Здравствуйте.
Как понимать отчет валидатора CSS W3C?
Ошибка разбора .navbar-inverse .navbar-nav .open .dropdown-menu>li>a { font-weight: bold; color: #af8337; }
Ошибка разбора .navbar-inverse .navbar-nav .open .dropdown-menu>li>a { color: #af8337; }
-
Вопрос заданболее трёх лет назад
-
1962 просмотра
медиа запросы не правильно написаны, из-за этого валидатор ломается и не может разобрать css
должно быть так:
@media screen and (max-width: 767px) {
.navbar-inverse .navbar-nav .open .dropdown-menu>li>a {
font-weight: bold;
color: #af8337;
}
}Пригласить эксперта
-
Показать ещё
Загружается…
25 июн. 2023, в 10:26
15000 руб./за проект
25 июн. 2023, в 09:57
7000 руб./за проект
25 июн. 2023, в 08:49
5000 руб./за проект
Минуточку внимания
Здравствуйте.
Как понимать отчет валидатора CSS W3C?
Ошибка разбора .navbar-inverse .navbar-nav .open .dropdown-menu>li>a { font-weight: bold; color: #af8337; }
Ошибка разбора .navbar-inverse .navbar-nav .open .dropdown-menu>li>a { color: #af8337; }
-
Вопрос заданболее трёх лет назад
-
1826 просмотров
медиа запросы не правильно написаны, из-за этого валидатор ломается и не может разобрать css
должно быть так:
@media screen and (max-width: 767px) {
.navbar-inverse .navbar-nav .open .dropdown-menu>li>a {
font-weight: bold;
color: #af8337;
}
}Пригласить эксперта
-
Показать ещё
Загружается…
30 янв. 2023, в 17:53
50000 руб./за проект
30 янв. 2023, в 17:32
550 руб./за проект
30 янв. 2023, в 17:27
4500 руб./за проект
Минуточку внимания
This is usually a cascading error caused by a an undefined entity
reference or use of an unencoded ampersand (&) in an URL or body
text. See the previous message for further details.
✉
Check that you are using a proper syntax for your comments, e.g: <!— comment here —>.
This error may appear if you forget the last «—» to close one comment, therefore including the rest
of the content in your comment.
✉
Did you forget to close a (double) quote mark?
✉
This error may appear if you are using a bad syntax for your comments, such as «<!invalid comment>»
The proper syntax for comments is <!— your comment here —>.
✉
This error may appear when the validator receives an empty document. Please make sure that the document you are uploading is not empty, and report any discrepancy.
✉
You have used character data somewhere it is not permitted to appear.
Mistakes that can cause this error include:
- putting text directly in the body of the document without wrapping
it in a container element (such as a <p>aragraph</p>), or - forgetting to quote an attribute value
(where characters such as «%» and «/» are common, but cannot appear
without surrounding quotes), or - using XHTML-style self-closing tags (such as <meta … />)
in HTML 4.01 or earlier. To fix, remove the extra slash (‘/’)
character. For more information about the reasons for this, see
Empty
elements in SGML, HTML, XML, and XHTML.
✉
The element named above was found in a context where it is not allowed.
This could mean that you have incorrectly nested elements — such as a
«style» element in the «body» section instead of inside «head» — or
two elements that overlap (which is not allowed).
One common cause for this error is the use of XHTML syntax in HTML
documents. Due to HTML’s rules of implicitly closed elements, this error
can create cascading effects. For instance, using XHTML’s «self-closing»
tags for «meta» and «link» in the «head» section of a HTML document may
cause the parser to infer the end of the «head» section and the
beginning of the «body» section (where «link» and «meta» are not
allowed; hence the reported error).
✉
The mentioned element is not allowed to appear in the context in which
you’ve placed it; the other mentioned elements are the only ones that
are both allowed there and can contain the element mentioned.
This might mean that you need a containing element, or possibly that
you’ve forgotten to close a previous element.
One possible cause for this message is that you have attempted to put a
block-level element (such as «<p>» or «<table>») inside an
inline element (such as «<a>», «<span>», or «<font>»).
✉
- You forgot to close a tag, or
- you used something inside this tag that was not allowed, and the validator
is complaining that the tag should be closed before such content can be allowed.
The next message, «start tag was here»
points to the particular instance of the tag in question); the
positional indicator points to where the validator expected you to close the
tag.
✉
This is not an error, but rather a pointer to the start tag of the element
the previous error referred to.
✉
You may have neglected to close an element, or perhaps you meant to
«self-close» an element, that is, ending it with «/>» instead of «>».
✉
This is not an error, but rather a pointer to the start tag of the element
the previous error referred to.
✉
Most likely, you nested tags and closed them in the wrong order. For
example <p><em>…</p> is not acceptable, as <em>
must be closed before <p>. Acceptable nesting is:
<p><em>…</em></p>
Another possibility is that you used an element which requires
a child element that you did not include. Hence the parent element
is «not finished», not complete. For instance, in HTML the <head>
element must contain a <title> child element, lists require
appropriate list items (<ul> and <ol> require <li>;
<dl> requires <dt> and <dd>), and so on.
✉
You have used the element named above in your document, but the
document type you are using does not define an element of that name.
This error is often caused by:
- incorrect use of the «Strict» document type with a document that
uses frames (e.g. you must use the «Frameset» document type to get
the «<frameset>» element), - by using vendor proprietary extensions such as «<spacer>»
or «<marquee>» (this is usually fixed by using CSS to achieve
the desired effect instead). - by using upper-case tags in XHTML (in XHTML attributes and elements
must be all lower-case).
✉
The Validator found an end tag for the above element, but that element is
not currently open. This is often caused by a leftover end tag from an
element that was removed during editing, or by an implicitly closed
element (if you have an error related to an element being used where it
is not allowed, this is almost certainly the case). In the latter case
this error will disappear as soon as you fix the original problem.
If this error occurred in a script section of your document, you should probably
read this FAQ entry.
✉
You have used a character that is not considered a «name character» in an
attribute value. Which characters are considered «name characters» varies
between the different document types, but a good rule of thumb is that
unless the value contains only lower or upper case letters in the
range a-z you must put quotation marks around the value. In fact, unless
you have extreme file size requirements it is a very very good
idea to always put quote marks around your attribute values. It
is never wrong to do so, and very often it is absolutely necessary.
✉
An attribute name (and some attribute values) must start with one of
a restricted set of characters. This error usually indicates that
you have failed to add a closing quotation mark on a previous
attribute value (so the attribute value looks like the start of a
new attribute) or have used an attribute that is not defined
(usually a typo in a common attribute name).
✉
«VI delimiter» is a technical term for the equal sign. This error message
means that the name of an attribute and the equal sign cannot be omitted
when specifying an attribute. A common cause for this error message is
the use of «Attribute Minimization» in document types where it is not allowed,
in XHTML for instance.
How to fix: For attributes such as compact, checked or selected, do not write
e.g <option selected … but rather <option selected=»selected» …
✉
You have used the attribute named above in your document, but the
document type you are using does not support that attribute for this
element. This error is often caused by incorrect use of the «Strict»
document type with a document that uses frames (e.g. you must use
the «Transitional» document type to get the «target» attribute), or
by using vendor proprietary extensions such as «marginheight» (this
is usually fixed by using CSS to achieve the desired effect instead).
This error may also result if the element itself is not supported in
the document type you are using, as an undefined element will have no
supported attributes; in this case, see the element-undefined error
message for further information.
How to fix: check the spelling and case of the element and attribute,
(Remember XHTML is all lower-case) and/or
check that they are both allowed in the chosen document type, and/or
use CSS instead of this attribute. If you received this error when using the
<embed> element to incorporate flash media in a Web page, see the
FAQ item on valid flash.
✉
Have you forgotten the «equal» sign marking the separation
between the attribute and its declared value?
Typical syntax is attribute="value".
✉
You have specified an attribute more than once. Example: Using
the «height» attribute twice on the same
«img» tag.
✉
This error almost always means that you’ve forgotten a closing quote on an attribute value. For instance,
in:
<img src="fred.gif>
<!-- 50 lines of stuff -->
<img src="joe.gif">
The «src» value for the first
<img> is the entire
fifty lines of stuff up to the next double quote, which probably
exceeds the SGML-defined
length limit for HTML
string literals. Note that the position indicator in the error
message points to where the attribute value ended — in
this case, the "joe.gif" line.
✉
The value of an attribute contained something that is not allowed by
the specified syntax for that type of attribute. For instance, the
“selected” attribute must be
either minimized as “selected”
or spelled out in full as “selected="selected"”; the variant
“selected=""” is not allowed.
✉
It is possible that you violated the naming convention for this attribute.
For example, id and name attributes must begin with
a letter, not a digit.
✉
This attribute cannot take a space-separated list of words as a value, but only one word («token»).
This may also be caused by the use of a space for the value of an attribute which does not permit it.
✉
The value of this attribute should be a number, and you probably used a wrong syntax.
✉
It is possible that you violated the naming convention for this attribute.
For example, id and name attributes must begin with
a letter, not a digit.
✉
The attribute given above is required for an element that you’ve used,
but you have omitted it. For instance, in most HTML and XHTML document
types the «type» attribute is required on the «script» element and the
«alt» attribute is required for the «img» element.
Typical values for type are
type="text/css" for <style>
and type="text/javascript" for <script>.
✉
The value of the attribute is defined to be one of a list of possible
values but in the document it contained something that is not allowed
for that type of attribute. For instance, the “selected” attribute must be either
minimized as “selected”
or spelled out in full as “selected="selected"”; a value like
“selected="true"” is not
allowed.
✉
Check that you are using a proper syntax for your comments, e.g: <!— comment here —>.
This error may appear if you forget the last «—» to close one comment, and later open another.
✉
You have used an illegal character in your text.
HTML uses the standard
UNICODE Consortium character repertoire,
and it leaves undefined (among others) 65 character codes (0 to 31 inclusive and 127 to 159
inclusive) that are sometimes used for typographical quote marks and similar in
proprietary character sets. The validator has found one of these undefined
characters in your document. The character may appear on your browser as a
curly quote, or a trademark symbol, or some other fancy glyph; on a different
computer, however, it will likely appear as a completely different
character, or nothing at all.
Your best bet is to replace the character with the nearest equivalent
ASCII character, or to use an appropriate character
entity.
For more information on Character Encoding on the web, see Alan
Flavell’s excellent HTML Character
Set Issues reference.
This error can also be triggered by formatting characters embedded in
documents by some word processors. If you use a word processor to edit
your HTML documents, be sure to use the «Save as ASCII» or similar
command to save the document without formatting information.
✉
An «id» is a unique identifier. Each time this attribute is used in a document
it must have a different value. If you are using this attribute as a hook for
style sheets it may be more appropriate to use classes (which group elements)
than id (which are used to identify exactly one element).
✉
This error can be triggered by:
- A non-existent input, select or textarea element
- A missing id attribute
- A typographical error in the id attribute
Try to check the spelling and case of the id you are referring to.
✉
The document type could not be determined, because the document had no correct DOCTYPE declaration. The document does not look like HTML, therefore automatic fallback could not be performed, and the document was only checked against basic markup syntax.
Learn how to add a doctype to your document
from our FAQ, or use the validator’s
Document Type option to validate your document against a specific Document Type.
✉
The construct <foo<bar> is valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
For the current document, the validator interprets strings like
<FOO /> according to legacy rules that
break the expectations of most authors and thus cause confusing warnings
and error messages from the validator. This interpretation is triggered
by HTML 4 documents or other SGML-based HTML documents. To avoid the
messages, simply remove the «/» character in such contexts. NB: If you
expect <FOO /> to be interpreted as an
XML-compatible «self-closing» tag, then you need to use XHTML or HTML5.
This warning and related errors may also be caused by an unquoted
attribute value containing one or more «/». Example:
<a href=http://w3c.org>W3C</a>.
In such cases, the solution is to put quotation marks around the value.
✉
The construct </foo<bar> is valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
A DOCTYPE declares the version of the language used, as well as what the root
(top) element of your document will be. For example, if the top element
of your document is <html>, the DOCTYPE declaration
will look like: «<!DOCTYPE html».
In most cases, it is safer not to type or edit the DOCTYPE declaration at all,
and preferable to let a tool include it, or copy and paste it from a
trusted list of DTDs.
✉
This is usually a cascading error caused by a an undefined entity
reference or use of an unencoded ampersand (&) in an URL or body
text. See the previous message for further details.
✉
The construct <> is sometimes valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
The construct </> is valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
An entity reference was found in the document, but there is no reference
by that name defined. Often this is caused by misspelling the reference
name, unencoded ampersands, or by leaving off the trailing semicolon (;).
The most common cause of this error is unencoded ampersands in
URLs as described by the WDG in «Ampersands
in URLs».
Entity references start with an ampersand (&) and end with a
semicolon (;). If you want to use a literal ampersand in your document
you must encode it as «&» (even inside URLs!). Be
careful to end entity references with a semicolon or your entity
reference may get interpreted in connection with the following text.
Also keep in mind that named entity references are case-sensitive;
&Aelig; and æ are different characters.
If this error appears in some markup generated by PHP’s session handling
code, this article has
explanations and solutions to your problem.
Note that in most documents, errors related to entity references will
trigger up to 5 separate messages from the Validator. Usually these
will all disappear when the original problem is fixed.
✉
The checked page did not contain a document type («DOCTYPE») declaration.
The Validator has tried to validate with a fallback DTD,
but this is quite likely to be incorrect and will generate a large number
of incorrect error messages. It is highly recommended that you insert the
proper DOCTYPE declaration in your document — instructions for doing this
are given above — and it is necessary to have this declaration before the
page can be declared to be valid.
✉
Your document includes a DOCTYPE declaration with a public identifier
(e.g. «-//W3C//DTD XHTML 1.0 Strict//EN») but no system identifier
(e.g. «http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd»). This is
authorized in HTML (based on SGML), but not in XML-based languages.
If you are using a standard XHTML document type, it is recommended to use exactly
one of the DOCTYPE declarations from the
recommended list on the W3C QA Website.
✉
This may happen if you have consecutive comments but did not close one of them properly.
The proper syntax for comments is <!— my comment —>.
✉
If you meant to include an entity that starts with «&», then you should
terminate it with «;». Another reason for this error message is that
you inadvertently created an entity by failing to escape an «&»
character just before this text.
✉
This is generally the sign of an ampersand that was not properly escaped for inclusion
in an attribute, in a href for example. You will need to escape all instances of ‘&’
into ‘&’.
✉
This message may appear in several cases:
- You tried to include the «<» character in your page: you should escape it as «<»
- You used an unescaped ampersand «&»: this may be valid in some contexts,
but it is recommended to use «&», which is always safe. - Another possibility is that you forgot to close quotes in a previous tag.
✉
This error may occur when there is a mistake in how a self-closing tag is closed, e.g ‘…/ >’.
The proper syntax is ‘… />’ (note the position of the space).
✉
You’ve included a character reference to a character that is not defined
in the document type you’ve chosen. This is most commonly caused by
numerical references to characters from vendor proprietary
character repertoires. Often the culprit will be fancy or typographical
quote marks from either the Windows or Macintosh character repertoires.
The solution is to reference UNICODE characters instead. A list of
common characters from the Windows character repertoire and their
UNICODE equivalents can be found in the document «On the use of some MS Windows characters in HTML» maintained by
Jukka Korpela
<jkorpela@cs.tut.fi>.
✉
The following validation errors do not have an explanation yet. We invite you to use the
feedback channels to send your suggestions.
0: length of name must not exceed NAMELEN (X)
✉
1: length of parameter entity name must not exceed NAMELEN less the length of the PERO delimiter (X)
✉
2: length of number must not exceed NAMELEN (X)
✉
3: length of attribute value must not exceed LITLEN less NORMSEP (X)
✉
4: a name group is not allowed in a parameter entity reference in the prolog
✉
5: an entity end in a token separator must terminate an entity referenced in the same group
✉
6: character X invalid: only Y and token separators allowed
✉
7: a parameter separator is required after a number that is followed by a name start character
✉
8: character X invalid: only Y and parameter separators allowed
✉
9: an entity end in a parameter separator must terminate an entity referenced in the same declaration
✉
10: an entity end is not allowed in a token separator that does not follow a token
✉
11: X is not a valid token here
✉
12: a parameter entity reference can only occur in a group where a token could occur
✉
13: token X has already occurred in this group
✉
14: the number of tokens in a group must not exceed GRPCNT (X)
✉
15: an entity end in a literal must terminate an entity referenced in the same literal
✉
16: character X invalid: only minimum data characters allowed
✉
18: a parameter literal in a data tag pattern must not contain a numeric character reference to a non-SGML character
✉
19: a parameter literal in a data tag pattern must not contain a numeric character reference to a function character
✉
20: a name group is not allowed in a general entity reference in a start tag
✉
21: a name group is not allowed in a general entity reference in the prolog
✉
22: X is not a function name
✉
23: X is not a character number in the document character set
✉
24: parameter entity X not defined
✉
26: RNI delimiter must be followed by name start character
✉
29: comment started here
✉
30: only one type of connector should be used in a single group
✉
31: X is not a reserved name
✉
32: X is not allowed as a reserved name here
✉
33: length of interpreted minimum literal must not exceed reference LITLEN (X)
✉
34: length of tokenized attribute value must not exceed LITLEN less NORMSEP (X)
✉
35: length of system identifier must not exceed LITLEN (X)
✉
36: length of interpreted parameter literal must not exceed LITLEN (X)
✉
37: length of interpreted parameter literal in data tag pattern must not exceed DTEMPLEN (X)
✉
39: X invalid: only Y and parameter separators are allowed
✉
40: X invalid: only Y and token separators are allowed
✉
41: X invalid: only Y and token separators are allowed
✉
43: X declaration not allowed in DTD subset
✉
44: character X not allowed in declaration subset
✉
45: end of document in DTD subset
✉
46: character X not allowed in prolog
✉
48: X declaration not allowed in prolog
✉
49: X used both a rank stem and generic identifier
✉
50: omitted tag minimization parameter can be omitted only if OMITTAG NO is specified
✉
51: element type X already defined
✉
52: entity reference with no applicable DTD
✉
53: invalid comment declaration: found X outside comment but inside comment declaration
✉
54: comment declaration started here
✉
55: X declaration not allowed in instance
✉
56: non-SGML character not allowed in content
✉
57: no current rank for rank stem X
✉
58: duplicate attribute definition list for notation X
✉
59: duplicate attribute definition list for element X
✉
60: entity end not allowed in end tag
✉
61: character X not allowed in end tag
✉
62: X invalid: only S separators and TAGC allowed here
✉
66: document type does not allow element X here; assuming missing Y start-tag
✉
67: no start tag specified for implied empty element X
✉
72: start tag omitted for element X with declared content
✉
74: start tag for X omitted, but its declaration does not permit this
✉
75: number of open elements exceeds TAGLVL (X)
✉
77: empty end tag but no open elements
✉
78: X not finished but containing element ended
✉
80: internal parameter entity X cannot be CDATA or SDATA
✉
81: character X not allowed in attribute specification list
✉
83: entity end not allowed in attribute specification list except in attribute value literal
✉
84: external parameter entity X cannot be CDATA, SDATA, NDATA or SUBDOC
✉
85: duplicate declaration of entity X
✉
86: duplicate declaration of parameter entity X
✉
87: a reference to a PI entity is allowed only in a context where a processing instruction could occur
✉
88: a reference to a CDATA or SDATA entity is allowed only in a context where a data character could occur
✉
89: a reference to a subdocument entity or external data entity is allowed only in a context where a data character could occur
✉
90: a reference to a subdocument entity or external data entity is not allowed in replaceable character data
✉
91: the number of open entities cannot exceed ENTLVL (X)
✉
92: a reference to a PI entity is not allowed in replaceable character data
✉
93: entity X is already open
✉
94: short reference map X not defined
✉
95: short reference map in DTD must specify associated element type
✉
96: short reference map in document instance cannot specify associated element type
✉
97: short reference map X for element Y not defined in DTD
✉
98: X is not a short reference delimiter
✉
99: short reference delimiter X already mapped in this declaration
✉
100: no document element
✉
102: entity end not allowed in processing instruction
✉
103: length of processing instruction must not exceed PILEN (X)
✉
104: missing PIC delimiter
✉
106: X is not a member of a group specified for any attribute
✉
109: an attribute value specification must start with a literal or a name character
✉
110: length of name token must not exceed NAMELEN (X)
✉
113: duplicate definition of attribute X
✉
114: data attribute specification must be omitted if attribute specification list is empty
✉
115: marked section end not in marked section declaration
✉
116: number of open marked sections must not exceed TAGLVL (X)
✉
117: missing marked section end
✉
118: marked section started here
✉
119: entity end in character data, replaceable character data or ignored marked section
✉
126: non-impliable attribute X not specified but OMITTAG NO and SHORTTAG NO
✉
128: first occurrence of CURRENT attribute X not specified
✉
129: X is not a notation name
✉
130: X is not a general entity name
✉
132: X is not a data or subdocument entity
✉
133: content model is ambiguous: when no tokens have been matched, both the Y and Z occurrences of X are possible
✉
134: content model is ambiguous: when the current token is the Y occurrence of X, both the a and b occurrences of Z are possible
✉
135: content model is ambiguous: when the current token is the Y occurrence of X and the innermost containing AND group has been matched, both the a and b occurrences of Z are possible
✉
136: content model is ambiguous: when the current token is the Y occurrence of X and the innermost Z containing AND groups have been matched, both the b and c occurrences of a are possible
✉
138: comment declaration started here
✉
140: data or replaceable character data in declaration subset
✉
142: ID X first defined here
✉
143: value of fixed attribute X not equal to default
✉
144: character X is not significant in the reference concrete syntax and so cannot occur in a comment in the SGML declaration
✉
145: minimum data of first minimum literal in SGML declaration must be «»ISO 8879:1986″» or «»ISO 8879:1986 (ENR)»» or «»ISO 8879:1986 (WWW)»» not X
✉
146: parameter before LCNMSTRT must be NAMING not X
✉
147: unexpected entity end in SGML declaration: only X, S separators and comments allowed
✉
148: X invalid: only Y and parameter separators allowed
✉
149: magnitude of X too big
✉
150: character X is not significant in the reference concrete syntax and so cannot occur in a literal in the SGML declaration except as the replacement of a character reference
✉
151: X is not a valid syntax reference character number
✉
152: a parameter entity reference cannot occur in an SGML declaration
✉
153: X invalid: only Y and parameter separators are allowed
✉
154: cannot continue because of previous errors
✉
155: SGML declaration cannot be parsed because the character set does not contain characters having the following numbers in ISO 646: X
✉
156: the specified character set is invalid because it does not contain the minimum data characters having the following numbers in ISO 646: X
✉
157: character numbers declared more than once: X
✉
158: character numbers should have been declared UNUSED: X
✉
159: character numbers missing in base set: X
✉
160: characters in the document character set with numbers exceeding X not supported
✉
161: invalid formal public identifier X: missing //
✉
162: invalid formal public identifier X: no SPACE after public text class
✉
163: invalid formal public identifier X: invalid public text class
✉
164: invalid formal public identifier X: public text language must be a name containing only upper case letters
✉
165: invalid formal public identifer X: public text display version not permitted with this text class
✉
166: invalid formal public identifier X: extra field
✉
167: public text class of public identifier in notation identifier must be NOTATION
✉
168: base character set X is unknown
✉
169: delimiter set is ambiguous: X and Y can be recognized in the same mode
✉
170: characters with the following numbers in the syntax reference character set are significant in the concrete syntax but are not in the document character set: X
✉
171: there is no unique character in the document character set corresponding to character number X in the syntax reference character set
✉
172: there is no unique character in the internal character set corresponding to character number X in the syntax reference character set
✉
173: the character with number X in ISO 646 is significant but has no representation in the syntax reference character set
✉
174: capacity set X is unknown
✉
175: capacity X already specified
✉
176: value of capacity X exceeds value of TOTALCAP
✉
177: syntax X is unknown
✉
178: UCNMSTRT must have the same number of characters as LCNMSTRT
✉
179: UCNMCHAR must have the same number of characters as LCNMCHAR
✉
180: number of open subdocuments exceeds quantity specified for SUBDOC parameter in SGML declaration (X)
✉
181: entity X declared SUBDOC, but SUBDOC NO specified in SGML declaration
✉
182: a parameter entity referenced in a parameter separator must end in the same declaration
✉
184: generic identifier X used in DTD but not defined
✉
185: X not finished but document ended
✉
186: cannot continue with subdocument because of previous errors
✉
188: no internal or external document type declaration subset; will parse without validation
✉
189: this is not an SGML document
✉
190: length of start-tag before interpretation of literals must not exceed TAGLEN (X)
✉
191: a parameter entity referenced in a token separator must end in the same group
✉
192: the following character numbers are shunned characters that are not significant and so should have been declared UNUSED: X
✉
193: there is no unique character in the specified document character set corresponding to character number X in ISO 646
✉
194: length of attribute value must not exceed LITLEN less NORMSEP (-X)
✉
195: length of tokenized attribute value must not exceed LITLEN less NORMSEP (-X)
✉
196: concrete syntax scope is INSTANCE but value of X quantity is less than value in reference quantity set
✉
197: public text class of formal public identifier of base character set must be CHARSET
✉
198: public text class of formal public identifier of capacity set must be CAPACITY
✉
199: public text class of formal public identifier of concrete syntax must be SYNTAX
✉
200: when there is an MSOCHAR there must also be an MSICHAR
✉
201: character number X in the syntax reference character set was specified as a character to be switched but is not a markup character
✉
202: character number X was specified as a character to be switched but is not in the syntax reference character set
✉
203: character numbers X in the document character set have been assigned the same meaning, but this is the meaning of a significant character
✉
204: character number X assigned to more than one function
✉
205: X is already a function name
✉
206: characters with the following numbers in ISO 646 are significant in the concrete syntax but are not in the document character set: X
✉
207: general delimiter X consists solely of function characters
✉
208: letters assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT: X
✉
209: digits assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT: X
✉
210: character number X cannot be assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT because it is RE
✉
211: character number X cannot be assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT because it is RS
✉
212: character number X cannot be assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT because it is SPACE
✉
213: separator characters assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT: X
✉
214: character number X cannot be switched because it is a Digit, LC Letter or UC Letter
✉
215: pointless for number of characters to be 0
✉
216: X cannot be the replacement for a reference reserved name because it is another reference reserved name
✉
217: X cannot be the replacement for a reference reserved name because it is the replacement of another reference reserved name
✉
218: replacement for reserved name X already specified
✉
219: X is not a valid name in the declared concrete syntax
✉
220: X is not a valid short reference delimiter because it has more than one B sequence
✉
221: X is not a valid short reference delimiter because it is adjacent to a character that can occur in a blank sequence
✉
222: length of delimiter X exceeds NAMELEN (Y)
✉
223: length of reserved name X exceeds NAMELEN (Y)
✉
224: character numbers assigned to both LCNMCHAR or UCNMCHAR and LCNMSTRT or UCNMSTRT: X
✉
225: when the concrete syntax scope is INSTANCE the syntax reference character set of the declared syntax must be the same as that of the reference concrete syntax
✉
226: end-tag minimization should be O for element with declared content of EMPTY
✉
227: end-tag minimization should be O for element X because it has CONREF attribute
✉
228: element X has a declared content of EMPTY and a CONREF attribute
✉
229: element X has a declared content of EMPTY and a NOTATION attribute
✉
230: declared value of data attribute cannot be ENTITY, ENTITIES, ID, IDREF, IDREFS or NOTATION
✉
231: default value of data attribute cannot be CONREF or CURRENT
✉
232: number of attribute names and name tokens (X) exceeds ATTCNT (Y)
✉
233: if the declared value is ID the default value must be IMPLIED or REQUIRED
✉
234: the attribute definition list already declared attribute X as the ID attribute
✉
235: the attribute definition list already declared attribute X as the NOTATION attribute
✉
236: token X occurs more than once in attribute definition list
✉
237: no attributes defined for notation X
✉
238: notation X for entity Y undefined
✉
239: entity X undefined in short reference map Y
✉
240: notation X is undefined but had attribute definition
✉
241: length of interpreted parameter literal in bracketed text plus the length of the bracketing delimiters must not exceed LITLEN (X)
✉
242: length of rank stem plus length of rank suffix must not exceed NAMELEN (X)
✉
243: document instance must start with document element
✉
244: content model nesting level exceeds GRPLVL (X)
✉
245: grand total of content tokens exceeds GRPGTCNT (X)
✉
249: DTDs other than base allowed only if CONCUR YES or EXPLICIT YES
✉
250: end of entity other than document entity after document element
✉
251: X declaration illegal after document element
✉
252: character reference illegal after document element
✉
253: entity reference illegal after document element
✉
254: marked section illegal after document element
✉
255: the X occurrence of Y in the content model for Z cannot be excluded at this point because it is contextually required
✉
256: the X occurrence of Y in the content model for Z cannot be excluded because it is neither inherently optional nor a member of an OR group
✉
257: an attribute value specification must be an attribute value literal unless SHORTTAG YES is specified
✉
258: value cannot be specified both for notation attribute and content reference attribute
✉
259: notation X already defined
✉
260: short reference map X already defined
✉
261: first defined here
✉
262: general delimiter role X already defined
✉
263: number of ID references in start-tag must not exceed GRPCNT (X)
✉
264: number of entity names in attribute specification list must not exceed GRPCNT (X)
✉
265: normalized length of attribute specification list must not exceed ATTSPLEN (X); length was Y
✉
266: short reference delimiter X already specified
✉
267: single character short references were already specified for character numbers: X
✉
268: default entity used in entity attribute X
✉
269: reference to entity X uses default entity
✉
270: entity X in short reference map Y uses default entity
✉
271: no DTD X declared
✉
272: LPD X has neither internal nor external subset
✉
273: element types have different link attribute definitions
✉
274: link set X already defined
✉
275: empty result attribute specification
✉
276: no source element type X
✉
277: no result element type X
✉
278: end of document in LPD subset
✉
279: X declaration not allowed in LPD subset
✉
280: ID link set declaration not allowed in simple link declaration subset
✉
281: link set declaration not allowed in simple link declaration subset
✉
282: attributes can only be defined for base document element (not X) in simple link declaration subset
✉
283: a short reference mapping declaration is allowed only in the base DTD
✉
284: a short reference use declaration is allowed only in the base DTD
✉
285: default value of link attribute cannot be CURRENT or CONREF
✉
286: declared value of link attribute cannot be ID, IDREF, IDREFS or NOTATION
✉
287: only fixed attributes can be defined in simple LPD
✉
288: only one ID link set declaration allowed in an LPD subset
✉
289: no initial link set defined for LPD X
✉
290: notation X not defined in source DTD
✉
291: result document type in simple link specification must be implied
✉
292: simple link requires SIMPLE YES
✉
293: implicit link requires IMPLICIT YES
✉
294: explicit link requires EXPLICIT YES
✉
295: LPD not allowed before first DTD
✉
296: DTD not allowed after an LPD
✉
297: definition of general entity X is unstable
✉
298: definition of parameter entity X is unstable
✉
299: multiple link rules for ID X but not all have link attribute specifications
✉
300: multiple link rules for element type X but not all have link attribute specifications
✉
301: link type X does not have a link set Y
✉
302: link set use declaration for simple link process
✉
303: no link type X
✉
304: both document type and link type X
✉
305: link type X already defined
✉
306: document type X already defined
✉
307: link set X used in LPD but not defined
✉
308: #IMPLIED already linked to result element type X
✉
309: number of active simple link processes exceeds quantity specified for SIMPLE parameter in SGML declaration (X)
✉
310: only one chain of explicit link processes can be active
✉
311: source document type name for link type X must be base document type since EXPLICIT YES 1
✉
312: only one implicit link process can be active
✉
313: sorry, link type X not activated: only one implicit or explicit link process can be active (with base document type as source document type)
✉
314: name missing after name group in entity reference
✉
315: source document type name for link type X must be base document type since EXPLICIT NO
✉
316: link process must be activated before base DTD
✉
317: unexpected entity end while starting second pass
✉
318: type X of element with ID Y not associated element type for applicable link rule in ID link set
✉
319: DATATAG feature not implemented
✉
320: generic identifier specification missing after document type specification in start-tag
✉
321: generic identifier specification missing after document type specification in end-tag
✉
322: a NET-enabling start-tag cannot include a document type specification
✉
324: invalid default SGML declaration
✉
326: entity was defined here
✉
327: content model is mixed but does not allow #PCDATA everywhere
✉
328: start or end of range must specify a single character
✉
329: number of first character in range must not exceed number of second character in range
✉
330: delimiter cannot be an empty string
✉
331: too many characters assigned same meaning with minimum literal
✉
332: earlier reference to entity X used default entity
✉
335: unused short reference map X
✉
336: unused parameter entity X
✉
337: cannot generate system identifier for public text X
✉
339: cannot generate system identifier for parameter entity X
✉
340: cannot generate system identifier for document type X
✉
341: cannot generate system identifier for link type X
✉
342: cannot generate system identifier for notation X
✉
343: element type X both included and excluded
✉
345: minimum data of AFDR declaration must be «»ISO/IEC 10744:1997″» not X
✉
346: AFDR declaration required before use of AFDR extensions
✉
347: ENR extensions were used but minimum literal was not «»ISO 8879:1986 (ENR)»» or «»ISO 8879:1986 (WWW)»»
✉
348: illegal numeric character reference to non-SGML character X in literal
✉
349: cannot convert character reference to number X because description Y unrecognized
✉
350: cannot convert character reference to number X because character Y from baseset Z unknown
✉
351: character reference to number X cannot be converted because of problem with internal character set
✉
352: cannot convert character reference to number X because character not in internal character set
✉
353: Web SGML adaptations were used but minimum literal was not «»ISO 8879:1986 (WWW)»»
✉
354: token X can be value for multiple attributes so attribute name required
✉
355: length of hex number must not exceed NAMELEN (X)
✉
356: X is not a valid name in the declared concrete syntax
✉
357: CDATA declared content
✉
358: RCDATA declared content
✉
359: inclusion
✉
360: exclusion
✉
361: NUMBER or NUMBERS declared value
✉
362: NAME or NAMES declared value
✉
363: NUTOKEN or NUTOKENS declared value
✉
364: CONREF attribute
✉
365: CURRENT attribute
✉
366: TEMP marked section
✉
367: included marked section in the instance
✉
368: ignored marked section in the instance
✉
369: RCDATA marked section
✉
370: processing instruction entity
✉
371: bracketed text entity
✉
372: internal CDATA entity
✉
373: internal SDATA entity
✉
374: external CDATA entity
✉
375: external SDATA entity
✉
376: attribute definition list declaration for notation
✉
377: rank stem
✉
379: comment in parameter separator
✉
380: named character reference
✉
381: AND group
✉
382: attribute value not a literal
✉
383: attribute name missing
✉
384: element declaration for group of element types
✉
385: attribute definition list declaration for group of element types
✉
386: empty comment declaration
✉
388: multiple comments in comment declaration
✉
389: no status keyword
✉
390: multiple status keywords
✉
391: parameter entity reference in document instance
✉
392: CURRENT attribute
✉
393: element type minimization parameter
✉
395: #PCDATA not first in model group
✉
396: #PCDATA in SEQ group
✉
397: #PCDATA in nested model group
✉
398: #PCDATA in model group that does not have REP occurrence indicator
✉
399: name group or name token group used connector other than OR
✉
400: processing instruction does not start with name
✉
401: S separator in status keyword specification in document instance
✉
402: reference to external data entity
✉
405: SGML declaration was not implied
✉
406: marked section in internal DTD subset
✉
408: entity end in different element from entity reference
✉
409: NETENABL IMMEDNET requires EMPTYNRM YES
✉
411: declaration of default entity
✉
412: reference to parameter entity in parameter separator in internal subset
✉
413: reference to parameter entity in token separator in internal subset
✉
414: reference to parameter entity in parameter literal in internal subset
✉
415: cannot generate system identifier for SGML declaration reference
✉
416: public text class of formal public identifier of SGML declaration must be SD
✉
417: SGML declaration reference was used but minimum literal was not «»ISO 8879:1986 (WWW)»»
✉
418: member of model group containing #PCDATA has occurrence indicator
✉
419: member of model group containing #PCDATA is a model group
✉
420: reference to non-predefined entity
✉
421: reference to external entity
✉
422: declaration of default entity conflicts with IMPLYDEF ENTITY YES
✉
423: parsing with respect to more than one active doctype not supported
✉
424: cannot have active doctypes and link types at the same time
✉
425: number of concurrent document instances exceeds quantity specified for CONCUR parameter in SGML declaration (X)
✉
426: datatag group can only be specified in base document type
✉
427: element not in the base document type can’t have an empty start-tag
✉
428: element not in base document type can’t have an empty end-tag
✉
429: immediately recursive element
✉
430: invalid URN X: missing «»:»»
✉
431: invalid URN X: missing «»urn:»» prefix
✉
432: invalid URN X: invalid namespace identifier
✉
433: invalid URN X: invalid namespace specific string
✉
434: invalid URN X: extra field
✉
435: prolog can’t be omitted unless CONCUR NO and LINK EXPLICIT NO and either IMPLYDEF ELEMENT YES or IMPLYDEF DOCTYPE YES
✉
436: can’t determine name of #IMPLIED document element
✉
437: can’t use #IMPLICIT doctype unless CONCUR NO and LINK EXPLICIT NO
✉
438: Sorry, #IMPLIED doctypes not implemented
✉
439: reference to DTD data entity ignored
✉
440: notation X for parameter entity Y undefined
✉
441: notation X for external subset undefined
✉
442: attribute X can’t be redeclared
✉
443: #IMPLICIT attributes have already been specified for notation X
✉
444: a name group is not allowed in a parameter entity reference in a start tag
✉
445: name group in a parameter entity reference in an end tag (SGML forbids them in start tags)
✉
446: if the declared value is NOTATION a default value of CONREF is useless
✉
447: Sorry, #ALL and #IMPLICIT content tokens not implemented
✉
I have a dynamic stylesheet which generates the following stylesheet.
body {
background-color: #3a3a3a;
}
div#header_text {
color: #3a3a3a;
}
div#footer_spacer {
background-color: #3a3a3a;
}
table#content_container {
border-top: 6px solid #3a3a3a;
}
iframe#producten_container {
border-left: 1px solid #3a3a3a;
}
div#footer_text {
background-color: #646080;
}
#page_title {
color: #646080;
}
This causes parse errors in the CSS validator. The following errors occur:
Value background-color Parse Error
Value Error : color Parse Error
Value Error : background-color Parse Error
Value Error : background-color Parse Error
Value Error : color Parse Error
I think this CSS looks fine. Can anyone see what I’m doing wrong here??
thirtydot
222k48 gold badges389 silver badges348 bronze badges
asked Mar 11, 2011 at 10:49
3
the w3c validator lists those as warnings, just to indicate that you are duplicating the same colour in multiple places
you could consolidate some of the colours into a general class to avoid duplication, but as i mentioned the validator just issued warnings at these, not full on errors.
answered Mar 11, 2011 at 10:53
jonezyjonezy
1,89313 silver badges21 bronze badges
I have a dynamic stylesheet which generates the following stylesheet.
body {
background-color: #3a3a3a;
}
div#header_text {
color: #3a3a3a;
}
div#footer_spacer {
background-color: #3a3a3a;
}
table#content_container {
border-top: 6px solid #3a3a3a;
}
iframe#producten_container {
border-left: 1px solid #3a3a3a;
}
div#footer_text {
background-color: #646080;
}
#page_title {
color: #646080;
}
This causes parse errors in the CSS validator. The following errors occur:
Value background-color Parse Error
Value Error : color Parse Error
Value Error : background-color Parse Error
Value Error : background-color Parse Error
Value Error : color Parse Error
I think this CSS looks fine. Can anyone see what I’m doing wrong here??
thirtydot
222k48 gold badges389 silver badges348 bronze badges
asked Mar 11, 2011 at 10:49
3
the w3c validator lists those as warnings, just to indicate that you are duplicating the same colour in multiple places
you could consolidate some of the colours into a general class to avoid duplication, but as i mentioned the validator just issued warnings at these, not full on errors.
answered Mar 11, 2011 at 10:53
jonezyjonezy
1,89313 silver badges21 bronze badges
Как проверить CSS и HTML-код на валидность и зачем это нужно.
В статье:
-
Что такое валидность кода
-
Чем ошибки в HTML грозят сайту
-
Как проверить код на валидность
-
HTML и CSS валидаторы — онлайн-сервисы для проверки кода
Разберем, насколько критическими для работы сайта и его продвижения могут быть ошибки в HTML-коде, и зачем нужны общие стандарты верстки.
Что такое валидность кода
После разработки дизайна программисты верстают страницы сайта — приводят их к единой структуре в формате HTML. Задача верстальщика — сделать так, чтобы страницы отображались корректно у всех пользователей на любых устройствах и браузерах. Такая верстка называется кроссплатформенной и кроссбраузерной — это обязательное требование при разработке любых сайтов.
Для этого есть специальные стандарты: если им следовать, страницу будут корректно распознавать все браузеры и гаджеты. Такой стандарт разработал Консорциумом всемирной паутины — W3C (The World Wide Web Consortium). HTML-код, который ему соответствует, называют валидным.
Валидность также касается файлов стилей — CSS. Если в CSS есть ошибки, визуальное отображение элементов может нарушиться.
Разработчикам рекомендуется следовать критериям этих стандартов при верстке — это поможет избежать ошибок в коде, которые могут навредить сайту.
Чем ошибки в HTML грозят сайту
Типичные ошибки кода — незакрытые или дублированные элементы, неправильные атрибуты или их отсутствие, отсутствие кодировки UTF-8 или указания типа документа.
Какие проблемы могут возникнуть из-за ошибок в HTML-коде
- страницы загружаются медленно;
- сайт некорректно отображается на разных устройствах или в браузерах;
- посетители видят не весь контент;
- программист не замечает скрытую рекламу и вредоносный код.
Как валидность кода влияет на SEO
Валидность не является фактором ранжирования в Яндекс или Google, так что напрямую она не влияет на позиции сайта в выдаче поисковых систем. Но она влияет на мобилопригодность сайта и на то, как поисковые боты воспринимают разметку, а от этого косвенно могут пострадать позиции или трафик.
Почитать по теме:
Главное о микроразметке: подборка знаний для веб-мастеров
Представитель Google Джон Мюллер говорил о валидности кода:
«Мы упомянули использование правильного HTML. Является ли фактором ранжирования валидность HTML стандарту W3C?
Это не прямой фактор ранжирования. Если ваш сайт использует HTML с ошибками, это не значит, что мы удалим его из индекса — я думаю, что тогда у нас будут пустые результаты поиска.
Но есть несколько важных аспектов:— Если у сайта действительно битый HTML, тогда нам будет очень сложно его отсканировать и проиндексировать.
— Иногда действительно трудно подобрать структурированную разметку, если HTML полностью нарушен, поэтому используйте валидатор разметки.
— Другой аспект касается мобильных устройств и поддержки кроссбраузерности: если вы сломали HTML, то сайт иногда очень трудно рендерить на новых устройствах».
Итак, критические ошибки в HTML мешают
- сканированию сайта поисковыми ботами;
- определению структурированной разметки на странице;
- рендерингу на мобильных устройствах и кроссбраузерности.
Даже если вы уверены в своем коде, лучше его проверить — ошибки могут возникать из-за установки тем, сторонних плагинов и других элементов, и быть незаметными. Не все программисты ориентируются на стандарт W3C, так что среди готовых решений могут быть продукты с ошибками, особенно среди бесплатных.
Как проверить код на валидность
Не нужно вычитывать код и считать символы — для этого есть сервисы и инструменты проверки валидности HTML онлайн.
Что они проверяют:
- Синтаксис
Синтаксические ошибки: пропущенные символы, ошибки в написании тегов. - Вложенность тэгов
Незакрытые и неправильно закрытые теги. По правилам теги закрываются также, как их открыли, но в обратном порядке. Частая ошибка — нарушенная вложенность.
- DTD (Document Type Definition)
Соответствие кода указанному DTD, правильность названий тегов, вложенности, атрибутов. Наличие пользовательских тегов и атрибутов — то, чего нет в DTD, но есть в коде.
Обычно сервисы делят результаты на ошибки и предупреждения. Ошибки — опечатки в коде, пропущенные или лишние символы, которые скорее всего создадут проблемы. Предупреждения — бессмысленная разметка, лишние символы, какие-то другие ошибки, которые скорее всего не навредят сайту, но идут вразрез с принятым стандартом.
Валидаторы не всегда правы — некоторые ошибки не мешают браузерам воспринимать код корректно, зато, к примеру, минификация сокращает длину кода, удаляя лишние пробелы, которые не влияют на его отображение.
Почитать по теме:
Уменьшить вес сайта с помощью gzip, brotli, минификации и других способов
Поэтому анализируйте предложения сервисов по исправлениям и ориентируйтесь на здравый смысл.
Перед исправлением ошибок не забудьте сделать резервное копирование. Если вы исправите код, но что-то пойдет не так и он перестанет отображаться, как должен, вы сможете откатить все назад.
HTML и CSS валидаторы — онлайн-сервисы для проверки кода
Есть довольно много валидаторов, выберите тот, в котором вам удобнее работать. Мы рекомендуем использовать известные сервисы от создателей стандартов. Если пояснения на английском воспринимать сложно, можно использовать автоматический перевод страницы.
Валидатор от W3C
Англоязычный сервис, онлайн проверяет соответствие HTML стандартам: можно проверить код по URL, залить файл или вставить код в окошко.
Инструмент покажет список ошибок и предупреждений с пояснениями — описанием ошибки и ее типом, а также укажет номер строки, в которой нужно что-то исправить. Цветом отмечены типы предупреждений и строчки с кодом.

Валидатор CSS от W3C
Инструмент от W3C для проверки CSS, есть русский язык. Работает по такому же принципу, анализирует стили на предмет ошибок и предупреждений. Первым идет блок ошибок, предупреждения собраны ниже отдельно.

Исправления ошибок и валидации HTML и CSS может быть недостаточно: всегда есть другие возможности испортить отображение сайта. Если что-то не работает, как надо, проведите полноценный аудит, чтобы найти ошибки.
С другой стороны, не зацикливайтесь на поиске недочетов в HTML — если код работает, а контент отображается корректно, лучше направить ресурсы на что-то другое — оптимизацию и ускорение загрузки, например.
Я пытался проверить свой CSS, и следующие строки постоянно возвращают ошибку Parse Error [empty string]
.content { width:80%; text-align:center; margin-left:auto; margin-right:auto;
max-width:400px; border-width:4px; border-style:solid; border-color:#339900;
padding:5px; margin-top:10px; margin-bottom:10px; border-radius:20px;
background-color:#ccffcc; }
#side_link { position:fixed; bottom:5px; right:-4px;
background-image:url('img/FruitfulLogo.png'); height:29px; width:22px;
border-style:solid; border-width:2px; border-bottom-left-radius:5px;
border-top-left-radius:5px; border-color:#F90; background-color:#FF9; }
#side_link:hover { background-image:url('img/FruitfulLogo_over.png'); }
Я упускаю что-то действительно очевидное или действительно неясное?
5 ответы
Создан 08 июн.
Вы используете элементы css3, пока это всего лишь черновик. Валидаторы w3 еще не приспособлены для работы с большим количеством новых свойств и атрибутов, и в некоторых случаях они будут выдавать ошибки на совершенно правильном css. Это одна из них.
Просто дайте им год или больше, чтобы все исправить. До тех пор используйте свое собственное суждение, css относительно прост с точки зрения синтаксиса.
ответ дан 16 авг.
Как также прокомментировал @BoltClock, это похоже на ошибку валидатора.
Удалите элементы border-radius в .content и #side_link, и все пройдет нормально. Насколько я вижу, они правы.
ответ дан 29 апр.
.content {
margin:10px auto;
padding:5px;
border:4px solid #390;
border-radius:20px;
width:80%;
max-width:400px;
background-color:#cfc;
text-align:center;
}
#side_link {
position:fixed;
bottom:5px;
right:-4px;
width:22px;
height:29px;
border:2px solid #F90;
border-radius:5px 0 5px 0;
background-color:#FF9;
background-image:url('img/FruitfulLogo.png');
}
#side_link:hover {
background-image:url('img/FruitfulLogo_over.png');
}
Я соглашусь с тем, что валидатор сходит с ума, потому что когда я ввожу вышеизложенное, он показывает ошибки. Но тогда вы должны заметить, что под ошибками он выводит все вышеперечисленное и говорит: «Все это действительно».
ответ дан 29 апр.
Я пропустил его через валидатор W3C и вот что получил.
3: .content — свойство border-radius не существует в уровне CSS 2.1, но существует в: 20px 20px
7: #side_link — свойство border-bottom-left-radius не существует в уровне CSS 2.1, но существует в: 5px 5px
8: #side_link — свойство border-top-left-radius не существует в уровне CSS 2.1, но существует в: 5px 5px
При проверке версии CSS3 это те же номера строк.
Создан 08 июн.
Не тот ответ, который вы ищете? Просмотрите другие вопросы с метками
css
validation
string
or задайте свой вопрос.
Я уже упоминал о том, что существует проверка сайта на ошибки с точки зрения валидности html кода. Это надо делать хотя бы время от времени, поскольку валидность как html, так и css сильно влияет на кроссбраузерность сайта, то есть тождественное отображение вашего ресурса в различных браузерах (тут о популярных и лучших вэб-обозревателях обобщающая статья, которая, надеюсь, поможет вам сделать выбор в пользу одного из них).

Кроме того, я уже упоминал, несмотря на то, что поисковые системы на данном этапе не учитывают ошибки CSS и HTML кода при ранжировании сайтов, в будущем все может измениться и можно получить ситуацию, когда великолепно оформленный, сделанный для людей проект может лишиться части потенциальной аудитории из-за того, что не прошел валидацию. Ну ладно, это все лирика, здесь каждый для себя решает сам, насколько все важно.
Я думаю, с моим мнением вы теперь знакомы, поскольку я пишу эту статью, а значит считаю это достойным внимания наряду, например, с такой важнейшей частью seo оптимизации как закрытие ссылок и фрагментов текста от индексации Google и Яндекс с помощью nofollow noindex или грамотным использованием анкора ссылки.
Ладно, как говорится ближе к делу. Сначала немного о CSS. CSS (Cascading Style Sheets — Каскадные таблицы стилей) является языком стилей, который определяет отображение HTML документов. То есть если HTML описывает содержимое страницы, то CSS форматирует это содержимое, иными словами придает ему завершенный вид. Кстати, для повышения скорости сайта полезно будет провести оптимизацию CSS файлов вашей темы.
Теперь перейдем к тому, как осуществить проверку на валидность того или иного документа (странички нашего сайта или блога WordPress). Также, как в случае проверки HTML кода, воспользуемся одним из инструментов Международного Консорциума W3C. Перейдем на сервис валидации CSS:

Как видите, есть три возможности проверки валидности CSS посредством W3C валидатора. Кстати, обратите внимание, что внизу страницы валидатора есть примечание, которое указывает на необходимость проверки кода HTML на валидность. Только оба правильных кода дают гарантию корректности всего документа. Для проверки вводим URL. Например, проверим главную страницу моего блога:

Итог проверки W3C валидатором в отношении ошибок CSS кода нельзя назвать неутешительным, поскольку обнаружены всего 2 ошибки. Конечно, эти ошибки бывают разными, в каждом конкретном случае они вызывают разные последствия. Посмотрим, как можно поступить для их ликвидации. Здесь все удобно, поскольку W3C валидатор выдает не только ссылку на документ, содержащий некорректный код, но и номер строки, на которой он расположен. Кстати, ниже, после списка предупреждений и ошибок будет отображен вариант корректного кода CSS, которым можно воспользоваться:

На странице результата проверки валидности CSS присутствует ссылка на документ css.ie, который расположен в папке темы. Он был создан для достижения кроссбраузерности блога (одинакового отображения в популярных браузерах). Причем именно для различных модификаций Internet Explorer, который грешит различными ”косяками” в плане искажения вида сайта, особенно его старые версии (IE9 значительно лучше в этом отношении). Кроссбраузерность имеет очень важное значение для продвижения проекта, однако при проверке оказалось, что в этом документе присутствуют свойства, которые не соответствуют стандартам W3C.
Итак, получаем строчки 3 и 12, на которых присутствуют ошибки. Для их исправления следует удалить ошибку разбора html {filter: expression(document.execCommand(«BackgroundImageCache», false, true));} и свойство .zoom. Сейчас не буду вдаваться в тонкости программирования и верстки сайтов, замечу только, что свойство expression помогает избавиться от неприятного эффекта мерцания фоновых изображений, которое происходит в IE6.
То есть в браузере, использование которого исходит на нет, а в последующих версиях этого ”глюка” уже не наблюдается. Сразу скажу, что я некоторое время еще буду использовать это ”лекарство”, до тех пор, пока количество потенциальных посетителей, иcпользующих IE6 не достигнет минимального уровня. Однако для наглядности, чтобы показать вам, как на это будет реагировать W3C валидатор, я удалю его.
Свойство .zoom, которое устанавливает коэффициент масштабирования элемента, не являющаяся частью Международного Стандарта W3C, поддерживается совсем старинными версиями браузеров Opera, Safari, в том числе IE8 (9 версия почти полностью ”законопослушная”, так что в скором времени, надеюсь, вебмастера будут освобождены от необходимости использовать хаки, то есть дополнительные коды, позволяющие достичь максимальной кроссбраузерности). Теперь посмотрим на документ, содержащий невалидные элементы и откорректируем его:

Этот документ находится в папке моей темы Cloudy, я удаляю вышеназванные элементы, которые не прошли проверку валидности. Далее, в результатах проверки на валидность, кроме ошибок, оказалась еще масса так называемых предупреждений:

Для примера я постараюсь показать наглядно, как избавиться от самых распространенных из них, ну и попутно, объяснить их значения. Как видим, W3C валидатор предупреждает о наличии одинаковых цветов для текста и фона. Надо сказать, что это вообще-то нежелательно в любом случае, поскольку поисковые системы такое положение вещей могут рассматривать как сокрытие информации, что чревато серьезными санкциями.
Конечно, это не всегда так происходит, однако недооценивать эту опасность нельзя. Итак, переходим непосредственно к исправлению ситуации. Лучше всего скопировать файл style.css вашей темы в HTML и PHP редактор notepad++, о котором я рассказывал тут и который упрощает поиск по номеру строки:

Теперь мы знаем, где расположены эти строчки в файле вашей темы, корректируем цвет, немного изменив оттенок. В шестнадцатеричной системе цветов #ffffff соответствует белому цвету. Изменяем его следующим образом: вместо последней f вписываем d, таким образом получаем немного другой оттенок белого цвета; теперь изменения для пользователей заметны не будут, однако поисковики увидят разницу:

Вот примерно так можно проводить корректировку невалидных частей кода CSS страничек вашего ресурса. Точно также находим остальные участки, отмеченные предупреждениями и которые необходимо исправить.Что касается предупреждений, касающихся строки 483 (таких оказалось, кстати, немало, порядка 10). При проверке я обнаружил, что их причиной является плагин WP Page Numbers, который обеспечивает постраничную навигацию.
Это подвинуло меня на деактивацию этого плагина и явилось причиной того, что я наконец заменил его внедрением кода, что явилось шажком по направлению к снижению нагрузки на сервер. Как только проделал это, предупреждения, касавшиеся нарушения валидности кода именно этим плагином, при повторной проверке тут же исчезли. После вышеописанных телодвижений проводим повторную проверку валидности CSS с помощью W3C валидатора:

Теперь вы знаете, как проверять валидность CSS документа (вебстраницы сайта или блога), прибегнув к помощи W3С валидатора. Напоследок хотелось бы отметить, что степень и частоту проверки валидности кода CSS каждый для себя решает сам, все зависит от обстоятельств, но тем не менее время от времени это надо делать обязательно, по моему глубокому убеждению. Подписывайтесь на обновления блога для получения свежих материалов на e-mail. Засим разрешите откланяться, надеюсь, расстаемся ненадолго.
я использую в своих стилях такие формулы для(размера шрифта, отступов и т.д.)
font-size: calc(30px + (45 - 30) * ((100vw - 320px) / (1280 - 320)));
в итоге в css-валидаторе вижу ошибку
Ошибка значения : font-size Ошибка разбора (1280 — 320)))
задан 6 апр 2021 в 6:30
3
Похоже, валидатор не любит скобки, потому что если их сократить, то он пропускает
font-size: calc(45px * ((100vw - 320px) / 960));
Ещё предположение — кривой валидатор.
Никто другой не ругается оригинальное решение, а браузеры спокойно выполняют код.
Получается, что ошибки и нет вовсе, но не для валидатора.
ответ дан 6 апр 2021 в 6:47
![]()
De.MinovDe.Minov
22.5k3 золотых знака32 серебряных знака65 бронзовых знаков
8
Разбор ошибок валидации сайта
Наконец-то появилось свободное время между бесконечной чередой заказов, и я решил заняться своим блогом. Попробуем его улучшить в плане валидации. Ниже в статье я расскажу, что такое валидация сайта, кода html и css, зачем она нужна и как привести сайт к стандартам на конкретном примере.
Что такое валидация сайта?
Простыми словами – это проверка на соответствие стандартам. Чтобы любой браузер мог отображать ваш сайт корректно. Большое влияние валидность сайта на продвижение не оказывает, но хуже точно не будет.
Конкретный пример прохождения валидации для страницы сайта
Возьмем первую попавшуюся страницу на моем сайте — Кодирование и декодирование base64 на Java 8. Забьем адрес страницы в валидатор и смотрим результат:
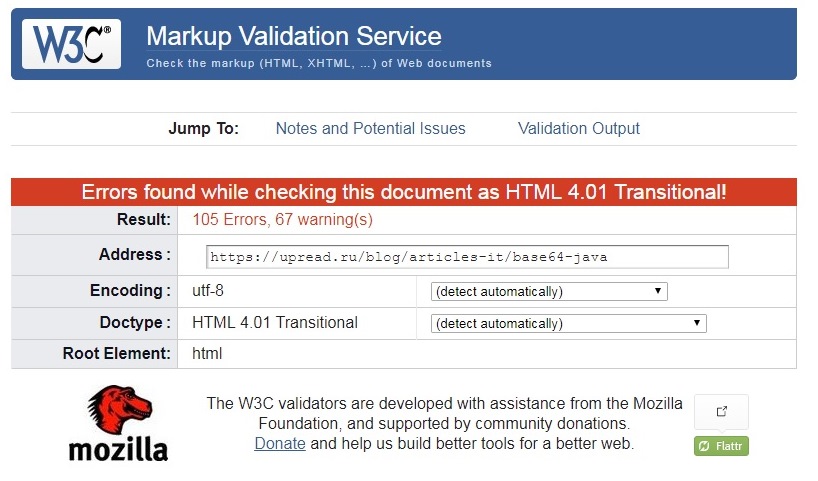
Errors found while checking this document as HTML 4.01 Transitional! Result: 105 Errors, 67 warning(s)
Да уж, картина вырисовывается неприятная: больше сотни ошибок и 67 предупреждений – как вообще поисковики индексируют мой блог, и заходят люди? Но не будем огорчаться, а научимся проходить валидацию, справлять ошибки. Итак, первое предупреждение:
Unable to Determine Parse Mode! The validator can process documents either as XML (for document types such as XHTML, SVG, etc.) or SGML (for HTML 4.01 and prior versions). For this document, the information available was not sufficient to determine the parsing mode unambiguously, because: the MIME Media Type (text/html) can be used for XML or SGML document types No known Document Type could be detected No XML declaration (e.g <?xml version="1.0"?>) could be found at the beginning of the document. No XML namespace (e.g <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">) could be found at the root of the document. As a default, the validator is falling back to SGML mode. Warning No DOCTYPE found! Checking with default HTML 4.01 Transitional Document Type. No DOCTYPE Declaration could be found or recognized in this document. This generally means that the document is not declaring its Document Type at the top. It can also mean that the DOCTYPE declaration contains a spelling error, or that it is not using the correct syntax. The document was checked using a default "fallback" Document Type Definition that closely resembles “HTML 4.01 Transitional”.
Это одно и тоже. А исправляется просто: в самом начале страницы добавить тег:
<!DOCTYPE html>
Проверяем ,что у нас получилось и видим, что одним этим тегом мы убрали 105 ошибок и 3 предупреждения! Теперь у нас осталось только 64 предупреждения. Начинаем разбирать их по одному.
Warning: The type attribute for the style element is not needed and should be omitted. From line 5, column 1; to line 5, column 23 /x-icon">↩<style type="text/css">↩↩↩↩A
Это значит, что для элемента style не нужен атрибут type – это лишнее. На странице у нас два таких замечания. Аналогичное предупреждение и по JavaScript:
Warning: The type attribute is unnecessary for JavaScript resources. From line 418, column 1; to line 418, column 31 </script>↩<script type="text/javascript">↩$(doc
Таких у нас 8 ошибок. Убираем данные атрибуты и ура – еще на 10 предупреждений меньше!
Error: CSS: background: The first argument to the linear-gradient function should be to top, not top. At line 39, column 61 0%,#E8E8E8 100%);↩ border-r
Следующая ошибка — первый аргумент у linear-gradient должен быть to top, а не top. Исправлем. Далее ошибка:
Error: CSS: Parse Error. From line 65, column 13; to line 65, column 16 margin: 0 auto;↩padd
Здесь у меня неверно закомментировано css. Надо просто убрать эту строку. Или закомментировать по-другому /* и */. Я так сделал, как привык так комментировать на Java.
Error: CSS: @import are not allowed after any valid statement other than @charset and @import.. At line 88, column 74 0,600,700,300);↩@import url(//
Теперь у нас идет ошибка импорта. Перенесем эти строчки в самое начало файла и она исчезнет.
Error: Bad value _blanck for attribute target on element a: Reserved keyword blanck used. From line 241, column 218; to line 241, column 295 cookies. <a href="//upread.ru/art.php?id=98" target="_blanck" style="display: inline;">Здесь
Далее не нравится значение атрибута target, нам сообщают, что надо использовать «blank» без нижнего подчеркивания спереди. Убираем.
Error: End tag li seen, but there were open elements. From line 379, column 2; to line 379, column 6 <ul>↩ </li>↩↩</ul
Теперь у нас идет div не на месте.
Error: Table columns in range 2…3 established by element td have no cells beginning in them. From line 262, column 5; to line 263, column 94 px;">↩<tr>↩<td colspan="3" style="width:100%; padding-bottom: 25px;padding-top: 0px; text-align:center;">↩<img
Следующая ошибка – лишний colspan у ячейки. В моем случае таблица состоит всего из одной ячейки, видимо, забыл убрать, когда менял дизайн. Теперь это и делаем.
Error: Element style not allowed as child of element div in this context. (Suppressing further errors from this subtree.) From line 486, column 1; to line 486, column 7 ↩</table>↩<tyle>↩.hleb Contexts in which element style may be used: Where metadata content is expected. In a noscript element that is a child of a head element. In the body, where flow content is expected. Content model for element div: If the element is a child of a dl element: one or more dt elements followed by one or more dd elements, optionally intermixed with script-supporting elements. If the element is not a child of a dl element: Flow content.
А эта ошибка говорит о том, что нельзя вставлять style внутри div. Переносим в начало файла.
Error: The width attribute on the table element is obsolete. Use CSS instead. From line 505, column 1; to line 505, column 21 >↩↩↩↩↩↩↩↩↩<table width ="100%">↩<tr>↩
Тут нам подсказывают, что не стоит устанавливать ширину атрибутом, а лучше сделать это отдельным тегом. Меняем на style=»width:100%;».
Error: Duplicate attribute style. At line 507, column 41 ign="top" style="padding-right
Переводим: дублируется атрибут style. Второй стиль при этом работать не будет. Объединяем
Error: Attribute name not allowed on element td at this point. From line 506, column 5; to line 507, column 82 0%;">↩<tr>↩<td style="width:1%;padding-right:10px;" valign="top" name="navigid" id="navigid">↩↩↩↩</ Attributes for element td: Global attributes colspan - Number of columns that the cell is to span rowspan - Number of rows that the cell is to span headers - The header cells for this cell
У ячейки не должно быть имени – атрибута name. Тут в принципе можно убрать, id вполне хватит.
Error: The valign attribute on the td element is obsolete. Use CSS instead. From line 506, column 5; to line 507, column 67 0%;">↩<tr>↩<td style="width:1%;padding-right:10px;" valign="top" id="navigid">↩↩↩↩</
Убираем valign. Вместо него ставим style=»vertical-align:top».
Error: & did not start a character reference. (& probably should have been escaped as &.) At line 543, column 232 при lineLength &t;= 0) и lineS
А эта ошибка вообще непонятно как оказалась ) Это я коде к статье ошибся. Меняем на <
Error: An img element must have an alt attribute, except under certain conditions. For details, consult guidance on providing text alternatives for images. From line 654, column 1; to line 654, column 30 /><br />↩<img src="img/art374-1.jpg" />↩<br /
У изображений должен быть alt. Добавляем альты с описанием картинок.
Error: CSS: padding: only 0 can be a unit. You must put a unit after your number. From line 260, column 18; to line 260, column 19 dding: 10 20;↩}↩↩#
Только ноль может быть без обозначений. Надо поставить что – это пиксели, или к примеру, проценты. Добавляем px после чисел.
Warning: The document is not mappable to XML 1.0 due to two consecutive hyphens in a comment. At line 974, column 8 ipt> ↩↩↩ <!--детектим адблок
Не нравятся комментарии. Да, в общем, их можно и убрать, не разбираясь, не особенно они и нужны.
Error: Stray end tag td. From line 982, column 1; to line 982, column 5 ↩</table>↩</td>↩↩<sty
Заблудившийся тег td. Убираем его.
Error: Bad value for attribute action on element form: Must be non-empty. From line 1102, column 6; to line 1102, column 98 /h6>↩ <form action="" id="jaloba-to-me" class="submit" method="POST" accept-charset="windows-1251"> <tabl
Здесь валидатор не устраивает пустое значение атрибута action – должен быть адрес страницы какой-то. У нас обрабатывается данная форма js, так что без разницы, поставим action=”self”
Все! Смотрим результат:
Нет ошибок или предупреждений, страница полностью валидна.
Если вам что-то непонятно в статье или вы хотите, чтобы ваш сайт полностью соответствовал спецификации и стандартам HTML ,вы можете обратиться ко мне. Я проверю и устраню любые шибки валидации.

Автор этого материала — я — Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML — то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.
![]() заметки, сайтостроение, html, валидация
заметки, сайтостроение, html, валидация
I know that there are many posts like that, but i realy can’t find an answer that solves my problem.
I really want to get my CSS 3.0 validated and I don’t know how to do it especially with those parse error on the begining. I have checked for any invisible characters but didn’t find any.
So my problem is what can be the reason for those parse error?
Also I do understand that if i want to provide the compatibility for browsers i can’t get rid of this error:
Sorry, the at-rule @-moz-keyframes is not implemented.
Here is the link to validator results and my css
EDIT: Thank you all for your answers regarding the «at-rule» but it was almost retoric question on which I had found the answer earlier, but wanted to be sure if anything has changed. Also the thing that rest of the vendor extensions are only warnings and those 6 (now 2) are errors.
But the main question was about the parse error which I don’t know how to remove and why it is there.
EDIT SOLUTION:
Yours answers and little bit of testing led me to the final answer:
— The vendor extensions are only warnings, but not in case of keyframes (i think that this feature is to new).
— The parse error was only because of the above conclusion (keyframes extension).
— I have also used for the @-webkit-keyframes the solution given by Kami and placed all animations in separate vendor.css which i have linked to the html with help of the javaScript.
Now everything is validating as it should be.
Я знаю, что таких сообщений много, но я действительно не могу найти ответ, который решает мою проблему.
Я действительно хочу, чтобы мой CSS 3.0 был проверен, и я не знаю, как это сделать, особенно с теми ошибками разбора в начале. Я проверил наличие невидимых символов, но не нашел ни одного.
Так что моя проблема в том, что может быть причиной этих ошибок разбора?
Также я понимаю, что если я хочу обеспечить совместимость для браузеров, я не могу избавиться от этой ошибки:Sorry, the at-rule @-moz-keyframes is not implemented.
Вот ссылка на результаты валидатора и мой CSS
РЕДАКТИРОВАТЬ: Спасибо всем за ваши ответы относительно «по правилу», но это был почти реторический вопрос, на который я нашел ответ ранее, но хотел быть уверен, что что-то изменилось. Также дело в том, что остальные расширения вендора — это только предупреждения, а те 6 (теперь 2) — ошибки.
Но главный вопрос был об ошибке разбора, которую я не знаю, как устранить и почему она там есть.
РЕДАКТИРОВАТЬ РЕШЕНИЕ:
Ваши ответы и немного испытаний привели меня к окончательному ответу:
— Расширения вендора являются только предупреждениями, но не в случае ключевых кадров (я думаю, что эта функция является новой).
— Ошибка разбора была только из-за вышеуказанного вывода (расширение ключевых кадров).
— Я также использовал для @-webkit-keyframes решение, данное Kami, и поместил все анимации в отдельный vendor.css, который я связал с html с помощью javaScript.
Теперь все проверяется, как и должно быть.
To query for the size of the viewport (or the page box on page media), the width, height and aspect-ratio media features should be used, rather than device-width, device-height and device-aspect-ratio, which refer to the physical size of the device regardless of how much space is available for the document being laid out. The device-* media features are also sometimes used as a proxy to detect mobile devices. Instead, authors should use media features that better represent the aspect of the device that they are attempting to style against.
The width media feature describes the width of the targeted display area of the output device. For continuous media, this is the width of the viewport including the size of a rendered scroll bar (if any).
In the following example, this media query expresses that the style sheet is only linked if the width of the viewport 768px maximum:
<link rel="stylesheet" media="only screen and (max-width: 768px)" href="styles.css">