Полученные
в результате статистического исследования
средние и относительные величины должны
отражать закономерности, характерные
для всей совокупности. Результаты
исследования обычно тем достовернее,
чем больше сделано наблюдений, и наиболее
точными они являются при сплошном
исследовании (т.е. при изучении генеральной
совокупности). Однако должны быть
достаточно надежные и данные, полученные
путем выборочных исследований, т.е. на
относительно небольшом числе наблюдений.
Различие
результатов выборочного исследования
и результатов, которые могут быть
получены на генеральной совокупности,
представляет собой ошибку выборочного
исследования, которую можно точно
определить математическим путем. Метод
ее оценки основан на закономерностях
случайных вариаций, установленных
теорией вероятности.
1.
Оценка достоверности средней
арифметической.
Средняя
арифметическая, полученная при обработке
результатов научно-практических
исследований, под влиянием случайных
явлений может отличаться от средних,
полученных при проведении повторных
исследований. Поэтому, чтобы иметь
представление о возможных пределах
колебаний средней, о том, с какой
вероятностью возможно перенести
результаты исследования с выборочной
совокупности на всю генеральную
совокупность, определяют степень
достоверности средней величины.
Мерой
достоверности средней является средняя
ошибка средней арифметической (ошибка
репрезентативности – m).
Ошибки репрезентативности возникают
в связи с тем, что при выборочным
наблюдении изучается только часть
генеральной совокупности, которая
недостаточно точно ее представляет.
Фактически ошибка репрезентативности
является разностью между средними,
полученными при выборочном статистическом
наблюдении, и средними, которые были бы
получены при сплошном наблюдении (т.е.
при изучении всей генеральной
совокупности).
Средняя
ошибка средней арифметической вычисляется
по формуле:
—
при числе наблюдений больше 30 (n
> 30):
![]()
—
при небольшом числе наблюдений (n
< 30):
![]()
Ошибка
репрезентативности прямо пропорциональна
колеблемости ряда (сигме) и обратно
пропорциональна числу наблюдений.
Следовательно,
чем больше
число наблюдений
(т.е. чем ближе по числу наблюдений
выборочная совокупность к генеральной),
тем меньше
ошибка репрезентативности.
Интервал,
в котором с заданным уровнем вероятности
колеблется истинное значение средней
величины или показателя, называется
доверительным
интервалом,
а его границы – доверительными
границами.
Они используются для определения
размеров средней или показателя в
генеральной совокупности.
Доверительные
границы
средней арифметической и показателя в
генеральной совокупности равны:
M
+
tm
P
+
tm,
где
t
– доверительный коэффициент.
Доверительный
коэффициент (t)
– это число, показывающее, во сколько
раз надо увеличить ошибку средней
величины или показателя, чтобы при
данном числе наблюдений с желаемой
степенью вероятности утверждать, что
они не выйдут за полученные таким образом
пределы.
С
увеличением t
степень вероятности возрастает.
Т.к.
известно, что полученная средняя или
показатель при повторных наблюдениях,
даже при одинаковых условиях, в силу
случайных колебаний будут отличаться
от предыдущего результат, теорией
статистики установлена степень
вероятности, с которой можно ожидать,
что колебания эти не выйдут за определенные
пределы. Так, колебания средней
в интервале M
+
1m
гарантируют ее точность с вероятностью
68.3% (такая
степень вероятности не удовлетворяет
исследователей), в
интервале M
+
2m
– 95.5%
(достаточная степень вероятности) и в
интервале M
+
3m
– 99,7% (большая
степень вероятности).
Для
медико-биологических исследований
принята степень вероятности 95% (t
= 2), что соответствует доверительному
интервалу M
+
2m.
Это
означает, что практически
с полной достоверностью (в 95%) можно
утверждать, что полученный средний
результат (М) отклоняется от истинного
значения не больше, чем на удвоенную (M
+
2m) ошибку.
Конечный
результат любого медико-статистического
исследования выражается средней
арифметической и ее параметрами:
![]()
2.
Оценка достоверности относительных
величин (показателей).
Средняя
ошибка показателя также служит для
определения пределов его случайных
колебаний, т.е. дает представление, в
каких пределах может находиться
показатель в различных выборках в
зависимости от случайных причин. С
увеличением численности выборки ошибка
уменьшается.
Мерой
достоверности показателя является его
средняя ошибка (m),
которая показывает, на сколько результат,
полученный при выборочным исследовании,
отличается от результата, который был
бы получен при изучении всей генеральной
совокупности.
Средняя
ошибка показателя определяется по
формуле:
![]() ,
,
где mp
– ошибка относительного показателя,
р
– показатель,
q
– величина, обратная показателю (100-p,
1000-р и т.д. в зависимости от того, на какое
основание рассчитан показатель);
n
– число наблюдений.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
2. Виды отбора.
3. Ошибки выборки, определение объема выборочной совокупности.
4. Способы распространения выборочных характеристик.
1. Понятие выборочного наблюдения, репрезентативность выборочного наблюдения.
1. Выборочное наблюдение несложное наблюдение, при котором обследуется не вся совокупность, а лишь часть, отобранная по определенным правилам выборки и обеспечивающая получение данных, характеризующих всю совокупность в целом.
При проведении выборочного наблюдения нельзя получить абсолютно точные данные, как при сплошном, т. к. обследованию подвергается не вся совокупность, а ее часть. Поэтому при проведении выборочного наблюдения неизбежна некоторая свойственная ему погрешность, ошибка.
Ошибки, свойственные выборочному наблюдению, называются ошибками репрезентативности, т. е. представительства. Они характеризуют размер расхождения между данными выборочного наблюдения и всей совокупности.
Ошибки репрезентативности делятся на случайные и систематические.
Случайные ошибки возникают вследствие того, что выборочная совокупность недостаточно точно воспроизводит совокупность, вследствие несплошного характера наблюдения. Случайные ошибки м. б. доведены до незначительных размеров, а главное размеры и пределы их можно определить с достаточной точностью на основании закона больших чисел и теории вероятности.
Систематические ошибки возникают в результате нарушения принципа случайности отбора единиц совокупности для наблюдения.
Вся совокупность единиц, из которой производится отбор, называется генеральной совокупностью и обозначается буквой N. Часть генеральной совокупности, попавшая в выборку, называется выборочной совокупностью и обозначается n.
Обобщающие показатели генеральной совокупности средняя, дисперсия, доля называются генеральными и соответственно обозначаются ![]() доля отнесения М единиц, обладающих определенным признаком, ко всей численности генеральной совокупности, т. е. М/N.
доля отнесения М единиц, обладающих определенным признаком, ко всей численности генеральной совокупности, т. е. М/N.
Обобщающие характеристики в выборочной совокупности называются выборочными и обозначаются соответственно x*, ![]() частость отношение числа единиц, обладающих данным признаком, в выборочной совокупности n, т. е.
частость отношение числа единиц, обладающих данным признаком, в выборочной совокупности n, т. е. ![]()
![]()
Теория выборочного метода дает возможность определить случайные ошибки обобщающих характеристик в выборочной совокупности.
Ошибка репрезентативности разность между выборочной средней и генеральной средней при достаточно большом числе наблюдений будет сколько угодно малой, т. е.
![]()
где ![]() абсолютная величина расхождения между генеральной средней и выборочной средней, составляющая ошибку репрезентативности.
абсолютная величина расхождения между генеральной средней и выборочной средней, составляющая ошибку репрезентативности.
![]() — среднее квадратическое отклонение вариантов выборочной средней от генеральной средней (средняя ошибка выборки). Она зависит от колеблемости признака в генеральной совокупности
— среднее квадратическое отклонение вариантов выборочной средней от генеральной средней (средняя ошибка выборки). Она зависит от колеблемости признака в генеральной совокупности ![]() и числа отобранных единиц n:
и числа отобранных единиц n: ![]() . Величина m зависит также от способа образования выборочной совокупности, т. к. между
. Величина m зависит также от способа образования выборочной совокупности, т. к. между ![]() средней ошибкой выборки и n числом отбираемых единиц существует обратно пропорциональная связь. Отсюда вытекает следующее правило: если надо уменьшить ошибку выборки, например, в 3 раза, необходимо увеличить объем выборки в девять раз.
средней ошибкой выборки и n числом отбираемых единиц существует обратно пропорциональная связь. Отсюда вытекает следующее правило: если надо уменьшить ошибку выборки, например, в 3 раза, необходимо увеличить объем выборки в девять раз.
Увеличение колеблемости признака в генеральной совокупности влечет за собой увеличение среднего квадратического отклонения, и следовательно и ошибки выборки.
Доказано, что соотношение между дисперсиями генеральной и выборочной совокупностей выражаются формулой:
![]() , т. к.
, т. к. ![]() при больших n приближается к 1, то
при больших n приближается к 1, то ![]()
Средняя ошибка выборки показывает, какие возможны отклонения характеристик выборочной совокупности от соответствующих характеристик генеральной совокупности. Однако о величине этой ошибки можно судить с определенной вероятностью, на величину которой указывает коэффициент доверия t.
Величина ![]() обозначается
обозначается ![]() называется предельной ошибкой выборки. Следовательно предельная ошибка выборки определяется формулой
называется предельной ошибкой выборки. Следовательно предельная ошибка выборки определяется формулой ![]() =
= ![]() . С увеличением t увеличивается вероятность нашего утверждения, но вместе с тем увеличивается и величина ошибки.
. С увеличением t увеличивается вероятность нашего утверждения, но вместе с тем увеличивается и величина ошибки.
2. Виды и схемы отбора.
Формирование выборочной совокупности из генеральной может осуществляться по-разному: в зависимости от вида и схемы отбора, и т. д. От их особенностей зависит размер ошибки и методы определения. Различаются 4 вида отбора:
1. собственно-случайный
2. механический
3. типический
4. серийный (гнездовой)
Собственно-случайный отбор включение единиц совокупности осуществляется наудачу. Наиболее распространенным способом отбора в случайной выборке является жеребьевка, при которой на каждую единицу заготавливают билет с порядковым номером. Затем в случайном порядке отбирают необходимое количество единиц совокупности. При этих условиях каждая из них имеет одинаковую вероятность попасть в выборку.
Механический отбор вся совокупность разбивается на равные по объему группы по случайному признаку. Затем из каждой группы случайно отбирается одна единица.
Типичный отбор совокупность расчленяется по существенному, типическому признаку на качественно однородные, однотипные группы. Затем из каждой группы случайным или механическим способом отбирается количество единиц, пропорциональное удельному весу группы во всей совокупности.
Типический отбор дает более точные результаты чем случайный или механический, потому что при нем в выборку в такой же пропорции как и в генеральной совокупности, попадают представители всех типических групп.
Серийный отбор (гнездовой) отбору подлежат не отдельные единицы совокупности, а целые группы, серии, гнезда, отобранные случайным или механическим способом. В каждой такой группе, серии проводится сплошное наблюдение, а результаты переносятся на всю совокупность.
Точность выборки зависит и от схемы отбора. Выборка м. б. проведена по схеме повторного или бесповторного отбора.
Повторный отбор каждая отобранная единица или серия возвращается во всю совокупность и может вновь попасть в выборку.
Бесповторный отбор каждая обследованная единица не возвращается в совокупность и не м. б. подвергнута повторному обследованию. Бесповторный отбор дает более точные результаты, т. к. при одном и том же объеме выборки наблюдение охватывает большее количество единиц изучаемой совокупности.
Обе схемы отбора могут применяться в сочетании с разными видами отбора, за исключением механического, который всегда бывает бесповторным.
3. Ошибки выборки, определение объема выборочной совокупности
Для суждения о праве распространения данных выборочного наблюдения на генеральную совокупность определяют величину ошибок между сводимыми показателями выборочной и генеральной совокупностей.
Обычно сопоставляют такие показатели:
1. Среднюю выборочной совокупности со средней генеральной совокупности, в результате чего получаем ошибку средней.
![]()
2. Частость выборочной совокупности с долей генеральной совокупности, что дает возможность определить ошибку частостей:
![]()
Разность между показателями выборочной и генеральной совокупностей называется ошибкой репрезентативности. Если эти показатели достаточно близки, то выборка считается репрезентативной.
Выборочная средняя и частость являются переменными величинами, т. е. могут принимать различные значения в зависимости от того, какие единицы совокупности попали в выборку. Следовательно, ошибки выборки также являются переменными величинами и также могут принимать различные значения в зависимости от единиц совокупности, попавшие в выборку. Вот почему определяется средняя из возможных ошибок, которая обозначается буквой ![]() . Величина
. Величина ![]() зависит от степени колеблемости значений признака в генеральной совокупности и от численности выборки n. Степень колеблемости в генеральной совокупности определяется средним квадратом отклонений или дисперсией
зависит от степени колеблемости значений признака в генеральной совокупности и от численности выборки n. Степень колеблемости в генеральной совокупности определяется средним квадратом отклонений или дисперсией ![]() . Из математических теорем и закона больших чисел следует, что при случайном отборе, проведенном по системе повторной выборки, между
. Из математических теорем и закона больших чисел следует, что при случайном отборе, проведенном по системе повторной выборки, между ![]() и п существует следующая зависимость:
и п существует следующая зависимость:
![]()
Ошибка выборочного наблюдения это разность между величиной параметра в генеральной совокупности и его величиной, вычисленной по результатам выборочного наблюдения
![]()
Чебышев доказал, что при достаточно большом числе независимых наблюдений можно с вероятностью, близкой к единице утверждать, что отклонение выборочной средней от генеральной будет сколь угодно малым.
![]() , величину
, величину ![]() называют средней ошибкой выборки.
называют средней ошибкой выборки.
Соотношение между дисперсиями генеральной и выборочной совокупности выражается формулой
![]()
Если выборочное наблюдение применяется для определения доли признака, то средняя ошибка доли исчисляется по формуле
![]() , т. к. дисперсия альтернативного признака
, т. к. дисперсия альтернативного признака ![]() , где p доля единиц совокупности, обладающих данным признаком, а q не обладающим данным признаком.
, где p доля единиц совокупности, обладающих данным признаком, а q не обладающим данным признаком.
В этих формулах ![]() и pq характеристики генеральной совокупности, которые при выборочном наблюдении неизвестны. На практике их заменяют аналогичными характеристиками выборочной совокупности, что вполне правомерно, т. к. основано на законе больших чисел, по которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
и pq характеристики генеральной совокупности, которые при выборочном наблюдении неизвестны. На практике их заменяют аналогичными характеристиками выборочной совокупности, что вполне правомерно, т. к. основано на законе больших чисел, по которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
При бесповторном отборе средняя ошибка выборки равна
![]() , а ошибка доли
, а ошибка доли ![]() , где N численность единиц генеральной совокупности.
, где N численность единиц генеральной совокупности.
Множитель ![]() всегда меньше единицы, т. к. n < N. Поэтому величина средней ошибки выборки при бесповторном отборе меньше чем при повторном.
всегда меньше единицы, т. к. n < N. Поэтому величина средней ошибки выборки при бесповторном отборе меньше чем при повторном.
Для решения практических задач выборочного обследования средней ошибки выборки недостаточно, потому что при исчислении ошибки конкретной выборки фактическая ошибка м. б. больше или меньше средней ошибки выборки ![]() . Поэтому пользуются не средней, а предельной ошибкой выборки, т. е. пределами, за которые не выйдет фактическая ошибка выборки.
. Поэтому пользуются не средней, а предельной ошибкой выборки, т. е. пределами, за которые не выйдет фактическая ошибка выборки.
Предельная ошибка выборки зависит от того, с какой вероятностью должна гарантироваться ошибка выборки. Уровень вероятности определяется на основе теорем Чебышева и Ляпунова при помощи специального коэффициента t.
Если предельную ошибку выборки обозначить буквой ![]() , то
, то 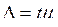 , где t коэффициент, зависящий от вероятности, с которой гарантируется ошибка выборки. Он называется еще коэффициентом доверия. Чтобы определить величину вероятности для различных значений t на практике пользуются готовой таблицей.
, где t коэффициент, зависящий от вероятности, с которой гарантируется ошибка выборки. Он называется еще коэффициентом доверия. Чтобы определить величину вероятности для различных значений t на практике пользуются готовой таблицей.
Систематизируем формулы для определения предельной ошибки средней и доли
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
Из формул видно, что предельная ошибка выборки прямо пропорциональна коэффициенту t, дисперсии ![]() и обратно пропорциональна корню квадратному из численности выборки.
и обратно пропорциональна корню квадратному из численности выборки.
Дисперсия ![]() величина конкретная, свойственная данной совокупности. Обычно она неизвестна, а известна
величина конкретная, свойственная данной совокупности. Обычно она неизвестна, а известна ![]() *, которой и заменяют величину
*, которой и заменяют величину ![]() , потому что в силу действия закона больших чисел при достаточно большом объеме выборки n распределение признака x в выборочной совокупности близко воспроизводит распределение этого признака в генеральной совокупности.
, потому что в силу действия закона больших чисел при достаточно большом объеме выборки n распределение признака x в выборочной совокупности близко воспроизводит распределение этого признака в генеральной совокупности.
Ошибка выборки зависит и от ее объема n. Чем больше объем выборки, тем меньше предельная ошибка (при данных ![]() и t)
и t)
Рассмотренные формулы средней и предельной ошибки и доли применяются при случайном и механическом видах отбора.
При типическом отборе предельная ошибка выборки и доли определяется по формулам:
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
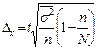
т. е. при типичном отборе надо брать средние из внутригрупповых дисперсий и доли, полученные по каждой типической группе.
Из этих формул видно, что при типическом отборе в отличие от случайного исключается влияние межгрупповой вариации на точность выборки, т. к. в выборку обязательно попадают представители всех групп в тех же пропорциях, что и в генеральной совокупности. Ошибка выборки при типичном отборе зависит только от средней из внутригрупповых дисперсий, а не от общей дисперсии, как при случайном отборе т. к.
![]() , откуда
, откуда 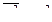
Следовательно ошибка выборки при типическом отборе всегда меньше ошибки выборки, проведенной случайным отбором.
При серийном отборе каждая серия рассматривается как единица совокупности, и мерой колеблемости будет межсерийная выборочная дисперсия, т. е. средний квадрат отклонений серийных средних от общей выборочной средней:
![]() , где
, где ![]() средняя по каждой серии, x* общая выборочная средняя, s число отобранных серий.
средняя по каждой серии, x* общая выборочная средняя, s число отобранных серий.
Предельная ошибка выборки и доли при серийном отборе с равновеликими сериями определяется по формулам, где S общее число серий в генеральной совокупности.
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
Выборочное наблюдение, объем которого превышает 20 единиц, называется малой выборкой. Для определения средней и предельной ошибок при малой выборке пользуются теми же формулами, что и при большой, но только с некоторыми особенностями, так ![]() , а
, а 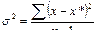 .
.
Кроме того, в случае малой выборки действует особый закон распределения величин t, и при определении вероятности учитывается не только коэффициент t, но и объем выборки n.
Необходимая численность выборки (n) определяется на основе формул предельной ошибки выборки.
Если выборка повторная, то при случайном и механическом отборах определяется по формуле
![]() , при бесповторном отборе
, при бесповторном отборе ![]()
4. Способы распространения выборочных характеристик.
Есть два способа распространения выборочных характеристик на всю совокупность прямой пересчет и способ коэффициентов
Способ прямого пересчета заключается в том, что средние или частости выборочной совокупности умножаются на числа единиц генеральной совокупности.
Когда выборочное обследование проводится в целях уточнения данных сплошного наблюдения, применяется способ коэффициентов. В этом случае данные сплошного наблюдения сопоставляют с данными выборочного наблюдения и устанавливают процент расхождения между ними, т. е. процент надоучета или переучета. Коэффициенты, полученные в результате такого сопоставления, используются для внесения поправок в данные сплошного учета.
Пример.
1) способ прямого пересчета
Для определения качества продукции проверено 500 изделий из 10000. В результате чего установлено, что средний % изделий 3-го сорта всей партии будет находиться в пределах 6,1-13,9%. Способом прямого пересчета определяем, что обще кол-во изделий 3-го сорта всей партии составит от 610 до 1390
10000*0,061= 610
10000*0,139 = 1390
2) способ коэффициентов
Пример
Необходимо определить численность выборки, которая позволила бы оценить долю брака в партии продукции с точностью до 2%, с вероятностью Р =0,954. Партия состоит из 10000 изделий
![]() ,
, ![]()
![]()
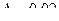 , P =0,954, t =2
, P =0,954, t =2
![]() pq=0,25 (p=0,5; q=0,5)
pq=0,25 (p=0,5; q=0,5)

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
2.1. Стандартное отклонение среднего выборочного значения (ошибка среднего) и доверительный интервал
Результаты измерений обычно показывают с так называемой «средней статистической ошибкой средней величины» и для нашего случая (см. табл. 1.1) это будет запись: «высота сеянцев в опыте составила 5,0 ± 0,28 см». Словосочетание «средняя статистическая ошибка» обычно сокращают до названия «ошибка среднего» или просто «ошибка», обозначают буквой m и определяют по очень простой формуле. Для итогов упомянутой таблицы, где расчеты по 25 высотам дали значение δ = 1,42 см, эта ошибка составит:
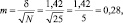 (2.1)
(2.1)
|
где δ – |
стандартное отклонение; |
|
N – |
число наблюдений или объем выборки, шт. |
Если объем выборки взять 100 шт., то ошибка снизится в 2 раза: 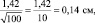 а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
Рассмотрим эту «среднюю статистическую ошибку» (далее просто ошибка) подробно, так как именно в ней скрыто понимание того, что называют статистическим мышлением. Интуитивно мы понимаем, что малая выборка дает большую ошибку, т.е. неточное определение среднего значения. Последний термин настолько привычен, что мы даже не задумываемся о том, что его правильное и полное название «среднее выборочное значение», т.е. среднее, определяемое в некоторой выборке. И выборки могут быть очень разные по численности. Начнем с самых малых. Например, что произойдет с ошибкой, если объем выборки сократить до 2 измерений? Такие выборки бывают, например, в почвенных исследованиях, когда каждое измерение достается дорогой ценой. Для этого вернемся к рис. 1.1. На нем стандартное отклонение ±δ, которое отражает разброс значений вокруг среднего в левую и правую сторону в виде холма, наблюдается при объеме выборки 1 шт. В этом случае ошибка среднего выборочного значения будет равна стандартному отклонению: m = δ = 1,42. С увеличением N ошибка уменьшается:
при объеме выборки N = 2 ошибка будет
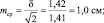
при объеме выборки N = 4 ошибка будет
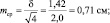
при объеме выборки N = 16 ошибка будет
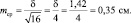
Важно понять, что ряд распределения частот этих выборочных средних будет постепенно как бы съеживаться и приближаться к центру, где находится так называемое «генеральное» среднее. Поясним, что в математике генеральное среднее значение называется математическим ожиданием и его обозначают буквой «М». Например, это может быть средняя высота, рассчитанная по всем измеренным в теплице сеянцам, или среднее число семян в 1 шишке у дерева после подсчета семян во всех собранных с дерева шишках (50, 100, 500 и т.д., т.е. весьма небольшая генеральная совокупность). Распределение частот значений выборочных средних, которых может быть множество, будет иметь форму такого же холма, как и распределение единичных значений на рис. 1.1. При этом, если выборка будет из 1 шт., то холм будет в точности таким же, но при выборках из 2 шт. его форма съежится в  = в 1,41 раза; при выборках из 4 шт. –
= в 1,41 раза; при выборках из 4 шт. –
в  = в 2 раза; при выборках из 9 шт. – в
= в 2 раза; при выборках из 9 шт. – в 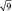 = в 3 раза и т.д.
= в 3 раза и т.д.
Для этих сокращающихся рядов распределения выборочных средних можно рассчитать свое, особое стандартное отклонение. Вероятно, чтобы не путать его со СТАНДОТКЛ, его стали называть по-другому, т.е. «средней статистической ошибкой средней величины». Чем больше по объему выборки, тем короче ряд распределения средних значений этих выборок с его «хвостами» в левую и правую сторону, и тем меньше величина этого особого стандартного отклонения. Закон распределения частот выборочных средних точно такой же, и имеет те же свойства: в пределах ±2m находится 95 % всех значений выборочных средних, в пределах ±3m – 99,5 %, а в пределах ±4m находится 100 % всех значений xср. Форма этого распределения меняется от пологой при малых выборках до очень крутой, вплоть до «схлопывания» в центре при выборках большого объема, когда ошибка среднего стремится к нулю.
Здесь следует пояснить, что, на наш взгляд, словосочетание «средняя статистическая ошибка средней величины», сокращаемое до «ошибки среднего значения» или просто до «ошибки», вводит нас в некоторое заблуждение, так как мы привыкли со школы, что ошибки надобно исправлять. Более правильным, вместо слов «ошибка среднего значения», будет использование слов «стандартное отклонение выборочных средних значений от генерального среднего». Не случайно математики выбрали для обозначения величины этого отклонения букву «m», а для обозначения генерального среднего (математического ожидания) – букву «М». Слова для объяснения этих сложных явлений могут быть разными, но и у математиков, и у биологов есть единодушие в понимании статистического смысла, лежащего за этими буквенными символами. Вообще, лучше было бы ввести некий иной термин вместо слов «ошибка» или «отклонение», так как они изначально имеют в нашем сознании иной смысл; на наш взгляд, более всего подходит слово «скачок» (чем сильнее отскакивает выборочное среднее от генерального среднего, тем реже оно встречается). Но так уж получилось, что не нашлось нейтрального (иностранного) слова, и слово «ошибка» традиционно используют, и мы также будем его использовать; важно понимать его иной, чем в обыденном употреблении, математический и статистический смысл.
Для самого точного определения средней высоты сеянцев нужно измерять все растения в питомнике, и тогда мы получим «генеральное среднее значение». Но так не делают, а измеряют несколько сотен растений в разных местах и этого бывает достаточно для определения среднего выборочного значения с приемлемой точностью. В нашем примере при 100 растениях ошибка его определения составит 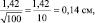 а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
Вообще, точность опыта не самоцель; гораздо важнее сократить численность (объем) выборки до минимума. Представим себе, что средняя высота сеянцев xср = 5,0 см, а ее ±δ = 1,42 см, рассмотренные выше, получены при измерении 1000 растений потомства сосны, например, из Кунгура. Поделив ±δ на корень из 1000 получаем ошибку опыта m = ±0,045 см. Далее получаем точность опыта
Р = m/xср×100 = 0,045/5,0×100 = 0,9 %.
Точность получилась очень высокой. Но в питомнике есть потомства и из других мест и такой уровень точности совершенно не нужен, так как нужно узнать еще высоты сеянцев, например, из Очера, Осы, Добрянки и других районов. Если выборку из 1 тыс. растений снижать, то будет увеличиваться ошибка в определении средней высоты. И нужно найти приемлемую величину такой ошибки, которая позволит нам, тем не менее, уверенно утверждать, что это потомство растет быстрее, либо медленнее других. Причем происхождений может быть несколько сотен и минимизация выборок крайне важна, так как масштабы работ ограничены физическими возможностями бригады селекционеров. Следовательно, надо сокращать объем выборки. Как это сделать правильно?
Рассмотрим два потомства. Первое – это упомянутые сеянцы происхождением из Кунгура (хср1), второе – сеянцы из Кизела с хср2 = 6,0 см и δ2 = ± 1,0 см (превышение высоты на 20 %). Надо это превышение доказать. При выборках из 100 растений ранее определенная ошибка m1 была равна 0,14 см, вторая ошибка m2 после расчетов по формуле (2.1) составит 0,1 см. По закону нормального распределения 99,5 % всех возможных значений этих средних хср1 и хср2 будут в пределах «плюс-минус три ошибки», что можно показать графически (рис. 2.1) или в виде формул:
хср1 ± 3m1 = 5,0 ± 3×0,14 = 5,0 ± 0,4 см
и
хср2 ± 3m2 = 6,0 ± 3×0,1 = 6,0 ± 0,3 см.
Возможные теоретические значения средних в генеральной совокупности не перекрывают друг друга, значит, различие достоверно. А если сократить выборки до 50 сеянцев? Тогда 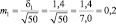 и
и 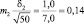 и пределы колебаний возможных значений средних будут:
и пределы колебаний возможных значений средних будут:
хср1 ± 3m1 = 5,0 ± 3×0,20 = 5,0 ± 0,6 см;
хср2 ± 3m2 = 6,0 ± 3×0,14 = 6,0 ± 0,3 см.

Рис. 2.1. Средние значения по выборкам из 100 растений и их тройные ошибки (пределы возможных значений выборочных средних в 99,5 % случаев)
Снова вынесем эти пределы на график (рис. 2.2).

Рис. 2.2. Средние значения при N = 50 растений и их тройные ошибки
Как видим, пределы сблизились и если еще сократить выборки, то они перекроются. Можно ли далее снижать объем выборки?
Можно, но здесь вступает в силу так называемое условие безошибочного прогноза. Мы это условие задали на уровне 99,5 % и для этого взяли ±3m для распределения ошибок. Но можно взять уровень пониже, с пределами ±2δ (уровень 95 %) и даже с пределами ±1,7δ (уровень 90 %).
При выборках из 25 штук сеянцев, получаем две ошибки: 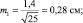
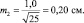 Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
хср1 ± 2m1 = 5,0 ± 2×0,28 = 5,0 ± 0,56 см;
хср2 ± 2m2 = 6,0 ± 2×0,20 = 6,0 ± 0,40 см.
Выносим эти пределы опять на график (рис. 2.3).
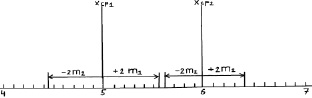
Рис. 2.3. Средние значения при N = 25 растений и их двойные ошибки (пределы возможных значений средних в 95 % случаев)
Как видим, просвет все еще есть, и поэтому между возможными значениями средних высот сеянцев в других выборках из происхождений Кунгур и Кизел различия будут опять доказаны. Но уровень доказательства понизился до 95 %, и для 5 % оставшихся случаев нет гарантии, что различия будут иметь место при выборке из 25 растений. Их может и не быть, но эту вероятность в 5 % мы допускаем.
Полученные
в результате статистического исследования
средние и относительные величины должны
отражать закономерности, характерные
для всей совокупности. Результаты
исследования обычно тем достовернее,
чем больше сделано наблюдений, и наиболее
точными они являются при сплошном
исследовании (т.е. при изучении генеральной
совокупности). Однако должны быть
достаточно надежные и данные, полученные
путем выборочных исследований, т.е. на
относительно небольшом числе наблюдений.
Различие
результатов выборочного исследования
и результатов, которые могут быть
получены на генеральной совокупности,
представляет собой ошибку выборочного
исследования, которую можно точно
определить математическим путем. Метод
ее оценки основан на закономерностях
случайных вариаций, установленных
теорией вероятности.
1.
Оценка достоверности средней
арифметической.
Средняя
арифметическая, полученная при обработке
результатов научно-практических
исследований, под влиянием случайных
явлений может отличаться от средних,
полученных при проведении повторных
исследований. Поэтому, чтобы иметь
представление о возможных пределах
колебаний средней, о том, с какой
вероятностью возможно перенести
результаты исследования с выборочной
совокупности на всю генеральную
совокупность, определяют степень
достоверности средней величины.
Мерой
достоверности средней является средняя
ошибка средней арифметической (ошибка
репрезентативности – m).
Ошибки репрезентативности возникают
в связи с тем, что при выборочным
наблюдении изучается только часть
генеральной совокупности, которая
недостаточно точно ее представляет.
Фактически ошибка репрезентативности
является разностью между средними,
полученными при выборочном статистическом
наблюдении, и средними, которые были бы
получены при сплошном наблюдении (т.е.
при изучении всей генеральной
совокупности).
Средняя
ошибка средней арифметической вычисляется
по формуле:
—
при числе наблюдений больше 30 (n
> 30):
![]()
—
при небольшом числе наблюдений (n
< 30):
![]()
Ошибка
репрезентативности прямо пропорциональна
колеблемости ряда (сигме) и обратно
пропорциональна числу наблюдений.
Следовательно,
чем больше
число наблюдений
(т.е. чем ближе по числу наблюдений
выборочная совокупность к генеральной),
тем меньше
ошибка репрезентативности.
Интервал,
в котором с заданным уровнем вероятности
колеблется истинное значение средней
величины или показателя, называется
доверительным
интервалом,
а его границы – доверительными
границами.
Они используются для определения
размеров средней или показателя в
генеральной совокупности.
Доверительные
границы
средней арифметической и показателя в
генеральной совокупности равны:
M
+
tm
P
+
tm,
где
t
– доверительный коэффициент.
Доверительный
коэффициент (t)
– это число, показывающее, во сколько
раз надо увеличить ошибку средней
величины или показателя, чтобы при
данном числе наблюдений с желаемой
степенью вероятности утверждать, что
они не выйдут за полученные таким образом
пределы.
С
увеличением t
степень вероятности возрастает.
Т.к.
известно, что полученная средняя или
показатель при повторных наблюдениях,
даже при одинаковых условиях, в силу
случайных колебаний будут отличаться
от предыдущего результат, теорией
статистики установлена степень
вероятности, с которой можно ожидать,
что колебания эти не выйдут за определенные
пределы. Так, колебания средней
в интервале M
+
1m
гарантируют ее точность с вероятностью
68.3% (такая
степень вероятности не удовлетворяет
исследователей), в
интервале M
+
2m
– 95.5%
(достаточная степень вероятности) и в
интервале M
+
3m
– 99,7% (большая
степень вероятности).
Для
медико-биологических исследований
принята степень вероятности 95% (t
= 2), что соответствует доверительному
интервалу M
+
2m.
Это
означает, что практически
с полной достоверностью (в 95%) можно
утверждать, что полученный средний
результат (М) отклоняется от истинного
значения не больше, чем на удвоенную (M
+
2m) ошибку.
Конечный
результат любого медико-статистического
исследования выражается средней
арифметической и ее параметрами:
![]()
2.
Оценка достоверности относительных
величин (показателей).
Средняя
ошибка показателя также служит для
определения пределов его случайных
колебаний, т.е. дает представление, в
каких пределах может находиться
показатель в различных выборках в
зависимости от случайных причин. С
увеличением численности выборки ошибка
уменьшается.
Мерой
достоверности показателя является его
средняя ошибка (m),
которая показывает, на сколько результат,
полученный при выборочным исследовании,
отличается от результата, который был
бы получен при изучении всей генеральной
совокупности.
Средняя
ошибка показателя определяется по
формуле:
![]() ,
,
где mp
– ошибка относительного показателя,
р
– показатель,
q
– величина, обратная показателю (100-p,
1000-р и т.д. в зависимости от того, на какое
основание рассчитан показатель);
n
– число наблюдений.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:

где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.
2. Виды отбора.
3. Ошибки выборки, определение объема выборочной совокупности.
4. Способы распространения выборочных характеристик.
1. Понятие выборочного наблюдения, репрезентативность выборочного наблюдения.
1. Выборочное наблюдение несложное наблюдение, при котором обследуется не вся совокупность, а лишь часть, отобранная по определенным правилам выборки и обеспечивающая получение данных, характеризующих всю совокупность в целом.
При проведении выборочного наблюдения нельзя получить абсолютно точные данные, как при сплошном, т. к. обследованию подвергается не вся совокупность, а ее часть. Поэтому при проведении выборочного наблюдения неизбежна некоторая свойственная ему погрешность, ошибка.
Ошибки, свойственные выборочному наблюдению, называются ошибками репрезентативности, т. е. представительства. Они характеризуют размер расхождения между данными выборочного наблюдения и всей совокупности.
Ошибки репрезентативности делятся на случайные и систематические.
Случайные ошибки возникают вследствие того, что выборочная совокупность недостаточно точно воспроизводит совокупность, вследствие несплошного характера наблюдения. Случайные ошибки м. б. доведены до незначительных размеров, а главное размеры и пределы их можно определить с достаточной точностью на основании закона больших чисел и теории вероятности.
Систематические ошибки возникают в результате нарушения принципа случайности отбора единиц совокупности для наблюдения.
Вся совокупность единиц, из которой производится отбор, называется генеральной совокупностью и обозначается буквой N. Часть генеральной совокупности, попавшая в выборку, называется выборочной совокупностью и обозначается n.
Обобщающие показатели генеральной совокупности средняя, дисперсия, доля называются генеральными и соответственно обозначаются ![]() доля отнесения М единиц, обладающих определенным признаком, ко всей численности генеральной совокупности, т. е. М/N.
доля отнесения М единиц, обладающих определенным признаком, ко всей численности генеральной совокупности, т. е. М/N.
Обобщающие характеристики в выборочной совокупности называются выборочными и обозначаются соответственно x*, ![]() частость отношение числа единиц, обладающих данным признаком, в выборочной совокупности n, т. е.
частость отношение числа единиц, обладающих данным признаком, в выборочной совокупности n, т. е. ![]()
![]()
Теория выборочного метода дает возможность определить случайные ошибки обобщающих характеристик в выборочной совокупности.
Ошибка репрезентативности разность между выборочной средней и генеральной средней при достаточно большом числе наблюдений будет сколько угодно малой, т. е.
![]()
где ![]() абсолютная величина расхождения между генеральной средней и выборочной средней, составляющая ошибку репрезентативности.
абсолютная величина расхождения между генеральной средней и выборочной средней, составляющая ошибку репрезентативности.
![]() — среднее квадратическое отклонение вариантов выборочной средней от генеральной средней (средняя ошибка выборки). Она зависит от колеблемости признака в генеральной совокупности
— среднее квадратическое отклонение вариантов выборочной средней от генеральной средней (средняя ошибка выборки). Она зависит от колеблемости признака в генеральной совокупности ![]() и числа отобранных единиц n:
и числа отобранных единиц n: ![]() . Величина m зависит также от способа образования выборочной совокупности, т. к. между
. Величина m зависит также от способа образования выборочной совокупности, т. к. между ![]() средней ошибкой выборки и n числом отбираемых единиц существует обратно пропорциональная связь. Отсюда вытекает следующее правило: если надо уменьшить ошибку выборки, например, в 3 раза, необходимо увеличить объем выборки в девять раз.
средней ошибкой выборки и n числом отбираемых единиц существует обратно пропорциональная связь. Отсюда вытекает следующее правило: если надо уменьшить ошибку выборки, например, в 3 раза, необходимо увеличить объем выборки в девять раз.
Увеличение колеблемости признака в генеральной совокупности влечет за собой увеличение среднего квадратического отклонения, и следовательно и ошибки выборки.
Доказано, что соотношение между дисперсиями генеральной и выборочной совокупностей выражаются формулой:
![]() , т. к.
, т. к. ![]() при больших n приближается к 1, то
при больших n приближается к 1, то ![]()
Средняя ошибка выборки показывает, какие возможны отклонения характеристик выборочной совокупности от соответствующих характеристик генеральной совокупности. Однако о величине этой ошибки можно судить с определенной вероятностью, на величину которой указывает коэффициент доверия t.
Величина ![]() обозначается
обозначается ![]() называется предельной ошибкой выборки. Следовательно предельная ошибка выборки определяется формулой
называется предельной ошибкой выборки. Следовательно предельная ошибка выборки определяется формулой ![]() =
= ![]() . С увеличением t увеличивается вероятность нашего утверждения, но вместе с тем увеличивается и величина ошибки.
. С увеличением t увеличивается вероятность нашего утверждения, но вместе с тем увеличивается и величина ошибки.
2. Виды и схемы отбора.
Формирование выборочной совокупности из генеральной может осуществляться по-разному: в зависимости от вида и схемы отбора, и т. д. От их особенностей зависит размер ошибки и методы определения. Различаются 4 вида отбора:
1. собственно-случайный
2. механический
3. типический
4. серийный (гнездовой)
Собственно-случайный отбор включение единиц совокупности осуществляется наудачу. Наиболее распространенным способом отбора в случайной выборке является жеребьевка, при которой на каждую единицу заготавливают билет с порядковым номером. Затем в случайном порядке отбирают необходимое количество единиц совокупности. При этих условиях каждая из них имеет одинаковую вероятность попасть в выборку.
Механический отбор вся совокупность разбивается на равные по объему группы по случайному признаку. Затем из каждой группы случайно отбирается одна единица.
Типичный отбор совокупность расчленяется по существенному, типическому признаку на качественно однородные, однотипные группы. Затем из каждой группы случайным или механическим способом отбирается количество единиц, пропорциональное удельному весу группы во всей совокупности.
Типический отбор дает более точные результаты чем случайный или механический, потому что при нем в выборку в такой же пропорции как и в генеральной совокупности, попадают представители всех типических групп.
Серийный отбор (гнездовой) отбору подлежат не отдельные единицы совокупности, а целые группы, серии, гнезда, отобранные случайным или механическим способом. В каждой такой группе, серии проводится сплошное наблюдение, а результаты переносятся на всю совокупность.
Точность выборки зависит и от схемы отбора. Выборка м. б. проведена по схеме повторного или бесповторного отбора.
Повторный отбор каждая отобранная единица или серия возвращается во всю совокупность и может вновь попасть в выборку.
Бесповторный отбор каждая обследованная единица не возвращается в совокупность и не м. б. подвергнута повторному обследованию. Бесповторный отбор дает более точные результаты, т. к. при одном и том же объеме выборки наблюдение охватывает большее количество единиц изучаемой совокупности.
Обе схемы отбора могут применяться в сочетании с разными видами отбора, за исключением механического, который всегда бывает бесповторным.
3. Ошибки выборки, определение объема выборочной совокупности
Для суждения о праве распространения данных выборочного наблюдения на генеральную совокупность определяют величину ошибок между сводимыми показателями выборочной и генеральной совокупностей.
Обычно сопоставляют такие показатели:
1. Среднюю выборочной совокупности со средней генеральной совокупности, в результате чего получаем ошибку средней.
![]()
2. Частость выборочной совокупности с долей генеральной совокупности, что дает возможность определить ошибку частостей:
![]()
Разность между показателями выборочной и генеральной совокупностей называется ошибкой репрезентативности. Если эти показатели достаточно близки, то выборка считается репрезентативной.
Выборочная средняя и частость являются переменными величинами, т. е. могут принимать различные значения в зависимости от того, какие единицы совокупности попали в выборку. Следовательно, ошибки выборки также являются переменными величинами и также могут принимать различные значения в зависимости от единиц совокупности, попавшие в выборку. Вот почему определяется средняя из возможных ошибок, которая обозначается буквой ![]() . Величина
. Величина ![]() зависит от степени колеблемости значений признака в генеральной совокупности и от численности выборки n. Степень колеблемости в генеральной совокупности определяется средним квадратом отклонений или дисперсией
зависит от степени колеблемости значений признака в генеральной совокупности и от численности выборки n. Степень колеблемости в генеральной совокупности определяется средним квадратом отклонений или дисперсией ![]() . Из математических теорем и закона больших чисел следует, что при случайном отборе, проведенном по системе повторной выборки, между
. Из математических теорем и закона больших чисел следует, что при случайном отборе, проведенном по системе повторной выборки, между ![]() и п существует следующая зависимость:
и п существует следующая зависимость:
![]()
Ошибка выборочного наблюдения это разность между величиной параметра в генеральной совокупности и его величиной, вычисленной по результатам выборочного наблюдения
![]()
Чебышев доказал, что при достаточно большом числе независимых наблюдений можно с вероятностью, близкой к единице утверждать, что отклонение выборочной средней от генеральной будет сколь угодно малым.
![]() , величину
, величину ![]() называют средней ошибкой выборки.
называют средней ошибкой выборки.
Соотношение между дисперсиями генеральной и выборочной совокупности выражается формулой
![]()
Если выборочное наблюдение применяется для определения доли признака, то средняя ошибка доли исчисляется по формуле
![]() , т. к. дисперсия альтернативного признака
, т. к. дисперсия альтернативного признака ![]() , где p доля единиц совокупности, обладающих данным признаком, а q не обладающим данным признаком.
, где p доля единиц совокупности, обладающих данным признаком, а q не обладающим данным признаком.
В этих формулах ![]() и pq характеристики генеральной совокупности, которые при выборочном наблюдении неизвестны. На практике их заменяют аналогичными характеристиками выборочной совокупности, что вполне правомерно, т. к. основано на законе больших чисел, по которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
и pq характеристики генеральной совокупности, которые при выборочном наблюдении неизвестны. На практике их заменяют аналогичными характеристиками выборочной совокупности, что вполне правомерно, т. к. основано на законе больших чисел, по которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
При бесповторном отборе средняя ошибка выборки равна
![]() , а ошибка доли
, а ошибка доли ![]() , где N численность единиц генеральной совокупности.
, где N численность единиц генеральной совокупности.
Множитель ![]() всегда меньше единицы, т. к. n < N. Поэтому величина средней ошибки выборки при бесповторном отборе меньше чем при повторном.
всегда меньше единицы, т. к. n < N. Поэтому величина средней ошибки выборки при бесповторном отборе меньше чем при повторном.
Для решения практических задач выборочного обследования средней ошибки выборки недостаточно, потому что при исчислении ошибки конкретной выборки фактическая ошибка м. б. больше или меньше средней ошибки выборки ![]() . Поэтому пользуются не средней, а предельной ошибкой выборки, т. е. пределами, за которые не выйдет фактическая ошибка выборки.
. Поэтому пользуются не средней, а предельной ошибкой выборки, т. е. пределами, за которые не выйдет фактическая ошибка выборки.
Предельная ошибка выборки зависит от того, с какой вероятностью должна гарантироваться ошибка выборки. Уровень вероятности определяется на основе теорем Чебышева и Ляпунова при помощи специального коэффициента t.
Если предельную ошибку выборки обозначить буквой ![]() , то , где t коэффициент, зависящий от вероятности, с которой гарантируется ошибка выборки. Он называется еще коэффициентом доверия. Чтобы определить величину вероятности для различных значений t на практике пользуются готовой таблицей.
, то , где t коэффициент, зависящий от вероятности, с которой гарантируется ошибка выборки. Он называется еще коэффициентом доверия. Чтобы определить величину вероятности для различных значений t на практике пользуются готовой таблицей.
Систематизируем формулы для определения предельной ошибки средней и доли
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
Из формул видно, что предельная ошибка выборки прямо пропорциональна коэффициенту t, дисперсии ![]() и обратно пропорциональна корню квадратному из численности выборки.
и обратно пропорциональна корню квадратному из численности выборки.
Дисперсия ![]() величина конкретная, свойственная данной совокупности. Обычно она неизвестна, а известна
величина конкретная, свойственная данной совокупности. Обычно она неизвестна, а известна ![]() *, которой и заменяют величину
*, которой и заменяют величину ![]() , потому что в силу действия закона больших чисел при достаточно большом объеме выборки n распределение признака x в выборочной совокупности близко воспроизводит распределение этого признака в генеральной совокупности.
, потому что в силу действия закона больших чисел при достаточно большом объеме выборки n распределение признака x в выборочной совокупности близко воспроизводит распределение этого признака в генеральной совокупности.
Ошибка выборки зависит и от ее объема n. Чем больше объем выборки, тем меньше предельная ошибка (при данных ![]() и t)
и t)
Рассмотренные формулы средней и предельной ошибки и доли применяются при случайном и механическом видах отбора.
При типическом отборе предельная ошибка выборки и доли определяется по формулам:
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
т. е. при типичном отборе надо брать средние из внутригрупповых дисперсий и доли, полученные по каждой типической группе.
Из этих формул видно, что при типическом отборе в отличие от случайного исключается влияние межгрупповой вариации на точность выборки, т. к. в выборку обязательно попадают представители всех групп в тех же пропорциях, что и в генеральной совокупности. Ошибка выборки при типичном отборе зависит только от средней из внутригрупповых дисперсий, а не от общей дисперсии, как при случайном отборе т. к.
![]() , откуда
, откуда
Следовательно ошибка выборки при типическом отборе всегда меньше ошибки выборки, проведенной случайным отбором.
При серийном отборе каждая серия рассматривается как единица совокупности, и мерой колеблемости будет межсерийная выборочная дисперсия, т. е. средний квадрат отклонений серийных средних от общей выборочной средней:
![]() , где
, где ![]() средняя по каждой серии, x* общая выборочная средняя, s число отобранных серий.
средняя по каждой серии, x* общая выборочная средняя, s число отобранных серий.
Предельная ошибка выборки и доли при серийном отборе с равновеликими сериями определяется по формулам, где S общее число серий в генеральной совокупности.
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
Выборочное наблюдение, объем которого превышает 20 единиц, называется малой выборкой. Для определения средней и предельной ошибок при малой выборке пользуются теми же формулами, что и при большой, но только с некоторыми особенностями, так ![]() , а .
, а .
Кроме того, в случае малой выборки действует особый закон распределения величин t, и при определении вероятности учитывается не только коэффициент t, но и объем выборки n.
Необходимая численность выборки (n) определяется на основе формул предельной ошибки выборки.
Если выборка повторная, то при случайном и механическом отборах определяется по формуле
![]() , при бесповторном отборе
, при бесповторном отборе ![]()
4. Способы распространения выборочных характеристик.
Есть два способа распространения выборочных характеристик на всю совокупность прямой пересчет и способ коэффициентов
Способ прямого пересчета заключается в том, что средние или частости выборочной совокупности умножаются на числа единиц генеральной совокупности.
Когда выборочное обследование проводится в целях уточнения данных сплошного наблюдения, применяется способ коэффициентов. В этом случае данные сплошного наблюдения сопоставляют с данными выборочного наблюдения и устанавливают процент расхождения между ними, т. е. процент надоучета или переучета. Коэффициенты, полученные в результате такого сопоставления, используются для внесения поправок в данные сплошного учета.
Пример.
1) способ прямого пересчета
Для определения качества продукции проверено 500 изделий из 10000. В результате чего установлено, что средний % изделий 3-го сорта всей партии будет находиться в пределах 6,1-13,9%. Способом прямого пересчета определяем, что обще кол-во изделий 3-го сорта всей партии составит от 610 до 1390
10000*0,061= 610
10000*0,139 = 1390
2) способ коэффициентов
Пример
Необходимо определить численность выборки, которая позволила бы оценить долю брака в партии продукции с точностью до 2%, с вероятностью Р =0,954. Партия состоит из 10000 изделий
![]() ,
, ![]()
![]() , P =0,954, t =2
, P =0,954, t =2
![]() pq=0,25 (p=0,5; q=0,5)
pq=0,25 (p=0,5; q=0,5)
Полученные
в результате статистического исследования
средние и относительные величины должны
отражать закономерности, характерные
для всей совокупности. Результаты
исследования обычно тем достовернее,
чем больше сделано наблюдений, и наиболее
точными они являются при сплошном
исследовании (т.е. при изучении генеральной
совокупности). Однако должны быть
достаточно надежные и данные, полученные
путем выборочных исследований, т.е. на
относительно небольшом числе наблюдений.
Различие
результатов выборочного исследования
и результатов, которые могут быть
получены на генеральной совокупности,
представляет собой ошибку выборочного
исследования, которую можно точно
определить математическим путем. Метод
ее оценки основан на закономерностях
случайных вариаций, установленных
теорией вероятности.
1.
Оценка достоверности средней
арифметической.
Средняя
арифметическая, полученная при обработке
результатов научно-практических
исследований, под влиянием случайных
явлений может отличаться от средних,
полученных при проведении повторных
исследований. Поэтому, чтобы иметь
представление о возможных пределах
колебаний средней, о том, с какой
вероятностью возможно перенести
результаты исследования с выборочной
совокупности на всю генеральную
совокупность, определяют степень
достоверности средней величины.
Мерой
достоверности средней является средняя
ошибка средней арифметической (ошибка
репрезентативности – m).
Ошибки репрезентативности возникают
в связи с тем, что при выборочным
наблюдении изучается только часть
генеральной совокупности, которая
недостаточно точно ее представляет.
Фактически ошибка репрезентативности
является разностью между средними,
полученными при выборочном статистическом
наблюдении, и средними, которые были бы
получены при сплошном наблюдении (т.е.
при изучении всей генеральной
совокупности).
Средняя
ошибка средней арифметической вычисляется
по формуле:
—
при числе наблюдений больше 30 (n
> 30):
![]()
—
при небольшом числе наблюдений (n
< 30):
![]()
Ошибка
репрезентативности прямо пропорциональна
колеблемости ряда (сигме) и обратно
пропорциональна числу наблюдений.
Следовательно,
чем больше
число наблюдений
(т.е. чем ближе по числу наблюдений
выборочная совокупность к генеральной),
тем меньше
ошибка репрезентативности.
Интервал,
в котором с заданным уровнем вероятности
колеблется истинное значение средней
величины или показателя, называется
доверительным
интервалом,
а его границы – доверительными
границами.
Они используются для определения
размеров средней или показателя в
генеральной совокупности.
Доверительные
границы
средней арифметической и показателя в
генеральной совокупности равны:
M
+
tm
P
+
tm,
где
t
– доверительный коэффициент.
Доверительный
коэффициент (t)
– это число, показывающее, во сколько
раз надо увеличить ошибку средней
величины или показателя, чтобы при
данном числе наблюдений с желаемой
степенью вероятности утверждать, что
они не выйдут за полученные таким образом
пределы.
С
увеличением t
степень вероятности возрастает.
Т.к.
известно, что полученная средняя или
показатель при повторных наблюдениях,
даже при одинаковых условиях, в силу
случайных колебаний будут отличаться
от предыдущего результат, теорией
статистики установлена степень
вероятности, с которой можно ожидать,
что колебания эти не выйдут за определенные
пределы. Так, колебания средней
в интервале M
+
1m
гарантируют ее точность с вероятностью
68.3% (такая
степень вероятности не удовлетворяет
исследователей), в
интервале M
+
2m
– 95.5%
(достаточная степень вероятности) и в
интервале M
+
3m
– 99,7% (большая
степень вероятности).
Для
медико-биологических исследований
принята степень вероятности 95% (t
= 2), что соответствует доверительному
интервалу M
+
2m.
Это
означает, что практически
с полной достоверностью (в 95%) можно
утверждать, что полученный средний
результат (М) отклоняется от истинного
значения не больше, чем на удвоенную (M
+
2m) ошибку.
Конечный
результат любого медико-статистического
исследования выражается средней
арифметической и ее параметрами:
![]()
2.
Оценка достоверности относительных
величин (показателей).
Средняя
ошибка показателя также служит для
определения пределов его случайных
колебаний, т.е. дает представление, в
каких пределах может находиться
показатель в различных выборках в
зависимости от случайных причин. С
увеличением численности выборки ошибка
уменьшается.
Мерой
достоверности показателя является его
средняя ошибка (m),
которая показывает, на сколько результат,
полученный при выборочным исследовании,
отличается от результата, который был
бы получен при изучении всей генеральной
совокупности.
Средняя
ошибка показателя определяется по
формуле:
![]() ,
,
где mp
– ошибка относительного показателя,
р
– показатель,
q
– величина, обратная показателю (100-p,
1000-р и т.д. в зависимости от того, на какое
основание рассчитан показатель);
n
– число наблюдений.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:
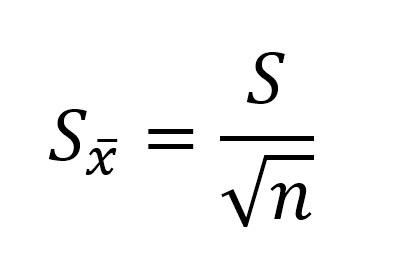
где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.
2.1. Стандартное отклонение среднего выборочного значения (ошибка среднего) и доверительный интервал
Результаты измерений обычно показывают с так называемой «средней статистической ошибкой средней величины» и для нашего случая (см. табл. 1.1) это будет запись: «высота сеянцев в опыте составила 5,0 ± 0,28 см». Словосочетание «средняя статистическая ошибка» обычно сокращают до названия «ошибка среднего» или просто «ошибка», обозначают буквой m и определяют по очень простой формуле. Для итогов упомянутой таблицы, где расчеты по 25 высотам дали значение δ = 1,42 см, эта ошибка составит:
(2.1)
|
где δ – |
стандартное отклонение; |
|
N – |
число наблюдений или объем выборки, шт. |
Если объем выборки взять 100 шт., то ошибка снизится в 2 раза: а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
Рассмотрим эту «среднюю статистическую ошибку» (далее просто ошибка) подробно, так как именно в ней скрыто понимание того, что называют статистическим мышлением. Интуитивно мы понимаем, что малая выборка дает большую ошибку, т.е. неточное определение среднего значения. Последний термин настолько привычен, что мы даже не задумываемся о том, что его правильное и полное название «среднее выборочное значение», т.е. среднее, определяемое в некоторой выборке. И выборки могут быть очень разные по численности. Начнем с самых малых. Например, что произойдет с ошибкой, если объем выборки сократить до 2 измерений? Такие выборки бывают, например, в почвенных исследованиях, когда каждое измерение достается дорогой ценой. Для этого вернемся к рис. 1.1. На нем стандартное отклонение ±δ, которое отражает разброс значений вокруг среднего в левую и правую сторону в виде холма, наблюдается при объеме выборки 1 шт. В этом случае ошибка среднего выборочного значения будет равна стандартному отклонению: m = δ = 1,42. С увеличением N ошибка уменьшается:
при объеме выборки N = 2 ошибка будет
при объеме выборки N = 4 ошибка будет
при объеме выборки N = 16 ошибка будет
Важно понять, что ряд распределения частот этих выборочных средних будет постепенно как бы съеживаться и приближаться к центру, где находится так называемое «генеральное» среднее. Поясним, что в математике генеральное среднее значение называется математическим ожиданием и его обозначают буквой «М». Например, это может быть средняя высота, рассчитанная по всем измеренным в теплице сеянцам, или среднее число семян в 1 шишке у дерева после подсчета семян во всех собранных с дерева шишках (50, 100, 500 и т.д., т.е. весьма небольшая генеральная совокупность). Распределение частот значений выборочных средних, которых может быть множество, будет иметь форму такого же холма, как и распределение единичных значений на рис. 1.1. При этом, если выборка будет из 1 шт., то холм будет в точности таким же, но при выборках из 2 шт. его форма съежится в = в 1,41 раза; при выборках из 4 шт. –
в = в 2 раза; при выборках из 9 шт. – в = в 3 раза и т.д.
Для этих сокращающихся рядов распределения выборочных средних можно рассчитать свое, особое стандартное отклонение. Вероятно, чтобы не путать его со СТАНДОТКЛ, его стали называть по-другому, т.е. «средней статистической ошибкой средней величины». Чем больше по объему выборки, тем короче ряд распределения средних значений этих выборок с его «хвостами» в левую и правую сторону, и тем меньше величина этого особого стандартного отклонения. Закон распределения частот выборочных средних точно такой же, и имеет те же свойства: в пределах ±2m находится 95 % всех значений выборочных средних, в пределах ±3m – 99,5 %, а в пределах ±4m находится 100 % всех значений xср. Форма этого распределения меняется от пологой при малых выборках до очень крутой, вплоть до «схлопывания» в центре при выборках большого объема, когда ошибка среднего стремится к нулю.
Здесь следует пояснить, что, на наш взгляд, словосочетание «средняя статистическая ошибка средней величины», сокращаемое до «ошибки среднего значения» или просто до «ошибки», вводит нас в некоторое заблуждение, так как мы привыкли со школы, что ошибки надобно исправлять. Более правильным, вместо слов «ошибка среднего значения», будет использование слов «стандартное отклонение выборочных средних значений от генерального среднего». Не случайно математики выбрали для обозначения величины этого отклонения букву «m», а для обозначения генерального среднего (математического ожидания) – букву «М». Слова для объяснения этих сложных явлений могут быть разными, но и у математиков, и у биологов есть единодушие в понимании статистического смысла, лежащего за этими буквенными символами. Вообще, лучше было бы ввести некий иной термин вместо слов «ошибка» или «отклонение», так как они изначально имеют в нашем сознании иной смысл; на наш взгляд, более всего подходит слово «скачок» (чем сильнее отскакивает выборочное среднее от генерального среднего, тем реже оно встречается). Но так уж получилось, что не нашлось нейтрального (иностранного) слова, и слово «ошибка» традиционно используют, и мы также будем его использовать; важно понимать его иной, чем в обыденном употреблении, математический и статистический смысл.
Для самого точного определения средней высоты сеянцев нужно измерять все растения в питомнике, и тогда мы получим «генеральное среднее значение». Но так не делают, а измеряют несколько сотен растений в разных местах и этого бывает достаточно для определения среднего выборочного значения с приемлемой точностью. В нашем примере при 100 растениях ошибка его определения составит а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
Вообще, точность опыта не самоцель; гораздо важнее сократить численность (объем) выборки до минимума. Представим себе, что средняя высота сеянцев xср = 5,0 см, а ее ±δ = 1,42 см, рассмотренные выше, получены при измерении 1000 растений потомства сосны, например, из Кунгура. Поделив ±δ на корень из 1000 получаем ошибку опыта m = ±0,045 см. Далее получаем точность опыта
Р = m/xср×100 = 0,045/5,0×100 = 0,9 %.
Точность получилась очень высокой. Но в питомнике есть потомства и из других мест и такой уровень точности совершенно не нужен, так как нужно узнать еще высоты сеянцев, например, из Очера, Осы, Добрянки и других районов. Если выборку из 1 тыс. растений снижать, то будет увеличиваться ошибка в определении средней высоты. И нужно найти приемлемую величину такой ошибки, которая позволит нам, тем не менее, уверенно утверждать, что это потомство растет быстрее, либо медленнее других. Причем происхождений может быть несколько сотен и минимизация выборок крайне важна, так как масштабы работ ограничены физическими возможностями бригады селекционеров. Следовательно, надо сокращать объем выборки. Как это сделать правильно?
Рассмотрим два потомства. Первое – это упомянутые сеянцы происхождением из Кунгура (хср1), второе – сеянцы из Кизела с хср2 = 6,0 см и δ2 = ± 1,0 см (превышение высоты на 20 %). Надо это превышение доказать. При выборках из 100 растений ранее определенная ошибка m1 была равна 0,14 см, вторая ошибка m2 после расчетов по формуле (2.1) составит 0,1 см. По закону нормального распределения 99,5 % всех возможных значений этих средних хср1 и хср2 будут в пределах «плюс-минус три ошибки», что можно показать графически (рис. 2.1) или в виде формул:
хср1 ± 3m1 = 5,0 ± 3×0,14 = 5,0 ± 0,4 см
и
хср2 ± 3m2 = 6,0 ± 3×0,1 = 6,0 ± 0,3 см.
Возможные теоретические значения средних в генеральной совокупности не перекрывают друг друга, значит, различие достоверно. А если сократить выборки до 50 сеянцев? Тогда и и пределы колебаний возможных значений средних будут:
хср1 ± 3m1 = 5,0 ± 3×0,20 = 5,0 ± 0,6 см;
хср2 ± 3m2 = 6,0 ± 3×0,14 = 6,0 ± 0,3 см.
Рис. 2.1. Средние значения по выборкам из 100 растений и их тройные ошибки (пределы возможных значений выборочных средних в 99,5 % случаев)
Снова вынесем эти пределы на график (рис. 2.2).
Рис. 2.2. Средние значения при N = 50 растений и их тройные ошибки
Как видим, пределы сблизились и если еще сократить выборки, то они перекроются. Можно ли далее снижать объем выборки?
Можно, но здесь вступает в силу так называемое условие безошибочного прогноза. Мы это условие задали на уровне 99,5 % и для этого взяли ±3m для распределения ошибок. Но можно взять уровень пониже, с пределами ±2δ (уровень 95 %) и даже с пределами ±1,7δ (уровень 90 %).
При выборках из 25 штук сеянцев, получаем две ошибки: Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
хср1 ± 2m1 = 5,0 ± 2×0,28 = 5,0 ± 0,56 см;
хср2 ± 2m2 = 6,0 ± 2×0,20 = 6,0 ± 0,40 см.
Выносим эти пределы опять на график (рис. 2.3).
Рис. 2.3. Средние значения при N = 25 растений и их двойные ошибки (пределы возможных значений средних в 95 % случаев)
Как видим, просвет все еще есть, и поэтому между возможными значениями средних высот сеянцев в других выборках из происхождений Кунгур и Кизел различия будут опять доказаны. Но уровень доказательства понизился до 95 %, и для 5 % оставшихся случаев нет гарантии, что различия будут иметь место при выборке из 25 растений. Их может и не быть, но эту вероятность в 5 % мы допускаем.
2. Виды отбора.
3. Ошибки выборки, определение объема выборочной совокупности.
4. Способы распространения выборочных характеристик.
1. Понятие выборочного наблюдения, репрезентативность выборочного наблюдения.
1. Выборочное наблюдение несложное наблюдение, при котором обследуется не вся совокупность, а лишь часть, отобранная по определенным правилам выборки и обеспечивающая получение данных, характеризующих всю совокупность в целом.
При проведении выборочного наблюдения нельзя получить абсолютно точные данные, как при сплошном, т. к. обследованию подвергается не вся совокупность, а ее часть. Поэтому при проведении выборочного наблюдения неизбежна некоторая свойственная ему погрешность, ошибка.
Ошибки, свойственные выборочному наблюдению, называются ошибками репрезентативности, т. е. представительства. Они характеризуют размер расхождения между данными выборочного наблюдения и всей совокупности.
Ошибки репрезентативности делятся на случайные и систематические.
Случайные ошибки возникают вследствие того, что выборочная совокупность недостаточно точно воспроизводит совокупность, вследствие несплошного характера наблюдения. Случайные ошибки м. б. доведены до незначительных размеров, а главное размеры и пределы их можно определить с достаточной точностью на основании закона больших чисел и теории вероятности.
Систематические ошибки возникают в результате нарушения принципа случайности отбора единиц совокупности для наблюдения.
Вся совокупность единиц, из которой производится отбор, называется генеральной совокупностью и обозначается буквой N. Часть генеральной совокупности, попавшая в выборку, называется выборочной совокупностью и обозначается n.
Обобщающие показатели генеральной совокупности средняя, дисперсия, доля называются генеральными и соответственно обозначаются ![]() доля отнесения М единиц, обладающих определенным признаком, ко всей численности генеральной совокупности, т. е. М/N.
доля отнесения М единиц, обладающих определенным признаком, ко всей численности генеральной совокупности, т. е. М/N.
Обобщающие характеристики в выборочной совокупности называются выборочными и обозначаются соответственно x*, ![]() частость отношение числа единиц, обладающих данным признаком, в выборочной совокупности n, т. е.
частость отношение числа единиц, обладающих данным признаком, в выборочной совокупности n, т. е. ![]()
![]()
Теория выборочного метода дает возможность определить случайные ошибки обобщающих характеристик в выборочной совокупности.
Ошибка репрезентативности разность между выборочной средней и генеральной средней при достаточно большом числе наблюдений будет сколько угодно малой, т. е.
![]()
где ![]() абсолютная величина расхождения между генеральной средней и выборочной средней, составляющая ошибку репрезентативности.
абсолютная величина расхождения между генеральной средней и выборочной средней, составляющая ошибку репрезентативности.
![]() — среднее квадратическое отклонение вариантов выборочной средней от генеральной средней (средняя ошибка выборки). Она зависит от колеблемости признака в генеральной совокупности
— среднее квадратическое отклонение вариантов выборочной средней от генеральной средней (средняя ошибка выборки). Она зависит от колеблемости признака в генеральной совокупности ![]() и числа отобранных единиц n:
и числа отобранных единиц n: ![]() . Величина m зависит также от способа образования выборочной совокупности, т. к. между
. Величина m зависит также от способа образования выборочной совокупности, т. к. между ![]() средней ошибкой выборки и n числом отбираемых единиц существует обратно пропорциональная связь. Отсюда вытекает следующее правило: если надо уменьшить ошибку выборки, например, в 3 раза, необходимо увеличить объем выборки в девять раз.
средней ошибкой выборки и n числом отбираемых единиц существует обратно пропорциональная связь. Отсюда вытекает следующее правило: если надо уменьшить ошибку выборки, например, в 3 раза, необходимо увеличить объем выборки в девять раз.
Увеличение колеблемости признака в генеральной совокупности влечет за собой увеличение среднего квадратического отклонения, и следовательно и ошибки выборки.
Доказано, что соотношение между дисперсиями генеральной и выборочной совокупностей выражаются формулой:
![]() , т. к.
, т. к. ![]() при больших n приближается к 1, то
при больших n приближается к 1, то ![]()
Средняя ошибка выборки показывает, какие возможны отклонения характеристик выборочной совокупности от соответствующих характеристик генеральной совокупности. Однако о величине этой ошибки можно судить с определенной вероятностью, на величину которой указывает коэффициент доверия t.
Величина ![]() обозначается
обозначается ![]() называется предельной ошибкой выборки. Следовательно предельная ошибка выборки определяется формулой
называется предельной ошибкой выборки. Следовательно предельная ошибка выборки определяется формулой ![]() =
= ![]() . С увеличением t увеличивается вероятность нашего утверждения, но вместе с тем увеличивается и величина ошибки.
. С увеличением t увеличивается вероятность нашего утверждения, но вместе с тем увеличивается и величина ошибки.
2. Виды и схемы отбора.
Формирование выборочной совокупности из генеральной может осуществляться по-разному: в зависимости от вида и схемы отбора, и т. д. От их особенностей зависит размер ошибки и методы определения. Различаются 4 вида отбора:
1. собственно-случайный
2. механический
3. типический
4. серийный (гнездовой)
Собственно-случайный отбор включение единиц совокупности осуществляется наудачу. Наиболее распространенным способом отбора в случайной выборке является жеребьевка, при которой на каждую единицу заготавливают билет с порядковым номером. Затем в случайном порядке отбирают необходимое количество единиц совокупности. При этих условиях каждая из них имеет одинаковую вероятность попасть в выборку.
Механический отбор вся совокупность разбивается на равные по объему группы по случайному признаку. Затем из каждой группы случайно отбирается одна единица.
Типичный отбор совокупность расчленяется по существенному, типическому признаку на качественно однородные, однотипные группы. Затем из каждой группы случайным или механическим способом отбирается количество единиц, пропорциональное удельному весу группы во всей совокупности.
Типический отбор дает более точные результаты чем случайный или механический, потому что при нем в выборку в такой же пропорции как и в генеральной совокупности, попадают представители всех типических групп.
Серийный отбор (гнездовой) отбору подлежат не отдельные единицы совокупности, а целые группы, серии, гнезда, отобранные случайным или механическим способом. В каждой такой группе, серии проводится сплошное наблюдение, а результаты переносятся на всю совокупность.
Точность выборки зависит и от схемы отбора. Выборка м. б. проведена по схеме повторного или бесповторного отбора.
Повторный отбор каждая отобранная единица или серия возвращается во всю совокупность и может вновь попасть в выборку.
Бесповторный отбор каждая обследованная единица не возвращается в совокупность и не м. б. подвергнута повторному обследованию. Бесповторный отбор дает более точные результаты, т. к. при одном и том же объеме выборки наблюдение охватывает большее количество единиц изучаемой совокупности.
Обе схемы отбора могут применяться в сочетании с разными видами отбора, за исключением механического, который всегда бывает бесповторным.
3. Ошибки выборки, определение объема выборочной совокупности
Для суждения о праве распространения данных выборочного наблюдения на генеральную совокупность определяют величину ошибок между сводимыми показателями выборочной и генеральной совокупностей.
Обычно сопоставляют такие показатели:
1. Среднюю выборочной совокупности со средней генеральной совокупности, в результате чего получаем ошибку средней.
![]()
2. Частость выборочной совокупности с долей генеральной совокупности, что дает возможность определить ошибку частостей:
![]()
Разность между показателями выборочной и генеральной совокупностей называется ошибкой репрезентативности. Если эти показатели достаточно близки, то выборка считается репрезентативной.
Выборочная средняя и частость являются переменными величинами, т. е. могут принимать различные значения в зависимости от того, какие единицы совокупности попали в выборку. Следовательно, ошибки выборки также являются переменными величинами и также могут принимать различные значения в зависимости от единиц совокупности, попавшие в выборку. Вот почему определяется средняя из возможных ошибок, которая обозначается буквой ![]() . Величина
. Величина ![]() зависит от степени колеблемости значений признака в генеральной совокупности и от численности выборки n. Степень колеблемости в генеральной совокупности определяется средним квадратом отклонений или дисперсией
зависит от степени колеблемости значений признака в генеральной совокупности и от численности выборки n. Степень колеблемости в генеральной совокупности определяется средним квадратом отклонений или дисперсией ![]() . Из математических теорем и закона больших чисел следует, что при случайном отборе, проведенном по системе повторной выборки, между
. Из математических теорем и закона больших чисел следует, что при случайном отборе, проведенном по системе повторной выборки, между ![]() и п существует следующая зависимость:
и п существует следующая зависимость:
![]()
Ошибка выборочного наблюдения это разность между величиной параметра в генеральной совокупности и его величиной, вычисленной по результатам выборочного наблюдения
![]()
Чебышев доказал, что при достаточно большом числе независимых наблюдений можно с вероятностью, близкой к единице утверждать, что отклонение выборочной средней от генеральной будет сколь угодно малым.
![]() , величину
, величину ![]() называют средней ошибкой выборки.
называют средней ошибкой выборки.
Соотношение между дисперсиями генеральной и выборочной совокупности выражается формулой
![]()
Если выборочное наблюдение применяется для определения доли признака, то средняя ошибка доли исчисляется по формуле
![]() , т. к. дисперсия альтернативного признака
, т. к. дисперсия альтернативного признака ![]() , где p доля единиц совокупности, обладающих данным признаком, а q не обладающим данным признаком.
, где p доля единиц совокупности, обладающих данным признаком, а q не обладающим данным признаком.
В этих формулах ![]() и pq характеристики генеральной совокупности, которые при выборочном наблюдении неизвестны. На практике их заменяют аналогичными характеристиками выборочной совокупности, что вполне правомерно, т. к. основано на законе больших чисел, по которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
и pq характеристики генеральной совокупности, которые при выборочном наблюдении неизвестны. На практике их заменяют аналогичными характеристиками выборочной совокупности, что вполне правомерно, т. к. основано на законе больших чисел, по которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
При бесповторном отборе средняя ошибка выборки равна
![]() , а ошибка доли
, а ошибка доли ![]() , где N численность единиц генеральной совокупности.
, где N численность единиц генеральной совокупности.
Множитель ![]() всегда меньше единицы, т. к. n < N. Поэтому величина средней ошибки выборки при бесповторном отборе меньше чем при повторном.
всегда меньше единицы, т. к. n < N. Поэтому величина средней ошибки выборки при бесповторном отборе меньше чем при повторном.
Для решения практических задач выборочного обследования средней ошибки выборки недостаточно, потому что при исчислении ошибки конкретной выборки фактическая ошибка м. б. больше или меньше средней ошибки выборки ![]() . Поэтому пользуются не средней, а предельной ошибкой выборки, т. е. пределами, за которые не выйдет фактическая ошибка выборки.
. Поэтому пользуются не средней, а предельной ошибкой выборки, т. е. пределами, за которые не выйдет фактическая ошибка выборки.
Предельная ошибка выборки зависит от того, с какой вероятностью должна гарантироваться ошибка выборки. Уровень вероятности определяется на основе теорем Чебышева и Ляпунова при помощи специального коэффициента t.
Если предельную ошибку выборки обозначить буквой ![]() , то , где t коэффициент, зависящий от вероятности, с которой гарантируется ошибка выборки. Он называется еще коэффициентом доверия. Чтобы определить величину вероятности для различных значений t на практике пользуются готовой таблицей.
, то , где t коэффициент, зависящий от вероятности, с которой гарантируется ошибка выборки. Он называется еще коэффициентом доверия. Чтобы определить величину вероятности для различных значений t на практике пользуются готовой таблицей.
Систематизируем формулы для определения предельной ошибки средней и доли
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
Из формул видно, что предельная ошибка выборки прямо пропорциональна коэффициенту t, дисперсии ![]() и обратно пропорциональна корню квадратному из численности выборки.
и обратно пропорциональна корню квадратному из численности выборки.
Дисперсия ![]() величина конкретная, свойственная данной совокупности. Обычно она неизвестна, а известна
величина конкретная, свойственная данной совокупности. Обычно она неизвестна, а известна ![]() *, которой и заменяют величину
*, которой и заменяют величину ![]() , потому что в силу действия закона больших чисел при достаточно большом объеме выборки n распределение признака x в выборочной совокупности близко воспроизводит распределение этого признака в генеральной совокупности.
, потому что в силу действия закона больших чисел при достаточно большом объеме выборки n распределение признака x в выборочной совокупности близко воспроизводит распределение этого признака в генеральной совокупности.
Ошибка выборки зависит и от ее объема n. Чем больше объем выборки, тем меньше предельная ошибка (при данных ![]() и t)
и t)
Рассмотренные формулы средней и предельной ошибки и доли применяются при случайном и механическом видах отбора.
При типическом отборе предельная ошибка выборки и доли определяется по формулам:
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
т. е. при типичном отборе надо брать средние из внутригрупповых дисперсий и доли, полученные по каждой типической группе.
Из этих формул видно, что при типическом отборе в отличие от случайного исключается влияние межгрупповой вариации на точность выборки, т. к. в выборку обязательно попадают представители всех групп в тех же пропорциях, что и в генеральной совокупности. Ошибка выборки при типичном отборе зависит только от средней из внутригрупповых дисперсий, а не от общей дисперсии, как при случайном отборе т. к.
![]() , откуда
, откуда
Следовательно ошибка выборки при типическом отборе всегда меньше ошибки выборки, проведенной случайным отбором.
При серийном отборе каждая серия рассматривается как единица совокупности, и мерой колеблемости будет межсерийная выборочная дисперсия, т. е. средний квадрат отклонений серийных средних от общей выборочной средней:
![]() , где
, где ![]() средняя по каждой серии, x* общая выборочная средняя, s число отобранных серий.
средняя по каждой серии, x* общая выборочная средняя, s число отобранных серий.
Предельная ошибка выборки и доли при серийном отборе с равновеликими сериями определяется по формулам, где S общее число серий в генеральной совокупности.
|
Схема отбора |
Предельная ошибка выборки |
|
|
Для средней |
Для доли |
|
|
Повторный отбор Бесповторный отбор |
|
|
Выборочное наблюдение, объем которого превышает 20 единиц, называется малой выборкой. Для определения средней и предельной ошибок при малой выборке пользуются теми же формулами, что и при большой, но только с некоторыми особенностями, так ![]() , а .
, а .
Кроме того, в случае малой выборки действует особый закон распределения величин t, и при определении вероятности учитывается не только коэффициент t, но и объем выборки n.
Необходимая численность выборки (n) определяется на основе формул предельной ошибки выборки.
Если выборка повторная, то при случайном и механическом отборах определяется по формуле
![]() , при бесповторном отборе
, при бесповторном отборе ![]()
4. Способы распространения выборочных характеристик.
Есть два способа распространения выборочных характеристик на всю совокупность прямой пересчет и способ коэффициентов
Способ прямого пересчета заключается в том, что средние или частости выборочной совокупности умножаются на числа единиц генеральной совокупности.
Когда выборочное обследование проводится в целях уточнения данных сплошного наблюдения, применяется способ коэффициентов. В этом случае данные сплошного наблюдения сопоставляют с данными выборочного наблюдения и устанавливают процент расхождения между ними, т. е. процент надоучета или переучета. Коэффициенты, полученные в результате такого сопоставления, используются для внесения поправок в данные сплошного учета.
Пример.
1) способ прямого пересчета
Для определения качества продукции проверено 500 изделий из 10000. В результате чего установлено, что средний % изделий 3-го сорта всей партии будет находиться в пределах 6,1-13,9%. Способом прямого пересчета определяем, что обще кол-во изделий 3-го сорта всей партии составит от 610 до 1390
10000*0,061= 610
10000*0,139 = 1390
2) способ коэффициентов
Пример
Необходимо определить численность выборки, которая позволила бы оценить долю брака в партии продукции с точностью до 2%, с вероятностью Р =0,954. Партия состоит из 10000 изделий
![]() ,
, ![]()
![]() , P =0,954, t =2
, P =0,954, t =2
![]() pq=0,25 (p=0,5; q=0,5)
pq=0,25 (p=0,5; q=0,5)
From Wikipedia, the free encyclopedia
In statistics, the mean squared error (MSE)[1] or mean squared deviation (MSD) of an estimator (of a procedure for estimating an unobserved quantity) measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss.[2] The fact that MSE is almost always strictly positive (and not zero) is because of randomness or because the estimator does not account for information that could produce a more accurate estimate.[3] In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk (the average loss on an observed data set), as an estimate of the true MSE (the true risk: the average loss on the actual population distribution).
The MSE is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
The MSE is the second moment (about the origin) of the error, and thus incorporates both the variance of the estimator (how widely spread the estimates are from one data sample to another) and its bias (how far off the average estimated value is from the true value).[citation needed] For an unbiased estimator, the MSE is the variance of the estimator. Like the variance, MSE has the same units of measurement as the square of the quantity being estimated. In an analogy to standard deviation, taking the square root of MSE yields the root-mean-square error or root-mean-square deviation (RMSE or RMSD), which has the same units as the quantity being estimated; for an unbiased estimator, the RMSE is the square root of the variance, known as the standard error.
Definition and basic properties[edit]
The MSE either assesses the quality of a predictor (i.e., a function mapping arbitrary inputs to a sample of values of some random variable), or of an estimator (i.e., a mathematical function mapping a sample of data to an estimate of a parameter of the population from which the data is sampled). The definition of an MSE differs according to whether one is describing a predictor or an estimator.
Predictor[edit]
If a vector of 



In other words, the MSE is the mean 

In matrix notation,

where 



The MSE can also be computed on q data points that were not used in estimating the model, either because they were held back for this purpose, or because these data have been newly obtained. Within this process, known as statistical learning, the MSE is often called the test MSE,[4] and is computed as

Estimator[edit]
The MSE of an estimator 

![{displaystyle operatorname {MSE} ({hat {theta }})=operatorname {E} _{theta }left[({hat {theta }}-theta )^{2}right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a0e1b3bac58f9ba2d2f4ff8b85b2e35a8f4bf78)
This definition depends on the unknown parameter, but the MSE is a priori a property of an estimator. The MSE could be a function of unknown parameters, in which case any estimator of the MSE based on estimates of these parameters would be a function of the data (and thus a random variable). If the estimator
The MSE can be written as the sum of the variance of the estimator and the squared bias of the estimator, providing a useful way to calculate the MSE and implying that in the case of unbiased estimators, the MSE and variance are equivalent.[5]

Proof of variance and bias relationship[edit]
![{displaystyle {begin{aligned}operatorname {MSE} ({hat {theta }})&=operatorname {E} _{theta }left[({hat {theta }}-theta )^{2}right]&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]+operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}+2left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)left(operatorname {E} _{theta }[{hat {theta }}]-theta right)+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+operatorname {E} _{theta }left[2left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)left(operatorname {E} _{theta }[{hat {theta }}]-theta right)right]+operatorname {E} _{theta }left[left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+2left(operatorname {E} _{theta }[{hat {theta }}]-theta right)operatorname {E} _{theta }left[{hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right]+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&&operatorname {E} _{theta }[{hat {theta }}]-theta ={text{const.}}&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+2left(operatorname {E} _{theta }[{hat {theta }}]-theta right)left(operatorname {E} _{theta }[{hat {theta }}]-operatorname {E} _{theta }[{hat {theta }}]right)+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&&operatorname {E} _{theta }[{hat {theta }}]={text{const.}}&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&=operatorname {Var} _{theta }({hat {theta }})+operatorname {Bias} _{theta }({hat {theta }},theta )^{2}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ac524a751828f971013e1297a33ca1cc4c38cd6)
An even shorter proof can be achieved using the well-known formula that for a random variable 


![{displaystyle {begin{aligned}operatorname {MSE} ({hat {theta }})&=mathbb {E} [({hat {theta }}-theta )^{2}]&=operatorname {Var} ({hat {theta }}-theta )+(mathbb {E} [{hat {theta }}-theta ])^{2}&=operatorname {Var} ({hat {theta }})+operatorname {Bias} ^{2}({hat {theta }})end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/864646cf4426e2b62a3caf9460382eec1a77fe4e)
But in real modeling case, MSE could be described as the addition of model variance, model bias, and irreducible uncertainty (see Bias–variance tradeoff). According to the relationship, the MSE of the estimators could be simply used for the efficiency comparison, which includes the information of estimator variance and bias. This is called MSE criterion.
In regression[edit]
In regression analysis, plotting is a more natural way to view the overall trend of the whole data. The mean of the distance from each point to the predicted regression model can be calculated, and shown as the mean squared error. The squaring is critical to reduce the complexity with negative signs. To minimize MSE, the model could be more accurate, which would mean the model is closer to actual data. One example of a linear regression using this method is the least squares method—which evaluates appropriateness of linear regression model to model bivariate dataset,[6] but whose limitation is related to known distribution of the data.
The term mean squared error is sometimes used to refer to the unbiased estimate of error variance: the residual sum of squares divided by the number of degrees of freedom. This definition for a known, computed quantity differs from the above definition for the computed MSE of a predictor, in that a different denominator is used. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n−p) for p regressors or (n−p−1) if an intercept is used (see errors and residuals in statistics for more details).[7] Although the MSE (as defined in this article) is not an unbiased estimator of the error variance, it is consistent, given the consistency of the predictor.
In regression analysis, «mean squared error», often referred to as mean squared prediction error or «out-of-sample mean squared error», can also refer to the mean value of the squared deviations of the predictions from the true values, over an out-of-sample test space, generated by a model estimated over a particular sample space. This also is a known, computed quantity, and it varies by sample and by out-of-sample test space.
Examples[edit]
Mean[edit]
Suppose we have a random sample of size 


which has an expected value equal to the true mean
![{displaystyle operatorname {MSE} left({overline {X}}right)=operatorname {E} left[left({overline {X}}-mu right)^{2}right]=left({frac {sigma }{sqrt {n}}}right)^{2}={frac {sigma ^{2}}{n}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4647a2cc4c8f9a4c90b628faad2dcf80c4aae84)
where 
For a Gaussian distribution, this is the best unbiased estimator (i.e., one with the lowest MSE among all unbiased estimators), but not, say, for a uniform distribution.
Variance[edit]
The usual estimator for the variance is the corrected sample variance:

This is unbiased (its expected value is

where 

However, one can use other estimators for 

then we calculate:
![{displaystyle {begin{aligned}operatorname {MSE} (S_{a}^{2})&=operatorname {E} left[left({frac {n-1}{a}}S_{n-1}^{2}-sigma ^{2}right)^{2}right]&=operatorname {E} left[{frac {(n-1)^{2}}{a^{2}}}S_{n-1}^{4}-2left({frac {n-1}{a}}S_{n-1}^{2}right)sigma ^{2}+sigma ^{4}right]&={frac {(n-1)^{2}}{a^{2}}}operatorname {E} left[S_{n-1}^{4}right]-2left({frac {n-1}{a}}right)operatorname {E} left[S_{n-1}^{2}right]sigma ^{2}+sigma ^{4}&={frac {(n-1)^{2}}{a^{2}}}operatorname {E} left[S_{n-1}^{4}right]-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}&&operatorname {E} left[S_{n-1}^{2}right]=sigma ^{2}&={frac {(n-1)^{2}}{a^{2}}}left({frac {gamma _{2}}{n}}+{frac {n+1}{n-1}}right)sigma ^{4}-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}&&operatorname {E} left[S_{n-1}^{4}right]=operatorname {MSE} (S_{n-1}^{2})+sigma ^{4}&={frac {n-1}{na^{2}}}left((n-1)gamma _{2}+n^{2}+nright)sigma ^{4}-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf22322412b8454c706d78671e5d94208675a6e0)
This is minimized when

For a Gaussian distribution, where 



Further, while the corrected sample variance is the best unbiased estimator (minimum mean squared error among unbiased estimators) of variance for Gaussian distributions, if the distribution is not Gaussian, then even among unbiased estimators, the best unbiased estimator of the variance may not be 
Gaussian distribution[edit]
The following table gives several estimators of the true parameters of the population, μ and σ2, for the Gaussian case.[9]
| True value | Estimator | Mean squared error |
|---|---|---|
 |
= the unbiased estimator of the population mean,  |

|
 |
= the unbiased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
Interpretation[edit]
An MSE of zero, meaning that the estimator
Values of MSE may be used for comparative purposes. Two or more statistical models may be compared using their MSEs—as a measure of how well they explain a given set of observations: An unbiased estimator (estimated from a statistical model) with the smallest variance among all unbiased estimators is the best unbiased estimator or MVUE (Minimum-Variance Unbiased Estimator).
Both analysis of variance and linear regression techniques estimate the MSE as part of the analysis and use the estimated MSE to determine the statistical significance of the factors or predictors under study. The goal of experimental design is to construct experiments in such a way that when the observations are analyzed, the MSE is close to zero relative to the magnitude of at least one of the estimated treatment effects.
In one-way analysis of variance, MSE can be calculated by the division of the sum of squared errors and the degree of freedom. Also, the f-value is the ratio of the mean squared treatment and the MSE.
MSE is also used in several stepwise regression techniques as part of the determination as to how many predictors from a candidate set to include in a model for a given set of observations.
Applications[edit]
- Minimizing MSE is a key criterion in selecting estimators: see minimum mean-square error. Among unbiased estimators, minimizing the MSE is equivalent to minimizing the variance, and the estimator that does this is the minimum variance unbiased estimator. However, a biased estimator may have lower MSE; see estimator bias.
- In statistical modelling the MSE can represent the difference between the actual observations and the observation values predicted by the model. In this context, it is used to determine the extent to which the model fits the data as well as whether removing some explanatory variables is possible without significantly harming the model’s predictive ability.
- In forecasting and prediction, the Brier score is a measure of forecast skill based on MSE.
Loss function[edit]
Squared error loss is one of the most widely used loss functions in statistics[citation needed], though its widespread use stems more from mathematical convenience than considerations of actual loss in applications. Carl Friedrich Gauss, who introduced the use of mean squared error, was aware of its arbitrariness and was in agreement with objections to it on these grounds.[3] The mathematical benefits of mean squared error are particularly evident in its use at analyzing the performance of linear regression, as it allows one to partition the variation in a dataset into variation explained by the model and variation explained by randomness.
Criticism[edit]
The use of mean squared error without question has been criticized by the decision theorist James Berger. Mean squared error is the negative of the expected value of one specific utility function, the quadratic utility function, which may not be the appropriate utility function to use under a given set of circumstances. There are, however, some scenarios where mean squared error can serve as a good approximation to a loss function occurring naturally in an application.[10]
Like variance, mean squared error has the disadvantage of heavily weighting outliers.[11] This is a result of the squaring of each term, which effectively weights large errors more heavily than small ones. This property, undesirable in many applications, has led researchers to use alternatives such as the mean absolute error, or those based on the median.
See also[edit]
- Bias–variance tradeoff
- Hodges’ estimator
- James–Stein estimator
- Mean percentage error
- Mean square quantization error
- Mean square weighted deviation
- Mean squared displacement
- Mean squared prediction error
- Minimum mean square error
- Minimum mean squared error estimator
- Overfitting
- Peak signal-to-noise ratio
Notes[edit]
- ^ This can be proved by Jensen’s inequality as follows. The fourth central moment is an upper bound for the square of variance, so that the least value for their ratio is one, therefore, the least value for the excess kurtosis is −2, achieved, for instance, by a Bernoulli with p=1/2.
References[edit]
- ^ a b «Mean Squared Error (MSE)». www.probabilitycourse.com. Retrieved 2020-09-12.
- ^ Bickel, Peter J.; Doksum, Kjell A. (2015). Mathematical Statistics: Basic Ideas and Selected Topics. Vol. I (Second ed.). p. 20.
If we use quadratic loss, our risk function is called the mean squared error (MSE) …
- ^ a b Lehmann, E. L.; Casella, George (1998). Theory of Point Estimation (2nd ed.). New York: Springer. ISBN 978-0-387-98502-2. MR 1639875.
- ^ Gareth, James; Witten, Daniela; Hastie, Trevor; Tibshirani, Rob (2021). An Introduction to Statistical Learning: with Applications in R. Springer. ISBN 978-1071614174.
- ^ Wackerly, Dennis; Mendenhall, William; Scheaffer, Richard L. (2008). Mathematical Statistics with Applications (7 ed.). Belmont, CA, USA: Thomson Higher Education. ISBN 978-0-495-38508-0.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- ^ Mood, A.; Graybill, F.; Boes, D. (1974). Introduction to the Theory of Statistics (3rd ed.). McGraw-Hill. p. 229.
- ^ DeGroot, Morris H. (1980). Probability and Statistics (2nd ed.). Addison-Wesley.
- ^ Berger, James O. (1985). «2.4.2 Certain Standard Loss Functions». Statistical Decision Theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. p. 60. ISBN 978-0-387-96098-2. MR 0804611.
- ^ Bermejo, Sergio; Cabestany, Joan (2001). «Oriented principal component analysis for large margin classifiers». Neural Networks. 14 (10): 1447–1461. doi:10.1016/S0893-6080(01)00106-X. PMID 11771723.
From Wikipedia, the free encyclopedia
In statistics, the mean squared error (MSE)[1] or mean squared deviation (MSD) of an estimator (of a procedure for estimating an unobserved quantity) measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss.[2] The fact that MSE is almost always strictly positive (and not zero) is because of randomness or because the estimator does not account for information that could produce a more accurate estimate.[3] In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk (the average loss on an observed data set), as an estimate of the true MSE (the true risk: the average loss on the actual population distribution).
The MSE is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
The MSE is the second moment (about the origin) of the error, and thus incorporates both the variance of the estimator (how widely spread the estimates are from one data sample to another) and its bias (how far off the average estimated value is from the true value).[citation needed] For an unbiased estimator, the MSE is the variance of the estimator. Like the variance, MSE has the same units of measurement as the square of the quantity being estimated. In an analogy to standard deviation, taking the square root of MSE yields the root-mean-square error or root-mean-square deviation (RMSE or RMSD), which has the same units as the quantity being estimated; for an unbiased estimator, the RMSE is the square root of the variance, known as the standard error.
Definition and basic properties[edit]
The MSE either assesses the quality of a predictor (i.e., a function mapping arbitrary inputs to a sample of values of some random variable), or of an estimator (i.e., a mathematical function mapping a sample of data to an estimate of a parameter of the population from which the data is sampled). The definition of an MSE differs according to whether one is describing a predictor or an estimator.
Predictor[edit]
If a vector of
In other words, the MSE is the mean
In matrix notation,
where
The MSE can also be computed on q data points that were not used in estimating the model, either because they were held back for this purpose, or because these data have been newly obtained. Within this process, known as statistical learning, the MSE is often called the test MSE,[4] and is computed as
Estimator[edit]
The MSE of an estimator
This definition depends on the unknown parameter, but the MSE is a priori a property of an estimator. The MSE could be a function of unknown parameters, in which case any estimator of the MSE based on estimates of these parameters would be a function of the data (and thus a random variable). If the estimator
The MSE can be written as the sum of the variance of the estimator and the squared bias of the estimator, providing a useful way to calculate the MSE and implying that in the case of unbiased estimators, the MSE and variance are equivalent.[5]
Proof of variance and bias relationship[edit]
An even shorter proof can be achieved using the well-known formula that for a random variable
But in real modeling case, MSE could be described as the addition of model variance, model bias, and irreducible uncertainty (see Bias–variance tradeoff). According to the relationship, the MSE of the estimators could be simply used for the efficiency comparison, which includes the information of estimator variance and bias. This is called MSE criterion.
In regression[edit]
In regression analysis, plotting is a more natural way to view the overall trend of the whole data. The mean of the distance from each point to the predicted regression model can be calculated, and shown as the mean squared error. The squaring is critical to reduce the complexity with negative signs. To minimize MSE, the model could be more accurate, which would mean the model is closer to actual data. One example of a linear regression using this method is the least squares method—which evaluates appropriateness of linear regression model to model bivariate dataset,[6] but whose limitation is related to known distribution of the data.
The term mean squared error is sometimes used to refer to the unbiased estimate of error variance: the residual sum of squares divided by the number of degrees of freedom. This definition for a known, computed quantity differs from the above definition for the computed MSE of a predictor, in that a different denominator is used. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n−p) for p regressors or (n−p−1) if an intercept is used (see errors and residuals in statistics for more details).[7] Although the MSE (as defined in this article) is not an unbiased estimator of the error variance, it is consistent, given the consistency of the predictor.
In regression analysis, «mean squared error», often referred to as mean squared prediction error or «out-of-sample mean squared error», can also refer to the mean value of the squared deviations of the predictions from the true values, over an out-of-sample test space, generated by a model estimated over a particular sample space. This also is a known, computed quantity, and it varies by sample and by out-of-sample test space.
Examples[edit]
Mean[edit]
Suppose we have a random sample of size
which has an expected value equal to the true mean
where
For a Gaussian distribution, this is the best unbiased estimator (i.e., one with the lowest MSE among all unbiased estimators), but not, say, for a uniform distribution.
Variance[edit]
The usual estimator for the variance is the corrected sample variance:
This is unbiased (its expected value is
where
However, one can use other estimators for
then we calculate:
This is minimized when
For a Gaussian distribution, where
Further, while the corrected sample variance is the best unbiased estimator (minimum mean squared error among unbiased estimators) of variance for Gaussian distributions, if the distribution is not Gaussian, then even among unbiased estimators, the best unbiased estimator of the variance may not be
Gaussian distribution[edit]
The following table gives several estimators of the true parameters of the population, μ and σ2, for the Gaussian case.[9]
| True value | Estimator | Mean squared error |
|---|---|---|
|
= the unbiased estimator of the population mean, |
|
|
= the unbiased estimator of the population variance, |
|
|
= the biased estimator of the population variance, |
|
|
= the biased estimator of the population variance, |
|
Interpretation[edit]
An MSE of zero, meaning that the estimator
Values of MSE may be used for comparative purposes. Two or more statistical models may be compared using their MSEs—as a measure of how well they explain a given set of observations: An unbiased estimator (estimated from a statistical model) with the smallest variance among all unbiased estimators is the best unbiased estimator or MVUE (Minimum-Variance Unbiased Estimator).
Both analysis of variance and linear regression techniques estimate the MSE as part of the analysis and use the estimated MSE to determine the statistical significance of the factors or predictors under study. The goal of experimental design is to construct experiments in such a way that when the observations are analyzed, the MSE is close to zero relative to the magnitude of at least one of the estimated treatment effects.
In one-way analysis of variance, MSE can be calculated by the division of the sum of squared errors and the degree of freedom. Also, the f-value is the ratio of the mean squared treatment and the MSE.
MSE is also used in several stepwise regression techniques as part of the determination as to how many predictors from a candidate set to include in a model for a given set of observations.
Applications[edit]
- Minimizing MSE is a key criterion in selecting estimators: see minimum mean-square error. Among unbiased estimators, minimizing the MSE is equivalent to minimizing the variance, and the estimator that does this is the minimum variance unbiased estimator. However, a biased estimator may have lower MSE; see estimator bias.
- In statistical modelling the MSE can represent the difference between the actual observations and the observation values predicted by the model. In this context, it is used to determine the extent to which the model fits the data as well as whether removing some explanatory variables is possible without significantly harming the model’s predictive ability.
- In forecasting and prediction, the Brier score is a measure of forecast skill based on MSE.
Loss function[edit]
Squared error loss is one of the most widely used loss functions in statistics[citation needed], though its widespread use stems more from mathematical convenience than considerations of actual loss in applications. Carl Friedrich Gauss, who introduced the use of mean squared error, was aware of its arbitrariness and was in agreement with objections to it on these grounds.[3] The mathematical benefits of mean squared error are particularly evident in its use at analyzing the performance of linear regression, as it allows one to partition the variation in a dataset into variation explained by the model and variation explained by randomness.
Criticism[edit]
The use of mean squared error without question has been criticized by the decision theorist James Berger. Mean squared error is the negative of the expected value of one specific utility function, the quadratic utility function, which may not be the appropriate utility function to use under a given set of circumstances. There are, however, some scenarios where mean squared error can serve as a good approximation to a loss function occurring naturally in an application.[10]
Like variance, mean squared error has the disadvantage of heavily weighting outliers.[11] This is a result of the squaring of each term, which effectively weights large errors more heavily than small ones. This property, undesirable in many applications, has led researchers to use alternatives such as the mean absolute error, or those based on the median.
See also[edit]
- Bias–variance tradeoff
- Hodges’ estimator
- James–Stein estimator
- Mean percentage error
- Mean square quantization error
- Mean square weighted deviation
- Mean squared displacement
- Mean squared prediction error
- Minimum mean square error
- Minimum mean squared error estimator
- Overfitting
- Peak signal-to-noise ratio
Notes[edit]
- ^ This can be proved by Jensen’s inequality as follows. The fourth central moment is an upper bound for the square of variance, so that the least value for their ratio is one, therefore, the least value for the excess kurtosis is −2, achieved, for instance, by a Bernoulli with p=1/2.
References[edit]
- ^ a b «Mean Squared Error (MSE)». www.probabilitycourse.com. Retrieved 2020-09-12.
- ^ Bickel, Peter J.; Doksum, Kjell A. (2015). Mathematical Statistics: Basic Ideas and Selected Topics. Vol. I (Second ed.). p. 20.
If we use quadratic loss, our risk function is called the mean squared error (MSE) …
- ^ a b Lehmann, E. L.; Casella, George (1998). Theory of Point Estimation (2nd ed.). New York: Springer. ISBN 978-0-387-98502-2. MR 1639875.
- ^ Gareth, James; Witten, Daniela; Hastie, Trevor; Tibshirani, Rob (2021). An Introduction to Statistical Learning: with Applications in R. Springer. ISBN 978-1071614174.
- ^ Wackerly, Dennis; Mendenhall, William; Scheaffer, Richard L. (2008). Mathematical Statistics with Applications (7 ed.). Belmont, CA, USA: Thomson Higher Education. ISBN 978-0-495-38508-0.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- ^ Mood, A.; Graybill, F.; Boes, D. (1974). Introduction to the Theory of Statistics (3rd ed.). McGraw-Hill. p. 229.
- ^ DeGroot, Morris H. (1980). Probability and Statistics (2nd ed.). Addison-Wesley.
- ^ Berger, James O. (1985). «2.4.2 Certain Standard Loss Functions». Statistical Decision Theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. p. 60. ISBN 978-0-387-96098-2. MR 0804611.
- ^ Bermejo, Sergio; Cabestany, Joan (2001). «Oriented principal component analysis for large margin classifiers». Neural Networks. 14 (10): 1447–1461. doi:10.1016/S0893-6080(01)00106-X. PMID 11771723.