4 Solutions Data Source Reference Is Not Valid

Резюме :

В чем ошибка ссылки на источник данных недействительна? Что вызывает ошибку ссылки на источник сводных данных недействительно? Как исправить ошибку ссылки на источник данных недопустимая сводка? Это сообщение от MiniTool покажет вам решения.
Что такое ошибка ссылки на источник данных не является действительной?
При попытке создать сводную таблицу вы можете столкнуться с ошибкой: ссылка на источник данных недействительна. Тогда что может вызвать ошибку, ссылка на источник данных сводной информации недействительна?
Как правило, это может быть вызвано несколькими причинами, например следующими:
- Файлы Excel не сохраняются на локальном диске.
- Имя файла Excel содержит квадратные скобки.
- Данные сводной таблицы относятся к несуществующему диапазону.
- Источник данных относится к именованному диапазону, который содержит недопустимые ссылки.
Итак, знаете ли вы, как исправить ошибку ссылки на источник данных недействительно? Если нет, продолжайте читать и найдите решения в следующем содержании.
 Исправьте Excel, который не отвечает, и спасите ваши данные (несколькими способами)
Исправьте Excel, который не отвечает, и спасите ваши данные (несколькими способами)
Вы хотите избавиться от Microsoft Excel, который не отвечает? В этом посте мы покажем вам несколько методов, которые могут эффективно решить эту проблему.
Читать больше
4 способа недействительной ссылки на источник данных
В этой части мы покажем вам, как исправить ошибку неверной ссылки на источник данных.
Способ 1. Снять скобки с имени файла
Чтобы исправить ошибку ссылки на источник данных недействительно, вы можете попробовать убрать скобки из имени файла.
А вот и руководство.
- Закройте окно Excel, в котором в данный момент используется файл.
- Затем перейдите к расположению файла Excel.
- Затем щелкните его правой кнопкой мыши и выберите Переименовать .
- Затем удалите квадратные скобки из имени файла, поскольку сводная таблица не настроена для их поддержки.
После этого заново создайте сводную таблицу и проверьте, исправлена ли ошибка ссылки на источник данных.
Способ 2. Сохраните файл на локальном диске
Ссылка на источник данных о проблеме недействительна, может возникнуть, если вы открываете файл непосредственно с веб-сайта или непосредственно из вложений электронной почты. В этом случае файл будет открыт из временного файла, что вызовет эту проблему.
В этом случае вам необходимо сохранить этот файл Excel на локальный диск.
А вот и руководство.
- Откройте файл Excel.
- Затем нажмите файл > Сохранить как .
- Затем сохраните файл Excel на физическом диске.
Когда все шаги выполнены, проверьте, является ли ошибка ссылки на источник данных недействительной.
Способ 3. Убедитесь, что диапазон существует и определен
Если вы пытаетесь вставить сводную таблицу в несуществующий или не определенный диапазон, вы можете обнаружить, что ссылка на источник данных ошибки недействительна.
Итак, чтобы решить эту проблему, вам нужно убедиться, что диапазон существует и определен.
А вот и руководство.
- Щелкните значок Формулы вкладку на панели ленты, а затем щелкните Имя Менеджер продолжать.
- В окне ‘Диспетчер имен’ нажмите Новый и назовите диапазон, который вы собираетесь создать. Затем используйте Относится к поле, чтобы установить ячейки, которые вы хотите использовать для диапазона. Вы можете набрать его самостоятельно или воспользоваться встроенным селектором.
После этого определяется диапазон. Вы можете успешно создать сводную таблицу, не обнаружив, что ссылка на источник данных ошибки недопустима.
Способ 4. Убедитесь, что ссылка на именованный диапазон действительна
Чтобы исправить ошибку ссылки на источник сводных данных недействительно, необходимо убедиться, что ссылка на именованный диапазон действительна.
А вот и руководство.
- Нажмите Формулы > Имя Менеджер .
- Посмотрите, относится ли диапазон к ячейкам, которые вы хотите проанализировать с помощью сводной таблицы.
- Если вы видите какие-либо несоответствия, используйте ссылку.
- Затем переключитесь на правильное значение.
После завершения всех шагов вы можете проверить, является ли ошибка ссылки на источник данных недействительной.
 Исправить Excel не может открыть файл | Восстановить поврежденный файл Excel
Исправить Excel не может открыть файл | Восстановить поврежденный файл Excel
Excel не может открыть файл из-за недопустимого расширения Excel 2019/2016/2013/2010/2007 или файл Excel поврежден? 5 решений для устранения проблемы.
Читать больше
Заключительные слова
Подводя итог, в этом посте показано, как исправить ошибку недействительной ссылки на источник данных 4 способами. Если вы столкнулись с той же проблемой, вы можете попробовать эти решения. Если у вас есть лучшее решение, чтобы исправить это, вы можете поделиться им в зоне комментариев.
 Привет, друзья. Сегодня я хочу поделиться еще одной наработкой из большого списка регламентов и инструкций нашей студии «АлаичЪ и Ко». Среди моих коллег есть фанат работы с Гугл Таблицами – это Алексей Степанов, совместно с которым мы готовили для вас прошлую публикацию про написание seo-текстов и подготовки ТЗ для копирайтеров. Уверен, что и среди читателей блога много тех, кто использует Гугл Таблицы вместо Экселя. Сегодняшняя публикация для вас, ее Алексей подготовил без моей помощи, поэтому без долгих вступлений я сразу передаю слово ему.
Привет, друзья. Сегодня я хочу поделиться еще одной наработкой из большого списка регламентов и инструкций нашей студии «АлаичЪ и Ко». Среди моих коллег есть фанат работы с Гугл Таблицами – это Алексей Степанов, совместно с которым мы готовили для вас прошлую публикацию про написание seo-текстов и подготовки ТЗ для копирайтеров. Уверен, что и среди читателей блога много тех, кто использует Гугл Таблицы вместо Экселя. Сегодняшняя публикация для вас, ее Алексей подготовил без моей помощи, поэтому без долгих вступлений я сразу передаю слово ему.
В этой статье мы рассмотрим на примерах, как парсить содержимое сайтов с помощью Google Таблиц. В частности, рассмотрим функции importHTML и importXML. Первую функцию очень удобно использовать если данные находятся в какой-то таблице или списке, а вторая функция является универсальной и практически не имеет ограничений.
Функция importHTML
С помощью функции importHTML можно настроить импорт данных из таблицы или списка на странице сайта.
Синтаксис
=IMPORTHTML(ссылка; запрос; индекс)
- ссылка — ссылка на веб-страницу, включая протокол (http:// или https://),
- запрос — значения «table» или «list», смотря, что нужно парсить (таблицу или список),
- индекс – порядковый номер списка или таблицы (отсчет начинается с 1).
Пример:
IMPORTHTML("http://ru.wikipedia.org/wiki/Население_Индии"; "table"; 4)
Переменные можно разместить в ячейках, тогда формула изменится так:
IMPORTHTML(A2; B2; C2)
Примеры использования importHTML
Выгрузка любых табличных данных
Однажды мне понадобилось собрать список минус-слов по городам России в существительном падеже. Первые пару нагугленных файлов с минус-словами были неполными, а в других меня не устроила словоформа. Поэтому я просто решил спарсить страницу Википедии, что заняло около двух минут, включая время на открытие Гугл Таблицы, поиск нужной страницы Википедии и настройку формулы. С этого примера я и начну.
Задача: выгрузить список всех городов России со страницы https://ru.wikipedia.org/wiki/Список_городов_России
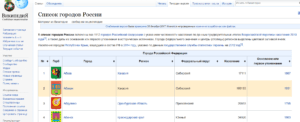
Чтобы выгрузить данные из этой таблицы нам нужно указать в формуле ее порядковый номер в коде страницы. Чтобы этот номер узнать, нужно открыть код сайта (в нормальных браузерах это сочетание Ctrl+U, либо клавиша F12, открывающая панель разработчика). А дальше поиском по коду определить порядковый номер:

В данном случае целевая таблица является первой в коде.
Составляем формулу:
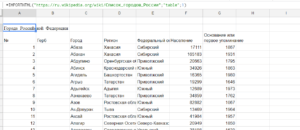
=IMPORTHTML("https://ru.wikipedia.org/wiki/Список_городов_России";"table";1)
Результат:
Выгрузка данных из списка
Как-то я работал с интернет-магазином у которого была обширная структура и очень неудобное меню. Надо было бегло оценить текущую структуру сайта, чтобы понять ассортимент и возможные очевидные проблемы, типа дублирования пунктов меню. Меню было реализовано в виде списка, чем я и воспользовался. Меньше чем через минуту полная иерархия сайта отображалась у меня в Гугл Табличке.
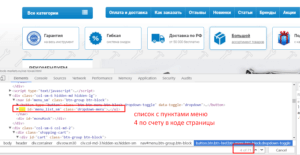
Задача: выгрузить все пункты меню, оформленного тегами <ul>…</ul>.
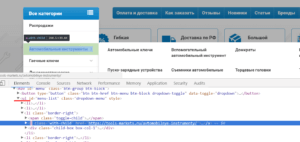
Как и в первом примере для формулы понадобится определить порядковый номер списка в коде сайта. В данном случае — четвертый.
Составляем формулу:
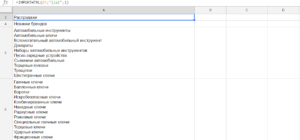
=IMPORTHTML("https://tools-markets.ru/";"list";3)
Результат:
Списки и таблицы — это хорошо, но чаще всего необходимо выдернуть с сайта информацию, оформленную другими тегами. Например, тексты, цены, заголовки и так дальше. Эти данные можно спарсить, используя формулу importXML, разберем ее подробнее.
Функция importXML
С помощью функции importXML можно настроить импорт данных из источников в формате XML, HTML, CSV, TSV, а также RSS и ATOM XML.
По сравнению с importHTML у данной функции гораздо более широкое применение. Она позволяет собирать практически любую информацию со страницы/документа, от частичных фрагментов до полного ее содержания. Ниже будут описаны примеры парсинга HTML-страниц сайта. Парсинг по файлам рассматривать не стану, т.к. такая задача возникает редко и большинство из вас с этим не столкнется никогда. Но если что, принцип работы везде одинаковый, главное понять суть.
Синтаксис
IMPORTXML(ссылка; "//XPath запрос")
- ссылка – адрес веб-страницы с указанием протокола (http:// или https://). Значение этого параметра должно быть заключено в кавычки или представлять собой ссылку на ячейку, содержащую URL страницы.
- //XPath запрос – то, что будем импортировать. Ниже мы разберем основные примеры запросов (а тут подробнее про XPath).
Пример:
IMPORTXML("https://en.wikipedia.org/wiki/Moon_landing"; "//a/@href")
Значения переменных можно хранить в ячейках, тогда формула будет такой:
IMPORTXML(A2; B2)
Примеры использования importХML
Пример 1. Импорт мета-тегов и заголовков со страниц
Самая простая и распространенная ситуация, которая может быть — узнать мета-теги или заголовки продвигаемых страниц. Для этих целей лучше подходит парсинг сайта специализированным софтом типа Comparser’a. Но бывают и исключения, например, если сайт очень большой и это сделать затруднительно, либо у вас нет под рукой программы. Или если вы собираетесь дальше использовать полученные данные в таблицах для мониторинга изменений мета-тегов и сверки целевых и фактических мета-тегов на страницах.
Формулы простые.
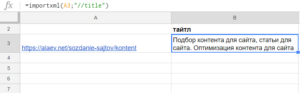
Получаем title страницы:
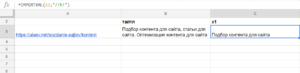
=importxml(A3;"//title")
Получаем заголовки h1:
=importxml(A3;"//h1")
Получаем description:
=importxml(A3;"//meta[@name='description']/@content")
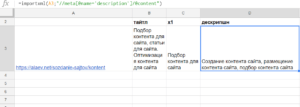
Последняя формула получилась сложнее т.к. нас интересует значение не самого тега, а его атрибута:
- ищем тег meta //meta
- у которого есть атрибут name=’description’ [@name=’description’]
- и парсим содержимое второго атрибута content /@content
Пример 2. Определяем наличие текста на странице и его длину в символах
Этот пример мне помог при работе с проектом, тексты для которого писал и размещал сам клиент, и ему было чрезвычайно лень сообщать мне о ходе процесса. Небольшой лайфхак с Гугл таблицами позволил мне мониторить динамику его работы, а ему с чистой совестью и дальше продолжать лениться и не сообщать мне ничего.
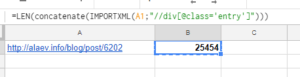
Рассмотрим ситуацию на примере нашего блога http://alaev.info, а конкретно на странице https://alaev.info/blog/post/6202. Если заглянуть в код, то мы увидим, что контент страницы расположен в теге <div> с классом entry.
Формула:
=LEN(concatenate(IMPORTXML(A1;"//div[@class='entry']")))
В ячейке А1 у нас ссылка на статью, в запросе XPath мы получаем содержимое тега div, у которого есть класс entry, то есть парсим весь текст страницы: =IMPORTXML(A1;"//div[@class='entry']")
Функция CONCATENATE (в русском варианте СЦЕПИТЬ) нужна, чтобы объединить все абзацы в один кусок контента. Без нее мы посчитаем только объем первого абзаца.
Функция LEN (в русском варианте ДЛСТР) считает количество символов.
Пример 3. Выгружаем актуальные цены
Однажды потребовалось не только заниматься оптимизацией сайта, но и следить за ценами конкурентов по схожим товарным позициям. Использование специализированного софта и сервисов я практически сразу отмел, т.к. специальные сервисы по мониторингу не укладывались в бюджет, а вручную сканировать сайты конкурентов несколько раз в неделю не комильфо.
К счастью, вариант с Гугл доками оказался подходящим и уже к концу дня я все настроил так, что данные подтягивались автоматически. От меня ничего не требовалось, кроме как отправить ссылку на документ клиенту и спокойно заниматься своими делами.
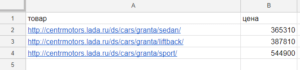
Я решил рассмотреть похожую ситуацию на случайном сайте. Итак, допустим, мы хотим мониторить цены на автомобили и, скажем, выгружать актуальные цены с сайта http://centrmotors.lada.ru/. Вот пример товарной карточки http://centrmotors.lada.ru/ds/cars/granta/sedan/.
Чтобы настроить формулу снова идем в код сайта и смотрим в каких тегах располагается цена. Примеры должны быть простыми, поэтому я буду выгружать только минимальную цену.

На данном сайте нам надо парсить содержимое тега <span> с id textspan7.
Формула:
=importxml(A2;"//span[@id='textspan7']")
В таблице ссылки на товары укажем в столбце А, а формулу вставим в столбец В.
Результат:
Поясню:
- A2 — номер ячейки из которой берется адрес страницы,
- //span[@id=’textspan7′] — блок из которого будем выводить информацию.
- Если бы у нас вместо span был div, а вместо id был бы class, то вторая часть формулы была такой:
//div[@class='textspan7']
Автоматизируем дальше.
Приведенное выше решение не идеальное, ведь нам надо предварительно собрать адреса товарных страниц, а это довольно муторно. Если на сайт добавят новые модели авто, то информация по ним не будет подгружаться в таблицу т.к. адреса страниц будут отсутствовать в документе.
Подключив логику и другие формулы, можно хакнуть рутину. Ссылки на все модели присутствуют в главном меню. А если есть ссылки, то скорее всего их тоже можно спарсить.

И действительно, заглянув в код, мы увидим, что ссылки на товарные страницы располагаются в теге <p> c классом CMtext4:
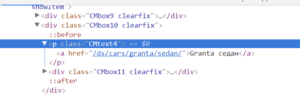
Формула:
=IMPORTXML(A8;"//p[@class='CMtext4']/a/@href")
- A8 – в этой ячейке ссылка на сайт,
- p[@class=’CMtext4′] – тут мы ищем содержимое тега <p> с классом CMtext4,
- /a/@href – а в этой части формулы мы уточняем, что из содержимого <p> хотим достать содержимое вложенного тега <a>, а если еще точнее, то ту часть, которая прописана в href=»».
После применения формулы в документе получится такой список:
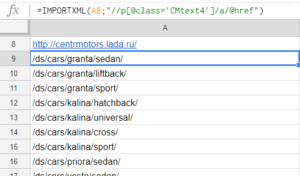
Мы получили ссылки на все товары, которые нас интересуют. Осталось настроить парсинг цен по этим адресам. Но ссылки на страницы относительные, а нам обязательно нужны абсолютные ссылки, включающие имя домена. Чтобы подставить в ссылку домен используем функцию CONCATENATE.
Формула:
=IMPORTXML(concatenate("http://centermotors.lada.ru";A9);"//span[@id='textspan7']")
Либо при условии, что у нас в ячейке А8 находится адрес домена:
=IMPORTXML(concatenate(A$8;A9);"//span[@id='textspan7']")
Размещаем мы ее справа от первой ссылки на товарную страницу и протягиваем вниз для всех ссылок или до конца листа на случай, если в будущем будет больше товаров.

Результат:
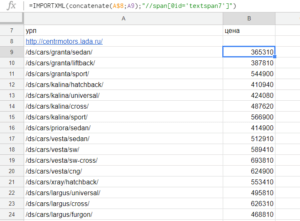
Поясню, если кто-то еще не разобрался:
- A$8 — ячейка, в которой указан домен сайта. Знаком $ фиксируем строку, чтобы это значение не изменилось, когда мы начнем протягивать формулу вниз.
- A9 — это первый URL товарной страницы, при перетаскивании формулы значение автоматически меняется, т.е. в 10 строке у нас вместо A9 будет A10, в 11 строке A11 и т.д.
Теперь если на сайте будут добавлены или удалены товары, то в нашем файле ссылки на них автоматически обновятся, и мы будем всегда видеть только актуальную информацию.
Пример универсальный и имеет применение не только в рабочих целях. Например, можно мониторить цены на товары в ожидании скидок. А если еще немного потрудиться, то и настроить оповещение на почту при изменении цены (или любого другого значения) ниже/выше определенного значения.
Пример 4. Узнать количество товаров в категориях
Очень полезный прием для тех, кто хоть раз продвигал интернет-магазины без товаров. Нет, это не шутка! Мне доводилось пару раз, как бы это смешно ни звучало.
Например, движок сайта не отображает те товары, которых нет на складе (или сам клиент может удалять их вручную). В этом случае есть риск возникновения ситуации, когда на складе вообще не окажется определенного типа товаров и категории будут висеть пустые, в лучшем случае на странице будет текстовое описание.
Но с помощью парсинга легко узнать на каких страницах есть беда с ассортиментом.
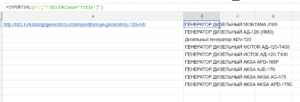
Для примера возьмем сайт http://bz2.ru. Категории с товарами выглядят вот так http://bz2.ru/katalog/generatory-dizelnye/dizelnye-generatory-100-kvt/.
Чтобы посчитать количество товаров идем в код сайта и смотрим какими тегами оформлены товары.
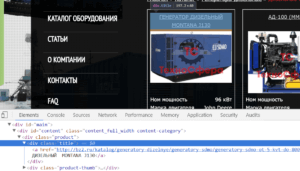
Товар оформлен в теге <div> с классом product, заголовок товара оформлен в теге <div> с классом title. Я решил посчитать заголовки:
Формула:
=COUNTA(IMPORTXML(A3;"//div[@class='title']"))
Результат:
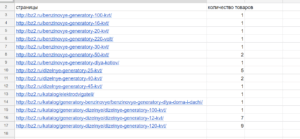
COUNTA нужна, чтобы подсчитать число значений, если бы мы не использовали эту функцию, то результат был бы таким:
Как и в примере выше, можно автоматизировать процесс, чтобы ссылки на все категории парсились автоматически и их не приходилось добавлять вручную.
Пример 5. Парсим код ответа сервера
Я очень редко встречаю сайты, где что-то постоянно отваливается, но все же бывает. В случае необходимости можно быстро проверить все продвигаемые страницы на доступность и корректный ответ сервера.
Обычно я такие вещи мониторю с помощью скриптов без использования формул, но с помощью рассматриваемой функции это можно реализовать. Данный способ, пожалуй, единственное исключение из общего списка примеров, потому что я к нему не прибегал ни разу, но уверен, что кому-то из вас он пригодится.
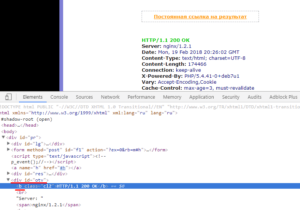
В сети много сервисов, которые проверяют страницы на код ответа сервера. Суть идеи в том, чтобы парсить данные с такого сервиса. Для примера я решил взять самый популярный — http://www.bertal.ru/ — если мы проверим в нем страницу, то он отобразит результат по URL вида https://bertal.ru/index.php?a4789763/alaev.info/blog/post/6202#h.
Я не знаю, что означают символы a4789763, но на результат они не влияют. Смотрим:
Формула:
=importxml(concatenate(A$4;A6);"//div[@id='otv']/b")
Результат:
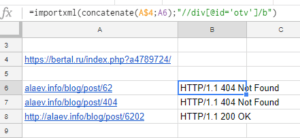
- A$4 — адрес ячейки с неизменяемой частью URL,
- A6 — ячейка с адресом страницы, код ответа, которой хотим проверить.
Функцией CONCATENATE склеиваем наши куски в один URL с которого и парсим данные.
Пример 6. Узнаем количество страниц в индексе ПС
Если мы введем в поисковик запрос типа [site:http://alaev.info], то узнаем сколько всего страниц данного сайта находится в выдаче.
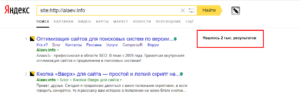
Результаты будут выведены на странице типа https://yandex.ru/search/?text=site%3Ahttp%3A%2F%2Falaev.info&lr=213, где после [https://yandex.ru/search/?text=site%3A] следует адрес сайта и необязательный параметр региона поиска [&lr=213].
Все, что нам нужно — это сформировать URL, по которому поисковик отдаст нам ответ, и определить из каких тегов парсить эту инфу.
В данном случае данные лежат в теге <div> с классом serp-adv__found.
Если мы поместим ссылку на сайт в ячейку A15, то формула будет такая:
=importxml(CONCATENATE("<a href="https://yandex.ru/search/?text=site%3A%22;A15">https://yandex.ru/search/?text=site%3A";</a>A15);"//div[@class='serp-adv__found']")
Результат:
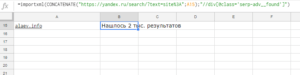
В таком виде результат не особо ценен, т.к. желательно не только узнать количество страниц, но и провести какие-то дальнейшие вычисления или сравнения. Для этого модернизируем формулу и приведем текстовое значение в числовое.
Для этих целей будем использовать функцию SUBSTITUTE (в русском варианте ПОДСТАВИТЬ). Суть идеи в том, чтобы убрать слово [Нашлось: ] и заменить надпись [тыс. результатов] на [000], чтобы в итоге надпись выглядела как просто число 2000.
Но есть нюанс. Окончание меняется в зависимости от результата, например, может выглядеть как [Нашёлся 1 результат], поэтому такие вариации тоже надо будет заменить.
Не буду вас утомлять, поэтому ближе к делу: сначала заменим надпись [Нашлось: ] на пустоту вот так:
=SUBSTITUTE(ссылка;"Нашлось ";"")
Дальше заменим [тыс. результатов] на [000] для этого добавим еще одну аналогичную функцию, и формула будет выглядеть так:
=SUBSTITUTE(SUBSTITUTE(ссылка;"Нашлось ";"");"тыс.";"000")
Проделаем тоже самое для остальных вариантов и вместо слова [ссылка] пропишем функцию импорта. Конечная формула будет следующей:
=SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(importxml(CONCATENATE("https://yandex.ru/search/?text=site%3A";A10);"//div[@class='serp-adv__found']");"Нашлось ";"");" результатов";"");" результата";"");" ";"");"Нашлась";"");"результат";"");"Нашёлся";"");"тыс.";"000")
Немного пугающе, правда? Возможно, есть более элегантные решения, но так как данный вариант универсальный и полностью рабочий, то я остановился на нем. Если вы найдете более красивое решение, то поделитесь в комментариях, мне будет интересно увидеть другие возможные построения формулы.
Ограничения
Минусом использования данных функций является то, что большие объемы данных обработать не получится. Существуют ограничение на число исходящих запросов, и если вам нужно, например, послать 1000 запросов, то вы столкнетесь с ситуацией, когда в большинстве ячеек у вас будет находиться надпись «Loading». Точных цифр Google не приводит, но по личному наблюдению — за один раз можно отправить около 100 запросов, после чего происходит таймаут примерно на 1 час до отправки следующей партии запросов. Поэтому вам подойдет этот функционал только в том случае, если не планируется обработка больших объемов данных.
На этом я закончу с примерами, на которых, конечно, возможности рассматриваемых функций не кончаются, однако, смысл статьи в том, чтобы познакомить вас с базовыми приемами и общими принципами работы.
Для меня возможности данных функций незаменимы для выполнения простых задач. Надеюсь, что и для вас эта информация оказалась полезной и позволит победить рутину в повседневных задачах.
Если у вас есть на заметке интересные примеры, обязательно делитесь в комментариях!
Спасибо за внимание. И до связи!
Это правда — результат работы IMPORTXML функции зависит от специфики того сайта, с какого делается попытка импорта.
Если пойти в обход и попытаться загрузить ту же страницу скриптом:
function importFrom(url) {
return UrlFetchApp.fetch(url, {muteHttpExceptions: true}).getContentText();
}
то в полученном тексте ответа сервера можно заметить важные подробности. А именно — то, что данный сайт защищен от DDoS атак средствами CLOUDFLARE, а проще говоря — скриптами, которые должны быть выполнены в браузере на стороне клиента — до того, как браузер получит настоящее содержимое страницы с товарами и ценами. В этот момент код ответа сервера равен 503 вместо «полноценного» 200. Обычный браузер проходит эту стадию автоматически, быстро и прозрачно для пользователя, отправляя следующий запрос на сервер и получая от него полный ответ. Однако в случае с функцией IMPORTXML никакой работы с клиент-сайд скриптами вообще не предусмотрено. Ответ сервера с кодом 503 функция IMPORTXML интерпретирует как невозможность получить информацию с данного ресурса, что мы и видим в ячейке таблиц.
То же самое происходит и при использовании IMPORTHTML.
Видимо данные пересекаются, т.е. верхняя и/или левая формула не может вывести весь массив, т.к. ниже и/или правее что-то уже есть.
Обойти можно так:
={
IMPORTRANGE(...);
IMPORTRANGE(...);
IMPORTRANGE(...)
}Данные выведутся в столбик, только надо чтобы у всех было равное кол-во столбцов
Неправильно ссылаетесь на лист, КМК. У вас "Доп данные!A2", должно же быть "'Доп данные'!A2" (название листа в одинарных кавычках).
Недавно сталкивался с такой же проблемой. В моем случае единственная ошибка заключалась в том, что я пытался ссылаться на xlsx файл лежащий на гугл диске. Через меню файл я сохранил его как Гугл таблицу, и при дальнейшем использовании ссылок на эту таблицу проблем не было
В этом руководстве мы покажем вам, как решить проблему, когда IMPORTXML и IMPORTHTML не работают в Google Таблицах. Это предложение электронных таблиц от гиганта Силиконовой долины имеет довольно много отличных функций. Одним из них является возможность напрямую получать общедоступные структурированные данные из Интернета. В зависимости от типа данных вы можете использовать IMPORTXML, IMPORTHTML, IMPORTDATA или IMPORTFEED.
Если мы возьмем первые два, то вы можете использовать формулу XML для импорта данных из каналов XML, HTML, CSV, TSV, RSS и ATOM XML с использованием синтаксиса IMPORTXML(url, xpath_query). Аналогичным образом, используя формулу IMPORTHTML(url, query, index), вы можете импортировать данные из таблицы или списка на странице HTML. Однако обе эти формулы работают не так, как ожидалось.
Многие пользователи выразили обеспокоенность тем, что IMPORTXML и IMPORTHTML не работают в Google Sheets. Всякий раз, когда пользователи пытаются использовать любую из этих двух формул, вместо этого они застревают на экране загрузки данных. Если у вас также возникают проблемы с тем же, то это руководство поможет вам. Следуйте инструкциям.
На данный момент единственный способ исправить эту проблему — создать новый лист, а затем использовать формулу на этом новом листе. Если ваши данные уже присутствовали на старом листе, вам придется перенести их на этот новый лист и соответствующим образом изменить его структуру. В конечном итоге это займет значительное количество времени и никоим образом не является наиболее осуществимым подходом. Но на данный момент это единственный способ решить проблему, когда IMPORTXML и IMPORTHTML не работают в Google Таблицах.
Что касается официальной позиции по этому вопросу, Google выкатить патч 8 марта, чтобы устранить эту ошибку. Однако, похоже, ему не удалось исправить основную проблему. Итак, 10 марта они уведомил пользователей чтобы опробовать вышеупомянутый обходной путь и сказал, что исправление будет выпущен на этой неделе, но это еще впереди. Когда это произойдет, мы соответствующим образом обновим это руководство. А пока у вас нет другого выбора, кроме как придерживаться вышеупомянутого метода.
На самом деле, конечно, UrlFetchApp срабатывает. Просто надо немножко разобраться.
Wildberries
Год назад Wildberries поддавался importxml, но всё течёт, всё изменяется и теперь даже стандартный UrlFetchApp по ссылке не выдает ничего.
Итак. Иду на вышеупомянутый сайт:

Как и писал выше, UrlFetchApp просто по ссылке https://www.wildberries.ru/catalog/16034937/detail.aspx не сработает.
Для того, чтобы все «взлетело» делаю следующее:
- Открываю код:

2. Перехожу в «Сеть»:

3. Нажимаю F5, обновляю страницу:

4. Нахожу details?spp:

5. Перехожу по URL запроса:

И это ни что иное, как объект, содержащий всю информацию по товару.
Script editor
Дальше все стандартно:
const link = "https://card.wb.ru/cards/detail?spp=0®ions=68,64,83,4,38,80,33,70,82,86,75,30,69,22,66,31,40,1,48,71&pricemarginCoeff=1.0®=0&appType=1&emp=0&locale=ru&lang=ru&curr=rub&couponsGeo=12,3,18,15,21&dest=-1029256,-51490,12358263,123585548&nm=16034937;43603695;43604494;49286601;75008593;119123172"
function parseWBPrice() {
const response = UrlFetchApp.fetch(link, { muteHttpExceptions: true }).getContentText();
const parsedResponse = JSON.parse(response);
const itemName = parsedResponse.data.products[2]['name']
const itemPrice = parsedResponse.data.products[2]['salePriceU'] / 100
console.log(itemName + " стоит: "+ itemPrice)
return itemPrice
}
запускаю, проверяю:

Комментарии к коду
const response = UrlFetchApp.fetch(link, { muteHttpExceptions: true }).getContentText();
const parsedResponse = JSON.parse(response);
Так как UrlFetchApp возвращает текст, а по ссылке это объект, то через JSON.parse делаю его в скрипте так же объектом.
const itemName = parsedResponse.data.products[2]['name']
const itemPrice = parsedResponse.data.products[2]['salePriceU'] / 100
Нахожу в массиве объектов нужную цену salePriceU.
return itemPrice — возвращаю цену, как результат работы функции.
Гугл таблицы
Чтобы парсить не в редакторе скриптов, а в таблицах, необходимо чуть-чуть поправить код:
function parseWBPrice(link) {
const response = UrlFetchApp.fetch(link, { muteHttpExceptions: true }).getContentText();
const parsedResponse = JSON.parse(response);
const itemPrice = parsedResponse.data.products[2]['salePriceU'] / 100
return itemPrice
}
Убираю жестко прописанный const link и передаю его как параметр функции function parseWBPrice(link)
Перехожу в таблицы:

в ячейку А1 вставляю ссылку запроса, в В1 — формулу =parseWBPrice(A2):

Вот и всё. Теперь здесь будет актуальная цена при каждом открытии таблицы или обращению по триггеру.