- sklearn.metrics.confusion_matrix(y_true, y_pred, *, labels=None, sample_weight=None, normalize=None)[source]¶
-
Compute confusion matrix to evaluate the accuracy of a classification.
By definition a confusion matrix (C) is such that (C_{i, j})
is equal to the number of observations known to be in group (i) and
predicted to be in group (j).Thus in binary classification, the count of true negatives is
(C_{0,0}), false negatives is (C_{1,0}), true positives is
(C_{1,1}) and false positives is (C_{0,1}).Read more in the User Guide.
- Parameters:
-
- y_truearray-like of shape (n_samples,)
-
Ground truth (correct) target values.
- y_predarray-like of shape (n_samples,)
-
Estimated targets as returned by a classifier.
- labelsarray-like of shape (n_classes), default=None
-
List of labels to index the matrix. This may be used to reorder
or select a subset of labels.
IfNoneis given, those that appear at least once
iny_trueory_predare used in sorted order. - sample_weightarray-like of shape (n_samples,), default=None
-
Sample weights.
New in version 0.18.
- normalize{‘true’, ‘pred’, ‘all’}, default=None
-
Normalizes confusion matrix over the true (rows), predicted (columns)
conditions or all the population. If None, confusion matrix will not be
normalized.
- Returns:
-
- Cndarray of shape (n_classes, n_classes)
-
Confusion matrix whose i-th row and j-th
column entry indicates the number of
samples with true label being i-th class
and predicted label being j-th class.
References
Examples
>>> from sklearn.metrics import confusion_matrix >>> y_true = [2, 0, 2, 2, 0, 1] >>> y_pred = [0, 0, 2, 2, 0, 2] >>> confusion_matrix(y_true, y_pred) array([[2, 0, 0], [0, 0, 1], [1, 0, 2]])
>>> y_true = ["cat", "ant", "cat", "cat", "ant", "bird"] >>> y_pred = ["ant", "ant", "cat", "cat", "ant", "cat"] >>> confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"]) array([[2, 0, 0], [0, 0, 1], [1, 0, 2]])
In the binary case, we can extract true positives, etc as follows:
>>> tn, fp, fn, tp = confusion_matrix([0, 1, 0, 1], [1, 1, 1, 0]).ravel() >>> (tn, fp, fn, tp) (0, 2, 1, 1)
Examples using sklearn.metrics.confusion_matrix¶
В компьютерном зрении обнаружение объекта — это проблема определения местоположения одного или нескольких объектов на изображении. Помимо традиционных методов обнаружения, продвинутые модели глубокого обучения, такие как R-CNN и YOLO, могут обеспечить впечатляющие результаты при различных типах объектов. Эти модели принимают изображение в качестве входных данных и возвращают координаты прямоугольника, ограничивающего пространство вокруг каждого найденного объекта.
В этом руководстве обсуждается матрица ошибок и то, как рассчитываются precision, recall и accuracy метрики.
Здесь мы рассмотрим:
- Матрицу ошибок для двоичной классификации.
- Матрицу ошибок для мультиклассовой классификации.
- Расчет матрицы ошибок с помощью Scikit-learn.
- Accuracy, Precision и Recall.
- Precision или Recall?
Матрица ошибок для бинарной классификации
В бинарной классификации каждая выборка относится к одному из двух классов. Обычно им присваиваются такие метки, как 1 и 0, или положительный и отрицательный (Positive и Negative). Также могут использоваться более конкретные обозначения для классов: злокачественный или доброкачественный (например, если проблема связана с классификацией рака), успех или неудача (если речь идет о классификации результатов тестов учащихся).
Предположим, что существует проблема бинарной классификации с классами positive и negative. Вот пример достоверных или эталонных меток для семи выборок, используемых для обучения модели.
positive, negative, negative, positive, positive, positive, negativeТакие наименования нужны в первую очередь для того, чтобы нам, людям, было проще различать классы. Для модели более важна числовая оценка. Обычно при передаче очередного набора данных на выходе вы получите не метку класса, а числовой результат. Например, когда эти семь семплов вводятся в модель, каждому классу будут назначены следующие значения:
0.6, 0.2, 0.55, 0.9, 0.4, 0.8, 0.5На основании полученных оценок каждой выборке присваивается соответствующий класс. Такое преобразование числовых результатов в метки происходит с помощью порогового значения. Данное граничное условие является гиперпараметром модели и может быть определено пользователем. Например, если порог равен 0.5, тогда любая оценка, которая больше или равна 0.5, получает положительную метку. В противном случае — отрицательную. Вот предсказанные алгоритмом классы:
positive (0.6), negative (0.2), positive (0.55), positive (0.9), negative (0.4), positive (0.8), positive (0.5)Сравните достоверные и полученные метки — мы имеем 4 верных и 3 неверных предсказания. Стоит добавить, что изменение граничного условия отражается на результатах. Например, установка порога, равного 0.6, оставляет только два неверных прогноза.
Реальность: positive, negative, negative, positive, positive, positive, negative
Предсказания: positive, negative, positive, positive, negative, positive, positiveДля получения дополнительной информации о характеристиках модели используется матрица ошибок (confusion matrix). Матрица ошибок помогает нам визуализировать, «ошиблась» ли модель при различении двух классов. Как видно на следующем рисунке, это матрица 2х2. Названия строк представляют собой эталонные метки, а названия столбцов — предсказанные.
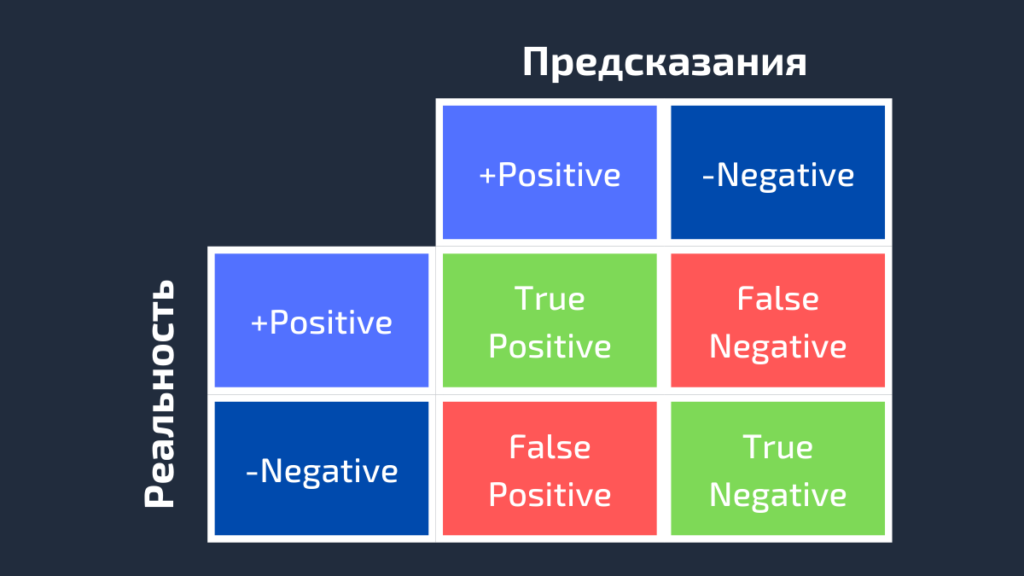
Четыре элемента матрицы (клетки красного и зеленого цвета) представляют собой четыре метрики, которые подсчитывают количество правильных и неправильных прогнозов, сделанных моделью. Каждому элементу дается метка, состоящая из двух слов:
- True или False.
- Positive или Negative.
True, если получено верное предсказание, то есть эталонные и предсказанные метки классов совпадают, и False, когда они не совпадают. Positive или Negative — названия предсказанных меток.
Таким образом, всякий раз, когда прогноз неверен, первое слово в ячейке False, когда верен — True. Наша цель состоит в том, чтобы максимизировать показатели со словом «True» (True Positive и True Negative) и минимизировать два других (False Positive и False Negative). Четыре метрики в матрице ошибок представляют собой следующее:
- Верхний левый элемент (True Positive): сколько раз модель правильно классифицировала Positive как Positive?
- Верхний правый (False Negative): сколько раз модель неправильно классифицировала Positive как Negative?
- Нижний левый (False Positive): сколько раз модель неправильно классифицировала Negative как Positive?
- Нижний правый (True Negative): сколько раз модель правильно классифицировала Negative как Negative?
Мы можем рассчитать эти четыре показателя для семи предсказаний, использованных нами ранее. Полученная матрица ошибок представлена на следующем рисунке.
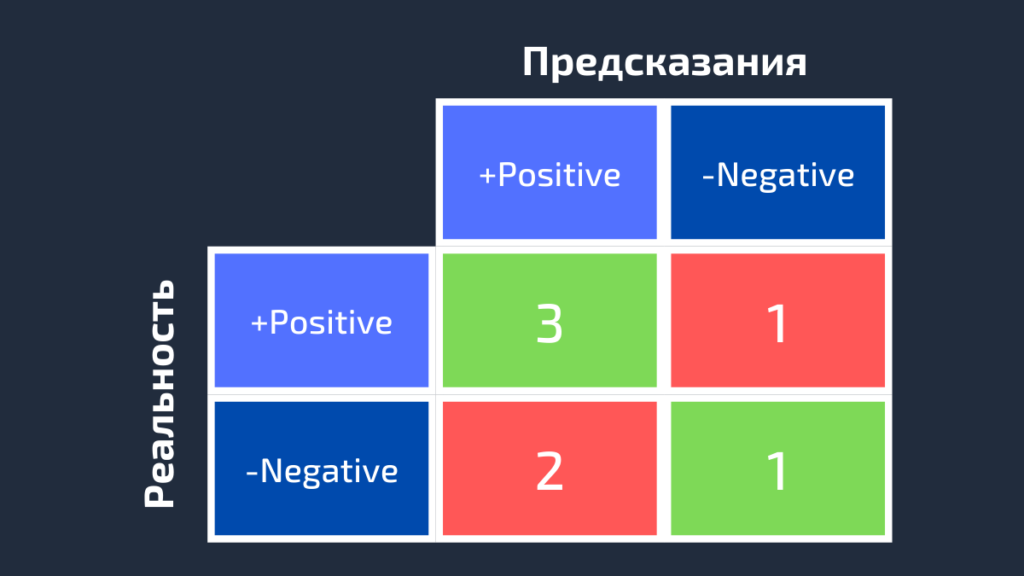
Вот так вычисляется матрица ошибок для задачи двоичной классификации. Теперь посмотрим, как решить данную проблему для большего числа классов.
Матрица ошибок для мультиклассовой классификации
Что, если у нас более двух классов? Как вычислить эти четыре метрики в матрице ошибок для задачи мультиклассовой классификации? Очень просто!
Предположим, имеется 9 семплов, каждый из которых относится к одному из трех классов: White, Black или Red. Вот достоверные метки для 9 выборок:
Red, Black, Red, White, White, Red, Black, Red, WhiteПосле загрузки данных модель делает следующее предсказание:
Red, White, Black, White, Red, Red, Black, White, RedДля удобства сравнения здесь они расположены рядом.
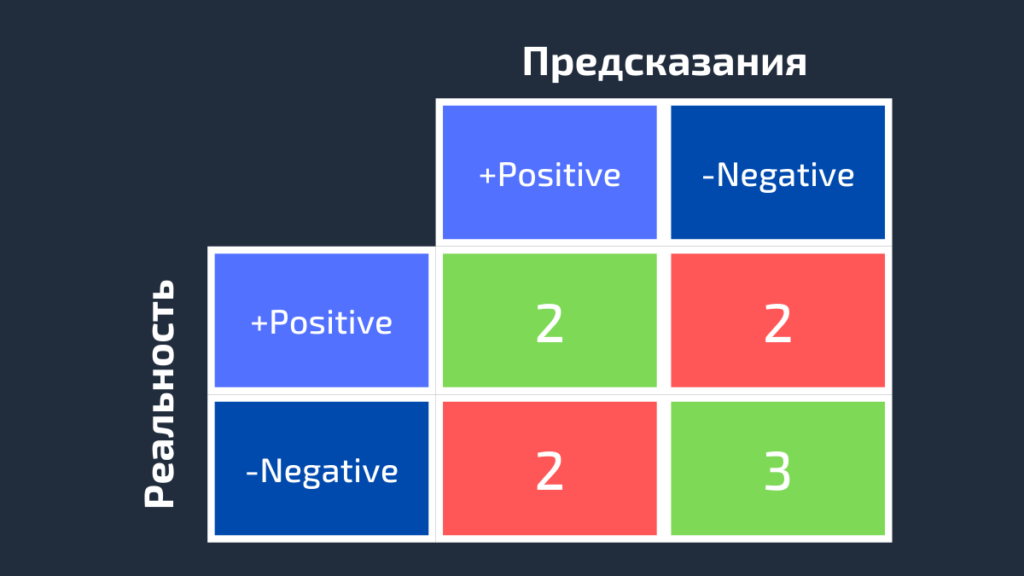
Реальность: Red, Black, Red, White, White, Red, Black, Red, White Предсказания: Red, White, Black, White, Red, Red, Black, White, RedПеред вычислением матрицы ошибок необходимо выбрать целевой класс. Давайте назначим на эту роль класс Red. Он будет отмечен как Positive, а все остальные отмечены как Negative.
Positive, Negative, Positive, Negative, Negative, Positive, Negative, Positive, Negative Positive, Negative, Negative, Negative, Positive, Positive, Negative, Negative, Positive11111111111111111111111После замены остались только два класса (Positive и Negative), что позволяет нам рассчитать матрицу ошибок, как было показано в предыдущем разделе. Стоит заметить, что полученная матрица предназначена только для класса Red.
Далее для класса White заменим каждое его вхождение на Positive, а метки всех остальных классов на Negative. Мы получим такие достоверные и предсказанные метки:
Negative, Negative, Negative, Positive, Positive, Negative, Negative, Negative, Positive Negative, Positive, Negative, Positive, Negative, Negative, Negative, Positive, NegativeНа следующей схеме показана матрица ошибок для класса White.
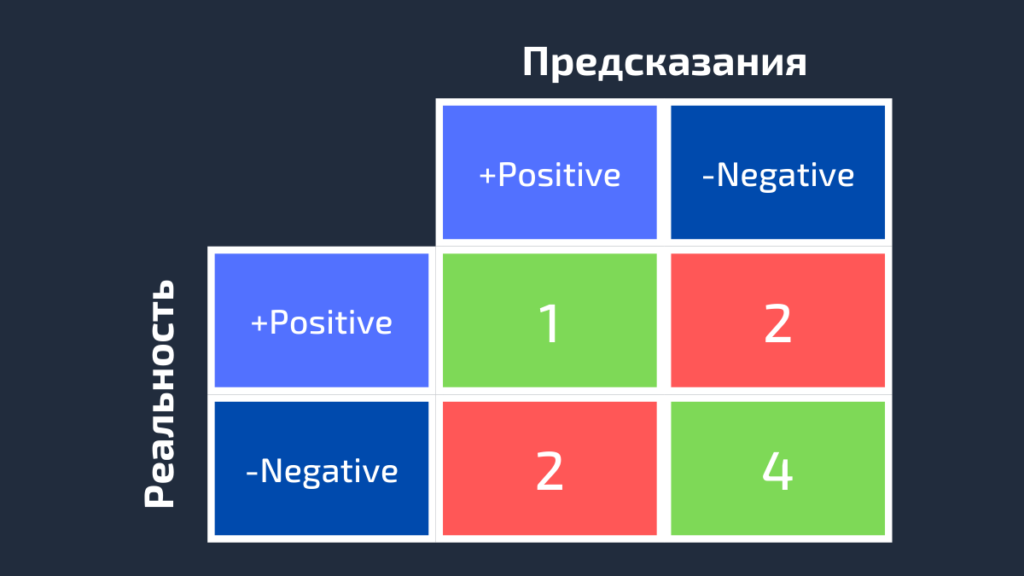
Точно так же может быть получена матрица ошибок для Black.
Расчет матрицы ошибок с помощью Scikit-Learn
В популярной Python-библиотеке Scikit-learn есть модуль metrics, который можно использовать для вычисления метрик в матрице ошибок.
Для задач с двумя классами используется функция confusion_matrix(). Мы передадим в функцию следующие параметры:
y_true: эталонные метки.y_pred: предсказанные метки.
Следующий код вычисляет матрицу ошибок для примера двоичной классификации, который мы обсуждали ранее.
import sklearn.metrics
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative"]
y_pred = ["positive", "negative", "positive", "positive", "negative", "positive", "positive"]
r = sklearn.metrics.confusion_matrix(y_true, y_pred)
print(r)
array([[1, 2],
[1, 3]], dtype=int64)Обратите внимание, что порядок метрик отличается от описанного выше. Например, показатель True Positive находится в правом нижнем углу, а True Negative — в верхнем левом углу. Чтобы исправить это, мы можем перевернуть матрицу.
import numpy
r = numpy.flip(r)
print(r)
array([[3, 1],
[2, 1]], dtype=int64)Чтобы вычислить матрицу ошибок для задачи с большим числом классов, используется функция multilabel_confusion_matrix(), как показано ниже. В дополнение к параметрам y_true и y_pred третий параметр labels принимает список классовых меток.
import sklearn.metrics
import numpy
y_true = ["Red", "Black", "Red", "White", "White", "Red", "Black", "Red", "White"]
y_pred = ["Red", "White", "Black", "White", "Red", "Red", "Black", "White", "Red"]
r = sklearn.metrics.multilabel_confusion_matrix(y_true, y_pred, labels=["White", "Black", "Red"])
print(r)
array([
[[4 2]
[2 1]]
[[6 1]
[1 1]]
[[3 2]
[2 2]]], dtype=int64)Функция вычисляет матрицу ошибок для каждого класса и возвращает все матрицы. Их порядок соответствует порядку меток в параметре labels. Чтобы изменить последовательность метрик в матрицах, мы будем снова использовать функцию numpy.flip().
print(numpy.flip(r[0])) # матрица ошибок для класса White
print(numpy.flip(r[1])) # матрица ошибок для класса Black
print(numpy.flip(r[2])) # матрица ошибок для класса Red
# матрица ошибок для класса White
[[1 2]
[2 4]]
# матрица ошибок для класса Black
[[1 1]
[1 6]]
# матрица ошибок для класса Red
[[2 2]
[2 3]]В оставшейся части этого текста мы сосредоточимся только на двух классах. В следующем разделе обсуждаются три ключевых показателя, которые рассчитываются на основе матрицы ошибок.
Как мы уже видели, матрица ошибок предлагает четыре индивидуальных показателя. На их основе можно рассчитать другие метрики, которые предоставляют дополнительную информацию о поведении модели:
- Accuracy
- Precision
- Recall
В следующих подразделах обсуждается каждый из этих трех показателей.
Метрика Accuracy
Accuracy — это показатель, который описывает общую точность предсказания модели по всем классам. Это особенно полезно, когда каждый класс одинаково важен. Он рассчитывается как отношение количества правильных прогнозов к их общему количеству.
Рассчитаем accuracy с помощью Scikit-learn на основе ранее полученной матрицы ошибок. Переменная acc содержит результат деления суммы True Positive и True Negative метрик на сумму всех значений матрицы. Таким образом, accuracy, равная 0.5714, означает, что модель с точностью 57,14% делает верный прогноз.
import numpy
import sklearn.metrics
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative"]
y_pred = ["positive", "negative", "positive", "positive", "negative", "positive", "positive"]
r = sklearn.metrics.confusion_matrix(y_true, y_pred)
r = numpy.flip(r)
acc = (r[0][0] + r[-1][-1]) / numpy.sum(r)
print(acc)
# вывод будет 0.571
В модуле sklearn.metrics есть функция precision_score(), которая также может вычислять accuracy. Она принимает в качестве аргументов достоверные и предсказанные метки.
acc = sklearn.metrics.accuracy_score(y_true, y_pred)
Стоит учесть, что метрика accuracy может быть обманчивой. Один из таких случаев — это несбалансированные данные. Предположим, у нас есть всего 600 единиц данных, из которых 550 относятся к классу Positive и только 50 — к Negative. Поскольку большинство семплов принадлежит к одному классу, accuracy для этого класса будет выше, чем для другого.
Если модель сделала 530 правильных прогнозов из 550 для класса Positive, по сравнению с 5 из 50 для Negative, то общая accuracy равна (530 + 5) / 600 = 0.8917. Это означает, что точность модели составляет 89.17%. Полагаясь на это значение, вы можете подумать, что для любой выборки (независимо от ее класса) модель сделает правильный прогноз в 89.17% случаев. Это неверно, так как для класса Negative модель работает очень плохо.
Precision
Precision представляет собой отношение числа семплов, верно классифицированных как Positive, к общему числу выборок с меткой Positive (распознанных правильно и неправильно). Precision измеряет точность модели при определении класса Positive.
Когда модель делает много неверных Positive классификаций, это увеличивает знаменатель и снижает precision. С другой стороны, precision высока, когда:
- Модель делает много корректных предсказаний класса Positive (максимизирует True Positive метрику).
- Модель делает меньше неверных Positive классификаций (минимизирует False Positive).
Представьте себе человека, который пользуется всеобщим доверием; когда он что-то предсказывает, окружающие ему верят. Метрика precision похожа на такого персонажа. Если она высока, вы можете доверять решению модели по определению очередной выборки как Positive. Таким образом, precision помогает узнать, насколько точна модель, когда она говорит, что семпл имеет класс Positive.
Основываясь на предыдущем обсуждении, вот определение precision:
Precision отражает, насколько надежна модель при классификации Positive-меток.
На следующем изображении зеленая метка означает, что зеленый семпл классифицирован как Positive, а красный крест – как Negative. Модель корректно распознала две Positive выборки, но неверно классифицировала один Negative семпл как Positive. Из этого следует, что метрика True Positive равна 2, когда False Positive имеет значение 1, а precision составляет 2 / (2 + 1) = 0.667. Другими словами, процент доверия к решению модели, что выборка относится к классу Positive, составляет 66.7%.
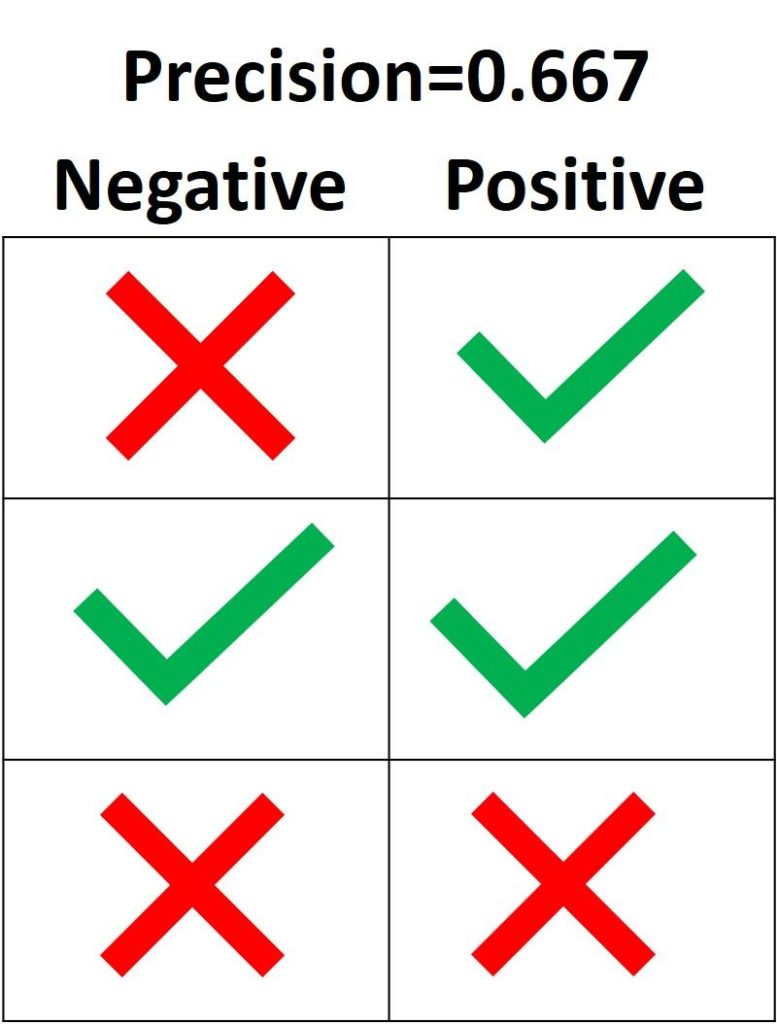
Цель precision – классифицировать все Positive семплы как Positive, не допуская ложных определений Negative как Positive. Согласно следующему рисунку, если все три Positive выборки предсказаны правильно, но один Negative семпл классифицирован неверно, precision составляет 3 / (3 + 1) = 0.75. Таким образом, утверждения модели о том, что выборка относится к классу Positive, корректны с точностью 75%.
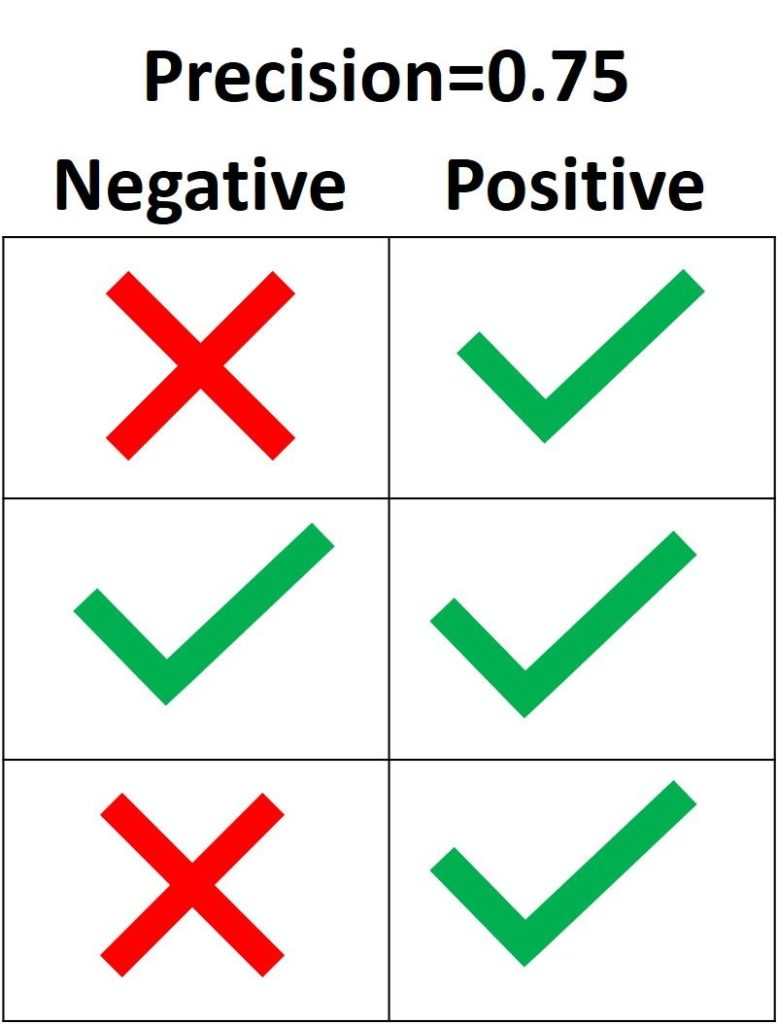
Единственный способ получить 100% precision — это классифицировать все Positive выборки как Positive без классификации Negative как Positive.
В Scikit-learn модуль sklearn.metrics имеет функцию precision_score(), которая получает в качестве аргументов эталонные и предсказанные метки и возвращает precision. Параметр pos_label принимает метку класса Positive (по умолчанию 1).
import sklearn.metrics
y_true = ["positive", "positive", "positive", "negative", "negative", "negative"]
y_pred = ["positive", "positive", "negative", "positive", "negative", "negative"]
precision = sklearn.metrics.precision_score(y_true, y_pred, pos_label="positive")
print(precision)
Вывод: 0.6666666666666666.
Recall
Recall рассчитывается как отношение числа Positive выборок, корректно классифицированных как Positive, к общему количеству Positive семплов. Recall измеряет способность модели обнаруживать выборки, относящиеся к классу Positive. Чем выше recall, тем больше Positive семплов было найдено.
Recall заботится только о том, как классифицируются Positive выборки. Эта метрика не зависит от того, как предсказываются Negative семплы, в отличие от precision. Когда модель верно классифицирует все Positive выборки, recall будет 100%, даже если все представители класса Negative были ошибочно определены как Positive. Давайте посмотрим на несколько примеров.
На следующем изображении представлены 4 разных случая (от A до D), и все они имеют одинаковый recall, равный 0.667. Представленные примеры отличаются только тем, как классифицируются Negative семплы. Например, в случае A все Negative выборки корректно определены, а в случае D – наоборот. Независимо от того, как модель предсказывает класс Negative, recall касается только семплов относящихся к Positive.

Из 4 случаев, показанных выше, только 2 Positive выборки определены верно. Таким образом, метрика True Positive равна 2. False Negative имеет значение 1, потому что только один Positive семпл классифицируется как Negative. В результате recall будет равен 2 / (2 + 1) = 2/3 = 0.667.
Поскольку не имеет значения, как предсказываются объекты класса Negative, лучше их просто игнорировать, как показано на следующей схеме. При расчете recall необходимо учитывать только Positive выборки.

Что означает, когда recall высокий или низкий? Если recall имеет большое значение, все Positive семплы классифицируются верно. Следовательно, модели можно доверять в ее способности обнаруживать представителей класса Positive.
На следующем изображении recall равен 1.0, потому что все Positive семплы были правильно классифицированы. Показатель True Positive равен 3, а False Negative – 0. Таким образом, recall вычисляется как 3 / (3 + 0) = 1. Это означает, что модель обнаружила все Positive выборки. Поскольку recall не учитывает, как предсказываются представители класса Negative, могут присутствовать множество неверно определенных Negative семплов (высокая False Positive метрика).

С другой стороны, recall равен 0.0, если не удается обнаружить ни одной Positive выборки. Это означает, что модель обнаружила 0% представителей класса Positive. Показатель True Positive равен 0, а False Negative имеет значение 3. Recall будет равен 0 / (0 + 3) = 0.
Когда recall имеет значение от 0.0 до 1.0, это число отражает процент Positive семплов, которые модель верно классифицировала. Например, если имеется 10 экземпляров Positive и recall равен 0.6, получается, что модель корректно определила 60% объектов класса Positive (т.е. 0.6 * 10 = 6).
Подобно precision_score(), функция repl_score() из модуля sklearn.metrics вычисляет recall. В следующем блоке кода показан пример ее использования.
import sklearn.metrics
y_true = ["positive", "positive", "positive", "negative", "negative", "negative"]
y_pred = ["positive", "positive", "negative", "positive", "negative", "negative"]
recall = sklearn.metrics.recall_score(y_true, y_pred, pos_label="positive")
print(recall)
Вывод: 0.6666666666666666.
После определения precision и recall давайте кратко подведем итоги:
- Precision измеряет надежность модели при классификации Positive семплов, а recall определяет, сколько Positive выборок было корректно предсказано моделью.
- Precision учитывает классификацию как Positive, так и Negative семплов. Recall же использует при расчете только представителей класса Positive. Другими словами, precision зависит как от Negative, так и от Positive-выборок, но recall — только от Positive.
- Precision принимает во внимание, когда семпл определяется как Positive, но не заботится о верной классификации всех объектов класса Positive. Recall в свою очередь учитывает корректность предсказания всех Positive выборок, но не заботится об ошибочной классификации представителей Negative как Positive.
- Когда модель имеет высокий уровень recall метрики, но низкую precision, такая модель правильно определяет большинство Positive семплов, но имеет много ложных срабатываний (классификаций Negative выборок как Positive). Если модель имеет большую precision, но низкий recall, то она делает высокоточные предсказания, определяя класс Positive, но производит всего несколько таких прогнозов.
Некоторые вопросы для проверки понимания:
- Если recall равен 1.0, а в датасете имеются 5 объектов класса Positive, сколько Positive семплов было правильно классифицировано моделью?
- Учитывая, что recall составляет 0.3, когда в наборе данных 30 Positive семплов, сколько представителей класса Positive будет предсказано верно?
- Если recall равен 0.0 и в датасете14 Positive-семплов, сколько корректных предсказаний класса Positive было сделано моделью?
Precision или Recall?
Решение о том, следует ли использовать precision или recall, зависит от типа вашей проблемы. Если цель состоит в том, чтобы обнаружить все positive выборки (не заботясь о том, будут ли negative семплы классифицированы как positive), используйте recall. Используйте precision, если ваша задача связана с комплексным предсказанием класса Positive, то есть учитывая Negative семплы, которые были ошибочно классифицированы как Positive.
Представьте, что вам дали изображение и попросили определить все автомобили внутри него. Какой показатель вы используете? Поскольку цель состоит в том, чтобы обнаружить все автомобили, используйте recall. Такой подход может ошибочно классифицировать некоторые объекты как целевые, но в конечном итоге сработает для предсказания всех автомобилей.
Теперь предположим, что вам дали снимок с результатами маммографии, и вас попросили определить наличие рака. Какой показатель вы используете? Поскольку он обязан быть чувствителен к неверной идентификации изображения как злокачественного, мы должны быть уверены, когда классифицируем снимок как Positive (то есть с раком). Таким образом, предпочтительным показателем в данном случае является precision.
Вывод
В этом руководстве обсуждалась матрица ошибок, вычисление ее 4 метрик (true/false positive/negative) для задач бинарной и мультиклассовой классификации. Используя модуль metrics библиотеки Scikit-learn, мы увидели, как получить матрицу ошибок в Python.
Основываясь на этих 4 показателях, мы перешли к обсуждению accuracy, precision и recall метрик. Каждая из них была определена и использована в нескольких примерах. Модуль sklearn.metrics применяется для расчета каждого вышеперечисленного показателя.
| title | date | categories | tags | |||||
|---|---|---|---|---|---|---|---|---|
|
How to create a confusion matrix with Scikit-learn? |
2020-05-05 |
frameworks |
|
After training a supervised machine learning model such as a classifier, you would like to know how well it works.
This is often done by setting apart a small piece of your data called the test set, which is used as data that the model has never seen before.
If it performs well on this dataset, it is likely that the model performs well on other data too — if it is sampled from the same distribution as your test set, of course.
Now, when you test your model, you feed it the data — and compare the predictions with the ground truth, measuring the number of true positives, true negatives, false positives and false negatives. These can subsequently be visualized in a visually appealing confusion matrix.
In today’s blog post, we’ll show you how to create such a confusion matrix with Scikit-learn, one of the most widely used frameworks for machine learning in today’s ML community. By means of an example created with Python, we’ll show you step-by-step how to generate a matrix with which you can visually determine the performance of your model easily.
All right, let’s go! 
[toc]
A confusion matrix in more detail
Training your machine learning model involves its evaluation. In many cases, you have set apart a test set for this.
The test set is a dataset that the trained model has never seen before. Using it allows you to test whether the model has overfit, or adapted to the training data too well, or whether it still generalizes to new data.
This allows you to ensure that your model does not perform very poorly on new data while it still performs really good on the training set. That wouldn’t really work in practice, would it
Evaluation with a test set often happens by feeding all the samples to the model, generating a prediction. Subsequently, the predictions are compared with the ground truth — or the true targets corresponding to the test set. These can subsequently be used for computing various metrics.
But they can also be used to demonstrate model performance in a visual way.
Here is an example of a confusion matrix:

To be more precise, it is a normalized confusion matrix. Its axes describe two measures:
- The true labels, which are the ground truth represented by your test set.
- The predicted labels, which are the predictions generated by the machine learning model for the features corresponding to the true labels.
It allows you to easily compare how well your model performs. For example, in the model above, for all true labels 1, the predicted label is 1. This means that all samples from class 1 were classified correctly. Great!
For the other classes, performance is also good, but a little bit worse. As you can see, for class 2, some samples were predicted as being part of classes 0 and 1.
In short, it answers the question «For my true labels / ground truth, how well does the model predict?».
It’s also possible to start from a prediction point of view. In this case, the question would change to «For my predicted label, how many predictions are actually part of the predicted class?». It’s the opposite point of view, but could be a valid question in many machine learning cases.
Most preferably, the entire set of true labels is equal to the set of predicted labels. In those cases, you would see zeros everywhere except for the line from the top left to the bottom right. In practice, however, this does not happen often. Likely, the plot is much more scattered, like this SVM classifier where many supporrt vectors are necessary to draw a decision boundary that does not work perfectly, but adequately enough:



Creating a confusion matrix with Python and Scikit-learn
Let’s now see if we can create a confusion matrix ourselves. Today, we will be using Python and Scikit-learn, one of the most widely used frameworks for machine learning today.
Creating a confusion matrix involves various steps:
- Generating an example dataset. This one makes sense: we need data to train our model on. We’ll therefore be generating data first, so that we can make an adequate choice for a ML model class next.
- Picking a machine learning model class. Obviously, if we want to evaluate a model, we need to train a model. We’ll choose a particular type of model first that fits the characteristics of our data.
- Constructing and training the ML model. The consequence of the first two steps is that we end up with a trained model.
- Generating the confusion matrix. Finally, based on the trained model, we can create our confusion matrix.
Software dependencies you need to install
Very briefly, but importantly: if you wish to run this code, you must make sure that you have certain software dependencies installed. Here they are:
- You need to install Python, which is the platform that our code runs on, version 3.6+.
- You need to install Scikit-learn, the machine learning framework that we will be using today:
pip install -U scikit-learn. - You need to install Numpy for numbers processing:
pip install numpy. - You need to install Matplotlib for visualizing the plots:
pip install matplotlib. - Finally, if you wish to generate a plot of decision boundaries (not required), you also need to install Mlxtend:
pip install mlxtend.
[affiliatebox]
Generating an example dataset
The first step is generating an example dataset. We will be using Scikit-learn for this purpose too. First, create a file called confusion-matrix.py, and open it in a code editor. The first thing we do is add the imports:
# Imports
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
The make_blobs function from Scikit-learn allows us to generate ‘blobs’, or clusters, of samples. Those blobs are centered around some point and are the samples are scattered around this point based on some standard deviation. This gives you flexibility about both the position and the structure of your generated dataset, in turn allowing you to experiment with a variety of ML models without having to worry about the data.
As we will evaluate the model, we need to ensure that the dataset is split between training and testing data. Scikit-learn also allows us to do this, with train_test_split. We therefore import that one too.
Configuration options
Next, we can define a number of configuration options:
# Configuration options
blobs_random_seed = 42
centers = [(0,0), (5,5), (0,5), (2,3)]
cluster_std = 1.3
frac_test_split = 0.33
num_features_for_samples = 4
num_samples_total = 5000
The random seed describes the initialization of the pseudo-random number generator used for generating the blobs of data. As you may know, no random number generator is truly random. What’s more, they are also initialized differently. Configuring a fixed seed ensures that every time you run the script, the random number generator initializes in the same way. If weird behavior occurs, you know that it’s likely not the random number generator.
The centers describe the centers in two-dimensional space of our blobs of data. As you can see, we have 4 blobs today.
The cluster standard deviation describes the standard deviation with which a sample is drawn from the sampling distribution used by the random point generator. We set it to 1.3; a lower number produces clusters that are better separable, and vice-versa.
The fraction of the train/test split determines how much data is split off for testing purposes. In our case, that’s 33% of the data.
The number of features for our samples is 4, and indeed describes how many targets we have: 4, as we have 4 blobs of data.
Finally, the number of samples generated is pretty self-explanatory. We set it to 5000 samples. That’s not too much data, but more than sufficient for the educational purposes of today’s blog post.
Generating the data
Next up is the call to make_blobs and to train_test_split for actually generating and splitting the data:
# Generate data
inputs, targets = make_blobs(n_samples = num_samples_total, centers = centers, n_features = num_features_for_samples, cluster_std = cluster_std)
X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=frac_test_split, random_state=blobs_random_seed)
Saving the data (optional)
Once the data is generated, you may choose to save it to file. This is an optional step — and I include it because I want to re-use the same dataset every time I run the script (e.g. because I am tweaking a visualization). If you use the code below, you can run it once — then, it’s saved in the .npy file. When you subsequently uncomment the np.save call, and possibly also the generate data calls, you’ll always have the same data load from file.
Then, you can tweak away your visualization easily without having to deal with new data all the time
# Save and load temporarily
np.save('./data_cf.npy', (X_train, X_test, y_train, y_test))
X_train, X_test, y_train, y_test = np.load('./data_cf.npy', allow_pickle=True)
Should you wish to visualize the data, this is of course possible:
# Generate scatter plot for training data
plt.scatter(X_train[:,0], X_train[:,1])
plt.title('Linearly separable data')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
Picking a machine learning model class
Now that we have our code for generating the dataset, we can take a look at the output to determine what kind of model we could use:

I can derive a few characteristics from this dataset (which, obviously, I also built-in up front  ).
).
First of all, the number of features is low: only two — as our data is two-dimensional. This is good, because then we likely don’t face the curse of dimensionality, and a wider range of ML models is applicable.
Next, when inspecting the data from a closer point of view, I can see a gap between what seem to be blobs of data (it is also slightly visible in the diagram above):

This suggests that the data may be separable, and possibly even linearly so (yes, of course, I know this is the case ).
Third, and finally, the number of samples is relatively low: only 5.000 samples are present. Neural networks with their relatively large amount of trainable parameters would likely start overfitting relatively quickly, so they wouldn’t be my preferable choice.
However, traditional machine learning techniques to the rescue. A Support Vector Machine, which attempts to construct a decision boundary between separable blobs of data, can be a good candidate here. Let’s give it a try: we’re going to construct and train an SVM and see how well it performs through its confusion matrix.
Constructing and training the ML model
As we have seen in the post linked above, we can also use Scikit-learn to construct and train a SVM classifier. Let’s do so next.
Model imports
First, we’ll have to add a few extra imports to the top of our script:
from sklearn import svm
from sklearn.metrics import plot_confusion_matrix
from mlxtend.plotting import plot_decision_regions
(The Mlxtend one is optional, as we discussed at ‘what you need to install’, but could be useful if you wish to visualize the decision boundary later.)
Training the classifier
First, we initialize the SVM classifier. I’m using a linear kernel because I suspect (actually, I’m confident, as we constructed the data ourselves) that the data is linearly separable:
# Initialize SVM classifier
clf = svm.SVC(kernel='linear')
Then, we fit the training data — starting the training process:
# Fit data
clf = clf.fit(X_train, y_train)
That’s it for training the machine learning model! The classifier variable, or clf, now contains a reference to the trained classifier. By calling clf.predict, you can now generate predictions for new data.
Generating the confusion matrix
But let’s take a look at generating that confusion matrix now. As we discussed, it’s part of the evaluation step, and we use it to visualize its predictive and generalization power on the test set.
Recall that we compare the predictions generated during evaluation with the ground truth available for those inputs.
The plot_confusion_matrix call takes care of this for us, and we simply have to provide it the classifier (clf), the test set (X_test and y_test), a color map and whether to normalize the data.
# Generate confusion matrix
matrix = plot_confusion_matrix(clf, X_test, y_test,
cmap=plt.cm.Blues,
normalize='true')
plt.title('Confusion matrix for our classifier')
plt.show(matrix)
plt.show()

Normalization, here, involves converting back the data into the [0, 1] format above. If you leave out normalization, you get the number of samples that are part of that prediction:

Here are some other visualizations that help us explain the confusion matrix (for the boundary plot, you need to install Mlxtend with pip install mlxtend):


# Get support vectors
support_vectors = clf.support_vectors_
# Visualize support vectors
plt.scatter(X_train[:,0], X_train[:,1])
plt.scatter(support_vectors[:,0], support_vectors[:,1], color='red')
plt.title('Linearly separable data with support vectors')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
# Plot decision boundary
plot_decision_regions(X_test, y_test, clf=clf, legend=2)
plt.show()
It’s clear that we need many support vectors (the red samples) to generate the decision boundary. Given the relative unclarity of the separability between the data points, this is not unexpected. I’m actually quite satisfied with the performance of the model, as demonstrated by the confusion matrix (relatively blue diagonal line).
The only class that underperforms is class 3, with a score of 0.68. It’s still acceptable, but is lower than preferred. This can be explained by looking at the class in the decision boundary plot. Here, it’s clear that it’s the middle class — the reds. As those samples are surrounded by the other ones, it’s clear that the model has had significant difficulty generating the decision boundary. We might for example counter this by using a different kernel function which takes this into account, ensuring better separability. However, that’s not the core of today’s post.
Full model code
Should you wish to obtain the full model code, that’s of course possible. Here you go
# Imports
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.metrics import plot_confusion_matrix
from mlxtend.plotting import plot_decision_regions
# Configuration options
blobs_random_seed = 42
centers = [(0,0), (5,5), (0,5), (2,3)]
cluster_std = 1.3
frac_test_split = 0.33
num_features_for_samples = 4
num_samples_total = 5000
# Generate data
inputs, targets = make_blobs(n_samples = num_samples_total, centers = centers, n_features = num_features_for_samples, cluster_std = cluster_std)
X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=frac_test_split, random_state=blobs_random_seed)
# Save and load temporarily
np.save('./data_cf.npy', (X_train, X_test, y_train, y_test))
X_train, X_test, y_train, y_test = np.load('./data_cf.npy', allow_pickle=True)
# Generate scatter plot for training data
plt.scatter(X_train[:,0], X_train[:,1])
plt.title('Linearly separable data')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
# Initialize SVM classifier
clf = svm.SVC(kernel='linear')
# Fit data
clf = clf.fit(X_train, y_train)
# Generate confusion matrix
matrix = plot_confusion_matrix(clf, X_test, y_test,
cmap=plt.cm.Blues)
plt.title('Confusion matrix for our classifier')
plt.show(matrix)
plt.show()
# Get support vectors
support_vectors = clf.support_vectors_
# Visualize support vectors
plt.scatter(X_train[:,0], X_train[:,1])
plt.scatter(support_vectors[:,0], support_vectors[:,1], color='red')
plt.title('Linearly separable data with support vectors')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
# Plot decision boundary
plot_decision_regions(X_test, y_test, clf=clf, legend=2)
plt.show()
[affiliatebox]
Summary
That’s it for today! In this blog post, we created a confusion matrix with Python and Scikit-learn. After studying what a confusion matrix is, and how it displays true positives, true negatives, false positives and false negatives, we gave a step-by-step example for creating one yourself.
The example included generating a dataset, picking a suitable machine learning model for the dataset, constructing, configuring and training it, and finally interpreting the results i.e. the confusion matrix. This way, you should be able to understand what is happening and why I made certain choices.
I hope you’ve learnt something from today’s blog post! If you did, I would really appreciate it if you left a comment in the comments section 💬 Please do the same if you have questions or remarks. I’ll happily answer and improve my blog post where necessary.
Thank you for reading MachineCurve today and happy engineering! 😎
[scikitbox]
References
Raschka, S. (n.d.). Home — mlxtend. Site not found · GitHub Pages. https://rasbt.github.io/mlxtend/
Scikit-learn. (n.d.). scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation. Retrieved May 3, 2020, from https://scikit-learn.org/stable/index.html
Scikit-learn. (n.d.). 1.4. Support vector machines — scikit-learn 0.22.2 documentation. scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation. Retrieved May 3, 2020, from https://scikit-learn.org/stable/modules/svm.html#classification
Scikit-learn. (n.d.). Confusion matrix — scikit-learn 0.22.2 documentation. scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation. Retrieved May 5, 2020, from https://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
Scikit-learn. (n.d.). Sklearn.metrics.plot_confusion_matrix — scikit-learn 0.22.2 documentation. scikit-learn: machine learning in Python — scikit-learn 0.16.1 documentation. Retrieved May 5, 2020, from https://scikit-learn.org/stable/modules/generated/sklearn.metrics.plot_confusion_matrix.html#sklearn.metrics.plot_confusion_matrix
27 февраля 2017 г.
Метрики качества классификаторов
Матрица ошибок (Confusion matrix)
Матрица ошибок — это способ разбить объекты на четыре категории в зависимости от комбинации истинного ответа и ответа алгоритма.
Основные термины:
- TPTP — истино-положительное решение;
- TNTN — истино-отрицательное решение;
- FPFP — ложно-положительное решение (Ошибка первого рода);
- FNFN — ложно-отрицательное решение (Ошибка второго рода).
Интерактивная картинка с большим числом метрик
Accuracy — доля правильных ответов:
Accuracy=TP+TNP+N=TP+TNTP+TN+FP+FN{displaystyle mathrm {Accuracy} ={frac {mathrm {TP} +mathrm {TN} }{P+N}}={frac {mathrm {TP} +mathrm {TN} }{mathrm {TP} +mathrm {TN} +mathrm {FP} +mathrm {FN} }}}
Данная матрика имеет существенный недостаток — её значение необходимо оценивать в контексте баланса классов. Eсли в выборке 950 отрицательных и 50 положительных объектов, то при абсолютно случайной классификации мы получим долю правильных ответов 0.95. Это означает, что доля положительных ответов сама по себе не несет никакой информации о качестве работы алгоритма a(x), и вместе с ней следует анализировать соотношение классов в выборке.
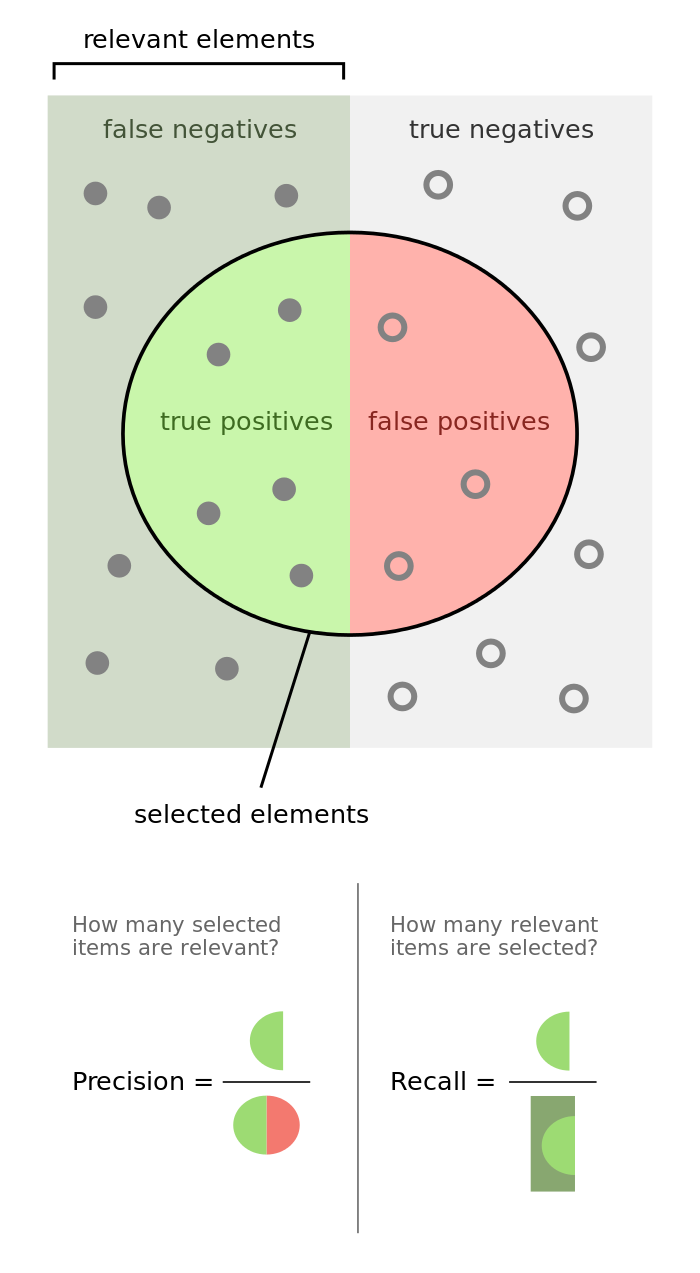
Гораздо более информативными критериями являются точность (precision) и полнота (recall).
Точность показывает, какая доля объектов, выделенных классификатором как положительные, действительно является положительными:
Precision=TPTP+FPPrecision = frac{TP}{TP+FP}
Полнота показывает, какая часть положительных объектов была выделена классификатором:
Recall=TPTP+FNRecall = frac{TP}{TP+FN}
Существует несколько способов получить один критерий качества на основе точности и полноты. Один из них — F-мера, гармоническое среднее точности и полноты:
F_beta = (1 + beta^2) cdot frac{mathrm{precision} cdot mathrm{recall}}{(beta^2 cdot mathrm{precision}) + mathrm{recall}} = frac {(1 + beta^2) cdot mathrm{true positive} }{(1 + beta^2) cdot mathrm{true positive} + beta^2 cdot mathrm{false negative} + mathrm{false positive}}
Среднее гармоническое обладает важным свойством — оно близко к нулю, если хотя бы один из аргументов близок к нулю. Именно поэтому оно является более предпочтительным, чем среднее арифметическое (если алгоритм будет относить все объекты к положительному классу, то он будет иметь recall = 1 и precision больше 0, а их среднее арифметическое будет больше 1/2, что недопустимо).
Чаще всего берут β=1beta=1, хотя иногда встречаются и другие модификации. F2F_2 острее реагирует на recall (т. е. на долю ложноположительных ответов), а F0.5F_{0.5} чувствительнее к точности (ослабляет влияние ложноположительных ответов).
В sklearn есть удобная функция sklearn.metrics.classification_report, возвращающая recall, precision и F-меру для каждого из классов, а также количество экземпляров каждого класса.
import pandas as pd import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, LabelEncoder from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn import datasets import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline %config InlineBackend.figure_format = 'svg'
from sklearn.metrics import classification_report y_true = [0, 1, 2, 2, 2] y_pred = [0, 0, 2, 2, 1] target_names = ['class 0', 'class 1', 'class 2'] print(classification_report(y_true, y_pred, target_names=target_names))
precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
micro avg 0.60 0.60 0.60 5
macro avg 0.50 0.56 0.49 5
weighted avg 0.70 0.60 0.61 5
Линейная классификация
Основная идея линейного классификатора заключается в том, что признаковое пространство может быть разделено гиперплоскостью на две полуплоскости, в каждой из которых прогнозируется одно из двух значений целевого класса.
Если это можно сделать без ошибок, то обучающая выборка называется линейно разделимой.

Указанная разделяющая плоскость называется линейным дискриминантом.
Логистическая регрессия
Логистическая регрессия является частным случаем линейного классификатора, но она обладает хорошим «умением» – прогнозировать вероятность отнесения наблюдения к классу. Таким образом, результат логистической регрессии всегда находится в интервале [0, 1].
iris = pd.read_csv("https://nagornyy.me/datasets/iris.csv")
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.057333 | 3.758000 | 1.199333 |
| std | 0.828066 | 0.435866 | 1.765298 | 0.762238 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
sns.pairplot(iris, hue="species")
/usr/local/lib/python3.7/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval
sns.lmplot(x="petal_length", y="petal_width", data=iris)
X = iris.iloc[:, 2:4].values y = iris['species'].values
array([‘setosa’, ‘setosa’, ‘setosa’, ‘setosa’, ‘setosa’], dtype=object)
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() le.fit(y) y = le.transform(y) y[:5]
iris_pred_names = le.classes_ iris_pred_names
array([‘setosa’, ‘versicolor’, ‘virginica’], dtype=object)
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=0)
from sklearn.preprocessing import StandardScaler sc = StandardScaler() sc.fit(X_train) X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test)
X_train[:5], X_train_std[:5]
(array([[3.5, 1. ],
[5.5, 1.8],
[5.7, 2.5],
[5. , 1.5],
[5.8, 1.8]]), array([[-0.18295039, -0.29318114],
[ 0.93066067, 0.7372463 ],
[ 1.04202177, 1.63887031],
[ 0.6522579 , 0.35083601],
[ 1.09770233, 0.7372463 ]]))
from sklearn.linear_model import LogisticRegression lr = LogisticRegression(C=100.0, random_state=1) lr.fit(X_train_std, y_train)
/usr/local/lib/python3.7/site-packages/sklearn/linear_model/logistic.py:433: FutureWarning: Default solver will be changed to ‘lbfgs’ in 0.22. Specify a solver to silence this warning.
FutureWarning)
/usr/local/lib/python3.7/site-packages/sklearn/linear_model/logistic.py:460: FutureWarning: Default multi_class will be changed to ‘auto’ in 0.22. Specify the multi_class option to silence this warning.
«this warning.», FutureWarning)
LogisticRegression(C=100.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class=’warn’,
n_jobs=None, penalty=’l2′, random_state=1, solver=’warn’,
tol=0.0001, verbose=0, warm_start=False)
lr.predict_proba(X_test_std[:3, :])
array([[2.77475804e-08, 6.31730607e-02, 9.36826912e-01],
[7.87476628e-03, 9.91707489e-01, 4.17744834e-04],
[8.15542033e-01, 1.84457967e-01, 8.14812482e-12]])
lr.predict_proba(X_test_std[:3, :]).sum(axis=1)
lr.predict_proba(X_test_std[:3, :]).argmax(axis=1)
Предсказываем класс первого наблюдения
lr.predict(X_test_std[0, :].reshape(1, -1))
На основе его коэффициентов:
array([0.70793846, 1.51006688])
X_test_std[0, :].reshape(1, -1)
array([[0.70793846, 1.51006688]])
y_pred = lr.predict(X_test_std)
print(classification_report(y_test, y_pred, target_names=iris_pred_names))
precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 1.00 0.94 0.97 18
virginica 0.92 1.00 0.96 11
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Машина опорных векторов
Основная идея метода — перевод исходных векторов в пространство более высокой размерности и поиск разделяющей гиперплоскости с максимальным зазором в этом пространстве. Две параллельных гиперплоскости строятся по обеим сторонам гиперплоскости, разделяющей классы. Разделяющей гиперплоскостью будет гиперплоскость, максимизирующая расстояние до двух параллельных гиперплоскостей. Алгоритм работает в предположении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора.
На практике случаи, когда данные можно разделить гиперплоскостью, довольно редки. В этом случае поступают так: все элементы обучающей выборки вкладываются в пространство X более высокой размерности, так, чтобы выборка была линейно разделима.
from sklearn.svm import SVC svm = SVC(kernel='linear', C=1.0, random_state=1) svm.fit(X_train_std, y_train)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=’ovr’, degree=3, gamma=’auto_deprecated’,
kernel=’linear’, max_iter=-1, probability=False, random_state=1,
shrinking=True, tol=0.001, verbose=False)
Kernel (ядро) отвечается за гиперплоскость и может принимать значения linear (для линейной), rbf (для нелинейной) и другие.
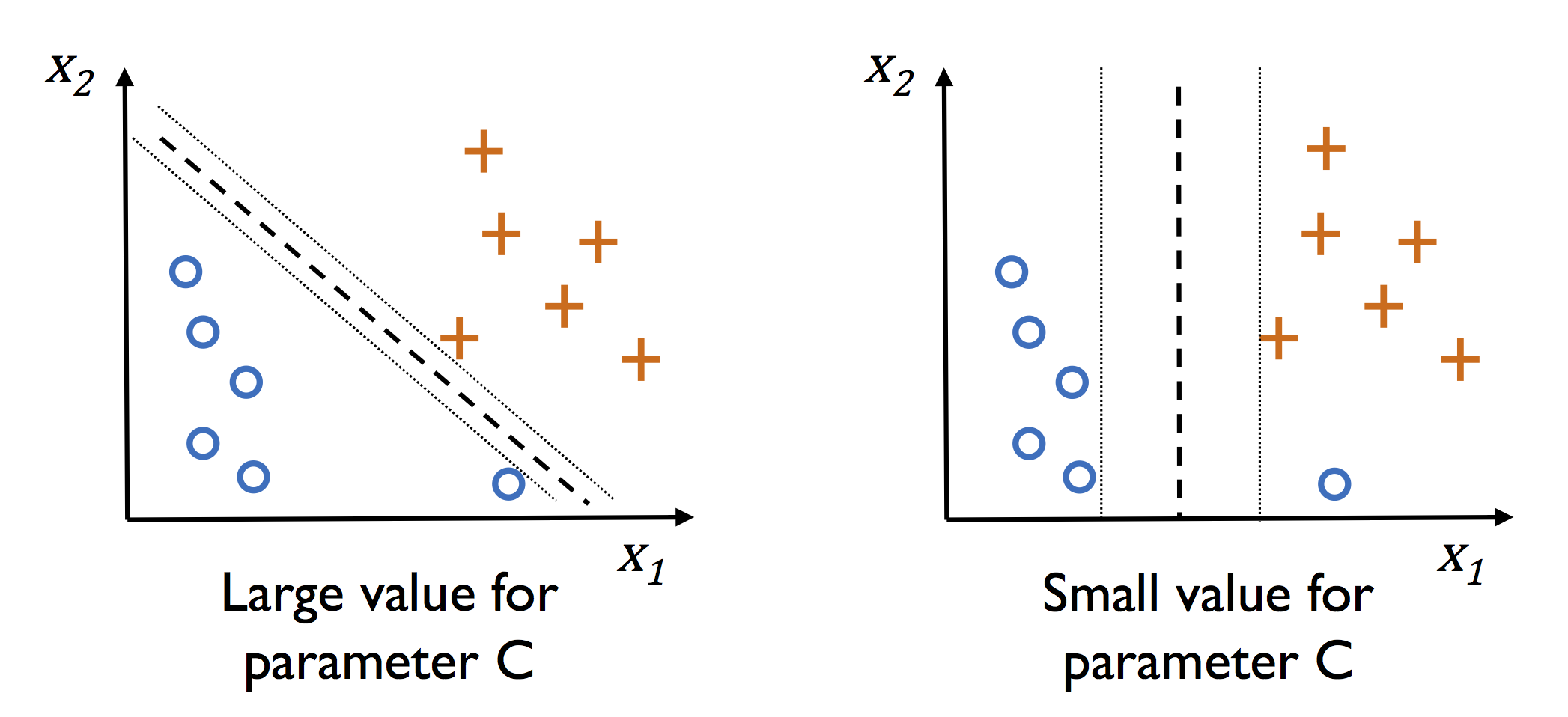
С — параметр регуляризации. Он в том числе контролирует соотношение между гладкой границей и корректной классификацией рассматриваемых точек.
gamma — это «ширина» rbf ядра (kernel). Она участвует в подгонке модели и может являться причиной переобучения.
y_pred_svm = svm.predict(X_test_std)
print(classification_report(y_test, y_pred_svm, target_names=iris_pred_names))
precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 1.00 0.94 0.97 18
virginica 0.92 1.00 0.96 11
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Нелинейная классификация
svm_rbf = SVC(kernel='rbf', random_state=1, gamma=0.10, C=10.0) svm_rbf.fit(X_train_std, y_train)
SVC(C=10.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=’ovr’, degree=3, gamma=0.1, kernel=’rbf’,
max_iter=-1, probability=False, random_state=1, shrinking=True,
tol=0.001, verbose=False)
y_pred_svm_rbf = svm_rbf.predict(X_test_std) print(classification_report(y_test, y_pred_svm_rbf, target_names=iris_pred_names))
precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 1.00 0.94 0.97 18
virginica 0.92 1.00 0.96 11
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Деревья решений
Деревья решений используются в повседневной жизни в самых разных областях человеческой деятельности.
До внедрения масштабируемых алгоритмов машинного обучения в банковской сфере задача кредитного скоринга решалась экспертами. Решение о выдаче кредита заемщику принималось на основе некоторых интуитивно (или по опыту) выведенных правил, которые можно представить в виде дерева решений:
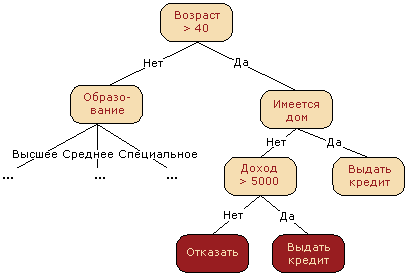
В этом случае можно сказать, что решается задача бинарной классификации (целевой класс имеет два значения: «Выдать кредит» и «Отказать») по признакам «Возраст», «Наличие дома», «Доход» и «Образование».
Дерево решений как алгоритм машинного обучения – по сути то же самое. Огромное преимущество деревьев решений в том, что они легко интерпретируемы, понятны человеку.
В основе популярных алгоритмов построения дерева решений лежит принцип жадной максимизации прироста информации – на каждом шаге выбирается тот признак, при разделении по которому прирост информации оказывается наибольшим. Дальше процедура повторяется рекурсивно, пока энтропия не окажется равной нулю или какой-то малой величине (если дерево не подгоняется идеально под обучающую выборку во избежание переобучения).
Плюсы:
- Порождение четких правил классификации, понятных человеку, например, «если возраст < 25 и интерес к мотоциклам, то отказать в кредите». Это свойство называют интерпретируемостью модели;
- Деревья решений могут легко визуализироваться, как сама модель (дерево), так и прогноз для отдельного взятого тестового объекта (путь в дереве);
- Быстрые процессы обучения и прогнозирования;
- Малое число параметров модели;
- Поддержка и числовых, и категориальных признаков.
Минусы:
- У порождения четких правил классификации есть и другая сторона: деревья очень чувствительны к шумам во входных данных, вся модель может кардинально измениться, если немного изменится обучающая выборка (например, если убрать один из признаков или добавить несколько объектов), поэтому и правила классификации могут сильно изменяться, что ухудшает интерпретируемость модели;
- Разделяющая граница, построенная деревом решений, имеет свои ограничения (состоит из гиперплоскостей, перпендикулярных какой-то из координатной оси), и на практике дерево решений по качеству классификации уступает некоторым другим методам;
from sklearn.tree import DecisionTreeClassifier tree = DecisionTreeClassifier(criterion='gini', max_depth=4, random_state=1) tree.fit(X_train_std, y_train)
DecisionTreeClassifier(class_weight=None, criterion=’gini’, max_depth=4,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=1,
splitter=’best’)
y_pred_tree = tree.predict(X_test_std) print(classification_report(y_test, y_pred_tree, target_names=iris_pred_names))
precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 1.00 0.94 0.97 18
virginica 0.92 1.00 0.96 11
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Collecting pydotplus
[?25l Downloading https://files.pythonhosted.org/packages/60/bf/62567830b700d9f6930e9ab6831d6ba256f7b0b730acb37278b0ccdffacf/pydotplus-2.0.2.tar.gz (278kB)
[K 100% |████████████████████████████████| 286kB 1.5MB/s
[?25hRequirement already satisfied: pyparsing>=2.0.1 in /usr/local/lib/python3.7/site-packages (from pydotplus) (2.3.0)
Building wheels for collected packages: pydotplus
Running setup.py bdist_wheel for pydotplus … [?25ldone
[?25h Stored in directory: /Users/hun/Library/Caches/pip/wheels/35/7b/ab/66fb7b2ac1f6df87475b09dc48e707b6e0de80a6d8444e3628
Successfully built pydotplus
Installing collected packages: pydotplus
Successfully installed pydotplus-2.0.2
from pydotplus import graph_from_dot_data from sklearn.tree import export_graphviz dot_data = export_graphviz(tree, filled=True, rounded=True, class_names=iris_pred_names, feature_names=['petal length', 'petal width'], out_file=None) graph = graph_from_dot_data(dot_data)
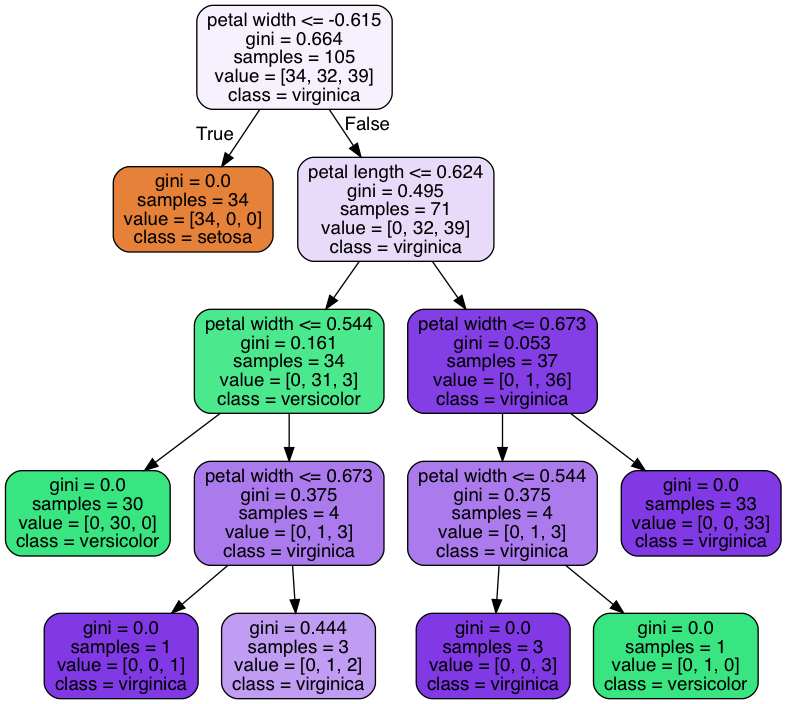
Метод ближайших соседей
Метод ближайших соседей (k Nearest Neighbors, или kNN) — тоже очень популярный метод классификации, также иногда используемый в задачах регрессии. Это, наравне с деревом решений, один из самых понятных подходов к классификации. На уровне интуиции суть метода такова: посмотри на соседей, какие преобладают, таков и ты. Формально основой метода является гипотеза компактности: если метрика расстояния между примерами введена достаточно удачно, то схожие примеры гораздо чаще лежат в одном классе, чем в разных.
Для классификации каждого из объектов тестовой выборки необходимо последовательно выполнить следующие операции:
- Вычислить расстояние до каждого из объектов обучающей выборки
- Отобрать k объектов обучающей выборки, расстояние до которых минимально
- Класс классифицируемого объекта — это класс, наиболее часто встречающийся среди k ближайших соседей
Под задачу регрессии метод адаптируется довольно легко – на 3 шаге возвращается не метка, а число – среднее (или медианное) значение целевого признака среди соседей.
Примечательное свойство такого подхода – его ленивость. Это значит, что вычисления начинаются только в момент классификации тестового примера, а заранее, только при наличии обучающих примеров, никакая модель не строится. В этом отличие, например, от ранее рассмотренного дерева решений, где сначала на основе обучающей выборки строится дерево, а потом относительно быстро происходит классификация тестовых примеров.
Качество классификации/регрессии методом ближайших соседей зависит от нескольких параметров:
- число соседей
- метрика расстояния между объектами (часто используются метрика Хэмминга, евклидово расстояние, косинусное расстояние и расстояние Минковского). Отметим, что при использовании большинства метрик значения признаков надо масштабировать. Условно говоря, чтобы признак «Зарплата» с диапазоном значений до 100 тысяч не вносил больший вклад в расстояние, чем «Возраст» со значениями до 100.
- веса соседей (соседи тестового примера могут входить с разными весами, например, чем дальше пример, тем с меньшим коэффициентом учитывается его «голос»)
Плюсы и минусы метода ближайших соседей
Плюсы:
- Простая реализация;
- Неплохо изучен теоретически;
- Как правило, метод хорош для первого решения задачи;
- Можно адаптировать под нужную задачу выбором метрики или ядра (ядро может задавать операцию сходства для сложных объектов типа графов, а сам подход kNN остается тем же);
- Неплохая интерпретация, можно объяснить, почему тестовый пример был классифицирован именно так.
Минусы:
- Метод считается быстрым в сравнении, например, с композициями алгоритмов, но в реальных задачах, как правило, число соседей, используемых для классификации, будет большим (100-150), и в таком случае алгоритм будет работать не так быстро, как дерево решений;
- Если в наборе данных много признаков, то трудно подобрать подходящие веса и определить, какие признаки не важны для классификации/регрессии;
- Зависимость от выбранной метрики расстояния между примерами. Выбор по умолчанию евклидового расстояния чаще всего ничем не обоснован. Можно отыскать хорошее решение перебором параметров, но для большого набора данных это отнимает много времени;
- Нет теоретических оснований выбора определенного числа соседей — только перебор (впрочем, чаще всего это верно для всех гиперпараметров всех моделей). В случае малого числа соседей метод чувствителен к выбросам, то есть склонен переобучаться;
- Как правило, плохо работает, когда признаков много, из-за «прояклятия размерности». Про это хорошо рассказывает известный в ML-сообществе профессор Pedro Domingos – тут в популярной статье «A Few Useful Things to Know about Machine Learning», также «the curse of dimensionality» описывается в книге Deep Learning в главе «Machine Learning basics».
Класс KNeighborsClassifier в Scikit-learn
Основные параметры класса sklearn.neighbors.KNeighborsClassifier:
- weights: «uniform» (все веса равны), «distance» (вес обратно пропорционален расстоянию до тестового примера) или другая определенная пользователем функция
- algorithm (опционально): «brute», «ball_tree», «KD_tree», или «auto». В первом случае ближайшие соседи для каждого тестового примера считаются перебором обучающей выборки. Во втором и третьем — расстояние между примерами хранятся в дереве, что ускоряет нахождение ближайших соседей. В случае указания параметра «auto» подходящий способ нахождения соседей будет выбран автоматически на основе обучающей выборки.
- leaf_size (опционально): порог переключения на полный перебор в случае выбора BallTree или KDTree для нахождения соседей
- metric: «minkowski», «manhattan», «euclidean», «chebyshev» и другие
from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski') knn.fit(X_train_std, y_train) y_pred_knn = knn.predict(X_test_std) print(classification_report(y_test, y_pred_knn, target_names=iris_pred_names))
precision recall f1-score support
setosa 1.00 1.00 1.00 16
versicolor 1.00 1.00 1.00 18
virginica 1.00 1.00 1.00 11
micro avg 1.00 1.00 1.00 45
macro avg 1.00 1.00 1.00 45
weighted avg 1.00 1.00 1.00 45
Домашнаяя работа
Примените изученные классификаторы для предсказания выживаемости на Титанике и постойте наилучший классификатор. Каковы значения основных его метрик?
Опирайтесь на эти статьи:
- Kaggle и Titanic — еще одно решение задачи с помощью Python
- Основы анализа данных на python с использованием pandas+sklearn
- Титаник на Kaggle: вы не дочитаете этот пост до конца
Evaluating the performance of classification models is crucial in machine learning, as it helps us understand how well our models are making predictions. One of the most effective ways to do this is by using a confusion matrix, a simple yet powerful tool that provides insights into the types of errors a model makes. In this tutorial, we will dive into the world of confusion matrices, exploring their components, the differences between binary and multi-class matrices, and how to interpret them.
By the end of this tutorial, you’ll have learned the following:
- What confusion matrices are and how to interpret them
- How to create them using Sklearn’s powerful functions
- How to create common confusion matrix metrics, such as accuracy and recall, using sklearn
- How to visualize a confusion matrix using Sklearn and Seaborn
What You’ll Learn About a Confusion Matrix in Python

What is a Confusion Matrix?
Understand what it is first
Read More

Creating a Confusion Matrix
Learn how to create a confusion matrix in Sklearn
Read More

Visualizing a Confusion Matrix
Visualize your confusion matrix using Seaborn
Read More
The Quick Answer: Use Sklearn’s confusion_matrix
To easily create a confusion matrix in Python, you can use Sklearn’s confusion_matrix function, which accepts the true and predicted values in a classification problem.
# Creating a Confusion Matrix in Python with sklearn
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
# Create a Model
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target, test_size=0.2)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# Create a Confusion Matrix
print(confusion_matrix(y_test, y_pred))
# Returns:
# [[37 3]
# [ 1 73]]Understanding a Confusion Matrix
A confusion matrix, also known as an error matrix, is a powerful tool used to evaluate the performance of classification models. The matrix is a tabular format that shows predicted values against their actual values.
This allows us to understand whether the model is performing well or not. Similarly, it allows you to identify where the model is making mistakes.
Definition and Explanation of a Confusion Matrix
A confusion matrix is a table that displays the number of correct and incorrect predictions made by a classification model. The table is presented in such a way that:
- The rows represent the instances of the actual class, and
- The columns represent the instances of the predicted class.
Take a look at the visualization below to see what a simple confusion matrix looks like:

Let’s break down what these sections of a confusion matrix mean.
Components of a Confusion Matrix
Similar to the image above, a confusion matrix is made up of four main components:
- True Positives (TP): instances where the model correctly predicted the positive class.
- True Negatives (TN): instances where the model correctly predicted the negative class.
- False Positives (FP): instances where the model incorrectly predicted the positive class (also known as Type I error).
- False Negatives (FN): instances where the model incorrectly predicted the negative class (also known as Type II error).

Understanding a Multi-Class Confusion Matrix
So far, we have discussed confusion matrices in the context of binary classification problems. This means that the model predicts something to either be one thing or not.
However, confusion matrices can also be used for multi-class classification problems, where there are more than two classes to predict. In this section, you’ll learn about the concept of multi-class confusion matrices and understand their components and differences from binary confusion matrices.
A multi-class confusion matrix builds on a simple, binary confusion matrix, designed to evaluate the performance of classification models with more than two classes. A multi-class confusion matrix is an n x n table, where n represents the number of classes in the problem.
Each row of the matrix corresponds to the instances of the actual class, and each column corresponds to the instances of the predicted class.
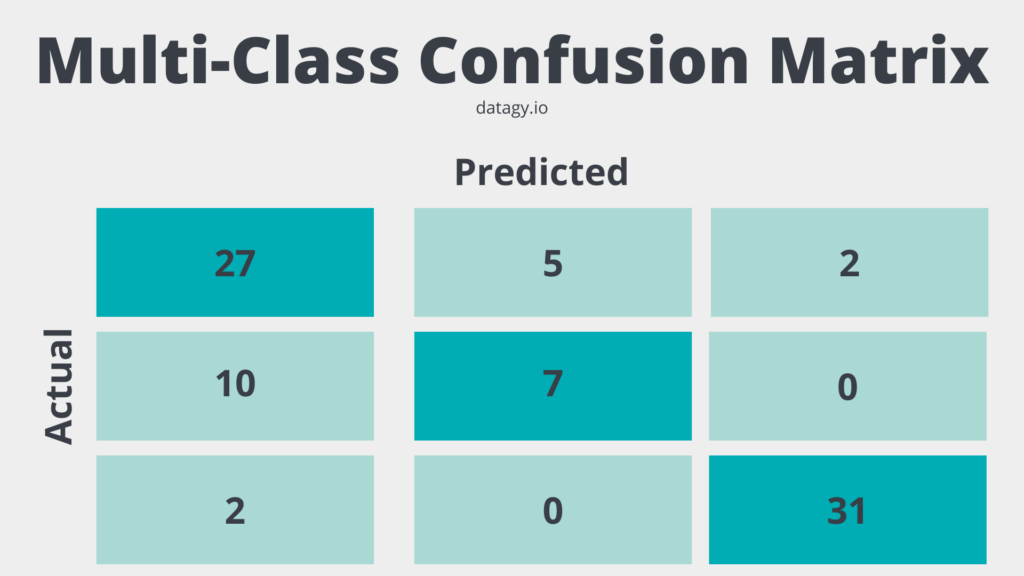
Components of a Multi-Class Confusion Matrix
A multi-class confusion matrix is different from a binary confusion matrix. Let’s explore how this is different:
- Diagonal elements: values along the diagonal represent the number of instances where the model correctly predicted the class. They are equivalent to True Positives (TP) in the binary case, but for each class.
- Off-diagonal elements: all values that aren’t on the diagonal represent the number of instances where the model incorrectly predicted the class. They correspond to False Positives (FP) and False Negatives (FN) in the binary case, but for each combination of classes.
In a multi-class confusion matrix, the sum of all diagonal elements gives the total number of correct predictions, and the sum of all off-diagonal elements gives the total number of incorrect predictions.
Differences and Similarities Between Binary and Multi-Class Confusion Matrices
While binary and multi-class confusion matrices serve the same purpose of evaluating classification models, there are some key differences and similarities between them:
- Structure: a binary confusion matrix is a 2 x 2 table, whereas a multi-class confusion matrix is a n x n table, where n is the number of classes.
- Components of a confusion matrix: Both binary and multi-class confusion matrices have diagonal elements representing correct predictions. Similarly, the off-diagonal elements represent incorrect predictions. However, in the multi-class case, there are multiple True Positives, False Positives, and False Negatives for each combination of classes.
Knowing how to work with both binary and multi-class confusion matrices will be essential in evaluating different types of machine learning models.
Importance of Using a Confusion Matrix for Classification Problems
A confusion matrix is useful for evaluating classification models by allowing you to understand the types of errors that a model is making. In particular, a classification matrix allows you to identify if a model is biased toward a particular class. Similarly, it allows you to better understand if a model is either too sensitive or too conservative.
How to Interpret a Confusion Matrix
Understanding the components of a confusion matrix is just the first step. In this section, you will learn how to interpret a confusion matrix. You’ll also learn how to calculate different performance metrics that can help us make informed decisions about your classification model.
Understanding the Components of a Confusion Matrix
As you learned earlier, a confusion matrix consists of four components: True Positives, True Negatives, False Positives, and False Negatives. To interpret a confusion matrix, we can examine these components and understand how they relate to the model’s performance.
Calculating Performance Metrics Using a Confusion Matrix
The values of a confusion matrix allow you to calculate a number of different performance metrics, including accuracy, precision, recall, and the F1 score. Let’s break these down a little bit more:
- Accuracy: The ratio of correct predictions (TP + TN) to the total number of predictions (TP + TN + FP + FN).
- Precision: The ratio of true positive predictions (TP) to the total number of positive predictions (TP + FP).
- Recall (Sensitivity): The ratio of true positive predictions (TP) to the total number of actual positive instances (TP + FN).
- F1 Score: The harmonic mean of precision and recall, which provides a balanced measure of the model’s performance.
Analyzing the Results and Making Informed Decisions
By calculating the performance metrics above, you’ll be able to better analyze how well your model is performing. By understanding the confusion matrix and the performance metrics, we can make informed decisions about our model, such as adjusting the classification threshold, balancing the dataset, or selecting a different algorithm to improve its performance.
For example, a model that shows high accuracy might indicate that the model is performing well. On the other hand, a model that has low precision or recall can indicate that a model may have issues in identifying classes correctly.
Creating a Confusion Matrix in Python
Now that you have learned how confusion matrices are valuable tools for evaluating classification problems in machine learning, let’s dive into how to create them using Python with sklearn. Sklearn is an invaluable tool for creating machine-learning models in Python.
Dataset Preparation and Model Training
For the purposes of this tutorial, we’ll be creating a confusion matrix using the sklearn breast cancer dataset, which identifies whether a tumor is malignant or benign. We won’t go through the model selection, creation, or prediction process in this tutorial. However, we’ll set up the baseline model so that we can create the confusion matrix.
# Loading a Binary Classification Model in Sklearn
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)In the code block above, we imported a number of different functions and classes from Sklearn. In particular, we followed best practices by splitting our dataset into training and testing datasets using the train_test_split function.
Generating a Confusion Matrix Using Sklearn
Now that we have a model created, we can build our first confusion matrix. Let’s take a look at the function and see what parameters it offers. The sklearn.metrics.confusion_matrix is a function that computes a confusion matrix and has the following parameters:
y_true: true labels for the test data.y_pred: predicted labels for the test data.labels: optional, list of labels to index the matrix. This may be used to reorder or select a subset of labels. If None is given, all labels are used.sample_weight: optional, sample weights.normalize: If set to ‘true’, the rows of the confusion matrix are normalized so that they sum up to 1. If set to ‘pred’, the columns of the confusion matrix are normalized so that they sum up to 1. If set to ‘all’, all values in the confusion matrix are normalized so that they sum up to 1. If set to None, no normalization is performed (default).
The only required parameters are the y_true and y_pred parameters. We created these in our previous code block. Let’s see how we can create our first confusion matrix:
# Create a confusion matrix
print(confusion_matrix(y_test, y_pred))
# Returns:
# [[37 3]
# [ 1 73]]In this example, there were:
- 37 true positives (i.e., cases where the model correctly predicted that the patient had breast cancer),
- 3 false positives (i.e., cases where the model incorrectly predicted that the patient had breast cancer),
- 1 false negative (i.e., a case where the model incorrectly predicted that the patient did not have breast cancer), and
- 73 true negatives (i.e., cases where the model correctly predicted that the patient did not have breast cancer).
Let’s now take a look at how we can interpret the generated confusion matrix.
Interpreting the Generated Confusion Matrix
The way in which you interpret a confusion matrix is determined by how accurate your model needs to be. For example, in our example, we are predicting whether or not someone has cancer. In these cases, the accuracy of our model is incredibly important. Even infrequent misclassifications can have significant impacts.
On the other hand, working with datasets with less profound consequences, there may be a larger margin for error. In my experience, it’s important to focus on truly understand the sensitivity and importance of misclassifications.
We can use Sklearn to calculate the accuracy, precision, recall, and F1 scores to help interpret our confusion matrix. Let’s see how we can do this in Python using sklearn:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# Calculate the accuracy
accuracy = accuracy_score(y_test, y_pred)
# Calculate the precision
precision = precision_score(y_test, y_pred)
# Calculate the recall
recall = recall_score(y_test, y_pred)
# Calculate the f1 score
f1 = f1_score(y_test, y_pred)
# Print the results
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1 Score:", f1)
# Returns:
# Accuracy: 0.956140350877193
# Precision: 0.9459459459459459
# Recall: 0.9859154929577465
# F1 Score: 0.9655172413793103Recall that these scores represent the following:
- Accuracy: The ratio of correct predictions (TP + TN) to the total number of predictions (TP + TN + FP + FN).
- Precision: The ratio of true positive predictions (TP) to the total number of positive predictions (TP + FP).
- Recall (Sensitivity): The ratio of true positive predictions (TP) to the total number of actual positive instances (TP + FN).
- F1 Score: The harmonic mean of precision and recall, which provides a balanced measure of the model’s performance.
We can simplify printing these values even further by using the sklearn classification_report function, which takes the true and predicted values as input:
# Using classification_report to Print Scores
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
# Returns:
# precision recall f1-score support
# 0 0.97 0.91 0.94 43
# 1 0.95 0.99 0.97 71
# accuracy 0.96 114
# macro avg 0.96 0.95 0.95 114
# weighted avg 0.96 0.96 0.96 114Finally, let’s take a look at how we can visualize the confusion matrix in Python, using Seaborn.
Visualizing a Confusion Matrix in Python
Sklearn provides a helpful class to help visualize a confusion matrix. While other tutorials will point you to the plot_confusion_matrix function, this function was recently deprecated. Because of this, it’s important to use the ConfusionMatrixDisplay class.
The ConfusionMatrixDisplay class lets you pass in a confusion matrix and the labels of your classes. You can then visualize the matrix by applying the .plot() method to your object. Take a look at what this looks like below:
# Plotting a Confusion Matrix with Sklearn
from sklearn.metrics import ConfusionMatrixDisplay
import matplotlib.pyplot as plt
conf_matrix = confusion_matrix(y_true=y_test, y_pred=y_pred)
vis = ConfusionMatrixDisplay(confusion_matrix=conf_matrix, display_labels=model.classes_)
vis.plot()
plt.show()In the code block above, we passed our confusion matrix into the ConfusionMatrixDisplay class constructor. We also included our display labels by accessing the classes. Finally, we applied the .plot() method and used the Matplotlib show() function to visualize the image below:
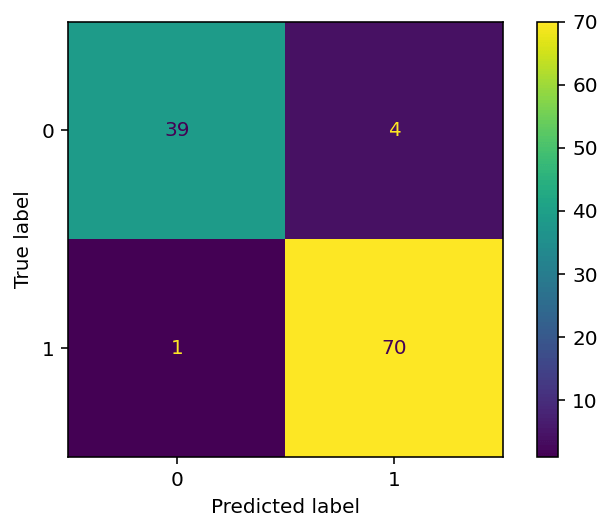
In the following section, you’ll learn how to plot a confusion matrix using Seaborn.
Using Seaborn to Plot a Confusion Matrix
Seaborn is a helpful Python data visualization library built on top of Matplotlib. Its mission is to make hard things easy, allowing you to create complex visualizations using a simple API.
Plotting a confusion matrix is similar to plotting a heatmap in Seaborn, indicating where values are higher or lower visually. In order to do this, let’s plot a confusion matrix for another model, where we have more than a binary class.
If you’re unfamiliar with KNN in Python using Sklearn, you can follow along with the tutorial link here. That said, the end result of the code block is a model with three classes, rather than two:
# Creating a Model with 3 Classes
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import seaborn as sns
df = sns.load_dataset('penguins')
df = df.dropna()
X = df.drop(columns = ['species', 'sex', 'island'])
y = df['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 100)
clf = KNeighborsClassifier(p=1)
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)In the code block above, we created a model that predicts three different classes. In order to plot the confusion matrix for this model, we can use the code below:
# Plotting a Confusion Matrix in Seaborn
conf_matrix = confusion_matrix(y_test, predictions, labels=clf.classes_)
sns.heatmap(conf_matrix,
annot=True,
fmt='g',
xticklabels=clf.classes_,
yticklabels=clf.classes_,
)
plt.ylabel('Prediction',fontsize=13)
plt.xlabel('Actual',fontsize=13)
plt.title('Confusion Matrix',fontsize=17)
plt.show()In the code block above, we used the heatmap function in Seaborn to plot our confusion matrix. We also modified the labels and titles using special functions.
This returned the following image:
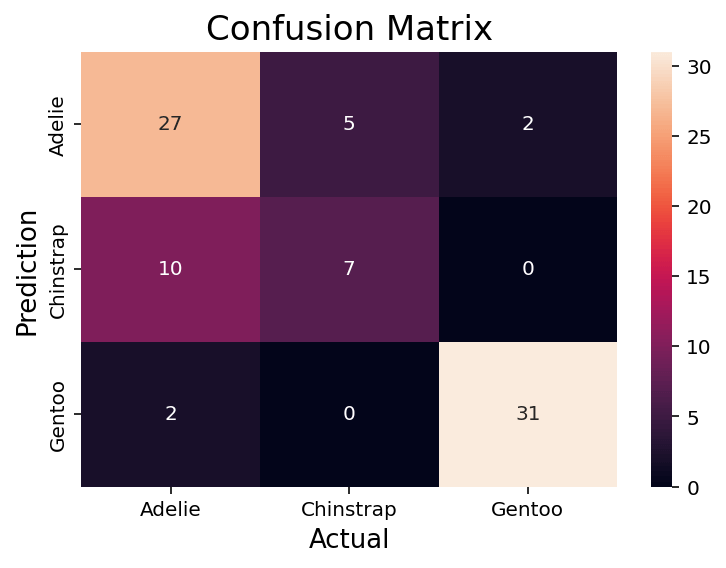
We can see that this returns an image very similar to the Sklearn one. One benefit of this approach is how declarative and familiar it is. If you’re familiar with Seaborn or matplotlib, customizing the confusion matrix is quite simple.
Frequently Asked Questions
What is a confusion matrix in Python?
A confusion matrix in Python is a table that displays the number of correct and incorrect predictions made by a classification model. It helps in evaluating the performance of the model by comparing its predictions against the actual values. Python libraries like sklearn provide functions to create and visualize confusion matrices, making it easier to analyze and interpret the results.
What does a confusion matrix tell you?
A confusion matrix tells you how well a classification model is performing by showing the number of correct and incorrect predictions. It highlights the instances where the model correctly predicted the positive and negative classes (True Positives and True Negatives) and the instances where the model incorrectly predicted the positive and negative classes (False Positives and False Negatives). By analyzing the confusion matrix, you can identify the types of errors the model is making, and make informed decisions to improve its performance.
How can you use Sklearn confusion_matrix?
The sklearn library provides a function called confusion_matrix that can be used to create a confusion matrix for a classification model. To use it, you need to pass the true labels (y_true) and the predicted labels (y_pred) as arguments. The function returns a confusion matrix that can be printed or visualized using other libraries like matplotlib or Seaborn.
Can you use a confusion matrix for multi-class classification problems?
Yes, you can use a confusion matrix for multi-class classification problems. In the case of multi-class classification, the confusion matrix is an n x n table, where n represents the number of classes. Each row corresponds to the instances of the actual class, and each column corresponds to the instances of the predicted class. The diagonal elements represent correct predictions, while the off-diagonal elements represent incorrect predictions. The process of interpreting a multi-class confusion matrix is similar to that of a binary confusion matrix, with the main difference being the presence of multiple classes.
Conclusion
In this tutorial, we have explored the concept of confusion matrices and their importance in evaluating the performance of classification models. We’ve learned about the components of binary and multi-class confusion matrices, how to interpret them, and how to calculate various performance metrics such as accuracy, precision, recall, and F1 score. Additionally, we’ve demonstrated how to create and visualize confusion matrices in Python using sklearn and Seaborn.
As you continue to work on machine learning projects, understanding and utilizing confusion matrices will be an invaluable skill in assessing the performance of your classification models. By identifying the types of errors a model makes, you can make informed decisions to improve its performance, such as adjusting the classification threshold, balancing the dataset, or selecting a different algorithm. Keep practicing and experimenting with confusion matrices, and you’ll be well-equipped to tackle the challenges of evaluating classification models in your future projects.
To learn more about the Sklearn confusion_matrix function, check out the official documentation.