ТЕСТИРОВАНИЕ ПРОГРАММ
В целом разработчики
различают дефекты программного обеспечения и сбои. В случае сбоя программа
ведет себя не так, как ожидает пользователь. Дефект — это ошибка/неточность,
которая может быть (а может и не быть) следствием сбоя.
Общепринятая практика
состоит в том, что после завершения
продукта и до передачи его заказчику независимой группой тестировщиков
проводится тестирование ПО. Эта практика
часто выражается в виде отдельной фазы тестирования (в общем цикле
разработки ПО), которая часто используется для
компенсирования задержек, возникающих на предыдущих стадиях разработки. Другая практика состоит в том,
что тестирование начинается вместе с
началом проекта и продолжается параллельно созданию продукта до завершения
проекта. Второй путь обычно требует больших трудозатрат, но качество
тестирования при этом будет выше.
Уровни тестирования:
•
модульное тестирование. Тестируется
минимально возможный для тестирования
компонент, например отдельный класс или функция;
•
интеграционное тестирование.
Проверяется, есть ли какие- либо проблемы в интерфейсах и взаимодействии между
интегрируемыми компонентами, например, не передается информация, передается
некорректная информация;
•
системное тестирование. Тестируется
интегрированная система на ее соответствие
исходным требованиям:
—
альфа-тестирование — имитация
реальной работы с системой штатными
разработчиками либо реальная работа с системой потенциальными пользователями/заказчиком на стороне
разработчика. Часто альфа-тестирование применяется для законченного продукта в
качестве внут-
реннего приемочного тестирования. Иногда альфа тестирование выполняется под отладчиком или
с использованием окружения, которое
помогает быстро выявлять найденные
ошибки. Обнаруженные ошибки могут быть переданы тестировщикам для
дополнительного исследования в
окружении, подобном тому, в котором
будет использоваться ПО;
— бета-тестирование — в
некоторых случаях выполняется распространение версии с ограничениями (по функциональности или времени работы) для
некоторой группы
лиц с тем, чтобы убедиться, что продукт содержит достаточно мало ошибок. Иногда
бета-тестирование выполняется для того,
чтобы получить обратную связь о продукте от его будущих пользователей.
5.1. Термины и определения
Выполнение программы с целью обнаружения ошибок называется тестированием. Виды ошибок и
способы их обнаружения приведены в табл.
5.1.
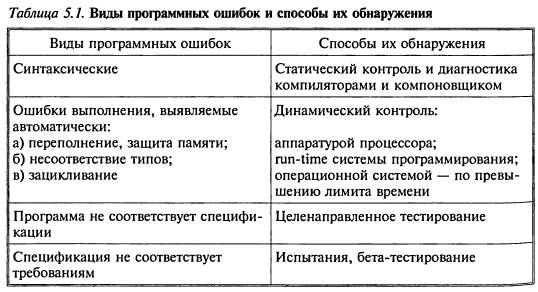
Эффективность контроля 1-го
вида зависит и от языка, и от компилятора. Контроль 2-го вида осуществляется с
помощью исключений — Exceptions и весьма полезен для проверки правдоподобности
промежуточных результатов. Тест — это набор контрольных входных данных
совместно с ожидаемыми результатами. В
число входных данных времязависимых программ
входят события и временные параметры. Ключевой вопрос — полнота
тестирования: какое количество каких тестов
гарантирует, возможно, более полную проверку программы?
Исчерпывающая проверка на всем множестве входных данных недостижима. Пример: программа, вычисляющая
функцию двух переменных: Y=f(X, Z). Если
X, Y, Z — real, то полное число тестов
(232) 2= 264= 1031 Если на
каждый тест тратить 1 мс, то 264 мс = = 800 млн лет. Следовательно:
• в любой нетривиальной программе на любой стадии ее готовности содержатся необнаруженные ошибки;
• тестирование — технико-экономическая проблема, основанная на компромиссе время — полнота.
Поэтому нужно стремиться к возможно меньшему количеству хороших тестов с желательными свойствами.
Детективность:
тест должен с большой вероятностью
обнаруживать возможные ошибки
Покрывающая способность:
один тест должен выявлять как можно больше ошибок.
Воспроизводимость:
ошибка должна выявляться независимо от изменяющихся условий (например, от
временных соотношений) — это
труднодостижимо для времязависимых программ,
результаты которых часто невоспроизводимы.
Только на основании выбранного
критерия можно определить тот момент
времени, когда конечное множество тестов
окажется достаточным для проверки программы с некоторой
полнотой (степень полноты, впрочем, определяется экспериментально). Используется два вида
критериев (табл. 5.2):
• функциональные тесты
составляются исходя из спецификации
программы;
• структурные тесты составляются
исходя из текста программы.

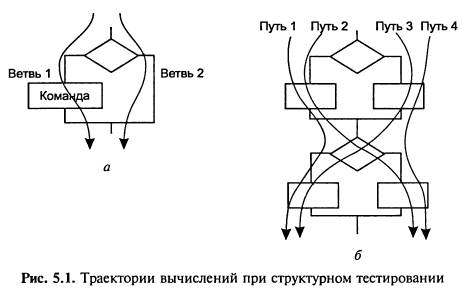
На рис. 5.1, а видно отличие
тестирования команд (достаточен один
тест) от С1 (необходимы два теста как минимум).
Рисунок 5.1, б иллюстрирует различие С1 (достаточно двух тестов,
покрывающих пути 1, 4 или 2, 3) от С2 (необходимо четыре теста для всех четырех путей). С2 недостижим
в реальных программах из-за их цикличности, поэтому ограничиваются тремя путями для каждого цикла: 0, 1 и N повторений
цикла.
Остаются проблемы назначения
классов входных/выходных данных для функционального тестирования и проектирования
тестов для структурного тестирования. Классы, как правило, назначаются исходя из семантики решаемой
задачи [6].
Рассмотрим пример. Найти
минимальный набор тестов для программы нахождения вещественных корней
квадратного уравнения ах2 + bх +
с — 0.
Решение представлено в табл. 5.3.

Таким образом, для этой программы предлагается минимальный набор функциональных тестов,
исходя из 7 классов выходных данных.
5.2. Тестирование «белого
ящика» и «черного ящика»
В терминологии профессионалов
тестирования (программного и некоторого
аппаратного обеспечения) фразы
тестирование «белого ящика» и тестирование «черного ящика» относятся к
тому, имеет ли разработчик тестов доступ к исходному коду тестируемого ПО, или
же тестирование выполняется через
пользовательский интерфейс либо прикладной программный интерфейс, предоставленный тестируемым
модулем.
При тестировании «белого ящика»
(англ. white-box testing, также говорят
— прозрачного ящика) разработчик теста имеет доступ к исходному коду и может
писать код, который связан с
библиотеками тестируемого ПО. Это типично для юнит-тестирования (англ.
unit testing), при котором тестируются только отдельные части системы. Оно
обеспечивает то, что компоненты
конструкции работоспособны и устойчивы до определенной степени.
При тестировании «черного
ящика» (англ. black-box testing) тестировщик имеет доступ к ПО только через те
же интерфейсы, что и заказчик или пользователь, либо через внешние
интерфейсы, позволяющие другому компьютеру либо другому процессу
подключиться к системе для тестирования. Например, тестирующий модуль может виртуально нажимать
клавиши или кнопки мыши в тестируемой программе с помощью механизма взаимодействия процессов с уверенностью в
том, что эти события вызывают тот же
отклик, что и реальные нажатия клавиш и кнопок мыши.
Если альфа- и бета-тестирование
относятся к стадиям до выпуска продукта
(а также, неявно, к объему тестирующего
сообщества и ограничениям на методы тестирования), тестирование «белого
ящика» и «черного ящика» имеет отношение к
способам, которыми тестировщик достигает цели.
Бета-тестирование в целом
ограничено техникой «черного ящика» (хотя постоянная часть тестировщиков
обычно продолжает тестирование «белого
ящика» параллельно бета-тестированию).
Таким образом, термин бета-тестирование может
указывать на состояние программы (ближе к выпуску, чем альфа) или может
указывать на некоторую группу тестировщиков и процесс, выполняемый этой
группой. Итак, тестировщик может продолжать
работу по тестированию «белого ящика», хотя ПО уже «в бете» (стадия), но в этом
случае он не является частью
бета-тестирования (группы/процесса).
5.3. Порядок разработки
тестов
По внешней спецификации
разрабатываются тесты [3]:
• для каждого класса входных данных;
• для граничных и особых значений входных данных.
Контролируется, все ли классы
выходных данных при этом проверяются, и добавляются при необхопимости нужные
тесты.
Разрабатываются тесты для тех
функций, которые не проверяются в п. 1.
По тексту программы проверяется,
все ли условные переходы выполнены в
каждом направлении (С1). При необходимости добавляются новые тесты.
Аналогично проверяется,
проходятся ли пути для каждого цикла: без выполнения тела, с однократным и
максимальным числом повторений.
Готовятся тесты, проверяющие
исключительные ситуации, недопустимые входные данные, аварийные ситуации.
Функциональное тестирование
дополняется здесь структурным. Классы
входных/выходных данных должны быть
определены в плане тестирования уже во внешней спецификации.
Согласно статистике 1-й и 2-й пункты обеспечивают степень охвата С1 в среднем 40—50 %. Проверка по С1
(пункт 3) обычно выявляет 90 % всех ошибок, найденных при тестировании. (Все
программное обеспечение ВВС США принимается с проверкой
по С1.)
Систематическое тестирование
предполагает также ведение журнала отладки (Bug Book), в котором фиксируется
ошибка (описание, дата обнаружения, автор модуля) и в дальнейшем — исправление
(дата, автор).
Приведем так называемые аксиомы
тестирования.
1. Тест должен быть направлен на обнаружение ошибки, а не на подтверждение
правильности программы.
2. Автор теста — не автор программы.
3. Тесты разрабатываются одновременно или до разработки программы.
4. Необходимо предсказывать ожидаемые результаты теста до его выполнения и
анализировать причины расхождения
результатов.
5. Предыдущее тестирование необходимо повторять после каждого внесения
исправлений в программу.
6. Следует повторять полное тестирование после внесения изменений в
программу или после переноса ее в другую среду.
7. В те программы, в которых обнаружено много ошибок, необходимо дополнить первоначальный набор
тестов [6].
5.4. Автоматизация
тестирования
A.Автоматизация прогона тестов
актуальна для 5-й и 6-й аксиом Майерса.
Пишутся командные файлы для запуска
программы с каждым тестом из набора и сравнением реального результата с ожидаемым. Существуют
специальные средства (например система MIL-S для PL/1 фирмы IBM). Разрабатывается
стандарт IEEE
скриптового языка для описания тестовых
наборов [3].
Б. Средства автоматизации
подготовки тестов и анализа их
результатов.
1. Генераторы случайных тестов в заданных областях входных данных.
2. Отладчики (для локализации ошибок).
3. Анализаторы динамики (profilers). Обычно входят в состав отладчиков;
применяются для проверки соответствия тестовых наборов структурным критериям
тестирования.
4. Средства автоматической генерации структурных тестов методом
«символического выполнения» Кинга.
5.5. Модульное тестирование
Модульное тестирование — это
тестирование программы на уровне отдельно взятых модулей, функций или классов.
Цель модульного тестирования заключается в выявлении
локализованных в модуле ошибок в реализации алгоритмов, а также в определении степени готовности системы к
переходу на следующий уровень разработки
и тестирования. Модульное тестирование
проводится по принципу «белого ящика», т. е. основывается на знании внутренней
структуры программы и часто включает те или иные методы анализа покрытия кода.
Модульное тестирование обычно
подразумевает создание вокруг каждого
модуля определенной среды, включающей
заглушки для всех интерфейсов тестируемого модуля. Некоторые из них могут
использоваться для подачи входных значений, другие — для анализа результатов,
присутствие третьих может быть продиктовано требованиями, накладываемыми
компилятором и сборщиком.
На уровне модульного
тестирования проще всего обнаружить дефекты, связанные с алгоритмическими
ошибками и ошибками кодирования алгоритмов, типа работы с условиями и счетчиками циклов, а также с использованием
локальных переменных и ресурсов. Ошибки, связанные с неверной трактовкой
данных, некорректной реализацией интерфейсов, совместимостью, производительностью и т. п., обычно
пропускаются на уровне модульного тестирования и выявляются на более поздних
стадиях тестирования.
Именно эффективность
обнаружения тех или иных типов дефектов
должна определять стратегию модульного тестирования, т. е. расстановку акцентов
при определении набора входных значений.
У организации, занимающейся разработкой программного
обеспечения, как правило, имеется историческая база данных (Repository)
разработок, хранящая конкретные сведения о
разработке предыдущих проектов: о версиях и сборках кода (build), зафиксированных в процессе разработки
продукта, о принятых решениях,
допущенных просчетах, ошибках, успехах и т. п. Проведя анализ характеристик
прежних проектов, подобных заказанному разработчику, можно предохранить новую
разработку от старых ошибок, например, определив типы дефектов, поиск которых
наиболее эффективен на различных этапах тестирования.
В данном случае анализируется
этап модульного тестирования. Если
анализ не дал нужной информации, например, в
случае проектов, в которых соответствующие данные не собирались, то основным правилом становится
поиск локальных дефектов, у которых код,
ресурсы и информация, вовлеченные в дефект, характерны именно для данного
модуля. В этом случае на модульном уровне ошибки, связанные, например, с неверным порядком или форматом параметров
модуля, могут быть пропущены, поскольку они вовлекают информацию, затрагивающую другие модули (а именно,
спецификацию интерфейса), в то время как ошибки в алгоритме обработки
параметров
довольно легко обнаруживаются.
Являясь по способу исполнения
структурным тестированием или тестированием «белого ящика», модульное
тестирование характеризуется степенью, в
которой тесты выполняют или покрывают
логику программы (исходный текст). Тесты, связанные со структурным
тестированием, строятся по следующим принципам:
• на основе анализа потока управления. В этом случае элементы, которые должны быть покрыты при
прохождении тестов, определяются на основе структурных критериев
тестирования СО, CI, C2. К ним относятся вершины, дуги, пути управляющего
графа программы (УГП), условия,
комбинации условий и т. п.
• на основе анализа потока данных, когда элементы, которые должны быть покрыты, определяются на
основе потока данных, т. е.
информационного графа программы.
Тестирование на основе потока управления.
Особенности использования структурных критериев тестирования СО, CI, С2 были
рассмотрены в разд. 5.2. К ним следует добавить критерий покрытия условий,
заключающийся в покрытии всех логических (булевых) условий в программе.
Критерии покрытия решений (ветвей — С1) и условий не заменяют друг друга,
поэтому на практике используется комбинированный критерий покрытия
условий/решений, совмещающий требования по покрытию и решений, и условий.
К популярным критериям
относится критерий покрытия функций программы, согласно которому каждая
функция программы должна быть вызвана
хотя бы 1 раз, и критерий
покрытия вызовов, согласно которому каждый вызов каждой функции в программе
должен быть осуществлен хотя бы 1 раз. Критерий покрытия вызовов известен также
как критерий покрытия пар вызовов (call pair coverage).
Тестирование на основе потока данных. Этот вид тестирования направлен на выявление ссылок на
неинициализированные переменные и избыточные присваивания (аномалий потока данных). Как основа для стратегии
тестирования поток данных впервые был описан в [14]. Предложенная там
стратегия требовала тестирования всех
взаимосвязей, включающих в себя ссылку
(использование) и определение переменной, на которую
указывает ссылка (т. е. требуется покрытие дут информационного графа
программы). Недостаток стратегии в том, что она не включает критерий С1 и не
гарантирует покрытия решений.
Стратегия требуемых пар [15]
также тестирует упомянутые взаимосвязи. Использование переменной в
предикате дублируется в соответствии с
числом выходов решения, и каждая из таких
требуемых взаимосвязей должна быть протестирована. К популярным критериям принадлежит критерий СР,
заключающийся в покрытии всех таких пар дуг v и w, что из дуги v достижима дуга
w, поскольку именно на дуге может произойти потеря значения переменной, которая в дальнейшем уже
не должна использоваться. Для покрытия
еще одного популярного критерия Cdu достаточно тестировать пары (вершина,
дуга), поскольку определение переменной происходит в вершине УГП, а ее использование — на дугах, исходящих из
решений, или в вычислительных вершинах.
Методы проектирования тестовых
путей для достижения заданной степени
тестированности в структурном тестировании.
Процесс построения набора тестов при структурном тестировании принято делить на три фазы:
• конструирование УГП;
• выбор тестовых путей;
• генерация тестов, соответствующих тестовым путям.
Первая фаза соответствует
статическому анализу программы, задача которого состоит в получении графа
программы и зависящего от него и от
критерия тестирования множества элементов, которые необходимо покрыть тестами.
На третьей фазе по известным
путям тестирования осуществляется поиск
подходящих тестов, реализующих прохождение этих путей.
Вторая фаза обеспечивает выбор тестовых путей. Выделяют три подхода к
построению тестовых путей:
• статические методы;
• динамические методы;
• методы реализуемых путей.
Статические методы.
Самое простое и легко реализуемое
решение — построение каждого пути посредством постепенного его удлинения
за счет добавления дуг, пока не будет достигнута выходная вершина управляющего
графа программы. Эта идея может быть усилена в так называемых адаптивных
методах, которые каждый раз добавляют
только один тестовый путь (входной
тест), используя предыдущие пути (тесты) как руководство для выбора последующих
путей в соответствии с некоторой стратегией. Чаще всего адаптивные стратегии
применяются по отношению к критерию С1. Основной недостаток статических методов
заключается в том, что не учитывается возможная
нереализуемость построенных путей тестирования.
Динамические методы.
Такие методы предполагают построение
полной системы тестов, удовлетворяющих заданному критерию, путем одновременного решения задачи
построения покрывающего множества путей
и тестовых данных. При этом можно
автоматически учитывать реализуемость или нереализуемость ранее
рассмотренных путей или их частей. Основной идеей динамических методов является подсоединение к
начальным реализуемым отрезкам путей
дальнейших их частей так, чтобы:
1) не терять при этом реализуемости вновь полученных путей;
2) покрыть требуемые элементы структуры программы.
Методы реализуемых путей.
Данная методика [16] заключается в
выделении из множества путей подмножества всех реализуемых путей. После этого
покрывающее множество путей строится из полученного подмножества реализуемых
путей.
Достоинство статических
методов состоит в сравнительно небольшом
количестве необходимых ресурсов как при
использовании, так и при разработке. Однако их реализация может содержать непредсказуемый процент брака (нереализуемых
путей).
Кроме того, в этих системах переход от покрывающего множества путей к полной системе тестов
пользователь должен осуществить вручную,
а эта работа достаточно трудоемкая.
Динамические методы требуют значительно больших ресурсов как при разработке, так и при эксплуатации, однако
увеличение затрат происходит в основном за счет разработки и эксплуатации аппарата определения реализуемости пути
(символический интерпретатор, решатель
неравенств). Достоинство этих методов
заключается в том, что их продукция имеет некоторый качественный уровень
— реализуемость путей. Методы реализуемых путей дают самый лучший результат
[33].
5.6. Интеграционное
тестирование
Интеграционное тестирование —
это тестирование части системы, состоящей из двух и более модулей. Основная
задача интеграционного тестирования — поиск дефектов, связанных с ошибками в
реализации и интерпретации интерфейсного
взаимодействия между модулями.
С технологической точки зрения
интеграционное тестирование является
количественным развитием модульного, поскольку так же, как и модульное
тестирование, оперирует интерфейсами модулей и подсистем и требует создания
тестового окружения,
включая заглушки (Stub) на месте отсутствующих модулей.
Основная разница между модульным и интеграционным тестированием состоит в целях, т. е. в типах
обнаруживаемых дефектов, которые, в свою очередь, определяют стратегию выбора
входных данных и методов анализа. В частности, на уровне интеграционного тестирования часто
применяются методы, связанные с
покрытием интерфейсов, например, вызовов функций или методов, или анализ использования
интерфейсных объектов, таких как глобальные ресурсы, средства коммуникаций, предоставляемых операционной системой.
На рис. 5.2 приведена структура
комплекса программ К, состоящего из
оттестированных на этапе модульного тестирования модулей М1, М,2
М11, М,12 М21, М22. Задача,
решаемая методом интеграционного
тестирования, — тестирование
межмодульных связей, реализующихся при исполнении программного
обеспечения комплекса К. Интеграционное тестирование использует модель «белого ящика» на модульном
уровне.
Поскольку тестировщику текст программы известен с детальностью до вызова
всех модулей, входящих в тестируемый комплекс,
применение структурных критериев на данном этапе возможно и оправданно.
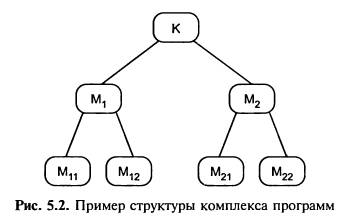
Рис. 5.2. Пример структуры комплекса программ
Интеграционное тестирование
применяется на этапе сборки модульно оттестированных модулей в единый
комплекс.
Известны два метода сборки модулей:
• монолитный, характеризующийся
одновременным объединением всех модулей
в тестируемый комплекс;
• инкрементальный,
характеризующийся пошаговым (помодульным) наращиванием комплекса программ с пошаговым тестированием собираемого
комплекса. В инкрементальном методе выделяют две стратегии добавления модулей:
— «сверху вниз» и соответствующее ему восходящее тестирование;
— «снизу вверх» и соответственно нисходящее
тестирование.
Особенности монолитного тестирования заключаются в следующем: для замены не разработанных к
моменту тестирования модулей, кроме самого верхнего (К на рис. 5.2),
необходимо дополнительно разрабатывать
драйверы (test driver) и/или заглушки(stub) [9], замещающие отсутствующие на
момент сеанса тестирования модули нижних
уровней.
Сравнение монолитного и
интегрального подходов дает следующие
результаты.
Монолитное тестирование требует
больших трудозатрат, связанных с дополнительной разработкой драйверов и
заглушек и со сложностью идентификации ошибок, проявляющихся в пространстве собранного кода.
Пошаговое тестирование связано
с меньшей трудоемкостью идентификации ошибок за счет постепенного
наращивания объема тестируемого кода и
соответственно локализации
добавленной области тестируемого кода.
Монолитное тестирование предоставляет
большие возможности распараллеливания
работ, особенно на начальной фазе тестирования.
Особенности нисходящего
тестирования заключаются в следующем:
организация среды для исполняемой очередности
вызовов оттестированными модулями тестируемых модулей, постоянная разработка и использование
заглушек, организация приоритетного
тестирования модулей, содержащих операции обмена с окружением, или модулей,
критичных для тестируемого алгоритма.
Например, порядок тестирования комплекса К (см. рис. 5.2) при нисходящем
тестировании может быть таким, как показано в примере 5.3, где тестовый набор,
разработанный для модуля Mi, обозначен как XYi =
(X, Y)i.
1) К -> XYk
2) М1 -> XY1
3)M11->XY
11
4) М2
-> XY2
5) М22
-> XY 22
6) M21
-> XY21
7) M12->
XY 12
Пример 5.1.
Возможный порядок тестов при нисходящем тестировании (html, txt).
Недостатки нисходящего
тестирования:
• проблема разработки достаточно «интеллектуальных» заглушек, т. е. заглушек, способных к использованию
при моделировании различных режимов работы комплекса,
необходимых для тестирования;
• сложность организации и разработки среды для реализации исполнения
модулей в нужной последовательности;
• параллельная разработка модулей верхних и нижних уровней приводит к не всегда эффективной
реализации модулей из-за подстройки
(специализации) еще не
тестированных модулей нижних уровней к уже оттестированным модулям верхних уровней.
Особенности восходящего
тестирования в организации
порядка сборки и перехода к тестированию модулей, соответствующему порядку их реализации.
Например, порядок тестирования комплекса К (см. рис. 5.2) при восходящем
тестировании может быть следующим (см.
пример 5.4).
1)М11->ХУ11
2) M12
-> XY12
3) Мi
-> XYi
4) М21
-> XY21
5) M2(M21,
Stub(M22))
-> XY2
6) К(М1 ,M2(M21,
Stub(M22))
-> XYk
7) М22
-> XY22
М2 -*
XY2
9) К -> XYk
Пример 5.2. Возможный порядок тестов при восходящем тестировании.
Недостатки восходящего тестирования:
• запаздывание проверки концептуальных особенностей тестируемого комплекса;
• необходимость в разработке и использовании драйверов [33].
5.7. Системное тестирование
Системное тестирование
качественно отличается от
интеграционного и модульного уровней. Системное тестирование рассматривает тестируемую систему в целом и
оперирует на уровне пользовательских интерфейсов, в отличие от последних
фаз
интеграционного тестирования, которое оперирует на уровне интерфейсов модулей. Различны и цели этих
уровней тестирования. На уровне системы часто
сложно и малоэффективно анализировать
прохождение тестовых траекторий внутри программы
или отслеживать правильность работы конкретных функций.
Основная задача системного тестирования — выявления дефектов, связанных с
работой системы в целом, таких как неверное
использование ресурсов системы, непредусмотренные комбинации данных
пользовательского уровня, несовместимость с
окружением, непредусмотренные сценарии использования, отсутствующая или неверная функциональность,
неудобство в применении и т. п.
Системное тестирование
производится над проектом в целом с помощью метода «черного ящика». Структура
программы не имеет никакого значения, для проверки доступны только входы и
выходы, видимые пользователю. Тестированию подлежат коды и пользовательская
документация.
Категории тестов системного
тестирования:
1. Полнота решения функциональных задач.
2. Стрессовое тестирование — на предельных объемах нагрузки входного потока.
3. Корректность использования ресурсов (утечка памяти, возврат ресурсов).
4. Оценка производительности.
5. Эффективность защиты от искажения данных и некорректных действий.
6. Проверка инсталляции и конфигурации на разных платформах.
7. Корректность документации.
Поскольку системное
тестирование проводится на
пользовательских интерфейсах, создается иллюзия того, что построение
специальной системы автоматизации тестирования не всегда необходимо. Однако объемы данных на этом уровне
таковы, что
обычно более эффективным подходом является полная или частичная автоматизация тестирования, что
приводит к созданию тестовой системы, гораздо более сложной, чем система тестирования, применяемая на уровне
тестирования модулей или их комбинаций.
5.8. Эффективность и
оптимизация программ
Эффективными считаются
программы, требующие минимального
времени выполнения и/или минимального объема оперативной памяти. Особые
требования к эффективности
программного обеспечения предъявляют при наличии ограничений (на время
реакции системы, на объем оперативной памяти и т. п.). В случаях, когда
обеспечение эффективности не требует серьезных временных и трудовых затрат, а
также не приводит к
существенному ухудшению технологических свойств, необходимо это требование иметь в виду [7].
Разумный подход к обеспечению
эффективности разрабатываемого
программного обеспечения состоит в том, чтобы в
первую очередь оптимизировать те фрагменты программы, которые
существенно влияют на характеристики эффективности. Для
уменьшения времени выполнения некоторой программы в первую очередь следует проанализировать
циклические фрагменты с большим количеством повторений: экономия времени выполнения одной итерации цикла будет
умножена на количество итераций.
Не следует забывать и о
том, что многие способы снижения временных затрат приводят к увеличению
емкостных и, наоборот, уменьшение объема
памяти может потребовать
дополнительного времени на обработку.
И тем более не следует
«платить» за увеличение эффективности
снижением технологичности разрабатываемого программного обеспечения. Исключения возможны
лишь при очень жестких требованиях и наличии соответствующего контроля за
качеством.
Частично проблему
эффективности программ решают за программиста компиляторы.
Средства оптимизации,
используемые компиляторами, делят на две группы:
• машинно-зависимые, т. е.
ориентированные на конкретный машинный язык, выполняют оптимизацию кодов
на уровне машинных команд, например,
исключение лишних
пересылок, использование более эффективных команд и т. п.
• машинно-независимые выполняют
оптимизацию на уровне входного языка, например, вынесение вычислений константных (независящих от индекса цикла)
выражений из
циклов и т. п.
Естественно, нельзя
вмешаться в работу компилятора, но
существует много возможностей оптимизации программы на уровне команд.
Способы экономии памяти. Принятие мер по
экономии памяти предполагает, что в
каких-то случаях эта память неэкономно использовалась. Учитывая, что
анализировать имеет смысл только
операции размещения данных, существенно влияющие на характеристику эффективности, следует
обращать особое внимание на выделение
памяти под данные структурных типов
(массивов, записей, объектов и т. п.).
Прежде всего при наличии
ограничений на использование памяти следует выбирать алгоритмы обработки, не
требующие дублирования исходных данных структурных типов в процессе обработки.
Примером могут служить алгоритмы сортировки
массивов, выполняющие операцию в заданном массиве, например хорошо
известная сортировка методом «пузырька».
Если в программе необходимы
большие массивы, используемые
ограниченное время, то их можно размещать в
динамической памяти и удалять при завершении обработки.
Также следует помнить, что
при передаче структурных данных в
подпрограмму «по значению» копии этих данных
размещаются в стеке. Избежать копирования иногда удается, если передавать данные «по ссылке», но как
неизменяемые (описанные
const). В последнем случае в стеке размещается только адрес данных,
например:
Type Mas.4iv array [I. 100] of real;
function Summa (Const a:Massiv; .)
Способы уменьшения времени выполнения. Как уже упоминалось выше, для уменьшения времени
выполнения в первую очередь необходимо
анализировать циклические участки
программы с большим количеством повторений. При их написании необходимо по возможности:
•
выносить вычисление константных, т. е. не зависящих от
параметров цикла, выражений из циклов;
•
избегать «длинных» операций умножения и деления, заменяя их сложением, вычитанием и сдвигами;
•
минимизировать преобразования типов в выражениях;
•
оптимизировать запись условных выражений — исключать
лишние проверки;
•
исключать многократные обращения к элементам массивов по
индексам (особенно многомерных, так как при
вычислении адреса элемента используются операции умножения на значение
индексов), первый раз прочитав из памяти элемент массива, следует запомнить его
в скалярной переменной и использовать в
нужных местах;
•
избегать использования различных типов в выражении и т.
п.
Рассмотрим следующие примеры.
Пример 5.3. Пусть имеется цикл следующей структуры (Pascal):
for у: 0 to 99 do
for x: 0 to 99 do
а [320*х+у] S [k,l];
В этом цикле операции
умножения и обращения к элементу S[k] выполняются 10 000 раз.
Оптимизируем цикл, используя, что 320 = 28 + 26:
ski: =S [k,l]; {выносим обращение к элементу массива из цикла}
for x: 0 to 99 do (меняем циклы местами}
begin
х shl 8 + х shl 6; {умножение заменяем на сдвиги и выносим из цикла)
for у; 0 to 99 do
a [i+y] =skl;
end;
В результате вместо 10 000 операций умножения будут выполняться 200 операций сдвига, а их время
приблизительно сравнимо со временем выполнения операции сложения.
Обращение к элементу массива S[k] будет выполнено 1 раз.
Пример 5.4. Пусть имеется цикл, в теле которого реализовано сложное условие:
for k: 2 to n do
begin
ifx[k] > ук then S: S+y[k]-x [к];
if (x [k]< = yk) and (y[k]<yk) then S: = S+yk-x[k];
end;…
В этом цикле можно убрать лишние проверки:
for k: =2 to n do
begin
ifx [k]>yk then S:=S+y[к]-х[к]
else
ify[k]<yk then S: =S+yk-x [k];
end;
Обратите внимание на то,
что в примере 5.3 понять, что делает
программа, стало сложнее, а в примере 5.4 — практически нет. Следовательно,
оптимизация, выполненная в первом
случае, может ухудшить технологичность программы, а потому не очень
желательна.
Поскольку тестировщику текст программы известен с детальностью до вызова
всех модулей, входящих в тестируемый комплекс,
применение структурных критериев на данном этапе возможно и оправданно.
Рис. 5.2. Пример структуры комплекса программ
Интеграционное тестирование
применяется на этапе сборки модульно оттестированных модулей в единый
комплекс.
• монолитный, характеризующийся
одновременным объединением всех модулей
в тестируемый комплекс;
• инкрементальный,
характеризующийся пошаговым (помодульным) наращиванием комплекса программ с пошаговым тестированием собираемого
комплекса. В инкрементальном методе выделяют две стратегии добавления модулей:
— «снизу вверх» и соответственно нисходящее
тестирование.
Особенности монолитного тестирования заключаются в следующем: для замены не разработанных к
моменту тестирования модулей, кроме самого верхнего (К на рис. 5.2),
необходимо дополнительно разрабатывать
драйверы (test driver) и/или заглушки(stub) [9], замещающие отсутствующие на
момент сеанса тестирования модули нижних
уровней.
Сравнение монолитного и
интегрального подходов дает следующие
результаты.
Монолитное тестирование требует
больших трудозатрат, связанных с дополнительной разработкой драйверов и
заглушек и со сложностью идентификации ошибок, проявляющихся в пространстве собранного кода.
Пошаговое тестирование связано
с меньшей трудоемкостью идентификации ошибок за счет постепенного
наращивания объема тестируемого кода и
соответственно локализации
добавленной области тестируемого кода.
Монолитное тестирование предоставляет
большие возможности распараллеливания
работ, особенно на начальной фазе тестирования.
Особенности нисходящего
тестирования заключаются в следующем:
организация среды для исполняемой очередности
вызовов оттестированными модулями тестируемых модулей, постоянная разработка и использование
заглушек, организация приоритетного
тестирования модулей, содержащих операции обмена с окружением, или модулей,
критичных для тестируемого алгоритма.
Например, порядок тестирования комплекса К (см. рис. 5.2) при нисходящем
тестировании может быть таким, как показано в примере 5.3, где тестовый набор,
разработанный для модуля Mi, обозначен как XYi =
(X, Y)i.
Аннотация: Рассматриваются особенности модульного тестирования, обсуждаются
подходы к тестированию на основе потока управления, потока данных.
Обсуждаются динамические и статические методы при структурном
подходе. Рассматривается пример модульного тестирования.
Рассматривается взаимосвязь сборки модулей и методов интеграционного
тестирования. Обсуждаются подходы монолитного, инкрементального,
нисходящего и восходящего тестирования. Рассматриваются особенности
интеграционного тестирования в процедурном программировании.
Модульное
Модульное тестирование — это тестирование программы на уровне
отдельно взятых модулей, функций или классов. Цель модульного
тестирования состоит в выявлении локализованных в модуле ошибок в
реализации алгоритмов, а также в определении степени готовности
системы к переходу на следующий уровень разработки и тестирования. Модульное тестирование проводится по принципу «белого ящика», то есть
основывается на знании внутренней структуры программы, и часто
включает те или иные методы анализа покрытия кода.
Модульное тестирование обычно подразумевает создание вокруг каждого
модуля определенной среды, включающей заглушки для всех интерфейсов
тестируемого модуля. Некоторые из них могут использоваться для подачи
входных значений, другие для анализа результатов, присутствие третьих
может быть продиктовано требованиями, накладываемыми компилятором и
сборщиком.
На уровне модульного тестирования проще всего обнаружить дефекты,
связанные с алгоритмическими ошибками и ошибками кодирования
алгоритмов, типа работы с условиями и счетчиками циклов, а также с
использованием локальных переменных и ресурсов. Ошибки, связанные с
неверной трактовкой данных, некорректной реализацией интерфейсов,
совместимостью, производительностью и т.п. обычно пропускаются на
уровне модульного тестирования и выявляются на более поздних стадиях
тестирования.
Именно эффективность обнаружения тех или иных типов дефектов должна
определять стратегию модульного тестирования, то есть расстановку
акцентов при определении набора входных значений. У организации,
занимающейся разработкой программного обеспечения, как правило,
имеется историческая база данных ( Repository ) разработок, хранящая
конкретные сведения о разработке предыдущих проектов: о версиях и
сборках кода ( build ) зафиксированных в процессе разработки продукта,
о принятых решениях, допущенных просчетах, ошибках, успехах и т.п.
Проведя анализ характеристик прежних проектов, подобных заказанному
организации, можно предохранить новую разработку от старых ошибок,
например, определив типы дефектов, поиск которых наиболее эффективен
на различных этапах тестирования.
В данном случае анализируется этап модульного тестирования. Если
анализ не дал нужной информации, например, в случае проектов, в
которых соответствующие данные не собирались, то основным правилом
становится поиск локальных дефектов, у которых код, ресурсы и
информация, вовлеченные в дефект, характерны именно для данного
модуля. В этом случае на модульном уровне ошибки, связанные,
например, с неверным порядком или форматом параметров модуля, могут
быть пропущены, поскольку они вовлекают информацию, затрагивающую
другие модули (а именно, спецификацию интерфейса), в то время как
ошибки в алгоритме обработки параметров довольно легко
обнаруживаются.
Являясь по способу исполнения структурным тестированием или
тестированием «белого ящика», модульное тестирование характеризуется
степенью, в которой тесты выполняют или покрывают логику программы
(исходный текст). Тесты, связанные со структурным тестированием,
строятся по следующим принципам:
- На основе анализа потока управления. В этом случае элементы,
которые должны быть покрыты при прохождении тестов, определяются на
основе структурных критериев тестирования С0, С1,С2. К ним относятся
вершины, дуги, пути управляющего графа программы (УГП), условия,
комбинации условий и т. п. - На основе анализа потока данных, когда элементы, которые должны
быть покрыты, определяются при помощи потока данных, т. е.
информационного графа программы.
Тестирование на основе потока управления. Особенности использования
структурных критериев тестирования С0,С1,С2 были рассмотрены в
лекции 3. К ним следует добавить критерий покрытия условий,
заключающийся в покрытии всех логических (булевских) условий в
программе. Критерии покрытия решений (ветвей — С1) и условий не
заменяют друг друга, поэтому на практике используется комбинированный
критерий покрытия условий/решений, совмещающий требования по покрытию
и решений, и условий.
К популярным критериям относятся критерий покрытия функций программы,
согласно которому каждая функция программы должна быть вызвана хотя
бы один раз, и критерий покрытия вызовов, согласно которому каждый
вызов каждой функции в программе должен быть осуществлен хотя бы один
раз. Критерий покрытия вызовов известен также как критерий покрытия
пар вызовов (call pair coverage).
Тестирование на основе потока данных. Этот вид тестирования направлен
на выявление ссылок на неинициализированные переменные и избыточные
присваивания (аномалий потока данных ). Как основа для стратегии
тестирования поток данных впервые был описан в
[
14
]
. Предложенная там
стратегия требовала тестирования всех взаимосвязей, включающих в себя
ссылку (использование) и определение переменной, на которую указывает
ссылка (т. е. требуется покрытие дуг информационного графа
программы). Недостаток стратегии в том, что она не включает критерий
С1, и не гарантирует покрытия решений.
Стратегия требуемых пар
[
15
]
также тестирует упомянутые взаимосвязи.
Использование переменной в предикате дублируется в соответствии с
числом выходов решения, и каждая из таких требуемых взаимосвязей
должна быть протестирована. К популярным критериям принадлежит
критерий СР, заключающийся в покрытии всех таких пар дуг v и w, что
из дуги v достижима дуга w, поскольку именно на дуге может произойти
потеря значения переменной, которая в дальнейшем уже не должна
использоваться. Для «покрытия» еще одного популярного критерия Cdu
достаточно тестировать пары (вершина, дуга), поскольку определение
переменной происходит в вершине УГП, а ее использование — на дугах,
исходящих из решений, или в вычислительных вершинах.
Методы проектирования тестовых путей для достижения заданной степени
тестированности в структурном тестировании. Процесс построения набора
тестов при структурном тестировании принято делить на три фазы:
- Конструирование УГП.
- Выбор тестовых путей.
- Генерация тестов, соответствующих тестовым путям.
Первая фаза соответствует статическому анализу программы, задача
которого состоит в получении графа программы и зависящего от него и
от критерия тестирования множества элементов, которые необходимо
покрыть тестами.
На третьей фазе по известным путям тестирования осуществляется поиск
подходящих тестов, реализующих прохождение этих путей.
Вторая фаза обеспечивает выбор тестовых путей. Выделяют три подхода к
построению тестовых путей:
- Статические методы.
- Динамические методы.
- Методы реализуемых путей.
Статические методы. Самое простое и легко реализуемое решение —
построение каждого пути посредством постепенного его удлинения за
счет добавления дуг, пока не будет достигнута выходная вершина
управляющего графа программы. Эта идея может быть усилена в так
называемых адаптивных методах, которые каждый раз добавляют только
один тестовый путь (входной тест), используя предыдущие пути (тесты)
как руководство для выбора последующих путей в соответствии с
некоторой стратегией. Чаще всего адаптивные стратегии применяются по
отношению к критерию С1. Основной недостаток статических методов
заключается в том, что не учитывается возможная нереализуемость
построенных путей тестирования.
Динамические методы. Такие методы предполагают построение полной
системы тестов, удовлетворяющих заданному критерию, путем
одновременного решения задачи построения покрывающего множества путей
и тестовых данных. При этом можно автоматически учитывать
реализуемость или нереализуемость ранее рассмотренных путей или их
частей. Основной идеей динамических методов является подсоединение к
начальным реализуемым отрезкам путей дальнейших их частей так, чтобы:
1) не терять при этом реализуемости вновь полученных путей; 2)
покрыть требуемые элементы структуры программы.
Методы реализуемых путей. Данная методика
[
16
]
заключается в
выделении из множества путей подмножества всех реализуемых путей.
После чего покрывающее множество путей строится из полученного
подмножества реализуемых путей.
Достоинство статических методов состоит в сравнительно небольшом
количестве необходимых ресурсов, как при использовании, так и при
разработке. Однако их реализация может содержать непредсказуемый
процент брака (нереализуемых путей). Кроме того, в этих системах
переход от покрывающего множества путей к полной системе тестов
пользователь должен осуществить вручную, а эта работа достаточно
трудоемкая. Динамические методы требуют значительно больших ресурсов
как при разработке, так и при эксплуатации, однако увеличение затрат
происходит, в основном, за счет разработки и эксплуатации аппарата
определения реализуемости пути (символический интерпретатор, решатель
неравенств). Достоинство этих методов заключается в том, что их
продукция имеет некоторый качественный уровень — реализуемость путей.
Методы реализуемых путей дают самый лучший результат.
Пример модульного тестирования
Предлагается протестировать класс TCommand, который реализует команду
для склада. Этот класс содержит единственный метод TCommand.GetFullName(), спецификация которого описана (Практикум,
Приложение 2 HLD) следующим образом:
| … | |
| Операция GetFullName() возвращает полное имя команды, соответствующее ее допустимому коду, указанному в поле NameCommand. В противном случае возвращается сообщение «ОШИБКА : Неверный код команды». Операция может быть применена в любой момент. |
|
| … |
Разработаем спецификацию тестового случая для тестирования метода GetFullName на основе приведенной спецификации класса (Табл. 5.1):
| Название класса: TСommand | Название тестового случая: TСommandTest1 |
|
Описание тестового случая: Тест проверяет правильность работы метода GetFullName — получения полного названия команды на основе кода команды. В тесте подаются следующие значения кодов команд (входные значения): -1, 1, 2, 4, 6, 20, (причем -1 — запрещенное значение). |
|
| Начальные условия: Нет. | |
|
Ожидаемый результат: Перечисленным входным значениям должны соответствовать следующие Коду команды -1 должно соответствовать сообщение «ОШИБКА: Неверный Коду команды 1 должно соответствовать полное название команды Коду команды 2 должно соответствовать полное название команды Коду команды 4 должно соответствовать полное название команды Коду команды 6 должно соответствовать полное название команды Коду команды 20 должно соответствовать полное название команды |
Для тестирования метода класса TCommand.GetFullName() был создан
тестовый драйвер — класс TCommandTester. Класс TCommandTester
содержит метод TCommandTest1(), в котором реализована вся
функциональность теста. В данном случае для покрытия спецификации
достаточно перебрать следующие значения кодов команд: -1, 1, 2, 4, 6,
20, (-1 — запрещенное значение) и получить соответствующее им полное
название команды с помощью метода GetFullName() (Пример 5.1 ). Пары
значений (X, Yв) при исполнении теста заносятся в log-файл для
последующей проверки на соответствие спецификации.
После завершения теста следует просмотреть журнал теста, чтобы
сравнить полученные результаты с ожидаемыми, заданными в спецификации
тестового случая TСommandTest1 (Пример 5.2).
class TCommandTester:Tester // Тестовый драйвер
{
...
TCommand OUT;
public TCommandTester()
{
OUT=new TCommand();
Run();
}
private void Run()
{
TCommandTest1();
}
private void TCommandTest1()
{
int[] commands = {-1, 1, 2, 4, 6, 20};
for(int i=0;i<=5;i++)
{
OUT.NameCommand=commands[i];
LogMessage(commands[i].ToString()+
" : "+OUT.GetFullName());
}
}
...
}
Пример
5.1.
Тестовый драйвер
-1 : ОШИБКА : Неверный код команды 1 : ПОЛУЧИТЬ ИЗ ВХОДНОЙ ЯЧЕЙКИ 2 : ОТПРАВИТЬ ИЗ ЯЧЕЙКИ В ВЫХОДНУЮ ЯЧЕЙКУ 4 : ПОЛОЖИТЬ В РЕЗЕРВ 6 : ПРОИЗВЕСТИ ЗАНУЛЕНИЕ 20 : ЗАВЕРШЕНИЕ КОМАНД ВЫДАЧИ
Пример
5.2.
Спецификация классов тестовых случаев
Модульное/юнит/компонентное тестирование (Module/Unit/Component testing)
С этими терминами часто происходит путаница. Если ссылаться на глоссарий ISTQB, то все они — синонимы:
- Модуль, юнит (module, unit): См. компонент.
- Модульное, юнит тестирование (module testing, unit testing): См. компонентное тестирование.
- Компонент (component): Наименьший элемент программного обеспечения, который может быть протестирован отдельно.
- Компонентное тестирование (component testing): Тестирование отдельных компонентов программного обеспечения (IEEE 610).
Тем не менее, некоторые источники описывают ситуацию несколько иначе и я решил выписать другую точку зрения.
Модульное тестирование (оно же юнит-тестирование) используется для тестирования какого-либо одного логически выделенного и изолированного элемента системы (отдельные методы класса или простая функция, subprograms, subroutines, классы или процедуры) в коде. Очевидно, что это тестирование методом белого ящика и чаще всего оно проводится самими разработчиками. Целью тестирования модуля является не демонстрация правильного функционирования модуля, а демонстрация наличия ошибки в модуле, а также в определении степени готовности системы к переходу на следующий уровень разработки и тестирования. На уровне модульного тестирования проще всего обнаружить дефекты, связанные с алгоритмическими ошибками и ошибками кодирования алгоритмов, типа работы с условиями и счетчиками циклов, а также с использованием локальных переменных и ресурсов. Ошибки, связанные с неверной трактовкой данных, некорректной реализацией интерфейсов, совместимостью, производительностью и т.п. обычно пропускаются на уровне модульного тестирования и выявляются на более поздних стадиях тестирования. Изоляция тестируемого блока достигается с помощью заглушек (stubs), манекенов (dummies) и макетов (mockups).
Компонентное тестирование — тип тестирования ПО, при котором тестирование выполняется для каждого отдельного компонента отдельно, без интеграции с другими компонентами. Его также называют модульным тестированием (Module testing), если рассматривать его с точки зрения архитектуры. Как правило, любое программное обеспечение в целом состоит из нескольких компонентов. Тестирование на уровне компонентов (Component Level testing) имеет дело с тестированием этих компонентов индивидуально. Это один из самых частых типов тестирования черного ящика, который проводится командой QA. Для каждого из этих компонентов будет определен сценарий тестирования, который затем будет приведен к Test case высокого уровня -> детальным Test case низкого уровня с предварительными условиями.
Исходя из глубины уровней тестирования, компонентное тестирование можно классифицировать как:
- Тестирование компонентов в малом (CTIS — Component testing In Small): тестирование компонентов может проводиться с или без изоляции остальных компонентов в тестируемом программном обеспечении или приложении. Если это выполняется с изоляцией другого компонента, то это называется CTIS;
- Тестирование компонентов в целом (CTIL — Component testing In Large) — тестирование компонентов, выполненное без изоляции других компонентов в тестируемом программном обеспечении или приложении;
| Module/Unit testing | Component testing |
|---|---|
| Тестирование отдельных классов, функций для демонстрации того, что программа выполняется согласно спецификации | Тестирование каждого объекта или частей программного обеспечения отдельно с или без изоляции других объектов |
| Проверка в(на) соответствии с design documents | Проверка в(на) соответствии с test requirements, use case |
| Пишутся и выполняются разработчиками | Тестировщиками |
| Выполняется первым | Выполняется после Unit |
Другой источник:
По-существу эти уровни тестирования представляют одно и тоже, разница лишь в том, что в компонентном тестировании в качестве параметров функций используют реальные объекты и драйверы, а в модульном/unit тестировании — конкретные значения.
*В контексте юнит-тестирования еще можно встретить понятие golden testing. Оно означает те же юнит тесты, но с ожидаемыми результатами хранящимися в отдельном файле. Таким образом после прогона выходные значения тестов сравниваются с golden (эталонным) файлом.
*Иногда юнит-тесты называют одинокими (solitary) в случае тотального применения имитаций и заглушек или общительными (sociable) в случае реальных коммуникаций с другими участниками.
*Правило трех А(AAA) (arrange, act, assert) или триада «дано, когда, тогда» — хорошая мнемоника, чтобы поддерживать хорошую структуру тестов.
Источники:
- What is Component Testing? Techniques, Example Test Cases
- Лекция 5: Модульное и интеграционное тестирование
Доп. материал:
- ГОСТ Р 56920-2016/ISO/IEC/IEEE 29119-1:2013 “D.11 Подпроцесс покомпонентного тестирования”
- Я сомневался в юнит-тестах, но…
- Юнит-тесты переоценены
- Elliotte Rusty Harold — Effective Unit Testing
- Kevlin Henney — What we talk about when we talk about unit testing
- Андрей Сербин — Компонентное тестирование инфраструктуры
- Анатомия юнит тестирования
- Unit Test
- Component Test
- Анатомия юнит-теста
- Почему большинство юнит тестов — пустая трата времени? (перевод статьи)
- Unit Testing Guide
- Лекция 2: Тестирование программного кода (методы+окружение)
- Starting to Unit Test: Not as Hard as You Think
- 6 оправданий для того, чтобы не писать юнит-тесты
- Принципы юнит-тестирования. Часть первая
Уровень сложности
Средний
Время на прочтение
5 мин
Количество просмотров 6.9K

1. Недостаточное покрытие
Иногда из-за нашей лени, невнимательности или чего-либо ещё получается неполный охват тестами всех важных сценариев, крайних случаев и потенциальных ошибок. Представим, что у нас есть очень простой класс Calculator, который умеет делать сложение:
public int Add(int a, int b)
{
return a + b;
}Порой, когда на работе заставляют чтобы код сопровождался юнит-тестами, может получиться класс, содержащий всего один тест:
[Test]
public void Add_WhenCalled_ReturnsSum()
{
// Arrange
var a = 40;
var b = 2;
var calculator = new Calculator();
// Act
var result = calculator.Add(a,b);
// Assert
Assert.AreEqual(42, result);
}Тестирует ли код выше метод Add? Да, тестирует и даже гарантирует правильность сложения чисел 40 и 2. Однако, ни отрицательные числа, ни большие числа, сумма которых выходит за пределы размера int, ни сложение с нулем здесь не проверены.
Как сделать правильно?
Ещё до написания кода желательно вместе с аналитиком/тестировщиком/другими разработчиками обсудить все возможные корнер-кейсы (крайние случаи) и то, как код должен реагировать при встрече с ними.
2. Переизбыток тестов
В противоположность к первому пункту можно увлечься и насоздавать много излишних тестов для тривиального или простого кода, что приведет к увеличению нагрузки на поддержку и замедлению выполнения тестов.
[Test]
public void Add_WithFortyAndTwo_ReturnsFortyTwo()
{
// ...
}
[Test]
public void Add_WithOneAndOne_ReturnsTwo()
{
// ...
}
[Test]
public void Add_WithTenAndTen_ReturnsTwenty()
{
// ...
}
[Test]
public void Add_WithZeroFirst_ReturnsSum()
{
// ...
}
[Test]
public void Add_WithZeroSecond_ReturnsSum()
{
// ...
}Как сделать правильно?
Совет по составлению списка проверок с другими людьми здесь так же актуален. Плюс, порой можно воспользоваться передачей параметров в тестовый метод, что сокращает размер файла с тестами и их чтение. Еще более продвинутый вариант — использовать генераторы данных, например, Bogus. Ну и самый хардкорный вариант — использование pairwise testing.
3. Нетестируемый код
После работы в Лаборатории Касперского, где код обкладывался кучами разных тестов, я наиболее явно ощутил весь смысл слова «тестопригодность», когда встретил код, который мне пришлось несколько дней рефакторить, чтобы добавить для него юнит-тесты. Один из примеров как сделать код нетестопригодным — использовать другие классы напрямую.
public class Calculator
{
private readonly ILogger _logger;
public Calculator()
{
_logger = new Logger();
}
public int Add(int a, int b)
{
_logger.Log("Add method called.");
return a + b;
}
}Ну и соответственно, чтобы сделать его тестопригодным, надо сделать инверсию зависимости, а если по-русски, то заменить зависимость от класса на зависимость от интерфейса:
public class Calculator
{
private readonly ILogger _logger;
public Calculator(ILogger logger)
{
_logger = logger;
}
public int Add(int a, int b)
{
_logger.Log("Add method called.");
return a + b;
}
}Как сделать правильно?
Не завязываться на конкретные реализации и как можно скорее убирать такие связи, если они есть — станет легче не только писать тесты, но и просто поддерживать код.
4. Игнорирование или пропуск тестов
Если бы сам не столкнулся с подобным в нескольких компаниях, то мне бы и в голову не пришло, что тесты можно (а порой даже нужно) игнорировать.
Как сделать правильно?
Назначить ответственного человека, либо самому следить за тем, чтобы игнорированием тестов не злоупотребляли, а использовали только когда необходимо. Например, когда идет крупномасштабное внедрение изменений — обновление кодстайла, сторонней или своей библиотеки.
5. Тестирование реализации
Довольно стандартная ловушка для новичков в юнит-тестировании — написать сначала нужный код и потом на основе этого кода писать тесты. Причем тесты пишутся так, чтобы покрыть логику этого написанного кода. Проблема такого подхода — то, что не было написано, не будет и протестировано. Например, если при добавлении в класс Calculator метода Divide мы не учтем в коде проверку деления на ноль, то и при написании тестов по уже существующему коду вероятность написать тест деления на ноль исчезающе мала.
Как сделать правильно?
Вспоминаем совет к первым двум пунктам — составлять тест-кейсы ДО написания кода и опираться в них на требуемую бизнес-логику, а не на уже реализованную функциональность. Хотя, сразу оговорюсь, что для написания тестов к уже существующему коду, по которому никаких зафиксированных бизнес-требований нет и никто их не знает/не помнит, подход на основе реализации вполне подходит. Но только для целей регрессионного тестирования.
6. Хрупкие тесты
Предположим, что мы написали класс А, который реализует необходимую нам бизнес-логику. Затем, в процессе рефакторинга, мы вынесли из класса А два вспомогательных класса — В и С. Нужно ли писать тесты на все три класса? Конечно, это зависит от логики, которая была вынесена во вспомогательные классы и того, будет ли она использоваться где-то ещё помимо класса А, однако, в 99% случаев писать тесты на классы В и С не нужно.
Как сделать правильно?
Рискуя набить оскомину, повторюсь, надо тестировать не написанный код, а бизнес-логику, которая реализуется этим кодом.
7. Отсутствие организации тестов
Видел я и такие проекты, гды пытались внедрить юнит-тесты, однако, все они лежали в корне тестового проекта и было тяжело разобраться есть ли уже нужные тебе тесты или нет. И вместо того, чтобы разбираться в этом бардаке и искать нужный класс, люди просто создавали ещё один, куда писали свои тесты. Хаос в таком случае только увеличивался.
Как сделать правильно?
Надо договориться о том, как будут организованы тесты в вашей компании/команде. Один из наиболее простых и распостраненных подходов — полностью копировать структуру основного проекта, добавляя постфикс «Tests». То есть, если был проект CalculationSolution и в нем был путь Calculations/Calculators/, по которому лежал файл Calculator.cs, для которого мы хотим добавить юнит-тесты, то юнит-тесты должны быть в проекте CalculationSolution.Tests по пути Calculations/Calculators/CalculatorTests.cs.
8. Божественные тесты
Как в процессе программирования может появиться god object — класс, который делает все и вся, так и при написании тестов могут получаться тесты, в которых проверяется не что-то одно, а сразу штук 10 разных аспектов. Да, такая «денормализация» тестов порой имеет место быть в end-to-end, UI или интеграционных тестах в целях экономии ресурсов (в т.ч. времени выполнения), однако, юнит-тесты должны проходить очень быстро и нет смысла усложнять себе разбор упавших тестов ради экономии пары миллисекунд.
Как сделать правильно?
Следить за тем, чтобы один тест тестировал только один аспект бизнес-логики.
9. Недостаточная обработка ошибок
Соблазн протестировать happy path и, возможно, парочку самых простых в тестировании ошибок может привести к тому, что непойманные на этапе автоматизированного тестирования ошибки приведут к проблемам в продакшн среде и цена этой ошибки будет намного выше. Отличие этого пункта от первого в том, что, если в первом пункте было наглядно видно маленькое количество тестов, их практически не было, то здесь тесты уже есть и их даже может быть много, однако, они могут быть направлены на количество, а не на качество.
Как сделать правильно?
Опять же, составлять список тестов заранее, плюс, можно добавить в чеклист ревьюера пункт о том, что все тест-кейсы должны быть реализованы.
10. Смешивание юнит-тестов с другими видами тестов
Как я писал выше, юнит-тесты обычно проходят очень быстро, так как не требуют сложной подготовки, подтягивания зависимостей и прочего. Остальные виды тестов уже несколько более продвинутые и более ресурсоемкие. Поэтому смешивание всех тестов в одну кучу является не очень хорошим вариантом.
Как сделать правильно?
Правильным будет разделять мух от котлет. Сделать это можно, например, разнеся тесты по разным проектам или используя идентифицирующие атрибуты. Далее с помощью этих атрибутов можно настроить так, чтобы ни один коммит не попадал ни в одну ветку до тех пор, пока все юнит-тесты, связанные с этим кодом, не пройдут успешно. Также, можно выделить под разные виды тестов разные виртуальные машины и/или стратегии запуска этих тестов.
Статья подготовлена в рамках набора на специализацию C# Developer. Узнать подробнее о специализации.
Поможем в ✍️ написании учебной работы
Словесную или графическую запись алгоритма обычно нельзя сразу ввести в ЭВМ, поэтому необходимо записать алгоритм на каком-либо языке программирования (ЯП). В результате получается программа на ЯП, которая вводится на ЭВМ и поступает на обработку в системную программу – транслятор (переводчик). Транслятор проверяет программу и выдаёт пользователю сообщение об ошибках. Если в программе ошибок нет, то транслятор переводит программу с ЯП на внутренний машинный язык ЭВМ. В результате получается машинная программа, которая управляет работой ЭВМ в процессе решения прикладной задачи. Переход от алгоритма к программе на ЯП называется кодированием алгоритма. Для каждого алгоритма можно построить несколько вариантов программы, поэтому при кодировании алгоритма нужно оптимизировать программу по лёгкости понимания, быстродействию и объёму памяти. Языки программирования можно разделить на 2 большие группы: алгоритмические и машинно-ориентированные.
Алгоритмический язык (АЯ) – это специальный искусственный язык, с помощью которого можно достаточно просто и удобно записать любой алгоритм. В настоящее время существуют сотни алгоритмических языков, например, наиболее известны следующие языки программирования: Фортран – язык для научно-технических расчётов; ПЛ/1, Кобол – языки для экономических расчётов; Бейсик – язык начального обучения; Паскаль – универсальный язык для обучения и программирования; Си – язык прикладного и системного программирования; Модула-2 и Ада – универсальные языки программирования; Лисп, Пролог – языки функционального и логического программирования; С++, Java, Object Pascal – языки объектно-ориентированного программирования. Часто вместо термина алгоритмический язык используется термин – язык программирования высокого уровня.
С технической точки зрения процесс кодирования алгоритма заключается в записи основных алгоритмических конструкций на языке программирования. Очень просто это можно представить в виде таблицы (табл.3), в которой сводятся основные алгоритмические конструкции и соответствующие им конструкции языка программирования.
Таблица 3.
Правила кодирования алгоритмов
| № | Язык Си | Язык Паскаль | ||
| Блок начало | ||||
| main() { |
PROGRAM Name; BEGIN |
|||
| Блок конец | ||||
| } | END. | |||
| Операция присваивания: переменой x присвоить значение Z: x←Z | ||||
| x = Z ; | x := Z; | |||
| Разделение команд (операторов). Символ разделитель | ||||
| ; | ; | |||
| Ввод данных | ||||
| scanf ( &перем1, &перем2,…) [1]; | READ ( перем1, перем2,…); или READLN ( перем1, перем2,…); |
|||
| Вывод данных | ||||
| printf ( перем1, перем2,…) 1; | WRITE ( перем1, перем2,…); или WRITELN ( перем1, перем2,…); |
|||
| Условие с двумя вариантами действий | ||||
| if (Условие) { A;} else {B;} |
IF (Условие) THEN BEGIN A; END ELSE BEGIN B; END; |
|||
| Условие с одним вариантом действий | ||||
| if (Условие) { A;} |
IF (Условие) THEN BEGIN A; END; |
|||
| Цикл с предусловием | ||||
| while (Условие) { A; } |
WHILE (Условие) DO BEGIN A; END |
|||
| Цикл с постусловием | ||||
| do { A; } while (Условие) ; |
REPEAT A; UNTIL (Условие ) ; |
|||
| Описание данных | ||||
| main() { int i, j,…; // целые данные double x,y,z,…; // вещественные char c,p,…; // символьные char str[50]; // строковые … |
PROGRAM FIRST; VAR i, j,… : INTEGER ; {целые данные} x,y,z,…: REAL ; {вещественные } c,p,… : CHAR; {символьные } str : STRING; {строковые} BEGIN … |
|||
| Подключение библиотек и модулей | ||||
| //ОБЯЗАТЕЛЬНО! #include <stdio.h> #include <stdlib.h> #include <math.h> main() { … |
{В случае необходимости} UNIT имямодуля-библиотеки; PROGRAM Name2; … |
|||
| Комментарий | ||||
| // текст в одной строке или /* многострочный текст */ |
{ текст комментария в одну или несколько строк } или (* текст в одну или несколько строк *) или // текст в одной строке |
|||
Машинно-ориентированный язык (МОЯ) – это язык машинных команд, записанных в символическом виде. Для обозначения таких языков применяются термины: язык ассемблера, автокод, мнемокод, язык символического кодирования и т.п. Программирование на машинно-ориентированном языке менее наглядно и более трудоёмко, чем программирование на АЯ. Однако в процессе работы с машинно-ориентированным языком можно учесть все особенности системы команд конкретной ЭВМ. Программа, составленная хорошим программистом на машинно-ориентированном языке, имеет лучшие характеристики по быстродействию и памяти, чем программа, полученная после трансляции с АЯ. Поэтому МОЯ применяются либо в системном, либо в высокоэффективном прикладном программировании.
Пример 5. Используя таблицу, закодируем на языках Си и Паскаль (рис.8) структурные алгоритмы решения задачи табулирования функции на основе цикла с постусловием (на языке Си) и цикла с предусловием (на языке Паскаль).
| #include <stdio.h> #include <stdlib.h> #include <math.h> main() { double a,b,h,x,f ; scanf (&a, &b, &h); x = a; do { f = sin(x*x) — x; printf(x, f); x = x+h; } while ( x>b ); } |
PROGRAM TABUL1; VAR a,b,h,x,f: REAL; BEGIN READLN (a, b, h); x := A; WHILE ( x<= B ) DO BEGIN f:=sin(x*x) — x; WRITELN(x, f); x:=x+h; END END. |
Рис.8. Реализация алгоритмов на языке Си и Паскаль
Примечание. На языке Си функции ввода-вывода scanf и printf имеют более сложный синтаксис, поэтому полученная в примере программа требует небольшой доработки. Программа на языке Паскаль получилась полностью работоспособной.
Тестирование и отладка
Тестирование – процесс поиска ошибок работы программы, посредством проверки правильности результатов ее функционирования на наборах данных, характерных для рабочего состояния программы. Как правило, при тестировании известны исходные данные и правильный результат, который должна выдавать программа. Такие данные часто называются тестовыми последовательностями или просто тестами. Цель тестирования – подготовить как можно больше тестовых последовательностей и проверить работоспособность программы на них.
Отладка – точное определение местоположения ошибок в программе, причин и условий их возникновения, с целью последующего их устранения.
Трассировка (раскрутка) алгоритма – это процесс пошагового выполнения алгоритма с записью в таблицу значений переменных, значений условий, номеров последующего шага (блока) для выполнения и комментариев по выполнению. Трассировка позволяет в ручном режиме, на бумаге проверить работу алгоритма и при необходимости найти ошибки. Фактически трассировка в таком виде заменяет стандартного исполнителя алгоритма – ЭВМ на исполнителя-человека. Важно, чтобы исполнитель действовал исключительно по инструкциям алгоритма, а не «фантазировал», что-то придумывал или изменял по ходу выполнения алгоритма.
Пример 6.Проведем трассировку структурного алгоритма на основе цикла с постусловием, приведенного в примере 4 (табл.4).
Таблица 4.
Трассировка(раскрутка) алгоритма
| № п/п | № шага | a | b | h | x | f | x>b | Примечание |
| Начало | ||||||||
| 0,2 | Ввели в ячейки данные для a, b, h | |||||||
| Записываем в ячейку x := a=1 | ||||||||
| 3, 3.1 | –0,159 | Начало цикла, вычисляем f:=sin 1 – 1 | ||||||
| 3.2 | На экран выводzтся ячейки x = 1 и f = –0,159 | |||||||
| 3.3 | 1,2 | x := x + h=1+0,2=1,2 | ||||||
| 3.4 | Нет | Проверка условия окончания цикла 1,2>2 | ||||||
| 3.1 | –0.209 | Вычисляем f:=sin (1,2) – 1,2= –0,209 | ||||||
| 3.2 | На экран выводится 1,2 и –0,209 | |||||||
| 3.3 | 1,4 | x := x + h=1,2+0,2=1,4 | ||||||
| 3.4 | Нет | Проверка условия окончания цикла 1,4>2 | ||||||
| 3.1 | –0.475 | Вычисляем f | ||||||
| 3.2 | На экран выводится 1,4 и –0,475 | |||||||
| 3.3 | 1,6 | x := x + h=1,4+0,2=1,6 | ||||||
| 3.4 | Нет | Проверка условия окончания цикла 1,6>2 | ||||||
| 3.1 | –1.051 | Вычисляем f | ||||||
| 3.2 | На экран выводится 1,6 и –1,051 | |||||||
| 3.3 | 1,8 | x := x + h=1,6+0,2=1,8 | ||||||
| 3.4 | Нет | Проверка условия окончания цикла 1,8>2 | ||||||
| 3.1 | –1.898 | Вычисляем f | ||||||
| 3.2 | На экран выводится 1,8 и –1,898 | |||||||
| 3.3 | 2,0 | x := x + h=1,8+0,2=2,0 | ||||||
| 3.4 | Нет | Проверка условия окончания цикла 2,0>2 | ||||||
| 3.1 | –2.757 | Вычисляем f | ||||||
| 3.2 | На экран выводится 2,0 и –2,757 | |||||||
| 3.3 | 2,2 | x := x + h=2,0+0,2=2,2 | ||||||
| 3.4 | Да | Проверка условия окончания цикла 2.2>2 | ||||||
| Конец цикла, Конец работы алгоритма |
Верификация – доказательство правильности программы. Проблема верификации программ все еще является открытой, и в настоящее время существуют методы, позволяющие доказывать правильность лишь небольших и однотипных алгоритмов. Для сложных и больших алгоритмов методов верификации, к сожалению, пока не придумано. Более того, существует такая аксиома: любая сложная программа содержит хотя бы одну ошибку. Такое утверждение основывается на том факте, что в любой сложной программе с наличием циклов и ветвлений существует бесконечное (или очень большое) количество путей, и проверить работоспособность каждого пути, как правило, не представляется возможным, а значит вероятность того, что на одном из таких путей возникнет ошибка, достаточно велика. Фактически большинство методов верификации программ пытаются строго математически обойти все пути алгоритма и доказать, что ни на одном из них нет ошибок. При отладке программы, программист делает то же самое, – он пытается пройти все возможные пути и проверить на них работоспособность программы, но только не теоретическими методами, а практическим способом, выбирая различные тестовые последовательности, что бы охватить как можно большее количество путей в программе. Ошибки возникают именно на том пути, где программист не проверил работоспособность алгоритма.
Поэтому, для более тщательного тестирования и отладки программы, план проведения испытаний работы программы должен быть составлен заранее и тестовые данные должны подбираться для проверки функций программы, а не разработанных алгоритмов. Т.е. тестовые примеры создаются на этапе проектирования программной системы, а не на этапе кодирования.
Можно выделить следующие виды тестирования:
· автономное (тестирование модулей программистами);
· комплексное (тестирование общих функций системы программистами);
· системное (оценочное) – тестирование, как правило, с участием заказчика.
Как уже упоминалось в § 2.3 при тестировании модулей программного обеспечения, так же, как при проектировании и кодировании возможно применение как восходящего, так и нисходящего подходов.
Восходящее тестирование.Восходящий подход предполагает,что каждый модуль тестируютотдельно на соответствие имеющимся спецификациям на него, затем собирают оттестированные модули в модули более высокой степени интеграции и тестируют их. При этом проверяют межмодульные интерфейсы, используемые для подключения модулей более низкого уровня ие-рархии. И так далее, пока не будет собран весь программный продукт (рис. 9.3).
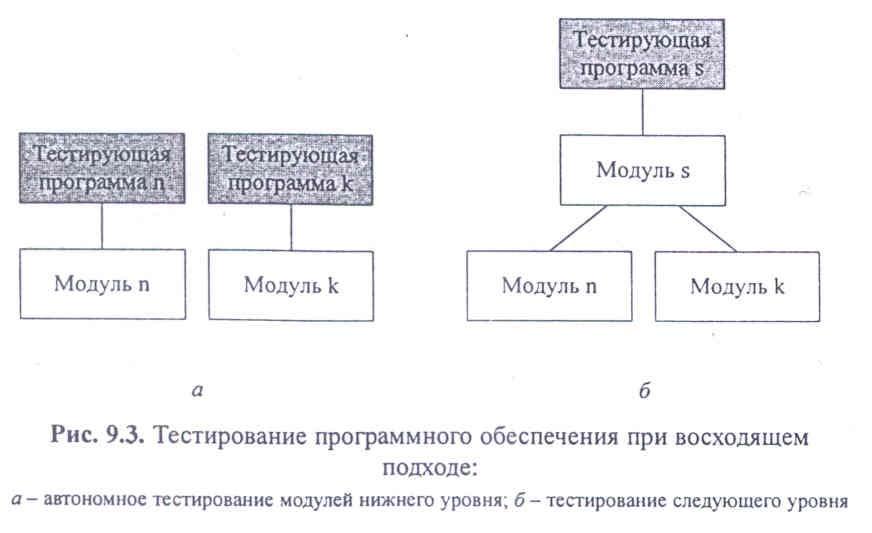
Такой подход обеспечивает полностью автономное тестирование, для которого просто генерировать тестовые последовательности, которые передаются в модуль напрямую. Однако он имеет и существенные недостатки. Во-первых, при восходящем тестировании так же, как при восходящем проектировании, серьезные ошибки в спецификациях, алгоритмах и интерфейсе могут быть обнаружены только на завершающей стадии работы над проектом. Во-вторых, для того, чтобы тестировать модули нижних уровней, необходимо разработать специальные тестирующие программы, которые обеспечивают вызов интересующих нас модулей с необходимыми параметрами. Причем эти тестирующие программы также могут содержать ошибки.
Нисходящее тестирование.Нисходящее тестирование органически связано с нисходящимпроектированием и разработкой; как только проектирование какого-либо модуля заканчивается, его кодируют и передают на тестирование.
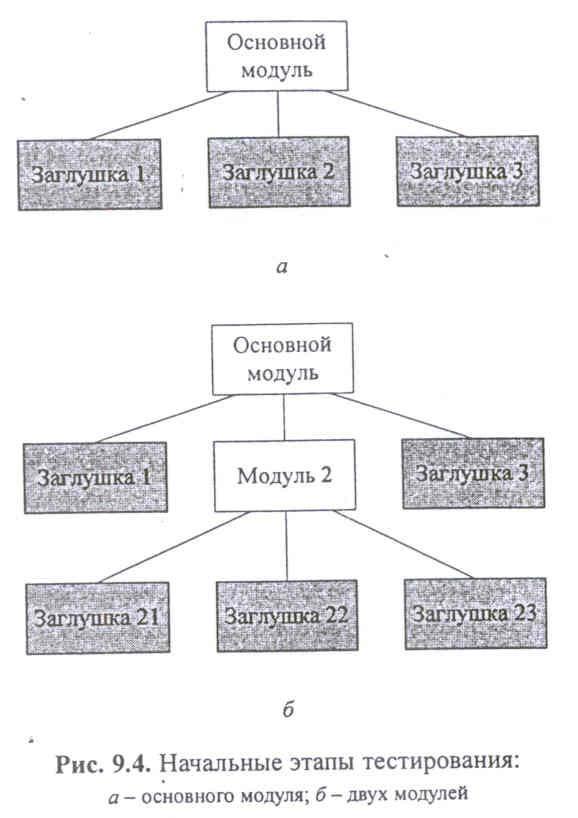
В этом случае автономно тестируется только основной модуль. При его тестировании все вызываемые им модули заменяют модулями, которые в той или иной степени имитируют поведение вызываемых модулей (рис . 9.4). Такие модули принято называть «заглушками». В отличие от тестирующих программ заглушки очень просты, например, они могут просто фиксировать, что им передано управление. Часто заглушки просто возвращают какие-либо фиксированные данные.
Как только тестирование основного модуля завершено, к нему подключают модули, непосредственно им вызываемые, и необходимые заглушки, а затем проводят их совместное тестирование. Далее последовательно подключают следующие модули, пока не будет собрана вся система. Желательная последовательность сборки обсуждалась в § 2.3, хотя на практике ее редко удается соблюдать.
Основной недостаток нисходящего тестирования — отсутствие автономного тестирования модулей. Поскольку модуль получает данные не непосредственно, а через вызывающий модуль, то гораздо сложнее обеспечить его «достаточное» тестирование.
Основным достоинством данного метода является ранняя проверка основных решений и качественное многократное тестирование сопряжения модулей в контексте программного обеспечения. При нисходящем тестировании есть возможность согласования с заказчиком внешнего вида (интерфейса) программного обеспечения.
Комбинированный подход.Чаще всего применяют комбинированный подход:модуливерхних уровней тестируют нисходящим способом, а модули нижних уровней — восходящим. Этот способ позволяет с одной стороны начать с тестирования интерфейса, с другой — обеспечивает качественное автономное тестирование модулей низших уровней.
Тестирование программного обеспечения специалистами.Согласно основнымпринципам нежелательно тестирование программного обеспечения его автором, поэтому эту работу, как правило, выполняют другие программисты, желательно — специалисты в этой области.
Задачей специалиста по тестированию является обнаружение максимального количества несоответствий тестируемого модуля и спецификаций на него. Для выполнения этой задачи специалист по тестированию формирует тесты, используя как структурный, так и функциональный подходы, обеспечивая всестороннее тестирование.
Каждое отклонение от спецификации обязательно документируют, заполняя специальный протокол (рис. 9.5). Наиболее интересными полями протокола являются тип проблемы и ее описание.

В поле тип проблемы указывают один из вариантов:
1 — ошибка кодирования — программа ведет себя не так, как следует из общепринятых представлений, например, 2 + 2 = 5 — на что разработчик может выдать резолюцию «соответствует проекту»;

2 — ошибка проектирования — программа ведет себя в соответствии с проектом, но специалист по тестированию не согласен с данным решением в проекте — на что разработчик может отреагировать, наложив резолюцию «не согласен с предложением»; .
3 — предложение — предложение по улучшению проекта;
4 — расхождение с документацией — обнаружено, что программа ведет себя не так, как указано в документации;
5 — взаимодействие с аппаратурой — обнаружены проблемы при использовании определенного вида аппаратуры;
6 — вопрос — программа делает что-то не совсем понятное.
Описание проблемы должно быть коротким и понятным, например: «Система не запоминает настройки принтера, выполняемые в окне настройки».
Если программист исправляет ошибку, то тестирование повторяют сначала, так как при исправлении ошибки программист может внести в программу новые ошибки. Такое тестирование называют «регрессионным».
Комплексное тестирование.Особенностью комплексного тестирования является то,чтоструктурное тестирование для него практически не применимо. В основном на данной стадии используют тесты, построенные по методам эквивалентных классов, граничных условий и предположении об ошибках.
Критерии завершения тестирования и отладки.Одним из самых сложных являетсявопрос о том, когда следует завершать тестирование, поскольку невозможно гарантировать, что
в разрабатываемом программном обеспечении не осталось ошибок.
Предложено очень много критериев. Все критерии можно разделить на три группы:
• основанные на методологиях проектирования тестов – определенное количество тестов, полученных по методам анализа причинно-следственных связей, анализа граничных значений и предположения об ошибке, перестают выявлять ошибки;
• основанные на оценке возможного количества ошибок — возможное количество ошибок оценивают экспертно, или по специальным методикам [21], а затем завершают тестирование при нахождении примерно 93-95% ошибок;
• основанные на исследовании результатов тестирования — строят график зависимости количества обнаруженных ошибок от времени тестирования, если он напоминает график, представленный на рис. 9.6, то тестирование можно завершать.
Часто тестирование завершают потому, что закончилось время, отведенное на выполнение данного этапа . В этом случае тестирование сворачивают, обходясь минимальным вариантом. Минимальное тестирование [31] предполагает:
тестирование граничных значений;
• тщательную проверку руководства;
• тестирование минимальных конфигураций технических средств;
• тестирование возможности редактирования команд и повторения их в любой последовательности;
• тестирование устойчивости к ошибкам пользователя.
Часть ошибок при этом остаются неисправленными «отложенными» до выпуска следующей версии.
Аннотация: Рассматриваются особенности модульного тестирования, обсуждаются
подходы к тестированию на основе потока управления, потока данных.
Обсуждаются динамические и статические методы при структурном
подходе. Рассматривается пример модульного тестирования.
Рассматривается взаимосвязь сборки модулей и методов интеграционного
тестирования. Обсуждаются подходы монолитного, инкрементального,
нисходящего и восходящего тестирования. Рассматриваются особенности
интеграционного тестирования в процедурном программировании.
Модульное
Модульное тестирование — это тестирование программы на уровне
отдельно взятых модулей, функций или классов. Цель модульного
тестирования состоит в выявлении локализованных в модуле ошибок в
реализации алгоритмов, а также в определении степени готовности
системы к переходу на следующий уровень разработки и тестирования. Модульное тестирование проводится по принципу «белого ящика», то есть
основывается на знании внутренней структуры программы, и часто
включает те или иные методы анализа покрытия кода.
Модульное тестирование обычно подразумевает создание вокруг каждого
модуля определенной среды, включающей заглушки для всех интерфейсов
тестируемого модуля. Некоторые из них могут использоваться для подачи
входных значений, другие для анализа результатов, присутствие третьих
может быть продиктовано требованиями, накладываемыми компилятором и
сборщиком.
На уровне модульного тестирования проще всего обнаружить дефекты,
связанные с алгоритмическими ошибками и ошибками кодирования
алгоритмов, типа работы с условиями и счетчиками циклов, а также с
использованием локальных переменных и ресурсов. Ошибки, связанные с
неверной трактовкой данных, некорректной реализацией интерфейсов,
совместимостью, производительностью и т.п. обычно пропускаются на
уровне модульного тестирования и выявляются на более поздних стадиях
тестирования.
Именно эффективность обнаружения тех или иных типов дефектов должна
определять стратегию модульного тестирования, то есть расстановку
акцентов при определении набора входных значений. У организации,
занимающейся разработкой программного обеспечения, как правило,
имеется историческая база данных ( Repository ) разработок, хранящая
конкретные сведения о разработке предыдущих проектов: о версиях и
сборках кода ( build ) зафиксированных в процессе разработки продукта,
о принятых решениях, допущенных просчетах, ошибках, успехах и т.п.
Проведя анализ характеристик прежних проектов, подобных заказанному
организации, можно предохранить новую разработку от старых ошибок,
например, определив типы дефектов, поиск которых наиболее эффективен
на различных этапах тестирования.
В данном случае анализируется этап модульного тестирования. Если
анализ не дал нужной информации, например, в случае проектов, в
которых соответствующие данные не собирались, то основным правилом
становится поиск локальных дефектов, у которых код, ресурсы и
информация, вовлеченные в дефект, характерны именно для данного
модуля. В этом случае на модульном уровне ошибки, связанные,
например, с неверным порядком или форматом параметров модуля, могут
быть пропущены, поскольку они вовлекают информацию, затрагивающую
другие модули (а именно, спецификацию интерфейса), в то время как
ошибки в алгоритме обработки параметров довольно легко
обнаруживаются.
Являясь по способу исполнения структурным тестированием или
тестированием «белого ящика», модульное тестирование характеризуется
степенью, в которой тесты выполняют или покрывают логику программы
(исходный текст). Тесты, связанные со структурным тестированием,
строятся по следующим принципам:
- На основе анализа потока управления. В этом случае элементы,
которые должны быть покрыты при прохождении тестов, определяются на
основе структурных критериев тестирования С0, С1,С2. К ним относятся
вершины, дуги, пути управляющего графа программы (УГП), условия,
комбинации условий и т. п. - На основе анализа потока данных, когда элементы, которые должны
быть покрыты, определяются при помощи потока данных, т. е.
информационного графа программы.
Тестирование на основе потока управления. Особенности использования
структурных критериев тестирования С0,С1,С2 были рассмотрены в
лекции 3. К ним следует добавить критерий покрытия условий,
заключающийся в покрытии всех логических (булевских) условий в
программе. Критерии покрытия решений (ветвей — С1) и условий не
заменяют друг друга, поэтому на практике используется комбинированный
критерий покрытия условий/решений, совмещающий требования по покрытию
и решений, и условий.
К популярным критериям относятся критерий покрытия функций программы,
согласно которому каждая функция программы должна быть вызвана хотя
бы один раз, и критерий покрытия вызовов, согласно которому каждый
вызов каждой функции в программе должен быть осуществлен хотя бы один
раз. Критерий покрытия вызовов известен также как критерий покрытия
пар вызовов (call pair coverage).
Тестирование на основе потока данных. Этот вид тестирования направлен
на выявление ссылок на неинициализированные переменные и избыточные
присваивания (аномалий потока данных ). Как основа для стратегии
тестирования поток данных впервые был описан в
[
14
]
. Предложенная там
стратегия требовала тестирования всех взаимосвязей, включающих в себя
ссылку (использование) и определение переменной, на которую указывает
ссылка (т. е. требуется покрытие дуг информационного графа
программы). Недостаток стратегии в том, что она не включает критерий
С1, и не гарантирует покрытия решений.
Стратегия требуемых пар
[
15
]
также тестирует упомянутые взаимосвязи.
Использование переменной в предикате дублируется в соответствии с
числом выходов решения, и каждая из таких требуемых взаимосвязей
должна быть протестирована. К популярным критериям принадлежит
критерий СР, заключающийся в покрытии всех таких пар дуг v и w, что
из дуги v достижима дуга w, поскольку именно на дуге может произойти
потеря значения переменной, которая в дальнейшем уже не должна
использоваться. Для «покрытия» еще одного популярного критерия Cdu
достаточно тестировать пары (вершина, дуга), поскольку определение
переменной происходит в вершине УГП, а ее использование — на дугах,
исходящих из решений, или в вычислительных вершинах.
Методы проектирования тестовых путей для достижения заданной степени
тестированности в структурном тестировании. Процесс построения набора
тестов при структурном тестировании принято делить на три фазы:
- Конструирование УГП.
- Выбор тестовых путей.
- Генерация тестов, соответствующих тестовым путям.
Первая фаза соответствует статическому анализу программы, задача
которого состоит в получении графа программы и зависящего от него и
от критерия тестирования множества элементов, которые необходимо
покрыть тестами.
На третьей фазе по известным путям тестирования осуществляется поиск
подходящих тестов, реализующих прохождение этих путей.
Вторая фаза обеспечивает выбор тестовых путей. Выделяют три подхода к
построению тестовых путей:
- Статические методы.
- Динамические методы.
- Методы реализуемых путей.
Статические методы. Самое простое и легко реализуемое решение —
построение каждого пути посредством постепенного его удлинения за
счет добавления дуг, пока не будет достигнута выходная вершина
управляющего графа программы. Эта идея может быть усилена в так
называемых адаптивных методах, которые каждый раз добавляют только
один тестовый путь (входной тест), используя предыдущие пути (тесты)
как руководство для выбора последующих путей в соответствии с
некоторой стратегией. Чаще всего адаптивные стратегии применяются по
отношению к критерию С1. Основной недостаток статических методов
заключается в том, что не учитывается возможная нереализуемость
построенных путей тестирования.
Динамические методы. Такие методы предполагают построение полной
системы тестов, удовлетворяющих заданному критерию, путем
одновременного решения задачи построения покрывающего множества путей
и тестовых данных. При этом можно автоматически учитывать
реализуемость или нереализуемость ранее рассмотренных путей или их
частей. Основной идеей динамических методов является подсоединение к
начальным реализуемым отрезкам путей дальнейших их частей так, чтобы:
1) не терять при этом реализуемости вновь полученных путей; 2)
покрыть требуемые элементы структуры программы.
Методы реализуемых путей. Данная методика
[
16
]
заключается в
выделении из множества путей подмножества всех реализуемых путей.
После чего покрывающее множество путей строится из полученного
подмножества реализуемых путей.
Достоинство статических методов состоит в сравнительно небольшом
количестве необходимых ресурсов, как при использовании, так и при
разработке. Однако их реализация может содержать непредсказуемый
процент брака (нереализуемых путей). Кроме того, в этих системах
переход от покрывающего множества путей к полной системе тестов
пользователь должен осуществить вручную, а эта работа достаточно
трудоемкая. Динамические методы требуют значительно больших ресурсов
как при разработке, так и при эксплуатации, однако увеличение затрат
происходит, в основном, за счет разработки и эксплуатации аппарата
определения реализуемости пути (символический интерпретатор, решатель
неравенств). Достоинство этих методов заключается в том, что их
продукция имеет некоторый качественный уровень — реализуемость путей.
Методы реализуемых путей дают самый лучший результат.
Пример модульного тестирования
Предлагается протестировать класс TCommand, который реализует команду
для склада. Этот класс содержит единственный метод TCommand.GetFullName(), спецификация которого описана (Практикум,
Приложение 2 HLD) следующим образом:
| … | |
| Операция GetFullName() возвращает полное имя команды, соответствующее ее допустимому коду, указанному в поле NameCommand. В противном случае возвращается сообщение «ОШИБКА : Неверный код команды». Операция может быть применена в любой момент. |
|
| … |
Разработаем спецификацию тестового случая для тестирования метода GetFullName на основе приведенной спецификации класса (Табл. 5.1):
| Название класса: TСommand | Название тестового случая: TСommandTest1 |
| Описание тестового случая: Тест проверяет правильность работы метода GetFullName — получения полного названия команды на основе кода команды. В тесте подаются следующие значения кодов команд (входные значения): -1, 1, 2, 4, 6, 20, (причем -1 — запрещенное значение). |
|
| Начальные условия: Нет. | |
|
Ожидаемый результат: Перечисленным входным значениям должны соответствовать следующие Коду команды -1 должно соответствовать сообщение «ОШИБКА: Неверный Коду команды 1 должно соответствовать полное название команды Коду команды 2 должно соответствовать полное название команды Коду команды 4 должно соответствовать полное название команды Коду команды 6 должно соответствовать полное название команды Коду команды 20 должно соответствовать полное название команды |
Для тестирования метода класса TCommand.GetFullName() был создан
тестовый драйвер — класс TCommandTester. Класс TCommandTester
содержит метод TCommandTest1(), в котором реализована вся
функциональность теста. В данном случае для покрытия спецификации
достаточно перебрать следующие значения кодов команд: -1, 1, 2, 4, 6,
20, (-1 — запрещенное значение) и получить соответствующее им полное
название команды с помощью метода GetFullName() (Пример 5.1 ). Пары
значений (X, Yв) при исполнении теста заносятся в log-файл для
последующей проверки на соответствие спецификации.
После завершения теста следует просмотреть журнал теста, чтобы
сравнить полученные результаты с ожидаемыми, заданными в спецификации
тестового случая TСommandTest1 (Пример 5.2).
class TCommandTester:Tester // Тестовый драйвер
{
...
TCommand OUT;
public TCommandTester()
{
OUT=new TCommand();
Run();
}
private void Run()
{
TCommandTest1();
}
private void TCommandTest1()
{
int[] commands = {-1, 1, 2, 4, 6, 20};
for(int i=0;i<=5;i++)
{
OUT.NameCommand=commands[i];
LogMessage(commands[i].ToString()+
" : "+OUT.GetFullName());
}
}
...
}
Пример
5.1.
Тестовый драйвер
-1 : ОШИБКА : Неверный код команды 1 : ПОЛУЧИТЬ ИЗ ВХОДНОЙ ЯЧЕЙКИ 2 : ОТПРАВИТЬ ИЗ ЯЧЕЙКИ В ВЫХОДНУЮ ЯЧЕЙКУ 4 : ПОЛОЖИТЬ В РЕЗЕРВ 6 : ПРОИЗВЕСТИ ЗАНУЛЕНИЕ 20 : ЗАВЕРШЕНИЕ КОМАНД ВЫДАЧИ
Пример
5.2.
Спецификация классов тестовых случаев