Исследовать зависимость между результатами зимней (Х) и летней (У) сессий.
В таблице приведена средняя оценка, полученная по итогам сессии, а также указана принадлежность студента к группе А или Б.
| № п/п | х | у | Группа |
|---|---|---|---|
| 1 | 3,7 | 4,8 | Б |
| 2 | 3,5 | 3,5 | Б |
| 3 | 4,3 | 5 | Б |
| 4 | 3 | 4 | Б |
| 5 | 4,6 | 4,2 | Б |
| 6 | 4,6 | 4,1 | Б |
| 7 | 3,8 | 4,8 | А |
| 8 | 3,6 | 3,5 | Б |
| 9 | 3,3 | 4,4 | Б |
| 10 | 3,9 | 3 | Б |
| 11 | 4,7 | 3,7 | Б |
| 12 | 4,6 | 4,4 | Б |
| 13 | 4,6 | 3,8 | Б |
| 14 | 3,3 | 3,1 | Б |
| 15 | 4,3 | 3,6 | Б |
| 16 | 3,1 | 4,8 | А |
| 17 | 3,2 | 3 | А |
| 18 | 4,2 | 4,8 | А |
| 19 | 3,3 | 3,4 | Б |
| 20 | 3,5 | 4,2 | А |
1. Построить линейную регрессионную модель У по Х.
2. Проверить значимость коэффициентов уравнения и самого уравнения регрессии.
3. Построить регрессионную модель У по Х с использованием фиктивной переменной «группа».
4. Проверить значимость коэффициентов уравнения и самого уравнения регрессии.
5. Вычислить коэффициенты детерминации для обычной модели и модели с фиктивной переменной.
Решение:
1. Для расчёта параметров а и b линейной регрессии
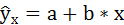
необходимо решить систему нормальных уравнений относительно a и b:
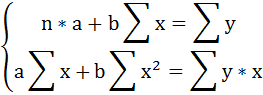
Число наблюдений n = 20.
Построим таблицу исходных и расчётных данных.
Таблица 1 Расчетные данные для оценки линейной регрессии
| № п/п | х | у | х2 | у2 | х*у | 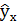 |
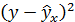 |
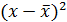 |
Группа | z |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3,7 | 4,8 | 13,69 | 23,04 | 17,76 | 3,973 | 0,684 | 0,024 | Б | 1 |
| 2 | 3,5 | 3,5 | 12,25 | 12,25 | 12,25 | 3,931 | 0,186 | 0,126 | Б | 1 |
| 3 | 4,3 | 5 | 18,49 | 25 | 21,5 | 4,098 | 0,814 | 0,198 | Б | 1 |
| 4 | 3 | 4 | 9 | 16 | 12 | 3,827 | 0,030 | 0,731 | Б | 1 |
| 5 | 4,6 | 4,2 | 21,16 | 17,64 | 19,32 | 4,160 | 0,002 | 0,555 | Б | 1 |
| 6 | 4,6 | 4,1 | 21,16 | 16,81 | 18,86 | 4,160 | 0,004 | 0,555 | Б | 1 |
| 7 | 3,8 | 4,8 | 14,44 | 23,04 | 18,24 | 3,994 | 0,650 | 0,003 | А | 0 |
| 8 | 3,6 | 3,5 | 12,96 | 12,25 | 12,6 | 3,952 | 0,204 | 0,065 | Б | 1 |
| 9 | 3,3 | 4,4 | 10,89 | 19,36 | 14,52 | 3,889 | 0,261 | 0,308 | Б | 1 |
| 10 | 3,9 | 3 | 15,21 | 9 | 11,7 | 4,014 | 1,029 | 0,002 | Б | 1 |
| 11 | 4,7 | 3,7 | 22,09 | 13,69 | 17,39 | 4,181 | 0,232 | 0,714 | Б | 1 |
| 12 | 4,6 | 4,4 | 21,16 | 19,36 | 20,24 | 4,160 | 0,057 | 0,555 | Б | 1 |
| 13 | 4,6 | 3,8 | 21,16 | 14,44 | 17,48 | 4,160 | 0,130 | 0,555 | Б | 1 |
| 14 | 3,3 | 3,1 | 10,89 | 9,61 | 10,23 | 3,889 | 0,623 | 0,308 | Б | 1 |
| 15 | 4,3 | 3,6 | 18,49 | 12,96 | 15,48 | 4,098 | 0,248 | 0,198 | Б | 1 |
| 16 | 3,1 | 4,8 | 9,61 | 23,04 | 14,88 | 3,848 | 0,907 | 0,570 | А | 0 |
| 17 | 3,2 | 3 | 10,24 | 9 | 9,6 | 3,868 | 0,754 | 0,429 | А | 0 |
| 18 | 4,2 | 4,8 | 17,64 | 23,4 | 20,16 | 4,077 | 0,523 | 0,119 | А | 0 |
| 19 | 3,3 | 3,4 | 10,89 | 11,56 | 11,22 | 3,889 | 0,239 | 0,308 | Б | 1 |
| 20 | 3,5 | 4,2 | 12,25 | 17,64 | 14,7 | 3,930 | 0,072 | 0,126 | А | 0 |
| Итого: | 77,1 | 80,1 | 303,67 | 328,73 | 310,13 | 80,1 | 7,649 | 6,45 | х | 15 |
| Среднее: | 3,855 | 4,005 | 15,184 | 16,4365 | 15,5065 | х | х | х | х | х |
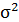 |
0,322 | 0,396 | х | х | х | х | х | х | х | х |
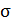 |
0,568 | 0,630 | х | х | х | х | х | х | х | х |
Среднее значение определим по формуле:
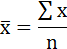
Среднее квадратическое отклонение рассчитаем по формуле:
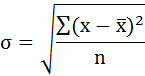
Возведя в квадрат полученное значение, получим дисперсию:
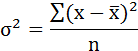
Параметры уравнения можно определить также и по формулам:
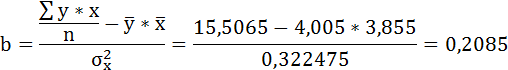
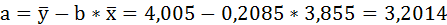
Таким образом, уравнение регрессии имеет вид:
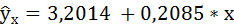
Следовательно, с повышением средней оценки, полученной по итогам зимней сессии, на один балл, средняя оценка по итогам летней сессии увеличивается в среднем на 0,2085.
2. Рассчитаем линейный коэффициент парной корреляции:
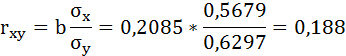
Связь очень слабая, практически отсутствует.
Определим коэффициент детерминации:
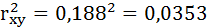
Вариация результата на 3,53% объясняется вариацией фактора х. На долю других, не учтённых в модели факторов, приходится 96,47%. Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчётные) значения .
Так как 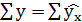 , следовательно, параметры уравнения определены верно.
, следовательно, параметры уравнения определены верно.
3. Проверим значимость коэффициентов уравнения и самого уравнения регрессии.
Оценку качества уравнения регрессии проведём с помощью F-критерия Фишера.
F-критерий состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера.
Fфакт определяется по формуле:
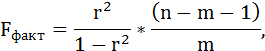
где n – число единиц совокупности;
m – число параметров при переменных х.
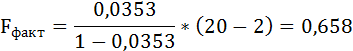
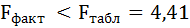
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик принимается и признаётся их статистическая незначимость и ненадёжность.
4. Оценку статистической значимости коэффициентов регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля: a = b = rxy = 0.
tтабл = 2,1 для числа степеней свободы df = n – 2 = 18 и α = 0,05.
Определим случайные ошибки ma, mb, mrxy:
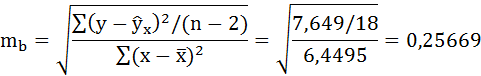
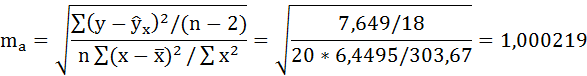
Фактические значения t-статистики определим по формулам:
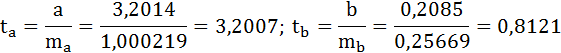
t-критерий для коэффициента корреляции можно рассчитать двумя способами:
1) 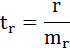
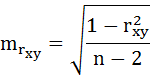 – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
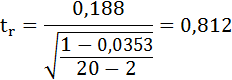
2) Кроме того
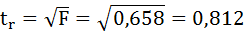
Сравним фактические значения t-статистики с табличными значениями.
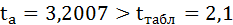
Так как фактическое значение t-критерия для коэффициента а превышает табличное, следовательно, гипотезу о несущественности коэффициента а можно отклонить.
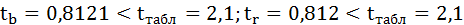
Величина t-критерия для коэффициента регрессии меньше табличного и совпадает с величиной tr.
Следовательно, полученная линейная зависимость является недостоверной.
5. По 20 наблюдениям уравнение линейной регрессии (без учёта принадлежности студента к группе А или Б) составило:
Введём в уравнение регрессии фиктивную переменную z для отражения принадлежности студента к группе, а именно: z = 1, для группы Б и z = 0 для группы А. Уравнение регрессии примет вид:
уxz = a + b*x + c*z + ɛ
Применяя метод наименьших квадратов для оценки параметров данного уравнения, получим следующую систему нормальных уравнений:
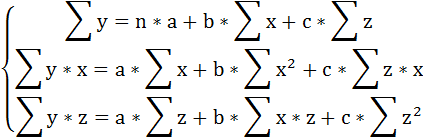
В виду того, что z принимает лишь два значения (1 и 0), Σz = n1 = 15 (число студентов группы Б), Σх*z =Σх1 =59,3 (сумма х по группе Б), Σz2 =Σz =15, Σy*z =Σy1 =58,5 (сумма у по группе Б).
Тогда система нормальных уравнений примет вид:
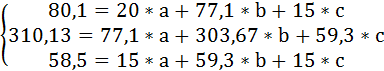
Решая её, получим уравнение регрессии:
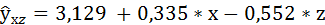
6. Найдём индекс детерминации для данной модели по формуле:
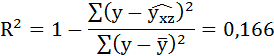
Добавление в регрессию фиктивной переменной существенно улучшило результат модели: доля объяснённой вариации выросла с 3,53% (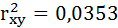 ) до 16,6% (Rухz2 = 0,166). Но, не смотря на это, связь между признаками остаётся слабой.
) до 16,6% (Rухz2 = 0,166). Но, не смотря на это, связь между признаками остаётся слабой.
7. Значимость уравнения множественной регрессии в целом, так же как и в парной регрессии, оценивается с помощью F-критерия Фишера:
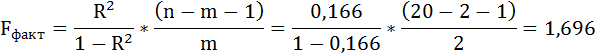
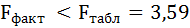
Так как фактическое значение F-критерия меньше табличного, то уравнение статистически не значимо.
8. Оценка значимости коэффициентов регрессии производится, как и в парной регрессии по t-критерию Стьюдента, по формуле:
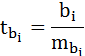
где bi – величина параметра регрессии (в наших обозначениях это a, b и с)
a = 3,129; b = 0,335; с = — 0,5516;
ma = 0,9578; mb = 0,2574; mc = 0,3376;
ta = 3,266; tb = 1,3; tc = -1,634.
Величина t-статистики коэффициентов регрессии b и c меньше табличного tтабл.=2,1 при уровне значимости α 0,05, что свидетельствует о случайной природе взаимосвязи, о статистической ненадёжности всего уравнения.
Таким образом, уравнение в целом незначимо и ненадёжно и не может использоваться в дальнейшем для анализа и прогноза.
Исследовать зависимость между результатами зимней (Х) и летней (У) сессий.
В таблице приведена средняя оценка, полученная по итогам сессии, а также указана принадлежность студента к группе А или Б.
| № п/п | х | у | Группа |
|---|---|---|---|
| 1 | 3,7 | 4,8 | Б |
| 2 | 3,5 | 3,5 | Б |
| 3 | 4,3 | 5 | Б |
| 4 | 3 | 4 | Б |
| 5 | 4,6 | 4,2 | Б |
| 6 | 4,6 | 4,1 | Б |
| 7 | 3,8 | 4,8 | А |
| 8 | 3,6 | 3,5 | Б |
| 9 | 3,3 | 4,4 | Б |
| 10 | 3,9 | 3 | Б |
| 11 | 4,7 | 3,7 | Б |
| 12 | 4,6 | 4,4 | Б |
| 13 | 4,6 | 3,8 | Б |
| 14 | 3,3 | 3,1 | Б |
| 15 | 4,3 | 3,6 | Б |
| 16 | 3,1 | 4,8 | А |
| 17 | 3,2 | 3 | А |
| 18 | 4,2 | 4,8 | А |
| 19 | 3,3 | 3,4 | Б |
| 20 | 3,5 | 4,2 | А |
1. Построить линейную регрессионную модель У по Х.
2. Проверить значимость коэффициентов уравнения и самого уравнения регрессии.
3. Построить регрессионную модель У по Х с использованием фиктивной переменной «группа».
4. Проверить значимость коэффициентов уравнения и самого уравнения регрессии.
5. Вычислить коэффициенты детерминации для обычной модели и модели с фиктивной переменной.
Решение:
1. Для расчёта параметров а и b линейной регрессии
необходимо решить систему нормальных уравнений относительно a и b:
Число наблюдений n = 20.
Построим таблицу исходных и расчётных данных.
Таблица 1 Расчетные данные для оценки линейной регрессии
| № п/п | х | у | х2 | у2 | х*у | |
|
|
Группа | z |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3,7 | 4,8 | 13,69 | 23,04 | 17,76 | 3,973 | 0,684 | 0,024 | Б | 1 |
| 2 | 3,5 | 3,5 | 12,25 | 12,25 | 12,25 | 3,931 | 0,186 | 0,126 | Б | 1 |
| 3 | 4,3 | 5 | 18,49 | 25 | 21,5 | 4,098 | 0,814 | 0,198 | Б | 1 |
| 4 | 3 | 4 | 9 | 16 | 12 | 3,827 | 0,030 | 0,731 | Б | 1 |
| 5 | 4,6 | 4,2 | 21,16 | 17,64 | 19,32 | 4,160 | 0,002 | 0,555 | Б | 1 |
| 6 | 4,6 | 4,1 | 21,16 | 16,81 | 18,86 | 4,160 | 0,004 | 0,555 | Б | 1 |
| 7 | 3,8 | 4,8 | 14,44 | 23,04 | 18,24 | 3,994 | 0,650 | 0,003 | А | 0 |
| 8 | 3,6 | 3,5 | 12,96 | 12,25 | 12,6 | 3,952 | 0,204 | 0,065 | Б | 1 |
| 9 | 3,3 | 4,4 | 10,89 | 19,36 | 14,52 | 3,889 | 0,261 | 0,308 | Б | 1 |
| 10 | 3,9 | 3 | 15,21 | 9 | 11,7 | 4,014 | 1,029 | 0,002 | Б | 1 |
| 11 | 4,7 | 3,7 | 22,09 | 13,69 | 17,39 | 4,181 | 0,232 | 0,714 | Б | 1 |
| 12 | 4,6 | 4,4 | 21,16 | 19,36 | 20,24 | 4,160 | 0,057 | 0,555 | Б | 1 |
| 13 | 4,6 | 3,8 | 21,16 | 14,44 | 17,48 | 4,160 | 0,130 | 0,555 | Б | 1 |
| 14 | 3,3 | 3,1 | 10,89 | 9,61 | 10,23 | 3,889 | 0,623 | 0,308 | Б | 1 |
| 15 | 4,3 | 3,6 | 18,49 | 12,96 | 15,48 | 4,098 | 0,248 | 0,198 | Б | 1 |
| 16 | 3,1 | 4,8 | 9,61 | 23,04 | 14,88 | 3,848 | 0,907 | 0,570 | А | 0 |
| 17 | 3,2 | 3 | 10,24 | 9 | 9,6 | 3,868 | 0,754 | 0,429 | А | 0 |
| 18 | 4,2 | 4,8 | 17,64 | 23,4 | 20,16 | 4,077 | 0,523 | 0,119 | А | 0 |
| 19 | 3,3 | 3,4 | 10,89 | 11,56 | 11,22 | 3,889 | 0,239 | 0,308 | Б | 1 |
| 20 | 3,5 | 4,2 | 12,25 | 17,64 | 14,7 | 3,930 | 0,072 | 0,126 | А | 0 |
| Итого: | 77,1 | 80,1 | 303,67 | 328,73 | 310,13 | 80,1 | 7,649 | 6,45 | х | 15 |
| Среднее: | 3,855 | 4,005 | 15,184 | 16,4365 | 15,5065 | х | х | х | х | х |
|
0,322 | 0,396 | х | х | х | х | х | х | х | х |
|
0,568 | 0,630 | х | х | х | х | х | х | х | х |
Среднее значение определим по формуле:
Среднее квадратическое отклонение рассчитаем по формуле:
Возведя в квадрат полученное значение, получим дисперсию:
Параметры уравнения можно определить также и по формулам:
Таким образом, уравнение регрессии имеет вид:
Следовательно, с повышением средней оценки, полученной по итогам зимней сессии, на один балл, средняя оценка по итогам летней сессии увеличивается в среднем на 0,2085.
2. Рассчитаем линейный коэффициент парной корреляции:
Связь очень слабая, практически отсутствует.
Определим коэффициент детерминации:
Вариация результата на 3,53% объясняется вариацией фактора х. На долю других, не учтённых в модели факторов, приходится 96,47%. Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчётные) значения .
Так как , следовательно, параметры уравнения определены верно.
3. Проверим значимость коэффициентов уравнения и самого уравнения регрессии.
Оценку качества уравнения регрессии проведём с помощью F-критерия Фишера.
F-критерий состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера.
Fфакт определяется по формуле:
где n – число единиц совокупности;
m – число параметров при переменных х.
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик принимается и признаётся их статистическая незначимость и ненадёжность.
4. Оценку статистической значимости коэффициентов регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля: a = b = rxy = 0.
tтабл = 2,1 для числа степеней свободы df = n – 2 = 18 и α = 0,05.
Определим случайные ошибки ma, mb, mrxy:
Фактические значения t-статистики определим по формулам:
t-критерий для коэффициента корреляции можно рассчитать двумя способами:
1)
– случайная ошибка коэффициента корреляции.
2) Кроме того
Сравним фактические значения t-статистики с табличными значениями.
Так как фактическое значение t-критерия для коэффициента а превышает табличное, следовательно, гипотезу о несущественности коэффициента а можно отклонить.
Величина t-критерия для коэффициента регрессии меньше табличного и совпадает с величиной tr.
Следовательно, полученная линейная зависимость является недостоверной.
5. По 20 наблюдениям уравнение линейной регрессии (без учёта принадлежности студента к группе А или Б) составило:
Введём в уравнение регрессии фиктивную переменную z для отражения принадлежности студента к группе, а именно: z = 1, для группы Б и z = 0 для группы А. Уравнение регрессии примет вид:
уxz = a + b*x + c*z + ɛ
Применяя метод наименьших квадратов для оценки параметров данного уравнения, получим следующую систему нормальных уравнений:
В виду того, что z принимает лишь два значения (1 и 0), Σz = n1 = 15 (число студентов группы Б), Σх*z =Σх1 =59,3 (сумма х по группе Б), Σz2 =Σz =15, Σy*z =Σy1 =58,5 (сумма у по группе Б).
Тогда система нормальных уравнений примет вид:
Решая её, получим уравнение регрессии:
6. Найдём индекс детерминации для данной модели по формуле:
Добавление в регрессию фиктивной переменной существенно улучшило результат модели: доля объяснённой вариации выросла с 3,53% () до 16,6% (Rухz2 = 0,166). Но, не смотря на это, связь между признаками остаётся слабой.
7. Значимость уравнения множественной регрессии в целом, так же как и в парной регрессии, оценивается с помощью F-критерия Фишера:
Так как фактическое значение F-критерия меньше табличного, то уравнение статистически не значимо.
8. Оценка значимости коэффициентов регрессии производится, как и в парной регрессии по t-критерию Стьюдента, по формуле:
где bi – величина параметра регрессии (в наших обозначениях это a, b и с)
a = 3,129; b = 0,335; с = — 0,5516;
ma = 0,9578; mb = 0,2574; mc = 0,3376;
ta = 3,266; tb = 1,3; tc = -1,634.
Величина t-статистики коэффициентов регрессии b и c меньше табличного tтабл.=2,1 при уровне значимости α 0,05, что свидетельствует о случайной природе взаимосвязи, о статистической ненадёжности всего уравнения.
Таким образом, уравнение в целом незначимо и ненадёжно и не может использоваться в дальнейшем для анализа и прогноза.
Задача 1.1.
По районам региона приводятся данные за 200Х г. (табл. 1.1).
Таблица 1.6
|
Номер района |
Среднедушевой прожиточный минимум в день одного трудоспособного, руб., Х |
Среднедневная заработная плата, руб., У |
|
1 |
78 |
133 |
|
2 |
82 |
148 |
|
3 |
87 |
134 |
|
4 |
79 |
154 |
|
5 |
89 |
162 |
|
6 |
106 |
195 |
|
7 |
67 |
139 |
|
8 |
88 |
158 |
|
9 |
73 |
152 |
|
10 |
87 |
162 |
|
11 |
76 |
159 |
|
12 |
115 |
173 |
Требуется:
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х, составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение:
1. Для расчета параметров уравнения линейной регрессии строим расчетную таблицу (табл. 1.2).
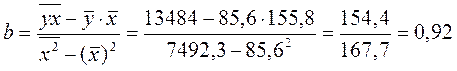 ;
;
Таблица 1.2
|
№ |
Х |
У |
Xy |
X2 |
Y2 |
|
YI— |
|
|
1 |
78 |
133 |
10374 |
6084 |
17689 |
149 |
-16 |
11,84962 |
|
2 |
82 |
148 |
12136 |
6724 |
21904 |
152 |
-4 |
3 |
|
3 |
87 |
134 |
11658 |
7569 |
17956 |
157 |
-23 |
17,19403 |
|
4 |
79 |
154 |
12166 |
6241 |
23716 |
150 |
4 |
2,805195 |
|
5 |
89 |
162 |
14418 |
7921 |
26244 |
159 |
3 |
1,925926 |
|
6 |
106 |
195 |
20670 |
11236 |
38025 |
175 |
20 |
10,50256 |
|
7 |
67 |
139 |
9313 |
4489 |
19321 |
139 |
0 |
0,258993 |
|
8 |
88 |
158 |
13904 |
7744 |
24964 |
158 |
0 |
0,025316 |
|
9 |
73 |
152 |
11096 |
5329 |
23104 |
144 |
8 |
5,157895 |
|
10 |
87 |
162 |
14094 |
7569 |
26244 |
157 |
5 |
3,061728 |
|
11 |
76 |
159 |
12084 |
5776 |
25281 |
147 |
12 |
7,597484 |
|
12 |
115 |
173 |
19895 |
13225 |
29929 |
183 |
-10 |
5,66474 |
|
Итого |
1027 |
1869 |
161808 |
89907 |
294377 |
69,0435 |
||
|
Среднее Значение |
85,6 |
156 |
13484 |
7492,25 |
24531,42 |
5,753625 |
||
|
S |
13,5 |
17,3 |
||||||
|
S2 |
183 |
298 |
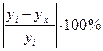
. ![]()
Получено уравнение регрессии: ![]() .
.
С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
2. Тесноту линейной связи оценит коэффициент корреляции:
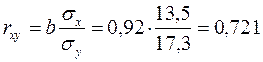 ;
; ![]() .
.
Это означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума.
Качество модели определяет средняя ошибка аппроксимации:
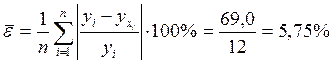 .
.
Качество построенной модели оценивается как хорошее, так как средняя относительная ошибка аппроксимации не превышает 8-10%.
3. Оценку статистической значимости параметров регрессии проведем с помощью t-статистики Стьюдента и путем расчета доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателя от нуля: ![]() .
.
Определим случайные ошибки Ma, mb, ![]() :
:
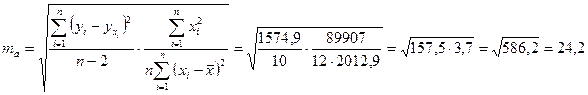 ;
;
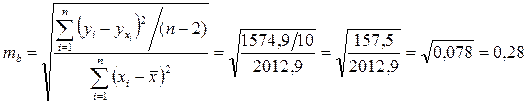 ;
;
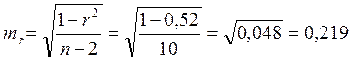 .
.
Тогда
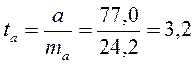 ;
; 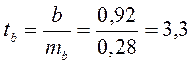 ;
;
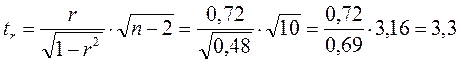 .
.
Фактические значения t-статистики превосходят табличные значения:
![]() ;
; ![]() ;
; ![]() ,
,
Поэтому гипотеза Н0 отклоняется, т. е. A, B и Rxy не случайно отличаются от нуля, а статистически значимы.
Рассчитаем доверительный интервал для A и B. Для этого определим предельную ошибку для каждого показателя:
![]() ;
; ![]() .
.
Доверительные интервалы:
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью ![]() параметры A и B, находясь в указанных границах, не принимают нулевые значения, т. е. не являются статистики незначимыми и существенно отличаются от нуля.
параметры A и B, находясь в указанных границах, не принимают нулевые значения, т. е. не являются статистики незначимыми и существенно отличаются от нуля.
4. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение промежуточного минимума составит: ![]() тыс. руб., тогда прогнозное значение прожиточного минимума составит:
тыс. руб., тогда прогнозное значение прожиточного минимума составит: ![]() тыс. руб.
тыс. руб.
5. Ошибка прогноза составит:
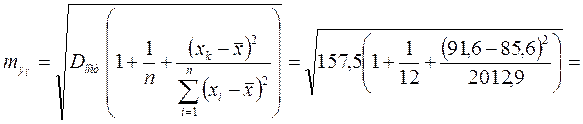
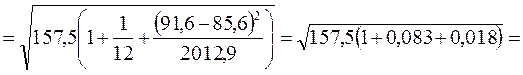
![]() тыс. руб.
тыс. руб.
Предельная ошибка прогноза, которая в 95% случаев не будет превышена, составит:
![]() .
.
Доверительный интервал прогноза:
![]() ;
;
![]() руб.;
руб.;
![]() руб.
руб.
Выполненный прогноз среднемесячной заработной платы оказался надежным, но неточным, т. к. диапазон верхней и нижней границ доверительного интервала составляет 1,95 раза (121/62,2).
Задача 1.2.
Зависимость потребления продукта А от среднедушевого дохода по данным 20 семей характеризуется следующим образом:
— уравнение регрессии ![]() ;
;
— индекс корреляции ![]() ;
;
— остаточная дисперсия ![]() .
.
Требуется провести дисперсионный анализ полученных результатов.
Решение:
Результаты дисперсионного анализа приведены в табл. 1.3.
Таблица 1.3
|
Вариация результата y |
Число степеней свободы |
Сумма квадратов отклонений, S |
Дисперсия на одну степень свободы, D |
Fрасч |
Fтабл A=0,05 K1=1, K2=18 |
|
Общая |
Df=n-1=19 |
6,316 |
|||
|
Факторная |
K1=m=1 |
5,116 |
5,116 |
76,7 |
4,41 |
|
Остаточная |
K2=n-m-1=18 |
1,200 |
0,0667 |
![]() ;
;
![]() ;
;
![]() ;
;
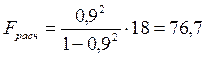 .
.
В силу того, что ![]() , гипотеза о случайности различий факторной и остаточной дисперсий отклоняется. Эти различия существенны, статистически значимы, уравнение надежно, значимо, показатель тесноты связи надежен и отражает устойчивую зависимость потребления продукта А от среднедушевого дохода.
, гипотеза о случайности различий факторной и остаточной дисперсий отклоняется. Эти различия существенны, статистически значимы, уравнение надежно, значимо, показатель тесноты связи надежен и отражает устойчивую зависимость потребления продукта А от среднедушевого дохода.
| < Предыдущая | Следующая > |
|---|
|
Регрессионная |
|
|
Множественный |
0,969117127 |
|
R-квадрат |
0,939188005 |
|
Нормированный |
0,929052672 |
|
Стандартная |
0,036690484 |
|
Наблюдения |
8 |
Посчитанные
результаты
Множественный
R- индекс корреляции (для парной регрессии
rxy) = 0.969
R-квадрат
— коэффициент детерминации, ![]() =0.939
=0.939
Стандартная
ошибка — стандартная ошибка оценки
=0.036
Наблюдения
— количество наблюдений, n=8
|
Дисперсионный |
|||||
|
df |
SS |
MS |
F |
Значимость |
|
|
Регрессия |
1 |
0,124745 |
0,124745 |
92,66475 |
7,19E-05 |
|
Остаток |
6 |
0,008077 |
0,001346 |
||
|
Итого |
7 |
0,132822 |
Посчитанные
результаты
df
— число степеней свободы m=1; n-m-1=6; n-1=7.
F-
критерий Фишера=92.66
|
Коэффициенты |
Стандартная |
t-статистика |
|
|
Y-пересечение |
1,031553029 |
0,034086 |
30,26334 |
|
Переменная |
-0,493795004 |
0,051297 |
-9,62625 |
Посчитанные
результаты
Коэффициенты-
коэффициенты уравнения регрессии
а=9.11 и b=-5.76
Стандартная
ошибка — стандартные ошибки коэффициентов
уравнения регрессии ma=0.199
и mb=7.261
t-статистика-
t-статистика ta=45.72
и tb=-7.93
|
ВЫВОД |
||
|
Наблюдение |
Предсказанное |
Остатки |
|
1 |
5,033016453 |
-2,033016453 |
|
2 |
3,773393274 |
2,226606726 |
|
3 |
5,340924342 |
-1,340924342 |
|
4 |
5,956740119 |
0,043259881 |
|
5 |
5,610343744 |
-1,610343744 |
|
6 |
6,156464154 |
1,843535846 |
|
7 |
6,418601951 |
-0,418601951 |
|
8 |
6,957440756 |
2,042559244 |
|
9 |
7,49627956 |
1,50372044 |
|
10 |
7,256795647 |
-2,256795647 |
Посчитанные
результаты
Предсказанное
Y – значения результирующего показателя,
рассчитанные по построенной модели;
Остатки
– разность между фактическими и
предсказанными значениями результирующего
показателя Y
![]() .
.
|
y* |
y-y* |
|
2,713517046 |
0,386483 |
|
5,274332794 |
-0,17433 |
|
6,234638699 |
-0,33464 |
|
6,810822243 |
-0,71082 |
|
7,057758047 |
0,142242 |
|
7,194944605 |
0,905055 |
|
4,314026888 |
-0,51403 |
|
4,999959678 |
0,30004 |
Для определения
наилучшей модели составим сравнительную
таблицу:
|
Модель |
Коэффициент детерминации |
F-критерий Фишера |
Индекс корреляции |
Средняя |
|
линейная |
0,915715696 |
65,1876319 |
0,956930351 |
0% |
|
Степенная |
0,923752509 |
72,69111418 |
0,961120445 |
7% |
|
гиперболическая |
0,939188005 |
92,66474522 |
-0,969117127 |
8% |
Наибольшее значение
коэффициента детерминации и критерия
Фишера имеет гиперболическая модель,
ее берем в качестве наилучшей.
По линейной модели
делаем прогноз выпуска готовой продукции
при прогнозном значении вооруженности
предприятия.
Определяем
случайные ошибки ma,
mb,
mrxy:
ma
=
6,66
mb
=
7,18
mrxy
=
0,2
Далее
ta
= 136867602
tb
= -0,802473
trxy
= -9,626253
Сравниваем
фактическое значение t-статистики
с табличным значением:
ta
= 136867602.6 > tтабл=2,45;
tb
= -0.802 < tтабл=2,45;
trxy
= 9.63 > tтабл=2,45,
получаем что параметры a,
b,
r
xy
статистически не значимы.

Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Всероссийский
заочный финансово-экономический институт
Ярославский филиал
Аудиторная работа
по Эконометрике
Вариант 13
Выполнили:
г. Ярославль
2006
Условие задачи:
По данным о потребительских
расходах на товар (продукты питания, одежду и обувь, жилье, книги, образование
– у) и располагаемых (совокупных) личных доходах (х), с использованием
приложения EXCEL:
1.
Построить модель линейной парной регрессии.
2.
Оценить качество полученной модели.
3.
Построить точечный и интервальный прогноз на один шаг.
Исходные
данные:
|
х |
3544.8 |
3576 |
3668.8 |
3905.3 |
4009.3 |
4135.8 |
4170.8 |
4316.3 |
4393.2 |
|
у |
497.8 |
500.9 |
511.8 |
531.8 |
551.1 |
565.5 |
583.4 |
600.9 |
614.6 |
Задания по
аудиторной работе:
1.
Построить модель линейной парной регрессии:
1.1. Построить линейную регрессию
вида ух= а + b*x. Дать интерпретацию
коэффициента регрессии b.
1.2. Построить линейную регрессию
вида уt = а0 + b0* t, где t –
фактор времени t = n; n – номер наблюдения. Дать интерпретацию коэффициента регрессии b0.
1.3. Определить значения коэффициентов корреляции ryx и ryt и
соответственно коэффициентов детерминации R2 yx и R2 yt.
1.4. Сравнить полученные в
пунктах 1.1. и 1.2. модели регрессии по значениям коэффициентов детерминации R2. Сделать вывод.
2.
Оценить качество регрессионной модели вида ух = а + b*x,
полученной в пункте 1.1.
2.1. Оценить статистическую
значимость уравнения линейной парной
регрессии по F – критерию Фишера.
2.2. Оценить статистическую
значимость коэффициентов уравнения регрессии a и b,
вычислив значения:
— t – критерия Стьюдента;
— доверительных интервалов для
коэффициентов регрессии a и b при 5%
уровне значимости, α=5%.
2.3. Вычислить среднюю
ошибку аппроксимации ![]() .
.
2.4. По показателям
адекватности и точности сделать выводы о качестве полученной модели
и её пригодности для
прогнозирования.
3. Выполнить
прогнозирование на один шаг вперед, используя полученную в п. 1.1. модель вида
ух = а + b*x .
3.1. Рассчитать значение точечного прогноза упр.
3.1.1. Рассчитать прогнозное значение фактора
хпр.
a) Построить временной ряд хt по
фактическим данным, используя встроенные функции «Мастер диаграмм» и «График».
б) Аппроксимировать полученный временной
ряд функциями:
— линейной;
—
степенной;
— полиномиальной (второй степени),
используя встроенные функции
EXCEL: «Диаграмма», «Добавить линию тренда»,
«Линейная», «Степенная», «Полиномиальная» (второй степени), с выводом
вида уравнения регрессия на диаграмме и значения коэффициента детерминации R2.
в) Выбрать по максимальному значению
коэффициента детерминации R2 функцию, наилучшим образом
аппроксимирующую исходные данные хt, и по ней рассчитать
прогнозное значение фактора хпр=хt(n+1), где n — последний номер наблюдений.
3.1.2. Рассчитать значение точечного прогноза
упр по уравнению ух = а + b*x (см. п. 1.1.), при значении х=хпр.
3.2. Рассчитать значения интервального прогноза для
уровня значимости 5%, α=5%.
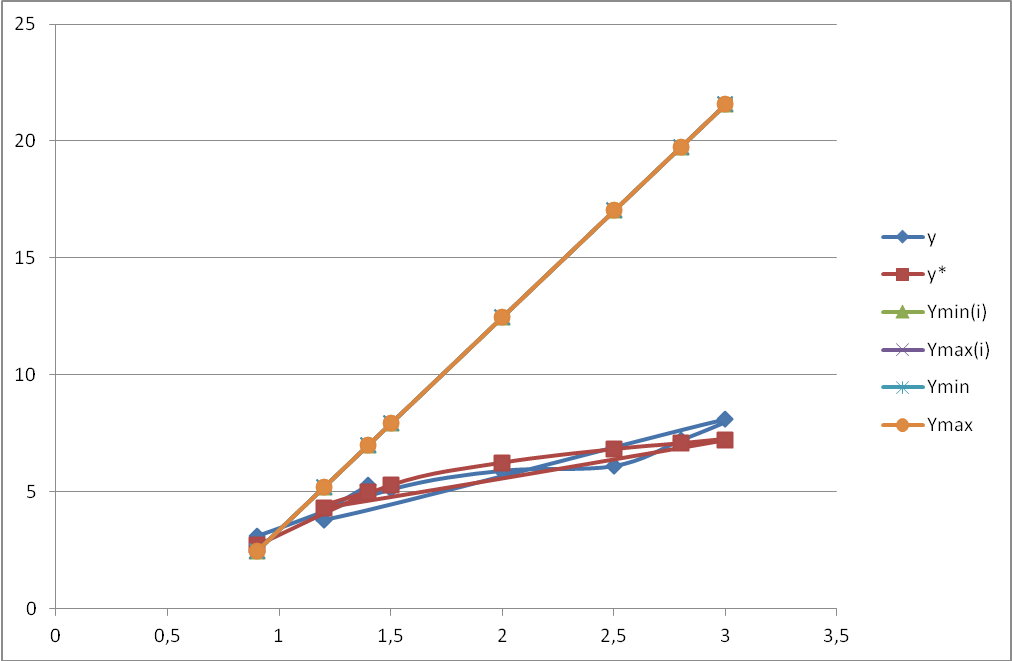
4. На рисунке в координатах Х0У привести:
—
исходные данные (хi; уi);
— график линейной регрессии вида ух =
а + b*x, полученной в
п. 1.1.;
—
значение точечного прогноза на один шаг
вперед и соответствующие значения интервального прогноза.
5. Сделать общий вывод по результатам исследования.
Решение:
1. Построим линейные модели
парной регрессии.
1.1.
Линейная регрессия вида ух= а + b*x
 |
Определим значения
параметров a и b линейной модели:
Уравнение линейной
регрессии имеет вид:
С
увеличением располагаемых личных доходов, потребительские расходы на товары
увеличатся в среднем на 13,6.


1.2.
Линейная регрессия вида уt = а0 + b0* t
Определим
значения параметров a0 и b0 линейной модели:

Уравнение линейной
регрессии имеет вид:
С
увеличением времени, потребительские расходы на товары увеличатся в среднем на 1573,5.


 |
1.3. Определим
линейные коэффициенты парной корреляции ryx и ryt:
 |
Определим
коэффициенты детерминации R2 yx и R2 yt :
R2 =r2

![]()
1.4. Большее значение
коэффициента детерминации имеет линейная модель
Поэтому
модель более точная и лучше по качеству для построения прогноза.
2.
Оценка
качества модели ух = а + b*x
2.1. Проверку значимости произведем на основе
вычислений F-критерия Фишера.
 |
Т.
к. Fрас>Fтабл, уравнение регрессии
следует признать адекватным.
2.2.
Выдвигаем гипотезу H0 о статистически не значимом отличии показателей от
нуля: a=b=rxy=0.
tтабл(0,05;7)=2,3646
Определим
случайные ошибки ma, mb, mrxy:

Тогда:
 |
Сравнивая фактические
значения t с табличным можно сделать вывод о том, что
параметры b и r не случайно отличаются от
нуля и являются статистически значимыми,
параметр а статистически незначим (ta<tтабл).
Рассчитаем
доверительный интервал для a и b. Для этого определим
предельную ошибку для каждого показателя:
 |
Доверительные
интервалы:
 |


Анализ
верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью
0,95 параметр a принимается
нулевым и является статистически незначимым, а параметр b не
принимает нулевых значений и не является статистически незначимым.
2.3.
Качество модели определяет средняя ошибка аппроксимации:
 |
Ошибка
аппроксимации не превышает 5%, значит модель является очень точной.
2.4.
Модель имеет достаточно большое значение критерия Фишера и коэффициента
детерминации. Модель достаточно точная, её можно взять для построения прогноза.
3. Построение прогноза.
3.1.
Рассчитаем значение точечного прогноза упр.
Строим
временной ряд xt:

Функция
наилучшим образом аппроксимирующая исходные данные xt
хt=-2,2634t2+136,78t+3356,7
хпр=хt(10)=-2,2634*102+136,78*10+3356,7=4498,16
упр=12,025+0,136*хпр=12,025+0,136*4498,16=623,77
3.2. Рассчитаем значения
интервального прогноза для уровня значимости 5%, α=5%.
Ошибка
прогноза составит:
 |
 |
tтабл(0,05;7)=2,3646
 |
|
Х прог |
Хпрог — Хсред |
(Хпрог — Хсред)2 |
Упрог |
Sу расч |
Дельта |
Верхняя граница |
Нижняя граница |
|
4498,16 |
529,26 |
280116,14 |
623,77 |
6,6268 |
18,9367 |
642,7067 |
604,8333 |
Выполненный прогноз оказался надежным, и достаточно
точным, так как диапазон верхней и нижней границ доверительного интервала
составляет 1,06 раза.

Задача 1.1.
По районам региона приводятся данные за 200Х г. (табл. 1.1).
Таблица 1.6
|
Номер района |
Среднедушевой прожиточный минимум в день одного трудоспособного, руб., Х |
Среднедневная заработная плата, руб., У |
|
1 |
78 |
133 |
|
2 |
82 |
148 |
|
3 |
87 |
134 |
|
4 |
79 |
154 |
|
5 |
89 |
162 |
|
6 |
106 |
195 |
|
7 |
67 |
139 |
|
8 |
88 |
158 |
|
9 |
73 |
152 |
|
10 |
87 |
162 |
|
11 |
76 |
159 |
|
12 |
115 |
173 |
Требуется:
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х, составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение:
1. Для расчета параметров уравнения линейной регрессии строим расчетную таблицу (табл. 1.2).
;
Таблица 1.2
|
№ |
Х |
У |
Xy |
X2 |
Y2 |
|
YI— |
|
|
1 |
78 |
133 |
10374 |
6084 |
17689 |
149 |
-16 |
11,84962 |
|
2 |
82 |
148 |
12136 |
6724 |
21904 |
152 |
-4 |
3 |
|
3 |
87 |
134 |
11658 |
7569 |
17956 |
157 |
-23 |
17,19403 |
|
4 |
79 |
154 |
12166 |
6241 |
23716 |
150 |
4 |
2,805195 |
|
5 |
89 |
162 |
14418 |
7921 |
26244 |
159 |
3 |
1,925926 |
|
6 |
106 |
195 |
20670 |
11236 |
38025 |
175 |
20 |
10,50256 |
|
7 |
67 |
139 |
9313 |
4489 |
19321 |
139 |
0 |
0,258993 |
|
8 |
88 |
158 |
13904 |
7744 |
24964 |
158 |
0 |
0,025316 |
|
9 |
73 |
152 |
11096 |
5329 |
23104 |
144 |
8 |
5,157895 |
|
10 |
87 |
162 |
14094 |
7569 |
26244 |
157 |
5 |
3,061728 |
|
11 |
76 |
159 |
12084 |
5776 |
25281 |
147 |
12 |
7,597484 |
|
12 |
115 |
173 |
19895 |
13225 |
29929 |
183 |
-10 |
5,66474 |
|
Итого |
1027 |
1869 |
161808 |
89907 |
294377 |
69,0435 |
||
|
Среднее Значение |
85,6 |
156 |
13484 |
7492,25 |
24531,42 |
5,753625 |
||
|
S |
13,5 |
17,3 |
||||||
|
S2 |
183 |
298 |
. ![]()
Получено уравнение регрессии: ![]() .
.
С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
2. Тесноту линейной связи оценит коэффициент корреляции:
; ![]() .
.
Это означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума.
Качество модели определяет средняя ошибка аппроксимации:
.
Качество построенной модели оценивается как хорошее, так как средняя относительная ошибка аппроксимации не превышает 8-10%.
3. Оценку статистической значимости параметров регрессии проведем с помощью t-статистики Стьюдента и путем расчета доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателя от нуля: ![]() .
.
Определим случайные ошибки Ma, mb, ![]() :
:
;
;
.
Тогда
; ;
.
Фактические значения t-статистики превосходят табличные значения:
![]() ;
; ![]() ;
; ![]() ,
,
Поэтому гипотеза Н0 отклоняется, т. е. A, B и Rxy не случайно отличаются от нуля, а статистически значимы.
Рассчитаем доверительный интервал для A и B. Для этого определим предельную ошибку для каждого показателя:
![]() ;
; ![]() .
.
Доверительные интервалы:
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью ![]() параметры A и B, находясь в указанных границах, не принимают нулевые значения, т. е. не являются статистики незначимыми и существенно отличаются от нуля.
параметры A и B, находясь в указанных границах, не принимают нулевые значения, т. е. не являются статистики незначимыми и существенно отличаются от нуля.
4. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение промежуточного минимума составит: ![]() тыс. руб., тогда прогнозное значение прожиточного минимума составит:
тыс. руб., тогда прогнозное значение прожиточного минимума составит: ![]() тыс. руб.
тыс. руб.
5. Ошибка прогноза составит:
![]() тыс. руб.
тыс. руб.
Предельная ошибка прогноза, которая в 95% случаев не будет превышена, составит:
![]() .
.
Доверительный интервал прогноза:
![]() ;
;
![]() руб.;
руб.;
![]() руб.
руб.
Выполненный прогноз среднемесячной заработной платы оказался надежным, но неточным, т. к. диапазон верхней и нижней границ доверительного интервала составляет 1,95 раза (121/62,2).
Задача 1.2.
Зависимость потребления продукта А от среднедушевого дохода по данным 20 семей характеризуется следующим образом:
— уравнение регрессии ![]() ;
;
— индекс корреляции ![]() ;
;
— остаточная дисперсия ![]() .
.
Требуется провести дисперсионный анализ полученных результатов.
Решение:
Результаты дисперсионного анализа приведены в табл. 1.3.
Таблица 1.3
|
Вариация результата y |
Число степеней свободы |
Сумма квадратов отклонений, S |
Дисперсия на одну степень свободы, D |
Fрасч |
Fтабл A=0,05 K1=1, K2=18 |
|
Общая |
Df=n-1=19 |
6,316 |
|||
|
Факторная |
K1=m=1 |
5,116 |
5,116 |
76,7 |
4,41 |
|
Остаточная |
K2=n-m-1=18 |
1,200 |
0,0667 |
![]() ;
;
![]() ;
;
![]() ;
;
.
В силу того, что ![]() , гипотеза о случайности различий факторной и остаточной дисперсий отклоняется. Эти различия существенны, статистически значимы, уравнение надежно, значимо, показатель тесноты связи надежен и отражает устойчивую зависимость потребления продукта А от среднедушевого дохода.
, гипотеза о случайности различий факторной и остаточной дисперсий отклоняется. Эти различия существенны, статистически значимы, уравнение надежно, значимо, показатель тесноты связи надежен и отражает устойчивую зависимость потребления продукта А от среднедушевого дохода.
| < Предыдущая | Следующая > |
|---|
|
Регрессионная |
|
|
Множественный |
0,969117127 |
|
R-квадрат |
0,939188005 |
|
Нормированный |
0,929052672 |
|
Стандартная |
0,036690484 |
|
Наблюдения |
8 |
Посчитанные
результаты
Множественный
R- индекс корреляции (для парной регрессии
rxy) = 0.969
R-квадрат
— коэффициент детерминации, ![]() =0.939
=0.939
Стандартная
ошибка — стандартная ошибка оценки
=0.036
Наблюдения
— количество наблюдений, n=8
|
Дисперсионный |
|||||
|
df |
SS |
MS |
F |
Значимость |
|
|
Регрессия |
1 |
0,124745 |
0,124745 |
92,66475 |
7,19E-05 |
|
Остаток |
6 |
0,008077 |
0,001346 |
||
|
Итого |
7 |
0,132822 |
Посчитанные
результаты
df
— число степеней свободы m=1; n-m-1=6; n-1=7.
F-
критерий Фишера=92.66
|
Коэффициенты |
Стандартная |
t-статистика |
|
|
Y-пересечение |
1,031553029 |
0,034086 |
30,26334 |
|
Переменная |
-0,493795004 |
0,051297 |
-9,62625 |
Посчитанные
результаты
Коэффициенты-
коэффициенты уравнения регрессии
а=9.11 и b=-5.76
Стандартная
ошибка — стандартные ошибки коэффициентов
уравнения регрессии ma=0.199
и mb=7.261
t-статистика-
t-статистика ta=45.72
и tb=-7.93
|
ВЫВОД |
||
|
Наблюдение |
Предсказанное |
Остатки |
|
1 |
5,033016453 |
-2,033016453 |
|
2 |
3,773393274 |
2,226606726 |
|
3 |
5,340924342 |
-1,340924342 |
|
4 |
5,956740119 |
0,043259881 |
|
5 |
5,610343744 |
-1,610343744 |
|
6 |
6,156464154 |
1,843535846 |
|
7 |
6,418601951 |
-0,418601951 |
|
8 |
6,957440756 |
2,042559244 |
|
9 |
7,49627956 |
1,50372044 |
|
10 |
7,256795647 |
-2,256795647 |
Посчитанные
результаты
Предсказанное
Y – значения результирующего показателя,
рассчитанные по построенной модели;
Остатки
– разность между фактическими и
предсказанными значениями результирующего
показателя Y
![]() .
.
|
y* |
y-y* |
|
2,713517046 |
0,386483 |
|
5,274332794 |
-0,17433 |
|
6,234638699 |
-0,33464 |
|
6,810822243 |
-0,71082 |
|
7,057758047 |
0,142242 |
|
7,194944605 |
0,905055 |
|
4,314026888 |
-0,51403 |
|
4,999959678 |
0,30004 |
Для определения
наилучшей модели составим сравнительную
таблицу:
|
Модель |
Коэффициент детерминации |
F-критерий Фишера |
Индекс корреляции |
Средняя |
|
линейная |
0,915715696 |
65,1876319 |
0,956930351 |
0% |
|
Степенная |
0,923752509 |
72,69111418 |
0,961120445 |
7% |
|
гиперболическая |
0,939188005 |
92,66474522 |
-0,969117127 |
8% |
Наибольшее значение
коэффициента детерминации и критерия
Фишера имеет гиперболическая модель,
ее берем в качестве наилучшей.
По линейной модели
делаем прогноз выпуска готовой продукции
при прогнозном значении вооруженности
предприятия.
Определяем
случайные ошибки ma,
mb,
mrxy:
ma
=
6,66
mb
=
7,18
mrxy
=
0,2
Далее
ta
= 136867602
tb
= -0,802473
trxy
= -9,626253
Сравниваем
фактическое значение t-статистики
с табличным значением:
ta
= 136867602.6 > tтабл=2,45;
tb
= -0.802 < tтабл=2,45;
trxy
= 9.63 > tтабл=2,45,
получаем что параметры a,
b,
r
xy
статистически не значимы.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Предложите, как улучшить StudyLib
(Для жалоб на нарушения авторских прав, используйте
другую форму
)
Ваш е-мэйл
Заполните, если хотите получить ответ
Оцените наш проект
1
2
3
4
5