Я использую iText в своей программе java для редактирования существующего pdf. Сгенерированный PDF файл не открывается и показывает, что подпись в заголовке PDF не найдена. Я использую оба файла ввода и вывода с тем же именем.
private static String INPUTFILE = "/sample.pdf";
private static String OUTPUTFILE = "/sample.pdf";
public static void main(String[] args)
throws DocumentException,
IOException
{
Document doc = new Document();
PdfWriter writer = PdfWriter.getInstance(doc,new FileOutputStream(OUTPUTFILE));
doc.open();
PdfReader reader = new PdfReader(INPUTFILE);
int n;
n = reader.getNumberOfPages();
System.out.println("No. of Pages :" +n);
for (int i = 1; i <= n; i++)
{
if (i == 1)
{
Rectangle rect = new Rectangle(85,650,800,833);
PdfFormField pushbutton = PdfFormField.createPushButton(writer);
pushbutton.setWidget(rect, PdfAnnotation.HIGHLIGHT_PUSH);
PdfContentByte cb = writer.getDirectContent();
PdfAppearance app = cb.createAppearance(380,201);
app.rectangle(62,100,50,-1);
app.fill();
pushbutton.setAppearance(PdfAnnotation.APPEARANCE_NORMAL,app);
writer.addAnnotation(pushbutton);
PdfImportedPage page = writer.getImportedPage(reader, i);
Image instance = Image.getInstance(page);
doc.add(instance);
}
Ответ 1
Вы можете импортировать из пустого источника или недопустимого pdf файла, в моем случае pdfCopy не работает, поэтому вот код, который я использовал.
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, OutputStream );
PdfReader reader = new PdfReader(dato.getBinaryStream());
PdfImportedPage page1 = writer.getImportedPage(reader, 1);
PdfContentByte cb = writer.getDirectContent();
cb.addTemplate(page1, 1, 0, 0, 1, 0, 0);
document.setPageSize(new Rectangle(page1.getWidth(),page1.getHeight()) );
…
Это должно работать.
Ответ 2
Затем попробуйте сначала переименовать входной файл в .bak и прочитайте .bak и напишите .pdf. Это может дать понять, является ли ошибка при чтении или записи.
Itext — это не один API, а несколько, смешанный. Довольно сложно. Я сделал:
Закройте оба PdfReader и FileInputStream.
Закройте оба Document и PdfWriter.
Ответ 3
Вы должны использовать PdfCopy вместо PdfWriter.getInstance, поскольку в противном случае он не обновляет ссылки на объекты PDF.
Кроме того, вместо добавления Image к документу вы можете использовать метод PdfCopy.addPage, который принимает параметр PdfImportedPage as.
Document doc = new Document();
PdfCopy writer = new PdfCopy(doc,new FileOutputStream(OUTPUTFILE));
doc.open();
PdfReader reader = new PdfReader(INPUTFILE);
int n = reader.getNumberOfPages();
System.out.println("No. of Pages :" +n);
for (int i = 1; i <= n; i++) {
if (i == 1) {
// removed code for clarity
PdfImportedPage page = writer.getImportedPage(reader, i);
writer.addPage(page);
}
}
Ответ 4
В моем случае файл с образцом PDF был поврежден. загрузите новый файл, он будет работать.
Ответ 5
У меня была такая же ошибка, и я просто изменил свой PdfReader на чтение InputStreams для чтения строк. Таким образом, он отлично работает с:
public static void doMerge(List<String> list, OutputStream outputStream)
throws DocumentException, IOException {
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, outputStream);
document.open();
PdfContentByte cb = writer.getDirectContent();
for (String in : list) {
PdfReader reader = new PdfReader(in);
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
document.newPage();
// import the page from source pdf
PdfImportedPage page = writer.getImportedPage(reader, i);
// add the page to the destination pdf
cb.addTemplate(page, 0, 0);
}
}
outputStream.flush();
document.close();
outputStream.close();
}
* Первоначально я взял этот код из http://www.mindfiresolutions.com/Java-Merging-multiple-PDFs-into-a-single-PDF-using-iText-671.php
Я использую iTextSharp для чтения содержания документов PDF :
PdfReader reader = new PdfReader(pdfPath);
using (StringWriter output = new StringWriter())
{
for (int i = 1; i <= reader.NumberOfPages; i++)
output.WriteLine(PdfTextExtractor.GetTextFromPage(reader, i, new SimpleTextExtractionStrategy()));
reader.Close();
pdfText = output.ToString();
}
99% времени он работает нормально. Однако есть один файл PDF , который иногда вызывает это исключение:
Подпись заголовка PDF не найдена. StackTrace:
iTextSharp.text.pdf.PRTokeniser.CheckPdfHeader () на
iTextSharp.text.pdf.PdfReader.ReadPdf () на
iTextSharp.text.pdf.PdfReader..ctor (String filename, Byte []> ownerPassword) в
Reader.PDF.DownloadPdf (строковый URL) в
Что раздражает, так это то, что я не всегда могу воспроизвести ошибку. Иногда это работает, иногда нет. Кто-нибудь сталкивался с этой проблемой?
4 ответа
Лучший ответ
После некоторых исследований я обнаружил, что эта проблема связана либо с повреждением файла во время создания PDF-файла, либо с ошибкой, связанной с объектом в документе, который не соответствует стандарту PDF, реализованному в iTextSharp. Кроме того, похоже, что это происходит только тогда, когда вы читаете PDF-файл с диска.
Я не нашел полного решения проблемы, а только временное решение. Я прочитал PDF-документ с помощью объекта PdfReader itextsharp и посмотрел, возникнет ли ошибка или исключение, перед чтением файла в обычном режиме.
Итак, запускаем что-то похожее на это:
private bool IsValidPdf(string filepath)
{
bool Ret = true;
PdfReader reader = null;
try
{
reader = new PdfReader(filepath);
}
catch
{
Ret = false;
}
return Ret;
}
24
Anonymous coward
20 Май 2012 в 23:50
Я обнаружил, что это произошло потому, что я вызвал new PdfReader(pdf) с позицией потока PDF в конце файла. Установка положения на ноль решила проблему.
Перед:
// Throws: InvalidPdfException: PDF header signature not found.
var pdfReader = new PdfReader(pdf);
После:
// Works correctly.
pdf.Position = 0;
var pdfReader = new PdfReader(pdf);
19
Bern
1 Июл 2020 в 18:13
В моем случае это было потому, что я вызывал файл .json, а iTextSharp, очевидно, принимает только файл pdf.
0
David Greenfeld
23 Июн 2020 в 04:31
Есть вероятность, что вы открываете файл другим методом или программой, как в моем случае. Убедитесь, что с вашим файлом ничего не работает. Вы также можете использовать монитор ресурсов, чтобы проверить, какие процессы работают с вашим файлом.
0
Alexis Ponce
2 Дек 2021 в 15:24
After converting file from MSword to PDF extraction i am getting a error PDF header signature not found.
public void Extract_inputpdf()
{
text_input_File = string.Empty;
StringBuilder sb_inputpdf = new StringBuilder();
PdfReader reader_inputPdf = new PdfReader(path); //read PDF
for (int i = 0; i <=reader_inputPdf.NumberOfPages ; i++)
{
TextWithFont_inputPdf inputpdf = new TextWithFont_inputPdf();
text_input_File = iTextSharp.text.pdf.parser.PdfTextExtractor.GetTextFromPage(reader_inputPdf, i, inputpdf);
sb_inputpdf.Append(text_input_File);
input_pdf = sb_inputpdf.ToString();
}
reader_inputPdf.Close();
clear();
}
can anyone tell me how to solve this.Thanku
// word to pdf
if (Extentsion_path == ".doc" || Extentsion_path == ".docx")
{
uploadFInput.SaveAs(targetPathip);
string wordFileName = targetPathip;
_Word.Visible = false;
_Word.ScreenUpdating = false;
// Cast as Object for word Open method
filename = (object)wordFileName;
// Use the dummy value as a placeholder for optional arguments
Microsoft.Office.Interop.Word.Document doc = _Word.Documents.Open(ref filename, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue);
doc.Activate();
object outputFileName = pdfFileName = Path.ChangeExtension(wordFileName, "pdf");
object fileFormat = WdSaveFormat.wdFormatPDF;
// Save document into PDF Format
doc.SaveAs(ref outputFileName, ref fileFormat, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue);
// Close the Word document, but leave the Word application open.
// doc has to be cast to type _Document so that it will find the
// correct Close method.
object saveChanges = WdSaveOptions.wdDoNotSaveChanges;
((_Document)doc).Close(ref saveChanges, ref _MissingValue, ref _MissingValue);
doc = null;
// word has to be cast to type _Application so that it will find
// the correct Quit method.
((_Application)_Word).Quit(ref _MissingValue, ref _MissingValue, ref _MissingValue);
_Word = null;
//uploadFInput.SaveAs(pdfFileName);
// = targetPathip;
uploadFInput.SaveAs(pdfFileName);
LblFleip.Text = pdfFileName;
}
else
{
uploadFInput.SaveAs(targetPathip);
LblFleip.Text = targetPathip;
}
After converting file from MSword to PDF extraction i am getting a error PDF header signature not found.
public void Extract_inputpdf()
{
text_input_File = string.Empty;
StringBuilder sb_inputpdf = new StringBuilder();
PdfReader reader_inputPdf = new PdfReader(path); //read PDF
for (int i = 0; i <=reader_inputPdf.NumberOfPages ; i++)
{
TextWithFont_inputPdf inputpdf = new TextWithFont_inputPdf();
text_input_File = iTextSharp.text.pdf.parser.PdfTextExtractor.GetTextFromPage(reader_inputPdf, i, inputpdf);
sb_inputpdf.Append(text_input_File);
input_pdf = sb_inputpdf.ToString();
}
reader_inputPdf.Close();
clear();
}
can anyone tell me how to solve this.Thanku
// word to pdf
if (Extentsion_path == ".doc" || Extentsion_path == ".docx")
{
uploadFInput.SaveAs(targetPathip);
string wordFileName = targetPathip;
_Word.Visible = false;
_Word.ScreenUpdating = false;
// Cast as Object for word Open method
filename = (object)wordFileName;
// Use the dummy value as a placeholder for optional arguments
Microsoft.Office.Interop.Word.Document doc = _Word.Documents.Open(ref filename, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue);
doc.Activate();
object outputFileName = pdfFileName = Path.ChangeExtension(wordFileName, "pdf");
object fileFormat = WdSaveFormat.wdFormatPDF;
// Save document into PDF Format
doc.SaveAs(ref outputFileName, ref fileFormat, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue);
// Close the Word document, but leave the Word application open.
// doc has to be cast to type _Document so that it will find the
// correct Close method.
object saveChanges = WdSaveOptions.wdDoNotSaveChanges;
((_Document)doc).Close(ref saveChanges, ref _MissingValue, ref _MissingValue);
doc = null;
// word has to be cast to type _Application so that it will find
// the correct Quit method.
((_Application)_Word).Quit(ref _MissingValue, ref _MissingValue, ref _MissingValue);
_Word = null;
//uploadFInput.SaveAs(pdfFileName);
// = targetPathip;
uploadFInput.SaveAs(pdfFileName);
LblFleip.Text = pdfFileName;
}
else
{
uploadFInput.SaveAs(targetPathip);
LblFleip.Text = targetPathip;
}
I’m using iText in my java program for editing an existing pdf.The generated pdf could not open and it shows pdf header signature not found error.I’m using both my input and output file in a same name.
private static String INPUTFILE = "/sample.pdf";
private static String OUTPUTFILE = "/sample.pdf";
public static void main(String[] args)
throws DocumentException,
IOException
{
Document doc = new Document();
PdfWriter writer = PdfWriter.getInstance(doc,new FileOutputStream(OUTPUTFILE));
doc.open();
PdfReader reader = new PdfReader(INPUTFILE);
int n;
n = reader.getNumberOfPages();
System.out.println("No. of Pages :" +n);
for (int i = 1; i <= n; i++)
{
if (i == 1)
{
Rectangle rect = new Rectangle(85,650,800,833);
PdfFormField pushbutton = PdfFormField.createPushButton(writer);
pushbutton.setWidget(rect, PdfAnnotation.HIGHLIGHT_PUSH);
PdfContentByte cb = writer.getDirectContent();
PdfAppearance app = cb.createAppearance(380,201);
app.rectangle(62,100,50,-1);
app.fill();
pushbutton.setAppearance(PdfAnnotation.APPEARANCE_NORMAL,app);
writer.addAnnotation(pushbutton);
PdfImportedPage page = writer.getImportedPage(reader, i);
Image instance = Image.getInstance(page);
doc.add(instance);
}
asked Dec 28, 2011 at 11:02
BobDroidBobDroid
1,8885 gold badges19 silver badges39 bronze badges
3
Then try at first renaming the input file to .bak, and reading the .bak, and writing the .pdf. That could give a clue whether the error is with reading or writing.
Itext is not a single API, but several ones, mixed together. Quite hard sometimes. I did:
Close both the PdfReader and FileInputStream.
Close both Document and PdfWriter.
answered Dec 28, 2011 at 11:11
![]()
Joop EggenJoop Eggen
106k7 gold badges83 silver badges135 bronze badges
2
You may be importing from an empty source, or a invalid pdf file, in my case pdfCopy dont work, so here is the code I used.
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, OutputStream );
PdfReader reader = new PdfReader(dato.getBinaryStream());
PdfImportedPage page1 = writer.getImportedPage(reader, 1);
PdfContentByte cb = writer.getDirectContent();
cb.addTemplate(page1, 1, 0, 0, 1, 0, 0);
document.setPageSize(new Rectangle(page1.getWidth(),page1.getHeight()) );
…
This should work.
answered Jun 19, 2012 at 17:17
![]()
Steven LizarazoSteven Lizarazo
5,2402 gold badges28 silver badges25 bronze badges
1
You should use PdfCopy instead of PdfWriter.getInstance, since it fails to update the PDF object references otherwise.
Furthermore instead of adding an Image to the document, you can utilize the PdfCopy.addPage method, which accepts a PdfImportedPage as parameter.
Document doc = new Document();
PdfCopy writer = new PdfCopy(doc,new FileOutputStream(OUTPUTFILE));
doc.open();
PdfReader reader = new PdfReader(INPUTFILE);
int n = reader.getNumberOfPages();
System.out.println("No. of Pages :" +n);
for (int i = 1; i <= n; i++) {
if (i == 1) {
// removed code for clarity
PdfImportedPage page = writer.getImportedPage(reader, i);
writer.addPage(page);
}
}
answered Feb 23, 2012 at 11:44
JesJes
2,74818 silver badges22 bronze badges
In My case PDF sample file was corrupted. upload new file it will works.
answered Sep 16, 2016 at 16:35
tikatika
3142 silver badges9 bronze badges
I had the same error and I just changed my PdfReader from reading InputStreams to read Strings. So, it works perfectly with:
public static void doMerge(List<String> list, OutputStream outputStream)
throws DocumentException, IOException {
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, outputStream);
document.open();
PdfContentByte cb = writer.getDirectContent();
for (String in : list) {
PdfReader reader = new PdfReader(in);
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
document.newPage();
// import the page from source pdf
PdfImportedPage page = writer.getImportedPage(reader, i);
// add the page to the destination pdf
cb.addTemplate(page, 0, 0);
}
}
outputStream.flush();
document.close();
outputStream.close();
}
*Originally I took this code from http://www.mindfiresolutions.com/Java-Merging-multiple-PDFs-into-a-single-PDF-using-iText-671.php
answered Sep 5, 2012 at 16:12
![]()
imTachuimTachu
3,7294 gold badges28 silver badges56 bronze badges
Your pdf should start with %PDF.You can check it.My file was corrupted.
answered Oct 5, 2020 at 12:43
Hello @icnocop!!
I just started using this for documentation for my library and so far it is great, but ran into this issue.
The versions that I used when I ran into the issue is below:
- docfx 👉🏼 v2.59.2.0
- wkhtmltopdf 👉🏼 v0.12.6 (with patched qt)
I did indeed get it working by adding noStdin: true to the pdf section of the docfx.json.
My questions are this:
- Is this an «issue» that is in the works on getting fixed and this is just a workaround?
- I did not see anything about
noStdinin the walkthrough or anything and stumbled on this issue for hours, if this is not a workaround and it is meant to be used like this, is the documentation/tutorial on the website going to be updated? - Is this a windows only thing? I did notice that somebody in the comments mentioned that they only ran into the issue with a windows runner with GitHub actions.
Just for clarity and to hopefully help with the issue, below is the error I got in windows terminal.
[22-05-12 03:40:51.420]Error:[PdfCommand.PDF]Error happen when converting pdf/toc.json to Pdf. Details: System.AggregateException: One or more errors occurred. ---> iTextSharp.text.exceptions.InvalidPdfException: PDF header signature not found.
at iTextSharp.text.pdf.PdfReader..ctor(ReaderProperties properties, IRandomAccessSource byteSource)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.Convert[T](String arguments, Func`2 readerFunc)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.<>c__DisplayClass7_0.<GetPartialPdfModels>b__1(String htmlFilePath)
at System.Threading.Tasks.Parallel.<>c__DisplayClass17_0`1.<ForWorker>b__1()
at System.Threading.Tasks.Task.InnerInvokeWithArg(Task childTask)
at System.Threading.Tasks.Task.<>c__DisplayClass176_0.<ExecuteSelfReplicating>b__0(Object <p0>)
--- End of inner exception stack trace ---
at System.Threading.Tasks.Task.ThrowIfExceptional(Boolean includeTaskCanceledExceptions)
at System.Threading.Tasks.Task.Wait(Int32 millisecondsTimeout, CancellationToken cancellationToken)
at System.Threading.Tasks.Parallel.ForWorker[TLocal](Int32 fromInclusive, Int32 toExclusive, ParallelOptions parallelOptions, Action`1 body, Action`2 bodyWithState, Func`4 bodyWithLocal, Func`1 localInit, Action`1 localFinally)
at System.Threading.Tasks.Parallel.ForEachWorker[TSource,TLocal](IEnumerable`1 source, ParallelOptions parallelOptions, Action`1 body, Action`2 bodyWithState, Action`3 bodyWithStateAndIndex, Func`4 bodyWithStateAndLocal, Func`5 bodyWithEverything, Func`1 localInit, Action`1 localFinally)
at System.Threading.Tasks.Parallel.ForEach[TSource](IEnumerable`1 source, ParallelOptions parallelOptions, Action`1 body)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.GetPartialPdfModels(IList`1 htmlFilePaths)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.ConvertOutlines()
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.GetOutlines()
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.SaveCore(Stream stream)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.Save(String outputFileName)
at Microsoft.DocAsCode.HtmlToPdf.ConvertWrapper.<>c__DisplayClass7_0.<ConvertCore>b__1(ManifestItem tocFile)
---> (Inner Exception #0) iTextSharp.text.exceptions.InvalidPdfException: PDF header signature not found.
at iTextSharp.text.pdf.PdfReader..ctor(ReaderProperties properties, IRandomAccessSource byteSource)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.Convert[T](String arguments, Func`2 readerFunc)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.<>c__DisplayClass7_0.<GetPartialPdfModels>b__1(String htmlFilePath)
at System.Threading.Tasks.Parallel.<>c__DisplayClass17_0`1.<ForWorker>b__1()
at System.Threading.Tasks.Task.InnerInvokeWithArg(Task childTask)
at System.Threading.Tasks.Task.<>c__DisplayClass176_0.<ExecuteSelfReplicating>b__0(Object <p0>)<---
---> (Inner Exception #1) iTextSharp.text.exceptions.InvalidPdfException: PDF header signature not found.
at iTextSharp.text.pdf.PdfReader..ctor(ReaderProperties properties, IRandomAccessSource byteSource)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.Convert[T](String arguments, Func`2 readerFunc)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.<>c__DisplayClass7_0.<GetPartialPdfModels>b__1(String htmlFilePath)
at System.Threading.Tasks.Parallel.<>c__DisplayClass17_0`1.<ForWorker>b__1()
at System.Threading.Tasks.Task.InnerInvokeWithArg(Task childTask)
at System.Threading.Tasks.Task.<>c__DisplayClass176_0.<ExecuteSelfReplicating>b__0(Object <p0>)<---
---> (Inner Exception #2) iTextSharp.text.exceptions.InvalidPdfException: PDF header signature not found.
at iTextSharp.text.pdf.PdfReader..ctor(ReaderProperties properties, IRandomAccessSource byteSource)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.Convert[T](String arguments, Func`2 readerFunc)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.<>c__DisplayClass7_0.<GetPartialPdfModels>b__1(String htmlFilePath)
at System.Threading.Tasks.Parallel.<>c__DisplayClass17_0`1.<ForWorker>b__1()
at System.Threading.Tasks.Task.InnerInvokeWithArg(Task childTask)
at System.Threading.Tasks.Task.<>c__DisplayClass176_0.<ExecuteSelfReplicating>b__0(Object <p0>)<---
---> (Inner Exception #3) iTextSharp.text.exceptions.InvalidPdfException: PDF header signature not found.
at iTextSharp.text.pdf.PdfReader..ctor(ReaderProperties properties, IRandomAccessSource byteSource)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.Convert[T](String arguments, Func`2 readerFunc)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.<>c__DisplayClass7_0.<GetPartialPdfModels>b__1(String htmlFilePath)
at System.Threading.Tasks.Parallel.<>c__DisplayClass17_0`1.<ForWorker>b__1()
at System.Threading.Tasks.Task.InnerInvokeWithArg(Task childTask)
at System.Threading.Tasks.Task.<>c__DisplayClass176_0.<ExecuteSelfReplicating>b__0(Object <p0>)<---
---> (Inner Exception #4) iTextSharp.text.exceptions.InvalidPdfException: PDF header signature not found.
at iTextSharp.text.pdf.PdfReader..ctor(ReaderProperties properties, IRandomAccessSource byteSource)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.Convert[T](String arguments, Func`2 readerFunc)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.<>c__DisplayClass7_0.<GetPartialPdfModels>b__1(String htmlFilePath)
at System.Threading.Tasks.Parallel.<>c__DisplayClass17_0`1.<ForWorker>b__1()
at System.Threading.Tasks.Task.InnerInvokeWithArg(Task childTask)
at System.Threading.Tasks.Task.<>c__DisplayClass176_0.<ExecuteSelfReplicating>b__0(Object <p0>)<---
---> (Inner Exception #5) iTextSharp.text.exceptions.InvalidPdfException: PDF header signature not found.
at iTextSharp.text.pdf.PdfReader..ctor(ReaderProperties properties, IRandomAccessSource byteSource)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.Convert[T](String arguments, Func`2 readerFunc)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.<>c__DisplayClass7_0.<GetPartialPdfModels>b__1(String htmlFilePath)
at System.Threading.Tasks.Parallel.<>c__DisplayClass17_0`1.<ForWorker>b__1()
at System.Threading.Tasks.Task.InnerInvokeWithArg(Task childTask)
at System.Threading.Tasks.Task.<>c__DisplayClass176_0.<ExecuteSelfReplicating>b__0(Object <p0>)<---
---> (Inner Exception #6) iTextSharp.text.exceptions.InvalidPdfException: PDF header signature not found.
at iTextSharp.text.pdf.PdfReader..ctor(ReaderProperties properties, IRandomAccessSource byteSource)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.Convert[T](String arguments, Func`2 readerFunc)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.<>c__DisplayClass7_0.<GetPartialPdfModels>b__1(String htmlFilePath)
at System.Threading.Tasks.Parallel.<>c__DisplayClass17_0`1.<ForWorker>b__1()
at System.Threading.Tasks.Task.InnerInvokeWithArg(Task childTask)
at System.Threading.Tasks.Task.<>c__DisplayClass176_0.<ExecuteSelfReplicating>b__0(Object <p0>)<---
---> (Inner Exception #7) iTextSharp.text.exceptions.InvalidPdfException: PDF header signature not found.
at iTextSharp.text.pdf.PdfReader..ctor(ReaderProperties properties, IRandomAccessSource byteSource)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.Convert[T](String arguments, Func`2 readerFunc)
at Microsoft.DocAsCode.HtmlToPdf.HtmlToPdfConverter.<>c__DisplayClass7_0.<GetPartialPdfModels>b__1(String htmlFilePath)
at System.Threading.Tasks.Parallel.<>c__DisplayClass17_0`1.<ForWorker>b__1()
at System.Threading.Tasks.Task.InnerInvokeWithArg(Task childTask)
at System.Threading.Tasks.Task.<>c__DisplayClass176_0.<ExecuteSelfReplicating>b__0(Object <p0>)<
Cheers!!
Использование ЭЦП открывает для владельца подписи дополнительные возможности. Но вместе с этим, иногда сопровождается небольшими техническими проблемами, связанными с необходимостью чёткого выполнения действий, связанных с загрузкой сертификатов, авторизацией, установкой необходимого программного обеспечения, а также системных требований к компьютеру.

Важно отметить, что большинство ошибок при работе с ЭЦП можно устранить в домашних условиях, без необходимости привлечения специалистов со стороны.
Содержание
- Какие виды ошибок ЭЦП бывают
- Проблема с подписанием ЭПЦ
- Как проявляется данная ошибка и что сделать, чтобы исправить
- Проблема с сертификатом
- Что делать если не найден сертификат или не верен
- Проблемы при авторизации
Какие виды ошибок ЭЦП бывают
Среди наиболее часто встречающихся ошибок в процессе подписания электронных документов электронной подписью выделяют три ключевых блока:
Проблема с подписанием ЭПЦ. Возникает в момент, когда владелец подписи желает использовать ее при подписании электронного документа.
Проблема с сертификатом. Здесь система информирует пользователя об отсутствии (не действительности), либо использовании незарегистрированного сертификата удостоверяющего центра, необходимого для внешней проверки ЭП.
Проблемы при авторизации. Появляется при проверке пользователя, когда владелец электронной подписи впервые пытается зайти на электронную площадку с подтверждением личности через ЭЦП.
Проблема с подписанием ЭПЦ
Причины, вызывающие подобную ошибку весьма разнообразны. Тут можно выделить такие основные направления:
- Закрытый ключ со съемного носителя (диска, флешки, Токена), не соответствует имеющемуся ключу открытого сертификата. Банальный человеческий фактор выбора не того носителя информации с ЭЦП. Если же «правильный» ключ утерян, придется обращаться в Удостоверяющий центр для перевыпуска.
- Недействительный сертификат. Чтобы устранить подобную ошибку потребуется переустановить открытый сертификат. Важно учитывать требования криптопровайдера (инструкции по необходимым действиям) для установки открытых сертификатов.
- Сертификат подписи определяется как не проверенный. Потребуется выполнить переустановку корневого сертификата, сформировавшего ЭП Удостоверяющего центра.
- Закончился срок действия криптопровайдера. Необходимо получить новый лицензионный ключ, позволяющий работать с программным обеспечением криптопровайдера. Информация запрашивается через УЦ, либо владельца ПО.
- Не виден сертификат на носителе. Помогает простая перезагрузка компьютера для устранения ошибка генерации.
- Алгоритм сертификата ЭЦП не поддерживается. Подобная ошибка может возникать при подписании электронной отчетности в налоговую. Потребуется переустановить КриптоПро CSP и проверить его на совместительство с имеющейся у вас на компьютере операционной системой.
Как проявляется данная ошибка и что сделать, чтобы исправить
Ошибка исполнения функции с информированием о невозможности подписать документ ЭЦП обычно появляется в момент подписания документа.
Система сразу выводит на экран уведомление о непредвиденной ошибке с кратким указанием причины ее возникновения.
Обычно для ее исправления требуются такие действия:
- проверка наличия, срока действия, подлинности сертификатов и выполнение их замены;
- выполнение проверки корректной работы операционной системы компьютера, ее обновление до минимальных допустимых параметров;
- проверка состояния съемного носителя закрытого ключа;
- выявление и устранение ошибок работы криптопровайдера.
Важно. Причина, из-за которой владелец ЭЦП не может нею воспользоваться, может быть комплексной. Поэтому, если не сработал один из предложенных вариантов, проверьте по другим направлениям.
Проблема с сертификатом
Распространенным явлением во время подписания электронных документов ЭЦП является получение уведомления, что системе не удалось получить доступ к сертификатам, пригодным для формирования подписи.
Здесь причины возникновения неисправности могут быть такими:
- Пользователь не установил на свой ПК корневые сертификаты УЦ, осуществлявшего формирование и выдачу ЭЦП. Для устранения – скачать и установить на компьютер такой сертификат, либо прописать доступ к нему.
- Система не видит личных сертификатов владельца ЭЦП. Выдаются одновременно с оформлением ЭП. Их необходимо загрузить на ваш ПК, и подтянуть в криптопровайдер. В дальнейшем можно загрузить через сайт УЦ. Устанавливаются и прописываются на рабочем месте, предназначенном для работы с ЭЦП. С незарегистрированным сертификатом вы не сможете осуществлять подписание электронных документов.
- Информирование о невалидности сертификатов. Обычно такое возможно в случае, когда заканчивается срок действия сертификата, либо их отзывают. Потребуется обращаться в УЦ, выдавший ЭЦП, для уточнения статуса сертификатов подписи. В некоторых случаях помогает обновление сертификатов на компьютере пользователя. Сделать это можно вручную.
Мнение эксперта
Владимир Аникеев
Специалист отдела технической поддержки УЦ
Внимательно читайте природу ошибки, что выдает система. Обычно это ключ к дальнейшему направлению поиска источника проблемы и ее устранению.
Что делать если не найден сертификат или не верен
Когда сертификат отсутствует в списке «Ваши Сертификаты», проблема может оказаться в отсутствии коренного сертификата УЦ.
Для устранения этой проблемы необходимо:
- проверить наличие такого сертификата на вашем ПК по пути: «Пуск» — дальше «Все программы» — после этого плагин «КриптоПро» — а уже там «Сертификаты»;
- дальше находим вкладку «Личное», выбираем «Сертификаты»;
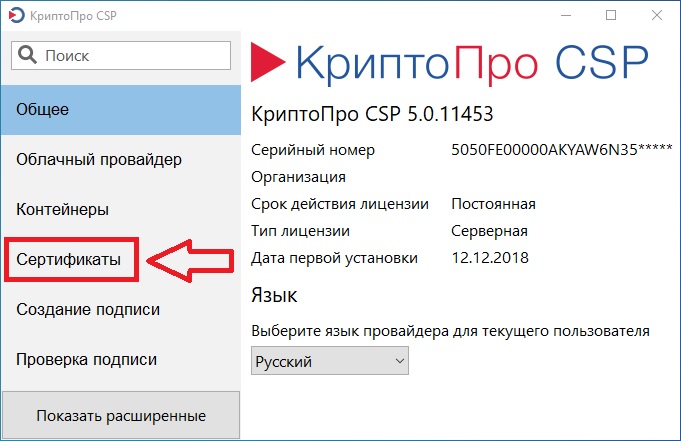
- потребуется открыть не отображенный во вкладке сертификат и просмотреть его «Путь сертификации»;
- тут отображаются все цепочки сертификатов в порядке ранжирования. Важно чтобы напротив какого-то из них не стоял желтый, либо красный значок предупреждения. Если подобное присутствует – нажмите на сам сертификат и ознакомьтесь с ошибкой, что выдаст система;
- в зависимости от причины (обычно это окончание действия сертификата, либо не верифицирован) выполните ее устранение.
Чтобы устранить ошибку и перезагрузить отозванный сертификат потребуется выполнить несколько не сложных действий:
- в окне «Свойства браузера» откройте личный сертификат. Попасть туда можно через «Поиск» меню «Пуск». В открытом окошке ищите вкладку «Содержание», дальше вкладку «Сертификаты»;
- после этого во вкладке «Состав» потребуется выбрать позицию «Точки распространения списков отзывов»;
- в следующем блоке под названием «Имя точки распространения» необходимо выполнить копирование ссылки загрузки файла списка отзывов;
- переходя по указанной ссылке необходимо скачать и установить файл списка отзывов (CRL);
- дальше переходим по подсказкам «Мастера импорта сертификатов».
Следующей распространенной проблемой, когда компьютер не видит сертификат на носителе, является сбой в работе программных продуктов компьютера либо Токена (флешки). Обычно помогает простая перезагрузка ПК. Среди прочих популярных проблем этого направления можно выделить такие:
- На носителе отсутствует драйвер, либо он установлен не корректно. Необходимо скачать последнюю версию драйвера с официального источника и установите его. Можно проверить работоспособность съемного носителя на другом ПК. В этом случае, если другой ПК нормально работает с носителем ЭЦП, переустановите драйверы на первом компьютере.
- Система долго распознает носитель ЭЦП. Тут проблема в операционной системе. Ее потребуется обновить до минимального уровня, требуемого для работы с ЭЦП.
- USB-порт работает не корректно. Попробуйте подсоединить Токен (флешку) через другой порт, либо на другом ПК, чтобы убедиться, что проблема не в носителе. Выполните перезагрузку компьютера.
- Если Токин (флешка) не открывается ни на одном компьютере, значит проблема в носителе. Когда ключ был записан в единственном экземпляре на этот носитель – потребуется обращаться в УЦ для перевыпуска ЭЦП.
Важно. Перед вынесением «окончательного вердикта» касательно работоспособности носителя и сертификата, не поленитесь выполнить их проверку через несколько различных источников.
Проблемы при авторизации
Часто с подобными неприятностями сталкиваются владельцы ЭЦП, пытающиеся пройти регистрацию, либо авторизацию на различных электронных торговых площадках. Пользователю появляется уведомление, что его подпись не авторизирована.
Обычно проблема кроется:
- Отсутствие регистрации. Потребуется попросту зарегистрироваться на избранном вами ресурсе.
- Не зарегистрирован сертификат. Возникает после обновления ключа ЭЦП. Устраняется путем регистрации нового сертификата ключа ЭЦП.
Мнение эксперта
Владимир Аникеев
Специалист отдела технической поддержки УЦ
На различных ресурсах процесс регистрации (авторизации) может существенно отличаться, иметь определенные ограничения, а также блокироваться защитным ПО. Поэтому перед началом процедуры не поленитесь ознакомиться с соответствующей инструкцией и правилами.
В дальнейшем, при работе на самой электронной площадке и попытке подписать электронные документы, могут возникать дополнительные трудности, связанные с такими моментами:
- Необходимости присоединиться к регламенту. Система не даст возможность полноценно работать, если вы не согласитесь с ее условиями.
- Невозможность загрузить файл (файлы). Обычно это ошибка превышения размера информации, что допустима для загрузки. Просто смените формат разрешения файла, чтобы уменьшить его размер.
- Требование использовать определенный браузер (определенную версию браузера). Это системные требования владельца площадки, которые необходимо соблюдать.
- Проблемы со считыванием сертификатов. Потребуется проверить не просрочены ли ваши сертификаты, а также все ли они установлены на ПК.
Что значит er 10002 неопределенная ошибка при проверке ЭЦП, что делать?
Возможно не прошла расшифровка файла ключа. Перезагрузите компьютер. Проверьте, отображается ли съемный носитель ключа ЭЦП, наличие и корректность отображения сертификатов, а также соответствие их (должен быть одинаковый владелец).
Ошибка 52 цифровая подпись
Связана с повреждением, либо отсутствием необходимых драйверов на носителе, либо ПК. Потребуется скачать с официального источника недостающий драйвер и переустановить его.
Почему компьютер не видит ЭЦП?
Несоответствие программного продукта операционной системы и съемного носителя (флешки), либо повреждение флешки. Устраняется путем обновления операционной системы до минимально необходимой версии. В случае обнаружения повреждения флешки – может потребоваться перевыпуск ЭЦП удостоверяющим центром.
Почему КриптоПро не отображает ЭЦП?
Потребуется выполнить определенные настройки вашего браузера и добавить программу в меню веб-обозревателя, а также загрузить недостающие сертификаты ЭЦП.
Где на компьютере искать сертификаты ЭЦП?
Хранение сертификатов в Windows (от 7 версии) осуществляется по адресу: C:UsersПОЛЬЗОВАТЕЛЬAppDataRoamingMicrosoftSystemCertificates
где вместо «ПОЛЬЗОВАТЕЛЬ» должно стоять наименование вашего ПК
Is there some other way around this issue, that can allow reading of the pdf despite this problem?
I have some code that reads pdf files. The code fails at the line :
iTextSharp.text.pdf.PRTokeniser.CheckPdfHeader() at
iTextSharp.text.pdf.PdfReader.ReadPdf()
I know from other entries that this issue is coming from some invalid formatting in the PDF. However I’m not in a position to tell my users to redo their PDFs. Is there some other way around this issue, that can allow reading of the pdf despite this problem?
Posted on StackOverflow on Sep 10, 2012 by David Choi
If a file doesn’t start with %PDF- then there’s nothing to fix: the file isn’t a PDF file.
However, there may be another problem: maybe you’re trying to access a file that has zero length due to some problem while creating the InputStream. Another context in which I’ve seen this happen, is a PDF loaded from a server, where the server returned a 404 message in HTML instead of a PDF file
Whenever that exception happens, you should store the bytes somewhere, and examine them. Without those bytes, nobody will be able to give you useful advice.
Click this link if you want to see how to answer this question in iText 5.
Я использую iText в своей программе java для редактирования существующего pdf. Сгенерированный PDF файл не открывается и показывает, что подпись в заголовке PDF не найдена. Я использую оба файла ввода и вывода с тем же именем.
private static String INPUTFILE = "/sample.pdf";
private static String OUTPUTFILE = "/sample.pdf";
public static void main(String[] args)
throws DocumentException,
IOException
{
Document doc = new Document();
PdfWriter writer = PdfWriter.getInstance(doc,new FileOutputStream(OUTPUTFILE));
doc.open();
PdfReader reader = new PdfReader(INPUTFILE);
int n;
n = reader.getNumberOfPages();
System.out.println("No. of Pages :" +n);
for (int i = 1; i <= n; i++)
{
if (i == 1)
{
Rectangle rect = new Rectangle(85,650,800,833);
PdfFormField pushbutton = PdfFormField.createPushButton(writer);
pushbutton.setWidget(rect, PdfAnnotation.HIGHLIGHT_PUSH);
PdfContentByte cb = writer.getDirectContent();
PdfAppearance app = cb.createAppearance(380,201);
app.rectangle(62,100,50,-1);
app.fill();
pushbutton.setAppearance(PdfAnnotation.APPEARANCE_NORMAL,app);
writer.addAnnotation(pushbutton);
PdfImportedPage page = writer.getImportedPage(reader, i);
Image instance = Image.getInstance(page);
doc.add(instance);
}
Ответ 1
Вы можете импортировать из пустого источника или недопустимого pdf файла, в моем случае pdfCopy не работает, поэтому вот код, который я использовал.
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, OutputStream );
PdfReader reader = new PdfReader(dato.getBinaryStream());
PdfImportedPage page1 = writer.getImportedPage(reader, 1);
PdfContentByte cb = writer.getDirectContent();
cb.addTemplate(page1, 1, 0, 0, 1, 0, 0);
document.setPageSize(new Rectangle(page1.getWidth(),page1.getHeight()) );
…
Это должно работать.
Ответ 2
Затем попробуйте сначала переименовать входной файл в .bak и прочитайте .bak и напишите .pdf. Это может дать понять, является ли ошибка при чтении или записи.
Itext — это не один API, а несколько, смешанный. Довольно сложно. Я сделал:
Закройте оба PdfReader и FileInputStream.
Закройте оба Document и PdfWriter.
Ответ 3
Вы должны использовать PdfCopy вместо PdfWriter.getInstance, поскольку в противном случае он не обновляет ссылки на объекты PDF.
Кроме того, вместо добавления Image к документу вы можете использовать метод PdfCopy.addPage, который принимает параметр PdfImportedPage as.
Document doc = new Document();
PdfCopy writer = new PdfCopy(doc,new FileOutputStream(OUTPUTFILE));
doc.open();
PdfReader reader = new PdfReader(INPUTFILE);
int n = reader.getNumberOfPages();
System.out.println("No. of Pages :" +n);
for (int i = 1; i <= n; i++) {
if (i == 1) {
// removed code for clarity
PdfImportedPage page = writer.getImportedPage(reader, i);
writer.addPage(page);
}
}
Ответ 4
В моем случае файл с образцом PDF был поврежден. загрузите новый файл, он будет работать.
Ответ 5
У меня была такая же ошибка, и я просто изменил свой PdfReader на чтение InputStreams для чтения строк. Таким образом, он отлично работает с:
public static void doMerge(List<String> list, OutputStream outputStream)
throws DocumentException, IOException {
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, outputStream);
document.open();
PdfContentByte cb = writer.getDirectContent();
for (String in : list) {
PdfReader reader = new PdfReader(in);
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
document.newPage();
// import the page from source pdf
PdfImportedPage page = writer.getImportedPage(reader, i);
// add the page to the destination pdf
cb.addTemplate(page, 0, 0);
}
}
outputStream.flush();
document.close();
outputStream.close();
}
* Первоначально я взял этот код из http://www.mindfiresolutions.com/Java-Merging-multiple-PDFs-into-a-single-PDF-using-iText-671.php
Я использую iTextSharp для чтения содержания документов PDF :
PdfReader reader = new PdfReader(pdfPath);
using (StringWriter output = new StringWriter())
{
for (int i = 1; i <= reader.NumberOfPages; i++)
output.WriteLine(PdfTextExtractor.GetTextFromPage(reader, i, new SimpleTextExtractionStrategy()));
reader.Close();
pdfText = output.ToString();
}
99% времени он работает нормально. Однако есть один файл PDF , который иногда вызывает это исключение:
Подпись заголовка PDF не найдена. StackTrace:
iTextSharp.text.pdf.PRTokeniser.CheckPdfHeader () на
iTextSharp.text.pdf.PdfReader.ReadPdf () на
iTextSharp.text.pdf.PdfReader..ctor (String filename, Byte []> ownerPassword) в
Reader.PDF.DownloadPdf (строковый URL) в
Что раздражает, так это то, что я не всегда могу воспроизвести ошибку. Иногда это работает, иногда нет. Кто-нибудь сталкивался с этой проблемой?
4 ответа
Лучший ответ
После некоторых исследований я обнаружил, что эта проблема связана либо с повреждением файла во время создания PDF-файла, либо с ошибкой, связанной с объектом в документе, который не соответствует стандарту PDF, реализованному в iTextSharp. Кроме того, похоже, что это происходит только тогда, когда вы читаете PDF-файл с диска.
Я не нашел полного решения проблемы, а только временное решение. Я прочитал PDF-документ с помощью объекта PdfReader itextsharp и посмотрел, возникнет ли ошибка или исключение, перед чтением файла в обычном режиме.
Итак, запускаем что-то похожее на это:
private bool IsValidPdf(string filepath)
{
bool Ret = true;
PdfReader reader = null;
try
{
reader = new PdfReader(filepath);
}
catch
{
Ret = false;
}
return Ret;
}
24
Anonymous coward
20 Май 2012 в 23:50
Я обнаружил, что это произошло потому, что я вызвал new PdfReader(pdf) с позицией потока PDF в конце файла. Установка положения на ноль решила проблему.
Перед:
// Throws: InvalidPdfException: PDF header signature not found.
var pdfReader = new PdfReader(pdf);
После:
// Works correctly.
pdf.Position = 0;
var pdfReader = new PdfReader(pdf);
19
Bern
1 Июл 2020 в 18:13
В моем случае это было потому, что я вызывал файл .json, а iTextSharp, очевидно, принимает только файл pdf.
0
David Greenfeld
23 Июн 2020 в 04:31
Есть вероятность, что вы открываете файл другим методом или программой, как в моем случае. Убедитесь, что с вашим файлом ничего не работает. Вы также можете использовать монитор ресурсов, чтобы проверить, какие процессы работают с вашим файлом.
0
Alexis Ponce
2 Дек 2021 в 15:24
Проблема:
При попытке распечатать форму Orbeon Forms (имеющую собственный шаблон pdf-ки) валится исключение:
java.io.IOException: PDF header signature not found.
at com.lowagie.text.pdf.PRTokeniser.checkPdfHeader(Unknown Source)
at com.lowagie.text.pdf.PdfReader.readPdf(Unknown Source)
at com.lowagie.text.pdf.PdfReader.<init>(Unknown Source)
at com.lowagie.text.pdf.PdfReader.<init>(Unknown Source)
…
Причина:
Вероятнее всего, pdf-ки просто нет там, куда ссылается соотв. элемент формы (instance(‘fr-form-attachments’)/pdf).
After converting file from MSword to PDF extraction i am getting a error PDF header signature not found.
public void Extract_inputpdf()
{
text_input_File = string.Empty;
StringBuilder sb_inputpdf = new StringBuilder();
PdfReader reader_inputPdf = new PdfReader(path); //read PDF
for (int i = 0; i <=reader_inputPdf.NumberOfPages ; i++)
{
TextWithFont_inputPdf inputpdf = new TextWithFont_inputPdf();
text_input_File = iTextSharp.text.pdf.parser.PdfTextExtractor.GetTextFromPage(reader_inputPdf, i, inputpdf);
sb_inputpdf.Append(text_input_File);
input_pdf = sb_inputpdf.ToString();
}
reader_inputPdf.Close();
clear();
}
can anyone tell me how to solve this.Thanku
// word to pdf
if (Extentsion_path == ".doc" || Extentsion_path == ".docx")
{
uploadFInput.SaveAs(targetPathip);
string wordFileName = targetPathip;
_Word.Visible = false;
_Word.ScreenUpdating = false;
// Cast as Object for word Open method
filename = (object)wordFileName;
// Use the dummy value as a placeholder for optional arguments
Microsoft.Office.Interop.Word.Document doc = _Word.Documents.Open(ref filename, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue);
doc.Activate();
object outputFileName = pdfFileName = Path.ChangeExtension(wordFileName, "pdf");
object fileFormat = WdSaveFormat.wdFormatPDF;
// Save document into PDF Format
doc.SaveAs(ref outputFileName, ref fileFormat, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue,
ref _MissingValue, ref _MissingValue, ref _MissingValue, ref _MissingValue);
// Close the Word document, but leave the Word application open.
// doc has to be cast to type _Document so that it will find the
// correct Close method.
object saveChanges = WdSaveOptions.wdDoNotSaveChanges;
((_Document)doc).Close(ref saveChanges, ref _MissingValue, ref _MissingValue);
doc = null;
// word has to be cast to type _Application so that it will find
// the correct Quit method.
((_Application)_Word).Quit(ref _MissingValue, ref _MissingValue, ref _MissingValue);
_Word = null;
//uploadFInput.SaveAs(pdfFileName);
// = targetPathip;
uploadFInput.SaveAs(pdfFileName);
LblFleip.Text = pdfFileName;
}
else
{
uploadFInput.SaveAs(targetPathip);
LblFleip.Text = targetPathip;
}