
Меня зовут Дмитрий Макаренко, я Mobile QA Engineer в Badoo и Bumble: занимаюсь тестированием новой функциональности в наших приложениях вручную и покрытием её автотестами.
За последние два года подход к автоматизации тестирования в нашей компании сильно изменился. Количество людей, активно вовлечённых в разработку тестов, увеличилось с десяти до 40 человек. А любая новая функциональность в приложениях теперь обязательно должна быть покрыта тестами до релиза.
В таких условиях нам очень важно разрабатывать тесты настолько быстро, насколько это возможно. И делать их при этом стабильными — чтобы поддержка не отнимала у нас много времени. Мы решили поделиться практиками, которые помогают нам ускорять разработку тестов и повышать их стабильность.
В подготовке текста мне помогал мой коллега Виктор Короневич: с этой темой мы вместе выступали на конференции Heisenbug.
В первой части статьи мы рассказали о роли автоматизации в наших процессах, деталях фреймворка и подробно разобрали три практики, которые мы применяем при создании автотестов. Во второй части мы будем разбираться с верификацией изменения состояния элементов, настройкой предусловий тестов, разработкой шагов для простых и сложных действий, а также с верификацией необязательных элементов (которую обязательно нужно делать :)).
Напомню, что примеры из обеих частей в равной степени актуальны для тех, кто только начинает внедрять автоматизацию тестирования в своём проекте, и тех, кто уже активно ею занимается.
Спойлер
В конце статьи будет ссылка на тестовый проект со всеми практиками.
Практика 4. Верификация изменения состояния элементов
Пожалуй, эта практика одна из самых важных в мобильной автоматизации в принципе, потому что в приложениях очень редко встречаются статические элементы, которые сразу же отображаются на экране и всегда на нём доступны. Чаще мы сталкиваемся с тем, что загрузка элементов занимает какое-то время.
Например, в случае медленного интернета элементы, получаемые с сервера, отображаются с существенной задержкой. И если мы попытаемся их проверить до того, как они появятся, тесты будут падать.
Таким образом, прежде чем начать проверять элементы, нам необходимо дождаться их появления на экране. Естественно, эта проблема не нова и существуют стандартные решения. Например, в Selenium это различные типы методов wait, а в Calabash — метод wait_for.
Зачем нам свой велосипед, или Почему мы отказались от стандартного решения
Когда мы начинали строить наш фреймворк автоматизации, мы использовали стандартный метод wait_for для ожидания появления или изменения состояния элементов. Но в какой-то момент столкнулись с проблемой. Иногда, раз в две-три недели, у нас зависали все тесты. Мы не могли понять, как и почему это происходит и что мы делаем не так.
После того как мы добавили логи и проанализировали их, оказалось, что эти зависания были связаны с реализацией метода wait_for, входящего в состав фреймворка Calabash. wait_for использует метод timeout модуля Ruby Timeout, который реализован на глобальном потоке. А тесты зависали, когда этот метод timeout использовался вложено в других методах: наших и фреймворка Calabash.
Например, рассмотрим прокрутку страницы профиля до кнопки блокировки пользователя.
def scroll_to_block_button
wait_for(timeout: 30) do
ui.scroll_down
ui.wait_until_no_animation
ui.element_displayed?(BLOCK_BUTTON)
end
endМы видим, что используется метод wait_for. Происходит прокрутка экрана вниз, потом ожидание окончания анимации и проверка отображения кнопки блокировки.
Рассмотрим реализацию метода wait_until_no_animation.
def wait_until_no_animation
wait_for(timeout: 10) do
!ui.any_element_animating?
end
endМетод wait_until_no_animation реализован так же с wait_for. Он ждёт, когда на экране закончится анимация. Получается, что wait_for, вызванный внутри wait_for, вызывает другие методы. Представьте себе, что вызовы wait_for также есть внутри методов Calabash. С увеличением цепочки wait_for внутри wait_for внутри wait_for риск зависания увеличивается. Поэтому мы решили отказаться от использования этого метода и придумать своё решение.
Требования к нему совпадали с требованиями к стандартным решениям. Нам нужен был метод, который бы повторял проверку до тех пор, пока не выполнится заданное условие либо пока не истечёт отведённое время. Если проверка не проходит успешно за отведённое время, наш метод должен выбрасывать ошибку.
Сначала мы создали модуль Poll с одним методом for, который повторял стандартный метод wait_for. Со временем собственная реализация позволила нам расширять функциональность модуля по мере того, как у нас появлялась такая необходимость. Мы добавили методы, ожидающие конкретные значения заданных условий. Например, Poll.for_true и Poll.for_false явно ожидают, что исполняемый код вернёт true либо false. В примерах ниже я покажу использование разных методов из модуля Poll.
Также мы добавили разные параметры методов. Рассмотрим подробнее параметр return_on_timeout. Его суть в том, что при использовании этого параметра наш метод Poll.for перестаёт выбрасывать ошибку, даже если заданное условие не выполняется, а просто возвращает результат выполнения проверки.
Предвижу вопросы «Как это работает?» и «Зачем это нужно?». Начнём с первого. Если в методе Poll.for мы будем ждать, пока 2 станет больше, чем 3, то мы всегда будем получать ошибку по тайм-ауту.
Poll.for { 2 > 3 }
> WaitErrorНо если мы добавим наш параметр return_on_timeout и всё так же будем ждать, пока 2 станет больше, чем 3, то после окончания тайм-аута, 2 всё ещё не станет больше, чем 3, но наш тест не упадёт, а метод Poll.for вернёт результат этой проверки.
Poll.for(return_on_timeout: true) { 2 > 3 }
> falseЗачем это нужно? Мы используем параметр return_on_timeout для верификации изменения состояния наших элементов. Но очень важно делать это аккуратно, так как он может скрывать реальные падения тестов. При некорректном использовании тесты будут продолжать выполняться, когда заданные условия не выполняются, в тех местах, где должны были бы выбросить ошибку.
Варианты изменения состояния элементов
А теперь перейдём к самому интересному — поговорим о том, как проверять различные изменения состояния и какие изменения состояния вообще существуют. Познакомьтесь с нашим объектом тестирования — чёрным квадратом:

Он умеет всего две вещи: появляться на экране и пропадать с экрана.
Первый вариант изменения состояния называется «Должен появиться». Он происходит в том случае, когда состояние 1 – на экране нет нашего объекта тестирования, а состояние 2 – он должен появиться.

Если он появляется, то проверка проходит успешно.
Второй вариант изменения состояния называется «Должен пропасть». Происходит он тогда, когда в состоянии 1 отображается наш объект тестирования, а в состоянии 2 его быть не должно.

Третий вариант не такой очевидный, как первые два, потому что в нём, по сути, мы проверяем неизменность состояния. Называется он «Не должен появиться». Это происходит, когда в состоянии 1 наш объект тестирования не отображается на экране и спустя какое-то время в состоянии 2 он всё ещё не должен появиться.

Вы, наверное, догадались, какой вариант — четвёртый. Он называется «Не должен пропасть». Происходит это, когда в состоянии 1 объект отображается на экране, и спустя какое-то время в состоянии 2 он всё ещё находится там.

Реализация проверок разных вариантов
Мы зафиксировали все возможные варианты изменения состояния элементов. Как же их проверить? Разобьём реализацию на проверки первых двух вариантов и проверки третьего и четвёртого.
В случае с первыми двумя вариантами всё довольно просто. Для проверки первого нам просто нужно подождать, пока элемент появится, используя наш метод Poll:
# вариант "Должен появиться"
Poll.for_true { ui.elements_displayed?(locator) }Для проверки второго — подождать, пока элемент пропадёт:
# вариант "Должен пропасть"
Poll.for_false { ui.elements_displayed?(locator) }Но в случае с третьим и четвёртым вариантами всё не так просто.

Рассмотрим вариант «Не должен появиться»:
# вариант "Не должен появиться"
ui.wait_for_elements_not_displayed(locator)
actual_state = Poll.for(return_on_timeout: true) { ui.elements_displayed?(locator) }
Assertions.assert_false(actual_state, "Element #{locator} should not appear")Здесь мы, во-первых, фиксируем состояние отсутствия элемента на экране.
Далее, используя Poll.for с параметром return_on_timeout, мы ждём появления элемента. При этом метод Poll.for не выбросит ошибку, а вернёт false, если элемент не появится. Значение, полученное из Poll.for, сохраняется в переменной actual_state.
После этого происходит проверка неизменности состояния элемента с использованием метода assert.
Для проверки варианта «Не должен пропасть» мы используем похожую логику, ожидая пропажи элемента с экрана вместо его появления:
# вариант "Не должен пропасть"
ui.wait_for_elements_displayed(locator)
actual_state = Poll.for(return_on_timeout: true) { !ui.elements_displayed?(locator) }
Assertions.assert_false(actual_state, "Element #{locator} should not disappear")Проверки этих четырёх вариантов изменения состояния актуальны для многих элементов мобильных приложений. А поскольку разработкой тестов у нас занимается много людей, всегда есть вероятность того, что кто-то забудет про некоторые варианты при создании новых проверок. Поэтому мы вынесли реализацию проверок всех вариантов изменения состояния в один метод:
def verify_dynamic_state(state:, timeout: 10, error_message:)
options = {
return_on_timeout: true,
timeout: timeout,
}
case state
when 'should appear'
actual_state = Poll.for(options) { yield }
Assertions.assert_true(actual_state, error_message)
when 'should disappear'
actual_state = Poll.for(options) { !yield }
Assertions.assert_true(actual_state, error_message)
when 'should not appear'
actual_state = Poll.for(options) { yield }
Assertions.assert_false(actual_state, error_message)
when 'should not disappear'
actual_state = Poll.for(options) { !yield }
Assertions.assert_false(actual_state, error_message)
else
raise("Undefined state: #{state}")
end
endyield – это код блока, переданного в данный метод. На примерах выше это был метод elements_displayed?. Но это может быть любой другой метод, результат выполнения которого отражает состояние необходимого нам элемента. Документация Ruby.
Таким образом, мы можем проверять любые варианты изменения состояния любых элементов вызовом одного метода, что существенно облегчает жизнь всем командам тестирования.
Выводы:
-
важно не забывать про все четыре варианта изменения состояния при проверках UI-элементов;
-
полезно вынести эти проверки в общий метод.
Мы рекомендуем использовать полную систему проверок всех вариантов изменения состояния. Что мы имеем в виду? Представьте, что когда элемент есть — это состояние true, а когда его нет — false.
|
Состояние 1 |
Состояние 2 |
|
|
Должен появиться |
FALSE |
TRUE |
|
Должен пропасть |
TRUE |
FALSE |
|
Не должен появиться |
FALSE |
FALSE |
|
Не должен пропасть |
TRUE |
TRUE |
Мы строим матрицу всех комбинаций. При появлении нового состояния таблицу можно расширить и получить новые комбинации.
Практика 5. Надёжная настройка предусловий тестов
Как можно догадаться из заголовка, задача этого раздела — разобраться, как настраивать предусловия перед началом выполнения теста.
Рассмотрим два примера. Первый – отключение сервиса локации на iOS в настройках. Второй – создание истории чата.
В первом примере реализация метода отключения сервиса локации на iOS выглядит следующим образом:
def switch_off_location_service
ui.wait_for_elements_displayed(SWITCH)
if ui.element_value(SWITCH) == ON
ui.tap_element(SWITCH)
ui.tap_element(TURN_OFF)
end
endМы ждём, пока переключатель (элемент switch) появится на экране. Потом проверяем его состояние. Если оно не соответствует ожидаемому, мы его изменяем.
После этого мы закрываем настройки и запускаем приложение. И иногда внезапно сталкиваемся с проблемой: почему-то сервис локации остаётся включённым. Как это получается? Мы же сделали всё, чтобы его отключить. Кажется, что это проблема работы системных настроек в iOS системе. При быстром выходе из настроек (а тест делает это моментально после нажатия на переключатель) их новое состояние не сохраняется. Но проблемы могут возникнуть и при настройке предусловий в нашем приложении.
Давайте обратимся ко второму примеру — созданию истории чата перед началом выполнения теста. Реализация метода выглядит следующим образом:
def send_message(from:, to:, message:, count:)
count.times do
QaApi.chat_send_message(user_id: from, contact_user_id: to, message: message)
end
endМы используем QAAPI для отправки сообщений по user_id. В цикле мы отправляем необходимое количество сообщений.
После этого мы заходим в чат и производим необходимые проверки, связанные с загрузкой истории сообщений. Но иногда в чате отображаются не все сообщения. Иногда мы продолжаем получать их, уже находясь в чате, а не до его открытия. Связано это с тем, что сервер не может отправлять нужное количество сообщений моментально. В некоторых случаях доставка задерживается.
Выделим общую проблему обоих примеров. Когда установка предусловий выполняется некорректно, тесты падают на последующих проверках, несмотря на то, что сами приложения работают как надо. Мы начинаем разбираться в причинах, а потом понимаем, что падение вызвано неправильной подготовкой предусловий. Такие ситуации расстраивают не только тестировщиков, но и разработчиков, которые анализируют прогоны тестов при разработке новой функциональности.
Как же решить эту проблему? Мы можем добавить гарантию выполнения действия в методы установки предусловий.
Тогда наш метод отключения сервиса локации будет выглядеть следующим образом:
def ensure_location_services_switch_in_state_off
ui.wait_for_elements_displayed(SWITCH)
if ui.element_value(SWITCH) == ON
ui.tap_element(SWITCH)
ui.tap_element(TURN_OFF)
Poll.for(timeout_message: 'Location Services should be disabled') do
ui.element_value(SWITCH) == OFF
end
end
endИспользуя метод Poll.for, мы убеждаемся, что состояние переключателя изменилось, прежде чем переходить к следующим действиям теста. Это позволяет избежать проблем, вызванных тем, что сервис локации время от времени был включён.
Во втором примере нам снова помогут наши методы QAAPI.
def send_message(from:, to:, message:, count:)
actual_messages_count = QaApi.received_messages_count(to, from)
expected_messages_count = actual_messages_count + count
count.times do
QaApi.chat_send_message(user_id: from, contact_user_id: to, message: message)
end
QaApi.wait_for_user_received_messages(from, to, expected_messages_count)
endПеред отправкой сообщений мы получаем текущее количество сообщений в чате, а после — убеждаемся, что необходимое количество сообщений было отправлено. Только после этой проверки тест продолжает своё выполнение. Таким образом, когда мы открываем чат в приложении, мы видим все необходимые сообщения и можем выполнять нужные проверки.
Итак, мы рекомендуем всегда использовать гарантию выполнения действий в процессе установки предусловий в ваших тестах. Это позволит сэкономить время на исследовании падений в тех случаях, когда не срабатывает установка предусловий, потому что тест упадёт сразу же на этапе подготовки.
В качестве общей рекомендации советуем добавлять в ваши тесты проверку выставления любых предустановок, когда выполняются асинхронные действия.
Более подробно о проблемах, описанных в этом разделе, можно прочитать в статье Мартина Фаулера.
Практика 6. Простые и сложные действия, или Независимость шагов в тестах
Простые действия
По выводам из предыдущего раздела может показаться, что нам стоит добавлять в тесты проверки выполнения всех действий. Но на деле это не так. В этом разделе мы поговорим о реализации шагов для разных действий и верификаций. Это очень общая формулировка, которая подходит практически для любого шага в наших тестах. Поэтому мы, как обычно, будем рассматривать конкретные примеры.
Начнём с теста поиска и отправки GIF-сообщений.
Сначала нам нужно открыть чат с пользователем, которому мы хотим отправить сообщение:
When primary_user opens Chat with chat_userПотом открыть поле ввода GIF-сообщений:
And primary_user switches to GIF input sourceДалее нам нужно ввести поисковый запрос для GIF-изображений, убедиться, что список обновился, отправить понравившееся изображение из списка и убедиться, что оно было отправлено.
And primary_user searches for "bee" GIFs
And primary_user sends 7th GIF in the list
Then primary_user verifies that the selected GIF has been sentЦеликом сценарий выглядит так:
Scenario: Searching and sending GIF in Chat
Given users with following parameters
| role | name |
| primary_user | Dima |
| chat_user | Lera |
And primary_user logs in
When primary_user opens Chat with chat_user
And primary_user switches to GIF input source
And primary_user searches for "bee" GIFs
And primary_user sends 7th GIF in the list
Then primary_user verifies that the selected GIF has been sentОбратим внимание на шаг, который отвечает за поиск гифки:
And(/^primary_user searches for "(.+)" GIFs$/) do |keyword|
chat_page = Pages::ChatPage.new.await
TestData.gif_list = chat_page.gif_list
chat_page.search_for_gifs(keyword)
Poll.for_true(timeout_message: 'Gif list is not updated') do
(TestData.gif_list & chat_page.gif_list).empty?
end
endЗдесь, как и почти во всех остальных шагах, мы делаем следующее:
-
сначала ожидаем открытия нужной страницы (ChatPage);
-
потом сохраняем список всех доступных GIF-изображений;
-
далее вводим ключевое слово для поиска;
-
затем ждём изменения состояния — обновления списка (ведь мы говорили о том, что полезно добавлять в тесты проверку выполнения действий).
Кажется, что всё реализовано правильно. После завершения поиска мы убеждаемся, что список изображений обновился, и только после этого отправляем одно из них. Но у нас появится проблема, если мы, например, захотим написать тест, проверяющий, что после ввода идентичного поискового запроса список изображений не обновится. В этом случае нам придётся создавать отдельный шаг для ввода поискового запроса для GIF-изображений, который во многом будет дублировать уже имеющийся.
Подобная проблема возникает в тех случаях, когда какое-то действие может приводить к разным результатам, а мы в шаге фиксируем лишь один из них в виде проверки выполнения действия. Это приводит к сложности переиспользования такого рода шагов, и, следовательно, к замедлению разработки тестов и дубликации кода.
Как же нам этого избежать? Как вы, возможно, заметили, наш шаг поиска GIF-изображений на самом деле включал в себя три действия:
-
сохранение текущего списка;
-
поиск;
-
проверку обновления списка.
Решением проблемы переиспользования будет разделение этого шага на три простых и независимых.
Первый шаг сохраняет текущий список изображений:
And(/^primary_user stores the current list of GIFs$/) do
TestData.gif_list = Pages::ChatPage.new.await.gif_list
endВторой шаг – поиск гифки — позволяет напечатать ключевое слово для поиска:
And(/^primary_user searches for "(.+)" GIFs$/) do |keyword|
Pages::ChatPage.new.await.search_for_gifs(keyword)
endНа третьем шаге мы ждём обновления списка:
And(/^primary_user verifies that list of GIFs is updated$/) do
chat_page = Pages::ChatPage.new.await
Poll.for_true(timeout_message: 'Gif list is not updated') do
(TestData.gif_list & chat_page.gif_list).empty?
end
endВ итоге наш первоначальный сценарий выглядит следующим образом:
Scenario: Searching and sending GIF in Chat
Given users with following parameters
| role | name |
| primary_user | Dima |
| chat_user | Lera |
And primary_user logs in
When primary_user opens Chat with chat_user
And primary_user switches to GIF input source
And primary_user stores the current list of GIFs
And primary_user searches for "bee" GIFs
Then primary_user verifies that list of GIFs is updated
When primary_user sends 7th GIF in the list
Then primary_user verifies that the selected GIF has been sentТаким образом, мы можем использовать первые два шага даже в том случае, если в тесте список не обновляется. Это помогает нам экономить время на разработку, так как мы можем переиспользовать простые шаги в разных тестах.
Но и здесь есть нюансы. Шаги не всегда можно сделать простыми и независимыми. В таких случаях мы будем называть их сложными.
Сложные действия
Под сложными шагами мы подразумеваем те, которые включают в себя переходы между разными экранами приложения либо работу с изменением состояния какого-либо экрана. Рассмотрим такую ситуацию на примере голосования в мини-игре.
Мини-игра — это экран, на котором пользователю предлагаются профили других людей, которые ему написали. Можно либо отвечать на сообщения, либо пропускать этих пользователей. Действие пропуска назовём «Голосовать “нет”».

Нам необходимо написать тест, который «проголосует “нет”» N раз, закроет экран игры, а потом откроет его снова и проверит, что пользователь находится на правильной позиции.
«Проголосовать “нет”» — простое действие. Но, если мы сделаем для него простой шаг, то для того чтобы проголосовать N раз, нам нужно будет использовать этот шаг столько же раз на уровне сценария. Читать такой сценарий неудобно. Поэтому есть смысл создать более сложный шаг с параметром «Количество голосов», который сможет проголосовать необходимое нам количество раз.
Кажется, что реализовать такой шаг довольно легко. Необходимо всего лишь проголосовать на странице нужное количество раз.
When(/^primary_user votes No in Messenger mini game (d+) times$/) do count
page = Pages::MessengerMiniGamePage.new.await
count.to_i.times do
page.vote_no
end
endНо тут мы сталкиваемся с проблемой: иногда тест голосует слишком быстро. То есть он нажимает на кнопку до того, как обрабатывается предыдущее нажатие. В этом случае приложение не отправит новый голос на сервер. Наш шаг при этом выполнится успешно. А на следующем шаге, когда мы захотим убедиться, что пользователь находится на правильной позиции в игре, тест упадёт, потому что предыдущий шаг не выполнил свою задачу и сделал меньше голосов, чем было нужно.
Как и в случае с установкой предусловий теста, здесь нам придётся разбираться с падениями на том шаге, где тест и приложение работают корректно, поскольку предыдущий шаг сработал неправильно. Конечно же, никто не любит такие ситуации, поэтому нам необходимо решить проблему.
When(/^primary_user votes No in Messenger mini game (d+) times$/) do count
page = Pages::MessengerMiniGamePage.new.await
count.to_i.times do
progress_before = page.progress
page.vote_no
Poll.for_true do
page.progress > progress_before
end
end
endПосле выполнения каждого голоса мы добавим проверку изменения прогресса в мини-игре. Только после этого мы будем делать следующую попытку проголосовать. Так все голоса будут успевать обрабатываться, а мы избежим падений наших тестов.
Подведём итоги. Мы создаём независимые шаги для простых действий. Это позволяет легко их переиспользовать и создавать различные сценарии за более короткое время, чем если бы нам нужно было переписывать похожие друг на друга шаги. В шаги для сложных действий мы добавляем проверки того, что действие выполнено, перед переходом к следующим действиям.
Обобщая эти рекомендации, советуем выделять независимые методы для простых действий в тестах и добавлять проверку предустановок в сложные действия.
Практика 7. Верификация необязательных элементов
Под необязательными элементами мы понимаем такие элементы, которые могут либо отображаться, либо не отображаться на одном и том же экране в зависимости от каких-либо условий. Здесь мы рассмотрим пример диалогов о подтверждении действий пользователя, или алёртов (alerts).

Наверняка вы сталкивались с подобными диалогами в различных мобильных приложениях. В наших двух приложениях, например, их больше 70. Они появляются в разных местах в ответ на разные действия пользователей. Что же представляют собой необязательные элементы на них?
Проанализируем скриншоты выше.
-
Скриншот 1: заголовок, описание и две кнопки.
-
Скриншот 2: заголовок, описание и одна кнопка.
-
Скриншот 3: описание и две кнопки.
Таким образом, необязательными элементами в этих диалогах являются заголовок и вторая кнопка. Локаторы у элементов на алёртах одинаковые — вне зависимости от того, в каком месте приложения или после какого действия пользователя они появляются. Поэтому мы хотим реализовать проверки для всех типов диалогов один раз на их базовой странице, а потом наследовать от неё каждый конкретный алёрт, чтобы не пришлось повторять этот код. Создание подобных проверок мы и рассмотрим в этом разделе.
Начнём с того, как выглядит вызов метода для верификации каждого из диалогов:
class ClearAccountAlert < AppAlertAndroid
def verify_alert_lexemes
verify_alert(title: ClearAccount::TITLE,
description: ClearAccount::MESSAGE,
first_button: ClearAccount::OK_BUTTON,
last_button: ClearAccount::CANCEL_BUTTON)
end
endclass WaitForAlert < AppAlertAndroid
def verify_alert_lexemes
verify_alert(title: WaitForTITLE,
description: WaitForMESSAGE,
first_button: WaitForCLOSE_BUTTON)
end
endclass SpecialOffersAlert < AppAlertAndroid
def verify_alert_lexemes
verify_alert(description: SpecialOffers::MESSAGE,
first_button: SpecialOffers::SURE_BUTTON,
last_button: SpecialOffers::NO_THANKS_BUTTON)
end
endВо всех примерах мы вызываем метод verify_alert, передавая ему лексемы для проверки необходимых элементов. При этом, как вы можете заметить, WaitForAlert мы не передаём лексему для второй кнопки, так как её не должно быть, а SpecialOffersAlert — лексему для заголовка.
Рассмотрим реализацию метода verify_alert:
def verify_alert(title: nil, description:, first_button:, last_button: nil)
ui.wait_for_elements_displayed([MESSAGE, FIRST_ALERT_BUTTON])
ui.wait_for_element_text(expected_lexeme: title, locator: ALERT_TITLE) if title
ui.wait_for_element_text(expected_lexeme: description, locator: MESSAGE)
ui.wait_for_element_text(expected_lexeme: first_button, locator: FIRST_ALERT_BUTTON)
ui.wait_for_element_text(expected_lexeme: last_button, locator: LAST_ALERT_BUTTON) if last_button
endСначала мы ожидаем появления на экране обязательных элементов. После этого убеждаемся, что их текст совпадает с переданными в метод лексемами. В случае же с необязательными элементами мы проверяем текст, если лексема была передана в метод, а если нет, то не делаем ничего.
В чём же проблема этого подхода? В том, что мы пропускаем проверку того, что необязательный элемент не отображается тогда, когда он не должен отображаться. Это может привести к комичным ситуациям. Например, может появиться такой алёрт:
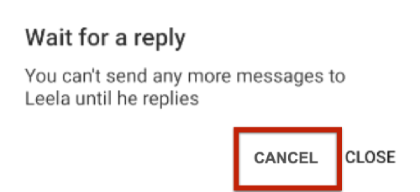
Пользователь не понимает, что выбрать: обе кнопки как будто бы закрывают диалог. Это похоже на критический баг. Даже если приложение не падает, это нужно исправить. А тесты нам нужно изменить так, чтобы они выявляли подобные проблемы.
Для этого в тестах мы меняем проверку
ui.wait_for_element_text(expected_lexeme: title, locator: ALERT_TITLE) if titleна
if title.nil?
Assertions.assert_false(ui.elements_displayed?(ALERT_TITLE), "Alert title should not be displayed")
else
ui.wait_for_element_text(expected_lexeme: title, locator: ALERT_TITLE)
endМы изменили условие if и добавили проверку второго состояния. Если мы не передаём лексему для необязательного элемента, значит, этого элемента не должно быть на экране, что мы и проверяем. Если же в title есть какой-то текст, мы понимаем, что элемент с этим текстом должен быть, и проверяем его. Мы решили выделить эту логику в общий метод, который назвали wait_for_optional_element_text. Этот метод мы можем применять не только для диалогов из этого примера, но и для любых других экранов приложения, на которых есть необязательные элементы. Видим, что if-условие из примера выше полностью находится внутри нового метода:
def wait_for_optional_element_text(expected_lexeme:, locator:)
GuardChecks.not_nil(locator, 'Locator should be specified')
if expected_lexeme.nil?
Assertions.assert_false(elements_displayed?(locator), "Element with locator #{locator} should not be displayed")
else
wait_for_element_text(expected_lexeme: expected_lexeme, locator: locator)
end
endРеализация метода verify_alert тоже изменилась:
def verify_alert(title: nil, description:, first_button:, last_button: nil)
ui.wait_for_elements_displayed([MESSAGE, FIRST_ALERT_BUTTON])
ui.wait_for_optional_element_text(expected_lexeme: title, locator: ALERT_TITLE)
ui.wait_for_element_text(expected_lexeme: description, locator: MESSAGE)
ui.wait_for_element_text(expected_lexeme: first_button, locator: FIRST_ALERT_BUTTON)
ui.wait_for_optional_element_text(expected_lexeme: last_button, locator: LAST_ALERT_BUTTON)
endМы всё так же ожидаем появления обязательных элементов на экране. После этого проверяем, что их текст совпадает с переданными в метод лексемами. В случае же с необязательными элементами теперь мы используем метод wait_for_optional_element_text, который помогает убедиться, что необязательный элемент не отображается тогда, когда не должен отображаться.
Подводя итоги, хотим обратить ваше внимание на то, что не бывает необязательных проверок, — бывают необязательные элементы, все состояния которых нужно обязательно проверять. А выделение проверки состояний необязательных элементов в общий метод позволяет нам легко переиспользовать его для разных экранов приложения.
Резюме: мы советуем использовать полную систему проверок всех состояний нужных элементов, а также выделять общие методы для однотипных действий.
Вы можете заметить, что подобные рекомендации уже звучали в этой статье. Фокус в том, что различались примеры их применения.
Общие рекомендации
Выделим основные рекомендации по автоматизации тестирования мобильных приложений из семи практик, которые мы описали:
-
так как проверки – это то, ради чего мы пишем тесты, всегда используйте полную систему проверок;
-
не забывайте добавлять проверку предустановки для асинхронных действий;
-
выделяйте общие методы для переиспользования однотипного кода — как в шагах, так и в методах на страницах;
-
делайте объект тестирования простым;
-
выделяйте независимые методы для простых действий в тестах.
Возможно, эти советы кому-то покажутся очевидными. Но мы хотим обратить ваше внимание на то, что применять их можно (и нужно) в разных ситуациях. Если вы хотите дополнить список другими полезными рекомендациями, добро пожаловать в комментарии!
Бонус
Мы подготовили тестовый проект, в котором отразили все практики, описанные в статье. Переходите по ссылке, изучайте и применяйте:
Mobile Automation Sample Project
Сегодня мы поговорим об основных, часто встречающихся ошибках, которые часто допускают разработчики при работе с состоянием (state) при разработке React-приложения.
Одна из моих любимых вещей в веб-разработке — всегда есть что-то новое для изучения. Вы могли бы посвятить всю свою жизнь освоению различных языков программирования, библиотек и фреймворков и все еще не знать всего этого.
Поскольку мы все учимся, это также означает, что мы все также склонны к ошибкам. Хорошо. Цель — стать лучше и стать лучше. Если ты ошибаешься и учишься на ней, у тебя все отлично! Но если вы не научились чему-то новому и продолжаете повторять одни и те же ошибки, ну … тогда, похоже, вы застаётесь в своей карьере.
В этом духе, вот три распространенных ошибки, которые я часто вижу во время обзоров кода, которые младшие разработчики делают при работе с состоянием компонента React. Мы рассмотрим каждую ошибку и затем обсудим, как ее исправить.
Изменение состояния напрямую.
При изменении состояния компонента важно, чтобы вы возвращали новую копию состояния с изменениями, а не изменяли текущее состояние напрямую. Если вы неправильно измените состояние компонента, алгоритм сравнения React не поймает изменение, и ваш компонент не будет обновляться должным образом. Давайте посмотрим на пример.
Скажем, у вас есть состояние, которое выглядит так:
this.state = {
colors: ['red', 'green', 'blue']
}
И теперь вы хотите добавить цвет «yellow» в этот массив. Может быть заманчиво сделать это:
this.state.colors.push('yellow')
Или даже это:
this.state.colors = [...this.state.colors, 'yellow']
Но оба эти подхода неверны! При обновлении состояния в компоненте класса вам всегда нужно использовать метод setState, и вы всегда должны быть осторожны, чтобы не изменять объекты. Вот правильный способ добавить элемент в массив:
this.setState(prevState => ({ colors: [...prevState.colors, 'yellow'] }))
И это приводит нас прямо к ошибке номер два.
Установка состояния, которое опирается на предыдущее состояние без использования функции
Есть два способа использовать метод setState.
Первый способ — предоставить объект в качестве аргумента.
Второй способ — предоставить функцию в качестве аргумента.
Итак, когда вы хотите использовать один поверх другого?
Если бы у вас была, например, кнопка, которую можно включить или отключить, у вас может быть элемент состояния под названием isDisabled, который содержит логическое значение. Если вы хотите переключить кнопку с включенного на отключенное, может возникнуть соблазн написать что-то вроде этого, используя объект в качестве аргумента:
this.setState({ isDisabled: !this.state.isDisabled })
Итак, что с этим не так? Проблема заключается в том, что обновления состояния React могут быть пакетными, а это означает, что в одном цикле обновления может происходить несколько обновлений состояния. Если ваши обновления должны были быть пакетными, и у вас было несколько обновлений до включенного / отключенного состояния, конечный результат может быть не тем, что вы ожидаете.
Более правильным способом обновления состояния здесь было бы предоставление функции предыдущего состояния в качестве аргумента:
this.setState(prevState => ({ isDisabled: !prevState.isDisabled }))
Теперь, даже если обновления вашего состояния являются пакетными, и несколько обновлений в состоянии включенного / выключенного состояния выполняются вместе, каждое обновление будет полагаться на правильное предыдущее состояние, чтобы вы всегда получали результат, который ожидали.
То же самое верно для чего-то вроде увеличения счетчика.
Не делайте этого!!!:
this.setState({ counterValue: this.state.counterValue + 1 })
Делайте правильно!!!:
this.setState(prevState => ({ counterValue: prevState.counterValue + 1 }))
Ключевым моментом здесь является то, что если ваше новое состояние зависит от значения старого состояния, вы всегда должны использовать функцию в качестве аргумента. Если вы устанавливаете значение, которое не зависит от значения старого состояния, то вы можете использовать объект в качестве аргумента.
Не забывайте, что setState является асинхронным
Наконец, важно помнить, что setState является асинхронным методом. В качестве примера, давайте представим, что у нас есть компонент с состоянием, которое выглядит так:
this.state = { name: 'John' }
И затем у нас есть метод, который обновляет состояние и затем выводит состояние на консоль:
this.setState({ name: 'Matt' })
console.log(this.state.name)
Вы можете подумать, что вывод будет 'Matt' на консоль, но это не так! Это будет — «Джон»!
Причина этого в том, что опять же setState является асинхронным. Это означает, что он собирается запустить обновление состояния, когда доберется до строки, которая вызывает setState, но код ниже будет продолжать выполняться, поскольку асинхронный код не является блокирующим.
Если у вас есть код, который необходимо запустить после обновления состояния, React позволяет предоставить функцию обратного вызова, которая запускается после завершения обновления.
Правильный способ записать текущее состояние после обновления:
this.setState({ name: 'Matt' }, () => console.log(this.state.name))
Намного лучше! Теперь вывод в консоль будет 'Matt', как и ожидалось.
Хотите освоить самые современные методы написания React приложений? Надоели простые проекты? Нужны курсы, книги, руководства, индивидуальные занятия по React и не только? Хотите стать разработчиком полного цикла, освоить стек MERN, или вы только начинаете свой путь в программировании, и не знаете с чего начать, то пишите через форму связи, подписывайтесь на мой канал в Телеге, вступайте в группу на Facebook.
This answer is to provide enough information to not change/mutate the state directly in React.
React follows Unidirectional Data Flow. Meaning, the data flow inside react should and will be expected to be in a circular path.
React’s Data flow without flux

To make React work like this, developers made React similar to functional programming. The rule of thumb of functional programming is immutability. Let me explain it loud and clear.
How does the unidirectional flow works?
statesare a data store which contains the data of a component.- The
viewof a component renders based on the state. - When the
viewneeds to change something on the screen, that value should be supplied from thestore. - To make this happen, React provides
setState()function which takes in anobjectof newstatesand does a compare and merge(similar toobject.assign()) over the previous state and adds the new state to the state data store. - Whenever the data in the state store changes, react will trigger an re-render with the new state which the
viewconsumes and shows it on the screen.
This cycle will continue throughout the component’s lifetime.
If you see the above steps, it clearly shows a lot of things are happening behind when you change the state. So, when you mutate the state directly and call setState() with an empty object. The previous state will be polluted with your mutation. Due to which, the shallow compare and merge of two states will be disturbed or won’t happen, because you’ll have only one state now. This will disrupt all the React’s Lifecycle Methods.
As a result, your app will behave abnormal or even crash. Most of the times, it won’t affect your app because all the apps which we use for testing this are pretty small.
And another downside of mutation of Objects and Arrays in JavaScript is, when you assign an object or an array, you’re just making a reference of that object or that array. When you mutate them, all the reference to that object or that array will be affected. React handles this in a intelligent way in the background and simply give us an API to make it work.
Most common errors done when handling states in React
// original state
this.state = {
a: [1,2,3,4,5]
}
// changing the state in react
// need to add '6' in the array
// bad approach
const b = this.state.a.push(6)
this.setState({
a: b
})
In the above example, this.state.a.push(6) will mutate the state directly. Assigning it to another variable and calling setState is same as what’s shown below. As we mutated the state anyway, there’s no point assigning it to another variable and calling setState with that variable.
// same as
this.state.a.push(6)
this.setState({})
Many people do this. This is so wrong. This breaks the beauty of React and is bad programming practice.
So, what’s the best way to handle states in React? Let me explain.
When you need to change ‘something’ in the existing state, first get a copy of that ‘something’ from the current state.
// original state
this.state = {
a: [1,2,3,4,5]
}
// changing the state in react
// need to add '6' in the array
// create a copy of this.state.a
// you can use ES6's destructuring or loadash's _.clone()
const currentStateCopy = [...this.state.a]
Now, mutating currentStateCopy won’t mutate the original state. Do operations over currentStateCopy and set it as the new state using setState().
currentStateCopy.push(6)
this.setState({
a: currentStateCopy
})
This is beautiful, right?
By doing this, all the references of this.state.a won’t get affected until we use setState. This gives you control over your code and this’ll help you write elegant test and make you confident about the performance of the code in production.
To answer your question,
Why can’t I directly modify a component’s state?
Well, you can. But, you need to face the following consequences.
- When you scale, you’ll be writing unmanageable code.
- You’ll lose control of
stateacross components. - Instead of using React, you’ll be writing custom codes over React.
Immutability is not a necessity because JavaScript is single threaded, but it’s a good to follow practices which will help you in the long run.
PS. I’ve written about 10000 lines of mutable React JS code. If it breaks now, I don’t know where to look into because all the values are mutated somewhere. When I realized this, I started writing immutable code. Trust me! That’s the best thing you can do it to a product or an app.
Сегодня мы поговорим об основных, часто встречающихся ошибках, которые часто допускают разработчики при работе с состоянием (state) при разработке React-приложения.
Одна из моих любимых вещей в веб-разработке — всегда есть что-то новое для изучения. Вы могли бы посвятить всю свою жизнь освоению различных языков программирования, библиотек и фреймворков и все еще не знать всего этого.
Поскольку мы все учимся, это также означает, что мы все также склонны к ошибкам. Хорошо. Цель — стать лучше и стать лучше. Если ты ошибаешься и учишься на ней, у тебя все отлично! Но если вы не научились чему-то новому и продолжаете повторять одни и те же ошибки, ну … тогда, похоже, вы застаётесь в своей карьере.
В этом духе, вот три распространенных ошибки, которые я часто вижу во время обзоров кода, которые младшие разработчики делают при работе с состоянием компонента React. Мы рассмотрим каждую ошибку и затем обсудим, как ее исправить.
Изменение состояния напрямую.
При изменении состояния компонента важно, чтобы вы возвращали новую копию состояния с изменениями, а не изменяли текущее состояние напрямую. Если вы неправильно измените состояние компонента, алгоритм сравнения React не поймает изменение, и ваш компонент не будет обновляться должным образом. Давайте посмотрим на пример.
Скажем, у вас есть состояние, которое выглядит так:
this.state = {
colors: ['red', 'green', 'blue']
}
И теперь вы хотите добавить цвет «yellow» в этот массив. Может быть заманчиво сделать это:
this.state.colors.push('yellow')
Или даже это:
this.state.colors = [...this.state.colors, 'yellow']
Но оба эти подхода неверны! При обновлении состояния в компоненте класса вам всегда нужно использовать метод setState, и вы всегда должны быть осторожны, чтобы не изменять объекты. Вот правильный способ добавить элемент в массив:
this.setState(prevState => ({ colors: [...prevState.colors, 'yellow'] }))
И это приводит нас прямо к ошибке номер два.
Установка состояния, которое опирается на предыдущее состояние без использования функции
Есть два способа использовать метод setState.
Первый способ — предоставить объект в качестве аргумента.
Второй способ — предоставить функцию в качестве аргумента.
Итак, когда вы хотите использовать один поверх другого?
Если бы у вас была, например, кнопка, которую можно включить или отключить, у вас может быть элемент состояния под названием isDisabled, который содержит логическое значение. Если вы хотите переключить кнопку с включенного на отключенное, может возникнуть соблазн написать что-то вроде этого, используя объект в качестве аргумента:
this.setState({ isDisabled: !this.state.isDisabled })
Итак, что с этим не так? Проблема заключается в том, что обновления состояния React могут быть пакетными, а это означает, что в одном цикле обновления может происходить несколько обновлений состояния. Если ваши обновления должны были быть пакетными, и у вас было несколько обновлений до включенного / отключенного состояния, конечный результат может быть не тем, что вы ожидаете.
Более правильным способом обновления состояния здесь было бы предоставление функции предыдущего состояния в качестве аргумента:
this.setState(prevState => ({ isDisabled: !prevState.isDisabled }))
Теперь, даже если обновления вашего состояния являются пакетными, и несколько обновлений в состоянии включенного / выключенного состояния выполняются вместе, каждое обновление будет полагаться на правильное предыдущее состояние, чтобы вы всегда получали результат, который ожидали.
То же самое верно для чего-то вроде увеличения счетчика.
Не делайте этого!!!:
this.setState({ counterValue: this.state.counterValue + 1 })
Делайте правильно!!!:
this.setState(prevState => ({ counterValue: prevState.counterValue + 1 }))
Ключевым моментом здесь является то, что если ваше новое состояние зависит от значения старого состояния, вы всегда должны использовать функцию в качестве аргумента. Если вы устанавливаете значение, которое не зависит от значения старого состояния, то вы можете использовать объект в качестве аргумента.
Не забывайте, что setState является асинхронным
Наконец, важно помнить, что setState является асинхронным методом. В качестве примера, давайте представим, что у нас есть компонент с состоянием, которое выглядит так:
this.state = { name: 'John' }
И затем у нас есть метод, который обновляет состояние и затем выводит состояние на консоль:
this.setState({ name: 'Matt' })
console.log(this.state.name)
Вы можете подумать, что вывод будет 'Matt' на консоль, но это не так! Это будет — «Джон»!
Причина этого в том, что опять же setState является асинхронным. Это означает, что он собирается запустить обновление состояния, когда доберется до строки, которая вызывает setState, но код ниже будет продолжать выполняться, поскольку асинхронный код не является блокирующим.
Если у вас есть код, который необходимо запустить после обновления состояния, React позволяет предоставить функцию обратного вызова, которая запускается после завершения обновления.
Правильный способ записать текущее состояние после обновления:
this.setState({ name: 'Matt' }, () => console.log(this.state.name))
Намного лучше! Теперь вывод в консоль будет 'Matt', как и ожидалось.
Хотите освоить самые современные методы написания React приложений? Надоели простые проекты? Нужны курсы, книги, руководства, индивидуальные занятия по React и не только? Хотите стать разработчиком полного цикла, освоить стек MERN, или вы только начинаете свой путь в программировании, и не знаете с чего начать, то пишите через форму связи, подписывайтесь на мой канал в Телеге, вступайте в группу на Facebook.
Здравствуйте, не понимаю, почему не изменяется состояние флажков при клике, самое интересное, если заменить todo.completed на todo.text и изменить текст, то состояние будет изменено, также если добавить console.log(«Clicked», id), то оно будет выводить слово Clicked и id флажка. Буду очень рад если поможете разобраться.
Вот код родительского компонента:
import React, { Component } from 'react'
import TodoItem from "./TodoItem"
import todosData from "./todosData"
class App extends Component {
constructor() {
super()
this.state = {
todos: todosData
}
this.handleChange = this.handleChange.bind(this)
}
handleChange(id) {
this.setState(prevState => {
const updatedTodos = prevState.todos.map(todo => {
if (todo.id === id) {
todo.completed = !todo.completed
}
return todo
})
return {
todos: updatedTodos
}
})
}
render() {
const todoItems = this.state.todos.map(item => <TodoItem key={item.id} item={item} handleChange={this.handleChange}/>)
return (
<div className="todo-list">
{todoItems}
</div>
)
}
}
export default AppВот код дочернего компонента:
import React from "react"
function TodoItem(props) {
return (
<div className="todo-item">
<input
type="checkbox"
checked={props.item.completed}
onChange={() => props.handleChange(props.item.id)}
/>
<p>{props.item.text}</p>
</div>
)
}
export default TodoItemВот код JSON-файла откуда всё берётся:
const todosData = [
{
id: 1,
text: "Take out the trash",
completed: true
},
{
id: 2,
text: "Grocery shopping",
completed: false
},
{
id: 3,
text: "Clean gecko tank",
completed: false
},
{
id: 4,
text: "Mow lawn",
completed: true
},
{
id: 5,
text: "Catch up on Arrested Development",
completed: false
}
]
export default todosData5 месяцев назад·7 мин. на чтение
Поскольку React становится все более и более популярным, все больше и больше React разработчиков сталкиваются с различными проблемами в процессе разработки.
В этой статье, мы обобщим некоторые распространенные ошибки в разработке React приложений, чтобы помочь вам их избежать.
Если вы только начинаете использовать React, рекомендуется внимательно ознакомиться с этой статьей. Если вы уже используете React для разработки проектов, также рекомендуется проверить и заполнить пробелы.
Прочитав эту статью, вы узнаете, как избежать эти 11 ошибок React:
- При рендеринге списка не используется
key - Изменение значения состояния прямым присваиванием
- Привязка значения состояния непосредственно к свойству value инпута
- Использование состояния сразу после выполнения
setState - Появление бесконечного цикла при использовании
useState+useEffect - Отсутствие очистки побочных эффектов в
useEffect - Неправильное использование логических операторов
- Тип пропсов компонента не типизирован
- Передача строк в качестве значений компонентам
- Имя компонента не начинается с заглавной буквы
- Неверная привязка события к элементу
Ошибка: При рендеринге списка не используется key
Проблема
Когда мы впервые изучали React, мы отображали список следующим образом:
const items = [ { id: 1, value: 'item1' }, { id: 2, value: 'item2' }, { id: 3, value: 'item3' }, { id: 4, value: 'item4' }, { id: 5, value: 'item5' } ]; const listItems = items.map((item) => { return <li>{item.value}</li> });После рендеринга консоль выдаст предупреждение, что для элементов списка необходимо указать ключ.
Решение
Вам просто нужно последовать этой подсказке и добавитьkeyк каждому элементу:const items = [ { id: 1, value: ‘item1’ }, { id: 2, value: ‘item2’ }, { id: 3, value: ‘item3’ }, { id: 4, value: ‘item4’ }, { id: 5, value: ‘item5’ } ]; const listItems = items.map((item) => { return <li key={item.id}>{item.value}</li> });
keyпомогает React определить, какие элементы были изменены, например, добавлены или удалены. Поэтому нам нужно установить уникальное значение ключа для каждого элемента в массиве.
Для значения ключа лучше всего установить уникальное значение. В приведенном выше примере используетсяid. Можно использовать индекс массива, но такой подход не рекомендуется.
Уникальный ключ помогает React следить за изменениями списка — какой элемент удалился или переместился.
Ошибка: Изменение значения состояния прямым присваиванием
Проблема
В React нельзя назначать состояние и изменять напрямую, иначе это вызовет проблемы.// классовый компонент handleChange = () => { this.state.name = "John"; };В этот момент будет выдано предупреждение не изменять состояние напрямую, а использовать
setState().
Решение
Классовые компоненты могут быть изменены с помощьюsetState(), а функциональные компоненты могут быть изменены с помощьюuseState():// Классовые компоненты: используйте setState() this.setState({ name: "John" }); // Функциональные компоненты:используйте useState() const [name, setName] = useState(""); setName("John");Ошибка: Привязка значения состояния непосредственно к свойству value инпута
Проблема
Когда мы напрямую привязываем значение состояния к свойствуvalueинпута, мы обнаружим, что независимо от того, что мы вводим в поле ввода, содержимое поля ввода не изменится.export default function App() { const [count, setCount] = useState(0); return <input type="text" value={count} />; }Это связано с тем, что мы используем переменную состояния в качестве значения по умолчанию для присвоения значения
<input>, а состояние в функциональном компоненте может быть изменено только функциейset*, возвращаемымuseState. Таким образом, решение также очень простое, просто используйте функциюset*при изменении. Подробнее о том как работать с инпутом в React можно прочитать в этой статье.
Решение
Просто привяжите событиеonChangeк<input>и измените его, вызвавsetCount:export default function App() { const [count, setCount] = useState(0); const handleChange= (event) => setCount(event.target.value); return <input type="text" value={count} onChange={handleChange} />; }Ошибка: Использование состояния сразу после выполнения
setStateПроблема
Когда мы изменяем данные черезsetState()и сразу же хотим получить новые данные, возникнет ситуация, что возвращаются старые данные:// Классовые компоненты // инициализация состояния this.state = { name: "John" }; // обновление состояния this.setState({ name: "Hello, John!" }); console.log(this.state.name); // => JohnЭто связано с тем, что
setState()является асинхронным. КогдаsetState()выполняется, реальная операция обновления будет помещена в асинхронную очередь для выполнения, а код, который будет выполняться следующим (т.е.console.logв примере), выполняется синхронно, поэтому выводимое в консоль состояние не является последним значением.
Решение
Просто передайте последующую операцию, которая будет выполняться как функция, в качестве второго параметраsetState(), эта функция обратного вызова будет выполнена после завершения обновления.this.setState({ name: "Hello, John!" }, () => { console.log(this.state.name); // => Hello, John! });Теперь обновленное значение выводится правильно.
Ошибка: Появление бесконечного цикла при использовании
useState+useEffectПроблема
Когда мы напрямую вызываем методset*(), возвращаемыйuseState()внутриuseEffect(), и не устанавливаем второй параметр вuseEffect(), мы столкнемся с бесконечным циклом:export default function App() { const [count, setCount] = useState(0); useEffect(() => { setCount(count + 1); }); return <div className="App">{count}</div>; }После этого можно увидеть, что данные на странице обновляются, и функция
useEffect()вызывается бесконечно, входя в состояние бесконечного цикла.
Решение
Это распространенная проблема неправильного использованияuseEffect().useEffect()можно рассматривать как комбинацию трех функций жизненного цикла:componentDidMount,componentDidUpdateиcomponentWillUnmountв классовых компонентах.useEffect(effect, deps)принимает 2 аргумента:
effectфункция, которая должна выполниться (побочный эффект)depsмассив зависимостей
При изменении массива deps выполняется функция эффекта. Чтобы изменить метод, вам нужно всего лишь передать [] в качестве второго аргумента useEffect() :
export default function App() { const [count, setCount] = useState(0); useEffect(() => { setCount(count + 1); }, []); return <div className="App">{count}</div>; }
Приведем 4 случая использованияuseEffect:
- Если второй параметр не передан: при обновлении любого состояния будет запущена функция эффекта
useEffect.
useEffect(() => { setCount(count + 1); });
- Если второй параметр — это пустой массив: функция эффекта
useEffectсрабатывает только при монтировании и размонтировании.
useEffect(() => { setCount(count + 1); }, []);
- Если второй параметр представляет собой массив с одним значением: функция эффекта
useEffectбудет запускаться только при изменении значения.
useEffect(() => { setCount(count + 1); }, [name]);
- Если второй параметр представляет собой массив c несколькими значениями: функция эффекта
useEffectбудет запускаться при изменении хотя бы одного из значений из списка зависимостей.
useEffect(() => { setCount(count + 1); }, [name, age]);Ошибка: Отсутствие очистки побочных эффектов в
useEffectПроблема
В классовых компонентах мы используем метод жизненного циклаcomponentWillUnmount()для очистки некоторых побочных эффектов, таких как таймеры, слушатели событий и т. д.
Решение
Из функции эффектаuseEffect()может быть возвращена функция очистки, которая аналогична роли метода жизненного циклаcomponentWillUnmount():useEffect(() => { // ... return () => clearInterval(id); }, [name, age]);Ошибка: Неправильное использование логических операторов
Проблема
В синтаксисе JSX/TSX мы часто используем логические значения для управления отображаемыми элементами, и во многих случаях мы используем оператор&&для обработки этой логики:const count = 0; const Comp = () => count && <h1>Chris1993</h1>;Мы думаем, что в это время страница будет отображать пустой контент, но на самом деле на ней отобразится
0.
Решение
Причина в том, что ложное выражение приводит к тому, что элементы после&&пропускаются, и будет возвращено значение ложного выражения. Поэтому нужно стараться написать условие оценки как можно более полным, не полагаясь на истинное и ложное логическое значение JavaScript для сравнения:const count = 0; const Comp = () => count > 0 && <h1>Chris1993</h1>;Теперь страница будет отображать пустой контент, как и ожидается.
Ошибка: Типы просов компонента не типизированы
Проблема
Если компоненты, разработанные разными членами команды, не имеют четко определенных типов для просов, то для коллег будет не очевидно, как использовать компоненты, например:const UserInfo = (props) => { return ( <div> {props.name} : {props.age} </div> ); };Решение
- Определить типы пропсов компонента, используя TypeScript.
// Классовые компоненты interface AppProps { value: string; } interface AppState { count: number; } class App extends React.Component<AppProps, AppStore> { // ... } // Функциональные компоненты interface AppProps { value?: string; } const App: React.FC<AppProps> = ({ value = "", children }) => { //... };
- Без использования TypeScript типы пропсов могут быть определены с помощью
propTypes.
const UserInfo = (props) => { return ( <div> {props.name} : {props.age} </div> ); }; UserInfo.propTypes = { name: PropTypes.string.isRequired, age: PropTypes.number.isRequired, };Ошибка: Передача строк в качестве значений компонентам
Проблема
Так как React имеет шаблонный синтаксис, очень похожий на HTML, часто бывает так, что числа передаются напрямую компонентам в пропсы, что приводит к неожиданному результату:<MyComp count="99"></MyComp>Сравнение
props.count === 99в компонентеMyCompвернетfalse.
Решение
Правильный способ должен заключаться в использовании фигурных скобок для передачи пропсов:<MyComp count={99}></MyComp>Передача строковых просов будет выглядеть следующим образом:
<MyComp count={"99"}></MyComp>Ошибка: Имя компонента не начинается с заглавной буквы
Проблема
Начинающие разработчики часто забывают называть свои компоненты с заглавной буквы. Компоненты, начинающиеся со строчной буквы в JSX/TSX, компилируются в элементы HTML, такие как<div />для тегов HTML.class myComponent extends React.component {}Решение
Просто измените первую букву на заглавную:class MyComponent extends React.component {}Ошибка: Неверная привязка события к элементу в классовых компонентах
Проблема
import { Component } from "react"; export default class HelloComponent extends Component { constructor() { super(); this.state = { name: "John", }; } update() { this.setState({ name: "Hello John!" }); } render() { return ( <div> <button onClick={this.update}>update</button> </div> ); } }При нажатии на кнопку
updateконсоль сообщит об ошибке, что невозможно прочитать свойстваundefined(чтениеsetState)
Решение
Это происходит потому, чтоthisне привязан к тому контексту, который мы ожидаем. Есть несколько решений:
- Привязать контекст в конструкторе при помощи метода
bind
constructor() { super(); this.state = { name: "John" }; this.update = this.update.bind(this); }
- Использовать стрелочные функции
update = () => { this.setState({ name: "Hello John!" }); };
- Привязать прямо в функции рендеринга
<button onClick={this.update.bind(this)}>update</button>
- Использовать стрелочные функции в функции рендеринга (не рекомендуется, т.к. это создает новую функцию каждый раз при рендеринге компонента, что влияет на производительность)
<button onClick={() => this.update()}>update</button>
4 месяца назад·6 мин. на чтение
Не существует единого мнения о том, как правильно организовать React-приложение. React дает вам много свободы, но вместе с этой свободой приходит ответственность за выбор собственной архитектуры. Часто бывает так, что тот, кто создает приложение в самом начале, сваливает почти все в папку components. Но есть способ получше. Нужно подходить к организации своих приложений обдуманно, чтобы их было легко использовать, понимать и расширять.
В этой статье рассмотрим вариант структуры Реакт приложения, который интуитивно понятен и может масштабироваться с ростом React приложения. Основная концепция, заключается в том, чтобы сделать архитектуру ориентированной на функциональность, а не на типы. Организовать только общие компоненты на глобальном уровне и собрать в один модуль все остальные связанные сущности вместе.
Технологии
Поскольку эта статья будет носить характер мнения. Сделаем несколько предположений о том, какие технологии будут использоваться в проекте:
- Приложение — React (Hooks)
- Глобальное управление состоянием — Redux, Redux Toolkit
- Маршрутизация — React Router
- Стили — CSS, Sass, Styled Components
- Тестирование — Jest, React Testing Library
Нет четкого мнения по поводу стилей, идеальны ли Styled Components, CSS-модули или пользовательский набор для Sass, поэтому можно использовать любой подходящий вариант.
Также предполагается, что тесты находятся рядом с кодом, а не в папке tests на верхнем уровне.
Все, что здесь написано, может быть применимо, если вы используете обычный Redux, а не Redux Toolkit. Можно настроить ваш Redux как feature slices.
Также будет удобно визуализировать созданные компоненты с помощью, например, Storybook. Также покажем, как проект будет выглядеть с этими файлами, если вы решите использовать его в своем проекте.
Для примера будем использовать приложение “Библиотека”, который имеет страницу со списком книг, страницу со списком авторов и систему аутентификации.
Структура каталога
Структура каталогов верхнего уровня будет выглядеть следующим образом:
assets— глобальные статические файлы, такие как изображения, svg, логотип компании и т.д.components— глобальные общие/повторно используемые компоненты, такие как макеты (обертки), компоненты форм, кнопкиservices— JavaScript модулиstore— глобальное хранилище Reduxutils— утилиты, помощники, константы и т.п.views— можно также назватьpages, здесь будет содержаться большая часть приложения.
Лучше сохранять привычные соглашения, где это возможно, поэтомуsrcсодержит все,index.jsявляется точкой входа, аApp.jsустанавливает аутентификацию и маршрутизацию.
. └── /src ├── /assets ├── /components ├── /services ├── /store ├── /utils ├── /views ├── index.js └── App.jsТакже в проекте могут присутствовать некоторые дополнительные папки, которые у вас могут быть, такие как
types, если это проект TypeScript,middlewares(промежуточное программное обеспечение), если необходимо, возможно, контекст для работы с Context API и т.д.
Псевдонимы (алиасы)
Полезно настроить систему на использование псевдонимов, чтобы все, что находится в папке компонентов, можно было импортировать как
@components, изображения как@assetsи т. д. Если у вас Webpack, это делается через конфигурациюresolve.module.exports = { resolve: { extensions: ['js', 'ts'], alias: { '@': path.resolve(__dirname, 'src'), '@assets': path.resolve(__dirname, 'src/assets'), '@components': path.resolve(__dirname, 'src/components'), // ...etc }, }, }Это просто облегчает импорт из любого места в проекте и перемещение файлов без изменения импорта, и вы никогда не получите что-то вроде
../../../../../../../components/.
Компоненты
В папке
componentsкомпоненты сгруппированы по типам — формы, таблицы, кнопки, макеты и т.д. Специфика зависит от конкретного приложения.
В данном примере предполагается, что вы либо создаете собственную систему форм, либо создаете привязку к существующей системе форм (например, комбинируяFormikиMaterial UI). В этом случае вы создадите папку для каждого компонента (TextField,Select,Radio,Dropdownи т.д.), а внутри будет файл для самого компонента, стили, тесты и Storybook, если он используется.
Component.js— собственно компонент ReactComponent.styles.js— файл стилей для компонентаComponent.test.js— тестыComponent.stories.js— файл Storybook.
Это имеет гораздо больше смысла, чем иметь одну папку, содержащую файлы для всех компонентов, одну папку, содержащую все тесты, одну папку, содержащую все файлы Storybook и т.д. Все связанное группируется вместе и легко находится.
. └── /src └── /components ├── /forms │ ├── /TextField │ │ ├── TextField.js │ │ ├── TextField.styles.js │ │ ├── TextField.test.js │ │ └── TextField.stories.js │ ├── /Select │ │ ├── Select.js │ │ ├── Select.styles.js │ │ ├── Select.test.js │ │ └── Select.stories.js │ └── index.js ├── /routing │ └── /PrivateRoute │ ├── /PrivateRoute.js │ └── /PrivateRoute.test.js └── /layout └── /navigation └── /NavBar ├── NavBar.js ├── NavBar.styles.js ├── NavBar.test.js └── NavBar.stories.js
Обратите внимание, что в каталогеcomponents/formsесть файлindex.js. Часто справедливо советуют избегать использования файловindex.js, поскольку они не являются явными, но в данном случае это имеет смысл — в конечном итоге он будет индексом всех форм и будет выглядеть примерно так:// src/components/forms/index.js import { TextField } from './TextField/TextField' import { Select } from './Select/Select' import { Radio } from './Radio/Radio' export { TextField, Select, Radio }Затем, когда вам понадобится использовать один или несколько компонентов, вы можете легко импортировать их все сразу.
import { TextField, Select, Radio } from '@components/forms'Иногда лучше использовать этот подход, чем создавать
index.jsвнутри каждой папки внутриforms, так что теперь у вас есть только одинindex.js, который фактически индексирует всю директорию, в отличие от десяти файловindex.jsтолько для того, чтобы упростить импорт для каждого отдельного файла.
Сервисы
Каталог
servicesменее важен, чем компоненты, но если вы создаете простой модуль JavaScript, который используется остальной частью приложения, он может быть полезен. Обычный пример — модульLocalStorage, который может выглядеть следующим образом:. └── /src └── /services ├── /LocalStorage │ ├── LocalStorage.service.js │ └── LocalStorage.test.js └── index.jsПример сервиса:
// src/services/LocalStorage/LocalStorage.service.js export const LocalStorage = { get(key) {}, set(key, value) {}, remove(key) {}, clear() {}, }import { LocalStorage } from '@services' LocalStorage.get('foo')Хранилище (стор, store)
Глобальное хранилище данных будет содержаться в директории
store— в данном случае Redux. Каждая функциональность будет иметь свою папку, в которой будет содержаться слайс Redux Toolkit, а также экшены и тесты. Эта настройка также может быть использована с обычным Redux, вы просто создадите файл.reducers.jsи.actions.jsвместоslice. Если вы используете саги, это может быть.saga.jsвместо.actions.jsдля действий Redux Thunk.. └── /src ├── /store │ ├── /authentication │ │ ├── /authentication.slice.js │ │ ├── /authentication.actions.js │ │ └── /authentication.test.js │ ├── /authors │ │ ├── /authors.slice.js │ │ ├── /authors.actions.js │ │ └── /authors.test.js │ └── /books │ ├── /books.slice.js │ ├── /books.actions.js │ └── /books.test.js ├── rootReducer.js └── index.jsВы также можете добавить что-то вроде
uiсекции стора для обработки модальных окон, всплывающих уведомлений, переключения боковой панели и других глобальных состояний пользовательского интерфейса, что, лучше, чем иметьconst [isOpen, setIsOpen] = useState(false)повсюду.
В rootReducer вы импортируете все свои фрагменты и объединяете их с помощью combineReducers, а в index.js настраиваете магазин.
Утилиты (Utils)
Нужна ли вашему проекту папка
utils— решать вам. Но обычно существуют некоторые глобальные функции, такие как валидация и конвертеры, которые могут легко использоваться в различных разделах приложения. Если вы упорядочите их — не будете иметь один файлhelpers.js, содержащий тысячи функций, — она может стать полезным дополнением к организации вашего проекта.. └── src └── /utils ├── /constants │ └── countries.constants.js └── /helpers ├── validation.helpers.js ├── currency.helpers.js └── array.helpers.jsОпять же, папка
utilsможет содержать все, что вы захотите, и что, по вашему мнению, имеет смысл держать на глобальном уровне. Если вам не нравятся «многоуровневые» имена файлов, вы можете просто назвать егоvalidation.js. Однако, это облегчает навигацию по именам файлов при поиске в IDE.
Views
Здесь находится основная часть вашего приложения: в каталоге
views. Любая страница в вашем приложении — это «представление» (view). В этом небольшом примере представления довольно хорошо согласуются со стором Redux, но не обязательно, что стор и представления будут полностью совпадать, поэтому они разделены. Кроме того, книги могут тянуть за собой авторов, и так далее.
Все, что находится внутри представления, является сущностью, которая, скорее всего, будет использоваться только в этом конкретном представлении —BookForm, который будет использоваться только на маршруте/books, иAuthorBlurb, который будет использоваться только на маршруте/authors. Это могут быть специфические формы, модальные окна, кнопки, любые компоненты, которые не будут глобальными.
Преимущество хранения всего в домене вместо объединения всех страниц в компоненты/страницы заключается в том, что это позволяет легко взглянуть на структуру приложения и узнать, сколько в нем представлений верхнего уровня, и понять, где находится все, что используется только этим представлением. Если есть вложенные маршруты, вы всегда можете добавить папку вложенных представлений в основной маршрут.. └── /src └── /views ├── /Authors │ ├── /AuthorsPage │ │ ├── AuthorsPage.js │ │ └── AuthorsPage.test.js │ └── /AuthorBlurb │ ├── /AuthorBlurb.js │ └── /AuthorBlurb.test.js ├── /Books │ ├── /BooksPage │ │ ├── BooksPage.js │ │ └── BooksPage.test.js │ └── /BookForm │ ├── /BookForm.js │ └── /BookForm.test.js └── /Login ├── LoginPage │ ├── LoginPage.styles.js │ ├── LoginPage.js │ └── LoginPage.test.js └── LoginForm ├── LoginForm.js └── LoginForm.test.jsХранение всего в папках может показаться раздражающим, если вы никогда не создавали свой проект таким образом — вы всегда можете сделать его более плоским или перенести тесты в свой собственный каталог, имитирующий остальную часть приложения.
Итоги
Эта структура приложения и организация React, которая хорошо масштабируется для большого enterprise приложения, удобна для тестирования и стилизации, а также сохраняет все вместе в функционально ориентированном виде. Она более вложенная, чем традиционная структура, в которой все находится в компонентах и контейнерах.
Легко взглянуть на эту систему и понять, что нужно для вашего приложения и куда идти, чтобы поработать над конкретным разделом или компонентом, который влияет на приложение глобально.