-
Ошибка выборки
2.1. Понятие и виды ошибок выборки
Поскольку изучаемая статистическая
совокупность состоит из единиц с
варьирующими признаками, то состав
выборочной совокупности может в той
или иной мере отличаться от состава
генеральной совокупности.
Расхождение
между характеристиками выборки и
генеральной совокупности составляет
ошибку
выборки.
Виды ошибок выборки
|
Ошибки выборки |
Систематические |
Случайные |
|
Ошибки регистрации |
Обусловлены |
Проявляются |
|
Ошибки репрезентативности |
Неправильный, |
Несмотря |
Основная
задача выборочного метода – изучение
случайных ошибок репрезентативности.
2.2. Средняя ошибка выборки
Случайная ошибка
репрезентативности зависит от следующих
фактов (при этом считается, что ошибок
регистрации нет):
-
Чем
больше численность выборки при прочих
равных условиях, тем меньше величина
ошибки выборки, т.е. ошибка выборки
обратно пропорциональна ее численности. -
Чем
меньше варьирование признака, тем
меньше ошибка выборки. Если признак
совсем не варьирует, а, следовательно,
величина дисперсии равна нулю, то ошибки
выборки не будет, т.к. любая единица
совокупности будет совершенно точно
характеризовать всю совокупность по
этому признаку. Таким образом, ошибка
выборки прямо пропорциональна величине
дисперсии.
В
математической статистике доказывается,
что величина средней ошибки случайной
повторной выборки может быть определена
по формуле
![]()
(6.1)
Однако
следует иметь в виду, что величина
дисперсии в генеральной совокупности
2
нам не известна, т.к. наблюдение выборочное.
Мы можем рассчитать лишь дисперсию в
выборочной совокупности S2.
Соотношение между дисперсиями генеральной
и выборочной совокупности выражается
формулой:
![]()
(6.2)
Если
n
велико, следовательно
![]()
Таким
образом, можно приблизительно считать,
что выборочная дисперсия равна генеральной
дисперсии.
2 =
S2
И формула средней ошибки повторной
выборки (6.1.) примет вид:
![]()
(6.3)
Но
здесь мы рассмотрели только ошибку
выборки для средней величины интересующего
признака. Существует также показатель
доли единиц с интересующим признаком.
Расчет ошибки этого показателя имеет
свои особенности.
Дисперсия
для показателя доли признака определяется
по формуле:
S2=(1-)
(6.4)
Тогда средняя ошибка повтора выборки
для показателя доли признака будет
равна:
![]()
(6.5)
Доказательство
формул (6.3) и (6.5) исходит из схемы повторной
выборки. Обычно же выборку организуют
бесповторным способом. Т.к. при бесповторном
отборе численность генеральной
совокупности N
в коде выборки сокращается, то в формулы
ошибки выборки включают дополнительный
множитель
![]() ,
,
и формулы
принимают вид:
![]()
(6.6)
![]()
(6.7)
Пример
1. Определим, на сколько отличаются
выборочные и генеральные показатели
по данным 10%-ной бесповторной выборки
успеваемости студентов.
|
Оценка, |
Число |
|
2 |
9 |
|
3 |
27 |
|
4 |
54 |
|
5 |
10 |
|
Итого |
100 |
Расчет ошибки бесповторной выборки для
средней величины:
![]()
n
= 100 N
= 1000
Найдем выборочную
дисперсию по формуле:
![]()
Здесь
не известна величина
![]() ,
,
которую можно найти как обычную среднюю
взвешенную величину:
![]()
![]()
Таким
образом,
![]()
Т.е.
можно сказать, что средний балл всех
студентов (![]() )
)
равен 3,650,07
Теперь
рассчитаем долю студентов в генеральной
совокупности, обучающихся на «4» и «5».
Найдем по выборке
долю студентов, получивших оценки «4»
и «5».
![]() (или
(или
64%)
Расчет
ошибки бесповторной выборки для доли
производится по формуле:
![]()
![]() (или
(или
4,5%)
Таким образом, доля студентов, обучающихся
на «4» и «5» по генеральной совокупности
(P) составляет
0,640,045 (или 64%4,5%).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Различают
ошибки регистрации, а
также ошибки
репрезентативности,
которые присущи только выборочному
наблюдению и возникают в результате
того, что выборочная совокупность не
полностью воспроизводит генеральную.
Они могут иметь случайный (непреднамеренный)
и систематический (тенденциозный)
характер.
При собственно-случайной
выборке
отбор из генеральной совокупности
осуществляется посредством жеребьевки
или с помощью таблиц случайных чисел.
Каждым единицам
обеспечивается равная возможность
попадания в выборку, а количество
отобранных в выборочную совокупность
единиц обычно определяется исходя из
принятой доли выборки – это отношение
числа единиц выборочной совокупности
![]() к числу единиц генеральной совокупности
к числу единиц генеральной совокупности![]() :
:![]() .
.
Применяя выборочный
метод в статистике, обычно используют
два основных вида обобщающих показателей:
среднюю ошибку количественного признака
и относительную величину альтернативного
признака.
Выборочная доля,
или частость, определяется отношением
числа единиц, обладающих изучаемым
признаком
![]() ,
,
к общему числу единиц выборочной
совокупности![]() :
:![]() .
.
Для характеристики
надежности выборочных показателей
различают среднюю
и предельную
ошибки выборки.
Ошибка выборки
или ошибка
репрезентативности
представляют собой разность соответствующих
выборочных и генеральных характеристик:
— для средней
количественного признака
![]() ,
,
где
![]() —
—
выборочная средняя;
![]() -среднее
-среднее
значение признака в генеральной
совокупности или генеральная средняя;
— для доли
(альтернативного признака)
![]() ,
,
где
![]() —
—
выборочная доля;
![]() —
—
генеральная доля
Средняя ошибка
выборки зависит от следующих моментов:
1) при соблюдении
принципа случайного отбора средняя
ошибка выборки определяется прежде
всего объемом выборки: чем больше
численность при прочих равных условиях,
тем меньше величины средне ошибки
выборки Н: при сокращении средней ошибки
в два раза, объем выборки нужно увеличить
в четыре раза.
2) степени варьирования
признака. Чем меньше вариация признака,
а следовательно, и дисперсия, тем меньше
средняя ошибка выборки, и наоборот.
При случайном
повторном отборе средние ошибки
теоретически рассчитываются по следующим
формулам:
— для средней
количественного признака
![]() ,
,
где
![]() —
—
дисперсия признака в генеральной
совокупности;
![]() — численность
— численность
выборочной совокупности.
— для доли
альтернативного признака
![]() ,
,
где
![]() — дисперсия доли признака в генеральной
— дисперсия доли признака в генеральной
совокупности
![]() — численность
— численность
выборочной совокупности.
Поскольку практически
дисперсия признака в генеральной
совокупности точно неизвестна, на
практике пользуются значением дисперсии,
рассчитанным для выборочной совокупности
на основании закона больших чисел,
согласно которому выборочная совокупность
при достаточно большом объеме выборки
достаточно точно воспроизводит
характеристики генеральной совокупности.
Т.о., расчетные формулы при случайном
повторном отборе будут выглядеть
следующим образом:
— для средней
количественного признака
![]() ,
,
где
![]() —
—
дисперсия признака в выборочной
совокупности.
— для доли
альтернативного признака
![]() ,
,
где
![]() — дисперсия доли признака в выборочной
— дисперсия доли признака в выборочной
совокупности.
Однако дисперсия
выборочной совокупности не равна
дисперсии генеральной совокупности и
в теории вероятностей доказано, что
генеральная дисперсия выражается через
выборочную следующим соотношением:
![]() ,
,
так как
![]() при достаточно больших
при достаточно больших![]() — величина близка к 1, то можно принять,
— величина близка к 1, то можно принять,
что![]() ,
,
но в случаях малой выборки, когда объем
выборки не превышает 30 единиц, необходимо
учитывать коэффициент![]() .
.
Тогда среднюю ошибку малой выборки
можно вычислить по формуле:
![]() .
.
При случайном
бесповторном отборе поскольку сокращается
численность единиц генеральной
совокупности, то в приведенные формулы
расчета средних ошибок выборки необходимо
подкоренное выражение умножить на
![]() ,
,
представляющий собой долю единиц
генеральной совокупности не попавших
в выборку. Следовательно формулы примут
вид:
— для средней
количественного признака
![]() .
.
— для доли
альтернативного признака
![]() .
.
Механическая
выборка
состоит в том, что отбор единиц в
выборочную совокупность из генеральной
разбитой по нейтральному признаку на
равные интервалы (группы) производится
так, что из каждой такой группы в выборку
отбирается лишь одна единица, т.е. он
бесповторный. И для того чтобы избежать
систематической ошибки, отбирается
единица, находящаяся в середине каждой
группы, при этом единицы совокупности
предварительно располагают в определенном
порядке (по алфавиту, или ранжируя
значения какого-либо показателя, не
связанного с изучаемым свойством и
др.).
При достаточно
большой совокупности механический
отбор точности результатов близок к
собственно-случайному. Поэтому для
определения средней ошибки механической
выборки используют формулы собственно
случайной бесповторной выборки.
Типическая
выборка
применяется
для отбора единиц из неоднородной
совокупности. Используется в тех случаях,
когда все единицы генеральной совокупности
можно разбить на несколько качественно
однородных групп по признакам, от которых
зависят изучаемые показатели. Затем из
каждой типической группы собственно-случайной
или механической выборкой производится
индивидуальный отбор единиц в выборочную
совокупность.
Типическая выборка
дает более точные результаты по сравнению
с другими способами отбора единиц в
выборочную совокупность, так как
представительство в ней каждой типической
группы позволяет исключить влияние
межгрупповой дисперсии на среднюю
ошибку выборки и в качестве показателя
вариации выступает средняя из
внутригрупповых дисперсий (остаточная).
Средние ошибки
типической выборки находят по формулам:
— для средней
количественного признака
повторный отбор
![]() ,
,
бесповторный отбор![]() ,
,
где
![]() —
—
средняя из внутригрупповых дисперсий
по выборочной совокупности.
— для доли
альтернативного признака
повторный отбор
![]() ,
,
бесповторный отбор![]() ,
,
где
![]() -средняя
-средняя
из внутригрупповых дисперсий доли
альтернативного признака по выборочной
совокупности.
Серийная выборка
предполагает случайный отбор из
генеральной совокупности не отдельных
единиц, а их равновеликих групп (гнезд,
серий), при этом все единицы без исключения
в таких группах подвергаются наблюдению.
Н: при транспортировке товар упакован
и при оценке качества рациональнее
проверить несколько упаковок, чем
вскрывать все упаковки и отбирать
необходимое количество товара.
Поскольку внутри
групп обследуются все без исключения
единицы, средняя ошибка выборки (при
отборе равновеликих серий), зависит
только от межгрупповой дисперсии.
Средние ошибки
серийной выборки находят по формулам:
— для средней
количественного признака
повторный отбор
![]() ,
,
бесповторный отбор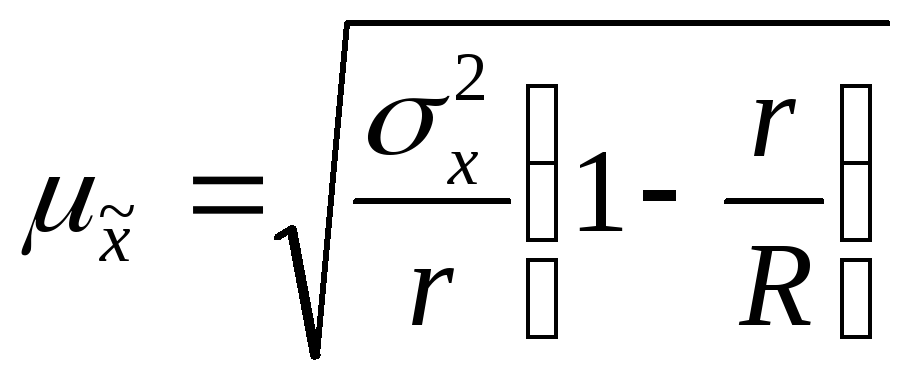 ,
,
при![]()
где
![]() — число отобранных серий;
— число отобранных серий;
![]() —
—
общее число серий;
![]() —
—
межгрупповая дисперсия,
![]() —
—
средняя![]() —
—
той серии,![]() -общая
-общая
средняя по всей выборочной совокупности.
— для доли
альтернативного признака
повторный отбор
![]() ,
,
бесповторный отбор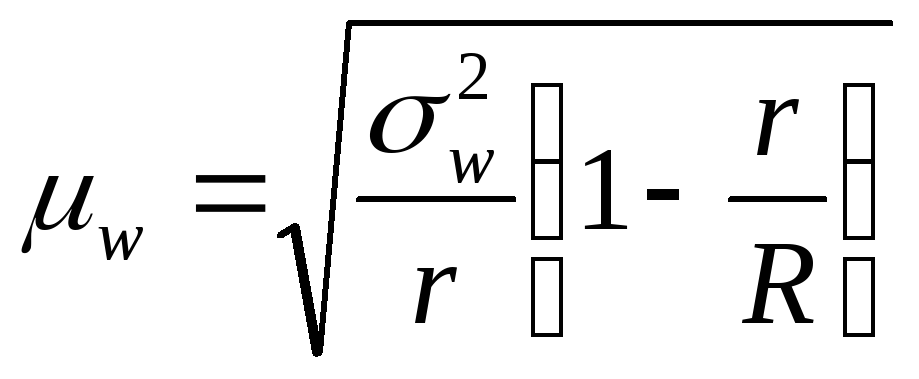 ,
,
при![]() ,
,
где
![]() —
—
межгрупповая дисперсия доли,![]() —
—
доля признака в![]() —
—
той серии,![]() —
—
общая доля признака во всей выборочной
совокупности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Выборка. Типы выборок. Расчет ошибки выборки
Калькуляторы
Калькулятор расчета ошибки и размера выборки
Калькулятор расчета статистической значимости различий
Генеральная совокупность
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих
определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и
времени. Примеры генеральных совокупностей
- Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
- Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
- Юридические лица России (2,2 млн. на начало 2005 года)
- Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и
т.д.
Выборка (Выборочная совокупность)
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей
генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на
всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и
нерепрезентативной для разных генеральных совокупностей.
Пример:
- Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население
Москвы. - Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
- Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать
москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках
соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от
ошибки никак не зависит от размера выборки.
Пример:
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой
всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера
выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной
вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об
ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих
результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни.
Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например,
дома). - Проблема респондентов, отказывающихся отвечать на вопросы
анкеты (доля «отказников» в Москве, для разных опросов,
колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот
или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
- вероятностные
- невероятностные
1. Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов,
наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата
рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер
генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы
(страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются
случайным образом. Объекты внутри групп обследуются сплошняком.
2.Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности,
типичности, равного представительства и т.д..
2.1. Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60
лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для
каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны
попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной
совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки
используются в маркетинговых исследованиях достаточно
часто.
2.2. Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег,
знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за
исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда
необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход,
респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения
и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – опросы в газетах/журналах, анкеты, отданные респондентам на самозаполнение, большинство
интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром –
активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает
проблема выбора признака и определения его типичного значения.
Курс лекций по теории статистики
Более подробную информацию по выборочным наблюдениям можно получить просмотрев видеокурс по теории статистики:
Выборочное наблюдение Способы формирование выборки
Специальные виды отбора
Калькулятор расчета ошибки и размера выборки (для простой случайной выборки)
Пояснения к полям:
Доверительная вероятность
Вероятность того, что доверительный интервал накроет неизвестное истинное значение параметра, оцениваемого по
выборочным данным. В практике исследований чаще всего используют 95%-ую доверительную вероятность
Ошибка выборки (доверительный интервал)
Интервал, вычисленный по выборочным данным, который с заданной вероятностью (доверительной) накрывает неизвестное
истинное значение оцениваемого параметра распределения.
Доля признака
Ожидаемая доля признака, для которого рассчитывается ошибка. В случае, если данные о доле признака отсутствуют,
необходимо использовать значение равное 50, при котором достигается максимальная ошибка.
Калькулятор расчета статистической значимости различий
Калькулятор позволяет проверить есть ли статистически значимая разница между долями признака, полученными из
независимых выборок.
Например, если до начала рекламной кампании марку знали 55% респондентов, а по окончании – 60% — есть ли между этими
долями статистически значимая разница, или же эта разница укладывается в ошибку выборки?
Примечание. Эта процедура может законно использоваться, только если обе выборки удовлетворяют следующему условию:
произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, должны быть не меньше 5.
Оставить свои комментарии по затронутой теме Вы можете на наших страницах в Facebook и Вконтакте.
При перепечатке материалов ссылка на маркетинговое агентство обязательна
FDF Group © 2023
Разработка сайта — Монохром
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.
3. Ошибки выборки
Каждая единица при выборочном наблюдении должна иметь равную с другими возможность быть отобранной – это является основой собственнослучайной выборки.
Собственнослучайная выборка – это отбор единиц из всей генеральной совокупности посредством жеребьевки или другим подобным способом.
Принципом случайности является то, что на включение или исключение объекта из выборки не может повлиять любой фактор, кроме случая.
Доля выборки – это отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:

Собственнослучайный отбор в чистом виде является исходным среди всех других видов отбора, в нем заключаются и реализуются основные принципы выборочного статистического наблюдения.
Два основных вида обобщающих показателей, которые используют в выборочном методе – это средняя величина количественного признака и относительная величина альтернативного признака.
Выборочная доля (w), или частность, определяется отношением числа единиц, обладающих изучаемым признаком m, к общему числу единиц выборочной совокупности (n):
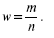
Для характеристики надежности выборочных показателей различают среднюю и предельную ошибки выборки.
Ошибка выборки, ее еще называют ошибкой репрезентативности, представляет собой разность соответствующих выборочных и генеральных характеристик:
1) для средней количественного признака:
?х =|х – х|;
2) для доли (альтернативного признака):
?w =|х – p|.
Только выборочным наблюдениям присуща ошибка выборки
Выборочная средняя и выборочная доля – это случайные величины, принимающие различные значения в зависимости от единиц изучаемой статистической совокупности, которые попали в выборку. Соответственно ошибки выборки – тоже случайные величины и также могут принимать различные значения. Поэтому определяют среднюю из возможных ошибок – среднюю ошибку выборки.
Средняя ошибка выборки определяется объемом выборки: чем больше численность при прочих равных условиях, тем меньше величина средней ошибки выборки. Охватывая выборочным обследованием все большее количество единиц генеральной совокупности, все более точно характеризуем всю генеральную совокупность.
Средняя ошибка выборки зависит от степени варьирования изучаемого признака, в свою очередь степень варьирования характеризуется дисперсией ?2 или w(l – w) – для альтернативного признака. Чем меньше вариация признака и дисперсия, тем меньше средняя ошибка выборки, и наоборот.
При случайном повторном отборе средние ошибки теоретически рассчитывают по следующим формулам:
1) для средней количественного признака:

где ?2 – средняя величина дисперсии количественного признака.
2) для доли (альтернативного признака):
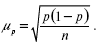
Так как дисперсия признака в генеральной совокупности ?2 точно неизвестна, на практике пользуются значением дисперсии S2 , рассчитанным для выборочной совокупности на основании закона больших чисел, согласно которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
Формулы средней ошибки выборки при случайном повторном отборе следующие. Для средней величины количественного признака: генеральная дисперсия выражается через выборную следующим соотношением:

где S2 – значение дисперсии.
Механическая выборка – это отбор единиц в выборочную совокупность из генеральной, которая разбита по нейтральному признаку на равные группы; производится так, что из каждой такой группы в выборку отбирается лишь одна единица.
При механическом отборе единицы изучаемой статистической совокупности предварительно располагают в определенном порядке, после чего отбирают заданное число единиц механически через определенный интервал. При этом размер интервала в генеральной совокупности равен обратному значению доли выборки.
При достаточно большой совокупности механический отбор по точности результатов близок к собственнослучайному Поэтому для определения средней ошибки механической выборки используют формулы собственнослучайной бесповторной выборки.
Для отбора единиц из неоднородной совокупности применяется так называемая типическая выборка, используется, когда все единицы генеральной совокупности можно разбить на несколько качественно однородных, однотипных групп по признакам, от которых зависят изучаемые показатели.
Затем из каждой типической группы собственнослучайной или механической выборкой производится индивидуальный отбор единиц в выборочную совокупность.
Типическая выборка обычно применяется при изучении сложных статистических совокупностей.
Типическая выборка дает более точные результаты. Типизация генеральной совокупности обеспечивает репрезентативность такой выборки, представительство в ней каждой типологической группы, что позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. Поэтому при определении средней ошибки типической выборки в качестве показателя вариации выступает средняя из внутригрупповых дисперсий.
Серийная выборка предполагает случайный отбор из генеральной совокупности равновеликих групп для того, чтобы в таких группах подвергать наблюдению все без исключения единицы.
Поскольку внутри групп (серий) обследуются все без исключения единицы, средняя ошибка выборки (при отборе равновеликих серий) зависит только от межгрупповой (межсерийной) дисперсии.
Данный текст является ознакомительным фрагментом.
Читайте также
Ошибки резидента
Ошибки резидента
Относиться к ошибкам можно по-разному: можно бояться их совершить и переживать из-за каждой из них, можно радоваться своим ошибкам и кризисам, как указателям на пути к успеху и личным победам. Неизменно в ошибках только одно – за них приходится платить.
Формирование выборки
Формирование выборки
Процедура выборки является неотъемлемым этапом проекта внутреннего аудита. Она подробно описана в различных источниках, посвященных теме аудита. Однако во многом такие описания носят академичный характер. Предлагаю заострить внимание на тех
Ошибки в инвестициях – это ошибки инвесторов
Ошибки в инвестициях – это ошибки инвесторов
Сейчас я больше, чем когда бы то ни было, убежден в том, что все ошибки в инвестициях на самом деле ошибки инвесторов.Инвестиции не совершают ошибок. В отличие от инвесторов.Инвестирование – это выбор. Именно об этой
29. Определение необходимой численности выборки
29. Определение необходимой численности выборки
Одним из научных принципов в теории выбороч–ного метода является обеспечение достаточного чи–сла отобранных единиц.Уменьшение стандартной ошибки выборки всег–да связано с увеличением объема выборки. Расчет
30. Способы отбора и виды выборки. Собственно случайная выборка
30. Способы отбора и виды выборки. Собственно случайная выборка
В теории выборочного метода разработаны раз–личные способы отбора и виды выборки, обеспечи–вающие репрезентативность. Под способом отбора понимают порядок отбора единиц из генеральной со–вокупности.
31. Механическая и типическая выборки
31. Механическая и типическая выборки
При чисто механической выборке вся ге–неральная совокупность единиц должна быть прежде всего представлена в виде списка единиц отбора, со–ставленного в каком-то нейтральном по отношению к изучаемому признаку порядке. Затем список
32. Серийная и комбинированная выборки
32. Серийная и комбинированная выборки
Серийная (гнездовая) выборка – это такой вид формирования выборочной совокупности, когда в случайном порядке отбираются не единицы, подле–жащие обследованию, а группы единиц (серии, гнез–да). Внутри отобранных серий (гнезд)
33. Многоступенчатая, многофазная и взаимопроникающая выборки.
33. Многоступенчатая, многофазная и взаимопроникающая выборки.
Особенность многоступенчатой выборки со–стоит в том, что выборочная совокупность формиру–ется постепенно, по ступеням отбора. На первой ступени с помощью заранее определенного спосо–ба и вида отбора
3. Определение необходимой численности выборки
3. Определение необходимой численности выборки
Одним из научных принципов в теории выборочного метода является обеспечение достаточного числа отобранных единиц. Теоретически необходимость соблюдения этого принципа представлена в доказательствах предельных теорем
4. Способы отбора и виды выборки
4. Способы отбора и виды выборки
В теории выборочного метода разработаны различные способы отбора и виды выборки, обеспечивающие репрезентативность. Под способом отбора понимают порядок отбора единиц из генеральной совокупности. Различают два способа отбора: повторный
36. Ошибки выборки
36. Ошибки выборки
Собственнослучайная выборка – это отбор единиц из всей генеральной совокупности посредством жеребьевки или другим подобным способом. Принципом случайности является то, что на включение или исключение объекта из выборки не может повлиять любой фактор,
Лексические ошибки
Лексические ошибки
1. Неправильное использование слов и терминовОсновная масса ошибок в деловых письмах относится к лексическим. Недостаточная грамотность приводит не только к курьезной бессмыслице, но и абсурду.Отдельные термины и профессиональные жаргонные слова
5 Наши ошибки
5
Наши ошибки
Мы настаиваем: выбранный курс рыночных реформ был верным. И они вовсе не потерпели неудачу, они только еще раз споткнулись. Но ошибки и упущения были. Это и наши ошибки, и ошибки руководства страны, которые мы не сумели предотвратить. Ошибки — во многом
Важность размера выборки
Важность размера выборки
Как я уже говорил, люди склонны уделять слишком много внимания редким случаям возникновения какого-то феномена, несмотря на то что со статистической точки зрения из нескольких случаев невозможно извлечь много информации. Это – основная причина
Репрезентативные выборки
Репрезентативные выборки
Репрезентативность наших тестов для целей предсказания будущего определяется двумя факторами:– Количество рынков: тесты, проводимые на различных рынках, будут, скорее всего, включать рынки с разной степенью волатильности типов
Размер выборки
Размер выборки
Концепция размера выборки проста: для того чтобы делать статистически достоверные заключения, нужно иметь достаточно большую выборку. Чем меньше выборка, тем грубее выводы, которые можно сделать; чем выборка больше, тем выводы качественнее. Нет никакого
Ошибка выборки — определение, типы, контроль и уменьшение ошибок
Опубликовано 2023-02-11 19:54 пользователем

Что такое ошибка выборки?
Ошибка выборки возникает, когда выборка, используемая в исследовании, не является репрезентативной для всей популяции. Ошибки выборки случаются часто, поэтому исследователи всегда рассчитывают предел ошибки при получении окончательных результатов в качестве статистической практики. Предел погрешности — это величина погрешности, допустимая при неправильном расчете, представляющая собой разницу между выборкой и реальной популяцией.
Выберите своих респондентов
Каковы наиболее распространенные ошибки выборки в маркетинговых исследованиях?
Вот четыре основные ошибки маркетинговых исследований при составлении выборки:
- Ошибка спецификации популяции: Ошибка спецификации популяции возникает, когда исследователи не знают, кого именно нужно опросить. Например, представьте себе исследование, посвященное детской одежде. Кого нужно опросить? Это могут быть оба родителя, только мать или ребенок. Родители принимают решение о покупке, но дети могут повлиять на их выбор.
- Ошибка выборочной совокупности: Ошибки выборочной совокупности возникают, когда исследователи неправильно ориентируются на субпопуляцию при отборе выборки. Например, выборка из телефонного справочника может иметь ошибочные включения, поскольку люди меняют свои города. Ошибочные исключения происходят, когда люди предпочитают не указывать свои номера. Богатые домохозяйства могут иметь более одного подключения, что приводит к многократным включениям.
- Ошибка отбора: Ошибка отбора происходит, когда респонденты сами выбирают себя для участия в исследовании. Отвечают только те, кто заинтересован. Ошибки отбора можно контролировать, если сделать дополнительный шаг и запросить ответы у всей выборки. Планирование перед опросом, последующие действия и аккуратный и чистый дизайн опроса повысят процент участия респондентов. Кроме того, попробуйте такие методы, как CATI-опросы и личные интервью, чтобы максимизировать количество ответов.
- Ошибки выборки: Ошибки выборки возникают из-за неравномерной репрезентативности респондентов. В основном это происходит, когда исследователь не планирует тщательно свою выборку. Эти ошибки выборки можно контролировать и устранять, создавая тщательный план выборки, имея достаточно большую выборку, отражающую все население, или используя для сбора ответов онлайн-выборку или аудиторию опроса.
Контроль ошибки выборки
Статистические теории помогают исследователям измерить вероятность ошибки выборки в зависимости от размера выборки и населения. Размер выборки, рассматриваемой из совокупности, в первую очередь определяет размер ошибки выборки. При больших размерах выборки вероятность ошибки ниже. Для понимания и оценки погрешности исследователи используют метрику, известную как предел погрешности. Обычно желаемым уровнем достоверности считается уровень достоверности в 95%.
Про совет: Если вам нужна помощь в расчете собственного предела погрешности, вы можете воспользоваться нашим калькулятором предела погрешности.
Каковы шаги по сокращению ошибок выборки?
Ошибки выборки легко выявить. Вот несколько простых шагов по уменьшению ошибки выборки:
- Увеличение размера выборки: Больший размер выборки дает более точный результат, поскольку исследование приближается к реальному размеру популяции.
- Разделение популяции на группы: Тестируйте группы в соответствии с их размером в популяции вместо случайной выборки. Например, если люди определенной демографической группы составляют 20% населения, убедитесь, что ваше исследование состоит из этой переменной, чтобы уменьшить смещение выборки.
- Знать свое население: Изучите свое население и поймите его демографический состав. Знайте, какие демографические группы используют ваш продукт и услугу, и убедитесь, что вы нацелены только на ту выборку, которая имеет значение.
Мы также создали инструмент, который поможет вам легко определить вашу выборку: Калькулятор размера выборки.
Ошибка выборки поддается измерению, и исследователи могут использовать ее в своих интересах, чтобы оценить точность своих выводов и оценить дисперсию.
Рубрика:
- Бизнес
Ключевые слова:
- аудитория
Автор:
- Dan Fleetwood
Источник:
- questionpro
Перевод:
- Дмитрий Л
What Is a Sampling Error?
A sampling error is a statistical error that occurs when an analyst does not select a sample that represents the entire population of data. As a result, the results found in the sample do not represent the results that would be obtained from the entire population.
Sampling is an analysis performed by selecting a number of observations from a larger population. The method of selection can produce both sampling errors and non-sampling errors.
Key Takeaways
- A sampling error occurs when the sample used in the study is not representative of the whole population.
- Sampling is an analysis performed by selecting a number of observations from a larger population.
- Even randomized samples will have some degree of sampling error because a sample is only an approximation of the population from which it is drawn.
- The prevalence of sampling errors can be reduced by increasing the sample size.
- In general, sampling errors can be placed into four categories: population-specific error, selection error, sample frame error, or non-response error.
Understanding Sampling Errors
A sampling error is a deviation in the sampled value versus the true population value. Sampling errors occur because the sample is not representative of the population or is biased in some way. Even randomized samples will have some degree of sampling error because a sample is only an approximation of the population from which it is drawn.
Calculating Sampling Error
The sampling error formula is used to calculate the overall sampling error in statistical analysis. The sampling error is calculated by dividing the standard deviation of the population by the square root of the size of the sample and then multiplying the resultant with the Z-score value, which is based on the confidence interval.
Sampling Error
=
Z
×
σ
n
where:
Z
=
Z
score value based on the
confidence interval (approx
=
1.96
)
σ
=
Population standard deviation
n
=
Size of the sample
begin{aligned}&text{Sampling Error}=Ztimesfrac{sigma}{sqrt{n}}\&textbf{where:}\&Z=Ztext{ score value based on the}\&qquad text{confidence interval (approx}=1.96)\&sigma=text{Population standard deviation}\&n=text{Size of the sample}end{aligned}
Sampling Error=Z×nσwhere:Z=Z score value based on the confidence interval (approx=1.96)σ=Population standard deviationn=Size of the sample
Types of Sampling Errors
There are different categories of sampling errors.
Population-Specific Error
A population-specific error occurs when a researcher doesn’t understand who to survey.
Selection Error
Selection error occurs when the survey is self-selected, or when only those participants who are interested in the survey respond to the questions. Researchers can attempt to overcome selection error by finding ways to encourage participation.
Sample Frame Error
A sample frame error occurs when a sample is selected from the wrong population data.
Non-response Error
A non-response error occurs when a useful response is not obtained from the surveys because researchers were unable to contact potential respondents (or potential respondents refused to respond).
Eliminating Sampling Errors
The prevalence of sampling errors can be reduced by increasing the sample size. As the sample size increases, the sample gets closer to the actual population, which decreases the potential for deviations from the actual population. Consider that the average of a sample of 10 varies more than the average of a sample of 100. Steps can also be taken to ensure that the sample adequately represents the entire population.
Researchers might attempt to reduce sampling errors by replicating their study. This could be accomplished by taking the same measurements repeatedly, using more than one subject or multiple groups, or by undertaking multiple studies.
Random sampling is an additional way to minimize the occurrence of sampling errors. Random sampling establishes a systematic approach to selecting a sample. For example, rather than choosing participants to be interviewed haphazardly, a researcher might choose those whose names appear first, 10th, 20th, 30th, 40th, and so on, on the list.
Examples of Sampling Errors
Assume that XYZ Company provides a subscription-based service that allows consumers to pay a monthly fee to stream videos and other types of programming via an Internet connection.
The firm wants to survey homeowners who watch at least 10 hours of programming via the Internet per week and that pay for an existing video streaming service. XYZ wants to determine what percentage of the population is interested in a lower-priced subscription service. If XYZ does not think carefully about the sampling process, several types of sampling errors may occur.
A population specification error would occur if XYZ Company does not understand the specific types of consumers who should be included in the sample. For example, if XYZ creates a population of people between the ages of 15 and 25 years old, many of those consumers do not make the purchasing decision about a video streaming service because they may not work full-time. On the other hand, if XYZ put together a sample of working adults who make purchase decisions, the consumers in this group may not watch 10 hours of video programming each week.
Selection error also causes distortions in the results of a sample. A common example is a survey that only relies on a small portion of people who immediately respond. If XYZ makes an effort to follow up with consumers who don’t initially respond, the results of the survey may change. Furthermore, if XYZ excludes consumers who don’t respond right away, the sample results may not reflect the preferences of the entire population.
Sampling Error vs. Non-sampling Error
There are different types of errors that can occur when gathering statistical data. Sampling errors are the seemingly random differences between the characteristics of a sample population and those of the general population. Sampling errors arise because sample sizes are inevitably limited. (It is impossible to sample an entire population in a survey or a census.)
A sampling error can result even when no mistakes of any kind are made; sampling errors occur because no sample will ever perfectly match the data in the universe from which the sample is taken.
Company XYZ will also want to avoid non-sampling errors. Non-sampling errors are errors that result during data collection and cause the data to differ from the true values. Non-sampling errors are caused by human error, such as a mistake made in the survey process.
If one group of consumers only watches five hours of video programming a week and is included in the survey, that decision is a non-sampling error. Asking questions that are biased is another type of error.
What Is Sampling Error vs. Sampling Bias?
In statistics, sampling means selecting the group that you will actually collect data from in your research.
Sampling bias is the expectation, which is known in advance, that a sample won’t be representative of the true population. For instance, if the sample ends up having proportionally more women or young people than the overall population.
Sampling errors are statistical errors that arise when a sample does not represent the whole population once analyses have been undertaken.
Why Is Sampling Error Important?
Being aware of the presence of sampling errors is important because it can be an indicator of the level of confidence that can be placed in the results. Sampling error is also important in the context of a discussion about how much research results can vary.
How Do You Find the Sampling Error?
In survey research, sampling errors occur because all samples are representative samples: a smaller group that stands in for the whole of your research population. It’s impossible to survey the entire group of people you’d like to reach.
It’s not usually possible to quantify the degree of sampling error in a study since it’s impossible to collect the relevant data from the entire population you are studying. This is why researchers collect representative samples (and representative samples are the reason why there are sampling errors).
What Is Sampling Error vs. Standard Error?
Sampling error is derived from the standard error (SE) by multiplying it by a Z-score value to produce a confidence interval.
The standard error is computed by dividing the standard deviation by the square root of the sample size.
The Bottom Line
Sampling error occurs when a sample drawn from a population deviates somewhat from that true population. Large sampling errors can lead to incorrect estimates or inferences made about the population based on statistical analysis of that sample.
In general, sampling errors can be placed into four categories: population-specific error, selection error, sample frame error, or non-response error. A population-specific error occurs when the researcher does not understand who they should survey. A selection error occurs when respondents self-select their participation in the study. (This results in only those that are interested in responding, which skews the results.) A sample frame error occurs when the wrong sub-population is used to select a sample. Finally, a non-response error occurs when potential respondents are not successfully contacted or refuse to respond.
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.