Тема 8. Доверительные интервалы прогноза. Оценка адекватности и точности моделей
Доверительные интервалы прогноза
Прогнозные значения исследуемого показателя вычисляют путем подстановки в уравнение кривой значений времени t, соответствующих периоду упреждения. Полученный таким образом прогноз называется точечным прогнозом. На практике в дополнение к точечному определяют границы возможного значения прогнозированного показателя, то есть вычисляют интервальный прогноз.
Несовпадение фактических данных с точечным прогнозом может быть вызвано:
1) субъективной ошибочностью выбора вида кривой;
2) погрешностью оценивания параметров кривых;
3) погрешностью, связанной с отклонением отдельных наблюдений от тренда.
Погрешность, связанная со вторым и третьим источником, может быть отражена в виде доверительного интервала прогноза. Доверительный интервал прогноза определяется в следующем виде:

Рекомендуемые материалы

Ширина доверительного интервала зависит от уровня значимости, периода упреждения, среднего квадратического отклонения от тренда и степени полинома. Чем выше степень полинома, тем шире доверительный интервал при одном и том же значении Sр, так как дисперсия уравнения тренда вычисляется как взвешенная сумма дисперсий соответствующих параметров уравнения
Доверительные интервалы прогнозов, полученных с использованием уравнения экспоненты, определяют аналогичным образом. Отличие состоит в том, что как при вычислении параметров кривой, так и при вычислении средней квадратической ошибки используют не сами значения уровней временного ряда, а их логарифмы.
По такой же схеме могут быть определены доверительные интервалы для ряда кривых, имеющих асимптоты, в случае, если значение асимптоты известно (например, для модифицированной экспоненты).
В таблице приведены значения K* в зависимости от длины временного ряда n и периода упреждения L для прямой и параболы. Очевидно, что при увеличении длины рядов (n) значения K* уменьшаются, с ростом периода упреждения L значения K* увеличиваются. При этом влияние периода упреждения неодинаково для различных значений n : чем больше длина ряда, тем меньшее влияние оказывает период упреждения L.

Например, для временного ряда розничного товарооборота региона, длиной 20, оценены параметры модели yt=10,2+1,2t, и дисперсия отклонений фактических значений от теоретических S2y=0.25. Используя эту модель рассчитать точечный и интервальный прогнозы в точке n=21.
Упрогн=10,2+1,2*21=35,4
Sy= =
=  =0.5
=0.5
K*=1.9117
Упрогн=35,4±0,5*1,9117=35,4±0,96=
Проверка адекватности выбранных моделей
Проверка адекватности выбранных моделей реальному процессу строится на анализе случайной компоненты. Случайная (остаточная) компонента получается после выделения из исследуемого ряда тренда и периодической составляющей. Предположим, что исходный временной ряд описывает процесс, не подверженный периодическими колебаниями, то есть примем гипотезу об аддитивной модели временного ряда:
Уt=ut+et
Тогда ряд случайной компоненты будет получен как отклонение фактических уровней временного ряда (yt) от выровненных, расчетных 


Принято считать, что модель адекватна описываемому процессу, если значения остаточной компоненты удовлетворяют свойствам независимости и подчиняются закону нормального распределения.
При правильном выборе вида тренда отклонения от него будут носить случайный характер. Это означает, что изменение остаточной случайной величины не связано с изменением времени. Таким образом, по выборке, полученной для всех моментов времени на изучаемом интервале, проверяется гипотеза о зависимости последовательности значений et от времени, или, что то же самое, о наличии тенденции в ее изменении. Поэтому для проверки данного свойства может быть использован один из критериев, например, критерий серий.
Если вид функции, описывающей тренд, выбран неудачно, то последовательные значения ряда остатков могут не обладать свойствами независимости, так как они могут коррелировать между собой. В этом случае имеет место явление автокорреляции.
В условиях автокорреляции оценки параметров модели будут обладать свойствами несмещенности и состоятельности.
Существует несколько приемов обнаружения автокорреляции. Наиболее распространенным является метод, предложенный Дарбиным и Уотсоном.
Критерий Дарбина-Уотсона связан с гипотезой о существовании автокорреляции первого порядка (то есть между соседними остаточными уровнями ряда). Значение этого критерия определяется по формуле:
d=
Можно показать, что величина d приближенно равна:

где r1- коэффициент автокорреляции первого порядка (т.е. парный коэффициент корреляции между двумя рядами e1, e2, … ,en-1 и e2, e3, …, en).
Из последней формулы видно, что если в значениях et имеется сильная положительная автокорреляция  ,то величина d=0 , в случае сильной отрицательной автокорреляции
,то величина d=0 , в случае сильной отрицательной автокорреляции  d=4. При отсутствии автокорреляции
d=4. При отсутствии автокорреляции  .
.
Для этого критерия найдены критические границы, позволяющие принять или отвергнуть гипотезу об отсутствии автокорреляции. Авторами критерия границы определены для 1, 2,5 и 5% уровней значимости.
Рассчитанные значения d сравнивают с табличными значениями. Здесь ( в таблице): d1 и d2 — соответственно нижняя и верхняя доверительная граница критерия d;
К – число переменных в модели
n – длина ряда.
При сравнении величины d с d1 и d2 возможны следующие ситуации:
1) d< d2, то гипотеза об отсутствии автокорреляции отвергается;
2) d> d2, то гипотеза об отсутствии автокорреляции не отвергается;
3) d1≤ d≤ d2, то нет достаточных основании для принятия решений, величина попадает в область неопределенности.
Рассмотренные варианты относятся к случаю, когда в остатках имеется положительная автокорреляция. Когда же расчетное значение d превышает 2, то можно говорить о том, что в et существует отрицательная автокорреляция. Для проверки отрицательной автокорреляции с критическими значениями d1 и d2 сравнивается не сам коэффициент d, а 4-d.
Поскольку временные ряды экономических показателей, как правило, небольшие, то проверка распределения на нормальность может быть произведена лишь приближенно на основе исследования показателей ассиметрии и эксцесса.
При нормальном распределении показатели ассиметрии и эксцесса равны нулю.
Можно рассчитать показатель ассиметрии и эксцесса, их средние квадратические ошибки:
А=

Э=

Если одновременно выполняются следующие неравенства:
 ,
,
то гипотеза о нормальном характере распределения случайной компоненты не отвергается.
Если выполняется хотя бы одно из следующих неравенств:
 ,
,
то гипотеза о нормальном характере распределения отвергается.
|
t |
Yt |
|
1 |
47 |
|
2 |
51 |
|
3 |
55 |
|
4 |
59 |
|
5 |
62 |
|
6 |
66 |
|
7 |
70 |
|
8 |
75 |
|
9 |
79 |
|
10 |
82 |
|
11 |
86 |
|
12 |
89 |
|
13 |
92 |
|
14 |
96 |
|
15 |
100 |
|
16 |
103 |
d=
Еt= уt-утеор
Yтеор=a0+a1t
а0= а1=
а1=
n=16
К´=1
d1=1.1
d2=1.37
d=1.4E-17
Гипотеза об отсутствии автокорреляции отвергается.
Характеристики точности моделей
Чтобы судить о качестве выбранной модели необходимо проанализировать систему показателей, характеризующих как адекватность модели, так и ее точность. О точности прогноза судят по величине ошибки прогноза.
Ошибка прогноза – это величина, характеризующая расхождения между прогнозным значением показателя и фактическим значением.
Абсолютная ошибка прогноза определяется по формуле:
 у прогн. – yt
у прогн. – yt
Относительная ошибка прогноза:
δt=
Используются также средние ошибки по модулю.
Абсолютная ошибка по модулю:

Относительная средняя ошибка по модулю:
S=
Если абсолютная и относительная ошибка >0, то это свидетельствует о завышенной прогнозной оценке, а если <0, то прогноз был занижен. Эти характеристики могут быть вычислены после того, как период упреждения уже закончился и имеются фактические данные о прогнозируемом показателе.
При проведении сравнительной оценки моделей прогнозирования применяются также дисперсия и среднее квадратическое отклонение:
S2=
S=
Чем меньше значение дисперсии и среднее квадратическое отклонение, тем выше точность модели.
О точности модели нельзя судить по одному значению ошибки прогноза, поскольку единичный хороший прогноз может быть получен и по плохой модели, поэтому о качестве применяемых моделей можно судить лишь по совокупности сопоставлений прогнозных значений с фактическими.
Простой мерой качества прогнозов может служить характеристика  . Это относительное число случаев, когда фактическое значение охватывалось интервальным прогнозом:
. Это относительное число случаев, когда фактическое значение охватывалось интервальным прогнозом:
 ,
,
где Р – число прогнозов, подтвержденных фактическими данными;
q – число прогнозов, не подтвержденных фактическими данными.
Сопоставление характеристик для разных моделей может иметь смысл при условии, что доверительные вероятности приняты одинаковыми.
|
t |
yt |
|
|
Условное время |
Утеор |
|
1 |
91,6 |
— |
— |
-5 |
91,64 |
|
2 |
91,5 |
-0,1 |
— |
-4 |
91,47 |
|
3 |
91,3 |
-0,2 |
-0,1 |
-3 |
92,3 |
|
4 |
91,1 |
-0,2 |
0 |
-2 |
91,13 |
|
5 |
91,0 |
-0,1 |
0,1 |
-1 |
90,96 |
|
6 |
90,8 |
-0,2 |
-0,1 |
0 |
90,79 |
|
7 |
90,6 |
-0,2 |
0 |
1 |
90,62 |
|
8 |
90,4 |
-0,2 |
0 |
2 |
90,45 |
|
9 |
90,2 |
-0,2 |
0 |
3 |
90,28 |
|
10 |
90,0 |
-0,2 |
0 |
4 |
90,11 |
|
11 |
89,9 |
-0,1 |
0,1 |
5 |
89,94 |
|
Итого |
-17 |
0 |


-0,1-(-0,2)=0,1

Утеор = 90,79-0,17t
|
Месяц |
Прогнозное значение |
Фактическое значение |
|
|
1 модель |
2 модель |
||
|
Апрель |
35400 |
36300 |
36505 |
|
Май |
41600 |
Ещё посмотрите лекцию «34 Девиация» по этой теме. 99200 |
40524 |
|
Июнь |
45600 |
43100 |
45416 |
Онлайн-тестыТестыМатематика и статистикаЭконометрикавопросы
211. Отличие одностороннего теста от двустороннего заключается в том, что он имеет только
• одно критическое значение
212. Относительная ошибка прогноза определяется как:
• 
213. Оценивание каждого параметра в уравнении регрессии поглощает __________________ свободы в выборке.
• одну степень
214. Оценка a для параметра уравнения парной регрессии при использовании МНК вычисляется по формуле a =
• 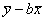
215. Оценка b для параметра уравнения парной регрессии при использовании МНК вычисляется по формуле b =
• 
216. Оценка ρ, полученная МНК для авторегрессионной схемы первого порядка рассчитывается по формуле __________________, ek — остатки в наблюдениях.
• cov (ek-1, ek) / var (ek-1)
217. Оценка параметра а для модели множественной регрессии в случае двух независимых переменных вычисляется по формуле: а =
• 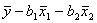
218. Оценка параметра находится __________________ доверительного интервала.
• в центре
219. Оценка параметров в лаговой структуре Койка делается:
• решетчатым методом
220. Оценка стандартного отклонения случайной величины, полученная по данным выборки, называется стандартной __________________ случайной величины.
• ошибкой
221. Первое условие Гаусса-Маркова заключается в том, что __________________ для любого i.
• М (ui) = 0
222. Первый шаг метода Зарембки заключается в вычислении __________________ y по выборке.
• среднего геометрического
223. Пересмотр оценок в методе Кокрана-Оркатта выполняется до тех пор, пока не будет __________________ оценок.
• получена требуемая точность
224. Плоскость регрессии y = a + b1x1 + b2x2 — двумерная плоскость в __________________ пространстве.
• трехмерном
225. Подбор порядка аппроксимирующего полинома производится при помощи
• метода последовательных разностей
211. Отличие одностороннего теста от двустороннего заключается в том, что он имеет только
• одно критическое значение
212. Относительная ошибка прогноза определяется как:
•
213. Оценивание каждого параметра в уравнении регрессии поглощает __________________ свободы в выборке.
• одну степень
214. Оценка a для параметра уравнения парной регрессии при использовании МНК вычисляется по формуле a =
•
215. Оценка b для параметра уравнения парной регрессии при использовании МНК вычисляется по формуле b =
•
216. Оценка ρ, полученная МНК для авторегрессионной схемы первого порядка рассчитывается по формуле __________________, ek — остатки в наблюдениях.
• cov (ek-1, ek) / var (ek-1)
217. Оценка параметра а для модели множественной регрессии в случае двух независимых переменных вычисляется по формуле: а =
•
218. Оценка параметра находится __________________ доверительного интервала.
• в центре
219. Оценка параметров в лаговой структуре Койка делается:
• решетчатым методом
220. Оценка стандартного отклонения случайной величины, полученная по данным выборки, называется стандартной __________________ случайной величины.
• ошибкой
221. Первое условие Гаусса-Маркова заключается в том, что __________________ для любого i.
• М (ui) = 0
222. Первый шаг метода Зарембки заключается в вычислении __________________ y по выборке.
• среднего геометрического
223. Пересмотр оценок в методе Кокрана-Оркатта выполняется до тех пор, пока не будет __________________ оценок.
• получена требуемая точность
224. Плоскость регрессии y = a + b1x1 + b2x2 — двумерная плоскость в __________________ пространстве.
• трехмерном
225. Подбор порядка аппроксимирующего полинома производится при помощи
• метода последовательных разностей
Тема 8. Доверительные интервалы прогноза. Оценка адекватности и точности моделей
Доверительные интервалы прогноза
Прогнозные значения исследуемого показателя вычисляют путем подстановки в уравнение кривой значений времени t, соответствующих периоду упреждения. Полученный таким образом прогноз называется точечным прогнозом. На практике в дополнение к точечному определяют границы возможного значения прогнозированного показателя, то есть вычисляют интервальный прогноз.
Несовпадение фактических данных с точечным прогнозом может быть вызвано:
1) субъективной ошибочностью выбора вида кривой;
2) погрешностью оценивания параметров кривых;
3) погрешностью, связанной с отклонением отдельных наблюдений от тренда.
Погрешность, связанная со вторым и третьим источником, может быть отражена в виде доверительного интервала прогноза. Доверительный интервал прогноза определяется в следующем виде:
Рекомендуемые материалы
Ширина доверительного интервала зависит от уровня значимости, периода упреждения, среднего квадратического отклонения от тренда и степени полинома. Чем выше степень полинома, тем шире доверительный интервал при одном и том же значении Sр, так как дисперсия уравнения тренда вычисляется как взвешенная сумма дисперсий соответствующих параметров уравнения
Доверительные интервалы прогнозов, полученных с использованием уравнения экспоненты, определяют аналогичным образом. Отличие состоит в том, что как при вычислении параметров кривой, так и при вычислении средней квадратической ошибки используют не сами значения уровней временного ряда, а их логарифмы.
По такой же схеме могут быть определены доверительные интервалы для ряда кривых, имеющих асимптоты, в случае, если значение асимптоты известно (например, для модифицированной экспоненты).
В таблице приведены значения K* в зависимости от длины временного ряда n и периода упреждения L для прямой и параболы. Очевидно, что при увеличении длины рядов (n) значения K* уменьшаются, с ростом периода упреждения L значения K* увеличиваются. При этом влияние периода упреждения неодинаково для различных значений n : чем больше длина ряда, тем меньшее влияние оказывает период упреждения L.
Например, для временного ряда розничного товарооборота региона, длиной 20, оценены параметры модели yt=10,2+1,2t, и дисперсия отклонений фактических значений от теоретических S2y=0.25. Используя эту модель рассчитать точечный и интервальный прогнозы в точке n=21.
Упрогн=10,2+1,2*21=35,4
Sy== =0.5
K*=1.9117
Упрогн=35,4±0,5*1,9117=35,4±0,96=
Проверка адекватности выбранных моделей
Проверка адекватности выбранных моделей реальному процессу строится на анализе случайной компоненты. Случайная (остаточная) компонента получается после выделения из исследуемого ряда тренда и периодической составляющей. Предположим, что исходный временной ряд описывает процесс, не подверженный периодическими колебаниями, то есть примем гипотезу об аддитивной модели временного ряда:
Уt=ut+et
Тогда ряд случайной компоненты будет получен как отклонение фактических уровней временного ряда (yt) от выровненных, расчетных
Принято считать, что модель адекватна описываемому процессу, если значения остаточной компоненты удовлетворяют свойствам независимости и подчиняются закону нормального распределения.
При правильном выборе вида тренда отклонения от него будут носить случайный характер. Это означает, что изменение остаточной случайной величины не связано с изменением времени. Таким образом, по выборке, полученной для всех моментов времени на изучаемом интервале, проверяется гипотеза о зависимости последовательности значений et от времени, или, что то же самое, о наличии тенденции в ее изменении. Поэтому для проверки данного свойства может быть использован один из критериев, например, критерий серий.
Если вид функции, описывающей тренд, выбран неудачно, то последовательные значения ряда остатков могут не обладать свойствами независимости, так как они могут коррелировать между собой. В этом случае имеет место явление автокорреляции.
В условиях автокорреляции оценки параметров модели будут обладать свойствами несмещенности и состоятельности.
Существует несколько приемов обнаружения автокорреляции. Наиболее распространенным является метод, предложенный Дарбиным и Уотсоном.
Критерий Дарбина-Уотсона связан с гипотезой о существовании автокорреляции первого порядка (то есть между соседними остаточными уровнями ряда). Значение этого критерия определяется по формуле:
d=
Можно показать, что величина d приближенно равна:
где r1- коэффициент автокорреляции первого порядка (т.е. парный коэффициент корреляции между двумя рядами e1, e2, … ,en-1 и e2, e3, …, en).
Из последней формулы видно, что если в значениях et имеется сильная положительная автокорреляция ,то величина d=0 , в случае сильной отрицательной автокорреляции d=4. При отсутствии автокорреляции .
Для этого критерия найдены критические границы, позволяющие принять или отвергнуть гипотезу об отсутствии автокорреляции. Авторами критерия границы определены для 1, 2,5 и 5% уровней значимости.
Рассчитанные значения d сравнивают с табличными значениями. Здесь ( в таблице): d1 и d2 — соответственно нижняя и верхняя доверительная граница критерия d;
К – число переменных в модели
n – длина ряда.
При сравнении величины d с d1 и d2 возможны следующие ситуации:
1) d< d2, то гипотеза об отсутствии автокорреляции отвергается;
2) d> d2, то гипотеза об отсутствии автокорреляции не отвергается;
3) d1≤ d≤ d2, то нет достаточных основании для принятия решений, величина попадает в область неопределенности.
Рассмотренные варианты относятся к случаю, когда в остатках имеется положительная автокорреляция. Когда же расчетное значение d превышает 2, то можно говорить о том, что в et существует отрицательная автокорреляция. Для проверки отрицательной автокорреляции с критическими значениями d1 и d2 сравнивается не сам коэффициент d, а 4-d.
Поскольку временные ряды экономических показателей, как правило, небольшие, то проверка распределения на нормальность может быть произведена лишь приближенно на основе исследования показателей ассиметрии и эксцесса.
При нормальном распределении показатели ассиметрии и эксцесса равны нулю.
Можно рассчитать показатель ассиметрии и эксцесса, их средние квадратические ошибки:
А=
Э=
Если одновременно выполняются следующие неравенства:
,
то гипотеза о нормальном характере распределения случайной компоненты не отвергается.
Если выполняется хотя бы одно из следующих неравенств:
,
то гипотеза о нормальном характере распределения отвергается.
|
t |
Yt |
|
1 |
47 |
|
2 |
51 |
|
3 |
55 |
|
4 |
59 |
|
5 |
62 |
|
6 |
66 |
|
7 |
70 |
|
8 |
75 |
|
9 |
79 |
|
10 |
82 |
|
11 |
86 |
|
12 |
89 |
|
13 |
92 |
|
14 |
96 |
|
15 |
100 |
|
16 |
103 |
d=
Еt= уt-утеор
Yтеор=a0+a1t
а0= а1=
n=16
К´=1
d1=1.1
d2=1.37
d=1.4E-17
Гипотеза об отсутствии автокорреляции отвергается.
Характеристики точности моделей
Чтобы судить о качестве выбранной модели необходимо проанализировать систему показателей, характеризующих как адекватность модели, так и ее точность. О точности прогноза судят по величине ошибки прогноза.
Ошибка прогноза – это величина, характеризующая расхождения между прогнозным значением показателя и фактическим значением.
Абсолютная ошибка прогноза определяется по формуле:
у прогн. – yt
Относительная ошибка прогноза:
δt=
Используются также средние ошибки по модулю.
Абсолютная ошибка по модулю:
Относительная средняя ошибка по модулю:
S=
Если абсолютная и относительная ошибка >0, то это свидетельствует о завышенной прогнозной оценке, а если <0, то прогноз был занижен. Эти характеристики могут быть вычислены после того, как период упреждения уже закончился и имеются фактические данные о прогнозируемом показателе.
При проведении сравнительной оценки моделей прогнозирования применяются также дисперсия и среднее квадратическое отклонение:
S2=
S=
Чем меньше значение дисперсии и среднее квадратическое отклонение, тем выше точность модели.
О точности модели нельзя судить по одному значению ошибки прогноза, поскольку единичный хороший прогноз может быть получен и по плохой модели, поэтому о качестве применяемых моделей можно судить лишь по совокупности сопоставлений прогнозных значений с фактическими.
Простой мерой качества прогнозов может служить характеристика . Это относительное число случаев, когда фактическое значение охватывалось интервальным прогнозом:
,
где Р – число прогнозов, подтвержденных фактическими данными;
q – число прогнозов, не подтвержденных фактическими данными.
Сопоставление характеристик для разных моделей может иметь смысл при условии, что доверительные вероятности приняты одинаковыми.
|
t |
yt |
|
|
Условное время |
Утеор |
|
1 |
91,6 |
— |
— |
-5 |
91,64 |
|
2 |
91,5 |
-0,1 |
— |
-4 |
91,47 |
|
3 |
91,3 |
-0,2 |
-0,1 |
-3 |
92,3 |
|
4 |
91,1 |
-0,2 |
0 |
-2 |
91,13 |
|
5 |
91,0 |
-0,1 |
0,1 |
-1 |
90,96 |
|
6 |
90,8 |
-0,2 |
-0,1 |
0 |
90,79 |
|
7 |
90,6 |
-0,2 |
0 |
1 |
90,62 |
|
8 |
90,4 |
-0,2 |
0 |
2 |
90,45 |
|
9 |
90,2 |
-0,2 |
0 |
3 |
90,28 |
|
10 |
90,0 |
-0,2 |
0 |
4 |
90,11 |
|
11 |
89,9 |
-0,1 |
0,1 |
5 |
89,94 |
|
Итого |
-17 |
0 |
-0,1-(-0,2)=0,1
Утеор = 90,79-0,17t
|
Месяц |
Прогнозное значение |
Фактическое значение |
|
|
1 модель |
2 модель |
||
|
Апрель |
35400 |
36300 |
36505 |
|
Май |
41600 |
Ещё посмотрите лекцию «34 Девиация» по этой теме. 99200 |
40524 |
|
Июнь |
45600 |
43100 |
45416 |
Для анализа результатов расчета прогноза, в продолжение ряда вы можете рассчитать следующие ошибки:
- MAPE – средняя абсолютная ошибка в % . Ошибка оценивает на сколько велики ошибки в сравнении со значением ряда и с ошибками в соседних рядах.
Подробнее читайте в статье на нашем сайте: http://4analytics.ru/metodi-analiza/mape-%E2%80%93-srednyaya-absolyutnaya-oshibka-praktika-primeneniya.html - MRPE – средняя относительная ошибка в %, оценивает на сколько велика дельта между фактом и прогнозом. Чем ближе к 100%, тем больше ошибка, чем ближе к нулю, тем ошибка меньше.
- MSE – средняя квадратическая ошибка, подчеркивает большие ошибки за счет возведения каждой ошибки в квадрат.
Подробнее читайте в статье на нашем сайте:
http://4analytics.ru/metodi-analiza/mse-%E2%80%93-srednekvadraticheskaya-oshibka-v-excel.html - MPE – средняя процентная ошибка – показывает завышен или занижен прогноз относительно факта. Если ошибка меньше нулю, то прогноз последовательно завышен, если ошибка больше нуля, то прогноз последовательно занижен.
Подробнее читайте в статье на нашем сайте:
http://4analytics.ru/metodi-analiza/mpe-%E2%80%93-srednyaya-procentnaya-oshibka-v-excel.html - MAD – среднее абсолютное отклонение. Используется, когда важно измерить ошибку в тех же единицах, что и исходный ряд.
Подробнее читайте в статье на нашем сайте:
http://4analytics.ru/planirovanie-i-prognozirovanie-praktika/dopolnitelnie-oborotnie-sredstva-za-schet-povisheniya-tochnosti-prognoza.html - A MAPE – ошибка, которая показывает отклонение средних значений ряда к средним значениям модели прогноза. Имеет значение при неравномерном перераспределении значений ряда по периодам.
- S MAPE – ошибка, которая показывает отклонение суммы значения ряда к сумме значений модели прогноза. Имеет значение при неравномерном перераспределении значений ряда по периодам.
А также 2 показателя «Точность прогноза»:
- Точность прогноза = 1 – МАРЕ
- Точность прогноза 2 = 1 – MRPE
Для расчета ошибок одновременно с прогнозом, нажимаем кнопку «Расчет ошибок» в меню «FORECAST»

В открывшемся окне выбираем нужные для расчета ошибки:
Теперь при расчете прогноза, в продолжение ряда, программа автоматически сделает расчет отмеченных Вами ошибок:

1. Оценка точности прогнозов.
оценка точности и надежности прогнозов.
Оценка точности прогнозов.
2.
Эмпирической мерой точности прогноза,
служит величина его ошибки, которая
определяется как разность между
прогнозным ( ) и фактическими (уt)
значениями исследуемого показателя.
3. Данный подход возможен только в двух случаях:
а) период упреждения известен, уже
закончился, и исследователь располагает
необходимыми фактическими значениями
прогнозируемого показателя;
б) строится ретроспективный прогноз, то есть
рассчитываются прогнозные значения
показателя для периода времени, за который
уже имеются фактические значения.
Это делается с целью проверки
разработанной методики прогнозирования.
4. Все показатели оценки точности статистических прогнозов условно можно разделить на три группы:
– аналитические;
– сравнительные;
– качественные.
5.
Аналитические показатели
точности прогноза позволяют
количественно определить
величину ошибки прогноза. К ним
относятся:
6. Абсолютная ошибка прогноза (D*)
Абсолютная ошибка прогноза (D*)
— определяется как разность между
эмпирическими и прогнозными значениями
признака и вычисляется по формуле:
где:
уt–фактическое значение признака;
–прогнозное значение признака.
7. Относительная ошибка прогноза (d*отн)
Относительная ошибка прогноза
(d*отн)
1.
2.
может быть определена как отношение
абсолютной ошибки прогноза (D*):
к фактическому значению признака (уt ) :
к прогнозному значению признака
8.
Абсолютная и относительная ошибки прогноза
являются оценкой проверки точности единичного
прогноза, что снижает их значимость в оценке
точности всей прогнозной модели, так как изучаемое
социально-экономическое явление подвержено
влиянию различных факторов внешнего и
внутреннего свойства. Единично удовлетворительный
прогноз может быть получен и на базе реализации
слабо обусловленной и недостаточно адекватной
прогнозной модели и наоборот – можно получить
большую ошибку прогноза по достаточно хорошо
аппроксимирующей модели.
9.
Поэтому на практике иногда определяют не
ошибку прогноза, а некоторый коэффициент
качества прогноза (Кк), который показывает
соотношение между числом совпавших (с) и
общим числом совпавших (с) и несовпавших (н)
прогнозов и определяется по формуле:
10.
Значение Кк = 1 означает, что имеет место
полное совпадение значений прогнозных и
фактических значений и модель на 100%
описывает изучаемое явление. Данный показатель
оценивает удовлетворительный вес совпавших
прогнозных значений в целом по временному
ряду и изменяется в пределах от 0 до 1.
Следовательно, оценку точности получаемых
прогнозных моделей целесообразно проводить по
совокупности сопоставлений прогнозных и
фактических значений изучаемых признаков.
11. Средним показателем точности прогноза
— является средняя абсолютная ошибка
прогноза ( ), которая определяется как
средняя арифметическая простая из
абсолютных ошибок прогноза по
формуле вида:
12.
где:
n–длина временного ряда.
Средняя абсолютная ошибка
прогноза показывает обобщенную
характеристику степени отклонения
фактических и прогнозных значений
признака и имеет ту же размерность,
что и размерность изучаемого
признака.
13. Для оценки точности прогноза используется средняя квадратическая ошибка прогноза, определяемая по формуле:
Для оценки точности прогноза
используется средняя квадратическая
ошибка прогноза, определяемая по
формуле:
14.
Размерность средней квадратической
ошибки прогноза также соответствует
размерности изучаемого признака.
Между средней абсолютной и средней
квадратической ошибками прогноза
существует следующее примерное
соотношение:
15.
Недостатками средней абсолютной и средней
квадратической ошибок прогноза является их
существенная зависимость от масштаба
измерения уровней изучаемых социальноэкономических явлений. Поэтому на практике в
качестве характеристики точности прогноза
определяют среднюю ошибку аппроксимации,
которая выражается в процентах относительно
фактических значений признака, и определяется
по формуле вида:
16.
В качестве сравнительного показателя
точности прогноза используется коэффициент
корреляции между прогнозными и
фактическими значениями признака, который
определяется по формуле:
17.
Г де:– средний уровень ряда динамики
прогнозных оценок.
18.
Одним из показателей оценки точности
статистических прогнозов
является коэффициент несоответствия
(КН), который был предложен Г. Тейлом и
может рассчитываться в различных
модификациях:
1. Коэффициент несоответствия
(КН1), определяемый как отношение
средней квадратической ошибки к
квадрату фактических значений признака:
19.
КН = 0, если
, то есть полное
совпадение фактических и прогнозных
значений признака.
20.
КН = 1, если при прогнозировании
получают среднюю квадратическую
ошибку адекватную по величине ошибке,
полученной одним из простейших
методов экстраполяции неизменности
абсолютных цепных приростов.
КН > 1, когда прогноз дает худшие
результаты, чем предположение о
неизменности исследуемого явления.
Верхней границы коэффициент
несоответствия не имеет.
21. 2.Коэффициент несоответствия (КН2)
определяется как отношение средней
квадратической ошибки прогноза к сумме квадратов
отклонений фактических значений признака от
среднего уровня исходного временного ряда за весь
рассматриваемый период.
Где:
–средний уровень исходного ряда динамики.
22.
3.Коэффициент несоответствия (КН3),
определяемый как отношение средней
квадратической ошибки прогноза к сумме
квадратов отклонений фактических значений
признака от теоретических, выравненных по
уравнению тренда:
где:
–теоретические уровни временного ряда,
полученные по модели тренда.
23. Оценка точности прогноза, построенного методом экстраполяции
Оценка точности прогноза,
построенного методом
экстраполяции
Существует несколько способов оценки
точности прогноза:
1. Cредняя абсолютная оценка:
2. Cредняяквадратическая оценка:
24.
3. Cредняя относительная ошибка:
25. Верификация.
1.
2.
3.
4.
5.
6.
Процедура проверки, оценки истинности прогноза не
эмпирическим путем носит название «верификации
прогноза» (валидность прогноза). По логике их
проведения различают следующие разновидности
верификации прогнозов :
Прямая
Косвенная
Инверсная
Консеквентная
Дублирующая
Оппонентная
26. 3 способа оценки точности прогноза и выбора оптимальной модели
1. Оценить отношение фактических продаж к
прогнозу;
2. Расчет показателя точность прогноза —
оценка на сколько точно выбранная модель
описывает анализируемые данные;
3. Графический анализ — строим график и
визуально оцениваем адекватность модели
прогноза относительно фактических продаж
за последний период ;
27. 1-й способ — Расчет отношения фактических продаж к прогнозу.
Сначала рассчитываем прогноз разными способами и
оцениваем отношение фактических продаж к прогнозу.
ВАЖНО протестировать модели не по одному товару
или направлению продаж, а сразу взять 10 и более
товарных позиций или направлений продаж и
рассчитать прогноз по ним на минимум на 3 периода
вперед (количество периодов и направления прогноза
зависят от ваших задач.Если задача — сделать точный
прогноз на 6 месяцев, то рассчитываем прогноз на 6
месяцев несколькими вариантами и оцениваем
отношение факта к прогнозу по сумме полугода).
28.
Рассчитаем прогноз 4 способами на полгода.
Протестируем следующие модели:
1.
2.
3.
4.
Линейный тренд + сезонность
Логарифмический тренд + сезонность
Скользящая средняя с сезонностью к 2-м
месяцам
Скользящая ясредняя с сезонностью к 3-м
месяцам
Для каждой из 4-х прогнозных моделей :
29.
Суммируем прогноз по каждой модели за 6 месяцев;
30.
Суммируем фактические продажи, которые мы
будем сравнивать с прогнозом;
31.
Рассчитываем отношение факта к прогнозу по
каждой позиции для каждой модели;
32.
Рассчитываем по каждой модели среднее отношение
факта к прогнозу;
33.
Выбираем модель прогноза, которая по
показателю «среднее отношение факта к
прогнозу» оказалась максимально приближена к
100%
34.
!
Для наших данных самой точной моделью оказалась
скользящая средняя к 3-м месяцам с сезонностью, среднее
отклонение факта от прогноза 97%.
!
Мы протестировали каждую модель прогноза на
реальных данных и выбрали для себя оптимальную,
которая в среднем показала минимальное отклонение от
фактических продаж
35. 2-й способ оценки модели прогноза — расчет показателя точность прогноза.
Показатель точность прогноза
показывает, на сколько точно выбранная
модель прогноза описывает данные. Идея в
том, чем точнее выбранная модель описывает
фактические данные, тем точнее она сделает
прогноз.
Как рассчитать точность прогноза?
Рассмотрим на примере расчета для модели
прогноза с линейным трендом и
сезонностью.
36.
Рассчитываем значения прогнозной модели для
каждого анализируемого момента времени в
прошлом
37.
Рассчитываем ошибку прогнозной модели. Для
этого за каждый период от фактических значений
вычитаем значения прогнозной модели.
38.
Рассчитываем квадратическое отклонение
ошибки от значений прогнозной
39.
Рассчитываем среднее значение
квадратического отклонения, т.е.
среднеквадратическое отклонение
40.
Точность прогноза = (1- среднеквадратическое
отклонение ошибки прогнозной модели)*100
41.
Показатель точности прогноза
выражается в процентах:
1.
Если точность прогноза равна
100%, то выбранная модель
описывает фактические значения на
100%, т.е. очень точно.
2.
Если 0% или отрицательное число,
то совсем не описывает, и данной
модели доверять не стоит.
42. 3. Способ оценки прогнозной модели — визуальный.
На график выводим анализируемые данные,
тренд, значение модели и прогноз (см.
вложенный файл). Обычно визуально видно,
какая модель адекватнее строит прогноз . 3-й
способ по своей сути схож с 1-м и вторым,
только мы верим не цифрам, а тому что мы
видим на графике.
43.
Линейная модель:
44.
Логарифмическая модель:
45. Какую модель прогноза выбрать?
1.
2.
3.
Которая на основании тестирования на реальных данных для
выбранного промежутка времени (месяца, 3-х месяцев, полугода,
года) будет делать максимально точный прогноз, т.е. отношение
факта к прогнозу будет близко к 1 или 100%.
Модель, которая будет максимально точно описывать фактические
данные, т.е. показатель точность прогноза будет приближаться к 1,
но не всегда модели точно описывающие данные делают
адекватные прогнозы (это надо понимать и оценивать
графически).
Модель, которой визуально вы больше доверяете с точки зрения
описания входящих данных и продления прогнозной модели в
будущее.