200
Ugh… (309, 400, 403, 409, 415, 422)… a lot of answers trying to guess, argue and standardize what is the best return code for a successful HTTP request but a failed REST call.
It is wrong to mix HTTP status codes and REST status codes.
However, I saw many implementations mixing them, and many developers may not agree with me.
HTTP return codes are related to the HTTP Request itself. A REST call is done using a Hypertext Transfer Protocol request and it works at a lower level than invoked REST method itself. REST is a concept/approach, and its output is a business/logical result, while HTTP result code is a transport one.
For example, returning «404 Not found» when you call /users/ is confuse, because it may mean:
- URI is wrong (HTTP)
- No users are found (REST)
«403 Forbidden/Access Denied» may mean:
- Special permission needed. Browsers can handle it by asking the user/password. (HTTP)
- Wrong access permissions configured on the server. (HTTP)
- You need to be authenticated (REST)
And the list may continue with ‘500 Server error» (an Apache/Nginx HTTP thrown error or a business constraint error in REST) or other HTTP errors etc…
From the code, it’s hard to understand what was the failure reason, a HTTP (transport) failure or a REST (logical) failure.
If the HTTP request physically was performed successfully it should always return 200 code, regardless is the record(s) found or not. Because URI resource is found and was handled by the HTTP server. Yes, it may return an empty set. Is it possible to receive an empty web-page with 200 as HTTP result, right?
Instead of this you may return 200 HTTP code with some options:
- «error» object in JSON result if something goes wrong
- Empty JSON array/object if no record found
- A bool result/success flag in combination with previous options for a better handling.
Also, some internet providers may intercept your requests and return you a 404 HTTP code. This does not means that your data are not found, but it’s something wrong at transport level.
From Wiki:
In July 2004, the UK telecom provider BT Group deployed the Cleanfeed
content blocking system, which returns a 404 error to any request for
content identified as potentially illegal by the Internet Watch
Foundation. Other ISPs return a HTTP 403 «forbidden» error in the same
circumstances. The practice of employing fake 404 errors as a means to
conceal censorship has also been reported in Thailand and Tunisia. In
Tunisia, where censorship was severe before the 2011 revolution,
people became aware of the nature of the fake 404 errors and created
an imaginary character named «Ammar 404» who represents «the invisible
censor».
Why not simply answer with something like this?
{
"result": false,
"error": {"code": 102, "message": "Validation failed: Wrong NAME."}
}
Google always returns 200 as status code in their Geocoding API, even if the request logically fails: https://developers.google.com/maps/documentation/geocoding/intro#StatusCodes
Facebook always return 200 for successful HTTP requests, even if REST request fails: https://developers.facebook.com/docs/graph-api/using-graph-api/error-handling
It’s simple, HTTP status codes are for HTTP requests. REST API is Your, define Your status codes.
Справочник ошибок и ответов API
При выполнении некорректного запроса к системе наше API может вернуть код ошибки, в случае же верного запроса, API вернёт ответ. Вы, конечно, уже обрабатывали ответ сервера в ходе отладки своих виджетов или написании скриптов, взаимодействующих с нашей системой. Для Вашего удобства, мы решили систематизировать все возможные ответы и ошибки, отдаваемые нашей системой и разместить их на отдельной странице. Надеемся это облегчит и ускорит интеграцию Ваших проектов с amoCRM.
Ошибки при валидации данных
Если переданные данные не совпадают с теми, что доступны для сущности, запрос вернет HTTP-код 400 Bad Request и массив с параметрами, которые не подошли под условия.
Пример ошибки валидации данных
{
"validation-errors": [
{
"request_id": "0",
"errors": [
{
"code": "NotSupportedChoice",
"path": "custom_fields_values.0.field_id",
"detail": "The value you selected is not a valid choice."
}
]
}
],
"title": "Bad Request",
"type": "https://httpstatus.es/400",
"status": 400,
"detail": "Request validation failed"
}
Ответы при авторизации
Подробнее об авторизации читайте здесь
| Код | HTTP код | Описание |
|---|---|---|
| 110 | 401 Unauthorized | Общая ошибка авторизации. Неправильный логин или пароль. |
| 111 | 401 Unauthorized | Возникает после нескольких неудачных попыток авторизации. В этом случае нужно авторизоваться в аккаунте через браузер, введя код капчи. |
| 112 | 401 Unauthorized | Возникает, когда пользователь выключен в настройках аккаунта “Пользователи и права” или не состоит в аккаунте. |
| 113 | 403 Forbidden | Доступ к данному аккаунту запрещён с Вашего IP адреса. Возникает, когда в настройках безопасности аккаунта включена фильтрация доступа к API по “белому списку IP адресов”. |
| 101 | 401 Unauthorized | Возникает в случае запроса к несуществующему аккаунту (субдомену). |
Ответы при работе с контактами
Подробнее о работе с контактами читайте здесь
| Код | Описание |
|---|---|
| 202 | Добавление контактов: нет прав |
| 203 | Добавление контактов: системная ошибка при работе с дополнительными полями |
| 205 | Добавление контактов: контакт не создан |
| 212 | Обновление контактов: контакт не обновлён |
| 219 | Список контактов: ошибка поиска, повторите запрос позднее |
| 330 | Добавление/Обновление контактов: количество привязанных сделок слишком большое |
Ответы при работе со сделками
Подробнее о работе со сделками читайте здесь
| Код | Описание |
|---|---|
| 330 | Добавление/Обновление сделок: количество привязанных контактов слишком большое |
Ответы при работе с событиями
Подробнее о работе с событиями читайте здесь
| Код | Описание |
|---|---|
| 244 | Добавление событий: недостаточно прав для добавления события |
| 225 | Обновление событий: события не найдены |
Ответы при работе с задачами
Подробнее о работе с задачами читайте здесь
| Код | Описание |
|---|---|
| 231 | Обновление задач: задачи не найдены |
| 233 | Добавление событий: по данному ID элемента не найдены некоторые контакты |
| 234 | Добавление событий: по данному ID элемента не найдены некоторые сделки |
| 235 | Добавление задач: не указан тип элемента |
| 236 | Добавление задач: по данному ID элемента не найдены некоторые контакты |
| 237 | Добавление задач: по данному ID элемента не найдены некоторые сделки |
| 244 | Добавление сделок: нет прав. |
Ответы при работе со списками
Подробнее о работе со списками читайте здесь
| Код | Описание |
|---|---|
| 244 | Добавление/Обновление/Удаление каталогов: нет прав. |
| 281 | Каталог не удален: внутренняя ошибка |
| 282 | Каталог не найден в аккаунте. |
Ответы при работе с элементами каталога
Подробнее о работе с элементами каталога читайте здесь
| Код | Описание |
|---|---|
| 203 | Добавление/Обновление элементов каталога: системная ошибка при работе с дополнительными полями |
| 204 | Добавление/Обновление элементов каталога: дополнительное поле не найдено |
| 244 | Добавление/Обновление/Удаление элементов каталога: нет прав. |
| 280 | Добавление элементов каталога: элемент создан. |
| 282 | Элемент не найден в аккаунте. |
Ответы при работе с покупателями
Подробнее о работе с покупателями читайте здесь
| Код | Описание |
|---|---|
| 288 | Недостаточно прав. Доступ запрещен. |
| 402 | Необходимо оплатить функционал |
| 425 | Функционал недоступен |
| 426 | Функционал выключен |
Другие ответы
Ошибки и ответы, не относящиеся к какому-либо конкретному разделу
| Код | Описание | Примечание |
|---|---|---|
| 400 | Неверная структура массива передаваемых данных, либо не верные идентификаторы кастомных полей | |
| 422 | Входящие данные не мог быть обработаны. | |
| 405 | Запрашиваемый HTTP-метод не поддерживается | |
| 402 | Подписка закончилась | Вместе с этим ответом отдаётся HTTP код №402 “Payment Required” |
| 403 | Аккаунт заблокирован, за неоднократное превышение количества запросов в секунду | Вместе с этим ответом отдаётся HTTP код №403 |
| 429 | Превышено допустимое количество запросов в секунду | Вместе с этим ответом отдаётся HTTP код №429 |
| 2002 | По вашему запросу ничего не найдено | Вместе с этим ответом отдаётся HTTP код №204 “No Content” |
200
Ugh… (309, 400, 403, 409, 415, 422)… a lot of answers trying to guess, argue and standardize what is the best return code for a successful HTTP request but a failed REST call.
It is wrong to mix HTTP status codes and REST status codes.
However, I saw many implementations mixing them, and many developers may not agree with me.
HTTP return codes are related to the HTTP Request itself. A REST call is done using a Hypertext Transfer Protocol request and it works at a lower level than invoked REST method itself. REST is a concept/approach, and its output is a business/logical result, while HTTP result code is a transport one.
For example, returning «404 Not found» when you call /users/ is confuse, because it may mean:
- URI is wrong (HTTP)
- No users are found (REST)
«403 Forbidden/Access Denied» may mean:
- Special permission needed. Browsers can handle it by asking the user/password. (HTTP)
- Wrong access permissions configured on the server. (HTTP)
- You need to be authenticated (REST)
And the list may continue with ‘500 Server error» (an Apache/Nginx HTTP thrown error or a business constraint error in REST) or other HTTP errors etc…
From the code, it’s hard to understand what was the failure reason, a HTTP (transport) failure or a REST (logical) failure.
If the HTTP request physically was performed successfully it should always return 200 code, regardless is the record(s) found or not. Because URI resource is found and was handled by the HTTP server. Yes, it may return an empty set. Is it possible to receive an empty web-page with 200 as HTTP result, right?
Instead of this you may return 200 HTTP code with some options:
- «error» object in JSON result if something goes wrong
- Empty JSON array/object if no record found
- A bool result/success flag in combination with previous options for a better handling.
Also, some internet providers may intercept your requests and return you a 404 HTTP code. This does not means that your data are not found, but it’s something wrong at transport level.
From Wiki:
In July 2004, the UK telecom provider BT Group deployed the Cleanfeed
content blocking system, which returns a 404 error to any request for
content identified as potentially illegal by the Internet Watch
Foundation. Other ISPs return a HTTP 403 «forbidden» error in the same
circumstances. The practice of employing fake 404 errors as a means to
conceal censorship has also been reported in Thailand and Tunisia. In
Tunisia, where censorship was severe before the 2011 revolution,
people became aware of the nature of the fake 404 errors and created
an imaginary character named «Ammar 404» who represents «the invisible
censor».
Why not simply answer with something like this?
{
"result": false,
"error": {"code": 102, "message": "Validation failed: Wrong NAME."}
}
Google always returns 200 as status code in their Geocoding API, even if the request logically fails: https://developers.google.com/maps/documentation/geocoding/intro#StatusCodes
Facebook always return 200 for successful HTTP requests, even if REST request fails: https://developers.facebook.com/docs/graph-api/using-graph-api/error-handling
It’s simple, HTTP status codes are for HTTP requests. REST API is Your, define Your status codes.
Почти все разработчики так или иначе постоянно работают с api по http, клиентские разработчики работают с api backend своего сайта или приложения, а бэкендеры «дергают» бэкенды других сервисов, как внутренних, так и внешних. И мне кажется, одна из самых главных вещей в хорошем API это формат передачи ошибок. Ведь если это сделано плохо/неудобно, то разработчик, использующий это API, скорее всего не обработает ошибки, а клиенты будут пользоваться молчаливо ломающимся продуктом.
За 7 лет я как поддерживал множество legacy API, так и разрабатывал c нуля. И я поработал, наверное, с большинством стратегий по возвращению ошибок, но каждая из них создавала дискомфорт в той или иной мере. В последнее время я нащупал оптимальный вариант, о котором и хочу рассказать, но с начала расскажу о двух наиболее популярных вариантах.
№1: HTTP статусы
Если почитать апологетов REST, то для кодов ошибок надо использовать HTTP статусы, а текст ошибки отдавать в теле или в специальном заголовке. Например:
Success:
HTTP 200 GET /v1/user/1
Body: { name: 'Вася' }Error:
HTTP 404 GET /v1/user/1
Body: 'Не найден пользователь'Если у вас примитивная бизнес-логика или API из 5 url, то в принципе это нормальный подход. Однако как-только бизнес-логика станет сложнее, то начнется ряд проблем.
Http статусы предназначались для описания ошибок при передаче данных, а про логику вашего приложения никто не думал. Статусов явно не хватает для описания всего разнообразия ошибок в вашем проекте, да они и не были для этого предназначены. И тут начинается натягивание «совы на глобус»: все начинают спорить, какой статус ошибки дать в том или ином случае. Пример: Есть API для task manager. Какой статус надо вернуть в случае, если пользователь хочет взять задачу, а ее уже взял в работу другой пользователь? Ссылка на http статусы. И таких проблемных примеров можно придумать много.
REST скорее концепция, чем формат общения из чего следует неоднозначность использования статусов. Разработчики используют статусы как им заблагорассудится. Например, некоторые API при отсутствии сущности возвращают 404 и текст ошибки, а некоторые 200 и пустое тело.
Бэкенд разработчику в проекте непросто выбрать статус для ошибки, а клиентскому разработчику неочевидно какой статус предназначен для того или иного типа ошибок бизнес-логики. По-хорошему в проекте придется держать enum для того, чтобы описать какие ошибки относятся к тому или иному статусу.
Когда бизнес-логика приложения усложняется, начинают делать как-то так:
HTTP 400 PUT /v1/task/1 { status: 'doing' }
Body: { error_code: '12', error_message: 'Задача уже взята другим исполнителем' }
Из-за ограниченности http статусов разработчики начинают вводить “свои” коды ошибок для каждого статуса и передавать их в теле ответа. Другими словами, пользователю API приходится писать нечто подобное:
if (status === 200) {
// Success
} else if (status === 500) {
// some code
} else if (status === 400) {
if (body.error_code === 1) {
// some code
} else if (body.error_code === 2) {
// some code
} else {
// some code
}
} else if (status === 404) {
// some code
} else {
// some code
}Из-за этого ветвление клиентского кода начинает стремительно расти: множество http статусов и множество кодов в самом сообщении. Для каждого ошибочного http статуса необходимо проверить наличие кодов ошибок в теле сообщения. От комбинаторного взрыва начинает конкретно пухнуть башка! А значит обработку ошибок скорее всего сведут к сообщению типа “Произошла ошибка” или к молчаливому некорректному поведению.
Многие системы мониторинга сервисов привязываются к http статусам, но это не помогает в мониторинге, если статусы используются для описания ошибок бизнес логики. Например, у нас резкий всплеск ошибок 429 на графике. Это началась DDOS атака, или кто-то из разработчиков выбрал неудачный статус?
Итог: Начать с таким подходом легко и просто и для простого API это вполне подойдет. Но если логика стала сложнее, то использование статусов для описания того, что не укладывается в заданные рамки протокола http приводит к неоднозначности использования и последующим костылям для работы с ошибками. Или что еще хуже к формализму, что ведет к неприятному пользовательскому опыту.
№2: На все 200
Есть другой подход, даже более старый, чем REST, а именно: на все ошибки связанные с бизнес-логикой возвращать 200, а уже в теле ответа есть информация об ошибке. Например:
Вариант 1:
Success:
HTTP 200 GET /v1/user/1
Body: { ok: true, data: { name: 'Вася' } }
Error:
HTTP 200 GET /v1/user/1
Body: { ok: false, error: { code: 1, msg: 'Не найден пользователь' } }Вариант 2:
Success:
HTTP 200 GET /v1/user/1
Body: { data: { name: 'Вася' }, error: null }
Error:
HTTP 200 GET /v1/user/1
Body: { data: null, error: { code: 1, msg: 'Не найден пользователь' } }
На самом деле формат зависит от вас или от выбранной библиотеки для реализации коммуникации, например JSON-API.
Звучит здорово, мы теперь отвязались от http статусов и можем спокойно ввести свои коды ошибок. У нас больше нет проблемы “впихнуть невпихуемое”. Выбор нового типа ошибки не вызывает споров, а сводится просто к введению нового числового номера (например, последовательно) или строковой константы. Например:
module.exports = {
NOT_FOUND: 1,
VALIDATION: 2,
// ….
}
module.exports = {
NOT_FOUND: ‘NOT_AUTHORIZED’,
VALIDATION: ‘VALIDATION’,
// ….
}
Клиентские разработчики просто основываясь на кодах ошибок могут создать классы/типы ошибок и притом не бояться, что сервер вернет один и тот же код для разных типов ошибок (из-за бедности http статусов).
Обработка ошибок становится менее ветвящейся, множество http статусов превратились в два: 200 и все остальные (ошибки транспорта).
if (status === 200) {
if (body.error) {
var error = body.error;
if (error.code === 1) {
// some code
} else if (error.code === 2) {
// some code
} else {
// some code
}
} else {
// Success
}
} else {
// transport erros
}
В некоторых случаях, если есть библиотека десериализации данных, она может взять часть работы на себя. Писать SDK вокруг такого подхода проще нежели вокруг той или иной имплементации REST, ведь реализация зависит от того, как это видел автор. Кроме того, теперь никто не вызовет случайное срабатывание alert в мониторинге из-за того, что выбрал неудачный код ошибки.
Но неудобства тоже есть:
-
Избыточность полей при передаче данных, т.е. нужно всегда передавать 2 поля: для данных и для ошибки. Это усложняет чтение логов и написание документации.
-
При использовании средств отладки (Chrome DevTools) или других подобных инструментов вы не сможете быстро найти ошибочные запросы бизнес логики, придется обязательно заглянуть в тело ответа (ведь всегда 200)
-
Мониторинг теперь точно будет срабатывать только на ошибки транспорта, а не бизнес-логики, но для мониторинга логики надо будет дописывать парсинг тела сообщения.
В некоторых случаях данный подход вырождается в RPC, то есть по сути вообще отказываются от использования url и шлют все на один url методом POST, а в теле сообщения передают все параметры. Мне кажется это не правильным, ведь url это прекрасный именованный namespace, зачем от этого отказываться, не понятно?! Кроме того, RPC создает проблемы:
-
нельзя кэшировать по http GET запросы, так как замешали чтение и запись в один метод POST
-
нельзя делать повторы для неудавшихся GET запросов (на backend) на реверс-прокси (например, nginx) по указанной выше причине
-
имеются проблемы с документированием – swagger и ApiDoc не подходят, а удобных аналогов я не нашел
Итог: Для сложной бизнес-логики с большим количеством типов ошибок такой подход лучше, чем расплывчатый REST, не зря в проектах c “разухабистой” бизнес-логикой часто именно такой подход и используют.
№3: Смешанный
Возьмем лучшее от двух миров. Мы выберем один http статус, например, 400 или 422 для всех ошибок бизнес-логики, а в теле ответа будем указывать код ошибки или строковую константу. Например:
Success:
HTTP 200 /v1/user/1
Body: { name: 'Вася' }Error:
HTTP 400 /v1/user/1
Body: { error: { code: 1, msg: 'Не найден пользователь' } }Коды:
-
200 – успех
-
400 – ошибка бизнес логики
-
остальное ошибки в транспорте
Тело ответа для удачного запроса у нас имеет произвольную структуру, а вот для ошибки есть четкая схема. Мы избавляемся от избыточности данных (поле ошибки/данных) благодаря использованию http статуса в сравнении со вторым вариантом. Клиентский код упрощается в плане обработки ошибки (в сравнении с первым вариантом). Также мы снижаем его вложенность за счет использования отдельного http статуса для ошибок бизнес логики (в сравнении со вторым вариантом).
if (status === 200) {
// Success
} else if (status === 400) {
if (body.error.code === 1) {
// some code
} else if (body.error.code === 2) {
// some code
} else {
// some code
}
} else {
// transport erros
}
Мы можем расширять объект ошибки для детализации проблемы, если хотим. С мониторингом все как во втором варианте, дописывать парсинг придется, но и риска “стрельбы” некорректными alert нету. Для документирования можем спокойно использовать Swagger и ApiDoc. При этом сохраняется удобство использования инструментов разработчика, таких как Chrome DevTools, Postman, Talend API.
Итог: Использую данный подход уже в нескольких проектах, где множество типов ошибок и все крайне довольны, как клиентские разработчики, так и бэкендеры. Внедрение новой ошибки не вызывает споров, проблем и противоречий. Данный подход объединяет преимущества первого и второго варианта, при этом код более читабельный и структурированный.
Самое главное какой бы формат ошибок вы бы не выбрали лучше обговорить его заранее и следовать ему. Если эту вещь пустить на “самотек”, то очень скоро обработка ошибок в проекте станет невыносимо сложной для всех.
P.S. Иногда ошибки любят передавать массивом
{ error: [{ code: 1, msg: 'Не найден пользователь' }] }Но это актуально в основном в двух случаях:
-
Когда наш API выступает в роли сервиса без фронтенда (нет сайта/приложения). Например, сервис платежей.
-
Когда в API есть url для загрузки какого-нибудь длинного отчета в котором может быть ошибка в каждой строке/колонке. И тогда для пользователя удобнее, чтобы ошибки в приложении сразу показывались все, а не по одной.
В противном случае нет особого смысла закладываться сразу на массив ошибок, потому что базовая валидация данных должна происходить на клиенте, зато код упрощается как на сервере, так и на клиенте. А user-experience хакеров, лезущих напрямую в наше API, не должен нас волновать?HTTP
Информационные
100
Continue
«Продолжить». Этот промежуточный ответ указывает, что запрос успешно
принят и клиент может продолжать присылать запросы либо проигнорировать
этот ответ, если запрос был завершён.
Только HTTP/1.1
101
Switching Protocol
«Переключение протокола». Этот код присылается в ответ на запрос
клиента, содержащий заголовок Upgrade:, и указывает, что
сервер переключился на протокол, который был указан в заголовке. Эта
возможность позволяет перейти на несовместимую версию протокола и обычно
не используется.
Только HTTP/1.1
102
Processing
«В обработке». Этот код указывает, что сервер получил запрос и
обрабатывает его, но обработка ещё не завершена.
Только HTTP/1.1
103
Early Hints
«Ранние подсказки». В ответе сообщаются ресурсы, которые могут быть
загружены заранее, пока сервер будет подготавливать основной ответ.
RFC 8297 (Experimental).
Только HTTP/1.1
Успешные
200
OK
«Успешно». Запрос успешно обработан. Что значит «успешно», зависит от
метода HTTP, который был запрошен:
- GET: «ПОЛУЧИТЬ». Запрошенный ресурс был найден и передан в теле
ответа. - HEAD: «ЗАГОЛОВОК». Заголовки переданы в ответе.
- POST: «ПОСЫЛКА». Ресурс, описывающий результат действия сервера на
запрос, передан в теле ответа. - TRACE: «ОТСЛЕЖИВАТЬ». Тело ответа содержит тело запроса полученного
сервером.
HTTP/0.9 и выше
201
Created
«Создано». Запрос успешно выполнен и в результате был создан ресурс.
Этот код обычно присылается в ответ на запрос PUT «ПОМЕСТИТЬ».
HTTP/0.9 и выше
202
Accepted
«Принято». Запрос принят, но ещё не обработан. Не поддерживаемо, т.е.,
нет способа с помощью HTTP отправить асинхронный ответ позже, который
будет показывать итог обработки запроса. Это предназначено для случаев,
когда запрос обрабатывается другим процессом или сервером, либо для
пакетной обработки.
HTTP/0.9 и выше
203
Non-Authoritative Information
«Информация не авторитетна». Этот код ответа означает, что информация,
которая возвращена, была предоставлена не от исходного сервера, а из
какого-нибудь другого источника. Во всех остальных ситуациях более
предпочтителен код ответа 200 OK.
HTTP/0.9 и 1.1
204
No Content
«Нет содержимого». Нет содержимого для ответа на запрос, но заголовки
ответа, которые могут быть полезны, присылаются. Клиент может
использовать их для обновления кешированных заголовков полученных ранее
для этого ресурса.
HTTP/0.9 и выше
205
Reset Content
«Сбросить содержимое». Этот код присылается, когда запрос обработан,
чтобы сообщить клиенту, что необходимо сбросить отображение документа,
который прислал этот запрос.
Только HTTP/1.1
206
Partial Content
«Частичное содержимое». Этот код ответа используется, когда клиент
присылает заголовок диапазона, чтобы выполнить загрузку отдельно, в
несколько потоков.
Только HTTP/1.1
Сообщения о перенаправлениях
300
Multiple Choice
«Множественный выбор». Этот код ответа присылается, когда запрос имеет
более чем один из возможных ответов. И User-agent или пользователь
должен выбрать один из ответов. Не существует стандартизированного
способа выбора одного из полученных ответов.
HTTP/1.0 и выше
301
Moved Permanently
«Перемещён на постоянной основе». Этот код ответа значит, что URI
запрашиваемого ресурса был изменён. Возможно, новый URI будет
предоставлен в ответе.
HTTP/0.9 и выше
302
Found
«Найдено». Этот код ответа значит, что запрошенный ресурс
временно изменён. Новые изменения в URI могут быть доступны в
будущем. Таким образом, этот URI, должен быть использован клиентом в
будущих запросах.
HTTP/0.9 и выше
303
See Other
«Просмотр других ресурсов». Этот код ответа присылается, чтобы
направлять клиента для получения запрашиваемого ресурса в другой URI с
запросом GET.
HTTP/0.9 и 1.1
304
Not Modified
«Не модифицировано». Используется для кеширования. Это код ответа
значит, что запрошенный ресурс не был изменён. Таким образом, клиент
может продолжать использовать кешированную версию ответа.
HTTP/0.9 и выше
305
Use Proxy
«Использовать прокси». Это означает, что запрошенный ресурс должен быть
доступен через прокси. Этот код ответа в основном не поддерживается из
соображений безопасности.
Только HTTP/1.1
306
Switch Proxy
Больше не использовать. Изначально подразумевалось, что » последующие
запросы должны использовать указанный прокси.»
Только HTTP/1.1
307
Temporary Redirect
«Временное перенаправление». Сервер отправил этот ответ, чтобы клиент
получил запрошенный ресурс на другой URL-адрес с тем же методом, который
использовал предыдущий запрос. Данный код имеет ту же семантику, что код
ответа 302 Found, за исключением того, что агент
пользователя не должен изменять используемый метод HTTP: если в первом
запросе использовался POST, то во втором запросе также
должен использоваться POST.
Только HTTP/1.1
308
Permanent Redirect
«Перенаправление на постоянной основе». Это означает, что ресурс
теперь постоянно находится в другом URI, указанном в заголовке
Location: HTTP Response. Данный код ответа имеет ту же
семантику, что и код ответа 301 Moved Permanently, за
исключением того, что агент пользователя не должен изменять
используемый метод HTTP: если POST использовался в первом
запросе, POST должен использоваться и во втором запросе.
Примечание: Это экспериментальный код ответа,
Спецификация которого в настоящее время находится в черновом виде.
draft-reschke-http-status-308
Клиентские
400
Bad Request
«Плохой запрос». Этот ответ означает, что сервер не понимает запрос
из-за неверного синтаксиса.
HTTP/0.9 и выше
401
Unauthorized
«Неавторизованно». Для получения запрашиваемого ответа нужна
аутентификация. Статус похож на статус 403, но,в этом случае,
аутентификация возможна.
HTTP/0.9 и выше
402
Payment Required
«Необходима оплата». Этот код ответа зарезервирован для будущего
использования. Первоначальная цель для создания этого кода была в
использовании его для цифровых платёжных систем(на данный момент не
используется).
HTTP/0.9 и 1.1
403
Forbidden
«Запрещено». У клиента нет прав доступа к содержимому, поэтому сервер
отказывается дать надлежащий ответ.
HTTP/0.9 и выше
404
Not Found
«Не найден». Сервер не может найти запрашиваемый ресурс. Код этого
ответа, наверно, самый известный из-за частоты его появления в вебе.
HTTP/0.9 и выше
405
Method Not Allowed
«Метод не разрешён». Сервер знает о запрашиваемом методе, но он был
деактивирован и не может быть использован. Два обязательных метода,
GET и HEAD, никогда не должны быть
деактивированы и не должны возвращать этот код ошибки.
Только HTTP/1.1
406
Not Acceptable
Этот ответ отсылается, когда веб сервер после выполнения
server-driven content negotiation, не нашёл контента, отвечающего критериям, полученным из user agent.
Только HTTP/1.1
407
Proxy Authentication Required
Этот код ответа аналогичен коду 401, только аутентификация требуется для
прокси сервера.
Только HTTP/1.1
408
Request Timeout
Ответ с таким кодом может прийти, даже без предшествующего запроса. Он
означает, что сервер хотел бы отключить это неиспользуемое соединение.
Этот метод используется все чаще с тех пор, как некоторые браузеры,
вроде Chrome и IE9, стали использовать
HTTP механизмы предварительного соединения
для ускорения сёрфинга (смотрите баг 634278, будущей
реализации этого механизма в Firefox). Также учитывайте, что некоторые
серверы прерывают соединения не отправляя подобных сообщений.
Только HTTP/1.1
409
Conflict
Этот ответ отсылается, когда запрос конфликтует с текущим состоянием
сервера.
Только HTTP/1.1
410
Gone
Этот ответ отсылается, когда запрашиваемый контент удалён с сервера.
Только HTTP/1.1
411
Length Required
Запрос отклонён, потому что сервер требует указание заголовка
Content-Length, но он не указан.
Только HTTP/1.1
412
Precondition Failed
Клиент указал в своих заголовках условия, которые сервер не может
выполнить
Только HTTP/1.1
413
Request Entity Too Large
Размер запроса превышает лимит, объявленный сервером. Сервер может
закрыть соединение, вернув заголовок Retry-After
Только HTTP/1.1
414
Request-URI Too Long
URI запрашиваемый клиентом слишком длинный для того, чтобы сервер смог
его обработать
Только HTTP/1.1
415
Unsupported Media Type
Медиа формат запрашиваемых данных не поддерживается сервером, поэтому
запрос отклонён
Только HTTP/1.1
416
Requested Range Not Satisfiable
Диапазон указанный заголовком запроса Range не может быть
выполнен; возможно, он выходит за пределы переданного URI
Только HTTP/1.1
417
Expectation Failed
Этот код ответа означает, что ожидание, полученное из заголовка запроса
Expect, не может быть выполнено сервером.
Только HTTP/1.1
Серверные
500
Internal Server Error
«Внутренняя ошибка сервера». Сервер столкнулся с ситуацией, которую он
не знает как обработать.
HTTP/0.9 и выше
501
Not Implemented
«Не реализовано». Метод запроса не поддерживается сервером и не может быть
обработан. Единственные методы, которые сервера должны поддерживать (и,
соответственно, не должны возвращать этот код) — GET и
HEAD.
HTTP/0.9 и выше
502
Bad Gateway
«Плохой шлюз». Эта ошибка означает что сервер, во время работы в
качестве шлюза для получения ответа, нужного для обработки запроса,
получил недействительный (недопустимый) ответ.
HTTP/0.9 и выше
503
Service Unavailable
«Сервис недоступен». Сервер не готов обрабатывать запрос. Зачастую
причинами являются отключение сервера или то, что он перегружен.
Обратите внимание, что вместе с этим ответом удобная для
пользователей(user-friendly) страница должна отправлять объяснение
проблемы. Этот ответ должен использоваться для временных условий и
Retry-After: HTTP-заголовок должен, если возможно,
содержать предполагаемое время до восстановления сервиса. Веб-мастер
также должен позаботиться о заголовках, связанных с кешем, которые
отправляются вместе с этим ответом, так как эти ответы, связанные с
временными условиями, обычно не должны кешироваться.
HTTP/0.9 и выше
504
Gateway Timeout
Этот ответ об ошибке предоставляется, когда сервер действует как шлюз и
не может получить ответ вовремя.
Только HTTP/1.1
505
HTTP Version Not Supported
«HTTP-версия не поддерживается». HTTP-версия, используемая в запросе, не
поддерживается сервером.
Только HTTP/1.1
Наличие ошибок в коде страницы сайта всегда влечет за собой негативные последствия – от ухудшения позиций в ранжировании до жалоб со стороны пользователей. Ошибки валидации могут наблюдаться как на главной, так и на иных веб-страницах, их наличие свидетельствует о том, что ресурс является невалидным. Некоторые проблемы замечают даже неподготовленные пользователи, другие невозможно обнаружить без предварительного аудита, анализа. О том, что такое ошибки валидации и как их обнаружить, мы сейчас расскажем.

Ошибка валидации, что это такое?
Для написания страниц используется HTML – стандартизированный язык разметки, применяемый в веб-разработке. HTML, как любой другой язык, имеет специфические особенности синтаксиса, грамматики и т. д. Если во время написания кода правила не учитываются, то после запуска сайта будут появляться различные виды проблем. Если HTML-код ресурса не соответствует стандарту W3C, то он является невалидным, о чем мы писали выше.
Почему ошибки валидации сайта оказывают влияние на ранжирование, восприятие?
Наличие погрешностей в коде – проблема, с которой необходимо бороться сразу после обнаружения. Поисковые системы «читают» HTML-код, если он некорректный, то процесс индексации и ранжирования может быть затруднен. Поисковые роботы должны понимать, каким является ресурс, что он предлагает, какие запросы использует. Особо критичны такие ситуации для ресурсов, имеющих большое количество веб-страниц.
Как проверить ошибки валидации?

Для этой работы используется либо технический аудит сайта, либо валидаторы, которые ищут проблемы автоматически. Одним из самых популярных является сервис The W3C Markup Validation Service, выполняющий сканирование с оглядкой на World Wide Web Consortium (W3C). Рассматриваемый валидатор предлагает три способа, с помощью которых можно осуществить проверку сайта:
- ввод URL-адреса страниц, которые необходимо просканировать;
- загрузка файла страницы;
- ввод части HTML-кода, нуждающегося в проверке.
После завершения проверки вы получите развернутый список выявленных проблем, дополненных описанием, ссылками на стандарты W3C. По ходу анализа вы увидите слабые места со ссылками на правила, что позволит самостоятельно исправить проблему.
Существуют другие сервисы, позволяющие выполнить проверку валидности кода:
- Dr. Watson. Проверяет скорость загрузки страниц, орфографию, ссылки, а также исходный код;
- InternetSupervision.com. Отслеживает производительность сайта, проверяет доступность HTML.
Плагины для браузеров, которые помогут найти ошибки в коде
Решить рассматриваемую задачу можно с помощью плагинов, адаптированных под конкретный браузер. Можно использовать следующие инструменты (бесплатные):
- HTML Validator для браузера Firefox;
- HTML Validator for Chrome;
- Validate HTML для Firefox.
После проверки нужно решить, будете ли вы устранять выявленные ошибки. Многие эксперты акцентируют внимание на том, что поисковые системы сегодня уделяют больше внимания качеству внешней/внутренней оптимизации, контенту, другим характеристикам. Однако валидность нельзя оставлять без внимания, ведь если даже обнаруженные проблемы не будут мешать поисковым ботам, то они точно начнут раздражать посетителей сайта.
Как исправить ошибку валидации?

В первую очередь нужно сосредоточить внимание на слабых местах, связанных с контентом – это то, что важно для поисковых систем. Если во время сканирования было выявлено более 25 проблем, то их нельзя игнорировать из-за ряда причин:
- частичная индексация;
- медленная загрузка;
- баги, возникающие во время непосредственной коммуникации пользователя с ресурсом.
Например, игнорирование ошибок может привести к тому, что некоторые страницы не будут проиндексированы. Для решения рассматриваемой проблемы можно привлечь опытного фрилансера, однако лучшее решение – заказ услуги в веб-агентстве, что позволит исправить, а не усугубить ситуацию.
Технический и SEO-аудит
Выявление ошибок – первый шаг, ведь их еще нужно будет устранить. При наличии большого пула проблем целесообразно заказать профессиональный аудит сайта. Он поможет найти разные виды ошибок, повысит привлекательность ресурса для поисковых ботов, обычных пользователей: скорость загрузки страниц, верстка, переспам, другое.
В заключение
На всех сайтах наблюдаются ошибки валидации – их невозможно искоренить полностью, но и оставлять без внимания не стоит. Например, если провести проверку сайтов Google или «Яндекс», то можно увидеть ошибки, однако это не означает, что стоит вздохнуть спокойно и закрыть глаза на происходящее. Владелец сайта должен ставить во главу угла комплексное развитие, при таком подходе ресурс будет наполняться, обновляться и «лечиться» своевременно. Если проблем мало, то можно попробовать устранить их своими силами или с помощью привлечения стороннего частного специалиста. В остальных случаях лучше заказать услугу у проверенного подрядчика.

Просмотров 1.2к. Опубликовано 19.12.2022
Обновлено 19.12.2022
Каждый сайт, который создает компания, должен отвечать принятым стандартам. В первую очередь затем, чтобы он попадал в поисковую выдачу и был удобен для пользователей. Если код страниц содержит ошибки, неточности, он становится “невалидным”, то есть не соответствующим требованиям. В результате интернет-ресурс не увидят пользователи или информация на нем будет отображаться некорректно.
В этой статье рассмотрим, что такое валидность, какие могут быть ошибки в HTML-разметке и как их устранить.
Содержание
- Что такое HTML-ошибка валидации и зачем она нужна
- Чем опасны ошибки в разметке
- Как проверить ошибки валидации
- Предупреждения
- Ошибки
- Пример прохождения валидации для страницы сайта
- Как исправить ошибку валидации
- Плагины для браузеров, которые помогут найти ошибки в коде
- Коротко о главном
Что такое HTML-ошибка валидации и зачем она нужна
Под понятием “валидация” подразумевается процесс онлайн-проверки HTML-кода страницы на соответствие стандартам w3c. Эти стандарты были разработаны Организацией всемирной паутины и стандартов качества разметки. Сама организация продвигает идею унификации сайтов по HTML-коду — чтобы каждому пользователю, вне зависимости от браузера или устройства, было удобно использовать ресурс.
Если код отвечает стандартам, то его называют валидным. Браузеры могут его прочитать, загрузить страницы, а поисковые системы легко находят страницу по соответствующему запросу.
Чем опасны ошибки в разметке
Ошибки валидации могут разными — видимыми для глаза простого пользователя или такими, которые можно засечь только с помощью специальных программ. В первом случае кроме технических проблем, ошибки в разметке приводят к негативному пользовательскому опыту.
К наиболее распространённым последствиям ошибок в коде HTML-разметки также относят сбои в нормальной работе сайта и помехи в продвижении ресурса в поисковых системах.
Рассмотрим несколько примеров, как ошибки могут проявляться при работе:
- Медленно подгружается страница
Согласно исследованию Unbounce, более четверти пользователей покидают страницу, если её загрузка занимает более 3 секунд, ещё треть уходит после 6 секунд;
- Не видна часть текстовых, фото и видео-блоков
Эта проблема делает контент для пользователей неинформативным, поэтому они в большинстве случаев уходят со страницы, не досмотрев её до конца;
- Страница может остаться не проиндексированной
Если поисковый робот распознает недочёт в разметке, он может пропустить страницу и прервать её размещение в поисковых системах;
- Разное отображение страниц на разных устройствах
Например, на компьютере или ноутбуке страница будет выглядеть хорошо, а на мобильных гаджетах половина кнопок и изображений будет попросту не видна.
Из-за этих ошибок пользователь не сможет нормально работать с ресурсом. Единственное решение для него — закрыть вкладку и найти нужную информацию на другом сайте. Так количество посетителей сайта постепенно уменьшается, он перестает попадать в поисковую выдачу — в результате ресурс становится бесполезным и пропадает в пучине Интернета.
Как проверить ошибки валидации
Владельцы ресурсов используют 2 способа онлайн-проверки сайтов на наличие ошибок — технический аудит или использование валидаторов.
Первый случай подходит для серьёзных проблем и масштабных сайтов. Валидаторами же пользуются ежедневно. Наиболее популярный — сервис The W3C Markup Validation Service. Он сканирует сайт и сравнивает код на соответствие стандартам W3C. Валидатор выдаёт 2 типа несоответствий разметки стандартам W3C: предупреждения и ошибки.
Давайте рассмотрим каждый из типов чуть подробнее.
Предупреждения
Предупреждения отмечают незначительные проблемы, которые не влияют на работу ресурса. Они появляются из-за расхождений написания разметки со стандартами W3C.
Тем не менее, предупреждения всё равно нужно устранять, так как из-за них сайт может работать медленнее — например, по сравнению с конкурентами с такими же сайтами.
Примером предупреждения может быть указание на отсутствие тега alt у изображения.
Ошибки
Ошибки — это те проблемы, которые требуют обязательного устранения.
Они представляют угрозу для корректной работы сайта: например, из-за них могут скрываться разные блоки — текстовые, фото, видео. А в некоторых более запущенных случаях содержимое страницы может вовсе не отображаться, и сам ресурс не будет загружаться. Поэтому после проверки уделять внимание ошибкам с красными отметками нужно в первую очередь.
Распространённым примером ошибки может быть отсутствие тега <!DOCTYPE html> в начале страницы, который помогает информации преобразоваться в разметку.
Пример прохождения валидации для страницы сайта
Рассмотрим процесс валидации на примере сайта avavax.ru, который создали на WordPress.
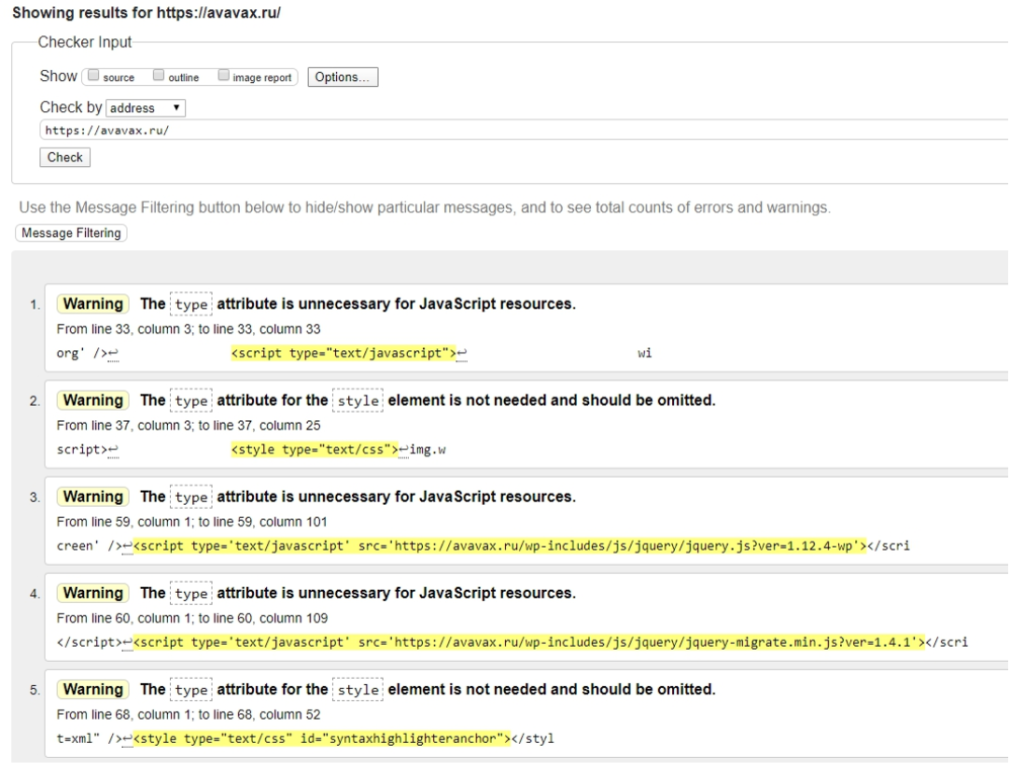
В результате проверки валидатор выдал 17 замечаний. После анализа отчета их можно свести к 3 основным:
- атрибут ‘text/javascript’ не требуется при подключении скрипта;
- атрибут ‘text/css’ не требуется при подключении стиля;
- у одного из элементов section нет внутри заголовка h1-h6.
Первое и второе замечания генерирует сам движок WordPress, поэтому разработчикам не нужно их убирать. Третье же замечание предполагает, что каждый блок текста должен иметь заголовок, даже если это не всегда необходимо или видно для читателя.
Решить проблемы с предупреждениями для стилей и скриптов можно через добавление кода в файл темы function.php.
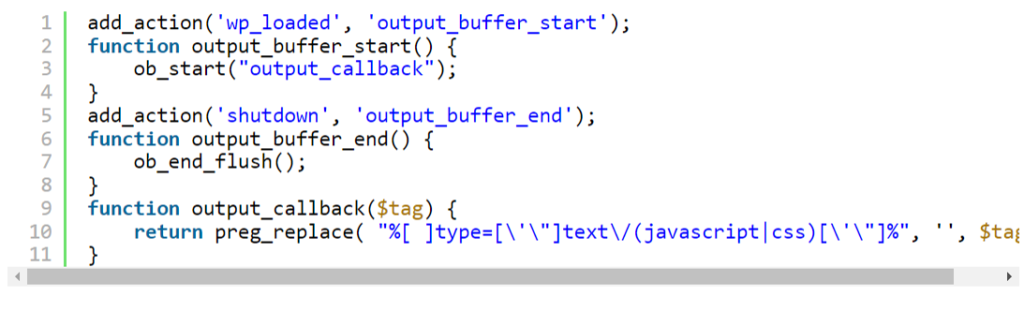
Для этого на хук wp_loaded нужно повесить функцию output_buffer_start(), которая загрузит весь генерируемый код html в буфер. При выводе в буфер вызывается функция output_callback($tag), которая просматривает все теги, находит нежелательные атрибуты с помощью регулярных выражений и заменяет их пробелами. Затем на хук ‘shutdown вешается функция output_buffer_end(), которая возвращает обработанное содержимое буфера.
Для исправления семантики на сайте нужно использовать заголовки. Валидатор выдаёт предупреждение на секцию about, которая содержит фото и краткий текст. Валидатор требует, чтобы в каждой секции был заголовок. Для исправления предупреждения нужно добавить заголовок, но сделать это так, чтобы его не было видно пользователям:
- Добавить заголовок в код: <h3>Обо мне</h3>
Отключить отображение заголовка:
1 #about h3 {
2 display: none;
3 }
После этой части заголовок будет в коде, но валидатор его увидит, а посетитель — нет.
За 3 действия удалось убрать все предупреждения, чтобы качество кода устроило валидатор. Это подтверждается зелёной строкой с надписью: “Document checking completed. No errors or warnings to show”.
Как исправить ошибку валидации
Всё зависит от того, какими техническими знаниями обладает владелец ресурса. Он может сделать это сам, вручную. Делать это нужно постепенно, разбирая ошибку за ошибкой. Но нужно понимать, что если при проверке валидатором было выявлено 100 проблем — все 100 нужно обязательно решить.
Поэтому если навыков и знаний не хватает, лучше привлечь сторонних специалистов для улучшения качества разметки. Это могут быть как фрилансеры, так и профессиональные веб-агентства. При выборе хорошего специалиста, результат будет гарантироваться в любом случае, но лучше, чтобы в договоре оказания услуг будут чётко прописаны цели проведения аудита и гарантии решения проблем с сайтом.
Если объём работ большой, выгоднее заказать профессиональный аудит сайта. С его помощью можно обнаружить разные виды ошибок, улучшить внешний вид и привлекательность интернет-ресурса для поисковых ботов, обычных пользователей, а также повысить скорость загрузки страниц, сделать качественную верстку и избавиться от переспама.
Плагины для браузеров, которые помогут найти ошибки в коде
Для поиска ошибок валидации можно использовать и встроенные в браузеры плагины. Они помогут быстро находить неточности еще на этапе создания кода.
Для каждого браузера есть свой адаптивный плагин:
- HTML Validator для браузера Firefox;
- HTML Validator for Chrome;
- HTML5 Editor для Opera.
С помощью этих инструментов можно не допускать проблем, которые помешают нормальному запуску сайта. Плагины помогут оценить качество внешней и внутренней оптимизации, контента и другие характеристики.
Коротко о главном
Валидация — процесс выявления проблем с HTML-разметкой сайта и ее соответствия стандартам W3C. Это унифицированные правила, с помощью которых сайт может нормально работать и отображаться и для поисковых роботов, и для пользователей.
Проверку ресурса можно проводить тремя путями: валидаторами, специалистам полномасштабного аудита и плагинами в браузере. В большинстве случаев валидатор — самое удобное и быстрое решение для поиска проблем. С его помощью можно выявить 2 типа проблем с разметкой — предупреждения и ошибки.
Работать необходимо сразу с двумя типами ошибок. Даже если предупреждение не приведет к неисправности сайта, оставлять без внимания проблемные блоки нельзя, так как это снизит привлекательность ресурса в глазах пользователя. Ошибки же могут привести к невозможности отображения блоков на сайте, понижению сайта в поисковой выдаче или полному игнорированию ресурса со стороны поискового бота.
Даже у крупных сайтов с миллионной аудиторией, например, Яндекс.Дзен или ВКонтакте, есть проблемы с кодом. Но комплексный подход к решению проблем помогает устранять серьёзные моменты своевременно. Нужно развивать сайт всесторонне, чтобы получить результат от его существования и поддержки. Если самостоятельно разобраться с проблемами не получается, не стоит “доламывать” — лучше обратиться за помощью к профессионалам, например, агентствам по веб-аудиту.
Here’s another interesting scenario to discuss.
What if its an type detection API that for instance accepts as input a reference to some locally stored parquet file, and after reading through some metadata of the blocks that compose the file, may realize that one or more of the block sizes exceed a configured threshold and therefor the server decided the file is not partitioning correctly and refuses to start the type detection process.
This validation is there to protect against one of two (or both) scenarios: (1) Long processing time, bad user experience ; (2) Server application explodes with OutOfMemoryError
What would be an appropriate response in this case?
400 (Bad Request) ? — sort of works, generically.
401 (Unauthorized i.e. Unauthenticated) ? — unrelated.
403 (Forbidden i.e. Unauthorized) ? — some would argue it may be somewhat appropriate in this case —
422 (Unprocessable entity) ? — many older answers mention this as appropriate option for input validation failure. What bothers me about using it in my case is the definition of this response code saying its «due to semantic error» while I couldn’t quite understand what semantic error means in that context and whether can we consider this failure indeed as a semantic error failure.
Also the allegedly simple concept of «input» as part of «input validation» can be confusing in cases like this where the physical input provided by the client is only but a pointer, a reference to some entity which is stored in the server, where the actual validation is done on data stored in the server (the parquet file metadata) in conjunction with the action the client tries to trigger (type detection).
413 (PayloadTooLarge)? Going through the different codes I encounter one that may be suitable in my case, one that no one mentioned here so far, that is 413 PayloadTooLarge which I also wonder if it may be suitable or again, not, since its not the actual payload sent in the request that is too large, but the payload of the resource stored in the server.
Which leads me to thinking maybe a 5xx response is more appropriate here.
507 Insufficient Storage ? If we say that «storage» is like «memory» and if we also say that we’re failing fast here with a claim that we don’t have enough memory (or we may blow out with out of memory trying) to process this job, then maybe 507 can me appropriate. but not really.
My conclusion is that in this type of scenario where the server refused to invoke an action on a resource due to space-time related constraints the most suitable response would be 413 PayloadTooLarge
Here’s another interesting scenario to discuss.
What if its an type detection API that for instance accepts as input a reference to some locally stored parquet file, and after reading through some metadata of the blocks that compose the file, may realize that one or more of the block sizes exceed a configured threshold and therefor the server decided the file is not partitioning correctly and refuses to start the type detection process.
This validation is there to protect against one of two (or both) scenarios: (1) Long processing time, bad user experience ; (2) Server application explodes with OutOfMemoryError
What would be an appropriate response in this case?
400 (Bad Request) ? — sort of works, generically.
401 (Unauthorized i.e. Unauthenticated) ? — unrelated.
403 (Forbidden i.e. Unauthorized) ? — some would argue it may be somewhat appropriate in this case —
422 (Unprocessable entity) ? — many older answers mention this as appropriate option for input validation failure. What bothers me about using it in my case is the definition of this response code saying its «due to semantic error» while I couldn’t quite understand what semantic error means in that context and whether can we consider this failure indeed as a semantic error failure.
Also the allegedly simple concept of «input» as part of «input validation» can be confusing in cases like this where the physical input provided by the client is only but a pointer, a reference to some entity which is stored in the server, where the actual validation is done on data stored in the server (the parquet file metadata) in conjunction with the action the client tries to trigger (type detection).
413 (PayloadTooLarge)? Going through the different codes I encounter one that may be suitable in my case, one that no one mentioned here so far, that is 413 PayloadTooLarge which I also wonder if it may be suitable or again, not, since its not the actual payload sent in the request that is too large, but the payload of the resource stored in the server.
Which leads me to thinking maybe a 5xx response is more appropriate here.
507 Insufficient Storage ? If we say that «storage» is like «memory» and if we also say that we’re failing fast here with a claim that we don’t have enough memory (or we may blow out with out of memory trying) to process this job, then maybe 507 can me appropriate. but not really.
My conclusion is that in this type of scenario where the server refused to invoke an action on a resource due to space-time related constraints the most suitable response would be 413 PayloadTooLarge
Содержание
Составили подробный классификатор кодов состояния HTTP. Добавляйте в закладки, чтобы был под рукой, когда понадобится.
Что такое код ответа HTTP
Когда посетитель переходит по ссылке на сайт или вбивает её в поисковую строку вручную, отправляется запрос на сервер. Сервер обрабатывает этот запрос и выдаёт ответ — трехзначный цифровой код HTTP от 100 до 510. По коду ответа можно понять реакцию сервера на запрос.
Первая цифра в ответе обозначает класс состояния, другие две — причину, по которой мог появиться такой ответ.
Как проверить код состояния страницы
Проверить коды ответа сервера можно вручную с помощью браузера и в панелях веб‑мастеров: Яндекс.Вебмастер и Google Search Console.
В браузере
Для примера возьмём Google Chrome.
-
Откройте панель разработчика в браузере клавишей F12, комбинацией клавиш Ctrl + Shift + I или в меню браузера → «Дополнительные инструменты» → «Инструменты разработчика». Подробнее об этом рассказывали в статье «Как открыть исходный код страницы».
-
Переключитесь на вкладку «Сеть» в Инструментах разработчика и обновите страницу:
В Яндекс.Вебмастере
Откройте инструмент «Проверка ответа сервера» в Вебмастере. Введите URL в специальное поле и нажмите кнопку «Проверить»:
Как добавить сайт в Яндекс.Вебмастер и другие сервисы Яндекса
В Google Search Console
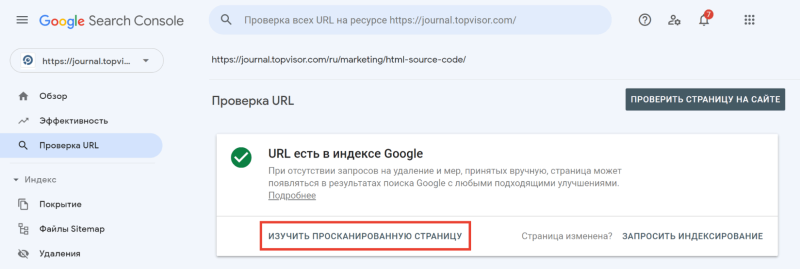
Чтобы посмотреть код ответа сервера в GSC, перейдите в инструмент проверки URL — он находится в самом верху панели:

Введите ссылку на страницу, которую хотите проверить, и нажмите Enter. В результатах проверки нажмите на «Изучить просканированную страницу» в блоке «URL есть в индексе Google».
А затем в открывшемся окне перейдите на вкладку «Подробнее»:
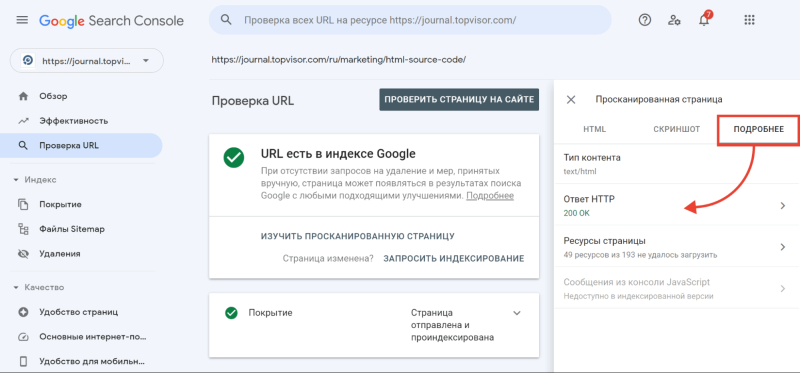
Теперь расскажем подробнее про все классы кодов состояния HTTP.
1* класс кодов (информационные сообщения)
Это системный класс кодов, который только информирует о процессе передачи запроса. Такие ответы не являются ошибкой, хотя и могут отображаться в браузере как Error Code.
100 Continue
Этот ответ сообщает, что полученные сведения о запросе устраивают сервер и клиент может продолжать отправлять данные. Такой ответ может требоваться клиенту, если на сервер отправляется большой объём данных.
101 Switching Protocols
Сервер одобрил переключение типа протокола, которое запросил пользователь, и в настоящий момент выполняет действие.
102 Processing
Запрос принят — он находится в обработке, и на это понадобится чуть больше времени.
103 Checkpoint
Контрольная точка — используется в запросах для возобновления после прерывания запросов POST или PUT.
POST отправляет данные на сервер, PUT создает новый ресурс или заменяет существующий данными, представленными в теле запроса.
Разница между ними в том, что PUT работает без изменений: повторное его применение даёт такой же результат, что и в первый раз, а вот повторный вызов одного и того же метода POST часто меняет данные.
Пример — оформленный несколько раз интернет‑заказ. Такое часто происходит как раз по причине неоднократного использования запроса PUT.
105 Name Not Resolved
Не удается преобразовать DNS‑адрес сервера — это означает ошибку в службе DNS. Эта служба преобразует IP‑адреса в знакомые нам доменные имена.
2* класс кодов (успешно обработанные запросы)
Эти коды информируют об успешности принятия и обработки запроса. Также сервер может передать заголовки или тело сообщений.
200 ОК
Все хорошо — HTTP‑запрос успешно обработан (не ошибка).
201 Created
Создано — транзакция успешна, сформирован новый ресурс или документ.
202 Accepted
Принято — запрос принят, но ещё не обработан.
203 Non‑Authoritative Information
Информация не авторитетна — запрос успешно обработан, но передаваемая информация была взята не из первичного источника (данные могут быть устаревшими).
204 No Content
Нет содержимого — запрос успешно обработан, однако в ответе только заголовки без контента сообщения. Не нужно обновлять содержимое документа, но можно применить к нему полученные метаданные.
205 Reset Content
Сбросить содержимое. Запрос успешно обработан — но нужно сбросить введенные данные. Страницу можно не обновлять.
206 Partial Content
Частичное содержимое. Сервер успешно обработал часть GET‑запроса, а другую часть вернул.
GET — метод для чтения данных с сайта. Он говорит серверу, что клиент хочет прочитать какой‑то документ.
Представим интернет‑магазин и страницы каталога. Фильтры, которые выбирает пользователь, передаются благодаря методу GET. GET‑запрос работает с получением данных, а POST‑запрос нужен для отправки данных.
При работе с подобными ответами следует уделить внимание кэшированию.
207 Multi‑Status
Успешно выполнено несколько операций — сервер передал результаты выполнения нескольких независимых операций. Они появятся в виде XML‑документа с объектом multistatus.
226 IM Used
Успешно обработан IM‑заголовок (специальный заголовок, который отправляется клиентом и используется для передачи состояния HTTP).
3* класс кодов (перенаправление на другой адрес)
Эти коды информируют, что для достижения успешной операции нужно будет сделать другой запрос, возможно, по другому URL.
300 Multiple Choices
Множественный выбор — сервер выдает список нескольких возможных вариантов перенаправления (максимум — 5). Можно выбрать один из них.
301 Moved Permanently
Окончательно перемещено — страница перемещена на другой URL, который указан в поле Location.
302 Found/Moved
Временно перемещено — страница временно перенесена на другой URL, который указан в поле Location.
303 See Other
Ищите другую страницу — страница не найдена по данному URL, поэтому смотрите страницу по другому URL, используя метод GET.
304 Not Modified
Модификаций не было — с момента последнего визита клиента изменений не было.
305 Use Proxy
Используйте прокси — запрос к нужному ресурсу можно сделать только через прокси‑сервер, URL которого указан в поле Location заголовка.
306 Unused
Зарезервировано. Код в настоящий момент не используется.
307 Temporary Redirect
Временное перенаправление — запрашиваемый ресурс временно доступен по другому URL.
Этот код имеет ту же семантику, что код ответа 302 Found, за исключением того, что агент пользователя не должен изменять используемый метод HTTP: если в первом запросе использовался POST, то во втором запросе также должен использоваться POST.
308 Resume Incomplete
Перемещено полностью (навсегда) — запрашиваемая страница была перенесена на новый URL, указанный в поле Location заголовка. Метод запроса (GET/POST) менять не разрешается.
4* класс кодов (ошибки на стороне клиента)
Эти коды указывают на ошибки со стороны клиентов.
400 Bad Request
Неверный запрос — запрос клиента не может быть обработан, так как есть синтаксическая ошибка (возможно, опечатка).
401 Unauthorized
Не пройдена авторизация — запрос ещё в обработке, но доступа нет, так как пользователь не авторизован.
Для доступа к запрашиваемому ресурсу клиент должен представиться, послав запрос, включив при этом в заголовок сообщения поле Authorization.
402 Payment Required
Требуется оплата — зарезервировано для использования в будущем. Код предусмотрен для платных пользовательских сервисов, а не для хостинговых компаний.
403 Forbidden
Запрещено — запрос принят, но не будет обработан, так как у клиента недостаточно прав. Может возникнуть, когда пользователь хочет открыть системные файлы (robots, htaccess) или не прошёл авторизацию.
404 Not Found
Не найдено — запрашиваемая страница не обнаружена. Сервер принял запрос, но не нашёл ресурса по указанному URL (возможно, была ошибка в URL или страница была перемещена).
405 Method Not Allowed
Метод не разрешён — запрос был сделан методом, который не поддерживается данным ресурсом. Сервер должен предложить доступные методы решения в заголовке Allow.
406 Not Acceptable
Некорректный запрос — неподдерживаемый поисковиком формат запроса (поисковый робот не поддерживает кодировку или язык).
407 Proxy Authentication Required
Нужно пройти аутентификацию прокси — ответ аналогичен коду 401, только нужно аутентифицировать прокси‑сервер.
408 Request Timeout
Тайм‑аут запроса — запрос клиента занял слишком много времени. На каждом сайте существует свое время тайм‑аута — проверьте интернет‑соединение и просто обновите страницу.
409 Conflict
Конфликт (что‑то пошло не так) — запрос не может быть выполнен из‑за конфликтного обращения к ресурсу (несовместимость двух запросов).
410 Gone
Недоступно — ресурс раньше был размещён по указанному URL, но сейчас удалён и недоступен (серверу неизвестно месторасположение).
411 Length Required
Добавьте длины — сервер отклоняет отправляемый запрос, так как длина заголовка не определена, и он не находит значение Content‑Length.
Нужно исправить заголовки на сервере, и в следующий раз робот сможет проиндексировать страницу.
412 Precondition Failed
Предварительное условие не выполнено — стоит проверить правильность HTTP‑заголовков данного запроса.
413 Request Entity Too Large
Превышен размер запроса — перелимит максимального размера запроса, принимаемого сервером. Браузеры поддерживают запросы от 2 до 8 килобайт.
414 Request‑URI Too Long
Превышена длина запроса — сервер не может обработать запрос из‑за длинного URL. Такая ошибка может возникнуть, например, когда клиент пытается передать чересчур длинные параметры через метод GET, а не POST.
415 Unsupported Media Type
Формат не поддерживается — сервер не может принять запрос, так как данные подгружаются в некорректном формате, и сервер разрывает соединение.
416 Requested Range Not Satisfiable
Диапазон не поддерживается — ошибка возникает в случаях, когда в самом HTTP‑заголовке прописывается некорректный байтовый диапазон.
Корректного диапазона в необходимом документе может просто не быть, или есть опечатка в синтаксисе.
417 Expectation Failed
Ожидания не оправдались — прокси некорректно идентифицировал содержимое поля «Expect: 100‑Continue».
418 I’m a teapot
Первоапрельская шутка разработчиков в 1998 году. В расшифровке звучит как «я не приготовлю вам кофе, потому что я чайник». Не используется в работе.
422 Unprocessable Entity
Объект не обработан — сервер принял запрос, но в нём есть логическая ошибка. Стоит посмотреть в сторону семантики сайта.
423 Locked
Закрыто — ресурс заблокирован для выбранного HTTP‑метода. Можно перезагрузить роутер и компьютер. А также использовать только статистический IP.
424 Failed Dependency
Неуспешная зависимость — сервер не может обработать запрос, так как один из зависимых ресурсов заблокирован.
Выполнение запроса напрямую зависит от успешности выполнения другой операции, и если она не будет успешно завершена, то вся обработка запроса будет прервана.
425 Unordered Collection
Неверный порядок в коллекции — ошибка возникает, если клиент указал номер элемента в неупорядоченном списке или запросил несколько элементов в порядке, отличном от серверного.
426 Upgrade Required
Нужно обновление — в заголовке ответа нужно корректно сформировать поля Upgrade и Connection.
Этот ответ возникает, когда серверу требуется обновление до SSL‑протокола, но клиент не имеет его поддержки.
428 Precondition Required
Нужно предварительное условие — сервер просит внести в запрос информацию о предварительных условиях обработки данных, чтобы выдавать корректную информацию по итогу.
429 Too Many Requests
Слишком много запросов — отправлено слишком много запросов за короткое время. Это может указывать, например, на попытку DDoS‑атаки, для защиты от которой запросы блокируются.
431 Request Header Fields Too Large
Превышена длина заголовков — сервер может и не отвечать этим кодом, вместо этого он может просто сбросить соединение.
Исправляется это с помощью сокращения заголовков и повторной отправки запроса.
434 Requested Host Unavailable
Адрес запрашиваемой страницы недоступен.
444 No Response
Нет ответа — код отображается в лог‑файлах, чтобы подтвердить, что сервер никак не отреагировал на запрос пользователя и прервал соединение. Возвращается только сервером nginx.
Nginx — программное обеспечение с открытым исходным кодом. Его используют для создания веб‑серверов, а также в качестве почтового или обратного прокси‑сервера. Nginx решает проблему падения производительности из‑за роста трафика.
449 Retry With
Повторите попытку — ошибка говорит о необходимости скорректировать запрос и повторить его снова. Причиной становятся неверно указанные параметры (возможно, недостаточно данных).
450 Blocked by Windows Parental Controls
Заблокировано родительским контролем — говорит о том, что с компьютера попытались зайти на заблокированный ресурс. Избежать этой ошибки можно изменением параметров системы родительского контроля.
451 Unavailable For Legal Reasons
Недоступно по юридическим причинам — доступ к ресурсу закрыт, например, по требованию органов государственной власти или по требованию правообладателя в случае нарушения авторских прав.
456 Unrecoverable Error
Неустранимая ошибка — при обработке запроса возникла ошибка, которая вызывает некорректируемые сбои в таблицах баз данных.
499 Client Closed Request
Запрос закрыт клиентом — нестандартный код, используемый nginx в ситуациях, когда клиент закрыл соединение, пока nginx обрабатывал запрос.
5* класс кодов (ошибки на стороне сервера)
Эти коды указывают на ошибки со стороны серверов.
При использовании всех методов, кроме HEAD, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя. И его можно использовать в работе.
500 Internal Server Error
Внутренняя ошибка сервера — сервер столкнулся с неким условием, из‑за которого не может выполнить запрос.
Проверяйте, корректно ли указаны директивы в системных файлах (особенно htaccess) и нет ли ошибки прав доступа к файлам. Обратите внимание на ошибки внутри скриптов и их медленную работу.
501 Not Implemented
Не выполнено — код отдается, когда сам сервер не может идентифицировать метод запроса.
Сами вы эту ошибку не исправите. Устранить её может только сервер.
502 Bad Gateway
Ошибка шлюза — появляется, когда сервер, выступая в роли шлюза или прокси‑сервера, получил ответное сообщение от вышестоящего сервера о несоответствии протоколов.
Актуально исключительно для прокси и шлюзовых конфигураций.
503 Service Unavailable
Временно не доступен — сервер временно не имеет возможности обрабатывать запросы по техническим причинам (обслуживание, перегрузка и прочее).
В поле Retry‑After заголовка сервер укажет время, через которое можно повторить запрос.
504 Gateway Timeout
Тайм‑аут шлюза — сервер, выступая в роли шлюза или прокси‑сервера, не получил ответа от вышестоящего сервера в нужное время.
Исправить эту ошибку самостоятельно не получится. Здесь дело в прокси, часто — в веб‑сервере.
Первым делом просто обновите веб‑страницу. Если это не помогло, нужно почистить DNS‑кэш. Для этого нажмите горячие клавиши Windows+R и введите команду cmd (Control+пробел). В открывшемся окне укажите команду ipconfig / flushdns и подтвердите её нажатием Enter.
505 HTTP Version Not Supported
Сервер не поддерживает версию протокола — отсутствует поддержка текущей версии HTTP‑протокола. Нужно обеспечить клиента и сервер одинаковой версией.
506 Variant Also Negotiates
Неуспешные переговоры — с такой ошибкой сталкиваются, если сервер изначально настроен неправильно. По причине ошибочной конфигурации выбранный вариант указывает сам на себя, из‑за чего процесс и прерывается.
507 Insufficient Storage
Не хватает места для хранения — серверу недостаточно места в хранилище. Нужно либо расчистить место, либо увеличить доступное пространство.
508 Loop Detected
Обнаружен цикл — ошибка означает провал запроса и выполняемой операции в целом.
509 Bandwidth Limit Exceeded
Превышена пропускная способность — используется при чрезмерном потреблении трафика. Владельцу площадки следует обратиться к своему хостинг‑провайдеру.
510 Not Extended
Не продлён — ошибка говорит, что на сервере отсутствует нужное для клиента расширение. Чтобы исправить проблему, надо убрать часть неподдерживаемого расширения из запроса или добавить поддержку на сервер.
511 Network Authentication Required
Требуется аутентификация — ошибка генерируется сервером‑посредником, к примеру, сервером интернет‑провайдера, если нужно ввести пароль для получения доступа к сети через платную точку доступа.
Ловили когда-нибудь ошибку 500 в ответе HTTP API, когда ожидаете 404 или 401?
Бывало так, что сервер отвечает кодом 200 на любой запрос, в том числе ошибочный?
Знакомо чувство, что для того, чтобы понять почему запрос не отработал, придётся заглянуть в логи сервера, или заниматься экспериментами?
А если это не наше API и доступов к логам и коду нет? Тогда нас скорее всего ожидают трудные времена.
Подумаем, как можно спроектировать своё API так, чтобы к нему было легко подключаться.
Коды статусов ответа HTTP группируются так:
1xx : Информационные запросы
2xx : Успешные запросы
3xx : Редиректы (перенаправления)
4xx : Ошибки клиента
5xx : Ошибки сервера
1xx — ошибки 100 — 199, 2xx — ошибки 200 — 299 и т.д.
Как выбрать код ответа?
Тот кто отправляет запрос на наш сервер, хочет получить как можно более осмысленный ответ.
Но чтобы дать такой ответ, сначала нужно самим определиться, в каких случаях мы даём одни коды, в каких другие.
Больше всего сомнений возникает, какую ошибку выбросить, 4xx или 5xx?
В чем разница между “ошибкой клиента” и “ошибкой сервера”?
Ошибка валидации — это ошибка на клиенте или на сервере?
Попытавшись ответить на эти вопросы, я вывел для себя два правила. Я стараюсь придерживаться этих правил в любом проекте.
Правило 1. Разделяем ошибки клиента и сервера, конкретизируем их.
2xx : Только успешные запросы.
Если запрос не может быть обработан, то в зависимости от причины возвращаем либо 4xx, либо 5xx.
Ошибки с кодом 2xx быть не может, этот код только для успешного выполненного запроса.
4xx : Сервер отвечает, что такой запрос не будет обработан.
Клиент отправил некорректный запрос, или сделал это недопустимым способом.
Примеры возможных причин:
-
Сервер не знает как обработать этот запрос.
-
Сервер не понял, что хотел сделать клиент.
-
Нехватает вводных данных, например не указаны обязательные поля.
-
Данные некорректны, допустим неправильный тип параметра или значение не попадает в нужный диапазон.
-
Ресурс не найден —
404. -
Пользователь должен быть авторизован для выполнения запроса, а пытается выполнить без авторизации —
401. -
Пользователю запрещено производить это действие, например он авторизован но ему ему не выдали доступ на указанный ресурс —
403.
5xx : Ошибка на сервере
Примеры возможных причин:
-
Нет ответа от сервиса, лежащего “за” веб-сервером, например “упал” сервис PHP-FPM —
502 -
Сервер пытался выполнить запрос, но код вылетел с ошибкой (Exception) —
500
В хорошем API, ошибка 5xx будет отдана в двух случаях — либо сбой инфраструктуры (502), либо запрос невозможно выполнить из-за ошибки в коде (500).
Если вины программиста или инфраструктуры нет, мы возвращаем 4xx.
Правило 2. По возможности указываем причину.
Если мы знаем дополнительную информацию по ошибке и она не секретная — хорошо бы сообщить об этом в ответе, а не просто вернуть код 400 или 500.
Это сильно облегчит задачу любому, кто будет интегрироваться с вашим API.
Плохо:
400 Bad Request
Хорошо:
400 Missing required field "accountId"
Что в итоге
Если коды ответов в нашем API систематизированы, то это существенно помогает в работе.
-
При тестировании API мы сразу можем определить результат по коду HTTP, не изучая тело ответа.
-
При отладке мы сразу определяем какой именно запрос вызывает ошибку.
-
В мониторинге мы можем очень легко настроить отслеживание кодов
500, чтобы сразу узнавать о сбоях нашего кода.
Your question is good, but I do believe it to be based on opinions. The choice of the appropriate code should be made according to the current RFC. However, like any other standard, the RFC is not always clear and can be interpreted in a variety of ways.
Here are my thoughts on the answers already given and my opinion.
1. Where and where should I look for sources for questions like this?
First of all, the RFC regarding this and what is in vogue at the moment is the 7231 < a>. If you are familiar with English, I suggest you read it to create your own opinions as well.
2. About not using 200 code
Although some web frameworks return 200 in the case of requests with invalid data, I do not believe that this should be the proper code.
According to item 6.3 of 7231, 2xx codes indicate that the customer request has been received, understood and accepted.
So if the purpose of a POST request is to create a new object on the server, and this is not done due to invalid data, I do not think that the code 200 should be returned saying that the request was a success , but rather a code indicating that an error occurred in the processing of sent data.
3. About using the 400 code
If we think that the data sent is also part of the request, if it is invalid and therefore wrong, it is not fair to return a code 400, which indicates a bad request.
Setting the POST method
Looking at the definition of the POST method in the RFC strengthens this idea. According to item 4.3.3, a POST request is requesting that a given resource (or resource ) process the data present in the request according to the semantics of the resource. So, if you send a data that has no meaning to the server, the request will not be understood and should not be processed.
Definition of class 4xx and code 400
Another argument to strengthen the use of the 400 code is the definition of the 4xx class and its own definition:
Class 4xx has codes for when the client makes a mistake. If you understand that the client is responsible for sending valid data (and that validation on the server is done by security measure) 4xx seems to be the appropriate class. It is important to note that class 4xx, according to the RFC, should always return an explanation of the error to the client.
The code 400, in turn, indicates that the server can not, is not able or will not simply process the request by error of the client (the error of sending data that does not have meaning according to the requested resource).
It is important to remember that the RFC does not list the errors that a client can commit, listing only a few examples (syntax error is one of them).
4. Soon …
In conclusion, the client is responsible for sending data that makes sense to the server, and if it does not, this should be considered a client error. Therefore, I suggest use code 400 and, as provided in the RFC, send a message explaining the error, saying that the data is not valid.
Bonus: Methods you definitely should not use
418: is not a code present in the current RFC and has no semantic value for data validation.
405: Should be used only when the request method is not accepted by the server and not the data itself.