Время на прочтение
5 мин
Количество просмотров 82K
В первой части были рассмотрены: структура, топология, функции активации и обучающее множество. В этой части попробую объяснить как происходит обучение сверточной нейронной сети.
Обучение сверточной нейронной сети
На начальном этапе нейронная сеть является необученной (ненастроенной). В общем смысле под обучением понимают последовательное предъявление образа на вход нейросети, из обучающего набора, затем полученный ответ сравнивается с желаемым выходом, в нашем случае это 1 – образ представляет лицо, минус 1 – образ представляет фон (не лицо), полученная разница между ожидаемым ответом и полученным является результат функции ошибки (дельта ошибки). Затем эту дельту ошибки необходимо распространить на все связанные нейроны сети.
Таким образом обучение нейронной сети сводится к минимизации функции ошибки, путем корректировки весовых коэффициентов синаптических связей между нейронами. Под функцией ошибки понимается разность между полученным ответом и желаемым. Например, на вход был подан образ лица, предположим, что выход нейросети был 0.73, а желаемый результат 1 (т.к. образ лица), получим, что ошибка сети является разницей, то есть 0.27. Затем веса выходного слоя нейронов корректируются в соответствии с ошибкой. Для нейронов выходного слоя известны их фактические и желаемые значения выходов. Поэтому настройка весов связей для таких нейронов является относительно простой. Однако для нейронов предыдущих слоев настройка не столь очевидна. Долгое время не было известно алгоритма распространения ошибки по скрытым слоям.
Алгоритм обратного распространения ошибки
Для обучения описанной нейронной сети был использован алгоритм обратного распространения ошибки (backpropagation). Этот метод обучения многослойной нейронной сети называется обобщенным дельта-правилом. Метод был предложен в 1986 г. Румельхартом, Макклеландом и Вильямсом. Это ознаменовало возрождение интереса к нейронным сетям, который стал угасать в начале 70-х годов. Данный алгоритм является первым и основным практически применимым для обучения многослойных нейронных сетей.
Для выходного слоя корректировка весов интуитивна понятна, но для скрытых слоев долгое время не было известно алгоритма. Веса скрытого нейрона должны изменяться прямо пропорционально ошибке тех нейронов, с которыми данный нейрон связан. Вот почему обратное распространение этих ошибок через сеть позволяет корректно настраивать веса связей между всеми слоями. В этом случае величина функции ошибки уменьшается и сеть обучается.
Основные соотношения метода обратного распространения ошибки получены при следующих обозначениях:

Величина ошибки определяется по формуле 2.8 среднеквадратичная ошибка:

Неактивированное состояние каждого нейрона j для образа p записывается в виде взвешенной суммы по формуле 2.9:

Выход каждого нейрона j является значением активационной функции
 , которая переводит нейрон в активированное состояние. В качестве функции активации может использоваться любая непрерывно дифференцируемая монотонная функция. Активированное состояние нейрона вычисляется по формуле 2.10:
, которая переводит нейрон в активированное состояние. В качестве функции активации может использоваться любая непрерывно дифференцируемая монотонная функция. Активированное состояние нейрона вычисляется по формуле 2.10:

В качестве метода минимизации ошибки используется метод градиентного спуска, суть этого метода сводится к поиску минимума (или максимума) функции за счет движения вдоль вектора градиента. Для поиска минимума движение должно быть осуществляться в направлении антиградиента. Метод градиентного спуска в соответствии с рисунком 2.7.

Градиент функции потери представляет из себя вектор частных производных, вычисляющийся по формуле 2.11:
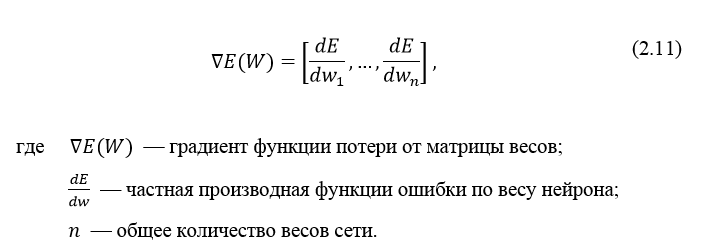
Производную функции ошибки по конкретному образу можно записать по правилу цепочки, формула 2.12:

Ошибка нейрона  обычно записывается в виде символа δ (дельта). Для выходного слоя ошибка определена в явном виде, если взять производную от формулы 2.8, то получим t минус y, то есть разницу между желаемым и полученным выходом. Но как рассчитать ошибку для скрытых слоев? Для решения этой задачи, как раз и был придуман алгоритм обратного распространения ошибки. Суть его заключается в последовательном вычислении ошибок скрытых слоев с помощью значений ошибки выходного слоя, т.е. значения ошибки распространяются по сети в обратном направлении от выхода к входу.
обычно записывается в виде символа δ (дельта). Для выходного слоя ошибка определена в явном виде, если взять производную от формулы 2.8, то получим t минус y, то есть разницу между желаемым и полученным выходом. Но как рассчитать ошибку для скрытых слоев? Для решения этой задачи, как раз и был придуман алгоритм обратного распространения ошибки. Суть его заключается в последовательном вычислении ошибок скрытых слоев с помощью значений ошибки выходного слоя, т.е. значения ошибки распространяются по сети в обратном направлении от выхода к входу.
Ошибка δ для скрытого слоя рассчитывается по формуле 2.13:

Алгоритм распространения ошибки сводится к следующим этапам:
- прямое распространение сигнала по сети, вычисления состояния нейронов;
- вычисление значения ошибки δ для выходного слоя;
- обратное распространение: последовательно от конца к началу для всех скрытых слоев вычисляем δ по формуле 2.13;
- обновление весов сети на вычисленную ранее δ ошибки.
Алгоритм обратного распространения ошибки в многослойном персептроне продемонстрирован ниже:
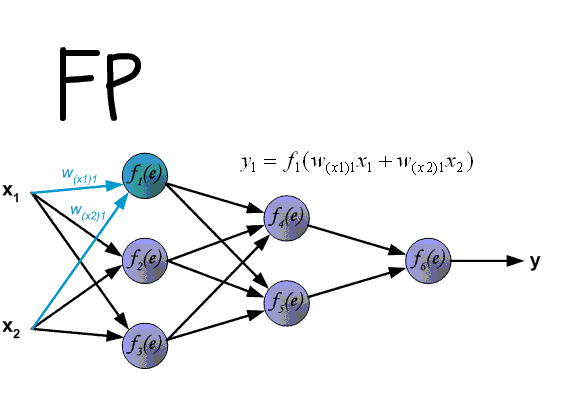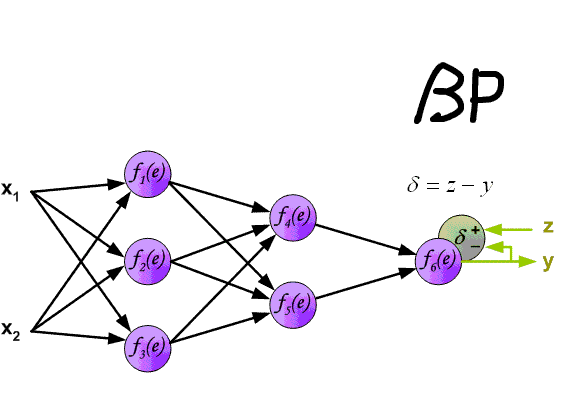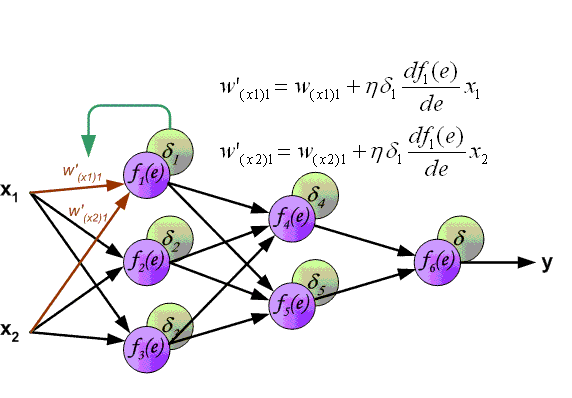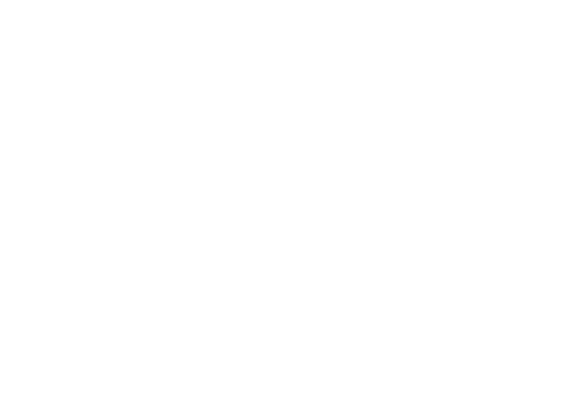
До этого момента были рассмотрены случаи распространения ошибки по слоям персептрона, то есть по выходному и скрытому, но помимо них, в сверточной нейросети имеются подвыборочный и сверточный.
Расчет ошибки на подвыборочном слое
Расчет ошибки на подвыборочном слое представляется в нескольких вариантах. Первый случай, когда подвыборочный слой находится перед полносвязным, тогда он имеет нейроны и связи такого же типа, как в полносвязном слое, соответственно вычисление δ ошибки ничем не отличается от вычисления δ скрытого слоя. Второй случай, когда подвыборочный слой находится перед сверточным, вычисление δ происходит путем обратной свертки. Для понимания обратно свертки, необходимо сперва понять обычную свертку и то, что скользящее окно по карте признаков (во время прямого распространения сигнала) можно интерпретировать, как обычный скрытый слой со связями между нейронами, но главное отличие — это то, что эти связи разделяемы, то есть одна связь с конкретным значением веса может быть у нескольких пар нейронов, а не только одной. Интерпретация операции свертки в привычном многослойном виде в соответствии с рисунком 2.8.
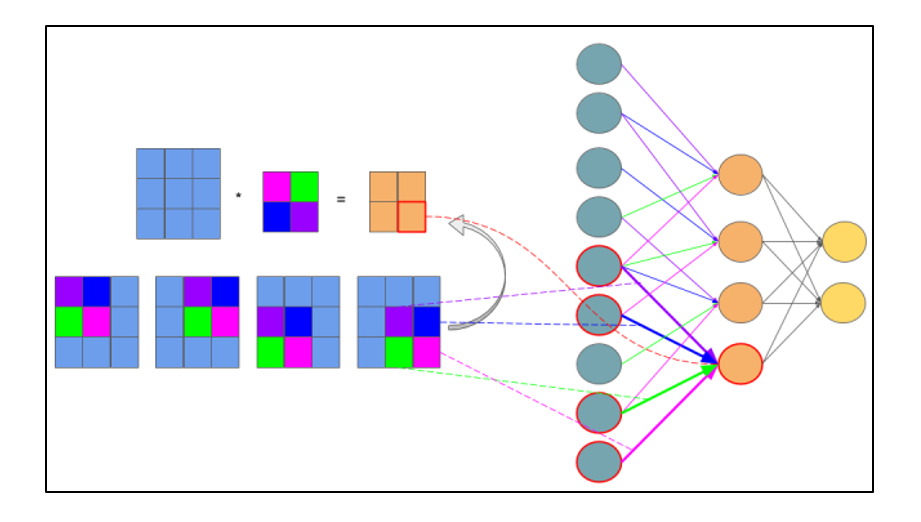
Рисунок 2.8 — Интерпретация операции свертки в многослойный вид, где связи с одинаковым цветом имеют один и тот же вес. Синим цветом обозначена подвыборочная карта, разноцветным – синаптическое ядро, оранжевым – получившаяся свертка
Теперь, когда операция свертки представлена в привычном многослойном виде, можно интуитивно понять, что вычисление дельт происходит таким же образом, как и в скрытом слое полносвязной сети. Соответственно имея вычисленные ранее дельты сверточного слоя можно вычислить дельты подвыборочного, в соответствии с рисунком 2.9.
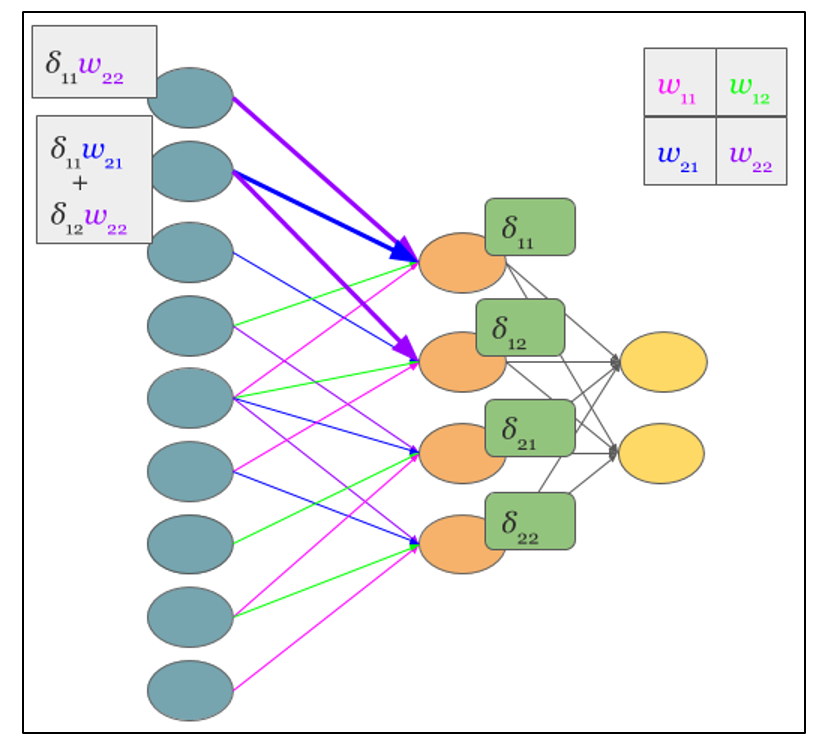
Рисунок 2.9 — Вычисление δ подвыборочного слоя за счет δ сверточного слоя и ядра
Обратная свертка – это тот же самый способ вычисления дельт, только немного хитрым способом, заключающийся в повороте ядра на 180 градусов и скользящем процессе сканирования сверточной карты дельт с измененными краевыми эффектами. Простыми словами, нам необходимо взять ядро сверточной карты (следующего за подвыборочным слоем) повернуть его на 180 градусов и сделать обычную свертку по вычисленным ранее дельтам сверточной карты, но так чтобы окно сканирования выходило за пределы карты. Результат операции обратной свертки в соответствии с рисунком 2.10, цикл прохода обратной свертки в соответствии с рисунком 2.11.

Рисунок 2.10 — Результат операции обратной свертки
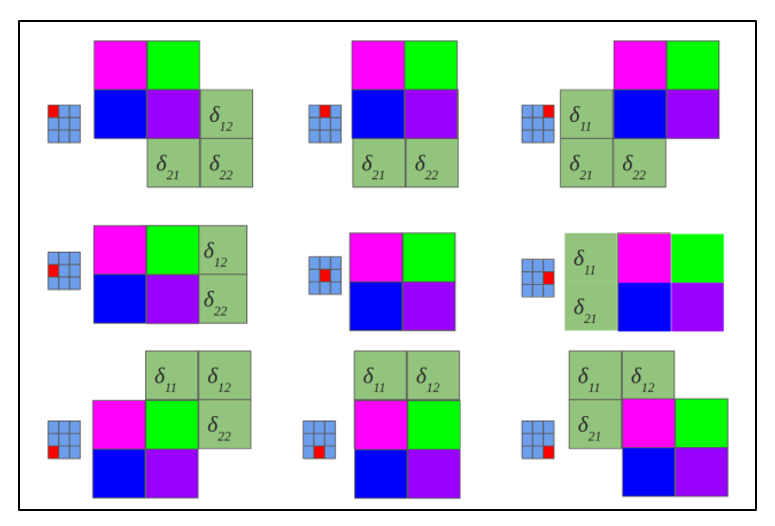
Рисунок 2.11 — Повернутое ядро на 180 градусов сканирует сверточную карту
Расчет ошибки на сверточном слое
Обычно впередиидущий слой после сверточного это подвыборочный, соответственно наша задача вычислить дельты текущего слоя (сверточного) за счет знаний о дельтах подвыборочного слоя. На самом деле дельта ошибка не вычисляется, а копируется. При прямом распространении сигнала нейроны подвыборочного слоя формировались за счет неперекрывающегося окна сканирования по сверточному слою, в процессе которого выбирались нейроны с максимальным значением, при обратном распространении, мы возвращаем дельту ошибки тому ранее выбранному максимальному нейрону, остальные же получают нулевую дельту ошибки.
Заключение
Представив операцию свертки в привычном многослойном виде (рисунок 2.8), можно интуитивно понять, что вычисление дельт происходит таким же образом, как и в скрытом слое полносвязной сети.
Источники
Алгоритм обратного распространения ошибки для сверточной нейронной сети
Обратное распространение ошибки в сверточных слоях
раз и два
Обратное распространение ошибки в персептроне
Еще можно почитать в РГБ диссертацию Макаренко: АЛГОРИТМЫ И ПРОГРАММНАЯ СИСТЕМА КЛАССИФИКАЦИИ
Рад снова всех приветствовать, и сегодня продолжим планомерно двигаться в выбранном направлении. Речь, конечно, о масштабном разборе искусственных нейронных сетей для решения широкого спектра задач. Продолжим ровно с того момента, на котором остановились в предыдущей части, и это означает, что героем данного поста будет ключевой процесс — обучение нейронных сетей.
- Градиентный спуск
- Функция ошибки
- Метод обратного распространения ошибки
- Пример расчета
Тема эта крайне важна, поскольку именно процесс обучения позволяет сети начать выполнять задачу, для которой она, собственно, и предназначена. То есть нейронная сеть функционирует не по какому-либо жестко заданному на этапе проектирования алгоритму, она совершенствуется в процессе анализа имеющихся данных. Этот процесс и называется обучением нейронной сети. Математически суть процесса обучения заключается в корректировке значений весов синапсов (связей между имеющимися нейронами). Изначально значения весов задаются случайно, затем производится обучение, результатом которого будут новые значения синаптических весов. Это все мы максимально подробно разберем как раз в этой статье.
На своем сайте я всегда придерживаюсь концепции, при которой теоретические выкладки по максимуму сопровождаются практическими примерами для максимальной наглядности. Так мы поступим и сейчас 👍
Итак, суть заключается в следующем. Пусть у нас есть простейшая нейронная сеть, которую мы хотим обучить (продолжаем рассматривать сети прямого распространения):

То есть на входы нейронов I1 и I2 мы подаем какие-либо числа, а на выходе сети получаем соответственно новое значение. При этом нам необходима некая выборка данных, включающая в себя значения входов и соответствующее им, правильное, значение на выходе:
| bold{I_1} | bold{I_2} | bold{O_{net}} |
|---|---|---|
| x_{11} | x_{12} | y_{1} |
| x_{21} | x_{22} | y_{2} |
| x_{31} | x_{32} | y_{3} |
| … | … | … |
| x_{N1} | x_{N2} | y_{N} |
Допустим, сеть выполняет суммирование значений на входе, тогда данный набор данных может быть таким:
| bold{I_1} | bold{I_2} | bold{O_{net}} |
|---|---|---|
| 1 | 4 | 5 |
| 2 | 7 | 9 |
| 3 | 5 | 8 |
| … | … | … |
| 1000 | 1500 | 2500 |
Эти значения и используются для обучения сети. Как именно — рассмотрим чуть ниже, пока сконцентрируемся на идее процесса в целом. Для того, чтобы иметь возможность тестировать работу сети в процессе обучения, исходную выборку данных делят на две части — обучающую и тестовую. Пусть имеется 1000 образцов, тогда можно 900 использовать для обучения, а оставшиеся 100 — для тестирования. Эти величины взяты исключительно ради наглядности и демонстрации логики выполнения операций, на практике все зависит от задачи, размер обучающей выборки может спокойно достигать и сотен тысяч образцов.
Итак, итог имеем следующий — обучающая выборка прогоняется через сеть, в результате чего происходит настройка значений синаптических весов. Один полный проход по всей выборке называется эпохой. И опять же, обучение нейронной сети — это процесс, требующий многократных экспериментов, анализа результатов и творческого подхода. Все перечисленные параметры (размер выборки, количество эпох обучения) могут иметь абсолютно разные значения для разных задач и сетей. Четкого правила тут просто нет, в этом и кроется дополнительный шарм и изящность )
Возвращаемся к разбору, и в результате прохода обучающей выборки через сеть мы получаем сеть с новыми значениями весов синапсов.
Далее мы через эту, уже обученную в той или иной степени, сеть прогоняем тестовую выборку, которая не участвовала в обучении. При этом сеть выдает нам выходные значения для каждого образца, которые мы сравниваем с теми верными значениями, которые имеем.
Анализируем нашу гипотетическую выборку:

Таким образом, для тестирования подаем на вход сети значения x_{(M+1)1}, x_{(M+1)2} и проверяем, чему равен выход, ожидаем очевидно значение y_{(M+1)}. Аналогично поступаем и для оставшихся тестовых образцов. После чего мы можем сделать вывод, успешно или нет работает сеть. Например, сеть дает правильный ответ для 90% тестовых данных, дальше уже встает вопрос — устраивает ли нас данная точность или процесс обучения необходимо повторить, либо провести заново, изменив какие-либо параметры сети.
В этом и заключается суть обучения нейронных сетей, теперь перейдем к деталям и конкретным действиям, которые необходимо осуществить для выполнения данного процесса. Двигаться снова будем поэтапно, чтобы сформировать максимально четкую и полную картину. Поэтому начнем с понятия градиентного спуска, который используется при обучении по методу обратного распространения ошибки. Обо всем этом далее…
Обучение нейронных сетей. Градиентный спуск.
Рассмотрев идею процесса обучения в целом, на данном этапе мы можем однозначно сформулировать текущую цель — необходимо определить математический алгоритм, который позволит рассчитать значения весовых коэффициентов таким образом, чтобы ошибка сети была минимальна. То есть грубо говоря нам необходима конкретная формула для вычисления:
Здесь Delta w_{ij} — величина, на которую необходимо изменить вес синапса, связывающего нейроны i и j нашей сети. Соответственно, зная это, необходимо на каждом этапе обучения производить корректировку весов связей между всеми элементами нейронной сети. Задача ясна, переходим к делу.
Пусть функция ошибки от веса имеет следующий вид:
Для удобства рассмотрим зависимость функции ошибки от одного конкретного веса:

В начальный момент мы находимся в некоторой точке кривой, а для минимизации ошибки попасть мы хотим в точку глобального минимума функции:
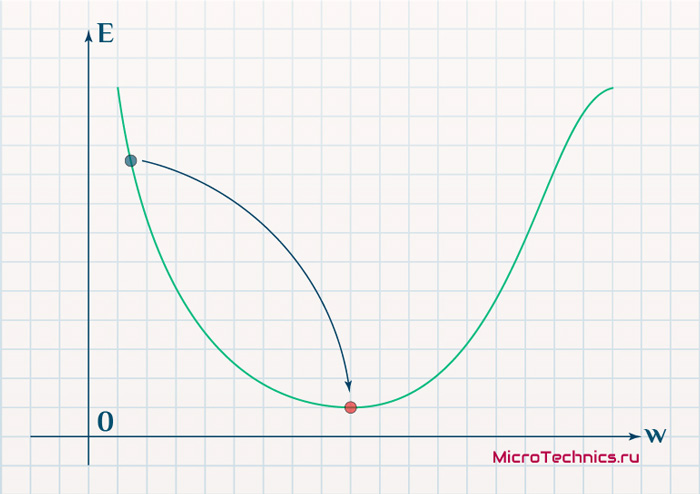
Нанесем на график вектора градиентов в разных точках. Длина векторов численно равна скорости роста функции в данной точке, что в свою очередь соответствует значению производной функции по данной точке. Исходя из этого, делаем вывод, что длина вектора градиента определяется крутизной функции в данной точке:
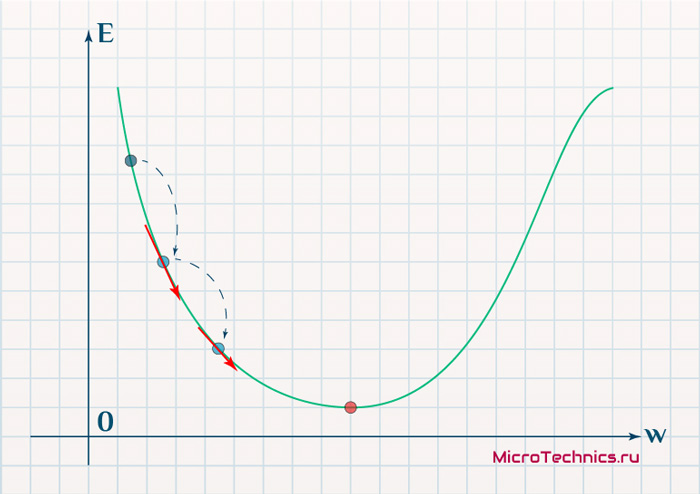
Вывод прост — величина градиента будет уменьшаться по мере приближения к минимуму функции. Это важный вывод, к которому мы еще вернемся. А тем временем разберемся с направлением вектора, для чего рассмотрим еще несколько возможных точек:
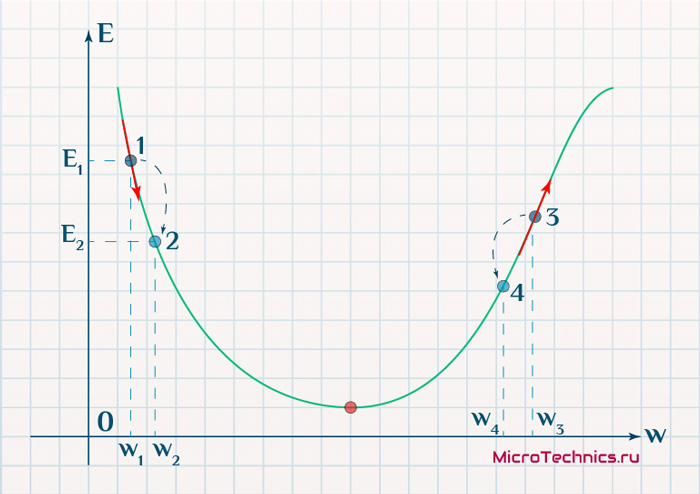
Находясь в точке 1, целью является перейти в точку 2, поскольку в ней значение ошибки меньше (E_2 < E_1), а глобальная задача по-прежнему заключается в ее минимизации. Для этого необходимо изменить величину w на некое значение Delta w (Delta w = w_2 — w_1 > 0). При всем при этом в точке 1 градиент отрицательный. Фиксируем данные факты и переходим к точке 3, предположим, что мы находимся именно в ней.
Тогда для уменьшения ошибки наш путь лежит в точку 4, а необходимое изменение значения: Delta w = w_4 — w_3 < 0. Градиент же в точке 3 положителен. Этот факт также фиксируем.
А теперь соберем воедино эту информацию в виде следующей иллюстрации:
| Переход | bold{Delta w} | Знак bold{Delta w} | Градиент |
|---|---|---|---|
| 1 rArr 2 | w_2 — w_1 | + | — |
| 3 rArr 4 | w_4 — w_3 | — | + |
Вывод напрашивается сам собой — величина, на которую необходимо изменить значение w, в любой точке противоположна по знаку градиенту. И, таким образом, представим эту самую величину в виде:
Delta w = -alpha cdot frac{dE}{dw}
Имеем в наличии:
- Delta w — величина, на которую необходимо изменить значение w.
- frac{dE}{dw} — градиент в этой точке.
- alpha — скорость обучения.
Собственно, логика метода градиентного спуска и заключается в данном математическом выражении, а именно в том, что для минимизации ошибки необходимо изменять w в направлении противоположном градиенту. В контексте нейронных сетей имеем искомый закон для корректировки весов синаптических связей (для синапса между нейронами i и j):
Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}}
Более того, вспомним о важном свойстве, которое мы отдельно пометили. И заключается оно в том, что величина градиента будет уменьшаться по мере приближения к минимуму функции. Что это нам дает? А то, что в том случае, если наша текущая дислокация далека от места назначения, то величина, корректирующая вес связи, будет больше. А это обеспечит скорейшее приближение к цели. При приближении к целевому пункту, величина frac{dE}{dw_{ij}} будет уменьшаться, что поможет нам точнее попасть в нужную точку, а кроме того, не позволит нам ее проскочить. Визуализируем вышеописанное:
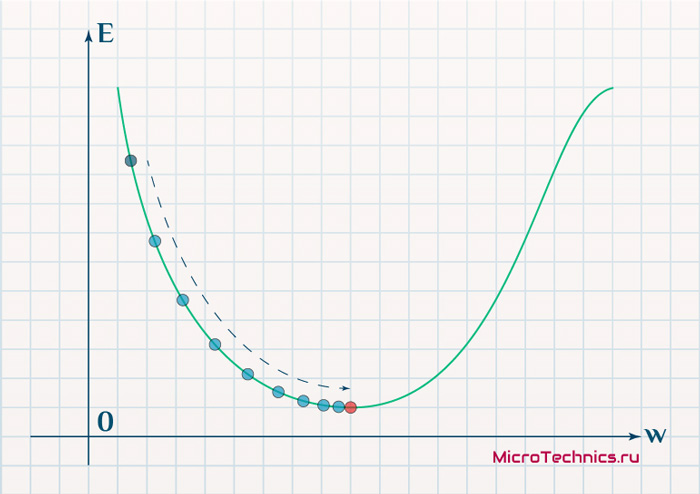
Скорость же обучения несет в себе следующий смысл. Она определяет величину каждого шага при поиске минимума ошибки. Слишком большое значение приводит к тому, что точка может «перепрыгнуть» через нужное значение и оказаться по другую сторону от цели:
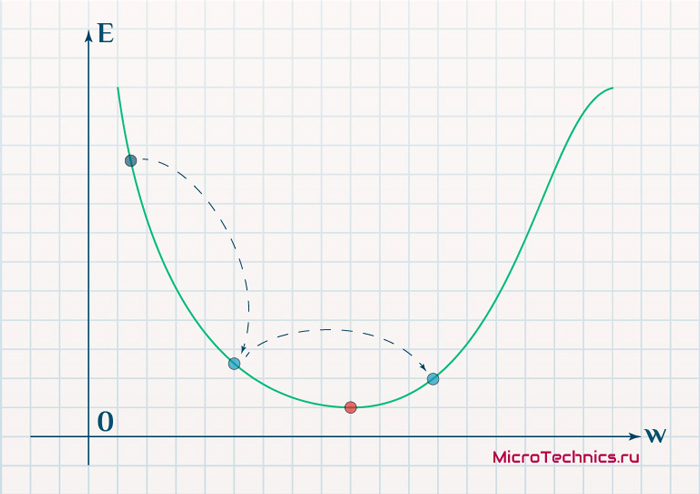
Если же величина будет мала, то это приведет к тому, что спуск будет осуществляться очень медленно, что также является нежелательным эффектом. Поэтому скорость обучения, как и многие другие параметры нейронной сети, является очень важной величиной, для которой нет единственно верного значения. Все снова зависит от конкретного случая и оптимальная величина определяется исключительно исходя из текущих условий.
И даже на этом еще не все, здесь присутствует один важный нюанс, который в большинстве статей опускается, либо вовсе не упоминается. Реальная зависимость может иметь совсем другой вид:
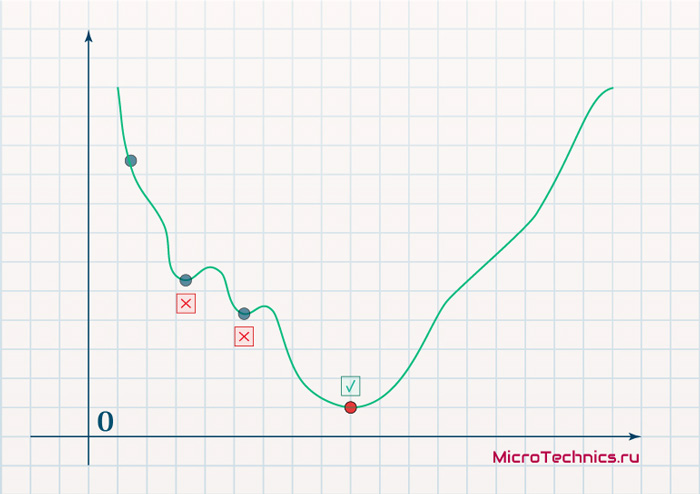
Из чего вытекает потенциальная возможность попадания в локальный минимум, вместо глобального, что является большой проблемой. Для предотвращения данного эффекта вводится понятие момента обучения и формула принимает следующий вид:
Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}} + gamma cdot Delta w_{ij}^{t - 1}
То есть добавляется второе слагаемое, которое представляет из себя произведение момента на величину корректировки веса на предыдущем шаге.
Итого, резюмируем продвижение к цели:
- Нашей задачей было найти закон, по которому необходимо изменять величину весов связей между нейронами.
- Наш результат — Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}} + gamma cdot Delta w_{ij}^{t — 1} — именно то, что и требовалось 👍
И опять же, полученный результат логичным образом перенаправляет нас на следующий этап, ставя вопросы — что из себя представляет функция ошибки, и как определить ее градиент.
Обучение нейронных сетей. Функция ошибки.
Начнем с того, что определимся с тем, что у нас в наличии, для этого вернемся к конкретной нейронной сети. Пусть вид ее таков:
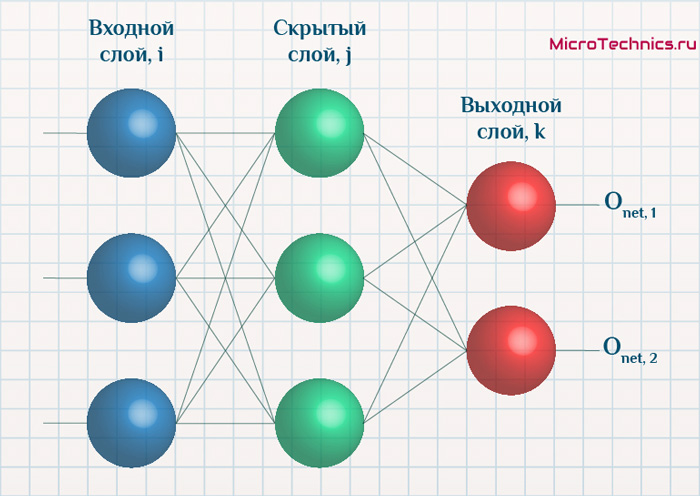
Интересует нас, в первую очередь, часть, относящаяся к нейронам выходного слоя. Подав на вход определенные значения, получаем значения на выходе сети: O_{net, 1} и O_{net, 2}. Кроме того, поскольку мы ведем речь о процессе обучения нейронной сети, то нам известны целевые значения: O_{correct, 1} и O_{correct, 2}. И именно этот набор данных на этом этапе является для нас исходным:
- Известно: O_{net, 1}, O_{net, 2}, O_{correct, 1} и O_{correct, 2}.
- Необходимо определить величины Delta w_{ij} для корректировки весов, для этого нужно вычислить градиенты (frac{dE}{dw_{ij}}) для каждого из синапсов.
Полдела сделано — задача четко сформулирована, начинаем деятельность по поиску решения.
В плане того, как определять ошибку, первым и самым очевидным вариантом кажется простая алгебраическая разность. Для каждого из выходных нейронов:
E_k = O_{correct, k} - O_{net, k}
Дополним пример числовыми значениями:
| Нейрон | bold{O_{net}} | bold{O_{correct}} | bold{E} |
|---|---|---|---|
| 1 | 0.9 | 0.5 | -0.4 |
| 2 | 0.2 | 0.6 | 0.4 |
Недостатком данного варианта является то, что в том случае, если мы попытаемся просуммировать ошибки нейронов, то получим:
E_{sum} = e_1 + e_2 = -0.4 + 0.4 = 0
Что не соответствует действительности (нулевая ошибка, говорит об идеальной работе нейронной сети, по факту оба нейрона дали неверный результат). Так что вариант с разностью откидываем за несостоятельностью.
Вторым, традиционно упоминаемым, методом вычисления ошибки является использование модуля разности:
E_k = | O_{correct, k} - O_{net, k} |
Тут в действие вступает уже проблема иного рода:
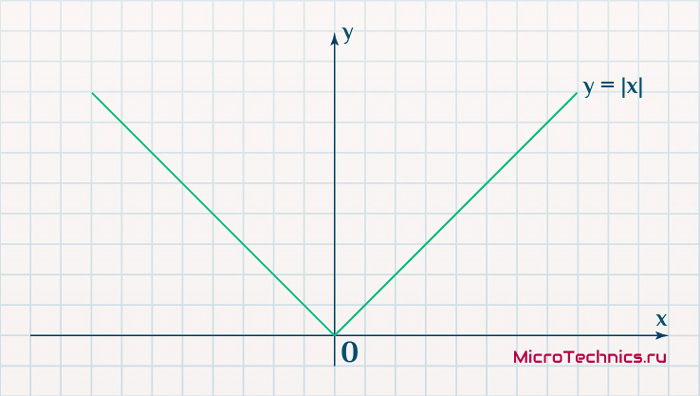
Функция, бесспорно, симпатична, но при приближении к минимуму ее градиент является постоянной величиной, скачкообразно меняясь при переходе через точку минимума. Это нас также не устраивает, поскольку, как мы обсуждали, концепция заключалась в том числе в том, чтобы по мере приближения к минимуму значение градиента уменьшалось.
В итоге хороший результат дает зависимость (для выходного нейрона под номером k):
E_k = (O_{correct, k} - O_{net, k})^2
Функция по многим своим свойствам идеально удовлетворяет нуждам обучения нейронной сети, так что выбор сделан, остановимся на ней. Хотя, как и во многих аспектах, качающихся нейронных сетей, данное решение не является единственно и неоспоримо верным. В каких-то случаях лучше себя могут проявить другие зависимости, возможно, что какой-то вариант даст большую точность, но неоправданно высокие затраты производительности при обучении. В общем, непаханное поле для экспериментов и исследований, это и привлекательно.
Краткий вывод промежуточного шага, на который мы вышли:
- Имеющееся: frac{dE}{dw_{jk}} = frac{d}{d w_{jk}}(O_{correct, k} — O_{net, k})^2.
- Искомое по-прежнему: Delta w_{jk}.
Несложные диффернциально-математические изыскания выводят на следующий результат:
frac{dE}{d w_{jk}} = -(O_{correct, k} - O_{net, k}) cdot f{Large{prime}}(sum_{j}w_{jk}O_j) cdot O_j
Здесь эти самые изыскания я все-таки решил не вставлять, дабы не перегружать статью, которая и так выходит объемной. Но в случае необходимости и интереса, отпишите в комментарии, я добавлю вычисления и закину их под спойлер, как вариант.
Освежим в памяти структуру сети:
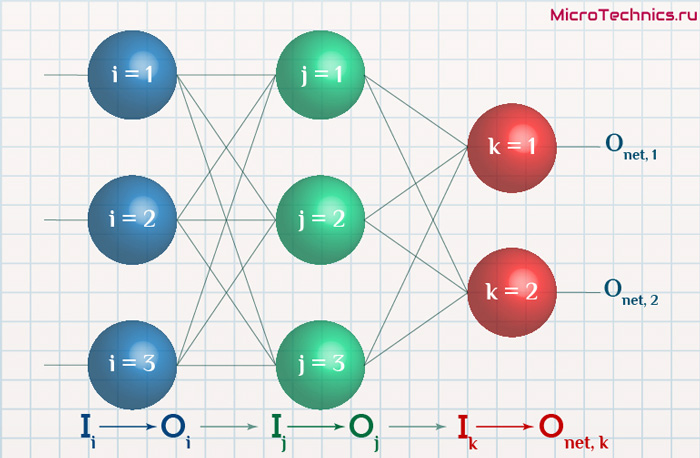
Формулу можно упростить, сгруппировав отдельные ее части:
- (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(sum_{j}w_{jk}O_j) — ошибка нейрона k.
- O_j — тут все понятно, выходной сигнал нейрона j.
f{Large{prime}}(sum_{j}w_{jk}O_j) — значение производной функции активации. Причем, обратите внимание, что sum_{j}w_{jk}O_j — это не что иное, как сигнал на входе нейрона k (I_{k}). Тогда для расчета ошибки выходного нейрона: delta_k = (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(I_k).
Итог: frac{dE}{d w_{jk}} = -delta_k cdot O_j.
Одной из причин популярности сигмоидальной функции активности является то, что ее производная очень просто выражается через саму функцию:
f{'}(x) = f(x)medspace (1medspace-medspace f(x))
Данные алгебраические вычисления справедливы для корректировки весов между скрытым и выходным слоем, поскольку для расчета ошибки мы используем просто разность между целевым и полученным результатом, умноженную на производную.
Для других слоев будут незначительные изменения, касающиеся исключительно первого множителя в формуле:
frac{dE}{d w_{ij}} = -delta_j cdot O_i
Который примет следующий вид:
delta_j = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j)
То есть ошибка для элемента слоя j получается путем взвешенного суммирования ошибок, «приходящих» к нему от нейронов следующего слоя и умножения на производную функции активации. В результате:
frac{dE}{d w_{ij}} = -(sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j) cdot O_i
Снова подводим промежуточный итог, чтобы иметь максимально полную и структурированную картину происходящего. Вот результаты, полученные нами на двух этапах, которые мы успешно миновали:
- Ошибка:
- выходной слой: delta_k = (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(I_k)
- скрытые слои: delta_j = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j)
- Градиент: frac{dE}{d w_{ij}} = -delta_j cdot O_i
- Корректировка весовых коэффициентов: Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}} + gamma cdot Delta w_{ij}^{t — 1}
Преобразуем последнюю формулу:
Delta w_{ij} = alpha cdot delta_j cdot O_i + gamma cdot Delta w_{ij}^{t - 1}
Из этого мы делаем вывод, что на данный момент у нас есть все, что необходимо для того, чтобы произвести обучение нейронной сети. И героем следующего подраздела будет алгоритм обратного распространения ошибки.
Метод обратного распространения ошибки.
Данный метод является одним из наиболее распространенных и популярных, чем и продиктован его выбор для анализа и разбора. Алгоритм обратного распространения ошибки относится к методам обучение с учителем, что на деле означает необходимость наличия целевых значений в обучающих сетах.
Суть же метода подразумевает наличие двух этапов:
- Прямой проход — входные сигналы двигаются в прямом направлении, в результате чего мы получаем выходной сигнал, из которого в дальнейшем рассчитываем значение ошибки.
- Обратный проход — обратное распространение ошибки — величина ошибки двигается в обратном направлении, в результате происходит корректировка весовых коэффициентов связей сети.
Начальные значения весов (перед обучением) задаются случайными, есть ряд методик для выбора этих значений, я опишу в отдельном материале максимально подробно. Пока вот можно полистать — ссылка.
Вернемся к конкретному примеру для явной демонстрации этих принципов:
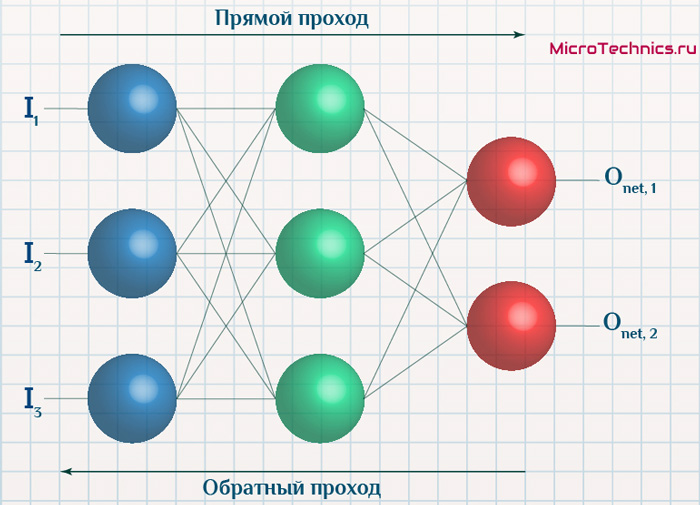
Итак, имеется нейронная сеть, также имеется набор данных обучающей выборки. Как уже обсудили в начале статьи — обучающая выборка представляет из себя набор образцов (сетов), каждый из которых состоит из значений входных сигналов и соответствующих им «правильных» значений выходных величин.
Процесс обучения нейронной сети для алгоритма обратного распространения ошибки будет таким:
- Прямой проход. Подаем на вход значения I_1, I_2, I_3 из обучающей выборки. В результате работы сети получаем выходные значения O_{net, 1}, O_{net, 2}. Этому целиком и полностью был посвящен предыдущий манускрипт.
- Рассчитываем величины ошибок для всех слоев:
- для выходного: delta_k = (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(I_k)
- для скрытых: delta_j = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j)
- Далее используем полученные значения для расчета Delta w_{ij} = alpha cdot delta_j cdot O_i + gamma cdot Delta w_{ij}^{t — 1}
- И финишируем, рассчитывая новые значения весов: w_{ij medspace new} = w_{ij} + Delta w_{ij}
- На этом один цикл обучения закончен, данные шаги 1 — 4 повторяются для других образцов из обучающей выборки.
Обратный проход завершен, а вместе с ним и одна итерация процесса обучения нейронной сети по данному методу. Собственно, обучение в целом заключается в многократном повторении этих шагов для разных образцов из обучающей выборки. Логику мы полностью разобрали, при повторном проведении операций она остается в точности такой же.
Таким образом, максимально подробно концентрируясь именно на сути и логике процессов, мы в деталях разобрали метод обратного распространения ошибки. Поэтому переходим к завершающей части статьи, в которой разберем практический пример, произведя полностью все вычисления для конкретных числовых величин. Все в рамках продвигаемой мной концепции, что любая теоретическая информация на порядок лучше может быть осознана при применении ее на практике.
Пример расчетов для метода обратного распространения ошибки.
Возьмем нейронную сеть и зададим начальные значения весов:
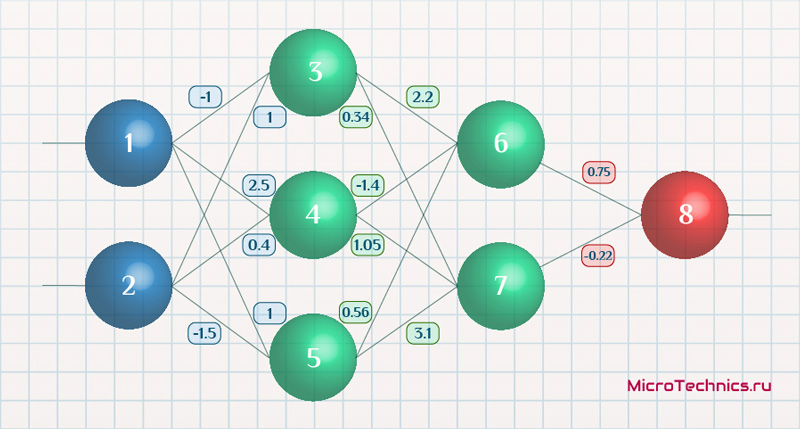
Здесь я задал значения не в соответствии с существующими на сегодняшний день методами, а просто случайным образом для наглядности примера.
В качестве функции активации используем сигмоиду:
f(x) = frac{1}{1 + e^{-x}}
И ее производная:
f{Large{prime}}(x) = f(x)medspace (1medspace-medspace f(x))
Берем один образец из обучающей выборки, пусть будут такие значения:
- Входные: I_1 = 0.6, I_1 = 0.7.
- Выходное: O_{correct} = 0.9.
Скорость обучения alpha пусть будет равна 0.3, момент — gamma = 0.1. Все готово, теперь проведем полный цикл для метода обратного распространения ошибки, то есть прямой проход и обратный.
Прямой проход.
Начинаем с выходных значений нейронов 1 и 2, поскольку они являются входными, то:
O_1 = I_1 = 0.6 \ O_2 = I_2 = 0.7
Значения на входе нейронов 3, 4 и 5:
I_3 = O_1 cdot w_{13} + O_2 cdot w_{23} = 0.6 cdot (-1medspace) + 0.7 cdot 1 = 0.1 \
I_4 = 0.6 cdot 2.5 + 0.7 cdot 0.4 = 1.78 \
I_5 = 0.6 cdot 1 + 0.7 cdot (-1.5medspace) = -0.45
На выходе этих же нейронов первого скрытого слоя:
O_3 = f(I3medspace) = 0.52 \ O_4 = 0.86\ O_5 = 0.39
Продолжаем аналогично для следующего скрытого слоя:
I_6 = O_3 cdot w_{36} + O_4 cdot w_{46} + O_5 cdot w_{56} = 0.52 cdot 2.2 + 0.86 cdot (-1.4medspace) + 0.39 cdot 0.56 = 0.158 \
I_7 = 0.52 cdot 0.34 + 0.86 cdot 1.05 + 0.39 cdot 3.1 = 2.288 \
O_6 = f(I_6) = 0.54 \
O_7 = 0.908
Добрались до выходного нейрона:
I_8 = O_6 cdot w_{68} + O_7 cdot w_{78} = 0.54 cdot 0.75 + 0.908 cdot (-0.22medspace) = 0.205 \
O_8 = O_{net} = f(I_8) = 0.551
Получили значение на выходе сети, кроме того, у нас есть целевое значение O_{correct} = 0.9. То есть все, что необходимо для обратного прохода, имеется.
Обратный проход.
Как мы и обсуждали, первым этапом будет вычисление ошибок всех нейронов, действуем:
delta_8 = (O_{correct} - O_{net}) cdot f{Large{prime}}(I_8) = (O_{correct} - O_{net}) cdot f(I_8) cdot (1-f(I_8)) = (0.9 - 0.551medspace) cdot 0.551 cdot (1-0.551medspace) = 0.0863 \
delta_7 = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_7) = (delta_8 cdot w_{78}) cdot f{Large{prime}}(I_7) = 0.0863 cdot (-0.22medspace) cdot 0.908 cdot (1 - 0.908medspace) = -0.0016 \
delta_6 = 0.086 cdot 0.75 cdot 0.54 cdot (1 - 0.54medspace) = 0.016 \
delta_5 = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_5) = (delta_7 cdot w_{57} + delta_6 cdot w_{56}) cdot f{Large{prime}}(I_7) = (-0.0016 cdot 3.1 + 0.016 cdot 0.56) cdot 0.39 cdot (1 - 0.39medspace) = 0.001 \
delta_4 = (-0.0016 cdot 1.05 + 0.016 cdot (-1.4)) cdot 0.86 cdot (1 - 0.86medspace) = -0.003 \
delta_3 = (-0.0016 cdot 0.34 + 0.016 cdot 2.2) cdot 0.52 cdot (1 - 0.52medspace) = -0.0087
С расчетом ошибок закончили, следующий этап — расчет корректировочных величин для весов всех связей. Для этого мы вывели формулу:
Delta w_{ij} = alpha cdot delta_j cdot O_i + gamma cdot Delta w_{ij}^{t - 1}
Как вы помните, Delta w_{ij}^{t — 1} — это величина поправки для данного веса на предыдущей итерации. Но поскольку у нас это первый проход, то данное значение будет нулевым, соответственно, в данном случае второе слагаемое отпадает. Но забывать о нем нельзя. Продолжаем калькулировать:
Delta w_{78} = alpha cdot delta_8 cdot O_7 = 0.3 cdot 0.0863 cdot 0.908 = 0.0235 \
Delta w_{68} = 0.3 cdot 0.0863 cdot 0.54= 0.014 \
Delta w_{57} = alpha cdot delta_7 cdot O_5 = 0.3 cdot (−0.0016medspace) cdot 0.39= -0.00019 \
Delta w_{47} = 0.3 cdot (−0.0016medspace) cdot 0.86= -0.0004 \
Delta w_{37} = 0.3 cdot (−0.0016medspace) cdot 0.52= -0.00025 \
Delta w_{56} = alpha cdot delta_6 cdot O_5 = 0.3 cdot 0.016 cdot 0.39= 0.0019 \
Delta w_{46} = 0.3 cdot 0.016 cdot 0.86= 0.0041 \
Delta w_{36} = 0.3 cdot 0.016 cdot 0.52= 0.0025 \
Delta w_{25} = alpha cdot delta_5 cdot O_2 = 0.3 cdot 0.001 cdot 0.7= 0.00021 \
Delta w_{15} = 0.3 cdot 0.001 cdot 0.6= 0.00018 \
Delta w_{24} = alpha cdot delta_4 cdot O_2 = 0.3 cdot (-0.003medspace) cdot 0.7= -0.00063 \
Delta w_{14} = 0.3 cdot (-0.003medspace) cdot 0.6= -0.00054 \
Delta w_{23} = alpha cdot delta_3 cdot O_2 = 0.3 cdot (−0.0087medspace) cdot 0.7= -0.00183 \
Delta w_{13} = 0.3 cdot (−0.0087medspace) cdot 0.6= -0.00157
И самый что ни на есть заключительный этап — непосредственно изменение значений весовых коэффициентов:
w_{78 medspace new} = w_{78} + Delta w_{78} = -0.22 + 0.0235 = -0.1965 \
w_{68 medspace new} = 0.75+ 0.014 = 0.764 \
w_{57 medspace new} = 3.1 + (−0.00019medspace) = 3.0998\
w_{47 medspace new} = 1.05 + (−0.0004medspace) = 1.0496\
w_{37 medspace new} = 0.34 + (−0.00025medspace) = 0.3398\
w_{56 medspace new} = 0.56 + 0.0019 = 0.5619 \
w_{46 medspace new} = -1.4 + 0.0041 = -1.3959 \
w_{36 medspace new} = 2.2 + 0.0025 = 2.2025 \
w_{25 medspace new} = -1.5 + 0.00021 = -1.4998 \
w_{15 medspace new} = 1 + 0.00018 = 1.00018 \
w_{24 medspace new} = 0.4 + (−0.00063medspace) = 0.39937 \
w_{14 medspace new} = 2.5 + (−0.00054medspace) = 2.49946 \
w_{23 medspace new} = 1 + (−0.00183medspace) = 0.99817 \
w_{13 medspace new} = -1 + (−0.00157medspace) = -1.00157\
И на этом данную масштабную статью завершаем, конечно же, не завершая на этом деятельность по использованию нейронных сетей. Так что всем спасибо за прочтение, любые вопросы пишите в комментариях и на форуме, ну и обязательно следите за обновлениями и новыми материалами, до встречи!
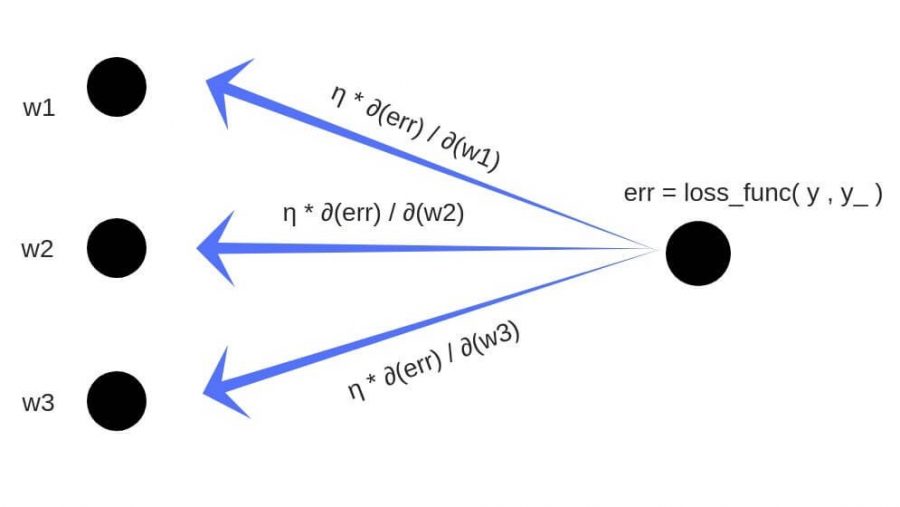
Обратное распространение ошибки — это способ обучения нейронной сети. Цели обратного распространения просты: отрегулировать каждый вес пропорционально тому, насколько он способствует общей ошибке. Если мы будем итеративно уменьшать ошибку каждого веса, в конце концов у нас будет ряд весов, которые дают хорошие прогнозы.
Обновление правила цепочки
Прямое распространение можно рассматривать как длинный ряд вложенных уравнений. Если вы так думаете о прямом распространении, то обратное распространение — это просто приложение правила цепочки (дифференцирования сложной функции) для поиска производных потерь по любой переменной во вложенном уравнении. С учётом функции прямого распространения:
f(x)=A(B(C(x)))
A, B, и C — функции активации на различных слоях. Пользуясь правилом цепочки, мы легко вычисляем производную f(x) по x:
f′(x)=f′(A)⋅A′(B)⋅B′(C)⋅C′(x)
Что насчёт производной относительно B? Чтобы найти производную по B, вы можете сделать вид, что B (C(x)) является константой, заменить ее переменной-заполнителем B, и продолжить поиск производной по B стандартно.
f′(B)=f′(A)⋅A′(B)
Этот простой метод распространяется на любую переменную внутри функции, и позволяет нам в точности определить влияние каждой переменной на общий результат.
Применение правила цепочки
Давайте используем правило цепочки для вычисления производной потерь по любому весу в сети. Правило цепочки поможет нам определить, какой вклад каждый вес вносит в нашу общую ошибку и направление обновления каждого веса, чтобы уменьшить ошибку. Вот уравнения, которые нужны, чтобы сделать прогноз и рассчитать общую ошибку или потерю:
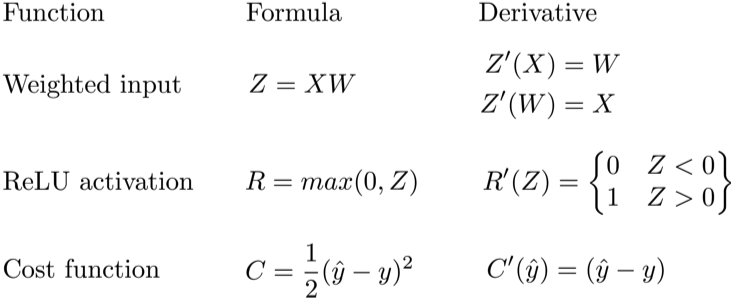
Учитывая сеть, состоящую из одного нейрона, общая потеря нейросети может быть рассчитана как:
Cost=C(R(Z(XW)))
Используя правило цепочки, мы легко можем найти производную потери относительно веса W.
C′(W)=C′(R)⋅R′(Z)⋅Z′(W)=(y^−y)⋅R′(Z)⋅X
Теперь, когда у нас есть уравнение для вычисления производной потери по любому весу, давайте обратимся к примеру с нейронной сетью:
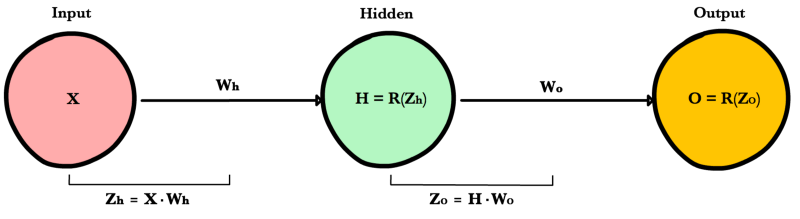
Какова производная от потери по Wo?
C′(WO)=C′(y^)⋅y^′(ZO)⋅Z′O(WO)=(y^−y)⋅R′(ZO)⋅H
А что насчет Wh? Чтобы узнать это, мы просто продолжаем возвращаться в нашу функцию, рекурсивно применяя правило цепочки, пока не доберемся до функции, которая имеет элемент Wh.
C′(Wh)=C′(y^)⋅O′(Zo)⋅Z′o(H)⋅H′(Zh)⋅Z′h(Wh)=(y^−y)⋅R′(Zo)⋅Wo⋅R′(Zh)⋅X
И просто забавы ради, что, если в нашей сети было бы 10 скрытых слоев. Что такое производная потери для первого веса w1?
C(w1)=(dC/dy^)⋅(dy^/dZ11)⋅(dZ11/dH10)⋅(dH10/dZ10)⋅(dZ10/dH9)⋅(dH9/dZ9)⋅(dZ9/dH8)⋅(dH8/dZ8)⋅(dZ8/dH7)⋅(dH7/dZ7)⋅(dZ7/dH6)⋅(dH6/dZ6)⋅(dZ6/dH5)⋅(dH5/dZ5)⋅(dZ5/dH4)⋅(dH4/dZ4)⋅(dZ4/dH3)⋅(dH3/dZ3)⋅(dZ3/dH2)⋅(dH2/dZ2)⋅(dZ2/dH1)⋅(dH1/dZ1)⋅(dZ1/dW1)
Заметили закономерность? Количество вычислений, необходимых для расчёта производных потерь, увеличивается по мере углубления нашей сети. Также обратите внимание на избыточность в наших расчетах производных. Производная потерь каждого слоя добавляет два новых элемента к элементам, которые уже были вычислены слоями над ним. Что, если бы был какой-то способ сохранить нашу работу и избежать этих повторяющихся вычислений?
Сохранение работы с мемоизацией
Мемоизация — это термин в информатике, имеющий простое значение: не пересчитывать одно и то же снова и снова. В мемоизации мы сохраняем ранее вычисленные результаты, чтобы избежать пересчета одной и той же функции. Это удобно для ускорения рекурсивных функций, одной из которых является обратное распространение. Обратите внимание на закономерность в уравнениях производных приведённых ниже.
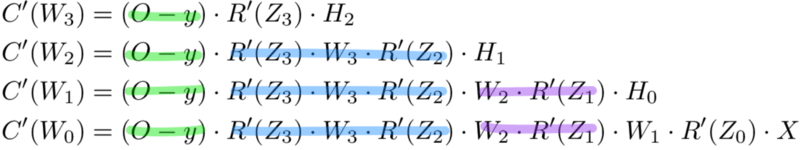
Каждый из этих слоев пересчитывает одни и те же производные! Вместо того, чтобы выписывать длинные уравнения производных для каждого веса, можно использовать мемоизацию, чтобы сохранить нашу работу, так как мы возвращаем ошибку через сеть. Для этого мы определяем 3 уравнения (ниже), которые вместе выражают в краткой форме все вычисления, необходимые для обратного распространения. Математика та же, но уравнения дают хорошее сокращение, которое мы можем использовать, чтобы отслеживать те вычисления, которые мы уже выполнили, и сохранять нашу работу по мере продвижения назад по сети.
Для начала мы вычисляем ошибку выходного слоя и передаем результат на скрытый слой перед ним. После вычисления ошибки скрытого слоя мы передаем ее значение обратно на предыдущий скрытый слой. И так далее и тому подобное. Возвращаясь назад по сети, мы применяем 3-ю формулу на каждом слое, чтобы вычислить производную потерь по весам этого слоя. Эта производная говорит нам, в каком направлении регулировать наши веса, чтобы уменьшить общие потери.
Примечание: термин ошибка слоя относится к производной потерь по входу в слой. Он отвечает на вопрос: как изменяется выход функции потерь при изменении входа в этот слой?
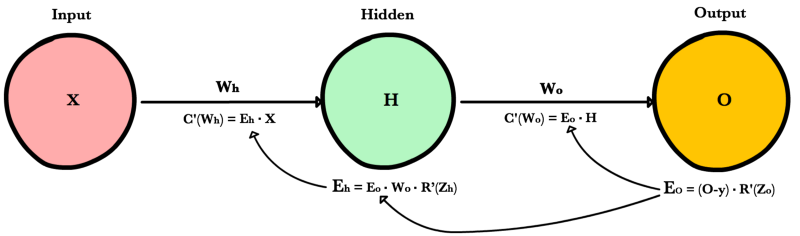
Ошибка выходного слоя
Для расчета ошибки выходного слоя необходимо найти производную потерь по входу выходному слою, Zo. Это отвечает на вопрос: как веса последнего слоя влияют на общую ошибку в сети? Тогда производная такова:
C′(Zo)=(y^−y)⋅R′(Zo)
Чтобы упростить запись, практикующие МО обычно заменяют последовательность (y^−y)∗R'(Zo) термином Eo. Итак, наша формула для ошибки выходного слоя равна:
Eo=(y^−y)⋅R′(Zo)
Ошибка скрытого слоя
Для вычисления ошибки скрытого слоя нужно найти производную потерь по входу скрытого слоя, Zh.
C′(Zh)=(y^−y)⋅R′(Zo)⋅Wo⋅R′(Zh)
Далее мы можем поменять местами элемент Eo выше, чтобы избежать дублирования и создать новое упрощенное уравнение для ошибки скрытого слоя:
Eh=Eo⋅Wo⋅R′(Zh)
Эта формула лежит в основе обратного распространения. Мы вычисляем ошибку текущего слоя и передаем взвешенную ошибку обратно на предыдущий слой, продолжая процесс, пока не достигнем нашего первого скрытого слоя. Попутно мы обновляем веса, используя производную потерь по каждому весу.
Производная потерь по любому весу
Вернемся к нашей формуле для производной потерь по весу выходного слоя Wo.
C′(WO)=(y^−y)⋅R′(ZO)⋅H
Мы знаем, что можем заменить первую часть уравнением для ошибки выходного слоя Eh. H представляет собой активацию скрытого слоя.
C′(Wo)=Eo⋅H
Таким образом, чтобы найти производную потерь по любому весу в нашей сети, мы просто умножаем ошибку соответствующего слоя на его вход (выход предыдущего слоя).
C′(w)=CurrentLayerError⋅CurrentLayerInput
Примечание: вход относится к активации с предыдущего слоя, а не к взвешенному входу, Z.
Подводя итог
Вот последние 3 уравнения, которые вместе образуют основу обратного распространения.
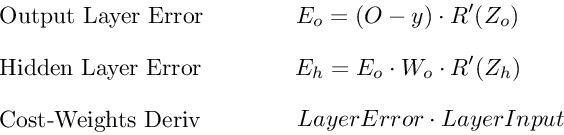
Вот процесс, визуализированный с использованием нашего примера нейронной сети выше:
Обратное распространение: пример кода
def relu_prime(z): if z > 0: return 1 return 0 def cost(yHat, y): return 0.5 * (yHat - y)**2 def cost_prime(yHat, y): return yHat - y def backprop(x, y, Wh, Wo, lr): yHat = feed_forward(x, Wh, Wo) # Layer Error Eo = (yHat - y) * relu_prime(Zo) Eh = Eo * Wo * relu_prime(Zh) # Cost derivative for weights dWo = Eo * H dWh = Eh * x # Update weights Wh -= lr * dWh Wo -= lr * dWo
Метод обратного распространения ошибок (англ. backpropagation) — метод вычисления градиента, который используется при обновлении весов в нейронной сети.
Содержание
- 1 Обучение как задача оптимизации
- 2 Дифференцирование для однослойной сети
- 2.1 Находим производную ошибки
- 3 Алгоритм
- 4 Недостатки алгоритма
- 4.1 Паралич сети
- 4.2 Локальные минимумы
- 5 Примечания
- 6 См. также
- 7 Источники информации
Обучение как задача оптимизации
Рассмотрим простую нейронную сеть без скрытых слоев, с двумя входными вершинами и одной выходной, в которых каждый нейрон использует линейную функцию активации, (обычно, многослойные нейронные сети используют нелинейные функции активации, линейные функции используются для упрощения понимания) которая является взвешенной суммой входных данных.
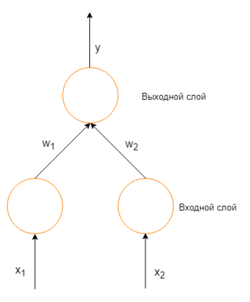
Простая нейронная сеть с двумя входными вершинами и одной выходной
Изначально веса задаются случайно. Затем, нейрон обучается с помощью тренировочного множества, которое в этом случае состоит из множества троек где и — это входные данные сети и — правильный ответ. Начальная сеть, приняв на вход и , вычислит ответ , который вероятно отличается от . Общепринятый метод вычисления несоответствия между ожидаемым и получившимся ответом — квадратичная функция потерь:
- где ошибка.
В качестве примера, обучим сеть на объекте , таким образом, значения и равны 1, а равно 0. Построим график зависимости ошибки от действительного ответа , его результатом будет парабола. Минимум параболы соответствует ответу , минимизирующему . Если тренировочный объект один, минимум касается горизонтальной оси, следовательно ошибка будет нулевая и сеть может выдать ответ равный ожидаемому ответу . Следовательно, задача преобразования входных значений в выходные может быть сведена к задаче оптимизации, заключающейся в поиске функции, которая даст минимальную ошибку.
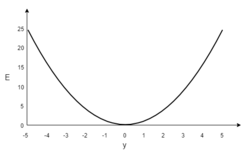
График ошибки для нейрона с линейной функцией активации и одним тренировочным объектом
В таком случае, выходное значение нейрона — взвешенная сумма всех его входных значений:
где и — веса на ребрах, соединяющих входные вершины с выходной. Следовательно, ошибка зависит от весов ребер, входящих в нейрон. И именно это нужно менять в процессе обучения. Распространенный алгоритм для поиска набора весов, минимизирующего ошибку — градиентный спуск. Метод обратного распространения ошибки используется для вычисления самого «крутого» направления для спуска.
Дифференцирование для однослойной сети
Метод градиентного спуска включает в себя вычисление дифференциала квадратичной функции ошибки относительно весов сети. Обычно это делается с помощью метода обратного распространения ошибки. Предположим, что выходной нейрон один, (их может быть несколько, тогда ошибка — это квадратичная норма вектора разницы) тогда квадратичная функция ошибки:
- где — квадратичная ошибка, — требуемый ответ для обучающего образца, — действительный ответ сети.
Множитель добавлен чтобы предотвратить возникновение экспоненты во время дифференцирования. На результат это не повлияет, потому что позже выражение будет умножено на произвольную величину скорости обучения (англ. learning rate).
Для каждого нейрона , его выходное значение определено как
Входные значения нейрона — это взвешенная сумма выходных значений предыдущих нейронов. Если нейрон в первом слое после входного, то входного слоя — это просто входные значения сети. Количество входных значений нейрона . Переменная обозначает вес на ребре между нейроном предыдущего слоя и нейроном текущего слоя.
Функция активации нелинейна и дифференцируема. Одна из распространенных функций активации — сигмоида:
у нее удобная производная:
Находим производную ошибки
Вычисление частной производной ошибки по весам выполняется с помощью цепного правила:
Только одно слагаемое в зависит от , так что
Если нейрон в первом слое после входного, то — это просто .
Производная выходного значения нейрона по его входному значению — это просто частная производная функции активации (предполагается что в качестве функции активации используется сигмоида):
По этой причине данный метод требует дифференцируемой функции активации. (Тем не менее, функция ReLU стала достаточно популярной в последнее время, хоть и не дифференцируема в 0)
Первый множитель легко вычислим, если нейрон находится в выходном слое, ведь в таком случае и
Тем не менее, если произвольный внутренний слой сети, нахождение производной по менее очевидно.
Если рассмотреть как функцию, берущую на вход все нейроны получающие на вход значение нейрона ,
и взять полную производную по , то получим рекурсивное выражение для производной:
Следовательно, производная по может быть вычислена если все производные по выходным значениям следующего слоя известны.
Если собрать все месте:
и
Чтобы обновить вес используя градиентный спуск, нужно выбрать скорость обучения, . Изменение в весах должно отражать влияние на увеличение или уменьшение в . Если , увеличение увеличивает ; наоборот, если , увеличение уменьшает . Новый добавлен к старым весам, и произведение скорости обучения на градиент, умноженный на , гарантирует, что изменения будут всегда уменьшать . Другими словами, в следующем уравнении, всегда изменяет в такую сторону, что уменьшается:
Алгоритм
- — скорость обучения
- — коэффициент инерциальности для сглаживания резких скачков при перемещении по поверхности целевой функции
- — обучающее множество
- — количество повторений
- — функция, подающая x на вход сети и возвращающая выходные значения всех ее узлов
- — количество слоев в сети
- — множество нейронов в слое i
- — множество нейронов в выходном слое
fun BackPropagation:
init
repeat :
for = to :
=
for :
=
for = to :
for :
=
for :
=
=
return
Недостатки алгоритма
Несмотря на многочисленные успешные применения обратного распространения, оно не является универсальным решением. Больше всего неприятностей приносит неопределённо долгий процесс обучения. В сложных задачах для обучения сети могут потребоваться дни или даже недели, она может и вообще не обучиться. Причиной может быть одна из описанных ниже.
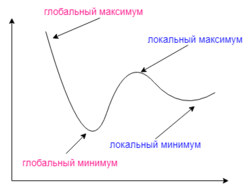
Градиентный спуск может найти локальный минимум вместо глобального
Паралич сети
В процессе обучения сети значения весов могут в результате коррекции стать очень большими величинами. Это может привести к тому, что все или большинство нейронов будут функционировать при очень больших выходных значениях, а производная активирующей функции будет очень мала. Так как посылаемая обратно в процессе обучения ошибка пропорциональна этой производной, то процесс обучения может практически замереть.
Локальные минимумы
Градиентный спуск с обратным распространением ошибок гарантирует нахождение только локального минимума функции; также, возникают проблемы с пересечением плато на поверхности функции ошибки.
Примечания
- Алгоритм обучения многослойной нейронной сети методом обратного распространения ошибки
- Neural Nets
- Understanding backpropagation
См. также
- Нейронные сети, перцептрон
- Стохастический градиентный спуск
- Настройка глубокой сети
- Практики реализации нейронных сетей
Источники информации
- https://en.wikipedia.org/wiki/Backpropagation
- https://ru.wikipedia.org/wiki/Метод_обратного_распространения_ошибки
Метод обратного распространения ошибки — метод обучения многослойного перцептрона. Впервые метод был описан в 1974 г. Полем Дж. Вербосом[1], а также независимо и одновременно А. И. Галушкиным[2]. Далее существенно развит в 1986 г. Дэвидом И. Румельхартом, Дж. Е. Хинтоном и Рональдом Дж. Вильямсом[3] и независимо и одновременно С. И. Барцевым и В. А. Охониным (Красноярская группа)[4]. Это итеративный градиентный алгоритм, который используется с целью минимизации ошибки работы многослойного перцептрона и получения желаемого выхода.
Основная идея этого метода состоит в распространении сигналов ошибки от выходов сети к её входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы. Барцев и Охонин предложили сразу общий метод («принцип двойственности»), приложимый к более широкому классу систем, включая системы с запаздыванием, распределённые системы, и т. п.[5]
Для возможноcти применения метода обратного распространения ошибки передаточная функция нейронов должна быть дифференцируема.
Cигмоидальные функции активации[]
Наиболее часто в качестве функций активации используются следующие виды сигмоид:
Функция Ферми (экспоненциальная сигмоида):

Рациональная сигмоида:

Гиперболический тангенс:

где s — выход сумматора нейрона, 
Менее всего, сравнительно с другими сигмоидами, процессорного времени требует расчет рациональной сигмоиды. Для вычисления гиперболического тангенса требуется больше всего тактов работы процессора. Если же сравнивать с пороговыми функциями активациями, то сигмоиды расчитываются очень медленно. Если после суммирования в пороговой функции сразу можно начинать сравнение с определенной величиной (порогом), то в случае сигмоидальной функции активации — нужно расчитать сигмоид (затратить время в лучшем случае на три операции: взятие модуля, сложение и деление), и только потом сравнивать с пороговой величиной (например, нулем). Если считать, что все простейшие операции расчитываются процессором за примерно одинаковое время, то работа сигмоидальной функции активации после произведенного суммирования (которое займет одинаковое время) будет медленее пороговой функции активации как 1:4.
Функция оценки работы сети[]
В тех случаях, когда удается оценить работу сети обучение нейронных сетей можно представить как задачу оптимизации. Оценить — означает указать количественно хорошо или плохо сеть решает поставленные ей задачи. Для этого строится функция оценки. Она, как правило, явно зависит от выходных сигналов сети и неявно (через функционирование) — от всех ее параметров. Простейший и самый распространенный пример оценки — сумма квадратов расстояний от выходных сигналов сети до их требуемых значений:

где 
Метод наименьших квадратов далеко не всегда является лучшим выбором оценки. Тщательное конструирование функции оценки позволяет на порядок поысить эффективность обучения сети, а также получать дополнительную информацию — «уровень уверенности» сети в даваемом ответе[6].
Описание алгоритма[]
Файл:Neuro.PNG Архитектура многослойного перцептрона
Алгоритм обратного распространения ошибки применяется для многослойного перцептрона. У сети есть входы 





Как модифицировать веса? Мы будем реализовывать стохастический градиентный спуск, то есть будем подправлять веса после каждого тестового примера. Нам нужно двигаться в сторону, противоположную градиенту, то есть добавлять к каждому весу

где

Производная считается следующим образом. Пусть сначала 


Аналогично, 


Если же j-й узел — не на последнем уровне, то у него есть выходы; обозначим их через Children(j). В этом случае

и

Ну а 



поправок алгоритм называется алгоритмом обратного распространения ошибки (backpropagation). Краткое резюме проделанной работы:
- для узла последнего уровня

- для внутреннего узла сети

- для всех узлов

Получающийся алгоритм представлен ниже. На вход алгоритму, кроме указанных параметров, нужно также подавать в каком-нибудь формате структуру сети. На практике очень хорошие результаты показывают сети достаточно простой структуры, состоящие из двух уровней нейронов — скрытого уровня (hidden units) и нейронов-выходов (output units); каждый вход сети соединен со всеми скрытыми нейронами, а результат работы каждого скрытого нейрона подается на вход каждому из нейронов-выходов. В таком случае достаточно подавать на вход количество нейронов скрытого уровня.
Алгоритм[]
Алгоритм:
BackPropagation 
- Инициализировать
маленькими случайными значениями.
- Повторить NUMBER_OF_STEPS раз:
- Для всех d от 1 до m:
- Подать
на вход сети и подсчитать выходы
- Для всех
.
- Для каждого уровня l, начиная с предпоследнего:
- Для каждого узла j уровня l вычислить
.
- Для каждого ребра сети {i, j}
.
- Выдать значения
.

Математическая интерпретация обучения нейронной сети[]
На каждой итерации алгоритма обратного распространения весовые коэффициенты нейронной сети модифицируются так, чтобы улучшить решение одного примера. Таким образом, в процессе обучения циклически решаются однокритериальные задачи оптимизации.
Обучение нейронной сети характеризуется четырьмя специфическими ограничениями, выделяющих обучение нейросетей из общих задач оптимизации: астрономическое число параметров, необходимость высокого параллелизма при обучении, многокритериальность решаемых задач, необходимость найти достаточно широкую область, в которой значения всех минимизируемых функций близки к минимальным. В остальном проблему обучения можно, как правило, сформулировать как задачу минимизации оценки. Осторожность предыдущей фразы («как правило») связана с тем, что на самом деле нам неизвестны и никогда не будут известны все возможные задачи для нейронных сетей, и, быть может, где-то в неизвестности есть задачи, которые несводимы к минимизации оценки. Минимизация оценки — сложная проблема: параметров астрономически много (для стандартных примеров, реализуемых на РС — от 100 до 1000000), адаптивный рельеф (график оценки как функции от подстраиваемых параметров) сложен, может содержать много локальных минимумов.
Недостатки алгоритма[]
Несмотря на многочисленные успешные применения обратного распространения, оно не является панацеей. Больше всего неприятностей приносит неопределенно долгий процесс обучения. В сложных задачах для обучения сети могут потребоваться дни или даже недели, она может и вообще не обучиться. Причиной может быть одна из описанных ниже.
Паралич сети[]
В процессе обучения сети значения весов могут в результате коррекции стать очень большими величинами. Это может привести к тому, что все или большинство нейронов будут функционировать при очень больших значениях OUT, в области, где производная сжимающей функции очень мала. Так как посылаемая обратно в процессе обучения ошибка пропорциональна этой производной, то процесс обучения может практически замереть. В теоретическом отношении эта проблема плохо изучена. Обычно этого избегают уменьшением размера шага η, но это увеличивает время обучения. Различные эвристики использовались для предохранения от паралича или для восстановления после него, но пока что они могут рассматриваться лишь как экспериментальные.
Локальные минимумы[]
Обратное распространение использует разновидность градиентного спуска, то есть осуществляет спуск вниз по поверхности ошибки, непрерывно подстраивая веса в направлении к минимуму. Поверхность ошибки сложной сети сильно изрезана и состоит из холмов, долин, складок и оврагов в пространстве высокой размерности. Сеть может попасть в локальный минимум (неглубокую долину), когда рядом имеется гораздо более глубокий минимум. В точке локального минимума все направления ведут вверх, и сеть неспособна из него выбраться. Статистические методы обучения могут помочь избежать этой ловушки, но они медленны.
Размер шага[]
Внимательный разбор доказательства сходимости[3] показывает, что коррекции весов предполагаются бесконечно малыми. Ясно, что это неосуществимо на практике, так как ведет к бесконечному времени обучения. Размер шага должен браться конечным, и в этом вопросе приходится опираться только на опыт. Если размер шага очень мал, то сходимость слишком медленная, если же очень велик, то может возникнуть паралич или постоянная неустойчивость. П. Д. Вассерман[7] описал адаптивный алгоритм выбора шага, автоматически корректирующий размер шага в процессе обучения. В книге А. Н. Горбаня[8] предложена разветвлённая технология оптимизации обучения.
См. также[]
- Сигмоид
- Многослойный перцептрон
Литература[]
- Уоссермен Ф. Нейрокомпьютерная техника: Теория и практика. — М.: «Мир», 1992.
- Хайкин С. Нейронные сети: Полный курс. Пер. с англ. Н. Н. Куссуль, А. Ю. Шелестова. 2-е изд., испр. — М.: Издательский дом Вильямс, 2008, 1103 с.
Внешние ссылки[]
- Копосов А.И., Щербаков И.Б., Кисленко Н.А., Кисленко О.П., Варивода Ю.В. и др. Отчет по научно-исследовательской работе «Создание аналитического обзора информационных источников по применению нейронных сетей для задач газовой технологии». — Москва: ВНИИГАЗ, 1995.
- Миркес Е. М., Нейроинформатика: Учеб. пособие для студентов с программами для выполнения лабораторных работ. Красноярск: ИПЦ КГТУ, 2002, 347 с. Рис. 58, табл. 59, библиогр. 379 наименований. ISBN 5-7636-0477-6
Примечания[]
- ↑ Werbos P. J., Beyond regression: New tools for prediction and analysis in the behavioral sciences. Ph.D. thesis, Harvard University, Cambridge, MA, 1974.
- ↑ Галушкин А. И. Синтез многослойных систем распознавания образов. — М.: «Энергия», 1974.
- ↑ 3,0 3,1 Rumelhart D.E., Hinton G.E., Williams R.J., Learning Internal Representations by Error Propagation. In: Parallel Distributed Processing, vol. 1, pp. 318—362. Cambridge, MA, MIT Press. 1986.
- ↑ Барцев С. И., Охонин В. А. Адаптивные сети обработки информации. Красноярск : Ин-т физики СО АН СССР, 1986. Препринт N 59Б. — 20 с.
- ↑ Барцев С. И., Гилев С. Е., Охонин В. А., Принцип двойственности в организации адаптивных сетей обработки информации, В кн.: Динамика химических и биологических систем. — Новосибирск: Наука, 1989. — С. 6-55.
- ↑ Миркес Е. М., — Новосибирск: Наука, Сибирская издательская фирма РАН, 1999. — 337 с. ISBN 5-02-031409-9 Другие копии онлайн: [1]
- ↑ Wasserman P. D. Experiments in translating Chinese characters using backpropagation. Proceedings of the Thirty-Third IEEE Computer Society International Conference.. — Washington: D. C.: Computer Society Press of the IEEE, 1988.
- ↑ Горбань А. Н. Обучение нейронных сетей.. — Москва: СП ПараГраф, 1990.