жидкости испаряется за время нахождения буханки в печи. В конечном счете в силу каждой из множества возможных причин вес буханки может вырасти или уменьшиться на несколько граммов, и в этом случае центральная предельная теорема утверждает, что итоговый вес буханок будет варьировать в соответствии с законом нормального распределения. Читая работу Гаусса, Лаплас сразу же понял, что может использовать его открытие в целях совершенствования собственной работы, а его собственная работа, в свою очередь, намного убедительнее, чем это удалось Гауссу, доказывает: нормальное распределение является отражением закона распределения ошибок. Лаплас немедленно опубликовал краткое продолжение статьи, посвященной центральной предельной теореме. В наши дни эта теорема и закон больших чисел — две наиболее важных наработки в рамках теории случайности.
Чтобы пояснить, каким образом центральная предельная теорема доказывает, что нормальное распределение адекватно отражает закон случайного распределения ошибки, вернемся к примеру Даниила Бернулли с лучником. Мне однажды довелось выступить в роли лучника во время вечера в приятном обществе с крепкими напитками и беседами не для детского уха: ко мне прибежал мой младший сын Николай, протянул мне лук и стрелу и начал упрашивать, чтобы я метким выстрелом сбил у него с головы яблоко. И хотя стрела была с мягким наконечником из губки, мне показалось разумным проанализировать свои возможные ошибки и оценить их вероятность. Естественно, больше всего меня беспокоили смещения по вертикали. Простая модель таких ошибок выглядит следующим образом: каждый случайный фактор (скажем, ошибка прицеливания, влияние воздушных потоков и т. п.) может с равной вероятностью сместить мой выстрел по вертикали либо вверх, либо вниз относительно мишени. Итоговая ошибка будет равна сумме всех этих ошибок. Если мне повезет, примерно половина из них сместит выстрел вверх, другая половина — вниз, и тогда я попаду точно в цель. А если мне (точнее, моему сыну) не повезет, то все ошибки подействуют в одном направлении, и в цель я не попаду, а попаду либо существенно ниже, либо существенно выше. Соответственно, мне хотелось знать, какова вероятность того, что ошибки нивелируют друг друга, или, напротив, их сумма достигнет максимального значения, или примет одно из промежуточных значений. Но это был в точности процесс Бернулли, как если бы я подбрасывал монеты и задавался при этом вопросом, с какой вероятностью у меня выпадет определенное число орлов. Ответ на этот вопрос дает треугольник Паскаля или, если попыток много, нормальное распределение. И ровно этому же посвящена центральная предельная теорема. (Кстати сказать, в итоге я не попал ни в яблоко, ни в сына, но зато сбил бокал превосходного каберне.)
К 1830-м гг. большинство ученых обрели уверенность в том, что любое измерение многосоставно, подвержено огромному числу источников отклонения, а следовательно, и закону распределения ошибок. Этот закон, наряду с центральной предельной теоремой, привел, таким образом, к новому, более глубокому пониманию получаемых данных и их отношения к физической реальности. В следующем веке эти за идеи ухватились ученые, занимающиеся исследованием человеческого общества. К своему удивлению, они обнаружили, что человеческое поведение и индивидуальные особенности нередко подчиняются тем же закономерностям, что и ошибка измерения. В связи с этим было решено расширить круг приложений закона распределения ошибок за пределы естествознания и применять его в новой науке о человеческих отношениях.
Результат любого измерения не определён однозначно и имеет случайную составляющую.
Поэтому адекватным языком для описания погрешностей является язык вероятностей.
Тот факт, что значение некоторой величины «случайно», не означает, что
она может принимать совершенно произвольные значения. Ясно, что частоты, с которыми
возникает те или иные значения, различны. Вероятностные законы, которым
подчиняются случайные величины, называют распределениями.
2.1 Случайная величина
Случайной будем называть величину, значение которой не может быть достоверно определено экспериментатором. Чаще всего подразумевается, что случайная величина будет изменяться при многократном повторении одного и того же эксперимента. При интерпретации результатов измерений в физических экспериментах, обычно случайными также считаются величины, значение которых является фиксированным, но не известно экспериментатору. Например смещение нуля шкалы прибора. Для формализации работы со случайными величинами используют понятие вероятности. Численное значение вероятности того, что какая-то величина примет то или иное значение определяется либо как относительная частота наблюдения того или иного значения при повторении опыта большое количество раз, либо как оценка на основе данных других экспериментов.
Замечание.
Хотя понятия вероятности и случайной величины являются основополагающими, в литературе нет единства в их определении. Обсуждение формальных тонкостей или построение строгой теории лежит за пределами данного пособия. Поэтому на начальном этапе лучше использовать «интуитивное» понимание этих сущностей. Заинтересованным читателям рекомендуем обратиться к специальной литературе: [5].
Рассмотрим случайную физическую величину x, которая при измерениях может
принимать непрерывный набор значений. Пусть
P[x0,x0+δx] — вероятность того, что результат окажется вблизи
некоторой точки x0 в пределах интервала δx: x∈[x0,x0+δx].
Устремим интервал
δx к нулю. Нетрудно понять, что вероятность попасть в этот интервал
также будет стремиться к нулю. Однако отношение
w(x0)=P[x0,x0+δx]δx будет оставаться конечным.
Функцию w(x) называют плотностью распределения вероятности или кратко
распределением непрерывной случайной величины x.
Замечание. В математической литературе распределением часто называют не функцию
w(x), а её интеграл W(x)=∫w(x)𝑑x. Такую функцию в физике принято
называть интегральным или кумулятивным распределением. В англоязычной литературе
для этих функций принято использовать сокращения:
pdf (probability distribution function) и
cdf (cumulative distribution function)
соответственно.
Гистограммы.
Проиллюстрируем наглядно понятие плотности распределения. Результат
большого числа измерений случайной величины удобно представить с помощью
специального типа графика — гистограммы.
Для этого область значений x, размещённую на оси абсцисс, разобьём на
равные малые интервалы — «корзины» или «бины» (англ. bins)
некоторого размера h. По оси ординат будем откладывать долю измерений w,
результаты которых попадают в соответствующую корзину. А именно,
пусть k — номер корзины; nk — число измерений, попавших
в диапазон x∈[kh,(k+1)h]. Тогда на графике изобразим «столбик»
шириной h и высотой wk=nk/n.
В результате получим картину, подобную изображённой на рис. 2.1.
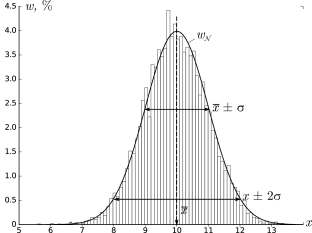
σ=1,0, h=0,1, n=104)
Высоты построенных столбиков будут приближённо соответствовать значению
плотности распределения w(x) вблизи соответствующей точки x.
Если устремить число измерений к бесконечности (n→∞), а ширину корзин
к нулю (h→0), то огибающая гистограммы будет стремиться к некоторой
непрерывной функции w(x).
Самые высокие столбики гистограммы будут группироваться вблизи максимума
функции w(x) — это наиболее вероятное значение случайной величины.
Если отклонения в положительную и отрицательную стороны равновероятны,
то гистограмма будет симметрична — в таком случае среднее значение ⟨x⟩
также будет лежать вблизи этого максимума. Ширина гистограммы будет характеризовать разброс
значений случайной величины — по порядку величины
она, как правило, близка к среднеквадратичному отклонению sx.
Свойства распределений.
Из определения функции w(x) следует, что вероятность получить в результате
эксперимента величину x в диапазоне от a до b
можно найти, вычислив интеграл:
| Px∈[a,b]=∫abw(x)𝑑x. | (2.1) |
Согласно определению вероятности, сумма вероятностей для всех возможных случаев
всегда равна единице. Поэтому интеграл распределения w(x) по всей области
значений x (то есть суммарная площадь под графиком w(x)) равен единице:
Это соотношение называют условием нормировки.
Среднее и дисперсия.
Вычислим среднее по построенной гистограмме. Если размер корзин
h достаточно мал, все измерения в пределах одной корзины можно считать примерно
одинаковыми. Тогда среднее арифметическое всех результатов можно вычислить как
Переходя к пределу, получим следующее определение среднего значения
случайной величины:
где интегрирование ведётся по всей области значений x.
В теории вероятностей x¯ также называют математическим ожиданием
распределения.
Величину
| σ2=(x-x¯)2¯=∫(x-x¯)2w𝑑x | (2.3) |
называют дисперсией распределения. Значение σ есть
срекднеквадратичное отклонение в пределе n→∞. Оно имеет ту
же размерность, что и сама величина x и характеризует разброс распределения.
Именно эту величину, как правило, приводят как характеристику погрешности
измерения x.
Доверительный интервал.
Обозначим как P|Δx|<δ вероятность
того, что отклонение от среднего Δx=x-x¯ составит величину,
не превосходящую по модулю значение δ:
| P|Δx|<δ=∫x¯-δx¯+δw(x)𝑑x. | (2.4) |
Эту величину называют доверительной вероятностью для
доверительного интервала |x-x¯|≤δ.
2.2 Нормальное распределение
Одним из наиболее примечательных результатов теории вероятностей является
так называемая центральная предельная теорема. Она утверждает,
что сумма большого количества независимых случайных слагаемых, каждое
из которых вносит в эту сумму относительно малый вклад, подчиняется
универсальному закону, не зависимо от того, каким вероятностным законам
подчиняются её составляющие, — так называемому нормальному
распределению (или распределению Гаусса).
Доказательство теоремы довольно громоздко и мы его не приводим (его можно найти
в любом учебнике по теории вероятностей). Остановимся
кратко на том, что такое нормальное распределение и его основных свойствах.
Плотность нормального распределения выражается следующей формулой:
| w𝒩(x)=12πσe-(x-x¯)22σ2. | (2.5) |
Здесь x¯ и σ
— параметры нормального распределения: x¯ равно
среднему значению x, a σ —
среднеквадратичному отклонению, вычисленным в пределе n→∞.
Как видно из рис. 2.1, распределение представляет собой
симметричный
«колокол», положение вершины которого
соответствует x¯ (ввиду симметрии оно же
совпадает с наиболее вероятным значением — максимумом
функции w𝒩(x)).
При значительном отклонении x от среднего величина
w𝒩(x)
очень быстро убывает. Это означает, что вероятность встретить отклонения,
существенно большие, чем σ, оказывается пренебрежимо
мала. Ширина «колокола» по порядку величины
равна σ — она характеризует «разброс»
экспериментальных данных относительно среднего значения.
Замечание. Точки x=x¯±σ являются точками
перегиба графика w(x) (в них вторая производная по x
обращается в нуль, w′′=0), а их положение по высоте составляет
w(x¯±σ)/w(x¯)=e-1/2≈0,61
от высоты вершины.
Универсальный характер центральной предельной теоремы позволяет широко
применять на практике нормальное (гауссово) распределение для обработки
результатов измерений, поскольку часто случайные погрешности складываются из
множества случайных независимых факторов. Заметим, что на практике
для приближённой оценки параметров нормального распределения
случайной величины используются выборочные значения среднего
и дисперсии: x¯≈⟨x⟩, sx≈σx.
Вычислим некоторые доверительные вероятности (2.4) для нормально Замечание. Значение интеграла вида ∫e-x2/2𝑑x Вероятность того, что результат отдельного измерения x окажется Вероятность отклонения в пределах x¯±2σ: а в пределах x¯±3σ: Иными словами, при большом числе измерений нормально распределённой Пример. В сообщениях об открытии бозона Хиггса на Большом адронном коллайдере Полученные значения доверительных вероятностей используются при означает, что измеренное значение лежит в диапазоне (доверительном Замечание. Хотя нормальный закон распределения встречается на практике довольно Теперь мы можем дать количественный критерий для сравнения двух измеренных Пусть x1 и x2 (x1≠x2) измерены с Допустим, одна из величин известна с существенно большей точностью: Пусть погрешности измерений сравнимы по порядку величины: Замечание. Изложенные здесь соображения применимы, только если x¯ иx-x0σ2=2w(x)σ1=1
Доверительные вероятности.
распределённых случайных величин.
(его называют интегралом ошибок) в элементарных функциях не выражается,
но легко находится численно.
в пределах x¯±σ оказывается равна
P|Δx|<σ=∫x¯-σx¯+σw𝒩𝑑x≈0,68.
величины можно ожидать, что лишь треть измерений выпадут за пределы интервала
[x¯-σ,x¯+σ]. При этом около 5%
измерений выпадут за пределы [x¯-2σ;x¯+2σ],
и лишь 0,27% окажутся за пределами
[x¯-3σ;x¯+3σ].
говорилось о том, что исследователи ждали подтверждение результатов
с точностью «5 сигма». Используя нормальное распределение (2.5)
нетрудно посчитать, что они использовали доверительную вероятность
P≈1-5,7⋅10-7=0,99999943. Такую точность можно назвать фантастической.
стандартной записи результатов измерений. В физических измерениях
(в частности, в учебной лаборатории), как правило, используется P=0,68,
то есть, запись
интервале) x∈[x¯-δx;x¯+δx] с
вероятностью 68%. Таким образом погрешность ±δx считается
равной одному среднеквадратичному отклонению: δx=σ.
В технических измерениях чаще используется P=0,95, то есть под
абсолютной погрешностью имеется в виду удвоенное среднеквадратичное
отклонение, δx=2σ. Во избежание разночтений доверительную
вероятность следует указывать отдельно.
часто, стоит помнить, что он реализуется далеко не всегда.
Полученные выше соотношения для вероятностей попадания значений в
доверительные интервалы можно использовать в качестве простейшего
признака нормальности распределения: в частности, если количество попадающих
в интервал ±σ результатов существенно отличается от 2/3 — это повод
для более детального исследования закона распределения ошибок.Сравнение результатов измерений.
величин или двух результатов измерения одной и той же величины.
погрешностями σ1 и σ2 соответственно.
Ясно, что если различие результатов |x2-x1| невелико,
его можно объяснить просто случайными отклонениями.
Если же теория предсказывает, что вероятность обнаружить такое отклонение
слишком мала, различие результатов следует признать значимым.
Предварительно необходимо договориться о соответствующем граничном значении
вероятности. Универсального значения здесь быть не может,
поэтому приходится полагаться на субъективный выбор исследователя. Часто
в качестве «разумной» границы выбирают вероятность 5%,
что, как видно из изложенного выше, для нормального распределения
соответствует отклонению более, чем на 2σ.
σ2≪σ1 (например, x1 — результат, полученный
студентом в лаборатории, x2 — справочное значение).
Поскольку σ2 мало, x2 можно принять за «истинное»:
x2≈x¯. Предполагая, что погрешность измерения
x1 подчиняется нормальному закону с и дисперсией σ12,
можно утверждать, что
различие считают будет значимы, если
σ1∼σ2. В теории вероятностей показывается, что
линейная комбинация нормально распределённых величин также имеет нормальное
распределение с дисперсией σ2=σ12+σ22
(см. также правила сложения погрешностей (2.7)). Тогда
для проверки гипотезы о том, что x1 и x2 являются измерениями
одной и той же величины, нужно вычислить, является ли значимым отклонение
|x1-x2| от нуля при σ=σ12+σ22.
Пример. Два студента получили следующие значения для теплоты испарения
некоторой жидкости: x1=40,3±0,2 кДж/моль и
x2=41,0±0,3 кДж/моль, где погрешность соответствует
одному стандартному отклонению. Можно ли утверждать, что они исследовали
одну и ту же жидкость?
Имеем наблюдаемую разность |x1-x2|=0,7 кДж/моль,
среднеквадратичное отклонение для разности
σ=0,22+0,32=0,36 кДж/моль.
Их отношение |x2-x1|σ≈2. Из
свойств нормального распределения находим вероятность того, что измерялась
одна и та же величина, а различия в ответах возникли из-за случайных
ошибок: P≈5%. Ответ на вопрос, «достаточно»
ли мала или велика эта вероятность, остаётся на усмотрение исследователя.
его стандартное отклонение σ получены на основании достаточно
большой выборки n≫1 (или заданы точно). При небольшом числе измерений
(n≲10) выборочные средние ⟨x⟩ и среднеквадратичное отклонение
sx сами имеют довольно большую ошибку, а
их распределение будет описываться не нормальным законом, а так
называемым t-распределением Стъюдента. В частности, в зависимости от
значения n интервал ⟨x⟩±sx будет соответствовать несколько
меньшей доверительной вероятности, чем P=0,68. Особенно резко различия
проявляются при высоких уровнях доверительных вероятностей P→1.
2.3 Независимые величины
Величины x и y называют независимыми если результат измерения одной
из них никак не влияет на результат измерения другой. Для таких величин вероятность того, что x окажется в некоторой области X, и одновременно y — в области Y,
равна произведению соответствующих вероятностей:
Обозначим отклонения величин от их средних как Δx=x-x¯ и
Δy=y-y¯.
Средние значения этих отклонений равны, очевидно, нулю: Δx¯=x¯-x¯=0,
Δy¯=0. Из независимости величин x и y следует,
что среднее значение от произведения Δx⋅Δy¯
равно произведению средних Δx¯⋅Δy¯
и, следовательно, равно нулю:
| Δx⋅Δy¯=Δx¯⋅Δy¯=0. | (2.6) |
Пусть измеряемая величина z=x+y складывается из двух независимых
случайных слагаемых x и y, для которых известны средние
x¯ и y¯, и их среднеквадратичные погрешности
σx и σy. Непосредственно из определения (1.1)
следует, что среднее суммы равно сумме средних:
Найдём дисперсию σz2. В силу независимости имеем
| Δz2¯=Δx2¯+Δy2¯+2Δx⋅Δy¯≈Δx2¯+Δy2¯, |
то есть:
Таким образом, при сложении независимых величин их погрешности
складываются среднеквадратичным образом.
Подчеркнём, что для справедливости соотношения (2.7)
величины x и y не обязаны быть нормально распределёнными —
достаточно существования конечных значений их дисперсий. Однако можно
показать, что если x и y распределены нормально, нормальным
будет и распределение их суммы.
Замечание. Требование независимости
слагаемых является принципиальным. Например, положим y=x. Тогда
z=2x. Здесь y и x, очевидно, зависят друг от друга. Используя
(2.7), находим σ2x=2σx,
что, конечно, неверно — непосредственно из определения
следует, что σ2x=2σx.
Отдельно стоит обсудить математическую структуру формулы (2.7).
Если одна из погрешностей много больше другой, например,
σx≫σy,
то меньшей погрешностью можно пренебречь, σx+y≈σx.
С другой стороны, если два источника погрешностей имеют один порядок
σx∼σy, то и σx+y∼σx∼σy.
Эти обстоятельства важны при планирования эксперимента: как правило,
величина, измеренная наименее точно, вносит наибольший вклад в погрешность
конечного результата. При этом, пока не устранены наиболее существенные
ошибки, бессмысленно гнаться за повышением точности измерения остальных
величин.
Пример. Пусть σy=σx/3,
тогда σz=σx1+19≈1,05σx,
то есть при различии двух погрешностей более, чем в 3 раза, поправка
к погрешности составляет менее 5%, и уже нет особого смысла в учёте
меньшей погрешности: σz≈σx. Это утверждение
касается сложения любых независимых источников погрешностей в эксперименте.
2.4 Погрешность среднего
Выборочное среднее арифметическое значение ⟨x⟩, найденное
по результатам n измерений, само является случайной величиной.
Действительно, если поставить серию одинаковых опытов по n измерений,
то в каждом опыте получится своё среднее значение, отличающееся от
предельного среднего x¯.
Вычислим среднеквадратичную погрешность среднего арифметического
σ⟨x⟩.
Рассмотрим вспомогательную сумму n слагаемых
Если {xi} есть набор независимых измерений
одной и той же физической величины, то мы можем, применяя результат
(2.7) предыдущего параграфа, записать
| σZ=σx12+σx22+…+σxn2=nσx, |
поскольку под корнем находится n одинаковых слагаемых. Отсюда с
учётом ⟨x⟩=Z/n получаем
Таким образом, погрешность среднего значения x по результатам
n независимых измерений оказывается в n раз меньше погрешности
отдельного измерения. Это один из важнейших результатов, позволяющий
уменьшать случайные погрешности эксперимента за счёт многократного
повторения измерений.
Подчеркнём отличия между σx и σ⟨x⟩:
величина σx — погрешность отдельного
измерения — является характеристикой разброса значений
в совокупности измерений {xi}, i=1..n. При
нормальном законе распределения примерно 68% измерений попадают в
интервал ⟨x⟩±σx;
величина σ⟨x⟩ — погрешность
среднего — характеризует точность, с которой определено
среднее значение измеряемой физической величины ⟨x⟩ относительно
предельного («истинного») среднего x¯;
при этом с доверительной вероятностью P=68% искомая величина x¯
лежит в интервале
⟨x⟩-σ⟨x⟩<x¯<⟨x⟩+σ⟨x⟩.
2.5 Результирующая погрешность опыта
Пусть для некоторого результата измерения известна оценка его максимальной
систематической погрешности Δсист и случайная
среднеквадратичная
погрешность σслуч. Какова «полная»
погрешность измерения?
Предположим для простоты, что измеряемая величина в принципе
может быть определена сколь угодно точно, так что можно говорить о
некотором её «истинном» значении xист
(иными словами, погрешность результата связана в основном именно с
процессом измерения). Назовём полной погрешностью измерения
среднеквадратичное значения отклонения от результата измерения от
«истинного»:
Отклонение x-xист можно представить как сумму случайного
отклонения от среднего δxслуч=x-x¯
и постоянной (но, вообще говоря, неизвестной) систематической составляющей
δxсист=x¯-xист=const:
Причём случайную составляющую можно считать независимой от систематической.
В таком случае из (2.7) находим:
| σполн2=⟨δxсист2⟩+⟨δxслуч2⟩≤Δсист2+σслуч2. | (2.9) |
Таким образом, для получения максимального значения полной
погрешности некоторого измерения нужно квадратично сложить максимальную
систематическую и случайную погрешности.
Если измерения проводятся многократно, то согласно (2.8)
случайная составляющая погрешности может быть уменьшена, а систематическая
составляющая при этом остаётся неизменной:
Отсюда следует важное практическое правило
(см. также обсуждение в п. 2.3): если случайная погрешность измерений
в 2–3 раза меньше предполагаемой систематической, то
нет смысла проводить многократные измерения в попытке уменьшить погрешность
всего эксперимента. В такой ситуации измерения достаточно повторить
2–3 раза — чтобы убедиться в повторяемости результата, исключить промахи
и проверить, что случайная ошибка действительно мала.
В противном случае повторение измерений может иметь смысл до
тех пор, пока погрешность среднего
σ⟨x⟩=σxn
не станет меньше систематической.
Замечание. Поскольку конкретная
величина систематической погрешности, как правило, не известна, её
можно в некотором смысле рассматривать наравне со случайной —
предположить, что её величина была определена по некоторому случайному
закону перед началом измерений (например, при изготовлении линейки
на заводе произошло некоторое случайное искажение шкалы). При такой
трактовке формулу (2.9) можно рассматривать просто
как частный случай формулы сложения погрешностей независимых величин
(2.7).
Подчеркнем, что вероятностный закон, которому подчиняется
систематическая ошибка, зачастую неизвестен. Поэтому неизвестно и
распределение итогового результата. Из этого, в частности, следует,
что мы не можем приписать интервалу x±Δсист какую-либо
определённую доверительную вероятность — она равна 0,68
только если систематическая ошибка имеет нормальное распределение.
Можно, конечно, предположить,
— и так часто делают — что, к примеру, ошибки
при изготовлении линеек на заводе имеют гауссов характер. Также часто
предполагают, что систематическая ошибка имеет равномерное
распределение (то есть «истинное» значение может с равной вероятностью
принять любое значение в пределах интервала ±Δсист).
Строго говоря, для этих предположений нет достаточных оснований.
Пример. В результате измерения диаметра проволоки микрометрическим винтом,
имеющим цену деления h=0,01 мм, получен следующий набор из n=8 значений:
Вычисляем среднее значение: ⟨d⟩≈386,3 мкм.
Среднеквадратичное отклонение:
σd≈9,2 мкм. Случайная погрешность среднего согласно
(2.8):
σ⟨d⟩=σd8≈3,2
мкм. Все результаты лежат в пределах ±2σd, поэтому нет
причин сомневаться в нормальности распределения. Максимальную погрешность
микрометра оценим как половину цены деления, Δ=h2=5 мкм.
Результирующая полная погрешность
σ≤Δ2+σd28≈6,0 мкм.
Видно, что σслуч≈Δсист и проводить дополнительные измерения
особого смысла нет. Окончательно результат измерений может быть представлен
в виде (см. также правила округления
результатов измерений в п. 4.3.2)
d=386±6мкм,εd=1,5%.
Заметим, что поскольку случайная погрешность и погрешность
прибора здесь имеют один порядок величины, наблюдаемый случайный разброс
данных может быть связан как с неоднородностью сечения проволоки,
так и с дефектами микрометра (например, с неровностями зажимов, люфтом
винта, сухим трением, деформацией проволоки под действием микрометра
и т. п.). Для ответа на вопрос, что именно вызвало разброс, требуются
дополнительные исследования, желательно с использованием более точных
приборов.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=±1 м/c.
Результаты измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=162,0м/с,
среднеквадратичное отклонение σv=13,8м/c, случайная
ошибка для средней скорости
σv¯=σv/6=5,6м/с.
Поскольку разброс экспериментальных данных существенно превышает погрешность
каждого измерения, σv≫δv, он почти наверняка связан
с реальным различием скоростей пули в разных выстрелах, а не с ошибками
измерений. В качестве результата эксперимента представляют интерес
как среднее значение скоростей ⟨v⟩=162±6м/с
(ε≈4%), так и значение σv≈14м/с,
характеризующее разброс значений скоростей от выстрела к выстрелу.
Малая инструментальная погрешность в принципе позволяет более точно
измерить среднее и дисперсию, и исследовать закон распределения выстрелов
по скоростям более детально — для этого требуется набрать
бо́льшую статистику по выстрелам.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=10 м/c. Результаты
измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=163,3м/с,
σv=12,1м/c, σ⟨v⟩=5м/с,
σполн≈11,2м/с. Инструментальная
погрешность каждого измерения превышает разброс данных, поэтому в
этом опыте затруднительно сделать вывод о различии скоростей от выстрела
к выстрелу. Результат измерений скорости пули:
⟨v⟩=163±11м/с,
ε≈7%. Проводить дополнительные выстрелы при такой
большой инструментальной погрешности особого смысла нет —
лучше поработать над точностью приборов и методикой измерений.
2.6 Обработка косвенных измерений
Косвенными называют измерения, полученные в результате расчётов,
использующих результаты прямых (то есть «непосредственных»)
измерений физических величин. Сформулируем основные правила пересчёта
погрешностей при косвенных измерениях.
2.6.1 Случай одной переменной
Пусть в эксперименте измеряется величина x, а её «наилучшее»
(в некотором смысле) значение равно x⋆ и оно известно с
погрешностью σx. После чего с помощью известной функции
вычисляется величина y=f(x).
В качестве «наилучшего» приближения для y используем значение функции
при «наилучшем» x:
Найдём величину погрешности σy. Обозначая отклонение измеряемой
величины как Δx=x-x⋆, и пользуясь определением производной,
при условии, что функция y(x) — гладкая
вблизи x≈x⋆, запишем
где f′≡dydx — производная фукнции f(x), взятая в точке
x⋆. Возведём полученное в квадрат, проведём усреднение
(σy2=⟨Δy2⟩,
σx2=⟨Δx2⟩), и затем снова извлечём
корень. В результате получим
Пример. Для степенной функции
y=Axn имеем σy=nAxn-1σx, откуда
σyy=nσxx,или εy=nεx,
то есть относительная погрешность степенной функции возрастает пропорционально
показателю степени n.
Пример. Для y=1/x имеем ε1/x=εx
— при обращении величины сохраняется её относительная
погрешность.
Упражнение. Найдите погрешность логарифма y=lnx, если известны x
и σx.
Упражнение. Найдите погрешность показательной функции y=ax,
если известны x и σx. Коэффициент a задан точно.
2.6.2 Случай многих переменных
Пусть величина u вычисляется по измеренным значениям нескольких
различных независимых физических величин x, y, …
на основе известного закона u=f(x,y,…). В качестве
наилучшего значения можно по-прежнему взять значение функции f
при наилучших значениях измеряемых параметров:
Для нахождения погрешности σu воспользуемся свойством,
известным из математического анализа, — малые приращения гладких
функции многих переменных складываются линейно, то есть справедлив
принцип суперпозиции малых приращений:
где символом fx′≡∂f∂x обозначена
частная производная функции f по переменной x —
то есть обычная производная f по x, взятая при условии, что
все остальные аргументы (кроме x) считаются постоянными параметрами.
Тогда пользуясь формулой для нахождения дисперсии суммы независимых
величин (2.7), получим соотношение, позволяющее вычислять
погрешности косвенных измерений для произвольной функции
u=f(x,y,…):
| σu2=fx′2σx2+fy′2σy2+… | (2.11) |
Это и есть искомая общая формула пересчёта погрешностей при косвенных
измерениях.
Отметим, что формулы (2.10) и (2.11) применимы
только если относительные отклонения всех величин малы
(εx,εy,…≪1),
а измерения проводятся вдали от особых точек функции f (производные
fx′, fy′ … не должны обращаться в бесконечность).
Также подчеркнём, что все полученные здесь формулы справедливы только
для независимых переменных x, y, …
Остановимся на некоторых важных частных случаях формулы
(2.11).
Пример. Для суммы (или разности) u=∑i=1naixi имеем
σu2=∑i=1nai2σxi2.
(2.12)
Пример. Найдём погрешность степенной функции:
u=xα⋅yβ⋅…. Тогда нетрудно получить,
что
σu2u2=α2σx2x2+β2σy2y2+…
или через относительные погрешности
εu2=α2εx2+β2εy2+…
(2.13)
Пример. Вычислим погрешность произведения и частного: u=xy или u=x/y.
Тогда в обоих случаях имеем
εu2=εx2+εy2,
(2.14)
то есть при умножении или делении относительные погрешности складываются
квадратично.
Пример. Рассмотрим несколько более сложный случай: нахождение угла по его тангенсу
u=arctgyx.
В таком случае, пользуясь тем, что (arctgz)′=11+z2,
где z=y/x, и используя производную сложной функции, находим
ux′=uz′zx′=-yx2+y2,
uy′=uz′zy′=xx2+y2, и наконец
σu2=y2σx2+x2σy2(x2+y2)2.
Упражнение. Найти погрешность вычисления гипотенузы z=x2+y2
прямоугольного треугольника по измеренным катетам x и y.
По итогам данного раздела можно дать следующие практические рекомендации.
-
•
Как правило, нет смысла увеличивать точность измерения какой-то одной
величины, если другие величины, используемые в расчётах, остаются
измеренными относительно грубо — всё равно итоговая погрешность
скорее всего будет определяться самым неточным измерением. Поэтому
все измерения имеет смысл проводить примерно с одной и той же
относительной погрешностью. -
•
При этом, как следует из (2.13), особое внимание
следует уделять измерению величин, возводимых при расчётах в степени
с большими показателями. А при сложных функциональных зависимостях
имеет смысл детально проанализировать структуру формулы
(2.11):
если вклад от некоторой величины в общую погрешность мал, нет смысла
гнаться за высокой точностью её измерения, и наоборот, точность некоторых
измерений может оказаться критически важной. -
•
Следует избегать измерения малых величин как разности двух близких
значений (например, толщины стенки цилиндра как разности внутреннего
и внешнего радиусов): если u=x-y, то абсолютная погрешность
σu=σx2+σy2
меняется мало, однако относительная погрешность
εu=σux-y
может оказаться неприемлемо большой, если x≈y.