15. Оценка дисперсии случайной ошибки модели регрессии
При проведении регрессионного анализа основная трудность заключается в том, что генеральная дисперсия случайной ошибки является неизвестной величиной, что вызывает необходимость в расчёте её несмещённой выборочной оценки.
Несмещённой оценкой дисперсии (или исправленной дисперсией) случайной ошибки линейной модели парной регрессии называется величина, рассчитываемая по формуле:
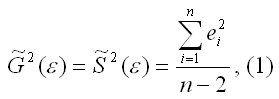
где n – это объём выборочной совокупности;
еi– остатки регрессионной модели:
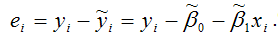
Для линейной модели множественной регрессии несмещённая оценка дисперсии случайной ошибки рассчитывается по формуле:
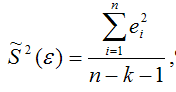
где k – число оцениваемых параметров модели регрессии.
Оценка матрицы ковариаций случайных ошибок Cov(?) будет являться оценочная матрица ковариаций:
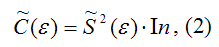
где In – единичная матрица.
Оценка дисперсии случайной ошибки модели регрессии распределена по ?2(хи-квадрат) закону распределения с (n-k-1) степенями свободы.
Для доказательства несмещённости оценки дисперсии случайной ошибки модели регрессии необходимо доказать справедливость равенства
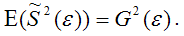
Доказательство. Примем без доказательства справедливость следующих равенств:
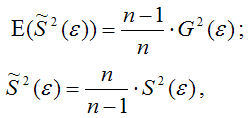
где G2(?) – генеральная дисперсия случайной ошибки;
S2(?) – выборочная дисперсия случайной ошибки;
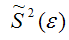
– выборочная оценка дисперсии случайной ошибки.
Тогда:
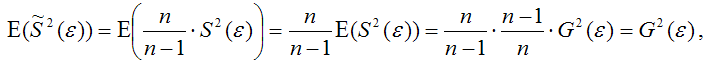
т. е.
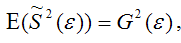
что и требовалось доказать.
Следовательно, выборочная оценка дисперсии случайной ошибки
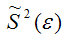
является несмещённой оценкой генеральной дисперсии случайной ошибки модели регрессии G2(?).
При условии извлечения из генеральной совокупности нескольких выборок одинакового объёма n и при одинаковых значениях объясняющих переменных х, наблюдаемые значения зависимой переменной у будут случайным образом колебаться за счёт случайного характера случайной компоненты ?. Отсюда можно сделать вывод, что будут варьироваться и зависеть от значений переменной у значения оценок коэффициентов регрессии и оценка дисперсии случайной ошибки модели регрессии.
Для иллюстрации данного утверждения докажем зависимость значения МНК-оценки
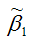
от величины случайной ошибки ?.
МНК-оценка коэффициента ?1 модели регрессии определяется по формуле:
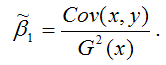
В связи с тем, что переменная у зависит от случайной компоненты ? (yi=?0+?1xi+?i), то ковариация между зависимой переменной у и независимой переменной х может быть представлена следующим образом:
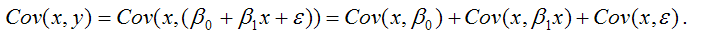
Для дальнейших преобразования используются свойства ковариации:
1) ковариация между переменной х и константой С равна нулю: Cov(x,C)=0, C=const;
2) ковариация переменной х с самой собой равна дисперсии этой переменной: Cov(x,x)=G2(x).
Исходя из указанных свойств ковариации, справедливы следующие равенства:
Cov(x,?0)=0 (?0=const);
Cov(x, ?1x)= ?1*Cov(x,x)= ?1*G2(x).
Следовательно, ковариация между зависимой и независимой переменными Cov(x,y) может быть записана как:
Cov(x,y)= ?1G2(x)+Cov(x,?).
В результате МНК-оценка коэффициента ?1 модели регрессии примет вид:
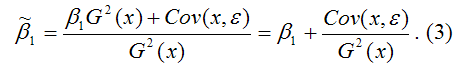
Таким образом, МНК-оценка
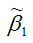
может быть представлена как сумма двух компонент:
1) константы ?1, т. е. истинного значения коэффициента;
2) случайной ошибки Cov(x,?), вызывающей вариацию коэффициента модели регрессии.
Однако на практике подобное разложение МНК-оценки невозможно, потому что истинные значения коэффициентов модели регрессии и значения случайной ошибки являются неизвестными. Теоретически данное разложение можно использовать при изучении статистических свойств МНК-оценок.
Аналогично доказывается, что МНК-оценка
коэффициента модели регрессии и несмещённая оценка дисперсии случайной ошибки
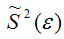
могут быть представлены как сумма постоянной составляющей (константы) и случайной компоненты, зависящей от ошибки модели регрессии ?.
Данный текст является ознакомительным фрагментом.
Читайте также
11. Критерии оценки неизвестных коэффициентов модели регрессии
11. Критерии оценки неизвестных коэффициентов модели регрессии
В ходе регрессионного анализа была подобрана форма связи, которая наилучшим образом отражает зависимость результативной переменной у от факторной переменной х:y=f(x).Необходимо оценить неизвестные
14. Оценка коэффициентов модели парной регрессии с помощью выборочного коэффициента регрессии
14. Оценка коэффициентов модели парной регрессии с помощью выборочного коэффициента регрессии
Помимо метода наименьших квадратов, с помощью которого в большинстве случаев определяются неизвестные параметры модели регрессии, в случае линейной модели парной регрессии
18. Характеристика качества модели регрессии
18. Характеристика качества модели регрессии
Качеством модели регрессии называется адекватность построенной модели исходным (наблюдаемым) данным.Для оценки качества модели регрессии используются специальные показатели.Качество линейной модели парной регрессии
22. Проверка гипотезы о значимости коэффициентов модели парной регрессии
22. Проверка гипотезы о значимости коэффициентов модели парной регрессии
Проверкой статистической гипотезы о значимости отдельных параметров модели называется проверка предположения о том, что данные параметры значимо отличаются от нуля.Необходимость проверки
25. Точечный и интервальный прогнозы для модели парной регрессии
25. Точечный и интервальный прогнозы для модели парной регрессии
Одна из задач эконометрического моделирования заключается в прогнозировании поведения исследуемого явления или процесса в будущем. В большинстве случаев данная задача решается на основе регрессионных
32. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии и коэффициент множественной детерминации
32. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии и коэффициент множественной детерминации
Помимо рекуррентных формул, которые используются для построения частных коэффициентов корреляции для
35. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом
35. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом
Проверка значимости коэффициентов регрессии означает проверку основной гипотезы об их значимом отличии от нуля.Основная гипотеза состоит в предположении о незначимости
39. Модели регрессии, нелинейные по факторным переменным
39. Модели регрессии, нелинейные по факторным переменным
При исследовании социально-экономических явлений и процессов далеко не все зависимости можно описать с помощью линейной связи. Поэтому в эконометрическом моделировании широко используется класс нелинейных
40. Модели регрессии, нелинейные по оцениваемым коэффициентам
40. Модели регрессии, нелинейные по оцениваемым коэффициентам
Нелинейными по оцениваемым параметрам моделями регрессииназываются модели, в которых результативная переменная yi нелинейно зависит от коэффициентов модели ?0…?n.К моделям регрессии, нелинейными по
41. Модели регрессии с точками разрыва
41. Модели регрессии с точками разрыва
Определение. Моделями регрессии с точками разрыва называются модели, которые нельзя привести к линейной форме, т. е. внутренне нелинейные модели регрессии.Модели регрессии делятся на два класса:1) кусочно-линейные модели регрессии;2)
44. Методы нелинейного оценивания коэффициентов модели регрессии
44. Методы нелинейного оценивания коэффициентов модели регрессии
Функцией потерь или ошибок называется функционал вида
Также в качестве функции потерь может быть использована сумма модулей отклонений наблюдаемых значений результативного признака у от теоретических
46. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии
46. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии
На нелинейные модели регрессии, которые являются внутренне линейными, т. е. сводимыми к линейному виду, распространяются все
57. Гетероскедастичность остатков модели регрессии
57. Гетероскедастичность остатков модели регрессии
Случайной ошибкой называется отклонение в линейной модели множественной регрессии:?i=yi–?0–?1x1i–…–?mxmiВ связи с тем, что величина случайной ошибки модели регрессии является неизвестной величиной, рассчитывается
60. Устранение гетероскедастичности остатков модели регрессии
60. Устранение гетероскедастичности остатков модели регрессии
Существует множество методов устранения гетероскедастичности остатков модели регрессии. Рассмотрим некоторые из них.Наиболее простым методом устранения гетероскедастичности остатков модели регрессии
63. Устранение автокорреляции остатков модели регрессии
63. Устранение автокорреляции остатков модели регрессии
В связи с тем, что наличие в модели регрессии автокорреляции между остатками модели может привести к негативным результатам всего процесса оценивания неизвестных коэффициентов модели, автокорреляция остатков
67. Модели регрессии с переменной структурой. Фиктивные переменные
67. Модели регрессии с переменной структурой. Фиктивные переменные
При построении модели регрессии может возникнуть ситуация, когда в неё необходимо включить не только количественные, но и качественные переменные (например, возраст, образование, пол, расовую
Результат любого измерения не определён однозначно и имеет случайную составляющую.
Поэтому адекватным языком для описания погрешностей является язык вероятностей.
Тот факт, что значение некоторой величины «случайно», не означает, что
она может принимать совершенно произвольные значения. Ясно, что частоты, с которыми
возникает те или иные значения, различны. Вероятностные законы, которым
подчиняются случайные величины, называют распределениями.
2.1 Случайная величина
Случайной будем называть величину, значение которой не может быть достоверно определено экспериментатором. Чаще всего подразумевается, что случайная величина будет изменяться при многократном повторении одного и того же эксперимента. При интерпретации результатов измерений в физических экспериментах, обычно случайными также считаются величины, значение которых является фиксированным, но не известно экспериментатору. Например смещение нуля шкалы прибора. Для формализации работы со случайными величинами используют понятие вероятности. Численное значение вероятности того, что какая-то величина примет то или иное значение определяется либо как относительная частота наблюдения того или иного значения при повторении опыта большое количество раз, либо как оценка на основе данных других экспериментов.
Замечание.
Хотя понятия вероятности и случайной величины являются основополагающими, в литературе нет единства в их определении. Обсуждение формальных тонкостей или построение строгой теории лежит за пределами данного пособия. Поэтому на начальном этапе лучше использовать «интуитивное» понимание этих сущностей. Заинтересованным читателям рекомендуем обратиться к специальной литературе: [5].
Рассмотрим случайную физическую величину x, которая при измерениях может
принимать непрерывный набор значений. Пусть
P[x0,x0+δx] — вероятность того, что результат окажется вблизи
некоторой точки x0 в пределах интервала δx: x∈[x0,x0+δx].
Устремим интервал
δx к нулю. Нетрудно понять, что вероятность попасть в этот интервал
также будет стремиться к нулю. Однако отношение
w(x0)=P[x0,x0+δx]δx будет оставаться конечным.
Функцию w(x) называют плотностью распределения вероятности или кратко
распределением непрерывной случайной величины x.
Замечание. В математической литературе распределением часто называют не функцию
w(x), а её интеграл W(x)=∫w(x)𝑑x. Такую функцию в физике принято
называть интегральным или кумулятивным распределением. В англоязычной литературе
для этих функций принято использовать сокращения:
pdf (probability distribution function) и
cdf (cumulative distribution function)
соответственно.
Гистограммы.
Проиллюстрируем наглядно понятие плотности распределения. Результат
большого числа измерений случайной величины удобно представить с помощью
специального типа графика — гистограммы.
Для этого область значений x, размещённую на оси абсцисс, разобьём на
равные малые интервалы — «корзины» или «бины» (англ. bins)
некоторого размера h. По оси ординат будем откладывать долю измерений w,
результаты которых попадают в соответствующую корзину. А именно,
пусть k — номер корзины; nk — число измерений, попавших
в диапазон x∈[kh,(k+1)h]. Тогда на графике изобразим «столбик»
шириной h и высотой wk=nk/n.
В результате получим картину, подобную изображённой на рис. 2.1.
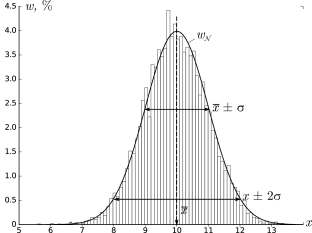
σ=1,0, h=0,1, n=104)
Высоты построенных столбиков будут приближённо соответствовать значению
плотности распределения w(x) вблизи соответствующей точки x.
Если устремить число измерений к бесконечности (n→∞), а ширину корзин
к нулю (h→0), то огибающая гистограммы будет стремиться к некоторой
непрерывной функции w(x).
Самые высокие столбики гистограммы будут группироваться вблизи максимума
функции w(x) — это наиболее вероятное значение случайной величины.
Если отклонения в положительную и отрицательную стороны равновероятны,
то гистограмма будет симметрична — в таком случае среднее значение ⟨x⟩
также будет лежать вблизи этого максимума. Ширина гистограммы будет характеризовать разброс
значений случайной величины — по порядку величины
она, как правило, близка к среднеквадратичному отклонению sx.
Свойства распределений.
Из определения функции w(x) следует, что вероятность получить в результате
эксперимента величину x в диапазоне от a до b
можно найти, вычислив интеграл:
| Px∈[a,b]=∫abw(x)𝑑x. | (2.1) |
Согласно определению вероятности, сумма вероятностей для всех возможных случаев
всегда равна единице. Поэтому интеграл распределения w(x) по всей области
значений x (то есть суммарная площадь под графиком w(x)) равен единице:
Это соотношение называют условием нормировки.
Среднее и дисперсия.
Вычислим среднее по построенной гистограмме. Если размер корзин
h достаточно мал, все измерения в пределах одной корзины можно считать примерно
одинаковыми. Тогда среднее арифметическое всех результатов можно вычислить как
Переходя к пределу, получим следующее определение среднего значения
случайной величины:
где интегрирование ведётся по всей области значений x.
В теории вероятностей x¯ также называют математическим ожиданием
распределения.
Величину
| σ2=(x-x¯)2¯=∫(x-x¯)2w𝑑x | (2.3) |
называют дисперсией распределения. Значение σ есть
срекднеквадратичное отклонение в пределе n→∞. Оно имеет ту
же размерность, что и сама величина x и характеризует разброс распределения.
Именно эту величину, как правило, приводят как характеристику погрешности
измерения x.
Доверительный интервал.
Обозначим как P|Δx|<δ вероятность
того, что отклонение от среднего Δx=x-x¯ составит величину,
не превосходящую по модулю значение δ:
| P|Δx|<δ=∫x¯-δx¯+δw(x)𝑑x. | (2.4) |
Эту величину называют доверительной вероятностью для
доверительного интервала |x-x¯|≤δ.
2.2 Нормальное распределение
Одним из наиболее примечательных результатов теории вероятностей является
так называемая центральная предельная теорема. Она утверждает,
что сумма большого количества независимых случайных слагаемых, каждое
из которых вносит в эту сумму относительно малый вклад, подчиняется
универсальному закону, не зависимо от того, каким вероятностным законам
подчиняются её составляющие, — так называемому нормальному
распределению (или распределению Гаусса).
Доказательство теоремы довольно громоздко и мы его не приводим (его можно найти
в любом учебнике по теории вероятностей). Остановимся
кратко на том, что такое нормальное распределение и его основных свойствах.
Плотность нормального распределения выражается следующей формулой:
| w𝒩(x)=12πσe-(x-x¯)22σ2. | (2.5) |
Здесь x¯ и σ
— параметры нормального распределения: x¯ равно
среднему значению x, a σ —
среднеквадратичному отклонению, вычисленным в пределе n→∞.
Как видно из рис. 2.1, распределение представляет собой
симметричный
«колокол», положение вершины которого
соответствует x¯ (ввиду симметрии оно же
совпадает с наиболее вероятным значением — максимумом
функции w𝒩(x)).
При значительном отклонении x от среднего величина
w𝒩(x)
очень быстро убывает. Это означает, что вероятность встретить отклонения,
существенно большие, чем σ, оказывается пренебрежимо
мала. Ширина «колокола» по порядку величины
равна σ — она характеризует «разброс»
экспериментальных данных относительно среднего значения.
Замечание. Точки x=x¯±σ являются точками
перегиба графика w(x) (в них вторая производная по x
обращается в нуль, w′′=0), а их положение по высоте составляет
w(x¯±σ)/w(x¯)=e-1/2≈0,61
от высоты вершины.
Универсальный характер центральной предельной теоремы позволяет широко
применять на практике нормальное (гауссово) распределение для обработки
результатов измерений, поскольку часто случайные погрешности складываются из
множества случайных независимых факторов. Заметим, что на практике
для приближённой оценки параметров нормального распределения
случайной величины используются выборочные значения среднего
и дисперсии: x¯≈⟨x⟩, sx≈σx.
x-x0σ2=2w(x)σ1=1
Доверительные вероятности.
Вычислим некоторые доверительные вероятности (2.4) для нормально
распределённых случайных величин.
Замечание. Значение интеграла вида ∫e-x2/2𝑑x
(его называют интегралом ошибок) в элементарных функциях не выражается,
но легко находится численно.
Вероятность того, что результат отдельного измерения x окажется
в пределах x¯±σ оказывается равна
| P|Δx|<σ=∫x¯-σx¯+σw𝒩𝑑x≈0,68. |
Вероятность отклонения в пределах x¯±2σ:
а в пределах x¯±3σ:
Иными словами, при большом числе измерений нормально распределённой
величины можно ожидать, что лишь треть измерений выпадут за пределы интервала
[x¯-σ,x¯+σ]. При этом около 5%
измерений выпадут за пределы [x¯-2σ;x¯+2σ],
и лишь 0,27% окажутся за пределами
[x¯-3σ;x¯+3σ].
Пример. В сообщениях об открытии бозона Хиггса на Большом адронном коллайдере
говорилось о том, что исследователи ждали подтверждение результатов
с точностью «5 сигма». Используя нормальное распределение (2.5)
нетрудно посчитать, что они использовали доверительную вероятность
P≈1-5,7⋅10-7=0,99999943. Такую точность можно назвать фантастической.
Полученные значения доверительных вероятностей используются при
стандартной записи результатов измерений. В физических измерениях
(в частности, в учебной лаборатории), как правило, используется P=0,68,
то есть, запись
означает, что измеренное значение лежит в диапазоне (доверительном
интервале) x∈[x¯-δx;x¯+δx] с
вероятностью 68%. Таким образом погрешность ±δx считается
равной одному среднеквадратичному отклонению: δx=σ.
В технических измерениях чаще используется P=0,95, то есть под
абсолютной погрешностью имеется в виду удвоенное среднеквадратичное
отклонение, δx=2σ. Во избежание разночтений доверительную
вероятность следует указывать отдельно.
Замечание. Хотя нормальный закон распределения встречается на практике довольно
часто, стоит помнить, что он реализуется далеко не всегда.
Полученные выше соотношения для вероятностей попадания значений в
доверительные интервалы можно использовать в качестве простейшего
признака нормальности распределения: в частности, если количество попадающих
в интервал ±σ результатов существенно отличается от 2/3 — это повод
для более детального исследования закона распределения ошибок.
Сравнение результатов измерений.
Теперь мы можем дать количественный критерий для сравнения двух измеренных
величин или двух результатов измерения одной и той же величины.
Пусть x1 и x2 (x1≠x2) измерены с
погрешностями σ1 и σ2 соответственно.
Ясно, что если различие результатов |x2-x1| невелико,
его можно объяснить просто случайными отклонениями.
Если же теория предсказывает, что вероятность обнаружить такое отклонение
слишком мала, различие результатов следует признать значимым.
Предварительно необходимо договориться о соответствующем граничном значении
вероятности. Универсального значения здесь быть не может,
поэтому приходится полагаться на субъективный выбор исследователя. Часто
в качестве «разумной» границы выбирают вероятность 5%,
что, как видно из изложенного выше, для нормального распределения
соответствует отклонению более, чем на 2σ.
Допустим, одна из величин известна с существенно большей точностью:
σ2≪σ1 (например, x1 — результат, полученный
студентом в лаборатории, x2 — справочное значение).
Поскольку σ2 мало, x2 можно принять за «истинное»:
x2≈x¯. Предполагая, что погрешность измерения
x1 подчиняется нормальному закону с и дисперсией σ12,
можно утверждать, что
различие считают будет значимы, если
Пусть погрешности измерений сравнимы по порядку величины:
σ1∼σ2. В теории вероятностей показывается, что
линейная комбинация нормально распределённых величин также имеет нормальное
распределение с дисперсией σ2=σ12+σ22
(см. также правила сложения погрешностей (2.7)). Тогда
для проверки гипотезы о том, что x1 и x2 являются измерениями
одной и той же величины, нужно вычислить, является ли значимым отклонение
|x1-x2| от нуля при σ=σ12+σ22.
Пример. Два студента получили следующие значения для теплоты испарения
некоторой жидкости: x1=40,3±0,2 кДж/моль и
x2=41,0±0,3 кДж/моль, где погрешность соответствует
одному стандартному отклонению. Можно ли утверждать, что они исследовали
одну и ту же жидкость?
Имеем наблюдаемую разность |x1-x2|=0,7 кДж/моль,
среднеквадратичное отклонение для разности
σ=0,22+0,32=0,36 кДж/моль.
Их отношение |x2-x1|σ≈2. Из
свойств нормального распределения находим вероятность того, что измерялась
одна и та же величина, а различия в ответах возникли из-за случайных
ошибок: P≈5%. Ответ на вопрос, «достаточно»
ли мала или велика эта вероятность, остаётся на усмотрение исследователя.
Замечание. Изложенные здесь соображения применимы, только если x¯ и
его стандартное отклонение σ получены на основании достаточно
большой выборки n≫1 (или заданы точно). При небольшом числе измерений
(n≲10) выборочные средние ⟨x⟩ и среднеквадратичное отклонение
sx сами имеют довольно большую ошибку, а
их распределение будет описываться не нормальным законом, а так
называемым t-распределением Стъюдента. В частности, в зависимости от
значения n интервал ⟨x⟩±sx будет соответствовать несколько
меньшей доверительной вероятности, чем P=0,68. Особенно резко различия
проявляются при высоких уровнях доверительных вероятностей P→1.
2.3 Независимые величины
Величины x и y называют независимыми если результат измерения одной
из них никак не влияет на результат измерения другой. Для таких величин вероятность того, что x окажется в некоторой области X, и одновременно y — в области Y,
равна произведению соответствующих вероятностей:
Обозначим отклонения величин от их средних как Δx=x-x¯ и
Δy=y-y¯.
Средние значения этих отклонений равны, очевидно, нулю: Δx¯=x¯-x¯=0,
Δy¯=0. Из независимости величин x и y следует,
что среднее значение от произведения Δx⋅Δy¯
равно произведению средних Δx¯⋅Δy¯
и, следовательно, равно нулю:
| Δx⋅Δy¯=Δx¯⋅Δy¯=0. | (2.6) |
Пусть измеряемая величина z=x+y складывается из двух независимых
случайных слагаемых x и y, для которых известны средние
x¯ и y¯, и их среднеквадратичные погрешности
σx и σy. Непосредственно из определения (1.1)
следует, что среднее суммы равно сумме средних:
Найдём дисперсию σz2. В силу независимости имеем
| Δz2¯=Δx2¯+Δy2¯+2Δx⋅Δy¯≈Δx2¯+Δy2¯, |
то есть:
Таким образом, при сложении независимых величин их погрешности
складываются среднеквадратичным образом.
Подчеркнём, что для справедливости соотношения (2.7)
величины x и y не обязаны быть нормально распределёнными —
достаточно существования конечных значений их дисперсий. Однако можно
показать, что если x и y распределены нормально, нормальным
будет и распределение их суммы.
Замечание. Требование независимости
слагаемых является принципиальным. Например, положим y=x. Тогда
z=2x. Здесь y и x, очевидно, зависят друг от друга. Используя
(2.7), находим σ2x=2σx,
что, конечно, неверно — непосредственно из определения
следует, что σ2x=2σx.
Отдельно стоит обсудить математическую структуру формулы (2.7).
Если одна из погрешностей много больше другой, например,
σx≫σy,
то меньшей погрешностью можно пренебречь, σx+y≈σx.
С другой стороны, если два источника погрешностей имеют один порядок
σx∼σy, то и σx+y∼σx∼σy.
Эти обстоятельства важны при планирования эксперимента: как правило,
величина, измеренная наименее точно, вносит наибольший вклад в погрешность
конечного результата. При этом, пока не устранены наиболее существенные
ошибки, бессмысленно гнаться за повышением точности измерения остальных
величин.
Пример. Пусть σy=σx/3,
тогда σz=σx1+19≈1,05σx,
то есть при различии двух погрешностей более, чем в 3 раза, поправка
к погрешности составляет менее 5%, и уже нет особого смысла в учёте
меньшей погрешности: σz≈σx. Это утверждение
касается сложения любых независимых источников погрешностей в эксперименте.
2.4 Погрешность среднего
Выборочное среднее арифметическое значение ⟨x⟩, найденное
по результатам n измерений, само является случайной величиной.
Действительно, если поставить серию одинаковых опытов по n измерений,
то в каждом опыте получится своё среднее значение, отличающееся от
предельного среднего x¯.
Вычислим среднеквадратичную погрешность среднего арифметического
σ⟨x⟩.
Рассмотрим вспомогательную сумму n слагаемых
Если {xi} есть набор независимых измерений
одной и той же физической величины, то мы можем, применяя результат
(2.7) предыдущего параграфа, записать
| σZ=σx12+σx22+…+σxn2=nσx, |
поскольку под корнем находится n одинаковых слагаемых. Отсюда с
учётом ⟨x⟩=Z/n получаем
Таким образом, погрешность среднего значения x по результатам
n независимых измерений оказывается в n раз меньше погрешности
отдельного измерения. Это один из важнейших результатов, позволяющий
уменьшать случайные погрешности эксперимента за счёт многократного
повторения измерений.
Подчеркнём отличия между σx и σ⟨x⟩:
величина σx — погрешность отдельного
измерения — является характеристикой разброса значений
в совокупности измерений {xi}, i=1..n. При
нормальном законе распределения примерно 68% измерений попадают в
интервал ⟨x⟩±σx;
величина σ⟨x⟩ — погрешность
среднего — характеризует точность, с которой определено
среднее значение измеряемой физической величины ⟨x⟩ относительно
предельного («истинного») среднего x¯;
при этом с доверительной вероятностью P=68% искомая величина x¯
лежит в интервале
⟨x⟩-σ⟨x⟩<x¯<⟨x⟩+σ⟨x⟩.
2.5 Результирующая погрешность опыта
Пусть для некоторого результата измерения известна оценка его максимальной
систематической погрешности Δсист и случайная
среднеквадратичная
погрешность σслуч. Какова «полная»
погрешность измерения?
Предположим для простоты, что измеряемая величина в принципе
может быть определена сколь угодно точно, так что можно говорить о
некотором её «истинном» значении xист
(иными словами, погрешность результата связана в основном именно с
процессом измерения). Назовём полной погрешностью измерения
среднеквадратичное значения отклонения от результата измерения от
«истинного»:
Отклонение x-xист можно представить как сумму случайного
отклонения от среднего δxслуч=x-x¯
и постоянной (но, вообще говоря, неизвестной) систематической составляющей
δxсист=x¯-xист=const:
Причём случайную составляющую можно считать независимой от систематической.
В таком случае из (2.7) находим:
| σполн2=⟨δxсист2⟩+⟨δxслуч2⟩≤Δсист2+σслуч2. | (2.9) |
Таким образом, для получения максимального значения полной
погрешности некоторого измерения нужно квадратично сложить максимальную
систематическую и случайную погрешности.
Если измерения проводятся многократно, то согласно (2.8)
случайная составляющая погрешности может быть уменьшена, а систематическая
составляющая при этом остаётся неизменной:
Отсюда следует важное практическое правило
(см. также обсуждение в п. 2.3): если случайная погрешность измерений
в 2–3 раза меньше предполагаемой систематической, то
нет смысла проводить многократные измерения в попытке уменьшить погрешность
всего эксперимента. В такой ситуации измерения достаточно повторить
2–3 раза — чтобы убедиться в повторяемости результата, исключить промахи
и проверить, что случайная ошибка действительно мала.
В противном случае повторение измерений может иметь смысл до
тех пор, пока погрешность среднего
σ⟨x⟩=σxn
не станет меньше систематической.
Замечание. Поскольку конкретная
величина систематической погрешности, как правило, не известна, её
можно в некотором смысле рассматривать наравне со случайной —
предположить, что её величина была определена по некоторому случайному
закону перед началом измерений (например, при изготовлении линейки
на заводе произошло некоторое случайное искажение шкалы). При такой
трактовке формулу (2.9) можно рассматривать просто
как частный случай формулы сложения погрешностей независимых величин
(2.7).
Подчеркнем, что вероятностный закон, которому подчиняется
систематическая ошибка, зачастую неизвестен. Поэтому неизвестно и
распределение итогового результата. Из этого, в частности, следует,
что мы не можем приписать интервалу x±Δсист какую-либо
определённую доверительную вероятность — она равна 0,68
только если систематическая ошибка имеет нормальное распределение.
Можно, конечно, предположить,
— и так часто делают — что, к примеру, ошибки
при изготовлении линеек на заводе имеют гауссов характер. Также часто
предполагают, что систематическая ошибка имеет равномерное
распределение (то есть «истинное» значение может с равной вероятностью
принять любое значение в пределах интервала ±Δсист).
Строго говоря, для этих предположений нет достаточных оснований.
Пример. В результате измерения диаметра проволоки микрометрическим винтом,
имеющим цену деления h=0,01 мм, получен следующий набор из n=8 значений:
Вычисляем среднее значение: ⟨d⟩≈386,3 мкм.
Среднеквадратичное отклонение:
σd≈9,2 мкм. Случайная погрешность среднего согласно
(2.8):
σ⟨d⟩=σd8≈3,2
мкм. Все результаты лежат в пределах ±2σd, поэтому нет
причин сомневаться в нормальности распределения. Максимальную погрешность
микрометра оценим как половину цены деления, Δ=h2=5 мкм.
Результирующая полная погрешность
σ≤Δ2+σd28≈6,0 мкм.
Видно, что σслуч≈Δсист и проводить дополнительные измерения
особого смысла нет. Окончательно результат измерений может быть представлен
в виде (см. также правила округления
результатов измерений в п. 4.3.2)
d=386±6мкм,εd=1,5%.
Заметим, что поскольку случайная погрешность и погрешность
прибора здесь имеют один порядок величины, наблюдаемый случайный разброс
данных может быть связан как с неоднородностью сечения проволоки,
так и с дефектами микрометра (например, с неровностями зажимов, люфтом
винта, сухим трением, деформацией проволоки под действием микрометра
и т. п.). Для ответа на вопрос, что именно вызвало разброс, требуются
дополнительные исследования, желательно с использованием более точных
приборов.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=±1 м/c.
Результаты измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=162,0м/с,
среднеквадратичное отклонение σv=13,8м/c, случайная
ошибка для средней скорости
σv¯=σv/6=5,6м/с.
Поскольку разброс экспериментальных данных существенно превышает погрешность
каждого измерения, σv≫δv, он почти наверняка связан
с реальным различием скоростей пули в разных выстрелах, а не с ошибками
измерений. В качестве результата эксперимента представляют интерес
как среднее значение скоростей ⟨v⟩=162±6м/с
(ε≈4%), так и значение σv≈14м/с,
характеризующее разброс значений скоростей от выстрела к выстрелу.
Малая инструментальная погрешность в принципе позволяет более точно
измерить среднее и дисперсию, и исследовать закон распределения выстрелов
по скоростям более детально — для этого требуется набрать
бо́льшую статистику по выстрелам.
Пример. Измерение скорости
полёта пули было осуществлено с погрешностью δv=10 м/c. Результаты
измерений для n=6 выстрелов представлены в таблице:
Усреднённый результат ⟨v⟩=163,3м/с,
σv=12,1м/c, σ⟨v⟩=5м/с,
σполн≈11,2м/с. Инструментальная
погрешность каждого измерения превышает разброс данных, поэтому в
этом опыте затруднительно сделать вывод о различии скоростей от выстрела
к выстрелу. Результат измерений скорости пули:
⟨v⟩=163±11м/с,
ε≈7%. Проводить дополнительные выстрелы при такой
большой инструментальной погрешности особого смысла нет —
лучше поработать над точностью приборов и методикой измерений.
2.6 Обработка косвенных измерений
Косвенными называют измерения, полученные в результате расчётов,
использующих результаты прямых (то есть «непосредственных»)
измерений физических величин. Сформулируем основные правила пересчёта
погрешностей при косвенных измерениях.
2.6.1 Случай одной переменной
Пусть в эксперименте измеряется величина x, а её «наилучшее»
(в некотором смысле) значение равно x⋆ и оно известно с
погрешностью σx. После чего с помощью известной функции
вычисляется величина y=f(x).
В качестве «наилучшего» приближения для y используем значение функции
при «наилучшем» x:
Найдём величину погрешности σy. Обозначая отклонение измеряемой
величины как Δx=x-x⋆, и пользуясь определением производной,
при условии, что функция y(x) — гладкая
вблизи x≈x⋆, запишем
где f′≡dydx — производная фукнции f(x), взятая в точке
x⋆. Возведём полученное в квадрат, проведём усреднение
(σy2=⟨Δy2⟩,
σx2=⟨Δx2⟩), и затем снова извлечём
корень. В результате получим
Пример. Для степенной функции
y=Axn имеем σy=nAxn-1σx, откуда
σyy=nσxx,или εy=nεx,
то есть относительная погрешность степенной функции возрастает пропорционально
показателю степени n.
Пример. Для y=1/x имеем ε1/x=εx
— при обращении величины сохраняется её относительная
погрешность.
Упражнение. Найдите погрешность логарифма y=lnx, если известны x
и σx.
Упражнение. Найдите погрешность показательной функции y=ax,
если известны x и σx. Коэффициент a задан точно.
2.6.2 Случай многих переменных
Пусть величина u вычисляется по измеренным значениям нескольких
различных независимых физических величин x, y, …
на основе известного закона u=f(x,y,…). В качестве
наилучшего значения можно по-прежнему взять значение функции f
при наилучших значениях измеряемых параметров:
Для нахождения погрешности σu воспользуемся свойством,
известным из математического анализа, — малые приращения гладких
функции многих переменных складываются линейно, то есть справедлив
принцип суперпозиции малых приращений:
где символом fx′≡∂f∂x обозначена
частная производная функции f по переменной x —
то есть обычная производная f по x, взятая при условии, что
все остальные аргументы (кроме x) считаются постоянными параметрами.
Тогда пользуясь формулой для нахождения дисперсии суммы независимых
величин (2.7), получим соотношение, позволяющее вычислять
погрешности косвенных измерений для произвольной функции
u=f(x,y,…):
| σu2=fx′2σx2+fy′2σy2+… | (2.11) |
Это и есть искомая общая формула пересчёта погрешностей при косвенных
измерениях.
Отметим, что формулы (2.10) и (2.11) применимы
только если относительные отклонения всех величин малы
(εx,εy,…≪1),
а измерения проводятся вдали от особых точек функции f (производные
fx′, fy′ … не должны обращаться в бесконечность).
Также подчеркнём, что все полученные здесь формулы справедливы только
для независимых переменных x, y, …
Остановимся на некоторых важных частных случаях формулы
(2.11).
Пример. Для суммы (или разности) u=∑i=1naixi имеем
σu2=∑i=1nai2σxi2.
(2.12)
Пример. Найдём погрешность степенной функции:
u=xα⋅yβ⋅…. Тогда нетрудно получить,
что
σu2u2=α2σx2x2+β2σy2y2+…
или через относительные погрешности
εu2=α2εx2+β2εy2+…
(2.13)
Пример. Вычислим погрешность произведения и частного: u=xy или u=x/y.
Тогда в обоих случаях имеем
εu2=εx2+εy2,
(2.14)
то есть при умножении или делении относительные погрешности складываются
квадратично.
Пример. Рассмотрим несколько более сложный случай: нахождение угла по его тангенсу
u=arctgyx.
В таком случае, пользуясь тем, что (arctgz)′=11+z2,
где z=y/x, и используя производную сложной функции, находим
ux′=uz′zx′=-yx2+y2,
uy′=uz′zy′=xx2+y2, и наконец
σu2=y2σx2+x2σy2(x2+y2)2.
Упражнение. Найти погрешность вычисления гипотенузы z=x2+y2
прямоугольного треугольника по измеренным катетам x и y.
По итогам данного раздела можно дать следующие практические рекомендации.
- •
Как правило, нет смысла увеличивать точность измерения какой-то одной
величины, если другие величины, используемые в расчётах, остаются
измеренными относительно грубо — всё равно итоговая погрешность
скорее всего будет определяться самым неточным измерением. Поэтому
все измерения имеет смысл проводить примерно с одной и той же
относительной погрешностью. - •
При этом, как следует из (2.13), особое внимание
следует уделять измерению величин, возводимых при расчётах в степени
с большими показателями. А при сложных функциональных зависимостях
имеет смысл детально проанализировать структуру формулы
(2.11):
если вклад от некоторой величины в общую погрешность мал, нет смысла
гнаться за высокой точностью её измерения, и наоборот, точность некоторых
измерений может оказаться критически важной. - •
Следует избегать измерения малых величин как разности двух близких
значений (например, толщины стенки цилиндра как разности внутреннего
и внешнего радиусов): если u=x-y, то абсолютная погрешность
σu=σx2+σy2
меняется мало, однако относительная погрешность
εu=σux-y
может оказаться неприемлемо большой, если x≈y.
В предыдущем параграфе мы выяснили, что дисперсия оценки (widehat {beta _2}) равна:
begin{equation*} mathit{var}left(widehat {beta _2}right)=frac{sigma ^2}{Sigma left(x_i-overline xright)^2}. end{equation*}
Это полезная информация, так как дисперсия (widehat {beta _2}) характеризует точность результатов оценивания соответствующего параметра (чем меньше дисперсия, тем точнее наша оценка). Проблема в том, что непосредственно величину (mathit{var}left(widehat {beta _2}right)) мы вычислить не можем: хотя мы наблюдаем значения (x_i,) (i=1,2,{dots},n), но мы не наблюдаем величину (sigma ^2). Этот параметр является неизвестным параметром классической линейной модели подобно величинам (beta _1) и (beta _2). Впрочем, как и в случае с (beta _1) и (beta _2), мы можем получить оценку неизвестного параметра (sigma ^2). Несмещенная оценка дисперсии случайной ошибки (sigma ^2) имеет вид:
begin{equation*} S^2=frac 1{n-2}{ast}sum _{i=1}^ne_i^2 end{equation*}
Чтобы доказать её несмещенность, достаточно осуществить выкладки, аналогичные преобразованиям из предыдущего параграфа, и убедиться, что (Eleft(S^2right)=sigma ^2).
Если в формуле для (mathit{var}left(widehat {beta _2}right)) вместо дисперсии случайной ошибки (sigma ^2) подставить её оценку (S^2), мы получим несмещенную оценку дисперсии МНК-оценки (widehat {beta _2}), которая будет иметь вид:
begin{equation*} widehat {mathit{var}}left(widehat {beta _2}right)=frac{S^2}{Sigma left(x_i-overline xright)^2} end{equation*}
Корень из этой величины называется стандартной ошибкой оценки коэффициента (widehat {beta _2}):
begin{equation*} mathit{se}left(widehat {beta _2}right)=sqrt{widehat {mathit{var}}left(widehat {beta _2}right)}=sqrt{frac{S^2}{Sigma left(x_i-overline xright)^2}} end{equation*}
Аналогичным образом вычисляется стандартная ошибка оценки коэффициента (widehat {beta _1}) (здесь мы опираемся на равенство 2.4, заменяя в нем дисперсию случайной ошибки её оценкой).
begin{equation*} mathit{se}left(widehat {beta _1}right)=sqrt{widehat {mathit{var}}left(widehat {beta _1}right)}=sqrt{frac{frac{S^2} n{ast}sum x_i^2}{sum left(x_i-overline xright)^2}} end{equation*}
Стандартные ошибки оценок коэффициентов пригодятся нам для тестирования гипотез.
Представим, что мы хотим выяснить, влияет ли уровень образования (переменная x) на заработную плату работника в некоторой отрасли (переменная y)? Ответы на такого сорта вопросы, как мы обсудили в первой главе, и есть одна из главных задач эконометрики.
Представим также, что все предпосылки классической линейной модели парной регрессии выполнены. Тогда в терминах нашей модели вопрос «Верно ли, что образование не влияет на заработную плату?» эквивалентен вопросу «Верно ли, что в регрессии (y_i=beta _1+beta _2x_i+varepsilon _i) коэффициент (beta _2) равен нулю?».
Как мы могли бы ответить на этот вопрос?
Естественная идея состоит в том, чтобы посмотреть оценки коэффициентов (widehat {beta _1}) и (widehat {beta _2}) и увидеть, равен ли коэффициент (widehat {beta _2}) нулю. Однако при этом возникает следующая проблема: (widehat {beta _1}) и (widehat {beta _2}) — оценки, полученные при помощи МНК на основе случайной выборки. Следовательно, они сами являются случайными величинами, которые могут принимать значения лишь «приблизительно» равные истинным. Поэтому, даже если истинное значение коэффициента (beta _2) равно нулю, его оценка (widehat {beta _2}), скорее всего, будет отклоняться от нуля.
Следовательно, нужно уметь определять, достаточно ли сильно (widehat {beta _2}) отличается от нуля для того, чтобы можно было с уверенностью утверждать, что и истинное значение коэффициента (beta _2) также не равно нулю. Опишем процедуру, которая позволяет это сделать.
Процедура тестирования незначимости коэффициента:
Формулируем тестируемую гипотезу (H_0:beta _2=0) («переменная x не влияет на переменную y») и альтернативную гипотезу (H_1:beta _2{neq}0) («переменная x влияет на переменную y»)
Находим расчетное значение тестовой статистки по формуле
(frac{widehat {beta _2}}{mathit{se}left(widehat {beta }_2right)}.)
Выбираем уровень значимости (alpha ). Уровнем значимости в математической статистике называется вероятность ошибки первого рода, то есть вероятность отклонить тестируемую гипотезу при условии, что в действительности эта гипотеза верна. Разумеется, нам хотелось бы ошибаться не слишком часто, поэтому данную вероятность обычно выбирают маленькой. Чаще всего в эконометрике используются уровни значимости 1% и 5%.
Из таблиц распределения Стьюдента находим критическое значение тестовой статистки (t_{n-2}^{alpha }) для выбранного уровня значимости и так называемого числа степеней свободы, которое в нашем случае равно (left(n-2right)).
Если (left|frac{widehat {beta _2}}{mathit{se}left(widehat {beta }_2right)}right|>t_{n-2}^{alpha }), то есть (widehat {beta _2}) достаточно велик по абсолютной величине, следует отвергнуть гипотезу (H_0:beta _2=0) и сделать вывод в пользу альтернативной гипотезы, то есть заключить, что переменная x влияет на переменную y. В этом случае переменную x называют статистически значимой при уровне значимости (alpha ). В противном случае, соответственно, гипотеза (H_0) не может быть отвергнута, и переменную x называют статистически незначимой при уровне значимости (alpha ).
Здесь и далее во всех тестах, если явно не указано иное, мы подразумеваем альтернативную гипотезу «(beta _2) не равно c» , а не (beta _2<c) или (beta _2>c). Поэтому под критическими значениями из таблиц распределения Стьюдента по умолчанию подразумеваются критические значения для двусторонних (а не односторонних) тестов. Все стандартные эконометрические пакеты используют такой же подход.}
Замечание 1. В этой процедуре мы опираемся на тот факт, что тестовая статистика имеет t-распределение Стьюдента. Чтобы это было верно, как раз и нужна предпосылка №6 КЛМПР, которую мы до этого никак не использовали.
В соответствии с этой предпосылкой случайные ошибки имеют нормальное распределение. Мы показали (см. равенство (2.2)), что (widehat {beta _2}) — это линейная комбинация случайных ошибок, то есть независимых, одинаково и нормально распределенных случайных величин.
Из математической статистики известно, что отсюда следуют два утверждения:
Во-первых, (widehat {beta _2}) имеет нормальное распределение (так как линейная комбинация нормальных случайных величин является нормальной случайной величиной), дисперсию и математическое ожидание которого мы вычислили в предыдущем параграфе. Иными словами (widehat {beta _2}) имеет вот такое распределение:
begin{equation*} Nleft(beta _2,frac{sigma ^2}{Sigma left(x_i-overline xright)^2}right) end{equation*}
Во-вторых, случайная величина (frac{widehat {beta _2}-beta _2}{mathit{se}left(widehat {beta _2}right)}) имеет t-распределение Стьюдента. В нашем случае это будет распределение с (n-2) степенями свободы: (frac{widehat {beta _2}-beta _2}{mathit{se}left(widehat {beta _2}right)})~(t_{n-2})
В частности, если верна сформулированная нами гипотеза (beta _2=0), то распределение Стьюдента имеет дробь (frac{widehat {beta }_2}{mathit{se}left(widehat {beta }_2right)}), которую мы используем в нашей процедуре. В этом случае критическое значение определяется из вот такого условия (его геометрическая интерпретация представлена в примере 2.3):
begin{equation*} Pleft(left|frac{widehat {beta }_2}{mathit{se}left(widehat {beta }_2right)}right|<t_{n-2}^{alpha }right)=1-alpha . end{equation*}
Замечание 2. Аналогичным образом можно тестировать гипотезу (H_0:beta _2=c) (против альтернативной гипотезы (H_0:beta _2{neq}c)), где c — это некоторая константа. В этом случае процедура тестирования остается такой же с одним исключением: расчетное значение тестовой статистики будет иметь вид (frac{widehat {beta }_2-c}{mathit{se}left(widehat {beta }_2right)}).
Замечание 3. Раньше для определения величины критического значения (t_{n-2}^{alpha }) было необходимо использовать таблицы распределения Стьюдента. Сейчас этот способ тоже доступен (например, соответствующая таблица представлена в Приложении 3.А в конце третьей главы), однако теперь это значение можно рассчитать непосредственно в эконометрическом пакете или, например, в MS Excel (см. пример ниже).
Альтернативным способом является использование для тестирования гипотезы так называемого p-значения. P-значением называют такой уровень значимости, при котором тестируемая гипотеза находится на грани между отвержением и принятием.
Поэтому использовать p-значение при принятии решения очень просто: если оно меньше заранее выбранного уровня значимости (alpha ), то тестируемая гипотеза отвергается при уровне значимости (alpha ). Например, если при тестировании незначимости коэффициента вы используете пятипроцентный уровень значимости ( (alpha =0,05)), а p-значение оказалось равно 0,0002, следует заключить, что соответствующий коэффициент является значимым. Удобство использования p-значения состоит в том, что эта величина автоматически рассчитывается всеми стандартными эконометрическими пакетами, поэтому для принятия решения о значимости или незначимости того или иного коэффициента (а также для проведения любых других тестов, которые мы обсудим далее) вам не требуется никаких таблиц распределения и никаких дополнительных расчетов.
Рассмотрим для большей наглядности еще один пример.
Пример 2.3. Тестирование незначимости коэффициента и графическая иллюстрация
Представим, что у нас 10 наблюдений ( (n=10)), оценка коэффициента оказалась равна (widehat {beta _2})= 8,0, а ее стандартная ошибка (mathit{se}left(widehat {beta }_2right))= 4,0. Если использовать подход, связанный с критическими значениями, нужно открыть таблицу распределения Стьюдента (см. Приложение 3.А), и найти критическое значение для пятипроцентного уровня значимости и (left(n-2right)=8) степеней свободы2. Это критическое значение (t_{mathit{text{к}text{р}}}=t_8^{0,05}{approx}2,3). Расчетное значение t-статистики здесь тоже посчитать несложно
begin{equation*} t_{mathit{text{р}text{а}text{с}text{ч}}}=frac{widehat {beta }_2}{mathit{se}left(widehat {beta }_2right)}=frac 8 4=2 end{equation*}
Если мы нанесем все указанные значения на картинку, у нас получится рисунок 2.4а. Критическое значение отсекает по 2,5% слева и справа (всего 5%). Следовательно, вероятность попасть между (-t_{mathit{text{к}text{р}}}) и (t_{mathit{text{к}text{р}}}) будет 95%. Нанесем также (-t_{mathit{text{р}text{а}text{с}text{ч}}}) и (t_{mathit{text{р}text{а}text{с}text{ч}}}). Эти значения отсекают по 3% справа и слева, как это показано на рисунке 2.4б.
Обозначим (xi ) — случайную величину, имеющую распредление стьюдента с (left(n-2right)=8) степенями свободы. Тогда формально P-значение в нашем случае — это вот такая вероятность:
p-значение (Pleft(left|xi right|>2right)).
То есть в нашем примере p-значение — это вероятность такого события, что случайная величина, имеющая t-распределение Стьюдента с 8 степенями свободы, по модулю превысит (t_{mathit{text{р}text{а}text{с}text{ч}}}=2). Как видно из рисунка, в нашем случае эта вероятность равна 0,03+0,03=0,06.
Рисунок 2.4а. Расчетное и критическое значения тестовой статистики для примера 2.3.
Рисунок 2.4б. P-значение для примера 2.3.
Как видно из нашего примера, P-значение больше заранее выбранного уровня значимости только тогда, когда (left|t_{mathit{text{р}text{а}text{с}text{ч}}}right|<t_{mathit{text{к}text{р}}}), что подтверждает сформулированное нами правило принятия решения при помощи P-значения: если P-значение больше уровня значимости, то нулевая гипотеза не отвергается. Если P-значение меньше уровня значимости, то нулевая гипотеза отвергается.
***
Решив неравенство (left|frac{widehat {beta }_2-beta _2}{mathit{se}left(widehat {beta }_2right)}right|<t_{n-2}^{alpha }) относительно (beta _2), получим:
begin{equation*} widehat {beta }_2-mathit{se}left(widehat {beta }_2right){ast}t_{n-2}^{alpha }<beta _2<widehat {beta }_2+mathit{se}left(widehat {beta }_2right){ast}t_{n-2}^{alpha } end{equation*}
Иными словами, с вероятностью (1-alpha ) интервал (left(widehat {beta }_2-mathit{se}left(widehat {beta }_2right){ast}t_{n-2}^{alpha },widehat {beta }_2+mathit{se}left(widehat {beta }_2right){ast}t_{n-2}^{alpha }right)) содержит истинное значение оцениваемого параметра. Например, если (alpha =0,05) и, следовательно, (1-alpha =0,95), этот интервал и называют 95-процентным доверительным интервалом для параметра (beta _2).
Возможность построения доверительных интервалов важна с практической точки зрения. Дело в том, что, так как (widehat {beta }_2) является лишь приблизительной оценкой параметра (beta _2), эта точечная оценка сама по себе несет гораздо меньше информации, чем интервал. Ведь без доверительного интервала невозможно понять, насколько она эта оценка на самом деле (не)точная. Например, утверждение « (widehat {beta }_2) равно 23,4» куда менее информативно, чем утверждение «истинное значение оцениваемого параметра с вероятностью 95 процентов содержится в пределах от 23,1 до 23,7».
Завершим раздел еще двумя примерами. В первом из них все расчеты проделаны вручную, чтобы, проследив их, можно было еще раз разобраться во взаимосвязях между введенными нами понятиями. Во втором примере используется эконометрический пакет, что позволяет продемонстрировать, как подобные вычисления осуществляются в реальных прикладных исследованиях.
Пример 2.4. Доходы индивидов и потребление риса
Исследователь анализирует зависимость потребления риса от уровня дохода (кривую Энгеля) для однородной группы из 20 потребителей. Все потребители из этой группы сталкиваются с одинаковыми ценами на рис и другие товары, и только уровни дохода у них различны, поэтому исследователь использует модель парной регрессии.
Обозначим:
(x_i) — ежемесячный располагаемый доход i-го потребителя (в тысячах денежных единиц),
(y_i) — ежемесячное потребление риса i-м потребителем (в килограммах).
Имеются следующие данные о переменных x и y:
begin{equation*} sum _{i=1}^{20}x_i=20,sum _{i=1}^{20}x_i^2=40,sum _{i=1}^{20}y_i=42,sum _{i=1}^{20}y_i^2=108, end{equation*}
begin{equation*} sum _{i=1}^{20}x_i{ast}y_i=60 end{equation*}
(а) Вычислите МНК-оценки коэффициентов в регрессии
begin{equation*} y_i=beta _1+beta _2{ast}x_i+varepsilon _i. end{equation*}
Выпишите полученное уравнение регрессии и коэффициент (R^2).
(б) При уровне значимости 5% проверьте значимость переменной x.
(в) Дайте содержательную интерпретацию коэффициента при переменной x.
(г) Вспомнив соответствующие определения из курса микроэкономики и вычислив необходимую эластичность, определите: является ли рис для этой группы потребителей низкокачественным товаром, товаром первой необходимости или предметом роскоши?
(д) При уровне значимости 5% проверьте гипотезу о том, что коэффициент (beta _2) равен единице.
(е) Постройте 95-процентный доверительный интервал для коэффициента (beta _2).
Решение:
(а) Вычислим средние значения:
begin{equation*} overline x=1,overline{x^2}=2,overline y=2,1,overline{y^2}=5,4,overline{mathit{xy}}=3 end{equation*}
Найдем оценки коэффициентов:
begin{equation*} widehat {beta _2}=frac{overline{mathit{xy}}-overline x{ast}overline y}{overline{x^2}-overline x^2}=frac{3-1{ast}2,1}{2-1}=0,9 end{equation*}
begin{equation*} widehat {beta _1}=overline y-widehat {beta _2}{ast}overline x=2,1-1{ast}0,9=1,2 end{equation*}
Таким образом, (widehat y_i=1,2+0,9{ast}x_i).
Теперь вычислим (R^2). Для этого воспользуемся тем, что по определению он равен отношению объясненной суммы квадратов к общей сумме квадратов:
begin{equation*} R^2=frac{sum _{i=1}^{20}left(widehat y_i-overline yright)^2}{sum _{i=1}^{20}left(y_i-overline yright)^2}. end{equation*}
Вычислим каждую из этих сумм по отдельности. Сначала найдем общую сумму квадратов:
begin{equation*} mathit{TSS}=sum _{i=1}^{20}left(y_i-overline yright)^2=sum _{i=1}^{20}y_i^2-2{ast}sum _{i=1}^{20}y_i{ast}overline y+sum _{i=1}^{20}overline y^2= end{equation*}
begin{equation*} sum _{i=1}^{20}y_i^2-2{ast}overline y{ast}sum _{i=1}^{20}y_i+20{ast}overline y^2=108-2{ast}2,1{ast}42+20{ast}2,1^2=19,8 end{equation*}
Теперь найдем объясненную сумму квадратов:
begin{equation*} sum _{i=1}^{20}left(widehat y_i-overline yright)^2=sum _{i=1}^{20}left(1,2+0,9{ast}x_i-2,1right)^2=sum _{i=1}^{20}left(0,9{ast}x_i-0,9right)^2= end{equation*}
begin{equation*} 0,9^2sum _{i=1}^{20}left(x_i-1right)^2=0,81{ast}left(sum _{i=1}^{20}x_i^2-2{ast}sum _{i=1}^{20}x_i+20right)=16,2 end{equation*}
Теперь можно вычислить коэффициент детерминации:
begin{equation*} R^2=frac{sum _{i=1}^{20}left(widehat y_i-overline yright)^2}{sum _{i=1}^{20}left(y_i-overline yright)^2}=frac{16,2}{19,8}=0,82 end{equation*}
Ответ на пункт (а): (widehat y_i=1,2+0,9{ast}x_i,R^2=0,82)
(б) Тестируемая гипотеза (H_0:beta _2=0). Альтернативная гипотеза (H_1:beta _2{neq}0).
Чтобы проверить значимость, нам понадобится стандартная ошибка оценки коэффициента. Для этого нам придется оценить сумму квадратов остатков. Воспользуемся тем фактом, что для регрессии с константой верно равенство:
begin{equation*} sum _{i=1}^{20}left(y_i-overline yright)^2=sum _{i=1}^{20}left(widehat y_i-overline yright)^2+sum _{i=1}^{20}e_i^2 end{equation*}
В этой формуле мы вычислили все элементы, кроме суммы квадратов остатков:
begin{equation*} 19,8=16,2+sum _{i=1}^{20}e_i^2 end{equation*}
Следовательно, (sum _{i=1}^{20}e_i^2=19,8-16,2=3,6).
Вычислим оценку дисперсии случайной ошибки:
begin{equation*} S^2=frac{sum _{i=1}^{20}e_i^2}{n-2}=frac{3,6}{20-2}=0,2 end{equation*}
Теперь вычислим стандартную ошибку оценки коэффициента:
begin{equation*} mathit{se}left(widehat {beta _2}right)=sqrt{frac{S^2}{sum _{i=1}^{20}left(x_i-overline xright)^2}}=end{equation*}
begin{equation*} =sqrt{frac{0,2}{sum _{i=1}^{20}x_i^2-n{ast}left(overline xright)^2}}=sqrt{frac{0,2}{40-20}}=0,1 end{equation*}
Расчетное значение t-статистики равно (frac{widehat {beta _2}}{mathit{se}left(widehat {beta _2}right)}=frac{0,9}{0,1}=9).
Критическое значение t-статистки из таблицы распределения Стьюдента при уровне значимости 5% и (20–2)=18 степенях свободы составляет 2,101. Расчетное значение больше критического, следовательно, мы отклоняем нулевую гипотезу и делаем вывод о том, что уровень дохода индивида значимо влияет на его спрос на рис.
Ответ на пункт (б): Переменная значима.
Ответ на пункт (в): При увеличении располагаемого дохода потребителя на одну тысячу денежных единиц его спрос на рис увеличивается в среднем на 0,9 кг.
(г) Вычислим эластичность спроса на рис по доходу. По определению эластичность равна:
begin{equation*} frac{frac{dwidehat y}{mathit{dx}}{ast}x}{widehat y}=frac{0,9{ast}x}{1,2+0,9{ast}x} end{equation*}
Легко видеть, что при любых положительных значениях (x) эластичность спроса по доходу лежит между нулем и единицей, следовательно, для рассматриваемой группы потребителей рис является товаром первой необходимости. Что, в общем-то, неудивительно.
Ответ на пункт (г): Товар первой необходимости.
(д) Тестируемая гипотеза (H_0:beta _2=1). Альтернативная гипотеза (H_1:beta _2{neq}1).
Для проверки значимости нам понадобится стандартная ошибка оценки коэффициента.
Расчетное значение t-статистики равно (frac{widehat {beta _2}-1}{mathit{se}left(widehat {beta _2}right)}=frac{0,9-1}{0,1}=-1).
Критическое значение t-статистки из таблицы распределения Стьюдента при уровне значимости 5% и (20–2)=18 степенях свободы составляет 2,101. Расчетное значение по модулю меньше критического, следовательно, мы принимаем (не отклоняем) нулевую гипотезу.
Ответ на пункт (д): Гипотеза не отклоняется.
(е) В рамках предпосылок классической линейной модели парной регрессии доверительный интервал может быть посчитан следующим образом:
begin{equation*} left(widehat {beta _2}-mathit{se}left(widehat {beta _2}right){ast}t_{n-2},widehat {beta _2}+mathit{se}left(widehat {beta _2}right){ast}t_{n-2}right) end{equation*}
begin{equation*} left(0,9-0,1{ast}2,101,0,9+0,1{ast}2,101right) end{equation*}
Таким образом, c вероятностью 95% интервал (left(0,69,1,11right)) содержит истинное значение коэффициента (beta _2).
Ответ на пункт (е): (left(0,69,1,11right)).
***
Пример 2.5. Площадь однокомнатной квартиры и её цена
В этом задании вам предлагается проанализировать взаимосвязь между площадью квартиры и ее ценой. Вам доступны следующие данные о московском рынке недвижимости в 2012 году (файл Price2012):
Price — рыночная цена однокомнатной квартиры в Москве (в тысячах руб.), выкуп которой был осуществлен с 10.01.2012 по 28.09.2012
TotalArea — общая площадь квартиры (кв. м)
(а) Оцените регрессию переменной Price на переменную TotalArea. Запишите оцененное уравнение регрессии, указав коэффициент детерминации и (в скобках под соответствующими коэффициентами) стандартные ошибки. Постройте диаграмму рассеяния с линией регрессии.
(б) Является ли коэффициент при переменной TotalArea статистически значимым при уровне значимости 1%? Дайте содержательную интерпретацию для этого коэффициента.
Решение:
(а) Ниже представлена распечатка результатов оценивания уравнения в эконометрическом пакете Gretl3. (Любой стандартный эконометрический пакет, например R, Stata или Econometric Views, выдаст аналогичную табличку. Пользуйтесь тем из них, который вам больше нравится. Ну или тем, который есть под рукой.)
Модель 1: МНК, использованы наблюдения 1-121
Зависимая переменная: Price
| Коэффициент | Ст. ошибка | t-статистика | P-значение | ||
| const | 786,456 | 583,051 | 1,349 | 0,1799 | |
| TotalArea | 135,317 | 16,5144 | 8,194 | 0,0001 | *** |
| Среднее зав. перемен | 5540,335 | Ст. откл. зав. перемен | 792,7127 | |
| Сумма кв. остатков | 48208118 | Ст. ошибка модели | 636,4827 | |
| R-квадрат | 0,360696 | Испр. R-квадрат | 0,355324 | |
| F(1, 119) | 67,14000 | Р-значение (F) | 3,30e-13 | |
| Лог. правдоподобие | $-$951,8540 | Крит. Акаике | 1907,708 | |
| Крит. Шварца | 1913,300 | Крит. Хеннана-Куинна | 1909,979 |
В столбце «Коэффициент» указаны оценки коэффициентов, а в столбце «Ст. ошибка» — их стандартные ошибки. В нижней части таблицы среди прочих показателей можно найти и коэффициент R-квадрат.
Общепринятый формат записи полученных результатов имеет следующий вид (в скобках под оценками коэффициентов указаны соответствующие стандартные ошибки):
begin{equation*} widehat {mathit{Price}}_i=underset{left(583,051right)}{786,456}+underset{left(16,514right)}{135,317}mathit{TotalArea}_i,R^2=0,36 end{equation*}
Обратите внимание, что в скобках под оценками коэффициентов мы указали их стандартные ошибки. Такой формат является хорошим тоном при записи результатов эконометрического моделирования, так как позволяет читателю оценить точность ваших результатов и прикинуть доверительные интервалы для коэффициентов.
(б) В столбце «P-значение» указано, что P-значение для оценки коэффициента при переменной TotalArea меньше, чем 0,0001 (и тем более меньше, чем 0,01). Следовательно, этот коэффициент является статистически значимым при уровне значимости 1%.
Содержательная интерпретация: при увеличении общей площади квартиры на один квадратный метр ее цена в среднем при прочих равных условиях увеличивается на 135 тысяч рублей.
Отметим, что свободное слагаемое в данном случае отличается от нуля статистически незначимо, так как соответствующее P-значение равно 0,18, что больше любого разумного уровня значимости. Да и если бы даже эта константа была значима, все равно отдельно интерпретировать её смысла не было бы, ведь константа показывает значение зависимой переменной при условии, что регрессор TotalArea равен нулю (то есть при условии, что анализируемая квартира имеет нулевую площадь). Вряд ли кто-то всерьез интересуется ценой квартиры площадью 0 квадратных метров.
- Вместо использования готовых таблиц распределения можно, например, ввести в MS Excel формулу =СТЬЮДЕНТ.ОБР( 1 — 0,05 / 2; 10 — 2) ↵
- Для получения этого результата достаточно запустить Gretl; используя пункт меню «Импорт», импортировать данные из файла MS Excel (или просто мышкой «перетащить» нужный файл в рабочую область эконометрического пакета); выбрать в меню «Модель» пункт «Метод наименьших квадратов» и указать в качестве зависимой переменной переменную Price, а в качестве объясняющей — переменную TotalArea. ↵
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В
MS
EXCEL
имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer
: Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей
Регрессионного анализа.
Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения
Регрессии
– плохая идея.
Статья про
Регрессионный анализ
получилась большая, поэтому ниже для удобства приведены ее разделы:
- Немного теории и основные понятия
- Предположения линейной регрессионной модели
- Задачи регрессионного анализа
- Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
- Оценка неизвестных параметров линейной модели (через статистики выборок)
- Оценка неизвестных параметров линейной модели (матричная форма)
- Построение линии регрессии
- Коэффициент детерминации
- Стандартная ошибка регрессии
- Стандартные ошибки и доверительные интервалы для наклона и сдвига
- Проверка значимости взаимосвязи переменных
- Доверительные интервалы для нового наблюдения Y и среднего значения
- Проверка адекватности линейной регрессионной модели
Примечание
: Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место
множественная регрессия
.
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание
: Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части —
оценке неизвестных параметров линейной модели
.
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем
прочность этого волокна
(Y) зависит только от
рабочей температуры процесса
в реакторе (Х), которая задается оператором.
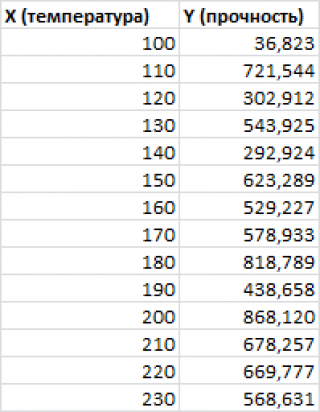
Построим
диаграмму рассеяния
(см.
файл примера лист Линейный
), созданию которой
посвящена отдельная статья
. Вообще, построение
диаграммы рассеяния
для целей
регрессионного анализа
де-факто является стандартом.
СОВЕТ
: Подробнее о построении различных типов диаграмм см. статьи
Основы построения диаграмм
и
Основные типы диаграмм
.
Приведенная выше
диаграмма рассеяния
свидетельствует о возможной
линейной взаимосвязи
между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание
: Наличие даже такой очевидной
линейной взаимосвязи
не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие
причинной
взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание
: Как известно, уравнение прямой линии имеет вид
Y
=
m
*
X
+
k
, где коэффициент
m
отвечает за наклон линии (
slope
),
k
– за сдвиг линии по вертикали (
intercept
),
k
равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х (
рабочую температуру процесса
) при некотором значении Х
i
и произвести несколько наблюдений переменной Y (
прочность нити
). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого
значения
. При увеличении количества измерений, среднее этих измерений, будет стремиться к
математическому ожиданию
случайной величины Y (при Х
i
) равному μy(i)=Е(Y
i
).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела
Проверка статистических гипотез
. В статье о
проверке гипотезы о среднем значении генеральной совокупности
в качестве
нулевой
гипотезы
предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае
простой линейной регрессии
в качестве
нулевой
гипотезы
предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ
y(i)
=α* Х
i
+β. Уравнение μ
y(i)
=α* Х
i
+β можно переписать в обобщенном виде (для всех Х и μ
y
) как μ
y
=α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
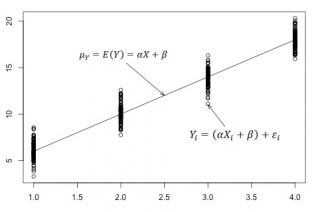
Данная линия называется
регрессионной линией генеральной совокупности
(population regression line), параметры которой (
наклон
a и
сдвиг β
) нам не известны (по аналогии с
гипотезой о среднем значении генеральной совокупности
, где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х +
β
, к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют
линейной регрессионной моделью
. Часто Х еще называют
независимой переменной
(еще
предиктором
и
регрессором
, английский термин
predictor
,
regressor
), а Y –
зависимой
(или
объясняемой
,
response
variable
). Так как
регрессор
у нас один, то такая модель называется
простой линейной регрессионной моделью
(
simple
linear
regression
model
). α часто называют
коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε
i
была адекватной — требуется:
-
Ошибки ε
i
должны быть независимыми переменными; -
При каждом значении Xi ошибки ε
i
должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε
i
]=0); -
При каждом значении Xi ошибки ε
i
должны иметь равные дисперсии (обозначим ее σ
2
).
Примечание
: Последнее условие называется
гомоскедастичность
— стабильность, гомогенность дисперсии случайной ошибки e. Т.е.
дисперсия
ошибки σ
2
не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε
i
]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε
i
]= Е[a*Xi+β]+ Е[ε
i
]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия
случайной переменной Y равна
дисперсии
ошибки ε, т.е. VAR(Y)= VAR(ε)=σ
2
. Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε
i
).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует
регрессионная линия генеральной совокупности
, т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений {X;Y}.
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно
a
и
b
. Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Таким образом:
Первая задача
регрессионного анализа
– оценка неизвестных параметров (
estimation
of
the
unknown
parameters
). Подробнее см. раздел
Оценки неизвестных параметров модели
.
Вторая задача
регрессионного анализа
–
Проверка адекватности модели
(
model
adequacy
checking
).
Примечание
: Оценки параметров модели обычно вычисляются
методом наименьших квадратов
(МНК),
которому посвящена отдельная статья
.
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры
простой линейной регрессионной модели
Y=a*X+β+ε оценим с помощью
метода наименьших квадратов
(в
статье про МНК подробно описано этот метод
).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
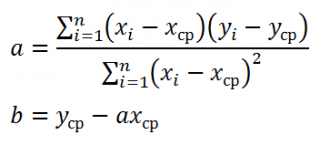
Таким образом, мы получим уравнение прямой линии Y=
a
*X+
b
, которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание
: В статье про
метод наименьших квадратов
рассмотрены случаи аппроксимации
линейной
и
квадратичной функцией
, а также
степенной
,
логарифмической
и
экспоненциальной функцией
.
Оценку параметров в MS EXCEL можно выполнить различными способами:
-
с помощью функций
НАКЛОН()
и
ОТРЕЗОК()
; -
с помощью функции
ЛИНЕЙН()
; см. статьюФункция MS EXCEL ЛИНЕЙН()
-
формулами через статистики выборок
;
-
в матричной форме
;
-
с помощью
инструмента Регрессия надстройки Пакет Анализа
.
Сначала рассмотрим функции
НАКЛОН()
,
ОТРЕЗОК()
и
ЛИНЕЙН()
.
Пусть значения Х и Y находятся соответственно в диапазонах
C
23:
C
83
и
B
23:
B
83
(см.
файл примера
внизу статьи).
Примечание
: Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью
Генерация данных для линейной регрессии в MS EXCEL
).
В MS EXCEL наклон прямой линии
а
(
оценку
коэффициента регрессии
), можно найти по
методу МНК
с помощью функции
НАКЛОН()
, а сдвиг
b
(
оценку
постоянного члена
или
константы регрессии
), с помощью функции
ОТРЕЗОК()
. В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции
ЛИНЕЙН()
, английская версия LINEST (см.
статью об этой функции
).
Формула
=ЛИНЕЙН(C23:C83;B23:B83)
вернет наклон
а
. А формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
— сдвиг
b
. Здесь требуются пояснения.
Функция
ЛИНЕЙН()
имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент
статистика
имеет значение ЛОЖЬ или опущен, то функция
ЛИНЕЙН()
возвращает только оценки параметров модели:
a
и
b
.
Примечание
: Остальные значения, возвращаемые функцией
ЛИНЕЙН()
, нам потребуются при вычислении
стандартных ошибок
и для
проверки значимости регрессии
. В этом случае аргумент
статистика
должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
-
ввести формулу в
Строке формул
-
нажать
CTRL
+
SHIFT
+
ENTER
(см. статью проформулы массива
).
Если в
Строке формул
выделить формулу =
ЛИНЕЙН(C23:C83;B23:B83)
и нажать
клавишу F9
, то мы увидим что-то типа {3,01279389265416;154,240057900613}. Это как раз значения
a
и
b
. Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу =
ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83))
. При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция
ТРАНСП()
транспонировала строку в столбец
).
Чтобы разобраться в этом подробнее необходимо ознакомиться с
формулами массива
.
Чтобы не связываться с вводом
формул массива
, можно
использовать функцию ИНДЕКС()
. Формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1)
или просто
ЛИНЕЙН(C23:C83;B23:B83)
вернет параметр, отвечающий за наклон линии, т.е.
а
. Формула
=ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
вернет параметр
b
.
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент
а
, можно также вычислить через
коэффициент корреляции
и
стандартные отклонения выборок
:
=
КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению
ковариации
выборок Х и Y и
дисперсии
выборки Х:
=
КОВАРИАЦИЯ.В(B23:B83;C23:C83)/ДИСП.В(B23:B83)
И, наконец, запишем еще одну формулу для нахождения сдвига
b
. Воспользуемся тем фактом, что
линия регрессии
проходит через точку
средних значений
переменных Х и Y.
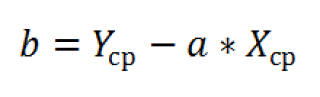
Вычислив
средние значения
и подставив в формулу ранее найденный наклон
а
, получим сдвиг
b
.
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры
линии регрессии
можно найти в матричной форме (см.
файл примера лист Матричная форма
).
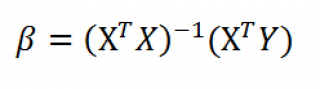
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг
b
), β1 (наклон
a
).
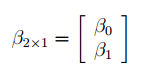
Матрица Х равна:
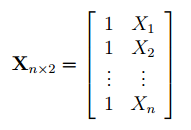
Матрица
Х
называется
регрессионной матрицей
или
матрицей плана
. Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица
Х
T
– это
транспонированная матрица
Х
. Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом
Y
обозначен столбец значений переменной Y.
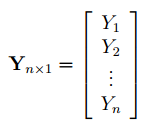
Чтобы
перемножить матрицы
используйте функцию
МУМНОЖ()
. Чтобы
найти обратную матрицу
используйте функцию
МОБР()
.
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
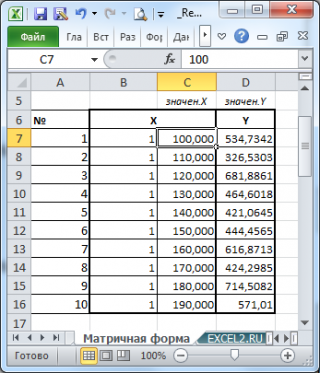
Слева от него достроим столбец с 1 для матрицы Х.
Записав формулу
=
МУМНОЖ(МОБР(МУМНОЖ(ТРАНСП(B7:C16);(B7:C16))); МУМНОЖ(ТРАНСП(B7:C16);(D7:D16)))
и введя ее как
формулу массива
в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае
множественной регрессии
.
Построение линии регрессии
Для отображения
линии регрессии
построим сначала
диаграмму рассеяния
, на которой отобразим все точки (см.
начало статьи
).
Для построения прямой линии используйте вычисленные выше оценки параметров модели
a
и
b
(т.е. вычислите
у
по формуле
y
=
a
*
x
+
b
) или функцию
ТЕНДЕНЦИЯ()
.
Формула =
ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23)
возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца
В2
.
Примечание
:
Линию регрессии
можно также построить с помощью функции
ПРЕДСКАЗ()
. Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции
ТЕНДЕНЦИЯ()
работает только в случае одного регрессора. Функция
ТЕНДЕНЦИЯ()
может быть использована и в случае
множественной регрессии
(в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
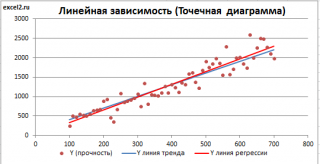
Как видно из диаграммы выше
линия тренда
и
линия регрессии
не обязательно совпадают: отклонения точек от
линии тренда
случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии
можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента
Линия тренда.
Для этого выделите диаграмму, в меню выберите
вкладку Макет
, в
группе Анализ
нажмите
Линия тренда
, затем
Линейное приближение.
В диалоговом окне установите галочку
Показывать уравнение на диаграмме
(подробнее см. в
статье про МНК
).
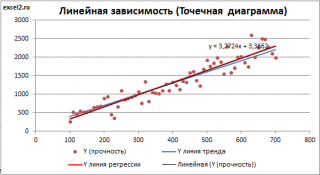
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами
линией регрессии,
а параметры уравнения
a
и
b
должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание:
Для того, чтобы вычисленные параметры уравнения
a
и
b
совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был
Точечная, а не График
, т.к. тип диаграммы
График
не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; … Именно эти значения и берутся при расчете параметров
линии тренда
. Убедиться в этом можно если построить диаграмму
График
(см.
файл примера
), а значения
Хнач
и
Хшаг
установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с
a
и
b
.
Коэффициент детерминации R
2
Коэффициент детерминации
R
2
показывает насколько полезна построенная нами
линейная регрессионная модель
.
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения
регрессионной модели
). Очевидно, что лучшей оценкой для yi будет
среднее значение
ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание
: Далее будет использована терминология и обозначения
дисперсионного анализа
.
После построения
регрессионной модели
для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
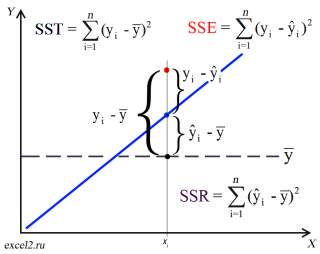
Очевидно, что используя
регрессионную модель
мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
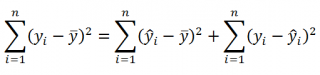
Доказательство:
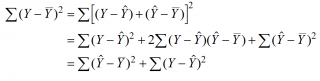
или в других, общепринятых в зарубежной литературе, обозначениях:
SST
=
SSR
+
SSE
Что означает:
Total Sum of Squares
=
Regression Sum of Squares
+
Error Sum of Squares
Примечание
: SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность
дисперсии
(вариации) и соответственно описывают разброс (изменчивость):
Общую изменчивость
(Total variation),
Изменчивость объясненную моделью
(Explained variation) и
Необъясненную изменчивость
(Unexplained variation).
По определению
коэффициент детерминации
R
2
равен:
R
2
=
Изменчивость объясненная моделью / Общая изменчивость.
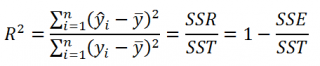
Этот показатель равен квадрату
коэффициента корреляции
и в MS EXCEL его можно вычислить с помощью функции
КВПИРСОН()
или
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3)
R
2
принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии
(
Standard Error of a regression
) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение
линейной регрессионной модели
Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со
средним значением
μ и
дисперсией
σ
2
.
Оценив значение
дисперсии
σ
2
и вычислив из нее квадратный корень – получим
Стандартную ошибку регрессии.
Чем точки наблюдений на диаграмме
рассеяния
ближе находятся к прямой линии, тем меньше
Стандартная ошибка.
Примечание
:
Вспомним
, что при построении модели предполагается, что
среднее значение
ошибки ε равно 0, т.е. E[ε]=0.
Оценим
дисперсию σ
2
. Помимо вычисления
Стандартной ошибки регрессии
эта оценка нам потребуется в дальнейшем еще и при построении
доверительных интервалов
для оценки параметров регрессии
a
и
b
.
Для оценки
дисперсии
ошибки ε используем
остатки регрессии
— разности между имеющимися значениями
yi
и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки
дисперсии σ
2
используют следующую формулу:
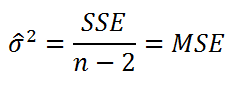
где SSE – сумма квадратов значений ошибок модели ε
i
=yi — ŷi (
Sum of Squared Errors
).
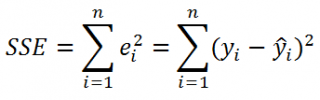
SSE часто обозначают и как SSres – сумма квадратов остатков (
Sum
of
Squared
residuals
).
Оценка
дисперсии
s
2
также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов
ошибок
или MSRES (Mean Square of Residuals), т.е. среднее квадратов
остатков
. Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание
: Напомним, что когда
мы использовали МНК
для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на
линии регрессии.
Математическое ожидание
случайной величины MSE равно
дисперсии ошибки
ε, т.е.
σ
2
.
Чтобы понять почему SSE выбрана в качестве основы для оценки
дисперсии
ошибки ε, вспомним, что
σ
2
является также
дисперсией
случайной величины Y (относительно
среднего значения
μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi =
a
* Хi +
b
(значение
уравнения регрессии
при Х= Хi), то логично использовать именно SSE в качестве основы для оценки
дисперсии
σ
2
. Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество
степеней свободы
(
df
–
degrees
of
freedom
), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае
простой линейной регрессии
число степеней свободы
равно n-2, т.к. при построении
линии регрессии
было оценено 2 параметра модели (на это было «потрачено» 2
степени свободы
).
Итак, как сказано было выше, квадратный корень из s
2
имеет специальное название
Стандартная ошибка регрессии
(
Standard Error of a regression
) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см.
этот раздел
). Если ошибки предсказания ε имеют
нормальное распределение
, то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от
линии регрессии
. SEy имеет размерность переменной Y и откладывается по вертикали. Часто на
диаграмме рассеяния
строят
границы предсказания
соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
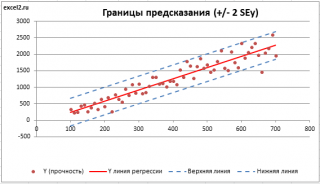
В MS EXCEL
стандартную ошибку
SEy можно вычислить непосредственно по формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе
Оценка неизвестных параметров линейной модели
мы получили точечные оценки наклона
а
и сдвига
b
. Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со
средним значением
и
дисперсией
. Но, чтобы перейти от
точечных оценок
к
интервальным
, необходимо вычислить соответствующие
стандартные ошибки
(т.е.
стандартные отклонения
).
Стандартная ошибка коэффициента регрессии
a
вычисляется на основании
стандартной ошибки регрессии
по следующей формуле:
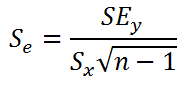
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
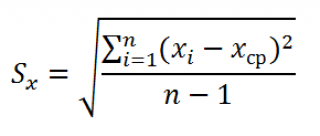
где Sey –
стандартная ошибка регрессии,
т.е. ошибка предсказания значения переменой Y
(
см. выше
).
В MS EXCEL
стандартную ошибку коэффициента регрессии
Se можно вычислить впрямую по вышеуказанной формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;1)
Формулы приведены в
файле примера на листе Линейный
в разделе
Регрессионная статистика
.
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
При построении
двухстороннего доверительного интервала
для
коэффициента регрессии
его границы определяются следующим образом:
![]()
где —
квантиль распределения Стьюдента
с n-2 степенями свободы. Величина
а
с «крышкой» является другим обозначением
наклона
а
.
Например для
уровня значимости
альфа=0,05, можно вычислить с помощью формулы
=СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
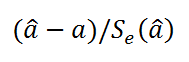
является
t-распределением Стьюдента
с n-2 степенью свободы (то же справедливо и для наклона
b
).
Примечание
: Подробнее о построении
доверительных интервалов
в MS EXCEL можно прочитать в этой статье
Доверительные интервалы в MS EXCEL
.
В результате получим, что найденный
доверительный интервал
с вероятностью 95% (1-0,05) накроет истинное значение
коэффициента регрессии.
Здесь мы считаем, что
коэффициент регрессии
a
имеет
распределение Стьюдента
с n-2
степенями свободы
(n – количество наблюдений, т.е. пар Х и Y).
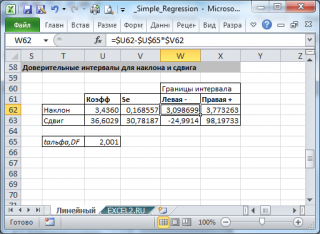
Примечание
: Подробнее о построении
доверительных интервалов
с использованием t-распределения см. статью про построение
доверительных интервалов
для среднего
.
Стандартная ошибка сдвига
b
вычисляется по следующей формуле:
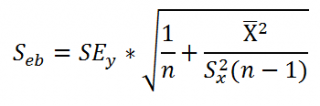
В MS EXCEL
стандартную ошибку сдвига
Seb можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;2)
При построении
двухстороннего доверительного интервала
для
сдвига
его границы определяются аналогичным образом как для
наклона
:
b
+/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда
коэффициент регрессии
a
равен 0.
Чтобы убедиться, что вычисленная нами оценка
наклона
прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют
проверку гипотез
. В качестве
нулевой гипотезы
Н
0
принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы
Н
1
принимают, что a <>0.
Ниже на рисунках показаны 2 ситуации, когда
нулевую гипотезу
Н
0
не удается отвергнуть.
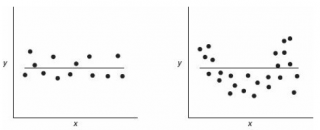
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом
коэффициент линейной корреляции
равен 0.
Ниже — 2 ситуации, когда
нулевая гипотеза
Н
0
отвергается.
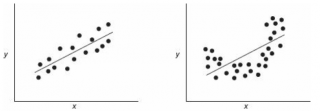
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
-
Установить
уровень значимости
, пусть альфа=0,05;
-
Рассчитать с помощью функции
ЛИНЕЙН()
стандартное отклонение
Se для
коэффициента регрессии
(см.предыдущий раздел
);
-
Рассчитать число степеней свободы: DF=n-2 или по формуле =
ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
-
Вычислить значение тестовой статистики t
0
=a/S
e
, которая имеетраспределение Стьюдента
с
числом степеней свободы
DF=n-2; -
Сравнить значение
тестовой статистики
|t0| с пороговым значением t
альфа
,n-2. Если значение
тестовой статистики
больше порогового значения, то
нулевая гипотеза
отвергается (
наклон
не может быть объяснен лишь случайностью при заданном уровне альфа) либо -
вычислить
p-значение
и сравнить его с
уровнем значимости
.
В
файле примера
приведен пример проверки гипотезы:
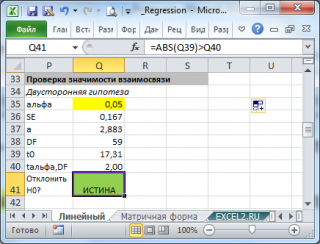
Изменяя
наклон
тренда k (ячейка
В8
) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание
: Проверка значимости взаимосвязи эквивалентна
проверке статистической значимости коэффициента корреляции
. В
файле примера
показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью
процедуры F-тест
.
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры
простой линейной регрессионной модели
Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ=
a
* Хi +
b
Ŷ также является точечной оценкой для
среднего значения
Yi при заданном Хi. Но, при построении
доверительных интервалов
используются различные
стандартные ошибки
.
Стандартная ошибка
нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
-
неопределенность связанную со случайностью оценок параметров модели
a
и
b
; - случайность ошибки модели ε.
Учет этих неопределенностей приводит к
стандартной ошибке
S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
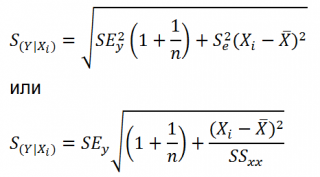
где SS
xx
– сумма квадратов отклонений от
среднего
значений переменной Х:
![]()
Примечание
: Se –
стандартная ошибка коэффициента регрессии
(
наклона
а
).
В
MS EXCEL 2010
нет функции, которая бы рассчитывала эту
стандартную ошибку
, поэтому ее необходимо рассчитывать по вышеуказанным формулам.
Доверительный интервал
или
Интервал предсказания для нового наблюдения
(Prediction Interval for a New Observation) построим по схеме показанной в разделе
Проверка значимости взаимосвязи переменных
(см.
файл примера лист Интервалы
). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х
ср
), то интервал будет постепенно расширяться при удалении от Х
ср
.
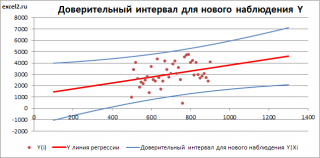
Границы
доверительного интервала
для
нового наблюдения
рассчитываются по формуле:
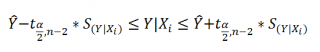
Аналогичным образом построим
доверительный интервал
для
среднего значения
Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае
доверительный интервал
будет уже, т.к.
средние значения
имеют меньшую изменчивость по сравнению с отдельными наблюдениями (
средние значения,
в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
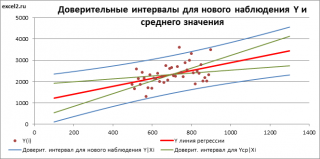
Стандартная ошибка
S(Yср|Xi) вычисляется по практически аналогичным формулам как и
стандартная ошибка
для нового наблюдения:
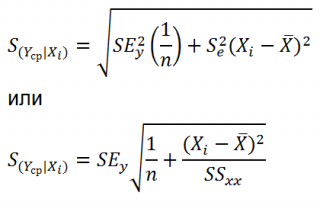
Как видно из формул,
стандартная ошибка
S(Yср|Xi) меньше
стандартной ошибки
S(Y|Xi) для индивидуального значения
.
Границы
доверительного интервала
для
среднего значения
рассчитываются по формуле:
![]()
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел
Предположения линейной регрессионной модели
).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках
простой линейной модели
n остатков имеют только n-2 связанных с ними
степеней свободы
. Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о
нормальности распределения
ошибок строят
график проверки на нормальность
(Normal probability Plot).
В
файле примера на листе Адекватность
построен
график проверки на нормальность
. В случае
нормального распределения
значения остатков должны быть близки к прямой линии.
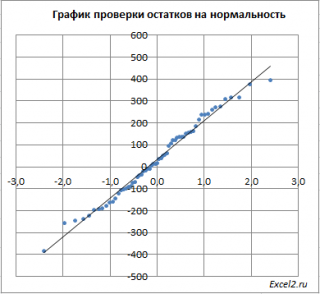
Так как значения переменной Y мы
генерировали с помощью тренда
, вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор
о
нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
В нашем случае точки располагаются примерно равномерно.
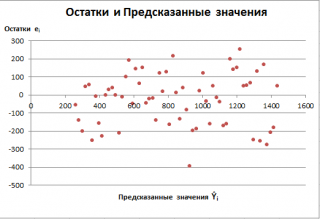
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе
Стандартная ошибка регрессии
оценкой
стандартного отклонения ошибок
является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
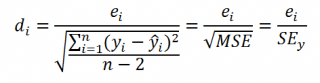
SEy можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Иногда нормирование остатков производится на величину
стандартного отклонения
остатков (это мы увидим в статье об инструменте
Регрессия
, доступного в
надстройке MS EXCEL Пакет анализа
), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.