Использование помехоустойчивых кодов для обнаружения ошибок в сети
Сигналы, непосредственно передаваемые по последовательным линиям (типа витой пары, коаксиального кабеля или телефонной линии), подвержены влиянию ряда факторов, воздействие которых может привести к возникновению ошибок в принятой информации. Ошибки могут возникать вследствие влияния на канал связи наводок и помех естественного или искусственного происхождения, а также вследствие изменения конфигурации системы передачи информации с временным нарушением или без нарушения целостности канала связи (например, в случае подключения новых абонентов к существующей локальной информационной сети). Некоторые из ошибок могут быть обнаружены на основании анализа вида принятого сигнала, так как в нем появляются характерные искажения. Примером может служить код Манчестер-II, используемый в сетях Ethernet. На передающем конце линии этот код обязательно содержит переход с низкого электрического уровня на высокий или обратно в середине каждого тактового интервала, требуемого для передачи одного бита информации. Он также имеет среднюю составляющую, близкую к нулю. Эти свойства кода Манчестер-II могут использоваться для обнаружения разного рода ошибок. В частности, отличие средней составляющей сигнала от нуля является одним из признаков возникновения коллизий (наложений пакетов от разных абонентов), характерных для метода доступа CSMA/CD в сетях типа Ethernet. Однако сколько-нибудь серьезную систему обнаружения ошибок, вызванных воздействием помех с непредсказуемым поведением, на этой основе построить невозможно. Стандартные протоколы обмена информации в сетях предусматривают введение обязательного поля для размещения помехоустойчивого (корректирующего) кода. Если в результате обработки принятого пакета обнаружится несоответствие принятого и вновь вычисленного помехоустойчивого кода, с большой долей вероятности можно утверждать, что среди принятых бит имеются ошибочные. Передачу такого пакета нужно будет повторить (в расчете на случайный характер помех).
Способы снижения числа ошибок в принятой информации
Имеется разрыв между требованиями к верности принимаемой информации и возможностями каналов связи. В частности, стандартами международных организаций ITU-T и МОС установлено, что вероятность ошибки при телеграфной связи не должна превышать 3 x 10-5 (на знак), а при передаче данных – 10-6 (на единичный элемент, бит). На практике допустимая вероятность ошибки при передаче данных может быть еще меньше – 10-9. В то же время каналы связи (особенно проводные каналы большой протяженности и радиоканалы) обеспечивают вероятность ошибки на уровне 10-3…10-4 даже при использовании фазовых корректоров, регенеративных ретрансляторов и других устройств, улучшающих качество каналов связи.
Кардинальным способом снижения вероятности ошибок при приеме является введение избыточности в передаваемую информацию. В системах передачи информации без обратной связи данный способ реализуется в виде помехоустойчивого кодирования, многократной передачи информации или одновременной передачи информации по нескольким параллельно работающим каналам. Помехоустойчивое кодирование доступнее, при прочих равных условиях позволяет обойтись меньшей избыточностью и за счет этого повысить скорость передачи информации.
Характеристики и разновидности помехоустойчивых кодов
Помехоустойчивое кодирование предполагает введение в передаваемое сообщение, наряду с информационными, так называемых проверочных разрядов, формируемых в устройствах защиты от ошибок (кодерах на передающем конце, декодерах – на приемном). Избыточность позволяет отличить разрешенную и запрещенную (искаженную за счет ошибок) комбинации при приеме, иначе одна разрешенная комбинация переходила бы в другую.
Помехоустойчивый код характеризуется тройкой чисел ( n, k, d0 ), где n – общее число разрядов в передаваемом сообщении, включая проверочные ( r ), k=n-r – число информационных разрядов, d0 – минимальное кодовое расстояние между разрешенными кодовыми комбинациями, определяемое как минимальное число различающихся бит в этих комбинациях. Число обнаруживаемых ( tо ) и (или) исправляемых ( tи ) ошибок (разрядов) связано с параметром d0 соотношениями:
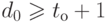 ,
,
 ,
,
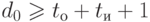
Иногда используются дополнительные показатели избыточности,производные от приведенных выше характеристик n,k: R = r / n – относительная избыточность, v = k / n – относительная скорость передачи.

Рис.
10.3.
Классификация помехоустойчивых кодов
Существующие помехоустойчивые коды можно разделить на ряд групп, только часть из которых применяются для обнаружения ошибок в
передаваемых по сети пакетах (на рис. 10.3 используемые для этой цели группы выделены утолщенными стрелками). В группе систематических (линейных) кодов общим свойством является то, что любая разрешенная комбинация может быть получена в результате линейных операций над линейно-независимыми векторами. Это способствует упрощению аппаратной и программной реализации данных кодов, повышает скорость выполнения необходимых операций. Простейшими систематическими кодами являются биты четности/нечетности. Они не позволяют обнаружить ошибки четной кратности (то есть ошибки одновременно в двух, четырех и т.д. битах) и поэтому используются при невысоких требованиях к верности принимаемых данных (или при малой вероятности ошибок в линии передачи). Примером может служить бит Parity (соответствие) в установках режимов работы последовательного порта с помощью команды MODE (MS DOS). Несмотря на ограниченные возможности обнаружения ошибок, биты четности / нечетности имеют большое значение в теории помехоустойчивого кодирования. Одни из первых математически обоснованных и практически использованных ранее для защиты информации в запоминающих устройствах помехоустойчивых кодов – коды Хэмминга представляют собой простую совокупность перекрестных проверок на четность/нечетность. Циклические коды могут рассматриваться как обобщенные проверки на четность/ нечетность (см. далее).
Подборка по базе: Курсовой проект.rtf, моя малая родина нальчик проект.odt, КУРСОВОЙ ПРОЕКТ.docx, Структура курсового проекта.docx, Курсовой проект.docx, Методология управления рисками проектов.docx, Курсовой проект по очистке природных вод.docx, 1.1 Краткая характеристика проектируемого процесса и выбор схемы, скелет курсовой работы.docx, Индивидуальный проект.docx
1.4.1. Способы снижения числа ошибок в принятой информации
Имеется разрыв между требованиями к верности, принимаемой информации и возможностями каналов связи. В частности, стандартами международных организаций ITU-T и МОС установлено, что вероятность ошибки при телеграфной связи не должна превышать 3 x 10-5 (на знак), а при передаче данных – 10-6 (на единичный элемент, бит). На практике допустимая вероятность ошибки при передаче данных может быть еще меньше – 10-9. В то же время каналы связи (особенно проводные каналы большой протяженности и радиоканалы) обеспечивают вероятность ошибки на уровне 10-3…10-4 даже при использовании фазовых корректоров, регенеративных ретрансляторов и других устройств, улучшающих качество каналов связи.
Кардинальным способом снижения вероятности ошибок при приеме является введение избыточности в передаваемую информацию. В системах передачи информации без обратной связи данный способ реализуется в виде помехоустойчивого кодирования, многократной передачи информации или одновременной передачи информации по нескольким параллельно работающим каналам. Помехоустойчивое кодирование доступнее, при прочих равных условиях позволяет обойтись меньшей избыточностью и за счет этого повысить скорость передачи информации.
1.4.2. Характеристики и разновидности помехоустойчивых кодов
Помехоустойчивое кодирование предполагает введение в передаваемое сообщение, наряду с информационными, так называемых проверочных разрядов, формируемых в устройствах защиты от ошибок (кодерах на передающем конце, декодерах – на приемном). Избыточность позволяет отличить разрешенную и запрещенную (искаженную за счет ошибок) комбинации при приеме, иначе одна разрешенная комбинация переходила бы в другую.
Помехоустойчивый код характеризуется тройкой чисел (n, k, d0), где n – общее число разрядов в передаваемом сообщении, включая проверочные (г), k=n-r – число информационных разрядов, d0 – минимальное кодовое расстояние между разрешенными кодовыми комбинациями, определяемое как минимальное число различающихся бит в этих комбинациях. Число обнаруживаемых (tо) и (или) исправляемых (tи) ошибок (разрядов) связано с параметром d0 соотношениями:
d0 ≥ tо +1,
d0 ≥ 2tи +1,
d0 ≥ tо + tи+ 1
Иногда используются дополнительные показатели избыточности, производные от приведенных выше характеристик n,k: R = г / n – относительная избыточность, v = k / n – относительная скорость передачи.

Рис. 3. Классификация помехоустойчивых кодов
Существующие помехоустойчивые коды можно разделить на ряд групп, только часть из которых применяются для обнаружения ошибок в передаваемых по сети пакетах (на
рис. 3 используемые для этой цели группы выделены утолщенными стрелками). В группе систематических (линейных) кодов общим свойством является то, что любая разрешенная комбинация может быть получена в результате линейных операций над линейно-независимыми векторами. Это способствует упрощению аппаратной и программной реализации данных кодов, повышает скорость выполнения необходимых операций. Простейшими систематическими кодами являются биты четности/нечетности. Они не позволяют обнаружить ошибки четной кратности (то есть ошибки одновременно в двух, четырех и т.д. битах) и поэтому используются при невысоких требованиях к верности принимаемых данных (или при малой вероятности ошибок в линии передачи). Примером может служить бит Parity (соответствие) в установках режимов работы последовательного порта с помощью команды MODE (MS DOS). Несмотря на ограниченные возможности обнаружения ошибок, биты четности / нечетности имеют большое значение в теории помехоустойчивого кодирования. Одни из первых математически обоснованных и практически использованных ранее для защиты информации в запоминающих устройствах помехоустойчивых кодов – коды Хэмминга представляют собой простую совокупность перекрестных проверок на четность/нечетность. Циклические коды могут рассматриваться как обобщенные проверки на четность/ нечетность (см. далее).
1.4.3. Циклические коды (CRC)
Циклические коды – это семейство помехоустойчивых кодов, включающее в себя в качестве одной из разновидностей коды Хэмминга. В целом оно обеспечивает большую гибкость с точки зрения возможности реализации кодов с необходимой способностью обнаружения и исправления ошибок, определяемой параметром d0, по сравнению с кодами Хэмминга (для которых d0=3 или d0=4). Широкое использование циклических кодов на практике обусловлено также простотой реализации соответствующих кодеров и декодеров.
Основные свойства и само название циклических кодов связаны с тем, что все разрешенные комбинации бит в передаваемом сообщении (кодовые слова) могут быть получены путем операции циклического сдвига некоторого исходного кодового слова:
(a0a1…an-2an-1);
(an-1a0a1…an-2);
……………………….
Циклические коды задаются с помощью так называемых порождающих полиномов (многочленов) g(x) или их корней. Порождающий полином имеет вид
G(x)=gr xr + gr-1 xr-1 + … + g0
где gi={0,1}, x=2. Кроме того, вводятся полином исходного сообщения
u(x) = uk-1 xk-1 + uk-2 xk-2 + … +u0
и кодированного сообщения
A(x) = an-1 xn-1 + an-2 xn-2 + … + a0
Для этих полиномов, представляющих собой по существу альтернативную запись чисел в двоичной системе счисления, определяются операции сложения, умножения и деления, необходимые для организации кодирования и декодирования сообщения. Все операции выполняются по модулю 2.
Последовательность кодирования на примере циклического кода (7,4,3), имеющего g(x) = x3 + x + 1, следующая:
1) информационная часть сообщения записывается в виде полинома:
u(x) = uk-1 xk-1 + uk-2 xk-2 + … +u0
В рассматриваемом примере k=4 и для сообщения 0111 получается
u(x) = x2 + x + 1
2) u(x) умножается xr, что соответствует циклическому сдвигу исходного сообщения на r разрядов влево:
u(x) x3 = (x2 + x + 1) x3 = x5 + x4 + x3
3) полученный многочлен делится на q(x):
u(x)•xr/q(x) = c(x) ⊕ R(x)/q(x)
где c(x) – полином-частное с максимальной степенью (k—1);
R(x) – полином-остаток с максимальной степенью (r-1);
⊕ – обозначение поразрядной операции суммирования по модулю 2 (исключающее ИЛИ). Кодированное сообщение представляется в виде
A(x)=u(x)xr ⊕ R(x)

Таким образом, в этом случае
A(x) = (x5 + x4 + x3) ⊕ x = x5 + x4 + x3 + x
Передаваемое кодированное сообщение в обычной двоичной форме имеет вид
0111 010
↔ ↔
k – бит r – бит
Один из возможных вариантов аппаратурной реализации кодера для рассматриваемого примера изображен на
рис. 4 вместе с последовательностью сигналов, подтверждающей получение тех же проверочных разрядов (010) на восьмом такте (r + k + 1=8). Кодер представляет собой сдвиговый регистр с обратными связями, организуемыми с помощью элементов М2 (исключающее ИЛИ, сумматор по модулю 2). Структура обратных связей полностью определяется ненулевыми коэффициентами порождающего полинома g(x). На первых восьми тактах ключ Кл. находится в верхнем положении, формируются проверочные разряды. Затем ключ Кл устанавливается в нижнее положение, что соответствует разрыву цепей обратных связей и передаче непосредственно в канал связи или на

Рис.4. Пример формирования циклического кода (сигнал обратной связи отличен от нуля на
5-м и 6-м тактах)
модулятор проверочных разрядов. Для временного хранения информационной части сообщения с целью последующей ее передачи вместе с проверочными разрядами кодер, очевидно, должен быть дополнен сдвиговым регистром длиной в k разрядов, ключами и соответствующими цепями управления. Однако в целом аппаратурные затраты при реализации кодеров в случае циклических кодов невелики – общее число триггеров и элементов М2 (исключая регистр временного хранения информационной части сообщения) не превышает 2r и не зависит от длины информационной части сообщения.
Двухвходовый элемент М2, на один из входов которого подается в последовательной форме сообщение, на выходе формирует бит четности или нечетности (в зависимости от значения сигнала на втором входе элемента М2-0 или 1) для этого сообщения. В схеме кодера (рис.4) элементы М2 включены между отдельными триггерами сдвигового регистра, причем сигналы обратной связи, поступающие на «свободные» входы элементов М2 (не связанные с передачей собственно сообщения через сдвиговый регистр), зависят как от предшествующих разрядов сообщения, так и от структуры обратных связей, принятой в кодере. В результате циклический код, формируемый таким кодером, можно считать совокупностью обобщенных бит четности и нечетности, тип которых (четность или нечетность) не определен заранее и может динамически меняться от такта к такту.
Порождающие полиномы, представляющие собой так называемые неприводимые многочлены (делятся лишь на единицу и на самих себя), табулированы для разных значений n, k и d0. Практически в компьютерных сетях используются циклические коды длиною в 2 или 4 байта (16 или 32 бита), а параметры n, k и d0 в явном виде не указываются. Это связано с возможностью выбора различной длины поля данных в пакете на этапе установления и выбора параметров соединения при неизменной длине поля циклического кода. Теоретическая вероятность ошибки при приеме в случае использования циклического кода не хуже pош ≤ 1/2r, так что для выполнения условия стандарта pош ≤ 10-6 необходимое число проверочных разрядов r ≥ log2106 ≈ 20. Кроме случайно распределенных, циклический код позволяет обнаруживать подряд следующие ошибки (так называемые пакеты ошибок) длиною l = r или меньше. Это особенно важно в связи с возможностью возникновения продолжительных во времени помех, действующих на протяженные линии передачи в компьютерных сетях.
Циклические коды обладают способностью исправления ошибок высокой кратности (при большом значении параметра d0) и известны технические решения декодеров с исправлением ошибок, однако практическая реализация таких декодеров на современном этапе представляется затруднительной, особенно в случае широкополосных (высокоскоростных) каналов связи. В настоящее время более распространены декодеры с обнаружением ошибок. При использовании обнаруживающего декодера неверно принятая информация может игнорироваться либо может быть запрошена повторная передача той же информации. В последнем случае предполагается наличие сигнала подтверждения правильности принятой информации, поступающего от приемника к передатчику. По мере развития элементной базы следует ожидать появления в интегральном исполнении декодеров циклических кодов, способных не только обнаруживать, но и исправлять ошибки.
Кроме систем передачи информации, циклические коды используются в запоминающих устройствах (ЗУ) для обнаружения возможных ошибок в считываемой информации. При записи файлов на диск (в том числе при их архивировании) вместе с файлами формируются и записываются соответствующие циклические коды. При чтении файлов (в том числе при извлечении файлов из архива) вычисленные циклические коды сравниваются с записанными и таким образом обнаруживаются возможные ошибки. Свойства циклического кода лежат в основе сигнатурного анализа (эффективного способа поиска аппаратных неисправностей в цифровых устройствах различной сложности). Варианты практической реализации соответствующих кодеров и сигнатурных анализаторов имеют между собой много общего.
Следует сделать два замечания относительно сложившейся терминологии. Понятие «циклические коды» достаточно широкое, тем не менее на практике его обычно используют для обозначения только одной разновидности, описанной выше и имеющей в англоязычной литературе название CRC (Cyclic Redundancy Check – циклическая избыточная проверка). Более того, поле пакета или кадра, фактически содержащее код CRC, часто называется «контрольной суммой» (FCS – контрольная сумма кадра), что в принципе не верно, так как контрольная сумма формируется иначе. Однако именно этот термин получил широкое распространение.
Перспективными с точки зрения аппаратурной реализации представляются коды БЧХ (коды Боуза – Чаудхури – Хоквингема), так же, как и коды Хэмминга, входящие в семейство циклических кодов. Коды БЧХ не слишком большой длины (примерно до п=1023) оптимальны или близки к оптимальным кодам, то есть обеспечивают максимальное значение d0 при минимальной избыточности. Эти коды уже нашли практическое применение в цифровых системах записи звука (речи, музыки), причем в варианте, предусматривающем исправление обнаруженных ошибок. Относительно невысокие частоты дискретизации звуковых сигналов (48 или 96 кГц) не препятствуют проведению дополнительных вычислений так жестко, как в случае высокоскоростных сетей
2. Аналитическая глава
Таблица2. Исходные данные для проектирования
| Данные для аналитической главы | |||||||
| №Варианта | Скорость передачи информации. Мбит/с | Число зданий отдела | Расстоя-ния между зданиями, м | Число этажей в каждом здании (число подразделений) | Число комнат на каждом этаже (число рабочих групп в каждом подразделении) | Число компьютеров в каждой комнате (в каждой рабочей группе) | Максимальная длина кабеля на этаже, м |
| 1 | 100 | 2 | 80 | 4 | 6 | 4 | 70 |
2.1.Выбор размера сети и ее структура
На основании исходных данных для проектирования сети, структура сети будет иметь вид, показанный ниже на рисунке:

Рис. 5. Структура сети отдела.
Компьютеров в отделе немного, поэтому можно отказаться не только от маршрутизаторов, но и от коммутаторов, оставив только репитерные концентраторы, которые соединяют компьютеры рабочих групп, рабочие группы, а также здания отдела между собой в единую сеть.
Области коллизий будут в данном случае включать в себя всю сеть. Для области коллизий надо проводить расчет работоспособности сети.
2.2.Оценка конфигурации сети
Необходимо оценить работоспособность сети в целом с использованием методик оценки, включающих правила модели 1 и расчета по модели 2.
Правила модели 1
Первая модель формулирует набор правил, которые необходимо соблюдать проектировщику сети при соединении отдельных компьютеров и сегментов:
1. Репитер или концентратор, подключенный к сегменту, снижает на единицу максимально допустимое число абонентов, подключаемых к сегменту.
2. Полный путь между двумя любыми абонентами должен включать в себя не более пяти сегментов, четырех концентраторов (репитеров) и двух трансиверов (MAU) для сегментов 10 BASE-Т.
3. Если путь между абонентами состоит из пяти сегментов и четырех концентраторов (репитеров), то количество сегментов, к которым подключены компьютеры, не должно превышать трех, а остальные сегменты должны просто связывать между собой концентраторы (репитеры). Это так называемое «правило 5—4—3».
4. Если путь между абонентами состоит из четырех сегментов и трех концентраторов (репитеров), то должны выполняться следующие условия:
— максимальная длина оптоволоконного кабеля сегмента 10BASE-Т, соединяющего между собой концентраторы (репитеры), не должна превышать 100 м;
— ко всем сегментам могут подключаться компьютеры.
На рис.2 показан пример максимальной конфигурации, не удовлетворяющей этим правилам. Но выводы о работоспособности сети делать рано: если она будет удовлетворять требованиям модели 2, то сеть будет работать нормально даже при невыполнении требований модели 1.
Расчет по модели 2
Вторая модель, применяемая для оценки конфигурации Ethernet, основана на точном расчете временных характеристик выбранной конфигурации сети. Она иногда позволяет выйти за пределы жестких ограничений модели 1. Применение модели 2 совершенно необходимо в том случае, когда размер проектируемой сети близок к максимально допустимому.
В модели 2 используются две системы расчетов:
— первая система предполагает вычисление двойного (кругового) времени прохождения сигнала по сети и сравнение его с максимально допустимой величиной;
— вторая система проверяет допустимость величины получаемого межкадрового временного интервала, межпакетной щели (IPG — Inter Packet Gap) в сети.
Максимальная конфигурация в соответствии с первой моделью представлена на рис.9. Длина кабеля выбирается в соответствии с исходными данными для проектирования в максимальном варианте. При выборе длины кабеля закладывается небольшой запас (около 10%) для учета различных непредвиденных обстоятельств. Тип кабеля выбирается исходя из расстояний между элементами сети (компьютеры, концентраторы), а так же учитывается подверженность кабеля электромагнитным помехам.

Сигналы, непосредственно
передаваемые по последовательным линиям
(типа витой пары, коаксиального кабеля
или телефонной линии), подвержены влиянию
ряда факторов, воздействие которых
может привести к возникновению ошибок
в принятой информации. Ошибки могут
возникать вследствие влияния на канал
связи наводок и помех естественного
или искусственного происхождения, а
также вследствие изменения конфигурации
системы передачи информации с временным
нарушением или без нарушения целостности
канала связи (например, в случае
подключения новых абонентов к существующей
локальной информационной сети). Некоторые
из ошибок могут быть обнаружены на
основании анализа вида принятого
сигнала, так как в нем появляются
характерные искажения. Примером может
служить код Манчестер-II,
используемый в сетях Ethernet.
На передающем конце линии этот код
обязательно содержит переход с низкого
электрического уровня на высокий или
обратно в середине каждого тактового
интервала, требуемого для передачи
одного бита информации. Он также имеет
среднюю составляющую, близкую к нулю.
Эти свойства кода Манчестер-II
могут использоваться для обнаружения
разного рода ошибок. В частности, отличие
средней составляющей сигнала от нуля
является одним из признаков возникновения
коллизий (наложений пакетов от разных
абонентов), характерных для метода
доступа CSMA/CD
в сетях типа Ethernet.
Однако сколько-нибудь серьезную систему
обнаружения ошибок, вызванных воздействием
помех с непредсказуемым поведением, на
этой основе построить невозможно.
Стандартные протоколы обмена информации
в сетях предусматривают введение
обязательного поля для размещения
помехоустойчивого (корректирующего)
кода. Если в результате обработки
принятого пакета обнаружится несоответствие
принятого и вновь вычисленного
помехоустойчивого кода, с большой долей
вероятности можно утверждать, что среди
принятых бит имеются ошибочные. Передачу
такого пакета нужно будет повторить (в
расчете на случайный характер помех).
Способы снижения числа
ошибок в принятой информации. Имеется
разрыв между требованиями к верности
принимаемой информации и возможностями
каналов связи. В частности, стандартами
международных организаций ITU-T
и МОС установлено, что вероятность
ошибки при телеграфной связи не должна
превышать 3·10-5
(на знак), а при передаче данных – 10-6
(на единичный элемент, бит). На практике
допустимая вероятность ошибки при
передаче данных может быть еще меньше
– 10-9.
В то же время каналы связи (особенно
проводные каналы большой протяженности
и радиоканалы) обеспечивают вероятность
ошибки на уровне 10-3…10-4
даже при использовании фазовых
корректоров, регенеративных ретрансляторов
и других устройств, улучшающих качество
каналов связи.
Кардинальным способом снижения
вероятности ошибок при приеме является
введение избыточности в передаваемую
информацию. В системах передачи информации
без обратной связи данный способ
реализуется в виде помехоустойчивого
кодирования, многократной передачи
информации или одновременной передачи
информации по нескольким параллельно
работающим каналам. Помехоустойчивое
кодирование доступнее, при прочих равных
условиях оно позволяет обойтись меньшей
избыточностью и за счет этого повысить
скорость передачи информации.
Характеристики и
разновидности помехоустойчивых кодов.
Помехоустойчивое
кодирование предполагает введение в
передаваемое сообщение, наряду с
информационными, так называемые
проверочные разряды, формируемые в
устройствах защиты от ошибок (кодерах
– на передающем конце, декодерах – на
приемном). Избыточность позволяет
отличить разрешенную и запрещенную
(искаженную за счет ошибок) комбинации
при приеме, иначе одна разрешенная
комбинация переходила бы в другую.
Помехоустойчивый код
характеризуется тройкой чисел (n,
k,
d0),
где n
– общее число разрядов в передаваемом
сообщении, включая проверочные (r),
k
= n
– r
– число информационных разрядов, d0
– минимальное кодовое расстояние между
разрешенными кодовыми комбинациями,
определяемое как минимальное число
различающихся бит в этих комбинациях.
Число обнаруживаемых (t0)
и (или) исправляемых (tи)
ошибок (разрядов) связано с параметром
d0
соотношениями:
![]() ,
,
![]() ,
,
![]() /
/
Иногда используются
дополнительные показатели избыточности,
производные от приведенных выше
характеристик n,
k:
R
= r
/ n
– относительная избыточность, v
= k
/ n
– относительная скорость передачи.
Существующие помехоустойчивые
коды можно разделить на ряд групп, из
которых лишь часть применяются для
обнаружения ошибок в передаваемых по
сети пакетах (на рис. 2.59 используемые
для этой цели группы выделены утолщенными
стрелками). В группе систематических
(линейных) кодов общим свойством является
то, что любая разрешенная комбинация
может быть получена в результате линейных
операций над линейно-независимыми
векторами. Это способствует упрощению
аппаратной и программной реализации
данных кодов, повышает скорость выполнения
необходимых операций. Простейшими
систематическими кодами являются биты
четности/нечетности. Они не позволяют
обнаружить ошибки четной кратности (то
есть ошибки одновременно в двух, четырех
и т.д. битах) и поэтому используются при
невысоких требованиях к верности
принимаемых данных (или при малой
вероятности ошибок в линии передачи).
Примером может служить бит Parity
(соответствие) в установках режимов
работы последовательного порта с помощью
команды MODE
(MS
DOS).
Несмотря на ограниченные возможности
обнаружения ошибок, биты четности/нечетности
имеют большое значение в теории
помехоустойчивого кодирования. Одни
из первых математически обоснованных
и практически использованных ранее для
защиты информации в запоминающих
устройствах помехоустойчивых кодов –
коды Хэмминга представляют собой простую
совокупность перекрестных проверок на
четность/нечетность. Циклические коды
могут рассматриваться как обобщенные
проверки на четность/нечетность (см.
далее).
|
|
|
Рис. |

Циклические коды (CRC).
Циклические коды –
это семейство помехоустойчивых кодов,
включающее в себя в качестве одной из
разновидностей коды Хэмминга. В целом
оно обеспечивает большую гибкость с
точки зрения возможности реализации
кодов с необходимой способностью
обнаружения и исправления ошибок,
определяемой параметром d0,
по сравнению с кодами Хэмминга (для
которых d0
= 3 или d0
= 4). Широкое использование
циклических кодов на практике обусловлено
также простотой реализации соответствующих
кодеров и декодеров.
Основные свойства и само название
циклических кодов связаны с тем, что
все разрешенные комбинации бит в
передаваемом сообщении (кодовые слова)
могут быть получены путем операции
циклического сдвига некоторого исходного
кодового слова:
![]() ;
;
![]() ;
;
………………..
Циклические коды задаются
с помощью так называемых порождающих
полиномов (многочленов) g
(х) или их корней. Порождающий полином
имеет вид
![]() ,
,
где
![]() ,
,
х =
2. Кроме того, вводятся полином исходного
сообщения
![]()
и кодированного сообщения
![]() .
.
Для этих полиномов, представляющих
собой по существу альтернативную запись
чисел в двоичной системе счисления,
определяются операции сложения, умножения
и деления, необходимые для организации
кодирования и декодирования сообщения.
Все операции выполняются по модулю 2.
Последовательность
кодирования на примере циклического
кода (7,4,3), имеющего
![]() ,
,
следующая:
1) информационная часть сообщения
записывается в виде полинома:
![]() .
.
В рассматриваемом примере
k
= 4 и для сообщения 0111 получается
![]() ;
;
2) u(х)
умножается хr,
что соответствует циклическому сдвигу
исходного сообщения на r
разрядов влево:
![]() ;
;
3) полученный многочлен
делится на g(х):
![]() ,
,
где с(х)
– полином-частное с максимальной
степенью (k
– 1); R(x)
– полином-остаток с максимальной
степенью (r
– 1);
![]()
– обозначение поразрядной операции
суммирования по модулю 2 (исключающее
ИЛИ). Кодированное сообщение представляется
в виде
![]() ?
?
то есть на место младших,
освобожденных после домножения на хr
разрядов, записываются
проверочные разряды аr-1,
аr-2,
а0.
Для данного примера:
таким образом, в этом случае

![]()
![]() .
.
Передаваемое кодированное сообщение
в обычной двоичной форме имеет вид

 .
.
Порождающие полиномы,
представляющие собой, так называемые
неприводимые многочлены (делятся лишь
на единицу и на самих себя), табулированы
для разных значений n,
k
и d0.
Практически в компьютерных сетях
используются циклические коды длиною
в 2 или 4 байта (16 или 32 бита), а параметры
n,
k
и d0
в явном виде не указываются. Это связано
с возможностью выбора различной длины
поля данных в пакете на этапе установления
и выбора параметров соединения при
неизменной длине поля циклического
кода. Теоретическая вероятность ошибки
при приеме в случае использования
циклического кода не хуже pош
≤ 1/2r,
так что для выполнения условия стандарта
pош
≤ 10-6
необходимое число проверочных разрядов
r
≥ 1og2106
≡ 20. Кроме случайно распределенных,
циклический код позволяет обнаруживать
подряд следующие ошибки (так называемые
пакеты ошибок) длиною l
= r
или меньше. Это особенно важно в связи
с возможностью возникновения
продолжительных во времени помех,
действующих на протяженные линии
передачи в компьютерных сетях.
Циклические коды обладают
способностью исправления ошибок высокой
кратности (при большом значении параметра
d0)
и известны технические решения декодеров
с исправлением ошибок, однако практическая
реализация таких декодеров на современном
этапе представляется затруднительной,
особенно в случае широкополосных
(высокоскоростных) каналов связи. В
настоящее время более распространены
декодеры с обнаружением ошибок. При
использовании обнаруживающего декодера
неверно принятая информация может
игнорироваться либо может быть запрошена
повторная передача той же информации.
В последнем случае предполагается
наличие сигнала подтверждения правильности
принятой информации, поступающего от
приемника к передатчику. По мере развития
элементной базы следует ожидать появления
в интегральном исполнении декодеров
циклических кодов, способных не только
обнаруживать, но и исправлять ошибки.
Кроме
систем передачи информации, циклические
коды используются в запоминающих
устройствах (ЗУ) для обнаружения возможных
ошибок в считываемой информации. При
записи файлов на диск (в том числе при
их архивировании) вместе с файлами
формируются и записываются соответствующие
циклические коды. При чтении файлов (в
том числе при извлечении файлов из
архива) вычисленные циклические коды
сравниваются с записанными и таким
образом обнаруживаются возможные
ошибки. Свойства циклического кода
лежат в основе сигнатурного анализа
(эффективного способа поиска аппаратных
неисправностей в цифровых устройствах
различной сложности). Варианты практической
реализации соответствующих кодеров и
сигнатурных анализаторов имеют между
собой много общего.
Следует
сделать два замечания относительно
сложившейся терминологии. Понятие
«циклические коды» достаточно широкое,
тем не менее на практике его обычно
используют для обозначения только одной
разновидности, описанной выше и имеющей
в англоязычной литературе название CRC
(Cyclic
Redundancy
Check
– циклическая избыточная проверка).
Более того, поле пакета или кадра,
фактически содержащее код CRC,
часто называется «контрольной суммой»
(FCS
– контрольная сумма кадра), что в принципе
не верно, так как контрольная сумма
формируется иначе. Однако именно этот
термин получил широкое распространение.
Перспективными
с точки зрения аппаратурной реализации
представляются коды БЧХ (коды Боуза –
Чаудхури – Хоквингема), также, как и
коды Хэмминга, входящие в семейство
циклических кодов. Коды БЧХ не слишком
большой длины (примерно до n
= 1023), оптимальны или близки к оптимальным
кодам, то есть обеспечивают максимальное
значение d0
при минимальной избыточности. Эти коды
уже нашли практическое применение в
цифровых системах записи звука (речи,
музыки), причем в варианте, предусматривающем
исправление обнаруженных ошибок.
Относительно невысокие частоты
дискретизации звуковых сигналов (48 или
96 кГц) не препятствуют проведению
дополнительных вычислений так жестко,
как в случае высокоскоростных сетей.
Вопросы для самоконтроля.
1. Какие сети называются локальными и
чем они характеризуются? 2. Что понимают
под размерами локальных сетей? 3. В чем
состоит основное отличие широковещательной
топологии локальной сети от сети с
передачей «точка – точка»? 4. В чем
состоят особенности шинной, кольцевой
и звездообразной топологии? 5. Что
понимают под свойством однородности?
6. Дайте определение понятию «доступ к
сети». 7. Перечислите наиболее
распространенные методы доступа к сети.
8. Какие вы знаете разновидности метода
случайного доступа? 9. Что понимают под
коллизией в локальной сети? 10. Перечислите
маркерные методы доступа и объясните
их основные принципы построения. 11. Для
чего используется маркер? 12. Что
входит в понятие доступа к физической
среде передачи данных? 13. Как реализуются
функции физического и MAC-уровней
ЛВС? 14. Какую длину имеет физический
адрес в сетях Ethernet?
15. Чем определяется выбор метода защиты
от ошибок в сетях? 16. Какие методы защиты
от ошибок в сетях получили наибольшее
распространение и какова их сущность?
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Использование кодов для обнаружения ошибок в сети
Использование кодов для обнаружения ошибок в сети
Сигналы, передаваемые по последовательным линиям связи (витая пара, телефонная линия, коаксиальный кабель), подвержены влиянию ряда факторов, воздействие которых часто приводит к возникновению ошибок в принятой информации. Ошибки могут возникать вследствие различных причин: влияния на канал связи наводок и помех естественного или искусственного происхождения, из-за изменения реконфигурирования системы передачи данных с временным нарушением целостности канала связи или без нарушения (при подключения новых абонентов к существующей локальной вычислительной сети). Некоторые из этих ошибок могут быть обнаружены на основании анализа вида принятого сигнала, так как в нем появляются характерные для них искажения его характеристик.
Способы снижения числа ошибок в принятой информации
В настоящее время имеется существенный разрыв между требованиями к верности принимаемой информации и возможностями современных каналов связи. Стандартами международных организаций ITU-T и МОС установлено, что вероятность ошибки при телеграфной связи не должна превышать 10-5(на знак), а при передаче двоичных данных – 10-6 (на бит — единичный элемент). На практике допустимая вероятность ошибки при передаче данных может быть еще меньше – 10-9. В то же время используемые каналы связи (особенно проводные каналы большой протяженности и радиоканалы) обеспечивают вероятность ошибки на уровне 10-3…10-4 даже при применении устройств, улучшающих качество информационных каналов.
Кардинальным способом уменьшения вероятности появления ошибок при приеме является введение избыточности в информацию при передаче. В системах информационного взаимодействия без обратной связи данный способ реализуется в виде одновременной передачи информации по нескольким параллельно работающим каналам, многократной передачи информации или помехоустойчивого кодирования. Последний способ доступнее, при прочих равных условиях он позволяет повысить скорость передачи информации за счет использования меньшей избыточностью.
Характеристики и разновидности помехоустойчивых кодов
Помехоустойчивое кодирование предполагает введение в передаваемое сообщение, наряду с информационными проверочных разрядов, формируемых в устройствах защиты от ошибок (кодерах на передающем конце, декодерах – на приемном). Эта избыточность позволяет при приеме отличить разрешенную и запрещенную (искаженную за счет ошибок) комбинации символов.
Циклические коды (CRC)
Циклические коды – это семейство помехоустойчивых кодов, являющихся одной из разновидностей кодов Хэмминга. Они обеспечивает достаточную гибкость с точки зрения возможности использования кодов с необходимой способностью обнаружения и исправления ошибок. Широкое применение циклических кодов в современных сетях обусловлено простотой реализации соответствующей аппаратуры (кодеров и декодеров).
Все свойства и название этих кодов связаны с тем, что разрешенные комбинации бит в передаваемом сообщении (кодовые слова) могут быть получены путем операции циклического сдвига, определенного исходного кодового слова. При обнаружении декодером неверно принятой информации она может быть проигнорирована либо может быть запрошена повторная передача тех же данных.
From Wikipedia, the free encyclopedia
Human error assessment and reduction technique (HEART) is a technique used in the field of human reliability assessment (HRA), for the purposes of evaluating the probability of a human error occurring throughout the completion of a specific task. From such analyses measures can then be taken to reduce the likelihood of errors occurring within a system and therefore lead to an improvement in the overall levels of safety. There exist three primary reasons for conducting an HRA; error identification, error quantification and error reduction. As there exist a number of techniques used for such purposes, they can be split into one of two classifications; first generation techniques and second generation techniques. First generation techniques work on the basis of the simple dichotomy of ‘fits/doesn’t fit’ in the matching of the error situation in context with related error identification and quantification and second generation techniques are more theory based in their assessment and quantification of errors. HRA techniques have been utilised in a range of industries including healthcare, engineering, nuclear, transportation and business sector; each technique has varying uses within different disciplines.
HEART method is based upon the principle that every time a task is performed there is a possibility of failure and that the probability of this is affected by one or more Error Producing Conditions (EPCs) – for instance: distraction, tiredness, cramped conditions etc. – to varying degrees. Factors which have a significant effect on performance are of greatest interest. These conditions can then be applied to a «best-case-scenario» estimate of the failure probability under ideal conditions to then obtain a final error chance. This figure assists in communication of error chances with the wider risk analysis or safety case. By forcing consideration of the EPCs potentially affecting a given procedure, HEART also has the indirect effect of providing a range of suggestions as to how the reliability may therefore be improved (from an ergonomic standpoint) and hence minimising risk.
Background[edit]
HEART was developed by Williams in 1986.[1] It is a first generation HRA technique, yet it is dissimilar to many of its contemporaries in that it remains to be widely used throughout the UK. The method essentially takes into consideration all factors which may negatively affect performance of a task in which human reliability is considered to be dependent, and each of these factors is then independently quantified to obtain an overall Human Error Probability (HEP), the collective product of the factors.
HEART methodology[edit]
1. The first stage of the process is to identify the full range of sub-tasks that a system operator would be required to complete within a given task.
2. Once this task description has been constructed a nominal human unreliability score for the particular task is then determined, usually by consulting local experts. Based around this calculated point, a 5th – 95th percentile confidence range is established.
3. The EPCs, which are apparent in the given situation and highly probable to have a negative effect on the outcome, are then considered and the extent to which each EPC applies to the task in question is discussed and agreed, again with local experts. As an EPC should never be considered beneficial to a task, it is calculated using the following formula:
- Calculated Effect = ((Max Effect – 1) × Proportion of Effect) + 1
4. A final estimate of the HEP is then calculated, in determination of which the identified EPC’s play a large part.
Only those EPC’s which show much evidence with regards to their affect in the contextual situation should be used by the assessor.[2]
Worked example[edit]
Context[edit]
A reliability engineer has the task of assessing the probability of a plant operator failing to carry out the task of isolating a plant bypass route as required by procedure. However, the operator is fairly inexperienced in fulfilling this task and therefore typically does not follow the correct procedure; the individual is therefore unaware of the hazards created when the task is carried out
Assumptions[edit]
There are various assumptions that should be considered in the context of the situation:
- the operator is working a shift in which he is in his 7th hour.
- there is talk circulating the plant that it is due to close down
- it is possible for the operator’s work to be checked at any time
- local management aim to keep the plant open despite a desperate need for re-vamping and maintenance work; if the plant is closed down for a short period, if the problems are unattended, there is a risk that it may remain closed permanently.
Method[edit]
A representation of this situation using the HEART methodology would be done as follows:
From the relevant tables it can be established that the type of task in this situation is of the type (F) which is defined as ‘Restore or shift a system to original or new state following procedures, with some checking’. This task type has the proposed nominal human unreliability value of 0.003.
Other factors to be included in the calculation are provided in the table below:
| Factor | Total HEART Effect | Assessed Proportion of Effect | Assessed Effect |
|---|---|---|---|
| Inexperience | x3 | 0.4 | (3.0-1) x 0.4 + 1 =1.8 |
| Opposite technique | x6 | 1.0 | (6.0-1) x 1.0 + 1 =6.0 |
| Risk Misperception | x4 | 0.8 | (4.0-1) x 0.8 + 1 =3.4 |
| Conflict of Objectives | x2.5 | 0.8 | (2.5-1) x 0.8 + 1 =2.2 |
| Low Morale | x1.2 | 0.6 | (1.2-1) x 0.6 + 1 =1.12 |
Result[edit]
The final calculation for the normal likelihood of failure can therefore be formulated as:
- 0.003 x 1.8 x 6.0 x 3.4 x 2.2 x 1.12 = 0.27
Advantages[edit]
- HEART is very quick and straightforward to use and also has a small demand for resource usage [3]
- The technique provides the user with useful suggestions as to how to reduce the occurrence of errors[4]
- It provides ready linkage between Ergonomics and Process Design, with reliability improvement measures being a direct conclusion which can be drawn from the assessment procedure.
- It allows cost benefit analyses to be conducted
- It is highly flexible and applicable in a wide range of areas which contributes to the popularity of its use [3]
Disadvantages[edit]
- The main criticism of the HEART technique is that the EPC data has never been fully released and it is therefore not possible to fully review the validity of Williams EPC data base. Kirwan has done some empirical validation on HEART and found that it had «a reasonable level of accuracy» but was not necessarily better or worse than the other techniques in the study.[5][6][7] Further theoretical validation is thus required.[2]
- HEART relies to a high extent on expert opinion, first in the point probabilities of human error, and also in the assessed proportion of EPC effect. The final HEPs are therefore sensitive to both optimistic and pessimistic assessors
- The interdependence of EPCs is not modelled in this methodology, with the HEPs being multiplied directly. This assumption of independence does not necessarily hold in a real situation.[2]
See also[edit]
- The curse of expertise
- Threat and error management
- Expert witnesses in English law
- Winner’s curse
- Sports Illustrated cover jinx
References[edit]
- ^ WILLIAMS, J.C. (1985) HEART – A proposed method for achieving high reliability in process operation by means of human factors engineering technology in Proceedings of a Symposium on the Achievement of Reliability in Operating Plant, Safety and Reliability Society (SaRS). NEC, Birmingham.
- ^ a b c Kirwan, B. (1994) A Guide to Practical Human Reliability Assessment. CPC Press.
- ^ a b Humphreys. P. (1995). Human Reliability Assessor’s Guide. Human Reliability in Factor’s Group.
- ^ «FAA Human Factors Workbench Display Page». Archived from the original on 2009-05-10. Retrieved 2008-08-27.
- ^ Kirwan, B. (1996) The validation of three human reliability quantification techniques — THERP, HEART, JHEDI: Part I — technique descriptions and validation issues. Applied Ergonomics. 27(6) 359-373.
- ^ Kirwan, B. (1997) The validation of three human reliability quantification techniques — THERP, HEART, JHEDI: Part II — Results of validation exercise. Applied Ergonomics. 28(1) 17-25.
- ^ Kirwan, B. (1997) The validation of three human reliability quantification techniques — THERP, HEART, JHEDI: Part III — practical aspects of the usage of the techniques. Applied Ergonomics. 28(1) 27-39.
External links[edit]
- HEART technique for Quantitative Human Error Assessment
- Human error analysis and reliability assessment — Michael Harrison
From Wikipedia, the free encyclopedia
Human error assessment and reduction technique (HEART) is a technique used in the field of human reliability assessment (HRA), for the purposes of evaluating the probability of a human error occurring throughout the completion of a specific task. From such analyses measures can then be taken to reduce the likelihood of errors occurring within a system and therefore lead to an improvement in the overall levels of safety. There exist three primary reasons for conducting an HRA; error identification, error quantification and error reduction. As there exist a number of techniques used for such purposes, they can be split into one of two classifications; first generation techniques and second generation techniques. First generation techniques work on the basis of the simple dichotomy of ‘fits/doesn’t fit’ in the matching of the error situation in context with related error identification and quantification and second generation techniques are more theory based in their assessment and quantification of errors. HRA techniques have been utilised in a range of industries including healthcare, engineering, nuclear, transportation and business sector; each technique has varying uses within different disciplines.
HEART method is based upon the principle that every time a task is performed there is a possibility of failure and that the probability of this is affected by one or more Error Producing Conditions (EPCs) – for instance: distraction, tiredness, cramped conditions etc. – to varying degrees. Factors which have a significant effect on performance are of greatest interest. These conditions can then be applied to a «best-case-scenario» estimate of the failure probability under ideal conditions to then obtain a final error chance. This figure assists in communication of error chances with the wider risk analysis or safety case. By forcing consideration of the EPCs potentially affecting a given procedure, HEART also has the indirect effect of providing a range of suggestions as to how the reliability may therefore be improved (from an ergonomic standpoint) and hence minimising risk.
Background[edit]
HEART was developed by Williams in 1986.[1] It is a first generation HRA technique, yet it is dissimilar to many of its contemporaries in that it remains to be widely used throughout the UK. The method essentially takes into consideration all factors which may negatively affect performance of a task in which human reliability is considered to be dependent, and each of these factors is then independently quantified to obtain an overall Human Error Probability (HEP), the collective product of the factors.
HEART methodology[edit]
1. The first stage of the process is to identify the full range of sub-tasks that a system operator would be required to complete within a given task.
2. Once this task description has been constructed a nominal human unreliability score for the particular task is then determined, usually by consulting local experts. Based around this calculated point, a 5th – 95th percentile confidence range is established.
3. The EPCs, which are apparent in the given situation and highly probable to have a negative effect on the outcome, are then considered and the extent to which each EPC applies to the task in question is discussed and agreed, again with local experts. As an EPC should never be considered beneficial to a task, it is calculated using the following formula:
- Calculated Effect = ((Max Effect – 1) × Proportion of Effect) + 1
4. A final estimate of the HEP is then calculated, in determination of which the identified EPC’s play a large part.
Only those EPC’s which show much evidence with regards to their affect in the contextual situation should be used by the assessor.[2]
Worked example[edit]
Context[edit]
A reliability engineer has the task of assessing the probability of a plant operator failing to carry out the task of isolating a plant bypass route as required by procedure. However, the operator is fairly inexperienced in fulfilling this task and therefore typically does not follow the correct procedure; the individual is therefore unaware of the hazards created when the task is carried out
Assumptions[edit]
There are various assumptions that should be considered in the context of the situation:
- the operator is working a shift in which he is in his 7th hour.
- there is talk circulating the plant that it is due to close down
- it is possible for the operator’s work to be checked at any time
- local management aim to keep the plant open despite a desperate need for re-vamping and maintenance work; if the plant is closed down for a short period, if the problems are unattended, there is a risk that it may remain closed permanently.
Method[edit]
A representation of this situation using the HEART methodology would be done as follows:
From the relevant tables it can be established that the type of task in this situation is of the type (F) which is defined as ‘Restore or shift a system to original or new state following procedures, with some checking’. This task type has the proposed nominal human unreliability value of 0.003.
Other factors to be included in the calculation are provided in the table below:
| Factor | Total HEART Effect | Assessed Proportion of Effect | Assessed Effect |
|---|---|---|---|
| Inexperience | x3 | 0.4 | (3.0-1) x 0.4 + 1 =1.8 |
| Opposite technique | x6 | 1.0 | (6.0-1) x 1.0 + 1 =6.0 |
| Risk Misperception | x4 | 0.8 | (4.0-1) x 0.8 + 1 =3.4 |
| Conflict of Objectives | x2.5 | 0.8 | (2.5-1) x 0.8 + 1 =2.2 |
| Low Morale | x1.2 | 0.6 | (1.2-1) x 0.6 + 1 =1.12 |
Result[edit]
The final calculation for the normal likelihood of failure can therefore be formulated as:
- 0.003 x 1.8 x 6.0 x 3.4 x 2.2 x 1.12 = 0.27
Advantages[edit]
- HEART is very quick and straightforward to use and also has a small demand for resource usage [3]
- The technique provides the user with useful suggestions as to how to reduce the occurrence of errors[4]
- It provides ready linkage between Ergonomics and Process Design, with reliability improvement measures being a direct conclusion which can be drawn from the assessment procedure.
- It allows cost benefit analyses to be conducted
- It is highly flexible and applicable in a wide range of areas which contributes to the popularity of its use [3]
Disadvantages[edit]
- The main criticism of the HEART technique is that the EPC data has never been fully released and it is therefore not possible to fully review the validity of Williams EPC data base. Kirwan has done some empirical validation on HEART and found that it had «a reasonable level of accuracy» but was not necessarily better or worse than the other techniques in the study.[5][6][7] Further theoretical validation is thus required.[2]
- HEART relies to a high extent on expert opinion, first in the point probabilities of human error, and also in the assessed proportion of EPC effect. The final HEPs are therefore sensitive to both optimistic and pessimistic assessors
- The interdependence of EPCs is not modelled in this methodology, with the HEPs being multiplied directly. This assumption of independence does not necessarily hold in a real situation.[2]
See also[edit]
- The curse of expertise
- Threat and error management
- Expert witnesses in English law
- Winner’s curse
- Sports Illustrated cover jinx
References[edit]
- ^ WILLIAMS, J.C. (1985) HEART – A proposed method for achieving high reliability in process operation by means of human factors engineering technology in Proceedings of a Symposium on the Achievement of Reliability in Operating Plant, Safety and Reliability Society (SaRS). NEC, Birmingham.
- ^ a b c Kirwan, B. (1994) A Guide to Practical Human Reliability Assessment. CPC Press.
- ^ a b Humphreys. P. (1995). Human Reliability Assessor’s Guide. Human Reliability in Factor’s Group.
- ^ «FAA Human Factors Workbench Display Page». Archived from the original on 2009-05-10. Retrieved 2008-08-27.
- ^ Kirwan, B. (1996) The validation of three human reliability quantification techniques — THERP, HEART, JHEDI: Part I — technique descriptions and validation issues. Applied Ergonomics. 27(6) 359-373.
- ^ Kirwan, B. (1997) The validation of three human reliability quantification techniques — THERP, HEART, JHEDI: Part II — Results of validation exercise. Applied Ergonomics. 28(1) 17-25.
- ^ Kirwan, B. (1997) The validation of three human reliability quantification techniques — THERP, HEART, JHEDI: Part III — practical aspects of the usage of the techniques. Applied Ergonomics. 28(1) 27-39.
External links[edit]
- HEART technique for Quantitative Human Error Assessment
- Human error analysis and reliability assessment — Michael Harrison
- Авторы
- Резюме
- Файлы
- Ключевые слова
- Литература
Шкердин А.Н.
1
Полянский И.С.
1
1 Академия ФСО России
В настоящей публикации представлена методика оценки вероятностных характеристик приема кодового слова: вероятность правильного приема, вероятность обнаружения ошибки, вероятность ошибочного приема. Оценка указанных характеристик выполнена для трех возможных ситуаций, определяющих три случая для разбиения исходного кодового слова на блоки и локализации участков с ошибкой: 1) передачи исходного кодового слова; 2) разбиения исходного кодового слова на блоки; 3) с учетом локализации участков блоков кода. Предложен подход к нахождению минимального расстояния по Хеммингу для кода с произвольными параметрами N и k, основанный на численном решении сформированной нелинейной оптимизационной задачи с учетом ограничений, определяемых из границ Хемминга и Плоткина. Работоспособность представленной методики проверена на конкретных примерах.
разделение на блоки
локализация участков ошибки
кодовое слово
вероятность ошибки
1. Бахвалов Н. С. Численные методы / Н. С. Бахвалов, Н. П. Жидков, Г. М. Кобельков. – М.: Бином, 2003. – 630 с.
2. Бояринов И. М. Помехоустойчивое кодирование числовой информации / И. М. Бояринов. – М.: Наука, 1983. – 196 с.
3. Васильев Ф. П. Численные методы решения экстремальных задач / Ф. П. Васильев. – М.: Наука, 1980. – 520 с.
4. Вентцель Е. С. Теория вероятности / Е. С. Вентцель, Л. А. Овчаров. 2-е изд. – М.: Наука, 1973. – 368 с.
5. Виленкин Н. Я. Комбинаторика / Н. Я. Виленкин, А. Н. Виленкин, П. А. Виленкин. – М.: ФИМА, МЦНМО, 2006. – 400 с.
6. Корн, Г. Справочник по математике для научных сотрудников и инженеров / Г. Корн, Т. Корн. – М.: Наука, 1970. – 720 с.
7. Полянский И. С. Алгоритм распределения неоднородных дискретных ограниченных ресурсов в системе физической защиты / И. С. Полянский, И. И. Беседин // Информационные системы и технологии. – Июль-август 2013. – № 4 (78). – С. 99–106.
8. Сидельников В. М. Теория кодирования / В. М. Сидельников. – М.: Физматлит, 2008. – 324 с.
9. Таха Хэмди А. Введение в исследование операций. – М.: Изд. дом «Вильямс», 2001. – 912 с.
10. Хабибулин Н. Ф. Методика исправления искаженных кадров ARQ / Н. Ф. Хабибулин, А. Н. Шкердин // НПК XXII ВНК в/ч 25714,1999.
11. Хабибулин Н. Ф. Возможность исправления ошибок при использовании полиномиальной проверки / Н. Ф. Хабибулин, А. Н. Шкердин // НТК ВАС, Ст.-Петербург, 1997. – С. 142–144.
Введение
Актуальность исследования методов помехоустойчивой обработки цифровых сигналов систем спутниковой связи (ССС) и сигналов вторичных сетей связи для модемов телефонного канала обусловлена необходимостью снижения вероятности ошибки в условиях приема, а также разделения сигналов с совмещением спектров. В работах [10, 11] предлагается использовать избыточность кадровых проверочных последовательностей и локализацию участков кадров для повышения качества приема, при невозможности переспроса искаженного сообщения.
При разработке новых алгоритмов и способов повышения качества приема сигналов возникает резонный вопрос, на какую величину улучшились параметры приема, т.е. имеет ли смысл использовать дополнительную обработку принятого сигнала. В данной работе предлагается оценить такой параметр, как вероятность ошибочного приема кодового слова (КС). Данный параметр будем оценивать для трех случаев – при передаче КС, кодированного помехоустойчивым кодом; при разбиении того же КС на блоки, кодированные канальным кодом и при локализации участков блоков КС, кодированных канальным кодом.
Оценка вероятности ошибочного приема КС для этих случаев поможет ответить на вопрос целесообразности использования способов дополнительной обработки для повышения качества приема сигналов.
Цель статьи заключается в разработке методики оценки вероятностей правильного приема, обнаружения ошибки и ошибочного приема кодового слова для случаев передачи исходного кодового слова, разбиения исходного КС на блоки, с учетом локализации участков блоков кода.
Методика оценки вероятностных характеристик приема кодового слова
На практике широко используется для анализа свойств кодов, исправляющих ошибки, [2] описание канала связи в виде двоичного симметричного канала (ДСК) без памяти. Для такого канала условная вероятность единичного символа, составляющего КС, при передаче в канале связи обычно задается представлением, изображенным на рисунке 1.
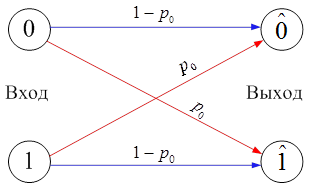
Рисунок 1. Граф переходов, задающий ДСК без памяти
В общем случае вероятность появления, по крайней мере, одной ошибки в КС определяется отношением (1)
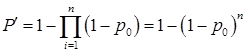 . (1)
. (1)
которое характеризует появление хотя бы одного из событий (ошибки КС), независимых в совокупности [4].
В выражении (1) n – число символов в КС; p0 – вероятность искажения 1-го символа в двоичном симметричном канале без памяти (см. рис. 1).
Вероятность того, что КС будет содержать e ошибок, задается отношением, определяющим вероятность совмещения всех событий, т.е.
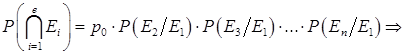
![]() (2)
(2)
где ![]() – задает событие искажения i-го символа в принимаемом КС;
– задает событие искажения i-го символа в принимаемом КС; ![]() – определяет число сочетаний из n по e и задается известным биномиальным коэффициентом [5]
– определяет число сочетаний из n по e и задается известным биномиальным коэффициентом [5]
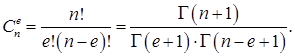 (3)
(3)
Здесь ![]() – гамма функция [6].
– гамма функция [6].
С учетом приведенных представлений, зададим следующие общие характеристики принимаемого (n, k) КС:
1) PПП – вероятность правильного приема КС:
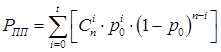 , (4)
, (4)
2) PОБ – вероятность обнаружения ошибки в КС:
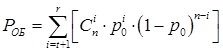 , (5)
, (5)
3) PОП – вероятность ошибочного приема КС:
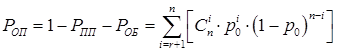 , (6)
, (6)
В данном случае t и r количественно характеризуют корректирующую и обнаруживающую способность исходного (n, k) кода и задаются соответствующими отношениями
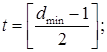
![]() (7)
(7)
где ![]()
![]() определяет минимальное расстояние по Хеммингу между всеми допустимыми кодовыми комбинациями исходно-заданного (n, k) кода;
определяет минимальное расстояние по Хеммингу между всеми допустимыми кодовыми комбинациями исходно-заданного (n, k) кода; ![]() – оператор, выделяющий целую часть.
– оператор, выделяющий целую часть.
Оценка ![]() для произвольного (n, k) кода, согласно [8], определяется из границ Плоткина и Хемминга:
для произвольного (n, k) кода, согласно [8], определяется из границ Плоткина и Хемминга:
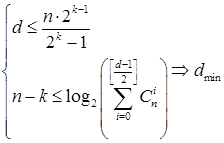 . (8)
. (8)
По существу решение (8) сводится к нахождению экстремума целевой функции
![]() , (9)
, (9)
с учетом ограничений, определяющих указанные ранее границы:
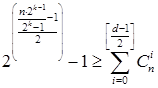 , (10)
, (10)
и ограничения на целочисленность переменной ![]() , определяемые согласно [7], в виде простых тригонометрических функций:
, определяемые согласно [7], в виде простых тригонометрических функций:
![]() , (11)
, (11)
Решение условной оптимизационной задачи (9) с учетом ограничений (10), (11) предлагается выполнить численно, с использованием метода множителей Лагранжа [9], при этом полином Лагранжа запишется в виде:
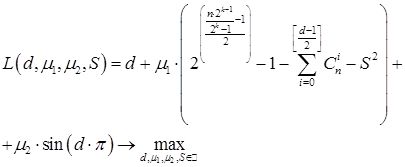 , (12)
, (12)
Нахождение экстремума (12) выполнено численно градиентным методом с переменной метрикой Дэвидона – Флэтчера – Пауэлла, стратегия которого подробно представлена в [3]. Определение вектора градиентов целевой функции (12) осуществляется численно методом Ньютона [1].
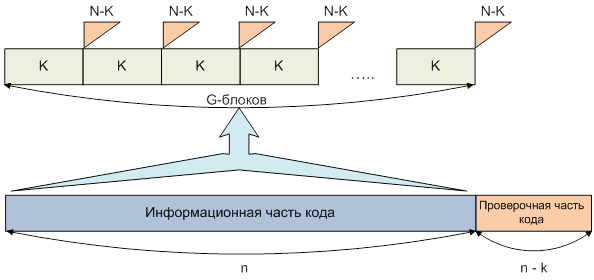
Рисунок 2. Разбиение информационной части кода на блоки
В случае предлагаемого разбиения информационной части КС на G блоков (рис. 2), причем каждый m-й блок ![]() представляет собой совокупность Km информационных частей (Nm, Km) кодовых слов, вероятность приема m-го блока КС будет определяться следующими характеристиками:
представляет собой совокупность Km информационных частей (Nm, Km) кодовых слов, вероятность приема m-го блока КС будет определяться следующими характеристиками:
1. ![]() – вероятность правильного приема m-го блока;
– вероятность правильного приема m-го блока;
2. ![]() – вероятность обнаружения ошибки в m-м блоке КС;
– вероятность обнаружения ошибки в m-м блоке КС;
3. ![]() – вероятность ошибочного приема m-го блока.
– вероятность ошибочного приема m-го блока.
Здесь ![]() и
и ![]() задают исправляющую и обнаруживающую характеристику (Nm, Km) кодовых слов, характеризующих m-й блок информационной части (n, k) КС, величина которых определяется по представленной выше методике.
задают исправляющую и обнаруживающую характеристику (Nm, Km) кодовых слов, характеризующих m-й блок информационной части (n, k) КС, величина которых определяется по представленной выше методике.
С учетом заданных представлений, вероятность ошибочного приема КС в случае разбиения информационной части на G блоков будет определяться отношением
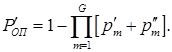 , (13)
, (13)
При условии того, что мы однозначно можем определить некоторое количество, например lm, символов в m-х блоках КС, приводящее к изменению исправляющей и обнаруживающей характеристик (Nm,Km) кодовых слов (![]() и
и ![]() ), заданные представления вероятностей для m-х блоков примут следующий вид:
), заданные представления вероятностей для m-х блоков примут следующий вид:
1. ![]() – вероятность правильного приема m-го блока;
– вероятность правильного приема m-го блока;
2. ![]() – вероятность обнаружения ошибки в m-м блоке КС;
– вероятность обнаружения ошибки в m-м блоке КС;
3. ![]() – вероятность ошибочного приема m-го блока.
– вероятность ошибочного приема m-го блока.
Последнее, по существу, приводит к снижению вероятности ошибочного приема КС, значение которой с учетом заданных представлений примет вид:
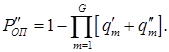 , (14)
, (14)
Для оценки полученных результатов проведена их экспериментальная проверка. В качестве исходного задан код (160, 144), применяемый для кодирования данных в системах Bluetooth. На передающей стороне КС, кодированное указанным кодом, разбивается на блоки и кодируется укороченным кодом Хэмминга (15, 10). Экспериментальная оценка вероятности ошибочного приема КС в соответствии с заданными представлениями выполнена для трех случаев:
– после кодирования КС кодом (160, 144);
– после кодирования КС кодом (160, 144) и разбиения на блоки КС кодированные кодом (15, 10);
– тоже, что в предыдущем пункте, но с учетом различного количества известных символов ![]() в блоке КС.
в блоке КС.
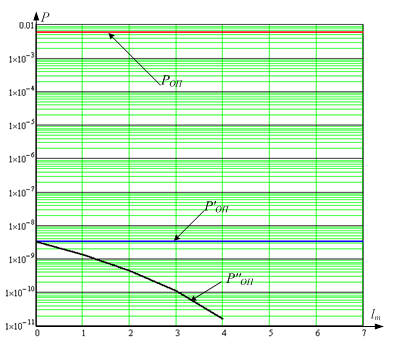
Рисунок 3. Вероятность ошибочного приема КС
Исследования выполнено с помощью системы математического моделирования MathCad 14. В ходе экспериментальной оценки получен график, отображающий вероятности ошибочного приема КС для трех указанных случаев (рис. 3).
Заключение
Из полученных результатов следует, что использование разбиения на блоки и локализация участков существенно уменьшают вероятность ошибочного приема КС. Увеличение длины локализованного участка в блоке также ведет к уменьшению вероятности ошибочного приема КС.
Таким образом, использование дополнительных способов обработки и локализации участков КС целесообразно использовать для повышения качества приема сигналов. Результаты математического моделирования продемонстрировали количественные параметры снижения вероятности ошибки в условиях приема при разбиении на блоки КС и локализации участков.
Рецензенты:
Архипов Н. С., д.т.н., доцент, сотрудник Академии ФСО России, г. Орел.
Иванов Б. Р., д.т.н., профессор, сотрудник Академии ФСО России, г. Орел.
Библиографическая ссылка
Шкердин А.Н., Полянский И.С. МЕТОДИКА ОЦЕНКИ ВЕРОЯТНОСТИ ОШИБОЧНОГО ПРИЕМА КОДОВОГО СЛОВА С УЧЕТОМ РАЗБИЕНИЯ НА БЛОКИ И ЛОКАЛИЗАЦИИ УЧАСТКОВ // Современные проблемы науки и образования. – 2013. – № 4.
;
URL: https://science-education.ru/ru/article/view?id=9789 (дата обращения: 29.01.2023).
Предлагаем вашему вниманию журналы, издающиеся в издательстве «Академия Естествознания»
(Высокий импакт-фактор РИНЦ, тематика журналов охватывает все научные направления)
1.
ПОМЕХОУСТОЙЧИВЫЕ
КОДЫ
1
2.
Введение
■ Подавляющее число современных систем связи работает при передаче самого
широкого спектра сообщений (от телеграфа до телевидения) в цифровом виде.
■ Из-за помех в каналах связи сбой при приеме любого элемента вызывает
искажение цифровых данных
2
3.
Стандартные протоколы обмена
информации в сетях
■ предусматривают введение обязательного поля для
размещения помехоустойчивого (корректирующего) кода.
■ Если в результате обработки принятого пакета обнаружится несоответствие
принятого и вновь вычисленного помехоустойчивого кода, с большой долей
вероятности можно утверждать, что среди принятых бит имеются ошибочные.
■ Передачу такого пакета нужно будет повторить (в расчете на случайный характер
помех).
3
4.
стандартами международных
организаций ITU-T и МОС установлено
■ , что вероятность ошибки при телеграфной связи не должна превышать 3×10-5 (на
знак),
■ а при передаче данных – 10-6 (на единичный элемент, бит).
■ На практике допустимая вероятность ошибки при передаче данных может быть
еще меньше – 10-9.
■ В то же время каналы связи (особенно проводные каналы большой протяженности
и радиоканалы) обеспечивают вероятность ошибки на уровне 10-3…10-4 даже при
использовании фазовых корректоров, регенеративных ретрансляторов и других
устройств, улучшающих качество каналов связи.
4
5.
Введение избыточности в
передаваемую информацию
является кардинальным способом снижения вероятности ошибок при
приеме является.
■ В системах передачи информации без обратной связи данный способ
реализуется в виде помехоустойчивого кодирования, многократной передачи
информации или одновременной передачи информации по нескольким
параллельно работающим каналам.
■ Помехоустойчивое кодирование доступнее, при прочих равных условиях
позволяет обойтись меньшей избыточностью и за счет этого повысить скорость
передачи информации.
5
6.
Цена введения кода
■ расширение используемой полосы частот и
■
уменьшение информационной скорости передачи.
6
7.
ИСТОРИЧЕСКИЙ
ОБЗОР
Помехоустойчивых кодов
8.
1946 г
«Работы по теории информации и кибернетике» К. Шеннона, где
■ сформулирована теорема Шеннона и
■ показано, что построение каналов связи с очень хорошими характеристиками
является дорогостоящим мероприятием, а экономически выгоднее использовать
избыточное, т.е. помехоустойчивое кодирование.
8
9.
Два направления развития теории
помехоустойчивого кодирования
■ Алгебраическое (слайды 12-18)
■ Вероятностное
Данные исследования привели к открытию алгоритмов последовательного
декодирования применительно к классу древовидных кодов, которые относятся к
классу сверточных кодов (СК), которые в свою очередь, являются дальнейшим
развитием непрерывных кодов.
9
10.
АЛГЕБРАИЧЕСКИЕ
коды
11.
1947г.
Хэммингом были построены
■ алгебраический блоковый (блочный) и
■ теория построения линейных блоковых кодов.
11
12.
1949г.
■ Абрамсон построил еще два блоковых кода
12
13.
1959 г. Хоквингейм
I960 г. Боузе и Чоудхури
предложили теорию построения линейных блоковых кодов, корректирующие
■ как независимые ошибки,
■ так и пакетные ошибки.
Эти коды получили название БЧХ-кодов.
13
14.
1960-61 гг. Рид и Соломон
независимо друг от друга разработали теорию построения линейных блоковых
кодов,
■ корректирующие пакетные ошибки
■ и группирующиеся пакеты ошибок,
■ при этом кодирование информации может быть выполнено как в двоичном поле
Галуа GF(2),
■ так и в недвоичном поле Галуа GF(2m ), m³2.
Эти коды получили название кодов Рида-Соломона или РС-кодов.
14
15.
1964 г. Прейндж
■ предложил теорию построения циклических кодов (ЦК) существенно упростивших
как алгоритм кодирования, так и алгоритм декодирования групповых кодов.
15
16.
1966 г. Файр
■ предложил теорию построения ЦК, корректирующих одиночные пакеты ошибок
произвольной кратности (длины), измеряемой в двоичных символах.
16
17.
1967 г. Форни, Блох и Зяблов
■ разработали теорию построения каскадных кодов, корректирующие
одновременно как независимые ошибки, так и пакетные ошибки.
17
18.
1967 г.
■ Витерби разработал для СК эффективный вероятностный алгоритм
декодирования, названный позднее алгоритмом Витерби (АВ).
■ С 1970 г. два направления исследований вновь стали пересекаться , в том
плане, что теорией построения СК занялись математики-алгебраисты,
представившие теорию построения СК в новом математическом изложении.
18
19.
ТЕОРИЯ
Теорема шеннона
20.
Двоичный симметричный канал (ДСК)
простейший канал с шумом
■ ДСК — это двоичный канал, по которому можно передать один из двух символов
(обычно это 0 или 1).
■ Передача не идеальна, поэтому принимающий в некоторых случаях получает другой
символ.
■ В теории связи множество проблем сводится к ДСК.
20
21.
ДСК с переходной вероятностью
■ называют канал с двоичным входом, двоичным выходом и вероятностью
ошибки
pош
21
22.
ДСК с переходной вероятностью
■ канал характеризуется набором возможных входов, набором возможных
выходов и набором условных вероятностей возможных выходов при условии
возможных входов
22
23.
Пропускная способность канала
■ метрическая характеристика, показывающая соотношение предельного
количества проходящих единиц информации в единицу времени через канал
■ Наибольшая возможная в данном канале скорость передачи информации
называется его пропускной способностью.
■ Пропускная способность канала есть скорость передачи информации при
использовании «наилучших» (оптимальных) для данного канала источника,
кодера и декодера, поэтому она характеризует только канал.
23
24.
Пропускная способность ДСК
C 1 H ( pош )
24
25.
Теорема Шеннона
■ При любой производительности источника сообщений, меньшей, чем
пропускная способность канала, существует такой способ кодирования, который
позволяет обеспечить передачу всей информации, создаваемой источником
сообщений, со сколь угодно малой вероятностью ошибки;
25
26.
Теорема Шеннона
■ Не существует способа кодирования, позволяющего вести передачу
информации со сколь угодно малой вероятностью ошибки, если
производительность источника сообщений больше пропускной способности
канала
26
27.
Суть
■ Доказывается только существование искомого способа кодирования,
■ Т.е. находят среднюю вероятность ошибки по всем возможным способам
кодирования и показывают, что она может быть сделана сколь угодно малой.
■ При этом существует хотя бы один способ кодирования, для которого вероятность
ошибки меньше средней.
27
28.
H ( x) V x H ( x)
Источник создает информацию
■ со скоростью
Vxбукв в секунду и энтропией каждой буквы в среднем H (x)
Т.е. производительность равна
H ( x) Vx H ( x)
(бит/сек).
28
29.
Вспомним т. Шеннона об
эффективном кодировании
■ Сообщения, составленные из букв некоторого алфавита, можно закодировать
так, что среднее число двоичных символов на букву будет сколь угодно близко к
энтропии источника этих сообщений, но не меньше этой величины
■ И предел эффективного кодирования
H ( x) lср log 2 M
lср H (x)
29
30.
В соответствии с теоремой Шеннона
об эффективном кодировании
■ т.е., возвращаясь к слайду 6, в первом приближении можно получить, что
производительность канала равна произведению скорости букв в секунду на
среднее число двоичных символов на букву
H ( x) Vx lср
30
31.
При наличии помех пропускная
способность канала связи падает,
■ Помня что в ДСК
C 1 H ( pош )
И учитывая условие пропуска информации по каналу
H ( x) C Vk
■ Получаем пропускную способность канала
C x Vk [1 H ( Pош )]
31
32.
Требование теоремы Шеннона для
помехоустойчивого кодирования
Vx lср H ( x) Ck Vk [1 H ( Pош )]
■ Где
lср — средняя длина кодовой комбинации для записи одной буквы
■ В сравнении с эффективным кодирование это значение увеличивается до
теоретического предела (в реальности нет )
lср1
lср
1 H ( Pош )
32
33.
ОБЩИЕ ПРИНЦИПЫ
ИЗБЫТОЧНОСТИ
Помехоустойчивых кодов
34.
К основным свойствам
помехоустойчивых кодов
■ относят их способность обнаруживать и исправлять ошибки в передаче
сообщений по дискретному каналу с помехами.
■ Рассмотрим возможность их применения для обнаружения ошибок в двоичных
кодовых комбинациях.
34
35.
Предположим, что
■ исходные кодовые комбинации состоят из k символов (разрядов).
■ Всего таких комбинаций может быть N = 2k, и их называют разрешенными.
■ Идея построения помехоустойчивого кода состоит в увеличении числа разрядов в
кодовых комбинациях с k до n (n k). При этом n – k вспомогательных символов
служат для обнаружения или исправления ошибок.
■ Общее число возможных комбинаций станет равным N0 = 2n.
■ Остальные (N0 – N) = 2n – 2k комбинаций для передачи информации не
используются и называются запрещенными.
35
36.
Если на приемной стороне
установлено, что
■ принятая комбинация относится к группе разрешенных комбинаций, то она
регистрируется неискаженной.
■ В противном случае делается вывод, что принятая комбинация искажена.
■ Однако это справедливо лишь для таких помех, когда исключена возможность
перехода одних разрешенных комбинаций в другие.
36
37.
Код с проверкой на четность
■ Для его построения необходимо ко всем 2k комбинациям безызбыточного кода
добавить по одному разряду и заполнить его проверочным символом 0 или 1 по
правилу четности числа единиц.
■ Увеличивая число дополнительных разрядов, и заполняя их (по определенным
правилам) проверочными символами 0 или 1, можно усилить корректирующие
свойства кода способностью исправлять как одиночные, так и ошибки более
высокой кратности.
37
38.
Пример. Покажем возможность
обнаружения ошибок при приеме
двоичных символов.
■ Пусть k = 2. При безызбыточном двоичном кодировании в этом случае можно
образовать четыре кодовые комбинации (2k = 4): k1 = 00; k2 = 01; k3 = 10; k4 =
11.
■ Любая одиночная ошибка приведет к тому, что одна из комбинаций будет
принята за другую. Введем один дополнительный разряд, т.е. n = 3, тогда общее
количество комбинаций: 23 = 8:
■ 000; 001; 010; 011; 100; 101; 110; 111.
■ Используем как разрешенные для передачи только те четыре комбинации, число
единиц в которых четно (они подчеркнуты), а остальные четыре (с нечетным
числом единиц) будем считать запрещенными.
38
39.
000; 001; 010; 011; 100; 101; 110;
111.
■ Теперь одиночная ошибка на любой позиции разрешенной кодовой комбинации
может быть обнаружена.
■
Действительно, одиночная ошибка в разрешенной кодовой комбинации делает
общее число единиц в этой комбинации нечетным, т.е. переводит разрешенную
комбинацию в запрещенную. Это является признаком ошибки.
■ Проверяя число единиц в каждой принятой комбинации, можно установить,
какие из этих комбинаций содержат ошибку.
39
40.
КОДЫ ХЭММИНГА
Подвид Блочных линейных кодов
41.
Блочными являются коды,
■ представляющие собой последовательности длиной n кодовых элементов, из
которых m элементов являются информационными, а остальные n – m
контрольными или проверочными.
■ Блочные коды обычно обозначаются так: (n, m) — код.
■ Например, код (7, 4) — это блочный код длины 7, который содержит 4
информационных и 3 проверочных позиции.
41
42.
Принципы построения кода Хемминга
■ Существует несколько разновидностей кода Хемминга, характеризуемых
различной корректирующей способностью. Работаю все по одному принципу.
■ Избыточная часть кода строится таким образом, чтобы при декодировании
можно было бы установить не только факт наличия ошибок в принятой
комбинации, но и указать номер позиции, в которой произошла ошибка. Это
достигается за счет многократной проверки (суммирования по по модулю 2)
принятой комбинации на четность.
■ Количество проверок равно количеству k избыточных символов.
42
43.
Принципы построения кода Хемминга
■ Каждой проверкой должны охватываться часть информационных символов и
один из избыточных символов. При каждой проверке получают двоичный
контрольный символ. Если результат проверки дает четное число, то
контрольному символу присваивается значение 0, если нечетное — 1.
■ В результате всех проверок получается k-разрядное двоичное число,
составленное из контрольных символов (сумм), называемое синдромом кода и
указывающее номер искаженного символа. Для исправления ошибки достаточно
лишь изменить значение данного символа на обратное.
43
44.
Определение количества
проверочных символов для кода Х.
k (n m) log 2 (n 1),
если
d 3
44
45.
Примерами таких кодов являются
коды типа
■ (3, 1), (5, 2), (6, 3), (7, 4), (9, 5), (10, 6), (11, 7) и т.д.
■ В таких кодах значения проверочных символов и номера их позиций
устанавливаются одновременно с выбором контролируемых групп кодовой
комбинации.
45
46.
Пример
Рассмотрим с помощью табл. двоичную запись номеров разрядов 13-разрядного
числа n, используемого в коде Хэмминга (13, 9).
НО ВНАЧАЛЕ РАССМОТРИМ БАЗОВЫЕ ПОНЯТИЯ:
■ ПРОВЕРОЧНЫЕ СИМВОЛЫ
■ КОНТРОЛЬНЫЕ СУММЫ
■ СИНДРОМ ОШИБКИ
46
47.
Проверочные символы
■ С целью упрощения операций кодирования и декодирования целесообразно
выбирать такое размещение проверочных символов в кодовой комбинации, при
котором каждый из них включается в минимальное число проверяемых групп
символов.
■ В связи с этим удобно размещать контрольные символы на позициях 1, 2, 4, 8,
16, …, номера которых встречаются только в одной из проверяемых групп.
Позиции с номерами, равными степеням двойки.
Действительно, символы A1, A2, A4, A8 встречаются только в одной из проверяемых
групп. Именно на этих позициях в коде Хэмминга располагаются проверочные
символы 1, 2, 3, 4, …
Тогда информационные символы будут располагаться на позициях A3, A5, A6, A7, A9,…
47
48.
Таблица номеров разрядности
48
49.
Контрольные суммы
■ При выборе контролируемых групп символов нужно исходить из следующих правил:
■ Контрольные суммы составляются так, чтобы в сумму Si входили символы Ai кодового
слова, имеющие единицу в i — разряде двоичной записи их порядкового номера в
пределах n — разрядной кодовой комбинации.
■ в первую контрольную сумму S1 должны входить символы A1, A3, A5, A7, A9, A11, A13,
содержащие единицу в первом разряде кодовой комбинации, т.е. первой проверкой
должны быть охвачены символы с нечетными номерами.
■ контрольный бит с номером N контролирует все последующие N бит через каждые N бит,
начиная с позиции N.
49
50.
Синдром ошибки
■ Как видно из табл., в первую контрольную сумму S1 должны входить символы A1, A3, A5, A7, A9,
A11, A13, A15, содержащие единицу в первом разряде кодовой комбинации, т.е. первой
проверкой должны быть охвачены символы с нечетными номерами.
■ Второй проверкой для формирования S2 охватываются 2-я проверочная и 3-я
информационная позиции кода, и далее A6, A7, A10, A11, A14, A15, A18, A19 и т.д. каждые два
информационных разряда, через два.
■ Аналогично третьей проверкой S3 охватываются 4-я проверочная, 5-я, 6-я, 7-я
информационные позиции кода, и далее A12, A13, A14, A15, A20, A21, A22, A23 и т.д. каждые
четыре информационные разряда, через четыре.
■ Совокупность значений проверок S4 S3 S2 S1 представляет собой двоичное число, которое
называют синдром ошибки. В коде Хемминга значение синдрома ошибки эквивалентно
номеру изменённой позиции, в которой произошла одиночная ошибка, исказившая код.
50
51.
ВЫЧИСЛЕНИЕ ПРОВЕРОЧНЫХ
СИМВОЛОВ
■ Значения проверочных символов 1, 2, 3, 4 должны выбираться таким
образом, чтобы обратить в нуль контрольные суммы S1, S2, S3, S4.
51
52.
52