Описательная статистика Excel позволяет за несколько минут обработать достаточно большое количество информации и найти необходимые значения, учитывая определенный набор условий и критерий. Обработка данных большого ряда значений согласно всем законам статистики – нет проблем, Microsoft Excel справиться со всем.
Для того чтобы сформировать вывод о результатах полученных данных с целого ряда массива значений можно использовать достаточно простую функцию из «Пакета анализа», которая позволит систематизировать эмпирические значения согласно определенным критериям.
Эта функция можем высчитывать большинство критериев, среди которых:
• Отклонение и стандартное отклонение;
• Ошибка и стандартная ошибка;
• Асимметричность значений;
• Мода;
• Дисперсия;
• Медиана;
• Другие значения.
По умолчанию, возможность работы с «Относительной статистикой» скрыта от большинства пользователей. Для того чтобы активировать данную панель, необходимо включить ее в параметрах документа.
Для этого нажмем на вкладку «Файл» — «Параметры».
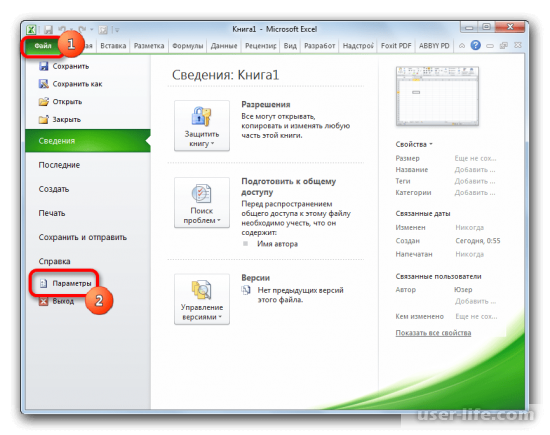
В появившемся диалоговом окне перейдем в меню «Надстройки», где внизу в подменю «Управление» нужно выбрать «Надстройки Excel» и перейти к последующим настройкам.
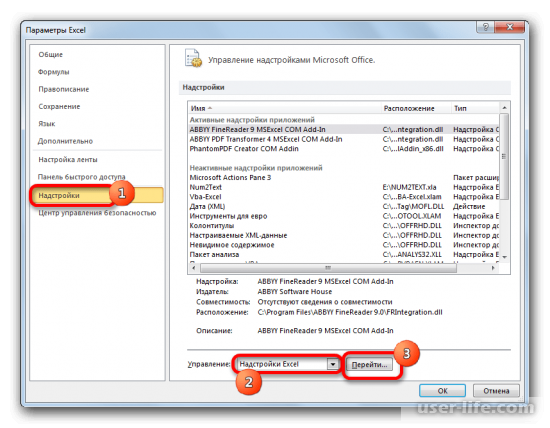
В новом окне ставим галочку напротив «Пакет анализа» и применяем операцию.
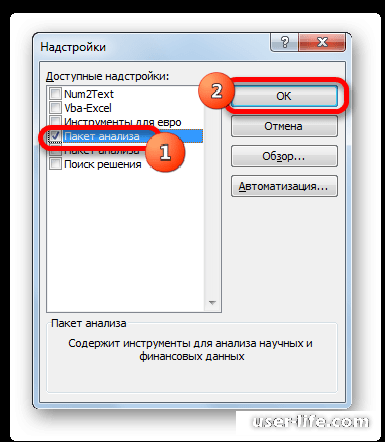
Весь функционал «Пакета анализа» был добавлен в рабочую область и появился во вкладке «Данные». Приступим непосредственно к «Описательной статистике» и попробуем на практике данный инструмент.
Перейдем во вкладку «Анализ данных», которая размещена в «Данных» и выбираем функцию «Описательная статистика».
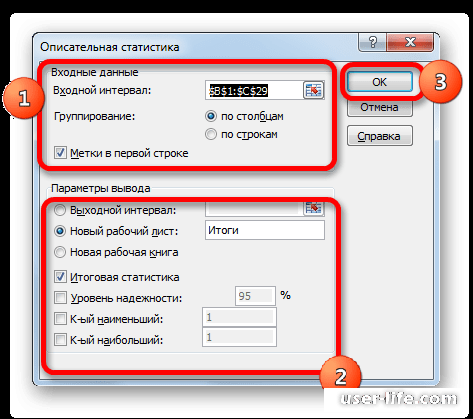
Теперь необходимо заполнить все поля и ввести аргументы функции.
• «Входной интервал» — укажем весь диапазон данных, для которых необходимо применить функцию «Описательной статистики» — выделяем весь столбец вместе с названием с включением функции «Метки в первой строке».
• Включим группирование «По строкам» и «По столбцам».
• Выберем место, куда будут сохраняться результаты работы функции, это могут быть и новая книга, новый лист либо просто выбранный интервал.
Теперь можно анализировать результаты работы функции. «Описательная статистика» рассчитала сразу несколько показателей, которые дают более четкое представление о выполненной работе: интервал, минимум и максимум, общую сумму и среднее значение и так далее.
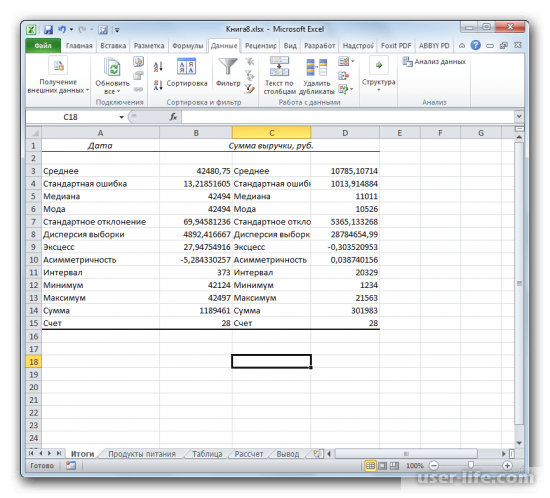
Пакет анализа предлагает пользователю результаты сразу по нескольким критериям. Это экономит большое количество времени, которое ушло бы на отдельный расчет по каждому показателю.
Описательная статистика в excel
Инструмент Описательная статистика входит в Пакет анализа (активация Пакета анализа смотри п.2.7.2). С его помощью можно в очень короткие сроки, использовав ресурсы программы, обработать массив данных и получить о нем информацию по целому ряду статистических критериев. Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим работу данного инструмента на примере задачи 4.2.
Переходим во вкладку «Данные» и выполняем щелчок по кнопке «Анализ данных», которая размещена на ленте в блоке инструментов «Анализ». Открывается список инструментов, представленных в Пакете анализа. Ищем наименование «Описательная статистика», выделяем его и щелкаем по кнопке «OK» (рис. 4.1).
 |
| Рис. 4.1. Описательная статистика |
После выполнения данных действий непосредственно запускается окно «Описательная статистика».
В поле «Входной интервал» указываем адрес диапазона, который будет подвергаться обработке этим инструментом. Причем указываем его вместе с шапкой таблицы. Так как мы захватили данные вместе с шапкой, то около параметра «Метки в первой строке» следует установить флажок. Тут же выбираем тип группирования, переставив переключатель в позицию «По столбцам» или «По строкам». В нашем случае подходит вариант «По столбцам», но в других случаях, возможно, придется выставить переключатель иначе.
Выше мы говорили исключительно о входных данных. Теперь переходим к разбору настроек параметров вывода, которые расположены в этом же окне формирования описательной статистики. Прежде всего, нам нужно определиться, куда именно будут выводиться обработанные данные:
- Выходной интервал;
- Новый рабочий лист;
- Новая рабочая книга.
В первом случае нужно указать конкретный диапазон на текущем листе или его верхнюю левую ячейку, куда будет выводиться обработанная информация. Во втором случае следует указать название конкретного листа данной книги, где будет отображаться результат обработки. Если листа с таким наименованием в данный момент нет, то он будет создан автоматически после того, как вы нажмете на кнопку «OK». В третьем случае никаких дополнительных параметров указывать не нужно, так как данные будут выводиться в отдельном файле Excel (книге). Мы выбираем вывод результатов на этом же рабочем листе (рис.4.2).
Далее, если вы хотите чтобы выводилась также итоговая статистика, то нужно установить флажок около соответствующего пункта. Также можно установить уровень надежности, поставив галочку около соответствующего значения. По умолчанию он будет равен 95%, но его можно изменить, внеся другие числа в поле справа.
Кроме этого, можно установить галочки в пунктах «K-ый наименьший» и «K-ый наибольший», установив значения в соответствующих полях. Этот параметр, также как и предыдущий, не является обязательным, поэтому флажки можно не ставить.
После того, как все указанные данные внесены, жмем на кнопку «OK».
Среди множества показателей Описательной статистики есть те, которые нас интересуют, они выделены цветом (рис. 4.3).
ВОПРОСЫ И УПРАЖНЕНИЯ
1. Дайте определение размаху, выборочной дисперсии, генеральной дисперсии, стандартному отклонению. Воспроизведите формулы для их нахождения.
2. Что характеризует выборочная дисперсия.
3. Вычислите для множества: 22, 15, 16, 21, 24, 24, 27, 28, 30, 30, 31, 31, 31, 34, 36 размах, дисперсию, стандартное отклонение.
4. В каких случаях можно проводить сравнение разных выборок по дисперсиям?
5. Выборочные дисперсии результатов контрольной работы в классе 7«А» и 7«Б» соответственно равны 0,44 и 1,38. Какой вывод можно сделать при сравнении результатов контрольной работы в двух классах?
6. Дисперсия каждой из групп A и В равна 5. Будет ли дисперсия 10 значений, полученных путем объединения групп, меньше, больше или равна 5?
Группа А: 13, 11, 10, 9, 7
Группа В: 28, 26, 25, 24, 22
Лабораторная работа №2
Описательная статистика
Этапы обработки данных:
1. Занести данные в таблицу Excel (две выборки).
2. Упорядочить данные (по возрастанию) в каждой выборке.
3. Рассчитать моду, медиану и среднее.
4. Посчитать дисперсию, стандартное отклонение.
5. Посчитать коэффициент вариации.
6. Сделать сравнительный анализ, полученных результатов.
Задания для вариантов 1 – 5
При определении степени выраженности некоторого психического свойства в двух группах, опытной и контрольной, баллы распределились следующим образом.
Дать сравнительную характеристику степени выраженности этого свойства в данных группах.
Вариант 1.
| Опытная | 18, 15, 16, 11, 14,15, 16, 16, 20, 22, 17, 12, 11, 12, 18, 19, 20 |
| Контрольная | 26, 8, 11, 12, 25, 22, 13, 14, 21, 20, 15, 16, 17, 16, 9, 11, 16 |
Вариант 2
| Опытная | 19, 16, 17, 12, 15,16, 17,17, 21, 23, 18, 13, 12, 13, 19, 20, 21 |
| Контрольная | 27, 9, 12, 13, 26, 23, 14, 15, 22, 21, 16, 16, 18, 17, 10, 12, 17 |
Вариант 3.
| Опытная | 16, 13, 14, 9, 10,13, 14,14, 18, 20, 15, 10, 9, 10, 16, 17, 18 |
| Контрольная | 24, 6, 9, 10, 23, 20, 11, 12, 19, 18, 13, 14, 12, 14, 7, 9, 14 |
| Опытная | 15, 12, 13, 8, 11,12, 13,13, 17, 19, 14, 9, 8, 9, 15, 16, 17 |
| Контрольная | 23, 5, 9, 9, 22, 19, 10, 11, 18, 17, 12, 13, 14, 13, 6, 8, 13 |
| Опытная | 15, 12, 13, 8, 11,12, 13,13, 17, 19, 14, 9, 8, 9, 15, 16, 17 |
| Контрольная | 24, 6, 9, 10, 23, 20, 11, 12, 19, 18, 13, 14, 12, 14, 7, 9, 14 |
Задания для вариантов 6 – 10
Была исследована группа детей с заболеванием крови до лечения препаратами и после лечения. В таблицу занесены показатели крови по результатам медицинского обследования. Сделать сравнительный анализ результативности лечения данным препаратом, используя методы описательной статистики.
| до лечения | 20,5 12,1 13,6 40,5 9,6 33 77,2 8,7 3,5 13,8 7,4 29,4 116 21,9 |
| после лечения | 2,3 7,5 3,8 3,8 8,8 13 4,7 3,9 4,8 5,7 9 13 0,9 |
| до лечения | 280 230 100 60 90 80 8 36 50 90 17 42 42 30 |
| после лечения | 86 280 30 170 210 230 230 156 102 161 15 60 20 |
| до лечения | 112 60 84 60 60 40 76 60 84 40 112 46 64 70 |
| после лечения | 82 78 110 130 130 104 108 129 110 88 105 73 85 80 |
| до лечения | 113 61 85 61 61 41 77 61 85 41 113 47 65 71 |
| после лечения | 81 77 109 129 129 103 107 128 109 87 104 72 84 79 |
| до лечения | 111 59 83 59 59 39 75 59 83 39 111 45 63 69 |
| после лечения | 83 79 111 131 131 105 109 130 111 89 106 74 86 81 |
Задания для вариантов 11 – 15
Для проверки эффективности новой развивающей программы были созданы две группы детей шестилетнего возраста. На первом этапе дети обеих групп были протестированы по методике Керна-Йерасика (школьная зрелость). Результаты тестирования по невербальной шкале занесены в таблицу. Сделать сравнительный анализ школьной зрелости детей этих групп.
| Эксперимент. | 29 31 31 25 25 19 22 20 14 16 27 24 32 27 14 24 |
| Контроль | 34 31 28 27 30 23 21 28 29 31 17 22 21 15 33 29 |
| Эксперимент. | 14 13 11 8 12 13 13 13 11 12 14 13 12 14 10 13 |
| Контроль | 13 13 14 12 14 14 12 13 15 13 11 12 14 9 14 13 |
| Эксперимент. | 33 33 37 33 34 33 31 29 29 35 31 29 31 34 26 26 |
| Контроль | 39 30 38 36 31 37 35 32 39 34 30 32 36 29 39 36 |
| Эксперимент. | 13 12 10 7 11 12 12 12 10 11 13 12 11 13 9 12 |
| Контроль | 12 12 13 11 13 13 11 12 14 12 10 11 13 8 13 12 |
| Эксперимент. | 30 32 32 26 26 20 23 21 15 17 28 25 33 28 15 25 |
| Контроль | 35 32 29 28 31 24 22 29 30 32 18 24 22 16 34 30 |
Задания для вариантов 16 – 20
У участников психологического исследования, в число которых входила группа педагогов и группа непедагогов, был исследован уровень конфликтности. Полученные данные занесены в таблицу. Можно ли утверждать, что уровень конфликтности педагогов выше, чем у непедагогов?
Использование пакета анализа
Если вам нужно провести сложный статистический или инженерный анализ, можно сэкономить время и этапы с помощью «Pak анализа». Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопку Анализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа».
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
Если вы используете Excel 2007, нажмите Microsoft Office кнопку и выберите «Параметры Excel»
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
Примечание: Чтобы включить Visual Basic для приложений (VBA) в надстройку «Надстройка «Анализ», можно загрузить его так же, как и надстройку «Надстройка «Анализ». В поле «Доступные надстройки» выберите «Надстройка анализа — VBA».
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ предоставляет проверку гипотезы о том, что все выборки взяты из одного и того же распределения вероятности относительно альтернативной гипотезы о том, что распределение вероятностей не одинаково для всех выборок. Если выборок всего два, можно использовать функцию T. ТЕСТ. В более чем двух примерах не существует удобного обобщения T. Ивместо нее можно использовать модель однофакторного коэффициента.
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий <удобрение, температура>, имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений <удобрение, температура>, используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар <удобрение, температура>превышает влияние отдельно удобрения и отдельно температуры.
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров <удобрение, температура>из предыдущего примера).
Функции КОРРЕЛ и PEARSON рассчитывают коэффициент корреляции между двумя переменными измерения, если измерения по каждой переменной наблюдались для каждого из N-объектов. (Отсутствуют результаты наблюдений по любой теме, которые при анализе игнорируются.) Инструмент анализа корреляции особенно удобен, если для каждого субъекта N существует более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение КОРРЕЛ (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две переменные измерения «различаются». В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц, в которых выражены две переменные измерения. (Например, если двумя переменными измерения являются вес и высота, коэффициент корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно (от -1 до +1).
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и ковариатора можно использовать в одном и том же параметре, если у вас есть N различных переменных измерения для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, в которую указывается коэффициент корреляции или коварианс между каждой парой переменных измерения. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансии не масштабироваться. Коэффициент корреляции и ковариатор — это меры, в которых две переменные «различаются».
Инструмент «Ковариана» вычисляет значение функции КОВАРИАНАС на этом компьютере. P для каждой пары переменных измерения. (Непосредственное использование КОВАРИАНС. Вместо ковариатора P лучше использовать ковариативную единицу, если имеется только две переменных измерения, то есть N=2.) Запись на диагонали выходной таблицы инструмента «Ковариальная» в строке i, столбце i — ковариальная величина i-й переменной. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕ. P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа «Экспоненциальное сглаживание» применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f 1, «P(F
Инструмент «Анализ Фурье» применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.
Инструмент «Гистограмма» применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа «Скользящее среднее» применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
N — число предшествующих периодов, входящих в скользящее среднее;
A j — фактическое значение в момент времени j;
F j — прогнозируемое значение в момент времени j.
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Инструмент анализа «Ранг» и «Процентиль» создает таблицу, которая содержит порядкованный и процентный ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая рассматривает связанные значения как связанные значения с одинаковым рангом, или использует РАНГ. Функция AVG, которая возвращает среднее ранг для связанных значений.
Инструмент анализа «Регрессия» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
Инструмент «Регрессия» использует функцию LINEST.
Инструмент анализа «Выборка» создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как «t-статистика» в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t =0 «P(T Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
Двухвыборочный t-тест с одинаковыми дисперсиями
Этот инструмент анализа выполняет двухуголовый t-тест учащегося. В этой форме t-теста предполагается, что два набора данных поступили из распределения с одинаковыми дисперсиями. Этот тест называется гомомоcedastic t-test. Этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами.
Двухвыборочный t-тест с различными дисперсиями
Этот инструмент анализа выполняет двухуголовый t-тест учащегося. В этой форме t-теста предполагается, что два набора данных поступили из распределений с неравными дисперсиями. Это называется гетероскестический t-тест. Как и в предыдущем случае с равными дисперсиями, этот t-тест можно использовать для определения вероятности того, что две выборки взяты из распределения с равными средствами. Этот тест можно использовать, если в двух примерах есть различные темы. Используйте парный тест, описанный в примере, если существует один набор субъектов и два примера представляют измерения для каждой темы до и после обработки.
Для определения тестовой величины t используется следующая формула.
Для вычисления степеней свободы (df) используется следующая формула: Так как результат вычисления обычно не является integer, значение df округлится до ближайшего ближайшего другого для получения критического значения из таблицы t. Функция листа Excel T. В этой проверке используется вычисляемая величина df без округления, так как ее можно вычислить для значения T. ТЕСТ с неинтегрным df. Из-за таких разных подходов к определению степеней свободы результаты T. Тест и этот t-тест различаются в случае неравных дисперсий.
Z-тест. Средство анализа «Две выборки для средств» выполняет два примера z-теста для средств со известными дисперсиями. Это средство используется для проверки гипотезы null о том, что между двумя значениями населения нет различий между односторонними или двухбокльными гипотезами. Если дисперсии не известны, функция Z. Вместо нее следует использовать тест.
При использовании этого инструмента следует внимательно просматривать результат. «P(Z = ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. «P(Z = ABS(z) или Z
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community, попросить помощи в сообществе Answers community, а также предложить новую функцию или улучшение на веб-сайте Excel User Voice.
ОПИСАТЕЛЬНАЯ СТАТИСТИКА
Первичный анализ скалярных экспериментальных данных начинается с вычисления описательных статистик. Добавив к этому графические характеристики, получим некоторые основания для выводов о характере распределения данных исследуемой совокупности. К тому же базовый анализ дает основу для дальнейшего проведения более сложного анализа данных.
Из множества инструментов надстройки «Анализ данных» будем использовать «Описательную статистику» для получения числовых характеристик и «Гистограмму» — для графических. Заметим, что наряду с этим можно использовать также встроенные «Статистические функции», которые дублируют возможности надстройки.
Рассмотрим работу с описательной статистикой на примере.
Пример 4.1. Имеются некоторые данные о стоимости новогодних туров (рис. 4.2). Каждый из столбцов можно рассматривать как отдельный признак или переменную. Требуется провести анализ данных о продолжительности туров.

Таблица исходных данных
Исходные данные содержат несколько переменных, характеризующих тур. «Название фирмы», «Страна», «Транспорт» — качественные переменные, которые относятся к номинальной шкале. «Отель» —качественная переменная, которую можно отнести к порядковой шкале, так как количество звездочек отражает уровень обслуживания в отеле. «Количество дней» и «Стоимость» —количественные данные, которые относятся к метрической шкале.
Вычислим основные описательные статистики для переменной «Количество дней», которая является числовой переменной, принимающей дискретные значения. Для этого используем инструмент «Описательная статистика», входящий в «Пакет анализа».
Для перехода к описательной статистике выполните: «Данные» —» «Анализ» —> «Анализ данных» —» «Описательная статистика» -> «Ок». В открывшемся диалоговом окне «Описательная статистика» (рис. 4.3) укажите «Входной интервал», диапазон В2:Б16, выберите «Труп-

Диалоговое окно «Описательной статистики»
иирование по столбцам», установите «Метки в первой строке», так как входной интервал содержит наименование столбца. Для «Выходного интервала» достаточно указать одну, первую, ячейку на текущем листе, как альтернативу можно выбрать «Новый рабочий лист» или «Новую рабочую книгу». И наконец, укажите хотя бы одну из выводимых статистик: «Итоговая статистика», «Уровень надежности», «К-й наименьший», «К-й наибольший».
В большинстве случаев достаточно выбрать «Итоговую статистику», которая рассчитывает основные числовые характеристики исследуемой совокупности. Три последних значения рассчитывают, только когда они действительно нужны.
«Описательная статистика» вычисляет 16 значений, из них 13 относятся к «Итоговой статистике», еще три определяют доверительный интервал и два выборочных значения.
Отметим главное — «Описательная статистка» надстройки «Анализ данных» предназначена для вычислений статистических характеристик, или статистик, одномерной выборки или нескольких выборок.
В литературе по статистике часто используют термин «генеральная совокупность». Обычно имеется в виду, что это множество всех доступных для наблюдения данных в противоположность «выборки» — которая подразумевает, что исследуется лишь часть данных выбранных из генеральной совокупности (может быть с помощью случайного отбора).
Обычно числовые характеристики генеральной совокупности называют параметрами, а числовые характеристики выборки — статистиками, или выборочными характеристиками, которые являются оценками параметров генеральной совокупности. Для более полного понимания выборочного метода следует обратиться к специальной литературе.
Результаты расчетов «Итоговой статистики» для переменной «Количество дней» приведены на рисунке 4.4. На этом же рисунке приведены альтернативные расчеты этих числовых характеристик с использованием встроенных функций категории «Статистические». Аргументом статистических функций является диапазон исходных данных, в данном случае D3:D16.
Таким образом, практически все расчеты «Описательной статистики» дублируются «Статистическими» функциями. Остальные характеристики можно посчитать, используя формулы. Для того чтобы на рабочем листе Excel отобразились не результаты, а формулы, следует выполнить: «Формулы» -» «Зависимости формул» -» «Показать формулы».
Отметим некоторое отличие в применении инструментов «Анализа данных» и использовании статистических функций. При изменении значений исходных данных формулы пересчитываются, в то время как результаты, полученные с помощью инструментов «Анализа данных»,

«Итоговая статистика» и «Статистические функции»
не изменяются. Чтобы обновить результаты, потребуется вызывать «Анализ данных» снова.
Числовые характеристики «Итоговой статистики» описывают средние, вариацию и форму распределения, всего 13 параметров:
- • среднее, или выборочное среднее, вычисляется как среднее арифметическое наблюдаемых значений выборки;
- • медиана определяется как значение, находящееся в середине распределения, полученного из исходного путем упорядочивания по возрастанию;
- • мода равна наиболее часто встречающемуся значению. Кроме того, выделяют две величины, характеризующие изменчивость, или разброс, значений распределения относительно среднего:
- 1) дисперсию выборки, или выборочную дисперсию, равную сумме квадратов отклонений каждого значения от среднего, деленной на (А — 1), где N — число значений в распределении, или объем выборки;
2) стандартное отклонение, или выборочное среднеквадратическое отклонение, равное квадратному корню из выборочной дисперсии.
Дополнительными мерами изменчивости являются три простые характеристики, отражающие границы распределения данных и его размах:
- • минимум равен наименьшему из выборочных значений;
- • максимум равен наибольшему из выборочных значений;
- • интервал составляет разность между максимумом и
минимумом, этот параметр называют также размахом.
Если набор данных рассматривается как множество
независимых реализаций случайной величины, то возникает вопрос, что можно сказать о функции распределения этой величины на основании выборки. Очень часто распределение оказывается нормальным или близким к нему.
Для отражения близости формы распределения к нормальному виду существует две основные характеристики:
- 1) эксцесс, или выборочный коэффициент эксцесса, который является мерой «сглаженности» распределения;
- 2) асимметричность, или выборочный коэффициент асимметрии, показывает, в какую сторону относительно среднего сдвинуто большинство значений выборки.
И наконец, сумма равна сумме всех выборочных значений, счет вычисляет объем выборки, стандартная ошибка равна выборочному стандартному отклонению, деленному на квадратный корень из объема выборки.
При необходимости можно вычислить три дополнительные характеристики (рис. 4.5). Результаты расчетов этих характеристик приведены на рисунке 4.6.
«К-й наибольший» выдает К-е выборочное значение, если бы выборка была отсортирована по убыванию. В рассматриваемом примере сортировка по убыванию имеет вид 14,12,12,12, 11, Юит. д., третье значение равно 12. «К-й наименьший» выдает К-е выборочное значение, если бы выборка была отсортирована по возрастанию, это значение равно 5.
Задав «Уровень надежности», например 95%, получим значение для построения доверительного интервала для

Описательная статистика, дополнительные параметры

Результаты расчетов дополнительных параметров
неизвестного математического ожидания генеральной средней с доверительным уровнем 95%. Доверительный интервал строится как выборочное среднее плюс-минус полученное значение. Обратим внимание, что граница здесь вычисляется с помощью распределения Стьюдента, что требует достаточного количества наблюдений на каждую степень свободы.
Таким образом, к вычислению доверительных интервалов нужно относиться с осторожностью, особенно при малых выборках. Использование функции расчета доверительного интервала без понимания статистического смысла может привести к ошибкам. Начинающим исследователям посоветуем обратиться к специальной литературе.
Например, для рассматриваемого примера полученный доверительный интервал не несет смыслового содержания.
Итак, на этапе проведения описательной статистики исследуемый ряд данных может быть как генеральной совокупностью, так и выборкой. Если для генеральной совокупности вычисляются значения параметров распределения, то для выборки находят оценки этих параметров. Рассмотрим ниже подробнее вычисление некоторых числовых характеристик в пакете Excel.
Построение доверительных интервалов для среднего. Описательная статистика в Excel
 2015-03-22
2015-03-22
 2255
2255




![]()
![]()
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 3
Описательная статистика в Excel
Вычисление границ доверительных интервалов в Excel
Использование инструмента Пакета анализа Описательная статистика.
Построение доверительных интервалов для среднего.
В пакете Excel помимо мастера функций имеется набор более мощных инструментов для работы с несколькими выборками углубленного анализа данных, называемый Пакет анализа, который может быть использован для решения задач статистической обработки выборочных данных.
Для установки раздела Анализ данных в пакете Excel сделайте следующее:
— в меню Сервис выберите команду Надстройки;
— в появившемся списке установите флажок Пакет анализа.
Ввод данных. Исследуемые данные следует представить в виде таблицы, где столбцами являются соответствующие показатели. При создании таблицы Excel информация вводится в отдельные ячейки. Совокупность ячеек, содержащих анализируемые данные, называется входным диапазоном.
Последовательность обработки данных. Для использования статистического пакета анализа данных необходимо:
— указать курсором мыши на пункт меню Сервис и щелкнуть левой кнопкой мыши;
— в раскрывающемся списке выбрать команду Анализ данных (если команда Анализ данных отсутствует в меню Сервис, то необходимо установить в Excel пакет анализа данных);
— выбрать необходимую строку в появившемся списке Инструменты анализа;
— ввести входной и выходной диапазоны и выбрать необходимые параметры.
Нахождение основных выборочных характеристик. Для определения характеристик выборки используется процедура Описательная статистика. Процедура позволяет получить статистический отчет, содержащий информацию о центральной тенденции и изменчивости входных данных. Для выполнения процедуры необходимо:
— выполнить команду Сервис > Анализ данных;
— в появившемся списке Инструменты анализа выбрать строку Описательная статистика и нажать кнопку ОК (рис. 1);
— в появившемся диалоговом окне указать входной диапазон, то есть ввести ссылку на ячейки, содержащие анализируемые данные. Для этого следует навести указатель мыши на левую верхнюю ячейку данных, нажать левую кнопку мыши и, не отпуская ее, протянуть указатель мыши к правой нижней ячейке, содержащей анализируемые данные, затем отпустить левую кнопку мыши;
Рис. 1. Окно выбора метода обработки данных
— указать выходной диапазон, то есть ввести ссылку на ячейки, в которые будут выведены результаты анализа. Для этого следует поставить переключатель в положение Выходной диапазон (навести указатель мыши и щелкнуть левой клавишей), далее навести указатель мыши в поле ввода Выходной диапазон и щелкнуть левой кнопкой мыши, затем указатель мыши навести на левую верхнюю ячейку выходного диапазона и щелкнуть левой кнопкой мыши;
— в разделе Группировка переключатель установить в положение по столбцам; о установить флажок в поле Итоговая статистика;
— нажать кнопку ОК.
В результате анализа в указанном выходном диапазоне для каждого столбца данных выводятся следующие статистические характеристики: среднее, стандартная ошибка (среднего), медиана, мода, стандартное отклонение, дисперсия выборки, эксцесс, асимметричность, интервал, минимум, максимум, сумма, счет, наибольшее, наименьшее, уровень надежности.
Пример 1. Рассматривается зарплата основных групп работников гостиницы: администрации, обслуживающего персонала и работников ресторана. Были получены следующие данные:
Необходимо определить основные статистические характеристики в группах данных.
1. Для использования инструментов анализа исследуемые данные следует представить в виде таблицы, где столбцами являются соответствующие показатели. Значения зарплат сотрудников администрации введите в диапазон А1:А5, обслуживающего персонала— в диапазон В1:В8 и т. д. В результате получится таблица, представленная на рис. 2.

Рис. 2. Таблица из примера
2. Далее необходимо провести элементарную статистическую обработку. Для этого, указав курсором мыши на пункт меню Сервис, выберите команду Анализ данных. Затем в появившемся списке Инструменты анализа выберите строку Описательная статистика.
Рис. 3. Пример заполнения диалогового окна Описательная статистика
3. В появившемся диалоговом окне (рис. 3) в рабочем поле Входной интервал укажите входной диапазон —А1:С8. Активировав переключателем рабочее поле Выходной интервал, укажите выходной диапазон — ячейку А9. В разделе Группировка переключатель установите в положение по столбцам. Установите флажок в поле Итоговая статистика и нажмите кнопку ОК. В результате анализа (рис. 4) в указанном выходном диапазоне для каждого столбца данных получим соответствующие результаты.
Рис. 4. Результаты работы инструмента Описательная статистика.
1. Найдите наиболее популярный туристический маршрут из четырех реализуемых фирмой (моду), если за неделю последовательно были реализованы следующие маршруты (приводятся номера маршрутов): 1, 3, 3, 2, 1, 1, 4, 4, 2, 4, 1, 3, 2, 4, 1, 4, 4, 3, 1, 2, 3, 4, 1, 1, 3.
2. В рабочей зоне производились замеры концентрации вредного вещества. Получен ряд значений (в мг/м3): 12, 16, 15, 14, 10, 20, 16, 14, 18, 14, 15, 17, 23, 16. Необходимо определить основные выборочные характеристики.
Рассмотрим инструмент Описательная статистика, входящий в надстройку Пакет Анализа. Рассчитаем показатели выборки: среднее, медиана, мода, дисперсия, стандартное отклонение и др.
Задача
описательной статистики
(descriptive statistics) заключается в том, чтобы с использованием математических инструментов свести сотни значений
выборки
к нескольким итоговым показателям, которые дают представление о
выборке
.В качестве таких статистических показателей используются:
среднее
,
медиана
,
мода
,
дисперсия, стандартное отклонение
и др.
Опишем набор числовых данных с помощью определенных показателей. Для чего нужны эти показатели? Эти показатели позволят сделать определенные
статистические выводы о распределении
, из которого была взята
выборка
. Например, если у нас есть
выборка
значений толщины трубы, которая изготавливается на определенном оборудовании, то на основании анализа этой
выборки
мы сможем сделать, с некой определенной вероятностью, заключение о состоянии процесса изготовления.
Содержание статьи:
- Надстройка Пакет анализа;
- Среднее выборки
;
- Медиана выборки
;
- Мода выборки
;
- Мода и среднее значение
;
- Дисперсия выборки
;
- Стандартное отклонение выборки
;
- Стандартная ошибка
;
- Ассиметричность
;
- Эксцесс выборки
;
- Уровень надежности
.
Надстройка Пакет анализа
Для вычисления статистических показателей одномерных
выборок
, используем
надстройку Пакет анализа
. Затем, все показатели рассчитанные надстройкой, вычислим с помощью встроенных функций MS EXCEL.
СОВЕТ
: Подробнее о других инструментах надстройки
Пакет анализа
и ее подключении – читайте в статье
Надстройка Пакет анализа MS EXCEL
.
Выборку
разместим на
листе
Пример
в файле примера
в диапазоне
А6:А55
(50 значений).
Примечание
: Для удобства написания формул для диапазона
А6:А55
создан
Именованный диапазон
Выборка.
В диалоговом окне
Анализ данных
выберите инструмент
Описательная статистика
.

После нажатия кнопки
ОК
будет выведено другое диалоговое окно,
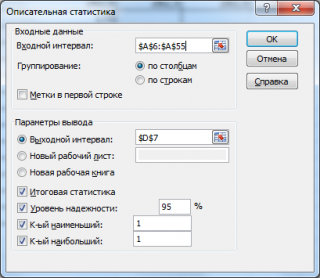
в котором нужно указать:
входной интервал
(Input Range) – это диапазон ячеек, в котором содержится массив данных. Если в указанный диапазон входит текстовый заголовок набора данных, то нужно поставить галочку в поле
Метки в первой строке (
Labels
in
first
row
).
В этом случае заголовок будет выведен в
Выходном интервале.
Пустые ячейки будут проигнорированы, поэтому нулевые значения необходимо обязательно указывать в ячейках, а не оставлять их пустыми;
выходной интервал
(Output Range). Здесь укажите адрес верхней левой ячейки диапазона, в который будут выведены статистические показатели;
Итоговая статистика (
Summary
Statistics
)
. Поставьте галочку напротив этого поля – будут выведены основные показатели выборки:
среднее, медиана, мода, стандартное отклонение
и др.;- Также можно поставить галочки напротив полей
Уровень надежности (
Confidence
Level
for
Mean
)
,
К-й наименьший
(Kth Largest) и
К-й наибольший
(Kth Smallest).
В результате будут выведены следующие статистические показатели:
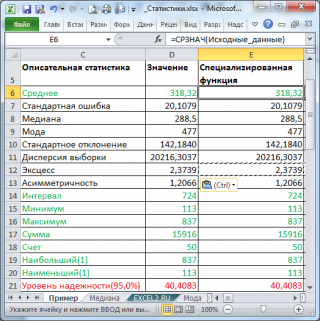
Все показатели выведены в виде значений, а не формул. Если массив данных изменился, то необходимо перезапустить расчет.
Если во
входном интервале
указать ссылку на несколько столбцов данных, то будет рассчитано соответствующее количество наборов показателей. Такой подход позволяет сравнить несколько наборов данных. При сравнении нескольких наборов данных используйте заголовки (включите их во
Входной интервал
и установите галочку в поле
Метки в первой строке
). Если наборы данных разной длины, то это не проблема — пустые ячейки будут проигнорированы.
Зеленым цветом на картинке выше и в
файле примера
выделены показатели, которые не требуют особого пояснения. Для большинства из них имеется специализированная функция:
Интервал
(Range) — разница между максимальным и минимальным значениями;
Минимум
(Minimum) – минимальное значение в диапазоне ячеек, указанном во
Входном интервале
(см.статью про функцию
МИН()
);
Максимум
(Maximum)– максимальное значение (см.статью про функцию
МАКС()
);
Сумма
(Sum) – сумма всех значений (см.статью про функцию
СУММ()
);
Счет
(Count) – количество значений во
Входном интервале
(пустые ячейки игнорируются, см.статью про функцию
СЧЁТ()
);
Наибольший
(Kth Largest) – выводится К-й наибольший. Например, 1-й наибольший – это максимальное значение (см.статью про функцию
НАИБОЛЬШИЙ()
);
Наименьший
(Kth Smallest) – выводится К-й наименьший. Например, 1-й наименьший – это минимальное значение (см.статью про функцию
НАИМЕНЬШИЙ()
).
Ниже даны подробные описания остальных показателей.
Среднее выборки
Среднее
(mean, average) или
выборочное среднее
или
среднее выборки
(sample average) представляет собой
арифметическое среднее
всех значений массива. В MS EXCEL для вычисления среднего выборки используется функция
СРЗНАЧ()
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) оценкой
математического ожидания
случайной величины (подробнее см. статью
Среднее и Математическое ожидание в MS EXCEL
).
Медиана выборки
Медиана
(Median) – это число, которое является серединой множества чисел (в данном случае выборки): половина чисел множества больше, чем
медиана
, а половина чисел меньше, чем
медиана
. Для определения
медианы
необходимо сначала
отсортировать множество чисел
. Например,
медианой
для чисел 2, 3, 3,
4
, 5, 7, 10 будет 4.
Если множество содержит четное количество чисел, то вычисляется
среднее
для двух чисел, находящихся в середине множества. Например,
медианой
для чисел 2, 3,
3
,
5
, 7, 10 будет 4, т.к. (3+5)/2.
Если имеется длинный хвост распределения, то
Медиана
лучше, чем
среднее значение
, отражает «типичное» или «центральное» значение. Например, рассмотрим несправедливое распределение зарплат в компании, в которой руководство получает существенно больше, чем основная масса сотрудников.
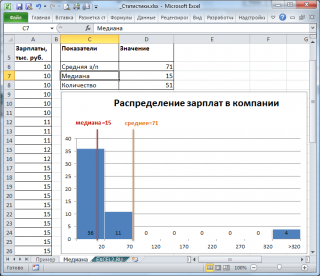
Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что
как минимум
у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Для определения
медианы
в MS EXCEL существует одноименная функция
МЕДИАНА()
, английский вариант — MEDIAN().
Медиану
также можно вычислить с помощью формул
=КВАРТИЛЬ.ВКЛ(Выборка;2) =ПРОЦЕНТИЛЬ.ВКЛ(Выборка;0,5).
Подробнее о
медиане
см. специальную статью
Медиана в MS EXCEL
.
СОВЕТ
: Подробнее про
квартили
см. статью, про
перцентили (процентили)
см. статью.
Мода выборки
Мода
(Mode) – это наиболее часто встречающееся (повторяющееся) значение в
выборке
. Например, в массиве (1; 1;
2
;
2
;
2
; 3; 4; 5) число 2 встречается чаще всего – 3 раза. Значит, число 2 – это
мода
. Для вычисления
моды
используется функция
МОДА()
, английский вариант MODE().
Примечание
: Если в массиве нет повторяющихся значений, то функция вернет значение ошибки #Н/Д. Это свойство использовано в статье
Есть ли повторы в списке?
Начиная с
MS EXCEL 2010
вместо функции
МОДА()
рекомендуется использовать функцию
МОДА.ОДН()
, которая является ее полным аналогом. Кроме того, в MS EXCEL 2010 появилась новая функция
МОДА.НСК()
, которая возвращает несколько наиболее часто повторяющихся значений (если количество их повторов совпадает). НСК – это сокращение от слова НеСКолько.
Например, в массиве (1; 1;
2
;
2
;
2
; 3;
4
;
4
;
4
; 5) числа 2 и 4 встречаются наиболее часто – по 3 раза. Значит, оба числа являются
модами
. Функции
МОДА.ОДН()
и
МОДА()
вернут значение 2, т.к. 2 встречается первым, среди наиболее повторяющихся значений (см.
файл примера
, лист
Мода
).
Чтобы исправить эту несправедливость и была введена функция
МОДА.НСК()
, которая выводит все
моды
. Для этого ее нужно ввести как
формулу массива
.
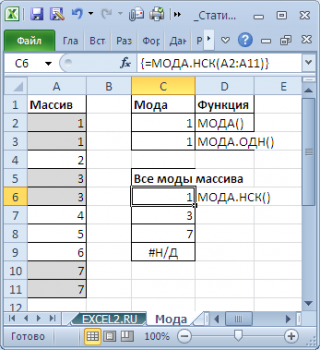
Как видно из картинки выше, функция
МОДА.НСК()
вернула все три
моды
из массива чисел в диапазоне
A2:A11
: 1; 3 и 7. Для этого, выделите диапазон
C6:C9
, в
Строку формул
введите формулу
=МОДА.НСК(A2:A11)
и нажмите
CTRL+SHIFT+ENTER
. Диапазон
C
6:
C
9
охватывает 4 ячейки, т.е. количество выделяемых ячеек должно быть больше или равно количеству
мод
. Если ячеек больше чем м
о
д, то избыточные ячейки будут заполнены значениями ошибки #Н/Д. Если
мода
только одна, то все выделенные ячейки будут заполнены значением этой
моды
.
Теперь вспомним, что мы определили
моду
для выборки, т.е. для конечного множества значений, взятых из
генеральной совокупности
. Для
непрерывных случайных величин
вполне может оказаться, что выборка состоит из массива на подобие этого (0,935; 1,211; 2,430; 3,668; 3,874; …), в котором может не оказаться повторов и функция
МОДА()
вернет ошибку.
Даже в нашем массиве с
модой
, которая была определена с помощью
надстройки Пакет анализа
, творится, что-то не то. Действительно,
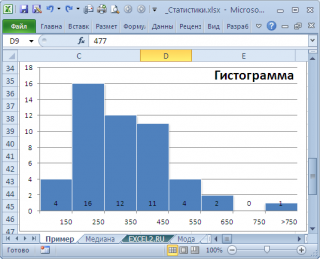
модой
нашего массива значений является число 477, т.к. оно встречается 2 раза, остальные значения не повторяются. Но, если мы посмотрим на
гистограмму распределения
, построенную для нашего массива, то увидим, что 477 не принадлежит интервалу наиболее часто встречающихся значений (от 150 до 250).
Проблема в том, что мы определили
моду
как наиболее часто встречающееся значение, а не как наиболее вероятное. Поэтому,
моду
в учебниках статистики часто определяют не для выборки (массива), а для функции распределения. Например, для
логнормального распределения
мода
(наиболее вероятное значение непрерывной случайной величины х), вычисляется как
exp
(
m
—
s
2
)
, где m и s параметры этого распределения.
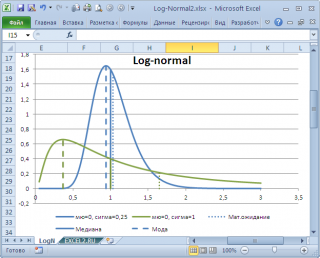
Понятно, что для нашего массива число 477, хотя и является наиболее часто повторяющимся значением, но все же является плохой оценкой для
моды
распределения, из которого взята
выборка
(наиболее вероятного значения или для которого плотность вероятности распределения максимальна).
Для того, чтобы получить оценку
моды
распределения, из
генеральной совокупности
которого взята
выборка
, можно, например, построить
гистограмму
. Оценкой для
моды
может служить интервал наиболее часто встречающихся значений (самого высокого столбца). Как было сказано выше, в нашем случае это интервал от 150 до 250.
Вывод
: Значение
моды
для
выборки
, рассчитанное с помощью функции
МОДА()
, может ввести в заблуждение, особенно для небольших выборок. Эта функция эффективна, когда случайная величина может принимать лишь несколько дискретных значений, а размер
выборки
существенно превышает количество этих значений.
Например, в рассмотренном примере о распределении заработных плат (см. раздел статьи выше, о Медиане),
модой
является число 15 (17 значений из 51, т.е. 33%). В этом случае функция
МОДА()
дает хорошую оценку «наиболее вероятного» значения зарплаты.
Примечание
: Строго говоря, в примере с зарплатой мы имеем дело скорее с
генеральной совокупностью
, чем с
выборкой
. Т.к. других зарплат в компании просто нет.
О вычислении
моды
для распределения
непрерывной случайной величины
читайте статью
Мода в MS EXCEL
.
Мода и среднее значение
Не смотря на то, что
мода
– это наиболее вероятное значение случайной величины (вероятность выбрать это значение из
Генеральной совокупности
максимальна), не следует ожидать, что
среднее значение
обязательно будет близко к
моде
.
Примечание
:
Мода
и
среднее
симметричных распределений совпадает (имеется ввиду симметричность
плотности распределения
).
Представим, что мы бросаем некий «неправильный» кубик, у которого на гранях имеются значения (1; 2; 3; 4; 6; 6), т.е. значения 5 нет, а есть вторая 6.
Модой
является 6, а среднее значение – 3,6666.
Другой пример. Для
Логнормального распределения
LnN(0;1)
мода
равна =EXP(m-s2)= EXP(0-1*1)=0,368, а
среднее значение
1,649.
Дисперсия выборки
Дисперсия выборки
или
выборочная дисперсия (
sample
variance
) характеризует разброс значений в массиве, отклонение от
среднего
.
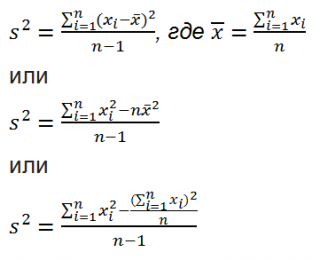
Из формулы №1 видно, что
дисперсия выборки
это сумма квадратов отклонений каждого значения в массиве
от среднего
, деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления
дисперсии выборки
используется функция
ДИСП()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог — функцию
ДИСП.В()
.
Дисперсию
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1) =(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1)
–
формула массива
Дисперсия выборки
равна 0, только в том случае, если все значения равны между собой и, соответственно, равны
среднему значению
.
Чем больше величина
дисперсии
, тем больше разброс значений в массиве относительно
среднего
.
Размерность
дисперсии
соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность
дисперсии
будет кг
2
. Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из
дисперсии – стандартное отклонение
.
Подробнее о
дисперсии
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартное отклонение выборки
Стандартное отклонение выборки
(Standard Deviation), как и
дисперсия
, — это мера того, насколько широко разбросаны значения в выборке
относительно их среднего
.
По определению,
стандартное отклонение
равно квадратному корню из
дисперсии
:
![]()
Стандартное отклонение
не учитывает величину значений в
выборке
, а только степень рассеивания значений вокруг их
среднего
. Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х
выборок
: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у
выборок
существенно отличается.
В MS EXCEL 2007 и более ранних версиях для вычисления
Стандартного отклонения выборки
используется функция
СТАНДОТКЛОН()
. С версии MS EXCEL 2010 рекомендуется использовать ее аналог
СТАНДОТКЛОН.В()
.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см.
файл примера
):
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Подробнее о
стандартном отклонении
см. статью
Дисперсия и стандартное отклонение в MS EXCEL
.
Стандартная ошибка
В
Пакете анализа
под термином
стандартная ошибка
имеется ввиду
Стандартная ошибка среднего
(Standard Error of the Mean, SEM).
Стандартная ошибка среднего
— это оценка
стандартного отклонения
распределения
выборочного среднего
.
Примечание
: Чтобы разобраться с понятием
Стандартная ошибка среднего
необходимо прочитать о
выборочном распределении
(см. статью
Статистики, их выборочные распределения и точечные оценки параметров распределений в MS EXCEL
) и статью про
Центральную предельную теорему
.
Стандартное отклонение распределения выборочного среднего
вычисляется по формуле σ/√n, где n — объём
выборки, σ — стандартное отклонение исходного
распределения, из которого взята
выборка
. Т.к. обычно
стандартное отклонение
исходного распределения неизвестно, то в расчетах вместо
σ
используют ее оценку
s
—
стандартное отклонение выборки
. А соответствующая величина s/√n имеет специальное название —
Стандартная ошибка среднего.
Именно эта величина вычисляется в
Пакете анализа.
В MS EXCEL
стандартную ошибку среднего
можно также вычислить по формуле
=СТАНДОТКЛОН.В(Выборка)/ КОРЕНЬ(СЧЁТ(Выборка))
Асимметричность
Асимметричность
или
коэффициент асимметрии
(skewness) характеризует степень несимметричности распределения (
плотности распределения
) относительно его
среднего
.
Положительное значение
коэффициента асимметрии
указывает, что размер правого «хвоста» распределения больше, чем левого (относительно среднего). Отрицательная асимметрия, наоборот, указывает на то, что левый хвост распределения больше правого.
Коэффициент асимметрии
идеально симметричного распределения или выборки равно 0.

Примечание
:
Асимметрия выборки
может отличаться расчетного значения асимметрии теоретического распределения. Например,
Нормальное распределение
является симметричным распределением (
плотность его распределения
симметрична относительно
среднего
) и, поэтому имеет асимметрию равную 0. Понятно, что при этом значения в
выборке
из соответствующей
генеральной совокупности
не обязательно должны располагаться совершенно симметрично относительно
среднего
. Поэтому,
асимметрия выборки
, являющейся оценкой
асимметрии распределения
, может отличаться от 0.
Функция
СКОС()
, английский вариант SKEW(), возвращает коэффициент
асимметрии выборки
, являющейся оценкой
асимметрии
соответствующего распределения, и определяется следующим образом:
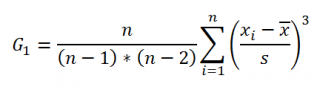
где n – размер
выборки
, s –
стандартное отклонение выборки
.
В
файле примера на листе СКОС
приведен расчет коэффициента
асимметрии
на примере случайной выборки из
распределения Вейбулла
, которое имеет значительную положительную
асимметрию
при параметрах распределения W(1,5; 1).
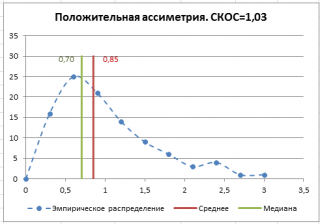
Эксцесс выборки
Эксцесс
показывает относительный вес «хвостов» распределения относительно его центральной части.
Для того чтобы определить, что относится к хвостам распределения, а что к его центральной части, можно использовать границы μ +/-
σ
.
Примечание
: Не смотря на старания профессиональных статистиков, в литературе еще попадается определение
Эксцесса
как меры «остроконечности» (peakedness) или сглаженности распределения. Но, на самом деле, значение
Эксцесса
ничего не говорит о форме пика распределения.
Согласно определения,
Эксцесс
равен четвертому
стандартизированному моменту:
![]()
Для
нормального распределения
четвертый момент равен 3*σ
4
, следовательно,
Эксцесс
равен 3. Многие компьютерные программы используют для расчетов не сам
Эксцесс
, а так называемый Kurtosis excess, который меньше на 3. Т.е. для
нормального распределения
Kurtosis excess равен 0. Необходимо быть внимательным, т.к. часто не очевидно, какая формула лежит в основе расчетов.
Примечание
: Еще большую путаницу вносит перевод этих терминов на русский язык. Термин Kurtosis происходит от греческого слова «изогнутый», «имеющий арку». Так сложилось, что на русский язык оба термина Kurtosis и Kurtosis excess переводятся как
Эксцесс
(от англ. excess — «излишек»). Например, функция MS EXCEL
ЭКСЦЕСС()
на самом деле вычисляет Kurtosis excess.
Функция
ЭКСЦЕСС()
, английский вариант KURT(), вычисляет на основе значений выборки несмещенную оценку
эксцесса распределения
случайной величины и определяется следующим образом:
![]()
Как видно из формулы MS EXCEL использует именно Kurtosis excess, т.е. для выборки из
нормального распределения
формула вернет близкое к 0 значение.
Если задано менее четырех точек данных, то функция
ЭКСЦЕСС()
возвращает значение ошибки #ДЕЛ/0!
Вернемся к
распределениям случайной величины
.
Эксцесс
(Kurtosis excess) для
нормального распределения
всегда равен 0, т.е. не зависит от параметров распределения μ и σ. Для большинства других распределений
Эксцесс
зависит от параметров распределения: см., например,
распределение Вейбулла
или
распределение Пуассона
, для котрого
Эксцесс
= 1/λ.
Уровень надежности
Уровень
надежности
— означает вероятность того, что
доверительный интервал
содержит истинное значение оцениваемого параметра распределения.
Вместо термина
Уровень
надежности
часто используется термин
Уровень доверия
. Про
Уровень надежности
(Confidence Level for Mean) читайте статью
Уровень значимости и уровень надежности в MS EXCEL
.
Задав значение
Уровня
надежности
в окне
надстройки Пакет анализа
, MS EXCEL вычислит половину ширины
доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Тот же результат можно получить по формуле (см.
файл примера
):
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95;s;n)
s —
стандартное отклонение выборки
, n – объем
выборки
.
Подробнее см. статью про
построение доверительного интервала для оценки среднего (дисперсия неизвестна)
.
Содержание
- При использовании функции линейная регрессия (ЛИНЕЙН) в Excel возвращается неверный результат
- Проблемы
- Причина
- Обходное решение
- Случай 1: диапазоны x-value и y перекрываются
- Случай 2: количество строк меньше числа столбцов x-Columns.
- Случай 3: указывается нулевая константа
- Дополнительная информация
- Ссылки
- Входной интервал содержит нечисловые данные что делать?
- Работа с инструментом «Регрессия» в Microsoft Excel
- Использование Пакета анализа EXCEL для построения простой линейной регрессионной модели
- Регрессия входной интервал содержит нечисловые данные
- Статистический анализ в excel Назначение и возможности пакета анализа
- Установка пакета анализа.
- Вызов пакета анализа
- Корреляция
- Регрессионный анализ. Построение статических однофакторных моделей
- Практическая работа 1. Регрессионный анализ. Построение статических однофакторных моделей.
- Часть I.
- Часть II.
- Варианты заданий к практической работе 1.
При использовании функции линейная регрессия (ЛИНЕЙН) в Excel возвращается неверный результат
Проблемы
При использовании функции ЛИНЕЙН на листе в Microsoft Excel результаты статистического вывода могут возвращать неверные значения. Средство регрессия в окне «пакет анализа» может также возвращать неверные значения.
Причина
Результат, возвращаемый функцией ЛИНЕЙН, может быть неправильным, если выполняется одно или несколько из указанных ниже условий.
Диапазон значений x перекрывает диапазон значений y.
Количество строк в диапазоне входных данных меньше числа столбцов в общем диапазоне (x-value + y-Value).
Вы задаете нулевую константу (для третьего аргумента функции ЛИНЕЙН установите значение истина).
Обходное решение
Случай 1: диапазоны x-value и y перекрываются
Если диапазоны x-value и y перекрываются, функция ЛИНЕЙН возвращает неверные значения во всех ячейках результата. Нормальная статистическая вероятность запрещает значения в диапазонах x и y для перекрытия (повторяющиеся друг друга). Не перекрывают диапазоны x и y при ссылке на ячейки в формуле.Примечание. Средство регрессия предупреждает об этой проблеме и не продолжает работу. Вы можете использовать средство регрессия вместо функции ЛИНЕЙН. В Microsoft Office Excel 2007 вы можете найти инструмент регрессия, щелкнув анализ данных в группе анализ на вкладке данные . В Microsoft Office Excel 2003 и более ранних версиях Excel можно найти инструмент регрессия, выбрав пункт анализ данных в меню Сервис .
Случай 2: количество строк меньше числа столбцов x-Columns.
Статистические функции не действительны, так как количество строк должно быть меньше числа столбцов x (переменных). Количество строк данных должно быть больше количества столбцов данных (столбцов x и y).
Случай 3: указывается нулевая константа
Не указывайте нулевые константы (b = 0) в функции.
Дополнительная информация
Средство регрессия входит в пакет анализа. Пакет анализа — это программа надстройки Excel. Оно доступно при установке Microsoft Office или Excel. Прежде чем использовать средство регрессия в Excel, вы должны загрузить анализ ToolPak.To в Excel 2007, выполнив указанные ниже действия.
Нажмите кнопку Microsoft Office, затем нажмите кнопку Параметры Excel.
Выберите пункт надстройки, а затем в поле Управление выберите пункт надстройки Excel .
Нажмите кнопку Перейти.
В окне Доступные надстройки установите флажок Пакет анализа , а затем нажмите кнопку ОК.Примечание. Если в списке Доступные надстройки не указан Пакет анализа , нажмите кнопку Обзор , чтобы найти его.
Чтобы сделать это в Excel 2003 и более ранних версиях Excel, выполните указанные ниже действия.
В меню Сервис выберите пунктнадстройки.
В диалоговом окне надстройки выберите Пакет анализаи нажмите кнопку ОК,Обратите внимание на то, что Пакет анализа не указан в поле Доступные надстройки, нажмите кнопку Обзор , чтобы найти его.
Ссылки
Статистические вычисления на цифровом компьютере. Уильям J. Hemmerle. Blaisdell компания публикации: 1967. Глава 3, «вычисления с несколькими регрессиями» и раздел 3.2.1, «теория для предварительной регрессии».
Источник
Входной интервал содержит нечисловые данные что делать?
Работа с инструментом «Регрессия» в Microsoft Excel
Открыв рабочую книгу и введя в нее исходные данные для построения уравнения регрессии, вызываем надстройку «Регрессия»: Данные — Анализ данных — Регрессия.
Диалоговое окно «Регрессия». В первое окно «Входной интервал Y» вводим данные объясняемой переменной — у, диапазон должен состоять из одного столбца. Во второе окно «Входной интервал X» вводим данные объясняющих переменных — х. На рис. П.1 представлены у. $С$2:$С$13, х: $В$2:$В$13. Длины интервалов должны быть одинаковы. Если строится уравнение множественной регрессии, то данные объясняющих переменных вводятся в окно «Входной интерват X» соответствующим образом. На рис. П.2 представлены у: $D$2:$D$13, xt—x2: $В2:$С$13. Максималь- ное число независимых объясняющих переменных равно 16.
![]()
Рис. П. 1. Задание парной регрессии
Ставим «галочку» в окно «Метки», если в отчете Microsoft Excel требуется знать, к какой из объясняющих переменных относятся результирующие данные.
Если исследователю не требуется константа Ь , то ставим «галочку» в окно «Константа — ноль». Линия регрессии пройдет через начало координат.
![]()
Рис. П.2. Задание множественной регрессии
«Уровень надежности». По умолчанию программа строит уравнение регрессии для доверительной вероятности (уровень надежности) 0,95. Если требуется другая величина, ставим «галочку» в окно «Уровень надежности» и в окно, помеченное символом «%», вводим требуемую величину уровня надежности десятичной дробью.
«Параметры вывода». Указываем, куда вывести результаты регрессионного анализа: на этом листе, как указано на обоих рисунках, на другой рабочий лист или в новую рабочую книгу.
«Остатки». Выбираем то, что требуется исследователю, и ставим «галочку». Можно одновременно пометить несколько окон. Подробная информация дана в справке но инструменту «Регрессия».
Заполнив диалоговое окно «Регрессия», нажимаем кнопку ОК. Программа выводит отчет «Вывод итогов» в виде трех таблиц (рис. П.З, приведено для двух объясняющих переменных).
Приведем описание таблиц (первых двух — в табл. П1.1 и П1.2 соответственно, третьей — в текстовом виде).
Описание первой таблицы
Наименование в отчете
Коэффициент множественной корреляции, индекс корреляции
Коэффициент детерминации, R 2
Скорректированный К 2
Наименование в отчете
Среднее квадратическое отклонение от модели
Рис. П.З. Результаты работы программы
Описание третьей таблицы
Данные первой строки относятся к коэффициенту уравнения регрессии Ь , данные второй строки — к коэффициенту Ьи третьей — к Ь2 и далее до коэффициента Ьт, но числу объясняющих переменных в уравнении.
Метки, если поставлена галочка в окно «Метки». У-пересечение для коэффициента/> , далее но всем объясняющим переменным.
Значения коэффициентов уравнения регрессии Ь , Ьь . Ьт.
Стандартная ошибка коэффициента регрессии 5^, 5Л). Sbm.
Статистическая значимость коэффициента регрессии (^-статистика) для а = 0,05 tw . tbm.
P-значение — это значение уровней значимости, соответствующее вычисленным ^статистикам коэффициентов.
Нижние 95% и Верхние 95% — это нижние и верхние границы 95%-ных доверительных интервалов для коэффициентов уравнения регрессии. Если в окно «Уровень надежности» не вводилось другое значение доверительной вероятности, то последние два столбца дублируют предыдущие два столбца. Если в окно «Уровень надежности» было введено другое значение доверительной вероятности у, то последние два столбца содержат значения соответственно нижней и верхней границы у-процентных доверительных интервалов.
Описание второй таблицы
df — число степеней свободы
SS — сумма квадратов
MS = SS/df — дисперсия на одну степень свободы
Использование Пакета анализа EXCEL для построения простой линейной регрессионной модели
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Проведем простой регрессионный анализ с помощью надстройки MS EXCEL Пакет анализа .
Эффективно использовать надстройку Пакет анализа для целей регрессионного анализа могут только пользователи знакомые с теорией регрессионного анализа .
В данной статье решены следующие задачи:
- Показано как в MS EXCEL выполнить регрессионный анализ с помощью надстройки Пакет анализа (инструмент Регрессия), т.е. как вызвать надстройку и правильно заполнить входные данные;
- Даны пояснения по разделам отчета, формированного надстройкой.
В надстройке Пакет анализа для построения линейной регрессионной модели (как простой , так и множественной ) имеется специальный инструмент Регрессия .
![]()
После выбора этого инструмента откроется окно, в котором требуется заполнить следующие поля (см. файл примера лист Надстройка ):
![]()
- Входной интервалY : ссылка на массив значений переменной Y. Ссылку можно указать с заголовком. В этом случае, при выводе результатов надстройка использует Ваш заголовок (для этого в окне требуется установить галочку Метки );
- Входной интервал Х : ссылка на значения переменной Х. В случае множественной регрессии (несколько переменных Х) нужно указать все столбцы со значениями Х. В случае множественной регрессии ссылку рекомендуется делать на диапазон с заголовками (в окне требуется установить галочку Метки );
- Константа-ноль : если галочка установлена, то надстройка подбирает линию регрессии, проходящую через точку Y=0 ( сдвиг будет равен 0);
- Уровень надежности : Это значение используется для построения доверительных интервалов для наклона и сдвига . Уровень надежности = 1- альфа. Если галочка не установлена или установлена, но уровень значимости = 95%, то надстройка все равно рассчитывает границы доверительных интервалов, причем дублирует их. Если галочка установлена, а уровень надежности отличен от 95%, то рассчитываются 2 доверительных интервала : один для 95%, другой для введенного значения. Для демонстрации вышесказанного введем 90%;
- Выходной интервал: диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона;
- Остатки : будут вычислены остатки модели , т.е. разница между наблюденными и предсказанными значениями Yi для всех наблюдений n;
- Стандартизированные остатки : Вышеуказанные значения остатков будут поделены на значение их стандартного отклонения ;
- График остатков : Будет построена точечная диаграмма : значения остатков для всех значений Хi;
- График подбора: Будет построена точечная диаграмма: точки данных (X;Y) и линия регрессии ;
- График нормальной вероятности: Будет построена точечная диаграмма с названием График нормального распределения . По сути — это график значений переменной Y, отсортированных по возрастанию .
В результате вычислений будет заполнен указанный Выходной интервал.
![]()
![]()
![]()
Тот же результат можно получить с помощью формул (см. файл примера лист Надстройка, столбцы I:T ):
![]()
Результаты вычислений, выполненных надстройкой, полностью совпадают с вычислениями сделанными нами в статье про простую линейную регрессию с помощью функций ЛИНЕЙН() , НАКЛОН() , ОТРЕЗОК() и др. Использование альтернативных формул помогает разобраться с алгоритмом расчета показателей регрессии.
Отчет, сформированный надстройкой, состоит из следующих разделов:
Раздел «Регрессионная статистика»:
- Множественный R. В случае простой линейной регрессии — это Коэффициент корреляции , функция КОРРЕЛ()
- R-квадрат . В случае простой линейной регрессии – это коэффициент детерминации , функция КВПИРСОН()
- Нормированный R-квадрат . См. про коэффициент детерминации .
- Стандартная ошибка . См. Стандартная ошибка регрессии ;
- Наблюдения . Количество значений Y.
Раздел « Дисперсионный анализ »:
- df – степени свободы (Degrees of Freedom).
- SS – сумма квадратов (Sum of Squares)
- MS – SS/df (MSR и MSE)
- F – значение статистики F (MSR/MSE)
- ЗначимостьF – p-значение, функция F.РАСП.ПХ()
- Коэффициенты : оценка параметров модели а и b. См. Оценка неизвестных параметров .
- Стандартная ошибка : Стандартные ошибки вышеуказанных статистик
- t-статистика : значение тестовой статистики t0. См. Проверка значимости взаимосвязи переменных
- P-Значение : См. Проверка значимости взаимосвязи переменных
- Нижние 95% и Верхние 95%: границы доверительных интервалов для оценок неизвестных параметров модели а и b .
Регрессия входной интервал содержит нечисловые данные
трюки • приёмы • решения
При импортировании данных из других источников вы, возможно, уже успели обнаружить, что Excel иногда некорректно импортирует значения. В частности, он может принять ваши числа за текст. И тогда, например, при суммировании диапазона значений формула СУММ возвращает 0 — хотя диапазон, по всей видимости, содержит числовые значения.
Часто Excel сообщает вам об этих «нечислах», отображая смарт-тег, который позволяет преобразовать текст в числа. Если смарт-тег не отображается, вы можете использовать следующий метод, чтобы указать Excel изменить эти «нечисловые» числа на их фактические значения. Выполните следующие действия.
- Активизируйте любую пустую ячейку на листе.
- Нажмите Ctrl+C, чтобы скопировать пустую ячейку.
- Выберите диапазон, содержащий проблематичные значения.
- Выберите Главная ► Буфер обмена ► Вставить ► Специальная вставка для открытия диалогового окна Специальная вставка.
- В окне Специальная вставка установите переключатель Операция в положение сложить.
- Нажмите кнопку ОК.
Excel ничего не добавит к значениям, но в процессе укажет этим ячейкам иметь фактические значения.
Входной интервал. Нужно ввести ссылку на интервал данных рабочего листа, подлежащих анализу. Excel также прелагает группирование входных данных по строкам или столбцам. Если во входной интервал включаются метки (заголовки строк или столбцов данных), необходимо установит флажок Метки,в противном случае Excel выдаст предупреждающее сообщение.
Метки. Если входной интервал не включает меток, снимите флажок Метки. Excel генерирует соответствующие метки данных для выходной таблицы (Строка 1, Строка 2, или Столбец 1, Столбец 2 и т.д.)
Выходные данные
Выходной интервал. Введите ссылку для верхней левой ячейки интервала, в который вы предполагаете вывести результирующую таблицу.
Новый рабочий лист. Этот параметр вставляет новый лист в рабочую книгу, где располагается текущий рабочий лист, и вставляет результаты в ячейку А1 нового листа. Используйте поле ввода рядом с параметром для задания имени нового листа.
Новая рабочая книга. Этот параметр создает новую рабочую книгу, добавляет новый рабочий лист и вставляет результаты в ячейку А1 нового листа.
Генерация случайных чисел
В имитационных моделях для описания реальных событий используются случайные величины и процессы. Когда имитационная модель рассчитывается на ЭВМ, то возникает необходимость реализации указанных процессов с максимально возможной точностью.
Для генерации случайных величин необходимо иметь возможность получать последовательность равномерно распределенных случайных чисел, т.е. чисел, которые ведут себя как независимые реализации или выборки случайной величины R, равномерно распределенной на единичном интервале [0,1]. Такие числа получают с помощью генераторов случайных чисел.
При помощи последовательности равномерно распределенных случайных чисел можно получить последовательности случайных величин, имеющих другие законы распределения.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Для студента самое главное не сдать экзамен, а вовремя вспомнить про него. 10663 — ![]() | 7824 —
| 7824 — ![]() или читать все.
или читать все.
Встроенные статистические функции используются для проведения статистического анализа данных.
Функция СРЗНАЧ вычисляет среднее арифметическое значение. Она игнорирует пустые, логические и текстовые ячейки и может использоваться вместо длинных формул. Например, для вычисления среднего значения данных в диапазоне ячеек В4:В15 можно использовать формулу:
Очевидно, что проще ввести = СРЗНАЧ(B4:B15).
Функция МЕДИАНА вычисляет медиану множества числовых значений.
Функция МОДА определяет значение, которое чаще других встречается во множестве чисел.
Функция МАКС вычисляет наибольшее значение в диапазоне.
Функция МИН вычисляет наименьшее значение в диапазоне.
Функция СЧЕТ определяет количество ячеек в заданном диапазоне, которые содержат числа, в том числе, даты и формулы, возвращающие числа.
Функции ДИСП и СТАНДОТКЛОН определяют дисперсию и стандартное отклонение чисел, в предположении что они образуют выборку.
Функции ДИСПР и СТАНДОТКЛОНП определяют дисперсию и стандартное отклонение для генеральной совокупности.
Функция НАКЛОН вычисляет коэффициент наклона линии линейной регрессии.
Функция ОТРЕЗОК вычисляет отрезок, отсекаемый на оси линией линейной регрессии.
Функция ПРЕДСКАЗ вычисляет теоретические значения y по линии линейной регрессии.
Если встроенных статистических функций недостаточно, можно обратиться к Пакету анализа .
Чтобы получить доступ к инструментам Пакета анализа необходимо:
· выполнить команду Сервис/Анализ данных;
· для использования инструмента анализа, выбрать его имя в списке и нажать кнопку ОК;
· заполнить открывшееся диалоговое окно (в большинстве случаев это означает задание входного диапазона с данными, которые вы собираетесь анализировать, указание верхней левой ячейки выходного диапазона, в который должны быть помещены результаты, и выбор нужных параметров. Группирование: установить переключатель в положение По столбцам или По строкам в зависимости от расположения данных во входном диапазоне. Установить переключатель в положение Метки в первой строке, если первая строка во входном диапазоне содержит названия столбцов или установить переключатель в положение Метки в первом столбце, если названия строк находятся в первом столбце входного диапазона. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически).
Если надстройка Анализ данных отсутствует, то ее можно подключить с помощью команды Сервис/Надстройки/Пакет анализа VBA ( Analysis ToolPak VBA ).
К инструментам Пакета анализа , например, относятся Описательная статистика , Корреляция , Регрессия .
Инструмент Описательная статистика предлагает таблицу основных статистических характеристик для одного или нескольких множеств входных значений ( Рис. 7.1 ):
Выходной интервал этого инструмента содержит следующие статистические характеристики: среднее, стандартная ошибка, медиана, мода, стандартное отклонение, дисперсия, коэффициент эксцесса, коэффициент асимметрии, интервал (размах), минимальное значение, максимальное значение, сумма, число значений, k -е наибольшее и наименьшее значения (для любого заданного значения k ) и уровень значимости для среднего. Установить флажок Итоговая статистика, если нужен полный список характеристик, в противном случае отметить конкретные характеристики, которые должны присутствовать в выходной таблице. Большинство из полученных характеристик, полученных с помощью пакета анализа Описательная статистика можно получить с помощью встроенных статистических формул.
Рис. 7 . 1 Диалоговое окно Описательная статистика
Корреляция используется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде. Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (корреляция близка к нулю). В диалоговом окне Корреляция ( REF _Ref12174106 h * MERGEFORMAT Рис. 7.2 ) указывается Входной интервал – ссылка на диапазон, содержащий анализируемые данные. Ссылка должна состоять как минимум из двух смежных диапазонов данных, организованных в виде столбцов или строк.
Рис. 7 . 2 Диалоговое окно Корреляция
Регрессия используется для подбора графика линии регрессии. Параметры диалогового окна Регрессия ( Рис. 7.3 ):
Входной интервал Y – ссылка на диапазон анализируемых зависимых данных (диапазон должен состоять из одного столбца). Входной интервал X – ссылка на диапазон независимых данных, подлежащих анализу. Уровень надежности – установить флажок, чтобы включить в выходной диапазон дополнительный уровень. В соответствующее поле ввести уровень надежности, который будет использован дополнительно к уровню 95%, применяемому по умолчанию. Константа-ноль – установить флажок, чтобы линия регрессии прошла через начало координат. Остатки – установить флажок, чтобы включить остатки в выходной диапазон. Стандартизированные остатки – установить флажок, чтобы включить стандартизированные остатки в выходной диапазон. График остатков – установить флажок, чтобы построить диаграмму остатков для каждой независимой переменной. График подбора – установить флажок, чтобы построить диаграммы наблюдаемых и предсказанных значений для каждой независимой переменной. График нормальной вероятности – установить флажок, чтобы построить диаграмму нормальной вероятности.
Статистический анализ в excel Назначение и возможности пакета анализа
В состав MicrosoftExcelвходит пакет анализа, который позволяет осуществлять статистическую обработку данных в таблицах. В состав этого пакета входят разнообразные статистические методы. Способы применения их всех аналогичны, поэтому мы рассмотрим лишь некоторые из них: экспоненциальное сглаживание, корреляцию, скользящее среднее, регрессию.
Корреляция используется для количественной оценки взаимосвязи двух наборов данных, представленных в безразмерном виде. Корреляционный анализ дает возможность установить ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (корреляция близка к нулю).
Скользящее среднее используется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Процедура может использоваться для прогноза сбыта, инвентаризации и других процессов. Мы спрогнозируем курс доллара США на основе данных за июль 1999 года.
Экспоненциальное сглаживание предназначается для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. Использует константу сглаживания, по величине которой определяет, насколько сильно влияют на прогнозы погрешности в предыдущем прогнозе. Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к сдвигу аргумента для предсказанных значений.
Линейный регрессионный анализ заключается в подборе графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или более независимых переменных. Мы рассмотрим, как влиял на курс ЕВРО по отношению к рублю курс доллара США в июле 1999 года.
Установка пакета анализа.
Если в Microsoft Excel в меню Сервисотсутствует командаАнализ данных, то необходимо установить статистический пакет анализа данных.
Чтобы установить пакет анализа данных
В![]() менюСервисвыберите командуНадстройки. Если в списке надстроек нет пакета анализа данных, нажмите кнопкуОбзори укажите диск, папку и имя файла для надстройки пакет анализа, Analys32.xll (как правило, папка LibraryAnalysis) или запустите программу Setup, чтобы установить эту надстройку.
менюСервисвыберите командуНадстройки. Если в списке надстроек нет пакета анализа данных, нажмите кнопкуОбзори укажите диск, папку и имя файла для надстройки пакет анализа, Analys32.xll (как правило, папка LibraryAnalysis) или запустите программу Setup, чтобы установить эту надстройку.
Установите флажок Пакет анализа,выберите кнопкуOK.
Вызов пакета анализа
Чтобы запустить пакет анализа:
В меню Сервисвыберите командуАнализ данных.
В списке Инструменты анализавыберите нужную строку.
![]()
Корреляция
При выборе строки Корреляцияв диалоговом запросеАнализ данныхпоявляется следующее окно.
![]()
Входной интервал. Введите ссылку на ячейки, содержащие анализируемые данные. Ссылка должна состоять как минимум из двух смежных диапазонов данных, организованных в виде столбцов или строк. (Для этого нужно мышью щелкнуть по кнопке ![]() в правом конце строки, установить мышь в верхний правый угол диапазона анализируемых данных и, удерживая нажатой левую кнопку мыши, отбуксировать мышь в левый нижний угол диапазона, нажать клавишуEnter).
в правом конце строки, установить мышь в верхний правый угол диапазона анализируемых данных и, удерживая нажатой левую кнопку мыши, отбуксировать мышь в левый нижний угол диапазона, нажать клавишуEnter).
![]()
Группирование. Установите переключатель в положениеПо столбцамилиПо строкамв зависимости от расположения данных во входном диапазоне.
Метки в первой строке/Метки в первом столбце. Установите переключатель в положениеМетки в первой строке, если первая строка во входном диапазоне содержит названия столбцов. Установите переключатель в положениеМетки в первом столбце, если названия строк находятся в первом столбце входного диапазона. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически. (В других видах анализа этот флажок выполняет аналогичную функцию).
Выходной интервал. Введите ссылку на левую верхнюю ячейку выходного диапазона. Поскольку коэффициент корреляции двух наборов данных не зависит от последовательности их обработки, то выходная область занимает только половину предназначенного для нее места. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждая строка или столбец во входном диапазоне полностью коррелирует с самим собой.
Новый лист. Установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая книга. Установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
Смотри лист Корреляция в примере.
Вернитесь в текущий документ через Панель задач
результате программа сформирует таблицу с коэффициентами корреляции между выбранными совокупностями.
Регрессионный анализ. Построение статических однофакторных моделей
![]()
Практическая работа 1. Регрессионный анализ. Построение статических однофакторных моделей.
Содержательная постановка задачи. Имеется статистическая информация по центральному федеральному округу, которая представлена в таблице1:
Таблица 1. Число гостиниц и число ночевок в гостиницах
Наименование субъекта Федерации
Число гостиниц и аналогичных средств размещения, ед.
Число ночевок в гостиницах и аналогичных средствах размещения, тыс. ночевок
* — на базе данных Федеральной службы государственной статистики.
Пусть ряд наблюдений X — число гостиниц и аналогичных средств размещения, ряд наблюдений Y — число ночевок в гостиницах и аналогичных средствах размещения, тыс.
Часть I.
Построить точечную диаграмму, предварительно отсортировав таблицу; Выдвинуть гипотезу о виде функции зависимости; Рассчитать параметры модели регрессии, построить тренды; Оценить адекватность построенного уравнения по величине достоверности аппроксимации; Рассчитать теоретические значения по модели и построить графики фактических и расчетных данных. Создать отчет в Word по всем пунктам задания, используя экранные копии Excel. Написать вывод о виде функции зависимости, наилучшим образом описывающей модель.
Пример. В исходной таблице произведем сортировку по столбцу С (число гостиниц и аналогичных средств размещения) по возрастанию числа гостиниц.
![]()
Рис.1. Сортировка по возрастанию числа гостиниц
Отсортированная таблица представлена на рисунке 2:
![]()
Рис.2. Отсортированная таблица по возрастанию числа гостиниц
По отсортированным данным, используя мастер диаграмм, построим точечную диаграмму (диапазон ячеек С1:D19) (Рис.3).
![]()
Рис. 3. Диаграмма по отсортированной таблице
После построения диаграммы, вызовем контекстовое меню, щелкнув правой кнопкой мыши по одной из точек диаграммы, и выберем в нем команду Добавить линию тренда…(Рис. 4):
![]()
Рис. 4. Вкладка Параметры линии тренда
Во вкладке Параметры линии тренда выберем Линейная и отметим флаги показывать уравнение на диаграмме и поместить на диаграмму величину достоверности аппроксимации (R^2). Чем R2 ближе к 1, тем удачнее регрессионная модель. На диаграмме появляется линия тренда (Рис. 5).
![]()
Рис.5. Диаграмма с линейной линией тренда
Чаще всего выбор производится среди следующих функций:
у = ах + b — линейная функция;
у = ах2 + bх + с — квадратичная (полиномиальная) функция;
у = аln(х) + b — логарифмическая функция;
у = аеbх — экспоненциальная функция;
у = ахb — степенная функция.
Отобразим на диаграмме все возможные тренды (Рис. 6.).
![]()
Рис. 6. Диаграмма с построенными линиями тренда
Часть II.
Требуется: рассчитать основные характеристики случайных величин.
Для расчета основных характеристик случайных величин используются следующие функции: СРЗНАЧ() – возвращает среднее арифметическое своих аргументов, КОРЕНЬ() – возвращает значение квадратного корня, а также ДИСП() и КОРРЕЛ().
ДИСП() — Оценивает дисперсию по выборке (Рис.7).
Синтаксис функции: ДИСП(число1;число2; . ).
Число1, число2. — от 1 до 255 числовых аргументов, соответствующих выборке из генеральной совокупности.
![]()
Рис. 7. Аргументы функции, оценивающей дисперсию по выборке — Дисп()
КОРРЕЛ() – возвращает коэффициент корреляции между интервалами ячеек «массив1» и «массив2». Коэффициент корреляции используется для определения взаимосвязи между двумя свойствами. Например, можно установить зависимость между средней температурой в помещении и использованием кондиционера (Рис. 8).
Синтаксис функции: КОРРЕЛ(массив1;массив2).
Массив1 — это интервал ячеек со значениями, Массив2 — второй интервал ячеек со значениями.
![]()
Рис.8. Аргументы функции, возвращающей коэффициент корреляции Коррел()
Получим следующие результаты (Рис. 9):
![]()
Рис. 9. Результаты расчетов с использованием математических функций
Можно сделать вывод о том, что линейная зависимость между числом гостиниц и аналогичных средств размещения (ряд X) и числом ночевок в гостиницах и аналогичных средствах размещения (ряд Y) существует, т. к. коэффициент корреляции равен 0,93729 и ![]() .
.
Коэффициент корреляции значим, т. к. расчетный критерий Стъюдента больше табличного критерия: 10,7566 > 2.1190.
Рассчитаем коэффициент корреляции для исходных данных с помощью функции Корреляция пакета Анализ данных.
Вызвать окно Анализ данных можно с помощью команды Анализ данных меню Данные (Рис. 10).
![]()
Рис. 10. Анализ данных
Пакет Корреляция позволяет определить коэффициенты корреляции для n-го количества рядов данных. Выбор команды Корреляция вызывает окно Корреляция (Рис. 11).
![]()
Рис. 11. Окно Корреляция
Это окно содержит две панели Входные данные и Параметры вывода. Окно Входной интервал: предназначено для ссылки на диапазон, содержащий анализируемые данные. Эта ссылка должна состоять не менее чем из двух смежных диапазонов данных, расположенных по строкам или столбцам. Флаги Группирование: зависят от расположения данных в диапазоне. Флаг Метки в первой строке (Метки в первом столбце) устанавливается в том случае, если входной интервал включал название диапазонов. Если название диапазонов были включены в интервал, а данный флаг не выставлен, после нажатия кнопки Ок, Excel выдаст сообщение об ошибке «Входной интервал содержит нечисловые данные». Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
Если результаты необходимо поместить на имеющемся листе, то нужно установить переключатель рядом с окном Выходной интервал:, а в самом окне следует ввести ссылку на левую верхнюю ячейку выходного диапазона.
Если установить переключатель рядом с окном Новый рабочий лист:, то в книге откроется новый лист и результаты анализа будут вставлены в него, начиная с ячейки A1. При необходимости в окно можно ввести имя нового листа. По умолчанию имя листа будет соответствовать следующему после последнего имеющегося в книге листа.
Если установить переключатель рядом с окном Новая рабочая книга, то откроется новая книга, и результаты анализа будут вставлены в нее, начиная с ячейки A1 на первом листе в этой книге.
Поскольку коэффициент корреляции двух наборов данных не зависит от последовательности их обработки, то выходная область занимает только половину предназначенного для нее места.
Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждая строка или столбец во входном диапазоне полностью коррелирует с самим собой.
Заполняем все необходимые поля окна Корреляция (Рис. 12).
Входной интервал – это данные, по которым необходимо провести корреляционный анализ, в данном случае это исходные данные по числу гостиниц и аналогичных средств размещения и числу ночевок в гостиницах и аналогичных средствах размещения (С2:D19). Строка 1 также указана во входном интервале, но в ней содержатся заголовки столбцов, поэтому ставим флаг Метки в первой строке.
В выходном интервале ставим Новый рабочий лист, в котором будут вынесены результаты расчета.
![]()
Рис. 12. Расчет коэффициента корреляции
Полученные данные абсолютно идентичны коэффициентам полученным с помощью функции КОРРЕЛ() (Рис. 13).
![]()
Рис. 13. Результаты расчета коэффициента корреляции
Пакет Описательная статистика предназначен для расчета основных статистических показателей. Окно Описательная статистика (Рис. 14) содержит:
![]()
Рис.14. Описательная статистика
панель Входные данные, аналогичную панели в окне Корреляция; панель Параметры вывода содержит указание на выходной интервал, аналогичный окну Корреляция; флаг Итоговая статистика обеспечивает вывод в выходной интервал среднего, стандартную ошибку (среднего), медиану, мода, стандартное отклонение, дисперсию выборки, эксцесс, асимметричность, интервал, минимум, максимум, сумму и количество значений; флаг Уровень надежности, установка которого выводит в выходной интервал строку для уровня надежности. Значение, введенное в поле, соответствует требуемому уровню надежности; флаг К-тый наименьший и К-тый наибольший, установка которых выводит в выходной интервал строки для k-го наибольшего и k-го наименьшего значения для каждого диапазона данных. В соответствующем окне необходимо ввести число k. Если k равно 1, эта строка будет содержать минимум или максимум из набора данных.
Далее вызовем функцию Описательная статистика из пакета Анализ данных (Рис. 15).
![]()
Рис. 15. Описательная статистика пакета Анализ данных
Выставив все необходимые флаги, нажимаем кнопку Ок, и получаем таблицу описательных статистик (Рис. 16).
![]()
Рис. 16. Таблица описательных статистик
Полученные данные совпадают с данными, рассчитанными с помощью математических функций (математическое ожидание по x и по y, дисперсия по x и по y, среднее квадратическое отклонение по x и по y).
Варианты заданий к практической работе 1.
Содержательная постановка задачи. Исходные данные:
построить точечную диаграмму, предварительно отсортировав таблицу; выдвинуть гипотезу о виде функции зависимости; рассчитать параметры модели регрессии, построить тренды; оценить адекватность построенного уравнения по величине достоверности аппроксимации; рассчитать теоретические значения по модели и построить графики фактических и расчетных данных. Создать отчет в Word по всем пунктам задания, используя экранные копии Excel. Написать вывод о виде функции зависимости, наилучшим образом описывающей модель.
Вариант 2. Имеется статистическая информация по Северо-Западному федеральному округу*, которая представлена в таблице:
Число гостиниц и аналогичных средств размещения
Число ночевок в гостиницах и аналогичных средствах размещения, тыс.
Источник
Содержание
- 1 Использование описательной статистики
- 1.1 Подключение «Пакета анализа»
- 1.2 Применение инструмента «Описательная статистика»
- 1.3 Помогла ли вам эта статья?
- 1.4 Статистические процедуры Пакета анализа
- 1.5 Статистические функции библиотеки встроенных функций Excel

Пользователи Эксель знают, что данная программа имеет очень широкий набор статистических функций, по уровню которых она вполне может потягаться со специализированными приложениями. Но кроме того, у Excel имеется инструмент, с помощью которого производится обработка данных по целому ряду основных статистических показателей буквально в один клик.
Этот инструмент называется «Описательная статистика». С его помощью можно в очень короткие сроки, использовав ресурсы программы, обработать массив данных и получить о нем информацию по целому ряду статистических критериев. Давайте взглянем, как работает данный инструмент, и остановимся на некоторых нюансах работы с ним.
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».

После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Применение инструмента «Описательная статистика»
Теперь посмотрим, как инструмент описательная статистика можно применить на практике. Для этих целей используем готовую таблицу.
- Переходим во вкладку «Данные» и выполняем щелчок по кнопке «Анализ данных», которая размещена на ленте в блоке инструментов «Анализ».
- Открывается список инструментов, представленных в Пакете анализа. Ищем наименование «Описательная статистика», выделяем его и щелкаем по кнопке «OK».
- После выполнения данных действий непосредственно запускается окно «Описательная статистика».
В поле «Входной интервал» указываем адрес диапазона, который будет подвергаться обработке этим инструментом. Причем указываем его вместе с шапкой таблицы. Для того, чтобы внести нужные нам координаты, устанавливаем курсор в указанное поле. Затем, зажав левую кнопку мыши, выделяем на листе соответствующую табличную область. Как видим, её координаты тут же отобразятся в поле. Так как мы захватили данные вместе с шапкой, то около параметра «Метки в первой строке» следует установить флажок. Тут же выбираем тип группирования, переставив переключатель в позицию «По столбцам» или «По строкам». В нашем случае подходит вариант «По столбцам», но в других случаях, возможно, придется выставить переключатель иначе.
Выше мы говорили исключительно о входных данных. Теперь переходим к разбору настроек параметров вывода, которые расположены в этом же окне формирования описательной статистики. Прежде всего, нам нужно определиться, куда именно будут выводиться обработанные данные:
- Выходной интервал;
- Новый рабочий лист;
- Новая рабочая книга.
В первом случае нужно указать конкретный диапазон на текущем листе или его верхнюю левую ячейку, куда будет выводиться обработанная информация. Во втором случае следует указать название конкретного листа данной книги, где будет отображаться результат обработки. Если листа с таким наименованием в данный момент нет, то он будет создан автоматически после того, как вы нажмете на кнопку «OK». В третьем случае никаких дополнительных параметров указывать не нужно, так как данные будут выводиться в отдельном файле Excel (книге). Мы выбираем вывод результатов на новом рабочем листе под названием «Итоги».
Далее, если вы хотите чтобы выводилась также итоговая статистика, то нужно установить флажок около соответствующего пункта. Также можно установить уровень надежности, поставив галочку около соответствующего значения. По умолчанию он будет равен 95%, но его можно изменить, внеся другие числа в поле справа.
Кроме этого, можно установить галочки в пунктах «K-ый наименьший» и «K-ый наибольший», установив значения в соответствующих полях. Но в нашем случае этот параметр так же, как и предыдущий, не является обязательным, поэтому флажки мы не ставим.
После того, как все указанные данные внесены, жмем на кнопку «OK».
- После выполнения этих действий таблица с описательной статистикой выводится на отдельном листе, который был нами назван «Итоги». Как видим, данные представлены сумбурно, поэтому их следует отредактировать, расширив соответствующие колонки для более удобного просмотра.
- После того, как данные «причесаны» можно приступать к их непосредственному анализу. Как видим, при помощи инструмента описательной статистики были рассчитаны следующие показатели:
- Асимметричность;
- Интервал;
- Минимум;
- Стандартное отклонение;
- Дисперсия выборки;
- Максимум;
- Сумма;
- Эксцесс;
- Среднее;
- Стандартная ошибка;
- Медиана;
- Мода;
- Счет.

Если какие-то из вышеуказанных данных для конкретного вида анализа не нужны, то их можно удалить, чтобы они не мешали. Далее производится анализ с учетом статистических закономерностей.
Урок: Статистические функции в Excel
Как видим, с помощью инструмента «Описательная статистика» можно сразу получить результат по целому ряду критериев, которые в ином случае рассчитывались с применением отдельно предназначенной для каждого расчета функцией, что заняло бы значительное время у пользователя. А так, все эти расчеты можно получить практически в один клик, использовав соответствующий инструмент — Пакета анализа.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет
Описательная статистика в Эксель. Описательная статистика в MS Excel позволяет представить статистическую информацию как совокупность данных, для характеристики которых могут быть использованы различные показатели.
Использование инструмента «Описательная статистика» рассмотрим на примере MS Excel 2010, а в качестве данных для анализа возьмем статистическую информацию по изменению курса доллара за месяц:

Для начала на вкладке «Данные» в группе «Анализ» выбрать пункт «Анализ данных»:

В открывшемся окне «Анализ данных» выбрать инструмент для анализа «Описательная статистика»:

В новом окне «Описательная статистика»,

следует выбрать исходные данные для анализа:
• Входной интервал – это диапазон ячеек с исходными данными для анализа. В случае, если в исходный диапазон входит текстовый заголовок, тогда следует поставить галочку в поле «Метки в первой строке»
• Выходной интервал – это адрес верхней левой ячейки диапазона, в котором будут представлены результаты статистического анализа.
• Итоговая статистика – позволяет вывести дополнительные расширенные результаты анализа исходных данных.
• Уровень надежности – показывает вероятность того, что исследуемый исходный интервал содержит истинное значение оцениваемого параметра. В математической статистике обычно используют значения: 90%, 95%, 99%. В нашем случае, по умолчанию установлено значение 95%.
• К-ый наименьший – показывает наименьшее значение из исследуемого исходного интервала.
• К-ый наибольший – показывает наибольшее значение из исследуемого исходного интервала.
В результате использования инструмента «Описательная статистика», на основании наших исходных данных, получим:

Таким образом, для проведения сложного статистического или инженерного анализа, чтобы упростить процесс и сэкономить время, следует использовать инструмент «Описательная статистика» MS Exсel.
Основными средствами анализа статистических данных в Excel являются статистические процедуры надстройки Пакет анализа (Analysis ToolРак) и статистические функции библиотеки встроенных функций. Основные сведения обо всех этих средствах имеются в электронной справочной системе Excel.
Однако качество описаний статистических процедур и функций, приведенных в этой системе, заставляет желать лучшего. Некоторые из этих описаний не очень понятны, в них имеются неточности, а подчас и просто ошибки (это относится как к англоязычному оригиналу, так и к русскому переводу). Эти недостатки с завидным постоянством повторяются и во многих пособиях по Excel. Найти необходимые пособия в интернете можно быстро если скачать бесплатно Амиго браузер с усовершенствованным поисковым алгоритмом.
Статистические процедуры Пакета анализа
Наиболее развитыми средствами анализа данных являются статистические процедуры Пакета анализа. Они обладают большими возможностями, чем статистические функции. С их помощью можно решать более сложные задачи обработки статистических данных и выполнять более тонкий анализ этих данных.
В Пакет анализа входят следующие статистические процедуры:
- генерация случайных чисел (Random number generation);
- выборка (Sampling);
- гистограмма (Histogram);
- описательная статистика (Descriptive statistics);
- ранги персентиль (Rank and percentile);
- двухвыборочный z-тест для средних (z-Test: Two Sample for Means);
- двухвыборочный t-тест для средних с одинаковыми дисперсиями (t-Test: Two-Sample Assuming Equal Variances);
- двухвыборочный t-тест для средних с различными дисперсиями (t-Test: Two-Sample Assuming Unequal Variances);
- парный двухвыборочный t-тест для средних (t-Test: Paired Two Sample for Means);
- двухвыборочный F-тест да я дисперсий (F-Test: Two Sample for Variances);
- коварнация (Covariance);
- корреляция (Correlation);
- рецессия (Regression);
- однофакторный дисперсионный анализ (ANOVA: Single Factor);
- двухфакторный дисперсионный анализ без повторений (ANOVA: Two Factor Without Replication);
- двухфакторный дисперсионный анализ с повторениями (ANOVA: Two Factor With Replication);
- скользящее среднее (Moving Average);
- экспоненциальное сглаживание (Exponential Smoothing);
- анализ Фурье (Fourier Analysis).
Для доступа к процедурам Пакета анализа необходимо в меню Сервис (Tools) щелкнуть указателем мыши на строке Анализ данных (Data Analysis). Откроется диалоговое окно с соответствующим названием, в котором перечислены процедуры статистического анализа данных (рис. 1).

Рис.1. Диалоговое окно Анализ данных
Для того чтобы запустить в работу нужную статистическую процедуру, нужно выделить ее указателем мыши и щелкнуть на кнопке ОК. На экране появится диалоговое окно вызванной процедуры. На рис. 2 для примера показано диалоговое окно процедуры Описательная статистика (Descriptive statistics).

Рис.2. Диалоговое окно процедуры Описательная статистика
Диалоговое окно каждой процедуры содержит элементы управления: поля ввода, раскрывающиеся списки, переключатели, флажки и т. п. Эти элементы позволяют задать нужные параметры используемой процедуры. Некоторые элементы управления имеют специфический характер, присущий одной процедуре или небольшой группе процедур. Назначение таких элементов управления будет рассмотрено при описании соответствующих процедур. Другие элементы управления присутствуют в диалоговых окнах почти всех статистических процедур.
К числу общих для большинства процедур элементов управления относятся:
- поле ввода Входной интервал (Input Range). В это поле вводится ссылка на диапазон, содержащий статистические данные, подлежащие обработке. Входной диапазон может быть столбцом пли группой столбцов (строкой или группой строк);
- переключатель Группирование (Grouped By). В том случае, когда входной диапазон представляет собой столбец или группу столбцов, переключатель устанавливается в положение по столбцам (Columns). Если же входной диапазон представляет собой строку или группу строк, то переключатель устанавливается в положение по строкам (Rows). Более точным названием этого переключателя было бы название Расположение;
- флажок Метки (Labels in First Row). Флажок устанавливается в тех случаях, когда первая строка (первый столбец) входного диапазона содержит заголовки. Если такие заголовки отсутствуют, флажок Метки не устанавливают. При этом Excel автоматически создает и выводит на экран стандартные названия для данных выходного диапазона (Столбец1, Столбец2,… или Строка 1. Строка2,…);
- переключатели Выходной интервал/Новый рабочий лист/Новая книга (Output Range/New Worksheet/New Workbook). Эти переключатели определяют место вывода таблицы, содержащей результаты реализации статистической процедуры. В группе может быть выбран только одни переключатель.
При выборе переключателя Выходной интервал таблица результатов решения выводится на тот же рабочий лист, на котором находятся исходные данные. Справа от переключателя открывается поле ввода, в которое надо ввести ссылку на левую верхнюю ячейку таблицы результатов. Если возникает опасность наложения таблицы результатов на уже заполненные ячейки, на экране появляется сообщение о такой опасности. В ответ на это сообщение пользователь должен разрешить удаление старых данных и вывод на их место новых.
В положении Новый рабочий лист открывается новый лист рабочей книги. На этот лист, начиная с ячейки А1, и выводится таблица результатов решения. Справа от переключателя имеется поле ввода, в которое в случае необходимости можно ввести имя нового рабочего листа. При выборе переключателя Новая рабочая книга открывается новая рабочая книга. На первый лист этой новой книги, начиная с ячейки А1, выводится таблица результатов решения.
Следует заметить, что результаты;, получаемые с помощью статистических процедур Пакета анализа, не имеют постоянной связи с исходными данными — в случае изменения исходных данных результаты решения автоматически не изменяются. В том случае, когда необходимо получить результаты, автоматически изменяющиеся вместе с исходными данными, нужно использовать подходящие статистические функции библиотеки встроенных функций.
Эффективным и очень удобным в использовании средством парного регрессионного анализа и анализа временных рядов является процедура Добавить линию тренда (Add Trendline), входящая в комплекс графических средств Excel.
Статистические функции библиотеки встроенных функций Excel
Табличный процессор Excel имеет библиотеку встроенных функции рабочего листа (Worksheet function). Одним из разделов этой библиотеки является раздел Статистические функции. В этот раздел входят 83 функции, предназначенные для решения некоторых наиболее востребованных задач теории вероятностей и математической статистики.
Аргументы статистических функций должны быть числами или ссылками на диапазоны, которые содержат числа Если аргумент, который является массивом или ссылкой, содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются, однако ячейки с нулевыми значениями учитываются.
Когда в качестве какого-либо аргумента встроенной статистической функции введен текст, функция выдает сообщение об ошибке #ЗНАЧ! (#VALUE!). Если в качестве аргумента, который по определению должен быть целым числом, введено число не целое, Excel использует в качестве аргумента целую часть этот числа. Никакие сообщения об этом «несанкционированном округлении» на экран не выводятся.
Стандартная ошибка появляется при прогнозировании каких-либо данных или арифметических вычислениях, поэтому важно научиться находить этот параметр. В этой публикации разбираем, как найти и исправить стандартную ошибку путем использования инструментов Excel.
Расчет средней арифметической ошибки
В Microsoft Excel цельность и однородность выборки определяется при помощи стандартной ошибки. Стандартная ошибка — это квадратный корень из дисперсии. В приложении предусмотрено два варианта поиска стандартной ошибки: при помощи пакетного анализа и расширенных функций программы.
Чтобы найти значение средней арифметической, необходимо выполнить деление суммарной величины выборки на ее количество в электронной книге.
Расчет стандартной ошибки при помощи встроенных функций
Для того, чтобы правильно вычислять, необходимо изучить пошаговую инструкцию. В этом способе подбор результатов будет осуществляться с помощью комбинированных манипуляций.
- Для расчетов будем использовать таблицу с выборкой чисел. Кликаем на любой пустой ячейке на листе, где будет отображаться результат. Затем нажимаем кнопку «Вставить функцию.
- Далее перед вами открывается диалоговое окно, в котором необходимо использовать «СТАНДОТКЛ.В», для этого в поле «Категория» необходимо выбрать «Полный алфавитный перечень». Затем нажмите кнопку «ОК».
- В окне «Аргументы функции» кликаем в первом поле «Число 1», затем выполняем выделение мышью диапазона ячеек со значениями таблицы и нажимаем кнопку «ОК».
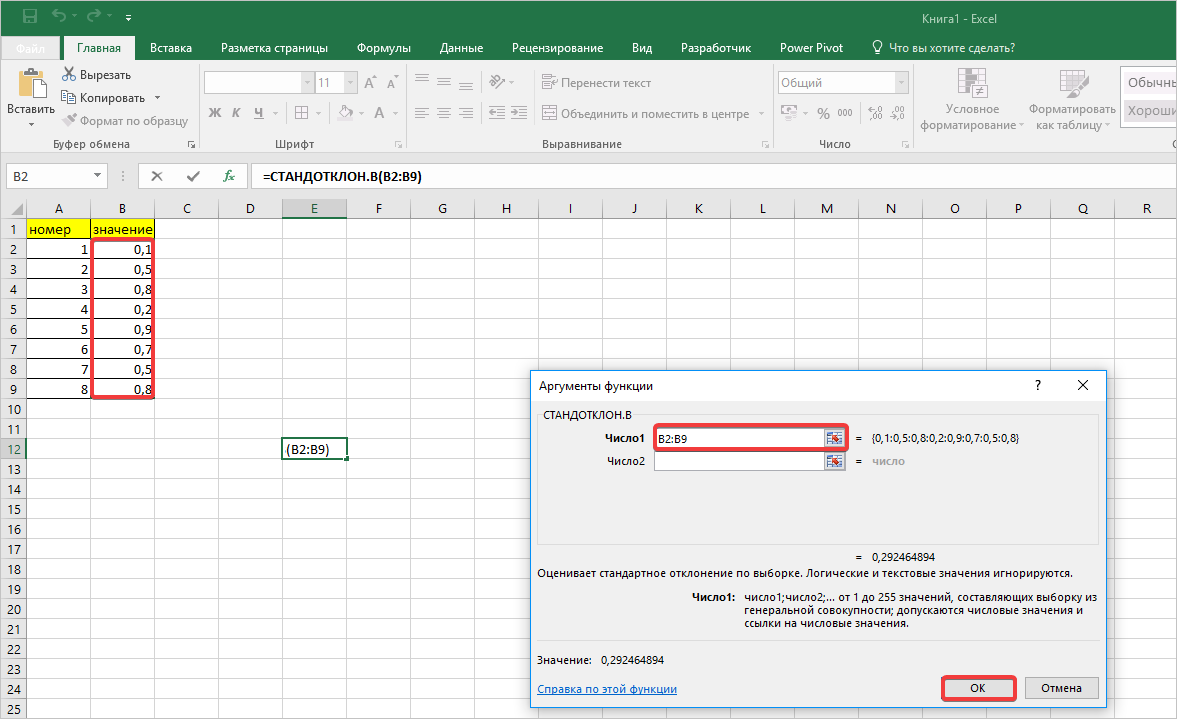
- Далее активируем ячейку с нашими значениями, переходим в строку формулы и ставим после значений наклонную линию. Переходим в поле наименования, кликаем на указывающий вниз флажок, где из списка выбираем «Другие функции».
- Снова активируется окно с перечнем функций, в котором необходимо выбрать категорию «Математические», затем функцию «Корень». Далее нажмите кнопку «ОК».
- Далее открывается окно, в котором необходимо заполнить поле с числом. Для этого переходим в поле «Имя», где спускаемся к пункту «Счет». Если его нет, ищите в дополнительных функциях.
После выполнения этих шагов, стандартная ошибка высчитывается автоматически, пользователю остается только сверить их и проверить значение на некорректное отображение.
Для малых и стандартных выборок необходимо использовать разные формулы. В первом случае (если находится до 30 значений), ее необходимо видоизменить.
Решение задачи с помощью опции «Описательная статистика»
Благодаря опции «Описательная статистика» удается выполнить вычисление по различным критериям. По этим правилам удается найти среднюю арифметическую ошибку. Для использования данного метода предварительно нужно запустить «Пакет анализа».
- Переходим во вкладку «Файл», где перемещаемся в пункт «Параметры». Далее нажимаем на запись «Надстройки».
- Открывается окошко, в нем в графе «Управление» должно быть прописано «Надстройки Excel», затем рядом нажимаем кнопку «Параметры».
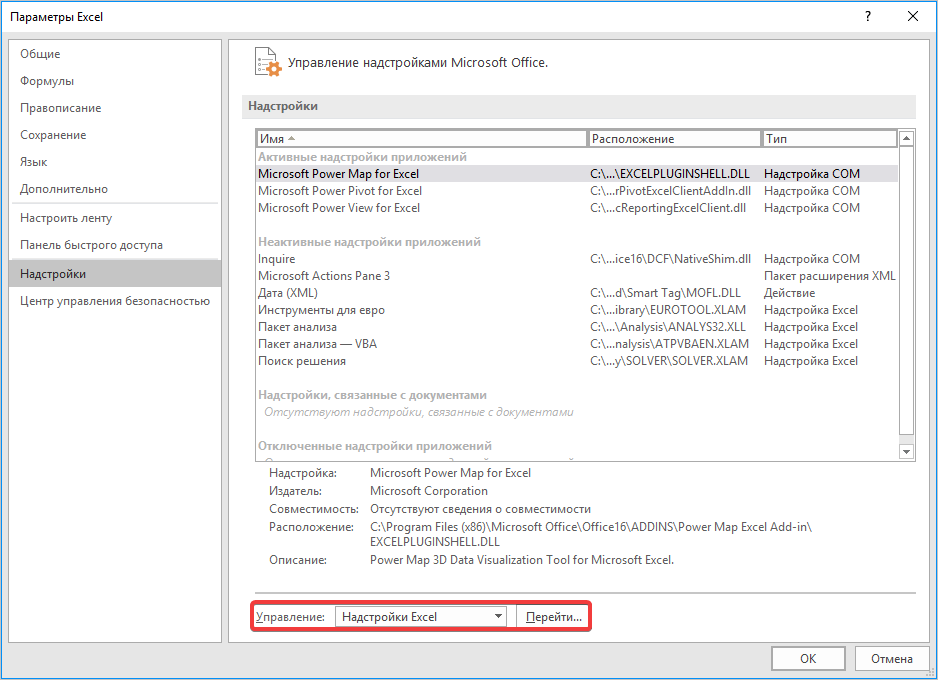
- В появившемся окне находим «Пакет анализа» и нажимаем кнопку «ОК».
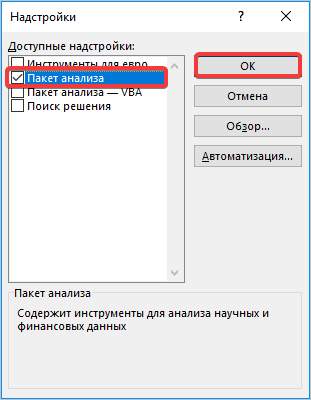
- Далее выбираем любую свободную ячейку, переходим во вкладку «Данные» и нажимаем «Анализ данных» в блоке «Анализ».

- Происходит запуск вспомогательного окошка, в котором необходимо выбрать из всех инструментов «Описательную статистику» и нажать кнопку «ОК».
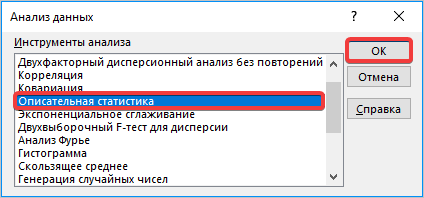
- Открывается новый мастер значений. Здесь нужно вводить данные предельно внимательно. В поле «Входной интервал» вносим адрес диапазона ячеек с выборкой. Затем указываем параметр «Группирование» «По столбцам». Затем выбираем место для «выходного интервала», его должно быть столько же, сколько и «входного». Ставим галочку напротив «Итоговая статистика» и нажимаем кнопку «ОК».
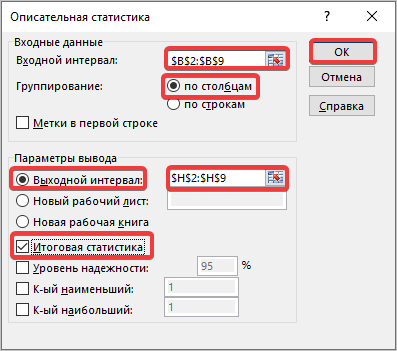
В результате вычислений вы получаете небольшую таблицу, в которой указаны все данные с определенной стандартной ошибкой.
Описательная статистика Excel позволяет за несколько минут обработать достаточно большое количество информации и найти необходимые значения, учитывая определенный набор условий и критерий. Обработка данных большого ряда значений согласно всем законам статистики – нет проблем, Microsoft Excel справиться со всем.
Для того чтобы сформировать вывод о результатах полученных данных с целого ряда массива значений можно использовать достаточно простую функцию из «Пакета анализа», которая позволит систематизировать эмпирические значения согласно определенным критериям.
Эта функция можем высчитывать большинство критериев, среди которых:
• Отклонение и стандартное отклонение;
• Ошибка и стандартная ошибка;
• Асимметричность значений;
• Мода;
• Дисперсия;
• Медиана;
• Другие значения.
По умолчанию, возможность работы с «Относительной статистикой» скрыта от большинства пользователей. Для того чтобы активировать данную панель, необходимо включить ее в параметрах документа.
Для этого нажмем на вкладку «Файл» — «Параметры».
В появившемся диалоговом окне перейдем в меню «Надстройки», где внизу в подменю «Управление» нужно выбрать «Надстройки Excel» и перейти к последующим настройкам.
В новом окне ставим галочку напротив «Пакет анализа» и применяем операцию.
Весь функционал «Пакета анализа» был добавлен в рабочую область и появился во вкладке «Данные». Приступим непосредственно к «Описательной статистике» и попробуем на практике данный инструмент.
Перейдем во вкладку «Анализ данных», которая размещена в «Данных» и выбираем функцию «Описательная статистика».
Теперь необходимо заполнить все поля и ввести аргументы функции.
• «Входной интервал» — укажем весь диапазон данных, для которых необходимо применить функцию «Описательной статистики» — выделяем весь столбец вместе с названием с включением функции «Метки в первой строке».
• Включим группирование «По строкам» и «По столбцам».
• Выберем место, куда будут сохраняться результаты работы функции, это могут быть и новая книга, новый лист либо просто выбранный интервал.
Теперь можно анализировать результаты работы функции. «Описательная статистика» рассчитала сразу несколько показателей, которые дают более четкое представление о выполненной работе: интервал, минимум и максимум, общую сумму и среднее значение и так далее.
Пакет анализа предлагает пользователю результаты сразу по нескольким критериям. Это экономит большое количество времени, которое ушло бы на отдельный расчет по каждому показателю.
Описательная статистика в excel
Инструмент Описательная статистика входит в Пакет анализа (активация Пакета анализа смотри п.2.7.2). С его помощью можно в очень короткие сроки, использовав ресурсы программы, обработать массив данных и получить о нем информацию по целому ряду статистических критериев. Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим работу данного инструмента на примере задачи 4.2.
Переходим во вкладку «Данные» и выполняем щелчок по кнопке «Анализ данных», которая размещена на ленте в блоке инструментов «Анализ». Открывается список инструментов, представленных в Пакете анализа. Ищем наименование «Описательная статистика», выделяем его и щелкаем по кнопке «OK» (рис. 4.1).
| |
| Рис. 4.1. Описательная статистика |
После выполнения данных действий непосредственно запускается окно «Описательная статистика».
В поле «Входной интервал» указываем адрес диапазона, который будет подвергаться обработке этим инструментом. Причем указываем его вместе с шапкой таблицы. Так как мы захватили данные вместе с шапкой, то около параметра «Метки в первой строке» следует установить флажок. Тут же выбираем тип группирования, переставив переключатель в позицию «По столбцам» или «По строкам». В нашем случае подходит вариант «По столбцам», но в других случаях, возможно, придется выставить переключатель иначе.
Выше мы говорили исключительно о входных данных. Теперь переходим к разбору настроек параметров вывода, которые расположены в этом же окне формирования описательной статистики. Прежде всего, нам нужно определиться, куда именно будут выводиться обработанные данные:
- Выходной интервал;
- Новый рабочий лист;
- Новая рабочая книга.
В первом случае нужно указать конкретный диапазон на текущем листе или его верхнюю левую ячейку, куда будет выводиться обработанная информация. Во втором случае следует указать название конкретного листа данной книги, где будет отображаться результат обработки. Если листа с таким наименованием в данный момент нет, то он будет создан автоматически после того, как вы нажмете на кнопку «OK». В третьем случае никаких дополнительных параметров указывать не нужно, так как данные будут выводиться в отдельном файле Excel (книге). Мы выбираем вывод результатов на этом же рабочем листе (рис.4.2).
Далее, если вы хотите чтобы выводилась также итоговая статистика, то нужно установить флажок около соответствующего пункта. Также можно установить уровень надежности, поставив галочку около соответствующего значения. По умолчанию он будет равен 95%, но его можно изменить, внеся другие числа в поле справа.
Кроме этого, можно установить галочки в пунктах «K-ый наименьший» и «K-ый наибольший», установив значения в соответствующих полях. Этот параметр, также как и предыдущий, не является обязательным, поэтому флажки можно не ставить.
После того, как все указанные данные внесены, жмем на кнопку «OK».
Среди множества показателей Описательной статистики есть те, которые нас интересуют, они выделены цветом (рис. 4.3).
ВОПРОСЫ И УПРАЖНЕНИЯ
1. Дайте определение размаху, выборочной дисперсии, генеральной дисперсии, стандартному отклонению. Воспроизведите формулы для их нахождения.
2. Что характеризует выборочная дисперсия.
3. Вычислите для множества: 22, 15, 16, 21, 24, 24, 27, 28, 30, 30, 31, 31, 31, 34, 36 размах, дисперсию, стандартное отклонение.
4. В каких случаях можно проводить сравнение разных выборок по дисперсиям?
5. Выборочные дисперсии результатов контрольной работы в классе 7«А» и 7«Б» соответственно равны 0,44 и 1,38. Какой вывод можно сделать при сравнении результатов контрольной работы в двух классах?
6. Дисперсия каждой из групп A и В равна 5. Будет ли дисперсия 10 значений, полученных путем объединения групп, меньше, больше или равна 5?
Группа А: 13, 11, 10, 9, 7
Группа В: 28, 26, 25, 24, 22
Лабораторная работа №2
Описательная статистика
Этапы обработки данных:
1. Занести данные в таблицу Excel (две выборки).
2. Упорядочить данные (по возрастанию) в каждой выборке.
3. Рассчитать моду, медиану и среднее.
4. Посчитать дисперсию, стандартное отклонение.
5. Посчитать коэффициент вариации.
6. Сделать сравнительный анализ, полученных результатов.
Задания для вариантов 1 – 5
При определении степени выраженности некоторого психического свойства в двух группах, опытной и контрольной, баллы распределились следующим образом.
Дать сравнительную характеристику степени выраженности этого свойства в данных группах.
Вариант 1.
| Опытная | 18, 15, 16, 11, 14,15, 16, 16, 20, 22, 17, 12, 11, 12, 18, 19, 20 |
| Контрольная | 26, 8, 11, 12, 25, 22, 13, 14, 21, 20, 15, 16, 17, 16, 9, 11, 16 |
Вариант 2
| Опытная | 19, 16, 17, 12, 15,16, 17,17, 21, 23, 18, 13, 12, 13, 19, 20, 21 |
| Контрольная | 27, 9, 12, 13, 26, 23, 14, 15, 22, 21, 16, 16, 18, 17, 10, 12, 17 |
Вариант 3.
| Опытная | 16, 13, 14, 9, 10,13, 14,14, 18, 20, 15, 10, 9, 10, 16, 17, 18 |
| Контрольная | 24, 6, 9, 10, 23, 20, 11, 12, 19, 18, 13, 14, 12, 14, 7, 9, 14 |
| Опытная | 15, 12, 13, 8, 11,12, 13,13, 17, 19, 14, 9, 8, 9, 15, 16, 17 |
| Контрольная | 23, 5, 9, 9, 22, 19, 10, 11, 18, 17, 12, 13, 14, 13, 6, 8, 13 |
| Опытная | 15, 12, 13, 8, 11,12, 13,13, 17, 19, 14, 9, 8, 9, 15, 16, 17 |
| Контрольная | 24, 6, 9, 10, 23, 20, 11, 12, 19, 18, 13, 14, 12, 14, 7, 9, 14 |
Задания для вариантов 6 – 10
Была исследована группа детей с заболеванием крови до лечения препаратами и после лечения. В таблицу занесены показатели крови по результатам медицинского обследования. Сделать сравнительный анализ результативности лечения данным препаратом, используя методы описательной статистики.
| до лечения | 20,5 12,1 13,6 40,5 9,6 33 77,2 8,7 3,5 13,8 7,4 29,4 116 21,9 |
| после лечения | 2,3 7,5 3,8 3,8 8,8 13 4,7 3,9 4,8 5,7 9 13 0,9 |
| до лечения | 280 230 100 60 90 80 8 36 50 90 17 42 42 30 |
| после лечения | 86 280 30 170 210 230 230 156 102 161 15 60 20 |
| до лечения | 112 60 84 60 60 40 76 60 84 40 112 46 64 70 |
| после лечения | 82 78 110 130 130 104 108 129 110 88 105 73 85 80 |
| до лечения | 113 61 85 61 61 41 77 61 85 41 113 47 65 71 |
| после лечения | 81 77 109 129 129 103 107 128 109 87 104 72 84 79 |
| до лечения | 111 59 83 59 59 39 75 59 83 39 111 45 63 69 |
| после лечения | 83 79 111 131 131 105 109 130 111 89 106 74 86 81 |
Задания для вариантов 11 – 15
Для проверки эффективности новой развивающей программы были созданы две группы детей шестилетнего возраста. На первом этапе дети обеих групп были протестированы по методике Керна-Йерасика (школьная зрелость). Результаты тестирования по невербальной шкале занесены в таблицу. Сделать сравнительный анализ школьной зрелости детей этих групп.
| Эксперимент. | 29 31 31 25 25 19 22 20 14 16 27 24 32 27 14 24 |
| Контроль | 34 31 28 27 30 23 21 28 29 31 17 22 21 15 33 29 |
| Эксперимент. | 14 13 11 8 12 13 13 13 11 12 14 13 12 14 10 13 |
| Контроль | 13 13 14 12 14 14 12 13 15 13 11 12 14 9 14 13 |
| Эксперимент. | 33 33 37 33 34 33 31 29 29 35 31 29 31 34 26 26 |
| Контроль | 39 30 38 36 31 37 35 32 39 34 30 32 36 29 39 36 |
| Эксперимент. | 13 12 10 7 11 12 12 12 10 11 13 12 11 13 9 12 |
| Контроль | 12 12 13 11 13 13 11 12 14 12 10 11 13 8 13 12 |
| Эксперимент. | 30 32 32 26 26 20 23 21 15 17 28 25 33 28 15 25 |
| Контроль | 35 32 29 28 31 24 22 29 30 32 18 24 22 16 34 30 |
Задания для вариантов 16 – 20
У участников психологического исследования, в число которых входила группа педагогов и группа непедагогов, был исследован уровень конфликтности. Полученные данные занесены в таблицу. Можно ли утверждать, что уровень конфликтности педагогов выше, чем у непедагогов?
Использование пакета анализа
Если вам нужно провести сложный статистический или инженерный анализ, можно сэкономить время и этапы с помощью «Pak анализа». Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопку Анализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа».
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
Если вы используете Excel 2007, нажмите Microsoft Office кнопку и выберите «Параметры Excel»
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
Примечание: Чтобы включить Visual Basic для приложений (VBA) в надстройку «Надстройка «Анализ», можно загрузить его так же, как и надстройку «Надстройка «Анализ». В поле «Доступные надстройки» выберите «Надстройка анализа — VBA».
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ предоставляет проверку гипотезы о том, что все выборки взяты из одного и того же распределения вероятности относительно альтернативной гипотезы о том, что распределение вероятностей не одинаково для всех выборок. Если выборок всего два, можно использовать функцию T. ТЕСТ. В более чем двух примерах не существует удобного обобщения T. Ивместо нее можно использовать модель однофакторного коэффициента.
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий <удобрение, температура>, имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений <удобрение, температура>, используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар <удобрение, температура>превышает влияние отдельно удобрения и отдельно температуры.
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров <удобрение, температура>из предыдущего примера).
Функции КОРРЕЛ и PEARSON рассчитывают коэффициент корреляции между двумя переменными измерения, если измерения по каждой переменной наблюдались для каждого из N-объектов. (Отсутствуют результаты наблюдений по любой теме, которые при анализе игнорируются.) Инструмент анализа корреляции особенно удобен, если для каждого субъекта N существует более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение КОРРЕЛ (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две переменные измерения «различаются». В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц, в которых выражены две переменные измерения. (Например, если двумя переменными измерения являются вес и высота, коэффициент корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно (от -1 до +1).
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и ковариатора можно использовать в одном и том же параметре, если у вас есть N различных переменных измерения для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, в которую указывается коэффициент корреляции или коварианс между каждой парой переменных измерения. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансии не масштабироваться. Коэффициент корреляции и ковариатор — это меры, в которых две переменные «различаются».
Инструмент «Ковариана» вычисляет значение функции КОВАРИАНАС на этом компьютере. P для каждой пары переменных измерения. (Непосредственное использование КОВАРИАНС. Вместо ковариатора P лучше использовать ковариативную единицу, если имеется только две переменных измерения, то есть N=2.) Запись на диагонали выходной таблицы инструмента «Ковариальная» в строке i, столбце i — ковариальная величина i-й переменной. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕ. P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа «Экспоненциальное сглаживание» применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f 1, «P(F
Инструмент «Анализ Фурье» применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.
Инструмент «Гистограмма» применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа «Скользящее среднее» применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
N — число предшествующих периодов, входящих в скользящее среднее;
A j — фактическое значение в момент времени j;
F j — прогнозируемое значение в момент времени j.
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Инструмент анализа «Ранг» и «Процентиль» создает таблицу, которая содержит порядкованный и процентный ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая рассматривает связанные значения как связанные значения с одинаковым рангом, или использует РАНГ. Функция AVG, которая возвращает среднее ранг для связанных значений.
Инструмент анализа «Регрессия» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
Инструмент «Регрессия» использует функцию LINEST.
Инструмент анализа «Выборка» создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как «t-статистика» в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t =0 «P(T Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
Двухвыборочный t-тест с одинаковыми дисперсиями
Этот инструмент анализа выполняет двухуголовый t-тест учащегося. В этой форме t-теста предполагается, что два набора данных поступили из распределения с одинаковыми дисперсиями. Этот тест называется гомомоcedastic t-test. Этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами.
Двухвыборочный t-тест с различными дисперсиями
Этот инструмент анализа выполняет двухуголовый t-тест учащегося. В этой форме t-теста предполагается, что два набора данных поступили из распределений с неравными дисперсиями. Это называется гетероскестический t-тест. Как и в предыдущем случае с равными дисперсиями, этот t-тест можно использовать для определения вероятности того, что две выборки взяты из распределения с равными средствами. Этот тест можно использовать, если в двух примерах есть различные темы. Используйте парный тест, описанный в примере, если существует один набор субъектов и два примера представляют измерения для каждой темы до и после обработки.
Для определения тестовой величины t используется следующая формула.
Для вычисления степеней свободы (df) используется следующая формула: Так как результат вычисления обычно не является integer, значение df округлится до ближайшего ближайшего другого для получения критического значения из таблицы t. Функция листа Excel T. В этой проверке используется вычисляемая величина df без округления, так как ее можно вычислить для значения T. ТЕСТ с неинтегрным df. Из-за таких разных подходов к определению степеней свободы результаты T. Тест и этот t-тест различаются в случае неравных дисперсий.
Z-тест. Средство анализа «Две выборки для средств» выполняет два примера z-теста для средств со известными дисперсиями. Это средство используется для проверки гипотезы null о том, что между двумя значениями населения нет различий между односторонними или двухбокльными гипотезами. Если дисперсии не известны, функция Z. Вместо нее следует использовать тест.
При использовании этого инструмента следует внимательно просматривать результат. «P(Z = ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. «P(Z = ABS(z) или Z
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community, попросить помощи в сообществе Answers community, а также предложить новую функцию или улучшение на веб-сайте Excel User Voice.
ОПИСАТЕЛЬНАЯ СТАТИСТИКА
Первичный анализ скалярных экспериментальных данных начинается с вычисления описательных статистик. Добавив к этому графические характеристики, получим некоторые основания для выводов о характере распределения данных исследуемой совокупности. К тому же базовый анализ дает основу для дальнейшего проведения более сложного анализа данных.
Из множества инструментов надстройки «Анализ данных» будем использовать «Описательную статистику» для получения числовых характеристик и «Гистограмму» — для графических. Заметим, что наряду с этим можно использовать также встроенные «Статистические функции», которые дублируют возможности надстройки.
Рассмотрим работу с описательной статистикой на примере.
Пример 4.1. Имеются некоторые данные о стоимости новогодних туров (рис. 4.2). Каждый из столбцов можно рассматривать как отдельный признак или переменную. Требуется провести анализ данных о продолжительности туров.
Таблица исходных данных
Исходные данные содержат несколько переменных, характеризующих тур. «Название фирмы», «Страна», «Транспорт» — качественные переменные, которые относятся к номинальной шкале. «Отель» —качественная переменная, которую можно отнести к порядковой шкале, так как количество звездочек отражает уровень обслуживания в отеле. «Количество дней» и «Стоимость» —количественные данные, которые относятся к метрической шкале.
Вычислим основные описательные статистики для переменной «Количество дней», которая является числовой переменной, принимающей дискретные значения. Для этого используем инструмент «Описательная статистика», входящий в «Пакет анализа».
Для перехода к описательной статистике выполните: «Данные» —» «Анализ» —> «Анализ данных» —» «Описательная статистика» -> «Ок». В открывшемся диалоговом окне «Описательная статистика» (рис. 4.3) укажите «Входной интервал», диапазон В2:Б16, выберите «Труп-
Диалоговое окно «Описательной статистики»
иирование по столбцам», установите «Метки в первой строке», так как входной интервал содержит наименование столбца. Для «Выходного интервала» достаточно указать одну, первую, ячейку на текущем листе, как альтернативу можно выбрать «Новый рабочий лист» или «Новую рабочую книгу». И наконец, укажите хотя бы одну из выводимых статистик: «Итоговая статистика», «Уровень надежности», «К-й наименьший», «К-й наибольший».
В большинстве случаев достаточно выбрать «Итоговую статистику», которая рассчитывает основные числовые характеристики исследуемой совокупности. Три последних значения рассчитывают, только когда они действительно нужны.
«Описательная статистика» вычисляет 16 значений, из них 13 относятся к «Итоговой статистике», еще три определяют доверительный интервал и два выборочных значения.
Отметим главное — «Описательная статистка» надстройки «Анализ данных» предназначена для вычислений статистических характеристик, или статистик, одномерной выборки или нескольких выборок.
В литературе по статистике часто используют термин «генеральная совокупность». Обычно имеется в виду, что это множество всех доступных для наблюдения данных в противоположность «выборки» — которая подразумевает, что исследуется лишь часть данных выбранных из генеральной совокупности (может быть с помощью случайного отбора).
Обычно числовые характеристики генеральной совокупности называют параметрами, а числовые характеристики выборки — статистиками, или выборочными характеристиками, которые являются оценками параметров генеральной совокупности. Для более полного понимания выборочного метода следует обратиться к специальной литературе.
Результаты расчетов «Итоговой статистики» для переменной «Количество дней» приведены на рисунке 4.4. На этом же рисунке приведены альтернативные расчеты этих числовых характеристик с использованием встроенных функций категории «Статистические». Аргументом статистических функций является диапазон исходных данных, в данном случае D3:D16.
Таким образом, практически все расчеты «Описательной статистики» дублируются «Статистическими» функциями. Остальные характеристики можно посчитать, используя формулы. Для того чтобы на рабочем листе Excel отобразились не результаты, а формулы, следует выполнить: «Формулы» -» «Зависимости формул» -» «Показать формулы».
Отметим некоторое отличие в применении инструментов «Анализа данных» и использовании статистических функций. При изменении значений исходных данных формулы пересчитываются, в то время как результаты, полученные с помощью инструментов «Анализа данных»,
«Итоговая статистика» и «Статистические функции»
не изменяются. Чтобы обновить результаты, потребуется вызывать «Анализ данных» снова.
Числовые характеристики «Итоговой статистики» описывают средние, вариацию и форму распределения, всего 13 параметров:
- • среднее, или выборочное среднее, вычисляется как среднее арифметическое наблюдаемых значений выборки;
- • медиана определяется как значение, находящееся в середине распределения, полученного из исходного путем упорядочивания по возрастанию;
- • мода равна наиболее часто встречающемуся значению. Кроме того, выделяют две величины, характеризующие изменчивость, или разброс, значений распределения относительно среднего:
- 1) дисперсию выборки, или выборочную дисперсию, равную сумме квадратов отклонений каждого значения от среднего, деленной на (А — 1), где N — число значений в распределении, или объем выборки;
2) стандартное отклонение, или выборочное среднеквадратическое отклонение, равное квадратному корню из выборочной дисперсии.
Дополнительными мерами изменчивости являются три простые характеристики, отражающие границы распределения данных и его размах:
- • минимум равен наименьшему из выборочных значений;
- • максимум равен наибольшему из выборочных значений;
- • интервал составляет разность между максимумом и
минимумом, этот параметр называют также размахом.
Если набор данных рассматривается как множество
независимых реализаций случайной величины, то возникает вопрос, что можно сказать о функции распределения этой величины на основании выборки. Очень часто распределение оказывается нормальным или близким к нему.
Для отражения близости формы распределения к нормальному виду существует две основные характеристики:
- 1) эксцесс, или выборочный коэффициент эксцесса, который является мерой «сглаженности» распределения;
- 2) асимметричность, или выборочный коэффициент асимметрии, показывает, в какую сторону относительно среднего сдвинуто большинство значений выборки.
И наконец, сумма равна сумме всех выборочных значений, счет вычисляет объем выборки, стандартная ошибка равна выборочному стандартному отклонению, деленному на квадратный корень из объема выборки.
При необходимости можно вычислить три дополнительные характеристики (рис. 4.5). Результаты расчетов этих характеристик приведены на рисунке 4.6.
«К-й наибольший» выдает К-е выборочное значение, если бы выборка была отсортирована по убыванию. В рассматриваемом примере сортировка по убыванию имеет вид 14,12,12,12, 11, Юит. д., третье значение равно 12. «К-й наименьший» выдает К-е выборочное значение, если бы выборка была отсортирована по возрастанию, это значение равно 5.
Задав «Уровень надежности», например 95%, получим значение для построения доверительного интервала для
Описательная статистика, дополнительные параметры
Результаты расчетов дополнительных параметров
неизвестного математического ожидания генеральной средней с доверительным уровнем 95%. Доверительный интервал строится как выборочное среднее плюс-минус полученное значение. Обратим внимание, что граница здесь вычисляется с помощью распределения Стьюдента, что требует достаточного количества наблюдений на каждую степень свободы.
Таким образом, к вычислению доверительных интервалов нужно относиться с осторожностью, особенно при малых выборках. Использование функции расчета доверительного интервала без понимания статистического смысла может привести к ошибкам. Начинающим исследователям посоветуем обратиться к специальной литературе.
Например, для рассматриваемого примера полученный доверительный интервал не несет смыслового содержания.
Итак, на этапе проведения описательной статистики исследуемый ряд данных может быть как генеральной совокупностью, так и выборкой. Если для генеральной совокупности вычисляются значения параметров распределения, то для выборки находят оценки этих параметров. Рассмотрим ниже подробнее вычисление некоторых числовых характеристик в пакете Excel.
Построение доверительных интервалов для среднего. Описательная статистика в Excel
2015-03-22
2255
![]()
![]()
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 3
Описательная статистика в Excel
Вычисление границ доверительных интервалов в Excel
Использование инструмента Пакета анализа Описательная статистика.
Построение доверительных интервалов для среднего.
В пакете Excel помимо мастера функций имеется набор более мощных инструментов для работы с несколькими выборками углубленного анализа данных, называемый Пакет анализа, который может быть использован для решения задач статистической обработки выборочных данных.
Для установки раздела Анализ данных в пакете Excel сделайте следующее:
— в меню Сервис выберите команду Надстройки;
— в появившемся списке установите флажок Пакет анализа.
Ввод данных. Исследуемые данные следует представить в виде таблицы, где столбцами являются соответствующие показатели. При создании таблицы Excel информация вводится в отдельные ячейки. Совокупность ячеек, содержащих анализируемые данные, называется входным диапазоном.
Последовательность обработки данных. Для использования статистического пакета анализа данных необходимо:
— указать курсором мыши на пункт меню Сервис и щелкнуть левой кнопкой мыши;
— в раскрывающемся списке выбрать команду Анализ данных (если команда Анализ данных отсутствует в меню Сервис, то необходимо установить в Excel пакет анализа данных);
— выбрать необходимую строку в появившемся списке Инструменты анализа;
— ввести входной и выходной диапазоны и выбрать необходимые параметры.
Нахождение основных выборочных характеристик. Для определения характеристик выборки используется процедура Описательная статистика. Процедура позволяет получить статистический отчет, содержащий информацию о центральной тенденции и изменчивости входных данных. Для выполнения процедуры необходимо:
— выполнить команду Сервис > Анализ данных;
— в появившемся списке Инструменты анализа выбрать строку Описательная статистика и нажать кнопку ОК (рис. 1);
— в появившемся диалоговом окне указать входной диапазон, то есть ввести ссылку на ячейки, содержащие анализируемые данные. Для этого следует навести указатель мыши на левую верхнюю ячейку данных, нажать левую кнопку мыши и, не отпуская ее, протянуть указатель мыши к правой нижней ячейке, содержащей анализируемые данные, затем отпустить левую кнопку мыши;
Рис. 1. Окно выбора метода обработки данных
— указать выходной диапазон, то есть ввести ссылку на ячейки, в которые будут выведены результаты анализа. Для этого следует поставить переключатель в положение Выходной диапазон (навести указатель мыши и щелкнуть левой клавишей), далее навести указатель мыши в поле ввода Выходной диапазон и щелкнуть левой кнопкой мыши, затем указатель мыши навести на левую верхнюю ячейку выходного диапазона и щелкнуть левой кнопкой мыши;
— в разделе Группировка переключатель установить в положение по столбцам; о установить флажок в поле Итоговая статистика;
— нажать кнопку ОК.
В результате анализа в указанном выходном диапазоне для каждого столбца данных выводятся следующие статистические характеристики: среднее, стандартная ошибка (среднего), медиана, мода, стандартное отклонение, дисперсия выборки, эксцесс, асимметричность, интервал, минимум, максимум, сумма, счет, наибольшее, наименьшее, уровень надежности.
Пример 1. Рассматривается зарплата основных групп работников гостиницы: администрации, обслуживающего персонала и работников ресторана. Были получены следующие данные:
Необходимо определить основные статистические характеристики в группах данных.
1. Для использования инструментов анализа исследуемые данные следует представить в виде таблицы, где столбцами являются соответствующие показатели. Значения зарплат сотрудников администрации введите в диапазон А1:А5, обслуживающего персонала— в диапазон В1:В8 и т. д. В результате получится таблица, представленная на рис. 2.
Рис. 2. Таблица из примера
2. Далее необходимо провести элементарную статистическую обработку. Для этого, указав курсором мыши на пункт меню Сервис, выберите команду Анализ данных. Затем в появившемся списке Инструменты анализа выберите строку Описательная статистика.
Рис. 3. Пример заполнения диалогового окна Описательная статистика
3. В появившемся диалоговом окне (рис. 3) в рабочем поле Входной интервал укажите входной диапазон —А1:С8. Активировав переключателем рабочее поле Выходной интервал, укажите выходной диапазон — ячейку А9. В разделе Группировка переключатель установите в положение по столбцам. Установите флажок в поле Итоговая статистика и нажмите кнопку ОК. В результате анализа (рис. 4) в указанном выходном диапазоне для каждого столбца данных получим соответствующие результаты.
Рис. 4. Результаты работы инструмента Описательная статистика.
1. Найдите наиболее популярный туристический маршрут из четырех реализуемых фирмой (моду), если за неделю последовательно были реализованы следующие маршруты (приводятся номера маршрутов): 1, 3, 3, 2, 1, 1, 4, 4, 2, 4, 1, 3, 2, 4, 1, 4, 4, 3, 1, 2, 3, 4, 1, 1, 3.
2. В рабочей зоне производились замеры концентрации вредного вещества. Получен ряд значений (в мг/м3): 12, 16, 15, 14, 10, 20, 16, 14, 18, 14, 15, 17, 23, 16. Необходимо определить основные выборочные характеристики.