На чтение 3 мин. Опубликовано 13.06.2019
Перевод статьи – Understanding Confusion Matrix – Sarang Narkhede

Когда мы получаем данные после очистки, предварительной обработки и обработки данных, первым шагом, который мы делаем, является создание модели и, конечно, получение результатов в вероятностях. Но держись! Как, черт возьми, мы можем измерить эффективность нашей модели? Лучшая эффективность, лучшая производительность и это именно то, что мы хотим. В данном случае мы начинаем использовать матрицу ошибок. Матрица ошибок (Confusion Matrix) – это измерение производительности для классификации машинного обучения.
Содержание
- Этот пост призван ответить на следующие вопросы:
- Что такое матрица ошибок, и зачем она нужна?
- Как вычислить матрицу ошибок для задачи классификации с бинарными классами?
Этот пост призван ответить на следующие вопросы:
- Что такое Матрица ошибок и зачем она нужна?
- Как вычислить матрицу ошибок для задач бинарной классификации?
Сегодня давайте разберемся с матрицей путаницы раз и навсегда.
Что такое матрица ошибок, и зачем она нужна?
Ну, это измерение производительности для задачи классификации машинного обучения, где выходной может быть два или более классов. Это таблица с 4 различными комбинациями прогнозируемых и фактических значений.

Это чрезвычайно полезно для вычисления Полноты, Точности, Специфичность, Точность и, что наиболее важно кривой ошибок AUC-ROC.
Давайте поймем термины TP, FP, FN, TN на примере аналогии с беременностью.

TP — истино-положительное решение:
Интерпретация: Вы предсказали положительное, и это правда.
Вы предсказали, что женщина беременна, и она на самом деле беременна.
TN — истино-отрицательное решение:
Интерпретация: Вы прогнозировали отрицательное значения, и это правда.
Вы предсказали, что мужчина не беременен, а он на самом деле не беременен.
FP — ложно-положительное решение (Ошибка типа 1):
Интерпретация: Вы предсказали положительное значение, и это неверно.
Вы предсказали, что мужчина беременен, но на самом деле это не так.
FN— ложно-отрицательное решение (Ошибка Типа 2):
Интерпретация: Вы предсказали отрицательное значение, и это неверно.
Вы предсказали, что женщина не беременна, но она на самом деле беременная.
Только помните, мы описываем прогнозируемые значения как положительные и отрицательные, а фактические значения как истинные и ложные.

How to Calculate Confusion Matrix for a 2-class classification problem?
Как вычислить матрицу ошибок для задачи классификации с бинарными классами?


Давайте разберемся с матрицей ошибок посредством математик
Полнота Recall

Из всех положительных классов, сколько мы предсказали правильно. Это должно быть как можно выше.
Точность Precision

Из всех классов, сколько мы предсказали правильно. Это должно быть как можно выше.
F-мера

Трудно сравнить две модели с низкой точностью и высокой отзывчивостью или наоборот. Поэтому, чтобы сделать их сопоставимыми, мы используем F-меру. F-мера помогает измерять Полноту и Точность одновременно. Она использует гармоническое среднее вместо среднего арифметического, наказывая экстремальные значения больше.
https://towardsdatascience.com/understanding-confusion-matrix-a9ad42dcfd62
В машинном обучении различают оценки качества для задачи классификации и регрессии. Причем оценка задачи классификации часто значительно сложнее, чем оценка регрессии.
Содержание
- 1 Оценки качества классификации
- 1.1 Матрица ошибок (англ. Сonfusion matrix)
- 1.2 Аккуратность (англ. Accuracy)
- 1.3 Точность (англ. Precision)
- 1.4 Полнота (англ. Recall)
- 1.5 F-мера (англ. F-score)
- 1.6 ROC-кривая
- 1.7 Precison-recall кривая
- 2 Оценки качества регрессии
- 2.1 Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
- 2.2 Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
- 2.3 Коэффициент детерминации
- 2.4 Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
- 2.5 Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
- 2.6 Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
- 2.7 Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
- 3 Кросс-валидация
- 4 Примечания
- 5 См. также
- 6 Источники информации
Оценки качества классификации
Матрица ошибок (англ. Сonfusion matrix)
Перед переходом к самим метрикам необходимо ввести важную концепцию для описания этих метрик в терминах ошибок классификации — confusion matrix (матрица ошибок).
Допустим, что у нас есть два класса и алгоритм, предсказывающий принадлежность каждого объекта одному из классов.
Рассмотрим пример. Пусть банк использует систему классификации заёмщиков на кредитоспособных и некредитоспособных. При этом первым кредит выдаётся, а вторые получат отказ. Таким образом, обнаружение некредитоспособного заёмщика () можно рассматривать как «сигнал тревоги», сообщающий о возможных рисках.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- Кредитоспособный заёмщик распознается моделью как некредитоспособный и ему отказывается в кредите. Данный случай можно трактовать как «ложную тревогу».
- Некредитоспособный заёмщик распознаётся как кредитоспособный и ему ошибочно выдаётся кредит. Данный случай можно рассматривать как «пропуск цели».
Несложно увидеть, что эти ошибки неравноценны по связанным с ними проблемам. В случае «ложной тревоги» потери банка составят только проценты по невыданному кредиту (только упущенная выгода). В случае «пропуска цели» можно потерять всю сумму выданного кредита. Поэтому системе важнее не допустить «пропуск цели», чем «ложную тревогу».
Поскольку с точки зрения логики задачи нам важнее правильно распознать некредитоспособного заёмщика с меткой , чем ошибиться в распознавании кредитоспособного, будем называть соответствующий исход классификации положительным (заёмщик некредитоспособен), а противоположный — отрицательным (заемщик кредитоспособен ). Тогда возможны следующие исходы классификации:
- Некредитоспособный заёмщик классифицирован как некредитоспособный, т.е. положительный класс распознан как положительный. Наблюдения, для которых это имеет место называются истинно-положительными (True Positive — TP).
- Кредитоспособный заёмщик классифицирован как кредитоспособный, т.е. отрицательный класс распознан как отрицательный. Наблюдения, которых это имеет место, называются истинно отрицательными (True Negative — TN).
- Кредитоспособный заёмщик классифицирован как некредитоспособный, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Наблюдения, для которых был получен такой исход классификации, называются ложно-положительными (False Positive — FP), а ошибка классификации называется ошибкой I рода.
- Некредитоспособный заёмщик распознан как кредитоспособный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Наблюдения, для которых был получен такой исход классификации, называются ложно-отрицательными (False Negative — FN), а ошибка классификации называется ошибкой II рода.
Таким образом, ошибка I рода, или ложно-положительный исход классификации, имеет место, когда отрицательное наблюдение распознано моделью как положительное. Ошибкой II рода, или ложно-отрицательным исходом классификации, называют случай, когда положительное наблюдение распознано как отрицательное. Поясним это с помощью матрицы ошибок классификации:
-
Истинно-положительный (True Positive — TP) Ложно-положительный (False Positive — FP) Ложно-отрицательный (False Negative — FN) Истинно-отрицательный (True Negative — TN)
Здесь — это ответ алгоритма на объекте, а — истинная метка класса на этом объекте.
Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP).
P означает что классификатор определяет класс объекта как положительный (N — отрицательный). T значит что класс предсказан правильно (соответственно F — неправильно). Каждая строка в матрице ошибок представляет спрогнозированный класс, а каждый столбец — фактический класс.
# код для матрицы ошибок # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import confusion_matrix from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (англ. Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе # Для расчета матрицы ошибок сначала понадобится иметь набор прогнозов, чтобы их можно было сравнивать с фактическими целями y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687], # [ 1891, 3530]])
Безупречный классификатор имел бы только истинно-положительные и истинно отрицательные классификации, так что его матрица ошибок содержала бы ненулевые значения только на своей главной диагонали (от левого верхнего до правого нижнего угла):
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.metrics import confusion_matrix
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist["data"], mnist["target"]
y = y.astype(np.uint8)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки
y_test_5 = (y_test == 5)
y_train_perfect_predictions = y_train_5 # притворись, что мы достигли совершенства
print(confusion_matrix(y_train_5, y_train_perfect_predictions))
# array([[54579, 0],
# [ 0, 5421]])
Аккуратность (англ. Accuracy)
Интуитивно понятной, очевидной и почти неиспользуемой метрикой является accuracy — доля правильных ответов алгоритма:
Эта метрика бесполезна в задачах с неравными классами, что как вариант можно исправить с помощью алгоритмов сэмплирования и это легко показать на примере.
Допустим, мы хотим оценить работу спам-фильтра почты. У нас есть 100 не-спам писем, 90 из которых наш классификатор определил верно (True Negative = 90, False Positive = 10), и 10 спам-писем, 5 из которых классификатор также определил верно (True Positive = 5, False Negative = 5).
Тогда accuracy:
Однако если мы просто будем предсказывать все письма как не-спам, то получим более высокую аккуратность:
При этом, наша модель совершенно не обладает никакой предсказательной силой, так как изначально мы хотели определять письма со спамом. Преодолеть это нам поможет переход с общей для всех классов метрики к отдельным показателям качества классов.
# код для для подсчета аккуратности: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import accuracy_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(accuracy_score(y_train_5, y_train_pred)) # == (53892 + 3530) / (53892 + 3530 + 1891 +687) # 0.9570333333333333
Точность (англ. Precision)
Точностью (precision) называется доля правильных ответов модели в пределах класса — это доля объектов действительно принадлежащих данному классу относительно всех объектов которые система отнесла к этому классу.
Именно введение precision не позволяет нам записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive.
Полнота (англ. Recall)
Полнота — это доля истинно положительных классификаций. Полнота показывает, какую долю объектов, реально относящихся к положительному классу, мы предсказали верно.
Полнота (recall) демонстрирует способность алгоритма обнаруживать данный класс вообще.
Имея матрицу ошибок, очень просто можно вычислить точность и полноту для каждого класса. Точность (precision) равняется отношению соответствующего диагонального элемента матрицы и суммы всей строки класса. Полнота (recall) — отношению диагонального элемента матрицы и суммы всего столбца класса. Формально:
Результирующая точность классификатора рассчитывается как арифметическое среднее его точности по всем классам. То же самое с полнотой. Технически этот подход называется macro-averaging.
# код для для подсчета точности и полноты: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import precision_score, recall_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(precision_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 687) print(recall_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 1891) # 0.8370879772350012 # 0.6511713705958311
F-мера (англ. F-score)
Precision и recall не зависят, в отличие от accuracy, от соотношения классов и потому применимы в условиях несбалансированных выборок.
Часто в реальной практике стоит задача найти оптимальный (для заказчика) баланс между этими двумя метриками. Понятно что чем выше точность и полнота, тем лучше. Но в реальной жизни максимальная точность и полнота не достижимы одновременно и приходится искать некий баланс. Поэтому, хотелось бы иметь некую метрику которая объединяла бы в себе информацию о точности и полноте нашего алгоритма. В этом случае нам будет проще принимать решение о том какую реализацию запускать в производство (у кого больше тот и круче). Именно такой метрикой является F-мера.
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
Данная формула придает одинаковый вес точности и полноте, поэтому F-мера будет падать одинаково при уменьшении и точности и полноты. Возможно рассчитать F-меру придав различный вес точности и полноте, если вы осознанно отдаете приоритет одной из этих метрик при разработке алгоритма:
где принимает значения в диапазоне если вы хотите отдать приоритет точности, а при приоритет отдается полноте. При формула сводится к предыдущей и вы получаете сбалансированную F-меру (также ее называют ).
-
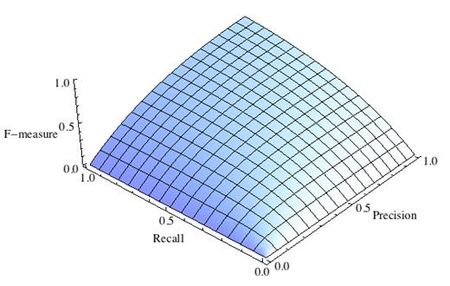
Рис.1 Сбалансированная F-мера,
-
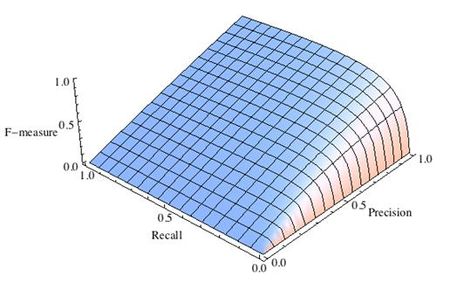
Рис.2 F-мера c приоритетом точности,
-
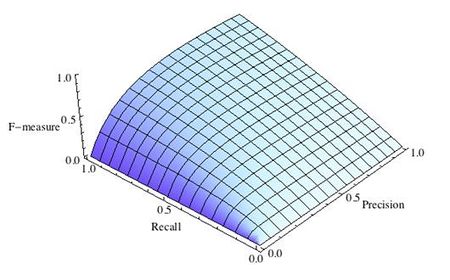
Рис.3 F-мера c приоритетом полноты,
F-мера достигает максимума при максимальной полноте и точности, и близка к нулю, если один из аргументов близок к нулю.
F-мера является хорошим кандидатом на формальную метрику оценки качества классификатора. Она сводит к одному числу две других основополагающих метрики: точность и полноту. Имея «F-меру» гораздо проще ответить на вопрос: «поменялся алгоритм в лучшую сторону или нет?»
# код для подсчета метрики F-mera: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier from sklearn.metrics import f1_score mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распознавать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(f1_score(y_train_5, y_train_pred)) # 0.7325171197343846
ROC-кривая
Кривая рабочих характеристик (англ. Receiver Operating Characteristics curve).
Используется для анализа поведения классификаторов при различных пороговых значениях.
Позволяет рассмотреть все пороговые значения для данного классификатора.
Показывает долю ложно положительных примеров (англ. false positive rate, FPR) в сравнении с долей истинно положительных примеров (англ. true positive rate, TPR).
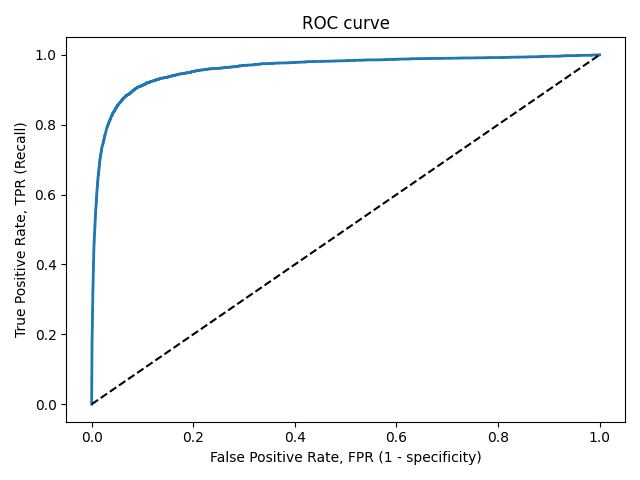
Доля FPR — это пропорция отрицательных образцов, которые были некорректно классифицированы как положительные.
- ,
где TNR — доля истинно отрицательных классификаций (англ. Тrие Negative Rate), представляющая собой пропорцию отрицательных образцов, которые были корректно классифицированы как отрицательные.
Доля TNR также называется специфичностью (англ. specificity). Следовательно, ROC-кривая изображает чувствительность (англ. seпsitivity), т.е. полноту, в сравнении с разностью 1 — specificity.
Прямая линия по диагонали представляет ROC-кривую чисто случайного классификатора. Хороший классификатор держится от указанной линии настолько далеко, насколько это
возможно (стремясь к левому верхнему углу).
Один из способов сравнения классификаторов предусматривает измерение площади под кривой (англ. Area Under the Curve — AUC). Безупречный классификатор будет иметь площадь под ROC-кривой (ROC-AUC), равную 1, тогда как чисто случайный классификатор — площадь 0.5.
# Код отрисовки ROC-кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import roc_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") fpr, tpr, thresholds = roc_curve(y_train_5, y_scores) def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], 'k--') # dashed diagonal plt.xlabel('False Positive Rate, FPR (1 - specificity)') plt.ylabel('True Positive Rate, TPR (Recall)') plt.title('ROC curve') plt.savefig("ROC.png") plot_roc_curve(fpr, tpr) plt.show()
Precison-recall кривая
Чувствительность к соотношению классов.
Рассмотрим задачу выделения математических статей из множества научных статей. Допустим, что всего имеется 1.000.100 статей, из которых лишь 100 относятся к математике. Если нам удастся построить алгоритм , идеально решающий задачу, то его TPR будет равен единице, а FPR — нулю. Рассмотрим теперь плохой алгоритм, дающий положительный ответ на 95 математических и 50.000 нематематических статьях. Такой алгоритм совершенно бесполезен, но при этом имеет TPR = 0.95 и FPR = 0.05, что крайне близко к показателям идеального алгоритма.
Таким образом, если положительный класс существенно меньше по размеру, то AUC-ROC может давать неадекватную оценку качества работы алгоритма, поскольку измеряет долю неверно принятых объектов относительно общего числа отрицательных. Так, алгоритм , помещающий 100 релевантных документов на позиции с 50.001-й по 50.101-ю, будет иметь AUC-ROC 0.95.
Precison-recall (PR) кривая. Избавиться от указанной проблемы с несбалансированными классами можно, перейдя от ROC-кривой к PR-кривой. Она определяется аналогично ROC-кривой, только по осям откладываются не FPR и TPR, а полнота (по оси абсцисс) и точность (по оси ординат). Критерием качества семейства алгоритмов выступает площадь под PR-кривой (англ. Area Under the Curve — AUC-PR)
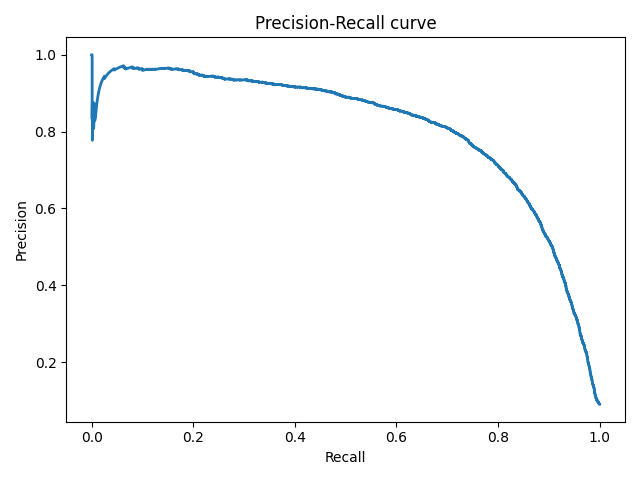
# Код отрисовки Precison-recall кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import precision_recall_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(recalls, precisions, linewidth=2) plt.xlabel('Recall') plt.ylabel('Precision') plt.title('Precision-Recall curve') plt.savefig("Precision_Recall_curve.png") plot_precision_recall_vs_threshold(precisions, recalls, thresholds) plt.show()
Оценки качества регрессии
Наиболее типичными мерами качества в задачах регрессии являются
Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
MSE применяется в ситуациях, когда нам надо подчеркнуть большие ошибки и выбрать модель, которая дает меньше больших ошибок прогноза. Грубые ошибки становятся заметнее за счет того, что ошибку прогноза мы возводим в квадрат. И модель, которая дает нам меньшее значение среднеквадратической ошибки, можно сказать, что что у этой модели меньше грубых ошибок.
- и
Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
Среднеквадратичный функционал сильнее штрафует за большие отклонения по сравнению со среднеабсолютным, и поэтому более чувствителен к выбросам. При использовании любого из этих двух функционалов может быть полезно проанализировать, какие объекты вносят наибольший вклад в общую ошибку — не исключено, что на этих объектах была допущена ошибка при вычислении признаков или целевой величины.
Среднеквадратичная ошибка подходит для сравнения двух моделей или для контроля качества во время обучения, но не позволяет сделать выводов о том, на сколько хорошо данная модель решает задачу. Например, MSE = 10 является очень плохим показателем, если целевая переменная принимает значения от 0 до 1, и очень хорошим, если целевая переменная лежит в интервале (10000, 100000). В таких ситуациях вместо среднеквадратичной ошибки полезно использовать коэффициент детерминации —
Коэффициент детерминации
Коэффициент детерминации измеряет долю дисперсии, объясненную моделью, в общей дисперсии целевой переменной. Фактически, данная мера качества — это нормированная среднеквадратичная ошибка. Если она близка к единице, то модель хорошо объясняет данные, если же она близка к нулю, то прогнозы сопоставимы по качеству с константным предсказанием.
Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
Это коэффициент, не имеющий размерности, с очень простой интерпретацией. Его можно измерять в долях или процентах. Если у вас получилось, например, что MAPE=11.4%, то это говорит о том, что ошибка составила 11,4% от фактических значений.
Основная проблема данной ошибки — нестабильность.
Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
Примерно такая же проблема, как и в MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня.
Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
MASE является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Обратите внимание, что в MASE мы имеем дело с двумя суммами: та, что в числителе, соответствует тестовой выборке, та, что в знаменателе — обучающей. Вторая фактически представляет собой среднюю абсолютную ошибку прогноза. Она же соответствует среднему абсолютному отклонению ряда в первых разностях. Эта величина, по сути, показывает, насколько обучающая выборка предсказуема. Она может быть равна нулю только в том случае, когда все значения в обучающей выборке равны друг другу, что соответствует отсутствию каких-либо изменений в ряде данных, ситуации на практике почти невозможной. Кроме того, если ряд имеет тенденцию к росту либо снижению, его первые разности будут колебаться около некоторого фиксированного уровня. В результате этого по разным рядам с разной структурой, знаменатели будут более-менее сопоставимыми. Всё это, конечно же, является очевидными плюсами MASE, так как позволяет складывать разные значения по разным рядам и получать несмещённые оценки.
Недостаток MASE в том, что её тяжело интерпретировать. Например, MASE=1.21 ни о чём, по сути, не говорит. Это просто означает, что ошибка прогноза оказалась в 1.21 раза выше среднего абсолютного отклонения ряда в первых разностях, и ничего более.
Кросс-валидация
Хороший способ оценки модели предусматривает применение кросс-валидации (cкользящего контроля или перекрестной проверки).
В этом случае фиксируется некоторое множество разбиений исходной выборки на две подвыборки: обучающую и контрольную. Для каждого разбиения выполняется настройка алгоритма по обучающей подвыборке, затем оценивается его средняя ошибка на объектах контрольной подвыборки. Оценкой скользящего контроля называется средняя по всем разбиениям величина ошибки на контрольных подвыборках.
Примечания
- [1] Лекция «Оценивание качества» на www.coursera.org
- [2] Лекция на www.stepik.org о кросвалидации
- [3] Лекция на www.stepik.org о метриках качества, Precison и Recall
- [4] Лекция на www.stepik.org о метриках качества, F-мера
- [5] Лекция на www.stepik.org о метриках качества, примеры
См. также
- Оценка качества в задаче кластеризации
- Кросс-валидация
Источники информации
- [6] Соколов Е.А. Лекция линейная регрессия
- [7] — Дьяконов А. Функции ошибки / функционалы качества
- [8] — Оценка качества прогнозных моделей
- [9] — HeinzBr Ошибка прогнозирования: виды, формулы, примеры
- [10] — egor_labintcev Метрики в задачах машинного обучения
- [11] — grossu Методы оценки качества прогноза
- [12] — К.В.Воронцов, Классификация
- [13] — К.В.Воронцов, Скользящий контроль
Разобраться в матрице неточностей Матрицы неточностей за секунды
Wiki:
В области машинного обучения и задач статистической классификации матрица путаницы (англ .: confusion matrix) является
Инструменты визуализации, особенно для обучения с учителем, в обучении без учителя обычно называют матрицами сопоставления. Матрица
Каждый столбец представляет собой прогноз экземпляра класса, а каждая строка представляет фактический экземпляр класса.
Он назван так потому, что легко увидеть, будет ли машина
Путаны два разных класса (например, один класс ошибочно принимается за другой).
Матрица неточностей (также называемая матрицей ошибок [1]) — это особый вид таблицы непредвиденных обстоятельств (английский: таблица непредвиденных обстоятельств) с двумя измерениями (фактическим и прогнозируемым), и оба измерения имеют одинаковый набор категорий.
Это введение содержитConfusion Matrix, True Positive, False Negative, False Positive, True Negative, Type I Error, Type II Error, Prevalence, Accuracy, Precision, Recall, F1 Measure, F Measure, Sensitivity, Specificity, ROC Curve, AUC, TPR, FNR, FPR, TNR, FDR, FOR, PPV, NPV, Среднее арифметическое, Среднее геометрическое, Гармоническое среднее。
Иногда бывает непросто сказать, хороша модель или плоха, поэтому нам нужно использовать некоторые показатели, чтобы судить о ее хорошей или плохой, что также является основанием для выбора модели. Если вы немного поинтересуетесь индикаторами, то обнаружите, что индикаторов так много, что люди просто поражены.
Существует часто используемый индекс для задач классификации, который называетсяConfusion Matrix, Это наименование очень интересно, эта таблица действительно очень сбивает с толку! По крайней мере, до прочтения этой статьи.Confusion MatrixЭто часто используемый индикатор для решения задач классификации. Он выводит множество различных индикаторов. На рисунке ниже яConfusion MatrixНарисуйте его и отметьте некоторые из наиболее важных производных индикаторов.

Думаю, вы, должно быть, неопределенно смотрите! Неважно, что я покажу вам все термины на этой картинке в этой статье.
Вначале мы начнем со следующей таблицы, которая называетсяConfusion Matrix,фронтTrueсFalseУказывает, верен или неверен результат самого прогноза, а также следующиеPositiveсNegativeОн показывает, является ли прогнозируемое направление положительным или отрицательным.

В качестве примера возьмем iphone. На iphone есть система распознавания и разблокировки отпечатков пальцев. Если iphone определяет, что отпечаток пальца принадлежит пользователю, он будет разблокирован. Таким образом, если вы нажмете его сегодня, и iphone также успешно разблокирован, тогда эта ситуация относится к левому верхнему углу. Ситуация называется True Positive, что означает «правильное прогнозирование вперед». Если вы нажмете на iPhone, к сожалению, iPhone не сможет распознать ваш отпечаток пальца. Это ситуация в левом нижнем углу, которая называетсяFalse Negativе, то есть «Ложноотрицательный прогноз«Затем позвольте другу протестировать его вместе. В нормальных условиях отпечаток пальца вашего друга не может разблокировать iphone. Это ситуация в правом нижнем углу, которая называетсяTrue Negative, Который «Правильный отрицательный прогноз«Если вас удивляет, что ваш друг разблокировал ваш телефон, вам лучше переключиться на блокировку паролем … Это ситуация в правом верхнем углу, называетсяFalse Positive, Который «Ложноположительный прогноз」。
Из приведенного выше описания мы, безусловно, надеемся, что наша модельTrue PositiveсTrue NegativeМожет появляться все больше и больше, иFalse PositiveсFalse NegativeВы можете попытаться не появляться, поэтому эти два состояния называются Ошибка, и они также называютсяType I ErrorсType II Error, Эти две ошибки очень разные.Если распознавание отпечатков пальцев происходит не на iphone, а на дверном замке, какую ошибку вы меньше всего хотите, чтобы она произошла? конечноType I Error, КоторыйFalse PositiveВ это время машина будет относиться к незнакомцу как к открывающейся двери хозяина, которую мы не хотим видеть, мы предпочли бы быть закрытыми снаружи (Type II Error)! Но если современная система идентификации используется в рекламе Google, Google Ad будет предсказывать потенциальных клиентов продукта и рекламировать его. В настоящее время это менее желательно.Type II ErrorПроизошло, что является ложноотрицательным, что называется ошибочным убийством сотни, а не отказом от потенциального клиента. Поэтому в следующий раз, когда вы будете тренировать свою модель, четко подумайте, что вы не хотитеType I Errorвсе ещеType II Error (Об: Я хочу все это …) и использовать некоторые методы, чтобы отпустить другую ошибку, чтобы уменьшить эту ошибку, которую мы не хотим случаться.
Confusion MatrixЕсть также много разных индикаторов, я представлю их один за другим.
Ставим все правильные ситуации, то естьTrue PositiveсTrue Negative, Сложите и разделите на количество всех случаев, то естьAccuracyЭто также наиболее часто используемый индикатор, но в некоторых случаях он не работает.Если сегодня есть несколько реальных положительных примеров, таких как робот для обнаружения мошенничества с кредитными картами, я просматривал записи кредитных карт в течение месяца. Количество украденных данных довольно мало, поэтому мне нужно всего лишь спроектировать свою модель за один простой шаг, чтобы сделать ееAccuracyЭто более 99%, вы догадались? То есть прогнозируется, что мошеннической чистки не будет, поэтому, очевидно, нам нужны другие индикаторы, чтобы справиться с этой ситуацией.
Precision(Точность) иRecall(Скорость отзыва) Это пригодится,PrecisionсRecallТакже обратите внимание наTrue Positive(Оба в числителе), но угол другой,PrecisionВы видите, насколько на самом деле «точность», когда прогноз положительный, иRecallОн должен предсказать фактический положительный ответ «сколько можно вспомнить», когда реальная ситуация положительна. То же самое, если это система контроля доступа, мы надеемсяPrecisionМожет быть очень высоким,RecallЭто относительно неважно: мы больше озабочены предсказанием правильного ответа в положительном направлении (открытие двери) и меньше озабочены правильным ответом в фактическом положительном направлении (владелец). Если это реклама, тоRecallОчень важный,PrecisionЭто не кажется таким важным, потому что в настоящее время нас больше беспокоит фактический положительный (потенциальный клиент) ответ, и относительно меньше — предсказание положительного (рекламного) ответа.
PrecisionсRecallДаже не считаяTrue NegativeПотому что обычноTrue NegativeБудет правильноNull HypothesisОдним словом, это самый скучный правильный результат. Проблема разблокировки контроля доступа заключается в том, что посторонний нажимает, а дверь не открывается; в примере с рекламой реклама не размещается, и человек не является потенциальным клиентом: в примере с украденной кредитной картой робот считает, что обычная запись кредитной карты действительно верна. это нормально. Согласно обычным предположениям, положительные результаты на самом деле меньше отрицательных. Конечно, положительные результаты прогнозируются меньше, чем отрицательные, поэтомуTrue NegativeОбычно самая большая сумма, но и самая скучная.
дополнение:Null HypothesisОбычно представляет собой более распространенную ситуацию. В статистике мы должны проверять достоверность определенной концепции. Обычно мы предполагаем, чтоNull HypothesisКак нормальная ситуация, попробуйте использовать экспериментальные данные, чтобы отрицать это.Null Hypothesis, Например: вы хотите доказать, что препарат эффективен, тогда вы должны предположить, чтоNull HypothesisНапример, если вы дадите пациенту плацебо (возможно, конфету), ваше лекарство должно иметь способ иNull HypothesisВнесите существенные изменения, прежде чем докажете, что ваше лекарство эффективно. Итак, в примерах машинного обучения наиболее распространенная ситуация обычно рассматривается какNegative, То есть какNull HypothesisСмотреть на.

Если сегодня я чувствуюPrecisionсRecallНе менее важны, я хочу использовать индикатор, чтобы интегрировать и отмечать его, этоF1 Scoreон жеF1 Measure,этоF MeasureЧастный случай, когда belta = 1F1 Measure, представительPrecisionсRecallНе менее важны, поэтому, если я хочу увидеть большеPrecision, Тогда belta может быть меньше, когда belta = 0,F MeasureПростоPrecision; Если я хочу увидеть большеRecall, Belta может быть больше, когда Belta бесконечна,F МераRecall`。
Если присмотретьсяF1 Measure, Вы обнаружите, что его средний метод «Гармоническое среднее«Перейдите к трем методам усреднения, и вы поймете, почему вы хотите использовать гармоническое усреднение. На следующем рисунке показаны сроки использования трех методов усреднения. Нам необходимо понять характеристики данных или числовой последовательности, прежде чем мы узнаем, какой метод усреднения более подходит. В большинстве случаев можно использовать арифметическое усреднение, поскольку мы предполагаем линейную зависимость. Существование, например, среднее расстояние; среднее геометрическое часто используется в расчетах численности населения, поскольку рост населения пропорционален увеличению; гармоническое среднее часто используется для расчета средней скорости на фиксированном расстоянии, затраченное время — это средняя скорость, эти данные являются взаимными отношениямиF1 MeasureТо же самое и с характеристиками данных: в случае фиксированного TP используются разные знаменатели, поэтому здесь больше подходит гармоническое среднее.

Просто посмотрите на существительные на картинке ниже, чтобы произвести впечатление.

На последней странице рассказывается об индикаторах, обычно используемых в медицине. Первая —Prevalence(Распространенность): если в качестве всех выборок взята популяция, фактическая доля пациентов, у которых возникла болезнь, представляет собой распространенность болезни.
Если сегодня существует диагностический метод, который может определить, есть ли у пациента заболевание, есть два индикатора, на которые следует обратить внимание, а именно:SensitivityсSpecificity,SensitivityПростоRecall, Он показывает, является ли метод диагностики достаточно чувствительным, чтобы диагностировать действительно больных людей. Фактически, сколько пациентов, которые действительно больны, можно обнаружить.SpecificityОн показывает, сколько людей, у которых действительно нет симптомов, были правильно протестированы. Оба показателя чем выше, тем лучше.

Обычно в медицине используются определенные пороговые значения, чтобы определить, есть ли у пациента заболевание, и этот порог влияет наSensitivityсSpecificity, Распределение различных пороговых значений чувствительности и специфичности можно представить какROC Curve,а такжеROC CurvПлощадь под e называетсяAUC,AUCЧем больше тем лучше.
Предположительно, на этот раз вы вернетесь и посмотрите на первую картинку, чтобы лучше понять.С этими показателями у нас будет дополнительная линейка, чтобы судить, хороша наша модель классификации или плохая.
Например:
Матрица неточностей — это таблица, которая часто используется для описания эффективности модели классификации (или «классификатора») на наборе тестовых данных с известными истинными значениями. Саму матрицу неточностей легче понять, но связанные с ней термины могут сбивать с толку.
Начнем с примера матрицы путаницы для двоичного классификатора (хотя ее можно легко расширить до более чем двух классов):

Что мы можем узнать из этой матрицы?
- Есть два возможных класса предсказания: «да» и «нет». Например, если мы предсказываем наличие болезни, «да» означает, что у них есть болезнь, а «нет» означает, что у них нет болезни.
- Всего классификатор делает 165 прогнозов (например, 165 пациентов проходят тестирование на наличие заболевания).
- В этих 165 случаях классификатор предсказал «да» 110 раз и «нет» 55 раз.
- Фактически, 105 пациентов в выборке имели болезнь, а 60 пациентов — нет.
Теперь давайте определим самые основные термины:
- true positives (TP): В этих случаях мы прогнозируем «да» (у них это заболевание), и у них действительно есть это заболевание.
- true negatives (TN): Мы предсказали «нет», ведь они не заболели.
- false positives (FP): Мы предсказали «да», но на самом деле они не больны. (Также называется «Ошибка первого типа».)
- false negatives (FN): Мы предсказывали «нет», но у них есть эта болезнь. (Также называются «ошибками 2-го типа».)
Я добавил эти элементы в матрицу путаницы и добавил общее количество строк и столбцов:

Это список соотношений, обычно получаемый из двоичного классификатора матрицы неточностей:
- Точность: А вообще какова точность классификатора?
(TP+TN)/total = (100+50)/165 = 0.91
- Коэффициент ошибочной классификации (коэффициент ошибочной классификации): В целом, какова частота ошибочной классификации?
- (FP+FN)/total = (10+5)/165 = 0.09
- Равно 1 минус точность
- Также известен как «частота ошибок».
- Истинно положительный рейтинг: Когда на самом деле «да», как часто это предсказывает «да»?
TP/actual yes = 100/105 = 0.95
Также называется «чувствительность» или «отзыв».
- Ложноположительная ставка: Когда на самом деле «нет», как часто это предсказывает «да»?
FP/actual no = 10/60 = 0.17
- Истинная отрицательная ставка: Когда на самом деле «нет», как часто он предсказывает «нет»?
- TN/actual no = 50/60 = 0.83
- Равно 1 минус количество ложных срабатываний
- Также известен как «Специфика».
- Точность): Когда он предсказывает класс «да», какова вероятность правильного предсказания?
TP/predicted yes = 100/110 = 0.91
- Prevalence: Как часто в нашем примере возникает условие «да»?
actual yes/total = 105/165 = 0.64
Также стоит упомянуть еще несколько терминов:
- Частота нулевых ошибок: Вот как часто вы будете ошибаться, если всегда будете предсказывать большинство классов. (В нашем примере нулевой коэффициент ошибок будет 60/165 = 0,36, потому что, если вы всегда прогнозируете «да», вы будете делать ошибки только с 60 «нет».) Это можно использовать в качестве эталона для сравнения классификаторов. мера. Однако для конкретного приложения лучший классификатор иногда имеет более высокий коэффициент ошибок, чем нулевой коэффициент ошибок, как доказывает «парадокс точности».
- Cohen’s Kappa: По сути, это мера производительности классификатора по сравнению с его простой случайной работой. Другими словами, если есть большая разница между уровнем точности модели и нулевым коэффициентом ошибок, то показатель Каппа модели будет высоким.
- F Score: Это средневзвешенное значение истинно положительной скорости (скорость отзыва) и правильной скорости.
- Кривая ROC: Это часто используемая диаграмма, которая суммирует производительность классификатора по всем возможным пороговым значениям. Когда вы изменяете порог для присвоения наблюдений заданному классу, сгенерируйте его, построив график истинных положительных результатов (ось y) и ложных положительных результатов (ось x).
Расшифровка матрицы путаницы
Перевод
Ссылка на автора
В случае проблемы классификации, имеющей только одну точность классификации, может не дать вам полную картину. Таким образом, матрица путаницы или матрица ошибок используется для суммирования производительности алгоритма классификации.

Вычисление матрицы путаницы может дать вам представление о том, где модель классификации верна и какие ошибки она допускает.
Путаница путаница используется для проверки производительности модели классификации на наборе тестовых данных, для которых известны истинные значения. Большинство показателей эффективности, таких как точность, отзыв, рассчитываются из матрицы путаницы.
Эта статья направлена на:
1. Что такое матрица путаницы и зачем она нужна?
2. Как рассчитать путаницу для двухклассовой задачи классификации на примере кошки-собаки.
3. Как создать путаницу в Python & R.
4. Краткое изложение и интуиция о различных мерах: точность, отзыв, точность и специфика
1. Матрица путаницы:
Матрица путаницы предоставляет сводку прогнозирующих результатов в задаче классификации. Правильные и неправильные прогнозы суммируются в таблице со своими значениями и разбиваются по каждому классу.

Мы не можем полагаться на одно значение точности в классификации, когда классы не сбалансированы. Например, у нас есть набор данных из 100 пациентов, 5 из которых имеют диабет, а 95 здоровы. Однако, если наша модель только предсказывает класс большинства, то есть все 100 человек здоровы, даже если у нас точность классификации составляет 95%. Поэтому нам нужна матрица путаницы.
2. Рассчитайте матрицу путаницы:
Давайте возьмем пример:
У нас всего 10 кошек и собак, и наша модель предсказывает, кошка это или нет.
Фактические значения = [«собака», «кошка», «собака», «кошка», «собака», «собака», «кошка», «собака», «кошка», «собака» »]
Прогнозируемые значения = [«собака», «собака», «собака», «собака», «собака», «собака», «кошка», «кошка», «кошка», «кошка»]

Помните, мы описываем прогнозируемые значения как положительные / отрицательные, а фактические значения как истинные / ложные.
Определение терминов:
Настоящий позитив: вы предсказали позитив, и это правда. Вы предсказали, что животное — это кошка, и это действительно так.
True Negative: вы предсказали отрицательный результат, и это правда. Вы предсказали, что животное — это не кошка, и на самом деле это не так (это собака).
Ложный положительный результат (ошибка типа 1). Вы предсказали положительный результат, и это неверно. Вы предсказали, что животное — это кошка, но на самом деле это не так (это собака).
Ложное отрицание (ошибка типа 2). Вы прогнозировали отрицательное значение, и оно ложно. Вы предсказали, что животное не кошка, но на самом деле это так.
Точность классификации:
Точность классификации определяется соотношением:

Напомним (Чувствительность ака):
Напомним, определяется как отношение общего количества правильно классифицированных положительных классов к общему количеству положительных классов. Или из всех положительных классов, сколько мы предсказали правильно. Отзыв должен быть высоким.

Точность:
Точность определяется как отношение общего количества правильно классифицированных положительных классов к общему количеству предсказанных положительных классов. Или из всех прогнозирующих положительных классов, сколько мы предсказали правильно. Точность должна быть высокой.

Уловка, чтобы помнить:дозрение имеетдоДиктивные результаты в знаменателе.
F-оценка или F1-оценка:
Сложно сравнивать две модели с разными Precision и Recall. Поэтому, чтобы сделать их сопоставимыми, мы используем F-Score. Это Гармоническое Средство Точности и Вспомнить. По сравнению с арифметическим средним, гармоническое среднее наказывает более экстремальные значения. F-оценка должна быть высокой.

Специфичность:
Специфичность определяет долю фактических негативов, которые правильно определены.

Пример для интерпретации матрицы путаницы:
Давайте вычислим матрицу путаницы, используя приведенный выше пример с кошкой и собакой:


Точность классификации:
Точность = (TP + TN) / (TP + TN + FP + FN) = (3 + 4) / (3 + 4 + 2 + 1) = 0,70
Отзыв:Напомним, дает нам представление о том, когда на самом деле да, как часто он предсказывает да.
Напомним = TP / (TP + FN) = 3 / (3 + 1) = 0,75
Точность:Точность говорит нам о том, когда он предсказывает, да, как часто это правильно.
Точность = TP / (TP + FP) = 3 / (3 + 2) = 0,60
F-оценка:
F-оценка = (2 * Recall * Precision) / (Recall + Presision) = (2 * 0,75 * 0,60) / (0,75 + 0,60) = 0,67
Специфичность:
Специфичность = TN / (TN + FP) = 4 / (4 + 2) = 0,67
3. Создать путаницу в Python & R
Давайте используем и коды Python, и R, чтобы понять приведенный выше пример с собакой и кошкой, который поможет вам лучше понять, что вы узнали о матрице путаницы до сих пор.
ПИТОН:Сначала давайте возьмем код Python для создания матрицы путаницы. Мы должны импортировать модуль матрицы путаницы из библиотеки sklearn, которая помогает нам генерировать матрицу путаницы
Ниже приведена реализация приведенного выше объяснения в Python:
OUTPUT ->Confusion Matrix :
[[3 1]
[2 4]]
Accuracy Score : 0.7
Classification Report :
precision recall f1-score supportcat 0.60 0.75 0.67 4
dog 0.80 0.67 0.73 6micro avg 0.70 0.70 0.70 10
macro avg 0.70 0.71 0.70 10
weighted avg 0.72 0.70 0.70 10
Р:Давайте теперь используем R-код для создания матрицы путаницы. Мы будем использовать библиотеку карет в R для вычисления матрицы путаницы.
OUTPUT ->Confusion Matrix and Statistics Reference
Prediction 0 1
0 4 1
1 2 3Accuracy : 0.7
95% CI : (0.3475, 0.9333)
No Information Rate : 0.6
P-Value [Acc > NIR] : 0.3823Kappa : 0.4Mcnemar's Test P-Value : 1.0000Sensitivity : 0.6667
Specificity : 0.7500
Pos Pred Value : 0.8000
Neg Pred Value : 0.6000
Prevalence : 0.6000
Detection Rate : 0.4000
Detection Prevalence : 0.5000
Balanced Accuracy : 0.7083'Positive' Class : 0
4. Резюме:
- Точность — это насколько вы уверены в своих истинных положительных сторонах. Вспомните, насколько вы уверены, что не пропускаете ни одного позитива.
- выберитеОтзывесли возникновениеложные негативы недопустимы / недопустимы.Например, в случае диабета у вас было бы больше ложных срабатываний (ложных срабатываний) вместо сохранения ложных отрицательных.
- выберитеточностьесли хочешь быть побольшеуверен в своих истинных позитивах, Например, в случае спам-писем вы бы предпочли иметь несколько спам-писем в вашем почтовом ящике, а не обычные электронные письма в вашем ящике для спама. Вы хотели бы быть уверены, что электронная почта X является спамом, прежде чем мы поместим ее в ящик для спама.
- выберитеспецифичностьесли хочешьпокрыть все истинные негативы,то есть мы не хотим ложных срабатываний или ложных срабатываний. Например, в случае теста на наркотики, при котором все люди с положительным тестом немедленно попадут в тюрьму, вы не хотели бы, чтобы кто-либо без наркотиков отправлялся в тюрьму.
Мы можем сделать вывод, что:
- Значение точности 70% означает, что идентификация 3 из каждых 10 кошек неверна, а 7 — правильна.
- Точность 60% означает, что метка 4 из каждых 10 кошек — это не кошка (то есть собака), а 6 — кошки.
- Напомним, что значение 70% означает, что 3 из каждых 10 кошек в действительности пропущены нашей моделью, а 7 правильно определены как кошки.
- Значение специфичности, равное 60%, означает, что 4 из каждых 10 собак (то есть не кошек) в действительности помечены как кошки, а 6 — как собаки.
Если у вас есть какие-либо комментарии или вопросы, не стесняйтесь оставлять свои отзывы ниже. Вы всегда можете связаться со мной по LinkedIn,
Метод прогонки решения систем с трехдиагональной матрицей –разложение трехдиагональной матрицы :

где
(проверить)
-




…..
……


……
…….



Формулы метода прогонки для системы :
сначала
вычисляем (рекуррентно):
![]()
и решаем
систему с матрицей
(прямой ход):

и, наконец,
решаем систему
![]()
(обратный ход):
![]()
.
|
Теорема. |
Если (т.е. –разложение |
|
Док–во. |
(от тогда и Разделим на и оценим
– противоречие |

Лекция 5. Итерационные методы решения
линейных уравнений
Мы будем
рассматривать только вещественные
системы линейных алгебраических
уравнений, так как система уравнений
над полем комплексных чисел сводится
(доказать) к системе

с
вещественными коэффициентами.
Пример и основные определения
Пример:
пусть для
матрицы системы
построена обратная
![]()
.
Из–за ошибок округления мы получим не
обратную матрицу, а к ней близкую:
![]()
.
Тогда
![]()
,
а для разности
![]()
имеем уравнение
![]()
,
приближенное решение которого
![]()
![]()
или итерационное уточнение
![]()
.
Одношаговый (двухслойный) итерационный
метод решения
:

![]()
–
-тое
приближение (к решению системы),
|
– ошибка -той |
– процесс
– матрица шага |
|
– невязка -той |
– процесс
– матрица шага |
Метод
называется сходящимся, если
![]()
.
(Так как
в
![]()
все нормы эквивалентны, то определение
сходимости от нормы не зависит.)
Стационарный одношаговый итерационный
метод решения
:

Впредь
мы будем предполагать, что
и
![]()
.
Условия сходимости стационарного
итерационного метода
![]()
Достаточные условия:
|
Теорема. |
Если |
|
Док–во. |
|

|
Теорема. |
Если , . |
|
Док–во. |
|

Необходимое и достаточное условие:
|
Теорема. |
|
|
Док–во. |
Необходимость. Пусть Так как
|
|
Достаточность. Если (нулевой матрице), то , Итак, – жорданова форма матрицы
Практически Пусть – порядка блока и
Т.к.
|
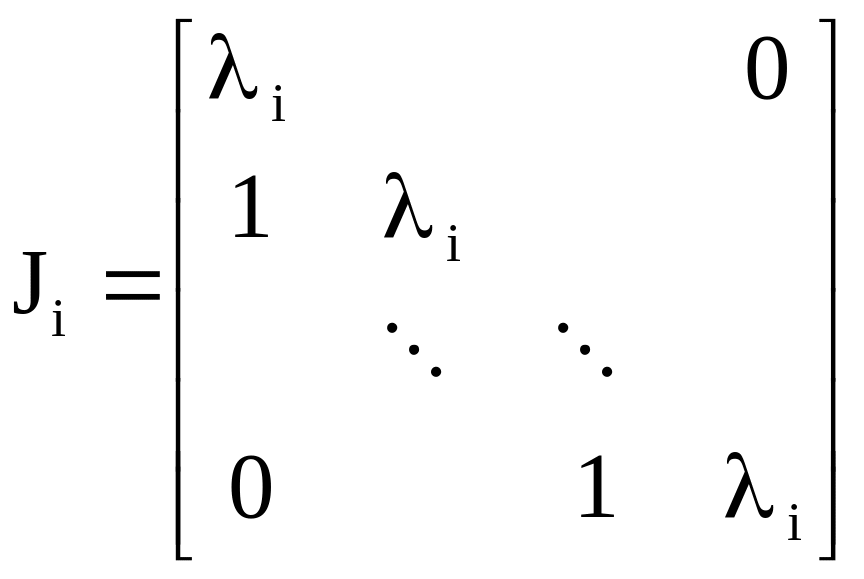


Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Процесс классификации помогает распределить набор данных по различным классам. Модель машинного обучения позволяет это сделать:
– сформулировать проблему,
– Соберите данные,
– Добавьте переменные,
– Обучи модель,
– Измерьте производительность,
– Усовершенствуйте модель с помощью функции затрат.
Но как измерить производительность модели? Сравнивая прогнозируемую и фактическую модель? Однако это не решит проблему классификации. Матрица путаницы может помочь вам проанализировать данные и решить проблему. Давайте разберемся, как эта методика помогает модели машинного обучения.
Путаница
Метод матричной путаницы помогает в измерении производительности для классификации машинного обучения. С помощью этого типа модели можно различать и классифицировать модель с известными истинными значениями на наборе тестовых данных. Термин “матрица путаницы” является простым и в то же время запутанным. Данная статья упростит концепцию, так что вы сможете легко разобраться в ней и самостоятельно создать матрицу путаницы.
Расчет путаницы
Следуйте этим простым шагам для расчета путаницы в матрице поиска данных:
Шаг 1
Оцените итоговые значения набора данных.
Шаг 2
Тестировать набор данных с помощью ожидаемого вывода.
Шаг 3
Прогнозируйте строки в вашем тестовом наборе данных.
Шаг 4
Рассчитать ожидаемые результаты и прогнозы. Вам необходимо рассмотреть:
– Полностью верные прогнозы класса
– Полностью неверные прогнозы класса
После выполнения этих шагов необходимо упорядочить номера в приведенных ниже методах:
– Связать каждую строку матрицы с прогнозируемым классом
– Соответствие каждого столбца матрицы фактическому классу
– Введите в таблицу правильную и неправильную классификацию модели.
– Включите общую сумму правильных прогнозов в колонку “Прогноз”. Также добавьте значение класса в ожидаемую строку.
– Включите суммарное количество неверных прогнозов в ожидаемую строку и значение класса в прогнозируемом столбце.
Понимание результата в матрице путаницы.
1. Истинный Положительный
Фактические и прогнозируемые значения одинаковы. Прогнозируемое значение модели является положительным наряду с фактическим положительным значением.
2. Истинный Отрицательный
Фактические и прогнозируемые значения одинаковы. Прогнозируемое значение модели является отрицательным наряду с фактическим отрицательным значением.
3. Ложноположительный (Ошибка типа 1).
Фактические и прогнозируемые значения не совпадают. Прогнозируемое значение модели является положительным и ложно прогнозируемым. Однако фактическое значение является отрицательным. Это можно назвать ошибкой типа 1.
4. Ложный отрицательный (Ошибка по типу 2).
Фактические и прогнозируемые значения не совпадают. Прогнозируемое значение модели отрицательно и ложно спрогнозировано. Однако фактическое значение является положительным. Эту ошибку можно назвать ошибкой по типу 2.
Важность путаницы
Прежде чем ответить на вопрос, необходимо понять гипотетическую проблему классификации. Предположим, вы предсказываете количество людей, зараженных вирусом, прежде чем проявить симптомы. Таким образом, вы сможете легко их изолировать и обеспечить здоровое население. Мы можем выбрать две переменные для определения целевой популяции: Зараженные и незараженные.
Теперь вы можете подумать, зачем использовать матрицу путаницы, когда переменные слишком просты. Ну, эта техника помогает с точностью классификации. Данные в этом примере – это несбалансированный набор данных. Предположим, что у нас 947 отрицательных точек данных и три положительных точки данных. Теперь вычислим точность по этой формуле:

С помощью следующей таблицы можно проверить точность:

Суммарные выходные значения будут:
TP = 30, TN = 930, FP = 30, FN = 10.
Таким образом, вы можете вычислить точность модели как:

96% точность для модели невероятна. Но вы можете сгенерировать только неверную идею из результата. По этой модели можно предсказать зараженных людей 96% времени. Однако, по расчетам, 96% населения не будет инфицировано. Однако, больные люди все еще распространяют вирус.
Похожа ли эта модель на идеальное решение проблемы, или мы должны измерить положительные случаи и изолировать их, чтобы остановить распространение вируса. Поэтому мы используем путаницу в матрице для решения такого рода проблем. Вот некоторые преимущества путаницы:
– Матрица помогает с классификацией модели при предсказании.
– Эта техника обозначает тип и понимание ошибок, чтобы вы могли легко разобраться в этом случае.
– Вы можете преодолеть это ограничение с помощью точной классификации данных.
– Столбцы матрицы путаницы будут представлять экземпляры прогнозируемого класса
– В каждой строке будут указаны экземпляры реального класса
– Матрица путаницы выделит ошибки, которые классификатор
Путаница в Питоне
Теперь, когда вы знаете концепцию матрицы замешательства, вы можете практиковаться, используя следующий код на Python с помощью библиотеки “Scikit-learn”.
# матрица замешательства в склирне
матрица fromsklearn.metricsimportconfusion_matrix
fromsklearn.metricsimportclassification_report
# фактические значения
фактический = [1,0,0,1,0,0,1,0,0,1]
# прогнозные значения
предсказано = [1,0,0,1,0,0,0,1,0,0]
# матрица путаницы
матрица =confusion_matrix(actual,predicted, labelels=[1,0])
print(‘Confusion matrix : n’,matrix)
# порядок значений результатов в склирне
tp, fn, fp, tn=confusion_matrix(actual,predicted,labels=[1,0]).reshape(-1)
print(‘Outcome values : n’, tp, fn, fp, tn )
# классификационный отчет по точности, отзыв f1-скопа и точность
матрица =classification_report(actual,predged,labelels=[1,0])
print(‘Classification report: n’,matrix)
Заключение
Матрица путаницы помогает ограничить точность метода классификации. Кроме того, она выделяет важные детали различных классов. Кроме того, она анализирует переменные и данные, чтобы можно было сравнить фактические данные с прогнозом.
На чтение 3 мин. Опубликовано 13.06.2019
Перевод статьи – Understanding Confusion Matrix – Sarang Narkhede
Когда мы получаем данные после очистки, предварительной обработки и обработки данных, первым шагом, который мы делаем, является создание модели и, конечно, получение результатов в вероятностях. Но держись! Как, черт возьми, мы можем измерить эффективность нашей модели? Лучшая эффективность, лучшая производительность и это именно то, что мы хотим. В данном случае мы начинаем использовать матрицу ошибок. Матрица ошибок (Confusion Matrix) – это измерение производительности для классификации машинного обучения.
Содержание
- Этот пост призван ответить на следующие вопросы:
- Что такое матрица ошибок, и зачем она нужна?
- Как вычислить матрицу ошибок для задачи классификации с бинарными классами?
Этот пост призван ответить на следующие вопросы:
- Что такое Матрица ошибок и зачем она нужна?
- Как вычислить матрицу ошибок для задач бинарной классификации?
Сегодня давайте разберемся с матрицей путаницы раз и навсегда.
Что такое матрица ошибок, и зачем она нужна?
Ну, это измерение производительности для задачи классификации машинного обучения, где выходной может быть два или более классов. Это таблица с 4 различными комбинациями прогнозируемых и фактических значений.
Это чрезвычайно полезно для вычисления Полноты, Точности, Специфичность, Точность и, что наиболее важно кривой ошибок AUC-ROC.
Давайте поймем термины TP, FP, FN, TN на примере аналогии с беременностью.
TP — истино-положительное решение:
Интерпретация: Вы предсказали положительное, и это правда.
Вы предсказали, что женщина беременна, и она на самом деле беременна.
TN — истино-отрицательное решение:
Интерпретация: Вы прогнозировали отрицательное значения, и это правда.
Вы предсказали, что мужчина не беременен, а он на самом деле не беременен.
FP — ложно-положительное решение (Ошибка типа 1):
Интерпретация: Вы предсказали положительное значение, и это неверно.
Вы предсказали, что мужчина беременен, но на самом деле это не так.
FN— ложно-отрицательное решение (Ошибка Типа 2):
Интерпретация: Вы предсказали отрицательное значение, и это неверно.
Вы предсказали, что женщина не беременна, но она на самом деле беременная.
Только помните, мы описываем прогнозируемые значения как положительные и отрицательные, а фактические значения как истинные и ложные.
How to Calculate Confusion Matrix for a 2-class classification problem?
Как вычислить матрицу ошибок для задачи классификации с бинарными классами?
Давайте разберемся с матрицей ошибок посредством математик
Полнота Recall
Из всех положительных классов, сколько мы предсказали правильно. Это должно быть как можно выше.
Точность Precision
Из всех классов, сколько мы предсказали правильно. Это должно быть как можно выше.
F-мера
Трудно сравнить две модели с низкой точностью и высокой отзывчивостью или наоборот. Поэтому, чтобы сделать их сопоставимыми, мы используем F-меру. F-мера помогает измерять Полноту и Точность одновременно. Она использует гармоническое среднее вместо среднего арифметического, наказывая экстремальные значения больше.
https://towardsdatascience.com/understanding-confusion-matrix-a9ad42dcfd62
Предложите, как улучшить StudyLib
(Для жалоб на нарушения авторских прав, используйте
другую форму
)
Ваш е-мэйл
Заполните, если хотите получить ответ
Оцените наш проект
1
2
3
4
5