Определение ошибок выборки
Разность между показателями выборочной
и генеральной совокупностей называется
ошибкой выборки:
![]()
—
генеральное среднее;
![]()
—
выборочное среднее;
![]()
—
генеральная дисперсия;
![]()
—
выборочная дисперсия;
Ошибки выборки подразделяют на ошибки
регистрации и ошибки репрезентативности.
Ошибки регистрации возникают из-за
неправильных или неточных сведений.
Источником таких ошибок могут быть
непонимание вопроса, невнимательность
регистратора, пропуск или повторный
счет некоторых единиц совокупности.
Среди ошибок регистрации выделяют
систематические, т.е. обусловленные
причинами, действующими в каком-то одном
направлении и искажающие результаты
работы (округление цифр, тяготение к
полным десяткам и сотням и т.д.), и
случайные, проявляющиеся в различных
направлениях, уравновешивающих друг
друга и лишь изредка дающих заметный
суммарный итог.
Ошибки репрезентативности также могут
быть систематическими и случайными.
Изучение и измерение случайных ошибок
репрезентативности является основной
задачей выборочного метода.
При случайном и механическом отборах
средняя ошибка выборки для средней
величины определяется по формуле:
![]()
—
при повторном отборе;
![]()
—
при бесповторном отборе,
![]()
—
объем выборки,
![]()
—
объем генеральной совокупности.
На практике значение генеральных
параметров, как правило, не известно.
Поэтому их заменяют исправленными
выборочными характеристиками:
![]()
При
![]()
Формулы для расчета средней ошибки
выборочной доли имеют следующий вид:
![]()
—
при повтор. отборе;
![]()
—
при бесповторном отборе;
![]()
—
дисперсия доли;
Это так называемые средние или стандартные
ошибки.
Предельная ошибка выборки
![]()
представляет
собой t-кратную среднюю
ошибку.
![]()
Здесь t – коэффициент
доверия, который определяется по таблице
значений интегральной функции Лапласа
при заданной доверительной вероятности.
|
|
0,683 |
0,954 |
0,997 |
|
t |
1 |
2 |
3 |
Зная предельную ошибку можно определить
доверительные интервалы, в которых
находятся значения генеральных
параметров.
![]()
Пример:
Для определения среднего срока пользования
краткосрочным кредитом в банке была
произведена 5% механическая выборка, в
которую попали 200 счетов. По результатам
выборки установлено, что средний срок
пользования кредитом составляет 60 дней
при среднеквадратичном отклонении 20
дней.
В 8 счетах срок пользования кредитом
превышал 6 месяцев. Необходимо с
вероятностью 0,99 определить пределы, в
которых находится срок пользования
краткосрочным кредитом банка и доля
краткосрочных кредитов со сроком
пользования более полугода.
Решение:
Среднюю ошибку выборки определяют по
формуле для бесповторного отбора.
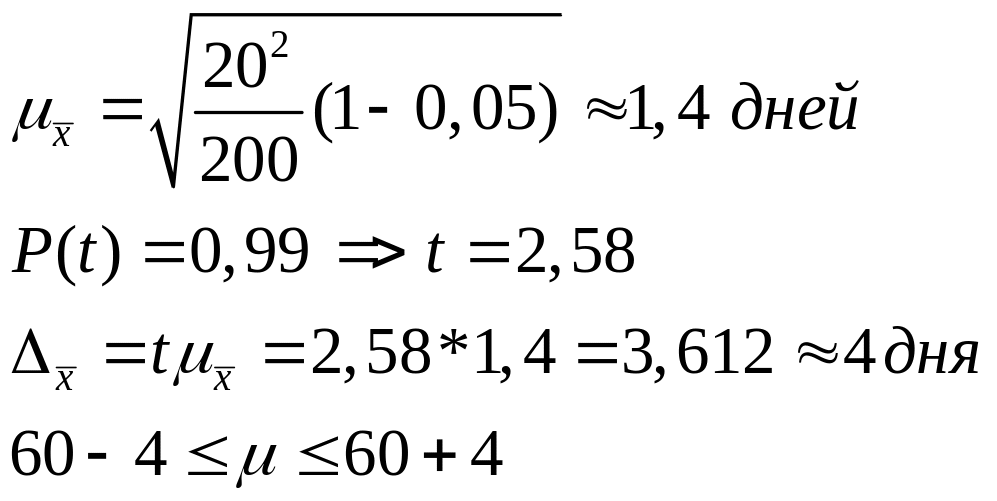
Т.е. с вероятностью 0,99 можно утверждать,
что средний срок пользования краткосрочным
кредитом составляет от 56 до 64 дней.
По итогам выборки определим долю кредитов
со сроком пользования более полугода.
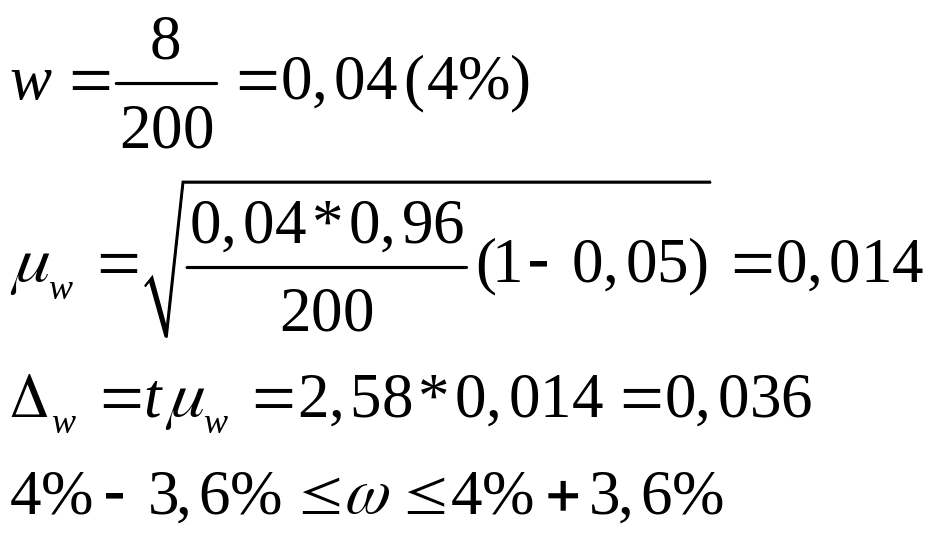
С вероятностью 0,99 можно гарантировать,
что доля кредитов банка со сроком
использования более полугода оставляет
![]()
общего числа кредитов.
Определение
оптимальной численности выборки
На
практике обычно расчет объема выборки
производят по формуле для повторного
отбора:
![]()
Если
полученный объем выборки превышает 5%
численности генеральной совокупности,
то расчеты корректируют на бесповторность:
![]()
В
данных формулах присутствуют значения
генеральной дисперсии, которые как
правило неизвестны. Для ее оценки можно
использовать:
1.
Выборочную дисперсию по данным прошлых
или пробных обследований.
2.
Дисперсию найденную из соотношения для
среднего квадратичного отклонения:
![]()
(если
все х >0 и х
min
0)
3.
Дисперсию, вычисленную из соотношения
для нормального распределения
![]()
4.
Дисперсию, определенную из соотношения
для асимметричного распределения
![]()
В
качестве оценки генеральной дисперсии
доли используют максимально возможную
дисперсию альтернативного признака:
![]()
Пример:
Определить численность выборки по
следующим данным. Для определения
средней цены говядины на 5000 рынках
города предполагается провести выборочную
регистрацию цен. Известно, что цены на
говядину колеблются от 40 до 70 руб/кг.
Сколько торговых точек необходимо
обследовать, чтобы с вероятностью 0,954
ошибка выборки при определении средней
цены не превышала 2 руб. за 1 кг.
Решение:
Предположим, что распределение цен
соответствует нормальному закону. Тогда
![]()
P(t)
= 0,954. Следовательно t
= 2.
![]()
![]()
Поскольку
доля отбора не превышает 5%, то к формуле
бемповторного отбора можно не переходить.
Т.е. для того, чтобы с вероятностью 0, 954
гарантировать, что ошибка при определении
функцией цены говядины не превысит 2
руб/кг необходимо исследовать 25 торговых
точек на рынках города.
Определение:
Относительная ошибка выборки– это
отношение предельной ошибки выборки к
среднему значению признака, выраженного
в %.
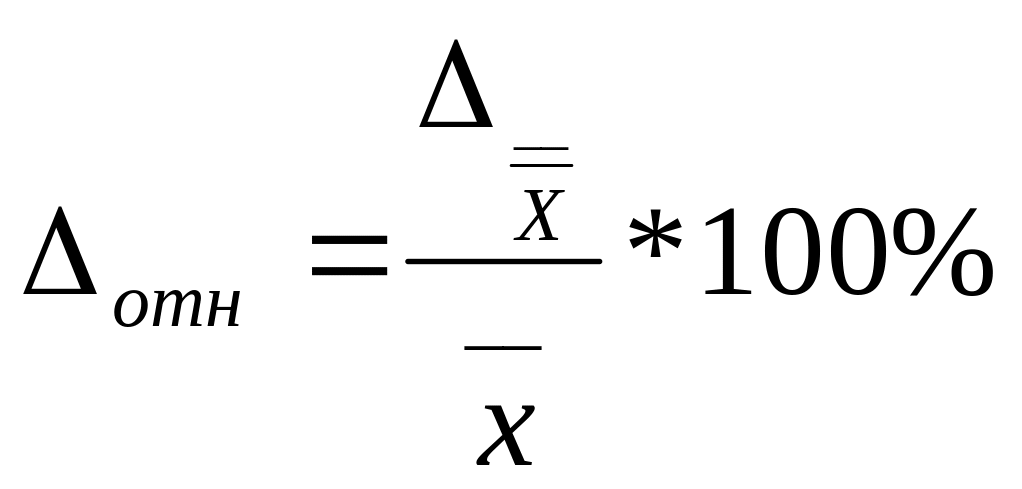
Расчёт
объема выборки при заданном уровне
относительной ошибки выборки осуществляется
по формулам:
![]()
![]()
![]()
—
коэффициент вариации
Пример:
В городе зарегистрировано 30000 безработных.
Для определения средней продолжительности
безработицы организуется выборочное
обследование. По данным прошлых лет
известно, что коэффициент вариации
объема продолжительности безработицы
составляет 40%. Какое число безработных
необходимо охватить выборочным
наблюдением, чтобы с вероятностью 0,997
утверждать, что полученным предельная
ошибка выборки не превышает 5% средней
продолжительности безработицы.
Решение:
P(t)
= 0,997. Следовательно t
= 3.
![]()
Объем выборки всегда округляют в большую
сторону.
Ответ: 566.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Определение ошибок выборки
Разность между показателями выборочной
и генеральной совокупностей называется
ошибкой выборки:
![]()
—
генеральное среднее;
![]()
—
выборочное среднее;
![]()
—
генеральная дисперсия;
![]()
—
выборочная дисперсия;
Ошибки выборки подразделяют на ошибки
регистрации и ошибки репрезентативности.
Ошибки регистрации возникают из-за
неправильных или неточных сведений.
Источником таких ошибок могут быть
непонимание вопроса, невнимательность
регистратора, пропуск или повторный
счет некоторых единиц совокупности.
Среди ошибок регистрации выделяют
систематические, т.е. обусловленные
причинами, действующими в каком-то одном
направлении и искажающие результаты
работы (округление цифр, тяготение к
полным десяткам и сотням и т.д.), и
случайные, проявляющиеся в различных
направлениях, уравновешивающих друг
друга и лишь изредка дающих заметный
суммарный итог.
Ошибки репрезентативности также могут
быть систематическими и случайными.
Изучение и измерение случайных ошибок
репрезентативности является основной
задачей выборочного метода.
При случайном и механическом отборах
средняя ошибка выборки для средней
величины определяется по формуле:
![]()
—
при повторном отборе;
![]()
—
при бесповторном отборе,
![]()
—
объем выборки,
![]()
—
объем генеральной совокупности.
На практике значение генеральных
параметров, как правило, не известно.
Поэтому их заменяют исправленными
выборочными характеристиками:
![]()
При
![]()
Формулы для расчета средней ошибки
выборочной доли имеют следующий вид:
![]()
—
при повтор. отборе;
![]()
—
при бесповторном отборе;
![]()
—
дисперсия доли;
Это так называемые средние или стандартные
ошибки.
Предельная ошибка выборки
![]()
представляет
собой t-кратную среднюю
ошибку.
![]()
Здесь t – коэффициент
доверия, который определяется по таблице
значений интегральной функции Лапласа
при заданной доверительной вероятности.
|
|
0,683 |
0,954 |
0,997 |
|
t |
1 |
2 |
3 |
Зная предельную ошибку можно определить
доверительные интервалы, в которых
находятся значения генеральных
параметров.
![]()
Пример:
Для определения среднего срока пользования
краткосрочным кредитом в банке была
произведена 5% механическая выборка, в
которую попали 200 счетов. По результатам
выборки установлено, что средний срок
пользования кредитом составляет 60 дней
при среднеквадратичном отклонении 20
дней.
В 8 счетах срок пользования кредитом
превышал 6 месяцев. Необходимо с
вероятностью 0,99 определить пределы, в
которых находится срок пользования
краткосрочным кредитом банка и доля
краткосрочных кредитов со сроком
пользования более полугода.
Решение:
Среднюю ошибку выборки определяют по
формуле для бесповторного отбора.
Т.е. с вероятностью 0,99 можно утверждать,
что средний срок пользования краткосрочным
кредитом составляет от 56 до 64 дней.
По итогам выборки определим долю кредитов
со сроком пользования более полугода.
С вероятностью 0,99 можно гарантировать,
что доля кредитов банка со сроком
использования более полугода оставляет
![]()
общего числа кредитов.
Определение
оптимальной численности выборки
На
практике обычно расчет объема выборки
производят по формуле для повторного
отбора:
![]()
Если
полученный объем выборки превышает 5%
численности генеральной совокупности,
то расчеты корректируют на бесповторность:
![]()
В
данных формулах присутствуют значения
генеральной дисперсии, которые как
правило неизвестны. Для ее оценки можно
использовать:
1.
Выборочную дисперсию по данным прошлых
или пробных обследований.
2.
Дисперсию найденную из соотношения для
среднего квадратичного отклонения:
![]()
(если
все х >0 и х
min
0)
3.
Дисперсию, вычисленную из соотношения
для нормального распределения
![]()
4.
Дисперсию, определенную из соотношения
для асимметричного распределения
![]()
В
качестве оценки генеральной дисперсии
доли используют максимально возможную
дисперсию альтернативного признака:
![]()
Пример:
Определить численность выборки по
следующим данным. Для определения
средней цены говядины на 5000 рынках
города предполагается провести выборочную
регистрацию цен. Известно, что цены на
говядину колеблются от 40 до 70 руб/кг.
Сколько торговых точек необходимо
обследовать, чтобы с вероятностью 0,954
ошибка выборки при определении средней
цены не превышала 2 руб. за 1 кг.
Решение:
Предположим, что распределение цен
соответствует нормальному закону. Тогда
![]()
P(t)
= 0,954. Следовательно t
= 2.
![]()
![]()
Поскольку
доля отбора не превышает 5%, то к формуле
бемповторного отбора можно не переходить.
Т.е. для того, чтобы с вероятностью 0, 954
гарантировать, что ошибка при определении
функцией цены говядины не превысит 2
руб/кг необходимо исследовать 25 торговых
точек на рынках города.
Определение:
Относительная ошибка выборки– это
отношение предельной ошибки выборки к
среднему значению признака, выраженного
в %.
Расчёт
объема выборки при заданном уровне
относительной ошибки выборки осуществляется
по формулам:
![]()
![]()
![]()
—
коэффициент вариации
Пример:
В городе зарегистрировано 30000 безработных.
Для определения средней продолжительности
безработицы организуется выборочное
обследование. По данным прошлых лет
известно, что коэффициент вариации
объема продолжительности безработицы
составляет 40%. Какое число безработных
необходимо охватить выборочным
наблюдением, чтобы с вероятностью 0,997
утверждать, что полученным предельная
ошибка выборки не превышает 5% средней
продолжительности безработицы.
Решение:
P(t)
= 0,997. Следовательно t
= 3.
![]()
Объем выборки всегда округляют в большую
сторону.
Ответ: 566.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
1.1. Ошибки
выборочного наблюдения
Средняя
ошибка выборки показывает, как генеральная средняя отклоняется в среднем от выборочной средней в ту или другую сторону. Формула
расчета средней ошибки выборки определяется видом исследуемого признака единиц
совокупности (количественный или альтернативный) и
способом отбора (бесповторный или повторный).
·
Если отбор повторный, а признак количественный
средняя ошибка выборки определяется по формуле
![]() , где
, где ![]() — дисперсия признака в выборочной совокупности
— дисперсия признака в выборочной совокупности
n- число единиц
в выборке
·
Если отбор бесповторный, а признак
количественный
 , где N—
, где N—
число единиц в генеральной совокупности
·
Если отбор повторный, а признак альтернативный
 , где w-выборочная
, где w-выборочная
доля
·
Если отбор бесповторный, а признак
альтернативный

Предельная ошибка выборки— показывающая с определенной степенью вероятности
отклонения средней от выборочной средней.
Предельная ошибка выборки
![]() , где параметр t зависит
, где параметр t зависит
от вероятности
Некоторые значения параметра t приведены
в таблице:
|
Вероятность, p |
0.95 |
0.954 |
0.9876 |
0.9907 |
0.9973 |
0.9999 |
|
Параметр t |
1.96 |
2.0 |
2.5 |
2.6 |
3.0 |
4.0 |
·
Если отбор повторный, а признак количественный
средняя ошибка выборки определяется по формуле
![]() , где
, где ![]() — дисперсия признака в выборочной совокупности
— дисперсия признака в выборочной совокупности
n- число единиц
в выборке
·
Если отбор бесповторный, а признак
количественный
 , где N—
, где N—
число единиц в генеральной совокупности
·
Если отбор повторный, а признак альтернативный
 , где w-выборочная
, где w-выборочная
доля
·
Если отбор бесповторный, а признак
альтернативный

Доверительный интервал для генеральной средней
![]()
Доверительный интервал для
генеральной доли
![]()
Пример расчета доверительного
интервала:
При выборочном обследовании 5% продукции по методу случайного
бесповторного отбора получены данные о содержании сахара в образцах:
|
Сахарность, % |
Число |
|
16-17 17-18 18-19 19-20 20-21 |
10 158 154 50 28 |
|
На основании этих данных вычислите:
1. Средний процент сахаристости.
2. Дисперсию и среднее квадратическое
отклонение.
3. С вероятностью 0.954 возможные пределы среднего значения
сахаристости продукции для всей партии.
4. С вероятностью 0.997 возможный процент продукции высшего
сорта по всей партии, если известно, что из 400 проб, попавших в выборку , 80
ед. отнесены к продукции высшего сорта.
Решение.
1.
Средний процент сахаристости найдем по формуле средней взвешенной
![]() , где xi–
, где xi–
середина i-го интервала
![]() =18,32 %
=18,32 %
2.
Дисперсия
![]()
![]()
![]() =336,49
=336,49
D(X)=336.49–
18.322=0.8676
Среднее квадратическое отклонение
![]() =0,93%
=0,93%
5. Предельная ошибка для
среднего процента сахаристости
![]()
для вероятности 0,954 параметр t=2.0
![]()
Доверительный интервал для среднего значения процента
сахаристости
![]()
![]()
![]()
С вероятностью 0,954 можно утверждать, что в генеральной
совокупности средний процент сахаристости лежит в пределах от 18,23% до 18,41%.
5. Доля продукции высшего сорта в выборочной совокупности
![]()
Предельная ошибка для
доли продукции высшего сорта
![]()
для вероятности 0,997 параметр t=3.0
![]()
Доверительный интервал для доли продукции высшего сорта
![]()
![]()
![]()
С вероятностью 0,997 можно утверждать, что в генеральной
совокупности доля продукции высшего сорта лежит в пределах от 14,0% до 26,0%.
2. Ошибки выборочного наблюдения
Между признаками выборочной совокупности и признаками генеральной совокупности, как правило, существует некоторое расхождение, которое называют ошибкой статистического наблюдения. При массовом наблюдении ошибки неизбежны, но возникают они в результате действия различных причин. Величина возможной ошибки выборочного признака слагается из ошибок регистрации и ошибок репрезентативности. Ошибки регистрации, или технические ошибки, связаны с недостаточной квалификацией наблюдателей, неточностью подсчетов, несовершенством приборов и т. п.
Под ошибкой репрезентативности (представительства) понимают расхождение между выборочной характеристикой и предполагаемой характеристикой генеральной совокупности. Ошибки репрезентативности бывают случайными и систематическими.
Систематические ошибки связаны с нарушением установленных правил отбора. Случайные ошибки объясняются недостаточно равномерным представлением в выборочной совокупности различных категорий единиц генеральной совокупности. В результате первой причины выборка легко может оказаться смещенной, так как при отборе каждой единицы допускается ошибка, всегда направленная в одну и ту же сторону. Эта ошибка получила название ошибки смещения. Ее размер может превышать величину случайной ошибки. Особенность ошибки смещения состоит в том, что, представляя собой постоянную часть ошибки репрезентативности, она увеличивается с увеличением объема выборки. Случайная же ошибка с увеличением объема выборки уменьшается. Кроме того, величину случайной ошибки можно определить, тогда как размер ошибки смещения непосредственно практически определить очень сложно, а иногда и невозможно. Поэтому важно знать причины, вызывающие ошибку смещения, и предусмотреть мероприятия по ее устранению.
Ошибки смещения бывают преднамеренными и непреднамеренными. Причиной возникновения преднамеренной ошибки является тенденциозный подход к выбору единиц из генеральной совокупности. Чтобы не допустить появления такой ошибки, необходимо соблюдать принцип случайности отбора единиц.
Непреднамеренные ошибки могут возникать на стадии подготовки выборочного наблюдения, формирования выборочной совокупности и анализа ее данных. Чтобы не допустить появления таких ошибок, необходима хорошая основа выборки, т. е. та генеральная совокупность, из которой предполагается производить отбор, например список единиц отбора. Основа выборки должна быть достоверной, полной и соответствовать цели исследования, а единицы отбора и их характеристики должны соответствовать действительному их состоянию на момент подготовки выборочного наблюдения. Нередки случаи, когда в отношении некоторых единиц, попавших в выборку, трудно собрать сведения из-за их отсутствия на момент наблюдения, нежелания дать сведения и т. п. В таких случаях эти единицы приходится заменять другими. Необходимо следить, чтобы замена осуществлялась равноценными единицами.
Случайная ошибка выборки возникает в результате случайных различий между единицами, попавшими в выборку, и единицами генеральной совокупности, т. е. она связана со случайным отбором. Теоретическим обоснованием появления случайных ошибок выборки являются теория вероятностей и ее предельные теоремы.
Сущность предельных теорем состоит в том, что в массовых явлениях совокупное влияние различных случайных причин на формирование закономерностей и обобщающих характеристик будет сколь угодно малой величиной или практически не зависит от случая. Так как случайная ошибка выборки возникает в результате случайных различий между единицами выборочной и генеральной совокупностей, то при достаточно большом объеме выборки она будет сколь угодно мала.
Предельные теоремы теории вероятностей позволяют определять размер случайных ошибок выборки. Различают среднюю (стандартную) и предельную ошибку выборки. Под средней (стандартной) ошибкой выборки понимают расхождение между средней выборочной и генеральной совокупностей. Предельной ошибкой выборки принято считать максимально возможное расхождение, т. е. максимум ошибки при заданной вероятности ее появления.
В математической теории выборочного метода сравниваются средние характеристики признаков выборочной и генеральной совокупностей и доказывается, что с увеличением объема выборки вероятность появления больших ошибок и пределы максимально возможной ошибки уменьшаются. Чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик. На основании теоремы, доказанной П. Л. Чебышевым, величину стандартной ошибки простой случайной выборки при достаточно большом объеме выборки (n) можно определить по формуле:

где µx– стандартная ошибка.
Из этой формулы средней (стандартной) ошибки простой случайной выборки видно, что величина µx зависит от изменчивости признака в генеральной совокупности (чем больше вариация признака, тем больше ошибка выборки) и от объема выборки n чем больше обследуется единиц, тем меньше будет величина расхождений выборочных и генеральных характеристик).
Академик А. М. Ляпунов доказал, что вероятность появления случайной ошибки выборки при достаточно большом ее объеме подчиняется закону нормального распределения. Эта вероятность определяется по формуле:

В математической статистике употребляют коэффициент доверия t, и значения функции F(t) табулированы при разных его значениях, при этом получают соответствующие уровни доверительной вероятности.
Коэффициент доверия позволяет вычислить предельную ошибку выборки, вычисляемую по формуле:

Из формулы вытекает, что предельная ошибка выборки равна -кратному числу средних ошибок выборки.
Таким образом, величина предельной ошибки выборки может быть установлена с определенной вероятностью.
Выборочное наблюдение дает возможность определить среднюю арифметическую выборочной совокупности x и величину предельной ошибки этой средней ?x, которая показывает с определенной вероятностью), насколько выборочная может отличаться от генеральной средней в большую или меньшую сторону. Тогда величина генеральной средней будет представлена интервальной оценкой, для которой нижняя граница будет равна

Интервал, в который с данной степенью вероятности будет заключена неизвестная величина оцениваемого параметра, называют доверительным, а вероятность Р – доверительной вероятностью. Чаще всего доверительную вероятность принимают равной 0,95 или 0,99, тогда коэффициент доверия t равен соответственно 1,96 и 2,58. Это означает, что доверительный интервал с заданной вероятностью заключает в себе генеральную среднюю.
Наряду с абсолютной величиной предельной ошибки выборки рассчитывается и относительная ошибка выборки, которая определяется как процентное отношение предельной ошибки выборки к соответствующей характеристике выборочной совокупности:
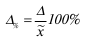
Чем больше величина предельной ошибки выборки, тем больше величина доверительного интервала и тем, следовательно, ниже точность оценки. Средняя (стандартная) ошибка выборки зависит от объема выборки и степени вариации признака в генеральной совокупности.
Данный текст является ознакомительным фрагментом.
Читайте также
Наблюдения за объемом
Наблюдения за объемом
Имеет значение не сам объем, а его соотношения в различные периоды рыночного движения. Соотношения объемов – очень важный, но и наименее объективный из технических инструментов, так как здесь нет никаких непреложных правил. Вместо этого есть набор
Закономерности и наблюдения
Закономерности и наблюдения
Я верю в существование закономерностей на рынке и считаю, что отношусь к числу людей, которые способны их улавливать. Но я также хорошо помню и о том, что все закономерности нечеткие. Нечеткие они потому, что в них присутствует фактор
Ошибки в инвестициях – это ошибки инвесторов
Ошибки в инвестициях – это ошибки инвесторов
Сейчас я больше, чем когда бы то ни было, убежден в том, что все ошибки в инвестициях на самом деле ошибки инвесторов.Инвестиции не совершают ошибок. В отличие от инвесторов.Инвестирование – это выбор. Именно об этой
8. Способы статистического наблюдения
8. Способы статистического наблюдения
Способами получения статистической информа–ции являются документальный способ наблюдения; способ непосредственного наблюдения: опрос.Документальное наблюдение основано на исполь–зовании в качестве источника информации данных
9. Формы статистического наблюдения
9. Формы статистического наблюдения
В теории статистики рассматриваются и формы статистического наблюдения: отчетность; специально организованное статистическое наблюдение; реги–стры.Статистическая отчетность – основная форма статистического наблюдения, которая
2. Ошибки выборочного наблюдения
2. Ошибки выборочного наблюдения
Между признаками выборочной совокупности и признаками генеральной совокупности, как правило, существует некоторое расхождение, которое называют ошибкой статистического наблюдения. При массовом наблюдении ошибки неизбежны, но
19. Наблюдения
19. Наблюдения
Наблюдение представляет собой сбор первичной информации об объекте наблюдения для построения гипотез, проверки исходных данных и т. д.К способам проведения наблюдения относят:1) прямой, который предполагает непосредственное наблюдение за объектом
6. Организация статистического наблюдения
6. Организация статистического наблюдения
Начальным этапом статистического исследования является статистическое наблюдение.В процессе статистического наблюдения формируется оснавная информация, которая является основной для статистического
11. Ошибки статистического наблюдения и контроль материалов наблюдения
11. Ошибки статистического наблюдения и контроль материалов наблюдения
Важнейшей задачей статистического наблюдения является достоверность и точность собираемой статистической информации.Любое статистическое наблюдение предполагает получение данных, которые будут
34. Определение выборочного наблюдения
34. Определение выборочного наблюдения
Так как сплошное наблюдение дорого и трудоемко, то его заменили выборочным.Выборочное наблюдение – это способ несплошного наблюдения, при котором лишь часть совокупности, отобранная по определенным правилам выборки и
Часть 5 Наблюдения
Часть 5
Наблюдения
За свою тридцатипятилетнюю карьеру в бизнесе я смотрел на мир с разных точек зрения. Я был свидетелем взлетов и падений в экономике и отрасли, появления на рынке новых продуктов и их исчезновения. Я представлял новые товары, возрождал старые, закрывал
Введение процедуры наблюдения
Введение процедуры наблюдения
Наблюдение вводится с целью сохранения активов должника, проведения оценки его финансового состояния, изучения объективной возможности восстановления платежеспособности и продолжения функционирования организации.С момента введения
1. Организация статистического наблюдения
1. Организация статистического наблюдения
Статистическое наблюдение – это организованная работа по сбору первичных сведений об изучаемых массовых явлениях и процессах общественной жизни. Статистическое наблюдение проводится организованно и по заранее разработанным
5. Ошибки статистического наблюдения и контроль материалов наблюдения
5. Ошибки статистического наблюдения и контроль материалов наблюдения
Важнейшей задачей статистического наблюдения является достоверность и точность собираемой статистической информации.Точность – это уровень соответствия значения какого–либо признака или
1. Определение выборочного наблюдения
1. Определение выборочного наблюдения
Статистические исследования очень трудоемки и дороги, поэтому возникла мысль о замене сплошного наблюдения выборочным.Основная цель несплошного наблюдения состоит в получении характеристик изучаемой статистической совокупности
Общие наблюдения и впечатления
Общие наблюдения и впечатления
Члены команды систематически выполняли требования восьми этапов цикла кайдзен и обнаружили, что с их помощью смогли построить процесс решения проблем в правильной последовательности. Использование таких инструментов, как «рыбий скелет»