I am using nginx and node server to serve update requests. I get a gateway timeout when I request an update on large data. I saw this error from the nginx error logs :
2016/04/07 00:46:04 [error] 28599#0: *1 upstream prematurely closed
connection while reading response header from upstream, client:
10.0.2.77, server: gis.oneconcern.com, request: «GET /update_mbtiles/atlas19891018000415 HTTP/1.1», upstream:
«http://127.0.0.1:7777/update_mbtiles/atlas19891018000415», host:
«gis.oneconcern.com»
I googled for the error and tried everything I could, but I still get the error.
My nginx conf has these proxy settings:
##
# Proxy settings
##
proxy_connect_timeout 1000;
proxy_send_timeout 1000;
proxy_read_timeout 1000;
send_timeout 1000;
This is how my server is configured
server {
listen 80;
server_name gis.oneconcern.com;
access_log /home/ubuntu/Tilelive-Server/logs/nginx_access.log;
error_log /home/ubuntu/Tilelive-Server/logs/nginx_error.log;
large_client_header_buffers 8 32k;
location / {
proxy_pass http://127.0.0.1:7777;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $http_host;
proxy_cache_bypass $http_upgrade;
}
location /faults {
proxy_pass http://127.0.0.1:8888;
proxy_http_version 1.1;
proxy_buffers 8 64k;
proxy_buffer_size 128k;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
I am using a nodejs backend to serve the requests on an aws server. The gateway error shows up only when the update takes a long time (about 3-4 minutes). I do not get any error for smaller updates. Any help will be highly appreciated.
Node js code :
app.get("/update_mbtiles/:earthquake", function(req, res){
var earthquake = req.params.earthquake
var command = spawn(__dirname + '/update_mbtiles.sh', [ earthquake, pg_details ]);
//var output = [];
command.stdout.on('data', function(chunk) {
// logger.info(chunk.toString());
// output.push(chunk.toString());
});
command.stderr.on('data', function(chunk) {
// logger.error(chunk.toString());
// output.push(chunk.toString());
});
command.on('close', function(code) {
if (code === 0) {
logger.info("updating mbtiles successful for " + earthquake);
tilelive_reload_and_switch_source(earthquake);
res.send("Completed updating!");
}
else {
logger.error("Error occured while updating " + earthquake);
res.status(500);
res.send("Error occured while updating " + earthquake);
}
});
});
function tilelive_reload_and_switch_source(earthquake_unique_id) {
tilelive.load('mbtiles:///'+__dirname+'/mbtiles/tipp_out_'+ earthquake_unique_id + '.mbtiles', function(err, source) {
if (err) {
logger.error(err.message);
throw err;
}
sources.set(earthquake_unique_id, source);
logger.info('Updated source! New tiles!');
});
}
Thank you.
I am using nginx and node server to serve update requests. I get a gateway timeout when I request an update on large data. I saw this error from the nginx error logs :
2016/04/07 00:46:04 [error] 28599#0: *1 upstream prematurely closed
connection while reading response header from upstream, client:
10.0.2.77, server: gis.oneconcern.com, request: «GET /update_mbtiles/atlas19891018000415 HTTP/1.1», upstream:
«http://127.0.0.1:7777/update_mbtiles/atlas19891018000415», host:
«gis.oneconcern.com»
I googled for the error and tried everything I could, but I still get the error.
My nginx conf has these proxy settings:
##
# Proxy settings
##
proxy_connect_timeout 1000;
proxy_send_timeout 1000;
proxy_read_timeout 1000;
send_timeout 1000;
This is how my server is configured
server {
listen 80;
server_name gis.oneconcern.com;
access_log /home/ubuntu/Tilelive-Server/logs/nginx_access.log;
error_log /home/ubuntu/Tilelive-Server/logs/nginx_error.log;
large_client_header_buffers 8 32k;
location / {
proxy_pass http://127.0.0.1:7777;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $http_host;
proxy_cache_bypass $http_upgrade;
}
location /faults {
proxy_pass http://127.0.0.1:8888;
proxy_http_version 1.1;
proxy_buffers 8 64k;
proxy_buffer_size 128k;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
I am using a nodejs backend to serve the requests on an aws server. The gateway error shows up only when the update takes a long time (about 3-4 minutes). I do not get any error for smaller updates. Any help will be highly appreciated.
Node js code :
app.get("/update_mbtiles/:earthquake", function(req, res){
var earthquake = req.params.earthquake
var command = spawn(__dirname + '/update_mbtiles.sh', [ earthquake, pg_details ]);
//var output = [];
command.stdout.on('data', function(chunk) {
// logger.info(chunk.toString());
// output.push(chunk.toString());
});
command.stderr.on('data', function(chunk) {
// logger.error(chunk.toString());
// output.push(chunk.toString());
});
command.on('close', function(code) {
if (code === 0) {
logger.info("updating mbtiles successful for " + earthquake);
tilelive_reload_and_switch_source(earthquake);
res.send("Completed updating!");
}
else {
logger.error("Error occured while updating " + earthquake);
res.status(500);
res.send("Error occured while updating " + earthquake);
}
});
});
function tilelive_reload_and_switch_source(earthquake_unique_id) {
tilelive.load('mbtiles:///'+__dirname+'/mbtiles/tipp_out_'+ earthquake_unique_id + '.mbtiles', function(err, source) {
if (err) {
logger.error(err.message);
throw err;
}
sources.set(earthquake_unique_id, source);
logger.info('Updated source! New tiles!');
});
}
Thank you.
Hi,
I’ve deployed my app with nginx + uwsgi.
It seems to be working fine except for the pact that every now and then, request will yield a 502 error code.
When this happens, I get a line like this in nginx/error.log:
2018/06/14 10:55:03 [error] 4674#4674: *18888 upstream prematurely closed connection while reading response header from upstream, client: 192.168.100.1, server: easyset.eu, request: "GET /main_menu_icons/paid_plans.svg HTTP/1.1", upstream: "uwsgi://unix:///tmp/mars.sock:", host: "www.easyset.eu", referrer: "https://www.easyset.eu/"
It does not matter what request is made — the error is completely random. On all types of requests.
The relevant section of nginx site.conf
upstream main {
server unix:///tmp/mars.sock; # for a file socket
# server 127.0.0.1:8001; # for a web port socket (we'll use this first)
}
location / {
include uwsgi_params;
uwsgi_pass main;
uwsgi_buffers 256 16k;
}
and uwsgi configuration:
master = true
#more processes, more computing power
processes = 32
threads = 3
post-buffering = 1
# this one must match net.core.somaxconn
listen = 8000
uid = mars
gid = mars
# add-gid = mars
# http-socket = 0.0.0.0:8080
socket = /tmp/mars.sock
stats = /tmp/mars_stats.sock
chown-socket = mars:mars
chmod-socket = 666
vacuum = true
socket-timeout = 300
harakiri = 300
max-worker-lifetime = 35
I’ve been researching this issue for more than a month now, but none of the remedies suggested seems to be working for me. I also did not detect the randomness factor in the other reported issues. Usually there was some misconfiguration involved, but not in my case: exactly the same command will work 90% of the time and fail the other 10% of the time.
It’s quite annoying as pages only load partially and one can never be sure what has loaded and what hasn’t.
I’d be grateful for any suggestions on what I’m missing here.
Jure
Do you guys offer paid support? This is killing me and i’m not afraid of paying for a solution.
Try increasing max-worker-lifetime. 35 seconds is very low.
It is set to 35 seconds only because otherwise there was even more of 502. A busy worker will not be restarted before it completes its current job, so I’ve seen no ill effects of lowering this setting (except for a bit of CPU usage).
Hi there,
Did you find a solution by chance? I have been struggling the same way you did for days now, it is truly driving me nuts. For the same page, sometimes it displays properly, sometimes not, I really hate this kind of random behavior! I logued my Django app but nothing, and the error in nginx/error.log is not explicit at all. The lifetime parameters is (of what I read on the internet) meant when you try to upload heavy files. But in my case, I am just talking about displaying light pages!
Many thanks for your answer!
Well, actually I was not. As a fallback I’m currently also running an instance of Apache with mod-wsgi. Considering just moving the whole thing back to it. Had no issues like this with that combination.
Damn it. I wanted to move to gunicorn because with Apache2+mod_wsgi, I have the same behavior (always on the same group of page I realize now), and reading apache2 log just gives Truncated or oversized response headers received from daemon process with a wonderful Segmentation fault (11). There must be something else, not related to apache2 nor gnix, but I can’t find what. Exhausting 😩
Thank you for your answer by the way!
@KrazyMax you are using threads, are you sure your app is thread-safe ? Try disabling them
Hi @rdeioris! Well I am not an Apache2/Gnix expert at all, and I also did not ask myself questions regarding threading actually. I did not define threads in particular.
I changed logging in Apache2 from warnto info to get further details, and I’ve got this:
[Thu Aug 16 15:23:56.868288 2018] [wsgi:info] [pid 21505:tid 139948258772864] mod_wsgi (pid=21505): Starting process 'mywebsite.fr' with uid=33, gid=33 and threads=15.
So I guess it means I multi-thread with 15 threads. Sorry to look like a noob, but that’s what I am regarding server confs.
I changed in mpm_event.conf those 2 parameters: ThreadsPerChild to 1 (default 25) and MaxSpareThreads to 1 (default is 4). Unfortunately, even after a reload and a stop/start of apache2, same issue.
Something interesting I noticed on one page which sometimes display correctly, sometimes throws a server error: when I have an error, almost everytime I do a force refresh in my web browser, it displays correctly!
Final comment @velis74: I identified the issue. I wanted to be able to use f-string. As this feature is only available on Python 3.6+, I did install Python 3.7, without thinking at all the issue could come from a stable release of Python. So, I decided to delete anything related to f-strings in my own code, then to go back to my Python 3.5, just to see. And that was it. I followed every tutorials I found on the internet, from Python website to mod_wsgi, installing Python 3.7 by sharing it as recommanded and so on, but I had no error message, no clue that Python would be at fault.
So maybe have a look on how your installed Python on your server, because now the issue for Apache2 as for Nginx is solved!
I’m mad at me, because I was too confident on my Python 3.7 install which did not throw any error at install or when Apache2/Nginx started to run.
@KrazyMax So you’re saying that using an unsupported feature (f-strings) with python 3.5 resulted in RANDOM 502s on your server? Wouldn’t that, like, fail EVERY time? How does one debug something like that????
I too got the same error upstream prematurely closed connection while reading response header from upstream , but for nginx-uwsgi-flask docker image. In my case, the issue was because in the Dockerfile, I had installed uwsgi using apt-get. So, to fix this I had 2 options.
- Update Dockerfile, to install a python plugin uwsgi-plugin-python through apt-get and add
plugins = pythonto the uwsgi app config. Reference - Update the Dockerfile, to install uwsgi using pip instead of apt-get.
i get the same problem ,do you resolve it ? @velis74
@velis74 you should probably get some hints in uwsgi log. I’ll give it a try removing selectively the following configurations:
post-buffering = 1
harakiri = 300
max-worker-lifetime = 35
i have solve this problem, by chang uwsgi protocal to http protocal.
uwsgi.ini
[uwsgi]
http=127.0.0.1:7020
chdir=/opt/www/sqdashi/savemoney/src/main/python/com
wsgi-file=savemoney/wsgi.py
processes=16
threads=2
master=True
pidfile=uwsgi.pid
daemonize=/opt/www/sqdashi/savemoney/src/main/python/com/log/uwsgi-@(exec://date +%%Y-%%m-%%d).log
nginx.conf
proxy_pass http://127.0.0.1:7020;
test
i task one thousand requests and no happend error
you can try this ,if you still want @velis74
Thanks, @hanhuizhu I will definitely try this. I thought sockets were the most reliable and fastest solution, so it never occurred to me to switch to something else…
@hanhuizhu , thank you! I was hitting on exactly the same issue and i was struggling to find a solution. Service worked randomly . Moving away from sockets did the trick for me as well… For the record, in case it helps someone else, my setup was dockerized and uwsgi was installed through pip.
Probably related/duplicate to this : #1702
Removing --threads=4 seems to fix the issue here ?!
I have met a similar question,when uwsgi set multi threads and reach the reload_on_rss,uwsgi worker respawn.However the nginx get 502 error. uwsgi seems not to wait for the resp complete.
I have tried shifting my workload from gunicorn to uwsgi and immediately hit this issue.
I have created a minimal example which allows everyone to reproduce this in seconds, all you need is Docker: https://github.com/joekohlsdorf/uwsgi-nginx-bug
If there is anything more we can contribute to fixing this bug I’ll be happy to help.
My biggest issue is that uwsgi is silent about these errors so I have no idea where to start looking.
Copying the README of my repo which has some additional info:
This repo is a minimal example to reliably reproduce a bug where uwsgi closes connections prematurely.
How To Run
You need Docker to run this demo.
- Checkout the code
- Run
make up - Wait a few seconds and you’ll see error messages
upstream prematurely closed connection while reading response header from upstreamfrom thennginxcontainer appearing - You will also see the logstream of
uwsgiwhich is clean. - Hit CTRL-C and everything will stop within in a couple of seconds.
What Does It Run
- The container
workloadis an empty Django project. Django is served by uwsgi in worker mode running 2 processes. - The container
nginxruns an nginx reverse proxy to uwsgi. - The container
abruns apachebench against thenginxcontainer.
Frequently Asked Questions
-
Change setting XYZ of uwsgi.
- I sadly haven’t found any setting which fixes this.
-
You are overflowing the listen backlog.
- uwsgi has a mechanism to alert when this happens, it isn’t the cause of the problem.
-
This is a benchmark problem.
- Exactly the same happens with real traffic.
-
The problem is caused by Nginx.
- This does not happend with gunicorn.
-
How can I change the uwsgi config?
- Adjust
uwsgi.iniand run again.
- Adjust
-
How can I change what is installed in the Docker images?
- Adjust the
Dockerfileand runmake rebuild.
- Adjust the
Further illustration of the problem
In the below graph you can see two days of these errors in a production environment.
First day is uwsgi, second day is gunicorn. Similar traffic, same amount of processes. gunicorn errors are due to timeout (gunicorns harakiri), unexpected errors on gunicorn are 0.
This environment is running with very low load, about 30% worker usage.

@joekohlsdorf have you tried enlarging the listen queue? gunicorn one is like 20x times the uwsgi default.
Mine is at 8000, that should be enough, I should think.
There are so many reasons to have this kind of error rates, that this issue is becaming a source of random solutions 
The (probably incomplete) list of things to check:
- listen queue (the listen/-l option of uWSGI is not enough, you need to check the operating system limits too)
- timeouts, the default socket timeout is low for this kind of benchmarks, you can raise it with —socket-timeout, check nginx timeouts too for the uwsgi protocol
- non thread-safe app, lot of users do not realize that apps are not thread safe by default (most of them are totally non thread safe), just disable multithreading if this is the case.
- non fork-safe app, your app could have issues with uWSGI preforking model, just disable it with —lazy-apps
- buffer-size limit, this is logged but some of the requests could overflow the 4k buffer limit (could happen for requests with lot of headers). Tune it with —buffer-size
- changing between —socket and http-socket is meaningful only if you are configuring nginx with different tuning values between uwsgi and http protocol
- adding —http (not —http-socket, they are different!) is wrong, as you will end adding another proxy between nginx and uWSGI. It generally solves the issue because the uWSGI http router is built for being exposed to the public so is way more tolerant and with bigger defaults.
- running external process, long story short: if you need to spawn processes during requests add —close-on-exec.
And please, please, stop creating huge backlog queues (they are ok for benchmarks, but then set them to meaningful values based on your QoS policies), they consume precious kernel memory.
Until now I was under the impression that uwsgi would warn when the listen queue gets full, there are several related settings but I never got any warning, this is why I never changed this setting. So these errors might not be shown when running with --http which is problematic.
I raised the listen queue to 500 and my test passes without a single error!
Can we please agree that the default listen queue is too small? This is not a benchmark, I showed you 48 hours of real world errors comparing uwsgi to gunicorn on a large scale deployment across hundreds of instances running with very low average worker load (30% target for the test). This is not a random hiccup but a consistent problem.
Let’s compare the default listen backlog of some other application servers to uwsgi:
- uwsgi: 100
- bjoern: 1024
- gunicorn: 2048
- meinheld: 2048
- nginx: 511 on Linux
- Apache: 511
- lighttpd: 1024
The webservers are not very comparable because they generally don’t have to wait for a worker to become available but for reference I still included them.
Test result with listen backlog 500 (0 errores) of my repo, as you can see from the response times this test is not at all trying to overflow the system:
ab_1 | Requests per second: 388.00 [#/sec] (mean)
ab_1 | Time per request: 515.457 [ms] (mean)
ab_1 | Time per request: 2.577 [ms] (mean, across all concurrent requests)
ab_1 | Transfer rate: 6260.37 [Kbytes/sec] received
ab_1 |
ab_1 | Connection Times (ms)
ab_1 | min mean[+/-sd] median max
ab_1 | Connect: 0 0 0.9 0 54
ab_1 | Processing: 13 515 54.1 505 885
ab_1 | Waiting: 13 514 53.8 504 881
ab_1 | Total: 35 515 53.9 505 885
ab_1 |
ab_1 | Percentage of the requests served within a certain time (ms)
ab_1 | 50% 505
ab_1 | 66% 521
ab_1 | 75% 538
ab_1 | 80% 551
ab_1 | 90% 581
ab_1 | 95% 607
ab_1 | 98% 650
ab_1 | 99% 697
ab_1 | 100% 885 (longest request)
After doing some synthetic tests I gave it another try in production with the listen backlog set to 4096. Deployment of the change from gunicorn to uwsgi starts at 23:30, rollback starts at 23:45.
We can conclude that the listen backlog is not the cause of the problem under low load.

@joekohlsdorf my comment was not an answer to your specific one, was a general consideration about this issue and the amount of ‘randomness’ of some of the solutions. Btw the warning about listen queue is only available for TCP sockets on Linux (where the operating system supports monitoring it). I have sent a patch for unix sockets years ago (5 or 6 at least) to the LKML but never got merged
I gave a quick look at your example github project, and i have seen you are using the http proxy. This is adding another layer to your stack, so nginx is sending requests to the uWSGI http proxy, that again sends another request to the backend (double proxying). Use http-socket for having a production-like setup, so you have nginx directly talking to uWSGI workers like gunicorn. Obviously this is not ‘the’ solution but should give you a simpler stack to debug/inspect/monitor. You can use tools like uwsgitop or strace to understand what is going on.
The uWSGI http proxy is useful for configurations without nginx or for when you want backends processes to configure the proxy (something generally useful only for hosting providers)
I hope it will be useful.
(additional note, add master = true too, it will add better workers management too)
I agree that this issue seems to have a great many facets.
However, it would seem that they all have one thing in common: uwsgi at some point or another decides to not process a particular request and simply «fails» doing so, resulting in a 502.
As far as I have seen, the causes for that were plenty, but mostly revolved around strict settings observations that resulted in a worker’s termination even though the worker was doing just fine and processing the request (e.g. the harakiri setting) or not processing the reqest at all due to one or another queue being full (this latest example with max socket connections)
I myself only have mod_wsgi to compare against, but I would call this an issue to be looked at. It simply won’t do to have a server «randomly» reject processing requests. There should at least be log entries showing that this happened and why. It’s not like uwsgi doesn’t know it did it!
@velis74 note that technically uWSGI here does not know what is happening because it is an error generated by nginx not being able to communicate with it, so it happens even before the accept() is completed (otherwise it would be an easy issue to manage). I agree that the defaults are maybe too low for 2020 (they have been set in 2009 
@joekohlsdorf just for completeness, another common cause are ‘stuck workers’. One of you request is blocked and the worker will not be able to manage other requests until the ‘blocked loop’ ends. The only way to solve this kind of issues is using harakiri (generally you set it to the maximum amount of time you want to allow a request to run, NOTE: this is a brutal kill of the worker, so you can potentially ends with half-baked stuff or corruptions).
The repo is just the minimal config I came up with to reproduce the problem. At least for that case we saw that modifying the listen backlog has a positive effect.
In the real config I also have master = True, no-defer-accept = True, harakiri = 30 (errors are not caused by harakiri or memory kill) and a bunch of other stuff. I experimented with many of these and other configurations and it made no difference.
Until now I was not aware that I should use http-socket instead of http so I’ll give it another go with that.
Having the same sort of issue here, and I can’t for the life of me figure out how to tune my uwsgi so it works properly… It seems when a certain throughput is reached, or certain requests are being processed my app performance starts to degrade and I get 502 errors, but the load isn’t very high… maybe throughput of 400-500ish
I forgot to leave feedback about another production test I did using http-socket:
Unfortunately I had exactly the same result.
Hello guys! First of all, let me thank you all for your work with uwsgi. It’s been my choice of tool for deploying django projects along with nginx for last decade. Although it’s really not always as easy to configure as I would like. When it works, it’s ok, but if something starts giving weird behavior… well you are basically in a big trouble…
So.. I am having the same exact problem here. I have one url that constantly accepts file uploads of 5 — 100Mb in size from multiple workers every ~5s. But about every few hours this thing goes in to some ill mode and I get a bunch of 502 errors with upstream prematurely closed connection while reading response header from upstream message. It takes about 15 minutes and it magically heals it self up until it happens again 2 or 3 hours later. Here is my simple uwsgi config file:
[uwsgi]
project = happyTree
uid = happyTree
base = /home/%(uid)
chdir = %(base)/website
home = /home/happyTree/.virtualenvs/happyTree
module = core.wsgi:application
master = true
processes = 192
socket = /run/uwsgi/%(project).sock
chown-socket = %(uid):www-data
chmod-socket = 660
vacuum = true
harakiri = 120
max-requests=5000
http-timeout = 120
socket-timeout = 120
daemonize=/var/log/uwsgi/happyTree.log
@rdeioris — Love your insights! Could you please kindly look in to this and give some advice. Do you have any ideas on how should I solve this?
To be 100% honest UWSGI is like a magic box to me… all I need from it is to work! Tweaking these parameters were never easy, nor do they give me what want every time. Internet is full of documentation on what every parameter means, but how do you put them all together in to one working instance? That’s still a mystery to me.
Seems like most of the devs suffer the same issue, therefore ending up just using http instead of socket, which is obviously not the way to go, but decent tutorial on how to tune your uwsgi instance is really lacking. A sea of python developers would be more than thankful if someone who deeply understands uwsgi would give a practical tutorial on how do you prepare your uwsgi for different tasks. What are the best practices and etc…
Appreciate your work. Looking forward for hearing back from someone who might explain my case and offer some aid.
Thank you!
Run into the same issue on different 5 hosts (osx, linux) all running the same service in docker.
If i turn off threading (enable-threads = false) i never got 502.
For test purposes to catch 502 more often on ‘threads-on’ configuration i wrote such configuration:
processes = 1
enable-threads = true
threads = 20
max-requests = 5
max-worker-lifetime = 5
min-worker-lifetime= 1
UPDATE:
found in sources, that on hitting max-worker-lifetime option, signal SIGWINCH is sending. Tried to send it manually and nothing happens — worker just get stuck. But it respawns if i manually send sigterm/sigkill
do you resolve it? i have same problem.
I have switched to gunicorn.
I had the same issue with uwsgi, tried tons of different configs, nothing helped really. It seemed the problem was happening, after workers respawned. Sometime workers would not respawn and get stuck… could not make it work. switched to gunicorn and have not have any issues ever since.
This problem seems only to happen when we enable multithreaded support.
In my case, I accidentally found out that enabling thunder-lock resolved the issue.
This feature is about to tackle the problem of thundering herd though, I’m not sure how its internal implementation affects the multithreading mechanism of uWSGI. Really appreciate it if someone could comprehend and explain.
I also noticed that increasing the computing resource (like number of CPUs of the server, etc.) seems to help, too.
Ran into the same problem the past few months with the python36 helper. Everything looks ok on the service but no matter how many tweaks I made (including thunder lock) uwsgi refused to cooperate with nginx returning «upstream prematurely closed connection».
Various searches finding no official support on this at all. I’ll get it working in a VM and come back if I find an answer at least for our case; it feels like something tricky in the way nginx communicates with uwsgi’s socket as the script works perfectly fine and uwsgi still throws errors if there are any in the script.. so it feels like a communication layer issue.
E: Solved it for our environment
We previously used —http on any IP with :xxxx --http :1234 and started using socket files instead and python3.
I thought we could get away with http-socket = /any/socket/file/path.sock with http-modifiers1 = 9 with nginx pointing to it with uwsgi_pass unix:/any/socket/file/path.sock, but in reality I needed to use uwsgi-socket = /any/socket/file/path.sock in the ini file. Also couldn’t forget need-plugins = cgi,http,python36 for our suite.
I follow the below instructions, and worked fine
- set request size limit: You could set a request size limit in Flask to avoid requests that are too large. To do this, you could use the MAX_CONTENT_LENGTH
app = Flask(__name__)
app.config['MAX_CONTENT_LENGTH'] = 16 * 1024 * 1024
- Tune the uWSGI worker settings: You could also tune the uWSGI worker settings to handle more requests. For example, you could increase the workers
- Increase the buffer size: You could increase the uWSGI buffer size to allow for larger requests. To do this, add the buffer-size option to the uWSGI
[uwsgi]
...
workers = 4
buffer-size = 32768
...
I solved this problem by changing the «threads» setting:
threads = 1.
Maybe it helps for somebody.
Upstream prematurely closed connection while reading response header from upstream
У меня установлено битрикс окружение. Частенько начала вылетать ошибка bitrix 502 bad gateway. Посмотрел логи nginx(/var/log/nginx/site_error.log). Там фигурирует одна и таже ошибка upstream prematurely closed connection while reading response header from upstream. Эта ошибка появляется тогда, когда страница генерируется больше времени, чем установленный timeout front-end’a. Обычно она возникает когда nginx отправляет запросы дальше на apache По умолчанию эти таймауты — 60 секунд. Поставим 180 (эти параметры прописываются в etcnginxnginx.conf):
proxy_send_timeout 180s; proxy_read_timeout 180s;
- На Centos конфиг nginx хранится здесь etcnginxnginx.conf
- Логи nginx храниятся здесь /var/log/nginx/site_error.log
Мне помогло это избавиться от 502 ошибки в bitrix
ЗЫ: Буква ‘s’ — обязательна. Без неё ошибок не будет, но и значения не будут учитываться.
Here at Bobcares, we help Website owners, SaaS providers and Hosting companies run highly reliable web services.
One way we achieve that is by having server experts monitor production servers 24/7 and quickly resolving any issue that can affect uptime.
Recently, engineers at our 24×7 monitoring service noticed that a site hosted by our customer in a Docker server was offline.
We quickly logged in to the Docker host system and looked at the log files. This error showed up from the Nginx Gateway Docker container:
16440 upstream prematurely closed connection while reading response header from upstream, client:
[ Not using Docker, and still getting this error? Our Server Experts can fix it for you in a few minutes. Click here for help. ]
What does this error mean?
Every site hosted in this Docker server used an Nginx gateway to act as a fast reverse proxy.
So, all visits to any site will first come to the Nginx container, and then to the website’s Docker container as shown here:
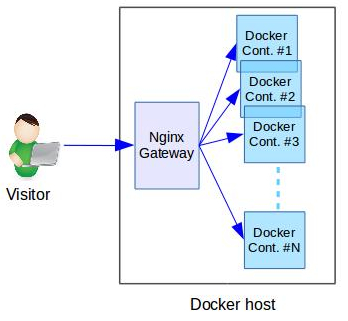
To understand the reason for a website downtime, it is important to look at both the gateway and website Docker containers.
The part of the error that says “upstream prematurely closed connection” means that the Nginx container was unable to get website content from the back-end website.
So, it is clear that the Website’s Docker container has a faulty web server.
[ Not using Docker, and still getting this error? Our Server Experts can fix it for you in a few minutes. Click here for help. ]
How we fixed “16440 upstream prematurely closed connection”
Getting at the root cause
Once we determined that the web server in the website’s Docker container isn’t working, we opened a terminal and looked at its log file.
We saw this error:
[10498834.773328] Memory cgroup out of memory: Kill process 19597 (apache2) score 171 or sacrifice child
[10498834.779985] Killed process 19597 (apache2) total-vm:326776kB, anon-rss:76648kB, file-rss:10400kB, shmem-rss:64kB
It means that the Docker container is killing the web server processes due to excess memory usage.
Determining how it happened
How did the website that worked fine till now suddenly start using up more memory?
We looked at the website’s file changes, and found that it was recently upgraded with additional plugins.
Additionally, we saw an increasing trend in the website traffic as well.
So, that means each visit to the site requires executing more scripts (there by taking more memory per connection), and there are a higher number of connections than 1 month back.
Solution alternatives
At this point, we had 2 solution alternatives:
- Remove the new plugins.
- Increase the memory allowance to the Docker container.
Considering that the website’s traffic is on an increasing trend, removing the plugins will only be a stopgap measure.
So, we contacted the website owner (on behalf of our customer, the Docker web host) and recommended to buy additional memory.
Resolving the issue
The website owner approved the upgrade and we increased the Docker memory by adjusting the “mem_limit” parameter in the Docker Compose configuration file.
mem_limit: 2500m
Once the container was recreated, the webserver started working fine again, and the site came back online.
Remember: There are other reasons for this error
While the issue presented here occurred in a Docker platform, it can happen in any system that runs Nginx web server.
Also, memory limit is one among the many reasons why a Docker container might fail.
So, if you are facing this error, and is finding it difficult to fix this error, we can fix it for you in a few minutes.
Click here to talk to our Server Experts. We are online 24/7.
SPEED UP YOUR SERVER TODAY!
Never again lose customers to poor page speed! Let us help you.
Contact Us once. Enjoy Peace Of Mind For Ever!
GET EXPERT ASSISTANCE
var google_conversion_label = «owonCMyG5nEQ0aD71QM»;