Борьба с null
Здесь будет описано и рассказано про null с точки зрения разработчика на Java.
- Борьба с null
- Да будет null
- Ближе к Java
- Техника безопасности
- Не доверяй и проверяй
- Проверяй
- Аккуратность в проверках
- Примитивы не так уж и примитивны
- Аккуратнее со строками
- Не плоди null
- Отсутствие значения не всегда null
- Optional
- Доверяйте, но с аннотациями
- Заключение
- Полезные ссылки
- Отдельная благодарность
Да будет null
Для начала надо понять, как к null пришло человечество.
Во время написания кода в объектно-ориентированной парадигме вы представляете свою программу в виде совокупности и взаимодействия объектов, каждый из которых является экземпляром определённого класса.
И всё бы ничего, но что делать, если вам необходимо обозначить отсутствие объекта?
Например, отсутствие пользователя, какого-то ресурса и т.д.
Представьте, что вы написали класс, описывающий пользователя, одним из полей класса является адрес электронной почты — email.
Но не у всех пользователей есть email: кто-то вообще его не использует, кто-то не хочет указывать его или собирается это сделать позже.
Т.е значения этого поля на данный момент нет, но в дальнейшем вполне возможно, что оно появится: например, пользователь его добавит в личном кабинете, или укажет в отделени банка сотруднику.
Вам необходимо обозначить отсутствие объекта, и вот тут-то на сцену и выходит null.
Казалось бы, всё и на этом тему можно закрывать, ведь все довольны и счастливы! Не совсем.
Если вы попытаетесь вызвать любой метод на null, то неизбежно получите java.lang.NullPointerException. А если исключение не будет обработано, то это неизбежно послужит тому, что ваше приложение аварийно завершится.
В этом и состоит основная проблема использования null: это потенциальный источник java.lang.NullPointerException.
Недаром null называют ошибкой стоимостью в миллиард долларов.
Что такое null в Java?
«There is also a special null type, the type of the expression null, which has no name. Because the null type has no name,
it is impossible to declare a variable of the null type or to cast to the null type. The null reference is the only
possible value of an expression of null type. The null reference can always be cast to any reference type. In practice, the
programmer can ignore the null type and just pretend that null is merely a special literal that can be of any reference type.»
JLS 4.1
Из чего следует, что null в Java — это особое значение, оно не ассоциируется ни с каким типом (оператор instanceOf возвращает false, если в качестве параметра указать любую ссылочную переменную со значением null или null сам по себе) и может быть присвоено любой ссылочной переменной, а также возвращено из метода.
Это значит, что:
- Каждое возвращаемое значение ссылочного типа может быть
null. - Каждое значение параметра ссылочного типа может также быть
null.
Чувствуете масштаб проблемы? Добавьте сюда ещё и тот факт, что null является значением по умолчанию для ссылочных типов, чтобы получить полное представление о ситуации с null-ами!

Однако, будет неверным считать, что null — это всегда зло, что он неуместен только из-за того, что его неаккуратное использование может привести к ошибкам. И ножом можно нанести повреждения, но это не делает нож плохим инструментом.
В итоге null стал жертвой того, что, благодаря возможности присвоить любому ссылочному значению или вернуть из метода, его стали использовать неправильно. И возненавидели.
Но, как и в ситуации с ножом, у null тоже есть правила безопасности и о них мы и поговорим.
Техника безопасности
Рассмотрим следущий код:
public String greeting() { if (/* no greeting */) { return null; } return "Hello World!" }
Подобный способ довольно распространен, вы пишите метод, а когда нет возвращаемого значения — отдаете null.
А теперь представьте как вы будете пользоваться (и как обрекаете на это других) этим методом?
Вы уже не можете просто взять и сделать:
String message = greeting(); int len = message.length();
Ведь у вас нет гарантии о том, что будет возвращено: значение или null. Вы теряете доверие к этому коду.
Это очень опасная и губительная практика: возвращение null из методов.
Но надо понимать, что нет ничего плохого в null как в значении, но null как reference — однозначное и чистое зло.
Это значит, что поле класса вполне может быть хранить внутри null, проблемы начинаются в момент, когда начинается работа с этим полем — использование его как ссылку.
Для примера рассмотрим старого доброго Person-а, который скоро уже в суд подаст на нас за преследования:
public class Person { private int age; private String userName; private String email; public Person(final int age, final String userName) { this.age = age; this.userName = userName; } // getters and setters }
Как уже было сказано не раз, null — это значение по умолчанию для ссылочных типов.
Соответственно, по умолчанию у объектов Person в поле email будет null.
В целом, подобный код часто встречается и это не плохо: у нас есть обязательные значения(name и age) и необязательные, которые могут отсутствовать — электронный адрес.
Не доверяй и проверяй
Самая явная и очевидная проверка на null в Java выглядит следующим образом:
if(person.getEmail() != null) { // do some work with email }
В Java 7+ появился вспомогательный класс java.util.Objects, который содержит вспомогательные методы проверки на null:
/** * Returns {@code true} if the provided reference is {@code null} otherwise * returns {@code false}. * * @apiNote This method exists to be used as a * {@link java.util.function.Predicate}, {@code filter(Objects::isNull)} * * @param obj a reference to be checked against {@code null} * @return {@code true} if the provided reference is {@code null} otherwise * {@code false} * * @see java.util.function.Predicate * @since 1.8 */ public static boolean isNull(Object obj) { return obj == null; } /** * Returns {@code true} if the provided reference is non-{@code null} * otherwise returns {@code false}. * * @apiNote This method exists to be used as a * {@link java.util.function.Predicate}, {@code filter(Objects::nonNull)} * * @param obj a reference to be checked against {@code null} * @return {@code true} if the provided reference is non-{@code null} * otherwise {@code false} * * @see java.util.function.Predicate * @since 1.8 */ public static boolean nonNull(Object obj) { return obj != null; }
Однако, эти методы были добавлены в основном для Java Stream API, для удобного использования в filter.
Да и на мой взгляд, обычная проверка более читабельна и явная, сравните:
if(Objects.nonNull(person.getEmail())) { // do some work with email } // vs if(person.getEmail() != null) { // do some work with email }
Проверяй
Несмотря на все наши усилия и договорённости, null может также просочиться в объект ещё на этапе его создания.
final Person person = new Person(20, null);
Объект будет создан, несмотря на то, что не ожидается, что поле userName может быть null.
Логичным решением будет потребовать уже на этапе создания объекта невозможность присвоения null значения такому полю.
Т.е. перед инициализацией проверить допустимость значений, которые получены конструктором.
К счастью, для этого в уже знакомом java.util.Objects есть необходимые методы:
public static <T> T requireNonNull(T obj) { if (obj == null) throw new NullPointerException(); return obj; } public static <T> T requireNonNull(T obj, String message) { if (obj == null) throw new NullPointerException(message); return obj; }
Благодаря чему, наш Person приобретает дополнительные проверки и вы всегда быстро поймёте какое поле было проинициализировано неправильно:
public Person(final int age, final String userName) { this.age = age; this.userName = Objects.requireNonNull(userName, "userName can't be null"); }
Вопрос:
Постойте, ведь в Java давно есть assert, а что насчёт них?
Ответ:
Да, есть и их также можно использовать для валидации значений:
public Person(final int age, final String userName) { assert userName != null; this.age = age; this.userName = userName; }
Однако, я ими пользоваться не рекомендую и вот почему:
- По умолчанию они отключены.
- Такая проверка, в случае проблемы, кидает
java.lang.AssertionError, что осложняет обработку исключений в проекте и дальнейшую отладку.
Более подробно о проверках.
Аккуратность в проверках
Помните, что вызов метода на null неизбежно породит java.lang.NullPointerException:
public void checkTag(final String tag) { tag.equals("UNKNOWN"); // может быть NPE, если tag = null "UNKNOWN".equals(tag); // безопасно }
Поэтому, при работе с константами, enum-ами и т.д. вызывайте методы на константах, как наиболее безопасном месте.
Примитивы не так уж и примитивны
Будьте аккуратны с boxing/unboxing.
Как вы думаете, что будет при выполнении следующего кода:
public void printInt(Integer num) { System.out.println((int) num); } printInt(null);
А будет уже знакомый и горячо любимый java.lang.NullPointerException, возникший как раз в unboxing-е.
Поэтому будьте аккуратнее с boxing/unboxing и null-ами, по возможности пользуйтесь примитивами.
Аккуратнее со строками
Помните, что при конкатенации строк, если там затесалось null значение, не будет java.lang.NullPointerException, но и игнорирования null не будет:
String s1 = "hello"; String s2 = null; String s3 = s1 + s2; String s4 = new StringBuilder(s1).append(s2).toString(); System.out.println(s3); System.out.println(s4);
В итоге в обоих случаях будет: hello null!
Человечество, кому повезло не быть разработчиками, ещё не готово к таким наскальным надписям, поэтому, дабы не удивляться null-ам в UI и логах, используйте java.util.Objects, Google Guava или Apache Commons библиотеки.
Например, как это сделано в java.util.Objects:
/** * Returns the result of calling {@code toString} on the first * argument if the first argument is not {@code null} and returns * the second argument otherwise. * * @param o an object * @param nullDefault string to return if the first argument is * {@code null} * @return the result of calling {@code toString} on the first * argument if it is not {@code null} and the second argument * otherwise. * @see Objects#toString(Object) */ public static String toString(Object o, String nullDefault) { return (o != null) ? o.toString() : nullDefault; }
В таком случае:
String s3 = Objects.toString(s1, "") + Objects.toString(s2, "");
Но я рекомендую использовать Apache Commons и класс StringUtils. Удобная и безопасная работа со строками с учётом null-ов.
Не плоди null
В случае написания функциональности, где не все параметры всегда предоставляются, обычно велик соблазн написать один метод и далее использовать его, передавая при необходимости null в параметры, которые могут отсутствовать.
Например, обновление статуса с дополнительной информацией (по возможности):
public void updateStatus(final String status, final String details) { // some code }
При этом, details вполне может отсутствовать и зачастую использование сводится к:
updateStatus("NEW", "Creating new order status"); updateStatus("NEW", null); // при отсутствии details
В таком случае, лучше перегрузить метод и сделать:
public void updateStatus(final String status, final String details) { // some code } public void updateStatus(final String status) { // some code }
Старайтесь минимизировать явную передачу null в методы.
Во-первых, null в методе делает его менее читабельным, особенно, если null значений несколько, например:
updateStatus("NEW", null, null, 200)
Во-вторых, закладывая возможность передачи в метод несколько null значений вы увеличиваете шанс появления ошибки, потому что следить за разрастающимся количеством null-ов тяжело, появляется возможность случайно передать его в метод.
Перегрузка является единственным способом борьбы с такой проблемой, так как в Java, к сожалению, нет поддержки значений по умолчанию.
Отсутствие значения не всегда null
Одной из самых популярных ошибок в использовании null является возвращение его там, где ожидается коллекция данных.
Разберём пример: вы написали телефонную книгу, где есть возможность получить список номеров по имени абонента:
public List<Person> findByName(final String name) { if(book.contains(name)) { return persons; } return null; }
Т.е происходит простое ветвление логики на случай, если в телефонной книге есть записи с таким именем, и на случай, если нет, возвращается то самое отсутствие значения, наш любимый null.
Казалось бы, всё правильно, но нет!
Там, где контракт метода говорит о том, что будет возвращена коллекция данных по какому-то фильтру (в нашем случае — имени)всегда возвращайте пустую коллекцию, при отсутствии данных.
Точно также, если вы разрабатываете функционал, где одним из параметров является необязательная коллекция данных: не делайте возможность передачи вместо неё null:
public List<Person> findByNameAndTags(final String name, final Set<Tag> tags) { // some code }
Если tags необязательное значение для поиска, то при отсутствии значения передавайте пустое множество:
findByNameAndTags("Kuchuk", ImmutableSet.of())
Либо сделайте два метода: с tags в сигнатуре и без.
// когда tags обязательно public List<Person> findByNameAndTags(final String name, final Set<Tag> tags) { // some code } // когда tags необязательно public List<Person> findByNameAndTags(final String name) { // some code }
Точно тот же совет, когда коллекция — это поле класса.
Например, вам необходимо множество кодов ошибок в валидаторе значений:
public class Validator { private Set<Integer> codes = new HashSet<>(); // some code }
Если нет множества(не инициализировали, отсутствует) — сделайте его пустым множеством. Но не делайте его null!
Как вариант можно возвращать ещё итератор.
Отстутствие значения при работе с коллекциями — это пустая коллекция.
При работе с коллекциями и отношением данных one-to-many отсутствие значения — это и есть пустая коллекция.
Optional
Начиная с Java 8+ для борьбы с null был добавлен класс java.util.Optional.
Класс был добавлен для того, чтобы дать возможность разработчикам явно показывать, что значения может не быть.
Если объяснять на пальцах, то java.util.Optional — это просто контейнер, в который вы оборачиваете значение. При отсутствии значения у вас пустой контейнер, при существовании значения — у вас контейнер со значением.
/** * A container object which may or may not contain a non-null value. * If a value is present, {@code isPresent()} will return {@code true} and * {@code get()} will return the value. * * <p>Additional methods that depend on the presence or absence of a contained * value are provided, such as {@link #orElse(java.lang.Object) orElse()} * (return a default value if value not present) and * {@link #ifPresent(java.util.function.Consumer) ifPresent()} (execute a block * of code if the value is present). * * <p>This is a <a href="../lang/doc-files/ValueBased.html">value-based</a> * class; use of identity-sensitive operations (including reference equality * ({@code ==}), identity hash code, or synchronization) on instances of * {@code Optional} may have unpredictable results and should be avoided. * * @since 1.8 */ public final class Optional<T> { // ... }
Для работы Optional с примитивами существует: java.util.OptionalInt, java.util.OptionalLong и java.util.OptionalDouble.
Для примера, пусть необходим метод, который в телефонной книге ищет пользователя по имени и фамилии (как уникальным идентификаторам пользователя в нашей реализации):
public Person findByNameAndSurname(final String name, final String surname) { // some code }
Очевидно, что может возникнуть ситуация, когда будет произведен поиск несуществующего пользователя (например, не зарегестрированного у нас).
Что делать в таком случае?
Варианта, на самом деле, три:
- Кинуть исключение
- Вернуть
null - Вернуть
Optional
Из всех этих вариантов предпочтимее всего в данном случае вернуть Optional. Т.е. обернуть возвращаемое значение в контейнер и явно показать этим, что по таким параметрам поиска(имени и фамилии) пользователя может не быть.
public Optional<Person> findByNameAndSurname(final String name, final String surname) { // some code }
В таком случае, использование может быть в виде:
Optional<Person> person = findByNameAndSurname("Aleksandr", "Kuchuk"); if(person.isPresent()) { // нашли пользователя } else { // не нашли }
Помимо примитивной проверки в if-е Optional можно(и нужно) использовать в Java Stream API:
// ifPresent - совершение действия при существовании значения final Optional.ofNullable(person.getEmail).ifPresent(email -> System.out.println(email)); // map и orElse - при существовании применить функцию к значению, если нет - вернуть unknown final String email = Optional.ofNullable(p.getEmail()).map(String::toLowerCase).orElse("unknown");
Однако, Optional, на мой взгляд, имеет смысл использовать только в качестве возвращаемых значений.
Определенно не стоит его использовать в качестве параметров метода, поскольку при использовании Optional в качестве параметров метода теряется читабельность, код становится более громоздким, проверят на null придеться всё равно и поэтому лучше предоставить действительное значение или сделать перегрузку метода в случаях, когда параметр необязателен.
Также и с полями класса. Нет смысла делать поля класса Optional, так как это будет не Java Bean, также Optional является не сериализуемым классом и т.д.
Есть три способа создать Optional:
/** * Returns an empty {@code Optional} instance. No value is present for this * Optional. * * @apiNote Though it may be tempting to do so, avoid testing if an object * is empty by comparing with {@code ==} against instances returned by * {@code Option.empty()}. There is no guarantee that it is a singleton. * Instead, use {@link #isPresent()}. * * @param <T> Type of the non-existent value * @return an empty {@code Optional} */ public static<T> Optional<T> empty() { @SuppressWarnings("unchecked") Optional<T> t = (Optional<T>) EMPTY; return t; } /** * Returns an {@code Optional} with the specified present non-null value. * * @param <T> the class of the value * @param value the value to be present, which must be non-null * @return an {@code Optional} with the value present * @throws NullPointerException if value is null */ public static <T> Optional<T> of(T value) { return new Optional<>(value); } /** * Returns an {@code Optional} describing the specified value, if non-null, * otherwise returns an empty {@code Optional}. * * @param <T> the class of the value * @param value the possibly-null value to describe * @return an {@code Optional} with a present value if the specified value * is non-null, otherwise an empty {@code Optional} */ public static <T> Optional<T> ofNullable(T value) { return value == null ? empty() : of(value); }
Используйте:
Optional.empty()в случае, если вы уверены, что необходимо вернуть пустой контейнер.Optional.of(value)в случае, если вы уверены, что значение,value, которое вы собираетесь положить в контейнер совершенно точно неnull.- В противном случае используйте
Optional.ofNullable(value).
Никогда не смешивайте null и Optional:
Optional<Object> optional = null; // Плохо! Optional<Object> optional = Optional.of(null); // exception
Это путь в ад и к ненависти.
Подробно о Optional.
Доверяйте, но с аннотациями
Но как быть тому, кто будет использовать ваш код, понять, какие поля вы какие поля могут по нашей задумке быть null, а какие — нет, и это явная ошибка?
Ведь это нам, как разработчикам этого кода, прозрачно и понятно, что email-а может не быть и это нормальное поведение кода.
Другим разработчикам, да и нам самим через неделю, это абсолютно не ясно — и из этого возникает мысль, что было бы удобно как-то разметить наш класс, показать, где ожидаем null и это заложено, а где не ожидаем и это ошибка на миллион долларов.
Может ли поле быть с null или нет — это уже метаинформация о поле. А, значит, логично воспользоваться аннотациями.
К сожалению, в Java нет какого-то общего стандарта, и существует несколько видов аннотаций для этого, например:
- javax.validation.constraints.NotNull
- javax.annotation.Nonnull
- org.jetbrains.annotations.NotNull
- lombok.NonNull
- org.eclipse.jdt.annotation.NonNull
В целом, я уверен, существуют еще несколько, но я выделил наиболее популярные (исключая Android специфичные) на данный момент.
Какую выбрать и как использовать?
На самом деле, вопрос сложный, но я в своих проектах пользуюсь тем, что предоставляет JSR-305, т.е javax.annotation.Nonnull и т.д.
Почему?
Дело в том, что я стараюсь избегать ссылок на IDE специфичные аннотации, поэтому jetbrains, lombok и eclipse отпадают.
Остается только javax.annotation и javax.validation.constraints.
Я сделал выбор в пользу первой как более простой, наглядной и распространённой.
Вообще, это довольно холиварный вопрос, но, если вы пишите на Java 8, то JSR-305 будет к месту.
Подробнее об этом тут и тут.
Благодаря плагину и аннотациям из JSR-305 получается разметить и сгенерировать код с билдерами и проверками на null:
import javax.annotation.Nonnull; import javax.annotation.Nullable; import javax.annotation.ParametersAreNonnullByDefault; import java.util.Objects; @ParametersAreNonnullByDefault public class Person { @Nonnull private final String name; @Nullable private final String email; private final int age; private Person(Builder builder) { this.name = Objects.requireNonNull(builder.name, "name"); this.age = Objects.requireNonNull(builder.age, "age"); this.email = builder.email; } public static Builder builder() { return new Builder(); } @Nonnull public String getName() { return name; } public int getAge() { return age; } @Nullable public String getEmail() { return email; } public static class Builder { private String name; private Integer age; private String email; private Builder() { } public Builder setName(String name) { this.name = name; return this; } public Builder setAge(int age) { this.age = age; return this; } public Builder setEmail(@Nullable String email) { this.email = email; return this; } public Builder of(Person person) { this.name = person.name; this.age = person.age; this.email = person.email; return this; } public Person build() { return new Person(this); } } }
Аннотация @ParametersAreNonnullByDefault на классе говорит о том, что все параметры в методах по умолчанию @Nonnull.
Но не возвращаемые значения!
Возвращаемые значения надо размечать вручную самому и явно.
Это довольно удобно и практично.
Однако, надо понимать, что эти аннотации — не более, чем разметка, чтобы облегчить и структурировать себе и потомкам понимание логики.
Грубо говоря, это как разметка на дороге, вы понимаете, где может быть опасное место, а где в целом безопасный отрезок трассы, но это не защитит вас от грузовика по встречной полосе, если кто-то на нём вырулит:
public void printStatus(@Nonnull String status) { // some code } printStatus(null); // тот самый грузовик по встречной полосе
Аннотации — не более, чем рекомендации и описание правил, которые в идеале должны соблюдать все участники проекта.
Но они могут и не соблюдать их!
Заключение
При разработке не бойтесь null, но старайтесь минимизировать его использование.
Нет ничего плохого в null как в значении, но null как reference — однозначное и чистое зло.
По возможности, избегайте использование null в качестве возвращаемых значений, предпочитая Optional или исключение.
Не задействуйте null для указания ошибок: лучше выбрасывайте явное исключение.
Помните, что отсутствие значения у коллекции — это чаще всего пустая коллекция или пустой итератор.
По возможности, явно размечайте аннотациями код, чтобы показать разработчикам, использующим ваш код, где null заложен в логике, а где — нет.
Старайтесь использовать pre-conditions с помощью Objects.requireNonNull — чем раньше вы поймёте где проблема и с чем, тем лучше.
Будьте аккуратнее со строками и boxing/unboxing!
Полезные ссылки
- Null pointer в разных языках программирования
- Спецификация Java про null
- Про null
- Когда использовать NonNull аннотации
- Про проверки на null
- Какие аннотации для null использовать
- Про Optional
- Java Optional — попытка избежать NullPoinerException
- Ещё про Optional
- Про Null.Часть 1
- Про Null.Часть 2
- Stop Abusing Nihil
- Java. Проблема с null. Null safety.
Отдельная благодарность
Отдельную благодарность за ревью и помощь автор хочет выразить следующим людям из твиттера:
- @norrittmobile
- @thecoldwine
- @mudasobwa
- @dmi3vim
- @ihavenoclue12
[Обновление 2015-10-31] Дополнительная трансляция, измененная из StackOverflowПочтовыйПараграф:
Чашка! В нашей компании фамилия сотрудника Null.При использовании его фамилии в качестве термина запроса все приложения запросов сотрудников вылетали из строя! Что я должен делать?
В 1965 году кто-то допустил худшую ошибку в области информатики. Ошибка уродливее, чем обратная косая черта в Windows, более странная, чем ===, более распространенная, чем PHP, более неудачная, чем CORS, и более тревожная, чем дженерики Java. XMLHttpRequest, более сложный для понимания, чем препроцессор C, более подверженный фрагментации, чем MongoDB, и более прискорбный, чем UTF-16.
«Я называю нулевую ссылку своей ошибкой на миллиард долларов. Она была изобретена в 1965 году, когда я разработал первую всеобъемлющую систему ссылочных типов на объектно-ориентированном языке (АЛГОЛ W). Моя цель — гарантировать, что использование всех ссылок абсолютно безопасно, компилятор проверит автоматически. Но я не смог устоять перед соблазном добавить нулевые ссылки только потому, что это очень легко реализовать. Это вызвало бесчисленное количество ошибок, уязвимостей и систем. Авария могла привести к убыткам в миллиарды долларов в следующий раз. 40 лет. В последние годы люди начали использовать различные программы анализа программ, такие как Microsoft PREfix и PREfast, чтобы проверять ссылки и предупреждать, если существует риск ненулевого значения. Новые языки программирования, такие как Spec #, имеют ввел объявление ненулевых ссылок. Это решение, которое я отверг в 1965 году »-« Нулевые ссылки: ошибка на миллиард долларов »Тони Хоар, лауреат премии Тьюринга

В ознаменование 50-летия нулевой ошибки мистера Хора в этой статье объясняется, что такое null, почему это так ужасно и как этого избежать.
Что не так с NULL?
Проще говоря: NULL — это значение, которое не является значением. Вот и проблема.
Эта проблема усугубилась в самом популярном языке всех времен, и теперь у него много имен: NULL, nil, null, None, Nothing, Nil и nullptr. У каждого языка есть свои нюансы.
Некоторые из проблем, вызванных NULL, связаны только с конкретным языком, в то время как другие универсальны; некоторые — просто разные аспекты проблемы.
NULL…
- Тип Subversion
- Это грязно
- Это особый случай
- Сделать API хуже
- Сделать неправильные языковые решения хуже
- Сложно отлаживать
- Не сочетается
1. Тип подрывной деятельности NULL
Статически типизированные языки могут проверять использование типов в программе без фактического выполнения программы и обеспечивать определенные гарантии поведения программы.
Например, в Java, если я напишуx.toUppercase(), Компилятор проверитx тип. в случае x Является String, То проверка типа прошла успешно; еслиx Является Socket, Тогда проверка типа не удалась.
При написании большого и сложного программного обеспечения статическая проверка типов является мощным инструментом. Но для Java эти отличные проверки во время компиляции имеют фатальный недостаток: любая ссылка может быть нулевой, а вызов метода нулевого объекта приведет кNullPointerException. и так,
toUppercase()Может быть произвольноStringВызов объекта. Пока неStringНулевой.read()Может быть произвольноInputStreamВызов объекта. Пока неInputStreamНулевой.toString()Может быть произвольноObjectВызов объекта. Пока неObjectНулевой.
Java — не единственный язык, вызывающий эту проблему; многие другие системы типов имеют те же недостатки, включая, конечно, язык AGOL W.
В этих языках NULL выходит за рамки проверки типов. Он незаметно превзошел проверку типа, дождался времени выполнения и, наконец, выпустил сразу большое количество ошибок. NULL — это ничто, и в то же время это ничто.
2. NULL беспорядочный
Во многих случаях null не имеет смысла. К сожалению, если язык позволяет чему-либо быть нулевым, ну, тогда все может быть нулевым.
Программисты на Java пишут о риске синдрома запястного канала
|
if (str == null || str.equals(«»)) { } |
И добавляем в C #String.IsNullOrEmptyОбычная грамматика
|
if (string.IsNullOrEmpty(str)) { } |
Черт!
Каждый раз, когда вы пишете код, который путает пустые строки с пустыми строками, команда Guava плачет. -Google Guava
хорошо сказано. Но когда ваша система типов (например, Java или C #) допускает NULL везде, вы не можете надежно исключить возможность NULL и неизбежно где-то запутаетесь.
Возможность нулевого повсюду вызвала такую проблему, добавлена Java 8@NonNullМарк, попробуй ретроспективно устранить этот дефект в системе его типов.
3. NULL — это особый случай.
Учитывая, что NULL не является значением, но также играет роль значения, NULL, естественно, становится предметом различных специальных методов обработки.
указатель
Например, рассмотрим следующий код C ++:
|
char c = ‘A’; char *myChar = &c; std::cout << *myChar << std::endl; |
myChar Является char *, Что означает, что это указатель, то есть сохранить адрес памяти вcharв. Компилятор это проверит. Следовательно, следующий код недействителен:
|
char *myChar = 123; // compile error std::cout << *myChar << std::endl; |
Потому что123Нет гарантии, что это одинchar, Итак, компиляция не удалась. В любом случае, если поменять номер на0(0 является NULL в C ++), тогда его можно скомпилировать с помощью:
|
char *myChar = 0; std::cout << *myChar << std::endl; // runtime error |
с 123То же самое, NULL на самом деле неcharадрес. Но на этот раз компилятор все еще позволяет его компилировать, потому что0(NULL) — особый случай.
Нить
Есть еще один особый случай, который встречается в символьной строке, оканчивающейся на NULL в языке C. Это немного отличается от других примеров, потому что здесь нет указателей или ссылок. Однако идея о том, что это не ценность, а также играет роль ценности, все еще существует, здесь нетcharНо это играетcharСуществуют в виде.
Строка C представляет собой последовательность байтов и заканчивается байтом NUL (0).
Следовательно, каждый символ строки C может быть любым из 256 байтов, кроме 0 (то есть символа NUL). Это не только делает длину строки линейной операцией времени; что еще хуже, это означает, что строки C не могут использоваться в ASCII или расширенном ASCII. Вместо этого они могут использоваться только для ASCIIZ, который обычно не используется.
Исключение одного символа NUL вызвало бесчисленное количество ошибок: странное поведение API, уязвимости безопасности и переполнение буфера.
NULL — это наихудшая ошибка в строках C; точнее, строка, заканчивающаяся на NUL, являетсяСамый дорогойОдин байтошибка。
4. NULL делает API плохим
В следующем примере мы отправимся в путешествие в царство динамически типизированных языков, где NULL еще раз докажет, что это ужасная ошибка.
Хранилище ключей и значений
Предположим, мы создаем класс Ruby, который будет действовать как хранилище значений ключей. Это может быть кеш, интерфейс для базы данных ключ-значение и т. Д. Создадим простой и универсальный API:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class Store ## # associate key with value # def set(key, value) ... end ## # get value associated with key, or return nil if there is no such key # def get(key) ... end end |
Мы можем представить подобные классы на многих языках (Python, JavaScript, Java, C # и т. Д.).
Теперь предположим, что наша программа имеет медленный или ресурсоемкий метод поиска чьего-либо номера телефона — возможно, путем подключения к сетевой службе.
Чтобы повысить производительность, мы будем использовать локальное хранилище в качестве кеша для сопоставления имени человека с его номером телефона.
|
store = Store.new() store.set(‘Bob’, ‘801-555-5555’) store.get(‘Bob’) # returns ‘801-555-5555’, which is Bob’s number store.get(‘Alice’) # returns nil, since it does not have Alice |
Однако у некоторых людей нет номера телефона (т.е. их номер телефона равен нулю). Мы по-прежнему будем кэшировать эту информацию, поэтому нам не нужно ее пополнять позже.
|
store = Store.new() store.set(‘Ted’, nil) # Ted has no phone number store.get(‘Ted’) # returns nil, since Ted does not have a phone number |
Но теперь это означает, что наши результаты неоднозначны! Это может означать:
- Этого человека нет в кеше (Алиса)
- Этот человек существует в кеше, но у него нет номера телефона (Том)
Одна ситуация требует дорогостоящего перерасчета, другая требует немедленного реагирования. Но наш код недостаточно сложен, чтобы различать эти два случая.
В реальном коде подобные ситуации часто возникают сложным и незаметным образом. Следовательно, простой и универсальный API может сразу стать особым случаем, сбивая с толку источник беспорядочного поведения с нулевым значением.
Используйте одинcontains()Способ ремонтаStoreКласс может быть полезным. Но это вводит повторные поиски, что приводит к снижению производительности и условиям гонки.
Двойные неприятности
У JavaScript такая же проблема, но она возникает вКаждый объект。
Если атрибуты объекта не существуют, JS вернет значение, указывающее, что у объекта отсутствуют атрибуты. Разработчики JavaScript выбрали это значение равным нулю.
Они беспокоятся о том, когда свойство существует и для него установлено значение null. «Талант» в том, что JavaScript добавляет undefined, чтобы отличать свойства с нулевыми значениями от несуществующих свойств.
Но что, если свойство существует и его значение не определено? Странно то, что JavaScript остановился на этом и не предоставил «super undefined».
JavaScript предлагает не только одну, но и две формы NULL.
5. NULL ухудшает неправильные языковые решения
Java незаметно преобразует ссылки в основные типы. Добавление null делает ситуацию еще более странной.
Например, следующий код не компилируется:
|
int x = null; // compile error |
Этот код компилируется и передается:
|
Integer i = null; int x = i; // runtime error |
Хотя он сообщит, когда код запускаетсяNullPointerException ошибка.
Обращение к нулевому методу члена достаточно плохо; еще хуже, если вы никогда не видели вызываемый метод.
6. NULL сложно отлаживать.
Чтобы объяснить, насколько проблематичным является NULL, хорошим примером является C ++. Вызов функции-члена для указания на NULL-указатель не обязательно приводит к сбою программы. Хуже того: этомайПриведет к сбою программы.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#include <iostream> struct Foo { int x; void bar() { std::cout << «La la la» << std::endl; } void baz() { std::cout << x << std::endl; } }; int main() { Foo *foo = NULL; foo->bar(); // okay foo->baz(); // crash } |
Когда я использую gcc для компиляции приведенного выше кода, первый вызов выполняется успешно, а второй — нет.
Почему?foo->bar()Это известно во время компиляции, поэтому компилятор избегает поиска в виртуальной таблице во время выполнения и преобразует его в статический вызов, аналогичныйFoo_bar(foo), Возьмите это как первый параметр. Потому чтоbarНет косвенной ссылки на указатель NULL, поэтому он работает успешно. НоbazИмеется ссылка на указатель NULL, который вызывает segfault.
Но мы будемbarСтаньте виртуальной функцией. Это означает, что его реализация может быть отменена подклассом.
|
... virtual void bar() { ... |
В качестве виртуальной функцииfoo->bar()ЯвляетсяfooВыполните поиск в виртуальной таблице для типа среды выполнения, чтобы предотвратитьbar()Был переписан. Потому чтоfooИмеет значение NULL, текущая программа будетfoo->bar()Это предложение рухнуло, потому что мы превратили функцию в виртуальную.
|
int main() { Foo *foo = NULL; foo->bar(); // crash foo->baz(); } |
NULL сделалmainДля программистов функций отладка этого кода становится очень сложной и неинтуитивной.
Действительно, ссылка на NULL не определена в стандарте C ++, поэтому технически мы не должнылюбая ситуацияУдивлен. Кроме того, это непатологический, распространенный, очень простой и реальный пример.Этот пример является одним из многих примеров, когда NULL на практике непостоянен.
7. NULL нельзя комбинировать
Языки программирования построены на возможности компоновки: способности применять одну абстракцию к другой. Это может быть наиболее важной особенностью любого языка, библиотеки, фреймворка, модели, API или шаблона проектирования: возможность использовать другие функции ортогонально.
Фактически, компоновка — действительно основная проблема, стоящая за многими из этих проблем. Например,StoreНет возможности компоновки между API, возвращающим nil несуществующему значению, и сохранением nil для несуществующего телефонного номера.
Для C #NullableЧтобы разобраться с некоторыми проблемами, связанными с NULL. Вы можете включить в тип необязательность (пустоту).
|
int a = 1; // integer int? b = 2; // optional integer that exists int? c = null; // optional integer that does not exist |
Но это вызвало серьезный недостаток, то естьNullableНе применимо ни к какомуT. Применяется только к непустымT. Например, это не сделаетStoreПроблема исправлена любым способом.
- Прежде всего
stringМожет быть пустым; вы не можете создать непустойstring - Даже если
stringНе пусто, поэтому создайтеstring? Может быть, но все равно нельзя исключить неоднозначность нынешней ситуации. Нетstring??
решение
NULL стало настолько распространенным явлением, что многие думают, что это необходимо. NULL присутствует во многих языках низкого и высокого уровня в течение долгого времени и кажется важным, как целочисленная арифметика или ввод-вывод.
не так! У вас может быть полный язык программирования без NULL. Проблема с NULL — это нечисловое значение, дозорный, особый случай, который концентрируется на всем остальном.
Вместо этого нам нужно, чтобы сущность содержала некоторую информацию о (1) содержит ли она значение и (2) содержащееся значение, если есть содержащееся значение. И эта сущность должна уметь «содержать» любой тип. Это идея Haskell’s Maybe, Java’s Optional, Swift’s Optional и т. Д.
Например, в ScalaSome[T]Сохранить одинTЗначение типа.NoneНет никакой ценности. Оба этиOption[T]Подтипы этих двух подтипов могут иметь значение или не иметь значения.

Читатели, не знакомые с Maybes / Options, могут подумать, что мы заменили одну форму (NULL) другой формой (None). Но есть одно отличие — обнаружить его непросто, но оно очень важно.
В языке со статической типизацией нельзя обойти систему типов, заменив любое значение None. Ничего нельзя использовать только там, где мы ожидаем появления опции. Необязательность явно выражена в типе.
В динамически типизированном языке вы не можете спутать использование Maybes / Options с содержащимися значениями.
Вернемся к предыдущемуStore, Но на этот раз можно использовать рубин. Если есть значение, тоStoreКласс возвращается со значениемSome, В противном случае вернутьNone. Для телефонных номеровSomeЭто номер телефона,NoneУказывает на отсутствие номера телефона. Так что естьДва уровня присутствия / отсутствия:Внешний MaybeУказывает, что он существует вStoreВ; внутреннийMaybeУказывает номер телефона, соответствующий этому имени. Мы успешно объединили несколькоMaybe, Это то, что мы не можем сделать с nil.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
cache = Store.new() cache.set(‘Bob’, Some(‘801-555-5555’)) cache.set(‘Tom’, None()) bob_phone = cache.get(‘Bob’) bob_phone.is_some # true, Bob is in cache bob_phone.get.is_some # true, Bob has a phone number bob_phone.get.get # ‘801-555-5555’ alice_phone = cache.get(‘Alice’) alice_phone.is_some # false, Alice is not in cache tom_phone = cache.get(‘Tom’) tom_phone.is_some # true, Tom is in cache tom_phone.get.is_some #false, Tom does not have a phone number |
Существенная разница в том, чтоБольше не существует союза между NULL и любым другим статически типизированным или динамически предполагаемым типом., Больше не существует объединения между существующим значением и несуществующим значением.
Используйте Maybes / Опции
Давайте продолжим обсуждение кода без NULL. Предположим, в Java 8+ у нас есть целое число, оно может существовать, а может и не существовать, и если оно существует, мы его распечатываем.
|
Optional<Integer> option = ... if (option.isPresent()) { doubled = System.out.println(option.get()); } |
Замечательно. Но большая частьMaybe/OptionalРеализация, включая Java, поддерживает более практичный метод:
|
option.ifPresent(x -> System.out.println(x)); // or option.ifPresent(System.out::println) |
Этот практический метод не только более краткий, но и более безопасный. Необходимо помнить, что если это значение не существует, тоoption.get()Произойдет ошибка. В предыдущем примереget()Получите одинifЗащита. В этом примереifPresent()Это полностью устраняет наши опасенияget()Необходимость. Это делает код явно свободным от ошибок, а не без ошибок.
Параметры можно рассматривать как набор с максимальным значением 1. Например, если есть значение, то мы можем умножить его на 2, в противном случае оставить его пустым.
При желании мы можем выполнить операцию, которая возвращает необязательное значение и стремится «сгладить» результат.
|
option.flatMap(x -> methodReturningOptional(x)) |
Если такового не существует, мы можем указать значение по умолчанию:
В целом,Maybe/OptionРеальная стоимость
- Избавьтесь от небезопасных предположений о существовании и несуществовании ценностей.
- Управляйте дополнительными данными проще и безопаснее
- Явно заявляйте о любых предположениях о небезопасном существовании (например,
.get()Метод)
Не быть NULL!
NULL — ужасный недостаток дизайна, постоянная и неизмеримая боль. Лишь немногим языкам удается избежать его ужаса.
Если вы все же выберете язык с NULL, то, по крайней мере, сознательно избегайте этой неприятности в своем собственном коде и используйте эквивалентMaybe/Option。
NULL в распространенных языках:

«Балл» определяется на основании следующих критериев:

редактировать
счет
Не относитесь слишком серьезно к «оценкам» в приведенной выше таблице. Настоящая проблема состоит в том, чтобы суммировать статус NULL на разных языках и представить альтернативы NULL, а не ранжировать часто используемые языки.
Информация на некоторых языках была изменена. По причинам совместимости во время выполнения в некоторых языках есть какие-то нулевые указатели, но они не имеют практического применения для самого языка.
- Пример: Haskell’s
Foreign.Ptr.nullPtrОн используется в FFI (интерфейсе внешних функций) для маршалинга значений в Haskell и обратно. - Пример: Swift
UnsafePointerДолжен быть сunsafeUnwrapИли же!использовать вместе. - Контрпример: Scala, несмотря на то, что обычно избегает null, по-прежнему обрабатывает null, как Java, для улучшения взаимодействия.
val x: String = null
Когда NULL ОК?
Стоит отметить, что при сокращении циклов ЦП специальное значение того же размера, например 0 или NULL, может быть очень полезным, жертвуя качеством кода на производительность. Когда это действительно важно, это удобно для низкоуровневых языков, таких как C, но на самом деле стоит оставить все как есть.
Настоящая проблема
Более распространенная проблема с NULL — это контрольные значения: эти значения такие же, как и другие значения, но имеют совершенно другое значение. Из indexOfХорошим примером является возврат индекса целого числа или целого числа -1. Другой пример — строки, оканчивающиеся на NULL. В этой статье основное внимание уделяется NULL, что придает его универсальность и реальное влияние, но так же, как Саурон — всего лишь слуга Моргота, NULL — это просто форма базовой проблемы дозорного устройства.
Java и null неразрывно связаны. Трудно найти Java-программиста, который не сталкивался с NullPointerException. Если даже автор понятия нулевого указателя признал его «ошибкой на миллиард долларов», почему он сохранился в Java? null присутствует в Java уже давно, и я уверен, что разработчики языка знают, что он создает больше проблем, чем решает. Это удивительно, ведь философия Java — делать вещи как можно более простыми. Если разработчики отказались от указателей, перегрузки операторов и множественного наследования, то почему они оставили null? Я не знаю ответа на этот вопрос. Однако не имеет значения, насколько много критики идет в адрес null в Java, нам придется с этим смириться. Вместо того, чтобы жаловаться, давайте лучше научимся правильно его использовать. Если быть недостаточно внимательным при использовании null, Java заставит вас страдать с помощью ужасного java.lang.NullPointerException. Наиболее частая причина NullPointerException — недостаточное понимание тонкостей использования null. Давайте вспомним самые важные вещи о нем в Java.
Что такое null в Java
Как мы уже выяснили, null очень важен в Java. Изначально он служил, чтобы обозначить отсутствие чего-либо, например, пользователя, ресурса и т. п. Но уже через год выяснилось, что он приносит много проблем. В этой статье мы рассмотрим основные вещи, которые следует знать о нулевом указателе в Java, чтобы свести к минимуму проверки на null и избежать неприятных NullPointerException.
1. В первую очередь, null — это ключевое слово в Java, как public, static или final. Оно регистрозависимо, поэтому вы не сможете написать Null или NULL, компилятор этого не поймет и выдаст ошибку:
Object obj1 = NULL; // Неверно
Object obj2 = null; // ОКЭта проблема часто возникает у программистов, которые переходят на Java с других языков, но с современными средами разработки это несущественно. Такие IDE, как Eclipse или Netbeans, исправляют эти ошибки, пока вы набираете код. Но во времена Блокнота, Vim или Emacs это было серьезной проблемой, которая отнимала много времени.
2. Так же, как и любой примитивный тип имеет значение по умолчанию (0 у int, false у boolean), null — значение по умолчанию любого ссылочного типа, а значит, и для любого объекта. Если вы объявляете булеву переменную, ей присваивается значение false. Если вы объявляете ссылочную переменную, ей присваивается значение null, вне зависимости от области видимости и модификаторов доступа. Единственное, компилятор предупредит о попытке использовать неинициализированную локальную переменную. Для того, чтобы убедиться в этом, вы можете создать ссылочную переменную, не инициализируя ее, и вывести ее на экран:
private static Object myObj;
public static void main(String args[]){
System.out.println("Значение myObj : " + myObj);
}
// Значение myObjc: nullЭто справедливо как для статических, так и для нестатических переменных. В данном случае мы объявили myObj как статическую переменную для того, чтобы ее можно было использовать в статическом методе main.
3. Несмотря на распространенное мнение, null не является ни объектом, ни типом. Это просто специальное значение, которое может быть присвоено любому ссылочному типу. Кроме того, вы также можете привести null к любому ссылочному типу:
String str = null; // null можно присвоить переменной типа String, ...
Integer itr = null; // ... и Integer, ...
Double dbl = null; // ... и Double.
String myStr = (String) null; // null может быть приведен к String ...
Integer myItr = (Integer) null; // ... и к Integer
Double myDbl = (Double) null; // без ошибок.Как видите, приведение null к ссылочному типу не вызывает ошибки ни при компиляции, ни при запуске. Также при запуске не будет NullPointerException, несмотря на распространенное заблуждение.
4. null может быть присвоен только переменной ссылочного типа. Примитивным типам — int, double, float или boolean — значение null присвоить нельзя. Компилятор не допустит этого и выдаст ошибку:
int i = null; // type mismatch: cannot convert from null to int
short s = null; // type mismatch: cannot convert from null to short
byte b = null: // type mismatch: cannot convert from null to byte
double d = null; // type mismatch: cannot convert from null to double
Integer itr = null; // все в порядке
int j = itr; // нет ошибки при компиляции, но NullPointerException при запускеИтак, попытка присвоения значения null примитивному типу — ошибка времени компиляции, но вы можете присвоить null типу-обертке, а затем присвоить это значение соответствуему примитиву. Компилятор ругаться не будет, но при выполнении кода будет брошено NullPointerException. Это происходит из-за автоматического заворачивания (autoboxing) в Java
5. Любой объект класса-обертки со значением null кинет NullPointerException при разворачивании (unboxing). Некоторые программисты думают, что обертка автоматически присвоит примитиву значение по умолчанию (0 для int, false для boolean и т. д.), но это не так:
Integer iAmNull = null;
int i = iAmNull; // компиляция пройдет успешноЕсли вы запустите этот код, вы увидите Exception in thread "main" java.lang.NullPointerException в консоли. Это часто случается при работе с HashMap с ключами типа Integer. Код ниже сломается, как только вы его запустите:
import java.util.HashMap;
import java.util.Map;
public class Test {
public static void main(String args[]) throws InterruptedException {
Map<Integer, Integer> numberAndCount = new HashMap<>();
int[] numbers = {3, 5, 7, 9, 11, 13, 17, 19, 2, 3, 5, 33, 12, 5};
for (int i : numbers) {
int count = numberAndCount.get(i); // NullPointerException
numberAndCount.put(i, count++);
}
}
}Вывод:
Exception in thread "main" java.lang.NullPointerException
at Test.main(Test.java:14)Этот код выглядит простым и понятным. Мы ищем, сколько каждое число встречается в массиве, это классический способ поиска дубликатов в массиве в Java. Мы берем предыдущее значение количества, инкрементируем его и кладем обратно в HashMap. Мы полагаем, что Integer позаботится о том, чтобы вернуть значение по умолчанию для int, однако если числа нет в HashMap, метод get() вернет null, а не 0. И при оборачивании выбросит NullPoinerException. Представьте, что этот код завернут в условие и недостаточно протестирован. Как только вы его запустите на продакшен – УПС!
6. Оператор instanceof вернет false, будучи примененным к переменной со значением null или к литералу null:
Integer iAmNull = null;
if (iAmNull instanceof Integer) {
System.out.println("iAmNull — экземпляр Integer");
} else {
System.out.println("iAmNull не является экземпляром Integer");
}Результат выполнения:
iAmNull не является экземпляром IntegerЭто важное свойство оператора instanceof, которое делает его полезным при приведении типов.
7. Возможно, вы уже знаете, что если вызвать нестатический метод по ссылке со значением null, результатом будет NullPointerException. Но зато вы можете вызвать по ней статический метод класса:
public class Testing {
public static void main(String args[]){
Testing myObject = null;
myObject.iAmStaticMethod();
myObject.iAmNonStaticMethod();
}
private static void iAmStaticMethod(){
System.out.println("I am static method, can be called by null reference");
}
private void iAmNonStaticMethod(){
System.out.println("I am NON static method, don't date to call me by null");
}
}Результат выполнения этого кода:
I am static method, can be called by null reference
Exception in thread "main" java.lang.NullPointerException
at Testing.main(Testing.java:5)8. Вы можете передавать null в любой метод, который принимает ссылочный тип, например, public void print(Object obj) может быть вызван так: print(null). С точки зрения компилятора ошибки здесь нет, но поведение такого кода целиком зависит от реализации метода. Безопасный метод не кидает NullPointerException в этом случае, а тихо завершает работу. Если бизнес-логика позволяет, лучше писать безопасные методы.
9. Вы можете сравнивать null, используя оператор == («равно») и != («не равно»), но не с арифметическими или логическими операторами (такими как «больше» или «меньше»). В отличие от SQL, в Java null == null вернет true:
public class Test {
public static void main(String args[]) throws InterruptedException {
String abc = null;
String cde = null;
if (abc == cde) {
System.out.println("null == null is true in Java");
}
if (null != null) {
System.out.println("null != null is false in Java");
}
// classical null check
if (abc == null) {
// do something
}
// not ok, compile time error
if (abc > null) {
// do something
}
}
}Вывод этого кода:
null == null is true in JavaВот и все, что надо знать о null в Java. При наличии небольшого опыта и с помощью простых приемов вы можете сделать свой код безопасным. Поскольку null может рассматриваться как пустая или неинициализированная переменная, важно документировать поведение метода при получении null. Помните, что любая созданная и не проинициализированная переменная имеет по умолчанию значение null и что вы не можете вызвать метод объекта или обратиться к его полю, используя null.
Перевод статьи «9 Things about Null in Java»
В мире Javascript и как с этим работать

Какие ошибки в мире программного обеспечения обходятся в миллиарды долларов?
- По словам Тони Хоара, ошибка 2000 года, класс ошибок, связанных с хранением и форматированием данных календаря, обойдется чуть менее чем в 4 миллиарда долларов.
- CodeRed Virus, компьютерный червь, внедрившийся в компании по всему миру, вывел из строя все сети. Прерывание бизнеса и всего обычного банковского дела обошлось мировой экономике в 4 миллиарда долларов.
- Null – ошибочное изобретение британского ученого-компьютерщика Тони Хоара (наиболее известного благодаря своему алгоритму быстрой сортировки) в 1964 году, который изобрел нулевые ссылки. как его «ошибка на миллиард долларов».
Кто придумал «обнулить» ошибку на миллиард долларов и почему?

Я называю это своей ошибкой на миллиард долларов. Это было изобретение нулевой ссылки в 1965 году. В то время я разрабатывал первую всеобъемлющую систему типов для ссылок в объектно-ориентированном языке (ALGOL W). Моя цель состояла в том, чтобы гарантировать, что любое использование ссылок должно быть абсолютно безопасным, с автоматической проверкой компилятором. Но я не мог устоять перед искушением добавить нулевую ссылку просто потому, что это было так легко реализовать. Это привело к бесчисленным ошибкам, уязвимостям и системным сбоям, которые, вероятно, причинили миллиарды долларов боли и ущерба за последние сорок лет. — Тони Хоар
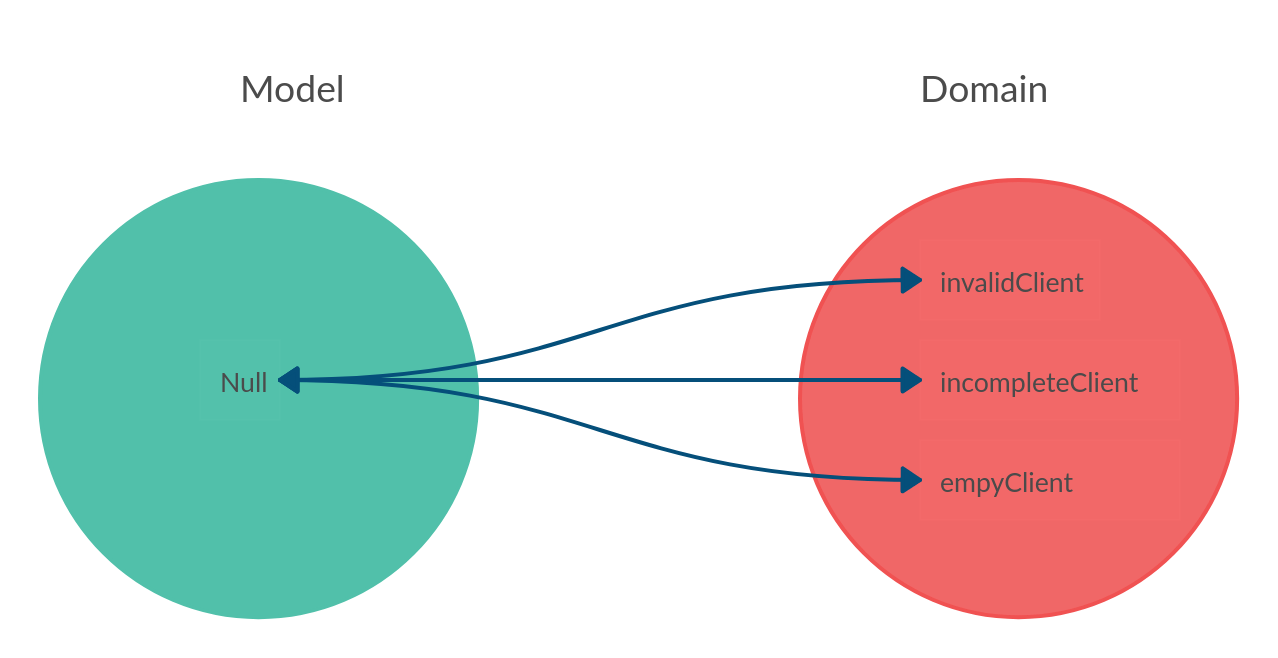
Ссылка на нулевой указатель может быть плохой идеей. Сравнивая ссылку нулевого указателя с неразборчивым в связях прелюбодеем, он заметил, что нулевое присвоение для каждого холостяка, представленного в объектной структуре, «будет выглядеть полиаморно женатым на одном и том же человеке Null. — Эдсгар Джикстра
Что такое ошибка на миллиард долларов в контексте мира Javascript?
У нас есть два кандидата в мире Javascript, подпадающие под эту категорию:
1⃣️ Нет
Значение null записывается литералом: null. null не является идентификатором свойства глобального объекта, как может быть undefined. Вместо этого null выражает отсутствие идентификации, указывая на то, что переменная не указывает ни на какой объект. В API-интерфейсах null часто извлекается в месте, где объект можно ожидать, но объект не является релевантным.
2⃣️ Не определено
undefined — это свойство глобального объекта. То есть это переменная в глобальной области видимости. Начальное значение undefined — это примитивное значение undefined.
примитивные типы данных Javascript (ES2020),
BooleanNullUndefinedNumberStringBigIntSymbol
Null и Undefined в Javascript называются «нулевыми» (ложными) значениями.
Ложные значения:
Undefined, null, 0, NaN, empty string‘’, false
Нулевой или неопределенный
Несмотря на то, что поведение обоих значений является ложным, если кто-то думает Null vs Undefined как Declared vs Undeclared, это не совсем так!
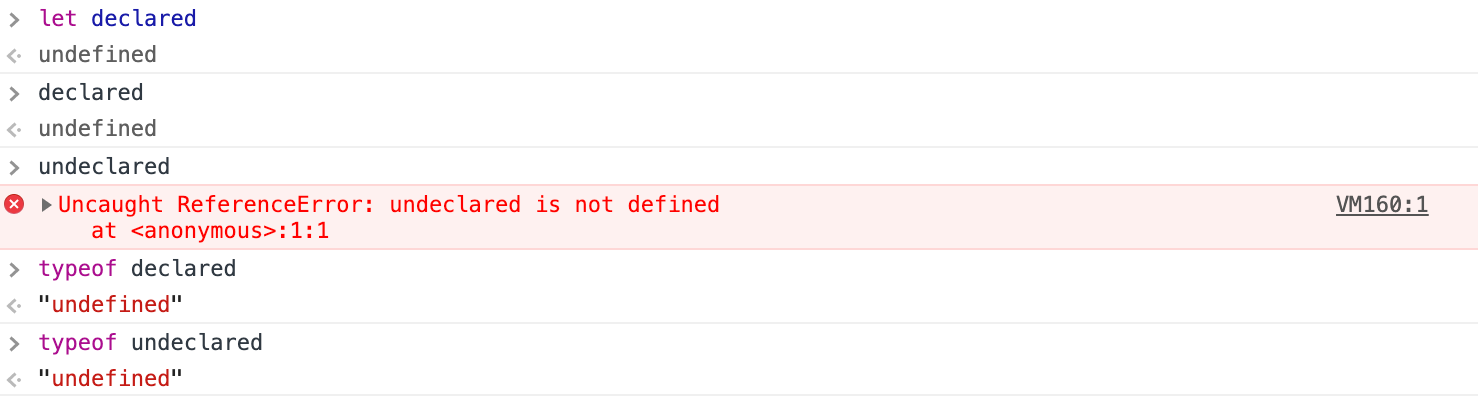
Undefined может быть как объявленным, так и необъявленным.
А как насчет Null?
У Null есть свои проблемы, с которыми нужно разобраться… отлично! Давайте посмотрим на это,

Ну, typeof null == “object” — это ошибка 25-летней давности, начиная с первой версии Javascript.
В первой версии JavaScript значения хранились в 32-битных единицах, которые состояли из небольшого тега типа (1–3 бита) и фактических данных значения. Теги типа хранились в младших битах единиц. Их было пятеро:
000: object. Данные являются ссылкой на объект.001: int. Данные представляют собой 31-битное целое число со знаком.010: double. Данные являются ссылкой на двойное число с плавающей запятой.100: string. Данные являются ссылкой на строку.110: boolean. Данные являются логическими.
Из исходного кода jsapi.h, (ссылка)
#define JSVAL_OBJECT 0x0 /* untagged reference to object */
#define JSVAL_INT 0x1 /* tagged 31-bit integer value */
#define JSVAL_DOUBLE 0x2 /* tagged reference to double */
#define JSVAL_STRING 0x4 /* tagged reference to string */
#define JSVAL_BOOLEAN 0x6 /* tagged boolean value */Два значения были особенными:
undefined(JSVAL_VOID), представляет собой целое минус (-) JSVAL_INT_POW2 (30), то есть число вне целочисленного диапазонаnull(JSVAL_NULL)— это указатель NULL машинного кода, тег типа объекта плюс ссылка, равная нулю(OBJECT_TO_JSVAL(0)).
#define JSVAL_VOID INT_TO_JSVAL(0 - JSVAL_INT_POW2(30))
#define JSVAL_NULL OBJECT_TO_JSVAL(0)
#define JSVAL_ZERO INT_TO_JSVAL(0)
#define JSVAL_ONE INT_TO_JSVAL(1)
#define JSVAL_FALSE BOOLEAN_TO_JSVAL(JS_FALSE)
#define JSVAL_TRUE BOOLEAN_TO_JSVAL(JS_TRUE)Теперь, когда рассмотрел его тег типа, а тег типа сказал объект. («источник»)
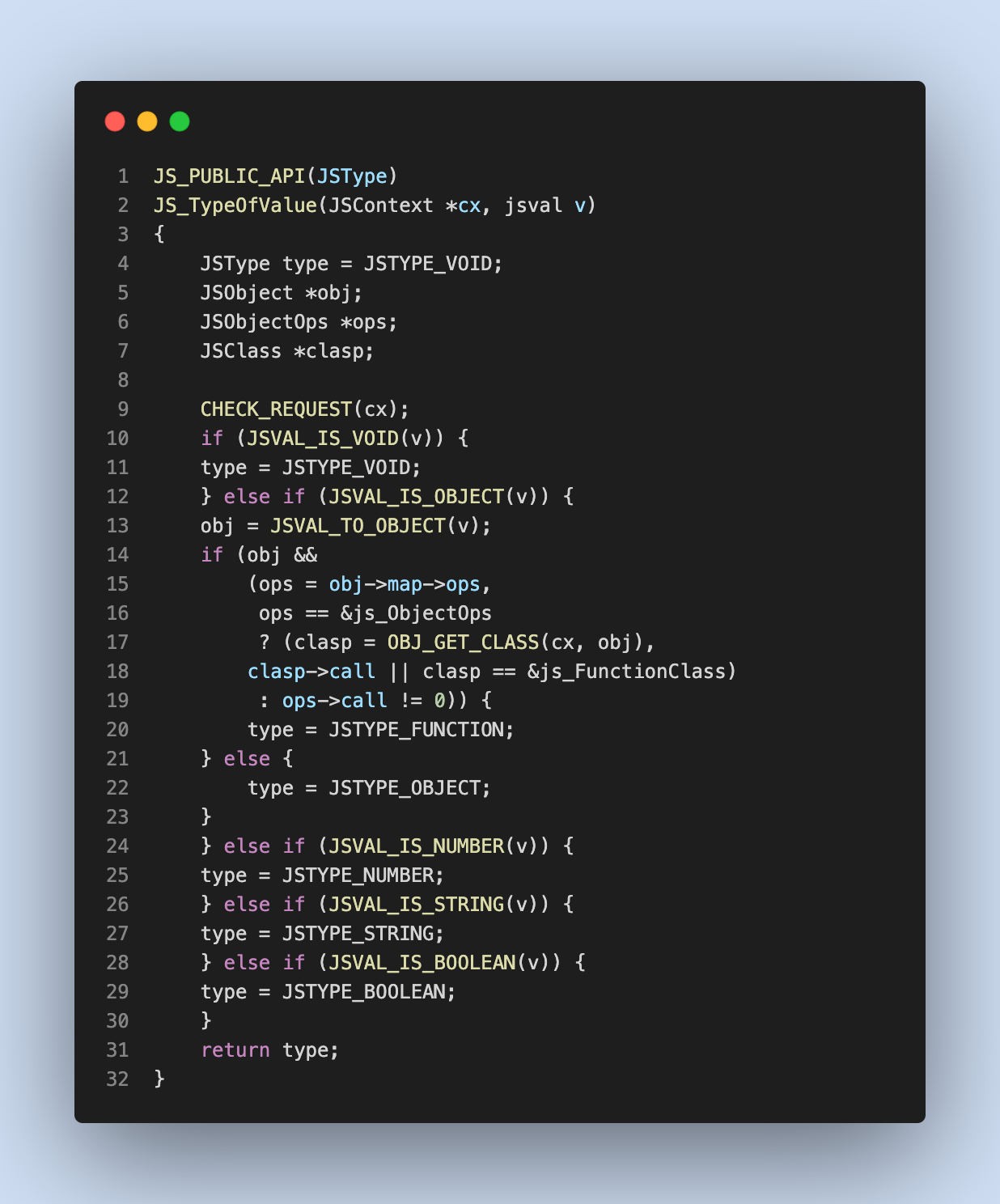
- Строка № 10, сначала проверяет, является ли значение
vundefined(VOID). - Следующая проверка в строке № 12 проверяет наличие объекта
JSVAL_IS_OBJECT, - Кроме того, вызывает функциональный класс (строка № 18, 19).
- И, следовательно, оценивается как
Object - Впоследствии есть проверки на число, строку и логическое значение, даже не проверка на Null
Возможно, это одна из причин, по которой первая версия JavaScript была завершена за 10 дней. Позже, продолжал жить с этой проблемой, а не исправлять из-за ее тесно связанной логики в исходном исходном коде. Исправление может привести к поломке многих вещей в коде.

Работа с Null и Undefined
Начиная с ES2020, у нас есть лучший способ обработки значений Nullish в Javascript. Для текущих проектов того же можно добиться с помощью Babel.js и/или Typescript.
- Необязательная цепочка (?.)
Также известен как безопасная оценка или оператор безопасности.
Длинные цепочки обращений к свойствам в Javascript приводят к ошибкам, вызывающим сбои, поскольку можно получить null или undefined (“nullish” values). Проверка наличия свойства в глубоко вложенной структуре — утомительная задача, например, рассмотрим ответ API погоды,
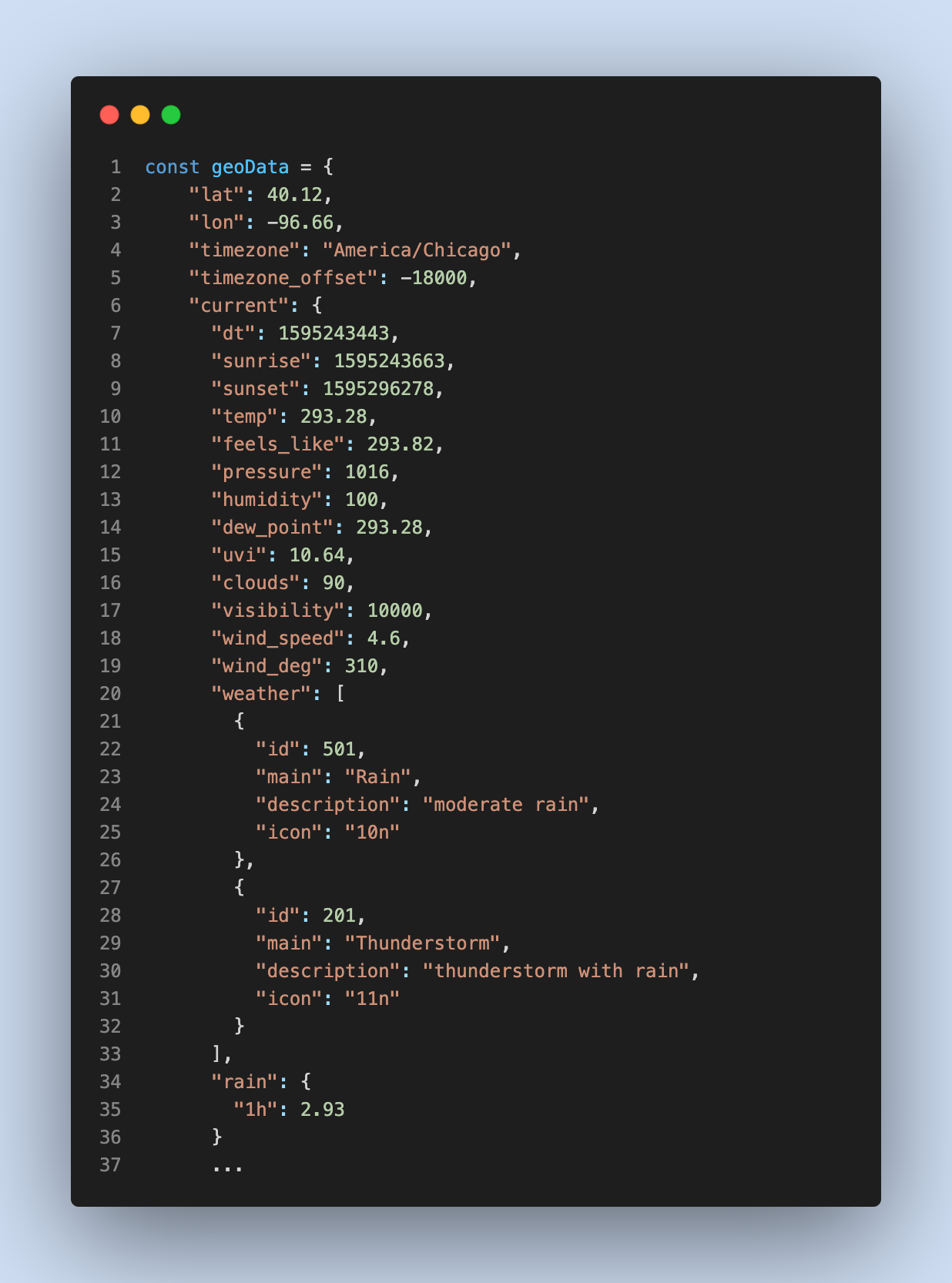
Чтобы получить данные о значении «Гроза», используются три подхода:
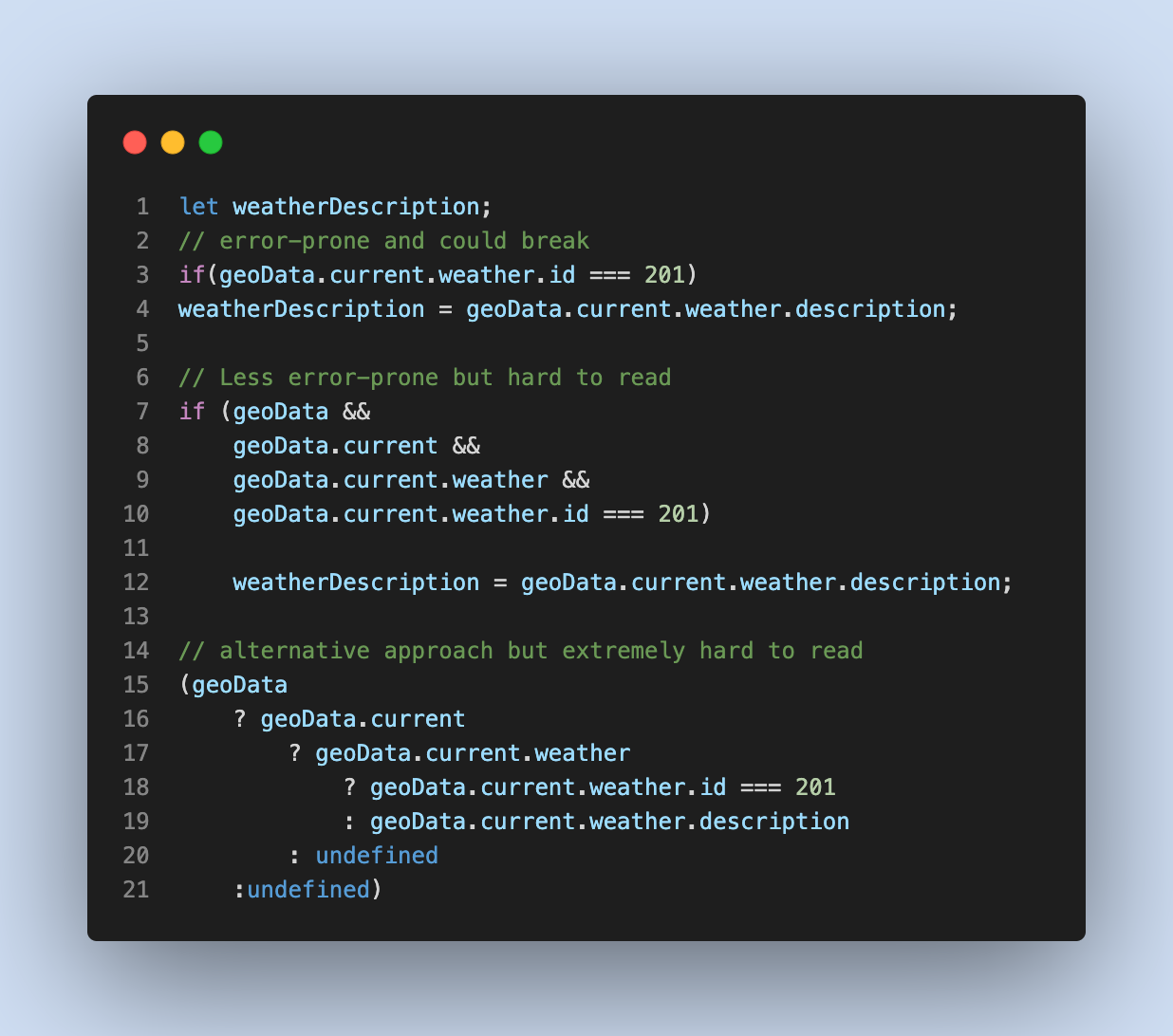
Теперь из ES2020 или TypeScript 3.7 или @babel/plugin-proposal-optional-chaining поддерживает необязательную цепочку, где можно написать так:
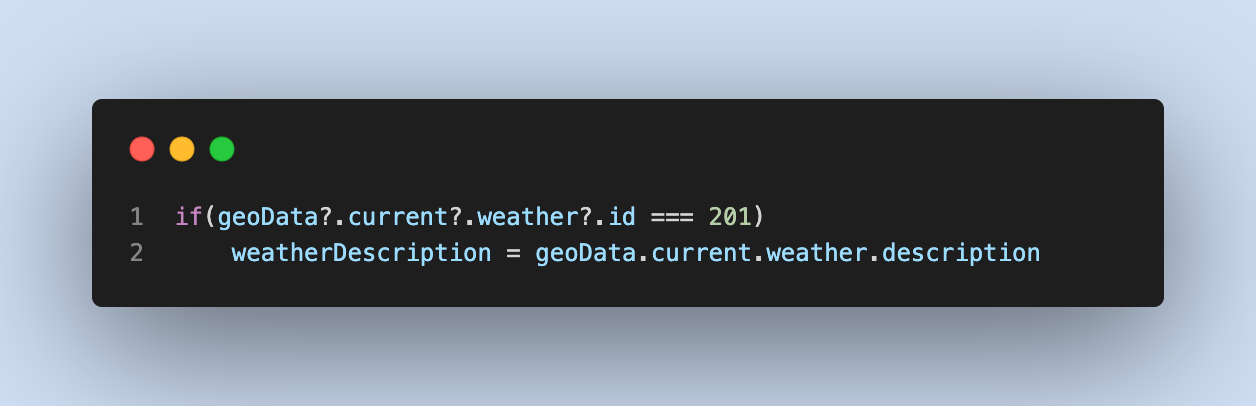
- Нулевое объединение (??)
Оператор Nullish Coalescing (??) действует очень похоже на оператор ||, за исключением того, что мы используем не ложные значения, а nullish, что означает, что значение строго равно null или undefined.
Поддерживается с ES2020, Typescript 3.7 и @babel/plugin-proposal-nullish-coalescing-operator
Избегайте Null всеми возможными способами
Шаблон NullObject
❌ НЕПРАВИЛЬНО
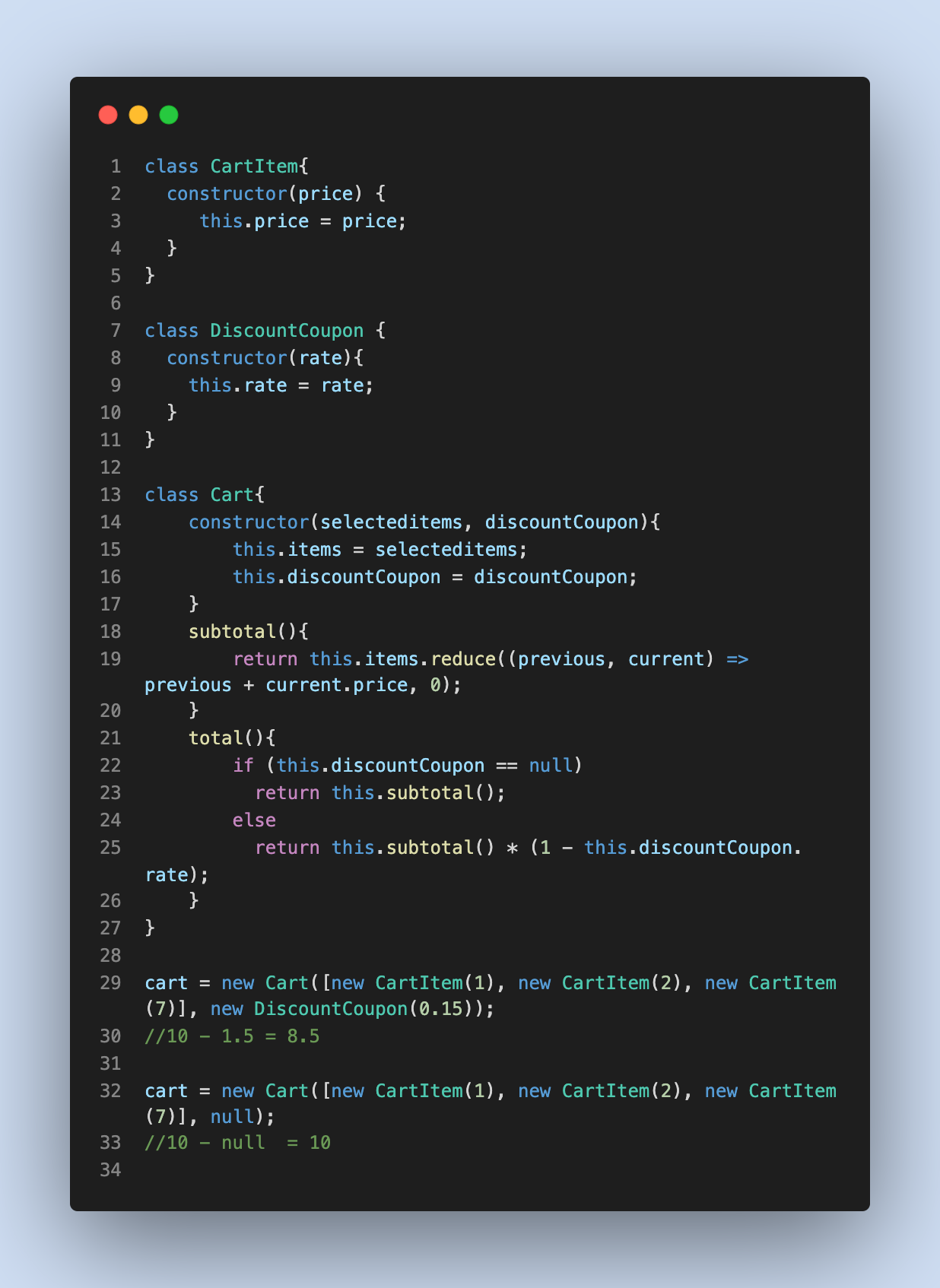
✅ ВПРАВО, Шаблон NullObject
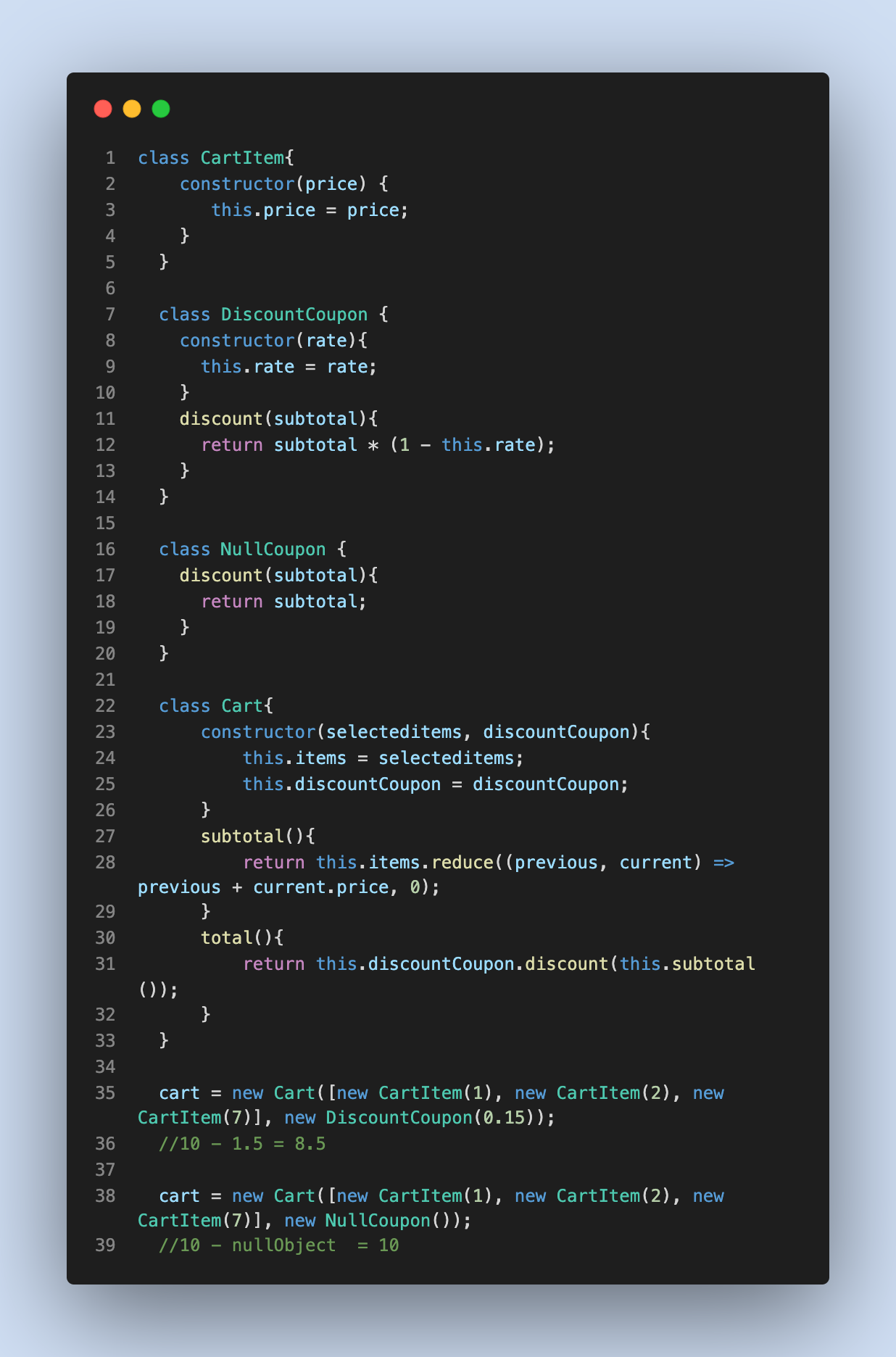
Заключительные слова
(любезно предоставлено: Максмиллиано Контьери)
Программисты используют Null как разные флаги. Он может намекать на отсутствие, неопределенность, значение, ошибку или ложное значение (значение “Nullish”). Множественная семантика приводит к ошибкам связывания.
Проблемы
- Связь между вызывающими и отправляющими
- Несоответствие между вызывающими и отправляющими
- Если/переключатель/случай загрязняет окружающую среду
- Null не полиморфен реальным объектам, поэтому
NullPointerException(TypeError: null or undefined has no properties) - Null не существует в реальном мире. Таким образом, нарушается принцип биекции
Решения
- Избегайте нуля
- Использовать Шаблон нулевого объекта
- Используйте необязательно
Исключения
- API, базы данных, внешние системы, где существует NULL
Поддержка Линтера
Добавьте no-null и no-undef к вашему .eslintrc
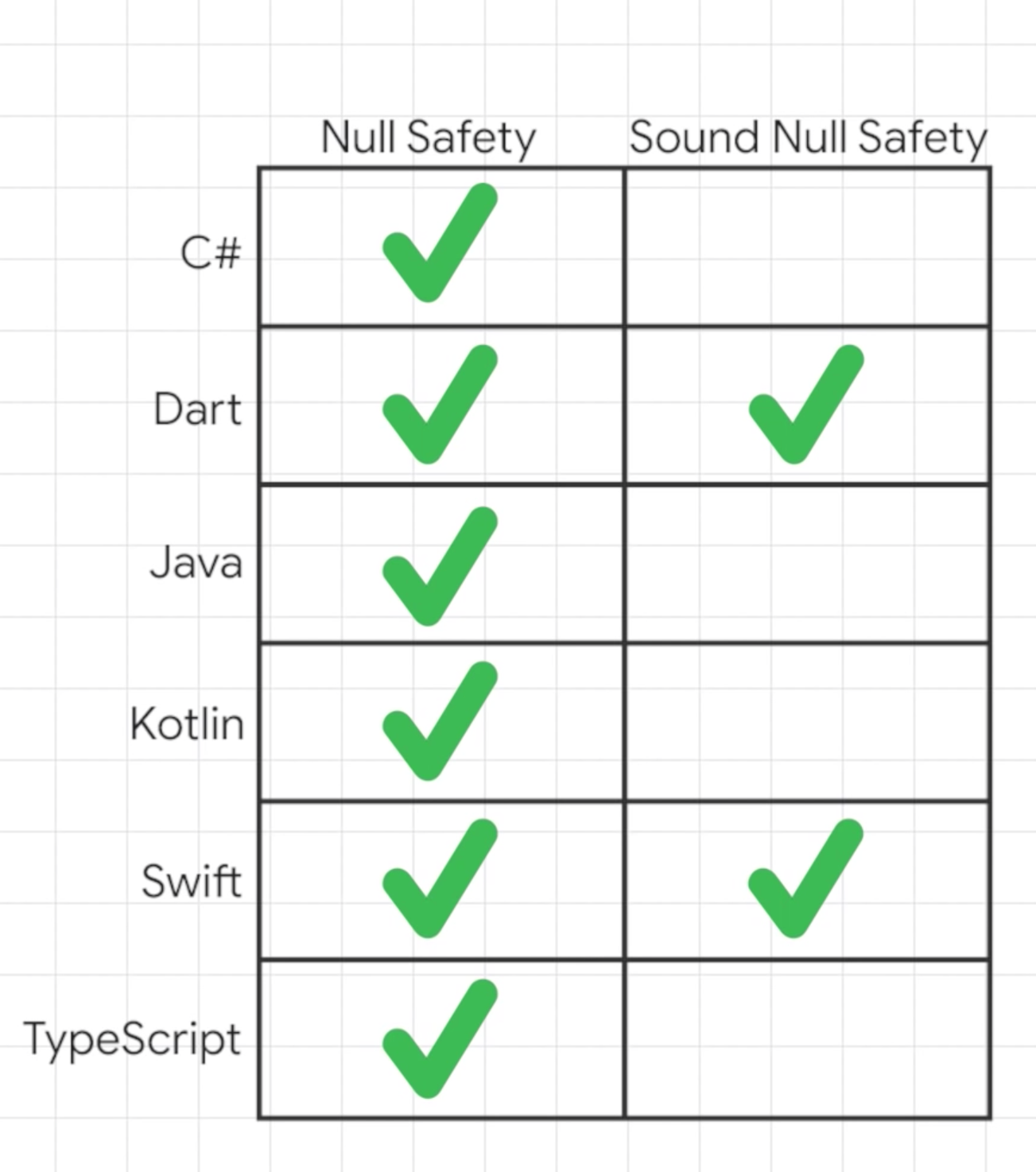
Звук Нулевая Безопасность
В современных языках введена Sound Null Safetyили иначе известная как Void Safety для более безопасного и удобного кода, что означает, что по умолчанию язык предполагает, что переменные являются ненулевыми значениями, если явно не указано иное. .
Когда вы выбираете нулевую безопасность, типы в вашем коде не могут быть нулевыми по умолчанию, а это означает, что значения не могут быть нулевыми, если только вы не скажете, что они могут быть такими. При нулевой безопасности ваша среда выполнения ошибки нулевого разыменования превращаются в ошибки анализа времени редактирования.
Например, Dart, Swift и другие следуют Sound Null Safety.
использованная литература
Преде тем, как разбираться в Optional, давайте выясним какую проблему он решает. Представим, что у нас есть класс UserRepository, который работает с хранилищем наших пользователей, в данном примере это будет обычная HashMap.
Допустим, мы хотим найти пользователя в базе данных по идентификатору. После чего нам требуется вывести на консоль длину имени пользователя. На первый взгляд это простой и безобидный пример.
final Person person = personRepository.findById(1L);
final String firstName = person.getFirstName();
System.out.println("Длина твоего имени: " + firstName.length());Выполнив этот код, мы можем получить исключение:
Exception in thread "main" java.lang.NullPointerException: Cannot invoke "dev.struchkov.example.optional.Person.getFirstName()" because "person" is null
at dev.struchkov.example.optional.Main.test(Main.java:18)
at dev.struchkov.example.optional.Main.main(Main.java:13)Почему это могло произойти? Дело в том, что мы не учли того факта, что пользователя с идентификатором 1L может не быть в нашей HashMap. И у нас нет варианта, кроме как вернуть null.
public class PersonRepository {
private final Map<Long, Person> persons;
public PersonRepository(Map<Long, Person> persons) {
this.persons = persons;
}
public Person findById(Long id) {
return persons.get(id);
}
}Во время вызова метода null-объекта вы получите NullPointerException. Это головная боль новичков в программировании. Но неважно, новичок ли вы в Java или за плечами у вас десять лет опыта — всегда есть вероятность, что вы столкнетесь с NullPointerException.
Тони Хоар, написал: «Изобретение null в 1965 году было мой ошибкой на миллиард долларов. Я не мог устоять перед искушением ввести нулевую ссылку просто потому, что ее было так легко реализовать».
А мы теперь имеем то, что имеем. Так что же делать в таком случае? Можно проверять все возвращаемые значения на null, вот так:
final Person person = personRepository.findById(1L);
if (person != null) {
final String firstName = person.getFirstName();
System.out.println("Длина твоего имени: " + firstName.length());
}Теперь если пользователя нет, то мы просто не выполняем код? Допустим, что пользователь с таким идентификатором все же есть, выполняем код:
Exception in thread "main" java.lang.NullPointerException: Cannot invoke "String.length()" because "firstName" is null
at dev.struchkov.example.optional.Main.test(Main.java:20)
at dev.struchkov.example.optional.Main.main(Main.java:13)И мы снова получили NullPointerException, только на этот раз проблема оказалась в поле firstName, теперь оно null, и уже вызов метода length() выбросил исключение. Не беда, добавим еще одну проверку:
final User user = userRepository.findById(1L);
if (user != null) {
final String firstName = user.getFirstName();
if (firstName != null) {
System.out.println("Длина твоего имени: " + firstName.length());
}
}Хм, где-то мы явно свернули не туда. Эти проверки просто мешают бизнес-логике и раздражают. Они снижают общую читаемость нашей программы.
Так приходилось жить до появления Optional в Java. Что же имеем теперь?
Спонсор поста
Используемые версии
Java 17
История обновлений статьи
17.06.2022: Исправил некоторые неточности и грамматические ошибки. Добавил информацию о методе orElseThrow(). Сделал примеры использования более наглядными.
Можно воспринимать Optional, как некую коробку, обертку, в которую кладется какой-либо объект. Optional всего лишь контейнер: он может содержать объект некоторого типа Т, а может быть пустым.

Перепишем наш пример с использованием Optional и посмотрим, что изменится:
package dev.struchkov.example.optional;
import java.util.Map;
import java.util.Optional;
public class PersonRepository {
private final Map<Long, Person> persons;
public PersonRepository(Map<Long, Person> persons) {
this.persons = persons;
}
public Optional<Person> findById(Long id) {
return Optional.ofNullable(persons.get(id));
}
}final Optional<Person> optPerson = personRepository.findById(1L);
if (optPerson.isPresent()) {
final Person person = optPerson.get();
final String firstName = person.getFirstName();
if (firstName != null) {
System.out.println("Длина твоего имени: " + firstName.length());
}
}Вы скажете: это не выглядит проще, даже более того, добавилась еще одна строка?!! Но на самом деле случилось концептуально важное событие, вы точно знаете что метод findById() возвращает контейнер, в котором объекта может не быть. Больше вы не ожидаете внезапного null значения, если только разработчик этого метода не сумашедший, ведь ничто не мешает ему вернуть null вместо Optional 🤪
Здесь мы с вами увидели два основных метода: isPresent() возвращает true, если внутри есть объект, а метод get() возвращает этот объект.
Возвращаемся к нашему примеру, давайте упростим этот код с помощью других методов Optional, чтобы увидеть какие преимущества нам это даст. Обо всех этих методах мы еще подробнее поговорим ниже.
final Optional<Person> optPerson = personRepository.findById(1L);
optUser.map(person -> person.getFirstName())
.ifPresent(
firstName -> System.out.println("Длина твоего имени: " + firstName.length())
);Мы воспользовались методом map(), который преобразует наш Optional в Optional другого типа. В данном случае мы получили фамилию пользователя, то есть преобразовали Optional<User> в Optional<String>.
Вот такой вариант показывает это нагляднее:
final Optional<Person> optPerson = personRepository.findById(1L);
final Optional<String> optFirstName = optPerson.map(user -> user.getFirstName());
optFirstName.ifPresent(
firstName -> System.out.println("Длина твоего имени: " + firstName.length())
);А дальше мы вызвали метод ifPresent(), в котором мы вызвали вывод на консоль, можно еще чуть-чуть сократить код:
personRepository.findById(1L)
.map(User::getFirstName)
.ifPresent(
firstName -> System.out.println("Длина твоего имени: " + firstName.length())
);Методы Optional
Теперь, когда мы поняли зачем нам нужен Optional и разобрали пример использования, давайте рассмотрим остальные методы этого класса. Optional обладает большим количеством методов, правильное использование которых позволяет добиться более простого и понятного кода.
Cоздание Optional
У данного класса нет конструкторов, но есть три статических метода, которые и создают экземпляры класса,
Метод Optional.ofNullable(T t)
Optional.ofNullable принимает любой тип и создает контейнер. Если в параметры этого метода передать null, то будет создан пустой контейнер.
Используйте этот метод, когда есть вероятность, что упаковываемый объект может иметь null значение.
public class PersonRepository {
private final Map<Long, Person> persons;
public PersonRepository(Map<Long, Person> persons) {
this.persons = persons;
}
public Optional<Person> findById(Long id) {
return Optional.ofNullable(persons.get(id));
}
}В этом примере мы используем ofNullable(), потому что метод Map#get() может вернуть нам null.
Метод Optional.of(T t)
Этот метод аналогичен Optional.ofNullable, но если передать в параметр null значение, то получим старый добрый NullPointerException.
Используйте этот метод, когда точно уверены, что упаковываемое значение не должно быть null.
public class PersonRepository {
private final Map<Long, Person> persons;
public PersonRepository(Map<Long, Person> persons) {
this.persons = persons;
}
public Optional<Person> findByLogin(String login) {
for (Person person : persons.values()) {
if (person.getLogin().equals(login)) {
return Optional.of(person);
}
}
return Optional.empty();
}
}Новый метод позволяет найти пользователя по логину. Для этого мы проходимся по значениям Map и сравниваем логины пользователей с переданным, как только находим совпадение вызываем метод Optional.of(), потому что мы уверены, что такой объект существует.
Метод Optional.empty()
Но что делать, если пользователь с переданным логином не был найден? Метод все равно должен вернуть Optional.
Можно вызвать Optional.ofNullable(null) и вернуть его, но лучше воспользоваться методом Optional.empty(), который возвращает пустой Optional.
Обратите внимание на последний пример, там мы как раз используем Optional.empty().
Получение содержимого
Мы разобрали методы, которые позволяют нам создавать объект Optional. Теперь изучим методы, которые позволят нам доставать значения из контейнера.
Метод isPresent()
Прежде, чем достать что-то, неплохо убедиться, что это что-то там действительно есть. И с этим нам поможет метод isPresent(), который возвращает true, если в контейнере есть объект и false в противном случае.
Optional<Person> optPerson = personRepository.findById(1L);
if(optPerson.isPresent()) {
// если пользователь найден, то выполняем этот блок кода
}Фактически это обычная проверка, как если бы мы сами написали if (value != null). И если зайти в реализацию метода isPresent(), то это мы там и увидим:
public boolean isPresent() {
return value != null;
}Метод isEmpty()
Метод isEmpty() это противоположность методу isPresent(). Метод вернет true, если объекта внутри нет и false в противном случае. Думаю, вы уже догадались, как выглядит реализация этого метода:
public boolean isEmpty() {
return value == null;
}Метод get()
После того, как вы убедились в наличии объекта с помощью предыдущих методов, вы можете смело достать объект из контейнера с помощью метода get().
Optional<Person> optPerson = personRepository.findById(1L);
if(optPerson.isPresent()) {
final Person person = optPerson.get();
// остальной ваш код
}Конечно, вы можете вызвать метод get() и без проверки. Но если объекта там не окажется, то вы получите NoSuchElementException.
Метод ifPresent()
Помимо метода isPresent(), имеется метод ifPresent(), который принимает в качестве аргумента функциональный интерфейс Consumer. Это позволяет нам выполнить какую-то логику над объектом, если объект имеется.
Давайте с помощью этого метода выведем имя и фамилию пользователя на консоль.
personRepository.findById(id).ifPresent(
person -> System.out.println(person.getFirstName() + " " + person.getLastName())
);Метод ifPresentOrElse()
Метод ifPresent() ничего не сделает, если у вас нет объекта, но если вам и в этом случае необходимо выполнить какой-то код, то используйте метод ifPresentOrElse(), который принимает в качестве параметра еще и функциональный интерфейс Runnable.
Возьмем наш пример выше и выведем в консоль Иван Иванов, если пользователь не был найден.
personRepository.findById(id).ifPresentOrElse(
person -> System.out.println(person.getFirstName() + " " + person.getLastName()),
() -> System.out.println("Иван Иванов")
);Метод orElse()
Метод делает ровно то, что ожидается от его названия: возвращает значение в контейнере или значение по-умолчанию, которое вы указали.
Например мы можем вернуть пользователя по идентификатору, а если такого пользователя нет, то вернем анонимного пользователя.
public Person getPersonOrAnon(Long id) {
return personRepository.findById(id)
.orElse(new Person(-1L, "anon", "anon", "anon"));
}Используйте этот метод, когда хотите вернуть значение по умолчанию, если контейнер пустой.
💢
Некоторым приходит в голову довольно странная конструкция: objectOptional.orElse(null), которая лишает использование Optional всякого смысла. Никогда так не делайте, и бейте по рукам тем, кто так делает.
Метод orElseGet()
Метод похож на предыдущий, но вместо возвращения значения, он выполнит функциональный интерфейс Supplier.
Возьмем пришлый пример и будем также выводить в консоль сообщение о том, что пользователь не был найден.
public Person getPersonOrAnonWithLog(Long id) {
return personRepository.findById(id)
.orElseGet(() -> {
System.out.println("Пользователь не был найден, отправляем анонимного");
return new Person(-1L, "anon", "anon", "anon");
});
}Используйте этот метод, когда вам не достаточно просто вернуть какое-то дефолтное значение, но и требуется выполнить какую-то более сложную логику.
Метод orElseThrow()
Этот метод вернет объект если он есть, в противном случае выбросит стандартное исключение NoSuchElementException("No value present").
Метод orElseThrow(Supplier s)
Этот метод позволяет вернуть любое исключение вместо стандартного NoSuchElementException, если объекта нет.
public Person getPersonOrThrow(Long id) {
return personRepository.findById(id)
.orElseThrow(() -> new NotFoundException("Пользователь не найден"));
}Элегантный orElseThrow
Как вам такой вариант использования orElseThrow()
public Person getPersonOrElegantThrow(Long id) {
return personRepository.findById(id)
.orElseThrow(notFoundException("Пользователь {0} не найден", id));
}На мой взгляд это самый эстетический вариант использования. Для этого вам нужно в классе исключения добавить метод, который будет возращать Supplier.
Вот пример NotFoundException, мы используем два метода notFoundException: один позволяет передать просто строку, а другой использует MessageFormat.format(), чтобы формировать сообщение с параметрами.
import java.text.MessageFormat;
import java.util.function.Supplier;
public class NotFoundException extends RuntimeException {
public NotFoundException(String message) {
super(message);
}
public NotFoundException(String message, Object... args) {
super(MessageFormat.format(message, args));
}
public static Supplier<NotFoundException> notFoundException(String message, Object... args) {
return () -> new NotFoundException(message, args);
}
public static Supplier<NotFoundException> notFoundException(String message) {
return () -> new NotFoundException(message);
}
}Преобразование
Optional также имеет ряд методов, которые могет быть знакомы вам по стримам: map, filter и flatMap. Они имеют такие же названия, и делают примерно то же самое.
Метод filter()
Если внутри контейнера есть значение и оно удовлетворяет переданному условию в виде функционального интерфейса Predicate, то будет возвращен новый объект Optional с этим значением, иначе будет возвращен пустой Optional.
Например, мы сделаем метод, который возвращает только взрослых пользователей по id.
public Optional<Person> getAdultById(Long id) {
return personRepository.findById(id)
.filter(person -> person.getAge() > 18);
}Используйте его, когда вам нужен контейнер, объект в котором удвлетворят какому-то условию.
Метод map()
Если внутри контейнера есть значение, то к значению применяется переданная функция, результат помещается в новый Optional и возвращается, в случае отсутствия значения будет возвращен пустой контейнер. Для преобразования используется функциональный интерфейс Function.
Сделаем метод, который по идентификатору пользователя возвращает Optional<String>, содержащий имя и фамилию этого пользователя.
public Optional<String> getFirstAndLastNames(Long id) {
return personRepository.findById(id)
.map(person -> person.getFirstName() + " " + person.getLastName());
}Используйте этот метод, когда необходимо преобразовать объект внутри контейнера в другой объект.
Метод flatMap()
Как уже было сказано, map() оборачивает возвращаемый результат лямбды Function. Но что, если эта лямбда у нас будет возвращать уже обернутый результат, у нас получится Optional<Optional<T>>. С таким дважды упакованным объектом будет сложно работать.
Для примера, мы можем запрашивать какие-то данные о пользователе из другого сервиса, и этих данных тоже может не быть, поэтому возникает второй контейнер. Вот как это будет выглядеть:
Optional<Optional<String>> optUserPhoneNumber = personRepository.findById(1L)
.map(person -> {
Optional<String> optPhoneNumber = phoneNumberRepository.findByPersonId(person.getId());
return optPhoneNumber;
});В таком случае используйте flatMap(), он позволит вам избавиться от лишнего контейнера.
Optional<String> optUserPhoneNumber = personRepository.findById(1L)
.flatMap(person -> {
Optional<String> optPhoneNumber = phoneNumberRepository.findByLogin(user.getLogin());
return optPhoneNumber;
});Метод stream()
В Java 9 в Optional был добавлен новый метод stream(), который позволяет удобно работать со стримом от коллекции Optional элементов.
Допустим, вы запрашивали множество пользователей по различным идентификаторам, а в ответ вам возвращался Optional<Person>. Вы сложили полученные объекты в коллекцию, и теперь с ними нужно как-то работать. Можно создать стрим от этой коллекции, и используя метод flatMap() стрима и метод stream() у Optional, чтобы получить стрим существующих пользователей. При этом все пустые контейнеры будут отброшены.
final List<Optional<Person>> optPeople = new ArrayList<>();
final List<Person> people = optPeople.stream()
.flatMap(optItem -> optItem.stream())
.toList();Метод or()
Начиная с Java 11 добавили новый метод or(). Он позволяет изменить пустой Optional передав новый объект, раньше так сделать было нельзя.
Важно понимать, что этот метод не изменяет объект Optional, а создает и возвращает новый.
Например мы запрашиваем пользователя по идентификатору, и если его нет в хранилище, то мы передаем Optional анонимного пользователя.
public Optional<Person> getPersonOrAnonOptional(Long id) {
return personRepository.findById(id)
.or(() -> Optional.of(new Person(-1L, "anon", "anon", "anon", 0L)));
}Комбинирование методов
Все перечисленные методы возвращают в ответ Optional, поэтому вы можете составлять из них цепочки, прямо как у стримов.
Пример оторванный от реальности, но иллюстрирующий цепочку методов:
final LocalDateTime now = LocalDateTime.now();
final DayOfWeek dayWeek = Optional.of(now)
.map(LocalDateTime::getDayOfWeek)
.filter(dayOfWeek -> DayOfWeek.SUNDAY.equals(dayOfWeek))
.orElse(DayOfWeek.MONDAY);Прочие нюансы
Далее идут дополнительные советы и житейские мудрости, которые помогут вам еще лучше овладеть этим инструментом.
Когда стоит использовать Optional
Если открыть javadoc Optional, можно найти там прямой ответ на данный вопрос.
Optional в первую очередь предназначен для использования в качестве типа возвращаемого значения метода, когда существует явная необходимость представлять «отсутствие результата» и где использование null может вызвать ошибки.
Как НЕ стоит использовать Optional
А теперь разберемся основные ошибки при использовании Optional.
Как параметр метода
Не стоит использовать Optional, в качестве параметра метода. Если пользователь метода с параметром Optional не знает об этом, он может передать методу null вместо Optional.empty(). И обработка null приведет к исключению NullPointerException.
Как свойство класса
Также не используйте Optional для объявления свойств класса.
Во-первых, у вас могут возникнуть проблемы с такими популярными фремворками, как Spring Data/Hibernate. Hibernate не может замапить значения из БД на Optional напрямую , без кастомных конвертеров.
Хотя некоторые фреймворки, такие как Jackson отлично интегрируют Optional в свою экосиситему. Как раз с Jackson можно подумать об использовании Optional в качестве свойства класса, если создание объекта этого класса вы никика не контролируете. Например, при использовании Webhook.
Во-вторых, не стоит забывать, что Optional это объект, который обычно нужен на пару секунд, после чего он может быть безболезненно удален сборщиком мусора. Но на создание объекта нужно время, и если мы храним Optional в качестве поля, он может оставаться там вплоть до самой остановки программы. Вряд ли это приведет к проблемам в небольших приложениях, но все же учтите это.
В-третьих, использование таких полей будет неудобным Optional не имплементирует интерфейс Serializable. Проще говоря, любой объект, который содержит хотя бы одно Optional поле, нельзя сериализовать. Хотя с приходом микросервисов платформенная сериализация не является настолько важной, как раньше.
Решением в такой ситуации может быть использование Optional для геттеров класса. Однако у этого подхода есть один недостаток. Его нельзя полностью интегрировать с Lombok. Optional getters не подерживаются библиотекой и, судя по некоторым обсуждениям на Github, не будут.
Как обертка коллекции
Не оборачивайте коллекции в Optional. Любая коллекция является контейнером сама по себе. Чтобы вернуть пустую коллекцию, вместо null, можно воспользоваться следующими методами Collections.emptyList(), Collections.emptySet() и прочими.
Optional не должен равняться null
Присваивание null вместо объекта Optional разрушает саму концепцию его использования. Никто из пользователей вашего метода не будет проверять Optional на эквивалентность с null. Вместо присваивания null следует использовать Optional.empty().
Примитивы и Optional
Для работы с обертками примитивов есть java.util.OptionalDouble, java.util.OptionalInt и java.util.OptionalLong, которые позволяют избегать лишних автоупаковок и распаковок. Однако не смотря на это, на практике используются они крайне редко.
Все эти классы похожи на Optional, но не имеют методов преобразования. В них доступны только: get, orElse, orElseGet, orElseThrow, ifPresent и isPresent.
Резюмирую
Класс Optional не решает проблему NullPointerException полностью, но при правильном применении позволяет снизить количество ошибок, сделать код более читабельным и компактным. Использование Optional не всегда уместно, но для возвращаемых значений из методов он подходит отлично.
Основные моменты, которые стоит запомнить
- Если методу требуется вернуть
null, вернитеOptional; - Не используйте
Optionalв качестве параметра методов и как свойство класса; - Проверяйте
Optionalперед тем, как достать его содержимое; - Никогда так не делайте:
optional.orElse(null);
Дополнительные ссылки по теме
- Какие аннотации можно использовать для защиты от null
[Обновление 2015-10-31] Дополнительная трансляция, измененная из StackOverflowПочтовыйПараграф:
Чашка! В нашей компании фамилия сотрудника Null.При использовании его фамилии в качестве термина запроса все приложения запросов сотрудников вылетали из строя! Что я должен делать?
В 1965 году кто-то допустил худшую ошибку в области информатики. Ошибка уродливее, чем обратная косая черта в Windows, более странная, чем ===, более распространенная, чем PHP, более неудачная, чем CORS, и более тревожная, чем дженерики Java. XMLHttpRequest, более сложный для понимания, чем препроцессор C, более подверженный фрагментации, чем MongoDB, и более прискорбный, чем UTF-16.
«Я называю нулевую ссылку своей ошибкой на миллиард долларов. Она была изобретена в 1965 году, когда я разработал первую всеобъемлющую систему ссылочных типов на объектно-ориентированном языке (АЛГОЛ W). Моя цель — гарантировать, что использование всех ссылок абсолютно безопасно, компилятор проверит автоматически. Но я не смог устоять перед соблазном добавить нулевые ссылки только потому, что это очень легко реализовать. Это вызвало бесчисленное количество ошибок, уязвимостей и систем. Авария могла привести к убыткам в миллиарды долларов в следующий раз. 40 лет. В последние годы люди начали использовать различные программы анализа программ, такие как Microsoft PREfix и PREfast, чтобы проверять ссылки и предупреждать, если существует риск ненулевого значения. Новые языки программирования, такие как Spec #, имеют ввел объявление ненулевых ссылок. Это решение, которое я отверг в 1965 году »-« Нулевые ссылки: ошибка на миллиард долларов »Тони Хоар, лауреат премии Тьюринга
В ознаменование 50-летия нулевой ошибки мистера Хора в этой статье объясняется, что такое null, почему это так ужасно и как этого избежать.
Что не так с NULL?
Проще говоря: NULL — это значение, которое не является значением. Вот и проблема.
Эта проблема усугубилась в самом популярном языке всех времен, и теперь у него много имен: NULL, nil, null, None, Nothing, Nil и nullptr. У каждого языка есть свои нюансы.
Некоторые из проблем, вызванных NULL, связаны только с конкретным языком, в то время как другие универсальны; некоторые — просто разные аспекты проблемы.
NULL…
- Тип Subversion
- Это грязно
- Это особый случай
- Сделать API хуже
- Сделать неправильные языковые решения хуже
- Сложно отлаживать
- Не сочетается
1. Тип подрывной деятельности NULL
Статически типизированные языки могут проверять использование типов в программе без фактического выполнения программы и обеспечивать определенные гарантии поведения программы.
Например, в Java, если я напишуx.toUppercase(), Компилятор проверитx тип. в случае x Является String, То проверка типа прошла успешно; еслиx Является Socket, Тогда проверка типа не удалась.
При написании большого и сложного программного обеспечения статическая проверка типов является мощным инструментом. Но для Java эти отличные проверки во время компиляции имеют фатальный недостаток: любая ссылка может быть нулевой, а вызов метода нулевого объекта приведет кNullPointerException. и так,
toUppercase()Может быть произвольноStringВызов объекта. Пока неStringНулевой.read()Может быть произвольноInputStreamВызов объекта. Пока неInputStreamНулевой.toString()Может быть произвольноObjectВызов объекта. Пока неObjectНулевой.
Java — не единственный язык, вызывающий эту проблему; многие другие системы типов имеют те же недостатки, включая, конечно, язык AGOL W.
В этих языках NULL выходит за рамки проверки типов. Он незаметно превзошел проверку типа, дождался времени выполнения и, наконец, выпустил сразу большое количество ошибок. NULL — это ничто, и в то же время это ничто.
2. NULL беспорядочный
Во многих случаях null не имеет смысла. К сожалению, если язык позволяет чему-либо быть нулевым, ну, тогда все может быть нулевым.
Программисты на Java пишут о риске синдрома запястного канала
|
if (str == null || str.equals(«»)) { } |
И добавляем в C #String.IsNullOrEmptyОбычная грамматика
|
if (string.IsNullOrEmpty(str)) { } |
Черт!
Каждый раз, когда вы пишете код, который путает пустые строки с пустыми строками, команда Guava плачет. -Google Guava
хорошо сказано. Но когда ваша система типов (например, Java или C #) допускает NULL везде, вы не можете надежно исключить возможность NULL и неизбежно где-то запутаетесь.
Возможность нулевого повсюду вызвала такую проблему, добавлена Java 8@NonNullМарк, попробуй ретроспективно устранить этот дефект в системе его типов.
3. NULL — это особый случай.
Учитывая, что NULL не является значением, но также играет роль значения, NULL, естественно, становится предметом различных специальных методов обработки.
указатель
Например, рассмотрим следующий код C ++:
|
char c = ‘A’; char *myChar = &c; std::cout << *myChar << std::endl; |
myChar Является char *, Что означает, что это указатель, то есть сохранить адрес памяти вcharв. Компилятор это проверит. Следовательно, следующий код недействителен:
|
char *myChar = 123; // compile error std::cout << *myChar << std::endl; |
Потому что123Нет гарантии, что это одинchar, Итак, компиляция не удалась. В любом случае, если поменять номер на0(0 является NULL в C ++), тогда его можно скомпилировать с помощью:
|
char *myChar = 0; std::cout << *myChar << std::endl; // runtime error |
с 123То же самое, NULL на самом деле неcharадрес. Но на этот раз компилятор все еще позволяет его компилировать, потому что0(NULL) — особый случай.
Нить
Есть еще один особый случай, который встречается в символьной строке, оканчивающейся на NULL в языке C. Это немного отличается от других примеров, потому что здесь нет указателей или ссылок. Однако идея о том, что это не ценность, а также играет роль ценности, все еще существует, здесь нетcharНо это играетcharСуществуют в виде.
Строка C представляет собой последовательность байтов и заканчивается байтом NUL (0).
Следовательно, каждый символ строки C может быть любым из 256 байтов, кроме 0 (то есть символа NUL). Это не только делает длину строки линейной операцией времени; что еще хуже, это означает, что строки C не могут использоваться в ASCII или расширенном ASCII. Вместо этого они могут использоваться только для ASCIIZ, который обычно не используется.
Исключение одного символа NUL вызвало бесчисленное количество ошибок: странное поведение API, уязвимости безопасности и переполнение буфера.
NULL — это наихудшая ошибка в строках C; точнее, строка, заканчивающаяся на NUL, являетсяСамый дорогойОдин байтошибка。
4. NULL делает API плохим
В следующем примере мы отправимся в путешествие в царство динамически типизированных языков, где NULL еще раз докажет, что это ужасная ошибка.
Хранилище ключей и значений
Предположим, мы создаем класс Ruby, который будет действовать как хранилище значений ключей. Это может быть кеш, интерфейс для базы данных ключ-значение и т. Д. Создадим простой и универсальный API:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class Store ## # associate key with value # def set(key, value) ... end ## # get value associated with key, or return nil if there is no such key # def get(key) ... end end |
Мы можем представить подобные классы на многих языках (Python, JavaScript, Java, C # и т. Д.).
Теперь предположим, что наша программа имеет медленный или ресурсоемкий метод поиска чьего-либо номера телефона — возможно, путем подключения к сетевой службе.
Чтобы повысить производительность, мы будем использовать локальное хранилище в качестве кеша для сопоставления имени человека с его номером телефона.
|
store = Store.new() store.set(‘Bob’, ‘801-555-5555’) store.get(‘Bob’) # returns ‘801-555-5555’, which is Bob’s number store.get(‘Alice’) # returns nil, since it does not have Alice |
Однако у некоторых людей нет номера телефона (т.е. их номер телефона равен нулю). Мы по-прежнему будем кэшировать эту информацию, поэтому нам не нужно ее пополнять позже.
|
store = Store.new() store.set(‘Ted’, nil) # Ted has no phone number store.get(‘Ted’) # returns nil, since Ted does not have a phone number |
Но теперь это означает, что наши результаты неоднозначны! Это может означать:
- Этого человека нет в кеше (Алиса)
- Этот человек существует в кеше, но у него нет номера телефона (Том)
Одна ситуация требует дорогостоящего перерасчета, другая требует немедленного реагирования. Но наш код недостаточно сложен, чтобы различать эти два случая.
В реальном коде подобные ситуации часто возникают сложным и незаметным образом. Следовательно, простой и универсальный API может сразу стать особым случаем, сбивая с толку источник беспорядочного поведения с нулевым значением.
Используйте одинcontains()Способ ремонтаStoreКласс может быть полезным. Но это вводит повторные поиски, что приводит к снижению производительности и условиям гонки.
Двойные неприятности
У JavaScript такая же проблема, но она возникает вКаждый объект。
Если атрибуты объекта не существуют, JS вернет значение, указывающее, что у объекта отсутствуют атрибуты. Разработчики JavaScript выбрали это значение равным нулю.
Они беспокоятся о том, когда свойство существует и для него установлено значение null. «Талант» в том, что JavaScript добавляет undefined, чтобы отличать свойства с нулевыми значениями от несуществующих свойств.
Но что, если свойство существует и его значение не определено? Странно то, что JavaScript остановился на этом и не предоставил «super undefined».
JavaScript предлагает не только одну, но и две формы NULL.
5. NULL ухудшает неправильные языковые решения
Java незаметно преобразует ссылки в основные типы. Добавление null делает ситуацию еще более странной.
Например, следующий код не компилируется:
|
int x = null; // compile error |
Этот код компилируется и передается:
|
Integer i = null; int x = i; // runtime error |
Хотя он сообщит, когда код запускаетсяNullPointerException ошибка.
Обращение к нулевому методу члена достаточно плохо; еще хуже, если вы никогда не видели вызываемый метод.
6. NULL сложно отлаживать.
Чтобы объяснить, насколько проблематичным является NULL, хорошим примером является C ++. Вызов функции-члена для указания на NULL-указатель не обязательно приводит к сбою программы. Хуже того: этомайПриведет к сбою программы.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#include <iostream> struct Foo { int x; void bar() { std::cout << «La la la» << std::endl; } void baz() { std::cout << x << std::endl; } }; int main() { Foo *foo = NULL; foo->bar(); // okay foo->baz(); // crash } |
Когда я использую gcc для компиляции приведенного выше кода, первый вызов выполняется успешно, а второй — нет.
Почему?foo->bar()Это известно во время компиляции, поэтому компилятор избегает поиска в виртуальной таблице во время выполнения и преобразует его в статический вызов, аналогичныйFoo_bar(foo), Возьмите это как первый параметр. Потому чтоbarНет косвенной ссылки на указатель NULL, поэтому он работает успешно. НоbazИмеется ссылка на указатель NULL, который вызывает segfault.
Но мы будемbarСтаньте виртуальной функцией. Это означает, что его реализация может быть отменена подклассом.
|
... virtual void bar() { ... |
В качестве виртуальной функцииfoo->bar()ЯвляетсяfooВыполните поиск в виртуальной таблице для типа среды выполнения, чтобы предотвратитьbar()Был переписан. Потому чтоfooИмеет значение NULL, текущая программа будетfoo->bar()Это предложение рухнуло, потому что мы превратили функцию в виртуальную.
|
int main() { Foo *foo = NULL; foo->bar(); // crash foo->baz(); } |
NULL сделалmainДля программистов функций отладка этого кода становится очень сложной и неинтуитивной.
Действительно, ссылка на NULL не определена в стандарте C ++, поэтому технически мы не должнылюбая ситуацияУдивлен. Кроме того, это непатологический, распространенный, очень простой и реальный пример.Этот пример является одним из многих примеров, когда NULL на практике непостоянен.
7. NULL нельзя комбинировать
Языки программирования построены на возможности компоновки: способности применять одну абстракцию к другой. Это может быть наиболее важной особенностью любого языка, библиотеки, фреймворка, модели, API или шаблона проектирования: возможность использовать другие функции ортогонально.
Фактически, компоновка — действительно основная проблема, стоящая за многими из этих проблем. Например,StoreНет возможности компоновки между API, возвращающим nil несуществующему значению, и сохранением nil для несуществующего телефонного номера.
Для C #NullableЧтобы разобраться с некоторыми проблемами, связанными с NULL. Вы можете включить в тип необязательность (пустоту).
|
int a = 1; // integer int? b = 2; // optional integer that exists int? c = null; // optional integer that does not exist |
Но это вызвало серьезный недостаток, то естьNullableНе применимо ни к какомуT. Применяется только к непустымT. Например, это не сделаетStoreПроблема исправлена любым способом.
- Прежде всего
stringМожет быть пустым; вы не можете создать непустойstring - Даже если
stringНе пусто, поэтому создайтеstring? Может быть, но все равно нельзя исключить неоднозначность нынешней ситуации. Нетstring??
решение
NULL стало настолько распространенным явлением, что многие думают, что это необходимо. NULL присутствует во многих языках низкого и высокого уровня в течение долгого времени и кажется важным, как целочисленная арифметика или ввод-вывод.
не так! У вас может быть полный язык программирования без NULL. Проблема с NULL — это нечисловое значение, дозорный, особый случай, который концентрируется на всем остальном.
Вместо этого нам нужно, чтобы сущность содержала некоторую информацию о (1) содержит ли она значение и (2) содержащееся значение, если есть содержащееся значение. И эта сущность должна уметь «содержать» любой тип. Это идея Haskell’s Maybe, Java’s Optional, Swift’s Optional и т. Д.
Например, в ScalaSome[T]Сохранить одинTЗначение типа.NoneНет никакой ценности. Оба этиOption[T]Подтипы этих двух подтипов могут иметь значение или не иметь значения.
Читатели, не знакомые с Maybes / Options, могут подумать, что мы заменили одну форму (NULL) другой формой (None). Но есть одно отличие — обнаружить его непросто, но оно очень важно.
В языке со статической типизацией нельзя обойти систему типов, заменив любое значение None. Ничего нельзя использовать только там, где мы ожидаем появления опции. Необязательность явно выражена в типе.
В динамически типизированном языке вы не можете спутать использование Maybes / Options с содержащимися значениями.
Вернемся к предыдущемуStore, Но на этот раз можно использовать рубин. Если есть значение, тоStoreКласс возвращается со значениемSome, В противном случае вернутьNone. Для телефонных номеровSomeЭто номер телефона,NoneУказывает на отсутствие номера телефона. Так что естьДва уровня присутствия / отсутствия:Внешний MaybeУказывает, что он существует вStoreВ; внутреннийMaybeУказывает номер телефона, соответствующий этому имени. Мы успешно объединили несколькоMaybe, Это то, что мы не можем сделать с nil.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
cache = Store.new() cache.set(‘Bob’, Some(‘801-555-5555’)) cache.set(‘Tom’, None()) bob_phone = cache.get(‘Bob’) bob_phone.is_some # true, Bob is in cache bob_phone.get.is_some # true, Bob has a phone number bob_phone.get.get # ‘801-555-5555’ alice_phone = cache.get(‘Alice’) alice_phone.is_some # false, Alice is not in cache tom_phone = cache.get(‘Tom’) tom_phone.is_some # true, Tom is in cache tom_phone.get.is_some #false, Tom does not have a phone number |
Существенная разница в том, чтоБольше не существует союза между NULL и любым другим статически типизированным или динамически предполагаемым типом., Больше не существует объединения между существующим значением и несуществующим значением.
Используйте Maybes / Опции
Давайте продолжим обсуждение кода без NULL. Предположим, в Java 8+ у нас есть целое число, оно может существовать, а может и не существовать, и если оно существует, мы его распечатываем.
|
Optional<Integer> option = ... if (option.isPresent()) { doubled = System.out.println(option.get()); } |
Замечательно. Но большая частьMaybe/OptionalРеализация, включая Java, поддерживает более практичный метод:
|
option.ifPresent(x -> System.out.println(x)); // or option.ifPresent(System.out::println) |
Этот практический метод не только более краткий, но и более безопасный. Необходимо помнить, что если это значение не существует, тоoption.get()Произойдет ошибка. В предыдущем примереget()Получите одинifЗащита. В этом примереifPresent()Это полностью устраняет наши опасенияget()Необходимость. Это делает код явно свободным от ошибок, а не без ошибок.
Параметры можно рассматривать как набор с максимальным значением 1. Например, если есть значение, то мы можем умножить его на 2, в противном случае оставить его пустым.
При желании мы можем выполнить операцию, которая возвращает необязательное значение и стремится «сгладить» результат.
|
option.flatMap(x -> methodReturningOptional(x)) |
Если такового не существует, мы можем указать значение по умолчанию:
В целом,Maybe/OptionРеальная стоимость
- Избавьтесь от небезопасных предположений о существовании и несуществовании ценностей.
- Управляйте дополнительными данными проще и безопаснее
- Явно заявляйте о любых предположениях о небезопасном существовании (например,
.get()Метод)
Не быть NULL!
NULL — ужасный недостаток дизайна, постоянная и неизмеримая боль. Лишь немногим языкам удается избежать его ужаса.
Если вы все же выберете язык с NULL, то, по крайней мере, сознательно избегайте этой неприятности в своем собственном коде и используйте эквивалентMaybe/Option。
NULL в распространенных языках:
«Балл» определяется на основании следующих критериев:
редактировать
счет
Не относитесь слишком серьезно к «оценкам» в приведенной выше таблице. Настоящая проблема состоит в том, чтобы суммировать статус NULL на разных языках и представить альтернативы NULL, а не ранжировать часто используемые языки.
Информация на некоторых языках была изменена. По причинам совместимости во время выполнения в некоторых языках есть какие-то нулевые указатели, но они не имеют практического применения для самого языка.
- Пример: Haskell’s
Foreign.Ptr.nullPtrОн используется в FFI (интерфейсе внешних функций) для маршалинга значений в Haskell и обратно. - Пример: Swift
UnsafePointerДолжен быть сunsafeUnwrapИли же!использовать вместе. - Контрпример: Scala, несмотря на то, что обычно избегает null, по-прежнему обрабатывает null, как Java, для улучшения взаимодействия.
val x: String = null
Когда NULL ОК?
Стоит отметить, что при сокращении циклов ЦП специальное значение того же размера, например 0 или NULL, может быть очень полезным, жертвуя качеством кода на производительность. Когда это действительно важно, это удобно для низкоуровневых языков, таких как C, но на самом деле стоит оставить все как есть.
Настоящая проблема
Более распространенная проблема с NULL — это контрольные значения: эти значения такие же, как и другие значения, но имеют совершенно другое значение. Из indexOfХорошим примером является возврат индекса целого числа или целого числа -1. Другой пример — строки, оканчивающиеся на NULL. В этой статье основное внимание уделяется NULL, что придает его универсальность и реальное влияние, но так же, как Саурон — всего лишь слуга Моргота, NULL — это просто форма базовой проблемы дозорного устройства.
[Обновление 2015-10-31] Дополнительная трансляция, измененная из StackOverflowПочтовыйПараграф:
Чашка! В нашей компании фамилия сотрудника Null.При использовании его фамилии в качестве термина запроса все приложения запросов сотрудников вылетали из строя! Что я должен делать?
В 1965 году кто-то допустил худшую ошибку в области информатики. Ошибка уродливее, чем обратная косая черта в Windows, более странная, чем ===, более распространенная, чем PHP, более неудачная, чем CORS, и более тревожная, чем дженерики Java. XMLHttpRequest, более сложный для понимания, чем препроцессор C, более подверженный фрагментации, чем MongoDB, и более прискорбный, чем UTF-16.
«Я называю нулевую ссылку своей ошибкой на миллиард долларов. Она была изобретена в 1965 году, когда я разработал первую всеобъемлющую систему ссылочных типов на объектно-ориентированном языке (АЛГОЛ W). Моя цель — гарантировать, что использование всех ссылок абсолютно безопасно, компилятор проверит автоматически. Но я не смог устоять перед соблазном добавить нулевые ссылки только потому, что это очень легко реализовать. Это вызвало бесчисленное количество ошибок, уязвимостей и систем. Авария могла привести к убыткам в миллиарды долларов в следующий раз. 40 лет. В последние годы люди начали использовать различные программы анализа программ, такие как Microsoft PREfix и PREfast, чтобы проверять ссылки и предупреждать, если существует риск ненулевого значения. Новые языки программирования, такие как Spec #, имеют ввел объявление ненулевых ссылок. Это решение, которое я отверг в 1965 году »-« Нулевые ссылки: ошибка на миллиард долларов »Тони Хоар, лауреат премии Тьюринга
В ознаменование 50-летия нулевой ошибки мистера Хора в этой статье объясняется, что такое null, почему это так ужасно и как этого избежать.
Что не так с NULL?
Проще говоря: NULL — это значение, которое не является значением. Вот и проблема.
Эта проблема усугубилась в самом популярном языке всех времен, и теперь у него много имен: NULL, nil, null, None, Nothing, Nil и nullptr. У каждого языка есть свои нюансы.
Некоторые из проблем, вызванных NULL, связаны только с конкретным языком, в то время как другие универсальны; некоторые — просто разные аспекты проблемы.
NULL…
- Тип Subversion
- Это грязно
- Это особый случай
- Сделать API хуже
- Сделать неправильные языковые решения хуже
- Сложно отлаживать
- Не сочетается
1. Тип подрывной деятельности NULL
Статически типизированные языки могут проверять использование типов в программе без фактического выполнения программы и обеспечивать определенные гарантии поведения программы.
Например, в Java, если я напишуx.toUppercase(), Компилятор проверитx тип. в случае x Является String, То проверка типа прошла успешно; еслиx Является Socket, Тогда проверка типа не удалась.
При написании большого и сложного программного обеспечения статическая проверка типов является мощным инструментом. Но для Java эти отличные проверки во время компиляции имеют фатальный недостаток: любая ссылка может быть нулевой, а вызов метода нулевого объекта приведет кNullPointerException. и так,
toUppercase()Может быть произвольноStringВызов объекта. Пока неStringНулевой.read()Может быть произвольноInputStreamВызов объекта. Пока неInputStreamНулевой.toString()Может быть произвольноObjectВызов объекта. Пока неObjectНулевой.
Java — не единственный язык, вызывающий эту проблему; многие другие системы типов имеют те же недостатки, включая, конечно, язык AGOL W.
В этих языках NULL выходит за рамки проверки типов. Он незаметно превзошел проверку типа, дождался времени выполнения и, наконец, выпустил сразу большое количество ошибок. NULL — это ничто, и в то же время это ничто.
2. NULL беспорядочный
Во многих случаях null не имеет смысла. К сожалению, если язык позволяет чему-либо быть нулевым, ну, тогда все может быть нулевым.
Программисты на Java пишут о риске синдрома запястного канала
|
if (str == null || str.equals(«»)) { } |
И добавляем в C #String.IsNullOrEmptyОбычная грамматика
|
if (string.IsNullOrEmpty(str)) { } |
Черт!
Каждый раз, когда вы пишете код, который путает пустые строки с пустыми строками, команда Guava плачет. -Google Guava
хорошо сказано. Но когда ваша система типов (например, Java или C #) допускает NULL везде, вы не можете надежно исключить возможность NULL и неизбежно где-то запутаетесь.
Возможность нулевого повсюду вызвала такую проблему, добавлена Java 8@NonNullМарк, попробуй ретроспективно устранить этот дефект в системе его типов.
3. NULL — это особый случай.
Учитывая, что NULL не является значением, но также играет роль значения, NULL, естественно, становится предметом различных специальных методов обработки.
указатель
Например, рассмотрим следующий код C ++:
|
char c = ‘A’; char *myChar = &c; std::cout << *myChar << std::endl; |
myChar Является char *, Что означает, что это указатель, то есть сохранить адрес памяти вcharв. Компилятор это проверит. Следовательно, следующий код недействителен:
|
char *myChar = 123; // compile error std::cout << *myChar << std::endl; |
Потому что123Нет гарантии, что это одинchar, Итак, компиляция не удалась. В любом случае, если поменять номер на0(0 является NULL в C ++), тогда его можно скомпилировать с помощью:
|
char *myChar = 0; std::cout << *myChar << std::endl; // runtime error |
с 123То же самое, NULL на самом деле неcharадрес. Но на этот раз компилятор все еще позволяет его компилировать, потому что0(NULL) — особый случай.
Нить
Есть еще один особый случай, который встречается в символьной строке, оканчивающейся на NULL в языке C. Это немного отличается от других примеров, потому что здесь нет указателей или ссылок. Однако идея о том, что это не ценность, а также играет роль ценности, все еще существует, здесь нетcharНо это играетcharСуществуют в виде.
Строка C представляет собой последовательность байтов и заканчивается байтом NUL (0).
Следовательно, каждый символ строки C может быть любым из 256 байтов, кроме 0 (то есть символа NUL). Это не только делает длину строки линейной операцией времени; что еще хуже, это означает, что строки C не могут использоваться в ASCII или расширенном ASCII. Вместо этого они могут использоваться только для ASCIIZ, который обычно не используется.
Исключение одного символа NUL вызвало бесчисленное количество ошибок: странное поведение API, уязвимости безопасности и переполнение буфера.
NULL — это наихудшая ошибка в строках C; точнее, строка, заканчивающаяся на NUL, являетсяСамый дорогойОдин байтошибка。
4. NULL делает API плохим
В следующем примере мы отправимся в путешествие в царство динамически типизированных языков, где NULL еще раз докажет, что это ужасная ошибка.
Хранилище ключей и значений
Предположим, мы создаем класс Ruby, который будет действовать как хранилище значений ключей. Это может быть кеш, интерфейс для базы данных ключ-значение и т. Д. Создадим простой и универсальный API:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class Store ## # associate key with value # def set(key, value) ... end ## # get value associated with key, or return nil if there is no such key # def get(key) ... end end |
Мы можем представить подобные классы на многих языках (Python, JavaScript, Java, C # и т. Д.).
Теперь предположим, что наша программа имеет медленный или ресурсоемкий метод поиска чьего-либо номера телефона — возможно, путем подключения к сетевой службе.
Чтобы повысить производительность, мы будем использовать локальное хранилище в качестве кеша для сопоставления имени человека с его номером телефона.
|
store = Store.new() store.set(‘Bob’, ‘801-555-5555’) store.get(‘Bob’) # returns ‘801-555-5555’, which is Bob’s number store.get(‘Alice’) # returns nil, since it does not have Alice |
Однако у некоторых людей нет номера телефона (т.е. их номер телефона равен нулю). Мы по-прежнему будем кэшировать эту информацию, поэтому нам не нужно ее пополнять позже.
|
store = Store.new() store.set(‘Ted’, nil) # Ted has no phone number store.get(‘Ted’) # returns nil, since Ted does not have a phone number |
Но теперь это означает, что наши результаты неоднозначны! Это может означать:
- Этого человека нет в кеше (Алиса)
- Этот человек существует в кеше, но у него нет номера телефона (Том)
Одна ситуация требует дорогостоящего перерасчета, другая требует немедленного реагирования. Но наш код недостаточно сложен, чтобы различать эти два случая.
В реальном коде подобные ситуации часто возникают сложным и незаметным образом. Следовательно, простой и универсальный API может сразу стать особым случаем, сбивая с толку источник беспорядочного поведения с нулевым значением.
Используйте одинcontains()Способ ремонтаStoreКласс может быть полезным. Но это вводит повторные поиски, что приводит к снижению производительности и условиям гонки.
Двойные неприятности
У JavaScript такая же проблема, но она возникает вКаждый объект。
Если атрибуты объекта не существуют, JS вернет значение, указывающее, что у объекта отсутствуют атрибуты. Разработчики JavaScript выбрали это значение равным нулю.
Они беспокоятся о том, когда свойство существует и для него установлено значение null. «Талант» в том, что JavaScript добавляет undefined, чтобы отличать свойства с нулевыми значениями от несуществующих свойств.
Но что, если свойство существует и его значение не определено? Странно то, что JavaScript остановился на этом и не предоставил «super undefined».
JavaScript предлагает не только одну, но и две формы NULL.
5. NULL ухудшает неправильные языковые решения
Java незаметно преобразует ссылки в основные типы. Добавление null делает ситуацию еще более странной.
Например, следующий код не компилируется:
|
int x = null; // compile error |
Этот код компилируется и передается:
|
Integer i = null; int x = i; // runtime error |
Хотя он сообщит, когда код запускаетсяNullPointerException ошибка.
Обращение к нулевому методу члена достаточно плохо; еще хуже, если вы никогда не видели вызываемый метод.
6. NULL сложно отлаживать.
Чтобы объяснить, насколько проблематичным является NULL, хорошим примером является C ++. Вызов функции-члена для указания на NULL-указатель не обязательно приводит к сбою программы. Хуже того: этомайПриведет к сбою программы.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#include <iostream> struct Foo { int x; void bar() { std::cout << «La la la» << std::endl; } void baz() { std::cout << x << std::endl; } }; int main() { Foo *foo = NULL; foo->bar(); // okay foo->baz(); // crash } |
Когда я использую gcc для компиляции приведенного выше кода, первый вызов выполняется успешно, а второй — нет.
Почему?foo->bar()Это известно во время компиляции, поэтому компилятор избегает поиска в виртуальной таблице во время выполнения и преобразует его в статический вызов, аналогичныйFoo_bar(foo), Возьмите это как первый параметр. Потому чтоbarНет косвенной ссылки на указатель NULL, поэтому он работает успешно. НоbazИмеется ссылка на указатель NULL, который вызывает segfault.
Но мы будемbarСтаньте виртуальной функцией. Это означает, что его реализация может быть отменена подклассом.
|
... virtual void bar() { ... |
В качестве виртуальной функцииfoo->bar()ЯвляетсяfooВыполните поиск в виртуальной таблице для типа среды выполнения, чтобы предотвратитьbar()Был переписан. Потому чтоfooИмеет значение NULL, текущая программа будетfoo->bar()Это предложение рухнуло, потому что мы превратили функцию в виртуальную.
|
int main() { Foo *foo = NULL; foo->bar(); // crash foo->baz(); } |
NULL сделалmainДля программистов функций отладка этого кода становится очень сложной и неинтуитивной.
Действительно, ссылка на NULL не определена в стандарте C ++, поэтому технически мы не должнылюбая ситуацияУдивлен. Кроме того, это непатологический, распространенный, очень простой и реальный пример.Этот пример является одним из многих примеров, когда NULL на практике непостоянен.
7. NULL нельзя комбинировать
Языки программирования построены на возможности компоновки: способности применять одну абстракцию к другой. Это может быть наиболее важной особенностью любого языка, библиотеки, фреймворка, модели, API или шаблона проектирования: возможность использовать другие функции ортогонально.
Фактически, компоновка — действительно основная проблема, стоящая за многими из этих проблем. Например,StoreНет возможности компоновки между API, возвращающим nil несуществующему значению, и сохранением nil для несуществующего телефонного номера.
Для C #NullableЧтобы разобраться с некоторыми проблемами, связанными с NULL. Вы можете включить в тип необязательность (пустоту).
|
int a = 1; // integer int? b = 2; // optional integer that exists int? c = null; // optional integer that does not exist |
Но это вызвало серьезный недостаток, то естьNullableНе применимо ни к какомуT. Применяется только к непустымT. Например, это не сделаетStoreПроблема исправлена любым способом.
- Прежде всего
stringМожет быть пустым; вы не можете создать непустойstring - Даже если
stringНе пусто, поэтому создайтеstring? Может быть, но все равно нельзя исключить неоднозначность нынешней ситуации. Нетstring??
решение
NULL стало настолько распространенным явлением, что многие думают, что это необходимо. NULL присутствует во многих языках низкого и высокого уровня в течение долгого времени и кажется важным, как целочисленная арифметика или ввод-вывод.
не так! У вас может быть полный язык программирования без NULL. Проблема с NULL — это нечисловое значение, дозорный, особый случай, который концентрируется на всем остальном.
Вместо этого нам нужно, чтобы сущность содержала некоторую информацию о (1) содержит ли она значение и (2) содержащееся значение, если есть содержащееся значение. И эта сущность должна уметь «содержать» любой тип. Это идея Haskell’s Maybe, Java’s Optional, Swift’s Optional и т. Д.
Например, в ScalaSome[T]Сохранить одинTЗначение типа.NoneНет никакой ценности. Оба этиOption[T]Подтипы этих двух подтипов могут иметь значение или не иметь значения.
Читатели, не знакомые с Maybes / Options, могут подумать, что мы заменили одну форму (NULL) другой формой (None). Но есть одно отличие — обнаружить его непросто, но оно очень важно.
В языке со статической типизацией нельзя обойти систему типов, заменив любое значение None. Ничего нельзя использовать только там, где мы ожидаем появления опции. Необязательность явно выражена в типе.
В динамически типизированном языке вы не можете спутать использование Maybes / Options с содержащимися значениями.
Вернемся к предыдущемуStore, Но на этот раз можно использовать рубин. Если есть значение, тоStoreКласс возвращается со значениемSome, В противном случае вернутьNone. Для телефонных номеровSomeЭто номер телефона,NoneУказывает на отсутствие номера телефона. Так что естьДва уровня присутствия / отсутствия:Внешний MaybeУказывает, что он существует вStoreВ; внутреннийMaybeУказывает номер телефона, соответствующий этому имени. Мы успешно объединили несколькоMaybe, Это то, что мы не можем сделать с nil.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
cache = Store.new() cache.set(‘Bob’, Some(‘801-555-5555’)) cache.set(‘Tom’, None()) bob_phone = cache.get(‘Bob’) bob_phone.is_some # true, Bob is in cache bob_phone.get.is_some # true, Bob has a phone number bob_phone.get.get # ‘801-555-5555’ alice_phone = cache.get(‘Alice’) alice_phone.is_some # false, Alice is not in cache tom_phone = cache.get(‘Tom’) tom_phone.is_some # true, Tom is in cache tom_phone.get.is_some #false, Tom does not have a phone number |
Существенная разница в том, чтоБольше не существует союза между NULL и любым другим статически типизированным или динамически предполагаемым типом., Больше не существует объединения между существующим значением и несуществующим значением.
Используйте Maybes / Опции
Давайте продолжим обсуждение кода без NULL. Предположим, в Java 8+ у нас есть целое число, оно может существовать, а может и не существовать, и если оно существует, мы его распечатываем.
|
Optional<Integer> option = ... if (option.isPresent()) { doubled = System.out.println(option.get()); } |
Замечательно. Но большая частьMaybe/OptionalРеализация, включая Java, поддерживает более практичный метод:
|
option.ifPresent(x -> System.out.println(x)); // or option.ifPresent(System.out::println) |
Этот практический метод не только более краткий, но и более безопасный. Необходимо помнить, что если это значение не существует, тоoption.get()Произойдет ошибка. В предыдущем примереget()Получите одинifЗащита. В этом примереifPresent()Это полностью устраняет наши опасенияget()Необходимость. Это делает код явно свободным от ошибок, а не без ошибок.
Параметры можно рассматривать как набор с максимальным значением 1. Например, если есть значение, то мы можем умножить его на 2, в противном случае оставить его пустым.
При желании мы можем выполнить операцию, которая возвращает необязательное значение и стремится «сгладить» результат.
|
option.flatMap(x -> methodReturningOptional(x)) |
Если такового не существует, мы можем указать значение по умолчанию:
В целом,Maybe/OptionРеальная стоимость
- Избавьтесь от небезопасных предположений о существовании и несуществовании ценностей.
- Управляйте дополнительными данными проще и безопаснее
- Явно заявляйте о любых предположениях о небезопасном существовании (например,
.get()Метод)
Не быть NULL!
NULL — ужасный недостаток дизайна, постоянная и неизмеримая боль. Лишь немногим языкам удается избежать его ужаса.
Если вы все же выберете язык с NULL, то, по крайней мере, сознательно избегайте этой неприятности в своем собственном коде и используйте эквивалентMaybe/Option。
NULL в распространенных языках:
«Балл» определяется на основании следующих критериев:
редактировать
счет
Не относитесь слишком серьезно к «оценкам» в приведенной выше таблице. Настоящая проблема состоит в том, чтобы суммировать статус NULL на разных языках и представить альтернативы NULL, а не ранжировать часто используемые языки.
Информация на некоторых языках была изменена. По причинам совместимости во время выполнения в некоторых языках есть какие-то нулевые указатели, но они не имеют практического применения для самого языка.
- Пример: Haskell’s
Foreign.Ptr.nullPtrОн используется в FFI (интерфейсе внешних функций) для маршалинга значений в Haskell и обратно. - Пример: Swift
UnsafePointerДолжен быть сunsafeUnwrapИли же!использовать вместе. - Контрпример: Scala, несмотря на то, что обычно избегает null, по-прежнему обрабатывает null, как Java, для улучшения взаимодействия.
val x: String = null
Когда NULL ОК?
Стоит отметить, что при сокращении циклов ЦП специальное значение того же размера, например 0 или NULL, может быть очень полезным, жертвуя качеством кода на производительность. Когда это действительно важно, это удобно для низкоуровневых языков, таких как C, но на самом деле стоит оставить все как есть.
Настоящая проблема
Более распространенная проблема с NULL — это контрольные значения: эти значения такие же, как и другие значения, но имеют совершенно другое значение. Из indexOfХорошим примером является возврат индекса целого числа или целого числа -1. Другой пример — строки, оканчивающиеся на NULL. В этой статье основное внимание уделяется NULL, что придает его универсальность и реальное влияние, но так же, как Саурон — всего лишь слуга Моргота, NULL — это просто форма базовой проблемы дозорного устройства.
В мире Javascript и как с этим работать

Какие ошибки в мире программного обеспечения обходятся в миллиарды долларов?
- По словам Тони Хоара, ошибка 2000 года, класс ошибок, связанных с хранением и форматированием данных календаря, обойдется чуть менее чем в 4 миллиарда долларов.
- CodeRed Virus, компьютерный червь, внедрившийся в компании по всему миру, вывел из строя все сети. Прерывание бизнеса и всего обычного банковского дела обошлось мировой экономике в 4 миллиарда долларов.
- Null – ошибочное изобретение британского ученого-компьютерщика Тони Хоара (наиболее известного благодаря своему алгоритму быстрой сортировки) в 1964 году, который изобрел нулевые ссылки. как его «ошибка на миллиард долларов».
Кто придумал «обнулить» ошибку на миллиард долларов и почему?

Я называю это своей ошибкой на миллиард долларов. Это было изобретение нулевой ссылки в 1965 году. В то время я разрабатывал первую всеобъемлющую систему типов для ссылок в объектно-ориентированном языке (ALGOL W). Моя цель состояла в том, чтобы гарантировать, что любое использование ссылок должно быть абсолютно безопасным, с автоматической проверкой компилятором. Но я не мог устоять перед искушением добавить нулевую ссылку просто потому, что это было так легко реализовать. Это привело к бесчисленным ошибкам, уязвимостям и системным сбоям, которые, вероятно, причинили миллиарды долларов боли и ущерба за последние сорок лет. — Тони Хоар

Ссылка на нулевой указатель может быть плохой идеей. Сравнивая ссылку нулевого указателя с неразборчивым в связях прелюбодеем, он заметил, что нулевое присвоение для каждого холостяка, представленного в объектной структуре, «будет выглядеть полиаморно женатым на одном и том же человеке Null. — Эдсгар Джикстра
Что такое ошибка на миллиард долларов в контексте мира Javascript?
У нас есть два кандидата в мире Javascript, подпадающие под эту категорию:
1⃣️ Нет
Значение null записывается литералом: null. null не является идентификатором свойства глобального объекта, как может быть undefined. Вместо этого null выражает отсутствие идентификации, указывая на то, что переменная не указывает ни на какой объект. В API-интерфейсах null часто извлекается в месте, где объект можно ожидать, но объект не является релевантным.
2⃣️ Не определено
undefined — это свойство глобального объекта. То есть это переменная в глобальной области видимости. Начальное значение undefined — это примитивное значение undefined.
примитивные типы данных Javascript (ES2020),
BooleanNullUndefinedNumberStringBigIntSymbol
Null и Undefined в Javascript называются «нулевыми» (ложными) значениями.
Ложные значения:
Undefined, null, 0, NaN, empty string‘’, false
Нулевой или неопределенный
Несмотря на то, что поведение обоих значений является ложным, если кто-то думает Null vs Undefined как Declared vs Undeclared, это не совсем так!

Undefined может быть как объявленным, так и необъявленным.
А как насчет Null?
У Null есть свои проблемы, с которыми нужно разобраться… отлично! Давайте посмотрим на это,

Ну, typeof null == “object” — это ошибка 25-летней давности, начиная с первой версии Javascript.
В первой версии JavaScript значения хранились в 32-битных единицах, которые состояли из небольшого тега типа (1–3 бита) и фактических данных значения. Теги типа хранились в младших битах единиц. Их было пятеро:
000: object. Данные являются ссылкой на объект.001: int. Данные представляют собой 31-битное целое число со знаком.010: double. Данные являются ссылкой на двойное число с плавающей запятой.100: string. Данные являются ссылкой на строку.110: boolean. Данные являются логическими.
Из исходного кода jsapi.h, (ссылка)
#define JSVAL_OBJECT 0x0 /* untagged reference to object */
#define JSVAL_INT 0x1 /* tagged 31-bit integer value */
#define JSVAL_DOUBLE 0x2 /* tagged reference to double */
#define JSVAL_STRING 0x4 /* tagged reference to string */
#define JSVAL_BOOLEAN 0x6 /* tagged boolean value */Два значения были особенными:
undefined(JSVAL_VOID), представляет собой целое минус (-) JSVAL_INT_POW2 (30), то есть число вне целочисленного диапазонаnull(JSVAL_NULL)— это указатель NULL машинного кода, тег типа объекта плюс ссылка, равная нулю(OBJECT_TO_JSVAL(0)).
#define JSVAL_VOID INT_TO_JSVAL(0 - JSVAL_INT_POW2(30))
#define JSVAL_NULL OBJECT_TO_JSVAL(0)
#define JSVAL_ZERO INT_TO_JSVAL(0)
#define JSVAL_ONE INT_TO_JSVAL(1)
#define JSVAL_FALSE BOOLEAN_TO_JSVAL(JS_FALSE)
#define JSVAL_TRUE BOOLEAN_TO_JSVAL(JS_TRUE)Теперь, когда рассмотрел его тег типа, а тег типа сказал объект. («источник»)

- Строка № 10, сначала проверяет, является ли значение
vundefined(VOID). - Следующая проверка в строке № 12 проверяет наличие объекта
JSVAL_IS_OBJECT, - Кроме того, вызывает функциональный класс (строка № 18, 19).
- И, следовательно, оценивается как
Object - Впоследствии есть проверки на число, строку и логическое значение, даже не проверка на Null
Возможно, это одна из причин, по которой первая версия JavaScript была завершена за 10 дней. Позже, продолжал жить с этой проблемой, а не исправлять из-за ее тесно связанной логики в исходном исходном коде. Исправление может привести к поломке многих вещей в коде.

Работа с Null и Undefined
Начиная с ES2020, у нас есть лучший способ обработки значений Nullish в Javascript. Для текущих проектов того же можно добиться с помощью Babel.js и/или Typescript.
- Необязательная цепочка (?.)
Также известен как безопасная оценка или оператор безопасности.
Длинные цепочки обращений к свойствам в Javascript приводят к ошибкам, вызывающим сбои, поскольку можно получить null или undefined (“nullish” values). Проверка наличия свойства в глубоко вложенной структуре — утомительная задача, например, рассмотрим ответ API погоды,

Чтобы получить данные о значении «Гроза», используются три подхода:

Теперь из ES2020 или TypeScript 3.7 или @babel/plugin-proposal-optional-chaining поддерживает необязательную цепочку, где можно написать так:

- Нулевое объединение (??)
Оператор Nullish Coalescing (??) действует очень похоже на оператор ||, за исключением того, что мы используем не ложные значения, а nullish, что означает, что значение строго равно null или undefined.
Поддерживается с ES2020, Typescript 3.7 и @babel/plugin-proposal-nullish-coalescing-operator
Избегайте Null всеми возможными способами
Шаблон NullObject
❌ НЕПРАВИЛЬНО

✅ ВПРАВО, Шаблон NullObject

Заключительные слова
(любезно предоставлено: Максмиллиано Контьери)
Программисты используют Null как разные флаги. Он может намекать на отсутствие, неопределенность, значение, ошибку или ложное значение (значение “Nullish”). Множественная семантика приводит к ошибкам связывания.
Проблемы
- Связь между вызывающими и отправляющими
- Несоответствие между вызывающими и отправляющими
- Если/переключатель/случай загрязняет окружающую среду
- Null не полиморфен реальным объектам, поэтому
NullPointerException(TypeError: null or undefined has no properties) - Null не существует в реальном мире. Таким образом, нарушается принцип биекции
Решения
- Избегайте нуля
- Использовать Шаблон нулевого объекта
- Используйте необязательно
Исключения
- API, базы данных, внешние системы, где существует NULL
Поддержка Линтера
Добавьте no-null и no-undef к вашему .eslintrc
Звук Нулевая Безопасность
В современных языках введена Sound Null Safetyили иначе известная как Void Safety для более безопасного и удобного кода, что означает, что по умолчанию язык предполагает, что переменные являются ненулевыми значениями, если явно не указано иное. .
Когда вы выбираете нулевую безопасность, типы в вашем коде не могут быть нулевыми по умолчанию, а это означает, что значения не могут быть нулевыми, если только вы не скажете, что они могут быть такими. При нулевой безопасности ваша среда выполнения ошибки нулевого разыменования превращаются в ошибки анализа времени редактирования.
Например, Dart, Swift и другие следуют Sound Null Safety.

использованная литература
UPDATE: интересно продолжение этой статьи? Читайте: “Контракты vs. Монады?”.
Вступление
В моих черновиках уже больше года лежит статья, в которой я хотел рассказать о проблеме разыменовывания пустых ссылок (null reference dereferencing), с подходами в разных языках и платформах. Но поскольку у меня все никак не доходили руки, а в комментариях к прошлой статье («Интервью с Бертраном Мейером») была затронута эта тема в контексте языка C#, то я решил к ней все-таки вернуться. Пусть получилось не столь фундаментально как я хотел изначально, но букв и так получилось довольно много.
Ошибка на миллиард долларов?
В марте 2009-го года сэр Тони Хоар (C.A.R. Hoare) выступил на конференции Qcon в Лондоне с докладом на тему «Нулевые ссылки: ошибка на миллиард долларов» (Null References: The Billion Dollar Mistake), в котором признался, что считает изобретение нулевых указателей одной из главных своих ошибок, стоившей индустрии миллиарды долларов.
“Я называю это своей ошибкой на миллиард долларов. Речь идет о изобретении нулевых ссылок (null reference) в 1965 году. В то время, я проектировал комплексную систему типов для ссылок в объекто-ориентированном языке программирования ALGOL W. Я хотел гарантировать, что любое использование всех ссылок будет абсолютно безопасным, с автоматической проверкой этого компилятором. Но я не смог устоять перед соблазном добавить нулевую ссылку (null reference), поскольку реализовать это было столь легко. Это решение привело к бесчисленному количеству ошибок, дыр в безопасности и падений систем, что привело, наверное, к миллиардным убыткам за последние 40 лет. В последнее время, ряд анализаторов, таких как PREfix и PREfast корпорации Microsoft были использованы для проверки валидности ссылок и выдачи предупреждений в случае, если они могли быть равными null. Совсем недавно появился ряд языков программирования, таких как Spec# с поддержкой ненулевых ссылок (non-null references). Это именно то решение, которое я отверг в 1965-м.”
Сегодня уже поздно говорить, чтоб бы было, если бы Хоар когда-то принял иное решение и более разумно посмотреть, как эти проблемы решаются в разных языках и, в частности, в языке C#.
Void Safety в Eiffel (с примерами на C#)
Одним из первых на выступление Тони Хоара отреагировал Бертран Мейер, гуру ООП и автор языка Eiffel. Предложенное Мейером решение заключается в разделении переменных всех ссылочных типов на две категории: на переменные, допускающие null (nullable references или detach references в терминах Eiffel) и на переменные, не допускающие null (not-nullable references или attach references в терминах Eiffel).
При этом по умолчанию, все переменные стали относится именно к non-nullable категории! Причина такого решения в том, что на самом деле, в подавляющем большинстве случаев нам нужны именно non-nullable ссылки, а nullable-ссылки являются исключением.
С таким разделением компилятор Eiffel может помочь программисту в обеспечении «Void Safety»: он свободно позволяет обращаться к любым членам not-nullable ссылок и требует определенного «обряда» для потенциально «нулевых» ссылок. Для этого используется несколько паттернов и синтаксических конструкций, но идея, думаю, понятна. Если переменная может быть null, то для вызова метода x.Foo() вначале требуется проверить, что x != null.
При этом, чтобы решить проблему с многопоточностью (дабы избавиться от гонок), вводится специальная синтаксическая конструкция, следующего вида:
if attached t as l then
l.f — здесь обеспечивается Void safety.
end
Если провести параллель между языком Eiffel и C#, то выглядело бы это примерно так. Все переменные ссылочного типа превратились бы в not-nullable переменные, что требовало бы их инициализации в месте объявления валидным (not null) объектом. А доступ к любым nullable переменным требовал бы какой-то магии:
// Где-то в идеальном мире
// s – not-nullable переменная
public void Foo(string s)
{
// Никакие проверки, контркты, атрибуты не нужны
Console.WriteLine(s.Length);
}
// str – nullable (detached) переменная.
//string! аналогичен типу Option<string>
public void Boo(string! str)
{
// Ошибка компиляции!
// Нельзя обращаться к членам "detached" строки!
// Console.WriteLine(str.Length);
str.IfAttached((string s) => Console.WriteLine(s));
// Или
if (str != null)
Console.WriteLine(str.Length);
}
public void Doo(string! str)
{
Contract.Requires(str != null);
// Наличие предусловия позволяет безопасным образом
// обращаться к объекте string через ссылку str!
Console.WriteLine(str.Length);
}
Такие изменения в языке, а также в стандартной библиотеке Eiffel позволили гарантировать отсутствие разыменовывания нулевых ссылок. Но даже с небольшим комьюнити, для внедрения этих изменений потребовалось несколько лет. Поэтому неудивительно, что нам не стоит ждать аналогичных изменений в таком языке как C#.
Более того, реалии таковы, что нам вряд ли стоит ждать появления not-nullable ссылочных типов (о чем не так давно поведал Эрик Липперт в своей статье «C#: Non-nullable Reference Types»), поэтому нам приходится изобретать различного вида велосипеды. Но прежде чем переходить к этим самым велосипедам, интересно посмотреть на подход другого языка платформы .NET – F#.
ПРИМЕЧАНИЕ
Подробнее о Void Safety в Eiffel можно почитать в статье Бертрана Мейера «Avoid a Void: The eradication of null dereferencing», а также в замечательной статье Жени Охотникова «Void safety в языке Eiffel».
Void Safety в F#
Большинство функциональных языков программирования (включая F#) решают проблему разыменовывания нулевых ссылок уже довольно давно, причем способом аналогичным рассмотренному ранее. Так, типы, объявленные в F# по умолчанию не могут быть null (нужно использовать специальный атрибут AllowNullLiteral, да и в этом случае это возможно не всегда). В F# разрешается использование литерала null, но лишь для взаимодействия со сторонним кодом, не столь продвинутым в вопросах Void Safety, написанном на таких языках как C# или VB (хотя и в этом случае иногда могут быть проблемы, см. «F# null trick»).
Для указания «отсутствующего» значения в F# вместо null принято использовать специальный тип – Option<T>. Это позволяет четко указать в сигнатуре метода, когда ожидается nullable аргумент или результат, а когда результат не должен быть null:
// Результат не может быть null
let findRecord (id: int) : Record =
...
// Результат тоже не может быть null,
// но результат завернут в Option<Record> и может отсутствовать
let tryFindRecord (id: int) : Option<Record> =
...
Так, в первом случае возвращаемое значение обязательно (и при его отсутствии будет сгенерировано исключение), а во втором случае результат может отсутствовать.
ПРИМЕЧАНИЕ
Именно этой идиоме следует стандартная библиотека F#. Так, вместо пары методов из LINQ: Single/SingleOrDefault в F# используются методы find/tryFind модулей Seq, List и других.
Поскольку «необязательные» значения может участвовать в целой цепочке событий, любой функциональный язык программирования поддерживает специальный «паттерн», который позволяет «протаскивать» значение через некоторую цепочку операций. Данный паттерн носит название «монада» и является фундаментальным в некоторых функциональных языках программирования. Я не хочу останавливаться на абстрактном описании, поскольку для этого уже есть ряд отличных источников (см. дополнительные источники в конце статьи).
Идея же достаточно простая: нам нужен простой способ работать с «завернутыми» значениями, такими как Option<T>, аналогично тому, как бы мы работали с самим типом T напрямую. Проще всего это показать на примере:
Предположим, у нас есть цепочка операций:
- Попытаться найти сотрудника (tryFindEmployee), если он найден, то
- взять свойство Department, если свойство не пустое, то
- взять свойство BaseSalary, если свойство не пустое, то
- вычислить размер заработной платы (computeSalary).
- если один из этапов возвращает не содержит результата (None в случае F#), то результат должен отсутствовать (должен быть равен None), в противном случае мы получим вычисленный результат.
Это можно сделать большим набором if-ов, а можно использовать Option.bind:
let salary =
tryFindEmployee 42
|> Option.bind(fun e -> e.Department)
|> Option.bind(fun d -> d.BaseSalary)
|> Option.bind computeSalary
Основная идея метода bind очень простая: если Option<T> содержит значение, тогда метод bind вызывает переданный делегат с «распакованным» значением, в противном случае – просто возвращается None (отсутствие значение в типе Option). При этом делегат, переданный в метод Bind также может вернуть значение, завернутое в Option или None, если значение не получено. Такой подход позволяет легко создавать цепочки операций, не заморачиваясь кучей проверок на null на каждом этапе.
Void Safety в C#
Поскольку популярность функциональных языков существенно возросла, то не удивительно, что многие паттерны функционального программирования начали перекачивать в такие исходно объектно-ориентированные языки, как C# (авторы C# серьезно думают о добавлении в одной из новых версий Pattern Matching-а!). Поэтому не удивительно, что для решения проблемы «нулевых ссылок» очень часто начали использоваться идиомы, заимствованные из функциональных языков.
«Монада» Maybe
Одна из причин появления этой статьи заключается в попытке выяснить, насколько полезно/разумно использовать тип Maybe<T> (аналогичный типу Option<T> из F#) в языке C#. В комментариях к предыдущей заметке было высказано мнение о пользе этого подхода, но хотелось бы рассмотреть «за» и «против» более подробно.
> Используйте монадки, и не нужно париться с null. Накладывайте рестрикшен через тип.
Действительно, строгая типизация и выражение намерений через систему типов – это лучший способ для разработчика передать свои намерения. Так, не зная существующих идиом платформы .NET, очень сложно понять, в чем же разница между методами First и FirstOrDefault в LINQ, или как понять, что будет делать метод GetEmployeeById в случае отсутствия данных по сотруднику: вернет null или сгенерирует исключение? В первом случае суффикс «Default» намекает, что в случае отсутствия элемента мы получим «значение по умолчанию» (т.е. null), но что будет во втором случае – не ясно.
В этом плане подход, принятый в F# выглядит намного более приятным, ведь там методы отличаются не только именем, но и возвращаемым значением: метод find возвращает T, а tryFind возвращает Option<T>. Так почему бы не пользоваться этой же идиомой в языке C#?
Главная причина, останавливающая от повсеместного использования Option<T> в C# заключается в отсутствии повсеместного использования Option<T> в C#. Звучт бредово, но все так и есть: использование Option<T> не является стандартной идиомой для библиотек на языке C#, а значит использование своего «велосипедного» Option<T> не принесет существенной пользы.
Теперь стоит понять, а стоит ли овчинка выделки и будет ли полезным использование Option<T> лишь в своем проекте.
Обеспечивает ли Maybe<T> Void Safety?
Особенность использования Maybe заключается в том, что это лишь смягчает, но не решает полностью проблему «разыменовывания нулевых указателей». Проблема в том, что нам все равно нужен способ сказать в коде, что данная переменная типа Maybe<T> должна содержать значение в определенный момент времени. Нам не только нужен безопасный способ обработать оба возможных варианта значения переменной Maybe, но и сказать о том, что один из них в данный момент не возможен.
Давайте рассмотрим такой пример. При реализации «R# Contract Extensions» мне понадобился класс для добавления предусловий/постусловий в абстрактные методы, и методы интерфейсов. Для тех, кто не очень в курсе библиотеки Code Contracts, контракты для абстрактных методов и интерфейсов задаются отдельным классом, который помечается специальным атрибутом – ContractClassFor:
[ContractClass(typeof (AbstractClassContract))]
public abstract class AbstractClass
{
public abstract void Foo(string str);
}
// Отдельный класс с контрактами абстрактного класса
[ContractClassFor(typeof (AbstractClass))]
abstract class AbstractClassContract : AbstractClass
{
public override void Foo(string str)
{
Contract.Requires(str != null);
throw new System.NotImplementedException();
}
}
Процесс добавления контракта для абстрактного метода AbstractClass.Foo такой:
- Получить «контрактный метод» текущего метода (в нашем случае нужно найти «дескриптор» метода AbstractClassContract.Foo).
- Если такого метода еще нет (или нет класса AbstractClassContract), сгенерировать класс контракта с этим методом.
- Получить «контрактный метод» снова (теперь мы точно должны получить «дескриптор» метода AbstractClassContract.Foo).
- Добавить предусловие/постусловие в «контрактный метод».
В результате метод добавления предусловия для абстрактного метод выглядит так (см. ComboRequiresContextAction метод ExecutePsiTransaction):
var contractFunction = GetContractFunction();
if (contractFunction == null)
{
AddContractClass();
contractFunction = GetContractFunction();
Contract.Assert(contractFunction != null);
}
...
[CanBeNull, System.Diagnostics.Contracts.Pure]
private ICSharpFunctionDeclaration GetContractFunction()
{
return _availability.SelectedFunction.GetContractFunction();
}
Метод GetContractFunction возвращает метод класса-контракта для абстрактного класса или интерфейса (в нашем примере, для метода AbstractClass.Foo этот метод вернет AbstractClassContract.Foo, если контрактный класс существует, или null, если класса-контракта еще нет).
Как бы изменился этот метод, если бы я использовал Maybe<T> или Option<T>? Я бы убрал атрибут CanBeNull и поменял тип возвращаемого значения. Но вопрос в том, как бы использование Maybe мне помогло бы выразить, что «постусловие» этого закрытого метода меняется в зависимости от контекста? Так, при первом вызове этого метода вполне нормально, что контрактного метода еще нет и возвращаемое значение равно null (или None, в случае «монадического» решения). Однако после вызова AddContractClass (т.е. после добавления класса-контракта) возвращаемое значение точно должно быть и метод GetContractFunction обязательно должен вернуть «непустое» значение! Я никак не могу отразить это в системе типов языка C# или F#, поскольку лишь я знаю ожидаемое поведение. (Напомню, что контракты выступают в роли спецификации и задают ожидаемое поведение, отклонение от которого означает наличие багов в реализации. Так и в этом случае, если второй вызов GetContractFunction вернул null, то это значит, что в консерватории что-то сломалось и нужно лезть в код и его чинить).
Этим маленьким примером я хотел показать, что не все проблемы с разыменовыванием нулевых указателей можно решить с помощью класса Maybe, а контракты и аннотации (такие как CanBeNull) вполне может поднять «описательность» методов не меняя тип возвращаемого значения.
Использование «неявной» монады Maybe
Как уже было сказано выше, польза от Maybe будет лишь в том случае, если он будет использован всеми типами приложения. Это значит, что если ваш метод TryFind возвращает Maybe<Person>, то нужно, чтобы все «nullable» свойства класса Person тоже возвращали Maybe<T>.
Добиться повсеместного использования Maybe в любом серьезном приложении, написанном на C#, весьма проблематично, поскольку все равно останется масса «внешнего» кода, который не знает об этой идиоме. Так почему бы не воспользоваться этой же идеей, но без «заворачивания» всех типов в Maybe<T>?
Так, класс Maybe<T> (или Option<T>) является своего рода оболочкой вокруг некоторого значения, со вспомогательным методом Bind (название метода является стандартным для паттерна монада), который «разворачивает коверт» и достает из него реальное значение и передает для обработки. При этом становится очень легко строить pipe line, который мы видели в разделе, посвященном языку F#.
Но почему бы не рассматривать любую ссылку, как некую «оболочку» вокруг объекта, для которого мы добавим метод расширения с тем же смыслом, что и метод Bind класса Option? В результате, мы создадим метод, который будет «разворачивать» нашу ссылку и вызывать метод Bind (который мы переименуем в With) лишь тогда, когда текущее значение не равно null:
public static U With<T, U>(this T callSite, Func<T, U> selector) where T : class
{
Contract.Requires(selector != null);
if (callSite == null)
return default(U);
return selector(callSite);
}
В этом случае, мы сможем использовать достаточно компактный синтаксис для обхода целого дерева, каждый узел которого может вернут null. И тогда, если все «узлы» этого дерева будут не null, мы получим непустой результат, если же на одном из этапов, значение будет отсутствовать, то результат всего выражения будет null.
С методом With наш пример, рассмотренный в предыдущем разделе будет выглядеть так:
var salary = Repository.GetEmployee(42)
.With(employee => employee.Department)
.With(department => department.BaseSalary)
.With(baseSalary => ComputeSalary(baseSalary));
В некоторых случаях такой простой «велосипед» может в разы сократить размер кода и здорово улучшить читабельность, особенно при работе с «глубокими» графами объектов, большинство узлов которого может содержать null. Примером такого «глубокого» графа является API Roslyn-а, а также ReSharper SDK. Именно поэтому в своем плагине для ReSharper-а я очень часто использую подобный код:
[CanBeNull]
public static IClrTypeName GetCallSiteType(this IInvocationExpression invocationExpression)
{
Contract.Requires(invocationExpression != null);
var type = invocationExpression
.With(x => x.InvokedExpression)
.With(x => x as IReferenceExpression)
.With(x => x.Reference)
.With(x => x.Resolve())
.With(x => x.DeclaredElement)
.With(x => x as IClrDeclaredElement)
.With(x => x.GetContainingType())
.Return(x => x.GetClrName());
return type;
}
Данный тип «расковыривает» выражение вызова метода и достает тип, на котором этот вызов происходит. При этом может возникнуть вопрос с отладкой, когда результат равен null и не понятно, что же конкретно пошло не так:

В этом плане очень полезна новая фича в VS2013 под названием Autos, которая показывает, на каком из этапов мы получили null:

(В данном случае мы видим, что Resolve вернул не нулевой элемент, но DeclaredElement этого значения равен null.)
Null propagating operator ?. в C# 6.0
Поскольку проблема обработки сложных графов объектов с потенциально отсутствующими значениями, столь распространена, разработчики C# решили добавить в C# 6.0 специальный синтаксис в виде оператора «?.» (null propagating operator). Основная его идея аналогична методу Bind класса Option<T> и приведенному выше методу расширения With.
Следующие три примера эквивалентны:
var customerName1 = GetCustomer() ?.Name;
var customerName2 = GetCustomer().With(x => x.Name);
var tempCustomer = GetCustomer();
string customerName3 = tempCustomer != null ? tempCustomer.Name : null;
ПРИМЕЧАНИЕ
Null propagating operator не может заменить приведенные ранее методы расширения With, поскольку справа от оператора ?. может быть лишь обращение к членам текущего объекта, а произвольное выражения использовать нельзя.
Так, в случае с With мы можем сделать следующее:
var result = GetCustomer().With(x => x.Name).With(x => string.Intern(x));
В случае с “?.” нам все же понадобится временная переменная.
Заключение
Так как же можно обеспечить Void Safety в языке C#? Обеспечить полностью? Никак. Если же мы хотим уменьшить эту проблему к минимуму, то тут есть варианты.
Мне правда нравится идея явного использования типа Maybe (или Option) для получения более декларативного дизайна, но меня напрягает неуниверсальность этого подхода: для собственного кода этот подход работает «на ура», но все равно будет непоследовательным, поскольку сторонний код этой идиомой не пользуется.
Для обработки сложных графов объектов мне нравится подход с методами расширения типа With/Return для ссылочных типов + контракты для декларативного описания наличия или отсутствия значения. Мне вообще кажется, что аннотации типа CanBeNull + контракты с соответствующей поддержкой со стороны среды разработки (как в плане редактирования, так и просмотра) могут существенно упростить понимание кода и проблема сейчас именно в отсутствии такой поддержки.
После выхода C# 6.0 и появления оператора “?.” в ряде случаев можно будет отказаться от методов расширения With/Return, но иногда такие велосипеды все равно будут нужны из-за ограничений оператора “?.”.
К сожалению, без полноценных not-nullable типов обеспечить Void Safety полностью просто невозможно. Поэтому сейчас нам остается использовать разные велосипеды и надеяться на усовершенствование средств разработки, которые упростят работу с контрактами и nullable-типами.
Дополнительные ссылки
- Интервью с Бертраном Мейером
- Null Reference: The Billion Dollar Mistake – выступление Тони Хоара на QCon 2009
- Bertrand Meyer. Avoid a Void: The eradication of null dereferencing – отличная статья Мейера о Void Safety в Eiffel.
- Евгений Охотников. Void safety в языке Eiffel – описание Void Safety в Eiffel на русском языке.
- Eric Lippert. «C#: Non-nullable Reference Types» – сказ о том, почему нам не стоит ждать nullable reference типов в языке C#.
- Functors, applicatives, and monads in pictures – отличная статья с графическим объяснением, что такое монада.
- Eric Lippert. Monads, part one – первая статья отличной серии постов Эрика Липперта о монадах. Одно из лучших описаний для C# разработчика
- F# for fun and profit: The “Computation Expressions” series – цикл статей о Computation Expressions в F#. Не о монадах напрямую, но это все равно лучшее описание принципов, которые лежат в основе монад. Если имеете представление об F#, то эта серия – лучший способ разобраться в монадах.
- Обсуждение null propagating operator на roslyn.codeplex.com
- R# Contract Extension – R# плагин для упрощения работы с контрактами
- Thinking Functionally in C# with monads.net
З.Ы. Понравился пост? Поделись с друзьями! Вам не сложно, а мне приятно;)
[Обновление 2015-10-31] Дополнительная трансляция, измененная из StackOverflowПочтовыйПараграф:
Чашка! В нашей компании фамилия сотрудника Null.При использовании его фамилии в качестве термина запроса все приложения запросов сотрудников вылетали из строя! Что я должен делать?
В 1965 году кто-то допустил худшую ошибку в области информатики. Ошибка уродливее, чем обратная косая черта в Windows, более странная, чем ===, более распространенная, чем PHP, более неудачная, чем CORS, и более тревожная, чем дженерики Java. XMLHttpRequest, более сложный для понимания, чем препроцессор C, более подверженный фрагментации, чем MongoDB, и более прискорбный, чем UTF-16.
«Я называю нулевую ссылку своей ошибкой на миллиард долларов. Она была изобретена в 1965 году, когда я разработал первую всеобъемлющую систему ссылочных типов на объектно-ориентированном языке (АЛГОЛ W). Моя цель — гарантировать, что использование всех ссылок абсолютно безопасно, компилятор проверит автоматически. Но я не смог устоять перед соблазном добавить нулевые ссылки только потому, что это очень легко реализовать. Это вызвало бесчисленное количество ошибок, уязвимостей и систем. Авария могла привести к убыткам в миллиарды долларов в следующий раз. 40 лет. В последние годы люди начали использовать различные программы анализа программ, такие как Microsoft PREfix и PREfast, чтобы проверять ссылки и предупреждать, если существует риск ненулевого значения. Новые языки программирования, такие как Spec #, имеют ввел объявление ненулевых ссылок. Это решение, которое я отверг в 1965 году »-« Нулевые ссылки: ошибка на миллиард долларов »Тони Хоар, лауреат премии Тьюринга
В ознаменование 50-летия нулевой ошибки мистера Хора в этой статье объясняется, что такое null, почему это так ужасно и как этого избежать.
Проще говоря: NULL — это значение, которое не является значением. Вот и проблема.
Эта проблема усугубилась в самом популярном языке всех времен, и теперь у него много имен: NULL, nil, null, None, Nothing, Nil и nullptr. У каждого языка есть свои нюансы.
Некоторые из проблем, вызванных NULL, связаны только с конкретным языком, в то время как другие универсальны; некоторые — просто разные аспекты проблемы.
NULL…
- Тип Subversion
- Это грязно
- Это особый случай
- Сделать API хуже
- Сделать неправильные языковые решения хуже
- Сложно отлаживать
- Не сочетается
1. Тип подрывной деятельности NULL
Статически типизированные языки могут проверять использование типов в программе без фактического выполнения программы и обеспечивать определенные гарантии поведения программы.
Например, в Java, если я напишуx.toUppercase(), Компилятор проверитx тип. в случае x Является String, То проверка типа прошла успешно; еслиx Является Socket, Тогда проверка типа не удалась.
При написании большого и сложного программного обеспечения статическая проверка типов является мощным инструментом. Но для Java эти отличные проверки во время компиляции имеют фатальный недостаток: любая ссылка может быть нулевой, а вызов метода нулевого объекта приведет кNullPointerException. и так,
toUppercase()Может быть произвольноStringВызов объекта. Пока неStringНулевой.read()Может быть произвольноInputStreamВызов объекта. Пока неInputStreamНулевой.toString()Может быть произвольноObjectВызов объекта. Пока неObjectНулевой.
Java — не единственный язык, вызывающий эту проблему; многие другие системы типов имеют те же недостатки, включая, конечно, язык AGOL W.
В этих языках NULL выходит за рамки проверки типов. Он незаметно превзошел проверку типа, дождался времени выполнения и, наконец, выпустил сразу большое количество ошибок. NULL — это ничто, и в то же время это ничто.
2. NULL беспорядочный
Во многих случаях null не имеет смысла. К сожалению, если язык позволяет чему-либо быть нулевым, ну, тогда все может быть нулевым.
Программисты на Java пишут о риске синдрома запястного канала
|
if (str == null || str.equals(«»)) { } |
И добавляем в C #String.IsNullOrEmptyОбычная грамматика
|
if (string.IsNullOrEmpty(str)) { } |
Черт!
Каждый раз, когда вы пишете код, который путает пустые строки с пустыми строками, команда Guava плачет. -Google Guava
хорошо сказано. Но когда ваша система типов (например, Java или C #) допускает NULL везде, вы не можете надежно исключить возможность NULL и неизбежно где-то запутаетесь.
Возможность нулевого повсюду вызвала такую проблему, добавлена Java 8@NonNullМарк, попробуй ретроспективно устранить этот дефект в системе его типов.
3. NULL — это особый случай.
Учитывая, что NULL не является значением, но также играет роль значения, NULL, естественно, становится предметом различных специальных методов обработки.
указатель
Например, рассмотрим следующий код C ++:
|
char c = ‘A’; char *myChar = &c; std::cout << *myChar << std::endl; |
myChar Является char *, Что означает, что это указатель, то есть сохранить адрес памяти вcharв. Компилятор это проверит. Следовательно, следующий код недействителен:
|
char *myChar = 123; // compile error std::cout << *myChar << std::endl; |
Потому что123Нет гарантии, что это одинchar, Итак, компиляция не удалась. В любом случае, если поменять номер на0(0 является NULL в C ++), тогда его можно скомпилировать с помощью:
|
char *myChar = 0; std::cout << *myChar << std::endl; // runtime error |
с 123То же самое, NULL на самом деле неcharадрес. Но на этот раз компилятор все еще позволяет его компилировать, потому что0(NULL) — особый случай.
Нить
Есть еще один особый случай, который встречается в символьной строке, оканчивающейся на NULL в языке C. Это немного отличается от других примеров, потому что здесь нет указателей или ссылок. Однако идея о том, что это не ценность, а также играет роль ценности, все еще существует, здесь нетcharНо это играетcharСуществуют в виде.
Строка C представляет собой последовательность байтов и заканчивается байтом NUL (0).
Следовательно, каждый символ строки C может быть любым из 256 байтов, кроме 0 (то есть символа NUL). Это не только делает длину строки линейной операцией времени; что еще хуже, это означает, что строки C не могут использоваться в ASCII или расширенном ASCII. Вместо этого они могут использоваться только для ASCIIZ, который обычно не используется.
Исключение одного символа NUL вызвало бесчисленное количество ошибок: странное поведение API, уязвимости безопасности и переполнение буфера.
NULL — это наихудшая ошибка в строках C; точнее, строка, заканчивающаяся на NUL, являетсяСамый дорогойОдин байтошибка。
4. NULL делает API плохим
В следующем примере мы отправимся в путешествие в царство динамически типизированных языков, где NULL еще раз докажет, что это ужасная ошибка.
Хранилище ключей и значений
Предположим, мы создаем класс Ruby, который будет действовать как хранилище значений ключей. Это может быть кеш, интерфейс для базы данных ключ-значение и т. Д. Создадим простой и универсальный API:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class Store ## # associate key with value # def set(key, value) ... end ## # get value associated with key, or return nil if there is no such key # def get(key) ... end end |
Мы можем представить подобные классы на многих языках (Python, JavaScript, Java, C # и т. Д.).
Теперь предположим, что наша программа имеет медленный или ресурсоемкий метод поиска чьего-либо номера телефона — возможно, путем подключения к сетевой службе.
Чтобы повысить производительность, мы будем использовать локальное хранилище в качестве кеша для сопоставления имени человека с его номером телефона.
|
store = Store.new() store.set(‘Bob’, ‘801-555-5555’) store.get(‘Bob’) # returns ‘801-555-5555’, which is Bob’s number store.get(‘Alice’) # returns nil, since it does not have Alice |
Однако у некоторых людей нет номера телефона (т.е. их номер телефона равен нулю). Мы по-прежнему будем кэшировать эту информацию, поэтому нам не нужно ее пополнять позже.
|
store = Store.new() store.set(‘Ted’, nil) # Ted has no phone number store.get(‘Ted’) # returns nil, since Ted does not have a phone number |
Но теперь это означает, что наши результаты неоднозначны! Это может означать:
- Этого человека нет в кеше (Алиса)
- Этот человек существует в кеше, но у него нет номера телефона (Том)
Одна ситуация требует дорогостоящего перерасчета, другая требует немедленного реагирования. Но наш код недостаточно сложен, чтобы различать эти два случая.
В реальном коде подобные ситуации часто возникают сложным и незаметным образом. Следовательно, простой и универсальный API может сразу стать особым случаем, сбивая с толку источник беспорядочного поведения с нулевым значением.
Используйте одинcontains()Способ ремонтаStoreКласс может быть полезным. Но это вводит повторные поиски, что приводит к снижению производительности и условиям гонки.
Двойные неприятности
У JavaScript такая же проблема, но она возникает вКаждый объект。
Если атрибуты объекта не существуют, JS вернет значение, указывающее, что у объекта отсутствуют атрибуты. Разработчики JavaScript выбрали это значение равным нулю.
Они беспокоятся о том, когда свойство существует и для него установлено значение null. «Талант» в том, что JavaScript добавляет undefined, чтобы отличать свойства с нулевыми значениями от несуществующих свойств.
Но что, если свойство существует и его значение не определено? Странно то, что JavaScript остановился на этом и не предоставил «super undefined».
JavaScript предлагает не только одну, но и две формы NULL.
5. NULL ухудшает неправильные языковые решения
Java незаметно преобразует ссылки в основные типы. Добавление null делает ситуацию еще более странной.
Например, следующий код не компилируется:
|
int x = null; // compile error |
Этот код компилируется и передается:
|
Integer i = null; int x = i; // runtime error |
Хотя он сообщит, когда код запускаетсяNullPointerException ошибка.
Обращение к нулевому методу члена достаточно плохо; еще хуже, если вы никогда не видели вызываемый метод.
6. NULL сложно отлаживать.
Чтобы объяснить, насколько проблематичным является NULL, хорошим примером является C ++. Вызов функции-члена для указания на NULL-указатель не обязательно приводит к сбою программы. Хуже того: этомайПриведет к сбою программы.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#include <iostream> struct Foo { int x; void bar() { std::cout << «La la la» << std::endl; } void baz() { std::cout << x << std::endl; } }; int main() { Foo *foo = NULL; foo->bar(); // okay foo->baz(); // crash } |
Когда я использую gcc для компиляции приведенного выше кода, первый вызов выполняется успешно, а второй — нет.
Почему?foo->bar()Это известно во время компиляции, поэтому компилятор избегает поиска в виртуальной таблице во время выполнения и преобразует его в статический вызов, аналогичныйFoo_bar(foo), Возьмите это как первый параметр. Потому чтоbarНет косвенной ссылки на указатель NULL, поэтому он работает успешно. НоbazИмеется ссылка на указатель NULL, который вызывает segfault.
Но мы будемbarСтаньте виртуальной функцией. Это означает, что его реализация может быть отменена подклассом.
|
... virtual void bar() { ... |
В качестве виртуальной функцииfoo->bar()ЯвляетсяfooВыполните поиск в виртуальной таблице для типа среды выполнения, чтобы предотвратитьbar()Был переписан. Потому чтоfooИмеет значение NULL, текущая программа будетfoo->bar()Это предложение рухнуло, потому что мы превратили функцию в виртуальную.
|
int main() { Foo *foo = NULL; foo->bar(); // crash foo->baz(); } |
NULL сделалmainДля программистов функций отладка этого кода становится очень сложной и неинтуитивной.
Действительно, ссылка на NULL не определена в стандарте C ++, поэтому технически мы не должнылюбая ситуацияУдивлен. Кроме того, это непатологический, распространенный, очень простой и реальный пример.Этот пример является одним из многих примеров, когда NULL на практике непостоянен.
7. NULL нельзя комбинировать
Языки программирования построены на возможности компоновки: способности применять одну абстракцию к другой. Это может быть наиболее важной особенностью любого языка, библиотеки, фреймворка, модели, API или шаблона проектирования: возможность использовать другие функции ортогонально.
Фактически, компоновка — действительно основная проблема, стоящая за многими из этих проблем. Например,StoreНет возможности компоновки между API, возвращающим nil несуществующему значению, и сохранением nil для несуществующего телефонного номера.
Для C #NullableЧтобы разобраться с некоторыми проблемами, связанными с NULL. Вы можете включить в тип необязательность (пустоту).
|
int a = 1; // integer int? b = 2; // optional integer that exists int? c = null; // optional integer that does not exist |
Но это вызвало серьезный недостаток, то естьNullableНе применимо ни к какомуT. Применяется только к непустымT. Например, это не сделаетStoreПроблема исправлена любым способом.
- Прежде всего
stringМожет быть пустым; вы не можете создать непустойstring - Даже если
stringНе пусто, поэтому создайтеstring? Может быть, но все равно нельзя исключить неоднозначность нынешней ситуации. Нетstring??
решение
NULL стало настолько распространенным явлением, что многие думают, что это необходимо. NULL присутствует во многих языках низкого и высокого уровня в течение долгого времени и кажется важным, как целочисленная арифметика или ввод-вывод.
не так! У вас может быть полный язык программирования без NULL. Проблема с NULL — это нечисловое значение, дозорный, особый случай, который концентрируется на всем остальном.
Вместо этого нам нужно, чтобы сущность содержала некоторую информацию о (1) содержит ли она значение и (2) содержащееся значение, если есть содержащееся значение. И эта сущность должна уметь «содержать» любой тип. Это идея Haskell’s Maybe, Java’s Optional, Swift’s Optional и т. Д.
Например, в ScalaSome[T]Сохранить одинTЗначение типа.NoneНет никакой ценности. Оба этиOption[T]Подтипы этих двух подтипов могут иметь значение или не иметь значения.
Читатели, не знакомые с Maybes / Options, могут подумать, что мы заменили одну форму (NULL) другой формой (None). Но есть одно отличие — обнаружить его непросто, но оно очень важно.
В языке со статической типизацией нельзя обойти систему типов, заменив любое значение None. Ничего нельзя использовать только там, где мы ожидаем появления опции. Необязательность явно выражена в типе.
В динамически типизированном языке вы не можете спутать использование Maybes / Options с содержащимися значениями.
Вернемся к предыдущемуStore, Но на этот раз можно использовать рубин. Если есть значение, тоStoreКласс возвращается со значениемSome, В противном случае вернутьNone. Для телефонных номеровSomeЭто номер телефона,NoneУказывает на отсутствие номера телефона. Так что естьДва уровня присутствия / отсутствия:Внешний MaybeУказывает, что он существует вStoreВ; внутреннийMaybeУказывает номер телефона, соответствующий этому имени. Мы успешно объединили несколькоMaybe, Это то, что мы не можем сделать с nil.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
cache = Store.new() cache.set(‘Bob’, Some(‘801-555-5555’)) cache.set(‘Tom’, None()) bob_phone = cache.get(‘Bob’) bob_phone.is_some # true, Bob is in cache bob_phone.get.is_some # true, Bob has a phone number bob_phone.get.get # ‘801-555-5555’ alice_phone = cache.get(‘Alice’) alice_phone.is_some # false, Alice is not in cache tom_phone = cache.get(‘Tom’) tom_phone.is_some # true, Tom is in cache tom_phone.get.is_some #false, Tom does not have a phone number |
Существенная разница в том, чтоБольше не существует союза между NULL и любым другим статически типизированным или динамически предполагаемым типом., Больше не существует объединения между существующим значением и несуществующим значением.
Используйте Maybes / Опции
Давайте продолжим обсуждение кода без NULL. Предположим, в Java 8+ у нас есть целое число, оно может существовать, а может и не существовать, и если оно существует, мы его распечатываем.
|
Optional<Integer> option = ... if (option.isPresent()) { doubled = System.out.println(option.get()); } |
Замечательно. Но большая частьMaybe/OptionalРеализация, включая Java, поддерживает более практичный метод:
|
option.ifPresent(x -> System.out.println(x)); // or option.ifPresent(System.out::println) |
Этот практический метод не только более краткий, но и более безопасный. Необходимо помнить, что если это значение не существует, тоoption.get()Произойдет ошибка. В предыдущем примереget()Получите одинifЗащита. В этом примереifPresent()Это полностью устраняет наши опасенияget()Необходимость. Это делает код явно свободным от ошибок, а не без ошибок.
Параметры можно рассматривать как набор с максимальным значением 1. Например, если есть значение, то мы можем умножить его на 2, в противном случае оставить его пустым.
При желании мы можем выполнить операцию, которая возвращает необязательное значение и стремится «сгладить» результат.
|
option.flatMap(x -> methodReturningOptional(x)) |
Если такового не существует, мы можем указать значение по умолчанию:
В целом,Maybe/OptionРеальная стоимость
- Избавьтесь от небезопасных предположений о существовании и несуществовании ценностей.
- Управляйте дополнительными данными проще и безопаснее
- Явно заявляйте о любых предположениях о небезопасном существовании (например,
.get()Метод)
Не быть NULL!
NULL — ужасный недостаток дизайна, постоянная и неизмеримая боль. Лишь немногим языкам удается избежать его ужаса.
Если вы все же выберете язык с NULL, то, по крайней мере, сознательно избегайте этой неприятности в своем собственном коде и используйте эквивалентMaybe/Option。
NULL в распространенных языках:
«Балл» определяется на основании следующих критериев:
редактировать
счет
Не относитесь слишком серьезно к «оценкам» в приведенной выше таблице. Настоящая проблема состоит в том, чтобы суммировать статус NULL на разных языках и представить альтернативы NULL, а не ранжировать часто используемые языки.
Информация на некоторых языках была изменена. По причинам совместимости во время выполнения в некоторых языках есть какие-то нулевые указатели, но они не имеют практического применения для самого языка.
- Пример: Haskell’s
Foreign.Ptr.nullPtrОн используется в FFI (интерфейсе внешних функций) для маршалинга значений в Haskell и обратно. - Пример: Swift
UnsafePointerДолжен быть сunsafeUnwrapИли же!использовать вместе. - Контрпример: Scala, несмотря на то, что обычно избегает null, по-прежнему обрабатывает null, как Java, для улучшения взаимодействия.
val x: String = null
Когда NULL ОК?
Стоит отметить, что при сокращении циклов ЦП специальное значение того же размера, например 0 или NULL, может быть очень полезным, жертвуя качеством кода на производительность. Когда это действительно важно, это удобно для низкоуровневых языков, таких как C, но на самом деле стоит оставить все как есть.
Настоящая проблема
Более распространенная проблема с NULL — это контрольные значения: эти значения такие же, как и другие значения, но имеют совершенно другое значение. Из indexOfХорошим примером является возврат индекса целого числа или целого числа -1. Другой пример — строки, оканчивающиеся на NULL. В этой статье основное внимание уделяется NULL, что придает его универсальность и реальное влияние, но так же, как Саурон — всего лишь слуга Моргота, NULL — это просто форма базовой проблемы дозорного устройства.
В мире Javascript и как с этим работать
Какие ошибки в мире программного обеспечения обходятся в миллиарды долларов?
- По словам Тони Хоара, ошибка 2000 года, класс ошибок, связанных с хранением и форматированием данных календаря, обойдется чуть менее чем в 4 миллиарда долларов.
- CodeRed Virus, компьютерный червь, внедрившийся в компании по всему миру, вывел из строя все сети. Прерывание бизнеса и всего обычного банковского дела обошлось мировой экономике в 4 миллиарда долларов.
- Null – ошибочное изобретение британского ученого-компьютерщика Тони Хоара (наиболее известного благодаря своему алгоритму быстрой сортировки) в 1964 году, который изобрел нулевые ссылки. как его «ошибка на миллиард долларов».
Кто придумал «обнулить» ошибку на миллиард долларов и почему?
Я называю это своей ошибкой на миллиард долларов. Это было изобретение нулевой ссылки в 1965 году. В то время я разрабатывал первую всеобъемлющую систему типов для ссылок в объектно-ориентированном языке (ALGOL W). Моя цель состояла в том, чтобы гарантировать, что любое использование ссылок должно быть абсолютно безопасным, с автоматической проверкой компилятором. Но я не мог устоять перед искушением добавить нулевую ссылку просто потому, что это было так легко реализовать. Это привело к бесчисленным ошибкам, уязвимостям и системным сбоям, которые, вероятно, причинили миллиарды долларов боли и ущерба за последние сорок лет. — Тони Хоар
Ссылка на нулевой указатель может быть плохой идеей. Сравнивая ссылку нулевого указателя с неразборчивым в связях прелюбодеем, он заметил, что нулевое присвоение для каждого холостяка, представленного в объектной структуре, «будет выглядеть полиаморно женатым на одном и том же человеке Null. — Эдсгар Джикстра
Что такое ошибка на миллиард долларов в контексте мира Javascript?
У нас есть два кандидата в мире Javascript, подпадающие под эту категорию:
1⃣️ Нет
Значение null записывается литералом: null. null не является идентификатором свойства глобального объекта, как может быть undefined. Вместо этого null выражает отсутствие идентификации, указывая на то, что переменная не указывает ни на какой объект. В API-интерфейсах null часто извлекается в месте, где объект можно ожидать, но объект не является релевантным.
2⃣️ Не определено
undefined — это свойство глобального объекта. То есть это переменная в глобальной области видимости. Начальное значение undefined — это примитивное значение undefined.
примитивные типы данных Javascript (ES2020),
BooleanNullUndefinedNumberStringBigIntSymbol
Null и Undefined в Javascript называются «нулевыми» (ложными) значениями.
Ложные значения:
Undefined, null, 0, NaN, empty string‘’, false
Нулевой или неопределенный
Несмотря на то, что поведение обоих значений является ложным, если кто-то думает Null vs Undefined как Declared vs Undeclared, это не совсем так!
Undefined может быть как объявленным, так и необъявленным.
А как насчет Null?
У Null есть свои проблемы, с которыми нужно разобраться… отлично! Давайте посмотрим на это,
Ну, typeof null == “object” — это ошибка 25-летней давности, начиная с первой версии Javascript.
В первой версии JavaScript значения хранились в 32-битных единицах, которые состояли из небольшого тега типа (1–3 бита) и фактических данных значения. Теги типа хранились в младших битах единиц. Их было пятеро:
000: object. Данные являются ссылкой на объект.001: int. Данные представляют собой 31-битное целое число со знаком.010: double. Данные являются ссылкой на двойное число с плавающей запятой.100: string. Данные являются ссылкой на строку.110: boolean. Данные являются логическими.
Из исходного кода jsapi.h, (ссылка)
#define JSVAL_OBJECT 0x0 /* untagged reference to object */
#define JSVAL_INT 0x1 /* tagged 31-bit integer value */
#define JSVAL_DOUBLE 0x2 /* tagged reference to double */
#define JSVAL_STRING 0x4 /* tagged reference to string */
#define JSVAL_BOOLEAN 0x6 /* tagged boolean value */Два значения были особенными:
undefined(JSVAL_VOID), представляет собой целое минус (-) JSVAL_INT_POW2 (30), то есть число вне целочисленного диапазонаnull(JSVAL_NULL)— это указатель NULL машинного кода, тег типа объекта плюс ссылка, равная нулю(OBJECT_TO_JSVAL(0)).
#define JSVAL_VOID INT_TO_JSVAL(0 - JSVAL_INT_POW2(30))
#define JSVAL_NULL OBJECT_TO_JSVAL(0)
#define JSVAL_ZERO INT_TO_JSVAL(0)
#define JSVAL_ONE INT_TO_JSVAL(1)
#define JSVAL_FALSE BOOLEAN_TO_JSVAL(JS_FALSE)
#define JSVAL_TRUE BOOLEAN_TO_JSVAL(JS_TRUE)Теперь, когда рассмотрел его тег типа, а тег типа сказал объект. («источник»)
- Строка № 10, сначала проверяет, является ли значение
vundefined(VOID). - Следующая проверка в строке № 12 проверяет наличие объекта
JSVAL_IS_OBJECT, - Кроме того, вызывает функциональный класс (строка № 18, 19).
- И, следовательно, оценивается как
Object - Впоследствии есть проверки на число, строку и логическое значение, даже не проверка на Null
Возможно, это одна из причин, по которой первая версия JavaScript была завершена за 10 дней. Позже, продолжал жить с этой проблемой, а не исправлять из-за ее тесно связанной логики в исходном исходном коде. Исправление может привести к поломке многих вещей в коде.
Работа с Null и Undefined
Начиная с ES2020, у нас есть лучший способ обработки значений Nullish в Javascript. Для текущих проектов того же можно добиться с помощью Babel.js и/или Typescript.
- Необязательная цепочка (?.)
Также известен как безопасная оценка или оператор безопасности.
Длинные цепочки обращений к свойствам в Javascript приводят к ошибкам, вызывающим сбои, поскольку можно получить null или undefined (“nullish” values). Проверка наличия свойства в глубоко вложенной структуре — утомительная задача, например, рассмотрим ответ API погоды,
Чтобы получить данные о значении «Гроза», используются три подхода:
Теперь из ES2020 или TypeScript 3.7 или @babel/plugin-proposal-optional-chaining поддерживает необязательную цепочку, где можно написать так:
- Нулевое объединение (??)
Оператор Nullish Coalescing (??) действует очень похоже на оператор ||, за исключением того, что мы используем не ложные значения, а nullish, что означает, что значение строго равно null или undefined.
Поддерживается с ES2020, Typescript 3.7 и @babel/plugin-proposal-nullish-coalescing-operator
Избегайте Null всеми возможными способами
Шаблон NullObject
❌ НЕПРАВИЛЬНО
✅ ВПРАВО, Шаблон NullObject
Заключительные слова
(любезно предоставлено: Максмиллиано Контьери)
Программисты используют Null как разные флаги. Он может намекать на отсутствие, неопределенность, значение, ошибку или ложное значение (значение “Nullish”). Множественная семантика приводит к ошибкам связывания.
Проблемы
- Связь между вызывающими и отправляющими
- Несоответствие между вызывающими и отправляющими
- Если/переключатель/случай загрязняет окружающую среду
- Null не полиморфен реальным объектам, поэтому
NullPointerException(TypeError: null or undefined has no properties) - Null не существует в реальном мире. Таким образом, нарушается принцип биекции
Решения
- Избегайте нуля
- Использовать Шаблон нулевого объекта
- Используйте необязательно
Исключения
- API, базы данных, внешние системы, где существует NULL
Поддержка Линтера
Добавьте no-null и no-undef к вашему .eslintrc
Звук Нулевая Безопасность
В современных языках введена Sound Null Safetyили иначе известная как Void Safety для более безопасного и удобного кода, что означает, что по умолчанию язык предполагает, что переменные являются ненулевыми значениями, если явно не указано иное. .
Когда вы выбираете нулевую безопасность, типы в вашем коде не могут быть нулевыми по умолчанию, а это означает, что значения не могут быть нулевыми, если только вы не скажете, что они могут быть такими. При нулевой безопасности ваша среда выполнения ошибки нулевого разыменования превращаются в ошибки анализа времени редактирования.
Например, Dart, Swift и другие следуют Sound Null Safety.
использованная литература
UPDATE: интересно продолжение этой статьи? Читайте: “Контракты vs. Монады?”.
Вступление
В моих черновиках уже больше года лежит статья, в которой я хотел рассказать о проблеме разыменовывания пустых ссылок (null reference dereferencing), с подходами в разных языках и платформах. Но поскольку у меня все никак не доходили руки, а в комментариях к прошлой статье («Интервью с Бертраном Мейером») была затронута эта тема в контексте языка C#, то я решил к ней все-таки вернуться. Пусть получилось не столь фундаментально как я хотел изначально, но букв и так получилось довольно много.
Ошибка на миллиард долларов?
В марте 2009-го года сэр Тони Хоар (C.A.R. Hoare) выступил на конференции Qcon в Лондоне с докладом на тему «Нулевые ссылки: ошибка на миллиард долларов» (Null References: The Billion Dollar Mistake), в котором признался, что считает изобретение нулевых указателей одной из главных своих ошибок, стоившей индустрии миллиарды долларов.
“Я называю это своей ошибкой на миллиард долларов. Речь идет о изобретении нулевых ссылок (null reference) в 1965 году. В то время, я проектировал комплексную систему типов для ссылок в объекто-ориентированном языке программирования ALGOL W. Я хотел гарантировать, что любое использование всех ссылок будет абсолютно безопасным, с автоматической проверкой этого компилятором. Но я не смог устоять перед соблазном добавить нулевую ссылку (null reference), поскольку реализовать это было столь легко. Это решение привело к бесчисленному количеству ошибок, дыр в безопасности и падений систем, что привело, наверное, к миллиардным убыткам за последние 40 лет. В последнее время, ряд анализаторов, таких как PREfix и PREfast корпорации Microsoft были использованы для проверки валидности ссылок и выдачи предупреждений в случае, если они могли быть равными null. Совсем недавно появился ряд языков программирования, таких как Spec# с поддержкой ненулевых ссылок (non-null references). Это именно то решение, которое я отверг в 1965-м.”
Сегодня уже поздно говорить, чтоб бы было, если бы Хоар когда-то принял иное решение и более разумно посмотреть, как эти проблемы решаются в разных языках и, в частности, в языке C#.
Void Safety в Eiffel (с примерами на C#)
Одним из первых на выступление Тони Хоара отреагировал Бертран Мейер, гуру ООП и автор языка Eiffel. Предложенное Мейером решение заключается в разделении переменных всех ссылочных типов на две категории: на переменные, допускающие null (nullable references или detach references в терминах Eiffel) и на переменные, не допускающие null (not-nullable references или attach references в терминах Eiffel).
При этом по умолчанию, все переменные стали относится именно к non-nullable категории! Причина такого решения в том, что на самом деле, в подавляющем большинстве случаев нам нужны именно non-nullable ссылки, а nullable-ссылки являются исключением.
С таким разделением компилятор Eiffel может помочь программисту в обеспечении «Void Safety»: он свободно позволяет обращаться к любым членам not-nullable ссылок и требует определенного «обряда» для потенциально «нулевых» ссылок. Для этого используется несколько паттернов и синтаксических конструкций, но идея, думаю, понятна. Если переменная может быть null, то для вызова метода x.Foo() вначале требуется проверить, что x != null.
При этом, чтобы решить проблему с многопоточностью (дабы избавиться от гонок), вводится специальная синтаксическая конструкция, следующего вида:
if attached t as l then
l.f — здесь обеспечивается Void safety.
end
Если провести параллель между языком Eiffel и C#, то выглядело бы это примерно так. Все переменные ссылочного типа превратились бы в not-nullable переменные, что требовало бы их инициализации в месте объявления валидным (not null) объектом. А доступ к любым nullable переменным требовал бы какой-то магии:
// Где-то в идеальном мире
// s – not-nullable переменная
public void Foo(string s)
{
// Никакие проверки, контркты, атрибуты не нужны
Console.WriteLine(s.Length);
}
// str – nullable (detached) переменная.
//string! аналогичен типу Option<string>
public void Boo(string! str)
{
// Ошибка компиляции!
// Нельзя обращаться к членам "detached" строки!
// Console.WriteLine(str.Length);
str.IfAttached((string s) => Console.WriteLine(s));
// Или
if (str != null)
Console.WriteLine(str.Length);
}
public void Doo(string! str)
{
Contract.Requires(str != null);
// Наличие предусловия позволяет безопасным образом
// обращаться к объекте string через ссылку str!
Console.WriteLine(str.Length);
}
Такие изменения в языке, а также в стандартной библиотеке Eiffel позволили гарантировать отсутствие разыменовывания нулевых ссылок. Но даже с небольшим комьюнити, для внедрения этих изменений потребовалось несколько лет. Поэтому неудивительно, что нам не стоит ждать аналогичных изменений в таком языке как C#.
Более того, реалии таковы, что нам вряд ли стоит ждать появления not-nullable ссылочных типов (о чем не так давно поведал Эрик Липперт в своей статье «C#: Non-nullable Reference Types»), поэтому нам приходится изобретать различного вида велосипеды. Но прежде чем переходить к этим самым велосипедам, интересно посмотреть на подход другого языка платформы .NET – F#.
ПРИМЕЧАНИЕ
Подробнее о Void Safety в Eiffel можно почитать в статье Бертрана Мейера «Avoid a Void: The eradication of null dereferencing», а также в замечательной статье Жени Охотникова «Void safety в языке Eiffel».
Void Safety в F#
Большинство функциональных языков программирования (включая F#) решают проблему разыменовывания нулевых ссылок уже довольно давно, причем способом аналогичным рассмотренному ранее. Так, типы, объявленные в F# по умолчанию не могут быть null (нужно использовать специальный атрибут AllowNullLiteral, да и в этом случае это возможно не всегда). В F# разрешается использование литерала null, но лишь для взаимодействия со сторонним кодом, не столь продвинутым в вопросах Void Safety, написанном на таких языках как C# или VB (хотя и в этом случае иногда могут быть проблемы, см. «F# null trick»).
Для указания «отсутствующего» значения в F# вместо null принято использовать специальный тип – Option<T>. Это позволяет четко указать в сигнатуре метода, когда ожидается nullable аргумент или результат, а когда результат не должен быть null:
// Результат не может быть null
let findRecord (id: int) : Record =
...
// Результат тоже не может быть null,
// но результат завернут в Option<Record> и может отсутствовать
let tryFindRecord (id: int) : Option<Record> =
...
Так, в первом случае возвращаемое значение обязательно (и при его отсутствии будет сгенерировано исключение), а во втором случае результат может отсутствовать.
ПРИМЕЧАНИЕ
Именно этой идиоме следует стандартная библиотека F#. Так, вместо пары методов из LINQ: Single/SingleOrDefault в F# используются методы find/tryFind модулей Seq, List и других.
Поскольку «необязательные» значения может участвовать в целой цепочке событий, любой функциональный язык программирования поддерживает специальный «паттерн», который позволяет «протаскивать» значение через некоторую цепочку операций. Данный паттерн носит название «монада» и является фундаментальным в некоторых функциональных языках программирования. Я не хочу останавливаться на абстрактном описании, поскольку для этого уже есть ряд отличных источников (см. дополнительные источники в конце статьи).
Идея же достаточно простая: нам нужен простой способ работать с «завернутыми» значениями, такими как Option<T>, аналогично тому, как бы мы работали с самим типом T напрямую. Проще всего это показать на примере:
Предположим, у нас есть цепочка операций:
- Попытаться найти сотрудника (tryFindEmployee), если он найден, то
- взять свойство Department, если свойство не пустое, то
- взять свойство BaseSalary, если свойство не пустое, то
- вычислить размер заработной платы (computeSalary).
- если один из этапов возвращает не содержит результата (None в случае F#), то результат должен отсутствовать (должен быть равен None), в противном случае мы получим вычисленный результат.
Это можно сделать большим набором if-ов, а можно использовать Option.bind:
let salary =
tryFindEmployee 42
|> Option.bind(fun e -> e.Department)
|> Option.bind(fun d -> d.BaseSalary)
|> Option.bind computeSalary
Основная идея метода bind очень простая: если Option<T> содержит значение, тогда метод bind вызывает переданный делегат с «распакованным» значением, в противном случае – просто возвращается None (отсутствие значение в типе Option). При этом делегат, переданный в метод Bind также может вернуть значение, завернутое в Option или None, если значение не получено. Такой подход позволяет легко создавать цепочки операций, не заморачиваясь кучей проверок на null на каждом этапе.
Void Safety в C#
Поскольку популярность функциональных языков существенно возросла, то не удивительно, что многие паттерны функционального программирования начали перекачивать в такие исходно объектно-ориентированные языки, как C# (авторы C# серьезно думают о добавлении в одной из новых версий Pattern Matching-а!). Поэтому не удивительно, что для решения проблемы «нулевых ссылок» очень часто начали использоваться идиомы, заимствованные из функциональных языков.
«Монада» Maybe
Одна из причин появления этой статьи заключается в попытке выяснить, насколько полезно/разумно использовать тип Maybe<T> (аналогичный типу Option<T> из F#) в языке C#. В комментариях к предыдущей заметке было высказано мнение о пользе этого подхода, но хотелось бы рассмотреть «за» и «против» более подробно.
> Используйте монадки, и не нужно париться с null. Накладывайте рестрикшен через тип.
Действительно, строгая типизация и выражение намерений через систему типов – это лучший способ для разработчика передать свои намерения. Так, не зная существующих идиом платформы .NET, очень сложно понять, в чем же разница между методами First и FirstOrDefault в LINQ, или как понять, что будет делать метод GetEmployeeById в случае отсутствия данных по сотруднику: вернет null или сгенерирует исключение? В первом случае суффикс «Default» намекает, что в случае отсутствия элемента мы получим «значение по умолчанию» (т.е. null), но что будет во втором случае – не ясно.
В этом плане подход, принятый в F# выглядит намного более приятным, ведь там методы отличаются не только именем, но и возвращаемым значением: метод find возвращает T, а tryFind возвращает Option<T>. Так почему бы не пользоваться этой же идиомой в языке C#?
Главная причина, останавливающая от повсеместного использования Option<T> в C# заключается в отсутствии повсеместного использования Option<T> в C#. Звучт бредово, но все так и есть: использование Option<T> не является стандартной идиомой для библиотек на языке C#, а значит использование своего «велосипедного» Option<T> не принесет существенной пользы.
Теперь стоит понять, а стоит ли овчинка выделки и будет ли полезным использование Option<T> лишь в своем проекте.
Обеспечивает ли Maybe<T> Void Safety?
Особенность использования Maybe заключается в том, что это лишь смягчает, но не решает полностью проблему «разыменовывания нулевых указателей». Проблема в том, что нам все равно нужен способ сказать в коде, что данная переменная типа Maybe<T> должна содержать значение в определенный момент времени. Нам не только нужен безопасный способ обработать оба возможных варианта значения переменной Maybe, но и сказать о том, что один из них в данный момент не возможен.
Давайте рассмотрим такой пример. При реализации «R# Contract Extensions» мне понадобился класс для добавления предусловий/постусловий в абстрактные методы, и методы интерфейсов. Для тех, кто не очень в курсе библиотеки Code Contracts, контракты для абстрактных методов и интерфейсов задаются отдельным классом, который помечается специальным атрибутом – ContractClassFor:
[ContractClass(typeof (AbstractClassContract))]
public abstract class AbstractClass
{
public abstract void Foo(string str);
}
// Отдельный класс с контрактами абстрактного класса
[ContractClassFor(typeof (AbstractClass))]
abstract class AbstractClassContract : AbstractClass
{
public override void Foo(string str)
{
Contract.Requires(str != null);
throw new System.NotImplementedException();
}
}
Процесс добавления контракта для абстрактного метода AbstractClass.Foo такой:
- Получить «контрактный метод» текущего метода (в нашем случае нужно найти «дескриптор» метода AbstractClassContract.Foo).
- Если такого метода еще нет (или нет класса AbstractClassContract), сгенерировать класс контракта с этим методом.
- Получить «контрактный метод» снова (теперь мы точно должны получить «дескриптор» метода AbstractClassContract.Foo).
- Добавить предусловие/постусловие в «контрактный метод».
В результате метод добавления предусловия для абстрактного метод выглядит так (см. ComboRequiresContextAction метод ExecutePsiTransaction):
var contractFunction = GetContractFunction();
if (contractFunction == null)
{
AddContractClass();
contractFunction = GetContractFunction();
Contract.Assert(contractFunction != null);
}
...
[CanBeNull, System.Diagnostics.Contracts.Pure]
private ICSharpFunctionDeclaration GetContractFunction()
{
return _availability.SelectedFunction.GetContractFunction();
}
Метод GetContractFunction возвращает метод класса-контракта для абстрактного класса или интерфейса (в нашем примере, для метода AbstractClass.Foo этот метод вернет AbstractClassContract.Foo, если контрактный класс существует, или null, если класса-контракта еще нет).
Как бы изменился этот метод, если бы я использовал Maybe<T> или Option<T>? Я бы убрал атрибут CanBeNull и поменял тип возвращаемого значения. Но вопрос в том, как бы использование Maybe мне помогло бы выразить, что «постусловие» этого закрытого метода меняется в зависимости от контекста? Так, при первом вызове этого метода вполне нормально, что контрактного метода еще нет и возвращаемое значение равно null (или None, в случае «монадического» решения). Однако после вызова AddContractClass (т.е. после добавления класса-контракта) возвращаемое значение точно должно быть и метод GetContractFunction обязательно должен вернуть «непустое» значение! Я никак не могу отразить это в системе типов языка C# или F#, поскольку лишь я знаю ожидаемое поведение. (Напомню, что контракты выступают в роли спецификации и задают ожидаемое поведение, отклонение от которого означает наличие багов в реализации. Так и в этом случае, если второй вызов GetContractFunction вернул null, то это значит, что в консерватории что-то сломалось и нужно лезть в код и его чинить).
Этим маленьким примером я хотел показать, что не все проблемы с разыменовыванием нулевых указателей можно решить с помощью класса Maybe, а контракты и аннотации (такие как CanBeNull) вполне может поднять «описательность» методов не меняя тип возвращаемого значения.
Использование «неявной» монады Maybe
Как уже было сказано выше, польза от Maybe будет лишь в том случае, если он будет использован всеми типами приложения. Это значит, что если ваш метод TryFind возвращает Maybe<Person>, то нужно, чтобы все «nullable» свойства класса Person тоже возвращали Maybe<T>.
Добиться повсеместного использования Maybe в любом серьезном приложении, написанном на C#, весьма проблематично, поскольку все равно останется масса «внешнего» кода, который не знает об этой идиоме. Так почему бы не воспользоваться этой же идеей, но без «заворачивания» всех типов в Maybe<T>?
Так, класс Maybe<T> (или Option<T>) является своего рода оболочкой вокруг некоторого значения, со вспомогательным методом Bind (название метода является стандартным для паттерна монада), который «разворачивает коверт» и достает из него реальное значение и передает для обработки. При этом становится очень легко строить pipe line, который мы видели в разделе, посвященном языку F#.
Но почему бы не рассматривать любую ссылку, как некую «оболочку» вокруг объекта, для которого мы добавим метод расширения с тем же смыслом, что и метод Bind класса Option? В результате, мы создадим метод, который будет «разворачивать» нашу ссылку и вызывать метод Bind (который мы переименуем в With) лишь тогда, когда текущее значение не равно null:
public static U With<T, U>(this T callSite, Func<T, U> selector) where T : class
{
Contract.Requires(selector != null);
if (callSite == null)
return default(U);
return selector(callSite);
}
В этом случае, мы сможем использовать достаточно компактный синтаксис для обхода целого дерева, каждый узел которого может вернут null. И тогда, если все «узлы» этого дерева будут не null, мы получим непустой результат, если же на одном из этапов, значение будет отсутствовать, то результат всего выражения будет null.
С методом With наш пример, рассмотренный в предыдущем разделе будет выглядеть так:
var salary = Repository.GetEmployee(42)
.With(employee => employee.Department)
.With(department => department.BaseSalary)
.With(baseSalary => ComputeSalary(baseSalary));
В некоторых случаях такой простой «велосипед» может в разы сократить размер кода и здорово улучшить читабельность, особенно при работе с «глубокими» графами объектов, большинство узлов которого может содержать null. Примером такого «глубокого» графа является API Roslyn-а, а также ReSharper SDK. Именно поэтому в своем плагине для ReSharper-а я очень часто использую подобный код:
[CanBeNull]
public static IClrTypeName GetCallSiteType(this IInvocationExpression invocationExpression)
{
Contract.Requires(invocationExpression != null);
var type = invocationExpression
.With(x => x.InvokedExpression)
.With(x => x as IReferenceExpression)
.With(x => x.Reference)
.With(x => x.Resolve())
.With(x => x.DeclaredElement)
.With(x => x as IClrDeclaredElement)
.With(x => x.GetContainingType())
.Return(x => x.GetClrName());
return type;
}
Данный тип «расковыривает» выражение вызова метода и достает тип, на котором этот вызов происходит. При этом может возникнуть вопрос с отладкой, когда результат равен null и не понятно, что же конкретно пошло не так:
В этом плане очень полезна новая фича в VS2013 под названием Autos, которая показывает, на каком из этапов мы получили null:
(В данном случае мы видим, что Resolve вернул не нулевой элемент, но DeclaredElement этого значения равен null.)
Null propagating operator ?. в C# 6.0
Поскольку проблема обработки сложных графов объектов с потенциально отсутствующими значениями, столь распространена, разработчики C# решили добавить в C# 6.0 специальный синтаксис в виде оператора «?.» (null propagating operator). Основная его идея аналогична методу Bind класса Option<T> и приведенному выше методу расширения With.
Следующие три примера эквивалентны:
var customerName1 = GetCustomer() ?.Name;
var customerName2 = GetCustomer().With(x => x.Name);
var tempCustomer = GetCustomer();
string customerName3 = tempCustomer != null ? tempCustomer.Name : null;
ПРИМЕЧАНИЕ
Null propagating operator не может заменить приведенные ранее методы расширения With, поскольку справа от оператора ?. может быть лишь обращение к членам текущего объекта, а произвольное выражения использовать нельзя.
Так, в случае с With мы можем сделать следующее:
var result = GetCustomer().With(x => x.Name).With(x => string.Intern(x));
В случае с “?.” нам все же понадобится временная переменная.
Заключение
Так как же можно обеспечить Void Safety в языке C#? Обеспечить полностью? Никак. Если же мы хотим уменьшить эту проблему к минимуму, то тут есть варианты.
Мне правда нравится идея явного использования типа Maybe (или Option) для получения более декларативного дизайна, но меня напрягает неуниверсальность этого подхода: для собственного кода этот подход работает «на ура», но все равно будет непоследовательным, поскольку сторонний код этой идиомой не пользуется.
Для обработки сложных графов объектов мне нравится подход с методами расширения типа With/Return для ссылочных типов + контракты для декларативного описания наличия или отсутствия значения. Мне вообще кажется, что аннотации типа CanBeNull + контракты с соответствующей поддержкой со стороны среды разработки (как в плане редактирования, так и просмотра) могут существенно упростить понимание кода и проблема сейчас именно в отсутствии такой поддержки.
После выхода C# 6.0 и появления оператора “?.” в ряде случаев можно будет отказаться от методов расширения With/Return, но иногда такие велосипеды все равно будут нужны из-за ограничений оператора “?.”.
К сожалению, без полноценных not-nullable типов обеспечить Void Safety полностью просто невозможно. Поэтому сейчас нам остается использовать разные велосипеды и надеяться на усовершенствование средств разработки, которые упростят работу с контрактами и nullable-типами.
Дополнительные ссылки
- Интервью с Бертраном Мейером
- Null Reference: The Billion Dollar Mistake – выступление Тони Хоара на QCon 2009
- Bertrand Meyer. Avoid a Void: The eradication of null dereferencing – отличная статья Мейера о Void Safety в Eiffel.
- Евгений Охотников. Void safety в языке Eiffel – описание Void Safety в Eiffel на русском языке.
- Eric Lippert. «C#: Non-nullable Reference Types» – сказ о том, почему нам не стоит ждать nullable reference типов в языке C#.
- Functors, applicatives, and monads in pictures – отличная статья с графическим объяснением, что такое монада.
- Eric Lippert. Monads, part one – первая статья отличной серии постов Эрика Липперта о монадах. Одно из лучших описаний для C# разработчика
- F# for fun and profit: The “Computation Expressions” series – цикл статей о Computation Expressions в F#. Не о монадах напрямую, но это все равно лучшее описание принципов, которые лежат в основе монад. Если имеете представление об F#, то эта серия – лучший способ разобраться в монадах.
- Обсуждение null propagating operator на roslyn.codeplex.com
- R# Contract Extension – R# плагин для упрощения работы с контрактами
- Thinking Functionally in C# with monads.net
З.Ы. Понравился пост? Поделись с друзьями! Вам не сложно, а мне приятно;)
Время на прочтение
5 мин
Количество просмотров 123K
Ошибка дизайна
Именно так и никак иначе: null в C# — однозначно ошибочное решение, бездумно скопированное из более ранних языков.
- Самое страшное: в качестве значения любого ссылочного типа может использоваться универсальный предатель — null, на которого никак не среагирует компилятор. Зато во время исполнения легко получить нож в спину — NullReferenceException. Обрабатывать это исключение бесполезно: оно означает безусловную ошибку в коде.
- Перец на рану: сбой (NRE при попытке разыменования) может находится очень далеко от дефекта (использование null там, где ждут полноценный объект).
- Упитанный пушной зверек: null неизлечим — никакие будущие нововведения в платформе и языке не избавят нас от прокаженного унаследованного кода, который физически невозможно перестать использовать.
Этот ящик Пандоры был открыт еще при создании языка ALGOL W великим Хоаром, который позднее назвал собственную идею ошибкой на миллиард долларов.
Лучшая историческая альтернатива
Разумеется, она была, причем очевидная по современным меркам
- Унифицированный Nullable для значимых и ссылочных типов.
- Разыменование Nullable только через специальные операторы (тернарный — ?:, Элвиса — ?., coalesce — ??), предусматривающие обязательную обработку обоих вариантов (наличие или отсутствие объекта) без выбрасывания исключений.
- Примеры:
object o = new object(); // ссылочный тип - корректная инициализация object o = null; // ссылочный тип - ошибка компиляции, так как null недопустим object? n = new object; // nullable тип - корректная инициализация object? n = null; // nullable тип - корректная инициализация object o = n; // ссылочный тип - ошибка компиляции, типы object и object? несовместимы object o = n ?? new object(); // разыменование с fallback значением (coalesce), дополнительное значение будет вычислено только если n != null Type t = n ? value.GetType() : typeof(object); // специальный тернарный оператор - value означает значение n, если оно не null Type? t = n ? value.GetType(); // бинарная форма оператора ? - возвращает null, если первый операнд null, иначе вычисляет второй операнд и возвращает его, завернутого в nullable - В этом случае NRE отсутствует по определению: возможность присвоить или передать null определяется типом значения, конвертация с выбросом исключения отсутствует.
Самое трагичное, что все это не было откровением и даже новинкой уже к моменту проектирования первой версии языка. Увы, тогда матерых функциональщиков в команде Хейлсберга не было.
Лекарства для текущей реальности
Хотя прогноз очень серьезный, летального исхода можно избежать за счет применения различных практик и инструментов. Способы и их особенности пронумерованы для удобства ссылок.
-
Явные проверки на null в операторе if. Очень прямолинейный способ с массой серьезных недостатков.
- Гигантская масса шумового кода, единственное назначение которого — выбросить исключение поближе к месту предательства.
- Основной сценарий, загроможденный проверками, читается плохо
- Требуемую проверку легко пропустить или полениться написать
- Проверки можно добавлять отнюдь не везде (например, это нельзя сделать для автосвойств)
- Проверки не бесплатны во время выполнения.
-
Атрибут NotNull. Немного упрощает использование явных проверок
- Позволяет использовать статический анализ
- Поддерживается R#
- Требует добавления изрядного количества скорее вредного, чем бесполезного кода: в львиной доле вариантов использования null недопустим, а значит атрибут придется добавлять буквально везде.
-
Паттерн проектирования Null object. Очень хороший способ, но с ограниченной сферой применения.
- Позволяет не использовать проверок на null там, где существует эквивалент нуля в виде объекта: пустой IEnumerable, пустой массив, пустая строка, ордер с нулевой суммой и т.п. Самое впечатляющее применение — автоматическая реализация интерфейсов в мок-библиотеках.
- Бесполезен в остальных ситуация: как только вам потребовалось отличать в коде нулевой объект от остальных — вы имеете эквивалент null вместо null object, что является уже двойным предательством: неполноценный объект, который даже NRE не выбрасывает.
-
Конвенция о возврате живых объектов по умолчанию. Очень просто и эффективно.
-
Любой метод или свойство, для которых явно не заявлена возможность возвращать null, должны всегда предоставлять полноценный объект. Для поддержания достаточно выработки хорошей привычки, например, посредством ревью кода.
- Разработчики сторонних библиотек ничего про ваше соглашение не знают
- Нарушения соглашения выявить непросто.
-
-
Конвенция о стандартных способах явно указать что свойство или метод может вернуть null: например, префикс Try или суффикс OrDefault в имени метода. Органичное дополнение к возврату полноценных объектов по умолчанию. Достоинства и недостатки те же.
-
Атрибут CanBeNull. Добрый антипод-близнец атрибута NotNull.
- Поддерживается R#
- Позволяет помечать явно опасные места, вместо массовой разметки по площадям как NotNull
- Неудобен в случае когда null возвращается часто.
-
Операторы C# (тернарный, Элвиса, coalesce)
- Позволяют элегантно и лаконично организовать проверку и обработку null значений без потери прозрачности основного сценария обработки.
- Практически не упрощают выброс ArgumentException при передаче null в качестве значения NotNull параметра.
- Покрывают лишь некоторую часть вариантов использования.
- Остальные недостатки те же, что и у проверок в лоб.
-
Тип Optional. Позволяет явно поддержать отсутствие объекта.
- Можно полностью исключить NRE
- Можно гарантировать наличие обработки обоих основных вариантов на этапе компиляции.
- Против легаси этот вариант немного помогает, вернее, помогает немного.
- Во время исполнения помимо дополнительных инструкций добавляется еще и memory traffic
-
Монада Maybe. LINQ для удобной обработки случаев как наличия, так и отсутствия объекта.
- Сочетает элегантность кода с полнотой покрытия вариантов использования.
- В сочетании с типом Optional дает кумулятивный эффект.
- Отладка затруднена, так как с точки зрения отладчика вся цепочка вызовов является одной строкой.
- Легаси по-прежнему остается ахиллесовой пятой.
-
Программирование по контракту.
- В теории почти идеал, на практике все гораздо печальнее.
- Библиотека Code Contracts скорее мертва, чем жива.
- Очень сильное замедление сборки, вплоть до невозможности использовать в цикле редактирование-компиляция-отладка.
-
Пакет Fody/NullGuard. Автоматические проверки на null на стероидах.
- Проверяется все: передача параметров, запись, чтение и возврат значений, даже автосвойства.
- Никакого оверхеда в исходном коде
- Никаких случайных пропусков проверок
- Поддержка атрибута AllowNull — с одной стороны это очень хорошо, а с другой — аналогичный атрибут у решарпера другой.
- С библиотеками, агрессивно использующими null, требуется довольно много ручной работы по добавлению атрибутов AllowNull
- Поддержка отключения проверки для отдельных классов и целых сборок
- Используется вплетение кода после компиляции, но время сборки растет умеренно.
- Сами проверки работают только во время выполнения.
- Гарантируется выброс исключения максимально близко к дефекту (возврату null туда, где ожидается реальный объект).
- Тотальность проверок помогает даже при работе с легаси, позволяя как можно быстрее обнаружить, пометить и обезвредить даже null, полученный из чужого кода.
- Если отсутствие объекта допустимо — NullGuard сможет помочь только при попытках передать его куда не следует.
- Вычистив дефекты в тестовой версии, можно собрать промышленную из тех же исходников с отключенными проверками, получив нулевую стоимость во время выполнения при гарантии сохранения всей прочей логики.
-
Ссылочные типы без возможности присвоения null (если добавят в одну из будущих версий C#)
- Проверки во время компиляции.
- Можно полностью ликвидировать NRE в новом коде.
- В реальности не реализовано, надеюсь, что только пока
- Единообразия со значимыми типами не будет.
- Легаси достанет и здесь.
Итоги
Буду краток — все выводы в таблице:
| Настоятельная рекомендация | Антипаттерн | На ваш вкус и потребности |
|---|---|---|
| 4, 5, 7, 11, 12 (когда и если будет реализовано) | 1, 2 | 3, 6, 8, 9, 10 |
На предвосхищение ООП через 20 лет не претендую, но дополнениям и критике буду очень рад.
Обновление
добавил примеры кода к утопической альтернативе.
Java и null неразрывно связаны. Трудно найти Java-программиста, который не сталкивался с NullPointerException. Если даже автор понятия нулевого указателя признал его «ошибкой на миллиард долларов», почему он сохранился в Java? null присутствует в Java уже давно, и я уверен, что разработчики языка знают, что он создает больше проблем, чем решает. Это удивительно, ведь философия Java — делать вещи как можно более простыми. Если разработчики отказались от указателей, перегрузки операторов и множественного наследования, то почему они оставили null? Я не знаю ответа на этот вопрос. Однако не имеет значения, насколько много критики идет в адрес null в Java, нам придется с этим смириться. Вместо того, чтобы жаловаться, давайте лучше научимся правильно его использовать. Если быть недостаточно внимательным при использовании null, Java заставит вас страдать с помощью ужасного java.lang.NullPointerException. Наиболее частая причина NullPointerException — недостаточное понимание тонкостей использования null. Давайте вспомним самые важные вещи о нем в Java.
Что такое null в Java
Как мы уже выяснили, null очень важен в Java. Изначально он служил, чтобы обозначить отсутствие чего-либо, например, пользователя, ресурса и т. п. Но уже через год выяснилось, что он приносит много проблем. В этой статье мы рассмотрим основные вещи, которые следует знать о нулевом указателе в Java, чтобы свести к минимуму проверки на null и избежать неприятных NullPointerException.
1. В первую очередь, null — это ключевое слово в Java, как public, static или final. Оно регистрозависимо, поэтому вы не сможете написать Null или NULL, компилятор этого не поймет и выдаст ошибку:
Object obj1 = NULL; // Неверно
Object obj2 = null; // ОКЭта проблема часто возникает у программистов, которые переходят на Java с других языков, но с современными средами разработки это несущественно. Такие IDE, как Eclipse или Netbeans, исправляют эти ошибки, пока вы набираете код. Но во времена Блокнота, Vim или Emacs это было серьезной проблемой, которая отнимала много времени.
2. Так же, как и любой примитивный тип имеет значение по умолчанию (0 у int, false у boolean), null — значение по умолчанию любого ссылочного типа, а значит, и для любого объекта. Если вы объявляете булеву переменную, ей присваивается значение false. Если вы объявляете ссылочную переменную, ей присваивается значение null, вне зависимости от области видимости и модификаторов доступа. Единственное, компилятор предупредит о попытке использовать неинициализированную локальную переменную. Для того, чтобы убедиться в этом, вы можете создать ссылочную переменную, не инициализируя ее, и вывести ее на экран:
private static Object myObj;
public static void main(String args[]){
System.out.println("Значение myObj : " + myObj);
}
// Значение myObjc: nullЭто справедливо как для статических, так и для нестатических переменных. В данном случае мы объявили myObj как статическую переменную для того, чтобы ее можно было использовать в статическом методе main.
3. Несмотря на распространенное мнение, null не является ни объектом, ни типом. Это просто специальное значение, которое может быть присвоено любому ссылочному типу. Кроме того, вы также можете привести null к любому ссылочному типу:
String str = null; // null можно присвоить переменной типа String, ...
Integer itr = null; // ... и Integer, ...
Double dbl = null; // ... и Double.
String myStr = (String) null; // null может быть приведен к String ...
Integer myItr = (Integer) null; // ... и к Integer
Double myDbl = (Double) null; // без ошибок.Как видите, приведение null к ссылочному типу не вызывает ошибки ни при компиляции, ни при запуске. Также при запуске не будет NullPointerException, несмотря на распространенное заблуждение.
4. null может быть присвоен только переменной ссылочного типа. Примитивным типам — int, double, float или boolean — значение null присвоить нельзя. Компилятор не допустит этого и выдаст ошибку:
int i = null; // type mismatch: cannot convert from null to int
short s = null; // type mismatch: cannot convert from null to short
byte b = null: // type mismatch: cannot convert from null to byte
double d = null; // type mismatch: cannot convert from null to double
Integer itr = null; // все в порядке
int j = itr; // нет ошибки при компиляции, но NullPointerException при запускеИтак, попытка присвоения значения null примитивному типу — ошибка времени компиляции, но вы можете присвоить null типу-обертке, а затем присвоить это значение соответствуему примитиву. Компилятор ругаться не будет, но при выполнении кода будет брошено NullPointerException. Это происходит из-за автоматического заворачивания (autoboxing) в Java
5. Любой объект класса-обертки со значением null кинет NullPointerException при разворачивании (unboxing). Некоторые программисты думают, что обертка автоматически присвоит примитиву значение по умолчанию (0 для int, false для boolean и т. д.), но это не так:
Integer iAmNull = null;
int i = iAmNull; // компиляция пройдет успешноЕсли вы запустите этот код, вы увидите Exception in thread "main" java.lang.NullPointerException в консоли. Это часто случается при работе с HashMap с ключами типа Integer. Код ниже сломается, как только вы его запустите:
import java.util.HashMap;
import java.util.Map;
public class Test {
public static void main(String args[]) throws InterruptedException {
Map<Integer, Integer> numberAndCount = new HashMap<>();
int[] numbers = {3, 5, 7, 9, 11, 13, 17, 19, 2, 3, 5, 33, 12, 5};
for (int i : numbers) {
int count = numberAndCount.get(i); // NullPointerException
numberAndCount.put(i, count++);
}
}
}Вывод:
Exception in thread "main" java.lang.NullPointerException
at Test.main(Test.java:14)Этот код выглядит простым и понятным. Мы ищем, сколько каждое число встречается в массиве, это классический способ поиска дубликатов в массиве в Java. Мы берем предыдущее значение количества, инкрементируем его и кладем обратно в HashMap. Мы полагаем, что Integer позаботится о том, чтобы вернуть значение по умолчанию для int, однако если числа нет в HashMap, метод get() вернет null, а не 0. И при оборачивании выбросит NullPoinerException. Представьте, что этот код завернут в условие и недостаточно протестирован. Как только вы его запустите на продакшен – УПС!
6. Оператор instanceof вернет false, будучи примененным к переменной со значением null или к литералу null:
Integer iAmNull = null;
if (iAmNull instanceof Integer) {
System.out.println("iAmNull — экземпляр Integer");
} else {
System.out.println("iAmNull не является экземпляром Integer");
}Результат выполнения:
iAmNull не является экземпляром IntegerЭто важное свойство оператора instanceof, которое делает его полезным при приведении типов.
7. Возможно, вы уже знаете, что если вызвать нестатический метод по ссылке со значением null, результатом будет NullPointerException. Но зато вы можете вызвать по ней статический метод класса:
public class Testing {
public static void main(String args[]){
Testing myObject = null;
myObject.iAmStaticMethod();
myObject.iAmNonStaticMethod();
}
private static void iAmStaticMethod(){
System.out.println("I am static method, can be called by null reference");
}
private void iAmNonStaticMethod(){
System.out.println("I am NON static method, don't date to call me by null");
}
}Результат выполнения этого кода:
I am static method, can be called by null reference
Exception in thread "main" java.lang.NullPointerException
at Testing.main(Testing.java:5)8. Вы можете передавать null в любой метод, который принимает ссылочный тип, например, public void print(Object obj) может быть вызван так: print(null). С точки зрения компилятора ошибки здесь нет, но поведение такого кода целиком зависит от реализации метода. Безопасный метод не кидает NullPointerException в этом случае, а тихо завершает работу. Если бизнес-логика позволяет, лучше писать безопасные методы.
9. Вы можете сравнивать null, используя оператор == («равно») и != («не равно»), но не с арифметическими или логическими операторами (такими как «больше» или «меньше»). В отличие от SQL, в Java null == null вернет true:
public class Test {
public static void main(String args[]) throws InterruptedException {
String abc = null;
String cde = null;
if (abc == cde) {
System.out.println("null == null is true in Java");
}
if (null != null) {
System.out.println("null != null is false in Java");
}
// classical null check
if (abc == null) {
// do something
}
// not ok, compile time error
if (abc > null) {
// do something
}
}
}Вывод этого кода:
null == null is true in JavaВот и все, что надо знать о null в Java. При наличии небольшого опыта и с помощью простых приемов вы можете сделать свой код безопасным. Поскольку null может рассматриваться как пустая или неинициализированная переменная, важно документировать поведение метода при получении null. Помните, что любая созданная и не проинициализированная переменная имеет по умолчанию значение null и что вы не можете вызвать метод объекта или обратиться к его полю, используя null.
Перевод статьи «9 Things about Null in Java»
Борьба с null
Здесь будет описано и рассказано про null с точки зрения разработчика на Java.
- Борьба с null
- Да будет null
- Ближе к Java
- Техника безопасности
- Не доверяй и проверяй
- Проверяй
- Аккуратность в проверках
- Примитивы не так уж и примитивны
- Аккуратнее со строками
- Не плоди null
- Отсутствие значения не всегда null
- Optional
- Доверяйте, но с аннотациями
- Заключение
- Полезные ссылки
- Отдельная благодарность
Да будет null
Для начала надо понять, как к null пришло человечество.
Во время написания кода в объектно-ориентированной парадигме вы представляете свою программу в виде совокупности и взаимодействия объектов, каждый из которых является экземпляром определённого класса.
И всё бы ничего, но что делать, если вам необходимо обозначить отсутствие объекта?
Например, отсутствие пользователя, какого-то ресурса и т.д.
Представьте, что вы написали класс, описывающий пользователя, одним из полей класса является адрес электронной почты — email.
Но не у всех пользователей есть email: кто-то вообще его не использует, кто-то не хочет указывать его или собирается это сделать позже.
Т.е значения этого поля на данный момент нет, но в дальнейшем вполне возможно, что оно появится: например, пользователь его добавит в личном кабинете, или укажет в отделени банка сотруднику.
Вам необходимо обозначить отсутствие объекта, и вот тут-то на сцену и выходит null.
Казалось бы, всё и на этом тему можно закрывать, ведь все довольны и счастливы! Не совсем.
Если вы попытаетесь вызвать любой метод на null, то неизбежно получите java.lang.NullPointerException. А если исключение не будет обработано, то это неизбежно послужит тому, что ваше приложение аварийно завершится.
В этом и состоит основная проблема использования null: это потенциальный источник java.lang.NullPointerException.
Недаром null называют ошибкой стоимостью в миллиард долларов.
Ближе к Java
Что такое null в Java?
«There is also a special null type, the type of the expression null, which has no name. Because the null type has no name,
it is impossible to declare a variable of the null type or to cast to the null type. The null reference is the only
possible value of an expression of null type. The null reference can always be cast to any reference type. In practice, the
programmer can ignore the null type and just pretend that null is merely a special literal that can be of any reference type.»
JLS 4.1
Из чего следует, что null в Java — это особое значение, оно не ассоциируется ни с каким типом (оператор instanceOf возвращает false, если в качестве параметра указать любую ссылочную переменную со значением null или null сам по себе) и может быть присвоено любой ссылочной переменной, а также возвращено из метода.
Это значит, что:
- Каждое возвращаемое значение ссылочного типа может быть
null. - Каждое значение параметра ссылочного типа может также быть
null.
Чувствуете масштаб проблемы? Добавьте сюда ещё и тот факт, что null является значением по умолчанию для ссылочных типов, чтобы получить полное представление о ситуации с null-ами!
Однако, будет неверным считать, что null — это всегда зло, что он неуместен только из-за того, что его неаккуратное использование может привести к ошибкам. И ножом можно нанести повреждения, но это не делает нож плохим инструментом.
В итоге null стал жертвой того, что, благодаря возможности присвоить любому ссылочному значению или вернуть из метода, его стали использовать неправильно. И возненавидели.
Но, как и в ситуации с ножом, у null тоже есть правила безопасности и о них мы и поговорим.
Техника безопасности
Рассмотрим следущий код:
public String greeting() { if (/* no greeting */) { return null; } return "Hello World!" }
Подобный способ довольно распространен, вы пишите метод, а когда нет возвращаемого значения — отдаете null.
А теперь представьте как вы будете пользоваться (и как обрекаете на это других) этим методом?
Вы уже не можете просто взять и сделать:
String message = greeting(); int len = message.length();
Ведь у вас нет гарантии о том, что будет возвращено: значение или null. Вы теряете доверие к этому коду.
Это очень опасная и губительная практика: возвращение null из методов.
Но надо понимать, что нет ничего плохого в null как в значении, но null как reference — однозначное и чистое зло.
Это значит, что поле класса вполне может быть хранить внутри null, проблемы начинаются в момент, когда начинается работа с этим полем — использование его как ссылку.
Для примера рассмотрим старого доброго Person-а, который скоро уже в суд подаст на нас за преследования:
public class Person { private int age; private String userName; private String email; public Person(final int age, final String userName) { this.age = age; this.userName = userName; } // getters and setters }
Как уже было сказано не раз, null — это значение по умолчанию для ссылочных типов.
Соответственно, по умолчанию у объектов Person в поле email будет null.
В целом, подобный код часто встречается и это не плохо: у нас есть обязательные значения(name и age) и необязательные, которые могут отсутствовать — электронный адрес.
Не доверяй и проверяй
Самая явная и очевидная проверка на null в Java выглядит следующим образом:
if(person.getEmail() != null) { // do some work with email }
В Java 7+ появился вспомогательный класс java.util.Objects, который содержит вспомогательные методы проверки на null:
/** * Returns {@code true} if the provided reference is {@code null} otherwise * returns {@code false}. * * @apiNote This method exists to be used as a * {@link java.util.function.Predicate}, {@code filter(Objects::isNull)} * * @param obj a reference to be checked against {@code null} * @return {@code true} if the provided reference is {@code null} otherwise * {@code false} * * @see java.util.function.Predicate * @since 1.8 */ public static boolean isNull(Object obj) { return obj == null; } /** * Returns {@code true} if the provided reference is non-{@code null} * otherwise returns {@code false}. * * @apiNote This method exists to be used as a * {@link java.util.function.Predicate}, {@code filter(Objects::nonNull)} * * @param obj a reference to be checked against {@code null} * @return {@code true} if the provided reference is non-{@code null} * otherwise {@code false} * * @see java.util.function.Predicate * @since 1.8 */ public static boolean nonNull(Object obj) { return obj != null; }
Однако, эти методы были добавлены в основном для Java Stream API, для удобного использования в filter.
Да и на мой взгляд, обычная проверка более читабельна и явная, сравните:
if(Objects.nonNull(person.getEmail())) { // do some work with email } // vs if(person.getEmail() != null) { // do some work with email }
Проверяй
Несмотря на все наши усилия и договорённости, null может также просочиться в объект ещё на этапе его создания.
final Person person = new Person(20, null);
Объект будет создан, несмотря на то, что не ожидается, что поле userName может быть null.
Логичным решением будет потребовать уже на этапе создания объекта невозможность присвоения null значения такому полю.
Т.е. перед инициализацией проверить допустимость значений, которые получены конструктором.
К счастью, для этого в уже знакомом java.util.Objects есть необходимые методы:
public static <T> T requireNonNull(T obj) { if (obj == null) throw new NullPointerException(); return obj; } public static <T> T requireNonNull(T obj, String message) { if (obj == null) throw new NullPointerException(message); return obj; }
Благодаря чему, наш Person приобретает дополнительные проверки и вы всегда быстро поймёте какое поле было проинициализировано неправильно:
public Person(final int age, final String userName) { this.age = age; this.userName = Objects.requireNonNull(userName, "userName can't be null"); }
Вопрос:
Постойте, ведь в Java давно есть assert, а что насчёт них?
Ответ:
Да, есть и их также можно использовать для валидации значений:
public Person(final int age, final String userName) { assert userName != null; this.age = age; this.userName = userName; }
Однако, я ими пользоваться не рекомендую и вот почему:
- По умолчанию они отключены.
- Такая проверка, в случае проблемы, кидает
java.lang.AssertionError, что осложняет обработку исключений в проекте и дальнейшую отладку.
Более подробно о проверках.
Аккуратность в проверках
Помните, что вызов метода на null неизбежно породит java.lang.NullPointerException:
public void checkTag(final String tag) { tag.equals("UNKNOWN"); // может быть NPE, если tag = null "UNKNOWN".equals(tag); // безопасно }
Поэтому, при работе с константами, enum-ами и т.д. вызывайте методы на константах, как наиболее безопасном месте.
Примитивы не так уж и примитивны
Будьте аккуратны с boxing/unboxing.
Как вы думаете, что будет при выполнении следующего кода:
public void printInt(Integer num) { System.out.println((int) num); } printInt(null);
А будет уже знакомый и горячо любимый java.lang.NullPointerException, возникший как раз в unboxing-е.
Поэтому будьте аккуратнее с boxing/unboxing и null-ами, по возможности пользуйтесь примитивами.
Аккуратнее со строками
Помните, что при конкатенации строк, если там затесалось null значение, не будет java.lang.NullPointerException, но и игнорирования null не будет:
String s1 = "hello"; String s2 = null; String s3 = s1 + s2; String s4 = new StringBuilder(s1).append(s2).toString(); System.out.println(s3); System.out.println(s4);
В итоге в обоих случаях будет: hello null!
Человечество, кому повезло не быть разработчиками, ещё не готово к таким наскальным надписям, поэтому, дабы не удивляться null-ам в UI и логах, используйте java.util.Objects, Google Guava или Apache Commons библиотеки.
Например, как это сделано в java.util.Objects:
/** * Returns the result of calling {@code toString} on the first * argument if the first argument is not {@code null} and returns * the second argument otherwise. * * @param o an object * @param nullDefault string to return if the first argument is * {@code null} * @return the result of calling {@code toString} on the first * argument if it is not {@code null} and the second argument * otherwise. * @see Objects#toString(Object) */ public static String toString(Object o, String nullDefault) { return (o != null) ? o.toString() : nullDefault; }
В таком случае:
String s3 = Objects.toString(s1, "") + Objects.toString(s2, "");
Но я рекомендую использовать Apache Commons и класс StringUtils. Удобная и безопасная работа со строками с учётом null-ов.
Не плоди null
В случае написания функциональности, где не все параметры всегда предоставляются, обычно велик соблазн написать один метод и далее использовать его, передавая при необходимости null в параметры, которые могут отсутствовать.
Например, обновление статуса с дополнительной информацией (по возможности):
public void updateStatus(final String status, final String details) { // some code }
При этом, details вполне может отсутствовать и зачастую использование сводится к:
updateStatus("NEW", "Creating new order status"); updateStatus("NEW", null); // при отсутствии details
В таком случае, лучше перегрузить метод и сделать:
public void updateStatus(final String status, final String details) { // some code } public void updateStatus(final String status) { // some code }
Старайтесь минимизировать явную передачу null в методы.
Во-первых, null в методе делает его менее читабельным, особенно, если null значений несколько, например:
updateStatus("NEW", null, null, 200)
Во-вторых, закладывая возможность передачи в метод несколько null значений вы увеличиваете шанс появления ошибки, потому что следить за разрастающимся количеством null-ов тяжело, появляется возможность случайно передать его в метод.
Перегрузка является единственным способом борьбы с такой проблемой, так как в Java, к сожалению, нет поддержки значений по умолчанию.
Отсутствие значения не всегда null
Одной из самых популярных ошибок в использовании null является возвращение его там, где ожидается коллекция данных.
Разберём пример: вы написали телефонную книгу, где есть возможность получить список номеров по имени абонента:
public List<Person> findByName(final String name) { if(book.contains(name)) { return persons; } return null; }
Т.е происходит простое ветвление логики на случай, если в телефонной книге есть записи с таким именем, и на случай, если нет, возвращается то самое отсутствие значения, наш любимый null.
Казалось бы, всё правильно, но нет!
Там, где контракт метода говорит о том, что будет возвращена коллекция данных по какому-то фильтру (в нашем случае — имени)всегда возвращайте пустую коллекцию, при отсутствии данных.
Точно также, если вы разрабатываете функционал, где одним из параметров является необязательная коллекция данных: не делайте возможность передачи вместо неё null:
public List<Person> findByNameAndTags(final String name, final Set<Tag> tags) { // some code }
Если tags необязательное значение для поиска, то при отсутствии значения передавайте пустое множество:
findByNameAndTags("Kuchuk", ImmutableSet.of())
Либо сделайте два метода: с tags в сигнатуре и без.
// когда tags обязательно public List<Person> findByNameAndTags(final String name, final Set<Tag> tags) { // some code } // когда tags необязательно public List<Person> findByNameAndTags(final String name) { // some code }
Точно тот же совет, когда коллекция — это поле класса.
Например, вам необходимо множество кодов ошибок в валидаторе значений:
public class Validator { private Set<Integer> codes = new HashSet<>(); // some code }
Если нет множества(не инициализировали, отсутствует) — сделайте его пустым множеством. Но не делайте его null!
Как вариант можно возвращать ещё итератор.
Отстутствие значения при работе с коллекциями — это пустая коллекция.
При работе с коллекциями и отношением данных one-to-many отсутствие значения — это и есть пустая коллекция.
Optional
Начиная с Java 8+ для борьбы с null был добавлен класс java.util.Optional.
Класс был добавлен для того, чтобы дать возможность разработчикам явно показывать, что значения может не быть.
Если объяснять на пальцах, то java.util.Optional — это просто контейнер, в который вы оборачиваете значение. При отсутствии значения у вас пустой контейнер, при существовании значения — у вас контейнер со значением.
/** * A container object which may or may not contain a non-null value. * If a value is present, {@code isPresent()} will return {@code true} and * {@code get()} will return the value. * * <p>Additional methods that depend on the presence or absence of a contained * value are provided, such as {@link #orElse(java.lang.Object) orElse()} * (return a default value if value not present) and * {@link #ifPresent(java.util.function.Consumer) ifPresent()} (execute a block * of code if the value is present). * * <p>This is a <a href="../lang/doc-files/ValueBased.html">value-based</a> * class; use of identity-sensitive operations (including reference equality * ({@code ==}), identity hash code, or synchronization) on instances of * {@code Optional} may have unpredictable results and should be avoided. * * @since 1.8 */ public final class Optional<T> { // ... }
Для работы Optional с примитивами существует: java.util.OptionalInt, java.util.OptionalLong и java.util.OptionalDouble.
Для примера, пусть необходим метод, который в телефонной книге ищет пользователя по имени и фамилии (как уникальным идентификаторам пользователя в нашей реализации):
public Person findByNameAndSurname(final String name, final String surname) { // some code }
Очевидно, что может возникнуть ситуация, когда будет произведен поиск несуществующего пользователя (например, не зарегестрированного у нас).
Что делать в таком случае?
Варианта, на самом деле, три:
- Кинуть исключение
- Вернуть
null - Вернуть
Optional
Из всех этих вариантов предпочтимее всего в данном случае вернуть Optional. Т.е. обернуть возвращаемое значение в контейнер и явно показать этим, что по таким параметрам поиска(имени и фамилии) пользователя может не быть.
public Optional<Person> findByNameAndSurname(final String name, final String surname) { // some code }
В таком случае, использование может быть в виде:
Optional<Person> person = findByNameAndSurname("Aleksandr", "Kuchuk"); if(person.isPresent()) { // нашли пользователя } else { // не нашли }
Помимо примитивной проверки в if-е Optional можно(и нужно) использовать в Java Stream API:
// ifPresent - совершение действия при существовании значения final Optional.ofNullable(person.getEmail).ifPresent(email -> System.out.println(email)); // map и orElse - при существовании применить функцию к значению, если нет - вернуть unknown final String email = Optional.ofNullable(p.getEmail()).map(String::toLowerCase).orElse("unknown");
Однако, Optional, на мой взгляд, имеет смысл использовать только в качестве возвращаемых значений.
Определенно не стоит его использовать в качестве параметров метода, поскольку при использовании Optional в качестве параметров метода теряется читабельность, код становится более громоздким, проверят на null придеться всё равно и поэтому лучше предоставить действительное значение или сделать перегрузку метода в случаях, когда параметр необязателен.
Также и с полями класса. Нет смысла делать поля класса Optional, так как это будет не Java Bean, также Optional является не сериализуемым классом и т.д.
Есть три способа создать Optional:
/** * Returns an empty {@code Optional} instance. No value is present for this * Optional. * * @apiNote Though it may be tempting to do so, avoid testing if an object * is empty by comparing with {@code ==} against instances returned by * {@code Option.empty()}. There is no guarantee that it is a singleton. * Instead, use {@link #isPresent()}. * * @param <T> Type of the non-existent value * @return an empty {@code Optional} */ public static<T> Optional<T> empty() { @SuppressWarnings("unchecked") Optional<T> t = (Optional<T>) EMPTY; return t; } /** * Returns an {@code Optional} with the specified present non-null value. * * @param <T> the class of the value * @param value the value to be present, which must be non-null * @return an {@code Optional} with the value present * @throws NullPointerException if value is null */ public static <T> Optional<T> of(T value) { return new Optional<>(value); } /** * Returns an {@code Optional} describing the specified value, if non-null, * otherwise returns an empty {@code Optional}. * * @param <T> the class of the value * @param value the possibly-null value to describe * @return an {@code Optional} with a present value if the specified value * is non-null, otherwise an empty {@code Optional} */ public static <T> Optional<T> ofNullable(T value) { return value == null ? empty() : of(value); }
Используйте:
Optional.empty()в случае, если вы уверены, что необходимо вернуть пустой контейнер.Optional.of(value)в случае, если вы уверены, что значение,value, которое вы собираетесь положить в контейнер совершенно точно неnull.- В противном случае используйте
Optional.ofNullable(value).
Никогда не смешивайте null и Optional:
Optional<Object> optional = null; // Плохо! Optional<Object> optional = Optional.of(null); // exception
Это путь в ад и к ненависти.
Подробно о Optional.
Доверяйте, но с аннотациями
Но как быть тому, кто будет использовать ваш код, понять, какие поля вы какие поля могут по нашей задумке быть null, а какие — нет, и это явная ошибка?
Ведь это нам, как разработчикам этого кода, прозрачно и понятно, что email-а может не быть и это нормальное поведение кода.
Другим разработчикам, да и нам самим через неделю, это абсолютно не ясно — и из этого возникает мысль, что было бы удобно как-то разметить наш класс, показать, где ожидаем null и это заложено, а где не ожидаем и это ошибка на миллион долларов.
Может ли поле быть с null или нет — это уже метаинформация о поле. А, значит, логично воспользоваться аннотациями.
К сожалению, в Java нет какого-то общего стандарта, и существует несколько видов аннотаций для этого, например:
- javax.validation.constraints.NotNull
- javax.annotation.Nonnull
- org.jetbrains.annotations.NotNull
- lombok.NonNull
- org.eclipse.jdt.annotation.NonNull
В целом, я уверен, существуют еще несколько, но я выделил наиболее популярные (исключая Android специфичные) на данный момент.
Какую выбрать и как использовать?
На самом деле, вопрос сложный, но я в своих проектах пользуюсь тем, что предоставляет JSR-305, т.е javax.annotation.Nonnull и т.д.
Почему?
Дело в том, что я стараюсь избегать ссылок на IDE специфичные аннотации, поэтому jetbrains, lombok и eclipse отпадают.
Остается только javax.annotation и javax.validation.constraints.
Я сделал выбор в пользу первой как более простой, наглядной и распространённой.
Вообще, это довольно холиварный вопрос, но, если вы пишите на Java 8, то JSR-305 будет к месту.
Подробнее об этом тут и тут.
Благодаря плагину и аннотациям из JSR-305 получается разметить и сгенерировать код с билдерами и проверками на null:
import javax.annotation.Nonnull; import javax.annotation.Nullable; import javax.annotation.ParametersAreNonnullByDefault; import java.util.Objects; @ParametersAreNonnullByDefault public class Person { @Nonnull private final String name; @Nullable private final String email; private final int age; private Person(Builder builder) { this.name = Objects.requireNonNull(builder.name, "name"); this.age = Objects.requireNonNull(builder.age, "age"); this.email = builder.email; } public static Builder builder() { return new Builder(); } @Nonnull public String getName() { return name; } public int getAge() { return age; } @Nullable public String getEmail() { return email; } public static class Builder { private String name; private Integer age; private String email; private Builder() { } public Builder setName(String name) { this.name = name; return this; } public Builder setAge(int age) { this.age = age; return this; } public Builder setEmail(@Nullable String email) { this.email = email; return this; } public Builder of(Person person) { this.name = person.name; this.age = person.age; this.email = person.email; return this; } public Person build() { return new Person(this); } } }
Аннотация @ParametersAreNonnullByDefault на классе говорит о том, что все параметры в методах по умолчанию @Nonnull.
Но не возвращаемые значения!
Возвращаемые значения надо размечать вручную самому и явно.
Это довольно удобно и практично.
Однако, надо понимать, что эти аннотации — не более, чем разметка, чтобы облегчить и структурировать себе и потомкам понимание логики.
Грубо говоря, это как разметка на дороге, вы понимаете, где может быть опасное место, а где в целом безопасный отрезок трассы, но это не защитит вас от грузовика по встречной полосе, если кто-то на нём вырулит:
public void printStatus(@Nonnull String status) { // some code } printStatus(null); // тот самый грузовик по встречной полосе
Аннотации — не более, чем рекомендации и описание правил, которые в идеале должны соблюдать все участники проекта.
Но они могут и не соблюдать их!
Заключение
При разработке не бойтесь null, но старайтесь минимизировать его использование.
Нет ничего плохого в null как в значении, но null как reference — однозначное и чистое зло.
По возможности, избегайте использование null в качестве возвращаемых значений, предпочитая Optional или исключение.
Не задействуйте null для указания ошибок: лучше выбрасывайте явное исключение.
Помните, что отсутствие значения у коллекции — это чаще всего пустая коллекция или пустой итератор.
По возможности, явно размечайте аннотациями код, чтобы показать разработчикам, использующим ваш код, где null заложен в логике, а где — нет.
Старайтесь использовать pre-conditions с помощью Objects.requireNonNull — чем раньше вы поймёте где проблема и с чем, тем лучше.
Будьте аккуратнее со строками и boxing/unboxing!
Полезные ссылки
- Null pointer в разных языках программирования
- Спецификация Java про null
- Про null
- Когда использовать NonNull аннотации
- Про проверки на null
- Какие аннотации для null использовать
- Про Optional
- Java Optional — попытка избежать NullPoinerException
- Ещё про Optional
- Про Null.Часть 1
- Про Null.Часть 2
- Stop Abusing Nihil
- Java. Проблема с null. Null safety.
Отдельная благодарность
Отдельную благодарность за ревью и помощь автор хочет выразить следующим людям из твиттера:
- @norrittmobile
- @thecoldwine
- @mudasobwa
- @dmi3vim
- @ihavenoclue12