Системный вызов readahead () сохраняет документ внутри кеша страниц при работе в операционной системе Linux. Каждый раз, когда ядро Linux считывает документы с диска, оно выполняет имитацию опережающего чтения. Когда возникает потребность в одной части документа, ядро немедленно читает следующую часть документа. Например, если другой запрос на эту часть создается позже при последовательном чтении документа, ядро автоматически вернет требуемую информацию. Такая оптимизация является относительно недорогой, поскольку на дисках есть кеши дорожек (очевидно, жесткие диски выполняют опережающее чтение изнутри), а документы обычно распределяются по системе последовательно. Более широкое окно упреждающего чтения может способствовать последовательному доступу к документу, тогда как опережение чтения может быть ненужными накладными расходами для спонтанно доступного документа. Ядро автоматически регулирует длину кадра опережающего чтения в ответ на процент успешных попыток в этом кадре, как указано в разделе «Внутренние части ядра». Если бы ударов было больше, было бы предпочтительнее рама побольше; более узкий экран был бы предпочтительнее, если бы попаданий было меньше. Вызов фреймворка madvise () позволяет программе немедленно управлять размером окна.
Содержание
- ВОЗВРАТ РЕЗУЛЬТАТ
- ОШИБКИ
- ОШИБКИ
- Предсказуемость опережения
- Преимущества системного вызова Readahead
- Меры предосторожности
- Заключение
ВОЗВРАТ РЕЗУЛЬТАТ
Каждый раз, когда системный вызов Readahead () завершается успешно, по завершении он возвращает 0. Если он не завершится сам, он вернет −1 при потере через errno, установленную для обозначения ошибки.
ОШИБКИ
- EBADF:эта ошибка возникает, когда файловый дескриптор fd не может использоваться и, следовательно, не доступен только для чтения.
- EINVAL:эта ошибка возникает, когда системный вызов readahead () может применяться к fd, потому что это не тип документа.
Чтобы использовать любой системный вызов, например системный вызов readahead, вы должны установить библиотеку manpages-dev, чтобы увидеть ее использование и синтаксис. Для этого напишите в оболочке следующую команду.
$ sudo apt install manpages-dev

Теперь вы можете просмотреть информацию о системном вызове с опережением чтения с помощью страниц руководства, воспользовавшись приведенной ниже инструкцией.
После этого откроется экран, показывающий синтаксис и данные о системном вызове readahead. Нажмите q для выхода с этой страницы.

Вы должны сначала включить библиотеку «fcntl.h» при использовании кода языка C. Параметр fd — это дескриптор документа, который указывает, какой документ должен быть прочитан из вашей системы Linux. Параметр смещения определяет контрольную точку для чтения информации, а счетчик определяет общее количество байтов, которые нужно прочитать. Поскольку ввод-вывод выполняется на страницах, смещение по существу корректируется с понижением до границы страницы, и байты становятся считанными до другого края страницы примерно равными или более чем (смещение + счетчик). Системный вызов readahead () не читает документ до конца. Смещение документа доступного определения файла, на которое ссылается файловый дескриптор fd, сохраняется.
Если кто-то хочет дополнительно использовать опережающее чтение на языке C, попробуйте следующую команду, чтобы настроить компилятор для языка C, компилятор GCC.

ОШИБКИ
Системный вызов readahead () возвращается сразу после попытки подготовить чтение на переднем плане. Тем не менее, он может приостановить чтение схемы файловой системы, необходимой для поиска требуемых блоков.
Предсказуемость опережения
Упреждающее чтение — это метод ускорения доступа к файлам за счет предварительной загрузки большей части компонента файла в кеш страницы до расписания. Как только будут открыты резервные службы ввода-вывода, это можно будет сделать. Предсказуемость — самое важное ограничение для наилучшего использования опережения чтения. Вот некоторые характеристики предсказуемости опережения чтения:
- Прогнозы, основанные на привычках чтения файлов. Если страницы интерпретируются последовательно из регистра, что является идеальной ситуацией для опережающего чтения, получение последующих блоков до того, как они были затребованы, имеет явные преимущества в производительности.
- Инициализация системы: серия init для машины остается неизменной. Определенные скрипты и файлы данных каждый раз интерпретируются в одной и той же последовательности.
- Инициализация приложения: очень идентичные общие библиотеки и определенные части программы монтируются каждый раз, когда программа выполняется.
Преимущества системного вызова Readahead
При большом количестве оперативной памяти системный вызов readahead имеет следующие преимущества:
- Уменьшено время инициализации устройства и программы.
- Производительность была улучшена. Это может быть достигнуто с помощью устройств хранения, таких как жесткие диски, где переключение головок диска между произвольными секторами занимает много времени. Забегая вперед предоставляет системе планирования ввода-вывода гораздо больше требований ввода-вывода гораздо более эффективным способом, объединяя более высокую долю смежных дисковых блоков и уменьшая перемещения головки диска.
- Ввод / вывод и энергия процессора в целом используются наиболее эффективно. Когда процессор активен, выполняется дополнительный ввод-вывод документа.
- Когда компьютеру больше не нужно спать в ожидании ввода-вывода, когда запрашиваемая информация действительно была извлечена, переключение контекста, которое потребляет ценные циклы ЦП, уменьшается.
Меры предосторожности
- Поскольку опережение чтения предотвращает до того, как вся информация действительно будет интерпретирована, его следует использовать с осторожностью. Его обычно запускает одновременный поток.
- Консультативные программы, такие как fadvise и madvise, являются более безопасным вариантом для чтения вперед.
- Пропускная способность аргумента опережающего чтения может быть рассчитана для повышения эффективности массовой передачи файлов, однако лишь до некоторой степени. Таким образом, после перезагрузки длины опережения чтения отслеживайте вывод системы и значительно улучшайте его, прежде чем скорость передачи перестанет увеличиваться.
Заключение
Системный вызов readahead () запускает опережающее чтение документа, так что последовательные чтения из такого документа могут выполняться из буфера, а не блокировать ввод-вывод (предположим, что опережение чтения запускается достаточно рано, а также другая операция устройства не может стереть страницы как из буфера тем временем). Хотя любое опережающее чтение обычно полезно, наилучшие результаты определяются количеством выполненного опережающего чтения.
I am currently running a spark job on Dataproc and am getting errors trying to re-join a group and read data from a kafka topic. I have done some digging and am not sure what the issue is. I have auto.offset.reset set to earliest so it should being reading from the earliest available non-committed offset and initially my spark logs look like this :
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-11 to offset 5553330.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-2 to offset 5555553.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-3 to offset 5555484.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-4 to offset 5555586.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-5 to offset 5555502.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-6 to offset 5555561.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-7 to offset 5555542.```
But then the very next line I get an error trying to read from a nonexistent offset on the server (you can see that the offset for the partition differs from the one listed above, so I have no idea why it would be attempting to read form that offset, here is the error on the next line:
org.apache.kafka.clients.consumer.OffsetOutOfRangeException: Offsets
out of range with no configured reset policy for partitions:
{demo.topic-11=4544296}
Any ideas to why my spark job is constantly going back to this offset (4544296), and not the one it outputs originally (5553330)?
It seems to be contradicting itself w a) the actual offset it says its on and the one it attempts to read and b) saying no configured reset policy
I am currently running a spark job on Dataproc and am getting errors trying to re-join a group and read data from a kafka topic. I have done some digging and am not sure what the issue is. I have auto.offset.reset set to earliest so it should being reading from the earliest available non-committed offset and initially my spark logs look like this :
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-11 to offset 5553330.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-2 to offset 5555553.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-3 to offset 5555484.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-4 to offset 5555586.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-5 to offset 5555502.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-6 to offset 5555561.
19/04/29 16:30:30 INFO
org.apache.kafka.clients.consumer.internals.Fetcher: [Consumer
clientId=consumer-1, groupId=demo-group] Resetting offset for
partition demo.topic-7 to offset 5555542.```
But then the very next line I get an error trying to read from a nonexistent offset on the server (you can see that the offset for the partition differs from the one listed above, so I have no idea why it would be attempting to read form that offset, here is the error on the next line:
org.apache.kafka.clients.consumer.OffsetOutOfRangeException: Offsets
out of range with no configured reset policy for partitions:
{demo.topic-11=4544296}
Any ideas to why my spark job is constantly going back to this offset (4544296), and not the one it outputs originally (5553330)?
It seems to be contradicting itself w a) the actual offset it says its on and the one it attempts to read and b) saying no configured reset policy
Посыпался или нет?
¶
От: AlexR 23 сентября 2012 г. 19:15
В общем, недавно переустановил систему на устаревшем компьютере (Windows 7 Professional x86), поставил все драйвера, установил парочку игр. Ну так вот, когда я поставил игру Crysis 2 и попытался поиграть, в момент загрузки 1 уровня игра зависла намертво. Повторная попытка загрузить игру не увенчалась успехом. Тогда я заглянул в журнал событий системы (на всякий случай) и увидел следующее:
Источник: NTFS Структура файловой системы на диске повреждена и непригодна к использованию. Запустите программу CHKDSK на томе DeviceHarddiskVolume4. К сведению, у меня диск размечен следующим образом: 100 МБ — зарезервированная область системы, 30 гб — раздел системы (C:), 32 ГБ — раздел для бекапов (D:), 403 ГБ — раздел для игр и информации (E:). Также есть второй жёсткий диск (76 ГБ), но он старый и вовсе без разделов (не размечен). В BIOS-е приоритетным при загрузке является новый жёсткий диск (который большого объёма около 460 МБ). Crysis 2 я ставил на диск E: в папку /Games/
В общем, таких ошибок ntfs появилось 20-25 штук. Я ушёл и выключил компьютер, через 2 часа снова включил, запустил снова Crysis 2 и на удивление она загрузилась нормально, но я снова заглянул в лог событий и увидел следующее:
Источник: Disk Неверный блок на устройстве DeviceHarddisk1DR1. И таких ошибок около 30.
Хотя, на удивление, игра загрузилась нормально (!).
Решил воспользоваться утилитой HDDScan, провёл SMART-тест, выдал всё зелёное, кроме:
197 Current Pending Errors Count 100 100 0000000000-0001 000
198 Uncorrectable Errors Count 100 100 0000000000-0001 000
Эти два параметра помечены жёлтой табличкой с восклицательным знаком.
Скажите пожалуйста, что это. Компьютер вроде работает, но судя по всему уже не так, как хотелось бы. И какие мне предпринять дальнейшие действия.
Re: Посыпался или нет?
¶
От: AlexR 23 сентября 2012 г. 22:38
Проверил диск E: (именно он Harddiskvolume4), как предлагала система, с помощью chkdsk E: /F /R
Программа Chkdsk была запущена в режиме чтения и записи.
Проверка файловой системы на E:
Тип файловой системы: NTFS.
Проверка файлов (этап 1 из 5)…
Обработано файловых записей: 4352. Проверка файлов завершена.
Обработано больших файловых записей: 0. Обработано поврежденных файловых записей: 0. Обработано записей дополнительных атрибутов: 0. Обработано записей повторного анализа: 0. Проверка индексов (этап 2 из 5)…
Обработано записей индекса: 5100. Проверка индексов завершена.
Проверено неиндексированных файлов: 0. Восстановлено неиндексированных файлов: 0. Проверка дескрипторов безопасности (этап 3 из 5)…
Обработано файловых SD/SID: 4352. Очистка от неиспользуемых индексных записей 1 в индексе $SII файла 0x9.
Очистка от неиспользуемых индексных записей 1 в индексе $SDH файла 0x9.
Очистка 1 неиспользованных дескрипторов безопасности.
Проверка дескрипторов безопасности завершена.
Обработано файлов данных: 375. CHKDSK проверяет журнал USN..
Обработано байтов USN: 2470744. Завершена проверка журнала USN
Проверка содержимого файла (этап 4 из 5)…
Ошибка чтения с кодом состояния 0xc000009c в смещении данных 0x30be11000 для 0x10000 Байт.
Ошибка чтения с кодом состояния 0xc000009c в смещении данных 0x30be1f000 для 0x1000 Байт.
Произведена замена поврежденных кластеров в файле 3440
под именем GamesCrysis 2GAMECR~1Textures.pak.
Обработано файлов: 4336. Проверка содержимого файла завершена.
CHKDSK проверяет свободное пространство на диске (этап 5 из 5)…
Обработано незанятых кластеров: 101742874. Проверка свободного места на диске завершена.
Добавление 1 поврежденных кластеров в файл поврежденных кластеров.
Исправление ошибок в битовой карте тома.
Windows сделала изменения в файловой системе.
423372799 КБ всего на диске.
16313968 КБ в 3954 файлах.
1548 КБ в 376 индексах.
4 КБ в поврежденных секторах.
85783 КБ используется системой.
65536 КБ занято под файл журнала.
406971496 КБ свободно на диске.
Размер кластера: 4096 байт.
Всего кластеров на диске: 105843199.
101742874 кластеров на диске.
Re: Посыпался или нет?
¶
От: OLiMP 24 сентября 2012 г. 14:33
Диск начал сыпаться. Рекомендую переписать с него важную информацию и прекратить использование.
Re: Посыпался или нет?
¶
От: VecH 17 февраля 2016 г. 3:08
У меня примерно схожая ситуация, в системе два диска
Samsung SSD 840 PRO Series 256Gb
ST3000DM001-1CH166
Еще установлен картридер на 4 устройства
Иногда игра зависает, помогает только перезагрузка
во время перезапуска никаких проверок не запускается, сейчас обратил внимание что в событиях есть ошибка
[quote]Неверный блок на устройстве DeviceHarddisk1DR1.[/quote]
как определять что это за Harddisk1 и что за DR1 ?
Раньше вместо DR1 видел C, D, E и т.д., так хоть понятно на какой HDD грешить, а тут непонятная нумерация, на всякий случай SMART с подозрительного Seagate, неужели ему крышка?!
[code]ID Описание атрибута Порог Значение Наихудшее Данные Статус
05 Reallocated Sector Count 10 100 100 0 OK: Значение нормальное
09 Power-On Hours Count 0 96 96 19168 OK: Всегда пройдено
0C Power Cycle Count 0 99 99 221 OK: Всегда пройдено
B1 Wear Leveling Count 0 94 94 204 OK: Всегда пройдено
B3 Used Reserved Block Count (Total) 10 100 100 0 OK: Значение нормальное
B5 Program Fail Count (Total) 10 100 100 0 OK: Значение нормальное
B6 Erase Fail Count (Total) 10 100 100 0 OK: Значение нормальное
B7 Runtime Bad Block (Total) 10 100 100 0 OK: Значение нормальное
BB Uncorrectable Error Count 0 100 100 0 OK: Всегда пройдено
BE Airflow Temperature 0 66 54 34 OK: Всегда пройдено
C3 ECC Error Rate 0 200 200 0 OK: Всегда пройдено
C7 CRC Error Count 0 100 100 0 OK: Всегда пройдено
EB POR Recovery Count 0 99 99 107 OK: Всегда пройдено
F1 Total LBAs Written 0 99 99 9.31 ТБ OK: Всегда пройдено
[/code]
Re: Посыпался или нет?
¶
От: OLiMP 17 февраля 2016 г. 13:40
По смарту диск пока в норме. К какому из дисков относится запись «Неверный блок на устройстве DeviceHarddisk1DR1.» понять не возможно.
Re: Посыпался или нет?
¶
От: VecH 17 февраля 2016 г. 14:06
В системе два диска:
система SSD Samsung 840 Pro 256GB (Диск 0)
помойка HDD ST3000DM001-1CH166 (Диск 1)
Если я правильно понял то виноват Диск 1
Прогнал его викторией Verify + remap
[url=http://rghost.ru/6hXhfL92C.view] SMART до VERIFY + REMAP[code]————————————————————————-
SMART до VERIFY + REMAP[code]————————————————————————-
ID Name Value Worst Tresh Raw Health
————————————————————————-
1 Raw read error rate 117 99 6 154385408 •••••
3 Spin-up time 94 94 0 0 ••••
4 Number of spin-up times 100 100 20 262 •••••
5 Reallocated sector count 100 100 10 0 •••••
7 Seek error rate 53 51 30 5051110223009 ••
9 Power-on time 71 71 0 25763 •••
10 Spin-up retries 100 100 97 0 •••••
12 Start/stop count 100 100 20 254 •••••
183 unknown attribut 100 100 0 0 •••••
184 End-to-End error 100 100 99 0 •••••
187 Reported UNC error 90 90 0 10 ••••
188 Command timeout 100 100 0 0 •••••
189 High Fly writes 98 98 0 2 ••••
190 Airflow temperature 63 37 45 37°C/98°F ••••
191 G-SENSOR shock counter 100 100 0 0 •••••
192 Power-off retract count 100 100 0 115 •••••
193 Load/unload cycle count 1 1 0 204820 •
194 HDA Temperature 37 63 0 37°C/98°F ••••
194 Minimum temperature 90 63 0 6°C/42°F —
197 Current pending sectors 100 100 0 8 •••••
198 Offline scan UNC sectors 100 100 0 8 •••••
199 Ultra DMA CRC errors 200 200 0 0 •••••
240 Head flying hours 100 253 0 151251568318039 •••••
241 unknown attribut 100 253 0 54759127168 •••••
242 unknown attribut 100 253 0 75892637693 •••••
[/code]
SMART после VERIFY + REMAP[code]————————————————————————-
ID Name Value Worst Tresh Raw Health
————————————————————————-
1 Raw read error rate 117 99 6 126713872 •••••
3 Spin-up time 94 94 0 0 ••••
4 Number of spin-up times 100 100 20 262 •••••
5 Reallocated sector count 100 100 10 0 •••••
7 Seek error rate 53 51 30 5051110226826 ••
9 Power-on time 71 71 0 25767 •••
10 Spin-up retries 100 100 97 0 •••••
12 Start/stop count 100 100 20 254 •••••
183 unknown attribut 100 100 0 0 •••••
184 End-to-End error 100 100 99 0 •••••
187 Reported UNC error 90 90 0 10 ••••
188 Command timeout 100 100 0 0 •••••
189 High Fly writes 98 98 0 2 ••••
190 Airflow temperature 60 37 45 40°C/104°F ••••
191 G-SENSOR shock counter 100 100 0 0 •••••
192 Power-off retract count 100 100 0 115 •••••
193 Load/unload cycle count 1 1 0 204820 •
194 HDA Temperature 40 63 0 40°C/104°F ••••
194 Minimum temperature 90 63 0 6°C/42°F —
197 Current pending sectors 100 100 0 8 •••••
198 Offline scan UNC sectors 100 100 0 8 •••••
199 Ultra DMA CRC errors 200 200 0 0 •••••
240 Head flying hours 100 253 0 36146444785244 •••••
241 unknown attribut 100 253 0 54759127208 •••••
242 unknown attribut 100 253 0 75894526549 •••••
[/code]
Всплывает эта ошибка [quote]Неверный блок на устройстве DeviceHarddisk1DR1.[/quote]
ночью поставил копирование данных на другой комп по сети, Total Commander завис на копировании 1 фотографии, мышка бегала, оживить не удалось, штатный shutdown не помогал, пришлось reset-ить, сейчас после тестов виктории (с LiveCD) продолжил копировать данные, кривой файл успешно считан и ошибок не наблюдается.
p.s. Знаю что диск имеет проблему в месте контактов под контроллером и сифонит пылью внутрь, полтора-два года назад залил там вокруг герметиком (почти сразу после покупки) т.к. гарантия все равно не светила из за удаленности магазина
Re: Посыпался или нет?
¶
От: OLiMP 17 февраля 2016 г. 18:12
Ещё раз повторяю, по смарту диск пока в норме. Ремапов нет. Если есть подозрение что с диском какие то проблемы то переписывайте с него данные и в помойку его или под файлопомойку которую не жалко потерять. У этих дисков нет проблем с контактами, у них есть ряд других проблем, самая распространённая это запил на поверхности, но пока эти проблемы Ваш диск не коснулись.
Re: Посыпался или нет?
¶
От: VecH 17 февраля 2016 г. 21:06
Сегодня пока бэкапил данные параметр[code]187 Reported UNC error 90 90 0 10 •••• [/code]в RAW дорос до 225
Это всёЮ он смертный?
во время копирования прерывалось на чтении файлов, при нажатии кнопки повторить копирование продолжалось успешно
только 1 файл так и не удалось скопировать
Re: Посыпался или нет?
¶
От: OLiMP 17 февраля 2016 г. 21:56
187 параметр смарт у сигейта задействован для своих нужд, и к тому что показывают программы типа виктория никакого отношения не имеет. Важны значения 5, 197, 198 и 199 атрибутов. Они в норме.
Re: Посыпался или нет?
¶
От: Accuser 24 февраля 2016 г. 15:45
[b]OLiMP[/b], здавствуйте!
Подскажите пожалуйста насколько надёжен или не надёжен данный жёсткий диск.
Предположительно после внезапного отключения электроэнергии RAW значения параметров C5 и C6 стали по 16 каждый, затем стали по 32 каждый, а теперь снизились до 24. Пока ещё программами Victoria, MHDD и им подобных диск не прогонял. Но на диске точно имеются два несчитываемых файла. На диске хранится рабочая информация, поэтому хочется знать ваше мнение можно ли на этом диске хранить важные данные или же диск требует замены.
Заранее спасибо за ответ!
Re: Посыпался или нет?
¶
От: OLiMP 24 февраля 2016 г. 20:45
Я бы отказался от дальнейшего использования диска. Он сыпется, и закончится это может плачевно. Очень часто такое происходит резко и без предупреждений.
Re: Посыпался или нет?
¶
От: Accuser 25 февраля 2016 г. 7:18
[b]OLiMP[/b], спасибо за ответ! Постараюсь убедить начальство приобрести новый диск взамен данному.
Re: Посыпался или нет?
¶
От: OLiMP 25 февраля 2016 г. 12:55
Пожалуйста. И я бы не затягивал с копированием с диска информации.
Пересказ статьи Chad Callihan. What is a Read-Ahead Read?
Что такое опережающие чтения, и как они влияют на производительность SQL Server? Опережающие чтения позволяют SQL Server заглянуть вперед, чтобы извлечь страницы в буферный кэш прежде, чем они фактически будут затребованы для запроса. До 64 последовательных страниц могут быть прочитаны из файла, а возможность опережающего чтения может применяться как для страниц данных, так и для индексных страниц. Когда страницы оказываются в буферном кэше, то отпадает необходимость извлекать их с диска для будущих запросов, пока они не будут сброшены другими задачами SQL Server.
Опережающее чтение в действии
Для начала нам нужно проверить, чтобы была включена статистика ввода-вывода. Тогда мы сможем узнать число сканирований, логических чтений и т.д., но, что нам более важно, мы сможем посмотреть число опережающих чтений:
SET STATISTICS IO ON;
GO
Мы можем также для нашего примера выполнить следующий оператор, чтобы почистить буферы буферного пула, прежде чем выполнять какие-либо операторы SELECT. Это гарантирует, что мы увидим опережающие чтения, когда выполним наш первый запрос.
DBCC DROPCLEANBUFFERS;
Например, мы хотим сделать запрос к базе данных StackOverFlow2013 для получения top 10000 пользователей c id, меньшими 10000. Выполнив запрос SELECT, увидим следующие результаты:
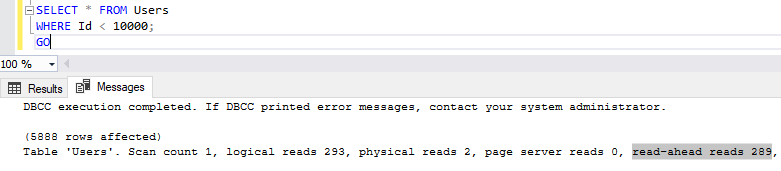
Я получил 5888 строк. Если мы перейдем на вкладку Messages и посмотрим на статистику, то увидим 289 опережающих чтений, означающее, что SQL Server извлек 289 страниц.
Что случится, если мы выполним тот же запрос еще раз? Увидим ли мы теперь опережающие чтения?
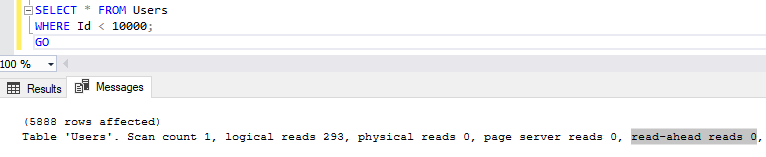
Никаких опережающих чтений на этот раз, поскольку данные уже загружены в буферный кэш.
Запрет опережающих чтений
Если вы по каким-либо причинам не хотите, чтобы выполнялись опережающие чтения, то можете включить флаг трассировки 652, чтобы запретить их:
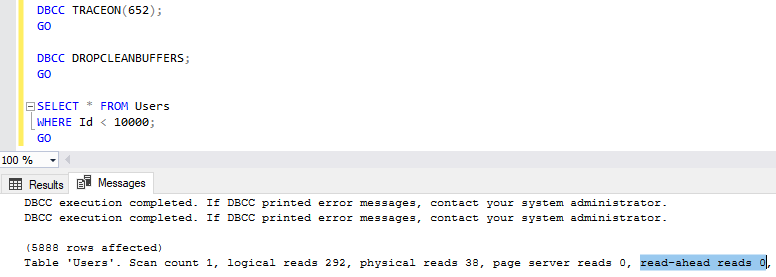
Как видно выше, что даже при предварительной очистке буферов (DBCC DROPCLEANBUFFERS), выполнение нашего оператора SELECT показало 0 в числе опережающих чтений, поскольку был включен флаг трассировки 652.
Вы разрешаете опережающие чтения?
Опережающие чтения полезны с точки зрения улучшения производительности запросов, и они включены по умолчанию. Весьма вероятно, что они всегда будут включены и никогда не вызовут проблем.
Проблема с опережающим чтением в драйвере
Я написал низкоуровневый драйвер SCSI для чтения компакт-дисков в формате mp3, и я могу успешно смонтировать компакт-диск в iso9600 fs. Я понимаю, что блочный уровень сначала выдает команду SCSI READ с количеством блоков 2 или 1, а затем / позже он выполняет чтение вперед с большим количеством блоков. Но в моем случае я всегда получаю запрос на два блока только в команде READ (10) из блочного уровня. Кто-нибудь имеет представление о проблеме?
Я назначал неправильное значение в поле .max_sectors в структуре scsi_host_template. Из-за этого я не получал количество запросов на блокировку больше 2 от блочного уровня. Теперь при назначении правильного значения я получаю даже количество запросов на блок 30 от блочного уровня что значительно увеличивает скорость чтения.
Создан 03 июля ’14, 07:07
![]()
Не тот ответ, который вы ищете? Просмотрите другие вопросы с метками
kernel
linux-device-driver
or задайте свой вопрос.
Время на прочтение
5 мин
Количество просмотров 13K
Данная статья адресована инженерам и консультантам работающим с производительностью операций, связанных с последовательным чтением файлов. В основном, это конечно бэкапы. Cюда же можно включить чтение больших файлов с файловых хранилищ, некоторые операции баз данных, например полное сканирование таблиц (зависит от размещения данных).
Примеры приведены для файловой системы VxFS (Symantec). Данная файловая система достаточно широко используется в серверных системах и поддерживается на HP-UX, AIX,Linux, Solaris.
Зачем это нужно?
Вопрос состоит в том, как получить максимальную скорость при последовательном чтении данных в один поток (!) из большого файла (бэкап большого числа мелких файлов за рамками данной статьи). Последовательным чтением считаем такое, когда блоки данных с физических дисков запрашиваются один за другим, по порядку. Считаем, что фрагментация файловых систем отсутствует. Это обоснованно, так как если на файловой системе расположено немного файлов большого размера, и они редко пересоздаются, то практически не фрагментированы. Это обычная ситуация для баз данных, типа Oracle. Чтение из файла в таком случае мало отличается от чтения с сырого устройства.
Чем ограничена скорость однопоточного чтения?
Самые быстрые из современных дисков (15K rpm) имеют время доступа (service time) около 5.5 мс (для почитателей queuing theory, считаем время ожидания равным 0).
Определим количество операций ввода-вывода, которое может выполнить процесс(бэкапа):
1/0.0055 = 182 IO per second (iops).
Если процесс последовательно выполняет операции, каждая из которых длится 5.5 мс, за секунду он выполнит 182 штуки. Предположим, что размер блока составляет 256KB. Таким образом, максимальная пропускная способность данного процесса составит: 182* 256= 46545 KB/s. (46 MB/s). Скромно, правда? Особенно скромно это выглядит для систем с сотнями физических шпинделей, когда мы расчитываем на гораздо большую скорость чтения. Возникает вопрос, как это оптимизировать. Уменьшить время доступа к диску нельзя, так как это технологические ограничения. Распараллелить бэкап тоже не всегда удается. Для снятия данного ограничения на файловых системах реализуется механизм опережающего чтения (read ahead).
Как работает опережающее чтение
В cовременных *nix системах существует два типа запросов ввода-вывода: синхронные и асинхронные. При синхронном запросе, процесс блокируется до получения ответа от дисковой подсистемы. При асинхронном, не блокируется и может делать что-либо еще. При последовательном чтении, мы читаем данные синхронно. Когда включается механизм опережающего чтения, код файловой системы, сразу после синхронного запроса, делает еще несколько асинхронных. Предположим, процесс запросил блок номер 1000. При включенном read ahead, кроме блока 1000 будут запрошены еще и 1001,1002,1003,1004. Таким образом, при запросе блока 1001 нам нет необходимости ждать 5.5 мс. C помощью настройки read ahead можно значительно (в разы) увеличить скорость последовательного чтения.
Как настраивается?
Ключевой настройкой опережающего чтения является его размер. Забегая вперед скажу, что с read ahead есть две основные проблемы: недостаточный read ahead и чрезмерный. Итак, на VxFS read ahead настраивается с помощью параметров “read_pref_io” и “read_nstream” команды vxtunefs. Когда на VxFS включается опережающее чтение, изначально запрашивается 4 блока размером “read_pref_io”. Если процесс продолжает читать последовательно, то прочитывается 4*read_pref_io*read_nstream.
Пример
:
Пусть read_pref_io=256k и read_nstream=4
Таким образом начальный read ahead составит: 4*256KB =1024KB.
Если последовательное чтение продолжается, то: 4*4*256KB=4096KB
Необходимо заметить, что в последнем случае, в дисковую подсистему отправятся практически одновременно 16 запросов с блоком 256KB. Это не мало и на короткое время может хорошенько подгрузить массив. В общем случае, в настройке read_pref_io и read_nstream сложно давать какие-то общие советы. Конкретные решения всегда зависят от числа дисков в массиве и характера нагрузки. Для некоторых нагрузок отлично работает read_pref_io=256k и read_nstream=32 (очень много). Иногда, read_ahead лучше отключить совсем. Так как настройка простая и ставится она на на лету, проще всего подбирать оптимальное значение. Единственное, что можно посоветовать, всегда ставить read_pref_io по степеням 2. Или как минимум, чтобы они были кратными размеру блока данных в кеше ОС. Иначе, последствия могут быть непредсказуемыми.
Влияние буферного кеша ОС
Когда read ahead асинхронно прочитывает данные, их надо хранить где-то в памяти. Для этого используется файловый кеш операционной системы. В ряде случаев, файловую систему можно смонтировать с отключенным файловым кешем (direct IO). Соответственно, функциональность read ahead в этом случае отключается.
Основные проблемы с опережающим чтением:
1) Недостаточный read ahead. Размер блока, который запросило приложение, больше блока считанного через read ahead. Например, команда ‘cp’ может читать блоком 1024 KB, а опережающее чтение настроено на чтение 256KB. То есть данных просто не хватит чтобы удовлетворить приложение и необходим еще один синхронный запрос ввода-вывода. В данном случае, включение read ahead не принесет увеличения скорости.
2) Чрезмерный read ahead
— слишком агрессивный read ahead может попросту перегрузить дисковую подсистему. Особенно, если в бэкенде установлено мало шпинделей. Большое число практически параллельных запросов свалившихся с хоста могут зафлудить дисковый массив. В этом случае, вместо ускорения вы увидите замедления в работе.
— другой проблемой с read ahead могут быть промахи, когда файловая система ошибочно определяет последовательное чтение прочитывает ненужные данные в кеш. Это приводит к паразитным операциям ввода-вывода, и создает дополнительную нагрузку на диски.
— так как данные read ahead хранятся в кеше файловой системы, большой объем read ahead может приводить к вымыванию из кеша более ценных блоков. Эти блоки потом придется прочитывать с диска снова.
3) Конфликт между read ahead файловой системы и read ahead дискового массива
К счастью, это крайне редкий случай. В большинстве современных дисковых массивов, оснащенных кеш-памятью и логикой, на аппаратном уровне реализован собственный механизм read ahead. Логика массива cама определяет последовательное чтение и контроллер оптом считывает данные с физических дисков в кеш массива. Это позволяет значительно сократить время отклика от дисковой подсистемы и увеличить скорость последовательного чтения. Опережающее чтение файловой системы несколько отличается от обычного синхронного чтения и может сбивать с толку контроллер дискового массива. Он может не распознать характер нагрузки и не включить аппаратный read ahead. Например, если дисковый массив подключен по SAN (Storage Area Networking) и до него есть несколько путей. Из-за балансировки нагрузки асинхронные запросы могут приходить на разные порты дискового массива практически одновременно. В таком случае, запросы могут быть обработаны контроллером не в том порядке, как они отправлены с сервера. Как следствие, массив не распознает последовательное чтение. Решение подобных проблем может быть наиболее долгим и трудоемким. Иногда решение лежит в области настройки, иногда помогает отключение одного из read ahead (если это возможно), иногда необходимо изменение кода одного из компонент.
Пример влияния опережающего чтения
Заказчик был неудовлетворен временем резервного копирования базы данных. В качестве теста, выполнялся бэкап одного файла размером 50 GB. Дальше приведены результаты трех тестов с различными настройками файловой системы.
Directories… 0
Regular files… 1
— Objects Total… 1
Total Size… 50.51 GB
1. Опережающее чтение выключено (Direct IO)
Run Time… 0:17:10
Backup Speed… 71.99 MB/s
2. Стандартные настройки опережающего чтения (read_pref_io = 65536, read_nstream = 1)
Run Time… 0:05:17
Backup Speed… 163.16 MB/s
3. Увеличенный (сильно) размер опережающего чтения (read_pref_io = 262144, read_nstream = 64)
Run Time… 0:02:27
Backup Speed… 222.91 MB/s
Как видно из примера, read ahead позволил значительно сократить время бэкапа. Дальнейшая эксплуатация показала, что все остальные задачи на системе нормально работали с таким большим размером read ahead (тест 3). Каких-либо проблем из-за чрезмерного read ahead не было замечено. В результате, эти настройки и оставили.
Вы можете столкнуться с хорошей ошибкой, указывающей на то, что при чтении в режиме смещения был обнаружен недопустимый идентификатор страницы. Однако есть несколько шагов, которые вы можете предпринять, чтобы решить эту проблему, и мы вскоре их обсудим.
Одна из моих компаний, выпускающих SQL Server 2000, недавно столкнулась с проблемой. Некоторые таблицы повреждены визуально.
select * while fgot — возвращает все записи и ОК.
выберите * где угодно из CRemployee , где Deeptid равен 25 — ‘Сервер сообщений ERROR: 823, уровень сообщения, часы a, указать некоторые, строка 1
Ошибка ввода-вывода (плохой) Идентификатор страницы) была обнаружена при чтении отмены 0x00000000a86000 в списке ‘E: rose HR.mdf’.
Точно так же несколько агентов сообщили об этой проблеме. Во всяком случае, я использовал эти штуки
Сервер: Сообщение 8909, уровень 16, состояние 1, строка 1
Ошибка таблицы: идентификатор объекта -1, идентификатор индекса 65535, идентификатор World Wide Web (1: 1347). PageId в заголовке страницы блога = (65535: -1) .Color = “# ff0000″> Сервер:
двойной идентификатор объекта: в тексте с использованием идентификатор 4391632896, используемый записью, идентифицированной посредством RID, равный (1: 426: 25), id означает 694397643 и indid, равный 7.
Любая помощь приветствуется. Кроме того, я имитирую .mdf и .ldf друг для друга, поэтому сервер подключает их и пытается выполнить какой-то запрос. Однако я сказал, что есть та же ошибка MSG … Так что я думаю, что это не неправильный способ обращения с физической безопасностью. Что-то, вероятно, повреждено ….. есть ли какой-нибудь другой план, чтобы исправить это ???? ПОЖАЛУЙСТА ПОМОГИ.
Называется
был предназначен для того, чтобы помочь вам создать администратора баз данных с системой хранения кадров, для многих из которых в феврале 2007 года не выполнялось резервное копирование. Были выполнены следующие связанные действия, которые немедленно дали следующие результаты. Любая помощь будет принята с благодарностью:
Версия базы данных: SQL 2000-8.00.194 (SQL Server 2000 RTM) – без пакетов обновления
Ошибка ввода-вывода (недопустимый идентификатор) обнаружена при чтении 0x000000034ee000 в файле E: SQL MSSQL data ls LongShine_Data.MDF.
CHECKDB обнаружил 0 ошибок расчета заработной платы и восемьдесят семь ошибок согласованности в репозитории LongShine.
repair_allow_data_loss 4. минимальный уровень исправления ошибок, выявляемых только DBCC CHECKDB (LongShine).
Согласование DBCC завершено. Если DBCC печатает неверные сообщения о продажах, обратитесь к администратору продукта.
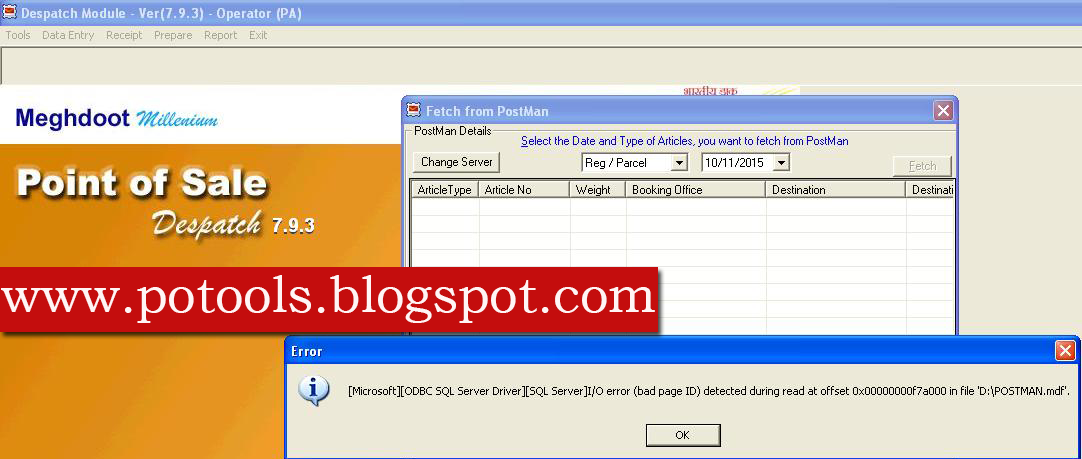
При чтении 0x00000002100000 в файле ‘E: SQL MSSQL data ls LongShine_Data.MDF’ обнаружена ошибка ввода -вывод (идентификатор дефектного матраса).
CHECKTABLE обнаружил 0 ошибок распределения и сорок пять ошибок согласованности на диаграмме “C41” (идентификатор объекта 821577965).
repair_allow_data_loss – минимальный уровень устранения, включая ошибки, обнаруженные DBCC CHECKTABLE (LongShine.dbo.C41).
Администратор базы данных сообщил нашей компании, что он пытался запустить определенный файл, и в repair_allow_data_loss не хватает примерно шестидесяти одной строки данных к тому году, который он пытается решить. Я хотел посмотреть, смогу ли я начать читать все фактические страницы данных, используя любую страницу dbcc traceon (3406) (‘longshine, 1, AnyPageNumber, 1) для сбора данных, но я не могу этого сделать. Я бы даже попытался построить что-то, что, конечно, невозможно, а если возможно. Желает ли кто-нибудь на рынке посоветовать мне или поработать со мной, выясняя, можно ли читать и / или собирать данные?
Название затруднительного положения требует указания на проблему.
Это действительно невероятно срочно, как вы можете видеть в это воскресенье, и в последнее время я занимаюсь организацией, а не в среде обитания.
Вышеупомянутая проблема определенно связана с этим vch table_detail, который, похоже, полностью поврежден. Различные файлы sql, применяемые к этому настольному программному обеспечению, предполагают, что обычно обычно повреждены только несколько строк.
Это подробный список, устройство и главная таблица – vch_master для Voucher_Nr, первичный ключ тега и столбец даты обнаружения, вероятно, будет Voucher_Date. Voucher_Date в vch_detail был записан Voucher_Date в конечном результате vch_master как их триггер. Обратите внимание, что я восстанавливаю фактическую дату (без значения времени).
Vch_detail связан с внешним ключом с vch_master (voucher_no, удаление надписи).
Моя таблица vch_master верна и
выберите (пробел) vch_master
отобразить все данные (12124 строки)
Выберите vch_master
где Voucher_Nr + Tag не рассматривается (выберите Voucher_Nr + Tag из vch_detail)
представит 12 124 стихов. К сожалению, vch_detail считается поврежденным.
Теперь определите * из vch_detail, устраните ошибки ввода-вывода
и
выберите * из vch_detail, где Voucher_no, похожий на ‘040%’, не вызывает серьезную ошибку
и
Выберите 35382 наиболее важных * вместо vch_detail Не распространять ошибку
и
* искать от vch_detail
где Voucher_Date < [любая дата] вызвала ошибки ввода-вывода
Я мог бы захотеть иметь свою таблицу vch_master. Это было законно, и, кроме того, в настоящее время невозможно использовать несколько хороших #. из мастера, для которого повреждены наиболее важные линии деталей в vch_detail, объединенном с помощью, чтобы восстановить vch_detail без этого ваучера. Я сделаю эти купоны еще раз.
Выбор программных программ / конструкций SQL широк, поэтому определенный особый тип SQL не читает вредоносные фан-страницы / области.
Я пытаюсь написать код в Apache Pig для добавления матрицы.
matrixM = LOAD 'Mmatrix.txt' USING PigStorage (',') AS (i,j,v);
matrixN = LOAD 'Nmatrix.txt' USING PigStorage (',') AS (i,j,v);
unionres = UNION matrixM, matrixN;
DUMP unionres;
res = GROUP unionres BY (i,j);
DUMP res;
ILLUSTRATE res;
final_res = FOREACH res GENERATE group.$0 AS i, group.$1 AS j, SUM(unionres.v) AS v;
DUMP final_res;
Я получаю следующее исключение при запуске кода в локальном режиме.
org.apache.hadoop.io.ReadaheadPool - Failed readahead on ifile
EBADF: Bad file descriptor
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posix_fadvise(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posixFadviseIfPossible(NativeIO.java:267)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX$CacheManipulator.posixFadviseIfPossible(NativeIO.java:146)
at org.apache.hadoop.io.ReadaheadPool$ReadaheadRequestImpl.run(ReadaheadPool.java:208)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Может ли кто-нибудь объяснить мне, где я ошибаюсь?
1 ответ
Обычно вышеприведенное сообщение является ПРЕДУПРЕЖДЕНИЕМ, а фактическое сообщение об ошибке отображается позже. Я видел этот тип сообщения WARN только тогда, когда диск неисправен или заполнен. Есть ли шансы, что ваш локальный /tmp заполнен?
0
Koji
19 Дек 2017 в 07:41
Пересказ статьи Chad Callihan. What is a Read-Ahead Read?
Что такое опережающие чтения, и как они влияют на производительность SQL Server? Опережающие чтения позволяют SQL Server заглянуть вперед, чтобы извлечь страницы в буферный кэш прежде, чем они фактически будут затребованы для запроса. До 64 последовательных страниц могут быть прочитаны из файла, а возможность опережающего чтения может применяться как для страниц данных, так и для индексных страниц. Когда страницы оказываются в буферном кэше, то отпадает необходимость извлекать их с диска для будущих запросов, пока они не будут сброшены другими задачами SQL Server.
Опережающее чтение в действии
Для начала нам нужно проверить, чтобы была включена статистика ввода-вывода. Тогда мы сможем узнать число сканирований, логических чтений и т.д., но, что нам более важно, мы сможем посмотреть число опережающих чтений:
SET STATISTICS IO ON;
GO
Мы можем также для нашего примера выполнить следующий оператор, чтобы почистить буферы буферного пула, прежде чем выполнять какие-либо операторы SELECT. Это гарантирует, что мы увидим опережающие чтения, когда выполним наш первый запрос.
DBCC DROPCLEANBUFFERS;
Например, мы хотим сделать запрос к базе данных StackOverFlow2013 для получения top 10000 пользователей c id, меньшими 10000. Выполнив запрос SELECT, увидим следующие результаты:
Я получил 5888 строк. Если мы перейдем на вкладку Messages и посмотрим на статистику, то увидим 289 опережающих чтений, означающее, что SQL Server извлек 289 страниц.
Что случится, если мы выполним тот же запрос еще раз? Увидим ли мы теперь опережающие чтения?
Никаких опережающих чтений на этот раз, поскольку данные уже загружены в буферный кэш.
Запрет опережающих чтений
Если вы по каким-либо причинам не хотите, чтобы выполнялись опережающие чтения, то можете включить флаг трассировки 652, чтобы запретить их:
Как видно выше, что даже при предварительной очистке буферов (DBCC DROPCLEANBUFFERS), выполнение нашего оператора SELECT показало 0 в числе опережающих чтений, поскольку был включен флаг трассировки 652.
Вы разрешаете опережающие чтения?
Опережающие чтения полезны с точки зрения улучшения производительности запросов, и они включены по умолчанию. Весьма вероятно, что они всегда будут включены и никогда не вызовут проблем.