У меня были проблемы с компиляцией программы. Я не уверен, что это значит, и буду благодарен, если кто-нибудь сможет помочь.

Решение
Похоже, что вы пытаетесь собрать 32-битный ассемблерный код с 64-битным ассемблером.
У вас есть 2 варианта:
- Используйте 32-битный ассемблер, например, используя —32 вариант;
- Изменить код путем замены 64-битных (расширенных) регистров, таких как %rax Например, вместо 32-битных регистров, таких как %eax используется с push / pop инструкции.
Поскольку система сборки выглядит как CMake, я отсылаю вас к этому руководство о том, как настроить сборку для различных сборочных диалектов в CMake.
Ошибка: неверный суффикс инструкции для `проталкивания» [дублированный]
December 2018
15.2k раз
Этот вопрос уже есть ответ здесь:
пытаюсь изучить передачу аргументов в функцию через стек в assmbly. Я использую Fedora 20, 64 бит системы.
когда я пытаюсь следующий код,
я получаю сообщение об ошибке, ошибка: неверный суффикс инструкции для `толчке»
как я преодолею эту ошибку!
Я составил его, как и -ggstabs -o Function_Stack.o Function_Stack.c
1 ответы
Ошибка вы получаете выходит из очень простого факта: push обучение в 32-битном режиме принимает 16-разрядные и 32-разрядные immediates в качестве аргументов. Тем не менее, push инструкция используется в 64-битном режиме принимает только 16-битовые и 64-битовые immediates. Поскольку вы явно компиляции кода , как 64-бит, ассемблер выдает ошибку, так как он не может кодировать такую инструкцию. Кроме того , имейте в виду , что вы вынуждаете размер операнда самостоятельно, добавив l суффикс к push инструкции. Все , что я только что написал здесь точно такой же , за pop исключением того , что он принимает регистры / память, а не immediates.
Тем не менее, вы также нужно иметь в виду различия в ABI между 32-битной и 64-битных систем Linux. ABI указывает, среди прочего, как параметры передаются функции, и как вызвать ядро из приложений пользовательского режима. Ваш код ясно написано для 32-битного режима, видя , как он использует стек для передачи аргументов и (очень) устаревшего int $0x80 способа вызова системных вызовов. Для того , чтобы узнать о 64-битном ABI см этого документа .
Кроме того , вы имеете возможность компиляции 32-битного кода на 64-битной системе. Такой исполняемый файл будет работать , если у вас есть необходимые 32-разрядные среды выполнения библиотек , установленных на вашем 64-битной системе. Большинство дистрибутивов позволит вам сделать это по — разному. Ваш компилятор, as , имеет —32 переключатель для излучения 32-битного кода.
MQL4: Исправляем ошибки и предупреждения при компиляции в MetaEditor
 Разработка торговых экспертов на языке MQL4 является не такой уж простой задачей. Во-первых – алгоритмизация любой сложной торговой системы уже представляет собой проблему, так как нужно учесть очень много деталей, начиная с особенностей ТС и заканчивая спецификой среды MetaTrader 4. Во-вторых, даже наличие детальнейшего алгоритма не избавляет от сложностей, возникающих при переносе разработанного алгоритма на язык программирования MQL4.
Разработка торговых экспертов на языке MQL4 является не такой уж простой задачей. Во-первых – алгоритмизация любой сложной торговой системы уже представляет собой проблему, так как нужно учесть очень много деталей, начиная с особенностей ТС и заканчивая спецификой среды MetaTrader 4. Во-вторых, даже наличие детальнейшего алгоритма не избавляет от сложностей, возникающих при переносе разработанного алгоритма на язык программирования MQL4.
Компилятор оказывает некоторую помощь при написании корректных экспертов. После начала компиляции MetaEditor сообщит обо всех синтаксических ошибках в вашем коде. Но, к сожалению, помимо синтаксических ошибок ваш советник может содержать еще и логические ошибки, которые компилятор выловить не может. Поэтому этим нам придется заняться самим. Как это сделать – в нашем сегодняшнем материале.
Самые распространенные ошибки компиляции

При наличии ошибок в коде программа не может быть скомпилирована. Для полного контроля всех ошибок рекомендуется использовать строгий режим компиляции, который устанавливается директивой:
Этот режим значительно упрощает поиск ошибок. Теперь перейдем к самым распространенным ошибкам при компиляции.
Идентификатор совпадает с зарезервированным словом
Если наименование переменной или функции совпадает с одним из зарезервированных слов:
то компилятор выводит сообщения об ошибках:
 Для исправления данной ошибки нужно исправить имя переменной или функции. Я рекомендую придерживаться следующей системы для именования:
Для исправления данной ошибки нужно исправить имя переменной или функции. Я рекомендую придерживаться следующей системы для именования:
Все функции должны обозначать действие. То есть это должен быть глагол. Например, OpenLongPosition() или ModifyStopLoss(). Ведь функции всегда именно что-то делают, верно?
Кроме того, функции желательно называть в так называемом CamelCase стиле. А переменные в cebab_case стиле. Это общепринятая практика.
Кстати, об именах переменных. Переменные – это существительные. Например, my_stop_loss, day_of_week, current_month. Не так страшно назвать переменную длинным именем, гораздо страшнее назвать ее непонятно. Что такое dow, индекс Dow Jones? Нет, это, оказывается, день недели. Конечно, сегодня вам и так понятно, что это за переменная. Но когда вы откроете код советника месяц спустя, все будет уже не так явно. А это время, упущенное на расшифровку посланий из прошлого – оно вам надо?
Специальные символы в наименованиях переменных и функций
Идем дальше. Если наименования переменных или функций содержат специальные символы ($, @, точка):
то компилятор выводит сообщения об ошибках:
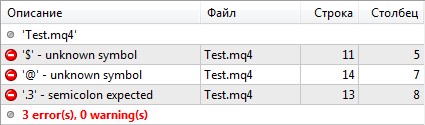 Для исправления данной ошибки снова нужно скорректировать имена переменных или функций, ну или сразу называть их по-человечески. В идеале код нужно писать так, чтобы даже человек, не знающий программирование, просто его прочел и понял, что там вообще происходит.
Для исправления данной ошибки снова нужно скорректировать имена переменных или функций, ну или сразу называть их по-человечески. В идеале код нужно писать так, чтобы даже человек, не знающий программирование, просто его прочел и понял, что там вообще происходит.
Ошибки использования оператора switch
Старая версия компилятора позволяла использовать любые значения в выражениях и константах оператора switch:
В новом компиляторе выражения и константы оператора switch должны быть целыми числами, поэтому при использовании подобных конструкций возникают ошибки:
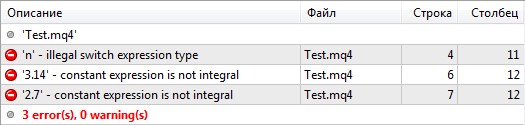 Поэтому, когда вы разбираете код классики, такой, как WallStreet, Ilan и прочей нетленки (что очень полезно для саморазвития), можно натолкнуться на эту ошибку. Лечится она очень просто, например, при использовании такой вот строки:
Поэтому, когда вы разбираете код классики, такой, как WallStreet, Ilan и прочей нетленки (что очень полезно для саморазвития), можно натолкнуться на эту ошибку. Лечится она очень просто, например, при использовании такой вот строки:
Вот так можно запросто решить проблему:
Возвращаемые значений функций
Все функции, кроме void, должны возвращать значение объявленного типа. Например:
При строгом режиме компиляции (strict) возникает ошибка:
 В режиме компиляции по умолчанию компилятор выводит предупреждение:
В режиме компиляции по умолчанию компилятор выводит предупреждение:
 Если возвращаемое значение функции не соответствует объявлению:
Если возвращаемое значение функции не соответствует объявлению:
Тогда при строгом режиме компиляции возникает ошибка:
 В режиме компиляции по умолчанию компилятор выводит предупреждение:
В режиме компиляции по умолчанию компилятор выводит предупреждение:
 Для исправления таких ошибок в код функции всего-навсего нужно добавить оператор возврата return c возвращаемым значением соответствующего типа.
Для исправления таких ошибок в код функции всего-навсего нужно добавить оператор возврата return c возвращаемым значением соответствующего типа.
Массивы в аргументах функций
Массивы в аргументах функций передаются только по ссылке. Раньше это было не так, поэтому в старых советниках можно встретить эту ошибку. Вот пример:
Данный код при строгом режиме компиляции (strict) приведет к ошибке:
 В режиме компиляции по умолчанию компилятор выводит предупреждение:
В режиме компиляции по умолчанию компилятор выводит предупреждение:
 Для исправления таких ошибок нужно явно указать передачу массива по ссылке, добавив префикс & перед именем массива:
Для исправления таких ошибок нужно явно указать передачу массива по ссылке, добавив префикс & перед именем массива:
Кстати, константные массивы (Time[], Open[], High[], Low[], Close[], Volume[]) не могут быть переданы по ссылке. Например, вызов:
вне зависимости от режима компиляции приводит к ошибке:
 Для устранения подобных ошибок нужно скопировать необходимые данные из константного массива:
Для устранения подобных ошибок нужно скопировать необходимые данные из константного массива:
Одна из самых распространенных ошибок – потеря советником индикатора. В таких случаях обычно пользователи эксперта на форумах гневно пишут: «Советник не работает!» или «Ставлю советник на график и ничего не происходит!». Решение этого вопроса на самом деле очень простое. Как всегда, достаточно просто заглянуть на вкладку «Журнал» терминала и обнаружить там запись вроде:
Говорит это нам о том, что индикатор в папку положить забыли, или же он назван по-другому. Если индикатор отсутствует, нужно добавить его в папку с индикаторами. Если он есть, стоит проверить его название в коде советника – скорее всего там он называется по-другому.
Предупреждения компилятора

Предупреждения компилятора носят информационный характер и не являются сообщениями об ошибках, однако они указывают на возможные источники ошибок и лучше их скорректировать. Чистый код не должен содержать предупреждений.
Пересечения имен глобальных и локальных переменных
Если на глобальном и локальном уровнях присутствуют переменные с одинаковыми именами:
то компилятор выводит предупреждение и укажет номер строки, на которой объявлена глобальная переменная:
 Для исправления таких предупреждений нужно скорректировать имена глобальных переменных.
Для исправления таких предупреждений нужно скорректировать имена глобальных переменных.
Несоответствие типов
В следующем примере:
при строгом режиме компиляции при несоответствии типов компилятор выводит предупреждения:
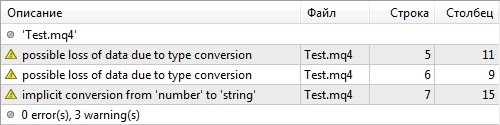 В данном примере компилятор предупреждает о возможной потере точности при присвоении различных типов данных и неявном преобразовании типа int в string.
В данном примере компилятор предупреждает о возможной потере точности при присвоении различных типов данных и неявном преобразовании типа int в string.
Для исправления нужно использовать явное приведение типов:
Неиспользуемые переменные
Наличие переменных, которые не используются в коде программы (лишние сущности) не является хорошим тоном.
Сообщения о таких переменных выводятся вне зависимости от режима компиляции:
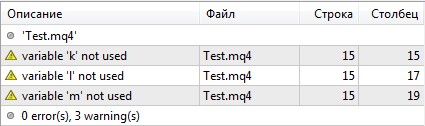 Для исправления нужно просто убрать неиспользуемые переменные из кода программы.
Для исправления нужно просто убрать неиспользуемые переменные из кода программы.
Диагностика ошибок при компиляции

Часто после написания программы возникают проблемы при компиляции, вызванные ошибками в коде. Это могут быть самые различные ошибки, но в любом случае возникает необходимость оперативного обнаружения участка кода, где допущена ошибка.
Нередко у людей уходит немало времени и масса нервов на поиски какой-нибудь лишней скобки. Однако, есть способ быстрого обнаружения ошибок, который основан на использовании комментирования.
Написать достаточно большой код без единой ошибки – очень приятно. Но, к сожалению, так получается не часто. Я не рассматриваю здесь ошибки, которые приводят к неверному исполнению кода. Здесь пойдёт речь об ошибках, из-за которых становится невозможной компиляция.
Весьма распространённые ошибки – вставка лишней скобки в сложном условии, нехватка скобки, не выставление двоеточия, запятой при объявлении переменных, опечатка в названии переменной и так далее. Часто при компиляции можно сразу увидеть, в какой строке допущена подобная ошибка. Но бывают и случаи, когда найти такую ошибку не так просто. Ни компилятор, ни зоркий глаз нам не могут помочь сразу найти ошибку. В таких случаях, как правило, начинающие программисты начинают “обходить” весь код, пытаясь визуально определить ошибку. И снова, и снова, пока выдерживают нервы.
Однако MQL, как и другие языки программирования, предлагает отличный инструмент – комментирование. Используя его, можно отключать какие-то участки кода. Обычно комментирование используют именно для вставки каких-то комментариев, или же отключения неиспользуемых участков кода. Комментирование можно также успешно применять и при поиске ошибок.
Поиск ошибок обычно сводится к определению участка кода, где допущена ошибка, а затем, в этом участке, визуально находится ошибка. Думаю, вряд ли кто-то будет сомневаться в том, что исследовать “на глаз” 5-10 строчек кода проще и быстрей, чем 100-500, а то и несколько тысяч.
При использовании комментирования задача предельно проста. Сначала нужно закомментировать различные участки кода (иногда чуть ли не весь код), тем самым “отключив” его. Затем, по очереди, комментирование снимается с этих участков кода. После очередного снятия комментирования совершается попытка компиляции. Если компиляция прошла успешно – ошибка не в этом участке кода. Затем открывается следующий участок кода и так далее. Когда находится проблемный участок кода, визуально ищется ошибка, затем устраняется. Опять происходит попытка компиляции. Если всё прошло успешно, ошибка устранена.
Важно правильно определять участки кода, которые необходимо комментировать. Если это условие (или иная логическая конструкция), то оно должно комментироваться полностью. Если комментируется участок кода, где объявляются переменные, важно, чтобы не был открыт участок, где происходит обращение к этим переменным. Иначе говоря – комментирование должно применяться по логике программирования. Несоблюдения такого подхода приводит к возникновению новых, вводящих в заблуждение, ошибок при компиляции.
 Вот отличный пример ошибки, когда неясно, где ее искать и нас может выручить комментирование кода.
Вот отличный пример ошибки, когда неясно, где ее искать и нас может выручить комментирование кода.
Ошибки времени выполнения

Ошибки, возникающие в процессе исполнения кода программы, принято называть ошибками времени выполнения (runtime errors). Такие ошибки обычно зависят от состояния программы и связаны с некорректными значениями переменных.
Например, если переменная используется в качестве индекса элементов массива, то ее отрицательные значения неизбежно приведут к выходу за пределы массива.
Выход за пределы массива (Array out of range)
Эта ошибка часто возникает в индикаторах при обращении к индикаторным буферам. Функция IndicatorCounted() возвращает количество баров, не изменившихся после последнего вызова индикатора. Значения индикаторов на уже рассчитанных ранее барах не нуждаются в пересчете, поэтому для ускорения расчетов достаточно обрабатывать только несколько последних баров.
Большинство индикаторов, в которых используется данный способ оптимизации вычислений, имеют такой вид:
Часто встречается некорректная обработка случая counted_bars==0 (начальную позицию limit нужно уменьшить на значение, равное 1 + максимальный индекс относительно переменной цикла).
Также следует помнить о том, что в момент исполнения функции start() мы можем обращаться к элементам массивов индикаторных буферов от 0 до Bars()-1. Если есть необходимость работы с массивами, которые не являются индикаторными буферами, то их размер следует увеличить при помощи функции ArrayResize() в соответствии с текущим размером индикаторных буферов. Максимальный индекс элемента для адресации также можно получить вызовом ArraySize() с одним из индикаторных буферов в качестве аргумента.
Деление на ноль (Zero divide)
Ошибка “Zero divide” возникает в случае, если при выполнении операции деления делитель оказывается равен нулю:
При выполнении данного скрипта во вкладке “Эксперты” возникает сообщение об ошибке и завершении работы программы:
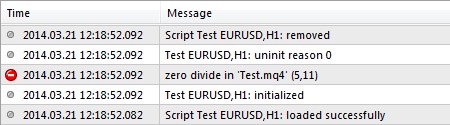 Обычно такая ошибка возникает в случаях, когда значение делителя определяется значениями каких-либо внешних данных. Например, если анализируются параметры торговли, то величина задействованной маржи оказывается равна 0, если нет открытых ордеров. Другой пример: если анализируемые данные считываются из файла, то в случае его отсутствия нельзя гарантировать корректную работу. По этой причине желательно стараться учитывать подобные случаи и корректно их обрабатывать.
Обычно такая ошибка возникает в случаях, когда значение делителя определяется значениями каких-либо внешних данных. Например, если анализируются параметры торговли, то величина задействованной маржи оказывается равна 0, если нет открытых ордеров. Другой пример: если анализируемые данные считываются из файла, то в случае его отсутствия нельзя гарантировать корректную работу. По этой причине желательно стараться учитывать подобные случаи и корректно их обрабатывать.
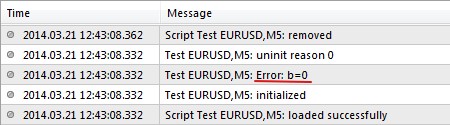
Самый простой способ – проверять делитель перед операцией деления и выводить сообщение о некорректном значении параметра:
В результате критической ошибки не возникает, но выводится сообщение о некорректном значении параметра и работа завершается:
 Использование 0 вместо NULL для текущего символа
Использование 0 вместо NULL для текущего символа
В старой версии компилятора допускалось использование 0 (нуля) в качестве аргумента в функциях, требующих указания финансового инструмента.
Например, значение технического индикатора Moving Average для текущего символа можно было запрашивать следующим образом:
В новом компиляторе для указания текущего символа нужно явно указывать NULL:
Кроме того, текущий символ и период графика можно указать при помощи функций Symbol() и Period().
Еще лучше, если вы будете использовать предопределенные переменные _Symbol и _Period – они обрабатываются быстрее:
Строки в формате Unicodе и их использование в DLL
Строки представляют собой последовательность символов Unicode. Следует учитывать этот факт и использовать соответствующие функции Windows. Например, при использовании функций библиотеки wininet.dll вместо InternetOpenA() и InternetOpenUrlA() следует вызывать InternetOpenW() и InternetOpenUrlW(). При передаче строк в DLL следует использовать структуру MqlString:
Совместное использование файлов
При открытии файлов необходимо явно указывать флаги FILE_SHARE_WRITE и FILE_SHARE_READ для совместного использования.
В случае их отсутствия, файл будет открыт в монопольном режиме, что не позволит больше никому его открывать, пока он не будет закрыт монополистом.
Например, при работе с оффлайновыми графиками требуется явно указывать флаги совместного доступа:
Особенность преобразования datetime
Следует иметь ввиду, что преобразование типа datetime в строку зависит от режима компиляции:
Например, попытка работы с файлами, имя которых содержит двоеточие, приведет к ошибке.
Обработка ошибок времени выполнения

Так как без использования встроенных пользовательских функций не сможет обойтись ни один торгующий эксперт, то в первую очередь попытаемся упростить себе жизнь при анализе ошибок, возвращаемых этими функциями.
В наборе “из коробки” доступны некоторые библиотеки для упрощения написания советников, в том числе и для работы с ошибками. Хранятся они в папке MQL4/Include:
 Нам понадобятся две библиотеки:
Нам понадобятся две библиотеки:
- stderror.mqh – содержит константы для номера каждой ошибки;
- stdlib.mqh – содержит несколько вспомогательных функций, в том числе и функцию возврата описания ошибки в виде строки:
Поэтому подключим в наш проект обе эти библиотеки:
Сами описания ошибок находятся в файле MQL4/Library/stdlib.mql4 и они на английском языке. Поэтому, если вы против иностранных языков, всегда можно переписать описания на свой родной.
Еще одна встроенная необходимая нам функция – GetLastError(). Именно она возвращает коды ошибок в виде целого числа (int), который мы потом будем обрабатывать. Сами коды ошибок и их описания на русском можно посмотреть в руководстве по mql4 от MetaQuotes. Оттуда же можно взять информацию для перевода файла stdlib.mql4 на русский.
Теперь, когда мы подключили необходимые библиотеки, рассмотрим результаты работы функций, непосредственно связанных с торговыми операциями, так как игнорирование сбоев в этих функциях может привести к критическим для бота последствиям.
К сожалению, средствами MQL4 нельзя написать обобщенную библиотеку для обработки всех возможных ошибочных ситуаций. В каждом отдельном случае придется обрабатывать ошибки отдельно. Но не все так плохо, – многие ошибки не нужно обрабатывать, их достаточно исключить на этапе разработки и тестирования эксперта, хотя для этого и нужно вовремя узнать об их наличии.
Рассмотрим для примера две типичные для экспертов на MQL4 ошибки:
- Ошибка 130 – ERR_INVALID_STOPS
- Ошибка 146 – ERR_TRADE_CONTEXT_BUSY
Одним из случаев, когда возникает первая ошибка, является попытка эксперта выставить отложенный ордер слишком близко к рынку. Ее наличие может серьезно ухудшить показатели эксперта в некоторых случаях. Например, допустим эксперт, открыв прибыльную позицию, поджимает прибыль каждые 150 пунктов. Если при очередной такой попытке возникнет ошибка 130, а цена безвозвратно вернется к предыдущему уровню стопа, эксперт может лишить вас законной прибыли. Несмотря на возможность таких последствий, данную ошибку можно исключить в корне, доработав код эксперта так, чтобы он учитывал минимальное допустимое расстояние между ценой и стопами.
Вторую ошибку, связанную с занятостью торгового контекста терминала, полностью исключить не получится. При работе нескольких экспертов в одном терминале всегда возможна ситуация, когда один из экспертов попытается открыть позицию, пока другой все еще делает то же самое. Следовательно, такую ошибку всегда нужно обрабатывать.
Таким образом, мы всегда должны быть в курсе, если какая-то из используемых встроенных функций возвращает ошибку во время работы эксперта. Добиться этого можно, используя следующую нехитрую вспомогательную функцию:
Использовать ее мы будем следующим образом:
Конечно, это упрощенный пример. Для написания более грамотных функций открытия, закрытия и модификации ордеров смотрите этот урок.
Первым параметром в функцию logError() передается имя функции, в которой была обнаружена ошибка, в нашем примере – в функции openLongTrade(). Если наш эксперт вызывает функцию OrderSend() в нескольких местах, это позволит нам точно установить, в каком из них произошла ошибка. Вторым параметром передается описание ошибки, чтобы можно было понять, где именно внутри функции openLongTrade() была обнаружена ошибка. Это может быть как краткое описание ошибки, так и более развернутое, с перечислением значений всех параметров, переданных во встроенную функцию.
Я предпочитаю последний вариант, так как при возникновении ошибки можно сразу получить всю необходимую для анализа информацию. Для примера допустим, что до вызова OrderSend() текущая цена успела сильно отклониться от последней известной нам цены. В результате при выполнении этого примера произойдет ошибка и в протоколе работы эксперта появятся следующие строки:
То есть сразу будет видно:
- в какой функции произошла ошибка;
- к чему она относится (в данном случае – к попытке открыть позицию);
- какая именно ошибка возникла (код ошибки и ее описание).
Теперь рассмотрим третий, необязательный, параметр функции logError(). Он необходим в тех случаях, когда мы хотим обработать конкретный вид ошибки, а об остальных будем отчитываться в протоколе работы эксперта, как и прежде:
Здесь в функции updateStopLoss() вызывается встроенная функция OrderModify(). Эта функция несколько отличается в плане обработки ошибок от OrderSend(). Если ни один из параметров изменяемого ордера не отличается от его текущих параметров, то функция вернет ошибку ERR_NO_RESULT. Если в нашем эксперте такая ситуация допустима, то мы должны игнорировать конкретно эту ошибку. Для этого мы анализируем значение, возвращаемое GetLastError(). Если произошла ошибка с кодом ERR_NO_RESULT, то мы ничего не выводим в протокол.
Однако если произошла другая ошибка, то необходимо полностью отрапортовать о ней, как мы делали это раньше. Именно для этого мы сохраняем результат функции GetLastError() в промежуточной переменной и передаем его третьим параметром в функцию logError(). Дело в том, что встроенная функция GetLastError() автоматически обнуляет код последней ошибки после своего вызова. Если бы мы не передали код ошибки явно в logError(), то в протоколе была бы отражена ошибка с кодом 0 и описанием “no error”.
Похожие действия необходимо совершать и при обработке других ошибок, например, реквотов. Основная идея заключается в том, чтобы обрабатывать только ошибки, требующие обработки, а остальные передавать в функцию logError(). Тогда мы всегда будем в курсе, если во время работы эксперта произошла непредвиденная ошибка. Проанализировав логи, мы сможем решить, требует ли данная ошибка отдельной обработки или же ее можно исключить, доработав код эксперта. Такой подход часто заметно упрощает жизнь и сокращает время, уходящее на борьбу с ошибками.
Диагностика логических ошибок

Логические ошибки в коде эксперта могут доставить много проблем. Отсутствие возможности пошаговой отладки экспертов делают борьбу с такими ошибками не очень приятным занятием. Основным средством для диагностики этого на данный момент является встроенная функция Print(). С ее помощью можно выполнять распечатку текущих значений важных переменных, а также протоколировать ход работы эксперта прямо в терминале во время тестирования. При отладке эксперта во время тестирования с визуализацией также может помочь встроенная функция Comment(), которая выводит сообщения на график. Как правило, убедившись, что эксперт работает не так, как было задумано, приходится добавлять временные вызовы функции Print() и протоколировать внутреннее состояние эксперта в предполагаемых местах возникновения ошибки.
Однако, для обнаружения сложных ошибочных ситуаций порой приходится добавлять десятки таких вызовов функции Print(), а после обнаружения и устранения проблемы их приходится удалять или комментировать, чтобы не загромождался код эксперта и не замедлялось его тестирование. Ситуация ухудшается, если в коде эксперта функция Print() уже используется для периодического протоколирования различных состояний. Тогда удаление временных вызовов Print() не удается выполнить путем простого поиска фразы ‘Print’ в коде эксперта. Приходится задумываться, чтобы не удалить еще и полезные вызовы этой функции.
Например, при протоколировании ошибок функций OrderSend(), OrderModify() и OrderClose() полезным бывает печатать в протокол текущее значение переменных Bid и Ask. Это несколько облегчает распознавание причин таких ошибок, как ERR_INVALID_STOPS и ERR_OFF_QUOTES.
Чтобы выделить такие диагностические выводы в протокол, я рекомендую использовать такую вспомогательную функцию:
Это желательно сделать по нескольким причинам. Во-первых, теперь такие вызовы не будут попадаться при поиске ‘Print’ в коде эксперта, ведь искать мы будем logInfo. Во-вторых, у этой функции есть еще одна полезная особенность, о которой мы поговорим чуть позже.
Добавление и удаление временных диагностических вызовов функции Print() отнимает у нас драгоценное время. Поэтому я предлагаю рассмотреть еще один подход, который эффективен при обнаружении логических ошибок в коде и позволяет немного сэкономить наше время. Рассмотрим следующую несложную функцию:
В данном случае, так как мы открываем длинную позицию, совершенно очевидно, что при нормальной работе эксперта значение параметра stopLoss никогда не будет больше или равно текущей цене Bid. То есть, при вызове функции openLongTrade() всегда выполняется условие stopLoss
источники:
http://askvoprosy.com/voprosy/error-invalid-instruction-suffix-for-push
http://tlap.com/mql4-vremya-na-poisk-oshibok/
The error you’re getting comes out from a very simple fact : the push instruction in 32-bit mode accepts 16-bit and 32-bit immediates as arguments. However, the push instruction used in 64-bit mode accepts only 16-bit and 64-bit immediates. Since you’re clearly compiling your code as 64-bit, the assembler throws an error, since it cannot possibly encode such an instruction. Also, do keep in mind that you force the operand size yourself by adding the l suffix to the push instruction. Everything I just wrote here is exactly the same for pop, except that it accepts registers/memory, not immediates.
However, you also need to keep in mind the differences in the ABI between 32-bit and 64-bit Linux systems. The ABI specifies, among other things, how parameters are passed to functions, and how to call the kernel from user-mode applications. Your code is clearly written for 32-bit mode, seeing how it uses the stack for passing arguments and the (very) obsolete int $0x80 way of invoking syscalls. In order to learn about the 64-bit ABI, see this document.
Alternatively, you have the option of compiling 32-bit code on a 64-bit system. Such an executable will work if you have the necessary 32-bit runtime libraries installed on your 64-bit system. Most distributions allow you to do that in different ways. Your compiler, as, has the --32 switch for emitting 32-bit code.
У меня были проблемы с компиляцией программы. Я не уверен, что это значит, и буду благодарен, если кто-нибудь сможет помочь.
C:UsersJoshuaDocumentsGitHubZeus-TSO_depslibmpg123dct64_sse.S: Assembler
messages:
C:UsersJoshuaDocumentsGitHubZeus-TSO_depslibmpg123dct64_sse.S:41: Error:
invalid instruction suffix for `push'
C:UsersJoshuaDocumentsGitHubZeus-TSO_depslibmpg123dct64_sse.S:46: Error:
invalid instruction suffix for `push'
C:UsersJoshuaDocumentsGitHubZeus-TSO_depslibmpg123dct64_sse.S:449: Error: invalid instruction suffix for `pop'
C:UsersJoshuaDocumentsGitHubZeus-TSO_depslibmpg123dct64_sse.S:451: Error: invalid instruction suffix for `pop'
_depslibmpg123CMakeFileslibmpg123_static.dirbuild.make:378: recipe for targe
t '_deps/libmpg123/CMakeFiles/libmpg123_static.dir/dct64_sse.S.obj' failed
mingw32-make[2]: [_deps/libmpg123/CMakeFiles/libmpg123_static.dir/dct64_sse.
S.obj] Error 1
CMakeFilesMakefile2:225: recipe for target '_deps/libmpg123/CMakeFiles/libmpg12
3_static.dir/all' failed
mingw32-make[1]: [_deps/libmpg123/CMakeFiles/libmpg123_static.dir/all] Error
2
Makefile:74: recipe for target 'all' failed
mingw32-make: [all] Error 2
1
Решение
Похоже, что вы пытаетесь собрать 32-битный ассемблерный код с 64-битным ассемблером.
У вас есть 2 варианта:
- Используйте 32-битный ассемблер, например, используя
--32вариант; - Изменить код путем замены 64-битных (расширенных) регистров, таких как
%raxНапример, вместо 32-битных регистров, таких как%eaxиспользуется сpush/popинструкции.
Поскольку система сборки выглядит как CMake, я отсылаю вас к этому руководство о том, как настроить сборку для различных сборочных диалектов в CMake.
Вы можете попробовать:
set(CMAKE_ASM_FLAGS "--32")
но я не проверял это.
3
Другие решения
Других решений пока нет …
Ошибка: неверный суффикс инструкции для `push ‘
У меня были проблемы с компиляцией программы. Я не уверен, что это значит, и буду благодарен, если кто-нибудь сможет помочь.
Решение
Похоже, что вы пытаетесь собрать 32-битный ассемблерный код с 64-битным ассемблером.
У вас есть 2 варианта:
- Используйте 32-битный ассемблер, например, используя —32 вариант;
- Изменить код путем замены 64-битных (расширенных) регистров, таких как %rax Например, вместо 32-битных регистров, таких как %eax используется с push / pop инструкции.
Поскольку система сборки выглядит как CMake, я отсылаю вас к этому руководство о том, как настроить сборку для различных сборочных диалектов в CMake.
Ошибка: неверный суффикс инструкции для `проталкивания» [дублированный]
December 2018
15.2k раз
Этот вопрос уже есть ответ здесь:
пытаюсь изучить передачу аргументов в функцию через стек в assmbly. Я использую Fedora 20, 64 бит системы.
когда я пытаюсь следующий код,
я получаю сообщение об ошибке, ошибка: неверный суффикс инструкции для `толчке»
как я преодолею эту ошибку!
Я составил его, как и -ggstabs -o Function_Stack.o Function_Stack.c
1 ответы
Ошибка вы получаете выходит из очень простого факта: push обучение в 32-битном режиме принимает 16-разрядные и 32-разрядные immediates в качестве аргументов. Тем не менее, push инструкция используется в 64-битном режиме принимает только 16-битовые и 64-битовые immediates. Поскольку вы явно компиляции кода , как 64-бит, ассемблер выдает ошибку, так как он не может кодировать такую инструкцию. Кроме того , имейте в виду , что вы вынуждаете размер операнда самостоятельно, добавив l суффикс к push инструкции. Все , что я только что написал здесь точно такой же , за pop исключением того , что он принимает регистры / память, а не immediates.
Тем не менее, вы также нужно иметь в виду различия в ABI между 32-битной и 64-битных систем Linux. ABI указывает, среди прочего, как параметры передаются функции, и как вызвать ядро из приложений пользовательского режима. Ваш код ясно написано для 32-битного режима, видя , как он использует стек для передачи аргументов и (очень) устаревшего int $0x80 способа вызова системных вызовов. Для того , чтобы узнать о 64-битном ABI см этого документа .
Кроме того , вы имеете возможность компиляции 32-битного кода на 64-битной системе. Такой исполняемый файл будет работать , если у вас есть необходимые 32-разрядные среды выполнения библиотек , установленных на вашем 64-битной системе. Большинство дистрибутивов позволит вам сделать это по — разному. Ваш компилятор, as , имеет —32 переключатель для излучения 32-битного кода.
MQL4: Исправляем ошибки и предупреждения при компиляции в MetaEditor
Разработка торговых экспертов на языке MQL4 является не такой уж простой задачей. Во-первых – алгоритмизация любой сложной торговой системы уже представляет собой проблему, так как нужно учесть очень много деталей, начиная с особенностей ТС и заканчивая спецификой среды MetaTrader 4. Во-вторых, даже наличие детальнейшего алгоритма не избавляет от сложностей, возникающих при переносе разработанного алгоритма на язык программирования MQL4.
Компилятор оказывает некоторую помощь при написании корректных экспертов. После начала компиляции MetaEditor сообщит обо всех синтаксических ошибках в вашем коде. Но, к сожалению, помимо синтаксических ошибок ваш советник может содержать еще и логические ошибки, которые компилятор выловить не может. Поэтому этим нам придется заняться самим. Как это сделать – в нашем сегодняшнем материале.
Самые распространенные ошибки компиляции
При наличии ошибок в коде программа не может быть скомпилирована. Для полного контроля всех ошибок рекомендуется использовать строгий режим компиляции, который устанавливается директивой:
Этот режим значительно упрощает поиск ошибок. Теперь перейдем к самым распространенным ошибкам при компиляции.
Идентификатор совпадает с зарезервированным словом
Если наименование переменной или функции совпадает с одним из зарезервированных слов:
то компилятор выводит сообщения об ошибках:
Для исправления данной ошибки нужно исправить имя переменной или функции. Я рекомендую придерживаться следующей системы для именования:
Все функции должны обозначать действие. То есть это должен быть глагол. Например, OpenLongPosition() или ModifyStopLoss(). Ведь функции всегда именно что-то делают, верно?
Кроме того, функции желательно называть в так называемом CamelCase стиле. А переменные в cebab_case стиле. Это общепринятая практика.
Кстати, об именах переменных. Переменные – это существительные. Например, my_stop_loss, day_of_week, current_month. Не так страшно назвать переменную длинным именем, гораздо страшнее назвать ее непонятно. Что такое dow, индекс Dow Jones? Нет, это, оказывается, день недели. Конечно, сегодня вам и так понятно, что это за переменная. Но когда вы откроете код советника месяц спустя, все будет уже не так явно. А это время, упущенное на расшифровку посланий из прошлого – оно вам надо?
Специальные символы в наименованиях переменных и функций
Идем дальше. Если наименования переменных или функций содержат специальные символы ($, @, точка):
то компилятор выводит сообщения об ошибках:
Для исправления данной ошибки снова нужно скорректировать имена переменных или функций, ну или сразу называть их по-человечески. В идеале код нужно писать так, чтобы даже человек, не знающий программирование, просто его прочел и понял, что там вообще происходит.
Ошибки использования оператора switch
Старая версия компилятора позволяла использовать любые значения в выражениях и константах оператора switch:
В новом компиляторе выражения и константы оператора switch должны быть целыми числами, поэтому при использовании подобных конструкций возникают ошибки:
Поэтому, когда вы разбираете код классики, такой, как WallStreet, Ilan и прочей нетленки (что очень полезно для саморазвития), можно натолкнуться на эту ошибку. Лечится она очень просто, например, при использовании такой вот строки:
Вот так можно запросто решить проблему:
Возвращаемые значений функций
Все функции, кроме void, должны возвращать значение объявленного типа. Например:
При строгом режиме компиляции (strict) возникает ошибка:
В режиме компиляции по умолчанию компилятор выводит предупреждение:
Если возвращаемое значение функции не соответствует объявлению:
Тогда при строгом режиме компиляции возникает ошибка:
В режиме компиляции по умолчанию компилятор выводит предупреждение:
Для исправления таких ошибок в код функции всего-навсего нужно добавить оператор возврата return c возвращаемым значением соответствующего типа.
Массивы в аргументах функций
Массивы в аргументах функций передаются только по ссылке. Раньше это было не так, поэтому в старых советниках можно встретить эту ошибку. Вот пример:
Данный код при строгом режиме компиляции (strict) приведет к ошибке:
В режиме компиляции по умолчанию компилятор выводит предупреждение:
Для исправления таких ошибок нужно явно указать передачу массива по ссылке, добавив префикс & перед именем массива:
Кстати, константные массивы (Time[], Open[], High[], Low[], Close[], Volume[]) не могут быть переданы по ссылке. Например, вызов:
вне зависимости от режима компиляции приводит к ошибке:
Для устранения подобных ошибок нужно скопировать необходимые данные из константного массива:
Одна из самых распространенных ошибок – потеря советником индикатора. В таких случаях обычно пользователи эксперта на форумах гневно пишут: «Советник не работает!» или «Ставлю советник на график и ничего не происходит!». Решение этого вопроса на самом деле очень простое. Как всегда, достаточно просто заглянуть на вкладку «Журнал» терминала и обнаружить там запись вроде:
Говорит это нам о том, что индикатор в папку положить забыли, или же он назван по-другому. Если индикатор отсутствует, нужно добавить его в папку с индикаторами. Если он есть, стоит проверить его название в коде советника – скорее всего там он называется по-другому.
Предупреждения компилятора
Предупреждения компилятора носят информационный характер и не являются сообщениями об ошибках, однако они указывают на возможные источники ошибок и лучше их скорректировать. Чистый код не должен содержать предупреждений.
Пересечения имен глобальных и локальных переменных
Если на глобальном и локальном уровнях присутствуют переменные с одинаковыми именами:
то компилятор выводит предупреждение и укажет номер строки, на которой объявлена глобальная переменная:
Для исправления таких предупреждений нужно скорректировать имена глобальных переменных.
Несоответствие типов
В следующем примере:
при строгом режиме компиляции при несоответствии типов компилятор выводит предупреждения:
В данном примере компилятор предупреждает о возможной потере точности при присвоении различных типов данных и неявном преобразовании типа int в string.
Для исправления нужно использовать явное приведение типов:
Неиспользуемые переменные
Наличие переменных, которые не используются в коде программы (лишние сущности) не является хорошим тоном.
Сообщения о таких переменных выводятся вне зависимости от режима компиляции:
Для исправления нужно просто убрать неиспользуемые переменные из кода программы.
Диагностика ошибок при компиляции
Часто после написания программы возникают проблемы при компиляции, вызванные ошибками в коде. Это могут быть самые различные ошибки, но в любом случае возникает необходимость оперативного обнаружения участка кода, где допущена ошибка.
Нередко у людей уходит немало времени и масса нервов на поиски какой-нибудь лишней скобки. Однако, есть способ быстрого обнаружения ошибок, который основан на использовании комментирования.
Написать достаточно большой код без единой ошибки – очень приятно. Но, к сожалению, так получается не часто. Я не рассматриваю здесь ошибки, которые приводят к неверному исполнению кода. Здесь пойдёт речь об ошибках, из-за которых становится невозможной компиляция.
Весьма распространённые ошибки – вставка лишней скобки в сложном условии, нехватка скобки, не выставление двоеточия, запятой при объявлении переменных, опечатка в названии переменной и так далее. Часто при компиляции можно сразу увидеть, в какой строке допущена подобная ошибка. Но бывают и случаи, когда найти такую ошибку не так просто. Ни компилятор, ни зоркий глаз нам не могут помочь сразу найти ошибку. В таких случаях, как правило, начинающие программисты начинают “обходить” весь код, пытаясь визуально определить ошибку. И снова, и снова, пока выдерживают нервы.
Однако MQL, как и другие языки программирования, предлагает отличный инструмент – комментирование. Используя его, можно отключать какие-то участки кода. Обычно комментирование используют именно для вставки каких-то комментариев, или же отключения неиспользуемых участков кода. Комментирование можно также успешно применять и при поиске ошибок.
Поиск ошибок обычно сводится к определению участка кода, где допущена ошибка, а затем, в этом участке, визуально находится ошибка. Думаю, вряд ли кто-то будет сомневаться в том, что исследовать “на глаз” 5-10 строчек кода проще и быстрей, чем 100-500, а то и несколько тысяч.
При использовании комментирования задача предельно проста. Сначала нужно закомментировать различные участки кода (иногда чуть ли не весь код), тем самым “отключив” его. Затем, по очереди, комментирование снимается с этих участков кода. После очередного снятия комментирования совершается попытка компиляции. Если компиляция прошла успешно – ошибка не в этом участке кода. Затем открывается следующий участок кода и так далее. Когда находится проблемный участок кода, визуально ищется ошибка, затем устраняется. Опять происходит попытка компиляции. Если всё прошло успешно, ошибка устранена.
Важно правильно определять участки кода, которые необходимо комментировать. Если это условие (или иная логическая конструкция), то оно должно комментироваться полностью. Если комментируется участок кода, где объявляются переменные, важно, чтобы не был открыт участок, где происходит обращение к этим переменным. Иначе говоря – комментирование должно применяться по логике программирования. Несоблюдения такого подхода приводит к возникновению новых, вводящих в заблуждение, ошибок при компиляции.
Вот отличный пример ошибки, когда неясно, где ее искать и нас может выручить комментирование кода.
Ошибки времени выполнения
Ошибки, возникающие в процессе исполнения кода программы, принято называть ошибками времени выполнения (runtime errors). Такие ошибки обычно зависят от состояния программы и связаны с некорректными значениями переменных.
Например, если переменная используется в качестве индекса элементов массива, то ее отрицательные значения неизбежно приведут к выходу за пределы массива.
Выход за пределы массива (Array out of range)
Эта ошибка часто возникает в индикаторах при обращении к индикаторным буферам. Функция IndicatorCounted() возвращает количество баров, не изменившихся после последнего вызова индикатора. Значения индикаторов на уже рассчитанных ранее барах не нуждаются в пересчете, поэтому для ускорения расчетов достаточно обрабатывать только несколько последних баров.
Большинство индикаторов, в которых используется данный способ оптимизации вычислений, имеют такой вид:
Часто встречается некорректная обработка случая counted_bars==0 (начальную позицию limit нужно уменьшить на значение, равное 1 + максимальный индекс относительно переменной цикла).
Также следует помнить о том, что в момент исполнения функции start() мы можем обращаться к элементам массивов индикаторных буферов от 0 до Bars()-1. Если есть необходимость работы с массивами, которые не являются индикаторными буферами, то их размер следует увеличить при помощи функции ArrayResize() в соответствии с текущим размером индикаторных буферов. Максимальный индекс элемента для адресации также можно получить вызовом ArraySize() с одним из индикаторных буферов в качестве аргумента.
Деление на ноль (Zero divide)
Ошибка “Zero divide” возникает в случае, если при выполнении операции деления делитель оказывается равен нулю:
При выполнении данного скрипта во вкладке “Эксперты” возникает сообщение об ошибке и завершении работы программы:
Обычно такая ошибка возникает в случаях, когда значение делителя определяется значениями каких-либо внешних данных. Например, если анализируются параметры торговли, то величина задействованной маржи оказывается равна 0, если нет открытых ордеров. Другой пример: если анализируемые данные считываются из файла, то в случае его отсутствия нельзя гарантировать корректную работу. По этой причине желательно стараться учитывать подобные случаи и корректно их обрабатывать.
Самый простой способ – проверять делитель перед операцией деления и выводить сообщение о некорректном значении параметра:
В результате критической ошибки не возникает, но выводится сообщение о некорректном значении параметра и работа завершается:
Использование 0 вместо NULL для текущего символа
В старой версии компилятора допускалось использование 0 (нуля) в качестве аргумента в функциях, требующих указания финансового инструмента.
Например, значение технического индикатора Moving Average для текущего символа можно было запрашивать следующим образом:
В новом компиляторе для указания текущего символа нужно явно указывать NULL:
Кроме того, текущий символ и период графика можно указать при помощи функций Symbol() и Period().
Еще лучше, если вы будете использовать предопределенные переменные _Symbol и _Period – они обрабатываются быстрее:
Строки в формате Unicodе и их использование в DLL
Строки представляют собой последовательность символов Unicode. Следует учитывать этот факт и использовать соответствующие функции Windows. Например, при использовании функций библиотеки wininet.dll вместо InternetOpenA() и InternetOpenUrlA() следует вызывать InternetOpenW() и InternetOpenUrlW(). При передаче строк в DLL следует использовать структуру MqlString:
Совместное использование файлов
При открытии файлов необходимо явно указывать флаги FILE_SHARE_WRITE и FILE_SHARE_READ для совместного использования.
В случае их отсутствия, файл будет открыт в монопольном режиме, что не позволит больше никому его открывать, пока он не будет закрыт монополистом.
Например, при работе с оффлайновыми графиками требуется явно указывать флаги совместного доступа:
Особенность преобразования datetime
Следует иметь ввиду, что преобразование типа datetime в строку зависит от режима компиляции:
Например, попытка работы с файлами, имя которых содержит двоеточие, приведет к ошибке.
Обработка ошибок времени выполнения
Так как без использования встроенных пользовательских функций не сможет обойтись ни один торгующий эксперт, то в первую очередь попытаемся упростить себе жизнь при анализе ошибок, возвращаемых этими функциями.
В наборе “из коробки” доступны некоторые библиотеки для упрощения написания советников, в том числе и для работы с ошибками. Хранятся они в папке MQL4/Include:
Нам понадобятся две библиотеки:
- stderror.mqh – содержит константы для номера каждой ошибки;
- stdlib.mqh – содержит несколько вспомогательных функций, в том числе и функцию возврата описания ошибки в виде строки:
Поэтому подключим в наш проект обе эти библиотеки:
Сами описания ошибок находятся в файле MQL4/Library/stdlib.mql4 и они на английском языке. Поэтому, если вы против иностранных языков, всегда можно переписать описания на свой родной.
Еще одна встроенная необходимая нам функция – GetLastError(). Именно она возвращает коды ошибок в виде целого числа (int), который мы потом будем обрабатывать. Сами коды ошибок и их описания на русском можно посмотреть в руководстве по mql4 от MetaQuotes. Оттуда же можно взять информацию для перевода файла stdlib.mql4 на русский.
Теперь, когда мы подключили необходимые библиотеки, рассмотрим результаты работы функций, непосредственно связанных с торговыми операциями, так как игнорирование сбоев в этих функциях может привести к критическим для бота последствиям.
К сожалению, средствами MQL4 нельзя написать обобщенную библиотеку для обработки всех возможных ошибочных ситуаций. В каждом отдельном случае придется обрабатывать ошибки отдельно. Но не все так плохо, – многие ошибки не нужно обрабатывать, их достаточно исключить на этапе разработки и тестирования эксперта, хотя для этого и нужно вовремя узнать об их наличии.
Рассмотрим для примера две типичные для экспертов на MQL4 ошибки:
- Ошибка 130 – ERR_INVALID_STOPS
- Ошибка 146 – ERR_TRADE_CONTEXT_BUSY
Одним из случаев, когда возникает первая ошибка, является попытка эксперта выставить отложенный ордер слишком близко к рынку. Ее наличие может серьезно ухудшить показатели эксперта в некоторых случаях. Например, допустим эксперт, открыв прибыльную позицию, поджимает прибыль каждые 150 пунктов. Если при очередной такой попытке возникнет ошибка 130, а цена безвозвратно вернется к предыдущему уровню стопа, эксперт может лишить вас законной прибыли. Несмотря на возможность таких последствий, данную ошибку можно исключить в корне, доработав код эксперта так, чтобы он учитывал минимальное допустимое расстояние между ценой и стопами.
Вторую ошибку, связанную с занятостью торгового контекста терминала, полностью исключить не получится. При работе нескольких экспертов в одном терминале всегда возможна ситуация, когда один из экспертов попытается открыть позицию, пока другой все еще делает то же самое. Следовательно, такую ошибку всегда нужно обрабатывать.
Таким образом, мы всегда должны быть в курсе, если какая-то из используемых встроенных функций возвращает ошибку во время работы эксперта. Добиться этого можно, используя следующую нехитрую вспомогательную функцию:
Использовать ее мы будем следующим образом:
Конечно, это упрощенный пример. Для написания более грамотных функций открытия, закрытия и модификации ордеров смотрите этот урок.
Первым параметром в функцию logError() передается имя функции, в которой была обнаружена ошибка, в нашем примере – в функции openLongTrade(). Если наш эксперт вызывает функцию OrderSend() в нескольких местах, это позволит нам точно установить, в каком из них произошла ошибка. Вторым параметром передается описание ошибки, чтобы можно было понять, где именно внутри функции openLongTrade() была обнаружена ошибка. Это может быть как краткое описание ошибки, так и более развернутое, с перечислением значений всех параметров, переданных во встроенную функцию.
Я предпочитаю последний вариант, так как при возникновении ошибки можно сразу получить всю необходимую для анализа информацию. Для примера допустим, что до вызова OrderSend() текущая цена успела сильно отклониться от последней известной нам цены. В результате при выполнении этого примера произойдет ошибка и в протоколе работы эксперта появятся следующие строки:
То есть сразу будет видно:
- в какой функции произошла ошибка;
- к чему она относится (в данном случае – к попытке открыть позицию);
- какая именно ошибка возникла (код ошибки и ее описание).
Теперь рассмотрим третий, необязательный, параметр функции logError(). Он необходим в тех случаях, когда мы хотим обработать конкретный вид ошибки, а об остальных будем отчитываться в протоколе работы эксперта, как и прежде:
Здесь в функции updateStopLoss() вызывается встроенная функция OrderModify(). Эта функция несколько отличается в плане обработки ошибок от OrderSend(). Если ни один из параметров изменяемого ордера не отличается от его текущих параметров, то функция вернет ошибку ERR_NO_RESULT. Если в нашем эксперте такая ситуация допустима, то мы должны игнорировать конкретно эту ошибку. Для этого мы анализируем значение, возвращаемое GetLastError(). Если произошла ошибка с кодом ERR_NO_RESULT, то мы ничего не выводим в протокол.
Однако если произошла другая ошибка, то необходимо полностью отрапортовать о ней, как мы делали это раньше. Именно для этого мы сохраняем результат функции GetLastError() в промежуточной переменной и передаем его третьим параметром в функцию logError(). Дело в том, что встроенная функция GetLastError() автоматически обнуляет код последней ошибки после своего вызова. Если бы мы не передали код ошибки явно в logError(), то в протоколе была бы отражена ошибка с кодом 0 и описанием “no error”.
Похожие действия необходимо совершать и при обработке других ошибок, например, реквотов. Основная идея заключается в том, чтобы обрабатывать только ошибки, требующие обработки, а остальные передавать в функцию logError(). Тогда мы всегда будем в курсе, если во время работы эксперта произошла непредвиденная ошибка. Проанализировав логи, мы сможем решить, требует ли данная ошибка отдельной обработки или же ее можно исключить, доработав код эксперта. Такой подход часто заметно упрощает жизнь и сокращает время, уходящее на борьбу с ошибками.
Диагностика логических ошибок
Логические ошибки в коде эксперта могут доставить много проблем. Отсутствие возможности пошаговой отладки экспертов делают борьбу с такими ошибками не очень приятным занятием. Основным средством для диагностики этого на данный момент является встроенная функция Print(). С ее помощью можно выполнять распечатку текущих значений важных переменных, а также протоколировать ход работы эксперта прямо в терминале во время тестирования. При отладке эксперта во время тестирования с визуализацией также может помочь встроенная функция Comment(), которая выводит сообщения на график. Как правило, убедившись, что эксперт работает не так, как было задумано, приходится добавлять временные вызовы функции Print() и протоколировать внутреннее состояние эксперта в предполагаемых местах возникновения ошибки.
Однако, для обнаружения сложных ошибочных ситуаций порой приходится добавлять десятки таких вызовов функции Print(), а после обнаружения и устранения проблемы их приходится удалять или комментировать, чтобы не загромождался код эксперта и не замедлялось его тестирование. Ситуация ухудшается, если в коде эксперта функция Print() уже используется для периодического протоколирования различных состояний. Тогда удаление временных вызовов Print() не удается выполнить путем простого поиска фразы ‘Print’ в коде эксперта. Приходится задумываться, чтобы не удалить еще и полезные вызовы этой функции.
Например, при протоколировании ошибок функций OrderSend(), OrderModify() и OrderClose() полезным бывает печатать в протокол текущее значение переменных Bid и Ask. Это несколько облегчает распознавание причин таких ошибок, как ERR_INVALID_STOPS и ERR_OFF_QUOTES.
Чтобы выделить такие диагностические выводы в протокол, я рекомендую использовать такую вспомогательную функцию:
Это желательно сделать по нескольким причинам. Во-первых, теперь такие вызовы не будут попадаться при поиске ‘Print’ в коде эксперта, ведь искать мы будем logInfo. Во-вторых, у этой функции есть еще одна полезная особенность, о которой мы поговорим чуть позже.
Добавление и удаление временных диагностических вызовов функции Print() отнимает у нас драгоценное время. Поэтому я предлагаю рассмотреть еще один подход, который эффективен при обнаружении логических ошибок в коде и позволяет немного сэкономить наше время. Рассмотрим следующую несложную функцию:
В данном случае, так как мы открываем длинную позицию, совершенно очевидно, что при нормальной работе эксперта значение параметра stopLoss никогда не будет больше или равно текущей цене Bid. То есть, при вызове функции openLongTrade() всегда выполняется условие stopLoss
источники:
http://askvoprosy.com/voprosy/error-invalid-instruction-suffix-for-push
http://tlap.com/mql4-vremya-na-poisk-oshibok/
@bmmajeed on GNU/Linux, tools are typically installed to some predefined locations (e.g. /usr/local/bin, /usr/local/lib…). Unlike Windows, there is no one specific subidr for each app/tool. All the binaries of all tools are put together, all the libs are put together, etc. As a result, it is very painful to manually install/uninstall all the files related to some tool. Unless you do it from a tarball and keep that around, to use diogratia’s trick.
At the same time, GNU/Linux distributions are known for having so-called «package managers» together with «repositories». A repository is a server containing thousands of pre-built tools. Unlike Windows, on Linux you don’t need to search each tool in the browser and then download and install it manually. On Linux, you use a package manager:
apt update: fetch the repository and update the local list of available packages.apt search ghdl: search if a package named ghdl exists.apt install ghdl: install ghdl for me.
Next time you do apt update and apt upgrade, it will automatically install a new version of GHDL (if available).
Moreover, the packages you get through the manager are guaranteed to work for your OS, because those were built specifically for the libraries and versions you have.
When you download a tarball for Linux, you have no guarantee about it working. In this case, we do generate pre-built tarballs for Ubuntu 20.04. However, if you used any othe Linux distribution, you might have issues. This is different from Windows, because there is one single officially supported Windows at a time, and there is very good backwards compatibility.
apt (or apt-get) is the default package manager on Debian/Ubuntu. On other distributions, managers are pacman, dnf, yum, etc. All of the are equivalent and serve the same purpose.
Therefore, installing GHDL from tarballs or building it from sources is only suggested in case the version available through the package manager is not enough. That might be because it is outdated or because it was built with some options that don’t fit your needs. In this specific case, it might be problematic if the GHDL installed through apt was built with openieee. However, that should be fixed as soon as they update to 1.0.0, which was released a month ago.
I’m new to the Linux so I want to get through the basic reasons of the stuff.
Please, do see some Youtube video or some introduction to the GNU/Linux file structure and how package managers are used. I’m sure you will find examples specific about Ubuntu which will be easy to follow. I did a very basic introduction above, but explaining it in deep is out of the scope of this project.
I am working my way through Professional Assembly Language by Richard Blum. Why? I like lower level programming and I find assembly language interesting.
My setup is a Mint Linux x64 box. Professional Assembly Language, and many of the other books on assembly language, tend to use i386 32-bit assembly. In fact there are more books on 32-bit assembly language on the market than there are on 64-bit assembly language. It is nice to learn by going through book examples, but I don’t want to have to change them too much. I don’t mind changing command line switches, but I don’t want to have to convert all code to 64-bit assembly while learning.
Trying to compile and link 32-bit assembly on an 64-bit machine, you can run into some issues. This post goes over how to get setup so you can assemble and link both 32-bit and 64-bit assembly on an x64 Linux machine.
You can compile assembly on Linux using just gcc. If you want to see how to do that, skip to the bottom of this post. Professional Assembly Language used the gnu assembler and linker, as and ld. My guess is for learning. The ability to see each step in the process is nice. We will use as and ld. To start, I am assembling and linking this program from the Chapter 04 of the book.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# cpuid.s View the CPUID Vendor ID string using c library calls .section .data output: .asciz «The processor Vendor ID is ‘%s’n» .section .bss .lcomm buffer, 12 .section .text .globl _start _start: movl $0, %eax cpuid movl $buffer, %edi movl %ebx, (%edi) movl %edx, 4(%edi) movl %ecx, 8(%edi) pushl $buffer pushl $output call printf addl $8, %esp pushl $0 call exit |
Using the as command to assemble.
as -o cpuid.o cpuid.s cpuid.s: Assembler messages: cpuid.s:16: Error: invalid instruction suffix for 'push' cpuid.s:17: Error: invalid instruction suffix for 'push' cpuid.s:20: Error: invalid instruction suffix for 'push'
The first error I ran into says I have invalid instructions. That’s valid, I am trying to use 32-bit assembly instructions on a 64-bit machine. To fix that I had to tell the as command it to use 32-bit assembly. This is done by passing the --32 parameter.
as --32 -o cpuid.o cpuid.s
That worked and I got a cpuid.o 32-bit object code file in the directory. Next I try to link it using the ld command.
ld -o cpuid2 cpuid.o
ld: i386 architecture of input file 'cpuid.o' is incompatible with i386:x86-64 output
cpuid.o: In function _start':
(.text+0x1f): undefined reference to 'printf'
cpuid.o: In function _start':
(.text+0x29): undefined reference to 'exit'
There are actually two errors here. The first is line one. The second is all the lines after. The first error is the `cpuid.o' is incompatible with i386 error. It is saying I assembled in 32-bit format but I am trying to link in 64-bit format. To fix that we tell the ld command to use a 32-bit architecture. This is done by passing the -m elf_i386 parameter. The -m parameter is the emulation linker. The man pages defines linker emulation as the “personality of the linker, which gives the linker default values for the other aspects of the target system” and specify that “the emulation can affect various aspects of linker behavior, particularly the default linker script”. I don’t know exactly what that means, but I think it means “act like a different architecture”.
ld -m elf_i386 -o cpuid2 cpuid.o
I run that and the first error has been fixed. We still get the second error.
cpuid.o: In function '_start': (.text+0x1f): undefined reference to 'printf' cpuid.o: In function '_start': (.text+0x29): undefined reference to 'exit'
This is saying it can’t find printf or exit functions. Those functions are in libc. We need to tell the linker how to find them. The book uses dynamic linking with the --dynamic-linker command. In the book it looks like a single dash, but the man page for ld says it is a double dash --. Your linker location may be different. Mine was at /lib/ld-linux.so.2. It is possible to link statically instead of dynamically but we won’t cover that.
We add in the -lc to link libc into our program.
ld --dynamic-linker /lib/ld-linux.so.2 -m elf_i386 -o cpuid -lc cpuid.o
When I run that I get a different error. Here is where things start to get interesting.
ld: cannot find -lc
It can’t find libc.
Looking into the Linker
We can see where the linker is looking for libraries using the --verbose parameter. We keep all of our dynamic linker and 32-bit parameters.
ld --dynamic-linker /lib/ld-linux.so.2 -m elf_i386 -lc --verbose
That gives a lot of output. At the end of the output there is a section where it attempts to open various libc.so files.
attempt to open //usr/local/lib/i386-linux-gnu/libc.so failed attempt to open //usr/local/lib/i386-linux-gnu/libc.a failed attempt to open //lib/i386-linux-gnu/libc.so failed attempt to open //lib/i386-linux-gnu/libc.a failed attempt to open //usr/lib/i386-linux-gnu/libc.so failed attempt to open //usr/lib/i386-linux-gnu/libc.a failed attempt to open //usr/local/lib32/libc.so failed attempt to open //usr/local/lib32/libc.a failed attempt to open //lib32/libc.so failed attempt to open //lib32/libc.a failed attempt to open //usr/lib32/libc.so failed attempt to open //usr/lib32/libc.a failed attempt to open //usr/local/lib/libc.so failed attempt to open //usr/local/lib/libc.a failed attempt to open //lib/libc.so failed attempt to open //lib/libc.a failed attempt to open //usr/lib/libc.so failed attempt to open //usr/lib/libc.a failed attempt to open //usr/i386-linux-gnu/lib32/libc.so failed attempt to open //usr/i386-linux-gnu/lib32/libc.a failed attempt to open //usr/x86_64-linux-gnu/lib32/libc.so failed attempt to open //usr/x86_64-linux-gnu/lib32/libc.a failed attempt to open //usr/i386-linux-gnu/lib/libc.so failed attempt to open //usr/i386-linux-gnu/lib/libc.a failed ld: cannot find -lc
All of its attempts failed.
Packages
At this point I am thinking “Maybe I don’t have the 32-bit libc on the box. I read some tutorials. There are various suggestions on adding in multiple architectures. I try some different commands. None help. It looks like I have all the packages and libraries installed already.
sudo dpkg --add-architecture i386 sudo apt-get update sudo apt-get dist-upgrade sudo apt-get install libc6:i386 libncurses5:i386 libstdc++6:i386 sudo apt-get install multiarch-support
Then this stack overflow post recommended installing g++ multiarch. Looks like I didn’t have that installed after all.
sudo apt-get install gcc-multilib g++-multilib
That installs a bunch of packages. The important one which installs a 32-bit libc is libc6-dev-i386. A lot of the packages look related to i386 32-bit development.
The following additional packages will be installed: g++-5-multilib gcc-5-multilib lib32asan2 lib32atomic1 lib32cilkrts5 lib32gcc-5-dev lib32gomp1 lib32itm1 lib32mpx0 lib32quadmath0 lib32stdc++-5-dev lib32ubsan0 libc6-dev-i386 libc6-dev-x32 libc6-x32 libx32asan2 libx32atomic1 libx32cilkrts5 libx32gcc-5-dev libx32gcc1 libx32gomp1 libx32itm1 libx32quadmath0 libx32stdc++-5-dev libx32stdc++6 libx32ubsan0
When the install is done.
attempt to open //usr/local/lib/i386-linux-gnu/libc.so failed attempt to open //usr/local/lib/i386-linux-gnu/libc.a failed attempt to open //lib/i386-linux-gnu/libc.so failed attempt to open //lib/i386-linux-gnu/libc.a failed attempt to open //usr/lib/i386-linux-gnu/libc.so failed attempt to open //usr/lib/i386-linux-gnu/libc.a failed attempt to open //usr/local/lib32/libc.so failed attempt to open //usr/local/lib32/libc.a failed attempt to open //lib32/libc.so failed attempt to open //lib32/libc.a failed attempt to open //usr/lib32/libc.so succeeded opened script file //usr/lib32/libc.so opened script file //usr/lib32/libc.so attempt to open /lib32/libc.so.6 succeeded /lib32/libc.so.6 attempt to open /usr/lib32/libc_nonshared.a succeeded attempt to open /lib32/ld-linux.so.2 succeeded /lib32/ld-linux.so.2 /lib32/ld-linux.so.2 ld-linux.so.2 needed by /lib32/libc.so.6 found ld-linux.so.2 at /lib32/ld-linux.so.2
The linker is now able to find libc under /lib32/libc.so.6 Another piece that is interesting is the output format and architecture at the top of the ld output.
OUTPUT_FORMAT("elf32-i386", "elf32-i386",
"elf32-i386")
OUTPUT_ARCH(i386)
This shows that we are linking a 32-bit elf executable.
Linking
With the linker being able to find our 32-bit libc we can now go back to our ld command.
ld --dynamic-linker /lib/ld-linux.so.2 -m elf_i386 -o cpuid -lc cpuid.o ./cpuid
The linker works. It finds libc and creates an executable from our 32-bit assembly code. Running that we get the output below.
The processor Vendor ID is 'GenuineIntel'
Summary
I took the round about way to show a train of thought and maybe give some insight into how all parts are working when trying assemble and link 32-bit assembly on an x64 machine. In short, if you want to assemble and link 32-bit assembly on an x64 machine make sure your computer is configured correctly for multi-architecture. Install all of the following packages if they aren’t already installed.
sudo dpkg --add-architecture i386 sudo apt-get update sudo apt-get dist-upgrade sudo apt-get install libc6:i386 libncurses5:i386 libstdc++6:i386 sudo apt-get install multiarch-support sudo apt-get install gcc-multilib g++-multilib
When assembling using the --32 parameter. When linking use the -m elf_i386 parameter. The entire flow looks like this.
as --32 -o cpuid.o cpuid.s ld --dynamic-linker /lib/ld-linux.so.2 -m elf_i386 -o cpuid -lc cpuid.o ./cpuid
If you use the file command on the cpuid executable you will see we have assembled, linked, and executed a 32-bit assembly on a 64-bit machine.
file cpuid cpuid: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux.so.2, not stripped
x64 Assembly Language
Can we still assemble x64 on the same machine? Yes. Easily. I took a hello world x64 example I found, saved it as hello.s assembled it, linked it, and executed it.
as -o hello.o hello.s ld -o hello hello.o ./hello
Using the file command again, we see we have assembled, linked, and executed a 64-bit elf executable.
file cpuid hello: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, not stripped
Using GCC instead
Instead of using as and ld, we can use gcc to handle both stages. We still need to have our environment setup correctly as with as and ld. We also need to change our assembly source code globl label from _start to main.
We use the -m32 parameter with gcc to assemble and link in 32-bit format in one step.
gcc -m32 cpuid.s -o cpuid ./cpuid The processor Vendor ID is 'GenuineIntel' file cpuid cpuid: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux.so.2, for GNU/Linux 2.6.32, ...
And that’s it. One machine, both 32-bit and 64-bit assembly.