Обновлено: 29.01.2023
XML ( англ. eXtensible Markup Language) — расширяемый язык разметки, предназначенный для хранения и передачи данных.
Простейший XML-документ выглядит следующим образом:
Первая строка — это XML декларация. Здесь определяется версия XML (1.0) и кодировка файла. На следующей строке описывается корневой элемент документа <book> (открывающий тег). Следующие 4 строки описывают дочерние элементы корневого элемента ( title , author , year , price ). Последняя строка определяет конец корневого элемента </book> (закрывающий тег).
Документ XML состоит из элементов (elements). Элемент начинается открывающим тегом (start-tag) в угловых скобках, затем идет содержимое (content) элемента, после него записывается закрывающий тег (end-teg) в угловых скобках.
Информация, заключенная между тегами, называется содержимым или значением элемента: <author>Erik T. Ray</author> . Т.е. элемент author принимает значение Erik T. Ray . Элементы могут вообще не принимать значения.
Элементы могут содержать атрибуты, так, например, открывающий тег <title lang=»en»> имеет атрибут lang , который принимает значение en . Значения атрибутов заключаются в кавычки (двойные или ординарные).
Некоторые элементы, не содержащие значений, допустимо записывать без закрывающего тега. В таком случае символ / ставится в конце открывающего тега:
XML документ должен содержать корневой элемент. Этот элемент является «родительским» для всех других элементов.
Все элементы в XML документе формируют иерархическое дерево. Это дерево начинается с корневого элемента и разветвляется на более низкие уровни элементов.
Все элементы могут иметь подэлементы (дочерние элементы):
Правила синтаксиса (Валидность)¶
Структура XML документа должна соответствовать определенным правилам. XML документ отвечающий этим правилам называется валидным (англ. Valid — правильный) или синтаксически верным. Соответственно, если документ не отвечает правилам, он является невалидным .
Основные правила синтаксиса XML:
- Теги XML регистрозависимы — теги XML являются регистрозависимыми. Так, тег <Letter> не то же самое, что тег <letter> .
Открывающий и закрывающий теги должны определяться в одном регистре:
- XML элементы должны соблюдать корректную вложенность:
- У XML документа должен быть корневой элемент — XML документ должен содержать один элемент, который будет родительским для всех других элементов. Он называется корневым элементом.
- Значения XML атрибутов должны заключаться в кавычки:
Сущности¶
Некоторые символы в XML имеют особые значения и являются служебными. Если вы поместите, например, символ < внутри XML элемента, то будет сгенерирована ошибка, так как парсер интерпретирует его, как начало нового элемента.
В примере ниже будет сгенерирована ошибка, так как в значении «ООО<Мосавтогруз>» атрибута НаимОрг содержатся символы < и > .
Также ошибка будет сгенерирована и в слудющем примере, если название организации взять в обычные кавычки (английские двойные):
Чтобы ошибки не возникали, нужно заменить символ < на его сущность. В XML существует 5 предопределенных сущностей:
| Сущность | Символ | Значение |
|---|---|---|
| < | < | меньше, чем |
| > | > | больше, чем |
| & | & | амперсанд |
| ' | ‘ | апостроф |
| " | « | кавычки |
Таблица I.1 — Сущности ¶
Только символы < и & строго запрещены в XML. Символ > допустим, но лучше его всегда заменять на сущность.
Таким образом, корректными будут следующие формы записей:
В последнем примере английские двойные кавычки заменены на французские кавычки («ёлочки»), которые не являются служебными символами.
Поиск информации в XML файлах (XPath)¶
XPath ( англ. XML Path Language) — язык запросов к элементам XML-документа. XPath расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой элемент (инструкция <?xml version=”1.0”?> к дереву отношения не имеет). У элемента дерева всегда существуют потомки и предки, кроме корневого элемента, у которого предков нет, а также тупиковых элементов (листьев дерева), у которых нет потомков. Каждый элемент дерева находится на определенном уровне вложенности (далее — «уровень»). У элементов на одном уровне бывают предыдущие и следующие элементы.
Это очень похоже на организацию каталогов в файловой системе, и строки XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример списка книг:
XPath запрос /bookstore/book/price вернет следующий результат:
Сокращенная форма этого запроса выглядит так: //price .
В приведенной ниже таблице представлены некоторые выражения XPath и результат их работы:
Кодировки¶
И еще один важный момент, который стоит рассмотреть — кодировки. Существует множество кодировок, о них подробнее можно прочитать в статье Набор символов.
Самыми распространенными кириллическими кодировками являются Windows-1251 и UTF-8 . Последняя является одним из стандартов, но большая часть ФНС отчетности имеет кодировку Windows-1251 .
В XML файле кодировка объявляется в декларации:
Часто можно столкнуться с ситуацией, когда текстовый редаткор некорректно распознает кодировку и отображает кракозябры. В такой случае, необходимо выбрать кодировку вручную, для этого выполните:
| Программа | Кодировка |
|---|---|
| Notepad++ | «Документ → Кодировка» |
| Geany | «Документ → Установить кодировку» |
| Firefox | «Вид → Кодировка» |
| Chrome | «Настройка → Дополнительные инструменты → Кодировка» |
Таблица I.3 — Смена кодировки в разных программах ¶
В большинстве случаев при работе с русскоязычными файлами помогает переключение кодировки на Windows-1251 или UTF-8 . Если все равно не удается прочитать содержимое XML документа, стоит открыть его в Mozilla Firefox, он отлично распознает кодировки.
Если ничего не помогает, вполне возможно, что файл был поврежден.
XSD схема¶
XML Schema — язык описания структуры XML-документа, его также называют XSD. Как большинство языков описания XML, XML Schema была задумана для определения правил, которым должен подчиняться документ. Но, в отличие от других языков, XML Schema была разработана так, чтобы её можно было использовать в создании программного обеспечения для обработки документов XML.
После проверки документа на соответствие XML Schema читающая программа может создать модель данных документа, которая включает:
- словарь (названия элементов и атрибутов);
- модель содержания (отношения между элементами и атрибутами и их структура);
- типы данных.
Каждый элемент в этой модели ассоциируется с определённым типом данных, позволяя строить в памяти объект, соответствующий структуре XML-документа. Языкам объектно-ориентированного программирования гораздо легче иметь дело с таким объектом, чем с текстовым файлом.
Файл abbyy pdf transformer.exe из ABBYY является частью ABBYY PDF Transformer v9 0 102 46. abbyy pdf transformer.exe, расположенный в d. dreamdisk 2014 christmas editionsoftwareofficepdf abbyy pdf transformer .exe с размером файла 189737804 байт, версия файла Unknown version, подпись a5040812c0bc670eb16bd0d493ef1fc4.
- Запустите приложение Asmwsoft Pc Optimizer.
- Потом из главного окна выберите пункт «Clean Junk Files».
- Когда появится новое окно, нажмите на кнопку «start» и дождитесь окончания поиска.
- потом нажмите на кнопку «Select All».
- нажмите на кнопку «start cleaning».

- Запустите приложение Asmwsoft Pc Optimizer.
- Потом из главного окна выберите пункт «Fix Registry problems».
- Нажмите на кнопку «select all» для проверки всех разделов реестра на наличие ошибок.
- 4. Нажмите на кнопку «Start» и подождите несколько минут в зависимости от размера файла реестра.
- После завершения поиска нажмите на кнопку «select all».
- Нажмите на кнопку «Fix selected».
P.S. Вам может потребоваться повторно выполнить эти шаги.
3- Настройка Windows для исправления критических ошибок abbyy pdf transformer.exe:

- Нажмите правой кнопкой мыши на «Мой компьютер» на рабочем столе и выберите пункт «Свойства».
- В меню слева выберите » Advanced system settings».
- В разделе «Быстродействие» нажмите на кнопку «Параметры».
- Нажмите на вкладку «data Execution prevention».
- Выберите опцию » Turn on DEP for all programs and services . » .
- Нажмите на кнопку «add» и выберите файл abbyy pdf transformer.exe, а затем нажмите на кнопку «open».
- Нажмите на кнопку «ok» и перезагрузите свой компьютер.
Как другие пользователи поступают с этим файлом?
Всего голосов ( 181 ), 115 говорят, что не будут удалять, а 66 говорят, что удалят его с компьютера.
В данной статье речь пойдёт о причинах возникновения фатальной ошибки «Ошибка разбора XML» и способах устранения данной неполадки. Также будет дана инструкция не по устранению, но «обходу» ошибки, то есть действиям на опережение.
XML (с английского – extensible markup language – расширяемый язык разметки) – это язык разметки, который рекомендует Консорциум Всемирной паутины. Обычно язык разметки XML служит для описания документации, соответствующего типа, а также описывает действия соответствующих процессоров. Расширяемый язык разметки имеет довольно простой синтаксис, поэтому используется по всему миру, чтобы создавать и обрабатывать документацию программным способом. Он создавался именно для использования в Интернете. XML назвали именно расширяемым языком разметки, так как в нём нет фиксации разметки, которая содержится внутри документа, а именно: программист может создавать любую разметку, а ограничения будут встречаться лишь в синтаксисе.
2. Устранение Ошибки разбора XML в 1С
«Ошибка разбора XML» возникает исключительно в тонком клиенте 1С. Также стоит отметить, что «Ошибка разбора XML» также довольна схожа с ошибкой по формату потока, которая возникает в толстом клиенте. Обычно в 1С «Ошибка разбора XML» возникает по причине наличия кэша метаданных. И если очистить кэш, то ошибка будет устранена. Выглядит окно с ошибкой, а также окно с комментариями от технической поддержки следующим образом:

Рис. 1 Окно Ошибки разбора XML в 1С
XML данные читаются по потокам, так что в каждый из моментов времени объект «сосредоточен» в некотором узле XML. Из-за этого также может возникать фатальная ошибка «Ошибка разбора XML». Для того чтобы её устранить, можно вызвать функцию «ИсключениеЧтенияXml», как показано на скриншоте примера ниже:

Рис. 2 Вызов функции ИсключениеЧтенияXML для устранения Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
Данные два способа (очистка кэша метаданных и функция «ИсключениеЧтенияXml») – не все возможные варианты устранения ошибки разбора XML. Далее рассмотрим нестандартный подход, который позволит избежать ошибки еще до её возникновения.
Для наглядности будем работать в конфигурации 1С:Бухгалтерия предприятия, одной из наиболее распространенных программ фирмы 1С. У многих людей, которые пользуются программой 1С:Отчётность появляются неполадки при попытках открыть данные/файлы от налоговой. Чтобы открыть такой файл повторяем следующие действия:
· Переходим по пути: «Настройки 1С:Отчётности → Журнал обмена с контролирующими органами», как показано на скриншоте ниже:

Рис. 3 Настройка 1С Отчетности
· Далее кликаем на «Запросы» и выделяем ту выписку, которую не было возможности открыть из-за ошибки, как продемонстрировано на скриншоте ниже:

Рис. 4 Выбор выписки с Ошибкой разбора XML в 1С

Рис. 5 Стадия отправки документа с Ошибкой разбора XML в 1С
Несколько пользователей сообщают о Ошибка синтаксического анализа XML всякий раз, когда они пытаются открыть документ Microsoft Word, который они ранее экспортировали. Эта проблема обычно возникает после того, как пользователь обновился до более новой версии Office или после того, как документ Word был ранее экспортирован из другой программы. Эта проблема обычно возникает на компьютерах с Windows 7 и Windows 9.

Ошибка разбора Word XML
Что вызывает ошибку синтаксического анализа XML в Microsoft Word?
Мы исследовали проблему, просматривая различные пользовательские отчеты и пытаясь воспроизвести проблему. Как выясняется, есть несколько преступников, которые могут в конечном итоге вызвать эту конкретную проблему:
Если вы в настоящее время пытаются решить Ошибка синтаксического анализа XML, эта статья предоставит вам список проверенных шагов по устранению неполадок. Ниже приведен список методов, которые другие пользователи в аналогичной ситуации использовали для решения проблемы.
Чтобы обеспечить наилучшие результаты, следуйте приведенным ниже методам, чтобы найти исправление, эффективное для решения проблемы. Давай начнем!
Способ 1: установка графического обновления Windows SVG
Этот метод обычно считается успешным в Windows 7 и Windows 8, но мы успешно воссоздали шаги для Windows 10. Эта проблема возникает из-за ошибки, которую WU (Центр обновления Windows) делает при установке определенных обновлений.
Как выясняется, это конкретное обновление (которое создает проблему) должно автоматически устанавливаться компонентом обновления, поскольку оно включено в число WSUS (службы обновления Windows Server) утвержденные обновления.
К счастью, вы также можете установить недостающее обновление (KB2563227) через онлайн-страницу Microsoft. Вот краткое руководство о том, как это сделать:
Если вы все еще сталкиваетесь с Ошибка синтаксического анализа XML ошибка, продолжайте следующим способом ниже.
Способ 2: устранение ошибки с помощью Notepad ++ и Winrar или Winzip
Если первый метод не помог решить проблему, вполне вероятно, что код XML, сопровождающий документ Word, не соответствует спецификации XML. Скорее всего, код XML, сопровождающий текст, содержит ошибки кодирования.
Вы можете заметить, что атрибут Location указывает на файл .xml, когда вы пытаетесь открыть файл word. Хотите знать, почему это? Это потому, что файл .doc на самом деле является файлом .zip, который содержит коллекцию файлов .xml.
Следуйте приведенным ниже инструкциям, чтобы использовать Notepad ++ и WinRar для решения проблемы и открыть документ Word без Ошибка синтаксического анализа XML:
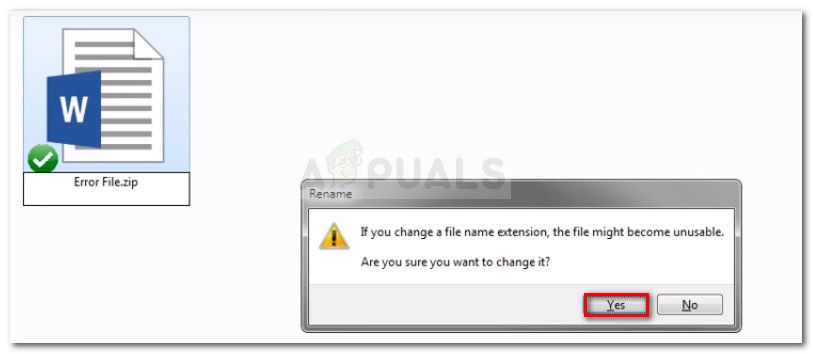
-
Щелкните правой кнопкой мыши документ, который вызывает ошибку, и измените форму расширения. .доктор кзастежка-молния. Когда вас попросят подтвердить изменение имени добавочного номера, нажмите да подтвердить.
Изменение расширения с .doc на .zip
Замечания: Если вы не можете просмотреть расширение файла, перейдите к Посмотреть вкладка в Проводник и убедитесь, что поле связано с Расширения имени файла проверено.
Замечания: Если вы не можете открыть документ .zip, загрузите Winzip по этой ссылке (Вот).
Читайте также:
- Vipnet coordinator hw1000 firewall настройка
- Как обновить яндекс дзен на компьютере
- Cassida zeus ошибка ps2
- Hyperx alloy origins core black usb обзор
- Как в bluestacks загрузить фото с компьютера
Обновлено: 29.01.2023
XML ( англ. eXtensible Markup Language) — расширяемый язык разметки, предназначенный для хранения и передачи данных.
Простейший XML-документ выглядит следующим образом:
Первая строка — это XML декларация. Здесь определяется версия XML (1.0) и кодировка файла. На следующей строке описывается корневой элемент документа <book> (открывающий тег). Следующие 4 строки описывают дочерние элементы корневого элемента ( title , author , year , price ). Последняя строка определяет конец корневого элемента </book> (закрывающий тег).
Документ XML состоит из элементов (elements). Элемент начинается открывающим тегом (start-tag) в угловых скобках, затем идет содержимое (content) элемента, после него записывается закрывающий тег (end-teg) в угловых скобках.
Информация, заключенная между тегами, называется содержимым или значением элемента: <author>Erik T. Ray</author> . Т.е. элемент author принимает значение Erik T. Ray . Элементы могут вообще не принимать значения.
Элементы могут содержать атрибуты, так, например, открывающий тег <title lang=»en»> имеет атрибут lang , который принимает значение en . Значения атрибутов заключаются в кавычки (двойные или ординарные).
Некоторые элементы, не содержащие значений, допустимо записывать без закрывающего тега. В таком случае символ / ставится в конце открывающего тега:
XML документ должен содержать корневой элемент. Этот элемент является «родительским» для всех других элементов.
Все элементы в XML документе формируют иерархическое дерево. Это дерево начинается с корневого элемента и разветвляется на более низкие уровни элементов.
Все элементы могут иметь подэлементы (дочерние элементы):
Правила синтаксиса (Валидность)¶
Структура XML документа должна соответствовать определенным правилам. XML документ отвечающий этим правилам называется валидным (англ. Valid — правильный) или синтаксически верным. Соответственно, если документ не отвечает правилам, он является невалидным .
Основные правила синтаксиса XML:
- Теги XML регистрозависимы — теги XML являются регистрозависимыми. Так, тег <Letter> не то же самое, что тег <letter> .
Открывающий и закрывающий теги должны определяться в одном регистре:
- XML элементы должны соблюдать корректную вложенность:
- У XML документа должен быть корневой элемент — XML документ должен содержать один элемент, который будет родительским для всех других элементов. Он называется корневым элементом.
- Значения XML атрибутов должны заключаться в кавычки:
Сущности¶
Некоторые символы в XML имеют особые значения и являются служебными. Если вы поместите, например, символ < внутри XML элемента, то будет сгенерирована ошибка, так как парсер интерпретирует его, как начало нового элемента.
В примере ниже будет сгенерирована ошибка, так как в значении «ООО<Мосавтогруз>» атрибута НаимОрг содержатся символы < и > .
Также ошибка будет сгенерирована и в слудющем примере, если название организации взять в обычные кавычки (английские двойные):
Чтобы ошибки не возникали, нужно заменить символ < на его сущность. В XML существует 5 предопределенных сущностей:
| Сущность | Символ | Значение |
|---|---|---|
| < | < | меньше, чем |
| > | > | больше, чем |
| & | & | амперсанд |
| ' | ‘ | апостроф |
| " | « | кавычки |
Таблица I.1 — Сущности ¶
Только символы < и & строго запрещены в XML. Символ > допустим, но лучше его всегда заменять на сущность.
Таким образом, корректными будут следующие формы записей:
В последнем примере английские двойные кавычки заменены на французские кавычки («ёлочки»), которые не являются служебными символами.
Поиск информации в XML файлах (XPath)¶
XPath ( англ. XML Path Language) — язык запросов к элементам XML-документа. XPath расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой элемент (инструкция <?xml version=”1.0”?> к дереву отношения не имеет). У элемента дерева всегда существуют потомки и предки, кроме корневого элемента, у которого предков нет, а также тупиковых элементов (листьев дерева), у которых нет потомков. Каждый элемент дерева находится на определенном уровне вложенности (далее — «уровень»). У элементов на одном уровне бывают предыдущие и следующие элементы.
Это очень похоже на организацию каталогов в файловой системе, и строки XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример списка книг:
XPath запрос /bookstore/book/price вернет следующий результат:
Сокращенная форма этого запроса выглядит так: //price .
В приведенной ниже таблице представлены некоторые выражения XPath и результат их работы:
Кодировки¶
И еще один важный момент, который стоит рассмотреть — кодировки. Существует множество кодировок, о них подробнее можно прочитать в статье Набор символов.
Самыми распространенными кириллическими кодировками являются Windows-1251 и UTF-8 . Последняя является одним из стандартов, но большая часть ФНС отчетности имеет кодировку Windows-1251 .
В XML файле кодировка объявляется в декларации:
Часто можно столкнуться с ситуацией, когда текстовый редаткор некорректно распознает кодировку и отображает кракозябры. В такой случае, необходимо выбрать кодировку вручную, для этого выполните:
| Программа | Кодировка |
|---|---|
| Notepad++ | «Документ → Кодировка» |
| Geany | «Документ → Установить кодировку» |
| Firefox | «Вид → Кодировка» |
| Chrome | «Настройка → Дополнительные инструменты → Кодировка» |
Таблица I.3 — Смена кодировки в разных программах ¶
В большинстве случаев при работе с русскоязычными файлами помогает переключение кодировки на Windows-1251 или UTF-8 . Если все равно не удается прочитать содержимое XML документа, стоит открыть его в Mozilla Firefox, он отлично распознает кодировки.
Если ничего не помогает, вполне возможно, что файл был поврежден.
XSD схема¶
XML Schema — язык описания структуры XML-документа, его также называют XSD. Как большинство языков описания XML, XML Schema была задумана для определения правил, которым должен подчиняться документ. Но, в отличие от других языков, XML Schema была разработана так, чтобы её можно было использовать в создании программного обеспечения для обработки документов XML.
После проверки документа на соответствие XML Schema читающая программа может создать модель данных документа, которая включает:
- словарь (названия элементов и атрибутов);
- модель содержания (отношения между элементами и атрибутами и их структура);
- типы данных.
Каждый элемент в этой модели ассоциируется с определённым типом данных, позволяя строить в памяти объект, соответствующий структуре XML-документа. Языкам объектно-ориентированного программирования гораздо легче иметь дело с таким объектом, чем с текстовым файлом.
Файл abbyy pdf transformer.exe из ABBYY является частью ABBYY PDF Transformer v9 0 102 46. abbyy pdf transformer.exe, расположенный в d. dreamdisk 2014 christmas editionsoftwareofficepdf abbyy pdf transformer .exe с размером файла 189737804 байт, версия файла Unknown version, подпись a5040812c0bc670eb16bd0d493ef1fc4.
- Запустите приложение Asmwsoft Pc Optimizer.
- Потом из главного окна выберите пункт «Clean Junk Files».
- Когда появится новое окно, нажмите на кнопку «start» и дождитесь окончания поиска.
- потом нажмите на кнопку «Select All».
- нажмите на кнопку «start cleaning».
- Запустите приложение Asmwsoft Pc Optimizer.
- Потом из главного окна выберите пункт «Fix Registry problems».
- Нажмите на кнопку «select all» для проверки всех разделов реестра на наличие ошибок.
- 4. Нажмите на кнопку «Start» и подождите несколько минут в зависимости от размера файла реестра.
- После завершения поиска нажмите на кнопку «select all».
- Нажмите на кнопку «Fix selected».
P.S. Вам может потребоваться повторно выполнить эти шаги.
3- Настройка Windows для исправления критических ошибок abbyy pdf transformer.exe:
- Нажмите правой кнопкой мыши на «Мой компьютер» на рабочем столе и выберите пункт «Свойства».
- В меню слева выберите » Advanced system settings».
- В разделе «Быстродействие» нажмите на кнопку «Параметры».
- Нажмите на вкладку «data Execution prevention».
- Выберите опцию » Turn on DEP for all programs and services . » .
- Нажмите на кнопку «add» и выберите файл abbyy pdf transformer.exe, а затем нажмите на кнопку «open».
- Нажмите на кнопку «ok» и перезагрузите свой компьютер.
Как другие пользователи поступают с этим файлом?
Всего голосов ( 181 ), 115 говорят, что не будут удалять, а 66 говорят, что удалят его с компьютера.
В данной статье речь пойдёт о причинах возникновения фатальной ошибки «Ошибка разбора XML» и способах устранения данной неполадки. Также будет дана инструкция не по устранению, но «обходу» ошибки, то есть действиям на опережение.
XML (с английского – extensible markup language – расширяемый язык разметки) – это язык разметки, который рекомендует Консорциум Всемирной паутины. Обычно язык разметки XML служит для описания документации, соответствующего типа, а также описывает действия соответствующих процессоров. Расширяемый язык разметки имеет довольно простой синтаксис, поэтому используется по всему миру, чтобы создавать и обрабатывать документацию программным способом. Он создавался именно для использования в Интернете. XML назвали именно расширяемым языком разметки, так как в нём нет фиксации разметки, которая содержится внутри документа, а именно: программист может создавать любую разметку, а ограничения будут встречаться лишь в синтаксисе.
2. Устранение Ошибки разбора XML в 1С
«Ошибка разбора XML» возникает исключительно в тонком клиенте 1С. Также стоит отметить, что «Ошибка разбора XML» также довольна схожа с ошибкой по формату потока, которая возникает в толстом клиенте. Обычно в 1С «Ошибка разбора XML» возникает по причине наличия кэша метаданных. И если очистить кэш, то ошибка будет устранена. Выглядит окно с ошибкой, а также окно с комментариями от технической поддержки следующим образом:
Рис. 1 Окно Ошибки разбора XML в 1С
XML данные читаются по потокам, так что в каждый из моментов времени объект «сосредоточен» в некотором узле XML. Из-за этого также может возникать фатальная ошибка «Ошибка разбора XML». Для того чтобы её устранить, можно вызвать функцию «ИсключениеЧтенияXml», как показано на скриншоте примера ниже:
Рис. 2 Вызов функции ИсключениеЧтенияXML для устранения Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
Данные два способа (очистка кэша метаданных и функция «ИсключениеЧтенияXml») – не все возможные варианты устранения ошибки разбора XML. Далее рассмотрим нестандартный подход, который позволит избежать ошибки еще до её возникновения.
Для наглядности будем работать в конфигурации 1С:Бухгалтерия предприятия, одной из наиболее распространенных программ фирмы 1С. У многих людей, которые пользуются программой 1С:Отчётность появляются неполадки при попытках открыть данные/файлы от налоговой. Чтобы открыть такой файл повторяем следующие действия:
· Переходим по пути: «Настройки 1С:Отчётности → Журнал обмена с контролирующими органами», как показано на скриншоте ниже:
Рис. 3 Настройка 1С Отчетности
· Далее кликаем на «Запросы» и выделяем ту выписку, которую не было возможности открыть из-за ошибки, как продемонстрировано на скриншоте ниже:
Рис. 4 Выбор выписки с Ошибкой разбора XML в 1С
Рис. 5 Стадия отправки документа с Ошибкой разбора XML в 1С
Несколько пользователей сообщают о Ошибка синтаксического анализа XML всякий раз, когда они пытаются открыть документ Microsoft Word, который они ранее экспортировали. Эта проблема обычно возникает после того, как пользователь обновился до более новой версии Office или после того, как документ Word был ранее экспортирован из другой программы. Эта проблема обычно возникает на компьютерах с Windows 7 и Windows 9.
Ошибка разбора Word XML
Что вызывает ошибку синтаксического анализа XML в Microsoft Word?
Мы исследовали проблему, просматривая различные пользовательские отчеты и пытаясь воспроизвести проблему. Как выясняется, есть несколько преступников, которые могут в конечном итоге вызвать эту конкретную проблему:
Если вы в настоящее время пытаются решить Ошибка синтаксического анализа XML, эта статья предоставит вам список проверенных шагов по устранению неполадок. Ниже приведен список методов, которые другие пользователи в аналогичной ситуации использовали для решения проблемы.
Чтобы обеспечить наилучшие результаты, следуйте приведенным ниже методам, чтобы найти исправление, эффективное для решения проблемы. Давай начнем!
Способ 1: установка графического обновления Windows SVG
Этот метод обычно считается успешным в Windows 7 и Windows 8, но мы успешно воссоздали шаги для Windows 10. Эта проблема возникает из-за ошибки, которую WU (Центр обновления Windows) делает при установке определенных обновлений.
Как выясняется, это конкретное обновление (которое создает проблему) должно автоматически устанавливаться компонентом обновления, поскольку оно включено в число WSUS (службы обновления Windows Server) утвержденные обновления.
К счастью, вы также можете установить недостающее обновление (KB2563227) через онлайн-страницу Microsoft. Вот краткое руководство о том, как это сделать:
Если вы все еще сталкиваетесь с Ошибка синтаксического анализа XML ошибка, продолжайте следующим способом ниже.
Способ 2: устранение ошибки с помощью Notepad ++ и Winrar или Winzip
Если первый метод не помог решить проблему, вполне вероятно, что код XML, сопровождающий документ Word, не соответствует спецификации XML. Скорее всего, код XML, сопровождающий текст, содержит ошибки кодирования.
Вы можете заметить, что атрибут Location указывает на файл .xml, когда вы пытаетесь открыть файл word. Хотите знать, почему это? Это потому, что файл .doc на самом деле является файлом .zip, который содержит коллекцию файлов .xml.
Следуйте приведенным ниже инструкциям, чтобы использовать Notepad ++ и WinRar для решения проблемы и открыть документ Word без Ошибка синтаксического анализа XML:
-
Щелкните правой кнопкой мыши документ, который вызывает ошибку, и измените форму расширения. .доктор кзастежка-молния. Когда вас попросят подтвердить изменение имени добавочного номера, нажмите да подтвердить.
Изменение расширения с .doc на .zip
Замечания: Если вы не можете просмотреть расширение файла, перейдите к Посмотреть вкладка в Проводник и убедитесь, что поле связано с Расширения имени файла проверено.
Замечания: Если вы не можете открыть документ .zip, загрузите Winzip по этой ссылке (Вот).
Читайте также:
- Vipnet coordinator hw1000 firewall настройка
- Как обновить яндекс дзен на компьютере
- Cassida zeus ошибка ps2
- Hyperx alloy origins core black usb обзор
- Как в bluestacks загрузить фото с компьютера
Обновлено: 11.04.2023
XML ( англ. eXtensible Markup Language) — расширяемый язык разметки, предназначенный для хранения и передачи данных.
Простейший XML-документ выглядит следующим образом:
Первая строка — это XML декларация. Здесь определяется версия XML (1.0) и кодировка файла. На следующей строке описывается корневой элемент документа <book> (открывающий тег). Следующие 4 строки описывают дочерние элементы корневого элемента ( title , author , year , price ). Последняя строка определяет конец корневого элемента </book> (закрывающий тег).
Документ XML состоит из элементов (elements). Элемент начинается открывающим тегом (start-tag) в угловых скобках, затем идет содержимое (content) элемента, после него записывается закрывающий тег (end-teg) в угловых скобках.
Информация, заключенная между тегами, называется содержимым или значением элемента: <author>Erik T. Ray</author> . Т.е. элемент author принимает значение Erik T. Ray . Элементы могут вообще не принимать значения.
Элементы могут содержать атрибуты, так, например, открывающий тег <title lang=»en»> имеет атрибут lang , который принимает значение en . Значения атрибутов заключаются в кавычки (двойные или ординарные).
Некоторые элементы, не содержащие значений, допустимо записывать без закрывающего тега. В таком случае символ / ставится в конце открывающего тега:
XML документ должен содержать корневой элемент. Этот элемент является «родительским» для всех других элементов.
Все элементы в XML документе формируют иерархическое дерево. Это дерево начинается с корневого элемента и разветвляется на более низкие уровни элементов.
Все элементы могут иметь подэлементы (дочерние элементы):
Правила синтаксиса (Валидность)¶
Структура XML документа должна соответствовать определенным правилам. XML документ отвечающий этим правилам называется валидным (англ. Valid — правильный) или синтаксически верным. Соответственно, если документ не отвечает правилам, он является невалидным .
Основные правила синтаксиса XML:
- Теги XML регистрозависимы — теги XML являются регистрозависимыми. Так, тег <Letter> не то же самое, что тег <letter> .
Открывающий и закрывающий теги должны определяться в одном регистре:
- XML элементы должны соблюдать корректную вложенность:
- У XML документа должен быть корневой элемент — XML документ должен содержать один элемент, который будет родительским для всех других элементов. Он называется корневым элементом.
- Значения XML атрибутов должны заключаться в кавычки:
Сущности¶
Некоторые символы в XML имеют особые значения и являются служебными. Если вы поместите, например, символ < внутри XML элемента, то будет сгенерирована ошибка, так как парсер интерпретирует его, как начало нового элемента.
В примере ниже будет сгенерирована ошибка, так как в значении «ООО<Мосавтогруз>» атрибута НаимОрг содержатся символы < и > .
Также ошибка будет сгенерирована и в слудющем примере, если название организации взять в обычные кавычки (английские двойные):
Чтобы ошибки не возникали, нужно заменить символ < на его сущность. В XML существует 5 предопределенных сущностей:
| Сущность | Символ | Значение |
|---|---|---|
| < | < | меньше, чем |
| > | > | больше, чем |
| & | & | амперсанд |
| ' | ‘ | апостроф |
| " | « | кавычки |
Таблица I.1 — Сущности ¶
Только символы < и & строго запрещены в XML. Символ > допустим, но лучше его всегда заменять на сущность.
Таким образом, корректными будут следующие формы записей:
В последнем примере английские двойные кавычки заменены на французские кавычки («ёлочки»), которые не являются служебными символами.
Поиск информации в XML файлах (XPath)¶
XPath ( англ. XML Path Language) — язык запросов к элементам XML-документа. XPath расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой элемент (инструкция <?xml version=”1.0”?> к дереву отношения не имеет). У элемента дерева всегда существуют потомки и предки, кроме корневого элемента, у которого предков нет, а также тупиковых элементов (листьев дерева), у которых нет потомков. Каждый элемент дерева находится на определенном уровне вложенности (далее — «уровень»). У элементов на одном уровне бывают предыдущие и следующие элементы.
Это очень похоже на организацию каталогов в файловой системе, и строки XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример списка книг:
XPath запрос /bookstore/book/price вернет следующий результат:
Сокращенная форма этого запроса выглядит так: //price .
В приведенной ниже таблице представлены некоторые выражения XPath и результат их работы:
Кодировки¶
И еще один важный момент, который стоит рассмотреть — кодировки. Существует множество кодировок, о них подробнее можно прочитать в статье Набор символов.
Самыми распространенными кириллическими кодировками являются Windows-1251 и UTF-8 . Последняя является одним из стандартов, но большая часть ФНС отчетности имеет кодировку Windows-1251 .
В XML файле кодировка объявляется в декларации:
Часто можно столкнуться с ситуацией, когда текстовый редаткор некорректно распознает кодировку и отображает кракозябры. В такой случае, необходимо выбрать кодировку вручную, для этого выполните:
| Программа | Кодировка |
|---|---|
| Notepad++ | «Документ → Кодировка» |
| Geany | «Документ → Установить кодировку» |
| Firefox | «Вид → Кодировка» |
| Chrome | «Настройка → Дополнительные инструменты → Кодировка» |
Таблица I.3 — Смена кодировки в разных программах ¶
В большинстве случаев при работе с русскоязычными файлами помогает переключение кодировки на Windows-1251 или UTF-8 . Если все равно не удается прочитать содержимое XML документа, стоит открыть его в Mozilla Firefox, он отлично распознает кодировки.
Если ничего не помогает, вполне возможно, что файл был поврежден.
XSD схема¶
XML Schema — язык описания структуры XML-документа, его также называют XSD. Как большинство языков описания XML, XML Schema была задумана для определения правил, которым должен подчиняться документ. Но, в отличие от других языков, XML Schema была разработана так, чтобы её можно было использовать в создании программного обеспечения для обработки документов XML.
После проверки документа на соответствие XML Schema читающая программа может создать модель данных документа, которая включает:
- словарь (названия элементов и атрибутов);
- модель содержания (отношения между элементами и атрибутами и их структура);
- типы данных.
Каждый элемент в этой модели ассоциируется с определённым типом данных, позволяя строить в памяти объект, соответствующий структуре XML-документа. Языкам объектно-ориентированного программирования гораздо легче иметь дело с таким объектом, чем с текстовым файлом.
Файл abbyy pdf transformer.exe из ABBYY является частью ABBYY PDF Transformer v9 0 102 46. abbyy pdf transformer.exe, расположенный в d. dreamdisk 2014 christmas editionsoftwareofficepdf abbyy pdf transformer .exe с размером файла 189737804 байт, версия файла Unknown version, подпись a5040812c0bc670eb16bd0d493ef1fc4.
- Запустите приложение Asmwsoft Pc Optimizer.
- Потом из главного окна выберите пункт «Clean Junk Files».
- Когда появится новое окно, нажмите на кнопку «start» и дождитесь окончания поиска.
- потом нажмите на кнопку «Select All».
- нажмите на кнопку «start cleaning».
- Запустите приложение Asmwsoft Pc Optimizer.
- Потом из главного окна выберите пункт «Fix Registry problems».
- Нажмите на кнопку «select all» для проверки всех разделов реестра на наличие ошибок.
- 4. Нажмите на кнопку «Start» и подождите несколько минут в зависимости от размера файла реестра.
- После завершения поиска нажмите на кнопку «select all».
- Нажмите на кнопку «Fix selected».
P.S. Вам может потребоваться повторно выполнить эти шаги.
3- Настройка Windows для исправления критических ошибок abbyy pdf transformer.exe:
- Нажмите правой кнопкой мыши на «Мой компьютер» на рабочем столе и выберите пункт «Свойства».
- В меню слева выберите » Advanced system settings».
- В разделе «Быстродействие» нажмите на кнопку «Параметры».
- Нажмите на вкладку «data Execution prevention».
- Выберите опцию » Turn on DEP for all programs and services . » .
- Нажмите на кнопку «add» и выберите файл abbyy pdf transformer.exe, а затем нажмите на кнопку «open».
- Нажмите на кнопку «ok» и перезагрузите свой компьютер.
Как другие пользователи поступают с этим файлом?
Всего голосов ( 181 ), 115 говорят, что не будут удалять, а 66 говорят, что удалят его с компьютера.
В данной статье речь пойдёт о причинах возникновения фатальной ошибки «Ошибка разбора XML» и способах устранения данной неполадки. Также будет дана инструкция не по устранению, но «обходу» ошибки, то есть действиям на опережение.
XML (с английского – extensible markup language – расширяемый язык разметки) – это язык разметки, который рекомендует Консорциум Всемирной паутины. Обычно язык разметки XML служит для описания документации, соответствующего типа, а также описывает действия соответствующих процессоров. Расширяемый язык разметки имеет довольно простой синтаксис, поэтому используется по всему миру, чтобы создавать и обрабатывать документацию программным способом. Он создавался именно для использования в Интернете. XML назвали именно расширяемым языком разметки, так как в нём нет фиксации разметки, которая содержится внутри документа, а именно: программист может создавать любую разметку, а ограничения будут встречаться лишь в синтаксисе.
2. Устранение Ошибки разбора XML в 1С
«Ошибка разбора XML» возникает исключительно в тонком клиенте 1С. Также стоит отметить, что «Ошибка разбора XML» также довольна схожа с ошибкой по формату потока, которая возникает в толстом клиенте. Обычно в 1С «Ошибка разбора XML» возникает по причине наличия кэша метаданных. И если очистить кэш, то ошибка будет устранена. Выглядит окно с ошибкой, а также окно с комментариями от технической поддержки следующим образом:
Рис. 1 Окно Ошибки разбора XML в 1С
XML данные читаются по потокам, так что в каждый из моментов времени объект «сосредоточен» в некотором узле XML. Из-за этого также может возникать фатальная ошибка «Ошибка разбора XML». Для того чтобы её устранить, можно вызвать функцию «ИсключениеЧтенияXml», как показано на скриншоте примера ниже:
Рис. 2 Вызов функции ИсключениеЧтенияXML для устранения Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
Данные два способа (очистка кэша метаданных и функция «ИсключениеЧтенияXml») – не все возможные варианты устранения ошибки разбора XML. Далее рассмотрим нестандартный подход, который позволит избежать ошибки еще до её возникновения.
Для наглядности будем работать в конфигурации 1С:Бухгалтерия предприятия, одной из наиболее распространенных программ фирмы 1С. У многих людей, которые пользуются программой 1С:Отчётность появляются неполадки при попытках открыть данные/файлы от налоговой. Чтобы открыть такой файл повторяем следующие действия:
· Переходим по пути: «Настройки 1С:Отчётности → Журнал обмена с контролирующими органами», как показано на скриншоте ниже:
Рис. 3 Настройка 1С Отчетности
· Далее кликаем на «Запросы» и выделяем ту выписку, которую не было возможности открыть из-за ошибки, как продемонстрировано на скриншоте ниже:
Рис. 4 Выбор выписки с Ошибкой разбора XML в 1С
Рис. 5 Стадия отправки документа с Ошибкой разбора XML в 1С
Несколько пользователей сообщают о Ошибка синтаксического анализа XML всякий раз, когда они пытаются открыть документ Microsoft Word, который они ранее экспортировали. Эта проблема обычно возникает после того, как пользователь обновился до более новой версии Office или после того, как документ Word был ранее экспортирован из другой программы. Эта проблема обычно возникает на компьютерах с Windows 7 и Windows 9.
Ошибка разбора Word XML
Что вызывает ошибку синтаксического анализа XML в Microsoft Word?
Мы исследовали проблему, просматривая различные пользовательские отчеты и пытаясь воспроизвести проблему. Как выясняется, есть несколько преступников, которые могут в конечном итоге вызвать эту конкретную проблему:
Если вы в настоящее время пытаются решить Ошибка синтаксического анализа XML, эта статья предоставит вам список проверенных шагов по устранению неполадок. Ниже приведен список методов, которые другие пользователи в аналогичной ситуации использовали для решения проблемы.
Чтобы обеспечить наилучшие результаты, следуйте приведенным ниже методам, чтобы найти исправление, эффективное для решения проблемы. Давай начнем!
Способ 1: установка графического обновления Windows SVG
Этот метод обычно считается успешным в Windows 7 и Windows 8, но мы успешно воссоздали шаги для Windows 10. Эта проблема возникает из-за ошибки, которую WU (Центр обновления Windows) делает при установке определенных обновлений.
Как выясняется, это конкретное обновление (которое создает проблему) должно автоматически устанавливаться компонентом обновления, поскольку оно включено в число WSUS (службы обновления Windows Server) утвержденные обновления.
К счастью, вы также можете установить недостающее обновление (KB2563227) через онлайн-страницу Microsoft. Вот краткое руководство о том, как это сделать:
Если вы все еще сталкиваетесь с Ошибка синтаксического анализа XML ошибка, продолжайте следующим способом ниже.
Способ 2: устранение ошибки с помощью Notepad ++ и Winrar или Winzip
Если первый метод не помог решить проблему, вполне вероятно, что код XML, сопровождающий документ Word, не соответствует спецификации XML. Скорее всего, код XML, сопровождающий текст, содержит ошибки кодирования.
Вы можете заметить, что атрибут Location указывает на файл .xml, когда вы пытаетесь открыть файл word. Хотите знать, почему это? Это потому, что файл .doc на самом деле является файлом .zip, который содержит коллекцию файлов .xml.
Следуйте приведенным ниже инструкциям, чтобы использовать Notepad ++ и WinRar для решения проблемы и открыть документ Word без Ошибка синтаксического анализа XML:
-
Щелкните правой кнопкой мыши документ, который вызывает ошибку, и измените форму расширения. .доктор кзастежка-молния. Когда вас попросят подтвердить изменение имени добавочного номера, нажмите да подтвердить.
Изменение расширения с .doc на .zip
Замечания: Если вы не можете просмотреть расширение файла, перейдите к Посмотреть вкладка в Проводник и убедитесь, что поле связано с Расширения имени файла проверено.
Замечания: Если вы не можете открыть документ .zip, загрузите Winzip по этой ссылке (Вот).
Читайте также:
- Vipnet coordinator hw1000 firewall настройка
- Как обновить яндекс дзен на компьютере
- Cassida zeus ошибка ps2
- Hyperx alloy origins core black usb обзор
- Как в bluestacks загрузить фото с компьютера
Содержание:
1. XML – расширяемый язык разметки
2. Устранение Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
1. XML – расширяемый язык разметки
В данной статье речь пойдёт о причинах возникновения фатальной ошибки «Ошибка разбора XML» и способах устранения данной неполадки. Также будет дана инструкция не по устранению, но «обходу» ошибки, то есть действиям на опережение.
XML (с английского – extensible markup language – расширяемый язык разметки) – это язык разметки, который рекомендует Консорциум Всемирной паутины. Обычно язык разметки XML служит для описания документации, соответствующего типа, а также описывает действия соответствующих процессоров. Расширяемый язык разметки имеет довольно простой синтаксис, поэтому используется по всему миру, чтобы создавать и обрабатывать документацию программным способом. Он создавался именно для использования в Интернете. XML назвали именно расширяемым языком разметки, так как в нём нет фиксации разметки, которая содержится внутри документа, а именно: программист может создавать любую разметку, а ограничения будут встречаться лишь в синтаксисе.
2. Устранение Ошибки разбора XML в 1С
«Ошибка разбора XML» возникает исключительно в тонком клиенте 1С. Также стоит отметить, что «Ошибка разбора XML» также довольна схожа с ошибкой по формату потока, которая возникает в толстом клиенте. Обычно в 1С «Ошибка разбора XML» возникает по причине наличия кэша метаданных. И если очистить кэш, то ошибка будет устранена. Выглядит окно с ошибкой, а также окно с комментариями от технической поддержки следующим образом:
Рис. 1 Окно Ошибки разбора XML в 1С
XML данные читаются по потокам, так что в каждый из моментов времени объект «сосредоточен» в некотором узле XML. Из-за этого также может возникать фатальная ошибка «Ошибка разбора XML». Для того чтобы её устранить, можно вызвать функцию «ИсключениеЧтенияXml», как показано на скриншоте примера ниже:

Рис. 2 Вызов функции ИсключениеЧтенияXML для устранения Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
Данные два способа (очистка кэша метаданных и функция «ИсключениеЧтенияXml») – не все возможные варианты устранения ошибки разбора XML. Далее рассмотрим нестандартный подход, который позволит избежать ошибки еще до её возникновения.
Для наглядности будем работать в конфигурации 1С:Бухгалтерия предприятия, одной из наиболее распространенных программ фирмы 1С. У многих людей, которые пользуются программой 1С:Отчётность появляются неполадки при попытках открыть данные/файлы от налоговой. Чтобы открыть такой файл повторяем следующие действия:
· Переходим по пути: «Настройки 1С:Отчётности → Журнал обмена с контролирующими органами», как показано на скриншоте ниже:

Рис. 3 Настройка 1С Отчетности
· Далее кликаем на «Запросы» и выделяем ту выписку, которую не было возможности открыть из-за ошибки, как продемонстрировано на скриншоте ниже:

Рис. 4 Выбор выписки с Ошибкой разбора XML в 1С
· Обращаем внимание на стадию отправки, которая располагается внизу этого сообщения, и кликаем два раза на зелёный круг:

Рис. 5 Стадия отправки документа с Ошибкой разбора XML в 1С
· Появляется транспортное сообщение, в нём кликаем на «Выгрузить» и выбираем папку, куда необходимо провести выгрузку, после чего сохраняем данный файл. Пробуем открыть его, при помощи любого из графических редакторов, который может поддерживать формат PDF, как показано на скриншоте ниже:

Рис. 6 Результат обхода Ошибки разбора XML в 1С
· Всё успешно открылось, а ошибка даже не успела возникнуть.
Специалист компании «Кодерлайн»
Айдар Фархутдинов
Содержание:
1. XML – расширяемый язык разметки
2. Устранение Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
1. XML – расширяемый язык разметки
В данной статье речь пойдёт о причинах возникновения фатальной ошибки «Ошибка разбора XML» и способах устранения данной неполадки. Также будет дана инструкция не по устранению, но «обходу» ошибки, то есть действиям на опережение.
XML (с английского – extensible markup language – расширяемый язык разметки) – это язык разметки, который рекомендует Консорциум Всемирной паутины. Обычно язык разметки XML служит для описания документации, соответствующего типа, а также описывает действия соответствующих процессоров. Расширяемый язык разметки имеет довольно простой синтаксис, поэтому используется по всему миру, чтобы создавать и обрабатывать документацию программным способом. Он создавался именно для использования в Интернете. XML назвали именно расширяемым языком разметки, так как в нём нет фиксации разметки, которая содержится внутри документа, а именно: программист может создавать любую разметку, а ограничения будут встречаться лишь в синтаксисе.
2. Устранение Ошибки разбора XML в 1С
«Ошибка разбора XML» возникает исключительно в тонком клиенте 1С. Также стоит отметить, что «Ошибка разбора XML» также довольна схожа с ошибкой по формату потока, которая возникает в толстом клиенте. Обычно в 1С «Ошибка разбора XML» возникает по причине наличия кэша метаданных. И если очистить кэш, то ошибка будет устранена. Выглядит окно с ошибкой, а также окно с комментариями от технической поддержки следующим образом:
Рис. 1 Окно Ошибки разбора XML в 1С
XML данные читаются по потокам, так что в каждый из моментов времени объект «сосредоточен» в некотором узле XML. Из-за этого также может возникать фатальная ошибка «Ошибка разбора XML». Для того чтобы её устранить, можно вызвать функцию «ИсключениеЧтенияXml», как показано на скриншоте примера ниже:
Рис. 2 Вызов функции ИсключениеЧтенияXML для устранения Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
Данные два способа (очистка кэша метаданных и функция «ИсключениеЧтенияXml») – не все возможные варианты устранения ошибки разбора XML. Далее рассмотрим нестандартный подход, который позволит избежать ошибки еще до её возникновения.
Для наглядности будем работать в конфигурации 1С:Бухгалтерия предприятия, одной из наиболее распространенных программ фирмы 1С. У многих людей, которые пользуются программой 1С:Отчётность появляются неполадки при попытках открыть данные/файлы от налоговой. Чтобы открыть такой файл повторяем следующие действия:
· Переходим по пути: «Настройки 1С:Отчётности → Журнал обмена с контролирующими органами», как показано на скриншоте ниже:
Рис. 3 Настройка 1С Отчетности
· Далее кликаем на «Запросы» и выделяем ту выписку, которую не было возможности открыть из-за ошибки, как продемонстрировано на скриншоте ниже:
Рис. 4 Выбор выписки с Ошибкой разбора XML в 1С
· Обращаем внимание на стадию отправки, которая располагается внизу этого сообщения, и кликаем два раза на зелёный круг:
Рис. 5 Стадия отправки документа с Ошибкой разбора XML в 1С
· Появляется транспортное сообщение, в нём кликаем на «Выгрузить» и выбираем папку, куда необходимо провести выгрузку, после чего сохраняем данный файл. Пробуем открыть его, при помощи любого из графических редакторов, который может поддерживать формат PDF, как показано на скриншоте ниже:
Рис. 6 Результат обхода Ошибки разбора XML в 1С
· Всё успешно открылось, а ошибка даже не успела возникнуть.
Специалист компании «Кодерлайн»
Айдар Фархутдинов
everyone, I’m new in Android and I’m trying to parse a XML file and get the info in a List. My XML file is this and what I want is get the objects.
What I am doing to parse it is something similar as the example on the android developeres website:
import android.content.Context;
import android.util.Xml;
import android.widget.Toast;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserException;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
/**
* Created by Álvaro on 31/08/2015.
*/
public class EntrelazadasXMLParser {
// We don't use namespaces
private static final String ns = null;
public List parse(InputStream in, Context context) throws /*XmlPullParserException,*/ IOException {
try {
XmlPullParser parser = Xml.newPullParser();
parser.setFeature(XmlPullParser.FEATURE_PROCESS_NAMESPACES, false);
parser.setInput(in, null);
parser.nextTag();
return readFeed(parser,context);
}catch (XmlPullParserException e){
Toast.makeText(context, "Error en el parser: " + e.toString(),
Toast.LENGTH_LONG).show();
return null;
}
finally {
in.close();
}
}
....
This steo is to instantiate a parser and start the parsing process. The parser is initialized Without namespaces and to use the provided InputStream as its input.It starts the parsing process with a call to nextTag() and invokes the readFeed() method, which extracts and processes the data the app is interested in. Here is where the exception happens and the error is the following.
Error en el parser: org.xmlpull.v1.XmlPullParserException: unexpected type (position:END_DOCUMENT null@1:1 in java.io.InputStreamReader@41e3d220).
The rest of this class s this:
vate List readFeed(XmlPullParser parser, Context context) throws /*XmlPullParserException,*/ IOException {
List entries = new ArrayList();
try {
parser.require(XmlPullParser.START_TAG, ns, "database");
while (parser.next() != XmlPullParser.END_TAG) {
if (parser.getEventType() != XmlPullParser.START_TAG) {
continue;
}
String name = parser.getName();
// Starts by looking for the table tag
if (name.equals("table")) {
entries.add(readEntry(parser));
} else {
skip(parser);
}
}
return entries;
}
catch (XmlPullParserException e){
Toast.makeText(context, "Error en el read feed: " + e.toString(),
Toast.LENGTH_LONG).show();
return null;
}
}
private void skip(XmlPullParser parser) throws XmlPullParserException, IOException {
if (parser.getEventType() != XmlPullParser.START_TAG) {
throw new IllegalStateException();
}
int depth = 1;
while (depth != 0) {
switch (parser.next()) {
case XmlPullParser.END_TAG:
depth--;
break;
case XmlPullParser.START_TAG:
depth++;
break;
}
}
}
private Producto readEntry(XmlPullParser parser) throws XmlPullParserException, IOException {
parser.require(XmlPullParser.START_TAG, ns, "table");
Producto Objeto =null;
String summary = null;
String link = null;
while (parser.next() != XmlPullParser.END_TAG) {
if (parser.getEventType() != XmlPullParser.START_TAG) {
continue;
}
String name = parser.getName();
if (name.equals("column")) {
Objeto = readColumn(parser);
} else {
skip(parser);
}
}
return Objeto;
}
private Producto readColumn(XmlPullParser parser) throws IOException, XmlPullParserException {
Producto Objeto ;
String Id = null;;
String Referencia = null;;
String Nombre = null;;
String Categoria = null;;
String SubFamilia = null;;
String Familia = null;;
String Descripcion = null;;
String Precio = null;;
String Image1 = null;
String Image2 = null;
String Image3 = null;
String Image4 = null;
String Image5 = null;
parser.require(XmlPullParser.START_TAG, ns, "column");
String tag = parser.getName();
String relType = parser.getAttributeValue(null, "name");
if (relType.equals("Id")){
Id = readId(parser);
} else if(relType.equals("Precio")){
Precio = readPrecio(parser);
}else if(relType.equals("Referencia")){
Referencia = readReferencia(parser);
}else if(relType.equals("Categoria")){
Categoria = readCategoria(parser);
}else if(relType.equals("Nombre")){
Nombre = readNombre(parser);
}else if(relType.equals("Subfamilia")){
SubFamilia = readSubfamilia(parser);
}else if(relType.equals("Familia")){
Familia = readFamilia(parser);
}else if(relType.equals("Descripcion")){
Descripcion = readDescripcion(parser);
}else{
Image1 = readImage(parser);
}
Objeto =new Producto(Id,Referencia,Nombre,Categoria,SubFamilia,Familia,Descripcion,Precio,Image1,Image2,Image3,Image4,Image5);
parser.require(XmlPullParser.END_TAG, ns, "column");
return Objeto;
}
// Processes Id tags in the feed.
private String readId (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readPrecio (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readReferencia (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readCategoria (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readNombre (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readSubfamilia (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readFamilia (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readDescripcion (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
private String readImage (XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "column");
String value = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "column");
return value;
}
// For the tags title and summary, extracts their text values.
private String readText(XmlPullParser parser) throws IOException, XmlPullParserException {
String result = "";
if (parser.next() == XmlPullParser.TEXT) {
result = parser.getText();
parser.nextTag();
}
return result;
}
}
And the call to the parser and the declaration of the inputStream:
EntrelazadasXMLParser XmlParser = new EntrelazadasXMLParser();
List<Producto> entries = null;
String root = Environment.getExternalStorageDirectory().toString();
File SDCardRoot = new File(root + "/Entrelazadas");
try {
InputStream raw = new FileInputStream(new File(SDCardRoot, "catalogo.xml"));
//FileInputStream fileInputStream = new FileInputStream(file);
entries = XmlParser.parse(raw,context);
}
catch (FileNotFoundException e){
Toast.makeText(context, "Fichero no encontrado: " +e.toString(),
Toast.LENGTH_LONG).show();
}
catch (IOException e){
Toast.makeText(context, "Error de IO: " +e.toString(),
Toast.LENGTH_LONG).show();
}
I hope any of you can help me.
Thanks a lot.
This is how the file appears in its very first lines:

Содержание
- Как исправить ошибку доступа к файлу в FineReader
- Ошибка при установке
- Ошибка при запуске
- Вопросы и ответы
![]()
FineReader — чрезвычайно полезная программа для конвертации текстов из растрового в цифровой формат. Ее часто применяют для редактирования конспектов, сфотографированных объявлений или статей, а также отсканированных текстовых документов. При установке или запуске FineReader может возникнуть ошибка, которая отображается как «Нет доступа к файлу».
Попробуем разобраться, как устранить эту проблему и пользоваться распознавателем текстов в своих целях.
Скачать последнюю версию FineReader
Ошибка при установке
Первое, что нужно проверить при возникновении ошибки доступа — проверить, не включен ли антивирус на вашем компьютере. Выключите его, если он активен.
В том случае, если проблема осталась, проделайте следующие шаги:
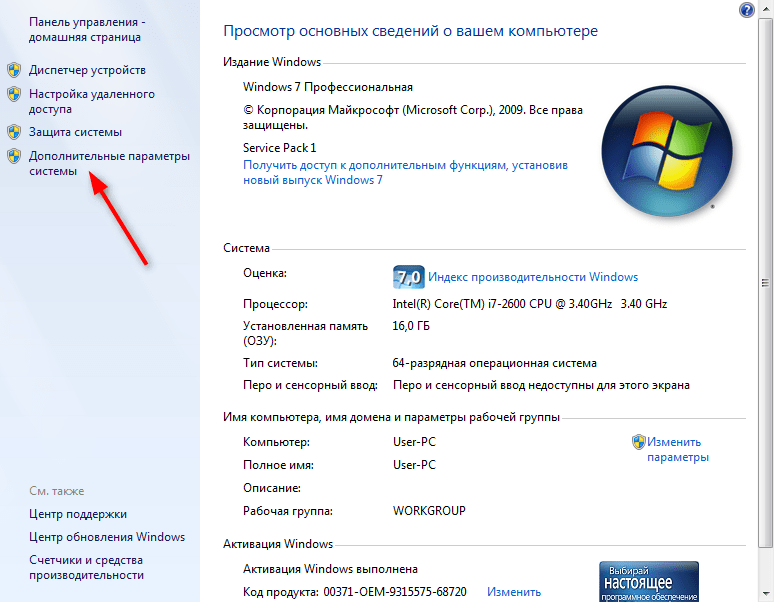
Нажмите «Пуск» и щелкните правой кнопкой мыши на «Компьютер». Выберите «Свойства».
Если у вас установлена Windows 7, щелкните на «Дополнительные параметры системы».
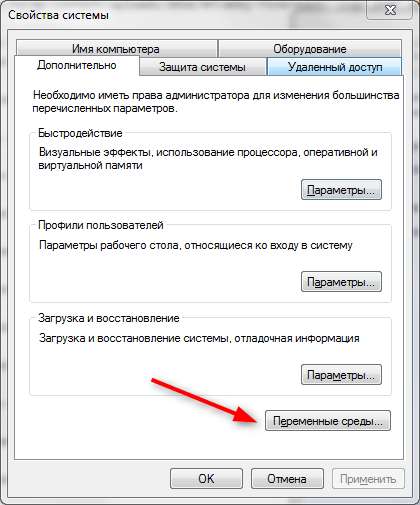
На вкладке «Дополнительно» найдите внизу окна свойств кнопку «Переменные среды» и нажмите ее.
В окне «Переменные среды выделите строку TMP и нажмите кнопку «Изменить».
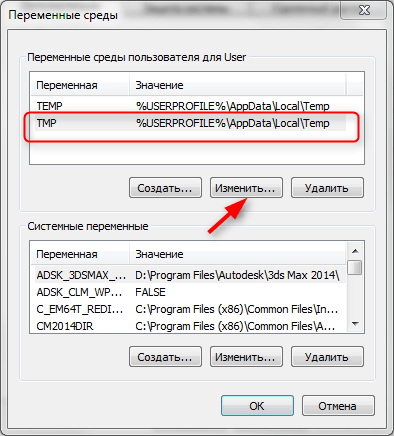
В строке «Значение переменной» пропишите C:Temp и нажмите «ОК».
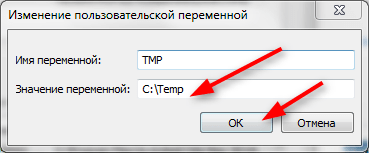

Проделайте тоже самое для строки TEMP. Щелкните «ОК» и «Применить».
После этого попробуйте начать установку заново.
Установочный файл всегда запускайте от имени администратора.
Ошибка при запуске
Ошибка доступа при запуске возникает в том случае, если пользователь не имеет полного доступа к папке «Licenses» на своем компьютере. Исправить это достаточно просто.
Нажмите сочетание клавиш Win+R. Откроется окно «Выполнить».
В строке этого окна введите C:ProgramDataABBYYFineReader12.0 (или другое место, куда установлена программа) и нажмите «ОК».
Обратите внимание на версию программы. Прописывайте ту, которая установлена у вас.

Найдите в каталоге папку «Licenses» и, щелкнув по ней правой кнопкой мыши, выберите «Свойства».
На вкладке «Безопасность» в окне «Группы или пользователи» выделите строку «Пользователи» и нажмите кнопку «Изменить».
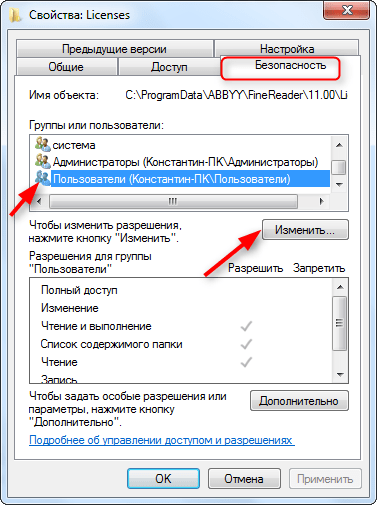
Снова выделите строку «Пользователи» и установите галочку напротив «Полный доступ». Нажмите «Применить». Закройте все окна, нажимая «ОК».
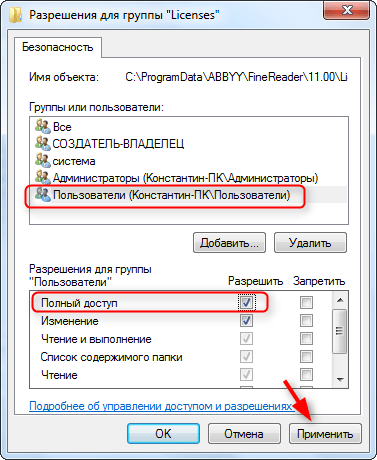
Читайте на нашем сайте: Как пользоваться FineReader
Таким образом исправляется ошибка доступа при установке и запуске FineReader. Надеемся, эта информация будет вам полезна.
Еще статьи по данной теме:
Помогла ли Вам статья?
|
Пользователь 47773 Заглянувший Сообщений: 4 |
#1 26.08.2010 09:24:07 Добрый день, настроил инфоблок Новости и экспорт новостей в RSS. Однако при клике на иконку RSS подписки на странице Новости появляется следующая ошибка «Ошибка разбора XML: синтаксическая ошибка (Строка: 1, Символ: 0)»
Подскажите пожалуйста как решить эту проблему? |
||
|
удалить первую строчку из вашего xml файла животное = зверь |
|
|
Пользователь 47773 Заглянувший Сообщений: 4 |
#3 26.08.2010 10:25:49
при удалении этой строчки, возникает ошибка уже во второй строчке <?xml version=»1.0″ encoding=»Windows-1251″?> |
||
|
Пользователь 57352 Посетитель Сообщений: 31 |
#4 26.08.2010 11:12:50 Ваш файл должен иметь вид подобный этому:
животное = зверь |
||
#1
Serg83
- Городсанкт-петербург
Отправлено 23 Апрель 2014 — 11:14
добрый день.
Яндекс-Маркет стал выдавать ошибки:
«Ошибки при разборе файла:
Предупреждение: Кодировка XML не определена (строка 0, столбец 0)
Фатальная ошибка: Ошибка парсинга XML: Error parsing XML feed: Unknown element ‘html’ (строка 1, столбец 6)»
Подскажите что случилось, если выгрузка идет с помощью встроенного сервиса Стореленд?
- Наверх
#2
Сake
Сake
-

- Модератоpы
-

- 5 979 сообщений
Активный участник
Отправлено 24 Апрель 2014 — 00:07
Пожалуйста, сообщите какой именно YML файл (приложите ссылку на файл) вы загружаете в яндекс.маркет?
- Наверх
#3
Serg83
Serg83
- Городсанкт-петербург
Отправлено 24 Апрель 2014 — 08:41
 Сake (24 Апрель 2014 — 00:07) писал:
Сake (24 Апрель 2014 — 00:07) писал:
Пожалуйста, сообщите какой именно YML файл (приложите ссылку на файл) вы загружаете в яндекс.маркет?
http://knife-for-lif…t/5803/1f538a64
- Наверх
#4
Serg83
Serg83
- Городсанкт-петербург
Отправлено 24 Апрель 2014 — 17:23
вопрос то как бы СРОЧНЫЙ!!! уже несколько дней не работает прайс на Маркете…
- Наверх
#5
Сake
Сake
-
- Модератоpы
-
- 5 979 сообщений
Активный участник
Отправлено 25 Апрель 2014 — 06:30
Вы верно адрес файла указываете маркету? Возможно проблема из-за определения типа документа. Сервер возвращает text/html, а должен по идее text/xml. Передам информацию о данной проблеме разработчикам.
- Наверх
#6
Serg83
Serg83
- Городсанкт-петербург
Отправлено 25 Апрель 2014 — 08:48
Сake (25 Апрель 2014 — 06:30) писал:
Вы верно адрес файла указываете маркету? Возможно проблема из-за определения типа документа. Сервер возвращает text/html, а должен по идее text/xml. Передам информацию о данной проблеме разработчикам.
Маркету адрес был сообщен года 1,5 назад и с тех пор ничего не менялось и работало отлично.
Прайс для Маркета генерирует Ваш сервис.
и до этой недели проблем не возникало.
еще раз повторюсь — уже неделю Маркет не работает из-за этих ошибок и мы теряем массу клиентов!
- Наверх
#7
support 2.0
support 2.0
-

- Модераторы
-
- 4 950 сообщений
Активный участник
Отправлено 25 Апрель 2014 — 20:03
Serg83 (25 Апрель 2014 — 08:48) писал:
Маркету адрес был сообщен года 1,5 назад и с тех пор ничего не менялось и работало отлично.
Прайс для Маркета генерирует Ваш сервис.
и до этой недели проблем не возникало.
еще раз повторюсь — уже неделю Маркет не работает из-за этих ошибок и мы теряем массу клиентов!
Возможно, фильтр, который у нас стоит от ddos периодически блокировал ip адрес от яндекс маркета. Бывало такое, что первый раз ошибка писалась в первой строчке и через 5 минут больше никаких ошибок не было обнаружено и файл корректно продолжал работать.
Мы написали в ДЦ. В течении сегодняшнего-завтрашнего дня ситуация должна пропасть.
- Наверх
#8
Serg83
Serg83
- Городсанкт-петербург
Отправлено 28 Апрель 2014 — 10:36
support 2.0 (25 Апрель 2014 — 20:03) писал:
Возможно, фильтр, который у нас стоит от ddos периодически блокировал ip адрес от яндекс маркета. Бывало такое, что первый раз ошибка писалась в первой строчке и через 5 минут больше никаких ошибок не было обнаружено и файл корректно продолжал работать.
Мы написали в ДЦ. В течении сегодняшнего-завтрашнего дня ситуация должна пропасть.
ок, пробуем снова включить Маркет
- Наверх
#9
Serg83
Serg83
- Городсанкт-петербург
Отправлено 28 Апрель 2014 — 15:52
благодарю, сейчас все работает корректно
- Наверх
#10
77mds77
77mds77
-

- Пользователи
-

- 3 сообщений
Новичок
Отправлено 07 Июль 2014 — 11:54
У меня такаже проблема:
Определена кодировка: utf-8 (строка 0, столбец 0)
Дата из файла: 2014-07-07 12:53 (строка 3, столбец 38)
Фатальная ошибка: Ошибка парсинга XML: Error parsing XML feed: Invalid character (Unicode: 0x15) (строка 1124, столбец 62)
SL-296570ПОМОГИТЕ!!!!СРОЧНО!!!!
- Наверх
#11
Сake
Сake
-
- Модератоpы
-
- 5 979 сообщений
Активный участник
Отправлено 08 Июль 2014 — 01:14
У вас по всей видимости некорректный символ расположен на строке 1124, столбец 62. Вам необходимо удалить этот символ. Например — если символ располагается в описании товара, то вам необходимо изменить описание товара. Если у вас не получится самостоятельно разобраться с данной проблемой, то приложите ссылку на ваш импортируемый файл с ошибкой.
- Наверх
#12
77mds77
77mds77
-
- Пользователи
-
- 3 сообщений
Новичок
Отправлено 09 Июль 2014 — 10:48
как это сделать, когда открывается этот yml файл в браузере???????
Цитата
- Наверх
#13
Сake
Сake
-
- Модератоpы
-
- 5 979 сообщений
Активный участник
Отправлено 10 Июль 2014 — 02:16
В браузере вам лучше не открывать содержимое файла, так как это будет не удобно для нахождения ошибки. Лучше всего скачать файл и открыть его для редактирования в блокноте, например notepad++. В данном случае будет отображаться номер строки и столбец. Главное не используйте стандартный windows блокнот для редактирования файла.
- Наверх
#14
77mds77
77mds77
-
- Пользователи
-
- 3 сообщений
Новичок
Отправлено 10 Июль 2014 — 14:13
Сake (10 Июль 2014 — 02:16) писал:
В браузере вам лучше не открывать содержимое файла, так как это будет не удобно для нахождения ошибки. Лучше всего скачать файл и открыть его для редактирования в блокноте, например notepad++. В данном случае будет отображаться номер строки и столбец. Главное не используйте стандартный windows блокнот для редактирования файла.
http://mds77.ru/expo…/12828/4c4e08e3
- Наверх
#15
Сake
Сake
-
- Модератоpы
-
- 5 979 сообщений
Активный участник
Отправлено 10 Июль 2014 — 23:55
По всей видимости анализатор яндекса не правильно информирует об возникшей ошибке, так как на строке 1124 проблем с символами нет. Проблема находится немного дальше, строка 1543 в товаре /goods/Setka-svarnaya-25-25-1-6-oc-1
Для исправления проблемы вам необходимо переписать название товара вручную. Ошибка могла возникнуть при копировании текста из другого документа.
- Наверх
#16
Serg83
Serg83
- Городсанкт-петербург
Отправлено 18 Август 2014 — 10:35
Господа админитраторы, снова началась такая же ошибка в Маркете!!!
исправьте уже свои ddos фильтры!
ошибка повторяется уже несколько дней
«Ошибки при разборе файла:
Предупреждение: Кодировка XML не определена (строка 0, столбец 0)
Фатальная ошибка: Ошибка парсинга XML: Error parsing XML feed: Unknown element ‘html’ (строка 1, столбец 6)»
- Наверх
#17
support 2.0
support 2.0
-
- Модераторы
-
- 4 950 сообщений
Активный участник
Отправлено 18 Август 2014 — 23:02
Serg83 (18 Август 2014 — 10:35) писал:
Господа админитраторы, снова началась такая же ошибка в Маркете!!!
исправьте уже свои ddos фильтры!
ошибка повторяется уже несколько дней
«Ошибки при разборе файла:
Предупреждение: Кодировка XML не определена (строка 0, столбец 0)
Фатальная ошибка: Ошибка парсинга XML: Error parsing XML feed: Unknown element ‘html’ (строка 1, столбец 6)»
DDOS не исправляют. Ddos это атака на сервера. Что касается фильтра от ddos, то работает он исправно. 17.08 около 12.00 по Московскому времени дос-атака прекратилась, соответственно все должно с этого момента работать исправно.
- Наверх
#18
Serg83
Serg83
- Городсанкт-петербург
Отправлено 21 Август 2014 — 09:29
прайс отправляется в яндекс на проверку ежедневно!!!
ответы идентичны, вот копия от 20-го августа:
Ошибки при разборе файла:
Предупреждение: Кодировка XML не определена (строка 0, столбец 0)
Фатальная ошибка: Ошибка парсинга XML: Error parsing XML feed: Unknown element ‘html’ (строка 1, столбец 6)
———————————-
С поисковиками тоже проблемы с 16-го числа.
все переходы считаются внутренними переходами с сайта… отдельно завел тему на этот счет.
——————————-
с Робокассой тоже проблемы!
уведомления не приходят (по крайней мере вчера-сегодня) и в админке сайта статус заказа также автоматически не меняетяс после оплаты заказа клиентом
- Наверх
#19
Serg83
Serg83
- Городсанкт-петербург
Отправлено 24 Август 2014 — 20:46
ау!!!!
и где обещанные решения проблемы?!
я вам уже каждый день в течение недели звоню и каждый день одно и тоже — «да, да, сегодня ответим»…
- Наверх
#20
Serg83
Serg83
- Городсанкт-петербург
Отправлено 25 Август 2014 — 11:17
Убрав скрипт аб теста по совету в соседней ветке, прайс прошел проверку.
Только вопросы остались.
1) почему именно с 16 августа аб тест стал мешать Яндекс-маркету
2) возможно ли проведение аб тестирования без подобных ошибок?
- Наверх
Содержание:
1. XML – расширяемый язык разметки
2. Устранение Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
1. XML – расширяемый язык разметки
В данной статье речь пойдёт о причинах возникновения фатальной ошибки «Ошибка разбора XML» и способах устранения данной неполадки. Также будет дана инструкция не по устранению, но «обходу» ошибки, то есть действиям на опережение.
XML (с английского – extensible markup language – расширяемый язык разметки) – это язык разметки, который рекомендует Консорциум Всемирной паутины. Обычно язык разметки XML служит для описания документации, соответствующего типа, а также описывает действия соответствующих процессоров. Расширяемый язык разметки имеет довольно простой синтаксис, поэтому используется по всему миру, чтобы создавать и обрабатывать документацию программным способом. Он создавался именно для использования в Интернете. XML назвали именно расширяемым языком разметки, так как в нём нет фиксации разметки, которая содержится внутри документа, а именно: программист может создавать любую разметку, а ограничения будут встречаться лишь в синтаксисе.
2. Устранение Ошибки разбора XML в 1С
«Ошибка разбора XML» возникает исключительно в тонком клиенте 1С. Также стоит отметить, что «Ошибка разбора XML» также довольна схожа с ошибкой по формату потока, которая возникает в толстом клиенте. Обычно в 1С «Ошибка разбора XML» возникает по причине наличия кэша метаданных. И если очистить кэш, то ошибка будет устранена. Выглядит окно с ошибкой, а также окно с комментариями от технической поддержки следующим образом:
Рис. 1 Окно Ошибки разбора XML в 1С
XML данные читаются по потокам, так что в каждый из моментов времени объект «сосредоточен» в некотором узле XML. Из-за этого также может возникать фатальная ошибка «Ошибка разбора XML». Для того чтобы её устранить, можно вызвать функцию «ИсключениеЧтенияXml», как показано на скриншоте примера ниже:
Рис. 2 Вызов функции ИсключениеЧтенияXML для устранения Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
Данные два способа (очистка кэша метаданных и функция «ИсключениеЧтенияXml») – не все возможные варианты устранения ошибки разбора XML. Далее рассмотрим нестандартный подход, который позволит избежать ошибки еще до её возникновения.
Для наглядности будем работать в конфигурации 1С:Бухгалтерия предприятия, одной из наиболее распространенных программ фирмы 1С. У многих людей, которые пользуются программой 1С:Отчётность появляются неполадки при попытках открыть данные/файлы от налоговой. Чтобы открыть такой файл повторяем следующие действия:
· Переходим по пути: «Настройки 1С:Отчётности → Журнал обмена с контролирующими органами», как показано на скриншоте ниже:
Рис. 3 Настройка 1С Отчетности
· Далее кликаем на «Запросы» и выделяем ту выписку, которую не было возможности открыть из-за ошибки, как продемонстрировано на скриншоте ниже:
Рис. 4 Выбор выписки с Ошибкой разбора XML в 1С
· Обращаем внимание на стадию отправки, которая располагается внизу этого сообщения, и кликаем два раза на зелёный круг:
Рис. 5 Стадия отправки документа с Ошибкой разбора XML в 1С
· Появляется транспортное сообщение, в нём кликаем на «Выгрузить» и выбираем папку, куда необходимо провести выгрузку, после чего сохраняем данный файл. Пробуем открыть его, при помощи любого из графических редакторов, который может поддерживать формат PDF, как показано на скриншоте ниже:
Рис. 6 Результат обхода Ошибки разбора XML в 1С
· Всё успешно открылось, а ошибка даже не успела возникнуть.
Специалист компании «Кодерлайн»
Айдар Фархутдинов