Всем привет, друзья! Если вы читаете этот текст, значит вы столкнулись со следующей проблемой. При связывании двух таблиц, при выставлении «обеспечение целостности данных», вы получаете следующую ошибку «не обнаружен уникальный индекс для адресуемого поля главной таблицы» в базе данных Microsoft Access. Давайте, я покажу как избежать появление такой ошибки.
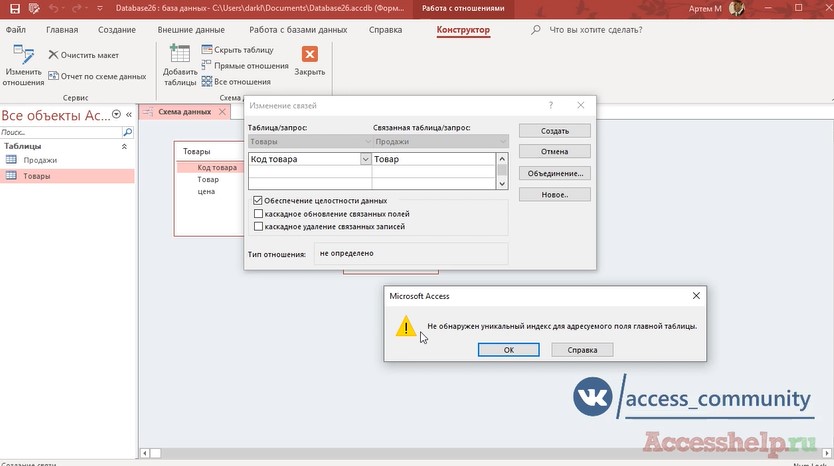
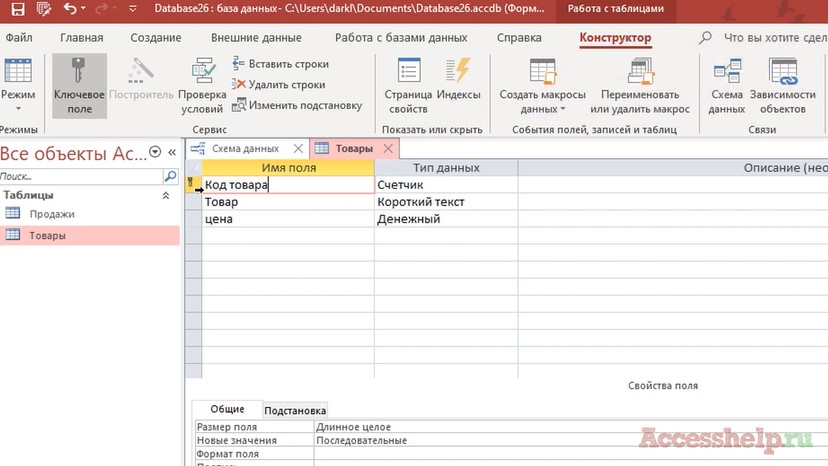
В данном примере мы пытаемся связать поле «код товара» таблицы «товары» с полем «товар» таблицы «продажи». Для тех кто только-только начинает работать в программе microsoft access, я поясню, что соединить две таблицы мы можем с помощью ключевого поля. Чтобы создать ключевое поле в таблице «товары» нужно перейти в конструктор таблиц и выделить нужное поле, нажать на соответствующую иконку на панели инструментов, после чего «код товара» у нас станет уникальным ключевым полем.
После того, как ключевое поле создано, мы закрываем таблицу «товары», перетаскиваем «код товара» таблицы «товары» на «товар» таблицы «продажи».
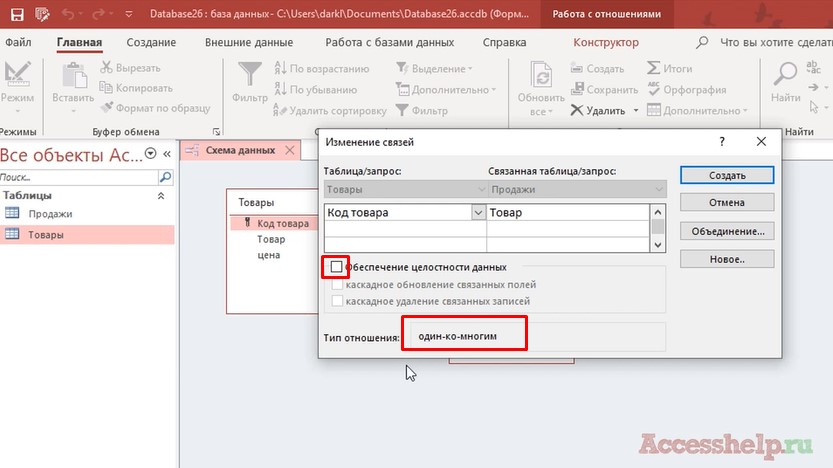
Обратите внимание, автоматически определяется тип отношения как «один ко многим». Мы выставляем «обеспечение целостности данных» и наша связь создана. Повторюсь, при связи двух таблиц, чтобы получить определенный тип отношений между двумя таблицами, нам нужно соединить эти две таблицы так, чтобы с одной стороны, где у нас цифра 1, поле было ключевым (его еще по-другому называют первичный ключ), а со стороны знака бесконечности (или еще говорят со стороны «многие») поле не обязательно должно быть ключевым. Это поле также называют внешним ключом.
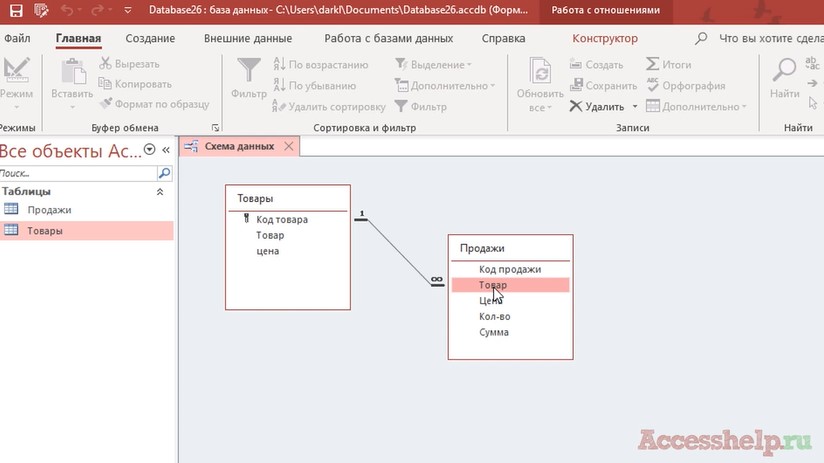
Друзья, надеюсь данное разъяснение было вам понятным, и теперь вы знаете, что делать, если появилась ошибка «Не обнаружен уникальный индекс для адресуемого поля главной таблицы» в программе Microsoft Access! Продолжайте изучать программу microsoft access и до новых встреч!

Всем привет, друзья! Если вы читаете этот текст, значит вы столкнулись со следующей проблемой. При связывании двух таблиц, при выставлении «обеспечение целостности данных», вы получаете следующую ошибку «не обнаружен уникальный индекс для адресуемого поля главной таблицы» в базе данных Microsoft Access. Давайте, я покажу как избежать появление такой ошибки.
В данном примере мы пытаемся связать поле «код товара» таблицы «товары» с полем «товар» таблицы «продажи». Для тех кто только-только начинает работать в программе microsoft access, я поясню, что соединить две таблицы мы можем с помощью ключевого поля. Чтобы создать ключевое поле в таблице «товары» нужно перейти в конструктор таблиц и выделить нужное поле, нажать на соответствующую иконку на панели инструментов, после чего «код товара» у нас станет уникальным ключевым полем.
После того, как ключевое поле создано, мы закрываем таблицу «товары», перетаскиваем «код товара» таблицы «товары» на «товар» таблицы «продажи».
Обратите внимание, автоматически определяется тип отношения как «один ко многим». Мы выставляем «обеспечение целостности данных» и наша связь создана. Повторюсь, при связи двух таблиц, чтобы получить определенный тип отношений между двумя таблицами, нам нужно соединить эти две таблицы так, чтобы с одной стороны, где у нас цифра 1, поле было ключевым (его еще по-другому называют первичный ключ), а со стороны знака бесконечности (или еще говорят со стороны «многие») поле не обязательно должно быть ключевым. Это поле также называют внешним ключом.
Друзья, надеюсь данное разъяснение было вам понятным, и теперь вы знаете, что делать, если появилась ошибка «Не обнаружен уникальный индекс для адресуемого поля главной таблицы» в программе Microsoft Access! Продолжайте изучать программу microsoft access и до новых встреч!
Понимаю, что база данных дурацкая, но требуется именно такая.
Вот пункты работы:
«2. В БД ZapBook создать таблицу Записная книжка, содержащую 10 записей.
Поля таблицы: Фамилия, Имя, Отчество, Домашний адрес, Телефон (типы данных задать самостоятельно).
В таблице задать ключевое поле.»
Наиболее логично сделать ключевым полем «Телефон» или «Домашний адрес». Я сделал «Телефон».
«7. Добавить в БД ZapBook таблицу Библиотека (аудио / видеотека).
Обязательные поля таблицы: Автор (исполнитель), Название книги (композиции, фильма), Кому выдал, Дата выдачи, Дата возврата.
Можно добавить свои поля.»
«8. Связать таблицы Записная книжка и Библиотека, тип связи один-ко-многим, вывести на экран Схему данных.»
Из пунктов 7-8 следует, что один человек может брать несколько книг, значит нужно ключевым полем сделать «Название книги» (это я сейчас понял что такое КП лучше, чем «Автор», но суть не в этом), а также для связи в «Библиотека» требуется поле аналогичное «Телефону» (из таблицы «Записной книжке») — «Телефон читателя».
Но при этом возникает излишняя информация («Фамилия» в «Записная книжка» и «Кому выдал» в «Библиотека»). Хотелось бы, чтобы эти 2 поля также были связаны, если это, конечно, возможно.
Содержание
- Microsoft access не обнаружен уникальный индекс для адресуемого поля главной таблицы
- Не обнаружен уникальный индекс для адресуемого поля главной таблицы
- MS-Access не может найти уникальный индекс для поля ссылки основной таблицы
- Предотвращение дублирования значений в поле таблицы с помощью индекса
- В этой статье
- Заблокируйте для свойства поля «Индексированные» (без повторов)
- Создание уникального индекса для поля с помощью запроса определения данных
- Не обнаружен уникальный индекс access
- Создание и использование индексов
- Не обнаружен уникальный индекс
- Уникальный индекс по полям, которые могут иметь null’евые значение¶
- Функциональный индекс¶
- Частичный индекс¶
- «Суррогатный» индекс¶
- Резюме¶
Microsoft access не обнаружен уникальный индекс для адресуемого поля главной таблицы
Не обнаружен уникальный индекс для адресуемого поля главной таблицы
Всем привет, друзья! Если вы читаете этот текст, значит вы столкнулись со следующей проблемой. При связывании двух таблиц, при выставлении «обеспечение целостности данных», вы получаете следующую ошибку «не обнаружен уникальный индекс для адресуемого поля главной таблицы» в базе данных Microsoft Access. Давайте, я покажу как избежать появление такой ошибки.
В данном примере мы пытаемся связать поле «код товара» таблицы «товары» с полем «товар» таблицы «продажи». Для тех кто только-только начинает работать в программе microsoft access, я поясню, что соединить две таблицы мы можем с помощью ключевого поля. Чтобы создать ключевое поле в таблице «товары» нужно перейти в конструктор таблиц и выделить нужное поле, нажать на соответствующую иконку на панели инструментов, после чего «код товара» у нас станет уникальным ключевым полем.
После того, как ключевое поле создано, мы закрываем таблицу «товары», перетаскиваем «код товара» таблицы «товары» на «товар» таблицы «продажи».
Обратите внимание, автоматически определяется тип отношения как «один ко многим». Мы выставляем «обеспечение целостности данных» и наша связь создана. Повторюсь, при связи двух таблиц, чтобы получить определенный тип отношений между двумя таблицами, нам нужно соединить эти две таблицы так, чтобы с одной стороны, где у нас цифра 1, поле было ключевым (его еще по-другому называют первичный ключ), а со стороны знака бесконечности (или еще говорят со стороны «многие») поле не обязательно должно быть ключевым. Это поле также называют внешним ключом.
Друзья, надеюсь данное разъяснение было вам понятным, и теперь вы знаете, что делать, если появилась ошибка «Не обнаружен уникальный индекс для адресуемого поля главной таблицы» в программе Microsoft Access! Продолжайте изучать программу microsoft access и до новых встреч!
Источник
MS-Access не может найти уникальный индекс для поля ссылки основной таблицы
Это моя задача . помогите пожалуйста!
Настройте ссылочную целостность между таблицей sec0808_departments и Таблица sec0808_employees. Таблица sec0808_depatrments содержит список всех допустимых значений поля dept_code.
sec0808_departments вид дизайна
sec0808_employees представление дизайна

Спасибо за любую помощь! Лучший 🙂





Просто переключите таблицы в команде ALTER , чтобы назначить внешний ключ в таблице Сотрудники, ссылающейся на первичный ключ таблицы отделение. Прямо сейчас вы пытаетесь добавить внешний ключ к Отделы, когда он уже поддерживает первичный ключ!
Таким образом, Отделы (уникальный dept_code в каждой строке) к Сотрудники (потенциально повторяющийся dept_code для сотрудников, которые работают в одном отделе) создают связь «один ко многим».
Источник
Предотвращение дублирования значений в поле таблицы с помощью индекса
Создать уникальный индекс можно предотвратить дублирование значений в поле таблицы Access. Уникальный индекс — это индекс, который требует, чтобы каждое значение индекса было уникальным.
Создать уникальный индекс можно двумя основными способами:
Заблокируйте для свойства поля «Индексированные» (без повторов) Для этого можно открыть таблицу в Конструктор. Этот способ прост, и его удобно выбирать, если нужно изменять только одно поле за раз.
Создание запрос определения данных для создания уникального индекса Это можно сделать с помощью режим SQL. Этот способ не так прост, как конструктор, но имеет преимущество: вы можете сохранить запрос определения данных и использовать его позже. Это полезно, если вы периодически удаляете и повторно создаете таблицы и хотите использовать уникальные индексы для некоторых полей.
В этой статье
Заблокируйте для свойства поля «Индексированные» (без повторов)
В области навигации щелкните правой кнопкой мыши таблицу с полем и выберите «Конструктор».
Выберите поле, которое должно иметь уникальные значения.
В области «Свойства поля» в нижней части конструктора таблицы на вкладке «Общие» установите для свойства «Индексированные» (без повторов)«Да».
Сохраните изменения в таблице.
Примечание: Если в поле для записей таблицы уже есть дубликаты, при попытке сохранить изменения таблицы с новым индексом в Access отображается сообщение об ошибке (ошибка 3022). Вам потребуется удалить повторяющиеся значения полей из записей таблицы, прежде чем можно будет установить и сохранить новый уникальный индекс.
Создание уникального индекса для поля с помощью запроса определения данных
На вкладке Создание в группе Запросы нажмите кнопку Конструктор запросов.
На вкладке «Конструктор» в группе «Результаты» щелкните стрелку под кнопкой «Вид»и выберите SQL «Вид».
Удалите все существующие SQL из запроса. (Скорее всего, в Access просто отобразит select, прежде чем удалять существующий текст.)
Введите или введите в SQL следующую SQL запрос:
В SQL замените переменные следующим образом:
Замените index_name именем указателя. Используйте имя, которое помогает определить, для чего используется индекс. Например, если в индексе нужно убедиться, что номера телефонов уникальны, можно назвать его unique_phone.
Замените таблицу именем таблицы, содержаной поле для индексации. Если имя таблицы имеет пробелы или специальные символы, необходимо в скобках.
Замените поле именем поля, которое нужно индексировать. Если имя поля имеет пробелы или специальные символы, его необходимо заключено в квадратные скобки.
Сохраните и закройте запрос.
Запустите запрос, чтобы создать индекс. Обратите внимание на то, что вы можете выполнить запрос из макроса с помощью макроса RunSQL.
Источник
Не обнаружен уникальный индекс access
Создание и использование индексов
С целью ускорения поиска и сортировки данных в любой СУБД используются индексы. Индекс является средством, которое обеспечивает быстрый доступ киданным в таблице на основе значений одного или нескольких столбцов. Индекс представляет собой упорядоченный список значений и ссылок на те записи, в которых хранятся эти значения. Чтобы найти нужные записи, СУБД сначала ищет требуемое значение в индексе, а затем по ссылкам быстро отбирает соответствующие записи. Индексы бывают двух типов: простые и составные. Простые индексы представляют собой индексы, созданные по одному столбцу. Индекс, построенный по нескольким столбцам, называется составным. Примером составного индекса может быть индекс, построенный по столбцам «Фамилия» и «Имя».
Однако применение индексов приносит не только преимущества, но и недостатки. Главным среди них является тот, что при добавлении и удалении записей или при обновлении значений в индексном столбце требуется обновлять индекс, что при большом количестве индексов в таблице может замедлять работу. Поэтому индексы обычно рекомендуется создавать только для тех столбцов таблицы, по которым наиболее часто выполняется поиск записей. Во многих СУБД (например, FoxPro) индексы хранятся в отдельных файлах и являются предметом заботы разработчиков, т. к. при нарушении индекса поиск данных выполняется некорректно. В Microsoft Access индексы хранятся в том же файле базы данных, что и таблицы и другие объекты Access. Индексировать можно любые поля, кроме МЕМО-полей, полей типа Гиперссылка и объектов OLE.
Чтобы создать простой индекс, необходимо:
- Открыть таблицу в режиме Конструктора.
- Выбрать поле, для которого требуется создать индекс.
- Открыть вкладку Общие (General) и выбрать для свойства Индексированное поле (Indexed) значение Да (Допускаются совпадения) (Yes (Duplicates OK)) или Да (Совпадения не допускаются) (Yes (No duplicates)) (рис. 2.24).
Ключевое поле таблицы автоматически индексируется и свойству Индексированное поле (Indexed) присваивается значение Да (Совпадения не допускаются) (Yes (No duplicates)).
Составной индекс создается в специальном диалоговом окне. Чтобы создать составной индекс, необходимо:
- Открыть таблицу в режиме Конструктора.
- На панели инструментов Конструктор таблиц (Table Design) нажать кнопку Индексы (Indexes.)
- В первой пустой строке (рис. 2.25) поля Индекс (Index Name) ввести имя индекса.
По умолчанию устанавливается порядок сортировки По возрастанию (Ascending). Для сортировки данных полей по убыванию в поле Порядок сортировки (Sort Order) в окне индексов укажите значение По убыванию (Descending).
Диалоговое окно Индексы (Indexes) используется также для просмотра, изменения и удаления существующих индексов. Изменить можно:
- название индекса в поле Индекс (Index Name);
- поле таблицы, соответствующее данному индексу, выбрав новое поле из списка в поле Имя поля (Field Name);
- порядок сортировки в поле Порядок сортировки (Sort Order); П свойства данного индекса в нижней части окна (рис. 2.26):
- Ключевое поле (Primary) определяет, является ли индексированное поле ключевым;
- Уникальный индекс (Unique) определяет, должно ли быть каждое значение в этом поле уникальным;
- Пропуск пустых полей (Ignore Nulls) определяет, включаются или не включаются в индекс записи с пустым (Null) значением данного поля.
Удаление индекса выполняется точно так же, как удаление поля в Конструкторе таблиц. Просто выделите строку с нужным индексом и нажмите клавишу или воспользуйтесь контекстным меню.
Не обнаружен уникальный индекс
Доброго времени суток!
В акцессе работаю 1 день, помогите разобратсья с парочкой проблем и советами..
(сразу говорю, чтобы не думали что прошу сделать за меня и это не задание в институте, просто делаю для себя и прошу помощи)
Введение в суть БД:
 Не обнаружен уникальный индекс
Не обнаружен уникальный индекс
Как можно связать дату с датой, Н рейса с Н рейса?
Не обнаружен уникальный индекс
Создаю базу данных ( работа по учебе ). Создано и заполнено 8 таблиц. Но на шаге создания схемы.
Не обнаружен уникальный индекс
CREATE TABLE TypeSpis( + Integer PRIMARY KEY, + .
Не обнаружен уникальный индекс
Всем доброго вечера! В общем, делал лабораторную по базам данных и наткнулся на ошибку во время.
17.05.2013, 23:39 [ТС] 2 18.05.2013, 02:40 3
1. Составные ключи однозначно фтопку: уникальным ключом должно быть поле счётчика, связанное с ним — числовое длинное целое (по крайней мере здесь в большинстве случаев принято так).
Каскадное удаление заодно туда же. При современных мощностях, ресурсах (очевидно опережающих спрос на такой объём, скорость и т.д.), предоставляемых производителями даже средних (и даже «слабых») машин, удалять что-либо неразумно: сейчас каждый палаточник-чебуречник пишет всё и имеет возможность хранить всё мультимедиа, взятое посредством его «ведётся наблюдение».
Добавлено через 5 минут
2. Связи между таблицами делаем только в Схеме данных, никаких подстановок в таблицах (это баг Микрософта, подобный автозапуску флэшек): однозначно потом будете переделывать эту околесицу (поиск по Форуму: Поля подстановок в таблицах)
Добавлено через 30 минут
3. Развитие Аксесс остановилось с выходом версии 2003; после него — почти только так наз «плюшки», больше мешающие нормальной работе, чем ей способствующие.
«Остановилось» — это не в негативном смысле, но, как я уже упомянул, по объективным (реальным) причинам: потому что фактически уже тогда был полностью решён вопрос потребностей в организации необходимого функционала по учётурасчёту деятельности как однопользовательских (индивидуальных, «под себя») систем, так и многопользовательских уровня малого (и даже среднего) бизнеса.
Магистральное направление сейчас — это взаимодействие пользователей не посредством локального, но вэб-интерфейса. Но на практике он, во-первых, пока мало приживается, во-вторых, очень мало спецов, умеющих его качественно делать, в третьих, ещё меньше заказчиков, которые в состоянии объяснить его необходимость и дать взвешенное технич задание на его исполнение. И это длится уже, наверное, год третий, и пока мало сдвигается с места. Реально.
Ещё раз: практически все фундаментальные практические решения (и не только в Аксе: для примера, Вай Фай и т.д.) внедрены ещё в самом начале нулевых и не имеют пока революционного продолжения, за исключением всяких мультимедийных плюшек (например, цифровое, интернет-тв и проч безтолковщина. )
Уникальный индекс по полям, которые могут иметь null’евые значение¶
Частенько разработчики и администраторы PostgreSQL сталкиваются с вроде бы ошибкой PostgreSQL — на таблицу создан уникальный индекс, который «не работает». То есть в таблице есть строки, которые должны содержать некоторый набор полей, значение которых должно быть уникальным для всей таблице, но это условие не выполняется. Более подробный анализ дублей показывает, что все проблемные строки содержат хотя бы одно null’евое значение в одном из полей. А null != null (см. статью Сравнение с NULL). Отсюда и все «проблемы».
Пример описанной проблемы
Есть таблица test_func_index и уникальный индекс по полям name, cdate
Проверим работу уникального индекса.
Инициализация таблицы начальными значениями
Проверяю работу уникального индекса с ненулевыми значениями. Индекс работает
Проверяю работу уникального индекса с NULL’евыми значениями. Индекс не работает
Проблема уникальности присутствует.
На данный момент есть три самых популярных решений описанной проблемы:
- Применение функционального индекса
- Использование частичного индекса
- Применение суррогатного уникального индекса
Функциональный индекс¶
Каждое поле уникального индекса оборачивается функцией COALESCE, в итоге NULL’евые значения полей в индексе заменяются специальными предопределенными значениями.
В данном примере нулевая строка заменяется пустой строкой, а нулевая дата — бесконечной датой
Проверим работу индекса.
Проверка работы уникального индекса для нулевых значений. Индекс работает.
Работа индекса в обычных запросах. Индекс не работает.
Работа индекса при использовании функции COALESCE, но с другими константами. Не работает
Работа индекса при использовании функции COALESCE и теми же параметрами. Работает.
Плюсы
- Уникальность достигается без дополнительных ухищрений в момент внесения данных в таблицу
- Индекс работает не только как уникальный, но и годен для фильтрации данных
Минусы
- Специальные значения, которыми заменяются NULL’евые, должны быть вне допустимого диапазона ненулевых значений
- Фильтрация работает только при использовании COALESCE с константами, которые были определены в индексе
Частичный индекс¶
Для каждого NULL’евого поля и/или комбинации NULL’евых полей создаётся свой индекс. Это необходимо, чтобы индексы не перекрывали друг друга (меньше нагрузки при вставке данных и меньше места для хранения индекс)
Индексы не перекрываются, но при этом поддерживают уникальность по полям name и cdate
Плюсы
- Никаких искусственно созданных ограничений при работе со значениями полей.
- Фильтрация работает без ограничений
- Никакого оверхеда при хранении
Минусы
- Сложность создания индексов. Количество индексов должно быть количество_полей в степени двойки (для трех полей — 8, для 4 — 16)
«Суррогатный» индекс¶
Все поля, по которым надо поддерживать уникальность, склеиваются/складываются особым образом, чтобы получилось уникальное значение, которое и будет обеспечивать уникальность.
Функция склеивания полей
Проверка работы индекса
Индекс работает как и ожидалось.
Плюсы
Минусы
- Требуется создавать склеивающую поля функцию
- Индекс работает только на уникальность, на фильтрацию — не работает.
Резюме¶
Самым технологичным и удобным в использовании является способ с использованием частичных индексов. Затраты времени на создание всех необходимых индексов компенсируются полноценной работой индексов как для поддержания уникальности, так и для фильтрации данных.
Использование функционального индекса (первый способ) не всегда возможен и очень плох в поддержке (необходимо выделять специальные значения для NULL’ов и фильтрация работает только при соблюдении определенных условий).
Третий способ с суррогатным индексом можно применять только, если необходимо только поддержка уникальности, так как большего он предоставить не может.
Хорошим компромиссом может стать синергия обычного уникального индекса и суррогатного индекса для нулевых полей. Для вышеописанной таблицы это будет выглядеть так.
Обычный уникальный индекс, обеспечивающий уникальность для ненулевых полей и полноценную фильтрацию
Суррогатный индекс, обеспечивающих уникальность для нулевых полей
Да, индексы в некоторых случаях дублируют друг друга, но это компенсируется их простотой (как в архитектуре, так и поддержке / использовании)
Источник
Уникальный индекс по полям, которые могут иметь null’евые значение¶
Частенько разработчики и администраторы PostgreSQL сталкиваются с вроде бы ошибкой PostgreSQL — на таблицу создан уникальный индекс, который «не работает». То есть в таблице есть строки, которые должны содержать некоторый набор полей, значение которых должно быть уникальным для всей таблице, но это условие не выполняется. Более подробный анализ дублей показывает, что все проблемные строки содержат хотя бы одно null’евое значение в одном из полей. А null != null (см. статью Сравнение с NULL). Отсюда и все «проблемы».
Пример описанной проблемы
Есть таблица test_func_index и уникальный индекс по полям name, cdate
Проверим работу уникального индекса.
Инициализация таблицы начальными значениями
Проверяю работу уникального индекса с ненулевыми значениями. Индекс работает
Проверяю работу уникального индекса с NULL’евыми значениями. Индекс не работает
Проблема уникальности присутствует.
На данный момент есть три самых популярных решений описанной проблемы:
- Применение функционального индекса
- Использование частичного индекса
- Применение суррогатного уникального индекса
Функциональный индекс¶
Каждое поле уникального индекса оборачивается функцией COALESCE, в итоге NULL’евые значения полей в индексе заменяются специальными предопределенными значениями.
В данном примере нулевая строка заменяется пустой строкой, а нулевая дата — бесконечной датой
Проверим работу индекса.
Проверка работы уникального индекса для нулевых значений. Индекс работает.
Работа индекса в обычных запросах. Индекс не работает.
Работа индекса при использовании функции COALESCE, но с другими константами. Не работает
Работа индекса при использовании функции COALESCE и теми же параметрами. Работает.
Плюсы
- Уникальность достигается без дополнительных ухищрений в момент внесения данных в таблицу
- Индекс работает не только как уникальный, но и годен для фильтрации данных
Минусы
- Специальные значения, которыми заменяются NULL’евые, должны быть вне допустимого диапазона ненулевых значений
- Фильтрация работает только при использовании COALESCE с константами, которые были определены в индексе
Частичный индекс¶
Для каждого NULL’евого поля и/или комбинации NULL’евых полей создаётся свой индекс. Это необходимо, чтобы индексы не перекрывали друг друга (меньше нагрузки при вставке данных и меньше места для хранения индекс)
Индексы не перекрываются, но при этом поддерживают уникальность по полям name и cdate
Плюсы
- Никаких искусственно созданных ограничений при работе со значениями полей.
- Фильтрация работает без ограничений
- Никакого оверхеда при хранении
Минусы
- Сложность создания индексов. Количество индексов должно быть количество_полей в степени двойки (для трех полей — 8, для 4 — 16)
«Суррогатный» индекс¶
Все поля, по которым надо поддерживать уникальность, склеиваются/складываются особым образом, чтобы получилось уникальное значение, которое и будет обеспечивать уникальность.
Функция склеивания полей
Проверка работы индекса
Индекс работает как и ожидалось.
Плюсы
Минусы
- Требуется создавать склеивающую поля функцию
- Индекс работает только на уникальность, на фильтрацию — не работает.
Резюме¶
Самым технологичным и удобным в использовании является способ с использованием частичных индексов. Затраты времени на создание всех необходимых индексов компенсируются полноценной работой индексов как для поддержания уникальности, так и для фильтрации данных.
Использование функционального индекса (первый способ) не всегда возможен и очень плох в поддержке (необходимо выделять специальные значения для NULL’ов и фильтрация работает только при соблюдении определенных условий).
Третий способ с суррогатным индексом можно применять только, если необходимо только поддержка уникальности, так как большего он предоставить не может.
Хорошим компромиссом может стать синергия обычного уникального индекса и суррогатного индекса для нулевых полей. Для вышеописанной таблицы это будет выглядеть так.
Обычный уникальный индекс, обеспечивающий уникальность для ненулевых полей и полноценную фильтрацию
Суррогатный индекс, обеспечивающих уникальность для нулевых полей
Да, индексы в некоторых случаях дублируют друг друга, но это компенсируется их простотой (как в архитектуре, так и поддержке / использовании)
Предотвращение дублирования значений в поле таблицы с помощью индекса
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
Чтобы предотвратить дублирование значений в поле таблицы Access, можно создать уникальный индекс. Уникальный индекс — это индекс, для которого каждое значение индексированного поля должно быть уникальным.
Создать уникальный индекс можно двумя способами:
Задайте для свойства Индексированное поле значение Да (совпадения не допускаются). Это можно сделать, открыв таблицу в Конструктор. Этот метод является простым и хорошим выбором, если вы хотите изменить только одно поле за один раз.
Создание запрос определения данных, создающего уникальный индекс Это можно сделать с помощью режим SQL. Этот способ не так прост, как в режиме конструктора, но имеет преимущество: вы можете сохранить запрос определения данных и использовать его снова. Это полезно, если вы будете периодически удалять и повторно создавать таблицы и хотите использовать уникальные индексы в некоторых полях.
В этой статье
Задание для свойства индексированного поля значения «Да» (совпадения не допускаются)
В области навигации щелкните правой кнопкой мыши таблицу, содержащую поле, и выберите команду конструктор.
Выберите поле, для которого нужно проверить уникальные значения.
В области Свойства поля в нижней части представления конструктор таблицы на вкладке Общие задайте для свойства индексированНое свойство значение Да (совпадения не допускаются).
Сохраните изменения в таблице.
Примечание: Если в поле для записей таблицы уже есть дубликаты, то при попытке сохранить изменения в таблице будет выводится сообщение об ошибке (ошибка 3022). Перед установкой и сохранением нового уникального индекса необходимо удалить эти повторяющиеся значения полей из записей таблицы.
Создание уникального индекса для поля с помощью запроса на определение данных
На вкладке Создание в группе Запросы нажмите кнопку Конструктор запросов.
Закройте диалоговое окно Добавление таблицы , когда оно откроется.
На вкладке конструктор для запросов в группе результаты щелкните стрелку рядом с кнопкой види выберите пункт режим SQL.
Удалите из запроса все существующие инструкции SQL. (Наиболее вероятный доступ только выводит » выделить»; перед удалением существующего текста).
В запросе введите или вставьте следующий код SQL:
В SQL замените переменные следующим образом:
Замените индекс_наме именем для своего индекса. Рекомендуется использовать имя, которое помогает определить, для чего предназначен индекс. Например, если вы уверены, что номера телефонов должны быть уникальными, вы можете назвать его уникуе_фоне.
Замените таблицу именем таблицы, содержащей индексируемое поле. Если имя таблицы содержит пробелы или специальные символы, необходимо заключить его в квадратные скобки.
Замените поле именем индексируемого поля. Если имя поля содержит пробелы или специальные символы, необходимо заключить его в квадратные скобки.
Сохраните и закройте запрос.
Выполните запрос, чтобы создать индекс. Обратите внимание, что вы можете выполнить запрос из макроса с помощью макрокоманды ЗапускЗапросаSQL.
Не обнаружен уникальный индекс
Доброго времени суток!
В акцессе работаю 1 день, помогите разобратсья с парочкой проблем и советами..
(сразу говорю, чтобы не думали что прошу сделать за меня и это не задание в институте, просто делаю для себя и прошу помощи)
Введение в суть БД:
Не обнаружен уникальный индекс
Как можно связать дату с датой, Н рейса с Н рейса?
Не обнаружен уникальный индекс
Создаю базу данных ( работа по учебе ). Создано и заполнено 8 таблиц. Но на шаге создания схемы.
Не обнаружен уникальный индекс
CREATE TABLE TypeSpis( + Integer PRIMARY KEY, + .
Не обнаружен уникальный индекс
Всем доброго вечера! В общем, делал лабораторную по базам данных и наткнулся на ошибку во время.
1. Составные ключи однозначно фтопку: уникальным ключом должно быть поле счётчика, связанное с ним — числовое длинное целое (по крайней мере здесь в большинстве случаев принято так).
Каскадное удаление заодно туда же. При современных мощностях, ресурсах (очевидно опережающих спрос на такой объём, скорость и т.д.), предоставляемых производителями даже средних (и даже «слабых») машин, удалять что-либо неразумно: сейчас каждый палаточник-чебуречник пишет всё и имеет возможность хранить всё мультимедиа, взятое посредством его «ведётся наблюдение».
Добавлено через 5 минут
2. Связи между таблицами делаем только в Схеме данных, никаких подстановок в таблицах (это баг Микрософта, подобный автозапуску флэшек): однозначно потом будете переделывать эту околесицу (поиск по Форуму: Поля подстановок в таблицах)
Добавлено через 30 минут
3. Развитие Аксесс остановилось с выходом версии 2003; после него — почти только так наз «плюшки», больше мешающие нормальной работе, чем ей способствующие.
«Остановилось» — это не в негативном смысле, но, как я уже упомянул, по объективным (реальным) причинам: потому что фактически уже тогда был полностью решён вопрос потребностей в организации необходимого функционала по учётурасчёту деятельности как однопользовательских (индивидуальных, «под себя») систем, так и многопользовательских уровня малого (и даже среднего) бизнеса.
Магистральное направление сейчас — это взаимодействие пользователей не посредством локального, но вэб-интерфейса. Но на практике он, во-первых, пока мало приживается, во-вторых, очень мало спецов, умеющих его качественно делать, в третьих, ещё меньше заказчиков, которые в состоянии объяснить его необходимость и дать взвешенное технич задание на его исполнение. И это длится уже, наверное, год третий, и пока мало сдвигается с места. Реально.
Ещё раз: практически все фундаментальные практические решения (и не только в Аксе: для примера, Вай Фай и т.д.) внедрены ещё в самом начале нулевых и не имеют пока революционного продолжения, за исключением всяких мультимедийных плюшек (например, цифровое, интернет-тв и проч безтолковщина. )
MS Access: оптимизация индекса
Допустим, у нас есть таблица [оценки], содержащая несколько значений на дату и на фонд:
-FundId
-ValDate
— Значение 1
-Значение2.
Первичный ключ, очевидно, FundId+ValDate.
Я также индексировал поле ValDate, так как я часто запрашиваю значения на определенную дату.
Мой вопрос: Должен ли я также создать определенный индекс для FundId, или MsAccess достаточно умен, чтобы использовать первичный ключ при запросе на определенный FundId ?
2 Ответа
Первичный ключ-это очевидно FundId + ValDate
В каком порядке? И как вы получаете доступ к своим данным?
Компонент Access Database Engine использует PRIMARY KEY в качестве кластеризованного индекса. Если бы ты это сделал
PRIMARY KEY (FundId, ValDate)
тогда вы получите другой порядок на диске, чем если бы вы сделали это
PRIMARY KEY (ValDate, FundId)
Чтобы показать порядок столбцов в PK при использовании Access GUI (если вы не использовали SQL DDL для создания PRIMARY KEY ): в режиме конструктора таблиц нажмите кнопку индексы или включите индексы в меню Вид. В списке будут показаны все индексы, а для нескольких полей-порядок, который можно изменить.
Порядок столбцов в кластеризованном индексе важен, поскольку он определяет один и единственный физический индекс для таблицы, так сказать, ваш индекс uber.
(ValDate, FundId) предпочтет BETWEEN (или эквивалентные) предикаты или GROUP BY на ValDate , например, запросы диапазона дат, возвращающие несколько средств.
(FundId, ValDate) бывшие могут поддержать конкретные запросы фонда . или может стимулировать блокировку страниц, в зависимости от того, как генерируются значения.
Теперь у вас должно сложиться впечатление, что с проблемами производительности связано много переменных: как был определен PK, генерация ключевых значений, как часто вы сжимаете файл, ваша стратегия блокировки (например, уровень страницы или уровень строки?), высокая или низкая окружающая среда деятельности, etc. Не говоря уже о характере запросов, которые вы выполняете к таблице (например, по дате или по ключу?)
вы уверены, что Access поддерживает кластеризацию индексы ?
Конечно, и вот некоторые заметные статьи о MSDN:
Новые возможности в Microsoft Jet версии 3.0 » сжатие базы данных теперь приводит к тому, что индексы хранятся в формате кластеризованных индексов. Хотя кластеризованный индекс не поддерживается до следующего компакта, производительность все равно повышается. Это отличается от Microsoft Jet 2.x, где строки данных хранились так, как они были введены. Новый метод компактного кластерного ключа основан на первичном ключе таблицы. Новые введенные данные будут располагаться во временном порядке.»
Дефрагментация и сжатие базы данных для повышения производительности в Microsoft Access » если первичный ключ существует в таблице, сжатие восстанавливает записи таблицы в их первичном порядке ключей. Это обеспечивает эквивалент не поддерживаемым кластеризованным индексам и делает возможности опережающего чтения компонента Microsoft Jet database engine намного более эффективными. Скорость выполнения запросов будет значительно увеличена, поскольку теперь они работают с данными, которые были переписаны в таблицы на смежных страницах. Сканирование последовательных страниц происходит гораздо быстрее, чем сканирование фрагментированных страниц.»
Как оптимизировать запросы в Visual Basic » в этой статье предполагается, что вы используете компонент Microsoft Jet database engine. По мере роста вашей базы данных она будет фрагментироваться. Сжатие записывает все данные в таблице в непрерывные страницы на жестком диске, повышая производительность последовательного сканирования.»
Информация о производительности запросов в базе данных Access «при сжатии базы данных можно ускорить выполнение запросов. При сжатии базы данных записи таблицы реорганизуются таким образом, чтобы они располагались на соседних страницах базы данных, упорядоченных по первичному ключу таблицы. Это повышает производительность последовательного сканирования записей в таблице, поскольку теперь для извлечения нужных записей требуется прочитать только минимальное количество страниц базы данных.»
Нет необходимости ставить индекс на столбец FundId. Доступ достаточно умен, чтобы использовать PK в описанной вами ситуации.
BTW, является ли FundId уникальным? Если это так, то нет необходимости включать и ValDate.
Похожие вопросы:
У меня есть небольшая дилемма о рабочем задании, которое я получил. Я являюсь помощником студента неполный рабочий день в этом учреждении, где мой босс хочет, чтобы я fix базы данных MS-Access у нас.
Мне нужно использовать Python ORM с базой данных MS-Access (в Windows). Мои первые поиски на самом деле не увенчались успехом : SQLAlchemy : нет поддержки MS Access в двух последних версиях. DAL от.
Я борюсь с оптимизацией индекса MySQL для некоторых запросов, которые должны быть простыми, но занимают вечность. Вместо того, чтобы публиковать конкретную проблему, я хотел бы спросить, есть ли.
Мы всегда используем индекс для оптимизации DB. Но что такое индексная оптимизация? в чем заключается сложность индексации? Нужна ли нам оптимизация индекса? Как нам это сделать в mysql году? Это.
У нас есть клиент, который имеет требование создать экспорт данных в базах данных MS Access. В настоящее время планируется использовать платформу Azure в качестве сервиса, который не позволит.
Может ли кто-нибудь помочь мне отсортировать и упорядочить диаграмму Pivot в MS-Access, пожалуйста. Я мог бы сделать это легко в MS-Excel, но не в MS — Access. Мне нужен разрыв между каждой задачей.
как открыть файл ms access 2007 в ms access 2003
Я пытаюсь вставить запись в таблицу с DAO (в MS-Access) и делаю это, я получаю ошибку 3022 (которая указывает, что уникальный индекс нарушен). Ошибка верна, так как на самом деле запись.
Я только начал использовать MS Access в качестве базы данных, и теперь моя проблема заключается в том, как отобразить мою фамилию и имя в сочетании как Name . Вот мой код MySQL: CONCAT(Surname, ‘.
Есть ли способ открыть отчет MS Access 2007, не открывая сам MS Access DB? У меня есть несколько отчетов в моем MS Access DB, который расположен в своего рода серверном компьютере. Некоторым людям.
Создание индекса для одного поля
Создание и использование индекса
Для увеличения производительности
Если необходимо постоянно выполнять поиск в таблице или сортировать записи по определенному полю, можно ускорить эти операции, создав индекс для этого поля. В таблицах Microsoft Office Access 2007 индексы используются точно так же, как предметные или именные указатели в книгах. Чтобы найти данные, Office Access 2007 проверяет местоположение этих данных по индексу. В некоторых случаях, например при определении первичного ключа, Access формирует индекс автоматически. В других случаях самому пользователю может потребоваться создание индекса.
Общие сведения об индексах.Индексы способствуют более быстрым поиску и сортировке записей в Microsoft Office Access 2007. В индексе хранится местоположение записей на основе одного или нескольких полей, которые были выбраны для индексирования. После того как Access получает сведения о местоположении данных, эти данные могут загружаться путем перемещения в нужное местоположение. Благодаря этому использование индекса гораздо эффективнее просмотра всех записей для поиска необходимых данных.
Выбор полей для индексирования.Можно создавать индексы, основанные на одном или нескольких полях. В основном требуется индексировать поля, в которых часто осуществляется поиск, сортируемые поля и поля, объединенные с полями в других таблицах, что часто используется в запросах по нескольким таблицам. Индексы ускоряют поиск и построение запросов, однако они могут привести и к снижению производительности при добавлении или обновлении данных. При вводе данных в таблицу, содержащую один или несколько индексов, приложение Access должно обновлять индексы при каждом добавлении или изменении записи. Добавление записей с помощью запроса на добавление или с помощью импортирования записей также будет происходить более медленно, если таблица-получатель содержит индексы.
Примечание. Первичный ключ таблицы индексируется автоматически. Индексирование полей с типом данных «Объект OLE» и «Вложение» невозможно. Индексировать другие поля следует в тех случаях, когда одновременно выполняются следующие условия:
— типом данных поля является «Текстовый», «Поле Memo», «Числовой», «Дата/время», «Счетчик», «Денежный», «Логический» или «Гиперссылка»;
— предполагается поиск значений в поле;
— предполагается сортировка значений в поле;
— предполагается сортировка большого числа различных значений в поле. Если поле содержит много одинаковых значений, то применение индекса незначительно ускорит выполнение запросов.
Составные индексы.Если предполагается частое выполнение одновременной сортировки или одновременного поиска в нескольких полях, можно создать для этих полей составной индекс. Например, если в одном и том же запросе задаются условия для полей «Студенты» и «Название предмета», то для этих двух полей имеет смысл создать составной индекс.
При сортировке таблицы по составному индексу Access сначала выполняет сортировку по первому полю, определенному для данного индекса. Последовательность полей определяется при создании составного индекса. Если в первом поле содержатся записи с повторяющимися значениями, то выполняется сортировка по второму полю, определенному для данного индекса, и т. д.
В составной индекс можно включить до 10 полей.
Создание индекса
Перед созданием индекса необходимо решить, следует ли создать индекс для одного поля или составной индекс. Индекс для одного поля создается с помощью установки свойства Индексированное поле. В следующей таблице приведены возможные параметры свойства Индексированное поле.
НЕ ОБНАРУЖЕН УНИКАЛЬНЫЙ ИНДЕКС ДЛЯ АДРЕСУЕМОГО ПОЛЯ ГЛАВНОЙ ТАБЛИЦЫ
Всем привет, друзья! Если вы читаете этот текст, значит вы столкнулись со следующей проблемой. При связывании двух таблиц, при выставлении «обеспечение целостности данных», вы получаете следующую ошибку «не обнаружен уникальный индекс для адресуемого поля главной таблицы» в базе данных Microsoft Access. Давайте, я покажу как избежать появление такой ошибки.
Ссылка

Ответ:
Надо было привести свойства и структура таблицы ном_накл. Но вообще, подобные страсти Аксесс пишет, когда в поле, ко которому хотите установить связь, имеюся неуникальные данные. В этом случае происходит дублирование индекса (который суть всего лишь простая функция от набора полей), а для той связи, которую Вы пытаетесь создать, индекс должен быть уникальным. Большего, увы, по приведенным данным сказать нельзя.
|
|
|
|



Работа со связаными таблицами
, Как лучше всего организовать сабж
- Подписаться на тему
- Сообщить другу
- Скачать/распечатать тему
|
|
|
|
Я делаю прогу с БД. Структуру БД делал в Access. Для доступа к БД использую ADO. Там есть связаные таблицы. К примеру их 3. Я их связывал программно. Сделал три отдельных цепочки ADODataSet->ADODataSource->DBGrid. Что бы реализовать связь я отображаю одну таблицу и обрабатываю событие onDataChange для DataSource связаного с этим гридом. В этом обработчике опререляю выбранную запись и для этой записи делаю SQL запрос «SELECT» что-бы отобразить соответствующие записи из второй таблицы. Такое же событие я обрабатываю и во второй таблице. Вот такая связь ручками Добавлено 01.08.05, 15:24
if(MessageBox(0,’Удалять связаные элементы?’ ,’Удаление’,MB_YESNO or MB_ICONQUESTION)=IDYES) then begin ADODataSetLL.Active:=false; ADODataSetLL.CommandText:=’DELETE * FROM TableLineLow WHERE Name=»‘+sTSnum+ ‘» AND NumKSO=’+IntToStr(iCurBoxLV)+’ AND NumKS=’+IntToStr(iCurKS); ShowMessage(ADODataSetLL.CommandText); ADODataSetLL.Open; end; Но выскакивае ошибка исполнения: Цитата Текущий проводник не поддерживает возврат нескольких наборов записей в результате одной операции. Не пойму какие еще несколько наборов?! Я просто хочу удалить записи. Что я неправильно делаю? |
 . Нет ли в Дельфи какого нииь автоматизированного способа? Ведь мне придется и удалять элементы из двух первых таблиц и в связи с этим удалять связаные с ними элементы в третьей. Мне идти по моему ручному пути? Или есть что-то изящнее?
. Нет ли в Дельфи какого нииь автоматизированного способа? Ведь мне придется и удалять элементы из двух первых таблиц и в связи с этим удалять связаные с ними элементы в третьей. Мне идти по моему ручному пути? Или есть что-то изящнее? 

|
BigMaK |
|
|
Для исполнение команды DELETE лучше использовать: Удалять из связанных таблиц, лично я так делаю, нужно ручками, а вот связь делается следующим образом: |
|
DDX |
|
|
Junior
Рейтинг (т): 0 |
отображение данных в подчиненном датасорсе можно сделать так, как сказал бигмак |


|
BigMaK |
|
|
А связь ведь делается программно, в Access’е только сами таблицы. Или я что-то не так понял? |
Bas |
|
|
Цитата DDX @ 02.08.05, 10:16 выставив там свойство «Каскадное удаление» у связи между таблицами. Цитата SexGenius @ 01.08.05, 15:16 Но выскакивае ошибка исполнения: Цитата Кажеться копать надо в эту сторону. |
|
BigMaK |
|
|
Цитата Кажеться копать надо в эту сторону. То есть? Как раз с этим сообщением все ясно: нужно не открывать,а исполнять запрос. |
Bas |
|
|
Цитата BigMaK @ 02.08.05, 12:02 нужно не открывать,а исполнять запрос
Полу правда, посмотри исходник.
Ошибка создания дескриптора курсора или Error creating cursor handle |
|
DDX |
|
|
Junior
Рейтинг (т): 0 |
Цитата BigMaK @ 02.08.05, 10:22 А связь ведь делается программно, в Access’е только сами таблицы. Или я что-то не так понял? см. первый пост Цитата Структуру БД делал в Access |
|
IzumeRoot |
|
|
Возможно я немножко запутал вас своей неправильной формулировкой. Связь таблиц в Ассесе я не делал. В нем я сделал лишь сами таблицы и не связывал их. Делал связь программно. Сейчас я понимаю что мне повезло — именно программно мне и надо делать связь, т.к. у программы будет иная логика по удалению записей. Связаные записи будут удаляться по согласию пользователя. Если пользователь ответит «нет», то в записях будут просто меняться кое какие поля (тоесть они будут связываться с другими объектами). Однако приятно что связь можно было реализовать в самом Ассесе. Это действительно будет работать? Кто-то уже делал подобное? Добавлено 02.08.05, 14:33 Цитата BigMaK, 01.08.2005, 20:51:54, 792457 Для исполнение команды DELETE лучше использовать:
Спасибо за совет. Правда в TADODataSet я не нашел метода ExecSQL, но зато я нашел его в TADOQuery. Удаление у меня получилось |
|
DDX |
|
|
Junior
Рейтинг (т): 0 |
Цитата Однако приятно что связь можно было реализовать в самом Ассесе. Это действительно будет работать? Кто-то уже делал подобное? я делал, действительно будет работать. только свою логику удаления связанных записей уже не реализуешь, по-моему. Сообщение отредактировано: DDX — 04.08.05, 09:00 |
|
IzumeRoot |
|
|
Я УСё понял. Спасибо всем! я счиатю вопрос решен. |
|
IzumeRoot |
|
|
Цитата DDX @ 04.08.05, 08:58 я делал, действительно будет работать. только свою логику удаления связанных записей уже не реализуешь, по-моему.
Тут такая проблема. В одной части моей проги реализовывать свою логику удаления неразумно. И вот в этой части я решил связать таблицы в Ассесе. Ну вот почитал хелп, начал делать как там написано и ничего не получается. Есть таблица — Шкаф, и есть несколько таблиц Аппарат1, Аппарат2, Аппарат3 … АппаратN. Во всех таблицах есть поле НомерШкафа. Я хочу сделать так Читал я этот тугой Аксессовский хелп. Делал так : Цитата Обнаружен повторяющийся индекс в адресуемом поле главной таблицы. (Ошибка 3609) И что то нифига я не пойму как же заставить это работать. Почему не работает? Добавлено 29.08.05, 08:32 |
Bas |
|
|
Тебе нужен Primary Key на таблицу шкафы и там не должно быть два одинаковых номера шкафа. Цитата SexGenius @ 29.08.05, 08:26 Поле НомераШкафа индексированое во всех таблицах. В главной таблице он должен быть еще и уникальный. |
|
IzumeRoot |
|
|
Цитата Bas, 29.08.2005, 12:34:25, 839968 и там не должно быть два одинаковых номера шкафа.
А как же сделать чтобы работало с повторяющимися номерами шкафа в таблице Шкафы ? У меня в таблице Шкафы они будут повторяться, так как там еще есть поле Здание. И в Аппаратах есть поле Здание. |
0 пользователей читают эту тему (0 гостей и 0 скрытых пользователей)
0 пользователей:
- Предыдущая тема
- Delphi: Базы данных
- Следующая тема
[ Script execution time: 0,0956 ] [ 16 queries used ] [ Generated: 25.06.23, 00:41 GMT ]