Описание ошибки:
Платоформа 1С: Предприятие 8.3.16.1148. Клиент-серверный вариант работы базы на СУБД PostgreSQL. Ошибка втречалась при попытке выгрузить базу через «Администрирование» — «Выгрузить информационную базу…», т.е. при попытке выгрузить информационную базу в архив .dt.
Найденные решения:

Как было указано в кратком описании ошибки — база клиент-серверная на СУБД PostgreSQL. Логично, если перевести формулировку «out of memory for query result» — «недостаточно памяти для результата запроса». Так же само «Ошибка СУБД» отправляет решать проблему не на стороне 1С, а на сторону СУБД. Поэтому необходимо изменить параметры использования ресурсов сервера — естественно в сторону увеличения объема используемых ресурсов. В СУБД PostgreSQL это делается путем редактирования соответствующего файла «postgresql.conf», который по умолчанию находится (при установке с параметрами «по умолчанию») в «C:Program Files (x86)PostgreSQL9.4.2-1.1Cdata» для x32-версии и в «C:Program FilesPostgreSQL9.4.2-1.1Cdata» для x64-версии.

В этот статье нет смысла описывать актуальные параметры настроек файла конфигурации «postgresql.conf», в помощь по этому вопросу соответствующая исчерпывающая публикация на сайте профессионального сообщества infostart.ru:
Настройка PostgreSQL для работы в связке с 1С 8.х на ОС Windows
После изменения и сохранения параметров в «postgresql.conf». Необходимо перезапустить службу «PostgreSQL Database Server …» в «Службах» операционной системы Windows сервера, чтобы новые параметры вступили в силу.

Если все-таки не получилось изменить параметры использования ресурсов в файле конфигурации СУБД «postgresql.conf» по каким-либо причинам, то попробуйте выполнить операцию, которая завершается ошибкой «Ошибка СУБД: out of memory for query result» не на самом сервере, а на одном из клиентских рабочих мест. Если не получится на одном, то попробуйте на другом — на практике так получалось обходить ошибку.
Оцените, помогло ли Вам предоставленное описание решения ошибки?



© www.azhur-c.ru 2014-2020. Все права защищены. Использование текстов и изображений с данной страницы без письменного разрешения владельца запрещено. При использовании материалов с данной страницы обязательно указание ссылки на данную страницу.
22-09-2020
Журавлев А.С.
(Сайт azhur-c.ru)
Пользуясь базами данных любой программы 1С, сотрудники предприятий и организаций часто сталкиваются с непредвиденными ситуациями. Пожалуй, одна из самых частых — когда работа программы внезапно завершается по причине того, что администратор разорвал контакт с сервером.
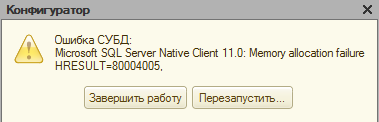
В данном случае Microsoft OLE DB Provider for SQL Server выдаёт такую информацию: «Неопознанная ошибка hresult 80004005». При этом главным признаком проблемы является невозможность выгрузить информацию в базу.
Следует отметить, что ошибки, содержащие именно код 80004005, встречаются постоянно. У них есть особая классификация, которую при желании можно найти в соответствующей литературе.
Для начала нужно провести проверку конфигурации. Там может содержаться мусор (иными, словами, информация, которая является некорректной). Необходимо проверить конфигурацию с помощью соответствующей команды. Вы увидите флажок, предназначенный для того, чтобы проверить её логическую целостность. Если имеются проблемы, пользователь будет уведомлен об этом с помощью сообщения.
Данные, являющиеся неверными, система удалит в автоматическом режиме, но для этого нужно дать ей доступ, чтобы она изменила главный объект. К примеру, если вы работаете в облачном хранилище, его надо просто захватить.
Поддержка конфигурации требует её проверки и у поставщиков. С этой целью:
- нужно сохранить данные о конфигурации поставщиков. Для этого используйте CF-файл;
- теперь необходимо провести загрузку файла в обновлённую базу;
- выполните операцию, которая описана в п.1.
При получении сообщения об исправлении ошибки имейте в виду то, что конфигурация, имеющаяся у поставщика, содержала неправильные данные. Если такое произошло, снимите свою конфигурацию с поддержки и установите её снова. При этом её надо объединить с новой (от поставщика).
Сейчас уже любой релиз, который выпускает 1С, не имеет таких сложностей.
Сопутствующая проблема и методы её решения
С ситуацией, описанной ранее, тесно связана ещё одна, происходящая параллельно. Выглядит она так: 10007066.
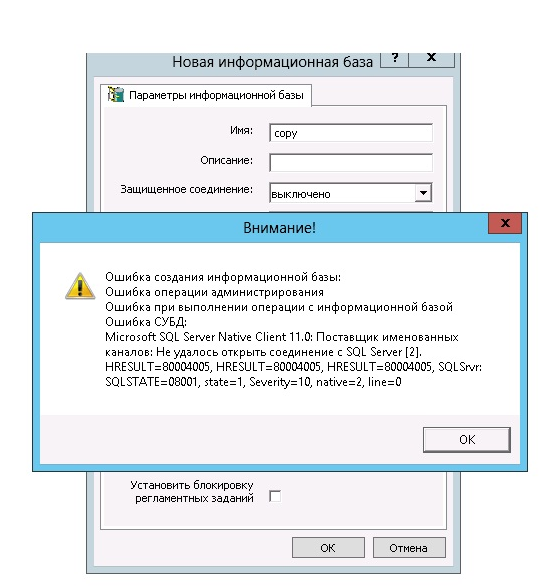
Суть проблемы: когда используется СУБД MS SQL SERVER, во время записи объекта из базы с несколькими колонками (например, «Значения» и «Хранилища»), часто случается другой тип ошибки.
Выглядит она таким образом:
Ошибка СУБД:Microsoft OLE DB Provider for SQL Server: String data length mismatchHRESULT=80004005.
Когда происходит ошибка 1с hresult clr 80004005, программа завершает свою работу в аварийном режиме.
Если вы ознакомитесь во время загрузки программы со специальным журналом (речь идёт о технологическом журнале), там есть табличка, содержащая информацию об этих хранилищах.
С помощью средств MS SQL Server Query Analizer нужно найти в табличке несколько колонок image и сделать для каждой следующий запрос
select top 10 DATALENGTH(_Fld4044 from _InfoReg4038 order by DATALENGTH(_Fld4044) desc
При этом, со стороны стандартных проверок, проводимых платформой (chdbfl), поступит информация о том, что база полностью в порядке.
Ошибка выделения памяти hresult 80004005 (на английском это out of memory for query result 1с) может происходить вследствие различных причин, имеющей общую черту. Для системы 1С это, прежде всего, недостаток оперативной памяти. Если говорить точнее, речь идёт о некорректном применении возможностей памяти, поэтому для решения задачи лучше использовать несколько косвенных алгоритмов.
Необходимо сделать рестарт (перезапуск) сервера. Таким образом памяти, которая доступна для работы, временно станет больше. Также есть возможность воспользоваться сервером в 64 разряда, содержащем приложения.
Исходя из опыта, ошибка СУБД hresult 80004005 чаще определяется двумя факторами:
- данные хранятся в хранилище значений (реквизите);
- в таблице конфигураций содержатся двоичные данные объёмом более 120 мегабайт.
Когда советы от сотрудников 1С не приносят результата (ошибка 1с hresult 80004005 остаётся), попробуйте воспользоваться другой пошаговой инструкцией:
Наши постоянные клиенты по 1С:









- используйте все базы, включив у них все фоновые задачи;
- в 8.1.11. должен появиться переключатель о запрете на фоновые задачи (во время создания базы);
- сделайте перезапуск сервера.
Имеет смысл проверки работоспособности. Тем не менее вследствие утечек памяти проблема может возникнуть снова — после перезапуска. В этом случае целесообразно:
- воспользоваться инструментами sql и сделать бэкап;
- снять базу с поддержки;
- выгрузить cf.
Во время любых действий следует копировать файлы в резерв, так как в любой момент может возникнуть необходимость возвращения к исходному статусу информации. Далее надо убрать в менеджменте консоли (config) запись «более 120 мегабайт» и провести загрузку конфигурации (не объединять, а загрузить).
Есть ещё один способ, с помощью которого неопознанная ошибка субд hresult 80004005 может быть исправлена. Нужно открыть конфигуратор и снять конфигурацию, не сохраняя её. Далее, сохранив, нужно поместить её в отдельный файл без сохранения её изменённого вида.
Выполните в SQL операцию, предназначенную для конкретной базы:
DELETE FROM dbo.Config WHERE DataSize > 125829120
После выполнения этой команды проведите загрузку сохранённой конфигурации.
Что касается радикальных шагов, используемых в особо трудных ситуациях, иногда помогает такая схема:
- удалите таблицу config из базы данных, воспользовавшись менеджментом консоли DROP TABLE [dbo].[Config];
- проведите загрузку конфигурации (не «объединить»,а именно «загрузить»).
После проведения проверки проблема должна уйти.
- Стоимость работ специалистов IT Rush — 2000 руб./час
- Абонемент от 50 часов в месяц – 1900 руб./час
- Абонемент от 100 часов в месяц – 1800 руб./час
Нам доверяют:

Александр Рудницкий
Программист 1С компании CorpSoft24
Ошибка системы «1С: Предприятие 8.3» из-за нехватки памяти — постоянный спутник администратора 1С. Разбираемся, из-за чего они возникают, и рассматриваем пример диагностики одного подобного эпизода из практики администрирования сервера 1С.
Природа проблемы
Сообщение «Недостаточно памяти» — одна из самых часто встречающихся ошибок при работе с 1С: Предприятие версии 8.3 и выше. Она происходит по самым разным причинам — от обработки системой нескольких массивных файлов и загрузки больших объёмов данных, до обновления ПО и перегрузки ресурсов при формирования сложных отчётов.
Она не так критична при возникновении на клиентском компьютере, а вот если сообщение об ошибке выдает сервер 1С, нужно отнестись к этому максимально внимательно. Это тот самый случай, когда очень важно установить правильный «диагноз» — то есть решения не будет, пока ответственный администратор не распознает источник проблемы, не поймёт её природу.
Проблема может заключаться в несвоевременном завершении процессов, запускаемых различным ПО. Они накапливаются и перегружают доступный объём памяти на сервере. Также может иметь место интенсивная работа различных программ с постоянным резервированием и освобождением ресурсов памяти.
Приведу пример расследования одной подобной ошибки из своей практики.
Инцидент
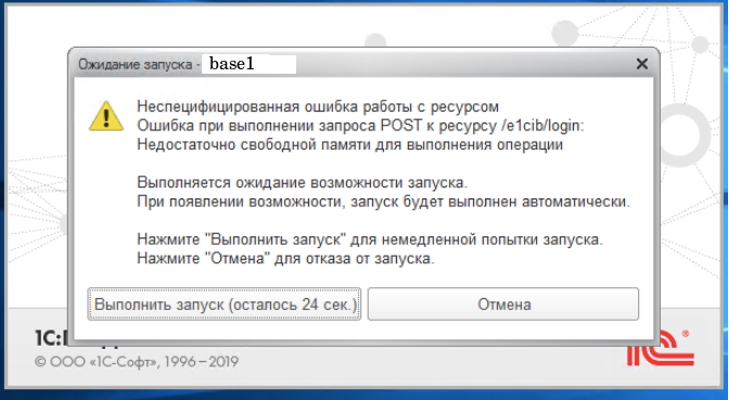
Поступило обращение со следующей ошибкой:
Смотрим журнал регистрации, там так же выводится ошибка с пояснением о нехватке памяти на сервере:


Настроив технологический журнал (ТЖ) системы 1С с событием EXCP — EXCPCNTX обнаруживаем запись:
Ошибка СУБД out of memory for query result
То есть, обе ошибки сообщают о проблеме объёма памяти, на основании чего нашим главным подозреваемым становится код конфигурации (возможно наличие неоптимальных запросов).
Находим код конфигурации, вызывающий ошибку.
В журнале регистрации указан следующий код:
{ОбщийМодуль.ДокументооборотСКОВызовСервера.Модуль(22)}: Ошибка при вызове метода контекста (Получить)
по причине:
Недостаточно памяти для получения результата запроса к базе данных
Открываем конфигуратор и переходим в указанный модуль к указанному номеру строки кода:
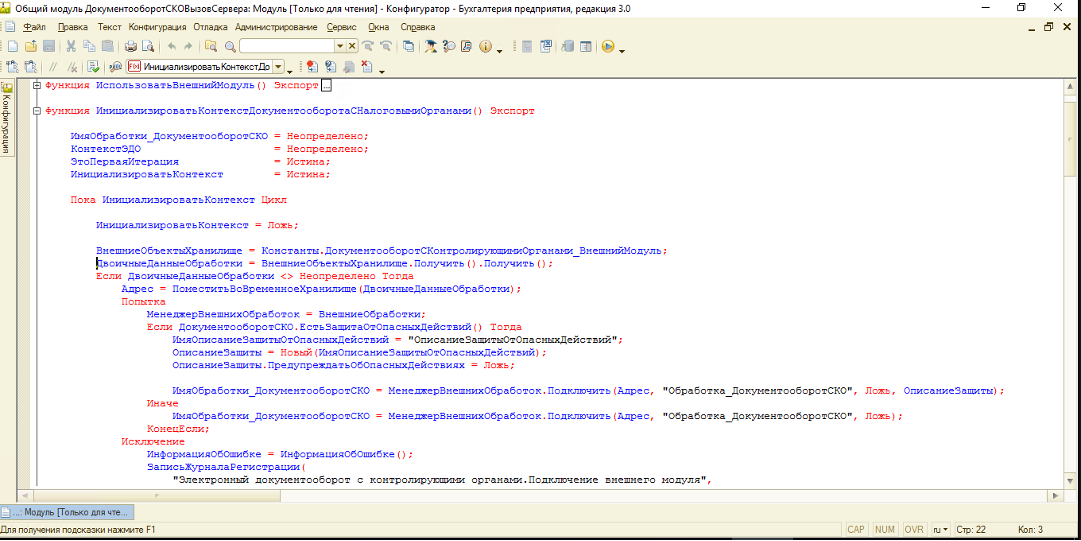
Строка, на которой произошла ошибка:
ВнешниеОбъектыХранилище = Константы.ДокументооборотСКонтролирующимиОрганами_ВнешнийМодуль;
ДвоичныеДанныеОбработки = ВнешниеОбъектыХранилище.Получить().Получить();Смотрим тип объекта (константы), к которой идёт обращение:
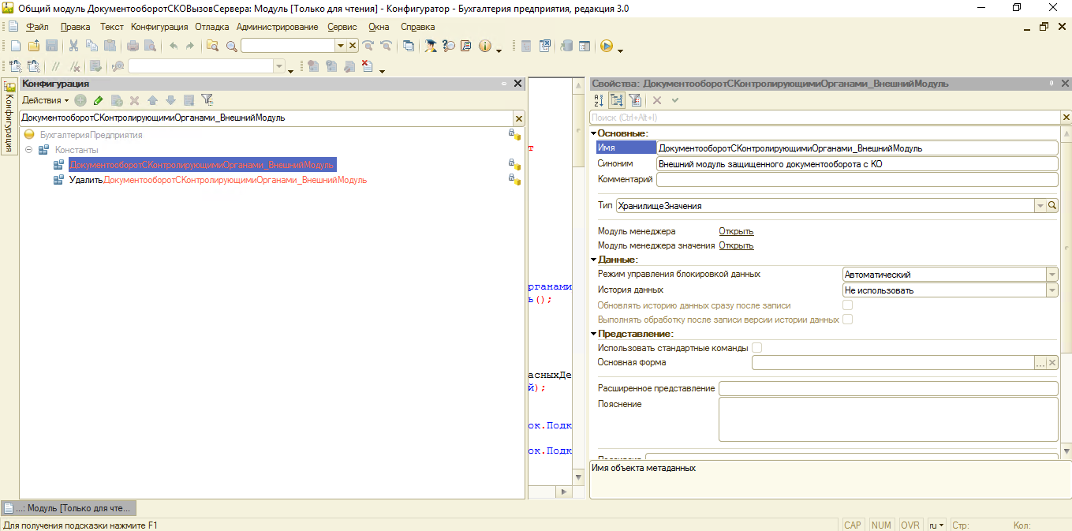
Итак, в конфигурации есть константа:
ДокументооборотСКонтролирующимиОрганами_ВнешнийМодульОна хранит в базе что-то неструктурированное (двоичные данные), что может занимать значительный объём памяти.
Проверяем, какой объем данных фактически занимает константа. Для этого узнаем имя таблицы хранения в базе PostgreSQL — таблица «_Const10013», индекс «_Const10013_ByKey».
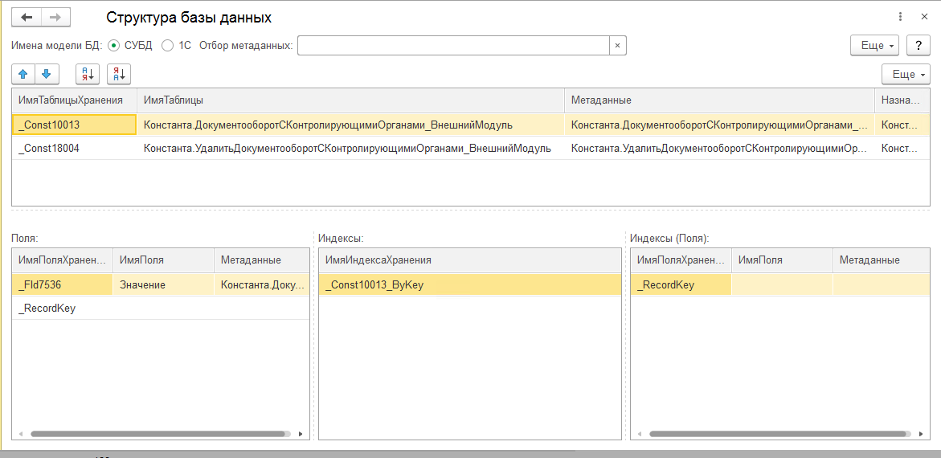
Узнаем размер таблиц «Const10013», «_Const10013_ByKey» на диске:

На диске таблица занимает всего 4688 Кб = 4,6 Мб. Размер является незначительным, значит, причина не в константе.
Обнаруживаем, что кластер 1С является 32-разрядным:

32-разрядный кластер 1С имеет ограничение примерно в 3.8 Гб, при достижении которого происходит падение процесса. В режиме отсутствия нагрузки rphost занял 3,2 Гб, что близко к порогу падения. Подобные инциденты будут происходить в любой момент времени.
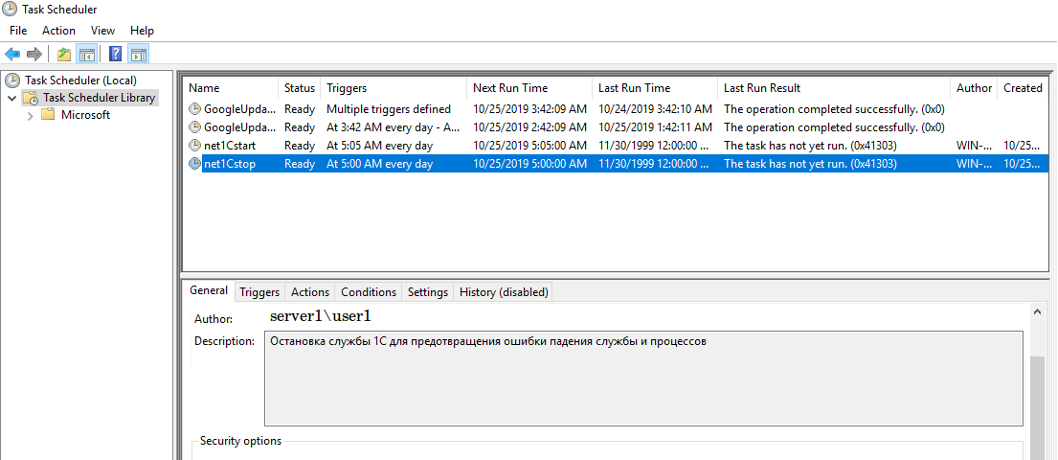
Внесены изменения:
- В кластере серверов 1С «Интервал превышения допустимого объёма памяти процессов» = 300. Настройка не избавляет от ошибки, но необходима для снижения частоты возникновения ошибки.
- В планировщике Windows настроен перезапуск службы 1С; такими образом освобождается виртуальное адресное пространство в памяти, создаётся новый рабочий процесс.
Настройка также не гарантирует от ошибки, но снижает вероятность её возникновения.
Для предотвращения повторной ошибки следует:
- Сменить 32-разрядный кластер серверов 1С на 64-разрядный.
- Так как на сервере используется 14 ядер процессора, необходимо осуществить переход на платформенные лицензии 1С КОРП для снятия ограничений по настройкам и обеспечения возможностей для гибкой настройки распределения памяти сервера.
Другие варианты
Зачастую, особенно в ситуации, когда нужно срочно вернуть систему в работоспособное состояние при возникновении подобной ошибки, можно попробовать такие «дедовские» способы, как перезагрузка сервера 1С или перезапуск рабочих процессов 1С, что приведёт к уменьшению объёма используемой памяти.
Источником проблемы также может быть недостаток пространства на жестком диске сервера. Здесь решение будет зависеть от устройство сервера или кластера, но здесь также могут помочь и перезапуск сервера, и наращивание ёмкости диска (или освобождение существующего пространства), а также оптимизация запросов или обновление версии ПО системы.
(8) # ——————————
# PostgreSQL configuration file
# ——————————
# — Connection Settings —
listen_addresses = ‘*’ # what IP address(es) to listen on;
# comma-separated list of addresses;
# defaults to ‘localhost’; use ‘*’ for all
# (change requires restart)
port = 5432 # (change requires restart)
max_connections = 100 # (change requires restart)
#superuser_reserved_connections = 3 # (change requires restart)
#unix_socket_directories = » # comma-separated list of directories
# (change requires restart)
#unix_socket_group = » # (change requires restart)
#unix_socket_permissions = 0777 # begin with 0 to use octal notation
# (change requires restart)
#bonjour = off # advertise server via Bonjour
# (change requires restart)
#bonjour_name = » # defaults to the computer name
# (change requires restart)
# — Security and Authentication —
#authentication_timeout = 1min # 1s-600s
#ssl = off # (change requires restart)
#ssl_ciphers = ‘HIGH:MEDIUM:+3DES:!aNULL’ # allowed SSL ciphers
# (change requires restart)
#ssl_prefer_server_ciphers = on # (change requires restart)
#ssl_ecdh_curve = ‘prime256v1’ # (change requires restart)
#ssl_cert_file = ‘server.crt’ # (change requires restart)
#ssl_key_file = ‘server.key’ # (change requires restart)
#ssl_ca_file = » # (change requires restart)
#ssl_crl_file = » # (change requires restart)
#password_encryption = on
#db_user_namespace = off
#row_security = on
# GSSAPI using Kerberos
#krb_server_keyfile = »
#krb_caseins_users = off
# — TCP Keepalives —
# see «man 7 tcp» for details
#tcp_keepalives_idle = 0 # TCP_KEEPIDLE, in seconds;
# 0 selects the system default
#tcp_keepalives_interval = 0 # TCP_KEEPINTVL, in seconds;
# 0 selects the system default
#tcp_keepalives_count = 0 # TCP_KEEPCNT;
# 0 selects the system default
#——————————————————————————
# RESOURCE USAGE (except WAL)
#——————————————————————————
# — Memory —
shared_buffers = 128MB # min 128kB
# (change requires restart)
#huge_pages = try # on, off, or try
# (change requires restart)
#temp_buffers = 8MB # min 800kB
#max_prepared_transactions = 0 # zero disables the feature
# (change requires restart)
# Caution: it is not advisable to set max_prepared_transactions nonzero unless
# you actively intend to use prepared transactions.
#work_mem = 4MB # min 64kB
#maintenance_work_mem = 64MB # min 1MB
#replacement_sort_tuples = 150000 # limits use of replacement selection sort
#autovacuum_work_mem = -1 # min 1MB, or -1 to use maintenance_work_mem
#max_stack_depth = 2MB # min 100kB
dynamic_shared_memory_type = windows # the default is the first option
# supported by the operating system:
# posix
# sysv
# windows
# mmap
# use none to disable dynamic shared memory
# — Disk —
#temp_file_limit = -1 # limits per-process temp file space
# in kB, or -1 for no limit
# — Kernel Resource Usage —
#max_files_per_process = 1000 # min 25
# (change requires restart)
shared_preload_libraries = ‘online_analyze, plantuner’ # (change requires restart)
# — Cost-Based Vacuum Delay —
#vacuum_cost_delay = 0 # 0-100 milliseconds
#vacuum_cost_page_hit = 1 # 0-10000 credits
#vacuum_cost_page_miss = 10 # 0-10000 credits
#vacuum_cost_page_dirty = 20 # 0-10000 credits
#vacuum_cost_limit = 200 # 1-10000 credits
# — Background Writer —
#bgwriter_delay = 200ms # 10-10000ms between rounds
#bgwriter_lru_maxpages = 100 # 0-1000 max buffers written/round
#bgwriter_lru_multiplier = 2.0 # 0-10.0 multiplier on buffers scanned/round
#bgwriter_flush_after = 0 # measured in pages, 0 disables
# — Asynchronous Behavior —
#effective_io_concurrency = 0 # 1-1000; 0 disables prefetching
#max_worker_processes = 8 # (change requires restart)
#max_parallel_workers_per_gather = 0 # taken from max_worker_processes
#old_snapshot_threshold = -1 # 1min-60d; -1 disables; 0 is immediate
# (change requires restart)
#backend_flush_after = 0 # measured in pages, 0 disables
#——————————————————————————
# WRITE AHEAD LOG
#——————————————————————————
# — Settings —
#wal_level = minimal # minimal, replica, or logical
# (change requires restart)
#fsync = on # flush data to disk for crash safety
# (turning this off can cause
# unrecoverable data corruption)
#synchronous_commit = on # synchronization level;
# off, local, remote_write, remote_apply, or on
#wal_sync_method = fsync # the default is the first option
# supported by the operating system:
# open_datasync
# fdatasync (default on Linux)
# fsync
# fsync_writethrough
# open_sync
#full_page_writes = on # recover from partial page writes
#wal_compression = off # enable compression of full-page writes
#wal_log_hints = off # also do full page writes of non-critical updates
# (change requires restart)
#wal_buffers = -1 # min 32kB, -1 sets based on shared_buffers
# (change requires restart)
#wal_writer_delay = 200ms # 1-10000 milliseconds
#wal_writer_flush_after = 1MB # measured in pages, 0 disables
#commit_delay = 0 # range 0-100000, in microseconds
#commit_siblings = 5 # range 1-1000
# — Checkpoints —
#checkpoint_timeout = 5min # range 30s-1d
#max_wal_size = 1GB
#min_wal_size = 80MB
#checkpoint_completion_target = 0.5 # checkpoint target duration, 0.0 — 1.0
#checkpoint_flush_after = 0 # measured in pages, 0 disables
#checkpoint_warning = 30s # 0 disables
# — Archiving —
#archive_mode = off # enables archiving; off, on, or always
# (change requires restart)
#archive_command = » # command to use to archive a logfile segment
# placeholders: %p = path of file to archive
# %f = file name only
# e.g. ‘test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f’
#archive_timeout = 0 # force a logfile segment switch after this
# number of seconds; 0 disables
#——————————————————————————
# REPLICATION
#——————————————————————————
# — Sending Server(s) —
# Set these on the master and on any standby that will send replication data.
#max_wal_senders = 0 # max number of walsender processes
# (change requires restart)
#wal_keep_segments = 0 # in logfile segments, 16MB each; 0 disables
#wal_sender_timeout = 60s # in milliseconds; 0 disables
#max_replication_slots = 0 # max number of replication slots
# (change requires restart)
#track_commit_timestamp = off # collect timestamp of transaction commit
# (change requires restart)
# — Master Server —
# These settings are ignored on a standby server.
#synchronous_standby_names = » # standby servers that provide sync rep
# number of sync standbys and comma-separated list of application_name
# from standby(s); ‘*’ = all
#vacuum_defer_cleanup_age = 0 # number of xacts by which cleanup is delayed
# — Standby Servers —
# These settings are ignored on a master server.
#hot_standby = off # «on» allows queries during recovery
# (change requires restart)
#max_standby_archive_delay = 30s # max delay before canceling queries
# when reading WAL from archive;
# -1 allows indefinite delay
#max_standby_streaming_delay = 30s # max delay before canceling queries
# when reading streaming WAL;
# -1 allows indefinite delay
#wal_receiver_status_interval = 10s # send replies at least this often
# 0 disables
#hot_standby_feedback = off # send info from standby to prevent
# query conflicts
#wal_receiver_timeout = 60s # time that receiver waits for
# communication from master
# in milliseconds; 0 disables
#wal_retrieve_retry_interval = 5s # time to wait before retrying to
# retrieve WAL after a failed attempt
#——————————————————————————
# QUERY TUNING
#——————————————————————————
# — Planner Method Configuration —
#enable_bitmapscan = on
#enable_hashagg = on
#enable_hashjoin = on
#enable_indexscan = on
#enable_indexonlyscan = on
#enable_material = on
#enable_mergejoin = on
#enable_nestloop = on
#enable_seqscan = on
#enable_sort = on
#enable_tidscan = on
# — Planner Cost Constants —
#seq_page_cost = 1.0 # measured on an arbitrary scale
#random_page_cost = 4.0 # same scale as above
#cpu_tuple_cost = 0.01 # same scale as above
#cpu_index_tuple_cost = 0.005 # same scale as above
#cpu_operator_cost = 0.0025 # same scale as above
#parallel_tuple_cost = 0.1 # same scale as above
#parallel_setup_cost = 1000.0 # same scale as above
#min_parallel_relation_size = 8MB
#effective_cache_size = 4GB
# — Genetic Query Optimizer —
#geqo = on
#geqo_threshold = 12
#geqo_effort = 5 # range 1-10
#geqo_pool_size = 0 # selects default based on effort
#geqo_generations = 0 # selects default based on effort
#geqo_selection_bias = 2.0 # range 1.5-2.0
#geqo_seed = 0.0 # range 0.0-1.0
# — Other Planner Options —
#default_statistics_target = 100 # range 1-10000
#constraint_exclusion = partition # on, off, or partition
#cursor_tuple_fraction = 0.1 # range 0.0-1.0
#from_collapse_limit = 8
#join_collapse_limit = 8 # 1 disables collapsing of explicit
# JOIN clauses
#force_parallel_mode = off
#——————————————————————————
# ERROR REPORTING AND LOGGING
#——————————————————————————
# — Where to Log —
log_destination = ‘stderr’ # Valid values are combinations of
# stderr, csvlog, syslog, and eventlog,
# depending on platform. csvlog
# requires logging_collector to be on.
# This is used when logging to stderr:
logging_collector = on # Enable capturing of stderr and csvlog
# into log files. Required to be on for
# csvlogs.
# (change requires restart)
# These are only used if logging_collector is on:
log_directory = ‘pg_log’ # directory where log files are written,
# can be absolute or relative to PGDATA
log_filename = ‘postgresql-%a.log’ # log file name pattern,
# can include strftime() escapes
#log_file_mode = 0600 # creation mode for log files,
# begin with 0 to use octal notation
log_truncate_on_rotation = on # If on, an existing log file with the
# same name as the new log file will be
# truncated rather than appended to.
# But such truncation only occurs on
# time-driven rotation, not on restarts
# or size-driven rotation. Default is
# off, meaning append to existing files
# in all cases.
log_rotation_age = 1d # Automatic rotation of logfiles will
# happen after that time. 0 disables.
log_rotation_size = 0 # Automatic rotation of logfiles will
# happen after that much log output.
# 0 disables.
# These are relevant when logging to syslog:
#syslog_facility = ‘LOCAL0’
#syslog_ident = ‘postgres’
#syslog_sequence_numbers = on
#syslog_split_messages = on
# This is only relevant when logging to eventlog (win32):
#event_source = ‘PostgreSQL’
# — When to Log —
#client_min_messages = notice # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# log
# notice
# warning
# error
#log_min_messages = warning # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# info
# notice
# warning
# error
# log
# fatal
# panic
#log_min_error_statement = error # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# info
# notice
# warning
# error
# log
# fatal
# panic (effectively off)
#log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements
# and their durations, > 0 logs only
# statements running at least this number
# of milliseconds
# — What to Log —
#debug_print_parse = off
#debug_print_rewritten = off
#debug_print_plan = off
#debug_pretty_print = on
#log_checkpoints = off
#log_connections = off
#log_disconnections = off
#log_duration = off
#log_error_verbosity = default # terse, default, or verbose messages
#log_hostname = off
log_line_prefix = ‘< %m >’ # special values:
# %a = application name
# %u = user name
# %d = database name
# %r = remote host and port
# %h = remote host
# %p = process ID
# %t = timestamp without milliseconds
# %m = timestamp with milliseconds
# %n = timestamp with milliseconds (as a Unix epoch)
# %i = command tag
# %e = SQL state
# %c = session ID
# %l = session line number
# %s = session start timestamp
# %v = virtual transaction ID
# %x = transaction ID (0 if none)
# %q = stop here in non-session
# processes
# %% = ‘%’
# e.g. ‘<%u%%%d> ‘
#log_lock_waits = off # log lock waits >= deadlock_timeout
#log_statement = ‘none’ # none, ddl, mod, all
#log_replication_commands = off
#log_temp_files = -1 # log temporary files equal or larger
# than the specified size in kilobytes;
# -1 disables, 0 logs all temp files
log_timezone = ‘Europe/Moscow’
# — Process Title —
#cluster_name = » # added to process titles if nonempty
# (change requires restart)
#update_process_title = off
#——————————————————————————
# RUNTIME STATISTICS
#——————————————————————————
# — Query/Index Statistics Collector —
#track_activities = on
#track_counts = on
#track_io_timing = off
#track_functions = none # none, pl, all
#track_activity_query_size = 1024 # (change requires restart)
#stats_temp_directory = ‘pg_stat_tmp’
# — Statistics Monitoring —
#log_parser_stats = off
#log_planner_stats = off
#log_executor_stats = off
#log_statement_stats = off
#——————————————————————————
# AUTOVACUUM PARAMETERS
#——————————————————————————
#autovacuum = on # Enable autovacuum subprocess? ‘on’
# requires track_counts to also be on.
#log_autovacuum_min_duration = -1 # -1 disables, 0 logs all actions and
# their durations, > 0 logs only
# actions running at least this number
# of milliseconds.
#autovacuum_max_workers = 3 # max number of autovacuum subprocesses
# (change requires restart)
#autovacuum_naptime = 1min # time between autovacuum runs
#autovacuum_vacuum_threshold = 50 # min number of row updates before
# vacuum
#autovacuum_analyze_threshold = 50 # min number of row updates before
# analyze
#autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum
#autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze
#autovacuum_freeze_max_age = 200000000 # maximum XID age before forced vacuum
# (change requires restart)
#autovacuum_multixact_freeze_max_age = 400000000 # maximum multixact age
# before forced vacuum
# (change requires restart)
#autovacuum_vacuum_cost_delay = 20ms # default vacuum cost delay for
# autovacuum, in milliseconds;
# -1 means use vacuum_cost_delay
#autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for
# autovacuum, -1 means use
# vacuum_cost_limit
#——————————————————————————
# CLIENT CONNECTION DEFAULTS
#——————————————————————————
# — Statement Behavior —
#search_path = ‘»$user», public’ # schema names
#default_tablespace = » # a tablespace name, » uses the default
#temp_tablespaces = » # a list of tablespace names, » uses
# only default tablespace
#check_function_bodies = on
#default_transaction_isolation = ‘read committed’
#default_transaction_read_only = off
#default_transaction_deferrable = off
#session_replication_role = ‘origin’
#statement_timeout = 0 # in milliseconds, 0 is disabled
#lock_timeout = 0 # in milliseconds, 0 is disabled
#idle_in_transaction_session_timeout = 0 # in milliseconds, 0 is disabled
#vacuum_freeze_min_age = 50000000
#vacuum_freeze_table_age = 150000000
#vacuum_multixact_freeze_min_age = 5000000
#vacuum_multixact_freeze_table_age = 150000000
#bytea_output = ‘hex’ # hex, escape
#xmlbinary = ‘base64’
#xmloption = ‘content’
#gin_fuzzy_search_limit = 0
#gin_pending_list_limit = 4MB
# — Locale and Formatting —
datestyle = ‘iso, dmy’
#intervalstyle = ‘postgres’
timezone = ‘Europe/Moscow’
#timezone_abbreviations = ‘Default’ # Select the set of available time zone
# abbreviations. Currently, there are
# Default
# Australia (historical usage)
# India
# You can create your own file in
# share/timezonesets/.
#extra_float_digits = 0 # min -15, max 3
#client_encoding = sql_ascii # actually, defaults to database
# encoding
# These settings are initialized by initdb, but they can be changed.
lc_messages = ‘Russian_Russia.1251’ # locale for system error message
# strings
lc_monetary = ‘Russian_Russia.1251’ # locale for monetary formatting
lc_numeric = ‘Russian_Russia.1251’ # locale for number formatting
lc_time = ‘Russian_Russia.1251’ # locale for time formatting
# default configuration for text search
default_text_search_config = ‘pg_catalog.russian’
# — Other Defaults —
#dynamic_library_path = ‘$libdir’
#local_preload_libraries = »
#session_preload_libraries = »
#——————————————————————————
# LOCK MANAGEMENT
#——————————————————————————
#deadlock_timeout = 1s
max_locks_per_transaction = 150 # min 10
# (change requires restart)
#max_pred_locks_per_transaction = 64 # min 10
# (change requires restart)
#——————————————————————————
# VERSION/PLATFORM COMPATIBILITY
#——————————————————————————
# — Previous PostgreSQL Versions —
#array_nulls = on
#backslash_quote = safe_encoding # on, off, or safe_encoding
#default_with_oids = off
#escape_string_warning = on
#lo_compat_privileges = off
#operator_precedence_warning = off
#quote_all_identifiers = off
#sql_inheritance = on
#standard_conforming_strings = on
#synchronize_seqscans = on
# — Other Platforms and Clients —
#transform_null_equals = off
#——————————————————————————
# ERROR HANDLING
#——————————————————————————
#exit_on_error = off # terminate session on any error?
#restart_after_crash = on # reinitialize after backend crash?
#——————————————————————————
# CONFIG FILE INCLUDES
#——————————————————————————
# These options allow settings to be loaded from files other than the
# default postgresql.conf.
#include_dir = ‘conf.d’ # include files ending in ‘.conf’ from
# directory ‘conf.d’
#include_if_exists = ‘exists.conf’ # include file only if it exists
#include = ‘special.conf’ # include file
#——————————————————————————
# CUSTOMIZED OPTIONS
#——————————————————————————
online_analyze.threshold = 50
online_analyze.scale_factor = 0.1
online_analyze.enable = off
online_analyze.verbose = off
online_analyze.local_tracking = on
online_analyze.min_interval = 10000
online_analyze.table_type = ‘temporary’
Расследование
возникшей ошибки нехватки памяти на
сервере 1С
Поступило
обращение со следующей
ошибкой:
«Неспецифицированная ошибка
работы с ресурсом
Ошибка при выполнении
запроса POST к ресурсу /e1cib/login:
Недостаточно
свободной памяти для выполнения
операции
Выполняется ожидание
возможности запуска.
При
появлении возможности, запуск будет
выполнен автоматически.
Нажмите «Выполнить запуск» для немедленной
попытки запуска.
Нажмите «Отмена» для отказа от запуска.»

Смотрим
журнал регистрации:


Настроив
ТЖ с событием EXCP, EXCPCNTX обнаруживаем
запись:
«Ошибка
СУБД out of memory for query result»
Обе
ошибки сообщают о проблеме объема
памяти, на основании которых подозреваемым
становится код конфигурации (возможно
наличие неоптимальных запросов).
Находим
код конфигурации, вызывающий ошибку:
В
журнале регистрации указан следующий
код:
{ОбщийМодуль.ДокументооборотСКОВызовСервера.Модуль(22)}:
Ошибка при вызове метода контекста
(Получить)
по
причине:
по
причине:
Недостаточно
памяти для получения результата запроса
к базе данных
Открываем
конфигуратор и переходим в указанный
модуль к указанному номеру строки кода:

Строка,
на которой произошла ошибка:
ВнешниеОбъектыХранилище
= Константы.ДокументооборотСКонтролирующимиОрганами_ВнешнийМодуль;
ДвоичныеДанныеОбработки
= ВнешниеОбъектыХранилище.Получить().Получить();
Смотрим
тип объекта (константы), к которой идет
обращение:

Итак,
в конфигурации есть константа
«ДокументооборотСКонтролирующимиОрганами_ВнешнийМодуль»,
которая хранит в базе что-то
неструктурированое (двоичные данные),
и это неструктурированное может занимать
значительный объем памяти.
Проверяем,
какой объем данных фактически занимает
константа.
Узнаем
имя таблицы хранения в базе PostgreSQL —
таблица «_Const10013», индекс «_Const10013_ByKey».

Узнаем
размер таблиц «Const10013», «_Const10013_ByKey» на
диске:

На
диске таблица занимает всего 4688 Кб = 4,6
Мб. Размер является незначительным,
причина не в константе.
Обнаруживаем,
что кластер 1С является 32-разрядным:

32-разрядный
кластер 1С имеет ограничение, примерно,
3.8 Гб, по достижении которого происходит
падение процесса, службы.
В
режиме отсутствия нагрузки rphost занял
3,2 Гб, что близко к порогу падения.
Подобные
падения будут происходить в любой момент
времени.
Внесены
изменения:
— в
кластере серверов 1С «Интервал превышения
допустимого объема памяти процессов»
= 300. Настройка не избавляет от ошибки,
но необходима для снижения частоты
возникновения ошибки.
— в
планировщике Windows настроен перезапуск
службы 1С; такими образом освобождается виртуальное адресное пространство
в памяти, создается новый рабочий
процесс. Настройка тоже не гарантирует исключение ошибки, но снижает
вероятность ее возникновения.
Для
предотвращения повторной ошибки
лучше:
—
сменить 32-разрядный кластер серверов
1С на 64-разрядный;
—
осуществить переход на платформенные
лицензии КОРП для снятия ограничений
по настройкам, возможности гибкой
настройки распределения памяти сервера.
Так
как на сервере используется 14 ядер
процессора, то необходим переход на
платформенные лицензии КОРП.