1.1.
Статистика – самостоятельная
общественная наука, изучающая
количественную сторону массовых
общественных явлений в неразрывной
связи с их качественной стороной с
целью выявления закономерностей.
Отличие статистики,
как науки, от математики заключается в
том, что предметом изучения статистики
являются количественные закономерности
материальных явлений, имеющие определенные
качественные характеристики. Тогда как
наука математика изучает только
количественные отношения, абстрагированные
от качественной стороны явлений.
Статистика,
изучающая массовые явления в общественном
здоровье и здравоохранении, носит
название медицинской статистики, которая
рассматривает человека как социальное
существо, а все стороны его жизни,
деятельности и состояния здоровья как
социально обусловленные.
Медицинская
статистика делится на два основных
раздела: статистика здоровья населения
и статистика здравоохранения.
Статистика здоровья
изучает основные показатели, характеризующие
санитарное состояние общества (смертность,
рождаемость, естественный прирост (или
убыль) населения, заболеваемость,
инвалидизация и основные параметры
физического развития) посредствам
исследований и анализа полученных
статистических данных; выявляет и
устанавливает взаимосвязь этих
показателей с различными факторами
окружающей среды, это служит основой
для разработки оздоровительных и
профилактических мероприятий.
В понятие статистики
здравоохранения входит сбор и изучение
данных о кадрах и сети лечебно-профилактических
учреждений с целью планирования лечебных
и профилактических мероприятий и оценки
качества работы отдельных ЛПУ и органов
здравоохранения регионов и всего
здравоохранения в целом и т.д.
Если методологической
основой медицинской статистики являются
законы диалектики (единства и борьбы
противоположностей, перехода количества
в качество, категории необходимости и
случайности и т.д.), то математическая
основа – закон больших чисел, который
представляет одно из выражений
диалектической связи между случайностью
и необходимостью, а также теория
вероятностей.
При использовании
закона больших чисел удается освободить
статистические показатели от влияния
случайных причин и выявить в массе
изучаемых явлений действие объективных
закономерностей. Теория вероятностей
позволяет установить шансы «за» и
«против» реальной возможности наступления
данного события.
Основными задачами
медицинской (санитарной) статистики
являются:
-
изучение здоровья
(санитарного состояния) населения,
которое характеризуется демографическими
показателями, заболеваемостью и
параметрами физического развития и
показателями инвалидности (статистика
здоровья населения); -
изучение и анализ
результатов деятельности медицинских
учреждений и оценка эффективности их
работы (статистика здравоохранения); -
оценка достоверности
результатов научных исследований.
Статистическое
исследование проводят с целью получения:
-
сведений о
заболеваемости и воспроизводстве
населения; -
данных о физическом
развитии отдельных групп населения; -
результатов
анализа деятельности лечебно-профилактических
учреждений и оценка эффективности их
функционирования, в т.ч. и диспансерного
наблюдения и т.д.
Статистическое
исследование строится на основе
определенных, выработанных в процессе
многолетней практики и научно обобщенных
принципах, правилах и приемах, составляющих
статистическую методологию. Работа,
как правило, проводится в строгой
последовательности по следующим этапам:
-
Составление плана
и программы исследования; -
Регистрация и
сбор материала; -
Группировка и
сводка материала; -
Анализ, оценка,
выводы, применение в практике полученных
данных.
Эти этапы работы
неразрывно связаны между собой. Достаточно
не выполнить или не учесть требования,
предъявленные к одному из них, чтобы в
конце исследования получить неверные
данные, на основе которых нельзя будет
сделать правильные, научно достоверные
выводы.
I
ЭТАП СТАТИСТИЧЕСКОГО ИССЛЕДОВАНИЯ.
Каждое исследование имеет целью
установить существующие в изучаемых
явлениях закономерности, их привычную
связь с другими явлениями, тенденцию
развития и прочее. При исследовании
одного и того же материала цели могут
быть различными. Поэтому необходимо
заранее, еще при планировании и подготовке,
четко определить цель исследования,
т.к. объект наблюдения, единица наблюдения,
исследуемые признаки объекта, место и
время исследования, методы обработки
собранных данных, их анализ и интерпретация
в конечном счете зависят от цели и задач,
поставленных перед исследователями.
Цель зависит также от возможностей,
имеющихся в распоряжении исследователя.
Составление плана начинают с определения
цели и задач исследования, рабочей
гипотезы на основании личного опыта и
изучения литературы; формулировки темы.
Цель – для чего изучать, какое применение
найдут результаты исследования. Задачи
– то, что хотим изучить (процессы
смертности, заболеваемости, рождаемости
и т.д). Опираясь на четко сформулированные
цель и задачи исследования можно точно
определить объект и единицу наблюдения.
В плане исследования определяются его
сроки, объем и время проведения, источники
финансирования, научные консультанты,
литературные источники, непосредственные
исполнители и т.д.
Объект наблюдения
– это явление, подлежащее исследованию
(статистическая совокупность), например:
все больные неспецифическими заболеваниями
легких в г. Ижевске. Затем устанавливается
единица наблюдения. Это элемент
статистической совокупности,
характеризуемый рядом признаков,
подлежащих учету. Единицей наблюдения
в нашем примере будет каждый больной
неспецифическими заболеваниями легких,
проживающий в г. Ижевске; больного будет
характеризовать ряд признаков (пол,
возраст, профессия, длительность
заболевания и т.д.). Признаки, характеризующие
единицу наблюдения, составляют ПРОГРАММУ
исследования. Уточнение и формулирование
признаков производится на основе
следующих общих правил:
-
признаки отбирают
с учетом целей изучения и возможностей
обработки и анализа, полученных при
обработке данных. Критерием оценки
важности признака является цель; -
отобранных
признаков должно быть оптимальное
число; -
признаки необходимо
комбинировать таким образом, чтобы они
взаимно дополняли и контролировали
друг друга.
Различают следующие
виды наблюдения:
-
по объему (сплошное
и несплошное); -
по времени
(единовременное и текущее).
Сплошным исследованием
пользуются тогда, когда изучают все
единицы, входящие в объект наблюдения.
Примером сплошного наблюдения может
служить перепись населения, регистрация
смертей и рождений по соответствующим
свидетельствам, регистрация острозаразных
заболеваний и т.п. При выборочном
исследовании изучают только часть
единиц, входящих в объект наблюдения.
Однако эта часть должна быть
РЕПРЕЗЕНТАТИВНОЙ, означает соответствие
(однотипность) качественных и количественных
признаков, характеризующих элементы
выборочной совокупности по отношению
к генеральной. Выборочное наблюдение,
в сравнении со сплошным, дешевле. Оно
может быть проведено при меньшем
количестве персонала и с меньшими
материальными затратами. Выборочное
исследование дает более точные результаты,
т.к. при сплошном исследовании допускается
большее число регистрационных ошибок.
По виду выборка
единиц наблюдения может быть:
-
случайная;
-
механическая;
-
типологическая,
в т.ч. гнездовая, основного массива,
монографическая.
В любой выборке
необходимо обеспечить случайность,
непреднамеренность отбора единиц
наблюдения. При механическом отборе
берут каждую 2-ую, 5-ую, 30-ую, и т.д. единицы
наблюдения; а при типологическом –
только по однородным признакам; при
случайном – любые, непреднамеренно
выбранные единицы наблюдения (тянуть
жребий, по таблицам случайных чисел, по
первой букве фамилии и т.д.). Выборка
должна быть достаточной по числу
наблюдений.
Как указывалось
выше во временном аспекте наблюдение
может быть текущим или единовременным,
т.е. явление может изучаться в динамике
и статике. При проведении 1-го этапа
исследования определяется также место
исследования.
II
ЭТАП СТАТИСТИЧЕСКОГО ИССЛЕДОВАНИЯ.
Этот этап заключается в сборе материала
путем регистрации, заполнения разработанных
учетных документов, которые могут быть
в форме списка или карт. В некоторых
случаях используются оперативно-учетные
документы органов здравоохранения.
Сбор материала проводят по заранее
составленной программе и плану
исследования. Статистические данные
могут собираться путем постоянной
регистрации или единовременной
регистрации. Способами сбора материала
являются: опрос; непосредственное
наблюдение; выкопировка данных;
анамнестический опрос или заполнение
анамнестической анкеты. Регистратор
должен иметь четкую инструкцию по
методике работы и по заполнению учетных
документов или разработанных карт.
В учетные документы
заносят сведения о каждой единице
наблюдения.
Методы
сбора информации: опрос; непосредственное
наблюдение (медицинские осмотры,
измерение артериального давления, числа
дыхательных движений и т.д.); выкопировка
сведений из учетной документации. Чаще
всего сочетают все три метода. При сборе
материала могут быть сделаны ошибки:
случайные (вписали информацию не в ту
строчку по невнимательности) или
систематические, связанные с непониманием
методики работы или другими факторами,
зависящими от опрашиваемых лиц (округление
возраста и т.д.). Систематические ошибки
могут повлиять на конечный результат.
В связи с этим к конце II-го
этапа или начале III-го
этапа следует провести проверку
собранного материала. Прежде всего,
собранный материал подвергают проверке
и контролю в отношении полноты учета и
точности записей. Можно провести
проверку количественно: проверить, все
ли лечебные учреждения сдали отчеты,
или на всех ли историях болезней
выкопированы сведения. Далее надо
проверить на все ли вопросы, занесенные
в статистическую карту, дан ответ. Затем
проводят проверку логическую. Она
сводится к качественной оценке записей,
произведенных в статистических
документах. Легче всего это сделать,
сопоставляя отдельные признаки между
собой, например, пол и диагноз, возраст
и диагноз, возраст и профессию, возраст
и причину смерти и т.д. Так, если в стоке
«возраст» указано 12 лет, а в строке
«профессия» — «учитель», то сопоставление
сразу дает возможность выявить неточность,
допущенную при регистрации материала.
Обнаруженные недостатки исправляют на
основании дополнительных сведений.
Совершенно дефектный материал, не
поддающийся исправлению, исключают из
обработки.
III
ЭТАП СТАТИСТИЧЕСКОГО ИССЛЕДОВАНИЯ.
После того, как собран статистический
материал, приступают к группировке и
сводке материала. Группировка представляет
собой расчленение совокупности изучаемых
данных на однородные группы по наиболее
существенным признакам. Она позволяет
выделить основные типы, взаимосвязь и
взаимозависимость явлений, а также
структуру изучаемой совокупности.
Сводка – это подсчет итоговых данных
для заполнения таблиц. В результате
сводки единичные индивидуальные
наблюдения обобщаются и дается сводная
характеристика полученных данных. Для
облегчения группировки и сводки
полученных данных проводят шифровку
материала. Зашифровать – это значит
признаки, подлежащие группировке,
обозначать в статистической карте
цифрами, буквами или другими значками
в соответствии с тем, каково разнообразие
признаков. Например, признак: «пол»
имеет только два варианта: «муж» или
«жен». ключ к шифру будет: «муж» — 1, «жен»
— 2, затем во всех картах в месте для
шифра против признака «пол» ставят 1
или 2, в зависимости от того, мужчина это
или женщина. Правильно составленные
группировки помогают выявить закономерности
изучаемого вопроса. Например, изучая
заболеваемость, обязательно нужно
выделить возрастные группы от 0 до 1
года, от 2лет до 4 лет, 5-9 лет, и затем по
5-летним или 10-летним интервалам. При
изучении рождаемости, например, нет
необходимости выделять отдельно группы
50-59, 60-69 лет и т.д., т.к. в этом возрасте
роды почти не встречаются, но целесообразно
выделить группу женщин в возрасте старше
49 лет. Признаки, по которым производится
группировка, делятся на количественные
и атрибутивные (качественные).
Количественным называется признак,
который выражается числом (возраст,
масса и длина тела, длительность
пребывания больного на койке и т.д.).
атрибутивный признак выражается словесно
(диагноз, пол, вид операции, профессии
и т.д.). После шифровки карты группируются,
раскладываются по номерам шифра, затем
подсчитываются и заносятся в заранее
составленные макеты таблиц. Программа
разработки материала предусматривает
составление макетов разного типа,
которые заполняются на III
этапе статистического исследования.
Каждая таблица должна иметь номер,
краткое и точное название, из которого
можно было бы сразу видеть, какой материал
освещен в этой таблице, заголовки для
каждой графы, строки и итоги. Каждая
таблица, подобно грамматическому
предложению имеет статистическое (или
табличное) подлежащее и сказуемое.
Подлежащее – это то, о чем говорится в
таблице, т.е. объект исследования в целом
или его часть (население, больницы,
врачи, больные и т.д.). Сказуемое – это
то, что говорит о подлежащем (признаки,
которые характеризуют основную
совокупность – пол, возраст, время, стаж
работы и т.д.). Обычно принято подлежащее
располагать по строкам таблицы, а
сказуемое – по графам, но это не является
непременным правилом. Например, при
печатании материала (для удобства
расположения статистических данных)
этот порядок может быть изменен. По
видам статистические таблицы делятся
на простые и сложные (групповые и
комбинационные). ПРОСТАЯ таблица состоит
из подлежащего и сказуемого или нескольких
сказуемых, не связанных между собой.
Она содержит только перечень явлений,
в ней нет никаких группировок. Простые
таблицы бывают территориальные,
хронологические и перечневые.
Простые таблицы,
не показывая взаимосвязи отдельных
признаков между собой, имеют ограниченное
познавательное значение, из указанных
таблиц мы узнаем только, сколько было
зарегистрировано заболеваний по
населенным пунктам и по месяцам года.
При изучении же заболеваемости важно
выявить, когда чаще болеют, какие
заболевания чаще встречаются.
Для более углубленного
анализа нужно составить более сложные
таблицы (групповые, а также комбинационные),
как более отвечающие существу статистики,
т.к. они выявляют взаимосвязь между
изучаемыми явлениями.
Групповой называется
таблица, в которой подлежащее и несколько
сказуемых, связанных между собой.
Групповая таблица состоит из сочетания
двух признаков (один признак в подлежащем,
другой – в сказуемом). Число признаков
сказуемого может быть увеличено, но
каждый из них сочетается с подлежащим
попарно, изолировано от других.
Однако,
чрезмерно усложнять комбинационную
таблицу не следует, т.к. она становится
трудной для прочтения.
IV
ЭТАП СТАТИСТИЧЕСКОГО ИССЛЕДОВАНИЯ. В
результате группировки табличной и
табличной сводки исследователь получает
абсолютные величины. В ряде случаев их
достаточно для характеристики размеров
изучаемых явлений и процессов. Например,
когда речь идет о численности среды
(населения городов, районов, численность
отдельных возрастно-половых групп
населения и т.п.) достаточно знать
абсолютные цифры. В тех же случаях, когда
речь идет о частоте явления, абсолютных
цифр для вывода, где она ниже, а где выше
недостаточно, т.к. неизвестно, какова
численность населения, среди которого
это явление зарегистрировано, за
исключением очень редко встречаются
заболеваний, когда даже единичные случаи
заболеваний имеют значение (трахома,
холера и др.) для вывода. Поэтому абсолютные
величины преобразуют в относительные.
Различают следующие виды относительных
величин или показателей: интенсивные,
экстенсивные, соотношения, показатели
динамического ряда: наглядности, темпы
роста, темп прироста.
ИНТЕНСИВНЫЙ
ПОКАЗАТЕЛЬ
характеризует частоту явления в среде,
которая это явление порождает. Для
расчета интенсивного показателя
необходимо наличие двух статистических
совокупностей, одна из которых представляет
среду, другая – явление (например,
больные и умершие из их числа, население
и случаи смерти т.д.), показатель
рассчитывается на 100, 1000, 10000, 100000 населения,
соответственно: в процентах — %, промилле
— %○, продецимилле — %○○, в просантимилле
— %○○○, в зависимости от частоты явления:
чем реже встречается явление, тем больше
основание, на которое делается расчет.
Так, общие показатели смертности и
заболеваемости рассчитываются в
промилле, а смертность от отдельных
причин и заболеваемость отдельными
нозологическими формами – в продецимилле.
Допустим, установлено, что в городе А.
в течение года зарегистрировано 1875
больных туберкулезом, а в городе В. –
9001 случай данного заболевания. Для того,
чтобы сделать вывод о том, в каком городе
чаще болеют туберкулезом, абсолютных
чисел недостаточно. Ответить на этот
вопрос можно лишь в том случае, если мы
имеем представление о численности
населения в этих городах. В городе В.
больных туберкулезом больше в 4,8 раза,
нежели в городе А., и на первый взгляд в
городе В. чаще болеют туберкулезом.
Когда же мы узнаем, что в городе А.
проживает 150200 человек, а в городе В.
975246 человек, то возникает сомнение в
правильности первого предположения,
т.к. в городе В. жителей в несколько раз
больше, чем в городе А. В таких случаях
принято переводить абсолютные цифры
в относительные. В данном случае
необходимо число заболеваний в городе
отнести к численности населения этого
города. Для города А. показатель
рассчитывается так:
из 150200 человек
заболело 1875,
а из 1000 человек
заболело Х .
Х=
1875
х 1000
= 12,48%○
150200
для города В: из
975246 человек заболело 9001, а из 1000 человек
заболело – Х.
Х
= 9001х1000
=9,23%○
975246
Из полученных
величин видно, что показатель заболеваемости
туберкулезом выше в городе А. Таким
образом, точный вывод о величине того
или иного явления можно получить только
на основании относительных величин или
показателей, которые представляют
результат соотношения статистических
величин друг с другом.
КОЭФФИЦИЕНТ
СООТНОШЕНИЯ применяют
при оценке взаимосвязи разнородных
величин (обеспеченность населения
врачами, средними медицинскими
работниками, койками). Коэффициент
соотношения можно вычислять на 100, 1000,
10000. В отличие от интенсивных коэффициентов
он может быть выражен дробными числами:
число средних медицинских работников,
приходящихся на 1 врача: 1.53 медсестры
на 1 врача.
По методике
вычисления он схож с интенсивным
показателем: в городе с населением 70000
коечный фонд составил 560 коек. Какова
обеспеченность населения койками?
Составляем пропорцию, определяем Х:
70000 – 560
10000 – Х,
Х=560х10000
= 8 коек на 10000 населения (продецимилле,
%○o )
70000
ЭКСТЕНСИВНЫЙ
ПОКАЗАТЕЛЬ
характеризует соотношение части к
целому (долю части в целом) и выражается
в процентах. Например: число умерших от
болезней органов дыхания в 2005 г. в области
А. составило 1720 человек, а число умерших
от всех причин смерти составило 8500
человек. Какова доля заболеваний органов
дыхания среди всех причин смерти?
8500 – 100%
1720 – Х
Х=1720х100
= 20,2%
8500
ПОКАЗАТЕЛЬ
ДИНАМИЧЕСКОГО РЯДА.
Динамический ряд – это ряд величин,
показывающих изменение каких-либо
явлений или признака во времени. Важно,
чтобы он состоял из однородных и,
следовательно, сопоставимых данных. Он
может быть составлен из абсолютных, и
относительных и средних величин. В
зависимости от составляющих его величин
различают три основных типа динамических
рядов:
-
Динамические
ряды, построенные из абсолютных величин
(численность населения в различные
годы или периоды, количество больничных
коек); -
Динамические
ряды, представленныеотносительными
величинами (рождаемость,смертность,
летальность); -
Динамические
ряды, состоящие из средних величин
(показатели физического развития,
средняя длительность пребывания на
койке, средняя длительность лечения).
Динамические
ряды в зависимости от сроков, какие они
отражают, делятся на моментные и
интервальные. Моментные динамические
ряды строятся из статистических величин,
относящихся к определенному моменту,
к точной дате. Интервальный ряд
характеризует изменения размеров
явления за определенный период (интервал
времени). При анализе динамических рядов
используют следующие показатели: темп
роста, темп прироста, показатель
наглядности. ТЕМП
РОСТА
– это отношение каждого последующего
члена динамического ряда к своему
предыдущему, выраженное в процентах.
ТЕМП
ПРИРОСТА
– это отношение абсолютного прироста
к предыдущему члену динамического ряда,
выраженное в процентах. АБСОЛЮТНЫЙ
ПРИРОСТ
– это разность между последующим и
предыдущим членом ряда.
КОЭФФИЦИЕНТ
НАГЛЯДНОСТИ
(относительная величина сравнения) –
соотношение величин одноименных
показателей, относящихся к разным
промежуткам времени, территориям и т.п.
Вычисляется в процентах. Например: если
число студентов, принятых на I
курс вуза, принять за 100%, то на II
курсе их, по отношению к численности
принятых в вуз – 99%.
Динамические ряды
можно использовать для прогнозирования
явлений, в частности здоровья населения.
Осуществить это можно с помощью системы
уравнений, выбор которых зависит от
вида кривой распределения величин в
реальном динамическом ряду (по параболе
1-ого, 2-ого и 3-го порядка). Удобнее это
делать с использовать ЭВМ.
Графические
изображения в статистике.
Различают плоскостные
(т.е. цифровые данные приводят в виде
геометрических фигур в двух измерениях)
и объемные диаграммы.
Интенсивный
показатель графически может быть
представлен в виде следующих диаграмм:
-
линейной;
-
столбиковой или
ленточной; -
радиальной;
-
картограммы;
-
картодиаграммы.
При построении
линейной диаграммы на оси абцисс
(горизонтальный уровень) отмечаются
анализируемые годы в соответствии с
заданным масштабом, на оси ординат
(вертикальный уровень) – частота
изучаемого явления.
При построении
графика на оси абсцисс отмечены
анализируемые годы, на оси ординат –
число посещений в поликлинику, приходящуюся
на одного жителя Удмуртской Республики.
На координатное поле наносятся точки
в соответствии с показателем, затем эти
точки последовательно соединяют и
получается непрерывная линия, отражающая
суть явления графически, что позволяет
наглядно представить изменение показателя
за определенный период времени.
Столбиковые и
ленточные диаграммы относятся к
плоскостным.
Столбиковая это,
или ленточная диаграмма, зависит от
того, в какой плоскости они отображены
(по вертикали – столбиковая, по горизонтали
– ленточная диаграммы).
На оси абсцисс
располагают основание столбика, на оси
ординат – величину изучаемого признака
в соответствии с избранным масштабом.
Столбики должны быть одинаковой ширины
и могут располагаться как рядом друг
с другом, так и на определенном расстоянии.
Радиальная
диаграмма строится на основе окружности,
которую делят на секторы, которые должны
соответствовать изучаемым временным
периодам (12 секторов при изучении явления
за год и т.д.); на каждом радиусе
соответственно определенному месяцу
откладывают величину явления в
соответствии с избранным масштабом.
Построение диаграммы осуществляется
по часовой стрелке, конечные точки
обрезков соединяют линиями. Величина
явления, отложенная на радиусе может
отходить далеко за пределы окружности,
такую разновидность радиальной диаграммы
называют полярной.
Картограмма
получается при изображении изучаемого
явления на контурной или географической
карте посредством обозначения разной
интенсивности окраски или штриховкой.
В картодиаграмме
частоту изучаемого явления изображают
на контурной или географической карте
в виде столбиков различной высоты,
соответствующей частоте изучаемого
явления.
Экстенсивный
показатель графически изображается
посредством внутристолбиковой и
секторной (круговой) диаграмм, которые
являются разновидностями плоскостных
диаграмм.
Для построения
внутристолбиковой диаграммы используется
прямоугольник, высота которого принимается
за 100%, доли составных частей этой фигуры
располагают снизу вверх в порядке
возрастания процентов; составные части
прямоугольника различают по штриховке
или расцветке. Доли составных частей
указывают внутри прямоугольника.
Секторная диаграмма
строится следующим образом:
Окружность
произвольного радиуса принимают за
100%, тогда 1% будет соответствовать 3,6°,
т.к. вся окружность составляет 360°
На окружности
откладывают дуги в соответствии с
углами в градусах, что соответствует
долям от целого. Концы отрезков,
соединяющих дуги, линиями соединяют с
центром окружности, таким образом
получая секторы. Сумма всех долей должна
быть равна 100%, или в градусах — 360°.
Показатель
соотношения графически может быть
отображен теми же диаграммами, что и
интенсивный показатель, а также фигурными
диаграммами.
В фигурной объемной
диаграмме на оси абсцисс отмечают
анализируемые годы, на оси ординат –
частоту явления. В соответствии с
построенными осями на координатное
поле наносят изображения в виде фигур
(обеспеченность населения койками в
виде схематически изображенных больничных
коек, обеспеченность врачами и ли
средними медицинскими работниками –
фигурки в медицинской форме и т.д.).
Задачи.
-
В стационаре МУЗ
ГБ №3 г. Ижевска в течение 2005 года
лечилось 500 больных с инфарктом миокарда,
из них умерли 10 человек. Рассчитать
показатель летальности от инфаркта
миокарда на 2005 год. Как изменился этот
показатель в сравнении с2004 годом, когда
он составлял 2,4%? -
Обеспеченность
России врачами (на 10000 населения) 1913 год
– 2,0; 1950 – 14,0; 1980 – 37,3; 1995 – 40,7, 2004 – 41,4.
Рассчитать показатель наглядности,
темп роста и темп прироста. -
В поликлинике,
обслуживающей 50000 населения в течение
2005 года было зарегистрировано 1890 случаев
острой дизентерии, 840 случаев – вирусного
гепатита, 1260 – эпидемического гепатита,
126 – брюшного тифа, 42 – бруцеллеза, 21 –
сыпного тифа.
Определить структуру
заболеваемости и показатели частоты
на 1000 человек.
-
Число впервые
зарегистрированных больных со
злокачественными опухолями кишечника
по Первомайскому Району г. Ижевска за
2000-2005 года:
2000 год — 96
2001 год – 118
2002 год – 108
2003 год – 123
2004 год – 135
2005 год – 134
Рассчитать
показатель наглядности, темп роста,
темп прироста.
-
Определить
обеспеченность населения врачами в г.
А. и г.Б., если в г. А. население
составляет 40000 человек, а врачей – 170,
в г. Б. проживает 50000 человек, а врачей
– 210. Как называется этот статистический
показатель? -
Определить
структуру распределения детей по
детским учреждениям и заболеваемость
острой пневмонией в каждой группе детей
по представленным данным:
-
Детские
учрежденияЧисло
детейЧисло
больныхшколы
21016
94
Д/сады
7449
37
Д/ясли
30572
29
Итого:
-
Рассчитать долю
патологических состояний во время
родов из общего числа осложнений по
роддому №6 г. Ижевска:
-
Всего
осложненных родов1505
В
т.ч. кровотечения14
Разрыв
промежности942
Разрыв
шейки матки16
2.1. ОЦЕНКА
ДОСТОВЕРНОСТИ РЕЗУЛЬТАТОВ СТАТИСТИЧЕСКОГО
ИССЛЕДОВАНИЯ И РАЗНОСТИ ОТНОСИТЕЛЬНЫХ
ВЕЛИЧИН.Врачу, как
правило, в своих исследованиях
приходится иметь дело с частью
изучаемого явления, с так называемой
выборочной совокупностью, а выводы
по результатам исследования переносить
на явление в целом, т.е. на генеральную
совокупность. Чтобы по результатам
выборочного исследования можно было
судить о совокупности в целом, надо
провести оценку достоверности
полученных данных (показателей)–Р
или средних– М.Под статистической
достоверностью показателя понимают
его право на обобщенную характеристику
явления, распространение полученных
выводов на другие аналогичные явления.Мерой
достоверности выборочных статистических
явлений являются их ошибки. Ошибка
репрезентативности (m)
определяет, насколько результаты,
полученные при выборочном наблюдении,
отличаются от результатов при
проведении сплошного исследования
(т. е. охвата всех элементов генеральной
совокупности). Ошибку репрезентативности
можно свести к достаточно малой
величине при условии достаточного
количества наблюдений при проведении
выборочных исследований.ОЦЕНКА ДОСТОВЕРНОСТИ
РЕЗУЛЬТАТОВ ИССЛЕДОВАНИЯСпособы
определения достоверностиВычисления
ошибки средней величины(m)
M
Вычисление
ошибки относительной величины (m)Р
Определение
доверительных границМ = М + mt
Ген
Выб nР =Р +mt
Ген
Выб рОпределение
достоверности разности между
средними или относительными
величинамиУсловия,
определяющие достоверностьРазнообразие
признака в статистической совокупности
(сигма δ)Число наблюдений
(n)Вероятность
безошибочного прогноза (р)Практическое
применениеОпределение
доверительных границ величины в
генеральной совокупности.Определение
существенных различий между средними
(или относительными) величинами.____
Ошибка
относительного показателя по формуле:
m
= √ p
g
,Р
nгде
р – величина показателя в процентах
(%), промилле (‰), продецимилле (‰o),
просантимилле (‰oo), g
– разность между условным числом, на
которое рассчитывался показатель и
его величиной. Например, величина g
– равна 100 – р, если показатель
вычисляется в процентах (%), n
– общее число наблюдений. Ошибка
средней величины определяется по
формуле:m
= ± δ ,М √n
где
δ – среднее квадратическое отклонение,
а n
– общее число наблюдений.Ошибка
репрезентативности позволяет
установить доверительные границы,
т.е., тот интервал, в пределах которого
с определенной степенью вероятности
будет находиться величина показателя
или средней, характеризующая всю
генеральную совокупность.Доверительные
границы определяются по формуле:p±tm
M±tm
р
(М)
± t
, p
– относительный показатель или М –
средняя величина, m
–M
ошибка
репрезентативности для показателя
или средней величины, t
— доверительный коэффициент или
критерий достоверности точности.
Критерий позволяет установить
достоверные границы с определенной
степенью вероятности. При числе
наблюдений >30, при t=1
доверительные границы, в которых
будут находиться генеральная средняя
или показатель, гарантируется с
вероятностью в 0,683 (68,3%). Эта вероятность
считается недостаточной. В медицинских
исследованиях в качестве минимально
допустимой вероятности для оценки
достоверности выборочных величин
принята вероятность 0,955 (95,5%), что
соответствует t=2
(точнее 1,96).При
t=1,96
достоверность выборочных величин
гарантируется с вероятностью 0,955
(95,5%), при t=3
– 0,997 (99,7%), при t=3,3
обеспечивается вероятность 0,999
(99,9%).Одним из основных
моментов в статистических исследованиях
является сравнительный анализ.
Полученные в результате исследования
данные сравниваются в динамике (с
аналогичными показателями или средними
величинами предыдущих исследований
в предыдущие годы), со стандартами
физического развития, с нормативными
данными, с данными других учреждений
и т. д. Результаты исследований можно
сравнить с аналогичными данными
контрольной (опытной) группы.Кроме того, врачу
в практической деятельности, а так
же при научных исследованиях, бывает
необходимо оценить достоверность
произошедшего сдвига в показателях
или средних. Определить достоверность
сдвига – это значит установить
является ли разность в показателях
или средних результатом нашей
целенаправленной деятельности
(проведение оздоровительных мероприятий,
улучшение качества лечебной,
диагностической работы, эффективности
диспансеризации и т. п.), апробированного
в наблюдении фактора (влияние нового
лекарственного препарата, нового
метода лечения, ведение послеоперационного
периода и т. п.) или это влияние было
случайным , от независящих от нас
причин. Например, показатель летальности,
являясь показателем качества лечебной
работы, зависит от сроков доставки в
стационар, возраста и пола больных,
тяжести течения заболевания и т. д.Достоверность
разности показателей определяется
по формуле Стъюдента:t=
_Р1-Р2___,√m1²+m2²
а
средних t=
_М1-М2___,√m1²+m2²
При
вычислении t
целесообразно в качестве Р1 и М1 брать
большую величину. Если вычисленное
значение окажется <2, то разность
между показателями или средними
считается случайной, т. е. независимой
от нашей деятельности или влияния
изучаемого фактора. Критерий t
достоверность разности показателей
или средних величин определяются
двумя способами:-
при
n<30
по таблицам Плахинского или Стъюдента. -
при
n>30
следующим образом:
t=1
достоверность составляет 68,3%t=2
достоверность составляет 95,5%t=3
достоверность составляет 99,7%t=3,3
достоверность составляет 99,9%При статистических,
клинических, санитарно-гигиенических
и клинико-социологических исследованиях
результат считается закономерным
при достоверности 95 и более процентов,
т. е. разрешается ошибка риска не более
5%.Например, из 140
детей больных пневмонией, леченных
новым способом умерло 3, а в контроле
среди лечившихся старым способом из
220 умерло 9 больных, летальность
составила соответственно 2,1% и 4,1%.
Летальность изменилась почти в 2 раза.
Значит ли это, что новый способ
эффективнее?Рассчитываем
ошибку показателей____________
_____ ___m1=±√4,1+(100-4,1)
= ±√393,2
= =± √ 1,8
= ±1,3-
220
____________
_____ ___m2
=±√2,1 +
(100-2,1) = ±
√205,6
= ±√ 1,4 = ± 1,2.140
140Подставив их
формулу:t=
4,1 – 2,1
= 2,0
= 2,0
= 1,1, т.е. <2,√1,8+1,4 √3,2
1,8Видим, что
разность в показателях случайна, т.
е. более низкая летальность обусловлена
независимыми от данного метода лечения
причинами: может быть в группу леченных
новым способом попало больше молодых
с ранними формами заболевания, не
отягощенными другой патологией и т.
п. Если клинический метод кажется
более эффективным, надо пересмотреть
контрольную и экспериментальную
группы (надо, что бы они были идентичными)
и увеличить число наблюдений.Задачи для
лечебного факультета.-
При изучении
успеваемости студентов медицинского
института неработающих и сочетающих
учебу с работой – были получены
следующие данные: у неработающих
средний балл (М)=4,1(m=
±0,09), у сочетавших учебу с работой
М=3,65
M1
(m=±0,05).
M2
Определить,
имеется ли достоверность снижения
среднего балла успеваемости у
студентов, сочетающих учебу с работой.2. При изучении
трудоспособности у больных, перенесших
инфаркт миокарда при наличии
гипертонической болезни и без нее,
были получены следующие данные: число
возвратившихся к труду из 149 больных,
перенесших инфаркт миокарда с
гипертонической болезнью (Р)=61,0%, а из
208 больных, перенесших инфаркт миокарда
без гипертонической болезни, (Р)=75,0%Определить
имеется ли достоверная разница в
утрате трудоспособности у больных,
перенесших более тяжелую форму
инфаркта миокарда, и у лиц с неотягощенным
гипертонической болезнью инфарктом
миокарда.-
При изучении
частоты нагноений после аппендэктомии
в двух группах больных, в одной из
которых применялся пенициллин, а в
другой не применялся, были получены
следующие данные: в первой группе из
81 больного нагноения имели 30,0% больных
(Р), во второй группе из 82 больных –
40,0% (Р).
Определить
имеется ли достоверное снижение
частоты нагноений после аппендэктомии
в связи с применением пенициллина.Задачи для педиатрического факультета.
-
Показатели
послеоперационной летальности в
двух детских больницах (Р и Р), где
распределение больных по видам
операций было примерно одинаковым,
составили в больнице А – 2,0%
(m=±0,3%), в больнице Б — 1,0% (m=±0,2%). Значит ли, что
P1
Р2
послеоперационная
летальность выше в ЛПУ №2?-
При
изучении эффективности иммунизации
детей против гриппа получены следующие
данные: процент заболеваемости (Р) в
группе иммунизированных 560 человек
составил 44,3% (m
=±2,1%),
P1
в
группе не иммунизированных численностью
1477 детей показатель (Р) составил 48,0%
(m
=±1,3%) определить, эффективна лиР2
иммунизация
детей.-
При
изучении заболеваемости болезнью
Боткина, детей 2 городов были получены
следующие данные: в городе А
заболеваемость детей (Р) составила
2,1% (m
=±0,1%), в городе Б (Р)=1,3%
P1
(m
=±0,1%), Определить, достоверно ли выше
заболеваемость детейР2
болезнью Боткина
в городе А.Задачи для
стоматологического факультета.-
В поселке А,
где питьевая вода содержит достаточное
количество фтора, из 3200 жителей 1800
обратилось с жалобами по поводу
кариозных поражений зубов, а в пос
Б, где содержание фтора в питьевой
воде недостаточно, из 5010 жителей
обратились за помощью в стоматологическую
поликлинику 3921. является ли фторирование
питьевой воды достаточно эффективным
средством для снижения заболеваемости
кариесом? -
В школе А, где
детей обучают методом профилактики
кариеса, из 1810 детей кариозным
поражением зубов страдают 603 ребенка,
в школе Б, где профилактика не
проводилась, соответственно из 2003
детей – 131 больной. Имеется ли
достоверная разница в заболеваемости
кариесом в школах А и Б? -
В городе А с
численностью населения 750 тыс.
онкологических заболеваний
челюстно-лицевой области были
зарегистрированы у 215 человек, в
городе Б – соответственно из 615 тыс.
– 189. имеется ли достоверная разница
в уровне заболеваемости в городе А
и в городе Б?
ЛИТЕРАТУРА
-
Применение
методов статистического анализа для
изучения общественного здоровья и
здравоохранения. Под ред. В.З. Кучеренко,
учебное пособие для вузов, издат.
группа «ГЭОТАР – Медиа», М., 2006 г., с.
122-126. -
Социальная
гигиена (медицина) и организация
здравоохранения. Под ред. А.Ф. Серенко,
В.В. Ермакова, М., Медицина, 1984 г., с.
139-145. -
Социальная
гигиена (медицина) и организация
здравоохранения под ред. Ю.П. Лисицына,
Казань, НПО «Медикосервис», 1998 г., с.
307-308. -
Лисицын Ю.П.
«Общественное здоровье и здравоохранение»,
М., Изд. дом «ГЭОТАР – МЕД», 2002 г., с.
304-305. -
В.М. Зайцев, В.Т.
Лифляндский , В.И. Маринкин «Прикладная
медицинская статистика», С.-Петербург,
«ФОЛИАНТ», 2003 г., с. 239-244.
Список литературы:
-
Санитарная
статистика /Под ред. Меркова А.М.,
Полякова Л.Е, Л., Медицина, 1974, с.
34-39,102-113. -
Социальная и
организация здравоохранения /Под
ред. А.Ф. Серенко и В.В. Ермакова – 2
изд. – М.: Медицина, 1984, с. 102-123,
160-164,168-183. -
Социальная
гигиена (медицина) и организация
здравоохранения/ Под ред. Ю.П. Лисицина,
Казань, НПО «Медикосервис», 1988, с.
253-292, 310-320. -
Лисицын Ю.П.
Общественное здоровье и здравоохранение:
учебник для вузов – М.: ГЭОТАР-МЕД,
2002 – 520с. -
Общественное
здоровье и здравоохранение: учебник
для студентов /Под ред. В.А. Миняева,
Н.И. Вишнякова – М.: Медпресс-информ,
2002 – 528 с. -
В.М. Зайцев, В.Г.
Лифляндский, В.И. Маринкин Прикладная
медицинская статистика, учебное
пособие, С.-Петербург, «Фолиант»,
2003, с. 7-417, 67-83. -
Применение
методов статистического анализа для
изучения общественного здоровья и
здравоохранения /учебное пособие
для вузов/Под ред. В.З. Кучеренко –
М.: ГЭОТАР – Медицина, 2006, с. 59-101,
177-178.
-
где
δ – среднее квадратическое отклонение,
а n
– общее число наблюдений.
Ошибка
репрезентативности позволяет установить
доверительные границы, т.е. тот интервал,
в пределах которого с определенной
степенью вероятности будет находиться
величина показателя или средней,
характеризующая всю генеральную
совокупность.
Доверительные
границы определяются по формуле:
p±tm
M±tm
р
(М)
± t
, p
– относительный показатель или М –
средняя величина, m
–
M
ошибка
репрезентативности для показателя или
средней величины, t
— доверительный коэффициент или
критерий достоверности точности.
Критерий позволяет установить достоверные
границы с определенной степенью
вероятности. При числе наблюдений >30,
при t=1
доверительные границы, в которых будут
находиться генеральная средняя или
показатель, гарантируется с вероятностью
в 0,683 (68,3%). Эта вероятность считается
недостаточной. В медицинских исследованиях
в качестве минимально допустимой
вероятности для оценки достоверности
выборочных величин принята вероятность
0,955 (95,5%), что соответствует t=2
(точнее 1,96).
При
t=1,96
достоверность выборочных величин
гарантируется с вероятностью 0,955 (95,5%),
при t=3
– 0,997 (99,7%), при t=3,3
обеспечивается вероятность 0,999 (99,9%).
Одним из основных
моментов в статистических исследованиях
является сравнительный анализ. Полученные
в результате исследования данные
сравниваются в динамике (с аналогичными
показателями или средними величинами
предыдущих исследований в предыдущие
годы), со стандартами физического
развития, с нормативными данными, с
данными других учреждений и т. д.
Результаты исследований можно сравнить
с аналогичными данными контрольной
(опытной) группы.
Кроме того, врачу
в практической деятельности, а так же
при научных исследованиях, бывает
необходимо оценить достоверность
произошедшего сдвига в показателях или
средних. Определить достоверность
сдвига – это значит установить является
ли разность в показателях или средних
результатом нашей целенаправленной
деятельности (проведение оздоровительных
мероприятий, улучшение качества лечебной,
диагностической работы, эффективности
диспансеризации и т. п.), апробированного
в наблюдении фактора (влияние нового
лекарственного препарата, нового метода
лечения, ведение послеоперационного
периода и т. п.) или это влияние было
случайным , от независящих от нас причин.
Например, показатель летальности,
являясь показателем качества лечебной
работы, зависит от сроков доставки в
стационар, возраста и пола больных,
тяжести течения заболевания и т. д.
Достоверность
разности показателей определяется по
формуле Стъюдента:
t=
_Р1-Р2___,
√m1²+m2²
а
средних t=
_М1-М2___,
√m1²+m2²
При
вычислении t
целесообразно в качестве Р1 и М1 брать
большую величину. Если вычисленное
значение окажется <2, то разность между
показателями или средними считается
случайной, т. е. независимой от нашей
деятельности или влияния изучаемого
фактора. Критерий t
достоверность разности показателей
или средних величин определяются двумя
способами:
-
при
n<30
по таблицам Плахинского или Стъюдента. -
при
n>30
следующим образом:
t=1
достоверность составляет 68,3%
t=2
достоверность составляет 95,5%
t=3
достоверность составляет 99,7%
t=3,3
достоверность составляет 99,9%
При статистических,
клинических, санитарно-гигиенических
и клинико-социологических исследованиях
результат считается закономерным при
достоверности 95 и более процентов, т.
е. разрешается ошибка риска не более
5%.
Например, из 140
детей больных пневмонией, леченных
новым способом умерли 3, а в контроле
среди лечившихся старым способом из
220 умерли 9 больных, летальность составила
соответственно 2,1% и 4,1%. Летальность
изменилась почти в 2 раза. Значит ли это,
что новый способ эффективнее?
Рассчитываем
ошибку показателей
____________
_____ ___
m1=±√4,1+(100-4,1)
= ±√393,2
= =± √ 1,8 =
±1,3
-
220
____________
_____ ___
m2
=±√2,1 +
(100-2,1) = ±
√205,6
= ±√ 1,4 = ± 1,2.
140
140
Подставив их
формулу:
t=
4,1 – 2,1
= 2,0
= 2,0
= 1,1, т.е. <2,
√1,8+1,4 √3,2
1,8
Видим, что разность
в показателях случайна, т. е. более низкая
летальность обусловлена независимыми
от данного метода лечения причинами:
может быть в группу леченных новым
способом попало больше молодых с ранними
формами заболевания, не отягощенными
другой патологией и т. п. Если клинический
метод кажется более эффективным, надо
пересмотреть контрольную и экспериментальную
группы (надо, что бы они были идентичными)
и увеличить число наблюдений.
Задачи для лечебного
факультета.
-
При
изучении успеваемости студентов
медицинского института неработающих
и сочетающих учебу с работой – были
получены следующие данные: у неработающих
средний балл (М1) =4,1 (m=
±0,09), у сочетавших учебу с работой
М2=3,65
M1
(m=±0,05).
M2
Определить, имеется
ли достоверность снижения среднего
балла успеваемости у студентов, сочетающих
учебу с работой.
2. При изучении
трудоспособности у больных, перенесших
инфаркт миокарда при наличии гипертонической
болезни и без нее, были получены следующие
данные: число возвратившихся к труду
из 149 больных, перенесших инфаркт миокарда
с гипертонической болезнью (Р1)=61,0%, а из
208 больных, перенесших инфаркт миокарда
без гипертонической болезни, (Р2)=75,0%
Определить имеется
ли достоверная разница в утрате
трудоспособности у больных, перенесших
более тяжелую форму инфаркта миокарда,
и у лиц с неотягощенным гипертонической
болезнью инфарктом миокарда.
-
При изучении
частоты нагноений после аппендэктомии
в двух группах больных, в одной из
которых применялся пенициллин, а в
другой не применялся, были получены
следующие данные: в первой группе из
81 больного нагноения имели 30,0% больных
(Р1), во второй группе из 82 больных –
40,0% (Р2).
Определить имеется
ли достоверное снижение частоты нагноений
после аппендэктомии в связи с применением
пенициллина.
Статистика – это наука, изучающая количественную сторону массовых явлений в неразрывной связи с их качественной стороной. А медицинская статистика изучает вопросы, связанные с медициной. Для того чтобы стать по-настоящему грамотным специалистом, студенты медицинского вуза должны изучать биометрию, статистику, медицинскую информатику. Роль этих наук в практической деятельности современного врача очень велика, их умелое применение позволяет своевременно оценить уровень здоровья пациентов, оперативно выбрать эффективные диагностические и лечебные мероприятия, повысить качество медицинской помощи и соответственно – качество жизни населения.
Основную цель данной работы составлял анализ методики статистического анализа клинико-лабораторных данных. В результате обзора научной литературы мы остановились на работе И.А. Зворыгина [1], в которой пошагово, в доступной форме, представлена последовательность статистического анализа клинико-лабораторных данных.
1. Описание исходных данных
Как правило, основными задачами статистического анализа являются:
— описание группы (либо нескольких групп) данных с расчетом параметров распределения;
— сравнение нескольких групп данных с учетом параметров распределения.
Компактное описание данных – задача так называемой описательной статистики, в фундаменте которой лежит понятие нормального распределения (распределения Гаусса) [2]. Такое распределение встречается достаточно часто в нормальных физиологических условиях, если значения изучаемого признака близки к их среднему арифметическому значению и примерно с равной вероятностью отклоняются от него в большую или меньшую сторону (рис. 1). Для описания такого распределения используются параметры: среднее значение М и стандартное отклонение s[3].
В качестве примера нормального распределения можно рассмотреть концентрацию гемоглобина крови: данный показатель отклоняется от среднего значения под действием различных слабо выраженных, не зависящих друг от друга факторов – таких, как поступление и потеря железа, интенсивность эритропоэза, время жизни эритроцитов и др. Исходные лабораторные данные – результаты определения концентрации гемоглобина у 30 дноров мужского пола [1].
Рассмотрим ход расчета параметров распределения и будем заносить результаты в табл. 1. Прежде всего, введем исходные показатели в первую колонку таблицы. Далее вычислим среднее арифметическое путем деления суммы исходных значений концентрации гемоглобина на число проб согласно формуле:
Во вторую колонку запишем отклонения данных от среднего значения, т.е. разности (X – M) (из каждого значения вычитается среднее арифметическое). Затем возведем полученные величины в квадрат и поместим их в третью колонку таблицы (X – M)2.
Теперь рассчитаем стандартное отклонение (среднее квадратическое отклонение) по формуле
т.е. сумму квадратов отклонений поделим на величину «число проб минус единица» и извлечем из полученного значения квадратный корень.
В результате проведенных расчетов у нас появятся два важных параметра: среднее значение и стандартное отклонение. Эти величины характеризуют распределение признака (концентрации гемоглобина) в совокупности данных. Полученные значения принято записывать формате M ± s с указанием единицы измерения: 147,13 ± 8,54 г/л.
2. Сравнение двух групп с использованием критерия Стьюдента
Полученную выше информацию систематизируем и дополним. По исходным данным о показателях гемоглобина крови, взятой в той же лаборатории у доноров женского пола, в соответствии с вышеприведенным алгоритмом вычислим М, (X – M), (X – M)2, s. Для сравнения показателей гемоглобина для мужчин и женщин составим табл. 2.
Из данных табл. 2 видно, что у некоторых женщин концентрация гемоглобина выше, чем у некоторых мужчин. Однако, концентрация гемоглобина может быть и не связана с гендерным фактором, а быть всего лишь «игрой случая» [1]. Данное предположение составляет суть «нулевой гипотезы» – предположения, что те или иные факторы не оказывают никакого влияния на исследуемую величину, а наблюдаемые различия между группами носят случайный характер.
Дальнейший статистический анализ при сравнении двух групп данных состоит в подтверждении либо опровержении выдвинутой нулевой гипотезы. Для этого используются статистические критерии – методы оценки статистической значимости различий, среди которых наиболее часто применяется критерий Стьюдента t.
Наиболее простая формула расчета критерия Стьюдента выглядит следующим образом:
В числителе – разность средних значений двух групп, в знаменателе – квадратный корень из суммы квадратов стандартных ошибок этих средних значений.
Существуют и другие варианты расчета критерия Стьюдента – например, с использованием числа наблюдений и стандартных отклонений:
Здесь тот же числитель, но в знаменателе – квадратный корень из суммы квадратов стандартных отклонений, деленных на число наблюдений в соответствующей группе. Отметим, что величина s2 – квадрат стандартного отклонения – отражает степень разброса данных в выборке и носит название «дисперсия» (от английского слова disperse –«рассеиваться»). Согласно исходным данным для рядов мужчин и женщин, s1 = 8,54, s2 = 6,21.
Рассмотрим последнюю формулу. Нулевая гипотеза подразумевает, что обе группы данных представляют собой случайные выборки из одной совокупности. В этом случае из двух квадратов стандартных отклонений s12 и s22 необходимо рассчитать объединенную оценку дисперсии для двух групп данных [1]:
Затем, зная объединенную оценку дисперсии s2 для двух выборок, можно рассчитать критерий Стьюдента по вышеприведенной формуле.
По данным табл. 2 мы видим, что группы доноров – мужчин и женщин неравнозначны по объему (n1 = 30; n2 = 21). В подобном случае необходимо вычислить объединенную оценку дисперсии:
По формуле для расчета критерия Стьюдента получаем
Полученную величину критерия Стьюдента t = 9,09 необходимо правильно оценить. Чем ближе к нулю полученный результат, тем больше вероятность нулевой гипотезы. И напротив – чем выше полученное значение t, тем больше оснований отвергнуть нулевую гипотезу и считать, что различия между исследуемыми выборками статистически значимы. Значение критерия, начиная с которого нулевая гипотеза считается отвергнутой, называется критическим значением t.
В задаче об отклонении либо принятии нулевой гипотезы есть следующие «подводные камни»: ошибки первого и второго рода. Если исследователь на основании статистического критерия отклоняет нулевую гипотезу там, где она на самом деле верна, т.е. находит различия там, где их нет, принято говорить об ошибке первого рода. Максимально допустимая вероятность ошибочно отвергнуть нулевую гипотезу называется уровнем значимости и обозначается греческим символом a, поэтому ошибка первого рода – это a-ошибка.
Формально уровень значимости может задаваться непосредственно исследователем. Традиционно в медицинских исследованиях считается достаточным, чтобы вероятность a-ошибки не превышала 5% (a = 0,05). Соответственно, чем меньше уровень значимости, тем выше критическое значение tкр. Уменьшая величину a, например до 0,01, мы снижаем вероятность найти несуществующие различия до 1%. Однако, следует учитывать, что слишком низкий уровень значимости (и, следовательно, слишком высокое критическое значение) приводит к риску не найти различий там, где они есть (иными словами, ошибочно подтвердить нулевую гипотезу) – в этом случае пойдет речь об ошибке второго рода (b-ошибке).
Фактором, влияющим на критическое значение, является также число наблюдений в исследуемой группе. Чем больше объем выборок, тем меньше критическое значение tкр, т.к. в больших выборках параметры распределения меньше зависят от случайных отклонений и точнее представляют исходную совокупность данных [2]. Величину, отражающую объем выборок и влияющую на критическое значение, называют числом степеней свободы и обозначают греческой буквой h: h = n1 + n2 – 2.
Итак, a и h – факторы, влияющее на критическое значение критерия Стьюдента. Примем уровень значимости a = 0,05, вычислим число степеней свободы:
h = 30 + 21 – 2 = 49.
Формулы расчета критических значений достаточно сложны, поэтому принято пользоваться готовыми таблицами, которые можно найти в учебниках и пособиях по статистике – например, в работе С. Гланца [2]. Выбирается строка с параметром h (при его отсутствии в рассматриваемой таблице берется ближайшее меньшее значение – в нашем случае 48 вместо 49). Далее определяем, что при уровне значимости a = 0,05 критическое значение критерия Стьюдента составляет t = 2,011.
Следовательно, полученное выше значение t > 2,011 позволяет отказаться от нулевой гипотезы и признать статистически значимыми различия между группами доноров – мужчин и женщин. Вычисленное значение критерия Стьюдента t = 9,09 с большим запасом превышает критическое значение даже для уровня значимости a = 0,001.
Далее, для завершения анализа нужна еще одна характеристика, которая фигурирует в большинстве научных работ – вероятность справедливости нулевой гипотезы, обозначаемая p. Дело в том, что кроме критерия Стьюдента существует довольно много других статистических критериев для оценки значимости различий. Способы расчета и критические значения каждый раз будут разные, но выводы в любом случае будут отражать вероятность справедливости нулевой гипотезыp. Иными словами, p представляет собой вероятность ошибки [1].
Например, если полученная величина t оказывается ниже критического значения для a = 0,05, то это означает p > 0,05 – вероятность отвергнуть справедливую нулевую гипотезу в этом случае превышает 5%, и это не позволяет считать различия статистически значимыми. В случае, когда величина t превышает критическое значение для a = 0,05, но все же остается меньше критического значения для a = 0,01, результат записывается как p < 0,05.
На основании изложенного, в примере с гемоглобином мы можем интерпретировать полученные данные следующим образом: вероятность справедливости нулевой гипотезы о независимости концентрации гемоглобина в донорской крови от гендерного фактора составляет менее 0,1%, т.е. p < 0,001, что соответствует максимально высокой оценке значимости различий.
3. Вычисление доверительного интервала
Выше, на основании вычисленного критерия Стьюдента, мы выяснили, что отличия средних значений концентрации гемоглобина в двух группах доноров (мужчин и женщин) являются статистически значимыми. Кроме того, было установлено, что вероятность ошибки этого заключения составляет менее 0,1% (p < 0,001). Иными словами, с вероятностью ошибки менее 0,1% мы отклонили нулевую гипотезу о равенстве средних значений концентрации гемоглобина в группах мужчин и женщин.
К числу наиболее распространенных ошибок в медицинской статистике, наряду с некорректным использованием критерия Стьюдента (например, при отсутствии нормального распределения данных либо при очень широко распространенном попарном сравнении более двух групп данных), относится подмена понятий «статистически значимый» и «клинически значимый». Собственно критерий Стьюдента не позволяет характеризовать величину выявленных различий. Даже очень малые различия средних значений (M1 – M2) при большой численности сравниваемых групп могут оказаться статистически значимыми: чем больше число наблюдений n, тем меньше становится стандартная ошибка среднего m, тем выше критерий Стьюдента t, рассчитанный согласно вышеприведенным формулам.
Характеристикой, которая дополняет и даже в определенной степени заменяет суждение «значимо – незначимо», является доверительный интервал. Смысл доверительного интервала в том, что, даже не зная точного значения какой-либо величины, можно с заданной вероятностью указать интервал, в котором эта величина находится [4].
Таким образом, доверительный интервал представляет собой интервал значений, рассчитанный для какого-либо параметра по выборке и с определенной вероятностью (в медицине, как правило, 95%), включающий истинное значение этого параметра во всей генеральной совокупности.
Доверительный интервал может быть построен не только для самых разных величин (например, для средних значений и их разности), но и для ожидаемых значений измеряемого признака, что часто используется при определении границ нормы лабораторных показателей. При этом построение доверительных интервалов основано на тех же математических принципах, что и проверка статистических гипотез с использованием критериев, поэтому для работы понадобятся те же самые параметры описательной статистики, что и при вычислении критерия Стьюдента. Составим табл. 3 и проведем дальнейшие расчеты, согласно методике, предложенной И.А. Зворыгиным [1].
Обозначим разность выборочных средних (М1 – М2), разность истинных средних генеральных совокупностей (µ1 – µ2), далее вычислим верхнее и нижнее предельные значения, между которыми и будет с заданной вероятностью находиться величина (µ1 – µ2). Для этого сначала найдем разность выборочных средних:
М1 – М2 = 147,13 – 127,29 = 19,84.
Выше мы рассчитали число степеней свободы h = 49, выбираем в таблице соответствующее значение tкр, принимая a = 0,05: t = 2,01.
Далее вычисляем объединенную оценку дисперсии s2 и стандартную ошибку разности средних по формулам:
Находим произведение стандартной ошибки разности и значения tкр: 2,18 × 2,01 = 4,38. Проводим построение 95%-ного доверительного интервала для разности средних, определяя верхнюю и нижнюю границы:
(М1 – М2) + (tкр × ) = 19,84 + 4,38 = 24,22
(М1 – М2) – (tкр × ) = 19,84 – 4,38 = 15,46
Составляем выражение:
15,46 < µ1 – µ2 < 24,22.
Смысл последнего выражения можно выразить так: наши выборочные данные позволяют с 95%-ной надежностью утверждать, что истинное среднее значение концентрации гемоглобина у доноров крови мужского пола выше аналогичного показателя у доноров-женщин на величину от 15,46 до 24,22 г/л.
Таким образом, благодаря доверительному интервалу можно не просто констатировать статистическую значимость различий между средними значениями гемоглобина в двух группах доноров, но и указать величину выявленных различий.
Далее имеет смысл указать и доверительный интервал для разности средних, дающий возможность судить о величине различий. В этом случае можно вовремя заметить, что статистическая значимость обнаружена всего лишь благодаря большому объему выборки, тогда как клиническая значимость исследования осталась весьма сомнительной.
Более того, доверительные интервалы вполне могут заменить статистические критерии и при оценке статистической значимости различий. Дело в том, что истинная разность средних может находиться в любой точке доверительного интервала. Поэтому, если полученный при работе с выборками доверительный интервал содержит нулевое значение, то это значит, что истинная разность средних также может быть равна нулю. Следовательно, не будет оснований отвергнуть нулевую гипотезу. В свою очередь, если доверительный интервал не содержит нуля, можно с заданной уверенностью отказаться от нулевой гипотезы и считать различия статистически значимыми.
Существует несколько несложных правил интерпретации доверительных интервалов с точки зрения проверки статистических гипотез:
— если доверительный интервал включает как клинически значимые, так и клинически незначимые значения, то результаты недостаточно точны для того, чтобы сделать определенный вывод;
— если доверительный интервал для разности средних включает ноль, то следует считать, что различия между группами по анализируемому признаку отсутствуют;
— если 95%-ный доверительный интервал не включает ноль, то следует считать, что различие между группами существует при уровне статистической значимости 0,05 [1].
В исследуемом случае с гемоглобином крови доноров доверительный интервал не содержит нулевого значения, не содержит и клинически незначимых чисел. На этих основаниях можно уверенно говорить как о статистической, так и клинической значимости выявленных различий.
Проведя данное исследование, следует отметить достаточно несложное описание последовательности шагов статистического анализа данных, представленное в работе И.А. Зворыгина [1]. Также необходимо подчеркнуть, что в настоящее время применяются оба подхода к сравнению двух групп по количественному признаку: посредством проверки статистических гипотез и посредством расчета доверительного интервала. Если критерий Стьюдента помогает установить наличие различий между генеральными совокупностями, то с помощью доверительного интервала можно понять, насколько эти различия велики. Оба подхода основаны на одних и тех же статистических принципах, поэтому в итоге дополняют друг друга.
В своей дальнейшей студенческой и врачебной практике мы предполагаем так же пошагово строить свои рассуждения, как в изученной работе И.А. Зворыгина. В этом случае статистический анализ данных будет казаться не бесконечным набором сложных формул и непонятно откуда берущихся числовых значений, а доступным и даже увлекательным поиском закономерностей, понятным любому студенту, а в дальнейшем врачу.
На протяжении всей своей истории медицина искала пути повышения эффективности результатов диагностики и лечения. Начиная с интуитивных обобщений, методом проб и ошибок, через осмысление разрозненного эмпирического опыта, она
вступила в эпоху доказательности. В настоящее время каждый вывод, предлагаемый специалистам и общественности, основывается на убедительных аргументах, а данные, из которых этот вывод вытекает, должны быть получены в ходе четко спланированного исследования, использующего адекватные методы статистического анализа.
Любое исследование начинается с определения его цели. Таковой, например, может быть изучение эффективности фармакологического препарата или новой процедуры в лечении заболевания. В протоколе будущего исследования четко указываются все данные, которые должны быть собраны в ходе его выполнения, методика получения каждого результата, а также, подчеркнем, заранее определяются методы статистической обработки. Производится предварительная оценка необходимой мощности исследования, также основывающаяся на статистических методах. Только при соблюдении такой методологии протокола результаты исследования могут считаться доказательными.
Ввиду того, что объемы данных и размеры групп (выборок) могут сильно варьировать, а данные могут быть весьма разнообразными, возникает необходимость использования методов статистического анализа, адекватных задаче. Расчет статистических показателей, которые позволяют оценить достоверность различия, корреляцию и взаимное влияние анализируемых факторов, происходит по определенной технологии с использованием математических функций и создания моделей. Назначение статистического анализа состоит в объективизации суждений о результатах исследования и обеспечении доказательствами правомочности сформулированных выводов.
Сегодня нет недостатка в статистических программных пакетах (SPSS, Statistical S-Plus, MedCalc, StatDirectn др.), а также в персональных компьютерах, производительность которых вполне достаточна для сложных математических вычислений. Необходимо отметить, что практически все статистические пакеты разработаны за рубежом и имеют оригинальный интерфейс на английском языке. Большинство научных публикаций в мире также выходит на английском языке. Все это предопределяет необходимость знания специальных иностранных терминов и определений. Чтобы успешно использовать имеющиеся программно-технические ресурсы клиницисту нужно также понимать основы и логику применения статистического анализа. Без этого даже наличие доступных программно-технических средств автоматически не приводит к доказательности. Скорее -аоборот, для неискушенного исследователя они представляют соблазнительную возможность попытаться быстро проанализировать свои данные с целью обнаружить статистическую значи- ость собственных результатов. Нередко это достигается путем за груз ки имеющихся данных в статистическую программу, после чего практически наугад выбирается статистический тест, который возвращает желаемый, предпочтительно максимально высокий, показатель «статистической значимости». Очевидно, подобный подход никак не отвечает принципу доказательности.
Несмотря на упомянутую доступность компьютерной техни- »и и программного обеспечения, комплексная статистическая : бработка представляет собой сложную задачу. Во многих слу- аях, если не в большинстве, для глубокого анализа клиниче- . ких данных необходимо участие специалиста с профессиональ- -:ой подготовкой в области математической статистики. Подобое сотрудничество является характерным примером того, что зэвременный уровень развития науки все больше нуждается в нтенсивном взаимодействии специалистов различных областей знания.
Целью данного обзора является попытка донести до клини- к истов в упрощенной и доступной для понимания форме логику методологию современной аналитической статистики, применяемой в мировой медицине. Хотелось бы надеяться, что это поможет врачам взвешенно осуществлять планирование (дизайн) исследования, корректно анализировать полученные дан- :ые и верно интерпретировать результаты анализа. В этой ра- 1 эте мы намеренно не углубляемся в математические расчеты и пассматриваем базисные концепции наиболее востребованных медицине методов статистического анализа.
1. Формирование статистической гипотезы
Статистическая обработка данных является инструментом для обоснования выводов, касающихся интересующей нас популяции (группы лиц, объединенных каким-либо признаком), а основе анализа репрезентативной (представительной) выборки из нее. К примеру, для изучения эффективности какой- либо операции невозможно собрать данные на всех пациентов, когда-либо ей подвергавшихся. Вместо этого подбирают и ана- изируют репрезентативную выборку. Если выборка обладает достаточной статистической мощностью и анализ выполнен корректно, то полученные выводы могут быть экстраполирова- -ы на весь контингент больных, которым данная операция выполнялась. При этом, однако, любой статистический анализ допускает, что обнаруженные (или не обнаруженные) закономер- -эсти до известной степени могут оказаться случайными.
Переходя от общей постановки проблемы и дизайна иссле- дзвания к расчетам, необходимо прежде всего сформулировать статистическую гипотезу. Она служит своеобразным связующим звеном между данными и возможностью применения ста- ‘истических методов анализа, формулируя вероятностный закон разброса данных.
Выдвинутая статистическая гипотеза дает описание ожидае- ых результатов исследования, с которыми сравниваются наблюдаемые. Если гипотеза верна, наблюдаемое отличается от ожидаемого лишь случайным образом, а именно — в соответствии с вероятностным законом этой гипотезы. Нулевая гипотеза (обозначается Но) предполагает отсутствие различий (корреляции, связи) между сравниваемыми выборками. В качестве контрольной выборки чаще всего выступает общепринятый стандарт (метод, подход). Если же нулевая гипотеза отвергается, то принимается альтернативная гипотеза (На) о наличии различия между группами.
Отличие наблюдаемого от ожидаемого измеряется вероятностной мерой. Если отличия между наблюдаемым и ожидаемым настолько велики, что вероятность того, что они являются случайными мала, — можно отвергнуть выдвинутую гипотезу как неверную. Обычно она отвергается, если вероятностная мера оказалась меньше или равна заранее установленному уровню значимости (см. раздел 5).
Во многих случаях исследователь интуитивно ставит перед собой задачу доказать, что «новый метод лучше старого», т. е. подтвердить альтернативную гипотезу. Это достаточно распространенное заблуждение относительно порядка применения статистических методов.
Типы данных, их независимость и распределение
Для правильного выбора статистического теста необходимо учитывать характер данных, включаемых в анализ: типы переменных, возможные зависимости между ними и формы их распределений.
Первая попытка классификации переменных в статистике, сохранившая свое значение до настоящего времени, была предпринята в 1946 г. Стэнли Смитом Стивенсом (Stanley Smith Stevens). Схема классификации была основана на типах операций, допустимых для данной переменной. Например, для переменных, обозначающих пол или религию, допустимы только сравнения типа равно — не равно, а сравнения типа больше — меньше или арифметические операции недопустимы; как следствие, для этих переменных может быть определена такая статистика, как мода (наиболее вероятное значение), и не может быть определено математическое ожидание (среднее значение).
В порядке возрастания числа допустимых операций С. Стивенс ввел следующие уровни классификации переменных: номинальный (nominal), порядковый (ordinal) и непрерывный (continuous), причем последний делился на подуровни: интервальный (interval) и относительный (ratio).
Дискуссия о «правильной» классификации переменных в статистике продолжается до сих пор. На сегодняшний день согласия в этом вопросе не достигнуто, и некоторые статистические компьютерные программы требуют определения типа переменных (например, PSPP). Пользователь должен тщательно следить по документации за схемой классификации, использующейся в компьютерной программе, чтобы гарантировать корректный выбор вычисляемых статистик и тестов.
Для простоты мы примем за основу 3 типа переменных: непрерывные, дискретные и категориальные (номинальные). Непрерывные переменные (continuous variables) могут принимать любые численные значения, которые естественным образом упорядочены на числовой оси (например, рост, масса тела, артериальное давление (АД), СОЭ).
49
Дискретные переменные (discrete variables) способны принимать счетное множество упорядоченных значений, которые могут просто обозначать целочисленные данные или ранжировать данные по степени проявления на упорядоченной ранговой шкале (клиническая стадия опухоли, тяжесть состояния пациента). Категориальные переменные (categorial variables) являются неупорядоченными и используются для качественной классификации (пол, цвет глаз, место жительства); в частности, они могут быть бинарными (дихотомическими) и иметь категорические значения: 1/0, да/нет, имеется/отсутствует.
Форма плотности распределения (distribution density) — для непрерывных переменных, или форма весовой функции (probability mass function) — для дискретных переменных, может выражаться эмпирической гистограммой, показывая, с какой частотой значения переменной попадают в определенные интервалы или принимают определенные значения.
Нормальное (или гауссово) распределение имеет колоколообразную форму, абсолютно симметричную относительно оси, проходящей через среднее значение (рис. 1) и математически описывается формулой, включающей 2 параметра — среднее и стандартное отклонение (см. раздел 3).
Оценка соответствия распределения данных гауссову выполняется в статистических программах с помощью критериев нормальности (например, Колмогорова—Смирнова). Визуальная проверка с помощью гистограммы также весьма наглядна. В тех случаях, когда данные не распределены нормально, но подчиняются другому распределению (что может быть определено с помощью статистических программ), приведение к нормальности может быть сделано путем математических операций, например, логарифмирования, извлечения квадратного корня или обращения.
Независимость (англ, independence) данных предполагает, что значения переменных в одной выборке не связаны со значениями переменных в другой, с которой производится сравнение. Примером независимых выборок могут быть показатели АД в группе мужчин по сравнению с группой женщин: АД у мужчин не зависит от аналогичного показателя у женщин. Примером зависимых выборок являются показатели АД, измеренного у пациентов в 9 ч утра и измеренного у них же в 5 ч вечера. Результаты этих измерений для каждого человека и в целом между выборками скорее всего будут коррелировать, поэтому они считаются парными и оцениваются как зависимые.
Описательная статистика
Для составления представления о выборке в целом существует ряд показателей, объединяемых понятием «описательная статистика». Каждому исследователю известен такой показатель как среднее (mean), который вычисляется путем деления суммы значений переменной на количество значений и характеризует «центральное положение» количественной переменной. Показатель среднего сильно зависит от разброса данных (т. е. наличия экстремально больших и малых значений) и размера выборки. Из-за того, что значения суммируются и делятся на количество случаев (наблюдений), очень высокие или низкие значения переменных (выбросы, англ, outlier) в малых выборках могут существенно влиять на значение среднего. По мере того, как выборка количественно увеличивается в размере, влияние экстремальных значений на среднее снижается.
Медиана (median) — значение, которое занимает среднее положение среди точек данных, разбивая выборку на две равные части. Половина значений переменной лежит по одну сторону значения медианы, и половина — по другую. Очевидно, что выбросы, т. е. экстремальные значения переменной оказывают на медиану гораздо меньшее воздействие, чем на среднее (сами значения, но не их количество). В связи с этим медиану часто используют для описания, например, среднего роста или массы тела в группах.
Стандартное отклонение (standard deviation, SD) отражает изменчивость (разброс, вариацию) значений переменной и оценивает степень их отличия от среднего. Оно рассчитывается на основании вычисленного показателя рассеяния данных, называемого дисперсией (variance), путем извлечения из него квадратного корня, в связи с чем в отечественной литературе его также называют «среднеквадратичным отклонением» и обозначают греческим символом о (сигма). Стандартное отклонение может меняться непредсказуемо, т. е. расти или уменьшаться с увеличением размера выборки, однако обычно не слишком сильно. Наверняка многие исследователи слышали о так называемом правиле трех сигм. Оно гласит, что практически все наблюдения укладываются в интервал «среднее ± Зо». Действительно, в интервал «±3о» попадают 99,7% наблюдений, «±2а» включает 95,4% всех наблюдений, а «±1о — всего 68,3. Это правило подходит для различных распределений, включая нормальное.
Стандартная ошибка (среднего) (англ, standard error SE, иногда standard error mean, SEM) является оценкой возможного отличия между значением среднего в анализируемой выборке, и истинным средним для всей популяции (которое на самом деле не может быть определено без анализа бесконечно большого числа наблюдений). Стандартную ошибку рассчитывают путем деления стандартного отклонения на квадратный корень из числа наблюдений в выборке и, следовательно, ее значение уменьшается с ростом размера выборки. Это уменьшение является естественным, поскольку чем больше имеется наблюдений, тем выше вероятность, что рассчитанное среднее приближается к истинному.
Доверительный интервал (англ, confidence interval, CI) — диапазон значений, область, в которой с определенным уровнем надежности (или доверия) содержится истинное значение параметра (например, среднего). 90% доверительный интервал означает, что истинное значение величины попадет в рассчитанный интервал с вероятностью 90%. В биомедицинских исследованиях доверительный интервал среднего обычно устанавливается на уровне 95% и определяется как ±1,96 стандартной ошибки (коэффициент 1,96 вытекает из предположения о нормальности распределения значения переменной при условии, что выборка достаточно велика). Для примера, если значение среднего систолического АД в исследованной группе составляет 125 мм рт. ст., а стандартная ошибка — 5 мм рт. ст., то при 95% доверительном интервале границы диапазона значений среднего будут
- и 134,8 мм рт. ст., что составляет ±9,8 (5 • 1,96) мм рт. ст. в обе стороны от значения среднего. Совмещая значение среднего и доверительный интервал, можно констатировать, что определенное значение систолического АД в группе составляет 125 мм рт. ст., и при этом мы на 95% уверены, что истинное значение находится в интервале между 115,2 и 134,8 мм рт. ст. (в англоязычной литературе описывается как 125,0 [115,2—134,8], mean [95%С1]).
У исследователей часто возникает вопрос, какие описательные статистические характеристики изучаемой выборки нужно указывать в тексте: среднее или медиану ± стандартное отклонение или стандартную ошибку? Это зависит от того, разброс чего — исходной случайной величины или оценки ее среднего значения (медианы) — изучает исследователь. Если непрерывные переменные распределены нормально (или близко к таковому) и разброс данных обусловлен естественными причинами (люди разного роста, массы тела и т. п.), то принято указывать среднее ± стандартное отклонение. Если же рассеяние связано с неточностью измерения (например, техническое ограничение или погрешность прибора), то рекомендуется приводить среднее ± (95%) доверительный интервал или стандартная ошибка. Во всяком случае необходимо указать, какие именно характеристики представлены. Когда непрерывные данные не подчиняются нормальному распределению, для их описания обычно используют медиану и (95%) доверительный интервал. На графиках при этом рекомендуется указать весь интервал значений и обозначить границы 25, 50% (собственно медиану) и 75% квартилей. Для описания дискретных данных, которые по определению принимают лишь ограниченное число значений и не подчиняются нормальному распределению, используется представление в виде пропорций (процента, доли) или таблиц сопряжения.
Размер выборки и статистическая мощность
На стадии планирования исследования очень важно определить, какое минимальное число наблюдений необходимо включить в изучаемую группу, чтобы результаты тестирования гипотезы оказались правомочными. Для ответа на этот вопрос необходимо понимать, что такое статистическая мощность и разбираться в сути ошибок 1-го и 2-го типа.
При проверке гипотезы принимается во внимание возможность ошибок измерений, что может стать причиной ложного результата. В зависимости от характера возможного ложного результата, ошибки бывают 1-го и 2-го типа. Ошибка 1-го типа (обозначается а) определяется как вероятность обнаружить различие, которое в действительности отсутствует («ложноположительный результат»). Другими словами, это вероятность неправомерно отбросить гипотезу (Но) в пользу гипотезы На. Ошибка 2-го типа (обозначается р) — это вероятность сделать вывод об отсутствии различия, в то время как фактически оно имеется ложноотрицательный результат»), т. е. неправомерно принять гипотезу Но. В биомедицинских исследованиях предельно допустимый предел ошибки 1-го типа обычно устанавливается на уровне 5%, а ошибки 2-го типа — не более 20% (а = 0,05; 3 < 0,2). Ошибка 1-го типа рассматривается как более критическая, потому что менее всего хотелось бы неправомерно отвергнуть общепринятую гипотезу (Но). На практике это отражает разумную консервативность, поскольку рекомендация нового метода лечения как более эффективного в то время как он таковым не является, может нанести больше вреда (например, здоровью пациента, экономический и моральный ущерб), чем отказ от его недрения (по крайней мере хуже не будет).
Понимая природу ошибок 1-го и 2-го типа, можно переходить к оценке мощности исследования. Статистическая мощ- — эсть (statistical power) вычисляется как 1 — р и означает вероятность сделать заключение о наличии различия, в то время как : но имеется на самом деле (т. е. получить «истинно положительный результат»). В табл. 1 показана взаимосвязь между шибками 1-го и 2-го типа и статистической мощностью.
Статистическая мощность напрямую зависит от размера вы- :орки (поскольку связана со стандартной ошибкой, которая в .гою очередь уменьшается с увеличением размера выборки), а также от степени различия, которое ожидается обнаружить. Выявление больших различий требует меньшего числа наблюдений . наоборот, для определения незначительных различий потребуется более многочисленная выборка. Если планируемая чис-
енность выборки не обеспечивает приемлемого уровня стати- .тической мощности (>80%), чтобы убедительно отвергнуть ги- этезу Но или согласиться с ней, результаты исследования не : удут доказательными. Например, если исследователь хочет оп- геделить различие в средней массе тела между двумя группами получавшими и не получавшими препарат, снижающий аппетит) и доказать разницу в 1 кг при стандартном отклонении 10 кг в контрольной и изучаемой группах, то при а — 0,05 и мощ- -эсти 80% необходимо иметь не менее 1570 людей в каждой группе. Однако, если необходимо оценить различие в 5 кг, дос- ■аточно включить в группы по 64 человека.
Расчет размера выборки для желаемого уровня статистиче- . кой мощности исследования не является сложной процедурой производится с помощью ряда статистических программных -зкетов (например, Statmate). В случае использования нужно : тратить внимание на правильную постановку задачи при оценке абсолютных (как в приведенном выше примере) или относи- гельных (например, снижение частоты рецидива в 1,5 раза) изменений.
Статистическая достоверность
При сравнении групп мы изначально исходим из того, что : ни не различаются (это — Но). Если вероятность того, что вы- •зленные различия являются случайным результатом весьма ала, тогда правомочным будет отвергнуть нулевую гипотезу и заключить, что различие действительно имеется (верна На). Податель достоверности различий обозначается р (probability, в 1 пглоязычной литературе встречается обозначение Р или Р). Ветчиной р (или «пи-величина», англ. P-value) для конкретной сборки называют вероятность получения по крайне мере таких или еще больших отличий наблюдаемого от ожидаемого, чем панной конкретной выборке, при условии, что выдвинутая гипотеза верна. Величина р меняется от выборки к выборке, т. е. зляется случайной на множестве выборок (причем с равномерным распределением на интервале 0—1).
С помощью статистических расчетов вычисляют значение р, которое затем сравнивают с заранее выбранным уровнем значимости, часто обозначаемым греческой буквой а (не путать с ошибкой 1-го типа). Обычно в биомедицинских исследованиях уровень значимости устанавливается на уровне а < 0,05 (< 5%). Если выбран уровень значимости а = 0,05, то все выборки, которые для выдвинутой гипотезы возвращают величину р < 0,05, отвергают эту гипотезу, а выборки с величиной р > 0,05, не дают оснований для того, чтобы ее отвергнуть. Величину уровня значимости следует понимать так: мы задаем, что не более чем в 5% попыток сравнения (какого-либо параметра в разных группах) обнаруженная разница может быть обусловлена чистой случайностью, а не ее реальным существованием. Иными словами, мы задаем вероятность ложного отказа от гипотезы Но (стандартной) в пользу гипотезы Но (изучаемой). В итоге, повторимся, если статистический анализ показывает, что р < 0,05, правомочным будет заключение о том, что выявленное различие неслучайно и, следовательно, оно является достоверным.
Для демонстрации достоверности различия часто используется наглядный метод доверительных интервалов. Напомним, что доверительный интервал устанавливается на уровне ±1,96 стандартной ошибки, в который попадает 95% данных при условии их нормального или близкого к нему распределения. Если доверительный интервал интересующего нас параметра в изучаемой группе «накрывает» значение среднего в группе сравнения, то априори следует вывод о том, что наблюдаемое различие статистически недостоверно. Если среднее значение параметра в контрольной группе лежит вне доверительного интервала изучаемой группы, то скорее всего различие является достоверным. Среди исследователей бытует представление, что для уверенности в наличии разницы по какому-либо параметру между сравниваемыми группами нужно, чтобы «усы ошибок» (границы доверительных интервалов) не пересекались. В определенном смысле это верно: непересечение «усов» служит гарантией достоверности различия. Однако даже если доверительные интервалы перекрываются, достоверность различий вполне может сохраняться — по крайней мере до тех пор, пока один из «усов» сравниваемых групп не достиг значения среднего другой группы.
Выбор одномерного статистического теста
Выбор статистического теста является чрезвычайно важной задачей. От его правильности будет зависеть качество анализа и, в конечном итоге, надежность выводов. Выбор теста — задача нетривиальная, но, разбираясь в статистических характеристиках данных и используя пошаговый алгоритм, исследователь в состоянии осуществить его корректно. Успешное продвижение по алгоритму выбора подходящего статистического метода анализа предполагает знание ответов на следующие вопросы: а) тип данных (непрерывные или дискретные); б) данные зависимые или независимые; в) распределение параметрическое (нормальное) или непараметрическое (отличное от нормального); г) количество сравниваемых групп.
Заметим, что в зависимости от количества сравниваемых параметров (переменных) различают одномерную (univariate) и многомерную (multivariate) статистику. Одномерная статистика применяется при анализе двух групп и более с целью сравнения лишь одной переменной. Многомерная статистика используется для анализа двух групп и более, но с учетом одновременного изменения двух или более переменных. В данной части работы приведены методы одномерной статистики, многомерная статистика рассматривается во второй части.
Еще на стадии планирования анализа полученных результатов нужно определить, какая статистика будет использоваться, одномерная или многомерная. При этом, даже если планируется использование многомерных методов, сперва все равно необходимо использовать описательную статистику и провести одномерный анализ. Это позволит лучше ориентироваться в наборе данных и сформировать первичное представление о соотношениях различных переменных в сравниваемых группах.
На рис. 2 показана блок-схема выбора методов одномерного статистического анализа, а ниже кратко обсуждаются области применения основных из них.
Параметрическая статистика
Параметрическая статистика используется для анализа непрерывных (численных) переменных, значения которых распределены нормально. Наиболее часто используется так называемый непарный t-тест (распространенное название — «тест Стьюдента»; t-test), с помощью которого возможно провести проверку гипотезы (Но) об отсутствии различия средних значений переменной в двух независимых выборках, исходя из предположения об одинаковости стандартного отклонения в них.
Если данные являются зависимыми (например, получены в процессе повторных наблюдений за одним и тем же пациентом (repeated measurements) или используются показатели пациентов, подобранных в пары (по возрасту или полу), рекомендуется парный (paired) t-тест.
Распространенной ошибкой является применение t-тестов к показателям состояния пациентов (пациента) до и после применения двух разных методов лечения (Но — методы не различаются или лечение не действует) без проверки равенства стандартных отклонений показателей. При неуверенности в одинаковых дисперсиях (стандартных отклонениях) выборок используют модифицированный t-тест Уэлча (Welch’s t-test), но он применим только к независимым выборкам (непарный тест).
Различают t-тесты односторонние и двусторонние. Термин двусторонний (двунаправленный, англ, two-tailed) означает, что поиск различий будет производиться в обе стороны: для увеличения показателей и для их уменьшения. В биомедицинских исследованиях рекомендуется применять двусторонние тесты, так как чаще всего неизвестно, будет ли знак отличия положительным или отрицательным.
Для сравнения независимой переменной в более чем двух выборках может выполняться дисперсионный анализ (ANalysis Of Variance, ANOVA). К примеру, его можно применить для выявления разницы среднего систолического АД в различных возрастных группах. Для зависимых данных, оцениваемых в более чем двух группах, используется дисперсионный анализ с повторным измерением (Repeated-Measures ANOVA, RM-ANO- VA).
Непараметрическая статистика
Непараметрические методы анализа применяются как к непрерывным, так и к дискретным данным.
Непрерывные переменные
U тест Манна-Уитни (Mann—Whitney U), также известный как тест Вилкоксона ранговых сумм (Wilcoxon Rank Sum) или тест Манна—Уитни—Вилкоксона (MWW), проверяет, являются ли две сравниваемые группы выборками из одного и того же распределения, используя в качестве статистики (U) медиану всевозможных разностей между элементами одной и второй выборки. По этой причине на результат практически не влияют редкие экстремальные значения. Для ранговых шкал, когда t- тест не применим, MWW-тест остается логичным выбором. Проблемы с интерпретацией теста, как и в случае t-тестов, возникают, когда распределения для двух выборок различаются по форме, например, имеют сильно отличающиеся дисперсии.
Для иллюстрации важности адекватного выбора статистического теста предположим, что исследователь сравнивает массу тела в двух независимых группах пациентов. В 1-й группе, помимо людей с «нормальной» массой тела, имеется два полных человека; средняя масса тела в группе составила 100,3 кг, а медиана — 75,1 кг. Во 2-й группе, напротив, есть несколько худощавых людей; средняя масса тела в группе — 60,8 кг, медиана — 72,5 кг. Известно, что в обеих группах распределение отклоняется от нормального, т. е. выборки не проходят тест на нормальность распределения данных. При сравнении средних показателей (100,3 и 60,8 кг) может создаться впечатление, что группы существенно отличаются и вполне возможно, что t-статистика выявит достоверность различий. Однако сравнение средних было бы оправданно в том случае, если распределение переменной массы тела в обеих группах оказалось нормальным. Но оно таковым не является, поэтому следует использовать непараметрическую статистику. Тест MWW обнаружит очень схожие медианы (75,1 и 72,5 кг) в группах сравнения и, скорее всего, будет сделан вывод об отсутствии различия между группами.
При сравнении переменной более чем в двух независимых группах непараметрическим аналогом дисперсионного анализа является тест Краскела—Уоллиса (Kruskal—Wallis), в котором данные заменены их рангами и сравниваются медианы выборок. Нормальность распределений не требуется, но они должны быть похожей формы и иметь сравнимые по величине дисперсии.
Если данные не распределены нормально, являются непрерывными и зависимыми (парными), может быть рекомендован тест знаковых рангов Вилкоксона (Wilcoxon signed-rank). Принцип метода заключается в вычислении разницы между парными данными с последовательным ранжированием по положительному или отрицательному значению разницы и определением критического (порогового) значения для опровержения нулевой гипотезы.
Таблица 2. Таблица сопряжения непарных дискретных данных
|
Воздействия фактора (применение препарата) |
Эффект имеется (наличие побочного действия) |
Эффект отсутствует (нет побочного действия) |
Ито го… |
|
Да (пациенты) |
А (45) |
Б (75) |
А + Б (120) |
|
Нет(контрольная группа) |
В (55) |
Г (85) |
В + Г (140) |
|
Всего… |
А + В (100) |
Б + Г (160) |
Ч (260) |
Дискретные переменные
Для независимых категориальных, в частности, бинарных данных обычно используются методы таблиц сопряжения (англ, contingency tables). Сравнительный анализ проводится чаще всего с помощью точного теста Фишера (англ. Fisher-s exact test) или хи-квадрат (х2) теста (англ, chi-square test; или «хи-квадрат Пирсона», англ. Pearson’s chi-square).
Х2-Тест может быть применен к таблицам практически любой размерности. В некоторых статистических программах реализовано продолжение точного теста Фишера для таблиц сопряжения размерностью большей, чем 2×2 (точный тест Фишера изначально разработан для таблиц сопряжения размерностью .•/), однако многие исследователи традиционно предпочитают статистику х-квадрат, что в принципе правомерно. Отметим, то последняя не может использоваться, если ожидаемое (но не -аблюдаемое) значение признака в какой-либо ячейке таблицы ченее 5.
Точный тест Фишера и %2-тест основываются на принципиально разной идеологии расчета. Точный тест Фишера исполь- .ет перебор вариантов заполнения таблицы сопряженности перестановочный тест), в то время как %2-квадрат нацелен на сравнение наблюдаемой и ожидаемой частоты появления признака. Их общее назначение состоит в проверке значимости ззязи между двумя категориальными переменными, но при разных выборочных схемах (например, при разных дизайнах ис- следования).
Какой тест более предпочтителен для расчетов? Для таблиц сопряжения размерностью 2×2 предпочтителен точный тест Фишера, поскольку он дает более точную оценку, чем х2-тест. Однако применение и х2-теста как для таблиц 2×2, так и для таблиц большей размерности, также правомерно.
Выбор остается за исследователем, необходимо всегда указывать, какой из методов использовался.
В большинстве случаев оценки значимости различия (т. е. значения /?), полученные с помощью этих двух разных тестов для одной и той же таблицы сопряжения, не совпадают. Вместе : тем и точный тест Фишера, и х2-тест, как правило, непроти- =• эречиво выдают значение р, которое будет либо больше, либо еньше установленного порогового уровня значимости, напри- ер. на уровне 0,05.
Пример данных, организованных в таблицу сопряжения гззмерностью 2×2, приведен в табл. 2, В ней рассматривается г’страктная ситуация возникновения побочного эффекта (на- “7 г’мер, тахикардии) после применения какого-либо препарата.
Расчеты, проведенные с помощью точного теста Фишера и /-теста, в рассматриваемом случае возвращают значения р, равные 0,80 и 0,87 соответственно. Это говорит о том, что связь побочного эффекта с применением данного препарата недостоверна.
Из таблицы сопряжения также можно рассчитать еще один важный статистический показатель. Он называется «отношение шансов» (англ, odds ratio, OR) и вычисляется как (А* Г)/(Б• В). Отношение шансов используется, чтобы оценить, насколько ве- глки шансы положительных и отрицательных исходов (например, развитие нежелательного побочного эффекта после применения препарата, как показано в примере выше). Если OR = 1 или очень близко к 1), то это означает, что шансы события в : бе их группах практически совпадают.
Для данных, приведенных в табл. 3, отношение шансов составляет 0,93, а 95% доверительный интервал от 0,56 до 1,53. В зчглоязычной литературе показатель часто записывается в таком виде: 0,93 [0,56—15,3] (т. е. OR [95% CI]). Из значения отношения шансов (0,93), которое меньше 1, можно составить тредставление о том, что побочный эффект в группе, принимавшей препарат, наблюдался несколько реже, чем в контрольной группе (соответственно 60 и 65%). Однако поскольку доверительный интервал включает значение 1, различие недостоверно.
Если категориальные данные являются зависимыми, используют тест Мак-Немара (McNemar test), который представляет собой модификацию х2-теста для парных или соотнесенных данных. Примером уместного использования теста Мак- Немара было бы сравнение доли пациентов, ответивших на лечение по какому-то показателю, когда сравнение проводится до и после лечения у одних и тех же людей. Тест Мак-Немара часто используется в исследованиях типа «случай-контроль» (casecontrol study), в которых каждому случаю противопоставляется конкретный контроль. Для расчетов с помощью теста Мак-Немара составляют таблицу сопряжения, подобную табл. 3, однако в каждой ячейке указывают не количество лиц, соответствующих какому-либо исходу, а количество пар (до/после лечения, случай/контроль).
Преимущества и недостатки непараметрических методов
К преимуществам непараметрических методов можно отнести следующие:
- могут быть использованы, когда характеристики популяции, из которой делается выборка, частично неизвестны;
- большая мощность (робастность);
- относительная несложность вычислений (в большинстве случаев);
- менее жесткие начальные допущения.
Недостатками являются:
- меньшая эффективность, чем у параметрических методов;
- меньшая специфичность;
- потенциальная трудоемкость при применении к большим массивам данных.
Корреляционный и регрессионный анализ
На практике часто возникают задачи, когда нужно проверить взаимосвязь между какими-либо непрерывными данными, например, между АД и массой тела. В этих случаях используют, корреляционный и регрессионный анализ. Корреляционный анализ определяет характер взаимосвязи переменных (прямой или обратный), а регрессионный — форму зависимости (насколько сильно изменяется одна переменная в ответ на изменение другой).
Корреляционный анализ
Корреляционный анализ является методом оценки линейных связей (общей пропорциональности) между переменными, т. е. определяет, насколько согласованно они меняются. В англоязычной литературе часто употребляется термин «линейная корреляция Пирсона». Корреляция Пирсона (обычно просто «корреляция”) между переменными может быть положительной, отрицательной или вовсе отсутствовать.
Две переменные коррелируются положительно, если большие значения одной переменной имеют тенденцию к ассоциации с большими значениями другой переменной, как показано на рис. 3.
Напротив, если большие значения одной переменной ассоциированы с меньшими значениями другой, говорят об отрицательной корреляции, как показано на рис. 4.
При отсутствии корреляции нет никакой закономерности взаимосвязи одних показателей с другими, как показано на рис. 5.
Показателем согласованности между значениями двух переменных служит коэффициент корреляции (correlation coefficient). Этот коэффициент является количественным, обозначается г (Pearson г) и имеет область значений от —1 до +1.
г — 1 означает максимально сильную положительную линейную взаимосвязь между X и Y;
г = -1 означает максимальную отрицательную линейную взаимосвязь между X и Y;
г = 0 означает отсутствие линейной взаимосвязи между X и Y.
Для оценки того, насколько сильно линейно связаны две переменные, рекомендуется использовать коэффициент детерминации, который представляет собой квадрат коэффициента корреляции Пирсона г2). Очевидно, что чем больше коэффициент корреляции отклоняется от 1 или — 1 (т. е. чем больше степень рассеяния точек от линии на рис. 3—5), тем меньше будет значение коэффициента детерминации и тем слабее будут две переменные коррелировать между собой.
Заметим, что корреляция Пирсона основывается на предположении о том, что значения переменных распределены нормально или близко к нормальному. Если распределение значений отличается от нормального или в силу каких-то причин это невозможно оценить, то можно воспользоваться непараметрической корреляцией Спирмана, с помощью которой также можно рассчитать коэффициент корреляции г (англ. Spearman г). Статистические программы также оценивают достоверность (значение р) отличия коэффициента гот 0, т. е. определяют, является ли оценка корреляции достоверной. Если выборки достаточно велики (приближаются к 100 наблюдениям), форма распределения не оказывает большого воздействия на результат корреляционного анализа. Выполняется ли он с использованием стандартного (корреляция Пирсона) или непараметрического (корреляция Спирмана) метода — уже не имеет большого значения.
Необходимо иметь в виду, что наличие в выборке выбросов может сильно повысить или понизить коэффициент корреляции. Выбросы несложно обнаружить при визуализации данных на простом графике Х-Y. Они представляют собой точки, далеко выступающие по одной или по обеим координатам от основного кластера, если таковой имеется. К выбросам следует относиться осторожно: они могут как обоснованно, так и необоснованно поддерживать или нарушать общую тенденцию («случайность — это непознанная закономерность»). Во всяком случае каждый выброс рекомендуется проверить на предмет правильности записи исходных данных и исключить возможность случайной ошибки.
Линейный регрессионный анализ
Линейная регрессия и линейная корреляция — сходные, но не идентичные методы анализа. С помощью линейного регрессионного анализа определяются параметры прямой, которая наилучшим способом предсказывает значение одной переменной на основании значения другой согласно формуле
у = а + Ьх,
где у — значение одной переменной, а — точка пересечения прямой с осью ординат (вертикальная ось, ось Y), b задает наклон линии, а х — значение другой переменной.
Линейный регрессионный анализ проводится, если корреляционный анализ выявил взаимосвязь между переменными.
Статистические программы, помимо коэффициента корреляции г, коэффициента детерминации г2, коэффициентов а и b регрессионной прямой, рассчитывают достоверность (значение р) отклонения наклона регрессионной прямой от 0, что также является оценкой наличия значимой корреляции между двумя переменными. Некоторые программы дополнительно оценивают вероятность того, что данные отклоняются от линейного взаимоотношения. В случае, если достоверность такого отклонения оказывается высокой (т. е. получено малое значение р для этого параметра), необходимо отказаться от линейного регрессионного анализа «сырых данных» и подумать над возможностью приведения их к линейности путем преобразования (например, извлечение квадратного корня, возведение в степень, логарифмирование или описание более сложной функцией). После этого в ряде случаев линейный регрессионный анализ становится вновь возможным.
Чувствительность, специфичность и точность
Способом оценить информативность и разрешающую способность диагностического метода является оценка его чувствительности, специфичности и точности. Эти показатели отражают шансы поставить правильный диагноз заболевания у больных и здоровых людей. Их сравнивают с аналогичными показателями общепринятого («золотого») стандарта диагностического теста.
Чувствительность определяется как доля пациентов, действительно имеющих заболевание, среди тех, у кого тест был положительным. Специфичность определяется как доля людей, не имеющих заболевания, среди всех, у кого тест оказался отрицательным. Точность показывает долю «правильных срабатываний теста» среди всех обследованных и является совокупным показателем информативности теста. Модель таблицы сопряжения для проведения расчетов представлена в табл. 2. По существу, она отражает соотношение между ошибками 1-го и 2-го типа (см. раздел 4).
Высокочувствительный диагностический тест — тот, который дает наибольшее число положительных результатов при фактическом наличии заболевания. С клинической точки зрения, нужно понимать, что высокочувствительный тест может отличаться гипердиагностикой, зато позволяет минимизировать риск пропустить заболевание. Это важно, например, при выявлении инфицированных людей при скрининге опасного инфекционного заболевания ввиду угрозы эпидемии. С другой стороны, высокоспецифичный тест дает отрицательные результаты при фактическом отсутствии заболевания с большей вероятностью. К примеру, это важно в случаях, когда дорогостоящее лечение связано с серьезными побочными эффектами и, следовательно, гипердиагностика крайне нежелательна.
Исходя из значений чувствительности и специфичности, рекомендуется построение характеристической кривой (ROC-кри- вая; англ. Receiver Operating Characteristic (ROC) curve), которая показывает зависимость количества верно диагностированных положительных случаев от количества неверно диагностированных отрицательных случаев (ось X — специфичность, ось Y — чувствительность). Идеальный диагностический тест должен иметь Г-образную форму характеристической кривой, проходящей через верхний левый угол, в котором доля истинно положительных случаев 100% (или 1), а доля ложноположительных случаев равна 0. Чем ближе проходит характеристическая кривая к значению 0;1 (идеальная чувствительность), тем выше эффективность теста. Наоборот, чем меньше кривая напоминает форму буквы «Г», т. е. чем ближе она проходит к диагонали графика («бесполезный тест»), тем эффективность теста меньше (рис. 6).
Количественную оценку характеристической кривой можно провести, рассчитав площадь под ней (англ. Area Under Curve, AUC). Приблизительная шкала значений AUC, отражающая качество диагностического теста, такова:
AUC — 0,91 — 1,0 — отличное качество;
AUC = 0,8—0,9 — высокое качество;
AUC = 0,7—0,8 — хорошее качество;
AUC = 0,6—0,7 — среднее качество;
AUC = 0,5—0,6 — плохое (неудовлетворительное) качество.
Для того чтобы новый диагностический метод заслужил признание, он должен продемонстрировать более высокие, чем золотой стандарт, значения чувствительности и специфичности.
Алгоритм построения характеристических кривых реализован во многих статистических программах, в интернете имеется большой выбор онлайн ROC-калькуляторов. На рис. 6 для примера показаны реальные расчетные характеристические кривые. Многие статистические программы способны генерировать сглаженные кривые и возвращать необходимые статистические оценки. В рассмотренном примере «новый» тест имеет достоверно лучшие характеристики по сравнению со «старым».
Заключение
Вышеизложенные методы описательной и одномерной статистики являются базовыми, с них рекомендуется начинать статистический анализ. Самостоятельное выполнение этих процедур вполне по силам исследователю, не имеющему специальной подготовки в математической статистике. С их помощью осуществляется первичная обработка и одномерный анализ имеющихся данных.
Во второй части обзора будут рассмотрены принципы анализа выживаемости и методы многомерной статистики.
Авторский коллектив выражает благодарность С. Ю. Чекину (МРНЦ РАМН) за конструктивную помощь и критические замечания при подготовке данной работы.
-
Средняя
ошибка средней арифметической величины
(ошибка репрезентативности) – это:
а)
средняя разность между средней
арифметической и вариантами ряда
б)
величина, на которую полученная средняя
величина выборочной совокупности
отличается от среднего результата
генеральной совокупности
в)
величина, на которую в среднем отличается
каждая варианта от средней арифметической
-
Размер
ошибки средней арифметической величины
зависит от:
а)
типа вариационного ряда
б)
числа наблюдений
в)
способа расчёта средней величины
г)
разнообразия изучаемого признака
-
Разность
между сравниваемыми величинами
(средними, относительными) при большом
числе наблюдений (n>20) считается
существенной (достоверной), если:
а)
t равно 1,0
б)
t больше 1,0 и меньше 2,0
в)
t больше или равно 2,0
-
Минимально
достаточной для медицинских статистических
исследований является вероятность
безошибочного прогноза:
а)
68 %
б)
90 %
в)
95 %
г)
99 %
-
Доверительный
интервал – это:
а)
интервал, в пределах которого находятся
не менее 68 % вариант, близких к средней
величине вариационного ряда
б)
пределы возможных колебаний средней
величины (показателя) в генеральной
совокупности
в)
разница между максимальной и минимальной
вариантами вариационного ряда
Вариант 2
-
Средняя
ошибка средней арифметической величины
(ошибка репрезентативности) – это:
а)
средняя разность между средней
арифметической и вариантами ряда
б)
величина, на которую полученная средняя
величина выборочной совокупности
отличается от среднего результата
генеральной совокупности
в)
величина, на которую в среднем отличается
каждая варианта от средней арифметической
-
Средняя
ошибка средней арифметической величины
обратно пропорциональна:
а)
числу наблюдений
б)
показателю разнообразия изучаемого
признака
в)
частоте изучаемого признака
-
Минимально
достаточной для медицинских статистических
исследований является вероятность
безошибочного прогноза:
а)
68 %
б)
90 %
в)
95 %
г)
99 %
-
При
оценке достоверности разности полученных
результатов исследования разность
является существенной (достоверной),
при n>30 величина t равна:
а)
1,0
б)
1,5
в)
2,0
г)
3 и более
-
Оценка
достоверности полученного значения
критерия Стьюдента (t) для малых выборок
производится:
а)
по специальной формуле
б)
по принципу: если t≥2, то P≥95%
в)
по таблице
Вариант 3
-
Средняя
ошибка средней арифметической величины
прямо пропорциональна:
а)
числу наблюдений
б)
частоте изучаемого признака в вариационном
ряду
в)
показателю разнообразия изучаемого
признака
-
Разность
между сравниваемыми величинами
(средними, относительными) при большом
числе наблюдений (n>30) считается
существенной (достоверной), если:
а)
t равно 1,0
б)
t больше 1,0 и меньше 2,0
в)
t больше или равно 2,0
-
Доверительный
интервал – это:
а)
интервал, в пределах которого находятся
не менее 68 % вариант, близких к средней
величине вариационного ряда
б)
пределы возможных колебаний средней
величины (показателя) в генеральной
совокупности
в)
разница между максимальной и минимальной
вариантами вариационного ряда
-
Минимально
достаточной для медицинских статистических
исследований является вероятность
безошибочного прогноза:
а)
68 %
б)
90 %
в)
95 %
г)
99 %
-
Оценка
достоверности полученного значения
критерия Стьюдента (t) для малых выборок
производится:
а)
по специальной формуле
б)
по принципу: если t≥2, то P≥95%
в)
по таблице
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
В практической и научно-практической работе
врачи обобщают результаты, полученные как правило на выборочных
совокупностях.
Для более широкого распространения и применения полученных при изучении
репрезентативной выборочной совокупности данных и выводов
надо уметь по части явления судить о явлении и его закономерностях в
целом.
Учитывая, что врачи, как правило, проводят исследования на
выборочных совокупностях, теория статистики позволяет с помощью
математического аппарата (формул) переносить данные с выборочного
исследования на генеральную совокупность. При этом врач должен
уметь не только воспользоваться математической формулой, но сделать
вывод, соответствующий каждому способу оценки достоверности
полученных данных. С этой целью врач должен знать способы оценки
достоверности.
Применяя метод оценки достоверности результатов исследования для изучения общественного здоровья и деятельности учреждений
здравоохранения, а также в своей научной деятельности, исследователь должен уметь правильно выбрать способ данного метода.
Среди методов оценки достоверности различают параметрические и непараметрические.
Параметрическими называют количественные методы статистической обработки данных, применение которых требует обязательного
знания закона распределения изучаемых признаков в совокупности и вычисления их основных параметров.
Непараметрическими являются количественные методы статистической обработки данных, применение которых не требует знания
закона распределения изучаемых признаков в совокупности и вычисления их основных параметров.
Как параметрические, так и непараметрические методы, используемые
для сравнения результатов исследований, т.е. для сравнения
выборочных совокупностей, заключаются в применении определенных формул и
расчете определенных показателей в соответствии с
предписанными алгоритмами. В конечном результате высчитывается
определенная числовая величина, которую сравнивают с табличными
пороговыми значениями. Критерием достоверности будет результат сравнения
полученной величины и табличного значения при данном числе
наблюдений (или степеней свободы) и при заданном уровне безошибочного
прогноза.
Таким образом, в статистической процедуре оценки основное
значение имеет полученный критерий достоверности, поэтому сам способ
оценки достоверности в целом иногда называют тем или иным критерием по
фамилии автора, предложившего его в качестве основы метода.
Применение параметрических методов
При проведении выборочных исследований полученный результат не обязательно совпадает с результатом, который мог бы быть получен
при исследовании всей генеральной совокупности. Между этими величинами существует определенная разница, называемая ошибкой
репрезентативности, т.е. это погрешность, обусловленная переносом результатов выборочного исследования на всю генеральную
совокупность.
Определение доверительных границ средних
и относительных величин
Формулы определения доверительных границ представлены следующим образом:
- для средних величин (М): Мген = Мвыб ± tm
- для относительных показателей (Р): Рген = Рвыб ± tm
где Мген и Рген — соответственно, значения средней величины и относительного показателя генеральной
совокупности;
Мвы6 и Рвы6 — значения средней величины и относительного показателя выборочной совокупности;
m — ошибка репрезентативности;
t — критерий достоверности (доверительный коэффициент).
Данный способ применяется в тех случаях, когда по результатам выборочной совокупности необходимо судить о размерах изучаемого
явления (или признака) в генеральной совокупности.
Обязательным условием для применения способа является репрезентативность выборочной совокупности. Для переноса результатов,
полученных при выборочных исследованиях, на генеральную совокупность необходима степень вероятности безошибочного прогноза (Р),
показывающая, в каком проценте случаев результаты выборочных исследований по изучаемому признаку (явлению) будут иметь место в
генеральной совокупности.
При определении доверительных границ средней величины или относительного показателя генеральной совокупности, исследователь сам
задает определенную (необходимую) степень вероятности безошибочного прогноза (Р).
Для большинства медико-биологических исследований считается
достаточной степень вероятности безошибочного прогноза, равная 95%,
а число случаев генеральной совокупности, в котором могут наблюдаться
отклонения от закономерностей, установленных при выборочном
исследовании, не будут превышать 5%. При ряде исследований, связанных,
например, с применением высокотоксичных веществ, вакцин,
оперативного лечения и т.п., в результате чего возможны тяжелые
заболевания, осложнения, летальные исходы, применяется степень
вероятности Р = 99,7%, т.е. не более чем у 1% случаев генеральной
совокупности возможны отклонения от закономерностей,
установленных в выборочной совокупности.
Заданной степени вероятности (Р) безошибочного прогноза соответствует определенное, подставляемое в формулу, значение критерия
t, зависящее также и от числа наблюдений.
При n>30 степени вероятности безошибочного прогноза Р = 99,7% — соответствует значение t = 3, а при Р = 95,5% — значение
t = 2.
При п<30 величина t при соответствующей степени вероятности безошибочного прогноза определяется по специальной таблице
(Н.А. Плохинского).
на определение ошибок репрезентативности (m) и доверительных границ средней величины генеральной совокупности (Мген)
при числе наблюдений больше 30
Условие задачи: при изучении комбинированного воздействия шума и низкочастотной вибрации на организм человека было
установлено, что средняя частота пульса у 36 обследованных водителей сельскохозяйственных машин через 1 ч работы составила 80
ударов в 1 минуту; σ = ± 6 ударов в минуту.
Задание: определить ошибку репрезентативности (mM) и доверительные границы средней величины генеральной
совокупности (Мген).
Решение.
- Вычисление средней ошибки средней арифметической (ошибки репрезентативности) (m):
m = σ / √n =
6 / √36 =
±1 удар в минуту - Вычисление доверительных границ средней величины генеральной совокупности (Мген). Для этого необходимо:
- а) задать степень вероятности безошибочного прогноза (Р = 95 %);
- б) определить величину критерия t. При заданной степени вероятности (Р=95%) и числе наблюдений меньше 30 величина критерия t,
определяемого по таблице, равна 2 (t = 2). Тогда Мген = Мвыб ± tm = 80 ± 2×1 = 80 ± 2
удара в минуту.
Вывод. Установлено с вероятностью безошибочного прогноза Р =
95%, что средняя частота пульса в генеральной совокупности,
т.е. у всех водителей сельскохозяйственных машин, через 1 ч работы в
аналогичных условиях будет находиться в пределах от 78 до 82
ударов в минуту, т.е. средняя частота пульса менее 78 и более 82 ударов в
минуту возможна не более, чем у 5% случаев генеральной
совокупности.
на определение ошибок репрезентативности (m) и доверительных границ относительного показателя генеральной совокупности
(Рген)
Условие задачи: при медицинском осмотре 164 детей 3 летнего возраста, проживающих в одном из районов городе Н., в 18%
случаев обнаружено нарушение осанки функционального характера.
Задание: определить ошибку репрезентативности (mp) и доверительные границы относительного показателя
генеральной совокупности (Рген).
Решение.
- Вычисление ошибки репрезентативности относительного показателя:
m = √P x q / n =
√18 x (100 — 18) / 164 =
± 3% - Вычисление доверительных границ средней величины генеральной совокупности (Рген) производится следующим образом:
- необходимо задать степень вероятности безошибочного прогноза (Р=95%);
- при заданной степени вероятности и числе наблюдений больше 30, величина критерия t равна 2 (t = 2).
Тогда Рген = Рвыб± tm = 18% ± 2 х 3 = 18% ± 6%.
Вывод. Установлено с вероятностью безошибочного прогноза Р=95%, что частота нарушения осанки функционального характера у
детей 3 летнего возраста, проживающих в городе Н., будет находиться в пределах от 12 до 24% случаев.
Оценка достоверности разности результатов исследования
Данный способ применяется в тех случаях, когда необходимо определить, случайны или достоверны (существенны), т.е. обусловлены
какой-то причиной, различия между двумя средними величинами или относительными показателями.
Обязательным условием для применения данного способа является репрезентативность выборочных совокупностей, а также наличие
причинно-следственной связи между сравниваемыми величинами (показателями) и факторами, влияющими на них.
Формулы определения достоверности разности представлены следующим образом:
Если вычисленный критерий t более или равен 2 (t ≥ 2), что соответствует вероятности безошибочного прогноза Р равном или
более 95% (Р ≥ 95%), то разность следует считать достоверной (существенной), т.е. обусловленной влиянием какого-то фактора, что
будет иметь место и в генеральной совокупности.
При t < 2, вероятность безошибочного прогноза Р < 95%, это означает, что разность недостоверна, случайна, т.е. не
обусловлена какой-то закономерностью (не обусловлена влиянием какого-то фактора).
Поэтому полученный критерий должен всегда оцениваться по отношению к конкретной цели исследования.
на оценку достоверности разности средних величин
Условие задачи: при изучении комбинированного воздействия шума
и низкочастотной вибрации на организм человека было
установлено, что средняя частота пульса у водителей сельскохозяйственных
машин через 1 ч после начала работы составила 80 ударов в
минуту; m = ± 1 удар в мин. Средняя частота пульса у этой же группы
водителей до начала работы равнялась 75 ударам в минуту;
m = ± 1 удар в минуту.
Задание: оценить достоверность различий средних значений пульса у водителей сельскохозяйственных машин до и после 1 ч
работы.
Решение.
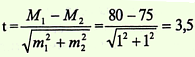
Вывод. Значение критерия t = 3,5 соответствует вероятности безошибочного прогноза Р > 99,7%, следовательно можно
утверждать, что различия в средних значениях пульса у водителей сельскохозяйственных машин до и после 1 ч работы не случайно, а
достоверно, существенно, т.е. обусловлено влиянием воздействия шума и низкочастотной вибрации.
на оценку достоверности разности относительных показателей
Условие задачи: при медицинском осмотре детей 3 летнего возраста в 18% (m = ± 3%) случаях обнаружено нарушение
осанки функционального характера. Частота аналогичных нарушений осанки при медосмотре детей 4-летнего возраста составила 24%
(m = ± 2,64%).
Задание: оценить достоверность различий в частоте нарушения осанки у детей 2 возрастных групп.
Решение.
![]()
Вывод. Значение критерия t=1,5 соответствует вероятности безошибочного прогноза Р<95%. Следовательно, различие в
частоте нарушений осанки среди детей, сравниваемых возрастных групп случайно, недостоверно, несущественно, т.е. не обусловлено
влиянием возраста детей.
Типичные ошибки, допускаемые исследователями при
применении способа оценки достоверности разности результатов исследования
- При оценке достоверности разности результатов исследования по критерию t часто делается вывод о достоверности (или
недостоверности) самих результатов исследования. В действительности же этот способ позволяет судить только о достоверности
(существенности) или случайности различий между результатами исследования. - При полученном значении критерия t<2 часто делается вывод о необходимости увеличения числа наблюдений. Если же
выборочные совокупности репрезентативны, то нельзя делать вывод о необходимости увеличения числа наблюдений, т.к. в данном
случае значение критерия t<2 свидетельствует о случайности, недостоверности различия между двумя сравниваемыми результатами
исследования.
Применение методов статистического анализа для изучения общественного здоровья и здравоохранения.
Под ред. чл.-корр. РАМН, проф. В.З.Кучеренко. М., «Гэотар-Медиа», 2007, учебное пособие для вузов
- Власов В.В. Эпидемиология. — М.: ГЭОТАР-МЕД, 2004. — 464 с.
- Лисицын Ю.П. Общественное здоровье и здравоохранение. Учебник для вузов. — М.: ГЭОТАР-МЕД, 2007. — 512 с.
- Медик В.А., Юрьев В.К. Курс лекций по общественному здоровью
и здравоохранению: Часть 1. Общественное здоровье. — М.: Медицина,
2003. — 368 с. - Миняев В.А., Вишняков Н.И. и др. Социальная медицина и организация здравоохранения (Руководство в 2 томах). — СПб, 1998. -528 с.
- Кучеренко В.З., Агарков Н.М. и др.Социальная гигиена и организация здравоохранения (Учебное пособие) — Москва, 2000. — 432 с.
- С. Гланц. Медико-биологическая статистика. Пер с англ. — М., Практика, 1998. — 459 с.
Статистика – это наука, изучающая количественную сторону массовых явлений в неразрывной связи с их качественной стороной. А медицинская статистика изучает вопросы, связанные с медициной. Для того чтобы стать по-настоящему грамотным специалистом, студенты медицинского вуза должны изучать биометрию, статистику, медицинскую информатику. Роль этих наук в практической деятельности современного врача очень велика, их умелое применение позволяет своевременно оценить уровень здоровья пациентов, оперативно выбрать эффективные диагностические и лечебные мероприятия, повысить качество медицинской помощи и соответственно – качество жизни населения.
Основную цель данной работы составлял анализ методики статистического анализа клинико-лабораторных данных. В результате обзора научной литературы мы остановились на работе И.А. Зворыгина [1], в которой пошагово, в доступной форме, представлена последовательность статистического анализа клинико-лабораторных данных.
1. Описание исходных данных
Как правило, основными задачами статистического анализа являются:
— описание группы (либо нескольких групп) данных с расчетом параметров распределения;
— сравнение нескольких групп данных с учетом параметров распределения.
Компактное описание данных – задача так называемой описательной статистики, в фундаменте которой лежит понятие нормального распределения (распределения Гаусса) [2]. Такое распределение встречается достаточно часто в нормальных физиологических условиях, если значения изучаемого признака близки к их среднему арифметическому значению и примерно с равной вероятностью отклоняются от него в большую или меньшую сторону (рис. 1). Для описания такого распределения используются параметры: среднее значение М и стандартное отклонение s[3].
В качестве примера нормального распределения можно рассмотреть концентрацию гемоглобина крови: данный показатель отклоняется от среднего значения под действием различных слабо выраженных, не зависящих друг от друга факторов – таких, как поступление и потеря железа, интенсивность эритропоэза, время жизни эритроцитов и др. Исходные лабораторные данные – результаты определения концентрации гемоглобина у 30 дноров мужского пола [1].
Рассмотрим ход расчета параметров распределения и будем заносить результаты в табл. 1. Прежде всего, введем исходные показатели в первую колонку таблицы. Далее вычислим среднее арифметическое путем деления суммы исходных значений концентрации гемоглобина на число проб согласно формуле:
Во вторую колонку запишем отклонения данных от среднего значения, т.е. разности (X – M) (из каждого значения вычитается среднее арифметическое). Затем возведем полученные величины в квадрат и поместим их в третью колонку таблицы (X – M)2.
Теперь рассчитаем стандартное отклонение (среднее квадратическое отклонение) по формуле
т.е. сумму квадратов отклонений поделим на величину «число проб минус единица» и извлечем из полученного значения квадратный корень.
В результате проведенных расчетов у нас появятся два важных параметра: среднее значение и стандартное отклонение. Эти величины характеризуют распределение признака (концентрации гемоглобина) в совокупности данных. Полученные значения принято записывать формате M ± s с указанием единицы измерения: 147,13 ± 8,54 г/л.
2. Сравнение двух групп с использованием критерия Стьюдента
Полученную выше информацию систематизируем и дополним. По исходным данным о показателях гемоглобина крови, взятой в той же лаборатории у доноров женского пола, в соответствии с вышеприведенным алгоритмом вычислим М, (X – M), (X – M)2, s. Для сравнения показателей гемоглобина для мужчин и женщин составим табл. 2.
Из данных табл. 2 видно, что у некоторых женщин концентрация гемоглобина выше, чем у некоторых мужчин. Однако, концентрация гемоглобина может быть и не связана с гендерным фактором, а быть всего лишь «игрой случая» [1]. Данное предположение составляет суть «нулевой гипотезы» – предположения, что те или иные факторы не оказывают никакого влияния на исследуемую величину, а наблюдаемые различия между группами носят случайный характер.
Дальнейший статистический анализ при сравнении двух групп данных состоит в подтверждении либо опровержении выдвинутой нулевой гипотезы. Для этого используются статистические критерии – методы оценки статистической значимости различий, среди которых наиболее часто применяется критерий Стьюдента t.
Наиболее простая формула расчета критерия Стьюдента выглядит следующим образом:
В числителе – разность средних значений двух групп, в знаменателе – квадратный корень из суммы квадратов стандартных ошибок этих средних значений.
Существуют и другие варианты расчета критерия Стьюдента – например, с использованием числа наблюдений и стандартных отклонений:
Здесь тот же числитель, но в знаменателе – квадратный корень из суммы квадратов стандартных отклонений, деленных на число наблюдений в соответствующей группе. Отметим, что величина s2 – квадрат стандартного отклонения – отражает степень разброса данных в выборке и носит название «дисперсия» (от английского слова disperse –«рассеиваться»). Согласно исходным данным для рядов мужчин и женщин, s1 = 8,54, s2 = 6,21.
Рассмотрим последнюю формулу. Нулевая гипотеза подразумевает, что обе группы данных представляют собой случайные выборки из одной совокупности. В этом случае из двух квадратов стандартных отклонений s12 и s22 необходимо рассчитать объединенную оценку дисперсии для двух групп данных [1]:
Затем, зная объединенную оценку дисперсии s2 для двух выборок, можно рассчитать критерий Стьюдента по вышеприведенной формуле.
По данным табл. 2 мы видим, что группы доноров – мужчин и женщин неравнозначны по объему (n1 = 30; n2 = 21). В подобном случае необходимо вычислить объединенную оценку дисперсии:
По формуле для расчета критерия Стьюдента получаем
Полученную величину критерия Стьюдента t = 9,09 необходимо правильно оценить. Чем ближе к нулю полученный результат, тем больше вероятность нулевой гипотезы. И напротив – чем выше полученное значение t, тем больше оснований отвергнуть нулевую гипотезу и считать, что различия между исследуемыми выборками статистически значимы. Значение критерия, начиная с которого нулевая гипотеза считается отвергнутой, называется критическим значением t.
В задаче об отклонении либо принятии нулевой гипотезы есть следующие «подводные камни»: ошибки первого и второго рода. Если исследователь на основании статистического критерия отклоняет нулевую гипотезу там, где она на самом деле верна, т.е. находит различия там, где их нет, принято говорить об ошибке первого рода. Максимально допустимая вероятность ошибочно отвергнуть нулевую гипотезу называется уровнем значимости и обозначается греческим символом a, поэтому ошибка первого рода – это a-ошибка.
Формально уровень значимости может задаваться непосредственно исследователем. Традиционно в медицинских исследованиях считается достаточным, чтобы вероятность a-ошибки не превышала 5% (a = 0,05). Соответственно, чем меньше уровень значимости, тем выше критическое значение tкр. Уменьшая величину a, например до 0,01, мы снижаем вероятность найти несуществующие различия до 1%. Однако, следует учитывать, что слишком низкий уровень значимости (и, следовательно, слишком высокое критическое значение) приводит к риску не найти различий там, где они есть (иными словами, ошибочно подтвердить нулевую гипотезу) – в этом случае пойдет речь об ошибке второго рода (b-ошибке).
Фактором, влияющим на критическое значение, является также число наблюдений в исследуемой группе. Чем больше объем выборок, тем меньше критическое значение tкр, т.к. в больших выборках параметры распределения меньше зависят от случайных отклонений и точнее представляют исходную совокупность данных [2]. Величину, отражающую объем выборок и влияющую на критическое значение, называют числом степеней свободы и обозначают греческой буквой h: h = n1 + n2 – 2.
Итак, a и h – факторы, влияющее на критическое значение критерия Стьюдента. Примем уровень значимости a = 0,05, вычислим число степеней свободы:
h = 30 + 21 – 2 = 49.
Формулы расчета критических значений достаточно сложны, поэтому принято пользоваться готовыми таблицами, которые можно найти в учебниках и пособиях по статистике – например, в работе С. Гланца [2]. Выбирается строка с параметром h (при его отсутствии в рассматриваемой таблице берется ближайшее меньшее значение – в нашем случае 48 вместо 49). Далее определяем, что при уровне значимости a = 0,05 критическое значение критерия Стьюдента составляет t = 2,011.
Следовательно, полученное выше значение t > 2,011 позволяет отказаться от нулевой гипотезы и признать статистически значимыми различия между группами доноров – мужчин и женщин. Вычисленное значение критерия Стьюдента t = 9,09 с большим запасом превышает критическое значение даже для уровня значимости a = 0,001.
Далее, для завершения анализа нужна еще одна характеристика, которая фигурирует в большинстве научных работ – вероятность справедливости нулевой гипотезы, обозначаемая p. Дело в том, что кроме критерия Стьюдента существует довольно много других статистических критериев для оценки значимости различий. Способы расчета и критические значения каждый раз будут разные, но выводы в любом случае будут отражать вероятность справедливости нулевой гипотезыp. Иными словами, p представляет собой вероятность ошибки [1].
Например, если полученная величина t оказывается ниже критического значения для a = 0,05, то это означает p > 0,05 – вероятность отвергнуть справедливую нулевую гипотезу в этом случае превышает 5%, и это не позволяет считать различия статистически значимыми. В случае, когда величина t превышает критическое значение для a = 0,05, но все же остается меньше критического значения для a = 0,01, результат записывается как p < 0,05.
На основании изложенного, в примере с гемоглобином мы можем интерпретировать полученные данные следующим образом: вероятность справедливости нулевой гипотезы о независимости концентрации гемоглобина в донорской крови от гендерного фактора составляет менее 0,1%, т.е. p < 0,001, что соответствует максимально высокой оценке значимости различий.
3. Вычисление доверительного интервала
Выше, на основании вычисленного критерия Стьюдента, мы выяснили, что отличия средних значений концентрации гемоглобина в двух группах доноров (мужчин и женщин) являются статистически значимыми. Кроме того, было установлено, что вероятность ошибки этого заключения составляет менее 0,1% (p < 0,001). Иными словами, с вероятностью ошибки менее 0,1% мы отклонили нулевую гипотезу о равенстве средних значений концентрации гемоглобина в группах мужчин и женщин.
К числу наиболее распространенных ошибок в медицинской статистике, наряду с некорректным использованием критерия Стьюдента (например, при отсутствии нормального распределения данных либо при очень широко распространенном попарном сравнении более двух групп данных), относится подмена понятий «статистически значимый» и «клинически значимый». Собственно критерий Стьюдента не позволяет характеризовать величину выявленных различий. Даже очень малые различия средних значений (M1 – M2) при большой численности сравниваемых групп могут оказаться статистически значимыми: чем больше число наблюдений n, тем меньше становится стандартная ошибка среднего m, тем выше критерий Стьюдента t, рассчитанный согласно вышеприведенным формулам.
Характеристикой, которая дополняет и даже в определенной степени заменяет суждение «значимо – незначимо», является доверительный интервал. Смысл доверительного интервала в том, что, даже не зная точного значения какой-либо величины, можно с заданной вероятностью указать интервал, в котором эта величина находится [4].
Таким образом, доверительный интервал представляет собой интервал значений, рассчитанный для какого-либо параметра по выборке и с определенной вероятностью (в медицине, как правило, 95%), включающий истинное значение этого параметра во всей генеральной совокупности.
Доверительный интервал может быть построен не только для самых разных величин (например, для средних значений и их разности), но и для ожидаемых значений измеряемого признака, что часто используется при определении границ нормы лабораторных показателей. При этом построение доверительных интервалов основано на тех же математических принципах, что и проверка статистических гипотез с использованием критериев, поэтому для работы понадобятся те же самые параметры описательной статистики, что и при вычислении критерия Стьюдента. Составим табл. 3 и проведем дальнейшие расчеты, согласно методике, предложенной И.А. Зворыгиным [1].
Обозначим разность выборочных средних (М1 – М2), разность истинных средних генеральных совокупностей (µ1 – µ2), далее вычислим верхнее и нижнее предельные значения, между которыми и будет с заданной вероятностью находиться величина (µ1 – µ2). Для этого сначала найдем разность выборочных средних:
М1 – М2 = 147,13 – 127,29 = 19,84.
Выше мы рассчитали число степеней свободы h = 49, выбираем в таблице соответствующее значение tкр, принимая a = 0,05: t = 2,01.
Далее вычисляем объединенную оценку дисперсии s2 и стандартную ошибку разности средних по формулам:
Находим произведение стандартной ошибки разности и значения tкр: 2,18 × 2,01 = 4,38. Проводим построение 95%-ного доверительного интервала для разности средних, определяя верхнюю и нижнюю границы:
(М1 – М2) + (tкр × ) = 19,84 + 4,38 = 24,22
(М1 – М2) – (tкр × ) = 19,84 – 4,38 = 15,46
Составляем выражение:
15,46 < µ1 – µ2 < 24,22.
Смысл последнего выражения можно выразить так: наши выборочные данные позволяют с 95%-ной надежностью утверждать, что истинное среднее значение концентрации гемоглобина у доноров крови мужского пола выше аналогичного показателя у доноров-женщин на величину от 15,46 до 24,22 г/л.
Таким образом, благодаря доверительному интервалу можно не просто констатировать статистическую значимость различий между средними значениями гемоглобина в двух группах доноров, но и указать величину выявленных различий.
Далее имеет смысл указать и доверительный интервал для разности средних, дающий возможность судить о величине различий. В этом случае можно вовремя заметить, что статистическая значимость обнаружена всего лишь благодаря большому объему выборки, тогда как клиническая значимость исследования осталась весьма сомнительной.
Более того, доверительные интервалы вполне могут заменить статистические критерии и при оценке статистической значимости различий. Дело в том, что истинная разность средних может находиться в любой точке доверительного интервала. Поэтому, если полученный при работе с выборками доверительный интервал содержит нулевое значение, то это значит, что истинная разность средних также может быть равна нулю. Следовательно, не будет оснований отвергнуть нулевую гипотезу. В свою очередь, если доверительный интервал не содержит нуля, можно с заданной уверенностью отказаться от нулевой гипотезы и считать различия статистически значимыми.
Существует несколько несложных правил интерпретации доверительных интервалов с точки зрения проверки статистических гипотез:
— если доверительный интервал включает как клинически значимые, так и клинически незначимые значения, то результаты недостаточно точны для того, чтобы сделать определенный вывод;
— если доверительный интервал для разности средних включает ноль, то следует считать, что различия между группами по анализируемому признаку отсутствуют;
— если 95%-ный доверительный интервал не включает ноль, то следует считать, что различие между группами существует при уровне статистической значимости 0,05 [1].
В исследуемом случае с гемоглобином крови доноров доверительный интервал не содержит нулевого значения, не содержит и клинически незначимых чисел. На этих основаниях можно уверенно говорить как о статистической, так и клинической значимости выявленных различий.
Проведя данное исследование, следует отметить достаточно несложное описание последовательности шагов статистического анализа данных, представленное в работе И.А. Зворыгина [1]. Также необходимо подчеркнуть, что в настоящее время применяются оба подхода к сравнению двух групп по количественному признаку: посредством проверки статистических гипотез и посредством расчета доверительного интервала. Если критерий Стьюдента помогает установить наличие различий между генеральными совокупностями, то с помощью доверительного интервала можно понять, насколько эти различия велики. Оба подхода основаны на одних и тех же статистических принципах, поэтому в итоге дополняют друг друга.
В своей дальнейшей студенческой и врачебной практике мы предполагаем так же пошагово строить свои рассуждения, как в изученной работе И.А. Зворыгина. В этом случае статистический анализ данных будет казаться не бесконечным набором сложных формул и непонятно откуда берущихся числовых значений, а доступным и даже увлекательным поиском закономерностей, понятным любому студенту, а в дальнейшем врачу.
Проверка гипотез является одним из краеугольных камней современных медицинских исследований. Цель многих исследований не ограничивается простым описанием данных, а включает в себя поиск различий между характеристиками тех или иных объектов наблюдений (пациентов, животных, клеточных культур) и оценку их значимости. Любое наблюдение за объектами реального мира с активным вмешательством исследователя или без него может называться экспериментом. В медицинской науке одним из способов проведения экспериментов является выполнение планируемых исследований [1]. Концепция планируемых исследований характеризуется четкими правилами проведения эксперимента с обозначением ряда жестких условий, которые должны быть обозначены и выполнены до его инициации:
- цель исследования сопровождается четко поставленным вопросом исследования;
- ясно сформулированы конкретные задачи, с помощью которых будет достигнута цель;
- обозначены одна или несколько исследовательских гипотез, требующих проверки в рамках вопроса исследования;
- дизайн исследования направлен на максимально эффективное и надежное достижение цели, получение достоверных и воспроизводимых результатов за счет снижения вероятности возникновения ошибок;
- критерии включения и невключения в исследование, а также критерии исключения обозначены однозначно;
- пошагово описаны методы статистического анализа, направленного на получение выводов по каждой задаче и поставленному вопросу исследования.
Таким образом, при планировании эксперимента исследователи моделируют некие идеальные условия, которые позволяют ответить на поставленный вопрос исследования. При этом планируемые исследования достаточно компактны по количеству участников и по времени проведения.
Примером несколько иного подхода являются наблюдательные поисковые исследования, основной задачей которых является не подтверждение заранее сформулированных гипотез о влиянии тех или иных факторов на исход, а поиск любых подобных взаимодействий и генерация гипотез. То есть в обсервационных исследованиях во главу угла ставят поиск любых важных с точки зрения цели исследования взаимодействий факторов внутри исследуемой популяции, при этом узкий основной вопрос исследования, требующий подтверждения, обычно отсутствует. Однако и в поисковых исследованиях должны быть заранее сформулированы: цель, задачи и четко обозначена исследуемая популяция (обычно довольно широкая по сравнению с выборками планируемых исследований).
Целью этого обзора является знакомство читателей с основными аспектами планируемых исследований и облегчение понимания связи между вопросом исследования и ответом на него с точки зрения методологии проведения исследований, ключевым аспектом которого является проверка статистических гипотез.
ИССЛЕДОВАТЕЛЬСКИЕ И СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ
Началом любого исследования (эксперимента) является гипотеза или научное предположение. Исследователи выдвигают такие предположения и пытаются их доказать или опровергнуть. Например, исследователи могут сделать предположение о том, что плохая экология региона оказывает влияние на здоровье жителей, или о том, что курение может быть сопряжено с повышенным риском сердечно-сосудистых заболеваний. Такие предположения получили название «исследовательские гипотезы». От исследовательской гипотезы следует отличать статистическую гипотезу. Последняя, по сути, представляет такую формулировку исследовательской гипотезы, которая может быть проанализирована с помощью статистических методов в рамках концепции дизайна эксперимента.
Статистическая гипотеза представляет собой некое суждение о параметрах, описывающих статистическую популяцию (генеральную совокупность), но не выборку из нее. В свою очередь, статистическая популяция представляет собой группу однородных элементов, например людей в группе риска, представляющих интерес в рамках настоящего исследования (эксперимента). Примером может служить население города или все пациенты стационара за определенный период времени. На начальном этапе исследователи выдвигают две гипотезы о возможной взаимосвязи наблюдаемых явлений (потенциальных факторов риска и исходов): нулевую и альтернативную.
Нулевая гипотеза утверждает, что наблюдаемые эффекты, явления или взаимодействия происходят в силу случайности, то есть связь между ними отсутствует. Нулевую гипотезу традиционно обозначают, как H0. Альтернативная гипотеза, наоборот, утверждает, что наблюдаемые явления неслучайны и между ними есть связь. Альтернативную гипотезу традиционно обозначают как H1 или HA.
Следует иметь в виду, что под связью в данном случае подразумевают любую ассоциацию, не обязательно причинно-следственную. Например, в небольшом исследовании оценивают различия средних значений (μ1 и μ2) вещественного числового признака – уровень общего холестерина плазмы крови – в двух группах: у пациентов с и без инфаркта миокарда в анамнезе. Исследовательская гипотеза может состоять в том, что группы как различаются, так и не различаются. При этом нулевая гипотеза будет утверждать, что уровень общего холестерина никак не связан с риском развития инфаркта миокарда, то есть истинных различий между средними значениями нет (наблюдаемые различия носят случайный характер):
H0 : μ1 = μ2.
Альтернативной гипотезой является утверждение о том, что различия в уровне холестерина между группами существуют, они значимы и неслучайны:
H1 : μ1 ≠ μ2.
Нулевая и альтернативная гипотезы являются взаимоисключающими, то есть если верна H0, то неверна H1, и наоборот. Таким образом, чтобы подтвердить альтернативную гипотезу – наличие истинных различий между группами, – нам нужно отклонить нулевую гипотезу.
СТАТИСТИЧЕСКИЕ ТЕСТЫ
Статистические тесты – это методы статистического доказательства (построения статистического вывода), которые используют для принятия решения о том, можно ли отклонить нулевую гипотезу H0. Следует отметить, что формально статистические тесты не позволяют принять нулевую гипотезу. Они лишь помогают оценить, может ли она быть отклонена в пользу альтернативной или нет.
Каждый статистический тест является математической функцией, вычисляющей так называемую тестовую статистику. Тестовая статистика показывает, насколько близко наблюдаемая величина соответствует ожидаемому распределению величин при условии, что нулевая гипотеза не была отклонена. Чем больше величина тестовой статистики, тем больше несоответствие между наблюдаемым и ожидаемым распределениями.
Совокупность тестовых статистик каждого теста подчиняется определенному закону распределения (подробнее о распределениях см. в [2]). Например, t-тест вычисляет t-статистики, подчиняющиеся t-распределению. Для того чтобы отклонить нулевую гипотезу, нужно обозначить некий порог среди распределения тестовых статистик. Такую величину пороговой тестовой статистики называют критическим значением, а соответствующую ей вероятность в распределении тестовых статистик – уровнем значимости.
Уровень значимости, обозначаемый α, является вероятностью того, что при текущем значении тестовой статистики нулевая гипотеза будет отклонена несмотря на то, что она верна (истинна). Иными словами, величина α отражает вероятность ошибочно отклонить верную нулевую гипотезу. Такая вероятность также получила название ошибка I рода. Величину α и соответствующее ей критическое значение статистического теста исследователи декларируют до проведения статистического теста, чтобы заранее определить вероятность ошибочного отклонения нулевой гипотезы. Чем меньше уровень значимости, тем более низкая вероятность отклонить нулевую гипотезу в случае, если она верна. Однако эта вероятность, пусть в ряде случаев и очень небольшая, существует всегда. Исследователи лишь могут выбрать такое пороговое значение, при котором эта вероятность будет чрезвычайно низкой. В разных областях знаний традиционно используют разные значения α; в частности, в медицинских исследованиях наиболее часто применяют пороговое значение, равное 0,05. Исследователь может использовать и более низкие пороговые значения, например 0,01 или ниже в экспериментах, где критически важно снизить вероятность ошибочного отклонения нулевой гипотезы (обнаружения различий между группами там, где их нет).
После вычисления результата статистического теста в виде тестовой статистики исследователи получают соответствующую ей вероятность получения таких же или более экстремальных по сравнению с наблюдаемыми результатов теста (то есть сильнее отклоняющихся от ожидаемого распределения), в случае если нулевая гипотеза верна. Такая вероятность получила название р-value (p-значение). Малые значения р-value говорят о том, что если нулевая гипотеза верна, то вероятность получения таких же или более экстремальных результатов тестовой статистики крайне мала. Следовательно, имеется высокая вероятность того, что нулевая гипотеза неверна и может быть отклонена. Если p ≤ α, то есть статистика теста равна или превышает критическое значение, результат считается статистически значимым (рис. 1). Именно поэтому в описании статистического анализа в разделе «Материалы и методы» всегда указывают, при каком значении p результаты считают статистически значимыми. Фактически фраза «различия считали значимыми при p < 0,05» означает, что исследователи выбрали для своей работы величину ошибки I рода α = 0,05.

РИС. 1. T-распределение для 50 степеней свободы
FIG. 1. T-distribution for 50 degrees of freedom
Примечания: зелеными пунктирными линиями указаны критические значения -1,96 и 1,96, соответствующие 2,5-му и 97,5-му процентилям – двустороннему уровню значимости α = 0,05. Красной сплошной линией обозначена t-статистика = 2,5, которая превышает критическое значение 1,96 при двустороннем t-тесте (p = 0,0126 при заданном α = 0,05). Таким образом нулевая гипотеза может быть отклонена и принята альтернативная.
Notes: green dotted lines indicate critical values of 1.96 and -1.96 corresponding to the 97.5th percentile and the 2.5th percentile, respectively, i.e. two-sided significance level α = 0,05. B. Red solid line indicates t-statistics = 2.5, which exceeds critical value of 1.96 using two-tailed t-test (p = 0.0126 with specified α = 0.05), thus the null hypothesis can be rejected, and we can accept the alternative one.
Представим себе, что мы проводим параллельное сравнительное исследование с двумя группами: одной группе назначаем антигипертензивный препарат A, другой группе назначаем плацебо. Наша нулевая гипотеза утверждает, что эффективность препарата А в отношении показателей артериального давления (АД) не отличается от плацебо, если мы оцениваем средние цифры АД по завершении исследования в обеих группах:
- μTRT – среднее значение АД среди пациентов, получавших препарат А (treatment, TRT);
- μPLC – среднее значение АД среди пациентов, получавших плацебо (placebo, PLC);
- H0 : μTRT = μPLC или μTRT – μPLC = 0;
- H1 : μTRT ≠ μPLC или μTRT – μPLC ≠ 0.
С помощью t-критерия проверяем, можем ли мы отклонить нулевую гипотезу о том, что μTRT – μPLC = 0. Мы можем построить график распределения t-статистик, соответствующего такой разнице (рис. 1, зеленые линии). После завершения эксперимента мы получили разницу μTRT – μPLC, соответствующую t-статистике 2,5 в случае, если нулевая гипотеза верна (рис. 1, красная линия). Мы видим, что наблюдаемый результат лежит за пределами критических значений, что позволяет отклонить нулевую гипотезу. Соответствующее значение р составляет 0,0126, следовательно, нулевая гипотеза может быть отклонена при выбранном значении α = 0,05, а различие между группами является статистически значимым.
РАЗМЕР ЭФФЕКТА
Исследовательские гипотезы наиболее часто связаны с поиском различий или ассоциаций между некими показателями. Однако существенное значение имеет не столько сам факт различий, сколько их клиническая значимость. Например, в одном исследовании сравнивали доли достижения терапевтического эффекта в группах лечения и плацебо, и они составили 10 и 80% соответственно. Мы видим, что доли различаются, и довольно существенно, разница составляет 70%. В другом исследовании аналогичные доли составили 45 и 55%. Мы снова видим, что доли различаются, однако уже не так сильно, разница всего 10%. Еще в одном исследовании эффективность терапии в двух группах составила 75 и 80%. Доли различаются, но разница очень невелика – всего 5%. Другой пример связан с новыми антигипертензивными препаратами. Новый препарат Х снижает систолическое артериальное давление (САД) в среднем на 15 мм рт. ст. Препарат Y также снижает САД, но в среднем на 8 мм рт. ст. Наконец, препарат Z снижает САД, но всего в среднем на 1 мм рт. ст. При использовании традиционной антигипертензивной терапии среднее снижение АД составило 1 мм рт. ст. Во всех примерах мы видим, что некий эффект есть, но он разный, в одних – больший, в других – меньший.
Размер эффекта – довольно широкое статистическое понятие, обозначающее некую статистику или показатель, показывающий величину различий или ассоциации между распределениями исследуемой величины в разных группах. Размер эффекта в медицине крайне важен: именно он привязан не только к статистике, но и к клинической значимости наблюдаемых в исследовании результатов. Например, мы используем среднее снижение САД в качестве размера эффекта. Среднее снижение САД в 1 мм рт. ст., скорее всего, не является клинически значимым – для пациента препарат Z не будет лучше традиционной терапии, таким образом, с практической точки зрения его назначение не дает преимуществ. Слишком большой размер эффекта (препарат X), напротив, может быть ассоциирован с развитием осложнений вследствие гипотензии. Препарат Y, вероятно, является оптимальным выбором среди новых препаратов в клинической практике – он имеет значимый и при этом не чрезмерный антигипертензивный эффект.
Крайне важно понимать, что, проверяя статистические гипотезы, мы пытаемся статистическими методами зафиксировать определенный размер эффекта. Абсолютная разница между средними редко бывает равна нулю, при этом разница может быть небольшой и клинически незначимой и принимать как положительные, так и отрицательные значения. С другой стороны, при проверке статистических гипотез необходимо четко ввести критерий наличия или отсутствия клинического смысла у того или иного эффекта. В примере с антигипертензивными препаратами среднее снижение САД на ≤2 мм рт. ст. можно определить как отсутствие клинического эффекта, на 3–10 мм рт. ст. – как умеренный эффект и на >10 мм рт. ст. – как сильный. В качестве проверяемой исследовательской гипотезы мы хотим выяснить, достигнет ли среднее снижение САД хотя бы умеренного размера эффекта под влиянием препаратов X, Y и Z.
Как оценивается размер эффекта?
Огромный вклад в концепцию размера эффекта внес психолог и статистик Jacob Cohen, который в одной из своих поздних работ писал: «Основным результатом исследования являются одна или несколько оценок размера эффекта, а не p-значения» [3]. Сегодня существует большое количество статистик, позволяющих оценить размер эффекта, фактически при проверке любых гипотез.
Выделяют стандартизованные методы оценки размера эффекта и нестандартизованные. В отличие от последних, стандартизованные методы позволяют оценивать эффект для переменных не только с одинаковой, но и с разной размерностью (например, оценка коэффициента корреляции для переменных, измеряемых в разных единицах), для оценки совокупных результатов разных исследований (метаанализ и метарегрессия), при сравнении результатов исследований с использованием разных метрик переменных (например, при использовании г/л в одном исследовании и ммоль/л в другом) [4].
Выделяют следующие методы оценки размера эффекта (таблицы S1–4 в приложении):
- размер эффекта, оценивающий ассоциацию между распределениями числовых переменных или насколько распределение одной переменной вносит вклад в распределение другой переменной (коэффициент корреляции, коэффициент детерминации и др.);
- размер эффекта, оценивающий разницу между статистиками (Cohen’s d, Glass’ Δ, разница рисков и др.);
- размер эффекта, оценивающий ассоциацию между категориальными переменными (Cohen’s h, отношение шансов и др.).
Исследовательские гипотезы и концепция размера эффекта
Размеру эффекта отдается ключевая роль при формировании исследовательских и статистических гипотез. Первоначально исследователи ставят вопрос о том, случаен ли наблюдаемый ими эффект? Например, различаются ли в действительности уровни общего холестерина в группе лечения новым препаратом и в контрольной группе? Наблюдаемые различия могут быть обусловлены случайностью. Для того чтобы проверить, существует ли эффект в действительности, проводят поисковые и пилотные исследования, основной целью которых является определение наличия эффекта или его отсутствия. Такие исследования получили названия гипотезообразующих (о различных подходах к оптимальному выбору дизайна исследований для различных целей – см. [5]). Безусловно, если удалось зафиксировать эффект, в пилотных исследованиях можно оценить его наблюдаемый или гипотетический размер. Однако пилотные исследования часто довольно компактны и дают возможность лишь ответить на вопрос наличия/отсутствия эффекта, но не позволяют достоверно определить его размер (рис. 2).

РИС. 2. Схема проведения гипотезообразующих исследований
FIG. 2. Flowchart of the hypothesis-generating studies
Следующий этап исследований после пилотных получил название подтверждающих исследований и направлен на то, чтобы зафиксировать эффект определенного размера. Например, в пилотном исследовании было установлено, что курение среди мужчин 35–45 лет, проживающих в городах, увеличивает риск развития сердечно-сосудистых заболеваний за 10 лет, а относительный риск (ОР) равен X. Перед исследователями встает вопрос о влиянии курения на аналогичную группу мужчин, проживающих в сельской местности. Для того, чтобы спланировать такое исследование, мы можем опираться на полученные ранее результаты в городской популяции и исходить из того, что нам нужно зафиксировать размер эффекта (ОР) не менее X (рис. 3). Или, если по нашим исследовательским предположениям эффект будет менее выражен, например в n раз, мы можем спланировать исследование так, чтобы зафиксировать размер эффекта (ОР) не менее X/n.

РИС. 3. Схема проведения подтверждающих исследований
FIG. 3. Flowchart of confirmatory studies
Использование размера эффекта позволяет не проводить пилотные исследования каждый раз, а опираться на опыт предшествующих работ. Концепция размера эффекта требует от врачей понимания концепции порога размера эффекта, который они хотят зафиксировать статистически, если такой порог является целесообразным с точки зрения медицины. И такой порог требует именно медицинского обоснования. Например, при исследовании нового препарата для похудения у пациентов с весом выше 200 кг получено статистически значимое снижение веса в течение одного года, которое составило 1 кг. В результате эффект зафиксирован, он статистически значим, но с точки зрения помощи пациентам такой эффект абсолютно лишен всякого смысла: в течение 1 года диетологи (и сами пациенты) наверняка хотели бы наблюдать более выраженное снижение веса. Вероятно, более оправданным было бы введение порога размера эффекта в 10 или 15 кг.
ОДНОСТОРОННИЕ И ДВУСТОРОННИЕ СТАТИСТИЧЕСКИЕ ТЕСТЫ
Двусторонние тесты
Вернемся к примеру с антигипертензивной терапией. Предположим, что существует новый перспективный препарат, назовем его TRT (treatment), который должен снижать САД исходя из своего механизма действия, но как он себя покажет в клиническом эксперименте с пациентами, мы не знаем. Существует и традиционная антигипертензивная терапия, которая будет использована в контрольной группе (CTRL, control treatment). Измеренное среднее снижение САД в конце исследования в группе TRT будет равно μTRT, а в группе CTRL составит μCTRL.
Если мы формулируем вопрос исследования, как «какая терапия более эффективна?», нулевая гипотеза декларирует, что H0 : μTRT = μCTRL. А альтернативная гипотеза утверждает обратное H1 : μTRT ≠ μCTRL, и, в свою очередь, может состоять из двух более простых утверждений:

То есть мы рассматриваем альтернативные гипотезы и для ситуации, когда новый препарат (TRT) оказался более эффективен, чем традиционное лечение (CTRL), и, наоборот, когда новый препарат (TRT) оказался менее эффективен. Тесты, используемые для такой проверки разнонаправленных по сути предположений, получили название двусторонних. Если рассмотреть диаграмму распределения, например t-статистики, мы увидим 2 зеркальных критических значения с разным знаком: при уровне значимости α = 0,05 для двустороннего теста критические значения будут -1,96 и 1,96 (рис. 1). При двусторонних тестах общий уровень значимости разделяется пополам и критические значения с каждой стороны соответствуют α/2:

При принятом уровне значимости в 5% нулевая гипотеза будет отклонена, если t-статистика наблюдаемого эффекта превысит любое из двух критических значений (зеленые линии) (рис. 1), соответствующие 2,5 и 97,5 процентиля.
Для чего исследователям двусторонние тесты? Так как мы не знаем истинного эффекта препарата TRT, двусторонний тест ответит на все варианты развития событий: TRT приблизительно одинаков по действию с CTRL, лучше или хуже CTRL.
Односторонние тесты
Если главный вопрос исследования «является ли новый препарат (TRT) лучшей альтернативой стандартному лечению (CTRL)?», наши гипотезы изменятся. Теперь нам важно зафиксировать только значимый размер эффекта, когда μTRT > μCTRL.
Таким образом, при формулировании нулевой и альтернативной гипотезы получаем:

Для проверки такой гипотезы используется односторонний тест, позволяющий зафиксировать не только определенный размер эффекта, но и его направление. В данном случае нам важно проверить, превышает ли статистика теста критическое значение, расположенное на распределении справа (рис. 4).

РИС. 4. Иллюстрация одностороннего t-теста
FIG. 4. One-sided t-test illustration
Примечания: зеленая линия обозначает критическое значение 1,65, соответствующее одностороннему уровню значимости α = 0,05. Для статистики t = 2,5 (красная линия) p-value = 0,006: результат статистически значим при выбранном значении ошибки I рода, поскольку p < α.
Notes: the green line indicates critical value of 1.65 which corresponds with one-sided significance level α = 0.05; p-value is 0.006 for t-statistic t = 2.5 (red line): the result is clinically significant, given the chose type I error value as p < α.
ОШИБКИ I И II РОДА
Мы подробно разобрали концепцию ошибки I рода, однако получение и интерпретация результатов исследований связано не с одним, а с двумя типами ошибок (табл.).
Таблица. Ошибки I и II рода
Table. Type I and II errors
|
В статистической популяции / In statistical population |
В ходе исследования / In the study |
Результат проверки H0 / After testing H0 |
Вероятность / Probability |
|
H0 верна / H0 true |
H0 не отклонена / H0 not rejected |
Решение не отклонять верное / Decision not to reject is correct |
P = 1 – α |
|
H0 верна / H0 true |
H0 отклонена / H0 rejected |
Ошибочное отклонение, ошибка I рода / Incorrect (false) rejection, Type I error |
P = α |
|
H0 неверна / H0 false |
H0 не отклонена / H0 not rejected |
Решение не отклонять ошибочное, ошибка II рода / Decision not to reject is incorrect (false), Type II error |
P = β |
|
H0 неверна / H0 false |
H0 отклонена / H0 rejected |
Верное отклонение / Correct rejection |
P = 1 – β |
Ошибка первого рода (α, ложноположительный результат) – ситуация, когда отклонена верная нулевая гипотеза. Принимается альтернативная гипотеза, которая неверна. Например, исследователи считают значимыми различия между группами, а на самом деле различия носят случайный характер.
Ошибка второго рода (β, ложноотрицательный результат) – ситуация, когда не отклонена ошибочная нулевая гипотеза. При этом верная альтернативная гипотеза отклоняется. Например, исследователи расценили как случайные различия между группами, которые на самом деле были значимы и не случайны.
Для планирования эксперимента важно попытаться минимизировать ошибки I и II рода. Ошибка I рода, как мы уже говорили, и является уровнем значимости теста, с которым сопоставляют величину p. Малое значение ошибки I рода позволяет с высокой вероятностью не отклонить нулевую гипотезу при условии, что она верна.
В свою очередь, ошибка II рода отражает возможность отклонить ошибочную нулевую гипотезу с вероятностью 1 – β. Такая вероятность получила название мощность статистического теста: power = 1 – β. В ряде медицинских исследований общепринятая минимальная мощность соответствует не менее 80% (то есть максимально допустимая ошибка II рода не превышает 20%).
ОБЪЕМ ТРЕБУЕМОЙ ВЫБОРКИ В КОНЦЕПЦИИ ПРОВЕРКИ СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Последним элементом, необходимым для проверки статистических гипотез, является минимальный объем требуемой выборки, необходимый для того, чтобы принять или отклонить нулевую гипотезу [6]. Таким образом, мы можем представить концепцию проверки статистических гипотез в виде схемы, представленной на рис. 5.

РИС. 5. Схема проверки статистических гипотез
FIG. 5. Flowchart of the statistical hypothesis testing
Сформулировав вопрос исследования и предположив ожидаемый размер эффекта, исследователь:
- выбирает наиболее подходящий статистический тест, связанный с законом распределения размера эффекта в статистической популяции;
- устанавливает подходящий уровень значимости и мощность исследования;
- после этого рассчитывает требуемый объем выборки.
Только после выполнения этих этапов можно переходить к выполнению статистического теста. Однако каким образом исследователь может связать мощность исследования, уровень значимости, размер эффекта и объем выборки? Представим себе, что мы пытаемся статистически зафиксировать размер эффекта Е с мощностью 1 – β, значимостью α (рис. 6А). Для этого нам потребуется объем выборки n [7]. Заранее отметим, что уровень значимости теста α должен оставаться фиксированным при любом развитии событий. Если исследователь хочет оставить объем выборки неизменным, но при этом повысить мощность, самое простое решение – предположить, что мы будем наблюдать больший размер эффекта, например в 2 раза (или Е × 2). При таких условиях мощность действительно увеличится (рис. 6B). Однако в реальной жизни исследователь не может по собственному желанию наблюдать больший или меньший эффект, более того, предположение о размере эффекта представляет из себя лишь исследовательскую гипотезу. В таком случае размер эффекта также на самом деле не должен увеличиться, однако при увеличении размера выборки увеличивается мощность исследования (рис. 6С). Следовательно, при желании зафиксировать определенный размер эффекта со строгим уровнем значимости единственной возможностью снизить риск ложного принятия ошибочной нулевой гипотезы (β) является увеличение объема требуемой выборки.

РИС. 6. Взаимосвязь между размером эффекта, ошибками I и II рода и размером выборки при проверке статистических гипотез:
А. Взаимосвязь размера эффекта, ошибок I и II рода.
B. Изменение величины ошибки II рода при увеличении размера эффекта.
C. Изменение величины ошибки II рода при увеличении размера выборки.
FIG. 6. The relationship between effect size, type I and II errors, and sample size, when testing statistical hypotheses:
А. Effect size and type I and II errors.
B. Type II error changing after the effect size increasing.
C. Type II error changing after sample size increasing.
Примечание: μ1 – среднее в группе 1, μ2 – среднее в группе 2.
Note: μ1 – mean in group 1, μ2 – mean in group 2.
ЗАКЛЮЧЕНИЕ
Грамотное формулирование исследовательских и статистических гипотез – важнейший навык врача- исследователя, без которого невозможно успешное планирование и проведение исследований в области медицины. Кроме того, концепции размера эффекта, ошибок I и II рода необходимы для интерпретации результатов своих собственных и опубликованных в литературе исследований. Эти идеи универсальны и применимы к любым статистическим тестам, более того, они имеют существенно большее значение для ученого, чем навык применения тех или иных частных методик.
ВКЛАД АВТОРОВ
А.Ю. Суворов, Н.М. Буланов, А.Н. Шведова в равной степени внесли вклад в эту работу и должны считаться первыми соавторами. А.Ю. Суворов, Н.М. Буланов, А.Н. Шведова, Е.А. Тао, А.А. Заикин и М.Ю. Надинская участвовали в написании текста рукописи. А.Ю. Суворов, Н.М. Буланов и А.Н. Шведова выполняли поиск и анализ литературы по теме обзора. А.Ю. Суворов и Д.В. Бутнару разработали общую концепцию статьи и осуществляли руководство ее написанием. Все авторы участвовали в обсуждении и редактировании работы. Все авторы утвердили окончательную версию публикации.
AUTHOR CONTRIBUTIONS
Alexander Yu. Suvorov, Nikolay М. Bulanov, and Anastasia N. Shvedova contributed equally to this work and should be considered as co-first authors. Alexander Yu.vSuvorov, Nikolay М. Bulanov, Anastasia N. Shvedova, Ekaterina A. Tao, Alexey A. Zaikin and Maria Yu. Nadinskaia, participated in writing the text of the manuscript. Alexander Yu. Suvorov, Nikolay M. Bulanov, and Anastasia N. Shvedova searched and analyzed the literature on the review topic. Alexander Yu. Suvorov and Denis V. Butnaru developed the general concept of the article and supervised its writing. All authors participated in the discussion and editing of the work. All authors approved the final version of the publication.
ДОПОЛНИТЕЛЬНЫЕ МАТЕРИАЛЫ
Дополнительные материалы, прилагаемые к этой статье, можно посмотреть в онлайн-версии по адресу: https://doi.org/10.47093/2218-7332.2022.426.08.S
SUPPLEMENTARY MATERIALS
Supplementary materials associated with this article can be found in the online version at doi: https://doi.org/10.47093/2218-7332.2022.426.08.S